CN109101552B - 一种基于深度学习的钓鱼网站url检测方法 - Google Patents
一种基于深度学习的钓鱼网站url检测方法 Download PDFInfo
- Publication number
- CN109101552B CN109101552B CN201810750707.2A CN201810750707A CN109101552B CN 109101552 B CN109101552 B CN 109101552B CN 201810750707 A CN201810750707 A CN 201810750707A CN 109101552 B CN109101552 B CN 109101552B
- Authority
- CN
- China
- Prior art keywords
- url
- character
- layer
- matrix
- vector
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images

Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Health & Medical Sciences (AREA)
- Computing Systems (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Life Sciences & Earth Sciences (AREA)
- Molecular Biology (AREA)
- Artificial Intelligence (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- Image Analysis (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
本发明公开了一种基于深度学习的钓鱼网站URL检测方法,该方法仅根据网站URL就能够实时检测互联网上的钓鱼网站。本发明首先将URL字符串序列编码成one‑hot二维稀疏矩阵,接着转化为稠密字符嵌入矩阵,输入到卷积神经网络中,抽取局部深度特征,然后将卷积神经网络的输出输入到长短期记忆网络,捕获URL序列的前后关联,最后接入softmax模型,对URL分类。本发明能避免繁冗的特征工程,通过卷积神经网络抽取局部深度关联性特征,通过长短期记忆网络学习URL中的长程依赖,能快速、准确地检测出钓鱼网站URL。
Description
技术领域
本发明涉及一种基于深度学习的钓鱼网站URL检测方法,该方法提取URL字符串序列相关特征,利用深度学习方法提高分类准确率,能实时检测互联网上的钓鱼网站,属于网络空间安全技术领域。
背景技术
近年来,随着互联网的飞速发展,互联网体系结构在安全方面所存在不足日渐显露,网络钓鱼、网络犯罪、隐私泄露等各类安全问题越来越突出。没有网络安全就没有国家安全,网络空间安全已经成为世界各国必须共同面对和解决的难题。在各类网络安全问题中,网络钓鱼是一种通过社会工程学或其它复杂技术手段窃取网站用户个人信息的犯罪行为,目前网络钓鱼呈逐年上升趋势。
当前主流钓鱼网站检测方法是基于机器学习的钓鱼网站检测方法,该方法将钓鱼网站检测视为一个二分类或聚类问题,首先根据钓鱼网站的URL结构及页面元素与正常网站的差异性提取特征,然后运用相应的机器学习算法达到钓鱼网站检测和防御的目的。常见的钓鱼特征有URL词汇特征、HTML特征、第三方网站特征等,根据所用特征的不同,又可分为基于URL特征的钓鱼网站检测和基于组合特征的钓鱼网站检测。其中基于URL特征的钓鱼网站检测方法不需要关注钓鱼页面,检测效率高,但不能全面反映URL的特点,准确率不高。
发明内容
发明目的:针对当前日益增多的钓鱼网站和已有基于URL特征的钓鱼网站检测方法准确率不高、漏报率和误报率较高的问题,本发明提出一种基于深度学习的钓鱼网站URL检测方法,首先将输入URL字符串规格化为固定长度,然后通过字符映射表将其转化为One-hot编码序号,接着嵌入层(Embedding Layer)将其转为稠密矩阵作为URL字符序列的特征表示,之后输入到CNN网络抽取局部深度特征,并通过LSTM解决长程依赖问题,最后将LSTM最后一个时刻的输出输入到softmax单元,该方法能实时检测互联网的钓鱼网站,相比传统基于URL特征的钓鱼网站检测方法,不需要手动抽取特征,能全面反映URL特征点,而且能够显著提供钓鱼网站检测准确率。
技术方案:一种基于深度学习的钓鱼网站URL检测方法,该方法涵盖钓鱼网站检测的全过程。该方法主要包括URL字符嵌入表示、CNN-LSTM分类模型和模型训练等过程,能够有效捕获URL字符序列中字符前后的关联和语义信息,有效解决传统基于URL特征的钓鱼网站检测方法不能全面反映钓鱼网站URL特征的问题,并且将卷积神经网络和长短期记忆网络模型应用于钓鱼网站检测,提高检测准确率和减少检测漏报率。该方法主要包括三个步骤,具体如下:
步骤1,URL字符嵌入表示。首先将URL看做字符串序列,从字符层面量化URL,规格化URL,然后将URL字符转换成独热码(one-hot encode),最后通过嵌入(Embedding)层生成二维稠密矩阵即Embedding矩阵。
步骤2,CNN-LSTM分类层Embedding矩阵首先通过CNN卷积层抽取局部关联性特征,接着抽取的局部关联性特征经池化层降低卷积神经网络模型复杂度;然后通过长短期记忆网络LSTM检测池化序列中的语义和长程依赖关系;最后将LSTM最后一个单元的输出到Softmax单元。
步骤3,模型训练。本发明采用交叉熵(Cross Entropy)损失函数,并利用Adam(Adaptive Moment Estimation)即自适应时刻估计算法迭代训练模型,优化损失函数。
有益效果:
1.URL字符嵌入表示不需要手动抽取特征,且不损失任何信息地表征了URL信息,能全面反映URL特点。
2.CNN-LSTM分类模型能够有效捕获URL字符序列中字符前后的关联和语义信息,具有更高的准确率、更低的漏报率和误报率。
附图说明
图1为本发明整体流程图,包括URL字符嵌入表示和CNN-LSTM分类。
具体实施方式
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
本方法具体实施步骤如下:
步骤1,URL字符嵌入表示。URL字符嵌入表示将URL字符串序列量化编码,作为卷积神经网络CNN的输入。为此,首先要确定URL中可能出现的所有字母字符、数字字符和特殊字符,并构建字符映射规则。根据ASCCI码表并结合URL字符的实际情况,构建了97个编号的字符映射表,其中包括52个大小写字母,10个数字,33个特征字符,一个补零字符及未知字符编号。字符映射表如表1所示。
表1字符映射表

假定每个URL字符序列长度固定为L,若URL长度超过L,则在URL末尾截取多余的字符,若URL长度少于L,则在URL首部补零直至长度达到L,如公式(1)所示。其中URLs为原始URL字符串,len(URLs)表示其总长度,PAD为首部补零字符串,其长度len(PAD)=L-len(URLs),URLs[0:L-1]为URLs前L个字符,URLf为规格化后的输入字符串。

根据字符映射表,其中首部补零字符对应编号为0,URL中的字符“0”对应编号为53,最终每个字符被转换为长度为m(97)的one-hot向量x,向量中字符对应编号位置为1,其余位置皆为0,例如字符“a”表示为(0,1,0,…0)。因此URL被转换为公式(2)所示矩阵X。
X=(x1,x2,...,xL) (2)
由于one-hot编码的矩阵X含有很多0,会带来稀疏编码且维度过高的问题,且这种表示不同字符之间完全没有空间及语义关联性,信息量太少。可将其转换到字符嵌入的低维稠密特征空间中,本文将矩阵X中的每个one-hot向量投影到d维连续向量空间 对应神经网络中的嵌入层,其可理解为一个输入为m个神经元,输出为d个神经元的全连接神经网络。
对应神经网络中的嵌入层,其可理解为一个输入为m个神经元,输出为d个神经元的全连接神经网络。
Embedding层的参数值随机初始化,并在模型训练过程中迭代更新。设输入为d个神经元,输出为m个神经元的Embedding全连接层的参数矩阵为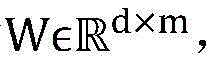 则对one-hot向量xt,xt表示矩阵X的一个列向量,其最终嵌入向量et如公式(3)所示。
则对one-hot向量xt,xt表示矩阵X的一个列向量,其最终嵌入向量et如公式(3)所示。

最后URL字符串序列被转换为如公式(4)所示的稠密矩阵序列E,作为URL的字符嵌入矩阵。
E=WX=(w1,w2,…,wd)T×(x1,x2,…,xL)=(e1,e2,…,eL) (4)
步骤2,CNN-LSTM分类模型。对步骤1中生成的URL字符嵌入矩阵E,将其输入到CNN-LSTM分类模型中,预测该URL为钓鱼网站的概率,该步骤实施过程分为3个子步骤:
子步骤2-1,卷积神经网络CNN层。CNN中卷积层对URL字符嵌入矩阵E进行卷积操作,抽取局部深度关联特征。具体而言,卷积层设置多个卷积核S,每个卷积核都对窗口大小为k的字符嵌入向量进行卷积从而产生新特征。对于第f个卷积核,其在第i个滑动窗口处的字符向量矩阵Ei如公式(5)所示。
Ei={ei,ei+1,…,ei+k-1} (5)
则卷积核f在第i个滑动窗口处产生的新特征 如公式(6)所示,其中σ是卷积层的非线性激活函数,本文采用relu激活函数,
如公式(6)所示,其中σ是卷积层的非线性激活函数,本文采用relu激活函数, 和bf分别为该卷积核权重和偏置项。
和bf分别为该卷积核权重和偏置项。

本发明设置卷积核滑动步长为1,则卷积核f遍历滑动窗口E0到EL-k+1后产生的特征图向量hf如公式(7)所示。

将S个卷积核产生的特征图堆叠,便可得到卷积层的序列矩阵HS,如公式(8)所示,其中HS的第i列
HS={h1,h2,…,hL-k+1} (8)
池化层对新的序列矩阵HS进行最大池化(Max Pooling)操作,获取池化窗口p内的最大特征值,从而最大化字符特征表示。设置池化层步长与池化窗口相同,则对特征图向量hf最大池化后的特征如公式(9)和(10)所示,其中 为第j块最大池化的特征值,pf表示池化后的向量,
为第j块最大池化的特征值,pf表示池化后的向量,


最终,将S个池化向量堆叠,即可得到池化层的序列矩阵HP,如公式(11)所示,其中HP的第i列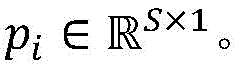
HP={p1,p2,…,pN} (11)
子步骤2-2,长短期记忆网络LSTM层。将池化序列矩阵HP输入到LSTM神经网络中,其中pi对应第i个时刻LSTM网络的输入,最终LSTM的输出隐藏状态序列H,如式(12)所示。
H=(h1,h2,…,hN) (12)
接着将序列最后的隐藏状态hN作为最后分类层的输入,如式(13)所示,其中n为LSTM网络隐藏单元个数,hNi为第i个隐藏单元。
hN=(hN1,hN2,…,hNn) (13)
子步骤2-3,softmax分类层。分类层是激活函数为sigmoid的softmax回归单元,预测概率如式(14)所示,x为输入向量,wk为权值向量,bk为偏置,其中K=2,当k=0时,表示预测为正常网站的概率,k=1时,表示预测为钓鱼网站的概率。

为了抑制过拟合现象,在隐藏状态hN和softmax分类层之间的全连接层中应用dropout策略。dropout是深度神经网络中一种防止过拟合的高效方法,其在训练过程中,对每个神经网络单元,按照一定的概率将其从网络中丢弃。
步骤3,模型训练。模型训练的关键是确定目标损失函数,本发明采用交叉熵(Cross Entropy)损失函数,如式(15)所示。其中N为训练样本总数,y为样本的真实类别(0表示正常网站,1表示钓鱼网站), 为模型预测为钓鱼网站的概率。
为模型预测为钓鱼网站的概率。
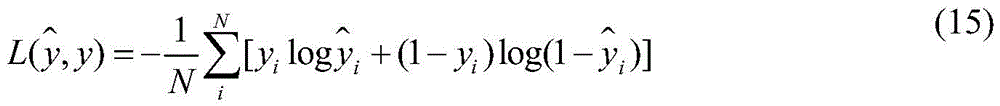
本发明采用Adam(Adaptive Moment Estimation)即自适应时刻估计算法训练模型优化交叉熵损失函数,其是对梯度下降算法的改进,通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率,避免了学习率消失、收敛过慢或损失函数波动较大的问题,具有高效的学习效果。
综上所述,本发明涉及的主要参数如表2所示。
表2主要参数

Claims (4)
1.一种基于深度学习的钓鱼网站URL检测方法,其特征在于,该方法主要包括三个步骤,具体如下:
步骤1,URL字符嵌入表示:首先将URL看做字符串序列,从字符层面量化URL,规格化URL,然后将URL字符转换成独热码(one-hot encode),最后通过卷积神经网络的嵌入(Embedding)层生成二维稠密矩阵即Embedding矩阵;
步骤2,CNN-LSTM分类层:Embedding矩阵首先通过卷积神经网络的CNN卷积层抽取局部关联性特征,接着抽取的局部关联性特征经池化层降低卷积神经网络模型复杂度;然后通过长短期记忆网络LSTM检测池化序列中的语义和长程依赖关系;最后输入到Softmax单元;
步骤3,模型训练:采用交叉熵损失函数,并利用Adam即自适应时刻估计算法迭代训练模型,优化损失函数;
步骤1中,URL字符嵌入表示将URL字符串序列量化编码,作为卷积神经网络CNN的输入;首先要确定URL中可能出现的所有字母字符、数字字符和特殊字符,并构建字符映射表;
假定每个URL字符序列长度固定为L,若URL长度超过L,则在URL末尾截取多余的字符,若URL长度少于L,则在URL首部补零直至长度达到L;
根据字符映射表,其中首部补零字符对应编号为0,URL中的字符“0”对应编号为53,最终每个字符被转换为长度为m的one-hot向量x,向量中字符对应编号位置为1,其余位置皆为0,因此URL被转换为公式(2)所示矩阵X;
X=(x1,x2,...,xL) (2)
将one-hot编码的矩阵X中的每个one-hot向量投影到d维连续向量空间 对应神经网络中的嵌入层,其可理解为一个输入为m个神经元,输出为d个神经元的全连接神经网络;
对应神经网络中的嵌入层,其可理解为一个输入为m个神经元,输出为d个神经元的全连接神经网络;
Embedding层的参数值随机初始化,并在模型训练过程中迭代更新;设输入为d个神经元,输出为m个神经元的Embedding全连接层参数矩阵为 则对one-hot向量xt,xt表示矩阵X的一个列向量,其最终嵌入向量et如公式(3)所示;
则对one-hot向量xt,xt表示矩阵X的一个列向量,其最终嵌入向量et如公式(3)所示;

最后URL字符串序列被转换为如公式(4)所示的稠密矩阵序列E,作为URL的字符嵌入矩阵;
E=WX=(w1,w2,…,wd)T×(x1,x2,…,xL)=(e1,e2,…,eL) (4)。
2.如权利要求1所述的基于深度学习的钓鱼网站URL检测方法,其特征在于,对步骤1中生成的URL字符嵌入矩阵E,将其输入到CNN-LSTM分类模型中,预测该URL为钓鱼网站的概率,步骤2实施过程分为3个子步骤:
子步骤2-1,卷积神经网络CNN层;CNN中卷积层对URL字符嵌入矩阵E进行卷积操作,抽取局部深度关联特征;具体而言,卷积层设置卷积核个数为S,每个卷积核都对窗口大小为k的字符嵌入向量进行卷积从而产生新特征;对于第f个卷积核,其在第i个滑动窗口处的字符向量矩阵Ei如公式(5)所示;
Ei={ei,ei+1,…,ei+k-1} (5)
则卷积核f在第i个滑动窗口处产生的新特征 如公式(6)所示,其中σ是卷积层的非线性激活函数,采用relu激活函数,
如公式(6)所示,其中σ是卷积层的非线性激活函数,采用relu激活函数, 和bf分别为该卷积核权重和偏置项;
和bf分别为该卷积核权重和偏置项;

设置卷积核滑动步长为1,则卷积核f遍历滑动窗口E0到EL-k+1后产生的特征图向量hf如公式(7)所示;

将S个卷积核产生的特征图堆叠,便可得到卷积层的序列矩阵HS,如公式(8)所示,其中HS的第i列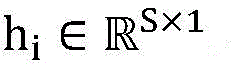 ;
;
HS={h1,h2,…,hL-k+1} (8)
池化层对新的序列矩阵HS进行最大池化操作,获取池化窗口p内的最大特征值,从而最大化字符特征表示;设置池化层步长与池化窗口相同,则对特征图向量hf最大池化后的特征如公式(9)和(10)所示,其中 为第j块最大池化的特征值,pf表示池化后的向量,
为第j块最大池化的特征值,pf表示池化后的向量,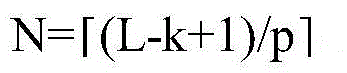 ;
;


最终,将S个池化向量堆叠,即可得到池化层的序列矩阵HP,如公式(11)所示,其中HP的第i列
HP={p1,p2,…,pN} (11)
子步骤2-2,长短期记忆网络LSTM层;将池化序列矩阵HP输入到LSTM神经网络中,其中pi对应第i个时刻LSTM网络的输入,最终LSTM的输出隐藏状态序列H,如式(12)所示;
H=(h1,h2,…,hN) (12)
接着将序列最后的隐藏状态hN作为最后分类层的输入,如式(13)所示,其中n为LSTM网络隐藏单元个数,hNi为第i个隐藏单元;
hN=(hN1,hN2,…,hNn) (13)
子步骤2-3,softmax分类层;分类层是激活函数为sigmoid的softmax回归单元,预测概率如式(14)所示,x为输入向量,wk为权值向量,bk为偏置,其中K=2,当k=0时,表示预测为正常网站的概率,k=1时,表示预测为钓鱼网站的概率;

为了抑制过拟合现象,在隐藏状态hN和softmax分类层之间的全连接层中应用dropout策略。
3.如权利要求2所述的基于深度学习的钓鱼网站URL检测方法,其特征在于,步骤3中模型训练的关键是确定目标损失函数,采用交叉熵损失函数,如式(15)所示;其中N为训练样本总数,y为样本的真实类别,0表示正常网站,1表示钓鱼网站, 为模型预测为钓鱼网站的概率;
为模型预测为钓鱼网站的概率;

采用自适应时刻估计算法训练模型优化交叉熵损失函数。
4.如权利要求1所述的基于深度学习的钓鱼网站URL检测方法,其特征在于,根据ASCCI码表并结合URL字符的实际情况,构建了97个编号的字符映射表,其中包括52个大小写字母a-Z,10个数字0-9,33个特征字符“—,;.!?:″′/\|_@#$%^&*~`+-=<>()[]{}”,一个补零字符及未知字符编号。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810750707.2A CN109101552B (zh) | 2018-07-10 | 2018-07-10 | 一种基于深度学习的钓鱼网站url检测方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810750707.2A CN109101552B (zh) | 2018-07-10 | 2018-07-10 | 一种基于深度学习的钓鱼网站url检测方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN109101552A CN109101552A (zh) | 2018-12-28 |
| CN109101552B true CN109101552B (zh) | 2022-01-28 |
Family
ID=64846082
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201810750707.2A Active CN109101552B (zh) | 2018-07-10 | 2018-07-10 | 一种基于深度学习的钓鱼网站url检测方法 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN109101552B (zh) |
Families Citing this family (20)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109194635A (zh) * | 2018-08-22 | 2019-01-11 | 杭州安恒信息技术股份有限公司 | 基于自然语言处理与深度学习的恶意url识别方法及装置 |
| CN110008337B (zh) * | 2019-01-24 | 2022-08-19 | 科大国创软件股份有限公司 | 基于响应度衡量的并行lstm结构海关商品分类方法 |
| CN111866196B (zh) * | 2019-04-26 | 2023-05-16 | 深信服科技股份有限公司 | 一种域名流量特征提取方法、装置、设备及可读存储介质 |
| US11303674B2 (en) | 2019-05-14 | 2022-04-12 | International Business Machines Corporation | Detection of phishing campaigns based on deep learning network detection of phishing exfiltration communications |
| CN110135566A (zh) * | 2019-05-21 | 2019-08-16 | 四川长虹电器股份有限公司 | 基于lstm二分类神经网络模型的注册用户名检测方法 |
| CN110298005A (zh) * | 2019-06-26 | 2019-10-01 | 上海观安信息技术股份有限公司 | 一种对url进行归一化的方法 |
| CN110602113B (zh) * | 2019-09-19 | 2021-05-25 | 中山大学 | 一种基于深度学习的层次化钓鱼网站检测方法 |
| CN111159588B (zh) * | 2019-12-19 | 2022-12-13 | 电子科技大学 | 一种基于url成像技术的恶意url检测方法 |
| CN111245820A (zh) * | 2020-01-08 | 2020-06-05 | 北京工业大学 | 基于深度学习的钓鱼网站检测方法 |
| CN111428789A (zh) * | 2020-03-25 | 2020-07-17 | 广东技术师范大学 | 一种基于深度学习的网络流量异常检测方法 |
| CN111556065A (zh) * | 2020-05-08 | 2020-08-18 | 鹏城实验室 | 钓鱼网站检测方法、装置及计算机可读存储介质 |
| CN111933217B (zh) * | 2020-06-17 | 2024-04-05 | 西安电子科技大学 | 一种基于深度学习的dna模体长度预测方法及预测系统 |
| CN111538929B (zh) * | 2020-07-08 | 2020-12-18 | 腾讯科技(深圳)有限公司 | 网络链接识别方法、装置、存储介质及电子设备 |
| CN112468501B (zh) * | 2020-11-27 | 2022-10-25 | 安徽大学 | 一种面向url的钓鱼网站检测方法 |
| CN112738034B (zh) * | 2020-12-17 | 2022-04-29 | 杭州趣链科技有限公司 | 一种基于垂直联邦学习的区块链钓鱼节点检测方法 |
| CN112699686B (zh) * | 2021-01-05 | 2024-03-08 | 浙江诺诺网络科技有限公司 | 基于任务型对话系统的语义理解方法、装置、设备及介质 |
| CN113012767B (zh) * | 2021-02-24 | 2024-08-20 | 大唐环境产业集团股份有限公司 | 基于时间序列的脱硫系统浆液pH值在线预测方法及装置 |
| CN113037729B (zh) * | 2021-02-27 | 2022-11-18 | 中国人民解放军战略支援部队信息工程大学 | 基于深度学习的钓鱼网页层次化检测方法及系统 |
| CN113132410B (zh) * | 2021-04-29 | 2023-12-08 | 深圳信息职业技术学院 | 一种用于检测钓鱼网址的方法 |
| CN115242484A (zh) * | 2022-07-19 | 2022-10-25 | 深圳大学 | 一种基于门控卷积和lstm的dga域名检测模型及方法 |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107169035A (zh) * | 2017-04-19 | 2017-09-15 | 华南理工大学 | 一种混合长短期记忆网络和卷积神经网络的文本分类方法 |
| CN107992469A (zh) * | 2017-10-13 | 2018-05-04 | 中国科学院信息工程研究所 | 一种基于词序列的钓鱼url检测方法及系统 |
| CN108009493A (zh) * | 2017-11-30 | 2018-05-08 | 电子科技大学 | 基于动作增强的人脸防欺骗识别方法 |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10154051B2 (en) * | 2016-08-31 | 2018-12-11 | Cisco Technology, Inc. | Automatic detection of network threats based on modeling sequential behavior in network traffic |
-
2018
- 2018-07-10 CN CN201810750707.2A patent/CN109101552B/zh active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107169035A (zh) * | 2017-04-19 | 2017-09-15 | 华南理工大学 | 一种混合长短期记忆网络和卷积神经网络的文本分类方法 |
| CN107992469A (zh) * | 2017-10-13 | 2018-05-04 | 中国科学院信息工程研究所 | 一种基于词序列的钓鱼url检测方法及系统 |
| CN108009493A (zh) * | 2017-11-30 | 2018-05-08 | 电子科技大学 | 基于动作增强的人脸防欺骗识别方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN109101552A (zh) | 2018-12-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109101552B (zh) | 一种基于深度学习的钓鱼网站url检测方法 | |
| CN111371806B (zh) | 一种Web攻击检测方法及装置 | |
| CN110602113B (zh) | 一种基于深度学习的层次化钓鱼网站检测方法 | |
| CN109829299B (zh) | 一种基于深度自编码器的未知攻击识别方法 | |
| CN110119765B (zh) | 一种基于Seq2seq框架的关键词提取方法 | |
| CN106980683B (zh) | 基于深度学习的博客文本摘要生成方法 | |
| CN112468501B (zh) | 一种面向url的钓鱼网站检测方法 | |
| Xu et al. | A hierarchical intrusion detection model combining multiple deep learning models with attention mechanism | |
| CN111984791B (zh) | 一种基于注意力机制的长文分类方法 | |
| CN112508085A (zh) | 基于感知神经网络的社交网络链路预测方法 | |
| CN109450845B (zh) | 一种基于深度神经网络的算法生成恶意域名检测方法 | |
| CN113315789B (zh) | 一种基于多级联合网络的Web攻击检测方法及系统 | |
| CN110196946A (zh) | 一种基于深度学习的个性化推荐方法 | |
| CN113691542B (zh) | 基于HTTP请求文本的Web攻击检测方法及相关设备 | |
| CN111460818B (zh) | 一种基于增强胶囊网络的网页文本分类方法及存储介质 | |
| CN113269228B (zh) | 一种图网络分类模型的训练方法、装置、系统及电子设备 | |
| CN113505307B (zh) | 一种基于弱监督增强的社交网络用户地域识别方法 | |
| Chen et al. | Malicious URL detection based on improved multilayer recurrent convolutional neural network model | |
| CN111046233B (zh) | 一种基于视频评论文本的视频标签确定方法 | |
| CN116821340B (zh) | 基于深度学习的多标签文本分类方法 | |
| CN113409157B (zh) | 一种跨社交网络用户对齐方法以及装置 | |
| CN110826056A (zh) | 一种基于注意力卷积自编码器的推荐系统攻击检测方法 | |
| CN114844682B (zh) | 一种dga域名检测方法及系统 | |
| CN112651025A (zh) | 一种基于字符级嵌入编码的webshell检测方法 | |
| CN112488149A (zh) | 一种基于1d-cnn特征重构的网络安全数据分类方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |