CN112948123A - 一种基于Spark的网格水文模型分布式计算方法 - Google Patents
一种基于Spark的网格水文模型分布式计算方法 Download PDFInfo
- Publication number
- CN112948123A CN112948123A CN202110330831.5A CN202110330831A CN112948123A CN 112948123 A CN112948123 A CN 112948123A CN 202110330831 A CN202110330831 A CN 202110330831A CN 112948123 A CN112948123 A CN 112948123A
- Authority
- CN
- China
- Prior art keywords
- grid
- calculation
- model
- component
- data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images

Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5061—Partitioning or combining of resources
- G06F9/5072—Grid computing
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/48—Program initiating; Program switching, e.g. by interrupt
- G06F9/4806—Task transfer initiation or dispatching
- G06F9/4843—Task transfer initiation or dispatching by program, e.g. task dispatcher, supervisor, operating system
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5061—Partitioning or combining of resources
- G06F9/5066—Algorithms for mapping a plurality of inter-dependent sub-tasks onto a plurality of physical CPUs
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5083—Techniques for rebalancing the load in a distributed system
Landscapes
- Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
本发明公开了一种基于Spark的网格水文模型分布式计算方法,步骤为:先对网格水文模型计算参数采用netCDF格式进行描述,再基于XML规范对网格水文模型构件及其依赖关系进行描述;然后采用Spark分布式计算模型对网格水文模型的构件进行调度和计算,最后对调度计算后各构件生成的结果进行输出。本发明定义了基于netCDF的模型参数以及模型计算结果描述格式,描述网格水文模型计算时使用到的流域特征、模型参数以及监测点和流域面上的水文数据;定义了基于XML的网格水文模型构件以及各构件之间的依赖关系描述规范;根据构件计算时网格之间的依赖关系,使用Hash分区法和动态数据分区法对网格进行任务划分,并分配到不同的节点进行计算,减少了数据分发量,提高计算速度。
Description
技术领域
本发明属于信息技术领域,特别涉及一种基于Spark的网格水文模型分布式计算方法。
背景技术
传统的集总式水文模型在流域上采用平均的、单一化的参数来描述整个流域的水文特征,没有考虑流域不同区域的空间异质性,因此对于复杂流域(下垫面变化大、空间降雨分布变化大)不能进行很好的模拟。分布式水文模型是根据流域下垫面的特征将流域划分成大小不同、空间不规则的子流域,以考虑流域的空间异质性,通过并行计算提高模型计算的效率。网格水文模型属于分布式水文模型的一种,它将流域划分为多个网格单元,每个矩形区域的网格拥有独立的参数和数据,用于描述本网格内流域的水文特征和产汇流,更加精细化地考虑流域各种地理要素的空间异质性,与集总式水文模型和普通的分布式水文模型相比,网格水文模型能更精细更准确的描述流域的水文过程,是探索和认识复杂水文循环过程的有效手段和解决众多水文实际问题的有效工具。
网格水文模型的计算过程包括每个网格的蒸散发、产流等,以及整个流域的不同网格之间的坡面和河道的汇流等,所以与集总式水文模型相比,网格水文模型的计算量要高的多。传统的串行计算模式已经无法满足网格水文模型在大流域上的实时模拟和预报需求,因此,提高网格水文模型的计算效率,是水文预报领域实现网格水文模型实用化迫切需要解决的问题。
现有的分布式水文模型通常采用基于超级计算机资源的并行化计算模式,以子流域为计算单元,在子流域与子流域的计算出口处进行数据交互,实现子流域级别的并行计算。存在的问题主要是,一方面,没有解决子流域内部的并行计算问题,子流域内部的计算依然采用串行计算方式,尤其是坡面与河道汇流模块,造成计算复杂度高;另一方面,现有分布式模型的并行计算方法以子流域单元的计算次序为依据进行任务分发与数据聚合操作,多次的任务分发与数据聚合操作会造成大量的运行时间浪费而且会造成内存溢出的情况。因此现有的并行计算方法,不能适应大流域的计算需求,同时对计算机资源要求较高,不能适应仅包含若干台性能有限的PC机的实验室环境下的水文预报模拟研究需求。同时为了预报成果能够与一些通用的处理软件无缝对接,采用netCDF(network Common DataForm)格式进行计算参数以及模型预报结果的描述。
分布式计算模式采用若干台独立计算机构成的集群作为计算资源,由任务分解服务器将应用分解成许多小的子任务,分配给集群中的多台计算节点进行处理,最后对各节点的计算结果进行聚合产生最终结果。分布式计算模式通过多台计算机的同时计算以节约整体计算时间,提高计算效率,对构成集群的独立计算机的性能要求不高,能够适应仅包含若干台性能有限的PC机的实验室环境下的水文预报模拟研究需求。Spark框架是目前主流的分布式计算框架之一,它可以把计算任务分配到多台计算机,让每一台计算机都承担着一部分计算和数据存储任务。相比于Hadoop的MapReduce离线数据处理框架来说,Spark分布式计算框架能够实现实时计算以及数据的流式计算,除此之外,Spark还具有基于内存计算、吞吐量达、容错率高等特点。
发明内容
发明目的:为了克服现有技术中存在的问题,本发明提供一种基于Spark的网格水文模型分布式计算方法,能够提高计算效率,同时计算结果能够与常见的通用软件进行无缝对接。
技术方案:为实现上述目的,本发明提供一种基于Spark的网格水文模型分布式计算方法,包括如下步骤:
(1)采用netCDF数据格式描述模型参数,建立参数描述文件PFile;
(2)采用XML描述模型构件及其依赖关系,建立模型描述文件MFile;
(3)基于Spark的模型构件调度和计算模型GridCSC分析模型描述文件MFile,根据模型计算构件之间的依赖关系、网格依赖关系以及相应的模型参数,进行模型的分布式计算;
(4)参数聚合构件在Master节点中聚合每个构件计算的RDD结果,并通过广播发送给各Worker节点,供后继构件计算使用;
(5)计算完毕后,参数聚合构件采用netCDF格式输出各构件的计算结果。
进一步的,所述步骤(1)中进行参数数据描述时,描述的参数包括:
模型参数:模型参数是指模型在执行时所需要的相关系数、常量;
流域下垫面参数:流域下垫面参数是描述流域下垫特征信息;包括流域高程、流域水系、流域网格依赖关系、植被覆盖、土质类型;
流域历史降雨和水文数据:流域历史降雨和水文数据是已经监测的流域降雨、流量水位数据、蒸散发数据以及土壤含水量数据;
流域实时、未来降雨参数:流域实时、未来降雨是从其他来源获取的流域当前时刻以及未来降雨的数据,用于模型的预报。
进一步的,所述步骤(1)中进行参数数据描述时,描述规范包括:
坐标系统、时间系统以及参属性的描述遵守netCDF-CF-1.6即Climate andForecast convension 1.6)版本的约束;对每个参数的描述包括:参数名称、参数标识、参数类型、参数值、参数说明五方面;其中,流域下垫面参数,流域历史降雨、水文数据,流域实时和未来降雨数据的描述采用多维向量的网格化进行描述;
网格化参数描述时,坐标系统采用经纬度坐标,定义坐标变量lon、lat分别标识经度和纬度,单位即untis属性分别为degree_east和degree_north;取值为float类型;时间系统通过时间坐标变量的untis属性设置起始时间,通过时间坐标变量的取值确定每个数据的时间点。
进一步的,所述步骤(2)中采用XML描述模型构件及其依赖关系时,描述规范包括:
(2.1)描述的构件根据网格水文模型不同而不同,包括:蒸散发模块、产流模块、分水源模块和汇流模块;构件属性包括:构件名称、构件标识、构件编号、构件访问接口方面描述构件的基本信息;
(2.2)通过模型构件前置属性描述构件之间的依赖关系,并确定构件计算顺序;每个构件有1个或者多个前置构件。
进一步的,所述步骤(3)中基于Spark的模型构件调度和计算模型GridCSC进行模型的分布式计算时,其步骤包括:
(3.1)从MFile获取模型构件信息以及构件之间的依赖关系,根据计算构件之间的依赖关系确定构件的计算顺序图;
(3.2)循环对所有同时计算的构件进行并行计算,每次循环计算没有任何前置依赖的构件,直到所有构件计算完毕;若构件a的前置构件已经计算时,则认为构件a没有前置依赖;
(3.3)构件计算时,如果该构件中的网格是独立的,则进行独立网格计算,如果待计算的网格之间具有依赖关系,则采用依赖网格计算;
(3.4)构件计算的结果通过处于Master的参数聚合构件聚合成RDD结构,并通过广播传递给下一个依赖的构件。
进一步的,所述步骤(3.3)中进行独立网格计算时,其步骤包括:
(3.3.1)利用Hash分区方法进行网格计算任务分区划分,确定分配到每个Worker上的待计算网格;
(3.3.2)Master节点将计算网格分配给对应的Worker节点,Master节点从参数文件PFile中或RDD中解析出计算所需参数,根据分区结果将网格参数传输给对应计算节点,Worker节点调用构件计算接口,进行网格计算;
(3.3.3)参数聚合构件聚合各Worker节点的计算结果,形成构件计算结果的RDD存储。
进一步的,所述步骤(3.3.1)中利用Hash分区方法进行网格划分时,其步骤包括:
(3.3.1.1)获取每个网格单元的坐标(x,y),将网格单元参数信息组织为<key,value>的形式,其中key对应网格单元坐标(x,y),value对应网格参数值;
(3.3.1.2)根据公式WorkerID=Key.hashCode%WorkerNum得到分区的坐标;其中WorkerID表示Key对应的数据应该被分配到的Worker节点标识,Key.hashCode表示Key在哈希运算中的哈希值,WorkerNum集群中Worker节点的个数。
进一步的,所述步骤(3.3)中进行依赖网格计算时,其步骤如图4所示,包括:
(3.3.1)通过“流域网格依赖关系”参数信息得到网格之间的依赖关系;
(3.3.2)根据网格依赖关系通过动态数据划分方法进行网格计算任务划分,确定当前可计算的网格中分配到每个Worker上的待计算网格;
(3.3.3)Master节点将计算网格分配给对应的Worker节点,Master节点从参数文件PFile中或RDD中解析出计算所需参数,根据分区结果将网格参数传输给对应计算节点,Worker节点调用构件计算接口,进行网格计算;
(3.3.4)参数聚合构件聚合各Worker节点的计算结果,形成构件计算结果的RDD存储;
(3.3.5)判断网格是否计算完毕,若没有计算完,则删除已完成计算网格,更新未计算网格对应的上游网格信息,然后转到(3.3.2)。
进一步的,所述步骤(3.3.2)中动态数据划分方法时,其步骤包括:
(3.3.2.1)计算集群可用资源:计算集群中的最大并行数,设有N个同构的计算机作为Worker节点,每个节点有M个CPU核数,那么该集群的最大并行数为N*M个,即集群一次最多可以执行N*M个任务;以这个为基础在构件计算中对数据进行分区;
(3.3.2.2)计算网格所有的上游网格坐标:根据计算网格计算次序对应的网格单元个数,先解析出栅格计算次序和流向信息参数,计算出计算次序i对应的网格单元坐标以及每个网格单元对应的上游网格坐标;
(3.3.2.3)根据计算次序对应网格个数对数据进行分区:假设首先寻找网格单元个数大于N*M的计算次序,设计算次序为P的节点有K个,其中K≥N*M,P为满足要求的最大计算次序;则上游网格个数集合表示为T={c1,c2,......,ck};其中ci为第i个网格对应的上游网格的数量;然后计算每个分区分配的网格数量为 将K个网格对应的上游网格坐标均等分为N*M份,得到每一个数据块的网格数量为Num={num1,num2,......,numN*M},若对于任意的
将K个网格对应的上游网格坐标均等分为N*M份,得到每一个数据块的网格数量为Num={num1,num2,......,numN*M},若对于任意的 均满足GNumequals*(1-Q)≤numi≤GNumequals*(1+Q),则计算次序P即为此次计算的次序,将计算次序P对应节点的上游网格数据等份的分配给N*M个执行器;
均满足GNumequals*(1-Q)≤numi≤GNumequals*(1+Q),则计算次序P即为此次计算的次序,将计算次序P对应节点的上游网格数据等份的分配给N*M个执行器;
(3.3.2.4)判断是否存在满足条件的次序,如果存在则对分区内部网格单元根据计算次序进行排序,至此完成动态数据划分操作。如果不存在则更新可分区个数再重新进行分区并返回步骤(3.3.2.3)。
有益效果:本发明与现有技术相比具有以下优点:
现有的网格水文模型计算通常基于超级服务器采用并行计算模式,对计算硬件资源要求较高,同时在计算时,以子流域为单元,子流域内部采用串行方式,没有充分提高计算效率,另外,分布式计算时,没有能够根据网格单元之间的关系,进行合理的任务划分,造成任务和数据分发不平衡,影响计算效率。本发明提出了基于Spark的分布式计算模式,普通的PC机构成的集群即可满足计算要求,减少了对计算硬件资源的需求,同时,在计算内容上,以网格为并行计算单元,提高了计算的并行效率,最后,在数据分发时,提出的基于集群计算能力的数据动态分配方法,解决了传统分布式计算中数据分发中的数据不平衡问题,在保证计算次序正确的基础上,最大程度上减少任务分发和数据聚合的操作,保证了每一次的网格计算操作都尽可能的利用集群的资源,从而提高模型整体的分布式计算效率。
附图说明
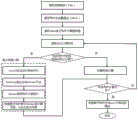
图1为本发明的流程图;
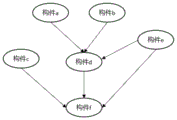
图2为构件依赖关系描述示例图;
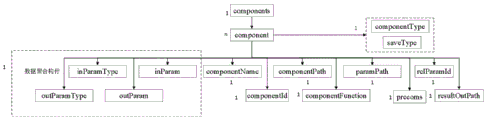
图3为具体实施例中基于XML的构件描述结构图;
图4为具体实施例中依赖网格计算流程图;
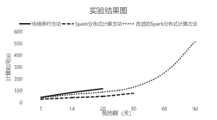
图5为具体实施例中的测试结果对比图。
具体实施方式
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
本发明提供一种基于Spark的网格水文模型分布式计算方法,包括如下步骤:
1.模型计算的总体流程为:首先采用netCDF(network Common Data Form)数据格式描述模型参数,建立参数描述文件PFile;然后采用XML描述模型构件及其依赖关系,建立模型描述文件MFile;然后基于Spark的模型构件调度和计算模型(GridCSC)分析模型描述文件MFile和参数文件PFile,根据模型计算构件之间的依赖关系、网格依赖关系以及相应的模型参数,进行模型的分布式计算;最后参数输出模块在Master节点中聚合每个构件计算的RDD结果,采用netCDF格式输出计算结果,计算结果可以包含模型计算过程的中间结果(即每个构件的计算结果)。
2.网格化水文模型参数描述方法为::
2.1基于netCDF的网格水文模型参数描述中,需要描述的参数包括:
(1)模型参数。模型参数是指模型在执行时所需要的相关系数、常量等,一般不随时间变化。如蒸散发折算系数、马斯京根系数等此类参数。
(2)流域下垫面参数。流域下垫面参数是描述流域下垫特征等信息,一般不随时间变化。包括流域高程、流域水系、流域网格依赖关系、植被覆盖、土质类型等。这些参数采用三维或者更高维网格化方式描述。其中,流域网格依赖关系确定了每个网格之间的计算先后顺序。
(3)流域历史降雨和水文数据。流域历史降雨和水文数据是已经监测的流域降雨、流量水位数据、蒸散发数据以及土壤含水量数据,用于模型的参数率定以及模型预热。包括:降雨量、蒸发量、水位、流量数据以及数据的时间(包含起始时间和结束时间以及时间间隔)。
(4)流域实时、未来降雨参数。流域实时、未来降雨是从其他来源获取的流域当前时刻以及未来降雨的数据,用于模型的预报。包括:降雨量以及数据的时间(包含起始时间和结束时间以及时间间隔)。
2.2采用netCDF进行网格水文模型参数描述中,坐标系统、时间系统以及参属性的描述遵守netCDF-CF-1.6(Climate and Forecast convension 1.6)版本的约束。对每个参数的描述包括:参数名称、参数标识、参数类型、参数值、参数说明五方面。其中,流域下垫面参数,流域历史降雨、水文数据,流域实时和未来降雨数据的描述采用多维向量的网格化进行描述。
2.3网格化参数描述时,坐标系统采用经纬度坐标,定义坐标变量lon、lat分别标识经度和纬度,单位(untis属性)分别为degree_east和degree_north;取值为float类型。时间系统通过时间坐标变量的untis属性设置起始时间,通过时间坐标变量的取值确定每个数据的时间点。
3.采用XML描述模型构件及其依赖关系。模型构件属性确定如何调用计算构件,构建之间的依赖关系决定了计算构件的调用先后顺序。
3.1描述的构件根据网格水文模型不同而不同,一般包括:蒸散发模块、产流模块、分水源模块和汇流模块。构件属性包括:构件名称、构件标识、构件编号、构件访问接口方面描述构件的基本信息,描述的XML结构如图3所示。
3.2模型构件依赖关系确定了构件计算顺序。构件之间的基本依赖关系包括:(1)1:1关系,如构件A是构件B的唯一前置构件;(2)n:1关系,即若干个构件为C构件的前置条件;(3)1:n多关系,如,A构件同时为B构件和C构件的前置条件。如,一般蒸散发模块、产流模块和分水源模块均为独立计算构件,这些构件计算完毕后才能计算汇流构件。在图3中,通过每个构件的precoms标签和precom标签描述该构件的前置构件。
4.基于Spark的网格水文模型调度和计算模型(GridCSC)的步骤包括:从MFile获取模型构件信息以及构件之间的依赖关系,根据计算构件之间的依赖关系确定构件的计算顺序图,然后循环对所有可同时计算的构件进行并行计算。对某个构件进行计算时,如果该构件中的网格计算是独立的,则进行独立网格计算,如果待计算的网格之间具有依赖关系,则采用依赖网格计算。构件计算的结果通过处于Master的参数聚合构件聚合成RDD结构,并通过广播传递给下一个依赖的构件。
4.1循环计算所有构件的流程为:每轮计算没有任何前置依赖的构件,直到所有构件计算完毕。若某个构件i依赖于构件j,但是构件j已经被计算,则构件i也认为是没有依赖的。如图2所示的构件依赖关系中,d依赖a和b,f依赖c,d和e,第一轮计算构件a、b、c、e,第二轮计算构件d,最后计算构件f,并产生输出。
4.2计算某个构件时,如果网格之间没有依赖关系,采用独立网格计算。利用Hash分区方法进行网格划分,确定分配到每个Worker上的待计算网格。通过Master节点将计算的网格分配任务给Worker节点,Master节点从参数文件PFile中解析出计算所需参数,根据分区结果将网格参数传输给对应计算节点,并调用构件计算接口,进行网格计算。Hash分区方法进行数据分区的步骤为:
(1)首先获取每个网格单元的坐标(x,y),将网格单元参数信息组织为<key,value>的形式,其中key对应网格单元坐标(x,y),value对应网格参数值。
(2)然后根据公式WorkerID=Key.hashCode%WorkerNum得到分区的坐标。其中WorkerID表示Key对应的数据应该被分配到的Worker节点标识,Key.hashCode表示Key在哈希运算中的哈希值,WorkerNum集群中Worker节点的个数。
4.3计算某个构件时,如果网格之间存在依赖关系,则进行依赖网格计算。通过“流域网格依赖关系”参数信息得到网格之间的依赖关系。计算流程如图4。根据网格依赖关系通过动态数据划分方法进行数据分区,完成分区之后Master节点将网格参数信息将按照分区结果分发给各个Worker节并调用构件接口进行计算,构件完成计算之后调用参数聚合构件将Worker节点的计算机过进行聚合操作。如果一次操作完成之后,流域网格均完成计算则该构件计算完毕,否则删除已完成计算网格,更新未计算网格对应的上游网格信息,再次进行数据分区操作。动态数据划分方法进行数据分区的步骤为:
(4.3.1)计算集群可用资源。计算集群中的最大并行数,设有N个同构的计算机作为Worker节点,每个节点有M个CPU核数,那么该集群的最大并行数为N*M个,即集群一次最多可以执行N*M个任务。以这个为基础在构件计算中对数据进行分区。
(4.3.2)计算网格所有的上游网格坐标。根据计算网格计算次序对应的网格单元个数,先解析出栅格计算次序和流向信息参数,计算出计算次序i对应的网格单元坐标以及每个网格单元对应的上游网格坐标。
(4.3.3)根据计算次序对应网格个数对数据进行分区。假设首先寻找网格单元个数大于N*M的计算次序,设计算次序为P的节点有K个,其中K≥N*M,P为满足要求的最大计算次序;则上游网格个数集合表示为T={c1,c2,......,ck};其中ci为第i个网格对应的上游网格的数量;然后计算每个分区分配的网格数量为 将K个网格对应的上游网格坐标均等分为N*M份,得到每一个数据块的网格数量为Num={num1,num2,......,numN*M},若对于任意的
将K个网格对应的上游网格坐标均等分为N*M份,得到每一个数据块的网格数量为Num={num1,num2,......,numN*M},若对于任意的 均满足GNumequals*(1-Q)≤numi≤GNumequals*(1+Q),则计算次序P即为此次计算的次序,将计算次序P对应节点的上游网格数据等份的分配给N*M个执行器。
均满足GNumequals*(1-Q)≤numi≤GNumequals*(1+Q),则计算次序P即为此次计算的次序,将计算次序P对应节点的上游网格数据等份的分配给N*M个执行器。
(4.3.4)判断是否存在满足条件的次序,如果存在则对分区内部网格单元根据计算次序进行排序,至此完成动态数据划分操作。如果不存在则更新可分区个数再重新进行分区并返回步骤(4.3.3)。
5.网格水文模型通过netCDF获取外部的参数信息,并通过netCDF格式将模型的计算结果返回,包括需要中间计算构件的计算结果。构件之间的数据交换通过Spark的RDD结构通过内存实现。每个构件计算完成之后,用RDD的形式保存计算结果,参数聚合构件聚合每个Worker传递的计算结果数据,形成该构件计算的结果RDD,包括网格信息和每个网格内的计算结果,然后广播到每个Worker节点。
6.参数输出构件负责所有构件的RDD向netCDF格式的转换,形成模型计算结果。
下面结合如图1所示的流程图,以网格化的栅格新安江模型为例,介绍基于Spark的网格水文模型分布式计算,说明本方法的具体实施方法:
1.栅格新安江模型的参数描述的NetCDF文件的dimensions(维度)和variables(变量)描述如下:



2.基于XML描述栅格新安江模型的构件及其之间的依赖关系。对于构件(components)的描述包括构件名称(componentName)、构件编号(componentId)、构件存储路径(componentPath)、构件函数入口(componentFunction)、参数路径(paramPath)、前置构件标识(precoms)、依赖参数标识(relParamId)和结果输出路径(resultOutPath)八个子元素和构件类型(componentType)及构件保存类型(saveType)两个属性。componentType为1,代表独立计算构件,componentType为2,代表数据依赖构件;saveType为1,代表exe的存储类型,saveType为2代表微服务的形式,saveType为3代表Jar的存储类型。若precoms有多个,则使用逗号进行分隔。此外,在计算过程构件之间需要进行参数传递,需要调用数据聚合构件,需要对输入参数类型(inParamType)和输出参数类型(outParamType)进行描述。栅格型新安江模型包括蒸散发构件、产流构件、分水源构件和汇流构件。描述如下所示:



3.基于Spark的网格水文模型调度和计算模型(GridCSC)。从MFile中获取栅格新安江模型构件计算依赖关系,栅格新安江模型的构件计算顺序为蒸散发构件、产流构件、分水源构件,最后是汇流构件。因此先计算蒸散发构件,再计算产流构件,接着计算分水源构件,最后计算汇流构件。最终通过参数聚合构件生成输出结果。
3.1计算蒸散发构件、产流构件和分水源构件时,网格之间没有依赖关系,采用Hash数据分区方法进行任务划分,确定分配到每个Worker上的待计算网格。通过Master节点将计算的网格分配任务给Worker节点,将参数文件PFile或者RDD广播给Worker计算节点,并调用构件计算接口,进行网格计算。
3.2计算汇流构件时,网格之间存在依赖关系,完成分区之后Master节点将网格参数信息将按照分区结果分发给各个Worker节并调用构件接口进行计算,构件完成计算之后调用参数聚合构件将Worker节点的计算机过进行聚合操作。如果一次操作完成之后,流域网格均完成计算则该构件计算完毕,否则删除已完成计算网格,更新未计算网格对应的上游网格信息,再次进行数据分区操作。动态数据划分方法进行数据分区的步骤为:
(3.2.1)计算集群的最大并行数。设有N个同构的计算机作为Worker节点,每个节点有M个CPU核数,那么该集群一次可分发的任务个数为N*M个,以这个为基础在构件计算中对数据进行分区。
(3.2.2)计算网格所有的上游网格坐标。根据计算网格计算次序对应的网格单元个数,先解析出栅格计算次序和流向信息参数,计算出计算次序i对应的网格单元坐标以及每个网格单元对应的上游网格坐标。
(3.2.3)根据计算次序对应网格个数对数据进行分区。假设首先寻找网格单元个数大于N*M的计算次序,设计算次序为P的节点有K个,其中K≥N*M,P为满足要求的最大计算次序;则上游网格个数集合表示为T={c1,c2,......,ck};其中ci为第i个网格对应的上游网格的数量;然后计算每个分区分配的网格数量为 将K个网格对应的上游网格坐标均等分为N*M份,得到每一个数据块的网格数量为Num={num1,num2,......,numN*M},若对于任意的
将K个网格对应的上游网格坐标均等分为N*M份,得到每一个数据块的网格数量为Num={num1,num2,......,numN*M},若对于任意的 均满足GNumequals*(1-Q)≤numi≤GNumequals*(1+Q),则计算次序P即为此次计算的次序,将计算次序P对应节点的上游网格数据等份的分配给N*M个执行器。
均满足GNumequals*(1-Q)≤numi≤GNumequals*(1+Q),则计算次序P即为此次计算的次序,将计算次序P对应节点的上游网格数据等份的分配给N*M个执行器。
(3.2.4)判断是否存在满足条件的次序,如果存在则对分区内部网格单元根据计算次序进行排序,至此完成动态数据划分操作。如果不存在则更新可分区个数再重新进行分区并返回步骤(3.2.3)。
4.对各个构件的计算结果进行保存。
4.1定义输出结果存储参数。每一个构件计算完成之后,根据从NetCDF模型模块描述信息中解析到的模块计算结果输出参数顺序,按照时间顺序和输出参数排列顺序进行排序,以PairRDD的格式进行读写操作,参数之间使用逗号作为分隔符。以分水源构件计算为例,解析NetCDF得到分水源构件的输出参数为RsResult,RiResult,RgResult,则网格单元(x,y)分水源构件结果的保存格式为:“T1时刻RsResult的值,T1时刻RiResult的值,T1时刻RgResult的值,T2时刻RsResult的值,T2时刻RiResult的值,T2时刻RgResult的值.......横坐标(x),纵坐标(y)”。
4.2解析存储构件计算结果的RDD并进行保存。对于每一个构件的计算结果,通过RDD的collect函数将RDD格式转换为转化为List<String>集合。假设模型共返回K个结果,使用split(“,”)函数将String类型转化为String[]数组,设数组的长度为Len,则时间节点共有Len/K个,则String[0]到String[K-1]为T1时间节点的计算结果,String[K]到String[2*K-1]为T2时刻的值,以此类推,一直到List遍历完毕。得到一个Map<Key,Value[][]>类型的计算结果,Key为时间节点,Value为与流域网格边界相对应的用来存储计算结果的二维数组。最后的计算结果以三维数组的形式使用NetCDF格式进行保存。
实验验证
(1)实验思路
为验证本发明方法在实际应用中的性能,分别利用本发明提出的网格水文模型分布式计算方法与传统的网格水文模型并行计算方法,在屯溪流域使用栅格新安江模型进行水文过程模拟,模拟的水文过程包括蒸散发、产流、分水源、坡面汇流和河道汇流。在空间分辨率为1km的情况下,参与计算的网格单元个数为8586个,水文模拟的时间间隔为1h。为了同时对比传统的串行计算方法、Spark分布式计算方法和本发明的改进的Spark分布式计算方法。
(2)实验环境
计算的集群环境由三台物理机构成,每台物理机的处理器为Intel i5-7300HQ,CPU的物理核数为4,使用Spark的standalone集群模式进行计算。
(3)实验结果分析
三种方法的测试结果如图5所示。从计算时间和内存溢出情况两方面对实验进行分析,首先计算时间方面,由图可以看出在7天、14天、20天预热期中,Spark分布式计算方法和改进的Spark分布式计算方法都优于传统的串行计算方法,但是由于本文的方法会造成小部分集群资源浪费的情况,所以运算速度略低于未改进的分布式计算方法;但是从内存溢出方面来说,传统的并行计算方法在预热期超过20天就存在内存溢出的现象,而未改进的Spark分布式计算方法由于大量的Shuffle操作在预热期超过60天出现了数据溢出的现象,而本发明提出的改进的Spark分布式计算方法由于使用了动态数据划分策略,大大减少了Shuffle操作,因此在预热期超过90天仍然未出现内存溢出的情况。水文模拟效率得到了大大的提升。
Claims (9)
1.一种基于Spark的网格水文模型分布式计算方法,其特征在于,包括如下步骤:
(1)采用netCDF数据格式描述模型参数,建立参数描述文件PFile;
(2)采用XML描述模型构件及其依赖关系,建立模型描述文件MFile;
(3)基于Spark的模型构件调度和计算模型GridCSC分析模型描述文件MFile,根据模型计算构件之间的依赖关系、网格依赖关系以及相应的模型参数,进行模型的分布式计算;
(4)参数聚合构件在Master节点中聚合每个构件计算的RDD结果,并通过广播发送给各Worker节点,供后继构件计算使用;
(5)计算完毕后,参数聚合构件采用netCDF格式输出各构件的计算结果。
2.根据权利要求1所述的一种基于Spark的网格水文模型分布式计算方法,其特征在于,所述步骤(1)中进行参数数据描述时,描述的参数包括:
模型参数:模型参数是指模型在执行时所需要的相关系数、常量;
流域下垫面参数:流域下垫面参数是描述流域下垫特征信息;包括流域高程、流域水系、流域网格依赖关系、植被覆盖、土质类型;
流域历史降雨和水文数据:流域历史降雨和水文数据是已经监测的流域降雨、流量水位数据、蒸散发数据以及土壤含水量数据;
流域实时、未来降雨参数:流域实时、未来降雨是从其他来源获取的流域当前时刻以及未来降雨的数据,用于模型的预报。
3.根据权利要求1所述的一种基于Spark的网格水文模型分布式计算方法,其特征在于,所述步骤(1)中进行参数数据描述时,描述规范包括:
坐标系统、时间系统以及参属性的描述遵守netCDF-CF-1.6即Climate and Forecastconvension 1.6版本的约束;对每个参数的描述包括:参数名称、参数标识、参数类型、参数值、参数说明五方面;其中,流域下垫面参数,流域历史降雨、水文数据,流域实时和未来降雨数据的描述采用多维向量的网格化进行描述;
网格化参数描述时,坐标系统采用经纬度坐标,定义坐标变量lon、lat分别标识经度和纬度,单位即untis属性分别为degree_east和degree_north;取值为float类型;时间系统通过时间坐标变量的untis属性设置起始时间,通过时间坐标变量的取值确定每个数据的时间点。
4.根据权利要求1所述的一种基于Spark的网格水文模型分布式计算方法,其特征在于,所述步骤(2)中采用XML描述模型构件及其依赖关系时,描述规范包括:
(2.1)描述的构件根据网格水文模型不同而不同,包括:蒸散发模块、产流模块、分水源模块和汇流模块;构件属性包括:构件名称、构件标识、构件编号、构件访问接口方面描述构件的基本信息;
(2.2)通过模型构件前置属性描述构件之间的依赖关系,并确定构件计算顺序;每个构件有1个或者多个前置构件。
5.根据权利要求1所述的一种基于Spark的网格水文模型分布式计算方法,其特征在于,所述步骤(3)中基于Spark的模型构件调度和计算模型GridCSC进行模型的分布式计算时,其步骤包括:
(3.1)从MFile获取模型构件信息以及构件之间的依赖关系,根据计算构件之间的依赖关系确定构件的计算顺序图;
(3.2)循环对所有同时计算的构件进行并行计算,每次循环计算没有任何前置依赖的构件,直到所有构件计算完毕;若构件a的前置构件已经计算时,则认为构件a没有前置依赖;
(3.3)构件计算时,如果该构件中的网格是独立的,则进行独立网格计算,如果待计算的网格之间具有依赖关系,则采用依赖网格计算;
(3.4)构件计算的结果通过处于Master的参数聚合构件聚合成RDD结构,并通过广播传递给下一个依赖的构件。
6.根据权利要求5所述的一种基于Spark的网格水文模型分布式计算方法,其特征在于,所述步骤(3.3)中进行独立网格计算时,其步骤包括:
(3.3.1)利用Hash分区方法进行网格计算任务分区划分,确定分配到每个Worker上的待计算网格;
(3.3.2)Master节点将计算网格分配给对应的Worker节点,Master节点从参数文件PFile中或RDD中解析出计算所需参数,根据分区结果将网格参数传输给对应计算节点,Worker节点调用构件计算接口,进行网格计算;
(3.3.3)参数聚合构件聚合各Worker节点的计算结果,形成构件计算结果的RDD存储。
7.根据权利要求6所述的一种基于Spark的网格水文模型分布式计算方法,其特征在于,所述步骤(3.3.1)中利用Hash分区方法进行网格划分时,其步骤包括:
(3.3.1.1)获取每个网格单元的坐标(x,y),将网格单元参数信息组织为<key,value>的形式,其中key对应网格单元坐标(x,y),value对应网格参数值;
(3.3.1.2)根据公式WorkerID=Key.hashCode%WorkerNum得到分区的坐标;其中WorkerID表示Key对应的数据应该被分配到的Worker节点标识,Key.hashCode表示Key在哈希运算中的哈希值,WorkerNum集群中Worker节点的个数。
8.根据权利要求5所述的一种基于Spark的网格水文模型分布式计算方法,其特征在于,所述步骤(3.3)中进行依赖网格计算时,其步骤包括:
(3.3.1)通过“流域网格依赖关系”参数信息得到网格之间的依赖关系;
(3.3.2)根据网格依赖关系通过动态数据划分方法进行网格计算任务划分,确定当前可计算的网格中分配到每个Worker上的待计算网格;
(3.3.3)Master节点将计算网格分配给对应的Worker节点,Master节点从参数文件PFile中或RDD中解析出计算所需参数,根据分区结果将网格参数传输给对应计算节点,Worker节点调用构件计算接口,进行网格计算;
(3.3.4)参数聚合构件聚合各Worker节点的计算结果,形成构件计算结果的RDD存储;
(3.3.5)判断网格是否计算完毕,若没有计算完,则删除已完成计算网格,更新未计算网格对应的上游网格信息,然后转到(3.3.2)。
9.根据权利要求8所述的一种基于Spark的网格水文模型分布式计算方法,其特征在于,所述步骤(3.3.2)中动态数据划分方法时,其步骤包括:
(3.3.2.1)计算集群可用资源:计算集群中的最大并行数,设有N个同构的计算机作为Worker节点,每个节点有M个CPU核数,那么该集群的最大并行数为N*M个,即集群一次最多可以执行N*M个任务;以这个为基础在构件计算中对数据进行分区;
(3.3.2.2)计算网格所有的上游网格坐标:根据计算网格计算次序对应的网格单元个数,先解析出栅格计算次序和流向信息参数,计算出计算次序i对应的网格单元坐标以及每个网格单元对应的上游网格坐标;
(3.3.2.3)根据计算次序对应网格个数对数据进行分区:假设首先寻找网格单元个数大于N*M的计算次序,设计算次序为P的节点有K个,其中K≥N*M,P为满足要求的最大计算次序;则上游网格个数集合表示为T={c1,c2,......,ck};其中ci为第i个网格对应的上游网格的数量;然后计算每个分区分配的网格数量为 将K个网格对应的上游网格坐标均等分为N*M份,得到每一个数据块的网格数量为Num={num1,num2,......,numN*M},若对于任意的
将K个网格对应的上游网格坐标均等分为N*M份,得到每一个数据块的网格数量为Num={num1,num2,......,numN*M},若对于任意的 均满足GNumequals*(1-Q)≤numi≤GNumequals*(1+Q),则计算次序P即为此次计算的次序,将计算次序P对应节点的上游网格数据等份的分配给N*M个执行器;
均满足GNumequals*(1-Q)≤numi≤GNumequals*(1+Q),则计算次序P即为此次计算的次序,将计算次序P对应节点的上游网格数据等份的分配给N*M个执行器;
(3.3.2.4)判断是否存在满足条件的次序,如果存在则对分区内部网格单元根据计算次序进行排序,至此完成动态数据划分操作。如果不存在则更新可分区个数再重新进行分区并返回步骤(3.3.2.3)。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110330831.5A CN112948123B (zh) | 2021-03-26 | 2021-03-26 | 一种基于Spark的网格水文模型分布式计算方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110330831.5A CN112948123B (zh) | 2021-03-26 | 2021-03-26 | 一种基于Spark的网格水文模型分布式计算方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN112948123A true CN112948123A (zh) | 2021-06-11 |
| CN112948123B CN112948123B (zh) | 2023-02-28 |
Family
ID=76227030
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110330831.5A Active CN112948123B (zh) | 2021-03-26 | 2021-03-26 | 一种基于Spark的网格水文模型分布式计算方法 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN112948123B (zh) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113449404A (zh) * | 2021-06-29 | 2021-09-28 | 中国水利水电科学研究院 | 基于逐层叶片单元识别的河网汇流与分水并行计算方法 |
| CN113570489A (zh) * | 2021-07-22 | 2021-10-29 | 生态环境部卫星环境应用中心 | 基于统计单元自适应的生态空间分析方法和系统 |
| CN114398592A (zh) * | 2021-12-27 | 2022-04-26 | 中国人民武装警察部队警官学院 | 一种基于异质格网高程线性分解模型的高程值解算方法 |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB201717138D0 (en) * | 2016-11-28 | 2017-12-06 | National Univ Of Defense Technology | Spark-based imaging satellite task preprocessing parallelization method |
| CN108920540A (zh) * | 2018-06-12 | 2018-11-30 | 武汉大学 | 一种基于Spark的并行栅格数据处理方法 |
| CN110598242A (zh) * | 2019-07-24 | 2019-12-20 | 浙江大学 | 一种新的基于网格化流域和分类率定的水文模型 |
| CN112256816A (zh) * | 2020-11-03 | 2021-01-22 | 亿景智联(北京)科技有限公司 | 一种基于分治网格的空间大数据算法 |
-
2021
- 2021-03-26 CN CN202110330831.5A patent/CN112948123B/zh active Active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB201717138D0 (en) * | 2016-11-28 | 2017-12-06 | National Univ Of Defense Technology | Spark-based imaging satellite task preprocessing parallelization method |
| CN108920540A (zh) * | 2018-06-12 | 2018-11-30 | 武汉大学 | 一种基于Spark的并行栅格数据处理方法 |
| CN110598242A (zh) * | 2019-07-24 | 2019-12-20 | 浙江大学 | 一种新的基于网格化流域和分类率定的水文模型 |
| CN112256816A (zh) * | 2020-11-03 | 2021-01-22 | 亿景智联(北京)科技有限公司 | 一种基于分治网格的空间大数据算法 |
Non-Patent Citations (1)
| Title |
|---|
| 杨应召: "基于Spark的物理海洋大数据云计算技术研究", 《中国优秀博硕士学位论文全文数据库(硕士)工程科技Ⅱ辑》 * |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113449404A (zh) * | 2021-06-29 | 2021-09-28 | 中国水利水电科学研究院 | 基于逐层叶片单元识别的河网汇流与分水并行计算方法 |
| CN113449404B (zh) * | 2021-06-29 | 2024-06-07 | 中国水利水电科学研究院 | 基于逐层叶片单元识别的河网汇流与分水并行计算方法 |
| CN113570489A (zh) * | 2021-07-22 | 2021-10-29 | 生态环境部卫星环境应用中心 | 基于统计单元自适应的生态空间分析方法和系统 |
| CN113570489B (zh) * | 2021-07-22 | 2022-05-03 | 生态环境部卫星环境应用中心 | 基于统计单元自适应的生态空间分析方法和系统 |
| CN114398592A (zh) * | 2021-12-27 | 2022-04-26 | 中国人民武装警察部队警官学院 | 一种基于异质格网高程线性分解模型的高程值解算方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN112948123B (zh) | 2023-02-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112948123B (zh) | 一种基于Spark的网格水文模型分布式计算方法 | |
| Khaleghzadeh et al. | A novel data-partitioning algorithm for performance optimization of data-parallel applications on heterogeneous HPC platforms | |
| CN106339351B (zh) | 一种sgd算法优化系统及方法 | |
| CN106547882A (zh) | 一种智能电网中营销大数据的实时处理方法及系统 | |
| CN106201651A (zh) | 神经形态芯片的模拟器 | |
| CN107609141A (zh) | 一种对大规模可再生能源数据进行快速概率建模方法 | |
| Huo et al. | An improved multi-cores parallel artificial Bee colony optimization algorithm for parameters calibration of hydrological model | |
| CN109657794B (zh) | 一种基于指令队列的分布式深度神经网络性能建模方法 | |
| CN104392147A (zh) | 面向区域尺度土壤侵蚀建模的地形因子并行计算方法 | |
| Wang et al. | Research on parallelized real-time map matching algorithm for massive GPS data | |
| CN105205052A (zh) | 一种数据挖掘方法及装置 | |
| CN115238899A (zh) | 面向超导量子计算机的量子程序并行处理方法及操作系统 | |
| Liu et al. | Parameter calibration in wake effect simulation model with stochastic gradient descent and stratified sampling | |
| CN111860621A (zh) | 一种数据驱动的分布式交通流量预测方法及系统 | |
| CN107301094A (zh) | 面向大规模动态事务查询的动态自适应数据模型 | |
| CN112766609A (zh) | 一种基于云计算的用电量预测方法 | |
| CN113704695A (zh) | 一种适用于区域数值模式集合模拟预报的初值小扰动法 | |
| CN116910467A (zh) | 面向复杂混部扰动的在线运行时环境预测方法及装置 | |
| CN106844024A (zh) | 一种自学习运行时间预测模型的gpu/cpu调度方法及系统 | |
| CN116303219A (zh) | 一种网格文件的获取方法、装置及电子设备 | |
| CN114676586A (zh) | 一种基于多维、多时空的数字模拟与仿真的建构方法 | |
| CN109190160B (zh) | 一种分布式水文模型的矩阵化模拟方法 | |
| Danner et al. | Hybrid MPI/GPU interpolation for grid DEM construction | |
| CN109062695B (zh) | 一种vic陆面模型网格数据计算方法 | |
| CN113010296A (zh) | 基于形式化模型的任务解析与资源分配方法及系统 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |