CN1256700C - 基于n元组或随机存取存储器的神经网络分类系统和方法 - Google Patents
基于n元组或随机存取存储器的神经网络分类系统和方法 Download PDFInfo
- Publication number
- CN1256700C CN1256700C CNB998099988A CN99809998A CN1256700C CN 1256700 C CN1256700 C CN 1256700C CN B998099988 A CNB998099988 A CN B998099988A CN 99809998 A CN99809998 A CN 99809998A CN 1256700 C CN1256700 C CN 1256700C
- Authority
- CN
- China
- Prior art keywords
- value
- global property
- decision rule
- standard
- local characteristics
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images
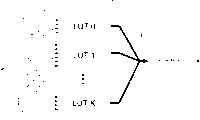

Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Evolutionary Computation (AREA)
- Biomedical Technology (AREA)
- Mathematical Physics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioinformatics & Computational Biology (AREA)
- Health & Medical Sciences (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Evolutionary Biology (AREA)
- Software Systems (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Data Exchanges In Wide-Area Networks (AREA)
- Magnetic Resonance Imaging Apparatus (AREA)
- Luminescent Compositions (AREA)
- Electrotherapy Devices (AREA)
- Catalysts (AREA)
- Image Analysis (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
本发明涉及基于N元组或随机存取存储器的神经网络分类方法和系统,更特别地说,涉及这样一种基于N元组或随机存取存储器的分类系统,在该系统中用来获得输出得分并比较这些输出得分以获得分类的判决标准在训练过程中确定。因此,本发明涉及训练一种计算机分类系统的系统和方法,其中的计算机系统可以由包括多个这样的N元组或查找表(LUTs)的网络定义,即每个N元组或LUT包括对应于可能的类别的至少一个子集的行数,并且包括由抽样的训练输入数据样本的信号或元素编址的列。
Description
技术领域
总的来说,本发明涉及基于N元组或随机存取存储器的神经网络分类系统,更特别地,涉及这样一种基于N元组或随机存取存储器的分类系统,在该系统中用来获得输出得分并比较这些输出得分(output score)以获得分类的判决标准在训练过程中确定。
背景技术
分类用电信号或二进制码,更精确地说,用施加到神经网络分类系统的输入中的信号向量表示的对象或模式(pattern)的已知方式,处于所谓的学习或训练阶段的实施中。这个阶段一般包括通过使用一个或多个被称作学习或训练集的信号集,尽可能有效地完成实现设想的分类功能的分类网络的配置,其中,要将分类进去类别之一中的这些信号的每一个的从属关系是已知的。这种方法被称为监督学习(supervised learning)或有教师学习(lear-ningwith a teacher)。
使用监督学习的分类网络的一种子类是使用基于存储器学习的网络。这里,最老的基于存储器的网络之一是由Bledsoe和Browning提出的“N元组网络”(Bledsoe,W.W.和Browning,I.,1959,“Pattern recognition and readingby machine”,Proceeding of the Eastern Joint Computer Conference,pp.225-232),较新的描述由Morciniec和Rohwer给出(Morciniec,M.和Rohwer,R.,1996,“A theoretical and experimental account of n-tuple classifierperformance”,Neural Comp.,pp.629-642)。
这种基于存储器的系统的优势之一是:在学习阶段和分类阶段中计算时间都很快。对于也被称作“随机存取存储器网络”或“无权值神经网络”的n元组网络的已知类型来说,学习可以通过在随机存取存储器(RAM)中纪录模式的特征来实现,对该系统来说,只需要训练集的一表示。
关于基于传统的RAM的神经网络的训练过程是由J
 rgensen(本发明的合作者)等人,投在最近的一本关于基于RAM的神经网络的书里的论文中描述的(T.M.J
rgensen(本发明的合作者)等人,投在最近的一本关于基于RAM的神经网络的书里的论文中描述的(T.M.J
 rgensen,S.S.Christensen,和C.Liisberg,“Cross-validation andinformation measures for RAM based neural networks”,RAM-based neuralnetworks,J.Austin,ed.,World Scientific London pp.78-88,1998)。该论文描述了基于RAM的神经网络如何看成包括多个查找表(LUTs,Look UpTables)。每一个LUT(Look Up Table)可以探查(probe)二进制输入向量的一个子集。在传统方案中,要使用的多个比特是随机选择的。该抽样的比特序列被用于构造地址。这种地址与LUT中的指定项(列)对应。LUT中的行号与可能的类号对应。对于每一个类,输出能够取成0或者1。值1对应于对于那个指定类的一票。当执行分类时,抽样输入向量,添加从所有LUTs来的输出向量,随后冠军取得所有为分类输入向量而作出的判决。为了执行对网络的简单训练,输出值可以在最初设置成0。然后,对于训练集中的每一个样本应该执行以下步骤:
rgensen,S.S.Christensen,和C.Liisberg,“Cross-validation andinformation measures for RAM based neural networks”,RAM-based neuralnetworks,J.Austin,ed.,World Scientific London pp.78-88,1998)。该论文描述了基于RAM的神经网络如何看成包括多个查找表(LUTs,Look UpTables)。每一个LUT(Look Up Table)可以探查(probe)二进制输入向量的一个子集。在传统方案中,要使用的多个比特是随机选择的。该抽样的比特序列被用于构造地址。这种地址与LUT中的指定项(列)对应。LUT中的行号与可能的类号对应。对于每一个类,输出能够取成0或者1。值1对应于对于那个指定类的一票。当执行分类时,抽样输入向量,添加从所有LUTs来的输出向量,随后冠军取得所有为分类输入向量而作出的判决。为了执行对网络的简单训练,输出值可以在最初设置成0。然后,对于训练集中的每一个样本应该执行以下步骤:
将输入向量和目标类送到网络;对所有的LUT,计算它们对应的列的项数;以及在所有的“活动”列中,设置目标类的输出值为1。
通过使用这样的训练策略,可以保证每一训练模式总是获得关于真类的最多票数。因此,这样的网络不会在训练集上作出任何错误分类,但可能发生含糊不清的判决。这里,该网络的推广(generalisation)能力与每个LUT的输入比特数直接关联。如果LUT抽样所有的输入比特,那么它就象纯粹的存储器设备一样起作用,而不会提供任何推广能力。当输入的比特数减少时,推广能力以增加含糊不清的判决数为代价增加。此外,LUT的分类和推广性能高度依赖于探查到的输入比特的实际子集。因此,“智能”训练过程的目的将是选择输入数据的最适当的子集。
J
 rgensen等人进一步描述了什么是“留一交叉确认测试”(leave-one-outcross-validation test),这种测试提出了一种用来选择最优输入连接数来使用每个LUT的方法,以便用较短的总体计算时间获得较低的分类错误率。为了执行这样的交叉确认测试,需要获得具有与编址的列和类别对立应的、已经访问或编址的单元或者元素的训练样本的实际数的知识。因此建议将这些数字存储在LUTs中。J
rgensen等人进一步描述了什么是“留一交叉确认测试”(leave-one-outcross-validation test),这种测试提出了一种用来选择最优输入连接数来使用每个LUT的方法,以便用较短的总体计算时间获得较低的分类错误率。为了执行这样的交叉确认测试,需要获得具有与编址的列和类别对立应的、已经访问或编址的单元或者元素的训练样本的实际数的知识。因此建议将这些数字存储在LUTs中。J
 rgensen等人还提出了如何能够以一种更优化的方法,通过连续不断地训练LUTs的新集,并在每个LUT上执行交叉确认测试,来选择网络中的LUTs。因此,有种RAM网络是众所周知的,在该网络中LUTs是通过给系统送几次训练集选出。
rgensen等人还提出了如何能够以一种更优化的方法,通过连续不断地训练LUTs的新集,并在每个LUT上执行交叉确认测试,来选择网络中的LUTs。因此,有种RAM网络是众所周知的,在该网络中LUTs是通过给系统送几次训练集选出。
来自RAM网络的输出向量包含多个输出得分,每个可能的类别一个。如上所述,通常通过将样本分类进具有最多输出得分的类别来判决。这种简单的冠军取得所有(winner-takes-all,WTA)的方案保证了训练样本的真类不会输给其它类别之一。RAM网的分类方案的一个问题是:当在训练类别之间的样本分布高度非对称的训练集上训练时无所作为。因此,需要了解训练材料的成分对RAM分类系统的行为的影响,还要大概了解该体系结构的指定参数对该性能的影响。根据这些了解,可以修改该分类方案以提高其性能以及与其它方案的竞争力。本发明提供基于RAM的分类系统的这种改进。
发明内容
Thomas Martini J
 rgensen和Christian Linneberg(本发明的合作者)最近提供了一种统计框架,该统计框架使得进行这样一种理论分析成为可能,即将期望的n元组网的输出得分与该样本分布的随机参数、可以利用的训练样本的数量以及每个LUT所使用的地址行n的数量联系起来。他们已经能够从获得的表达式研究不同方案中的体系结构的行为。此外,他们已经将反映修改n元组分类方案的建议的理论结果作为了基础,以使得将其作为最大后验估计或极大似然估计的近似进行操作。产生的修改的判决标准,例如,可以对付所谓的非对称类别的现有问题,即当在训练类别之间的样本分布高度非对称的训练集中训练时,引起该n元组网时常无所作为的问题。因此,关于该分类方案的建议的改变提供体系结构的本质改进。建议的判决标准的改变不仅适用于基于随机记忆的原来的n元组体系结构,而且可以应用于扩展的n元组方案,一些扩展方案使用更优化的地址行选择,一些应用扩展的加权方案。
rgensen和Christian Linneberg(本发明的合作者)最近提供了一种统计框架,该统计框架使得进行这样一种理论分析成为可能,即将期望的n元组网的输出得分与该样本分布的随机参数、可以利用的训练样本的数量以及每个LUT所使用的地址行n的数量联系起来。他们已经能够从获得的表达式研究不同方案中的体系结构的行为。此外,他们已经将反映修改n元组分类方案的建议的理论结果作为了基础,以使得将其作为最大后验估计或极大似然估计的近似进行操作。产生的修改的判决标准,例如,可以对付所谓的非对称类别的现有问题,即当在训练类别之间的样本分布高度非对称的训练集中训练时,引起该n元组网时常无所作为的问题。因此,关于该分类方案的建议的改变提供体系结构的本质改进。建议的判决标准的改变不仅适用于基于随机记忆的原来的n元组体系结构,而且可以应用于扩展的n元组方案,一些扩展方案使用更优化的地址行选择,一些应用扩展的加权方案。
根据本发明的第一方面,提供一种用于训练计算机分类系统的方法,所述系统能够由包括多个n元组或查找表LUT的网络定义,每个n元组或LUT(Look Up Table)包括多个与可能的类别的至少一个子集对应的行,此外还包括多个由被抽样的训练输入数据样本的信号或元素编址的列,每列由具有值的单元的向量定义,其中基于一个或多个关于不同类别的输入数据样本的训练集,确定列向量单元的值,以使得至少部分这种单元包括或指向基于相应的单元地址被从一个或多个训练输入样本中抽样的次数的信息,其特征在于所述方法包括:为每一类别确定一个或多个用于至少一个输出得分值的评估的输出得分函数;和确定与所获得的输出得分值的至少一部分组合起来使用以确定一个获胜类(winning class)的一个或多个判决准则,其中该输出得分函数的确定包括输出得分函数的初始化,其后跟着根据基于至少一部分确定的列向量单元值的信息的信息度量,对至少一部分输出得分函数的调整,和/或其中,该判决准则的确定包括判决准则的初始化,其后跟着根据基于至少一部分所确定的列向量单元值的信息的信息度量,对至少一部分判决准则的调整。
该输出得分值最好基于被确定的列向量单元值的至少一部分的信息评估和确定。
根据本发明,该输出得分函数和/或该判决准则最好基于被确定的列向量单元值的至少一部分的信息确定。
最好从一族由一组参数值确定的输出得分函数确定该输出得分函数。因此,该输出得分函数可以由该组参数值确定,也可以由被确定的列向量单元值的至少一部分的信息确定,还可以由该组参数值和被确定的列向量单元值的至少一部分的信息两者确定。
应该了解的是:本发明的训练过程可以被看作一种两步训练过程。第一步可以包括确定列向量单元值,而第二步可以包括确定输出得分函数和/或该判决准则。
如上所述,虽然基于已知类别的输入数据样本的一个或多个训练集确定列向量单元值,但可以基于已知类别的输入数据样本的确认集确定输出得分函数和/或该判决准则。这里,该确认集可以等于该个(组)训练集,也可以是该个(组)训练集的一部分,而且还可以是不包括在该个(组)训练集中的一个样本集。
根据本发明,训练和/或确认输入数据样本最好可以作为输入信号向量送到网络。
输出得分函数的确定最好以下面的方式执行:在计算用于在两个或多个类别中找出赢类的输出得分时,允许以不同的方式使用列向量单元的内容。使用列向量单元的内容来获得一个类别的得分的方式,可以依赖于与其比较的那个类。
当与输出空间的两个或多个类别比较时使用的判决准则最好允许偏离对应于WTA判决的判决准则。改变用于挑选两个或多个类别的判决准则等效于允许类别输出得分的个别变换以及保持WTA比较。这些相应的变换可以依赖于与已给类别比较的那个(些)类别。
确定怎样可以从列向量单元值计算输出得分函数以及怎样使用多个输出得分函数和/或将被应用在输出得分值上的判决准则,可以包括初始化一个或多个输出得分函数集和/或判决准则。
此外,最好基于评估该确认样本集上的性能的信息度量调整输出得分函数和/或判决准则的至少一部分。如果该确认集等于该训练集或是该训练集的一部分,那么最好使用留一交叉确认评估或这种原理的扩展。
为了根据本发明确定或调整输出得分函数和判决准则,应该确定列单元的值。这里,至少部分列向量单元的值最好作为相应的单元地址从训练输入样本集中被抽样的次数的函数来确定。作为选择,列单元的信息可以确定得使最大的列单元值为1,而至少部分这样的单元具有与相应的单元地址从训练输入样本集中被抽样的次数的函数相关联的值。列向量单元的值最好在确定或调整输出得分函数和/或判决准则之前,确定并且存储在存储装置中。
根据本发明,一种确定列向量单元的值的优选方式可以包括以下训练步:
a)向分类网施加已知类的训练输入数据样本,从而编址一个或多个列向量,
b)增加对应于已知类的列(多列)的编址向量单元的值或票,最好以1递增,和
c)重复(a)-(b)步,直到所有训练样本都已经施加到网络为止。
然而应该知道,本发明也覆盖了其列单元的信息由单元已经被输入训练集编址的次数的替代函数确定的实施例。因此,这些单元的信息不需要包括已经编址的全部次数的数量,但例如,可以包括一个指示,以指示该单元已经被访问零次、一次、多于一次、和/或两次以及多于两次等等。
为了确定输出得分函数和/或判决准则,最好调整这些输出得分函数和/或判决准则,该调整处理可以包括一个或多个重复步骤。输出得分函数和/或判决准则的调整可以包括:基于至少部分列向量单元的值确定全局特性(global quality)值的步骤;确定全局特性值是否达到要求的特性标准的步骤;以及调整至少部分输出得分函数和/或判决准则,直到达到全局特性标准的步骤。
该调整处理也包括对每一个抽样的确认输入样本确定局部特性值的确定,对选定的输入样本,如果局部特性值未达到指定或要求的局部特性标准,那么执行一次或多次调整。作为一例子,输出得分函数和/或判决准则的调整可以包括以下步骤:
a)从确认集(组)中选择一输入样本,
b)确定对应于抽样的确认输入样本的局部特性值,局部特性值是至少部分编址的列单元值的函数,
c)确定局部特性值是否达到要求的局部特性标准,否则,如果局部特性值未达到标准,则调整一个或多个输出得分函数和/或判决准则,
d)从确认集(组)的预定的样本数量中选择一个新的输入样本,
e)对所有预定的训练输入样本,重复局部特性测试步骤(b)-(d),
f)基于至少部分在局部特性测试期间被编址的列向量确定全局特性值,
g)确定全局特性值是否达到要求的特性标准,以及
h)重复(a)-(g)步直到达到全局特性标准。
以上提到的调整处理中的步骤(b)-(d)最好可以对确认集(组)中的所有样本实施。
局部和/或全局特性值可以定义为至少部分列单元的函数。
应该理解的是,当通过使用每一个都有对应的特性标准的一个或多个特性值调整输出得分函数和/或判决准则时,如果特性标准在给定数量的重复次数之后没有达到,那么最好终止调整的重复处理。
还应该理解的是,在调整处理中,被调整的输出得分函数和/或判决准则最好在每次调整之后存储起来,并且当调整处理包括确定全局特性值时,如果确定的全局特性值比对应于以前分开存储的输出得分函数和/或判决准则或配置值更接近达到全局特性标准,则在全局特性值的确定步之后,可以进一步包括分开存储这里获得的输出得分函数和/或判决准则或分类系统配置值的步骤。
根据本发明的实施例,用于训练一分类系统的主要理由是在未知类的输入样本的后续分类处理中获得高置信度。
因此,根据本发明的进一步的方面,提供一种使用根据本发明的以上部分描述过的任何一种方法配置的计算机分类系统,将输入数据样本分类进多个类之一的方法,由此,每一个n元组或LUT的列单元值和输出得分函数和/或判决准则,通过在输入数据样本的一个或多个训练或确认集上使用来确定,所述方法包括:
a)将要被分类的输入数据样本施加到配置过的分类网络,从而编址n元组或LUTs集中的列向量,
b)选择一个类别集,该集将使用一已给输出得分函数和/或判决准则集进行比较,从而编址n元组或LUTs集中的指定行,
c)作为列向量单元的函数确定输出得分值,并使用该被确定的输出得分值,
d)使用确定的判决准则比较计算出来的输出值,和
e)根据该判决准则选择获胜的一个类别或多个类别。
本发明也提供一个根据以上描述的训练和分类方法的训练和分类系统。
因此,根据本发明,提供了一种系统,用于训练能够由包含被存储的个数的n元组或多个查找表(LUTs)的网络定义的计算机分类系统,每个n元组或LUT包括多个与至少一个可能类别的子集对应的行,此外还包括多个被抽样的训练输入样本的信号或元素编址的列,每列由具有值的单元的向量定义,所述系统包括
·输入装置,用于接收已知类的训练输入数据样本;
·用于抽样被接收的输入数据样本并编址在被存储的n元组或LUTs集中的列向量的装置;
·用于编址在n元组或LUTs中的指定行的装置,所述行对应于已知的类别;
·存储装置,用于存储确定的n元组或LUTs;
·用于确定列向量单元的值以使得包括或指向基于对应的单元地址被从输入样本的训练集中抽样的次数的信息的装置;以及
·用于确定一个或多个输出得分函数和/或判决准则的装置。
这里,用于确定输出得分函数和/或判决准则的装置最好适用于基于至少部分确定的列向量单元的值的信息来确定这些函数和/或准则。
用于确定输出得分函数的装置可以适用于从一族由一组参数确定的输出得分函数中确定这样的函数。因此,用于确定输出得分函数的装置可以适用于由该参数集确定这样的函数,也可以由至少部分确定的列向量单元的值的信息确定这样的函数,还可以该参数集和至少部分确定的列向量单元的值的信息一起来确定这样的函数。
根据本发明,用于确定输出得分函数和/或判决准则的装置可以适用于基于已知类别的输入数据样本的确认集确定这样的函数和/或准则。这里,该确认集可以等于用来确定该列向量值的训练集(组),也可以是该个(组)训练集的一部分,而且还可以是不包括在该个(组)训练集中的一个样本集。
根据本发明的优选实施例,为了确定输出得分函数和/或判决准则,用于确定输出得分函数和判决准则的装置可以包括:
用于初始化一或多组输出得分函数和/或判决准则的装置;以及
用来通过利用至少部分输入样本的确认集,调整输出得分函数和判决准则的装置。
如以上所讨论的那样,为了确定输出得分函数和判决准则,应该确定列单元的值。这里,用于确定列向量单元的值的装置最好适用于将这些值作为相应的单元地址从训练输入样本集中被抽样的次数的函数来确定。作为选择,用于确定列向量单元的值的装置可以适用于确定这些单元值以得使最大值为1,而至少部分单元具有与相应的单元地址从训练输入样本集中被抽样的次数的函数相关联的值。
根据本发明的一个实施例,在属于已知类的输入数据样本施加到分类网络,从而编址一个或多个列向量时,用于确定列向量单元的值的装置最好适用于递增与已知类的行(多行)对应的编址的列向量(多个列向量)的单元的值或票数,所述值最好以1递增。
为了输出得分函数和判决准则的调整处理,用于调整输出得分函数和/或判决准则的装置最好适用于
基于至少部分列向量单元的值确定全局特性值;
确定全局特性值是否达到要求的特性标准;以及
调整至少部分输出得分函数和/或判决准则直到达到全局特性标准。
作为本发明的一个优选实施例的实例,用于调整输出得分函数和/或判决准则的装置可以适用于:
a)确定对应于被抽样的确认输入样本的局部特性值,局部特性值是至少部分编址的向量单元的值的函数;
b)确定局部特性值是否达到要求的局部特性标准;
c)如果局部特性值未达到标准,则调整一个或多个输出得分函数和/或判决准则;
d)对预定数量的训练输入样本重复该局部特性测试,
e)基于至少部分在局部特性测试中编址的列向量,确定全局特性值,
f)确定全局特性值是否达到要求的特性标准,以及
g)重复局部和全局特性测试直到全局特性标准达到为止。
用于调整输出得分函数和判决准则的装置可以进一步适用于:如果全局特性标准在给定数量的重复次数之后没有达到,则终止调整重复处理。在优选实施例中,存储n元组或多个LUT的装置包括:存储被调整的输出得分函数和判决准则的装置,以及存储目前为止最好的输出得分函数和判决准则或目前为止最好的分类系统配置值的分开装置。这里,用于调整输出得分函数和判决准则的装置可以进一步适用于:如果确定的全局特性值比以前分开存储的输出得分函数和判决准则或配置值更接近达到全局特性标准,则将以前分开存储的当时的最好输出得分函数和判决准则,替换为这里获得的输出得分函数和判决准则。因此,即使系统在给定的重复次数内不能达到全局特性标准,系统也可以总是包括“到目前为止最好”的系统配置。
根据本发明的进一步的方面,提供这样一种系统,用于将未知类别的输入数据样本分类进多个类别的至少之一,所述系统包括:
存储装置,用于存储n元组或查找表(LUTs)数或集,其中的每个n元组或LUT包括多个与至少一个可能类别的子集对应的行,此外还包括多个列向量,每个列向量由被抽样的训练输入数据样本的信号或元素编址,并且具有单元值的每个列向量在训练期间基于输入数据样本的一个或多个集确定;
存储装置,用于存储一个或多个输出得分函数和/或一个或多个判决准则,每个输出得分函数和判决准则在训练或确认处理期间基于确认输入数据样本的一个或多个集确定,所述系统进一步包括:
输入装置,用于接收将被分类的输入数据样本;
用于抽样接收到的输入数据样本,并编址在n元组或LUTs的存储集中的列向量的装置;
用于编址在n元组或LUTs的集中指定行的装置,所述行对应于指定的类;
用于使用存储的输出得分函数和至少一部分被存储的列向量值确定输出得分值的装置,以及
用于基于输出得分函数和存储的判决准则确定获胜一个或多个类别的装置。
应该理解的是,列向量的单元值以及根据本发明的分类系统的输出得分函数和/或判决准则最好利用根据以上描述的任何一个系统的训练系统确定。因此,根据以上描述的任何一种方法,可以在训练处理期间确定列向量的单元值以及输出得分函数和/或判决准则。
附图的简要描述
为了更好地理解本发明,也为了展示以上所述发明如何能实现,现在通过针对附图的实例的方式构造参考,其中:
图1展示的是带有多个查找表(LUTs)的RAM分类网络的方框图;
图2展示的是本发明的一个实施例的单个查找表(LUT)的详细方框图;
图3展示的是本发明的计算机分类系统的方框图;
图4展示的是根据本发明的一个实施例的关于LUT列单元的学习处理的流程图;
图5展示的是根据本发明的一个实施例的学习处理的流程图;
图6展示的是根据本发明的分类处理的流程图;
本发明的详细描述
以下将给出根据本发明得分类系统的体系结构和理论的更加详细的描述,包括该体系结构的列单元的训练处理的一个实例,以及分类处理的一个实例的描述。此外,还描述根据本发明的多个实施例的关于输出得分函数和判决准则的学习处理的不同实例。
记号
在以下描述和实例中使用的记号如下:
X: 训练集。
x: 训练集中的一个样本。
Nx: 训练集X中的样本数量。
xj: 给定顺序的训练集X中的第j个样本。
y; 一个指定样本(可能在训练集之外)。
C: 类别标志。
C(
x): 对应于样本
x的类别标志(真类(true class))。
CW: 通过分类获得的冠军类(Winner Class)。
CT: 通过分类获得的真类。
NC: 对应于一个LUT中的最大行数的训练类别数量。
Ω: LUTs集(每个LUT可以包含全部可能编址的列的唯一子集,
并且不同的列可以只登记现有类的子集)。
NLUT: LUTs的数量。
NCOL: 能在指定的LUT(依赖LUT)中编址的不同列的数量。
XC: 被标为C类的训练样本集。
viC: 由第i列和第C类编址的单元的项数。
ai(
y): 在第i个被样本
y编址的LUT中的列的索引。
v: 包含LUT网络中的所有viC元素的向量。
QL: 局部特性函数。
QC: 全局特性函数。
Bci,cj: 判决准则矩阵。
Mci,cj: 价值矩阵。
S·: 得分函数。
Γ·: 留一交叉确认得分函数。
P: 路径矩阵。
β: 参数向量。
Ξ: 判决准则集。
dc: 类别c的得分值。
D(·): 判决函数。
体系结构和原理的描述
以下参考展示带有多个查找表(LUTs)的RAM分类网络的方框图的图1,以及展示根据本发明一个实施例的单个查找表(LUT)的详细方框图的图2。
RAM网或LUT由许多个查找表(LUTs)(1.3)组成。让NLUT表示LUTs的数量。将要被分类的输入数据向量
y的一个样本可以被送给LUT网络的输入模块(1.1)。每个LUT可以抽样该输入数据的一部分,其中,对于不同的LUTs可以抽样不同数量的输入信号(1.2)(原则上也可能让一个LUT抽样整个输入空间)。LUTs的输出可以被馈给(1.4)RAM分类网络的输出模块(1.5)。
在图2中展示:对于每个LUT,送给LUT网的样本的被抽样的输入数据(2.1)可以被馈入地址选择模块(2.2)。这种地址选择模块(2.2)可以从输入数据中计算出在LUT中的一个或多个指定列(2.3)的地址。作为一个样本,让在第i个被输入样本
y编址的LUT中的列的索引作为ai(
y)计算。在指定的LUT中可编址的列数可以表示成NCOL,一般来说它是随不同的LUT变化的。存储在LUT的指定行中的信息对应于指定的C类(2.4)。而最大行数相当于类别数NC。一列中的单元数量相当于LUT中的行数。这些列向量单元可以相当于所述列的类指定项数计数器。由第i列和C类编址的单元的项数计数器的值表示成viC(2.5)。
被激活的LUT列(2.6)的viC值可以馈给(1.4)输出模块(1.5),在那里可以为每一个类别计算一个或多个输出得分,并且在那里将这些输出得分与一系列判决准则组合起来确定获胜类别。
让
x∈X表示用于训练的输入数据样本,而让
y表示不属于训练集的输入数据样本。让C(
x)表示
x所属的类。那么给样本
y的类指定通过计算每一类别的一个或多个输出得分来获得。对于C类所获得的输出得分作为通过样本
y编址的viC数的函数进行计算,但一般也与一系列参数
β有关。将类别C的第m个输出得分表示为SC,m(viC,
β)。通过将从全部类别中获得的输出得分与一系列判决准则组合获得一种分类。该判决准则的作用是在输出得分空间中定义区域,该输出得分空间必须由该输出得分值编址以获得已知的冠军类。该判决准则集被表示成Ξ,并对应于一个判决界线集(decision border)。
图3展示的是根据本发明的计算机分类系统的方框图。这里,象电视摄像机或数据库之类的信号源提供一个或一些描述将要分类的样本的输入数据信号(3.0)。这些数据被馈给一个预处理模块(3.1),该处理模块能够以预定的方式抽取特征、还原和变换输入数据。这样的一种预处理模块的实例是FFT板(Fast Fourier Transform,快速傅里叶变换)。然后把变换过的数据馈给包含根据本发明的RAM网络的分类单元(3.2)。分类单元(3.2)输出一个可能已经与置信度关联的排列整齐的分类表。该分类单元能够通过使用编程标准的个人计算机的软件,或者编程硬件设备来实现,例如,使用组合有RAM电路和数字信号处理器的可编程的门阵列。这些数据能够在事后处理设备(3.3)中进行解释,该事后处理设备能够是将已获得的分类和其它有关信息进行组合的计算机模块。最后,这种解释结果被馈给象激励器那样的输出设备(3.4)。
体系结构的初始训练
根据本发明的一个实施例,图4的流程图解释了一遍学习方案或者处理,该方案或者处理用于确定列向量的项数计算器或者单元分布viC-分布(4.0),可以描述如下:
1.过设置单元的值
v为0来初始化所有的项数计数器或列向量单元(4.1);
2.从训练集X将第一个输入样本
x1送给网络(4.2,4.3)。
3.计算关于第一LUT编址的列(4.4,4.5)。
4.将对应于
x的类标的编址的列的行中的项数计数器加1(递增在所有LUTs中vai(
x),C(
x)
)(4.6)。
5.对其余的LUTs重复第4步(4.7,4.8)。
6.对其余的训练输入样本重复第3-5步(4.9,4.10)。将训练样本的数量表示为Nx。
输出得分函数和判决准则的初始化
在训练过的网络可以用于分类之前,必须初始化该得分函数和判决准则。
未知输入样本的分类
当本发明的RAM网络已经被训练成为定义LUTs的列单元确定值时,该网络可以用于分类未知的输入数据样本。
在根据本发明的一个优选实施例中,分类是通过使用判决准则Ξ和从输出得分函数获得的该输出得分实施的。将调用Ξ的判决函数和输出得分表示成D(·)。该获胜类可以被写成:
Winner Class=D(Ξ,S1,1,S1,2,…,S1,j,…,S2,1,…,S2,k,…,S1,m)
图6展示了执行分类处理(6.0)的计算机分类系统的运行的方框图。该系统使用,例如光学传感系统,获得一个或者多个输入信号(6.1)。获得的输入数据在例如低通滤波器那样的预处理模块中被预处理(6.2),并被送到根据本发明的一个实施例,可以是LUT-网络的分类模块(6.3)。然后,从分类模块中输出的数据,在例如用于计算循环冗余校验和的CRC算法这样的事后处理模块(6.4)中作事后处理,并且把结果提交给输出设备(6.5),这种输出设备可以是监视器屏幕。
输出得分函数参数
β
以及判决准则Ξ的调整
β的初始确定值和准则Ξ的初始集通常不能代表最优的选择。因此,根据本发明的优选实施例,应该执行
β值和准则Ξ的优化或调整。
为了选择或调整参数值
β和准则Ξ,以便改进该分类系统的性能,根据本发明,建议定义专门的特性函数(quality function),用于度量
β值和准则Ξ的性能。因此可以定义一个局部特性函数QL(
v,
x,X,
β,Ξ),其中
v表示包含LUT网络中的所有viC元素的向量。局部特性函数可以给出指定样本
x的输出分类的置信度量。如果该特性值不能满足已知标准,则
β值和Ξ准则被调整成使特性值满足或者接近满足该标准(如果可能的话)。
此外,可以定义一个全局特性函数QG(
v,X,
β,Ξ)。该全局特性函数可以把输入训练集的性能作为全局进行度量。
图5展示的是根据本发明的
β值和Ξ准则的调整或学习的流程图。
例1
本实例解释了用于调整准则Ξ的一优化过程。我们考虑NC个训练集。该类标c是取值为1到NC的整数。对于每一类c我们定义一个简单的输出得分函数:
其中δi,j是克罗内克(Kroneckers)符号(如果i=j则δi,j=1,否则δi,j=0),而
输出得分函数的表达式解释了由参数向量
β确定的可能的函数族。但这个实例仅仅解释了用于调整判决准则Ξ而不调整
β的过程。为了简化记号,我们将
β中的全部值初始化为1。因此我们有:
由于
β的这种选择,Sc的可能输出值是从0到NLUT的整数(包括两者)。在一个已知的类别C上的留一交叉确认得分或票数为:
其中CT(
x)表示样本
x的真类。
对于全部可能的类别间的组合(c1,c2),(c1∈{1,2,...,Nc},c2∈{1,2,…,Nc})∧(c1≠c2),我们希望在由这两个类别张成的得分空间中确定一个适当的判决界线。定义矩阵Bci,cj包含对应于被应用到这两个相应的输出得分值的一个已知判决准则集的判决;即是c1类别还是c2类别获胜。行和列的维数由这两个输出得分值的允许范围给出,即该矩阵维数是(NLUT+1)×(NLUT+1)。因此,该行和列标从0变到NLUT。
每个矩阵元素包含以下三个值之一:c1,c2和KAMB,其中KAMB为不同于c1和c2的常数。这里我们使用KAMB=0。分别为c1类别和c2类别获得的两个输出得分值S1和S2用于编址矩阵Bci,cj中的元素bS1,S2 ci,cj。如果被编址的元素包含值c1,则意味着类别c1胜过类别c2。如果被编址的元素包含值c2,则意味着类别c2胜过类别c1。最后,如果被编址的元素包含值KAMB,则意味着该判决模棱两可。
该判决准则初始化为对应于WTA判决。这相当于沿矩阵Bci,cj的对角线具有的判决界线。沿该对角线的元素被初始化成取值KAMB,该对角线以上和以下的元素分别被标记成对立的类别值。
下面根据使用vai(
x),c
值的信息度量,概括一下用于调整被初始化的判决界线的策略。
以被给成如下的元素建立价值矩阵(cost matrix)Mci,cj:
αc1,c2表示与将一个样本从类别c1分类到类别c2有关的价值,而αc2,c1表示与对立的差有关的价值。这里假设:逻辑真评估为1,而逻辑假评估为0。
从m0,0到mNLUT,NLUT的极小价值(minimal-cost)路径可以使用例如象由如下的伪代码展示的动态编程法进行计算:(该代码使用与Bci,cj同样维数的路径矩阵Pci,cj)
//以逆序遍历(loop through)该价值矩阵的全部项:
for i:=NLUT to 0 step-1
{
for j:=NLUT to 0 step-1
{
if((i<>NLUT)and(j<>NLUT))
{
//对每一项计算最低者
//相关的总价值被给成
mi,j:=mi,j+min(mi+1,j,mi+1,j+1,mi,j+1);
//(该矩阵外边的下标被看作
//无穷大的编址值)
if(min(mi+1,j,mi+1,j+1,mi,j+1)==mi+1,j)pi,j:=1;
if(min(mi+1,j,mi+1,j+1,mi,j+1)==mi+1,j+1)pi,j:=2;
if(min(mi+1,j,mi+1,j+1,mi,j+1)==mi,j+1)pi,j:=3;
}
}
}
//根据该动态编程法,现在
//通过按下列方式转置P矩阵来获得拥有
//最小相关的总价值的路径,以获得位于由
//所述类别张成的得分空间中的判决界线,
i:=0;
j:=0;
repeat
{
for a:=i+1 to NLUT step+1
{
}
for a:=j+1 to NLUT step+1
{
}
iold:=i;
jold:=j;
if(Piold,jold<3)then i:=iold+1;
if(Piold,jold>1)then j:=jold+1;
}until((i==NLUT)and(j==NLUT)
该动态编程法可以用限制该界线形状的正则项展开。用于确定判决界线的替换方法是:可以以极小化相关的价值的方式拟合具有两个控制点的B样条。
使用从以上概述的策略确定出来的判决界线,现在可以按下列方式分类一个样本:
·将该样本送到该网络上,以便获得该得分值或票数数
·为所有类别定义得分值dc的一个新集,并将该得分初始化为0:dc=0,1≤c≤Nc。
·遍历所有可能类别间组合(c1,c2),并更新票数值
·该样本现在被分类成属于带有从
中找到的标签的类别。
使用从以上概述的策略确定出来的判决界线,按下列方式获得留一交叉确认测试:
·将该样本送到该网络上,以便获得该留一得分值或票数数
·为所有类别定义一个新的得分值dc的集,并将得分初始化为0:dc=0,1≤c≤Nc。
·遍历所有可能类别间组合(c1,c2),并更新票数值
该样本现在被分类成属于带有从
 中找到的标签的类别。
中找到的标签的类别。
参考图5,以上用于判决准则(界线)Ξ的调整过程可以描述如下:
·通过设置
β的所有值为1,以2×2的方式(on two by two basis)选择WTA方案以及根据图4中的流程训练n元组分类器(classifier)来初始化该系统。(5.0)
·选择批模式优化。(5.1)
·通过执行以上概述的留一分类来测试所有样本(5.12),并计算被获得的留一交叉确认误差率和将其用作QC度量。(5.13)
·存储
β值和相应的QC以及Ξ值(Bc1,c2矩阵)。(5.14)
·如果QC值不满足已给的标准或其它终止标准满足,则根据以上概述的动态编程法来调整Ξ值。(5.16,5.15)
·如果QC值不满足或其它终止标准满足,则选择与最低总误差率的组合。(5.17)
在以上情况下,人们总是作为替换的终止标准使用这样一个标准,即只允许两次遍历该调整方案的标准。
例2
本实例解释了用于调整
β的优化过程。
对每一类别再次定义一个简单的输出得分
用这些得分值,该样本现在被分类成属于带有从argmax(Sc)中找到的标签的类别。
在本实例中我们使用
而且当比较来自不同类别的输出得分时,初始Ξ值以描述WTA判决。
·通过设置所有kc值为1,选择WTA方案以及根据图4中的流程训练n元组分类器来初始化该系统。(5.0)
·选择批模式优化。(5.1)
·通过执行以上概述的留一分类来测试所有样本(5.12),并计算被获得的、用作QC的留一交叉确认误差率。(5.13)
·存储
β值和相应的QC值。(5.14)
·遍历kc1,kc2,K,kcNc的所有可能的组合,其中kj∈{1,2,3,...,kMAX}。(5.16,5.15)
·选择与最低总误差率的组合。(5.17)
对于实际使用,该kMAX值依赖于现有类别的非对称性以及用在RAM网系统的编址行的数量。
例3
本实例也解释用于调整β的优化过程,但使用局部特性函数QL。
对每一类别,我们现在定义与存在的竞争类别数同样多个输出得分,即NC-1个输出得分:
用这些得分值,按一下方式产生一个判决:
·为所有类别定义得分值dc的一个新集,并将此得分初始化为0:dc=0,1≤c≤Nc。
·遍历所有可能类别间的组合(c1,c2),并更新票数值:如果Sc1,c2>Sc2,c1,则
否则
·该样本现在被分类成属于带有从
 中找到的标签的类别。
中找到的标签的类别。
在本实例中我们使用
而且当比较来自不同类别的输出得分时,初始化Ξ值以描述WTA判决。
·通过设置所有kc1,c2值为比方说2,选择WTA方案以及根据图4中的流程训练n元组分类器来初始化该系统。(5.0)
·选择与批模式优化对立的在线模式(on line)。(5.1)
·对训练集中所有样本(5.2,5.7和5.8)执行:
·按留一交叉确认方式测试每个样本以获得冠军类CW。让QL度量将CW与真类CT比较。(5.3,5.4)
·如果CW≠CT,则产生一个留一误差,因此通过以一个小值,比方说0.1来递增kCW,CT,以及通过以一个小值,比方说0.1来递增kCT,CW,调整kCW,CT和kCT,CW的值。如果该调整产生的值低于1,则不执行任何调整。(5.5,5.6)
·当所有样本都处理之后,计算全局信息度量QC(例如留一误差率),以及存储该
β和QC的值。(5.9,5.10)
·如果QC或其它终止标准达不到,则重复以上的循环。(5.11)
·如果QC满足或其它终止标准达到,则存储的QC的值与相应的参数值
β和判决准则Ξ一起选中。(5.17,5.18)
本发明的优选示范实施例的前述描述,是为了解释和描述目的提出来的。它不意味着是本发明的详尽形式,或者限制发明于这种精确的公开形式,并且本领域的技术人员可根据本发明的精神,能够进行明显的多种修改和变化。保留了在这里被公开的和权利要求中要求的基本原则的所有这些修改,都在本发明的范围之内。
Claims (58)
1.一种训练计算机分类系统的方法,所述系统能够由包括多个n元组或查找表的网络定义,每个n元组或查找表包括多个与可能的类别的至少一个子集对应的行,此外还包括多个由被抽样的训练输入数据样本的信号或元素编址的列,每列由具有值的单元的向量定义,其中,
基于一个或多个关于不同类别的输入数据样本的训练集,确定列向量单元的值,以使得至少部分这种单元包括或指向基于相应的单元地址被从一个或多个训练输入样本中抽样的次数的信息,其特征在于所述方法包括:
为每一类别确定一个或多个用于至少一个输出得分值的评估的输出得分函数;和
确定与所获得的输出得分值的至少一部分组合起来使用以确定一个获胜类的一个或多个判决准则,
其中,该输出得分函数的确定包括输出得分函数的初始化,其后跟着根据基于至少一部分确定的列向量单元值的信息的信息度量,对至少一部分输出得分函数的调整,和/或
其中,该判决准则的确定包括判决准则的初始化,其后跟着根据基于至少一部分所确定的列向量单元值的信息的信息度量,对至少一部分判决准则的调整。
2.根据权利要求1所述的方法,其中基于输入数据样本的确认集确定该输出得分函数。
3.根据权利要求1所述的方法,其中基于输入数据样本的确认集确定该判决准则。
4.根据权利要求2所述的方法,其中基于输入数据样本的确认集确定该判决准则。
5.根据权利要求2所述的方法,其中该输出得分函数的确定基于评估该确认样本集的性能的信息度量进行。
6.根据权利要求3所述的方法,其中该判决准则的确定基于评估该确认样本集的性能的信息度量进行。
7.根据权利要求5所述的方法,其中该确认样本集等于该训练集的至少一部分,并且该信息度量是基于留一交叉确认评估的。
8.根据权利要求6所述的方法,其中该确认样本集等于该训练集的至少一部分,并且该信息度量是基于留一交叉确认评估的。
9.根据权利要求2所述的方法,其中该确认集包括输入数据样本的训练集或多个训练集的至少一部分。
10.根据权利要求3所述的方法,其中该确认集包括输入数据样本的训练集或多个训练集的至少一部分。
11.根据权利要求1所述的方法,其中该输出得分函数由一个参数集确定。
12.根据权利要求1所述的方法,其中该输出得分函数的初始化包括确定多个配置参数。
13.根据权利要求1所述的方法,其中该输出得分函数的初始化包括设置所有输出得分函数为一预定映射函数。
14.根据权利要求1所述的方法,其中该判决规则的初始化包括设置该准则为一预定判决方案。
15.根据权利要求12所述的方法,其中该调整包括改变该配置参数的值。
16.根据权利要求1所述的方法,其中该列向量单元的确定包括训练步骤
a)施加已知类的训练输入数据样本给分类网络,从而编址一个或多个列向量,
b)以1递增对应于已知类的行的编址的列向量的单元的值或票数,和
c)重复步骤(a)-(b),直到所有训练样本都已经被施加到该网络。
17.根据权利要求1所述的方法,其中该调整处理包括步骤
基于至少部分列向量单元的值确定全局特性值;
确定全局特性值是否达到要求的特性标准;以及
调整至少部分输出得分函数,直到达到全局特性标准。
18.根据权利要求17所述的方法,其中该局部特性值定义为至少部分列单元的函数。
19.根据权利要求17所述的方法,其中如果特性标准在给定数量的重复次数之后没有达到,则终止该调整重复处理。
20.根据权利要求2所述的方法,其中该调整处理包括步骤
a)从确认集或确认集组中选择一输入样本,
b)确定对应于抽样的确认输入样本的局部特性值,该局部特性值是至少部分编址的列单元值的函数,
c)确定局部特性值是否达到要求的局部特性标准,如果局部特性标准未达到,则调整一个或多个输出得分函数,
d)从确认集或确认集组的预定的样本数量中选择一个新的输入样本,
e)对所有预定的训练输入样本,重复局部特性测试步骤(b)-(d),
f)基于至少部分在局部特性测试期间被编址的列向量确定全局特性值,
g)确定全局特性值是否达到要求的特性标准,以及
h)重复(a)-(g)步直到达到全局特性标准。
21.根据权利要求20所述的方法,其中步骤(b)-(d)对确认集中的所有样本实施。
22.根据权利要求20所述的方法,其中该局部和/或全局特性值定义为至少部分列单元的函数。
23.根据权利要求20所述的方法,其中,如果特性标准在给定数量的重复次数之后没有达到,则终止该调整重复处理。
24.根据权利要求1所述的方法,其中该调整处理包括步骤
基于至少部分列向量单元的值确定全局特性值;
确定全局特性值是否达到要求的特性标准;以及
调整至少部分判决准则,直到达到全局特性标准。
25.根据权利要求24所述的方法,其中该全局特性值定义为至少部分列单元的函数。
26.根据权利要求24所述的方法,其中,如果特性标准在给定数量的重复次数之后没有达到,则终止该调整重复处理。
27.根据权利要求3所述的方法,其中该调整处理包括步骤
a)从确认集或确认集组中选择一输入样本,
b)确定对应于抽样的确认输入样本的局部特性值,该局部特性值是至少部分编址的列单元值的函数,
c)确定局部特性值是否达到要求的局部特性标准,如果局部特性标准未达到,则调整一个或多个判决准则,
d)从确认集或确认集组的预定的样本数量中选择一个新的输入样本,
e)对所有预定的训练输入样本,重复局部特性测试步骤(b)-(d),
f)基于至少部分在局部特性测试期间被编址的列向量确定全局特性值,
g)确定全局特性值是否达到要求的特性标准,以及
h)重复(a)-(g)步直到达到全局特性标准。
28.根据权利要求27所述的方法,其中步骤(b)-(d)对确认集中的所有样本实施。
29.根据权利要求27所述的方法,其中该局部和/或全局特性值定义为至少部分列单元的函数。
30.根据权利要求27所述的方法,其中如果特性标准在给定数量的重复次数之后没有达到,则终止该调整重复处理。
31.根据权利要求1所述的方法,其中该调整处理包括步骤
基于至少部分列向量单元的值确定全局特性值;
确定全局特性值是否达到要求的特性标准;以及
调整至少部分输出得分函数和判决准则,直到达到全局特性标准。
32.根据权利要求31所述的方法,其中该全局特性值定义为至少部分列单元的函数。
33.根据权利要求31所述的方法,其中,如果特性标准在给定数量的重复次数之后没有达到,则终止该调整重复处理。
34.根据权利要求4所述的方法,其中该调整处理包括步骤
a)从确认集或确认集组中选择一输入样本,
b)确定对应于所抽样的确认输入样本的局部特性值,该局部特性值是至少部分编址的列单元值的函数,
c)确定局部特性值是否达到要求的局部特性标准,如果局部特性标准未达到,则调整一个或多个输出得分函数和判决准则,
d)从确认集或确认集组的预定的样本数量中选择一个新的输入样本,
e)对所有预定的训练输入样本,重复局部特性测试步骤(b)-(d),
f)基于至少部分在局部特性测试期间被编址的列向量确定全局特性值,
g)确定全局特性值是否达到要求的特性标准,以及
h)重复(a)-(g)步直到达到全局特性标准。
35.根据权利要求34所述的方法,其中步骤(b)-(d)对确认集中的所有样本实施。
36.根据权利要求34所述的方法,其中该局部和/或全局特性值定义为至少部分列单元的函数。
37.根据权利要求34所述的方法,其中,如果特性标准在给定数量的重复次数之后没有达到,则终止该调整重复处理。
38.一种使用根据权利要求1配置的计算机分类系统将输入数据样本分类进多个类之一的方法,由此,每一个n元组或查找表的列单元值和输出得分函数和/或判决准则,通过在输入数据样本的一个或多个训练或确认集上使用来确定,所述方法包括:
a)将要被分类的输入数据样本施加到配置过的分类网络,从而编址n元组或查找表集中的列向量,
b)选择一个类别集,该集将使用一已给输出得分函数和/或判决准则集进行比较,从而编址n元组或查找表集中的指定行,
c)作为列向量单元的函数确定输出得分值,并使用所确定的输出得分值,
d)使用确定的判决准则比较计算出来的输出值,和
e)根据该判决准则选择获胜的一个类别或多个类别。
39.一种用于训练能够由包含所存储的个数的n元组或多个查找表查找表的网络定义的计算机分类系统的系统,每个n元组或查找表包括多个与至少一个可能类别的子集对应的行,还包括多个被抽样的训练输入样本的信号或元素编址的列,每列由具有值的单元的向量定义,所述系统包括
a)输入装置,用于接收已知类的训练输入数据样本;
b)用于抽样所接收的输入数据样本并编址在所存储的n元组或查找表集中的列向量的装置;
c)用于编址在n元组或查找表中的指定行的装置,所述行对应于已知的类别;
d)存储装置,用于存储确定的n元组或查找表;
e)用于确定列向量单元的值以使得包括或指向基于对应的单元地址被从输入样本的训练集中抽样的次数的信息的装置,其特征在于所述系统还包括
f)用于确定一个或多个输出得分函数和一个或多个判决准则的装置,其中所述输出得分函数和判决准则确定装置适用于
基于至少部分确定的列向量单元的值的信息以及已知类别的输入数据样本的确认集确定所述函数,和
基于至少部分确定的列向量单元的值的信息以及已知类别的输入数据样本的确认集确定所述判决规则,并且其中用于确定输出得分函数和判决准则的装置包括
用于初始化一或多组输出得分函数和/或判决准则的装置;以及
用来通过利用至少部分输入样本的确认集,调整输出得分函数和判决准则的装置。
40.根据权利要求39所述的系统,其中,用于确定输出得分函数的装置适用于从一族由一组参数值确定的输出得分函数中确定这样的函数。
41.根据权利要求39所述的系统,其中,所述确认集包括至少部分用于确定该列单元值的训练集。
42.根据权利要求39所述的系统,其中,用于确定列向量单元的值的装置适用于将这些值作为相应的单元地址从训练输入样本集中被抽样的次数的函数来确定。
43.根据权利要求39所述的系统,其中,当属于已知的类别的训练输入数据样本被施加到该分类网从而编址一个或多个列向量时,用于确定列向量单元的值的装置适用于递增与已知类的一行或多行对应的编址一列向量或多列向量的单元的值或票数,所述值以1递增。
44.根据权利要求39所述的系统,其中用于调整输出得分函数的装置适用于
基于至少部分列向量单元的值确定全局特性值;
确定全局特性值是否达到要求的特性标准;以及
调整至少部分输出得分函数直到达到全局特性标准。
45.根据权利要求44所述的系统,其中,用于调整输出得分函数和判决准则的装置还适用于:如果全局特性标准在给定数量的重复次数之后没有达到,则终止调整重复处理。
46.根据权利要求39所述的系统,其中用于调整输出得分函数和判决规则的装置适用于:
a)确定对应于被抽样的确认输入样本的局部特性值,局部特性值是至少部分编址的向量单元的值的函数;
b)确定局部特性值是否达到要求的局部特性标准;
c)如果局部特性值未达到标准,则调整一个或多个输出得分函数;
d)对预定数量的训练输入样本重复该局部特性测试,
e)基于至少部分在局部特性测试期间进行编址的列向量,确定全局特性值,
f)确定全局特性值是否达到要求的特性标准,以及
g)重复局部和全局特性测试直到全局特性标准达到为止。
47.根据权利要求46所述的系统,其中用于调整输出得分函数和判决准则的装置还适用于:如果全局特性标准在给定数量的重复次数之后没有达到,则终止调整重复处理。
48.根据权利要求39所述的系统,其中用于调整判决准则的装置适用于
基于至少部分列向量单元的值确定全局特性值;
确定全局特性值是否达到要求的特性标准;以及
调整至少部分判决准则直到达到全局特性标准。
49.根据权利要求48所述的系统,其中用于调整输出得分函数和判决准则的装置还适用于:如果全局特性标准在给定数量的重复次数之后没有达到,则终止调整重复处理。
50.根据权利要求39所述的系统,其中用于调整输出得分函数和判决准则的装置适用于:
a)确定对应于被抽样的确认输入样本的局部特性值,局部特性值是至少部分编址的向量单元的值的函数;
b)确定局部特性值是否达到要求的局部特性标准;
c)如果局部特性值未达到标准,则调整一个或多个判决准则;
d)对预定数量的训练输入样本重复该局部特性测试,
e)基于至少部分在局部特性测试期间进行编址的列向量,确定全局特性值,
f)确定全局特性值是否达到要求的特性标准,以及
g)重复局部和全局特性测试直到全局特性标准达到为止。
51.根据权利要求50所述的系统,其中用于调整输出得分函数和判决准则的装置还适用于:如果全局特性标准在给定数量的重复次数之后没有达到,则终止调整重复处理。
52.根据权利要求39所述的系统,其中用于调整判决准则的装置适用于
基于至少部分列向量单元的值确定全局特性值;
确定全局特性值是否达到要求的特性标准;以及
调整至少部分输出得分函数和判决准则直到达到全局特性标准。
53.根据权利要求52的系统,其中用于调整输出得分函数和判决准则的装置还适用于:如果全局特性标准在给定数量的重复次数之后没有达到,则终止调整重复处理。
54.根据权利要求39所述的系统,其中用于调整输出得分函数和判决准则的装置适用于:
a)确定对应于被抽样的确认输入样本的局部特性值,局部特性值是至少部分编址的向量单元的值的函数;
b)确定局部特性值是否达到要求的局部特性标准;
c)如果局部特性值未达到标准,则调整一个或多个输出得分函数和判决准则;
d)对预定数量的训练输入样本重复该局部特性测试,
e)基于至少部分在局部特性测试期间进行编址的列向量,确定全局特性值,
f)确定全局特性值是否达到要求的特性标准,以及
g)重复局部和全局特性测试直到全局特性标准达到为止。
55.根据权利要求54所述的系统,其中用于调整输出得分函数和判决准则的装置还适用于:如果全局特性标准在给定数量的重复次数之后没有达到,则终止调整重复处理。
56.根据权利要求39所述的系统,其中用于存储n元组或多个查找表的装置包括:用于存储被调整的输出得分函数和判决准则的装置,以及存储目前为止最好的输出得分函数和判决准则或目前为止最好的分类系统配置值的分开装置。
57.根据权利要求56所述的系统,其中用于调整输出得分函数和判决准则的装置还适用于:如果确定的全局特性值比以前分开存储的输出得分函数和判决准则或配置值更接近达到全局特性标准,则将以前分开存储的当时最好的输出得分函数和判决准则,替换为这里获得的输出得分函数和判决准则。
58.一种用于将未知类别的输入数据样本分类进多个类别的至少之一的系统,所述系统包括:
用于存储n元组或查找表的集的存储装置,其中的每个n元组或查找表包括多个与至少一个可能类别的子集对应的行,此外还包括多个列向量,每个列向量由被抽样的训练输入数据样本的信号或元素编址,并且具有单元值的每个列向量在训练期间基于输入数据样本的一个或多个集确定;
用于存储一个或多个输出得分函数和/或一个或多个判决准则的存储装置,每个输出得分函数和判决准则在训练或确认处理期间基于确认输入数据样本的一个或多个集确定,所述系统进一步包括:
输入装置,用于接收将被分类的输入数据样本;
用于抽样接收到的输入数据样本,并编址在n元组或查找表的存储集中的列向量的装置;
用于编址在n元组或查找表的集中指定行的装置,所述行对应于指定类;
用于使用存储的输出得分函数和至少一部分被存储的列向量值确定输出得分值的装置,以及
用于基于输出得分函数和存储的判决准则确定获胜一个或多个类别的装置。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| DKPA199800883 | 1998-06-23 | ||
| DKPA199800883 | 1998-06-23 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN1313975A CN1313975A (zh) | 2001-09-19 |
| CN1256700C true CN1256700C (zh) | 2006-05-17 |
Family
ID=8098603
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CNB998099988A Expired - Fee Related CN1256700C (zh) | 1998-06-23 | 1999-06-21 | 基于n元组或随机存取存储器的神经网络分类系统和方法 |
Country Status (12)
| Country | Link |
|---|---|
| US (1) | US6999950B1 (zh) |
| EP (1) | EP1093638B1 (zh) |
| JP (1) | JP2002519747A (zh) |
| CN (1) | CN1256700C (zh) |
| AT (1) | ATE228691T1 (zh) |
| AU (1) | AU753822B2 (zh) |
| CA (1) | CA2335060C (zh) |
| DE (1) | DE69904181D1 (zh) |
| IL (1) | IL140397A0 (zh) |
| NZ (1) | NZ508930A (zh) |
| PL (1) | PL345044A1 (zh) |
| WO (1) | WO1999067694A2 (zh) |
Families Citing this family (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7478192B2 (en) * | 2004-11-03 | 2009-01-13 | Saffron Technology, Inc. | Network of networks of associative memory networks |
| CN101639937B (zh) * | 2009-09-03 | 2011-12-14 | 复旦大学 | 一种基于人工神经网络的超分辨率方法 |
| CN106529609B (zh) * | 2016-12-08 | 2019-11-01 | 郑州云海信息技术有限公司 | 一种基于神经网络结构的图像识别方法及装置 |
| US11222260B2 (en) * | 2017-03-22 | 2022-01-11 | Micron Technology, Inc. | Apparatuses and methods for operating neural networks |
| JP6718405B2 (ja) * | 2017-03-31 | 2020-07-08 | 三菱重工業株式会社 | 情報提供装置、情報提供システム、情報提供方法及びプログラム |
| KR20200047551A (ko) | 2017-07-30 | 2020-05-07 | 뉴로블레이드, 리미티드. | 메모리 기반 분산 프로세서 아키텍처 |
| CN109948632B (zh) * | 2017-12-19 | 2021-03-26 | 杭州海康威视数字技术股份有限公司 | 数据训练方法、装置及系统、计算机设备 |
| CN108595211B (zh) * | 2018-01-05 | 2021-11-26 | 百度在线网络技术(北京)有限公司 | 用于输出数据的方法和装置 |
| US11688160B2 (en) | 2018-01-17 | 2023-06-27 | Huawei Technologies Co., Ltd. | Method of generating training data for training a neural network, method of training a neural network and using neural network for autonomous operations |
| US11836615B2 (en) | 2019-09-20 | 2023-12-05 | International Business Machines Corporation | Bayesian nonparametric learning of neural networks |
| US11379601B2 (en) | 2019-12-11 | 2022-07-05 | Paypal, Inc. | Detection of sensitive database information |
| US11768916B2 (en) * | 2019-12-11 | 2023-09-26 | Paypal, Inc. | Detection of sensitive database information |
Family Cites Families (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4975975A (en) | 1988-05-26 | 1990-12-04 | Gtx Corporation | Hierarchical parametric apparatus and method for recognizing drawn characters |
| JPH02195400A (ja) * | 1989-01-24 | 1990-08-01 | Canon Inc | 音声認識装置 |
| GB9014569D0 (en) | 1990-06-29 | 1990-08-22 | Univ London | Devices for use in neural processing |
| DE4131387A1 (de) | 1991-09-20 | 1993-03-25 | Siemens Ag | Verfahren zur erkennung von mustern in zeitvarianten messsignalen |
| US5359699A (en) | 1991-12-02 | 1994-10-25 | General Electric Company | Method for using a feed forward neural network to perform classification with highly biased data |
| US5790754A (en) * | 1994-10-21 | 1998-08-04 | Sensory Circuits, Inc. | Speech recognition apparatus for consumer electronic applications |
| US6581048B1 (en) * | 1996-06-04 | 2003-06-17 | Paul J. Werbos | 3-brain architecture for an intelligent decision and control system |
| US6571227B1 (en) * | 1996-11-04 | 2003-05-27 | 3-Dimensional Pharmaceuticals, Inc. | Method, system and computer program product for non-linear mapping of multi-dimensional data |
| EP0935212B9 (en) | 1998-02-05 | 2002-07-10 | Intellix A/S | N-Tuple or ram based neural network classification system and method |
| US6238342B1 (en) * | 1998-05-26 | 2001-05-29 | Riverside Research Institute | Ultrasonic tissue-type classification and imaging methods and apparatus |
-
1999
- 1999-06-21 AT AT99927732T patent/ATE228691T1/de not_active IP Right Cessation
- 1999-06-21 EP EP99927732A patent/EP1093638B1/en not_active Expired - Lifetime
- 1999-06-21 DE DE69904181T patent/DE69904181D1/de not_active Expired - Lifetime
- 1999-06-21 AU AU44986/99A patent/AU753822B2/en not_active Ceased
- 1999-06-21 IL IL14039799A patent/IL140397A0/xx unknown
- 1999-06-21 WO PCT/DK1999/000340 patent/WO1999067694A2/en active IP Right Grant
- 1999-06-21 US US09/720,587 patent/US6999950B1/en not_active Expired - Lifetime
- 1999-06-21 CA CA002335060A patent/CA2335060C/en not_active Expired - Lifetime
- 1999-06-21 CN CNB998099988A patent/CN1256700C/zh not_active Expired - Fee Related
- 1999-06-21 PL PL99345044A patent/PL345044A1/xx unknown
- 1999-06-21 JP JP2000556291A patent/JP2002519747A/ja active Pending
- 1999-06-21 NZ NZ508930A patent/NZ508930A/xx unknown
Also Published As
| Publication number | Publication date |
|---|---|
| WO1999067694A2 (en) | 1999-12-29 |
| AU753822B2 (en) | 2002-10-31 |
| CA2335060A1 (en) | 1999-12-29 |
| CA2335060C (en) | 2009-09-01 |
| US6999950B1 (en) | 2006-02-14 |
| IL140397A0 (en) | 2002-02-10 |
| EP1093638A2 (en) | 2001-04-25 |
| WO1999067694A3 (en) | 2000-02-10 |
| JP2002519747A (ja) | 2002-07-02 |
| EP1093638B1 (en) | 2002-11-27 |
| ATE228691T1 (de) | 2002-12-15 |
| NZ508930A (en) | 2002-12-20 |
| PL345044A1 (en) | 2001-11-19 |
| DE69904181D1 (de) | 2003-01-09 |
| AU4498699A (en) | 2000-01-10 |
| CN1313975A (zh) | 2001-09-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN1194319C (zh) | 对表格式数据进行查找、列表及分类的方法和装置 | |
| CN1256700C (zh) | 基于n元组或随机存取存储器的神经网络分类系统和方法 | |
| CN1159673C (zh) | 从图像中提取管理信息的设备与方法 | |
| CN1171162C (zh) | 基于字符分类检索字符串的装置和方法 | |
| CN1238833C (zh) | 语音识别装置以及语音识别方法 | |
| CN1144145C (zh) | 用于数据仓库的选择聚集层和交叉产品层的方法和装置 | |
| CN1145901C (zh) | 一种基于信息挖掘的智能决策支持构造方法 | |
| CN1098515C (zh) | 字符发生装置及其实现方法 | |
| CN1310825A (zh) | 用于分类文本以及构造文本分类器的方法和装置 | |
| CN1151465C (zh) | 利用候选表进行分类的模式识别设备及其方法 | |
| CN1190963C (zh) | 数据处理装置和方法,学习装置和方法 | |
| CN1940965A (zh) | 信息处理设备及其控制方法 | |
| CN1839397A (zh) | 用于处理诸如图像的具有现有拓扑的数据阵列的神经网络和网络应用 | |
| CN1846232A (zh) | 使用加权信息的对象姿态估计和匹配系统 | |
| CN1947150A (zh) | 虹彩注册方法、虹彩注册装置及虹彩注册程序 | |
| CN1701324A (zh) | 用于分类文档的系统,方法和软件 | |
| CN1331449A (zh) | 用于将粘着法构成的文本或文档分段成词的字符串划分或区分的方法及相关系统 | |
| CN1801183A (zh) | 信息处理装置和方法以及程序 | |
| CN1415103A (zh) | 多分辨率标签定位器 | |
| CN1794266A (zh) | 生物特征融合的身份识别和认证方法 | |
| CN1151573A (zh) | 声音识别方法,信息形成方法,声音识别装置和记录介质 | |
| CN1130731C (zh) | 半导体只读存储器 | |
| CN1973757A (zh) | 基于舌象特征的病证计算机分析系统 | |
| CN1251130C (zh) | 多字体多字号印刷体藏文字符识别方法 | |
| CN1200387C (zh) | 基于单个字符的统计笔迹鉴别和验证方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant | ||
| C19 | Lapse of patent right due to non-payment of the annual fee | ||
| CF01 | Termination of patent right due to non-payment of annual fee |