CN108229677B - 用于使用循环模型执行识别和训练循环模型的方法和设备 - Google Patents
用于使用循环模型执行识别和训练循环模型的方法和设备 Download PDFInfo
- Publication number
- CN108229677B CN108229677B CN201710810460.4A CN201710810460A CN108229677B CN 108229677 B CN108229677 B CN 108229677B CN 201710810460 A CN201710810460 A CN 201710810460A CN 108229677 B CN108229677 B CN 108229677B
- Authority
- CN
- China
- Prior art keywords
- window
- data
- training
- current window
- previous
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000012549 training Methods 0.000 title claims abstract description 163
- 238000000034 method Methods 0.000 title claims abstract description 79
- 125000004122 cyclic group Chemical group 0.000 title claims abstract description 42
- 238000013528 artificial neural network Methods 0.000 claims description 41
- 230000015654 memory Effects 0.000 claims description 25
- 230000004044 response Effects 0.000 claims description 21
- 239000000945 filler Substances 0.000 claims description 10
- 239000010410 layer Substances 0.000 description 110
- 230000000306 recurrent effect Effects 0.000 description 14
- 230000008569 process Effects 0.000 description 13
- 239000000284 extract Substances 0.000 description 9
- 210000004027 cell Anatomy 0.000 description 6
- 238000012545 processing Methods 0.000 description 5
- 238000003491 array Methods 0.000 description 3
- 238000004422 calculation algorithm Methods 0.000 description 3
- 230000014509 gene expression Effects 0.000 description 3
- 238000013461 design Methods 0.000 description 2
- 238000013507 mapping Methods 0.000 description 2
- 230000003278 mimic effect Effects 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 238000005070 sampling Methods 0.000 description 2
- 206010012239 Delusion Diseases 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 238000013500 data storage Methods 0.000 description 1
- 238000013135 deep learning Methods 0.000 description 1
- 238000010586 diagram Methods 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 239000011229 interlayer Substances 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 210000003061 neural cell Anatomy 0.000 description 1
- 210000002569 neuron Anatomy 0.000 description 1
- 238000012567 pattern recognition method Methods 0.000 description 1
- 230000001902 propagating effect Effects 0.000 description 1
- 230000006403 short-term memory Effects 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 230000005236 sound signal Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 238000013519 translation Methods 0.000 description 1
Images









Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/044—Recurrent networks, e.g. Hopfield networks
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/16—Speech classification or search using artificial neural networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/084—Backpropagation, e.g. using gradient descent
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- General Health & Medical Sciences (AREA)
- General Physics & Mathematics (AREA)
- Biophysics (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Life Sciences & Earth Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Image Analysis (AREA)
Abstract
公开一种用于使用循环模型执行识别和训练循环模型的方法和设备。一种识别方法包括:从序列数据提取与当前窗对应的目标数据和在目标数据之后的填充数据;获取与先前窗对应的状态参数;使用循环模型,基于状态参数、提取的目标数据和提取的填充数据,计算当前窗的识别结果。
Description
本申请要求于2016年12月14日提交到韩国知识产权局的第10-2016-0170198号韩国专利申请的权益,该韩国专利申请的全部公开出于所有目的通过引用包含于此。
技术领域
下面的描述涉及用于基于循环模型执行识别的技术和用于训练循环模型的技术。
背景技术
近来,为了分类人机输入模式,已经进行了关于将有效的人类的模式识别方法应用到实际计算机的积极研究。一个这样的研究领域集中在通过数学表达式对人类的生物神经细胞的特性建模的人工神经网络。为了分类输入模式,人工神经网络采用模拟人类的学习能力的算法。使用这种算法,人工神经网络产生输入模式与输出模式之间的映射。产生这样的映射的能力被称为人工神经网络的学习能力。基于学习结果,人工神经网络针对未曾用于学习的输入模式产生输出。
发明内容
提供本发明内容从而以简化的形式介绍在下面的具体实施方式中进一步描述的构思的选择。本发明内容不意在标识所要求保护的主题的关键特征或必要特征,也不意在用于帮助确定所要求保护的主题的范围。
在一个总体方面,一种识别方法包括:从序列数据提取与当前窗对应的目标数据和在目标数据之后的填充数据;获取与先前窗对应的状态参数;使用循环模型,基于状态参数、提取的目标数据和提取的填充数据,计算当前窗的识别结果。
所述识别方法还可包括:暂时存储与当前窗的最后帧对应的状态参数,以用于后续窗。
所述识别方法可还包括:排除与填充相关联的状态参数和基于循环模型计算的填充数据的输出数据。
计算识别结果的步骤可包括:以当前窗的窗长度和填充长度展开循环模型;针对每个帧将状态参数、提取的目标数据和提取的填充数据输入到展开的循环模型,并计算与包括在当前窗中的帧对应的输出数据。
计算识别结果的步骤可包括:基于与先前窗的最后帧对应的状态参数,更新与当前窗的第一帧对应的节点的输入值。
提取目标数据和填充数据的步骤可包括:从先前窗的最后帧数据之后的帧数据开始从序列数据提取与窗长度对应的数据作为与当前窗对应的目标数据。
提取目标数据和填充数据的步骤可包括:从当前窗的最后帧数据之后的帧数据开始从序列数据提取与填充长度对应的数据作为与填充对应的填充数据。
循环模型可以是被训练为响应于基于训练数据的训练输入输出训练输出的双向循环神经网络。
循环模型可包括:与包括在窗和填充中的每个帧对应的节点;计算识别结果的步骤可包括:基于所述节点的前向通路,顺序地从窗的第一帧到窗的最后帧更新状态参数;基于所述节点的反向通路,顺序地从窗的最后帧到窗的第一帧更新状态参数;将基于前向通路的状态参数和基于反向通路的状态参数提供给后续层的节点。
序列数据可对应于语音信号;计算识别结果的步骤可包括:从与当前窗对应的目标数据辨识发音。
获取与先前窗对应的状态参数的步骤可包括:响应于当前窗是相对于序列数据的第一窗,将与先前窗对应的状态参数确定为默认值。
提取目标数据和填充数据的步骤可包括:响应于当前窗是相对于序列数据的最后窗,排除填充数据。
在另一总体方面,一种非暂时性计算机可读介质存储指令,当所述指令由处理器执行时,使所述处理器执行上述识别方法。
在另一总体方面,一种识别设备包括:存储器,被配置为存储循环模型;处理器,被配置为:从序列数据提取与当前窗对应的目标数据和在目标数据之后的填充数据;获取与先前窗对应的状态参数;使用循环模型,基于状态参数、提取的目标数据和提取的填充数据,计算当前窗的识别结果。
在另一总体方面,一种训练方法包括:获取循环模型;从训练输入提取与当前窗对应的目标数据和在目标数据之后的填充数据;获取与先前窗对应的状态参数;训练循环模型,使得映射到训练输入的训练输出基于状态参数、提取的目标数据和提取的填充数据被计算。
所述训练方法还可包括:响应于训练输入中存在与后续窗对应的数据,暂时存储与当前窗的最后帧对应的状态参数,以用于基于后续窗的训练数据进行的训练。
所述训练方法还可包括:排除与使用循环模型基于与填充相关联的状态参数计算的与填充相关联的输出数据。
训练的步骤可包括:基于与先前窗的最后帧对应的状态参数,更新与当前窗的第一帧对应的节点的状态参数。
获取与先前窗对应的状态参数的步骤可包括:响应于当前窗是相对于训练输入的第一窗,将与先前窗对应的状态参数确定为默认值。
提取目标数据和填充数据的步骤可包括:响应于当前窗是相对于训练输入的最后窗,排除填充数据。
在另一总体方面,一种识别方法包括:从序列数据提取与当前窗对应的目标数据;获取与序列数据中在当前窗之前的数据对应的过去背景数据;获取与序列数据中在当前窗之后的数据对应的未来背景数据,其中,过去背景数据和未来背景数据是不同类型的数据;使用循环模型,基于过去背景数据、提取的目标数据和未来背景数据,计算当前窗的识别结果。
获取过去背景数据的步骤可包括:获取与序列数据中在当前窗之前的先前窗对应的状态参数作为过去背景数据;获取未来背景数据的步骤可包括:从序列数据提取在提取的目标数据之后的填充数据作为未来背景数据。
获取所述状态参数的步骤可包括:响应于当前窗是序列数据的第一窗,将所述状态参数设置为默认值;响应于当前窗不是序列数据的第一窗,获取在对先前窗执行的识别期间获得的状态参数作为所述状态参数。
在对先前窗执行的识别期间,可存储在对先前窗执行的识别期间获得的状态参数;获取在对先前窗执行的识别期间获得的状态参数的步骤可包括:检索存储的状态参数。
先前窗和当前窗均可包括多个帧;获取所述状态参数的步骤可包括:获取与先前窗的最后帧对应的状态参数。
在另一总体方面,一种训练方法包括:获取循环模型;从训练输入提取与当前窗对应的目标数据;在获取与训练输入中在当前窗之前的数据对应的过去背景数据;获取与训练输入中在当前窗之后的数据对应的未来背景数据,其中,过去背景数据和未来背景数据是不同类型的数据;训练循环模型,使得映射到训练输入的训练输出基于过去背景数据、提取的目标数据和未来背景数据被计算。
获取过去背景数据的步骤可包括:获取与训练输入中在当前窗之前的先前窗对应的状态参数作为过去背景数据;获取未来语境数据的步骤可包括:从训练输入提取在提取的目标数据之后的填充数据作为未来背景数据。
获取所述状态参数的步骤可包括:响应于当前窗是训练输入的第一窗,将所述状态参数设置为默认值;响应于当前窗不是训练输入的第一窗,获取在对先前窗执行的训练期间获得的状态参数作为所述状态参数。
在对先前窗执行的训练期间,可存储在对先前窗执行的训练期间获得的状态参数;获取在对先前窗执行的训练期间获得的状态参数的步骤可包括:检索存储的状态参数。
先前窗和当前窗均可包括多个帧;获取所述状态参数的步骤可包括:获取与先前窗的最后帧对应的状态参数。
其他特征和方面从下面的具体实施方式、附图和权利要求将是清楚的。
附图说明
图1示出循环神经网络的示例。
图2示出以窗长度展开的循环神经网络的示例。
图3示出双向循环神经网络的示例。
图4示出基于双向循环神经网络的语音识别的示例。
图5示出基于状态参数和填充(padding)使用循环神经网络的序列数据识别的示例。
图6示出将先前窗的状态参数应用于当前窗的示例。
图7示出更新循环神经网络的每个节点的示例。
图8示出识别设备的示例。
图9示出训练设备的示例。
图10示出识别方法的示例。
图11示出训练方法的示例。
图12示出在识别方法和训练方法中针对序列数据设置窗和填充的示例。
贯穿附图和具体实施方式,相同的参考标号表示相同的元件。为了清楚、说明和便利,附图可不按比例,并且附图中的元件的相对大小、比例和描写可被夸大。
具体实施方式
提供下面的具体实施方式以帮助读者获得对在此描述的方法、设备和/或系统的全面理解。然而,在理解本申请的公开之后,在此描述的方法、设备和/或系统的各种改变、修改和等同物将是清楚的。例如,在此描述的操作的顺序仅是示例,操作的顺序不局限于在此阐述的顺序,而是除了必须按特定次序发生的操作之外,可如理解本申请的公开之后将清楚的那样改变。此外,为了更加清楚和简洁,本领域中已知的功能和结构的描述可被省略。
在此描述的特征可以以不同的形式实现,并且不将被解释为受限于在此描述的示例。相反,提供在此描述的示例仅为示出实施在此描述的方法、设备和/或系统的许多可行方式中的一些方式,所述许多可行方式在理解本申请的公开之后将是清楚的。
在此使用的术语仅为了描述特定示例的目的,而不将用于限制本公开。如在此使用的,除非上下文另外明确指示,否则单数形式也包括复数形式。如在此使用的,术语“包括”、“包含”和“具有”指定存在叙述的特征、数量、操作、元件、组件和/或它们的组合,但不排除存在或添加一个或多个其他特征、数量、操作、元件、组件和/或它们的组合。
除非另外定义,否则在此使用的包括技术术语和科学术语的所有术语具有与本公开所属领域通常理解的含义相同的含义。除非在此明确定义,否则诸如在通用字典中定义的术语将被解释为具有与它们在现有技术的背景中的含义一致的含义,并且不将被解释为理想化或过于正式的意义。
图1示出循环神经网络的示例。
神经网络是使用通过连接线连接在一起的大量的人工神经元模仿生物系统的计算能力的实现在硬件中的识别模型。在本申请中,循环神经网络(RNN)100作为神经网络的示例来描述。
RNN 100是包括循环的神经网络。RNN 100是被训练为通过将输出循环地输入到神经网络而从输入xt输出新的输出ot的神经网络。RNN 100包括节点110,并且节点110(例如,隐含节点)的输出被循环地输入到RNN 100。尽管图1为了简明示出RNN 100包括节点110,但这仅是一个示例,其他示例是可行的。例如,节点110是配置包括在RNN 100中的隐含节点的单元。包括在隐含层中的节点110也被称为隐含节点。
在本申请中,指示与节点相关联的值的参数被称为状态参数。例如,状态参数包括节点110的输出值。例如,状态参数还可被称为节点参数。
例如,RNN 100可以是长短期记忆(LSTM)神经网络。LSTM神经网络的节点110包括一个或多个记忆细胞(memory cell)和多个门(例如,输入门、遗忘门和输出门)。例如,在LSTM神经网络中,节点110的状态参数包括隐含层的节点110的单元状态值和节点110的输出值。节点110的单元状态值和输出值通过节点110的门来控制。LSTM神经网络仅是一个示例,RNN100的配置不限于这个示例。
输入xt是在时间点t输出到RNN 100的帧数据。输出ot是在时间点t从RNN 100输出的帧数据。在下文中,时间点t也被称为时间t和时间戳t。帧数据是通过基于预定的长度(例如,以帧为单位)采样序列数据而获得的数据。帧单位可基于RNN 100的设计而变化。还将参照图5描述序列数据和帧数据。
图2示出以窗长度展开的循环神经网络的示例。
参照图2,RNN以循环连接以窗长度展开的形式来表示。RNN的节点被分类为前向节点211、221和231以及反向节点212、222和232。前向节点211、221和231中的每个前向节点对应于单个帧,反向节点212、222和232中的每个反向节点对应于单个帧。在图2中,每个帧对应于单个前向节点和单个反向节点。第t帧对应于前向节点211和反向节点212。然而,这仅是一个示例。在其他示例中,单个帧可对应于多个前向节点和多个反向节点。
前向节点211、221和231通过形成前向通路291的循环连接而彼此连接。反向节点212、222和232通过形成反向通路292的循环连接而彼此连接。例如,前向通路291是一个帧的前向节点的状态参数被传递到后续帧的前向节点使得该后续帧的前向节点基于数值表达式和所述一个帧的前向节点的传递的状态参数被更新的连接。例如,反向通路292是一个帧的反向节点的状态参数被传递到先前帧的反向节点使得先前帧的反向节点基于数值表达式和所述一个帧的反向节点的传递的状态参数被更新的连接。前向节点的更新路径可独立于反向节点的更新路径。
在图2的示例中,窗200的长度是三个帧,但窗可具有其他长度。识别设备在时间点t将输入帧数据(例如,输入xt)输入到与时间t的帧对应的前向节点211和反向节点212。识别设备基于前向通路291将时间t的状态参数从与时间t对应的帧的前向节点211传播到与时间点t+1对应的帧的前向节点221。在下文中,时间点t+1也被称为时间t+1。此外,识别设备基于反向通路292将时间t+1的状态参数从与时间t+1对应的帧的反向节点222传播到与时间t对应的帧的反向节点212。识别设备使用前向节点211的状态参数和基于反向通路292更新的反向节点212的状态参数从输入xt计算与第t帧对应的输出ot。
尽管图2为了简明示出窗长度是三个帧并且RNN中仅包括节点,但这仅是一个示例,其他示例也是可行的。
图3示出双向循环神经网络的示例。
RNN包括输入层、隐含层和输出层。如上所述,隐含层包括作为隐含节点的多个节点。当RNN是LSTM神经网络时,每个节点包括记忆细胞单元(memory cell unit),记忆细胞单元包括至少一个时间门。
输入层接收用于执行训练或识别的输入,并将输入传递到隐含层。输出层基于从隐含层的节点接收的信号产生神经网络的输出。隐含层在输入层与输出层之间,并将从输入层传递的待识别的数据或训练数据改变为可由输出层容易识别的数据。输入层和隐含层中的节点通过具有各自的连接权重的连接线彼此连接。此外,隐含层和输出层中的节点通过具有各自的连接权重的连接线彼此连接。输入层、隐含层和输出层均可包括多个节点。
尽管图3为了简明示出输入层和输出层均包括单个节点并且隐含层包括两个节点,但包括在每个层中的节点的类型和节点的数量可基于RNN的设计而变化。
神经网络可包括多个隐含层。包括多个隐含层的神经网络被称为深度神经网络,深度神经网络的训练被称为深度学习。包括在隐含层中的节点被称为隐含节点。在先前时间间隔中的状态参数(例如,隐含节点的输出值)被应用于当前时间间隔(例如,当前帧)的隐含节点。当前时间间隔中的隐含节点的状态参数被应用于后续时间间隔的隐含节点。具有不同时间间隔的隐含节点之间的循环连接的神经网络也被称为RNN。在图3的示例中,在隐含节点之中,前向节点循环地连接到另一前向节点,反向节点循环地连接到另一反向节点。
图3示出RNN以与三个帧对应的窗长度展开的情况。尽管图3示出RNN包括分别相对于窗300的第一帧310、中间帧320和最后帧330的输入层311、321和331、隐含层312、322和332、以及输出层313、323和333,但这仅是一个示例。在其他示例中,RNN可包括针对窗300的每个帧的多个隐含层。
RNN的每个层接收与当前时间对应的时间戳t。例如,当前时间可以是没有层间延迟的。时间戳t可对应于相位信号。相位信号可被应用于在相同的时间点更新的所有层。在窗300的第一帧310中,输入层311、隐含层312和输出层313是在时间t更新的层。在窗300的中间帧320中,输入层321、隐含层322和输出层323是在时间t+1更新的层。在窗300的最后帧330中,输入层331、隐含层332和输出层333是在时间点t+2更新的层。在下文中,时间点t+2也被称为时间t+2。
RNN的输入数据可基于连续的输入信号被采样。在下文中,连续的输入信号也被称为序列数据。RNN的输入数据可均匀地和同步地被采样,并且还可非均匀地和异步地被采样。
RNN的与每个帧对应的隐含层相对于后续帧中的相同级别的隐含层形成前向通路391。在RNN中,窗300中的与第一帧310对应的隐含层312的第i前向节点相对于与后续帧(例如,图3的中间帧320)对应的隐含层322的第i前向节点形成前向通路391,其中,i是大于或等于1的整数。
此外,RNN的每个帧的隐含层相对于先前帧中的相同级别的隐含层形成反向通路392。在RNN中,窗300的与中间帧320对应的隐含层322的第j反向节点相对于与先前帧(例如,图3的第一帧310)对应的隐含层312的第j反向节点形成反向通路392,其中,j是大于或等于1的整数。节点可被分类为基于前向通路391连接的前向节点和基于反向通路392连接的反向节点。
根据展开的RNN,例如,在隐含层之间形成前向通路和反向通路的RNN被称为双向RNN。
图4示出基于双向循环神经网络的语音识别的示例。
识别设备接收序列数据401。识别设备接收作为序列数据401的语音信号。在图4的示例中,识别设备接收语音信号“one oh five”。语音信号“one oh five”也使用音标被表示为“wahn ow fayv”。
识别设备参考基于当前帧的先前帧410的信息和基于当前帧的后续帧420的信息,以从序列数据401输出与预定的窗对应的目标数据的识别结果409。为了识别“oh”,识别设备参考与“one”和“five”对应的信息,并输出“ow”作为识别结果409。识别结果409可以是发音信息,但不限于此。识别设备基于发音信息估计与发音对应的单词。
通过使用双向RNN,识别设备被允许使用整个语音信息。这使得识别设备能够以更高的精度计算与当前窗对应的目标数据的识别结果。此外,由于识别设备以窗为单位识别序列数据,因此识别结果可以以更快的速度被计算。在这个示例中,训练在识别设备中使用的循环模型的训练设备可以以更快的速度训练具有高精度的循环模型。此外,识别设备使用先前窗的状态参数而不是添加针对过去背景(past context)的填充(padding),从而减小例如训练误差、训练时间、图形处理单元(GPU)存储器使用率、识别误差和识别时间。
在本申请中,识别结果可以是将从与当前窗对应的目标数据输出的标签。当序列数据是语音信号时,目标数据可以是被提取以对应于当前窗的语音信号的部分,识别结果可以是从语音信号的所述部分辨识的发音信息。例如,发音信息包括与语音信号的所述部分的每个帧对应的音素。
图5示出基于状态参数和填充使用双向循环神经网络的序列数据识别的示例。
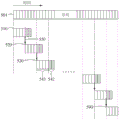
为了参考过去背景而不受过去背景的长度的制约,识别设备在考虑先前窗的状态参数的情况下计算与当前窗对应的目标数据的识别结果。识别设备参考与未来背景的填充对应的填充数据。因此,识别设备参考除了过去背景之外的未来背景,从而提高识别的精度和速度。
参照图5,序列数据501包括多个帧。识别设备顺序地接收构成序列数据501的帧数据。例如,帧数据是通过基于预定的时间间隔采样序列数据501获得的数据。
识别设备以窗为单位分割序列数据501。识别设备处理与第一窗510对应的目标数据,处理与第二窗520对应的目标数据,之后处理与第三窗530对应的目标数据。识别设备将序列数据501分割为与每个窗对应的目标数据,而不重叠窗与窗之间的帧数据。也就是说,任意给定的帧数据仅出现在一个窗中。
识别设备从序列数据501提取与当前窗对应的目标数据541和与在当前窗之后连接的填充对应的填充数据542。识别设备将目标数据541和填充数据542输入到循环模型,并计算目标数据541的识别结果。
识别设备在计算目标数据541的识别结果的处理中存储与当前窗的最后帧对应的状态参数550(例如,隐含节点的输出值)。在这个示例中,识别设备排除与在当前窗之后连接的填充的填充数据对应的状态参数。
为了计算后续窗的识别结果,如在图5中所示,识别设备将存储的状态参数550提供给与后续窗的第一帧对应的节点(例如,前向节点)作为前馈。这使识别设备在维持过去背景的同时参考在填充的尺寸内的未来背景。针对过去背景,由于仅存储在先前窗中的状态参数550被输入为与当前窗的第一帧对应的节点的初始值,因此减小了识别设备的计算复杂度。此外,识别设备使用状态参数550参考过去背景而不受过去背景的长度的约束,从而提高识别的精度。
当最后窗590的最后的帧数据是序列数据501的最后的帧数据时,识别设备不使用填充数据来执行识别。
因此,例如,识别设备可使用最小的开销在保证精度的同时逐步解码语音信号。
尽管基于识别的示例提供图5的描述,但这仅是一个示例。与识别设备的操作相似,训练设备可以以窗为单位分割训练数据的训练输入,并使用填充数据执行训练。
训练设备在输入到循环模型的训练输入的目标数据和填充数据的前馈的处理中存储当前窗的状态参数,并基于反向传播学习来更新循环模型。当完成对当前窗的训练时,训练设备通过前馈将训练输入中的当前窗的状态参数和与后续窗对应的目标数据提供给循环模型。还将参照图11描述循环模型的训练和反向传播学习。
图6示出将先前窗的状态参数应用于当前窗的示例。
识别设备在计算与第(n-1)窗610对应的目标数据的识别结果的处理中存储与第(n-1)窗610的最后帧对应的节点611(例如,前向节点)的状态参数。识别设备排除与在第(n-1)窗610之后布置的填充620相关联的信息,其中,n是大于或等于2的整数。
识别设备将与节点611对应的状态参数暂时存储在独立的存储器中。其后,识别设备基于前向通路601将与第(n-1)窗610的最后帧对应的节点611的状态参数传播到与第n窗630的第一帧对应的节点631(例如,后续的前向节点)。
第n窗630对应于当前窗。在下文中,第(n-1)窗610也被称为先前窗610,第n窗630也被称为当前窗630。识别设备基于先前窗610的最后帧的状态参数来确定与当前窗630的第一帧对应的节点631的初始状态参数。
识别设备基于先前窗610的状态参数、与当前窗630对应的目标数据、与分配到当前窗630的填充对应的填充数据,在当前窗630中更新循环模型的每个节点的状态参数。
尽管基于识别设备的示例提供图6的描述,但这仅是一个示例。与识别设备的操作相似,训练设备参考与先前窗的最后帧对应的状态参数和填充数据,以使用与当前窗对应的训练输入训练循环模型。
图7示出更新循环神经网络的每个节点的示例。
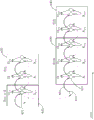
识别设备顺序更新相同级别的层中的状态参数,之后顺序更新RNN中的后续级别的层中的状态参数。
在图7的示例中,基于具有三个帧的窗设置RNN。此外,RNN包括输入层、两个级别的隐含层、和输出层。
识别设备每次将包括在与窗对应的目标数据中的帧数据xt、xt+1和xt+2输入到RNN的输入层711、721和731。识别设备通过前馈将输入到输入层711、721和731的目标数据的帧数据传递到隐含层。识别设备通过前馈781将目标数据从输入层711传递到第一帧的隐含层712,通过前馈782将目标数据从输入层721传递到中间帧的隐含层722,并通过前馈783将目标数据从输入层731传递到最后帧的隐含层732。
识别设备基于前向通路顺序更新隐含层的节点。识别设备基于前向通路784将第一帧的隐含层712的状态参数传递到中间帧的隐含层722,并更新隐含层722的状态参数。识别设备基于前向通路785将隐含层722的状态参数传递到最后帧的隐含层732,并更新隐含层732的状态参数。识别设备基于从第一帧到最后帧的前向通路重复执行状态参数的更新。
识别设备分别通过前馈793、792和791将输入到输入层711、721和731的目标数据传递到反向通路的隐含层713、723和733。识别设备基于反向通路顺序更新隐含层的节点。识别设备基于反向通路794将最后帧的隐含层733的状态参数传递到中间帧的隐含层723,并更新隐含层723的状态参数。识别设备基于反向通路795将隐含层723的状态参数传递到第一帧的隐含层713,并更新隐含层713的状态参数。识别设备基于从最后帧到第一帧的反向通路重复执行状态参数的更新。
同样地,识别设备更新后续级别的隐含层714、715、724、725、734和735的状态参数,并将识别结果输出到输出层716、726和736。
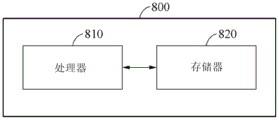
图8示出识别设备的示例。
识别设备800包括处理器810和存储器820。
处理器810从序列数据提取与当前窗对应的目标数据和在目标数据之后的填充数据。处理器810从存储器820获取与先前窗对应的状态参数。处理器810基于循环模型使用状态参数、提取的目标数据和提取的填充数据来计算当前窗的识别结果。
处理器810的操作不限于前述的示例,处理器810还可执行参照图1至图7、图10和图12描述的操作。
存储器820包括循环模型。循环模型是被训练使得训练输出从训练输入被输出的模型,并且包括例如RNN。如前所述,循环模型包括与窗和填充中的每个帧对应的节点。例如,节点包括在循环模型的隐含层中。此外,存储器820将每个节点的状态参数存储在循环模型中。
图9示出训练设备的示例。
训练设备900包括处理器910和存储器920。
处理器910获取循环模型921。处理器910从训练输入提取与当前窗对应的目标数据和在目标数据之后的填充数据。处理器910从存储器920获取与先前窗对应的状态参数。处理器910训练循环模型921,使得映射到训练输入的训练输出从状态参数、提取的目标数据和提取的填充数据被计算。处理器910的操作不限于前述的示例,处理器910还可执行参照图1至图7、图11和图12描述的操作。
训练数据901包括训练输入和训练输出。训练输出是映射到训练输入的输出。例如,训练输出是将从训练输入输出的标签。例如,从语音识别方面来说,训练输入是语音信号,训练输出是由语音信号指示的音素信息。
处理器910基于误差反向传播学习来执行节点的状态参数以及循环模型921的层与层之间的连接权重的训练。
处理器910基于监督学习来训练神经网络(例如,RNN)。例如,监督学习是这样的方法:将训练输入和与训练输入对应的训练输出输入到神经网络并更新神经网络的连接线的连接权重,使得与训练输入对应的训练输出被输出。例如,处理器910采用德尔塔定律(delta rule)和误差反向传播学习来更新节点之间的连接权重。
例如,误差反向传播学习是这样的方法:通过对训练数据执行前向计算来估计误差,沿反方向(从输出层通过隐含层到输入层)来传播估计的误差,并调节连接权重,以减小误差。神经网络的识别处理按照从输入层、隐含层和输出层的次序被执行。在误差反向传播学习中,连接权重按照从输出层、隐含层和输入层的次序被更新。
存储器920存储循环模型921。存储器920存储在训练处理中被顺序更新的循环模型921。存储器920还可存储训练数据901。
图10示出识别方法的示例。
在下文中,将参照操作1010至操作1030描述序列数据的单个窗的识别处理。识别设备以窗为单位分割序列数据,并对第一窗至最后窗重复执行操作1010至操作1030,从而获得识别结果。
在操作1010中,识别设备从序列数据提取与当前窗对应的目标数据和目标数据后续的填充数据。识别设备从先前窗的最后帧数据后续的帧数据开始从序列数据提取与窗长度对应的数据作为与当前窗对应的目标数据。此外,识别设备从当前窗的最后帧数据后续的帧数据开始从序列数据提取与填充长度对应的数据作为与填充对应的填充数据。例如,识别设备接收与声音信号对应的序列数据。
当当前窗是序列数据的最后窗时,识别设备排除填充数据。如参照图5所述,当当前窗时最后窗时,在序列数据中缺少将被获取作为填充的数据。因此,识别设备排除针对最后窗的填充。
在操作1020中,识别设备获取与先前窗对应的状态参数。当当前窗是序列数据的第一窗时,识别设备将与先前窗对应的状态参数确定为默认值(例如,0)。这使识别设备能够在排除循环模型中先前窗的影响的情况下输入与第一窗对应的目标数据。
在操作1030中,识别设备基于循环模型使用状态参数、提取的目标数据和提取的填充数据来计算当前窗的识别结果。识别设备从与当前窗对应的目标数据辨识发音。识别设备以当前窗的窗长度和填充长度展开循环模型。识别设备针对展开的循环模型的每个帧输入状态参数、提取的目标数据和提取的填充数据,并计算与包括在当前窗中的帧对应的输出数据。
识别设备基于与先前窗的最后帧对应的状态参数来更新与当前窗的第一帧对应的节点的输入值。如参照图6所述,识别设备暂时存储先前窗中的最后帧的状态参数,并使用存储的状态参数以更新将被输入到当前窗的值。
识别设备基于前向通路顺序地从窗的第一帧到最后帧更新状态参数。识别设备基于反向通路顺序地从窗的最后帧到第一帧更新状态参数。识别设备将基于前向通路的状态参数和基于反向通路的状态参数提供给后续层的节点。可如参照图7描述的一样更新基于前向通路的状态参数和基于反向通路的状态参数。
识别设备暂时存储与当前窗中的最后帧对应的状态参数,用于后续窗。
识别设备排除与填充相关联的状态参数和基于循环模型计算的与填充数据相关联的输出数据。例如,识别设备忽略与填充数据有关的识别结果,并从将用于后续窗的识别的信息排除与填充相关联的状态参数。
例如,识别设备可将循环模型应用于语音识别、手写识别、翻译、文本创作和自然语言理解(NLU)。
图11示出训练方法的示例。
在下文中,将参照操作1110至操作1140描述针对序列数据的单个窗的训练处理。训练设备以窗为单位分割序列数据,并对第一窗至最后窗重复执行操作1110至操作1140,从而顺序地执行训练。
在操作1110中,训练设备获取循环模型。训练设备从内部存储器加载循环模型,或从外部服务器接收循环模型。
在操作1120中,训练设备从训练输入提取与当前窗对应的目标数据和在目标数据之后的填充数据。当当前窗是训练输入的最后窗时,训练设备排除填充数据。
在操作1130中,训练设备获取与先前窗对应的状态参数。当当前窗是训练输入的第一窗时,训练设备将与先前窗对应的状态参数确定为默认值(例如,0)。因此,当当前窗是训练数据的第一窗时,因为不存在先前窗,所以训练设备忽略先前窗。
在操作1140中,训练设备训练循环模型,使得映射到训练输入的训练输出从状态参数、提取的目标数据和提取的填充数据被计算。训练设备基于与先前窗的最后帧对应的状态参数来更新与当前窗的第一帧对应的节点的状态参数。
训练设备排除使用循环模型基于与填充相关联的状态参数计算的与填充相关联的输出数据。当完成当前窗的训练时,训练设备使用当前窗中的最后帧的隐含层中的隐含节点的输出值用于后续窗的训练。此外,训练设备从后续窗的训练排除与填充相关联的状态参数和输出数据。
图12示出在识别方法和训练方法中针对序列数据设置窗和填充的示例。
识别设备或训练设备的处理器以窗为单位分割序列数据,并在操作1211至操作1240中执行识别或训练。
在操作1211中,处理器获取序列数据。例如,处理器通过与外部装置或内部数据接口的通信来获取序列数据。处理器随时间顺序地接收构成序列数据的帧数据。
在操作1212中,处理器分割序列数据以获得当前窗。处理器基于窗长度分割帧数据的一系列连续项,以获得当前窗作为用于识别或训练的目标数据。处理器分割序列数据而不在窗与窗之间重叠帧数据。也就是说,任意给定项的帧数据仅出现在一个窗中。
在操作1213中,处理器确定当前窗是否是第一窗。当序列数据中不存在当前窗之前的帧数据时,处理器确定当前窗是第一窗。
在操作1214中,当当前窗不是第一窗时,处理器获取与先前窗的最后帧对应的状态参数。当当前窗不是序列数据的第一窗时,处理器在对先前窗执行识别或训练的处理中计算与先前窗的最后帧对应的状态参数,并存储该状态参数。处理器加载存储的状态参数。
在操作1215中,处理器确定当前窗是否是最后窗。当序列数据中不存在当前窗之后的帧数据时,处理器确定当前窗是最后窗。
在操作1216中,当当前窗不是最后窗时,处理器在当前窗之后添加填充。处理器从序列数据额外地提取与填充对应的帧数据(例如,填充数据)。如此,处理器提取与窗对应的数据和与填充对应的填充数据。
在操作1222中,处理器执行识别或训练。例如,当处理器是实现在识别设备内部的装置时,处理器基于目标数据和在操作1216中提取的填充数据来产生与目标数据对应的识别结果。此外,例如,当处理器是实现在训练设备内部的装置时,处理器基于目标数据和在操作1216中提取的填充数据来训练循环模型,使得映射到目标数据的标签被输出。
在操作1230中,处理器存储与当前窗的最后帧对应的状态参数。存储的与当前窗的最后帧对应的状态参数被用于更新与后续窗的第一帧对应的节点的状态参数。
在操作1221中,当当前窗是最后窗时,处理器执行识别或训练。例如,当处理器是实现在识别设备内部的装置时,处理器基于与在操作1212中分割的当前窗对应的目标数据来产生与目标数据对应的识别结果。此外,例如,当处理器是实现在训练设备内部的装置时,处理器基于与在操作1212中分割的当前窗对应的目标数据来训练循环模型,使得映射到目标数据的标签被输出。
在操作1240中,处理器确定序列数据是否结束。当序列数据结束时,处理器终止识别或训练的操作。当存在与当前窗之后的窗对应的序列数据时,处理器返回到操作1211。
通过被配置为执行在本申请中描述的操作的硬件组件来实现执行在本申请中描述的操作的图1中的循环神经网络(RNN)100和节点110、图2中的前向节点211、221、231和反向节点212、222和232、图3中的输入层311、321和331、隐含层312、322和332以及输出层313、323和333、图6中的节点611和631以及其他未标记的节点、图7中的输入层711、721和731、隐含层712、713、714、715、722、723、724、725、732、733、734和735以及输出层716、726和736、图8中的识别设备800、处理器810、存储器820、以及图9中的训练设备900、处理器910和存储器920。可用于执行在本申请中的适当位置描述的操作的硬件组件的示例包括:控制器、传感器、产生器、驱动器、存储器、比较器、算术逻辑单元、加法器、减法器、乘法器、除法器、积分器和被配置为执行在本申请中描述的操作的任何其他电子组件。在其他示例中,执行在本申请中描述的操作的一个或多个硬件组件通过计算硬件(例如,通过一个或多个处理器或计算机)来实现。可通过一个或多个处理元件(诸如,逻辑门阵列、控制器和算术逻辑单元、数字信号处理器、微型计算机、可编程逻辑控制器、现场可编辑门阵列、可编程逻辑阵列、微处理器)或被配置为以限定的方式响应并执行指令以实现期望的结果的任何其他装置或装置的组合,来实现处理器或计算机。在一个示例中,处理器或计算机包括或连接到存储由处理器或计算机执行的指令或软件的一个或多个存储器。通过处理器或计算机实现的硬件组件可执行指令或软件(诸如,操作系统(OS)和在OS上运行的一个或多个软件应用),以执行在本申请中描述的操作。硬件组件还可响应于指令或软件的执行,访问、操纵、处理、创建和存储数据。为了简明,单数术语“处理器”或“计算机”可用于本申请中描述的示例的描述,但在其他示例中,可使用多个处理器或多个计算机,或者一个处理器或一个计算机可包括多个处理元件或多种类型的处理元件或者两者。例如,可通过单个处理器、或者两个或更多个处理器、或者一个处理器和一个控制器,来实现单个硬件组件、或者两个或更多个硬件组件。可通过一个或多个处理器、或者一个处理器和一个控制器,来实现一个或多个硬件组件,并且可通过一个或多个其他处理器、或者另一处理器和另一控制器,来实现一个或多个其他硬件组件。一个或多个处理器、或者一个处理器和一个控制器可实现单个硬件组件、或者两个或更多个硬件组件。硬件组件可具有多个不同的处理配置中的任意一个或多个,不同的处理配置的示例包括:单处理器、独立处理器、并行处理器、单指令单数据(SISD)多处理、单指令多数据(SIMD)多处理、多指令单数据(MISD)多处理以及多指令多数据(MIMD)多处理。
通过被实现为如上所述地执行指令或软件以执行在本申请中描述的由方法执行的操作的计算硬件(例如,通过一个或多个处理器或计算机)来执行在图10至图12中所示的执行在本申请中描述的操作的方法。例如,单个操作、或者两个或更多个操作可通过单个处理器、或者两个或更多个处理器、或者一个处理器和一个控制器来执行。一个或多个操作可通过一个或多个处理器、或者一个处理器和一个控制器来执行,并且一个或多个其他操作可通过一个或多个其他处理或者另一处理器和另一控制器来执行。一个或多个处理器、或者一个处理器和一个控制器可执行单个操作、或者两个或更多个操作。
用于控制计算硬件(例如,一个或多个处理器或计算机)实现硬件组件并执行如上所述的方法的指令或软件可被写为计算机程序、代码段、指令或它们的任意组合,以单独地或共同地指示或配置一个或多个处理器或计算机作为用于执行由硬件组件执行的操作和如上所述的方法的机器或专用计算机进行操作。在一个示例中,指令或软件包括直接由一个或多个处理器或计算机执行的机器代码(诸如,由编译器产生的机器代码)。在另一示例中,指令或软件包括由一个或多个处理器或计算机使用解释器执行的高级代码。可基于公开了用于执行由硬件组件执行的操作和如上所述的方法的算法的附图中示出的框图和流程图以及说明书中的相应描述使用任意编程语言编写指令或软件。
用于控制计算硬件(例如,一个或多个处理器或计算机)实现硬件组件并执行如上所述的方法的指令或软件、以及任何相关联的数据、数据文件以及数据结构可被记录、存储或固定在一个或多个非暂时性计算机可读存储介质中,或被记录、存储或固定在一个或多个非暂时性计算机可读存储介质上。非暂时性计算机可读存储介质的示例包括:只读存储器(ROM)、随机存取存储器(RAM)、闪存、CD-ROM、CD-R、CD+R、CD-RW、CD+RW、DVD-ROM、DVD-R、DVD+R、DVD-RW、DVD+RW、DVD-RAM、BD-ROM、BD-R、BD-R LTH、BD-RE、磁带、软盘、磁光数据存储装置、光学数据存储装置、硬盘、固态盘、和任何其他设备,该任何其他设备被配置为以非暂时方式存储指令或软件、以及任何相关联的数据、数据文件以及数据结构,并向一个或多个处理器或计算机提供指令或软件、以及任何相关联的数据、数据文件以及数据结构,以便一个或多个处理器或计算机能够执行指令。在一个示例中,指令或软件、以及任何相关联的数据、数据文件以及数据结构分布在联网的计算机系统上,以便指令和软件、以及任何相关联的数据、数据文件以及数据结构被一个或多个处理器或计算机以分布式方式存储、访问和执行。
尽管本公开包括特定示例,但是在理解本申请的公开后将清楚的是,在不脱离权利要求和它们的等同物的精神和范围的情况下,可对这些示例做出形式和细节上的各种改变。在此描述的示例将被认为仅是描述性的,而非为了限制的目的。在每个示例中的特征或方面的描述将被认为适用于其他示例中的相似特征或方面。如果描述的技术以不同的顺序被执行,和/或如果在描述的系统、架构、装置、或电路中的组件以不同的方式被组合和/或被其他组件或它们的等同物代替或补充,则可实现合适的结果。因此,本公开的范围不是由具体实施方式限定,而是由权利要求和它们的等同物限定,并且在权利要求和它们的等同物的范围内的所有变化将被解释为被包括在本公开中。
Claims (28)
1.一种语音信号的识别方法,包括:
从作为序列数据的语音信号提取与作为具有预定帧长度的时间窗的当前窗对应的目标数据和与作为具有预定帧长度的时间窗的未来窗对应的在目标数据之后的填充数据,目标数据是被提取以对应于当前窗的语音信号的部分并且包括多个帧,填充数据对应于目标数据的所述多个帧的未来背景;
获取与作为具有预定帧长度的时间窗的先前窗对应的状态参数,状态参数对应于目标数据的所述多个帧的过去背景并且不受过去背景的长度的制约;
使用循环模型,基于状态参数、提取的目标数据和提取的填充数据,计算当前窗的识别结果,识别结果是从语音信号的所述部分辨识的发音信息,所述发音信息包括与语音信号的所述部分的每个帧对应的音素,
其中,作为序列数据的语音信号以窗为单位被分割为多个窗,所述多个窗彼此不重叠,并且所述多个窗包括当前窗、先前窗和未来窗,
其中,当前窗对应于与所述发音信息对应的目标单词,先前窗对应于目标单词之前的单词,未来窗对应于目标单词之后的单词,
其中,所述识别方法还包括:排除与填充相关联的状态参数和基于循环模型计算的填充数据的输出数据。
2.如权利要求1所述的识别方法,还包括:暂时存储与当前窗的最后帧对应的状态参数,以用于后续窗。
3.如权利要求1所述的识别方法,其中,计算识别结果的步骤包括:
以当前窗的窗长度和填充长度展开循环模型;
针对每个帧将状态参数、提取的目标数据和提取的填充数据输入到展开的循环模型,并计算与包括在当前窗中的帧对应的输出数据。
4.如权利要求1所述的识别方法,其中,计算识别结果的步骤包括:基于与先前窗的最后帧对应的状态参数,更新与当前窗的第一帧对应的节点的输入值。
5.如权利要求1所述的识别方法,其中,提取目标数据和填充数据的步骤包括:从先前窗的最后帧数据之后的帧数据开始从语音信号提取与窗长度对应的数据作为与当前窗对应的目标数据。
6.如权利要求1所述的识别方法,其中,提取目标数据和填充数据的步骤包括:从当前窗的最后帧数据之后的帧数据开始从语音信号提取与填充长度对应的数据作为与填充对应的填充数据。
7.如权利要求1所述的识别方法,其中,循环模型是被训练为响应于基于训练数据的训练输入输出训练输出的双向循环神经网络。
8.如权利要求1所述的识别方法,其中,循环模型包括:与包括在窗和填充中的每个帧对应的节点;
计算识别结果的步骤包括:
基于所述节点的前向通路,顺序地从窗的第一帧到窗的最后帧更新状态参数;
基于所述节点的反向通路,顺序地从窗的最后帧到窗的第一帧更新状态参数;
将基于前向通路的状态参数和基于反向通路的状态参数提供给后续层的节点。
9.如权利要求1所述的识别方法,其中,计算识别结果的步骤包括:从与当前窗对应的目标数据辨识发音。
10.如权利要求1所述的识别方法,其中,获取与先前窗对应的状态参数的步骤包括:响应于当前窗是相对于语音信号的第一窗,将与先前窗对应的状态参数确定为默认值。
11.如权利要求1所述的识别方法,其中,提取目标数据和填充数据的步骤包括:响应于当前窗是相对于语音信号的最后窗,排除填充数据。
12.一种存储指令的非暂时性计算机可读介质,当所述指令由处理器执行时,使所述处理器执行如权利要求1所述的识别方法。
13.一种语音信号的识别设备,包括:
存储器,被配置为存储循环模型;
处理器,被配置为:
从作为序列数据的语音信号提取与作为具有预定帧长度的时间窗的当前窗对应的目标数据和与作为具有预定帧长度的时间窗的未来窗对应的在目标数据之后的填充数据,目标数据是被提取以对应于当前窗的语音信号的部分并且包括多个帧,填充数据对应于目标数据的所述多个帧的未来背景;
获取与作为具有预定帧长度的时间窗的先前窗对应的状态参数,状态参数对应于目标数据的所述多个帧的过去背景并且不受过去背景的长度的制约;
使用循环模型,基于状态参数、提取的目标数据和提取的填充数据,计算当前窗的识别结果,识别结果是从语音信号的所述部分辨识的发音信息,所述发音信息包括与语音信号的所述部分的每个帧对应的音素,其中,作为序列数据的语音信号以窗为单位被分割为多个窗,所述多个窗彼此不重叠,并且所述多个窗包括当前窗、先前窗和未来窗,
其中,当前窗对应于与所述发音信息对应的目标单词,先前窗对应于目标单词之前的单词,未来窗对应于目标单词之后的单词,
其中,处理器还被配置为:排除与填充相关联的状态参数和基于循环模型计算的填充数据的输出数据。
14.一种用于识别语音信号的循环模型的训练方法,包括:
获取循环模型;
从作为序列数据的训练语音输入提取与作为具有预定帧长度的时间窗的当前窗对应的目标数据和与作为具有预定帧长度的时间窗的未来窗对应的在目标数据之后的填充数据,目标数据是被提取以对应于当前窗的训练语音输入的部分并且包括多个帧,填充数据对应于目标数据的所述多个帧的未来背景;
获取与作为具有预定帧长度的时间窗的先前窗对应的状态参数,状态参数对应于目标数据的所述多个帧的过去背景并且不受过去背景的长度的制约;
训练循环模型,使得映射到训练语音输入的训练语音输出基于状态参数、提取的目标数据和提取的填充数据被计算,训练语音输出是从训练语音输入的所述部分辨识的发音信息,所述发音信息包括与训练语音输入的所述部分的每个帧对应的音素,
其中,作为序列数据的训练语音输入以窗为单位被分割为多个窗,所述多个窗彼此不重叠,并且所述多个窗包括当前窗、先前窗和未来窗,
其中,当前窗对应于与所述发音信息对应的目标单词,先前窗对应于目标单词之前的单词,未来窗对应于目标单词之后的单词,
其中,所述训练方法还包括:排除与使用循环模型基于与填充相关联的状态参数计算的与填充相关联的输出数据。
15.如权利要求14所述的训练方法,还包括:响应于训练语音输入中存在与后续窗对应的数据,暂时存储与当前窗的最后帧对应的状态参数,以用于基于后续窗的训练数据进行的训练。
16.如权利要求14所述的训练方法,其中,训练的步骤包括:基于与先前窗的最后帧对应的状态参数,更新与当前窗的第一帧对应的节点的状态参数。
17.如权利要求14所述的训练方法,其中,获取与先前窗对应的状态参数的步骤包括:响应于当前窗是相对于训练语音输入的第一窗,将与先前窗对应的状态参数确定为默认值。
18.如权利要求14所述的训练方法,其中,提取目标数据和填充数据的步骤包括:响应于当前窗是相对于训练语音输入的最后窗,排除填充数据。
19.一种语音信号的识别方法,包括:
从作为序列数据的语音信号提取与作为具有预定帧长度的时间窗的当前窗对应的目标数据,目标数据是被提取以对应于当前窗的语音信号的部分并且包括多个帧;
获取与语音信号中在当前窗之前的作为具有预定帧长度的时间窗的先前窗中的数据对应的过去背景数据,过去背景数据不受过去背景的长度的制约;
获取与语音信号中在当前窗之后的作为具有预定帧长度的时间窗的未来窗中的数据对应的未来背景数据,其中,过去背景数据和未来背景数据是不同类型的数据;
使用循环模型,基于过去背景数据、提取的目标数据和未来背景数据,计算当前窗的识别结果,识别结果是从语音信号的所述部分辨识的发音信息,所述发音信息包括与语音信号的所述部分的每个帧对应的音素,
其中,作为序列数据的语音信号以窗为单位被分割为多个窗,所述多个窗彼此不重叠,并且所述多个窗包括当前窗、先前窗和未来窗,
其中,当前窗对应于与所述发音信息对应的目标单词,先前窗对应于目标单词之前的单词,未来窗对应于目标单词之后的单词,
其中,所述识别方法还包括:排除与填充相关联的状态参数和基于循环模型计算的填充数据的输出数据。
20.如权利要求19所述的识别方法,其中,获取过去背景数据的步骤包括:获取与语音信号中在当前窗之前的先前窗对应的状态参数作为过去背景数据;
获取未来背景数据的步骤包括:从语音信号提取在提取的目标数据之后的填充数据作为未来背景数据。
21.如权利要求20所述的识别方法,其中,获取所述状态参数的步骤包括:
响应于当前窗是语音信号的第一窗,将所述状态参数设置为默认值;
响应于当前窗不是语音信号的第一窗,获取在对先前窗执行的识别期间获得的状态参数作为所述状态参数。
22.如权利要求21所述的识别方法,其中,在对先前窗执行的识别期间,存储在对先前窗执行的识别期间获得的状态参数;
获取在对先前窗执行的识别期间获得的状态参数的步骤包括:检索存储的状态参数。
23.如权利要求20所述的识别方法,其中,先前窗和当前窗均包括多个帧;
获取所述状态参数的步骤包括:获取与先前窗的最后帧对应的状态参数。
24.一种用于识别语音信号的循环模型的训练方法,包括:
获取循环模型;
从作为序列数据的训练语音输入提取与作为具有预定帧长度的时间窗的当前窗对应的目标数据,目标数据是被提取以对应于当前窗的训练语音输入的部分并且包括多个帧;
获取与训练语音输入中在当前窗之前的作为具有预定帧长度的时间窗的先前窗中的数据对应的过去背景数据,过去背景数据不受过去背景的长度的制约;
获取与训练语音输入中在当前窗之后的作为具有预定帧长度的时间窗的未来窗中的数据对应的未来背景数据,其中,过去背景数据和未来背景数据是不同类型的数据;
训练循环模型,使得映射到训练语音输入的训练语音输出基于过去背景数据、提取的目标数据和未来背景数据被计算,训练语音输出是从训练语音输入的所述部分辨识的发音信息,所述发音信息包括与训练语音输入的所述部分的每个帧对应的音素,
其中,作为序列数据的训练语音输入以窗为单位被分割为多个窗,所述多个窗彼此不重叠,并且所述多个窗包括当前窗、先前窗和未来窗,
其中,当前窗对应于与所述发音信息对应的目标单词,先前窗对应于目标单词之前的单词,未来窗对应于目标单词之后的单词,
其中,所述训练方法还包括:排除与使用循环模型基于与填充相关联的状态参数计算的与填充相关联的输出数据。
25.如权利要求24所述的训练方法,其中,获取过去背景数据的步骤包括:获取与训练语音输入中在当前窗之前的先前窗对应的状态参数作为过去背景数据;
获取未来背景数据的步骤包括:从训练语音输入提取在提取的目标数据之后的填充数据作为未来背景数据。
26.如权利要求25所述的训练方法,其中,获取所述状态参数的步骤包括:
响应于当前窗是训练语音输入的第一窗,将所述状态参数设置为默认值;
响应于当前窗不是训练语音输入的第一窗,获取在对先前窗执行的训练期间获得的状态参数作为所述状态参数。
27.如权利要求26所述的训练方法,其中,在对先前窗执行的训练期间,存储在对先前窗执行的训练期间获得的状态参数;
获取在对先前窗执行的训练期间获得的状态参数的步骤包括:检索存储的状态参数。
28.如权利要求25所述的训练方法,其中,先前窗和当前窗均包括多个帧;
获取所述状态参数的步骤包括:获取与先前窗的最后帧对应的状态参数。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR10-2016-0170198 | 2016-12-14 | ||
| KR1020160170198A KR20180068475A (ko) | 2016-12-14 | 2016-12-14 | 순환 모델에 기초한 인식 및 순환 모델을 트레이닝하는 방법과 장치 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN108229677A CN108229677A (zh) | 2018-06-29 |
| CN108229677B true CN108229677B (zh) | 2023-06-30 |
Family
ID=59887027
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201710810460.4A Active CN108229677B (zh) | 2016-12-14 | 2017-09-11 | 用于使用循环模型执行识别和训练循环模型的方法和设备 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US11562204B2 (zh) |
| EP (1) | EP3336775B1 (zh) |
| JP (1) | JP7058985B2 (zh) |
| KR (1) | KR20180068475A (zh) |
| CN (1) | CN108229677B (zh) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11501155B2 (en) * | 2018-04-30 | 2022-11-15 | EMC IP Holding Company LLC | Learning machine behavior related to install base information and determining event sequences based thereon |
| US11244673B2 (en) * | 2019-07-19 | 2022-02-08 | Microsoft Technologly Licensing, LLC | Streaming contextual unidirectional models |
| CN111091849B (zh) * | 2020-03-03 | 2020-12-22 | 龙马智芯(珠海横琴)科技有限公司 | 鼾声识别的方法及装置、存储介质止鼾设备和处理器 |
| US20230063489A1 (en) * | 2021-08-25 | 2023-03-02 | Bank Of America Corporation | Malware Detection with Multi-Level, Ensemble Artificial Intelligence Using Bidirectional Long Short-Term Memory Recurrent Neural Networks and Natural Language Processing |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104572892A (zh) * | 2014-12-24 | 2015-04-29 | 中国科学院自动化研究所 | 一种基于循环卷积网络的文本分类方法 |
| CN106156003A (zh) * | 2016-06-30 | 2016-11-23 | 北京大学 | 一种问答系统中的问句理解方法 |
Family Cites Families (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2996925B2 (ja) * | 1997-03-10 | 2000-01-11 | 株式会社エイ・ティ・アール音声翻訳通信研究所 | 音素境界検出装置及び音声認識装置 |
| JP2996926B2 (ja) | 1997-03-11 | 2000-01-11 | 株式会社エイ・ティ・アール音声翻訳通信研究所 | 音素シンボルの事後確率演算装置及び音声認識装置 |
| JP2007265345A (ja) | 2006-03-30 | 2007-10-11 | Sony Corp | 情報処理装置および方法、学習装置および方法、並びにプログラム |
| US8463721B2 (en) | 2010-08-05 | 2013-06-11 | Toyota Motor Engineering & Manufacturing North America, Inc. | Systems and methods for recognizing events |
| JP6065543B2 (ja) | 2012-06-08 | 2017-01-25 | 富士通株式会社 | ニューラルネットワーク設計方法、フィッティング方法、及びプログラム |
| US9263036B1 (en) | 2012-11-29 | 2016-02-16 | Google Inc. | System and method for speech recognition using deep recurrent neural networks |
| US9378733B1 (en) | 2012-12-19 | 2016-06-28 | Google Inc. | Keyword detection without decoding |
| US9721562B2 (en) | 2013-12-17 | 2017-08-01 | Google Inc. | Generating representations of acoustic sequences |
| KR102239714B1 (ko) | 2014-07-24 | 2021-04-13 | 삼성전자주식회사 | 신경망 학습 방법 및 장치, 데이터 처리 장치 |
| US9575952B2 (en) | 2014-10-21 | 2017-02-21 | At&T Intellectual Property I, L.P. | Unsupervised topic modeling for short texts |
| KR102380833B1 (ko) | 2014-12-02 | 2022-03-31 | 삼성전자주식회사 | 음성 인식 방법 및 음성 인식 장치 |
| US10540957B2 (en) | 2014-12-15 | 2020-01-21 | Baidu Usa Llc | Systems and methods for speech transcription |
| KR102305584B1 (ko) | 2015-01-19 | 2021-09-27 | 삼성전자주식회사 | 언어 모델 학습 방법 및 장치, 언어 인식 방법 및 장치 |
| DK179049B1 (en) * | 2016-06-11 | 2017-09-18 | Apple Inc | Data driven natural language event detection and classification |
-
2016
- 2016-12-14 KR KR1020160170198A patent/KR20180068475A/ko active Search and Examination
-
2017
- 2017-06-27 US US15/634,149 patent/US11562204B2/en active Active
- 2017-09-11 EP EP17190423.8A patent/EP3336775B1/en active Active
- 2017-09-11 CN CN201710810460.4A patent/CN108229677B/zh active Active
- 2017-11-22 JP JP2017224794A patent/JP7058985B2/ja active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104572892A (zh) * | 2014-12-24 | 2015-04-29 | 中国科学院自动化研究所 | 一种基于循环卷积网络的文本分类方法 |
| CN106156003A (zh) * | 2016-06-30 | 2016-11-23 | 北京大学 | 一种问答系统中的问句理解方法 |
Non-Patent Citations (1)
| Title |
|---|
| Training Deep Bidirectional LSTM Acoustic Model for LVCSR by a Context-Sensitive-Chunk BPTT Approach;Kai Chen 等;IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING;第24卷(第7期);1185-1193 * |
Also Published As
| Publication number | Publication date |
|---|---|
| EP3336775A1 (en) | 2018-06-20 |
| US11562204B2 (en) | 2023-01-24 |
| JP2018097860A (ja) | 2018-06-21 |
| CN108229677A (zh) | 2018-06-29 |
| KR20180068475A (ko) | 2018-06-22 |
| EP3336775B1 (en) | 2022-03-16 |
| JP7058985B2 (ja) | 2022-04-25 |
| US20180165572A1 (en) | 2018-06-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102305584B1 (ko) | 언어 모델 학습 방법 및 장치, 언어 인식 방법 및 장치 | |
| CN109871529B (zh) | 语言处理方法和设备 | |
| CN108229677B (zh) | 用于使用循环模型执行识别和训练循环模型的方法和设备 | |
| US10714077B2 (en) | Apparatus and method of acoustic score calculation and speech recognition using deep neural networks | |
| BR112019004524B1 (pt) | Sistema de redes neurais, um ou mais meios de armazenamento legíveis por computador não transitório e método para gerar autorregressivamente uma sequência de saída de dados de áudio | |
| US10825445B2 (en) | Method and apparatus for training acoustic model | |
| CN108510975A (zh) | 用于实时神经文本转语音的系统和方法 | |
| KR20200045128A (ko) | 모델 학습 방법 및 장치, 및 데이터 인식 방법 | |
| US20180047389A1 (en) | Apparatus and method for recognizing speech using attention-based context-dependent acoustic model | |
| KR20190018278A (ko) | 뉴럴 네트워크를 이용한 인식 방법 및 장치 및 상기 뉴럴 네트워크를 트레이닝하는 방법 및 장치 | |
| KR20200129639A (ko) | 모델 학습 방법 및 장치 | |
| KR20200128938A (ko) | 모델 학습 방법 및 장치 | |
| CN107408111A (zh) | 端对端语音识别 | |
| JP7257593B2 (ja) | 区別可能な言語音を生成するための音声合成のトレーニング | |
| JP2016110082A (ja) | 言語モデル学習方法及び装置、音声認識方法及び装置 | |
| KR20180045635A (ko) | 뉴럴 네트워크 간소화 방법 및 장치 | |
| JP2024510679A (ja) | 教師なし並列タコトロン非自己回帰的で制御可能なテキスト読上げ | |
| US11694677B2 (en) | Decoding method and apparatus in artificial neural network for speech recognition | |
| CN111192576A (zh) | 解码方法、语音识别设备和系统 | |
| CN110751260A (zh) | 电子设备、任务处理的方法以及训练神经网络的方法 | |
| KR102449840B1 (ko) | 사용자 적응적인 음성 인식 방법 및 장치 | |
| KR20210042696A (ko) | 모델 학습 방법 및 장치 | |
| CN116564270A (zh) | 基于去噪扩散概率模型的歌唱合成方法、设备及介质 | |
| KR102292921B1 (ko) | 언어 모델 학습 방법 및 장치, 음성 인식 방법 및 장치 | |
| Su et al. | Dependent bidirectional RNN with extended-long short-term memory |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |