CN101167363B - 处理视频数据的方法 - Google Patents
处理视频数据的方法 Download PDFInfo
- Publication number
- CN101167363B CN101167363B CN2006800140797A CN200680014079A CN101167363B CN 101167363 B CN101167363 B CN 101167363B CN 2006800140797 A CN2006800140797 A CN 2006800140797A CN 200680014079 A CN200680014079 A CN 200680014079A CN 101167363 B CN101167363 B CN 101167363B
- Authority
- CN
- China
- Prior art keywords
- pixel data
- pixel
- model
- coding
- relation
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images











Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
- H04N19/537—Motion estimation other than block-based
- H04N19/54—Motion estimation other than block-based using feature points or meshes
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/213—Feature extraction, e.g. by transforming the feature space; Summarisation; Mappings, e.g. subspace methods
- G06F18/2135—Feature extraction, e.g. by transforming the feature space; Summarisation; Mappings, e.g. subspace methods based on approximation criteria, e.g. principal component analysis
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/20—Analysis of motion
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/40—Scenes; Scene-specific elements in video content
- G06V20/46—Extracting features or characteristics from the video content, e.g. video fingerprints, representative shots or key frames
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Signal Processing (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Data Mining & Analysis (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Evolutionary Biology (AREA)
- Evolutionary Computation (AREA)
- General Engineering & Computer Science (AREA)
- Image Analysis (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
- Image Processing (AREA)
Abstract
这项发明描述用来处理视频数据的装置和方法。本发明提供一种视频数据的表达,该数据表达能用来评定所述数据和用于所述数据的特定参数表达的拟合模型之间的一致性。这允许比较不同的参数化技术和选择继续处理该特定视频数据的最佳技术。所述表达能以中间形式作为较大程序的一部分或作为反馈机制被用于处理视频数据。当以它的中间形式被利用的时候,本发明能被用于视频数据的储存、增强、提炼、特征提取、压缩、编码和传输的程序。本发明可用来以强健有效的方式提取显著的信息,同时确定通常与视频数据来源相关联的问题的地址。
Description
这份申请要求2005年3月31日以“System And Method ForVideo Compression Employing Principal Component Analysis”为题申请的美国专利临时申请第60/667,532号和2005年4月13日以“System and Method for Processing Video Data”为题申请的美国专利临时申请第60/670,951号的优先权。这份申请是作为2005年9月20日申请的美国专利申请第11/230,686号的部分继续申请的于2005年11月16日申请的美国专利申请第11/280,625号的部分继续申请,而其中所述的美国专利申请第11/230,686号又是2005年7月28日申请的美国专利申请第11/191,562号的部分继续申请。上述的每份申请在此通过引证被全部并入。
发明领域
本发明一般地涉及数字信号处理领域,更具体地说涉及用来有效地表达和处理信号或图像数据(最具体地说,视频数据)的计算机装置和计算机实现的方法。
背景技术
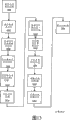
本发明存在于其中的现有技术的一般系统描述能用图1表示。在这里方框图显示典型的现有技术视频处理系统。这样的系统通常包括下列几级:输入级102、处理级104、输出级106和一个或多个数据储存机制108。
输入级102可能包括若干元素,例如,照相机敏感元件,照相机敏感元件阵列、测距敏感元件、或从储存机制取回数据的方法。输入级提供表达人造的和/或自然发生的现象的时间相关序列的视频数据。该数据的显著成份可能被噪音或其它不想要的信号掩盖或污染。
视频数据可以依照预先定义的转移协议以数据流、阵列或数据包的形式直接地或通过中间的储存元素108提交给处理级104。处理级104可以采用专用模拟或数字器件或可编程器件(例如,中央处理器(CPU)、数字信号处理器(DSP)、或现场可编程门阵列(FPGA))的形式来执行所需要的一组视频数据处理操作。处理级104通常包括一个或多个CODEC(编码/解码器)。
输出级106产生能够影响使用者或外部装置的信号、显示或其它响应。通常,输出器件被用来产生指示信号、显示、硬拷贝、处理过的数据在存储器中的表达,或开始向远程站点传输数据。它也可以用来提供在后面的处理操作中使用的中间信号或控制参数。
存储器在这个系统中是作为非必选元素出现的。在使用时,储存元素108可以是非易失的,例如,只读储存媒体,或易失的,例如,动态随机存取储存器(RAM)。单一的视频处理系统包括若干种储存元素并非是罕见的,这些元素对输入级、处理级和输出级有各种不同的关系。这样储存元素的例子包括输入缓冲器,输出缓冲器和处理高速缓冲存储器。
图1所示视频处理系统的主要目的是处理输入数据,产生对特定应用意义深长的输出。为了实现这个目标,可以利用多种处理操作,包括减少或消除噪音、特征提取、对象拆分和/或规范化、数据分类、事件探测、编辑、数据选择、数据重新编码和代码变换。
产生受不良约束的数据的许多数据来源(尤其是声音和可视图像)对人是重要的。在大多数情况下,这些来源信号的基本特征对有效数据处理的目标有不利的影响。来源数据固有的易变性是在不引进起因于在推导工程假定中使用的未试过的经验的和探索性的方法的误差的情况下以可靠且有效的方式处理数据的障碍。这种易变性对于某些应用当输入数据被自然地或故意地限制在定义狭窄的特征组(例如,一组有限的符号值或狭窄的带宽)之中的时候被减轻。这些限制时常导致商业价值低的处理技术。
信号处理系统的设计受该系统的预期用途和作为输入使用的来源信号的预期特征的影响。在大多数情况下,所需的完成效率也将是重要的设计因素。完成效率反过来受待处理的数据的数量与可用的数据储存器相比较的影响以及受该应用程序的计算复杂性与可得的计算能力相比较的影响。
传统的视频处理方法因具有许多低效率性质而蒙受损害,这些低效率性质是以数据通信速度慢、存储需求大和干扰感性假象的形式出现的。这些可能是严重的问题,因为人们希望有多种方法使用和操纵视频数据和人们对某些形式的可视信息有先天的敏感性。
“最佳的”视频处理系统在完成一组预期的处理操作方面是高效率的、可靠的和强健的。这样的操作可能包括数据的储存、传输、显示、压缩、编辑、加密、增强、分类、特征检测和确认。二次操作可能包括这样处理过的数据与其它数据来源的整合。在视频处理系统的情况下同等重要的是输出应该通过避免引进知觉人为现象与人类视觉相容。
视频处理系统如果它的速度、效率和质量不强烈地取决于输入数据的任何特定特征的细节则可以被描述为“强健的”。,强健也与在某些输入出现错误的时候完成操作的能力有关。许多视频处理系统未能强健到足以考虑到应用的一般类别,仅仅为在该系统的研发中使用的同样受狭窄限制的数据提供应用。
显著信息由于输入元素的抽样速率与感知现象的信号特性不匹配可能在连续取值的数据来源的离散化中丢失。另外,当信号强度超过传感器极限导致饱和的时候也有遗失。同样,当输入数据的精度下降的时候,数据也会遗失,这在输入数据的完整的数值范围用一组离散数值表达,借此降低数据表达的精度的时候发生在任何量化程序中。
总体易变性指的是一类数据或信息来源中的任何无法预测性。因为视觉信息通常不受限制,所以代表视觉信息特征的数据有非常大的总体易变性程度。视觉信息可以表达任何由于光线入射在传感器阵列上所形成的空间阵列序列或时间空间的序列。
在仿制视觉现象时,视频处理器通常把一些限制组和/或结构强加在表达或解释数据方式上。结果,这样的方法可能引进将会影响输出质量、可能用来考虑输出的置信水平和能在该数据上可靠地完成的后续处理工作的类型的系统误差。
一些量化方法降低视频画面中的数据精度同时试图保有那个数据的统计变化。通常,视频数据是这样分析的,以致数据值的分布被收集到概率分布之中。也有一些方法把数据映射到相空间之中,以便将数据的特色表示为空间频率的混合,借此允许精度下降以较少引起反对的方式扩散。这些量化方法在被大量地利用时往往导致知觉上难以相信的颜色和能在该视频画面原本平滑的区域中引起突然的怪异状态。
差分编码通常也用来利用数据的局部空间相似性。在画面的一个部分中的数据倾向于聚集在那个画面中的相似数据周围和后续画面中的相似位置。然后,根据它的空间毗连数据表达该数据能与量化组合起来,而最终结果是对于给定的准确性表达差分比使用数据的绝对值更精确。这个假定在原始视频数据的光谱分辨率有限的时候(例如,在黑白图像或颜色少的图像中)很好地工作。随着图像的光谱分辨率逐渐增加,相似性假定被严重破坏。这种破坏是由于没有能力有选择地保护视频数据准确性造成的。
残差编码与差分编码类似,因为这种表达的误差被进一步差分编码,以便把原始数据的准确性恢复到预期的准确性水平。
这些方法的变化尝试把视频数据变换成把数据相关关系暴露在空间相位和刻度之中的替代表达。一旦视频数据已经以这些方式变换,量化和差分编码的方法就能适用于被变换的数据,从而导致增加显著图像特征的保存。这些变换视频压缩技术中最普遍两种是离散余弦变换(DCT)和离散子波变换(DWT)。DCT变换的误差表明在视频数据数值方面有广泛的变化,因此,DCT通常被用在视频数据的区段上,为的是使这些错误的相关关系定位。来自这种定位的假象往往沿着这些区段的边界出现。就DWT而言,更复杂的假象在基础函数和某些纹理之间有误配的时候发生,而且这引起模糊效应。为了抵消DCT和DWT的负面效应,提高表达的准确性以便以宝贵的带宽为代价减少失真。
发明内容
本发明是一种在计算和分析两个方面均优于现有顶级技术的方法的计算机实现的视频处理方法。原则上本发明的方法是线性分解法,空间拆分法和空间规范化法的整合。从空间上限制视频数据大大提高线性分解法的强健性和适用性。此外,与空间规范化相对应的数据空间拆分能进一步用来增加单独来源于空间规范化的利益。
具体地说,本发明提供一种能有效地把信号数据处理成一个或多个有益的表达的方法。本发明在处理许多普遍发生的数据组时是有效的而且在处理视频和图像数据时是特别有效的。本发明的方法分析该数据并且提供那个数据的一种或多种简洁表达以使它的处理和编码变得容易。对于许多应用(包括但不限于:视频数据的编码、压缩、传输、分析、储存和显示),每种新的比较简洁的数据表达都允许减少计算处理、传输带宽和储存需求。本发明包括用来识别和提取视频数据的显著成份的方法,从而允许区分数据的处理和表达的优先次序。信号中的噪音和其它多余部分被看作是优先权比较低的,所以进一步处理能集中在分析和表达视频信号中优先权比较高的部分上。结果,视频信号的表达比先前可能的表达更简洁。而且把准确性的损失集中在视频信号中知觉上不重要的部分。
附图说明
图1是举例说明现有技术视频处理系统的方框图。
图2是提供本发明的概观的方框图,它展示用来处理影像的主要模块。
图3是举例说明本发明的运动评估方法的方框图。
图4是举例说明本发明的整体配准方法的方框图。
图5是举例说明本发明的规范化方法的方框图。
图6是举例说明混合式空间规范化压缩方法的方框图。
图7是举例说明本发明在局部规范化中使用的网孔生成方法的方框图。
图8是举例说明本发明在局部规范化中使用的基于网孔的规范化方法的方框图。
图9是举例说明本发明的组合式整体和局部规范化方法的方框图。
图10是举例说明本发明的GPCA-基本多项式拟合和微分方法的方框图。
图11是举例说明本发明的回归GPCA提炼方法的方框图。
图12是举例说明背景分辨方法的方框图。
图13是举例说明本发明的对象拆分方法的方框图。
图14是举例说明本发明的对象插值方法的方框图。
具体实施方法
在视频信号数据中,视频画面被组装成通常描绘在二维成像表面上投影(成像)的三维现场的图像序列。每个画面(或图像)都由代表响应抽样信号的成像敏感元件的象素组成。时常,抽样信号对应于被二维敏感元件阵列抽样的一些反射的、折射的或发射的能量(例如,电磁能、声能等)。连续的顺序抽样导致时空数据流,每个画面的两个空间维度和一个时间维度对应于该画面在视频序列中的次序。
本发明如同图2举例说明的那样分析信号数据和识别显著成份。当信号由视频数据组成的时候,时空流分析揭示时常作为特定对象(例如,面部)的显著成份。识别程序限定该显著成份的存在和重要性并且选择在那些被限定的显著成份之中最重要的一个或多个显著成份。这不限制在现在描述的处理之后或同时识别和处理其它显著性较低的成份。然后,上述的显著成份被进一步分析,以便识别易变的和不变的子成份。不变子成份的识别是该成份某个方面的建模程序,借此揭示该模型的参数表达法,以允许将该成份被合成到预期的准确性水平。
在本发明的一个实施方案中,探测和跟踪前景对象。识别该对象的象素并且把这些象素从每个视频画面中拆分出来。把基于区段的运动评估应用于从多个画面中拆分出来的对象。然后,把这些运动评估结果整合成一个高级的运动模型。该运动模型用来把该对象的例证隐藏到公用的空间配置中。对于特定的数据,在这个配置中,该对象更多的特征被对准。这种规范化允许紧凑地表达多个画面上的对象象素的数值的线性分解。属于对象外观的显著信息被包含在这个紧凑表达之中。
本发明的优选实施方案详细描述前景视频对象的线性分解。该对象是按空间规范化的,借此得出紧凑的线性外观模型。此外,进一步优选的实施方案在空间规范化之前先把前景对象从视频画面的背景中拆分出来。
本发明的优选实施方案将本发明应用于一个人对着摄像机边说话边进行少量运动的影像。
本发明的优选实施方案将本发明应用于影像中能通过空间转换很好地表达的任何对象。
本发明的优选实施方案明确地使用基于区段的运动评估来确定两个或多个视频画面之间的有限差分。为了要提供更有效的线性分解,高级运动模型是依据那些有限差分因式分解的。
探测&跟踪
技术上已经知道探测一幅画面中的某个对象并在预定数目的后续画面中跟踪那个对象。在能用来实现对象探测功能的算法和程序之中的是Viola/Jones:P.Viola和M.Jones发表在Proc.2ndInt′l Workshop on Statistical and Computational Theories of Vision-Modeling,Learning,Computing and Sampling中的“RobustReal-time Object Detection”。同样,有一些算法和程序能用来在连续的画面中跟踪探测到的对象。例子包括:C.Edwards、C.Taylor和T.Cootes发表在Proc.Int′l Conf.Auto.Face and GestureRecognition(1998年),260-265页中的“Learning to identify andtrack faces in an image sequence”。
对象探测程序的结果是一个数据组,该数据组详细说明在画面中对象中心的一般位置和关于对象比例(大小)的指示。跟踪程序的结果是一个数据组,该数据组代表该对象的时间标签和保证在连续画面中探测到的对象是同一对象的概率达到特定水平。
对象探测和跟踪算法可能适用于画面中的单一对象或画面中的两个或多个对象。
人们还知道在一组连续的画面中跟踪被探测对象的一个或多个特征。举例来说,如果对象是人的脸部,所述特征可能是眼睛或鼻子。在一种技术中,特征是用“线”的交叉点表示的,该交叉点可以被宽松地描述为“拐角”。优选的是将强壮的和空间上彼此完全不同的“拐角”选作特征。那些特征可以通过空间强度场梯度分析来识别。使用光学流的分层多分辨率判断允许确定那些特征在连续画面中的平移位移。M.J.Black和Y.Yacoob发表在1995年6月于马萨诸塞州波士顿市召开的计算机设想国际会议的会议录的第374-381页(Proc eedings of the InternationalConference on Computer Vision,pages 374-381,Boston,Mass.,June 1995.)中的“Tracking and recognizing rigid and non-rigidfacial motions using local parametric models of image motions”是使用这项技术跟踪特征的算法的一个例子。
一旦已经确定信号的显著构成成份,就可以保留这些成份,而且可以减少或除去所有其它的信号成份。探测显著成份的程序展示在图2,其中视频画面(202)是用一个或多个探测对象(206)程序处理的,从而导致一个或多个对象被识别并且随后被跟踪。保留的成份代表视频数据的中间形式。然后,可以使用对于现有的视频处理方法通常不可得的技术给这个中间数据编码。因为该中间数据以几种形式存在,所以标准的视频编码技术也能用来给这些中间形式中的几种形式编码。对于每个例证,本发明都先确定然后使用最有效的编码技术。
在一个优选实施方案中,显著特征分析程序完成显著信号模式的探测和分类。这个程序的一个实施方案使用专门为产生强度与在视频画面中探测到的对象显著特征有关的响应信号而设计的空间过滤器的组合。以不同的空间刻度在视频画面的不同位置应用该分类程序。来自该分类程序的响应的强度指出显著信号模式出现的可能性。在把中心置于十分显著的对象上的时候,该程序用对应的强烈响应给它分类。显著信号模式的探测通过激活对视频序列中的显著信息的后续处理和分析来辨别本发明。
给出显著信号模式在一个或多个视频画面中的探测位置,本发明分析显著信号模式的无变化特征。此外,对于无变化的特征,本发明分析该信号的残值,“较少显著的”信号模式。无变化特征的识别提供用来减少冗余信息和拆分(即,分离)信号模式的基础。
特征点跟踪
在本发明一个实施方案中,在一个或多个画面中的空间位置是通过空间强度场梯度分析确定的。这些特征对应于“一些线”的一些交点,这些交点能被宽松地描述为“拐角”。这样的实施方案进一步选择一组这样的拐角,这些拐角是强壮的而且在空间上是彼此异类的,在此称之为特征点。此外,使用光学流的分层次的多分辨率评估允许确定随着时间流逝特征点的平移位移。
在图2中,跟踪对象(220)程序是为了把来自探测对象程序(208)的探测例证和在许多视频画面(202和204)上一个或多个被探测对象的特征的进一步的识别对应关系(222)拉到一起而展示的。
特征跟踪的非限制性实施方案能被这样使用,以致这些特征被用来限定更规则的梯度分析法(例如,基于区段的运动评估)。
另一个实施方案期待以特征跟踪为基础的运动评估的预测。
基于对象的探测和跟踪
在本发明的一个非限制性实施方案中,强健的对象分类程序被用来跟踪视频画面中的面部。这样的分类程序以对已在面部上训练过的定向边缘的级联响应为基础。在这个分类程序中,边缘被定义为一组基本的Haar特征和那些特征的45度旋转。该级联分类程序是AdaBoost算法的变体。此外,响应计算能通过使用总面积表优化。
局部配准
配准包括在两个或多个视频画面中被识别对象的诸元素之间的对应关系的分配。这些对应关系变成建立该视频数据中时间点截然不同的视频数据之间的空间关系模型的基础。
为了根据广为人知的算法和那些算法的富有创造性的派生算法举例说明特定的实施方案和它们与实践相关联的缩减量,现在描述用于本发明的各种不同的非限制性的配准方法。
在时空序列中建立明显的光学流模型的一种方法可以通过从视频数据的两个或多个画面产生有限差分域来实现的。如果该对应关系在空间和强度双重意义上符合特定的恒定性限制,则光学流场能被稀疏地评估。
如图3所示,画面(302或304)有可能通过十取一程序(306)或一些其它的二次抽样程序(举例来说,低通过滤器)按空间被二次抽样。这些在空间上减少的图像(310&312)也可能被进一步二次抽样。
菱形搜寻
假定把一个视频画面分割成若干不重叠的区段,搜寻与每个区段匹配的先前的视频画面。以全面搜寻区段为基础(FSBB)的运动评估找出在先前的视频画面中与当前画面中的区段相比较时误差最小的位置。完成FSBB可能是计算费用十分浩大的,而且往往不产生比以局域化运动假设为基础的其它评估方案更好的匹配。以菱形搜寻区段为基础(DSBB)的梯度下降运动评估是FSBB的常见的替代品,它使用各种不同尺寸的菱形搜寻图案朝着对于某个区段最好的匹配的方向反复地横越误差梯度。
在本发明的一个实施方案中,为了产生数值稍后被因式分解成高阶运动模型的有限差分,DSBB被用于一个或多个视频画面之间的图像梯度域分析。
熟悉这项技术的人知道基于区段的运动评估能被视为规则网孔顶点分析的等同物。
基于网孔的运动评估
基于网孔的预测使用顶点被边缘连接起来的几何网孔描绘视频画面的不连续区域,随后通过受网孔顶点位置控制的变形模型预测后续画面中那些区域的变形和运动。为了预测当前画面,因为顶点是移动的,所以在用顶点定义的区域之内的象素也是移动的。原始象素数值的相对运动和由此产生的近似是通过一些插值方法完成的,这些插值方法将象素位置与邻近那个象素的顶点的位置联系起来。当这样的运动存在于视频信号中的时候,缩放和旋转的附加建模与纯粹的平移相比较能产生更精确的画面象素预测。
通常,网孔模型能被定义为是规则的或自适应的。规则的网孔模型是在不考虑基础信号特性的情况下设计的,而自适应的方法尝试按空间安排与基础视频信号的特征相关的顶点和边缘。
规则网孔表示法提供一种方法,倘若影像中的成像对象有较多的空间间断点与网孔边缘相对应,运动或运动中固有的变形就能用该方法预测或建模。
自适应网孔是在实质上比规则网孔更多地考虑基础视频信号的特征的情况下形成的。此外,这种网孔的自适应性质可以随着时间逝去考虑到网孔的各种不同的提炼。
为了实现网孔和象素配准,本发明使用同种判据调整顶点搜寻。空间上与异种强度梯度相关联的顶点是先于那些有比较同种的梯度的顶点完成运动评估的。
在优选的实施方案中,网孔的顶点运动评估是通过针对同等或近乎同等的同种顶点的运动评估的空间填注另外区分优先次序的。
在优选的实施方案中,最初的网孔空间配置和最后的网孔配置是通过使用标准的图解式填充例行程序用小平面标识符填充映射图像在小平面水平上相互映射的。与每个三角形相关联的仿射变换能很快地从变换表中查出,而在一个网孔中与小平面相关联的象素位置能很快地转换成在另一个网孔中的位置。
在优选的实施方案中,为了评定与每个运动评估匹配相关联的残留误差针对顶点进行初步的运动评估。这个初步的评估被另外用来区分顶点运动评估次序的优先次序。这样的残差分析的好处是与比较少的失真相关联的运动评估将导致维持更似乎真实的网孔拓扑。
在优选的实施方案中,网孔顶点运动评估被依比例缩减到某个有限范围,而且多种运动评估是通过一些迭代完成的,为的是允许网孔接近更全面优化的和拓扑正确的解。
在优选的实施方案中,利用中心在每个顶点上矩形瓦块邻域的基于区段的运动评估被用来确定考虑到内插多角形邻域的顶点位移。除了针对误差梯度由来避免象素的空间插值和变形之外,这项技术也允许运动评估的平行计算。
基于相位的运动评估
在现有技术中,基于区段的运动评估通常是作为导致一个或多个空间匹配的空间搜寻实现的。基于相位的规范化的互相关(PNCC)如同图3举例说明的那样把来自当前画面和先前画面的区段变换到“相空间”中,并且寻找那两个区段的互相关。这种互相关被表达为位置与两个区段之间边缘的“相移”相对应的数值域。这些位置通过定阈值被隔离,然后被逆变换成空间坐标。这些空间坐标是截然不同的边缘位移,而且对应于运动矢量。
PNCC的优势包括对比度遮掩,该对比度遮掩在视频流中预留增益/曝光调节的容许偏差。另外,PNCC允许来自单一步骤的结果,该单一步骤或许处理来自基于空间的运动评估程序的许多迭代。此外,该运动评估是子象素精确的。
本发明的一个实施方案在一个或多个视频画面之间的图像梯度域的分析中利用PNCC,为的是产生其数值稍后被因式分解成高阶运动模型的有限差分。
整体配准
在一个实施方案中,本发明使用在两幅或多幅视频画面中被探测对象的对应元素之间的关系产生对应关系模型。通过将来自有限差分评估域的一个或多个线性模型因式分解来分析这些关系。术语“域”指的是每个有空间位置的有限差分。这些有限差分可能是在探测&跟踪段落所描述的完全不同的视频画面中对应对象特征的平移位移。发生这样的抽样的域在此被称为有限差分的一般总体。所描述的方法使用与在文献“M.A.Fischler,R.C.Bolles.‘Random Sample Consensus:A Paradigm for Model Fittingwith Applications to Image Analysis and Automated Cartography’,Comm.of the ACM,VoI 24,pp 381-395,1981”中描述的RANSAC算法类似的强健的评估。
如图4所示,在建立整体运动模型的情况下,有限差分是收集到借助那些运动评估的随机抽样(410)被迭代处理的一般总体库(404)中的平移运动评估(402),而且线形模型被因式分解,提取那些样本的公因子(420)。然后,那些结果被用来调节总体(404)以便通过排除通过随机处理发现的该模型的异己样本更好地阐明该线性模型。
本发明能利用一个或多个强健的预估程序;其中之一可能是强健的RANSAC评估程序。这些强健的预估程序在现有技术中已得到很好的证明。
在线性模型评估算法的一个实施方案中,运动模型评估程序以线性最小二乘解为基础。这种相关性使该评估程序摆脱异己样本数据。基于RANSAC,所揭示的方法是一种通过反复评估数据子集抵消异己样本的效应从而探查将描述重要的数据子集的运动模型的强健方法。每个探头产生的模型都对它所代表的数据的百分比进行测试。如果有足够的迭代次数,则将发现与最大的数据子集拟合的模型。在文献“R.Dutter和PJ.Huber,‘Numericalmethods for the nonlinear robust regression problem’,Journal ofStatistical and Computational Simulation,13:79-113,1981”中有关于怎样完成这样强健的线性最小二乘回归的描述。
如同图4设想和举例说明的那样,本发明揭示一些在算法变更形式上超过RANSAC算法的改革,包括有限差分的初始抽样(样本)和线性模型的最小二乘评估。综合误差是使用已解的线性模型对一般总体中的所有样本评估的。根据残差与预先设定的阈值一致的样本的数目给该线性模型分配一个等级。这个等级被看作是“候选的共识”。
初始抽样、求解和归类是通过迭代完成的,直到终止判据得到满足为止。一旦该判据得到满足,等级最高的线性模型被看作是该总体的最后共识。
最初的抽样、求解和归类是通过迭代完成的,直到终止判据得到满足为止。一旦该判据得到满足,等级最高的线性模型被看作是该总体的最后共识。
非必选的改进步骤包括按照与候选模型拟合最好的次序反复分析该样本子集并且逐渐增加子集规模,直到再多加一个样本将超过整个子集的残留误差阈值。
如图4所示,整体模型评估程序(450)一直重复到共识等级可接受性测试令人满意(452)为止。当该等级尚未实现的时候,在设法揭示线性模型把与已发现的模型相关的有限差分的总体(404)分类。最好的(最高等级的)运动模型被添加到程序460的解集当中。然后,在程序470中再次评估该模型。完成后,该总体(404)被再次分类。
为了在将与某特定的线性模型相对应的另一个参数矢量空间中确定子空间簇,所描述的本发明的非限制性实施方案可以作为对矢量空间(前面被描述为有限差分矢量域)抽样的一般方法被进一步推广。
整体配准程序的进一步的结果是这个配准程序和局部配准程序之间的差异产生局部配准残差。这个残差是整体模型在近似局部模型时的误差。
规范化
规范化指的是朝着标准的或通常的空间配置方向再次抽取空间强度场样本。当这些相关的空间配置是在这样的配置之间可逆的空间变换的时候,象素的再次抽样和附带插值也是直到拓扑极限可逆的。本发明的规范化方法是用图5举例说明的。
当两个以上空间强度场被规范化的时候,提高的计算效率可以通过保存中间的规范化计算结果来实现。
为了配准的目的,或等效地为了规范化,用来再次抽取图像样本的空间变换模型包括总体模型和局部模型。总体模型有从平移变换到影射变换逐渐增加的阶次。局部模型是有限差分,该有限差分暗示在基本上用区段或更复杂地用分段线性网孔确定的关于邻近象素的内插式。
原始强度场向规范化强度场的插值增加基于强度场子集的PCA外观模型的直线性。
如图2所示,对象象素(232和234)能被再次抽样(240)以便得到所述对象象素的规范化版本(242和244)。
基于网孔的规范化
本发明进一步的实施方案把特征点镶嵌到基于三角形的网孔中,跟踪该网孔的顶点,并且使用每个三角形的顶点的相对位置来评估与那三个顶点一致的平面的三维表面法线。当该表面法线与摄影机的投影轴相符的时候,成像象素能提供与该三角形相对应的对象的扭曲最小的透视图。创造倾向于支持正交表面法线的规范化图像能产生保存中间数据类型的象素,这将提高后来以外观为基础的PCA模型的直线性。
另一个实施方案利用传统的以区段为基础的运动评估来含蓄地建立整体运动模型。在一个非限制性实施方案中,该方法将来自传统的以区段为基础的运动评估/预测所描述的运动矢量的整体仿射运动模型因式分解。
本发明的方法利用一项或多项整体运动评估技术,包括一组仿射投影方程的线性解。其它的投影模型和求解方法在现有技术中已有描述。
图9举例说明整体和局部规范化的组合方法。
渐进的几何规范化
空间间断点的分类被用来对准镶嵌的网孔,以便在它们与网孔边缘一致的时候含蓄地建立间断点模型。
同种区域的边界是用多角形轮廓近似的。为了确定每个多角形顶点的显著优先权,该轮廓是以逐次降低的精度逐次近似的。为了保护共享顶点的顶点优先权,顶点优先权在各个区域上传播。
在这项发明的一个实施方案中,多角形分解方法允许与视场的同种分类相关联的边界的优先排序。象素是依照一些同种标准(例如,光谱相似性)分类的,然后把分类标签按空间连接到各个区域之中。在进一步优选的非限制性实施方案中,4-或8-连通性判据被用来确定空间连通性。
在优选的实施方案中,这些空间区域的边界随后被离散成多角形。所有多角形对所有同种区域的空间覆盖呈棋盘格状并且结合在一起形成初步的网孔。使用一些判据将这种网孔的顶点分解,以揭示保有最初网孔的大多数知觉特征的较简单的网孔表达。
在优选的实施方案中,图像配准方法与这份说明书的另一部分揭示的一样用强壮的图像梯度向这些高优先权顶点偏置。由此产生的变形模型倾向于保护与成像对象的几何形状相关联的空间间断点。
在优选的实施方案中,活跃的轮廓用来改善区域边界。每个多角形区域的活跃轮廓都允许增殖一次迭代。在不同的区域中每个活跃轮廓顶点的“变形”或移动被结合在计算平均值操作中,以便考虑到隐式网孔受限制的增殖,对于该网孔它们有隶属关系。
在优选的实施方案中,顶点被分配在适合也作为不同区域的轮廓部分的毗邻顶点的网孔中它有的毗邻顶点数的计数。这些其它的顶点被定义为处在对立状态。如果顶点计数为1,则它有没有对立顶点,因此需要得到保护。如果两个毗邻的对立顶点的计数都为1(意味着这两个顶点在不同的多角形中而且彼此相邻),那么一个顶点对另一个是可分辩的。当计数为1的顶点与数值为2的邻近的多角形顶点对立的时候,计数为1的顶点被转化为计数为2的顶点,而且那个顶点的计数等于1。因此,如果出现另一个邻近的对立顶点,那么这个顶点能被再一次分辨。对于这种情况,保留最初的顶点计数是重要的,所以在分辩顶点的时候,我们能基于最初的顶点计数偏置求解方向。这是为了顶点a变得对顶点b清晰可见,那么顶点b对顶点c将不清晰可见,而顶点c应该对顶点b变得清晰可见,因为b已经被用于一种分辨率。
在优选的实施方案中,T-接合点被明确地处理。这些是在毗邻的多角形中没有点的多角形中的点。在这种情况下,每个多角形顶点都首先被画在图像点映射图上,这张映射图识别顶点的空间位置及其多角形标识符。然后横越和测试每个多角形的周长看看是否有任何来自另一个多角形的毗邻顶点。如果有来自另一个区域的邻近顶点,那么它们每个都被测试,看看它们是否已经有来自当前的多角形的邻近顶点。如果它们没有,那么当前的点作为当前的多角形的顶点被添加进去。这种额外的测试保证在另一个多角形中的孤立顶点被用来产生T-接合点。否则,这将在这个区域已经有匹配顶点的情况下仅仅添加新的顶点。所以,只有当邻近的顶点不与这个当前区域对立的时候才添加对立顶点。在进一步的实施方案中,通过使用掩模图像增加检测T-联接的效率。连续地访问多角形顶点,而且这样更新掩模,以致顶点的象素被确认为属于某个多角形顶点。然后多角形周长的象素被详细研究,如果它们与多角形顶点一致,那么它们被记录为在当前的多角形之内的顶点。
在优选的实施方案中,当一个光谱的区域已经被一个或多个交叠的同种图像梯度区域再映射,而且另一个同种光谱区域也重叠的时候,先前被再映射的区域全被赋予与当前被再映射的那些区域相同的标签。因此基本上,如果光谱区域被两个同种区域遮住,那么所有被那两个同种区域遮住的光谱区域都将获得同样的标签,因此一个光谱区域真的被一个同种区域而不是两个同种区域覆盖是相似的。
在本发明的一个实施方案中,为了找到邻接归并判据,处理区域映射图而不是处理区域目录是有利的。在进一步的实施方案中,光谱拆分分类器能被修正以便训练该分类器使用非同种区域。这允许将处理集中在光谱区域的边缘。此外,增加以使用边缘(例如,稳定的边缘检测器)为基础的不同的拆分并且把那个馈送给活跃的轮廓识别最初的那组多角形将考虑到同种区域的较大差别。
局部规范化
本发明提供能以“局部”方式完成象素在时空流中配准的方法。
一种这样的局域化方法使用几何网孔的空间应用提供分析象素的方法,以致在成像现象中局域相干性在分辨与成像现象(或明确地说成像对象)的局部变形有关的表观图像亮度恒定性模棱两可的时候得到解释。
这样的网孔被用来提供在像平面中表面变形的分段线性模型作为局部规范化的方法。当视像流的时间分辨率与视像中的运动相比高的时候,成像现象可能往往与这样的模型相对应。模型假设之例外是通过多种技术处理的,包括:象素和图像梯度区域的拓扑限制、邻近顶点限制和同种分析。
在一个实施方案中,特征点用来产生由顶点与特征点相对应的三角形元素构成的网孔。对应的特征点是其它画面暗示三角形及其对应象素的内插造成的“变形”产生局部变形模型。
图7举例说明这样的对象网孔的产生。图8举例说明使用这样的对象网孔局部地规范化画面。
在一个优选的实施方案中,产生一幅识别三角形的三角形映射图,其中所述映射图的每个象素都来自所述三角形。此外,与每个三角形相对应的仿射变换是作为优化步骤预先计算的。再者,在产生局部变形模型的时候,使用空间坐标在固定图像(先前的)上来回移动以确定来源象素的抽样坐标。这个被抽样的象素将代替当前象素位置。
在另一个实施方案中,局部变形是在整体变形之后预先形成的。在先前揭示的说明书中,整体规范化是作为使用整体配准方法从空间上规范化两幅或多幅视频画面中的象素的程序描述的。由此产生的整体规范化的视频画面能被进一步局部规范化。这两种方法的组合把局部规范化限制在整体上得到的解决办法的细分方面。这能大大减少求解所需要的局部方法的不明确性。
在另一个非限制性实施方案中,特征点或“规则网孔”情况下的顶点是通过分析那些点邻近区域的图像梯度限定的。这个图像梯度能直接地或通过一些间接计算(例如,Harris响应)被计算出来。此外,这些点能被用与图像梯度下降相关联的空间限制和运动评估结果误差过滤。合格的点能作为网孔的基础被许多棋盘格化技术之一使用,从而导致其元素是三角形的网孔。对于每个三角形,基于那些点和它们残留的运动矢量产生一个仿射模型。
本发明的方法利用一种或多种图像强度梯度分析方法,包括Harris响应。其它的图像强度梯度分析方法在现有技术中已有描述。
在优选的实施方案中,维持三角形仿射参数的目录。这个目录通过迭代构成当前的/早先的点目录(使用顶点查寻映射图)。当前的/早先的点目录被传送给用来评估为那个三角形计算仿射参数的变换的例行程序。然后,这些仿射参数或模型被保存在三角形仿射参数目录中。
在进一步的实施方案中,该方法横移三角形标识符图像映射图,在这种情况下该映射图中的每个象素包含在该象素有隶属关系的网孔中的三角形的标识符。而且对于属于某个三角形的每个象素,计算适合那个象素的对应的整体变形和局部变形坐标。那些坐标依次用来完成对应象素的抽样并且把它的数值用在对应者的“规范化”位置。
在进一步的实施方案中,以起因于图像梯度搜寻的密度和图像强度对应关系严格性为基础把空间限制应用于那些点。在基于某种图像强度残差基准完成运动评估结果之后将那些点分类。然后,以空间密度限制为基础对这些点进行过滤。
在进一步的实施方案中,使用空间光谱拆分,而且把小的同种光谱区域基于空间亲和力(它们的强度和/或颜色与邻近区域的相似性)合并。然后,使用同种合并把光谱区域以它们与同种质地(图像梯度)区域的重叠为基础组合在一起。进一步的实施方案然后使用中心周围点(那些点是被较大的区域包围的小区域)作为合格的感兴趣的点来支持网孔的顶点。在进一步的非限制性实施方案中,中心周围点的定义为其边界框在尺寸为3×3或5×5或7×7象素的一个象素之内而且对于那个边界框空间图像梯度是角落形状的区域。该区域的中心能被归类为角落,从而进一步限定那个位置为有利的顶点位置。
在进一步的实施方案中,水平和垂直的象素有限差分图像被用来分类每个网孔边缘的强度。如果边缘有许多与它的空间位置一致的有限差分,那么该边缘和那个边缘的顶点被认为是对于成像现象的局部变形非常重要的。如果在边缘的有限差分之和的平均值之间有大的派生差异,那么该区域边缘通常很可能对应于质地变化边缘,而不是量化步骤。
在进一步的实施方案中,空间密度模型终止条件被用来优化网孔顶点的处理。当检查过数目足以覆盖大部分检测矩形始端的空间区域的点的时候,于是可以结束该处理。终止产生得分。进入处理的顶点和特征点用这个得分来分类。如果那个点与现有的点在空间上挨得太近,或者那个点不与图像梯度的边缘相对应,则将它丢弃。否则,在那个点的邻近地区中的图像梯度下降,而且如果梯度的残差超过某个界限,那么那个点也被丢弃。
在优选实施方案中,局部变形建模是通过迭代完成的,随着每次迭代顶点位移减少收敛到解上。
在另一个实施方案中,局部变形模型被完成,而且如果该整体变形已经提供相同的规范化利益,则将该模型的参数丢弃。
规则网孔规范化
本发明利用规则网孔扩展上述的局部规范化方法。这种网孔是不考虑潜在象素构成的,然而它的位置和尺寸与被检测对象相对应。
给定被检测对象区域,空间画面位置和指出面部大小的刻度在面部区域的始端上产生规则网孔。在优选的实施方案中,使用一组不重叠的瓦片描绘矩形网孔,然后完成瓦片的对角线分割产生有三角形网孔元素的规则网孔。在进一步的优选实施方案中,瓦片与用于传统的视频压缩算法(例如,MPEG-4 AVC)的那些成比例。
在优选的实施方案中,与上述网孔相关联的顶点通过分析在用于训练的特定的视频画面中包围这些顶点的象素区域区分优先次序。分析这样的区域的梯度提供关于与每个顶点相关的将依靠局部图像梯度的处理(例如,基于区段的运动评估结果)的置信度。
顶点位置在多个画面的对应关系是通过简单的逐步降低图像梯度找到的。在优选实施方案中,这是通过基于区段的运动评估实现的。在目前的实施方案中,高置信度的顶点考虑到高置信度的对应关系。置信度较低的顶点对应关系是通过推理经过求解不明确的图像梯度从置信度较高的顶点对应关系获得的。
在一个优选实施方案中,规则网孔是在最初的跟踪矩形上制作的。产生16×16的瓦片,并且沿着对角线切割,形成三角形网孔。对这些三角形的顶点进行运动评估。运动评估结果取决于每个点的质地类型。质地被分为三类:角落、边缘和同种,它们也定义顶点的处理次序。角落顶点使用邻近顶点的评估结果,即,邻近点(如果可得)的运动评估被用于预言性运动矢量,而运动评估结果适用于每一个。提供最低的疯狂误差(mad error)的运动矢量是作为这个顶点运动矢量使用的。用于角落的搜寻策略是所有的(宽的、小的和原点)。对于边缘,再一次使用最近的相邻运动矢量作为预言性运动矢量,而且使用误差最小的那一个。边缘的搜寻策略是小的和原点。对于同种区域,搜寻邻近的顶点并且使用误差最小的运动评估。
在一个优选实施方案中,每个三角形顶点的图像梯度被计算出来,而且基于类别和大小被分类。所以,角落先于边缘,边缘先于同种区域。对于角落,强的角落先于弱的角落,对于边缘,强的边缘先于弱的边缘。
在一个优选实施方案中,每个三角形的局部变形以与那个三角形相关联的运动评估为基础。每个三角形都有对它评估的仿射。如果三角形不作拓扑逆转,或变成退化的,那么作为三角形部分的象素被用来以获得的评估仿射为基础抽取当前图像的样本。
拆分
通过进一步描述的拆分程序识别的空间间断点是通过它们各自边界的几何参数表达法(被称为空间间断点模型)有效地编码的。这些空间间断点模型可以以不断地考虑到与编码子集相对应的更简洁的边界描述的渐进方式编码。渐进式编码提供一种在保留空间间断点的许多显著方面的同时区分空间几何学优先次序的强健方法。
本发明的优选实施方案将多分辨率拆分分析与空间强度场的梯度分析结合起来,并且进一步使用时间稳定性限制来实现强健的拆分。
如图2所示,一旦已经随着时间的流逝跟踪对象的特征的对应关系(220)并且建立了模型(224),遵守这个运动/变形模型能用来拆分与那个对象相对应的象素(230)。可以对画面(202和204)中已探测到的许多对象(206和208)重复这个程序。
本发明使用的无变化特征分析的一种形式被集中在空间间断点的识别上。这些间断点是作为边缘、阴影、遮蔽、线、拐角或任何其它的在一个或多个视频成像画面中引起象素之间突然的可辨认的分离的可见特征出现的。此外,在颜色和/或纹理类似的对象之间的细微的空间间断点可能仅仅出现在视频画面中各个对象的象素相对于那些对象本身正在经历粘附运动而相对于其它对象正在经历不同的运动之时。本发明利用频谱拆分、纹理拆分和运动拆分的组合强健地识别与显著信号模式有关的空间间断点。
时间拆分
把平移运动矢量或在空间强度场中等价的有限差分测量结果按时间整合成高阶运动模型是现有技术描述的一种运动拆分形式。
在本发明的一个实施方案中,产生运动矢量的稠密域,表现视频画面中对象运动的有限差分。这些导数是通过规则地分割瓦片或借助某种初始化程序(例如,空间拆分)按空间集合的。每个集合的“导数”使用线性最小二乘评估程序整合成一个高阶运动模型。然后,由此产生的运动模型作为矢量在运动模型空间中使用K均值聚类技术。这些导数是基于与它们拟合最好的群分类的。然后,群标是作为空间分割的演化按空间群集的。该程序一直继续到空间分割稳定为止。
在本发明的进一步的实施方案中,适合给定的孔径的运动矢量被内插到一组与该孔径相对应的象素位置。当用这种内插定义的区段横越与对象边界相对应的象素时候,由此产生的分类是该区段的某种不规则的对角线分割。
在现有技术中,用来整合导数的最小二乘评估程序对离群值是非常敏感的。这种敏感性能产生使运动模型的群集方法严重地向迭代结果大大发散的点倾斜的运动模型。
在本发明中,运动拆分方法通过分析两个以上视频画面上明显的象素运动识别空间间断点。明显的运动是针对这些视频画面上的一致性分析的并且被整合成参数运动模型。与这种一致的运动相关联的空间间断点被识别出来。运动拆分也可以被称为时间拆分,因为时间变化可能是由运动引起的。然而,时间变化也可能是由一些其它的现象(例如,局部变形、照明变化,等等)引起的。
通过所描述的方法,与规范化方法相对应的显著信号模式能被识别而且能通过几种背景减法之一与环境信号模式(背景或非对象)分开。时常,这些方法从统计上建立背景模型,因为象素在每个时间例证都呈现最小的变化量。变化能被视为象素数值差异。
基于拆分周界的整体变形模型是通过先创造围绕对象的周界达成,然后使该周界向探测到的对象中心倒塌直到该周界的顶点已经实现位置与异种图像梯度一致。运动评估是针对这些新的顶点位置推断的,而强健的仿射评估被用来发现整体变形模型。
基于拆分网孔顶点图像世系的有限差分被整合成整体变形模型。
对象拆分
图13所示方框图展示对象拆分的一个优选实施方案。该程序由规范化图像(1302)的系综开始,然后所述规范化图像在该系综当中被逐对地计算差分(1304)。然后,这些差分被逐元素地积聚到积聚缓冲区之中(1306)。为了识别比较重要的误差区域,给该积聚缓冲区设定阈值(1310)。然后,为了确定累积误差区域的空间支持(1310),对通过阈值的元素掩模进行形态学分析(1312)。然后,由此产生的形态学分析(1312)的抽出物(1314)与探测到的对象位置进行比较相较(1320),以便将后来的处理集中在与该对象一致的累积误差区域。然后,用形成其凸壳(1324)的多角形近似孤立空间区域(1320)的边界(1322)。然后,调整壳的轮廓(1332),以便更好地初始化用于活跃轮廓分析(1332)的顶点位置。一旦活跃轮廓分析(1332)已经在累积误差空间中会聚在低能解上,该轮廓被用作最后轮廓(1334),而且被限制在该轮廓之中的象素被视为最有可能是对象象素的那些象素,而该轮廓之外的那些象素被视为非对象象素。
在优选的实施方案中,运动拆分能在给定显著图像模态的被探测位置和规模的情况下实现。距离变换能用来确定每个象素离开该被探测位置的距离。如果与最大距离相关联象素数值被保留,合理的背景模型能被求解。换句话说,环境信号是使用信号差衡量标准按时再次抽样的。
进一步的实施方案包括使用与当前探测位置相关的距离变换来把距离分配给每个象素。如果到某个象素的距离大于在某个最大象素距离表中的距离,那么该象素数值被记录下来。在适当的训练周期之后,如果适合于那个象素的最大距离是大的,则假定该象素有最高的作为背景象素的可能性。
给出环境信号模型,完全的显著信号模态能按每个时间例证计算差分。这些差分每个都能被再次抽样变成空间规范化的信号差(绝对差)。然后,这些差分彼此对准并且被累积。由于这些差分相对于显著信号模式是空间规范化的,所以差分的峰值将主要对应于与显著信号模式有关的象素位置。
在本发明的一个实施方案中,训练周期被定义,其中一些对象探测位置被确定而且那些位置的质心被用来与远离这个位置将考虑到画面差分化产生将有最高的作为非对象象素的概率的背景象素的的探测位置一起确定最佳的画面数。
在本发明的一个实施方案中,活跃轮廓模型被用来通过在累积误差“图像”中确定轮廓顶点位置把前景对象从非对象背景中拆分出来。在优选的实施方案中,活跃轮廓的边缘被细分得与被探测对象的比例相称,以便得到较大的自由度。在优选的实施方案中,最后轮廓的位置能快速灵活地移动到最接近的规则网孔顶点,以便得到有规律地隔开的轮廓。
在对象拆分的一个非限制性实施方案中,使用一个导向核来针对时间上成对的图像产生误差图像过滤器响应。对取向与总运动方向正交的过滤器的响应倾向于在相对于背景的运动从遮蔽背景到显露背景的时候增强误差表面。
规范化图像系综的规范化图像画面强度矢量是依据一个或多个创造残差矢量的参考画面计算差分的。这些残差矢量是逐元素地累积的,以形成累积残差矢量。然后,这个累积残差矢量被按空间地调查,以便定义适合对象象素和非对象象素的空间拆分的空间对象边界。
在一个优选实施方案中,为了得出能用来给累积残差矢量设定阈值的统计阈值,完成了最初的累积残差矢量统计分析。通过先腐蚀后膨胀的形态学操作,形成初步的对象区域掩模。然后,分析该区域的轮廓多角形点以揭示那些点的凸壳。然后,把该凸壳作为初始轮廓用于活跃轮廓分析法。该活跃轮廓在它会聚在该对象的累积残差空间边界上之前是一直增殖的。在进一步优选的实施方案中,初步的轮廓边缘通过添加中点顶点被进一步细分到实现适合于所有的边缘长度的最小边缘长度。这个进一步的实施方案意味着逐渐增加活跃轮廓模型的自由度以便更精确地适合该对象的轮廓。
在优选的实施方案中,细化的轮廓用来产生通过覆盖该轮廓暗示的多角形和覆盖规范化图像中的多角形指出该对象的象素的象素掩模。
非对象的分辨
图12所示的方框图揭示非对象拆分或同义地背景分辨的一个优选实施方案。通过背景缓冲区(1206)和初始最大距离值缓冲区(1204)的初始化,该程序是为通过把“稳定性”与距被探测对象位置(1202)的最大距离联系起来确定最稳定的非对象象素而工作的。给出新探测的对象位置(1202),该程序检查每个象素位置(1210)。对于每个象素位置(1210),使用距离变换计算离开被探测对象位置(1210)的距离。如果那个象素的距离大于在最大距离缓冲区(1204)中先前储存的位置(1216),那么先前的数值被当前的数值代替(1218),而且该象素数值被记录在象素缓冲区中(1220)。
给出清晰的背景图像,这个图像和当前画面之间的误差可以按空间规范化和按时间累积.这样的清晰背景图像是在“背景分辨”部分中描述的。通过这个方法背景的分辨率被视为基于时间的闭塞过滤器程序。
然后,由此产生的累积误差通过阈值检验提供初始轮廓。然后,该轮廓在空间上扩展以使残留误差与轮廓变形平衡。
在替代实施方案中,计算在当前画面和被分辨背景画面之间的绝对差别。然后,将元素状态的绝对差别拆分到截然不同的空间区域。这样计算这些区域边界框的平均象素值,以致当更新被分辨背景的时候,当前的和已分辨的背景平均象素值之间的差能用来实现反差变化,所以当前区域能更有效地掺混在被分辨的背景之中。在另一个实施方案中,在规范化画面掩模里面的顶点是针对每幅画面进行运动评估和保全的。然后,使用SVD处理这些顶点以产生用于每幅画面的局部变形预测。
梯度拆分
纹理拆分方法或同义的强度梯度拆分分析象素在一个或多个视频画面中的局部梯度。梯度响应是一种表征空间间断点的统计尺度,其中所述空间间断点对于该视频画面中的象素位置是局部的。然后,使用几种空间群集技术之一把这些梯度响应组合成一些空间区域。这些区域的边界在识别一个或多个视频画面中的空间间断点方面是有用的。
在本发明的一个实施方案中,来自计算机图形纹理生成的总面积表概念被用于加快强度场梯度计算的目的。累加值域的产生使通过与四次加法运算结合的四次查询计算任何长方形原始域的总和变得容易。
进一步的实施方案使用对一幅图像产生的Harris响应,而每个象素的邻近区域被归类为同种的、边缘或拐角。响应数值是依据这个信息产生的并且指出画面中每种元素的边缘化或拐角化的程度。
多刻度梯度分析
本发明的实施方案通过以几种空间刻度产生图像梯度值进一步约束图像梯度支持。这个方法能帮助限定图像梯度的资格,以致在不同刻度下的空间间断点能用来彼此相互支持,只要“边缘”在几种不同的空间刻度下能被分辨,该边缘应该是“显著的”。更有资格的图像梯度将倾向于与更显著的特征相对应。
在优选实施方案中,纹理响应区域是首先产生的,然后,这个区域的数值以k均值聚类算法分区间/分割为基础被量化成若干区间。然后,使用每个区间作为单一迭代能把分水岭拆分能应用于它的数值间隔渐进地处理最初的图像梯度数值。这种方法的好处是同种是在相对意义上用强烈的空间偏置定义的。
光谱拆分
光谱拆分方法分析视频信号中黑白象素、灰度象素或彩色象素的统计概率分布。频谱分类程序是通过完成关于那些象素的概率分布的群集操作构成的。然后,使用该分类程序把一个或多个象素分类,使之属于某个概率类别。然后,由此产生的概率类别和它的象素被赋予类别标签。然后,使这些类别标签在空间上合并成有截然不同的边界的象素区域。这些边界识别在一个或多个视频画面中的空间间断点。
本发明可以利用基于光谱分类的空间拆分来拆分视频画面中的象素。此外,各个区域之间的对应关系可以是基于各个光谱区域与先前拆分的区域的重叠确定的。
业已观察到当视频画面大体上由空间上被连接成与视频画面中的对象相对应的较大区域的连续彩色区域组成的时候,彩色(或光谱)区域的识别和跟踪能促进图像序列中对象的后续拆分。
背景拆分
本发明包括以每幅视频画面中的探测对象和每个个别象素之间的空间距离测量结果的瞬时最大值为基础建立视频画面背景模型的方法。给定探测到的对象位置,应用距离变换,产生适合画面中每个象素的标量距离数值。在所有的视频画面上每个象素的最大距离的映射图被保留。当最初分配最大数值的时候,或后来用不同的新数值更新该最大数值的时候,适合于那幅视频画面的对应的象素被保留在“清晰的背景”画面中。
建立外观模型
视频处理的共同目标往往是建立模型和保存视频画面序列的外观。本发明以允许通过预处理的运用以强健的和广泛适用的方式应用强制性外观建模技术为目标。先前描述的配准、拆分和规范化明显地适合这个目的。
本发明揭示建立外观变化模型的方法。建立外观变化模型的主要基础在线性模型的情况下是分析特征矢量,以揭示开发利用线性相关关系的坚实基础。表达空间强度场象素的特征矢量能被组装成外观变化模型。
在替代实施方案中,外观变化模型是依据被拆分的象素子集计算的。此外,该特征矢量能被分成若干空间上不重叠的特征矢量。这样的空间分解可以用空间铺瓦来实现。计算效率可以通过处理这些临时总体来实现,而不牺牲更普遍的PCA方法的维数减少。
在产生外观变化模型时,空间强度场规范化能用来减少空间变换的PCA建模。
建立变形模型
当顶点位移和插值函数能用来依照与那些象素相关联的顶点决定象素再次抽样的时候,能建立局部变形模型。这些顶点位移可以作为单一参数组提供很多横越许多顶点看到的运动变化。这些参数的相关关系能大大减少这个参数空间的维度。
PCA
产生外观变化模型的优选方法是通过把视频画面作为图案矢量组装成一个训练矩阵或总体然后把主要成份分析(PCA)应用在该训练矩阵上。当这样的展开式被截取的时候,由此产生的PCA变换矩阵被用来分析和合成后面的视频画面。基于截取水平,改变象素的初始外观质量水平能实现。
图案矢量的特定的构成和分解方法对于熟悉这项技术的人是广为人知的。
给出来自环境信号的显著信号模式的空间拆分和这个模式的空间规范化,象素本身或同义的由此产生的规范化信号的外观能被因式分解成线性相关的成份,其中低级参数表达考虑到适合表达象素外观的近似值误差和比特率之间的直接交换。用来实现低等级近似的一种方法是通过舍弃编码数据的一些字节和/或位。低等级近似值被视为原始数据的压缩,如同这项技术的特定应用所确定的那样。举例来说,在视频压缩中,如果数据的舍弃并非不适当地使感知质量降低,那么该应用的特定目标将连同压缩一起实现。
如图2所示,为了得到量纲上简明的数据版本(252和254),规范化的对象象素(242和244)能投射到矢量空间中而且线性对应关系能使用分解程序(250)建立模型。
连续的PCA
PCA使用PCA变换把图案编码成PCA系数。用PCA变换表达的图案越好,给该图案编码所需要的系数就越少。承认图案矢量可能随着时间在获得训练图案和待编码图案之间流逝降级,更新变换能帮助抵消这种降级。作为产生新变换的替代品,现有图案的连续更新在特定的情况下是计算上更有效的。
许多最新技术的视频压缩算法依据一个或多个其它画面预测某视频画面。预测模型通常基于把每个预测画面分割成与在另一画面中对应的补丁相匹配的不重叠的瓦片和相关联的用偏移运动矢量参数化的平移位移。这个非必选地与画面索引耦合的空间位移提供瓦片的“运动预测”版本。如果预测的误差在特定的阈值以下,则瓦片的象素适合残差编码;而且在压缩效率方面有对应的增益。否则,瓦片的象素被直接编码。这种基于瓦片的换句话说基于区段的运动预测方法通过平移包含象素的瓦片建立影像模型。当影像中的成像现象坚持这种建模的时候,对应的编码效率增加。为了与在基于区段的预测中固有的平移假定一致,这个建模限制为了与在基于区段的预测中固有的平移假设一致假定特定的时间分辨率水平(或帧频)对于正在运动的成像对象是存在的。这种平移模型的另一个必要条件是对于特定的时间分辨率空间位移必须受到限制;换言之,用来推导预测结果的画面和被预测的画面之间的时间差必须是比较短的绝对时间。这些时间分辨率和运动限制使存在于视频流中的某些多余的视频信号成份的识别和建模变得容易。
在本发明的方法中,连续的PCA与嵌零树子波结合以进一步提高混合压缩法的实用性。连续的PCA技术提供能针对有时间相干性或时间局部平滑性的信号提高传统的PCA的方法。嵌零树子波提供能为了提高特定处理的强健性和该算法的计算效率把局部平滑的空间信号分解成空间刻度表达的方法。对于本发明,将这两种技术结合起来,增加变异模型的表达能力和提供那些紧凑且安排好的模型的表达,以致该基础的许多表达能力是由该基础的舍弃提供的。
在另一个实施方案中,连续的PCA是与固定的输入区段大小和固定的允差一起应用的,以增加对第一个和大多数有力的PCA成份的加权偏移。对于较长的数据序列,这第一个PCA成份往往是唯一的PCA成份。这影响重建的画面质量而且能以某种方式限制所述方法的实效。本发明将不同的基准用于PCA成份的选择,这种选择对惯常使用的最小二乘基准是优选的。这种模型选择形式避免用第一个PCA成份过度近似。
在另一个实施方案中,区段PCA程序连同每个数据区段的固定的输入区段大小和规定的PCA成份数目一起用来提供有益的统一重建代替使用相对较多的成份。在进一步的实施方案中,区段PCA被用于与连续的PCA组合,在这种情况下区段PCA在一组步骤数目之后用一个区段PCA步骤重新初始化连续的PCA。这通过减少PCA成份的数目提供有益的统一近似值。
在另一个实施方案中,本发明利用PCA成份在编码-解码之前和之后视觉上相似的情形。图像序列重建质量在编码-解码之前和在之后也可能在视觉上相似,这往往取决于所用的量化程度。本发明的方法先将PCA成份解码,然后再次规范化它们使之有个体基准。对于适度的量化,解码后的PCA成份是近似正交的。在较高的量化水平,解码后的PCA成份被SVD的应用程序部分地恢复以获得一正交基础和一组修改过的重建系数。
在另一个实施方案中,可变的自适应的区段大小被应用于混合的继续PCA方法,为的是产生对于合成质量有所改善的结果。本发明将区段大小建立在PCA成份的最大数目和对于那些区段给定的容许误差的基础上。然后,该方法扩充当前的区段大小,直到达到PCA成份的最大数目。在进一步的实施方案中,PCA成份的序列被视为数据流,这导致维数进一步减少。该方法完成后处理步骤,在那里可变的数据区段是为来自每个区段的第一个PCA成份收集的,而SVD被应用,为的是进一步减少维度。然后,相同的程序被应用于第二个、第三个等成份的收集。
对称的分解
在本发明的一个实施方案中,分解是基于对称总体完成的。这个总体将正方形图像表示成六个正交成份之和。每个成份对应于该正方形的一种不同的对称。由于对称,每个正交成份都是用“基本区域”确定的,该基本区域借助对称作用被映入完全的成份。假定输入图像本身没有特别的对称性,那么基本区域之和有与输入图像一样的集容量。
基于残差的分解
在MPEG视频压缩中,当前的画面是通过先使用运动矢量对先前的画面进行运动补偿,然后把残差更新应用于那些补偿区段,最后将任何没有充份匹配的区段作为新区段完成编码构成的。
对应于残留区段的象素通过运动矢量映射到先前画面的象素上。结果是象素通过能通过连续应用残值合成的影像的瞬时路径。这些象素被确认为能使用PCA最明确地表达的象素。
基于遮挡的分解
本发明的进一步提高确定适用于多个区段的运动矢量是否将导致来自先前画面的任何象素被移动象素遮挡(覆盖)。对于每个遮挡事件,都把遮挡象素劈成新层。没有历史的象素也将暴露出来。暴露出来的象素被放到任何将在当前画面中与它们拟合而且历史拟合也能在那层上完成的层上。
象素的时间连续性是通过象素对不同层的接合和移植得到支持的。一旦获得稳定的层模型,每层中的象素就能基于对条理分明的运动模型的隶属关系编组。
分波段时间量化
本发明的替代实施方案使用离散余弦变换(DCT)或离散子波变换(DWT)把每个画面分解成分波段图像。然后,将主要成份分析(PCA)应用于这些“分波段”影像之中的每幅影像。概念是视频画面的分波段分解与原始视频画面相比较减少任何一个分波段中的空间变化。
就移动对象(人)的影像而言,空间变化倾向于支配用PCA建模的变化。分波段分解减少任何一个分解影像中的空间变化。
就DCT而言,任何一个分波段的分解系数都按空间安排在分波段影像之中。举例来说,DC系数是从每个区段获取的并且被安排在看起来像原始影像的邮票版本一样的分波段影像之中。这将对所有其它的分波段重复,而且使用PCA处理每个由此产生的分波段影像。
就DWT而言,分波段已经按针对DCT描述的方式排列好。
在非限制性实施方案中,PCA系数的截取是变化的。
子波
当使用离散子波变换(DWT)分解数据的时候,多个带通数据组以较低的空间分辨率为结果。变换程序能被递归地应用于导出数据直到仅仅产生单一的标量数值为止。在已分解的结构中标量元素通常以分等级的父母/孩子方式相关。由此产生的数据包含多分辨率的分等级结构以及有限差分。
当DWT被应用于空间强度场的时候,许多自然发生的图像现象由于空间频率低是用第一或第二低带通导出数据结构以微不足道的知觉损失表达的。截短该分等级结构在高频率空间数据不是不存在就是被视为噪音的时候提供简明的表达。
尽管PCA可以用来以为数不多的系数实现精确的重建,但是这种变换本身可能是相当大的。为了减少这个“初始”变换的规模,可以使用子波分解的嵌零树(EZT)结构来建立变换矩阵的越来越精确的版本。
子空间分类
如同实践这项技术的人充分理解的那样,离散抽样的现象数据和导出数据能被表达成一组与代数矢量空间相对应的数据矢量。这些数据矢量以非限制性方式包括拆分后对象的规范化外表中的象素、运动参数和特征或顶点的任何二或三维结构位置。这些矢量都存在于矢量空间之中,而且该空间的几何分析能用来产生样本或参数矢量的简洁表达。有益的几何条件是借助形成紧凑子空间的参数矢量代表的。当一个或多个子空间混合,形成表面上更复杂的单一子空间的时候,那些要素子空间可能难以辨别。有几种拆分方法考虑到通过检查通过原始矢量的一些交互作用(例如,内积)产生的高维矢量空间中的数据分离这样的子空间。
一种差分矢量空间的方法包括把矢量投射到表达多项式的Veronese矢量空间之中。这种方法在现有技术中是作为通用的PCA或GPCA技术广为人知的。通过这样的投射,多项式的法线被找到、聚集,而且与原始矢量相关联的那些法线能聚集在一起。这种技术的实用性的例子是把随着时间推移跟踪的二维空间点对应关系因式分解成三维结构模型和那个三维模型的运动。
GPCA技术在作为明确定义的仅仅在以少许噪音产生数据矢量的时候易受影响的结果应用的时候是不完全的。现有技术假定管理程序使用者介入对GPCA算法的管理。这个限制大大限制该技术的潜能。
本发明扩展了GPCA方法的概念基础,以便在有噪音和混合余维数存在时强健地处理多个子空间的识别和拆分。这种改革在技术状态上为该技术提供无人监督的改进。
在现有技术中,GPCA在Veronese映射图的多项式的法向矢量上操作,不考虑那些法向矢量的正切空间。本发明的方法扩充GPCA,以便找到与通常在Veronese映射图中找到的法向矢量的空间正交的正切空间。然后使用这个“正切空间”或Veronese映射图的子空间把该Veronese映射图因式分解。
正切空间是通过平面波膨胀和揭示几何对象(明确地说,Veronese映射图的多项式的法线的切线)的表达的二元性的Legendre变换在位置坐标和正切平面坐标之间的应用识别的。离散的Legendre变换是通过凸分析应用于定义与法向矢量相对应的导数的受约束形式。这种方法用来在有噪音存在的情况下通过计算法向矢量拆分数据矢量。这个凸分析与GPCA合并提供一种比较强健的算法。
本发明在应用GPCA的时候利用迭代的因子分解法。具体地说,在现有技术中发现的基于导数的落实被延伸到通过在此描述的同一GPCA方法细分分类数据矢量的总体。被重复应用,这项技术能用来强健地找出Veronese映射中的候选法向矢量,然后使用这种扩展的GPCA技术进一步限定那些矢量。就因子分解步骤而言,从原始数据组中除去与那组细分的矢量相关联的原始数据。剩余的数据组能用这种改进的GPCA技术分析。这种改进对于以无人监督的方式使用GPCA算法是至关重要的。图11举例说明数据矢量的递归细分。
人们将进一步确认,本发明对GPCA技术的改进在Veronese多项式矢量空间中有多个根的情况下有较大的优势。此外,当Veronese映射图的法线平行于矢量空间轴线之时现有技术在遇到退化情形的时候,本发明的方法不会退化。
图10举例说明基本的多项式拟合和求微分的方法。
在优选实施方案中,GPCA是用适合任意的余维子空间的多项式微分法实现的。SVD被用来得到对准每个数据点的正规空间的尺寸和依照该正规空间尺寸群集数据点。在每个群集里面的数据点当它们对某个允差全部属于最大的有同一等于共同的正规空间尺寸的等级的组的时候被指定给同一子空间。人们将认识到这种方法对于免于无噪音的数据是最佳的。
采用多项式微分的另一个非限制性GPCA实施方案有任意的余维子空间。这是“多项式微分”法的改编本。当噪音倾向于增加一组几乎排好的法向矢量的等级的时候,多项式除法步骤是依照SVD尺寸通过先群集数据点然后以最小的余维选择有最小残差的点初始化的。然后,在这个点的正规空间与多项式除法一起应用于近似地减少Veronese映射图。
在进一步的实施方案中,梯度加权的残差在所有数据点的范围内被减到最小,而SVD在最佳点被应用于估计余维和基础矢量。然后,该基础矢量与多项式区分一起被应用于近似地减少Veronese映射图。
在优选实施方案中,RCOP误差由于它随着噪音水平线性地缩放所以被用来设定数值允差。在优选实施方案中,GPCA是以这样的方式实现的,以便将SVD应用于每个点的预估法向矢量和识别其法向矢量SVD有相同等级的点。然后,将连续的SVD应用于每次用相同的等级在那些点收集正规矢量。那些连续SVD改变等级的点被确认为不同的子空间。
混合空间规范化压缩
本发明通过把拆分视频流添加到“规范化”的视频流之中充分发挥以区段为基础的运动预测编码方案的效率。然后,这些视频流分开编码以允许传统的编码解码器的平移运动假设是有效的。在完成规范化视频流的解码之时,视频流解除规范化,进入它们适当的位置并且被组合在一起产生原始的视频序列。
在一个实施方案中,一个或多个对象是在视频流中探测到的,而与探测到的每个个别对象有关的象素随后被拆分,离开非对象象素。接下来,针对对象象素和非对象象素产生整体空间运动模型。这个整体模型用来完成对象象素和非对象象素的空间规范化。这样的规范化已经有效地把非平移的运动从视频流中除去并且已经提供一组影像,这组影像的相互遮挡经被减到最少。这些是本发明的方法的两个有益的特征。
象素已按空间规范化的对象和非对象的新影像是作为给传统的以区段为基础的压缩算法的输入提供的。在这些影像解码时,整体运动模型的参数被用来还原规范化的解码画面,对象象素一起合成到非对象象素之上,产生最初的视频流的近似。
如图6所示,对于一个或多个对象(630和650)先前探测到的对象例证(206和208)每个都用传统视频压缩方法(632)的分开例证处理。此外,起因于对象的拆分(230)的非对象(602)也使用传统的视频压缩(632)压缩。这些分开的压缩编码(632)之中的每一个的结果是分开的传统编码流,每个编码流(634)分开地对应于每个视频流。在某个点,可能在传输之后,这些中间编码流(234)能被解压缩(636)成规范化的非对象(610)和许多对象(638和658)的合成物。这些合成后的象素能解除规范化(640),变成它们的已解除规范化的版本(622、642和662),把这些象素按空间相对于其它象素放置在正确的位置,以致合成程序(670)能把对象象素和非对象象素结合成完整的合成画面(672)。
在优选实施方案中,编码模式之间的切换是基于诸如将允许传统的随子空间方法改变的PSNR之类统计的变形度量标准完成的,以便完成视频画面的编码。
在本发明的另一个实施方案中,外貌、整体变形和局部变形的编码参数是为得到否则将不必编码的中间画面的预测而插值的。该插值方法可以是任何标准的插值方法,例如,线性插值、三次插值、样条内插,等等。
如图14所示,对象插值方法能通过一系列用外貌参数和变形参数表达的规范化对象(1402、1404&1406)的插值分析(1408)来实现。该分析确定能应用插值函数的时间范围(1410)。然后,可以将该范围的规格(1410)与规范化的对象规格(1414&1420)结合,以便近似和最后合成临时的规范化对象(1416&1418)。
混合编码解码的整合
在把传统的基于区段的压缩算法和本发明描述的规范化-拆分方案结合起来时,有一些已经产生结果的本发明的方法。首先,有专门的数据结构和必要的通信协议。
主要的数据结构包括整体空间变形参数和对象拆分规范掩模。主要的通信协议是包括传输整体空间变形参数和对象拆分规范掩模的各个层面。
Claims (24)
1.一种利用众多视频画面产生视频信号数据的编码形式的计算机实现方法,该方法包括:
在两幅或多幅视频画面中探测至少一个对象;
通过视频画面中的两幅或多幅画面跟踪所述至少一个对象;
在两幅或多幅视频画面中识别所述至少一个对象的对应元素;
分析所述对应元素以产生所述对应元素之间的关系;
通过使用所述对应元素之间的关系产生对应关系模型;
利用所述对应关系模型在两幅或多幅视频画面中对与所述至少一个对象相关联的象素数据再次抽样,借此产生再次抽样象素数据,所述再次抽样象素数据代表与所述至少一个对象相关联的象素数据的第一中间形式;以及
利用所述对应关系模型恢复所述再次抽样象素数据的空间位置,借此产生复原象素;以及
其中所述的探测和跟踪包括使用Viola/Jones脸部探测算法。
2.根据权利要求1的方法,进一步包括:
在两幅或多幅视频画面中将与所述至少一个对象相关联的象素数据从其它的象素数据中拆分出来以产生与所述至少一个对象相关联的象素数据的第二中间形式,所述拆分利用时间整合;以及
将所述复原象素与与所述至少一个对象相关联的象素数据的第二中间形式的相关部分重新组合在一起以产生原始视频画面。
3.根据权利要求1的方法,其中包括将所述对应关系模型因式分解成若干整体模型的方法,该方法包括:
把对应元素之间的关系整合成整体运动模型;
其中所述产生对应关系模型包括将强健的抽样共识用于二维仿射运动模型的解,以及
其中所述分析对应元素包括使用以依据两幅或多幅视频画面之间基于区段的运动评估产生的有限差分为基础的抽样总体。
4.根据权利要求1的方法,其中包括给与所述至少一个对象相关联的象素数据的第一中间形式编码,所述编码包括:
将所述再次抽样象素数据分解成编码表达,所述编码表达代表与所述至少一个对象相关联的象素数据的第三中间形式;
截掉所述编码表达的零或多个字节;以及
依据所述编码表达重组所述再次抽样象素数据;
其中所述的分解和重组两者都使用主成份分析。
5.根据权利要求2的方法,其中包括将所述对应关系模型因式分解成若干整体模型的方法,该方法包括:
把所述对应元素之间的关系整合成整体运动模型;
将所述再次抽样象素数据分解成编码表达,所述编码表达代表与所述至少一个对象相关联的象素数据的第四中间形式;
截掉所述编码表达的零或多个字节;以及
依据所述编码表达重组所述再次抽样象素数据;
其中所述的分解和重组两者都使用主成份分析;
其中所述产生对应关系模型包括将强健的抽样共识用于二维仿射运动模型的解,
其中所述分析对应元素包括使用以依据两幅或多幅视频画面之间基于区段的运动评估产生的有限差分为基础的抽样总体。
6.根据权利要求5的方法,其中所述两幅或多幅视频画面之中每幅画面都包括对象象素和非对象象素,该方法包括:
在两幅或多幅视频画面中识别非对象象素中的对应元素;
分析所述非对象象素中的对应元素以产生所述非对象象素中的对应元素之间的关系;
使用所述非对象象素中的对应元素之间的关系产生第二对应关系模型;
其中分析所述非对象象素中的和所述对象象素中的对应元素包括基于时间的闭塞过滤器。
7.根据权利要求6的方法,其中包括:
将所述对应关系模型因式分解成若干整体模型,其中被因式分解的所述对应关系模型包括所有对应元素和对应关系模型;
将所述对应元素之间的关系整合成整体运动模型;
将所述再次抽样象素数据分解成编码表达,所述编码表达代表与所述至少一个对象相关联的象素数据的第五中间形式;
截掉所述编码表达的零或多个字节;以及
依据所述编码表达重组所述再次抽样象素数据;
其中所述的分解和重组两者都使用传统的视频压缩/解压程序;
其中所述产生对应关系模型包括将强健的抽样共识用于二维仿射运动模型的解,
其中所述分析对应元素包括使用以依据两幅或多幅视频画面之间基于区段的运动评估产生的有限差分为基础的抽样总体。
8.根据权利要求4的方法,其中包括:
(a)完成关于与所述至少一个对象相关联的象素数据的第一中间形式的子空间拆分;
(b)通过正切矢量分析在隐含矢量空间中的应用限制子空间拆分判据;
保留与所述至少一个对象相关联的象素数据的第一中间形式子集;以及
在与所述至少一个对象相关联的象素数据的第一中间形式子集上完成(a)和(b);
其中所述完成子空间拆分包括使用GPCA;
其中所述隐含矢量空间包括Veronese映射图;
其中所述正切矢量分析包括Legendre变换。
9.根据权利要求6的方法,其中包括将所述对应关系模型因式分解成若干整体模型的方法,其中被因式分解的所述对应关系模型包括所有对应元素和对应关系模型,该方法包括:
(a)把所述对应元素之间的关系整合成整体运动模型;
(b)在一组数据矢量上完成子空间拆分;
(c)通过正切矢量分析在隐含矢量空间中的应用限制子空间拆分判据;
(d)保留所述一组数据矢量的子集;
(e)在所述一组数据矢量的子集上完成(b)和(c);
其中所述完成子空间拆分包括使用GPCA;
其中所述隐含矢量空间包括Veronese映射图;
其中所述正切矢量分析包括Legendre变换;而且
在(a)到(e)已经完成之后,该方法进一步包括:
(f)将所述再次抽样象素数据分解成编码表达,该编码表达代表与所述至少一个对象相关联的象素数据的第四中间形式;
(g)截掉所述编码表达的零或较多的字节;
(h)依据所述编码表达重组所述再次抽样象素数据;
其中所述的分解和重组两者都使用主成份分析;
其中所述产生对应关系模型包括将强健的抽样共识用于二维仿射运动模型的解,
其中所述分析对应元素包括使用以依据两幅或多幅视频画面之间基于区段的运动评估产生的有限差分为基础的抽样总体。
10.根据权利要求1的方法,其中包括将所述对应关系模型因式分解成局部变形模型的方法,该方法包括:
定义覆盖与所述至少一个对象相对应的象素的二维网孔,所述网孔以顶点和边缘的规则栅格为基础;
依据所述对应元素之间的关系产生局部运动模型,所述关系包括基于在两幅或多幅视频画面之间从以区段为基础的运动评估产生的有限差分的顶点位移。
11.根据权利要求10的方法,其中所述顶点对应于不连续的图像特征,所述方法包括通过使用图像梯度Harris响应分析识别与所述对象相对应的重要图像特征。
12.根据权利要求3的方法,进一步包括:
转发与所述至少一个对象相关联的象素数据的第一中间形式以便因式分解成局部变形模型;
定义覆盖与所述至少一个对象相对应的象素的二维网孔,所述网孔以顶点和边缘的规则格栅为基础;
依据所述对应元素之间的关系产生局部运动模型,所述关系包括基于在两幅或多幅视频画面之间从以区段为基础的运动评估产生的有限差分的顶点位移。
13.根据权利要求5的方法,其中包括:
转发与所述至少一个对象相关联的象素数据的第四中间形式以便因式分解成局部变形模型;
定义覆盖与所述至少一个对象相对应的象素的二维网孔,所述网孔以顶点和边缘的规则格栅为基础;
依据所述对应元素之间的关系产生局部运动模型,所述关系包括以在两幅或多幅视频画面之间从基于区段的运动评估产生的有限差分为基础的顶点位移;
其中所述局部运动模型以未用整体运动模型近似的残留运动为基础。
14.根据权利要求9的方法,其中包括:
转发与所述至少一个对象相关联的象素数据的第四中间形式以便因式分解成局部变形模型;
定义覆盖与所述至少一个对象相对应的象素的二维网孔,所述网孔以顶点和边缘的规则格栅为基础;
依据所述对应元素之间的关系产生局部运动模型,所述关系包括基于在两幅或多幅视频画面之间从以区段为基础的运动评估产生的有限差分的顶点位移;
其中所述局部运动模型以未用整体运动模型近似的残留运动为基础。
15.一种依据众多视频画面产生视频信号数据的编码形式的计算机实现方法,该方法包括:
在两幅或多幅视频画面探测至少一个对象;
通过视频画面中两幅或多幅画面跟踪所述至少一个对象;
在所述两幅或多幅视频画面中将与所述至少一个对象相关联的象素数据从其它的象素数据中拆分出来,以便产生与所述至少一个对象相关联的所述象素数据的第二中间形式,所述拆分利用所述象素数据的空间拆分;
识别两幅或多幅视频画面中至少一个对象的对应元素;
分析所述对应元素以产生所述对应元素之间的关系;
使用所述对应元素之间的关系产生对应关系模型;
把所述对应元素之间的关系整合成整体运动的模型;
利用所述对应关系模型对与所述两幅或多幅视频画面中的所述至少一个对象相关联的象素数据再次抽样,借此产生再次抽样象素数据,所述再次抽样象素数据代表与所述至少一个对象相关联的象素数据的第一中间形式;
利用所述对应关系模型恢复所述再次抽样象素数据的空间位置,借此产生复原象素;
将所述复原象素与与所述至少一个对象相关联的象素数据的第二中间形式的相关部分重新结合在一起以产生原始视频画面;
其中所述的探测和跟踪包括使用脸部探测算法;以及
其中所述产生对应关系模型包括将强健的预估程序用于多维投射运动模型的解,
其中所述分析对应元素包括在两幅或多幅视频画面之间使用基于外貌的运动评估。
16.根据权利要求15的方法,其中包括对与所述至少一个对象相关联的象素数据的第一中间形式进行编码,所述编码包括:
将所述再次抽样象素数据分解成编码表达,该编码表达代表与所述至少一个对象相关联的象素数据的第三中间形式;
截掉所述编码表达的零或更多的字节;
依据所述编码表达重组所述再次抽样象素数据;
其中所述的分解和重组两者都使用主成份分析。
17.根据权利要求15的方法,其中包括将所述对应关系模型因式分解成整体模型的方法,该方法包括:
把所述对应元素之间的关系整合成整体运动模型;
将所述再次抽样象素数据分解成编码表达,该编码表达代表与所述至少一个对象相关联的象素数据的第四中间形式;
截掉所述编码表达的零或更多的字节;
依据所述编码表达重组所述的再次抽样象素数据;
其中所述的分解和重组两者都使用主成份分析;
其中所述产生对应关系模型包括将强健的预估程序用于多维投射运动模型的解,
其中所述分析对应元素包括使用以依据两幅或多幅视频画面之间基于区段的运动评估产生的有限差分为基础的抽样总体。
18.根据权利要求17的方法,其中所述两幅或多幅视频画面之中每幅视频画面都包括对象象素和非对象象素,所述方法包括:
在所述两幅或多幅视频画面中识别非对象象素中的对应元素;
分析所述非对象象素中的对应元素以产生所述非对象象素的对应元素之间的关系;
通过使用所述非对象象素的对应元素之间的关系产生第二对应关系模型;
其中所述分析所述对象象素中的和所述非对象象素中的对应元素包括基于时间的闭塞过滤器。
19.根据权利要求18的方法,其中包括:
将所述对应关系模型因式分解成若干整体模型,其中被因式分的所述对应关系模型包括所有对应元素和对应关系模型;
把所述非对象象素中的和所述对象象素中的对应元素之间的关系整合成整体运动模型;
将所述再次抽样象素数据分解成编码表达,所述编码表达代表与所述至少一个对象相关联的象素数据的第五中间形式;
截掉编码表达的零或较多的字节;
依据编码表达重组所述再次抽样象素数据;
其中分解和重组两者都使用传统的视频压缩/解压缩程序;
其中产生所述非对象象素的和所述对象象素的对应关系模型包括将强健的预估程序用于多维投射运动模型的解,
其中分析所述非对象象素的和所述对象象素的对应元素包括使用以依据两幅或多幅视频画面之间基于区段的运动评估产生的有限差分为基础的抽样总体。
20.根据权利要求18的方法,其中包括将所述对应关系模型因式分解成若干整体模型的方法,其中被因式分解的所述对应关系模型包括所有对应元素和对应关系模型,该方法包括:
(a)把所述对应元素之间的关系整合成整体运动模型;
(b)在一组数据矢量上完成子空间拆分;
(c)通过正切矢量分析在隐含矢量空间中的应用限制子空间拆分判据;
(d)保留所述一组数据矢量的子集;
(e)在所述一组数据矢量的子集上完成(b)和(c);
其中所述完成子空间拆分包括使用GPCA;
其中所述隐含矢量空间包括Veronese映射图;
其中所述正切矢量分析包括Legendre变换;
在(a)到(e)已经完成之后,该方法进一步包括:
(f)将所述再次抽样象素数据分解成编码表达,所述编码表达代表与所述至少一个对象相关联的象素数据的第四中间形式;
(g)截掉所述编码表达的零或更多的字节;
(h)依据所述编码表达重组所述再次抽样象素数据;
其中所述的分解和重组两者都使用主成份分析;
其中所述产生对应关系模型包括将强健的预估程序用于多维投射运动模型的解,
其中所述分析对应元素包括使用以依据两幅或多幅视频画面之间基于区段的运动评估产生的有限差分为基础的抽样总体。
21.根据权利要求15的方法,其中包括将所述对应关系模型因式分解成局部变形模型的方法,该方法包括:
定义覆盖与所述至少一个对象相对应的象素数据的二维网孔,所述网孔以顶点和边缘的规则格栅为基础;
依据所述对应元素之间的关系产生局部运动模型,所述关系包括以依据两幅或多幅视频画面之间基于区段的运动评估产生的有限差分为基础的顶点位移。
22.根据权利要求21的方法,其中所述顶点对应于不连续的图像特征,该方法包括通过使用图像强度梯度分析识别与所述对象相对应的重要图像特征。
23.根据权利要求17的方法,其中包括:
转发与所述至少一个对象相关联的象素数据的第四中间形式以便因式分解成局部变形模型;
定义覆盖与所述至少一个对象相对应的象素数据的二维网孔,所述网孔以顶点和边缘的规则格栅为基础;
依据所述对应元素之间的关系产生局部运动模型,所述关系包括以依据两幅或多幅视频画面之间基于区段的运动评估产生的有限差分为基础的顶点位移;
其中所述局部运动模型以未用整体运动模型近似的残留运动为基础。
24.根据权利要求21的方法,其中包括:
定义覆盖与所述至少一个对象相对应的象素数据的二维网孔,所述网孔以顶点和边缘的规则格栅为基础;
依据对应元素之间的关系产生局部运动模型,所述关系包括以依据两幅或多幅视频画面之间基于区段的运动评估产生的有限差分为基础的顶点位移;
其中所述局部运动模型以未用整体运动模型近似的残留运动为基础。
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US66753205P | 2005-03-31 | 2005-03-31 | |
| US60/667,532 | 2005-03-31 | ||
| US67095105P | 2005-04-13 | 2005-04-13 | |
| US60/670,951 | 2005-04-13 | ||
| PCT/US2006/012160 WO2006105470A1 (en) | 2005-03-31 | 2006-03-30 | Apparatus and method for processing video data |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN101167363A CN101167363A (zh) | 2008-04-23 |
| CN101167363B true CN101167363B (zh) | 2010-07-07 |
Family
ID=37053728
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN2006800140797A Expired - Fee Related CN101167363B (zh) | 2005-03-31 | 2006-03-30 | 处理视频数据的方法 |
Country Status (7)
| Country | Link |
|---|---|
| EP (1) | EP1878256A4 (zh) |
| JP (2) | JP4573895B2 (zh) |
| KR (1) | KR101216161B1 (zh) |
| CN (1) | CN101167363B (zh) |
| AU (1) | AU2006230545B2 (zh) |
| CA (1) | CA2590869C (zh) |
| WO (1) | WO2006105470A1 (zh) |
Families Citing this family (22)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8902971B2 (en) | 2004-07-30 | 2014-12-02 | Euclid Discoveries, Llc | Video compression repository and model reuse |
| US9578345B2 (en) | 2005-03-31 | 2017-02-21 | Euclid Discoveries, Llc | Model-based video encoding and decoding |
| US9532069B2 (en) | 2004-07-30 | 2016-12-27 | Euclid Discoveries, Llc | Video compression repository and model reuse |
| US9743078B2 (en) | 2004-07-30 | 2017-08-22 | Euclid Discoveries, Llc | Standards-compliant model-based video encoding and decoding |
| EP1846892A4 (en) * | 2005-01-28 | 2011-04-06 | Euclid Discoveries Llc | DEVICES AND METHODS FOR PROCESSING VIDEO DATA |
| CN101622874A (zh) | 2007-01-23 | 2010-01-06 | 欧几里得发现有限责任公司 | 对象存档系统和方法 |
| CN101939991A (zh) | 2007-01-23 | 2011-01-05 | 欧几里得发现有限责任公司 | 用于处理图像数据的计算机方法和装置 |
| JP2010517427A (ja) | 2007-01-23 | 2010-05-20 | ユークリッド・ディスカバリーズ・エルエルシー | 個人向けのビデオサービスを提供するシステムおよび方法 |
| WO2009049681A1 (en) * | 2007-10-19 | 2009-04-23 | Vascops | Automatic geometrical and mechanical analyzing method and system for tubular structures |
| JP5080944B2 (ja) * | 2007-11-08 | 2012-11-21 | 興和株式会社 | パノラマ眼底画像合成装置及び方法 |
| CN102172026B (zh) | 2008-10-07 | 2015-09-09 | 欧几里得发现有限责任公司 | 基于特征的视频压缩 |
| JP5173873B2 (ja) * | 2008-11-20 | 2013-04-03 | キヤノン株式会社 | 画像符号化装置及びその制御方法 |
| KR101486177B1 (ko) * | 2010-10-18 | 2015-01-23 | 노키아 코포레이션 | 손 검출을 제공하기 위한 방법 및 장치 |
| WO2013148002A2 (en) * | 2012-03-26 | 2013-10-03 | Euclid Discoveries, Llc | Context based video encoding and decoding |
| JP2015011496A (ja) * | 2013-06-28 | 2015-01-19 | 大日本印刷株式会社 | 画像処理装置、画像処理方法、およびプログラム |
| JP6132700B2 (ja) * | 2013-08-05 | 2017-05-24 | 株式会社日立製作所 | 画像処理システム、及び、画像処理方法 |
| US10097851B2 (en) | 2014-03-10 | 2018-10-09 | Euclid Discoveries, Llc | Perceptual optimization for model-based video encoding |
| CA2942336A1 (en) | 2014-03-10 | 2015-09-17 | Euclid Discoveries, Llc | Continuous block tracking for temporal prediction in video encoding |
| US10091507B2 (en) | 2014-03-10 | 2018-10-02 | Euclid Discoveries, Llc | Perceptual optimization for model-based video encoding |
| US9363449B1 (en) * | 2014-11-13 | 2016-06-07 | Futurewei Technologies, Inc. | Parallax tolerant video stitching with spatial-temporal localized warping and seam finding |
| WO2020034663A1 (en) * | 2018-08-13 | 2020-02-20 | The Hong Kong Polytechnic University | Grid-based image cropping |
| CN111726475A (zh) * | 2020-06-28 | 2020-09-29 | 网易传媒科技(北京)有限公司 | 视频处理方法、系统、电子设备及存储介质 |
Family Cites Families (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH09182082A (ja) * | 1995-12-25 | 1997-07-11 | Nippon Telegr & Teleph Corp <Ntt> | 動画像の動き補償予測符号化方法とその装置 |
| JPH09307909A (ja) * | 1996-05-17 | 1997-11-28 | Oki Electric Ind Co Ltd | 動き補償装置 |
| US6047088A (en) * | 1996-12-16 | 2000-04-04 | Sharp Laboratories Of America, Inc. | 2D mesh geometry and motion vector compression |
| US6367210B1 (en) * | 1997-07-30 | 2002-04-09 | Framegard Anchoring Systems Limited | Apparatus and method for securing a pane against impact |
| JP3854721B2 (ja) * | 1998-06-01 | 2006-12-06 | キヤノン株式会社 | 画像処理装置及びその方法 |
| US6711278B1 (en) * | 1998-09-10 | 2004-03-23 | Microsoft Corporation | Tracking semantic objects in vector image sequences |
| US6307964B1 (en) * | 1999-06-04 | 2001-10-23 | Mitsubishi Electric Research Laboratories, Inc. | Method for ordering image spaces to represent object shapes |
| KR100455294B1 (ko) * | 2002-12-06 | 2004-11-06 | 삼성전자주식회사 | 감시 시스템에서의 사용자 검출 방법, 움직임 검출 방법및 사용자 검출 장치 |
| CN101036150B (zh) * | 2004-07-30 | 2010-06-09 | 欧几里得发现有限责任公司 | 用来处理视频数据的装置和方法 |
| WO2006055512A2 (en) * | 2004-11-17 | 2006-05-26 | Euclid Discoveries, Llc | Apparatus and method for processing video data |
| EP1846892A4 (en) * | 2005-01-28 | 2011-04-06 | Euclid Discoveries Llc | DEVICES AND METHODS FOR PROCESSING VIDEO DATA |
-
2006
- 2006-03-30 AU AU2006230545A patent/AU2006230545B2/en not_active Ceased
- 2006-03-30 KR KR1020077025308A patent/KR101216161B1/ko active IP Right Grant
- 2006-03-30 WO PCT/US2006/012160 patent/WO2006105470A1/en active Application Filing
- 2006-03-30 CN CN2006800140797A patent/CN101167363B/zh not_active Expired - Fee Related
- 2006-03-30 JP JP2008504465A patent/JP4573895B2/ja not_active Expired - Fee Related
- 2006-03-30 CA CA2590869A patent/CA2590869C/en not_active Expired - Fee Related
- 2006-03-30 EP EP06740318A patent/EP1878256A4/en not_active Withdrawn
-
2010
- 2010-06-22 JP JP2010141434A patent/JP5065451B2/ja not_active Expired - Fee Related
Non-Patent Citations (10)
| Title |
|---|
| HUANG K. ET AL.Sparse representation of images with hybrid linear models.PROC. ICIP2.2004,21281 - 1284. |
| HUANG K. ET AL.Sparse representation of images with hybrid linear models.PROC. ICIP2.2004,21281-1284. * |
| PIAMSA-NGA P. ET AL.Motion estimation and detection of complex objectbyanalyzing resampled movements of parts.PROC. ICIP'041.2004,1365 - 368. |
| PIAMSA-NGA P.ET AL.Motion estimation and detection of complex objectbyanalyzing resampled movements of parts.PROC. ICIP'041.2004,1365-368. * |
| RONG S. ET AL.Efficient spatiotemporal segmentation andvideoobjectgeneration for highway surveillance video.PROC. IEEE INT'L CONF. COMMUNICATIONS, CIRCUITS AND SYSTEMS AND WEST SINO EXPOSITIONS1.2002,1580 - 584. |
| RONG S.ET AL.Efficient spatiotemporal segmentation andvideoobjectgeneration for highway surveillance video.PROC.IEEE INT'L CONF. COMMUNICATIONS,CIRCUITS AND SYSTEMS AND WEST SINO EXPOSITIONS1.2002,1580-584. * |
| VIDAL R. ET AL.Generalized principal component analysis (GPCA).PROC. CVPR'031.2003,1I-621 - I-628. |
| VIDAL R. ET AL.Generalized principal component analysis (GPCA).PROC.CVPR'031.2003,1I-621-I-628. * |
| VIDAL R. ET AL.Motion segmentation with missing datausing PowerFactorization and GPCA.GPCA' PROC. CVPR'042.2004,2II-310 - II-316. |
| VIDAL R. ET AL.Motion segmentation with missing datausing PowerFactorization and GPCA.GPCA' PROC.CVPR'042.2004,2II-310-II-316. * |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2010259087A (ja) | 2010-11-11 |
| CA2590869C (en) | 2014-01-21 |
| JP5065451B2 (ja) | 2012-10-31 |
| JP2008537391A (ja) | 2008-09-11 |
| KR20080002915A (ko) | 2008-01-04 |
| WO2006105470A1 (en) | 2006-10-05 |
| KR101216161B1 (ko) | 2012-12-27 |
| CN101167363A (zh) | 2008-04-23 |
| EP1878256A4 (en) | 2011-06-08 |
| JP4573895B2 (ja) | 2010-11-04 |
| AU2006230545A1 (en) | 2006-10-05 |
| AU2006230545B2 (en) | 2010-10-28 |
| CA2590869A1 (en) | 2006-10-05 |
| EP1878256A1 (en) | 2008-01-16 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN101167363B (zh) | 处理视频数据的方法 | |
| CN101151640B (zh) | 用来处理视频数据的装置和方法 | |
| CN101536525B (zh) | 用来处理视频数据的装置和方法 | |
| CN101103364B (zh) | 用来处理视频数据的装置和方法 | |
| CN101061489B (zh) | 用来处理视频数据的装置和方法 | |
| CN101036150B (zh) | 用来处理视频数据的装置和方法 | |
| US7457472B2 (en) | Apparatus and method for processing video data | |
| US7457435B2 (en) | Apparatus and method for processing video data | |
| US7508990B2 (en) | Apparatus and method for processing video data | |
| US8908766B2 (en) | Computer method and apparatus for processing image data | |
| US20060177140A1 (en) | Apparatus and method for processing video data |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant | ||
| CF01 | Termination of patent right due to non-payment of annual fee |
Granted publication date: 20100707 Termination date: 20200330 |
|
| CF01 | Termination of patent right due to non-payment of annual fee |