CN115210255A - 靶向肿瘤抗原的mana抗体及其使用方法 - Google Patents
靶向肿瘤抗原的mana抗体及其使用方法 Download PDFInfo
- Publication number
- CN115210255A CN115210255A CN202080096879.8A CN202080096879A CN115210255A CN 115210255 A CN115210255 A CN 115210255A CN 202080096879 A CN202080096879 A CN 202080096879A CN 115210255 A CN115210255 A CN 115210255A
- Authority
- CN
- China
- Prior art keywords
- seq
- cells
- hla
- peptide
- scdb
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 206010028980 Neoplasm Diseases 0.000 title claims abstract description 161
- 239000000427 antigen Substances 0.000 title claims abstract description 131
- 108091007433 antigens Proteins 0.000 title claims abstract description 129
- 102000036639 antigens Human genes 0.000 title claims abstract description 129
- 238000000034 method Methods 0.000 title claims abstract description 61
- 230000008685 targeting Effects 0.000 title description 25
- 238000009739 binding Methods 0.000 claims abstract description 203
- 230000027455 binding Effects 0.000 claims abstract description 201
- 108091005601 modified peptides Proteins 0.000 claims abstract description 140
- 201000011510 cancer Diseases 0.000 claims abstract description 125
- 241000124008 Mammalia Species 0.000 claims abstract description 64
- 239000012634 fragment Substances 0.000 claims abstract description 17
- 210000004027 cell Anatomy 0.000 claims description 618
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 432
- 210000001744 T-lymphocyte Anatomy 0.000 claims description 198
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 174
- 150000001413 amino acids Chemical class 0.000 claims description 159
- 241000282414 Homo sapiens Species 0.000 claims description 80
- 102000016914 ras Proteins Human genes 0.000 claims description 78
- 101150040459 RAS gene Proteins 0.000 claims description 72
- 101150076031 RAS1 gene Proteins 0.000 claims description 63
- 108091008874 T cell receptors Proteins 0.000 claims description 35
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 claims description 35
- 102000017420 CD3 protein, epsilon/gamma/delta subunit Human genes 0.000 claims description 29
- 108050005493 CD3 protein, epsilon/gamma/delta subunit Proteins 0.000 claims description 29
- 229920001184 polypeptide Polymers 0.000 claims description 24
- 239000012636 effector Substances 0.000 claims description 19
- 108010019670 Chimeric Antigen Receptors Proteins 0.000 claims description 12
- 238000000375 direct analysis in real time Methods 0.000 claims description 9
- 238000012063 dual-affinity re-targeting Methods 0.000 claims description 9
- 108010021625 Immunoglobulin Fragments Proteins 0.000 claims description 8
- 102000008394 Immunoglobulin Fragments Human genes 0.000 claims description 8
- 206010017758 gastric cancer Diseases 0.000 claims description 8
- 101000917858 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-A Proteins 0.000 claims description 7
- 102100029193 Low affinity immunoglobulin gamma Fc region receptor III-A Human genes 0.000 claims description 7
- 229940045513 CTLA4 antagonist Drugs 0.000 claims description 6
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 claims description 6
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 claims description 6
- 102000008203 CTLA-4 Antigen Human genes 0.000 claims description 5
- 108010021064 CTLA-4 Antigen Proteins 0.000 claims description 5
- 101001109501 Homo sapiens NKG2-D type II integral membrane protein Proteins 0.000 claims description 5
- 101000716102 Homo sapiens T-cell surface glycoprotein CD4 Proteins 0.000 claims description 5
- 101000946843 Homo sapiens T-cell surface glycoprotein CD8 alpha chain Proteins 0.000 claims description 5
- 101000851370 Homo sapiens Tumor necrosis factor receptor superfamily member 9 Proteins 0.000 claims description 5
- 206010058467 Lung neoplasm malignant Diseases 0.000 claims description 5
- 201000003793 Myelodysplastic syndrome Diseases 0.000 claims description 5
- 102100022680 NKG2-D type II integral membrane protein Human genes 0.000 claims description 5
- 206010035226 Plasma cell myeloma Diseases 0.000 claims description 5
- 101710089372 Programmed cell death protein 1 Proteins 0.000 claims description 5
- 208000005718 Stomach Neoplasms Diseases 0.000 claims description 5
- 102100036011 T-cell surface glycoprotein CD4 Human genes 0.000 claims description 5
- 102100034922 T-cell surface glycoprotein CD8 alpha chain Human genes 0.000 claims description 5
- 102100022153 Tumor necrosis factor receptor superfamily member 4 Human genes 0.000 claims description 5
- 101710165473 Tumor necrosis factor receptor superfamily member 4 Proteins 0.000 claims description 5
- 102100036856 Tumor necrosis factor receptor superfamily member 9 Human genes 0.000 claims description 5
- 201000005202 lung cancer Diseases 0.000 claims description 5
- 208000020816 lung neoplasm Diseases 0.000 claims description 5
- 201000001441 melanoma Diseases 0.000 claims description 5
- 201000011549 stomach cancer Diseases 0.000 claims description 5
- 208000024893 Acute lymphoblastic leukemia Diseases 0.000 claims description 4
- 208000014697 Acute lymphocytic leukaemia Diseases 0.000 claims description 4
- 208000031261 Acute myeloid leukaemia Diseases 0.000 claims description 4
- 206010009944 Colon cancer Diseases 0.000 claims description 4
- 208000034578 Multiple myelomas Diseases 0.000 claims description 4
- 206010061902 Pancreatic neoplasm Diseases 0.000 claims description 4
- 208000006664 Precursor Cell Lymphoblastic Leukemia-Lymphoma Diseases 0.000 claims description 4
- 208000024770 Thyroid neoplasm Diseases 0.000 claims description 4
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 claims description 4
- 201000002528 pancreatic cancer Diseases 0.000 claims description 4
- 208000008443 pancreatic carcinoma Diseases 0.000 claims description 4
- 102000005962 receptors Human genes 0.000 claims description 4
- 108020003175 receptors Proteins 0.000 claims description 4
- 206010003571 Astrocytoma Diseases 0.000 claims description 3
- 206010005949 Bone cancer Diseases 0.000 claims description 3
- 208000018084 Bone neoplasm Diseases 0.000 claims description 3
- 206010006187 Breast cancer Diseases 0.000 claims description 3
- 208000026310 Breast neoplasm Diseases 0.000 claims description 3
- 208000001333 Colorectal Neoplasms Diseases 0.000 claims description 3
- 206010014733 Endometrial cancer Diseases 0.000 claims description 3
- 206010014759 Endometrial neoplasm Diseases 0.000 claims description 3
- 208000000461 Esophageal Neoplasms Diseases 0.000 claims description 3
- 201000010915 Glioblastoma multiforme Diseases 0.000 claims description 3
- 208000017604 Hodgkin disease Diseases 0.000 claims description 3
- 208000021519 Hodgkin lymphoma Diseases 0.000 claims description 3
- 208000010747 Hodgkins lymphoma Diseases 0.000 claims description 3
- 208000008839 Kidney Neoplasms Diseases 0.000 claims description 3
- 208000033776 Myeloid Acute Leukemia Diseases 0.000 claims description 3
- 208000034176 Neoplasms, Germ Cell and Embryonal Diseases 0.000 claims description 3
- 208000015914 Non-Hodgkin lymphomas Diseases 0.000 claims description 3
- 206010030155 Oesophageal carcinoma Diseases 0.000 claims description 3
- 206010033128 Ovarian cancer Diseases 0.000 claims description 3
- 206010061535 Ovarian neoplasm Diseases 0.000 claims description 3
- 206010060862 Prostate cancer Diseases 0.000 claims description 3
- 208000000236 Prostatic Neoplasms Diseases 0.000 claims description 3
- 206010038389 Renal cancer Diseases 0.000 claims description 3
- 208000032383 Soft tissue cancer Diseases 0.000 claims description 3
- 201000009036 biliary tract cancer Diseases 0.000 claims description 3
- 208000020790 biliary tract neoplasm Diseases 0.000 claims description 3
- 201000004101 esophageal cancer Diseases 0.000 claims description 3
- 208000005017 glioblastoma Diseases 0.000 claims description 3
- 201000010536 head and neck cancer Diseases 0.000 claims description 3
- 208000014829 head and neck neoplasm Diseases 0.000 claims description 3
- 201000010982 kidney cancer Diseases 0.000 claims description 3
- 201000007270 liver cancer Diseases 0.000 claims description 3
- 208000014018 liver neoplasm Diseases 0.000 claims description 3
- 201000002510 thyroid cancer Diseases 0.000 claims description 3
- 208000021309 Germ cell tumor Diseases 0.000 claims description 2
- 208000014767 Myeloproliferative disease Diseases 0.000 claims description 2
- 150000003839 salts Chemical class 0.000 claims description 2
- 125000003275 alpha amino acid group Chemical group 0.000 claims 4
- 102100023990 60S ribosomal protein L17 Human genes 0.000 claims 2
- 239000000463 material Substances 0.000 abstract description 16
- 102100025064 Cellular tumor antigen p53 Human genes 0.000 description 164
- 101000721661 Homo sapiens Cellular tumor antigen p53 Proteins 0.000 description 128
- 235000001014 amino acid Nutrition 0.000 description 122
- 229940024606 amino acid Drugs 0.000 description 119
- 102200006531 rs121913529 Human genes 0.000 description 107
- 238000002965 ELISA Methods 0.000 description 78
- 108090000623 proteins and genes Proteins 0.000 description 67
- 230000035772 mutation Effects 0.000 description 66
- 102000004169 proteins and genes Human genes 0.000 description 58
- 238000002474 experimental method Methods 0.000 description 56
- 230000014509 gene expression Effects 0.000 description 54
- 235000018102 proteins Nutrition 0.000 description 50
- 239000013612 plasmid Substances 0.000 description 47
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 45
- 102220197775 rs1057519695 Human genes 0.000 description 44
- 238000000684 flow cytometry Methods 0.000 description 43
- 239000002609 medium Substances 0.000 description 42
- 239000006228 supernatant Substances 0.000 description 41
- 239000000203 mixture Substances 0.000 description 40
- 102200007373 rs17851045 Human genes 0.000 description 39
- 238000010186 staining Methods 0.000 description 39
- 108700028369 Alleles Proteins 0.000 description 38
- 101000584612 Homo sapiens GTPase KRas Proteins 0.000 description 38
- 241000699670 Mus sp. Species 0.000 description 38
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 37
- 102100030708 GTPase KRas Human genes 0.000 description 36
- 230000003013 cytotoxicity Effects 0.000 description 35
- 231100000135 cytotoxicity Toxicity 0.000 description 35
- 238000004458 analytical method Methods 0.000 description 33
- 108010090804 Streptavidin Proteins 0.000 description 31
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 30
- 239000004698 Polyethylene Substances 0.000 description 30
- 238000012216 screening Methods 0.000 description 30
- 102200006525 rs121913240 Human genes 0.000 description 29
- 229910052739 hydrogen Inorganic materials 0.000 description 28
- 230000028327 secretion Effects 0.000 description 28
- 239000011324 bead Substances 0.000 description 27
- 239000000872 buffer Substances 0.000 description 27
- 108091033409 CRISPR Proteins 0.000 description 26
- 230000006044 T cell activation Effects 0.000 description 26
- 108010078814 Tumor Suppressor Protein p53 Proteins 0.000 description 26
- 239000001257 hydrogen Substances 0.000 description 25
- 238000011282 treatment Methods 0.000 description 25
- 210000004881 tumor cell Anatomy 0.000 description 23
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 22
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 22
- 102000025850 HLA-A2 Antigen Human genes 0.000 description 21
- 108010074032 HLA-A2 Antigen Proteins 0.000 description 21
- 239000012980 RPMI-1640 medium Substances 0.000 description 21
- 238000003556 assay Methods 0.000 description 21
- 238000003501 co-culture Methods 0.000 description 21
- 229960005322 streptomycin Drugs 0.000 description 21
- 238000011534 incubation Methods 0.000 description 20
- 102000004127 Cytokines Human genes 0.000 description 19
- 108090000695 Cytokines Proteins 0.000 description 19
- 108020004414 DNA Proteins 0.000 description 19
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 19
- 239000005090 green fluorescent protein Substances 0.000 description 19
- 239000002953 phosphate buffered saline Substances 0.000 description 19
- 239000011780 sodium chloride Substances 0.000 description 19
- 241000283973 Oryctolagus cuniculus Species 0.000 description 18
- 238000012054 celltiter-glo Methods 0.000 description 17
- 238000004949 mass spectrometry Methods 0.000 description 17
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 17
- PXIPVTKHYLBLMZ-UHFFFAOYSA-N Sodium azide Chemical compound [Na+].[N-]=[N+]=[N-] PXIPVTKHYLBLMZ-UHFFFAOYSA-N 0.000 description 16
- 238000005516 engineering process Methods 0.000 description 16
- 230000003993 interaction Effects 0.000 description 16
- 239000000178 monomer Substances 0.000 description 16
- 238000010354 CRISPR gene editing Methods 0.000 description 15
- 230000000694 effects Effects 0.000 description 15
- 238000011156 evaluation Methods 0.000 description 15
- 238000003384 imaging method Methods 0.000 description 15
- 101000744505 Homo sapiens GTPase NRas Proteins 0.000 description 14
- 108010002350 Interleukin-2 Proteins 0.000 description 14
- 102000000588 Interleukin-2 Human genes 0.000 description 14
- ZMXDDKWLCZADIW-UHFFFAOYSA-N N,N-Dimethylformamide Chemical compound CN(C)C=O ZMXDDKWLCZADIW-UHFFFAOYSA-N 0.000 description 14
- 239000003814 drug Substances 0.000 description 14
- 230000001404 mediated effect Effects 0.000 description 14
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 14
- 238000001262 western blot Methods 0.000 description 14
- 241000894006 Bacteria Species 0.000 description 13
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 13
- 102100039788 GTPase NRas Human genes 0.000 description 13
- 101000611183 Homo sapiens Tumor necrosis factor Proteins 0.000 description 13
- 229940127174 UCHT1 Drugs 0.000 description 13
- 238000011002 quantification Methods 0.000 description 13
- 239000013598 vector Substances 0.000 description 13
- 108020004705 Codon Proteins 0.000 description 12
- 241000699666 Mus <mouse, genus> Species 0.000 description 12
- 101150080074 TP53 gene Proteins 0.000 description 12
- 102100040247 Tumor necrosis factor Human genes 0.000 description 12
- FPPNZSSZRUTDAP-UWFZAAFLSA-N carbenicillin Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)C(C(O)=O)C1=CC=CC=C1 FPPNZSSZRUTDAP-UWFZAAFLSA-N 0.000 description 12
- 229960003669 carbenicillin Drugs 0.000 description 12
- 101100243447 Arabidopsis thaliana PER53 gene Proteins 0.000 description 11
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 11
- 239000004471 Glycine Substances 0.000 description 11
- 102000011786 HLA-A Antigens Human genes 0.000 description 11
- 108010075704 HLA-A Antigens Proteins 0.000 description 11
- 229930182555 Penicillin Natural products 0.000 description 11
- JGSARLDLIJGVTE-MBNYWOFBSA-N Penicillin G Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)CC1=CC=CC=C1 JGSARLDLIJGVTE-MBNYWOFBSA-N 0.000 description 11
- 230000005867 T cell response Effects 0.000 description 11
- 239000003636 conditioned culture medium Substances 0.000 description 11
- 239000000499 gel Substances 0.000 description 11
- 229940049954 penicillin Drugs 0.000 description 11
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 11
- 239000000243 solution Substances 0.000 description 11
- 230000004614 tumor growth Effects 0.000 description 11
- 108060001084 Luciferase Proteins 0.000 description 10
- 239000005089 Luciferase Substances 0.000 description 10
- 239000002202 Polyethylene glycol Substances 0.000 description 10
- 102000015736 beta 2-Microglobulin Human genes 0.000 description 10
- 108010081355 beta 2-Microglobulin Proteins 0.000 description 10
- 238000005415 bioluminescence Methods 0.000 description 10
- 230000029918 bioluminescence Effects 0.000 description 10
- 230000000903 blocking effect Effects 0.000 description 10
- 238000006243 chemical reaction Methods 0.000 description 10
- 210000004443 dendritic cell Anatomy 0.000 description 10
- 238000001514 detection method Methods 0.000 description 10
- 239000008103 glucose Substances 0.000 description 10
- 229920001223 polyethylene glycol Polymers 0.000 description 10
- 230000009257 reactivity Effects 0.000 description 10
- 239000000523 sample Substances 0.000 description 10
- 238000001890 transfection Methods 0.000 description 10
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 9
- 108010067902 Peptide Library Proteins 0.000 description 9
- 108010029485 Protein Isoforms Proteins 0.000 description 9
- 102000001708 Protein Isoforms Human genes 0.000 description 9
- 102000004389 Ribonucleoproteins Human genes 0.000 description 9
- 108010081734 Ribonucleoproteins Proteins 0.000 description 9
- 102000004265 STAT2 Transcription Factor Human genes 0.000 description 9
- 108010081691 STAT2 Transcription Factor Proteins 0.000 description 9
- 238000012512 characterization method Methods 0.000 description 9
- 230000009260 cross reactivity Effects 0.000 description 9
- 238000013461 design Methods 0.000 description 9
- 108010026228 mRNA guanylyltransferase Proteins 0.000 description 9
- 230000004048 modification Effects 0.000 description 9
- 238000012986 modification Methods 0.000 description 9
- 238000004091 panning Methods 0.000 description 9
- 238000002823 phage display Methods 0.000 description 9
- 210000001519 tissue Anatomy 0.000 description 9
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 8
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 8
- 101000976626 Homo sapiens Zinc finger protein 3 homolog Proteins 0.000 description 8
- 108091034117 Oligonucleotide Proteins 0.000 description 8
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 8
- 108091028113 Trans-activating crRNA Proteins 0.000 description 8
- 102100023553 Zinc finger protein 3 homolog Human genes 0.000 description 8
- 230000004913 activation Effects 0.000 description 8
- 210000004899 c-terminal region Anatomy 0.000 description 8
- 230000001419 dependent effect Effects 0.000 description 8
- 238000010790 dilution Methods 0.000 description 8
- 239000012895 dilution Substances 0.000 description 8
- 239000000975 dye Substances 0.000 description 8
- 238000004520 electroporation Methods 0.000 description 8
- 230000000670 limiting effect Effects 0.000 description 8
- 210000004379 membrane Anatomy 0.000 description 8
- 239000012528 membrane Substances 0.000 description 8
- 239000000546 pharmaceutical excipient Substances 0.000 description 8
- -1 scFv Proteins 0.000 description 8
- 238000012163 sequencing technique Methods 0.000 description 8
- 229940124597 therapeutic agent Drugs 0.000 description 8
- 238000010361 transduction Methods 0.000 description 8
- 238000005406 washing Methods 0.000 description 8
- 102000003839 Human Proteins Human genes 0.000 description 7
- 108090000144 Human Proteins Proteins 0.000 description 7
- 239000012124 Opti-MEM Substances 0.000 description 7
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 7
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 7
- 230000037396 body weight Effects 0.000 description 7
- 230000008859 change Effects 0.000 description 7
- 239000003085 diluting agent Substances 0.000 description 7
- 239000003937 drug carrier Substances 0.000 description 7
- 230000001965 increasing effect Effects 0.000 description 7
- 210000001616 monocyte Anatomy 0.000 description 7
- 230000002018 overexpression Effects 0.000 description 7
- 239000000047 product Substances 0.000 description 7
- 108010014186 ras Proteins Proteins 0.000 description 7
- 231100000205 reproductive and developmental toxicity Toxicity 0.000 description 7
- 230000000717 retained effect Effects 0.000 description 7
- 102200006538 rs121913530 Human genes 0.000 description 7
- 238000007480 sanger sequencing Methods 0.000 description 7
- 238000012353 t test Methods 0.000 description 7
- 230000026683 transduction Effects 0.000 description 7
- 102000001398 Granzyme Human genes 0.000 description 6
- 108060005986 Granzyme Proteins 0.000 description 6
- ODKSFYDXXFIFQN-BYPYZUCNSA-N L-arginine Chemical compound OC(=O)[C@@H](N)CCCN=C(N)N ODKSFYDXXFIFQN-BYPYZUCNSA-N 0.000 description 6
- KHGNFPUMBJSZSM-UHFFFAOYSA-N Perforine Natural products COC1=C2CCC(O)C(CCC(C)(C)O)(OC)C2=NC2=C1C=CO2 KHGNFPUMBJSZSM-UHFFFAOYSA-N 0.000 description 6
- 229920001213 Polysorbate 20 Polymers 0.000 description 6
- 238000000692 Student's t-test Methods 0.000 description 6
- 239000006180 TBST buffer Substances 0.000 description 6
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 6
- 230000003833 cell viability Effects 0.000 description 6
- 239000003153 chemical reaction reagent Substances 0.000 description 6
- 238000010367 cloning Methods 0.000 description 6
- 231100000673 dose–response relationship Toxicity 0.000 description 6
- BRZYSWJRSDMWLG-CAXSIQPQSA-N geneticin Chemical compound O1C[C@@](O)(C)[C@H](NC)[C@@H](O)[C@H]1O[C@@H]1[C@@H](O)[C@H](O[C@@H]2[C@@H]([C@@H](O)[C@H](O)[C@@H](C(C)O)O2)N)[C@@H](N)C[C@H]1N BRZYSWJRSDMWLG-CAXSIQPQSA-N 0.000 description 6
- RAXXELZNTBOGNW-UHFFFAOYSA-N imidazole Natural products C1=CNC=N1 RAXXELZNTBOGNW-UHFFFAOYSA-N 0.000 description 6
- 238000001727 in vivo Methods 0.000 description 6
- BPHPUYQFMNQIOC-NXRLNHOXSA-N isopropyl beta-D-thiogalactopyranoside Chemical compound CC(C)S[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1O BPHPUYQFMNQIOC-NXRLNHOXSA-N 0.000 description 6
- 238000004020 luminiscence type Methods 0.000 description 6
- 239000007758 minimum essential medium Substances 0.000 description 6
- 238000002156 mixing Methods 0.000 description 6
- 239000013642 negative control Substances 0.000 description 6
- 238000007481 next generation sequencing Methods 0.000 description 6
- 239000000137 peptide hydrolase inhibitor Substances 0.000 description 6
- 229930192851 perforin Natural products 0.000 description 6
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 6
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 6
- 238000011160 research Methods 0.000 description 6
- 102200006532 rs112445441 Human genes 0.000 description 6
- 210000002966 serum Anatomy 0.000 description 6
- 230000001988 toxicity Effects 0.000 description 6
- 231100000419 toxicity Toxicity 0.000 description 6
- 230000003612 virological effect Effects 0.000 description 6
- SSOORFWOBGFTHL-OTEJMHTDSA-N (4S)-5-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-6-amino-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[2-[(2S)-2-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-6-amino-1-[[(2S)-1-[[(2S)-1-[[(2S,3S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-6-amino-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-1-[[(2S)-5-amino-1-[[(2S)-1-[[(2S)-1-[[(2S)-6-amino-1-[[(2S)-6-amino-1-[[(2S)-1-[[(2S)-1-[[(2S)-5-amino-1-[[(2S)-5-carbamimidamido-1-[[(2S)-5-carbamimidamido-1-[[(1S)-4-carbamimidamido-1-carboxybutyl]amino]-1-oxopentan-2-yl]amino]-1-oxopentan-2-yl]amino]-1,5-dioxopentan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-1-oxohexan-2-yl]amino]-1-oxohexan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-1,5-dioxopentan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-3-hydroxy-1-oxopropan-2-yl]amino]-3-hydroxy-1-oxopropan-2-yl]amino]-3-hydroxy-1-oxopropan-2-yl]amino]-1-oxopropan-2-yl]amino]-1-oxohexan-2-yl]amino]-3-hydroxy-1-oxopropan-2-yl]amino]-1-oxo-3-phenylpropan-2-yl]amino]-3-methyl-1-oxopentan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-1-oxohexan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-1-oxopropan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]carbamoyl]pyrrolidin-1-yl]-2-oxoethyl]amino]-3-(1H-indol-3-yl)-1-oxopropan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-1-oxo-3-phenylpropan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-1-oxohexan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]amino]-5-carbamimidamido-1-oxopentan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-1-oxo-3-phenylpropan-2-yl]amino]-3-(1H-imidazol-4-yl)-1-oxopropan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]amino]-4-methyl-1-oxopentan-2-yl]amino]-4-[[(2S)-2-[[(2S)-2-[[(2S)-2,6-diaminohexanoyl]amino]-3-methylbutanoyl]amino]propanoyl]amino]-5-oxopentanoic acid Chemical compound CC[C@H](C)[C@H](NC(=O)[C@@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H]1CCCN1C(=O)CNC(=O)[C@H](Cc1c[nH]c2ccccc12)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](Cc1ccccc1)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](Cc1ccccc1)NC(=O)[C@H](Cc1c[nH]cn1)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@@H](N)CCCCN)C(C)C)C(C)C)C(C)C)C(C)C)C(C)C)C(C)C)C(=O)N[C@@H](Cc1ccccc1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SSOORFWOBGFTHL-OTEJMHTDSA-N 0.000 description 5
- 229940124158 Protease/peptidase inhibitor Drugs 0.000 description 5
- 239000007983 Tris buffer Substances 0.000 description 5
- 238000007792 addition Methods 0.000 description 5
- 239000002246 antineoplastic agent Substances 0.000 description 5
- 229960000074 biopharmaceutical Drugs 0.000 description 5
- 238000005119 centrifugation Methods 0.000 description 5
- 238000010828 elution Methods 0.000 description 5
- 230000012010 growth Effects 0.000 description 5
- 238000001802 infusion Methods 0.000 description 5
- 238000002347 injection Methods 0.000 description 5
- 239000007924 injection Substances 0.000 description 5
- 238000007912 intraperitoneal administration Methods 0.000 description 5
- 229930027917 kanamycin Natural products 0.000 description 5
- 229960000318 kanamycin Drugs 0.000 description 5
- SBUJHOSQTJFQJX-NOAMYHISSA-N kanamycin Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N SBUJHOSQTJFQJX-NOAMYHISSA-N 0.000 description 5
- 229930182823 kanamycin A Natural products 0.000 description 5
- 239000007788 liquid Substances 0.000 description 5
- 238000010859 live-cell imaging Methods 0.000 description 5
- 238000005259 measurement Methods 0.000 description 5
- 229930182817 methionine Natural products 0.000 description 5
- 238000011275 oncology therapy Methods 0.000 description 5
- 230000008569 process Effects 0.000 description 5
- 230000004044 response Effects 0.000 description 5
- 102220053950 rs121913238 Human genes 0.000 description 5
- 238000006467 substitution reaction Methods 0.000 description 5
- 238000001356 surgical procedure Methods 0.000 description 5
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 5
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 4
- 101000914947 Bungarus multicinctus Long neurotoxin homolog TA-bm16 Proteins 0.000 description 4
- 102100025570 Cancer/testis antigen 1 Human genes 0.000 description 4
- 241000282693 Cercopithecidae Species 0.000 description 4
- 108010087819 Fc receptors Proteins 0.000 description 4
- 102000009109 Fc receptors Human genes 0.000 description 4
- 102100029974 GTPase HRas Human genes 0.000 description 4
- 101000856237 Homo sapiens Cancer/testis antigen 1 Proteins 0.000 description 4
- 101000584633 Homo sapiens GTPase HRas Proteins 0.000 description 4
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 4
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 4
- 229920002594 Polyethylene Glycol 8000 Polymers 0.000 description 4
- QAOWNCQODCNURD-UHFFFAOYSA-N Sulfuric acid Chemical compound OS(O)(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-N 0.000 description 4
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Chemical compound CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 4
- 230000001580 bacterial effect Effects 0.000 description 4
- 238000004422 calculation algorithm Methods 0.000 description 4
- 229910052799 carbon Inorganic materials 0.000 description 4
- 229910002091 carbon monoxide Inorganic materials 0.000 description 4
- 125000002915 carbonyl group Chemical group [*:2]C([*:1])=O 0.000 description 4
- 238000004113 cell culture Methods 0.000 description 4
- 230000030833 cell death Effects 0.000 description 4
- 239000013078 crystal Substances 0.000 description 4
- 229960002433 cysteine Drugs 0.000 description 4
- 231100000433 cytotoxic Toxicity 0.000 description 4
- 230000001472 cytotoxic effect Effects 0.000 description 4
- 230000007717 exclusion Effects 0.000 description 4
- 238000009472 formulation Methods 0.000 description 4
- 239000001963 growth medium Substances 0.000 description 4
- 230000002209 hydrophobic effect Effects 0.000 description 4
- 125000002883 imidazolyl group Chemical group 0.000 description 4
- 230000001024 immunotherapeutic effect Effects 0.000 description 4
- 238000000338 in vitro Methods 0.000 description 4
- 230000005917 in vivo anti-tumor Effects 0.000 description 4
- 210000003000 inclusion body Anatomy 0.000 description 4
- 230000003834 intracellular effect Effects 0.000 description 4
- 238000004519 manufacturing process Methods 0.000 description 4
- 125000001360 methionine group Chemical group N[C@@H](CCSC)C(=O)* 0.000 description 4
- 238000002703 mutagenesis Methods 0.000 description 4
- 231100000350 mutagenesis Toxicity 0.000 description 4
- 239000002245 particle Substances 0.000 description 4
- 238000001556 precipitation Methods 0.000 description 4
- 238000011084 recovery Methods 0.000 description 4
- 230000008439 repair process Effects 0.000 description 4
- 239000011347 resin Substances 0.000 description 4
- 229920005989 resin Polymers 0.000 description 4
- 230000001177 retroviral effect Effects 0.000 description 4
- 230000002441 reversible effect Effects 0.000 description 4
- 102200006539 rs121913529 Human genes 0.000 description 4
- 239000012679 serum free medium Substances 0.000 description 4
- 239000002002 slurry Substances 0.000 description 4
- 238000003860 storage Methods 0.000 description 4
- 239000000758 substrate Substances 0.000 description 4
- 239000000725 suspension Substances 0.000 description 4
- 238000012360 testing method Methods 0.000 description 4
- 238000004448 titration Methods 0.000 description 4
- 238000012546 transfer Methods 0.000 description 4
- 241001430294 unidentified retrovirus Species 0.000 description 4
- 210000003462 vein Anatomy 0.000 description 4
- 102000007469 Actins Human genes 0.000 description 3
- 108010085238 Actins Proteins 0.000 description 3
- 102100023165 Alpha-mannosidase 2C1 Human genes 0.000 description 3
- 102100027207 CD27 antigen Human genes 0.000 description 3
- 108090000565 Capsid Proteins Proteins 0.000 description 3
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical group [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 3
- 102100023321 Ceruloplasmin Human genes 0.000 description 3
- 102100038214 Chromodomain-helicase-DNA-binding protein 4 Human genes 0.000 description 3
- XZWYTXMRWQJBGX-VXBMVYAYSA-N FLAG peptide Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(O)=O)CC1=CC=C(O)C=C1 XZWYTXMRWQJBGX-VXBMVYAYSA-N 0.000 description 3
- 206010064571 Gene mutation Diseases 0.000 description 3
- 101000979029 Homo sapiens Alpha-mannosidase 2C1 Proteins 0.000 description 3
- 101000914511 Homo sapiens CD27 antigen Proteins 0.000 description 3
- 101000883749 Homo sapiens Chromodomain-helicase-DNA-binding protein 4 Proteins 0.000 description 3
- 101001002657 Homo sapiens Interleukin-2 Proteins 0.000 description 3
- 101001043807 Homo sapiens Interleukin-7 Proteins 0.000 description 3
- 101000667092 Homo sapiens Vacuolar protein sorting-associated protein 13A Proteins 0.000 description 3
- 101150105104 Kras gene Proteins 0.000 description 3
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 3
- 241001465754 Metazoa Species 0.000 description 3
- 101710163270 Nuclease Proteins 0.000 description 3
- 108700020796 Oncogene Proteins 0.000 description 3
- 239000002033 PVDF binder Substances 0.000 description 3
- 102000004503 Perforin Human genes 0.000 description 3
- 108010056995 Perforin Proteins 0.000 description 3
- 229920002873 Polyethylenimine Polymers 0.000 description 3
- 102100040678 Programmed cell death protein 1 Human genes 0.000 description 3
- 108010076504 Protein Sorting Signals Proteins 0.000 description 3
- 108010026552 Proteome Proteins 0.000 description 3
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 3
- 239000012505 Superdex™ Substances 0.000 description 3
- 102100039114 Vacuolar protein sorting-associated protein 13A Human genes 0.000 description 3
- 102100022748 Wilms tumor protein Human genes 0.000 description 3
- 238000002835 absorbance Methods 0.000 description 3
- 230000008901 benefit Effects 0.000 description 3
- 239000011230 binding agent Substances 0.000 description 3
- 210000004369 blood Anatomy 0.000 description 3
- 239000008280 blood Substances 0.000 description 3
- 230000006037 cell lysis Effects 0.000 description 3
- 229960004316 cisplatin Drugs 0.000 description 3
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 description 3
- KRKNYBCHXYNGOX-UHFFFAOYSA-N citric acid Chemical compound OC(=O)CC(O)(C(O)=O)CC(O)=O KRKNYBCHXYNGOX-UHFFFAOYSA-N 0.000 description 3
- 238000012258 culturing Methods 0.000 description 3
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 3
- 235000018417 cysteine Nutrition 0.000 description 3
- 238000013480 data collection Methods 0.000 description 3
- 238000011033 desalting Methods 0.000 description 3
- 230000004069 differentiation Effects 0.000 description 3
- 239000003797 essential amino acid Substances 0.000 description 3
- 235000020776 essential amino acid Nutrition 0.000 description 3
- 239000012997 ficoll-paque Substances 0.000 description 3
- 239000000796 flavoring agent Substances 0.000 description 3
- 235000019634 flavors Nutrition 0.000 description 3
- 238000002523 gelfiltration Methods 0.000 description 3
- 239000008187 granular material Substances 0.000 description 3
- 125000000487 histidyl group Chemical group [H]N([H])C(C(=O)O*)C([H])([H])C1=C([H])N([H])C([H])=N1 0.000 description 3
- 102000052622 human IL7 Human genes 0.000 description 3
- 238000011502 immune monitoring Methods 0.000 description 3
- 230000016784 immunoglobulin production Effects 0.000 description 3
- 238000011081 inoculation Methods 0.000 description 3
- 238000012933 kinetic analysis Methods 0.000 description 3
- 208000032839 leukemia Diseases 0.000 description 3
- 230000004807 localization Effects 0.000 description 3
- 238000003032 molecular docking Methods 0.000 description 3
- 238000005457 optimization Methods 0.000 description 3
- 239000008194 pharmaceutical composition Substances 0.000 description 3
- 229920002981 polyvinylidene fluoride Polymers 0.000 description 3
- 239000001267 polyvinylpyrrolidone Substances 0.000 description 3
- 229920000036 polyvinylpyrrolidone Polymers 0.000 description 3
- 235000013855 polyvinylpyrrolidone Nutrition 0.000 description 3
- 239000013641 positive control Substances 0.000 description 3
- 238000000746 purification Methods 0.000 description 3
- 230000002829 reductive effect Effects 0.000 description 3
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 3
- 239000007787 solid Substances 0.000 description 3
- 239000002904 solvent Substances 0.000 description 3
- UNFWWIHTNXNPBV-WXKVUWSESA-N spectinomycin Chemical compound O([C@@H]1[C@@H](NC)[C@@H](O)[C@H]([C@@H]([C@H]1O1)O)NC)[C@]2(O)[C@H]1O[C@H](C)CC2=O UNFWWIHTNXNPBV-WXKVUWSESA-N 0.000 description 3
- 238000007619 statistical method Methods 0.000 description 3
- 239000003826 tablet Substances 0.000 description 3
- 230000001225 therapeutic effect Effects 0.000 description 3
- 230000007704 transition Effects 0.000 description 3
- 229910052720 vanadium Inorganic materials 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- MFRNYXJJRJQHNW-DEMKXPNLSA-N (2s)-2-[[(2r,3r)-3-methoxy-3-[(2s)-1-[(3r,4s,5s)-3-methoxy-5-methyl-4-[methyl-[(2s)-3-methyl-2-[[(2s)-3-methyl-2-(methylamino)butanoyl]amino]butanoyl]amino]heptanoyl]pyrrolidin-2-yl]-2-methylpropanoyl]amino]-3-phenylpropanoic acid Chemical compound CN[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(=O)N(C)[C@@H]([C@@H](C)CC)[C@H](OC)CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MFRNYXJJRJQHNW-DEMKXPNLSA-N 0.000 description 2
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 2
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 2
- GVJHHUAWPYXKBD-UHFFFAOYSA-N (±)-α-Tocopherol Chemical compound OC1=C(C)C(C)=C2OC(CCCC(C)CCCC(C)CCCC(C)C)(C)CCC2=C1C GVJHHUAWPYXKBD-UHFFFAOYSA-N 0.000 description 2
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 2
- UAIUNKRWKOVEES-UHFFFAOYSA-N 3,3',5,5'-tetramethylbenzidine Chemical compound CC1=C(N)C(C)=CC(C=2C=C(C)C(N)=C(C)C=2)=C1 UAIUNKRWKOVEES-UHFFFAOYSA-N 0.000 description 2
- IPJDHSYCSQAODE-UHFFFAOYSA-N 5-chloromethylfluorescein diacetate Chemical compound O1C(=O)C2=CC(CCl)=CC=C2C21C1=CC=C(OC(C)=O)C=C1OC1=CC(OC(=O)C)=CC=C21 IPJDHSYCSQAODE-UHFFFAOYSA-N 0.000 description 2
- GOZMBJCYMQQACI-UHFFFAOYSA-N 6,7-dimethyl-3-[[methyl-[2-[methyl-[[1-[3-(trifluoromethyl)phenyl]indol-3-yl]methyl]amino]ethyl]amino]methyl]chromen-4-one;dihydrochloride Chemical compound Cl.Cl.C=1OC2=CC(C)=C(C)C=C2C(=O)C=1CN(C)CCN(C)CC(C1=CC=CC=C11)=CN1C1=CC=CC(C(F)(F)F)=C1 GOZMBJCYMQQACI-UHFFFAOYSA-N 0.000 description 2
- 208000010507 Adenocarcinoma of Lung Diseases 0.000 description 2
- 229920000936 Agarose Polymers 0.000 description 2
- 101800002638 Alpha-amanitin Proteins 0.000 description 2
- 241001550224 Apha Species 0.000 description 2
- 101100424688 Arabidopsis thaliana ESK1 gene Proteins 0.000 description 2
- 241000370685 Arge Species 0.000 description 2
- 239000004475 Arginine Substances 0.000 description 2
- CIWBSHSKHKDKBQ-JLAZNSOCSA-N Ascorbic acid Chemical compound OC[C@H](O)[C@H]1OC(=O)C(O)=C1O CIWBSHSKHKDKBQ-JLAZNSOCSA-N 0.000 description 2
- 101100136076 Aspergillus oryzae (strain ATCC 42149 / RIB 40) pel1 gene Proteins 0.000 description 2
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 2
- 238000010356 CRISPR-Cas9 genome editing Methods 0.000 description 2
- 102100028914 Catenin beta-1 Human genes 0.000 description 2
- 238000003734 CellTiter-Glo Luminescent Cell Viability Assay Methods 0.000 description 2
- 229920002785 Croscarmellose sodium Polymers 0.000 description 2
- 238000007702 DNA assembly Methods 0.000 description 2
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 2
- 241001524679 Escherichia virus M13 Species 0.000 description 2
- 108700012941 GNRH1 Proteins 0.000 description 2
- 239000000579 Gonadotropin-Releasing Hormone Substances 0.000 description 2
- 108060003393 Granulin Proteins 0.000 description 2
- 101000937544 Homo sapiens Beta-2-microglobulin Proteins 0.000 description 2
- 101000916173 Homo sapiens Catenin beta-1 Proteins 0.000 description 2
- 229920002153 Hydroxypropyl cellulose Polymers 0.000 description 2
- 108010074328 Interferon-gamma Proteins 0.000 description 2
- 102000008070 Interferon-gamma Human genes 0.000 description 2
- 206010069755 K-ras gene mutation Diseases 0.000 description 2
- 125000002059 L-arginyl group Chemical group O=C([*])[C@](N([H])[H])([H])C([H])([H])C([H])([H])C([H])([H])N([H])C(=N[H])N([H])[H] 0.000 description 2
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 2
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 2
- 108010054278 Lac Repressors Proteins 0.000 description 2
- 102100025169 Max-binding protein MNT Human genes 0.000 description 2
- 102100025082 Melanoma-associated antigen 3 Human genes 0.000 description 2
- 101710204288 Melanoma-associated antigen 3 Proteins 0.000 description 2
- PXHVJJICTQNCMI-UHFFFAOYSA-N Nickel Chemical compound [Ni] PXHVJJICTQNCMI-UHFFFAOYSA-N 0.000 description 2
- 108091028043 Nucleic acid sequence Proteins 0.000 description 2
- 102000043276 Oncogene Human genes 0.000 description 2
- 108090000526 Papain Proteins 0.000 description 2
- 229920000776 Poly(Adenosine diphosphate-ribose) polymerase Polymers 0.000 description 2
- 239000004365 Protease Substances 0.000 description 2
- LCTONWCANYUPML-UHFFFAOYSA-M Pyruvate Chemical compound CC(=O)C([O-])=O LCTONWCANYUPML-UHFFFAOYSA-M 0.000 description 2
- VYGQUTWHTHXGQB-FFHKNEKCSA-N Retinol Palmitate Chemical compound CCCCCCCCCCCCCCCC(=O)OC\C=C(/C)\C=C\C=C(/C)\C=C\C1=C(C)CCCC1(C)C VYGQUTWHTHXGQB-FFHKNEKCSA-N 0.000 description 2
- 239000006146 Roswell Park Memorial Institute medium Substances 0.000 description 2
- RXGJTYFDKOHJHK-UHFFFAOYSA-N S-deoxo-amaninamide Natural products CCC(C)C1NC(=O)CNC(=O)C2Cc3c(SCC(NC(=O)CNC1=O)C(=O)NC(CC(=O)N)C(=O)N4CC(O)CC4C(=O)NC(C(C)C(O)CO)C(=O)N2)[nH]c5ccccc35 RXGJTYFDKOHJHK-UHFFFAOYSA-N 0.000 description 2
- 235000021355 Stearic acid Nutrition 0.000 description 2
- NKANXQFJJICGDU-QPLCGJKRSA-N Tamoxifen Chemical compound C=1C=CC=CC=1C(/CC)=C(C=1C=CC(OCCN(C)C)=CC=1)/C1=CC=CC=C1 NKANXQFJJICGDU-QPLCGJKRSA-N 0.000 description 2
- 239000004098 Tetracycline Substances 0.000 description 2
- 102000004142 Trypsin Human genes 0.000 description 2
- 108090000631 Trypsin Proteins 0.000 description 2
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 2
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 description 2
- 108700025716 Tumor Suppressor Genes Proteins 0.000 description 2
- 102000044209 Tumor Suppressor Genes Human genes 0.000 description 2
- XSQUKJJJFZCRTK-UHFFFAOYSA-N Urea Chemical compound NC(N)=O XSQUKJJJFZCRTK-UHFFFAOYSA-N 0.000 description 2
- 101710127857 Wilms tumor protein Proteins 0.000 description 2
- IEDXPSOJFSVCKU-HOKPPMCLSA-N [4-[[(2S)-5-(carbamoylamino)-2-[[(2S)-2-[6-(2,5-dioxopyrrolidin-1-yl)hexanoylamino]-3-methylbutanoyl]amino]pentanoyl]amino]phenyl]methyl N-[(2S)-1-[[(2S)-1-[[(3R,4S,5S)-1-[(2S)-2-[(1R,2R)-3-[[(1S,2R)-1-hydroxy-1-phenylpropan-2-yl]amino]-1-methoxy-2-methyl-3-oxopropyl]pyrrolidin-1-yl]-3-methoxy-5-methyl-1-oxoheptan-4-yl]-methylamino]-3-methyl-1-oxobutan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]-N-methylcarbamate Chemical compound CC[C@H](C)[C@@H]([C@@H](CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C)[C@@H](O)c1ccccc1)OC)N(C)C(=O)[C@@H](NC(=O)[C@H](C(C)C)N(C)C(=O)OCc1ccc(NC(=O)[C@H](CCCNC(N)=O)NC(=O)[C@@H](NC(=O)CCCCCN2C(=O)CCC2=O)C(C)C)cc1)C(C)C IEDXPSOJFSVCKU-HOKPPMCLSA-N 0.000 description 2
- 230000003213 activating effect Effects 0.000 description 2
- 230000002776 aggregation Effects 0.000 description 2
- 238000004220 aggregation Methods 0.000 description 2
- 125000001931 aliphatic group Chemical group 0.000 description 2
- 239000004007 alpha amanitin Substances 0.000 description 2
- CIORWBWIBBPXCG-SXZCQOKQSA-N alpha-amanitin Chemical compound O=C1N[C@@H](CC(N)=O)C(=O)N2C[C@H](O)C[C@H]2C(=O)N[C@@H]([C@@H](C)[C@@H](O)CO)C(=O)N[C@@H](C2)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@H]1C[S@@](=O)C1=C2C2=CC=C(O)C=C2N1 CIORWBWIBBPXCG-SXZCQOKQSA-N 0.000 description 2
- CIORWBWIBBPXCG-UHFFFAOYSA-N alpha-amanitin Natural products O=C1NC(CC(N)=O)C(=O)N2CC(O)CC2C(=O)NC(C(C)C(O)CO)C(=O)NC(C2)C(=O)NCC(=O)NC(C(C)CC)C(=O)NCC(=O)NC1CS(=O)C1=C2C2=CC=C(O)C=C2N1 CIORWBWIBBPXCG-UHFFFAOYSA-N 0.000 description 2
- 125000003277 amino group Chemical group 0.000 description 2
- 239000012491 analyte Substances 0.000 description 2
- 230000001093 anti-cancer Effects 0.000 description 2
- 230000001188 anti-phage Effects 0.000 description 2
- 239000000611 antibody drug conjugate Substances 0.000 description 2
- 229940049595 antibody-drug conjugate Drugs 0.000 description 2
- 230000000890 antigenic effect Effects 0.000 description 2
- 239000003963 antioxidant agent Substances 0.000 description 2
- 235000006708 antioxidants Nutrition 0.000 description 2
- 238000013459 approach Methods 0.000 description 2
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 2
- 235000009697 arginine Nutrition 0.000 description 2
- 125000000637 arginyl group Chemical group N[C@@H](CCCNC(N)=N)C(=O)* 0.000 description 2
- 125000004429 atom Chemical group 0.000 description 2
- 238000004364 calculation method Methods 0.000 description 2
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 2
- 239000006143 cell culture medium Substances 0.000 description 2
- 230000022534 cell killing Effects 0.000 description 2
- 239000013592 cell lysate Substances 0.000 description 2
- 229920002678 cellulose Chemical class 0.000 description 2
- 235000010980 cellulose Nutrition 0.000 description 2
- 229920003086 cellulose ether Polymers 0.000 description 2
- 239000003795 chemical substances by application Substances 0.000 description 2
- 230000004186 co-expression Effects 0.000 description 2
- 239000003086 colorant Substances 0.000 description 2
- 238000002591 computed tomography Methods 0.000 description 2
- 238000012937 correction Methods 0.000 description 2
- 235000010947 crosslinked sodium carboxy methyl cellulose Nutrition 0.000 description 2
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 2
- 230000003247 decreasing effect Effects 0.000 description 2
- 238000000432 density-gradient centrifugation Methods 0.000 description 2
- 238000003745 diagnosis Methods 0.000 description 2
- 239000002552 dosage form Substances 0.000 description 2
- 230000034431 double-strand break repair via homologous recombination Effects 0.000 description 2
- 229940079593 drug Drugs 0.000 description 2
- 239000013613 expression plasmid Substances 0.000 description 2
- 238000002073 fluorescence micrograph Methods 0.000 description 2
- 230000008014 freezing Effects 0.000 description 2
- 238000007710 freezing Methods 0.000 description 2
- 230000004927 fusion Effects 0.000 description 2
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 2
- 102000017941 granulin Human genes 0.000 description 2
- 125000002795 guanidino group Chemical group C(N)(=N)N* 0.000 description 2
- 230000036541 health Effects 0.000 description 2
- 239000000833 heterodimer Substances 0.000 description 2
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 2
- 102000047279 human B2M Human genes 0.000 description 2
- 102000049555 human KRAS Human genes 0.000 description 2
- 125000004435 hydrogen atom Chemical group [H]* 0.000 description 2
- 239000001863 hydroxypropyl cellulose Substances 0.000 description 2
- 235000010977 hydroxypropyl cellulose Nutrition 0.000 description 2
- 239000001866 hydroxypropyl methyl cellulose Substances 0.000 description 2
- 235000010979 hydroxypropyl methyl cellulose Nutrition 0.000 description 2
- 229920003088 hydroxypropyl methyl cellulose Polymers 0.000 description 2
- UFVKGYZPFZQRLF-UHFFFAOYSA-N hydroxypropyl methyl cellulose Chemical compound OC1C(O)C(OC)OC(CO)C1OC1C(O)C(O)C(OC2C(C(O)C(OC3C(C(O)C(O)C(CO)O3)O)C(CO)O2)O)C(CO)O1 UFVKGYZPFZQRLF-UHFFFAOYSA-N 0.000 description 2
- 230000028993 immune response Effects 0.000 description 2
- 239000002955 immunomodulating agent Substances 0.000 description 2
- 238000001114 immunoprecipitation Methods 0.000 description 2
- 238000002513 implantation Methods 0.000 description 2
- 238000000126 in silico method Methods 0.000 description 2
- 230000001939 inductive effect Effects 0.000 description 2
- 229960003130 interferon gamma Drugs 0.000 description 2
- 238000001990 intravenous administration Methods 0.000 description 2
- 238000010253 intravenous injection Methods 0.000 description 2
- 150000002500 ions Chemical class 0.000 description 2
- 210000000265 leukocyte Anatomy 0.000 description 2
- 238000011068 loading method Methods 0.000 description 2
- 230000007774 longterm Effects 0.000 description 2
- 238000003670 luciferase enzyme activity assay Methods 0.000 description 2
- 201000005249 lung adenocarcinoma Diseases 0.000 description 2
- HQKMJHAJHXVSDF-UHFFFAOYSA-L magnesium stearate Chemical compound [Mg+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O HQKMJHAJHXVSDF-UHFFFAOYSA-L 0.000 description 2
- 230000014759 maintenance of location Effects 0.000 description 2
- 238000002844 melting Methods 0.000 description 2
- 230000008018 melting Effects 0.000 description 2
- LXCFILQKKLGQFO-UHFFFAOYSA-N methylparaben Chemical compound COC(=O)C1=CC=C(O)C=C1 LXCFILQKKLGQFO-UHFFFAOYSA-N 0.000 description 2
- 238000012544 monitoring process Methods 0.000 description 2
- 108010093470 monomethyl auristatin E Proteins 0.000 description 2
- 108010059074 monomethylauristatin F Proteins 0.000 description 2
- 238000010172 mouse model Methods 0.000 description 2
- YIEDSISPYKQADU-UHFFFAOYSA-N n-acetyl-n-[2-methyl-4-[(2-methylphenyl)diazenyl]phenyl]acetamide Chemical compound C1=C(C)C(N(C(C)=O)C(=O)C)=CC=C1N=NC1=CC=CC=C1C YIEDSISPYKQADU-UHFFFAOYSA-N 0.000 description 2
- 210000000822 natural killer cell Anatomy 0.000 description 2
- 229910052757 nitrogen Inorganic materials 0.000 description 2
- QIQXTHQIDYTFRH-UHFFFAOYSA-N octadecanoic acid Chemical compound CCCCCCCCCCCCCCCCCC(O)=O QIQXTHQIDYTFRH-UHFFFAOYSA-N 0.000 description 2
- OQCDKBAXFALNLD-UHFFFAOYSA-N octadecanoic acid Natural products CCCCCCCC(C)CCCCCCCCC(O)=O OQCDKBAXFALNLD-UHFFFAOYSA-N 0.000 description 2
- 238000001543 one-way ANOVA Methods 0.000 description 2
- 229960001592 paclitaxel Drugs 0.000 description 2
- 229940055729 papain Drugs 0.000 description 2
- 235000019834 papain Nutrition 0.000 description 2
- 101150040383 pel2 gene Proteins 0.000 description 2
- 101150050446 pelB gene Proteins 0.000 description 2
- YBYRMVIVWMBXKQ-UHFFFAOYSA-N phenylmethanesulfonyl fluoride Chemical compound FS(=O)(=O)CC1=CC=CC=C1 YBYRMVIVWMBXKQ-UHFFFAOYSA-N 0.000 description 2
- 210000002381 plasma Anatomy 0.000 description 2
- 229920000642 polymer Polymers 0.000 description 2
- 239000000843 powder Substances 0.000 description 2
- QELSKZZBTMNZEB-UHFFFAOYSA-N propylparaben Chemical compound CCCOC(=O)C1=CC=C(O)C=C1 QELSKZZBTMNZEB-UHFFFAOYSA-N 0.000 description 2
- RXWNCPJZOCPEPQ-NVWDDTSBSA-N puromycin Chemical compound C1=CC(OC)=CC=C1C[C@H](N)C(=O)N[C@H]1[C@@H](O)[C@H](N2C3=NC=NC(=C3N=C2)N(C)C)O[C@@H]1CO RXWNCPJZOCPEPQ-NVWDDTSBSA-N 0.000 description 2
- 229940076788 pyruvate Drugs 0.000 description 2
- 238000011158 quantitative evaluation Methods 0.000 description 2
- 230000005855 radiation Effects 0.000 description 2
- 238000010814 radioimmunoprecipitation assay Methods 0.000 description 2
- 230000009467 reduction Effects 0.000 description 2
- 230000035945 sensitivity Effects 0.000 description 2
- 238000013207 serial dilution Methods 0.000 description 2
- 238000001542 size-exclusion chromatography Methods 0.000 description 2
- 150000003384 small molecules Chemical class 0.000 description 2
- 239000001509 sodium citrate Substances 0.000 description 2
- NLJMYIDDQXHKNR-UHFFFAOYSA-K sodium citrate Chemical compound O.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O NLJMYIDDQXHKNR-UHFFFAOYSA-K 0.000 description 2
- 239000012064 sodium phosphate buffer Substances 0.000 description 2
- DAEPDZWVDSPTHF-UHFFFAOYSA-M sodium pyruvate Chemical compound [Na+].CC(=O)C([O-])=O DAEPDZWVDSPTHF-UHFFFAOYSA-M 0.000 description 2
- 239000008117 stearic acid Substances 0.000 description 2
- 210000000130 stem cell Anatomy 0.000 description 2
- 230000000638 stimulation Effects 0.000 description 2
- 238000012916 structural analysis Methods 0.000 description 2
- 230000009897 systematic effect Effects 0.000 description 2
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 description 2
- 229930101283 tetracycline Natural products 0.000 description 2
- 229960002180 tetracycline Drugs 0.000 description 2
- 235000019364 tetracycline Nutrition 0.000 description 2
- 150000003522 tetracyclines Chemical class 0.000 description 2
- 238000002560 therapeutic procedure Methods 0.000 description 2
- 150000003573 thiols Chemical class 0.000 description 2
- 108091006107 transcriptional repressors Proteins 0.000 description 2
- 238000013519 translation Methods 0.000 description 2
- 230000014616 translation Effects 0.000 description 2
- 239000012588 trypsin Substances 0.000 description 2
- 125000001493 tyrosinyl group Chemical group [H]OC1=C([H])C([H])=C(C([H])=C1[H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 2
- 238000002604 ultrasonography Methods 0.000 description 2
- 239000004474 valine Substances 0.000 description 2
- 238000002424 x-ray crystallography Methods 0.000 description 2
- 239000002676 xenobiotic agent Substances 0.000 description 2
- 230000002034 xenobiotic effect Effects 0.000 description 2
- 229960005502 α-amanitin Drugs 0.000 description 2
- DPVHGFAJLZWDOC-PVXXTIHASA-N (2r,3s,4s,5r,6r)-2-(hydroxymethyl)-6-[(2r,3r,4s,5s,6r)-3,4,5-trihydroxy-6-(hydroxymethyl)oxan-2-yl]oxyoxane-3,4,5-triol;dihydrate Chemical compound O.O.O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 DPVHGFAJLZWDOC-PVXXTIHASA-N 0.000 description 1
- SLURUCSFDHKXFR-WWMWMSKMSA-N (7s,9s)-7-[[(1s,3r,4as,9s,9ar,10as)-9-methoxy-1-methyl-3,4,4a,6,7,9,9a,10a-octahydro-1h-pyrano[1,2][1,3]oxazolo[3,4-b][1,4]oxazin-3-yl]oxy]-6,9,11-trihydroxy-9-(2-hydroxyacetyl)-4-methoxy-8,10-dihydro-7h-tetracene-5,12-dione Chemical compound O=C1C2=CC=CC(OC)=C2C(=O)C(C(O)=C23)=C1C(O)=C3C[C@@](O)(C(=O)CO)C[C@@H]2O[C@H]1C[C@@H]2N3CCO[C@H](OC)[C@H]3O[C@@H]2[C@H](C)O1 SLURUCSFDHKXFR-WWMWMSKMSA-N 0.000 description 1
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 description 1
- IIZPXYDJLKNOIY-JXPKJXOSSA-N 1-palmitoyl-2-arachidonoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCC\C=C/C\C=C/C\C=C/C\C=C/CCCCC IIZPXYDJLKNOIY-JXPKJXOSSA-N 0.000 description 1
- 108010058566 130-nm albumin-bound paclitaxel Proteins 0.000 description 1
- CHHHXKFHOYLYRE-UHFFFAOYSA-M 2,4-Hexadienoic acid, potassium salt (1:1), (2E,4E)- Chemical compound [K+].CC=CC=CC([O-])=O CHHHXKFHOYLYRE-UHFFFAOYSA-M 0.000 description 1
- NFZZDOYBSGWASD-UHFFFAOYSA-N 4-amino-n-pyrimidin-2-ylbenzenesulfonamide;5-[(3,4,5-trimethoxyphenyl)methyl]pyrimidine-2,4-diamine Chemical compound C1=CC(N)=CC=C1S(=O)(=O)NC1=NC=CC=N1.COC1=C(OC)C(OC)=CC(CC=2C(=NC(N)=NC=2)N)=C1 NFZZDOYBSGWASD-UHFFFAOYSA-N 0.000 description 1
- UZOVYGYOLBIAJR-UHFFFAOYSA-N 4-isocyanato-4'-methyldiphenylmethane Chemical compound C1=CC(C)=CC=C1CC1=CC=C(N=C=O)C=C1 UZOVYGYOLBIAJR-UHFFFAOYSA-N 0.000 description 1
- NEEVCWPRIZJJRJ-LWRDCAMISA-N 5-(benzylideneamino)-6-[(e)-benzylideneamino]-2-sulfanylidene-1h-pyrimidin-4-one Chemical compound C=1C=CC=CC=1C=NC=1C(=O)NC(=S)NC=1\N=C\C1=CC=CC=C1 NEEVCWPRIZJJRJ-LWRDCAMISA-N 0.000 description 1
- GSRTWXVBHGOUBU-UHFFFAOYSA-N 6,7-diphenyl-2-sulfanylidene-1h-pteridin-4-one Chemical compound C=1C=CC=CC=1C=1N=C2C(=O)NC(S)=NC2=NC=1C1=CC=CC=C1 GSRTWXVBHGOUBU-UHFFFAOYSA-N 0.000 description 1
- 206010069754 Acquired gene mutation Diseases 0.000 description 1
- 208000036762 Acute promyelocytic leukaemia Diseases 0.000 description 1
- 108010012934 Albumin-Bound Paclitaxel Proteins 0.000 description 1
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical class O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 1
- BFYIZQONLCFLEV-DAELLWKTSA-N Aromasine Chemical compound O=C1C=C[C@]2(C)[C@H]3CC[C@](C)(C(CC4)=O)[C@@H]4[C@@H]3CC(=C)C2=C1 BFYIZQONLCFLEV-DAELLWKTSA-N 0.000 description 1
- 238000000035 BCA protein assay Methods 0.000 description 1
- 102000004506 Blood Proteins Human genes 0.000 description 1
- 108010017384 Blood Proteins Proteins 0.000 description 1
- 101001011741 Bos taurus Insulin Proteins 0.000 description 1
- 208000003174 Brain Neoplasms Diseases 0.000 description 1
- 108010029697 CD40 Ligand Proteins 0.000 description 1
- 102100032937 CD40 ligand Human genes 0.000 description 1
- 241000282472 Canis lupus familiaris Species 0.000 description 1
- GAGWJHPBXLXJQN-UORFTKCHSA-N Capecitabine Chemical compound C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1[C@H]1[C@H](O)[C@H](O)[C@@H](C)O1 GAGWJHPBXLXJQN-UORFTKCHSA-N 0.000 description 1
- GAGWJHPBXLXJQN-UHFFFAOYSA-N Capecitabine Natural products C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1C1C(O)C(O)C(C)O1 GAGWJHPBXLXJQN-UHFFFAOYSA-N 0.000 description 1
- BQENDLAVTKRQMS-SBBGFIFASA-L Carbenoxolone sodium Chemical compound [Na+].[Na+].C([C@H]1C2=CC(=O)[C@H]34)[C@@](C)(C([O-])=O)CC[C@]1(C)CC[C@@]2(C)[C@]4(C)CC[C@@H]1[C@]3(C)CC[C@H](OC(=O)CCC([O-])=O)C1(C)C BQENDLAVTKRQMS-SBBGFIFASA-L 0.000 description 1
- 229920002134 Carboxymethyl cellulose Polymers 0.000 description 1
- 208000005623 Carcinogenesis Diseases 0.000 description 1
- 102000014914 Carrier Proteins Human genes 0.000 description 1
- 102000000844 Cell Surface Receptors Human genes 0.000 description 1
- 108010001857 Cell Surface Receptors Proteins 0.000 description 1
- CMSMOCZEIVJLDB-UHFFFAOYSA-N Cyclophosphamide Chemical compound ClCCN(CCCl)P1(=O)NCCCO1 CMSMOCZEIVJLDB-UHFFFAOYSA-N 0.000 description 1
- 102100025698 Cytosolic carboxypeptidase 4 Human genes 0.000 description 1
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- ZZZCUOFIHGPKAK-UHFFFAOYSA-N D-erythro-ascorbic acid Natural products OCC1OC(=O)C(O)=C1O ZZZCUOFIHGPKAK-UHFFFAOYSA-N 0.000 description 1
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 1
- 102000053602 DNA Human genes 0.000 description 1
- 102100022874 Dexamethasone-induced Ras-related protein 1 Human genes 0.000 description 1
- 101100379627 Dictyostelium discoideum argJ gene Proteins 0.000 description 1
- 108010053187 Diphtheria Toxin Proteins 0.000 description 1
- 102000016607 Diphtheria Toxin Human genes 0.000 description 1
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 1
- 101100338242 Drosophila virilis His1.1 gene Proteins 0.000 description 1
- 206010059866 Drug resistance Diseases 0.000 description 1
- 208000037162 Ductal Breast Carcinoma Diseases 0.000 description 1
- 238000012286 ELISA Assay Methods 0.000 description 1
- 238000008157 ELISA kit Methods 0.000 description 1
- 241000196324 Embryophyta Species 0.000 description 1
- 241000792859 Enema Species 0.000 description 1
- 102000004190 Enzymes Human genes 0.000 description 1
- 108090000790 Enzymes Proteins 0.000 description 1
- 241000588724 Escherichia coli Species 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 239000012739 FreeStyle 293 Expression medium Substances 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- 108700004714 Gelonium multiflorum GEL Proteins 0.000 description 1
- 108010024636 Glutathione Proteins 0.000 description 1
- 108010053070 Glutathione Disulfide Proteins 0.000 description 1
- 108010069236 Goserelin Proteins 0.000 description 1
- BLCLNMBMMGCOAS-URPVMXJPSA-N Goserelin Chemical compound C([C@@H](C(=O)N[C@H](COC(C)(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1[C@@H](CCC1)C(=O)NNC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H]1NC(=O)CC1)C1=CC=C(O)C=C1 BLCLNMBMMGCOAS-URPVMXJPSA-N 0.000 description 1
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 1
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 1
- 208000012766 Growth delay Diseases 0.000 description 1
- 108020005004 Guide RNA Proteins 0.000 description 1
- 102100028976 HLA class I histocompatibility antigen, B alpha chain Human genes 0.000 description 1
- 102100028971 HLA class I histocompatibility antigen, C alpha chain Human genes 0.000 description 1
- 102100031547 HLA class II histocompatibility antigen, DO alpha chain Human genes 0.000 description 1
- 102100031546 HLA class II histocompatibility antigen, DO beta chain Human genes 0.000 description 1
- 102210042925 HLA-A*02:01 Human genes 0.000 description 1
- 108010058607 HLA-B Antigens Proteins 0.000 description 1
- 108010052199 HLA-C Antigens Proteins 0.000 description 1
- 108010010378 HLA-DP Antigens Proteins 0.000 description 1
- 102000015789 HLA-DP Antigens Human genes 0.000 description 1
- 108010062347 HLA-DQ Antigens Proteins 0.000 description 1
- 108010058597 HLA-DR Antigens Proteins 0.000 description 1
- 102000006354 HLA-DR Antigens Human genes 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 101001033280 Homo sapiens Cytokine receptor common subunit beta Proteins 0.000 description 1
- 101000932590 Homo sapiens Cytosolic carboxypeptidase 4 Proteins 0.000 description 1
- 101000620808 Homo sapiens Dexamethasone-induced Ras-related protein 1 Proteins 0.000 description 1
- 101000866278 Homo sapiens HLA class II histocompatibility antigen, DO alpha chain Proteins 0.000 description 1
- 101000866281 Homo sapiens HLA class II histocompatibility antigen, DO beta chain Proteins 0.000 description 1
- 101000599940 Homo sapiens Interferon gamma Proteins 0.000 description 1
- 101000917839 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-B Proteins 0.000 description 1
- 101000584702 Homo sapiens Ras-related protein Rab-7b Proteins 0.000 description 1
- 241000511976 Hoya Species 0.000 description 1
- 102000008100 Human Serum Albumin Human genes 0.000 description 1
- 108091006905 Human Serum Albumin Proteins 0.000 description 1
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 1
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 1
- 238000012404 In vitro experiment Methods 0.000 description 1
- 239000007760 Iscove's Modified Dulbecco's Medium Substances 0.000 description 1
- 102000010638 Kinesin Human genes 0.000 description 1
- 108010063296 Kinesin Proteins 0.000 description 1
- 229930064664 L-arginine Natural products 0.000 description 1
- 235000014852 L-arginine Nutrition 0.000 description 1
- 229930182816 L-glutamine Natural products 0.000 description 1
- BVHLGVCQOALMSV-JEDNCBNOSA-N L-lysine hydrochloride Chemical compound Cl.NCCCC[C@H](N)C(O)=O BVHLGVCQOALMSV-JEDNCBNOSA-N 0.000 description 1
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Chemical class OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 1
- 239000004166 Lanolin Substances 0.000 description 1
- 206010069360 Leukaemic infiltration Diseases 0.000 description 1
- 108010000817 Leuprolide Proteins 0.000 description 1
- 108700005089 MHC Class I Genes Proteins 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- 229930126263 Maytansine Natural products 0.000 description 1
- 229920000168 Microcrystalline cellulose Polymers 0.000 description 1
- 101001033003 Mus musculus Granzyme F Proteins 0.000 description 1
- 101000976619 Mus musculus Zinc finger protein 3 Proteins 0.000 description 1
- 108010021466 Mutant Proteins Proteins 0.000 description 1
- 102000008300 Mutant Proteins Human genes 0.000 description 1
- 208000026305 Myelodysplastic-Myeloproliferative disease Diseases 0.000 description 1
- WHNWPMSKXPGLAX-UHFFFAOYSA-N N-Vinyl-2-pyrrolidone Chemical compound C=CN1CCCC1=O WHNWPMSKXPGLAX-UHFFFAOYSA-N 0.000 description 1
- ZDZOTLJHXYCWBA-VCVYQWHSSA-N N-debenzoyl-N-(tert-butoxycarbonyl)-10-deacetyltaxol Chemical compound O([C@H]1[C@H]2[C@@](C([C@H](O)C3=C(C)[C@@H](OC(=O)[C@H](O)[C@@H](NC(=O)OC(C)(C)C)C=4C=CC=CC=4)C[C@]1(O)C3(C)C)=O)(C)[C@@H](O)C[C@H]1OC[C@]12OC(=O)C)C(=O)C1=CC=CC=C1 ZDZOTLJHXYCWBA-VCVYQWHSSA-N 0.000 description 1
- KYRVNWMVYQXFEU-UHFFFAOYSA-N Nocodazole Chemical compound C1=C2NC(NC(=O)OC)=NC2=CC=C1C(=O)C1=CC=CS1 KYRVNWMVYQXFEU-UHFFFAOYSA-N 0.000 description 1
- 101710160107 Outer membrane protein A Proteins 0.000 description 1
- 238000012408 PCR amplification Methods 0.000 description 1
- 229930012538 Paclitaxel Natural products 0.000 description 1
- 241000282579 Pan Species 0.000 description 1
- 241000282520 Papio Species 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 235000004522 Pentaglottis sempervirens Nutrition 0.000 description 1
- 239000004264 Petrolatum Substances 0.000 description 1
- 208000009052 Precursor T-Cell Lymphoblastic Leukemia-Lymphoma Diseases 0.000 description 1
- 241000288906 Primates Species 0.000 description 1
- 206010036790 Productive cough Diseases 0.000 description 1
- 208000033826 Promyelocytic Acute Leukemia Diseases 0.000 description 1
- 102000007327 Protamines Human genes 0.000 description 1
- 108010007568 Protamines Proteins 0.000 description 1
- 108700033844 Pseudomonas aeruginosa toxA Proteins 0.000 description 1
- 239000012083 RIPA buffer Substances 0.000 description 1
- 102100030008 Ras-related protein Rab-7b Human genes 0.000 description 1
- 241000700159 Rattus Species 0.000 description 1
- 108010039491 Ricin Proteins 0.000 description 1
- 241000283984 Rodentia Species 0.000 description 1
- 206010039491 Sarcoma Diseases 0.000 description 1
- BUGBHKTXTAQXES-UHFFFAOYSA-N Selenium Chemical compound [Se] BUGBHKTXTAQXES-UHFFFAOYSA-N 0.000 description 1
- 108020004682 Single-Stranded DNA Proteins 0.000 description 1
- 229920002472 Starch Chemical class 0.000 description 1
- 229930006000 Sucrose Natural products 0.000 description 1
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical class O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 1
- 241000282887 Suidae Species 0.000 description 1
- 208000029052 T-cell acute lymphoblastic leukemia Diseases 0.000 description 1
- 229940123237 Taxane Drugs 0.000 description 1
- GWEVSGVZZGPLCZ-UHFFFAOYSA-N Titan oxide Chemical compound O=[Ti]=O GWEVSGVZZGPLCZ-UHFFFAOYSA-N 0.000 description 1
- 101710120037 Toxin CcdB Proteins 0.000 description 1
- 102000001742 Tumor Suppressor Proteins Human genes 0.000 description 1
- 108010040002 Tumor Suppressor Proteins Proteins 0.000 description 1
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 description 1
- 241000700605 Viruses Species 0.000 description 1
- 229930003268 Vitamin C Natural products 0.000 description 1
- 229930003427 Vitamin E Natural products 0.000 description 1
- TVXBFESIOXBWNM-UHFFFAOYSA-N Xylitol Natural products OCCC(O)C(O)C(O)CCO TVXBFESIOXBWNM-UHFFFAOYSA-N 0.000 description 1
- DPXJVFZANSGRMM-UHFFFAOYSA-N acetic acid;2,3,4,5,6-pentahydroxyhexanal;sodium Chemical compound [Na].CC(O)=O.OCC(O)C(O)C(O)C(O)C=O DPXJVFZANSGRMM-UHFFFAOYSA-N 0.000 description 1
- 239000012190 activator Substances 0.000 description 1
- 201000011186 acute T cell leukemia Diseases 0.000 description 1
- 239000000654 additive Substances 0.000 description 1
- 239000003463 adsorbent Substances 0.000 description 1
- 238000001042 affinity chromatography Methods 0.000 description 1
- 239000000556 agonist Substances 0.000 description 1
- 108700025316 aldesleukin Proteins 0.000 description 1
- 229960005310 aldesleukin Drugs 0.000 description 1
- 229960000473 altretamine Drugs 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 229960002932 anastrozole Drugs 0.000 description 1
- YBBLVLTVTVSKRW-UHFFFAOYSA-N anastrozole Chemical compound N#CC(C)(C)C1=CC(C(C)(C#N)C)=CC(CN2N=CN=C2)=C1 YBBLVLTVTVSKRW-UHFFFAOYSA-N 0.000 description 1
- 238000004873 anchoring Methods 0.000 description 1
- 239000004037 angiogenesis inhibitor Substances 0.000 description 1
- 229940121369 angiogenesis inhibitor Drugs 0.000 description 1
- 230000000181 anti-adherent effect Effects 0.000 description 1
- 229940046836 anti-estrogen Drugs 0.000 description 1
- 230000001833 anti-estrogenic effect Effects 0.000 description 1
- 230000000692 anti-sense effect Effects 0.000 description 1
- 230000000259 anti-tumor effect Effects 0.000 description 1
- 239000003911 antiadherent Substances 0.000 description 1
- 238000011230 antibody-based therapy Methods 0.000 description 1
- 230000030741 antigen processing and presentation Effects 0.000 description 1
- 229940045985 antineoplastic platinum compound Drugs 0.000 description 1
- 239000003886 aromatase inhibitor Substances 0.000 description 1
- 229940046844 aromatase inhibitors Drugs 0.000 description 1
- 238000003491 array Methods 0.000 description 1
- VSRXQHXAPYXROS-UHFFFAOYSA-N azanide;cyclobutane-1,1-dicarboxylic acid;platinum(2+) Chemical compound [NH2-].[NH2-].[Pt+2].OC(=O)C1(C(O)=O)CCC1 VSRXQHXAPYXROS-UHFFFAOYSA-N 0.000 description 1
- 239000000987 azo dye Substances 0.000 description 1
- 210000003719 b-lymphocyte Anatomy 0.000 description 1
- 229940049706 benzodiazepine Drugs 0.000 description 1
- 150000001557 benzodiazepines Chemical class 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- 229960000397 bevacizumab Drugs 0.000 description 1
- 108091008324 binding proteins Proteins 0.000 description 1
- 230000004071 biological effect Effects 0.000 description 1
- 239000012472 biological sample Substances 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 238000007413 biotinylation Methods 0.000 description 1
- 230000006287 biotinylation Effects 0.000 description 1
- 239000002981 blocking agent Substances 0.000 description 1
- IXIBAKNTJSCKJM-BUBXBXGNSA-N bovine insulin Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@H]1CSSC[C@H]2C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@H](C(=O)N[C@H](C(N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=3C=CC(O)=CC=3)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=3C=CC(O)=CC=3)C(=O)N[C@@H](CSSC[C@H](NC(=O)[C@H](C(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=3C=CC(O)=CC=3)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=3NC=NC=3)NC(=O)[C@H](CO)NC(=O)CNC1=O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O)=O)CSSC[C@@H](C(N2)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](NC(=O)CN)[C@@H](C)CC)C(C)C)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC=1C=CC=CC=1)C(C)C)C1=CN=CN1 IXIBAKNTJSCKJM-BUBXBXGNSA-N 0.000 description 1
- 210000000481 breast Anatomy 0.000 description 1
- 229930195731 calicheamicin Natural products 0.000 description 1
- HXCHCVDVKSCDHU-LULTVBGHSA-N calicheamicin Chemical compound C1[C@H](OC)[C@@H](NCC)CO[C@H]1O[C@H]1[C@H](O[C@@H]2C\3=C(NC(=O)OC)C(=O)C[C@](C/3=C/CSSSC)(O)C#C\C=C/C#C2)O[C@H](C)[C@@H](NO[C@@H]2O[C@H](C)[C@@H](SC(=O)C=3C(=C(OC)C(O[C@H]4[C@@H]([C@H](OC)[C@@H](O)[C@H](C)O4)O)=C(I)C=3C)OC)[C@@H](O)C2)[C@@H]1O HXCHCVDVKSCDHU-LULTVBGHSA-N 0.000 description 1
- 230000036952 cancer formation Effects 0.000 description 1
- 238000002619 cancer immunotherapy Methods 0.000 description 1
- 229960004117 capecitabine Drugs 0.000 description 1
- 239000002775 capsule Substances 0.000 description 1
- 239000004202 carbamide Substances 0.000 description 1
- 229960004562 carboplatin Drugs 0.000 description 1
- 239000001768 carboxy methyl cellulose Substances 0.000 description 1
- 235000010948 carboxy methyl cellulose Nutrition 0.000 description 1
- 239000008112 carboxymethyl-cellulose Substances 0.000 description 1
- 231100000504 carcinogenesis Toxicity 0.000 description 1
- 101150038500 cas9 gene Proteins 0.000 description 1
- 238000005277 cation exchange chromatography Methods 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 230000005754 cellular signaling Effects 0.000 description 1
- 239000001913 cellulose Chemical class 0.000 description 1
- 210000001175 cerebrospinal fluid Anatomy 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 229960004106 citric acid Drugs 0.000 description 1
- 238000003776 cleavage reaction Methods 0.000 description 1
- 238000011198 co-culture assay Methods 0.000 description 1
- 238000012761 co-transfection Methods 0.000 description 1
- 239000011248 coating agent Substances 0.000 description 1
- 238000000576 coating method Methods 0.000 description 1
- 239000008119 colloidal silica Substances 0.000 description 1
- 208000029742 colonic neoplasm Diseases 0.000 description 1
- 238000002648 combination therapy Methods 0.000 description 1
- 239000000562 conjugate Substances 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 239000002872 contrast media Substances 0.000 description 1
- 239000002285 corn oil Substances 0.000 description 1
- 235000005687 corn oil Nutrition 0.000 description 1
- 239000006184 cosolvent Substances 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 229960001681 croscarmellose sodium Drugs 0.000 description 1
- 229960000913 crospovidone Drugs 0.000 description 1
- 230000037029 cross reaction Effects 0.000 description 1
- 239000001767 crosslinked sodium carboxy methyl cellulose Substances 0.000 description 1
- 238000002425 crystallisation Methods 0.000 description 1
- 230000008025 crystallization Effects 0.000 description 1
- 239000012228 culture supernatant Substances 0.000 description 1
- 210000004748 cultured cell Anatomy 0.000 description 1
- 229960004397 cyclophosphamide Drugs 0.000 description 1
- 230000009089 cytolysis Effects 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 230000008021 deposition Effects 0.000 description 1
- 239000003599 detergent Substances 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 239000008121 dextrose Substances 0.000 description 1
- 238000010586 diagram Methods 0.000 description 1
- 235000005911 diet Nutrition 0.000 description 1
- 230000037213 diet Effects 0.000 description 1
- 238000002022 differential scanning fluorescence spectroscopy Methods 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- GXGAKHNRMVGRPK-UHFFFAOYSA-N dimagnesium;dioxido-bis[[oxido(oxo)silyl]oxy]silane Chemical compound [Mg+2].[Mg+2].[O-][Si](=O)O[Si]([O-])([O-])O[Si]([O-])=O GXGAKHNRMVGRPK-UHFFFAOYSA-N 0.000 description 1
- ZPWVASYFFYYZEW-UHFFFAOYSA-L dipotassium hydrogen phosphate Chemical compound [K+].[K+].OP([O-])([O-])=O ZPWVASYFFYYZEW-UHFFFAOYSA-L 0.000 description 1
- 229910000396 dipotassium phosphate Inorganic materials 0.000 description 1
- 235000019797 dipotassium phosphate Nutrition 0.000 description 1
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 1
- 229940042399 direct acting antivirals protease inhibitors Drugs 0.000 description 1
- 239000007884 disintegrant Substances 0.000 description 1
- BNIILDVGGAEEIG-UHFFFAOYSA-L disodium hydrogen phosphate Chemical compound [Na+].[Na+].OP([O-])([O-])=O BNIILDVGGAEEIG-UHFFFAOYSA-L 0.000 description 1
- 238000006073 displacement reaction Methods 0.000 description 1
- 238000010494 dissociation reaction Methods 0.000 description 1
- 230000005593 dissociations Effects 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- 229960003668 docetaxel Drugs 0.000 description 1
- 239000012154 double-distilled water Substances 0.000 description 1
- 229960004679 doxorubicin Drugs 0.000 description 1
- 230000037437 driver mutation Effects 0.000 description 1
- 235000013399 edible fruits Nutrition 0.000 description 1
- 239000003792 electrolyte Substances 0.000 description 1
- 238000001962 electrophoresis Methods 0.000 description 1
- 239000007920 enema Substances 0.000 description 1
- 229940079360 enema for constipation Drugs 0.000 description 1
- 229940088598 enzyme Drugs 0.000 description 1
- 239000000328 estrogen antagonist Substances 0.000 description 1
- BEFDCLMNVWHSGT-UHFFFAOYSA-N ethenylcyclopentane Chemical compound C=CC1CCCC1 BEFDCLMNVWHSGT-UHFFFAOYSA-N 0.000 description 1
- VJJPUSNTGOMMGY-MRVIYFEKSA-N etoposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@H](C)OC[C@H]4O3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 VJJPUSNTGOMMGY-MRVIYFEKSA-N 0.000 description 1
- 229960000255 exemestane Drugs 0.000 description 1
- 210000002950 fibroblast Anatomy 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 235000003599 food sweetener Nutrition 0.000 description 1
- 238000007672 fourth generation sequencing Methods 0.000 description 1
- 238000005194 fractionation Methods 0.000 description 1
- 230000037433 frameshift Effects 0.000 description 1
- 239000012737 fresh medium Substances 0.000 description 1
- 229910021485 fumed silica Inorganic materials 0.000 description 1
- WIGCFUFOHFEKBI-UHFFFAOYSA-N gamma-tocopherol Natural products CC(C)CCCC(C)CCCC(C)CCCC1CCC2C(C)C(O)C(C)C(C)C2O1 WIGCFUFOHFEKBI-UHFFFAOYSA-N 0.000 description 1
- 238000001502 gel electrophoresis Methods 0.000 description 1
- 239000008273 gelatin Substances 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- 229960005277 gemcitabine Drugs 0.000 description 1
- SDUQYLNIPVEERB-QPPQHZFASA-N gemcitabine Chemical compound O=C1N=C(N)C=CN1[C@H]1C(F)(F)[C@H](O)[C@@H](CO)O1 SDUQYLNIPVEERB-QPPQHZFASA-N 0.000 description 1
- 125000000404 glutamine group Chemical group N[C@@H](CCC(N)=O)C(=O)* 0.000 description 1
- RWSXRVCMGQZWBV-WDSKDSINSA-N glutathione Chemical compound OC(=O)[C@@H](N)CCC(=O)N[C@@H](CS)C(=O)NCC(O)=O RWSXRVCMGQZWBV-WDSKDSINSA-N 0.000 description 1
- YPZRWBKMTBYPTK-BJDJZHNGSA-N glutathione disulfide Chemical compound OC(=O)[C@@H](N)CCC(=O)N[C@H](C(=O)NCC(O)=O)CSSC[C@@H](C(=O)NCC(O)=O)NC(=O)CC[C@H](N)C(O)=O YPZRWBKMTBYPTK-BJDJZHNGSA-N 0.000 description 1
- 229960002449 glycine Drugs 0.000 description 1
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 description 1
- 229910052737 gold Inorganic materials 0.000 description 1
- 239000010931 gold Substances 0.000 description 1
- 229960002913 goserelin Drugs 0.000 description 1
- 230000005484 gravity Effects 0.000 description 1
- 201000005787 hematologic cancer Diseases 0.000 description 1
- 208000024200 hematopoietic and lymphoid system neoplasm Diseases 0.000 description 1
- 238000005734 heterodimerization reaction Methods 0.000 description 1
- UUVWYPNAQBNQJQ-UHFFFAOYSA-N hexamethylmelamine Chemical compound CN(C)C1=NC(N(C)C)=NC(N(C)C)=N1 UUVWYPNAQBNQJQ-UHFFFAOYSA-N 0.000 description 1
- 238000004128 high performance liquid chromatography Methods 0.000 description 1
- 210000003630 histaminocyte Anatomy 0.000 description 1
- 102000055647 human CSF2RB Human genes 0.000 description 1
- 102000055277 human IL2 Human genes 0.000 description 1
- 102000057041 human TNF Human genes 0.000 description 1
- 210000005260 human cell Anatomy 0.000 description 1
- BHEPBYXIRTUNPN-UHFFFAOYSA-N hydridophosphorus(.) (triplet) Chemical compound [PH] BHEPBYXIRTUNPN-UHFFFAOYSA-N 0.000 description 1
- 229960001101 ifosfamide Drugs 0.000 description 1
- HOMGKSMUEGBAAB-UHFFFAOYSA-N ifosfamide Chemical compound ClCCNP1(=O)OCCCN1CCCl HOMGKSMUEGBAAB-UHFFFAOYSA-N 0.000 description 1
- 238000010191 image analysis Methods 0.000 description 1
- 230000005746 immune checkpoint blockade Effects 0.000 description 1
- 210000000987 immune system Anatomy 0.000 description 1
- 238000003119 immunoblot Methods 0.000 description 1
- 239000012535 impurity Substances 0.000 description 1
- 208000015181 infectious disease Diseases 0.000 description 1
- 239000003112 inhibitor Substances 0.000 description 1
- 230000002401 inhibitory effect Effects 0.000 description 1
- 238000013101 initial test Methods 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 230000002601 intratumoral effect Effects 0.000 description 1
- 229960004768 irinotecan Drugs 0.000 description 1
- UWKQSNNFCGGAFS-XIFFEERXSA-N irinotecan Chemical compound C1=C2C(CC)=C3CN(C(C4=C([C@@](C(=O)OC4)(O)CC)C=4)=O)C=4C3=NC2=CC=C1OC(=O)N(CC1)CCC1N1CCCCC1 UWKQSNNFCGGAFS-XIFFEERXSA-N 0.000 description 1
- 210000001503 joint Anatomy 0.000 description 1
- 210000002510 keratinocyte Anatomy 0.000 description 1
- 210000003734 kidney Anatomy 0.000 description 1
- 230000002147 killing effect Effects 0.000 description 1
- 101150077478 kra gene Proteins 0.000 description 1
- 238000002372 labelling Methods 0.000 description 1
- 239000008101 lactose Chemical class 0.000 description 1
- 229940039717 lanolin Drugs 0.000 description 1
- 235000019388 lanolin Nutrition 0.000 description 1
- 239000000787 lecithin Substances 0.000 description 1
- 235000010445 lecithin Nutrition 0.000 description 1
- 229940067606 lecithin Drugs 0.000 description 1
- 229960003881 letrozole Drugs 0.000 description 1
- HPJKCIUCZWXJDR-UHFFFAOYSA-N letrozole Chemical compound C1=CC(C#N)=CC=C1C(N1N=CN=C1)C1=CC=C(C#N)C=C1 HPJKCIUCZWXJDR-UHFFFAOYSA-N 0.000 description 1
- GFIJNRVAKGFPGQ-LIJARHBVSA-N leuprolide Chemical compound CCNC(=O)[C@@H]1CCCN1C(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H]1NC(=O)CC1)CC1=CC=C(O)C=C1 GFIJNRVAKGFPGQ-LIJARHBVSA-N 0.000 description 1
- 229960004338 leuprorelin Drugs 0.000 description 1
- 239000003446 ligand Substances 0.000 description 1
- 239000000314 lubricant Substances 0.000 description 1
- 201000005243 lung squamous cell carcinoma Diseases 0.000 description 1
- 229960005337 lysine hydrochloride Drugs 0.000 description 1
- 239000012516 mab select resin Substances 0.000 description 1
- 210000002540 macrophage Anatomy 0.000 description 1
- ZLNQQNXFFQJAID-UHFFFAOYSA-L magnesium carbonate Chemical compound [Mg+2].[O-]C([O-])=O ZLNQQNXFFQJAID-UHFFFAOYSA-L 0.000 description 1
- 239000001095 magnesium carbonate Substances 0.000 description 1
- 229910000021 magnesium carbonate Inorganic materials 0.000 description 1
- 239000000391 magnesium silicate Substances 0.000 description 1
- 235000019359 magnesium stearate Nutrition 0.000 description 1
- 229910000386 magnesium trisilicate Inorganic materials 0.000 description 1
- 229940099273 magnesium trisilicate Drugs 0.000 description 1
- 235000019793 magnesium trisilicate Nutrition 0.000 description 1
- 238000002595 magnetic resonance imaging Methods 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 239000003550 marker Substances 0.000 description 1
- WKPWGQKGSOKKOO-RSFHAFMBSA-N maytansine Chemical compound CO[C@@H]([C@@]1(O)C[C@](OC(=O)N1)([C@H]([C@@H]1O[C@@]1(C)[C@@H](OC(=O)[C@H](C)N(C)C(C)=O)CC(=O)N1C)C)[H])\C=C\C=C(C)\CC2=CC(OC)=C(Cl)C1=C2 WKPWGQKGSOKKOO-RSFHAFMBSA-N 0.000 description 1
- 230000010534 mechanism of action Effects 0.000 description 1
- SGDBTWWWUNNDEQ-LBPRGKRZSA-N melphalan Chemical compound OC(=O)[C@@H](N)CC1=CC=C(N(CCCl)CCCl)C=C1 SGDBTWWWUNNDEQ-LBPRGKRZSA-N 0.000 description 1
- 229960001924 melphalan Drugs 0.000 description 1
- HEBKCHPVOIAQTA-UHFFFAOYSA-N meso ribitol Natural products OCC(O)C(O)C(O)CO HEBKCHPVOIAQTA-UHFFFAOYSA-N 0.000 description 1
- 101150043924 metXA gene Proteins 0.000 description 1
- 208000037819 metastatic cancer Diseases 0.000 description 1
- 208000011575 metastatic malignant neoplasm Diseases 0.000 description 1
- 235000010270 methyl p-hydroxybenzoate Nutrition 0.000 description 1
- 239000004292 methyl p-hydroxybenzoate Substances 0.000 description 1
- 229960002216 methylparaben Drugs 0.000 description 1
- 239000011325 microbead Substances 0.000 description 1
- 235000019813 microcrystalline cellulose Nutrition 0.000 description 1
- 239000008108 microcrystalline cellulose Substances 0.000 description 1
- 229940016286 microcrystalline cellulose Drugs 0.000 description 1
- 210000000274 microglia Anatomy 0.000 description 1
- 230000003278 mimic effect Effects 0.000 description 1
- 239000002480 mineral oil Substances 0.000 description 1
- 235000010446 mineral oil Nutrition 0.000 description 1
- 239000012452 mother liquor Substances 0.000 description 1
- 229940126619 mouse monoclonal antibody Drugs 0.000 description 1
- 230000000869 mutational effect Effects 0.000 description 1
- 210000000440 neutrophil Anatomy 0.000 description 1
- 229910052759 nickel Inorganic materials 0.000 description 1
- 229950006344 nocodazole Drugs 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 239000002773 nucleotide Substances 0.000 description 1
- 125000003729 nucleotide group Chemical group 0.000 description 1
- YPZRWBKMTBYPTK-UHFFFAOYSA-N oxidized gamma-L-glutamyl-L-cysteinylglycine Natural products OC(=O)C(N)CCC(=O)NC(C(=O)NCC(O)=O)CSSCC(C(=O)NCC(O)=O)NC(=O)CCC(N)C(O)=O YPZRWBKMTBYPTK-UHFFFAOYSA-N 0.000 description 1
- 229910052760 oxygen Inorganic materials 0.000 description 1
- 108700025694 p53 Genes Proteins 0.000 description 1
- 238000004806 packaging method and process Methods 0.000 description 1
- 201000008129 pancreatic ductal adenocarcinoma Diseases 0.000 description 1
- 238000009595 pap smear Methods 0.000 description 1
- 238000007911 parenteral administration Methods 0.000 description 1
- 230000036961 partial effect Effects 0.000 description 1
- 230000001717 pathogenic effect Effects 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- 239000008188 pellet Substances 0.000 description 1
- QOFFJEBXNKRSPX-ZDUSSCGKSA-N pemetrexed Chemical compound C1=N[C]2NC(N)=NC(=O)C2=C1CCC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 QOFFJEBXNKRSPX-ZDUSSCGKSA-N 0.000 description 1
- 229960005079 pemetrexed Drugs 0.000 description 1
- 210000005259 peripheral blood Anatomy 0.000 description 1
- 239000011886 peripheral blood Substances 0.000 description 1
- 210000004976 peripheral blood cell Anatomy 0.000 description 1
- 210000003200 peritoneal cavity Anatomy 0.000 description 1
- 235000019271 petrolatum Nutrition 0.000 description 1
- 229940066842 petrolatum Drugs 0.000 description 1
- WVDDGKGOMKODPV-ZQBYOMGUSA-N phenyl(114C)methanol Chemical compound O[14CH2]C1=CC=CC=C1 WVDDGKGOMKODPV-ZQBYOMGUSA-N 0.000 description 1
- 230000001766 physiological effect Effects 0.000 description 1
- 239000006187 pill Substances 0.000 description 1
- 230000036470 plasma concentration Effects 0.000 description 1
- 210000004180 plasmocyte Anatomy 0.000 description 1
- 150000003058 platinum compounds Chemical class 0.000 description 1
- 229920000058 polyacrylate Polymers 0.000 description 1
- 235000013809 polyvinylpolypyrrolidone Nutrition 0.000 description 1
- 229920000523 polyvinylpolypyrrolidone Polymers 0.000 description 1
- 229910052700 potassium Inorganic materials 0.000 description 1
- 235000010241 potassium sorbate Nutrition 0.000 description 1
- 239000004302 potassium sorbate Substances 0.000 description 1
- 229940069338 potassium sorbate Drugs 0.000 description 1
- 230000003389 potentiating effect Effects 0.000 description 1
- 230000001376 precipitating effect Effects 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 230000002335 preservative effect Effects 0.000 description 1
- 210000004986 primary T-cell Anatomy 0.000 description 1
- 235000010232 propyl p-hydroxybenzoate Nutrition 0.000 description 1
- 239000004405 propyl p-hydroxybenzoate Substances 0.000 description 1
- 229960003415 propylparaben Drugs 0.000 description 1
- 229950008679 protamine sulfate Drugs 0.000 description 1
- 230000017854 proteolysis Effects 0.000 description 1
- 229950010131 puromycin Drugs 0.000 description 1
- 238000003908 quality control method Methods 0.000 description 1
- 230000002285 radioactive effect Effects 0.000 description 1
- 238000001959 radiotherapy Methods 0.000 description 1
- 108700042226 ras Genes Proteins 0.000 description 1
- 230000000306 recurrent effect Effects 0.000 description 1
- 235000019172 retinyl palmitate Nutrition 0.000 description 1
- 229940108325 retinyl palmitate Drugs 0.000 description 1
- 239000011769 retinyl palmitate Substances 0.000 description 1
- 108010056030 retronectin Proteins 0.000 description 1
- 102220195076 rs121913255 Human genes 0.000 description 1
- 102200114273 rs199714731 Human genes 0.000 description 1
- 210000003296 saliva Anatomy 0.000 description 1
- 238000003118 sandwich ELISA Methods 0.000 description 1
- 230000007017 scission Effects 0.000 description 1
- 238000007423 screening assay Methods 0.000 description 1
- 229910052711 selenium Inorganic materials 0.000 description 1
- 239000011669 selenium Substances 0.000 description 1
- 235000011649 selenium Nutrition 0.000 description 1
- 235000015170 shellfish Nutrition 0.000 description 1
- 239000000741 silica gel Substances 0.000 description 1
- 229910002027 silica gel Inorganic materials 0.000 description 1
- 210000003491 skin Anatomy 0.000 description 1
- 229940126586 small molecule drug Drugs 0.000 description 1
- 229960001790 sodium citrate Drugs 0.000 description 1
- 229940054269 sodium pyruvate Drugs 0.000 description 1
- 230000037439 somatic mutation Effects 0.000 description 1
- 235000010199 sorbic acid Nutrition 0.000 description 1
- 239000004334 sorbic acid Substances 0.000 description 1
- 229940075582 sorbic acid Drugs 0.000 description 1
- 235000010356 sorbitol Nutrition 0.000 description 1
- 239000000600 sorbitol Substances 0.000 description 1
- 230000009870 specific binding Effects 0.000 description 1
- 210000000952 spleen Anatomy 0.000 description 1
- 210000003802 sputum Anatomy 0.000 description 1
- 208000024794 sputum Diseases 0.000 description 1
- 239000008107 starch Chemical class 0.000 description 1
- 235000019698 starch Nutrition 0.000 description 1
- 229940071117 starch glycolate Drugs 0.000 description 1
- 239000008174 sterile solution Substances 0.000 description 1
- 238000003756 stirring Methods 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- 239000000126 substance Substances 0.000 description 1
- 239000005720 sucrose Substances 0.000 description 1
- 239000000829 suppository Substances 0.000 description 1
- 238000013268 sustained release Methods 0.000 description 1
- 239000012730 sustained-release form Substances 0.000 description 1
- 239000003765 sweetening agent Substances 0.000 description 1
- 230000001360 synchronised effect Effects 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 239000000454 talc Substances 0.000 description 1
- 229910052623 talc Inorganic materials 0.000 description 1
- 229960001603 tamoxifen Drugs 0.000 description 1
- 210000000115 thoracic cavity Anatomy 0.000 description 1
- 210000001685 thyroid gland Anatomy 0.000 description 1
- OGIDPMRJRNCKJF-UHFFFAOYSA-N titanium oxide Inorganic materials [Ti]=O OGIDPMRJRNCKJF-UHFFFAOYSA-N 0.000 description 1
- 229960000303 topotecan Drugs 0.000 description 1
- UCFGDBYHRUNTLO-QHCPKHFHSA-N topotecan Chemical compound C1=C(O)C(CN(C)C)=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 UCFGDBYHRUNTLO-QHCPKHFHSA-N 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 230000001052 transient effect Effects 0.000 description 1
- 206010044412 transitional cell carcinoma Diseases 0.000 description 1
- 229960000575 trastuzumab Drugs 0.000 description 1
- 229940074409 trehalose dihydrate Drugs 0.000 description 1
- 230000001960 triggered effect Effects 0.000 description 1
- 239000000225 tumor suppressor protein Substances 0.000 description 1
- 238000007492 two-way ANOVA Methods 0.000 description 1
- 229940105809 uniprim Drugs 0.000 description 1
- 210000002700 urine Anatomy 0.000 description 1
- 125000002987 valine group Chemical group [H]N([H])C([H])(C(*)=O)C([H])(C([H])([H])[H])C([H])([H])[H] 0.000 description 1
- 239000003981 vehicle Substances 0.000 description 1
- GBABOYUKABKIAF-GHYRFKGUSA-N vinorelbine Chemical compound C1N(CC=2C3=CC=CC=C3NC=22)CC(CC)=C[C@H]1C[C@]2(C(=O)OC)C1=CC([C@]23[C@H]([C@]([C@H](OC(C)=O)[C@]4(CC)C=CCN([C@H]34)CC2)(O)C(=O)OC)N2C)=C2C=C1OC GBABOYUKABKIAF-GHYRFKGUSA-N 0.000 description 1
- 229960002066 vinorelbine Drugs 0.000 description 1
- 235000019154 vitamin C Nutrition 0.000 description 1
- 239000011718 vitamin C Substances 0.000 description 1
- 235000019165 vitamin E Nutrition 0.000 description 1
- 229940046009 vitamin E Drugs 0.000 description 1
- 239000011709 vitamin E Substances 0.000 description 1
- 229940045997 vitamin a Drugs 0.000 description 1
- 239000008215 water for injection Substances 0.000 description 1
- 239000001993 wax Substances 0.000 description 1
- 238000007482 whole exome sequencing Methods 0.000 description 1
- 238000012070 whole genome sequencing analysis Methods 0.000 description 1
- 239000000811 xylitol Substances 0.000 description 1
- 235000010447 xylitol Nutrition 0.000 description 1
- HEBKCHPVOIAQTA-SCDXWVJYSA-N xylitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)CO HEBKCHPVOIAQTA-SCDXWVJYSA-N 0.000 description 1
- 229960002675 xylitol Drugs 0.000 description 1
- 239000011701 zinc Substances 0.000 description 1
- 229910052725 zinc Inorganic materials 0.000 description 1
Images

























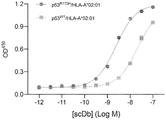

















































































Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
- A61P35/02—Antineoplastic agents specific for leukemia
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/46—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates
- C07K14/47—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals
- C07K14/4701—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals not used
- C07K14/4746—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals not used p53
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/82—Translation products from oncogenes
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2809—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against the T-cell receptor (TcR)-CD3 complex
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2833—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against MHC-molecules, e.g. HLA-molecules
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/32—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against translation products of oncogenes
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/46—Hybrid immunoglobulins
- C07K16/468—Immunoglobulins having two or more different antigen binding sites, e.g. multifunctional antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/545—Medicinal preparations containing antigens or antibodies characterised by the dose, timing or administration schedule
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2239/00—Indexing codes associated with cellular immunotherapy of group A61K39/46
- A61K2239/27—Indexing codes associated with cellular immunotherapy of group A61K39/46 characterized by targeting or presenting multiple antigens
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/32—Immunoglobulins specific features characterized by aspects of specificity or valency specific for a neo-epitope on a complex, e.g. antibody-antigen or ligand-receptor
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/33—Crossreactivity, e.g. for species or epitope, or lack of said crossreactivity
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/34—Identification of a linear epitope shorter than 20 amino acid residues or of a conformational epitope defined by amino acid residues
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/569—Single domain, e.g. dAb, sdAb, VHH, VNAR or nanobody®
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/622—Single chain antibody (scFv)
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Immunology (AREA)
- Organic Chemistry (AREA)
- Life Sciences & Earth Sciences (AREA)
- Medicinal Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Biochemistry (AREA)
- Genetics & Genomics (AREA)
- Molecular Biology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biophysics (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Animal Behavior & Ethology (AREA)
- Pharmacology & Pharmacy (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Cell Biology (AREA)
- General Chemical & Material Sciences (AREA)
- Oncology (AREA)
- Gastroenterology & Hepatology (AREA)
- Zoology (AREA)
- Toxicology (AREA)
- Microbiology (AREA)
- Mycology (AREA)
- Epidemiology (AREA)
- Hematology (AREA)
- Peptides Or Proteins (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
Abstract
本发明提供了评估患有或疑似患有癌症的哺乳动物和/或治疗患有癌症的哺乳动物的方法和材料。例如,本发明提供了包括一个或多个抗原结合域(例如,单链可变片段(scFv))的分子,其可结合修饰肽(例如,肿瘤抗原),以及使用此类分子的方法。
Description
相关申请的交叉参考
本申请要求2019年12月17日提交的美国专利申请系列号62/949,220以及2020年7月31日提交的美国专利申请系列号63/059,638的权益。在先申请的公开内容被视为本申请公开内容的一部分(并通过引用纳入)。
关于联邦资金的声明
本发明是在国立卫生研究院授予的基金CA062924的政府支持下完成的。政府对本发明享有一定的权利。
背景技术
1.技术领域
本发明涉及评估患有或疑似患有癌症的哺乳动物和/或治疗患有癌症的哺乳动物的方法和物质。例如,本文提供了使用包含一个或多个抗原结合域(例如,单链可变片段(scFv))的分子治疗患有癌症的哺乳动物的方法和材料,该分子可与修饰肽(例如肿瘤抗原)结合。
2.背景技术
癌症中的体细胞突变是癌症治疗的理想靶点,因为它们仅在肿瘤细胞中表达,而在正常细胞中不表达。靶向驱动基因蛋白(一般细分为癌基因蛋白和肿瘤抑制蛋白)具有额外的益处。首先,这些突变通常发生在肿瘤发生早期,因此基本上所有的子代癌细胞都含有突变。其次,肿瘤对其致癌基因赋予能力的依赖性降低了耐药的可能性。最后,驱动基因蛋白往往具有许多患者共有的热点突变,因此针对单一突变的治疗可以应用于广泛的患者群体。
大多数突变蛋白,包括大多数突变驱动基因蛋白,都是胞内的。虽然小分子可以靶向细胞内蛋白,但开发能够特异性抑制突变驱动基因而不是其野生型(WT)对应物的小分子对于大多数此类驱动基因蛋白质来说仍然遥不可及。能够区分单个氨基酸突变的抗体通常只能靶向胞外表位。
免疫系统通过抗原加工和递呈对胞内内容物进行采样。蛋白质水解后,一部分产生的肽被装载到人白细胞抗原(HLA)上,并被送到细胞表面,在那里它们通过T细胞受体(TCR)作为T细胞区分自身和非自身肽的途径。例如,病毒感染的细胞将在其HLA中递呈病毒肽,触发T细胞杀死该细胞。类似地,在癌症中,突变肽可以存在于癌细胞表面的HLA中,称为MANA,意为突变相关新抗原。在一些情况下,患者可能会对这些突变-肽-HLA新抗原产生不同程度的抗癌T细胞反应,检查点阻断抗体可以进一步增强这种反应。然而,许多患者,特别是那些突变负荷较低的患者,无法产生足够的抗癌T细胞反应。因此,特异性靶向MANA的治疗或诊断可以提供真正的肿瘤特异性方法来诊断或治疗癌症。
HLA I类蛋白存在于所有有核细胞上。有三种经典的HLA I类基因A、B和C,每种基因都具有高度多态性。每个HLA等位基因都有一个特定的肽结合基序,因此,只有特定的肽会与特定的HLA等位基因结合。
本领域持续需要开发诊断、监测和有效治疗癌症的新方法。
发明简述
鉴定对癌细胞高度特异的治疗靶点是开发有效癌症治疗的最大挑战之一。
本发明提供了治疗患有癌症的哺乳动物的方法和材料。例如,本发明提供了使用一种或多种分子治疗患有癌症(例如,表达修饰肽的癌症)的哺乳动物的方法和材料,所述分子包括可结合修饰肽(例如,肽HLA-β-2微球蛋白(b2M或β2M)复合物中存在的修饰肽)的一个或多个抗原结合域(例如scFv)。在一些情况下,可以向患有癌症(例如,表达修饰肽的癌症)的哺乳动物给予包括一个或多个抗原结合域(例如scFv)的一种或多种分子,这些分子可结合修饰肽(例如,肽HLA-β2M复合物中存在的修饰肽),以治疗该哺乳动物。
如本文所示,scFv被鉴定为靶向(例如结合)来自常见癌症驱动突变的HLA限制性MANA中存在的众多MANA,包括RAS Q61H/L/R和p53 R175H。同样如本文所示,scFv用于设计能够诱导MANA依赖性T细胞活化的双特异性抗体,从而识别和杀死表达MANA的细胞(例如癌细胞)。
MANA可用作高度特异性的癌症靶点,因为它们不存在于正常组织中。特异性靶向MANA的能力提供了诊断和/或治疗癌症的肿瘤特异性方法。例如,特异性靶向MANA的scFv可用于全长抗体或其片段、抗体-药物偶联物(ADC)、抗体-放射性核素偶联物、表达嵌合抗原受体的T细胞(CART)或双特异性抗体,以诊断和/或治疗患有癌症的哺乳动物。此外,能够结合MANA的抗体(MANA抗体)或其能够结合MANA的片段具有广泛应用和遗传可预测的现成靶向癌症免疫治疗的潜力。
一般而言,本发明的一个方面特征是具有抗原结合域的分子,其可结合肽HLA-β2M复合物,其中肽可衍生自修饰的p53多肽。修饰的p53多肽可包括7至25个氨基酸(例如修饰的p53多肽可包括9个氨基酸)。修饰的p53多肽可包括SEQ ID NO:1中所述的氨基酸序列。抗原结合域可以包括SEQ ID NO:137、SEQ ID NO:138、SEQ ID NO:139、SEQ ID NO:140和SEQID NO:141中任一项中所述的氨基酸序列。分子可以是选自抗体、抗体片段、单链可变片段(scFv)、嵌合抗原受体(CAR)、T细胞受体(TCR)、TCR模拟物、串联scFv、双特异性T细胞衔接子、双抗体、单链双抗体(scDb)、scFv-Fc、双特异性抗体和双亲和性重靶向抗体(DART)的任一种。该分子还可以包括抗原结合域,其可以结合选自CD3、CD28、CD4、CD8、CD16a、NKG2D、PD-1、CTLA-4、4-1BB、OX40、ICOS、CD27和Fc受体中的任何一种的效应细胞受体。在一些情况下,可结合效应细胞的抗原结合域可结合CD3,且所述抗原结合域可包含选自SEQ ID NO:170、SEQ ID NO:171、SEQ ID NO:172、SEQ ID NO:173、SEQ ID NO:174、SEQ ID NO:175、SEQID NO:176、SEQ ID NO:177、SEQ ID NO:178、SEQ ID NO:179、SEQ ID NO:180、SEQ ID NO:181、SEQ ID NO:182和SEQ ID NO:183的氨基酸序列。
在另一方面,本发明以具有抗原结合域的分子为特征,该抗原结合域可结合肽HLA-β2M复合物,其中肽可衍生自修饰的RAS肽。修饰的RAS肽可包括7至25个氨基酸(例如修饰的RAS肽可包括10个氨基酸)。修饰的RAS肽可包括SEQ ID NO:2、SEQ ID NO:3和SEQ IDNO:4中任一项所述的氨基酸序列。在一些情况下,修饰的RAS肽可以包括SEQ ID NO:2所述的氨基酸,抗原结合域可以包括SEQ IDNO:142、SEQ ID NO:143、SEQ ID NO:144、SEQ IDNO:145、SEQ ID NO:146、SEQ ID NO:147、SEQ ID NO:148和SEQ ID NO:149中任一项所述的氨基酸序列。在一些情况下,修饰的RAS肽可以包括SEQ ID NO:3中所述的氨基酸序列,并且抗原结合域可以包括SEQ ID NO:150、SEQ ID NO:151、SEQ ID NO:152、SEQ ID NO:153、SEQID NO:154、SEQ ID NO:155、SEQ ID NO:156、SEQ ID NO:157、SEQ ID NO:158、SEQ ID NO:159和SEQ ID NO:160中任一项所述的氨基酸序列。在一些情况下,修饰的RAS肽可以包括SEQ ID NO:4所述的氨基酸序列,抗原结合域可以包括SEQ ID NO:161、SEQ ID NO:162、SEQID NO:163、SEQ ID NO:164、SEQ ID NO:165、SEQ ID NO:166、SEQ ID NO:167、SEQ ID NO:168和SEQ ID NO:169中任一项所述的氨基酸序列。该分子可以是抗体、抗体片段、scFv、CAR、TCR、TCR模拟物、串联scFv,双特异性T细胞衔接子、双抗体、scDb、scFv-Fc、双特异性抗体和DART中的任何一种。该分子还可以包括抗原结合域,其可以结合选自CD3、CD28、CD4、CD8、CD16a、NKG2D、PD-1、CTLA-4、4-1BB、OX40、ICOS、CD27和Fc受体中的任何一种的效应细胞受体。在一些情况下,可结合效应细胞的抗原结合域可结合CD3,且所述抗原结合域可包含选自SEQ ID NO:170、SEQ ID NO:171、SEQ ID NO:172、SEQ ID NO:173、SEQ ID NO:174、SEQ ID NO:175、SEQ ID NO:176、SEQ ID NO:177、SEQ ID NO:178、SEQ ID NO:179、SEQ IDNO:180、SEQ ID NO:181、SEQ ID NO:182和SEQ ID NO:183的氨基酸序列。
在另一个方面,本发明的特征是患癌哺乳动物的治疗方法。所述方法可包括或主要由以下组成:向患有癌症的哺乳动物给予本文所述的一种或多种分子(例如,具有可与肽-HLA-β2M复合物结合的抗原结合域的分子,其中所述肽可衍生自修饰的p53多肽或修饰的RAS多肽),其中癌症包括表达修饰肽的癌细胞。哺乳动物可以是人。癌症可以是以下任一:霍奇金淋巴瘤、非霍奇金淋巴瘤、急性髓系白血病、急性淋巴母细胞白血病、多发性骨髓瘤、骨髓增生异常综合征(MDS)、骨髓增生性疾病、肺癌、胰腺癌、胃部恶性肿瘤(gastriccancer)、结直肠癌、卵巢癌、子宫内膜癌、胆道癌、肝癌、乳腺癌、前列腺癌、食管癌、胃癌(stomach cancer)、肾癌、骨癌、软组织癌、头颈癌、多形性胶质母细胞瘤、星形细胞瘤、甲状腺癌、生殖细胞瘤和黑色素瘤。
除非另外定义,本发明使用的所有技术和科学术语的意义与本发明所属领域普通技术人员通常所理解的相同。虽然在本发明的实施可以采用类似于或等同于本发明所述的那些方法和材料,但下文描述了合适的方法和材料。本发明中述及的所有出版物、专利申请、专利和其它参考文献都通过引用全文纳入本发明。若有抵触,以本包括定义在内的本申请说明书为准。此外,材料、方法和实施例都仅是说明性的,并不意在构成限制。
附图和以下说明进一步详细说明了本发明的一种或多种实施方式。本发明的其他特征、目的和优点将从说明书、附图以及权利要求中显而易见。
附图说明
图1包含显示肽-脉冲A2+细胞流式细胞分析的图表。T2细胞在37℃的无血清培养基中仅用β-2微球蛋白(β2M)蛋白,或β2M与p53-WT(168-176)肽(HMTEVVRRC;SEQ ID NO:135)或p53 R175H(168-176)肽(HMTEVVRHC;SEQ ID NO:1)进行肽脉冲过夜。每50μL细胞用50μL噬菌体上清液细胞染色,用兔抗-M13抗体洗涤,并染色,然后用抗-兔-PE抗体洗涤和染色。细胞用活/死近红外(IR)染料染色,洗涤,并通过iQue筛选仪(IntelliCyt,Albuquerque,NM)分析。
图2包含显示肽-脉冲A1+细胞流式细胞分析的图表。SigM5细胞在37℃下在无血清培养基中仅使用β2M,β2M与H/K/N RAS WT(55-64)肽(ILDTAGQEEY;SEQ ID NO:136),β2M和H/K/N RAS突变体Q61H(55-64H)肽(ILDTAGHEEY;SEQ ID NO:2)进行肽脉冲过夜。每50μL细胞用50μL噬菌体上清液细胞染色,用兔抗-M13抗体洗涤,并染色,然后用抗-兔-PE抗体洗涤和染色。细胞用活/死近-IR染料染色,洗涤,并通过iQue筛选仪(IntelliCyt,Albuquerque,NM)分析。
图3包含显示肽-脉冲A1+细胞流式细胞分析的图表。SigM5细胞在37℃下在无血清培养基中仅使用β2M,β2M与H/K/N RAS WT(55-64)肽(ILDTAGQEEY;SEQ ID NO:136),β2M和H/K/N RAS突变体Q61L(55-64H)肽(ILDTAGLEEY;SEQ ID NO:3)进行肽脉冲过夜。每50μL细胞用50μL噬菌体上清液细胞染色,用兔抗-M13抗体洗涤,并染色,然后用抗-兔-PE抗体洗涤和染色。细胞用活/死近-IR染料染色,洗涤,并通过iQue筛选仪(IntelliCyt,Albuquerque,NM)分析。
图4包含显示肽-脉冲A1+细胞流式细胞分析的图表。SigM5细胞在37℃下在无血清培养基中仅使用β2M,β2M与H/K/N RAS WT(55-64)肽(ILDTAGQEEY;SEQ ID NO:136),β2M和H/K/N RAS突变体Q61R(55-64H)肽(ILDTAGREEY;SEQ ID NO:4)进行肽脉冲过夜。每50μL细胞用50μL噬菌体上清液细胞染色,用兔抗-M13抗体洗涤,并染色,然后用抗-兔-PE抗体洗涤和染色。细胞用活/死近-IR染料染色,洗涤,并通过iQue筛选仪(IntelliCyt,Albuquerque,NM)分析。
图5包含的图表显示,scDb可诱导突变特异性T细胞细胞因子释放。将含有抗CD3克隆UCHT1的p53 R175H(168-176)-A2 cl.2、cl.6、cl.15、cl.16和cl.20scDb在指定浓度下与用编码HLA-A2、p53(WT)、p53(R175H)和GFP各种组合的质粒共转染的T细胞和COS-7细胞在37℃下孵育20小时。共培养后,收集条件培养基并通过ELISA分析分泌的IFNγ。
图6包含的图表显示,scDb可诱导突变特异性T细胞细胞因子释放。将含有抗CD3克隆hUCHT1v9的H/K/N RAS Q61H(55-64)-A1 cl.1、cl.2和cl.4scDb与用编码HLA-A1、KRAS(WT)、KRAS(Q61H)和GFP的各种组合的质粒共转染的T细胞和COS-7细胞在指定浓度下37℃孵育20小时。共培养后,收集条件培养基并通过ELISA分析分泌的IFNγ。
图7包含的图表显示,scDb可诱导突变特异性T细胞细胞因子释放。将含有抗CD3克隆hUCHT1v9的H/K/N RAS Q61L(55-64)-A1 cl.1、cl.2、c1.9和cl.13scDb与用编码HLA-A1、KRAS(WT)、KRAS(Q61L)和GFP的各种组合的质粒共转染的T细胞和COS-7细胞在指定浓度下37℃孵育20小时。共培养后,收集条件培养基并通过ELISA分析分泌的IFNγ。
图8包含的图表显示,scDb可诱导突变特异性T细胞细胞因子释放。将含有抗CD3克隆hUCHT1v9的H/K/N RAS Q61R(55-64)-A1 cl.6scDb与用编码HLA-A1、KRAS(WT)、KRAS(Q61R)和GFP的各种组合的质粒共转染的T细胞和COS-7细胞在指定浓度下37℃孵育20小时。共培养后,收集条件培养基并通过ELISA分析分泌的IFNγ。
图9A-9C包含的图表显示,scDb可以对所有3种RAS同种型(即HRA、KRAS和NRAS)中的Q61H、Q61L和Q61R突变产生反应。图9A将H/K/N RAS突变型Q61H(55-64)-A1 cl.1scDb与用编码HLA-A1,H/K/N RAS(WT)、H/K/N RAS(Q61H)、H/K/N RAS(Q61K)、H/K/N RAS(Q61L)和H/K/N RAS(Q61R)的各种组合的质粒共转染的T细胞和COS-7细胞在指定浓度下37℃孵育20小时。共培养后,收集条件培养基并通过ELISA分析分泌的IFNγ。图9B将H/K/N RAS突变型Q61L(55-64)-A1 cl.2scDb与用编码HLA-A1,H/K/N RAS(WT)、H/K/N RAS(Q61H)、H/K/N RAS(Q61K)、H/K/N RAS(Q61L)和H/K/N RAS(Q61R)的各种组合的质粒共转染的T细胞和COS-7细胞在指定浓度下37℃孵育20小时。共培养后,收集条件培养基并通过ELISA分析分泌的IFNγ。图9C将H/K/N RAS突变型Q61R(55-64)-A1 cl.6scDb与用编码HLA-A1,H/K/N RAS(WT)、H/K/N RAS(Q61H)、H/K/N RAS(Q61K)、H/K/N RAS(Q61L)和H/K/N RAS(Q61R)的各种组合的质粒共转染的T细胞和COS-7细胞在指定浓度下37℃孵育20小时。共培养后,收集条件培养基并通过ELISA分析分泌的IFNγ。
图10包含的图表显示scDb可诱导针对肿瘤细胞系的突变特异性T细胞细胞因子的释放。将p53 R175H(168-176)-A2 cl.2 UCHT1-scDb与T细胞和亲代TYKnu或p53敲除(KO)TYKnu以指定浓度37℃孵育20小时。共培养后,收集条件培养基并通过ELISA分析分泌的IFNγ。
图11包含的图表显示scDb可诱导针对肿瘤细胞系的突变特异性T细胞细胞因子的释放。将H/K/N RAS Q61L(55-64)-A1 cl.2 UCHT1 scDb与T细胞和亲代HL-60或HLA-A1 KOHL-60以指定浓度37℃孵育20小时。共培养后,收集条件培养基并通过ELISA分析分泌的IFNγ。
图12显示,转化为scDb的MANA抗体克隆可特异性杀死肿瘤细胞。将p53R175H(168-176)-A2 cl.2 UCHT1-scDb与T细胞和亲代TYKnu或p53 KO TYKnu以指定浓度37℃孵育20小时。共培养后,使用CellTiter-Glo测定每个孔中的活细胞。通过扣除仅T细胞孔的值并归一化为仅靶细胞孔的值来计算靶细胞活力百分比。
图13显示,转化为scDb的MANA抗体克隆可特异性杀死肿瘤细胞。将H/K/N RASQ61L(55-64)-A1 cl.2 UCHT1 scDb与T细胞和亲代HL-60或HLA-A1 KO HL-60以指定浓度37℃孵育20小时。共培养后,使用CellTiter-Glo测定每个孔中的活细胞。通过从仅T细胞孔中扣除值并归一化为仅靶细胞孔的值来计算靶细胞活力百分比。
图14A-14C显示了scFv克隆H2的生物学和生物物理学特征。(A)用ELISA评估了与固定化的p53R175H/HLA-A*02:01(红)或p53WT/HLA-A*02:01(灰)pHLA结合的H2-scDb。所示数据代表三次技术重复的平均值±标准差。(B)使用SPR通过单循环动力学测量与p53R175H/HLA-A*02:01结合的H2-scDb。H2-scDb以3、12、50、200至800nm的递增浓度上样。p53R175H/HLA-A*02:01(红色)和p53WT/HLA-A*02.01(灰色)显示了空白和参比扣除的结合。H2-scDb以一对一结合动力学结合p53R175H/HLA-A*02:01pHLA,KD为86nM(黑色拟合线)。存在可忽略的p53WT/HLA-A*02:01结合。(C)用p53R175H或p53WT肽脉冲的T2细胞与H2-scDb和T细胞以2:1的效应:靶(E:T)比共同孵育。通过ELISA(左)测量IFN-γ释放,通过CellTiter-Glo测定(右)评估细胞裂解。数据表示三次技术重复的平均值±SD,代表三次独立实验。
图15A-15C显示H2-scDb在存在递呈p53R175H的肿瘤细胞时活化T细胞。(A)具有不同HLA表达水平和p53R175H状态的HLA-A*02:01阳性肿瘤细胞系与H2-scDb和T细胞以2:1的E:T比共同孵育。通过ELISA测定IFN-γ的释放。数据表示6次技术重复的平均值±SD,代表两次独立实验。HLA-A*02中值荧光强度(MFI)比定义为MFI(抗-HLA-A*02)/MFI(同种型对照)。(B)通过发光细胞毒性和基于抗体的测试评估2:1的E:T比例下响应KMS26的H2-scDb介导的多功能T细胞活化(见补充材料)。每个测试的EC50(M)显示在相应的图表中。数据表示三次技术重复的平均值±SD,代表两次独立实验。(C)使用CellTracker Green CMFDA-标记的TYK-nu以5:1的E:T比实时活细胞显影T细胞,使用或不使用H2-scDb。显示了混合细胞后24小时(左)和60小时(右)拍摄的代表性相衬和绿色荧光图像。
图16A-16D显示了使用同基因靶细胞系测定H2-scDb特异性。(A)用全长p53WT、全长p53R175H转染或未转染的HEK293FT和Saos-2细胞系与T细胞在递增量H2-scDb存在下以2:1的E:T比共同孵育。通过ELISA测定IFN-γ的释放。数据显示三次技术重复的平均值±SD。(B)将表达p53R175H并用HLA-A*02:01转导或未转导的细胞系与T细胞以及H2-scDb共孵育。通过ELISA测定IFN-γ的释放。实验以2:1的E:T比进行,一式两份(AU565)或一式三份(其他3个品系)。(B)用HLA-A*02:01转导表达p53R175H的细胞系。通过IFN-γ释放评估H2-scDb对这些细胞系的识别。实验以2:1的E:T比进行,一式两份(AU565)或一式三份(其他3个品系)。数据表示平均值±SD。(C)通过ELISA测量H2-scDb介导的IFN-γ释放,以2:1(KMS26,TYK-nu)或5:1(KLE)的E:T比响应亲代肿瘤细胞系及其TP53 KO对应物。数据表示两次(TYK-nu)或三次(KMS26,KLE)技术重复的平均值±SD,代表两个独立实验。(D)使用实时活细胞成像通过孔汇合测量与H2-scDb和T细胞以5:1的E:T比共同孵育的亲代(左)或TP53-KO(右)TYK-nu细胞的生长。数据显示三次技术重复的平均±SD。使用单因素ANOVA和Tukey多重比较来评估统计显著性,*表示P<0.0001。
图17A-17H显示H2结合HLA-A*02:01和p53R175H新抗原的C末端。(A)与H2-Fab片段(PDB:6W51)结合的p53R175H/HLA-A*02:01的整体结构。相应地标记HLA-A*02:01、β2微球蛋白(β2M)、p53R175H肽以及H2-Fab的轻链和重链。p53R175H的9氨基酸肽位于HLA的螺旋α1和α2之间。(B)H2-Fab-p53R175H/HLA-A*02:01的结构与(A)所示成90°角。(C)p53R175H新抗原的电子密度图(2mFo-DFc)。(D)CDR-L3处残基95至99的H2-Fab选定区域的电子密度图(2mFo-DFc)。(E)放大H2-Fab与p53R175H/HLA-A*02:01的相互作用,CDR从左到右依次标记为:H2、H1、L3、H3、L1、L2。(F)HLA-A*02:01、p53R175H肽和根据H2-Fab的CDR标记的接触残基以表面形式显示的鸟瞰图。(G)(F)的示意性表示。(H)H2-Fab的取向角图。从两个向量计算取向角:一个来自肽的N和C末端,另一个位于VL和VH结构域的分子间二硫键之间。箭头线表示向量的方向。
图18A-18F显示了H2特异性的结构基础和推定交叉反应肽的鉴定。(A)p53R175H新抗原与HLA-A*02:01的具体相互作用。HLA-A*02:01相互作用残基的肽(绿色)和侧链(灰色)以棒状表示。氢键用虚线表示。(B)p53R175H肽结合裂隙的垂直视图。(C)p53肽(aa Val6-Cys9)的C末端,Arg7和His8被CDR-H1、-H2、-H3和-L3的相互作用残基包围,显示为棒状。氢键用虚线表示。(D)T2细胞负荷有来自位置扫描文库的10μM HMTEVVRHC(SEQ ID NO:1)肽变体,并与1nM H2-scDb和T细胞以2:1的E:T比共同孵育。通过流式细胞珠阵列测量IFN-γ释放,并使用三个重复孔的平均值绘制热图。黑框代表亲代p53R175H肽。(E)H2-scDb的结合模式如Seq2Logo图(SEQ ID NO:184)所示,通过IFN-γ值除以104并使用PSSM-Logo算法计算。(F)T2细胞负荷有10μM p53R175H(SEQ ID NO:1)、p53WT(SEQ ID NO:135)、STAT2(SEQ ID NO:185)、VP13A(SEQ ID NO:186)或ZFP3(SEQ ID NO:187)肽,并与1nM H2-scDb和T细胞以2:1的E:T比共同孵育。通过ELISA测定IFN-γ的分泌。数据显示三次技术重复的平均±SD。
图19A-19C显示了H2-scDb的体内抗肿瘤功效。在早期治疗模型中,NSG小鼠在第0天植入1x107人T细胞和1x106亲代KMS26(A)或1x106 TP53 KO KMS26(B)。在第1天,放置腹膜内输注泵以给予H2-scDb或同种型对照scDb。(C)在建立的肿瘤模型中,在第0天将1x107人T细胞和3.5x105亲代KMS26植入小鼠,然后在第6天以指定剂量给予H2-scDb或同种型scDb。通过生物发光成像监测肿瘤生长。N=4或5只小鼠/组。颜色条表示每个时间点的辐射(p/秒/cm2/sr)标尺。绘制的数据表示平均值±SD。*表示P<0.05,NS表示通过多重t-检验(具有Holm- 校正)与同种型对照相比无统计学意义。
校正)与同种型对照相比无统计学意义。
图20显示了细胞中p53R175H新抗原肽的检测和定量。分析用表达HLA-A*02:01和p53R175H的构建物转染的COS-7细胞,以及用内源性HLA-A*02:00和p53R175H表达的细胞系,以检测p53R175H新抗原肽HMTEVVRHC的表达(SEQ ID NO:1;上图)。将重同位素标记的p53R175H新抗原肽加入测试中,并作为绝对拷贝数定量的标准(下图)。
图21显示了通过淘洗富集的噬菌体克隆的流式细胞术筛选。在5轮淘洗后,通过限制稀释分离富集的噬菌体库中的噬菌体克隆,并在深96孔板中生长。使用含有单个噬菌体克隆的上清液通过流式细胞术评估与装载仅β2巨球蛋白(β2M)、β2M加p53WT肽或β2M+p53R175H肽的T2细胞的结合。中值荧光强度(MFI)比定义为MFI(R175H肽)/MFI(WT肽)。NC,无噬菌体对照。
图22为我们实验中使用的接合T细胞的双特异性单链双抗体(scDb)的结构示意图。VL,可变轻链结构域;VH,可变重链结构域;pHLA,肽-HLA复合物;LL,长接头;SL,短接头。
图23显示了通过表达p53的细胞IFN-γ刺激筛选scDb克隆。将通过将每个抗p53R175H/HLA-A*02:01pHLA scFv克隆与抗-CD3 scFv(UCHT1)连接产生的scDb与转染GFP、HLA-A*02:00 1+GFP、HLA-A*02:01+p53WT或HLA-A*01:01+p53R175H质粒的T细胞和COS-7细胞共培养,效应物:靶标(E:T)比为1:1。共培养20小时后,收集上清液,通过ELISA检测IFN-γ。箭头表示H2和H20克隆。A2,HLA-A*02:01。
图24显示了H20-scDb的表征。将H20-scDb与涂覆在链霉亲和素微孔板上的指定浓度的生物素化p53R175H/HLA-A*02:01(红色)和p53WT/HLA-A*02.01(灰色)pHLA单体一起孵育,然后用蛋白L和抗-蛋白L HRP检测结合。数据显示三次技术重复的平均±SD。
图25包含不同抗-CD3scFv产生的scDb的比较。H2以scDb形式与不同的抗-CD3scFv连接,并与用滴定浓度的p53R175H或p53WT肽以2:1的E:T比脉冲的T细胞和T2细胞共孵育。通过ELISA测定IFN-γ的释放。数据显示三次技术重复的平均±SD。
图26显示了H2-scDb-诱导的多功能T细胞反应。通过基于抗体的测定评估了H2-scDb以2:1的E:T比响应KMS26细胞系介导的T细胞细胞因子释放。每个分析物的EC50(M)显示在相应的图表中。数据显示三次技术重复的平均±SD。
图27显示了肿瘤细胞系上HLA-A*02表达的流式细胞术评估。通过流式细胞术评估肿瘤细胞系上HLA-A*02的表达。红色直方图表示抗HLA-A*02(克隆BB7.2)染色,灰色直方图表示同种型对照染色。中值荧光强度(MFI)比定义为MFI(抗-HLA-A*02)/MFI(同种型对照)。
图28显示了用编码HLA-A*02:01的逆转录病毒转导的肿瘤细胞系的流式细胞术评估。编码HLA-A*02:01的逆转录病毒转导入弱表达(AU565,SK-BR-3)或不可检测地表达(HuCCT1,CCRF-CEM)的HLA-A*02:01的细胞系中。通过流式细胞术评估亲代细胞系、转导细胞系和分选细胞系中HLA-A*02:01的表达。红色直方图表示抗HLA-A*02(克隆BB7.2)染色,灰色直方图表示同种型对照染色。
图29A-29B显示了使用CRISPR编辑的同基因细胞系测定H2-scDb特异性。(A)通过用抗p53抗体(克隆DO-1)进行Western印迹染色,评估KMS26、KLE和TYK-nu的亲代和TP53 KO克隆中p53蛋白的表达。(B)通过Bio-Glo(KMS-26)或CellTiter-Glo(TYK-nu,KLE)分析测定H2-scDb以2:1(KMS26,TYK-nu)或5:1(KLE)的E:T比响应亲代肿瘤细胞系及其TP53-KO对应物介导的细胞毒性。数据表示两次(TYK-nu)或三次(KMS26,KLE)技术重复的平均值±SD,代表两个独立实验。
图30A-30B显示了H2-Fab–p53R175H/HLA-A*02:01复合物。(A)pHLA-A*02:01与H2-Fab复合物的尺寸排阻色谱图。A280nm监测蛋白质,其具有一个主峰(~100kDa)。(B)从(A)中提取11-17ml的洗脱部分进行考马斯染色梯度SDS-PAGE凝胶。
图31A-31D显示新抗原p53R175H以经典方式结合HLA-A*02:01。(A)p53R175H新抗原与HLA-A*02:01相互作用的鸟瞰图。p53肽和HLA-A*02:01相互作用残基的侧链表示为棒状。氢键用虚线表示。N-末端His1由HLA-A*02:01的三个酪氨酸残基锚定,一个位于裂隙底部(Tyr7,未显示),两个位于α2(Tyr159,171),而其侧链位于Lys66(α1)和Thr163(α2)的氢键距离内。HLA-A*02:01的Glu63α1在P2处与Met169的骨架氨基形成氢键,P2是位于HLA疏水性B口袋内的p53R175H的锚定残基。Thr3的主链通过与位于裂隙底部的Tyr99的氢键稳定,而Glu4的侧链与Arg65的侧链形成盐桥。p53R175H新抗原的5-8位(Val172、Val173、Arg174、His175)由多个疏水和脂族残基稳定,与HLA-A*02:01没有直接氢键接触。向新抗原的C端,P9处Cys176的羧基(位于F口袋内的另一个锚定残基)由Tyr84(α1)和Lys146(α2)固定,而侧链巯基靠近α2上的Thr143。(B)带有p53R175H新抗原的HLA-A*02:01的表面显示,表示为棒状。锚定口袋B和F用黑色圈出。(C)结合口袋中以下HLA-A*02:01结合肽的结构比对:p53R175H(PDB ID 6W51),p1049(PDB ID 2JCC),NY-ESO-1(PDB ID 3HAE),和WT1(PDB ID 4WUU)。(D)放大(B)的视图,螺旋α1是透明的,第7位(P7,Arg174)和第8位(P8,His175)的残基显示为棒状。
图32显示了H2-Fab笼状构型的氢键键合模式。His175在P8处的咪唑环位于笼状结构的中心。Arg7的胍基与Ala31(CDR-H1)的骨架羰基之间为氢键键合距离。另一种新抗原-抗体直接接触涉及Val6的骨架羰基与Arg93的侧链氢键键合(CDR-L3)。
图33A-33P显示了TCRm-pHLA和TCR-pHLA复合物之间结合朝向的比较。(A)对H2-Fab与具有用如图17所示标记的CDR的p53R175H/HLA-A*02:01的结合进行了详细描述。(B)TCR与黑色素瘤相关抗原3(MAGE-A3)和HLA-A*01:01(PDB 5BRZ)的结合。与(A)朝向相同。MAGE-A3 TCR显示了与大多数已知TCR拓扑结构相同的经典对角结合基序。(C)识别NY-ESO-1157-165/HLA-A*02:01复合物(PDB 3HAE)的3M4E4 Fab。与(A)朝向相同。(D)ESK1 Fab与Wilms肿瘤1肽和HLA-A*02:01(PDB 4WUU)的结合。与(A)朝向相同。(E、F、G和H)具有H2-Fab、MAGE-A3 TCR、3M4E4 Fab和ESK1Fab的经标记的接触残基的HLA-A*02:01/*01:01表面显示的鸟瞰图,分别用箭头指示。(I,J,K和L)分别为E,F,G和H的示意图。H2-Fab-p53R175H/HLA-A*02:01显示出与其他Fab/TCR-pHLA复合物不同的抗体识别模式。(M、N、O和P)Fab/TCR朝向角度的示意图。
图34显示了p53R175H位置扫描文库肽与HLA-A*02:01的结合。通过用剩余的19种常见氨基酸中的每一种系统取代靶肽(HMTEVVRHC;SEQ ID NO:1)每个位置的氨基酸来生成肽文库。在10μg/mlβ2M和抗HLA-A*02抗体(克隆BB7.2)存在下,将100μM的变体肽的每一种加载到T2细胞上。通过流式细胞术评估肽结合。黑框代表亲代肽。MFI,中值荧光强度。
图35显示了H2-scDb对p53R175H位置扫描文库肽的识别。加载了位置扫描文库中的变体肽的T2细胞与1nM H2-scDb和T细胞以2:1的E:T比孵育。通过ELISA测定IFN-γ的释放。虚线表示亲代肽IFN-γ值的20%。位置1-9的肽分别为SEQ ID NO:188-196。通过20%反应性截留值建立的结合基序,以PROSITE模式表示,为x-[AILMVNQTC]-[ST]-[DE]-[IV]-[IMVST]-R-H-[AILVGHSTYC](SEQ ID NO:197)。数据显示三次技术重复的平均±SD。
图36A-36B包含H2-scDb交叉反应性的评估。H2-scDb与转染HLA-A*02:01和全长p53R175H、STAT2或ZFP3的T细胞和COS-7细胞共同孵育,E:T比为5:1。(A)通过Western印迹染色评估COS-7细胞的靶蛋白表达。(B)通过ELISA测定IFN-γ的分泌。除p53R175H外,所有转染子的信号都不可区分,并聚集在x轴附近。数据显示三次技术重复的平均±SD。
图37显示了建立的肿瘤模型中NSG小鼠的体重。在第0天,为NSG小鼠植入1x107人T细胞和3.5x105亲代KMS26,然后在第6天给予指定的scDb。系列监测小鼠的体重。N=每组5只小鼠。显示的数据代表平均值±SD。
图38A-38H。RAS MANAscFv的ELISA和流式细胞术表征。使用ELISA、流式细胞术和SPR对抗-RAS-MANA的scFv进行表征。(A,D-F)生物素化的G12V或G12WT pHLA-A3(A)或Q61WT、Q61H、Q61L或Q61R pHLA-A1(D-F),以指定浓度涂覆在链霉亲和素板上。将重组RASG12V克隆V2(A)、Q61H克隆H1(D)、Q61L克隆L2(E)或Q61R克隆R6(F)scFv以1μg/mL在孔中孵育,然后用蛋白L和辣根过氧化物酶(HRP)偶联的抗蛋白L检测。所有ELISA均以一式三份进行。(B,G)用50μM的指定肽对T2A3或SigM5细胞进行脉冲,然后进行流式细胞术分析。(B)T2A3细胞用与抗FLAG-藻红蛋白(PE)预偶联的V2 scFv染色,绘制平均荧光强度(MFI)。(G)SigM5细胞用克隆H1、L2或R6噬菌体染色,然后用兔抗-M13噬菌体和PE偶联的抗兔抗体检测。绘制扣除噬菌体背景的PE MFI。(C,H)通过用SPR的单循环动力学评估V2 scFv和L2单链双抗体(scDb)结合。(C)V2scFv与G12V pHLA-A3结合,具有一比一结合动力学和8.7nM的KD,与G12WT pHLA-A4的结合可忽略不计。(H)L2-U scDb以一比一结合动力学和65nM的KD与Q61L pHLA-A1结合,与Q61WT pHLA-Al的结合可忽略不计。
图39A-39E。MANA scDb的示意性和ELISA表征。(A)显示最佳双特异性形式,具有按以下顺序排列的可变轻(VL)和可变重(VH)链结构域的scDb的示意图:VLV2-VHUCHT1-VLUCHT1-VHV2。SL,短接头(GGGGS;SEQ ID NO:200);LL,长接头(GGGGS)3(SEQ ID NO:201)。(B-E)通过ELISA表征抗-MANA/抗CD3-scDb。将生物素化的pHLA-A3、pHLA-A1或重组CD3ε/δ蛋白涂覆在链霉亲和素板上。将重组V2-U(B)、H1-U(C)、L2-U(D)或R6-U(E)scDb以指定浓度孵育,然后用蛋白L和抗-蛋白L HRP检测。所有ELISA一式三份进行。
图40A-40D。与肽脉冲细胞共培养。(A,B)用指定浓度的G12V或G12WT肽对T2A3细胞进行脉冲。(C,D)用指定浓度的Q61L或Q61WT肽对SigM5细胞进行脉冲。将5x104(T2A3)或2.5x104(SigM5)肽脉冲细胞与5x104人T细胞(效:靶比或E:T=1:1或2:1)和V2-U(A,B)、V2-U2 scDb(A,B)或L2-U scDb(C,D)以1nM混合。孵育平板24小时,测定上清液的IFNγ(A,C)。使用CellTiter-Glo测定靶细胞的细胞毒性(B,D)。通过扣除T细胞信号并对无肽条件归一化来确定细胞毒性百分数。所有实验都进行三次。
图41A-41D。与转染的COS-7细胞共培养。用编码HLA-A3(“A3”)或HLA-A1(“A1”)和RAS变体或其他阴性对照的质粒1:1转染COS-7细胞。24小时后,将1x104 COS-7细胞与5x104人T细胞(E:T=5:1)和V2-U(A)、H1-U(B)、L2-U(C)或R6-U(D)scDb以特定浓度结合。平板孵育24小时,测定上清液的IFNγ。所有实验都进行三次。
图42A-42F。V2-U scDb对人T细胞与癌细胞共培养的影响。将来自亲代NCI-H441(A,B)、NCI-H 441同基因变体(C,D)或NCI-H358同基因变体(E,F)的2x104靶细胞与6x104人T细胞(E:T=3:1)和V2-U SCDB以指定浓度混合。细胞孵育24小时,并测定IFNγ释放(A,C,E)和使用CellTiter-Glo测定靶细胞毒性(B,D,F)。通过扣除单独的T细胞信号并对无scDb条件(视为0%细胞毒性)归一化来计算细胞毒性。所有实验都进行三次。对于KRAS基因型:V/Δ,G12V/frameshift(另见图55)。
图43A-43E。L2-U scDb对人T细胞与癌细胞共培养的影响。来自表达HLA-A1、RASQ61L或两者(A)、亲代HL-60细胞(B-C)或表达不同RAS Q61突变或具有HLA-Al敲除(KO)(D-E)的HLA-60同基因变体的不同癌细胞系的2.5x104靶细胞与5x104人T细胞(E:T=2:1)和L2-U scDb以指定浓度混合。细胞孵育24小时,并通过ELISA(A、B、D)和靶细胞细胞毒性(C、E)测定IFNγ释放。通过CellTiter-Glo评估靶细胞的细胞毒性。通过扣除单独的T细胞信号并对无scDb条件(视为0%细胞毒性)归一化来计算细胞毒性。所有实验都进行三次。(对于HL-60NRAS基因型,另见图55)。
图44A-44D。肽扫描以评估V2-U和L2-U scDb交叉反应性。G12V和Q61L10聚肽的每个氨基酸位置系统地改变为其他19种氨基酸,从而产生变异肽文库,每个变异肽与原始肽有一个氨基酸的不同。T2A3细胞用10μM的G12V肽扫描库(A,C)脉冲,SigM5细胞用10μM的Q61L肽扫描文库脉冲(B,D)。将2.5x104肽脉冲靶细胞与5x104人T细胞(E:T=2:1)和1nM的V2-U(A,C)或L2-U scDb(B,D)混合。(A,B)平板孵育24小时并测定IFNγ释放,三次技术重复的平均值绘制为热图。黑框表示亲代肽中的氨基酸。(C,D)将V2-U和L2-U scDb的结合模式绘制成Seq2Logo图(分别为SEQ ID NO:683和684),通过IFNγ值除以103计算,使用PSSM-Logo算法。
图45A-45C。通过MANA-SRM检测KRAS新抗原转变。(A-C)分析用表达HLA-A*03:01和KRAS G12V的构建体转染的COS-7细胞(A),以及具有内源性HLA-A*03:01和KRAS G12V表达的细胞系NCI-H441(B)和CFPAC-1(C),以获得G12V[7-16]VVVGGK(SEQ ID NO:205;左)和G12V[8-16]vVGG(SEQ ID NO:206;右)肽的递呈(下图)。这些肽的存在与否分别用红色箭头或“X”表示。将重同位素标记的RAS G12V肽加入分析中,并用作绝对拷贝数定量的标准(上图)。放大保留时间(x轴)后,每个样品中每个肽的转变细节显示在每个单独图的右侧。如前所述,基于图进行肽定量。
图46A-46C。噬菌体库CDR-H3的设计和测序。(A)使用Kabat编号,CDR-H3可变密码子处的预期氨基酸多样性。(B)存在于CDR-H3中的给定密码子的预期克隆百分比。(C)CDRH3中可变密码子处的预期氨基酸多样性对实际氨基酸多样性。实际的氨基酸多样性通过对部分文库进行MiSeq下一代测序(NGS)和随后对前100000个最频繁的读数分析确定的。T、理论分布;M:MiSeq NGS分析。
图47A-47E。V2 scFv的表征。(A)单克隆噬菌体的ELISA。经过4、5或6轮筛选后,在96孔板内的细菌中扩增单克隆噬菌体。不接种H12孔,从而作为无噬菌体对照。将单克隆噬菌体在G12V pHLA-A3或G12WT pHLA-A4包被的链霉亲和素ELISA板中孵育。洗涤平板并使用兔抗-M13和HRP偶联的抗兔抗体检测噬菌体。用红色箭头指定在四个孔中鉴定出的噬菌体克隆V2。(B)流式细胞术:将用指定肽脉冲或未脉冲的T2A3细胞与因其结合G12V pHLA-A3的能力而选择的前四个候选噬菌体克隆一起孵育。通过兔抗噬菌体M13和PE偶联的抗-兔抗体评估结合。MFI作图。(C)稀释后用V2噬菌体进行ELISA。用生物素化pHLA-A3包被链霉亲和素板。V2噬菌体在指定稀释度下孵育,并如(A)中所述检测。(D)用V2 scFv进行ELISA。与(C)相似,不同之处在于使用重组V2 scFv代替噬菌体,检测采用蛋白L和HRP-偶联的抗-蛋白L。所有ELISA一式三份进行。(E)T2A3细胞的肽脉冲。T2A3细胞在50μM下用指定肽脉冲。细胞用偶联到PE的抗HLA-A3单克隆抗体GAP.A3染色。MFI作图。
图48A-48F。RAS Q61H、Q61L和Q61R scFv的表征。(A)流式细胞术。经过5轮筛选,在96孔板形式的细菌中扩增单克隆噬菌体。对单克隆噬菌体进行测序并聚类到独特的噬菌体克隆。(A,C,E)用指定肽脉冲的SigM5细胞分别与来自Q61H、Q61L和Q61R筛选的噬菌体克隆一起孵育,并通过兔抗-噬菌体M13和PE偶联的抗兔抗体进行评估。绘制平均荧光强度(MFI)。最佳候选物用箭头指示。(B,D,F)用1:1比例的编码HLA-A1(“A1”)和KRAS Q61变体(或其他阴性对照)的质粒转染COS-7细胞。24小时后,将5x104COS-7细胞与5x104人T细胞(效:靶比或E:T=1:1)和由最佳流式细胞术候选物产生的单链双抗体(scDb)蛋白以指定浓度混合。平板孵育24小时,测定分泌的IFNγ。黑色箭头表示选择用于进一步研究的每个靶pHLA复合物的单个最特异和反应性的克隆。
图49A-49D。双特异性抗体形式和形式比较。(A)用靶向RAS G12V pHLA-A3的V2scFv测试的六种双特异性形式的卡通描述。(B)显示具有不同抗-CD3 scFv克隆的V2 scFv的可变轻(VL)和可变重(VH)链结构域的测试朝向的示意图。SL,短接头(GGGGS;SEQ ID NO:200);ML,中接头(GGGGS)2(SEQ ID NO:694);LL,长接头(GGGGS)3(SEQ ID NO:201)。(C)V2-双特异性抗体形式的ELISA,以评估与G12V pHLA-A3和重组CD3ε/δ蛋白的结合。将生物素化的G12V pHLA-A3或CD3ε/δ蛋白包被在链霉亲和素板上。不同的双特异性抗体形式以特定浓度在孔中孵育,然后用蛋白L和HRP偶联的抗蛋白L检测。(D)在T细胞和肽脉冲T2A3的共培养物中测试V2双特异性形式。用指定浓度的G12V或G12WT肽对T2A3细胞进行脉冲。将2.5x104肽脉冲的T2A3细胞与5x104T细胞(E:T=2:1)和V2双特异性形式在1nM或0.2nM双特异性抗体浓度下结合。平板孵育24小时,测定IFNγ释放。注意,scFv-Fc形式是FcKnob和FcHole蛋白的异二聚体,二价scFv-Fc含有一个V2部分和一个抗-CD3部分,三价scFv-Fc含两个V2部分和一个抗-CD3部分。
图50A-50D。用各种抗-CD3克隆制备的V2-scDb。以VLV2-VHCD3-VLCD3-VHV2形式测试了12个不同的抗CD3克隆。(A)在293FT细胞中表达scDb(均带有C末端6xHIS标签),并相同纯化。抗CD3克隆的序列见表12。Western印迹显示用抗6xHIS和HRP偶联的抗兔抗体检测的纯化scDb。(B)生物素化重组CD3ε/δ蛋白包被在链霉亲和素平板上。将V2-scDb以2μg/ml加到平板上,并用蛋白L和HRP偶联的抗蛋白L检测。(C)用1:1的编码HLA-A3和KRAS G12V的质粒转染COS-7细胞。24小时后,混合1x104COS-7细胞与5x104人T细胞(E:T=5:1)和指定浓度的V2-scDb。细胞孵育24小时,测定分泌的IFNγ。(D)将2x104NCI-H441靶细胞与6x104人T细胞(E:T=3:1)和V2-scDb蛋白以指定浓度混合。细胞孵育24小时,测定分泌的IFNγ。
图51A-51E。scDb的特异性。(A)生物素化pHLA-A3或生物素化重组CD3ε/δ蛋白包被在链霉亲和素板上。将V2-U2-scDb以指定浓度加到平板上,并用蛋白L和HRP偶联的抗蛋白L检测。每个ELISA一式三份进行。(B)将生物素化的pHLA-A3涂覆在链霉亲和素板上。将scDb与指定浓度的pHLA孵育,然后与含有人Fc标签的重组CD3ε/δ孵育,并用HRP偶联的抗-人Fc抗体检测。(C-E)生物素化RAS Q61 pHLA-A1(Q61WT、Q61H、Q61L或Q61R)以指定浓度涂覆在链霉亲和素板上。将重组H1-U(C)、L2-U(D)或R6-U(E)scDb以10nM加到孔中,并用蛋白L和HRP偶联的抗-蛋白L检测。
图52A-52N。其它肽脉冲数据。(A)用指定浓度的RAS G12V或G12WT肽脉冲T2A3细胞。在1nM的V2-U或V2-U2 scDb存在下,将5x104T2A3肽脉冲细胞与5x104人T细胞(E:T=1:1)共培养。细胞孵育24小时并测量TNFα分泌。(B)T2A3细胞表面G12V肽的定量。用指定浓度的G12V肽脉冲T2A3细胞。使用V2 scFv和基于Quantibrite和Quifikit的方法对细胞表面G12VpHLA复合物进行定量。(C,D)G12肽脉冲的树突细胞。HLA-A3+未成熟树突细胞(iDC)用指定浓度的G12V或G12WT肽脉冲。将1x104肽脉冲的iDCs细胞与5x104人T细胞(E:T=5:1)和1nM的V2-U或V2-U2 scDb混合。培养板孵育24小时并测定分泌的IFNγ(C)和TNFα(D)。(E-H)Q61肽脉冲SigM5细胞。用指定浓度的RAS Q61H、Q61R或Q61WT肽对SigM5细胞进行脉冲。将2.5x104肽脉冲的SigM5细胞与5x104人T细胞(E:T=2:1)和1nM的H1-U(E,F)或R6-U(G,H)scDb混合。细胞孵育24小时,测定分泌的IFNγ(E,G)。使用CellTiter-Glo测定靶细胞的细胞毒性(F,H)。(I-N)Q61肽脉冲树突细胞。用指定浓度的Q61H、Q61L、Q61R或Q61WT肽对HLA-A1+iDC进行脉冲。将1x104肽脉冲的iDC细胞与5x104人T细胞(E:T=5:1)和H1-U(I,L)、L2-U(J,M)或R6-U(K,N)scDb以1nM混合。细胞孵育24小时并测定分泌的IFNγ(I-K)或TNFα(L-N)。所有实验都进行三次。
图53A-53D。Western印迹和与转染的COS-7细胞共培养。用1:1比例的编码HLA-A3(“A3”)和KRAS变体(或其他阴性对照)的质粒转染COS-7细胞。24小时后,收获细胞进行western印迹(A)或共培养(B-D)。(A)转染COS-7中KRAS和HLA-A3的Western印迹。沉淀细胞并快速冷冻,通过Western分析KRAS、HLA-A3和β-肌动蛋白的表达。(B-D)将1x104COS-7细胞与5x104人T细胞(E:T=5:1)和指定浓度的V2-U(B)或V2-U2 scDb(C,D)混合。细胞孵育24小时,并测定上清液中分泌的IFNγ(C)或TNFα(B,D)。所有ELISA一式三份进行。
图54.靶细胞系中的HLA-A3表达。5x105靶细胞用PE偶联的抗HLA-A3克隆GAP.A3(红色阴影)或PE偶联的小鼠同种型IgG2a对照(灰色阴影)染色。直方图显示活细胞的PE强度。
图55.CRISPR修饰细胞系中RAS等位基因的Sanger测序。对来自NCI-H441亲代和G13D-KI克隆的KRAS基因座(SEQ ID NO:695)、来自NCI-H 358亲代和G2V-KI克隆的KRAS基因座(SEQ ID NO:696)以及来自HL-60亲代、Q61H-KI和Q61R-KI克隆的NRAS基因座(SEQ IDNO:697)的基因组DNA进行Sanger测序。注意,KRAS密码子显示为反义方向。
图56A-56B。V2-U2 scDb对T细胞与NCI-H441同基因细胞系共培养的影响。将2x104亲代NCI-H441细胞或其同基因克隆与6x104人T细胞(E:T=3:1)和V2-U2 scDb以指定浓度混合。细胞孵育24小时,测定IFNγ释放(A)或用CellTiter-Glo测定靶细胞毒性(B)。所有实验都进行三次。
图57.V2-U scDb诱导的多功能免疫应答。将指定浓度的V2-U scDb与2.5x104NCI-441细胞和5x104人T细胞孵育(E:T=2:1)。细胞孵育24小时,并使用Luminex珠检测分泌的IFNγ、TNFα、IL-2、颗粒酶B和穿孔素。所有实验都进行三次。
图58A-58B。V2-U2 scDb对T细胞与NCI-H358同基因细胞系共培养的影响。将2x104亲代NCI-H358细胞或其同基因克隆与6x104人T细胞(E:T=3:1)和V2-U2 scDb以指定浓度混合。细胞孵育24小时,测定IFNγ释放(A)或用CellTiter-Glo测定靶细胞毒性(B)。所有实验都进行三次。
图59A-59B。V2-scDb对与HLA-A3+细胞系共培养的T细胞分泌IFNγ的影响将2x104靶细胞与6x104人T细胞(E:T=3:1)和V2-U(A)或V2-U2(B)scDb以指定浓度混合。细胞孵育24小时,测定IFNγ释放。所有实验都进行三次。***表示P<0.001,NS表示CFPAC-1和每个其他无RAS G12V突变的细胞系之间无统计学意义,如通过给定细胞系的不同scDb浓度的双向ANOVA整合,Tukey校正用于多重比较。
图60.靶细胞系中的HAL-A1表达。将5x105靶细胞与抗HLA-A1/A11/A26克隆8.L.101(红色阴影)或小鼠IgM同种型对照(灰色阴影)一起孵育,然后用PE偶联的抗小鼠抗体染色。直方图显示活细胞的PE强度。
图61.L2-U scDb诱导的多功能免疫应答。将指定浓度的L2-U scDb与2.5x104HL-60细胞和5x104人T细胞孵育(E:T=2:1)。细胞孵育24小时,并使用Luminex珠检测分泌的IFNγ、TNFα、IL-2、颗粒酶B和穿孔素。所有实验都进行三次。
图62A-62F。测试可能的交叉反应肽。(A)用50μM指定肽脉冲T2A3细胞。脉冲细胞与V2噬菌体孵育,然后用兔抗M13噬菌体和PE-偶联抗兔抗体染色,或与PE偶联的抗HLA-A3单克隆抗体GAP.A3孵育。绘制PE MFI。(B)Western印迹显示PBMC、单核细胞(Mono)、未成熟DC(iDC)、成熟DC(mDC)和Hs 695T细胞中内源性Rab-7b的表达,以及HLA-A3和RAB7B共转染COS-7以及HCT116中相对于HLA-A3和GFP共转染对照的Rab-7b过表达。(C)将1x104NCI-H441细胞或5x104PBMC、Mono、iDC或mDC(用或不用G12V肽脉冲)与5x104人T细胞(E:T=5:1或1:1)和V2-U scDb以1nM混合。细胞孵育24小时,测定分泌的IFNγ。正常人细胞来自HLA-A3+供体。(D)用HLA-A3或HLA-A2(阴性对照)编码质粒转染Hs 695T,以评估Rab-7b肽的内源性递呈和V2-U scDb识别。作为阳性对照,HLA-A3转染的细胞仅用G12V肽或二甲基甲酰胺(DMF,溶剂)脉冲。将亲代NCI-H441细胞纳入作为阳性对照,将NCI-H 441HLA-A3-KO(A3-KI)和NCI-H441(KRAS G13D/WT)克隆1(G13D-KI)纳入作为阴性对照。在每个孔中,2x104靶细胞与5x104人T细胞(E:T=5:2)和V2-U scDb以指定浓度混合。平板孵育24小时,测定分泌的IFNγ。(E,F)COS-7(E)和HCT 116(F)细胞用仅载体(GFP)或1:1的编码HLA-A3和仅载体(GFP)、全长KRAS-WT、KRAS G12V或Rab-7b的质粒转染。在每个孔中,2x104靶细胞与5x104人T细胞(E:T=5:2)和V2-U scDb以指定浓度混合。细胞孵育24小时,测定分泌的IFNγ。
图63A-63C。可能与V2或L2 scDb反应的靶肽的位置扫描。(A)G12V肽的每个氨基酸被系统改变为其他19种氨基酸。用10μM的G12V肽文库脉冲T2A3细胞。将2.5x104肽脉冲的T2A3细胞与5x104人T细胞(E:T=2:1)和V2-U scDb以1nM混合。细胞孵育24小时,测定分泌的IFNγ。(B)Q61L肽的每个氨基酸被系统改变为其他19个氨基酸。用10μM的Q61L肽文库脉冲SigM5细胞。将2.5x104肽脉冲的SigM5细胞与5x104人T细胞(E:T=2:1)和L2-U scDb以1nM混合。细胞孵育24小时,测定分泌的IFNγ。(C)用Q61L、Q61WT或CHD4肽脉冲SigM5细胞。将2.5x104肽脉冲的SigM5细胞与5x104人T细胞(E:T=2:1)和L2-U scDb以1nM混合。细胞孵育24小时,测定分泌的IFNγ。
图64A-64B。小鼠模型系统中L2-U对肿瘤生长的影响。(A,B)在第0天用1x107人T细胞和5x105表达荧光素酶的亲代HL-60(A)或CRISPR编辑的HL-60(B)移植小鼠。一天后,在通过生物发光成像确定肿瘤植入后,根据肿瘤负荷对小鼠随机分组,静脉注射1x107人T细胞。然后立即植入等渗泵,以0.42g/kg/天的速度输送L2-U或同种型scDb(V2-U scDb)。通过生物发光成像监测肿瘤生长。N=每组7只小鼠。绘制的数据表示平均值±SD。*表示P<0.05,NS表示根据具有Bonferroni-Dunn校正的多重t检验,与同种型对照相比,无统计学意义。
图65A-65B。用scDb治疗的NSG小鼠的体重。(A,B)肿瘤植入NSG小鼠并按图64所述进行治疗。系列监测小鼠的体重。显示的数据代表平均值±SD。
图66.scFv噬菌体库噬菌粒图。将编码scFv并使用TRIM技术合成的寡核苷酸掺入pADL-10b噬菌粒中。该噬菌粒包含F1起始点、限制未诱导表达的转录阻遏子、lac操纵子和lac阻遏子。用pelB周质分泌信号合成scFv,并在lac操纵子下游亚克隆。接头(GGGSGGSGGGAS;SEQ ID NO:698)连接scFv的可变轻链和重链。一FLAG(DYKDDDDK;SEQ IDNO:190)表位标签直接位于可变重链的下游,在框内后接全长M13 pIII衣壳蛋白序列。
图67A-67C。scFv克隆H2的生物学和生理学特性。(A)用ELISA评估了与固定化的p53R175H/HLA-A*02:01(红)或p53WT/HLA-A*02:01(灰)pHLA结合的H2-scDb。所示数据代表三次技术重复的平均值±标准差。(B)使用SPR通过单循环动力学测量与p53R175H/HLA-A*02:01结合的H2-scDb。H2-scDb以3、12、50、200至800nM的递增浓度上样。p53R175H/HLA-A*02:01(红色)和p53WT/HLA-A*02.01(灰色)显示了空白和扣除参比的结合。H2-scDb以一对一结合动力学结合p53R175H/HLA-A*02:01pHLA,KD为86nm(黑色拟合线)。存在可忽略的p53WT/HLA-A*02:01结合。(C)用p53R175H或p53WT肽脉冲的T2细胞与H2-scDb和T细胞以2:1的效应:靶(E:T)比共同孵育。通过ELISA(左)测量IFN-γ释放,通过CellTiter-Glo测定(右)评估细胞裂解。数据表示三次技术重复的平均值±SD,代表三次独立实验。
图68A-68D。H2-scDb在递呈p53R175H的肿瘤细胞存在时活化T细胞。(A)描述H2-scDb作用机理的图示。(B)具有不同HLA表达水平和p53R175H状态的HLA-A*02:01阳性肿瘤细胞系与H2-scDb和T细胞以2:1的E:T比共同孵育。通过ELISA测定IFN-γ的释放。数据表示六次技术重复的平均值±SD,代表两次独立实验。HLA-A*02中值荧光强度(MFI)比定义为MFI(抗-HLA-A*02)/MFI(同种型对照)。(C)通过发光细胞毒性和基于抗体的测试评估2:1的E:T比例下响应KMS26的H2-scDb介导的多功能T细胞活化(见补充材料)。每个测定的EC50(M)显示在相应的图表中。数据表示三次技术重复的平均值±SD,代表两次独立实验。(D)使用GFP-标记的TYK-nu以5:1的E:T比实时活细胞显影T细胞,使用或不使用H2-scDb。显示了混合细胞后24小时(顶部)和96小时(底部)拍摄的代表性相衬和绿色荧光图像。
图69A-69E。使用同基因靶细胞系测定H2-scDb特异性。(A)在具有不同HLA和p53背景的细胞中产生同基因细胞系对的方法。(B)用全长p53WT、全长p53R175H转染或未转染的HEK293FT和Saos-2细胞系与T细胞在递增量H2-scDb存在下以2:1的E:T比共同孵育。通过ELISA测定IFN-γ的释放。数据表示成两次技术重复的平均值±SD。(C)将表达p53R175H并用HLA-A*02:01转导或未转导的细胞系与T细胞以及H2-scDb共孵育。通过ELISA测定IFN-γ的释放。在三次技术重复中以2:1的E:T比进行试验。(D)通过ELISA测量H2-scDb介导的IFN-γ释放,以2:1(KMS26,TYK-nu)或5:1(KLE)的E:T比响应亲代肿瘤细胞系及其TP53 KO对应物。数据表明两次(TYK-nu)或三次(KMS26,KLE)技术重复的平均值±SD,代表两个独立实验。双尾t检验*P<0.05,**P<0.01,***P<0.001。(E)将用核GFP标记的亲代(左)或TP53-KO(右)TYK-nu细胞与H2-scDb共孵育,并通过实时活细胞成像测量E:T比为2:1的T细胞。数据表示成12次技术重复的平均值±SD。使用单因素ANOVA和Tukey多重比较来评估统计显著性,****表示P<0.0001。
图70A-70H。H2-Fab结合HLA-A*02:01和p53R175H新抗原的C末端。(A)与H2-Fab片段结合的p53R175H/HLA-A*02:01的整体结构(PDB ID 6W51)。HLA-A*02:01和β2微球蛋白(β2M)分别为灰色和金色。H2-Fab根据Fab片段的重链(蓝色)和轻链(青色)着色。p53R175H9氨基酸肽在HLA的螺旋α1和α2之间显示为浅绿色。(B)H2-Fab-p53R175H/HLA-A*02:01的结构与(A)所示成90角。(C)p53R175H新抗原轮廓在1σ处的电子密度图(2mFo-DFc)。(D)CDR-L3处残基95至99的H2-Fab选定区域在1σ处轮廓的电子密度图(2mFo-DFc)。(E)H2-Fab与p53R175H/HLA-A*02:01相互作用的放大图,CDR着色如(A)所示。CDR按从左到右的顺序进行标记和着色:H2(紫色)、H1(品红色)、L3(黄色)、H3(橙色)、L1(红色)、L2(深绿色)。(F)HLA-A*02:01表面显示的鸟瞰图,显示为灰色,p53R175H肽显示为浅绿色,接触残基根据H2-Fab的CDR着色。(G)(F)的示意性表示。(H)H2-Fab与p53R175H/HLA-A*02:01的取向角度图。从基于VL结构域的二硫键Cys88的Calpha和H2-Fab的VH结构域二硫键的Cys96的Capha的网络服务器TCR3d计算取向的对接角(红色)。箭头线表示取向方向以及它们之间的角度。
图71A-71F。H2特异性的结构基础和推定交叉反应肽的鉴定。(A)p53R175H新抗原与HLA-A*02:01的具体相互作用。HLA-A*02:01相互作用残基的肽(绿色)和侧链(灰色)以棒状表示。氢键用虚线表示。(B)p53R175H肽结合裂隙的垂直视图。(C)肽(aa-Val173-Cys176)的C端,Arg174和His175被CDR-H1(洋红)、-H2(紫色)、-H3(橙色)和-L3(黄色)的相互作用残基包围,显示为棒状。氢键用虚线表示。(D)T2细胞负荷有来自位置扫描文库的10μMHMTEVVRHC(SEQ ID NO:1)肽变体,并与1nM H2-scDb和T细胞以2:1的E:T比共同孵育。通过流式细胞珠阵列(见补充材料)测量IFN-γ释放,并使用三个重复孔的平均值绘制热图。黑框代表亲代p53R175H肽。(E)H2-scDb的结合模式如Seq2Logo图所示,通过IFN-γ值除以104并使用PSSM Logo算法计算。(F)T2细胞加载有10μM的p53R175H、p53WT、STAT2、VPS13A或ZFP3肽,并与1nM H2-scDb和T细胞以2:1的E:T比共同孵育。通过ELISA测定IFN-γ的分泌。数据显示三次技术重复的平均±SD。
图72A-72B。H2-scDb的体内抗肿瘤效力。在早期治疗模型中,NSG小鼠在第0天植入1x107人T细胞和1x106亲代KMS26(A)或1x106TP53 KO KMS26(B)。在第1天,放置腹膜内输注泵以给予H2-scDb或同种型对照scDb。(C)在建立的肿瘤模型中,在第0天将1x107人T细胞和3.5x105亲代KMS26植入小鼠,然后在第6天以指定剂量给予H2-scDb或同种型scDb。通过生物发光成像监测肿瘤生长。N=4或5只小鼠/组。颜色条表示每个时间点的辐射(p/秒/cm2/sr)标尺。绘制的数据表示平均值±SD。**P<0.01,NS表示通过多重t-检验(具有Holm- 校正)与同型对照相比无统计学意义。
校正)与同型对照相比无统计学意义。
图73A-73C。细胞中p53R175H新抗原肽的检测和定量。(A)分析用表达HLA-A*02:01和p53WT或p53R175H的构建体转染的COS-7细胞是否递呈p53WT HMTEVVRC(SEQ ID NO:135)或p53R175H-HMTEVVRHC(SEQ ID NO:1)肽。同位素标记的肽掺入试验中,并作为绝对拷贝数定量的标准。通过质谱仪测量每个样品中从靶肽片段化的多个离子(用不同颜色表示),作为不同的SRM转变,其m/z值列于图例中。(B)用抗p53抗体(克隆DO-1)通过Western印迹法评估转染全长p53WT或p53R175H的COS-7细胞中p53蛋白的表达。(C)分析具有内源性HLA-A*02:01和p53R175H表达的细胞系,对如(A)所述的P53R175H新抗原肽的递呈。
图74A-74D。p53R175H/HLA-A*02:01反应性抗体的筛选及其转化为T细胞重靶向scDb。(A)通过淘洗富集的噬菌体克隆的流式细胞术筛选。在5轮淘洗后,通过限制稀释分离富集的噬菌体库中的噬菌体克隆,并在深96孔板中生长。使用含有单个噬菌体克隆的上清液通过流式细胞术评估与装载仅β2微球蛋白(β2M)、β2M加p53WT肽(HMTEVVRRC;SEQ ID NO:135)或β2M加上p53R175H肽(HMTEVVRHC;SEQ ID NO:1)的T2细胞的结合。中值荧光强度(MFI)比定义为MFI(p53R175H肽)/MFI(p53WT肽)。NC,无噬菌体对照。(B)我们实验中使用的与双特异性单链双抗体(scDb)接合的T细胞结构示意图。VL,可变轻链结构域;VH,可变重链结构域;pHLA,肽-HLA复合物;SL,短接头;LL,长接头。该图用BioRender.com创建。(C)通过p53表达细胞IFN-γ刺激筛选scDb克隆。将通过将每个抗p53R175H/HLA-A*02:01pHLA scFv克隆与抗-CD3 scFv(UCHT1)连接产生的scDb与转染GFP、HLA-A*02:01+GFP、HLA-A*02:01+p53WT或HLA-A*01:01+p53R175H质粒的T细胞和COS-7细胞共培养,效应物:靶标(E:T)比为1:1。共培养20小时后,收集上清液,通过ELISA检测IFN-γ。箭头表示H2和H20克隆。A2,HLA-A*02:01。(D)H20-scDb的表征。将H20-scDb与涂覆在链霉亲和素微孔板上的指定浓度的生物素化p53R175H/HLA-A*02:01(红色)和p53WT/HLA-A*02.01(灰色)pHLA单体一起孵育,然后用蛋白L和抗-蛋白LHRP检测结合。数据显示三次技术重复的平均±SD。
图75A-75E。通过将H2-scFv与抗CD3εscFv连接而产生的scDb的特性。(A)通过抗6x-His标记的Western印迹法评估由连接H2-scFv与不同抗CD3εscFv构成的scDb的表达。(B)使用ELISA比较scDb与CD3ε/δ异二聚体和CDε的结合。(C)将scDb与T细胞和T2细胞共同孵育,T2细胞以2:1的E:T比用滴定浓度的p53R175H或p53WT肽脉冲。通过ELISA测定IFN-γ的释放。数据显示三次技术重复的平均±SD。(D)纯化的H2-UCHT1-scDb(H2-scDb)的分析色谱图显示在280nm处的吸光度。H2-scDb的保留时间标记在峰上方。(E)H2-scDb负导数的DSF分析(RFU对温度)。解链温度Tm为69℃,对应于曲线一阶导数的峰值/最大值和一个过渡状态的观点。
图76A-76F。H2-scDb对表达p53R175H/HLA-A*02:01的肿瘤细胞的反应性。(A)TYK-nu及其顺铂耐药亚系TYK-nu.CP-r(75)与H2 scDb和T细胞以2:1的E:T比培养。通过ELISA测定IFN-γ的释放。数据表示六次技术重复的平均值±SD,代表两次独立实验。(B,C)在不存在或以2:1的E:T比存在T细胞的情况下,将KMS26细胞与H2-scDb或同种型scDb(针对与UCHT1-scFv连接的无关pHLA的scFv)一起培养。通过ELISA(B)测量IFN-γ释放,通过荧光素酶分析(C)评估细胞毒性。数据显示三次技术重复的平均值±SD。通过双尾t检验,**P<0.01,***P<0.001。(D-F)H2-scDb诱导的多功能T细胞反应。通过基于抗体的分析(见方法),评估了E:T比为2:1的(D)KMS26(细胞毒性和正文所示的其他效应蛋白),(E)KLE和(F)TYK-nu细胞系中H2-scDb介导的T细胞毒性和细胞因子释放。每个分析物的EC50(M)显示在相应的图表中。数据显示三次技术重复的平均±SD。
图77A-77B。流式细胞术评估HLA-A*02表达。(A)通过流式细胞术评估肿瘤细胞系上HLA-A*02的表达。红色直方图表示抗HLA-A*02(克隆BB7.2)染色,灰色直方图表示同种型对照染色。中值荧光强度(MFI)比定义为MFI(抗-HLA-A*02)/MFI(同种型对照)。(B)编码HLA-A*02:01的逆转录病毒转导入弱表达(AU565,SK-BR-3)或不可检测地表达(HuCCT1,CCRF-CEM)HLA-A*02:01的细胞系中。通过流式细胞术评估亲代细胞系、转导细胞系和分选细胞系中HLA-A*02:01的表达。红色直方图表示抗HLA-A*02(克隆BB7.2)染色,灰色直方图表示同种型对照染色。
图78A-78B。使用CRISPR-编辑的同基因细胞系测定H2-scDb特异性。(A)通过用抗p53抗体(克隆DO-1)进行Western印迹,评估KMS26、KLE和TYK-nu的亲代和TP53 KO克隆中p53蛋白的表达。(B)通过Bio-Glo(KMS-26)或CellTiter-Glo(TYK-nu,KLE)分析测定H2-scDb以2:1(KMS26,TYK-nu)或5:1(KLE)的E:T比响应亲代肿瘤细胞系及其TP53-KO对应物介导的细胞毒性。数据表明两次(TYK-nu)或三次(KMS26,KLE)技术重复的平均值±SD,代表两个独立实验。
图79A-79D。H2-Fab–p53R175H/HLA-A*02:01复合物。(A)将H2-scFv转化为全长IgG(H2-IgG),并与以规定浓度涂覆在链霉亲和素微孔板上生物素化的p53R175H/HLA-A*02:01(红色)和p53WT/HLA-A*02.01(灰色)pHLA单体一起孵育,然后用抗-人IgG HRP检测。数据显示三次技术重复的平均±SD。(B)图示描绘了从H2-IgG生成H2-Fab。(C)pHLA-A*02:01与H2-Fab复合物的尺寸排阻色谱图。A280nm监测蛋白质,其具有一个主峰(~100kDa)。(D)从(C)中提取11-17ml的洗脱部分进行考马斯染色梯度SDS-PAGE凝胶。
图80A-80D。新抗原p53R175H以经典方式与HLA-A*02:01结合。(A)p53R175H新抗原与HLA-A*02:01相互作用的鸟瞰图。HLA-A*02:01相互作用残基的肽(绿色)和侧链(灰色)以棒状表示。氢键用虚线表示。N-末端His168由HLA-A*02:01的三个酪氨酸残基锚定,一个位于裂隙底部(Tyr7,未显示),两个位于α2(Tyr159,171),而其侧链位于Lys66(α1)和Thr163(α2,未显示)的氢键距离内。HLA-A*02:01α1的Glu63与Met169的主链氨基形成氢键,其是位于HLA疏水性B口袋内的p53R175H的锚定残基。Thr170的主链通过与位于裂隙底部的Tyr99(未显示)的氢键稳定,而Glu4的侧链与Arg65的侧链形成盐桥。p53R175H新抗原的5-8位(Val172、Val173、Arg174、His175)由多个疏水和脂族残基稳定,与HLA-A*02:01没有直接氢键接触。向新抗原的C端,Cys176的羧基(位于F口袋内的另一个锚定残基)由Tyr84(α1)和Lys146(α2)固定,而侧链巯基靠近α2上的Thr143。(B)带有p53R175H新抗原的HLA-A*02:01(灰色)的表面显示(绿色),表示为棒状。锚定口袋B和F用橙色圈出。(C)结合口袋中以下HLA-A*02:01结合肽的结构比对:绿色(本发明,PDB ID 6W51),青色(p1049,PDB ID2JCC),品红色(NY-ESO-1,PDB ID 3HAE)和浅紫色(WT1,PDB ID 4WUU)。(D)放大(B)的视图,螺旋α1是透明的,第7位(P7)和第8位(P8)的残基显示为棒状。
图81.H2-Fab笼状构型的氢键图案。His175的咪唑环位于笼状结构的中心。Arg174的胍基与Ala31(CDR-H1)的骨架羰基之间为氢键键合距离。另一种新抗原-抗体直接接触涉及Val173的骨架羰基与Arg93的侧链氢键键合(CDR-L3)。
图82A-82P。比较TCRm–pHLA和TCR–pHLA复合物之间的结合方向。(A)对H2-Fab与具有用如图4着色的CDR的p53R175H/HLA-A*02:01的结合进行了详细描述。(B)TCR与黑色素瘤相关抗原3(MAGE-A3)和HLA-A*01:01(PDB ID 5BRZ)的结合。与(A)朝向相同。MAGE-A3 TCR显示了与大多数已知TCR拓扑结构相同的经典对角结合基序。(C)识别NY-ESO-1157-165/HLA-A*02:01复合物(PDB ID 3HAE)的3M4E4 Fab。与(A)朝向相同。(D)ESK1 Fab与Wilms肿瘤1肽和HLA-A*02:01(PDB ID 4WUU)的结合。与(A)朝向相同。(E、F、G和H)着色为灰色的分别具有H2-Fab、MAGE-A3 TCR、3M4E4 Fab和ESK1 Fab的接触残基的HLA-A*02:01/*01:01表面显示的鸟瞰图,分别根据CDR着色。(I,J,K和L)分别为E,F,G和H的示意图。H2-Fab-p53R175H/HLA-A*02:01显示出与其他Fab/TCR-pHLA复合物不同的抗体识别模式。Fab/TCR对接角度示意图。从基于TCR和每个抗体VL/α结构域的二硫键的Cys88的Calpha(或等价物)和VH/β结构域二硫键的Cys96的Capha(或等价物)的网络服务器TCR3d计算对接角。箭头线表示取向方向以及它们之间的角度。
图83A-83D。H2-scDb交叉反应性的评估。(A)通过用剩余的19种常见氨基酸中的每一种系统取代靶肽(HMTEVVRHC;SEQ ID NO:1)每个位置的氨基酸来生成肽文库。在10μg/mlβ2M和抗HLA-A*02抗体(克隆BB7.2)存在下,将100μM的不同肽的每一种加载到T2细胞上。HLA-A*02:01通过肽结合稳定,并通过流式细胞术进行评估(77)。黑框代表亲代肽。MFI,中值荧光强度。(B)H2-scDb识别p53R175H位置扫描文库肽。加载了位置扫描文库中的变体肽的T2细胞与1nM H2-scDb和T细胞以2:1的E:T比孵育。通过ELISA测定IFN-γ的释放。虚线表示亲代肽IFN-γ值的20%。通过20%反应性截留值建立的结合基序,以PROSITE模式表示,为x-[AILMVNQTC]-[ST]-[DE]-[IV]-[IMVST]-R-H-[AILVGHSTYC](SEQ ID NO:197)。数据显示三次技术重复的平均±SD。(C-D)将H2-scDb与转染HLA-A*02:01和全长p53R175H、STAT2或ZFP3的T细胞和COS-7细胞以5:1的E:T比共同孵育。(C)通过Western印迹染色评估COS-7细胞的靶蛋白表达。(D)通过ELISA测定IFN-γ的分泌。除p53R175H外,所有转染子的信号都不可区分,并聚集在x轴附近。数据表示三次技术重复的平均值±SD,代表两次独立实验。
图84A-84D。评估scDb在NSG小鼠体内效力。(A)注射KMS26细胞和人T细胞三天后,获得小鼠外周血,通过流式细胞术评估人T细胞植入。显示的图在活细胞上门控。(B)在腹腔泵植入前3天以及植入后3天和10天收集小鼠血浆。通过ELISA测定H2-scDb的血浆浓度。N=9只小鼠。所示数据代表图6B所示的已建立KMS26模型中小鼠体重的平均值±SEM(C)的系列监测。N=每组5只小鼠。显示的数据代表平均值±SD。(D)为了验证H2-scDb的作用是T细胞依赖性的,在第0天将5x105亲代KMS26细胞与和不与1x107人T细胞植入NSG小鼠,然后在第6天通过腹腔泵给予指定的scDb或载剂。通过生物发光成像监测肿瘤生长。N=4或5只小鼠/组。显示的数据代表平均值±SD。
具体实施方式
本发明提供了评估患有或疑似患有癌症的哺乳动物和/或治疗患有癌症的哺乳类动物的方法和物质。例如包括一个或多个抗原结合域(例如scFv)的一个或多个分子可用于评估患有癌症或疑似癌症的哺乳动物和/或治疗患有癌症(例如表达一种或多种修饰肽的癌症)的哺乳动物,所述抗原结合域可靶向(例如结合)一种或多种修饰肽(例如肽HLA复合物中存在的肽)。在一些情况下,一个或多个分子包括一个或多个可与修饰肽结合的抗原结合域,可用于检测从患有癌症或怀疑患有癌症的哺乳动物获得的样品中是否存在一种或多种修饰肽。在一些情况下,可以将包括一个或多个可结合修饰肽的抗原结合域的一个或更多个分子给予患有癌症的哺乳动物(例如,表达修饰肽的癌症)以治疗该哺乳动物。
如本文所用,修饰肽是衍生自修饰多肽的肽。修饰多肽可以是任何合适的修饰多肽(例如具有致病突变(例如致癌基因突变或抑癌基因突变)的多肽)。修饰肽可以相对于WT肽(例如衍生自衍生修饰多肽的WT多肽的肽)具有一个或多个氨基酸修饰(例如取代)。修饰肽也可称为突变肽。在一些情况下,修饰肽可以是肿瘤抗原。肿瘤抗原的实例包括但不限于MANA、肿瘤相关抗原和肿瘤特异性抗原。修饰肽可以是任何合适的长度。在一些情况下,修饰肽可以长约7个氨基酸至约25个氨基酸(例如从约8个氨基酸到约25个氨基酸,从约9个氨基酸到大约25个氨基酸,从约10个氨基酸到25个氨基酸,从约11至约25个氨基酸,从约12个氨基酸到25个氨基酸,从约13个氨基酸到25个氨基酸,从约15个氨基酸到25个氨基酸,从约18个氨基酸到25个氨基酸,从约20个氨基酸到25个氨基酸,从约7个氨基酸到22个氨基酸,从约7个氨基酸到20个氨基酸,从约7个氨基酸到18个氨基酸,从约7个氨基酸到15个氨基酸,从约7个氨基酸到12个氨基酸,从约7个氨基酸到10个氨基酸,从约7个氨基酸到9个氨基酸,从约8个氨基酸到22个氨基酸,从约10个氨基酸到18个氨基酸,从约12个氨基酸到15个氨基酸,从约8个氨基酸到12个氨基酸,从约12个氨基酸到18个氨基酸,从约18个氨基酸到22个氨基酸,或从约9个氨基酸至约10个氨基酸)。例如,修饰肽的长度可以是约9个氨基酸。例如,修饰肽的长度可以是约10个氨基酸。修饰的肽可以衍生自任何修饰的多肽。可衍生出本文所述修饰肽的修饰多肽的例子包括但不限于p53和RAS(例如KRAS、HRA和NRA)。修饰肽可包括任何适当的修饰。在一些情况下,本文所述的修饰肽可包括表1所示的一种或多种修饰(例如突变)。
表1.修饰肽

本文所述的修饰肽(例如,包括SEQ ID NO:1、SEQ ID NO:2、SEQ ID NO:3和SEQ IDNO:4中任一项所述氨基酸序列的修饰肽)可以与任何合适的HLA形成复合物。HLA可以是任何合适的HLA等位基因。在一些情况下,HLA可以是I类HLA(例如HLA-A、HLA-B和HLA-C)等位基因。在一些情况下,HLA可以是II类HLA(例如HLA-DP、HLA-DM、HLA-DOA、HLA-DOB、HLA-DQ和HLA-DR)等位基因。本文所述修饰肽可与之复合的HLA等位基因的例子包括但不限于HLA-A1和HLA-A2。表1显示了特定修饰肽的示例性HLA等位基因。例如,衍生自修饰的p53多肽的修饰肽(例如HMTEVVRHC(SEQ ID NO:1))可以与HLA-A2和β2M形成复合物。例如,衍生自修饰的H/K/N RAS多肽的修饰肽(例如ILDTAGHEEY(SEQ ID NO:2)、ILDTAGLEEY(SEQ ID NO:3)和ILDTAGREEY(SEQ ID NO:4))可以与HLA-A1形成复合物(例如,可以与HLA-A1和β2M形成复合物)。
本文提供了包括一个或多个抗原结合域(例如scFv)的分子,其可结合本文所述的修饰肽(例如,修饰肽,包括SEQ ID NO:1、SEQ ID NO:2、SEQ ID NO:3和SEQ ID NO:4中任一项所述的氨基酸序列)。在一些情况下,包含一个或多个可结合本文所述修饰肽的抗原结合域的分子不会靶向(例如,不结合)本文所述的未复合修饰肽(例如,本文所述不存在于复合物中的修饰肽(如肽HLA-β2M复合物))。在一些情况下,包含一个或多个可结合本文所述修饰肽的抗原结合域的分子不靶向(例如不结合)WT肽(例如,衍生自WT多肽的肽,从该多肽衍生出修饰多肽)。
包括一个或多个可结合本文所述修饰肽的抗原结合域(例如scFv)的分子可以是任何适当类型的分子。在一些情况下,分子可以是单价分子(例如,包含单个抗原结合域)。在一些情况下,分子可以是多价分子(例如,包含两个或更多个抗原结合域,同时靶向两个或更多抗原)。例如,一个双特异性分子可以包括两个抗原结合域,一个三特异性分子可能包括三个抗原结合区,一个四特异性分子可包括四个抗原结合结构域,等等。包含抗原结合域的分子的例子包括但不限于抗体、抗体片段、scFv、嵌合抗原受体(CAR)、T细胞受体(TCR)、TCR模拟物、串联scFv,双特异性T细胞衔接子、双抗体、scDb、scFv-Fc、双特异性抗体、双特异性单链fc、双亲和力重靶向抗体(DART),以及包括至少一个可变重链(VH)和至少一个可变轻链(VL)的任何其他分子。这些分子中的任何一种都可以根据本文所述的材料和方法使用。在一些情况下,抗原结合域可以是scFv。例如,包含一个或多个抗原结合域(例如,一个或更多scFv)的分子可以是CAR,该抗原结合域可以结合本文所述的修饰肽。例如,包含可结合本文所述修饰肽的两个scFv的分子可以是单链双抗体(scDb)。
在一些情况下,当包含一个或多个可结合本文所述修饰肽(例如,包含SEQ ID NO:1、SEQ ID NO:2、SEQ ID NO:3和SEQ ID NO:4中任一项所述氨基酸序列的修饰肽)的抗原结合域(例如scFv)的分子是多价分子(例如,双特异性分子)时,第一抗原结合域可结合本文所述的修饰肽,第二抗原结合域可结合效应细胞(例如存在于效应细胞上的抗原)。效应细胞的实例包括但不限于T细胞、天然杀伤(NK)细胞、天然杀伤T(NKT)细胞、B细胞、浆细胞、巨噬细胞、单核细胞、小胶质细胞、树突细胞、中性粒细胞、成纤维细胞和肥大细胞。效应细胞上存在的抗原的实例包括但不限于CD3、CD4、CD8、CD28、NKG2D、PD-1、CTLA-4、4-1BB、OX40、ICOS、CD27、Fc受体(例如CD16a)和任何其他效应细胞表面受体。在一些情况下,本文所述的分子可包括可结合本文所述修饰肽的第一抗原结合域和可结合T细胞上存在的抗原(例如CD3)的第二抗原结合域。在一些情况下,可结合CD3的序列(例如,scFv序列)可以如表4所示。在一些情况下,可以结合CD3的序列(例如scFv序列)可以如别处所述(见例如Rodrigues等人,1992 Int J Cancer Suppl.7:45-50;Shalaby等人,1992 J Exp Med.175:217-25;Brischwein等人,2006 Mol Immunol.43:1129-43;Li等人,2005 Immunology.116:487-98;WO2012162067;US20070065437;US20070065437;US20070065437;US20070065437;US20070065437;和US20070065437)。在一些情况下,本文所述的分子可包括可结合本文所述修饰肽的第一抗原结合域和可结合NK细胞上存在的抗原(例如CD16a或NKG2D)的第二抗原结合域。在一些情况下,可结合CD16a的序列(例如,scFv序列)可以如表5所示。通过结合修饰肽和效应细胞,多价分子可以使表达修饰肽的细胞(例如,作为HLA复合物的一部分)与效应细胞接近,从而允许效应细胞作用于表达修饰肽的细胞。
在一些情况下,当包含一个或多个可结合本文所述修饰肽(例如,包含SEQ ID NO:1、SEQ ID NO:2、SEQ ID NO:3和SEQ ID NO:4中任一项所述氨基酸序列的修饰肽)的抗原结合域(例如scFv)的分子是多价分子(例如双特异性分子)时,分子可以是包括至少一个VH和至少一个VL的任何适当形式。例如,VH和VL可以处于任何适当的朝向。在一些情况下,VH可以在VL的N端。在一些情况下,VH可以在VL的C端。在一些情况下,接头氨基酸序列可以定位在VH和VL之间。
在一些情况下,当双特异性分子包括串联scFv时,串联scFv可以处于任何适当朝向。包括scFv-A和scFv-B的串联scFv朝向的例子包括但不限于VLA-LL-VHA-SL-VLB-LL-VHB,VLA-LL-VHA-SL-VHB-LL-VLB,VHA-LL-VLA-SL-VLB-LL-VHB,VHA-LL-VLA-SL-VHB-LL-VLB,VLB-LL-VHB-SL-VLA-LL-VHA,VLB-LL-VHB-SL-VHA-LL-VLA,VHB-LL-VLB-SL-VLA-LL-VHA,和VHB-LL-VLB-SL-VHA-LL-VLA,其中SL是短接头,而LL是长接头。短接头的长度可以是约3个氨基酸至约10个氨基酸。短接头可以包括任何适当组合中的任何合适氨基酸(例如甘氨酸和丝氨酸)。长接头的长度可为约10个氨基酸至约25个氨基酸。长接头可以包括任何适当组合中的任何合适氨基酸(例如甘氨酸和丝氨酸)。
在一些情况下,当双特异性分子是双抗体时,双抗体可以处于任何适当的朝向。包括scFv-A和scFv-B的双抗体朝向的例子包括但不限于VLA-SL-VHB和VLB-SL-VHA,VLA-SL-VLB和VHB-SL-VHA,VHA-SL-VLB和VHB-SL-VLA,VLB-SL-VHA和VLA-SL-VHB,VLB-SL-VLA和VHA-SL-VHB,和VHB-SL-VLA和VHA-SL-VLB,其中SL是短接头。短接头的长度可以是约3个氨基酸至约10个氨基酸。短接头可以包括任何适当组合中的任何合适氨基酸(例如甘氨酸和丝氨酸)。
在一些情况下,当双特异性分子是scDb时,scDb可以处于任何适当的朝向。包括scFv-A和scFv-B的scDb朝向的例子包括但不限于VLA-SL-VHB-LL-VLB-SL-VHA,VHA-SL-VLB-LL-VHB-SL-VLA,VLA-SL-VLB-LL-VHB-SL-VHA,VHA-SL-VHB-LL-VLB-SL-VLA,VLB-SL-VHA-LL-VLA-SL-VHB,VHB-SL-VLA-LL-VHA-SL-VLB,VLB-SL-VLA-LL-VHA-SL-VHB,和VHB-SL-VHA-LL-VLA-SL-VLB,其中SL是短接头和LL是长接头。短接头的长度可以是约3个氨基酸至约10个氨基酸。短接头可以包括任何适当组合中的任何合适氨基酸(例如甘氨酸和丝氨酸)。长接头的长度可为约10个氨基酸至约25个氨基酸。长接头可以包括任何适当组合中的任何合适氨基酸(例如甘氨酸和丝氨酸)。
在一些情况下,当双特异性分子是scFv-Fc时,scFv-Fc可以处于任何适当朝向。包括scFv-Fc-A、scFv-Fc-B和Fc结构域的scFv-Fc朝向的例子包括但不限于VLA-LL-VHA-铰链-Fc和VLB-LL-VHB-铰链-Fc,VHA-LL-VLA-铰链-Fc和VHB-LL-VLB-铰链-Fc,VLA-LL-VHA-铰链-Fc和VHB-LL-VLB-铰链-Fc,VHA-LL-VLA-铰链-Fc和VLB-LL-VHB-铰链-Fc,其中LL是长接头。长接头的长度可为约10个氨基酸至约25个氨基酸。长接头可以包括任何适当组合中的任何合适氨基酸(例如甘氨酸和丝氨酸)。在一些情况下,scFv-Fc中的Fc结构域可以包括一个或多个修饰以增加scFv-Fc的异源二聚和/或减少其同源二聚。在一些情况下,scFv-Fc中的Fc结构域可以排除铰链结构域。在一些情况下,scFv-Fc中的Fc结构域可能位于scFv的N末端。
在一些情况下,当双特异性分子是双特异性单链Fc时,双特异性的单链Fc可以处于任何适当的朝向。双特异性单链Fc朝向的示例包括但不限于:VLA-LL-VHA-SL-VHB-LL-VLB-SL-铰链-CH2-CH3-LL-铰链-CH2-CH3,VLA-LL-VHA-SL-VLB-LL-VHB-SL-铰链-CH2-CH3-LL-铰链-CH2-CH3,VHA-LL-VLA-SL-VLB-LL-VHB-SL-铰链-CH2-CH3-LL-铰链-CH2-CH3,VHA-LL-VLA-SL-VHB-LL-VLB-SL-铰链-CH2-CH3-LL-铰链-CH2-CH3,和VLA-SL-VHB-LL-VLB-VHA-SL-铰链-CH2-CH3-LL-铰链-CH2-CH3,其中SL是短接头,LL是长接头。短接头的长度可以是约3个氨基酸至约8个氨基酸。短接头可以包括任何适当组合中的任何合适氨基酸(例如甘氨酸和丝氨酸)。长接头的长度可为约10个氨基酸至约25个氨基酸。长接头可以包括任何适当组合中的任何合适氨基酸(例如甘氨酸和丝氨酸)。任何合适的Fc结构域均可用于双特异性单链Fc。在一些情况下,Fc结构域可以包括衍生自IgG(例如天然IgG)的氨基酸序列。在一些情况下,Fc结构域可以包括包含一个或多个修饰(例如一个或多个修饰以增加分子的稳定性和/或增加或减少与一个或多个Fc受体的结合)的氨基酸序列。在一些情况下,可以用于双特异性单链Fc的Fc结构域可以排除铰链域。在一些情况下,可以用于双特异性单链Fc的Fc结构域可以位于scFv的N末端。在一些情况下,可用于双特异性单链Fc的Fc结构域可以如他处所述(例如,参见国际专利申请公开号WO 2017/134134A1的例如SEQ ID NO:25-32;以及国际专利申请公布号WO2017/134158A1的例如表38以及SEQ ID NO:25-32)。
包括可结合本文所述的修饰肽(例如,修饰肽包括SEQ ID NO:1、SEQ ID NO:2、SEQID NO:3和SEQ ID NO:4中任一项所述的氨基酸序列)的一个或多个抗原结合域(例如scFv)的分子可以包括任何合适的互补决定区(CDR)。例如,包含一个或多个可结合本文所述修饰肽的抗原结合域的分子可包括具有三个VH互补决定区(CDR VH)的可变重链(VH)和具有三个VL CDR(CDR-VL)的可变轻链(VL)。例如,可结合衍生自修饰p53多肽的修饰肽的分子(例如,HMTEVVRHC(SEQ ID NO:1))可以包括下述每种CDR中的一种:
CDR-VL1:QDVNTA(SEQ ID NO:5);
CDR-VL2:SAS和SAY;
CDR-VL3:QQYSRYSPVTF(SEQ ID NO:6),QQQSSTPVTF(SEQ ID NO:7),QQSSYYPNTF(SEQ ID NO:8),QQQWSSPDTF(SEQ ID NO:9),QQSNAYPITF(SEQ ID NO:10);
CDR-VH1:GFNVYASGM(SEQ ID NO:11),GFNVYQSDM(SEQ ID NO:12),GFNLYQRDM(SEQID NO:13),GFNLSYYDM(SEQ ID NO:14),GFNLNSYYM(SEQ ID NO:15);
CDR-VH2:KIYPDSDYTY(SEQ ID NO:16),TIWPYSGYTY(SEQ ID NO:17),GLLYGSDHTE(SEQ ID NO:18),LIYYGSGYTY(SEQ ID NO:19),MIIPGYGYTN(SEQ ID NO:20);和
CDR-VH3:SRDSSFYYVYAMDY(SEQ ID NO:21),SRDGMYAFDY(SEQ ID NO:22),SRATYEEAFDY(SEQ ID NO:23),SRGSYVSGMDY(SEQ ID NO:24),SRSYYMYMDY(SEQ ID NO:25)。
例如,可结合衍生自修饰H/K/N RAS多肽Q61H的修饰肽的分子(例如,ILDTAGHEEY(SEQ ID NO:2))可以包括下述每种CDR中的一种:
CDR-VL1:QDVNTA(SEQ ID NO:5);
CDR-VL2:SAS;
CDR-VL3:QQVIYYPFTF(SEQ ID NO:26),QQYDYYPFTF(SEQ ID NO:27),QQSIYYPFTF(SEQ ID NO:28),QQSSYSPWTF(SEQ ID NO:184),QQSFSTPITF(SEQ ID NO:29),QQGEYSPLTF(SEQ ID NO:30),QQTYYTPVTF,(SEQ ID NO:31);
CDR-VH1:GFNLYSYAI(SEQ ID NO:32),GFNISYEAM(SEQ ID NO:33),GFNLYTSQM(SEQID NO:34),GFNVFGYAI(SEQ ID NO:35),GFNISPWDM(SEQ ID NO:36),GFNISEYLM(SEQ IDNO:37),GFNVFESAM(SEQ ID NO:38),GFNISHYVM(SEQ ID NO:39);
CDR-VH2:LLYPDYGVTS(SEQ ID NO:40),LIYPNHGITS(SEQ ID NO:41),LVYPGYYVTS(SEQ ID NO:42),EVYPGYDVTS(SEQ ID NO:43),QLYPSSGYTN(SEQ ID NO:44),LLPPGLSYTN(SEQ ID NO:45),WVYGSYDYTY(SEQ ID NO:46),DFYPHSDSTY(SEQ ID NO:47);和
CDR-VH3:SRYRSYEYSVSSYSYSAMDY(SEQ ID NO:48),SRYSSSAMDY(SEQ ID NO:49),SRGAYYYSSAMDY(SEQ ID NO:50),SRYSWAGAFDY(SEQ ID NO:51),SRSVYWSLDY(SEQ ID NO:52),SRYGYYAFDY(SEQ ID NO:53),SRSFAYFQAMDY(SEQ ID NO:54),SRYQSYSFDY(SEQ ID NO:55)。
例如,可结合衍生自修饰H/K/N RAS多肽Q61L的修饰肽的分子(例如,ILDTAGLEEY(SEQ ID NO:3))可以包括下述每种CDR中的一种:
CDR-VL1:QDVNTA(SEQ ID NO:5);
CDR-VL2:SAS;
CDR-VL3:QQASRQPYTF(SEQ ID NO:56),QQAVSYPWTF(SEQ ID NO:57),QQTSSYPITF(SEQ ID NO:58),QQSWYSPSTF(SEQ ID NO:59),QQSYYAPITF(SEQ ID NO:60),QQSYYSPWTF(SEQ ID NO:61),QQAYYPPWTF(SEQ ID NO:62),QQSYSSGPVTF(SEQ ID NO:63),QQTYYYPFTF(SEQ ID NO:64),QQSYYPYYPWTF(SEQ ID NO:65),QQYDRPITF(SEQ ID NO:66);
CDR-VH1:GFNFSESGM(SEQ ID NO:67),GFNISSSGI(SEQ ID NO:68),GFNIYWYGM(SEQID NO:69),GFNISASGM(SEQ ID NO:70),GFNFSYYGM(SEQ ID NO:71),GFNISYSNI(SEQ IDNO:72),GFNVSRWAM(SEQ ID NO:73),GFNFSYGGI(SEQ ID NO:74),GFNLYAWGM(SEQ ID NO:75),GFNVSHSAM(SEQ ID NO:76),GFNIYYEAM(SEQ ID NO:77)
CDR-VH2:HFSGDSGYTY(SEQ ID NO:78),MVYGGSGYTN(SEQ ID NO:79),QVYPWSGFTY(SEQ ID NO:80),WIWGGSSYTY(SEQ ID NO:81),WIYPFSGYTN,(SEQ ID NO:82),MIYGTRGGTY(SEQ ID NO:83),RVYPSGYLTY(SEQ ID NO:84),MIYPLTGYTN(SEQ ID NO:85),LVYGGWGSTS(SEQ ID NO:86),TVHPDWGNTY(SEQ ID NO:87),QIYPWNDYTY(SEQ ID NO:88);和
CDR-VH3:SRYMYYSGYFDY(SEQ ID NO:89),SRWAHYSAYMDY(SEQ ID NO:90),SRDYYSYSLDY(SEQ ID NO:91),SRGQYLSYMDY(SEQ ID NO:92),SREYYSRAFDY(SEQ ID NO:93),SRYYSYAMDY(SEQ ID NO:94),SRNMQSYMDY
(SEQ ID NO:95),SRDYYYSVDV(SEQ ID NO:96),SRAGSSKMSAGAFDY(SEQ ID NO:97),SRWQQYYYSFDY(SEQ ID NO:98),SRNYYAATMDY(SEQ ID NO:99)
例如,可结合衍生自修饰H/K/N RAS多肽Q61R的修饰肽的分子(例如,ILDTAGREEY(SEQ ID NO:4))可以包括下述每种CDR中的一种:
CDR-VL1:QDVNTA(SEQ ID NO:5);
CDR-VL2:SAS;
CDR-VL3:QQSYTSPLTF(SEQ ID NO:100),QQYWYYYPITF(SEQ ID NO:101),QQSYYAPITF(SEQ ID NO:60),QQYYLYQPITF(SEQ ID NO:102),QQYSNYPLTF(SEQ ID NO:103),QQYASDPITF(SEQ ID NO:104),QQYSYDPITF(SEQ ID NO:105),QQYIYDPVTF(SEQ IDNO:106),QQLMYDPITF(SEQ ID NO:107);
CDR-VH1:GFNIYYGVM(SEQ ID NO:108),GFNIYSYDM(SEQ ID NO:109),GFNVQWSHM(SEQ ID NO:110),GFNIGMYTM(SEQ ID NO:111),GFNVFYGSM(SEQ ID NO:112),GFNLDYGWM(SEQ ID NO:113),GFNFSYSAM(SEQ ID NO:114),GFNVDWAWM(SEQ ID NO:115),GFNFGTYWM,(SEQ ID NO:116);
CDR-VH2:MIYPDSSWTY(SEQ ID NO:117),ISPGGSYTY(SEQ ID NO:118),RLSPPSGYTN(SEQ ID NO:119),LVYPDSGYTN(SEQ ID NO:120),FIGPDSTYTY(SEQ ID NO:121),WVVPGSDYTD(SEQ ID NO:122),DVVPDGDWTY(SEQ ID NO:123),WVVGGSDYTY(SEQ ID NO:124),WFLPDYDYTL(SEQ ID NO:125);和
CDR-VH3:SRDQDFHYMNYYLSYALDY(SEQ ID NO:126),SRSAFTGYFDV(SEQ ID NO:127),SRLILSKGGYGWAMDY(SEQ ID NO:128),SRYTWQSMDY(SEQ ID NO:129),SRDLGSAYAMDY(SEQ ID NO:130),SRFHYTAFDV(SEQ ID NO:131),SRGWYALDY(SEQ ID NO:132),SRSYYYAFDY(SEQ ID NO:133),SRHGEYAFDY(SEQ ID NO:134)。




在一些情况下,包括一个或多个可以结合本文所述修饰肽(例如,包括SEQ ID NO:1、SEQ ID NO:2、SEQ ID NO:3和SEQ ID NO:4中所述的氨基酸序列的修饰肽)的抗原结合域(例如,scFv)的分子可以包括任何适当的CDR序列组(例如,本文所述的任何CDR序列组中的任何一个)。
包括可结合本文所述的修饰肽(例如,修饰肽包括SEQ ID NO:1、SEQ ID NO:2、SEQID NO:3和SEQ ID NO:4中任一项所述的氨基酸序列)的一个或多个抗原结合域(例如scFv)的分子可以包括任何合适序列。例如,可以结合衍生自修饰p53多肽(例如,HMTEVVRHC(SEQID NO:1))的修饰肽的分子可以包括但不限于SEQ ID NO:137、SEQ ID NO:138、SEQ ID NO:139、SEQ ID NO:140或SEQ ID NO:141中任一个所示的scFv。例如,可结合衍生自修饰H/K/NRAS多肽(例如ILDTAGHEEY(SEQ ID NO:2),ILDTAGLEEY(SEQ ID NO:3),或ILDTAGREEY(SEQID NO:4))的修饰肽的分子可包括但不限于下列任一的scFv序列:SEQ ID NO:142,SEQ IDNO:143,SEQ ID NO:144,SEQ ID NO:145,SEQ ID NO:146,SEQ ID NO:147,SEQ ID NO:148,SEQ ID NO:149,SEQ ID NO:150,SEQ ID NO:151,SEQ ID NO:152,SEQ ID NO:153,SEQ IDNO:154,SEQ ID NO:155,SEQ ID NO:156,SEQ ID NO:157,SEQ ID NO:158,SEQ ID NO:159,SEQ ID NO:160,SEQ ID NO:161,SEQ ID NO:162,SEQ ID NO:163,SEQ ID NO:164,SEQ IDNO:165,SEQ ID NO:166,SEQ ID NO:167,SEQ ID NO:168,或SEQ ID NO:169。表3和表12中显示了可结合特定修饰肽的序列(例如scFv序列)的例子。在一些情况下,包含可以结合本文所述的修饰肽(例如,修饰肽,包括SEQ ID NO:1、SEQ ID NO:2、SEQ ID NO:3和SEQ IDNO:4中任一所示氨基酸序列)的一个或多个抗原结合域(例如scFv)的分子可具有衍生自表3和表12所示的序列,有时称为变体序列。例如包括一个或多个可与本文所述修饰肽结合的抗原结合域的分子可以与表3和表12中所示的任何序列具有至少75%的序列相同性(例如,至少80%的序列相同性、至少85%的序列相同性、至少90%的序列相同性、至少95%的序列相同性、至少96%的序列相同性、至少97%的序列相同性、至少98%的序列相同性、至少99%的序列相同性或更高),前提是变体序列保持与本文所述修饰肽结合的能力。例如,与表3和表12所示的序列相比,包含一个或多个可结合本文所述修饰肽的抗原结合域的分子可以具有一个或多个(例如,一个、两个、三个、四个、五个、六个、七个、八个、九个、十个或更多)修饰(例如一个或多个氨基酸取代),前提是变体序列保持与本文所述修饰肽结合的能力。在一些情况下,包含一个或多个可与本文所述修饰肽结合的抗原结合域的分子可以包括本文所述的任何适当的CDR序列组,并且与表3和表12所示序列的任何序列偏差都可以在支架序列中。
可以将包含可结合本文所述修饰肽(例如包括SEQ ID NO:1、SEQ ID NO:2、SEQ IDNO:3和SEQ ID NO:4所示氨基酸序列的修饰肽)的一个或多个抗原结合域(例如scFv)的一个分子连接(例如,共价或非共价连接)到标记物(例如,可检测标记物)上。可检测标记物可以是任何适当的标记物。在一些情况下,可以使用标记物来帮助检测本文所述的一种或多种修饰肽的存在与否。例如,本文所述标记的分子可在体外用于检测从哺乳动物获得的样品中的癌细胞(例如,表达本文所述修饰肽的癌细胞)。在一些情况下,可以使用标记物(例如,可检测标记物)来帮助确定本文所述的一种或多种修饰肽的位置。例如,本文所述标记的分子可在体内用于监测抗肿瘤治疗和/或检测哺乳动物中的癌细胞(例如,表达本文所述修饰肽的癌细胞)。可连接到本文所述分子的标记物的例子包括但不限于放射性核素、磁共振成像(MRI)、计算机断层扫描(CT)、超声(US)和其他成像模式中使用的造影剂、发色团、酶和荧光分子(例如,绿色荧光蛋白和近红外荧光)。
可以将包含可结合本文所述修饰肽(例如包括SEQ ID NO:1、SEQ ID NO:2、SEQ IDNO:3和SEQ ID NO:4所示氨基酸序列的修饰肽)的一个或多个抗原结合域(例如scFv)的一个分子连接(例如,共价或非共价连接)到治疗剂。治疗剂可以是任何治疗剂。在一些情况下,治疗剂可以是抗癌剂。可连接至本文所述分子的治疗剂的例子包括但不限于抗癌剂,例如单甲基奥瑞他汀E(MMAE)、单甲基奥瑞他汀F(MMAF)、美登素、美登素/爱玛塔新(DM1)、拉夫坦辛/索拉伐坦辛(DM4)、SN-38、卡奇霉素、D6.5、二聚吡咯并苯并二氮杂 (PBD),α-鹅膏蕈碱(AAMT)、PNU-159682、蓖麻毒蛋白、假单胞菌外毒素A、白喉毒素和白树毒素。
(PBD),α-鹅膏蕈碱(AAMT)、PNU-159682、蓖麻毒蛋白、假单胞菌外毒素A、白喉毒素和白树毒素。
本文还提供了使用包括一个或多个可结合本文所述的修饰肽(例如,修饰肽,包括SEQ ID NO:1、SEQ ID NO:2、SEQ ID NO:3和SEQ ID NO:4中任一项所述的氨基酸序列)的抗原结合域(例如scFv)的分子的方法。例如可以使用包括一个或多个可靶向一种或多种修饰肽的抗原结合域(例如scFv)的一种或多种分子来评估患有癌症或怀疑患有癌症的哺乳动物和/或治疗患有癌症(例如,表达一种或多种修饰肽如p53 R175H-MANA、RAS Q61H/L/R-MANA和/或RAS G12V-MANA的癌症)的哺乳动物。在一些情况下,一个或多个分子包括一个或多个可与修饰肽结合的抗原结合域,可用于检测从患有癌症或怀疑患有癌症的哺乳动物获得的样品中是否存在一个或一个以上修饰肽。在一些情况下,可以将包括一个或多个可结合修饰肽的抗原结合域的一个或更多个分子给予患有癌症的哺乳动物(例如,表达修饰肽的癌症)以治疗该哺乳动物。向患有癌症的哺乳动物(例如人类)给予一种或多种包括可结合本文所述修饰肽的一个或多个抗原结合域的分子,可有效治疗该哺乳动物。
可以如本文所述评估和/或治疗任何类型的哺乳动物。可按本文所述进行评估和/或治疗的哺乳动物的例子包括但不限于灵长类动物(例如,人类和非人灵长类,如黑猩猩、狒狒或猴子)、狗、猫、猪、羊、兔、小鼠和大鼠。在一些情况下,哺乳动物可以是人类。
可以评估和/或治疗哺乳动物的任何适当癌症。在一些情况下,癌症可表达本文所述的一种或多种修饰肽(例如,一种或几种MANA)。癌症可以是原发癌症。癌症可以是转移性癌症。癌症可以包括一个或多个实体瘤。癌症可以包括一个或多个非实体瘤。可按本文所述进行评估(例如,至少部分基于本文所述的一种或多种修饰肽的存在)和/或按本文所述进行治疗(例如,通过给予包括可结合本文所述修饰肽的一个或多个抗原结合域(例如scFv)的一种或多种分子)的癌症的例子包括但不限于:血癌(如霍奇金淋巴瘤、非霍奇金淋巴瘤、急性髓系白血病(AML)、急性淋巴细胞白血病(ALL)、多发性骨髓瘤、MDS和骨髓增生性疾病)、肺癌、胰腺癌、胃部恶性肿瘤(gastric cancer)、结肠癌(如结直肠癌)、卵巢癌、子宫内膜癌、胆道癌、肝癌、骨和软组织癌(如肉瘤)、乳腺癌、前列腺癌、食管癌、胃癌(stomachcancer)、肾癌、头颈癌、脑癌(如多形性胶质母细胞瘤和星形细胞瘤)、甲状腺癌、生殖细胞瘤和黑色素瘤。
当评估患有癌症或怀疑患有癌症的哺乳动物时,可以使用包括一个或多个可以结合本文所述修饰肽(例如,包括SEQ ID NO:1、SEQ ID NO:2、SEQ ID NO:3或SEQ ID NO:4所示氨基酸序列的修饰肽)的抗原结合域(例如,scFv)的一个或多个分子来评估是否存在本文所述的一种或多种修饰肽。例如,本文所述的一种或多种修饰肽在从人获得的样品中的存在与否或水平可用于确定此人是否患有癌症。在一些情况下,本文所述的一种或多种修饰肽在从哺乳动物获得的样品中的存在可用于鉴定该哺乳动物患有癌症。例如,当从哺乳动物获得的样品具有本文所述的一种或多种修饰肽时,可以将哺乳动物鉴定为患有癌症。
可以评估从哺乳动物获得的任何适当样品是否存在本文所述的一种或多种修饰肽或其水平。例如,可以从哺乳动物获得生物样品,例如组织样品(例如,乳腺组织和宫颈组织,例如来自巴氏(Pap)试验)、液体样品(例如血液、血清、血浆、尿液、唾液、痰和脑脊液)和固体样品(例如粪便),并评估本文所述一种或多种修饰肽的存在与否或水平。可以使用任何适当的方法来检测本文所述的一种或多种修饰肽的存在与否或水平。例如,测序技术(包括但不限于Sanger测序、化学测序、纳米孔测序、连接测序(SOLiD测序)、质谱测序、全外显子组测序、全基因组测序和/或下一代测序)可用于确定本文所述的一种或多种修饰肽在从哺乳动物获得的样品中是否存在或其水平。
当治疗患有癌症的哺乳动物时,可以向患有癌症的哺乳类动物给予包括一个或多个抗原结合域(例如scFv)的一种或多种分子,所述抗原结合域可以结合本文所述的修饰肽(例如,包括SEQ ID NO:1、SEQ ID NO:2、SEQ ID NO:3或SEQ ID NO:4中任一项所述的氨基酸序列的修饰肽),以治疗该哺乳动物。在一些情况下,哺乳动物可具有表达本文所述一种或多种修饰肽的癌症。例如,可以向具有表达该修饰肽的癌症的哺乳动物给予一种或多种分子,该分子包括可结合本文所述修饰肽的一个或多个抗原结合域,以治疗该哺乳动物。例如,可以向具有表达该修饰肽的癌症的哺乳动物给予一种或多种分子,该分子包括可结合本文所述修饰肽的一种或多种scFv(例如,一种或多种scDb),以治疗该哺乳动物。
在一些情况下,一种或多种包括一个或多个可结合本文所述的修饰肽(例如,包括SEQ ID NO:1、SEQ ID NO:2、SEQ ID NO:3或SEQ ID NO:4中任一项所述氨基酸序列的修饰肽)的抗原结合域(例如scFv)的分子可在几天到几周的时间段内给予哺乳动物(例如患有癌症的哺乳动物)一次或多次。
在一些情况下,可以将包括一个或多个可结合本文所述的修饰肽(例如,包括SEQID NO:1、SEQ ID NO:2、SEQ ID NO:3或SEQ ID NO:4中任一项所述氨基酸序列的修饰肽)的抗原结合域(例如scFv)的一个或多个分子配制成组合物(例如,药学上可接受的组合物),用于给予哺乳动物(例如患有癌症的哺乳动物)。例如,可以与本文所述的修饰肽结合的一个或多个抗原结合域可以与一种或多种药学上可接受的运载体(添加剂)、赋形剂和/或稀释剂一起配制。在一些情况下,药学上可接受的运载体、赋形剂或稀释剂可以是天然存在的药学上可接受的运载体、赋形剂或稀释剂。在一些情况下,药学上可接受的运载体、赋形剂或稀释剂可以是非天然存在的(例如,人工或合成的)药学上可接受的运载体、赋形剂或稀释剂。可用于本文所述组合物的药学上可接受的运载体、赋形剂和稀释剂的例子包括但不限于蔗糖、乳糖、淀粉(例如淀粉乙醇酸)、纤维素、纤维素衍生物(如微晶纤维素等改性纤维素,羟丙基纤维素(HPC)和纤维素醚羟丙基甲基纤维素(HPMC)等纤维素醚)、木糖醇、山梨醇、甘露醇、明胶、聚合物(如聚乙烯吡咯烷酮(PVP)、聚乙二醇(PEG)、交联聚乙烯吡咯烷酮(交聚维酮)、羧甲基纤维素、聚乙烯-聚氧丙烯-嵌段聚合物和交联羧甲基纤维素钠(交联羧甲基纤维素钠(croscarmellose)))、氧化钛、偶氮染料、硅胶、火成二氧化硅、滑石、碳酸镁、植物硬脂酸、硬脂酸镁、硬脂酸铝、硬脂酸、抗氧化剂(如维生素A、维生素E、维生素C、棕榈酸视黄酯和硒)、柠檬酸、柠檬酸钠、苯甲醇、赖氨酸盐酸盐、海藻糖二水合物、对羟基苯甲酸酯(如对羟基苯甲酸甲酯和对羟基苯甲酸丙酯)、凡士林、二甲亚砜、矿物油、血清蛋白(如人血清白蛋白)、甘氨酸、山梨酸、山梨酸钾、水、盐或电解质(如盐水、硫酸鱼精蛋白、磷酸氢二钠、磷酸氢钾、氯化钠和锌盐)、胶态二氧化硅、三硅酸镁、聚丙烯酸酯、蜡、羊毛脂、卵磷脂和玉米油。在一些情况下,药学上可接受的运载体、赋形剂或稀释剂可以是抗粘附剂、粘合剂、着色剂、崩解剂、香料(例如天然香料,如水果提取物或人工香料)、助溶剂、润滑剂、防腐剂、吸附剂和/或甜味剂。
含有一个或多个分子的组合物(例如药物组合物)可以配制成任何合适的剂型,所述分子包括一个或多个抗原结合域(例如scFv),所述抗原结合域可以结合本文所述的修饰肽(例如,修饰肽,包括SEQ ID NO:1、SEQ ID NO:2、SEQ ID NO:3或SEQ ID NO:4中任何一种所述的氨基酸序列)。剂型的例子包括固体或液体形式,包括但不限于胶、胶囊、片剂(例如咀嚼片和肠溶片)、栓剂、液体、灌肠剂、悬液、溶液(例如无菌溶液)、缓释制剂、慢释制剂、丸剂、粉末和颗粒。
可设计含有一个或多个分子的组合物用于口腔、胃肠外(包括皮下、肌肉内、静脉内和皮内)或肿瘤内给药,所述分子包括可结合本文所述修饰肽(例如,包含SEQ ID NO:1、SEQ ID NO:2、SEQ ID NO:3或SEQ ID NO:4中任一项所述氨基酸序列的修饰肽)的一个或多个抗原结合域(例如,scFv)。适用于肠胃外给药的组合物包括水性和非水性无菌注射溶液,其可以包含抗氧化剂、缓冲液、抑菌剂以及使制剂与预期接受者的血液等渗的溶质。制剂可存在于单位剂量或多剂量容器(例如,密封的安瓿和药瓶)中,并可以冷冻干燥(冻干)条件保存,临用前只需要加入无菌液体载体(例如,注射用水)即可使用。可由无菌粉末剂、颗粒剂和片剂制备临时注射溶液剂和混悬剂。
含有一个或多个分子的组合物可使用任何合适技术并向任何合适位置给药,所述分子包括可结合本文所述修饰肽(例如,包含SEQ ID NO:1、SEQ ID NO:2、SEQ ID NO:3或SEQ ID NO:4中任一项所述氨基酸序列的修饰肽)的一个或多个抗原结合域(例如,scFv)。包括一个或多个分子的组合物可以局部(例如瘤内)或全身给药,所述分子包括可结合本文所述修饰肽的一个或多个抗原结合域(例如scFv)。例如,本文提供的组合物可通过瘤内给药(例如,注射到肿瘤中)或通过给予肿瘤浸润的生物空间(例如,椎管内给药、小脑内给药,腹膜内给药和/或胸膜给药)局部给药。例如,本文提供的组合物可以通过口服给药或静脉给药(例如注射或输注)全身给予哺乳动物(例如人)。
有效剂量可根据癌症的风险和/或严重程度、给药途径、对象的年龄和一般健康状况、赋形剂的使用、与其他治疗方法(如使用其他药物)共同使用的可能性以及治疗医生的判断而变化。含有一个或多个分子的组合物的有效量可以是治疗对象体内存在的癌症而不会对对象产生任何显著毒性的任何量,所述分子包括一个或多个抗原结合域(例如,scFv),所述抗原结合域可以结合本文所述的修饰肽(例如,包括SEQ ID NO:1、SEQ ID NO:2、SEQID NO:3或SEQ ID NO:4。如果特定对象对特定量没有反应,则可以增加(例如,增加两倍、三倍、四倍或更多)包括一个或多个抗原结合域(例如scFv)的一个或多个分子的量。在接受较高量后,可以监测人哺乳动物治疗的反应和毒性症状,并据此做出相应调整。有效量可以保持恒定或可以根据对象对治疗的反应以滑动量或可变剂量进行调整。多种因素可以影响特定应用所需使用的实际有效量。例如,有效量,治疗持续时间,多种治疗剂的使用,给药途径以及病症(例如,癌症)的严重程度可能需要增加或减少给予的实际有效量。
一个或多个分子的给药频率可以是有效治疗患有癌症的哺乳动物而不对哺乳动物产生显著毒性的任何频率,所述分子包括可结合本文所述的修饰肽(例如,包括SEQ IDNO:1、SEQ ID NO:2、SEQ ID NO:3或SEQ ID NO:4中任一项所述的氨基酸序列的修饰肽)的一个或多个抗原结合域(例如,scFv)。例如,一个或多个分子(包括一个或多个可与本文所述修饰肽结合的抗原结合域(例如,scFv))的给药频率可以为每周约2至约3次至每年约2至3次。在一些情况下,患有癌症的对象可以单次给予本文所述的一种或多种抗体。一个或多个分子(包括可结合本文所述修饰肽的一个或多个抗原结合域(例如scFv))的给药频率可在治疗期间保持恒定或可变。使用包含一个或多个分子的组合物的治疗过程可以包括休息期,所述分子包括可结合本文所述修饰肽的一个或多个抗原结合域(例如scFv)。例如,含有一个或多个分子的组合物,包括可结合本文所述修饰肽的一个或多个抗原结合域(例如scFv),可在两年中每隔一个月给予一次然后休息6个月,且该方案可重复多次。与有效量一样,多种因素可以影响用于特定应用的实际给药频率。例如,有效量,治疗持续时间,多种治疗剂的使用,给药途径以及病症(例如,癌症)的严重程度可能需要增加或减少给药频率。
给予含有一个或多个分子的组合物的有效持续时间可以是有效治疗哺乳动物体内存在的癌症而不会对哺乳动物产生任何显著毒性的任何持续时间,所述分子包括一个或多个抗原结合域(例如,scFv),所述抗原结合域可以结合本文所述的修饰肽(例如,包括SEQID NO:1、SEQ ID NO:2、SEQ ID NO:3或SEQ ID NO:4所示的氨基酸序列的修饰肽)。在一些情况中,有效持续时间可以从几个月到几年不等。一般来说,治疗患有癌症的哺乳动物的有效持续时间可以从大约一个月或两个月到五年或更长。多种因素可以影响用于特定治疗的实际有效持续时间。例如,有效持续时间可随给药频率,有效量,多种治疗剂的使用,给药途径和正在治疗的病症的严重性而变化。
在一些情况下,可以监测哺乳动物内的癌症,以评估癌症治疗的有效性。可以使用任何适当的方法来确定是否治疗患有癌症的哺乳动物。例如,成像技术或实验室分析可用于评估哺乳动物体内癌细胞的数量和/或肿瘤的大小。例如,成像技术或实验室分析可用于评估哺乳动物体内癌细胞和/或肿瘤的位置。
在一些情况下,一种或多种包括一个或多个可结合本文所述的修饰肽(例如,包括SEQ ID NO:1、SEQ ID NO:2、SEQ ID NO:3或SEQ ID NO:4中任一项所述氨基酸序列的修饰肽)的抗原结合域(例如scFv)的分子可在几天到几周的时间段内作为与一种或多种其它癌症疗法(例如抗癌剂)的组合治疗给予患有癌症的哺乳动物。癌症治疗可以包括任何适当的癌症治疗。在一些情况下,癌症治疗可以包括手术。在一些情况下,癌症治疗可以包括辐照治疗。在一些情况下,癌症治疗可包括给予一种或多种治疗剂(例如一种或多种抗癌剂)。抗癌剂的实例包括但不限于铂化合物(例如顺铂或卡铂)、紫杉烷类(例如紫杉醇、多西它赛或白蛋白结合的紫杉醇,例如nab-紫杉醇)、六甲蜜胺、卡培他滨、环磷酰胺、依托泊苷(vp-16)、吉西他滨、异环磷酰胺和伊立替康(cpt-11)、脂质体阿霉素、美法仑、培美曲塞、托泊替康、长春瑞滨、黄体生成激素释放激素(LHRH)激动剂(如戈舍瑞林和亮丙瑞林)、抗雌激素(如他莫昔芬)、芳香化酶抑制剂(如来曲唑、阿那曲唑和依西美坦)、血管生成抑制剂(如贝伐单抗)、聚(ADP)-核糖聚合酶(PARP)抑制剂(如奥拉帕尼、瑞卡帕布和尼拉帕尼)、放射性磷、抗CTLA-4抗体、抗PD-1抗体、抗PD-L1抗体、IL-2和其他细胞因子、其他双特异性抗体及其任何组合。在包括一个或多个可结合本文所述的修饰肽的抗原结合域(例如,scFv)的一个或多个分子与一种或多种额外癌症治疗组合使用的情况下,可以同时或独立地给予所述一种或多种额外癌症治疗。例如,可以首先给予包含一个或多个分子的组合物,该分子包括可与本文所述修饰肽结合的一个或多个抗原结合域(例如,scFv),然后给予一种或多种额外癌症治疗,反之亦然。
还提供了包括一个或多个可结合本文所述的修饰肽(例如,修饰肽,包括SEQ IDNO:1、SEQ ID NO:2、SEQ ID NO:3和SEQ ID NO:4中任一项所述的氨基酸序列)的抗原结合域(例如scFv)的分子的试剂盒。例如,试剂盒可以包括含有一个或多个分子的组合物(例如,药学上可接受的组合物),所述分子包括一个或多个抗原结合域(例如,scFv),所述抗原结合域可以结合本文所述的修饰肽。在一些情况下,试剂盒可包括用于执行本文所述的任何方法的指令。在一些情况下,试剂盒可包含至少一剂本文所述的任何组合物(例如药物组合物)。在一些情况下,试剂盒可以提供用于给予本文所述的任何组合物(例如药物组合物)的手段(例如注射器)。
本发明将在以下实施例中进一步描述,其不限制权利要求中描述的本发明的范围。
实施例
实施例1:鉴定MANA抗体克隆并将MANA抗体克隆转化为基于T细胞的治疗形式
本研究设计并构建了噬菌体展示文库,在噬菌体表面展示单链可变片段(scFv)。文库中存在的scFv基于人源化4D5(曲妥珠单抗)框架,在scFv互补决定区(CDR)的关键位置引入氨基酸可变性。
噬菌体展示文库用于鉴定特异性识别含突变的肽的scFv,所述肽折叠成与重组HLA等位基因α链和β-2微球蛋白(β2M)复合物。这些复合物在本文中也称为单体,模拟癌细胞表面上的天然肽/HLA复合物。
肽-HLA靶可以包括表1所示的突变肽(例如MANA)。表3显示了能够特异性结合表1中肽-HLA靶的scFv。这些scFv也可以被称为MANA抗体,因为它们具有与MANA结合的能力。







特异性识别含有与HLA-A2复合物中R175H突变的p53肽(HMTEVVRHC;SEQ ID NO:1)的scFv的流式细胞术数据如图1所示。当这些细胞用突变肽脉冲而不是WT肽脉冲或根本不用肽脉冲时,scFv特异性染色HLA等位基因匹配的细胞系。图2-4显示了H/K/N RAS Q61H、Q61L和Q61R肽特异性scFv的流式细胞术数据。
为了证明MANA抗体克隆可以用作治疗模态,将选定的MANA抗体克隆工程改造为双特异性抗体,该抗体具有一个抗体片段,该抗体片段与HLA背景下呈现的突变肽结合,并且具有一个与T细胞表面CD3蛋白结合的抗体片段(表4)。双特异性抗体在下文中称为单链双抗体(scDb)。具体而言,工程改造了靶向HLA-A2和CD3背景下呈现的突变p53 R175H肽的双特异性抗体,工程改造了靶向HLA-A1和CD3环境中呈现的突变H/K/N RAS Q61H、Q61L和Q61R肽的双特异性抗体。
图5显示了五个p53 R175H HLA-A2 MANA抗体scFv克隆与抗CD3 scFv的代表性scDb共培养结果。在特定浓度的scDb存在下,将T细胞与共转染有编码HLA-A2、全长p53变体和/或GFP的质粒的COS-7细胞共培养。作为靶细胞上同源抗原活化T细胞的读数,通过ELISA测量共培养基上清液中IFNγ的释放。只有当COS-7细胞与HLA-A2和突变型p53 R175H质粒共转染时,才有超过背景的显著T细胞释放IFNγ,IFNγ水平取决于孔中的scDb浓度。与共转染HLA-A2和WT p53的COS-7细胞共培养的T细胞仅释放背景水平的IFNγ。图6-8显示了将H/K/N RAS Q61H、Q61L和Q61R HLA-A1 MANA抗体scFv克隆与抗CD3克隆组合到scDb中的代表性scDb共培养结果。在这些共培养中,只有当COS-7细胞与HLA-A1和突变全长KRAS Q61H、Q61L或Q61R质粒共转染时,才会有超越背景的显著T细胞释放IFNγ。与共转染HLA-A1和WT-KRAS的COS-7细胞共培养的T细胞仅释放背景水平的IFNγ,类似于在无scDb孔中观察到的IFN-γ水平。
为了评估H/K/N RAS Q61H、Q61L和Q61R scDb是否能对抗所有3种具有同源Q61突变的RAS同种型,用HLA-A1和编码全长HRA、KRAS或NRAS的质粒转染COS-7细胞,这些质粒为WT,或含有Q61H,Q61K,Q61L或Q61R突变。然后将转染的COS-7细胞与T细胞和代表性H/K/NRAS Q61H、Q61L和Q61RscDb共培养。图9a显示H/K/N RAS Q61H scDb仅在共转染HLA-A1和Q61H突变体HRA、KRAS或NRAS的COS-7细胞存在下诱导IFNγ。同样,H/K/N RAS Q61L scDb仅在与HLA-A1和Q61L突变体HRA、KRAS或NRAS共转染的COS-7细胞存在下诱导IFNγ(图9b),H/K/N RAS Q61R scDb只在与HLA-A1和Q61R突变体HRAS、KRAS或NRAS共转染的COS-7细胞存在下诱导IFNγ(图9c)。
为了评估MANA抗体克隆识别肿瘤细胞的能力,将具有内源性同源HLA和突变的肿瘤细胞系与T细胞和scDb共培养。内源性p53 R175H HLA-A2阳性细胞系TYKnu及其同基因p53敲除对照与T细胞和p53 R175H HLA-A2 scDb一起培养。IFNγ释放仅针对亲代TYKnu细胞系诱导,而非p53基因敲除的TYKnu(图10)。将内源性NRAS Q61L HLA-A1阳性细胞系HL-60及其同基因HLA-Al敲除对照与T细胞和H/K/N RAS Q61L HL-A1 scDb一起培养。仅在亲代HL-60细胞系中观察到IFNγ释放,而在HLA-A1敲除HL-60细胞系中未观察到IFNγ释放(图11)。总之,这些发现表明,含有MANA抗体克隆的双特异性抗体可以靶向在HLA分子背景下表现的表达MANA的肿瘤细胞。
为了评估使用MANA抗体克隆作为治疗模态的效力,使用Promega的CellTiter-Glo试剂检测p53 R175H HLA-A2和H/K/N RAS Q61L HLA-A1 scDb共培养物的靶细胞活性。CellTiter-Glo测量孔中的ATP浓度,该浓度与活细胞的数量成比例。通过扣除仅T细胞的孔的CellTiter-Glo值并对仅靶细胞的孔归一化来测量靶细胞存活率百分数。只有当亲代TYKnu细胞与T细胞在p53 R175H HLA-A2 scDb存在下孵育时,才会出现显著的靶细胞死亡(图12)。在TYKnu p53敲除孔中未观察到靶细胞死亡。类似地,只有当亲代HL-60细胞与T细胞在H/K/N RAS Q61L HLA-A1 scDb存在下孵育时,才会出现显著的靶细胞死亡(图13)。在HL-60HLA-A1敲除孔中未观察到靶细胞死亡。
总之,这些发现表明,MANA抗体可用于重定向和活化T细胞,以杀死表达特定突变蛋白和HLA等位基因对的肿瘤细胞(例如,具有HLA-A2的p53R175H和具有HLA-A1的H/K/NRAS Q61L)。




材料和方法
细胞和细胞系
RPMI-6666细胞(ATCC,Manassas,VA)在RPMI-1640(ATCC)中培养,其中含有20%的FBS(GE Hyclone,Logan,Utah,USA)和1%的青霉素链霉素(Life Technologies)。T2细胞(ATCC)和TYKnu(日本JCRB)在含有10%FBS(GE Hyclone)和1%青霉素链霉素(ThermoFisher)的RPMI-1640(ATCC中)中培养。SigM5细胞(DSMZ,Brunswick,德国)和HL-60细胞(ATCC)在补充了20%的FBS(GE Hyclone)和1%的青霉素链霉素(Thermo Fisher)的Iscove的MDM(ATCC)中培养。COS-7细胞(ATCC)在含有10%的FBS(GE-Hyclone)和1%的青霉素-链霉素(ThermoFisher)的McCoy的5A(改良)培养基(Thermo-Fisher)中培养。COS-7细胞(ATCC、CRL-1651TM)在补充了10%FBS(GE-Hyclone)和1%青霉素-链霉素(Thermo-Fisher)的DMEM(高糖、丙酮酸盐;Thermo-Fisher)中培养。293FT细胞(Thermo-Fisher)在补充有10%FBS(GE-Hyclone)、0.1mM MEM非必需氨基酸(NEAA、Thermo-Fisher)、6mM L-谷氨酰胺(Thermo Fisher)、1mM MEM丙酮酸钠(Thermo-Fisher),500μM遗传霉素(Thermo Fisher)的高葡萄糖D-MEM(Thermo Fisher)中培养。所有细胞系在5%CO2 37℃维持。
通过Ficoll-Paque PLUS(GE Healthcare)梯度离心来自健康志愿献血者的全血获得PBMC。为了活化和扩增T细胞,将PBMC与15ng/ml OKT3(加利福尼亚州圣地亚哥BioLegend)、100IU/ml重组人白介素-2(阿地白介素,加利福尼亚州圣迭戈普罗米修斯治疗和诊断公司)和5ng/ml重组人类白介素-7(加利福尼亚州圣迭戈Biolegend)在补充有1%青霉素-链霉素(Life Technologies)的RPMI-1640(ATCC)中,37℃下,5%CO2下培养3天。3天后,将扩增的T细胞保存在不含OKT3的相同含细胞因子的培养基中。
噬菌体展示文库构建。
寡核苷酸由GeneArt(Thermo Fisher Scientific)利用三核苷酸突变(TRIM)技术合成。将寡核苷酸掺入pADL-10b噬菌粒(抗体设计实验室,加利福尼亚州圣地亚哥)。该噬菌粒包含F1起始点、限制未诱导表达的转录阻遏子、lac操纵子和lac阻遏子。用pelB周质分泌信号合成scFv,并在lac操纵子下游亚克隆。一FLAG(DYKDDDDK;SEQ ID NO:190)表位标签直接位于可变重链的下游,在框内后接全长M13 pIII衣壳蛋白序列。
将10ng连接产物在冰上与10μL的电感受态SS320细胞(Lucigen,Middleton,WI)和14μL双蒸馏水混合。使用Gene Pulser电穿孔系统(Bio-Rad,Hercules,CA)对该混合物电穿孔(200欧姆,25微法,1.8kV),并使其在恢复培养基(Lucigen)中37℃恢复45分钟。合并用60ng连接产物转化的细胞并铺在含有2xYT培养基的24cm x 24cm平板上,该培养基补充有羧苄青霉素(100μg/mL)和2%葡萄糖。细胞在37℃下生长6小时,并在4℃下放置过夜。为了确定每一系列电穿孔的转化效率,取等分试样并通过系列稀释进行滴定。将在平板上生长的细胞刮入850mL含羧苄青霉素(100μg/mL)和2%葡萄糖的2xYT培养基中,最终OD600为5-15。取两毫升850毫升培养物,稀释至约1:200,最终OD600为0.05-0.07。在快速冷冻之前,向剩余培养物中加入150毫升无菌甘油,以生产甘油储液。将稀释的细菌培养至OD600为0.3-0.5,以MOI 4用M13K07辅助噬菌体(抗体设计实验室)感染,并在37℃下振摇1小时。将培养物离心,将细胞重悬浮在含有羧苄青霉素(100μg/mL)、卡那霉素(50μg/mL)和IPTG(50mM,Thermo Fisher)的2xYT培养基中,并在30℃下培养过夜以产生噬菌体。第二天早上,将细菌培养物等分到50mL Falcon管中,并高速沉淀两次,以获得澄清的上清液。用20%PEG-8000/2.5M NaCl溶液以PEG/NaCl∶上清液的4:1比例在冰上沉淀载有噬菌体的上清液40分钟。沉淀后,将噬菌体在12000g下离心40分钟,并重悬浮在1x TBS、2mM EDTA和1x完全蛋白酶抑制剂混合物中(密苏里州圣路易斯市Sigma-Aldrich)。合并来自多管的噬菌体并重新沉淀。获得的转化子总数确定为3.6x1010。将该文库等分并储存在-80℃的15%甘油中。
完整噬菌体文库的下一代测序。
使用CDR-H3区域两侧的引物扩增来自文库的DNA。这些引物5′端的序列掺入了分子条码,以便于明确计数不同的噬菌体序列。Kinde等人(2011PNAS.108:9530-35)描述了PCR扩增和测序的方案。使用定制SQL数据库处理和翻译序列,并使用Microsoft Excel分析核苷酸序列和氨基酸翻译。
肽和HLA-单体
使用NetMHC版本4.0预测突变肽和WT肽(列于表1中)与HLA等位基因结合。所有肽均通过肽2.0(Chantilly,VA)以>90%的纯度合成。肽以10mg/mL重悬于DMSO或DMF中,并在-20℃下储存。HLA单体通过用肽和β-2微球蛋白重折叠重组HLA合成,通过凝胶过滤纯化,并生物素化(Fred Hutchinson Immune Monitoring Lab,华盛顿州西雅图)。使用W6/32抗体(BioLegend,加利福尼亚州圣地亚哥)进行ELISA筛选前,确认单体已折叠。
与突变肽-HLA单体结合的噬菌体的筛选。
与他处描述的方法相似,鉴定了对突变pHLA复合物特异性的携带scFv的噬菌体克隆(参见例如,Skora等人,2015PNAS.112:9967-72)。淘选方案包括富集阶段、竞争阶段和最终筛选阶段。
在-20℃下储存在15%甘油中的噬菌体展示文库在淘选过程开始后一周内重新生长。将噬菌体感受态SS320细胞(Lucigen,米德尔顿,威斯康星州)集落接种在37℃的补充有四环素(20μg/mL)的2xYT培养基(密苏里州圣路易斯市Sigma-Aldrich)中过夜培养,第二天将其培养至2L的对数中期(OD600为0.3-0.5)细菌。噬菌体文库以MOI 0.5,M13K07辅助噬菌体(加利福尼亚州圣地亚哥Antibody Design Labs)以MOI 4感染细菌,同时添加2%(W/V)葡萄糖(密苏里州圣路易斯的Sigma-Aldrich),并在37℃下振摇1小时。培养物离心,将细胞重悬浮在含有羧苄青霉素(100μg/mL)、卡那霉素(50μg/mL)和50μM IPTG的2xYT培养基中,随后在30℃下振摇培养过夜以产生噬菌体。第二天早上,将细菌培养物等分到50mL Falcon管中,并高速沉淀两次,以获得澄清的上清液。用20%PEG-8000/2.5M NaCl溶液以PEG/NaCl∶上清液的1:4比例在冰上沉淀载有噬菌体的上清液40分钟。沉淀后,将噬菌体在12000x g下离心40分钟,并重新悬浮在补充有2mM EDTA、0.1%叠氮化钠和1X完全蛋白酶抑制剂混合物(密苏里州圣路易斯市Sigma-Aldrich)的1ml 1X TBS中。
生物素化pHLA单体复合物与M-280链霉亲和素磁性Dynabead(加利福尼亚州卡尔斯巴德Life Technologies)偶联。生物素化的pHLA在室温(RT)下与每1μg pHLA中25μLDynabeads珠在封闭缓冲液(PBS、0.5%BSA、2mM EDTA和0.1%叠氮化钠)中孵育1小时。初始孵育后,洗涤复合物并重悬浮在100μL封闭缓冲液中。
在富集阶段(第1轮),约2x1013个噬菌体(代表文库约500倍的覆盖率)在RT下与1ml未偶联的经洗涤Dynabead、1mg游离链霉亲和素蛋白(RayBiotech,Norcross,GA)的混合物进行1小时的负筛选,以去除识别未偶联Dynabead和链霉亲和素的任何噬菌体。负筛选后,用DynaMag-2磁体(加利福尼亚州卡尔斯巴德Life Technologies)分离珠,并将含有未结合噬菌体的上清液转移,在RT下对1μg与Dynabead偶联的突变pHLA正筛选1小时。洗脱前,用1mL TBST(1x TBS,含0.5%吐温-20)洗涤珠10次。通过在1ml pH为2.2的0.2M甘氨酸中重悬浮珠来洗脱噬菌体。孵育10分钟后,通过添加150μL pH为9.0的1M Tris中和溶液。使用中和的噬菌体感染10mL对数中期噬菌体SS320s培养物,添加M13K07辅助噬菌体(MOI为4)和2%葡萄糖。然后如前所述培养细菌,第二天早上用PEG/NaCl沉淀噬菌体。
在筛选阶段(第2-5轮),来自前一轮的噬菌体对不含感兴趣突变的HLA匹配的细胞系进行负筛选,对应于与Dynabead偶联的相应WT pHLA单体、与Danybead偶联的无关pHLA单体,以及游离链霉亲和素。负筛选后,用DynaMag-2磁体分离珠,转移未结合的噬菌体进行正筛选。通过将噬菌体与偶联到磁性Dynabead上的1μg(第2轮)、0.5μg的(第3轮、第4轮)或0.25μg突变pHLA(第5轮)孵育进行。在洗脱之前,将珠在1ml TBST中洗涤10次。如上所述,从磁性Dynabead中洗脱噬菌体并用于感染对数中期SS320细胞。
流式细胞术
单克隆噬菌体流式细胞术染色是通过选择用从最终筛选轮次获得的噬菌体的限制性稀释转化的SS320细胞的单个集落进行的。将单个集落接种到200μl含有100μg/mL羧苄青霉素和2%葡萄糖的2xYT培养基中,并在37℃下培养3小时。然后用1.6x107M13K07辅助噬菌体感染细胞,并在37℃下振荡培养1小时。沉淀细胞,重悬浮在300μL含有羧苄青霉素(100μg/mL)、卡那霉素(50μg/mL)和50μM IPTG的2xYT培养基中,并在30℃下培养过夜以产生噬菌体。沉淀细胞,并使用载有噬菌体的上清液进行染色。
对于肽脉冲,HLA匹配的细胞用PBS洗涤一次,用无血清RPMI-1640洗涤一次后,在37℃下以每毫升106个细胞在含有50μg/mL肽和10μg/mL人β-2微球蛋白(新泽西州东布伦瑞克ProSpec)的无血清RPMI-1640中孵育过夜。沉淀脉冲细胞,在冷染色缓冲液(含有0.5%BSA、2mM EDTA和0.1%叠氮化钠的PBS)中洗涤一次,然后重悬浮在50μL染色缓冲液中。用50μL单克隆噬菌体上清液在冰上进行噬菌体染色1小时,然后在800μL冷染色缓冲液中洗涤一次。然后用1μg兔抗M13抗体(Novus Biologics,Centennial,CO)以100μL总体积在冰上染色1小时,并用800μL冷染色缓冲液洗涤一次。然后用5μL抗-兔-PE(Biolegend)在冰上以100μL总体积染色1小时,然后按照制造商的说明在室温下用200μL活/死可固定近红外死细胞染色(Thermo Fisher)孵育10分钟。细胞在800μL染色缓冲液中洗涤一次。使用iQue筛选仪(IntelliCyt,Albuquerque,NM)分析染色细胞。
双特异性抗体生产。
编码双特异性抗体的gBLOCK购自IDT(伊利诺伊州Skokie)。按照制造商的方案,通过NEBuilder HiFi DNA组装(新英格兰生物实验室,马萨诸塞州伊普斯维奇)将gBLOCK克隆到pcDNA3.4质粒(Thermo Fisher)中。使用Lipofectamine 3000(Life Technologies),按照制造商的说明在T75烧瓶中用双特异性抗体pcDNA3.4质粒转染293FT细胞(ThermoFisher)。孵育5-8天后,收集培养基并在4℃下以500g离心10分钟。使用ClontechCapturemTMHis标记的纯化Mixiprep试剂盒(Takara Bio,加利福尼亚州山景城)根据制造商的说明纯化双特异性抗体蛋白。按照制造商的说明,使用Zeba spin 7k MWCO脱盐柱将双特异性抗体蛋白脱盐到PBS中。使用Mini- TGX Stain-FreeTM预浇铸凝胶(Biorad,Hercules,California)用已知浓度的标准蛋白质曲线定量双特异性抗体浓度。使用ChemiDoc XRS+成像仪(Biorad)对无染色凝胶成像。
TGX Stain-FreeTM预浇铸凝胶(Biorad,Hercules,California)用已知浓度的标准蛋白质曲线定量双特异性抗体浓度。使用ChemiDoc XRS+成像仪(Biorad)对无染色凝胶成像。
双特异性抗体共培养试验
按照制造商说明在T75烧瓶中,用Lipofectamine 3000(Life Technologies)用编码HLA-A2、HLA-A1、p53(WT,R175H)、HRA(WT、Q61H、Q61K、Q61L、Q61R)、KRAS(WT,Q61H,Q61K,Q61L,Q61R)的pcDNA3.1或pcDNA3.4(Life Technologies)质粒的各种组合转染COS-7细胞。将总共50000个T细胞与转染的50000个COS-7细胞、25000个TYKnu细胞或25000个HL-60细胞和指定浓度的双特异性抗体混合在96孔板中,并使共培养物在37℃和5%CO2下培养20小时。共培养后,收集条件培养基并通过 ELISA(R&D Systems,明尼苏达州明尼阿波利斯)测定分泌的IFNγ。或者,在共培养后,按照制造商的说明,使用CellTiter-Glo(Promega,麦迪逊,威斯康星州)测定靶细胞活力。
ELISA(R&D Systems,明尼苏达州明尼阿波利斯)测定分泌的IFNγ。或者,在共培养后,按照制造商的说明,使用CellTiter-Glo(Promega,麦迪逊,威斯康星州)测定靶细胞活力。
CRISPR细胞系工程改造。
Alt-R CRISPR系统(Integrated DNA Technologies,IDT)用于修饰TYKnu细胞系的p53和HL-60细胞系的HLA等位基因。将靶向TP53外显子3(CCCCGGACGATATTGAACAA;SEQ IDNO:191)和HLA-A外显子2(CAGACTGACCGAGCGAACCT;SEQ ID NO:192)的Alt- CRISPRCas9cRNA(IDT)以及Alt-
CRISPRCas9cRNA(IDT)以及Alt- CRISPR-Cas9tracrRNA(IDT)以100μM用无核酸酶双链体缓冲液(IDT)重悬浮。根据制造商的说明,在95℃下以1:1摩尔比将crRNA和tracrRNA双链化5分钟。使双链RNA冷却至室温,然后与Cas9核酸酶(IDT)以1.2:1摩尔比混合15分钟。为了敲除TYKnu细胞中的p53,将与p53-gRNA复合的40pmol Cas9-RNP与20μL OptiMEM中的200,000个TYKnu细胞混合。将该混合物装入0.1cm比色皿(Biorad)中,并使用ECM 2001(BTX)在120V和16ms下电穿孔。为了敲除HL-60细胞中的HLA-A等位基因,将40pmol与HLA-1gRNA复合的Cas9RNP与20μL OptiMEM中的200000个HL-6细胞混合。将该混合物装入0.1cm比色皿(Biorad)中,并使用ECM 2001(BTX)在150V和16ms下电穿孔。电穿孔后,立即将细胞转移到完全生长培养基中并培养10天,根据需要更换培养基并传代。
CRISPR-Cas9tracrRNA(IDT)以100μM用无核酸酶双链体缓冲液(IDT)重悬浮。根据制造商的说明,在95℃下以1:1摩尔比将crRNA和tracrRNA双链化5分钟。使双链RNA冷却至室温,然后与Cas9核酸酶(IDT)以1.2:1摩尔比混合15分钟。为了敲除TYKnu细胞中的p53,将与p53-gRNA复合的40pmol Cas9-RNP与20μL OptiMEM中的200,000个TYKnu细胞混合。将该混合物装入0.1cm比色皿(Biorad)中,并使用ECM 2001(BTX)在120V和16ms下电穿孔。为了敲除HL-60细胞中的HLA-A等位基因,将40pmol与HLA-1gRNA复合的Cas9RNP与20μL OptiMEM中的200000个HL-6细胞混合。将该混合物装入0.1cm比色皿(Biorad)中,并使用ECM 2001(BTX)在150V和16ms下电穿孔。电穿孔后,立即将细胞转移到完全生长培养基中并培养10天,根据需要更换培养基并传代。
p53和HLA-A修饰的多克隆合并库在96孔板中以每孔0.5个细胞的密度铺板,并培养2周。收获单个集落并接种到2块重复的96孔板中。使用Quick-DNATM96试剂盒(加利福尼亚州欧文市Zymo Research)从一块平板收集基因组DNA,使用 热启动高保真(Hot StartHigh-Fidleity)2X主混合物(新英格兰生物实验室)进行PCR扩增,并进行Sanger测序(新泽西州南普兰菲尔德市Genewiz),以选择具有所需修饰的克隆。
热启动高保真(Hot StartHigh-Fidleity)2X主混合物(新英格兰生物实验室)进行PCR扩增,并进行Sanger测序(新泽西州南普兰菲尔德市Genewiz),以选择具有所需修饰的克隆。
实施例2:靶向来源于普通TP53突变的新抗原
TP53是最常见的突变癌症驱动基因,但尽管进行了广泛的努力,但尚未批准靶向突变TP53的药物用于治疗大量肿瘤中含有p53突变的患者。本实施例描述了与细胞表面上的常见HLA-A等位基因复合的对最常见TP53突变(R175H)高度特异性的抗体的鉴定。例如,本实施例描述了对HLA-A*02:01限制性p53R175H新抗原特异性的TCRm抗体的鉴定,其特异性的结构基础,以及其转化为双特异性抗体的情况,该抗体可以根据新抗原的存在以某种方式裂解癌细胞。这种靶向普通TP53突变的免疫治疗剂可用于靶向含有其他肿瘤抑制基因突变的癌症。
结果
p53R175H新抗原存在于癌细胞表面
在NetMHCpan 4.0服务器上预测p53R175H(aa 168-176,HMTEVVRHC;SEQ ID NO:1)和p53WT(HMTEVVRRC;SEQ ID NO:135)肽,分别在5177.6nM(评分9.6%)和7121.5nM(11.6%)处结合HLA-A*02:01。为了提供实验证据并量化这种递呈,在四种不同的细胞培养系统中使用基于质谱(MS)的方法分析从HLA分子洗脱的肽。首先,人HLA-A*02:01和p53R175H或p53WT在猴COS-7细胞中共表达。用抗HLA抗体免疫纯化的肽的MS分析检测到p53R175H肽在每个细胞中约为1500拷贝(图20,表6)。虽然检测到相对丰富的p53R175H肽,但未观察到p53WT肽。其次,对三种人癌细胞系KMS26、TYK-nu和KLE进行了MS分析,所有这些细胞系均含有p53R175H突变,并携带HLA-A*02:01等位基因。在所有三种细胞系中都检测到p53R175H肽,并且如预期的那样,其水平远低于外源引入突变TP53和HLA基因的COS-7细胞(图20,表6)。基于与重同位素标记的对照比较,估计KMS26、TYK-nu和KLE细胞系的细胞表面上分别存在2.4、1.3和1.5个拷贝的细胞表面p53R175H/HLA-A*02:01复合物(表6)。
表6.p53R175H新抗原肽的定量评估。使用质谱法测定转染HLA-A*02:01和p53R175H或p53WT的COS-7细胞以及内源性表达HLA-A*02:01和p53R175H的细胞系中存在的p53R175H新抗原肽(HMTEVVRHC;SEQ ID NO:1)的量。

鉴定HLA-A*02:01限制性p53R175H肽特异性的表达scFv的噬菌体克隆并转换为scDb形式
为了鉴定选择性靶向突变pHLA复合物的TCR模拟性单链可变片段(scFv),筛选了一个展示scFv的噬菌体文库,估计复杂度>1x1010。针对含有p53R175H肽的HLA-A*02:01pHLA单体的正筛选与针对含有p53WT和无关肽的pHLA单体的负筛选相结合。扩增选定的噬菌体克隆,并通过流式细胞术评估其与递呈突变或野生型(WT)肽的T2细胞的结合(图21)。
然后将p53R175H比p53WT的中值荧光强度(MFI)比>4的23个噬菌体克隆转化为T细胞重靶向双特异性抗体(图21)。这是通过将每个scFv连接到单链双抗体(scDb)形式的抗CD3scFv上实现的(图22)。scDb形式是在评估了几种先前描述的双特异性抗体形式后筛选的,如在中试实验中的双特异性T细胞衔接子(BiTE)、双亲和性重靶向抗体(DART)和双抗体。在与过表达HLA-A*02:01和全长p53R175H或p53WT蛋白的COS-7细胞共同孵育后,通过释放干扰素-γ(IFN-γ)来评估scDb活化T细胞的能力。两个分别来自噬菌体克隆H2和H20的scDb克隆(命名为H2-scDb和H20-scDb)在p53R175H/HLA-A*02:01存在下显示出最有效和特异性T细胞活化(图23)。通过滴定酶联免疫吸附试验(ELISA)进一步评估这些scDb的特异性。如预期,H2和H20均以低浓度与p53R175H/HLA-A*02:01结合。在高浓度下,H20-scDb也与p53WT/HLA-A*02:01结合,而H2-scDb即使在非常高浓度的scDb下也不与野生型pHLA复合物结合(图1A、图24)。因此,选择H2-scDb进行进一步分析。通过表面等离子体共振(SPR)评估,H2-scDb与p53R175H/HLA-A*02:01结合,KD=86nM,kon为1.76x105M-1s-1,koff为1.48x10-2s-1(图14B)。1.76x105M-1s-1的kon表明p53R175H/HLA-A*02:01在结合时没有构象变化。在SPR实验中未观察到H2-scDb与p53WT/HLA-A*02:01的可检测结合(图14B)。
接下来,研究了scDb的抗-CD3臂(而不是原始的UCHT1)是否会影响H2诱导T细胞活化的能力。H2 scFv连接到一组常用的抗CD-3εscFv,包括UCHT1、hUCHT1v9、OKT3、TR66和hXR32。发现在所测试的抗-CD3 scFv中,当与H2scFv连接时,UCHT1以最低的p53R175H肽浓度活化T细胞(图25),并使用该特定双特异性抗体进行进一步实验。
H2-scDb特异性识别表达p53R175H新抗原的癌细胞
接下来评估了H2-scDb识别携带p53R175H突变并表达不同水平HLA-A*02:01的癌细胞系的能力。当T细胞与表达中到高水平HLA-a*02:01的三个品系共培养时,H2-scDb以剂量依赖性方式诱导T细胞应答(图15A)。即使在双特异性抗体的非常低(亚纳摩尔)浓度下也观察到这种活化。T细胞反应是多功能的,如细胞毒性颗粒蛋白颗粒酶B和穿孔素的释放、细胞毒性,以及细胞因子IFN-γ、肿瘤坏死因子α(TNF-α)、白介素-2(IL-2)等的产生所示(图15B、图26)。实时活细胞成像也显示了肿瘤细胞周围的T细胞聚集,导致它们在H2-scDb存在下裂解(图15C)。通过观察发现,携带p53R175H突变但HLA-A*02:01表达水平低的细胞(AU565或SK-BR3)或未携带P53R175H但HLA-A*02:01表达水平相对较高的细胞诱导的IFN-γ水平低得多,由此证实双特异性抗体对p53R175H肽和HLA-A*02:01的特异性(图15A,图27)。
使用九对在HLA-A*02:01表达或p53R175H突变方面不同的同基因细胞系进一步验证了H2-scDb的特异性。首先,用表达全长p53R175H或p53WT的质粒转染人HEK293FT(Tp53WT/HLA-A*02:01)或Saos-2(TP53null/HLA-A*02:01)细胞。当与两种过表达p53R175H的细胞系,但不和过表达p53WT或亲代细胞共同培养时,H2-scDb诱导了强大的T细胞活化(图16A)。其次,将编码HLA-A*02:01的逆转录病毒转导到四个细胞系(AU565、SK-BR-3、HuCCT1、CCRF-CEM)中,这些细胞系携带p53R175H突变,但HLA-A*02:01表达水平较低(图28)。所有四个品系中HLA-A*02:01的外源性表达通过H2-scDb赋予T细胞活化(图16B)。第三,使用基于CRISPR的技术,TP53在携带内源性p53R175H的KMS26、TYK-nu和KLE癌细胞系中被遗传破坏(图29A)。当TP53在所有三种细胞系中被敲除时,如IFN-γ分泌评估,T细胞活化降低到对照水平(图16C)。H2-scDb介导的细胞毒性同样通过这些细胞中的TP53敲除(KO)而减轻(图16D、图29B)。
H2-Fab-p53R175H/HLA-A*02:01三元复合物的整体结构
为了理解H2克隆对p53R175H/HLA-A*02:01的高特异性的结构基础,纯化了H2片段抗原结合(H2-Fab)-p53R175H/HLA-A*02:01复合物(图30),并通过分子置换确定其晶体结构,并将其优化至 分辨率(PDB ID 6W51,表7)。每个不对称单元有四个H2-Fab和四个p53R175H/HLA-A*02:01(图17A,B)。所有四个H2-Fab都牢固地定位在p53R175H/HLA-A*02:01上,没有摇摆的迹象,均方根偏差(rmsd)为0.45至
分辨率(PDB ID 6W51,表7)。每个不对称单元有四个H2-Fab和四个p53R175H/HLA-A*02:01(图17A,B)。所有四个H2-Fab都牢固地定位在p53R175H/HLA-A*02:01上,没有摇摆的迹象,均方根偏差(rmsd)为0.45至 H2-Fab-p53R175H/HLA-A*02:01界面的总埋置表面积为
H2-Fab-p53R175H/HLA-A*02:01界面的总埋置表面积为 重链和轻链的贡献大致相等(表8中分别为
重链和轻链的贡献大致相等(表8中分别为 和
和 )。尽管整个结构优化到
)。尽管整个结构优化到 的分辨率,但观察到p53R175H新抗原、H2-Fab的CDR和HLA-A*02:01的电子密度特别清晰(图17C,D)。
的分辨率,但观察到p53R175H新抗原、H2-Fab的CDR和HLA-A*02:01的电子密度特别清晰(图17C,D)。
表7.X-射线晶体学数据收集和优化统计。

p53R175H肽与HLA-A*02:01的结合
p53R175H新抗原占据HLA-A*02:01的结合裂隙α1-α2,掩埋了 的溶剂可及表面积,略大于其他肽/HLA-A*02:01复合物(图18A、B、图31A),并具有指向上方脱离凹槽的位于第7位的C端精氨酸(p53中的P7、Arg7、Arg 174)和位于第8位的组氨酸(突变型p53中的P8、His8、His175)。相反,肽的N末端位于肽结合裂隙的深处,由HLA-A*02:01中的多个残基锚定(图18A、B、图31A)。肽的锚定残基,第2位的甲硫氨酸(p53中的P2,Met2,Met169)和第9位的半胱氨酸残基(P9)(图31B),与P2处的亮氨酸和P9处的缬氨酸或亮氨酸的经典锚定残基相分离。已经报道了通过P2处的甲硫氨酸或P9处的半胱氨酸与HLA-A*02:01结合(但非两者)的肽。基于与TCR或TCRm复合物中其他HLA-A*02:01肽的结构比对,p53R175H的非常规锚定并未导致肽构象或定位剧烈变化(图31C,D)。
的溶剂可及表面积,略大于其他肽/HLA-A*02:01复合物(图18A、B、图31A),并具有指向上方脱离凹槽的位于第7位的C端精氨酸(p53中的P7、Arg7、Arg 174)和位于第8位的组氨酸(突变型p53中的P8、His8、His175)。相反,肽的N末端位于肽结合裂隙的深处,由HLA-A*02:01中的多个残基锚定(图18A、B、图31A)。肽的锚定残基,第2位的甲硫氨酸(p53中的P2,Met2,Met169)和第9位的半胱氨酸残基(P9)(图31B),与P2处的亮氨酸和P9处的缬氨酸或亮氨酸的经典锚定残基相分离。已经报道了通过P2处的甲硫氨酸或P9处的半胱氨酸与HLA-A*02:01结合(但非两者)的肽。基于与TCR或TCRm复合物中其他HLA-A*02:01肽的结构比对,p53R175H的非常规锚定并未导致肽构象或定位剧烈变化(图31C,D)。
H2-Fab识别p53R175H/HLA-A*02:01的结构基础
H2-Fab对HLA-A*02:01的识别由所有六个CDR介导。H2-Fab CDR与HLA-A*02:01的α1和α2之间共有79次接触,其中轻链贡献了61%。H2-Fab在HLA中掩埋了 的溶剂可接触表面积,其中轻链贡献了
的溶剂可接触表面积,其中轻链贡献了 重链贡献了
重链贡献了 (表8)。相反,六个H2-Fab CDR中只有四个(H1、H2、H3和L3)与p53R175H肽相互作用。总体而言,H2-Fab与p53R175H新抗原进行了36次接触,包括五个氢键和大量范德华相互作用。重要的是,P8位的His175在与H2-Fab的所有直接接触中占47%。重链的CDR-H1、H2和H3以及轻链的CDR-L3在p53R175H肽的C末端周围形成笼状构型,通过提供稳定的相互作用将P7处的Arg174和P8处的His175捕获到位(图18C)。P8处的His175的咪唑侧链通过具有Asp54(CDR-H2)和Tyr94(CDR-L3)的氢键网络锚定(图18C、图32)。Tyr52(CDR-H2)起到顶板的作用,并通过形成π-π相互作用在His8周围捕获笼状结构(图18C、图32)。
(表8)。相反,六个H2-Fab CDR中只有四个(H1、H2、H3和L3)与p53R175H肽相互作用。总体而言,H2-Fab与p53R175H新抗原进行了36次接触,包括五个氢键和大量范德华相互作用。重要的是,P8位的His175在与H2-Fab的所有直接接触中占47%。重链的CDR-H1、H2和H3以及轻链的CDR-L3在p53R175H肽的C末端周围形成笼状构型,通过提供稳定的相互作用将P7处的Arg174和P8处的His175捕获到位(图18C)。P8处的His175的咪唑侧链通过具有Asp54(CDR-H2)和Tyr94(CDR-L3)的氢键网络锚定(图18C、图32)。Tyr52(CDR-H2)起到顶板的作用,并通过形成π-π相互作用在His8周围捕获笼状结构(图18C、图32)。
表8.H2-Fab-p53R175H/HLA-A*02:01与不同TCR和Fab抗体-pHLA的结构比较。使用 截留值计算总键,其中包括氢键和范德华键。PDB,蛋白数据库;BSA,埋藏的表面积;α、TCRα链;β,TCRβ链;H,VH结构域;L,VL结构域;pep,HLA递呈肽。
截留值计算总键,其中包括氢键和范德华键。PDB,蛋白数据库;BSA,埋藏的表面积;α、TCRα链;β,TCRβ链;H,VH结构域;L,VL结构域;pep,HLA递呈肽。


从p53R175H肽的C端到N端的轴来看,CDR按H2、H1、L3、H3、L1、L2的顺序排列(图17E、F、G)。有趣的是,H2-Fab的轴几乎平行于HLA凹槽内肽的轴,结合角为27°(图17G,H)。该朝向与大多数先前描述的针对pHLA复合物的TCR或TCRm抗体的方向非常不同,其中轴是对角的(图33)。
评估候选交叉反应肽
新免疫治疗抗体面临的主要挑战之一是非靶向结合,这可能导致对正常细胞的毒性。为了解决这一重要问题,已经开发了几种分析TCR和TCRm特异性的强大方法。扫描诱变用于鉴定人蛋白质组中H2-scDb可能交叉反应的肽。通过用剩余的19种常见氨基酸中的每一种系统取代靶p53R175H肽(HMTEVVRHC;SEQ ID NO:1)每个位置的氨基酸来生成肽文库。然后,通过测量与H2-scDb孵育后的IFN-γ释放,使用装载有171种变异肽中每种的T2细胞来评估T细胞活化(图18D)。与X射线结构分析一致,突变组氨酸残基所在的P8的任何变化,以及被CDR环包裹在P8中的P7的任何变化都消除了对肽的识别。重要的是,在这些位置具有取代的肽保留了它们与HLA-A*02:01结合的能力(图34),但不与H2-scDb结合。位置3-6处的其他非锚定残基也高度偏好存在于靶肽中的亲代氨基酸。该识别模式绘制成Seq2Logo图(图18E)。
接下来,使用20%的靶肽反应性作为每个位置允许氨基酸的截留值,生成九聚体结合基序x-[AILMVNQTC]-[ST]-[DE]-[IV]-[IMVST]-R-H-[AILVGHSTYC](SEQ ID NO:197)(图35)。使用ScanProsite在UnitProtPK人蛋白质数据库中搜索该基序,从STAT2(PLTEIIRHY;SEQ ID NO:185)、VP13A(LQSEVIRHY;SEQID NO:186)和ZFP3(QNSEIIRHI;SEQID NO:187)中得到3种同源肽(表9)。NetMHCpan 4.0(%评分均>2.0)预测这3种肽均不是HLA-A*02:01的有效结合物,并且预测的结合亲和力低于亲代p53R175H肽(表9)。然而,为了在实验上排除交叉反应的可能性,T2细胞用这些肽中的每一种进行脉冲。H2-scDb仅在用p53R175H肽脉冲的T2存在下活化T细胞(图18F)。此外,用HLA-A*02:01和STAT2或ZFP3的表达质粒共转染COS-7细胞;全长VP13A因其尺寸较大(3000aa)而未测试。同样,在与表达含有候选交叉反应肽的两种蛋白质的COS-7细胞的共培养试验中未检测到T细胞活化(图36)。
表9.通过肽扫描鉴定出可能的交叉反应肽。通过p53R175H HMTEVVRHC(SEQ ID NO:1)肽的位置扫描确定H2-scDb的结合基序。使用ScanProsite鉴定了三种与UniProtPK人蛋白质数据库中的基序一致的肽。NetMHCPan4.0用于预测这些肽与HLA-A*02:01的结合亲和力和%评分。列出了亲代p53R175H靶肽以供比较。

H2-scDb的体内抗肿瘤活性
为了确定H2-scDb是否能在体内控制肿瘤生长,通过静脉注射将KMS26细胞植入NOD-SCID-Il2rg-/-(NSG)小鼠,在全身建立广泛、活跃生长的癌细胞。使用两种模型评估H2-scDb与人T细胞组合的效果。在早期治疗模型中,根据肿瘤负荷的发光定量对小鼠进行随机分组,随后从肿瘤接种后一天开始,通过腹膜内输注泵以0.3mg/kg/天的剂量给予H2-scDb。作为对照,平行给予不相关的同种型scDb。H2-scDb显著抑制亲代KMS26细胞的生长(图19A)。相反,H2-scDb对使用CRISPR破坏TP53基因的KMS26细胞没有影响(图19B)。在第二个模型中,小鼠在肿瘤接种后6天随机分组。以两种剂量(0.15和0.3mg/kg/天)给予H2-scDb。两种剂量均导致重大肿瘤消退,并通过体重无显著变化进行评估,耐受性良好(图19C,图37)。
综上所述,这些结果表明---可以用于靶向p53,这是人类癌症中最常突变的抑癌基因的最常见突变,因此,它可以特异性靶向携带突变的癌细胞。
材料和方法
细胞系和原代T细胞
COS-7,T2(174 x CEM.T2),Raji,HH,AU565,SK-BR-3,KLE,HCT116,SW480,NCI-H441,Saos-2,和CCRF-CEM细胞购自美国典型培养物保藏中心(ATCC,Manassas,VA)。KMS26、TYK nu和HuCCT1购自日本研究生物资源细胞库(日本大阪JCRB)。SigM5获自DSMZ(德国布伦瑞克)。HEK293FT从Invitrogen(Thermo Fisher Scientific,马萨诸塞州沃尔瑟姆)获得。T2、Raji、Jurkat、HH、AU565、NCI-H441、TOV-112D、CCRF-CEM、KMS26、TYK nu和HuCCT1在含有10%的FBS(GE Healthcare,SH30070.03)和1%的青霉素链霉素(Thermo FisherScientificific,15140163)的RPMI-1640(ATCC,30-2001)中培养。COS-7、SK-BR-3、HCT116、SW480和Saos-2在含有10%的FBS和1%的青霉素链霉素的McCoy的5A改良培养基(ThermoFisher Scientific,16600108)中进行培养。SigM5在含有20%FBS和1%青霉素链霉素的IMDM(Thermo Fisher Scientific,12440061)中培养。HEK293FT在含有10%的FBS、额外的2mM谷氨酰胺(Thermo Fisher Sciencific,35050061)、0.1mM的MEM非必需氨基酸(ThermoFisher Scenical,11140050)、1%的青霉素链霉素和500μg/mL的遗传霉素(Therm FisherScenetic,10131027)的DMEM(高葡萄糖、丙酮酸盐,Thermo Fisher Scientific,11995065)中培养。通过用Ficoll Paque Plus(GE Healthcare,17-1440-03)进行标准密度梯度离心,从白细胞分离样品(Stem Cell Technologies,Vancouver,BC)中分离出PBMC。在加入15ng/mL抗人CD3抗体(OKT3,BioLegend,San Diego,317347)的情况下,从PBMC扩增T细胞三天。T细胞在含有10%FBS、1%青霉素链霉素、100IU/mL重组人IL-2(阿地白介素,PrometheusTherapeutics and Diagnostics,加利福尼亚州圣地亚哥),和5ng/mL重组人类IL-7(BioLegend,581908)的RPMI-1640中培养。所有细胞均在37℃、5%CO2和加湿条件下生长。
新抗原肽的检测
在转染了HLA-A*02:01和p53R175H的COS-7细胞和在表达HLA-A*02:01和P53R175H的人癌细胞系中,通过MANA-SRM直接检测并定量HLA-B*02:01限制性p53R175H肽。特别是,MANA-SRM中描述的双还原方法对于该检测至关重要,因为p53R175H肽中同时存在半胱氨酸和甲硫氨酸。在分析之前,向每个样品中加入100飞摩尔重同位素标记的肽HMTEVVRHC(SEQ ID NO:1;New England Peptide Inc,Gardner,MA)。MANA-SRM分析在Complete Omics(马里兰州巴尔的摩)进行。
噬菌体展示文库构建
他处描述了携带scFv的噬菌体文库(见例如Miller等人,J.Biol.Chem.294:19322-19334(2019);和Skora等人,Proc.Natl.Acad.Sci.U.S.A.112:9967-9972(2015))。GeneArt(Thermo Fisher Scientific)利用三核苷酸诱变(TRIM)技术合成寡核苷酸,以使互补决定区(CDR)-L2、CDR-L3、CDR-H1、CDR-H2和CDR-H3多样化。一FLAG(DYKDDDDK;SEQ IDNO:190)表位标签直接位于scFv的下游,在框内后接全长M13 pIII衣壳蛋白序列。获得的转化子总数确定为3.6x1010。
肽和单体
除使用粗制肽的位置扫描文库外,所有肽均由Peptide 2.0(Chantilly,VA)或ELIM Biopharm(Hayward,CA)以>90%的纯度合成。肽在二甲基甲酰胺中以10mg/mL重悬,并在-20℃下储存。肽-HLA单体通过用肽和β2微球蛋白(β2M)与重组HLA重折叠合成,凝胶过滤纯化,并进行生物素化(Fred Hutchinson Immune Monitoring Lab,华盛顿州西雅图)。通过使用仅识别折叠HLA的W6/32抗体(BioLegend,311402)进行ELISA,确认单体在选择之前折叠。
突变pHLA特异性噬菌体克隆的筛选
使用其他地方描述的方法(Skora等人,Proc.Natl.Acad.Sci.U.S.A.112:9967-9972(2015))鉴定了携带p53R175H/HLA-A*02:01pHLA特异性scFv的噬菌体克隆。生物素化HLA-A*02:01pHLA单体复合物以每1μg pHLA与25μL的M-280链霉亲和素磁性Dynabead(Thermo Fisher Scientific,11206D)偶联。在富集阶段(第1轮),用未偶联的Dynabead和游离链霉亲和素蛋白(RayBiotech,Norcross,GA,228-11469)的混合物对约4x1013噬菌体进行了负筛选,代表了库的约1000倍覆盖率。负筛选后,移出含有未结合噬菌体的上清液,使用1μg p53R175H/HLA-A*02:01pHLA进行正筛选。然后洗涤珠并洗脱噬菌体以感染对数中期的SS320细菌,同时添加M13K07辅助噬菌体(MOI为4)。然后在30℃下培养细菌过夜以产生噬菌体,第二天早上用PEG/NaCl沉淀噬菌体。
在筛选阶段(第2-5轮),前一轮的噬菌体经历两个阶段的负筛选:1)针对不含p53R175H/HLA-A*02:01(RPMI-6666、Jurkat、Raji、SigM5、HH、T2和NCI-H441)的细胞系,以及2)针对p53WT/HLA-A*02:01pHLA、无关HLA-A*02:01pHLA和游离链霉亲和素。对于使用细胞系的负筛选,将噬菌体与总数为5x106–1x107的细胞在4℃下孵育过夜。负筛选后,分离珠并通过与1μg(第2轮),0.5μg(第3轮),或0.25μg(第4,5轮)p53R175H/HLA-A*02:01pHLA孵育正筛选转移未结合噬菌体。然后如上所述通过感染SS320洗脱和扩增噬菌体。
经过五轮筛选后,用有限稀释的富集噬菌体感染SS320细胞。挑出总共190个SS320的独立集落,使用Q5热启动高保真2X主混合物(新英格兰生物实验室,M0494L)通过侧接CDR的引物(正向:GGCCATGGCAGATATTCAGA(SEQ ID NO:198),反向:CCGGGCCTTTATCATCATC(SEQID NO:199))PCR扩增噬菌体DNA,并由GENEWIZ(South Plainfield,NJ)对噬菌体DNA进行Sanger测序。使用DNA Baser Sequence Assembler v4(Arges,罗马尼亚)修剪CDR侧翼的序列,并使用CD-HIT套件对跨越CDR的序列进行聚类。选择含有独特噬菌体克隆的集落,并在添加M13K07辅助噬菌体的深96孔板(Thermo Fisher Scientific,278743)中的400μL培养基内过夜。第二天沉淀细菌,并将载有噬菌体的上清液用于下游分析。
肽脉冲
对于肽脉冲,用无血清RPMI-1640培养基洗涤T2细胞,然后在37℃下以每毫升5x105–1x106个细胞在含指定浓度肽的无血清RPMI-1640中培养2小时。对于通过流式细胞术评估的实验,向10μg/mL人β2M(ProSpec,新泽西州东布伦瑞克,PRO-337)中添加肽,并在此类实验的图例中指定。
流式细胞术
用50μL噬菌体上清液在冰上对肽脉冲T2细胞进行噬菌体染色1小时,然后用1μg兔抗M13抗体(Novus Biologicals,NB100-1633)和抗-兔-PE(BioLegend,406421)进行染色。通过用荧光标记的抗人HLA-A*02(BB7.2,BioLegend,343308)或小鼠同种型IgG2b,κ(BioLedge,402206)对细胞进行染色来进行HLA-A*02染色。使用LSRII流式细胞仪(马萨诸塞州曼斯菲尔德,Becton Dickinson)或IQE筛选仪(明尼苏达州阿尔伯克基的IntelliCyt)分析染色细胞。
ELISA
链霉亲和素涂覆的96孔板(R&D Systems,明尼苏达州明尼阿波利斯市,CP004)在4℃下用50μL封闭缓冲液(含有0.5%BSA、2mM EDTA和0.1%叠氮化钠的PBS)中的50ng生物素化HLA-A*02:01pHLA单体包被过夜。使用BioTek 405TS洗板机(BioTek,Winooski,VT)用1XTBST(TBS+0.05%吐温-20)洗涤板。将系列稀释的单链双抗体(scDbB)在板上室温下孵育1小时,洗涤,然后在室温下与1μg/mL重组蛋白L(Thermo Fisher Scientific,77679)孵育1小时,冲洗,然后在室温下与抗蛋白L HRP(1:10000,Abcam,ab63506)孵育1小时。洗涤平板,向每个孔中加入50μL 3,3’,5,5’-四甲基联苯胺(TMB)底物(BioLegend,圣地亚哥,CA,4211101),并用50μL 2N硫酸(Thermo Fisher Scientific)猝灭反应。使用Synergy H1多模式阅读器(BioTek)测量450nm处的吸光度。
双特异性抗体产生
通过将从N到C端编码以下形式的变体中每一个的gBlock(IDT,Coralville,Iowa):IL-2信号序列,抗-pHLA可变轻链(VL),GGGGS接头(SEQ ID NO:200),抗-CD3可变重链(VH),(GGGGS)3接头(SEQ ID NO:201),抗-CD3 VL,GGGGS接头(SEQ ID NO:200),抗-pHLAVH,和6x HIS标签克隆入线性化的pcDNA3.4载体(Thermo Fisher Scientific,A14697),产生单链双抗体(scDb)。这些蛋白质由约翰·霍普金斯大学的真核组织培养核心设施(Eukaryotic Tissue Culture Core Facility of Johns Hopkins University.)表达。简而言之,用PEI以1:3的比例将1mg质粒DNA转染到2-2.5x106细胞/mL的密度的1L FreeStyle293-F细胞中,并在37℃下培养。转染后五天,收集培养基并通过0.22μm单位过滤。使用HisPur Ni-NTA树脂(Thermo Fisher Scientific,88222)纯化scDb,并使用7k MWCO Zeba旋转脱盐柱(Thermo Fisher Scenetic,89890)将其脱盐至PBS pH 7.4或20mM Tris pH9.0、150mM NaCl中。使用4-15%Mini-PROTEAN TGX凝胶(Bio-Rad,Hercules,CA,4568085)和/或nanodrop(Thermo Fisher Scientific)对蛋白质进行定量。蛋白质在4℃下用于短期储存,或在添加7%甘油的情况下快速冷冻,并储藏在-80℃下用于长期储存。或者,scDb蛋白由GeneArt(Thermo Fisher Scientific)在Expi293s中生产,用HisTrap柱(GEHealthcare,17-5255-01)纯化,然后用HiLoad Superdex 20026/600柱(GE Heathcare,28989335)尺寸排阻层析。
p53R175H/HLA-A*02:01对H2-scDb的表面等离子体共振亲和性测量
使用Biacore T200 SPR仪器(GE Healthcare),在25℃下进行生物素化的p53R175H/HLA-A*02:01、p53WT/HLA-A*02:01和H2-scDb结合实验。使用链霉亲和素芯片在流动池(Fc)2和4中分别捕获了生物素化的p53R175H/HLA-A*02:01和p53WT/HLA-A*02:01的约100-110个反应单位(RU)。通过注入递增浓度(3、12、50、200至800nM)的流经Fc 1-4的纯化克隆H2-scDb,进行单循环动力学分析。动力学分析的结合反应均扣除空白和参比。使用Biacore Insight评估软件,用1:1结合模型拟合两条结合曲线。
TP53的CRISPR介导的敲除
使用Alt-R CRISPR系统(IDT)从KMS26、TYK-nu和KLE细胞系中敲除TP53基因。将靶向TP53外显子3(p53-5:CCCCGGACGATATTGACAA(SEQ ID NO:191)或p53-6:CCCCTTGCCGTCCAAGCA(SEQ ID NO:202))的CRISPR Cas9 crRNA以及CRISPR-Cas9 tracrRNA以100μM重悬浮在无核酸酶的双链体缓冲液中。在95℃下以1:1摩尔比将crRNA和tracrRNA双链化5分钟。使双链RNA冷却至室温,然后与Cas9核酸酶以1.2:1摩尔比混合15分钟。将总共40pmol的Cas9 RNP与TP53 gRNA复合物与200000个细胞在20μL OptiMEM中混合。将该混合物加到0.1cm比色皿(Bio-Rad,1652089)内,并使用ECM 2001(BTX,Holliston,MA)在120V和16ms电穿孔。立即将细胞转移到完全生长培养基中培养7天。通过限制性稀释建立单细胞克隆,并使用Quick-DNA 96试剂盒(Zymo Research,Irvine,CA,D3012)收集基因组DNA。PCR扩增CRISPR切割位点两侧的区域(正向引物:GCTGCCCTGGTAGGTTTCT(SEQ ID NO:203),反向引物:GAGACCTGTGGGAAGCGAAA(SEQ ID NO:204)),并进行Sanger测序以筛选具有所需TP53状态的克隆。
免疫印迹分析
细胞在补充有蛋白酶抑制剂混合物(Thermo Fisher Scientific,87785)的冷RIPA缓冲液(Thermo Fisher Scientific,89901)中裂解。使用BCA分析测定蛋白质浓度(Thermo Fisher Scientific,23227)。将等量的总蛋白(20-50μg)装载在4-15%Mini-PROTEAN TGX凝胶(Bio-Rad,4568085)的每条泳道中,并在电泳后转移到聚偏二氟乙烯膜上。将膜与适当的一抗(p53[DO-1],1:1000,Santa Cruz,sc-126;STAT2,1:1000;ThermoFisher Scientific,44-362G;ZFP3,1:1000,Thermo Fisher Sciencific,PA5-62726;β-肌动蛋白[13E5],1:1000,Cell Signaling Technology,5125S;β-肌动蛋白[8H10D10],1:1000,Cell Signaling Technologies,3700S)和物种特异性HRP-偶联二抗(1:5000-10000)一起孵育。信号由ChemiDoc MP化学发光系统(Bio-Rad)检测。
细胞系的转染
编码HLA和靶蛋白的gBlock(IDT)被克隆到pcDNA3.1或pcDNA3.4载体中(ThermoFisher Scientific,V79020,A14697)。使用Lipofectamine 3000(Thermo FisherScientific,L300015)在70-80%汇合时转染COS-7、Saos-2和HEK293FT细胞,并在37℃下孵育过夜。总共15μg和30μg质粒(共转染中HLA质粒/靶蛋白质粒的1:1比例)分别用于T25和T75烧瓶。
细胞系的病毒转导
使用MSCV逆转录病毒表达系统(Clontech,加利福尼亚州山景城,634401)产生编码HLA-A*02:01的逆转录病毒。简而言之,通过HiFi DNA组件(New England Biolabs,Ipswich,MA,E2621L)将编码HLA-a*02:01-T2A-GFP(IDT)的gBlock克隆到pMSCVpuro逆转录病毒载体中。然后将pMSCVpuro-HLA-A*02:01-T2A-GFP质粒与pVSV-G包膜载体共转染到GP2-293包装细胞系中。转染48小时后收集病毒上清液,并使用Retro-X浓缩器(Clontech,631456)将其浓缩20倍。使用RediFect Red-Fluc-GFP慢病毒颗粒(Perkin Elmer,Waltham,MA,CLS960003)产生荧光素酶表达细胞系。
对于转导,非组织培养处理的48孔板在4℃下用200μL的10μg/mL RetroNectin(Clontech,T100B)/孔包被过夜,并在室温下用10%FBS封闭一小时。在总体积为500μL的细胞培养基中向每个孔中加入病毒颗粒和2x105靶细胞,并在2000x g下旋转1小时,然后在37℃下孵育。三天后开始用1μg/mL嘌呤霉素(Thermo Fisher Scientific,A1113803)进行筛选。转导后10-14天,使用FACSAria fusion(BD Biosciences,San Jose,CA)基于GFP的存在对转导细胞进行分选。
体外scDb共孵育分析
在96孔平板的每个孔中,在100μL的最终体积含10%FBS、1%青霉素链霉素,和100IU/mL IL-2的RPMI-1640中混合以下组分:双特异性抗体,稀释至指定浓度,5x104人T细胞和1-5x104靶细胞(COS-7、T2或其他肿瘤细胞系)。效靶细胞比标记在每个实验的图例中。将共培养板在37℃下孵育20小时,并使用人IFN-γQuantikine试剂盒(R&D Systems,Minneapolis,MN,SIF50)、人IFN-γFlex-Set流式细胞术珠阵列(BD,558269)、或在Bioplex200平台(Bio-Rad)上读取的MILLIPLEX Luminex分析(Millipore Sigma、HSTCMAG28SPMX13、HCD8MAG-15K)分析条件培养基的细胞因子和细胞毒性颗粒蛋白分泌。根据制造商的说明,通过CellTiter-Glo发光细胞活力分析(Promega,麦迪逊,WI,G7571)或Bio-Glo荧光素酶分析(Promega,G7941)测定细胞毒性。对于CellTiter-Glo分析,通过减去从仅T细胞孔的平均值的发光信号并对无scDb条件归一化来计算细胞毒性百分比:1-(scDb孔-仅T细胞)/(无scDb孔-仅T细胞)x 100。对于Bio-Glo分析,通过将发光信号归一化为无scDb条件来计算细胞毒性百分数:1-(scDb孔)/(无scDb孔)x 100。
实时活细胞成像
总共将1x104CellTracker Green CMFDA(Thermo Fisher Scientific,C7025)标记的靶细胞铺在96孔平底平板的每个孔中,并在以所示的E:T比和浓度分别添加T细胞和scDb之前使其附着8小时。每个条件以一式三份铺板。使用Inucyte ZOOM活细胞分析系统(Essen Bioscience,Ann Arbor,MI)每3小时对平板进行一次成像,共60小时。在每个时间点,每孔采集四张10倍放大的图像。使用相相差通道定量每个孔中的细胞汇合。
p53R175H/HLA-A*02:01的表达、纯化和重折叠
HLA-A*02:01和β2M的质粒来自NIH Tetramer Facility(佐治亚州亚特兰大),并分别转化到BL21(DE3)细胞中。如其他地方所述,使用自动诱导培养基在包涵体中表达每个质粒(Skora等人,Proc.Natl.Acad.Sci.U.S.A.,112:9967-9972(2015);Martayan等人,TheJournal of Immunology,182:3609-3617(2009);和Huang等人,Bioinformatics 26:680-682(2010))。HLA-A*02:01和β2M包涵体的纯化是通过一系列去污剂洗涤,然后用8M尿素溶解而实现的。HLA-A*02:01、β2M和突变p53R175H肽的重折叠如其他地方所述进行(Myszka,J.Mol.Recognit.12:279-284(1999))。简而言之,HLA-A*02:01和β2M包涵体在重折叠缓冲液中混合,该缓冲液包含100mM Tris pH 8.3、400mM L-精氨酸、2mM EDTA、5mM还原型谷胱甘肽、0.5mM氧化型谷胱甘肽、2mM PMSF和30mg溶于1mL DMSO的突变p53R175H肽(氨基酸168-176,HMTEVVRHC(SEQ ID NO:1))。将所得溶液在4℃下搅拌2天,第2天再添加两次HLA-A*02:01包涵体,浓缩至10ml,并在HiLoad 26/60Superdex 75预备级柱(GE Healthcare,28989334)上通过尺寸排阻色谱法纯化。为了与H2-Fab孵育,将纯化的pHLA-A*02:01浓缩至约1-3mg/mL,并在-80℃下储存,直至使用。
H2-Fab抗体片段的生产
移植H2 scFv的轻链(LC)和重链(HC)可变区序列,分别与人IgG1的相应恒定区序列连接,并分别克隆到pcDNA3.4载体(Thermo Fisher Scientific,A14697)中。两条链的前面都有小鼠IgKVIII信号肽。在大规模表达全长抗体之前,对转染的LC:HC DNA比进行优化,以确定最佳重组蛋白产量。对于1L表达,用PEI以1:3的比例将总共50μg纯化质粒(1:1LC:HC比例)转染到FreeStyle 293-F细胞中,密度为2-2.5x106个细胞/mL,并在37℃下培养7天。离心收集培养基,通过0.22μm单位过滤,并通过HiTrap MabSelectTM SuReTM柱(GEHealthcare,29-0491-04)的蛋白A亲和层析纯化全长抗体。使用0-100mM柠檬酸钠(pH 3.5)的线性梯度洗脱全长抗体。合并含有纯H2抗体的蛋白A级分,通过SDS-PAGE凝胶电泳定量,并透析至pH 7.0、10mM EDTA的20mM磷酸钠缓冲液中。
为了产生H2-Fab片段,将约1-3mg全长抗体与0.5ml 50%固定化木瓜蛋白酶浆料(Thermo Fisher Scientific,20341)混合,该浆料用含有20mM半胱氨酸-HCl的消化缓冲液(20mM磷酸钠缓冲液,pH 7.0,10mM EDTA)预活化。混合物在37℃下孵育过夜,并以200rpm持续振荡。通过重力树脂分离器将H2抗体消化物与固定化树脂分离,并用pH 7.5的10mMTris-HCl洗涤。使用Mono-S柱(GE Healthcare,17516801)通过阳离子交换色谱法进一步纯化新生成的H2-Fab片段,并使用0-500mM NaCl的线性梯度洗脱。
将H2-Fab片段浓缩,与等摩尔p53R175H/HLA-A*02:01混合,并在4℃下孵育过夜。H2-Fab–p53R175H/HLA-A*02:01混合物通过尺寸排阻色谱法在SuperdexTM200Increase 10/300柱(GE Healthcare,28990944)上进行评估。将约98%纯的pHLA-A*02:01–H2-Fab复合物的级分合并,浓缩至12.6mg/mL,并交换到含有25mM HEPES、pH 7.0、200mM NaCl的缓冲液中。
结晶、数据收集和结构确定
三重复合物H2-Fab-p53R175H/HLA-A*02:01的晶体在悬滴蒸气扩散中生长,液滴由TTP蚊子机器人设置,储液罐溶液为0.2M氯化铵和20%(w/v)PEG 3350MME。晶体在母液中快速冷冻。在National Synchrotron Light Source-II的位于DECTRIS Eiger X 9M探测器上的光束线17-ID-1(AMX)和位于Dectlis Einger X 16M探测器上的光束线17-ID-2(FMX)处收集数据。使用fastdp、XDS和aimless对数据集进行索引、整合和放大。H2-Fab-p53R175H/HLA-A*02:01的单斜晶体衍射分辨率为 H2-Fab–p53R175H/HLA-A*02:01复合物的结构通过使用PDB ID6O4Y(11)和6UJ9作为检索模型的PHASER分子置换来确定。使用REFMAC5迭代优化和在Coot中手动重建,将数据优化至最终分辨率
H2-Fab–p53R175H/HLA-A*02:01复合物的结构通过使用PDB ID6O4Y(11)和6UJ9作为检索模型的PHASER分子置换来确定。使用REFMAC5迭代优化和在Coot中手动重建,将数据优化至最终分辨率 使用Coot和PDB沉积工具验证结构。根据Ramachandran统计(表7),该模型在优选和允许区域中有94.11%的残基。图以PyMOL(v2.2.3,
使用Coot和PDB沉积工具验证结构。根据Ramachandran统计(表7),该模型在优选和允许区域中有94.11%的残基。图以PyMOL(v2.2.3, LLC,New York,NY)呈现。使用PDBePISA计算掩埋面积。通过由肽P1-P9的α碳位置确定的向量和由VH和VL结构域中二硫键确定的向量点积计算决定pHLA和Fab/TCR之间相对取向的角度。
LLC,New York,NY)呈现。使用PDBePISA计算掩埋面积。通过由肽P1-P9的α碳位置确定的向量和由VH和VL结构域中二硫键确定的向量点积计算决定pHLA和Fab/TCR之间相对取向的角度。
小鼠异植物模型
6-8周龄的雌性NOD.Cg-PrkdcscidIl2rgtm1Wjl/SzJ(NSG)小鼠从杰克逊实验室(缅因州巴尔港,005557)获得,并按照机构动物护理和使用委员会批准的方案进行治疗。在早期治疗模型中,在第0天通过侧尾静脉注射将1x106表达荧光酶的KMS26或KMS26-TP53 KO细胞和1x107体外扩增的人T细胞静脉接种到小鼠体内。在第1天,使用IVIS成像系统和LivingImage软件(Perkin Elmer)基于发光定量对小鼠进行随机分组,以确保类似的预处理肿瘤负荷。随机化后,使用无菌手术技术,将注入了H2-scDb或同种型对照scDb(针对与UCHT1scFv连接的无关pHLA的scFv)的两周微渗透泵(ALZET,Cupertino,CA,1002)置于腹膜内,该泵已在37℃下在1ml PBS中引发过夜。通过生物发光成像系列监测肿瘤生长。在建立的肿瘤模型中,在第0天通过侧尾静脉注射将3.5x105表达荧光素酶的KMS26细胞和1x107人T细胞接种给小鼠。在第6天,与早期治疗模型中相似地给予H2-scDb或同种型对照scDb。
统计分析
数据表示成平均值±SD。用图例中指明的特定测试进行统计学分析。用P值<0.05表示统计学显著。所有分析用Prism8.0版(GraphPad,San Diego,CA)进行分析。
实施例3:靶向突变RAS新抗原的双特异性抗体
RAS癌基因的突变发生在多种癌症中,几十年来,靶向这些突变的新方法一直是密切研究的主题。由于RAS蛋白是细胞内的,因此这些研究大多集中在传统的小分子药物上,而不是基于抗体的治疗。
本实施例鉴定了源于两种复发性RAS突变G12V和Q61H/L/R的肽的特异性scFv,这两种突变分别在两种常见的人白细胞抗原等位基因HLA-A3和HLA-A1的情况下存在于癌细胞上。scFv不识别来自野生型(WT)形式的RAS蛋白的肽或其他相关肽。鉴于它们在癌细胞的抗原密度极低,开发了一种非常灵敏的免疫治疗剂来杀死携带RAS基因突变的细胞。对源自G12V或Q61H/L/R的肽具有特异性的单链双抗体(scDb)能够诱导T细胞活化并杀死表达内源水平的突变RAS蛋白和同源HLA等位基因的靶癌细胞。
结果
来源于临床相关RAS基因突变的MANA
计算机预测表明,密码子5-14的10肽(KLVVVGAVGV,“G12V[5-14]”;SEQ ID NO:209,其中下划线的缬氨酸残基(V)代表G12V突变)将与HLA-A*02:01(以下称为HLA-A2)结合(参见Skora等人,Proc Natl Acad Sci U S A 112:9967-9972(2015);和Andreatta,Bioinformatics 32:511-517(2016))。先前报道了一种结合到该pHLA-A2复合物但未结合到野生型(WT)对应物的MANA抗体(称为D10),其通过连接到人工表面的pHLA复合物以及使用突变肽脉冲的细胞证明具有选择性结合(Skora等人,Proc Natl Acad Sci U S A112:9967-9972(2015))。然而,不能证明D10 MANA抗体可以与表达内源水平的突变KRAS基因的细胞结合,或甚至与过表达外源性突变KRA基因的细胞结合。据推测,尽管采用了计算机算法进行预测,KRAS蛋白并未加工成G12V[5-14]肽并转运至细胞表面。这种计算机预测确实存在不准确的先例(Schmidt等人,J Biol Chem 292:11840-11849(2017))。为了评估这种可能性,开发了一种基于高灵敏度质谱(MS)的方法(MANA-SRM)来分析HLA结合肽。在用SV40病毒不死化的猴肾COS-7细胞中表达人HLA-A2和含G12V的全长人KRAS,并免疫纯化HLA结合肽。洗脱肽的MS分析表明,即使突变KRAS基因过表达,也无法检测到G12V[5-14]肽(表10)。得出的结论是,该肽未被加工并递呈在携带KRAS G12V突变基因的HLA-A2+细胞上。
表10.MANA-SRM定量。使用基于质谱的方法MANA-SRM对每个细胞的突变相关新抗原(MANA)肽进行定量。COS-7细胞与编码HLA等位基因和全长KRAS变体的质粒共转染。为了评估MANA的内源性表达,分析了携带HLA等位基因和感兴趣的RAS变体的细胞系。

因此,关注的是两种肽,一种是来自密码子8到16(“G12V[8-16]”的9-聚体(VVGAVGVGK;SEQ ID NO:206),另一种是密码子7到16(“G22V[7-16]”)的10-聚体,含有RASG12V突变,NetMHCv4.0预测该突变以高亲和力结合HLA-A*03:01(此后称为HLA-A3)(Andreatta,Bioinformatics 32:511-517(2016))。HLA-A3是最常见的HLA-A等位基因之一。MANA-SRM用于确认计算机预测,即在筛选MANA抗体之前,这些肽复合物将显示在细胞表面。人HLA-A3和全长人KRAS G12V在COS-7细胞中表达,然后用抗人HLA抗体进行免疫纯化。从捕获的肽-HLA复合物洗脱的肽的MS分析检测到G12V[7-16]肽在每个细胞有102个拷贝,G12V[8-16]肽的水平相当低(每个细胞24个拷贝)(图45A,表10)。重要的是,当用HLA-A2和KRAS G12V转染COS-7细胞作为阴性对照时,未检测到这些肽(表10)。然后对两种人癌细胞系进行MANA-SRM分析,即肺腺癌细胞系NCI-H441和胰腺导管腺癌细胞系CFPAC-1,两者均表达内源水平的HLA-A3并携带KRAS G12V突变。CFPAC-1和NCI-H441品系平均每个细胞分别呈现3和9个拷贝的G12V[7-16]肽(图45,B和C,表10),未检测到G12V[8-16]肽。鉴于10-聚体G12V[7-16](此后称为“G12V”)肽的丰度更高,致力于靶向该MANA。
RAS基因中另一个常见的突变残基是密码子61处的谷氨酰胺。RAS密码子61突变存在于多种癌症中,包括黑色素瘤、多发性骨髓瘤、甲状腺癌和膀胱癌。使用NetMHCv4.0,预测10-聚体RAS肽(密码子55至64)可以与另一种常见的HLA-A等位基因HLA-A*01:01(此后称为HLA-A1)高亲和力结合(Maiers等人,Hum Immunol 68:779-788(2007))。该肽(ILDTAGQEEY;SEQ ID NO:136)以及侧翼氨基酸在所有三种RAS蛋白中都是保守的。使用MANA-SRM,先前评估了包含Q61H、Q61L和Q61R突变的密码子55至64的10聚肽(分别为ILDTAGHEEY(SEQ ID NO:2),ILDTAGLEEY(SEQ ID NO:3),和ILDTAGREEY(SEQ ID NO:4)的细胞表面表达,在转染的COS-7过表达系统中,发现每个细胞的Q61H,Q61L和Q61R肽为平均583,512和127个拷贝(Wang等人,Cancer Immunol Res 7:1748-1754(2019))。这些肽也被鉴定存在于表达内源水平的Q61突变体RAS蛋白的细胞系上,特别是在急性早幼粒细胞白血病细胞系HL-60中发现每个细胞有4个Q61L肽拷贝(表10)。
总之,这些数据表明,G12V和Q61突变RAS蛋白可以加工成在癌细胞系表面递呈的肽,尽管抗原密度低于基于常规抗体的免疫治疗剂识别所需的最低值。
针对HLA限制性RAS突变肽的scFv表达噬菌体克隆的鉴定
为了开发靶向上述RAS肽的MANA抗体,构建了展示scFv的第二个噬菌体文库。该文库是根据其他地方描述的原理设计的(Skora等人,Proc Natl Acad Sci U S A 112:9967-9972(2015)),但进行了重要修改。特别是,使用三核苷酸诱变(TRIM)技术合成前体文库DNA,允许在被认为对抗原结合最关键的特定密码子处微调氨基酸多样性。在六个互补决定区(CDR)中的五个引入多样性,在重链的第三个CDR(CDR-H3)中引入了最多的氨基酸多样性和长度多样性(图46A和B)。完成的文库估计包含约3.6x1010个独特克隆。作为质量控制步骤,对文库的一分进行了重链CDR3区域的大规模平行测序,表明预期和实际的氨基酸多样性非常一致(图46C)。
对于RAS G12V HLA-A3 MANA靶,将HLA-A3和β-2-微球蛋白与化学合成的G12V肽或其WT[7-16](G12WT)对应物折叠在一起,形成pHLA复合物(表11)。然后使用这些pHLA-A3筛选上述噬菌体展示文库。筛选过程包括四到六轮噬菌体筛选,类似于前面描述的方案,材料和方法中描述了关键差异。在该筛选过程中,噬菌体对可溶性链霉亲和素、链霉亲和蛋白磁珠、变性HLA-A3、非相关pHLA-A3和G12WT pHLA-A1负筛选,对G12V pHLA-A3正筛选。在筛选过程之后,扩增单个噬菌体克隆并进行酶联免疫吸附试验(ELISA),以评估其结合特异性(图47A)。虽然多个克隆最初似乎在ELISA上对质体结合的pHLA复合物很有前景,但在随后对展示这些复合物的细胞进行的流式细胞术分析中,一个噬菌体克隆(V2)脱颖而出(图47B,表12)。与其他pHLA-A3相比,V2噬菌体与G12V pHLA-A3的结合显著更大,这些pHLA-A3包括与G12WT肽、G12C或G12D变体或非相关CTNNB肽折叠的HLA-A3形成的噬菌体(图47C,表11)。V2噬菌体也未能检测到与G12V[8-16]或G12WT[8-16]肽折叠的HLA-A3的相互作用(图47C,表11)。
表11.对于pHLA复合物的肽。使用NetMHCv4.0预测用于pHLA复合物的肽与感兴趣的HLA等位基因的结合。






然后在细菌中表达和纯化噬菌体的scFv组分以进一步表征。重组V2scFv保留与其噬菌体对应物相同的结合情况(图47D),在测试的最高浓度下与WT-pHLA复合物的结合最小(图38A)。用G12V肽或多种对照肽脉冲经修饰以表达HLA-A3的TAP缺陷型T2细胞(T2A3),并评估细胞与V2 scFv或HLA-A3特异性单克隆抗体的结合。流式细胞术分析显示,与用G12WT、G12C或G12D RAS肽脉冲的细胞相比,V2 scFv与G12V肽脉冲的T2A3细胞具有显著的特异性结合(图38B、图47E)。如ELISA分析,V2 scFv无法检测到与9-聚[8-16]肽脉冲的细胞结合,无论是突变型还是WT。V2 scFv的表面等离子体共振(SPR)结合分析显示G12V pHLA-A3的KD值为8.7nM,而未发现与G12WT pHLA-A3的明显结合(图38C)。
对RAS Q61H、Q61L和Q61R pHLA-A1 MANA靶使用了类似的筛选程序(见材料和方法)。使用噬菌体染色和基于T细胞的分析,鉴定出一个噬菌体克隆,对三个靶标中的每一个都显示出高特异性:克隆H1对于Q61H,克隆L2对于Q61 L,克隆R6对于Q61R(图48,A至F和表12)。这些克隆与其同源突变体pHLA结合,没有检测到与RAS Q61WT pHLA-A1结合(图38,D至F)。为了进一步评估与细胞表面pHLA复合物的结合,用同源肽或对照物对HLA-A1+急性髓系白血病细胞系SigM5进行脉冲。所有三个克隆特异性结合来自突变RAS基因的预期pHLA复合物(图38G)。鉴于Q61L肽在转染的COS-7细胞上的高效递呈(27)及其与肽脉冲的SigM5细胞的更高水平结合,大多数后续实验集中在Q61L克隆L2上。L2克隆的SPR分析显示Q61L pHLA-A1的KD为65nM,并且没有明显的与Q61WT pHLA-A1的结合(图38H)。
与双特异性抗体接合的T细胞可以识别突变RAS衍生的pHLA复合物
已经开发了多种接合T细胞的双特异性抗体形式,用于将T细胞靶向特定配体。然而,关于这些形式中的任何一种在细胞表面以低密度递呈时是否能够识别靶标的数据很少。为了说明这一点,评估了六种双特异性形式:双抗体、单链双抗体(scDbs)、双特异性T细胞接合子(BiTE)、双亲和性重靶向分子(DART)、二价scFv-Fc和三价scFv-FC(图49A)。scFv-Fcs通过杵臼法异源二聚。V2 scFv用作pHLA靶向部分,不同的抗CD3抗体用于接合T细胞(表12和13)。在几种形式中,测试了V2和抗CD3 scFv的重链(“H”)和轻链(“L”)的不同构型(图49B)。
















总之,在HEK293细胞中表达了42种重组蛋白,以确定最有效的形式和构型(图49,A和B)。在不同的双特异性蛋白浓度下,通过ELISA评估与G12V pHLA-A3和重组CD3ε/δ蛋白的结合(图49C)。虽然少数形式表现出与一种或两种抗原的弱结合,但大多数在ELISA上具有相似的性能特征(图49C)。为了进一步比较形式,用两种浓度的G12V肽脉冲T2A3细胞,并以两种浓度与T细胞和每种V2双特异性蛋白共培养,然后测量IFNγ释放以评估T细胞活化(图49D)。尽管它们在ELISA分析中表现相似,但双特异性形式在细胞上低抗原密度下识别G12V肽的能力是高度可变的。scDb通常比其他形式表现更好,尤其是在抗体浓度较低的情况下。切换类似蛋白质中的重可变域和轻可变域的顺序(“LHLH”转换为“HLHL”)消除了它们活化T细胞的能力,尽管这些形式在ELISA上显示出同等的功能(图49)。类似地,虽然二价scFv-Fc和三价scFv-Fc在ELISA中表现特别好,但在肽脉冲细胞中评估时,它们的表现一直很差。
在形式和构型的初始测试中,使用了五种不同的抗CD3 scFv。基于表明scDb表现最佳的结果,测试了另外七个抗CD3克隆(表12和13)。总共表达、纯化了12个V2 scDb(图50A),然后用ELISA测试其结合CD3ε/δ蛋白的能力(图50B)。使用两个靶细胞系进一步评估这些V2 scDb。第一种是KRAS G12V和HLA-A3共转染的COS-7,第二种是肺癌细胞系NCI-H441,其表达内源性HLA-A3和突变KRAS G12V。在与COS-7过表达系统的共培养实验中,10个scDb活化了T细胞,如大量IFNγ释放所示(图50C)。然而,对于NCI-H441细胞,只有含有UCHT1(“U”)和UCHT1.v9(“U2”)抗-CD3克隆的scDb活化T细胞(图50D),基于UCHT1的scDb(图39A)表现特别好。两种scDb(以下分别称为V2-U和V2-U2)(表12和13)保留了V2噬菌体对G12V pHLA-A3的显著特异性,因为它们未能与和其他RAS肽或不相关的CTNNB肽折叠的pHLA-A3相互作用(图39B、图51A)。它们还与CD3ε/δ异二聚体结合(图2B、图51A)。如“夹心”ELISA所示(图51B),两种scDb可同时与G12V pHLA-A3和CD3ε/δ异二聚体相互作用,表明蛋白质折叠并正常发挥功能。鉴于所有这些关于相对表达、ELISA和细胞反应性的数据,V2-UscDb(N-端-LV2-HU-LU-HV2-C-端)被选为大多数进一步研究的重点(图39A),尽管V2-U2也被用于筛选分析。
基于对G12V克隆V2的研究,将Q61 scFv克隆H1、L2和R6移植到优化的scDb格式中,以产生H1-U、L2-U和R6-U scDb。所有三种scDb在ELISA上均保持与其同源突变体衍生的Q61pHLA-A1和重组CD3ε/δ的结合,并且没有一种与Q61WT pHLA或其他包括无关的CMV pHLA的对照pHLA表现出明显的结合(图39,C至E和图51,C至E,表11)。这一结果表明,基于RASG12VscFv选择的形式和构型是可推广的,并适用于其他三种具有不同氨基酸序列和独立靶点的scFv。
SCDB识别用低纳摩尔浓度外源肽脉冲的细胞
为了评估活化T细胞所需的靶抗原的最小浓度,用G12V或G12WT肽脉冲T2A3细胞,然后在V2-U scDb存在下与健康供体T细胞共培养。T细胞在低至1nM的G12V肽浓度下活化,IFNγ和TNFα分泌证明了这一点(图40A、图52A)。此外,即使在低肽浓度下,scDb也介导肽脉冲T2A3细胞的抗原依赖性裂解(图40B)。当细胞用G12WT肽脉冲时,没有明显背景细胞因子分泌或细胞杀伤。类似地,V2-U2 scDb也出现了特异性活化(图40,A和B)。
为了确定肽脉冲-T2A3细胞上的大致抗原密度,用V2 scFv对细胞进行染色,并通过流式细胞术进行评估。使用QIFIKIT和Quantibrite珠测定抗原密度,从而可以定量测定细胞表面抗原分子的数量(图52B)。发现用320nM G12V肽脉冲的细胞表达300至800个抗原分子/细胞。这种流式细胞术方法不具有检测用小于320nM的G12V肽脉冲的细胞所需的灵敏度。然而,低300倍浓度的脉冲G12V肽可以活化T细胞(图40B)。虽然脉冲肽的浓度与细胞表面显示的肽抗原的数量之间可能没有线性关系,但这些结果表明,V2-U scDb识别的每个细胞的抗原分子数量远小于300。用HLA-A3+单核细胞来源的未成熟树突细胞(iDC)进行类似的肽脉冲实验,以递呈肽并测定T细胞的IFNγ和TNFα分泌。当iDC在低纳摩尔范围内用G12V肽脉冲时,V2-U和V2-U2 SCDB都能够活化T细胞(图52、C和D)。
用肽脉冲的SigM5细胞和iDC对靶向RAS Q61的scDb进行了类似的实验。当用浓度低至1nM的Q61L肽脉冲靶细胞时,L2-U scDb引发T细胞活化,如IFNγ分泌和SigM5细胞毒性所示,而与Q61WT肽无交叉反应(图40、C和D)。虽然H1-U和R6-U scDb也没有显示出明显的Q61WT肽交叉反应性,但它们需要多100倍的肽(100nM)才能活化T细胞(图52,E至H)。同样,与H1-U和R6-U scDb相比,L2-U scDb可以在iDC存在下以更低的肽浓度活化T细胞(图52,I至N)。
scDb识别过表达HLA和突变RAS基因的COS-7细胞
COS-7细胞用编码HLA-A3和突变型或WT全长KRAS的质粒共转染(图53A),然后与T细胞共培养。如结果第一节所述,COS-7细胞每细胞表达约100拷贝的G12V pHLA复合物。添加V2-U scDb导致仅在与编码HLA-A3和KRAS G12V的质粒共转染的COS-7细胞存在的情况下,以剂量依赖性方式从T细胞分泌IFNγ和TNFα(图41A、图53B)。在本实验中,仅10pM的V2-U scDb也可以活化T细胞(图41A、图53B)。在存在30pM V2-U2 scDb的情况下,观察到转染的COS-7细胞对T细胞的类似活化(图53、C和D)。IFNγ和TNFα的分泌具有高度特异性,因为表达HLA-A3和WT、G12C或G12D KRAS的靶细胞不会触发这些细胞因子的分泌(图41A、图53、B至D)。
用靶向突变RAS Q61的H1-U、L2-U和R6-U scDb进行了类似实验。用编码HLA-A1和全长WT或突变HRAS、KRAS或NRAS的质粒共转染COS-7细胞,以评估每个scDb是否能够识别源自每个RAS蛋白的同源突变肽。无论评估的RAS基因是什么,每个scDb都会引发对表达具有感兴趣的Q61突变的RAS基因的COS-7细胞高度特异的T细胞反应(图41,B至D)。亚纳摩尔浓度的scDb足以在与三个基因中任何一个携带Q61突变的COS-7细胞共培养时活化T细胞。此外,当与表达WT或含有非同源Q61突变的HRAS、KRAS或NRAS基因的COS-7细胞共培养时,未观察到T细胞活化(图41,B至D)。
当接触含有内源性突变RAS基因的癌细胞时,scDb活化T细胞
如上所述,NCI-H441癌细胞系的每个细胞仅递呈约9个拷贝的突变衍生KRAS G12VpHLA复合物(表10)。尽管靶肽水平极低,但在V2-U scDb存在下,NCI-H441细胞可活化T细胞,IFNγ分泌和细胞毒性证明了这一点(图42,A和B)。V2-U的效力很高,IFNγ分泌和细胞毒性的EC50分别为140pM和76pM(图42,A和B)。为了严格评估V2-U scDb的特异性,通过基于CRISPR的技术在NCI-H441细胞中破坏HLA-A3等位基因,并通过流式细胞术确认敲除(KO)(图54)。HLA-A3等位基因的KO消除了V2-U scDb在暴露于靶NCI-H441细胞时诱导T细胞分泌IFNγ或细胞毒性的能力(图42、C和D)。然后使用基于CRISPR的技术在含有内源性HLA-A3等位基因的亲代NCI-H441细胞中用KRAS G13D替换(“敲入”[KI])KRAS G12V(图55)。G12V被G13D替换,而不是敲除G12V等位基因,因此维持细胞的活力,这需要突变KRAS基因。测试了两个具有KRAS G13D取代的独立NCI-H441克隆,两个克隆均基本上消除了在NCI-H 441细胞存在下V2-U scDb活化T细胞的能力(图42、C和D)。类似地,使用V2-U2 scDb观察到与NCI-H441细胞共培养的T细胞的特异性活化,但正如预期的那样,V2-U2 SCDB的效力不如V2-UscDb大(图56)。在所有具有内源性水平的HLA-A3和G12V等位基因的实验中(图42、A和C,图56A),T细胞的IFNγ分泌明显低于被转染的COS-7细胞活化的T细胞(图41A、图539C),这与转染的COS-7细胞上较大量的pHLA复合物一致。即便如此,SCDB仍能够通过以KRAS G12V和HLA依赖性方式活化T细胞诱导高效的NCI-H441靶细胞裂解(图42、B和D、图56B)。此外,其他T细胞活化标志物(TNFα、IL-2、颗粒酶B和穿孔素)以剂量依赖性方式释放,表明V2-U scDb能够诱导针对表达极低水平抗原的细胞的多功能T细胞反应(图57)。
为了进一步评估V2-U scDb的特异性,使用了第二个细胞系NCI-H358。该肺癌细胞系含有HLA-A3等位基因和KRAS G12C突变。使用CRISPR,在三个独立克隆的KRAS基因座引入G12V突变(图55)。所有三个G12V克隆都能够在V2-U scDb存在下诱导T细胞分泌细胞因子,而亲代细胞或保留G12C等位基因的克隆则不能(图42E)。对G12V克隆的细胞毒性也比对没有G12V等位基因的同基因NCI-H358细胞的细胞毒性大得多,尤其是在亚纳摩尔scDb浓度下(图42F)。类似地,在V2-U2 scDb存在下将这些细胞与T细胞共培养时,观察到特异性细胞因子分泌和细胞毒性(图58)。所有NCI-H358变体表达的HLA-A3水平大致相同(图54)。
评估了T细胞与其他几种没有RAS G12V突变的HLA-A3+癌细胞系共培养中的IFNγ分泌。这些细胞系包括A-427(肺腺癌)、COLO 741(黑色素瘤)、Hs578T(乳腺浸润性导管癌)、Jurkat(急性T细胞白血病)、SK-MES-1(肺鳞状细胞癌)和SW780(膀胱移行细胞癌)。还评估了CFPAC-1、KRAS G12V和HLA-A3+胰腺癌细胞系,该细胞系平均每个细胞仅有约3个G12V肽拷贝(表10)。通过流式细胞术证实所有这些细胞系中HLA-A3的表达(图54)。V2-U和V2-U2scDb均未使得与没有KRAS G12V突变的癌细胞系共培养的T细胞产生明显的IFNγ释放(图59)。V2-U scDb诱导CFPAC-1细胞释放低但显著更高水平的IFNγ(图59A);然而当使用V2-U2时,没有统计学显著差异(图59B)。
为了研究L2-U scDb诱导T细胞活化的能力,与RAS突变状态和HLA-A1表达不同的一组细胞系共培养(图43A,图60)。仅在含有HLA-A1和RAS Q61L等位基因的一个细胞系(HL-60)中观察到T细胞大量剂量依赖性IFNγ分泌(图43A)。如上所述,HL-60平均每个细胞呈现四个Q61L pHLA复合物。在滴定实验中,L2-U scDb能够诱导EC50为60pM的T细胞释放IFNγ(图43B),EC50为34pM的HL-60细胞死亡(图43C),尽管每个细胞的Q61L肽水平非常低。T细胞活化的其他标志物也以剂量依赖性方式释放,表明L2-U scDb与V2-U scDb一样,能够诱导多功能T细胞反应(图61)。为了评估HL-60细胞中L2-U scDb抗原决定簇的特异性,产生了这些细胞的NRAS Q61H-KI、Q61R-KI和HLA-A1-KO变体(图55)。这些实验证实,IFNγ分泌(图43D)和靶细胞毒性(图43E)取决于HL-60细胞中NRAS Q61L和HLA-A1基因的共同存在。
评估与其他假定的HLA-A1和HLA-A3结合肽的潜在交叉反应性
为了研究V2 scFv是否能与来自其他蛋白质的类似肽结合,使用G12V肽或其G12WT、G12C或G12D对应物的氨基酸序列进行了人RefSeq蛋白质组的蛋白质BLAST(BLASTp)检索。通过该检索鉴定出32种含有类似肽的蛋白质。其中,NetMHC v4.0预测17种肽与HLA-A3有强或弱结合(表14)。这17种肽中的每一种都被合成并用于脉冲T2A3细胞。虽然这些肽中的大多数结合HLA-A3,如GAP.A3抗体染色评估,V2噬菌体仅识别肽IIVGAIGVGK(“Blast2”;SEQ ID NO:260),一种源自蛋白Rab-7b的肽(图62A,表14)。




Rab-7b是一种在单核细胞和角质形成细胞中表达的RAS相关蛋白。为了研究该肽是否代表真实的替代靶点,从而可能导致V2-U scDb的脱靶毒性,T细胞首先与外周血单核细胞(PBMC)、单核细胞、iDC和从HLA-A3+供体制备的成熟树突细胞(mDC)共培养(图62、B和C)。如在V2-U scDb存在下通过IFNγ分泌评估的,这些细胞中没有一个能够显著活化T细胞至背景以上(图62C)。重要的是,当用G12V肽脉冲时,这些细胞具有活化T细胞的能力(图62C)。接下来,针对高度表达Rab-7b的皮肤衍生细胞系Hs 695T测试V2-U scDb(图62B)。由于这些细胞不表达HLA-A3等位基因,因此用HLA-A3或HLA-A2转染它们并与T细胞共培养。尽管内源性Rab-7b的表达水平较高,但在V2-U scDb存在下,Hs695T细胞并未活化T细胞。(图62D)。作为阳性对照,在用G12V肽脉冲Hs 695T细胞后进行相同的实验,在这些情况下,实现了T细胞强烈活化(图62D)。
作为与Rab-7b肽潜在交叉反应性的最终评估,将编码全长Rab-7b、KRAS WT或KRASG12V的质粒与HLA-A3组合转染入COS-7。在存在V2-U scDb的情况下,过表达突变KRAS的细胞诱导了强大的T细胞活化(图62E),而表达对照蛋白KRAS WT和Rab-7b的COS-7细胞仅显示非常低的非剂量依赖型相同T细胞的活化(图62,B和E)。在转染相同基因的HCT 116细胞中重复该实验,再次发现KRAS以突变依赖性方式活化T细胞,但在表达Rab-7b的细胞中未观察到活化(图62,B和F)。
为了进一步测定V2-U和L2-U scDb的潜在交叉反应性,评估了它们与位置扫描变体肽库的结合。肽库是通过用其他19种氨基酸系统取代原始肽的每个氨基酸而生成的。这导致V2和L2 scDb的G12V和Q61L肽各有190个变体。用变体肽脉冲T2A3细胞(V2-U scDb)或SigM5细胞(L2-U scDb),并与T细胞共培养。通过IFNγ释放评估变体肽的识别(图44、A和B、图63、A和B)。对于两种scDB,突变体残基所在的肽C端那半的氨基酸位置显示出更大的特异性。这些位置的大多数氨基酸变化消除了scDb的识别。另一方面,在许多情况下,肽N端的氨基酸可以被取代,而不会显著改变与scDb的相互作用。这些识别模式也如Seq2Logo图所示(图44C和D)。接下来,使用20%同源肽反应性作为每个位置允许氨基酸的截留值,为每个候选靶肽生成十聚体结合基序(材料和方法)。使用ScanProsite在UniProtKB人类蛋白质数据库中搜索这些基序,得到了162个可能结合V2的肽(包括Rab-7b IIVGAIGVGK(SEQ ID NO:260)),以及232个可能结合L2的肽(表15和16)。将这些肽与通过质谱评估的HLA实际呈现的肽的广泛数据库进行比较,发现162个肽中没有一个已知由同源HLA递呈,232个肽中只有一个已知由同源HLA呈现。然而,当该肽(来自色域-螺旋酶-DNA-结合蛋白4[CHD4]的DTELQGMNEY(SEQ ID NO:310))脉冲到SigM5细胞上,然后与T细胞和L2-U scDb共同培养时,它没有引发IFNγ释放(图63C),表明L2-U scDb没有结合CHD4肽。
表15.与V2结合基序匹配的人肽。基于肽库分析结果,使用20%同源肽反应性作为每个位置允许氨基酸的截留值,生成V2的十聚体结合基序。使用ScanProsite在UniProtKB人蛋白质数据库中搜索这些基序,以鉴定与基序匹配的肽。





表16.与L2结合基序匹配的人肽。基于肽库分析结果,使用20%同源肽反应性作为每个位置允许氨基酸的截留值,生成L2的十聚体结合基序。使用ScanProsite在UniProtKB人蛋白质数据库中搜索这些基序,以鉴定与基序匹配的肽。







scDb在小鼠模型中的评估
为了确定L2-U scDb是否能在体内控制肿瘤生长,将HL-60白血病细胞(NRASQ61L/WT)和人T细胞静脉注射到NSG小鼠中,以建立广泛的白血病浸润。作为对照,在一组单独的小鼠中使用了经工程改造携带Q61H而不是Q61L/WT等位基因的HL-60细胞。生物发光确定了肿瘤摄取,并随机编组小鼠,通过腹膜内14天输注泵接受L2-U scDb或对照scDb。L2-UscDb减缓了Q61L白血病细胞的生长(图64C),但没有减缓HL-60Q61H细胞的生长。尽管肿瘤生长延迟显著(p<0.05,Bonferroni-Dunn校正的多重t检验),但效应值为中等。由于泵的使用寿命,在以后的时间点没有评估治疗效果。在任何V2-U或L2-U scDb处理的小鼠中未观察到体重的实质性变化(图65)。
这些结果共同证明,可以针对癌细胞中常见突变产生的pHLA复合物产生高度特异性的双特异性抗体。本发明开发的双特异性抗体的形式和构型是针对癌细胞中含有突变的蛋白质产物的高度特异和灵敏的scDb。
材料和方法
研究设计
本研究的目的是产生针对RAS基因常见突变的治疗剂。这是通过使用噬菌体展示来鉴定对已经通过质谱确定呈递的MANA特异性的scFv来实现的。将这些scFv移植到优化的双特异性抗体形式scDb中。然后显示scDb在过表达和内源性水平表达模型系统中介导MANA特异性T细胞活化和靶细胞毒性。提交的所有数据都代表了本研究期间收集的数据。除非另有说明,否则所有实验均为一式三份,技术重复三次。所有实验均以最小化混杂变量(如平板布局效应)的方式进行。
质粒
编码KRAS(同种型B)、HRAS(同种型1)和NRAS变体(WT和突变型)以及HLA I类等位基因A*01:01和A*03:01的质粒由GeneArt合成并克隆到pcDNA3.1(Thermo FisherScientific,Waltham,MA)中,或合成到gBlocks(IDT,Coralville,Iowa)中,并使用 HiFi DNA装配克隆试剂盒(NEB,Ipswich,MA)装配到pcDNA3.4中。
HiFi DNA装配克隆试剂盒(NEB,Ipswich,MA)装配到pcDNA3.4中。
细胞系和原代细胞
所有细胞均在37℃和5%CO2下生长。HEK293F细胞(Thermo Fisher Scientific)在FreeStyle表达培养基中培养。T2A3细胞(Eric Lutz和Elizabeth Jaffee,JHU赠送的礼物)在RPMI-1640(ATCC,Manassas,VA)中培养,其中含有10%的HyClone FBS(GEHealthcare,芝加哥,伊利诺伊州),1%的青霉素-链霉素(Thermo Fisher Scientific),500μg/mL的遗传霉素(Therm Fisher Scenical)和1X非必需氨基酸(Thermo FisherScenetic)。COS-7、NCI-H441、CFPAC-1、NCI-H358和HCT 116细胞(均来自弗吉尼亚州马纳萨斯的ATCC)在补充有10%的HyClone FBS和1%的青霉素链霉素的McCoy的5A(改良)(ThermoFisher Scientific)中培养。Jurkat(克隆E6-1,ATCC)、COLO 741(密苏里州圣路易斯的Sigma-Aldrich)和SW780(ATCC)细胞在含有10%HyClone FBS和1%青霉素-链霉素的RPMI-1640中培养。KMS-21-BM(日本大阪JCRB细胞库)细胞在含有20%HyClone FBS和1%青霉素-链霉素的RPMI-1640中培养。A-427、Hep G2、Hs 695T、SK-MES-1(均来自ATCC)细胞在含有10%HyClone FBS和1%青霉素-链霉素的伊氏最小必需培养基(ATCC)中培养。SigM5(DSMZ)和HL-60(ATCC)细胞在含有20%HyClone FBS和1%青霉素-链霉素的Iscove改良Dulbecco培养基(ATCC)中培养。RD(ATCC)细胞培养在补充有10%的HyClone FBS和1%的青霉素-链霉素的Dulbecco改良伊氏培养基(ATCC)中培养。Hs 578T(ATCC)细胞在补充有10%的HyClone FBS、1%的青霉素-链霉素和0.01mg/ml的牛胰岛素(Sigma-Aldrich)的Dulbecco改良伊氏培养基(ATCC)中培养。
外周血细胞取自健康志愿捐献者或作为白细胞分离样本购买(Stem CellTechnologies,不列颠哥伦比亚省温哥华)。使用Ficoll Paque Plus(GE Healthcare)通过密度梯度离心纯化PMBC。用15ng/mL的抗-人CD3抗体(克隆OKT3,BioLegend,圣地亚哥,CA)或用人T活化剂CD3/CD28 Dynabead(Thermo Fisher Scientific)以1:5的珠/细胞比例从PBMC扩增T细胞三天,然后用磁体去除珠并更换培养基。T细胞在含有10%HyClone FBS、1%青霉素链霉素、100IU/mL重组人IL-2(阿地白介素,Prometheus Therapeutics andDiagnostics,加利福尼亚州圣地亚哥),和5ng/mL重组人类IL-7(BioLegend,581908)的的RPMI-1640中培养。培养基每3-4天更换一次,细胞保持在约100万细胞/mL。
为了产生树突细胞,使用微珠(Miltenyi)从PBMC中负分离单核细胞,并在Mo-DC分化培养基(Miltenyi)中培养5天,以诱导分化为未成熟树突细胞。为了产生成熟的树突细胞,将未成熟的树突细胞与0.5mg/mL CD40配体寡聚物(Enzo)在Mo-DC分化培养基中再培养2天。
噬菌体展示文库构建。
所有克隆均在SnapGene(加利福尼亚州圣地亚哥GSL Biotech LLC)中建模。寡核苷酸由GeneArt(Thermo Fisher Scientific)利用三核苷酸突变(TRIM)技术合成。将寡核苷酸掺入pADL-10b噬菌粒(抗体设计实验室,加利福尼亚州圣地亚哥)(图66)。
将10ng连接产物在冰上与10μL的电感受态SS320细胞(Lucigen,Middleton,WI)和14μL双蒸馏水混合。使用Gene Pulser电穿孔系统(Bio-Rad,Hercules,CA)对该混合物电穿孔(200欧姆,25微法,1.8kV),并使其在恢复培养基(Lucigen)中37℃恢复45分钟。合并用60ng连接产物转化的细胞并铺在含有2xYT培养基的24cm x 24cm平板上,该培养基补充有羧苄青霉素(100μg/mL)和2%葡萄糖。细胞在37℃下生长6小时,并在4℃下放置过夜。为了确定每一系列电穿孔的转化效率,取等分试样并通过系列稀释进行滴定。将在平板上生长的细胞刮入850mL含羧苄青霉素(100μg/mL)和2%葡萄糖的2xYT培养基中,最终OD600为5-15。取两毫升850毫升培养物,稀释至1:200,最终OD600为0.05-0.07。在快速冷冻之前,向剩余培养物中加入150毫升无菌甘油,以生产甘油储液。将稀释的细菌培养至OD600为0.3-0.5,以MOI 4用M13K07辅助噬菌体(抗体设计实验室)转导,并在37℃下振摇1小时。将培养物离心,将细胞重悬浮在含有羧苄青霉素(100μg/mL)、卡那霉素(50μg/mL)和IPTG(50mM,ThermoFisher Scientific)的2xYT培养基中,并在30℃下培养过夜以产生噬菌体。第二天早上,将细菌培养物等分到50mL Falcon管中,并高速沉淀两次,以获得澄清的上清液。用20%PEG-8000/2.5M NaCl溶液以PEG/NaCl∶上清液的1:4比例在冰上沉淀载有噬菌体的上清液40分钟。沉淀后,将噬菌体在12000g下离心40分钟,并重悬浮在含有2mM EDTA的1x TBS(25mMTris-HCl,150mM NaCl,pH 7.5)中。合并来自多管的噬菌体并重新沉淀以获得更高浓度。将最终噬菌体重新悬浮在1x TBS、2mM EDTA和1x完全蛋白酶抑制剂混合物(密苏里州圣路易斯市Sigma-Aldrich)中。获得的转化子总数确定为3.6x1010。将该文库分成等份并储存在-80℃的15%甘油中和-20℃的50%甘油中。
用以下引物扩增来自文库的DNA(正向:CGACGTAAAACGACGGCCAGTNNNNNNNNNNNNNNCGTGCAGAGGATACAGCAGTG(SEQ ID NO:681),反向:CACACAGGAAACAGCTATGACCATGCTAACGGTAACCAGGGTGCCCTG(SEQ ID NO:682))其侧接CDR-H3区。(本文列出的所有寡核苷酸序列均以最5'的核苷酸开始。)这些引物5′端的序列结合了分子条形码,以便于明确计数不同的噬菌体序列以及通用引物位点。其他地方描述了PCR扩增和测序的方案(Kinde等人,Proc NatlAcad Sci U S A 108:9530-9535(2011))。使用自定义SQL数据库处理和翻译序列,并评估核苷酸序列和氨基酸翻译。
肽和pHLA
肽(表11)由Peptide 2.0(Chantilly,VA)或ELIM Biopharm(Hayward,CA)以>90%的纯度合成,但用于位置扫描文库的粗肽除外。肽以10mg/mL重新悬浮在DMF中,并在-80℃下储存。用肽和β-2微球蛋白再折叠重组HLA-A*01:01(HLA-A1)或HLA-A*03:01(HLA-A3)合成pHLA,通过凝胶过滤纯化,并进行生物素化(Fred Hutchinson Immune Monitoring Lab,华盛顿州西雅图;或Baylor MHC Tetramer Production Lab,德克萨斯州休斯敦)。使用W6/32抗体(BioLegend,圣地亚哥,CA)通过ELISA进行选择之前确认这些pHLA的折叠,该抗体仅识别折叠的HLA。如上所述合成Blast肽(表14),以10mg/mL重悬浮在DMF中,并在-80℃下储存。使用结合基序,以20%亲代肽IFNγ值为截留值,使用ScanProsite对UniProtKB人蛋白质数据库进行同源肽反应性检索。V2基序是{FWDY}-[ILMVTC]-{RE}-{ILV}-x-[ILV]-[GNST]-[VP]-[AG]-[HKY](SEQ ID NO:683)。L2基序是x-{PWRHDEY}-[APRDEQSC]-{DE}-[AMFPGHDNQSTYC]-[AG]-[ILM]-[AIMGRDENQ]-[DE]-[AY](SEQ ID NO:684)。
突变pHLA特异性噬菌体克隆的筛选
使用与其他地方描述的方法(Skora等人,Proc Natl Acad Sci U S A 112:9967-9972(2015);和Miller等人,J Biol Chem 294:19322-19334(2019))类似的方法鉴定了pHLA-A1中对RAS G12V[7-16]“G12V”pHLA-A3和RAS Q61H、Q61L、Q61R(统称为“Q61X”)特异性的携带scFv的噬菌体。噬菌体展示文库在选择过程开始后一周内再次生长。将噬菌体感受态SS320细胞(Lucigen,米德尔顿,威斯康星州)集落接种在补充有四环素(20μg/mL)的2xYT培养基(密苏里州圣路易斯市Sigma-Aldrich)中37℃过夜培养,然后将其培养至2L的对数中期(OD600为0.3-0.5)细菌。噬菌体文库以MOI5,M13K07辅助噬菌体(加利福尼亚州圣地亚哥Antibody Design Labs)以MOI4转导细菌,同时添加2%(W/V)葡萄糖(密苏里州圣路易斯的Sigma-Aldrich),并在37℃下振摇(而非搅拌)1小时。沉淀细胞并重悬浮在含有羧苄青霉素(100μg/mL)、卡那霉素(50μg/mL)和50μM IPTG的2xYT培养基中,随后在30℃下振荡并生长过夜以产生噬菌体。第二天早上,将细菌培养物等分加入50mL Falcon管中,并通过12000x g离心两次沉淀,以获得澄清的上清液。用20%PEG-8000/2.5M NaCl溶液以PEG/NaCl∶上清液的1:4比例在冰上沉淀载有噬菌体的上清液40分钟。沉淀后,将噬菌体在12000x g下离心40分钟,并重新悬浮在补充有2mM EDTA、0.1%叠氮化钠和1X完全蛋白酶抑制剂混合物(密苏里州圣路易斯市Sigma-Aldrich)的1ml 1X TBS中。
对于G12V pHLA-A3靶标MANA,筛选方案包括一个富集期(一轮)、一个竞赛期(最多三轮)和一个最终筛选阶段(两轮)。将生物素化pHLA与每1μg pHLA 25μL M-280链霉亲和素Dynabead(Invitrogen,Thermo Fisher Scientific)或100μL链霉亲和素涂层琼脂糖珠(Novagen EMD Millipore,Burlington,MA)在封闭缓冲液(磷酸盐缓冲盐或PBS,0.5%BSA,0.1%叠氮化钠)室温(RT)孵育1小时。初始孵育后,洗涤复合物并重悬浮在100μL封闭缓冲液中。在富集期(第1轮),4℃下隔夜对500μL未偶联的经洗涤Dynabead、500μg游离链霉亲和素蛋白(RayBiotech,Norcross,GA)和3μg热变性等位基因匹配的HLA偶联Dynabead负选择约4x1012噬菌体,代表库的约100倍覆盖率。该步骤旨在去除识别噬菌体的Dynabead、链霉亲和素或变性HLA-A3。负筛选后,用DynaMag-2磁体(加利福尼亚州卡尔斯巴德Afternegative selection,beads were isolated with a DynaMag-2magnet(LifeTechnologies,)分离珠,并通过与偶联到Dynabead的0.5μg G12V pHLA-A3在RT下孵育1小时,使用含有未结合噬菌体的上清液进行正筛选。使用DynaMag-2磁体,用1x TBS和0.5%吐温-20洗涤珠10次,通过在1ml pH 2.2的0.2M甘氨酸中重悬浮,从珠中洗脱噬菌体。孵育10分钟后,通过添加150μL pH为9.0的1M Tris中和溶液pH。用该中和的溶液转导10ml对数中期SS320s培养物,其中添加了M13K07辅助噬菌体(MOI为4)和2%葡萄糖。然后如前所述培养细菌,第二天早上用PEG/NaCl沉淀噬菌体。
在竞争期(第2-4轮),每轮使用的输入噬菌体数量分别减少到前一轮总沉淀噬菌体的5%、1%和0.1%。这些噬菌体在RT条件下对1μg热变性HLA-A3、1μg总非相关pHLA-A3和20μg游离链霉亲和素进行1小时的负筛选。负筛选后,用DynaMag-2磁体分离珠粒,用未结合的噬菌体进行正筛选。这是通过同时将噬菌体与0.5μg G12V pHLA-A3(与磁性Dynabead偶联)和相应的1μg G12WT pHLA-A3(与链霉亲和素包被的琼脂糖珠偶联作为竞争物)共孵育来实现的。洗脱前,用含有0.5%吐温-20的1ml 1x TBS洗涤珠10次。如上所述,从磁性Dynabead中洗脱噬菌体并用于转导对数中期SS320细胞。
在最终筛选期,第2轮、第3轮和第4轮产生的噬菌体分别经历额外的、更严格的筛选轮次。这些轮中0.1%的沉淀噬菌体对0.5μg G12WT pHLA-A3进行了两次负筛选,然后对0.5ug G12V pHLA-A3进行了正筛选。用含有0.5%吐温-20的1ml 1x TBS洗涤珠10次,洗脱噬菌体,并用于如上所述转导对数中期的SS320细胞。第二次重复上述最终筛选步骤,因此噬菌体总共经历了四到六轮负/正筛选。
如上所述选择对RAS Q61X-HLA-A1 MANA靶标特异性的携带scFv的噬菌体,其具有以下差异。Q61X pHLA-A1淘选方案涉及一轮富集和四轮更严格的筛选。在富集轮次中,针对1ml未偶联的经洗涤Dynabead和1mg游离链霉亲和素蛋白,负筛选了约2.6x1013噬菌体,代表了约720倍的文库覆盖率。随后使用2μg突变体Q61X pHLA-A1对未结合的噬菌体进行正筛选。在随后的四轮筛选中,分别使用前一轮中10%、1%、0.1%和0.02%的噬菌体作为输入物用于淘选。在每一轮中,使用2μg Q61WT pHLA-A1、2μg非相关pHLA-A1和5x108细胞从缺乏感兴趣RAS突变的HLA-A1+细胞系中负筛选噬菌体。使用未结合的噬菌体与1μg、0.5μg,0.5μg和0.25μg Q61X pHLA-A1在四轮连续循环中进行正筛选。
为了获得单克隆噬菌体,将用限制稀释的噬菌体转导的SS320细胞的单集落接种到200μL含有100μg/mL羧苄青霉素和2%葡萄糖的2xYT培养基中,并在37℃下生长3小时。然后用1.6x107M13K07辅助噬菌体转导细胞,并在37℃下振荡培养1小时。沉淀细胞,重悬浮在300μL含有羧苄青霉素(100μg/mL)、卡那霉素(50μg/mL)和50μM IPTG的2xYT培养基中,并在30℃下培养过夜以产生噬菌体。沉淀细胞,并使用载有噬菌体的上清液进行下游分析。
PCR和Sanger测序
使用1μL单克隆噬菌体上清液在包含CDR侧翼的引物(正向:GGCCATGGCAGATATTCAGA(SEQ ID NO:198),反向:CCGGGCCTTTATCATCATC(SEQ ID NO:199))和Q5热启动高保真2X主混合物(New England BioLabs)的反应中PCR扩增单克隆噬菌体DNA。PCR产物由Genewiz(新泽西州南普兰菲尔德)进行Sanger测序。使用DNABaserSequence Assembler v4(Arges,Romania)修剪CDR侧翼的序列,并使用CD-HIT套件对跨越CDR的序列进行聚类。选择含有独特噬菌体克隆的集落进行进一步分析。
ELISA
链霉亲和素涂覆的96孔板(R&D Systems,明尼苏达州明尼阿波利斯)在4℃下用50μL封闭缓冲液(含有0.5%BSA、2mM EDTA和0.1%叠氮化钠的PBS)中的50ng生物素化pHLA-A3或pHLA-A1(除非另外说明)或25ng生物素化重组异二聚CD3ε/δ(马萨诸塞州剑桥市Abcam)涂覆。使用BioTek 405 TS洗板机(BioTek,Winooski,VT)用1X TBST(TBS+0.05%吐温-20)洗涤板。
通过单克隆ELISA对来自RAS G12V pHLA-A3淘选的噬菌体克隆进行表征,其中通过ELISA分别调查各个单克隆噬菌体克隆是否与G12V pHLA-A3和G12WT pHLA-A3结合。将50μL噬菌体上清液添加到涂有G12V或G12WT pHLA-A3的经洗涤链霉亲和素ELISA板中。平板在室温下孵育2小时,然后洗涤6次。然后将结合的噬菌体与50μL在1x-TBST中1:3000稀释的兔抗-fd/M13噬菌体抗体(英国阿宾顿Novus Biologicals)在室温下孵育1小时,然后洗涤,并与50μL在1x-TBST中1:10000稀释的山羊抗兔HRP(Thermo Fisher Scientific)在室温下孵育1小时。洗涤后,向每个孔中加入50μL 3,3’,5,5’-四甲基联苯胺(TMB)底物(BioLegend),并用1N硫酸(Fisher Scientific,Thermo Fisher Scenetific)猝灭反应。使用Synergy H1多模式阅读器(BioTek)测量450nm处的吸光度。
使用纯化的scFv、scDb和其他双特异性抗体形式进行的ELISA基本上如上所述,将感兴趣的重组蛋白连续稀释,在RT下孵育1小时,然后在RT下与1μg/mL重组蛋白L(Pierce,Thermo Fisher)孵育一小时,然后与抗蛋白L HRP(Abcam)孵育。洗涤平板,接触,并如上所述读数。pHLA滴定ELISA评估scFv(在固定浓度下)与突变和WT pHLA(在不同浓度下)的结合由AxioMx Inc(Abcam)进行。
夹心ELISA通过在链霉亲和素板上涂覆生物素化的pHLA-A3并如上所述与scDb孵育,然后与含有人Fc结构域的重组异二聚CD3ε/δ蛋白在RT下以1μg/mL孵育1小时,然后在RT下用1:10000的抗人Fc-HRP(Abcam)检测1小时来进行。洗涤平板,接触,并如上所述读数。
流式细胞术
对于细胞的肽脉冲,细胞用PBS洗涤一次,用含有1%青霉素-链霉素的不含血清的RPMI-1640洗涤一次。然后将细胞在37℃下以每毫升5x105–1x106个细胞在含有50μg/mL或特定浓度肽和10μg/mL人β-2微球蛋白(新泽西州东布伦瑞克ProSpec)的无血清RPMI-1640中孵育4小时。在染色之前,旋转细胞并重悬浮在冷染色缓冲液(含有0.5%BSA、2mM EDTA和0.1%叠氮化钠的PBS)中。
通过流式细胞术对来自RAS Q61X pHLA-A1筛选的噬菌体克隆进行表征,其中单独调查各个单克隆噬菌体克隆是否与突变Q61X和Q61WT肽脉冲SigM5细胞结合。如上所述培养单克隆噬菌体并测序。从每个独特克隆的代表孔中筛选噬菌体上清液进行流式细胞术分析。在深96孔2ml平板的每个孔中,将50μL单克隆噬菌体与2.5x105肽脉冲SigM5细胞在50μL染色缓冲液中孵育。平板在冰上孵育1小时,然后用1ml染色缓冲液洗涤。然后用1μg兔抗M13抗体(Novus Biologicals)对细胞进行染色,洗涤,用抗兔PE(BioLegend)染色,与另外100μL在PBS中1:1000稀释的活/死可固定近红外染料在室温下避光孵育10分钟,然后在分析前用染色缓冲液洗涤。使用Intellicyt iQue3流式细胞仪(德国哥廷根Sartorius)分析染色细胞。
通过将5x105–1x106细胞与1x1010噬菌体在冰上的100μL染色缓冲液中孵育1小时,然后在染色缓冲液内洗涤一次,进行肽脉冲T2A3噬菌体染色分析。然后用1μg兔抗-M13抗体(Novus Biologicals)对细胞进行染色,洗涤,用抗兔PE(BioLegend)染色,用另外500μL在PBS中1:1000稀释的活/死可固定近红外染料在室温下避光孵育10分钟,并在分析前用染色缓冲液洗涤。使用0.33μg V2 scFv与1μg抗FLAG PE抗体(BioLegend)预混合,在4℃下过夜,然后与如上所述的肽脉冲T2A3细胞孵育,进行V2 scFv染色。通过用0.125μg克隆GAP.A3-PE(eBioscience,Thermo Fisher Scientific)或小鼠同种型IgG2a PE(BioLegend)对5x105细胞进行染色来进行抗HLA-A3染色。通过用0.5μg抗HLA-A1/A11/A26抗体克隆8.L.101(Abcam)或小鼠同种型IgM(Thermo-Fisher)对5x105细胞进行染色,然后用0.25μg的抗小鼠PE(BioLegend)进行抗-HLA-A1染色。使用LSRII流式细胞仪(马萨诸塞州曼斯菲尔德的Becton Dickinson)分析染色细胞。
使用两种商业试剂盒对细胞表面结合的G12V肽进行定量:PE Quantibrite珠(BD,新泽西州富兰克林湖)和QIFIKIT(Agilient,加利福尼亚州圣克拉拉)。对于基于Quantibrite的定量,肽脉冲T2A3用0.5μg V2 scFv染色,该scFv与1.5μg克隆L5抗-FLAG-PE(BioLegend)预偶联,然后根据制造商的说明进行流式细胞术和定量。对于基于QIFIKIT的定量,肽脉冲T2A3用0.5μg V2 scFv染色,该scFv与1.5μg克隆M2抗-FLAG(Sigma-Aldrich)预偶联,然后用抗小鼠PE(BioLegend)染色,根据制造商说明进行流式细胞术和定量。
重组scFv和双特异性抗体产生
重组scFv蛋白由AxioMx公司(Abcam)生产和纯化。简言之,将V2、H1、L2和R6 scFv序列亚克隆到包含周质定位序列和C端flag和His标签的载体中。scFv在大肠杆菌中表达并通过镍层析纯化。
用编码具有IL-2信号序列和C末端6xHIS标签的每个变体的gBlock(IDT,Coralville,Iowa)亚克隆到pcDNA3.4载体(Thermo Fisher Scientific)中后产生双特异性抗体。双特异性蛋白质由约翰霍普金斯大学的真核组织培养核心设施产生。·简言之,使用聚乙烯亚胺(PEI)将1mg质粒转染到HEK293F细胞中,然后在37℃、170rpm和5%CO2下在FreeStyle 293表达培养基(Thermo Fisher Scientific)中以2x106细胞/mL的密度进行悬浮培养。蛋白表达5天,然后通过离心收集细胞,并使用0.22μm滤器过滤所得上清液。向每1L上清液中加入2mL Ni-NTA-His-Bind(Millipore Sigma)树脂浆料,并允许其在4℃下在定轨振荡器上孵育过夜。将含有浆料的上清液通过离心柱(Pierce,Thermo FisherScientific),由此用PBS中的20mM咪唑洗涤浆料,并在50mM、100mM和250mM咪唑级分中洗脱。蛋白质组分在mini-PROTEAN TGX无染料凝胶(Bio-Rad,Hercules,California)上跑样,合并合适的级分,使用7k MWCO Zeba旋转脱盐柱(Thermo Fisher Scientific)脱盐至pH7.4的PBS或20mM Tris,150mM NaCl,pH 9中。通过无染料凝胶和BCA蛋白质测定对蛋白质进行定量(Pierce,Thermo Fisher Scientific)。对于scDb蛋白质印迹,使用Trans-Blot-Turbo转移系统(Bio-Rad)将蛋白质从无染料凝胶转移到Trans-Blot-Turbo Mini 0.2μmPVDF膜(Bio-Rad)上。在室温下用封闭缓冲液(1x TBST中的5%Bio-Rad印迹级封闭剂)在定轨振荡器(VWR)上封闭膜1小时,然后在4℃下与封闭缓冲液中1:1000的抗6x His标签抗体克隆ab9108孵育过夜,在1x TBST中洗涤,并在室温下在封闭缓冲溶液中与1:10000的抗兔HRP(Thermo Fisher Scientificific)孵育1小时。膜在1x TBST中洗涤,然后用ddH2O洗涤,然后使用SuperSignal West Pico PLUS化学发光底物(Thermo Fisher Scientific)在ChemiDoc XRS+成像仪(Bio-Rad)上成像。蛋白质在4℃下储存用于短期储存或添加7%甘油快速冷冻,并在-80℃下储存以用于长期储存。或者,V2-U scDb和L2-U scDb蛋白质由GeneArt在Expi293中生产,用HisTrap柱纯化,然后使用HiLoad Superdex 200 26/600柱进行尺寸排阻色谱。
SPR
使用Biacore T200 SPR仪器(GE Healthcare,伊利诺伊州芝加哥)在25℃下进行RAS G12V pHLA-A3、G12WT pHLA-A4和V2 scFv结合实验。使用链霉亲和素芯片,分别在流动池(Fc)2和4中捕获约130-140个反应单位(RU)的生物素化pHLA-A3。通过注入递增浓度(1.56、6.25、25、100、400nM)的纯化V2 scFv(流经Fc 1-4),进行单循环动力学。动力学分析的结合反应均扣除空白和参比。使用Biacore Insight评估软件,用1:1结合模型拟合两条结合曲线。使用生物素化的Q61L pHLA-A1和Q61WT pHLA-A1,同样进行L2-U scDb的测量。
pHLA免疫沉淀和质谱分析
pHLA免疫沉淀和质谱如他处所述进行(Wang等人,Cancer Immunol Res7:1748-1754(2019))。简而言之,使用Lipofectamine 3000试剂(Thermo Fisher Scientific)转染接种在24.5x24.5cm2板中95%汇合的COS-7细胞。对于每块平板,将125μg质粒(50μg HLA质粒和75μg突变体或WT蛋白质粒)与200μL Lipofectamine P3000在6ml Opti-MEM(ThermoFisher Scientific)中混合。在单独的试管中,将200μL Lipofectamine 3000试剂与6mLOpti MEM混合。将两管中的内容物混合并使其复合10分钟。去除浸润细胞的培养基,加入50ml新鲜的完全培养基,然后加入Lipofectamine-DNA混合物。转染后48小时收集细胞。通过流式细胞仪(BD-LSRII)上的GFP+细胞分数评估COS-7的转染效率>90%。
细胞(转染或未转染)在24.5x24.5cm2的平板中生长至接近汇合。培养的细胞用PBS洗涤两次,然后用在4℃下预冷的含有1x蛋白酶抑制剂的PBS再次洗涤。刮取细胞并收集在500ml离心瓶中。将瓶在1000g下离心5分钟,并弃去上清液。将细胞沉淀在液氮中快速冷冻,并在-80℃下储存,以备将来进行实验。
如他处所述处理新抗原表达细胞(Wang等人,Cancer Immunol Res 7:1748-1754(2019))。简言之,裂解了5亿个细胞。用与抗人HLA-A、B、C抗体克隆W6/32(Bio-X-Cell)预偶联的蛋白质G Dynal磁珠(Thermo Fisher Scientific)免疫沉淀了pHLA复合物。在洗脱、解离和过滤后,肽在进一步分析之前冻干。然后进行HPLC分馏和双重还原程序(Wang等人,Cancer Immunol Res 7:1748-1754(2019))。使用同一序列的AQUATM重同位素标记的肽(Sigma-Aldrich)建立RAS G12V[7-16]和[8-16]肽的检测对照。在每次实验中,将这些AQUA肽添加到细胞裂解液中。手动检查并调整转变参数,以排除因与杂质共洗脱而产生过多噪声的离子。基于使用AQUATM重同位素标记的肽和他处所述的流程回收率(Wang等人,CancerImmunol Res 7:1748-1754(2019))的MANA-SRM定量计算细胞表面呈现的肽的绝对拷贝数。
细胞系上的CRISPR
用Alt-R CRISPR系统(Integrated DNA Technologies,IDT)修饰HLA等位基因、NCI-H358和NCI-H 441细胞系的KRAS突变状态以及HL-60细胞系的NRAS突变状态。用无核酸酶双链体缓冲液(IDT)以100μM重悬浮Alt- CRISPR Cas9 crRNAs(IDT)和Alt-
CRISPR Cas9 crRNAs(IDT)和Alt- CRISPR-Cas9 tracrRNA(IDT)。以1:1的摩尔比混合crRNA和tracrRNA,并在95℃下变性5分钟,然后缓慢冷却至室温成为双链体,然后以1.2:1的摩尔比与Cas9核酸酶(IDT)混合15分钟。为了敲除NCI-H441细胞中的HLA-A3等位基因,在20μL的OptiMEM中混合含有tracrRNA/HLA-A crRNA(GCTGCGACGTGGGGTCGGAC;SEQ ID NO:685)双链体的40皮摩尔Cas9核糖核蛋白(RNP)与2x105NCI-H441细胞。将该混合物装入0.1cm比色皿(Bio-Rad)中,并使用ECM 2001(BTX)在150V下电穿孔10毫秒。在HL-60细胞中,通过将含有tracrRNA/HLA-A1 crRNA(CAGACTGACCGAGCGAAACCTG;SEQ ID NO:686)双链体的Cas9 RNP与5x105HL-60细胞混合,类似地敲除HLA-A1,并在120V下电穿孔16毫秒。立即将细胞转移到完全生长培养基中培养10天。
CRISPR-Cas9 tracrRNA(IDT)。以1:1的摩尔比混合crRNA和tracrRNA,并在95℃下变性5分钟,然后缓慢冷却至室温成为双链体,然后以1.2:1的摩尔比与Cas9核酸酶(IDT)混合15分钟。为了敲除NCI-H441细胞中的HLA-A3等位基因,在20μL的OptiMEM中混合含有tracrRNA/HLA-A crRNA(GCTGCGACGTGGGGTCGGAC;SEQ ID NO:685)双链体的40皮摩尔Cas9核糖核蛋白(RNP)与2x105NCI-H441细胞。将该混合物装入0.1cm比色皿(Bio-Rad)中,并使用ECM 2001(BTX)在150V下电穿孔10毫秒。在HL-60细胞中,通过将含有tracrRNA/HLA-A1 crRNA(CAGACTGACCGAGCGAAACCTG;SEQ ID NO:686)双链体的Cas9 RNP与5x105HL-60细胞混合,类似地敲除HLA-A1,并在120V下电穿孔16毫秒。立即将细胞转移到完全生长培养基中培养10天。
为了将NCI-H358的KRAS突变状态从G12C/WT改变为G12V,NCI-H441的KRAS突变状态从G2V/WT变为G13D/WT(“KI”),将Cas9 RNP与单链DNA同源性定向修复模板共电穿孔。对于KRAS-G12V crRNA(AATGACTGAATATAAACTTG;SEQ ID NO:688),G12V修饰模板是ATTAGCTGTATCGTCAAGGCACTCTTGCCTACGCCAACGGCGCCGACAACGACGAGTTTATATTCAGTCATTTTCAGCAGGCCTTATAA(SEQ ID NO:687)。对于KRAS-G13D-1crRNA(CTTGTGGTAGTTGGAGCTGT;SEQ ID NO:690),G13D修复模板是AACAAGATTTACCTCTATTGTTGGATCATATTCGTCCACAAAATGATTCTGAATTAGCTGTATCGTCAAGGCACTCTTGCCTACGTCACCAGCTCCAACTACCACAAGTTTATATTCAGTCATTTTC(SEQ IDNO:689)。这两种修复模板都是来自IDT的 寡核苷酸。为了提高同源性定向修复率,在电穿孔前用200ng/mL的诺考达唑(Sigma-Aldrich)和1μM的SCR7吡嗪(SigmaAldrich)预处理NCI-H441细胞17小时。电穿孔混合物包含20μL OptiMEM中的40皮摩尔Cas9RNP、20皮摩尔修复模板和2x105细胞。NCI-H441细胞在150V下电穿孔10毫秒,而NCI-H 358细胞在120V下电穿16毫秒。电穿孔后,将两种细胞转移到含有1μM SCR7的完全生长培养基中72小时。细胞在使用前在培养物中再生长5至10天。
寡核苷酸。为了提高同源性定向修复率,在电穿孔前用200ng/mL的诺考达唑(Sigma-Aldrich)和1μM的SCR7吡嗪(SigmaAldrich)预处理NCI-H441细胞17小时。电穿孔混合物包含20μL OptiMEM中的40皮摩尔Cas9RNP、20皮摩尔修复模板和2x105细胞。NCI-H441细胞在150V下电穿孔10毫秒,而NCI-H 358细胞在120V下电穿16毫秒。电穿孔后,将两种细胞转移到含有1μM SCR7的完全生长培养基中72小时。细胞在使用前在培养物中再生长5至10天。
HL-60中的NRAS突变状态类似修饰。将5x105HL-60细胞在120V下与含有tracrRNA/NRAS crRNA(CCTCATGTGTCTCTCATGG;SEQ ID NO:691)双链体和Q61H(AAACCTGTTTGTTGGACATACTGGATACAGCTGGACATGAGGAATATTCTGCAATGAGAGACCAATACATGAGGACAGGCGAAGGCTTCCT;SEQID NO:692)或Q61R(AAACCTGTTTGTTGGACATACTGGATACAGCTGGAAGAGAGGAATATTCTGCAATGAGAGACCAATACATGAGGACAGGCGAAGGCTTCCT;SEQ ID NO:693)修复模板的Cas9 RNP共电穿孔16毫秒。
将HLA-A和RAS修饰的多克隆合并物以每孔0.5至2个细胞的密度接种在96孔板中,并培养3周。将单个集落转移到2或3块重复的96孔板中。对于HLA-A修饰的NCI-H441细胞,使用两块复制平板。使用一块平板,用HLA-A3特异性抗体GAP.A3-PE对细胞染色,另一块用抗HLA-A2特异性抗体BB7.2-PE(BioLegend)染色。通过染色比较,可以鉴定出只有HLA-A3等位基因被敲除的克隆,因为NCI-H441通常同时表达HLA-A2和HLA-A3。用抗HLA-A1(克隆8.L.101)染色HL-60细胞,以筛选HLA-Al敲除的克隆。对于RAS修饰的细胞,使用Quick-DNATM96试剂盒(Zymo Research)从其中一块平板收集基因组DNA,使用 热启动高保真2X主混合物(新英格兰生物实验室)进行PCR扩增,并Sanger测序,以确定具有所需RAS突变状态的克隆。进行靶向下一代测序以确认所选克隆的突变状态。
热启动高保真2X主混合物(新英格兰生物实验室)进行PCR扩增,并Sanger测序,以确定具有所需RAS突变状态的克隆。进行靶向下一代测序以确认所选克隆的突变状态。
共培养
将COS-7细胞接种在T25烧瓶中,并在70%汇合时转染。对于每个烧瓶,将10μg质粒DNA(1:1的HLA质粒:RAS质粒)或对照质粒DNA与20μL P3000试剂在250μL Opti-MEM(ThermoFisher Scientific)中混合。在单独的试管中,将20μL Lipofectamine 3000试剂与250μLOpti MEM混合。将两管中的内容物混合并使其在室温下复合10分钟。去除预铺板的COS-7细胞上的现有培养基,加入新鲜培养基,然后加入Lipofectamine-DNA混合物。转染后24小时收获细胞,在用PBS洗涤一次后进行共培养,加入1ml 0.05%胰蛋白酶(Thermo FisherScientific)并在37℃下孵育5-10分钟。用含血清的培养基淬灭胰蛋白酶,并计数细胞。在96孔平底组织培养处理板中建立共培养。在每个孔中,合并以下组分:在完全RPMI-1640中稀释至所需浓度的50μL抗体,最终IL-2浓度为100IU/mL,100μL完全RPMI-1640中1x104COS-7,50μL完全RPMI-1640中5x104人T细胞。37℃孵育共培养物24小时。根据制造商的说明,使用人IFNγQuantikine和人TNFαQuantikine ELISA试剂盒(均为R&D Systems Bio-techne,明尼苏达州明尼阿波利斯)测定所得上清液中的细胞因子。
对于与脉冲细胞的共培养,通过将50μL无血清RPMI-1640培养基(用于T2A3、SigM5、Hs 695T)或含血清RPMI-1640培养基(用于PBMC、单核细胞、iDC、mDC)中指定数量的靶细胞与50μL无血清RPMI-1640培养基中系列稀释的肽混合,在96孔板中对细胞进行肽脉冲。将细胞在37℃下孵育4小时,然后将5x104人T细胞和抗体加入额外的100μL含血清RPMI-1640培养基中,最终IL-2浓度为100IU/mL。将共培养物在37℃下孵育24小时,500g离心沉淀细胞,并如上所述测定无细胞上清液中的细胞因子。根据制造商的说明,通过CellTiter-Glo发光细胞活力分析((Promega,麦迪逊,WI)测定细胞活力。通过获取给定孔的荧光素酶信号,扣除仅T细胞孔的荧光素酶信号,并对不含scDb的孔的荧光素酶的信号归一化计算细胞毒性。
类似建立了与其他靶细胞系的共培养物,靶细胞和人T细胞按照图例中指定混合。对于Luminex分析,使用MILLIPLEX面板(MilliporeSigma,Burlington,MA)测量IFNγ、IL-2、TNFα、颗粒酶B和穿孔素。
蛋白质印迹
如上转染COS-7并在24小时后收集。沉淀细胞,快速冷冻,并重新悬浮在放射免疫沉淀分析(RIPA)缓冲液(Thermo Fisher Scientific)中。在mini-PROTEAN TGX无染料凝胶(Bio-Rad,Hercules,California)上运行25μg细胞裂解物或约0.5-1.5μg重组蛋白。使用Trans-Blot-Turbo转移系统(Bio-Rad)将蛋白质从无染料凝胶转移到Trans-Blot-TurboMini 0.2μm PVDF膜(Bio-Rad)上。在室温下,用封闭缓冲液(5%Bio-Rad印迹级封闭剂(Bio-Rad),在1xTBST中)在定轨振荡器(VWR)上封闭膜1小时。所有抗体孵育也使用该封闭缓冲液进行。所有与一抗的孵育均在4℃下过夜进行(β-肌动蛋白除外,如下所述)。所有与二抗的孵育在RT下进行1小时。所有洗涤均采用1x TBST进行。用小鼠单克隆抗体(mAb)F234(德克萨斯州达拉斯Santa Cruz Biotechnology,1:500),然后用抗-小鼠HRP(ThermoFisher Scientific,1:10k)检测KRAS。用小鼠mAb7g7h8(Abcam,以1:500),然后用抗-小鼠HRP(Thermo Fisher Scientific,1:10k)检测HLA-A3。用兔抗Rab7b mAb ab193360(Abcam,以1:500),然后用抗兔HRP(Thermo Fisher Scientific,1:10k)检测Rab-7b。用与HRP偶联的兔单克隆抗体13E5(Cell Signaling Technology,Danvers,MA,1:3000)在RT下检测β-肌动蛋白1小时。用抗6x HIS标签兔多克隆抗体ab9108(Abcam,1:1000),然后用抗兔HRP(Thermo Fisher Scientific,1:10k)检测带有6xHIS标签的重组蛋白。成像前,用ddH2O洗涤膜,然后使用SuperSignal West Pico PLUS化学发光底物(Thermo Fisher Scientific)在ChemiDoc XRS+成像仪(Bio-Rad)上成像。
细胞系的病毒转导
为了产生用于体内实验的表达荧光素酶的NCI-H358和HL-60细胞系,用RediFectRed-Fluc-GFP慢病毒颗粒(Perkin Elmer,Waltham,MA)转导NCI-H358和HL-60。经非组织培养物处理的48孔板在RT下用250μL的20μg/mLRetroNectin(Clontech)每孔涂覆2小时,然后在RT下使用10%的FBS封闭1小时。向每个孔中加入总体积为275μL的细胞培养基中的病毒颗粒和2x105靶细胞,并在20℃下以1200x g离心1小时。使用完全培养基将细胞培养体积增至500μL。然后在37℃下培养细胞3天,然后更换培养基。转导后18天,使用FACSAria Fusion(BD Biosciences)基于GFP的存在对转导细胞进行分选。
小鼠异植物模型
6-10周龄的雌性NOD.Cg-PrkdcscidIl2rgtm1Wjl/SzJ(NSG)小鼠获自Johns HopkinsSidney Kimmel综合癌症中心动物资源中心,并按照Johns Hopkins大学动物护理和使用委员会批准的研究方案进行处理。用经辐照的Uniprim啮齿动物饮食(印第安纳波利斯的Envigo)维持小鼠。所有实验均采用同窝对照。
对于NCI-H358脾内模型,在第0天使用无菌手术技术将表达5x105荧光素酶的NCI-H358细胞(CRISPR KRAS G12V-KI克隆1)或同基因亲代NCI-H358克隆(KRAS G2C/WT)接种到小鼠脾脏中。术中,腹膜内放置两周的微渗透泵(型号1002,ALZET,Cupertino,CA),内装有V2-U scDb或同种型对照(L2-U scDb)。一天后通过生物发光成像确保肿瘤接种成功,随后通过侧尾静脉静脉内注射1x107人T细胞。根据制造商的说明(Perkin Elmer)使用RediJectD-荧光素Ultra(Perkin Elmer)进行生物发光成像(IVIS成像系统)。使用Living Image软件进行图像分析。将单个发光测量值对胸腔区域内注射标记物染料(745ex/800em)的平均荧光归一化。
对于HL-60白血病细胞模型,通过侧尾静脉注射,向小鼠静脉接种1x107人T细胞和5x105表达荧光素酶的亲代HL-6(NRAS WT/Q61L)或同基因对照HL-10(NRAS Q61H/Q61H)。在第1天,根据发光情况将小鼠随机分组,以确保类似肿瘤负荷预处理。然后使用无菌外科技术将装有L2-U scDb或同种型对照scDb(V2-U scDb)的两周微渗透泵(在37℃下在1ml PBS中引发过夜)置于腹腔内。通过生物发光成像系列监测肿瘤生长。
统计学
使用Prism 8(加利福尼亚州拉霍亚的GraphPad Software)进行统计分析。除非另有说明,误差条代表独立组装的三次技术重复的标准偏差。未显示小于用于表示这些重复的平均值的符号的误差条。如上所述计算用于体外实验的靶细胞的细胞毒性百分数。对于体内实验,多重比较采用Bonferroni-Dunn校正的非配对双尾t检验进行统计学显著性检验。
实施例4:靶向来源于常见TP53突变的新抗原
本实施例描述了靶向常见TP53突变的免疫治疗剂。用额外的样品重新分析实施例2的结果,并包括在下文中。
结果
p53R175H新抗原存在于癌细胞表面
在NetMHCpan 4.0服务器上预测p53R175H(aa 168-176,HMTEVVRHC;SEQ ID NO:1)和p53WT(HMTEVVRRC;SEQ ID NO:135)肽,分别在5177.6nm(评分9.7%)和7121.5nm(11.6%)处结合HLA-A*02:01。为了提供实验证据并量化这种递呈,在四种不同的细胞培养系统中使用基于质谱(MS)的方法分析从HLA分子洗脱的肽。首先,人HLA-A*02:01和全长p53R175H或p53WT在猴COS-7细胞中共表达。用抗HLA抗体免疫纯化的肽的MS分析检测到p53R175H肽在每个细胞中约为700拷贝(图73A,表17)。尽管在pHLA复合物中检测到相对丰富的p53R175H肽,但在转染细胞中的pHLA复合物中未观察到p53WT肽,尽管通过Western印迹法评估了等量的p53WT和p53R175H总蛋白表达(图73B)。其次,对三种人癌细胞系KMS26、TYK-nu和KLE进行了MS分析,所有这些细胞系均含有p53R175H突变,并携带HLA-A*02:01等位基因。在所有三种细胞系中都检测到p53R175H肽,并且其水平远低于外源引入突变TP53和HLA基因的COS-7细胞(图73C,表17)。基于与重同位素标记的对照比较,估计KMS26、TYK-nu和KLE细胞系的细胞表面上分别存在2.4、1.3和1.5个拷贝的细胞表面p53R175H/HLA-A*02:01复合物(表17)。
表17.p53R175H新抗原肽的定量评估。使用质谱法测定转染HLA-A*02:01和p53R175H或p53WT的COS-7细胞以及内源性表达HLA-A*02:01和p53R175H的细胞系中存在的p53R175H新抗原肽(HMTEVVRHC)的量。*对肽回收率(所有细胞系)和转染效率(COS-7)校正。

鉴定HLA-A*02:01限制性p53R175H肽特异性的表达scFv的噬菌体克隆并转换为scDb形式
为了鉴定选择性靶向突变pHLA复合物的TCRm单链可变片段(scFv),筛选了一个展示scFv的噬菌体文库,估计复杂度>1x1010。针对含有p53R175H肽的HLA-A*02:01pHLA单体的正筛选与针对含有p53WT和无关肽的pHLA单体的负筛选相结合。扩增选定的噬菌体克隆,并通过流式细胞术评估其与递呈突变或野生型(WT)肽的T2细胞的结合(图74A)。
然后将p53R175H比p53WT的中值荧光强度(MFI)比>4的23个噬菌体克隆转化为T细胞重靶向双特异性抗体。这是通过将每个scFv连接到单链双抗体(scDb)形式的抗CD3εscFv(UCHT1)上实现的(图74B)。在评估蛋白质表达和体外T细胞活化的试点实验中,在评估了几种先前描述的双特异性抗体形式后,选择了scDb形式,如双特异性T细胞衔接子(BiTE)、双亲和性重靶向抗体(DART)和双抗体。在与过表达HLA-A*02:01和全长p53R175H或p53WT蛋白的COS-7细胞共同孵育后,通过释放干扰素-γ(IFN-γ)来评估scDb活化T细胞的能力。两个分别来自噬菌体克隆H2和H20的scDb克隆(命名为H2-scDb和H20-scDb)在p53R175H/HLA-A*02:01存在下显示出最有效和特异性T细胞活化(图74C、表18)。通过滴定酶联免疫吸附试验(ELISA)进一步评估这些scDb的特异性。在低浓度下,H2-和H20-scDb均与p53R175H/HLA-A*02:01结合。在高浓度下,H20-scDb也与p53WT/HLA-A*02:01结合,而H2-scDb即使在非常高浓度的scDb下也不与WT pHLA复合物结合(图67A,图74D)。因此,选择H2-scDb进行进一步分析。通过表面等离子体共振(SPR)评估,H2-scDb与p53R175H/HLA-A*02:01结合,KD=86nM,kon为1.76x105M-1s-1,koff为1.48x10-2s-1(图67B)。1.76x105M-1s-1的kon表明p53R175H/HLA-A*02:01在结合时没有整体构象变化。在SPR实验中未观察到H2-scDb与p53WT/HLA-A*02:01的可检测结合(图67B)。

接下来,研究了scDb的抗-CD3臂(而不是原始的UCHT1)是否会影响H2诱导T细胞活化的能力。H2-scFv连接到一组常用的抗-CD3εscFv,包括UCHT1、UCHT1v9、L2K-07、OKT3和hXR32(图75A、B)。发现在所测试的抗CD3εscFv中,具有最高报道亲和力的UCHT1(表19)在与H2-scFv连接时以最低的p53R175H肽浓度活化T细胞(图75C、图67C)。因此,H2-UCHT1-scDb(以下简称H2-scDb)用于进一步的实验。通过差示扫描荧光法测量的H2-scDb的热稳定性表明,单一解链温度(Tm)为69℃,表明它是稳定的分子(图75D,E)。
表19.报道了研究中使用的抗人CD3εscFv的亲和力。
| 抗-CD3<sub>ε</sub>scFv克隆 | 报道的亲和力(K<sub>D</sub>,nM) | 测量亲和力的形式 |
| UCHT1 | 1.8 | 全长抗体 |
| UCHT1v9 | 4.7 | 全长双特异性抗体 |
| L2K-07 | 110 | BiTE |
| OKT3 | 2730 | Fab |
| hXR32 | 21.2 | 携带Fc的DART |
H2-scDb特异性识别表达p53R175H新抗原的癌细胞
接下来评估H2-scDb识别表达不同水平HLA-A*02:01并具有不同p53突变状态的癌细胞系的能力。当T细胞与表达中到高水平HLA-a*02:01并携带p53R175H(KMS26、KLE、TYK-nu以及TYK-nu的顺铂抗性变体)的三个细胞系共培养时,H2-scDb以剂量依赖性方式引发T细胞反应(图68A、B,图76A)。即使在非常低(亚纳摩尔)浓度的双特异性抗体中也观察到这种活化,并且反应性是严格T细胞和H2-scDb依赖性的(图76B,C)。T细胞反应是多功能的,如细胞毒性颗粒蛋白颗粒酶B和穿孔素的释放、细胞毒性,以及细胞因子IFN-γ、肿瘤坏死因子α(TNF-α)、白介素-2(IL-2)等的产生所示(图68C,图76D-F)。实时活细胞成像也显示了肿瘤细胞周围的T细胞聚集,导致它们在H2-scDb存在下裂解(图68D)。通过观察发现,携带p53R175H突变但HLA-A*02:01表达水平低的细胞(AU565或SK-BR3)或未携带P53R175H但HLA-A*02:01表达水平相对较高的细胞诱导的IFN-γ水平低得多,由此证实双特异性抗体对p53R175H肽和HLA-A*02:01的特异性(图68B,图77A)。
使用九对在HLA-A*02:01表达或p53R175H突变方面不同的同基因细胞系进一步验证了H2-scDb的特异性(图69A)。首先,用表达全长p53R175H或p53WT的质粒转染人HEK293FT(Tp53WT/HLA-A*02:01)或Saos-2(TP53null/HLA-A*02-01)细胞。当与两种过表达p53R175H的细胞系,但不和过表达p53WT或亲代细胞共同培养时,H2-scDb诱导了强大的T细胞活化(图69B)。其次,将编码HLA-A*02:01的逆转录病毒转导到四个细胞系(AU565、SK-BR-3、HuCCT1、CCRF-CEM)中,这些细胞系携带p53R175H突变,但HLA-A*02:00表达水平较低(图77B)。所有四个品系中HLA-A*02:01的外源性表达通过H2-scDb赋予T细胞活化(图69C)。第三,使用基于CRISPR的技术,TP53在携带内源性p53R175H的KMS26、TYK-nu和KLE癌细胞系中被遗传破坏(图78A)。当TP53在所有三种细胞系中被敲除时,如IFN-γ分泌评估,T细胞活化降低到对照水平(图69D)。H2-scDb介导的细胞毒性同样通过这些细胞中的TP53敲除(KO)而减轻(图69E,图78B)。
H2-Fab-p53R175H/HLA-A*02:01三元复合物的整体结构
为了理解H2克隆对p53R175H/HLA-A*02:01的高特异性的结构基础,将H2转化为全长IgG(H2-IgG),并确认以这种形式保留了结合特异性(图79A)。然后用木瓜蛋白酶将H2-IgG消化成抗原结合片段(H2-Fab)(图79B)。纯化H2-Fab–p53R175H/HLA-A*02:01复合物(图79C,D),并通过分子置换确定其晶体结构并优化至 分辨率(PDB ID 6W51,表20)。每个不对称单元有四个H2-Fab和四个p53R175H/HLA-A*02:01(图70A,B)。根据PyMOL计算,所有四个H2-Fab均牢固定位在p53R175H/HLA-A*02:01上,其382至419Calpha碳的成对均方根偏差(rmsd)范围为0.27至
分辨率(PDB ID 6W51,表20)。每个不对称单元有四个H2-Fab和四个p53R175H/HLA-A*02:01(图70A,B)。根据PyMOL计算,所有四个H2-Fab均牢固定位在p53R175H/HLA-A*02:01上,其382至419Calpha碳的成对均方根偏差(rmsd)范围为0.27至 (表21)。H2-Fab–p53R175H/HLA-A*02:01界面的总埋置表面积为
(表21)。H2-Fab–p53R175H/HLA-A*02:01界面的总埋置表面积为 重链和轻链的贡献大致相等(表22中分别为
重链和轻链的贡献大致相等(表22中分别为 和
和 )。尽管整个结构解析到
)。尽管整个结构解析到 的分辨率,但观察到p53R175H新抗原、H2-Fab的互补决定区(CDR)和HLA-A*02:01的电子密度特别清晰(图70C,D)。
的分辨率,但观察到p53R175H新抗原、H2-Fab的互补决定区(CDR)和HLA-A*02:01的电子密度特别清晰(图70C,D)。
表20.X-射线晶体学数据收集和优化统计。


*括号中的值用于最高分辨率壳。所有原子指非H原子。
表21.不对称单元中的四种H2-Fab配对rmsd。均方根偏差(rmsd)和Calpha碳数由PyMOL(v2.2.3, LLC,纽约州纽约市)计算。对于链参考值,见PDB ID6W51。
LLC,纽约州纽约市)计算。对于链参考值,见PDB ID6W51。

表22.H2-Fab-p53R175H/HLA-A*02:01与不同TCR和Fab抗体-pHLA的结构比较。使用 截留值计算总键,该截留值包括氢键和范德华相互作用,如使用CCP4套件中的CONTACTS计算。PDB,蛋白数据库;BSA,埋藏的表面积;α、TCRα链;β,TCRβ链;H,VH结构域;L,VL结构域;pep,HLA递呈肽。
截留值计算总键,该截留值包括氢键和范德华相互作用,如使用CCP4套件中的CONTACTS计算。PDB,蛋白数据库;BSA,埋藏的表面积;α、TCRα链;β,TCRβ链;H,VH结构域;L,VL结构域;pep,HLA递呈肽。

p53R175H肽与HLA-A*02:01的结合
p53R175H肽(HMTEVVRHC;SEQ ID NO:1)占据HLA-A*02:01的结合裂隙α1-α2,掩埋了 的溶剂可及表面积,略大于其他肽/HLA-A*02:01复合物(图71A、B、图80A)并具有指向上方脱离凹槽的位于第7位的C端精氨酸(Arg174)和位于第8位的突变组氨酸(His175)。相反,肽的N末端位于肽结合裂隙的深处,由HLA-A*02:01中的多个残基锚定(图71A、B,图80A)。肽的锚定残基,第2位的甲硫氨酸(P2,Met169)和第9位的半胱氨酸残基(P9,Cys176)(图80B),与P2处的亮氨酸和P9处的缬氨酸或亮氨酸的经典锚定残基相分离。已经报道了通过P2处的甲硫氨酸或P9处的半胱氨酸但非两者与HLA-A*02:01结合的肽(Webb等人,J.Biol.Chem.279:23438-23446(2004);和Ataie等人,J.Mol.Biol.428:194-205(2016))。基于与TCR或TCRm复合物中其他HLA-A*02:01肽的结构比对,p53R175H的非常规锚定并未导致肽构象或定位剧烈变化(图80C,D)。
的溶剂可及表面积,略大于其他肽/HLA-A*02:01复合物(图71A、B、图80A)并具有指向上方脱离凹槽的位于第7位的C端精氨酸(Arg174)和位于第8位的突变组氨酸(His175)。相反,肽的N末端位于肽结合裂隙的深处,由HLA-A*02:01中的多个残基锚定(图71A、B,图80A)。肽的锚定残基,第2位的甲硫氨酸(P2,Met169)和第9位的半胱氨酸残基(P9,Cys176)(图80B),与P2处的亮氨酸和P9处的缬氨酸或亮氨酸的经典锚定残基相分离。已经报道了通过P2处的甲硫氨酸或P9处的半胱氨酸但非两者与HLA-A*02:01结合的肽(Webb等人,J.Biol.Chem.279:23438-23446(2004);和Ataie等人,J.Mol.Biol.428:194-205(2016))。基于与TCR或TCRm复合物中其他HLA-A*02:01肽的结构比对,p53R175H的非常规锚定并未导致肽构象或定位剧烈变化(图80C,D)。
H2-Fab识别p53R175H/HLA-A*02:01的结构基础
H2-Fab对HLA-A*02:01的识别由所有六个CDR介导。H2-Fab CDR与HLA-A*02:01的α1和α2之间共有79次接触,截留值为 其中轻链贡献了61%的接触(表22)。H2-Fab在HLA中掩埋了
其中轻链贡献了61%的接触(表22)。H2-Fab在HLA中掩埋了 的溶剂可接触表面积,其中轻链贡献了
的溶剂可接触表面积,其中轻链贡献了 重链贡献了
重链贡献了 (表22)。相反,六个H2-Fab CDR(H1、H2、H3和L3)中只有四个与p53R175H肽相互作用。总体而言,H2-Fab与p53R175H新抗原进行了36次接触,包括五个氢键和大量范德华相互作用。His175在与H2-Fab的所有直接接触中占47%。重链的CDR-H1、H2和H3以及轻链的CDR-L3在p53R175H肽的C末端周围形成笼状构型,通过提供稳定的相互作用将Arg174和His175捕获到位(图71C)。His175的咪唑侧链通过具有Asp54(CDR-H2)和Tyr94(CDR-L3)的氢键网络锚定(图71C、图81)。Tyr52(CDR-H2)起到顶板的作用,并通过形成π-π相互作用在His175周围捕获笼状结构(图71C、图81)。
(表22)。相反,六个H2-Fab CDR(H1、H2、H3和L3)中只有四个与p53R175H肽相互作用。总体而言,H2-Fab与p53R175H新抗原进行了36次接触,包括五个氢键和大量范德华相互作用。His175在与H2-Fab的所有直接接触中占47%。重链的CDR-H1、H2和H3以及轻链的CDR-L3在p53R175H肽的C末端周围形成笼状构型,通过提供稳定的相互作用将Arg174和His175捕获到位(图71C)。His175的咪唑侧链通过具有Asp54(CDR-H2)和Tyr94(CDR-L3)的氢键网络锚定(图71C、图81)。Tyr52(CDR-H2)起到顶板的作用,并通过形成π-π相互作用在His175周围捕获笼状结构(图71C、图81)。
从p53R175H肽的C端到N端的轴来看,CDR按H2、H1、L3、H3、L1、L2的顺序排列(图70E、F、G)。H2-Fab与HLA凹槽内的肽的对接角为36°(图70G,H)。该朝向与大多数先前描述的针对pHLA复合物的TCR或TCRm抗体的方向非常不同,其中肽的轴几乎垂直于VL/α至VH/β链的二硫键确定的轴(图82)。
评估候选交叉反应肽
新免疫治疗抗体面临的主要挑战之一是非靶向结合,这可能导致对正常细胞的毒性。扫描诱变用于鉴定人蛋白质组中H2-scDb可能交叉反应的肽。通过用剩余的19种常见氨基酸中的每一种系统取代靶p53R175H肽(HMTEVVRHC;SEQ ID NO:1)每个位置的氨基酸来生成肽文库。然后,通过测量与T细胞和H2-scDb孵育后的IFN-γ释放,使用装载有171种变异肽中每种的T2细胞来评估T细胞活化(图71D)。与X射线结构分析一致,突变组氨酸残基所在的P8的任何变化,以及被CDR环包裹在P8中的P7的任何变化都消除了对肽的识别。在这些位置具有取代的肽保留了它们与HLA-A*02:01结合的能力(图83A),但不与H2-scDb结合。位置3-6处的其他非锚定残基也高度偏好存在于靶肽中的亲代氨基酸。该识别模式绘制成Seq2Logo图(图71E)。
接下来,使用20%的靶肽反应性作为每个位置允许氨基酸的截留值,生成九聚体结合基序x-[AILMVNQTC]-[ST]-[DE]-[IV]-[IMVST]-R-H-[AILVGHSTYC](SEQ ID NO:197)(图83B)。使用ScanProsite在UnitProtKB人蛋白质数据库中搜索该基序,从STAT2(PLTEIIRHY;SEQ ID NO:185)、VPS13A(LQSEVIRHY;SEQID NO:186)和ZFP3(QNSEIIRHI;SEQID NO:187)中得到3种同源肽(表9)。NetMHCpan 4.0(%评分均>2.0)预测这3种肽均不是HLA-A*02:01的有效结合物,并且预测的结合亲和力低于亲代p53R175H肽(表9)。然而,为了在实验上排除交叉反应的可能性,T2细胞用这些肽中的每一种进行脉冲。H2-scDb仅在用p53R175H肽脉冲的T2存在下活化T细胞(图71F)。此外,用HLA-A*02:01和全长STAT2或ZFP3的表达质粒共转染COS-7细胞;VPS13A因其尺寸较大(>3000aa)而未测试。同样,在与表达含有候选交叉反应肽的两种蛋白质的COS-7细胞的共培养试验中未检测到T细胞活化(图83C,D)。
H2-scDb的体内抗肿瘤活性
为了确定H2-scDb是否能在体内控制肿瘤生长,通过静脉注射将KMS26多发性骨髓瘤细胞植入NOD-SCID-Il2rg-/-(NSG)小鼠,在全身建立广泛、活跃生长的癌。用两种模型评估H2-scDb与移植到这些小鼠中的人T细胞的组合效果(图84A)。在早期治疗模型中,根据肿瘤负荷的发光定量对小鼠进行随机分组,随后从肿瘤接种后一天开始,通过连续腹膜内输注泵以0.3mg/kg/天的剂量给予H2-scDb。泵能够在两周内维持显著的scDb血浆浓度(图84B)。作为对照,平行给予小鼠不相关的同种型scDb。H2-scDb显著抑制亲代KMS26肿瘤的生长(图72A)。相反,H2-scDb对使用CRISPR破坏TP53基因的KMS26肿瘤没有影响(图72A)。在第二个模型中,小鼠在肿瘤接种后6天随机分组。以两种剂量(0.15和0.3mg/kg/天)给予H2-scDb。两种剂量均导致重大肿瘤消退,并通过体重无显著变化进行评估,耐受性良好(图72B,图84C)。在没有人T细胞存在的情况下未观察到H2-scDb的治疗效果,支持H2-scDb的T细胞依赖性性质(图84D)。
这些结果共同证明,可以针对癌细胞中常见突变产生的pHLA复合物产生高度特异性的双特异性抗体。本发明开发的双特异性抗体的形式和构型是针对癌细胞中含有突变的蛋白质产物的高度特异和灵敏的SCDB。
材料和方法
细胞系和原代T细胞
COS-7,RPMI 6666,T2(174x CEM.T2),Raji,HH,AU565,SK-BR-3,KLE,HCT116,SW480,NCI-H441,Saos-2,和CCRF-CEM细胞购自美国典型培养物保藏中心(ATCC,Manassas,VA)。KMS26、TYK nu和HuCCT1购自日本研究生物资源细胞库(日本大阪JCRB)。SigM5获自DSMZ(德国布伦瑞克)。HEK293FT从Invitrogen(Thermo Fisher Scientific,马萨诸塞州沃尔瑟姆)获得。T2、Raji、Jurkat、HH、AU565、NCI-H441、TOV-112D、CCRF-CEM、KMS26、TYK nu、TYK-nu.CP-r和HuCCT1在含有10%的FBS(GE Healthcare,SH30070.03)和1%的青霉素链霉素(Thermo Fisher Scientificific,15140163)的RPMI-1640(ATCC,30-2001)中培养。RPMI6666在含有20%FBS和1%青霉素链霉素的RPMI-1640中培养。COS-7、SK-BR-3、HCT116、SW480和Saos-2在含有10%的FBS和1%的青霉素链霉素的McCoy的5A改良培养基(ThermoFisher Scientific,16600108)中进行培养。SigM5在含有20%FBS和1%青霉素链霉素的IMDM(Thermo Fisher Scientific,12440061)中培养。HEK293FT在含有10%的FBS、额外的2mM谷氨酰胺(Thermo Fisher Sciencific,35050061)、0.1mM的MEM非必需氨基酸(ThermoFisher Scenical,11140050)、1%的青霉素链霉素和500μg/mL的遗传霉素(Therm FisherScenetic,10131027)的DMEM(高糖、丙酮酸盐,Thermo Fisher Scientific,11995065)中培养。通过用Ficoll Paque Plus(GE Healthcare,17-1440-03)进行标准密度梯度离心,从白细胞分离样品(Stem Cell Technologies,Vancouver,BC)中分离出PBMC。在加入15ng/mL抗人CD3抗体(OKT3,BioLegend,San Diego,317347)的情况下,从PBMC扩增T细胞三天。T细胞在含有10%FBS、1%青霉素链霉素、100IU/mL重组人IL-2(阿地白介素,PrometheusTherapeutics and Diagnostics,加利福尼亚州圣地亚哥),和5ng/mL重组人类IL-7(BioLegend,581908)的的RPMI-1640中培养。一般来说,在体外试验中测试了来自至少两个不同供体的T细胞。所有细胞均在37℃、5%CO2和加湿条件下生长。
新抗原肽的检测
在转染了HLA-A*02:01和p53R175H的COS-7细胞和在携带p53R175H并表达HLA-A*02:01的人癌细胞系中,通过MANA-SRM直接检测并定量携带p53R175H突变的人癌细胞中的HLA-A*02:01限制性p53R175H肽。特别是,MANA-SRM中描述的双还原方法对于该检测至关重要,因为p53R175H肽中存在半胱氨酸和甲硫氨酸。在分析之前,向每个样品中加入100飞摩尔重同位素标记的p53R175H肽
HMTEVVRHC(SEQ ID NO:1)和p53WT肽HMTEVVRRC(SEQ ID NO:135;New EnglandPeptide Inc,Gardner,MA)。MANA-SRM分析在Complete Omics Inc.(马里兰州巴尔的摩)进行。
肽和单体
除使用粗制肽的位置扫描文库外,所有肽均由Peptide 2.0(Chantilly,VA)或ELIM Biopharm(Hayward,CA)以>90%的纯度合成。肽以10mg/mL重悬于二甲基甲酰胺中,并在-20℃下储存。由Fred Hutchinson Cancer Research Center Immune Monitoring Lab(Seattle,WA)合成生物素化pHLA单体。通过使用仅识别折叠HLA的W6/32抗体(BioLegend,311402)进行ELISA,确认单体在选择之前折叠。
噬菌体展示文库构建
他处描述了本研究中使用的携带scFv的噬菌体文库(见例如Miller等人,J.Biol.Chem.294:19322-19334(2019))。简单说,GeneArt(Thermo Fisher Scientific)利用三核苷酸诱变(TRIM)技术合成寡核苷酸,以使互补决定区(CDR)-L2、CDR-L3、CDR-H1、CDR-H2和CDR-H3多样化。一FLAG(DYKDDDDK;SEQ ID NO:190)表位标签直接位于scFv的下游,在框内后接全长M13 pIII衣壳蛋白序列。获得的转化子总数确定为3.6x1010。
突变pHLA特异性噬菌体克隆的筛选
使用其他地方描述的方法(见例如Skora等人,PNAS 112:9967-9972(2015))鉴定了携带p53R175H/HLA-A*02:01pHLA特异性scFv的噬菌体克隆。1μg生物素化HLA-A*02:01pHLA单体复合物与25μL的M-280链霉亲和素磁性Dynabead(Thermo Fisher Scientific,11206D)偶联。在富集阶段(第1轮),用未偶联的Dynabead和游离链霉亲和素蛋白(RayBiotech,Norcross,GA,228-11469)的混合物负筛选噬菌体。。负筛选后,移出含有未结合噬菌体的上清液,使用1μg p53R175H/HLA-A*02:01pHLA进行正筛选。然后洗涤珠并洗脱噬菌体以感染对数中期的SS320细菌,同时添加M13K07辅助噬菌体(感染复数为4)。然后在30℃下培养细菌过夜以产生噬菌体,第二天早上用PEG/NaCl沉淀噬菌体。
在筛选阶段(第2-5轮),前一轮的噬菌体经历两个阶段的负筛选:1)针对不含p53R175H/HLA-A*02:01(RPMI6666、Jurkat、Raji、SigM5、HH、T2和NCI-H441)的细胞系,以及2)针对p53WT/HLA-A*02:01pHLA、无关HLA-A*02:01pHLA和游离链霉亲和素的细胞系。对于使用细胞系的负筛选,将噬菌体与总数为0.5–1x107的细胞在4℃下孵育过夜。负筛选后,分离珠并转移未结合的噬菌体,通过与1μg(第2轮),0.5μg(第3轮),或0.25μg(第4,5轮)p53R175H/HLA-A*02:01pHLA孵育正筛选转移未结合噬菌体。然后如上所述通过感染SS320洗脱和扩增噬菌体。
经过五轮筛选后,用有限稀释的富集噬菌体感染SS320细胞。挑出总共190个SS320的独立集落,使用Q5热启动高保真2X主混合物(新英格兰生物实验室,M0494L)通过侧接CDR的引物(正向:GGCCATGGCAGATATTCAGA(SEQ ID NO:198),反向:CCGGGCCTTTATCATCATC(SEQID NO:199))PCR扩增噬菌体DNA,并由GENEWIZ(South Plainfield,NJ)对噬菌体DNA进行Sanger测序。使用DNA Baser Sequence Assembler v4(Arges,罗马尼亚)修剪CDR侧翼的序列,并使用CD-HIT套件对跨越CDR的序列进行聚类。选择含有独特噬菌体克隆的集落,并在添加M13K07辅助噬菌体的深96孔板(Thermo Fisher Scientific,278743)中的400μL培养基内过夜。第二天沉淀细菌,并将载有噬菌体的上清液用于下游分析。
肽脉冲
对于肽脉冲,用无血清RPMI-1640培养基洗涤T2细胞,然后在37℃下以每毫升0.5–1x106个细胞在含指定浓度肽的无血清RPMI-1640中培养2小时。对于通过流式细胞术评估的实验,向10μg/mL人β2M(ProSpec,新泽西州东布伦瑞克,PRO-337)中添加肽,并在此类实验的图例中指定。
流式细胞术
用50μL噬菌体上清液在冰上对肽脉冲T2细胞进行噬菌体染色1小时,然后用1μg兔抗M13抗体(Novus Biologicals,NB100-1633)和抗-兔-PE(BioLegend,406421)进行染色。通过用荧光标记的抗人HLA-A*02(BB7.2,BioLegend,343308)或小鼠同种型IgG2b,κ(BioLedge,402206)对细胞进行染色来进行HLA-A*02染色。使用LSRII流式细胞仪(马萨诸塞州曼斯菲尔德,Becton Dickinson)或IQE筛选仪(明尼苏达州阿尔伯克基的IntelliCyt)分析染色细胞。
ELISA
链霉亲和素涂覆的96孔板(R&D Systems,明尼苏达州明尼阿波利斯市,CP004)在4℃下用50μL封闭缓冲液(含有0.5%BSA、2mM EDTA和0.1%叠氮化钠的PBS)中的50ng生物素化HLA-A*02:01pHLA单体,或25ng重组人CD3ε/δ(Acro Biosystems,DE,CDD-H52W4)涂覆过夜。使用BioTek 405TS洗板机(BioTek,Winooski,VT)用1X TBST(TBS+0.05%吐温-20)洗涤板。室温下在平板上孵育系列稀释的scDb或IgG持续1小时,并洗涤。对于scDb,接着将平板与1μg/mL重组蛋白L(Thermo Fisher Scientific,77679)在室温下孵育1小时,洗涤,然后在室温下与抗-蛋白L HRP(1:10000,Abcam,ab63506)孵育1小时。对于IgG,将平板与抗人IgG HRP(1:1000,Thermo Fisher Scientific 62-8420)在室温下孵育1小时。洗涤平板,向每个孔中加入50μL 3,3’,5,5’-四甲基联苯胺(TMB)底物(BioLegend,4211101),并用50μL2N硫酸(Thermo Fisher Scientific)猝灭反应。使用Synergy H1多模式阅读器(BioTek)测量450nm处的吸光度。
scDb产生
通过克隆从N到C端编码以下形式的变体中每一个的gBlock(IDT,Coralville,Iowa)产生scDb:IL-2信号序列,抗-pHLA可变轻链(VL),GGGGS(SEQ ID NO:200)短接头,抗-CD3可变重链(VH),(GGGGS)3(SEQ ID NO:201)长接头,抗-CD3 VL,GGGGS(SEQ ID NO:200)短接头,抗-pHLA VH,和6x HIS标签克隆入线性化的pcDNA3.4载体(Thermo FisherScientific,A14697)。这些蛋白质由约翰霍普金斯大学的真核组织培养核心设施表达。·简而言之,用聚乙烯亚胺(PEI)以1:3的比例将1mg质粒DNA以2-2.5x106细胞/mL的密度转染到1L FreeStyle 293-F细胞中,并在37℃下培养转染的细胞。转染后五天,收集培养基并通过0.22μm单位过滤。使用HisPur Ni-NTA树脂(Thermo Fisher Scientific,88222)纯化scDb,并使用7k MWCO Zeba旋转脱盐柱(Thermo Fisher Scenetic,89890)将其脱盐至PBSpH 7.4或20mM Tris pH 9.0、150mM NaCl中。使用4-15%Mini-PROTEAN TGX凝胶(Bio-Rad,Hercules,CA,4568085)和/或NanoDrop(Thermo Fisher Scientific)对蛋白质进行定量。或者,scDb蛋白由GeneArt(Thermo Fisher Scientific)在Expi293s中生产,用HisTrap柱(GE Healthcare,17-5255-01)纯化,然后用HiLoad Superdex 20026/600柱(GEHeathcare,28989335)尺寸排阻层析。使用TSKgel G3000SWxl柱(TOSOH Bioscience,日本东京),在pH 7下使用50mM磷酸钠和300mM氯化钠的流动缓冲液,以1.0ml/分钟的流速进行分析色谱。
p53R175H/HLA-A*02:01和H2-scDb相互作用的表面等离子体共振亲和性测量
使用Biacore T200 SPR仪器(GE Healthcare),在25℃下进行生物素化的p53R175H/HLA-A*02:01、p53WT/HLA-A*02:01和H2-scDb结合实验。使用链霉亲和素芯片在流动细胞(Fc)2和4中分别捕获了生物素化的p53R175H/HLA-A*02:01和p53WT/HLA-A*02:01的约100-110个反应单位(RU)。通过注入递增浓度(3、12、50、200和800nM)的流经Fc 1-4的纯化克隆H2-scDb,进行单循环动力学。动力学分析的结合反应均扣除空白和参比。使用BiacoreInsight评估软件,用1:1结合模型拟合两条结合曲线。
差示扫描荧光法
通过差示扫描荧光测定法(DSF)评估H2-scDb的热稳定性,该测定法监测与在温度诱导变性时暴露出来的蛋白质疏水区结合的染料的荧光。通过混合2μL浓度为1mg/mL的纯化H2-scDb(终浓度约为2μg)和2μL 50X SYPRO橙色染料(Invitrogen,S6650,最终浓度的5倍)在PBS,pH 7.4中,在白色低剖面96孔未衬里聚合酶链式反应板(BioRad,MLL9651)中建立反应混合物(20μL)。用光学透明膜密封板,并离心1000xg 30秒。热扫描在25至100℃(1℃/分钟温度梯度)使用CFX9 Connect实时聚合酶链反应装置(BioRad)进行。使用CFX管理软件(BioRad),从解链曲线负一阶导数的最大值计算蛋白质去折叠/解链温度Tm。
TP53的CRISPR介导的敲除
使用Alt-R CRISPR系统(IDT)从KMS26、TYK-nu和KLE细胞系中敲除TP53基因。将靶向TP53外显子3(p53-5:CCCCGGACGATATTGACAA(SEQ ID NO:191)或p53-6:CCCCTTGCCGTCCAAGCA(SEQ ID NO:202))的CRISPR Cas9 crRNA以及CRISPR-Cas9 tracrRNA以100μM重悬浮在无核酸酶的双链体缓冲液中。根据制造商的说明,在95℃下以1:1摩尔比将crRNA和tracrRNA双链化5分钟,然后缓慢冷却至室温。然后使双链化RNA与Cas9核酸酶以1.2:1摩尔比混合15分钟。将总共40皮摩尔的Cas9 RNP与TP53 gRNA复合物与2x105个细胞在20μL OptiMEM中混合。将该混合物加到0.1cm比色皿(Bio-Rad,1652089)内,并使用ECM2001(BTX,Holliston,MA)在120V和16ms电穿孔。将细胞转移到完全生长培养基中培养7天。通过限制性稀释建立单细胞克隆,并使用Quick-DNA 96试剂盒(Zymo Research,Irvine,CA,D3012)收集基因组DNA。PCR扩增CRISPR切割位点两侧的区域(正向引物:GCTGCCCTGGTAGGTTTCT(SEQ ID NO:203),反向引物:GAGACCTGTGGGAAGCGAAA(SEQ ID NO:204)),并进行Sanger测序以筛选具有所需TP53状态的克隆。
免疫印迹分析
细胞在补充有蛋白酶抑制剂混合物(Thermo Fisher Scientific,87785)的冷RIPA缓冲液(Thermo Fisher Scientific,89901)中裂解。使用BCA分析测定蛋白质浓度(Thermo Fisher Scientific,23227)。将等量的总蛋白(20-50μg)装载在4-15%Mini-PROTEAN TGX凝胶(Bio-Rad,4568085)的每条泳道中,并在电泳后转移到聚偏二氟乙烯膜上。将膜与适当的一抗(抗-6x His标签,1:2000,Abcam,ab9108;p53[DO-1],1:1000,SantaCruz,sc-126;STAT2,1:1000;Thermo Fisher Scientific,44-362G;ZFP3,1:1000,ThermoFisher Sciencific,PA5-62726;β-肌动蛋白[13E5],1:1000,Cell SignalingTechnology,5125S;β-肌动蛋白[8H10D10],1:1000,Cell Signaling Technologies,3700S)和物种特异性HRP-偶联二抗(1:5000-10000)一起孵育。信号由ChemiDoc MP化学发光系统(Bio-Rad)检测。
细胞系的转染
编码HLA和靶蛋白的gBlock(IDT)被克隆到pcDNA3.1或pcDNA3.4载体中(ThermoFisher Scientific,V79020,A14697)。使用Lipofectamine 3000(Thermo FisherScientific,L300015)以70-80%的汇合率转染COS-7、HEK293FT和Sao-2细胞,并在37℃下孵育过夜。总共15μg和30μg质粒(共转染中HLA质粒/靶蛋白质粒的1:1比例)分别用于T25和T75烧瓶。
细胞系的病毒转导
使用MSCV逆转录病毒表达系统(Clontech,加利福尼亚州山景城,634401)产生编码HLA-A*02:01的逆转录病毒。简而言之,通过HiFi DNA组件(New England Biolabs,Ipswich,MA,E2621L)将编码HLA-a*02:01-T2A-GFP(IDT)的gBlock克隆到pMSCVpuro逆转录病毒载体中。然后将pMSCVpuro-HLA-A*02:01-T2A-GFP质粒与pVSV-G包膜载体共转染到GP2-293包装细胞系中。转染48小时后收集病毒上清液,并使用Retro-X浓缩器(Clontech,631456)将其浓缩20倍。使用RediFect Red-Fluc-GFP慢病毒颗粒(Perkin Elmer,Waltham,MA,CLS960003)产生荧光素酶表达细胞系。NucLight绿色慢病毒(Essen Bioscience,密歇根州安娜堡,4624)用于产生具有核GFP表达的TYK-nu细胞系。
对于转导,非组织培养处理的48孔板在4℃下用200μL的10μg/mL RetroNectin(Clontech,T100B)/孔涂覆过夜,并在室温下用10%FBS封闭一小时。在总体积为500μL的细胞培养基中向每个孔中加入病毒颗粒和2x105靶细胞,并在2000x g下旋转1小时,然后在37℃下孵育。三天后开始用1μg/mL嘌呤霉素(Thermo Fisher Scientific,A1113803)进行筛选。转导后10-14天,使用FACSAria fusion(BD Biosciences,San Jose,CA)基于GFP的存在对转导细胞进行分选。
体外scDb共孵育分析
在96孔平底平板的每个孔中,在100μL的最终体积的含10%FBS、1%青霉素-链霉素,和100IU/mL IL-2的RPMI-1640中混合以下组分:scDb,稀释至指定浓度,5x104人T细胞和1-5x104靶细胞(COS-7、T2或其他肿瘤细胞系)。效靶细胞比标记在每个实验的图例中。将共培养板在37℃下孵育20小时,并使用人IFN-γQuantikine试剂盒(R&D Systems,Minneapolis,MN,SIF50)、人IFN-γFlex-Set流式细胞术珠阵列(BD,558269)、或在Bioplex200平台(Bio-Rad)上读取的MILLIPLEX Luminex分析(Millipore Sigma、HSTCMAG28SPMX13、HCD8MAG-15K)分析条件培养基的细胞因子和细胞毒性颗粒蛋白分泌。根据制造商的说明,通过CellTiter-Glo发光细胞活力分析(Promega,麦迪逊,WI,G7571),Bio-Glo荧光素酶分析(Promega,G7941),或Steady-Glo荧光素酶分析(Promega,E2510)测定细胞毒性。对于CellTiter-Glo分析,通过从仅T细胞孔的平均值中减去发光信号并对无scDb条件归一化来计算细胞毒性百分比:1-(scDb孔-仅T细胞)/(无scDb孔-仅T细胞)x100。对于Bio-Glo分析,通过将发光信号归一化为无scDb条件来计算细胞毒性百分数:1-(scDb孔)/(无scDb孔)x 100。
实时活细胞成像
总共将1x104用NucLight Green标记的靶细胞铺在96孔平底平板的每个孔中,并在以所示浓度添加2x104T细胞和scDb之前使其附着4小时。每个条件以一式三份铺板。使用IncuCyte ZOOM活细胞分析系统(Essen Bioscience)每6小时对平板进行一次成像,共120小时。在每个时间点,每孔采集四张10倍放大的图像。使用绿色荧光通道定量每个孔中每mm2的GFP阳性物的数量。
p53R175H/HLA-A*02:01的表达、纯化和重折叠
HLA-A*02:01和β2M的质粒来自NIH Tetramer Facility(佐治亚州亚特兰大),并分别转化到BL21(DE3)细胞中。使用自动诱导培养基在包涵体中表达每个质粒。HLA-A*02:01和β2M包涵体的纯化是通过一系列去污剂洗涤,然后用8M尿素溶解而实现的。进行HLA-A*02:01、β2M和突变p53R175H肽的重折叠。简而言之,溶解的HLA-A*02:01和β2M在重折叠缓冲液中混合,该缓冲液包含100mM Tris pH 8.3、400mM L-精氨酸、2mM EDTA、5mM还原型谷胱甘肽、0.5mM氧化型谷胱甘肽、2mM PMSF和30mg溶于1mL DMSO的突变p53R175H肽(aa168-176,HMTEVVRHC(SEQ ID NO:1))。将所得溶液在4℃下搅拌2天,第2天再添加两次HLA-A*02:01,浓缩至10ml,并在HiLoad 26/60Superdex 75预备级柱(GE Healthcare,28989334)上通过尺寸排阻色谱法纯化。为了与H2-Fab孵育,将纯化的pHLA-A*02:01浓缩至~1-3mg/mL,并在-80℃下储存,直至使用。
H2-Fab抗体片段的生产
移植H2 scFv的轻链(LC)和重链(HC)可变区序列,分别与曲妥珠单抗的相应恒定区序列连接,并分别克隆到pcDNA3.4载体(Thermo Fisher Scientific,A14697)中。两条链的前面都有小鼠IgKVIII信号肽。在大规模表达全长抗体之前,对转染的LC:HC DNA比进行优化,以确定最佳重组蛋白产量。对于1L表达,用PEI以1:3的比例将总共50μg纯化质粒(1:1LC:HC比例)转染到FreeStyle 293-F细胞中,浓度为2-2.5x106个细胞/mL,并在37℃下孵育7天。离心收集培养基,通过0.22μm单位过滤,并通过HiTrap MabSelectTM SuReTM柱(GEHealthcare,29-0491-04)的蛋白A亲和层析纯化全长抗体。使用0-100mM柠檬酸钠(pH 3.5)的线性梯度洗脱全长抗体。合并含有纯H2抗体的蛋白A级分,通过SDS-PAGE凝胶电泳定量,并透析至pH 7.0、10mM EDTA的20mM磷酸钠缓冲液中。
为了产生H2-Fab片段,将约1-3mg全长抗体与0.5ml 50%固定化木瓜蛋白酶浆料(Thermo Fisher Scientific,20341)混合,该浆料用含有20mM半胱氨酸-HCl的消化缓冲液(20mM磷酸钠缓冲液,pH 7.0,10mM EDTA)预活化。混合物在37℃下孵育过夜,并以200rpm持续振荡。通过重力树脂分离器将H2抗体消化物与固定化树脂分离,并用pH 7.5的10mMTris-HCl洗涤。使用Mono-S柱(GE Healthcare,17516801)通过阳离子交换色谱法进一步纯化新生成的H2-Fab片段,并使用0-500mM NaCl的线性梯度洗脱。
将H2-Fab片段浓缩,与等摩尔p53R175H/HLA-A*02:01混合,并在4℃下孵育过夜。H2-Fab–p53R175H/HLA-A*02:01混合物通过尺寸排阻色谱法在SuperdexTM 200Increase 10/300柱(GE Healthcare,28990944)上进行评估。将约98%纯的pHLA-A*02:01–H2-Fab复合物的级分合并,浓缩至12.6mg/mL,并交换到含有25mM HEPES、pH 7.0、200mM NaCl的缓冲液中。
结晶、数据收集和结构确定
三重复合物H2-Fab-p53R175H/HLA-A*02:01的晶体在悬滴蒸气扩散中生长,液滴由TTP蚊子机器人设置,储液罐溶液为0.2M氯化铵和20%(w/v)PEG 3350MME。晶体在母液中快速冷却。在National Synchrotron Light Source-II的位于Dectris EIGER X16M探测器上的光束线17-ID-1(AMX)处收集数据。使用fastdp、XDS和aimless对数据集进行索引、整合和放大。H2-Fab-p53R175H/HLA-A*02:01的单斜晶体衍射分辨率为 H2-Fab–p53R175H/HLA-A*02:01复合物的结构通过使用PDB ID 6O4Y和6UJ9作为检索模型的PHASER分子置换来确定。使用REFMAC5迭代优化和在Coot中手动重建,将数据优化至最终分辨率
H2-Fab–p53R175H/HLA-A*02:01复合物的结构通过使用PDB ID 6O4Y和6UJ9作为检索模型的PHASER分子置换来确定。使用REFMAC5迭代优化和在Coot中手动重建,将数据优化至最终分辨率 使用Coot和PDB沉积工具验证结构。根据Ramachandran统计(表20),该模型在优选和允许区域中分别有95.2%和3.8%的残基。数字以PyMOL(v2.2.3,
使用Coot和PDB沉积工具验证结构。根据Ramachandran统计(表20),该模型在优选和允许区域中分别有95.2%和3.8%的残基。数字以PyMOL(v2.2.3, LLC,New York,NY)呈现。使用PDBePISA计算掩埋面积。用网络服务器TCR3d计算决定pHLA和Fab/TCR之间相对取向的对接角度。
LLC,New York,NY)呈现。使用PDBePISA计算掩埋面积。用网络服务器TCR3d计算决定pHLA和Fab/TCR之间相对取向的对接角度。
小鼠异植物模型
6-8周龄的雌性NOD.Cg-PrkdcscidIl2rgtm1Wjl/SzJ(NSG)小鼠从杰克逊实验室(缅因州巴尔港,005557)获得,并按照机构动物护理和使用委员会批准的方案进行处理。在早期治疗模型中,在第0天通过侧尾静脉注射将1x106表达荧光酶的KMS26或KMS26-TP53 KO细胞和1x107体外扩增的人T细胞静脉接种到小鼠体内。在第1天,使用IVIS成像系统和LivingImage软件(Perkin Elmer)基于发光定量对小鼠进行随机分组,以确保类似的预处理肿瘤负荷。成像前,小鼠腹腔注射荧光素(150μl,RediJect D-荧光素超生物发光底物PerkinElmer,770505),在诱导室中吸入异氟醚麻醉5分钟。随机化后,使用无菌手术技术,将注入了H2-scDb,同种型对照scDb(针对与UCHT1scFv连接的无关pHLA的scFv)或仅载剂的两周微渗透泵(ALZET,Cupertino,CA,1002)置于腹膜内,该泵已在37℃下在1ml PBS中引发过夜。通过生物发光成像系列监测肿瘤生长。在建立的肿瘤模型中,在第0天通过侧尾静脉注射给小鼠接种3.5x105或5x105表达荧光素酶的KMS26细胞和1x107人T细胞。在第6天,与早期治疗模型中相似地给予H2-scDb或同种型对照scDb。
对于基于小鼠血液的分析,通过脸颊放血在经EDTA处理的微孔(arstedt,Nümbrecht,Germany,20.1278.100)中收集200μL血液,然后在1000x g离心3分钟。收集血浆并储藏在-80℃直到分析。用100μL PBS重悬浮血细胞沉淀,然后用1mL ACK裂解缓冲液(Thermo Fisher Scientific,A1049201)孵育两次每次5分钟,其间加入一次PBS洗涤液,然后用含有TruStain FcX(抗小鼠CD16/32)抗体(BioLegend,101320)和细胞表面染色抗体的流动染色缓冲液重悬浮。为了进行scDb定量,将血浆解冻并在生物素化的重组人CD3ε/δ涂覆的链霉亲和素板中孵育,并按照“ELISA”中的描述进行检测。
统计分析
除非另外说明,数据表示成平均值±SD。用图例中指明的特定检验进行统计学分析。用P值<0.05表示统计学显著。所有分析用Prism8.0版(GraphPad,San Diego,CA)进行分析。在所有图中,NS,P>0.05;*P<0.05;**P<0.01,***P<0.001,****P<0.0001。
实施例5:靶向TP53突变的示范性双特异性分子
表23.靶向TP53突变的双特异性分子的氨基酸序列



其他实施方式
应理解,虽然本发明已经结合具体实施方式进行了描述,但前述描述旨在说明而不是限制由所附权利要求书的范围所限定的本发明的范围。其它方面、优点和改进均在权利要求书的范围内。
Claims (21)
1.一种包含可结合肽-HLA复合物的抗原结合域的分子,其中所述肽衍生自修饰的p53多肽。
2.如权利要求1所述的分子,其中所述修饰的p53多肽包含7至25个氨基酸。
3.如权利要求2所述的分子,其中所述修饰的p53多肽包含9个氨基酸。
4.如权利要求1至3中任一项所述的分子,其中所述修饰的p53多肽包含SEQ ID NO:1中所示的氨基酸序列。
5.如权利要求4所述的分子,其中所述抗原结合域包含SEQ ID NO:137、SEQ ID NO:138、SEQ ID NO:139、SEQ ID NO:140或SEQ ID NO:141中所示的氨基酸序列。
6.如权利要求1至5中任一项所述的分子,其中所述分子选自抗体、抗体片段、单链可变片段(scFv)、嵌合抗原受体(CAR)、T细胞受体(TCR)、TCR模拟物、串联scFv、双特异性T细胞衔接子、双抗体、单链双抗体(scDb)、scFv-Fc、双特异性抗体和双亲和性重靶向抗体(DART)。
7.如权利要求1至6中任一项所述的分子,其中所述分子进一步包含抗原结合域,所述抗原结合域可结合选自CD3、CD28、CD4、CD8、CD16a、NKG2D、PD-1、CTLA-4、4-1BB、OX40、ICOS和CD27的效应细胞受体。
8.如权利要求7所述的分子,其中所述可结合效应细胞的抗原结合域可结合CD3,其中所述抗原结合域包含选自SEQ ID NO:170、SEQ ID NO:171、SEQ ID NO:172、SEQ ID NO:173、SEQ ID NO:174、SEQ ID NO:175、SEQ ID NO:176、SEQ ID NO:177、SEQ ID NO:178、SEQID NO:179、SEQ ID NO:180、SEQ ID NO:181、SEQ ID NO:182和SEQ ID NO:183的氨基酸序列。
9.一种包含可结合肽-HLA复合物的抗原结合域的分子,其中所述肽衍生自修饰的RAS肽。
10.如权利要求9所述的分子,其中所述修饰的RAS肽包含7至25个氨基酸。
11.如权利要求10所述的分子,其中所述修饰的RAS肽包含10个氨基酸。
12.如权利要求9至11中任一项所述的分子,其中所述修饰的RAS肽包含SEQ ID NO:2、SEQ ID NO:3或SEQ ID NO:4中所述的氨基酸序列。
13.如权利要求12所述的分子,其中所述修饰的RAS肽包含SEQ ID NO:2,并且其中所述抗原结合域包含SEQ ID NO:142、SEQ ID NO:143,、SEQ ID NO:144,、SEQ ID NO:145、SEQID NO:146、SEQ ID NO:147、SEQ ID NO:148或SEQ ID NO:149中所述的氨基酸序列。
14.如权利要求12所述的分子,其中所述修饰的RAS肽包含SEQ ID NO:3,并且其中所述抗原结合域包含SEQ ID NO:150、SEQ ID NO:151、SEQ ID NO:152、SEQ ID NO:153、SEQ IDNO:154、SEQ ID NO:155、SEQ ID NO:156、SEQ ID NO:157、SEQ ID NO:158、SEQ IDS NO:159或SEQ ID NO:160中所述的氨基酸序列。
15.如权利要求12所述的分子,其中所述修饰的RAS肽包含SEQ ID NO:4,并且其中所述抗原结合域包含SEQ ID NO:161、SEQ ID NO:162、SEQ ID NO:163、SEQ ID NO:164、SEQ IDNO:165、SEQ ID NO:166、SEQ ID NO:167、SEQ ID NO:168或SEQ ID NO:169中所述的氨基酸序列。
16.如权利要求9至15中任一项所述的分子,其中所述分子选自抗体、抗体片段、单链可变片段(scFv)、嵌合抗原受体(CAR)、T细胞受体(TCR)、TCR模拟物、串联scFv、双特异性T细胞衔接子、双抗体、单链双抗体(scDb)、scFv-Fc、双特异性抗体和双亲和性重靶向抗体(DART)。
17.如权利要求9至16中任一项所述的分子,其中所述分子进一步包含抗原结合域,所述抗原结合域可结合选自CD3、CD28、CD4、CD8、CD16a、NKG2D、PD-1、CTLA-4、4-1BB、OX40、ICOS和CD27的效应细胞受体。
18.如权利要求17所述的分子,其中所述可结合效应细胞的抗原结合域可结合CD3,其中所述抗原结合域包含选自SEQ ID NO:170、SEQ ID NO:171、SEQ ID NO:172、SEQ ID NO:173、SEQ ID NO:174、SEQ ID NO:175、SEQ ID NO:176、SEQ ID NO:177、SEQ ID NO:178、SEQID NO:179、SEQ ID NO:180、SEQ ID NO:181、SEQ ID NO:182和SEQ ID NO:183的氨基酸序列。
19.一种治疗患有癌症的哺乳动物的方法,所述方法包括:
向所述哺乳动物给予权利要求1至权利要求20中任一项所述的分子,其中所述癌症包括表达所述修饰肽的癌细胞。
20.如权利要求19所述的方法,其中,所述哺乳动物是人。
21.如权利要求19至20中任一项所述的方法,其中所述癌症选自霍奇金淋巴瘤、非霍奇金淋巴瘤、急性髓系白血病、急性淋巴母细胞白血病、多发性骨髓瘤、骨髓增生异常综合征(MDS)、骨髓增生性疾病、肺癌、胰腺癌、胃部恶性肿瘤、结直肠癌、卵巢癌、子宫内膜癌、胆道癌、肝癌、乳腺癌、前列腺癌、食管癌、胃癌、肾癌、骨癌、软组织癌、头颈癌、多形性胶质母细胞瘤、星形细胞瘤、甲状腺癌、生殖细胞瘤和黑色素瘤。
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201962949220P | 2019-12-17 | 2019-12-17 | |
| US62/949,220 | 2019-12-17 | ||
| US202063059638P | 2020-07-31 | 2020-07-31 | |
| US63/059,638 | 2020-07-31 | ||
| PCT/US2020/065617 WO2021127184A1 (en) | 2019-12-17 | 2020-12-17 | MANAbodies TARGETING TUMOR ANTIGENS AND METHODS OF USING |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN115210255A true CN115210255A (zh) | 2022-10-18 |
Family
ID=76478564
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202080096879.8A Pending CN115210255A (zh) | 2019-12-17 | 2020-12-17 | 靶向肿瘤抗原的mana抗体及其使用方法 |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US20230051847A1 (zh) |
| EP (1) | EP4077370A4 (zh) |
| JP (1) | JP2023507729A (zh) |
| CN (1) | CN115210255A (zh) |
| AU (1) | AU2020407591A1 (zh) |
| CA (1) | CA3164446A1 (zh) |
| WO (1) | WO2021127184A1 (zh) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AU2018269370A1 (en) | 2017-05-16 | 2019-12-05 | The Johns Hopkins University | Manabodies and methods of using |
| CR20200014A (es) | 2017-07-14 | 2020-06-11 | Immatics Biotechnologies Gmbh | Molécula de polipéptido con especificidad dual mejorada |
| US20220372165A1 (en) | 2021-05-05 | 2022-11-24 | Immatics Biotechnologies Gmbh | Antigen binding proteins specifically binding prame |
| IL313491A (en) * | 2021-12-16 | 2024-08-01 | Univ Johns Hopkins | Managbodies directed to P53 tumor antigens and methods of use |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AU2018269370A1 (en) * | 2017-05-16 | 2019-12-05 | The Johns Hopkins University | Manabodies and methods of using |
-
2020
- 2020-12-17 AU AU2020407591A patent/AU2020407591A1/en active Pending
- 2020-12-17 CA CA3164446A patent/CA3164446A1/en active Pending
- 2020-12-17 WO PCT/US2020/065617 patent/WO2021127184A1/en unknown
- 2020-12-17 EP EP20902329.0A patent/EP4077370A4/en active Pending
- 2020-12-17 US US17/783,506 patent/US20230051847A1/en active Pending
- 2020-12-17 CN CN202080096879.8A patent/CN115210255A/zh active Pending
- 2020-12-17 JP JP2022536937A patent/JP2023507729A/ja active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| AU2020407591A1 (en) | 2022-06-23 |
| JP2023507729A (ja) | 2023-02-27 |
| CA3164446A1 (en) | 2021-06-24 |
| WO2021127184A1 (en) | 2021-06-24 |
| US20230051847A1 (en) | 2023-02-16 |
| EP4077370A4 (en) | 2024-02-28 |
| EP4077370A1 (en) | 2022-10-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11242388B2 (en) | ROR1 antibody compositions and related methods | |
| US11834501B2 (en) | ROR2 antibody compositions and related methods | |
| CN115210255A (zh) | 靶向肿瘤抗原的mana抗体及其使用方法 | |
| JP7513605B2 (ja) | 新規な抗体ならびにそれを調製および使用するための方法 | |
| CN113825771B (zh) | 针对密蛋白18a2的抗体及其应用 | |
| US11306141B2 (en) | Antibody against human DLK1 and use thereof | |
| US12012455B2 (en) | Human monoclonal antibodies specific for FLT3 and uses thereof | |
| AU2017306507A1 (en) | Antibody to programmed death-ligand 1 (PD-L1) and use thereof | |
| CN112442122B (zh) | 阻断型pd-1纳米抗体及其编码序列和用途 | |
| EP3495390A1 (en) | Novel antibody against programmed cell death protein (pd-1), and use thereof | |
| TW202019475A (zh) | Cd137結合分子 | |
| JP2024514855A (ja) | Dll3に対する結合分子及びその使用 | |
| RU2811431C2 (ru) | Антитело против клаудина 18a2 и его применение | |
| EP4342914A1 (en) | Anti-bcam antibody or antigen-binding fragment thereof |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |