EP0539103A2 - Verallgemeinerte Analyse-durch-Synthese Methode und Einrichtung zur Sprachkodierung - Google Patents
Verallgemeinerte Analyse-durch-Synthese Methode und Einrichtung zur Sprachkodierung Download PDFInfo
- Publication number
- EP0539103A2 EP0539103A2 EP92309442A EP92309442A EP0539103A2 EP 0539103 A2 EP0539103 A2 EP 0539103A2 EP 92309442 A EP92309442 A EP 92309442A EP 92309442 A EP92309442 A EP 92309442A EP 0539103 A2 EP0539103 A2 EP 0539103A2
- Authority
- EP
- European Patent Office
- Prior art keywords
- original signal
- trial
- coding
- error
- trial original
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000000034 method Methods 0.000 title claims abstract description 62
- 238000003786 synthesis reaction Methods 0.000 title claims abstract description 22
- 238000012854 evaluation process Methods 0.000 claims abstract 6
- 230000003044 adaptive effect Effects 0.000 claims description 15
- 238000004891 communication Methods 0.000 claims description 5
- 230000002194 synthesizing effect Effects 0.000 claims 5
- 230000008569 process Effects 0.000 abstract description 29
- 238000001308 synthesis method Methods 0.000 abstract 1
- 230000006870 function Effects 0.000 description 30
- 230000005284 excitation Effects 0.000 description 19
- 239000013598 vector Substances 0.000 description 18
- 230000007774 longterm Effects 0.000 description 8
- 230000004044 response Effects 0.000 description 8
- 238000013507 mapping Methods 0.000 description 5
- 238000005070 sampling Methods 0.000 description 4
- 230000015572 biosynthetic process Effects 0.000 description 3
- 230000003595 spectral effect Effects 0.000 description 3
- 230000008859 change Effects 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 238000001914 filtration Methods 0.000 description 2
- 239000011159 matrix material Substances 0.000 description 2
- 230000007704 transition Effects 0.000 description 2
- 238000013459 approach Methods 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 230000007423 decrease Effects 0.000 description 1
- 238000006731 degradation reaction Methods 0.000 description 1
- 238000012938 design process Methods 0.000 description 1
- 230000000873 masking effect Effects 0.000 description 1
- 230000003534 oscillatory effect Effects 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 238000007670 refining Methods 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
Images

Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/08—Determination or coding of the excitation function; Determination or coding of the long-term prediction parameters
- G10L19/12—Determination or coding of the excitation function; Determination or coding of the long-term prediction parameters the excitation function being a code excitation, e.g. in code excited linear prediction [CELP] vocoders
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L2019/0001—Codebooks
- G10L2019/0011—Long term prediction filters, i.e. pitch estimation
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L2019/0001—Codebooks
- G10L2019/0012—Smoothing of parameters of the decoder interpolation
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L2019/0001—Codebooks
- G10L2019/0013—Codebook search algorithms
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/03—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters
- G10L25/06—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters the extracted parameters being correlation coefficients
Definitions
- the present invention relates generally to speech coding systems and more specifically to a reduction of bandwidth requirements in analysis-by-synthesis speech coding systems.
- Speech coding systems function to provide codeword representations of speech signals for communication over a channel or network to one or more system receivers. Each system receiver reconstructs speech signals from received codewords. The amount of codeword information communicated by a system in a given time period defines system bandwidth and affects the quality of speech reproduced by system receivers.
- speech signals are coded through a waveform matching procedure.
- a candidate speech signal is synthesized from one or more parameters for comparison to an original speech signal to be encoded.
- different synthesized candidate speech signals may be determined.
- the parameters of the closest matching candidate speech signal may then be used to represent the original speech signal.
- LTP long-term predictor
- a coder employing an LTP subtracts a scaled version of the closest matching past speech signal (i.e. , the best approximation) from the current speech signal to yield a signal (sometimes referred to as a residual or excitation ) with reduced long-term correlation.
- This signal is then coded, typically with a fixed stochastic codebook (FSCB).
- FSCB index and LTP delay are transmitted to a CELP decoder which can recover an estimate of the original speech from these parameters.
- the quality of reconstructed speech at a decoder may be enhanced.
- This enhancement is not achieved without a significant increase in bandwidth.
- conventional CELP coders may transmit 8-bit delay information every 5 or 7.5 ms (referred to as a subframe ).
- Such time-varying delay parameters require, e.g. , between one and two additional kilobits (kb) per second of bandwidth.
- kb additional kilobits
- One approach to reducing the extra bandwidth requirements of analysis-by-synthesis coders employing an LTP might be to transmit LTP delay values less often and determine intermediate LTP delay values by interpolation.
- interpolation may lead to suboptimal delay values being used by the LTP in individual subframes of the speech signal. For example, if the delay is suboptimal, then the LTP will map past speech signals into the present in a suboptimal fashion. As a result, any remaining excitation signal will be larger than it might otherwise be.
- the FSCB must then work to undo the effects of this suboptimal time-shift rather than perform its normal function of refining waveform shape. Without such refinement, significant audible distortion may result.
- the present invention provides a method and apparatus for reducing bandwidth requirements in analysis-by-synthesis speech coding systems.
- the present invention provides multiple trial original signals based upon an actual original signal to be encoded. These trial original signals are constrained to be audibly similar to the actual original signal and are used in place of or supplement the use of the actual original in coding.
- the original signal, and hence the trial original signals may take the form of actual speech signals or any of the excitation signals present in analysis-by-synthesis coders.
- the present invention affords generalized analysis-by-synthesis coding by allowing for the variation of original speech signals to reduce coding error and bit rate.
- the invention is applicable to, among other things, networks for communicating speech information, such as, for example, cellular and conventional telephone networks.
- trial original signals are used in a coding and synthesis process to yield reconstructed original signals. Error signals are formed between the trial original signals and the reconstructed signals.
- the trial original signal which is determined to yield the minimum error is used as the basis for coding and communication to a receiver. By reducing error in this fashion, a coding process may be modified such that required system bandwidth may be reduced.
- one or more trial original signals are provided by application of a codebook of time-warps to the actual original signal.
- trial original signals are compared with a candidate past speech signal provided by an adaptive codebook.
- the trial original signal which most closely compares to the candidate is identified.
- the candidate is subtracted from the identified trial original signal to form a residual.
- the residual is then coded by application of a fixed stochastic codebook.
- the illustrative embodiment of the present invention provides improved mapping of past signals to the present and, as a result, reduced residual error. This reduced residual error affords less frequent transmission of LTP delay information and allows for delay interpolation with little or no degradation in the quality of reconstructed speech.
- Another illustrative embodiment of the present invention provides multiple trial original signals through a time-shift technique.
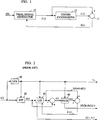
- Figure 1 presents an illustrative embodiment of the present invention.
- Figure 2 presents a conventional CELP coder.
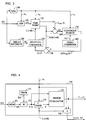
- Figure 3 presents an illustrative embodiment of the present invention.
- Figure 4 presents an illustrative time-warp function for the embodiment presented in Figure 3.
- Figure 5 presents an illustrative embodiment of the present invention concerning time-shifting.
- Figure 6 presents an illustrative time-shifting function for the embodiment presented in Figure 5.
- Figure 1 presents an illustrative embodiment of the present invention.
- An original speech signal to be encoded, S(i) is provided to a trial original signal generator 10.
- the trial original signal generator 10 produces a trial original signal (i) which is audibly similar to the original signal S(i).
- Trial original signal (i) is provided to a speech coder/synthesizer 15 which (i) determines a coded representation for (i) and (ii) further produces a reconstructed speech signal, ⁇ (i), based upon the coded representation of (i).
- a difference or error signal, E(i) is formed between trial original speech signal (i) and ⁇ (i) by subtraction circuit 17.
- E(i) is fed back to the trial original signal generator 10 which selects another trial original signal in an attempt to reduce the magnitude of the error signal, E(i).
- the embodiment thereby functions to determine, within certain constraints, which trial original signal, (i), yields a minimum error, E min (i).
- parameters used by the coder/synthesizer 15 to synthesize the corresponding ⁇ (i) may serve as the coded representation of (i) and hence, S(i).
- the present invention provides generalization for conventional analysis-by-synthesis coding by recognizing that the original signals may be varied to reduce error in the coding process.
- the coder/synthesizer 15 may be any conventional analysis-by-synthesizer coder, such as conventional CELP.
- a conventional analysis-by-synthesis CELP coder is presented in Figure 2.
- a sampled speech signal, s(i), (where i is the sample index) is provided to a short-term linear prediction filter (STP) 20 of order N, optimized for a current segment of speech.
- Signal x(i) is an excitation obtained after filtering with the STP: where parameters a n are provided by linear prediction analyzer 10. Since N is usually about 10 samples (for an 8 kHz sampling rate), the excitation signal x(i) retains the long-term periodicity of the original signal, s(i).
- An LTP 30 is provided to remove this redundancy.
- Values for x(i) are usually determined on a blockwise basis. Each block is referred to as a subframe .
- the linear prediction coefficients, a n are determined by the analyzer 10 on a frame -by- frame basis, with a frame having a fixed duration which is generally an integral multiple of subframe durations, and usually 20-30 ms in length.
- Subframe values for a n are usually determined through interpolation.
- the LTP 30 provides the quantity ⁇ (i) x ⁇ (i-d(i)).
- Signal r(i) is the excitation signal remaining after ⁇ (i) x ⁇ (i-d(i)) is subtracted from x(i).
- Signal r(i) is then coded with a FSCB 40.
- the FSCB 40 yields an index indicating the codebook vector and an associated scaling factor, ⁇ (i). Together these quantities provide a scaled excitation which most closely matches r(i).
- Data representative of each subframe of speech namely, LTP parameters ⁇ (i) and d(i), and the FSCB index, are collected for the integer number of subframes equalling a frame (typically 2, 4 or 6). Together with the coefficients a n , this frame of data is communicated to a CELP decoder where it is used in the reconstruction of speech.
- a CELP decoder performs the reverse of the coding process discussed above.
- the FSCB index is received by a FSCB of the receiver (sometimes referred to as a synthesizer) and the associated vector e(i) (an excitation signal) is retrieved from the codebook.
- Excitation e(i) is used to excite an inverse LTP process (wherein long-term correlations are provided) to yield a quantized equivalent of x(i), x ⁇ (i).
- a reconstructed speech signal, y(i) is obtained by filtering x ⁇ (i) with an inverse STP process (wherein short-term correlations are provided).
- the reconstructed excitation x ⁇ (i) can be interpreted as the sum of scaled contributions from the adaptive and fixed codebooks.
- a perceptually relevant error criterion may be used. This can be done by taking advantage of the spectral masking existing in the human auditory system. Thus, instead of using the difference between the original and reconstructed speech signals, this error criterion considers the difference of perceptually weighted signals.
- the perceptual weighting of signals deemphasizes the formants present in speech.
- the formants are described by an all-pole filter in which spectral deemphasis can be obtained by moving the poles inward. This is equivalent to replacing the filter with predictor coefficients a1 , a2 , ⁇ , a N , by a filter with coefficients ⁇ a1, ⁇ 2a 2, ⁇ , ⁇ N a N , where ⁇ is a perceptual weighting factor (usually set to a value around 0.8).
- the sampled error signal in the perceptually weighted domain, g(i) is:
- the error criterion of analysis-by-synthesis coders is formulated on a subframe-by-subframe basis. For a subframe length of L samples, a commonly used criterion is: where î is the first sample of the subframe. Note that this criterion weighs the excitation samples unevenly over the subframe; the sample x ⁇ (î+L-1) affects only g(î+L-1), while x ⁇ (î) affects all samples of g(i) in the present subframe.
- the criterion of equation (4) includes the effects of differences in x(i) and x ⁇ (i) prior to î, i.e. , prior to the beginning of the present subframe. It is convenient to define an excitation in the present subframe to represent this zero-input response of the weighted synthesis filter.
- z(i) is the zero-input response of the perceptually-weighted synthesis filter when excited with x(i)-x ⁇ (i).
- the spectral deemphasis by the factor ⁇ results in a quicker attenuation of the impulse response of the all-pole filter.
- the impulse response of the all-pole filter 1/(1 - ⁇ a1z ⁇ 1 ⁇ - ⁇ N a N z -N ) can be approximated by a finite-impulse-response filter.
- Let h0, h1, ⁇ , h R-1 denote the impulse response of the latter filter. This allows vector notation for the error criterion operating on the perceptually-weighted speech. Because the coders operate on a subframe-by-subframe basis, it is convenient to define vectors with the length of the subframe in samples, L. For example, for the excitation signal:
- the spectral-weighting matrix H is defined as: H has dimensions (L+ R-1) ⁇ L.
- the vector (i) approximates the entire response of the IIR filter 1/(1 - ⁇ a1z ⁇ 1 ⁇ - ⁇ N a N z -N ) to the vector (i).
- an appropriate perceptually-weighted criterion is:
- the error criterion of equation (8) is of the autocorrelation type (note that H T H is Toeplitz). If the matrix H is truncated to be square L ⁇ L, equation (8) approximates equation (4), which is the more common covariance criterion, as used in the original CELP.
- Figure 3 presents an illustrative embodiment of the present invention as it may be applied to CELP coding.
- a sampled speech signal, s(i) is presented for coding.
- Signal s(i) is provided to a linear predictive analyzer 100 which produces linear predictive coefficients, a n .
- Signal s(i) is also provided to an STP 120, which operates according to a process described by Eq. (1), and to a delay estimator 140.
- Delay estimator 140 operates to search the recent past history of s(i) (e.g ., between 20 and 160 samples in the past) to determine a set of consecutive past samples (of length equal to a subframe) which most closely matches the current subframe of speech, s(i), to be coded. Delay estimator 140 may make its determination through a correlation procedure of the current subframe with the contiguous set of past sample s(i) values in the interval i-160 ⁇ i ⁇ i-20.
- An illustrative correlation technique is that used by conventional open-loop LTPs of CELP coders. (The term open-loop refers to an LTP delay estimation process using original rather than reconstructed past speech signals.
- a delay estimation process which uses reconstructed speech signals is referred to as closed-loop .
- the delay estimator 140 determines a delay estimate by the above described procedure once per frame.
- Delay estimator 140 computes delay values M for each subframe by interpolation of delay values determined at frame boundaries.
- Adaptive codebook 150 maintains an integer number (typically 128 or 256) of vectors of reconstructed past speech signal information.
- Each such vector, x ⁇ (i), is L samples in length (the length of a subframe) and partially overlaps neighbor codebook vectors, such that consecutive vectors are distinct by one sample.
- each vector is formed of the sum of past adaptive codebook 150 and fixed codebook 180 contributions to the basic waveform matching procedure of the CELP coder.
- the delay estimate, M is used as an index to stored adaptive codebook vectors.
- adaptive codebook 150 Responsive to receiving M, adaptive codebook 150 provides a vector, x ⁇ (i-M), comprising L samples beginning M+L samples in the past and ending M samples in the past.
- This vector of past speech information serves as an LTP estimate of the present speech information to be coded.
- the LTP process functions to identify a past speech signal which best matches a present speech signal so as to reduce the long term correlation in coded speech.
- multiple trial original speech signals are provided for the LTP process. Such multiple trial original signals are provided by time-warp function 130.
- Time-warp function 130 provides a codebook 133 of time-warps (TWCB) for application to original speech to produce multiple trial original signals.
- the codebook 133 of time-warp function 130 may include any time-warp, ⁇ (t) ⁇ ⁇ d ⁇ dt (where ⁇ is a warped time-scale), which does not change the perceptual quality of the original signal: where t j and ⁇ j denote the start of the current subframe j in the original and warped domains.
- pitch pulses fall near the right hand boundary of the subframes. This can be done by defining sub-frame boundaries to fall just to the right of such pulses using known techniques. Assuming that the pitch pulses of the speech signal to be coded are at the boundary points, it is preferred that warping functions satisfy: If the pitch pulses are somewhat before the subframe boundaries, ⁇ (t) should maintain its end value in this neighborhood of the subframe boundary. If equation (10) is not satisfied, oscillating warps may be obtained.
- the warping function converges towards A with increasing t. At t j the value of the warping function is just A+B.
- the value of C can be used to satisfy equation (10) exactly.
- original speech signal x(i) is received by the time-warping process 130 and stored in memory 131.
- Original speech signal x(i) is made available to the warping process 132 as needed.
- Warping process receives a warping function ⁇ (t) from a time-warp codebook 133 and applies the function to the original signal according to equation (9).
- a time-warped original speech signal, (i), referred to as a trial original, is supplied to process 134 which determines a squared difference or error quantity, ⁇ ′, as follows: Equation (12) is similar to equation (8) except that, unlike equation (8), equation (12) has been normalized thus making a least squares error process sensitive to differences of shape only.
- the error quantity ⁇ ′ is provided to an error evaluator 135 which functions to determine the minimum error quantity, ⁇ ′ min , from among all values of ⁇ ′ presented to it (there will be a value ⁇ ′ for each time warp in the TWCB) and store the value of (i) associated with ⁇ ′ min , namely (i).
- the scale factor ⁇ (i) is determined by process 136 as follows: This scale factor is multiplied by x ⁇ (i-M) and provided as output.
- Codebook search process 170 operates conventionally to determine which of the fixed stochastic codebook vectors, z(i), scaled by a factor, ⁇ (i), most closely matches r(i) in a least squares, perceptually weighted sense.
- the chosen scaled fixed codebook vector, ⁇ (i)z min (i) is added to the scaled adaptive codebook vector, ⁇ (i)x ⁇ (i-M), to yield the best estimate of a current reconstructed speech signal, x ⁇ (i). This best estimate, x ⁇ (i), is stored in the adaptive codebook 150.
- LTP delay and scale factor values, ⁇ and M, a FSCB index, and linear prediction coefficents, a n are supplied to a decoder across a channel for reconstruction by a conventional CELP receiver.
- LTP delay information, M once per frame, rather than once per subframe.
- Subframe values for M may be provided at the receiver by interpolating the delay values in a fashion identical to that done by delay estimator 140 of the transmitter.
- a stepped delay contour For a conventional LTP, delay is constant within each subframe, changing discontinuously at subframe boundaries. This discontinuous behavior is referred to as a stepped delay contour. With stepped delay contours, the discontinuous changes in delay from subframe to subframe correspond to discontinuities in the LTP mapping of past excitation into the present. These discontinuities are modified by interpolation, and they may prevent the construction of a signal with a smoothly evolving pitch-cycle waveform. Because interpolation of delay values is called for in the illustrative embodiments discussed above, it may prove advantageous to provide an LTP with a continuous delay contour more naturally facilitating interpolation. Since this reformulated LTP provides a delay contour with no discontinuities, it is referred to as a continuous delay contour LTP.
- each of the delay contours of the set are chosen to be linear within a subframe.
- d(t) d(t j ) + ⁇ (t-t j ), t j ⁇ t ⁇ t j+1 , where ⁇ is a constant.
- Equation (15) is evaluated for the samples t j , t j +T, ⁇ , t j +(N-1)T.
- the signal value x ⁇ (t-d(t)) must be obtained with interpolation.
- the optimal piecewise-linear delay contour we have a set of Q trial slopes ⁇ 1 , ⁇ 2, ⁇ , ⁇ Q , for each of which the sequence u(t j ), u(t j +T), ⁇ , u(t j +(N-1)T) is evaluated. The best quantized value of d(t j ) can then be found using equation (8).
- equation (8) may be used to provide a perceptually weighted, least squares error estimate between x ⁇ (t) and x ⁇ (t-d(t)).
- the value of d(t j ) is passed from delay estimator 140 to adaptive codebook 150 in lieu of M.
- the slope of the delay contour be less than unity: d(t) ⁇ 1. If this proposition is violated, local time-reversal of the mapped waveform may occur. Also, a continuous delay contour cannot accurately describe pitch doubling. To model pitch doubling, the delay contour must be discontinuous. Consider again the delay contour of equation (14). Because each pitch period is usually dominated by one major center of energy (the pitch pulse), it is preferred the delay contour be provided with one degree of freedom per pitch cycle. Thus, the illustrative continuous delay-contour LTP provides subframes with an adaptive length of approximately one pitch cycle.
- This adaptive length is used to provide for subframe boundaries being placed just past the pitch pulses. By so doing, an oscillatory delay contour can be avoided. Since the LTP parameters are transmitted at fixed time intervals, the subframe size does not affect the bit rate.
- known methods for locating the pitch pulses, and thus delay frame boundaries are applicable. These methods may be applied as part of the adaptive codebook process 150.
- a time-shifting embodiment of the present invention may be employed.
- a time-shifting embodiment may take the form of that presented in Figure 5, which is similar to that of Figure 3 with the time-warp function 130 replaced with a time-shift function 200.
- the time-shift function 200 provides multiple trial original signals which are constrained to be audibly similar to the original signal to be coded. Like the time-warp function 130, the time-shift function 200 seeks to determine which of the trial original signals generated is closest in form to an identified past speech signal. However, unlike the time-warp function 130, the time-shift function 200 operates by sliding a subframe of the original speech signal, preferably the excitation signal x(i), in time by an amount ⁇ , ⁇ min ⁇ max , to determine a position of the original signal which yields minimum error when compared with a past speech signal (typically,
- 2.5 samples, achieved with up-sampling).
- the shifting of the original speech signal by an amount ⁇ to the right is accomplished by repeating the last section of length ⁇ of the previous subframe thereby padding the left edge of the original speech subframe.
- the shifting of the original speech signal by an amount ⁇ to the left is accomplished by simply removing ( i.e ., omitting) a length of the original signal equal to ⁇ from the left edge of the subframe.
- minimum error is generally associated with time-matching the major pitch pulses in a subframe as between two signals.
- the subframe size need not be a function of the pitch-period. It is preferred, however, that the subframe size be always less than a pitch period. Then the location of each pitch pulse can be determined independently. A subframe size of 2.5 ms can be used. Since the LTP parameters are transmitted at fixed time intervals, the subframe size does not affect the bit rate. To prevent subframes from falling between pitch pulses, the change in shift must be properly restricted (of the order of .25 ms for a 2.5 ms subframe). Alternatively, the delay can be kept constant for subframes where the energy is much lower than that of surrounding subframes.
- FIG. 6 An illustrative time-shift function 200 is presented in Figure 6.
- the function 200 is similar to the time-warp function 130 discussed above with a pad/omit process 232 in place of warping process 132 and associated codebook 133.
- a closed-loop fitting procedure searches for the value of ⁇ min ⁇ ⁇ ⁇ ⁇ max , which minimizes an error criterion similar to equation (12): This procedure is carried out by process 234 (which determines ⁇ ′ according to equation (17)) and error evaluator 135 (which determines ⁇ ′ min ).
- ⁇ associated with ⁇ ′ min ⁇ j .
- this embodiment of the present invention provides scaling and delay information, linear prediction coefficients, and fixed stochastic codebook indices to a conventional CELP receiver.
- delay information may be transmitted every frame, rather than every subframe.
- the receiver may interpolate delay information to determine delay values for individual subframes as done by delay estimator 140 of the transmitter.
- Interpolation with a stepped-delay contour may proceed as follows. Let t A and t B denote the beginning and end of the present interpolation interval, for the original signal. Further, we denote with the index j A the first LTP subframe of the present interpolation interval, and j B the first LTP subframe of the next interpolation interval. First, an open-loop estimate of the delay at the end of the present interpolation interval, d B , is obtained by, for example, a cross-correlation process between past and present speech signals. (In fact the value used for t B for this purpose must be an estimate, since the final value results after conclusion of the interpolation.) Let the delay at the end of the previous interpolation interval be denoted as d A .
- delay doubling or halving can be accommodated as follows. As a first step, the open-loop delay estimate for the endpoint in the present interpolation interval is compared with the last delay in the previous interpolation interval. When ever it is close to a multiple or submultiple of the previous interpolation interval endpoint, then delay multiplication or division is considered to have occurred. What follows is a discussion of how to address delay doubling and delay halving; other multiples may be addressed similarly.
- Equation (22) describes two sequential mappings by an LTP. A simple multiplication of the delay by two does not result in a correct mapping when the pitch period is not constant.
- Equation (24) shows that, within a restricted range, d2( ⁇ ) is linear. However, in general, D2( ⁇ ) is not linear in the range where ⁇ A ⁇ ⁇ ⁇ ⁇ A +d1( ⁇ ). The following procedure can be used for delay doubling.
- Equation (28) provides also a boundary value for the present interpolation interval, d1( ⁇ A ). From this value and d1( ⁇ B ), the value of ⁇ for equation (23) can be computed. Again, equation (22) can be used to compute d2( ⁇ ) in the present interpolation interval. The transition from d2( ⁇ ) to d1( ⁇ ) is again performed by using equation 22, but now ⁇ ( ⁇ ) decreases from 1 to 0 in the interpolation interval.
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
- Compression Of Band Width Or Redundancy In Fax (AREA)
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US78268691A | 1991-10-25 | 1991-10-25 | |
| US782686 | 1991-10-25 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| EP0539103A2 true EP0539103A2 (de) | 1993-04-28 |
| EP0539103A3 EP0539103A3 (en) | 1993-08-11 |
| EP0539103B1 EP0539103B1 (de) | 1998-04-29 |
Family
ID=25126860
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP92309442A Expired - Lifetime EP0539103B1 (de) | 1991-10-25 | 1992-10-16 | Verallgemeinerte Analyse-durch-Synthese Methode und Einrichtung zur Sprachkodierung |
Country Status (4)
| Country | Link |
|---|---|
| EP (1) | EP0539103B1 (de) |
| JP (1) | JP3662597B2 (de) |
| DE (1) | DE69225293T2 (de) |
| ES (1) | ES2115646T3 (de) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP0602826A2 (de) * | 1992-12-14 | 1994-06-22 | AT&T Corp. | Zeitverschiebung zur Kodierung von Analyse durch Synthese |
| EP0773533B1 (de) * | 1995-11-09 | 2000-04-26 | Nokia Mobile Phones Ltd. | Verfahren zur Synthetisierung eines Sprachsignalblocks in einem CELP-Kodierer |
| KR100444635B1 (ko) * | 1995-09-19 | 2005-02-02 | 에이티 앤드 티 코포레이션 | 개량형 음성 코딩 방법 |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6113653A (en) * | 1998-09-11 | 2000-09-05 | Motorola, Inc. | Method and apparatus for coding an information signal using delay contour adjustment |
-
1992
- 1992-10-16 EP EP92309442A patent/EP0539103B1/de not_active Expired - Lifetime
- 1992-10-16 ES ES92309442T patent/ES2115646T3/es not_active Expired - Lifetime
- 1992-10-16 DE DE69225293T patent/DE69225293T2/de not_active Expired - Lifetime
- 1992-10-23 JP JP28480892A patent/JP3662597B2/ja not_active Expired - Lifetime
Non-Patent Citations (4)
| Title |
|---|
| IEEE TRANSACTIONS ON ACOUSTICS,SPEECH AND SIGNAL PROCESSING. vol. 36, no. 9, September 1988, NEW YORK US pages 1437 - 1444 SHIRAKI, HONDA 'LPC speech coding based on variable length segment quantization' * |
| IEEE TRANSACTIONS ON COMMUNICATIONS vol. 38, no. 11, November 1990, NEW YORK US pages 1935 - 1937 LEE, UN 'On reducing computational complexity of codebook search in CELP coding' * |
| INTERNATIONAL CONFERENCE ON ACOUSTICS SPEECH AND SIGNAL PROCESSING vol. 1, 23 March 1992, SAN FRANCISCO USA pages 337 - 340 KLEIJN ET AL 'Generalized analysis by synthesis coding and its application to pitch prediction' * |
| INTERNATIONAL JOURNAL OF ELECTRONICS vol. 67, no. 2, August 1989, LONDON GB pages 173 - 178 PALIWAL 'Reduced complexity stochastically excited coder for the low bit rate coding of speech' * |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP0602826A2 (de) * | 1992-12-14 | 1994-06-22 | AT&T Corp. | Zeitverschiebung zur Kodierung von Analyse durch Synthese |
| EP0602826A3 (de) * | 1992-12-14 | 1994-12-07 | At & T Corp | Zeitverschiebung zur Kodierung von Analyse durch Synthese. |
| KR100444635B1 (ko) * | 1995-09-19 | 2005-02-02 | 에이티 앤드 티 코포레이션 | 개량형 음성 코딩 방법 |
| EP0773533B1 (de) * | 1995-11-09 | 2000-04-26 | Nokia Mobile Phones Ltd. | Verfahren zur Synthetisierung eines Sprachsignalblocks in einem CELP-Kodierer |
Also Published As
| Publication number | Publication date |
|---|---|
| EP0539103A3 (en) | 1993-08-11 |
| JPH05232995A (ja) | 1993-09-10 |
| DE69225293D1 (de) | 1998-06-04 |
| ES2115646T3 (es) | 1998-07-01 |
| DE69225293T2 (de) | 1998-09-10 |
| JP3662597B2 (ja) | 2005-06-22 |
| EP0539103B1 (de) | 1998-04-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP0409239B1 (de) | Verfahren zur Sprachkodierung und -dekodierung | |
| US5127053A (en) | Low-complexity method for improving the performance of autocorrelation-based pitch detectors | |
| US5138661A (en) | Linear predictive codeword excited speech synthesizer | |
| US8538747B2 (en) | Method and apparatus for speech coding | |
| EP0745971A2 (de) | Einrichtung zur Schätzung der Abstandsverzögerung unter Verwendung von Kodierung linearer Vorhersagereste | |
| WO1992016930A1 (en) | Speech coder and method having spectral interpolation and fast codebook search | |
| US6169970B1 (en) | Generalized analysis-by-synthesis speech coding method and apparatus | |
| EP1420391B1 (de) | Verfahren zur Sprachkodierung mittels verallgemeinerter Analyse durch Synthese und Sprachkodierer zur Durchführung dieses Verfahrens | |
| US6148282A (en) | Multimodal code-excited linear prediction (CELP) coder and method using peakiness measure | |
| US5751901A (en) | Method for searching an excitation codebook in a code excited linear prediction (CELP) coder | |
| EP0578436B1 (de) | Selektive Anwendung von Sprachkodierungstechniken | |
| EP0602826B1 (de) | Zeitverschiebung zur Kodierung von Analyse durch Synthese | |
| EP1204092B1 (de) | Sprachdekoder zum hochqualitativen Dekodieren von Signalen mit Hintergrundrauschen | |
| EP1103953B1 (de) | Verschleierungsverfahren bei Verlust von Sprachrahmen | |
| US5692101A (en) | Speech coding method and apparatus using mean squared error modifier for selected speech coder parameters using VSELP techniques | |
| EP0539103B1 (de) | Verallgemeinerte Analyse-durch-Synthese Methode und Einrichtung zur Sprachkodierung | |
| JPH0782360B2 (ja) | 音声分析合成方法 | |
| JPH08328597A (ja) | 音声符号化装置 | |
| JP3299099B2 (ja) | 音声符号化装置 | |
| EP0713208A2 (de) | System zur Schätzung der Grundfrequenz | |
| EP0537948B1 (de) | Verfahren und Vorrichtung zur Glättung von Grundperiodewellenformen | |
| JPH08185199A (ja) | 音声符号化装置 | |
| JP2001142499A (ja) | 音声符号化装置ならびに音声復号化装置 | |
| JPH08320700A (ja) | 音声符号化装置 | |
| JP2000029499A (ja) | 音声符号化装置ならびに音声符号化復号化装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| AK | Designated contracting states |
Kind code of ref document: A2 Designated state(s): DE ES FR GB IT |
|
| PUAL | Search report despatched |
Free format text: ORIGINAL CODE: 0009013 |
|
| AK | Designated contracting states |
Kind code of ref document: A3 Designated state(s): DE ES FR GB IT |
|
| 17P | Request for examination filed |
Effective date: 19940127 |
|
| RAP3 | Party data changed (applicant data changed or rights of an application transferred) |
Owner name: AT&T CORP. |
|
| 17Q | First examination report despatched |
Effective date: 19961018 |
|
| GRAG | Despatch of communication of intention to grant |
Free format text: ORIGINAL CODE: EPIDOS AGRA |
|
| GRAG | Despatch of communication of intention to grant |
Free format text: ORIGINAL CODE: EPIDOS AGRA |
|
| GRAH | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOS IGRA |
|
| GRAH | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOS IGRA |
|
| GRAA | (expected) grant |
Free format text: ORIGINAL CODE: 0009210 |
|
| AK | Designated contracting states |
Kind code of ref document: B1 Designated state(s): DE ES FR GB IT |
|
| ITF | It: translation for a ep patent filed | ||
| ET | Fr: translation filed | ||
| REF | Corresponds to: |
Ref document number: 69225293 Country of ref document: DE Date of ref document: 19980604 |
|
| REG | Reference to a national code |
Ref country code: ES Ref legal event code: FG2A Ref document number: 2115646 Country of ref document: ES Kind code of ref document: T3 |
|
| PLBE | No opposition filed within time limit |
Free format text: ORIGINAL CODE: 0009261 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: NO OPPOSITION FILED WITHIN TIME LIMIT |
|
| 26N | No opposition filed | ||
| REG | Reference to a national code |
Ref country code: GB Ref legal event code: IF02 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: DE Payment date: 20101022 Year of fee payment: 19 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: GB Payment date: 20101021 Year of fee payment: 19 Ref country code: IT Payment date: 20101026 Year of fee payment: 19 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: FR Payment date: 20111103 Year of fee payment: 20 Ref country code: ES Payment date: 20111026 Year of fee payment: 20 |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R071 Ref document number: 69225293 Country of ref document: DE |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R071 Ref document number: 69225293 Country of ref document: DE |
|
| REG | Reference to a national code |
Ref country code: GB Ref legal event code: PE20 Expiry date: 20121015 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: GB Free format text: LAPSE BECAUSE OF EXPIRATION OF PROTECTION Effective date: 20121015 |
|
| REG | Reference to a national code |
Ref country code: ES Ref legal event code: FD2A Effective date: 20130808 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: ES Free format text: LAPSE BECAUSE OF EXPIRATION OF PROTECTION Effective date: 20121017 |