CN111488198A - Virtual machine scheduling method, system and medium in super-fusion environment - Google Patents
Virtual machine scheduling method, system and medium in super-fusion environment Download PDFInfo
- Publication number
- CN111488198A CN111488198A CN202010300695.0A CN202010300695A CN111488198A CN 111488198 A CN111488198 A CN 111488198A CN 202010300695 A CN202010300695 A CN 202010300695A CN 111488198 A CN111488198 A CN 111488198A
- Authority
- CN
- China
- Prior art keywords
- virtual machine
- directory
- host
- hash value
- file
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images

Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45533—Hypervisors; Virtual machine monitors
- G06F9/45558—Hypervisor-specific management and integration aspects
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45533—Hypervisors; Virtual machine monitors
- G06F9/45558—Hypervisor-specific management and integration aspects
- G06F2009/4557—Distribution of virtual machine instances; Migration and load balancing
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Abstract
The invention discloses a virtual machine storage management method, a system and a medium under a super-fusion environment, wherein the implementation step of preparing a virtual machine in the method comprises the following steps: copying the system mirror image template file to each host; creating a corresponding directory D in a virtual storage pool of the distributed storage system according to the user information of each user and the information of the system image template file required to be used; and respectively writing the system image difference file and the user disk image file required by each user for running the virtual machine into a directory D of the distributed storage system, so that the system image difference file and the user disk image file required by each user for running the virtual machine are stored in the same target host H of the distributed storage system. The invention optimizes the distribution position of the file required by the virtual machine, schedules the virtual machine of the user to run on the host where the file is located, and can improve the access performance of the virtual machine and reduce the network overhead.
Description
Technical Field
The invention relates to a super-fusion technology of computer networks, cloud computing, virtual computing and cloud desktops, in particular to a virtual machine storage management method, a virtual machine storage management system and a virtual machine storage management medium in a super-fusion environment.
Background
The super-fusion infrastructure is based on a standard general hardware platform (such as an x 86-based host and an arm-based host), resources and technologies such as computation, network, storage and virtualization are provided in the same host device, and multiple hosts can realize the fusion of the computation, storage and network resources of each host in a software-defined manner through a network, so that the technical architecture of a software-defined data center with virtualization as the center is realized.
The core of the super-converged infrastructure is the fusion of storage. Generally, a storage device of a single host comprises a plurality of physical disks, wherein a part of the physical disks form a local storage of the host, a host operating system, virtualization software and the like are installed on the local storage, the local storage can be directly accessed by an application program running on the host, other physical disks are used as data storage, the data storage of the plurality of hosts forms a virtual storage pool of the super-fusion system, and the virtual storage pool can be mounted to all the hosts in the super-fusion cluster and accessed by the application program on any host. The data storage is fused into the virtual storage pool and is realized by distributed storage software, such as closed source distributed storage software self-developed by various manufacturers or glusterfs, ceph and the like based on open sources, and a distributed storage algorithm in the software is a key for determining which host storage devices the file is actually stored in.
In the specific implementation, for the storage position of a file under a specific directory, the directory can be created on the data storage of each host, the directory of each host is allocated with a non-overlapping hash value range, the hash value ranges of all hosts form a complete [0, FFFFFFFF ] 4-byte 32-bit value space, and each hash value range can be the average allocation of the 32-bit value space among the hosts, can be the proportional allocation according to the size of the data storage on each host, and can also be the random allocation; when saving the file under the directory, if the hash value of the file name falls in the hash range of the directory of a certain host, writing the file into the data storage of the host; for multi-copy distributed storage, the copy can use host data storage as a unit, the number of hosts in the same copy group is generally 2 to 3, the hash value ranges of the same directories of the hosts in the same group are the same, and the same file can be written into all member hosts in the group of hosts, so that the multi-copy target of the file is achieved.
Although the ultra-converged infrastructure can bring the advantages of horizontal expansion and low cost, compared with the traditional centralized storage device, the standard general hardware platform cannot use some optimization means of special storage devices, so that the storage performance is often the key of the bottleneck and the project success or failure of the whole ultra-converged system. In order to make up for the performance gap between general storage hardware and special storage equipment, various optimizations are performed on the storage used by the virtual machine in the super-fusion system, for example, the file of the system volume of the virtual machine is fragmented, and a group of complete fragmented copies are ensured to be stored on the data storage provided by the same host; when the virtual machine consists of a plurality of virtual machine storage components, scheduling and storing the primary copy of each component in the virtual storage pool on the same host; the optimization aims to operate the virtual machine on the host which needs to be stored the same or closest as possible, improve the data read-write performance and reduce the network delay and bandwidth overhead in the read-write process.
The running of the virtual machines with different specifications also depends on the availability of other resources on the host, such as cpu, memory, network, GPU resources, etc., which also affect the scheduling of the virtual machines. When the host where the storage resources required by the virtual machine are located cannot satisfy the resources beyond the storage, the virtual machine can be scheduled to run on other hosts, and the access performance of the virtual machine on the storage is reduced. Therefore, how to improve the performance of each storage component required by virtual machine access in the super-fusion infrastructure system from a specific technical scheme is still a problem to be optimized and improved in various existing super-fusion implementation technologies.
Disclosure of Invention
The technical problems to be solved by the invention are as follows: aiming at the problems in the prior art, the invention provides a virtual machine storage management method, a system and a medium under a super-fusion environment.
In order to solve the technical problems, the invention adopts the technical scheme that:
a virtual machine scheduling method under a super-fusion environment comprises the following implementation steps of:
1) copying the system mirror image template file to each host;
2) creating a corresponding directory D in a virtual storage pool of the distributed storage system according to the user information of each user and the information of the system image template file required to be used;
3) and respectively writing the system image difference file and the user disk image file required by each user for running the virtual machine into a directory D of the distributed storage system, so that the system image difference file and the user disk image file required by each user for running the virtual machine are stored in the same target host H of the distributed storage system.
Optionally, creating a corresponding directory D in the virtual storage pool of the distributed storage system in step 2) specifically means creating a nested two-layer sub-directory structure of a user name and a system mirror image template name at a specified position in the virtual storage pool of the distributed storage system as the directory D, where the nested two-layer sub-directory structure of the user name and the system mirror image template file name specifically means taking the user name as a first-layer sub-directory and the system mirror image template name as a second-layer sub-directory under the first-layer sub-directory, or taking the system mirror image template name as a first-layer sub-directory and taking the user name as a second-layer sub-directory under the first-layer sub-directory.
Optionally, the step of processing a file write request by the distributed storage system when writing the directory D of the distributed storage system in step 3) includes: acquiring a write directory name corresponding to the file write request in the virtual storage pool; judging whether the written directory name meets a preset format requirement, wherein the preset format requirement refers to a mode of generating the directory D in the step 2), and if the written directory name meets the preset format requirement, calculating a hash value of the written directory name by adopting a preset hash algorithmh(ii) a Otherwise, calculating the hash value by adopting a preset hash algorithm according to the file name of the file writing requesth(ii) a The hash valuehAnd matching with a preset hash value range, acquiring one or a group of hosts corresponding to the matched hash value interval in the hash value range, determining a target host H according to the one or the group of hosts, and writing the file of the file writing request into the target host H.
Optionally, the following steps of starting the virtual machine are further included after the virtual machine is prepared:
s1), determining a directory D of the target user for running the virtual machine;
s2), determining a target host H of the target user for running the virtual machine;
s3) finding the local system image template file in the target host H based on the system image template file and the position information specified in the system image difference file in the directory D, taking the corresponding system image difference file and the user disk image file in the directory D as the operating parameters of the local system image template file, and starting the virtual machine of the target user on the target host H.
Optionally, the detailed step of step S2) includes:
s2.1) calculating a hash value by adopting a preset hash algorithm according to the file name of the system image difference file in the directory D of the target user running virtual machineh(ii) a The hash valuehMatching with a preset hash value range, and if the matching is successful, skipping to execute the step S2.3), otherwise skipping to execute the step S2.2);
s2.2) calculating a hash value by adopting a preset hash algorithm according to the directory Dh(ii) a The hash valuehMatching with a preset hash value range;
s2.3) obtaining one or a group of hosts corresponding to the matched hash value interval in the hash value range, and determining a target host H according to the one or the group of hosts.
Optionally, when one or a group of hosts corresponding to the hash value interval matched in the hash value range is obtained, each host or a group of hosts has a static hash value interval; or each host or a group of hosts has a dynamic hash value interval, and the hash value is dividedhBefore matching with a preset hash value range, the method comprises the following steps of dynamically allocating a hash value interval for each host or a group of hosts: the method comprises the steps of obtaining the hardware requirement of a user for running the virtual machine, obtaining the hosts meeting the hardware requirement in the distributed storage system, and averagely distributing the hash value range to the hosts meeting the hardware requirement, so that the hash value interval of each host meeting the hardware requirement is determined, and the hash value interval of the host not meeting the hardware requirement is enabled to be empty.
Optionally, the detailed step of determining the target host H according to one or a group of hosts includes: if the hash value interval corresponds to a host, directly taking the host as a target host H; if the hash value section corresponds to a plurality of hosts, selecting one host from the plurality of hosts as a target host H, wherein the selection mode is any one of the following modes: mode 1, randomly selecting one host as a target host H; mode 2, selecting a host with the lowest CPU utilization rate as a target host H; mode 3, selecting a host with the lowest memory utilization rate as a target host H; and 4, weighting and summing the CPU utilization rate and the memory utilization rate, and selecting the host with the lowest weighted sum as the target host H.
Optionally, the method further includes, after starting the virtual machine, the following steps: and checking the locally stored system image template file and the locally operated virtual machine, and if a certain locally stored system image template file is not used by any locally operated virtual machine, deleting the system image template file from the local.
In addition, the invention also provides a virtual machine scheduling device in the super-fusion environment, which comprises a computer device, and is characterized in that the computer device is programmed or configured to execute the steps of the virtual machine scheduling method in the super-fusion environment, or a computer program programmed or configured to execute the virtual machine scheduling method in the super-fusion environment is stored on a memory of the computer device.
Furthermore, the present invention also provides a computer readable storage medium having stored thereon a computer program programmed or configured to execute the virtual machine scheduling method in the hyper-converged environment.
Compared with the prior art, the invention has the following advantages: the invention divides the files needed by the operation of the virtual machine into a system image template file, a system image difference file and a user disk image file, the system image difference file and the user disk image file are stored in a virtual storage pool through the local storage of the system image template file in a host, a directory D is generated by adopting a specific mapping mode, the system image difference file and the user disk image file are stored in the same target host H of a distributed storage system, the operation and the access storage performance of the virtual machine are improved on the premise of keeping the transverse expansion and the low cost advantage of a super-fusion basic framework, the system image template copy of the virtual machine is stored in the local storage of each host, the access efficiency of the virtual machine to the system disk is improved, the hash algorithm in the distributed storage is optimized, the difference image file of the system image and the user disk image file of the virtual machine are stored in the data disk of the same host to provide a scheduling basis for the scheduling of the virtual machine, the virtual machine is scheduled to run on one or a group of hosts where the system image difference file and the user disk image file are located, so that the virtual machine can directly access the storage equipment of the host where the virtual machine is located, the access performance can be improved, the network delay and the bandwidth occupation can be reduced, storage components required by the virtual machine are not stored in the local storage and data storage of the hosts which do not meet the specification requirement by comprehensively evaluating other factors except the storage requirement in the specification of the virtual machine, and the storage space overhead and the probability that the virtual machine cannot be scheduled to a proper host can be reduced.
Drawings
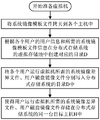
Fig. 1 is a flowchart of preparing a virtual machine according to an embodiment of the present invention.
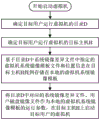
FIG. 2 is a flowchart illustrating processing a file write request according to an embodiment of the present invention.
Fig. 3 is a flowchart of starting a virtual machine according to an embodiment of the present invention.
Detailed Description
As shown in fig. 1, in the virtual machine scheduling method under the hyper-fusion environment of the embodiment, the implementation step of preparing the virtual machine includes:
1) copying the system mirror image template file to each host;
2) creating a corresponding directory D in a virtual storage pool of the distributed storage system according to the user information of each user and the information of the system image template file required to be used;
3) and respectively writing the system image difference file and the user disk image file required by each user for running the virtual machine into a directory D of the distributed storage system, so that the system image difference file and the user disk image file required by each user for running the virtual machine are stored in the same target host H of the distributed storage system.
In this embodiment, the files (storage components) required by the user to run the virtual machine include a system image template file, a system image difference file, and a user disk image file. The system mirror image template file is shared by a plurality of users, the back-end file of the system mirror image difference file is the system mirror image template file, and the system mirror image difference file and the user disk mirror image file are independently owned by each user virtual machine. In this embodiment, a system image template file required by the operation of a virtual machine all stores a copy in the local storage of each host, the directory name and the file name of the same system image template file on each host are the same, a system image differential file and a user disk image file required by the operation of the virtual machine are stored in a virtual storage pool, and a full file name (including the host local storage directory name) pointing to the system image template file is stored in the system image differential file; when different hosts access the system image difference file, the back-end system image template of the system image difference file is the system image difference file stored locally on the host, and the system image difference files are the same copy.
In this embodiment, step 2) creates a corresponding directory D in the virtual storage pool of the distributed storage system as directory D, the nested two-layer sub-directory structure of the user name and the system image template name in the virtual storage pool of the distributed storage system specifically refers to the user name as the first-layer sub-directory, the system image template name as the second-layer sub-directory under the first-layer sub-directory, or the system image template name as the first-layer sub-directory, the user name as the second-layer sub-directory under the first-layer sub-directory, for example, assuming that the designated mount location of the virtual directory of the distributed storage system on each host (which may be referred to as mount directory or mount point) is "/home/kylin-data/", the system image template employs kylos system 3.3 and the name is kylins 33 ", the user1 may also use a virtual directory p-directory generated by the virtual machine V of system image template 33 as" L.3. imjs-3 ", and the user image is stored in a directory g-r 3. No. 7. when the system image is created by this example, the system image directory g-directory b.7. i.7. the directory is a directory, the directory is also the aforementioned example, the system image directory is specified directory g.7.
As shown in fig. 2, the step of processing the file write request by the distributed storage system when writing the directory D of the distributed storage system in step 3) includes: acquiring a write directory name corresponding to the file write request in the virtual storage pool; judging whether the written directory name meets a preset format requirement (meeting a mode M) or not, wherein the preset format requirement refers to a mode (namely the mode M in the embodiment) for generating the directory D in the step 2), and if the preset format requirement is met, calculating a hash value of the written directory name by adopting a preset hash algorithm A (such as DM-hash, MD5, SHA and other common hash algorithms)h(ii) a Otherwise, calculating the hash value by adopting a hash algorithm A according to the file name of the file writing requesth(ii) a The hash valuehAnd matching with a preset hash value range, acquiring one or a group of hosts corresponding to the matched hash value interval in the hash value range, determining a target host H according to the one or the group of hosts, and writing the file of the file writing request into the target host H. When the written directory name meets the mode M, the written directory name can be directly calculated by adopting a preset hash algorithm A to calculate a hash valuehAccording to the hash valuehDetermining the data storage of the written file stored in which host, because the system image difference file of the same system image template file of the same user and the directory stored by the user disk image file are the same directory D, the two files can generate the same hash valuehThe distributed storage software stores the two filesTo the data store of the same target host H. Needless to say, the hash value of the written directory name is calculated by adopting a preset hash algorithm (denoted as hash algorithm A)hIn the meantime, the hash value can be calculated by adopting the hash algorithm A by adopting the full name or the short name written in the directory name according to the requirementhAs long as the full names or short names used by the target host H can be distinguished from each other, mapping to different target hosts H can be realized.
In this embodiment, a consistent hash algorithm is used as a distribution algorithm of a distributed storage system, in the algorithm, a directory structure on a storage pool is created on a data storage for the storage pool by each host, a hash value interval is written in an extended attribute of each directory structure, the hash value intervals of all hosts form a 4-byte 32-bit range of [0, FFFFFFFF ] (preset hash value range), and the hash value intervals of the directory structures on each host do not overlap with each other. In the embodiment, a hash value h is calculated according to whether the directory D is matched with the mode M or not by using a hash algorithm A as a basis for the name of the file or the name of the directory D where the file is located, and when the hash value h falls on the range of the directory attribute on a certain host, the file is stored in the data storage of the host; when the hyper-fusion hypervisor prepares the storage components needed by the virtual machine for the user, the distributed storage writes the storage components into the data storage of the selected host, and the hyper-fusion hypervisor starts the virtual machine process on the selected target host H.
For example, in a super-converged cloud desktop system composed of 3 servers, each host bisects the 32-bit hash value range of the directory, and the hash value intervals of the 1 st, 2 nd and 3 rd servers are [0xAAAAAAA, 0 xFFFFFFFFFF]、[0x00000000,0x55555554]、[0x55555555, 0xAAAAAAA9](the starting point may be at any station, in this example, station 2 is the starting point of range 0), the consistent hash algorithm uses a pattern M of/kylin-desktops/. the word "represents a single character,". the word "represents any string (which may be an empty string)," represents any string of at least one character, the first "is used to match any user name, and the second" is used to match any system image template file name. Cloud desktop management system in order of/home/kylin-data/user 1/kylinos33Record creation DE L TA.IMG, USER.IMG, because can match the mode M, directly use the string/home/kylin-data/user 1/kylinos33 instead of the string DE L TA.IMG or USER.IMG to calculate the hash value, calculate and get the hash valuehIf the number is 0x91c3e25f, the number falls in the hash value interval of the 3 rd host, the distributed storage subsystem stores the two IMG files in the data storage of the 3 rd host, when a user requests to start the virtual machine V, the cloud desktop management system obtains the hash value of the directory/home/kylin-data/user 1/kylinos33 to obtain the 3 rd host, and then schedules the virtual machine V to run on the 3 rd host.
For example, if a super-converged cloud desktop system is composed of 8 servers (with serial numbers 1-8), the distributed storage is divided into 4 groups (1,2) (3,4) (5,6) (7,8), data storage of the two servers in the same group is a copy group and stores the same file copy, an operating system installed in a mirroring template file guest.img of kylins 33 requires GPU support, 8 servers have GPU resources on 1,2, 3,4, 7,8, 5,6, the mirroring template file guest.img is stored under 1,2, 3,4, 7,8, a virtual storage pool composed of server data storage is hung on/home/kylins-data directory except 5,6, the virtual storage pool is hung on/home/kylins-data directory, user1 obtains a hash value of a virtual desktop file generated by a virtual machine V of kylins 33 based on a mirroring template of 5,6, a hash table file management table, a hash table, a database, a hash table.
As shown in fig. 3, the following steps of starting the virtual machine are included after preparing the virtual machine:
s1), determining a directory D of the target user for running the virtual machine;
s2), determining a target host H of the target user for running the virtual machine;
s3) finding the local system image template file in the target host H based on the system image template file and the position information specified in the system image difference file in the directory D, taking the corresponding system image difference file and the user disk image file in the directory D as the operating parameters of the local system image template file, and starting the virtual machine of the target user on the target host H.
In this embodiment, the detailed step of step S2) includes:
s2.1) calculating a hash value by adopting a preset hash algorithm according to the file name of the system image difference file in the directory D of the target user running virtual machineh(ii) a The hash valuehMatching with a preset hash value range, and if the matching is successful, skipping to execute the step S2.3), otherwise skipping to execute the step S2.2);
s2.2) calculating a hash value by adopting a preset hash algorithm according to the directory Dh(ii) a The hash valuehMatching with a preset hash value range;
s2.3) obtaining one or a group of hosts corresponding to the matched hash value interval in the hash value range, and determining a target host H according to the one or the group of hosts.
As an optional implementation manner, in this embodiment, when one or a group of hosts corresponding to the matched hash value interval in the hash value range is obtained, each host or the group of hosts has a static hash value interval.
As another alternative, consider that some virtual machines have specific requirements for hardware resources, such as the need for a GPU or other hardware accelerator, etc., in the above-mentioned embodimentsThe following problem can be solved by dynamically allocating hash value intervals according to hardware requirements: each host or group of hosts has a dynamic hash value interval, and the hash values are dividedhBefore matching with a preset hash value range, the method comprises the following steps of dynamically allocating a hash value interval for each host or a group of hosts: acquiring the hardware requirement of the user for running the virtual machine, acquiring the hosts meeting the hardware requirement in the distributed storage system, and averagely distributing the hash value range to the hosts meeting the hardware requirement, thereby determining the hash value interval of each host meeting the hardware requirement and enabling the hash value interval of the host not meeting the hardware requirement to be empty (namely, the hash value interval is not matched with any hash value)h)。
In this embodiment, one hash value interval may correspond to one host, or may correspond to a group of hosts as needed, for example, when the distributed storage used by the super-fusion architecture has multiple (2 to 3) copies in units of host data storage, the hosts with the same data storage are regarded as a group in the above method, the system image difference file of the user and the user disk image file calculate the hosts actually stored in units of a group, and each host in the group stores the same difference file and disk image file copy. In this embodiment, the detailed steps of determining the target host H according to one or a group of hosts include: if the hash value interval corresponds to a host, directly taking the host as a target host H; if the hash value section corresponds to a plurality of hosts, selecting one host from the plurality of hosts as a target host H, wherein the selection mode is any one of the following modes: mode 1, randomly selecting one host as a target host H; mode 2, selecting a host with the lowest CPU utilization rate as a target host H; mode 3, selecting a host with the lowest memory utilization rate as a target host H; and 4, weighting and summing the CPU utilization rate and the memory utilization rate, and selecting the host with the lowest weighted sum as the target host H.
In addition, in order to further prevent the system image template file from wasting space in the host, in this embodiment, the following steps are further included after the virtual machine is started: and checking the locally stored system image template file and the locally operated virtual machine, and if a certain locally stored system image template file is not used by any locally operated virtual machine, deleting the system image template file from the local.
In summary, in the embodiment 1, the system image template is stored locally in the host by identifying three image files required by the running of the virtual machine, and the system image difference file and the user disk image file are stored in the storage cluster and stored in the directory of the directory name in the specific mode; 2. the consistent hash algorithm of the embodiment is associated with a specific mode, when a file is stored in a distributed storage mode, a hash interval is distributed on a directory according to the consistent algorithm, and a data storage node to be distributed to the file is calculated by using a file name hash value, but when the file directory is matched with the specific mode, the file name hash value is not used, and the path name is used for calculating the hash interval, so that the data storage of a system image difference file and a user disk image file which are required by the same system image virtual machine of the same user and are positioned in the same host are ensured; 3, the hash value interval of the directory is obtained during the virtual machine scheduling of the embodiment, and the path hash value is calculated, so that the host node can be obtained; in the embodiment, the specification requirements of the virtual machine and the resources of the server host are associated with the storage position of the image file, and when the specification of the virtual machine has special requirements and some hosts cannot meet the special requirements, the storage component file of the virtual machine is not stored in the hosts; and 5, under the environment of multiple copies, the data storage contents of all copy nodes are consistent, and the virtual machine can be conveniently scheduled to any one of the copy nodes or the preferred node in the method of the embodiment. The virtual machine scheduling method under the super-fusion environment can improve the running and access storage performance of the virtual machine on the premise of keeping the advantages of the transverse expansion and low cost of a super-fusion infrastructure, improve the efficiency of accessing a system disk by the virtual machine by locally storing and storing a copy of a system image template of the virtual machine in each host, provide a scheduling basis for the virtual machine by optimizing a consistent hash algorithm in distributed storage and storing a difference image file of a system image and a user disk image file of the virtual machine in a data disk of the same host, enable the virtual machine to directly access storage equipment of the host where the virtual machine is located by running the virtual machine in the system image difference file and the user disk image file, improve the access performance, reduce network delay and bandwidth occupation and comprehensively evaluate other factors except for the storage requirement in the specification of the virtual machine, the storage components required by the virtual machine are not stored in the local storage and the data storage of the host which do not meet the specification requirement, and the storage space overhead and the probability that the virtual machine cannot be scheduled to the proper host can be reduced.
In addition, the invention also provides a virtual machine scheduling device in the super-fusion environment, which comprises a computer device, wherein the computer device is programmed or configured to execute the steps of the virtual machine scheduling method in the super-fusion environment, or a computer program which is programmed or configured to execute the virtual machine scheduling method in the super-fusion environment is stored in a memory of the computer device.
Furthermore, the present invention also provides a computer readable storage medium having stored thereon a computer program programmed or configured to execute the virtual machine scheduling method in the above-described hyper-convergence environment.
As will be appreciated by one skilled in the art, embodiments of the present application may be provided as a method, system, or computer program product. Accordingly, the present application may take the form of an entirely hardware embodiment, an entirely software embodiment or an embodiment combining software and hardware aspects. Furthermore, the present application may take the form of a computer program product embodied on one or more computer-usable storage media (including, but not limited to, disk storage, CD-ROM, optical storage, and the like) having computer-usable program code embodied therein. The present application is directed to methods, apparatus (systems), and computer program products according to embodiments of the application wherein instructions, which execute via a flowchart and/or a processor of the computer program product, create means for implementing functions specified in the flowchart and/or block diagram block or blocks. These computer program instructions may also be stored in a computer-readable memory that can direct a computer or other programmable data processing apparatus to function in a particular manner, such that the instructions stored in the computer-readable memory produce an article of manufacture including instruction means which implement the function specified in the flowchart flow or flows and/or block diagram block or blocks. These computer program instructions may also be loaded onto a computer or other programmable data processing apparatus to cause a series of operational steps to be performed on the computer or other programmable apparatus to produce a computer implemented process such that the instructions which execute on the computer or other programmable apparatus provide steps for implementing the functions specified in the flowchart flow or flows and/or block diagram block or blocks.
The above description is only a preferred embodiment of the present invention, and the protection scope of the present invention is not limited to the above embodiments, and all technical solutions belonging to the idea of the present invention belong to the protection scope of the present invention. It should be noted that modifications and embellishments within the scope of the invention may occur to those skilled in the art without departing from the principle of the invention, and are considered to be within the scope of the invention.
Claims (10)
1. A virtual machine scheduling method under a super-fusion environment is characterized in that the implementation step of preparing a virtual machine comprises the following steps:
1) copying the system mirror image template file to each host;
2) creating a corresponding directory D in a virtual storage pool of the distributed storage system according to the user information of each user and the information of the system image template file required to be used;
3) and respectively writing the system image difference file and the user disk image file required by each user for running the virtual machine into a directory D of the distributed storage system, so that the system image difference file and the user disk image file required by each user for running the virtual machine are stored in the same target host H of the distributed storage system.
2. The virtual machine scheduling method under the ultra-fusion environment according to claim 1, wherein the creating of the corresponding directory D in the virtual storage pool of the distributed storage system in step 2) specifically means creating a nested two-layer sub-directory structure of a user name and a system image template name at a specified position in the virtual storage pool of the distributed storage system as the directory D, and the nested two-layer sub-directory structure of the user name and the system image template file name specifically means taking the user name as a first-layer sub-directory and the system image template name as a second-layer sub-directory under the first-layer sub-directory, or taking the system image template name as a first-layer sub-directory and the user name as a second-layer sub-directory under the first-layer sub-directory.
3. The virtual machine scheduling method under the super-convergence environment according to claim 1, wherein the step of processing the file write request by the distributed storage system when writing the directory D of the distributed storage system in step 3) comprises: acquiring a write directory name corresponding to the file write request in the virtual storage pool; judging whether the written directory name meets a preset format requirement, wherein the preset format requirement refers to a mode of generating the directory D in the step 2), and if the written directory name meets the preset format requirement, calculating a hash value of the written directory name by adopting a preset hash algorithmh(ii) a Otherwise, calculating the hash value by adopting a preset hash algorithm according to the file name of the file writing requesth(ii) a The hash valuehAnd matching with a preset hash value range, acquiring one or a group of hosts corresponding to the matched hash value interval in the hash value range, determining a target host H according to the one or the group of hosts, and writing the file of the file writing request into the target host H.
4. The method for scheduling a virtual machine in a hyper-converged environment according to claim 1, wherein the step of starting the virtual machine after preparing the virtual machine further comprises the following steps:
s1), determining a directory D of the target user for running the virtual machine;
s2), determining a target host H of the target user for running the virtual machine;
s3) finding the local system image template file in the target host H based on the system image template file and the position information specified in the system image difference file in the directory D, taking the corresponding system image difference file and the user disk image file in the directory D as the operating parameters of the local system image template file, and starting the virtual machine of the target user on the target host H.
5. The virtual machine scheduling method in the hyper-converged environment according to claim 4, wherein the detailed step of the step S2) comprises:
s2.1) calculating a hash value by adopting a preset hash algorithm according to the file name of the system image difference file in the directory D of the target user running virtual machineh(ii) a The hash valuehMatching with a preset hash value range, and if the matching is successful, skipping to execute the step S2.3), otherwise skipping to execute the step S2.2);
s2.2) calculating a hash value by adopting a preset hash algorithm according to the directory Dh(ii) a The hash valuehMatching with a preset hash value range;
s2.3) obtaining one or a group of hosts corresponding to the matched hash value interval in the hash value range, and determining a target host H according to the one or the group of hosts.
6. The virtual machine scheduling method under the hyper-fusion environment according to claim 3 or 5, wherein when one or a group of hosts corresponding to the matched hash value interval in the hash value range is obtained, each host or a group of hosts has a static hash value interval; or each host or a group of hosts has a dynamic hash value interval, and the hash value is dividedhBefore matching with a preset hash value range, the method comprises the following steps of dynamically allocating a hash value interval for each host or a group of hosts: the method comprises the steps of obtaining the hardware requirement of a user for running the virtual machine, obtaining the hosts meeting the hardware requirement in the distributed storage system, and averagely distributing the hash value range to the hosts meeting the hardware requirement, so that the hash value interval of each host meeting the hardware requirement is determined, and the hash value interval of the host not meeting the hardware requirement is enabled to be empty.
7. The virtual machine scheduling method in the hyper-converged environment according to claim 3 or 5, wherein the detailed step of determining the target host H according to one or a group of hosts comprises: if the hash value interval corresponds to a host, directly taking the host as a target host H; if the hash value section corresponds to a plurality of hosts, selecting one host from the plurality of hosts as a target host H, wherein the selection mode is any one of the following modes: mode 1, randomly selecting one host as a target host H; mode 2, selecting a host with the lowest CPU utilization rate as a target host H; mode 3, selecting a host with the lowest memory utilization rate as a target host H; and 4, weighting and summing the CPU utilization rate and the memory utilization rate, and selecting the host with the lowest weighted sum as the target host H.
8. The method for scheduling the virtual machine under the hyper-converged environment according to claim 4, further comprising the following steps after the virtual machine is started: and checking the locally stored system image template file and the locally operated virtual machine, and if a certain locally stored system image template file is not used by any locally operated virtual machine, deleting the system image template file from the local.
9. A virtual machine scheduling apparatus in a hyper-converged environment, comprising a computer device, wherein the computer device is programmed or configured to execute the steps of the virtual machine scheduling method in the hyper-converged environment according to any one of claims 1 to 8, or a computer program programmed or configured to execute the virtual machine scheduling method in the hyper-converged environment according to any one of claims 1 to 8 is stored in a memory of the computer device.
10. A computer-readable storage medium having stored thereon a computer program programmed or configured to perform the method for scheduling virtual machines in a hyper-converged environment according to any one of claims 1 to 8.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010300695.0A CN111488198B (en) | 2020-04-16 | 2020-04-16 | Virtual machine scheduling method, system and medium in super fusion environment |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010300695.0A CN111488198B (en) | 2020-04-16 | 2020-04-16 | Virtual machine scheduling method, system and medium in super fusion environment |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111488198A true CN111488198A (en) | 2020-08-04 |
| CN111488198B CN111488198B (en) | 2023-05-23 |
Family
ID=71812909
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010300695.0A Active CN111488198B (en) | 2020-04-16 | 2020-04-16 | Virtual machine scheduling method, system and medium in super fusion environment |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111488198B (en) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112685131A (en) * | 2020-12-18 | 2021-04-20 | 湖南麒麟信安科技股份有限公司 | Method and device for opening local file based on application virtualization |
| CN113535330A (en) * | 2021-07-26 | 2021-10-22 | 北京计算机技术及应用研究所 | Super-fusion system data localization storage method based on node evaluation function |
| CN113986124A (en) * | 2021-10-25 | 2022-01-28 | 深信服科技股份有限公司 | User configuration file access method, device, equipment and medium |
| CN114003350A (en) * | 2022-01-04 | 2022-02-01 | 北京志凌海纳科技有限公司 | Data distribution method and system of super-fusion system |
| CN114661676A (en) * | 2022-04-19 | 2022-06-24 | 重庆紫光华山智安科技有限公司 | Distributed database management system, method, electronic device and readable storage medium |
| CN114840488A (en) * | 2022-07-04 | 2022-08-02 | 柏科数据技术(深圳)股份有限公司 | Distributed storage method, system and storage medium based on super-fusion structure |
Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102185928A (en) * | 2011-06-01 | 2011-09-14 | 广州杰赛科技股份有限公司 | Method for creating virtual machine in cloud computing system and cloud computing system |
| CN102819599A (en) * | 2012-08-15 | 2012-12-12 | 华数传媒网络有限公司 | Method for constructing hierarchical catalogue based on consistent hashing data distribution |
| CN102855284A (en) * | 2012-08-03 | 2013-01-02 | 北京联创信安科技有限公司 | Method and system for managing data of cluster storage system |
| CN103019802A (en) * | 2012-11-20 | 2013-04-03 | 中标软件有限公司 | Virtual machine management method and virtual machine management platform |
| CN103491144A (en) * | 2013-09-09 | 2014-01-01 | 中国科学院计算技术研究所 | Method for constructing wide area network virtual platform |
| US8676809B1 (en) * | 2008-06-30 | 2014-03-18 | Symantec Corporation | Method and apparatus for mapping virtual machine incremental images |
| US20160092261A1 (en) * | 2014-09-30 | 2016-03-31 | Sangfor Technologies Company Limited | Method and system for physical computer system virtualization |
| CN105677256A (en) * | 2016-01-08 | 2016-06-15 | 中电科华云信息技术有限公司 | Virtual disk system based on local caching and scheduling method |
| US9537745B1 (en) * | 2014-03-07 | 2017-01-03 | Google Inc. | Distributed virtual machine disk image deployment |
| CN108089913A (en) * | 2017-12-28 | 2018-05-29 | 创新科存储技术(深圳)有限公司 | A kind of virtual machine deployment method of super emerging system |
| US20180248949A1 (en) * | 2017-02-25 | 2018-08-30 | Vmware, Inc. | Distributed storage resource management in a hyper converged infrastructure |
| CN110221868A (en) * | 2019-05-31 | 2019-09-10 | 新华三云计算技术有限公司 | Dispositions method, device, electronic equipment and the storage medium of host system |
-
2020
- 2020-04-16 CN CN202010300695.0A patent/CN111488198B/en active Active
Patent Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8676809B1 (en) * | 2008-06-30 | 2014-03-18 | Symantec Corporation | Method and apparatus for mapping virtual machine incremental images |
| CN102185928A (en) * | 2011-06-01 | 2011-09-14 | 广州杰赛科技股份有限公司 | Method for creating virtual machine in cloud computing system and cloud computing system |
| CN102855284A (en) * | 2012-08-03 | 2013-01-02 | 北京联创信安科技有限公司 | Method and system for managing data of cluster storage system |
| CN102819599A (en) * | 2012-08-15 | 2012-12-12 | 华数传媒网络有限公司 | Method for constructing hierarchical catalogue based on consistent hashing data distribution |
| CN103019802A (en) * | 2012-11-20 | 2013-04-03 | 中标软件有限公司 | Virtual machine management method and virtual machine management platform |
| CN103491144A (en) * | 2013-09-09 | 2014-01-01 | 中国科学院计算技术研究所 | Method for constructing wide area network virtual platform |
| US9537745B1 (en) * | 2014-03-07 | 2017-01-03 | Google Inc. | Distributed virtual machine disk image deployment |
| US20160092261A1 (en) * | 2014-09-30 | 2016-03-31 | Sangfor Technologies Company Limited | Method and system for physical computer system virtualization |
| CN105677256A (en) * | 2016-01-08 | 2016-06-15 | 中电科华云信息技术有限公司 | Virtual disk system based on local caching and scheduling method |
| US20180248949A1 (en) * | 2017-02-25 | 2018-08-30 | Vmware, Inc. | Distributed storage resource management in a hyper converged infrastructure |
| CN108089913A (en) * | 2017-12-28 | 2018-05-29 | 创新科存储技术(深圳)有限公司 | A kind of virtual machine deployment method of super emerging system |
| CN110221868A (en) * | 2019-05-31 | 2019-09-10 | 新华三云计算技术有限公司 | Dispositions method, device, electronic equipment and the storage medium of host system |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112685131A (en) * | 2020-12-18 | 2021-04-20 | 湖南麒麟信安科技股份有限公司 | Method and device for opening local file based on application virtualization |
| CN113535330A (en) * | 2021-07-26 | 2021-10-22 | 北京计算机技术及应用研究所 | Super-fusion system data localization storage method based on node evaluation function |
| CN113535330B (en) * | 2021-07-26 | 2023-08-08 | 北京计算机技术及应用研究所 | Super fusion system data localization storage method based on node evaluation function |
| CN113986124A (en) * | 2021-10-25 | 2022-01-28 | 深信服科技股份有限公司 | User configuration file access method, device, equipment and medium |
| CN113986124B (en) * | 2021-10-25 | 2024-02-23 | 深信服科技股份有限公司 | User configuration file access method, device, equipment and medium |
| CN114003350A (en) * | 2022-01-04 | 2022-02-01 | 北京志凌海纳科技有限公司 | Data distribution method and system of super-fusion system |
| CN114661676A (en) * | 2022-04-19 | 2022-06-24 | 重庆紫光华山智安科技有限公司 | Distributed database management system, method, electronic device and readable storage medium |
| CN114840488A (en) * | 2022-07-04 | 2022-08-02 | 柏科数据技术(深圳)股份有限公司 | Distributed storage method, system and storage medium based on super-fusion structure |
Also Published As
| Publication number | Publication date |
|---|---|
| CN111488198B (en) | 2023-05-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10394847B2 (en) | Processing data in a distributed database across a plurality of clusters | |
| CN111488198B (en) | Virtual machine scheduling method, system and medium in super fusion environment | |
| JP7163430B2 (en) | Systems, methods, and non-transitory computer-readable media for providing resources | |
| JP6607901B2 (en) | Scalable distributed storage architecture | |
| US10129333B2 (en) | Optimization of computer system logical partition migrations in a multiple computer system environment | |
| LU102666B1 (en) | Small-file storage optimization system based on virtual file system in kubernetes user-mode application | |
| JP6542909B2 (en) | File operation method and apparatus | |
| JP5309043B2 (en) | Storage system and method for duplicate data deletion in storage system | |
| US9201896B2 (en) | Managing distributed storage quotas | |
| JP2017228323A (en) | Virtual disk blueprints for virtualized storage area network | |
| JP2018520402A (en) | Object-based storage cluster with multiple selectable data processing policies | |
| US20050234966A1 (en) | System and method for managing supply of digital content | |
| WO2019000535A1 (en) | Cloud platform construction method and cloud platform | |
| WO2022175080A1 (en) | Cache indexing using data addresses based on data fingerprints | |
| CN107329798B (en) | Data replication method and device and virtualization system | |
| CN106970830B (en) | Storage control method of distributed virtual machine and virtual machine | |
| CN111475279B (en) | System and method for intelligent data load balancing for backup | |
| CN107168646B (en) | Distributed data storage control method and server | |
| CN107168645B (en) | Storage control method and system of distributed system | |
| CN107153513B (en) | Storage control method of distributed system server and server | |
| CN107145305B (en) | Use method of distributed physical disk and virtual machine | |
| CN107066206B (en) | Storage control method and system for distributed physical disk | |
| CN113986117A (en) | File storage method, system, computing device and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| CB02 | Change of applicant information |
Address after: 4 / F, Qilin science and Technology Park, No.20, Qiyun Road, high tech Zone, Changsha City, Hunan Province, 410000 Applicant after: Hunan Qilin Xin'an Technology Co.,Ltd. Address before: 4 / F, Qilin science and Technology Park, No.20, Qiyun Road, high tech Zone, Changsha City, Hunan Province, 410000 Applicant before: HUNAN KYLIN XINAN TECHNOLOGY Co.,Ltd. |
|
| CB02 | Change of applicant information | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |