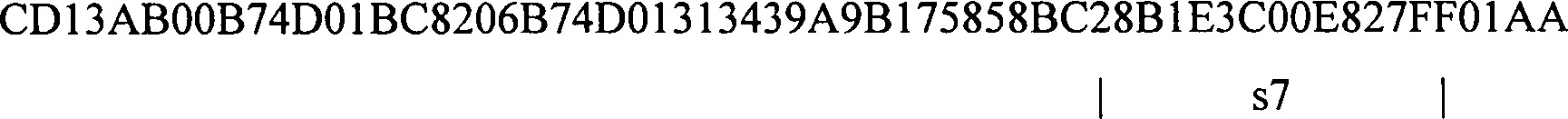-
Die
vorliegende Erfindung bezieht sich auf die Erfassung von Dateneigenschaften,
z.B. der Infizierung mit bestimmten Computerviren, welche Datenfolgen
möglicherweise
besitzen. Insbesondere bezieht sich diese Erfindung auf Verfahren
zum Erfassen von Dateneigenschaften, welche mit der Verwendung eines
Minimums des Systemhauptspeichers einhergehen.
-
Es
bestehen mehrere anerkannte Verfahren zur Erfassung von Computerviren
im Speicher, in Programmen, Dokumenten oder anderen potentiellen
Hosts, welche diese unter Umständen
beherbergen. Ein gängiges
Verfahren, welches in den meisten Antivirusprodukten Einsatz findet,
wird „Scanning" genannt.
-
Ein
Scanner sucht nach potentiellen Hosts für eine Menge aus einem oder
mehreren (typischerweise aus mehreren tausend) als „Signaturen" bezeichneten spezifischen
Codemustern, welche auf besonders bekannte Viren oder Virenfamilien
hindeuten oder bei denen die Wahrscheinlichkeit besteht, dass sie
in neuen Viren enthalten sind. Die typische Signatur besteht aus
einem Muster, dessen Entsprechung es zu finden gilt, sowie aus impliziten
oder expliziten Hilfsinformationen über die Art der Entsprechung,
und eventuell über Transformationen,
die an den Eingabedaten vor der Suche nach einer Entsprechung für das Muster
durchzuführen
sind. Bei dem Muster könnte
es sich um eine Bytesequenz handeln, zu welcher in dem potentiellen
Host eine exakte oder inexakte Entsprechung zu suchen ist. Allgemeiner
ausgedrückt,
könnte
das Muster ein regulärer
Ausdruck sein. Die Hilfsinformationen könnten Informationen über die
Anzahl und/oder den Ort der zulässigen
fehlangepassten Bytes enthalten. Ebenso könnten sie die Übereinstimmung
in verschiedener Weise einschränken;
z.B. könnte
die Übereinstimmung
auf Eingabedaten begrenzt werden, welche Computerprogramme im .EXE-Format
darstellen, und eine weitere Einschränkung könnte festlegen, dass Übereinstimmungen nur
dann angegeben werden, wenn sie in einem Bereich innerhalb eines
Kilobytes zu beiden Seiten des Eingangspunkts auftreten. Die Hilfsinformationen
können
außerdem
Transformationen präzisieren;
z.B. könnte die Notwendigkeit
bestehen, Eingabedaten dadurch zu transformieren, dass aneinander
angrenzende Bytes vor dem Scannen nach der angegebenen Bytesequenz
durch Xoring vereint werden. (Dies gestattet Mustern, in Daten lokalisiert
zu werden, welche verschlüsselt
wurden, indem jedes Byte mit einem beliebigen 1 Byte Schlüssel einem
Xoring unterzogen wurde; eine detaillierte Beschreibung ist zu finden
in dem am 15. August 1995 an William C. Arnold, u.a. erteilten US
Patent 5442699 mit dem Titel „Searching
for patterns in encrypted data".)
Weitere Beispiele für
Transformationen, die gegenwärtig
allgemein eingesetzt werden, umfassen die Anwendung eines Emulators
auf dem Eingabeprogramm, damit ein polymorpher Virus ermutigt wird,
sich vor dem Scannen nach Mustern (nahezu) selbst zu entschlüsseln, und
das Parsing eines Microsoft Word Dokuments, um die Makrodaten vor
dem Scannen nach Makroviren zu entschlüsseln.
-
Ein
weiteres Beispiel für
einen Virusscanner wird in NL-A-9100084 angeführt.
-
Bezeichnenderweise
geht ein Scanner so vor, dass er zunächst die Signaturdaten für einen
oder mehrere Viren in den Speicher lädt und dann eine Menge von
potentiellen Hosts auf Entsprechungen zu einer oder mehreren der
Signaturen untersucht. Wird irgendeine Signatur gefunden, können weitere
Maßnahmen
ergriffen werden, um den Benutzer vor dem wahrscheinlichen Vorhandensein
eines Virus zu warnen und um das Virus in einigen Fällen zu
beseitigen.
-
Da
die Anzahl bekannter Computerviren rapide über die Zehntausend-Marke hinauswächst, spitzt
sich das Problem hinsichtlich der Aufbewahrung von Signaturen und
zugehörigen
Informationen im Speicher immer mehr zu. Dies gilt insbesondere
im Fall des DOS-Betriebssystems, welches normalerweise gerade einmal
640 Kilobytes für
sämtliche
Programme und Daten im Systemspeicher zur Verfügung stellt, einschließlich der
Virussignaturen, des Antivirus-Programmcodes, der anti-viralen Terminator-
und Stay Resident Prozessen sowie jedes beliebigen anderen nicht
zugehörigen
Codes und ebensolcher Daten, welche eventuell in den Systemspeicher
geladen wurden.
-
Eine
mögliche
Lösung
für das
Problem der Speicherknappheit in auf DOS basierenden Systemen besteht
darin, dass das Antivirusprogramm einen DOS-Extender einsetzt, welcher
Programmen gestattet, mehr als 640 Kilobytes an Speicher zu verwenden,
falls ein derartiger „erweiterter
Speicher" auf dem
Computer vorhanden ist. Obgleich viele der heutigen PCs über einen
erweiterten Speicher verfügen,
können
DOS-Extender den Betrieb eines Antivirusprogramms erheblich verlangsamen.
Jedenfalls ist es selbst bei anderen Betriebssystemen als DOS wünschenswert,
die Speicherverwendung zu minimieren, vorausgesetzt, dass sich dies ohne
eine erhebliche Herabsetzung der Geschwindigkeit des Scanners bewerkstelligen
lässt.
-
Die
Erfassung von Computerviren bietet nur ein Beispiel für das generelle
Problem bezüglich
der Bestimmung, ob eine gegebene Datenfolge irgendeine aus einer
gegebenen Menge von Eigenschaften besitzt. Unter einer Datenfolge
ist eine Sequenz von Bytes zu verstehen, welche Informationen auf
einem Computer repräsentieren,
z.B. ein Programm oder ein Dokument. Ein Beispiel für eine Eigenschaft
von Datenfolgen, welche Computerprogramme bilden, stellt deren Infizierung
mit dem Jerusalem Virus dar. Die Menge von Eigenschaften könnte allen
bekannten Viren oder einer ihrer Untermengen zugehören. Ein
zweites Beispiel für
eine Eigenschaft von Computerprogrammen ist die, von einem bestimmten
Kompilierer kompiliert worden zu sein. Für Datenfolgen, welche Text
darstellen, gehören
zu den Beispielen für
Dateneigenschaften, dass der Text in einer bestimmten Sprache abgefasst
ist, z.B. in Französisch,
oder dass er Informationen über
ein bestimmtes Sachgebiet enthält,
z.B. über
Sport oder die Aufführungen
von Händel-Oratorien.
-
Ein
gängiges
Verfahren zur Erfassung von Dateneigenschaften in Datenfolgen besteht
in der Suche nach einer Menge von Mustern, welche auf diese Eigenschaften
hinweisen. Bei Computerviren sind die Muster typischerweise Computervirussignaturen,
wie oben beschrieben. Der Kompilierer, der zur Erzeugung eines gegebenen
Körpers
eines Maschinencodes verwendet wird, stellt eine Eigenschaft dar,
welche sich ebenfalls mit Hilfe von Signaturen identifizieren lässt. Um
Sprachen oder Sachgebiete zu identifizieren, kann ein Text nach Mengen
von Schlüsselwörtern abgescannt
werden, und aus der Häufigkeit
des Auftretens dieser Schlüsselwörter oder
deren ungefährer
Entsprechungen lässt
sich folgern ob, und wenn ja, welche Eigenschaften vorhanden sind.
Recht häufig
gibt es ein Abbild von den lokalisierten Ereignissen des Vorkommens
der Muster auf eine (möglicherweise
leere) Menge von gefolgerten Dateneigenschaften. Das Abbild kann
die Orte der Ereignisse des Vorkommens innerhalb der Datenfolge
berücksichtigen
oder auch nicht. Das Abbild kann ein eins-zu-eins, ein eins-zu-viele
oder ein viele-zu-eins Verhältnis
darstellen. Beispielsweise ist das Abbild bei Computervirusanwendungen
ungefähr
eins-zu-eins, aber einige Signaturen treten in mehreren Viren auf,
und zur Identifizierung eines einzigen Virus werden mitunter mehrere
Signaturen benützt.
-
Ungeachtet
der Besonderheiten einer Anwendung kommt es häufig vor, dass eine effiziente
Erfassung von Dateneigenschaften innerhalb einer Datenfolge eine
simultane Suche nach einer großen
Anzahl von Mustern in eben dieser Datenfolge verlangt. In solchen
Fällen
kann der zur Speicherung der Muster und jeglicher Hilfsdaten benötigte Speicherplatz
erheblich sein. Gemeinhin ist es wünschenswert, dass ein Detektor
von Dateneigenschaften in jeglicher Hinsicht so effizient wie möglich arbeitet;
insbesondere ist von Belang, dass der Detektor den geringst möglichen
Speicherplatz in Anspruch nimmt.
-
Grob
umrissen, bietet die vorliegende Erfindung sowohl ein effizientes
Verfahren zum Erfassen der Wahrscheinlichkeit des Vorhandenseins
von bekannten Dateneigenschaften in einer Datenfolge als auch eine Programmspeichereinheit
(z.B. eine Diskette), welche von einem Rechner gelesen werden kann
und konkret ein Programm von Befehlen beinhaltet, welche durch den
Rechner ausgeführt
werden können,
um die Schritte dieses Verfahrens durchzuführen.
-
Aufgrund
dessen bietet die vorliegende Erfindung ein Verfahren zum Erfassen
der Wahrscheinlichkeit des Vorhandenseins einer Dateneigenschaft
aus einer ersten Menge von bekannten Dateneigenschaften in einer
Datenfolge durch Verwendung einer zweiten Menge G von allgemeinen
Merkmalen und einer dritten Menge S von Signaturen, wobei die allgemeinen
Merkmale und die Signaturen für
die erste Menge von Dateneigenschaften kennzeichnend sind, wobei
das Verfahren die folgenden Schritte umfasst:
- a)
Laden der Menge G in einen Speicher eines Computers,
- b) Lokalisieren der Ereignisse des Vorkommens jedes allgemeinen
Merkmals der Menge G in der Datenfolge,
- c) Erstellen eines ersten Abbilds von den Ereignissen des Vorkommens,
die in Schritt b) lokalisiert wurden, um eine Teilmenge S* von S
zu erhalten,
- d) Laden aller Signaturen aus der Teilmenge S* in einen Speicher
des Computers,
- e) Lokalisieren der Ereignisse des Vorkommens aller Signaturen
aus der Teilmenge S* in der Datenfolge, und
- f) Erstellen eines zweiten Abbilds von den Ereignissen des Vorkommens,
die in Schritt b) lokalisiert wurden, um eine Menge von Dateneigenschaften
zu identifizieren, die in der Datenfolge wahrscheinlich vorhanden sind.
-
In
Abhängigkeit
von der Wahrscheinlichkeit, dass irgendeine identifizierte Menge
von Dateneigenschaften in besagter Datenfolge vorhanden ist, kann
das Verfahren nach Wunsch einen weiteren Schritt umfassen, welcher
darin besteht, dass die Identität
der Dateneigenschaften in der identifizierten Menge signalisiert
wird.
-
Gemäß einer
weiteren bevorzugten Ausführungsform
und in Abhängigkeit
davon, ob irgendwelche Signaturen gemäß Schritt (d) in den Speicher
geladen werden, kann das Verfahren einen weiteren Schritt umfassen,
welcher in dem Entladen der Signaturen aus dem Speicher nach Ausführung von
Schritt (e) besteht.
-
In
einer bevorzugten Ausführungsform
des erfinderischen Verfahrens ist jede Dateneigenschaft ein Computervirus,
der durch eine Signatur s der dritten Menge S identifizierbar ist.
-
In
einer bevorzugten Ausführungsform
des erfinderischen Verfahrens benötigt die zweite Menge G von allgemeinen
Merkmalen eine geringere Speichergröße für die Speicherung als die dritte
Menge S von Signaturen.
-
Vorzugsweise
umfasst das besagte erste Abbild wie folgt:
- c1)
für jedes
allgemeine Merkmal, das in der Datenfolge wenigstens einmal vorkommt,
Abrufen einer zugehörigen
Liste von Signaturen der ersten Menge S aus einer ersten Nachschlagtabelle,
- c2) Verknüpfen
aller abgerufenen zugehörigen
Signaturlisten, um eine verknüpfte
Signaturliste zu bilden,
- c3) Zählen
der Häufigkeit
des Vorkommens jeder Signatur in der verknüpften Signaturliste,
- c4) Bilden der Teilmenge S* aus allen Signaturen s, für welche
die gezählte
Häufigkeit
des Vorkommens in der verknüpften
Signaturliste nicht kleiner als ein Schwellenwert für s ist,
der aus einem Wert berechnet wird, der aus einer zweiten Nachschlagtabelle
erhalten wird.
-
Gemäß einer
bevorzugten Ausführungsform
des erfinderischen Verfahrens wird die erste Nachschlagtabelle aus
einer Sammlung von Datenfolgen automatisch abgeleitet, wobei jede
Datenfolge wenigstens eine der Dateneigenschaften besitzt, wobei
dieses Verfahren die folgenden Schritte umfasst:
- L1a)
Lokalisieren aller Ereignisse des Vorkommens jedes allgemeinen Merkmals
der Menge G und jeder Signatur der Menge S in jeder Datenfolge in
der Sammlung,
- L1b) Definieren einer zugehörigen
Merkmalliste für
jede Signatur s, die alle allgemeinen Merkmale enthält, die
in jedem Element einer definierten Teilmenge der Menge von Datenfolgen,
in denen die Signatur s vorhanden ist, vorkommen,
- L1c) für
jedes allgemeine Merkmal g Definieren einer zugehörigen Signaturliste
aller Signaturen, die g in ihren zugehörigen Merkmallisten enthalten,
und
- L1d) Bilden der ersten Nachschlagtabelle durch Speichern jedes
allgemeinen Merkmals g mit seiner zugehörigen Signaturliste.
-
Vorzugsweise
wird die zweite Nachschlagtabelle aus einer Sammlung von Datenfolgen
automatisch abgeleitet, wobei jede Datenfolge wenigstens eine der
Dateneigenschaften enthält,
wobei dieses Verfahren die folgenden Schritte umfasst:
- L2a) Lokalisieren aller Ereignisse des Vorkommens aller allgemeinen
Merkmale der Menge G und aller Signaturen der Menge S in jeder Datenfolge
in der Sammlung,
- L2b) für
jede Signatur s,
- i) Definieren einer zugehörigen
Merkmalliste für
jede Signatur s, die alle allgemeinen Merkmale enthält, die in
jedem Element einer definierten Teilmenge der Menge von Datenfolgen,
in denen die Signatur s vorhanden ist, vorkommen,
- ii) Zählen
der Anzahl unterschiedlicher allgemeiner Merkmale in der zugehörigen Merkmalliste,
und
- iii) Berechnen einer Funktion des Zählers für die Signatur s;
- L2c) Bilden der zweiten Nachschlagtabelle durch Speichern jeder
Signatur s mit der Funktion ihres Zählers.
-
In
einer bevorzugten Ausführungsform
ist die Funktion des Zählers
der Zählerstand
selbst. In einer weiteren Ausführungsform
kann die Funktion des Zählers
der größere Wert
von einer ersten gewählten
Konstanten und dem Zählerstand,
verringert um eine zweite gewählte
Konstante, sein.
-
Wie
zuvor erwähnt,
bietet die Erfindung weiterhin allgemein eine Programmspeichereinheit
(z.B. ein Computerband oder eine Diskette), welche durch einen Rechner
gelesen werden kann und konkret ein Programm aus Anweisungen beinhaltet,
welche durch den Rechner ausgeführt
werden können,
und zwar zwecks Durchführung
von Schritten eines Verfahrens zum Erfassen der Wahrscheinlichkeit
des Vorhandenseins einer Dateneigenschaft aus einer ersten Menge
von bekannten Dateneigenschaften in einer Datenfolge durch Verwendung
einer zweiten Menge G von allgemeinen Merkmalen und einer dritten
Menge S von Signaturen, wobei die allgemeinen Merkmale und die Signaturen
kennzeichnend für
die erste Menge von Dateneigenschaften sind, wobei besagtes Verfahren
die folgenden Schritte umfasst:
- a) Laden der
Menge G in einen Speicher eines Computers,
- b) Lokalisieren der Ereignisse des Vorkommens jedes allgemeinen
Merkmals der Menge G in der Datenfolge,
- c) Erstellen eines ersten Abbilds von den Ereignissen des Vorkommens,
die in Schritt b) lokalisiert wurden, um eine Teilmenge S* von S
zu erhalten,
- d) Laden aller Signaturen aus der Teilmenge S* in einen Speicher
des Computers,
- e) Lokalisieren der Ereignisse des Vorkommens aller Signaturen
aus der Teilmenge S* in der Datenfolge, und
- f) Erstellen eines zweiten Abbilds von den Ereignissen des Vorkommens,
die während
Schritt e) lokalisiert wurden, um eine Menge von Dateneigenschaften
zu identifizieren, die in der Datenfolge wahrscheinlich vorhanden
sind.
-
Anders
formuliert, stellt die vorliegende Erfindung fest, wenn überhaupt,
welche Dateneigenschaften aus einer ersten Menge T derartiger Eigenschaften
eine gegebene Datenfolge D wahrscheinlich besitzt. Bei ihrer Verwendung
von Speicherplatz erweist sich die vorliegende Erfindung effizient,
und in einigen Fällen
kann sie außerdem
einen Geschwindigkeitsvorteil gegenüber bestehenden Techniken verschaffen.
-
Die
Erfindung kann als eine Klassifiziereinrichtung für Datenfolgen
betrachtet werden, welche zwei wesentliche Komponenten beinhaltet.
Bei der ersten Komponente handelt es sich um eine „Standard"-Klassifiziereinrichtung,
welche innerhalb einer gegebenen Datenfolge D nach einer Menge S
(d.h. nach einer „dritten Menge") von Mustern und
zugehörigen
Hilfsdaten sucht (welche nachfolgend als „Signaturen" bezeichnet werden);
wenn sie derartige Signaturen findet, verwendet die Einrichtung
ein Abbild zwischen den lokalisierten Ereignissen des Vorkommens
(d.h. den Identitäten
beliebiger vorkommender Signaturen und möglicherweise deren Ort in D)
und den Dateneigenschaften, um daraus auf das wahrscheinliche Vorhandensein
einer oder mehrerer Dateneigenschaften in D zu schließen. Typischerweise
gehört
jede Signatur zu nur einer oder vielleicht zu einigen wenigen der
Dateneigenschaften in T, so dass das Abbild zwischen Signaturen
und Dateneigenschaften gewöhnlich
recht einfach ausfällt,
vielleicht sogar eins-zu-eins ist. Bei der zweiten Komponente handelt
es sich um eine „Filter"-Klassifiziereinrichtung,
welche vor der „Standard"-Klassifiziereinrichtung
zum Einsatz kommt. Die Filter-Klassifiziereinrichtung sucht innerhalb
der gegebenen Datenfolge D nach Ereignissen des Vorkommens einer anderen
Menge (d.h. einer „zweiten
Menge") G von Mustern
und zugehörigen
Hilfsdaten (welche nachfolgend als „allgemeine Merkmale" bezeichnet werden).
Typischerweise gehören
die von dem „Filter" verwendeten allgemeinen
Merkmale tendenziell zu mehreren der Dateneigenschaften, und sind
sowohl kompakter in ihrer Darstellung als auch geringer in ihrer
Anzahl als jene, die von der „Standard"-Klassifiziereinrichtung
benützt
werden. Daher neigt der von der Menge G benützte Speicherplatz dazu, weitaus
niedriger zu sein als jene, die von der Menge S in Anspruch genommen
wird. Die in D vorgefundene Teilmenge von Ereignissen des Vorkommens
allgemeiner Merkmale wird, falls sie irgendwelche Elemente enthält, eingesetzt, um
eine Teilmenge von Signaturen S* zu konstruieren, welche in D vorhanden
sein könnte.
Anstatt die ganze Menge von Signaturen S zu verwenden, muss die „Standard"-Klassifiziereinrichtung
lediglich S* aus einem sekundären
Speichermedium (z.B. einer Festplatte, Diskette oder einem CD-ROM)
in den Speicher laden. Daraufhin arbeitet die Standard-Klassifiziereinrichtung
in normaler Weise, wobei sie das Vorhandensein jeder beliebigen
Signatur verwendet, die in D gefunden wird, um daraus auf das wahrscheinliche
Vorhandensein von zugehörigen
Dateneigenschaften innerhalb D zu schließen.
-
In
Situationen der Praxis, z.B. beim Scannen nach Computerviren, sind
die kombinierten Speichererfordernisse der „Filter"-Klassifiziereinrichtung und der kennzeichnenderweise
kleinen Teilmenge S* von Signaturen, welche von der „Standard"-Klassifiziereinrichtung geladen wird,
geringer als die Speichererfordernisse der nicht erweiterten „Standard"-Klassifiziereinrichtung,
welche die gesamte Menge S von Signaturen einsetzen muss. Anders
ausgedrückt,
sind die Speichererfordernisse für
G, S* und den Extracode, welcher durch das Filter eingeführt wird,
erheblich geringer als die Speichererfordernisse für S. Dadurch,
dass die Speichererfordernisse in dieser Weise reduziert werden,
besteht keine Notwendigkeit, die Geschwindigkeit der Klassifiziereinrichtung
zu senken; tatsächlich
trug die Speicherverringerung bei einer Ausführung dieser Erfindung dazu
bei, die Gesamtgeschwindigkeit der Klassifiziereinrichtung zu verbessern.
-
Die
Menge von Signaturen S kann manuell oder automatisch abgeleitet
werden; das automatische Extrahieren wird in US Patent 5452442 beschrieben.
Auch die Menge allgemeiner Merkmale G lässt sich manuell oder automatisch
ableiten; eine automatische Ableitung kann durch Mittel erfolgen,
welche beschrieben sind in US Patent 5675711 mit dem Titel: „Adaptive
Statistical Regression and Classification of Data Strings, with Application
to the Generic Detection of Computer Viruses". Dieses Patent wurde am 13. Mai 1994
an G. J. Tesauro, G. B. Sorkin und J. O. Kephart erteilt. Das Abbild
zwischen einer Teilmenge allgemeiner Merkmale und der zugehörigen Teilmenge
von Signaturen, welche zu überprüfen sind,
lässt sich
zwar auch manuell ableiten, aber in einer bevorzugten Ausführungsform
wird das Abbild automatisch durch Verfahren abgeleitet, welche in der
detaillierten Beschreibung der vorliegenden Erfindung ausführlicher
zu erläutern
sind.
-
In
einer Ausführungsform
der vorliegenden Erfindung handelt es sich bei besagter Datenfolge
um jede beliebige Bytesequenz, welche ausführbare Anweisungen und zugehörige Daten
darstellt, welche als potentieller Host für ein Computervirus dienen
können,
und die Klassifiziereinrichtung wird eingesetzt, um das wahrscheinliche
Vorhandensein irgendeines Virus unter einer spezifizierten Menge
von Computerviren zu erfassen. Die „Standard"-Komponente
der Klassifiziereinrichtung besteht aus einem Virusscanner, z.B.
jenem der in IBM AntiVirus eingegliedert ist, oder nahezu jedem
anderen Standardvirusscanner.
-
Eine
zweite Ausführungsform
der vorliegenden Erfindung besteht in ihrer Anwendung hinsichtlich
des Problems der Bestimmung, welcher Kompilierer zur Erzeugung eines
gegebenen ausführbaren
Computerprogramms eingesetzt wurde, wenn überhaupt. Bei dieser Anwendung
ist die Datenfolge, welche der Klassifiziereinrichtung präsentiert
wird, der Maschinencode des gegebenen Computerprogramms. Das Verfahren
beinhaltet zunächst
das Abscannen des Programms nach einer Menge von allgemeinen Merkmalen,
wobei jedes Merkmal durch eine Bytesequenz dargestellt wird, für welche
eine Entsprechung benötigt
wird, die exakt ist oder eine vorgegebene Anzahl von Fehlübereinstimmungen
aufweist; ferner das Abbilden der Teilmenge allgemeiner Merkmale
auf eine Teilmenge von Signaturen, wobei jede Signatur aus einer
Bytesequenz besteht, der exakt oder mit einer vorgegebenen Anzahl
von Fehlübereinstimmungen
zu entsprechen ist; des Weitern das Abscannen des Programms nach
jeder Signatur in der Teilmenge; und, falls irgendwelche Signaturen
innerhalb des Programms lokalisiert werden, die Schlussfolgerung,
dass das Programm unter Verwendung des zu der Signatur/den Signaturen
gehörenden
Kompilierers kompiliert wurde.
-
Eine
Ausführungsform
der Erfindung wird nun unter Bezugnahme auf die begleitenden Zeichnungen beschrieben,
in welchen:
-
1 ein
Blockdiagramm eines Computersystems zur Ausführung der vorliegenden Erfindung
ist.
-
2 ein
Flussdiagramm ist, welches ein Verfahren zum Erfassen von Dateneigenschaften
in einer gegebenen Datenfolge in Übereinstimmung mit der vorliegenden
Erfindung beschreibt.
-
3 ein
Flussdiagramm ist, welches eine Funktion zur Abbildung beschreibt,
welche eine Menge allgemeiner Merkmale in eine Teilmenge von Signaturen
in Übereinstimmung
mit der vorliegenden Erfindung abbildet.
-
4 ein
Flussdiagramm ist, welches ein Verfahren zur Ableitung zweier Nachschlagtabellen
in Übereinstimmung
mit der vorliegenden Erfindung erläutert.
-
Zunächst wird
auf 1 Bezug genommen, welche ein Blockdiagramm eines
Systems 10 zeigt, das sich zur Veranschaulichung der Erfindung
eignet.
-
Ein
Bus 12 besteht aus einer Mehrzahl von Signalleitungen zum
Transport von Adressen, Daten und Steuerungsbefehlen zwischen einer
Zentraleinheit (ZE) 14 und einer Anzahl anderer Einheiten
des Systembusses. An den Systembus 12 ist ein RAM 16 gekoppelt,
welches Speicherplatz für
Programmbefehle und Arbeitsspeicher für die ZE 14 zur Verfügung stellt.
Weiterhin ist mit dem Systembus 12 ein Subsystem 18 zur Terminal-Steuerung
verbunden, welches Ausgänge
an ein Display 20, typischerweise ein CRT-Monitor, liefert und
Eingänge
von einem Gerät 22 für manuelle
Eingabe, z.B. von einer Tastatur oder einem Zeigegerät (z.B. einer
Maus), erhält.
Ein Subsystem 24 zur Festplattensteuerung koppelt eine
rotierende Festplatte, oder Festplatte 26, bidirektional
mit den Systembus 12. Die Steuerung 24 und die
Festplatte 26 verschaffen Massenspeicher für ZE-Befehle
und -Daten. Ein Subsystem 28 zur Floppy Disk Steuerung,
welches gemeinsam mit den Floppy Disk Laufwerken 30 als
Eingabemittel bei dem Transfer von Computerdaten von Floppy Disketten 30a zum
Systemspeicher nützlich
ist, verbindet bidirektional ein oder mehrere Floppy Disk Laufwerke 30 mit dem
Systembus 12.
-
Selbstverständlich können die
in 1 veranschaulichten Komponenten in einem Personal
Computer, einem tragbaren Computer, einer Workstation, einem Minicomputer, einem
Supercomputer oder jedem beliebigen anderen System enthalten sein,
welches einen Computer umfasst. Dementsprechend sind die Einzelheiten
der physischen Ausführung
der Hardware des Datenverarbeitungssystems 10, wie etwa
die Struktur des Busses 12 oder die Anzahl der an den Bus
gekoppelten Zentraleinheiten 14 nicht entscheidend für den Betrieb
der Erfindung und werden daher nicht weiter erläutert.
-
Das
erfindungsgemäße Verfahren
wird nun anhand eines spezifischen, in 2 dargestellten
Beispiels dargelegt. 2 zeigt ein Flussdiagramm, welches
die Logik der Abläufe
veranschaulicht, durch welche auf die Wahrscheinlichkeit des Vorhandenseins
beliebiger erheblicher Dateneigenschaften innerhalb einer gegebenen
Datenfolge D, sowie auf die Identitäten solcher Dateneigenschaften,
geschlossen wird.
-
Zunächst wird
die vollständige
zweite Menge G von allgemeinen Merkmalen in einen Speicher eines Computers
geladen 202. Die Daten der allgemeinen Merkmale spezifizieren
Muster, für
die es eine Entsprechung zu finden gilt, und zugehörige Hilfsdaten,
wie bereits zuvor im Bezug auf den Stand der Technik erklärt wurde.
Dann erfolgt die Suche 204 nach Datenfolge D, um Ereignisse
des Vorkommens jedes allgemeinen Merkmals zu finden, welches zu
der Menge G gehört.
Die Daten auf den lokalisierten Ereignissen des Vorkommens können genaue
Einzelheiten darüber
enthalten, wo jedes Merkmal in D vorkommt, oder lediglich die Anzahl
von Ereignissen des Vorkommens jedes Musters innerhalb D oder innerhalb
bestimmter Bereiche von D zählen
(z.B. in einem Bereich von 1000 Bytes vor oder nach dem Eintrittspunkt,
wenn D ein potentiell infiziertes Host-Programm darstellt), oder auch lediglich
vermerken, ob jedes allgemeine Merkmal überhaupt innerhalb D vorgekommen
ist oder nicht. Dann bildet in Schritt 206 eine erste Abbildungsfunktion
M1 die lokalisierten Ereignisse des Vorkommens in jeglicher Form,
in welcher diese ausgedrückt
sind, in einer Signaturreferenzliste Sref* ab,
welche die Identitäten
einer Teilmenge S* von Signaturen enthält, die aus der vollständigen dritten Menge
S von Signaturen ausgewählt
werden. In Schritt 208 wird eine Bestimmung durchgeführt, ob
die Teilmenge S* Signaturen enthält.
Ist dies nicht der Fall, wird daraus der Schluss gezogen 210,
dass wahrscheinlich keine erheblichen Dateneigenschaften vorhanden
sein. Wenn die Teilmenge S* jedoch Signaturen enthält, dann
werden in Schritt 212 jene Signaturen, auf welche in der
Signaturreferenzliste Sref* verwiesen wird,
aus einer Datenbank der vollständigen
Menge von Signaturen S, welche sich auf einem sekundären Speichermedium,
z.B. einer Festplatte, einer Floppy Disk oder einem CD-ROM, befindet,
ausgelesen und in ein primäres Speichermedium,
d.h. einen Computerspeicher, geladen. Nun ist die Signaturteilmenge
S* in dem Speicher vorhanden. Die Datenfolge D wird durchsucht 214,
um Ereignisse des Vorkommens jeder Signatur in der Teilmenge S*
zu finden. Erneut können
die lokalisierten Ereignisse des Vorkommens so spezifisch oder unspezifisch
bezüglich
des genauen Ortes oder der Häufigkeit
des Auftretens jedes Musters sein, wie dies von der Anwendung garantiert
wird. Daraufhin bildet eine zweite Abbildungsfunktion M2 die lokalisierten
Ereignisse des Vorkommens in eine gefolgerte Gruppe von Dateneigenschaften
ab 216, welche wahrscheinlich innerhalb D vorhanden sind.
Das zweite Abbild M2 ist häufig
recht einfach; im Fall von Computerviren wird es typischerweise
als Nachschlagtabelle implementiert, welche jeder Signatur eine
Liste von einem oder mehreren Viren zuordnet, bei denen die Wahrscheinlichkeit
besteht, dass sie vorhanden sind, wenn diese Signatur gefunden wird.
Nachdem gefolgert wurde, dass eine oder mehrere Dateneigenschaften
innerhalb der Datenfolge vorhanden sein können, besteht die Möglichkeit
zur Erzeugung 218 eines entsprechenden Signals, z.B. ein
Message Listing, oder die Anzeige einer Beschreibung von Dateneigenschaften,
welche wahrscheinlich vorhanden sind, auf dem Computerdisplay, oder
auch ein Trigger, der weitere Abläufe auslöst, welche dem Vorhandensein
der Dateneigenschaften angemessen sind. In Schritt 220 kann
die Signaturteilmenge S* optional aus dem Speicher entladen oder
im Zwischenspeicher untergebracht werden, um eventuell zu Lasten
irgendeines Speichers an Geschwindigkeit zu gewinnen.
-
Typischerweise
ist eine Signatur gerade einmal einer oder vielleicht ein paar der
Dateneigenschaften in der erheblichen Menge zugehörig, obgleich
dies nicht wesentlich ist. Das Ableiten der Menge von Signaturen lässt sich
mittels einer Vielzahl von Verfahren durchführen, einschließlich einer
manuellen Bestimmung durch einen Fachmann oder einer automatischen
Extraktion von Signaturen aus zwei Mengen von Datenfolgen, nämlich einer
ersten Menge von Datenfolgen, von der bekannt ist, dass sie die
Dateneigenschaften besitzt, und einer zweiten Menge von Datenfolgen,
von der bekannt ist, dass sie die Dateneigenschaften nicht besitzt. Die
Einzelheiten eines solchen automatischen Verfahrens zur Signaturextraktion
werden in US Patent 5452442 beschrieben.
-
Kennzeichnenderweise
ist ein allgemeines Merkmal mehreren Dateneigenschaften in der erheblichen Menge
zugehörig,
obgleich dies nicht wesentlich ist. Die Menge von allgemeinen Merkmalen
kann manuell durch einen Fachmann oder automatisch aus zwei Mengen
von Datenfolgen abgeleitet werden, nämlich einer ersten Menge von
Datenfolgen, von der bekannt ist, dass sie die Dateneigenschaften
besitzt, und einer zweiten Menge von Datenfolgen, von der bekannt
ist, dass sie die Dateneigenschaften nicht besitzt. Die Einzelheiten der
automatisierten Extraktion allgemeiner Merkmale werden in dem von
Tesauro, u.a. gestellten US Patentantrag S.N. 08/242757 beschrieben.
-
Die
Abbildungsfunktion M1, welche die lokalisierten Ereignisse des Vorkommens
der allgemeinen Merkmale in der Datenfolge in eine Signaturreferenzliste
Sref* abbildet, kann auf vielerlei Arten
funktionieren. Wie zuvor ausgeführt,
kann das Abbild von den genauen Orten oder der Anzahl von Zeitpunkten,
zu denen ein bestimmtes allgemeines Merkmal erscheint, abhängen oder
nicht. Wenn besagte Datenfolgen potentielle Hosts für Computerviren
sind, besteht die Möglichkeit,
Einzelheiten des genauen Orts zu ignorieren (vorausgesetzt, dass
die Entsprechung in allgemeine Bereiche fällt, welche durch die Hilfsdaten
zugelassen werden), und es ist weiterhin möglich, die Details der Häufigkeit
des Vorkommens der Ereignisse zu ignorieren (d.h. ausschlaggebend
ist einzig, ob ein gegebenes Merkmal erscheint oder nicht). Ein
Flussdiagramm einer bevorzugten Ausführungsform der Abbildungsfunktion,
welche für
den Fall eingeführt
wurde, dass die Datenfolgen Computerprogramme sind, ist in 3 erläutert. Für jedes
allgemeine Merkmal g wird aus einer im Voraus errechneten Nachschlagtabelle
L1 eine zugehörige
Signaturliste erhalten 302, wenn die Anzahl der Zeitpunkte,
zu denen es innerhalb der Datenbereiche vorkommt, die durch die
Hilfsdaten für
g definiert werden, größer Null ist.
In Schritt 304 werden sämtliche
zugehörigen
Signaturlisten, die so abgerufen wurden, zwecks Bildung einer verknüpften Signaturliste
VSL verbunden. Daraufhin wird in Schritt 306 die Häufigkeit
des Vorkommens jeder Signatur s innerhalb der verknüpften Signaturliste,
O(s), gezählt.
Für jede
Signatur s, für
welche O(s) Null überschreitet,
wird ein maximaler Schwellenwert MT(s) aus einer Nachschlagtabelle
L2 abgerufen 308, welcher maximale Schwellenwerte für jede Signatur
in Menge S enthält.
In Schritt 310 kann eine Funktion F auf jeden abgerufenen
maximalen Schwellenwert MT(s) angewandt werden, um einen gleichen
oder kleineren Schwellenwert T(s) zu erhalten, welcher die minimale
Anzahl von Zeitpunkten darstellt, die s innerhalb VSL erscheinen
muss, um sich für
die Einbeziehung in die Menge S* zu qualifizieren. Die logische
Maßnahme
zur Verringerung des Schwellenwerts von MT(s) auf einen kleineren
Wert T(s) wäre,
einige Fehlübereinstimmungen
zu akzeptieren, z.B. als Reaktion auf den ausdrücklichen Wunsch eines Benutzers,
dies so zu handhaben. In einem solchen Fall könnte die Funktion F z.B. T(s)
als den größeren Wert
von einer ersten gewählten
Konstante (z.B. 1) oder den MT(s) weniger einer zweiten gewählten Konstante
berechnen. In Schritt 312 wird die Signatur s zu der Signaturreferenzliste
Sref* zugefügt, wenn, und nur dann, wenn
die Zahl O(s) nicht unter dem Schwellenwert T(s) liegt.
-
Die
im Voraus berechnete Nachschlagtabelle L1, welche für jedes
allgemeine Merkmal eine Liste zugehöriger Signaturen enthält, lässt sich
manuell oder automatisch erzeugen. In einer bevorzugten Ausführungsform
erfolgt die Erzeugung automatisch durch ein Verfahren, welches in
dem Flussdiagramm aus 4 dargestellt ist. Zunächst wird
eine Sammlung von Sample-Datenfolgen, von denen jede bekanntermaßen mindestens
eine der erheblichen Dateneigenschaften besitzt, gesucht 402,
um alle Ereignisse des Vorkommens jedes allgemeinen Merkmals und
jede Signatur in jeder Datenfolge in der Sammlung zu finden. (Die
Einbeziehung von Samples, welche keine der Dateneigenschaften besitzen,
führt nicht
zum Scheitern des Verfahrens; es findet lediglich eine Verschwendung
statt). Dann wird für
jede Signatur s eine Teilmenge aller Datenfolgensamples, welche
s enthalten, identifiziert 404. Die Teilmenge von Datensamples
könnte
allen Datensamples in der Sammlung entsprechen, welche s enthalten,
oder sie könnte
durch andere Kriterien weiter eingeschränkt sein; z.B. könnten bei
der sich auf Computerviren beziehenden Ausführungsform Datensamples, welche „unechte" Entsprechungen zu
Signaturen enthalten, von der Teilmenge ausgeschlossen werden.
-
Von
einer gegebenen Signatur s kann gesagt werden, dass sie einem gegebenen
Element D der Sammlung von Datenfolgen nur fälschlich entspricht, wenn beide
der folgenden Bedingungen erfüllt
sind. Zunächst
ist/sind die Dateneigenschaft(en), welche D besitzt, bekannt oder
kann/können
durch ein unabhängiges Verfahren,
welches kein Scannen nach Signaturen in der Menge S mit sich bringt,
und anschließendes
Erstellen des Abbilds M2 zwecks Folgerung der Dateneigenschaften
erschlossen werden. (Von jedem Element einer Menge von Selbstreproduzenten,
welche dadurch erhalten wird, dass ein Sampel eines Virus X absichtlich dazu
gebracht wird, sich zu vermehren, wäre bekannt, dass es die Dateneigenschaft „mit X
infiziert" besitzt). Zweitens
enthält
die Menge von Dateneigenschaften, welche zu s gehören (jene,
welche durch Erstellen des Abbilds M2 aus s erhalten werden) jene
Dateneigenschaften) nicht, von der/denen unabhängig bekannt ist, dass D diese
besitzt. (Selbst wenn das gegebene Element D nur mit Virus X infiziert
ist, enthält
es möglicherweise
andere Virussignaturen bedingt durch die Tatsache, dass Viren untereinander
häufig
Familienähnlichkeit aufweisen
und daher mitunter ähnliche
Bytesequenzen enthalten.)
-
In
Schritt 406 wird für
jede Signatur eine Liste zugehöriger
Merkmale dadurch festgelegt, dass in diese Liste alle allgemeinen
Merkmale aufgenommen werden, welche in jedem Element der Datensampleteilmenge für s vorkommen.
Als nächstes
wird für
jedes allgemeine Merkmal g eine Liste zugehöriger Signaturen bestimmt 408,
welche aus allen Signaturen besteht, die g unter ihren zugehörigen Merkmallisten
enthalten. Schließlich
wird die Nachschlagtabelle L1 gebildet, indem jedes allgemeine Merkmal
g mit seiner in Schritt 408 erhaltenen zugehörigen Signaturliste
gespeichert wird 410.
-
Die
Schwellenwertnachschlagtabelle L2 (welche die minimale Anzahl von
Zeitpunkten enthält,
zu denen eine gegebene Signatur in der verknüpften Signaturliste erscheinen
muss, damit sie der Signaturreferenzliste Sref* zugefügt werden
kann) lässt
sich ebenfalls manuell oder automatisch erzeugen. Eine bevorzugte
Ausführungsform
ist in 4 dargestellt. Sobald die Liste zugehöriger Merkmale
für jede
Signatur s erzeugt ist 406, wird eine Funktion F2 der Anzahl
unterschiedlicher allgemeiner Merkmale in jeder zugehörigen Merkmalliste
in Schritt 412 errechnet, um den maximalen Schwellenwert
MT(s) zu erhalten. Typischerweise ist die Funktion F2 die Identität, d.h.
die Funktion der Anzahl ist die Anzahl selbst. Allgemeiner ausgedrückt, ist
F2 kleiner oder gleich der Anzahl selbst; in letzterem Fall gestattet
dies Fehlübereinstimmungen.
Zu beachten gilt, dass derartige Fehlübereinstimmungen entweder bei
der Ableitung der Schwellenwertnachschlagtabelle L2 oder bei der
Ableitung eines Schwellenwerts aus dem Wert in der Nachschlagtabelle
in Schritt 308 zugelassen werden können. Anders ausgedrückt, erfüllen die
Funktionen F1 und F2 im Wesentlichen den gleichen Zweck – nämlich die
Berücksichtigung
von Fehlübereinstimmungen
-, und jeder bestimmten Ausführung
der Erfindung können
beide, eine oder keine von diesen angewandt werden. Schließlich wird
die zweite Nachschlagtabelle durch Speichern jeder Signatur s mit
dem maximalen Schwellenwert MT(s) gebildet 414.
-
Die
Klassifizierungsdaten, einschließlich der vollständigen Menge
allgemeiner Merkmale G, der vollständigen Menge von Signaturen
S, der im Voraus berechneten Nachschlagtabelle L1 und der Schwellenwertnachschlagtabelle
L2, können
zu einem beliebigen Zeitpunkt vor der Erfassungsphase auf einem
Computersystem berechnet werden, welches sich von jenem völlig unterscheidet,
auf welchem die Erfassung der Dateneigenschaften stattfindet. Die
Klassifizierungsdaten können
als eine oder mehrere Dateien gespeichert werden, aus welchen sich
eine unbegrenzte Anzahl von Kopien anfertigen und auf Computern
speichern lässt,
auf welchen das Vorhandensein der erheblichen Dateneigenschaften
erfasst werden soll. Wenn zu einem späteren Zeitpunkt eine Datenfolge
auf einem solchen Computer klassifiziert werden soll, können die
Klassifizierungsdaten aus der Datei/den Dateien in den Speicher
des Computers geladen werden, gemeinsam mit Verfahren zur Verwendung
der Klassifizierungsdaten, um die Datenfolgen zu klassifizieren.
-
BEISPIEL
-
Zum
besseren Verständnis
der Erfindung erfolgt deren Beschreibung anhand eines spezifischen
Beispiels für
deren Verwendung zur Viruserfassung in zwei Phasen, und zwar einer
Phase der „Vorbereitung" oder Ableitung der
Nachschlag- und Schwellenwerttabellen, und einer Erfassungsphase.
-
Vorbereitungsphase
-
- 1. Eingaben: Bei Ableitung einer Nachschlagtabelle
werden in diesem Beispiel die drei folgenden Eingaben getätigt:
- A) Eine Sammlung von Samples virusinfizierter Datenfolgen. Hierbei
wird angenommen, dass 17 derartige Samples vorhanden sind, von denen
das erste und das letzte gezeigt werden:
Sample V1: CD13AB00B74D01BC820631343004914009A9B175858BCAF37CD2180E9004A
...
...
...
Sample
V17: 906453C7CD2180D1C56803A32400A16A0A42CC9B511175858B2CF44A2E8E0
- B) Eine Menge G allgemeiner Merkmale, abgeleitet aus der Sammlung
virusinfizierter Samples von Datenfolgen in a) durch Mittel, welche
in dem von Tesauro, u.a. gestellten US Patentantrag S.N. 08/242757
beschrieben sind (gängiger
Praxis zufolge liegt die Anzahl allgemeiner Merkmale typischerweise
in einem Bereich von mehreren Dutzend bis mehreren Tausend.) Hierbei
wird davon ausgegangen, dass vier derartige allgemeine Merkmale,
also g1, g2, g3 und g4, bestehen, von denen jedes als eine Bytesequenz
zu verstehen ist, für
welche die genaue Entsprechung benötigt wird, und jedes an einer
beliebigen Stelle innerhalb der gegebenen Datenfolge zu finden ist:
g1:
B74D01
g2: CD2180
g3: C3E807
g4: 175858
- C) Eine Menge S von Signaturen, die aus der Sammlung virusinfizierter
Datenfolgen in Übereinstimmung mit
Verfahren abgeleitet werden, welche in dem am 19. September 1995
an Jeffrey O. Kephart erteilten US Patent Nr. 5452442 offenbart
sind. Hierbei wird von 8 derartigen Signaturen ausgegangen, also
s1, s2, ..., s8, von denen jede als eine Bytesequenz zu verstehen
ist, für
welche die genaue Entsprechung benötigt wird, und jede an einer
beliebigen Stelle innerhalb der gegebenen Datenfolge gefunden werden
kann:
s1: 4D01BC820631343
s2: 4D01BC850631343
s3:
FA8BCDE800005B8
s4: 8ED0BC000750B8C
s5: 4F0026A0FE032EA
s6:
2BCB2E8A0732C2D
s7: 28B1E3C00E827FF
s8: 6803A32400A16A0
- 2. Scannen jedes Samples nach Signaturen und allgemeinen Merkmalen.
Der nächste
Schritt beim Ableiten der Nachschlagtabelle besteht im Scannen jedes
virusinfizierten Samples, um die Ereignisse des Vorkommens sämtlicher
Signaturen und allgemeiner Merkmale zu lokalisieren; für Samples
V1 und V17 ergaben sich aus diesem Schritt die folgenden Ergebnisse: Die Ergebnisse
der Scanvorgänge
mit V1, V2, ..., V17 sind in Tabelle A festgehalten: Tabelle
A
- 3. Erzeugen einer Tabelle allgemeiner Merkmale, welche zu jeder
Signatur gehören.
Für jede
distinkte Signatur besteht der nächste
Schritt darin, sämtliche
allgemeinen Merkmale zu identifizieren („Liste zugehöriger Merkmale"), welche stets mit
ihr zusammen in der zuvor genannten Tabelle A auftreten, und zwar
in der zweiten Spalte einer Tabelle B. Daraufhin kann die Anzahl
derartiger distinkter allgemeiner Merkmale, welche in der zweiten
Spalte zu finden sind, (in einer dritten Spalte von Tabelle B) festgehalten
werden. Anhand dieser dritten Spalte werden während der Phase der Erfassung
Schwellenwerte berechnet. Unter Verwendung von Tabelle A in besagter
Weise lässt
sich die folgende Tabelle B herleiten:
-
-
Aus
Tabelle A geht beispielsweise hervor, dass s4 in den Samples V7,
V8 und V9 erschien. Das einzige allgemeine Merkmal, das in jedem
einzelnen dieser Samples auftrat, war g2, weshalb in Tabelle B nur
g2 zu s4 gehört.
-
Nun
lässt sich
die Nachschlagtabelle L2 ableiten, indem eine Funktion F2 auf die
Anzahl der jeder Signatur zugehörigen
Merkmale angewandt wird. Der Einfachheit halber wird F2 als Identität angenommen. Dann
wird die Nachschlagtabelle L2 verbatim der ersten und der dritten
Spalte von Tabelle B schlicht entnommen: Nachschlagtabelle
L2
| Signatur | Maximaler
Schwellenwert |
| s1 | 2 |
| s2 | 2 |
| s3 | 3 |
| s4 | 1 |
| s5 | 2 |
| s6 | 3 |
| s7 | 1 |
| s8 | 2 |
- 4. Invertieren zwecks Erhalt
von Signaturen, welche jedem allgemeinen Merkmal zugehörig sind.
Tabelle B wird schließlich
invertiert, um eine Nachschlagtabelle L1 zu erhalten, welche, für jedes
allgemeine Merkmal, alle Signaturen auflistet, denen es in Tabelle
B zugehörig
ist. Beispielsweise ist g3 in der zweiten Spalte von Tabelle B als
zugehöriges
allgemeines Merkmal für
Signaturen s2, s3 und s6 gelistet, und dies ist in Tabelle L1 festgehalten.
Nachschlagtabelle
L1 | Allgemeines
Merkmal | Zugehörige Signaturliste |
| g1 | s1
s3 s5 s7 |
| g2 | s2
s4 s5 s6 s8 |
| g3 | s2
s3 s6 |
| g4 | s1
s3 s6 s8 |
-
Nun
stehen sämtliche
Elemente, welche zur Erfassung von Viren in Übereinstimmung mit der Erfindung
benötigt
werden, zur Verfügung:
sowohl die Mengen G und S als auch die Nachschlagtabellen L1 und
L2.
-
DETEKTIONSPHASE
-
Anhand
dieser Phase des Beispiels wird erläutert, wie sich die vorliegende
Erfindung zwecks Bestimmung einsetzen lässt, ob irgendeine der 8 Virussignaturen
in einer Datenfolge D vorhanden ist, welche Gegenstand der Untersuchungen
ist. Anstatt der aus s1–s8
bestehenden Menge S muss lediglich die aus g1–g4 bestehende Menge G in den
Speicher geladen werden, welche weitaus weniger Speicherplatz benötigt. Im
Anschluss daran werden gängige
Scantechniken zur Suche nach g1, g2, g3 und g4 in der Datenfolge
D eingesetzt:
-
-
Um
die Signaturreferenzliste Sref* zu erhalten,
muss nun das Abbild M1 erstellt werden. In diesem Beispiel tritt
G1 zweimal und G4 einmal auf; des weiteren ist das Abbild M1 so
beschaffen, dass die exakten Stellen des Vorkommens von G1 und G4
belanglos sind, genauso wie die Tatsache, dass GI mehr als einmal
erschienen ist. Da G1 und G4 die einzigen allgemeinen Merkmale darstellen,
welche in D erscheinen, werden sie beide als Nachschlagschlüssel in
Nachschlagtabelle L1 eingesetzt, und ihre zugehörigen Signaturlisten werden
zwecks Erzeugung einer verknüpften
Signaturliste verbunden:
-
Verknüpfte Signaturliste: s1 s3 s5
s7 s1 s3 s6 s8
-
Die
Ereignisse des Vorkommens jeder Signatur in der verknüpften Signaturliste
werden gezählt
und in der zweiten Spalte von Tabelle D angezeigt. Dann werden die
maximalen Schwellenwerte MT(s) für
jede Signatur s aus Nachschlagtabelle L2 abgerufen, und eine Funktion
F1 wird auf jeden davon angewandt, um T(s) zu ermitteln. In diesem
Beispiel wird von Funktion F1 als der Identität ausgegangen, so dass die
Schwellenwerte in der dritten Spalte von Tabelle D verbatim aus
der zweiten Spalte der Nachschlagtabelle L2 übernommen werden. Danach werden
Spalten zwei und drei von Tabelle D verglichen, und jene, bei denen
die Zahl in der zweiten Spalte den Schwellenwert in der dritten
Spalte erreicht oder übertrifft,
werden in der vierten Spalte angegeben.
-
-
Mit
s1 und s7 erfüllen
in diesem Fall zwei Signaturen das Kriterium, und die Signaturreferenzliste
Sref* besteht aus s1 und s7.
-
Dementsprechend
wird nur die aus den Signaturen s1 und s7 bestehende Menge S* von
der Diskette in den Speicher geladen, und gängige Scanverfahren (z.B. jene,
die von IBM AntiVirus eingesetzt werden) können dann bei dem Versuch verwendet
werden, s1 und s7 innerhalb der Datenfolge D zu lokalisieren.
-
Das
Ergebnis dieses Scanvorgangs lautet wie folgt:
-
-
Das
Vorhandensein von s7 innerhalb der Datenfolge D wird folglich erfasst,
und ein Abbild M2 kann erstellt werden, um eine Liste von Viren
zu erhalten, welche zu s7 gehören
(typischerweise nur einer). Dadurch lassen sich die geeigneten Maßnahmen
ergreifen, z.B. das Warnen des Benutzers vor der wahrscheinlichen Anwesenheit
des Virus. Eine Alternative dazu stellt das Senden eines entsprechenden
Signals an andere, nicht von der Tragweite dieser Erfindung erfasste
Abläufe
dar, welche über
das Vorhandensein der Dateneigenschaft informiert werden müssen.
-
An
diesem Punkt können
s1 und s7 aus dem Speicher entfernt werden, wenn dies gewünscht wird; allerdings
wird bei Caching mitunter bevorzugt, diese zu behalten.
-
Wie
die vorangehenden Ausführungen
belegen, verlangt die dargelegte Erfindung lediglich jene Speichergröße, welche
erforderlich ist, um g1, g2, g3, g4, s1 und s7 zum Zwecke des Scannens
zu speichern, und nicht die weitaus beträchtlichere Größe zur Speicherung
aller acht der möglichen
Virussignaturen s1, s2, ... s8 aus diesem Beispiel.
-
Obgleich
diese Erfindung unter Bezugnahme auf eine bevorzugte Anwendungsmöglichkeit
erläutert wurde,
welche sich auf Computerviren bezieht, sind für Fachleute auch weitere Anwendungen
des hierin offenbarten erfinderischen Konzepts offenkundig.
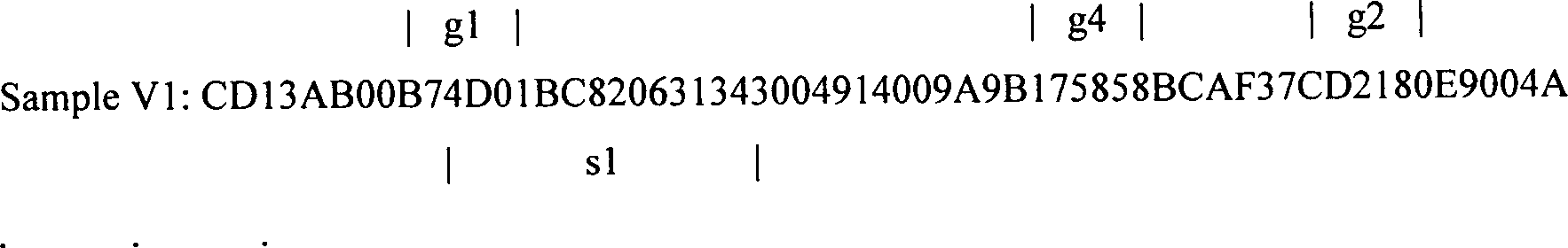 Die Ergebnisse der Scanvorgänge mit V1, V2, ..., V17 sind in Tabelle A festgehalten: Tabelle A
Die Ergebnisse der Scanvorgänge mit V1, V2, ..., V17 sind in Tabelle A festgehalten: Tabelle A