CN1148720C - 说话者识别 - Google Patents
说话者识别 Download PDFInfo
- Publication number
- CN1148720C CN1148720C CNB008048932A CN00804893A CN1148720C CN 1148720 C CN1148720 C CN 1148720C CN B008048932 A CNB008048932 A CN B008048932A CN 00804893 A CN00804893 A CN 00804893A CN 1148720 C CN1148720 C CN 1148720C
- Authority
- CN
- China
- Prior art keywords
- speaker
- feature vector
- vector sequence
- eigenvector
- conversion
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Lifetime
Links
- 239000013598 vector Substances 0.000 claims abstract description 80
- 238000000034 method Methods 0.000 claims abstract description 28
- 230000001419 dependent effect Effects 0.000 claims abstract description 6
- 238000006243 chemical reaction Methods 0.000 claims description 42
- 230000005055 memory storage Effects 0.000 claims description 17
- 230000008569 process Effects 0.000 claims description 13
- 238000001514 detection method Methods 0.000 claims description 11
- 230000008878 coupling Effects 0.000 claims description 5
- 238000010168 coupling process Methods 0.000 claims description 5
- 238000005859 coupling reaction Methods 0.000 claims description 5
- 238000012546 transfer Methods 0.000 claims description 3
- 238000011067 equilibration Methods 0.000 claims description 2
- 230000001755 vocal effect Effects 0.000 abstract 1
- 239000011159 matrix material Substances 0.000 description 21
- 230000009466 transformation Effects 0.000 description 18
- 230000000875 corresponding effect Effects 0.000 description 16
- 230000006870 function Effects 0.000 description 14
- 238000005516 engineering process Methods 0.000 description 13
- 238000001228 spectrum Methods 0.000 description 10
- 238000012545 processing Methods 0.000 description 8
- 238000001914 filtration Methods 0.000 description 5
- 238000010606 normalization Methods 0.000 description 5
- 238000010586 diagram Methods 0.000 description 4
- 230000002596 correlated effect Effects 0.000 description 3
- 238000012549 training Methods 0.000 description 3
- 230000007704 transition Effects 0.000 description 3
- 238000012795 verification Methods 0.000 description 3
- 230000009471 action Effects 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- 238000009795 derivation Methods 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 230000001537 neural effect Effects 0.000 description 2
- 238000005070 sampling Methods 0.000 description 2
- 240000004859 Gamochaeta purpurea Species 0.000 description 1
- 239000000654 additive Substances 0.000 description 1
- 230000000996 additive effect Effects 0.000 description 1
- 238000003491 array Methods 0.000 description 1
- 238000013528 artificial neural network Methods 0.000 description 1
- LFYJSSARVMHQJB-QIXNEVBVSA-N bakuchiol Chemical compound CC(C)=CCC[C@@](C)(C=C)\C=C\C1=CC=C(O)C=C1 LFYJSSARVMHQJB-QIXNEVBVSA-N 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 230000008676 import Effects 0.000 description 1
- 238000013507 mapping Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000003071 parasitic effect Effects 0.000 description 1
- 230000008447 perception Effects 0.000 description 1
- 230000001105 regulatory effect Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 238000004088 simulation Methods 0.000 description 1
Images



Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L17/00—Speaker identification or verification techniques
- G10L17/02—Preprocessing operations, e.g. segment selection; Pattern representation or modelling, e.g. based on linear discriminant analysis [LDA] or principal components; Feature selection or extraction
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L17/00—Speaker identification or verification techniques
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L17/00—Speaker identification or verification techniques
- G10L17/04—Training, enrolment or model building
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/06—Creation of reference templates; Training of speech recognition systems, e.g. adaptation to the characteristics of the speaker's voice
Landscapes
- Engineering & Computer Science (AREA)
- Acoustics & Sound (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Multimedia (AREA)
- Health & Medical Sciences (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Image Analysis (AREA)
- Telephonic Communication Services (AREA)
- Complex Calculations (AREA)
- Measuring Fluid Pressure (AREA)
- Magnetic Resonance Imaging Apparatus (AREA)
- Measuring Pulse, Heart Rate, Blood Pressure Or Blood Flow (AREA)
- Character Discrimination (AREA)
Abstract
本发明涉及一种用于说话者识别的方法和设备。在本发明中,在将从语音导出的特征矢量与一存储的参考模型进行比较之前,通过施加一与说话者相关的变换对这些特征矢量进行处理,该变换匹配于一特定的说话者的发声带的特性。从具有与该变换所依据的说话者的特性不类似的特性的语音导出的特征通过该变换被严重地变形,而从具有与该变换所依据的说话者的特性类似的特性的语音导出的特征通过该变换所产生的变形非常小。
Description
技术领域
本发明涉及说话者识别。在说话者识别中,说话者的身份被识别或验证。在说话者识别中,一说话者或者被识别为一组已知说话者之一,或者作为一未知的说话者而被拒绝。在说话者识别中,说话者或者作为具有一声称的身份而被接受或者被拒绝。说话者可例如通过一口令、一个人身份识别号或一卡而输入一要求的身份。
背景技术
通常,对于说话者识别,语音处理目的在于提高对于不同说话者的所说词的影响,而对于语音识别,其中一特定的词(或有时一个短语或者一个音素,或者其他所说的内容)被识别,语音处理目的在于减少对不同说话者的所说词的影响。
输入语音数据(通常是数字形式的)到一前端处理器是共同的,该前端处理器从输入语音数据流导出更紧凑、感性上更明显的称之为输入特征矢量的数据(或有时称之为前端特征矢量)。其中说话者说一对于识别设备和说话者是已知的预定的词(例如在银行中的个人身份识别号),该技术已知为“正文相关(text-dependent)”技术。在说话者识别的一些应用中,使用一种技术,其中该技术不要求语音的内容是预定的,这样的技术别已知为“正文无关(text independent)”技术。
在正文相关技术中,存储的该词的一表示,称之为模板或模型,被预先从一已知是真实的说话者导出。从待被识别的说话者导出的输入特征矢量被与该模板进行比较且两者之间的类似性的测量被与一接受判定的阈值进行比较。可借助于在Chollet&Gagnoulet所著的“On the evaluation of Speech Recognisers and Data Bases usinga Reference System(使用参考系统的语音识别器及数据基础的评估)”,1982 IEEE,International Conference on Acoustics(国际声学会),Speech and Signal Processing(语音及信号处理),pp2026-2029(2026-2029页)中所述的动态时间扭曲(Dynamic timewarping-DTW)来进行该比较。其他比较的手段包括隐藏马克夫模型(Hidden Markov Model-HMM)处理和神经网络。这些技术在BritishTelecom Technology Journal,Vol.6,No.2 April 1988(英国电信技术刊物,第6卷,第2号,1988年4月)中105-115页的由SJCox所著的“Hidden Markov Models for Automatic SpeechRecognition:Theory And Application(用于自动语音识别的隐藏马克夫模型:理论及应用)”;131-139页的由McCullogh等人所著的“Multi-layer perceptrons applied to speech technology(用于语音技术的多层感知器)”和140-163页的由Tattershall等人所著的“Neural arrays for speech recognition(用于语音识别的神经阵列)”中被进行了描述。
各种类型的特征已被用于或被建议用于语音处理。通常,由于用于语音识别的特征类型倾向于从对于说话者是不敏感的另一词中分辨出一词,而用于说话者识别的特征类型倾向于对于一(些)已知的词而言在若干个说话者之间进行辨别,适用于一种识别的一种特征对于另一种识别可能是不合适的。在Atal所著的“AutomaticRecognition of Speakers from their voices(从他们的话音自动识别说话者)”,Proc IEEE vol 64 pp 460-475,April 1976(Proc IEEE第64卷460-475页,1976年4月)中描述了适用于说话者识别的一些特征。
发明内容
根据本发明,提供有一种说话者识别方法,包括有步骤:接收来自一未知的说话者的语音信号;根据一变换(transform)对该接收的语音信号进行变换,该变换是与一特定的说话者相关联的;将该变换的语音信号与一代表所述特定的说话者的模型进行比较;且将依据于该未知的说话者是所述的特定说话者的似然性的一参数提供作为输出。
较佳地,该变换步骤包括有子步骤:检测该接收的语音信号内的一语音开始点和一语音结束点;生成从该接收的语音信号导出的一特征矢量序列;及将对应于该检测的开始点和检测的结束点之间的语音信号的该特征矢量序列与用于所述特定说话者的代表性的特征矢量序列相对准以使在被对准的特征矢量序列中的各特征矢量对应于该代表性的特征矢量序列中的一特征矢量。
有利地,该变换步骤还包括有子步骤:平均带有该代表性的特征矢量序列中的对应特征矢量的该被对准的特征矢量序列中的各特征矢量。
较佳地,该模型是一隐藏的马克夫模型且可以是一左至右(leftto right)隐藏的马克夫模型。
有利地,该代表性的特征矢量序列包括与隐藏的马克夫模型中的状态数相同数量的特征矢量。
根据本发明的另一方面,提供有一种用于说话者识别的设备,包括有:用于接收来自一未知的说话者的语音信号的接收装置;用于存储多个说话者变换的说话者变换存储装置,各变换与多个说话者中对应的一个相关联;用于存储多个说话者模型的说话者模型存储装置,各说话者模型与所述多个说话者中对应的一个相关联;与该接收装置和说话者变换存储装置耦合的变换装置,被配置用于根据一选择的说话者变换对该接收的语音信号进行变换;耦合至该变换装置和说话者模型存储装置的比较装置,被配置用于将该变换的语音信号与对应的说话者的模型进行比较;和用于提供一指示该未知的说话者是与该选择的说话者变换相关联的说话者的似然性的一信号的输出装置。
较佳地,该变换存储装置存储各所述变换作为一代表性的特征矢量序列;且该变换装置包括一起始点和结束点检测器,用于检测该接收的语音信号内的一语音开始点和一语音结束点;一特征矢量生成器,用于生成从该接收的语音信号导出的一特征矢量序列;及一对准装置,用于将对应于该检测的开始点和检测的结束点之间的语音信号的该特征矢量序列与用于所述特定说话者的代表性的特征矢量序列相对准以使在得到的被对准的特征矢量序列中的各特征矢量对应于该代表性的特征矢量序列中的一特征矢量。
有利地,该变换装置还包括有:平均装置,用于平均带有该代表性的特征矢量序列中的对应特征矢量的该被对准的特征矢量序列中的各特征矢量。
较佳地,该说话者模型存储装置被配置用于存储一隐藏的马克夫模型形式的说话者模型且可被配置以存储是一左至右(left toright)隐藏的马克夫模型形式的说话者模型。
有利地,该存储的代表性的特征矢量序列包括与隐藏的马克夫模型中的状态数相同数量的特征矢量。
众所周知,发音期间的说话者的发声道可被模型化为一时间变化滤波器。在本发明中,在将从语音导出的特征矢量与一存储的参考模型进行比较之前,通过施加与一特定的说话者的发声道的特性匹配的与说话者相关的变换,对这些特征矢量进行处理。从具有与该变换所依据的说话者的特性非常不类似的特性的语音导出的特征通过该变换可被严重地失真,而具有与该变换所依据的说话者的特性类似的特性的语音导出的特征则被失真小得多。这样一与说话者相关的变换可被看作为与常规的匹配的滤波处理(其中使用一匹配的滤波器使滤波的信号不发生失真)类似的一处理。这样被变换的特征因此提供说话者之间的更多辨别。这样变换的特征然后被用于常规的说话者识别比较过程。
附图说明
图1示出了结合有一识别处理器的一电信系统;
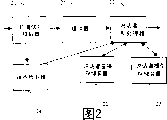
图2示出了结合有一频谱信号抽取器的图11中的识别处理器的部分;
图3示出了图2中的频谱信号抽取器;
图4a是说明载荷说话者验证期间图1中的识别处理器的操作的流程图;
图4b是说明在说话者识别期间图1中的识别处理器的操作的流程图;
图5示出了两特征矢量M和R之间的一扭曲函数(warpingfunction)的例子;
图6示出了在扭曲期间可被施加的一加权函数的例子;
图7是说明在两特征矢量之间的时间正规化距离的计算的流程图;
图8是一马克夫模型的例子;
图9示出了该转变矩阵和图8的马克夫模型的一起始(initialisation)矢量的例子;
图10示出了一六状态隐藏的马克夫模型的前向概率的计算;及
图11示出了使用韦特比算法计算的一可能状态序列。
具体实施方式
下面参照附图,通过例子对本发明进行描述。
在图1中,示出了包括有说话者识别设备的一电信系统,该电信系统包括有一麦克风1(通常形成电话手机的部分)、一电信网络2(例如公共交换电信网(PSTN)或数字电信网)、一被连接以接收来自网络2的话音信号的识别处理器3、和一应用设备4,其被连接至该识别处理器3且被配置以从识别处理器3接收一话音识别信号,指示一特定说话者的识别或未识别,并响应其而采取行动。例如该应用设备4可以是远程操作的银行终端,用于影响银行交易。在许多情况下,该应用设备4将生成对用户的一音频响应,经网络2发送给一扬声器5(通常形成电话手机的部分)。
在操作中,一说话者对麦克风1说话且一模拟语音信号被从麦克风1发送进网络2到识别处理器3,其中该语音信号被分析且生成指示一特定说话者的识别或未识别的信号并发送给该应用设备4,应用发备4然后在一特定说话者的识别或未识别的情况下采取适当的动作。如果识别处理器正执行说话者识别,则该信号或者指示被识别的说话者或者指示该说话者已被拒绝。如果该识别处理器正执行说话者验证,则该信号指示该说话者是否是所声称的说话者。
该识别处理器需要获取涉及该语音信号与其比较的说话者的身份的数据。该数据获取可由识别处理器在操作的第二模型中执行,其中识别处理器3未被连接至应用设备4,而接收来自麦克风1的语音信号以形成用于该说话者的识别数据。然而,获取说话者识别数据的其他方法也是可能的;例如,说话者识别数据可被容纳于由说话者携带的一卡上且可被插入一卡读取器中,从而读取该数据并在传送该语音信号之前,通过网络发送给该识别处理器。
通常,识别处理器3不知道自麦克风1及通过网络2到其所经由的路径;麦克风1例如可通过一移动模拟或数字无线电链路被连接至网络2,或可自另一城市始发。该麦克风可以是多种接收机手机之一的部分。类似地,在网络2内,可采取多条传输路径中的任一条,包括无线电链路、模拟及数字路径等。
图2示出了识别处理器3的部分。一频谱信号抽取器20例如从一数字电话网络或者从一模数转换器接收数字语音。从该数字语音导出多个特征矢量,各特征矢量代表多个连续数字样本。例如,这些语音样本可以8khz的取样率被接收,且一特征矢量可代表256个连续样本的一帧,即32ms的语音。
频谱信号抽取器20将特征矢量提供给一端点检测器24,该端点检测器24提供指示该接收的语音的开始点和结束点的输出信号。这些特征矢量在由说话者识别处理器21进行处理之前还被存储在帧缓冲器25中。
使用一常规的基于能量的端点器(endpointer)提供这些语音的开始和结束点。在一改进的技术中,来自被配置用于识别特定词的一语音识别器的信号可被使用。
说话者识别处理器21接收多个特征矢量,其从说话者变换存储装置22读取与一特定说话者相关联的与说话者相关的变换矩阵并从一说话者模型存储装置23读取与该特定说话者相关联的一参考模型。该说话者识别处理器然后根据所抽取的说话者变换矩阵处理接收的特征矢量,并根据由所抽取的模型代表的说话者和产生由接收的特征矢量代表的语音的与说话者相关的变换的似然性而生成一输出信号。该说话者识别处理器的操作将参照图4a和4b进行更全面的描述。该说话者识别处理器21构成本发明的变换装置、比较装置和输出装置。
现参见图3,将更详细地描述频谱信号抽取器20的操作。一高频加重滤波器10以例如8khz的取样率接收数字化的语音波形作为一序列8位数并执行高频加重滤波处理(例如通过执行一1-0.95-1滤波器)以增加较高频率的幅度。被滤波的信号的连续样本的一帧通过一窗口处理器11被开窗(即这些样本被乘以预定的加权常数),使用例如汉明窗,以减少由这些帧边缘生成的寄生污迹。在一优选实施例中,这些帧被重叠例如50%,以使在该例中每16ms提供一帧。
256开窗样本的各帧然后由一MFCC(Mel Frequency CepstralCoefficient-美频率倒谱系数)发生器12处理以生成一MFCC特征矢量,该MFCC特征矢量包括一组MFCC系数(例如8个系数)。
该MFCC特征矢量是这样被导出的:对一语音信号的各帧执行一频谱变换例如快速傅里叶变换(FFT)以导出一信号频谱;将该频谱的这些项集成为一系列宽带,该些宽带沿频率轴以“美-频率”标度分布;取各带中的幅度的对数;且然后执行进一步的变换(例如离散余弦变换DCT)以生成用于该帧的MFCC系数组。可发现有用的信息通常被限制在下级系数。该美-频率标度是在0和1khz之间的一线性频率标度上均匀间隔的、且在1khz上的一对数频率标度上均匀间隔的频带。
通过一或多个适当编程的数字信号处理器(DSP)和/或微处理器,可提供高频加重滤波器10、MFCC发生器12、端点检测器24和说话者识别处理器21。帧缓冲器25、说话者变换存储装置22和说话者模型存储装置23可被设置在连接至这些处理器装置的读/写存储器装置中。
图4a概略地示出了在说话者验证期间说话者识别处理器21的操作。在步骤40,说话者识别处理器接收一特征矢量序列和来自端点检测器11的一检测的开始点和一检测的结束点。在步骤41,对于使用者被声称是该说话者,说话者识别处理器从说话者变换存储装置22选择一与说话者相关的变换矩阵并从该说话者模型存储装置23读取表示与该代表的特征矩阵相同的说话者的一对应模型。
该与说话者相关的变换矩阵表示用于一特定说话者的特定词。它包括当由该代表的说话者说出时的该代表的词的一代表性特征矢量序列。该与说话者相关的变换矩阵在这里也被称作为代表性的特征矢量序列。在步骤42,使用动态时间扭曲(DTW)处理,对应于检测的开始点和检测的结束点之间的语音信号的该接收的特征矢量序列与该与说话者相关的变换矩阵进行时间对准。
现将参照图5、6和7更加详细地描述在步骤42执行的时间对准。
该与说话者相关的变换矩阵包括用于一特定词的一代表性的特征矢量序列。
M=m1,m2,...mi...mI
一特征矢量序列
R=r1,r2,...rj...rJ
被接收。如下所述,该接收的特征矢量序列与该代表性的特征矢量序列进行时间对准。
参见图5,该代表性序列被沿i轴表示且该接收的序列沿j轴表示。
点序列C=(i,j)表示一“扭曲”函数,其近似地实现从该接收的特征矢量序列的时间轴到该代表性的特征矢量序列的时间轴的映射。
F=c(1),c(2),...,c(k),...c(K)where c(k)=(r(k),m(k))
作为两特征矢量M和R之间的差的测量,使用一距离
d(c)=d(i,j)=‖mi-rj‖在该扭曲函数上这些距离的求和是
其给出了该扭曲函数F如何将一组特征矢量映射到另一组特征矢量上的量度。当F被确定最佳地调节该两特征矢量序列之间的时间差时,该量度达到一最小值。可替换地,可采用一加权函数以使一加权的求和被使用
且ω(k)被使用以对该距离量度进行加权。加权函数的一个例子是
ω(K)=(i(K)-i(K-1))+(j(K)-j(K-1))
其被概略地示出在图6中。
两特征矢量序列之间的时间正规化的距离被定义为
如Sskoe和Chiba所著的“Dynamic Programming AlgorihtmOptimisation for Spoken Word Recognition(用于所说的词识别的动态编程算法最优化)”,IEEE Transactions on Acoustics Speechand Signal Processing,vol 26,No.1,February 1978(声学语音和信号处理学报,第6卷,第1期,1978年2月)中所述的,可对该扭曲函数施加各种不同的约束。计算时间正规化距离连同提供所需的最小值的扭曲函数一起的方程如下:
其被称之为“动态编程”方程
该时间正规化距离是
如果先前示出的加权函数被使用,则该动态编程(DP)方程变为
及
在图7中示出使用图6的加权函数计算该时间正规化距离的流程图。
在步骤74,i和j被初始化等于1。在步骤76,g(1,1)的初始值被设置等于乘以2的m1-r1(d(1,1))(根据加权函数w)。然后,在步骤78,i被增加1且除非在步骤80,i大于1,在步骤86,该动态编程方程被进行计算。如果i大于1,则在步骤88,j被增加且在步骤96,i被复位至1。然后重复步骤78和86直至最后对于所有的I和J的值,该动态编程方程已被进行了计算,则在步骤92,计算了该时间正规化距离。
在一更加有效的算法中,该动态编程方程仅对于在一大小为r的限制窗口内的值进行计算,以使
j-r≤i≤j+r
然后如下通过“退回(backtracking )”来确定该扭曲函数F:
C(K)=(I,J)
C(k-1)=i,j
其中当扭曲函数F
=C(1),C(2),C(3),..C(k),.C(K)时
为最小值
其中C(k)=(r(k),m(k))
然后可能确定…“时间对准的”接收的特征矢量序列
ω=ω1,ω2,...,ωI
在图5中所示的例子中
C(1)=(1,1)
C(2)=(1,2)
C(3)=(2,2)
C(4)=(3,3)
C(5)=(4,3)
即r1被映射至m1,r1被映射至m2,r2被映射至m2,r3被映射至m3等。
可看到在此情况下r1和r2两者都已被映射到m2且对于那个接收的特征矢量应被用于时间对准的特征矢量作出确定。选择接收的特征矢量之一的另一种方法是计算映射到一单个的代表性特征矢量上的接收的特征矢量的平均值。
如果第一个这样的接收的特征矢量被使用,则ωp=rq
其中
或者如果最后一个这样的接收的特征矢量被使用,则ωp=rs
其中
或者如果使用一平均值
ωp=Ave(rj(k))i(k)=p
这样,在图5所示的例子中,假定第一个这样接收的矢量被使用
ω1=r1
ω2=r2
ω3=r3
ω4=r4等。
显然这样一对准处理导致一对准的特征矢量序列,其中该对准的特征矢量序列中的各特征矢量对应于该代表性特征矢量序列中的一特征矢量。
再参见图4a,在该变换处理的一改进的版本中,在任选的步骤43中,各被时间对准的接收的特征矢量还用该与说话者相关的变换矩阵的对应的特征矢量进行平均。如果该时间对准的接收的特征矢量与该与说话者相关的变换矩阵的对应的特征矢量明显不同,则这样一平均步骤将严重地变形改时间对准的接收的特征矢量,而如果这些时间对准的接收的特征矢量类似于改与说话者相关的变换矩阵,则该平均处理将很少地变形该接收的特征矢量矩阵。这些变换的特征将增强在任何随后的比较过程中的辨别。
然后在步骤44中,这些变换的特征在一常规的说话者识别比较过程中被使用。在本发明的该实施例中,由一左至右隐藏的马克夫模型提供该说话者模型,且使用韦特比算法进行比较(在后将参照图8至11进行描述)。在步骤45,指示该被表示的说话者产生由这些接收的特征矢量代表的语音的似然性的一距离量度被生成且随后与一阈值进行比较。如果其间的差异小于该阈值,在步骤47,该说话者被接受位对应于该存储的模板;否则在步骤46,该说话者被拒绝。
现将参照图8至11对使用隐藏的马克夫模型和韦特比算法模型化语音的原理进行描述。
图8示出了一例子HMM。五个圆圈100、102、104、106和108表示该HMM的状态且在一离散时间瞬间t,该模型被认为处于这些状态之一且被认为发出一观测值(observation)Ot。在语音或说话者识别中,各观测值通常对应于一特征矢量。
在瞬间t+1,该模型或者移至一新的状态或者呆在相同的状态中且在另一情况下发出另一观测值等等。该发出的观测值仅取决于该模型的状态。在时间t+1占用的状态仅取决于在时间t占用的状态(该特性被称之为马克夫特性)。从一状态移至另一状态的概率可被列表在一N×N状态转变矩阵(A=[ai,j])中,如图9所示。在该矩阵的第i行和第j列的项是从在时间t的状态Si移至在时间t+1的状态Sj的概率。当从一状态移动的概率是1.0(如果该模型呆在相同的状态下,则被认为是到其自身的一转变),该矩阵的各行求和至1.0。在示出的该例子中,该状态转变矩阵仅具有在上三角形中的项,因为该例子是一左至右模型,其中不允许“向后”转变。在一更加通常的HMM中,转变可从任何状态到任何其他的状态。还示出一起始矢量(π),其第i分量是在时间t=1占用状态Si的概率。
假定W个这样的模型存在M1,...Mw,各表示一特定的说话者且假定来自一未知的说话者的语音信号由一T个观测值O1,O2,O3,...,OT的序列表示,则问题是确定哪个模型最有可能已发出了该观测值序列,即确定k,其中
Pr(O|M)被如下地递归地计算:
该前向概率αt(j)被确定是一模型发出该特定的观测值序列O1,O2,O3,...,Ot且在时间t占用状态Sj的概率。
因此
该模型在时间t+1占用状态Sj且发出观测值Ot+1的概率可从在时间t的前向概率、状态转变概率(ai,j)和状态Sj发出观测值Ot+1的概率bj(Oi+1)被计算如下
图10示出了对于一个六状态HMM的计算。
通过设置α1(j)=π(j)b1(O1)来初始化该递归。
上述算法的一个计算上更加有效的变型被称之为是韦特比算法。在替代如上所述的求和前向概率的韦特比算法中,使用前向概率的最大值。
即
如果要求恢复该最大可能的状态序列,则每次φi被计算ψt(j)被记录,其中假定在时间t是状态Sj,ψt(j)是在时间t-1的最大可能的状态,即最大化上述方程的右于侧的状态。在时间T的最大可能状态是对于其φT(j)是最大的状态Sk且ψT(k)给出了在时间T-1的最大可能状态等等。
图11示出了对于十六个帧的观测值(特征矢量)序列及一个五状态左至右隐藏的马克夫模型,使用韦特比算法计算的一可能状态序列。
图4b示出了在说话者识别中说话者识别处理器的对应操作;在此情况下,使用多个说话者变换和对应的说话者模型。进而选择各与说话者相关的变换并使用其在步骤42时间对准接收的特征矢量。然后在步骤48,将该时间对准的接收的特征矢量序列与对应的说话者模型进行比较。如先前参照图4a所述,在任选的步骤43,各时间对准的接收的特征矢量还用与说话者相关的变换矩阵的对应的特征矢量被进行平均。然后由于具有指示该已知的说话者对应于该未知的说话者的最大似然性的距离量度,该说话者被识别为已知的说话者。然而,如果在步骤53,该最小的距离量度大于一阈值,指示没有说话者具有是该已知说话者的特定的高似然性,则在步骤54,由于对于该系统是未知的,该说话者被拒绝。
历史上,DTW比较处理相比于HMM比较处理,对于说话者识别的效果更佳。将一特征矢量序列与一隐藏的马克夫模型进行比较和使用一动态时间扭曲(DTW)算法将相同序列与一代表性模板进行比较之间的差异在于图形匹配阶段。在DTW方案中,一接收的特征矢量可被匹配至两或更多的代表性特征矢量,对应于图5中的水平路径。然而,在HMM方案中,各接收的特征矢量可仅被匹配至一个状态。它不可能具有图11中的一水平路径。将接收的特征矢量序列与与说话者相关的变换矩阵对准,允许将接收的特征矢量映射至HMM状态的更多的可能性,且因此可改善基于HMM的说话者识别器的性能。
基于HMM说话者的识别器和基于DTW的说话者识别器之间的另一差异是DTW模板是整体地基于一个个体(individual)的语音,而一单个的HMM拓扑经常在用一个体的语音训练一组模型之前被定义。在本发明的一改善的实施例中,根据各个体的训练语音,由具有不同数量的状态的HMM提供这些说话者模型。例如,用于一特定词的一组特定个体的训练发声中的最小数量的特征矢量可被用于选择用于该特定个体的该特定词的HMM的状态数目。在与说话者相关的变换矩阵中的特征的数量可被类似地确定,其中在该代表性特征矢量序列中的特征数量将与隐藏的马克夫模型中的状态数量相同。
已参照MFCC对本发明进行了描述,但显然任何适当的频谱表示可以使用。例如,线性预测系数(LPC)倒谱系数、快速傅里叶变换(FFT)倒谱系数、线谱对(LSP)系数等。
尽管已讨论了使用隐藏的马克夫模型的比较处理,本发明同等地适用于采用其他类型的比较处理的说话者识别,例如动态时间扭曲技术或神经网络技术。
本发明采用用于各待被识别的说话者的一与说话者相关的变换。在此所述的本发明的实施例中,借助于用于各词的一代表性特征矢量序列,提供与说话者相关的变换矩阵。
导出代表性的特征矢量序列的方法是众所周知的,且对于理解本发明,指出各代表性特征矢量序列可通过接收由一说话者对于同一词的多个发声并如上所述地对于各发声导出一组特征矢量的处理而被形成是足够的。这些序列然后被时间对准,例如先前所述,且然后对用于该多个发声的时间对准的特征矢量序列进行平均以导出提供该与说话者相关的变换矩阵的一平均的特征矢量序列。
Claims (12)
1、一种说话者识别方法,包括有步骤:
接收来自一未知的说话者的语音信号;
根据一变换对该接收的语音信号进行变换,该变换是与一特定的说话者相关联的;
将该变换的语音信号与一代表所述特定的说话者的模型进行比较;且
将依据于该未知的说话者是所述的特定说话者的似然性的一参数提供作为输出。
2、根据权利要求1的方法,其中该变换步骤包括有子步骤:
检测该接收的语音信号内的一语音开始点和一语音结束点;
生成从该接收的语音信号导出的一特征矢量序列;及
将对应于该检测的开始点和检测的结束点之间的语音信号的该特征矢量序列与用于所述特定说话者的一代表性的特征矢量序列相对准以使在被对准的特征矢量序列中的各特征矢量对应于该代表性的特征矢量序列中的一特征矢量。
3、根据权利要求2的方法,其中该变换步骤还包括有子步骤:用该代表性的特征矢量序列中的对应特征矢量对该被对准的特征矢量序列中的各特征矢量进行平均。
4、根据以上任一权利要求的方法,其中该模型是一隐藏的马克夫模型。
5、根据权利要求4的方法,其中该模型是一左至右隐藏的马克夫模型。
6、根据权利要求5的方法,当权利要求4是从属于权利要求2或权利要求3时,其中该代表性的特征矢量序列包括与隐藏的马克夫模型中的状态数量相同数量的特征矢量。
7、一种用于说话者识别的设备,包括有:
用于接收来自一未知的说话者的语音信号的接收装置;
用于存储多个说话者变换的说话者变换存储装置,各变换与多个说话者中对应的一个相关联;
用于存储多个说话者模型的说话者模型存储装置,各说话者模型与所述多个说话者中对应的一个相关联;
与该接收装置和说话者变换存储装置耦合的变换装置,被配置用于根据一选择的说话者变换对该接收的语音信号进行变换;
耦合至该变换装置和说话者模型存储装置的比较装置,被配置用于将该变换的语音信号与对应的说话者模型进行比较;和
用于提供一指示该未知的说话者是与该选择的说话者变换相关联的说话者的似然性的一信号的输出装置。
8、根据权利要求7的设备,其中该变换存储装置存储各所述变换作为一代表性的特征矢量序列;且其中该变换装置包括
一起始点和结束点检测器,用于检测该接收的语音信号内的一语音开始点和一语音结束点;
一特征矢量发生器,用于生成从该输入语音导出的一特征矢量序列;及
一对准装置,用于将对应于该检测的开始点和检测的结束点之间的语音信号的该特征矢量序列与一代表性的特征矢量序列相对准以使在得到的被对准的特征矢量序列中的各特征矢量对应于该代表性的特征矢量序列中的一特征矢量。
9、根据权利要求8的设备,其中该变换装置还包括有:平均装置,用于用该代表性的特征矢量序列中的对应特征矢量对该被对准的特征矢量序列中的各特征矢量进行平均。
10、根据权利要求7至9中任一的设备,其中该说话者模型存储装置被配置用于存储一隐藏的马克夫模型形式的说话者模型。
11、根据权利要求10的设备,其中该说话者模型存储装置被配置以存储是一左至右隐藏的马克夫模型形式的说话者模型。
12、根据权利要求11的设备,当权利要求10从属于权利要求8或权利要求9时,其中该存储的代表性的特征矢量序列包括与对应的隐藏的马克夫模型中的状态数量相同数量的特征矢量。
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| GBGB9905627.7A GB9905627D0 (en) | 1999-03-11 | 1999-03-11 | Speaker recognition |
| GB9905627.7 | 1999-03-11 | ||
| EP99305278.6 | 1999-07-02 | ||
| EP99305278 | 1999-07-02 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN1343352A CN1343352A (zh) | 2002-04-03 |
| CN1148720C true CN1148720C (zh) | 2004-05-05 |
Family
ID=26153521
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CNB008048932A Expired - Lifetime CN1148720C (zh) | 1999-03-11 | 2000-02-25 | 说话者识别 |
Country Status (11)
| Country | Link |
|---|---|
| US (1) | US6922668B1 (zh) |
| EP (1) | EP1159737B9 (zh) |
| KR (1) | KR20010102549A (zh) |
| CN (1) | CN1148720C (zh) |
| AT (1) | ATE246835T1 (zh) |
| AU (1) | AU2684100A (zh) |
| CA (1) | CA2366892C (zh) |
| DE (1) | DE60004331T2 (zh) |
| ES (1) | ES2204516T3 (zh) |
| IL (1) | IL145285A0 (zh) |
| WO (1) | WO2000054257A1 (zh) |
Families Citing this family (26)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7437286B2 (en) * | 2000-12-27 | 2008-10-14 | Intel Corporation | Voice barge-in in telephony speech recognition |
| AU2003222132A1 (en) * | 2002-03-28 | 2003-10-13 | Martin Dunsmuir | Closed-loop command and response system for automatic communications between interacting computer systems over an audio communications channel |
| GB2388947A (en) * | 2002-05-22 | 2003-11-26 | Domain Dynamics Ltd | Method of voice authentication |
| US20060129399A1 (en) * | 2004-11-10 | 2006-06-15 | Voxonic, Inc. | Speech conversion system and method |
| JP4672003B2 (ja) * | 2005-02-18 | 2011-04-20 | 富士通株式会社 | 音声認証システム |
| US7769583B2 (en) * | 2006-05-13 | 2010-08-03 | International Business Machines Corporation | Quantizing feature vectors in decision-making applications |
| KR100826875B1 (ko) * | 2006-09-08 | 2008-05-06 | 한국전자통신연구원 | 온라인 방식에 의한 화자 인식 방법 및 이를 위한 장치 |
| CN101154380B (zh) * | 2006-09-29 | 2011-01-26 | 株式会社东芝 | 说话人认证的注册及验证的方法和装置 |
| JP5396044B2 (ja) * | 2008-08-20 | 2014-01-22 | 株式会社コナミデジタルエンタテインメント | ゲーム装置、ゲーム装置の制御方法、及びプログラム |
| WO2010067118A1 (en) * | 2008-12-11 | 2010-06-17 | Novauris Technologies Limited | Speech recognition involving a mobile device |
| US8719019B2 (en) * | 2011-04-25 | 2014-05-06 | Microsoft Corporation | Speaker identification |
| ES2605779T3 (es) * | 2012-09-28 | 2017-03-16 | Agnitio S.L. | Reconocimiento de orador |
| US10013996B2 (en) * | 2015-09-18 | 2018-07-03 | Qualcomm Incorporated | Collaborative audio processing |
| US10141009B2 (en) | 2016-06-28 | 2018-11-27 | Pindrop Security, Inc. | System and method for cluster-based audio event detection |
| US9824692B1 (en) | 2016-09-12 | 2017-11-21 | Pindrop Security, Inc. | End-to-end speaker recognition using deep neural network |
| WO2018053531A1 (en) * | 2016-09-19 | 2018-03-22 | Pindrop Security, Inc. | Dimensionality reduction of baum-welch statistics for speaker recognition |
| WO2018053537A1 (en) | 2016-09-19 | 2018-03-22 | Pindrop Security, Inc. | Improvements of speaker recognition in the call center |
| WO2018053518A1 (en) | 2016-09-19 | 2018-03-22 | Pindrop Security, Inc. | Channel-compensated low-level features for speaker recognition |
| WO2018106971A1 (en) * | 2016-12-07 | 2018-06-14 | Interactive Intelligence Group, Inc. | System and method for neural network based speaker classification |
| US10397398B2 (en) | 2017-01-17 | 2019-08-27 | Pindrop Security, Inc. | Authentication using DTMF tones |
| US11475113B2 (en) * | 2017-07-11 | 2022-10-18 | Hewlett-Packard Development Company, L.P. | Voice modulation based voice authentication |
| US11114103B2 (en) | 2018-12-28 | 2021-09-07 | Alibaba Group Holding Limited | Systems, methods, and computer-readable storage media for audio signal processing |
| US11355103B2 (en) | 2019-01-28 | 2022-06-07 | Pindrop Security, Inc. | Unsupervised keyword spotting and word discovery for fraud analytics |
| WO2020163624A1 (en) | 2019-02-06 | 2020-08-13 | Pindrop Security, Inc. | Systems and methods of gateway detection in a telephone network |
| WO2020198354A1 (en) | 2019-03-25 | 2020-10-01 | Pindrop Security, Inc. | Detection of calls from voice assistants |
| US12015637B2 (en) | 2019-04-08 | 2024-06-18 | Pindrop Security, Inc. | Systems and methods for end-to-end architectures for voice spoofing detection |
Family Cites Families (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP0380489B1 (en) * | 1987-07-03 | 1993-08-25 | Btg International Limited | Method of manufacturing a vaporiser nozzle |
| US5129002A (en) * | 1987-12-16 | 1992-07-07 | Matsushita Electric Industrial Co., Ltd. | Pattern recognition apparatus |
| JP2733955B2 (ja) | 1988-05-18 | 1998-03-30 | 日本電気株式会社 | 適応型音声認識装置 |
| US6236964B1 (en) * | 1990-02-01 | 2001-05-22 | Canon Kabushiki Kaisha | Speech recognition apparatus and method for matching inputted speech and a word generated from stored referenced phoneme data |
| US5167004A (en) | 1991-02-28 | 1992-11-24 | Texas Instruments Incorporated | Temporal decorrelation method for robust speaker verification |
| JP2795058B2 (ja) * | 1992-06-03 | 1998-09-10 | 松下電器産業株式会社 | 時系列信号処理装置 |
| US5528728A (en) * | 1993-07-12 | 1996-06-18 | Kabushiki Kaisha Meidensha | Speaker independent speech recognition system and method using neural network and DTW matching technique |
| JP2797949B2 (ja) * | 1994-01-31 | 1998-09-17 | 日本電気株式会社 | 音声認識装置 |
| US5522012A (en) * | 1994-02-28 | 1996-05-28 | Rutgers University | Speaker identification and verification system |
| US5864810A (en) * | 1995-01-20 | 1999-01-26 | Sri International | Method and apparatus for speech recognition adapted to an individual speaker |
| US5706397A (en) | 1995-10-05 | 1998-01-06 | Apple Computer, Inc. | Speech recognition system with multi-level pruning for acoustic matching |
| US5778341A (en) * | 1996-01-26 | 1998-07-07 | Lucent Technologies Inc. | Method of speech recognition using decoded state sequences having constrained state likelihoods |
| US5995927A (en) * | 1997-03-14 | 1999-11-30 | Lucent Technologies Inc. | Method for performing stochastic matching for use in speaker verification |
| US5893059A (en) * | 1997-04-17 | 1999-04-06 | Nynex Science And Technology, Inc. | Speech recoginition methods and apparatus |
| US6076055A (en) * | 1997-05-27 | 2000-06-13 | Ameritech | Speaker verification method |
| CA2304747C (en) * | 1997-10-15 | 2007-08-14 | British Telecommunications Public Limited Company | Pattern recognition using multiple reference models |
-
2000
- 2000-02-25 AT AT00905216T patent/ATE246835T1/de not_active IP Right Cessation
- 2000-02-25 KR KR1020017011470A patent/KR20010102549A/ko not_active Application Discontinuation
- 2000-02-25 WO PCT/GB2000/000660 patent/WO2000054257A1/en not_active Application Discontinuation
- 2000-02-25 ES ES00905216T patent/ES2204516T3/es not_active Expired - Lifetime
- 2000-02-25 CN CNB008048932A patent/CN1148720C/zh not_active Expired - Lifetime
- 2000-02-25 EP EP00905216A patent/EP1159737B9/en not_active Expired - Lifetime
- 2000-02-25 IL IL14528500A patent/IL145285A0/xx unknown
- 2000-02-25 AU AU26841/00A patent/AU2684100A/en not_active Abandoned
- 2000-02-25 DE DE60004331T patent/DE60004331T2/de not_active Expired - Lifetime
- 2000-02-25 CA CA002366892A patent/CA2366892C/en not_active Expired - Fee Related
- 2000-02-25 US US09/913,295 patent/US6922668B1/en not_active Expired - Lifetime
Also Published As
| Publication number | Publication date |
|---|---|
| AU2684100A (en) | 2000-09-28 |
| ES2204516T3 (es) | 2004-05-01 |
| WO2000054257A1 (en) | 2000-09-14 |
| ATE246835T1 (de) | 2003-08-15 |
| CA2366892C (en) | 2009-09-08 |
| US6922668B1 (en) | 2005-07-26 |
| IL145285A0 (en) | 2002-06-30 |
| EP1159737B9 (en) | 2004-11-03 |
| KR20010102549A (ko) | 2001-11-15 |
| DE60004331T2 (de) | 2005-05-25 |
| CN1343352A (zh) | 2002-04-03 |
| EP1159737B1 (en) | 2003-08-06 |
| DE60004331D1 (de) | 2003-09-11 |
| CA2366892A1 (en) | 2000-09-14 |
| EP1159737A1 (en) | 2001-12-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN1148720C (zh) | 说话者识别 | |
| CN105161093B (zh) | 一种判断说话人数目的方法及系统 | |
| Murthy et al. | Robust text-independent speaker identification over telephone channels | |
| JP4218982B2 (ja) | 音声処理 | |
| JP4802135B2 (ja) | 話者認証登録及び確認方法並びに装置 | |
| US8401861B2 (en) | Generating a frequency warping function based on phoneme and context | |
| JP2768274B2 (ja) | 音声認識装置 | |
| GB2552722A (en) | Speaker recognition | |
| Thakur et al. | Speech recognition using euclidean distance | |
| JP4391701B2 (ja) | 音声信号の区分化及び認識のシステム及び方法 | |
| JPH075892A (ja) | 音声認識方法 | |
| TWI223792B (en) | Speech model training method applied in speech recognition | |
| Schulze-Forster et al. | Joint phoneme alignment and text-informed speech separation on highly corrupted speech | |
| Gudepu et al. | Whisper Augmented End-to-End/Hybrid Speech Recognition System-CycleGAN Approach. | |
| US20070129946A1 (en) | High quality speech reconstruction for a dialog method and system | |
| JP2006235243A (ja) | 音響信号分析装置及び音響信号分析プログラム | |
| US7509257B2 (en) | Method and apparatus for adapting reference templates | |
| JP4696418B2 (ja) | 情報検出装置及び方法 | |
| CN109817196B (zh) | 一种噪音消除方法、装置、系统、设备及存储介质 | |
| TWI297487B (en) | A method for speech recognition | |
| JP2009116278A (ja) | 話者認証の登録及び評価のための方法及び装置 | |
| Lee | Silent speech interface using ultrasonic Doppler sonar | |
| JP2009042552A (ja) | 音声処理装置及び方法 | |
| JP2001356793A (ja) | 音声認識装置、及び音声認識方法 | |
| JP4749990B2 (ja) | 音声認識装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant | ||
| CX01 | Expiry of patent term | ||
| CX01 | Expiry of patent term |
Granted publication date: 20040505 |