CN107077321B - 用于执行融合的单个周期递增-比较-跳转的指令和逻辑 - Google Patents
用于执行融合的单个周期递增-比较-跳转的指令和逻辑 Download PDFInfo
- Publication number
- CN107077321B CN107077321B CN201580063903.7A CN201580063903A CN107077321B CN 107077321 B CN107077321 B CN 107077321B CN 201580063903 A CN201580063903 A CN 201580063903A CN 107077321 B CN107077321 B CN 107077321B
- Authority
- CN
- China
- Prior art keywords
- instruction
- processor
- jump
- instructions
- compare
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000012545 processing Methods 0.000 claims abstract description 43
- 238000013519 translation Methods 0.000 claims abstract description 28
- 230000015654 memory Effects 0.000 claims description 146
- 238000000034 method Methods 0.000 claims description 14
- 230000001143 conditioned effect Effects 0.000 claims 3
- VOXZDWNPVJITMN-ZBRFXRBCSA-N 17β-estradiol Chemical compound OC1=CC=C2[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 VOXZDWNPVJITMN-ZBRFXRBCSA-N 0.000 description 69
- 238000010586 diagram Methods 0.000 description 44
- 238000006073 displacement reaction Methods 0.000 description 40
- 238000007667 floating Methods 0.000 description 32
- 238000003860 storage Methods 0.000 description 14
- 239000000872 buffer Substances 0.000 description 12
- 230000003416 augmentation Effects 0.000 description 10
- 239000012634 fragment Substances 0.000 description 10
- 230000000873 masking effect Effects 0.000 description 10
- 238000004891 communication Methods 0.000 description 8
- 239000003795 chemical substances by application Substances 0.000 description 7
- 230000006870 function Effects 0.000 description 7
- 238000006243 chemical reaction Methods 0.000 description 6
- 230000003068 static effect Effects 0.000 description 6
- 230000006835 compression Effects 0.000 description 5
- 238000007906 compression Methods 0.000 description 5
- 238000005516 engineering process Methods 0.000 description 5
- 230000007246 mechanism Effects 0.000 description 5
- 230000008901 benefit Effects 0.000 description 4
- 238000004364 calculation method Methods 0.000 description 4
- 230000008859 change Effects 0.000 description 4
- 230000000295 complement effect Effects 0.000 description 4
- 238000013501 data transformation Methods 0.000 description 4
- 230000001419 dependent effect Effects 0.000 description 4
- 238000013507 mapping Methods 0.000 description 4
- 238000013461 design Methods 0.000 description 3
- 238000004519 manufacturing process Methods 0.000 description 3
- 238000012986 modification Methods 0.000 description 3
- 230000004048 modification Effects 0.000 description 3
- 238000003491 array Methods 0.000 description 2
- 230000008878 coupling Effects 0.000 description 2
- 238000010168 coupling process Methods 0.000 description 2
- 238000005859 coupling reaction Methods 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 238000005457 optimization Methods 0.000 description 2
- 238000005192 partition Methods 0.000 description 2
- 230000008569 process Effects 0.000 description 2
- 238000004088 simulation Methods 0.000 description 2
- 238000012360 testing method Methods 0.000 description 2
- 238000004458 analytical method Methods 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 230000006399 behavior Effects 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 230000002457 bidirectional effect Effects 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 230000003139 buffering effect Effects 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 238000004883 computer application Methods 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 230000004927 fusion Effects 0.000 description 1
- 230000009249 intrinsic sympathomimetic activity Effects 0.000 description 1
- 238000007726 management method Methods 0.000 description 1
- 239000003607 modifier Substances 0.000 description 1
- 229910052754 neon Inorganic materials 0.000 description 1
- GKAOGPIIYCISHV-UHFFFAOYSA-N neon atom Chemical compound [Ne] GKAOGPIIYCISHV-UHFFFAOYSA-N 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 238000000638 solvent extraction Methods 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- 230000001629 suppression Effects 0.000 description 1
- 230000002123 temporal effect Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F7/00—Methods or arrangements for processing data by operating upon the order or content of the data handled
- G06F7/02—Comparing digital values
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30145—Instruction analysis, e.g. decoding, instruction word fields
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/3001—Arithmetic instructions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30021—Compare instructions, e.g. Greater-Than, Equal-To, MINMAX
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30036—Instructions to perform operations on packed data, e.g. vector, tile or matrix operations
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30036—Instructions to perform operations on packed data, e.g. vector, tile or matrix operations
- G06F9/30038—Instructions to perform operations on packed data, e.g. vector, tile or matrix operations using a mask
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/3005—Arrangements for executing specific machine instructions to perform operations for flow control
- G06F9/30058—Conditional branch instructions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/3017—Runtime instruction translation, e.g. macros
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30181—Instruction operation extension or modification
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3824—Operand accessing
- G06F9/383—Operand prefetching
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/455—Emulation; Interpretation; Software simulation, e.g. virtualisation or emulation of application or operating system execution engines
- G06F9/45504—Abstract machines for programme code execution, e.g. Java virtual machine [JVM], interpreters, emulators
- G06F9/45516—Runtime code conversion or optimisation
- G06F9/45525—Optimisation or modification within the same instruction set architecture, e.g. HP Dynamo
Landscapes
- Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Mathematical Physics (AREA)
- Computational Mathematics (AREA)
- Mathematical Optimization (AREA)
- Pure & Applied Mathematics (AREA)
- Mathematical Analysis (AREA)
- Advance Control (AREA)
- Executing Machine-Instructions (AREA)
Abstract
在一个实施例中,使用二进制转化将指令集架构的多个宏指令融合成单个宏指令。可融合指令序列包括递增、比较和跳转指令的序列。在一个实施例中,处理装置为融合宏指令提供支持。在一个实施例中,处理装置在处理器管线的单个执行阶段内执行融合宏指令。在一个实施例中,融合宏指令在单个执行周期内执行。
Description
技术领域
本公开涉及处理逻辑、微处理器和关联的指令集架构的领域,其当由处理器或其它处理逻辑执行时,执行逻辑、数学或其它功能操作(包括将多个指令融合成单个机器指令)。
背景技术
指令集或指令集架构(ISA)是与编程有关的计算机架构的一部分,包括本机数据类型、指令、寄存器架构、寻址模式、存储器架构,中断和异常处处置以及外部输入和输出(I/ O)。二进制转化(“BT”)是将为一个源(“客户机”)ISA构建的二进制文件(binaries)转化为另一个目标(“主机”)ISA的一般技术。使用BT,可能的是在具有不同的架构的处理器上执行为一个处理器ISA构建的应用二进制文件,而无需重新编译高级源代码或重写低级汇编代码。由于大多数传统计算机应用仅在二进制格式中可用,因此BT非常有吸引力(因为它允许处理器执行不是为其构建的并且对其不可用的应用的潜力)。可以动态或静态执行二进制转化。在应用被执行时动态BT(DBT)在运行时间执行二进制转化。在执行二进制文件之前,对二进制文件执行静态BT(SBT)。
附图说明
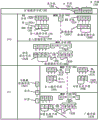
作为示例而不是限制在附图的图形中示出实施例,其中:
图1A是示出根据实施例的示范有序获取、解码、引退管线和示范寄存器重命名、无序发布/执行管线的框图;
图1B是示出根据实施例的要包括在处理器中的有序获取、解码、引退核和示范寄存器重命名、无序发布/执行架构核的示范实施例的框图;
图2A-B是更特定的示范有序核架构的框图;
图3是具有集成存储器控制器和专用逻辑的单核处理器和多核处理器的框图;
图4示出根据实施例的系统的框图;
图5示出根据实施例的第二系统的框图;
图6示出根据实施例的第三系统的框图;
图7示出根据实施例的片上系统(SoC)的框图;
图8示出根据实施例的对比使用软件指令转换器将源指令集中的二进制指令转换为目标指令集中的二进制指令的框图;
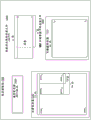
图9A-B是示出根据实施例的用于执行融合increment_compare_jump操作的位操纵操作的框图;
图10A-B是示出根据实施例的increment_compare_jump指令的示范处理器实现的框图;
图11是根据实施例的包括用于执行融合increment_compare_jump操作的逻辑的处理系统的框图;
图12是根据实施例的用于处理示范融合increment_compare_jump指令的逻辑的流程图;
图13A-B是示出根据实施例的通用向量友好指令格式及其指令模板的框图;
图14A-D是示出根据本发明的实施例的示范特定向量友好指令格式的框图;以及
图15是根据实施例的标量和向量寄存器架构的框图。
详细说明
除了客户机和主机ISA之间的二进制转化之外,SBT和DBT都可以用于优化单个ISA内的二进制执行。例如,二进制转化可用于将指令集架构的多个宏指令融合成单个宏指令。在一个实施例中,处理装置为融合宏指令提供支持。应当注意到,术语“指令”本文中一般指宏指令,其是提供给处理器供执行的指令,与微指令或处理器从宏指令解码的微操作(例如,微-op)或微指令相对。微指令或微-op可以被配置成命令处理器上的执行单元执行操作以实现与宏指令关联的逻辑。
下面描述的是处理器核架构,接着是根据本文描述的实施例的示范处理器和计算机架构的描述。阐述了许多特定细节,以便提供对下面描述的本发明的实施例的透彻理解。然而,对于本领域技术人员将显而易见的是,可以在没有这些特定细节中的一些的情况下实践实施例。在其它实例中,以框图形式示出众所周知的结构和装置,以避免模糊各种实施例的基础原理。
处理器核可按照不同方式为了不同目的并且在不同的处理器中实现。例如,这类核的实现可包括:1) 预计用于通用计算的通用有序核;2) 预计用于通用计算的高性能通用无序核;3) 预计主要用于图形和/或科学(吞吐量)计算的专用核。处理器可使用单个处理器核来实现或可以包括多个处理器核。处理器内的处理器核在架构指令集方面可以是同构或异构的。
不同处理器的实现包括:1) 中央处理器,包括用于通用计算的一个或多个通用有序核和/或预计用于通用计算的一个或多个通用无序核;以及2) 协处理器,包括预计主要用于图形和/或科学的一个或多个专用核(例如,集成众核处理器)。这类不同的处理器导致不同的计算机系统架构,其可包括:1) 与中央系统处理器分开的芯片上的协处理器;2) 在独立管芯上的但在与中央系统处理器相同的封装中的协处理器;3) 与其它处理器核相同的管芯上的协处理器(在这种情况下,这类协处理器有时称作专用逻辑,例如集成图形和/或科学(吞吐量)逻辑,或者称作专用核);以及4) 可在相同管芯上包括所描述的CPU(有时称作(一个或多个)应用核或(一个或多个)应用处理器)、上述协处理器和附加功能性的片上系统。
示范核架构
有序和无序核框图
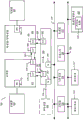
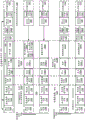
图1A是示出根据实施例的示范有序管线和示范寄存器重命名、无序发布/执行管线的框图。图1B是示出根据实施例的要包含在处理器中的有序架构核和示范寄存器重命名、无序发布/执行架构核的框图。图1A-B中的实线框示出有序管线和有序核,而虚线框的可选添加示出寄存器重命名、无序发布/执行管线和核。给定有序方面是无序方面的子集,将描述无序方面。
图1A中,处理器管线100包括获取阶段(stage)102、长度解码阶段104、解码阶段106、分配阶段108、重命名阶段110、调度(又称作分派或发布)阶段112、寄存器读/存储器读阶段114、执行阶段116、写回/存储器写阶段118、异常处置阶段122和提交阶段124。
图1B示出包括耦合到执行引擎单元150并且均耦合到存储器单元170的前端单元130的处理器核190。核190可以是精简指令集计算(RISC)核、复杂指令集计算(CISC)核、超长指令字(VLIW)核或者混合或备选核类型。作为又一个选项,核190可以是专用核(例如诸如网络或通信核)、压缩引擎、协处理器核、通用计算图形处理单元(GPGPU)核、图形核等。
前端单元130包括耦合到指令高速缓存单元134的分支预测单元132,指令高速缓存单元134耦合到指令转化后备缓冲器 (TLB)136,指令转化后备缓冲器(TLB)136耦合到指令获取单元138,指令获取单元138耦合到解码单元140。解码单元140(或解码器)可对指令进行解码,并且作为输出生成一个或多个微操作、微代码入口点、微指令、其它指令或其它控制信号,其从原始指令来解码或导出或者以其它方式反映原始指令。解码单元140可使用各种不同的机制来实现。适当机制的示例包括但不限于查找表、硬件实现、可编程逻辑阵列(PLA)、微代码只读存储器(ROM)等。在一个实施例中,核190包括微代码ROM或其它介质,其存储某些宏指令的微代码(例如在解码单元140中或者否则在前端单元130内)。解码单元140耦合到执行引擎单元150中的重命名/分配器单元152。
执行引擎单元150包括重命名/分配器单元152,其耦合到引退单元154和一个或多个调度器单元156的集合。(一个或多个)调度器单元156表示任何数量的不同调度器,包括保留站、中心指令窗口等。(一个或多个)调度器单元156耦合到(一个或多个)物理寄存器文件(register file)单元158。(一个或多个)物理寄存器文件单元158的每个表示一个或多个物理寄存器文件,其中不同的寄存器文件存储一个或多个不同的数据类型,例如标量整数、标量浮点、压缩整数、压缩浮点、向量整数、向量浮点、状态(例如,作为要执行的下一个指令的地址的指令指针)等。在一个实施例中,(一个或多个)物理寄存器文件单元158包括向量寄存器单元、写掩蔽寄存器单元和标量寄存器单元。这些寄存器单元可提供架构向量寄存器、向量掩蔽寄存器和通用寄存器。(一个或多个)物理寄存器文件单元158被引退单元154重叠,以示出可实现寄存器重命名和无序执行的各种方式(例如使用(一个或多个)重排序缓冲器和(一个或多个)引退寄存器文件;使用(一个或多个)将来文件(file)、(一个或多个)历史缓冲器和(一个或多个)引退寄存器文件;使用寄存器映射和寄存器池等)。引退单元154和(一个或多个)物理寄存器文件单元158耦合到(一个或多个)执行集群160。(一个或多个)执行集群160包括一个或多个执行单元162的集合和一个或多个存储器访问单元164的集合。执行单元162可执行各种操作(例如移位、加法、减法、乘法)并且对各种类型的数据(例如,标量浮点、压缩整数、压缩浮点、向量整数、向量浮点)来执行。虽然一些实施例可包括专用于特定功能或功能集合的多个执行单元,但是其它实施例可以仅包括一个执行单元或多个执行单元,其全部执行全部功能。(一个或多个)调度器单元156、(一个或多个)物理寄存器文件单元158和(一个或多个)执行集群160示为可能是多个的,因为某些实施例创建某些类型的数据/操作的独立管线(例如标量整数管线、标量浮点/压缩整数/压缩浮点/向量整数/向量浮点管线和/或存储器访问管线(其各具有其自己的调度器单元)、(一个或多个)物理寄存器文件单元和/或执行集群)—以及在独立存储器访问管线的情况下,实现只有这个管线的执行集群具有(一个或多个)存储器访问单元164的某些实施例)。还应当理解,在使用独立管线的情况下,这些管线的一个或多个可以是无序发布/执行,而其余的是有序的。
存储器访问单元164的集合耦合到存储器单元170,其包括耦合到数据高速缓存单元174(其耦合到2级(L2)高速缓存单元176)的数据TLB单元172。在一个示范实施例中,存储器访问单元164可包括加载单元、存储地址单元和存储数据单元,其各耦合到存储器单元170中的数据TLB单元172。指令高速缓存单元134还耦合到存储器单元170中的2级(L2)高速缓存单元176。L2高速缓存单元176耦合到一个或多个其它等级的高速缓存,并且最终耦合到主存储器。
作为示例,示范寄存器重命名、无序发布/执行核架构可按如下所述实现管线100:1) 指令获取138执行获取和长度解码阶段102和104;2) 解码单元140执行解码阶段106;3)重命名/分配器单元152执行分配阶段108和重命名阶段110;4) (一个或多个)调度器单元156执行调度阶段112;5) (一个或多个)物理寄存器文件单元158和存储器单元170执行寄存器读/存储器读阶段114;执行集群160执行执行阶段116;6) 存储器单元170和(一个或多个)物理寄存器文件单元158执行写回/存储器写阶段118;7) 各种单元可涉及异常处置阶段122;以及8) 引退单元154和(一个或多个)物理寄存器文件单元158执行提交阶段124。
核190可支持一个或多个指令集(例如x86指令集(具有随较新版本已经添加的一些扩展);加利福尼亚,圣尼维尔的MIPS技术公司的MIPS指令集;英国剑桥的ARM公司的ARM®指令集(具有可选附加扩展,例如NEON)),包括本文所描述的(一个或多个)指令。在一个实施例中,核190包括支持压缩数据指令集扩展的逻辑(例如AVX1、AVX2等),允许许多多媒体应用所使用的操作使用压缩数据来执行。
应当理解,核可支持多线程(执行操作或线程的两个或更多并行集合),并且可按照多种方式这样做,包括时间分片的多线程、同时多线程(其中单个物理核为物理核同时多线程的线程的每个提供逻辑核)或者其组合(例如,诸如在Intel®超线程技术中的时间分片的获取和解码以及此后的同时多线程)。
虽然在无序执行的上下文中描述寄存器重命名,但是应当理解,寄存器重命名可用于有序架构中。虽然处理器的所示实施例还包括独立指令和数据高速缓存单元134/174和共享L2高速缓存单元176,但是备选实施例可具有用于指令和数据的单个内部高速缓存,例如诸如1级(L1)内部高速缓存或者多级内部高速缓存。在一些实施例中,系统可包括内部高速缓存以及核和/或处理器外部的外部高速缓存的组合。备选地,高速缓存全部可以在核和/或处理器外部。
特定示范有序核架构
图2A-B是更特定的示范有序核架构的框图,该核会是芯片中的若干逻辑块其中之一(包括相同类型和/或不同类型的其它核)。逻辑块通过具有某种固定功能逻辑、存储器I/O接口和其它必要I/O逻辑(这取决于应用)的高带宽互连网络(例如环形网络)进行通信。
图2A是根据实施例的单个处理器核连同到管芯上互连网络202的其连接并且与其2级(L2)高速缓存204的本地子集的连接的框图。在一个实施例中,指令解码器200支持具有压缩数据指令集扩展的x86指令集。L1高速缓存206允许对高速缓冲存储器的低延迟访问到标量和向量单元中。虽然在一个实施例中(为了简化设计),标量单元208和向量单元210使用独立寄存器集合(分别为标量寄存器212和向量寄存器214),以及在它们之间所传递的数据被写到存储器并且然后从1级(L1)高速缓存206读回,但是备选实施例可使用不同方式(例如使用单个寄存器集合,或者包括允许数据在两个寄存器文件之间来传递(而没有被写和读回)的通信路径)。
L2高速缓存204的本地子集是全局L2高速缓存(其划分为独立本地子集,每处理器核一个)的部分。各处理器核具有到L2高速缓存204的其自己的本地子集的直接访问路径。由处理器核所读的数据存储在其L2高速缓存子集204中,并且能够被与访问其自己的本地L2高速缓存子集的其它处理器核并行且快速地访问。由处理器核所写入的数据存储在其自己的L2高速缓存子集204中,并且如果需要则从其它子集来刷新。环形网络确保共享数据的相干性。环形网络是双向的,以便允许诸如处理器核、L2高速缓存和其它逻辑块之类的代理在芯片内相互通信。各环形数据路径每方向为1012位宽。
图2B是根据实施例的图2A中的处理器核的部分的扩充视图。图2B包括L1高速缓存204的L1数据高速缓存206A部分以及与向量单元210和向量寄存器214有关的更多细节。具体来说,向量单元210是16宽向量处理单元(VPU)(参见16宽算术逻辑单元ALU 228),其执行整数、单精度浮点和双精度浮点指令的一个或多个。VPU支持采用拌和(swizzle)单元220来拌和寄存器输入、采用数字转换单元222A-B的数字转换以及采用复制单元224对存储器输入的复制。写掩蔽寄存器226允许判定所产生向量写。
具有集成存储器控制器和专用逻辑的处理器
图3是根据实施例的可具有一个以上核、可具有集成存储器控制器并且可具有集成图形的处理器300的框图。图3中的实线框示出具有单个核302A、系统代理310、一个或多个总线控制器单元316的集合的处理器300,而虚线框的可选添加示出具有多个核302A-N、系统代理单元310中的一个或多个集成存储器控制器单元314的集合和专用逻辑308的备选处理器300。
因此,处理器300的不同实现可包括:1) 具有作为集成图形和/或科学(吞吐量)逻辑(其可包括一个或多个核)的专用逻辑308和作为一个或多个通用核(例如通用有序核、通用无序核、两者的组合)的核302A-N的CPU;2) 具有作为预计主要用于图形和/或科学(吞吐量)的大量专用核的核302A-N的协处理器;以及3) 具有作为大量通用有序核的核302A-N的协处理器。因此,处理器300可以是通用处理器、协处理器或专用处理器,例如诸如网络或通信处理器、压缩引擎、图形处理器、GPGPU(通用图形处理单元)、高吞吐量集成众核(MIC)协处理器(包括30个或更多核)、嵌入式处理器等。处理器可在一个或多个芯片上实现。处理器300可以是一个或多个衬底的一部分和/或可使用多种工艺技术的任一种(例如,诸如BiCMOS、CMOS或NMOS)在一个或多个衬底上实现。
存储器分级结构包括核内的一级或多级高速缓存、一个或多个共享高速缓存单元306的集合以及耦合到集成存储器控制器单元314的集合的外部存储器(未示出)。共享高速缓存单元306的集合可包括一个或多个中间级高速缓存,例如2级(L2)、3级(L3)、4级(L4)或者其它高速缓存级、末级高速缓存(LLC)和/或其组合。虽然在一个实施例中,基于环的互连单元312互连集成图形逻辑308、共享高速缓存单元306的集合和系统代理单元310/(一个或多个)集成存储器控制器单元314,但是备选实施例可将任何数量的众所周知技术用于互连这类单元。在一个实施例中,在一个或多个高速缓存单元306与核302A-N之间维持相干性。
在一些实施例中,核302A-N的一个或多个能够进行多线程。系统代理310包括协调和操作核302A-N的那些组件。系统代理单元310可包括例如功率控制单元(PCU)和显示单元。PCU可以是或者包括用于调节核302A-N和集成图形逻辑308的功率状态所需的逻辑和组件。显示单元用于驱动一个或多个外部连接的显示器。
核302A-N在架构指令集方面可以是同构或异构的;也就是说,核302A-N的两个或更多可以能够执行相同指令集,而其它核可以能够仅执行那个指令集的子集或者不同的指令集。
示范计算机架构
图4-7是示范计算机架构的框图。用于膝上型、台式、手持PC、个人数字助理、工程工作站、服务器、网络装置、网络集线器、交换机、嵌入式处理器,数字信号处理器(DSP)、图形装置、视频游戏装置、机顶盒、微控制器,蜂窝电话、便携媒体播放机、手持装置和各种其它电子装置的本领域已知的其它系统设计和配置也是适合的。一般来说,能够结合如本文所公开的处理器和/或其它执行逻辑的大量系统或电子装置一般是适合的。
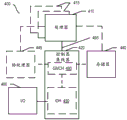
图4示出根据实施例的系统400的框图。系统400可包括一个或多个处理器410、415,其耦合到控制器集线器420。在一个实施例中,控制器集线器420包括图形存储器控制器集线器(GMCH)490和输入/输出集线器(IOH)450(其可在独立芯片上);GMCH 490包括存储器和图形控制器(存储器440和协处理器445与其耦合);IOH 450将输入/输出(I/O)装置460耦合到GMCH 490。备选地,存储器和图形控制器的一个或两者集成在处理器内(如本文所描述的),存储器440和协处理器445直接耦合到处理器410以及具有IOH 450的单个芯片中的控制器集线器420。
附加处理器415的可选性质在图4中采用虚线表示。各处理器410、415可包括本文所描述的处理核的一个或多个,并且可以是处理器300的某个版本。
存储器440可以是例如动态随机存取存储器(DRAM)、相变存储器(PCM)或者两者的组合。对于至少一个实施例,控制器集线器420经由多点总线(例如前侧总线(FSB))、点对点接口(例如快速通道互连(QPI))或者类似连接495与(一个或多个)处理器410、415进行通信。
在一个实施例中,协处理器445是专用处理器,例如诸如高吞吐量MIC处理器、网络或通信处理器、压缩引擎、图形处理器、GPGPU、嵌入式处理器等。在一个实施例中,控制器集线器420可包括集成图形加速器。
在包括架构、微架构、热、功率消耗特性等的优点的衡量标准范围方面,在物理资源410、415之间存在各种差异。
在一个实施例中,处理器410执行控制一般类型的数据处理操作的指令。嵌入在指令内的可以是协处理器指令。处理器410将这些协处理器指令辨别为应当由所附连的协处理器445来执行的类型。相应地,处理器410在协处理器总线或其它互连上向协处理器445发布这些协处理器指令(或者表示协处理器指令的控制信号)。(一个或多个)协处理器445接受和执行所接收的协处理器指令。
图5示出根据实施例的第一更特定示范系统500的框图。如图5中所示的,多处理器系统500是点对点互连系统,并且包括经由点对点互连550所耦合的第一处理器570和第二处理器580。处理器570和580的每个可以是处理器300的某种版本。在本发明的一个实施例中,处理器570和580分别是处理器410和415,而协处理器538是协处理器445。在另一个实施例中,处理器570和580分别是处理器410、协处理器445。
示出处理器570和580,其分别包括集成存储器控制器(IMC)单元572和582。处理器570还包括作为其总线控制器单元的部分的点对点(P-P)接口576和578;类似地,第二处理器580包括P-P接口586和588。处理器570、580可使用点对点(P-P)接口电路578、588经由P-P接口550来交换信息。如图5中所示的,IMC 572和582将处理器耦合到相应存储器(即存储器532和存储器534),其可以是本地附连到相应处理器的主存储器的部分。
处理器570、580每个可使用点对点接口电路576、594、586、598经由单独P-P接口552、554与芯片集590交换信息。芯片集590可选地可经由高性能接口539与协处理器538交换信息。在一个实施例中,协处理器538是专用处理器,例如诸如高吞吐量MIC处理器、网络或通信处理器、压缩引擎、图形处理器、GPGPU、嵌入式处理器等。
共享高速缓存(未示出)可包含在处理器中或者两个处理器外部,但是仍然经由P-P互连与处理器连接,使得如果将处理器置入低功耗模式,则任一个或两个处理器的本地高速缓存信息可存储在共享高速缓存中。
芯片集590可经由接口596耦合到第一总线516。在一个实施例中,第一总线516可以是外设组件互连(PCI)总线或者例如PCI Express总线等总线或另一种第三代I/O互连总线(尽管本发明的范围并不这样限制)。
如图5中所示的,各种I/O装置514可连同总线桥518(其将第一总线516耦合到第二总线520)一起耦合到第一总线516。在一个实施例中,诸如协处理器、高吞吐量MIC处理器、GPGPU的、加速器(例如,图形加速器或数字信号处理(DSP)单元)、现场可编程门阵列或者任何其它处理器之类的一个或多个附加处理器515耦合到第一总线516。在一个实施例中,第二总线520可以是低引脚数(LPC)总线。在一个实施例中,各种装置可耦合到第二总线520,包括例如键盘和/或鼠标522、通信装置527以及可包括指令/代码和数据530的诸如磁盘驱动器或其它大容量存储装置之类的存储单元528。此外,音频I/O 524可耦合到第二总线520。注意,其它架构是可能的。例如,代替图5的点对点架构,系统可实现多点总线或其它这类架构。
图6示出根据实施例的第二更特定示范系统600的框图。图5和图6中的相同元件具有相同参考标号,并且从图6中省略图5的某些方面,以避免模糊图6的其它方面。
图6示出处理器570、580可分别包括集成存储器和I/O控制逻辑(“CL”)572和582。因此,CL 572、582包括集成存储器控制器单元,并且包括I/O控制逻辑。图6示出不仅存储器532、534耦合到CL 572、582,而且还示出I/O装置614也耦合到控制逻辑572、582。传统I/O装置615耦合到芯片集590。
图7示出根据实施例的SoC 700的框图。图3中的类似元件具有相同参考标号。而且,虚线框是更高级SoC上的可选特征。图7中,(一个或多个)互连单元702耦合到:应用处理器710,其包括一个或多个核202A-N和(一个或多个)共享高速缓存单元306的集合;系统代理单元310;(一个或多个)总线控制器单元316;(一个或多个)集成存储器控制器单元314;一个或多个协处理器720的集合,其可包括集成图形逻辑、图像处理器、音频处理器和视频处理器;静态随机存取存储器(SRAM)单元730;直接存储器访问(DMA)单元732;以及显示单元740,用于耦合到一个或多个外部显示器。在一个实施例中,(一个或多个)协处理器720包括专用处理器,例如诸如网络或通信处理器、压缩引擎、GPGPU、高吞吐量MIC处理器、嵌入式处理器等。
本文所公开的机制的实施例可通过硬件、软件、固件或者这类实现方式的组合来实现。实施例可实现为在可编程系统上执行的计算机程序或程序代码,其中可编程系统包括至少一个处理器、存储系统(包括易失性和非易失性存储器和/或存储元件)、至少一个输入装置和至少一个输出装置。
例如图5中所示的代码530等程序代码可应用于输入指令,以执行本文所描述的功能并且生成输出信息。输出信息可按照已知方式应用于一个或多个输出装置。为了本申请的目的,处理系统包括具有例如诸如数字信号处理器(DSP)、微控制器、专用集成电路(ASIC)或者微处理器的处理器的任何系统。
程序代码可通过高级过程或面向对象的编程语言来实现,以便与处理系统进行通信。如果期望,程序代码也可通过汇编或机器语言来实现。实际上,本文所描述的机制在范围方面并不局限于任何具体编程语言。在任何情况下,语言可以是编译或解释语言。
至少一个实施例的一个或多个方面可通过机器可读介质上存储的、表示处理器内的各种逻辑的代表性数据来实现,其在由机器读时使机器制作执行本文所描述的技术的逻辑。称作“IP核”的这类表示可存储在有形机器可读介质(“|磁带”)上,并且供应给各种客户或制造设施,以加载到实际制作逻辑或处理器的制作机器中。例如,IP核(诸如由ARM公司,Ltd.和中国科学院计算技术研究所(ICT)开发的处理器)可被许可或卖给各种客户或被许可人并且在由这些客户或被许可人生产的处理器中实现。
这类机器可读存储媒体可以非限制性地包括通过机器或装置所制造或形成的产品的非暂时性有形布置,包括:例如硬盘等存储媒体;任何其它类型的盘,包括软盘、光盘、光盘只读存储器(CD-ROM)、可重写光盘(CD-RW)和磁光盘;半导体器件(例如只读存储器(ROM))、随机存取存储器(RAM)(例如动态随机存取存储器(DRAM)、静态随机存取存储器(SARAM))、可擦可编程只读存储器(EPROM)、闪速存储器、电可擦可编程只读存储器(EEPROM)、相变存储器(PCM);磁卡或光卡;或者适合于存储电子指令的任何其它类型的媒体。
相应地,实施例还包括非暂时性有形机器可读媒体,其包含指令或者包含定义本文所描述的结构、电路、设备、处理器和/或系统特征的设计数据(例如硬件描述语言(HDL))。这类实施例又可称作程序产品。
仿真(包括二进制转化、代码变形等)
除了本文描述的单个指令集优化之外,指令转换器可用来将指令从源指令集转换成目标指令集。例如,指令转换器可将指令转化(例如使用静态二进制转化、包括动态编译的动态二进制转化)、变形、仿真或者以其它方式将指令转换成将要由核来处理的一个或多个其它指令。指令转换器可通过软件、硬件、固件或其何组合来实现。指令转换器可以在处理器上、处理器外或者部分处理器上和部分处理器外。
图8是根据实施例的与使用软件指令转换器来将源指令集中的二进制指令转换成目标指令集中的二进制指令相对照的框图。在所示实施例中,指令转换器是软件指令转换器,尽管备选地,指令转换器可通过软件、固件、硬件或者其各种组合来实现。图8示出以高级语言802的程序可使用x86编译器804来编译,以生成x86二进制代码806,其可由具有至少一个x86指令集核的处理器816本机执行。
具有至少一个x86指令集核的处理器816表示任何处理器,其能够通过兼容地执行或者以其它方式处理下列方面来执行与具有至少一个x86指令集核的Intel®处理器基本上相同的功能:(1) Intel® x86指令集核的指令集的相当大部分;或者(2) 针对在具有至少一个x86指令集核的Intel®处理器上运行的应用或其它软件的对象代码版本,以便实现与具有至少一个x86指令集核的Intel®处理器基本上相同的结果。x86编译器804表示可操作以生成x86二进制代码806(例如对象代码)(其能够在具有或没有附加链接处理的情况下在具有至少一个x86指令集核的处理器816上执行)的编译器。类似地,图8示出以高级语言802的程序可使用备选指令集编译器808来编译,以便生成备选指令集二进制代码810,其可由没有至少一个x86指令集核的处理器814(例如具有执行加利福尼亚,圣尼维尔的MIPSTechnologies的MIPS指令集和/或执行英国剑桥的ARM公司的ARM指令集的核的处理器)本机执行。
指令转换器812用来将x86二进制代码806转换为可由没有x86指令集核的处理器814本机执行的代码。这个转换的代码不可能与备选指令集二进制代码810是相同的,因为能够进行这个操作的指令转换器难以制作;然而,转换的代码将实现一般操作,并且由来自备选指令集的指令来组成。因此,指令转换器812表示软件、固件、硬件或者其组合,其通过仿真、模拟或者任何其它过程允许处理器或者没有x86指令集处理器或核的其它电子装置执行x86二进制代码806。
优化动态二进制转化系统
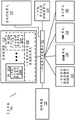
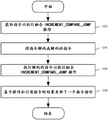
DBT系统可以配置为能够发现可融合指令序列并且通过将多个指令融合成单个指令来优化那些指令序列的优化动态二进制转化系统。图9A-B示出用于执行运行时间二进制优化(包括将多个指令融合成融合指令)的示范二进制转化系统和逻辑。图9A是根据实施例的配置用于动态二进制转化的计算系统的框图。图9B是用于将源代码块中的指令融合成单个融合指令的逻辑的流程图。
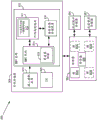
图9A的系统900包括耦合到系统存储器904的处理器902。在一个实施例中,系统另外包括高速缓冲存储器905(例如,图1的数据高速缓存单元174或L2高速缓存单元176)以及与处理器902耦合或集成在处理器902内的高速暂存(scratchpad)存储器907。处理器902包括物理寄存器集合906和一个或多个核处理单元(例如,“核”903A-N)。在一个实施例中,每个核处理单元配置成执行多个同时线程。
系统存储器904可以托管源二进制应用910、动态二进制转化系统915和主机操作系统(“OS”)920。动态二进制转化系统915可以包括目标二进制代码912的块、包括寄存器映射模块916的动态二进制转化器代码914和/或源寄存器存储装置918。源二进制应用910包括源二进制代码块集合,其可以是汇编低级代码或编译的高级代码。源二进制代码块是可以包括分支逻辑(包括递增、比较和跳转指令)的指令序列。
在一个实施例中,(一个或多个)目标二进制代码块912存储在指定为“代码高速缓存”911的系统存储器的区域中。代码高速缓存911用作一个或多个目标二进制代码块912的存储装置,其已从源二进制代码块的一个或多个对应块转化。系统存储器904可以托管配置成向/从处理器寄存器906加载/存储数据的源寄存器存储装置918。在一些实施例中,高速缓冲存储器905和/或高速暂存存储器907配置成向/从(一个或多个)处理器寄存器906加载/存储数据。
在一个实施例中,动态二进制转化器代码914和寄存器映射模块916由一个或多个核执行以在源二进制应用910上操作来将源二进制应用910的一个或多个块变换成一个或多个目标二进制代码块。一个或多个目标二进制代码块912配置成包括源二进制应用910的对应源二进制代码块的功能性。在一个实施例中,源二进制应用的源二进制代码块的多个指令被组合(例如,融合)成更少数量的指令,以创建优化的目标二进制代码912,其包括与通过较少数量的指令执行的源二进制应用相同的功能性。例如,源二进制应用910可以包括比较和跳转指令序列,其包括递增或递减计数器、将计数器与常数进行比较以及然后如果满足某些限制(例如,如果循环变量尚未递增到N,其中N是循环迭代的期望的次数)则调用跳转。在一个实施例中,DBT系统915配置成将三个独立的递增、比较和跳转指令压缩(例如,融合)成单个指令。
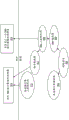
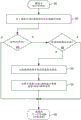
当系统900接收到用于执行二进制代码块的调用时,DBT系统915为了可融合指令而扫描代码块,并将指令序列组合成融合指令。用于扫描和优化指令的典型逻辑在图9B中示出。虽然示出了DBT系统915,但是在一个实施例中,在执行二进制之前对二进制执行SBT,并且可以融合发现的任何静态可融合指令序列(例如,经静态分析确定为安全的指令序列)以创建优化的二进制供执行。
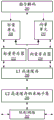
如在图9B的920所示的,系统接收用于执行二进制代码块的调用。在一个实施例中,系统为了递增、比较和跳转指令序列而扫描,如在922所示的。在图9B中在924如果检测到指令序列,则转化逻辑可以执行附加操作,包括在926确定在检测到序列内是否存在任何数据相关性。否则,如果存在下一个代码块,则在932系统继续到下一个可用代码块。示范检测的代码序列在下面表1中示出。
表1:示例程序代码

在表1的示范指令中,在行(1)示出递增指令、在行(3)示出比较指令并且在行(5)示出跳转指令。行(2)表示代码fragment_A,其可以包括在行(1)的递增与在行(3)的比较之间的零个或更多个指令。行(4)表示代码fragment_B,其可以包括在行(3)的比较和在行(5)的跳转之间的零个或更多个指令。虽然在线(5)示出JE(如果相等则跳转)指令,但是实施例不限于任何具体跳转指令。此外,虽然示出CMP(比较)指令,但也可以融合其它比较操作(例如TEST)。
ADD、CMP和JE指令之间的指令段可以不包括任何其它指令。在这类情况下,ADD /CMP / JE序列会是连续的。然而,其它指令可能存在于段内的代码序列中。在重排序代码序列中的任何附加指令之前,转化逻辑扫描代码序列以在926确定是否存在任何数据相关性。如果fragment_A或fragment_B中的指令的任何操作数取决于添加、比较或跳转指令的操作数,可能不允许重排序指令,并且如果存在这类代码块,则在932转化逻辑继续到下一个可用的代码块。另外,如果在fragment_A或fragment_B的任一个中存在任何附加分支指令,则可能不允许重排序指令。然而,在一些实施例中,允许紧跟着跳转指令的附加分支指令。
然而,如果fragment_A或fragment_B的指令与添加、比较或跳转指令的操作数没有数据相关性,则允许传入代码流中的附加指令是合法的并且转化器应该是空闲的以重排序这些指令,而没有违反任何数据相关性。相应地,在框928,转化逻辑可以对所检测的指令序列内的代码段中的任何指令进行重排序。在框930,转化逻辑用单个increment_compare_jump指令替换独立的递增、比较、跳转指令,包括执行指令序列所要求的操作数、包括用于比较操作的常数值和寄存器以及用于跳转操作的跳转标签。示范的重排序代码序列在下表2中示出。
表2:示例程序代码

如上表2中所示的,对于fragment_A和fragment_B的指令可以重排序,如在行(6)和行(7)所示的。如在行8所示的,融合increment_compare_jump操作被插入,包括递增、比较和跳转操作的操作数。
示范融合指令处理器实现
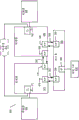
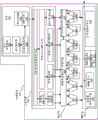
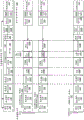
图10A-B是示出increment_compare_jump指令的示范处理器实现的框图。在若干实施例中,实现处理器包括用于实现该指令的若干架构特征。图10A是根据实施例的包括用于执行操作的逻辑的处理器核的框图。图10B是根据实施例的用于实现increment_compare_jump指令的示范特定微架构的框图。
如图10A中所示的,在一个实施例中,处理器核1000包括用于获取要执行的指令的有序前端1001,并准备稍后要在处理器管线中使用的指令。在一个实施例中,前端1001类似于图1的前端单元130,另外包括组件,所述组件包括预先从存储器获取指令的指令预获取器1026。获取的指令可以被馈送到指令解码器1028以解码或解释指令。
在一个实施例中,指令解码器1028将接收到的指令解码成机器可以执行的称为“微指令”或“微操作”(也称为微op或uop)的一个或多个操作。在其它实施例中,解码器将指令解析成由微架构用于执行根据一个实施例的操作的操作码和对应的数据和控制字段。在一个实施例中,追踪高速缓存1029取得解码的uop并且将它们组合成在uop队列1034中的程序排序的序列或追踪以供执行。
在一个实施例中,处理器核1000实现复杂指令集。当追踪高速缓存1029遇到复杂指令时,微代码ROM 1032提供完成操作所需要的uop。一些指令被转换为单个微-op,而其它指令需要若干微操作来完成完全操作。在一个实施例中,指令可以被解码成少量的微op以用于在指令解码器1028处理。在另一个实施例中,如果需要多个微-op来完成操作,则指令可以存储在微代码ROM 1032内。例如,在一个实施例中,如果需要多于四个微-op以完成指令,则解码器1028访问微代码ROM 1032以执行指令。
追踪高速缓存1029参考入口点可编程逻辑阵列(PLA),以根据一个实施例从微代码ROM 1032确定用于读微代码序列来完成一个或多个指令的正确的微指令指针。在微代码ROM 1032完成排序针对指令的微-op之后,机器的前端1001从追踪高速缓存1029恢复获取微-op。在一个实施例中,处理器核1000包括其中指令被准备用于执行的无序执行引擎1003。无序执行逻辑具有用于重排序指令流的多个缓冲器以当指令继续通过指令管线时优化性能。对于配置用于微代码支持的实施例,分配器逻辑分配每个uop在执行期间使用的机器缓冲器和资源。另外,寄存器重命名逻辑将逻辑寄存器重命名到寄存器文件中物理寄存器中的物理寄存器。
在一个实施例中,分配器为指令调度器:存储器调度器、快速调度器1002、慢速/一般浮点调度器1004和简单浮点调度器1006前面的两个Uop队列(一个用于存储器操作以及一个用于非存储器操作)之一中的每个uop分配条目。uop调度器1002、1004、1006基于它们的相关输入寄存器操作数源的准备度以及uop完成它们的操作需要的执行资源的可用性来确定uop何时准备执行。一个实施例的快速调度器1002可以在主时钟周期的每一半上进行调度,而其它调度器只能每主处理器时钟周期调度一次。调度器对于分派端口进行仲裁以调度uop供执行。
寄存器文件1008、1010位于执行块1011中的调度器1002、1004、1006和执行单元1012、1014、1016、1018、1020、1012、1024之间。在一个实施例中,存在独立的寄存器文件1008、1010,分别用于整数和浮点操作。在一个实施例中,每个寄存器文件1008、1010包括旁路网络,其可以旁路或转发尚未被写到寄存器文件中的已完成的结果到新的相关uop。整数寄存器文件1008和浮点寄存器文件1010还能够相互传递数据。对于一个实施例,整数寄存器文件1008被分成两个独立的寄存器文件,一个寄存器文件用于低位32位数据并且第二寄存器文件用于高位32位数据。在一个实施例中,浮点寄存器文件1010具有128位宽条目。
执行块1011包含用于执行指令的执行单元1012、1014、1016、1018、1020、1022、1024。寄存器文件1008、1010存储微指令需要执行的整数和浮点数据操作数值。一个实施例的处理器核1000包括多个执行单元:地址生成单元(AGU)1012、AGU 1014、快速ALU 1016、快速ALU 1018,慢速ALU 1020、浮点ALU 1022、浮点移动单元1024。对于一个实施例,浮点执行块1022、1024执行浮点、MMX、SIMD和SSE,或其它操作。一个实施例的浮点ALU 1022包括64位乘64位浮点除法器,以执行除法、平方根和余数微-op。
在一个实施例中,涉及浮点值的指令可以用浮点硬件来处置。ALU操作去往高速ALU执行单元1016、1018。一个实施例的快速ALU 1016、1018可以以半个时钟周期的有效延迟执行快速操作。对于一个实施例,大多数复杂整数操作去往慢速ALU 1020,因为慢速ALU1020包括用于长延迟类型的操作(例如乘法器,移位,标志逻辑和分支处理)的整数执行硬件。存储器加载/存储操作由AGU 1012、1014执行。对于一个实施例,在对64位数据操作数执行整数操作的上下文中描述整数ALU 1016、1018、1020。在备选实施例中,可以实现ALU1016、1018、1020以支持包括16、32、128、256等的各种数据位。类似地,浮点单元1022、1024可被实现以支持具有各种宽度的位的一系列操作数。对于一个实施例,浮点单元1022、1024可以结合SIMD和多媒体指令在128位宽压缩数据操作数上操作。
在一个实施例中,在父加载完成执行之前,uop调度器1002、1004、1006分派相关操作。在推测性地调度和执行uop时,处理器核1000还包括用于处置存储器丢失的逻辑。如果数据高速缓存中的数据加载丢失,则在管线中可能存在给调度器留下临时不正确数据的执行中(in flight)相关操作。重放机制跟踪并重新执行使用不正确数据的指令。在一个实施例中,只需要重放相关操作,并且允许独立操作完成。
在一个实施例中,包括存储器执行单元(MEI)1041。 MEU 1041包括存储器顺序缓冲器(MOB)1042、SRAM单元1030、数据TLB单元1072、数据高速缓存单元1074和L2高速缓存单元1076。
处理器核1000可以配置用于通过共享或分区各种组件的同时多线程的操作。处理器上执行的任何线程都可以访问共享组件。例如,共享缓冲器或共享高速缓存中的空间可以分配到线程操作,而不考虑请求线程。在一个实施例中,每线程分配分区的组件。具体来说,哪些组件是共享的以及哪些组件被分区根据实施例而变化。在一个实施例中,诸如执行单元(例如,执行块1011)和数据高速缓存(例如,数据TLB单元1072、数据高速缓存单元1074)的处理器执行资源是共享资源。在一个实施例中,包括L2高速缓存单元1076和其它更高级高速缓存单元(例如,L3高速缓存,L4高速缓存)的多级高速缓存在所有执行线程之间共享。其它处理器资源在每线程的基础上分部分和指配或分配,其中分区的资源的特定分区专用于特定线程。示范分区资源包括MOB 1042、无序引擎1003的寄存器别名表(RAT)和重排序缓冲器(ROB)(例如,在图1B的重命名/分配器单元152和退出单元154内的),以及与前端1001的指令解码器1028关联的一个或多个指令解码队列。在一个实施例中,指令TLB(例如,图1B的指令TLB单元136)和分支预测单元(例如,图1B的分支预测单元132)也被分区。
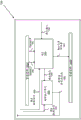
执行块1011的示范部分包括如图10B中所示的逻辑,其示出用于实现单个周期increment_compare_jump指令的微架构1050。在一个实施例中,所示的微架构1050被配置成在处理器执行管线内执行执行阶段。微架构1050包括算术逻辑单元(ALU)1054和跳转执行单元(JEU)1056,并且能够执行分支和算术指令。管道(piping)逻辑1052A-B将微架构与先前和相继管线级的逻辑链接,向ALU 1054供应操作数(例如,operand_A 1060、operand_B1061)供计算以及传递ALU计算的结果1063(例如,B+1)到相继管线阶段。在一个实施例中,递增操作的结果被提交到由输入操作数指示的适当寄存器。到ALU 1054的来自控制单元的控制信号1066用于在ALU操作中进行选择,或者在一个实施例中向ALU提供操作码。还从控制单元向JEU提供控制信号1067以控制JEU操作。
在一个实施例中,ALU 1054用于执行比较操作。可以使用提供给预修改比较指令的operand_A 1060和operand_B 1101来执行减法操作。执行减法操作(例如A-B)以生成供应给JEU 1056的标志(例如,用于条件分支1064的ALU标志)以确定是否采取条件分支(例如,跳转相等、跳转不相等,等)。
为了在单个执行周期内执行increment_compare_jump指令,每个组件在周期内在适当点要求适当的输入。例如,ALU标志1064应该在周期中早到达JEU 1056,并且它们不能是多周期旁路的结果。在一个实施例中,基于定时限制,将特定的标志子集(例如,进位、零、符号、溢出等)用于条件跳转。在一个实施例中,架构标志寄存器中的所有标志可以用于跳转条件,包括奇偶性标志。
在一个实施例中,通过利用到ALU 1054的进位输入1062,在单个周期内执行increment_compare_jump操作。例如,可以断言(assert)到第0位片加法器的进位输入1062,使ALU 1054执行递增和比较(例如,比较A-B+1),而没有对定时的任何实质的影响。可以在周期的早期执行计算,以便如果需要及时生成跳转执行单元1056的ALU标志以执行跳转计算。至少部分地基于ALU标志1064标志,JEU 1056生成包括提供给处理器前端的跳转目标地址的控制重定向信息1065,以发起控制流程改变并更新下一个指令指针(NIP)。
图11是根据实施例的包括用于执行increment_compare_jump指令的逻辑的处理系统的框图。示范处理系统包括耦合到主存储器1100的处理器1155。处理器1155包括具有解码逻辑1131的解码单元1130,用于解码increment_compare_jump指令。另外,处理器执行引擎单元1140包括用于执行指令的附加执行逻辑1141。当执行单元1140执行指令流时,寄存器1105为操作数、控制数据和其它类型的数据提供寄存器存储。
为简单起见,在图11中示出单个处理器核(“核0”)的细节。然而,将理解,图11中所示的每个核可以具有与核0相同的逻辑集合。如所示出的,每个核还可以包括用于根据指定的高速缓存管理策略缓存指令和数据的专用1级(LI)高速缓存1112和2级(L2)高速缓存1111。 LI高速缓存1111包括用于存储指令的独立指令高速缓存1320和用于存储数据的独立数据高速缓存1121。存储在各种处理器高速缓存内的指令和数据以高速缓存线的粒度进行管理,高速缓存线可以是固定大小(例如,长度为64、128、512字节)。此示范实施例的每个核具有用于从主存储器1100和/或共享3级(L3)高速缓存1116获取指令的指令获取单元1110;用于解码指令的解码单元1130;用于执行指令的执行单元1340;以及用于引退指令并写回结果的写回/引退单元1150。
指令获取单元1110包括各种众所周知的组件,包括用于存储要从存储器1100(或其中一个高速缓存)获取的下一个指令的地址的下一个指令指针1103;用于存储最近使用的虚拟到物理指令地址的映射的以改进地址转化速度的指令转化后备缓冲器(ITLB)1104;用于推测性地预测指令分支地址的分支预测单元1102;以及用于存储分支地址和目标地址的分支目标缓冲器(BTB)1101。一旦获取,指令则被流传输到包括解码单元1130、执行单元1140和写回/引退单元1150的指令管线的剩余阶段。
图12是根据实施例的用于处理increment_compare_jump指令的逻辑的流程图。在框1202,指令管线具有指令的获取以执行increment_compare_jump操作。指令接受指令的递增和比较部分的第一和第二输入操作数,以及指令的条件跳转部分的跳转标记操作数。在一个实施例中,第一操作数可以是寄存器或立即值,而第二操作数可以是寄存器、立即值或存储器地址。在一些实施例中,跳转标签是从转换为跳转目标地址的跳转指令的立即值偏移。
在框1204,解码单元将increment_compare_jump指令解码成解码的指令。在一个实施例中,解码的指令是在单个处理器周期中执行的单个操作。在一个实施例中,解码的指令包括用于执行指令的每个子元素的一个或多个微操作。微操作可以是硬连线的,或者微代码操作可以使诸如执行单元的处理器的组件执行各种操作来实现该指令。
在框1206,处理器的执行单元执行解码的指令以执行融合的increment_compare_jump操作以递增、比较和来基于比较有条件地跳转(例如,分支)到跳转目标标签。在一个实施例中,基于从ALU比较(例如,减法)操作产生的状态标志和任何其它状态标志,如果相关,则生成跳转目标地址并将其传送到处理器前端。
在框1208,处理器前端基于操作的结果来更新下一个指令指针,并且处理器的引退单元引退该指令。在一个实施例中,基于是否执行跳转,下一个指令指针被按顺序更新到跳转目标地址或下一个指令。在一个实施例中,无序处理器是分支预测处理器,并且处理器使用指令的结果来解析分支预测。如果分支预测正确则管线中的指令流无中断地继续。然而,如果分支预测不正确,则处理器执行误预测恢复操作来解决分支误预测。
在一个实施例中,当检测到误预测时,JEU断言信号(例如,JE清除),其清除由在分支误预测之后获取的指令生成的状态的前端,并向前端指示地址以开始获取新的指令。从分支误预测中恢复所花费的处理器周期有助于处理器分支误预测惩罚,其是从误预测的分支中完全恢复所要求的周期数。在一个实施例中,与独立的指令场景相比,指令融合将分支误预测惩罚减少了两个周期。为了从涉及独立的递增、比较和跳转指令的分支误预测中恢复,在一个实施例中,要求三个处理器周期。
下表中示出了独立递增、比较和跳转指令之间的比较。表3示出了独立递增、比较和跳转指令的示范管线定时。表4示出了融合的单个周期increment_compare_jump的定时。
表3:独立递增、比较和跳转指令定时

如上表3中所示的,独立的递增(INC)、比较(CMP)和跳转(JCC)指令被调度、进行寄存器文件读并且由无序处理器(例如,无序引擎1003)不按指令顺序执行。当独立执行指令时,处理器的JEU不能将分支地址分派到前端直到N+4,扩展了误预测的惩罚(如果处理器不正确地预测分支)。
表4:独立递增、比较和跳转指令定时

如上表4中所示的,融合increment_compare_jump指令被调度、进行寄存器文件读并且比独立指令更早两个周期执行。另外,减少执行独立动作所要求的硬件指令的数量可以减少对各种功能单元的压力,使那些单元自由执行其它操作。在一个实施例中,由于在处理器硬件内调度和管理减少数量的指令,所以融合指令减少对调度和簿记(bookkeeping)硬件的需求。另外,重排序缓冲器和保留站要求减少的资源。
在一个实施例中,指令融合还减少对在二进制转化逻辑内和处理器内的寄存器分配硬件的压力,给定在单独指令的寄存器之间会存在明确的相关性,并且当使用单个指令时,所有的寄存器操作数都是单个指令的操作数。另外,融合指令减少了二进制转化系统的指令高速缓存占用(footprint)并减少了解码带宽和指令获取的使用以及改进了代码密度。
示范指令格式
本文中描述的(一个或多个)指令的实施例可以用不同的格式(包括向量友好指令格式)实施。向量友好指令格式是适合用于向量指令的指令格式(例如,存在对于向量操作特定的某些字段)。尽管描述了其中通过向量友好指令格式支持向量和标量操作的实施例,但是备选实施例只使用向量友好指令格式的向量操作。
图13A-13B是示出根据实施例的通用向量友好指令格式及其指令模板的框图。图13A是示出根据实施例的通用向量友好指令格式及其类A指令模板的框图;而图13B是示出根据实施例的通用向量友好指令格式及其类B指令模板的框图。具体来说,为通用向量友好指令格式1300定义类A和类B指令模板,这两个指令模板均包括非存储器访问1305指令模板和存储器访问1320指令模板。向量友好指令格式的上下文中的术语“通用”是指指令格式不束缚于任何特定的指令集。
将描述其中向量友好指令格式支持以下格式的实施例:具有32位(4字节)或64位(8字节)数据元素宽度(或大小)的64字节向量操作数长度(或大小)(并且因此,64字节向量由16个双字大小的元素或备选地由8个四字大小的元素组成);具有16位(2字节)或8位(1字节)数据元素宽度(或大小)的64字节向量操作数长度(或大小);具有32位(4字节)、64位(8字节)、16位(2字节)或8位(1字节)数据元素宽度(或大小)的32字节向量操作数长度(或大小);以及具有32位(4字节)、64位(8字节)、16位(2字节)或8位(1字节)数据元素宽度(或大小)的16字节向量操作数长度(或大小);然而,备选实施例支持具有更大、更小或不同数据元素宽度(例如,128位(16字节)数据元素宽度)的更大、更小和/或不同的向量操作数大小(例如,256字节向量操作数)。
图13A中的类A指令模板包括:1)在非存储器访问1305指令模板内,示出有非存储器访问、全部舍入控制型操作1310指令模板和非存储器访问、数据变换类型操作1315指令模板;以及2)在存储器访问1320指令模板内,示出有存储器访问、临时1325指令模板和存储器访问、非临时1330指令模板。图13B中的类B指令模板包括:1)在非存储器访问1305指令模板内,示出有非存储器访问、写掩蔽控制、部分舍入控制型操作1312指令模板和非存储器访问、写掩蔽控制、vsize型操作1317指令模板;以及2)在存储器访问1320指令模板内,示出有存储器访问、写掩蔽控制1327指令模板。
通用向量友好指令格式1300包括下文按图13A-13B所示的顺序列出的以下字段。
格式字段1340——此字段中的特定值(指令格式标识符值)唯一地识别向量友好指令格式、以及因此处于向量友好指令格式的指令在指令流中的出现。因此,在对于只具有通用向量友好指令格式的指令集而言不需要此字段的意义上,此字段是可选的。
基本操作字段1342——它的内容区分不同的基本操作。
寄存器索引字段1344——如果源和目的地操作数在寄存器或存储器中,则此字段的内容直接或通过地址生成指定源和目的地操作数的位置。它们包括充足数量的位以从P×Q(例如,32×512、16×128、32×1024、64×1024)寄存器文件中选择N个寄存器。尽管在一个实施例中,N可以是多达三个源和一个目的地寄存器,但是备选实施例可支持更多或更少的源和目的地寄存器(例如,可支持多达两个源,其中这些源之一还充当目的地;可支持多达三个源,其中这些源之一还充当目的地;可支持多达两个源和一个目的地)。
修改符字段1346——它的内容区分处于指定存储器访问的通用向量指令格式的指令的出现与不指定存储器访问的通用向量指令格式的指令的出现;即,在非存储器访问1305指令模板和存储器访问1320指令模板之间。存储器访问操作对存储器层级进行读和/或写(在一些情况下,使用寄存器中的值指定源和/或目的地地址),而非存储器访问操作不这样做(例如,源和目的地是寄存器)。尽管在一个实施例中,此字段也在三种不同方法之间选择以便执行存储器地址计算,但是备选实施例可支持更多、更少或不同的方法来执行存储器地址计算。
扩增操作字段1350——它的内容区分除了基本操作之外各种不同操作中的哪个操作还要被执行。此字段是上下文特定的。在一个实施例中,此字段划分成类字段1368、α字段1352和β字段1354。扩增操作字段1350允许在单个指令而不是在2、3或4个指令中执行共同操作群组。
缩放字段1360——它的内容允许对索引字段的内容进行缩放以便用于存储器地址生成(例如,用于使用2scale* index+base的地址生成)。
位移字段1362A——它的内容用作存储器地址生成的一部分(例如,用于使用2scale*index+base+displacement的地址生成)。
位移因子字段1362B(注意,位移字段1362A直接并置在位移因子字段1362B上指示一个或另一个被使用)——它的内容用作地址生成的一部分;它指定要缩放存储器访问的大小(N)的位移因子,其中N是存储器访问中的字节数(例如,用于使用2scale*index+base+scaled displacement的地址生成)。忽略冗余低阶位,并且因此,将位移因子字段的内容乘以存储器操作数总大小(N),从而生成最终位移以便在计算有效地址时使用。N的值由处理器硬件在运行时间基于完整操作码字段1374(本文稍后描述的)和数据操纵字段1354C确定。位移字段1362A和位移因子字段1362B是可选的(在不将它们用于非存储器访问1305指令模板和/或不同实施例可只实现这两个中的仅一个或不实现这两个中的任一个的意义上)。
数据元素宽度字段1364——它的内容区分要使用多个数据元素宽度中的哪个数据元素宽度(在一些实施例中对于所有指令;在其它实施例中只对于一些指令)。在如果只支持一个数据元素宽度而不需要此字段和/或使用操作码的某个方面支持数据元素宽度的意义上,此字段是可选的。
写掩蔽字段1370——它的内容在每数据元素位置的基础上控制目的地向量操作数中的数据元素位置是否反映基本操作和扩增操作的结果。类A指令模板支持合并-写掩蔽,而类B指令模板支持合并和归零-写掩蔽。当合并时,向量掩蔽允许保护目的地中的任何元素集合以免在执行任何操作(由基本操作和扩增操作指定的)期间更新;在其它一个实施例中,在对应掩蔽位具有0的情况下,保存目的地的每个元素的旧值。反之,当归零时,向量掩蔽允许在执行任何操作(由基本操作和扩增操作指定的)期间将目的地中的任何元素集合归零;在一个实施例中,当对应掩蔽位具有0值时,将目的地的元素设置成0。此功能性的子集是控制所执行的操作的向量长度(即,所修改的元素从第一个到最后一个的跨距)的能力;然而,修改的元素不一定是连续的。因此,写掩蔽字段1370允许部分向量操作,包括加载、存储、算术、逻辑等。尽管描述了其中写掩蔽字段1370的内容选择多个写掩蔽寄存器中包含要使用的写掩蔽的一个写掩蔽寄存器(并且因此,写掩蔽字段1370的内容间接地识别要执行的该掩蔽)的实施例,但是备选实施例替代地或另外允许掩蔽写字段1370的内容直接指定要执行的掩蔽。
立即数(immediate)字段1372——它的内容允许规定立即数。此字段是可选的(在在不支持立即数的通用向量友好格式的实现中此字段不存在并且在不使用立即数的指令中此字段不存在的意义上)。
类字段1368—它的内容在不同类的指令之间区分。参考图13A-B,此字段的内容在类A和类B指令之间选择。在图13A-B中,用圆角方形来指示在字段中存在特定值(例如,在图13A-B中,对于类字段1368分别为类A 1368A和类B 1368B)。
类A的指令模板
在类A的非存储器访问1305指令模板的情况下,将α字段1352解释为RS字段1352A,其内容区分要执行不同扩增操作类型中的哪个扩增操作类型(例如,分别为非存储器访问、舍入型操作1310和非存储器访问、数据变换类型操作1315指令模板指定舍入1352A.1和数据变换1352A.2);而β字段1354区分要执行指定类型的操作中的哪个操作。在非存储器访问1305指令模板中,不存在缩放字段1360、位移字段1362A和位移缩放字段1362B。
非存储器访问指令模板——全部舍入控制型操作
在非存储器访问全部舍入控制型操作1310指令模板中,将β字段1354解释为舍入控制字段1354A,其(一个或多个)内容提供静态舍入。尽管在所描述的实施例中,舍入控制字段1354A包括抑制所有浮点异常(SAE)字段1356和舍入操作控制字段1358,但是备选实施例可支持可将这些概念编码到相同字段中,或者只具有这些概念/字段中的一个或另一个(例如,可只具有舍入操作控制字段1358)。
SAE字段1356——它的内容区分是否禁用异常事件报告;当SAE字段1356的内容指示启用抑制时,给定指令不报告任何种类的浮点异常标志,并且不引发任何浮点异常处处置程序。
舍入操作控制字段1358——它的内容区分执行舍入操作群组中的哪个操作(例如,向上舍入、向下舍入、向零舍入和最近舍入)。因此,舍入操作控制字段1358允许在每指令基础上改变舍入模式。在一个实施例中,处理器包括用于指定舍入模式的控制寄存器,并且舍入操作控制字段1350的内容覆盖该寄存器值。
非存储器访问指令模板——数据变换类型操作
在非存储器访问数据变换类型操作1315指令模板中,将β字段1354解释为数据变换字段1354B,其内容区分要执行多个数据变换中的哪个数据变换(例如,非数据变换、拌和、广播)。
在类A的存储器访问1320指令模板的情况下,将α字段1352解释为驱逐提示字段1352B,其内容区分要使用驱逐提示中的哪个驱逐提示(在图13A中,分别为存储器访问、临时1325指令模板和存储器访问、非临时1330指令模板指定临时1352B.1和非临时1352B.2);而将β字段1354解释为数据操纵字段1354C,其内容区分要执行多个数据操纵操作(又称为原语)中的哪个数据操纵操作(例如,非操纵;广播;源的向上转换;以及目的地的向下转换)。存储器访问1320指令模板包括缩放字段1360以及可选地包括位移字段1362A或位移缩放字段1362B。
向量存储器指令通过转换支持执行从存储器的向量加载以及到存储器的向量存储。正如常规向量指令一样,向量存储器指令以逐数据元素的方式从存储器传送数据和/或将数据传送到存储器,其中通过选择作为写掩蔽的向量掩蔽的内容规定实际传送的元素。
存储器访问指令模板——临时
临时数据是可能足够快再使用以从缓存获益的数据。然而,这是提示,并且不同处理器可以用不同方式实现它,包括完全忽略所述提示。
存储器访问指令模板——非临时
非临时数据是不可能足够快再使用以从第一级高速缓存中的缓存获益的数据,并且应当给予其驱逐优先级。然而,这是提示,并且不同处理器可以用不同方式实现它,包括完全忽略该提示。
类B的指令模板
在类B的指令模板的情况下,将α字段1352解释为写掩蔽控制(Z)字段1352C,其内容区分由写掩蔽字段1370控制的写掩蔽应当是合并还是归零。
在类B的非存储器访问1305指令模板的情况下,将β字段1354的部分解释为RL字段1357A,其内容区分要执行不同扩增操作类型中的哪个扩增操作类型(例如,分别为非存储器访问、写掩蔽控制、部分舍入控制型操作1312指令模板和非存储器访问、写掩蔽控制、向量长度(VSIZE)型操作1317指令模板指定舍入1357A.1和VSIZE 1357A.2);而β字段1354的剩余部分区分要执行指定类型的操作中的哪个操作。在非存储器访问1305指令模板中,不存在缩放字段1360、位移字段1362A和位移缩放字段1362B。
在非存储器访问、写掩蔽控制、部分舍入控制型操作1310指令模板中,将β字段1354的剩余部分解释为舍入操作字段1359A,并禁用异常事件报告(给定指令不报告任何种类的浮点异常标志,并且不引发任何浮点异常处置程序)。
舍入操作控制字段1359A——正如舍入操作控制字段1358一样,它的内容区分执行舍入操作群组中的哪个舍入操作(例如,向上舍入、向下舍入、向零舍入和最近舍入)。因此,舍入操作控制字段1359A允许在每指令基础上改变舍入模式。在一个实施例中,处理器包括用于指定舍入模式的控制寄存器并且舍入操作控制字段1350的内容覆盖该寄存器值。
在非存储器访问、写掩蔽控制、VSIZE型操作1317指令模板中,将β字段1354的剩余部分解释为向量长度字段1359B,其内容区分要执行多个数据向量长度中的哪个数据向量长度(例如,128、256或512字节)。
在类B的存储器访问1320指令模板的情况下,将β字段1354的部分解释为广播字段1357B,其内容区分是否要执行广播型数据操纵操作;而将β字段1354的剩余部分解释为向量长度字段1359B。存储器访问1320指令模板包括缩放字段1360,并且可选地包括位移字段1362A或位移缩放字段1362B。
关于通用向量友好指令格式1300,示出包括格式字段1340、基本操作字段1342和数据元素宽度字段1364的完整操作码字段1374。尽管示出其中完整操作码字段1374包括所有这些字段的一个实施例,但是在不支持它们中的全部的实施例中,完整操作码字段1374包括少于全部这些字段。完整操作码字段1374提供操作代码(操作码)。
扩增操作字段1350、数据元素宽度字段1364和写掩蔽字段1370允许在通用向量友好指令格式中在每指令基础上指定这些特征。
写掩蔽字段和数据元素宽度字段的组合创建了类型化指令,因为它们允许基于不同数据元素宽度应用掩蔽。
类A和类B内发现的各种指令模板在不同情形中都是有益的。在一些实施例中,不同处理器或处理器内的不同核可只支持类A、只支持类B或支持两个类。例如,预计用于通用计算的高性能通用无序核可只支持类B,预计主要用于图形和/或科学(吞吐量)计算的核可只支持类A,而预计用于两者的核可支持两者(当然,具有来自两个类的模板和指令的一些混合而并非具有来自两个类的所有模板和指令的核也在本发明的范围内)。并且,单个处理器可包括多个核,所有这些核支持相同类或在这些核中不同核支持不同类。例如,在具有独立的图形和通用核的处理器中,预计主要用于图形和/或科学计算的图形核之一可只支持类A;而通用核中的一个或多个核可以是具有预计用于通用计算的无序执行和寄存器重命名的高性能通用核,其只支持类B。不具有独立图形核的另一个处理器可包括支持类A和类B的一个或多个通用有序或无序核。当然,在不同实施例中,来自一个类的特征也可在另一类中实现。用高级语言编写的程序会放到(例如,及时编译或静态地编译到)各种不同的可执行形式中,包括:1)只具有由目标处理器支持以用于执行的一个或多个类的指令的形式;或2)具有使用所有类的指令的不同组合编写的备选例程并且具有基于由当前执行代码的处理器支持的指令选择这些例程用于执行的控制流代码的形式。
示范特定向量友好指令格式
图14是示出根据实施例的示范特定向量友好指令格式的框图。图14示出特定向量友好指令格式1400,其在它指定字段的位置、大小、解释和顺序以及那些字段中的一些字段的值的意义上是特定的。特定向量友好指令格式1400可用于扩展x86指令集,并且因此其中一些字段与现有x86指令集及其扩展(例如,AVX)中所使用的字段类似或相同。此格式保持与具有扩展的现有x86指令集的前缀编码字段、真实操作码字节字段、MOD R/M字段、SIB字段、位移字段和立即数字段一致。示出来自图13的字段(来自图14的字段映射到来自图13的字段)。
应当理解,尽管为了说明的目的,在通用向量友好指令格式1300的上下文中参考特定向量友好指令格式1400描述实施例,但是除非在声明的情况下,本发明不限于特定向量友好指令格式1400。例如,通用向量友好指令格式1300预期各种字段的各种可能的大小,而特定向量友好指令格式1400示出为具有特定大小的字段。作为特定示例,尽管将数据元素宽度1364示为是特定向量友好指令格式1400中的一位字段,但是本发明不限于此(即,通用向量友好指令格式1300预期数据元素宽度字段1364的其它大小)。
通用向量友好指令格式1300包括下文按图14A中示出的顺序列出的以下字段。
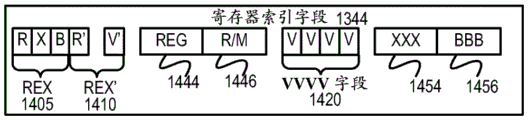
EVEX 前缀(字节0-3)1402——用四字节形式编码。
格式字段1340(EVEX字节0,位[7:0])——第一字节(EVEX字节0)是格式字段1340,并且它包含0×62(在本发明的一个实施例中,用于区分向量友好指令格式的唯一值)。
第二-第四字节(EVEX字节1-3)包括提供特定能力的多个位字段。
REX字段1405(EVEX字节1、位[7-5])——由EVEX.R位字段(EVEX字节1,位[7]-R)、EVEX.X位字段(EVEX字节1,位[6]-X)和1357 BEX字节1,位[5]-B)组成。EVEX.R、EVEX.X和EVEX.B位字段提供与对应的VEX位字段相同的功能性,并且使用1s补码形式编码,即,将ZMM0编码为1111B,将ZMM15编码为0000B。如本领域中已知的,指令的其它字段编码寄存器索引的较低三个位(rrr、xxx和bbb),以使得可通过添加EVEX.R、EVEX.X和EVEX.B而形成Rrrr、Xxxx和Bbbb。
REX’字段1310——这是REX’字段1310的第一部分,并且是用于编码扩展的32寄存器集合的较上16个或较下16个寄存器的EVEX.R’的位字段(EVEX字节1,位[4]-R’)。在一个实施例中,以位倒转格式存储此位连同如下文所指示的其它位,以区别于(以众所周知的x86 32位模式)BOUND指令,其真实操作码字节是62,但在MOD R/M字段(下面所描述的)中不接受MOD字段中的值11;备选实施例下面不以倒转格式存储此位和其它指示的位。值1用于编码较低的16个寄存器。换句话说,通过组合EVEX.R’、EVEX.R和来自其它字段的其它RRR形成R’Rrrr。
操作码映射字段1415(EVEX字节1,位[3:0]-mmmm)——它的内容编码暗示的引导操作码字节(0F、0F 38或0F 3)。
数据元素宽度字段1364(EVEX字节2,位[7]-W)——由符号EVEX.W表示。EVEX.W用于定义数据类型的粒度(大小)(32位数据元素或64位数据元素)。
EVEX.vvvv 1420(EVEX字节2,位[6:3]-vvvv)—EVEX.vvvv的作用可包括如下:1)EVEX.vvvv编码以倒转(1s补码)形式指定的第一源寄存器操作数,并且对于具有2个或更多个源操作数的指令有效;2)EVEX.vvvv编码对于某些向量移位以1s补码形式指定的目的地寄存器操作数;或3)EVEX.vvvv不编码任何操作数,此字段保留并且应当包含1111b。因此,EVEX.vvvv字段1420编码以倒转(1s补码)形式存储的第一源寄存器指定符的4个低阶位。取决于指令,要使用额外的不同EVEX位字段来将指定符大小扩展为32个寄存器。
EVEX.U 1368类字段(EVEX字节2,位[2]-U)——如果EVEX.U=0,则它指示类A或EVEX.U0;如果EVEX.U=1,则它指示类B或EVEX.U1。
前缀编码字段1425(EVEX字节2,位[1:0]-pp)——为基本操作字段提供附加位。除了为EVEX前缀格式的传统SSE指令提供支持以外,这还具有紧缩SIMD前缀的益处(而不是要求字节来表达SIMD前缀,EVEX前缀只要求2个位)。在一个实施例中,为了支持使用处于传统格式和处于EVEX前缀格式的SIMD前缀(66H、F2H、F3H)的传统SSE指令,将这些传统SIMD前缀编码到SIMD前缀编码字段中;并且在运行时间将其扩充到传统SIMD前缀中(在提供给解码器的PLA之前(因此,PLA可执行这些传统指令的传统和EVEX格式,而无需修改))。尽管更新的指令可直接使用EVEX前缀编码字段的内容作为操作码扩展,但是某些实施例以类似方式扩充以便实现一致性,但允许通过这些传统SIMD前缀来指定不同含义。备选实施例可重新设计PLA以支持2位SIMD前缀编码,并且因此不要求扩充。
α字段1352(EVEX字节3,位[7]-EH;又称为EVEX.EH、EVEX.rs、EVEX.RL、EVEX.写掩蔽控制和EVEX.N;还用α示出)——如先前所描述的,此字段是上下文特定的。
β字段1354(EVEX字节3、位[6:4]-SSS,又称为EVEX.s2-0、EVEX.r2-0、EVEX.rr1、EVEX.LL0、EVEX.LLB;还用βββ示出)——如先前所描述的,此字段是上下文特定的。
REX’字段1310——这是REX’字段的剩余部分,并且是可用于编码扩展的32寄存器集合的较上16个或较下16个寄存器的EVEX.V’位字段(EVEX字节3,位[3]-V’)。以位倒转格式存储此位。值1用于编码较低的16个寄存器。换句话说,通过组合EVEX.V’和EVEX.vvvv而形成V’VVVV。
写掩蔽字段1370(EVEX字节3,位[2:0]-kkk)——如先前所描述的,它的内容指定写掩蔽寄存器中的寄存器的索引。在一个实施例中,特定值EVEK.kkk=000具有暗示没有写掩蔽用于具体指令的特殊行为(这可以用多种方式实现,包括使用硬接线到所有的写掩蔽或绕过掩蔽硬件的硬件)。
真实操作码字段1430(字节4)又称为操作码字节。此字段中指定操作码的部分。
MOD R/M字段1440(字节5)包括MOD字段1442、Reg字段1444和R/M字段1446。如先前所描述的,MOD字段1442的内容在存储器访问和非存储器访问操作之间区分。Reg字段1444的作用可总结为两种情形:编码目的地寄存器操作数或源寄存器操作数;或视作是操作码扩展而不用于编码任何指令操作数。R/M字段1446的作用可包括如下:编码引用存储器地址的指令操作数;或编码目的地寄存器操作数或源寄存器操作数。
缩放、索引、基本(SIB)字节(字节6)——如先前所描述的,缩放字段1350的内容用于存储器地址生成。SIB.xxx 1454和SIB.bbb 1456——先前已经关于寄存器索引Xxxx和Bbbb提到过这些字段的内容。
位移字段1362A(字节7-10)——当MOD字段1442包含10时,字节7-10是位移字段1362A,并且它与传统32位位移(disp32)相同地工作,并且按字节粒度工作。
位移因子字段1362B(字节7)——当MOD字段1442包含01时,字节7是位移因子字段1362B。此字段的位置与按字节粒度工作的传统x86指令集8位位移(disp8)相同。由于disp8进行了符号扩展,所以它只可在-128和127字节偏移之间寻址;在64字节高速缓存线方面,disp8使用8个位,这8个位可设置成只有4个真实有用的值-128、-64、0和64;由于通常需要更大范围,所以使用disp32;然而,disp32要求4个字节。与disp8和disp32相对照,位移因子字段1362B是disp8的重新解释;当使用位移因子字段1362B时,实际位移由位移因子字段的内容乘以存储器操作数存取的大小(N)决定。这种类型的位移称为disp8*N。这减少了平均指令长度(单个字节用于位移,但是具有大得多的范围)。这类压缩位移基于如下假定:即,有效位移是存储器访问的粒度的倍数,并且因此,无需编码地址偏移的冗余低阶位。换句话说,位移因子字段1362B代替传统x86指令集8位位移。因此,以与x86指令集8位位移相同的方式编码位移因子字段1362B(因此,ModRM/SIB编码规则没有变化),其中唯一例外是disp8过载为disp8*N。换句话说,编码规则或编码长度没有变化,但只是在通过硬件解释位移值方面有所变化(这需要将位移缩放存储器操作数的大小以便获得逐字节地址偏移)。
立即数字段1372如先前所描述地那样操作。
完整操作码字段
图14B是示出根据一个实施例的构成完整操作码字段1374的特定向量友好指令格式1400的字段的框图。具体来说,完整操作码字段1374包括格式字段1340、基本操作字段1342和数据元素宽度(W)字段1364。基本操作字段1342包括前缀编码字段1425、操作码映射字段1415和真实操作码字段1430。
寄存器索引字段
图14C是示出根据一个实施例的构成寄存器索引字段1344的特定向量友好指令格式1400的字段的框图。具体来说,寄存器索引字段1344包括REX字段1405、REX’字段1410、MODR/M.reg字段1444、MODR/M.r/m字段1446、VVVV字段1420、xxx字段1454和bbb字段1456。
扩增操作字段
图14D是示出根据一个实施例的构成扩增操作字段1350的特定向量友好指令格式 1400的字段的框图。当类(U)字段1368包含0时,它意味着EVEX.U0(类A 1368A);当它包含1时,它意味着EVEX.U1(类B 1368B)。当U=0并且MOD字段1442包含11(意味着非存储器访问操作)时,α字段1352(EVEX字节3,位[7]-EH)解释为rs字段1352A。当rs字段1352A包含1(舍入1352A.1)时,β字段1354(EVEX字节3,位[6:4]-SSS)解释为舍入控制字段1354A。舍入控制字段1354A包含一位SAE字段1356和两位舍入操作字段1358。当rs字段1352A包含0(数据变换1352A.2)时,β字段1354(EVEX字节3、位[6:4]-SSS)解释为三位数据变换字段1354B。当U=0并且MOD字段1442包含00、01或10(意味着存储器访问操作)时,α字段1352(EVEX字节3,位[7]-EH)解释为驱逐提示(EH)字段1352B,并且β字段1354(EVEX字节3,位[6:4]-SSS)解释为三位数据操纵字段1354C。
当U=1时,α字段1352(EVEX字节3,位[7]-EH)解释为写掩蔽控制(Z)字段1352C。当U=1并且MOD字段1442包含11(意味着非存储器访问操作)时,β字段1354的部分(EVEX字节3,位[4]-S0)解释为RL字段1357A;当它包含1(舍入1357A.1)时,β字段1354的剩余部分(EVEX字节3,位[6:5]-S2-1)解释为舍入操作字段1359A;而当RL字段1357A包含0(VSIZE1357.A2)时,β字段1354的剩余部分(EVEX字节3,位[6:5]-S2-1)解释为向量长度字段1359B(EVEX字节3,位[6-5]-L1-0)。当U=1并且MOD字段1442包含00、01或10(意味着存储器访问操作)时,β字段1354(EVEX字节3、位[6:4]-SSS)解释为向量长度字段1359B(EVEX字节3,位[6-5]-L1-0)和广播字段1357B(EVEX字节3,位[4]-B)。
示范寄存器架构
图15是根据一个实施例的寄存器架构1500的框图。在所示实施例中,有32个512位宽的向量寄存器1510;这些寄存器称为zmm0至zmm31。较低16个zmm寄存器的低阶256位覆盖在寄存器ymm0-16上。较低16个zmm寄存器的低阶128位(ymm寄存器的低阶128位)覆盖在寄存器xmm0-15上。特定向量友好指令格式1400在这些覆盖的寄存器文件上操作,如下面在表5中所示的。
表5-寄存器文件

换句话说,向量长度字段1359B在最大长度和一个或多个其它较短长度之间选择,其中每个这类较短长度是之前长度的长度的一半;并且不具有向量长度字段1359B的指令模板在最大向量长度上操作。此外,在一个实施例中,特定向量友好指令格式1400的类B指令模板在压缩或标量单/双精度浮点数据和压缩或标量整数数据上操作。标量操作是在zmm/ymm/xmm寄存器中的最低阶数据元素位置上执行的操作;取决于实施例,较高阶数据元素位置留下与它们在指令之前一样或归零。
写掩蔽寄存器1515——在所示实施例中,有8个写掩蔽寄存器(k0至k7),每个大小为64位。在备选实施例中,写掩蔽寄存器1515的大小为16位。如先前所描述的,在一个实施例中,向量掩蔽寄存器k0可不用作写掩蔽;当会通常指示k0的编码用于写掩蔽时,它选择0xFFFF的硬接线写掩蔽,从而对该指令有效地禁用写掩蔽。
通用寄存器1525——在所示实施例中,有16个64位通用寄存器,它们与现有x86寻址模式一起用于寻址存储器操作数。这些寄存器称为名称RAX、RBX、RCX、RDX、RBP、RSI、RDI、RSP和R8至R15。
标量浮点栈寄存器文件(x87栈)1545,其上混叠了MMX压缩整数平寄存器文件1550——在所示实施例中,x87栈是用于使用x87指令集扩展对32/64/80位浮点数据执行标量浮点操作的8元素栈;而使用MMX寄存器来对64位压缩整数数据执行操作,并为在MMX和XMM寄存器之间执行的一些操作保持操作数。
备选实施例可使用更宽或更窄的寄存器。另外,备选实施例可使用更多、更少或不同的寄存器文件和寄存器。
在一个实施例中,本文描述的指令指配置成执行某些操作或具有预定功能性的硬件(诸如专用集成电路(ASIC))的特定配置。这类电子装置通常包括耦合到一个或多个其它组件的一个或多个处理器集合,诸如一个或多个存储装置(非暂时性机器可读存储媒体)、用户输入输出装置(例如,键盘、触摸屏和/或显示器)以及网络连接。处理器集合和其它组件的耦合通常通过一个或多个总线和桥(也称为总线控制器)。携带网络业务的存储装置和信号分别表示一个或多个机器可读存储媒体和机器可读通信媒体。因此,给定电子装置的存储装置通常存储代码和/或数据供在该电子装置的一个或多个处理器集合上执行。
在前面的说明书中,已经描述了本发明(参考其特定示范实施例)。然而,将明显的是,在不脱离如所附权利要求中阐述的本发明的更宽的精神和范围的情况下,可以对其进行各种修改和改变。在某些实例中,没有以详尽的细节描述总所周知的结构和功能以便避免模糊本发明的主题。相应地,说明书和附图要被视为是以说明性的而不是限制性的意义。相应地,本发明的范围和精神应根据随附的权利要求来判断。
Claims (30)
1.一种处理设备,包括:
二进制转换逻辑,适合于扫描源二进制代码块以检测包括递增、比较和跳转指令的指令序列,并且在检测到所述指令序列之后,如果在所述指令序列的操作数内未检测到数据相关性,则用单个融合指令替换所述指令序列;
解码逻辑,适合于将融合指令解码成包括第一操作数和第二操作数的解码的融合指令;以及
执行单元,适合于执行所述解码的融合指令以作为单个机器级宏指令来执行递增、比较和跳转操作。
2.根据权利要求1所述的处理设备,还包括用于获取所述融合指令的指令获取单元和用于将所述递增操作结果提交到由所述第一或第二操作数指定的寄存器的寄存器文件单元。
3.根据权利要求1所述的处理设备,其中所述执行单元包括用于执行所述递增和比较操作的算术逻辑单元(ALU)和用于执行所述跳转操作的跳转执行单元。
4.根据权利要求1所述的处理设备,其中所述第一操作数和第二操作数与所述比较操作关联,并且所述第一或第二操作数与所述递增操作关联。
5.如权利要求4所述的处理设备,其中所述解码的融合指令另外包括与所述跳转操作关联的跳转目标操作数。
6.根据权利要求5所述的处理设备,其中所述执行单元还用于在单个周期中执行所述递增、比较和跳转操作。
7.根据权利要求5所述的处理设备,其中所述跳转操作以所述比较操作为条件。
8.根据权利要求7所述的处理设备,其中所述跳转操作以通过所述比较操作设置的零标志为条件。
9.根据权利要求7所述的处理设备,其中所述跳转操作以通过所述比较操作设置的进位标志为条件。
10.根据权利要求7所述的处理设备,其中所述跳转操作以通过所述比较操作设置的溢出标志或符号标志为条件。
11.一种用于将多个宏指令融合成单个宏指令的数据处理系统,所述系统包括:
耦合至系统总线的处理器,所述处理器包括执行单元,所述执行单元适合于执行融合宏指令以作为单个机器级宏指令执行递增、比较和跳转操作;以及
二进制转换系统,适合于扫描源二进制代码块以检测可融合指令序列,以及在检测到所述可融合指令序列之后,如果在所述可融合指令序列的操作数内未检测到数据相关性,则生成包括所述融合宏指令的目标二进制代码块。
12.根据权利要求11所述的数据处理系统,其中所述处理器另外包括用于获取所述融合宏指令的指令获取单元,并且所述执行单元用于在单个周期中执行所述融合宏指令。
13.根据权利要求11所述的数据处理系统,其中所述处理器包括多个处理器核。
14.根据权利要求13所述的数据处理系统,其中所述多个处理器核是同构的核,每个核包括用于执行所述融合宏指令的执行单元。
15.根据权利要求13所述的数据处理系统,其中所述多个处理器核是异构的核,并且至少一个核包括用于执行所述融合宏指令的执行单元。
16.根据权利要求11所述的数据处理系统,还包括耦合至所述系统总线的系统存储器,所述系统存储器用于存储所述二进制转换系统。
17.根据权利要求16所述的数据处理系统,其中所述系统存储器包括用于存储所述目标二进制代码块的代码高速缓存。
18.根据权利要求11所述的数据处理系统,还包括耦合至所述系统总线的系统存储器,所述系统存储器用于存储所述二进制转换系统。
19.根据权利要求11所述的数据处理系统,其中所述二进制转换系统还用于使所述处理器在所述指令序列中重排序检测到的代码段以及在所述指令序列中用所述融合宏指令替换各个递增、比较和跳转指令。
20.一种用于将多个宏指令融合成单个宏指令的方法,所述方法包括:
为了包括递增、比较和跳转指令的指令序列而扫描第一源代码块;
在检测到所述指令序列后,扫描所述指令序列以检测数据相关性;
如果在所述指令序列的操作数内未检测到数据相关性,则在所述指令序列中重排序代码段;以及
用单个融合指令替换递增、比较和跳转指令集合,所述单个融合指令当由处理器执行时,使所述处理器执行递增、比较和跳转操作。
21.根据权利要求20所述的方法,其中所述处理器在单个处理器管线执行周期中执行所述融合指令。
22.根据权利要求21所述的方法,其中所述处理器通过使用算术逻辑单元(ALU)执行与所述递增和比较指令关联的第一和第二操作数的比较操作同时通过断言到所述ALU的进位输入递增所述第一或第二操作数而在所述周期中执行所述融合指令。
23.根据权利要求22所述的方法,还包括通过使用所述处理器内的跳转执行单元的所述比较操作来评估从所述ALU输出的标志以确定是否要执行所述跳转操作。
24.根据权利要求23所述的方法,其中所述处理器是分支预测处理器,并且还包括预测要执行与所述跳转指令关联的分支、确定是否执行了所述融合指令的所述跳转操作以及解析为所述跳转指令预测的所述分支。
25.一种用于将多个宏指令融合成单个宏指令的设备,所述设备包括:
为了包括递增、比较和跳转指令的指令序列而用于扫描第一源代码块的部件;
用于在检测到所述指令序列后扫描所述指令序列以检测数据相关性的部件;
用于如果在所述指令序列的操作数内未检测到数据相关性,则在所述指令序列中重排序代码段的部件;以及
用于用单个融合指令替换递增、比较和跳转指令集合的部件,所述单个融合指令当由处理器执行时,使所述处理器执行递增、比较和跳转操作。
26.根据权利要求25所述的设备,其中所述处理器在单个处理器管线执行周期中执行所述融合指令。
27.根据权利要求26所述的设备,其中所述处理器通过使用算术逻辑单元(ALU)执行与所述递增和比较指令关联的第一和第二操作数的比较操作同时通过断言到所述ALU的进位输入递增所述第一或第二操作数而在所述周期中执行所述融合指令。
28.根据权利要求27所述的设备,还包括用于通过使用所述处理器内的跳转执行单元的所述比较操作来评估从所述ALU输出的标志以确定是否要执行所述跳转操作的部件。
29.根据权利要求28所述的设备,其中所述处理器是分支预测处理器,并且还包括用于预测要执行与所述跳转指令关联的分支的部件、用于确定是否执行了所述融合指令的所述跳转操作的部件以及用于解析为所述跳转指令预测的所述分支的部件。
30.一种计算机可读介质,其上存储有指令,所述指令在由计算装置执行时,促使所述计算装置执行根据权利要求20-24中任一项的所述方法。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US14/582,053 US20160179542A1 (en) | 2014-12-23 | 2014-12-23 | Instruction and logic to perform a fused single cycle increment-compare-jump |
| US14/582053 | 2014-12-23 | ||
| PCT/US2015/062098 WO2016105767A1 (en) | 2014-12-23 | 2015-11-23 | Instruction and logic to perform a fused single cycle increment-compare-jump |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN107077321A CN107077321A (zh) | 2017-08-18 |
| CN107077321B true CN107077321B (zh) | 2021-08-17 |
Family
ID=56129480
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201580063903.7A Active CN107077321B (zh) | 2014-12-23 | 2015-11-23 | 用于执行融合的单个周期递增-比较-跳转的指令和逻辑 |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US20160179542A1 (zh) |
| EP (1) | EP3238046A4 (zh) |
| JP (1) | JP6849274B2 (zh) |
| KR (1) | KR102451950B1 (zh) |
| CN (1) | CN107077321B (zh) |
| TW (1) | TWI691897B (zh) |
| WO (1) | WO2016105767A1 (zh) |
Families Citing this family (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7958181B2 (en) * | 2006-09-21 | 2011-06-07 | Intel Corporation | Method and apparatus for performing logical compare operations |
| US10275217B2 (en) | 2017-03-14 | 2019-04-30 | Samsung Electronics Co., Ltd. | Memory load and arithmetic load unit (ALU) fusing |
| US10360034B2 (en) * | 2017-04-18 | 2019-07-23 | Samsung Electronics Co., Ltd. | System and method for maintaining data in a low-power structure |
| US11150908B2 (en) * | 2017-08-18 | 2021-10-19 | International Business Machines Corporation | Dynamic fusion of derived value creation and prediction of derived values in a subroutine branch sequence |
| US11256509B2 (en) | 2017-12-07 | 2022-02-22 | International Business Machines Corporation | Instruction fusion after register rename |
| US11157280B2 (en) * | 2017-12-07 | 2021-10-26 | International Business Machines Corporation | Dynamic fusion based on operand size |
| US11475951B2 (en) | 2017-12-24 | 2022-10-18 | Micron Technology, Inc. | Material implication operations in memory |
| US10424376B2 (en) * | 2017-12-24 | 2019-09-24 | Micron Technology, Inc. | Material implication operations in memory |
| US11194578B2 (en) | 2018-05-23 | 2021-12-07 | International Business Machines Corporation | Fused overloaded register file read to enable 2-cycle move from condition register instruction in a microprocessor |
| CN111209044B (zh) * | 2018-11-21 | 2022-11-25 | 展讯通信(上海)有限公司 | 指令压缩方法及装置 |
| US10996952B2 (en) * | 2018-12-10 | 2021-05-04 | SiFive, Inc. | Macro-op fusion |
| US10831496B2 (en) | 2019-02-28 | 2020-11-10 | International Business Machines Corporation | Method to execute successive dependent instructions from an instruction stream in a processor |
| KR20210012335A (ko) | 2019-07-24 | 2021-02-03 | 에스케이하이닉스 주식회사 | 반도체장치 |
| US11216278B2 (en) * | 2019-08-12 | 2022-01-04 | Advanced New Technologies Co., Ltd. | Multi-thread processing |
| US11537323B2 (en) | 2020-01-07 | 2022-12-27 | SK Hynix Inc. | Processing-in-memory (PIM) device |
| US11422803B2 (en) | 2020-01-07 | 2022-08-23 | SK Hynix Inc. | Processing-in-memory (PIM) device |
| US12008369B1 (en) * | 2021-08-31 | 2024-06-11 | Apple Inc. | Load instruction fusion |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20050177705A1 (en) * | 2001-10-23 | 2005-08-11 | Ip-First Llc | Pop-compare micro instruction for repeat string operations |
| US20100312991A1 (en) * | 2008-05-08 | 2010-12-09 | Mips Technologies, Inc. | Microprocessor with Compact Instruction Set Architecture |
| CN102163139A (zh) * | 2010-04-27 | 2011-08-24 | 威盛电子股份有限公司 | 微处理器融合载入算术/逻辑运算及跳跃宏指令 |
| CN104050077A (zh) * | 2013-03-15 | 2014-09-17 | 英特尔公司 | 利用多个测试源来提供或(or)测试和与(and)测试功能的可融合指令和逻辑 |
Family Cites Families (19)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA1254661A (en) * | 1985-06-28 | 1989-05-23 | Allen J. Baum | Method and means for instruction combination for code compression |
| US5051940A (en) * | 1990-04-04 | 1991-09-24 | International Business Machines Corporation | Data dependency collapsing hardware apparatus |
| JPH09265400A (ja) * | 1996-03-28 | 1997-10-07 | Hitachi Ltd | コンパイル最適化方式 |
| US5717910A (en) * | 1996-03-29 | 1998-02-10 | Integrated Device Technology, Inc. | Operand compare/release apparatus and method for microinstrution sequences in a pipeline processor |
| JPH09288564A (ja) * | 1996-06-17 | 1997-11-04 | Takeshi Sakamura | データ処理装置 |
| US6675376B2 (en) * | 2000-12-29 | 2004-01-06 | Intel Corporation | System and method for fusing instructions |
| US6857063B2 (en) * | 2001-02-09 | 2005-02-15 | Freescale Semiconductor, Inc. | Data processor and method of operation |
| US7051190B2 (en) * | 2002-06-25 | 2006-05-23 | Intel Corporation | Intra-instruction fusion |
| US7451294B2 (en) * | 2003-07-30 | 2008-11-11 | Intel Corporation | Apparatus and method for two micro-operation flow using source override |
| GB2414308B (en) * | 2004-05-17 | 2007-08-15 | Advanced Risc Mach Ltd | Program instruction compression |
| GB2424727B (en) * | 2005-03-30 | 2007-08-01 | Transitive Ltd | Preparing instruction groups for a processor having a multiple issue ports |
| US8082430B2 (en) * | 2005-08-09 | 2011-12-20 | Intel Corporation | Representing a plurality of instructions with a fewer number of micro-operations |
| US7797517B1 (en) * | 2005-11-18 | 2010-09-14 | Oracle America, Inc. | Trace optimization via fusing operations of a target architecture operation set |
| US7596681B2 (en) * | 2006-03-24 | 2009-09-29 | Cirrus Logic, Inc. | Processor and processing method for reusing arbitrary sections of program code |
| US7958181B2 (en) * | 2006-09-21 | 2011-06-07 | Intel Corporation | Method and apparatus for performing logical compare operations |
| US9690591B2 (en) * | 2008-10-30 | 2017-06-27 | Intel Corporation | System and method for fusing instructions queued during a time window defined by a delay counter |
| US8856496B2 (en) * | 2010-04-27 | 2014-10-07 | Via Technologies, Inc. | Microprocessor that fuses load-alu-store and JCC macroinstructions |
| US8850164B2 (en) * | 2010-04-27 | 2014-09-30 | Via Technologies, Inc. | Microprocessor that fuses MOV/ALU/JCC instructions |
| US9886277B2 (en) * | 2013-03-15 | 2018-02-06 | Intel Corporation | Methods and apparatus for fusing instructions to provide OR-test and AND-test functionality on multiple test sources |
-
2014
- 2014-12-23 US US14/582,053 patent/US20160179542A1/en not_active Abandoned
-
2015
- 2015-11-23 EP EP15873974.8A patent/EP3238046A4/en not_active Withdrawn
- 2015-11-23 JP JP2017527588A patent/JP6849274B2/ja active Active
- 2015-11-23 WO PCT/US2015/062098 patent/WO2016105767A1/en active Application Filing
- 2015-11-23 TW TW104138808A patent/TWI691897B/zh not_active IP Right Cessation
- 2015-11-23 CN CN201580063903.7A patent/CN107077321B/zh active Active
- 2015-11-23 KR KR1020177013959A patent/KR102451950B1/ko active IP Right Grant
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20050177705A1 (en) * | 2001-10-23 | 2005-08-11 | Ip-First Llc | Pop-compare micro instruction for repeat string operations |
| US20100312991A1 (en) * | 2008-05-08 | 2010-12-09 | Mips Technologies, Inc. | Microprocessor with Compact Instruction Set Architecture |
| CN102163139A (zh) * | 2010-04-27 | 2011-08-24 | 威盛电子股份有限公司 | 微处理器融合载入算术/逻辑运算及跳跃宏指令 |
| CN104050077A (zh) * | 2013-03-15 | 2014-09-17 | 英特尔公司 | 利用多个测试源来提供或(or)测试和与(and)测试功能的可融合指令和逻辑 |
Non-Patent Citations (1)
| Title |
|---|
| 64 Mb 6.8 ns random ROW access DRAM macro for ASICs;T. Kimuta;K. Takeda etc.;《1999 IEEE International Solid-State Circuits Conference. Digest of Technical Papers. ISSCC. First Edition》;19991231;全文 * |
Also Published As
| Publication number | Publication date |
|---|---|
| KR20170097633A (ko) | 2017-08-28 |
| JP6849274B2 (ja) | 2021-03-24 |
| EP3238046A1 (en) | 2017-11-01 |
| WO2016105767A1 (en) | 2016-06-30 |
| JP2018500657A (ja) | 2018-01-11 |
| KR102451950B1 (ko) | 2022-10-11 |
| US20160179542A1 (en) | 2016-06-23 |
| EP3238046A4 (en) | 2018-07-18 |
| TW201643706A (zh) | 2016-12-16 |
| CN107077321A (zh) | 2017-08-18 |
| TWI691897B (zh) | 2020-04-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN107077321B (zh) | 用于执行融合的单个周期递增-比较-跳转的指令和逻辑 | |
| CN107092465B (zh) | 用于提供向量混合和置换功能的指令和逻辑 | |
| CN107077329B (zh) | 用于实现和维持判定值的栈的方法和设备 | |
| JP6711480B2 (ja) | ベクトルインデックスロードおよびストアのための方法および装置 | |
| EP3547119B1 (en) | Apparatus and method for speculative conditional move operation | |
| WO2013095608A1 (en) | Apparatus and method for vectorization with speculation support | |
| TWI603261B (zh) | 用以執行離心操作的指令及邏輯 | |
| KR20170097015A (ko) | 마스크를 마스크 값들의 벡터로 확장하기 위한 방법 및 장치 | |
| US10545735B2 (en) | Apparatus and method for efficient call/return emulation using a dual return stack buffer | |
| JP2017538215A (ja) | 逆分離演算を実行するための命令及びロジック | |
| US20220318014A1 (en) | Method and apparatus for data-ready memory operations | |
| US20160170767A1 (en) | Temporary transfer of a multithreaded ip core to single or reduced thread configuration during thread offload to co-processor | |
| US10095517B2 (en) | Apparatus and method for retrieving elements from a linked structure | |
| US11036501B2 (en) | Apparatus and method for a range comparison, exchange, and add | |
| WO2017172297A1 (en) | Apparatus and method for re-execution of faulting operations |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |