CN115190332A - 一种基于全局视频特征的密集视频字幕生成方法 - Google Patents
一种基于全局视频特征的密集视频字幕生成方法 Download PDFInfo
- Publication number
- CN115190332A CN115190332A CN202210801636.0A CN202210801636A CN115190332A CN 115190332 A CN115190332 A CN 115190332A CN 202210801636 A CN202210801636 A CN 202210801636A CN 115190332 A CN115190332 A CN 115190332A
- Authority
- CN
- China
- Prior art keywords
- video
- event
- features
- feature
- global
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images



Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/43—Processing of content or additional data, e.g. demultiplexing additional data from a digital video stream; Elementary client operations, e.g. monitoring of home network or synchronising decoder's clock; Client middleware
- H04N21/44—Processing of video elementary streams, e.g. splicing a video clip retrieved from local storage with an incoming video stream or rendering scenes according to encoded video stream scene graphs
- H04N21/44008—Processing of video elementary streams, e.g. splicing a video clip retrieved from local storage with an incoming video stream or rendering scenes according to encoded video stream scene graphs involving operations for analysing video streams, e.g. detecting features or characteristics in the video stream
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/762—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using clustering, e.g. of similar faces in social networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/764—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using classification, e.g. of video objects
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/20—Servers specifically adapted for the distribution of content, e.g. VOD servers; Operations thereof
- H04N21/23—Processing of content or additional data; Elementary server operations; Server middleware
- H04N21/234—Processing of video elementary streams, e.g. splicing of video streams or manipulating encoded video stream scene graphs
- H04N21/23418—Processing of video elementary streams, e.g. splicing of video streams or manipulating encoded video stream scene graphs involving operations for analysing video streams, e.g. detecting features or characteristics
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/47—End-user applications
- H04N21/488—Data services, e.g. news ticker
- H04N21/4884—Data services, e.g. news ticker for displaying subtitles
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N5/00—Details of television systems
- H04N5/222—Studio circuitry; Studio devices; Studio equipment
- H04N5/262—Studio circuits, e.g. for mixing, switching-over, change of character of image, other special effects ; Cameras specially adapted for the electronic generation of special effects
- H04N5/278—Subtitling
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Theoretical Computer Science (AREA)
- Evolutionary Computation (AREA)
- Signal Processing (AREA)
- Artificial Intelligence (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Computing Systems (AREA)
- Databases & Information Systems (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Medical Informatics (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
本发明公开了一种基于全局视频特征的密集视频字幕生成方法,本发明通过自适应聚类的方法在只输入整段视频的情况下编码其全局特征,进而以端到端的方式指导事件定位和字幕生成,略去了先前模型利用先验阈值进行事件提案划分的步骤,从而在保证字幕生成准确性的条件下大大降低了计算复杂度。本发明在处理长序列特征时能够自适应地将相近的特征查询聚类进而降低冗余,节省内存。同时,作为传统Transformer中完整自注意力机制的快速近似,该方法在编码准确性方面也表现优异。
Description
技术领域
本发明属于视频特征提取领域,具体涉及一种基于全局视频特征的密集视频字幕生成方法。
背景技术
随着多媒体平台的快速发展,越来越多的人们习惯从视频中获取信息。平均每天有数以千万计的视频被上传到互联网,而审核这些视频会消耗大量的时间。因此为视频自动生成描述性字幕的工作变得十分有价值,这不仅可以大大减少视频审核的时间,还可以借助语音朗读软件为视障患者获取信息。但是通常一个视频中包含多个相互关联的事件,只为视频生成单个的简短描述会丢失大量的信息,因此密集视频字幕生成任务应运而生。总的来说,该任务旨在对视频包含的每个事件进行定位并为其生成对应的字幕,整个过程主要包括两个子任务,即事件定位和字幕生成。而一个有竞争力的密集视频字幕生成模型应该在两个子任务上均具有良好的表现。
现有的工作通常采用“事件定位-字幕生成”的串联式两阶段方案,该方案通常需要引入先验阈值对众多事件提案进行筛选,从而不可避免地增加了计算量和内存消耗;另外,该方案所生成的字幕质量严重依赖于事件定位的准确性,导致模型的性能很不稳定。
发明内容
本发明的目的在于克服上述不足,提供一种基于全局视频特征的密集视频字幕生成方法,能够确保生成的视频字幕准确性的前提下尽可能提升计算效率。
为了达到上述目的,本发明包括以下步骤:
运用预训练的动作识别网络提取视频的初级编码特征;
对初级编码特征进行处理,确定视觉中心和权重后再进行若干层堆叠,得到全局特征编码;
将全局特征编码作为指导,使用并行多头解码器来进行事件个数预测、事件定位以及字幕生成,最终生成视频字幕。
提取视频的初级编码特征通过C3D模型、双流网络结构或时间敏感视频编码器。
得到全局特征编码的具体方法如下:
使用局部敏感哈希方法对初级编码特征中的视频特征进行处理,确定视频特征的视觉中心;
查询每一组视频特征,得到具有最高关注度的前k个视频特征键并确定权重;
重复上述步骤对所有编码的视频特征的赋予权重,得到全局特征编码。
使用局部敏感哈希方法对初级编码特征中的视频特征进行处理的具体方法如下:
计算每个初级编码特征中视频特征查询的哈希值;
将欧几里得局部敏感哈希作为哈希函数:
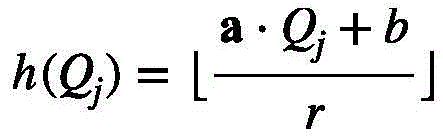
其中,Qj是Q的分量,r是超参数,a和b是随机变量,满足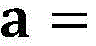
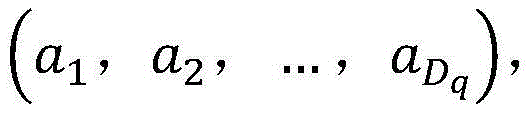 且
且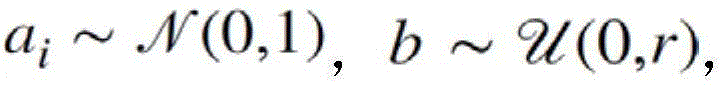 应用到H个LSH,得到每个视频分量的哈希值:
应用到H个LSH,得到每个视频分量的哈希值:
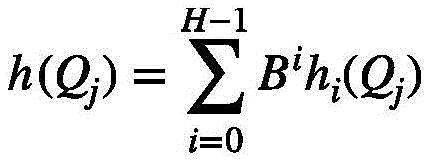
其中,B为常数;
设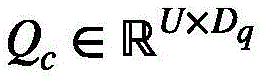 是具有相同哈希值的视频特征查询的中心,Ii是类别索引,表示视频特征查询分量Qi属于哪一组,第j组视觉中心Qc(j)表示成下式:
是具有相同哈希值的视频特征查询的中心,Ii是类别索引,表示视频特征查询分量Qi属于哪一组,第j组视觉中心Qc(j)表示成下式:

相应的集群注意力矩阵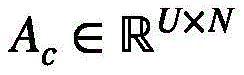 按照如下方式得到:
按照如下方式得到:

得到具有最高关注度的前k个视频特征键并确定权重的具体方法如下:
设P∈{0,1}U×C是一组指示向量,其中Pji=1当且仅当第i个视频特征键是第j组的关注度位于前k个的键之一,否则为0;
通过这种方式将在第j组中对关注度排在前k个的键和其它键分开并为它们计算如下的注意力系数:

按照上述方式改进之后的注意力矩阵表示成:
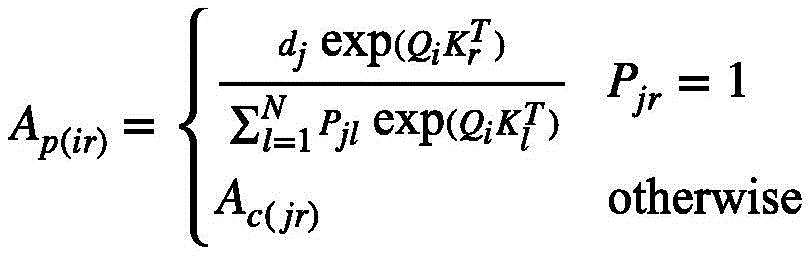
其中i表示的是第j个视频特征组中包含的第i个视频特征查询;
新的视频特征值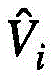 可以被分成如下两个部分:
可以被分成如下两个部分:
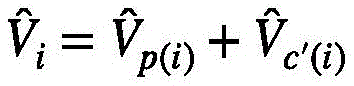
其中,
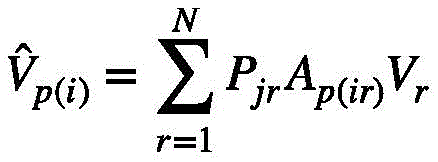
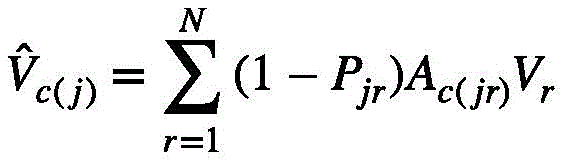
其中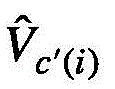 由
由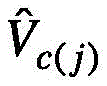 广播得到。
广播得到。
得到全局特征编码的具体方法如下:
经过J层堆叠的包含自适应聚类注意的编码层,提取视频最终的全局特征编码S={s1,...,sN},所得到的全局视频特征不仅包含整段视频的背景信息,还应具有事物敏感性和事件敏感性。
事件个数预测采用事件个数预测头,具体方法如下:
将事件查询特征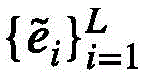 压缩为向量,然后运用全连接层预测一个固定长度的向量
压缩为向量,然后运用全连接层预测一个固定长度的向量 其中每一个元素代表事件个数为该值的概率;
其中每一个元素代表事件个数为该值的概率;
在推理阶段,选择置信度位于前Linf的提案作为最终的事件划分结果,每个事件生成字幕的置信度得分可以通过下式获得:

其中, 表示在第i个事件中生成第t个目标单词的概率,γ为调制因子,μ为平衡因子,用来削弱字幕长度对置信度得分的影响。
表示在第i个事件中生成第t个目标单词的概率,γ为调制因子,μ为平衡因子,用来削弱字幕长度对置信度得分的影响。
事件定位采用事件提案定位头,具体方法如下:
事件提案定位头旨在对每个事件级特征生成框预测以及进行二分类,框预测的作用是为每个事件级特征预测其起始位置;二分类则为每个事件查询预测其前景置信度,这两部分预测都是将多层感知机运用在事件级特征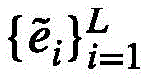 上得到的:
上得到的:
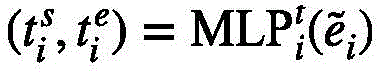

经过事件提案定位头,得到一组元组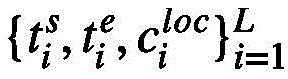 来表示检测到的事件,其中
来表示检测到的事件,其中 表示事件提案的起止时间,
表示事件提案的起止时间, 表示对于事件特征
表示对于事件特征 的定位置信度。
的定位置信度。
字幕生成采用字幕生成头,具体方法如下:
对于初步编码的视频的初级特征F,为了提取其不同尺度的特征,将F输入ResNet并提取该网络C3到C5阶段的输出,记为 其中M=4,第M个尺度的视频特征图是通过将一个卷积核为3×3,步长为2的卷积应用于C5阶段的输出得到;
其中M=4,第M个尺度的视频特征图是通过将一个卷积核为3×3,步长为2的卷积应用于C5阶段的输出得到;
将语义查询hi,t-1和事件级特征 拼接作为查询,hi,t-1表示字幕生成LSTM中的隐藏特征,对每个尺度的初级特征生成D个参考点,,基本流程如下:
拼接作为查询,hi,t-1表示字幕生成LSTM中的隐藏特征,对每个尺度的初级特征生成D个参考点,,基本流程如下:


其中gi直接由线性映射和sigmoid激活函数作用在查询 上得到,它表示归一化的参考点的坐标,即gi∈[0,1]2,φm将归一化参考点映射到对应尺度的特征图上,Δgidm表示采样偏移量,Aimd代表对于第i个语义事件查询,采样点d在m尺度上的注意力。
上得到,它表示归一化的参考点的坐标,即gi∈[0,1]2,φm将归一化参考点映射到对应尺度的特征图上,Δgidm表示采样偏移量,Aimd代表对于第i个语义事件查询,采样点d在m尺度上的注意力。
与现有技术相比,本发明通过自适应聚类的方法在只输入整段视频的情况下编码其全局特征,进而以端到端的方式指导事件定位和字幕生成,略去了先前模型利用先验阈值进行事件提案划分的步骤,从而在保证字幕生成准确性的条件下大大降低了计算复杂度。本发明在处理长序列特征时能够自适应地将相近的特征查询聚类进而降低冗余,节省内存。同时,作为传统Transformer中完整自注意力机制的快速近似,该方法在编码准确性方面也表现优异。
附图说明
图1为本发明中全局视频特征提取的流程图;
图2为本发明中字幕生成头的整体流程图;
图3为本发明的模型流程图。
具体实施方式
下面结合附图对本发明做进一步说明。
参见图1,基于自适应聚类的全局视频特征提取:
本文通过自适应聚类的方法在只输入整段视频的情况下编码其全局特征,进而以端到端的方式指导事件定位和字幕生成,略去了先前模型利用先验阈值进行事件提案划分的步骤,从而在保证字幕生成准确性的条件下大大降低了计算复杂度。
首先运用预训练的动作识别网络(C3D,TSN,TSP)来提取视频的初级编码特征{v1,...,vN}。接着对这一初级编码特征进行处理得到有代表性的全局视频特征。
运用插值将视频特征的时间维度重新缩放到N,从而得到视频的初级特征 之后将初级特征展平并嵌入位置编码,作为包含自适应聚类编码器的Transformer模型的输入:
之后将初级特征展平并嵌入位置编码,作为包含自适应聚类编码器的Transformer模型的输入:
F=CNN(v1,...,vN) (1)
S=ACTAtt(FWQ,FWK,FWV) (2)
其中 是可学习的参数,它们将视频的初级特征映射到编码器的输入空间。方便起见,不妨设所得到的视频特征查询为
是可学习的参数,它们将视频的初级特征映射到编码器的输入空间。方便起见,不妨设所得到的视频特征查询为 视频特征键
视频特征键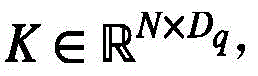 视频特征值
视频特征值 式(2)中的ACTAtt(·)是本文的核心:基于自适应聚类注意力的编码器。主要思想是,首先将视频特征查询分到U个视频特征组,其中U<<N。然后仅计算这些组的注意力,并对同一组的视频特征查询赋相同的注意力权重。进一步,为了使一些本应该获得较高关注度的视频特征键获得高度关注,还需要对关注度排在前k的键进行注意力重计算。总得来说,为了依据(2)式得到全局视频特征S,具体步骤如下(下面是对(2)式的具体解释,其中FWQ代表Q,FWK代表K,FWV代表V):
式(2)中的ACTAtt(·)是本文的核心:基于自适应聚类注意力的编码器。主要思想是,首先将视频特征查询分到U个视频特征组,其中U<<N。然后仅计算这些组的注意力,并对同一组的视频特征查询赋相同的注意力权重。进一步,为了使一些本应该获得较高关注度的视频特征键获得高度关注,还需要对关注度排在前k的键进行注意力重计算。总得来说,为了依据(2)式得到全局视频特征S,具体步骤如下(下面是对(2)式的具体解释,其中FWQ代表Q,FWK代表K,FWV代表V):
为了确定视频特征组,本文首先使用局部敏感哈希(LSH)方法对视频特征查询进行处理。考虑到LSH是解决最近邻搜索问题的强大工具:如果临近的向量能够以高概率获得相同的哈希值即落入相同的哈希桶中,而远距离的向量的哈希值不同,则称哈希方案局部敏感。因此通过控制哈希函数的相关参数和轮数,本文可以依据哈希值将所有距离小于ε的视频特征查询以大于p的概率分入同一视频特征组(哈希桶)中。具体来说,首先计算每个视频特征查询的哈希值,本文选择欧几里得局部敏感哈希作为哈希函数:

其中Qj是Q的分量,r是超参数,a和b是随机变量,满足 且
且 应用H个LSH,最终得到的每个视频分量的哈希值如下:
应用H个LSH,最终得到的每个视频分量的哈希值如下:

其中B是一个常数。从式(3)可以看出哈希函数实际上可以看成是一组具有随机法向量a和偏移量b的超平面,超参数r控制超平面的间距,r越大间距越大。而式(3)表明H个哈希函数将空间分成若干个单元格,落入同一单元格的向量将获得相同的哈希值。
为了获得视觉中心,设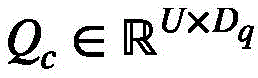 是具有相同哈希值的视频特征查询的中心,Ii是类别索引,表示视频特征查询分量Qi属于哪一组。因此,第j组视觉中心Qc(j)可以被表示成下式:
是具有相同哈希值的视频特征查询的中心,Ii是类别索引,表示视频特征查询分量Qi属于哪一组。因此,第j组视觉中心Qc(j)可以被表示成下式:
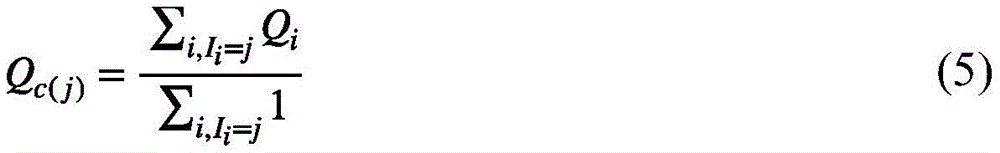
基于此,相应的集群注意力矩阵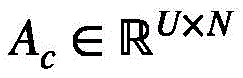 和视频特征值
和视频特征值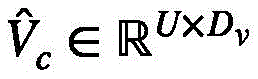 可以按照如下方式得到:
可以按照如下方式得到:

进一步,对每一组视频特征查询找到具有最高关注度的前k个视频特征键并详细计算该部分的权重,剩余部分的权重依然按照上述聚类方式进行计算。
具体来说,设P∈{0,1}U×C是一组指示向量,其中Pji=1当且仅当第i个视频特征键是第j组的关注度位于前k个的键之一,否则为0。通过这种方式可以将在第j组中对关注度排在前k个的键和其它键分开并为它们计算如下的注意力系数(这样做的目的是保证前k个视频特征键和其余视频特征键所对应的值的注意力和为1):

式(8)实际上就是第j个视频特征组中关注度位于前k个视频特征键的总概率。那么按照上述方式改进之后的注意力矩阵可以表示成:
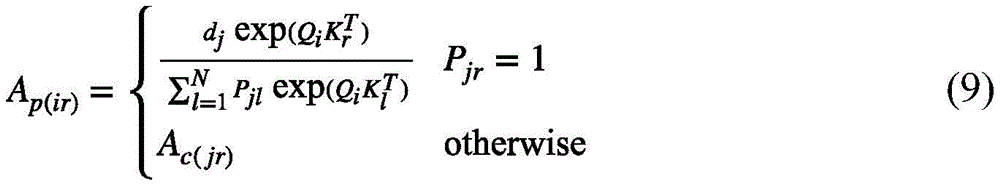
其中i表示的是第j个视频特征组中包含的第i个视频特征查询。换句话说,根据式(6)选择出每一个视频特征组关注度位于前k个的视频特征键,在注意力系数的缩放下,与该视频特征组中的每一个视频特征查询Qi进行点积,再用softmax重新精细计算获得新的权值。对于不属于上述的视频特征键,依然按照式(6)仅在每一个视频特征组的视觉中心计算权重。总的来说,新的视频特征值 可以被分成如下两个部分:
可以被分成如下两个部分:

其中,


其中 由
由 广播得到。
广播得到。
基于此,模型在每一个编码层中都对编码的视频特征执行上述操作,便可以得到一个具有代表性的视频全局特征。
设经过J层堆叠的包含自适应聚类注意的上述编码层,模型就可以提取视频最终的全局特征编码S={s1,...,sN}。所得到的全局视频特征不仅包含整段视频的背景信息,还应具有事物敏感性和事件敏感性。
参见图2(这里参见的应该是整体的模型图,补充的那个),并行多头解码器
将上面得到的全局视频特征S作为指导,使用并行多头解码器来同时进行事件个数预测、事件定位以及字幕生成三个下游子任务,从而促进子任务的交互并最终为视频生成准确的密集视频字幕描述。具体来说,本文的解码器并没有对输入的事件查询进行顺序递归处理,而是并行处理L个可学习的事件查询,旨在直接从以L个可学习嵌入为条件的带有丰富聚类信息的全局视频特征中查询事件级特征。若初始化的可学习事件查询表示为 则在每一层解码层中注意力的计算流程可以表示为:
则在每一层解码层中注意力的计算流程可以表示为:


其中,Att(·)是自注意力机制。需要说明的是,式(14)中的键和值均来自编码器输出的全局视频特征S,解码层中自注意力的输出作为查询,本文称该注意力机制为交叉注意力机制。简单起见,这里依然只描述了一层解码层中的注意力部分,设经过J层解码层的迭代细化所得到的Transformer解码器的输出 即为运用全局视频特征指导的事件级特征。
即为运用全局视频特征指导的事件级特征。
事件提案定位头
事件提案定位头旨在对每个事件级特征生成框预测以及进行二分类。具体来说,框预测的作用是为每个事件级特征预测其起始位置;二分类则为每个事件查询预测其前景置信度,这两部分预测都是将多层感知机运用在事件级特征 上得到的:
上得到的:


这样,经过事件提案定位头,模型可以得到一组元组 来表示检测到的事件,其中
来表示检测到的事件,其中 表示事件提案的起止时间,
表示事件提案的起止时间, 表示对于事件特征
表示对于事件特征 的定位置信度。
的定位置信度。
参见图2,字幕生成头
对于初步编码的视频的初级特征F,为了提取其不同尺度的特征,将F输入ResNet并提取该网络C3到C5阶段的输出,记为 其中M=4,第M个尺度的视频特征图是通过将一个卷积核为3×3,步长为2的卷积应用于C5阶段的输出得到的。尽管不同尺度的特征图的分辨率不同,但是可以通过1×1的卷积操作将它们的通道数转换成256。这样就得到了用来对字幕生成头进行视觉信息补充的多尺度视频初级特征,记为
其中M=4,第M个尺度的视频特征图是通过将一个卷积核为3×3,步长为2的卷积应用于C5阶段的输出得到的。尽管不同尺度的特征图的分辨率不同,但是可以通过1×1的卷积操作将它们的通道数转换成256。这样就得到了用来对字幕生成头进行视觉信息补充的多尺度视频初级特征,记为 需要说明的是,这里没有选择经过自适应聚类编码器处理的全局视频特征作为视觉信息补充,原因是在没有经过聚类的特征上能够采样到更加丰富的视觉信息。
需要说明的是,这里没有选择经过自适应聚类编码器处理的全局视频特征作为视觉信息补充,原因是在没有经过聚类的特征上能够采样到更加丰富的视觉信息。
进一步,当生成第i个事件查询的第t个单词时,首先需要对每个尺度的特征生成D个采样点,基本流程如下:

其中,

具体来说,将语义查询hi,t-1和事件级特征 拼接作为查询,这里hi,t-1表示字幕生成LSTM中的隐藏特征。然后根据式(17),对每个尺度的初级特征生成D个参考点,其中gi直接由线性映射和sigmoid激活函数作用在查询
拼接作为查询,这里hi,t-1表示字幕生成LSTM中的隐藏特征。然后根据式(17),对每个尺度的初级特征生成D个参考点,其中gi直接由线性映射和sigmoid激活函数作用在查询 上得到,它表示归一化的参考点的坐标,即gi∈[0,1]2。φm直接将归一化参考点映射到对应尺度的特征图上,Δgidm表示采样偏移量,Aimd代表对于第i个语义事件查询,采样点d在m尺度上的注意力,这二者都是通过将线性投影作用到语义事件查询上得到的。
上得到,它表示归一化的参考点的坐标,即gi∈[0,1]2。φm直接将归一化参考点映射到对应尺度的特征图上,Δgidm表示采样偏移量,Aimd代表对于第i个语义事件查询,采样点d在m尺度上的注意力,这二者都是通过将线性投影作用到语义事件查询上得到的。
这样,本文依据语义和事件查询,就可以得到在不同尺度的初级视频特征上采样的视频视觉信息的补充 接下来,根据软注意力的思想,可以对这些视觉信息采样点依照语义和事件查询进行加权处理:
接下来,根据软注意力的思想,可以对这些视觉信息采样点依照语义和事件查询进行加权处理:

αit=softmax(ait) (20)
其中wa,Wx,Wha都是可学习的参数, 表示补充视觉信息的每一个分量。于是,加权后的视觉上下文特征可以表示为:
表示补充视觉信息的每一个分量。于是,加权后的视觉上下文特征可以表示为:

接下来,本文将补充的上下文视觉特征zit,事件级特征 以及之前的词嵌入wi,t-1输入到LSTM中,得到时间步t的隐藏状态hit,并进一步利用全连接层对下一个词wit进行预测。那么对于第i个事件查询ei,即可得到其对应的字幕
以及之前的词嵌入wi,t-1输入到LSTM中,得到时间步t的隐藏状态hit,并进一步利用全连接层对下一个词wit进行预测。那么对于第i个事件查询ei,即可得到其对应的字幕 其中Bi表示字幕的长度。
其中Bi表示字幕的长度。
事件个数预测头
考虑到事件查询的个数L是一个人为设定的超参数,在实际的密集视频字幕生成任务中,并不需要对全部L个事件查询产生字幕。因为太多的事件会导致生成的字幕中有大量的重复,缺少可读性;而太少的事件又会导致重要信息的缺失。因此,本小节设计了一个事件个数预测头,旨在为每个视频预测一个合适的事件个数。
具体来说,事件个数预测头包含一个最大值池化头和一个带有softmax激活的全连接层。首先,将事件查询特征 压缩为向量,然后运用全连接层预测一个固定长度的向量
压缩为向量,然后运用全连接层预测一个固定长度的向量 其中每一个元素代表事件个数为该值的概率。在推理阶段,选择置信度位于前Linf的提案作为最终的事件划分结果,每个事件生成字幕的置信度得分可以通过下式获得:
其中每一个元素代表事件个数为该值的概率。在推理阶段,选择置信度位于前Linf的提案作为最终的事件划分结果,每个事件生成字幕的置信度得分可以通过下式获得:

其中, 表示在第i个事件中生成第t个目标单词的概率,γ为调制因子,μ为平衡因子,用来削弱字幕长度对置信度得分的影响。
表示在第i个事件中生成第t个目标单词的概率,γ为调制因子,μ为平衡因子,用来削弱字幕长度对置信度得分的影响。
为了证明本发明模型的优越性,本小节将本发明的模型与一些经典的密集视频字幕生成模型在事件定位准确性、字幕生成质量以及推理时间三方面进行对比。
对事件定位准确性的评估:在早期的工作中,事件提案是通过预训练的模型提前生成的,不是端到端的结构。因此,在这一部分,本发明与经典的两阶段模型,也就是采用“定位-选择-描述”的管道式结构模型进行比较,以体现子任务并行策略的优点。具体来说:
1.MT:作为本文的基线模型,该模型也基于Transformer的编-解码结构,首先将视频编码为适当的表示,事件提案解码器从带有不同锚点的编码中解码生成事件提案,字幕解码器根据提案解码器的输出生成字幕;
2.MFT:将事件提案生成和字幕生成设计为一个循环网络,使得之前的字幕描述可以指导当前的事件提案划分;
3.SDVC:考虑了事件的时间依赖性,并运用强化学习的手段在事件和情节连贯性两个方面进行两级奖励。
那么,模型事件定位的精度、召回率以及F1结果如下表所示:
表1ActivityNet验证集上事件定位结果(使用C3D编码)

本发明和现有的方法采用的“事件定位-字幕生成”的串联式方案不同,本发明摒弃了这种方法,直接使用并行的方式输出事件提案定位,这可以大大减少方案中先验阈值的设置,而且比串联式方案更有效。从图中可以看出,本发明的事件提案定位结果远远超过了MFT和MT,并且能够和非端到端模型且拥有更多参数量的SDVC相当。特别地,当IOU阈值较高时,本发明模型的两个版本展示了更加有竞争力的结果和更加准确的定位性能。此外,当模型使用更精细的字幕生成头时,事件提案定位的平均精度也有所提升,这也表明两个并行头对应的子任务是相互影响相互促进的。
为了分析全局视频特征在指导解码操作时的作用,本实验选取视频片段并通过全连接层标准化为帧级重要性输出,不同的事件以及事件中不同帧之间都有不同的权重,这为下游解码器生成事件提案和生成字幕提供了十分重要的指导。
考虑到ActivityNet数据集上共包含203个动作类,并且字幕的性能可能跟动作的类别有关,本文还继续探索了在不同类别上GDC模型的表现。具体来说,本文选择了10个代表性类别,分别在上面评估得到GDC生成字幕的METEOR指标,并对比了在真实事件提案和预测事件提案上的性能,实验结果如表2所示:
表2不同类别的动作上生成字幕的METEOR指标

从上表中可以看出,本发明在不同动作类型的视频数据上的表现是不同的。具体来说,对于一些大型的动作或者动作背景有一定的特异性的活动,比如开碰碰车、打壁球、滑冰等,本发明生成的字幕结果已经十分具有竞争力。但是对于一些更加小型以及细致的活动,比如空手道、跳尊巴等视频,本发明的表现略有下降。但是,基于表2的结果可以看出,通过更先进的视频特征提取模型对视频进行初步编码时捕捉更多的细粒度特征,GDC将有望实现更大的性能提升。需要说明的是,尽管对于运用自适应聚类提取全局视频特征的方法,修改部分超参数会带来字幕准确性的提升,但也会增大内存消耗,这将在下面的消融实验中进行更进一步的分析。
综上所述,基于定量分析和定性分析的结果,GDC在两个数据集上均得到了十分有竞争力的表现,它比现有的密集视频字幕生成模型不论在事件定位还是字幕生成任务上都有十分显著的提升,这进一步证明了GDC的有效性。
本发明在ActivityNet数据集和YouCookII数据集上将本发明与现有的密集视频字幕生成方法进行对比,实验结果表明不论在事件定位,字幕生成方面还是推理效率方面,本发明的模型都取得了领先。在预测提案以及真实提案上本发明都保证了其生成字幕的准确性。这些表现都进一步证实了本发明模型的有效性。另外,通过消融实验进一步分析了全局视频特征在下游任务中的行为。可视化的视频特征组进一步表明了全局视频特征的指导作用并增加了模型的可解释性。最后,分析了编码器的超参数H和r以及解码器中事件查询数量L对实验结果的影响,最终超参数的选择很好地平衡了模型在各项指标中的表现。
Claims (9)
1.一种基于全局视频特征的密集视频字幕生成方法,其特征在于,包括以下步骤:
运用预训练的动作识别网络提取视频的初级编码特征;
对初级编码特征进行处理,确定视觉中心和权重后再进行若干层堆叠,得到全局特征编码;
将全局特征编码作为指导,使用并行多头解码器来进行事件个数预测、事件定位以及字幕生成,最终生成视频字幕。
2.根据权利要求1所述的一种基于全局视频特征的密集视频字幕生成方法,其特征在于,提取视频的初级编码特征通过C3D模型、双流网络结构或时间敏感视频编码器。
3.根据权利要求1所述的一种基于全局视频特征的密集视频字幕生成方法,其特征在于,得到全局特征编码的具体方法如下:
使用局部敏感哈希方法对初级编码特征中的视频特征进行处理,确定视频特征的视觉中心;
查询每一组视频特征,得到具有最高关注度的前k个视频特征键并确定权重;
重复上述步骤对所有编码的视频特征赋予权重,得到全局特征编码。
4.根据权利要求3所述的一种基于全局视频特征的密集视频字幕生成方法,其特征在于,使用局部敏感哈希方法对初级编码特征中的视频特征进行处理的具体方法如下:
计算每个初级编码特征中视频特征查询的哈希值;
将欧几里得局部敏感哈希作为哈希函数:

其中,Qj是Q的分量,r是超参数,a和b是随机变量,满足
 且
且 应用到H个LSH,得到每个视频分量的哈希值:
应用到H个LSH,得到每个视频分量的哈希值:

其中,B为常数;
设 是具有相同哈希值的视频特征查询的中心,Ii是类别索引,表示视频特征查询分量Qi属于哪一组,第j组视觉中心Qc(j)表示成下式:
是具有相同哈希值的视频特征查询的中心,Ii是类别索引,表示视频特征查询分量Qi属于哪一组,第j组视觉中心Qc(j)表示成下式:

相应的集群注意力矩阵 按照如下方式得到:
按照如下方式得到:

5.根据权利要求3所述的一种基于全局视频特征的密集视频字幕生成方法,其特征在于,得到具有最高关注度的前k个视频特征键并确定权重的具体方法如下:
设P∈{0,1}U×C是一组指示向量,其中Pji=1当且仅当第i个视频特征键是第j组的关注度位于前k个的键之一,否则为0;
通过这种方式将在第j组中对关注度排在前k个的键和其它键分开并为它们计算如下的注意力系数:

按照上述方式改进之后的注意力矩阵表示成:

其中i表示的是第j个视频特征组中包含的第i个视频特征查询;
新的视频特征值 可以被分成如下两个部分:
可以被分成如下两个部分:

其中,


其中 由
由 广播得到。
广播得到。
6.根据权利要求3所述的一种基于全局视频特征的密集视频字幕生成方法,其特征在于,得到全局特征编码的具体方法如下:
经过J层堆叠的包含自适应聚类注意的编码层,提取视频最终的全局特征编码S={s1,...,sN},所得到的全局视频特征不仅包含整段视频的背景信息,还应具有事物敏感性和事件敏感性。
7.根据权利要求1所述的一种基于全局视频特征的密集视频字幕生成方法,其特征在于,事件个数预测采用事件个数预测头,具体方法如下:
将事件查询特征 压缩为向量,然后运用全连接层预测一个固定长度的向量
压缩为向量,然后运用全连接层预测一个固定长度的向量 其中每一个元素代表事件个数为该值的概率;
其中每一个元素代表事件个数为该值的概率;
在推理阶段,选择置信度位于前Linf的提案作为最终的事件划分结果,每个事件生成字幕的置信度得分可以通过下式获得:

其中, 表示在第i个事件中生成第t个目标单词的概率,γ为调制因子,μ为平衡因子,用来削弱字幕长度对置信度得分的影响。
表示在第i个事件中生成第t个目标单词的概率,γ为调制因子,μ为平衡因子,用来削弱字幕长度对置信度得分的影响。
8.根据权利要求1所述的一种基于全局视频特征的密集视频字幕生成方法,其特征在于,事件定位采用事件提案定位头,具体方法如下:
事件提案定位头旨在对每个事件级特征生成框预测以及进行二分类,框预测的作用是为每个事件级特征预测其起始位置;二分类则为每个事件查询预测其前景置信度,这两部分预测都是将多层感知机运用在事件级特征 上得到的:
上得到的:


经过事件提案定位头,得到一组元组 来表示检测到的事件,其中
来表示检测到的事件,其中 表示事件提案的起止时间,
表示事件提案的起止时间, 表示对于事件特征
表示对于事件特征 的定位置信度。
的定位置信度。
9.根据权利要求1所述的一种基于全局视频特征的密集视频字幕生成方法,其特征在于,字幕生成采用字幕生成头,具体方法如下:
对于初步编码的视频的初级特征F,为了提取其不同尺度的特征,将F输入ResNet并提取该网络C3到C5阶段的输出,记为 其中M=4,第M个尺度的视频特征图是通过将一个卷积核为3×3,步长为2的卷积应用于C5阶段的输出得到;
其中M=4,第M个尺度的视频特征图是通过将一个卷积核为3×3,步长为2的卷积应用于C5阶段的输出得到;
将语义查询hi,t-1和事件级特征 拼接作为查询,hi,t-1表示字幕生成LSTM中的隐藏特征,对每个尺度的初级特征生成D个参考点,流程如下:
拼接作为查询,hi,t-1表示字幕生成LSTM中的隐藏特征,对每个尺度的初级特征生成D个参考点,流程如下:


其中gi直接由线性映射和sigmoid激活函数作用在查询 上得到,它表示归一化的参考点的坐标,即gi∈[0,1]2,φm将归一化参考点映射到对应尺度的特征图上,Δgidm表示采样偏移量,Aimd代表对于第i个语义事件查询,采样点d在m尺度上的注意力。
上得到,它表示归一化的参考点的坐标,即gi∈[0,1]2,φm将归一化参考点映射到对应尺度的特征图上,Δgidm表示采样偏移量,Aimd代表对于第i个语义事件查询,采样点d在m尺度上的注意力。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210801636.0A CN115190332B (zh) | 2022-07-08 | 2022-07-08 | 一种基于全局视频特征的密集视频字幕生成方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210801636.0A CN115190332B (zh) | 2022-07-08 | 2022-07-08 | 一种基于全局视频特征的密集视频字幕生成方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN115190332A true CN115190332A (zh) | 2022-10-14 |
| CN115190332B CN115190332B (zh) | 2025-01-07 |
Family
ID=83518132
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210801636.0A Active CN115190332B (zh) | 2022-07-08 | 2022-07-08 | 一种基于全局视频特征的密集视频字幕生成方法 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN115190332B (zh) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115880604A (zh) * | 2022-11-22 | 2023-03-31 | 大连民族大学 | 用于少数民族舞蹈密集视频描述的凹形解码结构及实现方法 |
| CN119152420A (zh) * | 2024-11-18 | 2024-12-17 | 西北工业大学 | 一种基于参数持续性进化的目标个体行为描述方法 |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10198671B1 (en) * | 2016-11-10 | 2019-02-05 | Snap Inc. | Dense captioning with joint interference and visual context |
| US20190149834A1 (en) * | 2017-11-15 | 2019-05-16 | Salesforce.Com, Inc. | Dense Video Captioning |
| CN110929092A (zh) * | 2019-11-19 | 2020-03-27 | 国网江苏省电力工程咨询有限公司 | 一种基于动态注意力机制的多事件视频描述方法 |
| CN111860162A (zh) * | 2020-06-17 | 2020-10-30 | 上海交通大学 | 一种视频人群计数系统及方法 |
| CN112055263A (zh) * | 2020-09-08 | 2020-12-08 | 西安交通大学 | 基于显著性检测的360°视频流传输系统 |
| CN114627162A (zh) * | 2022-04-01 | 2022-06-14 | 杭州电子科技大学 | 一种基于视频上下文信息融合的多模态密集视频描述方法 |
-
2022
- 2022-07-08 CN CN202210801636.0A patent/CN115190332B/zh active Active
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10198671B1 (en) * | 2016-11-10 | 2019-02-05 | Snap Inc. | Dense captioning with joint interference and visual context |
| US20190149834A1 (en) * | 2017-11-15 | 2019-05-16 | Salesforce.Com, Inc. | Dense Video Captioning |
| CN110929092A (zh) * | 2019-11-19 | 2020-03-27 | 国网江苏省电力工程咨询有限公司 | 一种基于动态注意力机制的多事件视频描述方法 |
| CN111860162A (zh) * | 2020-06-17 | 2020-10-30 | 上海交通大学 | 一种视频人群计数系统及方法 |
| CN112055263A (zh) * | 2020-09-08 | 2020-12-08 | 西安交通大学 | 基于显著性检测的360°视频流传输系统 |
| CN114627162A (zh) * | 2022-04-01 | 2022-06-14 | 杭州电子科技大学 | 一种基于视频上下文信息融合的多模态密集视频描述方法 |
Non-Patent Citations (2)
| Title |
|---|
| V. K. JEEVITHA 等: "Natural Language Description for Videos Using NetVLAD and Attentional LSTM", 2020 INTERNATIONAL CONFERENCE FOR EMERGING TECHNOLOGY (INCET), 3 August 2020 (2020-08-03), pages 1 - 6 * |
| 陈尧森: "面向视频理解的时序建模方法研究", 中国博士学位论文全文数据库信息科技辑, no. 04, 15 April 2022 (2022-04-15) * |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115880604A (zh) * | 2022-11-22 | 2023-03-31 | 大连民族大学 | 用于少数民族舞蹈密集视频描述的凹形解码结构及实现方法 |
| CN119152420A (zh) * | 2024-11-18 | 2024-12-17 | 西北工业大学 | 一种基于参数持续性进化的目标个体行为描述方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN115190332B (zh) | 2025-01-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN114443827B (zh) | 基于预训练语言模型的局部信息感知对话方法及系统 | |
| CN110929092B (zh) | 一种基于动态注意力机制的多事件视频描述方法 | |
| CN114627162A (zh) | 一种基于视频上下文信息融合的多模态密集视频描述方法 | |
| CN110322446A (zh) | 一种基于相似性空间对齐的域自适应语义分割方法 | |
| CN115309939B (zh) | 基于时空语义分解的视频片段定位系统 | |
| CN115617955B (zh) | 分级预测模型训练方法、标点符号恢复方法及装置 | |
| CN118982030B (zh) | 一种使用大语言模型推理的多回合对话情感四重提取方法 | |
| Chen et al. | A transformer-based threshold-free framework for multi-intent NLU | |
| CN115190332B (zh) | 一种基于全局视频特征的密集视频字幕生成方法 | |
| CN115964497B (zh) | 一种融合注意力机制与卷积神经网络的事件抽取方法 | |
| CN112488063B (zh) | 一种基于多阶段聚合Transformer模型的视频语句定位方法 | |
| CN107665356A (zh) | 一种图像标注方法 | |
| CN118351553B (zh) | 一种基于笔顺动态学习的可解释性少样本字体生成方法 | |
| CN112417890A (zh) | 一种基于多样化语义注意力模型的细粒度实体分类方法 | |
| CN120107854A (zh) | 基于时序标记的高性能视频推理分割方法 | |
| CN120162731A (zh) | 一种视觉大模型持续更新方法及系统 | |
| CN116882398B (zh) | 基于短语交互的隐式篇章关系识别方法和系统 | |
| CN117609866A (zh) | 基于triz发明原理的多特征融合中文专利文本分类方法 | |
| CN120541693B (zh) | 基于多信息融合的单阶段多事件检测方法、装置和设备 | |
| CN120219769A (zh) | 一种图像描述生成系统、训练方法、生成方法及电子设备 | |
| CN120316308A (zh) | 一种基于稀疏表示和重排序的视频检索生成方法及装置 | |
| CN119829745A (zh) | 一种基于混合提示调优的文档级关系抽取方法 | |
| CN117151121B (zh) | 一种基于波动阈值与分割化的多意图口语理解方法 | |
| CN116050465B (zh) | 文本理解模型的训练方法和文本理解方法、装置 | |
| CN118428447A (zh) | 基于预训练语言模型的学生模型训练方法及其应用方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |