CN115994327B - 基于边缘计算的设备故障诊断方法及装置 - Google Patents
基于边缘计算的设备故障诊断方法及装置 Download PDFInfo
- Publication number
- CN115994327B CN115994327B CN202310280499.5A CN202310280499A CN115994327B CN 115994327 B CN115994327 B CN 115994327B CN 202310280499 A CN202310280499 A CN 202310280499A CN 115994327 B CN115994327 B CN 115994327B
- Authority
- CN
- China
- Prior art keywords
- data
- feature
- characteristic
- signal data
- training set
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000003745 diagnosis Methods 0.000 title claims abstract description 81
- 238000004364 calculation method Methods 0.000 title claims abstract description 70
- 238000000034 method Methods 0.000 title claims abstract description 65
- 230000006870 function Effects 0.000 claims abstract description 135
- 238000012360 testing method Methods 0.000 claims abstract description 80
- 238000012706 support-vector machine Methods 0.000 claims abstract description 38
- 238000013145 classification model Methods 0.000 claims abstract description 26
- 238000012545 processing Methods 0.000 claims abstract description 16
- 238000012216 screening Methods 0.000 claims description 104
- 238000012549 training Methods 0.000 claims description 102
- 239000013598 vector Substances 0.000 claims description 57
- 238000004422 calculation algorithm Methods 0.000 claims description 48
- 238000003066 decision tree Methods 0.000 claims description 47
- 239000011159 matrix material Substances 0.000 claims description 45
- 238000007637 random forest analysis Methods 0.000 claims description 27
- 230000004913 activation Effects 0.000 claims description 23
- 230000005484 gravity Effects 0.000 claims description 14
- 238000013527 convolutional neural network Methods 0.000 claims description 12
- 230000002159 abnormal effect Effects 0.000 claims description 11
- 238000004891 communication Methods 0.000 claims description 9
- 238000011156 evaluation Methods 0.000 claims description 9
- 230000015572 biosynthetic process Effects 0.000 claims description 7
- 238000005259 measurement Methods 0.000 claims description 7
- 238000003786 synthesis reaction Methods 0.000 claims description 7
- 238000010276 construction Methods 0.000 claims description 5
- 238000005070 sampling Methods 0.000 claims description 4
- 238000012163 sequencing technique Methods 0.000 claims description 3
- 230000000694 effects Effects 0.000 description 13
- 238000000605 extraction Methods 0.000 description 9
- 230000008569 process Effects 0.000 description 9
- 238000001514 detection method Methods 0.000 description 7
- 238000010586 diagram Methods 0.000 description 6
- 238000003860 storage Methods 0.000 description 6
- 238000013461 design Methods 0.000 description 5
- 238000005516 engineering process Methods 0.000 description 5
- 239000003245 coal Substances 0.000 description 4
- 238000004590 computer program Methods 0.000 description 4
- 238000004458 analytical method Methods 0.000 description 3
- 238000011161 development Methods 0.000 description 3
- 239000000284 extract Substances 0.000 description 3
- 238000010606 normalization Methods 0.000 description 3
- 230000002093 peripheral effect Effects 0.000 description 3
- 238000011176 pooling Methods 0.000 description 3
- 206010063385 Intellectualisation Diseases 0.000 description 2
- 230000005540 biological transmission Effects 0.000 description 2
- 238000002790 cross-validation Methods 0.000 description 2
- 238000013135 deep learning Methods 0.000 description 2
- 230000006872 improvement Effects 0.000 description 2
- 238000010801 machine learning Methods 0.000 description 2
- 238000007726 management method Methods 0.000 description 2
- 238000005065 mining Methods 0.000 description 2
- 230000010355 oscillation Effects 0.000 description 2
- 238000006467 substitution reaction Methods 0.000 description 2
- 239000004677 Nylon Substances 0.000 description 1
- 238000003491 array Methods 0.000 description 1
- 238000013528 artificial neural network Methods 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 238000007405 data analysis Methods 0.000 description 1
- 238000013075 data extraction Methods 0.000 description 1
- 238000013523 data management Methods 0.000 description 1
- 238000012217 deletion Methods 0.000 description 1
- 230000037430 deletion Effects 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 238000009776 industrial production Methods 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 229920001778 nylon Polymers 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 238000010223 real-time analysis Methods 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 230000002194 synthesizing effect Effects 0.000 description 1
- 238000012800 visualization Methods 0.000 description 1
- 230000003245 working effect Effects 0.000 description 1
Images






Landscapes
- Testing And Monitoring For Control Systems (AREA)
Abstract
本发明提供了一种基于边缘计算的设备故障诊断方法及装置,涉及数据处理技术领域,该方法应用于信号测试设备,信号测试设备与云端平台通信,包括:获取待测设备的待测信号数据;将待测信号数据输入至预先构建的边缘计算模型中,通过边缘计算模型对待测信号数据进行数据诊断,得到诊断结果;将诊断结果和待测信号数据发送至云端平台,通过云端平台对待测信号数据进行分析处理,以对待测设备的运行状态进行监管;其中,本发明通过边缘计算模型对待测设备的待测信号数据进行数据诊断,边缘计算模型包括基于加权支持向量机的分类模型,加权支持向量机通过多种基础核函数进行加权得到,可以对待测信号数据充分处理,有效提高分类精度。
Description
技术领域
本发明涉及数据处理技术领域,尤其涉及一种基于边缘计算的设备故障诊断方法及装置。
背景技术
为将信息化与智能化技术在工业领域进行高度发展与深度融合,积极开展在机器学习、边缘计算、可视化、先进测量与智能控制等系统上的应用是未来工业生产专业化运营的发展趋势。设备故障诊断和预警系统已经广泛用于工业企业,辅助保障机组等关键性设备的安全可靠与高效运行,是工业企业的运营核心保障。随着深度学习领域的快速发展,采用深度学习技术的设备故障诊断技术获得了令人满意的工作效果。其中,为保证数据传输的时效性,以及避免用户隐私泄露或者数据安全隐患等问题,本地化的离线工作方式开始得到了人们的广泛关注,边缘计算成为了设备故障诊断的主要手段。
设备故障诊断和预警系统虽然取得了一定的应用效果,但是在实际应用时,实时性差、自动化程度及精细化程度不够,无法达到期望的诊断效果,原因主要包括:1)工业企业对机组等关键性设备的故障诊断业务处理主要集中在管理侧,业务系统从生产侧采集数据,复杂的数据传输流程与大量的冗余数据导致时间敏感性业务功能无法得到有效地运行与价值的发挥;2)现有大部分工业企业故障诊断业务不具备高性能的机器学习能力,设备的故障诊断需要在设备模型的基础上动态调整算法,通过高实时性分析计算推导出与预估正常模型的偏差,而预估正常模型,目前的设备故障诊断系统均是人为地调整与导出预估正常模型,导致故障模型与配套算法的时效性、维护性较差,从而无法做到准确及时的故障定位;3)现有的设备故障诊断算法对训练样本质量要求较高,而设备故障诊断中的数据采集绝大多数样本为正例样本,因此容易导致模型的检测精度下降,同时导致模型的鲁棒性和泛化能力受到影响。
设备故障诊断通常采集数十种信号或参数进行数据分析,现有的方法在设备故障诊断算法模型的设计上,通常对设备故障诊断数据的特征提取不够精细化,导致特征提取不足而影响故障诊断时对故障的分类精度不足;在设备故障诊断的模型使用中,现有的方法在特征提取模型的激活函数、分类函数的核函数设计通常难以与设备故障数据进行匹配,进而容易对设备故障诊断的检测精度造成影响。
发明内容
有鉴于此,本发明的目的在于提供一种基于边缘计算的设备故障诊断方法及装置,可以提高设备故障诊断的诊断效果。
第一方面,本发明实施例提供了一种基于边缘计算的设备故障诊断方法,该方法应用于信号测试设备,信号测试设备与云端平台通信;方法包括:获取待测设备的待测信号数据;将待测信号数据输入至预先构建的边缘计算模型中,通过边缘计算模型对待测信号数据进行数据诊断,得到诊断结果;将诊断结果和待测信号数据发送至云端平台,通过云端平台对待测信号数据进行分析处理,以对待测设备的运行状态进行监管;其中,边缘计算模型包括基于加权支持向量机的分类模型,加权支持向量机通过多种基础核函数进行加权得到。
结合第一方面,本发明实施例提供了第一方面的第一种可能的实施方式,其中,该方法还包括:获取预先存储的信号数据集;其中,信号数据集中包括表征设备一种正常运行状态的特征参数和多种非正常状态的特征参数;对信号数据集中的每个特征参数进行筛选,提取信号数据对应的目标特征参数;将目标特征参数输入至预先设置的分类模型中,构建对应于待测信号数据的边缘计算模型。
结合第一方面,本发明实施例提供了第一方面的第二种可能的实施方式,其中,上述分类模型包括基于加权支持向量机的分类模型;加权支持向量机包括多种基础核函数;多种基础核函数包括线性核函数、多项式核函数和径向基核函数;线性核函数包括:

多项式核函数包括:

径向基核函数包括:

其中, 为核函数,
为核函数, 为以e为底的指数函数,
为以e为底的指数函数, 为输入的目标特征参数对应的矩阵,
为输入的目标特征参数对应的矩阵, 为矩阵的转置;
为矩阵的转置; 均为不同基础核函数的参数;上述将目标特征参数输入至预先设置的分类模型中,构建对应于待测信号数据的边缘计算模型的步骤,包括:将目标特征参数输入至加权支持向量机中,确定目标特征参数基于每种基础核函数的函数结果;按照预先设定的权重系数将每种基础核函数的函数结果线性相加,构建多核函数模型,训练加权支持向量机,得到边缘计算模型;其中,多核函数模型包括合成核函数,合成核函数为:
均为不同基础核函数的参数;上述将目标特征参数输入至预先设置的分类模型中,构建对应于待测信号数据的边缘计算模型的步骤,包括:将目标特征参数输入至加权支持向量机中,确定目标特征参数基于每种基础核函数的函数结果;按照预先设定的权重系数将每种基础核函数的函数结果线性相加,构建多核函数模型,训练加权支持向量机,得到边缘计算模型;其中,多核函数模型包括合成核函数,合成核函数为:


其中, 为目标特征参数矢量的总数目,
为目标特征参数矢量的总数目, 为单个的基础核函数;
为单个的基础核函数; 为每个目标特征参数对应的最优单个核函数的权重大小,且权重总和为1。
为每个目标特征参数对应的最优单个核函数的权重大小,且权重总和为1。
结合第一方面,本发明实施例提供了第一方面的第三种可能的实施方式,其中,上述对信号数据集中的每个特征参数进行筛选,提取信号数据对应的目标特征参数的步骤,包括:通过费希尔准则算法提取特征参数的初始筛选特征;将初始筛选特征按照预设比例划分为训练集和测试集;将训练集输入至基于加权影响因子的随机森林算法中,确定目标筛选特征;将训练集对应的目标筛选特征和测试集对应的初始筛选特征按照特征索引方式进行特征抽取,得到目标特征参数。
结合第一方面,本发明实施例提供了第一方面的第四种可能的实施方式,其中,上述通过费希尔准则算法提取特征参数的初始筛选特征的步骤,包括:确定特征参数对应的特征向量矩阵;特征向量矩阵中包括特征参数对应的维度数据,以及维度数据指示的特征向量集合;针对特征向量矩阵的维度数据,通过费希尔准则算法确定维度数据指示的特征向量集合的判别系数; 根据判别系数指示的数值大小,对多个特征参数进行筛选,得到信号数据对应的初始筛选特征;费希尔准则算法包括:

其中, 为第
为第 维的维度数据对应的特征向量集合的判别系数,
维的维度数据对应的特征向量集合的判别系数, 、
、 分别为两个相邻类别对应的第
分别为两个相邻类别对应的第 维的维度数据对应的特征值的均值,
维的维度数据对应的特征值的均值, 、
、 分别为两个相邻类别对应的第
分别为两个相邻类别对应的第 维的维度数据对应的特征值的方差,特征值为特征向量矩阵的一列特征向量的值,
维的维度数据对应的特征值的方差,特征值为特征向量矩阵的一列特征向量的值, 为设数据类别的总数,
为设数据类别的总数, 为特征参数对应的总维度数,
为特征参数对应的总维度数, 为每个特征值的基尼系数;基尼系数通过下述公式计算:
为每个特征值的基尼系数;基尼系数通过下述公式计算:

其中, 为第
为第 维的维度数据的特征值的基尼系数,
维的维度数据的特征值的基尼系数, 为上述特征参数矢量的总数目,
为上述特征参数矢量的总数目, 为训练样本的数量;
为训练样本的数量; 为统一去掉第
为统一去掉第 维特征值后训练集的误差。
维特征值后训练集的误差。
结合第一方面,本发明实施例提供了第一方面的第五种可能的实施方式,其中,上述将训练集输入至基于加权影响因子的随机森林算法中,确定目标筛选特征的步骤,包括:通过随机森林算法定义的多种影响因子公式计算训练集中的每个初始筛选特征分别对应的多种影响因子数据;按照每种影响因子数据分别对应的加权系数对每种影响因子数据加权处理,确定初始筛选特征对应的综合权值;根据综合权值对每个初始筛选特征按照从大到小进行排序;基于排序的结果,确定目标筛选特征。
结合第一方面,本发明实施例提供了第一方面的第六种可能的实施方式,其中,上述多种影响因子包括特征重要性度量值;通过随机森林算法定义的多种影响因子公式计算训练集中的每个初始筛选特征分别对应的多种影响因子数据的步骤,包括:对训练集进行随机抽样,构建训练集对应的子训练集和测试子集;构建子训练集对应的决策树,确定决策树对应的分类精度数据和权重数据;根据分类精度数据和权重数据计算特征重要性度量值;分类精度数据通过下述公式确定:

其中, 为第
为第 棵决策树的分类精度,S为测试子集的数量,
棵决策树的分类精度,S为测试子集的数量, 为所有测试子集样本数量;
为所有测试子集样本数量; 为在第
为在第 个测试子集中第
个测试子集中第 棵决策树对测试子集样本的分类与样本真实分类相同的样本的数量;权重数据通过下述公式确定:
棵决策树对测试子集样本的分类与样本真实分类相同的样本的数量;权重数据通过下述公式确定:

其中, 代表第
代表第 棵决策树的权重数据,E为当前决策树的数量,
棵决策树的权重数据,E为当前决策树的数量, 代表第
代表第 棵决策树对测试子集样本的分类与随机森林所有决策树对测试子集样本的分类相同的样本数目;
棵决策树对测试子集样本的分类与随机森林所有决策树对测试子集样本的分类相同的样本数目; 代表测试子集的样本数量;特征重要性度量值通过下述公式确定:
代表测试子集的样本数量;特征重要性度量值通过下述公式确定:

其中, 为决策树总数量,
为决策树总数量, 为剔除掉的决策树数量;
为剔除掉的决策树数量; 为第
为第 棵决策树中第
棵决策树中第 个特征的重要性度量值;
个特征的重要性度量值; 通过下述公式确定:
通过下述公式确定:

其中, 定义为给测试子集中第
定义为给测试子集中第 个特征加入高斯噪声后的平均分类精度,
个特征加入高斯噪声后的平均分类精度, 为第
为第 棵决策树的分类精度,
棵决策树的分类精度, 为测试子集中样本的特征数量。
为测试子集中样本的特征数量。
结合第一方面,本发明实施例提供了第一方面的第七种可能的实施方式,其中,上述多种影响因子包括特征信息熵和特征熵权指数;通过随机森林算法定义的多种影响因子公式计算训练集中的每个初始筛选特征分别对应的多种影响因子数据的步骤,包括:基于训练集的每个初始筛选特征,构建训练集对应的初始评价矩阵;确定初始评价矩阵中的特征值对应的特征比重;根据特征比重和特征比重对应的对数数据,计算特征信息熵;其中,特征信息熵通过下述公式确定:









结合第一方面,本发明实施例提供了第一方面的第八种可能的实施方式,其中,上述将初始筛选特征按照预设比例划分为训练集和测试集的步骤之后,方法还包括:将训练集和测试集分别输入至卷积神经网络中进行卷积运算,对训练集和测试集进行深度特征提取;其中,卷积神经网络中包括激活函数,通过激活函数对训练集和测试集进行卷积运算;激活函数包括:

其中, 和
和 分别为激活函数的输入数据和输出数据,
分别为激活函数的输入数据和输出数据, 为预设的参数系数。
为预设的参数系数。
第二方面,本发明实施例还提供一种基于边缘计算的设备故障诊断装置,该装置应用于信号测试设备,信号测试设备与云端平台通信;装置包括:数据采集模块,用于获取待测设备的待测信号数据;数据处理模块,用于将待测信号数据输入至预先构建的边缘计算模型中,通过边缘计算模型对待测信号数据进行数据诊断,得到诊断结果;通信模块,用于将诊断结果和待测信号数据发送至云端平台,通过云端平台对待测信号数据进行分析处理,以对待测设备的运行状态进行监管。其中,边缘计算模型包括基于加权支持向量机的分类模型,加权支持向量机通过多种基础核函数进行加权得到。
本发明实施例带来了以下有益效果:本发明提供的一种基于边缘计算的设备故障诊断方法及装置,通过边缘计算模型对待测设备的待测信号数据进行数据诊断,该边缘计算模型包括基于加权支持向量机的分类模型,且,该加权支持向量机通过多种基础核函数进行加权得到,不同基础核函数对应的输出结果不同,再对多种基础核函数进行加权生成对应的边缘计算模型,该边缘计算模型可以对待测信号数据充分处理,有效提高分类精度,对设备故障诊断的检测分类具有促进作用,以保证设备故障诊断的诊断效果。此外,还应用边缘计算模型配合云端平台进行设备故障诊断,能够对待测信号数据有效监管。
本发明的其他特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点在说明书以及附图中所特别指出的结构来实现和获得。
为使本发明的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。
附图说明
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的一种基于边缘计算的设备故障诊断方法的流程图;
图2为本发明实施例提供的另一种基于边缘计算的设备故障诊断方法的流程图;
图3为本发明实施例提供的一种提取目标特征参数的流程图;
图4为本发明实施例提供的一种基于边缘计算的设备故障诊断装置的结构示意图;
图5为本发明实施例提供的另一种基于边缘计算的设备故障诊断装置的结构示意图;
图6为本发明实施例提供的一种电子设备的结构示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合附图对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
基于此,本发明实施例提供的一种基于边缘计算的设备故障诊断方法及装置,可以保证设备故障诊断的诊断效果。
为便于对本实施例进行理解,首先对本发明实施例所公开的一种基于边缘计算的设备故障诊断方法进行详细介绍,该方法应用于信号测试设备,该信号测试设备与云端平台通信;图1示出了本发明实施例提供的一种基于边缘计算的设备故障诊断方法的流程图,如图1所示,该方法包括以下步骤:
步骤S102,获取待测设备的待测信号数据。
步骤S104,将待测信号数据输入至预先构建的边缘计算模型中,通过边缘计算模型对待测信号数据进行数据诊断,得到诊断结果。
具体的,本发明实施例利用设备信号采集传感器对待测设备的待测信号数据进行采集,其中,可以将上述设备信号采集传感器放置在固定位置或设备上,采集被检测的设备的信号数据。之后,可以通过边缘计算模型对该待测信号数据进行诊断,该边缘计算模型配置于边缘计算网关上,且,搭载有智能分析算法,以进行设备故障检测。其中,边缘计算模型包括基于加权支持向量机的分类模型,加权支持向量机通过多种基础核函数进行加权得到。其中,每种基础核函数的输出结果均不同,该加权支持向量机按照多种基础核函数对数据进行处理,能够对待测信号数据精准分类,以保证故障检测效果。
步骤S106,将诊断结果和待测信号数据发送至云端平台,通过云端平台对待测信号数据进行分析处理,以对待测设备的运行状态进行监管。
通过上述边缘计算模型对待测信号数据诊断后,信号测试设备可以将对应的诊断结果和待测信号数据通过有线或无线网络传输至通信连接的云端平台,在云端平台对采集的待测信号数据和诊断结果进行数据管理、数据呈现、数据分析等操作。同时,还可以将对应的分析结果实时推送至手机或电脑客户端,实现设备故障或异常情况的预警。此外,还可以在云端平台控制中心对上述分析结果进行可视化展示,有助于管理人员对设备故障或异常情况的实时监管。
本发明实施例提供的一种基于边缘计算的设备故障诊断方法,通过边缘计算模型对待测设备的待测信号数据进行数据诊断,该边缘计算模型包括基于加权支持向量机的分类模型,且,该加权支持向量机通过多种基础核函数进行加权得到,不同基础核函数对应的输出结果不同,再对多种基础核函数进行加权生成对应的边缘计算模型,该边缘计算模型可以对待测信号数据充分处理,有效提高分类精度,对设备故障诊断的检测分类具有促进作用,以保证设备故障诊断的诊断效果。此外,还应用边缘计算模型配合云端平台进行设备故障诊断,能够对待测信号数据有效监管。
为了便于理解,在上述实施例的基础上,本发明实施例还提供了另一种基于边缘计算的设备故障诊断方法,该方法主要在于介绍构建上述边缘计算模型的步骤,图2示出了本发明实施例提供的另一种基于边缘计算的设备故障诊断方法的流程图,如图2所示,该方法包括以下步骤:
步骤S202,获取预先存储的信号数据集。
步骤S204,对信号数据集中的每个特征参数进行筛选,提取信号数据对应的目标特征参数。
信号数据集中包括表征设备一种正常运行状态的特征参数和多种非正常状态的特征参数。具体的,预先存储的信号数据集由设备的历史故障数据组成,在本发明实施例中,该历史故障数据以煤矿设备采煤机的历史故障数据进行说明。该信号数据集涵盖了煤矿设备采煤机的多种运行状态,包括一种正常运行状态和多种非正常状态,上述多种非正常状态为21种常见的故障状态。此外,信号数据集中的每一种运行状态均包括48个特征参数进行表示,包括设备输出电压、输出电流、输入电流等参数,每一种运行状态都由唯一的标签标定。
其中,为了得到有效数据,本发明实施例还对上述信号数据集中的每个特征参数进行筛选,提取信号数据对应的目标特征参数。在具体实现时,图3示出了本发明实施例提取目标特征参数的流程图,如图3所示,通过下述步骤S10-S13提取上述目标特征参数:
步骤S10,通过费希尔准则算法提取特征参数的初始筛选特征。
首先,本发明实施例设计有前置特征选择模块,通过费希尔准则算法提取特征参数的初始筛选特征,其中,费希尔判决准则是一种常用的线性判决方法,本发明实施例对该费希尔判决准则进行改进,提出一种基于基尼系数的费希尔准则算法特征筛选方式,再以该改进的费希尔准则算法提取上述初始筛选特征。
具体的,基于基尼系数的费希尔准则算法通过特征参数的均值、方差、基尼系数3个指标来评价特征参数的优劣,首先确定特征参数对应的特征向量矩阵,再针对特征向量矩阵的维度数据,通过费希尔准则算法确定维度数据指示的特征向量集合的判别系数。最后根据判别系数指示的数值大小,对多个特征参数进行筛选,得到信号数据对应的初始筛选特征。
其中,上述维度数据也即特征参数的维度,在具体实现时,设第 类设备的故障数据的特征向量矩阵为
类设备的故障数据的特征向量矩阵为 ,公式如下:
,公式如下:

上述特征向量矩阵中包括特征参数对应的维度数据及维度数据指示的特征向量集合。具体的, 为特征值,N为特征向量的总维度数,M为特征向量矩阵中的特征向量数量。用
为特征值,N为特征向量的总维度数,M为特征向量矩阵中的特征向量数量。用 来表示第1类设备故障数据的第d维特征向量的集合,则向量
来表示第1类设备故障数据的第d维特征向量的集合,则向量 ;用
;用 来表示第2类设备故障数据的第d维特征向量的集合,则向量
来表示第2类设备故障数据的第d维特征向量的集合,则向量 ;以此类推,上述特征向量矩阵中包括N个维度,M个特征向量。具体地,上述N的数值根据特征参数的数量确定,也即上述48种特征参数,每种特征参数对应一种维度。
;以此类推,上述特征向量矩阵中包括N个维度,M个特征向量。具体地,上述N的数值根据特征参数的数量确定,也即上述48种特征参数,每种特征参数对应一种维度。
对于第 维特征,基于基尼系数的费希尔准则算法的判别系数定义为下述公式:
维特征,基于基尼系数的费希尔准则算法的判别系数定义为下述公式:

其中, 为第
为第 维的维度数据对应的特征向量集合的判别系数,
维的维度数据对应的特征向量集合的判别系数, 、
、 分别为两个相邻类别对应的第
分别为两个相邻类别对应的第 维的维度数据对应的特征值的均值,
维的维度数据对应的特征值的均值, 、
、 分别为两个相邻类别对应的第
分别为两个相邻类别对应的第 维的维度数据对应的特征值的方差,
维的维度数据对应的特征值的方差, 为设数据类别的总数,
为设数据类别的总数, 为特征向量的总维度数,
为特征向量的总维度数, 为每个特征值的基尼系数。其中,特征值为特征向量矩阵的一列特征向量的值,如,以一列特征向量为[123,123123,2,43324]进行说明,该特征向量中包括4个特征值,其中,这4个特征值指示了4个维度。
为每个特征值的基尼系数。其中,特征值为特征向量矩阵的一列特征向量的值,如,以一列特征向量为[123,123123,2,43324]进行说明,该特征向量中包括4个特征值,其中,这4个特征值指示了4个维度。
上述基尼系数通过下述公式计算:

其中, 为第
为第 维的维度数据的特征值的基尼系数,
维的维度数据的特征值的基尼系数, 为上述特征参数矢量的总数目,
为上述特征参数矢量的总数目, 为训练样本的数量;
为训练样本的数量; 为统一去掉第
为统一去掉第 维特征值后训练集的误差。如,当去掉第1个特征值,训练精度为80%,而去掉第2个特征值,训练精度是60%,则表示第一个特征值比第二个特征值的贡献度高。
维特征值后训练集的误差。如,当去掉第1个特征值,训练精度为80%,而去掉第2个特征值,训练精度是60%,则表示第一个特征值比第二个特征值的贡献度高。
参照上述计算公式,根据基尼系数得到上述判别系数,该基尼系数结合 (训练集的误差)使用,上述
(训练集的误差)使用,上述 的值越大时,则表明该维特征对于区分这个类别的贡献度就越高。故,计算出各个特征参数的重要性后,选择整个数据集中重要性排名前
的值越大时,则表明该维特征对于区分这个类别的贡献度就越高。故,计算出各个特征参数的重要性后,选择整个数据集中重要性排名前 个特征作为特征筛选后的数据,得到上述初始筛选特征。通常
个特征作为特征筛选后的数据,得到上述初始筛选特征。通常 取所有特征总数的前60%数量特征。
取所有特征总数的前60%数量特征。
进一步地,本发明实施例还可以对上述信号数据集进行预处理。一般来说,设备的原始运行状态数据往往是残缺的、有噪声的、不一致的。针对这种情况,本发明实施例设计以下数据处理规则,对设备的运行数据进行清洗和纠正:(1)缺失值的处理。数据丢失是运行数据采集过程中最常见的问题。在设备运行过程中,会出现一些传感器测量点不能正常工作的情况,从而导致收集到的运行状态信息部分丢失。这时,需要根据数据的重要性采取不同的措施,如插值、删除等。(2)异常数据的处理。由于传感器故障或其他原因,上传数据中可能存在一些不合理的数据。本发明实施例中对该异常数据进行删除操作。(3)数据的归一化。设备的上传数据有很多类型,包括电压、电流、温度等。由于收集的数据有不同的数值范围和取值范围,因此需要进行归一化操作,以更好地反映数据和故障类型之间的关系,并减小不同的量级给故障诊断结果带来的影响。其中,本发明实施例采用极差标准化方法对数据进行归一化:

其中, 、
、 别表示同一组设备运行状态数据样本中的最小值和最大值,
别表示同一组设备运行状态数据样本中的最小值和最大值, 表示输入的数据,
表示输入的数据, 表示归一化后的数据。
表示归一化后的数据。
步骤S11,将初始筛选特征按照预设比例划分为训练集和测试集。
在上述信号数据集中,设备的每一种运行状态都有对应的多条故障数据,在本发明实施例中按照3:1的比例对数据集进行分割,即随机选择每种运行状态75%的数据当作训练集,其余25%的数据当作测试集。之后,再利用下述加权影响因子的随机森林算法对该训练集进行数据提取,得到目标筛选特征,并在筛选出该目标筛选特征后,对训练集和测试集按照特征索引进行特征抽取,将训练集与测试集的特征维度保持一致。
此外,本发明实施例还可以将步骤S11的数据集划分获得的数据特征,也即上述训练集和上述测试集输入到卷积神经网络中,通过卷积神经网络中进行卷积运算,对训练集和测试集进行深度特征提取。卷积神经网络主要包括输入层、卷积层、池化层和输出层。卷积层在训练时通过学习卷积核的权重提取特征。池化层用于保留有用特征,舍去多余无用特征,达到降维的效果。具体的,将上述数据集划分后的数据,输入训练好的卷积神经网络模型中,依次进行3 1尺寸的卷积运算、5
1尺寸的卷积运算、5 1尺寸的卷积运算。其中,
1尺寸的卷积运算。其中, 为乘法符号。本步骤设计的卷积层数为3层,全连接神经网络层数为1层,池化层为1层。
为乘法符号。本步骤设计的卷积层数为3层,全连接神经网络层数为1层,池化层为1层。
具体的,卷积神经网络中包括激活函数,传统的ReLU激活函数如下:

其中, 和
和 分别是ReLU激活函数的输入和输出。在传统应用ReLU函数进行设备故障诊断时,在输入信号存在振荡时,函数会舍去这类振动信号,削弱了模型的分类预测能力。对此,本发明实施例对激活函数进行了改进,采用改进的ReLU激活函数来解决当输入信号存在振荡时产生的问题。
分别是ReLU激活函数的输入和输出。在传统应用ReLU函数进行设备故障诊断时,在输入信号存在振荡时,函数会舍去这类振动信号,削弱了模型的分类预测能力。对此,本发明实施例对激活函数进行了改进,采用改进的ReLU激活函数来解决当输入信号存在振荡时产生的问题。
本发明实施例可以通过下述激活函数对信号数据集进行卷积运算。其中,该激活函数如下式所示:

上述 和
和 分别为激活函数的输入数据和输出数据,
分别为激活函数的输入数据和输出数据, 为预设的参数系数,根据实际经验来取值,通常
为预设的参数系数,根据实际经验来取值,通常 的取值范围在0-0.5之间。
的取值范围在0-0.5之间。
步骤S12,将训练集输入至基于加权影响因子的随机森林算法中,确定目标筛选特征。
针对上述数据集划分后的训练集数据,本发明实施例采用基于加权影响因子的随机森林算法进行特征的进一步筛选。在具体实现时,将训练集输入至基于加权影响因子的随机森林算法中后,通过随机森林算法定义的多种影响因子公式计算训练集中的每个初始筛选特征分别对应的多种影响因子数据,之后按照每种影响因子数据分别对应的加权系数对每种影响因子数据加权处理,确定初始筛选特征对应的综合权值,再根据综合权值对每个初始筛选特征按照从大到小进行排序,基于排序的结果,确定目标筛选特征。
具体的,针对数据集划分后的训练集S,将其输入至基于加权影响因子的随机森林算法中,设训练集 的样本数为
的样本数为 ,样本特征为
,样本特征为 ,
, 为特征数量。构建用于特征筛选的随机森林,随机森林中决策树的个数为
为特征数量。构建用于特征筛选的随机森林,随机森林中决策树的个数为 。本发明实施例所提出的基于加权影响因子的随机森林算法对3种影响因子进行加权,分别是特征重要性度量值
。本发明实施例所提出的基于加权影响因子的随机森林算法对3种影响因子进行加权,分别是特征重要性度量值 、特征信息熵
、特征信息熵 和特征熵权指数
和特征熵权指数 ,接下来分别阐述各影响因子的获得方式。
,接下来分别阐述各影响因子的获得方式。
当上述影响因子包括特征重要性度量值时,可以采用随机抽样的方式对训练集进行随机抽样,在训练集内部再构建 个子训练集,记为:
个子训练集,记为: ;1个测试子集
;1个测试子集 ,每个训练子集中有
,每个训练子集中有 个样本数据,
个样本数据, 个样本特征。
个样本特征。
然后,对子训练集集合 进行决策树的构建,之后计算所有决策树对应的分类精度数据
进行决策树的构建,之后计算所有决策树对应的分类精度数据 和权重数据
和权重数据 ,以根据分类精度数据
,以根据分类精度数据 和权重数据
和权重数据 计算特征重要性度量值
计算特征重要性度量值 。上述分类精度数据
。上述分类精度数据 通过下述公式确定:
通过下述公式确定:

上述公式中, 为第
为第 棵决策树的分类精度,S为测试子集的数量,
棵决策树的分类精度,S为测试子集的数量, 为所有测试子集样本数量;
为所有测试子集样本数量; 为在第
为在第 个测试子集中第
个测试子集中第 棵决策树对测试子集样本的分类与样本真实分类相同的样本的数量。
棵决策树对测试子集样本的分类与样本真实分类相同的样本的数量。
得到上述分类精度数据后,可以将所有决策树的精度 按照由大到小排序,逐次去除后
按照由大到小排序,逐次去除后 棵决策树并计算最终的分类精度。
棵决策树并计算最终的分类精度。 是由人为设置,通常取2。完成上述操作后,再计算决策树的权重数据,上述权重数据
是由人为设置,通常取2。完成上述操作后,再计算决策树的权重数据,上述权重数据 通过下述公式确定:
通过下述公式确定:

上述公式中, 代表第
代表第 棵决策树的权重数据,E为当前决策树的数量,
棵决策树的权重数据,E为当前决策树的数量, 代表第
代表第 棵决策树对测试子集样本的分类与随机森林所有决策树对测试子集样本的分类相同的样本数目;
棵决策树对测试子集样本的分类与随机森林所有决策树对测试子集样本的分类相同的样本数目; 代表测试子集的样本数量。
代表测试子集的样本数量。
之后,计算第 棵决策树中第
棵决策树中第 个特征的重要性度量值
个特征的重要性度量值 ,
, 通过下述公式确定:
通过下述公式确定:

其中, 定义为给测试子集中第
定义为给测试子集中第 个特征加入高斯噪声后的平均分类精度,
个特征加入高斯噪声后的平均分类精度, 为第
为第 棵决策树的分类精度,
棵决策树的分类精度, 为测试子集中样本的特征数量。再计算最终的特征重要性度量值
为测试子集中样本的特征数量。再计算最终的特征重要性度量值 ,上述特征重要性度量值
,上述特征重要性度量值 通过下述公式确定:
通过下述公式确定:

其中, 为决策树总数量,
为决策树总数量, 为剔除掉的决策树数量;通过上述计算,即获得上述分类精度
为剔除掉的决策树数量;通过上述计算,即获得上述分类精度 的最终特征重要性度量值
的最终特征重要性度量值 。
。
当上述影响因子包括特征信息熵和特征熵权指数时,可以基于训练集的每个初始筛选特征,构建训练集对应的初始评价矩阵,再确定初始评价矩阵中的特征值对应的特征比重,之后根据特征比重和特征比重对应的对数数据,计算特征信息熵。最后根据特征信息熵和每个初始筛选特征对应的特征信息熵的和值的比值,确定特征熵权指数。具体的,对于训练集的 个样本,每个样本有
个样本,每个样本有 c个特征,则可以构成
c个特征,则可以构成 维的初始评价矩阵
维的初始评价矩阵 ,公式如下:
,公式如下:

其中, 为第i个样本的第j个特征值。
为第i个样本的第j个特征值。
然后,计算特征比重,公式如下:

其中, 代表
代表 的第
的第 个特征的第
个特征的第 个指标所占的特征比重。
个指标所占的特征比重。
然后,计算第 个特征的特征信息熵
个特征的特征信息熵 和特征熵权指数
和特征熵权指数 ,公式如下:
,公式如下:



其中, 为训练集中样本的数量,
为训练集中样本的数量, 用于表征每个初始筛选特征对应的特征信息熵的和值;
用于表征每个初始筛选特征对应的特征信息熵的和值; 为样本的特征数量,
为样本的特征数量, 为所述特征熵权指数。
为所述特征熵权指数。
当得到上述特征信息熵 、上述特征熵权指数
、上述特征熵权指数 和上述特征重要性度量值
和上述特征重要性度量值 这3种影响因子后,分别对3种影响因子进行加权,得到综合权值
这3种影响因子后,分别对3种影响因子进行加权,得到综合权值 ,公式如下:
,公式如下:

其中, 、
、 、
、 分别为加权系数,由人为设置。通常设置为0.3、0.14、0.3。在计算完综合权值
分别为加权系数,由人为设置。通常设置为0.3、0.14、0.3。在计算完综合权值 后,需要摒弃部分特征,对各特征对应的综合权值
后,需要摒弃部分特征,对各特征对应的综合权值 进行排序,选取前
进行排序,选取前 个特征作为特征筛选后的特征。通常,
个特征作为特征筛选后的特征。通常, 取所有特征总数的60%。
取所有特征总数的60%。
步骤S13,将训练集对应的目标筛选特征和测试集对应的初始筛选特征按照特征索引方式进行特征抽取,得到目标特征参数。
通过上述步骤S12可以得到对应的目标筛选特征,此时,可以将该目标筛选特征和数据集划分后得到的测试集进行特征抽取,将训练集与测试集的特征维度保持一致。其中,该数据集划分操作是针对初始筛选特征执行,故,该特征索引方式是同时对目标筛选特征和初始筛选特征进行特征抽取,得到上述目标特征参数。
步骤S206,将目标特征参数输入至预先设置的分类模型中,构建对应于待测信号数据的边缘计算模型。
具体的,可以将目标特征参数输入至上述加权支持向量机中,确定目标特征参数基于每种基础核函数的函数结果,之后按照预先设定的权重系数将每种基础核函数的函数结果线性相加,构建多核函数模型,训练加权支持向量机,得到边缘计算模型。在具体实现时,将目标特征参数输入至预先设置的分类模型中,该分类模型包括基于加权支持向量机的分类模型,将该目标特征参数作为训练样本进行分类器的训练。常用的支持向量机都是单核的,即基于单个特征空间进行分类。在实际应用中往往需要根据经验选择不同的核函数、指定不同的参数,当数据集特征为异构时,分类效果并不理想。
本发明实施例考虑采用多种基础核函数进行加权,其中,本发明实施例以3种核函数进行说明,分别包括线性核函数、多项式核函数和径向基核函数。
上述线性核函数通过下述函数确定:

多项式核函数通过下述函数确定:

径向基核函数通过下述函数确定:

上述函数中,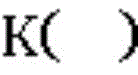 为核函数,
为核函数, 为以e为底的指数函数,
为以e为底的指数函数, 为输入的目标特征参数对应的矩阵,
为输入的目标特征参数对应的矩阵, 为矩阵的转置,
为矩阵的转置, 均为不同基础核函数的参数。
均为不同基础核函数的参数。
本发明实施例采用加权多核支持向量机集成的方法构建新的合成核,利用权重将不同的核函数线性相加构建多核函数模型,以此训练分类器,不同的特征将被分别映射到最优的核函数以达到较高的分类效果。
多核支持向量机中,使用交叉验证等技术来选择最佳的核函数和参数。具体而言,通过网格搜索等技术来搜索最佳的核函数和参数组合,并使用交叉验证来评估它们的性能。最终,选择具有最佳性能的核函数和参数组合,以获得最佳的分类效果。上述多核函数模型包括合成核函数,该合成核函数通过下述函数确定:


其中, 为上述目标特征参数矢量的总数目,
为上述目标特征参数矢量的总数目, 为单个的基础核函数;
为单个的基础核函数; 为每个目标特征参数对应的最优单个核函数的权重大小,且权重总和为1。
为每个目标特征参数对应的最优单个核函数的权重大小,且权重总和为1。
本发明实施例提供的另一种基于边缘计算的设备故障诊断方法,对边缘计算的架构进行设计,构建出包括合成核函数的加权支持向量机的分类模型,能够将不同的特征参数映射到最优核函数中得出分类结果,有效提高分类精度,以对特征参数精准分类。且,还预先准备了用于训练边缘计算模型的信号数据集,针对该信号数据集进行多种筛选,得到目标特征参数,再以该目标特征参数构建上述边缘计算模型,其中,经过多种筛选后的目标特征参数为有效数据,使用该目标特征参数能够使构建的边缘计算模型的分类结果更加准确。
其中,目标特征参数是经过筛选得到初始筛选特征,再根据初始筛选特征确定训练集和测试集,之后对训练集进行筛选,得到目标筛选特征后得到的,初始筛选特征利用基于基尼系数的费希尔准则算法特征筛选方式得到,该方式能够有效剔除冗余特征,并将有用特征进行保留,提高了数据的质量。目标筛选特征是利用基于加权影响因子的随机森林算法进行特征的进一步筛选得到的,通过考虑多种因素,能够进一步对特征进行处理,有助于后续对数据进行检测分类时精度的提高。此外,还对数据集划分后的训练集和测试集进行深度提取,提出使用卷积神经网络进行特征提取,并对激活函数进行改进,通过对激活函数的改进有效提高了深度特征提取的效果,有助于后续对数据进行检测分类时精度的提高。此外,本发明实施例所提出的特征筛选、特征提取、分类器的设计,具有较高的鲁棒性和泛化能力,能够有效实现设备故障诊断的检测。
进一步地,在上述方法实施例的基础上,本发明实施例还提供一种基于边缘计算的设备故障诊断装置,该装置应用于信号测试设备,所述信号测试设备与云端平台通信,图4示出了本发明实施例提供的一种基于边缘计算的设备故障诊断装置的结构示意图,如图4所示,该装置包括:数据采集模块100,用于获取待测设备的待测信号数据。数据处理模块200,用于将待测信号数据输入至预先构建的边缘计算模型中,通过边缘计算模型对待测信号数据进行数据诊断,得到诊断结果;通信模块300,用于将诊断结果和待测信号数据发送至云端平台,通过云端平台对待测信号数据进行分析处理,以对待测设备的运行状态进行监管。其中,边缘计算模型包括基于加权支持向量机的分类模型,加权支持向量机通过多种基础核函数进行加权得到。
本发明实施例提供的一种基于边缘计算的设备故障诊断装置,与上述实施例提供的一种基于边缘计算的设备故障诊断方法具有相同的技术特征,所以也能解决相同的技术问题,达到相同的技术效果。
进一步地,在图4的基础上,本发明实施例还提供另一种基于边缘计算的设备故障诊断装置,图5示出了本发明实施例提供的另一种基于边缘计算的设备故障诊断装置的结构示意图,如图5所示,上述装置还包括模型构建模块400,用于获取预先存储的信号数据集;其中,信号数据集中包括表征设备一种正常运行状态的特征参数和多种非正常状态的特征参数;对信号数据集中的每个特征参数进行筛选,提取信号数据对应的目标特征参数;将目标特征参数输入至预先设置的分类模型中,构建对应于待测信号数据的边缘计算模型。
上述模型构建模块400,还用于将目标特征参数输入至加权支持向量机中,确定目标特征参数基于每种基础核函数的函数结果;按照预先设定的权重系数将每种基础核函数的函数结果线性相加,构建多核函数模型,训练加权支持向量机,得到边缘计算模型。其中,分类模型包括基于加权支持向量机的分类模型;加权支持向量机包括多种基础核函数;多种基础核函数包括线性核函数、多项式核函数和径向基核函数。
线性核函数包括:

多项式核函数包括:

径向基核函数包括:

其中, 为核函数,
为核函数, 为以e为底的指数函数,
为以e为底的指数函数, 为输入的目标特征参数对应的矩阵,
为输入的目标特征参数对应的矩阵, 为矩阵的转置;
为矩阵的转置; 均为不同基础核函数的参数;多核函数模型包括合成核函数,合成核函数为:
均为不同基础核函数的参数;多核函数模型包括合成核函数,合成核函数为:


其中, 为上述目标特征参数矢量的总数目,
为上述目标特征参数矢量的总数目, 为单个的基础核函数;
为单个的基础核函数; 为每个目标特征参数对应的最优单个核函数的权重大小,且权重总和为1。
为每个目标特征参数对应的最优单个核函数的权重大小,且权重总和为1。
上述模型构建模块400,还用于通过费希尔准则算法提取特征参数的初始筛选特征;将初始筛选特征按照预设比例划分为训练集和测试集;将训练集输入至基于加权影响因子的随机森林算法中,确定目标筛选特征;将训练集对应的目标筛选特征和测试集对应的初始筛选特征按照特征索引方式进行特征抽取,得到目标特征参数。
上述模型构建模块400,还用于确定特征参数对应的特征向量矩阵;特征向量矩阵中包括特征参数对应的维度数据,以及维度数据指示的特征向量集合;针对特征向量矩阵的维度数据,通过费希尔准则算法确定维度数据指示的特征向量集合的判别系数; 根据判别系数指示的数值大小,对多个特征参数进行筛选,得到信号数据对应的初始筛选特征;费希尔准则算法包括:

其中, 为第
为第 维的维度数据对应的特征向量集合的判别系数,
维的维度数据对应的特征向量集合的判别系数, 、
、 分别为两个相邻类别对应的第
分别为两个相邻类别对应的第 维的维度数据对应的特征值的均值,
维的维度数据对应的特征值的均值, 、
、 分别为两个相邻类别对应的第
分别为两个相邻类别对应的第 维的维度数据对应的特征值的方差,特征值为特征向量矩阵的一列特征向量的值,
维的维度数据对应的特征值的方差,特征值为特征向量矩阵的一列特征向量的值, 为设数据类别的总数,
为设数据类别的总数, 为特征参数对应的总维度数,
为特征参数对应的总维度数, 为每个特征值的基尼系数;
为每个特征值的基尼系数;
基尼系数通过下述公式计算:

其中, 为第
为第 维的维度数据的特征值的基尼系数,
维的维度数据的特征值的基尼系数, 为上述特征参数矢量的总数目,
为上述特征参数矢量的总数目, 为训练样本的数量;
为训练样本的数量; 为统一去掉第
为统一去掉第 维特征值后训练集的误差。
维特征值后训练集的误差。
上述模型构建模块400,还用于通过随机森林算法定义的多种影响因子公式计算训练集中的每个初始筛选特征分别对应的多种影响因子数据;按照每种影响因子数据分别对应的加权系数对每种影响因子数据加权处理,确定初始筛选特征对应的综合权值;根据综合权值对每个初始筛选特征按照从大到小进行排序;基于排序的结果,确定目标筛选特征。
其中,多种影响因子包括特征重要性度量值;上述模型构建模块400,还用于对训练集进行随机抽样,构建训练集对应的子训练集和测试子集;构建子训练集对应的决策树,确定决策树对应的分类精度数据和权重数据;根据分类精度数据和权重数据计算特征重要性度量值;分类精度数据通过下述公式确定:

其中, 为第
为第 棵决策树的分类精度,S为测试子集的数量,
棵决策树的分类精度,S为测试子集的数量, 为所有测试子集样本数量;
为所有测试子集样本数量; 为在第
为在第 个测试子集中第
个测试子集中第 棵决策树对测试子集样本的分类与样本真实分类相同的样本的数量;
棵决策树对测试子集样本的分类与样本真实分类相同的样本的数量;
权重数据通过下述公式确定:

其中, 代表第
代表第 棵决策树的权重数据,E为当前决策树的数量,
棵决策树的权重数据,E为当前决策树的数量, 代表第
代表第 棵决策树对测试子集样本的分类与随机森林所有决策树对测试子集样本的分类相同的样本数目;
棵决策树对测试子集样本的分类与随机森林所有决策树对测试子集样本的分类相同的样本数目; 代表测试子集的样本数量;
代表测试子集的样本数量;
特征重要性度量值通过下述公式确定:

其中, 为决策树总数量,
为决策树总数量, 为剔除掉的决策树数量;
为剔除掉的决策树数量; 为第
为第 棵决策树中第
棵决策树中第 个特征的重要性度量值;
个特征的重要性度量值; 通过下述公式确定:
通过下述公式确定:

其中, 定义为给测试子集中第
定义为给测试子集中第 个特征加入高斯噪声后的平均分类精度,
个特征加入高斯噪声后的平均分类精度, 为第
为第 棵决策树的分类精度,
棵决策树的分类精度, 为测试子集中样本的特征数量。
为测试子集中样本的特征数量。
上述多种影响因子还包括特征信息熵和特征熵权指数;上述模型构建模块400,还用于基于训练集的每个初始筛选特征,构建训练集对应的初始评价矩阵;确定初始评价矩阵中的特征值对应的特征比重;根据特征比重和特征比重对应的对数数据,计算特征信息熵;
其中,特征信息熵通过下述公式确定:









上述模型构建模块400,还用于将训练集和测试集分别输入至卷积神经网络中进行卷积运算,对训练集和测试集进行深度特征提取;其中,卷积神经网络中包括激活函数,通过激活函数对训练集和测试集进行卷积运算;激活函数包括:

其中, 和
和 分别为激活函数的输入数据和输出数据,
分别为激活函数的输入数据和输出数据, 为预设的参数系数。
为预设的参数系数。
本发明实施例还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行计算机程序时实现上述图1至图3所示的方法的步骤。本发明实施例还提供一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序,计算机程序被处理器运行时执行上述图1至图3所示的方法的步骤。
本发明实施例还提供了一种电子设备的结构示意图,如图6所示,为该电子设备的结构示意图,其中,该电子设备包括处理器61和存储器60,该存储器60存储有能够被该处理器61执行的计算机可执行指令,该处理器61执行该计算机可执行指令以实现上述图1至图3所示的方法。
在图6示出的实施方式中,该电子设备还包括总线62和通信接口63,其中,处理器61、通信接口63和存储器60通过总线62连接。其中,存储器60可能包含高速随机存取存储器(RAM,Random Access Memory),也可能还包括非易失性存储器(non-volatile memory),例如至少一个磁盘存储器。通过至少一个通信接口63(可以是有线或者无线)实现该系统网元与至少一个其他网元之间的通信连接,可以使用互联网,广域网,本地网,城域网等。总线62可以是ISA(Industry Standard Architecture,工业标准体系结构)总线、PCI(PeripheralComponent Interconnect,外设部件互连标准)总线或EISA(Extended Industry StandardArchitecture,扩展工业标准结构)总线等,还可以是AMBA(Advanced MicrocontrollerBus Architecture,片上总线的标准)总线,其中,AMBA定义了三种总线,包括APB(AdvancedPeripheral Bus)总线、AHB(Advanced High-performance Bus)总线和AXI(AdvancedeXtensible Interface)总线。总线62可以分为地址总线、数据总线、控制总线等。为便于表示,图6中仅用一个双向箭头表示,但并不表示仅有一根总线或一种类型的总线。
处理器61可能是一种集成电路芯片,具有信号的处理能力。在实现过程中,上述方法的各步骤可以通过处理器61中的硬件的集成逻辑电路或者软件形式的指令完成。上述的处理器61可以是通用处理器,包括中央处理器(Central Processing Unit,简称CPU)、网络处理器(Network Processor,简称NP)等;还可以是数字信号处理器(Digital SignalProcessor,简称DSP)、专用集成电路(Application Specific Integrated Circuit,简称ASIC)、现场可编程门阵列(Field-Programmable Gate Array,简称FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。结合本申请实施例所公开的方法的步骤可以直接体现为硬件译码处理器执行完成,或者用译码处理器中的硬件及软件模块组合执行完成。软件模块可以位于随机存储器,闪存、只读存储器,可编程只读存储器或者电可擦写可编程存储器、寄存器等本领域成熟的存储介质中。该存储介质位于存储器,处理器61读取存储器中的信息,结合其硬件完成前述图1至图3任一所示的方法。
本发明实施例所提供的一种基于边缘计算的设备故障诊断方法及装置的计算机程序产品,包括存储了程序代码的计算机可读存储介质,所述程序代码包括的指令可用于执行前面方法实施例中所述的方法,具体实现可参见方法实施例,在此不再赘述。
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。另外,在本发明实施例的描述中,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
所述功能如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random Access Memory)、磁碟或者光盘等各种可以存储程序代码的介质。
在本发明的描述中,需要说明的是,术语“中心”、“上”、“下”、“左”、“右”、“竖直”、“水平”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”、“第三”仅用于描述目的,而不能理解为指示或暗示相对重要性。
最后应说明的是:以上实施例,仅为本发明的具体实施方式,用以说明本发明的技术方案,而非对其限制,本发明的保护范围并不局限于此,尽管参照前述实施例对本发明进行了详细的说明,本领域技术人员应当理解:任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,其依然可以对前述实施例所记载的技术方案进行修改或可轻易想到变化,或者对其中部分技术特征进行等同替换;而这些修改、变化或者替换,并不使相应技术方案的本质脱离本发明实施例技术方案的精神和范围,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
Claims (7)
1.一种基于边缘计算的设备故障诊断方法,其特征在于,所述方法应用于信号测试设备,所述信号测试设备与云端平台通信;所述方法包括:
获取待测设备的待测信号数据;
将所述待测信号数据输入至预先构建的边缘计算模型中,通过所述边缘计算模型对所述待测信号数据进行数据诊断,得到诊断结果;
将所述诊断结果和所述待测信号数据发送至云端平台,通过所述云端平台对所述待测信号数据进行分析处理,以对所述待测设备的运行状态进行监管;
其中,所述边缘计算模型包括基于加权支持向量机的分类模型,所述加权支持向量机通过多种基础核函数进行加权得到;
所述边缘计算模型通过下述步骤构建:
获取预先存储的信号数据集;其中,所述信号数据集中包括表征设备一种正常运行状态的特征参数和多种非正常状态的特征参数;
对所述信号数据集中的每个特征参数进行筛选,提取所述信号数据对应的目标特征参数;
将所述目标特征参数输入至预先设置的分类模型中,构建对应于所述待测信号数据的边缘计算模型;
所述对所述信号数据集中的每个特征参数进行筛选,提取所述信号数据对应的目标特征参数的步骤,包括:
通过费希尔准则算法提取所述特征参数的初始筛选特征;
将所述初始筛选特征按照预设比例划分为训练集和测试集;
将所述训练集输入至基于加权影响因子的随机森林算法中,确定目标筛选特征;
将训练集对应的所述目标筛选特征和所述测试集对应的初始筛选特征按照特征索引方式进行特征抽取,得到所述目标特征参数;
所述通过费希尔准则算法提取所述特征参数的初始筛选特征的步骤,包括:
确定所述特征参数对应的特征向量矩阵;所述特征向量矩阵中包括所述特征参数对应的维度数据,以及所述维度数据指示的特征向量集合;
针对所述特征向量矩阵的所述维度数据,通过所述费希尔准则算法确定所述维度数据指示的特征向量集合的判别系数;
根据所述判别系数指示的数值大小,对多个所述特征参数进行筛选,得到所述信号数据对应的初始筛选特征;
所述费希尔准则算法包括:

其中, 为第
为第 维的维度数据对应的特征向量集合的判别系数,
维的维度数据对应的特征向量集合的判别系数, 、
、 分别为两个相邻类别对应的第
分别为两个相邻类别对应的第 维的维度数据对应的特征值的均值,所述特征值为所述特征向量矩阵的一列特征向量的值,
维的维度数据对应的特征值的均值,所述特征值为所述特征向量矩阵的一列特征向量的值, 、
、 分别为两个相邻类别对应的第
分别为两个相邻类别对应的第 维的维度数据对应的特征值的方差,
维的维度数据对应的特征值的方差, 为设数据类别的总数,
为设数据类别的总数,  为特征向量的总维度数,
为特征向量的总维度数, 为每个特征值的基尼系数;所述基尼系数通过下述公式计算:
为每个特征值的基尼系数;所述基尼系数通过下述公式计算:

其中, 为第
为第 维的维度数据的特征值的基尼系数,
维的维度数据的特征值的基尼系数, 为所述特征参数矢量的总数目,
为所述特征参数矢量的总数目, 为训练样本的数量;
为训练样本的数量; 为统一去掉第
为统一去掉第 维特征值后训练集的误差。
维特征值后训练集的误差。
2.根据权利要求1所述的方法,其特征在于,所述分类模型包括基于加权支持向量机的分类模型;所述加权支持向量机包括多种基础核函数;多种所述基础核函数包括线性核函数、多项式核函数和径向基核函数;
所述线性核函数包括:

所述多项式核函数包括:

所述径向基核函数包括:

其中, 为核函数,
为核函数, 为以e为底的指数函数,
为以e为底的指数函数, 为输入的所述目标特征参数对应的矩阵,
为输入的所述目标特征参数对应的矩阵, 为矩阵的转置;
为矩阵的转置; 均为不同基础核函数的参数;
均为不同基础核函数的参数;
所述将所述目标特征参数输入至预先设置的分类模型中,构建对应于所述待测信号数据的边缘计算模型的步骤,包括:
将所述目标特征参数输入至所述加权支持向量机中,确定所述目标特征参数基于每种所述基础核函数的函数结果;
按照预先设定的权重系数将每种所述基础核函数的函数结果线性相加,构建多核函数模型,训练所述加权支持向量机,得到所述边缘计算模型;
其中,所述多核函数模型包括合成核函数,所述合成核函数为:


其中, 为所述目标特征参数矢量的总数目,
为所述目标特征参数矢量的总数目, 为单个的基础核函数;
为单个的基础核函数; 为每个目标特征参数对应的最优单个核函数的权重大小,且权重总和为1。
为每个目标特征参数对应的最优单个核函数的权重大小,且权重总和为1。
3.根据权利要求1所述的方法,其特征在于,将所述训练集输入至基于加权影响因子的随机森林算法中,确定目标筛选特征的步骤,包括:
通过随机森林算法定义的多种影响因子公式计算所述训练集中的每个初始筛选特征分别对应的多种影响因子数据;
按照每种影响因子数据分别对应的加权系数对每种影响因子数据加权处理,确定所述初始筛选特征对应的综合权值;
根据所述综合权值对每个所述初始筛选特征按照从大到小进行排序;
基于所述排序的结果,确定所述目标筛选特征。
4.根据权利要求3所述的方法,其特征在于,所述多种影响因子包括特征重要性度量值;
所述通过随机森林算法定义的多种影响因子公式计算所述训练集中的每个初始筛选特征分别对应的多种影响因子数据的步骤,包括:
对所述训练集进行随机抽样,构建所述训练集对应的子训练集和测试子集;
构建所述子训练集对应的决策树,确定所述决策树对应的分类精度数据和权重数据;
根据所述分类精度数据和所述权重数据计算所述特征重要性度量值;
所述分类精度数据通过下述公式确定:

其中, 为第
为第 棵决策树的分类精度,S为测试子集的数量,
棵决策树的分类精度,S为测试子集的数量, 为所有测试子集样本数量;
为所有测试子集样本数量; 为在第
为在第 个测试子集中第
个测试子集中第 棵决策树对测试子集样本的分类与样本真实分类相同的样本的数量;
棵决策树对测试子集样本的分类与样本真实分类相同的样本的数量;
所述权重数据通过下述公式确定:

其中, 代表第
代表第 棵决策树的权重数据,E为当前决策树的数量,
棵决策树的权重数据,E为当前决策树的数量, 代表第
代表第 棵决策树对测试子集样本的分类与随机森林所有决策树对测试子集样本的分类相同的样本数目;
棵决策树对测试子集样本的分类与随机森林所有决策树对测试子集样本的分类相同的样本数目; 代表测试子集的样本数量;
代表测试子集的样本数量;
所述特征重要性度量值通过下述公式确定:

其中, 为决策树总数量,
为决策树总数量, 为剔除掉的决策树数量;所述
为剔除掉的决策树数量;所述 为第
为第 棵决策树中第
棵决策树中第 个特征的重要性度量值;所述
个特征的重要性度量值;所述 通过下述公式确定:
通过下述公式确定:

其中, 定义为给测试子集中第
定义为给测试子集中第 个特征加入高斯噪声后的平均分类精度,
个特征加入高斯噪声后的平均分类精度, 为第
为第 棵决策树的分类精度,
棵决策树的分类精度, 为测试子集中样本的特征数量。
为测试子集中样本的特征数量。
5.根据权利要求3所述的方法,其特征在于,所述多种影响因子包括特征信息熵和特征熵权指数;
所述通过随机森林算法定义的多种影响因子公式计算所述训练集中的每个初始筛选特征分别对应的多种影响因子数据的步骤,包括:
基于所述训练集的每个初始筛选特征,构建所述训练集对应的初始评价矩阵;
确定所述初始评价矩阵中的特征值对应的特征比重;
根据所述特征比重和所述特征比重对应的对数数据,计算所述特征信息熵;
其中,所述特征信息熵通过下述公式确定:

所述 为所述特征比重,
为所述特征比重, 为训练集中样本的数量,所述
为训练集中样本的数量,所述 为所述特征信息熵;
为所述特征信息熵;
根据所述特征信息熵和每个初始筛选特征对应的所述特征信息熵的和值的比值,确定所述特征熵权指数;
所述特征熵权指数通过下述公式确定:


所述 为所述特征熵权指数,所述
为所述特征熵权指数,所述 为样本的特征数量,所述
为样本的特征数量,所述 用于表征每个初始筛选特征对应的所述特征信息熵的和值。
用于表征每个初始筛选特征对应的所述特征信息熵的和值。
6.根据权利要求1所述的方法,其特征在于,所述将所述初始筛选特征按照预设比例划分为训练集和测试集的步骤之后,所述方法还包括:
将所述训练集和所述测试集分别输入至卷积神经网络中进行卷积运算,对所述训练集和所述测试集进行深度特征提取;
其中,所述卷积神经网络中包括激活函数,通过所述激活函数对所述训练集和所述测试集进行卷积运算;所述激活函数包括:

其中, 和
和 分别为所述激活函数的输入数据和输出数据,
分别为所述激活函数的输入数据和输出数据, 为预设的参数系数。
为预设的参数系数。
7.一种基于边缘计算的设备故障诊断装置,其特征在于,所述装置应用于信号测试设备,所述信号测试设备与云端平台通信;所述装置包括:
数据采集模块,用于获取待测设备的待测信号数据;
数据处理模块,用于将所述待测信号数据输入至预先构建的边缘计算模型中,通过所述边缘计算模型对所述待测信号数据进行数据诊断,得到诊断结果;
通信模块,用于将所述诊断结果和所述待测信号数据发送至所述云端平台,通过所述云端平台对所述待测信号数据进行分析处理,以对所述待测设备的运行状态进行监管;其中,所述边缘计算模型包括基于加权支持向量机的分类模型,所述加权支持向量机通过多种基础核函数进行加权得到;
所述装置还包括模型构建模块,用于获取预先存储的信号数据集;其中,所述信号数据集中包括表征设备一种正常运行状态的特征参数和多种非正常状态的特征参数;对所述信号数据集中的每个特征参数进行筛选,提取所述信号数据对应的目标特征参数;将所述目标特征参数输入至预先设置的分类模型中,构建对应于所述待测信号数据的边缘计算模型;
所述模型构建模块,还用于通过费希尔准则算法提取所述特征参数的初始筛选特征;将所述初始筛选特征按照预设比例划分为训练集和测试集;将所述训练集输入至基于加权影响因子的随机森林算法中,确定目标筛选特征;将训练集对应的所述目标筛选特征和所述测试集对应的初始筛选特征按照特征索引方式进行特征抽取,得到所述目标特征参数;
所述模型构建模块,还用于确定所述特征参数对应的特征向量矩阵;所述特征向量矩阵中包括所述特征参数对应的维度数据,以及所述维度数据指示的特征向量集合;针对所述特征向量矩阵的所述维度数据,通过所述费希尔准则算法确定所述维度数据指示的特征向量集合的判别系数; 根据所述判别系数指示的数值大小,对多个所述特征参数进行筛选,得到所述信号数据对应的初始筛选特征;所述费希尔准则算法包括:

其中, 为第
为第 维的维度数据对应的特征向量集合的判别系数,
维的维度数据对应的特征向量集合的判别系数, 、
、 分别为两个相邻类别对应的第
分别为两个相邻类别对应的第 维的维度数据对应的特征值的均值,所述特征值为所述特征向量矩阵的一列特征向量的值,
维的维度数据对应的特征值的均值,所述特征值为所述特征向量矩阵的一列特征向量的值, 、
、 分别为两个相邻类别对应的第
分别为两个相邻类别对应的第 维的维度数据对应的特征值的方差,
维的维度数据对应的特征值的方差, 为设数据类别的总数,
为设数据类别的总数, 为特征向量的总维度数,
为特征向量的总维度数, 为每个特征值的基尼系数;所述基尼系数通过下述公式计算:
为每个特征值的基尼系数;所述基尼系数通过下述公式计算:

其中, 为第
为第 维的维度数据的特征值的基尼系数,
维的维度数据的特征值的基尼系数, 为所述特征参数矢量的总数目,
为所述特征参数矢量的总数目, 为训练样本的数量;
为训练样本的数量; 为统一去掉第
为统一去掉第 维特征值后训练集的误差。
维特征值后训练集的误差。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310280499.5A CN115994327B (zh) | 2023-03-22 | 2023-03-22 | 基于边缘计算的设备故障诊断方法及装置 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310280499.5A CN115994327B (zh) | 2023-03-22 | 2023-03-22 | 基于边缘计算的设备故障诊断方法及装置 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN115994327A CN115994327A (zh) | 2023-04-21 |
| CN115994327B true CN115994327B (zh) | 2023-06-23 |
Family
ID=85992312
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202310280499.5A Active CN115994327B (zh) | 2023-03-22 | 2023-03-22 | 基于边缘计算的设备故障诊断方法及装置 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN115994327B (zh) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116432091B (zh) * | 2023-06-15 | 2023-09-26 | 山东能源数智云科技有限公司 | 基于小样本的设备故障诊断方法、模型的构建方法及装置 |
| CN117782198B (zh) * | 2023-12-01 | 2024-06-25 | 湖南省衡永高速公路建设开发有限公司 | 一种基于云边端架构的公路机电设备运行监测方法及系统 |
| CN117706270B (zh) * | 2023-12-11 | 2024-09-06 | 重庆东电通信技术有限公司 | 一种基于边缘计算的输电线路故障诊断方法 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113468794A (zh) * | 2020-12-29 | 2021-10-01 | 重庆大学 | 一种小型密闭空间温湿度预测及反向优化方法 |
| CN113962819A (zh) * | 2021-10-08 | 2022-01-21 | 无锡学院 | 一种基于极限学习机的工厂化水产养殖溶解氧预测方法 |
Family Cites Families (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7310624B1 (en) * | 2000-05-02 | 2007-12-18 | International Business Machines Corporation | Methods and apparatus for generating decision trees with discriminants and employing same in data classification |
| CN104794368A (zh) * | 2015-05-15 | 2015-07-22 | 哈尔滨理工大学 | 基于foa-mksvm的滚动轴承故障分类方法 |
| CN106568923A (zh) * | 2016-11-10 | 2017-04-19 | 北京农业质量标准与检测技术研究中心 | 一种土壤重金属含量影响因子评价方法 |
| US11205103B2 (en) * | 2016-12-09 | 2021-12-21 | The Research Foundation for the State University | Semisupervised autoencoder for sentiment analysis |
| CN108375808A (zh) * | 2018-03-12 | 2018-08-07 | 南京恩瑞特实业有限公司 | Nriet基于机器学习的大雾预报方法 |
| CN110942088A (zh) * | 2019-11-04 | 2020-03-31 | 山东大学 | 一种基于监狱服刑人员有效影响因子的危险性等级评估方法及其实现系统 |
| CN111931827B (zh) * | 2020-07-22 | 2023-07-18 | 上海交通大学 | 基于多传感器信息融合的液压泵健康状况检测系统 |
| CN112926625B (zh) * | 2020-11-25 | 2023-12-22 | 北方工业大学 | 一种卫星辐射数据的偏差影响因子分析方法 |
| CN112819207B (zh) * | 2021-01-19 | 2024-02-06 | 武汉中地云申科技有限公司 | 基于相似性度量的地质灾害空间预测方法、系统及存储介质 |
| CN113256066B (zh) * | 2021-04-23 | 2022-05-06 | 新疆大学 | 基于PCA-XGBoost-IRF的作业车间实时调度方法 |
| CN114676550A (zh) * | 2022-01-17 | 2022-06-28 | 重庆大学 | 一种边坡稳定性评价方法 |
| CN114881165A (zh) * | 2022-05-24 | 2022-08-09 | 大连理工大学 | 一种基于随机森林的碳强度关键影响因子识别方法 |
| CN115660795A (zh) * | 2022-10-26 | 2023-01-31 | 中国建设银行股份有限公司 | 数据处理方法、装置、设备、存储介质及程序产品 |
-
2023
- 2023-03-22 CN CN202310280499.5A patent/CN115994327B/zh active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113468794A (zh) * | 2020-12-29 | 2021-10-01 | 重庆大学 | 一种小型密闭空间温湿度预测及反向优化方法 |
| CN113962819A (zh) * | 2021-10-08 | 2022-01-21 | 无锡学院 | 一种基于极限学习机的工厂化水产养殖溶解氧预测方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN115994327A (zh) | 2023-04-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN115994327B (zh) | 基于边缘计算的设备故障诊断方法及装置 | |
| CN112034789B (zh) | 一种数控机床关键部件及整机的健康评估方法,系统及评估终端机 | |
| CN116150676B (zh) | 基于人工智能的设备故障诊断与识别方法及装置 | |
| WO2017143919A1 (zh) | 一种建立数据识别模型的方法及装置 | |
| CN115412455B (zh) | 一种基于时间序列的服务器多性能指标异常检测方法及装置 | |
| CN117056734B (zh) | 基于数据驱动的设备故障诊断模型的构建方法及装置 | |
| CN116450399B (zh) | 微服务系统故障诊断及根因定位方法 | |
| CN116595463B (zh) | 窃电识别模型的构建方法、窃电行为识别方法及装置 | |
| CN112766342A (zh) | 一种电气设备的异常检测方法 | |
| CN116910493B (zh) | 基于多源特征提取的设备故障诊断模型的构建方法及装置 | |
| CN113158935B (zh) | 一种酒类光谱峭度回归模式的年份鉴定系统及年份鉴定方法 | |
| CN115798516B (zh) | 一种可迁移的端到端声信号诊断方法及系统 | |
| CN112149909A (zh) | 船舶油耗预测方法、装置、计算机设备和存储介质 | |
| CN114113471A (zh) | 一种基于机器学习的人工鼻冰箱食品新鲜度检测方法及系统 | |
| CN115935286A (zh) | 铁路轴承状态监测数据的异常点检测方法、装置及终端 | |
| CN117094184A (zh) | 基于内网平台的风险预测模型的建模方法、系统及介质 | |
| Oliveira-Santos et al. | Submersible motor pump fault diagnosis system: A comparative study of classification methods | |
| CN113487223B (zh) | 一种基于信息融合的风险评估方法和评估系统 | |
| CN117112336B (zh) | 智能通信设备异常检测方法、设备、存储介质及装置 | |
| CN113553319A (zh) | 基于信息熵加权的lof离群点检测清洗方法、装置、设备及存储介质 | |
| CN113110961A (zh) | 设备异常检测方法、装置、计算机设备及可读存储介质 | |
| CN117272145A (zh) | 转辙机的健康状态评估方法、装置和电子设备 | |
| CN116934558A (zh) | 一种无人机自动巡护监测方法及其系统 | |
| CN110852322A (zh) | 感兴趣区域的确定方法及装置 | |
| CN114137915B (zh) | 一种工业设备的故障诊断方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |