EP1333424B1 - Einbettung von Daten in kodierte Sprache und Extrahierung von Daten aus kodierter Sprache - Google Patents
Einbettung von Daten in kodierte Sprache und Extrahierung von Daten aus kodierter Sprache Download PDFInfo
- Publication number
- EP1333424B1 EP1333424B1 EP03250682A EP03250682A EP1333424B1 EP 1333424 B1 EP1333424 B1 EP 1333424B1 EP 03250682 A EP03250682 A EP 03250682A EP 03250682 A EP03250682 A EP 03250682A EP 1333424 B1 EP1333424 B1 EP 1333424B1
- Authority
- EP
- European Patent Office
- Prior art keywords
- data
- code
- voice
- embedding
- embedded
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Lifetime
Links
- 238000000034 method Methods 0.000 claims description 29
- 238000012545 processing Methods 0.000 claims description 26
- 238000010586 diagram Methods 0.000 description 61
- 230000003044 adaptive effect Effects 0.000 description 53
- 230000005540 biological transmission Effects 0.000 description 37
- 230000005284 excitation Effects 0.000 description 33
- 238000004891 communication Methods 0.000 description 30
- 239000013598 vector Substances 0.000 description 21
- 230000015572 biosynthetic process Effects 0.000 description 19
- 238000003786 synthesis reaction Methods 0.000 description 19
- 239000000284 extract Substances 0.000 description 17
- 238000000605 extraction Methods 0.000 description 16
- 238000013075 data extraction Methods 0.000 description 13
- 238000013139 quantization Methods 0.000 description 12
- 238000005070 sampling Methods 0.000 description 12
- 230000000737 periodic effect Effects 0.000 description 7
- 230000008859 change Effects 0.000 description 6
- 230000000694 effects Effects 0.000 description 5
- 238000013500 data storage Methods 0.000 description 4
- 230000007423 decrease Effects 0.000 description 4
- 238000012937 correction Methods 0.000 description 3
- 238000011156 evaluation Methods 0.000 description 3
- 238000010295 mobile communication Methods 0.000 description 3
- 230000002159 abnormal effect Effects 0.000 description 2
- 230000008901 benefit Effects 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- 230000006835 compression Effects 0.000 description 2
- 238000007906 compression Methods 0.000 description 2
- 238000003780 insertion Methods 0.000 description 2
- 230000037431 insertion Effects 0.000 description 2
- 230000008439 repair process Effects 0.000 description 2
- 238000004088 simulation Methods 0.000 description 2
- 230000001360 synchronised effect Effects 0.000 description 2
- 238000010420 art technique Methods 0.000 description 1
- 230000006837 decompression Effects 0.000 description 1
- 230000000593 degrading effect Effects 0.000 description 1
- 230000003111 delayed effect Effects 0.000 description 1
- 239000002360 explosive Substances 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 238000013507 mapping Methods 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 238000001228 spectrum Methods 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
Images


























Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/018—Audio watermarking, i.e. embedding inaudible data in the audio signal
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
Definitions
- This invention relates to a technique for processing a digital voice signal, in the fields of application of packet voice communication and digital voice storage. More particularly, the invention relates to a data embedding technique in which a portion of encoded voice code (digital code) that has been produced by a voice compression technique is replaced with optional data to thereby embed the optional data in the encoded voice code while maintaining conformance to the specifications of the data format and without sacrificing voice quality.
- a portion of encoded voice code digital code
- Such a data embedding technique in conjunction with voice encoding techniques applied to digital mobile wireless systems, packet voice transmission systems typified by VoIP, and digital voice storage, is meeting with greater demand and is becoming more important as an digital watermark technique, through which the concealment of communication is enhanced by embedding copyright or ID information in a transmit bit sequence without affecting the bit sequence, and as a functionality extending technique.
- the explosive growth of the Internet has been accompanied by increasing demand for Internet telephony for the transmission of voice data by IP packets.
- the transmission of voice data by packets has the advantage of making possible the unified transmission of different media, such as commands and image data.
- multimedia communication has mainly been transmission independently over different channels.
- services through which telephone rates for users are lowered by the insertion of advertisements and the like are also available, such services are provided only at the outset when the call is initiated.
- voice data in the form of packets different media such as commands and image data can be transmitted in unified fashion. Since the transmission format is well known, however, a problem arises in terms of concealment of information. With this as a background, digital watermark techniques for embedding copyright information in compressed voice data (code) have been proposed.
- voice encoding techniques for the highly efficient compression of voice have been adopted.
- voice encoding techniques such as those compliant with G.729 standardized by the ITU-T (International Telecommunications Union - Telecommunications Standards Section) are dominant.
- Voice encoding techniques such as AMR (Adaptive Multi-Rate) standardized by 3GPP (3 rd Generation Partnership Project) have been adopted even in the field of mobile communications. What these techniques have in common is that they are based upon an algorithm referred to as CELP (Code Excited Linear Prediction).
- CELP Code Excited Linear Prediction
- Fig. 41 is a diagram illustrating the structure of an encoder compliant with ITU-T Recommendation G.729.
- LPC Linear Prediction Coefficient
- the LPC analyzer 1 performs LPC analysis using 80 samples of the input signal, 40 pre-read samples and 120 past signal samples, for a total of 240 samples, and obtains the LPC coefficients.
- a parameter converter 2 converts the LPC coefficients to LSP (Line Spectrum Pair) parameters.
- An LSP parameter is a parameter of a frequency region in which mutual conversion with LPC coefficients is possible. Since a quantization characteristic is superior to LPC coefficients, quantization is performed in the LSP domain.
- An LSP quantizer 3 quantizes an LSP parameter obtained by the conversion and obtains an LSP code and an LSP dequantized value.
- An LSP interpolator 4 obtains an LSP interpolated value from the LSP dequantized value found in the present frame and the LSP dequantized value found in the previous frame.
- one frame is divided into two subframes, namely first and second subframes, of 5 ms each, and the LPC analyzer 1 determines the LPC coefficients of the second subframe but not of the first subframe.
- the LSP interpolator 4 uses the LSP dequantized value found in the present frame and the LSP dequantized value found in the previous frame, the LSP interpolator 4 predicts the LSP dequantized value of the first subframe by interpolation.
- a parameter deconverter 5 converts the LSP dequantized value and the LSP interpolated value to LPC coefficients and sets these coefficients in an LPC synthesis filter 6.
- the LPC coefficients converted from the LSP interpolated values in the first subframe of the frame and the LPC coefficients converted from the LSP dequantized values in the second subframe are used as the filter coefficients of the LPC synthesis filter 6.
- the "l” in items having a subscript attached to the "l”, e.g., lspi, li (n) , ⁇ , is the letter "l" in the alphabet.
- excitation and gain search processing is executed. Excitation and gain are processed on a per-subframe basis.
- a excitation signal is divided into a periodic component and a non periodic component, an adaptive codebook 7 storing a sequence of past excitation signals is used to quantize the periodic component and an algebraic codebook or fixed codebook is used to quantize the non periodic component. Described below will be voice encoding using the adaptive codebook 7 and a fixed codebook 8 as excitation codebooks.
- the adaptive codebook 7 is adapted to output N samples of excitation signals (referred to as "periodicity signals"), which are delayed successively by one sample, in association with indices 1 to L, where N represents the number of samples in one subframe.
- the adaptive codebook 7 has a buffer for storing the periodic component of the latest (L+39) samples.
- a periodicity signal comprising 1 st to 40 th samples is specified by index 1
- a periodicity signal comprising 2 nd to 41 st samples is specified by index 2
- ⁇ a periodicity signal comprising Lth to (L+39)th samples is specified by index L.
- the content of the adaptive codebook 7 is such that all signals have amplitudes of zero. Operation is such that a subframe length of the oldest signals is discarded subframe by subframe in terms of time so that the excitation signal obtained in the present frame will be stored in the adaptive codebook 7.
- the non periodic component contained in the excitation signal is quantized using the fixed codebook 8.
- the latter is constituted by a plurality of pulses of amplitude 1 or -1.
- Table 1 illustrates pulse positions for a case where subframe length is 40 samples.
- Fig. 42 is a diagram useful in describing sampling points assigned to each of the pulse-system groups 1 to 4.
- the pulse positions of each of the pulse systems are limited, as illustrated in Table 1.
- a combination of pulses for which the error power relative to the input voice is minimized in the reconstruction region is decided from among the combinations of pulse positions of each of the pulse systems. More specifically, with ⁇ opt as the optimum pitch gain found by the adaptive-codebook search, the output P L of the adoptive codebook is multiplied by ⁇ opt and the product is input to an adder 11.
- the pulsed excitation signals are input successively to the adder 11 from the fixed codebook 8 and a pulsed excitation signal is specified that will minimize the difference between the input signal X and a reproduced signal obtained by inputting the adder output to the LPC synthesis filter 6.
- the error-power evaluation unit 10 searches for the combination of pulse position and polarity that will afford the largest normalized cross-correlation value (Rcx*Rcx/Rcc) obtained by normalizing the square of a cross-correlation value Rcx between a noise synthesis signal AC K and input signal X' by an autocorrelation value Rcc of the noise synthesis signal.
- the method of the gain codebook search includes 1extracting one set of table values from the gain quantization table with regard to an output vector from the adaptive codebook and an output vector from the fixed codebook and setting these values in gain varying units 13, 14, respectively; 2 multiplying these vectors by gains G a , G c using the gain varying units 13, 14, respectively, and inputting the products to the LPC synthesis filter 6; and 3 selecting, by way of the error-power evaluation unit 10, the combination for which the error power relative to the input signal X is smallest.
- a channel multiplexer 15 creates channel data by multiplexing 1 an LSP code, which is the quantization index of the LSP, 2 a pitch-lag code Lopt, which is the quantization index of the adaptive codebook, 3 a noise code, which is an fixed codebook index, and 4 a gain code, which is a quantization index of gain.
- LSP code which is the quantization index of the LSP
- Lopt which is the quantization index of the adaptive codebook
- 3 a noise code
- 4 a gain code, which is a quantization index of gain.
- Fig. 43 is a block diagram illustrating a G.729A-compliant decoder.
- Channel data received from the channel side is input to a channel demultiplexer 21, which proceeds to separate and output an LSP code, pitch-lag code, noise code and gain code.
- the decoder decodes speech data based upon these codes. The operation of the decoder will now be described in brief, though parts of the description will be redundant because functions of the decoder are included in the encoder.
- an LSP dequantizer 22 Upon receiving the LSP code as an input, an LSP dequantizer 22 applies dequantization and outputs an LSP dequantized value.
- An LSP interpolator 23 interpolates an LSP dequantized value of the first subframe of the present frame from the LSP dequantized value in the second subframe of the present frame and the LSP dequantized value in the second subframe of the previous frame.
- a parameter deconverter 24 converts the LSP interpolated value and the LSP dequantized value to LPC synthesis filter coefficients.
- a G.729A-compliant synthesis filter 25 uses the LPC coefficient converted from the LSP interpolated value in the initial first subframe and uses the LPC coefficient converted from the LSP dequantized value in the ensuing second subframe.
- a gain dequantizer 28 calculates an adaptive codebook gain dequantized value and a fixed codebook gain dequantized value from the gain code applied thereto and sets these values in gain varying units 29, 30, respectively.
- An adder 31 creates a excitation signal by adding a signal, which is obtained by multiplying the output of the adaptive codebook by the adaptive codebook gain dequantized value, and a signal obtained by multiplying the output of the fixed codebook by the fixed codebook gain dequantized value.
- the excitation signal is input to an LPC synthesis filter 25. As a result, reproduced voice can be obtained from the LPC synthesis filter 25.
- the content of the adaptive codebook 26 on the decoder side is such that all signals have amplitudes of zero. Operation is such that a subframe length of the oldest signals is discarded subframe by subframe in terms of time so that the excitation signal obtained in the present frame will be stored in the adaptive codebook 26.
- the adaptive codebook 7 of the encoder and the adaptive codebook 26 of the decoder are always maintained in the identical, latest state.
- Fig. 44 is a diagram useful in describing such an digital watermark technique.
- Table 1 refer to the fourth pulse system i 3 .
- the pulse position m 3 of the fourth pulse system i 3 differs in that there are mutually adjacent candidates for this position.
- pulse position in the fourth pulse system i 3 is such that it does not matter if either of the adjacent pulse positions is selected.
- mapping is performed in this manner, all of the candidates of m 3 can be labeled "0" or "1" in accordance with the key Kp. If a watermark bit "0" is to be embedded in encoded voice code under these conditions, m 3 is selected from candidates that have been labeled “0” in accordance with the key Kp. If a watermark bit "1" is to be embedded, on the other hand, m 3 is selected from candidates that have been labeled "1” in accordance with the key Kp.
- This method makes it possible to embed binarized watermark information is encoded voice code. Accordingly, by furnishing both the transmitter and receiver with the key Kp, it is possible to embed and extract watermark information. Since 1-bit watermark information can be embedded every 5-ms subframe, 200 bits can be embedded per second.
- EP-A2-1 020 848 discloses a method for embedding data in encoded voice code for sending secret messages in the bits allocated to a vocoder's codebook's output by setting the gain for the corresponding codebook to zero, and a corresponding embedded-data extracting method.
- an object of the present invention is to so arrange it that data can be embedded in encoded voice code on the encoder side and extracted correctly on the decoder side without both the encoder and decoder sides possessing a key.
- Another object of the present invention is to so arrange it that there is almost no decline in sound quality even if data is embedded in encoded voice code, thereby making the embedding of data concealed to the listener of reproduced voice.
- a further object of the present invention is to make the leakage and falsification of embedded data difficult to achieve.
- Still another object of the present invention is to so arrange it that both data and control code can be embedded, thereby enabling the decoder side to execute processing in accordance with the control code.
- Another object of the present invention is to so arrange it that the transmission capacity of embedded data can be increased.
- Another object of the present invention is to make it possible to transmit multimedia such as voice, images and personal information on a voice channel alone.
- Another object of the present invention is to so arrange it that any information such as advertisement information can be provided to end users performing mutual communication of voice data.
- Another object of the present invention is to so arrange it that sender, recipient, receive time and call category, etc., can be embedded and stored in voice data that has been received.
- a threshold value can be changed using this control code, and the amount of embedded data transmitted can be adjusted by changing the threshold value.
- whether to embed only a data sequence, or whether to embed a data / control code sequence in a format that makes it possible to identify the type of data and control code is decided in dependence upon a gain value. In a case where only a data sequence is embedded, therefore, it is unnecessary to include data-type information. This makes possible improvements relating to transmission capacity.
- a excitation signal is generated based upon an index, which specifies a excitation sequence, and gain information
- voice is generated (reproduced) using a synthesis filter constituted by linear prediction coefficients, and reproduced voice is expressed by the following equation:
- Srp represents reproduced voice
- H an LPC synthesis filter Gp adaptive code vector gain (pitch gain), P an adaptive code vector (pitch-lag code), Gc noise code vector gain (fixed codebook gain), and C a noise code vector.
- the first term on the right side is a pitch-period synthesis signal and the second term is a noise synthesis signal.
- digital codes (transmit parameters) encoded according to CELP correspond to feature parameters in a voice generating system. Taking note of these features, is possible to ascertain the status of each transmit parameter. For example, taking note of two types of code vectors of a excitation signal, namely an adaptive code vector corresponding to a pitch excitation and a noise code vector corresponding to a noise excitation, it is possible to regard gains Gp, Gc as being factors that indicate the degree of contribution of the code vectors P, C, respectively. More specifically, in a case where the gains Gp, Gc are low, the degrees of contribution of the corresponding code vectors are low. Accordingly, the gains Gp, Gc are defined as decision parameters.
- gain is less than a threshold value, it is determined that the degree of contribution of the corresponding excitation code vector P, C is low and the index of this excitation code vector is replaced with an optional data sequence. As a result, it is possible to embed optional data while suppressing the effects of this replacement. Further, by controlling the threshold value, the amount of embedded data can be adjusted while taking into account the effect upon reproduced speech quality.
- This technique is such that if only an initial value of a threshold value is defined in advance on both the transmitting and receiving sides, whether or not embedded data exists and the location of embedded data can be determined and, moreover, the writing/reading of embedded data can be performed based solely upon decision parameters (pitch gain and fixed codebook gain) and embedding target parameters (pitch lag and noise code). In other words, transmission of a specific key is not required. Further, if a control code is defined as embedded data, the amount of embedded data transmitted can be adjusted merely by specifying a change in the threshold value by the control code.
- control specifications are stipulated by parameters common to CELP. This means that the invention is not limited to a specific scheme and therefore can be applied to a wide range of schemes. For example, G.729 suited to VoIP and AMR suited to mobile communications can be supported.
- Fig. 1 is a block diagram showing the general arrangement of structural components on the side of an encoder which is part of the present invention.
- a voice/audio CODEC (encoder) 51 encodes input voice in accordance with a prescribed encoding scheme and outputs the encoded voice code (code data) thus obtained.
- the encoded voice code is composed of a plurality of element codes.
- An embed data generator 52 generates prescribed data for being embedded in encoded voice code.
- a data embedding controller 53 which has an embedding decision unit 54 and a data embedding unit 55 constructed as a selector, embeds data in encoded voice code as appropriate.
- the embedding decision unit 54 determines whether data embedding conditions are satisfied. If these conditions are satisfied, the data embedding unit 55 replaces a second element code with optional embed data to thereby embed the optional data in the encoded voice code. If the data embedding condition are not satisfied, the data embedding unit 55 outputs the second element code as is.
- a multiplexer 56 multiplexes and transmits the element codes that construct the encoded voice code.
- Fig. 2 is a block diagram of the embedding decision unit.
- a dequantizer 54a dequantizes the first element code and outputs a dequantized value G, and a threshold value generator 54b outputs the threshold value TH.
- a comparator 54c compares the dequantized value G and the threshold value TH and inputs the result of the comparison to a data embedding decision unit 54d, If G ⁇ TH holds, for example, the data embedding decision unit 54d determines that the embedding of data is not possible and generates a select signal SL for selecting the second element code, which is output from the encoder 51.
- the data embedding decision unit 54d determines that embedding of data is possible and generates a select signal S for selecting embed data that is output from the embed data generator 52. As a result, based upon the select signal SL, the data embedding unit 55 selectively outputs the second element code or the embed data.
- the first element code is dequantized and compared with the threshold value.
- the comparison can be performed on the code level by setting the threshold value in the form of a code. In such case dequantization is not necessarily required.
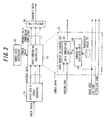
- Fig. 3 is a block diagram of an embedding/encoding part of a first embodiment for a case where use is made of an encoder for performing encoding in accordance with a G.729-compliant encoding scheme.
- Components identical with those shown in Fig. 1 are designated by like reference characters. This arrangement differs from that of Fig. 1 in that a gain code (fixed codebook gain) is used as the first element code and a noise code, which is an index of a fixed codebook, is used as the second element code.
- a gain code fixed codebook gain
- noise code which is an index of a fixed codebook
- the codec 51 encodes input voice in accordance with G.729 and inputs the encoded voice code thus obtained to the data embedding controller 53.
- the G.729-compliant encoded voice code has the following as element codes: an LSP code, an adaptive codebook index (pitch-lag code), a fixed codebook index (noise code) and a gain code.
- the gain code is obtained by combining and encoding pitch gain and fixed codebook gain.
- the embedding decision unit 54 of the data embedding controller 53 uses the dequantized value of the gain code and the threshold value TH to determine whether data embedding conditions are satisfied, and the data embedding unit 55 replaces noise code with prescribed data to thereby embed the data in the encoded voice code if the data embedding conditions are satisfied. If the data embedding conditions are not satisfied, the data embedding unit 55 outputs the noise element code as is.
- the multiplexer 56 multiplexes and transmits the element codes that construct the encoded voice code.
- the embedding decision unit 54 has the structure shown in Fig. 4 . Specifically, the dequantizer 54a dequantizes the gain code and the comparator 54c compares the dequantized value (fixed codebook gain) Gc with the threshold value TH. When the dequantized value Gc is smaller than the threshold value TH, the data embedding decision unit 54d determines that the data embedding conditions are satisfied and generates a select signal SL for selecting embed data that is output from the embed data generator 52. When the dequantized value Gc is equal to or greater than the threshold value TH, the data embedding decision unit 54d determines that the data embedding conditions are not satisfied and generates a select signal SL for selecting a noise code that is output from the encoder 51. Based upon the select signal SL, the data embedding unit 55 selectively outputs the noise code or the embed data.
- the dequantizer 54a dequantizes the gain code and the comparator 54c compares the dequantized value (fixed codebook gain) Gc with the threshold value
- Fig. 5 illustrates the standard format of encoded voice code
- Fig. 6 is a diagram useful in describing transmit code based upon embedding control.
- the encoded voice code is composed of five codes (LSP code, adaptive codebook index, adaptive codebook gain, fixed codebook index, fixed codebook gain).
- LSP code adaptive codebook index
- Gc fixed codebook gain
- the fixed codebook gain Gc is equal to or greater than the threshold value
- data is not embedded in the encoded voice code, as indicated at (1) in Fig. 6
- the fixed codebook gain Gc is less than the threshold value TH
- data is embedded in the fixed codebook index portion of the encoded voice code, as indicated at (2) in Fig. 6 .
- MSB most significant bit
- data and a control code can be embedded in the remaining (M-1)-number of bits in a form distinguished from each other, as illustrated in Fig. 7 .
- M-1 most significant bit
- Table 3 illustrates the result of a simulation in a case where the noise code (17 bits) serving as the fixed codebook index is replaced with any data if gain is less than a certain value in the G.729 voice encoding scheme.
- Table 3 illustrates the results of evaluating, by SNR, a change in sound quality in a case where voice is reproduced upon adopting randomly generated data as any data and regarding this random data as noise code, as well as the proportion of a frame replaced with embedded data.
- the threshold values in Table 3 are gain index numbers; the greater the number of index values, the larger the gain serving as the threshold value.
- SNR is the ratio (in dB) of the excitation signal in a case where the noise code in the encoded voice code is not replaced with data, to an error signal representing the difference between the excitation signal in a case where the noise code is not replaced with data and the excitation signal in a case where the noise code is replaced with data;
- SNRseg represents the SNR on a per-frame basis;
- SNRtot represents the average SNR over the entire voice interval.
- the proportion (%) is that at which data is embedded once the gain has fallen below the corresponding threshold value in a case where a standard signal is input as the voice signal.
- the transmission capacity (proportion) of embedded data can also be adjusted while taking into account the effect upon sound quality. For example, if a change in sound quality of 0.2 dB is allowed, the transmission capacity can be increased to 46% (1564 bits/s) by setting the threshold value to 20.
- Fig. 8 is a block diagram of an embedding/encoding part of a second embodiment for a case where use is made of an encoder for performing encoding in accordance with a G.729-compliant encoding scheme.
- Components identical with those shown in Fig. 1 are designated by like reference characters. This arrangement differs from that of Fig. 1 in that a gain code (pitch-gain gain) is used as the first element code and a pitch-lag code, which is an index of an adaptive codebook, is used as the second element code.
- a gain code pitch-gain gain
- pitch-lag code which is an index of an adaptive codebook
- the codec 51 encodes input voice in accordance with G.729 and inputs the encoded voice code thus obtained to the data embedding controller 53.
- the embedding decision unit 54 of the data embedding controller 53 uses the dequantized value (pitch gain) of the gain code and the threshold value TH to determine whether data embedding conditions are satisfied, and the data embedding unit 55 replaces pitch-lag code with prescribed data to thereby embed the data in the encoded voice code if the data embedding conditions are satisfied. If the data embedding conditions are not satisfied, the data embedding unit 55 outputs the pitch-lag element code as is.
- the multiplexer 56 multiplexes and transmits the element codes that construct the encoded voice code.
- the embedding decision unit 54 has the structure shown in Fig. 9 . Specifically, the dequantizer 54a dequantizes the gain code and the comparator 54c compares the dequantized vale (pitch gain) Gp with the threshold value TH. When the dequantized value Gp is smaller than the threshold value TH, the data embedding decision unit 54d determines that the data embedding conditions are satisfied and generates a select signal SL for selecting embed data that is output from the embed data generator 52. When the dequantized value Gp is equal to or greater than the threshold value TH, the data embedding decision unit 54d determines that the data embedding conditions are not satisfied and generates a select signal SL for selecting a pitch-lag code that is output from the encoder 51. Based upon the select signal SL, the data embedding unit 55 selectively outputs the pitch-lag code or the embed data.
- Fig. 10 illustrates the standard format of encoded voice code
- Fig. 11 is a diagram useful in describing transmit code based upon embedding control.
- the encoded voice code is composed of five codes (LSP code, adaptive codebook index, adaptive codebook gain, fixed codebook index, fixed codebook gain).
- LSP code adaptive codebook index
- Gp fixed codebook gain
- data is not embedded in the encoded voice code, as indicated at (1) in Fig. 11 .
- the fixed codebook gain Gp is less than the threshold value TH
- data is embedded in the adaptive codebook index portion of the encoded voice code, as indicated at (2) in Fig. 11 .
- Table 4 illustrates the result of a simulation in a case where the pitch-lag code (13 bits/10 ms) serving as the adaptive codebook index is replaced with optional data if gain is less than a certain value in the G.729 voice encoding scheme.
- Table 4 illustrates the results of evaluating, by SNR, a change in sound quality in a case where voice is reproduced upon adopting randomly generated data as the optional data and regarding this random data as pitch-lag code, as well as the proportion of a frame replaced with embedded data.
- Fig. 12 is a block diagram showing the general arrangement of structural components on the side of a decoder which is part of the present invention.
- a demultiplexer 61 demultiplexes the encoded voice code into element codes and inputs these to a data extraction unit 62.
- the latter extracts data from a second element code from among the demultiplexed element codes, inputs this data to a data processor 63 and applies each of the entered element codes to a voice/audio CODEC (decoder) 64 as is.
- the decoder 64 decodes the entered encoded voice code, reproduces voice and outputs the same.
- the data extraction unit 62 which has an embedding decision unit 65 and an assignment unit 66, extracts data from encoded voice code as appropriate. Using a first element code, which is from among element codes constituting the encoded voice code, and a threshold value TH, the embedding decision unit 65 determines whether data embedding conditions are satisfied. If these conditions are satisfied, the assignment unit 66 regards a second element code from among the element codes as embedded data, extracts the embedded data and sends this data to the data processor 63. The assignment unit 66 inputs the entered second element code to the decoder 64 as is regardless of whether the data embedding conditions are satisfied or not.
- Fig. 13 is a block diagram of the embedding decision unit.
- a dequantizer 65a dequantizes the first element code and outputs a dequantized value G, and a threshold value generator 65b outputs the threshold value TH.
- a comparator 65c compares the dequantized value G and the threshold value TH and inputs the result of the comparison to a data embedding decision unit 65d. If G ⁇ TH holds, the data embedding decision unit 65d determines that data has not been embedded and generates an assign signal BL; if G ⁇ TH holds, the data embedding decision unit 65d determines that data has been embedded and generates the assign signal BL.
- the assignment unit 66 extracts this data from the second element code, inputs the data to the data processor 63 and inputs the second element code to the decoder 64 as is on the basis of the assign signal BL. If data has not been embedded, the assignment unit 66 inputs the second element code to the decoder 64 as is on the basis of the assign signal BL.
- the first element code is dequantized and compared with the threshold value. However, there is also a case where the comparison can be performed on the code level by setting the threshold value in the form of a code. In such case dequantization is not necessarily required.
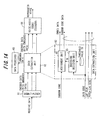
- Fig. 14 is a block diagram of an extracting/decoding part of a first embodiment for a case where data has been embedded in G.729-compliant noise code. Components identical with those shown in Fig. 12 are designated by like reference characters. This arrangement differs from that of Fig. 12 in that a gain code (fixed codebook gain) is used as the first element code and a noise code, which is an index of a fixed codebook, is used as the second element code.
- a gain code fixed codebook gain
- noise code which is an index of a fixed codebook
- the demultiplexer 61 Upon receiving encoded voice code, the demultiplexer 61 demultiplexes the encoded voice code into element codes and inputs these to the data extraction unit 62. On the assumption that encoding has been performed in accordance with G.729, the demultiplexer 61 demultiplexes the encoded voice code into LSP code, pitch-lag code, noise code and gain code and inputs these to the data extraction unit 62. It should be noted that the gain code is the result of combining pitch gain and fixed codebook gain and quantizing (encoding) these using a quantization table.
- the embedding decision unit 65 of the data extraction unit 62 determines whether data embedding conditions are satisfied. If data embedding conditions are satisfied, the assignment unit 66 regards the noise code as embedded data, inputs the embedded data to the data processor 63 and inputs the fixed codebook to the decoder 64 in the form in which it was applied thereto. If the data embedding conditions are not satisfied, the assignment unit 66 inputs the noise code to the decoder 64 in the form in which it was applied thereto.
- the embedding decision unit 65 has the structure shown in Fig. 15 . Specifically, the dequantizer 65a dequantizes the gain code and the comparator 65c compares the dequantized value (fixed codebook gain) Gc with the threshold value TH. When the dequantized value Gc is smaller than the threshold value TH, the data embedding decision unit 65d determines that data has not been embedded and generates the assign signal BL. When the dequantized value Gc is equal to or greater than the threshold value TH, the data embedding decision unit 65d determines that data has not been embedded and generates the assign signal BL. On the basis of the assign signal BL, the assignment unit 66 inputs the data, which has been embedded in the fixed codebook, to the data processor 63 and inputs the fixed codebook to the decoder 64.
- the dequantizer 65a dequantizes the gain code and the comparator 65c compares the dequantized value (fixed codebook gain) Gc with the threshold value TH. When the dequantized value Gc is smaller
- Fig. 16 illustrates the standard format of a receive encoded voice code
- Fig. 17 is a diagram useful in describing the results of determination processing by the data embedding decision unit.
- LSP code adaptive codebook index
- adaptive codebook gain fixed codebook index
- fixed codebook gain fixed codebook gain
- TH threshold value
- the fixed codebook gain Gc is equal to or greater than the threshold value TH, then data has not been embedded in the fixed codebook index portion, as illustrated at (1) in Fig. 17 . If the fixed codebook gain Gc is less than the threshold value TH, on the other hand, then data has been embedded in the fixed codebook index portion, as illustrated at (2) in Fig. 17 .
- the data processor 63 may refer to the most significant bit and, if the bit is indicative of the control code, may execute processing that conforms to the control code, e.g., processing to change the threshold value, synchronous control processing, etc.
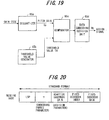
- Fig. 18 is a block diagram of an extracting/decoding part of a second embodiments for a case where data has been embedded in G.729-compliant pitch-lag code. Components identical with those shown in Fig. 12 are designated by like reference characters. This arrangement differs from that of Fig. 12 in that a gain code (pitch-gain code) is used as the first element code and a pitch-lag code, which is an index of an adaptive codebook, is used as the second element code.
- a gain code pitch-gain code
- pitch-lag code which is an index of an adaptive codebook
- the demultiplexer 61 Upon receiving encoded voice code, the demultiplexer 61 demultiplexes the encoded voice code into element codes and inputs these to the data extraction unit 62. On the assumption that encoding has been performed in accordance with G.729, the demultiplexer 61 demultiplexes the encoded voice code into LSP code, pitch-lag code, noise code and gain code and inputs these to the data extraction unit 62. It should be noted that the gain code is the result of combining pitch gain and fixed codebook gain and quantizing (encoding) these using a quantization table.
- the embedding decision unit 65 of the data extraction unit 62 determines whether data embedding conditions are satisfied. If data embedding conditions are satisfied, the assignment unit 66 regards the pitch-lag code as embedded data, inputs the embedded data to the data processor 63 and inputs the pitch-lag code to the decoder 64 in the form in which it was applied thereto. If the data embedding conditions are not satisfied, the assignment unit 66 inputs the pitch-lag code to the decoder 64 in the form in which it was applied thereto.
- the embedding decision unit 65 has the structure shown in Fig. 19 . Specifically, the dequantizer 65a dequantizes the gain code and the comparator 65c compares the dequantized value (pitch-gain) Gp with the threshold value TH. When the dequantized value Gp is smaller than the threshold value TH, the data embedding decision unit 65d determines that data has not been embedded and generates the assign signal BL. When the dequantized value Gp is equal to or greater than the threshold value TH, the data embedding decision unit 65d determines that data has not been embedded and generates the assign signal BL. On the basis of the assign signal BL, the assignment unit 66 inputs the data, which has been embedded in the pitch-lag code, to the data processor 63 and inputs the fixed codebook to the decoder 64.
- Fig. 20 illustrates the standard format of a receive encoded voice code
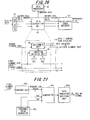
- Fig. 21 is a diagram useful in describing the results of determination processing by the data embedding decision unit.
- LSP code adaptive codebook index
- adaptive codebook gain fixed codebook index
- fixed codebook gain fixed codebook gain
- the adaptive codebook gain Gp is equal to or greater than the threshold value TH, then data has not been embedded in the adaptive codebook index portion, as illustrated at (1) in Fig. 21 . If the adaptive codebook gain Gp is less than the threshold value TH, on the other hand, then data has been embedded in the fixed codebook index portion, as illustrated at (2) in Fig. 21 .
- Fig. 22 is a block diagram of structure on the side of an encoder in which multiple threshold values are set. Components identical with those shown in Fig. 1 are designated by like reference characters. This arrangement differs from that of Fig. 1 in that 1 two threshold values are provided; 2 whether to embed only a data sequence, or whether to embed a data / control code sequence having a bit indicative of the type of data, is decided in dependence upon the magnitude of the dequantized value of a first element code; and 3 data is embedded based upon the above-mentioned determination.
- the voice/audio CODEC (encoder) 51 encodes input voice in accordance with, e.g., G.729, and outputs the encoded voice code (encoded data) obtained.
- the encoded voice code is composed of a plurality of element codes.
- the embed data generator 52 generates two types of data sequences to be embedded, in the encoded voice code.
- the first data sequence is one comprising only media data, for example, and the second data sequence is a data / control code sequence having the data-type bit illustrated in Fig. 7 .
- the media data and control code can be mixed in accordance with the "1", "0" logic of the data-type bit.
- the data embedding controller 53 which has the embedding decision unit 54 and the data embedding unit 55 constructed as a selector, embeds data in encoded voice code as appropriate.
- a first element code which is from among element codes constituting the encoded voice code, and threshold values TH1, TH2 (TH2>TH1)
- the embedding decision unit 54 determines whether data embedding conditions are satisfied. If these conditions are satisfied, the embedding decision unit 54 then determines whether the embedding conditions satisfied concern a data sequence comprising only media data or a data / control code sequence having the data-type bit.
- the embedding decision unit 54 determines that the data embedding conditions are satisfied if the dequantized value of the first element code satisfies the relation 1 TH2 ⁇ G, that embedding conditions concerning a data / control code sequence having the data-type bit are satisfied if the relation 2 TH1 ⁇ G ⁇ TH2 holds, and that embedding conditions concerning a data sequence comprising only media data are satisfied if the relation 3 G ⁇ TH1 holds.
- the data embedding unit 55 replaces a second element code with a data / control code sequence having the data-type bit, which is generated by the embed data generator 52, thereby embedding this data in the encoded voice code. If 2 G ⁇ TH1 holds, the data embedding unit 55 replaces the second element code with a media data sequence, which is generated by the embed data generator 52, thereby embedding this data in the encoded voice code. If 3 TH2 ⁇ G holds, the data embedding unit 55 outputs the second element code as is.
- the multiplexer 56 multiplexes and transmits the element codes that construct the encoded voice code.
- Fig. 24 is a block diagram of the embedding decision unit.
- the dequantizer 54a dequantizes the first element code and output a dequantized value G
- the threshold value generator 54b outputs the threshold values TH1, TH2.
- the comparator 54c compares the dequantized value G and the threshold values TH1, HH2 and inputs the result of the comparison to the data embedding decision unit 54d.
- the latter outputs the prescribed select signal SL in accordance with whether 1 TH2 ⁇ G holds, 2 TH1 ⁇ G ⁇ TH2 holds or 3 G ⁇ TH1 holds.
- the data embedding unit 55 selects and outputs either the second element code, the data / control code sequence having the data-type bit, or the media data sequence, based upon the select signal SL.
- the value conforming to the first element code is either fixed codebook gain or pitch gain
- the second element code is either a noise code or a pitch-lag code
- Fig. 25 is a diagram useful in describing embedding of data in a case where the value conforming to the dequantized value of the first element code is fixed codebook gain Gp and the second element code is noise code. If Gp ⁇ TH1 holds, any data such as media data is embedded in all 17 bits of the noise code portion. If TH1 ⁇ Gp ⁇ TH2 holds, the most significant bit is made "1", control code is embedded in 16 bits, the most significant bit is made "0" and optional data is embedded in the remaining 16 bits.
- Fig. 26 is a block diagram of structure on the side of an encoder in which multiple threshold values are set. Components identical with those shown in Fig. 12 are designated by like reference characters. This arrangement differs from that of Fig. 12 in that 1 two threshold values are provided; 2 the determination as to whether a data sequence or a data / control code sequence halving a bit indicative of the type of data has been embedded is determined in dependence upon the magnitude of the dequantized value of a first element code; and 3 data is assigned based upon the above-mentioned determination.
- the demultiplexer 61 Upon receiving encoded voice code, the demultiplexer 61 demultiplexes the encoded voice code into element codes and inputs these to the data extraction unit 62. The latter extracts a data sequence or data / control code sequence from a first element code from among the demultiplexed element codes, inputs this data to a data processor 63 and applies each of the entered element codes to a voice/audio CODEC (decoder) 64 as is.
- the decoder 64 decodes the entered encoded voice code, reproduces voice and outputs the same.
- the data extraction unit 62 which has an embedding decision unit 65 and an assignment unit 66, extracts a data sequence or a data / control code sequence from encoded voice code as appropriate. Using a value conforming to the first element code, which is a code from among element codes constituting the encoded voice code, and threshold values TH1, TH2 (TH2 > TH1) shown in Fig. 23 , the embedding decision unit 65 determines whether data embedding conditions are satisfied. If these conditions are satisfied, the embedding decision unit 65 then determines whether the embedding conditions satisfied concern a data sequence comprising only media data or a data / control code sequence having the data-type bit.
- the embedding decision unit 65 determines that the data embedding conditions are satisfied if the dequantized value of the first element code satisfies the relation 1 TH2 ⁇ G, that embedding conditions concerning a data / control code sequence having the data-type bit are satisfied if the relation 2 TH1 ⁇ G ⁇ TH2 holds, and that embedding conditions concerning a data sequence comprising only media data are satisfied if the relation 3 G ⁇ TH1 holds.
- the assignment unit 66 regards the second element code as the data / control code sequence having the data-type bit, inputs this to the data processor 63 and the inputs the second element code to the decoder 64. If 2 G ⁇ TH1 holds, the assignment unit 66 regards the second element code as a data sequence comprising media data, inputs this to the data processor 63 and the inputs the second element code to the decoder 64. If 3 TH2 ⁇ G holds, the assignment unit 66 regards this as indicating that data has not been embedded in the second element code and inputs the second element code to the decoder 64.
- Fig. 27 is a block diagram of the embedding decision unit 65.
- the dequantizer 65a dequantizes the first element code and outputs the dequantized value G
- the threshold value generator 65b outputs the first and second threshold values TH1, TH2.
- the comparator 65c compares the dequantized value G and the threshold values TH1, TH2 and inputs the result of the comparison to a data embedding decision unit 65d.
- the data embedding decision unit 65d outputs the prescribed assign signal BL in accordance with whether 1 TH2 ⁇ G, 2 TH1 ⁇ G ⁇ TH2 or 3 G ⁇ TH1 holds.
- the assignment unit 66 performs the above-mentioned assignment based upon the assign signal BL.
- the value conforming to the first element code is fixed codebook gain or pitch gain
- the second element code is noise code or pitch-lag code
- the present invention is not limited to such a voice communication system but is applicable to other systems as well.
- the present invention can be applied to a recording/playback system in which voice is encoded and recorded on a storage medium by a recording apparatus having an encoder, and voice is reproduced from the storage medium by a playback apparatus having a decoder.
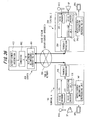
- Fig. 28 is a block diagram illustrating the configuration of a digital voice communication system that implements multimedia transmission for transmitting an image at the same time as voice by embedding the image.
- a terminal A 100 and a terminal B 100 are illustrated as being connected via a public network 300.
- the terminals A and B are identically constructed.
- the terminal A 100 includes a voice encoder 101 for encoding voice data, which has entered from a microphone MIC, in accordance with, e.g., G.729A, and inputting the encoded voice data to an embedding unit 103, and an image data generator 102 for generating image data to be transmitted and inputting the generated image data to the embedding unit 103.
- the image data generator 102 compresses and encodes an image such as a photo of surroundings or a portrait photo of the user per se taken by a digital camera (not shown), stores the encoded image data in memory, and then encodes this image data or map image data of the user's surroundings and inputs the encoded data to the embedding unit 103.
- the embedding unit 103 embeds the image data in the encoded voice code data, which enters from the voice encoder 101, in accordance with an embedding criterion identical with that of the above part of the embodiment, and outputs the resulting encoded voice code data.
- a transmit processor 104 transmits the encoded voice code data having the embedded image data to the other party's terminal B 200 via the public network 300.
- the other party's terminal B 200 has a transmit processor 204 for receiving the encoded voice code data from the public network 300 and inputting this data to an extraction unit 205.
- the latter corresponds to the data extraction unit 62 illustrated in the extracting/decoding part of the embodiment of Fig. 14 of Fig.
- the extraction unit 205 also inputs the encoded voice code data to a voice decoder 207.
- the image output unit 206 decodes the entered image data, generates an image and displays the image on a display unit.
- the voice decoder 207 decodes the entered encoded voice code data and outputs the decoded signal from a speaker SP.
- control for embedding image data in encoded voice code data, transmitting the resultant data from the terminal B to the terminal A and outputting the image at terminal A also is executed in a manner similar to that described above.
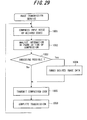
- Fig. 29 is a flowchart of transmit processing executed by a transmitting terminal in an image transmission service.
- Input voice is encoded and compressed in accordance with a desired encoding scheme, e.g., G.729A (steep 1001)
- the information in an encoded voice frame is analyzed (step 1002), it is determined based upon the result of analysis whether embedding is possible (step 1003) and, if embedding is possible, image data is embedded in the encoded voice code data (step 1004), the encoded voice code data in which the image data has been embedded is transmitted (step 1005), and the above operation is repeated until transmission is completed (step 1006).
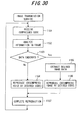
- Fig. 30 is a flowchart of receive processing executed by a receiving terminal in an image transmission service. If encoded voice code data is received (step 1101), the information in an encoded voice frame is analyzed (step 1102), it is determined based upon the result of analysis whether image data has been embedded (step 1103) and, if image data has not been embedded, then the encoded voice code data is decoded and reproduced voice is output from the speaker (step 1104). If image data has been embedded, on the other hand, the image data is extracted (step 1105) in parallel with the voice reproduction of step 1104, the image data is decoded to reproduce the image and the image is displayed on a display unit (step 1106). The above operation is then repeated until reproduction is completed (step 1107).
- additional data can be transmitted at the same time as voice using the ordinary voice transmission protocol as is. Further, since the additional information is embedded under the voice data, there is no auditory overlap, the additional information is not obtrusive and does not result in abnormal sounds. Multimedia communication becomes possible by adopting image information (video of present surroundings and map images, etc.) and personal information (a portrait photograph or voice print), etc., as the additional information.
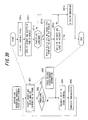
- Fig. 31 is a block diagram illustrating the configuration of a digital voice communication system that transmits authentication information at the same time as voice by embedding the authentication information. Components identical with those shown in Fig. 28 are designated by like reference characters. This system differs in that authentication data generators 111, 211 are provided instead of the image data generators 102, 202, and in that authentication units 112, 212 are provided instead of the image output units 106, 206.
- Fig. 31 illustrates a case where a voice print is embedded as the authentication information.
- the authentication data generator 111 creates voice print information using encoded voice code data or raw voice data prior to the embedding of data and then stores the created information.
- authentication units 112, 212 extract the voice print information, perform authentication by comparing this voice print information with the voice print of the user registered beforehand, and allow the decoding of voice if the individual is found to be authorized. It should be noted that authentication information is not limited to a voice print. Other examples of authentication information are a unique code (serial number) of the terminal, a unique code of the user per se or a unique code that is a combination of these codes.
- Fig. 32 is a flowchart of transmit processing executed by a transmitting terminal in an authentication information transmission service.
- Input voice is encoded and compressed in accordance with a desired encoding scheme, e.g., G.729A (step 2001)
- the information in an encoded voice frame is analyzed (step 2002), it is determined based upon the result of analysis whether embedding is possible (step 2003) and, if embedding is possible, personal authentication data is embedded in the encoded voice code data (step 2004), the encoded voice code data in which the authentication data has been embedded is transmitted (step 2005), and the above operation is repeated until transmission is completed (step 2006).
- a desired encoding scheme e.g., G.729A
- Fig. 33 is a flowchart of receive processing executed by a receiving terminal in an authentication information transmission service. If encoded voice code data is received (step 2101), the information in an encoded voice frame is analyzed (step 2102), it is determined based upon the result of analysis whether authentication information has been embedded (step 2103) and, if authentication information has not been embedded, then the encoded voice code data is decoded and reproduced voice is output from the speaker (step 2104). If authentication information has been embedded, on the other hand, the authentication information is extracted (step 2105) and authentication processing is executed (step 2106). For example, this authentication information is compared with that of an individual registered in advance and whether authentication is NG or OK is judged (step 2107).
- step 2108 If the decision is NG, i.e., if the individual is not an authorized individual, then decoying (reproduction and decompression) of the encoded voice code data is aborted (step 2108). If the decision is OK, i.e., if the individual is the authorized individual, then decoding of the encoded voice code data is allowed, voice is reproduced and reproduced voice is output from the speaker (step 2104). The above operation is repeated until transmission from the other party is completed (step 2109).
- additional data can be transmitted at the same time as voice using the ordinary voice transmission protocol as is. Further, since the additional information is embedded under the voice data, there is no auditory overlap, the additional information is not obtrusive and does not result in abnormal sounds. By embedding authentication information as the additional information, the performance of authentication as to whether or not an individual is an authorized user can be enhanced. Moreover, it is possible to improve the security of voice data.
- Fig. 34 is a block diagram illustrating the configuration of a digital voice communication system that transmits key information at the same time as voice by embedding the key information.
- Components in Fig. 34 identical with those shown in Fig. 28 are designated by like reference characters.
- This system differs in that key generators 121, 221 are provided instead of the image data generators 102, 202, and in that key collation units 122, 222 are provided instead of the image output units 106, 206.
- the key generator 121 is so adapted that previously set key information is stored in an internal memory beforehand.
- an embedding criterion identical with that of the embedding/encoding part of the embodiment of Fig. 3 or Fig.
- the embedding unit 103 embeds the key information, which enters from the key generator 121, in the encoded voice code data that enters from the voice encoder 101 and outputs the resultant encoded voice code data.
- the transmit processor 104 transmits the encoded voice code data having the embedded key information to the other party's terminal B 200 via the public network 300.
- the transmit processor 204 of the other party's terminal B 200 receives the encoded voice code data from the public network 300 and inputs this data to the extraction unit 205.
- the extraction unit 205 extracts the key information and inputs this information to the collation unit 222.
- the extraction unit 205 also inputs the encoded voice code data to the voice decoder 207.
- the collation unit 222 performs authentication by comparing the entered information with key information registered in advance, allows decoding of voice if the two items of information match and prohibits the decoding of voice if the two items of information do not match. If the arrangement described above is adopted, it is possible to reproduce voice data solely from a specific user.
- Fig. 35 is a block diagram illustrating the configuration of a digital voice communication system that transmits IP telephone address information at the same time as voice by embedding the relation address information.
- Components in Fig. 35 identical with those shown in Fig. 28 are designated by like reference characters.
- This system differs in that IP telephone address input units 131, 231 are provided instead of the image data generators 102, 202, relation storage units 132, 232 are provided instead of the image output units 106, 206, and display/key units DPK are provided.
- a previously set relation address has been stored in an internal memory or the relation address input unit 131 in advance.
- This relation address may be an alternative IP telephone address or e-mail address of terminal A or an TP telephone number or an e-mail address of a facility other than terminal A or of another site.
- the embedding unit 103 embeds the relation address, which enters from the relation address input unit 131, in the encoded voice code data that enters from the voice encoder 101 and outputs the resultant encoded voice code data.
- the transmit processor 104 transmits the encoded voice code data having the embedded relation address to the other party's terminal B 200 via the public network 300.
- the transmit processor 204 of the other party's terminal B 200 receives the encoded voice code data from the public network 300 and inputs this data to the extraction unit 205.
- the extraction unit 205 extracts the relation address and inputs this information to the relation address storage unit 232.
- the extraction unit 205 also inputs the encoded voice code data to the voice decoder 207.
- the relation address storage unit 232 stores the entered IP telephone address.
- the display-key unit DPK displays the relation address that has been stored in the relation address storage unit 232. As a result, this relation address can be selected to telephone the address or transfer a mail to the address by a single click.
- Fig. 36 is a block diagram illustrating the configuration of a digital voice communication system that implements a service for embedding advertisement information.
- a server gateway
- the server embeds advertisement information in encoded voice code data, whereby advertisement information is provided directly to an end users in mutual communication.
- Components in Fig. 36 identical with those sown in Fig. 28 are designated by like reference characters. This system differs from that of Fig.
- the server 400 includes a bit-stream decomposing/generating unit 401 for extracting a transmit packet from a bit stream that enters from the terminal 100 on the transmitting side, specifying the sender and recipient from the IF header of this packet, specifying the media type and encoding scheme from the RTP header, determining whether advertisement-information insertion conditions are satisfied based upon these items of information and inputs encoded voice code data of the transmit packet to an embedding unit 402.
- an embedding criterion identical with that of the embedding/encoding part of the embodiment of Fig. 3 or Fig.
- the embedding unit 402 determines whether embedding is possible or not and, if embedding is possible, embeds advertisement information, which has been provided separately by an advertiser (information provider) and stored in a memory 403, in the encoded voice code data and inputs the resultant encoded voice code data to the bit-stream decomposing/generating unit 401.
- the latter generates a transmit packet using the encoded voice code data and transmits the encoded voice code data to the terminal B 200 on the receiving side.
- the transmit processor 204 of the other party's terminal B 200 receives the encoded voice code data from the public network 300 and inputs this data to the extraction unit 205.
- the extraction unit 205 extracts the advertisement information and inputs this information to an advertisement information reproducing unit 242.
- the extraction unit 205 also inputs the encoded voice code data to the voice decoder 207.
- the advertisement information reproducing unit 242 reproduces the entered advertisement information and displays it on the display unit of the display/key unit DPK.
- the voice decoder 207 reproduces voice and outputs reproduced voice from the speaker SP.
- Fig. 37 shows an example of the structure of an IP packet in an Internet telephone service.
- a header is composed of an IP header, a UDP (User Datagram Protocol) header and an RTP (Real-time Transport Protocol) header.
- the IP header includes an originating source address and a transmission destination address (neither of which are shown).
- Media type and CODEC type are stipulated by payload type PT of the RTP header. Accordingly, the bit-stream decomposing/generating unit 401 refers to the header of the transmit packet, thereby making it possible to identify the sender, recipient, media type and encoding scheme.
- Fig. 38 is a flowchart of processing, which is for inserting advertising information, executed by the server 400.
- the server 400 analyzes the header of a transmit packet and the encoded voice data (step 3001). More specifically, the server 400 extracts a transmit packet from the bit stream (step 3001a), extracts the transmit address and receive address from the IP header (step 3001b), determines whether the sender and recipient have concluded an advertising agreement (step 3001c) and, if such an agreement has been concluded, refers to the RTP header to identify the media type and CODE type (step 3001d).
- the server determines whether embedding is allowed (step 3001f) and judges that embedding is allowed or not allowed (steps 3001g, 3001h) in accordance with the result of the determination.
- the server judges that embedding is not allowed (step 3001h) if it is found at step 3001c that an advertising agreement has not been concluded, or if it is found at step 3001e that the media is not voice, or if it is found at step 3001e that the CODEC type is not allowed.
- the server 400 If the server 400 subsequently determines that embedding is possible ("YES" at step 3002), the server embeds the advertisement information provided by the advertiser (the information provider) in the encoded voice code data (step 3003). If the server 400 determines that embedding is not possible (“NO" at step 3002), then the server transmits the advertisement information to the terminal on the receiving side (step 3004) without embedding it in the encoded voice code data. The server then repeats the above operation until transmission is completed (step 3005).
- Fig. 39 is a flowchart of processing for receiving advertisement information executed by a receiving terminal in a service for embedding advertisement information. If encoded voice code data is received (step 3101), the terminal analyzes the information in the encoded voice frame (step 3102), determines whether advertisement information has been embedded based upon the result of analysis (step 3101) and, if advertisement information has not been embedded, decodes the encoded voice code data and outputs reproduced voice from the speaker (step 3104). If advertisement information has been embedded, on the other hand, then the terminal extracts the advertisement information (step 3105) in parallel with the reproduction of voice at step 3104 and displays this advertisement information on the display/key unit DPK (step 3106). The terminal then repeats the above operation until reproduction is completed (step 3107).
- advertisement information is embedded.
- the information is not limited to advertisement information; any information can be embedded. Further, it can be so arranged that by inserting an IP telephone address together with advertisement information, the destination of this IP telephone address can be telephoned to input detailed advertisement information and other detailed information by a single click.
- a server apparatus for relaying voice data is provided and the server is capable of providing optional information, such as advertisement information, to end users performing mutual communication of voice data.
- Fig. 40 is a block diagram illustrating the configuration of an information storage system that is linked to a digital voice communication system.
- the terminal A 100 and a center 500 are illustrated as being connected via the public network 300.
- the center 500 is a business call center, which is a facility that accepts and responds to complaints, repair requests and other user demands.
- the terminal A 100 includes the voice encoder 101 for encoding voice, which has entered from the microphone MIC, and sending encoded voice to the network 300 via the transmit processor 104, and a voice decoder 107 for decoding encoded voice code data that enters from the network 300 via the transmit processor 104 and outputting reproduced voice from the speaker SP.
- the center 500 has a voice communication terminal B the structure of which is identical with that of the terminal A.
- the terminal B includes a voice encoder 501 for encoding voice, which has entered from the microphone MIC, and sending the encoded voice data to the network 300 via a transmit processor 504, and a voice decoder 507 for decoding encoded voice code data, which enters from the network 300 via the transmit processor 504, and outputting reproduced voice from the speaker SP.
- the above arrangement is such that when terminal A (the user) places a telephone call to the center, an operator responds to the user.
- the side of the center 500 that is for storing digital voice includes an additional-information embedding unit 510 for embedding additional information in encoded voice code data that has been sent from the terminal A and storing the resultant data in a voice data storage unit 520, and an additional-data extraction unit 530 for extracting embedded information from prescribed encoded voice code data that has been read out of the voice data storage unit 520, displaying the extracted information on the display unit of a control panel 540 and inputting the encoded voice code data to a voice decoder 550.
- the latter decodes the entered encoded voice code data and outputs reproduced voice from a speaker 560.
- the additional-information embedding unit 510 includes an additional-data generating unit 511 for encoding, and inputting to an embedding unit 512 as additional information, the sender name, recipient name, receive time and call category (classified by complaint, consultation and repair request, etc.) that enter from the control panel 540.
- the embedding unit 512 determines whether it is possible to embed the additional information in encoded voice code data sent from the terminal A 100 via the transmit processor 504.
- the embedding unit 512 embeds the code information, which enters from the additional-data generating unit 511, in the encoded voice code data and stores the resultant encoded voice code data as a voice file in the voice data storage unit 520.
- the additional-data extraction unit 530 includes an extraction unit 531.
- the extraction unit 531 determines whether encoded voice code data has been embedded. If encoded voice code data has been embedded, then the extraction unit 531 extracts the embedded code and inputs this code to an additional-data utilization unit 532.
- the extraction unit 531 also inputs the encoded voice code data to the voice decoder 550.
- the additional-data utilization unit 532 decodes the extracted code and displays the sender name, recipient name, receive time and call category, etc., on the display unit of the control panel 540. Further, the voice decoder 550 reproduces voice and outputs this voice from the speaker.
- encoded voice code data when encoded voice code data is read out of the voice data storage unit 520, desired encoded voice code data can be retrieved and output using the embedded information.
- a search keyword e.g., the sender name
- the extraction unit 531 retrieves the voice file in which the specified sender name has been embedded, outputs the embedded information, inputs the encoded voice code data to the voice decoder 550 and outputs decoded voice from the speaker.
- sender, recipient, receive time and call category, etc. are embedded in encoded voice code data and the encoded voice code data is then stored in storage means.
- the stored encoded voice code data is read out and reproduced as necessary and the embedded information can be extracted and displayed. Further, it is possible to put voice data into file form using embedded data.
- embedded data can be used as a search keyword to rapidly retrieve, reproduce and output a desired voice file.
- data can be embedded in encoded voice code on the side of an encoder side and extracted correctly on the side of a decoder without both the encoder and decoder sides possessing a key.
- a threshold value can be changed using this control code and the amount of embedded data transmitted can be adjusted without transmitting additional information on another path.
- whether to embed only a data sequence, or whether to embed a data / control code sequence in a format that makes it possible to identify the type of data and control code is decided in dependence upon a gain value. In a case where only a data sequence is embedded, therefore, it is unnecessary to include data-type information. This makes possible improvements relating to transmission capacity.
- control specifications are stipulated by parameters common to CELP. This means that the invention is not limited to a specific scheme and can be applied to a wide range of schemes. For example, G.729 suited to VoIP and AMR suited to mobile communications can be supported.
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
- Editing Of Facsimile Originals (AREA)
- Image Processing (AREA)
Claims (3)
- Dateneinbettungs- und -extraktionsverfahren für ein System, das eine Sprachcodiervorrichtung zum Codieren von Sprache gemäß einem vorgeschriebenen Sprachcodierschema und zum Einbetten von optionalen Daten in einen so erhaltenen codierten Sprachcode hat, sowie eine Sprachwiedergabevorrichtung zum Extrahieren von eingebetteten Daten aus dem codierten Sprachcode und zum Wiedergeben der Sprache von diesem codierten Sprachcode, mit den Schritten:Definieren, im Voraus, eines ersten Elementcodes von Elementcodes, die den codierten Sprachcode bilden, und eines Schwellenwertes, der verwendet wird, um zu bestimmen, ob Dateneinbettungsbedingungen erfüllt sind oder nicht, und eines zweiten Elementcodes, in den Daten auf der Basis des Resultates der Bestimmung eingebettet werden;in der Sprachcodiervorrichtung: Bestimmen, ob Datencinbettungsbedingungen erfüllt sind, unter Verwendung des ersten Elementcodes und des Schwellenwertes; und Einbetten von optionalen Daten in den codierten Sprachcode durch Ersetzen des zweiten Elementcodes durch die optionalen Daten, falls die Dateneinbettungsbedingung erfüllt ist; undin der Sprachwiedergabevorrichtung: Bestimmen, ob die Dateneinbettungsbedingung erfüllt ist, unter Verwendung des ersten Elementcodes und des Schwellenwertes; Bestimmen, dass optionale Daten in den zweiten Elementcode des codierten Sprachcodes eingebettet worden sind, falls die Datcneinbettungsbedingung erfüllt ist; und Extrahieren der eingebetteten Daten.
- Dateneinbettungs- und -extraktionsverfahren nach Anspruch 1, bei dem ein Abschnitt der eingebetteten Daten als Datentyp-Identifikationsdaten verwendet wird und der Typ der eingebetteten Daten durch diese Datentyp-Identifikationsdatcn spezifiziert wird.
- Sprachcodier-/-decodiersystem zum Codieren von Sprache gemäß einem vorgeschriebenen Sprachcodierschema und zum Einbetten von optionalen Daten in einen so erhaltenen codierten Sprachcode, sowie zum Extrahieren von eingebetteten Daten aus dem codierten Sprachcodc und zum Wiedergeben von Sprache von diesem codierten Sprachcode, mit:einer Sprachcodiervorrichtung zum Einbetten von optionalen Daten in einen codierten Sprachcode, der durch Codieren von Sprache gemäß einem vorgeschriebenen Sprachcodierschema erhalten wird; undeiner Sprachdecodiervorrichtung zum Wiedergeben von Sprache durch Anwenden einer Decodierverarbeitung auf den codierten Sprachcode, der durch das vorgeschriebene Sprachcodierschema codiert worden ist, und zum Extrahieren von Daten, die in diesen codierten Sprachcode eingebettet worden sind;welche Sprachcodiervorrichtung enthält:einen Codierer (51) zum Codieren von Sprache gemäß dem vorgeschriebenen Sprachcodierschema;eine Einbettungsentscheidungseinheit (54) zum Bestimmen, ob eine Dateneinbettungsbedingung erfüllt ist, unter Verwendung eines ersten Elementcodes von Elementcodes, die den codierten Sprachcode bilden, und eines Schwellenwertes; undeine Dateneinbettungseinheit (55) zum Einbetten von optionalen Daten in den codierten Sprachcode durch Ersetzen eines zweiten Elementcodes durch die optionalen Daten, falls die Dateneinbettungsbedingung erfüllt ist; undwelche Sprachdecodiervorrichtung enthält:einen Demultiplexer (61) zum Demultiplexen des codierten Sprachcodes in Elementcodes;eine Einbettungsentscheidungseinheit (65) zum Bestimmen, ob die Dateneinbettungsbedingung erfüllt ist, unter Verwendung eines ersten Elementcodes von Elementcodes, die den empfangenen codierten Sprachcode bilden, und eines Schwellenwertes;eine Extraktionseinheit eingebetteter Daten (62) zum Bestimmen, dass optionale Daten in einen zweiten Elementcode des codierten Sprachcodes eingebettet worden sind, falls die Dateneinbettungsbedingung erfüllt ist, und zum Extrahieren der eingebetteten Daten; undeinen Decodierer (64) zum Decodieren des empfangenen codierten Sprachcodes und Wiedergeben von Sprache;bei dem der erste Elementcode und der Schwellenwert, die verwendet werden, um zu bestimmen, ob Daten eingebettet worden sind oder nicht, und der zweite Elementcode, in den Daten auf der Basis des Resultats der Bestimmung eingebettet werden, im Voraus in der Sprachcodiervorrichtung und der Sprachdecodiervorrichtung definiert werden.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP06007029A EP1693832B1 (de) | 2002-02-04 | 2003-02-03 | Verfahren und Vorrichtung zur Dateneinbettung in einen kodierten Sprachkode |
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2002026958 | 2002-02-04 | ||
| JP2002026958 | 2002-02-04 | ||
| JP2003015538A JP4330346B2 (ja) | 2002-02-04 | 2003-01-24 | 音声符号に対するデータ埋め込み/抽出方法および装置並びにシステム |
| JP2003015538 | 2003-01-24 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP06007029A Division EP1693832B1 (de) | 2002-02-04 | 2003-02-03 | Verfahren und Vorrichtung zur Dateneinbettung in einen kodierten Sprachkode |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| EP1333424A2 EP1333424A2 (de) | 2003-08-06 |
| EP1333424A3 EP1333424A3 (de) | 2005-07-13 |
| EP1333424B1 true EP1333424B1 (de) | 2009-12-09 |
Family
ID=26625679
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP03250682A Expired - Lifetime EP1333424B1 (de) | 2002-02-04 | 2003-02-03 | Einbettung von Daten in kodierte Sprache und Extrahierung von Daten aus kodierter Sprache |
| EP06007029A Expired - Lifetime EP1693832B1 (de) | 2002-02-04 | 2003-02-03 | Verfahren und Vorrichtung zur Dateneinbettung in einen kodierten Sprachkode |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP06007029A Expired - Lifetime EP1693832B1 (de) | 2002-02-04 | 2003-02-03 | Verfahren und Vorrichtung zur Dateneinbettung in einen kodierten Sprachkode |
Country Status (4)
| Country | Link |
|---|---|
| EP (2) | EP1333424B1 (de) |
| JP (1) | JP4330346B2 (de) |
| CN (1) | CN100514394C (de) |
| DE (2) | DE60330716D1 (de) |
Families Citing this family (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2004069963A (ja) * | 2002-08-06 | 2004-03-04 | Fujitsu Ltd | 音声符号変換装置及び音声符号化装置 |
| KR100732659B1 (ko) | 2003-05-01 | 2007-06-27 | 노키아 코포레이션 | 가변 비트 레이트 광대역 스피치 음성 코딩시의 이득양자화를 위한 방법 및 장치 |
| JP4789430B2 (ja) * | 2004-06-25 | 2011-10-12 | パナソニック株式会社 | 音声符号化装置、音声復号化装置、およびこれらの方法 |
| KR100565682B1 (ko) * | 2004-07-12 | 2006-03-29 | 엘지전자 주식회사 | 이동통신 단말기를 이용한 통화중 디지털 데이터 전송방법및 전송장치 |
| JP4780375B2 (ja) * | 2005-05-19 | 2011-09-28 | 大日本印刷株式会社 | 音響信号への制御コード埋込装置、および音響信号を用いた時系列駆動装置の制御システム |
| JP4896455B2 (ja) * | 2005-07-11 | 2012-03-14 | 株式会社エヌ・ティ・ティ・ドコモ | データ埋込装置、データ埋込方法、データ抽出装置、及び、データ抽出方法 |
| US8055903B2 (en) * | 2007-02-15 | 2011-11-08 | Avaya Inc. | Signal watermarking in the presence of encryption |
| US8054969B2 (en) * | 2007-02-15 | 2011-11-08 | Avaya Inc. | Transmission of a digital message interspersed throughout a compressed information signal |
| EP2133871A1 (de) * | 2007-03-20 | 2009-12-16 | Fujitsu Limited | Dateneinbettungseinrichtung, datenextrahiereinrichtung und audiokommunikationssystem |
| JP2011504313A (ja) * | 2007-10-26 | 2011-02-03 | シェラキ、ジャン | 既存のデジタル音声転送プロトコルを用いてマルチメディアコンテンツを転送する方法およびシステム |
| JP5697395B2 (ja) * | 2010-10-05 | 2015-04-08 | ヤマハ株式会社 | 歌唱音声評価装置およびプログラム |
| US9767822B2 (en) | 2011-02-07 | 2017-09-19 | Qualcomm Incorporated | Devices for encoding and decoding a watermarked signal |
| US9767823B2 (en) | 2011-02-07 | 2017-09-19 | Qualcomm Incorporated | Devices for encoding and detecting a watermarked signal |
| US8880404B2 (en) * | 2011-02-07 | 2014-11-04 | Qualcomm Incorporated | Devices for adaptively encoding and decoding a watermarked signal |
| CN110970038B (zh) * | 2019-11-27 | 2023-04-18 | 云知声智能科技股份有限公司 | 语音解码方法及装置 |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP1020848A2 (de) * | 1999-01-11 | 2000-07-19 | Lucent Technologies Inc. | Verfahren zur Übertragung von zusätzlichen informationen in einem Vokoder-Datenstrom |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| FI103700B1 (fi) * | 1994-09-20 | 1999-08-13 | Nokia Mobile Phones Ltd | Samanaikainen puheen ja datan siirto matkaviestinjärjestelmässä |
| TW312770B (en) * | 1996-10-15 | 1997-08-11 | Japen Ibm Kk | The hiding and taking out method of data |
| US6363339B1 (en) * | 1997-10-10 | 2002-03-26 | Nortel Networks Limited | Dynamic vocoder selection for storing and forwarding voice signals |
| JP3022462B2 (ja) * | 1998-01-13 | 2000-03-21 | 興和株式会社 | 振動波の符号化方法及び復号化方法 |
| JP3321767B2 (ja) * | 1998-04-08 | 2002-09-09 | 株式会社エム研 | 音声データに透かし情報を埋め込む装置とその方法及び音声データから透かし情報を検出する装置とその方法及びその記録媒体 |
| ID25532A (id) * | 1998-10-29 | 2000-10-12 | Koninkline Philips Electronics | Penanaman data tambahan dalam sinyal informasi |
| WO2001067671A2 (en) * | 2000-03-06 | 2001-09-13 | Meyer Thomas W | Data embedding in digital telephone signals |
-
2003
- 2003-01-24 JP JP2003015538A patent/JP4330346B2/ja not_active Expired - Fee Related
- 2003-01-30 CN CNB031023223A patent/CN100514394C/zh not_active Expired - Fee Related
- 2003-02-03 DE DE60330716T patent/DE60330716D1/de not_active Expired - Lifetime
- 2003-02-03 DE DE60330413T patent/DE60330413D1/de not_active Expired - Lifetime
- 2003-02-03 EP EP03250682A patent/EP1333424B1/de not_active Expired - Lifetime
- 2003-02-03 EP EP06007029A patent/EP1693832B1/de not_active Expired - Lifetime
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP1020848A2 (de) * | 1999-01-11 | 2000-07-19 | Lucent Technologies Inc. | Verfahren zur Übertragung von zusätzlichen informationen in einem Vokoder-Datenstrom |
Also Published As
| Publication number | Publication date |
|---|---|
| EP1693832B1 (de) | 2009-12-23 |
| EP1333424A3 (de) | 2005-07-13 |
| EP1693832A3 (de) | 2007-06-20 |
| CN1437169A (zh) | 2003-08-20 |
| DE60330716D1 (de) | 2010-02-04 |
| EP1333424A2 (de) | 2003-08-06 |
| JP2003295879A (ja) | 2003-10-15 |
| CN100514394C (zh) | 2009-07-15 |
| EP1693832A2 (de) | 2006-08-23 |
| DE60330413D1 (de) | 2010-01-21 |
| JP4330346B2 (ja) | 2009-09-16 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US7310596B2 (en) | Method and system for embedding and extracting data from encoded voice code | |
| EP1333424B1 (de) | Einbettung von Daten in kodierte Sprache und Extrahierung von Daten aus kodierter Sprache | |
| JP4518714B2 (ja) | 音声符号変換方法 | |
| EP2360682B1 (de) | Verbergen von Audiopaketverlust durch Transformationsinterpolation | |
| JP4263412B2 (ja) | 音声符号変換方法 | |
| Hwang | Multimedia networking: From theory to practice | |
| CN1957399B (zh) | 语音/音频解码装置以及语音/音频解码方法 | |
| Kheddar et al. | High capacity speech steganography for the G723. 1 coder based on quantised line spectral pairs interpolation and CNN auto-encoding | |
| US20040068404A1 (en) | Speech transcoder and speech encoder | |
| CN101320564B (zh) | 数字语音通信系统 | |
| EP1665234B1 (de) | Informationsfluss-übertragungsverfahren, wobei der fluss in einen sprach-datenfluss eingefügt wird, und zu seiner implementierung verwendeter parametrischer codec | |
| EP1617411B1 (de) | Codeumsetzungsverfahren und einrichtung | |
| Ding | Wideband audio over narrowband low-resolution media | |
| JP4236675B2 (ja) | 音声符号変換方法および装置 | |
| US7949016B2 (en) | Interactive communication system, communication equipment and communication control method | |
| Licai et al. | Information hinding based on GSM full rate speech coding | |
| Janicki | Novel method of hiding information in IP telephony using pitch approximation | |
| JP2006293405A (ja) | 音声符号変換方法及び装置 | |
| EP1542422B1 (de) | Zweiwegekommunikationssystem, kommunikationsinstrument und kommunikationssteuerverfahren | |
| JP4330303B2 (ja) | 音声符号変換方法及び装置 | |
| JP4900402B2 (ja) | 音声符号変換方法及び装置 | |
| Lin | A Synchronization Scheme for Hiding Information in Encoded Bitstream of Inactive Speech Signal. | |
| JP4985743B2 (ja) | 音声符号変換方法 | |
| Montminy | A study of speech compression algorithms for Voice over IP. | |
| Lin | Imperceptible data hiding in the encoded bits of ACELP codebook |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| AK | Designated contracting states |
Designated state(s): AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HU IE IT LI LU MC NL PT SE SI SK TR |
|
| AX | Request for extension of the european patent |
Extension state: AL LT LV MK RO |
|
| RIC1 | Information provided on ipc code assigned before grant |
Ipc: 7H 04M 3/50 B Ipc: 7G 10L 19/00 A Ipc: 7H 04Q 7/22 B |
|
| PUAL | Search report despatched |
Free format text: ORIGINAL CODE: 0009013 |
|
| AK | Designated contracting states |
Kind code of ref document: A3 Designated state(s): AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HU IE IT LI LU MC NL PT SE SI SK TR |
|
| AX | Request for extension of the european patent |
Extension state: AL LT LV MK RO |
|
| 17P | Request for examination filed |
Effective date: 20050919 |
|
| AKX | Designation fees paid |
Designated state(s): DE FR GB |
|
| 17Q | First examination report despatched |
Effective date: 20051024 |
|
| GRAP | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOSNIGR1 |
|
| RTI1 | Title (correction) |
Free format text: EMBEDDING DATA IN ENCODED VOICE AND EXTRACTING DATA FROM ENCODED VOICE |
|
| RIC1 | Information provided on ipc code assigned before grant |
Ipc: G10L 19/00 20060101AFI20090618BHEP |
|
| GRAS | Grant fee paid |
Free format text: ORIGINAL CODE: EPIDOSNIGR3 |
|
| GRAA | (expected) grant |
Free format text: ORIGINAL CODE: 0009210 |
|
| AK | Designated contracting states |
Kind code of ref document: B1 Designated state(s): DE FR GB |
|
| REG | Reference to a national code |
Ref country code: GB Ref legal event code: FG4D |
|
| REF | Corresponds to: |
Ref document number: 60330413 Country of ref document: DE Date of ref document: 20100121 Kind code of ref document: P |
|
| PLBE | No opposition filed within time limit |
Free format text: ORIGINAL CODE: 0009261 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: NO OPPOSITION FILED WITHIN TIME LIMIT |
|
| 26N | No opposition filed |
Effective date: 20100910 |
|
| REG | Reference to a national code |
Ref country code: FR Ref legal event code: PLFP Year of fee payment: 14 |
|
| REG | Reference to a national code |
Ref country code: FR Ref legal event code: PLFP Year of fee payment: 15 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: DE Payment date: 20170131 Year of fee payment: 15 Ref country code: FR Payment date: 20170112 Year of fee payment: 15 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: GB Payment date: 20170201 Year of fee payment: 15 |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R119 Ref document number: 60330413 Country of ref document: DE |
|
| GBPC | Gb: european patent ceased through non-payment of renewal fee |
Effective date: 20180203 |
|
| REG | Reference to a national code |
Ref country code: FR Ref legal event code: ST Effective date: 20181031 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: DE Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20180901 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: FR Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20180228 Ref country code: GB Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20180203 |