EP1005016A2 - Method and circuit arrangement for measuring speech level in a speech processing system - Google Patents
Method and circuit arrangement for measuring speech level in a speech processing system Download PDFInfo
- Publication number
- EP1005016A2 EP1005016A2 EP99440312A EP99440312A EP1005016A2 EP 1005016 A2 EP1005016 A2 EP 1005016A2 EP 99440312 A EP99440312 A EP 99440312A EP 99440312 A EP99440312 A EP 99440312A EP 1005016 A2 EP1005016 A2 EP 1005016A2
- Authority
- EP
- European Patent Office
- Prior art keywords
- speech
- detector
- speech signal
- signal
- pause
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
- 238000000034 method Methods 0.000 title claims abstract description 16
- 238000012545 processing Methods 0.000 title claims abstract description 11
- 230000006870 function Effects 0.000 claims abstract description 13
- 238000005259 measurement Methods 0.000 claims abstract description 8
- 238000012935 Averaging Methods 0.000 claims description 10
- 238000012546 transfer Methods 0.000 claims description 4
- 230000007774 longterm Effects 0.000 claims description 3
- 230000005284 excitation Effects 0.000 claims description 2
- 230000000873 masking effect Effects 0.000 claims description 2
- 230000005540 biological transmission Effects 0.000 abstract 1
- MEFKEPWMEQBLKI-AIRLBKTGSA-N S-adenosyl-L-methioninate Chemical compound O[C@@H]1[C@H](O)[C@@H](C[S+](CC[C@H](N)C([O-])=O)C)O[C@H]1N1C2=NC=NC(N)=C2N=C1 MEFKEPWMEQBLKI-AIRLBKTGSA-N 0.000 description 12
- 238000005070 sampling Methods 0.000 description 7
- 230000006399 behavior Effects 0.000 description 5
- 206010011224 Cough Diseases 0.000 description 2
- 230000006978 adaptation Effects 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 238000010586 diagram Methods 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 230000008569 process Effects 0.000 description 2
- 230000009471 action Effects 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 238000013500 data storage Methods 0.000 description 1
- 230000004069 differentiation Effects 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 238000012905 input function Methods 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 230000008447 perception Effects 0.000 description 1
- 230000029058 respiratory gaseous exchange Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 230000000630 rising effect Effects 0.000 description 1
- 238000001228 spectrum Methods 0.000 description 1
- 230000002123 temporal effect Effects 0.000 description 1
Images



Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/48—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/78—Detection of presence or absence of voice signals
- G10L2025/783—Detection of presence or absence of voice signals based on threshold decision
Definitions
- the current speech level for example for scaling signals, for threshold value decisions, for speech pause detection and / or for automatic Gain setting used.
- The has particular importance Speech level measurement for successful echo cancellation in Telecommunications systems, for noise cancellation in noisy environment, for example in military vehicles, or in the Speech recognition and in speech coding and Speech decoding devices.
- the mean value SL takes on one of the number N of Samples determine the value of the quiet noise for a certain time.
- an averager needs one of the number N certain time to determine the speech level.
- the averaging in one Time interval of 125 ms requires a data storage of 1000 data words at a sampling rate of 8 kHz. Except for the there is considerable computing and storage effort for the simple one Averaging the risk that with a short averaging time Interference influences Errors occur when determining the speech level.
- join Speech level changes Incorrect measurements of the speech level.
- the method is linear Prediction (linear predictive coding, LPC) known with the principle distinguishing features of speech and noise can also be determined are.
- LPC linear predictive coding
- the LPC analysis is very accurate and can be done very quickly and is a powerful process with which, among other things, the Fundamental frequency, the spectrum and the formats of a speech signal can be determined, cf. Eppinger, Herter: language processing, Kunststoff, Vienna: Hanser 1983, pages 73-77. Such an elaborate However, the process is for commercial reasons for mass products, such as Telecommunication terminals, not suitable.
- the essence of the invention is that a measured Speech level value only then for further processing in one Voice signal processing system is allowed when characteristic Characteristics of speech recognized and interference signals and speech pauses at the Measurement were hidden.
- the circuit arrangement consists essentially of a Speech pause detector 1, a speech detector 2, an averager 3, a memory 4 and a circuit 5 for forming a Absolute value.
- the sampling function x (k) is at the circuit input Speech signal, at the circuit output the value of a speech level SL spent. If a speech pause, output signal P of Speech pause detector 1, and no speech, output signal F des Speech detector 2, recognized, there are a first according to FIG. 1 Switch S1, a second switch S2 and a third switch S3 in the drawn position. There is a voice signal in the form of the sampling function x (k) before, i.e.
- a speech pause P is not recognized, the Voice detector 2 activated via the closed first switch S1 and the averaging over the circuit 5 and the closed second Switch S2 initiated with the averager 3.
- the output signal F of the speech detector 2 detects the third switch S3 closed and the output signal SAM (x) of Averager 3 is transferred to memory 4 via third switch S3 accepted.
- the last one measured during the pauses in speech Speech level SL from the memory 4 via the second switch S2 Transfer mean value generator 3.
- the short-term average SAM (x) (short Average Magnitude) so that the time behavior of the Short - term mean SAM (x) of the subjective perception function of the human ear is largely adapted.
- a dynamic leap from soft to loud tones is done with a small time constant ⁇ s, for example less than 6.5 ms.
- a dynamic leap from loud to soft tones is according to the after masking effect of the human ear with a large time constant ⁇ l, for example 65 ms to 300 ms. Briefly spoken vowels are added to this Way well grasped. Nasal sounds or consonants compared to Lower level vowels are measured by the large time constant ⁇ l largely suppressed with falling levels.
- the signal curve becomes a fast adaptation of the short-term mean value SAM (x) reached the current peak value of the short-term level of the speech signal. This peak value of the short-term level of the speech signal thus determines the relative speech level regardless of the speech content.
- FIG. 2 shows the time behavior of the samples for three functions.
- the Input function x (k) of the speech level measuring circuit according to FIG. 1 is as Functional curve 6 of a speech sample is shown.
- the course of functions 7 shows the course of the short-term mean SAM (x (k)), short SAM (x), below Taking into account the mode of action of the different time constants ⁇ s, ⁇ l as previously described.
- a third is for comparison Functional curve 8 shown, the effect of a simple low pass reproduces. It follows that a low pass for a quick and precise Determining the current language level is unsuitable.
- the mean value generator 3 shows details of the mean value generator 3, which contains a recursive filter, a IIR filter 9 (Infinite Impulse Response Filter) known per se, and a circuit arrangement 10 for switching over the time constants ⁇ s, ⁇ l.
- the circuit 5 for forming the absolute value corresponds to the circuit shown in FIG. 1.
- the time constants ⁇ s, ⁇ l must be switched according to the following equation G2:
- a method is used with which the temporal behavior of the sampling function x (k) of the speech signal is evaluated.
- the short-term mean value SAM (x) of the sampling function x (k) is compared with a long-term minimum value determined in a time interval from a number of short-term mean values SAM (x).
- time constants ⁇ s, ⁇ l of the averager 3 vary by one adapted to the respective application Obtain speech level SL.
- the one described in the embodiment Formation of a short-term mean value SAM (x) advantageously becomes strong noisy environment, used for example in a tank. If the speakers are indistinct, it is cheaper to use an average (medium Average Magnitude) MAM (x) by the small time constant ⁇ s enlarged and the large time constant ⁇ l of the averager 3 is reduced.
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Cable Transmission Systems, Equalization Of Radio And Reduction Of Echo (AREA)
- Noise Elimination (AREA)
- Telephone Function (AREA)
Abstract
Description
In Sprachsignalverarbeitungssystemen wird der aktuelle Sprachpegel beispielsweise zur Skalierung von Signalen, zur Schwellwertentscheidung, zur Sprachpausendetektion und/oder zur automatischen Verstärkungseinstellung verwendet. Besondere Bedeutung hat die Sprachpegelmessung für eine erfolgreiche Echokompensation in Telekommunikationssystemen, für eine Geräuschunterdrückung in lärmerfüllter Umgebung, beispielsweise in Militärfahrzeugen, oder bei der Spracherkennung und in Sprachkodierungs- und Sprachdekodierungseinrichtungen.In speech signal processing systems, the current speech level for example for scaling signals, for threshold value decisions, for speech pause detection and / or for automatic Gain setting used. The has particular importance Speech level measurement for successful echo cancellation in Telecommunications systems, for noise cancellation in noisy environment, for example in military vehicles, or in the Speech recognition and in speech coding and Speech decoding devices.
Es ist allgemein bekannt, einen Mittelwert SL (speech level) aus den
Abtastwerten x(k) eines Sprachsignals x(t) innerhalb eines Zeitintervalls
gemäß Gleichung G1 zu bilden.

Bei Sprachpausen nimmt der Mittelwert SL in einer von der Anzahl N der Abtastwerte bestimmten Zeit den Wert des Ruhegeräuschs an. Zu Beginn der Sprachaktivität benötigt ein Mittelwertbildner eine von der Anzahl N bestimmte Zeit, um den Sprachpegel zu bestimmen. Die Mittelung in einem Zeitintervall von 125 ms erfordert einen Datenspeicher von 1000 Datenworten bei einer Abtastrate von 8 kHz. Abgesehen von dem beträchtlichen Rechen- und Speicheraufwand besteht bei der einfachen Mittelwertbildung die Gefahr, daß bei kurzer Mittelungszeit durch Störeinflüsse Fehler bei der Bestimmung des Sprachpegels auftreten. Bei langer Mittelungszeit ist einerseits die Information über die Größe des Sprachpegels sehr spät verfügbar, andererseits treten bei Sprachpegeländerungen Fehlmessungen des Sprachpegels auf.During pauses in speech, the mean value SL takes on one of the number N of Samples determine the value of the quiet noise for a certain time. At the start of the speech activity, an averager needs one of the number N certain time to determine the speech level. The averaging in one Time interval of 125 ms requires a data storage of 1000 data words at a sampling rate of 8 kHz. Except for the there is considerable computing and storage effort for the simple one Averaging the risk that with a short averaging time Interference influences Errors occur when determining the speech level. At long averaging time is on the one hand the information about the size of the Language levels available very late, on the other hand, join Speech level changes Incorrect measurements of the speech level.
Weiterhin ist bekannt, rekursive Filter zur Mittelwertbildung zu verwenden, vgl. Hentschke: Grundzüge der Digitaltechnik, Stuttgart: Teubner 1988, Seiten 52-54. Der Rechen- und Speicheraufwand für diese digitalen Filter ist relativ gering, jedoch werden alle Signalwerte gemittelt, so daß eine Unterscheidung zwischen Sprache und Störgeräusch ausgeschlossen ist.It is also known to use recursive filters for averaging, see. Hentschke: Fundamentals of digital technology, Stuttgart: Teubner 1988, Pages 52-54. The computing and storage effort for these digital filters is relatively low, but all signal values are averaged, so that a Differentiation between speech and noise is excluded.
Aus dem Gebiet der Sprachverarbeitung ist das Verfahren der linearen Prädiktion (linear predictive coding, LPC) bekannt, mit dem grundsätzlich auch Unterscheidungsmerkmale von Sprache und Störgeräusch ermittelbar sind. Die LPC-Analyse ist sehr genau und kann sehr schnell durchgeführt werden und ist ein leistungsfähiges Verfahren, mit dem unter anderem die Grundfrequenz, das Spektrum und die Formate eines Sprachsignals bestimmt werden können, vgl. Eppinger, Herter: Sprachverarbeitung, München, Wien: Hanser 1983, Seiten 73-77. Ein solches aufwendiges Verfahren ist jedoch aus kommerziellen Gründen für Massenprodukte, wie Telekommunikationsendgeräte, nicht geeignet.From the field of speech processing, the method is linear Prediction (linear predictive coding, LPC) known with the principle distinguishing features of speech and noise can also be determined are. The LPC analysis is very accurate and can be done very quickly and is a powerful process with which, among other things, the Fundamental frequency, the spectrum and the formats of a speech signal can be determined, cf. Eppinger, Herter: language processing, Munich, Vienna: Hanser 1983, pages 73-77. Such an elaborate However, the process is for commercial reasons for mass products, such as Telecommunication terminals, not suitable.
Mit der Erfindung wird nun die Aufgabe gelöst, ein kostengünstig realisierbares Verfahren zur Sprachpegelmessung und eine Schaltungsanordnung zur Realisierung des Verfahrens anzugeben, die folgende Eigenschaften haben:
- Aus einem Zeitsignal soll der aktuelle Sprachpegel möglichst rasch und präzise ermittelt werden,
- Die Adaptionszeit der Sprachpegelmeßschaltung soll kurz sein, um hörbare Fehler, wie Lautstärkeschwankungen zu vermeiden,
- Der gemessene Sprachpegel soll unabhängig von Pegelschwankungen der Sprache, hervorgerufen beispielsweise durch nasale Laute oder offene Vokale, sein,
- Der gemessene Sprachpegel soll unabhängig von kurzzeitigen Störeinflüssen, wie beispielsweise Räuspern, Husten, Klatschen, Türenschlagen, sein, obwohl gerade diese Störer eine großen Energieinhalt haben,
- In Sprachpausen soll der gemessene Wert des Sprachpegels erhalten bleiben, um das von der automatischen Verstärkungsregelung (Automatic Gain Control, AGC) bekannte Atmen der Lautstärke zu unterdrücken.
- The current speech level should be determined as quickly and precisely as possible from a time signal,
- The adaptation time of the speech level measuring circuit should be short in order to avoid audible errors such as volume fluctuations.
- The measured speech level should be independent of fluctuations in the level of speech caused, for example, by nasal sounds or open vowels.
- The measured speech level should be independent of short-term interferences, such as clearing the throat, coughing, clapping, knocking on the door, even though these interferers have a large energy content,
- During speech pauses, the measured value of the speech level should be retained in order to suppress the breathing of the volume known from the automatic gain control (AGC).
Diese Aufgabe wird durch das im ersten Patentanspruch beschriebene Verfahren und durch die im siebenten Patentanspruch beschriebene Schaltungsanordnung gelöst.This object is achieved by that described in the first claim Method and by that described in the seventh claim Circuit arrangement solved.
Das Wesen der Erfindung besteht darin, daß ein gemessener Sprachpegelwert nur dann zur Weiterverarbeitung in einem Sprachsignalverarbeitungssystem zugelassen wird, wenn charakteristische Merkmale der Sprache erkannt und Störsignale und Sprachpausen bei der Messung ausgeblendet wurden.The essence of the invention is that a measured Speech level value only then for further processing in one Voice signal processing system is allowed when characteristic Characteristics of speech recognized and interference signals and speech pauses at the Measurement were hidden.
Die Erfindung wird nachstehend an einem Ausführungsbeispiel beschrieben. In der dazugehörigen Zeichnung zeigen
- Fig. 1
- ein Blockschaltbild der erfindungsgemäßen Schaltungsanordnung,
- Fig. 2
- eine Darstellung der Zeitfunktionen der Abtastwerte eines Sprachsignals, eines Kurzzeitmittelwertes und eines tiefpaßgefilterten Sprachsignals und
- Fig. 3
- ein Blockschaltbild einer Anordnung zur Ermittlung des Kurzzeitmittelwertes.
- Fig. 1
- 2 shows a block diagram of the circuit arrangement according to the invention,
- Fig. 2
- a representation of the time functions of the samples of a speech signal, a short-term average and a low-pass filtered speech signal and
- Fig. 3
- a block diagram of an arrangement for determining the short-term average.
Gemäß Fig. 1 besteht die Schaltungsanordnung im wesentlichen aus einem
Sprachpausendetektor 1, einem Sprachdetektor 2, einem Mittelwertbildner
3, einem Speicher 4 sowie einer Schaltung 5 zur Bildung eines
Absolutwertes. Am Schaltungseingang liegt die Abtastfunktion x(k) eines
Sprachsignals, am Schaltungsausgang wird der Wert eines Sprachpegels SL
ausgegeben. Wird eine Sprachpause, Ausgangssignal P des
Sprachpausendetektors 1, und wird keine Sprache, Ausgangssignal F des
Sprachdetektors 2, erkannt, so befinden sich gemäß Fig. 1 ein erster
Schalter S1, ein zweiter Schalter S2 und ein dritter Schalter S3 in der
gezeichneten Stellung. Liegt ein Sprachsignal in Form der Abtastfunktion
x(k) vor, d.h. eine Sprachpause P wird nicht erkannt, wird der
Sprachdetektor 2 über den geschlossenen ersten Schalter S1 aktiviert und
die Mittelwertbildung über die Schaltung 5 und den geschlossenen zweiten
Schalter S2 mit dem Mittelwertbildner 3 eingeleitet. Wurde ein Sprachsignal
erkannt, so wird über das Ausgangssignal F des Sprachdetektors 2 der
dritte Schalter S3 geschlossen und das Ausgangssignal SAM(x) des
Mittelwertbildners 3 wird über den dritten Schalter S3 in den Speicher 4
übernommen. Während der Sprachpausen wird der zuletzt gemessene
Sprachpegel SL aus dem Speicher 4 über den zweiten Schalter S2 dem
Mittelwertbildner 3 übergeben.1, the circuit arrangement consists essentially of a
Mit dem Mittelwertbildner 3 wird ein Kurzzeitmittelwert SAM(x) (Short Average Magnitude) so gebildet, daß das Zeitverhalten des Kurzzeitmittelwertes SAM(x) der subjektiven Wahrnehmungsfunktion des menschlichen Ohres weitgehend angepaßt ist. Ein Dynamiksprung von leisen zu lauten Tönen wird dazu mit einer kleinen Zeitkonstanten τs, beispielsweise kleiner als 6,5 ms, berechnet. Ein Dynamiksprung von lauten zu leisen Tönen wird entsprechend dem Nachverdeckungseffekt des menschlichen Ohres mit einer großen Zeitkonstanten τl, beispielsweise 65 ms bis 300 ms, berechnet. Kurz gesprochene Vokale werden auf diese Weise gut erfaßt. Nasale Laute oder Konsonanten mit im Vergleich zu Vokalen geringerem Pegel werden bei der Sprachpegelmessung durch die große Zeitkonstante τl bei fallenden Pegeln weitgehend unterdrückt. Durch die unterschiedlichen Zeitkonstanten τs, τl für steigenden und fallenden Signalverlauf wird eine schnelle Adaption des Kurzzeitmittelwertes SAM(x) an den aktuellen Spitzenwert des Kurzzeitpegels des Sprachsignals erreicht. Dieser Spitzenwert des Kurzzeitpegels des Sprachsignals bestimmt somit unabhängig vom Sprachinhalt den relativen Sprachpegel.The short-term average SAM (x) (short Average Magnitude) so that the time behavior of the Short - term mean SAM (x) of the subjective perception function of the human ear is largely adapted. A dynamic leap from soft to loud tones is done with a small time constant τs, for example less than 6.5 ms. A dynamic leap from loud to soft tones is according to the after masking effect of the human ear with a large time constant τl, for example 65 ms to 300 ms. Briefly spoken vowels are added to this Way well grasped. Nasal sounds or consonants compared to Lower level vowels are measured by the large time constant τl largely suppressed with falling levels. By the different time constants τs, τl for rising and falling The signal curve becomes a fast adaptation of the short-term mean value SAM (x) reached the current peak value of the short-term level of the speech signal. This peak value of the short-term level of the speech signal thus determines the relative speech level regardless of the speech content.
Figur 2 zeigt das Zeitverhalten der Abtastwerte für drei Funktionen. Die
Eingangsfunktion x(k) der Sprachpegelmeßschaltung gemäß Fig. 1 ist als
Funktionsverlauf 6 einer Sprachprobe dargestellt. Der Funktionsverlauf 7
zeigt den Verlauf des Kurzzeitmittelwertes SAM (x(k)), kurz SAM (x), unter
Berücksichtigung der Wirkungsweise der unterschiedlichen Zeitkonstanten
τs, τl wie zuvor beschrieben. Zum Vergleich ist noch ein dritter
Funktionsverlauf 8 dargestellt, der die Wirkung eines einfachen Tiefpasses
wiedergibt. Daraus geht hervor, daß ein Tiefpaß für eine rasche und präzise
Ermittlung des aktuellen Sprachpegels ungeeignet ist.FIG. 2 shows the time behavior of the samples for three functions. The
Input function x (k) of the speech level measuring circuit according to FIG. 1 is as
Functional curve 6 of a speech sample is shown. The course of functions 7
shows the course of the short-term mean SAM (x (k)), short SAM (x), below
Taking into account the mode of action of the different time constants
τs, τl as previously described. A third is for comparison
In Fig. 3 sind Einzelheiten des Mittelwertbildners 3 dargestellt, der ein
rekursives Filter, ein an sich bekanntes IIR-Filter 9 (Infinite Impulse Response
Filter), und eine Schaltungsanordnung 10 zur Umschaltung der
Zeitkonstanten τs, τl enthält. Die Schaltung 5 zur Bildung des Absolutwertes
entspricht der in Fig. 1 dargestellten Schaltung. Um den zuvor
beschriebenen Verlauf des Kurzzeitmittelwertes SAM (x) zu erzielen, ist eine
Umschaltung der Zeitkonstanten τs, τl nach folgender Gleichung G2
erforderlich:

Das bedeutet, wenn der Abtastwert x(k) des Sprachsignals x(t) größer ist als
der Kurzzeitmittelwert SAM (x), beispielsweise in Fig. 2 Funktionsverlauf 6,
Abtastzeitpunkte 0 bis 12, wird für die Zeitkonstanten α, β der Wert der
kurzen Zeitkonstanten τs zur Berechnung des Kurzzeitmittelwertes SAM (x)
verwendet.This means if the sample value x (k) of the speech signal x (t) is greater than
the short-term mean value SAM (x), for example in FIG. 2, function curve 6,
Zur Realisierung des Sprachpausendetektors 1 in Fig. 1 wird ein Verfahren
verwendet, mit dem das zeitliche Verhalten der Abtastfunktion x(k) des
Sprachsignals ausgewertet wird. Der Kurzzeitmittelwert SAM (x) der
Abtastfunktion x(k) wird mit einem in einem Zeitintervall ermittelten
Langzeitminimalwert aus einer Anzahl Kurzzeitmittelwerte SAM (x)
verglichen.
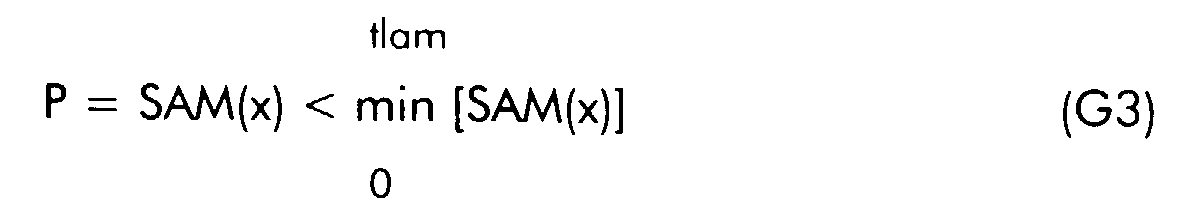
Der Minimalwert der Kurzzeitmittelwerte SAM (x) wird in einem Zeitintervall
von t = 0 ... tlam, beispielsweise tlam = 3s bis 7s gesucht. Ist der aktuelle
Kurzzeitmittelwert SAM (x) kleiner als dieser Minimalwert, so wird das
Eingangssignal x(k) an der Sprachpegelmeßschaltung als Pause P gewertet.
Sprachsignale würden immer größer als der ermittelte Minimalwert sein.
Zur sicheren Bestimmung des aktuellen Sprachpegels ist nicht nur die
Unterscheidung zwischen Sprache und Sprachpause erforderlich, sondern
auch die Unterscheidung zwischen Sprache und Störern. Dazu dient der in
Fig. 1 dargestellte Sprachdetektor 2, dessen Ausgangssignal F als
Entscheidungskriterium für die Übernahme des Kurzzeitmittelwertes SAM (x)
in den Speicher 4 dient. Unterscheidungsmerkmale zwischen Sprache und
Störer sind beispielsweise das Zeitverhalten, die Periodizität oder die LPC-Koeffizientendarstellung
eines LPC-Filters. Für die vorliegende
Aufgabenstellung ist die Auswertung des Zeitverhaltens vorteilhaft. Dazu
wird die Tatsache ausgenutzt, daß Störer kurzzeitig wirken, im allgemeinen
kürzer als 200 ms, während ein Sprecher eine größere Zeit, mindestens 1 s,
aktiv ist, um eine Information abzugeben und die Sprachfunktion keine
kurzzeitigen hohen Momentanwerte aufweist. Die Ungleichung G4
beschreibt die Bedingung, die für die Detektion des Eingangssignals x(k) als
Sprache erfüllt sein muß.

[SAM (x) ... SAM (x-i)] bedeutet, daß eine Anregung für eine bestimmte
Mindestzeit vorhanden sein muß, damit nicht bereits ein Rauschen als
Anregung detektiert wird. Die rechte Seite der Ungleichung G4 wurde bei
der Beschreibung der Ungleichung G3 erläutert. Die Zeitüberwachung für
die Sprechzeit τ(s) wird mit einem hier nicht dargestellten Zähler
durchgeführt, der durch den Sprachpausendetektor 1 gestartet und
zurückgesetzt wird. Beim Überschreiten der definierten Sprechzeit τ(s) wird
der zuvor vom Mittelwertbildner 3 gemessene Kurzzeitmttelwert SAM (x) in
den Speicher 4 übernommen. Es ist praktisch vorteilhaft, als Sprechzeit τ(s)
eine Dauer von 300 ms zu definieren.[SAM (x) ... SAM (x-i)] means that a suggestion for a particular
Minimum time must be available so that no noise is already as
Excitation is detected. The right side of inequality G4 was at
the description of inequality G3. Time monitoring for
the speaking time τ (s) is with a counter, not shown here
performed, started by the
Es ist auch möglich, die Zeitkonstanten τs, τl des Mittelwertbildners 3 zu
variieren, um einen für den jeweiligen Anwendungsfall angepaßten
Sprachpegel SL zu erhalten. Die in dem Ausführungsbeispiel beschriebene
Bildung eines Kurzzeitmittelwertes SAM(x) wird vorteilhafterweise in stark
geräuschbehafteter Umgebung, beispielsweise in einem Panzer eingesetzt.
Bei undeutlichen Sprechern ist es günstiger, einen Mittelwert (Medium
Average Magnitude) MAM(x) zu bilden, indem die kleine Zeitkonstante τs
vergrößert und die große Zeitkonstante τl des Mittelwertbildners 3
verkleinert wird.It is also possible to add the time constants τs, τl of the
Mit geringem Rechen- und Speicheraufwand wird wie beschrieben eine kostengünstige und zuverlässige Sprachpegelmessung realisiert.With little computation and storage effort, one is described as Cost-effective and reliable speech level measurement implemented.
Claims (9)
dadurch gekennzeichnet, daß
mit dem Sprachpausendetektor (1) eine Pause (P) im Sprachsignal (x(k)) erkannt wird, wenn der Kurzzeitmittelwert des Sprachsignals (x(k)) kleiner ist als der in einem definierten Zeitintervall ermittelte Langzeitmittelwert des Sprachsignals (x(k)). Method according to claim 1,
characterized in that
the speech pause detector (1) detects a pause (P) in the speech signal (x (k)) when the short-term mean value of the speech signal (x (k)) is smaller than the long-term mean value of the speech signal (x (k) determined in a defined time interval ).
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| DE19854341A DE19854341A1 (en) | 1998-11-25 | 1998-11-25 | Method and circuit arrangement for speech level measurement in a speech signal processing system |
| DE19854341 | 1998-11-25 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| EP1005016A2 true EP1005016A2 (en) | 2000-05-31 |
| EP1005016A3 EP1005016A3 (en) | 2000-11-29 |
Family
ID=7888949
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP99440312A Withdrawn EP1005016A3 (en) | 1998-11-25 | 1999-11-12 | Method and circuit arrangement for measuring speech level in a speech processing system |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US6539350B1 (en) |
| EP (1) | EP1005016A3 (en) |
| DE (1) | DE19854341A1 (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP1278185A2 (en) * | 2001-07-13 | 2003-01-22 | Alcatel | Method for improving noise reduction in speech transmission |
Families Citing this family (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE19939102C1 (en) * | 1999-08-18 | 2000-10-26 | Siemens Ag | Speech recognition method for dictating system or automatic telephone exchange |
| KR100406307B1 (en) * | 2001-08-09 | 2003-11-19 | 삼성전자주식회사 | Voice recognition method and system based on voice registration method and system |
| EP1429314A1 (en) * | 2002-12-13 | 2004-06-16 | Sony International (Europe) GmbH | Correction of energy as input feature for speech processing |
| EP2560410B1 (en) * | 2011-08-15 | 2019-06-19 | Oticon A/s | Control of output modulation in a hearing instrument |
| US8255218B1 (en) * | 2011-09-26 | 2012-08-28 | Google Inc. | Directing dictation into input fields |
| US8543397B1 (en) | 2012-10-11 | 2013-09-24 | Google Inc. | Mobile device voice activation |
| CN107690089A (en) * | 2016-08-05 | 2018-02-13 | 阿里巴巴集团控股有限公司 | Data processing method, live broadcasting method and device |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4696039A (en) * | 1983-10-13 | 1987-09-22 | Texas Instruments Incorporated | Speech analysis/synthesis system with silence suppression |
| JPH07326981A (en) * | 1994-05-31 | 1995-12-12 | Japan Radio Co Ltd | Vox controlled communication equipment |
Family Cites Families (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4032710A (en) * | 1975-03-10 | 1977-06-28 | Threshold Technology, Inc. | Word boundary detector for speech recognition equipment |
| US4481593A (en) * | 1981-10-05 | 1984-11-06 | Exxon Corporation | Continuous speech recognition |
| DE3276732D1 (en) * | 1982-04-27 | 1987-08-13 | Philips Nv | Speech analysis system |
| DE3276731D1 (en) * | 1982-04-27 | 1987-08-13 | Philips Nv | Speech analysis system |
| DE3230391A1 (en) * | 1982-08-14 | 1984-02-16 | Philips Kommunikations Industrie AG, 8500 Nürnberg | Method for improving speech signals affected by interference |
| US4625083A (en) * | 1985-04-02 | 1986-11-25 | Poikela Timo J | Voice operated switch |
| FR2631147B1 (en) * | 1988-05-04 | 1991-02-08 | Thomson Csf | METHOD AND DEVICE FOR DETECTING VOICE SIGNALS |
| US5204906A (en) * | 1990-02-13 | 1993-04-20 | Matsushita Electric Industrial Co., Ltd. | Voice signal processing device |
| US5216702A (en) * | 1992-02-27 | 1993-06-01 | At&T Bell Laboratories | Nonintrusive speech level and dynamic noise measurements |
| US5305422A (en) * | 1992-02-28 | 1994-04-19 | Panasonic Technologies, Inc. | Method for determining boundaries of isolated words within a speech signal |
-
1998
- 1998-11-25 DE DE19854341A patent/DE19854341A1/en not_active Withdrawn
-
1999
- 1999-11-12 EP EP99440312A patent/EP1005016A3/en not_active Withdrawn
- 1999-11-18 US US09/442,392 patent/US6539350B1/en not_active Expired - Fee Related
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4696039A (en) * | 1983-10-13 | 1987-09-22 | Texas Instruments Incorporated | Speech analysis/synthesis system with silence suppression |
| JPH07326981A (en) * | 1994-05-31 | 1995-12-12 | Japan Radio Co Ltd | Vox controlled communication equipment |
Non-Patent Citations (1)
| Title |
|---|
| BAUER B B ET AL: "THE MEASUREMENT OF LOUDNESS LEVEL" JOURNAL OF THE ACOUSTICAL SOCIETY OF AMERICA,US,AMERICAN INSTITUTE OF PHYSICS. NEW YORK, Bd. 50, Nr. 2, PART 01, August 1971 (1971-08), Seiten 405-414, XP000795762 ISSN: 0001-4966 * |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP1278185A2 (en) * | 2001-07-13 | 2003-01-22 | Alcatel | Method for improving noise reduction in speech transmission |
| EP1278185A3 (en) * | 2001-07-13 | 2005-02-09 | Alcatel | Method for improving noise reduction in speech transmission |
Also Published As
| Publication number | Publication date |
|---|---|
| DE19854341A1 (en) | 2000-06-08 |
| US6539350B1 (en) | 2003-03-25 |
| EP1005016A3 (en) | 2000-11-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| DE3856280T2 (en) | Noise reduction system | |
| DE69535709T2 (en) | Method and apparatus for selecting the coding rate in a variable rate vocoder | |
| DE69926851T2 (en) | Method and apparatus for voice activity detection | |
| DE60009206T2 (en) | Noise suppression by means of spectral subtraction | |
| DE69816610T2 (en) | METHOD AND DEVICE FOR NOISE REDUCTION, ESPECIALLY WITH HEARING AIDS | |
| DE69614989T2 (en) | Method and device for determining speech activity in a speech signal and a communication device | |
| DE3752288T2 (en) | Speech processor | |
| DE69913262T2 (en) | DEVICE AND METHOD FOR ADJUSTING THE NOISE THRESHOLD FOR DETECTING VOICE ACTIVITY IN A NON-STATIONARY NOISE ENVIRONMENT | |
| DE112009000805B4 (en) | noise reduction | |
| EP0690436B1 (en) | Detection of the start/end of words for word recognition | |
| DE3233637C2 (en) | Device for determining the duration of speech signals | |
| EP1088300B1 (en) | Method for executing automatic evaluation of transmission quality of audio signals | |
| EP0698986A2 (en) | Method for adaptive echo compensation | |
| EP0747880B1 (en) | System for speech recognition | |
| DE69918635T2 (en) | Apparatus and method for speech processing | |
| DE69616724T2 (en) | Method and system for speech recognition | |
| WO1998023130A1 (en) | Hearing-adapted quality assessment of audio signals | |
| DE19957221A1 (en) | Exponential echo and noise reduction during pauses in speech | |
| EP1005016A2 (en) | Method and circuit arrangement for measuring speech level in a speech processing system | |
| DE69922769T2 (en) | Apparatus and method for speech processing | |
| DE2021126A1 (en) | Speech recognition device | |
| EP1382034B1 (en) | Method for determining intensity parameters of background noise in speech pauses of voice signals | |
| EP1202253B1 (en) | Adaptive noise level estimator | |
| EP1453355A1 (en) | Signal processing in a hearing aid | |
| EP0902416B1 (en) | Method and device for recognizing a speech input during an announcement |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| AK | Designated contracting states |
Kind code of ref document: A2 Designated state(s): AT BE CH CY DE DK ES FI FR GB GR IE IT LI LU MC NL PT SE |
|
| AX | Request for extension of the european patent |
Free format text: AL;LT;LV;MK;RO;SI |
|
| PUAL | Search report despatched |
Free format text: ORIGINAL CODE: 0009013 |
|
| AK | Designated contracting states |
Kind code of ref document: A3 Designated state(s): AT BE CH CY DE DK ES FI FR GB GR IE IT LI LU MC NL PT SE |
|
| AX | Request for extension of the european patent |
Free format text: AL;LT;LV;MK;RO;SI |
|
| RIC1 | Information provided on ipc code assigned before grant |
Free format text: 7G 10L 11/00 A, 7G 01H 3/12 B |
|
| 17P | Request for examination filed |
Effective date: 20001129 |
|
| AKX | Designation fees paid |
Free format text: AT BE CH CY DE DK ES FI FR GB GR IE IT LI LU MC NL PT SE |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE APPLICATION HAS BEEN WITHDRAWN |
|
| 18W | Application withdrawn |
Effective date: 20031218 |