CN112036552B - 一种卷积神经网络运转方法和装置 - Google Patents
一种卷积神经网络运转方法和装置 Download PDFInfo
- Publication number
- CN112036552B CN112036552B CN202011107128.XA CN202011107128A CN112036552B CN 112036552 B CN112036552 B CN 112036552B CN 202011107128 A CN202011107128 A CN 202011107128A CN 112036552 B CN112036552 B CN 112036552B
- Authority
- CN
- China
- Prior art keywords
- activation value
- memory
- activation
- value
- convolution
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images


Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- Complex Calculations (AREA)
Abstract
本发明公开了一种卷积神经网络运转方法和装置,方法包括:从激活值存储器依次读取本卷积模块的第一激活值、第二激活值、第三激活值,在临时值存储器中使用第一卷积核卷积第一激活值以获得第二激活值、使用第二卷积核卷积第二激活值以获得第三激活值、使用第三卷积核卷积第三激活值以获得第四激活值,并依次覆盖写入激活值存储器;从激活值存储器读取第一激活值和第四激活值,在临时值存储器中基于线性修正而叠加第一激活值和第四激活值以获得具有残差的第五激活值,并覆盖写入激活值存储器。本发明能够降低卷积神经网络在运行中的显存占用率,提高资源利用率和运行速度。
Description
技术领域
本发明涉及神经网络领域,更具体地,特别是指一种卷积神经网络运转方法和装置。
背景技术
深度学习网络近年来朝着更深、更大的方向发展,ResNet系列的网络证明了更深的网络可以拟合更多的数据,但深层网络对GPU的显存提出了要求。现代GPU(图形处理单元)支持的显存最大只有32G,由于GPU的价格昂贵,扩展GPU数量对企业成本造成很高的压力,因而节省计算过程中占用的GPU显存,显得尤为重要。
ResNet50是一个50层的卷积神经网络,被广泛用于计算机视觉的图像分类、目标检测等任务。ResNet50由多个模块组成,在其前向计算会保存中间计算出的激活值,这占用很多显存,而大部分激活值在后续的计算过程中并不会用到,因而造成了资源浪费。
针对现有技术中卷积神经网络的中间激活值复用率低、占用显存、拖慢运行速度的问题,目前尚无有效的解决方案。
发明内容
有鉴于此,本发明实施例的目的在于提出一种卷积神经网络运转方法和装置,能够降低卷积神经网络在运行中的显存占用率,提高资源利用率和运行速度。
基于上述目的,本发明实施例的第一方面提供了一种卷积神经网络运转方法,包括基于由图形处理单元提供的激活值存储器和临时值存储器而使用多个卷积模块来执行卷积运算,并且在每个卷积模块中分别执行基于以下步骤的前向运算:
从激活值存储器读取本卷积模块的第一激活值,在临时值存储器中使用第一卷积核卷积第一激活值以获得第二激活值,并覆盖写入激活值存储器;
从激活值存储器读取第二激活值,在临时值存储器中使用第二卷积核卷积第二激活值以获得第三激活值,并覆盖写入激活值存储器;
从激活值存储器读取第三激活值,在临时值存储器中使用第三卷积核卷积第三激活值以获得第四激活值,并覆盖写入激活值存储器;
从激活值存储器读取第一激活值和第四激活值,在临时值存储器中基于线性修正而叠加第一激活值和第四激活值以获得具有残差的第五激活值,并覆盖写入激活值存储器。
在一些实施方式中,激活值存储器配置为具有足以存储三个激活值的显存空间,临时值存储器配置为具有足以存储一个激活值的显存空间。
在一些实施方式中,将第二激活值、第三激活值、第四激活值、第五激活值覆盖写入激活值存储器包括:
将第二激活值覆盖上一卷积模块的第一激活值写入激活值存储器;
将第三激活值覆盖第二激活值写入激活值存储器;
将第四激活值覆盖第三激活值写入激活值存储器;
将第五激活值覆盖上一卷积模块的第四激活值写入激活值存储器。
在一些实施方式中,将第二激活值、第三激活值、第四激活值、第五激活值覆盖写入激活值存储器包括:
将第二激活值覆盖上一卷积模块的第四激活值写入激活值存储器;
将第三激活值覆盖第二激活值写入激活值存储器;
将第四激活值覆盖第三激活值写入激活值存储器;
将第五激活值覆盖上一卷积模块的第一激活值写入激活值存储器。
在一些实施方式中,从激活值存储器读取本卷积模块的第一激活值包括:从激活值存储器读取上一卷积模块的第五激活值作为本卷积模块的第一激活值。
在一些实施方式中,方法还包括:在将第五激活值覆盖写入激活值存储器之后,还由下一卷积模块读取第五激活值作为下一卷积模块的第一激活值。
在一些实施方式中,每个卷积模块具有分别使用第一卷积核、第二卷积核、和第三卷积核来执行卷积运算的3个卷积层;卷积神经网络具有50个卷积层,包括头卷积层、尾卷积层、以及处于头卷积层和尾卷积层之间的16个卷积模块所具有的48个卷积层。
本发明实施例的第二方面提供了一种卷积神经网络运转装置,包括:
处理单元;和
存储单元,存储有处理单元可运行的程序代码,程序代码在被运行时基于由图形处理单元提供的激活值存储器和临时值存储器而使用多个卷积模块来执行卷积运算,并且在每个卷积模块中分别执行基于以下步骤的前向运算:
从激活值存储器读取本卷积模块的第一激活值,在临时值存储器中使用第一卷积核卷积第一激活值以获得第二激活值,并覆盖写入激活值存储器;
从激活值存储器读取第二激活值,在临时值存储器中使用第二卷积核卷积第二激活值以获得第三激活值,并覆盖写入激活值存储器;
从激活值存储器读取第三激活值,在临时值存储器中使用第三卷积核卷积第三激活值以获得第四激活值,并覆盖写入激活值存储器;
从激活值存储器读取第一激活值和第四激活值,在临时值存储器中基于线性修正而叠加第一激活值和第四激活值以获得具有残差的第五激活值,并覆盖写入激活值存储器。
在一些实施方式中,激活值存储器配置为具有足以存储三个激活值的显存空间,临时值存储器配置为具有足以存储一个激活值的显存空间;
将第二激活值、第三激活值、第四激活值、第五激活值覆盖写入激活值存储器包括:将第二激活值覆盖上一卷积模块的第一激活值写入激活值存储器、将第三激活值覆盖第二激活值写入激活值存储器、将第四激活值覆盖第三激活值写入激活值存储器、将第五激活值覆盖上一卷积模块的第四激活值写入激活值存储器;或将第二激活值覆盖上一卷积模块的第四激活值写入激活值存储器、将第三激活值覆盖第二激活值写入激活值存储器、将第四激活值覆盖第三激活值写入激活值存储器、将第五激活值覆盖上一卷积模块的第一激活值写入激活值存储器。
在一些实施方式中,从激活值存储器读取本卷积模块的第一激活值包括:从激活值存储器读取上一卷积模块的第五激活值作为本卷积模块的第一激活值;
步骤还包括:在将第五激活值覆盖写入激活值存储器之后,还由下一卷积模块读取第五激活值作为下一卷积模块的第一激活值。
本发明具有以下有益技术效果:本发明实施例提供的卷积神经网络运转方法和装置,通过从激活值存储器依次读取本卷积模块的第一激活值、第二激活值、第三激活值,在临时值存储器中使用第一卷积核卷积第一激活值以获得第二激活值、使用第二卷积核卷积第二激活值以获得第三激活值、使用第三卷积核卷积第三激活值以获得第四激活值,并依次覆盖写入激活值存储器;从激活值存储器读取第一激活值和第四激活值,在临时值存储器中基于线性修正而叠加第一激活值和第四激活值以获得具有残差的第五激活值,并覆盖写入激活值存储器的技术方案,能够降低卷积神经网络在运行中的显存占用率,提高资源利用率和运行速度。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
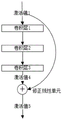
图1为本发明提供的卷积神经网络运转方法的流程示意图;
图2为本发明提供的卷积神经网络运转方法的单个卷积模块的前向计算流程图;
图3为本发明提供的卷积神经网络运转方法的整体的前向计算流程图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明实施例进一步详细说明。
需要说明的是,本发明实施例中所有使用“第一”和“第二”的表述均是为了区分两个相同名称非相同的实体或者非相同的参量,可见“第一”“第二”仅为了表述的方便,不应理解为对本发明实施例的限定,后续实施例对此不再一一说明。
基于上述目的,本发明实施例的第一个方面,提出了一种降低卷积神经网络在运行中的显存占用率,提高资源利用率和运行速度的卷积神经网络运转方法的一个实施例。图1示出的是本发明提供的卷积神经网络运转方法的流程示意图。
所述的卷积神经网络运转方法,如图1所示,包括基于由图形处理单元提供的激活值存储器和临时值存储器而使用多个卷积模块来执行卷积运算,并且在每个卷积模块中分别执行基于以下步骤的前向运算:
步骤S101:从激活值存储器读取本卷积模块的第一激活值,在临时值存储器中使用第一卷积核卷积第一激活值以获得第二激活值,并覆盖写入激活值存储器;
步骤S103:从激活值存储器读取第二激活值,在临时值存储器中使用第二卷积核卷积第二激活值以获得第三激活值,并覆盖写入激活值存储器;
步骤S105:从激活值存储器读取第三激活值,在临时值存储器中使用第三卷积核卷积第三激活值以获得第四激活值,并覆盖写入激活值存储器;
步骤S107:从激活值存储器读取第一激活值和第四激活值,在临时值存储器中基于线性修正而叠加第一激活值和第四激活值以获得具有残差的第五激活值,并覆盖写入激活值存储器。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,可以通过计算机程序来指令相关硬件来完成,的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,的存储介质可为磁碟、光盘、只读存储记忆体(ROM)或随机存储记忆体(RAM)等。计算机程序的实施例,可以达到与之对应的前述任意方法实施例相同或者相类似的效果。
在一些实施方式中,激活值存储器配置为具有足以存储三个激活值的显存空间,临时值存储器配置为具有足以存储一个激活值的显存空间。
在一些实施方式中,将第二激活值、第三激活值、第四激活值、第五激活值覆盖写入激活值存储器包括:
将第二激活值覆盖上一卷积模块的第一激活值写入激活值存储器;
将第三激活值覆盖第二激活值写入激活值存储器;
将第四激活值覆盖第三激活值写入激活值存储器;
将第五激活值覆盖上一卷积模块的第四激活值写入激活值存储器。
在一些实施方式中,将第二激活值、第三激活值、第四激活值、第五激活值覆盖写入激活值存储器包括:
将第二激活值覆盖上一卷积模块的第四激活值写入激活值存储器;
将第三激活值覆盖第二激活值写入激活值存储器;
将第四激活值覆盖第三激活值写入激活值存储器;
将第五激活值覆盖上一卷积模块的第一激活值写入激活值存储器。在一些实施方式中,从激活值存储器读取本卷积模块的第一激活值包括:从激活值存储器读取上一卷积模块的第五激活值作为本卷积模块的第一激活值。
在一些实施方式中,方法还包括:在将第五激活值覆盖写入激活值存储器之后,还由下一卷积模块读取第五激活值作为下一卷积模块的第一激活值。
在一些实施方式中,每个卷积模块具有分别使用第一卷积核、第二卷积核、和第三卷积核来执行卷积运算的3个卷积层;卷积神经网络具有50个卷积层,包括头卷积层、尾卷积层、以及处于头卷积层和尾卷积层之间的16个卷积模块所具有的48个卷积层。
下面根据图2、3所示的具体实施例进一步阐述本发明的具体实施方式。
本发明实施例只会保留在前向中后续会用的激活值,其余的激活值都会被覆盖。具体到ResNet50中的某个模块,参见图2、3可知,我们只会保留残差连接上的激活值1,以及修正线性单元的输入输出激活值4、5。从整个网络结构来看,每计算完一个模块,就能释放掉该模块的激活值1、4,并且激活值5成为下一个模块的输入以及残差连接上的激活值。这样在前向计算时,新的模块计算出的激活值,就能复用被激活值1、4释放的显存空间。因此,从整个网络来看,其前向过程只需要3块显存空间来存储激活值,这大大减少了前向计算时所需要的显存空间。在实际实现中还需要一块显存空间来存储临时值,因此在ResNet50的前向计算中共需要4块显存空间。
因此在执行卷积神经网络运算时,本发明实施例首先定义ResNet50模型结构,将图像数据输入网络。然后预先分配4块显存空间,存储网络前向计算过程中的激活值,并且在每个层计算完毕后,检测激活值会不会被后续计算过程使用,当不被使用时就释放该激活值所占空间,以供后续激活值使用;在计算过程中,最多只使用4块显存空间,用来保存三个激活值以及一个临时值。照此一直计算到第50层,即可获得所需分类、检测等结果。
从上述实施例可以看出,本发明实施例提供的卷积神经网络运转方法,通过从激活值存储器依次读取本卷积模块的第一激活值、第二激活值、第三激活值,在临时值存储器中使用第一卷积核卷积第一激活值以获得第二激活值、使用第二卷积核卷积第二激活值以获得第三激活值、使用第三卷积核卷积第三激活值以获得第四激活值,并依次覆盖写入激活值存储器;从激活值存储器读取第一激活值和第四激活值,在临时值存储器中基于线性修正而叠加第一激活值和第四激活值以获得具有残差的第五激活值,并覆盖写入激活值存储器的技术方案,能够降低卷积神经网络在运行中的显存占用率,提高资源利用率和运行速度。
需要特别指出的是,上述卷积神经网络运转方法的各个实施例中的各个步骤均可以相互交叉、替换、增加、删减,因此,这些合理的排列组合变换之于卷积神经网络运转方法也应当属于本发明的保护范围,并且不应将本发明的保护范围局限在所述实施例之上。
基于上述目的,本发明实施例的第二个方面,提出了一种降低卷积神经网络在运行中的显存占用率,提高资源利用率和运行速度的卷积神经网络运转装置的一个实施例。卷积神经网络运转装置包括:
处理单元;和
存储单元,存储有处理单元可运行的程序代码,程序代码在被运行时基于由图形处理单元提供的激活值存储器和临时值存储器而使用多个卷积模块来执行卷积运算,并且在每个卷积模块中分别基于执行以下步骤的前向运算:
从激活值存储器读取本卷积模块的第一激活值,在临时值存储器中使用第一卷积核卷积第一激活值以获得第二激活值,并覆盖写入激活值存储器;
从激活值存储器读取第二激活值,在临时值存储器中使用第二卷积核卷积第二激活值以获得第三激活值,并覆盖写入激活值存储器;
从激活值存储器读取第三激活值,在临时值存储器中使用第三卷积核卷积第三激活值以获得第四激活值,并覆盖写入激活值存储器;
从激活值存储器读取第一激活值和第四激活值,在临时值存储器中基于线性修正而叠加第一激活值和第四激活值以获得具有残差的第五激活值,并覆盖写入激活值存储器。
在一些实施方式中,激活值存储器配置为具有足以存储三个激活值的显存空间,临时值存储器配置为具有足以存储一个激活值的显存空间;
将第二激活值、第三激活值、第四激活值、第五激活值覆盖写入激活值存储器包括:将第二激活值覆盖上一卷积模块的第一激活值写入激活值存储器、将第三激活值覆盖第二激活值写入激活值存储器、将第四激活值覆盖第三激活值写入激活值存储器、将第五激活值覆盖上一卷积模块的第四激活值写入激活值存储器;或将第二激活值覆盖上一卷积模块的第四激活值写入激活值存储器、将第三激活值覆盖第二激活值写入激活值存储器、将第四激活值覆盖第三激活值写入激活值存储器、将第五激活值覆盖上一卷积模块的第一激活值写入激活值存储器。
在一些实施方式中,从激活值存储器读取本卷积模块的第一激活值包括:从激活值存储器读取上一卷积模块的第五激活值作为本卷积模块的第一激活值;
步骤还包括:在将第五激活值覆盖写入激活值存储器之后,还由下一卷积模块读取第五激活值作为下一卷积模块的第一激活值。
从上述实施例可以看出,本发明实施例提供的卷积神经网络运转装置,通过从激活值存储器依次读取本卷积模块的第一激活值、第二激活值、第三激活值,在临时值存储器中使用第一卷积核卷积第一激活值以获得第二激活值、使用第二卷积核卷积第二激活值以获得第三激活值、使用第三卷积核卷积第三激活值以获得第四激活值,并依次覆盖写入激活值存储器;从激活值存储器读取第一激活值和第四激活值,在临时值存储器中基于线性修正而叠加第一激活值和第四激活值以获得具有残差的第五激活值,并覆盖写入激活值存储器的技术方案,能够降低卷积神经网络在运行中的显存占用率,提高资源利用率和运行速度。
需要特别指出的是,上述卷积神经网络运转装置的实施例采用了所述卷积神经网络运转方法的实施例来具体说明各模块的工作过程,本领域技术人员能够很容易想到,将这些模块应用到所述卷积神经网络运转方法的其他实施例中。当然,由于所述卷积神经网络运转方法实施例中的各个步骤均可以相互交叉、替换、增加、删减,因此,这些合理的排列组合变换之于所述卷积神经网络运转装置也应当属于本发明的保护范围,并且不应将本发明的保护范围局限在所述实施例之上。
以上是本发明公开的示例性实施例,但是应当注意,在不背离权利要求限定的本发明实施例公开的范围的前提下,可以进行多种改变和修改。根据这里描述的公开实施例的方法权利要求的功能、步骤和/或动作不需以任何特定顺序执行。此外,尽管本发明实施例公开的元素可以以个体形式描述或要求,但除非明确限制为单数,也可以理解为多个。
所属领域的普通技术人员应当理解:以上任何实施例的讨论仅为示例性的,并非旨在暗示本发明实施例公开的范围(包括权利要求)被限于这些例子;在本发明实施例的思路下,以上实施例或者不同实施例中的技术特征之间也可以进行组合,并存在如上所述的本发明实施例的不同方面的许多其它变化,为了简明它们没有在细节中提供。因此,凡在本发明实施例的精神和原则之内,所做的任何省略、修改、等同替换、改进等,均应包含在本发明实施例的保护范围之内。
Claims (6)
1.一种卷积神经网络运转方法,其特征在于,包括基于由图形处理单元提供的激活值存储器和临时值存储器而使用多个卷积模块来执行卷积运算,并且在每个卷积模块中分别执行基于以下步骤的前向运算:
从所述激活值存储器读取本卷积模块的第一激活值,在所述临时值存储器中使用第一卷积核卷积所述第一激活值以获得第二激活值,并覆盖写入所述激活值存储器;
从所述激活值存储器读取所述第二激活值,在所述临时值存储器中使用第二卷积核卷积所述第二激活值以获得第三激活值,并覆盖写入所述激活值存储器;
从所述激活值存储器读取所述第三激活值,在所述临时值存储器中使用第三卷积核卷积所述第三激活值以获得第四激活值,并覆盖写入所述激活值存储器;
从所述激活值存储器读取所述第一激活值和所述第四激活值,在所述临时值存储器中基于线性修正而叠加所述第一激活值和所述第四激活值以获得具有残差的第五激活值,并覆盖写入所述激活值存储器;
其中,所述激活值存储器配置为具有足以存储三个激活值的显存空间,所述临时值存储器配置为具有足以存储一个激活值的显存空间,将所述第二激活值、所述第三激活值、所述第四激活值、所述第五激活值覆盖写入所述激活值存储器包括:
将所述第二激活值覆盖上一卷积模块的第四激活值写入所述激活值存储器;
将所述第三激活值覆盖所述第二激活值写入所述激活值存储器;
将所述第四激活值覆盖所述第三激活值写入所述激活值存储器;
将所述第五激活值覆盖上一卷积模块的第一激活值写入所述激活值存储器;或者
将所述第二激活值覆盖上一卷积模块的第一激活值写入所述激活值存储器;
将所述第三激活值覆盖所述第二激活值写入所述激活值存储器;
将所述第四激活值覆盖所述第三激活值写入所述激活值存储器;
将所述第五激活值覆盖上一卷积模块的第四激活值写入所述激活值存储器。
2.根据权利要求1所述的方法,其特征在于,从所述激活值存储器读取本卷积模块的第一激活值包括:
从所述激活值存储器读取上一卷积模块的第五激活值作为本卷积模块的所述第一激活值。
3.根据权利要求1所述的方法,其特征在于,还包括:
在将所述第五激活值覆盖写入所述激活值存储器之后,还由下一卷积模块读取所述第五激活值作为所述下一卷积模块的第一激活值。
4.根据权利要求1所述的方法,其特征在于,每个卷积模块具有分别使用所述第一卷积核、所述第二卷积核、和所述第三卷积核来执行卷积运算的3个卷积层;卷积神经网络具有50个卷积层,包括头卷积层、尾卷积层、以及处于所述头卷积层和所述尾卷积层之间的16个卷积模块所具有的48个卷积层。
5.一种卷积神经网络运转装置,其特征在于,包括:
处理单元;和
存储单元,存储有处理单元可运行的程序代码,所述程序代码在被运行时基于由图形处理单元提供的激活值存储器和临时值存储器而使用多个卷积模块来执行卷积运算,并且在每个卷积模块中分别执行基于以下步骤的前向运算:
从所述激活值存储器读取本卷积模块的第一激活值,在所述临时值存储器中使用第一卷积核卷积所述第一激活值以获得第二激活值,并覆盖写入所述激活值存储器;
从所述激活值存储器读取所述第二激活值,在所述临时值存储器中使用第二卷积核卷积所述第二激活值以获得第三激活值,并覆盖写入所述激活值存储器;
从所述激活值存储器读取所述第三激活值,在所述临时值存储器中使用第三卷积核卷积所述第三激活值以获得第四激活值,并覆盖写入所述激活值存储器;
从所述激活值存储器读取所述第一激活值和所述第四激活值,在所述临时值存储器中基于线性修正而叠加所述第一激活值和所述第四激活值以获得具有残差的第五激活值,并覆盖写入所述激活值存储器;
其中,所述激活值存储器配置为具有足以存储三个激活值的显存空间,所述临时值存储器配置为具有足以存储一个激活值的显存空间,将所述第二激活值、所述第三激活值、所述第四激活值、所述第五激活值覆盖写入所述激活值存储器包括:
将所述第二激活值覆盖上一卷积模块的第四激活值写入所述激活值存储器;
将所述第三激活值覆盖所述第二激活值写入所述激活值存储器;
将所述第四激活值覆盖所述第三激活值写入所述激活值存储器;
将所述第五激活值覆盖上一卷积模块的第一激活值写入所述激活值存储器;或者
将所述第二激活值覆盖上一卷积模块的第一激活值写入所述激活值存储器;
将所述第三激活值覆盖所述第二激活值写入所述激活值存储器;
将所述第四激活值覆盖所述第三激活值写入所述激活值存储器;
将所述第五激活值覆盖上一卷积模块的第四激活值写入所述激活值存储器。
6.根据权利要求5所述的装置,其特征在于,从所述激活值存储器读取本卷积模块的第一激活值包括:从所述激活值存储器读取上一卷积模块的第五激活值作为本卷积模块的所述第一激活值;
所述步骤还包括:在将所述第五激活值覆盖写入所述激活值存储器之后,还由下一卷积模块读取所述第五激活值作为所述下一卷积模块的第一激活值。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011107128.XA CN112036552B (zh) | 2020-10-16 | 2020-10-16 | 一种卷积神经网络运转方法和装置 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011107128.XA CN112036552B (zh) | 2020-10-16 | 2020-10-16 | 一种卷积神经网络运转方法和装置 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN112036552A CN112036552A (zh) | 2020-12-04 |
| CN112036552B true CN112036552B (zh) | 2022-11-08 |
Family
ID=73572823
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202011107128.XA Active CN112036552B (zh) | 2020-10-16 | 2020-10-16 | 一种卷积神经网络运转方法和装置 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN112036552B (zh) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115357381B (zh) * | 2022-08-11 | 2026-03-17 | 山东浪潮科学研究院有限公司 | 用于嵌入式设备深度学习推理的内存优化方法及系统 |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109117939A (zh) * | 2018-06-11 | 2019-01-01 | 西北大学 | 神经网络及在移动感知设备上部署神经网络的方法 |
| CN109784483A (zh) * | 2019-01-24 | 2019-05-21 | 电子科技大学 | 基于fd-soi工艺的二值化卷积神经网络内存内计算加速器 |
| US20200110995A1 (en) * | 2018-10-04 | 2020-04-09 | Apical Limited | Neural network optimization |
| CN111652353A (zh) * | 2020-05-18 | 2020-09-11 | 东莞理工学院城市学院 | 一种求解不适定问题的卷积神经网络模型及其求解方法 |
-
2020
- 2020-10-16 CN CN202011107128.XA patent/CN112036552B/zh active Active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109117939A (zh) * | 2018-06-11 | 2019-01-01 | 西北大学 | 神经网络及在移动感知设备上部署神经网络的方法 |
| US20200110995A1 (en) * | 2018-10-04 | 2020-04-09 | Apical Limited | Neural network optimization |
| CN109784483A (zh) * | 2019-01-24 | 2019-05-21 | 电子科技大学 | 基于fd-soi工艺的二值化卷积神经网络内存内计算加速器 |
| CN111652353A (zh) * | 2020-05-18 | 2020-09-11 | 东莞理工学院城市学院 | 一种求解不适定问题的卷积神经网络模型及其求解方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN112036552A (zh) | 2020-12-04 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN105630507B (zh) | 一种WebView控件界面绘制的方法和装置 | |
| CN112965660B (zh) | 一种双存储池信息反馈的方法、系统、设备及介质 | |
| CN115237599B (zh) | 一种渲染任务处理方法和装置 | |
| CN112036552B (zh) | 一种卷积神经网络运转方法和装置 | |
| CN104424030A (zh) | 多进程操作共享内存的方法和装置 | |
| CN101430677A (zh) | 一种保留文档编辑痕迹的方法及系统 | |
| CN104750227A (zh) | 休眠唤醒方法及电子装置 | |
| CN103413569B (zh) | 一读且一写静态随机存储器 | |
| CN113741811A (zh) | 一种存储系统的磁盘阵列的重构方法、系统、设备及介质 | |
| CN108228168A (zh) | 一种撤销、恢复操作的抽象方法 | |
| CN111899191A (zh) | 一种文本图像修复方法、装置及存储介质 | |
| US12608130B2 (en) | Compacted memory transactions for local data shares | |
| CN105302488A (zh) | 一种存储系统的数据写入方法及系统 | |
| CN105302494A (zh) | 一种压缩策略选择方法及装置 | |
| CN104866388A (zh) | 数据处理方法及装置 | |
| CN103294658A (zh) | 一种文档保存方法及装置 | |
| CN105824583A (zh) | 纠删码集群文件系统提高顺序写效率的处理方法及装置 | |
| CN104240284A (zh) | 一种基于Flash游戏图像渲染方法及系统 | |
| CN100473028C (zh) | 一种内存管理方法 | |
| CN109189505B (zh) | 一种减少对象序列化占用存储空间的方法及系统 | |
| US20210224655A1 (en) | Method and apparatus for pruning based on the number of updates | |
| CN110288340B (zh) | 一种基于Java智能合约的数据集合存储方法 | |
| CN113656414A (zh) | 一种数据处理方法、装置、设备及介质 | |
| CN101799793B (zh) | 闪存控制方法及装置 | |
| CN110516466A (zh) | 一种数据脱敏方法与装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| CP03 | Change of name, title or address | ||
| CP03 | Change of name, title or address |
Address after: Building 9, No.1, guanpu Road, Guoxiang street, Wuzhong Economic Development Zone, Wuzhong District, Suzhou City, Jiangsu Province Patentee after: Suzhou Yuannao Intelligent Technology Co.,Ltd. Country or region after: China Address before: Building 9, No.1, guanpu Road, Guoxiang street, Wuzhong Economic Development Zone, Wuzhong District, Suzhou City, Jiangsu Province Patentee before: SUZHOU LANGCHAO INTELLIGENT TECHNOLOGY Co.,Ltd. Country or region before: China |