CN111479110B - Fast Affine Motion Estimation Method for H.266/VVC - Google Patents
Fast Affine Motion Estimation Method for H.266/VVC Download PDFInfo
- Publication number
- CN111479110B CN111479110B CN202010293694.8A CN202010293694A CN111479110B CN 111479110 B CN111479110 B CN 111479110B CN 202010293694 A CN202010293694 A CN 202010293694A CN 111479110 B CN111479110 B CN 111479110B
- Authority
- CN
- China
- Prior art keywords
- prediction
- motion estimation
- uni
- current
- affine motion
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images






Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/103—Selection of coding mode or of prediction mode
- H04N19/109—Selection of coding mode or of prediction mode among a plurality of temporal predictive coding modes
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/119—Adaptive subdivision aspects, e.g. subdivision of a picture into rectangular or non-rectangular coding blocks
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
- H04N19/537—Motion estimation other than block-based
- H04N19/543—Motion estimation other than block-based using regions
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
- H04N19/567—Motion estimation based on rate distortion criteria
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
Abstract
Description
技术领域technical field
本发明涉及图像处理技术领域,特别是指一种针对H.266/VVC的快速仿射运动估计方法。The present invention relates to the technical field of image processing, in particular to a fast affine motion estimation method for H.266/VVC.
背景技术Background technique
在如今的信息化时代,三维影像、超高清视频和虚拟现实等视频服务需求日益增长,高清晰度视频的编码和传输日益成为研究的热点问题。随着H.266/VVC标准的发展与完善,视频处理效率的提高也带动了视频产业的发展,为新一代视频编码技术的发展奠定了基础。高度密集的数据给带宽和存储带来巨大挑战,当前主流的视频编码标准开始无法满足目前新兴的应用,因此,新一代视频编码标准H.266/VVC应运而生,满足人们对视频的清晰度、流畅度以及实时度的要求。国际标准化组织ISO/IEC MPEG和ITU-T VCEG成立了联合视频小组(Joint Video Exploration Team,JVET),负责进行下一代视频编码标准H.266/通用视频编码(Versatile Video Coding,VVC)的开发。H.266/VVC的制定是针对4K及以上的高清视频,位深以10比特为主,这与H.265/HEVC的定位不同,这导致目前编码器的最大块尺寸变为128,编码中间处理的像素都为10比特,即使输入的8比特的序列,都会转为10比特处理。In today's information age, the demand for video services such as 3D images, ultra-high-definition video, and virtual reality is increasing, and the coding and transmission of high-definition video has increasingly become a hot research issue. With the development and improvement of the H.266/VVC standard, the improvement of video processing efficiency has also driven the development of the video industry, laying the foundation for the development of a new generation of video coding technology. Highly dense data brings huge challenges to bandwidth and storage. The current mainstream video coding standards cannot meet the current emerging applications. Therefore, a new generation of video coding standards H.266/VVC came into being to meet people's requirements for video clarity. , fluency and real-time requirements. The International Organization for Standardization ISO/IEC MPEG and ITU-T VCEG established the Joint Video Exploration Team (JVET), responsible for the development of the next-generation video coding standard H.266/Versatile Video Coding (VVC). The formulation of H.266/VVC is aimed at 4K and above high-definition video, and the bit depth is mainly 10 bits. This is different from the positioning of H.265/HEVC, which leads to the current maximum block size of the encoder becoming 128. The processed pixels are all 10-bit, even if the input 8-bit sequence will be converted to 10-bit for processing.
H.266/VVC使用混合编码技术框架,图像划分从单一、固定划分不断朝着多样、灵活的划分结构发展,能够更加高效的适配高分辨率图像的编解码处理。此外,H.266/VVC针对新一代视频数据对原有H.265/HEVC编码器的帧间-帧内预测,预测信号滤波,变换,量化/缩放,熵编码等新元素进行了扩展,并考虑新一代视频编码标准的特性,添加了新的模型预测模式。具体地,H.266/VVC沿用了高效视频编码H.265/HEVC帧间编码的运动估计、运动补偿和运动矢量预测技术,并在此基础上引入了一些新的技术。如对Merge模式进行扩展添加基于历史的预测运动矢量,添加了新的预测方法如仿射变换技术,自适应运动矢量精度方法,1/16采样精度的运动预测补偿等。众多先进编码工具的引入,大大提高新一代视频编码标准H.266/VVC的编码效率。但也因率失真成本计算而显著提高H.266/VVC帧间编码的运算复杂性,从而显著降低了新一代视频的编码速度。H.266/VVC uses a hybrid coding technology framework, and the image division is constantly developing from a single, fixed division to a diverse and flexible division structure, which can more efficiently adapt to the encoding and decoding processing of high-resolution images. In addition, H.266/VVC extends the original H.265/HEVC encoder's inter-intra prediction, prediction signal filtering, transformation, quantization/scaling, entropy coding and other new elements for the new generation of video data, and Considering the characteristics of next-generation video coding standards, a new model prediction mode has been added. Specifically, H.266/VVC follows the motion estimation, motion compensation, and motion vector prediction technologies of H.265/HEVC inter-frame coding in high-efficiency video coding, and introduces some new technologies on this basis. For example, the Merge mode is extended to add prediction motion vector based on history, and new prediction methods such as affine transformation technology, adaptive motion vector precision method, motion prediction compensation with 1/16 sampling precision, etc. are added. The introduction of many advanced coding tools has greatly improved the coding efficiency of the new generation video coding standard H.266/VVC. But it also significantly increases the computational complexity of H.266/VVC inter-frame coding due to rate-distortion cost calculation, thereby significantly reducing the coding speed of the new generation of video.
帧间预测的主要原理是为当前图像的每个像素块在之前已经编码的图像中找一个最佳匹配块,该过程称为运动估计ME,其中,用于预测的图像称为参考图像,参考块为参考图像中最佳匹配块,即参考像素块,参考块到当前像素块的位移称为运动矢量MV,当前像素块与参考块的差值称为预测残差。其中,运动估计ME算法是H.266/VVC视频编码过程中最为关键的算法,它占用了整个视频编码一半以上的计算量和绝大部分的运算时间,是决定视频压缩效率的主导因素。运动估计ME通过有效地去除连续图像间的时间冗余而成为视频压缩技术中的一个研究热点。为了提高压缩效率,最近的视频编解码器尝试估计不同形状和大小的运动。此外,通过添加多类型树,可以对非常薄的块执行运动估计ME(例如,宽度是高度的八分之一)。因此,在多类型树(multi-type trees,MTT)的各个模块中,运动估计ME是VVC中编码复杂度最高的工具。由于在MTT的精细划分块中递归地执行更高级的帧间预测方案,运动估计ME的计算复杂度甚至比HEVC中增加更多,因为未来视频编码(Future videocoding,FVC)中ME还尝试了仿射运动估计等新技术。仿射运动估计AME以旋转和缩放等非平移运动为特征,以牺牲较高的编码复杂度为代价,在率失真(Rate distortion,RD)性能上是有效的。在整个运动估计ME处理时间中,仿射运动估计AME的计算复杂度占很大一部分,因此降低其复杂度是非常重要的。因此,要降低VTM编码器的复杂度,需要加快AME模块。The main principle of inter-frame prediction is to find the best matching block in the previously encoded image for each pixel block of the current image. This process is called motion estimation ME, where the image used for prediction is called the reference image. The block is the best matching block in the reference image, that is, the reference pixel block, the displacement from the reference block to the current pixel block is called the motion vector MV, and the difference between the current pixel block and the reference block is called the prediction residual. Among them, the motion estimation ME algorithm is the most critical algorithm in the H.266/VVC video encoding process. It occupies more than half of the calculation amount and most of the calculation time of the entire video encoding, and is the dominant factor determining the video compression efficiency. Motion estimation ME has become a research hotspot in video compression technology by effectively removing temporal redundancy between consecutive images. To improve compression efficiency, recent video codecs try to estimate motion of different shapes and sizes. Furthermore, by adding multi-type trees, motion estimation ME can be performed on very thin blocks (e.g., width is one-eighth of height). Therefore, among the various modules of multi-type trees (MTT), motion estimation ME is the tool with the highest coding complexity in VVC. Due to the recursive execution of more advanced inter-frame prediction schemes in the finely divided blocks of MTT, the computational complexity of motion estimation ME is even more than that of HEVC, because ME in Future video coding (Future videocoding, FVC) also tries to imitate New technologies such as shot motion estimation. Affine Motion Estimation AME, characterized by non-translational motions such as rotation and scaling, is effective in rate distortion (RD) performance at the expense of higher encoding complexity. In the whole processing time of motion estimation ME, the computational complexity of affine motion estimation AME accounts for a large part, so it is very important to reduce its complexity. Therefore, to reduce the complexity of the VTM encoder, it is necessary to speed up the AME module.
事实上,针对H.265/HEVC帧间预测复杂度高的问题,许多文献已经进行了大量的研究。J.Xiong等人根据椎体运动散度提出了一种快速CU选择算法,该算法可以提前跳过H.265/HEVC中个别帧间CU。L.Shen等人提出了一种用于H.265/HEVC的自适应模式间决策算法,该算法联合利用了层间和时空相关性,基于统计分析提出了早期跳过模式决策,基于预测大小相关的模式决策和基于速率失真(RD)成本相关的模式决策三种方法。H.Lee等人提出了在计算2N×2N的Merge模式的RD代价后,利用其失真特性提出了一种早期的跳过模式决策方法。Q.Zhang等人针对纹理视频和深度图内容的高相关性,提出了提前判决编码单元深度级别和自适应模式判决方法,用以降低视频编码的计算复杂度。Q.Hu等人提出了一种基于Neyman-Pearson规则的快速帧间模式决策算法,该算法包括早期的SKIP模式决策和快速的CU大小决策来降低H.265/HEVC复杂度。Z.Pan等人提出了一种基于内容相似度的快速参考帧选择算法,以减少基于多个参考帧的帧间预测的计算复杂性。Z.Pan等人基于不同尺寸预测模式之间最佳的运动矢量选择相关性,提出一种快速运动估计ME方法,以降低H.265/HEVC编码器的编码复杂度。J.Zhang等人提出了一种基于贝叶斯方法和条件随机场的两阶段快速帧间CU决策方法,以降低HEVC编码器的编码复杂度。T.S.Kim等人提出了一种基于HEVC的快速运动估计算法,该算法支持高度灵活的块分区结构。通过搜索多个精确运动矢量预测周围的狭窄区域,该算法大大降低了其计算复杂性。C.Ma等人提出了一种基于神经网络的算术编码方法,对HEVC中的帧间预测信息进行编码。L.Shen等人提出了一种快速模式决策算法来减少编码器的计算复杂度。所提出方法利用了三个调整参数后的优化编码器,即SKIP/Merge模式的条件概率,运动特性和模式复杂度。D.Wang等人提出了快速的深度级别和帧间模式预测算法。该算法使用层间相关性,空间相关性及其相关程度来加快HEVC帧间编码。以上的快速帧间方法都能够保证编码性能的同时,有效降低H.265/HEVC的计算复杂度。但是,这些方法并非是为H.266/VVC编码器设计的,而H.266/VVC编码器采用了新帧间预测技术,如采用更先进的仿射运动补偿预测、扩展Merge模式、自适应运动矢量精度、三角划分模式等技术。基于此,H.266/VVC与基于H.265/HEVC帧间预测的空间和层间相关性必然存在着较大的差别,因而需要重新研究基于H.266/VVC的低复杂度帧间编码方法。In fact, a lot of research has been done in many literatures on the high complexity of H.265/HEVC inter-frame prediction. J. Xiong et al. proposed a fast CU selection algorithm based on the vertebral body motion divergence, which can skip individual inter-frame CUs in H.265/HEVC in advance. L.Shen et al. proposed an adaptive inter-mode decision algorithm for H.265/HEVC. This algorithm jointly utilizes inter-layer and spatio-temporal correlation, and proposes an early skip mode decision based on statistical analysis. Based on the prediction size Correlation mode decision and mode decision based on rate-distortion (RD) cost correlation are three methods. H.Lee et al. proposed an early skip mode decision-making method by using its distortion characteristics after calculating the RD cost of the 2N×2N Merge mode. Aiming at the high correlation between texture video and depth map content, Q. Zhang et al. proposed an early decision coding unit depth level and adaptive mode decision method to reduce the computational complexity of video coding. Q.Hu et al proposed a fast inter-frame mode decision algorithm based on the Neyman-Pearson rule, which includes early SKIP mode decision and fast CU size decision to reduce the complexity of H.265/HEVC. Z. Pan et al. proposed a fast reference frame selection algorithm based on content similarity to reduce the computational complexity of inter-frame prediction based on multiple reference frames. Z.Pan et al. proposed a fast motion estimation ME method based on the best motion vector selection correlation between different size prediction modes to reduce the coding complexity of the H.265/HEVC encoder. J. Zhang et al. proposed a two-stage fast inter-frame CU decision method based on Bayesian method and conditional random field to reduce the coding complexity of HEVC encoder. T.S.Kim et al. proposed a HEVC-based fast motion estimation algorithm that supports a highly flexible block partition structure. The algorithm greatly reduces its computational complexity by searching a narrow region around multiple accurate motion vector predictions. C. Ma et al. proposed a neural network-based arithmetic coding method to encode inter-frame prediction information in HEVC. L.Shen et al proposed a fast mode decision algorithm to reduce the computational complexity of the encoder. The proposed method utilizes three optimized encoders with tuned parameters, namely conditional probability of SKIP/Merge modes, motion characteristics and mode complexity. D.Wang et al. proposed a fast depth-level and inter-mode prediction algorithm. This algorithm uses inter-layer correlation, spatial correlation and their degree of correlation to speed up HEVC inter-coding. The above fast inter-frame methods can effectively reduce the computational complexity of H.265/HEVC while ensuring the coding performance. However, these methods are not designed for H.266/VVC encoders, and H.266/VVC encoders use new inter-frame prediction techniques, such as more advanced affine motion compensation prediction, extended Merge mode, adaptive Motion vector accuracy, triangulation mode and other technologies. Based on this, the spatial and inter-layer correlation between H.266/VVC and H.265/HEVC-based inter-frame prediction must be quite different, so it is necessary to re-study the low-complexity inter-frame coding based on H.266/VVC method.
针对H.266/VVC帧间编码复杂度高的问题,极少一部分文献对此进行了探索。S.Park等人提出了一种有效限制正常运动估计以及仿射运动估计的参考帧搜索范围的方法,它主要利用了H.266/VVC预测结构内的依赖性。该方法基于父节点的预测信息来最小化CU的参考帧搜索范围的最大值来降低编码复杂度。Z.Wang等人提出了一种基于置信区间的四叉树加二叉树(quadtree plus binary tree,QTBT)划分结构的提前终止方案,建立了基于运动发散场的率失真(rate distortion,RD)模型,来估计每个分区模式的率失真RD成本;并基于该模型早期终止了H.266/VVC的块划分,以消除不必要的分区迭代,使H.266/VVC编码性能和编码复杂度之间取得良好的平衡。Z.Wang等人提出了一种面向卷积神经网络(convolutional neural networks,CNN)的快速QTBT分区决策算法,用于H.266/VVC帧间编码,该算法以统计方式来分析QTBT,从而设计卷积神经网络CNN的体系结构,并利用时间相关性来控制错误预测风险,以提高卷积神经网络CNN方案的鲁棒性。D.García-Lucas等人提出了一种用于提取帧运动信息的预分析算法,该算法在运动估计模块中用于加速H.266/VVC编码器。S.Park等人提出了一种快速H.266/VVC帧间编码方法,以有效降低使用多类型树MTT时VTM中仿射运动估计的编码复杂度。该方法包括两个过程:提前终止方案和减少仿射运动估计的参考帧的数量。H.Gao等人提出了一种低复杂度的解码器侧运动矢量细化方案,通过在先前解码的参考图片中搜索匹配成本最小的块,从Merge模式中优化初始运动矢量MV,并被添加到的基于双边匹配的解码器侧运动矢量细化方法中。N.Tang等人针对H.266/VVC帧间编码提出了一种快速块划分算法,使用三帧差来判断当前块是否为静态对象;当前块为静止时,无需进一步拆分,从而提前终止分区以提高帧间编码速度。然而,在VVC中减轻仿射运动估计AME复杂度的工作很少。对于VTM,有很大的空间进一步降低多类型树MTT结构中的运动估计ME复杂度,特别是在仿射运动估计AME中。Aiming at the high complexity of H.266/VVC inter-frame coding, very few literatures have explored it. S.Park et al. proposed a method to effectively limit the search range of reference frames for normal motion estimation and affine motion estimation, which mainly utilizes the dependence within the H.266/VVC prediction structure. This method minimizes the maximum value of the reference frame search range of the CU based on the prediction information of the parent node to reduce the coding complexity. Z.Wang et al. proposed an early termination scheme based on a confidence interval-based quadtree plus binary tree (QTBT) partition structure, and established a rate distortion (RD) model based on the motion divergence field. To estimate the rate-distortion RD cost of each partition mode; and based on this model, the block division of H.266/VVC is terminated early to eliminate unnecessary partition iterations, making the relationship between H.266/VVC coding performance and coding complexity strike a good balance. Z.Wang et al. proposed a fast QTBT partition decision algorithm for convolutional neural networks (CNN) for H.266/VVC inter-frame coding. The algorithm analyzes QTBT in a statistical way to design Architecture of Convolutional Neural Network (CNN) and exploiting temporal correlation to control misprediction risk to improve the robustness of Convolutional Neural Network (CNN) schemes. D.García-Lucas et al proposed a pre-analysis algorithm for extracting frame motion information, which is used in the motion estimation module to accelerate the H.266/VVC encoder. S. Park et al proposed a fast H.266/VVC interframe coding method to effectively reduce the coding complexity of affine motion estimation in VTM when using multi-type tree MTT. The method consists of two processes: an early termination scheme and reducing the number of reference frames for affine motion estimation. H.Gao et al. proposed a low-complexity decoder-side motion vector refinement scheme, by searching the block with the smallest matching cost in the previously decoded reference picture, optimizing the initial motion vector MV from the Merge mode, and adding In the decoder-side motion vector refinement method based on bilateral matching. N.Tang et al. proposed a fast block division algorithm for H.266/VVC inter-frame coding, using three-frame difference to judge whether the current block is a static object; when the current block is static, no further splitting is required, thereby terminating early Partitioning for faster inter-coding. However, little work has been done to alleviate the AME complexity of affine motion estimation in VVC. For VTM, there is a lot of room to further reduce the ME complexity of motion estimation in multi-type tree MTT structure, especially in affine motion estimation AME.
发明内容Contents of the invention
针对上述背景技术中存在的不足,本发明提出了一种针对H.266/VVC的快速仿射运动估计方法,解决了在VTM中的仿射运动估计AME编码复杂度高的技术问题。Aiming at the deficiencies in the above-mentioned background technology, the present invention proposes a fast affine motion estimation method for H.266/VVC, which solves the technical problem of high AME encoding complexity of affine motion estimation in VTM.
本发明的技术方案是这样实现的:Technical scheme of the present invention is realized like this:
一种针对H.266/VVC的快速仿射运动估计方法,其步骤如下:A fast affine motion estimation method for H.266/VVC, the steps are as follows:
S1、利用标准差计算当前CU的纹理复杂度SD,并根据纹理复杂度SD将当前CU分为静态区域或非静态区域;S1. Calculate the texture complexity SD of the current CU by using the standard deviation, and divide the current CU into a static area or a non-static area according to the texture complexity SD;
S2、对于静态区域的CU,跳过仿射运动估计AME,直接利用运动估计CME对当前CU进行预测,并通过率失真优化的方法选择最佳的预测方向模式;S2. For the CU in the static area, skip the affine motion estimation AME, directly use the motion estimation CME to predict the current CU, and select the best prediction direction mode through the method of rate-distortion optimization;
S3、对于非静态区域的CU,利用训练好的随机森林分类器RFC模型对当前CU进行分类,输出最佳的预测方向模式。S3. For the CU in the non-static area, use the trained random forest classifier RFC model to classify the current CU, and output the best prediction direction mode.
所述利用标准差计算当前CU的纹理复杂度SD的方法为:The method for calculating the texture complexity SD of the current CU by using the standard deviation is:

其中,W代表CU的宽度,H代表CU的高度,P(a,b)表示在CU中位置为(a,b)的像素值。Among them, W represents the width of the CU, H represents the height of the CU, and P(a, b) represents the pixel value at the position (a, b) in the CU.
所述利用运动估计CME对当前CU进行预测,并通过率失真优化的方法选择最佳的预测方向模式的方法为:The method of using motion estimation CME to predict the current CU and selecting the best prediction direction mode through the method of rate-distortion optimization is as follows:
S21、当前CU首先经过单向预测Uni-L0,然后经过单向预测Uni-L1,最后经过双向预测Bi;S21. The current CU first undergoes unidirectional prediction Uni-L0, then unidirectional prediction Uni-L1, and finally bidirectional prediction Bi;
S22、利用率失真优化分别计算步骤S21中的当前CU分别经过单向预测Uni-L0、单向预测Uni-L1和双向预测Bi的率失真代价;S22. Utilization rate-distortion optimization calculates the rate-distortion cost of the current CU in step S21 respectively through unidirectional prediction Uni-L0, unidirectional prediction Uni-L1 and bidirectional prediction Bi;
S23、将率失真代价最小的预测模式作为最佳的预测方向模式。S23. Taking the prediction mode with the smallest rate-distortion cost as the best prediction direction mode.
所述单向预测Uni-L0、单向预测Uni-L1和双向预测Bi的率失真代价的计算方法均为:The calculation methods of the rate-distortion cost of the unidirectional prediction Uni-L0, unidirectional prediction Uni-L1 and bidirectional prediction Bi are:


其中,


所述步骤S3中的随机森林分类器RFC模型的训练方法为:The training method of the random forest classifier RFC model in the described step S3 is:
S31、从通用测试序列中选用不同分辨率下的Traffic、Kimono、BQSquare、RaceHorseC、和FourPeople视频序列,在VTM上分别编码前M帧,同时记录VTM中CU的形状、CU的纹理复杂度及CU的三种预测方向模式作为数据集,数据集包括样本集S和测试集T,其中,三种预测方向模式包括单向预测Uni-L0、单向预测Uni-L1和双向预测Bi;S31. Select Traffic, Kimono, BQSquare, RaceHorseC, and FourPeople video sequences at different resolutions from the general test sequence, respectively encode the first M frames on the VTM, and record the shape of the CU in the VTM, the texture complexity of the CU, and the CU The three prediction direction modes of are used as a data set, and the data set includes a sample set S and a test set T, where the three prediction direction modes include unidirectional prediction Uni-L0, unidirectional prediction Uni-L1 and bidirectional prediction Bi;
S32、利用Bootstrap法重采样样本集S,生成K个训练样本集

S33、从根节点开始训练,在决策树的每个中间节点上随机选择m个特征属性,计算每个特征属性的Gini指标系数,从中选择Gini指标系数最小的特征属性作为当前节点的最优分裂属性,以最小Gini指标系数为分裂阈值,将m个特征属性划分为左子树、右子树;S33, start training from the root node, randomly select m feature attributes on each intermediate node of the decision tree, calculate the Gini index coefficient of each feature attribute, and select the feature attribute with the smallest Gini index coefficient as the optimal split of the current node attribute, with the minimum Gini index coefficient as the splitting threshold, divide m feature attributes into left subtree and right subtree;
S34、重复步骤S33,训练K’次,直到K’棵决策树训练完成,每棵决策树都完整生长而不进行剪枝;S34, repeating step S33, training K' times, until the K' decision tree training is completed, and each decision tree is fully grown without pruning;
S35、生成的多棵决策树即为随机森林分类器RFC模型,并利用随机森林分类器RFC模型对测试集T进行判别分类,分类结果采用投票方式,将K’棵决策树输出最多的类别作为测试集T的所属类别,得到当前CU的最佳的预测方向模式。S35. The multiple decision trees generated are the random forest classifier RFC model, and the random forest classifier RFC model is used to discriminate and classify the test set T, and the classification result adopts the voting method, and the category with the most output of K' decision trees is used as The category of the test set T to obtain the best prediction direction mode of the current CU.
所述步骤S31中获得数据集的方法为:The method for obtaining the data set in the step S31 is:
S31.1、利用运动估计CME对视频序列进行预测;S31.1. Using motion estimation CME to predict the video sequence;
S31.2、利用4参数仿射运动模型对步骤S31.1中预测后的视频序列进行仿射预测,其中,仿射预测包括单向预测Uni-L0、单向预测Uni-L1和双向预测Bi;S31.2. Use the 4-parameter affine motion model to perform affine prediction on the video sequence predicted in step S31.1, wherein the affine prediction includes unidirectional prediction Uni-L0, unidirectional prediction Uni-L1 and bidirectional prediction Bi ;
S31.3、利用6参数仿射运动模型对步骤S31.2中仿射预测后的视频序列进行放射预测;S31.3, using the 6-parameter affine motion model to perform radial prediction on the video sequence after the affine prediction in step S31.2;
S31.4、分别计算步骤S31.2和S31.3进行仿射预测后的率失真代价,将最小的率失真代价对应的预测模式为视频序列的预测方向模式。S31.4. Calculate the rate-distortion cost after the affine prediction in steps S31.2 and S31.3 respectively, and set the prediction mode corresponding to the smallest rate-distortion cost as the prediction direction mode of the video sequence.
所述特征属性包括二维哈尔小波变换水平系数、二维哈尔小波变换垂直系数、二维哈尔小波变换角度系数、角二阶矩、对比度、熵、逆差矩、最小差值和和梯度。The feature attributes include two-dimensional Haar wavelet transform horizontal coefficients, two-dimensional Haar wavelet transform vertical coefficients, two-dimensional Haar wavelet transform angle coefficients, second-order moments of angles, contrast, entropy, inverse moments, minimum difference sums and gradients .
所述4参数仿射运动模型,CU中样本位置(x,y)的运动矢量为:In the 4-parameter affine motion model, the motion vector of the sample position (x, y) in the CU is:

其中,(mv0x,mv0y)是左上角控制点的运动矢量,(mv1x,mv1y)是右上角控制点的运动矢量,W表示CU的宽;Among them, (mv 0x , mv 0y ) is the motion vector of the control point in the upper left corner, (mv 1x , mv 1y ) is the motion vector of the control point in the upper right corner, and W represents the width of the CU;
所述6参数仿射运动模型,CU中样本位置(x,y)的运动矢量为:In the 6-parameter affine motion model, the motion vector of the sample position (x, y) in the CU is:

其中,(mv2x,mv2y)是左下角的运动矢量控制点,H表示CU的高。Wherein, (mv 2x , mv 2y ) is the motion vector control point in the lower left corner, and H represents the height of the CU.
本技术方案能产生的有益效果:本发明首先利用标准差SD将CU分为静态区域和非静态区域,如果CU属于静态区域,选择SKIP模式进行帧间预测的概率较高,并且倾向于选择SKIP模式进行帧间预测的静态区域不需要进行仿射预测,因此,在静态区域可以提前终止仿射运动估计AME模块,并且当前CU的最佳方向模式为运动估计CME的最佳方向模式;如果CU属于非静态区域,则根据随机森林分类模型判断CU的帧间预测模式,最终提前得到最优的预测方向模式;因此,本发明降低了计算复杂度并节省了编码时间,从而实现H.266/VVC的快速编码。Beneficial effects that can be produced by this technical solution: the present invention first uses the standard deviation SD to divide the CU into a static area and a non-static area. If the CU belongs to the static area, the probability of selecting SKIP mode for inter-frame prediction is relatively high, and SKIP tends to be selected Affine prediction is not required for the static area where inter-frame prediction is performed. Therefore, the affine motion estimation AME module can be terminated early in the static area, and the best direction mode of the current CU is the best direction mode of the motion estimation CME; if the CU If it belongs to a non-static area, the inter-frame prediction mode of the CU is judged according to the random forest classification model, and finally the optimal prediction direction mode is obtained in advance; therefore, the present invention reduces the computational complexity and saves encoding time, thereby realizing H.266/ Fast encoding for VVC.
附图说明Description of drawings
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。In order to more clearly illustrate the technical solutions in the embodiments of the present invention or the prior art, the following will briefly introduce the drawings that need to be used in the description of the embodiments or the prior art. Obviously, the accompanying drawings in the following description are only These are some embodiments of the present invention. Those skilled in the art can also obtain other drawings based on these drawings without creative work.
图1为本发明的流程图;Fig. 1 is a flowchart of the present invention;
图2为本发明的预测方向模式复杂度分布图;Fig. 2 is the distribution diagram of the prediction direction pattern complexity of the present invention;
图3为本发明的4-参数仿射模型;Fig. 3 is 4-parameter affine model of the present invention;
图4为本发明的6-参数仿射模型;Fig. 4 is 6-parameter affine model of the present invention;
图5为本发明的运动估计ME的整体过程图;FIG. 5 is an overall process diagram of the motion estimation ME of the present invention;
图6为本发明方法与FAME方法的整体运行时间对比结果图。Fig. 6 is a comparison result graph of the overall running time between the method of the present invention and the FAME method.
具体实施方式detailed description
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有付出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。The following will clearly and completely describe the technical solutions in the embodiments of the present invention with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only some, not all, embodiments of the present invention. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
如图1所示,本发明实施例提供了一种针对H.266/VVC的快速仿射运动估计方法,具体步骤如下:As shown in Figure 1, the embodiment of the present invention provides a fast affine motion estimation method for H.266/VVC, and the specific steps are as follows:
S1、在图像编码过程中,单一区域的图像内容往往采用较大的CU进行编码。相反,具有丰富细节的区域通常使用较小的CU进行编码。由此可知,利用编码块的纹理复杂度程度决定CU是否使用SKIP模式进行帧间预测。在图像编码过程中,图像内容单一的区域更趋向于使用SKIP模式进行帧间预测进行编码,而细节丰富的区域很小几率使用SKIP模式进行帧间预测。一个CU的方差代表当前块的两个像素间能量的分散程度,因此一个块的纹理复杂度可以粗略的用它标准差SD来衡量,因此,利用标准差计算当前CU的纹理复杂度SD,并根据纹理复杂度SD将当前CU分为静态区域或非静态区域;标准差的公式为:S1. During the image coding process, the image content of a single region is often coded using a relatively large CU. In contrast, regions with rich details are usually encoded with smaller CUs. It can be seen that whether the CU uses the SKIP mode for inter-frame prediction is determined by the degree of texture complexity of the coding block. In the image coding process, areas with single image content tend to use SKIP mode for inter-frame prediction for encoding, while areas with rich details are less likely to use SKIP mode for inter-frame prediction. The variance of a CU represents the degree of energy dispersion between two pixels of the current block, so the texture complexity of a block can be roughly measured by its standard deviation SD. Therefore, the standard deviation is used to calculate the texture complexity SD of the current CU, and According to the texture complexity SD, the current CU is divided into a static area or a non-static area; the formula for the standard deviation is:

其中,W代表CU的宽度,H代表CU的高度,P(a,b)表示在CU中位置为(a,b)的像素值。由于相邻块的纹理复杂度与CU具有相关性,通过相邻块的纹理复杂度来导出分类的阈值。根据大量的实验数据,将CU的相邻块的标准差SD中的最小值作为Thstatic是合理的。通过阈值可以将CU进行分类。如果当前标准差SD小于阈值Thstatic,则表明当前CU是静态区域。相反,如果标准差SD的值大于Thstatic,则当前的CU属于非静态区域。Among them, W represents the width of the CU, H represents the height of the CU, and P(a, b) represents the pixel value at the position (a, b) in the CU. Since the texture complexity of adjacent blocks is correlated with the CU, the threshold for classification is derived from the texture complexity of adjacent blocks. According to a large amount of experimental data, it is reasonable to take the minimum value of the standard deviation SD of adjacent blocks of the CU as Th static . CUs can be classified by thresholds. If the current standard deviation SD is smaller than the threshold Th static , it indicates that the current CU is a static area. On the contrary, if the value of the standard deviation SD is greater than Th static , the current CU belongs to the non-static area.
S2、现有的视频编码标准(如H.265/HEVC)对于运动估计CME,使用覆盖平移运动的运动矢量MV,然而,仿射运动估计AME不仅可以预测平移运动,还可以预测线性变换运动,如缩放和旋转。如果相机缩放或旋转以捕获视频,仿射运动估计AME比运动估计CME更准确地预测运动。在H.266/VVC中,仿射运动估计AME和运动估计CME一样,从单向预测Uni-prediction L0开始,然后是单向预测Uni-prediction L1,最后是双向预测Bi-prediction。在计算了三种预测方向模式后,利用率失真优化(rate distortionoptimization,RDO)的方法选择最佳的预测方向模式。图2示出了仿射运动估计AME帧间预测模式的复杂度的分布,并且单向预测Uni-prediction L0比单向预测Uni-prediction L1需要更多的预测时间。如果单向预测Uni-prediction L0和单向预测Uni-prediction L1的参考帧不同,单向预测的编码复杂度是一样。否则,如果单向预测Uni-prediction L0和单向预测Uni-prediction L1之间的参考帧相同,则从单向预测Uni-prediction L0的运动矢量复制单向预测Uni-prediction L1的运动矢量MV,以避免冗余仿射运动估计AME处理。因此,单向预测Uni-prediction L0预测比单向预测Uni-prediction L1消耗更多的预测时间。虽然在单向预测中需要最大的编码复杂度,但双向预测模式作为最佳帧间预测模式的概率较高。在仿射运动估计AME模块中,计算率失真RD代价是导致复杂度大的重要原因。S2. Existing video coding standards (such as H.265/HEVC) use motion vector MV covering translational motion for motion estimation CME, however, affine motion estimation AME can predict not only translational motion, but also linear transformation motion, such as scaling and rotation. If the camera is scaled or rotated to capture the video, affine motion estimation (AME) predicts motion more accurately than motion estimation (CME). In H.266/VVC, the affine motion estimation AME is the same as the motion estimation CME, starting from the unidirectional prediction Uni-prediction L0, then the unidirectional prediction Uni-prediction L1, and finally the bidirectional prediction Bi-prediction. After calculating the three predicted direction modes, a rate distortion optimization (RDO) method is used to select the best predicted direction mode. Fig. 2 shows the distribution of the complexity of AME inter-prediction modes, and Uni-prediction L0 requires more prediction time than Uni-prediction L1. If the reference frames of Uni-prediction L0 and Uni-prediction L1 are different, the coding complexity of Uni-prediction is the same. Otherwise, if the reference frame between Uni-prediction L0 and Uni-prediction L1 is the same, the motion vector MV of Uni-prediction L1 is copied from the motion vector of Uni-prediction L0, To avoid redundant affine motion estimation AME processing. Therefore, Uni-prediction L0 prediction consumes more prediction time than Uni-prediction L1. Although the greatest coding complexity is required in unidirectional prediction, the bidirectional prediction mode has a higher probability as the best inter prediction mode. In the AME module of Affine Motion Estimation, calculating the rate-distortion RD cost is an important reason for the high complexity.
为了获得最佳运动矢量MV和最佳参考帧,编码器搜索多个可用的参考帧,使用拉格朗日乘子方法计算率失真RD代价J(·)并比较预测结果的代价,拉格朗日乘子方法计算率失真RD代价函数J(·)表示为:
对于静态区域的CU,跳过仿射运动估计AME,直接利用运动估计CME对当前CU进行预测,并通过率失真优化的方法选择最佳的预测方向模式;具体方法为:For the CU in the static area, skip the affine motion estimation AME, directly use the motion estimation CME to predict the current CU, and select the best prediction direction mode through the method of rate-distortion optimization; the specific method is:
S21、当前CU首先经过单向预测Uni-L0,然后经过单向预测Uni-L1,最后经过双向预测Bi。S21. The current CU first undergoes unidirectional prediction Uni-L0, then undergoes unidirectional prediction Uni-L1, and finally undergoes bidirectional prediction Bi.
S22、利用率失真优化分别计算经过单向预测Uni-L0、单向预测Uni-L1和双向预测Bi的率失真代价;S22. Utilization rate-distortion optimization calculates the rate-distortion cost after unidirectional prediction Uni-L0, unidirectional prediction Uni-L1 and bidirectional prediction Bi respectively;
所述单向预测Uni-L0、单向预测Uni-L1和双向预测Bi的率失真代价分别为:The rate-distortion costs of the unidirectional prediction Uni-L0, unidirectional prediction Uni-L1, and bidirectional prediction Bi are respectively:
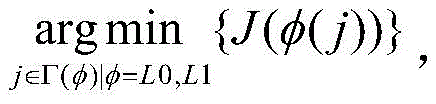

其中,

S23、将率失真代价最小的预测模式作为最佳的预测方向模式。S23. Taking the prediction mode with the smallest rate-distortion cost as the best prediction direction mode.
S3、对于非静态区域的CU,则不满足跳过仿射运动估计AME进程的条件,利用训练好的随机森林分类器RFC模型对当前CU进行分类,输出最佳的预测方向模式,来进一步降低计算复杂性。随机森林算法基于Bootstrap重采样生成K个自助样本集,每个样本集的数据生长为一棵决策树;在每棵树的节点处,基于随机子空间方法RSM,从M’个特征向量中随机抽取m(m<<M’)个特征。按照一定的节点分裂算法,从m个特征属性中选择最优属性进行分支生长;最终将K’棵决策树组合起来进行众数投票。随机森林分类器生成后,对随机森林分类器模型进行测试,森林中的每棵树都会独立判定分类结果,最终决策取相同判定最多的分类类别,用公式表示如下,S3. For the CU in the non-static area, the condition of skipping the AME process of affine motion estimation is not met, and the current CU is classified by using the trained random forest classifier RFC model, and the best prediction direction mode is output to further reduce Computational complexity. The random forest algorithm generates K self-service sample sets based on Bootstrap resampling, and the data of each sample set grows into a decision tree; at the node of each tree, based on the random subspace method RSM, randomly select from M' feature vectors Extract m(m<<M') features. According to a certain node splitting algorithm, the optimal attribute is selected from m feature attributes for branch growth; finally, K'decision trees are combined for majority voting. After the random forest classifier is generated, the random forest classifier model is tested. Each tree in the forest will independently judge the classification results, and the final decision will take the classification category with the most identical judgments. The formula is expressed as follows,

其中,H(t)表示组合分类模型,hi(t)是单个分类树模型,t表示决策树的特征属性,Y表示输出变量,I(·)表示集合性示性函数(即当集合内有出现某个分类结果时,函数值为1,否则为0)。Among them, H(t) represents the combined classification model, h i (t) is a single classification tree model, t represents the characteristic attribute of the decision tree, Y represents the output variable, and I( ) represents the set indicative function (that is, when the set When there is a classification result, the function value is 1, otherwise it is 0).
在遍历CU时,记录CU的特征及CU的预测方向模式,不干扰正常编码过程。通过Bagging集成方法重采样产生多个训练集,从原始训练样本集中随机等量抽取样本,重复有放回抽取生成K个新的训练样本集,最终得到K个新的训练样本集。样本提取后,进入随进森林分类器模型的训练模块。表1显示了随机森林分类器RFC模型建立的相关训练参数设置。When traversing a CU, record the characteristics of the CU and the prediction direction mode of the CU, without interfering with the normal encoding process. Multiple training sets are generated by resampling through the Bagging integration method, random and equal samples are drawn from the original training sample set, and K new training sample sets are generated by repeated extraction with replacement, and finally K new training sample sets are obtained. After the sample is extracted, it enters the training module of the random forest classifier model. Table 1 shows the relevant training parameter settings established by the random forest classifier RFC model.
表1训练参数配置Table 1 Training parameter configuration

根据表1的参数,随机森林分类器RFC模型的训练方法为:According to the parameters in Table 1, the training method of the random forest classifier RFC model is:
S31、训练分类器的关键之一是样本集的选取,从通用测试序列中选能够涵盖丰富的纹理复杂度的用不同分辨率下的Traffic、Kimono、BQSquare、RaceHorseC和FourPeople视频序列,在VTM上分别编码前M=50帧,同时记录VTM中CU的形状、CU的纹理复杂度及CU的三种预测方向模式作为数据集,数据集包括样本集S=20和测试集T=30,其中,三种预测方向模式包括单向预测Uni-L0、单向预测Uni-L1和双向预测Bi;S31. One of the keys to training a classifier is the selection of sample sets. Select Traffic, Kimono, BQSquare, RaceHorseC, and FourPeople video sequences with different resolutions that can cover rich texture complexity from the general test sequence, and respectively on the VTM M=50 frames before coding, record the shape of the CU in the VTM, the texture complexity of the CU and the three prediction direction modes of the CU as a data set, the data set includes a sample set S=20 and a test set T=30, among which, three The prediction direction modes include unidirectional prediction Uni-L0, unidirectional prediction Uni-L1 and bidirectional prediction Bi;
在VTM中,仿射运动的块也通过三种方式进行预测:单向预测Uni-L0、单向预测Uni-L1和双向预测Bi。同时,仿射预测还包括4-参数和6-参数的仿射模型。仿射运动估计AME模块的单向预测或双向预测都需要相关的参考帧,从而增加了VTM的编码复杂度。当仅计算每个仿射运动估计AME模块所需的参考帧数时,仿射运动估计AME进程需要两倍的运动估计CME进程的参考帧数。整个运动估计ME过程如图5所示。由图5可知,步骤S31中获得数据集的方法为:In VTM, blocks with affine motion are also predicted in three ways: unidirectional prediction Uni-L0, unidirectional prediction Uni-L1, and bidirectional prediction Bi. Meanwhile, affine prediction also includes 4-parameter and 6-parameter affine models. Affine Motion Estimation The unidirectional prediction or bidirectional prediction of the AME module requires related reference frames, which increases the coding complexity of VTM. The affine motion estimation AME process requires twice as many reference frames as the motion estimation CME process when only the number of reference frames required by each affine motion estimation AME module is calculated. The whole ME process of motion estimation is shown in Fig. 5. As can be seen from Figure 5, the method for obtaining the data set in step S31 is:
S31.1、利用运动估计CME对视频序列进行预测,预测方法同步骤S21;S31.1. Using motion estimation CME to predict the video sequence, the prediction method is the same as step S21;
S31.2、利用4参数仿射运动模型对步骤S31.1中预测后的视频序列进行仿射预测,其中,仿射预测包括单向预测Uni-L0、单向预测Uni-L1和双向预测Bi;S31.2. Use the 4-parameter affine motion model to perform affine prediction on the video sequence predicted in step S31.1, wherein the affine prediction includes unidirectional prediction Uni-L0, unidirectional prediction Uni-L1 and bidirectional prediction Bi ;
如图3所示,4参数仿射运动模型的CU中样本位置(x,y)的运动矢量为:As shown in Figure 3, the motion vector of the sample position (x, y) in the CU of the 4-parameter affine motion model is:

其中,(mv0x,mv0y)是左上角控制点的运动矢量,(mv1x,mv1y)是右上角控制点的运动矢量,W表示CU的宽;Among them, (mv 0x , mv 0y ) is the motion vector of the control point in the upper left corner, (mv 1x , mv 1y ) is the motion vector of the control point in the upper right corner, and W represents the width of the CU;
S31.3、利用6参数仿射运动模型对步骤S31.2中仿射预测后的视频序列进行放射预测;S31.3, using the 6-parameter affine motion model to perform radial prediction on the video sequence after the affine prediction in step S31.2;
如图4所示,6参数仿射运动模型的块中样本位置(x,y)的运动矢量为:As shown in Fig. 4, the motion vector of the sample position (x, y) in the block of the 6-parameter affine motion model is:

其中,(mv2x,mv2y)是左下角的运动矢量控制点,H表示CU的高。Wherein, (mv 2x , mv 2y ) is the motion vector control point in the lower left corner, and H represents the height of the CU.
S31.4、分别计算步骤S31.2和S31.3进行仿射预测后的率失真代价,将最小的率失真代价对应的预测模式为视频序列的预测方向模式。S31.4. Calculate the rate-distortion cost after the affine prediction in steps S31.2 and S31.3 respectively, and set the prediction mode corresponding to the smallest rate-distortion cost as the prediction direction mode of the video sequence.
S32、利用Bootstrap法重采样样本集S,生成K个训练样本集

S33、从根节点开始训练,在决策树的每个中间节点上随机选择m个特征属性,计算每个特征属性的Gini指标系数,从中选择Gini指标系数最小的特征属性作为当前节点的最优分裂属性,以最小Gini指标系数为分裂阈值,将m个特征属性划分为左子树、右子树;S33, start training from the root node, randomly select m feature attributes on each intermediate node of the decision tree, calculate the Gini index coefficient of each feature attribute, and select the feature attribute with the smallest Gini index coefficient as the optimal split of the current node attribute, with the minimum Gini index coefficient as the splitting threshold, divide m feature attributes into left subtree and right subtree;
机器学习的有效性与训练数据集的多样性和相关性高度相关。尽管随机森林分类器RFC可以处理超高维特征数据,但选取出真正相关的特征向量可以更好地推广分类模型。由于CU的预测方向模式和图像的纹理、纹理方向以及运动状态有关,因此将这些作为分类依据,即作为随机森林分类器模型的特征向量。本发明选取的特征属性包括二维哈尔小波变换水平系数(2D Haar wavelet transform horizontal coefficient,HL)、二维哈尔小波变换垂直系数(2D Haar wavelet transform vertical coefficient,LH)、二维哈尔小波变换角度系数(2D Haar wavelet transform angle coefficient,HH)、角二阶矩(angular second moment,ASM)、对比度(contrast,CON)、熵(entropy,ENT)、逆差矩(inverse difference moment,IDM)、最小差值和(Sum of Absolute Difference,SAD)和梯度(gradient)作为随机森林分类器模型的特征属性,特征属性的计算如下:The effectiveness of machine learning is highly related to the diversity and relevance of the training dataset. Although the random forest classifier RFC can handle ultra-high-dimensional feature data, selecting truly relevant feature vectors can better generalize the classification model. Since the prediction direction mode of the CU is related to the texture, texture direction and motion state of the image, these are used as the classification basis, that is, as the feature vector of the random forest classifier model. The feature attributes selected by the present invention include two-dimensional Haar wavelet transform horizontal coefficient (2D Haar wavelet transform horizontal coefficient, HL), two-dimensional Haar wavelet transform vertical coefficient (2D Haar wavelet transform vertical coefficient, LH), two-dimensional Haar wavelet transform Transform angle coefficient (2D Haar wavelet transform angle coefficient, HH), angular second moment (angular second moment, ASM), contrast (contrast, CON), entropy (entropy, ENT), inverse difference moment (inverse difference moment, IDM), The minimum difference and (Sum of Absolute Difference, SAD) and gradient (gradient) are used as the characteristic attributes of the random forest classifier model, and the calculation of the characteristic attributes is as follows:
图像的二维哈尔小波变换水平系数HL表示图像水平方向的纹理,值越大说明水平方向的纹理越丰富,值越小表示水平方向的纹理越平坦;图像的二维哈尔小波变换垂直系数LH表示图像垂直方向的纹理,值越大说明垂直方向的纹理越丰富,值越小表示垂直方向的纹理越平坦;图像的二维哈尔小波变换角度系数HH表示图像垂直方向的纹理,值越大说明45°方向的纹理越丰富,值越小表示45°方向的纹理越平坦,二维哈尔小波变换水平系数HL、二维哈尔小波变换垂直系数LH和二维哈尔小波变换角度系数HH分别表示为:The horizontal coefficient HL of the two-dimensional Haar wavelet transform of the image represents the texture in the horizontal direction of the image. The larger the value, the richer the texture in the horizontal direction, and the smaller the value, the flatter the texture in the horizontal direction; the vertical coefficient of the two-dimensional Haar wavelet transform of the image LH represents the texture in the vertical direction of the image, the larger the value, the richer the texture in the vertical direction, the smaller the value, the flatter the texture in the vertical direction; the two-dimensional Haar wavelet transform angle coefficient HH of the image represents the texture in the vertical direction of the image, the smaller the value A larger value indicates that the texture in the 45° direction is richer, and a smaller value indicates that the texture in the 45° direction is flatter. The two-dimensional Haar wavelet transform horizontal coefficient HL, the two-dimensional Haar wavelet transform vertical coefficient LH and the two-dimensional Haar wavelet transform angle coefficient HH are expressed as:



其中,W代表CU的宽,H代表CU的高,P(a,b)代表在位置为(a,b)的像素值。Among them, W represents the width of the CU, H represents the height of the CU, and P(a, b) represents the pixel value at the position (a, b).
角二阶矩ASM反应灰度分布均匀程度和纹理粗细度,值越大说明图像纹理分布越均匀;对比度CON反应图像的纹理深度,值越大说明纹理深度越大;熵ENT表示图像的信息量,值越大说明图像的信息量越大;逆差矩IDM反应图像局部纹理变化的大小,图像的纹理的不同区域间较均匀,变化缓慢,角二阶矩ASM、对比度CON、熵ENT和逆差矩IDE分别表示为:Angular second moment ASM reflects the uniformity of gray distribution and texture thickness. The larger the value, the more uniform the texture distribution of the image; the contrast CON reflects the texture depth of the image. The larger the value, the greater the texture depth; the entropy ENT represents the amount of information in the image , the larger the value, the greater the information content of the image; the inverse difference moment IDM reflects the size of the local texture change of the image, the texture of the image is relatively uniform between different regions, and the change is slow, the second-order moment of angle ASM, contrast CON, entropy ENT and inverse difference moment IDEs are represented as:




在基于块匹配的运动估计算法中,最佳匹配块的判断准则有很多,我们使用最小差值和SAD,SAD越小,表明参考块越接近当前预测块,最小差值和SAD表示为:In the motion estimation algorithm based on block matching, there are many criteria for judging the best matching block. We use the minimum difference and SAD. The smaller the SAD, the closer the reference block is to the current prediction block. The minimum difference and SAD are expressed as:

其中,Pk(a,b)代表当前像素的值,(a,b)表示当前像素的坐标,Pk-1(a+i',b+j')是参考像素值,(a+i',b+j')表示参考像素的坐标。Among them, P k (a, b) represents the value of the current pixel, (a, b) represents the coordinates of the current pixel, P k-1 (a+i', b+j') is the reference pixel value, (a+i ',b+j') represent the coordinates of the reference pixel.
梯度表示CU的纹理方向,使用亮度样本的水平和垂直方向的梯度作为特征属性。水平和垂直方向的梯度表示为:The gradient represents the texture direction of the CU, using the horizontal and vertical gradients of luma samples as feature attributes. The gradients in the horizontal and vertical directions are expressed as:
Gx(a,b)=P(a+1,b)-P(a,b)+P(a+1,b+1)-P(a,b+1),G x (a,b)=P(a+1,b)-P(a,b)+P(a+1,b+1)-P(a,b+1),
Gy(a,b)=P(a,b)-P(a,b+1)+P(a+1,b)-P(a+1,b+1),G y (a,b)=P(a,b)-P(a,b+1)+P(a+1,b)-P(a+1,b+1),
其中Gx(a,b)和Gy(a,b)分别表示当前像素在水平和垂直方向上的梯度分量。(a,b)代表像素的坐标,P(a,b)代表像素值。Among them, G x (a, b) and G y (a, b) represent the gradient components of the current pixel in the horizontal and vertical directions, respectively. (a,b) represents the coordinates of the pixel, and P(a,b) represents the pixel value.
S34、重复步骤S33,训练K’=25次,直到K’棵决策树训练完成,每棵决策树都完整生长而不进行剪枝;S34, step S33 is repeated, training K'=25 times, until the K' decision tree training is completed, and each decision tree is fully grown without pruning;
S35、生成的多棵决策树即为随机森林分类器RFC模型,并利用随机森林分类器RFC模型对测试集T进行判别分类,分类结果采用投票方式,将K’棵决策树输出最多的类别作为测试集T的所属类别,得到当前CU的最佳的预测方向模式,降低仿射运动估计AME模块的计算复杂度。S35. The multiple decision trees generated are the random forest classifier RFC model, and the random forest classifier RFC model is used to discriminate and classify the test set T, and the classification result adopts the voting method, and the category with the most output of K' decision trees is used as The category of the test set T, the best prediction direction mode of the current CU is obtained, and the computational complexity of the affine motion estimation AME module is reduced.
为了评估本发明的方法,在最新的H.266/VVC编码器(VTM 7.0)上进行了仿真测试。测试视频序列在“Random Access”配置中使用默认参数进行编码。BDBR反映了本发明的压缩性能,时间的下降体现了复杂性的降低。表2给出了本发明的编码特性,本发明的总编码时间平均减少到87%,仿射运动估计AME时间平均减少到56%。因此,本发明可以有效地节省编码时间,并且RD性能的损失可以忽略不计。In order to evaluate the method of the present invention, simulation tests are carried out on the latest H.266/VVC encoder (VTM 7.0). The test video sequences were encoded with default parameters in the "Random Access" configuration. BDBR reflects the compression performance of the present invention, and the reduction in time reflects the reduction in complexity. Table 2 shows the encoding characteristics of the present invention, the total encoding time of the present invention is reduced to 87% on average, and the AME time of affine motion estimation is reduced to 56% on average. Therefore, the present invention can effectively save encoding time, and the loss of RD performance can be neglected.
表2本发明的编码特性Encoding characteristic of the present invention of table 2

从表2可以看出本发明与VTM相比RD性能和节省的编码运行时间。对于不同的测试视频,可能实验结果可能会有所波动,但是本发明提出的方法是有效的。与VTM相比,本发明可以有效地降低仿射运动估计AME模块的复杂度,并且具有良好的RD性能。It can be seen from Table 2 that the present invention has RD performance and saved encoding running time compared with VTM. For different test videos, the experimental results may fluctuate, but the method proposed by the present invention is effective. Compared with VTM, the invention can effectively reduce the complexity of AME module of affine motion estimation, and has good RD performance.
仿射运动估计AME模块时间是根据不同的量化参数(Quantization parameter,QP)测量的。当量化参数QP为22时,从图6可以看出,所有视频序列的仿射运动估计AME模块时间总计约为36小时。但是,在本发明的方法中,仿射运动估计AME模块的时间减少了大约9个小时。可以看出,在其他量化参数QPs下,这种趋势是相似的。因此,从图6更直观地观察到,所提出的方法减少了仿射运动估计AME模块的编码时间,从而降低了计算复杂度。Affine motion estimation AME module time is measured according to different quantization parameters (Quantization parameter, QP). When the quantization parameter QP is 22, it can be seen from Fig. 6 that the total time of AME module for all video sequences is about 36 hours. However, in the method of the present invention, the time of the affine motion estimation AME module is reduced by about 9 hours. It can be seen that this trend is similar under other quantization parameters QPs. Therefore, it is more intuitively observed from Fig. 6 that the proposed method reduces the encoding time of the AME module for affine motion estimation, thereby reducing the computational complexity.
以上结合附图详细说明了本发明的技术方案,本发明的技术方案提出了一种针对H.266/VVC的快速仿射运动估计方法,有效地降低了在VTM中的仿射运动估计AME编码复杂度。首先利用标准差SD将CU分为静态区域和非静态区域,如果CU属于静态区域,选择SKIP模式进行帧间预测的概率较高,并且倾向于选择SKIP模式进行帧间预测的静态区域不需要进行仿射预测,因此,在静态区域可以提前终止仿射运动估计AME模块,并且当前CU的最佳方向模式为运动估计CME的最佳方向模式。如果CU属于非静态区域,则根据随机森林分类模型判断CU的帧间预测模式,最终提前得到最优的预测方向模式。因此,本发明降低了计算复杂度并节省了编码时间,从而实现H.266/VVC的快速编码。The technical solution of the present invention has been described in detail above in conjunction with the accompanying drawings. The technical solution of the present invention proposes a fast affine motion estimation method for H.266/VVC, which effectively reduces the AME encoding of affine motion estimation in VTM. the complexity. First, the standard deviation SD is used to divide the CU into a static area and a non-static area. If the CU belongs to a static area, the probability of selecting SKIP mode for inter-frame prediction is higher, and the static area that tends to select SKIP mode for inter-frame prediction does not need to be performed. Affine prediction, therefore, the affine motion estimation AME module can be terminated early in the static region, and the best direction mode of the current CU is the best direction mode of the motion estimation CME. If the CU belongs to a non-static area, the inter-frame prediction mode of the CU is judged according to the random forest classification model, and finally the optimal prediction direction mode is obtained in advance. Therefore, the present invention reduces computational complexity and saves coding time, thereby realizing fast coding of H.266/VVC.
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。The above descriptions are only preferred embodiments of the present invention, and are not intended to limit the present invention. Any modifications, equivalent replacements, improvements, etc. made within the spirit and principles of the present invention shall be included in the scope of the present invention. within the scope of protection.
Claims (8)







Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010293694.8A CN111479110B (en) | 2020-04-15 | 2020-04-15 | Fast Affine Motion Estimation Method for H.266/VVC |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010293694.8A CN111479110B (en) | 2020-04-15 | 2020-04-15 | Fast Affine Motion Estimation Method for H.266/VVC |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111479110A CN111479110A (en) | 2020-07-31 |
| CN111479110B true CN111479110B (en) | 2022-12-13 |
Family
ID=71752555
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010293694.8A Active CN111479110B (en) | 2020-04-15 | 2020-04-15 | Fast Affine Motion Estimation Method for H.266/VVC |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111479110B (en) |
Families Citing this family (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112689146B (en) * | 2020-12-18 | 2022-07-22 | 重庆邮电大学 | Heuristic learning-based VVC intra-frame prediction rapid mode selection method |
| CN112911308B (en) * | 2021-02-01 | 2022-07-01 | 重庆邮电大学 | A fast motion estimation method and storage medium for H.266/VVC |
| CN113225552B (en) * | 2021-05-12 | 2022-04-29 | 天津大学 | Intelligent rapid interframe coding method |
| CN113630601B (en) * | 2021-06-29 | 2024-04-02 | 杭州未名信科科技有限公司 | An affine motion estimation method, device, equipment and storage medium |
| CN115278260B (en) * | 2022-07-15 | 2024-11-19 | 重庆邮电大学 | VVC fast CU division method and storage medium based on space-time characteristics |
| CN115442620B (en) * | 2022-09-06 | 2025-04-22 | 杭州电子科技大学 | A low-complexity affine motion estimation method based on AME |
| CN116684577A (en) * | 2023-06-02 | 2023-09-01 | 北京联合大学 | Fast Affine Mode Decision Based on Motion Vector Difference |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN1934871A (en) * | 2003-08-25 | 2007-03-21 | 新加坡科技研究局 | Mode decision for inter prediction in video coding |
| CN104320658A (en) * | 2014-10-20 | 2015-01-28 | 南京邮电大学 | HEVC (High Efficiency Video Coding) fast encoding method |
| WO2018124332A1 (en) * | 2016-12-28 | 2018-07-05 | 엘지전자(주) | Intra prediction mode-based image processing method, and apparatus therefor |
| CN110213584A (en) * | 2019-07-03 | 2019-09-06 | 北京电子工程总体研究所 | Coding unit classification method and coding unit sorting device based on Texture complication |
-
2020
- 2020-04-15 CN CN202010293694.8A patent/CN111479110B/en active Active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN1934871A (en) * | 2003-08-25 | 2007-03-21 | 新加坡科技研究局 | Mode decision for inter prediction in video coding |
| CN104320658A (en) * | 2014-10-20 | 2015-01-28 | 南京邮电大学 | HEVC (High Efficiency Video Coding) fast encoding method |
| WO2018124332A1 (en) * | 2016-12-28 | 2018-07-05 | 엘지전자(주) | Intra prediction mode-based image processing method, and apparatus therefor |
| CN110213584A (en) * | 2019-07-03 | 2019-09-06 | 北京电子工程总体研究所 | Coding unit classification method and coding unit sorting device based on Texture complication |
Non-Patent Citations (1)
| Title |
|---|
| 基于随机森林和多特征融合的青苹果图像分割;吴庆岗等;《信阳师范学院学报(自然科学版)》;20181031;681-686 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN111479110A (en) | 2020-07-31 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111479110B (en) | Fast Affine Motion Estimation Method for H.266/VVC | |
| Chen et al. | Learning for video compression | |
| US10848765B2 (en) | Rate/distortion/RDcost modeling with machine learning | |
| CN110087087B (en) | VVC inter-frame coding unit prediction mode early decision and block division early termination method | |
| CN114286093B (en) | A fast video encoding method based on deep neural network | |
| CN103475880B (en) | A kind of based on statistical analysis by H.264 to HEVC low complex degree video transcoding method | |
| WO2020117412A1 (en) | Hybrid motion-compensated neural network with side-information based video coding | |
| WO2024083100A1 (en) | Method and apparatus for talking face video compression | |
| US12225221B2 (en) | Ultra light models and decision fusion for fast video coding | |
| CN103491334B (en) | Video transcode method from H264 to HEVC based on region feature analysis | |
| WO2020190297A1 (en) | Using rate distortion cost as a loss function for deep learning | |
| CN115706798B (en) | Entropy encoding and decoding methods and apparatus | |
| CN101184233A (en) | A method of digital video compression coding based on CFRFS | |
| CN102075757B (en) | Video foreground object coding method by taking boundary detection as motion estimation reference | |
| CN107018412A (en) | A kind of DVC HEVC video transcoding methods based on key frame coding unit partition mode | |
| CN121620919A (en) | Sub-block-based temporal motion vector prediction | |
| Jillani et al. | Multi-view clustering for fast intra mode decision in HEVC | |
| Cherigui et al. | Correspondence map-aided neighbor embedding for image intra prediction | |
| CN111212292B (en) | Adaptive CU Partitioning and Skip Mode Method Based on H.266 | |
| Bachu et al. | Adaptive order search and tangent-weighted trade-off for motion estimation in H. 264 | |
| CN109168000B (en) | HEVC intra-frame prediction rapid algorithm based on RC prediction | |
| Khodarahmi et al. | ReMove: Leveraging Motion Estimation for Computation Reuse in CNN-Based Video Processing | |
| Pientka et al. | Deep video coding with gradient-descent optimized motion compensation and Lanczos filtering | |
| CN108184114B (en) | A Fast Decision Method of Intra Prediction Mode in P Frame Based on Support Vector Machine SVM | |
| CN115484461B (en) | Video encoding method and device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| TA01 | Transfer of patent application right |
Effective date of registration: 20221118 Address after: Floor 20-23, block a, Ximei building, no.6, Changchun Road, high tech Industrial Development Zone, Zhengzhou City, Henan Province, 450000 Applicant after: Zhengzhou Light Industry Technology Research Institute Co.,Ltd. Applicant after: Zhengzhou University of light industry Address before: 450002 No. 5 Dongfeng Road, Jinshui District, Henan, Zhengzhou Applicant before: Zhengzhou University of light industry |
|
| TA01 | Transfer of patent application right | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |