CN115035552B - 跌倒检测方法、装置、设备终端和可读存储介质 - Google Patents
跌倒检测方法、装置、设备终端和可读存储介质 Download PDFInfo
- Publication number
- CN115035552B CN115035552B CN202210958234.1A CN202210958234A CN115035552B CN 115035552 B CN115035552 B CN 115035552B CN 202210958234 A CN202210958234 A CN 202210958234A CN 115035552 B CN115035552 B CN 115035552B
- Authority
- CN
- China
- Prior art keywords
- human
- image
- layer
- target image
- target
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images



Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/103—Static body considered as a whole, e.g. static pedestrian or occupant recognition
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/20—Image preprocessing
- G06V10/34—Smoothing or thinning of the pattern; Morphological operations; Skeletonisation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/40—Extraction of image or video features
- G06V10/44—Local feature extraction by analysis of parts of the pattern, e.g. by detecting edges, contours, loops, corners, strokes or intersections; Connectivity analysis, e.g. of connected components
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/764—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using classification, e.g. of video objects
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/50—Context or environment of the image
- G06V20/52—Surveillance or monitoring of activities, e.g. for recognising suspicious objects
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Multimedia (AREA)
- Evolutionary Computation (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Software Systems (AREA)
- Computing Systems (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Artificial Intelligence (AREA)
- Medical Informatics (AREA)
- Databases & Information Systems (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Molecular Biology (AREA)
- General Engineering & Computer Science (AREA)
- Mathematical Physics (AREA)
- Human Computer Interaction (AREA)
- Image Analysis (AREA)
Abstract
本申请涉及跌倒检测方法、装置、设备终端和可读存储介质,该跌倒检测方法包括:基于YOLOv5目标检测模型,对输入的视频帧图像数据中的行人进行检测,以输出得到人形目标图像;将预设数量的人形目标数据帧图输像入至预设时间段网络进行判断,以得到对应的人体动作类别信息;根据所述人体动作类别信息,判断对应人体是否处于跌倒状态,上述跌倒检测方法在不同的场景覆盖情况下能够准确的对人体跌倒状态进行判断。
Description
技术领域
本申请涉及图像数据处理领域,具体涉及一种跌倒检测方法、装置、设备终端和可读存储介质。
背景技术
OpenPose为一个基于骨骼点识别的关键点识别技术,其中,OpenPose依赖于PAF通道输出,在复杂场景下,当人体跌倒时,例如昏暗、背景混乱等场景下容易出现误判情况,极易将雨伞架或桌子腿识别成人体一部分,从而影响到对人体跌倒行为的识别准确度。
发明内容
鉴于此,本申请提供一种跌倒检测方法、装置、设备终端和可读存储介质,能够提高对复杂场景下的人体跌倒行为的识别准确度。
一种跌倒检测方法,包括:
基于YOLOv5目标检测模型,对输入的视频帧图像数据中的行人进行检测,以输出得到人形目标图像;
将预设数量的人形目标数据帧图输像入至预设时间段网络进行判断,以得到对应的人体动作类别信息;
根据人体动作类别信息,判断对应人体是否处于跌倒状态。
在一个实施例中,YOLOv5目标检测模型包括依次连接的输入层、特征提取层、预测输出层和图像输出处理层,基于YOLOv5目标检测模型,对输入的视频帧图像数据中的行人进行检测,以输出得到人形目标图像的步骤包括:
基于输入层、特征提取层和预测输出层,对输入的视频帧图像数据中的行人进行检测,得到初步人形目标图像;
基于图像输出处理层,对初步人形目标图像的大小进行调整,以得到正方形的人形目标图像。
在一个实施例中,基于图像输出处理层,对初步人形目标图像的大小进行调整,以得到正方形的人形目标图像的步骤包括:
基于图像输出处理层,获取初步人形目标图像,判断初步人形目标图像是否为正方形;
若否,则获取初步人形目标图像中的最长边;
根据初步人形目标图像中的最长边计算缩放系数,根据缩放系数对初步人形目标图像进行缩放,得到缩放后的初步人形目标图像;
以缩放后的初步人形目标图像的最长边为基准边长,输出正方形的人形目标图像。
在一个实施例中,以缩放后的初步人形目标图像的最长边为基准边长,输出正方形的人形目标图像的步骤包括:
以缩放后的初步人形目标图像的最长边为基准边长,生成对应的黑色正方形背景图;
将缩放后的初步人形目标图像中的最长边与黑色正方形背景图中的一边相对齐,生成并输出正方形的人形目标图像。
在一个实施例中,特征提取层和预测输出层之间还设置有平滑网络层,
特征提取层和预测输出层之间还设置有平滑网络层,基于YOLOv5目标检测模型,对输入的视频帧图像数据中的行人进行检测,以输出得到人形目标图像的步骤包括:
基于输入层和特征提取层,对输入的视频帧图像数据进行处理,提取得到对应目标的中间特征图;
获取相邻视频帧图像数据中同一目标各自对应的中间特征图;
基于平滑网络层对输入的各个中间特征图进行平滑处理,获取相邻视频帧图像数据中同一目标各自对应中间特征图之间的速度、位置、加速度以及面积的变化信息;
将变化信息输入到预测输出层进行特征融合,以输出得到初步人形目标图像;
基于图像输出处理层,对初步人形目标图像的大小进行调整,以得到正方形的人形目标图像。
在一个实施例中,YOLOv5目标检测模型中对应的损失函数为:
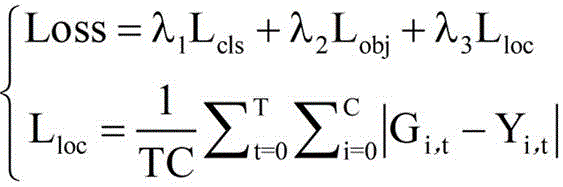
其中,Loss为YOLOv5目标检测模型中对应的损失函数,Lcls为分类损失,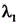 为Lcls的对应系数,Lobj为目标损失,
为Lcls的对应系数,Lobj为目标损失,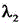 为Lobj的对应系数,Lloc为平滑处理损失,
为Lobj的对应系数,Lloc为平滑处理损失,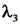 为Lloc的对应系数,C为目标检测框中的关键坐标点数目,T为中间特征图对应的视频帧图像数据的总帧数,t为帧变量,
为Lloc的对应系数,C为目标检测框中的关键坐标点数目,T为中间特征图对应的视频帧图像数据的总帧数,t为帧变量,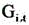 表示第t帧视频帧图像数据所对应的目标检测框经过所述平滑处理后的预测值,i表示关键坐标点变量,Yi,t表示第t帧视频帧图像数据所对应的目标检测框的真实值。
表示第t帧视频帧图像数据所对应的目标检测框经过所述平滑处理后的预测值,i表示关键坐标点变量,Yi,t表示第t帧视频帧图像数据所对应的目标检测框的真实值。
在一个实施例中,特征提取层包括backbone单元、空间效率度量单元和Neck单元,基于输入层和特征提取层,对输入的视频帧图像数据进行处理,提取得到对应目标的中间特征图的步骤包括:
基于输入层和backbone单元,对输入的视频帧图像数据进行切片操作以及卷积操作,以获得初始特征图;
基于空间效率度量单元,对初始特征图进行空间特征增强处理,以得到对应的增强特征图;
基于Neck单元对增强特征图进行二次特征提取,以得到对应目标的中间特征图。
此外,还提供一种跌倒检测装置,包括:
图像生成单元,用于基于YOLOv5目标检测模型,对输入的视频帧图像数据中的行人进行检测,以输出得到人形目标图像;
类别信息生成单元,用于将预设数量的人形目标数据帧图输像入至预设时间段网络进行判断,以得到对应的人体动作类别信息;
状态判断单元,用于根据人体动作类别信息,判断对应人体是否处于跌倒状态。
此外,还提供一种设备终端,设备终端包括处理器和存储器,存储器用于存储计算机程序,处理器运行计算机程序以使设备终端执行上述跌倒检测方法。
此外,还提供一种可读存储介质,可读存储介质存储有计算机程序,计算机程序在被处理器执行时实施上述跌倒检测方法。
上述跌倒检测方法通过基于YOLOv5目标检测模型,对输入的视频帧图像数据中的行人进行检测,以输出得到人形目标图像;将预设数量的人形目标数据帧图输像入至预设时间段网络进行判断,以得到对应的人体动作类别信息;根据所述人体动作类别信息,判断对应人体是否处于跌倒状态,将YOLOv5目标检测模型与预设时间段网络结合起来,直接通过利用YOLOv5目标检测模型直接对输入的视频帧图像数据中的行人进行检测识别,得到人形目标图像,然后将人形目标图像进一步输入到预设时间段网络进行进一步的判断识别,上述跌倒检测方法不需要依赖于人体的骨骼点识别,克服了单纯依赖基于骨骼点识别的跌倒检测方法所存在的准确度不高以及应用场景有限的缺点,相对于依赖于骨骼点识别的跌倒检测方法,上述跌倒检测方法基于算法层面,速度和精度大大提高。
附图说明
为了更清楚地说明本申请实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本申请实施例提供的一种跌倒检测方法的流程示意图;
图2是本申请实施例提供的一种YOLOv5目标检测模型的结构框图;
图3是本申请实施例提供的一种得到正方形的人形目标图像的流程示意图;
图4是本申请实施例提供的另一种得到正方形的人形目标图像的流程示意图;
图5是本申请实施例提供的又一种得到正方形的人形目标图像的流程示意图;
图6是本申请实施例提供的一种得到初步人形目标图像的流程示意图;
图7是本申请实施例提供的一种得到对应目标的中间特征图的流程示意图;
图8是本申请实施例提供的一种跌倒检测装置的结构框图。
具体实施方式
下面结合附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本申请一部分实施例,而非全部实施例。基于本申请中的实施例。在不冲突的情况下,下述各个实施例及其技术特征可以相互组合。
如图1所示,提供一种跌倒检测方法,该检测方法包括:
步骤S110,基于YOLOv5目标检测模型,对输入的视频帧图像数据中的行人进行检测,以输出得到人形目标图像。
其中,YOLOv5目标检测模型为预先训练好的目标模型,在训练过程中,训练数据集通常采用COCO2017,其中只针对行人部分进行训练,并且通过旋转图像的方式在训练时对图像进行顺时针和逆时针90度的随机扩增,从而增强YOLOv5目标检测模型对跌倒状态下的人体的检测能力。
其中,输入的视频帧图像数据中,基于YOLOv5目标检测模型,对输入的每个视频帧图像中的行人进行检测,以输出得到对应的人形目标图像。
步骤S120,将预设数量的人形目标数据帧图输像入至预设时间段网络进行判断,以得到对应的人体动作类别信息。
其中,预设时间段网络为TSN(Temporal Segment Networks),TSN采样一系列短片段,每个片段都将给出其本身对于行为类别的初步预测,从这些片段的“共识”来得到视频级的预测结果。
本实施例中,通过将预设数量的人形目标数据帧图输像入至预设时间段网络进行判断,进而得到对应的人体动作类别信息。
步骤S130,根据人体动作类别信息,判断对应人体是否处于跌倒状态。
其中,人体动作类别信息包括人体的姿态信息,通过对人体的姿态信息的变化程度,可判断人体是否处于跌倒状态。
在一个实施例中,YOLOv5目标检测模型对输入的视频帧图像数据中的行人进行检测,每秒钟检测预设数量帧数的视频帧图像(例如每秒钟30帧视频帧图像),得到对应的人形目标图像,然后进一步将对应的人形目标图像输入预设时间段网络进行判断,得到人体动作类别信息,最后根据人体动作类别信息,判断对应人体是否处于跌倒状态。
在一个实施例中,预设时间段网络中的主干网络可采用修改为更为轻量的Mobilenetv3网络,从整体上提高上述跌倒检测方法的检测速度。
上述跌倒检测方法通过基于YOLOv5目标检测模型,对输入的视频帧图像数据中的行人进行检测,以输出得到人形目标图像;将预设数量的人形目标数据帧图输像入至预设时间段网络进行判断,以得到对应的人体动作类别信息;根据所述人体动作类别信息,判断对应人体是否处于跌倒状态,将YOLOv5目标检测模型与预设时间段网络结合起来,直接通过利用YOLOv5目标检测模型直接对输入的视频帧图像数据中的行人进行检测识别,得到人形目标图像,然后将人形目标图像进一步输入到预设时间段网络进行进一步的判断识别,上述跌倒检测方法不需要依赖于人体的骨骼点识别,克服了单纯依赖基于骨骼点识别的跌倒检测方法所存在的准确度不高以及应用场景有限的缺点,相对于依赖于骨骼点识别的跌倒检测方法,上述跌倒检测方法基于算法层面,速度和精度大大提高。
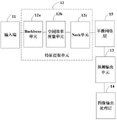
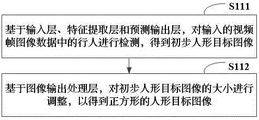
在一个实施例中,如图2所示,YOLOv5目标检测模型包括依次连接的输入层11、特征提取层12、预测输出层13和图像输出处理层14,如图3所示,步骤S110包括:
步骤S111,基于输入层、特征提取层和预测输出层,对输入的视频帧图像数据中的行人进行检测,得到初步人形目标图像。
目标各自对应的输入特征图进行比较,以得到当前视频帧的变化信息,该变化信息通常包括对应目标的位置、速度和加速度信息。
步骤S112,基于图像输出处理层,对初步人形目标图像的大小进行调整,以得到正方形的人形目标图像。
在一个实施例中,如图4所示,步骤S112包括:
S112a,基于图像输出处理层,获取初步人形目标图像,判断初步人形目标图像是否为正方形,若否,则进入步骤S112b。
步骤S112b,获取初步人形目标图像中的最长边。
步骤S112c,根据初步人形目标图像中的最长边计算缩放系数,根据缩放系数对初步人形目标图像进行缩放,得到缩放后的初步人形目标图像。
步骤S112d,以缩放后的初步人形目标图像的最长边为基准边长,输出正方形的人形目标图像。
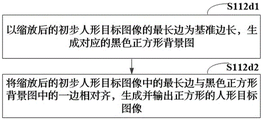
在一个实施例中,如图5所示,步骤S112d包括:
步骤S112d1,以缩放后的初步人形目标图像的最长边为基准边长,生成对应的黑色正方形背景图。
步骤S112d2,将缩放后的初步人形目标图像中的最长边与黑色正方形背景图中的一边相对齐,生成并输出正方形的人形目标图像。
在一个实施例中,如图3所示,特征提取层12和预测输出层13之间还设置有平滑网络层14,如图6所示,步骤S110包括:
步骤S113,基于输入层和特征提取层,对输入的视频帧图像数据进行处理,提取得到对应目标的中间特征图。
步骤S114,获取相邻视频帧图像数据中同一目标各自对应的中间特征图。
步骤S115,基于平滑网络层对输入的各个中间特征图进行平滑处理,获取相邻视频帧图像数据中同一目标各自对应中间特征图之间的速度、位置、加速度以及面积的变化信息。然而,行人跌倒时,视频帧图像往往存在更大的抖动,对于行人是否跌倒的动态检测还需要进一步考虑行人目标的形态变化,即对通常的平滑网络进行改进,增加形态变化参数检测,例如,通过对各个中间特征图(即检测框)的面积进行比较,以确定行人目标的形态变化。
步骤S116,将变化信息输入到预测输出层进行特征融合,以输出得到初步人形目标图像。
其中,在将变化信息输入到预测输出层时,通常在预测输出层中的融合层(FusionLayer)进行融合。
步骤S117,基于图像输出处理层,对初步人形目标图像的大小进行调整,以得到正方形的人形目标图像。
其中,图3以及图4中的步骤S112与步骤S117相同,这里不再赘述步骤S117。
本实施例中,从目标的位置、速度、加速度和检测框面积信息的变化构建对应的平滑网络层,能够进一步提高对视频帧图像中的行人进行检测的准确度,得到更为准确的正方形的人形目标图像。
在一个实施例中,YOLOv5目标检测模型中对应的损失函数为:

其中,Loss为YOLOv5目标检测模型中对应的损失函数,Lcls为分类损失, 为Lcls的对应系数,Lobj为目标损失,
为Lcls的对应系数,Lobj为目标损失,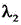 为Lobj的对应系数,Lloc为平滑处理损失,
为Lobj的对应系数,Lloc为平滑处理损失,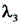 为Lloc的对应系数,C为目标检测框中的关键坐标点数目,T为中间特征图对应的视频帧图像数据的总帧数,t为帧变量,
为Lloc的对应系数,C为目标检测框中的关键坐标点数目,T为中间特征图对应的视频帧图像数据的总帧数,t为帧变量,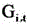 表示第t帧视频帧图像数据所对应的目标检测框经过所述平滑处理后的预测值,i表示关键坐标点变量,Yi,t表示第t帧视频帧图像数据所对应的目标检测框的真实值。
表示第t帧视频帧图像数据所对应的目标检测框经过所述平滑处理后的预测值,i表示关键坐标点变量,Yi,t表示第t帧视频帧图像数据所对应的目标检测框的真实值。
在一个实施例中,如图3所示,特征提取层12包括backbone单元12a、空间效率度量单元12b和Neck单元12c,如图7所示,步骤S111包括:
步骤S111a,基于输入层和backbone单元,对输入的视频帧图像数据进行切片操作以及卷积操作,以获得初始特征图。
步骤S111b,基于空间效率度量单元,对初始特征图进行空间特征增强处理,以得到对应的增强特征图。
步骤S111c,基于Neck单元对增强特征图进行二次特征提取,以得到对应目标的中间特征图。
本实施例中,通过进一步设置空间效率度量单元,即针对每个主干网络提取出来的特征分支(即对应的初始特征图),通过空间效率度量单元进行空间特征增强处理,能够从整体上扩大检测网络的感受野,从整体上提高上述跌倒检测方法的准确度。
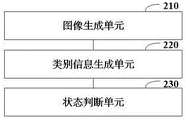
此外,如图8所示,还提供一种跌倒检测装置200,包括:
图像生成单元210,用于基于YOLOv5目标检测模型,对输入的视频帧图像数据中的行人进行检测,以输出得到人形目标图像;
类别信息生成单元220,用于将预设数量的人形目标数据帧图输像入至预设时间段网络进行判断,以得到对应的人体动作类别信息;
状态判断单元230,用于根据人体动作类别信息,判断对应人体是否处于跌倒状态。
此外,还提供一种设备终端,设备终端包括处理器和存储器,存储器用于存储计算机程序,处理器运行计算机程序以使设备终端执行上述跌倒检测方法。
此外,还提供一种可读存储介质,可读存储介质存储有计算机程序,计算机程序在被处理器执行时实施上述跌倒检测方法。
上述跌倒检测装置200中各个单元的划分仅用于举例说明,在其他实施例中,可将上述跌倒检测装置200按照需要划分为不同的单元,以完成上述跌倒检测装置200的全部或部分功能。关于的上述跌倒检测装置200具体限定可以参见上文中对于方法的限定,在此不再赘述。
即,以上仅为本申请的实施例,并非因此限制本申请的专利范围,凡是利用本申请说明书及附图内容所作的等效结构或等效流程变换,例如各实施例之间技术特征的相互结合,或直接或间接运用在其他相关的技术领域,均同理包括在本申请的专利保护范围内。
另外,对于特性相同或相似的结构元件,本申请可采用相同或者不相同的标号进行标识。此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个特征。在本申请的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
在本申请中,“例如”一词是用来表示“用作例子、例证或说明”。本申请中被描述为“例如”的任何一个实施例不一定被解释为比其它实施例更加优选或更加具优势。为了使本领域任何技术人员能够实现和使用本申请,本申请给出了以上描述。在以上描述中,为了解释的目的而列出了各个细节。
应当明白的是,本领域普通技术人员可以认识到,在不使用这些特定细节的情况下也可以实现本申请。在其它实施例中,不会对公知的结构和过程进行详细阐述,以避免不必要的细节使本申请的描述变得晦涩。因此,本申请并非旨在限于所示的实施例,而是与符合本申请所公开的原理和特征的最广范围相一致。
Claims (8)
1.一种跌倒检测方法,其特征在于,包括:
基于YOLOv5目标检测模型,对输入的视频帧图像数据中的行人进行检测,以输出得到人形目标图像;
将预设数量的人形目标数据帧图输像入至预设时间段网络进行判断,以得到对应的人体动作类别信息;
根据所述人体动作类别信息,判断对应人体是否处于跌倒状态;
所述YOLOv5目标检测模型包括依次连接的输入层、特征提取层、预测输出层和图像输出处理层;
所述特征提取层和所述预测输出层之间还设置有平滑网络层,所述基于YOLOv5目标检测模型,对输入的视频帧图像数据中的行人进行检测,以输出得到人形目标图像的步骤包括:
基于所述输入层和所述特征提取层,对输入的视频帧图像数据进行处理,提取得到对应目标的中间特征图;
获取相邻视频帧图像数据中同一目标各自对应的中间特征图;
基于所述平滑网络层对输入的各个中间特征图进行平滑处理,获取相邻视频帧图像数据中同一目标各自对应中间特征图之间的速度、位置、加速度以及面积的变化信息;
将所述变化信息输入到所述预测输出层进行特征融合,以输出得到初步人形目标图像;
基于所述图像输出处理层,对所述初步人形目标图像的大小进行调整,以得到正方形的人形目标图像。
2.根据权利要求1所述的跌倒检测方法,其特征在于,所述基于所述图像输出处理层,对所述初步人形目标图像的大小进行调整,以得到正方形的人形目标图像的步骤包括:
基于所述图像输出处理层,获取所述初步人形目标图像,判断所述初步人形目标图像是否为正方形;
若否,则获取所述初步人形目标图像中的最长边;
根据所述初步人形目标图像中的最长边计算缩放系数,根据所述缩放系数对所述初步人形目标图像进行缩放,得到缩放后的初步人形目标图像;
以所述缩放后的初步人形目标图像的最长边为基准边长,输出正方形的人形目标图像。
3.根据权利要求2所述的跌倒检测方法,其特征在于,所述以所述缩放后的初步人形目标图像的最长边为基准边长,输出正方形的人形目标图像的步骤包括:
以所述缩放后的初步人形目标图像的最长边为基准边长,生成对应的黑色正方形背景图;
将所述缩放后的初步人形目标图像中的最长边与所述黑色正方形背景图中的一边相对齐,生成并输出正方形的人形目标图像。
4.根据权利要求1所述的跌倒检测方法,其特征在于,所述YOLOv5目标检测模型中对应的损失函数为:

其中,Loss为YOLOv5目标检测模型中对应的损失函数,Lcls为分类损失, 为Lcls的对应系数,Lobj为目标损失,
为Lcls的对应系数,Lobj为目标损失, 为Lobj的对应系数,Lloc为平滑处理损失,
为Lobj的对应系数,Lloc为平滑处理损失,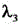 为Lloc的对应系数,C为目标检测框中的关键坐标点数目,T为所述中间特征图对应的视频帧图像数据的总帧数,t为帧变量,
为Lloc的对应系数,C为目标检测框中的关键坐标点数目,T为所述中间特征图对应的视频帧图像数据的总帧数,t为帧变量,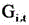 表示第t帧视频帧图像数据所对应的目标检测框经过所述平滑处理后的预测值,i表示关键坐标点变量,Yi,t表示第t帧视频帧图像数据所对应的目标检测框的真实值。
表示第t帧视频帧图像数据所对应的目标检测框经过所述平滑处理后的预测值,i表示关键坐标点变量,Yi,t表示第t帧视频帧图像数据所对应的目标检测框的真实值。
5.根据权利要求1所述的跌倒检测方法,其特征在于,所述特征提取层包括backbone单元、空间效率度量单元和Neck单元,所述基于所述输入层和所述特征提取层,对输入的视频帧图像数据进行处理,提取得到对应目标的中间特征图的步骤包括:
基于所述输入层和所述backbone单元,对输入的视频帧图像数据进行切片操作以及卷积操作,以获得初始特征图;
基于所述空间效率度量单元,对所述初始特征图进行空间特征增强处理,以得到对应的增强特征图;
基于所述Neck单元对增强特征图进行二次特征提取,以得到对应目标的中间特征图。
6.一种跌倒检测装置,其特征在于,包括:
图像生成单元,用于基于YOLOv5目标检测模型,对输入的视频帧图像数据中的行人进行检测,以输出得到人形目标图像;
类别信息生成单元,用于将预设数量的人形目标数据帧图输像入至预设时间段网络进行判断,以得到对应的人体动作类别信息;
状态判断单元,用于根据所述人体动作类别信息,判断对应人体是否处于跌倒状态;
所述YOLOv5目标检测模型包括依次连接的输入层、特征提取层、预测输出层和图像输出处理层;
所述特征提取层和所述预测输出层之间还设置有平滑网络层,所述图像生成单元包括:
第一特征提取子单元,用于基于所述输入层和所述特征提取层,对输入的视频帧图像数据进行处理,提取得到对应目标的中间特征图;
第二特征提取子单元,用于获取相邻视频帧图像数据中同一目标各自对应的中间特征图;
平滑处理子单元,用于基于所述平滑网络层对输入的各个中间特征图进行平滑处理,获取相邻视频帧图像数据中同一目标各自对应中间特征图之间的速度、位置、加速度以及面积的变化信息;
特征融合子单元,用于将所述变化信息输入到所述预测输出层进行特征融合,以输出得到初步人形目标图像;
图像调整子单元,用于基于所述图像输出处理层,对所述初步人形目标图像的大小进行调整,以得到正方形的人形目标图像。
7.一种设备终端,其特征在于,所述设备终端包括处理器和存储器,所述存储器用于存储计算机程序,所述处理器运行所述计算机程序以使所述设备终端执行权利要求1至5中任一项所述的跌倒检测方法。
8.一种可读存储介质,其特征在于,所述可读存储介质存储有计算机程序,所述计算机程序在被处理器执行时实施权利要求1至5中任一项所述的跌倒检测方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210958234.1A CN115035552B (zh) | 2022-08-11 | 2022-08-11 | 跌倒检测方法、装置、设备终端和可读存储介质 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210958234.1A CN115035552B (zh) | 2022-08-11 | 2022-08-11 | 跌倒检测方法、装置、设备终端和可读存储介质 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN115035552A CN115035552A (zh) | 2022-09-09 |
| CN115035552B true CN115035552B (zh) | 2023-01-17 |
Family
ID=83129959
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210958234.1A Active CN115035552B (zh) | 2022-08-11 | 2022-08-11 | 跌倒检测方法、装置、设备终端和可读存储介质 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN115035552B (zh) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN117315777B (zh) * | 2023-09-20 | 2026-03-31 | 四川弘和数智集团有限公司 | 一种实时火车卸油员工跌落识别方法 |
| CN117953306B (zh) * | 2024-02-23 | 2024-11-15 | 深圳职业技术大学 | 一种摔倒检测方法、系统、电子设备及介质 |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AU2019101142A4 (en) * | 2019-09-30 | 2019-10-31 | Dong, Qirui MR | A pedestrian detection method with lightweight backbone based on yolov3 network |
| CN112580778A (zh) * | 2020-11-25 | 2021-03-30 | 江苏集萃未来城市应用技术研究所有限公司 | 基于YOLOv5和Pose-estimation的工地工人手机使用检测方法 |
| CN113255797A (zh) * | 2021-06-02 | 2021-08-13 | 通号智慧城市研究设计院有限公司 | 一种基于深度学习模型的危险品检测方法和系统 |
| CN113744262A (zh) * | 2021-09-17 | 2021-12-03 | 浙江工业大学 | 一种基于GAN和YOLO-v5的目标分割检测方法 |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| IL251519A0 (en) * | 2017-04-02 | 2017-06-29 | Fst21 Ltd | Systems and methods for identification |
| CN109145696B (zh) * | 2017-06-28 | 2021-04-09 | 安徽清新互联信息科技有限公司 | 一种基于深度学习的老人跌倒检测方法及系统 |
| CN111553212B (zh) * | 2020-04-16 | 2022-02-22 | 中国科学院深圳先进技术研究院 | 一种基于平滑边框回归函数的遥感图像目标检测方法 |
-
2022
- 2022-08-11 CN CN202210958234.1A patent/CN115035552B/zh active Active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AU2019101142A4 (en) * | 2019-09-30 | 2019-10-31 | Dong, Qirui MR | A pedestrian detection method with lightweight backbone based on yolov3 network |
| CN112580778A (zh) * | 2020-11-25 | 2021-03-30 | 江苏集萃未来城市应用技术研究所有限公司 | 基于YOLOv5和Pose-estimation的工地工人手机使用检测方法 |
| CN113255797A (zh) * | 2021-06-02 | 2021-08-13 | 通号智慧城市研究设计院有限公司 | 一种基于深度学习模型的危险品检测方法和系统 |
| CN113744262A (zh) * | 2021-09-17 | 2021-12-03 | 浙江工业大学 | 一种基于GAN和YOLO-v5的目标分割检测方法 |
Non-Patent Citations (2)
| Title |
|---|
| "基于光流场的时间分段网络行为识别";焦红虹等;《云南大学学报( 自然科学版)》;20190110;第41卷(第1期);第36-45页 * |
| "基于复杂场景的跌倒行为检测研究";朱泽宇;《中国优秀硕士学位论文全文数据库(信息科技辑)》;20210915;I138-376 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN115035552A (zh) | 2022-09-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109255352B (zh) | 目标检测方法、装置及系统 | |
| JP6942488B2 (ja) | 画像処理装置、画像処理システム、画像処理方法、及びプログラム | |
| CN108875676B (zh) | 活体检测方法、装置及系统 | |
| CN109829398B (zh) | 一种基于三维卷积网络的视频中的目标检测方法 | |
| US10872262B2 (en) | Information processing apparatus and information processing method for detecting position of object | |
| US10452893B2 (en) | Method, terminal, and storage medium for tracking facial critical area | |
| CN112381104B (zh) | 一种图像识别方法、装置、计算机设备及存储介质 | |
| JP6332937B2 (ja) | 画像処理装置、画像処理方法及びプログラム | |
| CN108986152B (zh) | 一种基于差分图像的异物检测方法及装置 | |
| JP6397379B2 (ja) | 変化領域検出装置、方法、及びプログラム | |
| CN113065379B (zh) | 融合图像质量的图像检测方法、装置、电子设备 | |
| CN109299658B (zh) | 脸部检测方法、脸部图像渲染方法、装置及存储介质 | |
| CN110569731A (zh) | 一种人脸识别方法、装置及电子设备 | |
| CN115035552B (zh) | 跌倒检测方法、装置、设备终端和可读存储介质 | |
| CN112560857B (zh) | 文字区域边界检测方法、设备、存储介质及装置 | |
| CN108875500B (zh) | 行人再识别方法、装置、系统及存储介质 | |
| CN113762249B (zh) | 图像攻击检测、图像攻击检测模型训练方法和装置 | |
| CN115049731A (zh) | 一种基于双目摄像头的视觉建图和定位方法 | |
| CN111814846B (zh) | 属性识别模型的训练方法、识别方法及相关设备 | |
| CN114758124B (zh) | 目标对象的遮挡检测方法、装置、设备及计算机可读介质 | |
| CN107977948B (zh) | 一种面向社群图像的显著图融合方法 | |
| CN113544701B (zh) | 关联对象的检测方法及装置、电子设备及存储介质 | |
| CN119180997A (zh) | 目标检测模型训练方法、装置、电子设备及存储介质 | |
| CN115862090A (zh) | 人脸异常行为检测方法、装置、设备及存储介质 | |
| JP6132996B1 (ja) | 画像処理装置,画像処理方法,画像処理プログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| TR01 | Transfer of patent right |
Effective date of registration: 20230705 Address after: 13C-18, Caihong Building, Caihong Xindu, No. 3002, Caitian South Road, Gangsha Community, Futian Street, Futian District, Shenzhen, Guangdong 518033 Patentee after: Core Computing Integrated (Shenzhen) Technology Co.,Ltd. Address before: 518000 1001, building G3, TCL International e city, Shuguang community, Xili street, Nanshan District, Shenzhen City, Guangdong Province Patentee before: Shenzhen Aishen Yingtong Information Technology Co.,Ltd. |
|
| TR01 | Transfer of patent right |