WO2011011767A1 - Method for genome editing - Google Patents
Method for genome editing Download PDFInfo
- Publication number
- WO2011011767A1 WO2011011767A1 PCT/US2010/043167 US2010043167W WO2011011767A1 WO 2011011767 A1 WO2011011767 A1 WO 2011011767A1 US 2010043167 W US2010043167 W US 2010043167W WO 2011011767 A1 WO2011011767 A1 WO 2011011767A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- sequence
- protein
- receptor
- cell
- alpha
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 126
- 238000010362 genome editing Methods 0.000 title description 9
- 230000002759 chromosomal effect Effects 0.000 claims abstract description 184
- 241001465754 Metazoa Species 0.000 claims abstract description 135
- 108010017070 Zinc Finger Nucleases Proteins 0.000 claims abstract description 119
- 210000004027 cell Anatomy 0.000 claims description 130
- 238000003776 cleavage reaction Methods 0.000 claims description 82
- 230000007017 scission Effects 0.000 claims description 82
- 102000040430 polynucleotide Human genes 0.000 claims description 81
- 108091033319 polynucleotide Proteins 0.000 claims description 81
- 239000002157 polynucleotide Substances 0.000 claims description 81
- 150000007523 nucleic acids Chemical class 0.000 claims description 68
- 102000039446 nucleic acids Human genes 0.000 claims description 48
- 108020004707 nucleic acids Proteins 0.000 claims description 48
- 230000035772 mutation Effects 0.000 claims description 46
- 210000001161 mammalian embryo Anatomy 0.000 claims description 43
- 230000010354 integration Effects 0.000 claims description 40
- 239000002773 nucleotide Substances 0.000 claims description 40
- 125000003729 nucleotide group Chemical group 0.000 claims description 40
- 238000011144 upstream manufacturing Methods 0.000 claims description 33
- 230000014509 gene expression Effects 0.000 claims description 22
- 230000008569 process Effects 0.000 claims description 19
- 230000008859 change Effects 0.000 claims description 13
- 241000282414 Homo sapiens Species 0.000 claims description 12
- 230000006780 non-homologous end joining Effects 0.000 claims description 9
- 238000012258 culturing Methods 0.000 claims description 6
- 230000034431 double-strand break repair via homologous recombination Effects 0.000 claims description 6
- 210000000130 stem cell Anatomy 0.000 claims description 3
- 244000144972 livestock Species 0.000 claims description 2
- 210000004748 cultured cell Anatomy 0.000 claims 2
- 241000283984 Rodentia Species 0.000 claims 1
- 241000251539 Vertebrata <Metazoa> Species 0.000 claims 1
- 230000002538 fungal effect Effects 0.000 claims 1
- 210000005260 human cell Anatomy 0.000 claims 1
- 210000004962 mammalian cell Anatomy 0.000 claims 1
- 108090000623 proteins and genes Proteins 0.000 description 163
- 102000004169 proteins and genes Human genes 0.000 description 137
- 235000018102 proteins Nutrition 0.000 description 132
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 78
- 208000035475 disorder Diseases 0.000 description 47
- 206010012335 Dependence Diseases 0.000 description 45
- 238000012217 deletion Methods 0.000 description 43
- 230000037430 deletion Effects 0.000 description 43
- 108091028043 Nucleic acid sequence Proteins 0.000 description 35
- 108020004414 DNA Proteins 0.000 description 32
- 201000010099 disease Diseases 0.000 description 31
- 230000027455 binding Effects 0.000 description 30
- HCHKCACWOHOZIP-UHFFFAOYSA-N Zinc Chemical compound [Zn] HCHKCACWOHOZIP-UHFFFAOYSA-N 0.000 description 29
- 229910052725 zinc Inorganic materials 0.000 description 29
- 239000011701 zinc Substances 0.000 description 29
- 239000012634 fragment Substances 0.000 description 28
- 230000000694 effects Effects 0.000 description 22
- 239000000178 monomer Substances 0.000 description 22
- -1 immunoliposomes Substances 0.000 description 21
- 238000003556 assay Methods 0.000 description 20
- 208000002780 macular degeneration Diseases 0.000 description 20
- 208000029560 autism spectrum disease Diseases 0.000 description 18
- 238000011161 development Methods 0.000 description 18
- 230000018109 developmental process Effects 0.000 description 18
- 206010061218 Inflammation Diseases 0.000 description 17
- 208000018737 Parkinson disease Diseases 0.000 description 17
- 230000004054 inflammatory process Effects 0.000 description 17
- 150000001875 compounds Chemical class 0.000 description 16
- 230000000670 limiting effect Effects 0.000 description 16
- 102000004190 Enzymes Human genes 0.000 description 15
- 108090000790 Enzymes Proteins 0.000 description 15
- 206010028980 Neoplasm Diseases 0.000 description 15
- 229940088598 enzyme Drugs 0.000 description 15
- 201000000980 schizophrenia Diseases 0.000 description 15
- 102000002659 Amyloid Precursor Protein Secretases Human genes 0.000 description 14
- 108010043324 Amyloid Precursor Protein Secretases Proteins 0.000 description 14
- 102000000589 Interleukin-1 Human genes 0.000 description 14
- 108010002352 Interleukin-1 Proteins 0.000 description 14
- 230000006399 behavior Effects 0.000 description 14
- 208000024172 Cardiovascular disease Diseases 0.000 description 12
- 239000003550 marker Substances 0.000 description 12
- 108020004999 messenger RNA Proteins 0.000 description 12
- 239000000047 product Substances 0.000 description 12
- 239000000126 substance Substances 0.000 description 12
- 102000013691 Interleukin-17 Human genes 0.000 description 11
- 108050003558 Interleukin-17 Proteins 0.000 description 11
- 108700020796 Oncogene Proteins 0.000 description 11
- 230000003542 behavioural effect Effects 0.000 description 11
- 210000000349 chromosome Anatomy 0.000 description 11
- 238000004519 manufacturing process Methods 0.000 description 11
- 102000005962 receptors Human genes 0.000 description 11
- 108020003175 receptors Proteins 0.000 description 11
- 230000005760 tumorsuppression Effects 0.000 description 11
- 230000003612 virological effect Effects 0.000 description 11
- 241000271566 Aves Species 0.000 description 10
- 102100028914 Catenin beta-1 Human genes 0.000 description 10
- 102100025064 Cellular tumor antigen p53 Human genes 0.000 description 10
- 108010042407 Endonucleases Proteins 0.000 description 10
- 101000721661 Homo sapiens Cellular tumor antigen p53 Proteins 0.000 description 10
- 102000010909 Monoamine Oxidase Human genes 0.000 description 10
- 108010062431 Monoamine oxidase Proteins 0.000 description 10
- 230000000994 depressogenic effect Effects 0.000 description 10
- 230000006870 function Effects 0.000 description 10
- 238000011331 genomic analysis Methods 0.000 description 10
- 239000013612 plasmid Substances 0.000 description 10
- 238000000575 proteomic method Methods 0.000 description 10
- 108091008146 restriction endonucleases Proteins 0.000 description 10
- 102100029470 Apolipoprotein E Human genes 0.000 description 9
- 241000700159 Rattus Species 0.000 description 9
- 239000011543 agarose gel Substances 0.000 description 9
- 235000001014 amino acid Nutrition 0.000 description 9
- 150000001413 amino acids Chemical class 0.000 description 9
- 239000003795 chemical substances by application Substances 0.000 description 9
- 230000001105 regulatory effect Effects 0.000 description 9
- 230000035939 shock Effects 0.000 description 9
- 102000004219 Brain-derived neurotrophic factor Human genes 0.000 description 8
- 108090000715 Brain-derived neurotrophic factor Proteins 0.000 description 8
- 108091026890 Coding region Proteins 0.000 description 8
- 102100028183 Cytohesin-interacting protein Human genes 0.000 description 8
- 101000859758 Homo sapiens Cartilage-associated protein Proteins 0.000 description 8
- 101000916686 Homo sapiens Cytohesin-interacting protein Proteins 0.000 description 8
- 101000726740 Homo sapiens Homeobox protein cut-like 1 Proteins 0.000 description 8
- 101000761460 Homo sapiens Protein CASP Proteins 0.000 description 8
- 102100026019 Interleukin-6 Human genes 0.000 description 8
- 101000761459 Mesocricetus auratus Calcium-dependent serine proteinase Proteins 0.000 description 8
- 108700011259 MicroRNAs Proteins 0.000 description 8
- 102100024193 Mitogen-activated protein kinase 1 Human genes 0.000 description 8
- 108700015928 Mitogen-activated protein kinase 13 Proteins 0.000 description 8
- 102100038831 Peroxisome proliferator-activated receptor alpha Human genes 0.000 description 8
- 102100033237 Pro-epidermal growth factor Human genes 0.000 description 8
- 102100038280 Prostaglandin G/H synthase 2 Human genes 0.000 description 8
- 229940024606 amino acid Drugs 0.000 description 8
- 210000002459 blastocyst Anatomy 0.000 description 8
- 229940077737 brain-derived neurotrophic factor Drugs 0.000 description 8
- 239000000539 dimer Substances 0.000 description 8
- 210000002257 embryonic structure Anatomy 0.000 description 8
- 238000003780 insertion Methods 0.000 description 8
- 230000037431 insertion Effects 0.000 description 8
- NOESYZHRGYRDHS-UHFFFAOYSA-N insulin Chemical compound N1C(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(NC(=O)CN)C(C)CC)CSSCC(C(NC(CO)C(=O)NC(CC(C)C)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CCC(N)=O)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(N)=O)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CSSCC(NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2C=CC(O)=CC=2)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2NC=NC=2)NC(=O)C(CO)NC(=O)CNC2=O)C(=O)NCC(=O)NC(CCC(O)=O)C(=O)NC(CCCNC(N)=N)C(=O)NCC(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC(O)=CC=3)C(=O)NC(C(C)O)C(=O)N3C(CCC3)C(=O)NC(CCCCN)C(=O)NC(C)C(O)=O)C(=O)NC(CC(N)=O)C(O)=O)=O)NC(=O)C(C(C)CC)NC(=O)C(CO)NC(=O)C(C(C)O)NC(=O)C1CSSCC2NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)C(C)C)CC1=CN=CN1 NOESYZHRGYRDHS-UHFFFAOYSA-N 0.000 description 8
- 239000002679 microRNA Substances 0.000 description 8
- 230000004044 response Effects 0.000 description 8
- 238000012360 testing method Methods 0.000 description 8
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 7
- 102100022704 Amyloid-beta precursor protein Human genes 0.000 description 7
- 101710151993 Amyloid-beta precursor protein Proteins 0.000 description 7
- 108010039209 Blood Coagulation Factors Proteins 0.000 description 7
- 102000015081 Blood Coagulation Factors Human genes 0.000 description 7
- 102000009660 Cholinergic Receptors Human genes 0.000 description 7
- 108010009685 Cholinergic Receptors Proteins 0.000 description 7
- 241000255581 Drosophila <fruit fly, genus> Species 0.000 description 7
- 101000916173 Homo sapiens Catenin beta-1 Proteins 0.000 description 7
- 101000599951 Homo sapiens Insulin-like growth factor I Proteins 0.000 description 7
- 101000611183 Homo sapiens Tumor necrosis factor Proteins 0.000 description 7
- 102100037852 Insulin-like growth factor I Human genes 0.000 description 7
- 102100023181 Neurogenic locus notch homolog protein 1 Human genes 0.000 description 7
- 101710163270 Nuclease Proteins 0.000 description 7
- 102000001742 Tumor Suppressor Proteins Human genes 0.000 description 7
- 108010040002 Tumor Suppressor Proteins Proteins 0.000 description 7
- 239000003114 blood coagulation factor Substances 0.000 description 7
- 238000001514 detection method Methods 0.000 description 7
- 239000003814 drug Substances 0.000 description 7
- 108091008725 peroxisome proliferator-activated receptors alpha Proteins 0.000 description 7
- 210000001519 tissue Anatomy 0.000 description 7
- 102100024458 Cyclin-dependent kinase inhibitor 2A Human genes 0.000 description 6
- 102100029815 D(4) dopamine receptor Human genes 0.000 description 6
- 102000004533 Endonucleases Human genes 0.000 description 6
- 101000865206 Homo sapiens D(4) dopamine receptor Proteins 0.000 description 6
- 101001123834 Homo sapiens Neprilysin Proteins 0.000 description 6
- 101000622137 Homo sapiens P-selectin Proteins 0.000 description 6
- 101000577696 Homo sapiens Proline-rich transmembrane protein 2 Proteins 0.000 description 6
- 101000635938 Homo sapiens Transforming growth factor beta-1 proprotein Proteins 0.000 description 6
- 102100023915 Insulin Human genes 0.000 description 6
- 102100036721 Insulin receptor Human genes 0.000 description 6
- 108090000176 Interleukin-13 Proteins 0.000 description 6
- 108090001005 Interleukin-6 Proteins 0.000 description 6
- 102000001776 Matrix metalloproteinase-9 Human genes 0.000 description 6
- 108010015302 Matrix metalloproteinase-9 Proteins 0.000 description 6
- 102100038357 Metabotropic glutamate receptor 5 Human genes 0.000 description 6
- 108700027654 Mitogen-Activated Protein Kinase 10 Proteins 0.000 description 6
- 108700027648 Mitogen-Activated Protein Kinase 8 Proteins 0.000 description 6
- 102100026931 Mitogen-activated protein kinase 10 Human genes 0.000 description 6
- 102100037808 Mitogen-activated protein kinase 8 Human genes 0.000 description 6
- 241000699666 Mus <mouse, genus> Species 0.000 description 6
- 102100028782 Neprilysin Human genes 0.000 description 6
- 102100023472 P-selectin Human genes 0.000 description 6
- 102100034539 Peptidyl-prolyl cis-trans isomerase A Human genes 0.000 description 6
- 108010069820 Pro-Opiomelanocortin Proteins 0.000 description 6
- 239000000683 Pro-Opiomelanocortin Substances 0.000 description 6
- 102100027467 Pro-opiomelanocortin Human genes 0.000 description 6
- 102100040126 Prokineticin-1 Human genes 0.000 description 6
- 102100028840 Proline-rich transmembrane protein 2 Human genes 0.000 description 6
- 102000015840 Protein kinase C, epsilon Human genes 0.000 description 6
- 108050004067 Protein kinase C, epsilon Proteins 0.000 description 6
- 102100030416 Stromelysin-1 Human genes 0.000 description 6
- 102100030742 Transforming growth factor beta-1 proprotein Human genes 0.000 description 6
- 102100040247 Tumor necrosis factor Human genes 0.000 description 6
- 208000021841 acute erythroid leukemia Diseases 0.000 description 6
- 210000004556 brain Anatomy 0.000 description 6
- 230000000875 corresponding effect Effects 0.000 description 6
- 230000002526 effect on cardiovascular system Effects 0.000 description 6
- 230000006801 homologous recombination Effects 0.000 description 6
- 238000002744 homologous recombination Methods 0.000 description 6
- 230000006798 recombination Effects 0.000 description 6
- 238000005215 recombination Methods 0.000 description 6
- 238000007894 restriction fragment length polymorphism technique Methods 0.000 description 6
- 239000000523 sample Substances 0.000 description 6
- 241000894007 species Species 0.000 description 6
- 230000009154 spontaneous behavior Effects 0.000 description 6
- 238000001890 transfection Methods 0.000 description 6
- 102100029077 3-hydroxy-3-methylglutaryl-coenzyme A reductase Human genes 0.000 description 5
- 101710158485 3-hydroxy-3-methylglutaryl-coenzyme A reductase Proteins 0.000 description 5
- 101710137189 Amyloid-beta A4 protein Proteins 0.000 description 5
- 101710095339 Apolipoprotein E Proteins 0.000 description 5
- 102100035080 BDNF/NT-3 growth factors receptor Human genes 0.000 description 5
- 102100021943 C-C motif chemokine 2 Human genes 0.000 description 5
- 101100290380 Caenorhabditis elegans cel-1 gene Proteins 0.000 description 5
- 108010051219 Cre recombinase Proteins 0.000 description 5
- 101800003838 Epidermal growth factor Proteins 0.000 description 5
- 102000003971 Fibroblast Growth Factor 1 Human genes 0.000 description 5
- 108090000386 Fibroblast Growth Factor 1 Proteins 0.000 description 5
- 101000596896 Homo sapiens BDNF/NT-3 growth factors receptor Proteins 0.000 description 5
- 101001076408 Homo sapiens Interleukin-6 Proteins 0.000 description 5
- 101000605122 Homo sapiens Prostaglandin G/H synthase 1 Proteins 0.000 description 5
- 101000861454 Homo sapiens Protein c-Fos Proteins 0.000 description 5
- 101000779418 Homo sapiens RAC-alpha serine/threonine-protein kinase Proteins 0.000 description 5
- 108010074328 Interferon-gamma Proteins 0.000 description 5
- 108090000174 Interleukin-10 Proteins 0.000 description 5
- 102000003816 Interleukin-13 Human genes 0.000 description 5
- 108090000978 Interleukin-4 Proteins 0.000 description 5
- 102000016267 Leptin Human genes 0.000 description 5
- 108010092277 Leptin Proteins 0.000 description 5
- 102100027998 Macrophage metalloelastase Human genes 0.000 description 5
- 102100025725 Mothers against decapentaplegic homolog 4 Human genes 0.000 description 5
- 101710143112 Mothers against decapentaplegic homolog 4 Proteins 0.000 description 5
- 108090000556 Neuregulin-1 Proteins 0.000 description 5
- 102100021582 Neurexin-1-beta Human genes 0.000 description 5
- 102100022676 Nuclear receptor subfamily 4 group A member 2 Human genes 0.000 description 5
- 108010016731 PPAR gamma Proteins 0.000 description 5
- 102000012132 Peroxisome proliferator-activated receptor gamma Human genes 0.000 description 5
- 102100039419 Plasminogen activator inhibitor 2 Human genes 0.000 description 5
- 102100038277 Prostaglandin G/H synthase 1 Human genes 0.000 description 5
- 102100027584 Protein c-Fos Human genes 0.000 description 5
- 102100033810 RAC-alpha serine/threonine-protein kinase Human genes 0.000 description 5
- 108090000190 Thrombin Proteins 0.000 description 5
- 125000000539 amino acid group Chemical group 0.000 description 5
- DZHSAHHDTRWUTF-SIQRNXPUSA-N amyloid-beta polypeptide 42 Chemical compound C([C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(=O)NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](C)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(=O)NCC(=O)NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O)[C@@H](C)CC)C(C)C)NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC(O)=O)C(C)C)C(C)C)C1=CC=CC=C1 DZHSAHHDTRWUTF-SIQRNXPUSA-N 0.000 description 5
- 102000014082 cAMP-responsive element-binding protein 1 Human genes 0.000 description 5
- 108050003802 cAMP-responsive element-binding protein 1 Proteins 0.000 description 5
- 201000011510 cancer Diseases 0.000 description 5
- 229940079593 drug Drugs 0.000 description 5
- 229940116977 epidermal growth factor Drugs 0.000 description 5
- 238000001415 gene therapy Methods 0.000 description 5
- 230000001965 increasing effect Effects 0.000 description 5
- 229940100601 interleukin-6 Drugs 0.000 description 5
- 229940039781 leptin Drugs 0.000 description 5
- NRYBAZVQPHGZNS-ZSOCWYAHSA-N leptin Chemical compound O=C([C@H](CO)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)CNC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC(C)C)CCSC)N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CS)C(O)=O NRYBAZVQPHGZNS-ZSOCWYAHSA-N 0.000 description 5
- 230000001404 mediated effect Effects 0.000 description 5
- 229920001184 polypeptide Polymers 0.000 description 5
- 102000004196 processed proteins & peptides Human genes 0.000 description 5
- 108090000765 processed proteins & peptides Proteins 0.000 description 5
- 230000001225 therapeutic effect Effects 0.000 description 5
- 229960004072 thrombin Drugs 0.000 description 5
- VBEQCZHXXJYVRD-GACYYNSASA-N uroanthelone Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CS)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)C(C)C)[C@@H](C)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](CCSC)NC(=O)[C@H](CS)NC(=O)[C@@H](NC(=O)CNC(=O)CNC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CS)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CS)NC(=O)CNC(=O)[C@H]1N(CCC1)C(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O)C(C)C)[C@@H](C)CC)C1=CC=C(O)C=C1 VBEQCZHXXJYVRD-GACYYNSASA-N 0.000 description 5
- FQVLRGLGWNWPSS-BXBUPLCLSA-N (4r,7s,10s,13s,16r)-16-acetamido-13-(1h-imidazol-5-ylmethyl)-10-methyl-6,9,12,15-tetraoxo-7-propan-2-yl-1,2-dithia-5,8,11,14-tetrazacycloheptadecane-4-carboxamide Chemical compound N1C(=O)[C@@H](NC(C)=O)CSSC[C@@H](C(N)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](C)NC(=O)[C@@H]1CC1=CN=CN1 FQVLRGLGWNWPSS-BXBUPLCLSA-N 0.000 description 4
- 102100035923 4-aminobutyrate aminotransferase, mitochondrial Human genes 0.000 description 4
- 102100038074 5'-AMP-activated protein kinase subunit beta-1 Human genes 0.000 description 4
- 102100026802 72 kDa type IV collagenase Human genes 0.000 description 4
- 102100033350 ATP-dependent translocase ABCB1 Human genes 0.000 description 4
- 102100033639 Acetylcholinesterase Human genes 0.000 description 4
- 108010044688 Activating Transcription Factor 2 Proteins 0.000 description 4
- 102100034035 Alcohol dehydrogenase 1A Human genes 0.000 description 4
- 102100032187 Androgen receptor Human genes 0.000 description 4
- 108010059886 Apolipoprotein A-I Proteins 0.000 description 4
- 102000005666 Apolipoprotein A-I Human genes 0.000 description 4
- 102100040202 Apolipoprotein B-100 Human genes 0.000 description 4
- 102100029361 Aromatase Human genes 0.000 description 4
- 102100036597 Basement membrane-specific heparan sulfate proteoglycan core protein Human genes 0.000 description 4
- 102100023995 Beta-nerve growth factor Human genes 0.000 description 4
- 108010049931 Bone Morphogenetic Protein 2 Proteins 0.000 description 4
- 102100024506 Bone morphogenetic protein 2 Human genes 0.000 description 4
- 102100025401 Breast cancer type 1 susceptibility protein Human genes 0.000 description 4
- 102100028989 C-X-C chemokine receptor type 2 Human genes 0.000 description 4
- 102100034798 CCAAT/enhancer-binding protein beta Human genes 0.000 description 4
- 102100032937 CD40 ligand Human genes 0.000 description 4
- 102100032912 CD44 antigen Human genes 0.000 description 4
- 102100027221 CD81 antigen Human genes 0.000 description 4
- 102100039196 CX3C chemokine receptor 1 Human genes 0.000 description 4
- 102100023073 Calcium-activated potassium channel subunit alpha-1 Human genes 0.000 description 4
- 102100033868 Cannabinoid receptor 1 Human genes 0.000 description 4
- 102100036806 Carboxylesterase 5A Human genes 0.000 description 4
- 101710117416 Carboxylesterase 5A Proteins 0.000 description 4
- 102000016938 Catalase Human genes 0.000 description 4
- 108010053835 Catalase Proteins 0.000 description 4
- 108020002739 Catechol O-methyltransferase Proteins 0.000 description 4
- 102000006378 Catechol O-methyltransferase Human genes 0.000 description 4
- 102100021633 Cathepsin B Human genes 0.000 description 4
- 102100032219 Cathepsin D Human genes 0.000 description 4
- 102100037182 Cation-independent mannose-6-phosphate receptor Human genes 0.000 description 4
- 101710145225 Cation-independent mannose-6-phosphate receptor Proteins 0.000 description 4
- 102100035888 Caveolin-1 Human genes 0.000 description 4
- 108020004705 Codon Proteins 0.000 description 4
- 102100029376 Cryptochrome-1 Human genes 0.000 description 4
- 102100023033 Cyclic AMP-dependent transcription factor ATF-2 Human genes 0.000 description 4
- 108050006400 Cyclin Proteins 0.000 description 4
- 108010060273 Cyclin A2 Proteins 0.000 description 4
- 102100025191 Cyclin-A2 Human genes 0.000 description 4
- 108010009392 Cyclin-Dependent Kinase Inhibitor p16 Proteins 0.000 description 4
- 102100030497 Cytochrome c Human genes 0.000 description 4
- 101710103962 Cytochrome c, somatic Proteins 0.000 description 4
- 102100020756 D(2) dopamine receptor Human genes 0.000 description 4
- 108010067722 Dipeptidyl Peptidase 4 Proteins 0.000 description 4
- 102100025012 Dipeptidyl peptidase 4 Human genes 0.000 description 4
- 102000004073 Dopamine D3 Receptors Human genes 0.000 description 4
- 108090000525 Dopamine D3 Receptors Proteins 0.000 description 4
- 102000001301 EGF receptor Human genes 0.000 description 4
- 108060006698 EGF receptor Proteins 0.000 description 4
- 102100037241 Endoglin Human genes 0.000 description 4
- 108010036395 Endoglin Proteins 0.000 description 4
- 102100031780 Endonuclease Human genes 0.000 description 4
- 102100020997 Fractalkine Human genes 0.000 description 4
- 108010001498 Galectin 1 Proteins 0.000 description 4
- 102100021736 Galectin-1 Human genes 0.000 description 4
- 102100021023 Gamma-glutamyl hydrolase Human genes 0.000 description 4
- 102100021337 Gap junction alpha-1 protein Human genes 0.000 description 4
- 102100037260 Gap junction beta-1 protein Human genes 0.000 description 4
- 101000892220 Geobacillus thermodenitrificans (strain NG80-2) Long-chain-alcohol dehydrogenase 1 Proteins 0.000 description 4
- 102000053171 Glial Fibrillary Acidic Human genes 0.000 description 4
- 101710193519 Glial fibrillary acidic protein Proteins 0.000 description 4
- 102100030652 Glutamate receptor 1 Human genes 0.000 description 4
- 102100030651 Glutamate receptor 2 Human genes 0.000 description 4
- 102100022645 Glutamate receptor ionotropic, NMDA 1 Human genes 0.000 description 4
- 102100029458 Glutamate receptor ionotropic, NMDA 2A Human genes 0.000 description 4
- 102000003886 Glycoproteins Human genes 0.000 description 4
- 108090000288 Glycoproteins Proteins 0.000 description 4
- 102100020948 Growth hormone receptor Human genes 0.000 description 4
- 229940121710 HMGCoA reductase inhibitor Drugs 0.000 description 4
- 102100021866 Hepatocyte growth factor Human genes 0.000 description 4
- 102100038720 Histone deacetylase 9 Human genes 0.000 description 4
- 101710177326 Histone deacetylase 9 Proteins 0.000 description 4
- 102100035081 Homeobox protein TGIF1 Human genes 0.000 description 4
- 101000742701 Homo sapiens 5'-AMP-activated protein kinase subunit beta-1 Proteins 0.000 description 4
- 101000780443 Homo sapiens Alcohol dehydrogenase 1A Proteins 0.000 description 4
- 101000919395 Homo sapiens Aromatase Proteins 0.000 description 4
- 101000868273 Homo sapiens CD44 antigen Proteins 0.000 description 4
- 101000914479 Homo sapiens CD81 antigen Proteins 0.000 description 4
- 101001049859 Homo sapiens Calcium-activated potassium channel subunit alpha-1 Proteins 0.000 description 4
- 101000715467 Homo sapiens Caveolin-1 Proteins 0.000 description 4
- 101000931901 Homo sapiens D(2) dopamine receptor Proteins 0.000 description 4
- 101000894966 Homo sapiens Gap junction alpha-1 protein Proteins 0.000 description 4
- 101000954104 Homo sapiens Gap junction beta-1 protein Proteins 0.000 description 4
- 101001010445 Homo sapiens Glutamate receptor 1 Proteins 0.000 description 4
- 101001010449 Homo sapiens Glutamate receptor 2 Proteins 0.000 description 4
- 101000972838 Homo sapiens Glutamate receptor ionotropic, NMDA 1 Proteins 0.000 description 4
- 101000596925 Homo sapiens Homeobox protein TGIF1 Proteins 0.000 description 4
- 101001046870 Homo sapiens Hypoxia-inducible factor 1-alpha Proteins 0.000 description 4
- 101000935043 Homo sapiens Integrin beta-1 Proteins 0.000 description 4
- 101001033279 Homo sapiens Interleukin-3 Proteins 0.000 description 4
- 101001056128 Homo sapiens Mannose-binding protein C Proteins 0.000 description 4
- 101000990902 Homo sapiens Matrix metalloproteinase-9 Proteins 0.000 description 4
- 101000669513 Homo sapiens Metalloproteinase inhibitor 1 Proteins 0.000 description 4
- 101001124991 Homo sapiens Nitric oxide synthase, inducible Proteins 0.000 description 4
- 101000735539 Homo sapiens Pituitary adenylate cyclase-activating polypeptide Proteins 0.000 description 4
- 101000609261 Homo sapiens Plasminogen activator inhibitor 2 Proteins 0.000 description 4
- 101001051777 Homo sapiens Protein kinase C alpha type Proteins 0.000 description 4
- 101001051767 Homo sapiens Protein kinase C beta type Proteins 0.000 description 4
- 101000581112 Homo sapiens Rho-related GTP-binding protein RhoB Proteins 0.000 description 4
- 101000990915 Homo sapiens Stromelysin-1 Proteins 0.000 description 4
- 101000611023 Homo sapiens Tumor necrosis factor receptor superfamily member 6 Proteins 0.000 description 4
- 101000638886 Homo sapiens Urokinase-type plasminogen activator Proteins 0.000 description 4
- 102000003839 Human Proteins Human genes 0.000 description 4
- 108090000144 Human Proteins Proteins 0.000 description 4
- 102100039283 Hyaluronidase-1 Human genes 0.000 description 4
- 102100022875 Hypoxia-inducible factor 1-alpha Human genes 0.000 description 4
- 108090001061 Insulin Proteins 0.000 description 4
- 102100025947 Insulin-like growth factor II Human genes 0.000 description 4
- 102100025304 Integrin beta-1 Human genes 0.000 description 4
- 102100037850 Interferon gamma Human genes 0.000 description 4
- 102000004289 Interferon regulatory factor 1 Human genes 0.000 description 4
- 108090000890 Interferon regulatory factor 1 Proteins 0.000 description 4
- 102000008070 Interferon-gamma Human genes 0.000 description 4
- 102000003814 Interleukin-10 Human genes 0.000 description 4
- 102000003812 Interleukin-15 Human genes 0.000 description 4
- 108090000172 Interleukin-15 Proteins 0.000 description 4
- 102100039064 Interleukin-3 Human genes 0.000 description 4
- 102000004388 Interleukin-4 Human genes 0.000 description 4
- 102000000853 LDL receptors Human genes 0.000 description 4
- 108010001831 LDL receptors Proteins 0.000 description 4
- 108010015340 Low Density Lipoprotein Receptor-Related Protein-1 Proteins 0.000 description 4
- 108010018650 MEF2 Transcription Factors Proteins 0.000 description 4
- 102100028123 Macrophage colony-stimulating factor 1 Human genes 0.000 description 4
- 102100026553 Mannose-binding protein C Human genes 0.000 description 4
- 102100030412 Matrix metalloproteinase-9 Human genes 0.000 description 4
- 101710151321 Melanostatin Proteins 0.000 description 4
- 108010093175 Member 2 Group A Nuclear Receptor Subfamily 4 Proteins 0.000 description 4
- 108010065028 Metabotropic Glutamate 5 Receptor Proteins 0.000 description 4
- 102100039364 Metalloproteinase inhibitor 1 Human genes 0.000 description 4
- 102100026261 Metalloproteinase inhibitor 3 Human genes 0.000 description 4
- 102100039124 Methyl-CpG-binding protein 2 Human genes 0.000 description 4
- 108700027649 Mitogen-Activated Protein Kinase 3 Proteins 0.000 description 4
- 102100024192 Mitogen-activated protein kinase 3 Human genes 0.000 description 4
- 102100024134 Myeloid differentiation primary response protein MyD88 Human genes 0.000 description 4
- 108010084867 N-methyl D-aspartate receptor subtype 2A Proteins 0.000 description 4
- 102000034570 NR1 subfamily Human genes 0.000 description 4
- 108020001305 NR1 subfamily Proteins 0.000 description 4
- 102400000064 Neuropeptide Y Human genes 0.000 description 4
- 102100029438 Nitric oxide synthase, inducible Human genes 0.000 description 4
- 102100035733 Pituitary adenylate cyclase-activating polypeptide Human genes 0.000 description 4
- 102100026534 Procathepsin L Human genes 0.000 description 4
- 102100024622 Proenkephalin-B Human genes 0.000 description 4
- 102100036691 Proliferating cell nuclear antigen Human genes 0.000 description 4
- 102100021923 Prolow-density lipoprotein receptor-related protein 1 Human genes 0.000 description 4
- 102100024924 Protein kinase C alpha type Human genes 0.000 description 4
- 102100024923 Protein kinase C beta type Human genes 0.000 description 4
- 108090000783 Renin Proteins 0.000 description 4
- 102100028255 Renin Human genes 0.000 description 4
- 102100039313 Rho-associated protein kinase 1 Human genes 0.000 description 4
- 101710088411 Rho-associated protein kinase 1 Proteins 0.000 description 4
- 102100039314 Rho-associated protein kinase 2 Human genes 0.000 description 4
- 101710088493 Rho-associated protein kinase 2 Proteins 0.000 description 4
- 102100027611 Rho-related GTP-binding protein RhoB Human genes 0.000 description 4
- 102100037282 Secretoglobin family 1D member 4 Human genes 0.000 description 4
- 102100023085 Serine/threonine-protein kinase mTOR Human genes 0.000 description 4
- 102100024040 Signal transducer and activator of transcription 3 Human genes 0.000 description 4
- 102000006633 Sodium-Bicarbonate Symporters Human genes 0.000 description 4
- 108010068542 Somatotropin Receptors Proteins 0.000 description 4
- 108010053551 Sp1 Transcription Factor Proteins 0.000 description 4
- 102100038836 Superoxide dismutase [Cu-Zn] Human genes 0.000 description 4
- 101710139715 Superoxide dismutase [Cu-Zn] Proteins 0.000 description 4
- 102100032891 Superoxide dismutase [Mn], mitochondrial Human genes 0.000 description 4
- 101710202572 Superoxide dismutase [Mn], mitochondrial Proteins 0.000 description 4
- 102100024547 Tensin-1 Human genes 0.000 description 4
- 102100031344 Thioredoxin-interacting protein Human genes 0.000 description 4
- 101710114149 Thioredoxin-interacting protein Proteins 0.000 description 4
- 102100036034 Thrombospondin-1 Human genes 0.000 description 4
- 102100030246 Transcription factor Sp1 Human genes 0.000 description 4
- 102100029613 Transient receptor potential cation channel subfamily V member 1 Human genes 0.000 description 4
- 102100040403 Tumor necrosis factor receptor superfamily member 6 Human genes 0.000 description 4
- 102100031358 Urokinase-type plasminogen activator Human genes 0.000 description 4
- 108010073929 Vascular Endothelial Growth Factor A Proteins 0.000 description 4
- 108010073923 Vascular Endothelial Growth Factor C Proteins 0.000 description 4
- 102100039037 Vascular endothelial growth factor A Human genes 0.000 description 4
- 102100038232 Vascular endothelial growth factor C Human genes 0.000 description 4
- 102100033177 Vascular endothelial growth factor receptor 2 Human genes 0.000 description 4
- 102000053200 Von Hippel-Lindau Tumor Suppressor Human genes 0.000 description 4
- 108700031765 Von Hippel-Lindau Tumor Suppressor Proteins 0.000 description 4
- 125000003275 alpha amino acid group Chemical group 0.000 description 4
- 108010080146 androgen receptors Proteins 0.000 description 4
- 210000001106 artificial yeast chromosome Anatomy 0.000 description 4
- 239000002585 base Substances 0.000 description 4
- 108700000707 bcl-2-Associated X Proteins 0.000 description 4
- 102000055102 bcl-2-Associated X Human genes 0.000 description 4
- 230000022131 cell cycle Effects 0.000 description 4
- 238000013461 design Methods 0.000 description 4
- VYFYYTLLBUKUHU-UHFFFAOYSA-N dopamine Chemical compound NCCC1=CC=C(O)C(O)=C1 VYFYYTLLBUKUHU-UHFFFAOYSA-N 0.000 description 4
- 230000004064 dysfunction Effects 0.000 description 4
- 230000002068 genetic effect Effects 0.000 description 4
- 210000005046 glial fibrillary acidic protein Anatomy 0.000 description 4
- 229940125396 insulin Drugs 0.000 description 4
- 229940028885 interleukin-4 Drugs 0.000 description 4
- URPYMXQQVHTUDU-OFGSCBOVSA-N nucleopeptide y Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(N)=O)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)CNC(=O)[C@H]1N(CCC1)C(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CO)NC(=O)[C@H]1N(CCC1)C(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 URPYMXQQVHTUDU-OFGSCBOVSA-N 0.000 description 4
- 108010049224 perlecan Proteins 0.000 description 4
- 108010028075 procathepsin L Proteins 0.000 description 4
- 230000008439 repair process Effects 0.000 description 4
- 238000011160 research Methods 0.000 description 4
- 208000024891 symptom Diseases 0.000 description 4
- 108020001588 κ-opioid receptors Proteins 0.000 description 4
- 102100036506 11-beta-hydroxysteroid dehydrogenase 1 Human genes 0.000 description 3
- 102100039769 39S ribosomal protein L28, mitochondrial Human genes 0.000 description 3
- 102000000872 ATM Human genes 0.000 description 3
- 102100035991 Alpha-2-antiplasmin Human genes 0.000 description 3
- 102100026882 Alpha-synuclein Human genes 0.000 description 3
- 208000024827 Alzheimer disease Diseases 0.000 description 3
- 102100030988 Angiotensin-converting enzyme Human genes 0.000 description 3
- 208000019901 Anxiety disease Diseases 0.000 description 3
- 102100040214 Apolipoprotein(a) Human genes 0.000 description 3
- 108010014223 Armadillo Domain Proteins Proteins 0.000 description 3
- 108010008184 Aryldialkylphosphatase Proteins 0.000 description 3
- 108700020463 BRCA1 Proteins 0.000 description 3
- 101150023944 CXCR5 gene Proteins 0.000 description 3
- 102100025805 Cadherin-1 Human genes 0.000 description 3
- 101710187010 Cannabinoid receptor 1 Proteins 0.000 description 3
- 102100029855 Caspase-3 Human genes 0.000 description 3
- 108010075016 Ceruloplasmin Proteins 0.000 description 3
- 102100023321 Ceruloplasmin Human genes 0.000 description 3
- 108010025464 Cyclin-Dependent Kinase 4 Proteins 0.000 description 3
- 102100036252 Cyclin-dependent kinase 4 Human genes 0.000 description 3
- 102100030878 Cytochrome c oxidase subunit 1 Human genes 0.000 description 3
- 230000033616 DNA repair Effects 0.000 description 3
- 230000004568 DNA-binding Effects 0.000 description 3
- 241000289632 Dasypodidae Species 0.000 description 3
- 102100031817 Delta-type opioid receptor Human genes 0.000 description 3
- 102100032248 Dysferlin Human genes 0.000 description 3
- 108010044063 Endocrine-Gland-Derived Vascular Endothelial Growth Factor Proteins 0.000 description 3
- 102100037362 Fibronectin Human genes 0.000 description 3
- 102000004315 Forkhead Transcription Factors Human genes 0.000 description 3
- 108090000852 Forkhead Transcription Factors Proteins 0.000 description 3
- 108010051975 Glycogen Synthase Kinase 3 beta Proteins 0.000 description 3
- 102100038104 Glycogen synthase kinase-3 beta Human genes 0.000 description 3
- 102000002812 Heat-Shock Proteins Human genes 0.000 description 3
- 108010004889 Heat-Shock Proteins Proteins 0.000 description 3
- 101000928753 Homo sapiens 11-beta-hydroxysteroid dehydrogenase 1 Proteins 0.000 description 3
- 101000919849 Homo sapiens Cytochrome c oxidase subunit 1 Proteins 0.000 description 3
- 101000992305 Homo sapiens Delta-type opioid receptor Proteins 0.000 description 3
- 101001027128 Homo sapiens Fibronectin Proteins 0.000 description 3
- 101000854520 Homo sapiens Fractalkine Proteins 0.000 description 3
- 101000898034 Homo sapiens Hepatocyte growth factor Proteins 0.000 description 3
- 101000852815 Homo sapiens Insulin receptor Proteins 0.000 description 3
- 101001076292 Homo sapiens Insulin-like growth factor II Proteins 0.000 description 3
- 101001078133 Homo sapiens Integrin alpha-2 Proteins 0.000 description 3
- 101000599940 Homo sapiens Interferon gamma Proteins 0.000 description 3
- 101000917826 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor II-a Proteins 0.000 description 3
- 101000577881 Homo sapiens Macrophage metalloelastase Proteins 0.000 description 3
- 101000645293 Homo sapiens Metalloproteinase inhibitor 3 Proteins 0.000 description 3
- 101001030211 Homo sapiens Myc proto-oncogene protein Proteins 0.000 description 3
- 101000978766 Homo sapiens Neurogenic locus notch homolog protein 1 Proteins 0.000 description 3
- 101001073216 Homo sapiens Period circadian protein homolog 2 Proteins 0.000 description 3
- 101000851176 Homo sapiens Pro-epidermal growth factor Proteins 0.000 description 3
- 101000610537 Homo sapiens Prokineticin-1 Proteins 0.000 description 3
- 101000605127 Homo sapiens Prostaglandin G/H synthase 2 Proteins 0.000 description 3
- 101001136986 Homo sapiens Proteasome subunit beta type-8 Proteins 0.000 description 3
- 101000931462 Homo sapiens Protein FosB Proteins 0.000 description 3
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 description 3
- 101000742859 Homo sapiens Retinoblastoma-associated protein Proteins 0.000 description 3
- 101000785063 Homo sapiens Serine-protein kinase ATM Proteins 0.000 description 3
- 101000633069 Homo sapiens Transient receptor potential cation channel subfamily V member 1 Proteins 0.000 description 3
- 101000788548 Homo sapiens Tubulin alpha-4A chain Proteins 0.000 description 3
- 108010001127 Insulin Receptor Proteins 0.000 description 3
- 102100039688 Insulin-like growth factor 1 receptor Human genes 0.000 description 3
- 101710184277 Insulin-like growth factor 1 receptor Proteins 0.000 description 3
- 102100025305 Integrin alpha-2 Human genes 0.000 description 3
- 108090000193 Interleukin-1 beta Proteins 0.000 description 3
- 102000003777 Interleukin-1 beta Human genes 0.000 description 3
- 102000003810 Interleukin-18 Human genes 0.000 description 3
- 108090000171 Interleukin-18 Proteins 0.000 description 3
- 108010082786 Interleukin-1alpha Proteins 0.000 description 3
- 102000004125 Interleukin-1alpha Human genes 0.000 description 3
- 108010065637 Interleukin-23 Proteins 0.000 description 3
- 102100031819 Kappa-type opioid receptor Human genes 0.000 description 3
- 102100029204 Low affinity immunoglobulin gamma Fc region receptor II-a Human genes 0.000 description 3
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 3
- 102000000380 Matrix Metalloproteinase 1 Human genes 0.000 description 3
- 102000018697 Membrane Proteins Human genes 0.000 description 3
- 108010052285 Membrane Proteins Proteins 0.000 description 3
- 208000036626 Mental retardation Diseases 0.000 description 3
- 102100036837 Metabotropic glutamate receptor 2 Human genes 0.000 description 3
- 108010072388 Methyl-CpG-Binding Protein 2 Proteins 0.000 description 3
- 241000699670 Mus sp. Species 0.000 description 3
- 102100038895 Myc proto-oncogene protein Human genes 0.000 description 3
- 102000007339 Nerve Growth Factor Receptors Human genes 0.000 description 3
- 108010032605 Nerve Growth Factor Receptors Proteins 0.000 description 3
- 102000048238 Neuregulin-1 Human genes 0.000 description 3
- 101710203761 Neurexin-1 Proteins 0.000 description 3
- 102100030411 Neutrophil collagenase Human genes 0.000 description 3
- 108010029755 Notch1 Receptor Proteins 0.000 description 3
- 108010029756 Notch3 Receptor Proteins 0.000 description 3
- 102100029441 Nucleotide-binding oligomerization domain-containing protein 2 Human genes 0.000 description 3
- 108010049358 Oncogene Protein p65(gag-jun) Proteins 0.000 description 3
- 101150014691 PPARA gene Proteins 0.000 description 3
- 102100034850 Peptidyl-prolyl cis-trans isomerase G Human genes 0.000 description 3
- 102100035787 Period circadian protein homolog 2 Human genes 0.000 description 3
- 102100032543 Phosphatidylinositol 3,4,5-trisphosphate 3-phosphatase and dual-specificity protein phosphatase PTEN Human genes 0.000 description 3
- 101710132081 Phosphatidylinositol 3,4,5-trisphosphate 3-phosphatase and dual-specificity protein phosphatase PTEN Proteins 0.000 description 3
- 102100033616 Phospholipid-transporting ATPase ABCA1 Human genes 0.000 description 3
- 102100031950 Polyunsaturated fatty acid lipoxygenase ALOX15 Human genes 0.000 description 3
- 102100022033 Presenilin-1 Human genes 0.000 description 3
- 102100022036 Presenilin-2 Human genes 0.000 description 3
- 108050003267 Prostaglandin G/H synthase 2 Proteins 0.000 description 3
- 108090000708 Proteasome Endopeptidase Complex Proteins 0.000 description 3
- 102000004245 Proteasome Endopeptidase Complex Human genes 0.000 description 3
- 102100035760 Proteasome subunit beta type-8 Human genes 0.000 description 3
- 102100020847 Protein FosB Human genes 0.000 description 3
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 description 3
- 101710100963 Receptor tyrosine-protein kinase erbB-4 Proteins 0.000 description 3
- 102100038042 Retinoblastoma-associated protein Human genes 0.000 description 3
- 206010039491 Sarcoma Diseases 0.000 description 3
- 102100020867 Secretogranin-1 Human genes 0.000 description 3
- 102100032782 Semaphorin-5A Human genes 0.000 description 3
- 102000019208 Serotonin Plasma Membrane Transport Proteins Human genes 0.000 description 3
- 108010012996 Serotonin Plasma Membrane Transport Proteins Proteins 0.000 description 3
- 102100035476 Serum paraoxonase/arylesterase 1 Human genes 0.000 description 3
- 102100032416 Solute carrier family 22 member 1 Human genes 0.000 description 3
- 102000040945 Transcription factor Human genes 0.000 description 3
- 108091023040 Transcription factor Proteins 0.000 description 3
- 102000004893 Transcription factor AP-2 Human genes 0.000 description 3
- 108090001039 Transcription factor AP-2 Proteins 0.000 description 3
- 102100023132 Transcription factor Jun Human genes 0.000 description 3
- 102100025239 Tubulin alpha-4A chain Human genes 0.000 description 3
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 3
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 description 3
- 102100039094 Tyrosinase Human genes 0.000 description 3
- 102100037160 Ubiquitin-like modifier-activating enzyme 1 Human genes 0.000 description 3
- 230000005856 abnormality Effects 0.000 description 3
- 230000036506 anxiety Effects 0.000 description 3
- 210000004436 artificial bacterial chromosome Anatomy 0.000 description 3
- 238000010276 construction Methods 0.000 description 3
- 230000001086 cytosolic effect Effects 0.000 description 3
- 238000009510 drug design Methods 0.000 description 3
- 210000003754 fetus Anatomy 0.000 description 3
- 229940029303 fibroblast growth factor-1 Drugs 0.000 description 3
- 230000012010 growth Effects 0.000 description 3
- 238000000338 in vitro Methods 0.000 description 3
- 229940068935 insulin-like growth factor 2 Drugs 0.000 description 3
- 229940076144 interleukin-10 Drugs 0.000 description 3
- 239000002502 liposome Substances 0.000 description 3
- 238000013507 mapping Methods 0.000 description 3
- 238000000520 microinjection Methods 0.000 description 3
- 239000013641 positive control Substances 0.000 description 3
- 230000002269 spontaneous effect Effects 0.000 description 3
- 238000001262 western blot Methods 0.000 description 3
- LOGFVTREOLYCPF-KXNHARMFSA-N (2s,3r)-2-[[(2r)-1-[(2s)-2,6-diaminohexanoyl]pyrrolidine-2-carbonyl]amino]-3-hydroxybutanoic acid Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H]1CCCN1C(=O)[C@@H](N)CCCCN LOGFVTREOLYCPF-KXNHARMFSA-N 0.000 description 2
- 108091064702 1 family Proteins 0.000 description 2
- 102100030388 1-phosphatidylinositol 4,5-bisphosphate phosphodiesterase beta-3 Human genes 0.000 description 2
- NCYCYZXNIZJOKI-IOUUIBBYSA-N 11-cis-retinal Chemical compound O=C/C=C(\C)/C=C\C=C(/C)\C=C\C1=C(C)CCCC1(C)C NCYCYZXNIZJOKI-IOUUIBBYSA-N 0.000 description 2
- AQQSXKSWTNWXKR-UHFFFAOYSA-N 2-(2-phenylphenanthro[9,10-d]imidazol-3-yl)acetic acid Chemical compound C1(=CC=CC=C1)C1=NC2=C(N1CC(=O)O)C1=CC=CC=C1C=1C=CC=CC=12 AQQSXKSWTNWXKR-UHFFFAOYSA-N 0.000 description 2
- KISWVXRQTGLFGD-UHFFFAOYSA-N 2-[[2-[[6-amino-2-[[2-[[2-[[5-amino-2-[[2-[[1-[2-[[6-amino-2-[(2,5-diamino-5-oxopentanoyl)amino]hexanoyl]amino]-5-(diaminomethylideneamino)pentanoyl]pyrrolidine-2-carbonyl]amino]-3-hydroxypropanoyl]amino]-5-oxopentanoyl]amino]-5-(diaminomethylideneamino)p Chemical compound C1CCN(C(=O)C(CCCN=C(N)N)NC(=O)C(CCCCN)NC(=O)C(N)CCC(N)=O)C1C(=O)NC(CO)C(=O)NC(CCC(N)=O)C(=O)NC(CCCN=C(N)N)C(=O)NC(CO)C(=O)NC(CCCCN)C(=O)NC(C(=O)NC(CC(C)C)C(O)=O)CC1=CC=C(O)C=C1 KISWVXRQTGLFGD-UHFFFAOYSA-N 0.000 description 2
- 102100036285 25-hydroxyvitamin D-1 alpha hydroxylase, mitochondrial Human genes 0.000 description 2
- 102100036734 26S proteasome non-ATPase regulatory subunit 10 Human genes 0.000 description 2
- 102100040962 26S proteasome non-ATPase regulatory subunit 13 Human genes 0.000 description 2
- 102100029511 26S proteasome regulatory subunit 6B Human genes 0.000 description 2
- 101710094518 4-aminobutyrate aminotransferase Proteins 0.000 description 2
- 102100027278 4-trimethylaminobutyraldehyde dehydrogenase Human genes 0.000 description 2
- 102100036009 5'-AMP-activated protein kinase catalytic subunit alpha-2 Human genes 0.000 description 2
- 102100024626 5'-AMP-activated protein kinase subunit gamma-2 Human genes 0.000 description 2
- 101710169336 5'-deoxyadenosine deaminase Proteins 0.000 description 2
- 102000004023 5-Lipoxygenase-Activating Proteins Human genes 0.000 description 2
- 108090000411 5-Lipoxygenase-Activating Proteins Proteins 0.000 description 2
- 102100022738 5-hydroxytryptamine receptor 1A Human genes 0.000 description 2
- 102100027499 5-hydroxytryptamine receptor 1B Human genes 0.000 description 2
- 102100036321 5-hydroxytryptamine receptor 2A Human genes 0.000 description 2
- 102100024954 5-hydroxytryptamine receptor 3A Human genes 0.000 description 2
- 102100040385 5-hydroxytryptamine receptor 4 Human genes 0.000 description 2
- 108010029731 6-phosphogluconolactonase Proteins 0.000 description 2
- 102100031126 6-phosphogluconolactonase Human genes 0.000 description 2
- 102100038222 60 kDa heat shock protein, mitochondrial Human genes 0.000 description 2
- 102100032533 ADP/ATP translocase 1 Human genes 0.000 description 2
- 102100024378 AF4/FMR2 family member 2 Human genes 0.000 description 2
- 102100032123 AMP deaminase 1 Human genes 0.000 description 2
- 101150037123 APOE gene Proteins 0.000 description 2
- 102000004146 ATP citrate synthases Human genes 0.000 description 2
- 108090000662 ATP citrate synthases Proteins 0.000 description 2
- 102100028187 ATP-binding cassette sub-family C member 6 Human genes 0.000 description 2
- 102100033106 ATP-binding cassette sub-family G member 5 Human genes 0.000 description 2
- 102100033092 ATP-binding cassette sub-family G member 8 Human genes 0.000 description 2
- 102000010583 ATR Human genes 0.000 description 2
- 102100022997 Acidic leucine-rich nuclear phosphoprotein 32 family member A Human genes 0.000 description 2
- 108010085238 Actins Proteins 0.000 description 2
- 102000007469 Actins Human genes 0.000 description 2
- 102000007481 Activating Transcription Factor 6 Human genes 0.000 description 2
- 108010085405 Activating Transcription Factor 6 Proteins 0.000 description 2
- 102100033647 Activity-regulated cytoskeleton-associated protein Human genes 0.000 description 2
- 101710177131 Activity-regulated cytoskeleton-associated protein Proteins 0.000 description 2
- 208000036762 Acute promyelocytic leukaemia Diseases 0.000 description 2
- 102100034542 Acyl-CoA (8-3)-desaturase Human genes 0.000 description 2
- 101710102367 Acyl-CoA (8-3)-desaturase Proteins 0.000 description 2
- 102100034544 Acyl-CoA 6-desaturase Human genes 0.000 description 2
- 101710200145 Acyl-CoA 6-desaturase Proteins 0.000 description 2
- 101710159293 Acyl-CoA desaturase 1 Proteins 0.000 description 2
- 102100022089 Acyl-[acyl-carrier-protein] hydrolase Human genes 0.000 description 2
- 108010060263 Adenosine A1 Receptor Proteins 0.000 description 2
- 102000030814 Adenosine A1 receptor Human genes 0.000 description 2
- 102000055025 Adenosine deaminases Human genes 0.000 description 2
- 102100033346 Adenosine receptor A1 Human genes 0.000 description 2
- 102100027236 Adenylate kinase isoenzyme 1 Human genes 0.000 description 2
- 102100036792 Adhesion G protein-coupled receptor L4 Human genes 0.000 description 2
- 102100031786 Adiponectin Human genes 0.000 description 2
- 102000004379 Adrenomedullin Human genes 0.000 description 2
- 101800004616 Adrenomedullin Proteins 0.000 description 2
- 102100029599 Advanced glycosylation end product-specific receptor Human genes 0.000 description 2
- 102000009027 Albumins Human genes 0.000 description 2
- 108010088751 Albumins Proteins 0.000 description 2
- 102100034042 Alcohol dehydrogenase 1C Human genes 0.000 description 2
- 101710150756 Aldehyde dehydrogenase, mitochondrial Proteins 0.000 description 2
- 102100026448 Aldo-keto reductase family 1 member A1 Human genes 0.000 description 2
- 102100024321 Alkaline phosphatase, placental type Human genes 0.000 description 2
- 102100026663 All-trans-retinol dehydrogenase [NAD(+)] ADH7 Human genes 0.000 description 2
- 102100022524 Alpha-1-antichymotrypsin Human genes 0.000 description 2
- 102100022712 Alpha-1-antitrypsin Human genes 0.000 description 2
- 102100024349 Alpha-1A adrenergic receptor Human genes 0.000 description 2
- 102100027165 Alpha-2-macroglobulin receptor-associated protein Human genes 0.000 description 2
- 101710126837 Alpha-2-macroglobulin receptor-associated protein Proteins 0.000 description 2
- 102100036666 Alpha-2B adrenergic receptor Human genes 0.000 description 2
- 102100034033 Alpha-adducin Human genes 0.000 description 2
- 102100040743 Alpha-crystallin B chain Human genes 0.000 description 2
- 102100032381 Alpha-hemoglobin-stabilizing protein Human genes 0.000 description 2
- 101710198436 Alpha-hemoglobin-stabilizing protein Proteins 0.000 description 2
- 102100030461 Alpha-ketoglutarate-dependent dioxygenase FTO Human genes 0.000 description 2
- 102100034452 Alternative prion protein Human genes 0.000 description 2
- 102100036439 Amyloid beta precursor protein binding family B member 1 Human genes 0.000 description 2
- 102100034594 Angiopoietin-1 Human genes 0.000 description 2
- 102100022014 Angiopoietin-1 receptor Human genes 0.000 description 2
- 102100034608 Angiopoietin-2 Human genes 0.000 description 2
- 102100025674 Angiopoietin-related protein 4 Human genes 0.000 description 2
- 102100033394 Angiotensinogen Human genes 0.000 description 2
- 102000015427 Angiotensins Human genes 0.000 description 2
- 108010064733 Angiotensins Proteins 0.000 description 2
- 102000004121 Annexin A5 Human genes 0.000 description 2
- 108090000672 Annexin A5 Proteins 0.000 description 2
- 102100034273 Annexin A7 Human genes 0.000 description 2
- 108010039940 Annexin A7 Proteins 0.000 description 2
- 102100030343 Antigen peptide transporter 2 Human genes 0.000 description 2
- 102100022977 Antithrombin-III Human genes 0.000 description 2
- 102100037320 Apolipoprotein A-IV Human genes 0.000 description 2
- 102100040197 Apolipoprotein A-V Human genes 0.000 description 2
- 108010061118 Apolipoprotein A-V Proteins 0.000 description 2
- 108010008150 Apolipoprotein B-100 Proteins 0.000 description 2
- 102000011772 Apolipoprotein C-I Human genes 0.000 description 2
- 108010076807 Apolipoprotein C-I Proteins 0.000 description 2
- 102000007592 Apolipoproteins Human genes 0.000 description 2
- 108010071619 Apolipoproteins Proteins 0.000 description 2
- 108010025628 Apolipoproteins E Proteins 0.000 description 2
- 102000013918 Apolipoproteins E Human genes 0.000 description 2
- 108010062544 Apoptotic Protease-Activating Factor 1 Proteins 0.000 description 2
- 102100034524 Apoptotic protease-activating factor 1 Human genes 0.000 description 2
- 102100033367 Appetite-regulating hormone Human genes 0.000 description 2
- 102000004888 Aquaporin 1 Human genes 0.000 description 2
- 108090001004 Aquaporin 1 Proteins 0.000 description 2
- 108010048907 Arachidonate 15-lipoxygenase Proteins 0.000 description 2
- 239000004475 Arginine Substances 0.000 description 2
- 102100026440 Arrestin-C Human genes 0.000 description 2
- 102000003984 Aryl Hydrocarbon Receptors Human genes 0.000 description 2
- 108090000448 Aryl Hydrocarbon Receptors Proteins 0.000 description 2
- 102100037211 Aryl hydrocarbon receptor nuclear translocator-like protein 1 Human genes 0.000 description 2
- 102100034193 Aspartate aminotransferase, mitochondrial Human genes 0.000 description 2
- 108010032963 Ataxin-1 Proteins 0.000 description 2
- 102100039339 Atrial natriuretic peptide receptor 1 Human genes 0.000 description 2
- 102000004000 Aurora Kinase A Human genes 0.000 description 2
- 108090000461 Aurora Kinase A Proteins 0.000 description 2
- 102100027205 B-cell antigen receptor complex-associated protein alpha chain Human genes 0.000 description 2
- 102100035634 B-cell linker protein Human genes 0.000 description 2
- 102100035656 BCL2/adenovirus E1B 19 kDa protein-interacting protein 3 Human genes 0.000 description 2
- 102100037140 BCL2/adenovirus E1B 19 kDa protein-interacting protein 3-like Human genes 0.000 description 2
- 102000017915 BDKRB2 Human genes 0.000 description 2
- 102100028048 BRCA1-associated RING domain protein 1 Human genes 0.000 description 2
- 108700020462 BRCA2 Proteins 0.000 description 2
- 102100035584 BRCA2 and CDKN1A-interacting protein Human genes 0.000 description 2
- 101710159765 BRCA2 and CDKN1A-interacting protein Proteins 0.000 description 2
- 201000009177 Bardet-Biedl syndrome 4 Diseases 0.000 description 2
- 102100027884 Bardet-Biedl syndrome 4 protein Human genes 0.000 description 2
- 102100032305 Bcl-2 homologous antagonist/killer Human genes 0.000 description 2
- 102100021971 Bcl-2-interacting killer Human genes 0.000 description 2
- 102100040794 Beta-1 adrenergic receptor Human genes 0.000 description 2
- 102100039705 Beta-2 adrenergic receptor Human genes 0.000 description 2
- 102100030802 Beta-2-glycoprotein 1 Human genes 0.000 description 2
- 102100021738 Beta-adrenergic receptor kinase 1 Human genes 0.000 description 2
- 102100026189 Beta-galactosidase Human genes 0.000 description 2
- 102100021257 Beta-secretase 1 Human genes 0.000 description 2
- 101710150192 Beta-secretase 1 Proteins 0.000 description 2
- 102100027991 Beta/gamma crystallin domain-containing protein 1 Human genes 0.000 description 2
- 101710154744 Beta/gamma crystallin domain-containing protein 1 Proteins 0.000 description 2
- 102100025991 Betaine-homocysteine S-methyltransferase 1 Human genes 0.000 description 2
- 102100037674 Bis(5'-adenosyl)-triphosphatase Human genes 0.000 description 2
- 102000000169 Bradykinin receptor B1 Human genes 0.000 description 2
- 108050008513 Bradykinin receptor B1 Proteins 0.000 description 2
- 108050000671 Bradykinin receptor B2 Proteins 0.000 description 2
- 206010006187 Breast cancer Diseases 0.000 description 2
- 102100025399 Breast cancer type 2 susceptibility protein Human genes 0.000 description 2
- 208000026310 Breast neoplasm Diseases 0.000 description 2
- 102100022595 Broad substrate specificity ATP-binding cassette transporter ABCG2 Human genes 0.000 description 2
- 108010053652 Butyrylcholinesterase Proteins 0.000 description 2
- 102100031151 C-C chemokine receptor type 2 Human genes 0.000 description 2
- 102100036302 C-C chemokine receptor type 6 Human genes 0.000 description 2
- 102100036842 C-C motif chemokine 19 Human genes 0.000 description 2
- 102100036848 C-C motif chemokine 20 Human genes 0.000 description 2
- 102100036846 C-C motif chemokine 21 Human genes 0.000 description 2
- 102100021936 C-C motif chemokine 27 Human genes 0.000 description 2
- 102100032367 C-C motif chemokine 5 Human genes 0.000 description 2
- 102100036166 C-X-C chemokine receptor type 1 Human genes 0.000 description 2
- 102100028990 C-X-C chemokine receptor type 3 Human genes 0.000 description 2
- 102100031650 C-X-C chemokine receptor type 4 Human genes 0.000 description 2
- 102100032752 C-reactive protein Human genes 0.000 description 2
- 102100028667 C-type lectin domain family 4 member A Human genes 0.000 description 2
- 102100031478 C-type natriuretic peptide Human genes 0.000 description 2
- 102100037084 C4b-binding protein alpha chain Human genes 0.000 description 2
- 102100025752 CASP8 and FADD-like apoptosis regulator Human genes 0.000 description 2
- 101710100501 CASP8 and FADD-like apoptosis regulator Proteins 0.000 description 2
- 108700013048 CCL2 Proteins 0.000 description 2
- 102100031168 CCN family member 2 Human genes 0.000 description 2
- 101150083327 CCR2 gene Proteins 0.000 description 2
- 108010045374 CD36 Antigens Proteins 0.000 description 2
- 108010080422 CD39 antigen Proteins 0.000 description 2
- 108010029697 CD40 Ligand Proteins 0.000 description 2
- 102100022002 CD59 glycoprotein Human genes 0.000 description 2
- 102100022617 COMM domain-containing protein 7 Human genes 0.000 description 2
- 102100021975 CREB-binding protein Human genes 0.000 description 2
- 108091005471 CRHR1 Proteins 0.000 description 2
- 108091011896 CSF1 Proteins 0.000 description 2
- 108090000835 CX3C Chemokine Receptor 1 Proteins 0.000 description 2
- 102100035680 Cadherin EGF LAG seven-pass G-type receptor 2 Human genes 0.000 description 2
- 102100024123 Calcineurin-binding protein cabin-1 Human genes 0.000 description 2
- 102100025588 Calcitonin gene-related peptide 1 Human genes 0.000 description 2
- 102100024654 Calcitonin gene-related peptide type 1 receptor Human genes 0.000 description 2
- 108010050543 Calcium-Sensing Receptors Proteins 0.000 description 2
- 102100025227 Calcium/calmodulin-dependent protein kinase type II subunit gamma Human genes 0.000 description 2
- 108030005456 Calcium/calmodulin-dependent protein kinases Proteins 0.000 description 2
- 102100025465 Calpain-10 Human genes 0.000 description 2
- 102100030006 Calpain-5 Human genes 0.000 description 2
- 102100035037 Calpastatin Human genes 0.000 description 2
- 102000008906 Cannabinoid receptor type 2 Human genes 0.000 description 2
- 108050000860 Cannabinoid receptor type 2 Proteins 0.000 description 2
- 102100035023 Carboxypeptidase B2 Human genes 0.000 description 2
- 102100024533 Carcinoembryonic antigen-related cell adhesion molecule 1 Human genes 0.000 description 2
- 102100028892 Cardiotrophin-1 Human genes 0.000 description 2
- 102100026619 Cartilage intermediate layer protein 2 Human genes 0.000 description 2
- 101710181689 Cartilage intermediate layer protein 2 Proteins 0.000 description 2
- 102100040751 Casein kinase II subunit alpha Human genes 0.000 description 2
- 102100040753 Casein kinase II subunit alpha' Human genes 0.000 description 2
- 102100027992 Casein kinase II subunit beta Human genes 0.000 description 2
- 108090000397 Caspase 3 Proteins 0.000 description 2
- 102100026548 Caspase-8 Human genes 0.000 description 2
- 102100028906 Catenin delta-1 Human genes 0.000 description 2
- 102100038608 Cathelicidin antimicrobial peptide Human genes 0.000 description 2
- 101710140438 Cathelicidin antimicrobial peptide Proteins 0.000 description 2
- 108090000712 Cathepsin B Proteins 0.000 description 2
- 108090000258 Cathepsin D Proteins 0.000 description 2
- 102100032215 Cathepsin E Human genes 0.000 description 2
- 102100025975 Cathepsin G Human genes 0.000 description 2
- 102100024940 Cathepsin K Human genes 0.000 description 2
- 102100035654 Cathepsin S Human genes 0.000 description 2
- 102000011068 Cdc42 Human genes 0.000 description 2
- 108091007854 Cdh1/Fizzy-related Proteins 0.000 description 2
- 108010072135 Cell Adhesion Molecule-1 Proteins 0.000 description 2
- 102100024649 Cell adhesion molecule 1 Human genes 0.000 description 2
- 102100025051 Cell division control protein 42 homolog Human genes 0.000 description 2
- 102100031214 Centromere protein N Human genes 0.000 description 2
- 108050001186 Chaperonin Cpn60 Proteins 0.000 description 2
- 102000052603 Chaperonins Human genes 0.000 description 2
- 108010078239 Chemokine CX3CL1 Proteins 0.000 description 2
- 108010008951 Chemokine CXCL12 Proteins 0.000 description 2
- 102100038196 Chitinase-3-like protein 1 Human genes 0.000 description 2
- 102100023509 Chloride channel protein 2 Human genes 0.000 description 2
- 102100037637 Cholesteryl ester transfer protein Human genes 0.000 description 2
- 102100023460 Choline O-acetyltransferase Human genes 0.000 description 2
- 102100031065 Choline kinase alpha Human genes 0.000 description 2
- 101710106334 Choline kinase alpha Proteins 0.000 description 2
- 102100032404 Cholinesterase Human genes 0.000 description 2
- 102100028758 Chondroitin sulfate proteoglycan 5 Human genes 0.000 description 2
- 101710173787 Chondroitin sulfate proteoglycan 5 Proteins 0.000 description 2
- 108010038447 Chromogranin A Proteins 0.000 description 2
- 102000010792 Chromogranin A Human genes 0.000 description 2
- 102100024539 Chymase Human genes 0.000 description 2
- 102100038419 Circadian locomoter output cycles protein kaput Human genes 0.000 description 2
- 108010044213 Class 5 Receptor-Like Protein Tyrosine Phosphatases Proteins 0.000 description 2
- 102000006452 Class 5 Receptor-Like Protein Tyrosine Phosphatases Human genes 0.000 description 2
- 108010003305 Class II Phosphatidylinositol 3-Kinases Proteins 0.000 description 2
- 108010067494 Class Ib Phosphatidylinositol 3-Kinase Proteins 0.000 description 2
- 102100040836 Claudin-1 Human genes 0.000 description 2
- 102000005221 Cleavage Stimulation Factor Human genes 0.000 description 2
- 108010081236 Cleavage Stimulation Factor Proteins 0.000 description 2
- 102100037529 Coagulation factor V Human genes 0.000 description 2
- 102100029057 Coagulation factor XIII A chain Human genes 0.000 description 2
- 208000028698 Cognitive impairment Diseases 0.000 description 2
- 102100033601 Collagen alpha-1(I) chain Human genes 0.000 description 2
- 102100031162 Collagen alpha-1(XVIII) chain Human genes 0.000 description 2
- 102100036213 Collagen alpha-2(I) chain Human genes 0.000 description 2
- 102100033780 Collagen alpha-3(IV) chain Human genes 0.000 description 2
- 102100027995 Collagenase 3 Human genes 0.000 description 2
- 102100032778 Colorectal mutant cancer protein Human genes 0.000 description 2
- 101710190564 Colorectal mutant cancer protein Proteins 0.000 description 2
- 108010053085 Complement Factor H Proteins 0.000 description 2
- 102100035432 Complement factor H Human genes 0.000 description 2
- 108010039419 Connective Tissue Growth Factor Proteins 0.000 description 2
- 101710103814 Conserved oligomeric Golgi complex subunit 2 Proteins 0.000 description 2
- 102100030797 Conserved oligomeric Golgi complex subunit 2 Human genes 0.000 description 2
- 102100029767 Copper transport protein ATOX1 Human genes 0.000 description 2
- 102100027587 Copper-transporting ATPase 1 Human genes 0.000 description 2
- 108010043471 Core Binding Factor Alpha 2 Subunit Proteins 0.000 description 2
- 102100021752 Corticoliberin Human genes 0.000 description 2
- 108010022152 Corticotropin-Releasing Hormone Proteins 0.000 description 2
- 239000000055 Corticotropin-Releasing Hormone Substances 0.000 description 2
- 102100038018 Corticotropin-releasing factor receptor 1 Human genes 0.000 description 2
- 102100022786 Creatine kinase M-type Human genes 0.000 description 2
- 101710119765 Cryptochrome-1 Proteins 0.000 description 2
- 102100026280 Cryptochrome-2 Human genes 0.000 description 2
- 102100026398 Cyclic AMP-responsive element-binding protein 3 Human genes 0.000 description 2
- 101710128029 Cyclic AMP-responsive element-binding protein 3 Proteins 0.000 description 2
- 102000006311 Cyclin D1 Human genes 0.000 description 2
- 108010058546 Cyclin D1 Proteins 0.000 description 2
- 108010024986 Cyclin-Dependent Kinase 2 Proteins 0.000 description 2
- 108010025454 Cyclin-Dependent Kinase 5 Proteins 0.000 description 2
- 108010025468 Cyclin-Dependent Kinase 6 Proteins 0.000 description 2
- 108010016788 Cyclin-Dependent Kinase Inhibitor p21 Proteins 0.000 description 2
- 102100036239 Cyclin-dependent kinase 2 Human genes 0.000 description 2
- 102100026804 Cyclin-dependent kinase 6 Human genes 0.000 description 2
- 102100033270 Cyclin-dependent kinase inhibitor 1 Human genes 0.000 description 2
- 102100026805 Cyclin-dependent-like kinase 5 Human genes 0.000 description 2
- 108010072220 Cyclophilin A Proteins 0.000 description 2
- 102100035429 Cystathionine gamma-lyase Human genes 0.000 description 2
- 102100026897 Cystatin-C Human genes 0.000 description 2
- 102100038496 Cysteinyl leukotriene receptor 1 Human genes 0.000 description 2
- 108050009460 Cysteinyl leukotriene receptor 1 Proteins 0.000 description 2
- 102000004155 Cysteinyl leukotriene receptor 2 Human genes 0.000 description 2
- 108090000655 Cysteinyl leukotriene receptor 2 Proteins 0.000 description 2
- 102100031476 Cytochrome P450 1A1 Human genes 0.000 description 2
- 102100026533 Cytochrome P450 1A2 Human genes 0.000 description 2
- 102100029358 Cytochrome P450 2C9 Human genes 0.000 description 2
- 102100021704 Cytochrome P450 2D6 Human genes 0.000 description 2
- 102100031461 Cytochrome P450 2J2 Human genes 0.000 description 2
- 102100039205 Cytochrome P450 3A4 Human genes 0.000 description 2
- 102100038637 Cytochrome P450 7A1 Human genes 0.000 description 2
- 102100025620 Cytochrome b-245 light chain Human genes 0.000 description 2
- 102100032218 Cytokine-inducible SH2-containing protein Human genes 0.000 description 2
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 description 2
- 102100020802 D(1A) dopamine receptor Human genes 0.000 description 2
- 102100039524 DNA endonuclease RBBP8 Human genes 0.000 description 2
- 108050008316 DNA endonuclease RBBP8 Proteins 0.000 description 2
- 102100037799 DNA-binding protein Ikaros Human genes 0.000 description 2
- 108010031042 Death-Associated Protein Kinases Proteins 0.000 description 2
- 102000005721 Death-Associated Protein Kinases Human genes 0.000 description 2
- 102100039694 Death-associated protein 1 Human genes 0.000 description 2
- 101710088194 Dehydrogenase Proteins 0.000 description 2
- 102100030312 Dendrin Human genes 0.000 description 2
- 102100036912 Desmin Human genes 0.000 description 2
- 108010044052 Desmin Proteins 0.000 description 2
- 102100034274 Diamine acetyltransferase 1 Human genes 0.000 description 2
- 102100024746 Dihydrofolate reductase Human genes 0.000 description 2
- 102000028526 Dihydrolipoamide Dehydrogenase Human genes 0.000 description 2
- 108010028127 Dihydrolipoamide Dehydrogenase Proteins 0.000 description 2
- 102100028572 Disabled homolog 2 Human genes 0.000 description 2
- 102100031111 Disintegrin and metalloproteinase domain-containing protein 17 Human genes 0.000 description 2
- 102100033156 Dopamine beta-hydroxylase Human genes 0.000 description 2
- 108010038530 Dual Specificity Phosphatase 6 Proteins 0.000 description 2
- 102100028944 Dual specificity protein phosphatase 13 isoform B Human genes 0.000 description 2
- 102100027274 Dual specificity protein phosphatase 6 Human genes 0.000 description 2
- 102100021179 Dynamin-3 Human genes 0.000 description 2
- 108010065372 Dynorphins Proteins 0.000 description 2
- 102100024108 Dystrophin Human genes 0.000 description 2
- 102100023471 E-selectin Human genes 0.000 description 2
- 108010063774 E2F1 Transcription Factor Proteins 0.000 description 2
- 102000005718 E2F6 Transcription Factor Human genes 0.000 description 2
- 108010031068 E2F6 Transcription Factor Proteins 0.000 description 2
- 102100032353 E3 ubiquitin-protein ligase CHFR Human genes 0.000 description 2
- 102100031918 E3 ubiquitin-protein ligase NEDD4 Human genes 0.000 description 2
- 102100034116 E3 ubiquitin-protein ligase RNF123 Human genes 0.000 description 2
- 102100021765 E3 ubiquitin-protein ligase RNF139 Human genes 0.000 description 2
- 102100040278 E3 ubiquitin-protein ligase RNF19A Human genes 0.000 description 2
- 101710157279 E3 ubiquitin-protein ligase RNF19A Proteins 0.000 description 2
- 102100021838 E3 ubiquitin-protein ligase SIAH1 Human genes 0.000 description 2
- 102100031748 E3 ubiquitin-protein ligase SIAH2 Human genes 0.000 description 2
- 102000017914 EDNRA Human genes 0.000 description 2
- 101150062404 EDNRA gene Proteins 0.000 description 2
- 102000017930 EDNRB Human genes 0.000 description 2
- 102100029722 Ectonucleoside triphosphate diphosphohydrolase 1 Human genes 0.000 description 2
- 102100021977 Ectonucleotide pyrophosphatase/phosphodiesterase family member 2 Human genes 0.000 description 2
- 102000016942 Elastin Human genes 0.000 description 2
- 108010014258 Elastin Proteins 0.000 description 2
- 102100021658 Embigin Human genes 0.000 description 2
- 102100023882 Endoribonuclease ZC3H12A Human genes 0.000 description 2
- 102000009839 Endothelial Protein C Receptor Human genes 0.000 description 2
- 108010009900 Endothelial Protein C Receptor Proteins 0.000 description 2
- 102100031375 Endothelial lipase Human genes 0.000 description 2
- 101710194572 Endothelin receptor type B Proteins 0.000 description 2
- 102100029109 Endothelin-3 Human genes 0.000 description 2
- 102000048186 Endothelin-converting enzyme 1 Human genes 0.000 description 2
- 108030001679 Endothelin-converting enzyme 1 Proteins 0.000 description 2
- 102100023688 Eotaxin Human genes 0.000 description 2
- 102100030322 Ephrin type-A receptor 1 Human genes 0.000 description 2
- 102100031968 Ephrin type-B receptor 2 Human genes 0.000 description 2
- 102100023721 Ephrin-B2 Human genes 0.000 description 2
- 108010044090 Ephrin-B2 Proteins 0.000 description 2
- 102000003951 Erythropoietin Human genes 0.000 description 2
- 108090000394 Erythropoietin Proteins 0.000 description 2
- 108010007005 Estrogen Receptor alpha Proteins 0.000 description 2
- 102100038595 Estrogen receptor Human genes 0.000 description 2
- 102100029951 Estrogen receptor beta Human genes 0.000 description 2
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 2
- 102100035549 Eukaryotic translation initiation factor 2 subunit 1 Human genes 0.000 description 2
- 101710196290 Eukaryotic translation initiation factor 2-alpha kinase 2 Proteins 0.000 description 2
- 102100034295 Eukaryotic translation initiation factor 3 subunit A Human genes 0.000 description 2
- 102100039735 Eukaryotic translation initiation factor 4 gamma 1 Human genes 0.000 description 2
- 102100039737 Eukaryotic translation initiation factor 4 gamma 2 Human genes 0.000 description 2
- 102100027304 Eukaryotic translation initiation factor 4E Human genes 0.000 description 2
- 101710091918 Eukaryotic translation initiation factor 4E Proteins 0.000 description 2
- 102000008968 Eukaryotic translation initiation factor 4E-binding protein 1 Human genes 0.000 description 2
- 108050000946 Eukaryotic translation initiation factor 4E-binding protein 1 Proteins 0.000 description 2
- 102100040002 Eukaryotic translation initiation factor 6 Human genes 0.000 description 2
- 101710204615 Eukaryotic translation initiation factor 6 Proteins 0.000 description 2
- 108700024394 Exon Proteins 0.000 description 2
- 102100035650 Extracellular calcium-sensing receptor Human genes 0.000 description 2
- 102100027186 Extracellular superoxide dismutase [Cu-Zn] Human genes 0.000 description 2
- 108700001268 Extracellular superoxide dismutase [Cu-Zn] Proteins 0.000 description 2
- 102100028138 F-box/WD repeat-containing protein 7 Human genes 0.000 description 2
- 102000016627 Fanconi Anemia Complementation Group N protein Human genes 0.000 description 2
- 108010067741 Fanconi Anemia Complementation Group N protein Proteins 0.000 description 2
- 108010039731 Fatty Acid Synthases Proteins 0.000 description 2
- 101710177999 Fatty acid desaturase 2 Proteins 0.000 description 2
- 102100030431 Fatty acid-binding protein, adipocyte Human genes 0.000 description 2
- 102100026748 Fatty acid-binding protein, intestinal Human genes 0.000 description 2
- 102100029111 Fatty-acid amide hydrolase 1 Human genes 0.000 description 2
- 241000282326 Felis catus Species 0.000 description 2
- 102100031509 Fibrillin-1 Human genes 0.000 description 2
- 102100031752 Fibrinogen alpha chain Human genes 0.000 description 2
- 101710137044 Fibrinogen alpha chain Proteins 0.000 description 2
- 102100028313 Fibrinogen beta chain Human genes 0.000 description 2
- 101710170765 Fibrinogen beta chain Proteins 0.000 description 2
- 102100024783 Fibrinogen gamma chain Human genes 0.000 description 2
- 102000003974 Fibroblast growth factor 2 Human genes 0.000 description 2
- 108090000379 Fibroblast growth factor 2 Proteins 0.000 description 2
- 102100024785 Fibroblast growth factor 2 Human genes 0.000 description 2
- 102100023600 Fibroblast growth factor receptor 2 Human genes 0.000 description 2
- 101710182389 Fibroblast growth factor receptor 2 Proteins 0.000 description 2
- 102100031812 Fibulin-1 Human genes 0.000 description 2
- 102100028314 Filaggrin Human genes 0.000 description 2
- 101710088660 Filaggrin Proteins 0.000 description 2
- 102100037813 Focal adhesion kinase 1 Human genes 0.000 description 2
- 102000016970 Follistatin Human genes 0.000 description 2
- 108010014612 Follistatin Proteins 0.000 description 2
- 108010009306 Forkhead Box Protein O1 Proteins 0.000 description 2
- 102100023371 Forkhead box protein N1 Human genes 0.000 description 2
- 102100035427 Forkhead box protein O1 Human genes 0.000 description 2
- 102100021237 G protein-activated inward rectifier potassium channel 4 Human genes 0.000 description 2
- 102100025353 G-protein coupled bile acid receptor 1 Human genes 0.000 description 2
- 101710154531 G-protein coupled bile acid receptor 1 Proteins 0.000 description 2
- 102100030708 GTPase KRas Human genes 0.000 description 2
- 102100039558 Galectin-3 Human genes 0.000 description 2
- 102100035924 Gamma-aminobutyric acid type B receptor subunit 2 Human genes 0.000 description 2
- 102100028652 Gamma-enolase Human genes 0.000 description 2
- 108020004206 Gamma-glutamyltransferase Proteins 0.000 description 2
- 102100030525 Gap junction alpha-4 protein Human genes 0.000 description 2
- 102100037156 Gap junction beta-2 protein Human genes 0.000 description 2
- 102100039397 Gap junction beta-3 protein Human genes 0.000 description 2
- 102100039401 Gap junction beta-6 protein Human genes 0.000 description 2
- 102100025623 Gap junction delta-2 protein Human genes 0.000 description 2
- 102100039290 Gap junction gamma-1 protein Human genes 0.000 description 2
- 108010004460 Gastric Inhibitory Polypeptide Proteins 0.000 description 2
- 102100039994 Gastric inhibitory polypeptide Human genes 0.000 description 2
- 102400000921 Gastrin Human genes 0.000 description 2
- 108010052343 Gastrins Proteins 0.000 description 2
- 108090001064 Gelsolin Proteins 0.000 description 2
- 102000004878 Gelsolin Human genes 0.000 description 2
- 102000034615 Glial cell line-derived neurotrophic factor Human genes 0.000 description 2
- 108091010837 Glial cell line-derived neurotrophic factor Proteins 0.000 description 2
- 102000051325 Glucagon Human genes 0.000 description 2
- 108060003199 Glucagon Proteins 0.000 description 2
- 102100033417 Glucocorticoid receptor Human genes 0.000 description 2
- 108010018962 Glucosephosphate Dehydrogenase Proteins 0.000 description 2
- 102000016354 Glucuronosyltransferase Human genes 0.000 description 2
- 108010092364 Glucuronosyltransferase Proteins 0.000 description 2
- 102100035902 Glutamate decarboxylase 1 Human genes 0.000 description 2
- 102100035857 Glutamate decarboxylase 2 Human genes 0.000 description 2
- 102100022630 Glutamate receptor ionotropic, NMDA 2B Human genes 0.000 description 2
- 102100025783 Glutamyl aminopeptidase Human genes 0.000 description 2
- 108010063907 Glutathione Reductase Proteins 0.000 description 2
- 102100037473 Glutathione S-transferase A1 Human genes 0.000 description 2
- 102100030943 Glutathione S-transferase P Human genes 0.000 description 2
- 101710190974 Glutathione S-transferase alpha-1 Proteins 0.000 description 2
- 102100038055 Glutathione S-transferase theta-1 Human genes 0.000 description 2
- 102100033039 Glutathione peroxidase 1 Human genes 0.000 description 2
- 102100036442 Glutathione reductase, mitochondrial Human genes 0.000 description 2
- 102100039619 Granulocyte colony-stimulating factor Human genes 0.000 description 2
- 102100037544 Group 10 secretory phospholipase A2 Human genes 0.000 description 2
- 108010044858 Group X Phospholipases A2 Proteins 0.000 description 2
- 108010041834 Growth Differentiation Factor 15 Proteins 0.000 description 2
- 102100031154 Growth arrest and DNA damage-inducible protein GADD45 gamma Human genes 0.000 description 2
- 102100036683 Growth arrest-specific protein 1 Human genes 0.000 description 2
- 102100031487 Growth arrest-specific protein 6 Human genes 0.000 description 2
- 102100040896 Growth/differentiation factor 15 Human genes 0.000 description 2
- 102100032134 Guanine nucleotide exchange factor VAV2 Human genes 0.000 description 2
- 102100035346 Guanine nucleotide-binding protein G(I)/G(S)/G(T) subunit beta-3 Human genes 0.000 description 2
- 102100028972 HLA class I histocompatibility antigen, A alpha chain Human genes 0.000 description 2
- 102100028640 HLA class II histocompatibility antigen, DR beta 5 chain Human genes 0.000 description 2
- 102100039330 HMG box-containing protein 1 Human genes 0.000 description 2
- 101710201214 HMG box-containing protein 1 Proteins 0.000 description 2
- 101150017422 HTR1 gene Proteins 0.000 description 2
- 102100031561 Hamartin Human genes 0.000 description 2
- 101710175981 Hamartin Proteins 0.000 description 2
- 102000000039 Heat Shock Transcription Factor Human genes 0.000 description 2
- 108050008339 Heat Shock Transcription Factor Proteins 0.000 description 2
- 102100039165 Heat shock protein beta-1 Human genes 0.000 description 2
- 102100028006 Heme oxygenase 1 Human genes 0.000 description 2
- 102100024025 Heparanase Human genes 0.000 description 2
- 101800001649 Heparin-binding EGF-like growth factor Proteins 0.000 description 2
- 102100031415 Hepatic triacylglycerol lipase Human genes 0.000 description 2
- 108090000100 Hepatocyte Growth Factor Proteins 0.000 description 2
- 102000006752 Hepatocyte Nuclear Factor 4 Human genes 0.000 description 2
- 102100022057 Hepatocyte nuclear factor 1-alpha Human genes 0.000 description 2
- 102100036284 Hepcidin Human genes 0.000 description 2
- 102100035108 High affinity nerve growth factor receptor Human genes 0.000 description 2
- 102100037907 High mobility group protein B1 Human genes 0.000 description 2
- 102100032509 Histamine H1 receptor Human genes 0.000 description 2
- 108010024124 Histone Deacetylase 1 Proteins 0.000 description 2
- 102100034533 Histone H2AX Human genes 0.000 description 2
- 102100022846 Histone acetyltransferase KAT2B Human genes 0.000 description 2
- 102100039996 Histone deacetylase 1 Human genes 0.000 description 2
- 102100021454 Histone deacetylase 4 Human genes 0.000 description 2
- 101710177324 Histone deacetylase 4 Proteins 0.000 description 2
- 102100038970 Histone-lysine N-methyltransferase EZH2 Human genes 0.000 description 2
- 102100028092 Homeobox protein Nkx-3.1 Human genes 0.000 description 2
- 102100029330 Homeobox protein PKNOX2 Human genes 0.000 description 2
- 102100028798 Homeodomain-only protein Human genes 0.000 description 2
- 101000583069 Homo sapiens 1-phosphatidylinositol 4,5-bisphosphate phosphodiesterase beta-3 Proteins 0.000 description 2
- 101000875403 Homo sapiens 25-hydroxyvitamin D-1 alpha hydroxylase, mitochondrial Proteins 0.000 description 2
- 101001136581 Homo sapiens 26S proteasome non-ATPase regulatory subunit 10 Proteins 0.000 description 2
- 101000612536 Homo sapiens 26S proteasome non-ATPase regulatory subunit 13 Proteins 0.000 description 2
- 101001125524 Homo sapiens 26S proteasome regulatory subunit 6B Proteins 0.000 description 2
- 101000640855 Homo sapiens 3-oxo-5-alpha-steroid 4-dehydrogenase 1 Proteins 0.000 description 2
- 101000667524 Homo sapiens 39S ribosomal protein L28, mitochondrial Proteins 0.000 description 2
- 101001000686 Homo sapiens 4-aminobutyrate aminotransferase, mitochondrial Proteins 0.000 description 2
- 101000836407 Homo sapiens 4-trimethylaminobutyraldehyde dehydrogenase Proteins 0.000 description 2
- 101000783681 Homo sapiens 5'-AMP-activated protein kinase catalytic subunit alpha-2 Proteins 0.000 description 2
- 101000760987 Homo sapiens 5'-AMP-activated protein kinase subunit gamma-2 Proteins 0.000 description 2
- 101000724725 Homo sapiens 5-hydroxytryptamine receptor 1B Proteins 0.000 description 2
- 101000964065 Homo sapiens 5-hydroxytryptamine receptor 4 Proteins 0.000 description 2
- 101000883686 Homo sapiens 60 kDa heat shock protein, mitochondrial Proteins 0.000 description 2
- 101000627872 Homo sapiens 72 kDa type IV collagenase Proteins 0.000 description 2
- 101000775844 Homo sapiens AMP deaminase 1 Proteins 0.000 description 2
- 101000986621 Homo sapiens ATP-binding cassette sub-family C member 6 Proteins 0.000 description 2
- 101001017818 Homo sapiens ATP-dependent translocase ABCB1 Proteins 0.000 description 2
- 101000614701 Homo sapiens ATP-sensitive inward rectifier potassium channel 11 Proteins 0.000 description 2
- 101000801359 Homo sapiens Acetylcholinesterase Proteins 0.000 description 2
- 101000757200 Homo sapiens Acidic leucine-rich nuclear phosphoprotein 32 family member A Proteins 0.000 description 2
- 101000799712 Homo sapiens Adenosine receptor A1 Proteins 0.000 description 2
- 101000928172 Homo sapiens Adhesion G protein-coupled receptor L4 Proteins 0.000 description 2
- 101000775469 Homo sapiens Adiponectin Proteins 0.000 description 2
- 101000780463 Homo sapiens Alcohol dehydrogenase 1C Proteins 0.000 description 2
- 101000718007 Homo sapiens Aldo-keto reductase family 1 member A1 Proteins 0.000 description 2
- 101000690766 Homo sapiens All-trans-retinol dehydrogenase [NAD(+)] ADH7 Proteins 0.000 description 2
- 101000678026 Homo sapiens Alpha-1-antichymotrypsin Proteins 0.000 description 2
- 101000823116 Homo sapiens Alpha-1-antitrypsin Proteins 0.000 description 2
- 101000689685 Homo sapiens Alpha-1A adrenergic receptor Proteins 0.000 description 2
- 101000783712 Homo sapiens Alpha-2-antiplasmin Proteins 0.000 description 2
- 101000929512 Homo sapiens Alpha-2B adrenergic receptor Proteins 0.000 description 2
- 101000799076 Homo sapiens Alpha-adducin Proteins 0.000 description 2
- 101000891982 Homo sapiens Alpha-crystallin B chain Proteins 0.000 description 2
- 101000834898 Homo sapiens Alpha-synuclein Proteins 0.000 description 2
- 101000928670 Homo sapiens Amyloid beta precursor protein binding family B member 1 Proteins 0.000 description 2
- 101000753291 Homo sapiens Angiopoietin-1 receptor Proteins 0.000 description 2
- 101000773743 Homo sapiens Angiotensin-converting enzyme Proteins 0.000 description 2
- 101000757319 Homo sapiens Antithrombin-III Proteins 0.000 description 2
- 101000889953 Homo sapiens Apolipoprotein B-100 Proteins 0.000 description 2
- 101000785755 Homo sapiens Arrestin-C Proteins 0.000 description 2
- 101000799549 Homo sapiens Aspartate aminotransferase, mitochondrial Proteins 0.000 description 2
- 101000961044 Homo sapiens Atrial natriuretic peptide receptor 1 Proteins 0.000 description 2
- 101000914489 Homo sapiens B-cell antigen receptor complex-associated protein alpha chain Proteins 0.000 description 2
- 101000803266 Homo sapiens B-cell linker protein Proteins 0.000 description 2
- 101000803294 Homo sapiens BCL2/adenovirus E1B 19 kDa protein-interacting protein 3 Proteins 0.000 description 2
- 101000740545 Homo sapiens BCL2/adenovirus E1B 19 kDa protein-interacting protein 3-like Proteins 0.000 description 2
- 101000697486 Homo sapiens BRCA1-associated RING domain protein 1 Proteins 0.000 description 2
- 101000697660 Homo sapiens Bardet-Biedl syndrome 4 protein Proteins 0.000 description 2
- 101000798320 Homo sapiens Bcl-2 homologous antagonist/killer Proteins 0.000 description 2
- 101000970576 Homo sapiens Bcl-2-interacting killer Proteins 0.000 description 2
- 101000892264 Homo sapiens Beta-1 adrenergic receptor Proteins 0.000 description 2
- 101000959437 Homo sapiens Beta-2 adrenergic receptor Proteins 0.000 description 2
- 101000793425 Homo sapiens Beta-2-glycoprotein 1 Proteins 0.000 description 2
- 101000751445 Homo sapiens Beta-adrenergic receptor kinase 1 Proteins 0.000 description 2
- 101000765010 Homo sapiens Beta-galactosidase Proteins 0.000 description 2
- 101001111439 Homo sapiens Beta-nerve growth factor Proteins 0.000 description 2
- 101001027506 Homo sapiens Bis(5'-adenosyl)-triphosphatase Proteins 0.000 description 2
- 101000716068 Homo sapiens C-C chemokine receptor type 6 Proteins 0.000 description 2
- 101000713106 Homo sapiens C-C motif chemokine 19 Proteins 0.000 description 2
- 101000713099 Homo sapiens C-C motif chemokine 20 Proteins 0.000 description 2
- 101000713085 Homo sapiens C-C motif chemokine 21 Proteins 0.000 description 2
- 101000897494 Homo sapiens C-C motif chemokine 27 Proteins 0.000 description 2
- 101000797762 Homo sapiens C-C motif chemokine 5 Proteins 0.000 description 2
- 101000947174 Homo sapiens C-X-C chemokine receptor type 1 Proteins 0.000 description 2
- 101000916059 Homo sapiens C-X-C chemokine receptor type 2 Proteins 0.000 description 2
- 101000916050 Homo sapiens C-X-C chemokine receptor type 3 Proteins 0.000 description 2
- 101000922348 Homo sapiens C-X-C chemokine receptor type 4 Proteins 0.000 description 2
- 101000942118 Homo sapiens C-reactive protein Proteins 0.000 description 2
- 101000766908 Homo sapiens C-type lectin domain family 4 member A Proteins 0.000 description 2
- 101000796277 Homo sapiens C-type natriuretic peptide Proteins 0.000 description 2
- 101000740685 Homo sapiens C4b-binding protein alpha chain Proteins 0.000 description 2
- 101000945963 Homo sapiens CCAAT/enhancer-binding protein beta Proteins 0.000 description 2
- 101000868215 Homo sapiens CD40 ligand Proteins 0.000 description 2
- 101000897400 Homo sapiens CD59 glycoprotein Proteins 0.000 description 2
- 101000899983 Homo sapiens COMM domain-containing protein 7 Proteins 0.000 description 2
- 101000746022 Homo sapiens CX3C chemokine receptor 1 Proteins 0.000 description 2
- 101000715674 Homo sapiens Cadherin EGF LAG seven-pass G-type receptor 2 Proteins 0.000 description 2
- 101001077334 Homo sapiens Calcium/calmodulin-dependent protein kinase type II subunit gamma Proteins 0.000 description 2
- 101000946518 Homo sapiens Carboxypeptidase B2 Proteins 0.000 description 2
- 101000892026 Homo sapiens Casein kinase II subunit alpha Proteins 0.000 description 2
- 101000892015 Homo sapiens Casein kinase II subunit alpha' Proteins 0.000 description 2
- 101000858625 Homo sapiens Casein kinase II subunit beta Proteins 0.000 description 2
- 101000916264 Homo sapiens Catenin delta-1 Proteins 0.000 description 2
- 101000898449 Homo sapiens Cathepsin B Proteins 0.000 description 2
- 101000934426 Homo sapiens Cell division control protein 42 homolog Proteins 0.000 description 2
- 101000906633 Homo sapiens Chloride channel protein 2 Proteins 0.000 description 2
- 101000880514 Homo sapiens Cholesteryl ester transfer protein Proteins 0.000 description 2
- 101000909983 Homo sapiens Chymase Proteins 0.000 description 2
- 101000882921 Homo sapiens Circadian locomoter output cycles protein kaput Proteins 0.000 description 2
- 101000918352 Homo sapiens Coagulation factor XIII A chain Proteins 0.000 description 2
- 101000940068 Homo sapiens Collagen alpha-1(XVIII) chain Proteins 0.000 description 2
- 101000875067 Homo sapiens Collagen alpha-2(I) chain Proteins 0.000 description 2
- 101000710873 Homo sapiens Collagen alpha-3(IV) chain Proteins 0.000 description 2
- 101000710883 Homo sapiens Complement C4-B Proteins 0.000 description 2
- 101000727865 Homo sapiens Copper transport protein ATOX1 Proteins 0.000 description 2
- 101000919351 Homo sapiens Cryptochrome-1 Proteins 0.000 description 2
- 101000855613 Homo sapiens Cryptochrome-2 Proteins 0.000 description 2
- 101000980932 Homo sapiens Cyclin-dependent kinase inhibitor 2A Proteins 0.000 description 2
- 101000737584 Homo sapiens Cystathionine gamma-lyase Proteins 0.000 description 2
- 101000941690 Homo sapiens Cytochrome P450 1A1 Proteins 0.000 description 2
- 101000919359 Homo sapiens Cytochrome P450 2C9 Proteins 0.000 description 2
- 101000896586 Homo sapiens Cytochrome P450 2D6 Proteins 0.000 description 2
- 101000941723 Homo sapiens Cytochrome P450 2J2 Proteins 0.000 description 2
- 101000745711 Homo sapiens Cytochrome P450 3A4 Proteins 0.000 description 2
- 101000957672 Homo sapiens Cytochrome P450 7A1 Proteins 0.000 description 2
- 101000856723 Homo sapiens Cytochrome b-245 light chain Proteins 0.000 description 2
- 101000889276 Homo sapiens Cytotoxic T-lymphocyte protein 4 Proteins 0.000 description 2
- 101000931925 Homo sapiens D(1A) dopamine receptor Proteins 0.000 description 2
- 101000599038 Homo sapiens DNA-binding protein Ikaros Proteins 0.000 description 2
- 101000886250 Homo sapiens Death-associated protein 1 Proteins 0.000 description 2
- 101000641077 Homo sapiens Diamine acetyltransferase 1 Proteins 0.000 description 2
- 101000915391 Homo sapiens Disabled homolog 2 Proteins 0.000 description 2
- 101000927562 Homo sapiens Dopamine beta-hydroxylase Proteins 0.000 description 2
- 101000838551 Homo sapiens Dual specificity protein phosphatase 13 isoform A Proteins 0.000 description 2
- 101000838549 Homo sapiens Dual specificity protein phosphatase 13 isoform B Proteins 0.000 description 2
- 101001016184 Homo sapiens Dysferlin Proteins 0.000 description 2
- 101000622123 Homo sapiens E-selectin Proteins 0.000 description 2
- 101000942970 Homo sapiens E3 ubiquitin-protein ligase CHFR Proteins 0.000 description 2
- 101000636713 Homo sapiens E3 ubiquitin-protein ligase NEDD4 Proteins 0.000 description 2
- 101000616722 Homo sapiens E3 ubiquitin-protein ligase SIAH1 Proteins 0.000 description 2
- 101000707245 Homo sapiens E3 ubiquitin-protein ligase SIAH2 Proteins 0.000 description 2
- 101000897035 Homo sapiens Ectonucleotide pyrophosphatase/phosphodiesterase family member 2 Proteins 0.000 description 2
- 101000896275 Homo sapiens Embigin Proteins 0.000 description 2
- 101000976212 Homo sapiens Endoribonuclease ZC3H12A Proteins 0.000 description 2
- 101000941275 Homo sapiens Endothelial lipase Proteins 0.000 description 2
- 101000938354 Homo sapiens Ephrin type-A receptor 1 Proteins 0.000 description 2
- 101001064462 Homo sapiens Ephrin type-B receptor 2 Proteins 0.000 description 2
- 101001020112 Homo sapiens Eukaryotic translation initiation factor 2 subunit 1 Proteins 0.000 description 2
- 101000925957 Homo sapiens Eukaryotic translation initiation factor 3 subunit A Proteins 0.000 description 2
- 101001034825 Homo sapiens Eukaryotic translation initiation factor 4 gamma 1 Proteins 0.000 description 2
- 101001034811 Homo sapiens Eukaryotic translation initiation factor 4 gamma 2 Proteins 0.000 description 2
- 101000866286 Homo sapiens Excitatory amino acid transporter 1 Proteins 0.000 description 2
- 101001060231 Homo sapiens F-box/WD repeat-containing protein 7 Proteins 0.000 description 2
- 101000911337 Homo sapiens Fatty acid-binding protein, intestinal Proteins 0.000 description 2
- 101001052035 Homo sapiens Fibroblast growth factor 2 Proteins 0.000 description 2
- 101000878536 Homo sapiens Focal adhesion kinase 1 Proteins 0.000 description 2
- 101000907576 Homo sapiens Forkhead box protein N1 Proteins 0.000 description 2
- 101000614712 Homo sapiens G protein-activated inward rectifier potassium channel 4 Proteins 0.000 description 2
- 101000584612 Homo sapiens GTPase KRas Proteins 0.000 description 2
- 101000608757 Homo sapiens Galectin-3 Proteins 0.000 description 2
- 101001001400 Homo sapiens Gamma-aminobutyric acid receptor subunit alpha-6 Proteins 0.000 description 2
- 101001073581 Homo sapiens Gamma-aminobutyric acid receptor subunit epsilon Proteins 0.000 description 2
- 101001000703 Homo sapiens Gamma-aminobutyric acid type B receptor subunit 2 Proteins 0.000 description 2
- 101001058231 Homo sapiens Gamma-enolase Proteins 0.000 description 2
- 101001075374 Homo sapiens Gamma-glutamyl hydrolase Proteins 0.000 description 2
- 101000726582 Homo sapiens Gap junction alpha-4 protein Proteins 0.000 description 2
- 101000954092 Homo sapiens Gap junction beta-2 protein Proteins 0.000 description 2
- 101000889136 Homo sapiens Gap junction beta-3 protein Proteins 0.000 description 2
- 101000856653 Homo sapiens Gap junction delta-2 protein Proteins 0.000 description 2
- 101000746078 Homo sapiens Gap junction gamma-1 protein Proteins 0.000 description 2
- 101000926939 Homo sapiens Glucocorticoid receptor Proteins 0.000 description 2
- 101000719019 Homo sapiens Glutamyl aminopeptidase Proteins 0.000 description 2
- 101001010139 Homo sapiens Glutathione S-transferase P Proteins 0.000 description 2
- 101001066163 Homo sapiens Growth arrest and DNA damage-inducible protein GADD45 gamma Proteins 0.000 description 2
- 101001072723 Homo sapiens Growth arrest-specific protein 1 Proteins 0.000 description 2
- 101000923005 Homo sapiens Growth arrest-specific protein 6 Proteins 0.000 description 2
- 101000775776 Homo sapiens Guanine nucleotide exchange factor VAV2 Proteins 0.000 description 2
- 101001079623 Homo sapiens Heme oxygenase 1 Proteins 0.000 description 2
- 101000941289 Homo sapiens Hepatic triacylglycerol lipase Proteins 0.000 description 2
- 101001045751 Homo sapiens Hepatocyte nuclear factor 1-alpha Proteins 0.000 description 2
- 101001021253 Homo sapiens Hepcidin Proteins 0.000 description 2
- 101000596894 Homo sapiens High affinity nerve growth factor receptor Proteins 0.000 description 2
- 101001025337 Homo sapiens High mobility group protein B1 Proteins 0.000 description 2
- 101001016841 Homo sapiens Histamine H1 receptor Proteins 0.000 description 2
- 101001067891 Homo sapiens Histone H2AX Proteins 0.000 description 2
- 101001047006 Homo sapiens Histone acetyltransferase KAT2B Proteins 0.000 description 2
- 101000882127 Homo sapiens Histone-lysine N-methyltransferase EZH2 Proteins 0.000 description 2
- 101000578249 Homo sapiens Homeobox protein Nkx-3.1 Proteins 0.000 description 2
- 101001125949 Homo sapiens Homeobox protein PKNOX2 Proteins 0.000 description 2
- 101000839095 Homo sapiens Homeodomain-only protein Proteins 0.000 description 2
- 101000962530 Homo sapiens Hyaluronidase-1 Proteins 0.000 description 2
- 101000983515 Homo sapiens Inactive caspase-12 Proteins 0.000 description 2
- 101001001429 Homo sapiens Inositol monophosphatase 1 Proteins 0.000 description 2
- 101000976075 Homo sapiens Insulin Proteins 0.000 description 2
- 101001044940 Homo sapiens Insulin-like growth factor-binding protein 2 Proteins 0.000 description 2
- 101001015004 Homo sapiens Integrin beta-3 Proteins 0.000 description 2
- 101001054334 Homo sapiens Interferon beta Proteins 0.000 description 2
- 101001076418 Homo sapiens Interleukin-1 receptor type 1 Proteins 0.000 description 2
- 101001055144 Homo sapiens Interleukin-2 receptor subunit alpha Proteins 0.000 description 2
- 101001055145 Homo sapiens Interleukin-2 receptor subunit beta Proteins 0.000 description 2
- 101000599056 Homo sapiens Interleukin-6 receptor subunit beta Proteins 0.000 description 2
- 101001026236 Homo sapiens Intermediate conductance calcium-activated potassium channel protein 4 Proteins 0.000 description 2
- 101001013150 Homo sapiens Interstitial collagenase Proteins 0.000 description 2
- 101001027192 Homo sapiens Kelch-like protein 41 Proteins 0.000 description 2
- 101001050606 Homo sapiens Ketohexokinase Proteins 0.000 description 2
- 101000971521 Homo sapiens Kinetochore scaffold 1 Proteins 0.000 description 2
- 101001139134 Homo sapiens Krueppel-like factor 4 Proteins 0.000 description 2
- 101001018097 Homo sapiens L-selectin Proteins 0.000 description 2
- 101001042351 Homo sapiens LIM and senescent cell antigen-like-containing domain protein 1 Proteins 0.000 description 2
- 101001023271 Homo sapiens Laminin subunit gamma-2 Proteins 0.000 description 2
- 101001004821 Homo sapiens Late cornified envelope-like proline-rich protein 1 Proteins 0.000 description 2
- 101001077840 Homo sapiens Lipid-phosphate phosphatase Proteins 0.000 description 2
- 101000917824 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor II-b Proteins 0.000 description 2
- 101000917858 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-A Proteins 0.000 description 2
- 101000764535 Homo sapiens Lymphotoxin-alpha Proteins 0.000 description 2
- 101001088892 Homo sapiens Lysine-specific demethylase 5A Proteins 0.000 description 2
- 101001088883 Homo sapiens Lysine-specific demethylase 5B Proteins 0.000 description 2
- 101001043321 Homo sapiens Lysyl oxidase homolog 1 Proteins 0.000 description 2
- 101001043352 Homo sapiens Lysyl oxidase homolog 2 Proteins 0.000 description 2
- 101001043354 Homo sapiens Lysyl oxidase homolog 3 Proteins 0.000 description 2
- 101001043351 Homo sapiens Lysyl oxidase homolog 4 Proteins 0.000 description 2
- 101000615657 Homo sapiens MAM domain-containing glycosylphosphatidylinositol anchor protein 2 Proteins 0.000 description 2
- 101000916628 Homo sapiens Macrophage colony-stimulating factor 1 Proteins 0.000 description 2
- 101000990912 Homo sapiens Matrilysin Proteins 0.000 description 2
- 101000954986 Homo sapiens Merlin Proteins 0.000 description 2
- 101001071429 Homo sapiens Metabotropic glutamate receptor 2 Proteins 0.000 description 2
- 101001032845 Homo sapiens Metabotropic glutamate receptor 5 Proteins 0.000 description 2
- 101001032837 Homo sapiens Metabotropic glutamate receptor 6 Proteins 0.000 description 2
- 101001027295 Homo sapiens Metabotropic glutamate receptor 8 Proteins 0.000 description 2
- 101000645296 Homo sapiens Metalloproteinase inhibitor 2 Proteins 0.000 description 2
- 101000831266 Homo sapiens Metalloproteinase inhibitor 4 Proteins 0.000 description 2
- 101001116314 Homo sapiens Methionine synthase reductase Proteins 0.000 description 2
- 101000615613 Homo sapiens Mineralocorticoid receptor Proteins 0.000 description 2
- 101000957106 Homo sapiens Mitotic spindle assembly checkpoint protein MAD1 Proteins 0.000 description 2
- 101000946889 Homo sapiens Monocyte differentiation antigen CD14 Proteins 0.000 description 2
- 101001122476 Homo sapiens Mu-type opioid receptor Proteins 0.000 description 2
- 101000972284 Homo sapiens Mucin-3A Proteins 0.000 description 2
- 101000982010 Homo sapiens Myelin proteolipid protein Proteins 0.000 description 2
- 101000981728 Homo sapiens Myeloid differentiation primary response protein MyD88 Proteins 0.000 description 2
- 101000585663 Homo sapiens Myocilin Proteins 0.000 description 2
- 101000588964 Homo sapiens Myosin-14 Proteins 0.000 description 2
- 101000906927 Homo sapiens N-chimaerin Proteins 0.000 description 2
- 101000973778 Homo sapiens NAD(P)H dehydrogenase [quinone] 1 Proteins 0.000 description 2
- 101000636665 Homo sapiens NADH dehydrogenase [ubiquinone] 1 alpha subcomplex subunit 13 Proteins 0.000 description 2
- 101000961071 Homo sapiens NF-kappa-B inhibitor alpha Proteins 0.000 description 2
- 101000780028 Homo sapiens Natriuretic peptides A Proteins 0.000 description 2
- 101000928278 Homo sapiens Natriuretic peptides B Proteins 0.000 description 2
- 101001108436 Homo sapiens Neurexin-1 Proteins 0.000 description 2
- 101001108433 Homo sapiens Neurexin-1-beta Proteins 0.000 description 2
- 101000603245 Homo sapiens Neuropeptide Y receptor type 2 Proteins 0.000 description 2
- 101000990908 Homo sapiens Neutrophil collagenase Proteins 0.000 description 2
- 101000851058 Homo sapiens Neutrophil elastase Proteins 0.000 description 2
- 101001124309 Homo sapiens Nitric oxide synthase, endothelial Proteins 0.000 description 2
- 101001109719 Homo sapiens Nucleophosmin Proteins 0.000 description 2
- 101000812677 Homo sapiens Nucleotide pyrophosphatase Proteins 0.000 description 2
- 101001125026 Homo sapiens Nucleotide-binding oligomerization domain-containing protein 2 Proteins 0.000 description 2
- 101001086210 Homo sapiens Osteocalcin Proteins 0.000 description 2
- 101000839399 Homo sapiens Oxidoreductase HTATIP2 Proteins 0.000 description 2
- 101000585555 Homo sapiens PCNA-associated factor Proteins 0.000 description 2
- 101001123306 Homo sapiens PR domain zinc finger protein 10 Proteins 0.000 description 2
- 101000613565 Homo sapiens PRKC apoptosis WT1 regulator protein Proteins 0.000 description 2
- 101001131972 Homo sapiens PX domain-containing protein kinase-like protein Proteins 0.000 description 2
- 101000601661 Homo sapiens Paired box protein Pax-7 Proteins 0.000 description 2
- 101000610206 Homo sapiens Pappalysin-1 Proteins 0.000 description 2
- 101001135738 Homo sapiens Parathyroid hormone-related protein Proteins 0.000 description 2
- 101001129187 Homo sapiens Patatin-like phospholipase domain-containing protein 2 Proteins 0.000 description 2
- 101000693243 Homo sapiens Paternally-expressed gene 3 protein Proteins 0.000 description 2
- 101001067833 Homo sapiens Peptidyl-prolyl cis-trans isomerase A Proteins 0.000 description 2
- 101001091194 Homo sapiens Peptidyl-prolyl cis-trans isomerase G Proteins 0.000 description 2
- 101000579484 Homo sapiens Period circadian protein homolog 1 Proteins 0.000 description 2
- 101000755630 Homo sapiens Peripheral-type benzodiazepine receptor-associated protein 1 Proteins 0.000 description 2
- 101000801684 Homo sapiens Phospholipid-transporting ATPase ABCA1 Proteins 0.000 description 2
- 101000692259 Homo sapiens Phosphoprotein associated with glycosphingolipid-enriched microdomains 1 Proteins 0.000 description 2
- 101000595669 Homo sapiens Pituitary homeobox 2 Proteins 0.000 description 2
- 101000595923 Homo sapiens Placenta growth factor Proteins 0.000 description 2
- 101000692455 Homo sapiens Platelet-derived growth factor receptor beta Proteins 0.000 description 2
- 101000613343 Homo sapiens Polycomb group RING finger protein 2 Proteins 0.000 description 2
- 101000613355 Homo sapiens Polycomb group RING finger protein 6 Proteins 0.000 description 2
- 101001074444 Homo sapiens Polycystin-1 Proteins 0.000 description 2
- 101001002235 Homo sapiens Polypeptide N-acetylgalactosaminyltransferase 2 Proteins 0.000 description 2
- 101000772905 Homo sapiens Polyubiquitin-B Proteins 0.000 description 2
- 101001135489 Homo sapiens Potassium voltage-gated channel subfamily D member 1 Proteins 0.000 description 2
- 101000974726 Homo sapiens Potassium voltage-gated channel subfamily E member 1 Proteins 0.000 description 2
- 101001047090 Homo sapiens Potassium voltage-gated channel subfamily H member 2 Proteins 0.000 description 2
- 101000610118 Homo sapiens Pre-B-cell leukemia transcription factor 4 Proteins 0.000 description 2
- 101000904173 Homo sapiens Progonadoliberin-1 Proteins 0.000 description 2
- 101000945496 Homo sapiens Proliferation marker protein Ki-67 Proteins 0.000 description 2
- 101001080624 Homo sapiens Proline/serine-rich coiled-coil protein 1 Proteins 0.000 description 2
- 101001135402 Homo sapiens Prostaglandin-H2 D-isomerase Proteins 0.000 description 2
- 101000605534 Homo sapiens Prostate-specific antigen Proteins 0.000 description 2
- 101001090813 Homo sapiens Proteasome subunit alpha type-6 Proteins 0.000 description 2
- 101001046603 Homo sapiens Protein KIBRA Proteins 0.000 description 2
- 101000585703 Homo sapiens Protein L-Myc Proteins 0.000 description 2
- 101000772227 Homo sapiens Protein TSSC4 Proteins 0.000 description 2
- 101000804792 Homo sapiens Protein Wnt-5a Proteins 0.000 description 2
- 101001026864 Homo sapiens Protein kinase C gamma type Proteins 0.000 description 2
- 101000735566 Homo sapiens Protein-arginine deiminase type-4 Proteins 0.000 description 2
- 101001098560 Homo sapiens Proteinase-activated receptor 2 Proteins 0.000 description 2
- 101000655540 Homo sapiens Protransforming growth factor alpha Proteins 0.000 description 2
- 101000920560 Homo sapiens Putative endoplasmin-like protein Proteins 0.000 description 2
- 101000848724 Homo sapiens Rap guanine nucleotide exchange factor 3 Proteins 0.000 description 2
- 101000712958 Homo sapiens Ras association domain-containing protein 1 Proteins 0.000 description 2
- 101000712972 Homo sapiens Ras association domain-containing protein 4 Proteins 0.000 description 2
- 101001074548 Homo sapiens Regulating synaptic membrane exocytosis protein 2 Proteins 0.000 description 2
- 101001106672 Homo sapiens Regulator of G-protein signaling 2 Proteins 0.000 description 2
- 101000650945 Homo sapiens Renalase Proteins 0.000 description 2
- 101000801643 Homo sapiens Retinal-specific phospholipid-transporting ATPase ABCA4 Proteins 0.000 description 2
- 101001112293 Homo sapiens Retinoic acid receptor alpha Proteins 0.000 description 2
- 101001132698 Homo sapiens Retinoic acid receptor beta Proteins 0.000 description 2
- 101000665882 Homo sapiens Retinol-binding protein 4 Proteins 0.000 description 2
- 101001106322 Homo sapiens Rho GTPase-activating protein 7 Proteins 0.000 description 2
- 101000581122 Homo sapiens Rho-related GTP-binding protein RhoD Proteins 0.000 description 2
- 101001055594 Homo sapiens S-adenosylmethionine synthase isoform type-1 Proteins 0.000 description 2
- 101000708835 Homo sapiens SET and MYND domain-containing protein 4 Proteins 0.000 description 2
- 101000740659 Homo sapiens Scavenger receptor class B member 1 Proteins 0.000 description 2
- 101000880431 Homo sapiens Serine/threonine-protein kinase 4 Proteins 0.000 description 2
- 101000904787 Homo sapiens Serine/threonine-protein kinase ATR Proteins 0.000 description 2
- 101000576901 Homo sapiens Serine/threonine-protein kinase MRCK alpha Proteins 0.000 description 2
- 101000864057 Homo sapiens Serine/threonine-protein kinase SMG1 Proteins 0.000 description 2
- 101000628562 Homo sapiens Serine/threonine-protein kinase STK11 Proteins 0.000 description 2
- 101000623857 Homo sapiens Serine/threonine-protein kinase mTOR Proteins 0.000 description 2
- 101000869480 Homo sapiens Serum amyloid A-1 protein Proteins 0.000 description 2
- 101000621057 Homo sapiens Serum paraoxonase/lactonase 3 Proteins 0.000 description 2
- 101000826373 Homo sapiens Signal transducer and activator of transcription 3 Proteins 0.000 description 2
- 101000651890 Homo sapiens Slit homolog 2 protein Proteins 0.000 description 2
- 101001026232 Homo sapiens Small conductance calcium-activated potassium channel protein 3 Proteins 0.000 description 2
- 101000654386 Homo sapiens Sodium channel protein type 9 subunit alpha Proteins 0.000 description 2
- 101000631929 Homo sapiens Sodium-dependent serotonin transporter Proteins 0.000 description 2
- 101000753197 Homo sapiens Sodium/potassium-transporting ATPase subunit alpha-2 Proteins 0.000 description 2
- 101000868152 Homo sapiens Son of sevenless homolog 1 Proteins 0.000 description 2
- 101000785978 Homo sapiens Sphingomyelin phosphodiesterase Proteins 0.000 description 2
- 101000631826 Homo sapiens Stearoyl-CoA desaturase Proteins 0.000 description 2
- 101000861263 Homo sapiens Steroid 21-hydroxylase Proteins 0.000 description 2
- 101000585255 Homo sapiens Steroidogenic factor 1 Proteins 0.000 description 2
- 101000631695 Homo sapiens Succinate dehydrogenase assembly factor 3, mitochondrial Proteins 0.000 description 2
- 101001131204 Homo sapiens Sulfhydryl oxidase 1 Proteins 0.000 description 2
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 description 2
- 101000653663 Homo sapiens T-complex protein 1 subunit epsilon Proteins 0.000 description 2
- 101000799181 Homo sapiens TP53-binding protein 1 Proteins 0.000 description 2
- 101000626142 Homo sapiens Tensin-1 Proteins 0.000 description 2
- 101000659879 Homo sapiens Thrombospondin-1 Proteins 0.000 description 2
- 101000653005 Homo sapiens Thromboxane-A synthase Proteins 0.000 description 2
- 101000800116 Homo sapiens Thy-1 membrane glycoprotein Proteins 0.000 description 2
- 101000702545 Homo sapiens Transcription activator BRG1 Proteins 0.000 description 2
- 101000596771 Homo sapiens Transcription factor 7-like 2 Proteins 0.000 description 2
- 101000819074 Homo sapiens Transcription factor GATA-4 Proteins 0.000 description 2
- 101000845264 Homo sapiens Transcription termination factor 2 Proteins 0.000 description 2
- 101001051166 Homo sapiens Transcriptional activator MN1 Proteins 0.000 description 2
- 101000835093 Homo sapiens Transferrin receptor protein 1 Proteins 0.000 description 2
- 101000755529 Homo sapiens Transforming protein RhoA Proteins 0.000 description 2
- 101000625727 Homo sapiens Tubulin beta chain Proteins 0.000 description 2
- 101000830570 Homo sapiens Tumor necrosis factor alpha-induced protein 3 Proteins 0.000 description 2
- 101000830603 Homo sapiens Tumor necrosis factor ligand superfamily member 11 Proteins 0.000 description 2
- 101000648503 Homo sapiens Tumor necrosis factor receptor superfamily member 11A Proteins 0.000 description 2
- 101000801254 Homo sapiens Tumor necrosis factor receptor superfamily member 16 Proteins 0.000 description 2
- 101000733249 Homo sapiens Tumor suppressor ARF Proteins 0.000 description 2
- 101000613251 Homo sapiens Tumor susceptibility gene 101 protein Proteins 0.000 description 2
- 101000772122 Homo sapiens Twisted gastrulation protein homolog 1 Proteins 0.000 description 2
- 101000864342 Homo sapiens Tyrosine-protein kinase BTK Proteins 0.000 description 2
- 101001135589 Homo sapiens Tyrosine-protein phosphatase non-receptor type 22 Proteins 0.000 description 2
- 101000807306 Homo sapiens Ubiquitin-like modifier-activating enzyme 1 Proteins 0.000 description 2
- 101000671637 Homo sapiens Upstream stimulatory factor 1 Proteins 0.000 description 2
- 101000671649 Homo sapiens Upstream stimulatory factor 2 Proteins 0.000 description 2
- 101000851018 Homo sapiens Vascular endothelial growth factor receptor 1 Proteins 0.000 description 2
- 101000851007 Homo sapiens Vascular endothelial growth factor receptor 2 Proteins 0.000 description 2
- 101000954157 Homo sapiens Vasopressin V1a receptor Proteins 0.000 description 2
- 101000621390 Homo sapiens Wee1-like protein kinase Proteins 0.000 description 2
- 101000964562 Homo sapiens Zinc finger FYVE domain-containing protein 9 Proteins 0.000 description 2
- 101001098858 Homo sapiens cGMP-dependent 3',5'-cyclic phosphodiesterase Proteins 0.000 description 2
- 101001098812 Homo sapiens cGMP-inhibited 3',5'-cyclic phosphodiesterase B Proteins 0.000 description 2
- 101000795753 Homo sapiens mRNA decay activator protein ZFP36 Proteins 0.000 description 2
- 102100026020 Hormone-sensitive lipase Human genes 0.000 description 2
- 101150065069 Hsp90b1 gene Proteins 0.000 description 2
- 101710199679 Hyaluronidase-1 Proteins 0.000 description 2
- 102100039285 Hyaluronidase-2 Human genes 0.000 description 2
- 102100021082 Hyaluronidase-3 Human genes 0.000 description 2
- 206010020772 Hypertension Diseases 0.000 description 2
- 108010028501 Hypoxia-Inducible Factor 1 Proteins 0.000 description 2
- 102000016878 Hypoxia-Inducible Factor 1 Human genes 0.000 description 2
- 102000018071 Immunoglobulin Fc Fragments Human genes 0.000 description 2
- 108010091135 Immunoglobulin Fc Fragments Proteins 0.000 description 2
- 102100026212 Immunoglobulin heavy constant epsilon Human genes 0.000 description 2
- 101710160774 Immunoglobulin heavy constant epsilon Proteins 0.000 description 2
- 102100026556 Inactive caspase-12 Human genes 0.000 description 2
- 102100035679 Inositol monophosphatase 1 Human genes 0.000 description 2
- 102000009433 Insulin Receptor Substrate Proteins Human genes 0.000 description 2
- 108010034219 Insulin Receptor Substrate Proteins Proteins 0.000 description 2
- 102000004374 Insulin-like growth factor binding protein 3 Human genes 0.000 description 2
- 108090000965 Insulin-like growth factor binding protein 3 Proteins 0.000 description 2
- 102000004375 Insulin-like growth factor-binding protein 1 Human genes 0.000 description 2
- 108090000957 Insulin-like growth factor-binding protein 1 Proteins 0.000 description 2
- 102100022710 Insulin-like growth factor-binding protein 2 Human genes 0.000 description 2
- 102100029228 Insulin-like growth factor-binding protein 7 Human genes 0.000 description 2
- 102100023350 Integral membrane protein 2B Human genes 0.000 description 2
- 101710180845 Integral membrane protein 2B Proteins 0.000 description 2
- 102100022338 Integrin alpha-M Human genes 0.000 description 2
- 102100025390 Integrin beta-2 Human genes 0.000 description 2
- 102100032999 Integrin beta-3 Human genes 0.000 description 2
- 102100020944 Integrin-linked protein kinase Human genes 0.000 description 2
- 108010064593 Intercellular Adhesion Molecule-1 Proteins 0.000 description 2
- 102100037877 Intercellular adhesion molecule 1 Human genes 0.000 description 2
- 102100026720 Interferon beta Human genes 0.000 description 2
- 108010047761 Interferon-alpha Proteins 0.000 description 2
- 102000006992 Interferon-alpha Human genes 0.000 description 2
- 102100034170 Interferon-induced, double-stranded RNA-activated protein kinase Human genes 0.000 description 2
- 101710089751 Interferon-induced, double-stranded RNA-activated protein kinase Proteins 0.000 description 2
- 108700003107 Interleukin-1 Receptor-Like 1 Proteins 0.000 description 2
- 102100026016 Interleukin-1 receptor type 1 Human genes 0.000 description 2
- 102100036706 Interleukin-1 receptor-like 1 Human genes 0.000 description 2
- 102000003815 Interleukin-11 Human genes 0.000 description 2
- 108090000177 Interleukin-11 Proteins 0.000 description 2
- 102000013462 Interleukin-12 Human genes 0.000 description 2
- 108010065805 Interleukin-12 Proteins 0.000 description 2
- 102000000588 Interleukin-2 Human genes 0.000 description 2
- 108010002350 Interleukin-2 Proteins 0.000 description 2
- 102100026878 Interleukin-2 receptor subunit alpha Human genes 0.000 description 2
- 102100026879 Interleukin-2 receptor subunit beta Human genes 0.000 description 2
- 102000013264 Interleukin-23 Human genes 0.000 description 2
- 102100036671 Interleukin-24 Human genes 0.000 description 2
- 108010066979 Interleukin-27 Proteins 0.000 description 2
- 102100033501 Interleukin-32 Human genes 0.000 description 2
- 102000017761 Interleukin-33 Human genes 0.000 description 2
- 108010067003 Interleukin-33 Proteins 0.000 description 2
- 102100039897 Interleukin-5 Human genes 0.000 description 2
- 108010038501 Interleukin-6 Receptors Proteins 0.000 description 2
- 102100037792 Interleukin-6 receptor subunit alpha Human genes 0.000 description 2
- 102100037795 Interleukin-6 receptor subunit beta Human genes 0.000 description 2
- 102100026236 Interleukin-8 Human genes 0.000 description 2
- 108090001007 Interleukin-8 Proteins 0.000 description 2
- 108010018951 Interleukin-8B Receptors Proteins 0.000 description 2
- 102100037441 Intermediate conductance calcium-activated potassium channel protein 4 Human genes 0.000 description 2
- 102000011845 Iodide peroxidase Human genes 0.000 description 2
- 108010036012 Iodide peroxidase Proteins 0.000 description 2
- 108010041872 Islet Amyloid Polypeptide Proteins 0.000 description 2
- 102100027670 Islet amyloid polypeptide Human genes 0.000 description 2
- 102000006503 Janus Kinase 2 Human genes 0.000 description 2
- 108010019437 Janus Kinase 2 Proteins 0.000 description 2
- 108010019421 Janus Kinase 3 Proteins 0.000 description 2
- 102000012322 Junction plakoglobin Human genes 0.000 description 2
- 102100037644 Kelch-like protein 41 Human genes 0.000 description 2
- 102100040445 Keratin, type I cytoskeletal 14 Human genes 0.000 description 2
- 102100033421 Keratin, type I cytoskeletal 18 Human genes 0.000 description 2
- 102100022905 Keratin, type II cytoskeletal 1 Human genes 0.000 description 2
- 102100021540 Keratin-associated protein 19-3 Human genes 0.000 description 2
- 101710165998 Keratin-associated protein 19-3 Proteins 0.000 description 2
- 102100023418 Ketohexokinase Human genes 0.000 description 2
- 102100021464 Kinetochore scaffold 1 Human genes 0.000 description 2
- 102100035792 Kininogen-1 Human genes 0.000 description 2
- 102100020880 Kit ligand Human genes 0.000 description 2
- 102100020677 Krueppel-like factor 4 Human genes 0.000 description 2
- XNSAINXGIQZQOO-UHFFFAOYSA-N L-pyroglutamyl-L-histidyl-L-proline amide Natural products NC(=O)C1CCCN1C(=O)C(NC(=O)C1NC(=O)CC1)CC1=CN=CN1 XNSAINXGIQZQOO-UHFFFAOYSA-N 0.000 description 2
- 102100033467 L-selectin Human genes 0.000 description 2
- 102100021754 LIM and senescent cell antigen-like-containing domain protein 1 Human genes 0.000 description 2
- 102100035159 Laminin subunit gamma-2 Human genes 0.000 description 2
- 102100025972 Late cornified envelope-like proline-rich protein 1 Human genes 0.000 description 2
- 102100031775 Leptin receptor Human genes 0.000 description 2
- 108010020246 Leucine-Rich Repeat Serine-Threonine Protein Kinase-2 Proteins 0.000 description 2
- 102100032693 Leucine-rich repeat serine/threonine-protein kinase 2 Human genes 0.000 description 2
- 102100023758 Leukotriene C4 synthase Human genes 0.000 description 2
- 102100025357 Lipid-phosphate phosphatase Human genes 0.000 description 2
- 102000052508 Lipopolysaccharide-binding protein Human genes 0.000 description 2
- 108010053632 Lipopolysaccharide-binding protein Proteins 0.000 description 2
- 108010013563 Lipoprotein Lipase Proteins 0.000 description 2
- 102000043296 Lipoprotein lipases Human genes 0.000 description 2
- 102100029193 Low affinity immunoglobulin gamma Fc region receptor III-A Human genes 0.000 description 2
- 102000018671 Lymphocyte Antigen 96 Human genes 0.000 description 2
- 108010066789 Lymphocyte Antigen 96 Proteins 0.000 description 2
- 102100026238 Lymphotoxin-alpha Human genes 0.000 description 2
- 102100033246 Lysine-specific demethylase 5A Human genes 0.000 description 2
- 102100033247 Lysine-specific demethylase 5B Human genes 0.000 description 2
- 102100037611 Lysophospholipase Human genes 0.000 description 2
- 108010009491 Lysosomal-Associated Membrane Protein 2 Proteins 0.000 description 2
- 102100038225 Lysosome-associated membrane glycoprotein 2 Human genes 0.000 description 2
- 102100021958 Lysyl oxidase homolog 1 Human genes 0.000 description 2
- 102100021948 Lysyl oxidase homolog 2 Human genes 0.000 description 2
- 102100021949 Lysyl oxidase homolog 3 Human genes 0.000 description 2
- 102100021968 Lysyl oxidase homolog 4 Human genes 0.000 description 2
- 102100021319 MAM domain-containing glycosylphosphatidylinositol anchor protein 2 Human genes 0.000 description 2
- 102100034069 MAP kinase-activated protein kinase 2 Human genes 0.000 description 2
- 101710141394 MAP kinase-activated protein kinase 2 Proteins 0.000 description 2
- 102100028396 MAP kinase-activated protein kinase 5 Human genes 0.000 description 2
- 101710140998 MAP kinase-activated protein kinase 5 Proteins 0.000 description 2
- 108700012928 MAPK14 Proteins 0.000 description 2
- 108010059343 MM Form Creatine Kinase Proteins 0.000 description 2
- 101150053046 MYD88 gene Proteins 0.000 description 2
- 108030001712 Macrophage elastases Proteins 0.000 description 2
- 102100037791 Macrophage migration inhibitory factor Human genes 0.000 description 2
- 102100030417 Matrilysin Human genes 0.000 description 2
- 108010016165 Matrix Metalloproteinase 2 Proteins 0.000 description 2
- 108010016160 Matrix Metalloproteinase 3 Proteins 0.000 description 2
- 108010093157 Member 1 Group A Nuclear Receptor Subfamily 4 Proteins 0.000 description 2
- 108010047230 Member 1 Subfamily B ATP Binding Cassette Transporter Proteins 0.000 description 2
- 102100027159 Membrane primary amine oxidase Human genes 0.000 description 2
- 102100037106 Merlin Human genes 0.000 description 2
- 102100038300 Metabotropic glutamate receptor 6 Human genes 0.000 description 2
- 102100037636 Metabotropic glutamate receptor 8 Human genes 0.000 description 2
- 102000005741 Metalloproteases Human genes 0.000 description 2
- 108010006035 Metalloproteases Proteins 0.000 description 2
- 102100026262 Metalloproteinase inhibitor 2 Human genes 0.000 description 2
- 102100024289 Metalloproteinase inhibitor 4 Human genes 0.000 description 2
- 102100031551 Methionine synthase Human genes 0.000 description 2
- 102100024614 Methionine synthase reductase Human genes 0.000 description 2
- 108010030837 Methylenetetrahydrofolate Reductase (NADPH2) Proteins 0.000 description 2
- 102000005954 Methylenetetrahydrofolate Reductase (NADPH2) Human genes 0.000 description 2
- 102100031545 Microsomal triglyceride transfer protein large subunit Human genes 0.000 description 2
- 102100040243 Microtubule-associated protein tau Human genes 0.000 description 2
- 101710115937 Microtubule-associated protein tau Proteins 0.000 description 2
- 102100021316 Mineralocorticoid receptor Human genes 0.000 description 2
- 102100040200 Mitochondrial uncoupling protein 2 Human genes 0.000 description 2
- 108700036166 Mitogen-Activated Protein Kinase 11 Proteins 0.000 description 2
- 108700027650 Mitogen-Activated Protein Kinase 7 Proteins 0.000 description 2
- 102100026929 Mitogen-activated protein kinase 11 Human genes 0.000 description 2
- 102000054819 Mitogen-activated protein kinase 14 Human genes 0.000 description 2
- 102100037805 Mitogen-activated protein kinase 7 Human genes 0.000 description 2
- 102100033127 Mitogen-activated protein kinase kinase kinase 5 Human genes 0.000 description 2
- 101710164337 Mitogen-activated protein kinase kinase kinase 5 Proteins 0.000 description 2
- 102100035877 Monocyte differentiation antigen CD14 Human genes 0.000 description 2
- 102100029814 Monoglyceride lipase Human genes 0.000 description 2
- 102100025748 Mothers against decapentaplegic homolog 3 Human genes 0.000 description 2
- 101710143111 Mothers against decapentaplegic homolog 3 Proteins 0.000 description 2
- 102100030608 Mothers against decapentaplegic homolog 7 Human genes 0.000 description 2
- 101150097381 Mtor gene Proteins 0.000 description 2
- 102100028647 Mu-type opioid receptor Human genes 0.000 description 2
- 102100022497 Mucin-3A Human genes 0.000 description 2
- 101100268830 Mus musculus Chrna7 gene Proteins 0.000 description 2
- 102000047918 Myelin Basic Human genes 0.000 description 2
- 101710107068 Myelin basic protein Proteins 0.000 description 2
- 102100026784 Myelin proteolipid protein Human genes 0.000 description 2
- 102100032977 Myelin-associated oligodendrocyte basic protein Human genes 0.000 description 2
- 101710091862 Myelin-associated oligodendrocyte basic protein Proteins 0.000 description 2
- 102000003896 Myeloperoxidases Human genes 0.000 description 2
- 108090000235 Myeloperoxidases Proteins 0.000 description 2
- 102100030217 Myocardin Human genes 0.000 description 2
- 108010081823 Myocardin Proteins 0.000 description 2
- 102100029839 Myocilin Human genes 0.000 description 2
- 102100021148 Myocyte-specific enhancer factor 2A Human genes 0.000 description 2
- 102100039229 Myocyte-specific enhancer factor 2C Human genes 0.000 description 2
- 102100035044 Myosin light chain kinase, smooth muscle Human genes 0.000 description 2
- 102100032972 Myosin-14 Human genes 0.000 description 2
- 108010074596 Myosin-Light-Chain Kinase Proteins 0.000 description 2
- 108010052185 Myotonin-Protein Kinase Proteins 0.000 description 2
- 102100022437 Myotonin-protein kinase Human genes 0.000 description 2
- 102100023648 N-chimaerin Human genes 0.000 description 2
- 102100022365 NAD(P)H dehydrogenase [quinone] 1 Human genes 0.000 description 2
- 102100031455 NAD-dependent protein deacetylase sirtuin-1 Human genes 0.000 description 2
- 102100031924 NADH dehydrogenase [ubiquinone] 1 alpha subcomplex subunit 13 Human genes 0.000 description 2
- 108010082699 NADPH Oxidase 4 Proteins 0.000 description 2
- 102100021872 NADPH oxidase 4 Human genes 0.000 description 2
- 102100039337 NF-kappa-B inhibitor alpha Human genes 0.000 description 2
- 102000002451 NPR2 Human genes 0.000 description 2
- 108010054200 NR2B NMDA receptor Proteins 0.000 description 2
- 102100034296 Natriuretic peptides A Human genes 0.000 description 2
- 102100036836 Natriuretic peptides B Human genes 0.000 description 2
- 108010025020 Nerve Growth Factor Proteins 0.000 description 2
- 102100024012 Netrin-1 Human genes 0.000 description 2
- 108010074223 Netrin-1 Proteins 0.000 description 2
- 102400000058 Neuregulin-1 Human genes 0.000 description 2
- 102100021310 Neurexin-3 Human genes 0.000 description 2
- 102000007530 Neurofibromin 1 Human genes 0.000 description 2
- 108010085793 Neurofibromin 1 Proteins 0.000 description 2
- 102100025246 Neurogenic locus notch homolog protein 2 Human genes 0.000 description 2
- 102100025247 Neurogenic locus notch homolog protein 3 Human genes 0.000 description 2
- 108010040718 Neurokinin-1 Receptors Proteins 0.000 description 2
- 102100038991 Neuropeptide Y receptor type 2 Human genes 0.000 description 2
- 102400001103 Neurotensin Human genes 0.000 description 2
- 101800001814 Neurotensin Proteins 0.000 description 2
- 102100033174 Neutrophil elastase Human genes 0.000 description 2
- 102100024403 Nibrin Human genes 0.000 description 2
- 108050003990 Nibrin Proteins 0.000 description 2
- 102100022397 Nitric oxide synthase, brain Human genes 0.000 description 2
- 102100028452 Nitric oxide synthase, endothelial Human genes 0.000 description 2
- 102100028646 Nociceptin receptor Human genes 0.000 description 2
- 101150083031 Nod2 gene Proteins 0.000 description 2
- 108010032107 Non-Receptor Type 11 Protein Tyrosine Phosphatase Proteins 0.000 description 2
- 108020004485 Nonsense Codon Proteins 0.000 description 2
- 102000014736 Notch Human genes 0.000 description 2
- 108010070047 Notch Receptors Proteins 0.000 description 2
- 108010029751 Notch2 Receptor Proteins 0.000 description 2
- 102000001753 Notch4 Receptor Human genes 0.000 description 2
- 108010029741 Notch4 Receptor Proteins 0.000 description 2
- 108010077850 Nuclear Localization Signals Proteins 0.000 description 2
- 102100023050 Nuclear factor NF-kappa-B p105 subunit Human genes 0.000 description 2
- 101710082694 Nuclear factor NF-kappa-B p105 subunit Proteins 0.000 description 2
- 102100036961 Nuclear mitotic apparatus protein 1 Human genes 0.000 description 2
- 101710104794 Nuclear mitotic apparatus protein 1 Proteins 0.000 description 2
- 102100038494 Nuclear receptor subfamily 1 group I member 2 Human genes 0.000 description 2
- 102100022679 Nuclear receptor subfamily 4 group A member 1 Human genes 0.000 description 2
- 102100022678 Nucleophosmin Human genes 0.000 description 2
- 102100039306 Nucleotide pyrophosphatase Human genes 0.000 description 2
- 108010058765 Oncogene Protein pp60(v-src) Proteins 0.000 description 2
- 102100021079 Ornithine decarboxylase Human genes 0.000 description 2
- 101710120430 Ornithine decarboxylase 1 Proteins 0.000 description 2
- 102100031475 Osteocalcin Human genes 0.000 description 2
- 102000004264 Osteopontin Human genes 0.000 description 2
- 108010081689 Osteopontin Proteins 0.000 description 2
- 102100027952 Oxidoreductase HTATIP2 Human genes 0.000 description 2
- 102100034925 P-selectin glycoprotein ligand 1 Human genes 0.000 description 2
- 102100026171 P2Y purinoceptor 12 Human genes 0.000 description 2
- 102100029879 PCNA-associated factor Human genes 0.000 description 2
- 238000012408 PCR amplification Methods 0.000 description 2
- 102100028955 PR domain zinc finger protein 10 Human genes 0.000 description 2
- 102100040853 PRKC apoptosis WT1 regulator protein Human genes 0.000 description 2
- 102100034602 PX domain-containing protein kinase-like protein Human genes 0.000 description 2
- 102100037504 Paired box protein Pax-5 Human genes 0.000 description 2
- 102100037503 Paired box protein Pax-7 Human genes 0.000 description 2
- 102100040156 Pappalysin-1 Human genes 0.000 description 2
- 102100036893 Parathyroid hormone Human genes 0.000 description 2
- 108090000445 Parathyroid hormone Proteins 0.000 description 2
- 102100036899 Parathyroid hormone-related protein Human genes 0.000 description 2
- 102100031248 Patatin-like phospholipase domain-containing protein 2 Human genes 0.000 description 2
- 102100025757 Paternally-expressed gene 3 protein Human genes 0.000 description 2
- 102000018546 Paxillin Human genes 0.000 description 2
- ACNHBCIZLNNLRS-UHFFFAOYSA-N Paxilline 1 Natural products N1C2=CC=CC=C2C2=C1C1(C)C3(C)CCC4OC(C(C)(O)C)C(=O)C=C4C3(O)CCC1C2 ACNHBCIZLNNLRS-UHFFFAOYSA-N 0.000 description 2
- 101710111198 Peptidyl-prolyl cis-trans isomerase A Proteins 0.000 description 2
- 102100028293 Period circadian protein homolog 1 Human genes 0.000 description 2
- 102000007456 Peroxiredoxin Human genes 0.000 description 2
- 102100038824 Peroxisome proliferator-activated receptor delta Human genes 0.000 description 2
- 108010011964 Phosphatidylcholine-sterol O-acyltransferase Proteins 0.000 description 2
- 102100031538 Phosphatidylcholine-sterol acyltransferase Human genes 0.000 description 2
- 102100036052 Phosphatidylinositol 4,5-bisphosphate 3-kinase catalytic subunit gamma isoform Human genes 0.000 description 2
- 102100025058 Phosphatidylinositol 4-phosphate 3-kinase C2 domain-containing subunit alpha Human genes 0.000 description 2
- 102100031014 Phosphatidylinositol-binding clathrin assembly protein Human genes 0.000 description 2
- 108010058864 Phospholipases A2 Proteins 0.000 description 2
- 102000003867 Phospholipid Transfer Proteins Human genes 0.000 description 2
- 108090000216 Phospholipid Transfer Proteins Proteins 0.000 description 2
- 102100026066 Phosphoprotein associated with glycosphingolipid-enriched microdomains 1 Human genes 0.000 description 2
- 102100035846 Pigment epithelium-derived factor Human genes 0.000 description 2
- 102100036090 Pituitary homeobox 2 Human genes 0.000 description 2
- 102100035194 Placenta growth factor Human genes 0.000 description 2
- 102000013566 Plasminogen Human genes 0.000 description 2
- 108010051456 Plasminogen Proteins 0.000 description 2
- 102100031574 Platelet glycoprotein 4 Human genes 0.000 description 2
- 102100026547 Platelet-derived growth factor receptor beta Human genes 0.000 description 2
- 102100040990 Platelet-derived growth factor subunit B Human genes 0.000 description 2
- RVGRUAULSDPKGF-UHFFFAOYSA-N Poloxamer Chemical compound C1CO1.CC1CO1 RVGRUAULSDPKGF-UHFFFAOYSA-N 0.000 description 2
- 108010064218 Poly (ADP-Ribose) Polymerase-1 Proteins 0.000 description 2
- 102100023712 Poly [ADP-ribose] polymerase 1 Human genes 0.000 description 2
- 108010061844 Poly(ADP-ribose) Polymerases Proteins 0.000 description 2
- 102000012338 Poly(ADP-ribose) Polymerases Human genes 0.000 description 2
- 229920000776 Poly(Adenosine diphosphate-ribose) polymerase Polymers 0.000 description 2
- 102100040919 Polycomb group RING finger protein 2 Human genes 0.000 description 2
- 102100040917 Polycomb group RING finger protein 6 Human genes 0.000 description 2
- 102100036143 Polycystin-1 Human genes 0.000 description 2
- 102100020950 Polypeptide N-acetylgalactosaminyltransferase 2 Human genes 0.000 description 2
- 102100030432 Polyubiquitin-B Human genes 0.000 description 2
- 102100037935 Polyubiquitin-C Human genes 0.000 description 2
- 102100022364 Polyunsaturated fatty acid 5-lipoxygenase Human genes 0.000 description 2
- 102100031949 Polyunsaturated fatty acid lipoxygenase ALOX12 Human genes 0.000 description 2
- 102100033164 Potassium voltage-gated channel subfamily D member 1 Human genes 0.000 description 2
- 102100022755 Potassium voltage-gated channel subfamily E member 1 Human genes 0.000 description 2
- 102100022807 Potassium voltage-gated channel subfamily H member 2 Human genes 0.000 description 2
- 102100037444 Potassium voltage-gated channel subfamily KQT member 1 Human genes 0.000 description 2
- 102100040167 Pre-B-cell leukemia transcription factor 4 Human genes 0.000 description 2
- 108010071690 Prealbumin Proteins 0.000 description 2
- 108010001511 Pregnane X Receptor Proteins 0.000 description 2
- 102100026531 Prelamin-A/C Human genes 0.000 description 2
- 108010036933 Presenilin-1 Proteins 0.000 description 2
- 108010036908 Presenilin-2 Proteins 0.000 description 2
- 102100024028 Progonadoliberin-1 Human genes 0.000 description 2
- 102100033762 Proheparin-binding EGF-like growth factor Human genes 0.000 description 2
- 102100030363 Prokineticin receptor 2 Human genes 0.000 description 2
- 102100034836 Proliferation marker protein Ki-67 Human genes 0.000 description 2
- 102100026126 Proline-tRNA ligase Human genes 0.000 description 2
- 102100027427 Proline/serine-rich coiled-coil protein 1 Human genes 0.000 description 2
- 102100038955 Proprotein convertase subtilisin/kexin type 9 Human genes 0.000 description 2
- 101710180553 Proprotein convertase subtilisin/kexin type 9 Proteins 0.000 description 2
- 102100026476 Prostacyclin receptor Human genes 0.000 description 2
- 102100033076 Prostaglandin E synthase Human genes 0.000 description 2
- 108090000748 Prostaglandin-E Synthases Proteins 0.000 description 2
- 102100033279 Prostaglandin-H2 D-isomerase Human genes 0.000 description 2
- 102100034664 Proteasome subunit alpha type-6 Human genes 0.000 description 2
- 102100022309 Protein KIBRA Human genes 0.000 description 2
- 102100030128 Protein L-Myc Human genes 0.000 description 2
- 102100029812 Protein S100-A12 Human genes 0.000 description 2
- 102100023089 Protein S100-A2 Human genes 0.000 description 2
- 102100032442 Protein S100-A8 Human genes 0.000 description 2
- 102100021487 Protein S100-B Human genes 0.000 description 2
- 102100029345 Protein TSSC4 Human genes 0.000 description 2
- 102100032702 Protein jagged-1 Human genes 0.000 description 2
- 102100037314 Protein kinase C gamma type Human genes 0.000 description 2
- 102000017332 Protein kinase C, delta Human genes 0.000 description 2
- 108050005326 Protein kinase C, delta Proteins 0.000 description 2
- 108010003894 Protein-Lysine 6-Oxidase Proteins 0.000 description 2
- 102100035731 Protein-arginine deiminase type-4 Human genes 0.000 description 2
- 102100026858 Protein-lysine 6-oxidase Human genes 0.000 description 2
- 102100037787 Protein-tyrosine kinase 2-beta Human genes 0.000 description 2
- 102100037132 Proteinase-activated receptor 2 Human genes 0.000 description 2
- 102100032350 Protransforming growth factor alpha Human genes 0.000 description 2
- 108010007127 Pulmonary Surfactant-Associated Protein D Proteins 0.000 description 2
- 102100027845 Pulmonary surfactant-associated protein D Human genes 0.000 description 2
- 102100031916 Putative endoplasmin-like protein Human genes 0.000 description 2
- 102100031269 Putative peripheral benzodiazepine receptor-related protein Human genes 0.000 description 2
- 102100026872 RNA-binding E3 ubiquitin-protein ligase MEX3C Human genes 0.000 description 2
- 102100034584 Rap guanine nucleotide exchange factor 3 Human genes 0.000 description 2
- 102100033243 Ras association domain-containing protein 1 Human genes 0.000 description 2
- 102100033240 Ras association domain-containing protein 4 Human genes 0.000 description 2
- 102100022122 Ras-related C3 botulinum toxin substrate 1 Human genes 0.000 description 2
- 102100022129 Ras-related C3 botulinum toxin substrate 2 Human genes 0.000 description 2
- 101100489893 Rattus norvegicus Abcg2 gene Proteins 0.000 description 2
- 101000823071 Rattus norvegicus Amyloid-beta precursor protein Proteins 0.000 description 2
- 108010045108 Receptor for Advanced Glycation End Products Proteins 0.000 description 2
- 102100029986 Receptor tyrosine-protein kinase erbB-3 Human genes 0.000 description 2
- 101710100969 Receptor tyrosine-protein kinase erbB-3 Proteins 0.000 description 2
- 102100029981 Receptor tyrosine-protein kinase erbB-4 Human genes 0.000 description 2
- 102100036266 Regulating synaptic membrane exocytosis protein 2 Human genes 0.000 description 2
- 102100021258 Regulator of G-protein signaling 2 Human genes 0.000 description 2
- 102100030814 Regulator of G-protein signaling 9 Human genes 0.000 description 2
- 102100029771 Remodeling and spacing factor 1 Human genes 0.000 description 2
- 101710201736 Remodeling and spacing factor 1 Proteins 0.000 description 2
- 102100027725 Renalase Human genes 0.000 description 2
- 102100024735 Resistin Human genes 0.000 description 2
- 108010047909 Resistin Proteins 0.000 description 2
- 102100029831 Reticulon-4 Human genes 0.000 description 2
- 102100023606 Retinoic acid receptor alpha Human genes 0.000 description 2
- 102100033909 Retinoic acid receptor beta Human genes 0.000 description 2
- 102100038246 Retinol-binding protein 4 Human genes 0.000 description 2
- 102100021433 Rho GTPase-activating protein 1 Human genes 0.000 description 2
- 101710116876 Rho GTPase-activating protein 1 Proteins 0.000 description 2
- 102100021446 Rho GTPase-activating protein 7 Human genes 0.000 description 2
- 102100027609 Rho-related GTP-binding protein RhoD Human genes 0.000 description 2
- 102100040756 Rhodopsin Human genes 0.000 description 2
- 108090000820 Rhodopsin Proteins 0.000 description 2
- 102100025373 Runt-related transcription factor 1 Human genes 0.000 description 2
- 102100026115 S-adenosylmethionine synthase isoform type-1 Human genes 0.000 description 2
- 102100032725 SET and MYND domain-containing protein 4 Human genes 0.000 description 2
- 102100022340 SHC-transforming protein 1 Human genes 0.000 description 2
- 102000037054 SLC-Transporter Human genes 0.000 description 2
- 108091006207 SLC-Transporter Proteins 0.000 description 2
- 108091006744 SLC22A1 Proteins 0.000 description 2
- 101700026522 SMAD7 Proteins 0.000 description 2
- 102000001332 SRC Human genes 0.000 description 2
- 108060006706 SRC Proteins 0.000 description 2
- 108010017324 STAT3 Transcription Factor Proteins 0.000 description 2
- 101100024116 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) MPT5 gene Proteins 0.000 description 2
- 101000995838 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) Nucleotide pyrophosphatase Proteins 0.000 description 2
- 102100037118 Scavenger receptor class B member 1 Human genes 0.000 description 2
- 102100037629 Serine/threonine-protein kinase 4 Human genes 0.000 description 2
- 102100025352 Serine/threonine-protein kinase MRCK alpha Human genes 0.000 description 2
- 102100032771 Serine/threonine-protein kinase SIK1 Human genes 0.000 description 2
- 101710083834 Serine/threonine-protein kinase SIK1 Proteins 0.000 description 2
- 102100029938 Serine/threonine-protein kinase SMG1 Human genes 0.000 description 2
- 102100026715 Serine/threonine-protein kinase STK11 Human genes 0.000 description 2
- 102100030333 Serpin B5 Human genes 0.000 description 2
- 102100032277 Serum amyloid A-1 protein Human genes 0.000 description 2
- 102100022824 Serum paraoxonase/arylesterase 2 Human genes 0.000 description 2
- 102100022833 Serum paraoxonase/lactonase 3 Human genes 0.000 description 2
- 102000034755 Sex Hormone-Binding Globulin Human genes 0.000 description 2
- 108010089417 Sex Hormone-Binding Globulin Proteins 0.000 description 2
- 102100023105 Sialin Human genes 0.000 description 2
- 101000873420 Simian virus 40 SV40 early leader protein Proteins 0.000 description 2
- 208000013738 Sleep Initiation and Maintenance disease Diseases 0.000 description 2
- 102100037442 Small conductance calcium-activated potassium channel protein 3 Human genes 0.000 description 2
- 102100032799 Smoothened homolog Human genes 0.000 description 2
- 101710090597 Smoothened homolog Proteins 0.000 description 2
- 102000018674 Sodium Channels Human genes 0.000 description 2
- 108010052164 Sodium Channels Proteins 0.000 description 2
- 102100027198 Sodium channel protein type 5 subunit alpha Human genes 0.000 description 2
- 102100031367 Sodium channel protein type 9 subunit alpha Human genes 0.000 description 2
- 108010087132 Sodium-Bicarbonate Symporters Proteins 0.000 description 2
- 102100027215 Sodium-coupled monocarboxylate transporter 1 Human genes 0.000 description 2
- 102100028874 Sodium-dependent serotonin transporter Human genes 0.000 description 2
- 102100035088 Sodium/calcium exchanger 1 Human genes 0.000 description 2
- 102100030980 Sodium/hydrogen exchanger 1 Human genes 0.000 description 2
- 102100021955 Sodium/potassium-transporting ATPase subunit alpha-2 Human genes 0.000 description 2
- 102100023536 Solute carrier family 2, facilitated glucose transporter member 1 Human genes 0.000 description 2
- 102100023102 Solute carrier family 22 member 18 Human genes 0.000 description 2
- 102100032417 Solute carrier family 22 member 2 Human genes 0.000 description 2
- 102000005157 Somatostatin Human genes 0.000 description 2
- 108010056088 Somatostatin Proteins 0.000 description 2
- 102100038803 Somatotropin Human genes 0.000 description 2
- 108050007673 Somatotropin Proteins 0.000 description 2
- 102100025639 Sortilin-related receptor Human genes 0.000 description 2
- 102100026263 Sphingomyelin phosphodiesterase Human genes 0.000 description 2
- 102100028897 Stearoyl-CoA desaturase Human genes 0.000 description 2
- 101710119798 Stearoyl-CoA desaturase 2 Proteins 0.000 description 2
- 102100027545 Steroid 21-hydroxylase Human genes 0.000 description 2
- 102000049867 Steroidogenic acute regulatory protein Human genes 0.000 description 2
- 108010018411 Steroidogenic acute regulatory protein Proteins 0.000 description 2
- 102100029856 Steroidogenic factor 1 Human genes 0.000 description 2
- 102100021993 Sterol O-acyltransferase 1 Human genes 0.000 description 2
- 102100022760 Stress-70 protein, mitochondrial Human genes 0.000 description 2
- 102100021669 Stromal cell-derived factor 1 Human genes 0.000 description 2
- 208000007271 Substance Withdrawal Syndrome Diseases 0.000 description 2
- 102100037346 Substance-P receptor Human genes 0.000 description 2
- 102100028996 Succinate dehydrogenase assembly factor 3, mitochondrial Human genes 0.000 description 2
- 102100034371 Sulfhydryl oxidase 1 Human genes 0.000 description 2
- 102100023983 Sulfotransferase 1A3 Human genes 0.000 description 2
- 108700027337 Suppressor of Cytokine Signaling 3 Proteins 0.000 description 2
- 102100024283 Suppressor of cytokine signaling 3 Human genes 0.000 description 2
- 108010016672 Syk Kinase Proteins 0.000 description 2
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 description 2
- 102100034107 TP53-binding protein 1 Human genes 0.000 description 2
- 108010017842 Telomerase Proteins 0.000 description 2
- 102100032938 Telomerase reverse transcriptase Human genes 0.000 description 2
- 102000007000 Tenascin Human genes 0.000 description 2
- 108010008125 Tenascin Proteins 0.000 description 2
- 101710100613 Tensin-1 Proteins 0.000 description 2
- 102100024545 Tensin-4 Human genes 0.000 description 2
- 102100034915 Tetraspanin-32 Human genes 0.000 description 2
- 108700031954 Tgfb1i1/Leupaxin/TGFB1I1 Proteins 0.000 description 2
- 102000002933 Thioredoxin Human genes 0.000 description 2
- 108010022394 Threonine synthase Proteins 0.000 description 2
- 102100026966 Thrombomodulin Human genes 0.000 description 2
- 108010079274 Thrombomodulin Proteins 0.000 description 2
- 102000036693 Thrombopoietin Human genes 0.000 description 2
- 108010041111 Thrombopoietin Proteins 0.000 description 2
- 102000002938 Thrombospondin Human genes 0.000 description 2
- 108060008245 Thrombospondin Proteins 0.000 description 2
- 108010046722 Thrombospondin 1 Proteins 0.000 description 2
- 102100036704 Thromboxane A2 receptor Human genes 0.000 description 2
- 108090000300 Thromboxane Receptors Proteins 0.000 description 2
- 102100030973 Thromboxane-A synthase Human genes 0.000 description 2
- 102100033523 Thy-1 membrane glycoprotein Human genes 0.000 description 2
- 102100031372 Thymidine phosphorylase Human genes 0.000 description 2
- 102100035000 Thymosin beta-4 Human genes 0.000 description 2
- 239000000627 Thyrotropin-Releasing Hormone Substances 0.000 description 2
- 102400000336 Thyrotropin-releasing hormone Human genes 0.000 description 2
- 101800004623 Thyrotropin-releasing hormone Proteins 0.000 description 2
- 102000003978 Tissue Plasminogen Activator Human genes 0.000 description 2
- 108090000373 Tissue Plasminogen Activator Proteins 0.000 description 2
- 102100030951 Tissue factor pathway inhibitor Human genes 0.000 description 2
- 108010060804 Toll-Like Receptor 4 Proteins 0.000 description 2
- 102000008228 Toll-like receptor 2 Human genes 0.000 description 2
- 108010060888 Toll-like receptor 2 Proteins 0.000 description 2
- 102100039360 Toll-like receptor 4 Human genes 0.000 description 2
- 101710105965 Trafficking protein particle complex subunit 10 Proteins 0.000 description 2
- 102100037456 Trafficking protein particle complex subunit 10 Human genes 0.000 description 2
- 108010048992 Transcription Factor 4 Proteins 0.000 description 2
- 102100031027 Transcription activator BRG1 Human genes 0.000 description 2
- 102100023489 Transcription factor 4 Human genes 0.000 description 2
- 102100035101 Transcription factor 7-like 2 Human genes 0.000 description 2
- 102100022972 Transcription factor AP-2-alpha Human genes 0.000 description 2
- 102100024026 Transcription factor E2F1 Human genes 0.000 description 2
- 102100021380 Transcription factor GATA-4 Human genes 0.000 description 2
- 102100030798 Transcription factor HES-1 Human genes 0.000 description 2
- 102100031080 Transcription termination factor 2 Human genes 0.000 description 2
- 102100024592 Transcriptional activator MN1 Human genes 0.000 description 2
- 102100031873 Transcriptional coactivator YAP1 Human genes 0.000 description 2
- 101710193680 Transcriptional coactivator YAP1 Proteins 0.000 description 2
- 102100026144 Transferrin receptor protein 1 Human genes 0.000 description 2
- 102000014172 Transforming Growth Factor-beta Type I Receptor Human genes 0.000 description 2
- 108010011702 Transforming Growth Factor-beta Type I Receptor Proteins 0.000 description 2
- 108010040625 Transforming Protein 1 Src Homology 2 Domain-Containing Proteins 0.000 description 2
- 102100022387 Transforming protein RhoA Human genes 0.000 description 2
- 102000014701 Transketolase Human genes 0.000 description 2
- 108010043652 Transketolase Proteins 0.000 description 2
- 102100029290 Transthyretin Human genes 0.000 description 2
- 108050009309 Tuberin Proteins 0.000 description 2
- 102000044633 Tuberous Sclerosis Complex 2 Human genes 0.000 description 2
- 102100024717 Tubulin beta chain Human genes 0.000 description 2
- 102000018252 Tumor Protein p73 Human genes 0.000 description 2
- 108010091356 Tumor Protein p73 Proteins 0.000 description 2
- 108700025716 Tumor Suppressor Genes Proteins 0.000 description 2
- 102000044209 Tumor Suppressor Genes Human genes 0.000 description 2
- 102100024596 Tumor necrosis factor alpha-induced protein 3 Human genes 0.000 description 2
- 102100024568 Tumor necrosis factor ligand superfamily member 11 Human genes 0.000 description 2
- 102100028787 Tumor necrosis factor receptor superfamily member 11A Human genes 0.000 description 2
- 102100033725 Tumor necrosis factor receptor superfamily member 16 Human genes 0.000 description 2
- 102100040245 Tumor necrosis factor receptor superfamily member 5 Human genes 0.000 description 2
- 102100040879 Tumor susceptibility gene 101 protein Human genes 0.000 description 2
- 102100029320 Twisted gastrulation protein homolog 1 Human genes 0.000 description 2
- 108010037581 Type 5 Cyclic Nucleotide Phosphodiesterases Proteins 0.000 description 2
- 108060008724 Tyrosinase Proteins 0.000 description 2
- 108091000117 Tyrosine 3-Monooxygenase Proteins 0.000 description 2
- 102000048218 Tyrosine 3-monooxygenases Human genes 0.000 description 2
- 102100029823 Tyrosine-protein kinase BTK Human genes 0.000 description 2
- 102100025387 Tyrosine-protein kinase JAK3 Human genes 0.000 description 2
- 102100038183 Tyrosine-protein kinase SYK Human genes 0.000 description 2
- 102100033019 Tyrosine-protein phosphatase non-receptor type 11 Human genes 0.000 description 2
- 102100033138 Tyrosine-protein phosphatase non-receptor type 22 Human genes 0.000 description 2
- 108010056354 Ubiquitin C Proteins 0.000 description 2
- 108010005656 Ubiquitin Thiolesterase Proteins 0.000 description 2
- 102100021013 Ubiquitin carboxyl-terminal hydrolase 7 Human genes 0.000 description 2
- 102100025038 Ubiquitin carboxyl-terminal hydrolase isozyme L1 Human genes 0.000 description 2
- 102100025040 Ubiquitin carboxyl-terminal hydrolase isozyme L3 Human genes 0.000 description 2
- 102100040105 Upstream stimulatory factor 1 Human genes 0.000 description 2
- 102100040103 Upstream stimulatory factor 2 Human genes 0.000 description 2
- 102000005630 Urocortins Human genes 0.000 description 2
- 108010059705 Urocortins Proteins 0.000 description 2
- 102000004504 Urokinase Plasminogen Activator Receptors Human genes 0.000 description 2
- 108010042352 Urokinase Plasminogen Activator Receptors Proteins 0.000 description 2
- 102100029097 Urotensin-2 Human genes 0.000 description 2
- 102000003848 Uteroglobin Human genes 0.000 description 2
- 108090000203 Uteroglobin Proteins 0.000 description 2
- 108010032099 V(D)J recombination activating protein 2 Proteins 0.000 description 2
- 108010000134 Vascular Cell Adhesion Molecule-1 Proteins 0.000 description 2
- 108010053099 Vascular Endothelial Growth Factor Receptor-2 Proteins 0.000 description 2
- 102100023543 Vascular cell adhesion protein 1 Human genes 0.000 description 2
- 102100038217 Vascular endothelial growth factor B Human genes 0.000 description 2
- 102100033178 Vascular endothelial growth factor receptor 1 Human genes 0.000 description 2
- 102100037187 Vasopressin V1a receptor Human genes 0.000 description 2
- 102100039066 Very low-density lipoprotein receptor Human genes 0.000 description 2
- 101710177612 Very low-density lipoprotein receptor Proteins 0.000 description 2
- 102100038039 Vesicular glutamate transporter 1 Human genes 0.000 description 2
- 102100038036 Vesicular glutamate transporter 2 Human genes 0.000 description 2
- 102000003970 Vinculin Human genes 0.000 description 2
- 108090000384 Vinculin Proteins 0.000 description 2
- 102100028885 Vitamin K-dependent protein S Human genes 0.000 description 2
- 102100035140 Vitronectin Human genes 0.000 description 2
- 108010031318 Vitronectin Proteins 0.000 description 2
- 108010022133 Voltage-Dependent Anion Channel 1 Proteins 0.000 description 2
- 102100037820 Voltage-dependent anion-selective channel protein 1 Human genes 0.000 description 2
- 102100023037 Wee1-like protein kinase Human genes 0.000 description 2
- 102000043366 Wnt-5a Human genes 0.000 description 2
- 108010091383 Xanthine dehydrogenase Proteins 0.000 description 2
- 102000005773 Xanthine dehydrogenase Human genes 0.000 description 2
- 108010093894 Xanthine oxidase Proteins 0.000 description 2
- 102100040801 Zinc finger FYVE domain-containing protein 9 Human genes 0.000 description 2
- 102100023406 Zinc finger RNA-binding protein Human genes 0.000 description 2
- 101710150392 Zinc finger RNA-binding protein Proteins 0.000 description 2
- 101710185494 Zinc finger protein Proteins 0.000 description 2
- 102100023597 Zinc finger protein 816 Human genes 0.000 description 2
- 102100035558 Zinc finger protein GLI2 Human genes 0.000 description 2
- 102100028959 Zinc finger protein ZPR1 Human genes 0.000 description 2
- 102100025446 Zinc transporter ZIP3 Human genes 0.000 description 2
- 230000035508 accumulation Effects 0.000 description 2
- 238000009825 accumulation Methods 0.000 description 2
- 239000002253 acid Substances 0.000 description 2
- 230000002378 acidificating effect Effects 0.000 description 2
- 108010066695 adenylate kinase 1 Proteins 0.000 description 2
- ULCUCJFASIJEOE-NPECTJMMSA-N adrenomedullin Chemical compound C([C@@H](C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)NCC(=O)N[C@@H]1C(N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)NCC(=O)N[C@H](C(=O)N[C@@H](CSSC1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(N)=O)[C@@H](C)O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=CC=C1 ULCUCJFASIJEOE-NPECTJMMSA-N 0.000 description 2
- 102000012005 alpha-2-HS-Glycoprotein Human genes 0.000 description 2
- 108010075843 alpha-2-HS-Glycoprotein Proteins 0.000 description 2
- 230000003321 amplification Effects 0.000 description 2
- 210000004102 animal cell Anatomy 0.000 description 2
- 230000006907 apoptotic process Effects 0.000 description 2
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 2
- 125000000637 arginyl group Chemical group N[C@@H](CCCNC(N)=N)C(=O)* 0.000 description 2
- 208000013404 behavioral symptom Diseases 0.000 description 2
- 102000015736 beta 2-Microglobulin Human genes 0.000 description 2
- 108010081355 beta 2-Microglobulin Proteins 0.000 description 2
- 102000000472 beta-Transducin Repeat-Containing Proteins Human genes 0.000 description 2
- 108010080842 beta-Transducin Repeat-Containing Proteins Proteins 0.000 description 2
- 238000010256 biochemical assay Methods 0.000 description 2
- 102100038953 cGMP-dependent 3',5'-cyclic phosphodiesterase Human genes 0.000 description 2
- 102100022422 cGMP-dependent protein kinase 1 Human genes 0.000 description 2
- 102100037094 cGMP-inhibited 3',5'-cyclic phosphodiesterase B Human genes 0.000 description 2
- 102100029175 cGMP-specific 3',5'-cyclic phosphodiesterase Human genes 0.000 description 2
- 108010044208 calpastatin Proteins 0.000 description 2
- ZXJCOYBPXOBJMU-HSQGJUDPSA-N calpastatin peptide Ac 184-210 Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(N)=O)NC(=O)[C@@H](NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@H](CCSC)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CC(O)=O)NC(C)=O)[C@@H](C)O)C1=CC=C(O)C=C1 ZXJCOYBPXOBJMU-HSQGJUDPSA-N 0.000 description 2
- 230000000711 cancerogenic effect Effects 0.000 description 2
- 231100000315 carcinogenic Toxicity 0.000 description 2
- 239000003183 carcinogenic agent Substances 0.000 description 2
- 108010051348 cdc42 GTP-Binding Protein Proteins 0.000 description 2
- AOXOCDRNSPFDPE-UKEONUMOSA-N chembl413654 Chemical compound C([C@H](C(=O)NCC(=O)N[C@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@H](CCSC)C(=O)N[C@H](CC(O)=O)C(=O)N[C@H](CC=1C=CC=CC=1)C(N)=O)NC(=O)[C@@H](C)NC(=O)[C@@H](CCC(O)=O)NC(=O)[C@@H](CCC(O)=O)NC(=O)[C@@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H]1N(CCC1)C(=O)CNC(=O)[C@@H](N)CCC(O)=O)C1=CC=C(O)C=C1 AOXOCDRNSPFDPE-UKEONUMOSA-N 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- 208000029664 classic familial adenomatous polyposis Diseases 0.000 description 2
- ZPUCINDJVBIVPJ-LJISPDSOSA-N cocaine Chemical compound O([C@H]1C[C@@H]2CC[C@@H](N2C)[C@H]1C(=O)OC)C(=O)C1=CC=CC=C1 ZPUCINDJVBIVPJ-LJISPDSOSA-N 0.000 description 2
- 208000010877 cognitive disease Diseases 0.000 description 2
- 229940041967 corticotropin-releasing hormone Drugs 0.000 description 2
- KLVRDXBAMSPYKH-RKYZNNDCSA-N corticotropin-releasing hormone (human) Chemical compound C([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)CC)C(N)=O)[C@@H](C)CC)NC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](C)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H]1N(CCC1)C(=O)[C@H]1N(CCC1)C(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CO)[C@@H](C)CC)C(C)C)C(C)C)C1=CNC=N1 KLVRDXBAMSPYKH-RKYZNNDCSA-N 0.000 description 2
- 235000018417 cysteine Nutrition 0.000 description 2
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 2
- 108010012154 cytokine inducible SH2-containing protein Proteins 0.000 description 2
- 230000006735 deficit Effects 0.000 description 2
- 108010014851 dendrin Proteins 0.000 description 2
- 210000005045 desmin Anatomy 0.000 description 2
- 229960003638 dopamine Drugs 0.000 description 2
- 229920002549 elastin Polymers 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 239000003623 enhancer Substances 0.000 description 2
- 230000006353 environmental stress Effects 0.000 description 2
- 229960001123 epoprostenol Drugs 0.000 description 2
- 229940105423 erythropoietin Drugs 0.000 description 2
- 108010046094 fatty-acid amide hydrolase Proteins 0.000 description 2
- 108010048325 fibrinopeptides gamma Proteins 0.000 description 2
- 238000002073 fluorescence micrograph Methods 0.000 description 2
- 102000037865 fusion proteins Human genes 0.000 description 2
- 108020001507 fusion proteins Proteins 0.000 description 2
- 108010084448 gamma Catenin Proteins 0.000 description 2
- 108010062699 gamma-Glutamyl Hydrolase Proteins 0.000 description 2
- 102000006640 gamma-Glutamyltransferase Human genes 0.000 description 2
- 239000000499 gel Substances 0.000 description 2
- MASNOZXLGMXCHN-ZLPAWPGGSA-N glucagon Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O)C(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC=1NC=NC=1)[C@@H](C)O)[C@@H](C)O)C1=CC=CC=C1 MASNOZXLGMXCHN-ZLPAWPGGSA-N 0.000 description 2
- 229960004666 glucagon Drugs 0.000 description 2
- 108010024847 glutamate decarboxylase 1 Proteins 0.000 description 2
- 108010024780 glutamate decarboxylase 2 Proteins 0.000 description 2
- 108010027853 glutathione S-transferase T1 Proteins 0.000 description 2
- 108010086596 glutathione peroxidase GPX1 Proteins 0.000 description 2
- 239000008187 granular material Substances 0.000 description 2
- 108010037536 heparanase Proteins 0.000 description 2
- 108091008634 hepatocyte nuclear factors 4 Proteins 0.000 description 2
- 238000001727 in vivo Methods 0.000 description 2
- 230000001939 inductive effect Effects 0.000 description 2
- 230000002401 inhibitory effect Effects 0.000 description 2
- 206010022437 insomnia Diseases 0.000 description 2
- 108010008598 insulin-like growth factor binding protein-related protein 1 Proteins 0.000 description 2
- 108010059517 integrin-linked kinase Proteins 0.000 description 2
- 229940117681 interleukin-12 Drugs 0.000 description 2
- 229940124829 interleukin-23 Drugs 0.000 description 2
- 229940096397 interleukin-8 Drugs 0.000 description 2
- XKTZWUACRZHVAN-VADRZIEHSA-N interleukin-8 Chemical compound C([C@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@@H](NC(C)=O)CCSC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCSC)C(=O)N1[C@H](CCC1)C(=O)N1[C@H](CCC1)C(=O)N[C@@H](C)C(=O)N[C@H](CC(O)=O)C(=O)N[C@H](CCC(O)=O)C(=O)N[C@H](CC(O)=O)C(=O)N[C@H](CC=1C=CC(O)=CC=1)C(=O)N[C@H](CO)C(=O)N1[C@H](CCC1)C(N)=O)C1=CC=CC=C1 XKTZWUACRZHVAN-VADRZIEHSA-N 0.000 description 2
- 238000002955 isolation Methods 0.000 description 2
- 108010019813 leptin receptors Proteins 0.000 description 2
- 108010087711 leukotriene-C4 synthase Proteins 0.000 description 2
- 238000001638 lipofection Methods 0.000 description 2
- 102000004311 liver X receptors Human genes 0.000 description 2
- 108090000865 liver X receptors Proteins 0.000 description 2
- 239000006166 lysate Substances 0.000 description 2
- 102100031622 mRNA decay activator protein ZFP36 Human genes 0.000 description 2
- 230000013011 mating Effects 0.000 description 2
- 239000011159 matrix material Substances 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 125000001360 methionine group Chemical group N[C@@H](CCSC)C(=O)* 0.000 description 2
- 108010038232 microsomal triglyceride transfer protein Proteins 0.000 description 2
- 102000035118 modified proteins Human genes 0.000 description 2
- 108091005573 modified proteins Proteins 0.000 description 2
- 238000012544 monitoring process Methods 0.000 description 2
- 210000000472 morula Anatomy 0.000 description 2
- 230000003551 muscarinic effect Effects 0.000 description 2
- 230000001537 neural effect Effects 0.000 description 2
- 230000004770 neurodegeneration Effects 0.000 description 2
- PCJGZPGTCUMMOT-ISULXFBGSA-N neurotensin Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]1NC(=O)CC1)C1=CC=C(O)C=C1 PCJGZPGTCUMMOT-ISULXFBGSA-N 0.000 description 2
- 108010020615 nociceptin receptor Proteins 0.000 description 2
- 230000037434 nonsense mutation Effects 0.000 description 2
- 238000003199 nucleic acid amplification method Methods 0.000 description 2
- 210000004940 nucleus Anatomy 0.000 description 2
- 238000005457 optimization Methods 0.000 description 2
- 210000000056 organ Anatomy 0.000 description 2
- 108700025694 p53 Genes Proteins 0.000 description 2
- 239000000199 parathyroid hormone Substances 0.000 description 2
- 229960001319 parathyroid hormone Drugs 0.000 description 2
- 230000001575 pathological effect Effects 0.000 description 2
- ACNHBCIZLNNLRS-UBGQALKQSA-N paxilline Chemical compound N1C2=CC=CC=C2C2=C1[C@]1(C)[C@@]3(C)CC[C@@H]4O[C@H](C(C)(O)C)C(=O)C=C4[C@]3(O)CC[C@H]1C2 ACNHBCIZLNNLRS-UBGQALKQSA-N 0.000 description 2
- 108030002458 peroxiredoxin Proteins 0.000 description 2
- 108091008765 peroxisome proliferator-activated receptors β/δ Proteins 0.000 description 2
- 229960000502 poloxamer Drugs 0.000 description 2
- 229920001983 poloxamer Polymers 0.000 description 2
- OXCMYAYHXIHQOA-UHFFFAOYSA-N potassium;[2-butyl-5-chloro-3-[[4-[2-(1,2,4-triaza-3-azanidacyclopenta-1,4-dien-5-yl)phenyl]phenyl]methyl]imidazol-4-yl]methanol Chemical compound [K+].CCCCC1=NC(Cl)=C(CO)N1CC1=CC=C(C=2C(=CC=CC=2)C2=N[N-]N=N2)C=C1 OXCMYAYHXIHQOA-UHFFFAOYSA-N 0.000 description 2
- 108010074732 preproenkephalin Proteins 0.000 description 2
- 108010067415 progelatinase Proteins 0.000 description 2
- 102000003998 progesterone receptors Human genes 0.000 description 2
- 108090000468 progesterone receptors Proteins 0.000 description 2
- 102000016670 prohibitin Human genes 0.000 description 2
- 108010028138 prohibitin Proteins 0.000 description 2
- KAQKFAOMNZTLHT-OZUDYXHBSA-N prostaglandin I2 Chemical compound O1\C(=C/CCCC(O)=O)C[C@@H]2[C@@H](/C=C/[C@@H](O)CCCCC)[C@H](O)C[C@@H]21 KAQKFAOMNZTLHT-OZUDYXHBSA-N 0.000 description 2
- XNSAINXGIQZQOO-SRVKXCTJSA-N protirelin Chemical compound NC(=O)[C@@H]1CCCN1C(=O)[C@@H](NC(=O)[C@H]1NC(=O)CC1)CC1=CN=CN1 XNSAINXGIQZQOO-SRVKXCTJSA-N 0.000 description 2
- 238000010188 recombinant method Methods 0.000 description 2
- 108010064950 regulator of g-protein signaling 9 Proteins 0.000 description 2
- 239000003488 releasing hormone Substances 0.000 description 2
- 238000003757 reverse transcription PCR Methods 0.000 description 2
- 238000012216 screening Methods 0.000 description 2
- NHXLMOGPVYXJNR-ATOGVRKGSA-N somatostatin Chemical compound C([C@H]1C(=O)N[C@H](C(N[C@@H](CO)C(=O)N[C@@H](CSSC[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@@H](CC=2C3=CC=CC=C3NC=2)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(=O)N1)[C@@H](C)O)NC(=O)CNC(=O)[C@H](C)N)C(O)=O)=O)[C@H](O)C)C1=CC=CC=C1 NHXLMOGPVYXJNR-ATOGVRKGSA-N 0.000 description 2
- 229960000553 somatostatin Drugs 0.000 description 2
- 108010016093 sterol O-acyltransferase 1 Proteins 0.000 description 2
- 238000006467 substitution reaction Methods 0.000 description 2
- 230000009182 swimming Effects 0.000 description 2
- 108010057210 telomerase RNA Proteins 0.000 description 2
- WWJZWCUNLNYYAU-UHFFFAOYSA-N temephos Chemical compound C1=CC(OP(=S)(OC)OC)=CC=C1SC1=CC=C(OP(=S)(OC)OC)C=C1 WWJZWCUNLNYYAU-UHFFFAOYSA-N 0.000 description 2
- 230000002123 temporal effect Effects 0.000 description 2
- 229940124597 therapeutic agent Drugs 0.000 description 2
- 238000002560 therapeutic procedure Methods 0.000 description 2
- 108060008226 thioredoxin Proteins 0.000 description 2
- 229940094937 thioredoxin Drugs 0.000 description 2
- 229940034199 thyrotropin-releasing hormone Drugs 0.000 description 2
- 230000035897 transcription Effects 0.000 description 2
- 238000013518 transcription Methods 0.000 description 2
- 238000011282 treatment Methods 0.000 description 2
- 201000007906 type 1 diabetes mellitus 2 Diseases 0.000 description 2
- 239000000777 urocortin Substances 0.000 description 2
- 239000003981 vehicle Substances 0.000 description 2
- 239000013603 viral vector Substances 0.000 description 2
- 108010047303 von Willebrand Factor Proteins 0.000 description 2
- 102100036537 von Willebrand factor Human genes 0.000 description 2
- 229960001134 von willebrand factor Drugs 0.000 description 2
- 108020001612 μ-opioid receptors Proteins 0.000 description 2
- SNICXCGAKADSCV-JTQLQIEISA-N (-)-Nicotine Chemical compound CN1CCC[C@H]1C1=CC=CN=C1 SNICXCGAKADSCV-JTQLQIEISA-N 0.000 description 1
- KWTSXDURSIMDCE-QMMMGPOBSA-N (S)-amphetamine Chemical compound C[C@H](N)CC1=CC=CC=C1 KWTSXDURSIMDCE-QMMMGPOBSA-N 0.000 description 1
- 102100031236 11-beta-hydroxysteroid dehydrogenase type 2 Human genes 0.000 description 1
- SVUOLADPCWQTTE-UHFFFAOYSA-N 1h-1,2-benzodiazepine Chemical compound N1N=CC=CC2=CC=CC=C12 SVUOLADPCWQTTE-UHFFFAOYSA-N 0.000 description 1
- VWFJDQUYCIWHTN-YFVJMOTDSA-N 2-trans,6-trans-farnesyl diphosphate Chemical compound CC(C)=CCC\C(C)=C\CC\C(C)=C\CO[P@](O)(=O)OP(O)(O)=O VWFJDQUYCIWHTN-YFVJMOTDSA-N 0.000 description 1
- 102100036659 26S proteasome non-ATPase regulatory subunit 9 Human genes 0.000 description 1
- 102100034254 3-oxo-5-alpha-steroid 4-dehydrogenase 1 Human genes 0.000 description 1
- LKDMKWNDBAVNQZ-UHFFFAOYSA-N 4-[[1-[[1-[2-[[1-(4-nitroanilino)-1-oxo-3-phenylpropan-2-yl]carbamoyl]pyrrolidin-1-yl]-1-oxopropan-2-yl]amino]-1-oxopropan-2-yl]amino]-4-oxobutanoic acid Chemical compound OC(=O)CCC(=O)NC(C)C(=O)NC(C)C(=O)N1CCCC1C(=O)NC(C(=O)NC=1C=CC(=CC=1)[N+]([O-])=O)CC1=CC=CC=C1 LKDMKWNDBAVNQZ-UHFFFAOYSA-N 0.000 description 1
- 101710138638 5-hydroxytryptamine receptor 1A Proteins 0.000 description 1
- 101710138091 5-hydroxytryptamine receptor 2A Proteins 0.000 description 1
- 101710138027 5-hydroxytryptamine receptor 3A Proteins 0.000 description 1
- 102100027123 55 kDa erythrocyte membrane protein Human genes 0.000 description 1
- 102000017304 72kDa type IV collagenases Human genes 0.000 description 1
- 108050005269 72kDa type IV collagenases Proteins 0.000 description 1
- BSFODEXXVBBYOC-UHFFFAOYSA-N 8-[4-(dimethylamino)butan-2-ylamino]quinolin-6-ol Chemical compound C1=CN=C2C(NC(CCN(C)C)C)=CC(O)=CC2=C1 BSFODEXXVBBYOC-UHFFFAOYSA-N 0.000 description 1
- 102100037991 85/88 kDa calcium-independent phospholipase A2 Human genes 0.000 description 1
- 102100032290 A disintegrin and metalloproteinase with thrombospondin motifs 13 Human genes 0.000 description 1
- 101150092476 ABCA1 gene Proteins 0.000 description 1
- 102000029791 ADAM Human genes 0.000 description 1
- 108091022885 ADAM Proteins 0.000 description 1
- 108091007505 ADAM17 Proteins 0.000 description 1
- 108091005670 ADAMTS13 Proteins 0.000 description 1
- 101710184468 AF4/FMR2 family member 2 Proteins 0.000 description 1
- 101150005096 AKR1 gene Proteins 0.000 description 1
- 101150054149 ANGPTL4 gene Proteins 0.000 description 1
- 101150063992 APOC2 gene Proteins 0.000 description 1
- 101150111620 AQP1 gene Proteins 0.000 description 1
- 108010088547 ARNTL Transcription Factors Proteins 0.000 description 1
- 108700005241 ATP Binding Cassette Transporter 1 Proteins 0.000 description 1
- 102000005416 ATP-Binding Cassette Transporters Human genes 0.000 description 1
- 108010006533 ATP-Binding Cassette Transporters Proteins 0.000 description 1
- 102100027447 ATP-dependent DNA helicase Q1 Human genes 0.000 description 1
- 102100032814 ATP-dependent zinc metalloprotease YME1L1 Human genes 0.000 description 1
- 102100021177 ATP-sensitive inward rectifier potassium channel 11 Human genes 0.000 description 1
- 108091006112 ATPases Proteins 0.000 description 1
- 206010000117 Abnormal behaviour Diseases 0.000 description 1
- 102100035785 Acyl-CoA-binding protein Human genes 0.000 description 1
- 101710106492 Acyl-CoA-binding protein Proteins 0.000 description 1
- 108090001079 Adenine Nucleotide Translocator 1 Proteins 0.000 description 1
- 102000057290 Adenosine Triphosphatases Human genes 0.000 description 1
- 102100022455 Adrenocorticotropic hormone receptor Human genes 0.000 description 1
- 101150029691 Aff2 gene Proteins 0.000 description 1
- 201000011374 Alagille syndrome Diseases 0.000 description 1
- 102100036475 Alanine aminotransferase 1 Human genes 0.000 description 1
- 108010021809 Alcohol dehydrogenase Proteins 0.000 description 1
- 102000007698 Alcohol dehydrogenase Human genes 0.000 description 1
- 102000005369 Aldehyde Dehydrogenase Human genes 0.000 description 1
- 108020002663 Aldehyde Dehydrogenase Proteins 0.000 description 1
- 102100040069 Aldehyde dehydrogenase 1A1 Human genes 0.000 description 1
- 102100039074 Aldehyde dehydrogenase X, mitochondrial Human genes 0.000 description 1
- 102100033816 Aldehyde dehydrogenase, mitochondrial Human genes 0.000 description 1
- 102100027265 Aldo-keto reductase family 1 member B1 Human genes 0.000 description 1
- 102100034044 All-trans-retinol dehydrogenase [NAD(+)] ADH1B Human genes 0.000 description 1
- 102100031795 All-trans-retinol dehydrogenase [NAD(+)] ADH4 Human genes 0.000 description 1
- 108700028369 Alleles Proteins 0.000 description 1
- 108010016119 Alpha-Ketoglutarate-Dependent Dioxygenase FTO Proteins 0.000 description 1
- 102100034561 Alpha-N-acetylglucosaminidase Human genes 0.000 description 1
- 102100024085 Alpha-aminoadipic semialdehyde dehydrogenase Human genes 0.000 description 1
- 208000026833 Alzheimer disease 4 Diseases 0.000 description 1
- 108010028700 Amine Oxidase (Copper-Containing) Proteins 0.000 description 1
- 102000016893 Amine Oxidase (Copper-Containing) Human genes 0.000 description 1
- 108010048154 Angiopoietin-1 Proteins 0.000 description 1
- 108010048036 Angiopoietin-2 Proteins 0.000 description 1
- 108700042530 Angiopoietin-Like Protein 4 Proteins 0.000 description 1
- 101710185050 Angiotensin-converting enzyme Proteins 0.000 description 1
- 108090001067 Angiotensinogen Proteins 0.000 description 1
- 101100379125 Anguilla japonica npr2 gene Proteins 0.000 description 1
- 102100039182 Ankyrin repeat and protein kinase domain-containing protein 1 Human genes 0.000 description 1
- 108010049777 Ankyrins Proteins 0.000 description 1
- 102000008102 Ankyrins Human genes 0.000 description 1
- 102100030942 Apolipoprotein A-II Human genes 0.000 description 1
- 102100039998 Apolipoprotein C-II Human genes 0.000 description 1
- 108010056301 Apolipoprotein C-III Proteins 0.000 description 1
- 102000030169 Apolipoprotein C-III Human genes 0.000 description 1
- 102100030970 Apolipoprotein C-III Human genes 0.000 description 1
- 102000018619 Apolipoproteins A Human genes 0.000 description 1
- 108010027004 Apolipoproteins A Proteins 0.000 description 1
- 108010012927 Apoprotein(a) Proteins 0.000 description 1
- 102100021569 Apoptosis regulator Bcl-2 Human genes 0.000 description 1
- 101100181122 Arabidopsis thaliana KIN14C gene Proteins 0.000 description 1
- 101100234530 Arabidopsis thaliana KIN14M gene Proteins 0.000 description 1
- 101100234532 Arabidopsis thaliana KIN14N gene Proteins 0.000 description 1
- 101100288145 Arabidopsis thaliana KNAT2 gene Proteins 0.000 description 1
- 108010076676 Arachidonate 12-lipoxygenase Proteins 0.000 description 1
- 108010093579 Arachidonate 5-lipoxygenase Proteins 0.000 description 1
- 206010003591 Ataxia Diseases 0.000 description 1
- 102100035029 Ataxin-1 Human genes 0.000 description 1
- 102000007372 Ataxin-1 Human genes 0.000 description 1
- 201000001320 Atherosclerosis Diseases 0.000 description 1
- 101150076489 B gene Proteins 0.000 description 1
- 101150035467 BDNF gene Proteins 0.000 description 1
- 101000588395 Bacillus subtilis (strain 168) Beta-hexosaminidase Proteins 0.000 description 1
- 102000012304 Bestrophin Human genes 0.000 description 1
- 108050002823 Bestrophin Proteins 0.000 description 1
- 108050003623 Bestrophin-1 Proteins 0.000 description 1
- 102100022794 Bestrophin-1 Human genes 0.000 description 1
- 102100030686 Beta-sarcoglycan Human genes 0.000 description 1
- 108010088623 Betaine-Homocysteine S-Methyltransferase Proteins 0.000 description 1
- 102000001893 Bone Morphogenetic Protein Receptors Human genes 0.000 description 1
- 108010040422 Bone Morphogenetic Protein Receptors Proteins 0.000 description 1
- 102100025422 Bone morphogenetic protein receptor type-2 Human genes 0.000 description 1
- 101100283975 Bos taurus GSTM1 gene Proteins 0.000 description 1
- 101710149815 C-C chemokine receptor type 2 Proteins 0.000 description 1
- 102100035875 C-C chemokine receptor type 5 Human genes 0.000 description 1
- 102100036845 C-C motif chemokine 22 Human genes 0.000 description 1
- 102100031092 C-C motif chemokine 3 Human genes 0.000 description 1
- 102100031102 C-C motif chemokine 4 Human genes 0.000 description 1
- 101150052909 CCL2 gene Proteins 0.000 description 1
- 108700012434 CCL3 Proteins 0.000 description 1
- 108010017009 CD11b Antigen Proteins 0.000 description 1
- 102000049320 CD36 Human genes 0.000 description 1
- 101150013553 CD40 gene Proteins 0.000 description 1
- 108010062802 CD66 antigens Proteins 0.000 description 1
- 101150039781 CLU gene Proteins 0.000 description 1
- 108010070033 COP9 Signalosome Complex Proteins 0.000 description 1
- 101150083464 CP gene Proteins 0.000 description 1
- 108010040163 CREB-Binding Protein Proteins 0.000 description 1
- 108010021064 CTLA-4 Antigen Proteins 0.000 description 1
- 101150085973 CTSD gene Proteins 0.000 description 1
- 101150062345 CX3CR1 gene Proteins 0.000 description 1
- 102000000905 Cadherin Human genes 0.000 description 1
- 108050007957 Cadherin Proteins 0.000 description 1
- 101100180602 Caenorhabditis elegans csnk-1 gene Proteins 0.000 description 1
- 101100497948 Caenorhabditis elegans cyn-1 gene Proteins 0.000 description 1
- 101710111871 Calcineurin-binding protein 1 Proteins 0.000 description 1
- 108700010390 Calcitonin Receptor-Like Proteins 0.000 description 1
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 1
- 108090000451 Calpain-10 Proteins 0.000 description 1
- 101710099825 Calpain-5 Proteins 0.000 description 1
- 101001110283 Canis lupus familiaris Ras-related C3 botulinum toxin substrate 1 Proteins 0.000 description 1
- 102000014914 Carrier Proteins Human genes 0.000 description 1
- 102100037398 Casein kinase I isoform epsilon Human genes 0.000 description 1
- 108090000425 Caspase 6 Proteins 0.000 description 1
- 108090000567 Caspase 7 Proteins 0.000 description 1
- 102100035904 Caspase-1 Human genes 0.000 description 1
- 108090000426 Caspase-1 Proteins 0.000 description 1
- 102000004066 Caspase-12 Human genes 0.000 description 1
- 108090000570 Caspase-12 Proteins 0.000 description 1
- 102100032616 Caspase-2 Human genes 0.000 description 1
- 108090000552 Caspase-2 Proteins 0.000 description 1
- 102100025597 Caspase-4 Human genes 0.000 description 1
- 101710090338 Caspase-4 Proteins 0.000 description 1
- 102100038918 Caspase-6 Human genes 0.000 description 1
- 102100038902 Caspase-7 Human genes 0.000 description 1
- 108090000538 Caspase-8 Proteins 0.000 description 1
- 102100026550 Caspase-9 Human genes 0.000 description 1
- 108090000566 Caspase-9 Proteins 0.000 description 1
- 102000016362 Catenins Human genes 0.000 description 1
- 108010067316 Catenins Proteins 0.000 description 1
- 108090000611 Cathepsin E Proteins 0.000 description 1
- 108090000617 Cathepsin G Proteins 0.000 description 1
- 108090000625 Cathepsin K Proteins 0.000 description 1
- 108090000613 Cathepsin S Proteins 0.000 description 1
- 101710084071 Centromere protein N Proteins 0.000 description 1
- 108010082548 Chemokine CCL11 Proteins 0.000 description 1
- 108010066813 Chitinase-3-Like Protein 1 Proteins 0.000 description 1
- 108010058699 Choline O-acetyltransferase Proteins 0.000 description 1
- 208000005590 Choroidal Neovascularization Diseases 0.000 description 1
- 206010060823 Choroidal neovascularisation Diseases 0.000 description 1
- 108010038439 Chromogranin B Proteins 0.000 description 1
- 102100031186 Chromogranin-A Human genes 0.000 description 1
- 208000017667 Chronic Disease Diseases 0.000 description 1
- 108090000600 Claudin-1 Proteins 0.000 description 1
- 102000003780 Clusterin Human genes 0.000 description 1
- 108090000197 Clusterin Proteins 0.000 description 1
- 102100022641 Coagulation factor IX Human genes 0.000 description 1
- 102100023804 Coagulation factor VII Human genes 0.000 description 1
- 102100026735 Coagulation factor VIII Human genes 0.000 description 1
- 102100029117 Coagulation factor X Human genes 0.000 description 1
- 102100030556 Coagulation factor XII Human genes 0.000 description 1
- 108010048623 Collagen Receptors Proteins 0.000 description 1
- 102100033772 Complement C4-A Human genes 0.000 description 1
- 102100033777 Complement C4-B Human genes 0.000 description 1
- 102100030886 Complement receptor type 1 Human genes 0.000 description 1
- 102100027826 Complexin-1 Human genes 0.000 description 1
- 206010010219 Compulsions Diseases 0.000 description 1
- 102000010970 Connexin Human genes 0.000 description 1
- 108050001175 Connexin Proteins 0.000 description 1
- 108010022637 Copper-Transporting ATPases Proteins 0.000 description 1
- 108010079362 Core Binding Factor Alpha 3 Subunit Proteins 0.000 description 1
- 102400000739 Corticotropin Human genes 0.000 description 1
- 101800000414 Corticotropin Proteins 0.000 description 1
- 101150091887 Ctla4 gene Proteins 0.000 description 1
- 102100023580 Cyclic AMP-dependent transcription factor ATF-4 Human genes 0.000 description 1
- 108010017222 Cyclin-Dependent Kinase Inhibitor p57 Proteins 0.000 description 1
- 102000004480 Cyclin-Dependent Kinase Inhibitor p57 Human genes 0.000 description 1
- 102100032857 Cyclin-dependent kinase 1 Human genes 0.000 description 1
- 102100033233 Cyclin-dependent kinase inhibitor 1B Human genes 0.000 description 1
- 102100033269 Cyclin-dependent kinase inhibitor 1C Human genes 0.000 description 1
- 108010037464 Cyclooxygenase 1 Proteins 0.000 description 1
- 108010037462 Cyclooxygenase 2 Proteins 0.000 description 1
- 102100034976 Cystathionine beta-synthase Human genes 0.000 description 1
- 108010073644 Cystathionine beta-synthase Proteins 0.000 description 1
- 108010061642 Cystatin C Proteins 0.000 description 1
- 108010074922 Cytochrome P-450 CYP1A2 Proteins 0.000 description 1
- 108010077090 Cytochrome P-450 CYP1B1 Proteins 0.000 description 1
- 102100024329 Cytochrome P450 11B2, mitochondrial Human genes 0.000 description 1
- 102100027417 Cytochrome P450 1B1 Human genes 0.000 description 1
- 102100039208 Cytochrome P450 3A5 Human genes 0.000 description 1
- 102000013816 Cytotoxic T-lymphocyte antigen 4 Human genes 0.000 description 1
- WQZGKKKJIJFFOK-QTVWNMPRSA-N D-mannopyranose Chemical compound OC[C@H]1OC(O)[C@@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-QTVWNMPRSA-N 0.000 description 1
- 230000005778 DNA damage Effects 0.000 description 1
- 231100000277 DNA damage Toxicity 0.000 description 1
- 102000005768 DNA-Activated Protein Kinase Human genes 0.000 description 1
- 108010006124 DNA-Activated Protein Kinase Proteins 0.000 description 1
- 101100193633 Danio rerio rag2 gene Proteins 0.000 description 1
- 206010012289 Dementia Diseases 0.000 description 1
- 108010008532 Deoxyribonuclease I Proteins 0.000 description 1
- 102000007260 Deoxyribonuclease I Human genes 0.000 description 1
- 108010039287 Diazepam Binding Inhibitor Proteins 0.000 description 1
- 102100030074 Dickkopf-related protein 1 Human genes 0.000 description 1
- 102100022273 Disrupted in schizophrenia 1 protein Human genes 0.000 description 1
- 101710118116 Disrupted in schizophrenia 1 protein Proteins 0.000 description 1
- 108010030483 Dynamin III Proteins 0.000 description 1
- 108090000620 Dysferlin Proteins 0.000 description 1
- 208000012661 Dyskinesia Diseases 0.000 description 1
- 108010069091 Dystrophin Proteins 0.000 description 1
- 102000012199 E3 ubiquitin-protein ligase Mdm2 Human genes 0.000 description 1
- 108050002772 E3 ubiquitin-protein ligase Mdm2 Proteins 0.000 description 1
- 102100032257 E3 ubiquitin-protein ligase Mdm2 Human genes 0.000 description 1
- 102100039793 E3 ubiquitin-protein ligase RAG1 Human genes 0.000 description 1
- 101710162560 E3 ubiquitin-protein ligase RNF123 Proteins 0.000 description 1
- 101710162545 E3 ubiquitin-protein ligase RNF139 Proteins 0.000 description 1
- 102100038591 Endothelial cell-selective adhesion molecule Human genes 0.000 description 1
- 102100030024 Endothelial protein C receptor Human genes 0.000 description 1
- 102400000686 Endothelin-1 Human genes 0.000 description 1
- 101800004490 Endothelin-1 Proteins 0.000 description 1
- 108090000387 Endothelin-2 Proteins 0.000 description 1
- 102000003965 Endothelin-2 Human genes 0.000 description 1
- 102100029110 Endothelin-2 Human genes 0.000 description 1
- 108010072844 Endothelin-3 Proteins 0.000 description 1
- 108010092674 Enkephalins Proteins 0.000 description 1
- 102100021469 Equilibrative nucleoside transporter 1 Human genes 0.000 description 1
- 102000044591 ErbB-4 Receptor Human genes 0.000 description 1
- 108010075944 Erythropoietin Receptors Proteins 0.000 description 1
- 102100036509 Erythropoietin receptor Human genes 0.000 description 1
- 108090000371 Esterases Proteins 0.000 description 1
- 108010041356 Estrogen Receptor beta Proteins 0.000 description 1
- 102100031563 Excitatory amino acid transporter 1 Human genes 0.000 description 1
- 102100031562 Excitatory amino acid transporter 2 Human genes 0.000 description 1
- 108060002716 Exonuclease Proteins 0.000 description 1
- 101150107205 FCGR2 gene Proteins 0.000 description 1
- 101150061264 FXR1 gene Proteins 0.000 description 1
- 108010076282 Factor IX Proteins 0.000 description 1
- 108010014172 Factor V Proteins 0.000 description 1
- 108010014173 Factor X Proteins 0.000 description 1
- VWFJDQUYCIWHTN-FBXUGWQNSA-N Farnesyl diphosphate Natural products CC(C)=CCC\C(C)=C/CC\C(C)=C/COP(O)(=O)OP(O)(O)=O VWFJDQUYCIWHTN-FBXUGWQNSA-N 0.000 description 1
- 108010007508 Farnesyltranstransferase Proteins 0.000 description 1
- 102000007317 Farnesyltranstransferase Human genes 0.000 description 1
- 108050003772 Fatty acid-binding protein 4 Proteins 0.000 description 1
- 241000282324 Felis Species 0.000 description 1
- 108010030229 Fibrillin-1 Proteins 0.000 description 1
- 102100028043 Fibroblast growth factor 3 Human genes 0.000 description 1
- 108090000378 Fibroblast growth factor 3 Proteins 0.000 description 1
- 102000003969 Fibroblast growth factor 4 Human genes 0.000 description 1
- 108090000381 Fibroblast growth factor 4 Proteins 0.000 description 1
- 102000003967 Fibroblast growth factor 5 Human genes 0.000 description 1
- 108090000380 Fibroblast growth factor 5 Proteins 0.000 description 1
- 101710170731 Fibulin-1 Proteins 0.000 description 1
- 108010009307 Forkhead Box Protein O3 Proteins 0.000 description 1
- 102100035421 Forkhead box protein O3 Human genes 0.000 description 1
- 102100036334 Fragile X mental retardation syndrome-related protein 1 Human genes 0.000 description 1
- 102100036336 Fragile X mental retardation syndrome-related protein 2 Human genes 0.000 description 1
- 201000011240 Frontotemporal dementia Diseases 0.000 description 1
- 108010038179 G-protein beta3 subunit Proteins 0.000 description 1
- 102220621888 G-protein coupled estrogen receptor 1_L18Q_mutation Human genes 0.000 description 1
- 102000017691 GABRA6 Human genes 0.000 description 1
- 102000017707 GABRB3 Human genes 0.000 description 1
- 102000017705 GABRE Human genes 0.000 description 1
- 102100027346 GTP cyclohydrolase 1 Human genes 0.000 description 1
- 101710094136 GTP cyclohydrolase 1 Proteins 0.000 description 1
- 102400001370 Galanin Human genes 0.000 description 1
- 101800002068 Galanin Proteins 0.000 description 1
- 208000001613 Gambling Diseases 0.000 description 1
- 102100040864 Gamma-aminobutyric acid receptor subunit alpha-2 Human genes 0.000 description 1
- 102100040868 Gamma-aminobutyric acid receptor subunit alpha-3 Human genes 0.000 description 1
- 102100040866 Gamma-aminobutyric acid receptor subunit alpha-4 Human genes 0.000 description 1
- 102100035681 Gamma-aminobutyric acid receptor subunit alpha-6 Human genes 0.000 description 1
- 102100035939 Gamma-aminobutyric acid receptor subunit epsilon Human genes 0.000 description 1
- 102100035938 Gamma-aminobutyric acid receptor subunit gamma-1 Human genes 0.000 description 1
- 102100028260 Gamma-secretase subunit PEN-2 Human genes 0.000 description 1
- 101800001586 Ghrelin Proteins 0.000 description 1
- 102100033299 Glia-derived nexin Human genes 0.000 description 1
- 108010086246 Glucagon-Like Peptide-1 Receptor Proteins 0.000 description 1
- 102100032882 Glucagon-like peptide 1 receptor Human genes 0.000 description 1
- 102100036534 Glutathione S-transferase Mu 1 Human genes 0.000 description 1
- 101710153770 Glutathione S-transferase Mu 1 Proteins 0.000 description 1
- 102100033366 Glutathione hydrolase 1 proenzyme Human genes 0.000 description 1
- 101710205562 Glutathione hydrolase 1 proenzyme Proteins 0.000 description 1
- 102100022975 Glycogen synthase kinase-3 alpha Human genes 0.000 description 1
- 102000010956 Glypican Human genes 0.000 description 1
- 108050001154 Glypican Proteins 0.000 description 1
- 108050007237 Glypican-3 Proteins 0.000 description 1
- 102100032530 Glypican-3 Human genes 0.000 description 1
- 102100039620 Granulocyte-macrophage colony-stimulating factor Human genes 0.000 description 1
- 108091008113 H19 Proteins 0.000 description 1
- 101710081050 HLA class II histocompatibility antigen, DR beta 5 chain Proteins 0.000 description 1
- 102100040485 HLA class II histocompatibility antigen, DRB1 beta chain Human genes 0.000 description 1
- 108010075704 HLA-A Antigens Proteins 0.000 description 1
- 108010039343 HLA-DRB1 Chains Proteins 0.000 description 1
- 108010016996 HLA-DRB5 Chains Proteins 0.000 description 1
- 102000014702 Haptoglobin Human genes 0.000 description 1
- 108050005077 Haptoglobin Proteins 0.000 description 1
- 206010019280 Heart failures Diseases 0.000 description 1
- 102100034051 Heat shock protein HSP 90-alpha Human genes 0.000 description 1
- 101710100504 Heat shock protein beta-1 Proteins 0.000 description 1
- 208000018565 Hemochromatosis Diseases 0.000 description 1
- 102000003745 Hepatocyte Growth Factor Human genes 0.000 description 1
- GVGLGOZIDCSQPN-PVHGPHFFSA-N Heroin Chemical compound O([C@H]1[C@H](C=C[C@H]23)OC(C)=O)C4=C5[C@@]12CCN(C)[C@@H]3CC5=CC=C4OC(C)=O GVGLGOZIDCSQPN-PVHGPHFFSA-N 0.000 description 1
- 102100029237 Hexokinase-4 Human genes 0.000 description 1
- 102100027619 Histidine-rich glycoprotein Human genes 0.000 description 1
- 108091016366 Histone-lysine N-methyltransferase EHMT1 Proteins 0.000 description 1
- 101000845090 Homo sapiens 11-beta-hydroxysteroid dehydrogenase type 2 Proteins 0.000 description 1
- 101001136710 Homo sapiens 26S proteasome non-ATPase regulatory subunit 9 Proteins 0.000 description 1
- 101000822895 Homo sapiens 5-hydroxytryptamine receptor 1A Proteins 0.000 description 1
- 101000783617 Homo sapiens 5-hydroxytryptamine receptor 2A Proteins 0.000 description 1
- 101000761343 Homo sapiens 5-hydroxytryptamine receptor 3A Proteins 0.000 description 1
- 101000796932 Homo sapiens ADP/ATP translocase 1 Proteins 0.000 description 1
- 101000833172 Homo sapiens AF4/FMR2 family member 2 Proteins 0.000 description 1
- 101000800387 Homo sapiens ATP-binding cassette sub-family G member 5 Proteins 0.000 description 1
- 101000800430 Homo sapiens ATP-binding cassette sub-family G member 8 Proteins 0.000 description 1
- 101000580659 Homo sapiens ATP-dependent DNA helicase Q1 Proteins 0.000 description 1
- 101000708560 Homo sapiens ATP-dependent zinc metalloprotease YME1L1 Proteins 0.000 description 1
- 101000756632 Homo sapiens Actin, cytoplasmic 1 Proteins 0.000 description 1
- 101000678419 Homo sapiens Adrenocorticotropic hormone receptor Proteins 0.000 description 1
- 101000928460 Homo sapiens Alanine aminotransferase 1 Proteins 0.000 description 1
- 101000959038 Homo sapiens Aldehyde dehydrogenase X, mitochondrial Proteins 0.000 description 1
- 101000836540 Homo sapiens Aldo-keto reductase family 1 member B1 Proteins 0.000 description 1
- 101000688194 Homo sapiens Alkaline phosphatase, placental type Proteins 0.000 description 1
- 101000780453 Homo sapiens All-trans-retinol dehydrogenase [NAD(+)] ADH1B Proteins 0.000 description 1
- 101000775437 Homo sapiens All-trans-retinol dehydrogenase [NAD(+)] ADH4 Proteins 0.000 description 1
- 101000690235 Homo sapiens Alpha-aminoadipic semialdehyde dehydrogenase Proteins 0.000 description 1
- 101000924727 Homo sapiens Alternative prion protein Proteins 0.000 description 1
- 101000924552 Homo sapiens Angiopoietin-1 Proteins 0.000 description 1
- 101000924533 Homo sapiens Angiopoietin-2 Proteins 0.000 description 1
- 101000693076 Homo sapiens Angiopoietin-related protein 4 Proteins 0.000 description 1
- 101000732617 Homo sapiens Angiotensinogen Proteins 0.000 description 1
- 101000889403 Homo sapiens Ankyrin repeat and protein kinase domain-containing protein 1 Proteins 0.000 description 1
- 101000652582 Homo sapiens Antigen peptide transporter 2 Proteins 0.000 description 1
- 101000793406 Homo sapiens Apolipoprotein A-II Proteins 0.000 description 1
- 101000806793 Homo sapiens Apolipoprotein A-IV Proteins 0.000 description 1
- 101000793223 Homo sapiens Apolipoprotein C-III Proteins 0.000 description 1
- 101000889990 Homo sapiens Apolipoprotein(a) Proteins 0.000 description 1
- 101000971171 Homo sapiens Apoptosis regulator Bcl-2 Proteins 0.000 description 1
- 101000997570 Homo sapiens Appetite-regulating hormone Proteins 0.000 description 1
- 101000740484 Homo sapiens Aryl hydrocarbon receptor nuclear translocator-like protein 1 Proteins 0.000 description 1
- 101000961040 Homo sapiens Atrial natriuretic peptide receptor 2 Proteins 0.000 description 1
- 101000903449 Homo sapiens Bestrophin-1 Proteins 0.000 description 1
- 101000703495 Homo sapiens Beta-sarcoglycan Proteins 0.000 description 1
- 101000933413 Homo sapiens Betaine-homocysteine S-methyltransferase 1 Proteins 0.000 description 1
- 101000934635 Homo sapiens Bone morphogenetic protein receptor type-2 Proteins 0.000 description 1
- 101000934870 Homo sapiens Breast cancer type 1 susceptibility protein Proteins 0.000 description 1
- 101000823298 Homo sapiens Broad substrate specificity ATP-binding cassette transporter ABCG2 Proteins 0.000 description 1
- 101000777599 Homo sapiens C-C chemokine receptor type 2 Proteins 0.000 description 1
- 101000946926 Homo sapiens C-C chemokine receptor type 5 Proteins 0.000 description 1
- 101000713083 Homo sapiens C-C motif chemokine 22 Proteins 0.000 description 1
- 101000777471 Homo sapiens C-C motif chemokine 4 Proteins 0.000 description 1
- 101000896987 Homo sapiens CREB-binding protein Proteins 0.000 description 1
- 101000984015 Homo sapiens Cadherin-1 Proteins 0.000 description 1
- 101000910452 Homo sapiens Calcineurin-binding protein cabin-1 Proteins 0.000 description 1
- 101000741445 Homo sapiens Calcitonin Proteins 0.000 description 1
- 101000932890 Homo sapiens Calcitonin gene-related peptide 1 Proteins 0.000 description 1
- 101000760563 Homo sapiens Calcitonin gene-related peptide type 1 receptor Proteins 0.000 description 1
- 101000984149 Homo sapiens Calpain-10 Proteins 0.000 description 1
- 101000793666 Homo sapiens Calpain-5 Proteins 0.000 description 1
- 101000710899 Homo sapiens Cannabinoid receptor 1 Proteins 0.000 description 1
- 101000981093 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 1 Proteins 0.000 description 1
- 101000916283 Homo sapiens Cardiotrophin-1 Proteins 0.000 description 1
- 101001026376 Homo sapiens Casein kinase I isoform epsilon Proteins 0.000 description 1
- 101000793880 Homo sapiens Caspase-3 Proteins 0.000 description 1
- 101000869031 Homo sapiens Cathepsin E Proteins 0.000 description 1
- 101000933179 Homo sapiens Cathepsin G Proteins 0.000 description 1
- 101000761509 Homo sapiens Cathepsin K Proteins 0.000 description 1
- 101000776412 Homo sapiens Centromere protein N Proteins 0.000 description 1
- 101000883515 Homo sapiens Chitinase-3-like protein 1 Proteins 0.000 description 1
- 101000993094 Homo sapiens Chromogranin-A Proteins 0.000 description 1
- 101000749331 Homo sapiens Claudin-1 Proteins 0.000 description 1
- 101001027836 Homo sapiens Coagulation factor V Proteins 0.000 description 1
- 101001049020 Homo sapiens Coagulation factor VII Proteins 0.000 description 1
- 101000911390 Homo sapiens Coagulation factor VIII Proteins 0.000 description 1
- 101001062763 Homo sapiens Coagulation factor XII Proteins 0.000 description 1
- 101000945357 Homo sapiens Collagen alpha-1(I) chain Proteins 0.000 description 1
- 101000577887 Homo sapiens Collagenase 3 Proteins 0.000 description 1
- 101000710884 Homo sapiens Complement C4-A Proteins 0.000 description 1
- 101000727061 Homo sapiens Complement receptor type 1 Proteins 0.000 description 1
- 101000859600 Homo sapiens Complexin-1 Proteins 0.000 description 1
- 101000936277 Homo sapiens Copper-transporting ATPase 1 Proteins 0.000 description 1
- 101000974934 Homo sapiens Cyclic AMP-dependent transcription factor ATF-2 Proteins 0.000 description 1
- 101000944380 Homo sapiens Cyclin-dependent kinase inhibitor 1 Proteins 0.000 description 1
- 101000944361 Homo sapiens Cyclin-dependent kinase inhibitor 1B Proteins 0.000 description 1
- 101000944365 Homo sapiens Cyclin-dependent kinase inhibitor 1C Proteins 0.000 description 1
- 101000912205 Homo sapiens Cystatin-C Proteins 0.000 description 1
- 101000761956 Homo sapiens Cytochrome P450 11B2, mitochondrial Proteins 0.000 description 1
- 101000855342 Homo sapiens Cytochrome P450 1A2 Proteins 0.000 description 1
- 101000745710 Homo sapiens Cytochrome P450 3A5 Proteins 0.000 description 1
- 101000864646 Homo sapiens Dickkopf-related protein 1 Proteins 0.000 description 1
- 101000777461 Homo sapiens Disintegrin and metalloproteinase domain-containing protein 17 Proteins 0.000 description 1
- 101000817599 Homo sapiens Dynamin-3 Proteins 0.000 description 1
- 101001015963 Homo sapiens E3 ubiquitin-protein ligase Mdm2 Proteins 0.000 description 1
- 101000744443 Homo sapiens E3 ubiquitin-protein ligase RAG1 Proteins 0.000 description 1
- 101000711573 Homo sapiens E3 ubiquitin-protein ligase RNF123 Proteins 0.000 description 1
- 101000619542 Homo sapiens E3 ubiquitin-protein ligase parkin Proteins 0.000 description 1
- 101000882622 Homo sapiens Endothelial cell-selective adhesion molecule Proteins 0.000 description 1
- 101001012038 Homo sapiens Endothelial protein C receptor Proteins 0.000 description 1
- 101000841197 Homo sapiens Endothelin-2 Proteins 0.000 description 1
- 101000841213 Homo sapiens Endothelin-3 Proteins 0.000 description 1
- 101000978392 Homo sapiens Eotaxin Proteins 0.000 description 1
- 101001010910 Homo sapiens Estrogen receptor beta Proteins 0.000 description 1
- 101000866287 Homo sapiens Excitatory amino acid transporter 2 Proteins 0.000 description 1
- 101100067102 Homo sapiens FOXN1 gene Proteins 0.000 description 1
- 101100335685 Homo sapiens FXR2 gene Proteins 0.000 description 1
- 101000846893 Homo sapiens Fibrillin-1 Proteins 0.000 description 1
- 101001065276 Homo sapiens Fibulin-1 Proteins 0.000 description 1
- 101000930945 Homo sapiens Fragile X mental retardation syndrome-related protein 1 Proteins 0.000 description 1
- 101000930952 Homo sapiens Fragile X mental retardation syndrome-related protein 2 Proteins 0.000 description 1
- 101000893333 Homo sapiens Gamma-aminobutyric acid receptor subunit alpha-2 Proteins 0.000 description 1
- 101000893321 Homo sapiens Gamma-aminobutyric acid receptor subunit alpha-3 Proteins 0.000 description 1
- 101000893324 Homo sapiens Gamma-aminobutyric acid receptor subunit alpha-4 Proteins 0.000 description 1
- 101001073597 Homo sapiens Gamma-aminobutyric acid receptor subunit beta-3 Proteins 0.000 description 1
- 101001073577 Homo sapiens Gamma-aminobutyric acid receptor subunit gamma-1 Proteins 0.000 description 1
- 101000579663 Homo sapiens Gamma-secretase subunit PEN-2 Proteins 0.000 description 1
- 101000889125 Homo sapiens Gap junction beta-6 protein Proteins 0.000 description 1
- 101000997803 Homo sapiens Glia-derived nexin Proteins 0.000 description 1
- 101000893424 Homo sapiens Glucokinase regulatory protein Proteins 0.000 description 1
- 101000903717 Homo sapiens Glycogen synthase kinase-3 alpha Proteins 0.000 description 1
- 101001014668 Homo sapiens Glypican-3 Proteins 0.000 description 1
- 101000746367 Homo sapiens Granulocyte colony-stimulating factor Proteins 0.000 description 1
- 101000746373 Homo sapiens Granulocyte-macrophage colony-stimulating factor Proteins 0.000 description 1
- 101001024245 Homo sapiens Guanine nucleotide-binding protein G(I)/G(S)/G(T) subunit beta-3 Proteins 0.000 description 1
- 101000990566 Homo sapiens HEAT repeat-containing protein 6 Proteins 0.000 description 1
- 101000986086 Homo sapiens HLA class I histocompatibility antigen, A alpha chain Proteins 0.000 description 1
- 101001016865 Homo sapiens Heat shock protein HSP 90-alpha Proteins 0.000 description 1
- 101001036709 Homo sapiens Heat shock protein beta-1 Proteins 0.000 description 1
- 101000840558 Homo sapiens Hexokinase-4 Proteins 0.000 description 1
- 101000962526 Homo sapiens Hyaluronidase-2 Proteins 0.000 description 1
- 101001041128 Homo sapiens Hyaluronidase-3 Proteins 0.000 description 1
- 101001056180 Homo sapiens Induced myeloid leukemia cell differentiation protein Mcl-1 Proteins 0.000 description 1
- 101001046686 Homo sapiens Integrin alpha-M Proteins 0.000 description 1
- 101000935040 Homo sapiens Integrin beta-2 Proteins 0.000 description 1
- 101001002634 Homo sapiens Interleukin-1 alpha Proteins 0.000 description 1
- 101001076407 Homo sapiens Interleukin-1 receptor antagonist protein Proteins 0.000 description 1
- 101000853009 Homo sapiens Interleukin-24 Proteins 0.000 description 1
- 101000998139 Homo sapiens Interleukin-32 Proteins 0.000 description 1
- 101000960969 Homo sapiens Interleukin-5 Proteins 0.000 description 1
- 101000614436 Homo sapiens Keratin, type I cytoskeletal 14 Proteins 0.000 description 1
- 101000998020 Homo sapiens Keratin, type I cytoskeletal 18 Proteins 0.000 description 1
- 101001046960 Homo sapiens Keratin, type II cytoskeletal 1 Proteins 0.000 description 1
- 101001091590 Homo sapiens Kininogen-1 Proteins 0.000 description 1
- 101000716729 Homo sapiens Kit ligand Proteins 0.000 description 1
- 101001014223 Homo sapiens MAPK/MAK/MRK overlapping kinase Proteins 0.000 description 1
- 101000573901 Homo sapiens Major prion protein Proteins 0.000 description 1
- 101000962483 Homo sapiens Max dimerization protein 1 Proteins 0.000 description 1
- 101000581402 Homo sapiens Melanin-concentrating hormone receptor 1 Proteins 0.000 description 1
- 101000694615 Homo sapiens Membrane primary amine oxidase Proteins 0.000 description 1
- 101001033726 Homo sapiens Methyl-CpG-binding protein 2 Proteins 0.000 description 1
- 101000587058 Homo sapiens Methylenetetrahydrofolate reductase Proteins 0.000 description 1
- 101000747587 Homo sapiens Mitochondrial uncoupling protein 2 Proteins 0.000 description 1
- 101001059982 Homo sapiens Mitogen-activated protein kinase kinase kinase kinase 5 Proteins 0.000 description 1
- 101000896657 Homo sapiens Mitotic checkpoint serine/threonine-protein kinase BUB1 Proteins 0.000 description 1
- 101000794228 Homo sapiens Mitotic checkpoint serine/threonine-protein kinase BUB1 beta Proteins 0.000 description 1
- 101001012646 Homo sapiens Monoglyceride lipase Proteins 0.000 description 1
- 101001000104 Homo sapiens Myosin-11 Proteins 0.000 description 1
- 101000654472 Homo sapiens NAD-dependent protein deacetylase sirtuin-1 Proteins 0.000 description 1
- 101001128156 Homo sapiens Nanos homolog 3 Proteins 0.000 description 1
- 101000969961 Homo sapiens Neurexin-3 Proteins 0.000 description 1
- 101000969963 Homo sapiens Neurexin-3-beta Proteins 0.000 description 1
- 101000577199 Homo sapiens Neurogenic locus notch homolog protein 2 Proteins 0.000 description 1
- 101000974009 Homo sapiens Nitric oxide synthase, brain Proteins 0.000 description 1
- 101000711744 Homo sapiens Non-secretory ribonuclease Proteins 0.000 description 1
- 101001109698 Homo sapiens Nuclear receptor subfamily 4 group A member 2 Proteins 0.000 description 1
- 101000979629 Homo sapiens Nucleoside diphosphate kinase A Proteins 0.000 description 1
- 101000873418 Homo sapiens P-selectin glycoprotein ligand 1 Proteins 0.000 description 1
- 101001120086 Homo sapiens P2Y purinoceptor 12 Proteins 0.000 description 1
- 101100246021 Homo sapiens PTPN22 gene Proteins 0.000 description 1
- 101000601724 Homo sapiens Paired box protein Pax-5 Proteins 0.000 description 1
- 101000735484 Homo sapiens Paired box protein Pax-9 Proteins 0.000 description 1
- 101001090065 Homo sapiens Peroxiredoxin-2 Proteins 0.000 description 1
- 101000619805 Homo sapiens Peroxiredoxin-5, mitochondrial Proteins 0.000 description 1
- 101001123331 Homo sapiens Peroxisome proliferator-activated receptor gamma coactivator 1-alpha Proteins 0.000 description 1
- 101000583474 Homo sapiens Phosphatidylinositol-binding clathrin assembly protein Proteins 0.000 description 1
- 101000983161 Homo sapiens Phospholipase A2, membrane associated Proteins 0.000 description 1
- 101001073422 Homo sapiens Pigment epithelium-derived factor Proteins 0.000 description 1
- 101001091365 Homo sapiens Plasma kallikrein Proteins 0.000 description 1
- 101000777658 Homo sapiens Platelet glycoprotein 4 Proteins 0.000 description 1
- 101000611951 Homo sapiens Platelet-derived growth factor subunit B Proteins 0.000 description 1
- 101001113440 Homo sapiens Poly [ADP-ribose] polymerase 2 Proteins 0.000 description 1
- 101000620009 Homo sapiens Polyunsaturated fatty acid 5-lipoxygenase Proteins 0.000 description 1
- 101001064864 Homo sapiens Polyunsaturated fatty acid lipoxygenase ALOX12 Proteins 0.000 description 1
- 101001064853 Homo sapiens Polyunsaturated fatty acid lipoxygenase ALOX15 Proteins 0.000 description 1
- 101000578474 Homo sapiens Polyunsaturated fatty acid lipoxygenase ALOX15B Proteins 0.000 description 1
- 101001126582 Homo sapiens Post-GPI attachment to proteins factor 3 Proteins 0.000 description 1
- 101001026226 Homo sapiens Potassium voltage-gated channel subfamily KQT member 1 Proteins 0.000 description 1
- 101001003584 Homo sapiens Prelamin-A/C Proteins 0.000 description 1
- 101000617536 Homo sapiens Presenilin-1 Proteins 0.000 description 1
- 101000617546 Homo sapiens Presenilin-2 Proteins 0.000 description 1
- 101000583209 Homo sapiens Prokineticin receptor 2 Proteins 0.000 description 1
- 101000692650 Homo sapiens Prostacyclin receptor Proteins 0.000 description 1
- 101001135385 Homo sapiens Prostacyclin synthase Proteins 0.000 description 1
- 101000685726 Homo sapiens Protein S100-A2 Proteins 0.000 description 1
- 101000821885 Homo sapiens Protein S100-B Proteins 0.000 description 1
- 101000994437 Homo sapiens Protein jagged-1 Proteins 0.000 description 1
- 101000613615 Homo sapiens Protein mono-ADP-ribosyltransferase PARP14 Proteins 0.000 description 1
- 101000845206 Homo sapiens Putative peripheral benzodiazepine receptor-related protein Proteins 0.000 description 1
- 101000798015 Homo sapiens RAC-beta serine/threonine-protein kinase Proteins 0.000 description 1
- 101000798007 Homo sapiens RAC-gamma serine/threonine-protein kinase Proteins 0.000 description 1
- 101000629826 Homo sapiens RNA-binding E3 ubiquitin-protein ligase MEX3C Proteins 0.000 description 1
- 101000708222 Homo sapiens Ras and Rab interactor 2 Proteins 0.000 description 1
- 101001110286 Homo sapiens Ras-related C3 botulinum toxin substrate 1 Proteins 0.000 description 1
- 101001110313 Homo sapiens Ras-related C3 botulinum toxin substrate 2 Proteins 0.000 description 1
- 101000738769 Homo sapiens Receptor-type tyrosine-protein phosphatase alpha Proteins 0.000 description 1
- 101000727472 Homo sapiens Reticulon-4 Proteins 0.000 description 1
- 101000637699 Homo sapiens Ryanodine receptor 1 Proteins 0.000 description 1
- 101000709370 Homo sapiens S-phase kinase-associated protein 2 Proteins 0.000 description 1
- 101000716809 Homo sapiens Secretogranin-1 Proteins 0.000 description 1
- 101001059454 Homo sapiens Serine/threonine-protein kinase MARK2 Proteins 0.000 description 1
- 101000605835 Homo sapiens Serine/threonine-protein kinase PINK1, mitochondrial Proteins 0.000 description 1
- 101000701928 Homo sapiens Serpin B5 Proteins 0.000 description 1
- 101001094647 Homo sapiens Serum paraoxonase/arylesterase 1 Proteins 0.000 description 1
- 101000621061 Homo sapiens Serum paraoxonase/arylesterase 2 Proteins 0.000 description 1
- 101000685690 Homo sapiens Sialin Proteins 0.000 description 1
- 101000651893 Homo sapiens Slit homolog 3 protein Proteins 0.000 description 1
- 101000694017 Homo sapiens Sodium channel protein type 5 subunit alpha Proteins 0.000 description 1
- 101000693900 Homo sapiens Sodium-coupled monocarboxylate transporter 1 Proteins 0.000 description 1
- 101001023149 Homo sapiens Sodium/calcium exchanger 1 Proteins 0.000 description 1
- 101000702479 Homo sapiens Sodium/hydrogen exchanger 1 Proteins 0.000 description 1
- 101000906283 Homo sapiens Solute carrier family 2, facilitated glucose transporter member 1 Proteins 0.000 description 1
- 101000685678 Homo sapiens Solute carrier family 22 member 18 Proteins 0.000 description 1
- 101000869716 Homo sapiens Solute carrier family 22 member 2 Proteins 0.000 description 1
- 101000713288 Homo sapiens Solute carrier family 22 member 5 Proteins 0.000 description 1
- 101000878981 Homo sapiens Squalene synthase Proteins 0.000 description 1
- 101000903318 Homo sapiens Stress-70 protein, mitochondrial Proteins 0.000 description 1
- 101000826390 Homo sapiens Sulfotransferase 1A3 Proteins 0.000 description 1
- 101000706156 Homo sapiens Syntaxin-11 Proteins 0.000 description 1
- 101000713602 Homo sapiens T-box transcription factor TBX21 Proteins 0.000 description 1
- 101100260031 Homo sapiens TBX21 gene Proteins 0.000 description 1
- 101000626155 Homo sapiens Tensin-4 Proteins 0.000 description 1
- 101000658608 Homo sapiens Tetraspanin-32 Proteins 0.000 description 1
- 101000809797 Homo sapiens Thymidylate synthase Proteins 0.000 description 1
- 101000635804 Homo sapiens Tissue factor Proteins 0.000 description 1
- 101000653189 Homo sapiens Tissue factor pathway inhibitor Proteins 0.000 description 1
- 101000757378 Homo sapiens Transcription factor AP-2-alpha Proteins 0.000 description 1
- 101000843556 Homo sapiens Transcription factor HES-1 Proteins 0.000 description 1
- 101000636213 Homo sapiens Transcriptional activator Myb Proteins 0.000 description 1
- 101000845233 Homo sapiens Translocator protein Proteins 0.000 description 1
- 101000766332 Homo sapiens Tribbles homolog 1 Proteins 0.000 description 1
- 101000830742 Homo sapiens Tryptophan 5-hydroxylase 1 Proteins 0.000 description 1
- 101000851865 Homo sapiens Tryptophan 5-hydroxylase 2 Proteins 0.000 description 1
- 101000788517 Homo sapiens Tubulin beta-2A chain Proteins 0.000 description 1
- 101000611185 Homo sapiens Tumor necrosis factor receptor superfamily member 5 Proteins 0.000 description 1
- 101000606090 Homo sapiens Tyrosinase Proteins 0.000 description 1
- 101000643908 Homo sapiens Ubiquitin carboxyl-terminal hydrolase 7 Proteins 0.000 description 1
- 101000841325 Homo sapiens Urotensin-2 Proteins 0.000 description 1
- 101000777301 Homo sapiens Uteroglobin Proteins 0.000 description 1
- 101000742579 Homo sapiens Vascular endothelial growth factor B Proteins 0.000 description 1
- 101000805515 Homo sapiens Vesicular glutamate transporter 1 Proteins 0.000 description 1
- 101000805528 Homo sapiens Vesicular glutamate transporter 2 Proteins 0.000 description 1
- 101001125402 Homo sapiens Vitamin K-dependent protein C Proteins 0.000 description 1
- 101000577630 Homo sapiens Vitamin K-dependent protein S Proteins 0.000 description 1
- 101000867811 Homo sapiens Voltage-dependent L-type calcium channel subunit alpha-1C Proteins 0.000 description 1
- 101000964713 Homo sapiens Zinc finger protein 395 Proteins 0.000 description 1
- 101001074035 Homo sapiens Zinc finger protein GLI2 Proteins 0.000 description 1
- 101000915742 Homo sapiens Zinc finger protein ZPR1 Proteins 0.000 description 1
- 101000693468 Homo sapiens Zinc transporter ZIP3 Proteins 0.000 description 1
- 101001046426 Homo sapiens cGMP-dependent protein kinase 1 Proteins 0.000 description 1
- 206010020400 Hostility Diseases 0.000 description 1
- 101710199674 Hyaluronidase-2 Proteins 0.000 description 1
- 108050004076 Hyaluronidase-3 Proteins 0.000 description 1
- 208000006083 Hypokinesia Diseases 0.000 description 1
- 108010091358 Hypoxanthine Phosphoribosyltransferase Proteins 0.000 description 1
- 102100029098 Hypoxanthine-guanine phosphoribosyltransferase Human genes 0.000 description 1
- 101150106931 IFNG gene Proteins 0.000 description 1
- 101150088952 IGF1 gene Proteins 0.000 description 1
- 108010073807 IgG Receptors Proteins 0.000 description 1
- 102000009490 IgG Receptors Human genes 0.000 description 1
- 101150002416 Igf2 gene Proteins 0.000 description 1
- 206010061598 Immunodeficiency Diseases 0.000 description 1
- 208000029462 Immunodeficiency disease Diseases 0.000 description 1
- 102100034061 Inactive glutathione hydrolase 2 Human genes 0.000 description 1
- 101710092346 Inactive glutathione hydrolase 2 Proteins 0.000 description 1
- 102100026539 Induced myeloid leukemia cell differentiation protein Mcl-1 Human genes 0.000 description 1
- 101000668058 Infectious salmon anemia virus (isolate Atlantic salmon/Norway/810/9/99) RNA-directed RNA polymerase catalytic subunit Proteins 0.000 description 1
- 108090001117 Insulin-Like Growth Factor II Proteins 0.000 description 1
- 102000000507 Integrin alpha2 Human genes 0.000 description 1
- 108010042918 Integrin alpha5beta1 Proteins 0.000 description 1
- 102000014150 Interferons Human genes 0.000 description 1
- 108010050904 Interferons Proteins 0.000 description 1
- 229940119178 Interleukin 1 receptor antagonist Drugs 0.000 description 1
- 102000051628 Interleukin-1 receptor antagonist Human genes 0.000 description 1
- 101710194995 Interleukin-12 subunit alpha Proteins 0.000 description 1
- 101710187487 Interleukin-12 subunit beta Proteins 0.000 description 1
- 101710181615 Interleukin-32 Proteins 0.000 description 1
- 108010002616 Interleukin-5 Proteins 0.000 description 1
- 206010022998 Irritability Diseases 0.000 description 1
- 101150113031 Jag1 gene Proteins 0.000 description 1
- 108700003486 Jagged-1 Proteins 0.000 description 1
- 108010040082 Junctional Adhesion Molecule A Proteins 0.000 description 1
- 102000017792 KCNJ11 Human genes 0.000 description 1
- 108010011185 KCNQ1 Potassium Channel Proteins 0.000 description 1
- 108010070514 Keratin-1 Proteins 0.000 description 1
- 108010066321 Keratin-14 Proteins 0.000 description 1
- 108010066327 Keratin-18 Proteins 0.000 description 1
- 108050007394 Kinesin-like protein KIF20B Proteins 0.000 description 1
- 101710111227 Kininogen-1 Proteins 0.000 description 1
- PWOLHTNHGNWQMH-UHFFFAOYSA-N LGPVTQE Natural products CC(C)CC(N)C(=O)NCC(=O)N1CCCC1C(=O)NC(C(C)C)C(=O)NC(C(C)O)C(=O)NC(CCC(N)=O)C(=O)NC(CCC(O)=O)C(O)=O PWOLHTNHGNWQMH-UHFFFAOYSA-N 0.000 description 1
- 108010047294 Lamins Proteins 0.000 description 1
- 229930186657 Lat Natural products 0.000 description 1
- URLZCHNOLZSCCA-VABKMULXSA-N Leu-enkephalin Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)CNC(=O)CNC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=CC=C1 URLZCHNOLZSCCA-VABKMULXSA-N 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- 108010033266 Lipoprotein(a) Proteins 0.000 description 1
- 206010048911 Lissencephaly Diseases 0.000 description 1
- 208000035752 Live birth Diseases 0.000 description 1
- 206010025323 Lymphomas Diseases 0.000 description 1
- 102100031520 MAPK/MAK/MRK overlapping kinase Human genes 0.000 description 1
- 101150070547 MAPT gene Proteins 0.000 description 1
- 101150031456 MDGA2 gene Proteins 0.000 description 1
- 101150083522 MECP2 gene Proteins 0.000 description 1
- 108091008065 MIR21 Proteins 0.000 description 1
- 108010048043 Macrophage Migration-Inhibitory Factors Proteins 0.000 description 1
- 101710119980 Macrophage migration inhibitory factor Proteins 0.000 description 1
- 108700018351 Major Histocompatibility Complex Proteins 0.000 description 1
- 101710091439 Major capsid protein 1 Proteins 0.000 description 1
- 208000007466 Male Infertility Diseases 0.000 description 1
- 108010016113 Matrix Metalloproteinase 1 Proteins 0.000 description 1
- 108010076503 Matrix Metalloproteinase 13 Proteins 0.000 description 1
- 102100039185 Max dimerization protein 1 Human genes 0.000 description 1
- 102100027375 Melanin-concentrating hormone receptor 1 Human genes 0.000 description 1
- 108090000950 Melanocortin Receptors Proteins 0.000 description 1
- 102000004378 Melanocortin Receptors Human genes 0.000 description 1
- 108010090306 Member 2 Subfamily G ATP Binding Cassette Transporter Proteins 0.000 description 1
- 108010090837 Member 5 Subfamily G ATP Binding Cassette Transporter Proteins 0.000 description 1
- 108010090822 Member 8 Subfamily G ATP Binding Cassette Transporter Proteins 0.000 description 1
- 101710132836 Membrane primary amine oxidase Proteins 0.000 description 1
- 108050006600 Metalloproteinase inhibitor 3 Proteins 0.000 description 1
- 206010027476 Metastases Diseases 0.000 description 1
- 101710163328 Methionine synthase Proteins 0.000 description 1
- 102100029684 Methylenetetrahydrofolate reductase Human genes 0.000 description 1
- 108010059724 Micrococcal Nuclease Proteins 0.000 description 1
- 108091062154 Mir-205 Proteins 0.000 description 1
- 102100028195 Mitogen-activated protein kinase kinase kinase kinase 5 Human genes 0.000 description 1
- 102100021691 Mitotic checkpoint serine/threonine-protein kinase BUB1 Human genes 0.000 description 1
- 102100030144 Mitotic checkpoint serine/threonine-protein kinase BUB1 beta Human genes 0.000 description 1
- 102100038828 Mitotic spindle assembly checkpoint protein MAD1 Human genes 0.000 description 1
- 108020002334 Monoacylglycerol lipase Proteins 0.000 description 1
- 206010027951 Mood swings Diseases 0.000 description 1
- 108010086093 Mung Bean Nuclease Proteins 0.000 description 1
- 101000590284 Mus musculus 26S proteasome non-ATPase regulatory subunit 14 Proteins 0.000 description 1
- 101000715673 Mus musculus Cadherin EGF LAG seven-pass G-type receptor 2 Proteins 0.000 description 1
- 101100456965 Mus musculus Mex3c gene Proteins 0.000 description 1
- 101100409157 Mus musculus Prl2c2 gene Proteins 0.000 description 1
- 101100193635 Mus musculus Rag2 gene Proteins 0.000 description 1
- 101100365003 Mus musculus Scel gene Proteins 0.000 description 1
- 208000002740 Muscle Rigidity Diseases 0.000 description 1
- 206010028347 Muscle twitching Diseases 0.000 description 1
- 108700006140 Myeloid Cell Leukemia Sequence 1 Proteins 0.000 description 1
- 102000046234 Myeloid Cell Leukemia Sequence 1 Human genes 0.000 description 1
- 102000036675 Myoglobin Human genes 0.000 description 1
- 108010062374 Myoglobin Proteins 0.000 description 1
- 102000003505 Myosin Human genes 0.000 description 1
- 108060008487 Myosin Proteins 0.000 description 1
- 102100036639 Myosin-11 Human genes 0.000 description 1
- 108010008868 NAV1.5 Voltage-Gated Sodium Channel Proteins 0.000 description 1
- 102100028719 NEDD8-activating enzyme E1 catalytic subunit Human genes 0.000 description 1
- 108700037255 NEDD8-activating enzyme E1 catalytic subunit Proteins 0.000 description 1
- 108010071382 NF-E2-Related Factor 2 Proteins 0.000 description 1
- 108010081372 NM23 Nucleoside Diphosphate Kinases Proteins 0.000 description 1
- 102000005238 NM23 Nucleoside Diphosphate Kinases Human genes 0.000 description 1
- 101150060710 NPR1 gene Proteins 0.000 description 1
- 208000009869 Neu-Laxova syndrome Diseases 0.000 description 1
- 101710203763 Neurexin-3 Proteins 0.000 description 1
- 101710154380 Neurexin-3-beta Proteins 0.000 description 1
- 108700037638 Neurogenic locus notch homolog protein 1 Proteins 0.000 description 1
- 102000008822 Neuroligin 4 Human genes 0.000 description 1
- 108050000725 Neuroligin 4 Proteins 0.000 description 1
- 102100038940 Neuroligin-3 Human genes 0.000 description 1
- 101100228519 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) gch-1 gene Proteins 0.000 description 1
- 101100215778 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) ptr-1 gene Proteins 0.000 description 1
- 102000005665 Neurotransmitter Transport Proteins Human genes 0.000 description 1
- 108010084810 Neurotransmitter Transport Proteins Proteins 0.000 description 1
- 108030001564 Neutrophil collagenases Proteins 0.000 description 1
- 108010008858 Nitric Oxide Synthase Type I Proteins 0.000 description 1
- 108700002045 Nod2 Signaling Adaptor Proteins 0.000 description 1
- 108010077641 Nogo Proteins Proteins 0.000 description 1
- 102100034217 Non-secretory ribonuclease Human genes 0.000 description 1
- 102000001756 Notch2 Receptor Human genes 0.000 description 1
- 101150056078 Nrxn1 gene Proteins 0.000 description 1
- 102000007999 Nuclear Proteins Human genes 0.000 description 1
- 108010089610 Nuclear Proteins Proteins 0.000 description 1
- 102100031701 Nuclear factor erythroid 2-related factor 2 Human genes 0.000 description 1
- 102100023252 Nucleoside diphosphate kinase A Human genes 0.000 description 1
- 101150004818 OCT1 gene Proteins 0.000 description 1
- 108010054076 Oncogene Proteins v-myb Proteins 0.000 description 1
- 239000008896 Opium Substances 0.000 description 1
- 102000009890 Osteonectin Human genes 0.000 description 1
- 108010077077 Osteonectin Proteins 0.000 description 1
- 108010035042 Osteoprotegerin Proteins 0.000 description 1
- 102000004316 Oxidoreductases Human genes 0.000 description 1
- 108090000854 Oxidoreductases Proteins 0.000 description 1
- 101710137390 P-selectin glycoprotein ligand 1 Proteins 0.000 description 1
- 108010045055 PAX5 Transcription Factor Proteins 0.000 description 1
- 108010067946 PAX9 Transcription Factor Proteins 0.000 description 1
- 102000016828 PAX9 Transcription Factor Human genes 0.000 description 1
- 101150095793 PICALM gene Proteins 0.000 description 1
- 101710125553 PLA2G6 Proteins 0.000 description 1
- 229910019142 PO4 Inorganic materials 0.000 description 1
- 101150035190 PSEN1 gene Proteins 0.000 description 1
- 101150073900 PTEN gene Proteins 0.000 description 1
- 101150021299 PTPN22 gene Proteins 0.000 description 1
- 208000002193 Pain Diseases 0.000 description 1
- 102100034901 Paired box protein Pax-9 Human genes 0.000 description 1
- 206010033664 Panic attack Diseases 0.000 description 1
- 206010033864 Paranoia Diseases 0.000 description 1
- 208000027099 Paranoid disease Diseases 0.000 description 1
- 102100037499 Parkinson disease protein 7 Human genes 0.000 description 1
- 208000027089 Parkinsonian disease Diseases 0.000 description 1
- 206010034010 Parkinsonism Diseases 0.000 description 1
- 229940122344 Peptidase inhibitor Drugs 0.000 description 1
- 101710111200 Peptidyl-prolyl cis-trans isomerase G Proteins 0.000 description 1
- 108010056995 Perforin Proteins 0.000 description 1
- 102100028467 Perforin-1 Human genes 0.000 description 1
- 102100022369 Peripheral-type benzodiazepine receptor-associated protein 1 Human genes 0.000 description 1
- 102100034763 Peroxiredoxin-2 Human genes 0.000 description 1
- 102100022078 Peroxiredoxin-5, mitochondrial Human genes 0.000 description 1
- 108090000029 Peroxisome Proliferator-Activated Receptors Proteins 0.000 description 1
- 102100028960 Peroxisome proliferator-activated receptor gamma coactivator 1-alpha Human genes 0.000 description 1
- 101710169596 Phosphatidylinositol-binding clathrin assembly protein Proteins 0.000 description 1
- 102100026831 Phospholipase A2, membrane associated Human genes 0.000 description 1
- 229940124154 Phospholipase inhibitor Drugs 0.000 description 1
- 102000045595 Phosphoprotein Phosphatases Human genes 0.000 description 1
- 108700019535 Phosphoprotein Phosphatases Proteins 0.000 description 1
- 208000000609 Pick Disease of the Brain Diseases 0.000 description 1
- 208000024571 Pick disease Diseases 0.000 description 1
- 102100034869 Plasma kallikrein Human genes 0.000 description 1
- 108010022233 Plasminogen Activator Inhibitor 1 Proteins 0.000 description 1
- 108010077971 Plasminogen Inactivators Proteins 0.000 description 1
- 102100039418 Plasminogen activator inhibitor 1 Human genes 0.000 description 1
- 102000015795 Platelet Membrane Glycoproteins Human genes 0.000 description 1
- 108010010336 Platelet Membrane Glycoproteins Proteins 0.000 description 1
- 101710103494 Platelet-derived growth factor subunit B Proteins 0.000 description 1
- 102100023652 Poly [ADP-ribose] polymerase 2 Human genes 0.000 description 1
- 102100027921 Polyunsaturated fatty acid lipoxygenase ALOX15B Human genes 0.000 description 1
- 101150100678 Pon1 gene Proteins 0.000 description 1
- 101150104557 Ppargc1a gene Proteins 0.000 description 1
- 102000015499 Presenilins Human genes 0.000 description 1
- 108010050254 Presenilins Proteins 0.000 description 1
- 102100038632 Presequence protease, mitochondrial Human genes 0.000 description 1
- 108091000054 Prion Proteins 0.000 description 1
- 208000024777 Prion disease Diseases 0.000 description 1
- 102100040918 Pro-glucagon Human genes 0.000 description 1
- 101710113072 Probable methionine synthase Proteins 0.000 description 1
- 108010048233 Procalcitonin Proteins 0.000 description 1
- 102100038931 Proenkephalin-A Human genes 0.000 description 1
- 101710111765 Prokineticin receptor 2 Proteins 0.000 description 1
- 102000003946 Prolactin Human genes 0.000 description 1
- 108010057464 Prolactin Proteins 0.000 description 1
- 102000056251 Prolyl Oligopeptidases Human genes 0.000 description 1
- 101710178372 Prolyl endopeptidase Proteins 0.000 description 1
- 101710170814 Prostacyclin receptor Proteins 0.000 description 1
- 102100033075 Prostacyclin synthase Human genes 0.000 description 1
- 206010060862 Prostate cancer Diseases 0.000 description 1
- 102100038358 Prostate-specific antigen Human genes 0.000 description 1
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 1
- 102000004885 Protease-activated receptor 4 Human genes 0.000 description 1
- 108090001010 Protease-activated receptor 4 Proteins 0.000 description 1
- 101800001072 Protein 1A Proteins 0.000 description 1
- 102000017975 Protein C Human genes 0.000 description 1
- 101800004937 Protein C Proteins 0.000 description 1
- 108010032428 Protein Deglycase DJ-1 Proteins 0.000 description 1
- 101710110949 Protein S100-A12 Proteins 0.000 description 1
- 101710156962 Protein S100-A2 Proteins 0.000 description 1
- 101710156987 Protein S100-A8 Proteins 0.000 description 1
- 101710122255 Protein S100-B Proteins 0.000 description 1
- 108700037966 Protein jagged-1 Proteins 0.000 description 1
- 102100040848 Protein mono-ADP-ribosyltransferase PARP14 Human genes 0.000 description 1
- 102000004022 Protein-Tyrosine Kinases Human genes 0.000 description 1
- 108090000412 Protein-Tyrosine Kinases Proteins 0.000 description 1
- 101150096148 Psen2 gene Proteins 0.000 description 1
- 101100244562 Pseudomonas aeruginosa (strain ATCC 15692 / DSM 22644 / CIP 104116 / JCM 14847 / LMG 12228 / 1C / PRS 101 / PAO1) oprD gene Proteins 0.000 description 1
- 208000001431 Psychomotor Agitation Diseases 0.000 description 1
- 208000028017 Psychotic disease Diseases 0.000 description 1
- 101150069748 Ptpra gene Proteins 0.000 description 1
- 108010014270 Purinergic P2Y12 Receptors Proteins 0.000 description 1
- 101710132082 Pyrimidine/purine nucleoside phosphorylase Proteins 0.000 description 1
- 102000015799 Qa-SNARE Proteins Human genes 0.000 description 1
- 108010010469 Qa-SNARE Proteins Proteins 0.000 description 1
- 102100032315 RAC-beta serine/threonine-protein kinase Human genes 0.000 description 1
- 102100032314 RAC-gamma serine/threonine-protein kinase Human genes 0.000 description 1
- 102000001183 RAG-1 Human genes 0.000 description 1
- 108060006897 RAG1 Proteins 0.000 description 1
- 101150075516 RAG2 gene Proteins 0.000 description 1
- 230000004570 RNA-binding Effects 0.000 description 1
- 108091007364 RNF139 Proteins 0.000 description 1
- 102000004913 RYR1 Human genes 0.000 description 1
- 108060007240 RYR1 Proteins 0.000 description 1
- 101710091141 Ras-related C3 botulinum toxin substrate 2 Proteins 0.000 description 1
- 101100170538 Rattus norvegicus Disc1 gene Proteins 0.000 description 1
- 101000629598 Rattus norvegicus Sterol regulatory element-binding protein 1 Proteins 0.000 description 1
- 102100037405 Receptor-type tyrosine-protein phosphatase alpha Human genes 0.000 description 1
- 102000018120 Recombinases Human genes 0.000 description 1
- 108010091086 Recombinases Proteins 0.000 description 1
- 206010038743 Restlessness Diseases 0.000 description 1
- 201000007737 Retinal degeneration Diseases 0.000 description 1
- 102100033617 Retinal-specific phospholipid-transporting ATPase ABCA4 Human genes 0.000 description 1
- 201000000582 Retinoblastoma Diseases 0.000 description 1
- 101100497944 Rhizopus delemar (strain RA 99-880 / ATCC MYA-4621 / FGSC 9543 / NRRL 43880) cyp11 gene Proteins 0.000 description 1
- 102100025369 Runt-related transcription factor 3 Human genes 0.000 description 1
- 102100032122 Ryanodine receptor 1 Human genes 0.000 description 1
- 102000000341 S-Phase Kinase-Associated Proteins Human genes 0.000 description 1
- 108010055623 S-Phase Kinase-Associated Proteins Proteins 0.000 description 1
- 102100034374 S-phase kinase-associated protein 2 Human genes 0.000 description 1
- 108700016890 S100A12 Proteins 0.000 description 1
- 108010005173 SERPIN-B5 Proteins 0.000 description 1
- 108050003189 SH2B adapter protein 1 Proteins 0.000 description 1
- 101150052097 SH2B1 gene Proteins 0.000 description 1
- 108091006161 SLC17A5 Proteins 0.000 description 1
- 108091006162 SLC17A6 Proteins 0.000 description 1
- 108091006283 SLC17A7 Proteins 0.000 description 1
- 102000012977 SLC1A3 Human genes 0.000 description 1
- 108091006750 SLC22A18 Proteins 0.000 description 1
- 108091006735 SLC22A2 Proteins 0.000 description 1
- 108091006716 SLC25A4 Proteins 0.000 description 1
- 108091006551 SLC29A1 Proteins 0.000 description 1
- 108091006296 SLC2A1 Proteins 0.000 description 1
- 108091006932 SLC39A3 Proteins 0.000 description 1
- 108091006262 SLC4A4 Proteins 0.000 description 1
- 108091006264 SLC4A7 Proteins 0.000 description 1
- 108091006274 SLC5A8 Proteins 0.000 description 1
- 108091006253 SLC8A1 Proteins 0.000 description 1
- 108091006647 SLC9A1 Proteins 0.000 description 1
- 108060009345 SORL1 Proteins 0.000 description 1
- 101150003482 SORL1 gene Proteins 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- 101001025539 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) Homothallic switching endonuclease Proteins 0.000 description 1
- 101000995829 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) Nucleotide pyrophosphatase Proteins 0.000 description 1
- 101100267551 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) YME1 gene Proteins 0.000 description 1
- 101800001700 Saposin-D Proteins 0.000 description 1
- 102000006308 Sarcoglycans Human genes 0.000 description 1
- 108010083379 Sarcoglycans Proteins 0.000 description 1
- 101100023124 Schizosaccharomyces pombe (strain 972 / ATCC 24843) mfr2 gene Proteins 0.000 description 1
- 101710192385 Secretogranin-1 Proteins 0.000 description 1
- 102100027066 Selenoprotein F Human genes 0.000 description 1
- 101710095009 Selenoprotein F Proteins 0.000 description 1
- 101710199403 Semaphorin-5A Proteins 0.000 description 1
- 102100028904 Serine/threonine-protein kinase MARK2 Human genes 0.000 description 1
- 102100038376 Serine/threonine-protein kinase PINK1, mitochondrial Human genes 0.000 description 1
- 102000008847 Serpin Human genes 0.000 description 1
- 108050000761 Serpin Proteins 0.000 description 1
- 108010005113 Serpin E2 Proteins 0.000 description 1
- 102000005821 Serpin E2 Human genes 0.000 description 1
- 108010041191 Sirtuin 1 Proteins 0.000 description 1
- 102100027340 Slit homolog 2 protein Human genes 0.000 description 1
- 102100027339 Slit homolog 3 protein Human genes 0.000 description 1
- 101710102694 Solute carrier family 22 member 1 Proteins 0.000 description 1
- 101710126735 Sortilin-related receptor Proteins 0.000 description 1
- 208000009415 Spinocerebellar Ataxias Diseases 0.000 description 1
- 102100037997 Squalene synthase Human genes 0.000 description 1
- 108010039445 Stem Cell Factor Proteins 0.000 description 1
- 108010055297 Sterol Esterase Proteins 0.000 description 1
- 108010087999 Steryl-Sulfatase Proteins 0.000 description 1
- 102100038021 Steryl-sulfatase Human genes 0.000 description 1
- 208000006011 Stroke Diseases 0.000 description 1
- 102100021997 Synphilin-1 Human genes 0.000 description 1
- 101710140334 Synphilin-1 Proteins 0.000 description 1
- 102100031115 Syntaxin-11 Human genes 0.000 description 1
- 102000052935 T-box transcription factor Human genes 0.000 description 1
- 108700035811 T-box transcription factor Proteins 0.000 description 1
- 102100036840 T-box transcription factor TBX21 Human genes 0.000 description 1
- 102100029886 T-complex protein 1 subunit epsilon Human genes 0.000 description 1
- 101150074137 TBX21 gene Proteins 0.000 description 1
- 208000001871 Tachycardia Diseases 0.000 description 1
- 101800000849 Tachykinin-associated peptide 2 Proteins 0.000 description 1
- 208000034799 Tauopathies Diseases 0.000 description 1
- 206010043189 Telangiectasia Diseases 0.000 description 1
- 101710173511 Tensin homolog Proteins 0.000 description 1
- 101710100614 Tensin-4 Proteins 0.000 description 1
- 101710132098 Tetraspanin-32 Proteins 0.000 description 1
- 102000005497 Thymidylate Synthase Human genes 0.000 description 1
- 102100038618 Thymidylate synthase Human genes 0.000 description 1
- UGPMCIBIHRSCBV-XNBOLLIBSA-N Thymosin beta 4 Chemical compound N([C@@H](CC(O)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(C)C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O)C(=O)[C@@H]1CCCN1C(=O)[C@H](CCCCN)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(C)=O UGPMCIBIHRSCBV-XNBOLLIBSA-N 0.000 description 1
- 101150079992 Timp3 gene Proteins 0.000 description 1
- 102100030859 Tissue factor Human genes 0.000 description 1
- 108010048999 Transcription Factor 3 Proteins 0.000 description 1
- 108010037468 Transcription Factor HES-1 Proteins 0.000 description 1
- 102000005747 Transcription Factor RelA Human genes 0.000 description 1
- 108010031154 Transcription Factor RelA Proteins 0.000 description 1
- 101710189834 Transcription factor AP-2-alpha Proteins 0.000 description 1
- 102100038313 Transcription factor E2-alpha Human genes 0.000 description 1
- 102100030780 Transcriptional activator Myb Human genes 0.000 description 1
- 102000004338 Transferrin Human genes 0.000 description 1
- 108090000901 Transferrin Proteins 0.000 description 1
- 102000004060 Transforming Growth Factor-beta Type II Receptor Human genes 0.000 description 1
- 108010082684 Transforming Growth Factor-beta Type II Receptor Proteins 0.000 description 1
- 102000009618 Transforming Growth Factors Human genes 0.000 description 1
- 108010009583 Transforming Growth Factors Proteins 0.000 description 1
- 108050004388 Transient receptor potential cation channel subfamily V member 1 Proteins 0.000 description 1
- 206010044565 Tremor Diseases 0.000 description 1
- 102100026387 Tribbles homolog 1 Human genes 0.000 description 1
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 1
- 102100024971 Tryptophan 5-hydroxylase 1 Human genes 0.000 description 1
- 102100036474 Tryptophan 5-hydroxylase 2 Human genes 0.000 description 1
- 102100032236 Tumor necrosis factor receptor superfamily member 11B Human genes 0.000 description 1
- 102100033733 Tumor necrosis factor receptor superfamily member 1B Human genes 0.000 description 1
- 101710187830 Tumor necrosis factor receptor superfamily member 1B Proteins 0.000 description 1
- 101150044377 UBA1 gene Proteins 0.000 description 1
- 101150035006 UBA3 gene Proteins 0.000 description 1
- 101150020913 USP7 gene Proteins 0.000 description 1
- 101150045341 Ubb gene Proteins 0.000 description 1
- 102000044159 Ubiquitin Human genes 0.000 description 1
- 108090000848 Ubiquitin Proteins 0.000 description 1
- 101710186831 Ubiquitin carboxyl-terminal hydrolase isozyme L3 Proteins 0.000 description 1
- 108700011958 Ubiquitin-Specific Peptidase 7 Proteins 0.000 description 1
- 101710191412 Ubiquitin-like modifier-activating enzyme 1 Proteins 0.000 description 1
- 229940126752 Ubiquitin-specific protease 7 inhibitor Drugs 0.000 description 1
- 101150038861 Uchl1 gene Proteins 0.000 description 1
- 101150051860 Uchl3 gene Proteins 0.000 description 1
- 108010021111 Uncoupling Protein 2 Proteins 0.000 description 1
- 108010092464 Urate Oxidase Proteins 0.000 description 1
- 101710095163 Urotensin-2 Proteins 0.000 description 1
- 102100031083 Uteroglobin Human genes 0.000 description 1
- 102100029591 V(D)J recombination-activating protein 2 Human genes 0.000 description 1
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 1
- 108010073925 Vascular Endothelial Growth Factor B Proteins 0.000 description 1
- 102000055135 Vasoactive Intestinal Peptide Human genes 0.000 description 1
- 108010003205 Vasoactive Intestinal Peptide Proteins 0.000 description 1
- 101710101493 Viral myc transforming protein Proteins 0.000 description 1
- 102100033364 Vitamin D3 receptor Human genes 0.000 description 1
- 101710203223 Vitamin D3 receptor Proteins 0.000 description 1
- 102000004210 Vitamin K Epoxide Reductases Human genes 0.000 description 1
- 108090000779 Vitamin K Epoxide Reductases Proteins 0.000 description 1
- 102100029477 Vitamin K-dependent protein C Human genes 0.000 description 1
- 101710193896 Vitamin K-dependent protein S Proteins 0.000 description 1
- 101150115477 Vldlr gene Proteins 0.000 description 1
- 102100032574 Voltage-dependent L-type calcium channel subunit alpha-1C Human genes 0.000 description 1
- 201000011032 Werner Syndrome Diseases 0.000 description 1
- 210000001766 X chromosome Anatomy 0.000 description 1
- 241000269368 Xenopus laevis Species 0.000 description 1
- 108010088665 Zinc Finger Protein Gli2 Proteins 0.000 description 1
- 101710123549 Zinc finger protein ZPR1 Proteins 0.000 description 1
- 230000001594 aberrant effect Effects 0.000 description 1
- 210000001789 adipocyte Anatomy 0.000 description 1
- 230000016571 aggressive behavior Effects 0.000 description 1
- 150000001299 aldehydes Chemical class 0.000 description 1
- 108010029483 alpha 1 Chain Collagen Type I Proteins 0.000 description 1
- 108090000183 alpha-2-Antiplasmin Proteins 0.000 description 1
- HXXFSFRBOHSIMQ-FPRJBGLDSA-N alpha-D-galactose 1-phosphate Chemical compound OC[C@H]1O[C@H](OP(O)(O)=O)[C@H](O)[C@@H](O)[C@H]1O HXXFSFRBOHSIMQ-FPRJBGLDSA-N 0.000 description 1
- 108010009380 alpha-N-acetyl-D-glucosaminidase Proteins 0.000 description 1
- 108090000185 alpha-Synuclein Proteins 0.000 description 1
- AWUCVROLDVIAJX-UHFFFAOYSA-N alpha-glycerophosphate Natural products OCC(O)COP(O)(O)=O AWUCVROLDVIAJX-UHFFFAOYSA-N 0.000 description 1
- 229940025084 amphetamine Drugs 0.000 description 1
- 210000004727 amygdala Anatomy 0.000 description 1
- 230000003941 amyloidogenesis Effects 0.000 description 1
- 206010002022 amyloidosis Diseases 0.000 description 1
- 206010002026 amyotrophic lateral sclerosis Diseases 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 239000000427 antigen Substances 0.000 description 1
- 102000036639 antigens Human genes 0.000 description 1
- 108091007433 antigens Proteins 0.000 description 1
- 239000002249 anxiolytic agent Substances 0.000 description 1
- 230000000949 anxiolytic effect Effects 0.000 description 1
- 101150089041 aph-1 gene Proteins 0.000 description 1
- 108010073614 apolipoprotein A-IV Proteins 0.000 description 1
- 101150031224 app gene Proteins 0.000 description 1
- 230000004596 appetite loss Effects 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 210000003719 b-lymphocyte Anatomy 0.000 description 1
- 230000001580 bacterial effect Effects 0.000 description 1
- HNYOPLTXPVRDBG-UHFFFAOYSA-M barbiturate Chemical class O=C1CC(=O)[N-]C(=O)N1 HNYOPLTXPVRDBG-UHFFFAOYSA-M 0.000 description 1
- 229940049706 benzodiazepine Drugs 0.000 description 1
- 108010079452 beta Adrenergic Receptors Proteins 0.000 description 1
- 102000012740 beta Adrenergic Receptors Human genes 0.000 description 1
- 108091008324 binding proteins Proteins 0.000 description 1
- 230000003115 biocidal effect Effects 0.000 description 1
- 230000033228 biological regulation Effects 0.000 description 1
- 239000000090 biomarker Substances 0.000 description 1
- 230000004397 blinking Effects 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- 230000008499 blood brain barrier function Effects 0.000 description 1
- 210000001218 blood-brain barrier Anatomy 0.000 description 1
- 210000001775 bruch membrane Anatomy 0.000 description 1
- 239000000872 buffer Substances 0.000 description 1
- 101710143429 cGMP-dependent protein kinase 1 Proteins 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 229910052791 calcium Inorganic materials 0.000 description 1
- 239000001506 calcium phosphate Substances 0.000 description 1
- 229910000389 calcium phosphate Inorganic materials 0.000 description 1
- 235000011010 calcium phosphates Nutrition 0.000 description 1
- 108010041776 cardiotrophin 1 Proteins 0.000 description 1
- 230000003197 catalytic effect Effects 0.000 description 1
- 206010007776 catatonia Diseases 0.000 description 1
- 125000002091 cationic group Chemical group 0.000 description 1
- 230000021164 cell adhesion Effects 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 238000012832 cell culture technique Methods 0.000 description 1
- 230000003915 cell function Effects 0.000 description 1
- 239000013592 cell lysate Substances 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- ZGOVYTPSWMLYOF-QEADGSHQSA-N chembl1790180 Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)NC(=O)[C@H]1NC(=O)[C@H](CC=2C=CC(O)=CC=2)NC(=O)[C@@H](CC=2C=CC(O)=CC=2)NC(=O)[C@H](C(C)C)NC(=O)[C@H]2CSSC[C@@H](C(N[C@H](CC=3C=CC=CC=3)C(=O)N[C@H](C(=O)N[C@H](CCC=3C=CC(O)=CC=3)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N2)[C@H](C)O)=O)NC(=O)[C@@H]([C@@H](C)O)NC(=O)[C@H](N)CSSC1)C1=CNC=N1 ZGOVYTPSWMLYOF-QEADGSHQSA-N 0.000 description 1
- 239000002975 chemoattractant Substances 0.000 description 1
- 230000008711 chromosomal rearrangement Effects 0.000 description 1
- 238000010367 cloning Methods 0.000 description 1
- 229940105774 coagulation factor ix Drugs 0.000 description 1
- 229940105756 coagulation factor x Drugs 0.000 description 1
- 229960003920 cocaine Drugs 0.000 description 1
- 210000001072 colon Anatomy 0.000 description 1
- 230000030944 contact inhibition Effects 0.000 description 1
- 230000001276 controlling effect Effects 0.000 description 1
- 230000036461 convulsion Effects 0.000 description 1
- IDLFZVILOHSSID-OVLDLUHVSA-N corticotropin Chemical compound C([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](C(C)C)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)NC(=O)[C@@H](N)CO)C1=CC=C(O)C=C1 IDLFZVILOHSSID-OVLDLUHVSA-N 0.000 description 1
- 229960000258 corticotropin Drugs 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 235000019788 craving Nutrition 0.000 description 1
- ILRYLPWNYFXEMH-UHFFFAOYSA-N cystathionine Chemical compound OC(=O)C(N)CCSCC(N)C(O)=O ILRYLPWNYFXEMH-UHFFFAOYSA-N 0.000 description 1
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 1
- 210000000805 cytoplasm Anatomy 0.000 description 1
- 230000006378 damage Effects 0.000 description 1
- 210000003785 decidua Anatomy 0.000 description 1
- 230000007547 defect Effects 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 102000048124 delta Opioid Receptors Human genes 0.000 description 1
- 108700023159 delta Opioid Receptors Proteins 0.000 description 1
- 239000000412 dendrimer Substances 0.000 description 1
- 229920000736 dendritic polymer Polymers 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000002405 diagnostic procedure Methods 0.000 description 1
- 229960002069 diamorphine Drugs 0.000 description 1
- 238000001152 differential interference contrast microscopy Methods 0.000 description 1
- FOCAHLGSDWHSAH-UHFFFAOYSA-N difluoromethanethione Chemical compound FC(F)=S FOCAHLGSDWHSAH-UHFFFAOYSA-N 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- 108020001096 dihydrofolate reductase Proteins 0.000 description 1
- 230000000447 dimerizing effect Effects 0.000 description 1
- 230000003292 diminished effect Effects 0.000 description 1
- 230000035622 drinking Effects 0.000 description 1
- 238000012377 drug delivery Methods 0.000 description 1
- 238000007876 drug discovery Methods 0.000 description 1
- 238000002651 drug therapy Methods 0.000 description 1
- 230000007937 eating Effects 0.000 description 1
- 235000013601 eggs Nutrition 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- 210000001671 embryonic stem cell Anatomy 0.000 description 1
- 230000002124 endocrine Effects 0.000 description 1
- MLFJHYIHIKEBTQ-IYRKOGFYSA-N endothelin 2 Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)NC(=O)[C@H]1NC(=O)[C@H](CC=2C=CC=CC=2)NC(=O)[C@H](CC=2C=CC(O)=CC=2)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]2CSSC[C@@H](C(N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC=3C4=CC=CC=C4NC=3)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N2)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CSSC1)C1=CNC=N1 MLFJHYIHIKEBTQ-IYRKOGFYSA-N 0.000 description 1
- 238000012407 engineering method Methods 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- 238000001976 enzyme digestion Methods 0.000 description 1
- 102000013165 exonuclease Human genes 0.000 description 1
- 238000000249 far-infrared magnetic resonance spectroscopy Methods 0.000 description 1
- 101150088071 fgfr2 gene Proteins 0.000 description 1
- 108091006047 fluorescent proteins Proteins 0.000 description 1
- 102000034287 fluorescent proteins Human genes 0.000 description 1
- 230000037406 food intake Effects 0.000 description 1
- 230000005021 gait Effects 0.000 description 1
- 238000003209 gene knockout Methods 0.000 description 1
- 239000003292 glue Substances 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- 125000000404 glutamine group Chemical group N[C@@H](CCC(N)=O)C(=O)* 0.000 description 1
- 108010092115 glutamyl-prolyl-tRNA synthetase Proteins 0.000 description 1
- 102000006602 glyceraldehyde-3-phosphate dehydrogenase Human genes 0.000 description 1
- 108020004445 glyceraldehyde-3-phosphate dehydrogenase Proteins 0.000 description 1
- 210000002768 hair cell Anatomy 0.000 description 1
- 239000000380 hallucinogen Chemical class 0.000 description 1
- 239000000833 heterodimer Substances 0.000 description 1
- 108010044853 histidine-rich proteins Proteins 0.000 description 1
- 230000000147 hypnotic effect Effects 0.000 description 1
- 230000003483 hypokinetic effect Effects 0.000 description 1
- 230000006303 immediate early viral mRNA transcription Effects 0.000 description 1
- 230000007813 immunodeficiency Effects 0.000 description 1
- 238000000530 impalefection Methods 0.000 description 1
- 238000002513 implantation Methods 0.000 description 1
- 230000000937 inactivator Effects 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 229940079322 interferon Drugs 0.000 description 1
- 229960003130 interferon gamma Drugs 0.000 description 1
- 239000003407 interleukin 1 receptor blocking agent Substances 0.000 description 1
- 229940074383 interleukin-11 Drugs 0.000 description 1
- 108090000237 interleukin-24 Proteins 0.000 description 1
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 1
- 229960000310 isoleucine Drugs 0.000 description 1
- 125000000741 isoleucyl group Chemical group [H]N([H])C(C(C([H])([H])[H])C([H])([H])C([H])([H])[H])C(=O)O* 0.000 description 1
- 102000048260 kappa Opioid Receptors Human genes 0.000 description 1
- 210000003734 kidney Anatomy 0.000 description 1
- 229940043355 kinase inhibitor Drugs 0.000 description 1
- 210000005053 lamin Anatomy 0.000 description 1
- 231100000518 lethal Toxicity 0.000 description 1
- 230000001665 lethal effect Effects 0.000 description 1
- 125000001909 leucine group Chemical group [H]N(*)C(C(*)=O)C([H])([H])C(C([H])([H])[H])C([H])([H])[H] 0.000 description 1
- 208000032839 leukemia Diseases 0.000 description 1
- 108010013555 lipoprotein-associated coagulation inhibitor Proteins 0.000 description 1
- 208000014817 lissencephaly spectrum disease Diseases 0.000 description 1
- 210000004185 liver Anatomy 0.000 description 1
- 230000033001 locomotion Effects 0.000 description 1
- 239000003202 long acting thyroid stimulator Substances 0.000 description 1
- 208000019017 loss of appetite Diseases 0.000 description 1
- 235000021266 loss of appetite Nutrition 0.000 description 1
- 240000004308 marijuana Species 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 230000002503 metabolic effect Effects 0.000 description 1
- 108010038421 metabotropic glutamate receptor 2 Proteins 0.000 description 1
- 230000009401 metastasis Effects 0.000 description 1
- 108091029119 miR-34a stem-loop Proteins 0.000 description 1
- 108091079013 miR-34b Proteins 0.000 description 1
- 108091084018 miR-34b stem-loop Proteins 0.000 description 1
- 108091063470 miR-34b-1 stem-loop Proteins 0.000 description 1
- 108091049916 miR-34b-2 stem-loop Proteins 0.000 description 1
- 108091057222 miR-34b-3 stem-loop Proteins 0.000 description 1
- 108091092639 miR-34b-4 stem-loop Proteins 0.000 description 1
- 230000002438 mitochondrial effect Effects 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000000051 modifying effect Effects 0.000 description 1
- SLZIZIJTGAYEKK-CIJSCKBQSA-N molport-023-220-247 Chemical compound C([C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=1N=CNC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC=1N=CNC=1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(N)=O)NC(=O)[C@H]1N(CCC1)C(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)CN)[C@@H](C)O)C1=CNC=N1 SLZIZIJTGAYEKK-CIJSCKBQSA-N 0.000 description 1
- 108010083982 monoamine-sulfating phenol sulfotransferase Proteins 0.000 description 1
- 210000001616 monocyte Anatomy 0.000 description 1
- 108010072187 mortalin Proteins 0.000 description 1
- 230000008450 motivation Effects 0.000 description 1
- 102000051367 mu Opioid Receptors Human genes 0.000 description 1
- 230000017311 musculoskeletal movement, spinal reflex action Effects 0.000 description 1
- 208000010125 myocardial infarction Diseases 0.000 description 1
- 239000013642 negative control Substances 0.000 description 1
- 210000001577 neostriatum Anatomy 0.000 description 1
- 238000007857 nested PCR Methods 0.000 description 1
- 230000001722 neurochemical effect Effects 0.000 description 1
- 108090001073 neuroligin 3 Proteins 0.000 description 1
- 239000002858 neurotransmitter agent Substances 0.000 description 1
- 229960002715 nicotine Drugs 0.000 description 1
- SNICXCGAKADSCV-UHFFFAOYSA-N nicotine Natural products CN1CCCC1C1=CC=CN=C1 SNICXCGAKADSCV-UHFFFAOYSA-N 0.000 description 1
- 108091027963 non-coding RNA Proteins 0.000 description 1
- 102000042567 non-coding RNA Human genes 0.000 description 1
- 238000010606 normalization Methods 0.000 description 1
- 108091006527 nucleoside transporters Proteins 0.000 description 1
- 102000037831 nucleoside transporters Human genes 0.000 description 1
- 210000001009 nucleus accumben Anatomy 0.000 description 1
- 229960001027 opium Drugs 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 238000012261 overproduction Methods 0.000 description 1
- 208000019906 panic disease Diseases 0.000 description 1
- 102000045222 parkin Human genes 0.000 description 1
- 102000014187 peptide receptors Human genes 0.000 description 1
- 108010011903 peptide receptors Proteins 0.000 description 1
- 238000002823 phage display Methods 0.000 description 1
- 230000000144 pharmacologic effect Effects 0.000 description 1
- 210000003800 pharynx Anatomy 0.000 description 1
- JTJMJGYZQZDUJJ-UHFFFAOYSA-N phencyclidine Chemical compound C1CCCCN1C1(C=2C=CC=CC=2)CCCCC1 JTJMJGYZQZDUJJ-UHFFFAOYSA-N 0.000 description 1
- 229950010883 phencyclidine Drugs 0.000 description 1
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 1
- 239000010452 phosphate Substances 0.000 description 1
- 239000003428 phospholipase inhibitor Substances 0.000 description 1
- 239000003757 phosphotransferase inhibitor Substances 0.000 description 1
- 108090000102 pigment epithelium-derived factor Proteins 0.000 description 1
- 108010031345 placental alkaline phosphatase Proteins 0.000 description 1
- 230000003169 placental effect Effects 0.000 description 1
- 239000002797 plasminogen activator inhibitor Substances 0.000 description 1
- 230000001402 polyadenylating effect Effects 0.000 description 1
- 201000008519 polycystic kidney disease 1 Diseases 0.000 description 1
- 230000036544 posture Effects 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 210000002442 prefrontal cortex Anatomy 0.000 description 1
- 108010041071 proenkephalin Proteins 0.000 description 1
- 201000002212 progressive supranuclear palsy Diseases 0.000 description 1
- 230000000135 prohibitive effect Effects 0.000 description 1
- 239000003380 propellant Substances 0.000 description 1
- 210000002307 prostate Anatomy 0.000 description 1
- 230000009993 protective function Effects 0.000 description 1
- 230000004845 protein aggregation Effects 0.000 description 1
- 229960000856 protein c Drugs 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 108010062302 rac1 GTP Binding Protein Proteins 0.000 description 1
- 101150013400 rag1 gene Proteins 0.000 description 1
- 230000000384 rearing effect Effects 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 230000002829 reductive effect Effects 0.000 description 1
- 230000009711 regulatory function Effects 0.000 description 1
- 230000001718 repressive effect Effects 0.000 description 1
- 230000029058 respiratory gaseous exchange Effects 0.000 description 1
- 210000004189 reticular formation Anatomy 0.000 description 1
- 230000004258 retinal degeneration Effects 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 102200006187 rs749714198 Human genes 0.000 description 1
- 239000000932 sedative agent Substances 0.000 description 1
- 230000001624 sedative effect Effects 0.000 description 1
- 230000035945 sensitivity Effects 0.000 description 1
- 239000003001 serine protease inhibitor Substances 0.000 description 1
- 238000002741 site-directed mutagenesis Methods 0.000 description 1
- 210000002460 smooth muscle Anatomy 0.000 description 1
- 230000003997 social interaction Effects 0.000 description 1
- 101150062190 sod1 gene Proteins 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 230000009870 specific binding Effects 0.000 description 1
- 238000012453 sprague-dawley rat model Methods 0.000 description 1
- 206010041823 squamous cell carcinoma Diseases 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 230000004936 stimulating effect Effects 0.000 description 1
- 230000035882 stress Effects 0.000 description 1
- 208000011117 substance-related disease Diseases 0.000 description 1
- 210000003523 substantia nigra Anatomy 0.000 description 1
- 230000001629 suppression Effects 0.000 description 1
- 238000001356 surgical procedure Methods 0.000 description 1
- 230000005062 synaptic transmission Effects 0.000 description 1
- 210000001179 synovial fluid Anatomy 0.000 description 1
- 230000006794 tachycardia Effects 0.000 description 1
- 230000008685 targeting Effects 0.000 description 1
- 208000009056 telangiectasis Diseases 0.000 description 1
- 208000011317 telomere syndrome Diseases 0.000 description 1
- 210000001103 thalamus Anatomy 0.000 description 1
- 230000008719 thickening Effects 0.000 description 1
- 108010079996 thymosin beta(4) Proteins 0.000 description 1
- 230000001256 tonic effect Effects 0.000 description 1
- 239000003053 toxin Substances 0.000 description 1
- 231100000765 toxin Toxicity 0.000 description 1
- 108700012359 toxins Proteins 0.000 description 1
- 230000002103 transcriptional effect Effects 0.000 description 1
- 239000012581 transferrin Substances 0.000 description 1
- 238000013519 translation Methods 0.000 description 1
- 230000014616 translation Effects 0.000 description 1
- 230000005945 translocation Effects 0.000 description 1
- 102000035160 transmembrane proteins Human genes 0.000 description 1
- 108091005703 transmembrane proteins Proteins 0.000 description 1
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 1
- 125000000430 tryptophan group Chemical group [H]N([H])C(C(=O)O*)C([H])([H])C1=C([H])N([H])C2=C([H])C([H])=C([H])C([H])=C12 0.000 description 1
- 230000005740 tumor formation Effects 0.000 description 1
- 239000000225 tumor suppressor protein Substances 0.000 description 1
- 238000010396 two-hybrid screening Methods 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- 229940005267 urate oxidase Drugs 0.000 description 1
- HFNHAPQMXICKCF-USJMABIRSA-N urotensin-ii Chemical compound N([C@@H](CC(O)=O)C(=O)N[C@H]1CSSC[C@H](NC(=O)[C@H](CC=2C=CC(O)=CC=2)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC=2C3=CC=CC=C3NC=2)NC(=O)[C@H](CC=2C=CC=CC=2)NC1=O)C(=O)N[C@@H](C(C)C)C(O)=O)C(=O)[C@@H]1CCCN1C(=O)[C@@H](NC(=O)[C@@H](N)CCC(O)=O)[C@@H](C)O HFNHAPQMXICKCF-USJMABIRSA-N 0.000 description 1
- 210000004291 uterus Anatomy 0.000 description 1
- 238000010200 validation analysis Methods 0.000 description 1
- 239000004474 valine Substances 0.000 description 1
- 125000002987 valine group Chemical group [H]N([H])C([H])(C(*)=O)C([H])(C([H])([H])[H])C([H])([H])[H] 0.000 description 1
- 210000004515 ventral tegmental area Anatomy 0.000 description 1
- 210000002845 virion Anatomy 0.000 description 1
- 239000000277 virosome Substances 0.000 description 1
- 102000009310 vitamin D receptors Human genes 0.000 description 1
- 108050000156 vitamin D receptors Proteins 0.000 description 1
- 230000001755 vocal effect Effects 0.000 description 1
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K67/00—Rearing or breeding animals, not otherwise provided for; New or modified breeds of animals
- A01K67/027—New or modified breeds of vertebrates
- A01K67/0275—Genetically modified vertebrates, e.g. transgenic
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/8509—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells for producing genetically modified animals, e.g. transgenic
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/10—Cells modified by introduction of foreign genetic material
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2217/00—Genetically modified animals
- A01K2217/07—Animals genetically altered by homologous recombination
- A01K2217/075—Animals genetically altered by homologous recombination inducing loss of function, i.e. knock out
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2227/00—Animals characterised by species
- A01K2227/10—Mammal
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2227/00—Animals characterised by species
- A01K2227/10—Mammal
- A01K2227/103—Ovine
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2227/00—Animals characterised by species
- A01K2227/10—Mammal
- A01K2227/105—Murine
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2227/00—Animals characterised by species
- A01K2227/10—Mammal
- A01K2227/107—Rabbit
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2227/00—Animals characterised by species
- A01K2227/10—Mammal
- A01K2227/108—Swine
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2227/00—Animals characterised by species
- A01K2227/70—Invertebrates
- A01K2227/706—Insects, e.g. Drosophila melanogaster, medfly
Definitions
- the invention encompasses a method for creating an animal or cell with at least one chromosomal edit.
- the invention relates to the use of targeted zinc finger nucleases to edit chromosomal sequences.
- Rational genome engineering has enormous potential across basic research, drug discovery, and cell-based medicines.
- Existing methods for targeted gene knock-out or site-specific gene insertion rely on homologous recombination.
- the low rate of spontaneous recombination in certain cell types has been an enormous hurdle to universal genome editing.
- the scale of screening effort and the time required to isolate the targeted event was prohibitive.
- One aspect of the present invention encompasses a method for editing a chromosomal sequence.
- the method comprises, in part, (a) introducing into a cell comprising the chromosomal sequence at least one nucleic acid encoding a zinc finger nuclease that recognizes a target sequence in the chromosomal sequence and is able to cleave a cleavage site in the chromosomal sequence, and, optionally, (i) at least one donor polynucleotide comprising a donor sequence for integration, an upstream sequence, and a downstream sequence, wherein the donor sequence is flanked by the upstream sequence and the downstream sequence, and wherein the upstream sequence and the downstream sequence share substantial sequence identity with either side of the cleavage site, or (ii) at least one exchange polynucleotide comprising an exchange sequence that is substantially identical to a portion of the chromosomal sequence at the cleavage site, and further comprising at least one nucleotide change; and
- the non-human animal may be created in part, by (a) introducing into a cell comprising the chromosomal sequence at least one nucleic acid encoding a zinc finger nuclease that recognizes a target sequence in the chromosomal sequence and is able to cleave a cleavage site in the chromosomal sequence, and, optionally, (i) at least one donor polynucleotide comprising a donor sequence for integration, an upstream sequence, and a downstream sequence, wherein the donor sequence is flanked by the upstream sequence and the downstream sequence, and wherein the upstream sequence and the downstream sequence share substantial sequence identity with either side of the cleavage site, or (ii) at least one exchange polynucleotide comprising an exchange sequence that is substantially identical to a portion of the chromosomal sequence at the cleavage site, and further comprising at least one nucleotide change; and (b) at least one donor polynucleotide comprising an exchange sequence that is
- the cell may be created in part, by in part, by (a) introducing into the cell comprising the chromosomal sequence at least one nucleic acid encoding a zinc finger nuclease that recognizes a target sequence in the chromosomal sequence and is able to cleave a cleavage site in the chromosomal sequence, and, optionally, (i) at least one donor polynucleotide comprising a donor sequence for integration, an upstream sequence, and a downstream sequence, wherein the donor sequence is flanked by the upstream sequence and the downstream sequence, and wherein the upstream sequence and the downstream sequence share substantial sequence identity with either side of the cleavage site, or (ii) at least one exchange polynucleotide comprising an exchange sequence that is substantially identical to a portion of the chromosomal sequence at the cleavage site, and further comprising at least one nucleotide change; and (b)
- a further aspect of the present invention encompasses an embryo.
- the embryo comprises at least one nucleic acid encoding a zinc finger nuclease that recognizes a target sequence in the chromosomal sequence and is able to cleave a cleavage site in the chromosomal sequence, and, optionally, (i) at least one donor polynucleotide comprising a donor sequence for integration, an upstream sequence and a downstream sequence, wherein the donor sequence is flanked by the upstream sequence and the downstream sequence and wherein the upstream sequence and the downstream sequence share substantial sequence identity with either side of the cleavage site, or (ii) at least one exchange polynucleotide comprising an exchange sequence that is substantially identical to a portion of the chromosomal sequence at the cleavage site and which further comprises at least one nucleotide change.
- FIG. 1 is a schematic depicting the repair outcomes after a targeted ZFN-induced double stranded break. Shaded bars represent the donor fragment, whereas white bars depict target site for ZFN double stranded break.
- FIG. 2 is a schematic depicting the construction of RFLP donor plasmids. Shown, are the plasmid, and left and right PCR-amplified fragments homologous to the integration target site. Restriction enzymes used for cloning are denoted. The left fragment used Kpnl and Notl or Pmel. The right fragment used Notl or Pmel and Sacll.
- FIG. 3 is a schematic depicting the construction of GFP- expressing donor plasmids. The GFP cassette was PCR amplified from an existing plasmid and cloned into the Notl RFLP donor using a Notl site.
- FIG. 4 is a schematic depicting methods of detecting (A) RFLP integration and restriction enzyme digestion and (B) integration of the GFP expression cassette using PCR amplification.
- FIG. 5 is a photographic image of fluorescently stained PCR fragments resolved on an agarose gel.
- the leftmost lane contains a DNA ladder.
- Lanes 1 to 6 contain PCR fragments amplified using mouse Mdri a-specific primers from a whole or a fraction of a mouse blastocyst. Lanes 1 and 2 were amplified from 5/6 and 1/6 of a blastocyst, respectively. Lane 3 was from one whole blastocyst. Lanes 4 to 6 were from ⁇ A, 1/3, and 1/6 of the same blastocyst, respective. Lane 7 contains a positive control PCR fragment amplified using the same primers from extracted mouse toe DNA.
- FIG. 6 is a photographic image of fluorescently stained DNA fragments resolved on an agarose gel. The leftmost lanes contain a DNA ladder.
- Lanes 1 to 39 contain PCR fragments amplified using mMdri a-specific primers from 37 mouse embryos cultured in vitro after being microinjected with ZFN RNA against mouse MdM a and RFLP donor with Notl site, along with one positive and negative control for PCR amplification.
- Lanes 1 to 39 contain the PCR fragments in (A) after performing the Surveyor's mutation detection assay.
- FIG. 7 is a photographic image of fluorescently stained DNA fragments resolved on an agarose gel. The leftmost and rightmost lanes contain a DNA ladder.
- Lanes contain PCR fragments amplified using mMdria- specific primers from mouse embryos in FIG 6, and digested with Notl without purifying the PCR product.
- FIG. 7B is a longer run of the same gel in FIG. 7A. The uncut PCR products are around 1.8 kb, and the digested products are two bands around 900 bp.
- FIG. 8 is a photographic image of fluorescently stained DNA fragments resolved on an agarose gel. The leftmost lane contains a DNA ladder.
- Lanes 1 to 6 contain some of the PCR fragments from FIG 7 digested with Notl after the PCR products were column purified so that Notl can work in its optimal buffer.
- Lines 7 and 8 are two of the samples digested with Notl as in FIG 7. This gel shows Notl digestion in PCR reactions was complete.
- FIG. 9 is a photographic image of fluorescently stained PCR fragments resolved on an agarose gel.
- the leftmost lane contains a DNA ladder.
- Lanes 1 to 5 contain PCR fragments amplified using PXR-specific primers from 1 , 14, 1/6, 1/10, 1/30 of a rat blastocyst.
- Lane 6 is a positive control amplified using the same primers from purified Sprague Dawley genomic DNA.
- FIG. 10 is a photographic image of fluorescently stained
- Lanes contain PCR fragments amplified from rat embryos cultured in vitro after microinjection of PXR ZFN mRNA and the Notl RFLP donor, using PXR-specific primers and digested with Notl.
- Lanes contain the same PCR fragments as in FIG. 10A after performing the Surveyor's mutation detection assay.
- FIG. 11 is a photographic image of fluorescently stained
- DNA fragments resolved on an agarose gel The first 4 lanes are PCR amplified from 4 well developed fetus at 12.5 days post conception from embryos injected with mMdria ZFN mRNA with the Notl RFLP donor. The PCR was digested with Notl. Lane 4 is positive one. Lanes 5-8 are 4 decidua, aborted implantations. All four were negative.
- FIG. 12 is a schematic and photographic image of
- FIG. 13 is a photographic image of DNA fragments resolved on an agarose gel. Lane 8 represents a 13 dpc fetus positive for the Notl site.
- FIG. 14 illustrates ZFN-mediated cleavage of SMAD4 in human and feline cells, as detected by a Cel-1 surveyor nuclease assay.
- G GFP (no ZFN control).
- Z SMAD4 ZFN (191160/19159). Arrows denote cleavage products.
- FIG. 15 depicts Cel-1 assays confirming SMAD4 ZFN activity in cat embryos.
- FIG. 16 illustrates cleavage of FeI d1 in AKD cells.
- FIG. 17 illustrates cleavage of FeI d1 chain 1 -exon 2 in AKD cells by the FeI d1 ZFN pair 7, 9.
- FIG. 18 depicts Cel-1 analysis of the FeI d1 ZFN pair 12/13 cleavage of chain 1 -exon 2 in AKD cells.
- FIG. 19 illustrates cleavage of FeI d1 locus in cat embryos by ZFN pairs 17, 18 and 12, 13.
- Lanes 1 , 2, 7, and 8 contain samples from individual blastocysts derived from embryos injected with 40 ng/ ⁇ L of ZFNs.
- Lane 3 presents a sample from a blastocyst derived an embryo injected with 20 ng/ ⁇ L of ZFNs.
- Lanes 4, 9, and 10 contain samples from individual morulas derived from embryos injected with 40 ng/ ⁇ L of ZFNs.
- Lane 3 presents a sample from a morula derived an embryo injected with 20 ng/ ⁇ L of ZFNs.
- Lane 6 presents a sample from a control blastocyst.
- FIG. 20 presents the DNA sequence of an edited FeI d1 locus comprising a 4541 bp deletion (SEQ ID NO:51 ) between the regions coding for chain 2 and chain 1.
- FIG. 21 aligns the edited FeI d1 locus (designated by red dotted line, labeled "sample 5") comprising the 4541 bp deletion with the sequence of the wild-type FeI d1 locus (SEQ ID NO:52).
- the binding site for ZFN 13 is truncated (and the binding sire for ZFN 12 is missing), but the binding site for ZFN pair 17, 18 is intact.
- FIG. 22 depicts cleavage of the cauxin locus by cauxin ZFN pair 1/2 (lane 2), ZFN pair 9/10 (lane 4), and ZFN pair 17/18 (lane 5) in AKD cells.
- Lanes 1 and 3 contain samples from control (GFP) cells.
- FIG. 23 illustrates cleavage of the cauxin locus by cauxin
- Lane 2 contains a control (GFP) sample.
- FIG. 24 depicts integration at the TUBA1 B locus.
- A is a schematic showing the chromosome sequence (SEQ ID NO:85) at the target region for integration of the heterologous coding sequence, ZFN binding sites (yellow sequence) on the chromosome target region, the ZFN cut site (yellow arrow), and the integration site (green arrow).
- B presents schematics of the TUBA1 B locus, site of integration, design of the SH2 biosensor, and the proteins expressed after successful integration.
- C presents an image of a Western blot of wild-type and integrated cells.
- FIG. 25 depicts the map of a donor plasmid comprising the
- FIG. 26 presents differential interference contrast (DIC) and fluorescence microscopy images of individual isolated cell clones expressing the GFP-2xSH2-Grb1 -2A protein. Fluorescent images show a time course of biosensor translocation after exposure to 100 ng/mL of EGF.
- DIC differential interference contrast
- FIG. 27 presents the map of a donor plasmid comprising the
- FIG. 28 depicts fluorescence microscopy images of individual isolated cell clones expressing GFP-2xSH2-Grb1 -2A (upper panels) and RFP- ⁇ -actin (lower panels). Presented is a time course after exposure to 100 ng/mL of EGF.
- FIG. 29 presents the DNA sequences of two edited LRRK2 loci.
- the upper sequence (SEQ ID NO:92) has a 10 bp deletion in the target sequence of exon 30, and the lower sequence (SEQ ID NO:93) has a 8 bp deletion in the target sequence of exon 30.
- the exon is shown in green; the target site is presented in yellow, and the deletions are shown in dark blue.
- FIG. 30 presents the DNA sequences of two edited ApoE loci.
- the upper sequence (SEQ ID NO:114) has a 16 bp deletion in the target sequence of exon 2
- the lower sequence (SEQ ID NO:115) has a 1 bp deletion in the target sequence of exon 2.
- the exon sequence is shown in green; the target site is presented in yellow, and the deletions are shown in dark blue.
- FIG. 31 shows the DNA sequence of an edited leptin locus.
- FIG. 32 presents the DNA sequences of edited APP loci in two animals.
- A Shows a region of the rat APP locus (SEQ ID NO:127) in which 292 bp is deleted from exon 9.
- B Presents a region of the rat APP locus (SEQ ID NO:128) in which there is a 309 bp deletion in exon 9. The exon is shown in green; the target site is presented in yellow, and the deletion is shown in dark blue.
- FIG. 33 presents the DNA sequences of edited Rag1 loci in two animals.
- the upper sequence (SEQ ID NO:131 ) has a 808 bp deletion in exon 2
- the lower sequence (SEQ ID NO:132) has a 29 bp deletion in exon 2.
- the exon sequence is shown in green; the target site is presented in yellow, and the deletions are shown in dark blue.
- FIG. 34 presents the DNA sequences of edited Rag2 loci in two animals.
- the upper sequence (SEQ ID NO:133) has a 13 bp deletion in the target sequence in exon 3
- the lower sequence (SEQ ID NO:134) has a 2 bp deletion in the target sequence in exon 2.
- the exon sequence is shown in green; the target site is presented in yellow, and the deletions are shown in dark blue.
- FIG. 35 presents the DNA sequences of edited Mdri a loci in two animals.
- the upper sequence (SEQ ID NO:157) has a 20 bp deletion in exon 7
- the lower sequence (SEQ ID NO:158) has a 15 bp deletion and a 3 bp insertion (GCT) in exon 7.
- the exon sequence is shown in green; the target sequence is presented in yellow, and the deletions are shown in dark blue.
- FIG. 36 illustrates knockout of the Mdri a gene in rat.
- FIG. 37 presents the DNA sequences of edited Mrp1 loci in two animals.
- the upper sequence (SEQ ID NO:159) has a 43 bp deletion in exon 11
- the lower sequence (SEQ ID NO:160) has a 14 bp deletion in exon 11.
- the exon sequence is shown in green; the target sequence is presented in yellow, the deletions are shown in dark blue; and overlap between the target sequence and the exon is shown in grey.
- FIG. 38 shows the DNA sequence of an edited Mrp2 locus.
- the sequence (SEQ ID NO:161 ) has a 726 bp deletion in exon 7.
- the exon is shown in green; the target sequence is presented in yellow, and the deletion is shown in dark blue.
- FIG. 39 presents the DNA sequences of edited BCRP loci in two animals.
- A Shows a region of the rat BCRP locus (SEQ ID NO:162) comprising a 588 bp deletion in exon 7.
- B Presents a region of the rat BCRP locus (SEQ ID NO:163) comprising a 696 bp deletion in exon 7. The exon sequence is shown in green; the target site is presented in yellow, and the deletions are shown in dark blue.
- FIG. 40 presents target sites and ZFN validation of Mdri a, and two additional genes, Jag1 , and Notch3.
- A shows ZFN target sequences. The ZFN binding sites are underlined.
- B shows results of a mutation detection assay in NIH 3T3 cells to validate the ZFN mRNA activity. Each ZFN mRNA pair was cotransfected into NIH 3T3 cells. Transfected cells were harvested 24 h later. Genomic DNA was analyzed with the mutation detection assay to detect NHEJ products, indicative of ZFN activity.
- M PCR marker
- G las 1 , 3, and 5): GFP transfected control
- Z lanes 2, 4, and 6
- Uncut and cleaved bands are marked with respective sizes in base pairs.
- FIG. 41 presents identification of genetically engineered
- Mdri a founders using a mutation detection assay. Uncut and cleaved bands are marked with respective sizes in base pairs. Cleaved bands indicate a mutation is present at the target site. M, PCR marker. 1 -44, 44 pups born from injected eggs. The numbers of founders are underlined.
- FIG. 42 presents amplification of large deletions in MdM a founders. PCR products were amplified using primers located 800 bp upstream and downstream of the ZFN target site. Bands significantly smaller than the 1.6 kb wild-type band indicate large deletions in the target locus. Four founders that were not identified in Figure 7 are underlined.
- FIG. 43 presents the results of a mutation detection assay at the Mdri b site in 44 MdM a ZFN injected pups.
- M PCR marker
- WT toe DNA from FVB/N mice that were not injected with Mdri a ZFNs
- FIG. 44 presents detection of Mdri a expression by using
- RT-PCR in MdM a-/- mice is a schematic illustration of Mdria genomic and mRNA structures around the target site. Exons are represented by open rectangles with respective numbers. The size of each exon in base pairs is labeled directly underneath, lntron sequences are represented by broken bars with size in base pairs underneath. The ZFN target site in exon 7 is marked with a solid rectangle. The position of the 396 bp deletion in founder #23 is labeled above intron 6 and exon 7.
- RT-F and RT-R are the primers used in RT-PCR, located in exons 5 and 9, respectively. In the RT reaction, 40 ng of total RNA was used as template. Normalization of the input RNA is confirmed by GAPDH amplification with or without RT.
- FIG. 45 presents the results of band isolation following isolation and purification of the species at the wild-type size in the MdM a-/- samples, and then use as a template in a nested PCR.
- FIG. 46 shows the DNA sequences of edited BDNF loci in two animals. The upper sequence (SEQ ID NO:211 ) has a 14 bp deletion in the target sequence in exon 2, and the lower sequence (SEQ ID NO:212) has a 7 bp deletion in the target sequence in exon 2. The exon is shown in green; the target site is presented in yellow, and the deletions are shown in dark blue.
- FIG. 47 presents the DNA sequence of an edited DISC1 locus.
- a region of the rat DISC1 (SEQ ID NO:225) in which there is a 20 bp deletion in the target sequence in exon 5. The exon is shown in green; the target site is presented in yellow, and the deletion is shown in dark blue.
- FIG. 48 illustrates editing of the p53 locus in rats.
- a Cel-1 assay in which the presence of cleavage products indicated editing of the p53 gene.
- FIG. 49 illustrates knockout of the p53 gene in rats.
- the present disclosure provides a method for creating a genetically modified animal or animal cell comprising at least one edited chromosomal sequence.
- the edited chromosomal sequence may be (1 ) inactivated, (2) modified, or (3) comprise an integrated sequence.
- An inactivated chromosomal sequence is altered such that a functional protein is not made or a control sequence no longer functions the same as a wild-type control sequence.
- a genetically modified animal comprising an inactivated chromosomal sequence may be termed a "knock-out” or a “conditional knock-out.”
- a genetically modified animal comprising an integrated sequence may be termed a "knock-in” or a “conditional knock-in.”
- a knock-in animal may be a humanized animal.
- a genetically modified animal comprising a modified chromosomal sequence may comprise a targeted point mutation(s) or other modification such that an altered protein product is produced.
- chromosomal sequence generally is edited using a zinc finger nuclease- mediated process.
- the process comprises introducing into a cell at least one nucleic acid encoding a targeted zinc finger nuclease and, optionally, at least one accessory polynucleotide.
- the method further comprises incubating the cell to allow expression of the zinc finger nuclease, wherein a double-stranded break introduced into the targeted chromosomal sequence by the zinc finger nuclease is repaired by an error-prone non-homologous end-joining DNA repair process or a homology-directed DNA repair process.
- the cell is an embryo.
- the method of editing chromosomal sequences using targeted zinc finger nuclease technology as described herein is rapid, precise, and highly efficient.
- the invention encompasses an animal or a cell comprising at least one edited chromosomal sequence.
- a method of the invention, an animal of the invention, a cell of the invention, and applications thereof are described in more detail below.
- chromosomal editing refers to editing a chromosomal sequence such that the sequence is (1 ) inactivated, (2) modified, or (3) comprises an integrated sequence.
- a method for editing a chromosomal sequence comprises: (a) introducing into a cell at least one nucleic acid encoding a zinc finger nuclease that recognizes a target sequence in the chromosomal sequence and is able to cleave a site in the chromosomal sequence, and, optionally, (i) at least one donor polynucleotide comprising a sequence for integration, the sequence flanked by an upstream sequence and a downstream sequence that share substantial sequence identity with either side of the cleavage site, or (ii) at least one exchange polynucleotide comprising a sequence that is substantially identical to a portion of the
- chromosomal sequence at the cleavage site and which further comprises at least one nucleotide change and (b) culturing the cell to allow expression of the zinc finger nuclease such that the zinc finger nuclease introduces a double-stranded break into the chromosomal sequence, and wherein the double-stranded break is repaired by (i) a non-homologous end-joining repair process such that a mutation is introduced into the chromosomal sequence, or (ii) a homology-directed repair process such that the sequence in the donor polynucleotide is integrated into the chromosomal sequence or the sequence in the exchange polynucleotide is exchanged with the portion of the chromosomal sequence.
- the method comprises, in part, introducing into a cell at least one nucleic acid encoding a zinc finger nuclease.
- a zinc finger nuclease comprises a DNA binding domain (i.e., zinc finger) and a cleavage domain (i.e., nuclease).
- the DNA binding and cleavage domains are described below.
- the nucleic acid encoding a zinc finger nuclease may comprise DNA or RNA.
- the nucleic acid encoding a zinc finger nuclease may comprise mRNA.
- the nucleic acid encoding a zinc finger nuclease comprises mRNA
- the mRNA molecule may be 5' capped.
- the nucleic acid encoding a zinc finger nuclease comprises mRNA
- the mRNA molecule may be polyadenylated.
- An exemplary nucleic acid according to the method is a capped and polyadenylated mRNA molecule encoding a zinc finger nuclease. Methods for capping and polyadenylating mRNA are known in the art.
- a zinc finger nuclease of the invention once introduced into a cell, creates a double-stranded break in the chromosomal sequence.
- the double-stranded break may be repaired, in certain embodiments, by a non-homologous end-joining repair process of the cell, such that a mutation is introduced into the chromosomal sequence.
- a homology-directed repair process is used to edit the chromosomal sequence.
- Zinc finger binding domains may be engineered to recognize and bind to any nucleic acid sequence of choice. See, for example, Beerli et al. (2002) Nat. Biotechnol. 20:135-141 ; Pabo et al. (2001 ) Ann. Rev. Biochem. 70:313-340; lsalan et al. (2001 ) Nat. Biotechnol. 19:656-660; Segal et al. (2001 ) Curr. Opin. Biotechnol. 12:632-637; Choo et al. (2000) Curr. Opin. Struct. Biol. 10:411 -416; Zhang et al. (2000) J. Biol. Chem.
- An engineered zinc finger binding domain may have a novel binding specificity compared to a naturally-occurring zinc finger protein.
- Engineering methods include, but are not limited to, rational design and various types of selection.
- Rational design includes, for example, using databases comprising doublet, triplet, and/or quadruplet nucleotide sequences and individual zinc finger amino acid sequences, in which each doublet, triplet or quadruplet nucleotide sequence is associated with one or more amino acid sequences of zinc fingers which bind the particular triplet or quadruplet sequence.
- databases comprising doublet, triplet, and/or quadruplet nucleotide sequences and individual zinc finger amino acid sequences, in which each doublet, triplet or quadruplet nucleotide sequence is associated with one or more amino acid sequences of zinc fingers which bind the particular triplet or quadruplet sequence.
- U.S. Patent Nos. 6,453,242 and 6,534,261 the disclosures of which are incorporated by reference herein in their entireties.
- the algorithm described in U.S. Patent No. 6,453,242 may be used to design a zinc finger binding domain to target a preselected sequence.
- a zinc finger DNA binding domain may be designed to recognize a DNA sequence ranging from about 3 nucleotides to about 21 nucleotides in length, or from about 8 to about 19 nucleotides in length.
- the zinc finger binding domains of the zinc finger nucleases disclosed herein comprise at least three zinc finger recognition regions (i.e., zinc fingers).
- the zinc finger binding domain may comprise four zinc finger recognition regions.
- the zinc finger binding domain may comprise five zinc finger recognition regions.
- the zinc finger binding domain may comprise six zinc finger recognition regions.
- a zinc finger binding domain may be designed to bind to any suitable target DNA sequence. See for example, U.S. Patent Nos. 6,607,882; 6,534,261 and
- Exemplary methods of selecting a zinc finger recognition region may include phage display and two-hybrid systems, and are disclosed in U.S. Patent. Nos. 5,789,538; 5,925,523; 6,007,988; 6,013,453; 6,410,248;
- Zinc finger binding domains and methods for design and construction of fusion proteins are known to those of skill in the art and are described in detail in U.S. Patent Application Publication Nos. 20050064474 and 20060188987, each incorporated by reference herein in its entirety.
- Zinc finger recognition regions and/or multi- fingered zinc finger proteins may be linked together using suitable linker sequences, including for example, linkers of five or more amino acids in length. See, U.S. Patent Nos. 6,479,626; 6,903,185; and 7,153,949, the disclosures of which are incorporated by reference herein in their entireties, for non-limiting examples of linker sequences of six or more amino acids in length.
- the zinc finger binding domain described herein may include a combination of suitable linkers between the individual zinc fingers of the protein.
- the zinc finger nuclease may further comprise a nuclear localization signal or sequence (NLS).
- NLS nuclear localization signal or sequence
- a NLS is an amino acid sequence which facilitates targeting the zinc finger nuclease protein into the nucleus to introduce a double stranded break at the target sequence in the chromosome.
- Nuclear localization signals are known in the art. See, for example, Makkerh et al. (1996) Current Biology 6:1025-1027.
- a zinc finger nuclease also includes a cleavage domain.
- the cleavage domain portion of the zinc finger nucleases disclosed herein may be obtained from any endonuclease or exonuclease.
- Non-limiting examples of endonucleases from which a cleavage domain may be derived include, but are not limited to, restriction endonucleases and homing endonucleases. See, for example, 2002-2003 Catalog, New England Biolabs, Beverly, Mass.; and Belfort et al. (1997) Nucleic Acids Res. 25:3379-3388 or www.neb.com.
- cleave DNA e.g., S1 Nuclease; mung bean nuclease; pancreatic DNase I; micrococcal nuclease; yeast HO endonuclease. See also Linn et al. (eds.) Nucleases, Cold Spring Harbor Laboratory Press, 1993. One or more of these enzymes (or functional fragments thereof) may be used as a source of cleavage domains.
- a cleavage domain also may be derived from an enzyme or portion thereof, as described above, that requires dimehzation for cleavage activity.
- Two zinc finger nucleases may be required for cleavage, as each nuclease comprises a monomer of the active enzyme dimer.
- a single zinc finger nuclease may comprise both monomers to create an active enzyme dimer.
- an "active enzyme dimer” is an enzyme dimer capable of cleaving a nucleic acid molecule.
- the two cleavage monomers may be derived from the same endonuclease (or functional fragments thereof), or each monomer may be derived from a different endonuclease (or functional fragments thereof).
- the recognition sites for the two zinc finger nucleases are preferably disposed such that binding of the two zinc finger nucleases to their respective recognition sites places the cleavage monomers in a spatial orientation to each other that allows the cleavage monomers to form an active enzyme dimer, e.g., by dimerizing.
- the near edges of the recognition sites may be separated by about 5 to about 18 nucleotides. For instance, the near edges may be separated by about 5, 6, 7, 8, 9, 10, 11 , 12, 13, 14, 15, 16, 17 or 18 nucleotides.
- any integral number of nucleotides or nucleotide pairs may intervene between two recognition sites (e.g., from about 2 to about 50 nucleotide pairs or more).
- the near edges of the recognition sites of the zinc finger nucleases such as for example those described in detail herein, may be separated by 6 nucleotides.
- the site of cleavage lies between the recognition sites.
- Restriction endonucleases are present in many species and are capable of sequence-specific binding to DNA (at a recognition site), and cleaving DNA at or near the site of binding.
- Certain restriction enzymes e.g., Type IIS
- Fok I catalyzes double-stranded cleavage of DNA, at 9 nucleotides from its recognition site on one strand and 13 nucleotides from its recognition site on the other. See, for example, U.S. Patent Nos.
- a zinc finger nuclease may comprise the cleavage domain from at least one Type IIS restriction enzyme and one or more zinc finger binding domains, which may or may not be engineered.
- Exemplary Type IIS restriction enzymes are described for example in
- An exemplary Type MS restriction enzyme whose cleavage domain is separable from the binding domain, is Fok I.
- This particular enzyme is active as a dimer (Bitinaite et al. (1998) Proc. Natl. Acad. Sci. USA 95: 10, 570- 10, 575).
- the portion of the Fok I enzyme used in a zinc finger nuclease is considered a cleavage monomer.
- two zinc finger nucleases each comprising a Fokl cleavage monomer, may be used to reconstitute an active enzyme dimer.
- a single polypeptide molecule containing a zinc finger binding domain and two Fok I cleavage monomers may also be used.
- the cleavage domain may comprise one or more engineered cleavage monomers that minimize or prevent
- amino acid residues at positions 446, 447, 479, 483, 484, 486, 487, 490, 491 , 496, 498, 499, 500, 531 , 534, 537, and 538 of Fok I are all targets for influencing dimehzation of the Fok I cleavage half-domains.
- Exemplary engineered cleavage monomers of Fok I that form obligate heterodimers include a pair in which a first cleavage monomer includes mutations at amino acid residue positions 490 and 538 of Fok I and a second cleavage monomer that includes mutations at amino-acid residue positions 486 and 499.
- the engineered cleavage monomers may be prepared by mutating positions 490 from E to K and 538 from I to K in one cleavage monomer to produce an engineered cleavage monomer designated "E49OK:I538K” and by mutating positions 486 from Q to E and 499 from I to L in another cleavage monomer to produce an engineered cleavage monomer designated "Q486E:I499L.”
- the above described engineered cleavage monomers are obligate heterodimer mutants in which aberrant cleavage is minimized or abolished.
- Engineered cleavage monomers may be prepared using a suitable method, for example, by site-directed mutagenesis of wild-type cleavage monomers (Fok I) as described in U.S. Patent Publication No. 20050064474 (see Example 5).
- the zinc finger nuclease described above may be any zinc finger nuclease.
- the double stranded break may be at the targeted site of integration, or it may be up to 1 , 2, 3, 4, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 100, or 1000 nucleotides away from the site of integration. In some embodiments, the double stranded break may be up to 1 , 2, 3, 4, 5, 10, 15, or 20 nucleotides away from the site of integration. In other embodiments, the double stranded break may be up to 10, 15, 20, 25, 30, 35, 40, 45, or 50 nucleotides away from the site of integration. In yet other embodiments, the double stranded break may be up to 50, 100, or 1000 nucleotides away from the site of integration.
- a zinc finger nuclease of the invention may have an amino acid sequence that is at least 80% identical to a sequence chosen from a zinc finger nuclease having a SEQ ID NO chosen from 53, 54, 57- 62, 69-76, 104-113, 123-126, 147-156, 201 -210, 219-222, 223-224, 230-233, 240-243.
- sequence identity may be about 81 , 82, 83, 84, 85, 86, 87, 88, 89, 90, 91 , 92, 93, 94, 95, 96, 97, 98, 99, or 100%.
- NO chosen from 53, 54, 57-62, 69-76, 104-113, 123-126, 147-156, 201 -210, 219-222, 223-224, 230-233, 240-243 may recognize and bind a chromosomal sequence having at least about 80, 81 , 82, 83, 84, 85, 86, 87, 88, 89, 90, 91 , 92, 93, 94, 95, 96, 97, 98, 99, or 100% sequence identity to a chromosomal SEQ ID NO 55, 56, 63-68, 77-84, 86- 91 , 94-103, 117-122, 129, 130, 135, 136, 137, 138, 139-146, 164-173, 213-218, 226-229, 234, 235, 236, 237, 238, 239.
- nuclease having a target site in a chromosome may be used in the methods disclosed herein.
- homing endonucleases and meganucleases have very long recognition sequences, some of which are likely to be present, on a statistical basis, once in a human-sized genome.
- Any such nuclease having a unique target site in a genome may be used instead of, or in addition to, a zinc finger nuclease, for targeted cleavage of a chromosome.
- Non-limiting examples of homing endonucleases include I-
- endonucleases is not absolute with respect to their recognition sites, the sites are of sufficient length that a single cleavage event per mammalian-sized genome may be obtained by expressing a homing endonuclease in a cell containing a single copy of its recognition site. It has also been reported that the specificity of homing endonucleases and meganucleases may be engineered to bind non- natural target sites. See, for example, Chevalier et al. (2002) Molec. Cell 10:895- 905; Epinat et al. (2003) Nucleic Acids Res. 31 :2952-2962; Ashworth et al.
- a method for editing chromosomal sequences may further comprise introducing into a cell at least one exchange polynucleotide comprising a sequence that is substantially identical to the chromosomal sequence at the site of cleavage and which further comprises at least one specific nucleotide change.
- the exchange polynucleotide will be DNA.
- the exchange polynucleotide may be a DNA plasmid, a bacterial artificial
- chromosome BAC
- yeast artificial chromosome a viral vector
- BAC chromosome
- YAC yeast artificial chromosome
- viral vector a linear piece of DNA, a PCR fragment, a naked nucleic acid, or a nucleic acid
- An exemplary exchange polynucleotide may be a DNA plasmid.
- sequence of the exchange polynucleotide will share enough sequence identity with the chromosomal sequence such that the two sequences may be exchanged by homologous recombination.
- sequence in the exchange polynucleotide may be at least about 80, 81 , 82, 83, 84, 85, 86, 87, 88, 89, 90, 91 , 92, 93, 94, 95, 96, 97, 98, or 99% identical to a region of the chromosomal sequence.
- the sequence in the exchange polynucleotide comprises at least one specific nucleotide change with respect to the sequence of the corresponding chromosomal sequence.
- one nucleotide in a specific codon may be changed to another nucleotide such that the codon codes for a different amino acid.
- the sequence in the exchange polynucleotide may comprise one specific nucleotide change such that the encoded protein comprises one amino acid change.
- the sequence in the exchange polynucleotide may comprise two, three, four, or more specific nucleotide changes such that the encoded protein comprises one, two, three, four, or more amino acid changes.
- sequence in the exchange polynucleotide may comprise a three nucleotide deletion or insertion such that the reading frame of the coding reading is not altered (and a functional protein may be produced).
- the expressed protein would comprise a single amino acid deletion or insertion.
- the length of the sequence in the exchange polynucleotide that is substantially identical to a portion of the chromosomal sequence at the site of cleavage can and will vary.
- the sequence in the exchange polynucleotide may range from about 25 bp to about 10,000 bp in length.
- the sequence in the exchange polynucleotide may be about 50, 100, 200, 400, 600, 800, 1000, 1200, 1400, 1600, 1800, 2000, 2200, 2400, 2600, 2800, 3000, 3200, 3400, 3600, 3800, 4000, 4200, 4400, 4600, 4800, or 5000 bp in length.
- the sequence in the exchange polynucleotide may be about 5500, 6000, 6500, 6000, 6500, 7000, 7500, 8000, 8500, 9000, 9500, or 10,000 bp in length.
- a double stranded break introduced into the chromosomal sequence by the zinc finger nuclease is repaired, via homologous recombination with the exchange polynucleotide, such that the sequence in the exchange polynucleotide may be exchanged with a portion of the chromosomal sequence.
- the presence of the double stranded break facilitates homologous recombination and repair of the break.
- the exchange polynucleotide may be physically integrated or, alternatively, the exchange polynucleotide may be used as a template for repair of the break, resulting in the exchange of the sequence information in the exchange polynucleotide with the sequence information in that portion of the chromosomal sequence.
- a portion of the endogenous chromosomal sequence may be converted to the sequence of the exchange polynucleotide.
- the changed nucleotide(s) may be at or near the site of cleavage. Alternatively, the changed nucleotide(s) may be anywhere in the exchanged sequences. As a consequence of the exchange, however, the chromosomal sequence is modified.
- a method for editing chromosomal sequences may alternatively comprise introducing at least one donor polynucleotide comprising a sequence for integration into a cell.
- a donor polynucleotide comprises at least three components: the sequence to be integrated that is flanked by an upstream sequence and a downstream sequence, wherein the upstream and downstream sequences share sequence similarity with either side of the site of integration in the chromosome.
- the donor polynucleotide will be DNA.
- the donor polynucleotide may be a DNA plasmid, a bacterial artificial chromosome (BAC), a yeast artificial chromosome (YAC), a viral vector, a linear piece of DNA, a PCR fragment, a naked nucleic acid, or a nucleic acid complexed with a delivery vehicle such as a liposome or poloxamer.
- An exemplary donor polynucleotide may be a DNA plasmid.
- the donor polynucleotide comprises a sequence for integration.
- the sequence for integration may be a sequence endogenous to the animal or cell or it may be an exogenous sequence.
- the sequence for integration may encode a protein or a non-coding RNA (e.g., a microRNA).
- sequence for integration may be operably linked to an appropriate control sequence or sequences.
- sequence for integration may provide a regulatory function. Accordingly, the size of the sequence for integration can and will vary. In general, the sequence for integration may range from about one nucleotide to several million nucleotides.
- the donor polynucleotide also comprises upstream and downstream sequence flanking the sequence to be integrated.
- the upstream and downstream sequences in the donor polynucleotide are selected to promote recombination between the chromosomal sequence of interest and the donor polynucleotide.
- the upstream sequence refers to a nucleic acid sequence that shares sequence similarity with the chromosomal sequence upstream of the targeted site of integration.
- the downstream sequence refers to a nucleic acid sequence that shares sequence similarity with the chromosomal sequence downstream of the targeted site of integration.
- the upstream and downstream sequences in the donor polynucleotide may share about 75%, 80%, 85%, 90%, 95%, or 100% sequence identity with the targeted chromosomal sequence. In other embodiments, the upstream and downstream sequences in the donor polynucleotide may share about 95%, 96%, 97%, 98%, 99%, or 100% sequence identity with the targeted chromosomal sequence. In an exemplary embodiment, the upstream and downstream sequences in the donor polynucleotide may share about 99% or 100% sequence identity with the targeted chromosomal sequence.
- An upstream or downstream sequence may comprise from about 20 bp to about 2500 bp.
- an upstream or downstream sequence may comprise about 50, 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100, 1200, 1300, 1400, 1500, 1600, 1700, 1800, 1900, 2000, 2100, 2200, 2300, 2400, or 2500 bp.
- An exemplary upstream or downstream sequence may comprise about 200 bp to about 2000 bp, about 600 bp to about 1000 bp, or more particularly about 700 bp to about 1000 bp.
- the donor polynucleotide may further comprise a marker.
- a marker may make it easy to screen for targeted integrations.
- suitable markers include restriction sites, fluorescent proteins, or selectable markers.
- a donor polynucleotide may be physically integrated or, alternatively, the donor polynucleotide may be used as a template for repair of the break, resulting in the introduction of the sequence as well as all or part of the upstream and downstream sequences of the donor polynucleotide into the chromosome.
- the endogenous chromosomal sequence may be converted to the sequence of the donor polynucleotide.
- At least one nucleic acid molecule encoding a zinc finger nuclease and, optionally, at least one exchange polynucleotide or at least one donor polynucleotide is introduced into a cell.
- the term "cell” encompasses any animal cell that comprises a chromosomal sequence.
- the term "cell” may refer to an embryo.
- the embryo is a fertilized one-cell stage embryo. In other exemplary embodiments, the embryo may be an embryo of any stage.
- Suitable methods of introducing the nucleic acids to the embryo or cell may include microinjection, electroporation, sonoporation, biolistics, calcium phosphate-mediated transfection, cationic transfection, liposome transfection, dendrimer transfection, heat shock transfection, nucleofection transfection, magnetofection, lipofection, impalefection, optical transfection, proprietary agent-enhanced uptake of nucleic acids, and delivery via liposomes, immunoliposomes, virosomes, or artificial virions.
- biolistics calcium phosphate-mediated transfection, cationic transfection, liposome transfection, dendrimer transfection, heat shock transfection, nucleofection transfection, magnetofection, lipofection, impalefection, optical transfection, proprietary agent-enhanced uptake of nucleic acids, and delivery via liposomes, immunoliposomes, virosomes, or artificial virions.
- the nucleic acids may be introduced into an embryo by
- the nucleic acids may be microinjected into the nucleus or the cytoplasm of the embryo. In another embodiment, the nucleic acids may be introduced into a cell by nucleofection.
- the ratio of exchange (or donor) polynucleotide to nucleic acid encoding a zinc finger nuclease may range from about 1 :10 to about 10:1.
- the ratio of exchange (or donor) polynucleotide to nucleic acid encoding a zinc finger nuclease may be about 1 :10, 1 :9, 1 :8, 1 :7, 1 :6, 1 :5, 1 :4, 1 :3, 1 :2, 1 :1 , 2:1 , 3:1 , 4:1 , 5:1 , 6:1 , 7:1 , 8:1 , 9:1 , or 10:1.
- the ratio of exchange (or donor) polynucleotide to nucleic acid encoding a zinc finger nuclease may be about 1 :10, 1 :9, 1 :8, 1 :7, 1 :6, 1 :5, 1 :4, 1 :3, 1 :2, 1 :1 , 2:1 , 3:1 , 4:1 , 5:1 , 6:1 , 7:1 , 8:1 , 9:1 , or 10:1.
- the ratio may be about 1 :1.
- nucleic acids may be introduced simultaneously or sequentially.
- nucleic acids encoding the zinc finger nucleases, each specific for a distinct recognition sequence, as well as the optional exchange (or donor) polynucleotides may be introduced at the same time.
- each nucleic acid encoding a zinc finger nuclease, as well as the optional exchange (or donor) polynucleotides may be introduced sequentially.
- At least one nucleic acid molecule encoding a zinc finger nuclease is introduced into a cell. In another embodiment, at least 2, 3, 4, 5, or more than 5 nucleic acid molecules encoding a zinc finger nuclease are introduced into a cell. In each of the above embodiments, one or more corresponding donor or exchange polynucleotides may also be introduced into the cell, in a ratio from about 1 : 10 to about 10:1 donor or exchange
- polynucleotides to zinc finger nuclease nucleic acids as described above.
- a method for editing a chromosomal sequence using a zinc finger nuclease-mediated process as described herein further comprises culturing the cell comprising the introduced nucleic acid(s) to allow expression of the at least one zinc finger nuclease.
- Cells comprising the introduced nucleic acids may be cultured using standard procedures to allow expression of the zinc finger nuclease. Standard cell culture techniques are described, for example, in
- the embryo may be cultured in vitro (e.g., in cell culture). Typically, the embryo is cultured for a short period of time at an appropriate temperature and in appropriate media with the necessary O2/CO2 ratio to allow the expression of the zinc finger nuclease.
- culture conditions can and will vary depending on the embryo species. Routine optimization may be used, in all cases, to determine the best culture conditions for a particular species of embryo.
- a cell line may be derived from an in vitro-cultured embryo (e.g., an embryonic stem cell line).
- the embryo will be cultured in vivo by transferring the embryo into the uterus of a female host.
- the female host is from the same or a similar species as the embryo.
- the female host is pseudo-pregnant. Methods of preparing pseudo-pregnant female hosts are known in the art. Additionally, methods of transferring an embryo into a female host are known. Culturing an embryo in vivo permits the embryo to develop and may result in a live birth of an animal derived from the embryo. Such an animal generally will comprise the disrupted chromosomal sequence(s) in every cell of its body.
- the chromosomal sequence of the cell may be edited.
- the zinc finger nuclease recognizes, binds, and cleaves the target sequence in the chromosomal sequence of interest.
- the double-stranded break introduced by the zinc finger nuclease is repaired by an error-prone nonhomologous end-joining DNA repair process. Consequently, a deletion, or insertion resulting in a missense or nonsense mutation may be introduced in the chromosomal sequence such that the sequence is inactivated.
- the zinc finger nuclease recognizes, binds, and cleaves the target sequence in the chromosome.
- the double-stranded break introduced by the zinc finger nuclease is repaired, via homologous recombination with the exchange (or donor) polynucleotide, such that a portion of the chromosomal sequence is converted to the sequence in the exchange polynucleotide or the sequence in the donor polynucleotide is integrated into the chromosomal sequence.
- the chromosomal sequence is edited.
- the genetically modified animals disclosed herein may be crossbred to create animals comprising more than one edited chromosomal sequence or to create animals that are homozygous for one or more edited chromosomal sequences. Those of skill in the art will appreciate that many combinations are possible. Moreover, the genetically modified animals disclosed herein may be crossed with other animals to combine the edited chromosomal sequence with other genetic backgrounds.
- suitable genetic backgrounds include wild-type, natural mutations giving rise to known phenotypes, targeted chromosomal integration, non-targeted integrations, etc.
- an edited chromosomal sequence may be inactivated such that the sequence is not transcribed, the coded protein is not produced, or the sequence does not function as the wild-type sequence does.
- a protein coding sequence may be inactivated such that the protein is not produced.
- a microRNA coding sequence may be inactivated such that the microRNA is not produced.
- a control sequence may be inactivated such that it no longer functions as a control sequence.
- control sequence refers to any nucleic acid sequence that effects the transcription, translation, or accessibility of a nucleic acid sequence.
- a promoter, a transcription terminator, and an enhancer are control sequences.
- the inactivated chromosomal sequence may include a deletion mutation (i.e., deletion of one or more nucleotides), an insertion mutation (i.e., insertion of one or more nucleotides), or a nonsense mutation (i.e., substitution of a single nucleotide for another nucleotide such that a stop codon is introduced).
- a chromosomal sequence that is inactivated may be termed a "knock-out.”
- a "knock-out" animal created by a method of the invention does not comprise any exogenous sequence.
- an edited chromosomal sequence may be modified such that it codes for an altered gene product or the function of the sequence is altered.
- a chromosomal sequence encoding a protein may be modified to include at least one changed nucleotide such that the codon comprising the changed nucleotide codes for a different amino acid.
- the resultant protein therefore, comprises at least one amino acid change.
- a protein coding sequence may be modified by insertions or deletions such that the reading from of the sequence is not altered and a modified protein is produced.
- the modified sequence may result in a phenotype change.
- a chromosomal sequence that functions as a control sequence may be modified.
- a promoter may be modified such that it is always active or is regulated by an exogenous signal.
- At least one chromosomal sequence encoding a protein of interest may be edited such that the expression pattern of the protein is altered.
- regulatory regions controlling the expression of the protein such as a promoter or transcription factor binding site, may be altered such that the protein of interest is over-produced, or the tissue- specific or temporal expression of the protein is altered, or a combination thereof. / ' / ' / ' . integrate a sequence
- an edited chromosomal sequence may comprise an integrated sequence.
- Such a sequence may encode an endogenous protein, an exogenous or heterologous protein, a wild-type protein, a modified protein, a fusion protein, a microRNA, or the like.
- An integrated protein coding sequence may be linked to a reporter sequence (the reporter sequence may be linked 5' or 3' to the protein coding sequence).
- An integrated protein coding sequence may also be placed under control of an endogenous promoter, may be operably linked to an exogenous promoter, or may be fused in-frame with an endogenous protein coding sequence.
- the integrated sequence may function as a control element.
- the integrated sequence may be endogenous or exogenous to the cell.
- An animal or cell comprising such an integrated sequence may be termed "knock-in.” In one iteration of the above embodiments, it should be understood that no selectable marker is present.
- a sequence may be integrated to alter the expression pattern of a protein of interest. For instance, a conditional knock-out system may be created.
- a sequence may be edited to alter the expression pattern of a protein of interest. For instance, a conditional knockout system may be created.
- conditional knock-out system is a model where the expression of a nucleic acid molecule is disrupted in a particular organ, tissue, or cell type, as opposed to the entire animal, and/or in a temporally controlled manner.
- a conditional knock-out allows, for example, the study of a gene function even when global disruption of the gene is lethal.
- a non-limiting example of a conditional knock-out system includes a Cre-lox recombination system.
- a Cre-lox recombination system comprises a Cre recombinase enzyme, a site-specific DNA recombinase that can catalyse the recombination of a nucleic acid sequence between specific sites (lox sites) in a nucleic acid molecule.
- Methods of using this system to produce temporal and tissue specific expression are known in the art.
- a genetically modified cell is generated with lox sites flanking a chromosomal sequence of interest.
- a genetically modified animal comprising a cell with the lox-flanked chromosomal sequence of interest may then be crossed with another genetically modified animal expressing Cre recombinase in one or more cells.
- Progeny animals comprising one or more cells comprising a lox-flanked chromosomal sequence and one or more cells comprising a Cre recombinase are then produced.
- the lox-flanked chromosomal sequence encoding a protein of interest is recombined, leading to deletion or inversion of the chromosomal sequence encoding the protein of interest.
- Expression of Cre recombinase may be temporally and conditionally regulated to effect temporally and conditionally regulated recombination of the chromosomal sequence encoding the protein of interest.
- a method of the invention may be used to integrate a mutation that disrupts an endogenous locus.
- a chromosomal sequence may be disrupted by the substitution of an exogenous sequence for an endogenous sequence, such that the exogenous sequence is under the control of the endogenous promoter.
- the disrupted endogenous sequence would not be expressed, but the integrated exogenous sequence would be expressed.
- the exogenous sequence may be a homolog of the endogenous sequence.
- the exogenous sequence may be a human sequence when the endogenous sequence is non-human.
- the exogenous sequence may be unrelated to the endogenous sequence it is replacing.
- an endogenous sequence may be substituted for an exogenous marker such that when the endogenous promoter is active, the marker is detectable.
- the marker may be an enzymatic marker that can amplify the detectable signal of the marker.
- a method of the invention may be used to substitute an endogenous promoter or other regulatory sequence with an exogenous promoter or regulator sequence.
- the expression pattern of the locus would be dictated by the exogenous promoter or regulatory sequence, as opposed to the endogenous promoter or regulatory sequence.
- Such an exogenous promoter or regulatory sequence may be a homolog of the endogenous promoter or regulatory sequence.
- the exogenous sequence may be a human sequence when the endogenous sequence is non-human.
- the exogenous sequence may be unrelated to the endogenous sequence it is replacing.
- a method of the invention may be used to integrate an exogenous sequence, with or without a promoter, into a chromosomal sequence without disrupting the expression of an endogenous locus.
- integration may be in a "safe harbor" locus, such as Rosa26 locus in the rat (or an equivalent in another animal) or the HPRT locus on the X chromosome in the rat (or an equivalent in another animal).
- a cassette comprising an exogenous promoter operably linked to an exogenous nucleic acid sequence may be integrated into a safe harbor locus.
- the exogenous promoter may be conditional.
- a conditional promoter may be a tissue-specific promoter, an organ specific promoter, or a cell-type specific promoter (such as a stem cell promoter, a B-cell promoter, a hair cell promoter, etc.) or an inducible promoter.
- An inducible promoter is a promoter that is active only in the presence of a particular substance, such as an antibiotic, a drug, or other exogenous compound.
- the integration of a cassette comprising a conditional promoter may be used to track cell lineages.
- an exogenous nucleic acid sequence may be integrated to serve as a detectable marker for a particular nucleic acid sequence.
- the genetically modified animal may be a "humanized" animal comprising at least one chromosomally integrated sequence encoding a functional human protein.
- the functional human protein may have no corresponding ortholog in the genetically modified animal.
- the wild-type animal from which the genetically modified animal is derived may comprise an ortholog corresponding to the functional human protein.
- the orthologous sequence in the "humanized” animal is inactivated such that no endogenous functional protein is made and the "humanized” animal comprises at least one chromosomally integrated sequence encoding the human protein.
- "humanized” animals may be generated by crossing a knock-out animal with a knock-in animal comprising the chromosomally integrated sequence.
- a further embodiment of the above invention comprises performing a method of the invention serially, such that a cell is developed with more than one chromosomal edit. For instance, an embryo with a first edit may be cultured to produce an animal comprising the first genomic edit. An embryo deriving from this animal may then be used in a method of the invention to create a second genomic edit. The same process may be repeated to create an embryo with three, four, five, six, seven, eight, nine, ten or more than ten genomic edits.
- a cell with multiple genomic edits may be developed by simultaneoulsy introducing more than one zinc finger nuclease, each specific for a distinct edit site.
- a corresponding number of donor and/or exchange polynucleotides may optionally be introduced as well. The number of zinc finger nucleases and optional corresponding donor or exchange
- polynucleotides introduced into a cell may be two, three, four, five or more than five.
- a method of the invention may be used to create an animal or cell comprising an edited chromosomal sequence.
- Such an animal or cell may be used for several different applications, including, for instance, research applications, livestock applications, companion animal applications, or
- biomolecule production applications Non-limiting examples of such applications are detailed in sections (a) - (d) below.
- a method of the invention may be used to create an animal or cell that may be used in research applications.
- Such applications may include disease models, pharmacological models,
- a method of the invention may be used to create an animal or cell that may be used as a disease model.
- disease refers to a disease, disorder, or indication in a subject.
- a method of the invention may be used to create an animal or cell that comprises a chromosomal edit in one or more nucleic acid sequences associated with a disease.
- nucleic acid sequence may encode a disease associated protein sequence or may be a disease associated control sequence.
- an animal or cell created by a method of the invention may be used to study the effects of mutations on the animal or cell and development and/or progression of the disease using measures commonly used in the study of the disease.
- such an animal or cell may be used to study the effect of a pharmaceutically active compound on the disease.
- an animal or cell created by a method of the invention may be used to assess the efficacy of a potential gene therapy strategy. That is, a chromosomal sequence encoding a protein associated with a disease may be modified such that the disease development and/or progression is inhibited or reduced.
- the method comprises editing a chromosomal sequence encoding a protein associated with the disease such that an altered protein is produced and, as a result, the animal or cell has an altered response.
- a genetically modified animal may be compared with an animal predisposed to development of the disease such that the effect of the gene therapy event may be assessed.
- a method of the invention may be used to create an animal or cell that maybe used as a disease model for a disease listed in Table A. Such an animal or cell may comprise a chromosomal edit in a gene listed in Table A. In another embodiment, a method of the invention may be used to create an animal or cell that maybe used as a disease model for a disease listed in Table B. Such an animal or cell may comprise a chromosomal edit in a gene listed in Table B. In Table B, a six-digit number following an entry in the Disease/Disorder/Indication column is an OMIM number (Online Mendelian Inheritance in Man, OMIM (TM).
- OMIM number Online Mendelian Inheritance in Man
- disease models created by a method of the invention include a Parkinson's disease model, an addiction model, an inflammation model, a cardiovascular disease model, an Alzheimer's disease model, an autism spectrum disorder model, a macular degeneration model, a schizophrenia model, a tumor suppression model, a trinucleotide repeat disorder model, a neurotransmission disorder model, a secretase-associated disorder model, an ALS model, a prion disease model, on ABC transporter protein - associated disorder model, and an immunodeficiency model.
- a Parkinson's disease model an addiction model, an inflammation model, a cardiovascular disease model, an Alzheimer's disease model, an autism spectrum disorder model, a macular degeneration model, a schizophrenia model, a tumor suppression model, a trinucleotide repeat disorder model, a neurotransmission disorder model, a secretase-associated disorder model, an ALS model, a prion disease model, on ABC transporter protein - associated disorder model, and an immunodeficiency model.
- a method of the invention may be used to create an animal or cell in which at least one chromosomal sequence associated with Parkinsons disease (PD) has been edited.
- Suitable chromosomal edits may include, but are not limited to, the type of edits detailed in section l(f) above.
- one or more chromosomal cells are selected from one or more chromosomal cells.
- sequences encoding a protein or control sequence associated with PD may be edited.
- a PD-associated protein or control sequence may typically be selected based on an experimental association of the PD-associated protein or control sequence to PD.
- the production rate or circulating concentration of a PD-related protein may be elevated or depressed in a population having PD relative to a population not having PD. Differences in protein levels may be assessed using proteomic or genomic analysis techniques known in the art.
- Parkinson's disease include but are not limited to ⁇ -synuclein, DJ-1 , LRRK2, PINK1 , Parkin, UCHL1 , Synphilin-1 , and NURR1.
- an animal created by a method of the invention may be used to study the effects of mutations on the animal and development and/or progression of PD using measures commonly used in the study of PD.
- measures commonly used in the study of PD are known in the art.
- Commonly used measures in the study of PD may include without limit, amyloidogenesis or protein aggregation, dopamine response, neurodegeneration, development of mitochondrial related dysfunction
- PD phenotypes, as well as functional, pathological or biochemical assays.
- Other relevant indicators regarding development or progression of PD include
- Addiction is defined as a chronic disease of brain reward, motivation, memory, and related neuronal circuitry contained within various brain structures.
- Specific examples of brain structures that may experience dysfunction associated with an addiction disorder include nucleus accumbens, ventral pallidum, dorsal thalamus, prefrontal cortex, striatum, substantia nigra, pontine reticular formation, amygdala, and ventral tegmental area. Dysfunction in these neural circuits may lead to various biological, psychological, social and behavioral symptoms of addiction.
- Biological symptoms of addiction may include
- addiction-related proteins overproduction or underproduction of one or more addiction-related proteins; redistribution of one or more addiction-related proteins within the brain; the development of tolerance, reverse tolerance, or other changes in sensitivity to the effects of an addictive substance or a neurotransmitter within the brain; high blood pressure; and withdrawal symptoms such as insomnia, restlessness, loss of appetite, depression, weakness, irritability, anger, pain, and craving.
- Psychological symptoms of addiction may vary depending on the particular addictive substance and the duration of the addiction.
- Non-limiting examples of psychological symptoms of addiction include mood swings, paranoia, insomnia, psychosis, schizophrenia, tachycardia panic attacks, cognitive impairments, and drastic changes in the personality that can lead to aggressive, compulsive, criminal and/or erratic behaviors.
- Social symptoms of addiction may include low self-esteem, verbal hostility, ignorance of interpersonal means, focal anxiety such as fear of crowds, rigid interpersonal behavior, grossly playful behavior, rebelliousness, and diminished recognition of significant problems with an individual's behaviors and interpersonal relationships.
- Non-limiting examples of behavioral symptoms of addiction include impairment in behavioral control, inability to consistently abstain from the use of addictive substances, cycles of relapse and remission, risk-taking behavior, pleasure-seeking behavior, novelty-seeking behavior, relief-seeking behavior, and reward-seeking behavior.
- Addictions may be substance addictions typically associated with the ingestion of addictive substances.
- Addictive substances may include psychoactive substances capable of crossing the blood-brain barrier and temporarily altering the chemical milieu of the brain.
- addictive substances include alcohol; opioid compounds such as opium and heroin; sedative, hypnotic, or anxiolytic compounds such as benzodiazepine and barbiturate compounds; cocaine and related compounds; cannabis and related compounds; amphetamine and amphetamine-like compounds; hallucinogen compounds; inhalants such as glue or aerosol propellants; phencyclidine or phencyclidine-like compounds; and nicotine.
- addictions may be behavioral addictions associated with compulsions that are not substance- related, such as problem gambling and computer addiction.
- a method of the invention may be used to create an animal or cell in which at least one addiction-related chromosomal sequence has been edited.
- Suitable edits may include, but are not limited to, the type of edits detailed in section l(f) above.
- Addiction-related nucleic acid sequences are a diverse set of sequences associated with susceptibility for developing an addiction, the presence of an addiction, the severity of an addiction or any combination thereof.
- An addiction-related nucleic acid sequence may typically be selected based on an experimental association of the addiction-related nucleic acid sequence to an addiction disorder.
- An addiction-related nucleic acid sequence may encode an addiction-related protein or may be an addiction-related control sequence.
- the production rate or circulating concentration of an addiction-related protein may be elevated or depressed in a population having an addiction disorder relative to a population lacking the addiction disorder.
- Non-limiting examples of addiction-related proteins include
- ABAT (4-aminobutyrate aminotransferase); ACN9 (ACN9 homolog (S.
- ADCYAP1 Addenylate cyclase activating polypeptide 1
- ADH1 B Alcohol dehydrogenase IB (class I), beta polypeptide
- ADH1 C Alcohol dehydrogenase 1 C (class I), gamma polypeptide
- ADH4 Alcohol
- ADH7 Alcohol dehydrogenase 7 (class IV), mu or sigma polypeptide); ADORA1 (Adenosine A1 receptor); ADRA1A (Adrenergic, alpha- 1A-, receptor); ALDH2 (Aldehyde dehydrogenase 2 family); ANKK1 (Ankyrin repeat, Taql A1 allele); ARC (Activity-regulated cytoskeleton-associated protein); ATF2 (Corticotropin in-releasing factor); AVPR1A (Arginine vasopressin receptor 1A); BDNF (Brain-derived neurotrophic factor); BMAL1 (Aryl hydrocarbon receptor nuclear translocator-like); CDK5 (Cyclin-dependent kinase 5); CHRM2 (Cholinergic receptor, muscarinic 2); CHRNA3 (Cholinergic receptor, nicotinic, alpha 3); CHRNA4 (Cholinergic receptor, nicotinic
- Responsive element binding protein 1 Responsive element binding protein 1 ); CREB2 (Activating transcription factor 2); CRHR1 (Corticotropin releasing hormone receptor 1 ); CRY1 (Cryptochrome 1 ); CSNK1 E (Casein kinase 1 , epsilon); CSPG5 (Chondroitin sulfate proteoglycan 5); CTNNB1 (Catenin (cadherin-associated protein), beta 1 , 88kDa); DBI
- DRD1 Dopamine receptor D1
- DRD2 Dopamine receptor D2
- DRD3 Dopamine receptor D3
- EGR1 Early growth response 1
- ELTD1 EGF, latrophilin and seven transmembrane domain containing 1
- FAAH Fatty acid amide hydrolase
- FOSB FBJ murine osteosarcoma viral oncogene homolog
- FOSB FBJ murine osteosarcoma viral oncogene homolog B
- GABBR2 GABBR2
- GABA Gamma-aminobutyric acid
- GABRA2 Gamma- aminobutyric acid (GABA) A receptor, alpha 2
- GABRA4 Gamma-aminobutyric acid (GABA) A receptor, alpha 4
- GABRA6 Gamma-aminobutyric acid (GABA) A receptor, alpha 6
- GABRB3 Gamma-aminobutyric acid (GABA) A receptor, alpha 3
- GABRE Gamma-aminobutyric acid (GABA) A receptor, epsilon);
- GABRG1 Gamma-aminobutyric acid (GABA) A receptor, gamma 1 ); GAD1 (Glutamate decarboxylase 1 ); GAD2 (Glutamate decarboxylase 2); GAL (Galanin prepropeptide); GDNF (Glial cell derived neurotrophic factor); GRIA1 (Glutamate receptor, ionotropic, AMPA 1 ); GRIA2 (Glutamate receptor, ionotropic, AMPA 2); GRIN1 (Glutamate receptor, ionotropic, N-methyl D-aspartate 1 ); GRIN2A
- Glutamate receptor ionotropic, N-methyl D-aspartate 2A
- GRM2 Glutamate receptor, metabotropic 2, mGluR2
- GRM5 Metabotropic glutamate receptor 5
- GRM6 Glutamate receptor, metabotropic 6
- GRM8 Glutamate receptor, metabotropic 8
- HTR1 B (5-Hydroxytryptamine (serotonin) receptor 1 B
- HTR3A 5-Hydroxytryptamine (serotonin) receptor 3A
- IL1 Interleukin 1
- IL15 Interleukin 1
- IL15 Interleukin 1
- IL15 Interleukin 1
- IL15 Interleukin 1
- IL15 Interleukin 15
- IL1 A Interleukin 1 alpha
- IL1 B Interleukin 1 beta
- KCNMA1 Potassium large conductance calcium-activated channel, subfamily M, alpha member 1
- LGALS1 lectin galactoside-binding soluble 1
- MAOA Monoamine oxidase A
- MAOB Monoamine oxidase B
- MAPK1 Mitogen-activated protein kinase 1
- MAPK3 Mitogen-activated protein kinase 3
- MBP Myelin basic protein
- MC2R Melanocortin receptor type 2
- MGLL Monoglyceride lipase
- MOBP Myelin-associated oligodendrocyte basic protein
- NPY Neuropeptide Y
- NR4A1 Nuclear receptor subfamily 4, group A, member 1
- NR4A2 Nuclear receptor subfamily 4, group A, member 2
- NRXN Neuropeptide Y
- NR4A1 Nu
- NTRK2 Neurotrophic tyrosine kinase, receptor, type 2
- NTRK2 Neurotrophin receptor
- OPRD1 delta-Opioid receptor
- OPRK1 kappa-Opioid receptor
- OPRM 1 mi-Opioid receptor
- PDYN kappa-Opioid receptor
- PENK Enkephalin
- PER2 Period homolog 2 ⁇ Drosophila
- PKNOX2 PBX/knotted 1 homeobox 2
- PLP1 Proteolipid protein 1
- POMC Proopiomelanocortin
- PRKCE Protein kinase C, epsilon
- PROKR2 Protein kinase C, epsilon
- SLC17A6 Solute carrier family 17 (sodium- dependent inorganic phosphate cotransporter), member 6
- SLC17A7 Solute carrier family 17 (sodium-dependent inorganic phosphate cotransporter), member 7
- SLC1 A2 Solute carrier family 1 (glial high affinity glutamate transporter), member 2
- SLC1A3 Solute carrier family 1 (glial high affinity glutamate transporter), member 3
- SLC29A1 solute carrier family 29
- SLC4A7 Solute carrier family 4, sodium bicarbonate cotransporter, member 7
- SLC6A3 Solute carrier family 6
- Neurotransmitter transporter dopamine
- SLC6A4 Solute carrier family 6 (neurotransmitter transporter, serotonin), member 4); SNCA (Synuclein, alpha (non A4 component of amyloid precursor)); TFAP2B (Transcription factor AP-2 beta); and TRPV1 (Transient receptor potential cation channel, subfamily V, member 1 ).
- Preferred addiction-related proteins may include ABAT (4- aminobutyrate aminotransferase), DRD2 (Dopamine receptor D2), DRD3
- GRIA1 Glutamate receptor, ionotropic, AMPA 1
- GRIA2 Glutamate receptor, ionotropic, AMPA 2
- GRIN1 Glutamate receptor, ionotropic, N-methyl D-aspartate 1
- GRIN2A Glutamate receptor, ionotropic, N-methyl D-aspartate 2A
- GRM5 Metalabotropic glutamate receptor 5
- HTR1 B (5-Hydroxytryptamine (serotonin) receptor 1 B), PDYN (Dynorphin), PRKCE (Protein kinase C, epsilon), LGALS1 (lectin galactoside-binding soluble 1 ), TRPV1 (transient receptor potential cation channel subfamily V member 1 ), SCN9A (sodium channel voltage-gated type IX alpha subunit), OPRD1 (opio
- an animal created by a method of the invention may be used as a model for indications of addiction disorders by comparing the measurements of an assay obtained from a genetically modified animal comprising at least one edited chromosomal sequence encoding an addiction-related protein to the measurements of the assay using a wild-type animal.
- assays used to assess for indications of an addictive disorder include behavioral assays, physiological assays, whole animal assays, tissue assays, cell assays, biomarker assays, and combinations thereof.
- the indications of addiction disorders may occur spontaneously, or may be promoted by exposure to exogenous agents such as addictive substances or addiction-related proteins. Alternatively, the indications of addiction disorders may be induced by withdrawal of an addictive substance or other compound such as an exogenously administered addiction-related protein.
- An additional aspect of the present disclosure encompasses a method of assessing the efficacy of a treatment for inhibiting addictive behaviors and/or reducing withdrawal symptoms of a genetically modified animal comprising at least one edited chromosomal sequence associated with addiction.
- Treatments for addiction that may be assessed include the administering of one or more novel candidate therapeutic compounds, a novel combination of established therapeutic compounds, a novel therapeutic method, and any combination thereof.
- Novel therapeutic methods may include various drug delivery mechanisms, nanotechnology applications in drug therapy, surgery, and combinations thereof.
- Behavioral testing of a genetically modified animal comprising at least one edited addiction-related protein and/or a wild-type animal may be used to assess the side effects of a therapeutic compound or
- the genetically modified animal and optionally a wild-type animal may be treated with the therapeutic compound or combination of therapeutic agents and subjected to behavioral testing.
- the behavioral testing may assess behaviors including but not limited to learning, memory, anxiety, depression, addiction, and sensory-motor functions.
- An additional aspect provides a method for assessing the therapeutic potential of an agent in an animal that may include contacting a genetically modified animal comprising at least one edited chromosomal sequence encoding an addiction-related protein, and comparing results of a selected parameter to results obtained from a wild-type animal with no contact with the same agent.
- Selected parameters include but are not limited to a) spontaneous behaviors; b) performance during behavioral testing; c)
- a method of the invention may be used to create an animal or cell in which at least one chromosomal sequence associated with inflammation has been edited.
- Suitable chromosomal edits may include, but are not limited to, the type of edits detailed in section l(f) above.
- chromosomal sequences associated with inflammation may be edited.
- An inflammation-related chromosomal sequence may typically be selected based on an experimental association of the inflammation-related sequence to an inflammation disorder.
- An inflammation-related sequence may encode an inflammation-related protein or may be an inflammation-related control sequence. For example, the production rate or circulating concentration of an inflammation-related protein may be elevated or depressed in a population having an inflammation disorder relative to a population lacking the inflammation disorder. Differences in protein levels may be assessed using proteomic or genomic analysis techniques known in the art.
- Non-limiting examples of inflammation-related proteins whose chromosomal sequence may be edited include the monocyte
- MCP1 chemoattractant protein-1
- chemokine receptor type 5 CCR5 encoded by the Ccr ⁇ gene
- the IgG receptor MB FCGR2b, also termed CD32
- FCERIg Fc epsilon R1g protein encoded by the Fcerig gene
- the forkhead box N1 transcription factor FXN1 ) encoded by the FOXN1 gene
- Interferon-gamma IFN- ⁇
- IL-4 interleukin 4
- perforin-1 encoded by the PRF-1 gene perforin-1 encoded by the PRF-1 gene
- the cyclooxygenase 1 protein COX1
- COX2 cyclooxygenase 2 protein
- T-box transcription factor TBX21 protein encoded by the TBX21 gene
- SH2-B PH domain containing signaling mediator 1 protein SH2BPSM1
- an animal created by a method of the invention may be used to study the effects of mutations on the animal and development and/or progression of inflammation using measures commonly used in the study of inflammation.
- an animal created by a method of the invention may be used to study the effects of the mutations on the progression of a disease state or disorder associated with inflammation-related proteins using measures commonly used in the study of said disease state or disorder.
- measures include spontaneous behaviors of the genetically modified animal, performance during behavioral testing, physiological anomalies, differential responses to a
- Cardiovascular diseases generally include high blood pressure, heart attacks, heart failure, and stroke and TIA.
- a method of the invention may be used to create an animal or cell in which at least one chromosomal sequence associated with cardiovascular disease has been edited.
- Suitable chromosomal edits may include, but are not limited to, the type of edits detailed in section l(f) above.
- Any chromosomal sequence involved in cardiovascular disease or the protein encoded by any chromosomal sequence involved in cardiovascular disease may be utilized in a method of the invention.
- a cardiovascular-related sequence may typically be selected based on an experimental association of the cardiovascular-related sequence to the development of cardiovascular disease.
- a cardiovascular-related nucleic acid sequence may encode a cardiovascular-related protein or may be a
- cardiovascular-related control sequence For example, the production rate or circulating concentration of a cardiovascular-related protein may be elevated or depressed in a population having a cardiovascular disorder relative to a population lacking the cardiovascular disorder. Differences in protein levels may be assessed using proteomic or genomic analysis techniques known in the art.
- the chromosomal sequence may comprise, but is not limited to, IL1 B (interleukin 1 , beta), XDH (xanthine dehydrogenase), TP53 (tumor protein p53), PTGIS (prostaglandin I2
- angiopoietin 1 ABCG8 (ATP-binding cassette, sub-family G (WHITE), member 8), CTSK (cathepsin K), PTGIR (prostaglandin I2 (prostacyclin) receptor (IP)), KCNJ11 (potassium inwardly-rectifying channel, subfamily J, member 11 ), INS (insulin), CRP (C-reactive protein, pentraxin-related), PDGFRB (platelet-derived growth factor receptor, beta polypeptide), CCNA2 (cyclin A2), PDGFB (platelet- derived growth factor beta polypeptide (simian sarcoma viral (v-sis) oncogene homolog)), KCNJ5 (potassium inwardly-rectifying channel, subfamily J, member 5), KCNN3 (potassium intermediate/small conductance calcium-activated channel, subfamily N, member 3), CAPN10 (calpain 10), PTGES (prostaglandin E synthase), ADRA2B
- ACE angiotensin I converting enzyme peptidyl- dipeptidase A 1
- TNF tumor necrosis factor
- IL6 interleukin 6 (interferon, beta 2)
- STN statin
- SERPINE1 serotonin peptidase inhibitor
- clade E nonin, plasminogen activator inhibitor type 1
- member 1 member 1
- ALB albumin
- ADIPOQ adiponectin, C1 Q and collagen domain containing
- APOB apolipoprotein B (including Ag(x) antigen)
- APOE apolipoprotein E
- LEP laeptin
- MTHFR 5,10-methylenetetrahydrofolate reductase (NADPH)
- APOA1 apolipoprotein A-I
- EDN 1 endothelin 1
- NPPB natriuretic peptide precursor B
- NOS3 nitric oxide synthas
- coagulation factor Il thrombin
- ICAM1 intercellular adhesion molecule 1
- TGFB1 transforming growth factor, beta 1
- NPPA natriuretic peptide precursor A
- IL10 interleukin 10
- EPO erythropoietin
- SOD1 superoxide dismutase 1 , soluble
- VCAM1 vascular cell adhesion molecule 1
- IFNG interferon, gamma
- LPA lipoprotein, Lp(a)
- MPO myeloperoxidase
- ESR1 esterogen receptor 1
- MAPK1 mitogen-activated protein kinase 1
- HP haptoglobin
- F3 coagulation factor III (thromboplastin, tissue factor)
- CST3 cystatin C
- COG2 component of oligomeric golgi complex 2
- MMP9 matrix metallopeptidase 9
- gelatinase B 92kDa ge
- NOS1 nitric oxide synthase 1 (neuronal)
- NR3C1 nuclear receptor subfamily 3, group C, member 1 (glucocorticoid receptor)
- FGB finogen beta chain
- HGF hepatocyte growth factor
- hepapoietin A scatter factor
- IL1A interleukin 1 , alpha
- RETN resistin
- AKT1 v-akt murine thymoma viral oncogene homolog 1
- LIPC lipase, hepatic
- HSPD1 heat shock 6OkDa protein 1 (chaperonin)
- MAPK14 mitogen-activated protein kinase 14
- SPP1 secreted phosphoprotein 1
- ITGB3 integhn, beta 3 (platelet glycoprotein Ilia, antigen CD61 )
- CAT catalase
- UTS2 urotensin 2
- THBD thrombomodulin
- F10 coagulation factor X
- CP ceruloplasmin
- TNFRSF11 B tumor necrosis factor receptor superfamily, member 11 b
- EDNRA endothelin receptor type A
- EGFR epidermal growth factor receptor
- MMP2 matrix metallopeptidase 2 (gelatinase A, 72kDa gelatinase, 72kDa type IV collagenase)
- PLG plasma metallopeptidase 2
- NPY neuropeptide Y
- RHOD ras homolog gene family, member D
- MAPK8 mitogen-activated protein kinase 8
- MYC v-myc myelocytomatosis viral oncogene homolog (avian)
- FN 1 fibronectin 1
- CMA1 chymase 1 , mast cell
- PLAU plasminogen activator, urokinase
- GNB3 guan
- VDR vitamin D (1 ,25- dihydroxyvitamin D3) receptor
- ALOX5 arachidonate 5-lipoxygenase
- HLA-DRB1 major structural protein
- progelatinase progelatinase
- ELN elastin
- USF1 upstream transcription factor 1
- CFH complement factor H
- HSPA4 heat shock 7OkDa protein 4
- MMP12 matrix metallopeptidase 12 (macrophage elastase)
- MME membrane metallo- endopeptidase
- F2R coagulation factor Il (thrombin) receptor
- SELL selectin L
- CTSB cathepsin B
- ANXA5 annexin A5)
- ADRB1 adrenergic, beta-1 -, receptor
- CYBA cytochrome b-245, alpha polypeptide
- FGA farnesogen alpha chain
- GGT1 gamma-glutamyltransferase 1
- LIPG lipase, endothelial
- HIF1A hypooxia inducible factor 1 , alpha subunit (basic helix-loop-he
- lymphotoxin alpha TNF superfamily, member 1
- GDF15 growth differentiation factor 15
- BDNF brain-derived neurotrophic factor
- CYP2D6 cytochrome P450, family 2, subfamily D, polypeptide 6
- NGF nerve growth factor (beta polypeptide)
- SP1 Sp1 transcription factor
- TGIF1 TGFB-induced factor homeobox 1
- SRC v-src sarcoma (Schmidt-Ruppin A-2) viral oncogene homolog (avian)
- EGF epidermal growth factor (beta-urogastrone)
- PIK3CG phosphoinositide-3-kinase, catalytic, gamma polypeptide
- HLA-A major histocompatibility complex, class I, A
- KCNQ1 potassium voltage-gated channel, KQT-like subfamily, member 1
- CNR1 cannabinoid receptor 1 (brain)
- FBN
- PRKAB1 protein kinase, AMP-activated, beta 1 non-catalytic subunit
- TPO thyroid peroxidase
- ALDH7A1 aldehyde
- dehydrogenase 7 family member A1
- CX3CR1 chemokine (C-X3-C motif) receptor 1
- TH tyrosine hydroxylase
- F9 coagulation factor IX
- GH1 growth hormone 1
- TF transferrin
- HFE hemochromatosis
- IL17A interleukin 17A
- PTEN phosphatase and tensin homolog
- GSTM 1 (glutathione S-transferase mu 1 ), DMD (dystrophin), GATA4 (GATA binding protein 4), F13A1 (coagulation factor XIII, A1 polypeptide), TTR (transthyretin), FABP4 (fatty acid binding protein 4, adipocyte), PON3 (paraoxonase 3), APOC1 (apolipoprotein C-I), INSR (insulin receptor), TNFRSF1 B (tumor necrosis factor receptor superfamily, member 1 B), HTR2A (5-hydroxy
- THBS1 THBS1
- KDR kinase insert domain receptor (a type III receptor tyrosine kinase)
- PLA2G2A phospholipase A2, group MA (platelets, synovial fluid)
- B2M beta-2-microglobulin
- THBS1 THBS1
- TCF7L2 TCF7L2
- T-cell specific, HMG-box transcription factor 7-like 2
- BDKRB2 bradykinin receptor B2
- NFE2L2 nuclear factor (erythroid-derived 2)-like 2)
- NOTCH1 Notch homolog 1 , translocation-associated (Drosophila)
- UGT1A1 UDP glucuronosyltransferase 1 family, polypeptide A1
- IFNA1 interferon, alpha 1
- PPARD peroxisome proliferator-activated receptor delta
- SIRT1 sirtuin (silent mating type information regulation 2 homolog) 1 (S. cerevisiae)
- GNRH1 GNRH1
- cytochrome P450 family 1 , subfamily A, polypeptide 2
- HNF4A hepatocyte nuclear factor 4, alpha
- SLC6A4 solute carrier family 6 (neurotransmitter transporter, serotonin), member 4
- PLA2G6 phospholipase A2, group Vl (cytosolic, calcium-independent)
- TNFSF11 tumor necrosis factor (ligand) superfamily, member 11
- SLC8A1 solute carrier family 8 (sodium/calcium exchanger), member 1
- F2RL1 coagulation factor Il (thrombin) receptor-like 1
- AKR1A1 aldo-keto reductase family 1 , member A1 (aldehyde reductase)
- ALDH9A1 aldehyde dehydrogenase 9 family, member A1
- BGLAP bone gamma-carboxyglutamate (gla) protein
- MTTP microsomal triglyceride transfer
- metallopeptidase 13 (collagenase 3)), TIMP2 (TIMP metallopeptidase inhibitor 2)
- CYP19A1 cytochrome P450, family 19, subfamily A, polypeptide 1
- CYP21A2 cytochrome P450, family 21 , subfamily A, polypeptide 2
- PTPN22 protein tyrosine phosphatase, non-receptor type 22 (lymphoid)
- MYH14 myosin, heavy chain 14, non-muscle
- MBL2 mannose-binding lectin (protein C) 2, soluble (opsonic defect)
- SELPLG selectivein P ligand
- AOC3 amine oxidase, copper containing 3 (vascular adhesion protein 1 )
- CTSL1 cathepsin L1
- PCNA metallopeptidase inhibitor 2
- IGF2 insulin-like growth factor 2
- ITGB1 insulin receptor, beta 1 (fibronectin receptor, beta polypeptide, antigen CD29 includes MDF2, MSK12)
- CAST calpastatin
- KCNE1 immunoglobulin heavy constant epsilon
- KCNE1 potassium voltage-gated channel, Isk-related family, member 1
- TFRC transferrin receptor (p90, CD71 )
- COL1A1 collagen, type I, alpha 1
- COL1A2 collagen, type I, alpha 2
- IL2RB interleukin 2 receptor, beta
- PLA2G10 phospholipase A2, group X
- ANGPT2 angiopoietin 2
- PROCR protein C receptor, endothelial (EPCR)
- NOX4 immunoglobulin heavy constant epsilon
- KCNE1 potassium voltage-gated channel, Isk-related family, member 1
- TFRC transferrin receptor (p90, CD71 )
- COL1A1 collagen, type I, alpha 1
- COL1A2 collagen, type I, alpha 2
- IL2RB interleukin 2 receptor
- NADPH oxidase 4 HAMP (hepcidin antimicrobial peptide), PTPN11 (protein tyrosine phosphatase, non-receptor type 11 ), SLC2A1 (solute carrier family 2 (facilitated glucose transporter), member 1 ), IL2RA (interleukin 2 receptor, alpha), CCL5 (chemokine (C-C motif) ligand 5), IRF1 (interferon regulatory factor 1 ), CFLAR (CASP8 and FADD-like apoptosis regulator), CALCA (calcitonin- related polypeptide alpha), EIF4E (eukaryotic translation initiation factor 4E), GSTP1 (glutathione S-transferase pi 1 ), JAK2 (Janus kinase 2), CYP3A5
- cytochrome P450 family 3, subfamily A, polypeptide 5
- HSPG2 heparan sulfate proteoglycan 2
- CCL3 chemokine (C-C motif) ligand 3
- MYD88 myeloid differentiation primary response gene (88)
- VIP vaactive intestinal peptide
- SOAT1 sterol O-acyltransferase 1
- ADRBK1 adrenergic, beta, receptor kinase 1
- NR4A2 nuclear receptor subfamily 4, group A, member 2
- MMP8 matrix metallopeptidase 8 (neutrophil collagenase)
- NPR2 natriuretic peptide receptor B/guanylate cyclase B (athonathuretic peptide receptor B)
- GCH 1 GTP cyclohydrolase 1
- EPRS glutamyl-prolyl-tRNA synthetase
- PPARGC1A glutamyl-prolyl-
- ZC3H12A zinc finger CCCH-type containing 12A
- AKR1 B1 aldo-keto reductase family 1 , member B1 (aldose reductase)
- DES desmin
- MMP7 matrix metallopeptidase 7 (mathlysin, uterine)
- AHR aryl hydrocarbon receptor
- CSF1 colony stimulating factor 1 (macrophage)
- HDAC9 histone deacetylase 9
- CTGF connective tissue growth factor
- KCNMA1 potassium large conductance calcium-activated channel, subfamily M, alpha member 1
- UGT1A UDP glucuronosyltransferase 1 family, polypeptide A complex locus
- PRKCA protein kinase C, alpha
- COMT catechol-O-methyltransferase
- S100B S100 calcium binding protein B
- EGR1 early growth response 1
- PRL prolactin
- CD16a (CD16a)), LEPR (leptin receptor), ENG (endoglin), GPX1 (glutathione peroxidase 1 ), GOT2 (glutamic-oxaloacetic transaminase 2, mitochondrial (aspartate aminotransferase 2)), HRH1 (histamine receptor H1 ), NR112 (nuclear receptor subfamily 1 , group I, member 2), CRH (corticotropin releasing hormone), HTR1A (5-hydroxytryptamine (serotonin) receptor 1A), VDAC1 (voltage-dependent anion channel 1 ), HPSE (heparanase), SFTPD (surfactant protein D), TAP2
- transcription factor AP-2 alpha activating enhancer binding protein 2 alpha
- C4BPA complement component 4 binding protein, alpha
- SERPINF2 serpin peptidase inhibitor
- clade F alpha-2 antiplasmin, pigment epithelium derived factor
- member 2 transcription factor AP-2 alpha (activating enhancer binding protein 2 alpha)
- C4BPA complement component 4 binding protein, alpha
- SERPINF2 serpin peptidase inhibitor
- clade F alpha-2 antiplasmin, pigment epithelium derived factor
- member 2 member 2
- TYMP thymidine phosphorylase
- ALPP alkaline
- CXCR2 chemokine (C-X-C motif) receptor 2
- SLC39A3 solute carrier family 39 (zinc transporter), member 3
- ABCG2 ATP-binding cassette, sub-family G (WHITE), member 2)
- ADA ADA
- vascular endothelial growth factor B vascular endothelial growth factor B
- MEF2C myocyte enhancer factor 2C
- MAPKAPK2 mitogen-activated protein kinase-activated protein kinase 2
- TNFRSF11A tumor necrosis factor receptor superfamily, member 11 a, NFKB activator
- HSPA9 heat shock 7OkDa protein 9 (mortalin)
- CYSLTR1 cystyl leukotriene receptor 1
- MAT1A methionine adenosyltransferase I, alpha
- OPRL1 opiate receptor-like 1
- IMPA1 inositol(myo)-1 (or 4)-monophosphatase 1
- CLCN2 chloride channel 2)
- DLD dihydrolipoamide dehydrogenase
- PSMA6 proteasome (prosome, macropain) subunit, alpha type, 6
- PSMB8 proteasome (prosome, macropai
- EDN2 endothelin 2
- CCR6 chemokine (C-C motif) receptor 6
- GJB3 gap junction protein, beta 3, 31 kDa
- IL1 RL1 interleukin 1 receptor-like 1
- ENTPD1 ectonucleoside triphosphate diphosphohydrolase 1
- BBS4 Bardet-Biedl syndrome 4
- CELSR2 cadherin, EGF LAG seven-pass G- type receptor 2 (flamingo homolog, Drosophila)
- F11 R F 11 receptor
- RAPGEF3 Ras guanine nucleotide exchange factor (GEF) 3
- HYAL1 hyaluronoglucosaminidase 1
- ZNF259 zinc finger protein 259
- ATOX1 ATX1 antioxidant protein 1 homolog (yeast)
- ATF6 activating transcription factor 6
- KHK ketohexokinase (fructokinase)
- SAT1 spermidine/spermine N1- acetyltransferase 1
- GGH gamma-glutamyl hydrolase
- TIMP4 TIMP metallopeptidase inhibitor 4
- SLC4A4 solute carrier family 4, sodium bicarbonate cotransporter, member 4
- PDE2A phosphodiesterase 2A, cGMP-stimulated
- PDE3B phosphodiesterase 3B, cGMP-inhibited
- FADS1 fatty acid desaturase 1
- FADS2 fatty acid desaturase 2
- TMSB4X thymosin beta 4, X-linked
- TXNIP thioredoxin interacting protein
- LIMS1 LIM and senescent cell antigen-like domains 1
- RHOB ras homolog gene family, member B
- LY96 lymphocyte antigen 96
- FOXO1 forkhead box 01
- PNPLA2 patatin-like phospholipase domain containing 2
- TRH thyrotropin-releasing hormone
- GJC1 gap junction protein, gammase inhibitor 4
- GGT2 gamma-glutamyltransferase 2
- MT-CO1 mitochondrially encoded cytochrome c oxidase I
- UOX urate oxidase, pseudogene
- the chromosomal sequence may further be selected from Pon1 (paraoxonase 1 ), LDLR (LDL receptor), ApoE (Apolipoprotein E), Apo B-100 (Apolipoprotein B-100), ApoA (Apolipoprotein(a)), ApoA1 (Apolipoprotein A1 ), CBS (Cystathione B-synthase), Glycoprotein llb/llb, MTHRF (5,10-methylenetetrahydrofolate reductase (NADPH), and combinations thereof.
- Pon1 paraoxonase 1
- LDLR LDL receptor
- ApoE Apolipoprotein E
- Apo B-100 Apolipoprotein B-100
- ApoA Apolipoprotein(a)
- ApoA1 Adpolipoprotein A1
- CBS Cystathione B-synthase
- Glycoprotein llb/llb Glycoprotein llb/llb
- the chromosomal sequences and proteins encoded by chromosomal sequences involved in cardiovascular disease may be chosen from Cacnai C, Sod1 , Pten, Ppar(alpha), Apo E, Leptin, and combinations thereof.
- an animal created by a method of the invention may be used to study the effects of mutations on the animal and development and/or progression of cardiovascular disease using measures commonly used in the study of cardiovascular disease.
- suitable disease measures may include behavioral, electrophysiological, neurochemical, biochemical, or cellular dysfunctions which can be evaluated using any of a number of well-known diagnostic tests or assays.
- a method of the invention may be used to create an animal or cell in which at least one chromosomal sequence associated with Alheimer's disease (AD) has been edited.
- Suitable chromosomal edits may include, but are not limited to, the type of edits detailed in section l(f) above.
- one or more chromosomal sequences associated with AD may be edited.
- the AD-related nucleic acid sequence may typically be selected based on an experimental association of the AD-related nucleic acid sequence to an AD disorder.
- An AD-related nucleic acid sequence may encode an AD-related protein or may be an AD-related control sequence.
- the production rate or circulating concentration of an AD-related protein may be elevated or depressed in a population having an AD disorder relative to a population lacking the AD disorder. Differences in protein levels may be assessed using proteomic or genomic analysis techniques known in the art.
- proteins associated with AD include but are not limited to the very low density lipoprotein receptor protein (VLDLR) encoded by the VLDLR gene, the ubiquitin-like modifier activating enzyme 1 (UBA1 ) encoded by the UBA1 gene, the NEDD8-activating enzyme E1 catalytic subunit protein (UBE1 C) encoded by the UBA3 gene, the aquaporin 1 protein (AQP1 ) encoded by the AQP1 gene, the ubiquitin carboxyl-terminal esterase L1 protein (UCHL1 ) encoded by the UCHL1 gene, the ubiquitin carboxyl-terminal hydrolase isozyme L3 protein (UCHL3) encoded by the UCHL3 gene, the ubiquitin B protein (UBB) encoded by the UBB gene, the microtubule- associated protein tau (MAPT) encoded by the MAPT gene, the protein tyrosine phosphatase receptor type A protein (PTPRA) encode
- VLDLR very low density lipoprotein
- an animal created by a method of the invention may be used to study the effects of mutations on the animal and development and/or progression of AD using measures commonly used in the study of AD.
- measures commonly used in the study of AD include without limit, learning and memory, anxiety, depression, addiction, and sensory-motor functions, as well as functional, pathological, metabolic, or biochemical assays.
- Those of skill in the art are familiar with other suitable measures or indicators of AD. In general, such measures may be made in comparison to wild type littermates.
- Other measures of behavior may include assessments of spontaneous behavior.
- Spontaneous behavior may be assessed using any one or more methods of spontaneous behavioral observations known in the art.
- any spontaneous behavior within a known behavioral repertoire of an animal may be observed, including movement, posture, social interaction, rearing, sleeping, blinking, eating, drinking, urinating, defecating, mating, and aggression.
- An extensive battery of observations for quantifying the spontaneous behavior may be assessed using any one or more methods of spontaneous behavioral observations known in the art.
- any spontaneous behavior within a known behavioral repertoire of an animal may be observed, including movement, posture, social interaction, rearing, sleeping, blinking, eating, drinking, urinating, defecating, mating, and aggression.
- mice and rats spontaneous behavior of mice and rats is well-known in the art, including but not limited to home-cage observations such as body position, respiration, tonic involuntary movement, unusual motor behavior such as pacing or rocking, catatonic behavior, vocalization, palpebral closure, mating frequency, running wheel behavior, nest building, and frequency of aggressive interactions.
- home-cage observations such as body position, respiration, tonic involuntary movement, unusual motor behavior such as pacing or rocking, catatonic behavior, vocalization, palpebral closure, mating frequency, running wheel behavior, nest building, and frequency of aggressive interactions.
- the animals of the invention may be used to study the effects of the mutations on the progression of a disease state or disorder other than AD, but which is also associated with AD-related proteins, using measures commonly used in the study of said disease state or disorder.
- disease states or disorders other than AD that may be associated with AD-related proteins include dementia, congenital cerebellar ataxia, mental retardation such as learning and memory defects, lissencephaly, tauopathy or fibrilization, amyloidosis, neurodegeneration, Parkinsonism, progressive supranuclear palsy, Pick disease, male infertility, prostate and breast cancer, squamous cell carcinoma, lymphoma, leukemia, and atherosclerosis.
- Yet another aspect encompasses a method for assessing the efficacy of a potential gene therapy strategy. That is, a chromosomal sequence encoding a protein associated with AD may be modified such that the genetically modified animal may have an altered response to the development and/or progression of AD as compared to a non treated animal. Stated another way, a mutated gene that predisposes an animal to AD may be "corrected" through gene therapy.
- a method of the invention may be used to create an animal or cell in which at least one chromosomal sequence associated with autism spectrum disorder (ASD) has been edited.
- Suitable chromosomal edits may include, but are not limited to, the type of edits detailed in section l(f) above.
- chromosomal sequences associated with ASD may be edited.
- associated protein or control sequence may typically be selected based on an experimental association of the protein or control sequence to an incidence or indication of an ASD. For example, the production rate or circulating
- concentration of a protein associated with ASD may be elevated or depressed in a population having an ASD relative to a population lacking the ASD.
- Differences in protein levels may be assessed using proteomic or genomic analysis techniques known in the art.
- the proteins associated with ASD whose chromosomal sequence is edited can and will vary.
- the proteins associated with ASD whose chromosomal sequence is edited may be the benzodiazapine receptor (peripheral) associated protein 1 (BZRAP1 ) encoded by the BZRAP1 gene, the AF4/FMR2 family member 2 protein (AFF2) encoded by the AFF2 gene (also termed MFR2), the fragile X mental retardation autosomal homolog 1 protein (FXR1 ) encoded by the FXR1 gene, the fragile X mental retardation autosomal homolog 2 protein (FXR2) encoded by the FXR2 gene, the MAM domain containing glycosylphosphatidylinositol anchor 2 protein (MDGA2) encoded by the MDGA2 gene, the methyl CpG binding protein 2 (MECP2) encoded by the MECP2 gene, the metabotropic glutamate receptor 5 (MGLUR5) encoded by the
- BZRAP1 benz
- the edited or integrated chromosomal sequence may be modified to encode an altered protein associated with ASD.
- mutations in proteins associated with ASD include the L18Q mutation in neurexin 1 where the leucine at position 18 is replaced with a glutamine, the R451 C mutation in neuroligin 3 where the arginine at position 451 is replaced with a cysteine, the R87W mutation in neuroligin 4 where the arginine at position 87 is replaced with a tryptophan, and the 1425V mutation in serotonin transporter where the isoleucine at position 425 is replaced with a valine.
- an animal created by a method of the invention may be used to study the effects of mutations on the animal and development and/or progression of ASD using measures commonly used in the study of ASD.
- a method of the invention may be used to create an animal or cell in which at least one chromosomal sequence associated with macular degeneration (MD) has been edited.
- MD macular degeneration
- chromosomal edits may include, but are not limited to, the type of edits detailed in section l(f) above.
- chromosomal sequences associated with MD may be edited.
- a MD-associated protein or control sequence may typically be selected based on an experimental association of the protein associated with MD to an MD disorder. For example, the production rate or circulating concentration of a protein associated with MD may be elevated or depressed in a population having an MD disorder relative to a population lacking the MD disorder. Differences in protein levels may be assessed using proteomic or genomic analysis techniques known in the art.
- the proteins associated with MD whose chromosomal sequence is edited can and will vary.
- the proteins associated with MD whose chromosomal sequence is edited may be the ATP-binding cassette, sub-family A (ABC1 ) member 4 protein (ABCA4) encoded by the ABCR gene, the apolipoprotein E protein (APOE) encoded by the APOE gene, the chemokine (C-C motif) Ligand 2 protein (CCL2) encoded by the CCL2 gene, the chemokine (C-C motif) receptor 2 protein (CCR2) encoded by the CCR2 gene, the ceruloplasmin protein (CP) encoded by the CP gene, the cathepsin D protein (CTSD) encoded by the CTSD gene, or the
- TIMP3 metalloproteinase inhibitor 3 protein
- a genetically modified animal created by a method of the invention may be used to study the effects of mutations on the progression of MD using measures commonly used in the study of MD.
- the genetically modified animals of the invention may be used to study the effects of the mutations on the progression of a disease state or disorder associated with proteins associated with MD using measures commonly used in the study of said disease state or disorder.
- measures include drusen accumulation, lipofuscin accumulation, thickening of Bruch's membrane, retinal degeneration, choroidal neovascularization, differential responses to a compound, abnormalities in tissues or cells, biochemical or molecular differences between genetically modified animals and wild type animals or a combination thereof.
- a method of the invention may be used to create an animal or cell in which at least one chromosomal sequence associated with schizophrenia has been edited.
- Suitable chromosomal edits may include, but are not limited to, the type of edits detailed in section l(f) above.
- chromosomal sequences associated with schizophrenia may be edited.
- a schizophrenia-associated protein or control sequence may typically be selected based on an experimental association of the protein associated with
- schizophrenia to the development or progression of schizophrenia.
- the production rate or circulating concentration of a protein associated with schizophrenia may be elevated or depressed in a population having
- chromosomal sequences associated with schizophrenia include NRG1 , ErbB4, CPLX1 , TPH1 , TPH2, NRXN1 , GSK3A, BDNF, DISCI , GSK3B, and combinations thereof, each of which is described in more detail below.
- an animal created by a method of the invention may be used to study the effects of mutations on the animal and development and/or progression of MD using measures commonly used in the study of MD.
- the incidence or indication of the schizophrenia or related disorder may occur spontaneously in the genetically modified animal.
- the incidence or indication of the schizophrenia or related disorder may be promoted by exposure to a disruptive agent.
- disruptive agents include a protein associated with schizophrenia such as any of those described above, a drug, a toxin, a chemical, an activated retrovirus, and an environmental stress.
- environmental stresses include forced swimming, cold swimming, platform shaker stimuli, loud noises, and immobilization stress.
- Tumor suppression genes are genes whose protein products protect a cell from one step on the path to cancer.
- a mutation in a tumor suppressor gene may cause a loss or reduction in the protective function of its protein product, thereby increasing the probability that a tumor will form, leading to cancer, usually in combination with other genetic changes.
- the proteins encoded by tumor suppressor genes have a dampening or repressive effect on the regulation of the cell cycle or promote apoptosis, and sometimes both.
- Tumor suppressor proteins are involved in the repression of genes essential for the continuing cell cycle; coupling the cell cycle to DNA damage so that the cell cycle can continue; initiating apoptosis in the cell if the damage cannot be repaired; and cell adhesion to prevent tumors from dispersing, blocking a loss of contact inhibition, and inhibiting metastasis.
- a method of the invention may be used to create an animal or cell in which at least one chromosomal sequence associated with tumor suppresion has been edited.
- Suitable chromosomal edits may include, but are not limited to, the type of edits detailed in section l(f) above.
- chromosomal sequences associated with tumor suppression may be edited.
- a tumor suppression-associated protein or control sequence may typically selected based on an experimental association of the protein of interest with a cancer. For example, the production rate or circulating concentration of a protein associated with tumor suppression may be elevated or depressed in a population having cancer relative to a population not having cancer. Differences in protein levels may be assessed using proteomic or genomic analysis techniques known in the art.
- proteins involved in tumor suppression may comprise, but are not limited to, TNF (tumor necrosis factor (TNF)
- TNF tumor necrosis factor
- TP53 tumor protein p53
- ERBB2 v-erb-b2
- erythroblastic leukemia viral oncogene homolog 2 neuro/glioblastoma derived oncogene homolog (avian)
- FN1 fibronectin 1
- TSC1 tuberous sclerosis 1
- PTGS2 prostaglandin-endoperoxide synthase 2 (prostaglandin G/H synthase and cyclooxygenase)
- PTEN phosphatase and tensin homolog
- CDKN2A cyclin-dependent kinase inhibitor 2A (melanoma, p16, inhibits CDK4)
- CDKN1A cyclin-dependent kinase inhibitor 1A (p21 , Cip1 )
- CCND1 cyclin D1
- AKT1 v-akt murine thymoma viral oncogene homolog 1
- MYC v-myc
- myelocytomatosis viral oncogene homolog (avian)), CTNNB1 (catenin (cadherin- associated protein), beta 1 , 88kDa), MDM2 (Mdm2 p53 binding protein homolog (mouse)), SERPINB5 (serpin peptidase inhibitor, clade B (ovalbumin), member 5), EGF (epidermal growth factor (beta-urogastrone)), FOS (FBJ murine osteosarcoma viral oncogene homolog), NOS2 (nitric oxide synthase 2, inducible), CDK4 (cyclin-dependent kinase 4), SOD2 (superoxide dismutase 2, mitochondrial), SMAD3 (SMAD family member 3), CDKN1 B (cyclin-dependent kinase inhibitor 1 B (p27, Kip1 )), SOD1 (superoxide dismutase 1 , soluble), CCNA2 (cyclin A2), LO
- telangiectasia mutated telangiectasia mutated
- STAT3 signal transducer and activator of transcription 3 (acute-phase response factor)
- HIF1A hyperoxia inducible factor 1 , alpha subunit (basic helix-loop-helix transcription factor)
- IGF1 R insulin-like growth factor 1 receptor
- MTOR mechanistic target of rapamycin (serine/threonine kinase)
- TSC2 tuberous sclerosis 2)
- CDC42 cell division cycle 42 (GTP binding protein, 25kDa)
- ODC1 ornithine decarboxylase 1
- SPARC secreted protein, acidic, cysteine-rich (osteonectin)
- HDAC1 histone deacetylase 1
- CDK2 cyclin- dependent kinase 2
- BARD1 BRCA1 associated RING domain 1
- CDH1 cadhehn 1 , type 1 , E-cadher
- EIF2AK2 eukaryotic translation initiation factor 2-alpha kinase 2
- GJA1 gap junction protein, alpha 1 , 43kDa
- MYD88 myeloid differentiation primary response gene (88)
- IFI27 interferon, alpha-inducible protein 27
- RBMX RNA binding motif protein, X-linked
- EPHA1 EPH receptor A1
- TWSG1 twisted gastrulation homolog 1 (Drosophila)
- H2AFX H2A histone family, member X
- LGALS3 lectin, galactoside-binding, soluble, 3
- MUC3A mucin 3A, cell surface associated
- ILK integratedin-linked kinase
- APAF1 apoptotic peptidase activating factor 1
- MAOA monoamine oxidase A
- ERBB3 v-erb-b2
- EIF2S1 eukaryotic translation initiation factor 2, subunit 1 alpha, 35kDa
- PER2 period homolog 2 (Drosophila)
- IGFBP7 insulin-like growth factor binding protein 7
- KDM5B lysine (K)-specific demethylase 5B
- SMARCA4 SWI/SNF related, matrix associated, actin dependent regulator of chromatin, subfamily a, member 4
- NME1 non-metastatic cells 1 , protein (NM23A) expressed in
- F2RL1 non-metastatic cells 1 , protein (NM23A) expressed in
- coagulation factor Il thrombin receptor-like 1
- ZFP36 zinc finger protein 36, C3H type, homolog (mouse)
- HSPA8 heat shock 7OkDa protein 8
- WNT5A wingless-type MMTV integration site family, member 5A
- ITGB4 integhn, beta 4
- RARB retinoic acid receptor, beta
- VEGFC vascular endothelial growth factor C
- CCL20 chemokine (C-C motif) ligand 20
- EPHB2 EPH receptor B2
- CSNK2A1 casein kinase 2, alpha 1 polypeptide
- PSMD9 proteasome
- SERPINB2 serotonin peptidase inhibitor, clade B (ovalbumin), member 2), RHOB (ras homolog gene family, member B), DUSP6 (dual specificity phosphatase 6), CDKN1C (cyclin- dependent kinase inhibitor 1 C (p57, Kip2)), SLIT2 (slit homolog 2 (Drosophila)), CEACAM1 (carcinoembryonic antigen-related cell adhesion molecule 1 (biliary glycoprotein)), UBC (ubiquitin C), STS (steroid sulfatase (microsomal), isozyme S), FST (follistatin), KRT1 (keratin 1 ), EIF6 (eukaryotic translation initiation factor 6), JUP (junction plakoglobin), HDAC4 (histone deacetylase 4), NEDD4 (neural precursor cell expressed, development
- BTRC beta-transducin repeat containing
- NKX3-1 NK3 homeobox 1
- GPC3 glypican 3
- CREB3 cAMP responsive element binding protein 3
- PLCB3 phospholipase C, beta 3 (phosphatidylinositol-specific)
- DMPK distrophia myotonica-protein kinase
- BLNK B-cell linker
- PPIA peptidylprolyl isomerase A (cyclophilin A)
- DAB2 disabled homolog 2, mitogen-responsive phosphoprotein (Drosophila)
- KLF4 Kruppel-like factor 4 (gut)
- RUNX3 runt-related
- transcription factor 3 FLG (filaggrin), IVL (involuchn), CCT5 (chaperonin containing TCP1 , subunit 5 (epsilon)), LRPAP1 (low density lipoprotein receptor- related protein associated protein 1 ), IGF2R (insulin-like growth factor 2 receptor), PER1 (period homolog 1 (Drosophila)), BIK (BCL2-interacting killer (apoptosis-inducing)), PSMC4 (proteasome (prosome, macropain) 26S subunit, ATPase, 4), USF2 (upstream transcription factor 2, c-fos interacting), GAS1 (growth arrest-specific 1 ), LAMP2 (lysosomal-associated membrane protein 2), PSMD10 (proteasome (prosome, macropain) 26S subunit, non-ATPase, 10), IL24 (interleukin 24), GADD45G (growth arrest and DNA-damage-inducible, gamma), ARHGAP
- EIF4G2 eukaryotic translation initiation factor 4 gamma, 2), LOXL2 (lysyl oxidase-like 2), PSMD13 (proteasome (prosome, macropain) 26S subunit, non-ATPase, 13), ANP32A (acidic (leucine-rich) nuclear phosphoprotein 32 family, member A), COL4A3 (collagen, type IV, alpha 3 (Goodpasture antigen)), SCGB1A1 (secretoglobin, family 1A, member 1 (uteroglobin)), BNIP3L (BCL2/adenovirus E1 B 19kDa interacting protein 3-like), MCC (mutated in colorectal cancers), EFNB3 (ephrin- B3), RBBP8 (retinoblastoma binding protein 8), PALB2 (partner and localizer of BRCA2), HBP1
- tumor suppression proteins include ATM (ataxia telangiectasia mutated), ATR (ataxia telangiectasia and Rad3 related), EGFR (epidermal growth factor receptor), ERBB2 (v-erb-b2 erythroblastic leukemia viral oncogene homolog 2), ERBB3 (v-erb-b2
- erythroblastic leukemia viral oncogene homolog 3 erythroblastic leukemia viral oncogene homolog 3
- ERBB4 v-erb-b2
- erythroblastic leukemia viral oncogene homolog 4 Notch 1 , Notch2, Notch 3, Notch 4, ATK1 (v-akt murine thymoma viral oncogene homolog 1 ), ATK2 (v-akt murine thymoma viral oncogene homolog 2), ATK3 (v-akt murine thymoma viral oncogene homolog 3), HIFI a (hypoxia-inducible factor 1 a), HIF3a (hypoxia- inducible factor 1 a), Met (met pronto-oncogene), HRG (histidine-hch
- Bd 2 PPAR(alpha) (peroxisome proliferator-activated receptor alpha), Ppar(gamma) (peroxisome proliferator-activated receptor gamma), WT1 (Wilmus Tumor 1 ), FGF1 R(fibroblast growth factor 1 receptor) , FGF2R
- fibroblast growth factor 1 receptor fibroblast growth factor 1 receptor
- FGF3R fibroblast growth factor 3 receptor
- FGF4R fibroblast growth factor 4 receptor
- FGF5R fibroblast growth factor 5 receptor
- CDKN2a cyclin-dependent kinase inhibitor 2A
- APC adenomatous polyposis coli
- Rb1 retinoblastoma 1
- MEN1 multiple endocrine neoplasial
- VHL von-Hippel-Lindau tumor suppressor
- BRCA1 breast cancer 1
- BRCA2 breast cancer 2
- AR androgen receptor
- TSG101 tumor susceptibility gene 101
- Igf1 insulin-like growth factor 1
- Igf2 insulin-like growth factor 2
- lgf 1 R insulin-like growth factor 1 receptor
- lgf 2R insulin-like growth factor 2 receptor
- CASP 7 (Caspase 7) , CASP 8 (Caspase 8), CASP 9 (Caspase 9), CASP 12 (Caspase 12), Kras (v-Ki-ras2 Kirsten rate sarcoma viral oncogene homolog), PTEN (phosphate and tensin homolog), BCRP (breast cancer receptor protein), p53, and combinations thereof.
- an animal created by a method of the invention may be used to study the effects of mutations on the animal and on tumor suppression using measures commonly used in the study of tumor suppression.
- a genetically modified animal comprising an inactivated chromosomal sequence involved with tumor suppression may be used to determine susceptibility to developing tumors.
- the method comprises exposing the genetically modified animal comprising an inactivated tumor suppressor sequence and a wild-type animal to a carcinogenic agent, and then monitoring the development of tumors.
- the animal comprising the inactivated tumor suppressor sequence may have an increased risk for tumor formation.
- an animal homozygous for the inactivated tumor suppressor sequence may have increased risk relative to an animal heterozygous for the same inactivated sequence, which in turn may have increased risk relative to a wild- type animal.
- a similar method may be used to screen for spontaneous tumors, wherein the animals described above are not exposed to a carcinogenic agent.
- an animal comprising an inactivated chromosomal sequence associated with tumor suppression may be used to evaluate the carcinogenic potential of a test agent.
- the method comprises contacting the genetically modified animal comprising an inactivated tumor suppressor sequence and a wild-type animal to the test agent, and then monitoring the development of tumors. If the animal comprising an inactivated tumor suppressor sequence has an increased incidence of tumors relative to the wild-type animal, the test agent may be carcinogenic.
- Secretases make up a diverse set of proteins that affect susceptibility for numerous disorders, the presence of a disorder, the severity of a disorder, or any combination thereof.
- Secretases are enzymes that clip off smaller pieces of another transmembrane protein.
- Secretases are implicated in many disorders including, for example, Alzheimer's disease.
- a method of the invention may be used to create an animal or cell in which at least one chromosomal sequence associated with secretase associated disorders has been edited. Suitable chromosomal edits may include, but are not limited to, the type of edits detailed in section l(f) above.
- chromosomal sequences associated with a secretase associated disorder may be edited.
- a secretase associated disorder-associated protein or control sequence may typically be selected based on an experimental association of the secretase-related proteins with the development of a secretase disorder. For example, the production rate or circulating concentration of a protein associated with a secretase disorder may be elevated or depressed in a population with a secretase disorder relative to a population without a secretase disorder.
- Differences in protein levels may be assessed using proteomic or genomic analysis techniques known in the art.
- proteins associated with a secretase disorder include PSENEN (presenilin enhancer 2 homolog (C.
- CTSB cathepsin B
- PSEN1 presenilin 1
- APP amphide precursor protein
- APH 1 B anterior pharynx defective 1 homolog B (C.
- apolipoprotein E apolipoprotein E
- ACE angiotensin I converting enzyme (peptidyl-dipeptidase A) 1
- STN statin
- TP53 tumor protein p53
- IL6 interleukin 6 (interferon, beta 2)
- NGFR nerve growth factor receptor (TNFR superfamily, member 16)
- IL1 B interleukin 1 , beta
- ACHE acetylcholinesterase (Yt blood group)
- CTNNB1 catenin (cadhehn-associated protein), beta 1 , 88kDa), IGF1 (insulin-like growth factor 1 (somatomedin C)), IFNG (interferon, gamma), NRG1 (neuregulin 1 ), CASP3 (caspase 3, apoptosis-related cysteine peptidase), MAPK1 (mitogen- activated protein kinase 1 ), CDH1 (cadherin 1 , type 1
- metallopeptidase 12 microphage elastase
- JAG1 jagged 1 (Alagille syndrome)
- CD40LG CD40 ligand
- PPARG peroxisome proliferator-activated receptor gamma
- FGF2 fibroblast growth factor 2 (basic)
- IL3 interleukin 3 (colony-stimulating factor, multiple)
- LRP1 low density lipoprotein receptor- related protein 1
- NOTCH4 Notch homolog 4 ⁇ Drosophila
- MAPK8 mitogen- activated protein kinase 8
- PREP prolyl endopeptidase
- NOTCH3 Notch homolog 3 ⁇ Drosophila
- PRNP prion protein
- CTSG cathepsin G
- EGF epidermal growth factor (beta-urogastrone)
- REN renin
- CD44 CD44 molecule (Indian blood group)
- SELP selectin P (granule membrane protein 14
- IL1 R1 interleukin 1 receptor, type I
- PROK1 prokineticin 1
- MAPK3 mitogen-activated protein kinase 3
- NTRK1 neurotrophic tyrosine kinase, receptor, type 1
- MME membrane metallo-endopeptidase
- TKT transketolase
- CXCR2 chemokine (C-X-C motif) receptor 2
- IGF1 R insulin-like growth factor 1 receptor
- RARA retinoic acid receptor, alpha
- CREBBP CREB binding protein
- PTGS1 prostaglandin-endoperoxide synthase 1 (prostaglandin G/H synthase and cyclooxygenase)
- GALT galactose-1 -phosphate
- CHRM1 Cholinergic receptor, muscarinic 1 ), ATXN1 (ataxin 1 ), PAWR (PRKC, apoptosis, WT1 , regulator), NOTCH2 (Notch homolog 2 (Drosophila)), M6PR (mannose-6-phosphate receptor (cation dependent)), CYP46A1 (cytochrome P450, family 46, subfamily A, polypeptide 1 ), CSNK1 D (casein kinase 1 , delta), MAPK14 (mitogen-activated protein kinase 14), PRG2 (proteoglycan 2, bone marrow (natural killer cell activator, eosinophil granule major basic protein)), PRKCA (protein kinase C, alpha), L1 CAM (L1 cell adhesion molecule), CD40 (CD40 molecule, TNF receptor superfamily member 5), NR112 (nuclear receptor subfamily 1 , group I,
- ERBB2 v-erb-b2 erythroblastic leukemia viral oncogene homolog 2, neuro/glioblastoma derived oncogene homolog (avian)
- CAV1 caveolin 1 , caveolae protein, 22kDa
- MMP7 matrix metallopeptidase 7 (matrilysin, uterine)
- TGFA transforming growth factor, alpha
- RXRA retinoid X receptor, alpha
- STX1A syntaxin 1A (brain)
- PSMC4 proteasome (prosome, macropain) 26S subunit, ATPase, 4
- P2RY2 puhnergic receptor P2Y, G-protein coupled, 2), TNFRSF21 (tumor necrosis factor receptor superfamily, member 21 ), DLG1 (discs, large homolog 1 (Drosophila)), NUMBL (numb homolog (Drosophila
- HES5 hairy and enhancer of split 5 (Drosophila)
- GCC1 GRIP and coiled-coil domain containing 1
- Preferred proteins associated with a secretase disorder include APH-1 A (anterior pharynx-defective 1 , alpha), APH-1 B (anterior pharynx- defective 1 , beta), PSEN-1 (presenilin-1 ), NCSTN (nicastrin), PEN-2 (presenilin enhancer 2), and any combination thereof.
- an animal created by a method of the invention may be used to study the effects of mutations on the animal and development and/or progression of a secretase associated disorder using measures commonly used in the study of secretase disorders.
- the incidence or indication of a secretase disorder may occur spontaneously in the genetically modified animal.
- the incidence or indication of the secretase disorder may be promoted by exposure to a disruptive agent.
- disruptive agents include a protein associated with a secretase disorder such as any of those described above, a drug, a toxin, a chemical, an activated retrovirus, and an environmental stress.
- environmental stresses include forced swimming, cold swimming, platform shaker stimuli, loud noises, and
- nucleic acid sequences and the proteins encoded by them, are associated with motor neuron disorders. These sequences make up a diverse set of sequences that affect susceptibility for developing a motor neuron disorder, the presence of the motor neuron disorder, the severity of the motor neuron disorder or any combination thereof.
- a method of the invention may be used to create an animal or cell in which at least one chromosomal sequence associated with a specific motor neuron disorder, amyotrophic lateral sclerosis (ALS), has been edited.
- Suitable chromosomal edits may include, but are not limited to, the type of edits detailed in section l(f) above.
- chromosomal sequences associated with ALS may be edited.
- a chromosomal sequence associated with ALS may typically be selected based on an
- An ALS-related nucleic acid sequence may encode an ALS-related protein or may be an ALS- related control sequence.
- the production rate or circulating concentration of a protein associated with ALS may be elevated or depressed in a population with ALS relative to a population without ALS. Differences in protein levels may be assessed using proteomic or genomic analysis techniques known in the art.
- ALS include but are not limited to SOD1 (superoxide dismutase 1 ), ALS2
- VAGFA vascular endothelial growth factor A
- VAGFB vascular endothelial growth factor B
- VAGFC vascular endothelial growth factor C
- an animal created by a method of the invention may be used to study the effects of mutations on the animal and development and/or progression of ALS using measures commonly used in the study of ALS.
- a method of the invention may be used to create an animal or cell in which at least one chromosomal sequence associated with a prion disease has been edited.
- Suitable chromosomal edits may include, but are not limited to, the type of edits detailed in section l(f) above.
- chromosomal sequences encoding a protein or control sequence associated with prion disorders may be edited.
- a prion disorder-related nucleic acid sequence may typically be selected based on an experimental association of the prion disorder-related nucleic acid sequence to a prion disorder.
- a prion disorder- related nucleic acid sequence may encode a prion disorder-related protein or isoform thereof, or may be a prion disorder-related control sequence. For example, the production rate or circulating concentration of a prion disorder- related protein or isoform may be elevated or depressed in a population having a prion disorder relative to a population lacking the prion disorder.
- Differences in protein or certain isoform levels may be assessed using proteomic techniques including but not limited to Western blot, immunohistochemical staining, enzyme linked immunosorbent assay (ELISA), and mass spectrometry.
- proteomic techniques including but not limited to Western blot, immunohistochemical staining, enzyme linked immunosorbent assay (ELISA), and mass spectrometry.
- the prion disorder-related proteins may be identified by obtaining gene expression profiles of the genes encoding the proteins using genomic techniques including but not limited to DNA microarray analysis, serial analysis of gene expression (SAGE), and quantitative real-time polymerase chain reaction (Q-PCR).
- Non-limiting examples of prion disorder-related proteins include PrP c and its isoforms, PrP Sc and its isoforms, HECTD2 (e3-ubipuitin ligase protein), STM (stress inducible protein 1 ), DPL (residue Doppel protein, encoded by Prnd), APOA1 (Apolipoprotein A1 ), BCL-2 (B-cell lymphoma 2), HSP60 (Heat shock 6OkDa protein), BAX- inhibiting peptide (Bcl-2-associated X protein inhibitor), NRF2 (nuclear respiratory factor 2), NCAMs (neural cell- adhesion molecules), heparin, laminin and laminin receptor.
- HECTD2 e3-ubipuitin ligase protein
- STM stress inducible protein 1
- DPL desidue Doppel protein, encoded by Prnd
- APOA1 Apolipoprotein A1
- BCL-2 B-cell lymphoma 2
- genes that may be related to neurodegenerative conditions in prion disorders include A2M (Alpha-2- Macroglobulin), AATF (Apoptosis antagonizing transcription factor), ACPP (Acid phosphatase prostate), ACTA2 (Actin alpha 2 smooth muscle aorta), ADAM22 (ADAM metallopeptidase domain), ADORA3 (Adenosine A3 receptor), ADRA1 D (Alpha-1 D adrenergic receptor for Alpha-1 D adrenoreceptor), AHSG (Alpha-2- HS-glycoprotein), AIF1 (Allograft inflammatory factor 1 ), ALAS2 (Delta- aminolevulinate synthase 2), AMBP (Alpha-1 -microglobulin/bikunin precursor), ANK3 (Ankryn 3), ANXA3 (Annexin A3), APCS (Amyloid P component serum), APOA1 (Apolios), APOA1 (Apoli
- B4GALNT1 Beta-M-N-acetyl-galactosaminyl transferase 1
- BAX Bcl-2-associated X protein
- BCAT Branched chain amino-acid
- BCKDHA Branched chain keto acid dehydrogenase E1 alpha
- BCKDK Branched chain alpha-ketoacid dehydrogenase kinase
- BCL2 B-cell lymphoma 2
- BCL2L1 BCL2-like 1
- BDNF Brain-derived neurotrophic factor
- BHLHE40 Class E basic helix-loop-helix protein 40
- BHLHE41 Class E basic helix-loop-helix protein 41
- BMP2 Bone
- BTC morphogenetic protein 2A
- BMP3 Bone morphogenetic protein 3
- BMP5 Bone morphogenetic protein 5
- BRD1 Bromodomain containing 1
- BTC Bromodomain containing 1
- CCAAT/enhancer-binding protein beta CEBPD (CCAAT/enhancer-binding protein delta), CEBPG (CCAAT/enhancer-binding protein gamma), CENPB (Centromere protein B), CGA (Glycoprotein hormone alpha chain), CGGBP1 (CGG triplet repeat-binding protein 1 ), CHGA (Chromogranin A), CHGB
- IFNAR2 Interferon alpha/beta/omega receptor 2
- IGF1 Insulin-like growth factor 1
- IGF2 Insulin-like growth factor 2
- IGFBP2 Insulin-like growth factor binding protein 2, 36kDa
- IGFBP7 Insulin-like growth factor binding protein 7
- IL10 Interleukin 10
- IL10RA Interleukin 10 receptor alpha
- IL11 Interleukin 11
- IL11 RA Interleukin 11 receptor alpha
- IL11 RB Interleukin 11 receptor beta
- IL13 Interleukin 13
- IL15 Interleukin 15
- IL17A Interleukin 17A
- IL17RB Interleukin 17 receptor B
- IL18 Interleukin 18
- IL18RAP Interleukin 18 receptor accessory protein
- IL1 R2 Interleukin 1 receptor type II
- IL1 RN Interleukin 1 receptor type II
- MAOB Mantonidase alpha class 1A member 1
- MAOB Monoamine oxidase B
- MAP3K1 Mitogen-activated protein kinase kinase kinase 1
- MAPK1 Mitogen- activated protein kinase 1
- MAPK3 Mitogen-activated protein kinase 3
- MAPRE2 Microtubule-associated protein RP/EB family member 2
- MARCKS Myristoylated alanine-hch protein kinase C substrate
- MAS1 MAS1 oncogene
- MASL1 MAS1 oncogene-like
- MBP Myelin basic protein
- MCL1 Myeloid cell leukemia sequence 1
- MDMX MDM2-like p53-binding protein
- MECP2 Metal CpG binding protein 2
- MFGE8 Milk fat globule-EGF factor 8 protein
- MIF Macrophage migration inhibitory factor
- MMP2 Mestrix metallopeptidase 2
- MOBP Myelin-associated oligodendrocyte basic protein
- MUC16 Cancer antigen 125
- MX2 Myxovirus (influenza virus) resistance 2
- MYBBP1A MYB binding protein 1 a
- NCOA2 Nuclear receptor coactivator 2
- NEDD9 Neuronal precursor cell expressed developmentally down-regulated 9
- NFATC1 Nuclear factor of activated T-cells cytoplasmic calcineurin-dependent 1
- NFE2L2 Nuclear factor erythroid-derived 2-like 2
- NFIC Nuclear factor I/C
- NFKBIA Nuclear factor of kappa light polypeptide gene enhancer in B-cells inhibitor alpha
- NGFR Neve growth factor receptor
- NIACR2 neuron receptor 2
- NLGN3 Neuroroligin 3
- NPFFR2 neuropeptide FF receptor 2
- NPY Neuropeptide Y
- NR3C2 Nuclear receptor subfamily 3 group C member 2
- NRAS Neuroroblastoma RAS viral (v-ras) oncogene homolog
- NRCAM Neuroonal cell adhesion molecule
- NRG1 Neuroregulin 1
- POU2AF1 POU domain class 2 associating factor 1
- PRKAA1 5'-AMP-activated protein kinase catalytic subunit alpha-1
- PRL Prolactin
- PSCDBP Cytohesin 1 interacting protein
- PSPN Persephin
- PTAFR Platinum-activating factor receptor
- PTGS2 Prostaglandin-endoperoxide synthase 2
- PTN Pleiotrophin
- PTPN11 Protein tyrosine phosphatase non-receptor type 11
- PYY Peptide YY
- RAB6A RAB6A member RAS oncogene family
- RAD17 RAD17 homolog
- RAF1 RAF proto-oncogene sehne/threonine-protein kinase
- RANBP2 RAN binding protein 2
- RAP1A RAP1 A member of RAS oncogene family
- RB1 Retinoblastoma 1
- RBL2 Retinoblastoma-like 2 (p130)
- RCVRN Recoverin
- REM2 RS/RAD/GEM-like GTP binding 2
- RFRP RFamide-related peptide
- RPS6KA3 Rosulft-related protein S6 kinase 9OkDa polypeptide 3
- RTN4 Reticulon 4
- RUNX1 Runt-related transcription factor 1
- S100A4 S100 calcium binding protein A4
- S1 PR1 Sphingosine-1 -phosphate receptor 1
- TGFA Transforming growth factor alpha
- TGFB1 Transforming growth factor beta 1
- TGFB2 Transforming growth factor beta 2
- TGFB3 Transforming growth factor beta 3
- TGFBR1 Transforming growth factor beta receptor I
- TGM2 Transglutaminase 2
- THPO Thrombopoietin
- TIMP1 TIMP metallopeptidase inhibitor 1
- TIMP3 TIMP metallopeptidase inhibitor 3
- TMEM129 Transmembrane protein 129
- TNFRC6 TNFR/NGFR cysteine-rich region
- TNFRSF10A Tuor necrosis factor receptor superfamily member 10a
- TNFRSF10C Tuor necrosis factor receptor superfamily member 10c decoy without an intracellular domain
- TNFRSF1 A Tuor necrosis factor receptor superfamily member 1A
- TOB2 Transducer of ERBB2 2
- Exemplary prion disorder-related proteins include PrP c and isoforms thereof, PrP Sc and isoforms thereof, HECTD2 (e3-ubipuitin ligase protein), STM (stress inducible protein 1 ), DPL (residue Doppel protein, encoded by Prnd), APOA1 (Apolipoprotein A1 ), BCL-2 (B-cell lymphoma 2), HSP60 (Heat shock 6OkDa protein), BAX- inhibiting peptide (Bcl-2-associated X protein inhibitor), NRF2 (nuclear respiratory factor 2), NCAMs (neural cell-adhesion molecules), heparin, laminin and laminin receptor and any combination thereof.
- HECTD2 e3-ubipuitin ligase protein
- STM stress inducible protein 1
- DPL desidue Doppel protein, encoded by Prnd
- APOA1 Apolipoprotein A1
- BCL-2 B-cell lymphom
- an animal created by a method of the invention may be used to study the effects of mutations on the animal and development and/or progression of a prion disorder using measures commonly used in the study of prion disorders.
- a method of the invention may be used to create an animal or cell in which at least one chromosomal sequence associated with immunodeficiency has been edited.
- Suitable chromosomal edits may include, but are not limited to, the type of edits detailed in section l(f) above.
- immunodeficiency protein or control sequence is a protein or control sequence for which an alteration in activity is linked to an immunodeficiency, which may be the primary or a secondary symptom of an animal disease or condition, preferably a mammalian, e.g., a human, disease or condition.
- An immunodeficiency protein or control sequence is a protein or control sequence for which an alteration in activity is linked to an immunodeficiency, which may be the primary or a secondary symptom of an animal disease or condition, preferably a mammalian, e.g., a human, disease or condition.
- immunodeficiency sequence may typically be selected based on an experimental association of the immunodeficiency sequence to an immunodeficiency disease or condition, especially a mammalian, e.g., a human, disease or condition.
- an immunodeficiency disease or condition especially a mammalian, e.g., a human, disease or condition.
- the expression of an immunodeficiency protein in a particular tissue may be elevated or depressed in a population having an immunodeficiency disease or condition relative to a population lacking the disease or condition. Differences in protein levels may be assessed using proteomic or genomic analysis techniques known in the art.
- Non-limiting examples of human immunodeficiency genes include A2M [alpha-2-macroglobulin]; AANAT [arylalkylamine N- acetyltransferase]; ABCA1 [ATP-binding cassette, sub-family A (ABC1 ), member 1]; ABCA2 [ATP-binding cassette, sub-family A (ABC1 ), member 2]; ABCA3
- ABC1 [ATP-binding cassette, sub-family A (ABC1 ), member 3]; ABCA4 [ATP-binding cassette, sub-family A (ABC1 ), member 4]; ABCB1 [ATP-binding cassette, subfamily B (MDR/TAP), member 1]; ABCC1 [ATP-binding cassette, sub-family C (CFTR/MRP), member 1]; ABCC2 [ATP-binding cassette, sub-family C
- ABCG1 [ATP-binding cassette, sub-family G (WHITE), member 1]; ABCG2 [ATP- binding cassette, sub-family G (WHITE), member 2]; ABCG5 [ATP-binding cassette, sub-family G (WHITE), member 5]; ABCG8 [ATP-binding cassette, subfamily G (WHITE), member 8]; ABHD2 [abhydrolase domain containing 2]; ABL1 [c-abl oncogene 1 , receptor tyrosine kinase]; ABO [ABO blood group (transferase A, alpha 1-3-N-acetylgalactosaminyltransferase; transferase B, alpha 1 -3- galactosyltransferase)]; ABP1 [amiloride binding protein 1 (amine oxidase
- ACAA1 [acetyl-Coenzyme A acyltransferase 1]; ACACA [acetyl-Coenzyme A carboxylase alpha]; ACAN [aggrecan]; ACAT1 [acetyl- Coenzyme A acetyltransferase 1]; ACAT2 [acetyl-Coenzyme A acetyltransferase 2]; ACCN5 [amiloride-sensitive cation channel 5, intestinal]; ACE [angiotensin I converting enzyme (peptidyl-dipeptidase A) 1]; ACE2 [angiotensin I converting enzyme (peptidyl-dipeptidase A) 2]; ACHE [acetylcholinesterase (Yt blood group)]; ACLY [ATP citrate lyase]; ACOT9 [acyl-CoA thioesterase 9]; ACOX1 [acyl-Coenzyme A oxid
- ACVRL1 activin A receptor type ll-like 1
- ACY1 aminoacylase 1
- ADA aminoacylase 1
- ADAM10 [ADAM metallopeptidase domain 10]; ADAM12 [ADAM metallopeptidase domain 12]; ADAM17 [ADAM metallopeptidase domain 17]; ADAM23 [ADAM metallopeptidase domain 23]; ADAM33 [ADAM
- ADAM8 ADAM metallopeptidase domain 8
- ADAM9 [ADAM metallopeptidase domain 9 (meltrin gamma)]; ADAMTS1 [ADAM metallopeptidase with thrombospondin type 1 motif, 1]; ADAMTS12 [ADAM metallopeptidase with thrombospondin type 1 motif, 12]; ADAMTS13 [ADAM metallopeptidase with thrombospondin type 1 motif, 13]; ADAMTS15 [ADAM metallopeptidase with thrombospondin type 1 motif, 15]; ADAMTSL1 [ADAMTS- like 1]; ADAMTSL4 [ADAMTS-like 4]; ADAR [adenosine deaminase, RNA- specific]; ADCY1 [adenylate cyclase 1 (brain)]; ADCY10 [adenylate cyclase 10 (soluble)]; ADCY3 [adenylate cyclase 3]; ADCY9 [adenylate
- ADCYAP1 [adenylate cyclase activating polypeptide 1 (pituitary)]; ADCYAP1 R1 [adenylate cyclase activating polypeptide 1 (pituitary) receptor type I]; ADD1
- ADIPOR1 [adducin 1 (alpha)]; ADH5 [alcohol dehydrogenase 5 (class III), chi polypeptide]; ADIPOQ [adiponectin, C1Q and collagen domain containing]; ADIPOR1
- ADK adenosine kinase
- ADM adrenomedullin
- ADORA1 [adenosine A1 receptor]; ADORA2A [adenosine A2a receptor]; ADORA2B [adenosine A2b receptor]; ADORA3 [adenosine A3 receptor];
- ADRA1 B [adrenergic, alpha-1 B-, receptor]; ADRA2A [adrenergic, alpha-2A-, receptor]; ADRA2B [adrenergic, alpha-2B-, receptor]; ADRB1 [adrenergic, beta- 1 -, receptor]; ADRB2 [adrenergic, beta-2-, receptor, surface]; ADSL
- Adenylosuccinate lyase [adenylosuccinate lyase]; ADSS [adenylosuccinate synthase]; AEBP1 [AE binding protein 1]; AFP [alpha-fetoprotein]; AGER [advanced glycosylation end product-specific receptor]; AGMAT [agmatine ureohydrolase (agmatinase)]; AGPS [alkylglycerone phosphate synthase]; AGRN [agrin]; AGRP [agouti related protein homolog (mouse)]; AGT [angiotensinogen (serpin peptidase inhibitor, clade A, member 8)]; AGTR1 [angiotensin Il receptor, type 1]; AGTR2
- Abelson helper integration site 1 [Abelson helper integration site 1]; AHR [aryl hydrocarbon receptor]; AHSP
- AIRE alpha hemoglobin stabilizing protein
- AICDA activation-induced cytidine deaminase
- AIDA axin interactor, dorsalization associated
- AIMP1 aminoacyl tRNA synthetase complex-interacting multifunctional protein 1]
- AIRE alpha hemoglobin stabilizing protein
- AK1 adenylate kinase 1
- AK2 adenylate kinase 2
- AKR1A1 aldo-keto reductase family 1 , member A1 (aldehyde reductase)];
- AKR1 B1 [aldo-keto reductase family 1 , member B1 (aldose reductase)]
- AKR1 C3 aldo-keto reductase family 1 , member C3 (3-alpha hydroxysteroid
- AKT1 [v-akt murine thymoma viral oncogene homolog 1]; AKT2 [v-akt murine thymoma viral oncogene homolog 2]; AKT3 [v-akt murine thymoma viral oncogene homolog 3 (protein kinase B, gamma)]; ALB [albumin]; ALCAM [activated leukocyte cell adhesion molecule]; ALDH1A1 [aldehyde dehydrogenase 1 family, member A1]; ALDH2 [aldehyde dehydrogenase 2 family (mitochondrial)]; ALDH3A1 [aldehyde dehydrogenase 3 family, memberAI]; ALDH7A1 [aldehyde dehydrogenase 7 family, member A1]; ALDH9A1 [aldehyde dehydrogenase 9 family, member AI]; ALG1 [v-akt murine thymom
- ALG12 asparagine- linked glycosylation 12, alpha-1 ,6-mannosyltransferase homolog (S. cerevisiae)]; ALK [anaplastic lymphoma receptor tyrosine kinase]; ALOX12 [arachidonate 12- lipoxygenase]; ALOX15 [arachidonate 15-lipoxygenase]; ALOX15B [arachidonate 15-lipoxygenase, type B]; ALOX5 [arachidonate 5-lipoxygenase]; ALOX5AP
- ALPI alkaline phosphatase, intestinal
- ALPL alkaline phosphatase, liver/bone/kidney
- ALPP alkaline phosphatase, placental (Regan isozyme)]
- AMACR alpha-methylacyl-CoA racemase
- AMBP alpha-1 -microglobulin/bikunin precursor]
- AMPD3 adenosine monophosphate deaminase 3]
- ANG angiogenin, ribonuclease, RNase A family, 5]
- ANGPT1 angiopoietin 1]
- ANGPT2 angiopoietin 2]
- ANK1 ankyrin 1 , erythrocytic]
- ANKH ankylosis, progressive homolog (mouse)]
- ANKRD1 ankyrin repeat domain 1 (cardiac muscle)]
- ANKRD1 ankyrin repeat domain 1 (cardiac muscle)];
- AOC2 [amine oxidase, copper containing 2 (retina-specific)]; AP2B1 [adaptor-related protein complex 2, beta 1 subunit]; AP3B1 [adaptor-related protein complex 3, beta 1 subunit]; APC [adenomatous polyposis coli]; APCS [amyloid P component, serum]; APEX1 [APEX nuclease (multifunctional DNA repair enzyme) 1]; APLNR [apelin receptor]; APOA1 [apolipoprotein A-I]; APOA2 [apolipoprotein A-Il]; APOA4 [apolipoprotein A-IV]; APOB [apolipoprotein B (including Ag(x) antigen)]; APOBEC1 [apolipoprotein B mRNA editing enzyme, catalytic polypeptide 1]; APOBEC3G [apolipoprotein B mRNA editing enzyme, catalytic polypeptide-like 3G];
- A4 precursor protein [apolipoprotein D]; APOE [apolipoprotein E]; APOH [apolipoprotein H (beta-2- glycoprotein I)]; APP [amyloid beta (A4) precursor protein]; APRT [adenine phosphohbosyltransferase]; APTX [aprataxin]; AQP1 [aquaporin 1 (Colton blood group)]; AQP2 [aquaporin 2 (collecting duct)]; AQP3 [aquaporin 3 (Gill blood group)]; AQP4 [aquaporin 4]; AQP5 [aquaporin 5]; AQP7 [aquaporin 7]; AQP8 [aquaporin 8]; AR [androgen receptor]; AREG [amphiregulin]; ARF6 [ADP- ribosylation factor 6]; ARG1 [arginase, liver]; ARG2 [
- ASNS argininosuccinate lyase
- ASNS asparagine synthetase
- ASPA aspartoacylase (Canavan disease)
- ASPG asparaginase homolog (S. cerevisiae)]
- ASPH argininosuccinate lyase
- ASRGL1 [aspartate beta-hydroxylase]
- ASRGL1 [asparaginase like 1]
- ASS1 [asparaginase like 1]
- ATF1 activating transcription factor 1
- ATF2 activating transcription factor 2
- ATF3 activating transcription factor 3
- ATF4 activating transcription factor 4 (tax-responsive enhancer element B67)];
- ATG16L1 [ATG16 autophagy related 16-like 1 (S. cerevisiae)]; ATM [ataxia telangiectasia mutated]; ATMIN [ATM interactor]; ATN 1 [atrophin 1]; ATOH 1 [atonal homolog 1 (Drosophila)]; ATP2A2 [ATPase, Ca++ transporting, cardiac muscle, slow twitch 2]; ATP2A3 [ATPase, Ca++ transporting, ubiquitous];
- ATP2C1 [ATPase, Ca++ transporting, type 2C, member 1]; ATP5E [ATP synthase, H+ transporting, mitochondrial F1 complex, epsilon subunit]; ATP7B [ATPase, Cu++ transporting, beta polypeptide]; ATP8B1 [ATPase, class I, type 8B, member 1]; ATPAF2 [ATP synthase mitochondrial F1 complex assembly factor 2]; ATR [ataxia telangiectasia and Rad3 related]; ATRIP [ATR interacting protein]; ATRN [attracting AURKA [aurora kinase A]; AURKB [aurora kinase B]; AURKC [aurora kinase C]; AVP [arginine vasopressin]; AVPR2 [arginine vasopressin receptor 2]; AXL [AXL receptor tyrosine kinase]; AZGP1 [alpha-2- glyco
- B4GALNT1 beta-1 ,4-N-acetyl-galactosaminyl transferase 1]
- B4GALT1 [UDP-GaI :betaGlcNAc beta 1 ,4- galactosyltransferase, polypeptide 1]
- BACE1 beta-site APP-cleaving enzyme 1
- BACE2 beta-site APP-cleaving enzyme 2
- BACH1 [BTB and CNC homology 1 , basic leucine zipper transcription factor 1]
- BAD BCL2-associated agonist of cell death]
- BAD BCL2-associated agonist of cell death
- BAIAP2 [BAM -associated protein 2]; BAK1 [BCL2-antagonist/killer 1]; BARX2 [BARX homeobox 2]; BAT1 [HLA-B associated transcript 1]; BAT2 [HLA-B associated transcript 2]; BAX [BCL2-associated X protein]; BBC3 [BCL2 binding component 3]; BCAR1 [breast cancer anti-estrogen resistance 1]; BCAT1
- BRCA1 [breast cancer 1 , early onset]; BRCA2 [breast cancer 2, early onset]; BRCC3 [BRCA1/BRCA2- containing complex, subunit 3]; BRD8 [bromodomain containing 8]; BRIP1 [BRCA1 interacting protein C-terminal helicase 1]; BSG [basigin (Ok blood group)]; BSN [bassoon (presynaptic cytomatrix protein)]; BSX [brain-specific homeobox]; BTD [biotinidase]; BTK [Bruton agammaglobulinemia tyrosine kinase]; BTLA [B and T lymphocyte associated]; BTNL2 [butyrophilin-like 2 (MHC class Il associated)]; BTRC [beta-transducin repeat containing]; C10orf67
- CABIN1 [calcineurin binding protein 1]; CACNA1 C [calcium channel, voltage-dependent, L type, alpha 1 C subunit]; CACNA1 S [calcium channel, voltage-dependent, L type, alpha 1 S subunit]; CAD [carbamoyl- phosphate synthetase 2, aspartate transcarbamylase, and dihydroorotase]; CALB1 [calbindin 1 , 28kDa]; CALB2 [calbindin 2]; CALCA [calcitonin-related polypeptide alpha]; CALCRL [calcitonin receptor-like]; CALD
- CASP2 caspase 2, apoptosis-related cysteine peptidase]; CASP3 [caspase 3, apoptosis-related cysteine peptidase]; CASP5 [caspase 5, apoptosis-related cysteine peptidase]; CASP6 [caspase 6, apoptosis-related cysteine peptidase]; CASP7 [caspase 7, apoptosis-related cysteine peptidase]; CASP8 [caspase 8, apoptosis-related cysteine peptidase]; CASP8AP2 [caspase 8 associated protein 2]; CASP9 [caspase 9, apoptosis-related cysteine peptidase]; CASR [calcium- sensing receptor]; CAST [calpastatin]; CAT [catalase]; CAV1 [caveolin 1 , caveolae protein, 22kDa]; CAV2 [caveolin 2
- CCDC144A [coiled-coil domain containing 144A]; CCDC144B [coiled-coil domain containing 144B]; CCDC68 [coiled-coil domain containing 68]; CCK [cholecystokinin]; CCL1 [chemokine (C-C motif) ligand 1]; CCL11 [chemokine (C- C motif) ligand 11]; CCL13 [chemokine (C-C motif) ligand 13]; CCL14
- C-C motif [chemokine (C-C motif) ligand 14]; CCL17 [chemokine (C-C motif) ligand 17]; CCL18 [chemokine (C-C motif) ligand 18 (pulmonary and activation-regulated)]; CCL19 [chemokine (C-C motif) ligand 19]; CCL2 [chemokine (C-C motif) ligand 2]; CCL20 [chemokine (C-C motif) ligand 20]; CCL21 [chemokine (C-C motif) ligand 21]; CCL22 [chemokine (C-C motif) ligand 22]; CCL24 [chemokine (C-C motif) ligand 24]; CCL25 [chemokine (C-C motif) ligand 25]; CCL26 [chemokine (C-C motif) ligand 26]; CCL27 [chemokine (C-C motif) ligand 27]; CCL28
- chemokine (C-C motif) ligand 28 [chemokine (C-C motif) ligand 28]; CCL3 [chemokine (C-C motif) ligand 3]; CCL4 [chemokine (C-C motif) ligand 4]; CCL4L1 [chemokine (C-C motif) ligand 4-like 1]; CCL5 [chemokine (C-C motif) ligand 5]; CCL7 [chemokine (C-C motif) ligand I]; CCL8 [chemokine (C-C motif) ligand 8]; CCNA1 [cyclin A1]; CCNA2 [cyclin A2]; CCNB1 [cyclin B1]; CCNB2 [cyclin B2]; CCNC [cyclin C]; CCND1 [cyclin D1]; CCND2 [cyclin D2]; CCND3 [cyclin D3]; CCNE1 [cyclin E1]; CCNG1 [cyclin G1
- chemokine (C-C motif) receptor 8 [chemokine (C-C motif) receptor 8]; CCR9 [chemokine (C-C motif) receptor 9]; CCRL1 [chemokine (C-C motif) receptor-like 1]; CD14 [CD14 molecule]; CD151 [CD151 molecule (Raph blood group)]; CD160 [CD160 molecule]; CD163
- CD274 [CD274 molecule]; CD28 [CD28 molecule]; CD2AP [CD2-associated protein]; CD300LF [CD300 molecule-like family member f]; CD34 [CD34 molecule]; CD36 [CD36 molecule (thrombospondin receptor)]; CD37 [CD37 molecule]; CD38 [CD38 molecule]; CD3E [CD3e molecule, epsilon (CD3-TCR complex)]; CD4 [CD4 molecule]; CD40 [CD40 molecule, TNF receptor
- CD40LG CD40 ligand
- CD44 CD44 molecule (Indian blood group)]
- CD46 CD46 molecule, complement regulatory protein]
- CD47 CD47 molecule
- CD48 CD48 molecule
- CD5 CD5 molecule
- CD52 CD52 molecule
- CD53 CD53 molecule
- CD55 CD55 molecule, decay accelerating factor for complement (Cromer blood group)]
- CD58 CD58 molecule
- CD79A [CD79a molecule, immunoglobulin-associated alpha]
- CD79B [CD79b molecule, immunoglobulin- associated beta]
- CD80 [CD80 molecule]; CD81 [CD81 molecule]; CD82 [CD82 molecule]; CD83 [CD83 molecule]; CD86 [CD86 molecule]; CD8A [CD8a molecule]; CD9 [CD9 molecule]; CD93 [CD93 molecule]; CD97 [CD97 molecule]; CDC20 [cell division cycle 20 homolog (S. cerevisiae)]; CDC25A [cell division cycle 25 homolog A (S.
- CDH1 [cadherin 1 , type 1 , E-cadherin (epithelial)]; CDH2 [cadherin 2, type 1 , N-cadherin (neuronal)]; CDH26 [cadherin 26]; CDH3 [cadherin 3, type 1 , P-cadherin (placental)]; CDH5 [cadherin 5, type 2 (vascular endothelium)]; CDIPT [CDP-diacylglycerol-inositol 3- phosphatidyltransferase (phosphatidylinositol synthase)]; CDK1 [cyclin- dependent kinase 1]; CDK2 [cycl in-dependent kinase 2]; CDK4 [cyclin-dependent kinase 4]; CDK5 [cyclin-dependent kinase 5]; CDK5R1 [cyclin-dependent kinase 5, regulatory subunit
- CDKN2B cyclin-dependent kinase inhibitor 2B (p15, inhibits CDK4)]
- CDKN3 cyclin-dependent kinase inhibitor 3]
- CEACAM3 Carcinoembryonic antigen-related cell adhesion molecule 3
- CEACAM5 Carcinoembryonic antigen-related cell adhesion molecule 5
- CEACAM6 Carcinoembryonic antigen-related cell adhesion molecule 6 (non-specific cross reacting antigen)]
- CEACAM7 Carcinoembryonic antigen-related cell adhesion molecule 7]
- CEBPB CCAAT/enhancer binding protein (C/EBP), beta]
- CEL carbboxyl ester lipase (bile salt-stimulated lipase)]
- CENPJ centromere protein J]
- CENPV centromere protein V]
- CEP290 CEP290
- CGA glycoprotein hormones, alpha polypeptide
- CGB chorionic gonadotropin, beta polypeptide
- CGB5 chorionic gonadotropin, beta polypeptide 5
- CHGA chromogranin A (parathyroid secretory protein 1 )]; CHGB [chromogranin B (secretogranin 1 )]; CHI3L1 [chitinase 3-like 1 (cartilage glycoprotein-39)]; CHIA [chitinase, acidic]; CHIT1 [chitinase 1 (chitothosidase)]; CHKA [choline kinase alpha]; CHML [choroideremia-like (Rab escort protein 2)]; CHRD [chordin];
- CLEC12A [C-type lectin domain family 12, member A]; CLEC16A [C-type lectin domain family 16, member A]; CLEC4A [C-type lectin domain family 4, member A]; CLEC4D [C- type lectin domain family 4, member D]; CLEC4M [C-type lectin domain family 4, member M]; CLEC7A [C-type lectin domain family 7, member A]; CLIP2 [CAP- GLY domain containing linker protein 2]; CLK2 [CDC-like kinase 2]; CLSPN
- CMKLR1 [claspin homolog (Xenopus laevis)]; CLSTN2 [calsyntenin 2]; CLTCL1 [clathrin, heavy chain-like 1]; CLU [clusterin]; CMA1 [chymase 1 , mast cell]; CMKLR1
- CNBP CCHC-type zinc finger, nucleic acid binding protein
- CNDP2 CNDP dipeptidase 2 (metallopeptidase M20 family)]
- CNN1 Calponin 1 , basic, smooth muscle]
- CNP [2',3'-cyclic nucleotide 3' phosphodiesterase]
- CNR1 cannabinoid receptor 1 (brain)]
- CNR2 cannabinoid receptor 2 (macrophage)]
- CNTF ciliary neurotrophic factor]
- CNTN2 contactin 2 (axonal)]
- COG1 component of oligomeric golgi complex 1]
- COG2 Component of oligomeric golgi complex 2]
- COIL coilin]
- COL11 A1 collagen, type Xl, alpha 1]
- COL11A2 [collagen, type Xl, alpha 2]
- COL17A1 [collagen, type X
- COL6A1 [collagen, type Vl, alpha 1]
- COL6A2 [collagen, type Vl, alpha 2]
- COL6A3 [collagen, type Vl, alpha 3]
- COL7A1 [collagen, type VII, alpha 1]
- COL8A2 [collagen, type VIII, alpha 2]
- COL9A1 [collagen, type IX, alpha 1]
- COMT catechol-O-methyltransferase
- COQ3 coenzyme Q3 homolog, methyltransferase (S. cerevisiae)]
- COQ7 coenzyme Q7 homolog, ubiquinone (yeast)]
- CORO1A coronin, actin binding protein, 1A]
- COX10 COX10 homolog, cytochrome c oxidase assembly protein, heme A: farnesyltransferase (yeast)]
- COX15 COX15 homolog, cytochrome c oxidase assembly protein (yeast)]
- COX5A [cytochrome c oxidase subunit Va]
- COX8A [cytochrome c oxidase subunit VIIIA (ubiquitous)]
- CP ceruloplasmin (ferroxidase)]
- CPN1 [carboxypeptidase N, polypeptide 1]; CPOX [coproporphyrinogen oxidase]; CPS1 [carbamoyl-phosphate synthetase 1 , mitochondrial]; CPT2 [carnitine palmitoyltransferase 2]; CR1 [complement component (3b/4b) receptor 1 (Knops blood group)]; CR2 [complement component (3d/Epstein Barr virus) receptor 2]; CRAT [carnitine O-acetyltransferase]; CRB1 [crumbs homolog 1 (Drosophila)]; CREB1 [cAMP responsive element binding protein 1]; CREBBP [CREB binding protein]; CREM [cAMP responsive element modulator]; CRH [corticotropin releasing hormone]; CRHR1 [corticotropin releasing hormone receptor 1]; CRHR2 [corticotropin releasing hormone receptor 2]; CRK [v-crk sar
- CSF2 colony stimulating factor 2
- CSF2RB colony stimulating factor 2 receptor, beta, low-affinity (granulocyte-macrophage)]
- CSF3 colony stimulating factor 3
- CTNNB1 [catenin (cadherin-associated protein), beta 1 , 88kDa]; CTNND1
- CTNS cystinosis, nephropathy
- CTRL chymotrypsin-like
- CTSB cathepsin B
- CTSC cathepsin C
- CXCL1 chemokine (C-X-C motif) ligand 1 (melanoma growth stimulating activity, alpha)]
- CXCL10 chemokine (C- X-C motif) ligand 1 O]
- CXCL11 chemokine (C-X-C motif) ligand 11]
- CXCL12 chemokine (C-X-C motif) ligand 12 (stromal cell-derived factor 1 )]
- CXCL13 chemokine (C-X-C motif) ligand 1 (melanoma growth stimulating activity, alpha)
- CXCL10 chemokine (C- X-C motif) ligand 1 O]
- CXCL11 chemokine (C-X-C motif) ligand 11]
- CXCL12 chemokine (C-X-C motif) ligand 12 (stromal cell-derived factor 1 )]
- CXCL13 chemokine (C-X-C motif) ligand 1 (mela
- CYP19A1 [cytochrome P450, family 19, subfamily A, polypeptide 1]; CYP1A1 [cytochrome P450, family 1 , subfamily A, polypeptide 1]; CYP1A2 [cytochrome P450, family 1 , subfamily A, polypeptide 2]; CYP1 B1 [cytochrome P450, family 1 , subfamily B, polypeptide 1]; CYP21A2 [cytochrome P450, family 21 , subfamily A, polypeptide 2]; CYP24A1 [cytochrome P450, family 24, subfamily A, polypeptide 1]; CYP27A1 [cytochrome P450, family 27, subfamily A, polypeptide 1];
- CYP27B1 [cytochrome P450, family 27, subfamily B, polypeptide 1]; CYP2A6 [cytochrome P450, family 2, subfamily A, polypeptide 6]; CYP2B6 [cytochrome P450, family 2, subfamily B, polypeptide 6]; CYP2C19 [cytochrome P450, family 2, subfamily C, polypeptide 19]; CYP2C8 [cytochrome P450, family 2, subfamily C, polypeptide 8]; CYP2C9 [cytochrome P450, family 2, subfamily C, polypeptide 9]; CYP2D6 [cytochrome P450, family 2, subfamily D, polypeptide 6]; CYP2E1 [cytochrome P450, family 2, subfamily E, polypeptide 1]; CYP2J2 [cytochrome P450, family 2, subfamily J, polypeptide 2]; CYP2R1 [cytochrome P450, family 2, subfamily R, polypeptide 1]; CYP3
- tautomerase (dopachrome delta-isomerase, tyrosine-related protein 2)]; DCTN2 [dynactin 2 (p50)]; DDB1 [damage-specific DNA binding protein 1 , 127kDa];
- DDB2 [damage-specific DNA binding protein 2, 48kDa]
- DDC [dopa]
- DDIT3 DNA-damage- inducible transcript 3
- DDR1 discoidin domain receptor tyrosine kinase 1
- DDX1 DEAD (Asp-Glu-Ala-Asp) box polypeptide 1]
- DDX41 DEAD (Asp-Glu-Ala-Asp) box polypeptide 41]
- DDX42 DEAD (Asp-Glu-Ala-Asp) box polypeptide 42];
- DDX58 [DEAD (Asp-Glu-Ala-Asp) box polypeptide 58]; DEFA1 [defensin, alpha 1]; DEFA5 [defensin, alpha 5, Paneth cell-specific]; DEFA6 [defensin, alpha 6, Paneth cell-specific]; DEFB1 [defensin, beta 1]; DEFB103B [defensin, beta 103B]; DEFB104A [defensin, beta 104A]; DEFB4A [defensin, beta 4A]; DEK
- DGAT1 diacylglycerol O-acyltransferase homolog 1 (mouse)]
- DGCR14 [DiGeorge syndrome critical region gene 14]; DGCR2 [DiGeorge syndrome critical region gene 2]; DGCR6 [DiGeorge syndrome critical region gene 6]; DGCR6L [DiGeorge syndrome critical region gene 6-like]; DGCR8 [DiGeorge syndrome critical region gene 8]; DGUOK [deoxyguanosine kinase]; DHFR [dihydrofolate reductase]; DHODH [dihydroorotate dehydrogenase]; DHPS [deoxyhypusine synthase]; DHRS7B [dehydrogenase/reductase (SDR family) member 7B]; DHRS9 [dehydrogenase/reductase (SDR family) member 9];
- DIAPH1 diaphanous homolog 1 (Drosophila)]; DICER1 [dicer 1 , ribonuclease type III]; DIO2 [deiodinase, iodothyronine, type M]; DKC1 [dyskeratosis congenita 1 , dyskerin]; DKK1 [dickkopf homolog 1 (Xenopus laevis)]; DLAT
- Drosophila (Drosophila)]; DLG5 [discs, large homolog 5 ⁇ Drosophila)]; DMBT1 [deleted in malignant brain tumors 1]; DMC1 [DMC1 dosage suppressor of mck1 homolog, meiosis-specific homologous recombination (yeast)]; DMD [dystrophin]; DMP1 [dentin matrix acidic phosphoprotein 1]; DMPK [dystrophia myotonica-protein kinase]; DMRT1 [doublesex and mab-3 related transcription factor 1]; DMXL2 [Dmx-like 2]; DNA2 [DNA replication helicase 2 homolog (yeast)]; DNAH1
- DPP10 Downstream of tyrosine kinase 1 )]; DOLK [dolichol kinase]; DPAGT1 [dolichyl- phosphate (UDP-N-acetylglucosamine) N-acetylglucosaminephosphotransferase 1 (GlcNAc-1 -P transferase)]; DPEP1 [dipeptidase 1 (renal)]; DPH1 [DPH1 homolog (S. cerevisiae)]; DPMI [dolichyl-phosphate mannosyltransferase polypeptide 1 , catalytic subunit]; DPP10 [dipeptidyl-peptidase 1 O]; DPP4
- EIF4G1 eukaryotic translation initiation factor 4 gamma, 1
- EIF6 eukaryotic translation initiation factor 6
- ELAC2 elaC homolog 2 (E.
- ELANE elastase, neutrophil expressed
- ELAVL1 ELAV (embryonic lethal, abnormal vision, Drosophila)- ⁇ ke 1 (Hu antigen R)]
- ELF3 E74-like factor 3 (ets domain transcription factor, epithelial-specific )]
- ELF5 E74-like factor 5 (ets domain transcription factor)]
- ELN elastin
- ELOVL4 elongation of very long chain fatty acids (FEN1/Elo2, SUR4/Elo3, yeast)-like 4]
- EMD [emerin]
- EMILIN1 elastin microfibril interfacer 1]
- EMR2 egf-like module containing, mucin-like, hormone receptor-like 2]
- EN2 engagerailed homeobox 2]
- ENG Endoglin]
- ENO1 enolase 1 , (alpha)]
- ENO2 elastase, neutrophil expressed
- EPCAM epidermal cell adhesion molecule
- EPHB6 EPH receptor B6
- EPHX1 epoxide hydrolase 1 , microsomal
- EPHX2 epoxide hydrolase 2, cytoplasmic]; EPO [erythropoietin]; EPOR [erythropoietin receptor]; EPRS [glutamyl-prolyl-tRNA synthetase]; EPX [eosinophil peroxidase]; ERBB2 [v-erb-b2 erythroblastic leukemia viral oncogene homolog 2, neuro/glioblastoma derived oncogene homolog (avian)]; ERBB2IP [erbb2 interacting protein]; ERBB3 [v-erb-b2 erythroblastic leukemia viral oncogene homolog 3 (avian)]; ERBB4 [v-erb-a erythroblastic leukemia viral oncogene homolog 4 (avian)]; ERCC1 [excision repair cross-complementing rodent repair deficiency, complementation group 1 (includes overlapping antis
- ESR1 estradiosine receptor 1
- ESR2 esterogen receptor 2 (ER beta)
- ESRRA estrogen-related receptor alpha
- ETS1 [estrogen-related receptor beta]
- ETS2 [v-ets erythroblastosis virus E26 oncogene homolog 2 (avian)]
- EWSR1 Ewing sarcoma breakpoint region 1]
- TNFRSF6 TNFRSF6-associated via death domain
- FADS1 fatty acid desaturase 1
- FADS2 [fatty acid desaturase 2]; FAF1 [Fas (TNFRSF6) associated factor 1]; FAH [fumarylacetoacetate hydrolase (fumarylacetoacetase)]; FAM189B [family with sequence similarity 189, member B]; FAM92B [family with sequence similarity 92, member B]; FANCA [Fanconi anemia, complementation group A]; FANCB [Fanconi anemia, complementation group B]; FANCC [Fanconi anemia, complementation group C]; FANCD2 [Fanconi anemia, complementation group D2]; FANCE [Fanconi anemia, complementation group E]; FANCF [Fanconi anemia, complementation group F]; FANCG [Fanconi anemia, complementation group G]; FANCI [Fanconi anemia, complementation group I]; FANCL [Fanconi anemia, complementation group L]; FANCM [Fanconi anemia
- FDX1 [ferredoxin 1]; FEN1 [flap structure-specific endonuclease 1]; FERMT1 [fermitin family homolog 1 (Drosophila)]; FERMT3 [fermitin family homolog 3 (Drosophila)]; FES [feline sarcoma oncogene]; FFAR2 [free fatty acid receptor 2]; FGA [fibrinogen alpha chain]; FGB [fibrinogen beta chain]; FGF1 [fibroblast growth factor 1 (acidic)]; FGF2 [fibroblast growth factor 2 (basic)]; FGF5 [fibroblast growth factor 5]; FGF7 [fibroblast growth factor 7 (keratinocyte growth factor)]; FGF8 [fibroblast growth factor 8 (androgen-induced)]; FGFBP2 [fibroblast growth factor binding protein 2]; FGFR1 [fibroblast growth factor receptor 1];
- FKBP4 [FK506 binding protein 4, 59kDa]; FKBP5 [FK506 binding protein 5]; FLCN [folliculin]; FLG [filaggrin]; FLG2 [filaggrin family member 2]; FLNA [filamin A, alpha]; FLNB [filamin B, beta]; FLT1 [fms-related tyrosine kinase 1 (vascular endothelial growth factor/vascular permeability factor receptor)]; FLT3 [fms- related tyrosine kinase 3]; FLT3LG [fms-related tyrosine kinase 3 ligand]; FLT4 [fms-related tyrosine kinase 4]; FMN1 [formin 1]; FMOD [fibromodulin]; FMR1 [fragile X mental retardation 1]; FN1 [fibronectin 1]; FOLH1 [folate hydrolase (prostate-specific membrane anti
- FTH1 [ferritin, heavy polypeptide 1]
- FTL [ferritin, light polypeptide]
- FURIN furin (paired basic amino acid cleaving enzyme)]
- FUT1 [fucosyltransferase 1 (galactoside 2-alpha-L-fucosyltransferase, H blood group)]
- FUT2 [fucosyltransferase 2 (secretor status included)]
- FUT3 [fucosyltransferase 3 (galactoside 3(4)-L-fucosyltransferase, Lewis blood group)]
- FUT4
- GAST [phosphohbosylglycinamide formyltransferase, phosphohbosylglycinamide synthetase, phosphoribosylaminoimidazole synthetase]; GAST [gastrin]; GATA1 [GATA binding protein 1 (globin transcription factor 1 )]; GATA2 [GATA binding protein 2]; GATA3 [GATA binding protein 3]; GATA4 [GATA binding protein 4]; GATA6 [GATA binding protein 6]; GBA [glucosidase, beta, acid]; GBA3
- GCG [glucosidase, beta, acid 3 (cytosolic)]; GBE1 [glucan (1 [4-alpha-), branching enzyme 1]; GC [group-specific component (vitamin D binding protein)]; GCG
- GCH1 GTP cyclohydrolase 1
- GCKR glucokinase (hexokinase 4) regulator
- GCLC glutamate-cysteine ligase, catalytic subunit
- GCLM glutamate-cysteine ligase, catalytic subunit
- Glutaminase [glutaminase]; GLT25D1 [glycosyltransferase 25 domain containing 1]; GLUL [glutamate-ammonia ligase (glutamine synthetase)]; GLYAT [glycine-N- acyltransferase]; GM2A [GM2 ganglioside activator]; GMDS [GDP-mannose 4 [6- dehydratase]; GNA12 [guanine nucleotide binding protein (G protein) alpha 12]; GNA13 [guanine nucleotide binding protein (G protein), alpha 13]; GNAM
- G protein [guanine nucleotide binding protein (G protein), alpha inhibiting activity
- polypeptide 1 polypeptide 1]; GNAO1 [guanine nucleotide binding protein (G protein), alpha activating activity polypeptide O]; GNAQ [guanine nucleotide binding protein (G protein), q polypeptide]; GNAS [GNAS complex locus]; GNAZ [guanine
- G protein nucleotide binding protein
- GNB1 nucleotide binding protein (G protein), beta polypeptide 1]
- GNB1 L guanine nucleotide binding protein (G protein), beta polypeptide 1 -like]
- GNB2L1 guanine nucleotide binding protein (G protein), beta polypeptide 2-like 1]
- GNB3 guanine nucleotide binding protein (G protein), beta polypeptide 3]
- GNE glucosamine (UDP-N-acetyl)-2-epimerase/N-acetylmannosamine kinase]
- GNG2 guanine nucleotide binding protein (G protein), gamma 2]
- GNLY granulysin]
- GNPAT glycosamine O-acyltransferase]
- GNPDA2 glucosamine-6-phosphate deaminase 2]
- GNRH1 gonado
- GOT1 glutamic-oxaloacetic transaminase 1 , soluble (aspartate aminotransferase 1 )]
- GOT2 glutamic- oxaloacetic transaminase 2, mitochondrial (aspartate aminotransferase 2)];
- GP1 BA [glycoprotein Ib (platelet), alpha polypeptide]; GP2 [glycoprotein 2 (zymogen granule membrane)]; GP6 [glycoprotein Vl (platelet)]; GPBAR1 [G protein-coupled bile acid receptor 1]; GPC5 [glypican 5]; GPI [glucose phosphate isomerase]; GPLD1 [glycosylphosphatidyl inositol specific phospholipase D1]; GPN1 [GPN-loop GTPase 1]; GPR1 [G protein-coupled receptor 1]; GPR12 [G protein-coupled receptor 12]; GPR123 [G protein-coupled receptor 123]; GPR143 [G protein-coupled receptor 143]; GPR15 [G protein-coupled receptor 15];
- GPR182 [G protein-coupled receptor 182]; GPR44 [G protein-coupled receptor 44]; GPR77 [G protein-coupled receptor 77]; GPRASP1 [G protein-coupled receptor associated sorting protein 1]; GPRC6A [G protein-coupled receptor, family C, group 6, member A]; GPT [glutamic-pyruvate transaminase (alanine aminotransferase)]; GPX1 [glutathione peroxidase 1]; GPX2 [glutathione peroxidase 2 (gastrointestinal)]; GPX3 [glutathione peroxidase 3 (plasma)];
- GRAP2 [GRB2-related adaptor protein 2]; GRB2 [growth factor receptor-bound protein 2]; GRIA2 [glutamate receptor, ionotropic, AMPA 2]; GRIN1 [glutamate receptor, ionotropic, N-methyl D-aspartate 1]; GRIN2A [glutamate receptor, ionotropic, N-methyl D-aspartate 2A]; GRIN2B [glutamate receptor, ionotropic, N- methyl D-aspartate 2B]; GRIN2C [glutamate receptor, ionotropic, N-methyl D- aspartate 2C]; GRIN2D [glutamate receptor, ionotropic, N-methyl D-aspartate 2D]; GRIN3A [glutamate receptor, ionotropic, N-methyl-D-aspartate 3A]; GRIN3B [glutamate receptor, ionotropic, N-methyl-D-aspartate 3
- GTF2A1 general transcription factor MA, 1 , 19/37kDa
- GTF2F1 general transcription factor MF, polypeptide 1 , 74kDa
- GTF2H2 general transcription factor MF, polypeptide 1 , 74kDa
- GULP1 [GULP, engulfment adaptor PTB domain containing 1]; GUSB
- GZMA granzyme A (granzyme 1 , cytotoxic T-lymphocyte-associated serine esterase 3)]; GZMB [granzyme B (granzyme 2, cytotoxic T-lymphocyte- associated serine esterase 1 )]; GZMK [granzyme K (granzyme 3; tryptase II)]; H1 FO [H1 histone family, member O]; H2AFX [H2A histone family, member X]; HABP2 [hyaluronan binding protein 2]; HACL1 [2-hydroxyacyl-CoA lyase 1];
- HADHA hydroxyacyl-Coenzyme A dehydrogenase/3-ketoacyl-Coenzyme A thiolase/enoyl-Coenzyme A hydratase (thfunctional protein), alpha subunit]
- HAL histidine ammonia-lyase
- HAMP hepcidin antimicrobial peptide
- HAVCR1 hepatitis A virus cellular receptor 1
- HAVCR2 hepatitis A virus cellular receptor 2
- HAX1 HCLS1 associated protein X-1]
- HBA1 hemoglobin, alpha 1]
- HBA2 hemoglobin, alpha 2]
- HBB hemoglobin, beta
- HBE1 hemoglobin, epsilon 1
- HBEGF heparin- binding EGF-like growth factor]
- HBG2 hemoglobin, gamma G]
- HCCS heparin- binding EGF-like growth factor
- HCRTR1 hemocytochrome c synthase (cytochrome c heme-lyase)]; HCK [hemopoietic cell kinase]; HCRT [hypocretin (orexin) neuropeptide precursor]; HCRTR1
- HES1 [hypocretin (orexin) receptor 1]; HCRTR2 [hypocretin (orexin) receptor 2]; HCST [hematopoietic cell signal transducer]; HDAC1 [histone deacetylase 1]; HDAC2 [histone deacetylase 2]; HDAC6 [histone deacetylase 6]; HDAC9 [histone deacetylase 9]; HDC [histidine decarboxylase]; HERC2 [hect domain and RLD 2]; HES1 [hairy and enhancer of split 1 , (Drosophila)]; HES6 [hairy and enhancer of split 6 ⁇ Drosophila)]; HESX1 [HESX homeobox 1]; HEXA [hexosaminidase A (alpha polypeptide)]; HEXB [hexosaminidase B (beta polypeptide)]; HFE
- HGF hepatocyte growth factor (hepapoietin A; scatter factor)
- HGS hepatocyte growth factor-regulated tyrosine kinase substrate
- HGSNAT heparan-alpha-glucosaminide N-acetyltransferase
- HIF1A hypooxia inducible factor 1 , alpha subunit (basic helix-loop-helix transcription factor)];
- HINFP histone H4 transcription factor
- HINT1 histidine triad nucleotide binding protein 1
- HIPK2 homeodomain interacting protein kinase 2
- HIRA HIRA
- HIST1 H1 B histone cluster 1 , HI b]
- HIST1 H3E histone cluster 1 , H3e]
- HIST2H2AC histone cluster 2, H2ac]
- HIST2H3C histone cluster 2, H3c]
- HIST4H4 histone cluster 4, H4]
- HJURP Holliday junction recognition protein]
- HK2 [hexokinase 2]
- HLA-A major histocompatibility complex, class I, A]
- HLA-B major histocompatibility complex, class I, B]
- HLA-C major histocompatibility complex, class I, C]
- HLA-DMA major histocompatibility complex, class II, DM alpha]
- HLA-DMB major histocompatibility complex, class II, DM alpha
- HLA-DOA major histocompatibility complex, class II, DO alpha
- HLA-DOB major histocompatibility complex, class II, DO beta
- HLA-DPA1 major histocompatibility complex, class II, DP alpha 1
- HLA-DPB1 major histocompatibility complex, class II, DP beta 1
- HLA-DQA1 major histocompatibility complex, class II, DQ alpha 1
- HLA-DQA2 major histocompatibility complex, class II, DQ alpha 2]
- HLA-DQB1 major histocompatibility complex, class II, DM beta]
- HLA-DOA major histocompatibility complex, class II, DO alpha
- HLA-DOB major histocompatibility complex, class II, DO beta
- HLA-DPA1 major histocompatibility complex, class II, DP alpha 1
- HLA-DPB1 major histocompatibility complex, class II, DP beta 1
- HLA-DRB1 histocompatibility complex, class II, DR alpha
- HLA-E major histocompatibility complex, class I, E
- HLA-F major histocompatibility complex, class I, F
- HLA-G major histocompatibility complex, class I, G
- HLCS holocarboxylase synthetase (biotin-(proprionyl-Coenzyme A-carboxylase (ATP-hydrolysing)) ligase)]
- HLTF helicase-like transcription factor]
- HLX H2.0-like homeobox]
- HMBS histocompatibility complex
- HMGA1 high mobility group AT-hook 1
- HMGB1 high-mobility group box 1]; HMGCR [3-hydroxy-3-methylglutaryl- Coenzyme A reductase]; HMOX1 [heme oxygenase (decycling) 1]; HMOX2 [heme oxygenase (decycling) 2]; HNF1 A [HNF1 homeobox A]; HNF4A
- HNMT hepatocyte nuclear factor 4, alpha
- HNMT histamine N-methyltransferase
- HNRNPA1 heterogeneous nuclear ribonucleoprotein A1
- HNRNPH2 heterogeneous nuclear ribonucleoprotein H2 (H')]
- HNRNPUL1 heterogeneous nuclear ribonucleoprotein U-like 1
- HOXA13 homeobox A13
- HOXA4 homeobox A4
- HOXA9 homeobox A9
- HPXB4 homeobox B4
- HPGDS haptoglobin
- HPR hematopoietic prostaglandin D synthase
- HPR haptoglobin-related protein
- HPRT1 hyperxanthine phosphoribosyltransferase 1
- HPS1 Hermansky-Pudlak syndrome 1]
- HPS3 Hermansky-Pudlak syndrome 3
- HPS4 Hermansky-Pudlak syndrome 4]
- HPSE Heparanase]
- HPX Hepexin
- HRAS v-Ha-ras Harvey rat sarcoma viral oncogene homolog
- HRG histidine-rich glycoprotein
- HSD11 B1 hydroxysteroid (11 -beta) dehydrogenase 1]
- HSD11 B2 hydroxysteroid (11 -beta) dehydrogenase 2];
- HSD17B1 [hydroxysteroid (17-beta) dehydrogenase 1]; HSD17B4
- HSF1 heat shock transcription factor 1
- HSP90AA1 heat shock protein 9OkDa alpha (cytosolic), class A member 1
- HSP90AB1 heat shock protein 9OkDa alpha (cytosolic), class B member 1
- HSP90B1 heat shock protein 9OkDa beta (Grp94), member 1];
- HSPA14 [heat shock 7OkDa protein 14]; HSPA1A [heat shock 7OkDa protein 1A]; HSPA1 B [heat shock 7OkDa protein 1 B]; HSPA2 [heat shock 7OkDa protein 2]; HSPA4 [heat shock 7OkDa protein 4]; HSPA5 [heat shock 7OkDa protein 5 (glucose-regulated protein, 78kDa)]; HSPA8 [heat shock 7OkDa protein 8];
- HSPB1 heat shock 27kDa protein 1
- HSPB2 heat shock 27kDa protein 2
- HSPD1 heat shock 6OkDa protein 1 (chaperonin)
- HSPE1 heat shock 1 OkDa protein 1 (chaperonin 10)
- HSPG2 heparan sulfate proteoglycan 2]
- HTR1A 5-hydroxytryptamine (serotonin) receptor 1A
- HTR2A 5- hydroxytryptamine (serotonin) receptor 2A
- HTR3A 5-hydroxytryptamine
- HTRA1 HtrA serine peptidase 1]
- HTT huntingtin
- HUS1 HUS1 checkpoint homolog (S. pombe)]
- HUWE1 HECT, UBA and WE domain containing 1]
- HYAL1 hyaluronoglucosaminidase 1]
- HYLS1 HYaluronoglucosaminidase 1
- IAPP hydrolethalus syndrome 1
- IAPP islet amyloid polypeptide
- IBSP integrated protein-binding sialoprotein
- ICAM1 intercellular adhesion molecule 1]
- ICAM2 intercellular adhesion molecule 2
- intercellular adhesion molecule 2 [intercellular adhesion molecule 2]; ICAM3 [intercellular adhesion molecule 3]; ICAM4 [intercellular adhesion molecule 4 (Landsteiner-Wiener blood group)]; ICOS [inducible T-cell co-stimulator]; ICOSLG [inducible T-cell co-stimulator ligand]; ID1 [inhibitor of DNA binding 1 , dominant negative helix-loop-helix protein]; ID2 [inhibitor of DNA binding 2, dominant negative helix-loop-helix protein]; IDO1 [indoleamine 2 [3-dioxygenase 1]; IDS [iduronate 2-sulfatase]; IDUA [iduronidase, alpha-L-]; IFI27 [interferon, alpha-inducible protein 27]; IFI30 [interferon, gamma-inducible protein 30]; IFITM1 [interferon induced
- transmembrane protein 1 (9-27)]; IFNA1 [interferon, alpha 1]; IFNA2 [interferon, alpha 2]; IFNAR1 [interferon (alpha, beta and omega) receptor 1]; IFNAR2
- IGF1 insulin growth factor 1 (somatomedin C)]; IGF1 R [insulin-like growth factor 1 receptor]; IGF2 [insulin-like growth factor 2 (somatomedin A)]; IGF2R [insulin-like growth factor 2 receptor]; IGFBP1 [insulin-like growth factor binding protein 1]; IGFBP2 [insulin-like growth factor binding protein 2, 36kDa]; IGFBP3 [insulin-like growth factor binding protein 3]; IGFBP4 [insulin-like growth factor binding protein 4]; IGFBP5 [insulin-like growth factor binding protein 5]; IGHA1 [imm
- IGHMBP2 [immunoglobulin mu binding protein 2]
- IGKC immunoglobulin kappa constant]
- IGKV2D-29 immunoglobulin kappa variable 2D-29
- IGLL1 immunoglobulin lambda-like polypeptide 1]
- IGSF1 immunoglobulin superfamily, member 1]
- IKBKAP inhibitor of kappa light polypeptide gene enhancer in B-cells, kinase complex-associated protein]
- IKBKB [inhibitor of kappa light polypeptide gene enhancer in B-cells, kinase beta]; IKBKE [inhibitor of kappa light polypeptide gene enhancer in B-cells, kinase epsilon]; IKBKG [inhibitor of kappa light polypeptide gene enhancer in B- cells, kinase gamma]; IKZF1 [IKAROS family zinc finger 1 (Ikaros)]; IKZF2
- IL10 interleukin 1 O
- IL10RA interleukin 10 receptor, alpha
- IL10RB interleukin 10 receptor, beta
- IL11 interleukin 11
- IL12A interleukin 12A (natural killer cell stimulatory factor 1 , cytotoxic
- lymphocyte maturation factor 1 lymphocyte maturation factor 1 , p35)]; IL12B [interleukin 12B (natural killer cell stimulatory factor 2, cytotoxic lymphocyte maturation factor 2, p40) ]; IL12RB1 [interleukin 12 receptor, beta 1]; IL12RB2 [interleukin 12 receptor, beta 2]; IL13 [interleukin 13]; IL13RA1 [interleukin 13 receptor, alpha 1]; IL13RA2 [interleukin 13 receptor, alpha 2]; IL15 [interleukin 15]; IL15RA [interleukin 15 receptor, alpha]; IL16 [interleukin 16 (lymphocyte chemoattractant factor)]; IL17A
- IL18BP interleukin 18 binding protein
- IL18R1 interleukin 18 receptor 1
- IL18RAP interleukin 18 receptor accessory protein
- IL19 interleukin 19
- IL1A interleukin 1 , alpha]
- IL1 B interleukin 1 , beta]
- IL1 F9 interleukin 1 family, member 9]
- IL1 R1 interleukin 1 receptor, type I]
- IL1 RAP interleukin 1 receptor accessory protein]
- IL1 receptor-like 1 [interleukin 1 receptor-like 1]; IL1 RN [interleukin 1 receptor antagonist]; IL2
- IL20 [interleukin 20]; IL21 [interleukin 21]; IL21 R [interleukin 21 receptor]; IL22 [interleukin 22]; IL23A [interleukin 23, alpha subunit p19]; IL23R [interleukin 23 receptor]; IL24 [interleukin 24]; IL25 [interleukin 25]; IL26
- IL27 [interleukin 27]; IL27RA [interleukin 27 receptor, alpha]; IL29 [interleukin 29 (interferon, lambda 1 )]; IL2RA [interleukin 2 receptor, alpha];
- IL2RB interleukin 2 receptor, beta
- IL2RG interleukin 2 receptor, gamma (severe combined immunodeficiency)]
- IL3 interleukin 3 (colony-stimulating factor, multiple)]
- IL31 interleukin 31]
- IL32 interleukin 32
- IL33 interleukin 33
- IL3RA interleukin 3 receptor, alpha (low affinity)]
- IL4 interleukin 4]
- IL4R interleukin 4
- IL5 interleukin 5 (colony-stimulating factor, eosinophil)]; IL5RA [interleukin 5 receptor, alpha]; IL6 [interleukin 6 (interferon, beta 2)]; IL6R [interleukin 6 receptor]; IL6ST [interleukin 6 signal transducer (gp130, oncostatin M receptor)]; IL7 [interleukin 7]; IL7R [interleukin 7 receptor]; IL8 [interleukin 8]; IL9 [interleukin 9]; IL9R [interleukin 9 receptor]; ILK [integrin-linked kinase]; IMP5 [intramembrane protease 5]; INCENP [inner centromere protein antigens
- ING1 [inhibitor of growth family, member 1]; INHA [inhibin, alpha]; INHBA [inhibin, beta A]; INPP4A [inositol polyphosphate-4-phosphatase, type I, 107kDa]; INPP5D [inositol polyphosphate-5-phosphatase, 145kDa]; INPP5E [inositol polyphosphate-5-phosphatase, 72 kDa]; INPPL1 [inositol polyphosphate phosphatase-like 1]; INS [insulin]; INSL3 [insulin-like 3 (Leydig cell)]; INSR
- IRS1 insulin receptor substrate 1
- IRS2 insulin receptor substrate 2
- IRS4 insulin receptor substrate 4
- ISG15 ISG15 ubiquitin-like modifier]
- ITCH itchy E3 ubiquitin protein ligase homolog (mouse)]
- ITFG1 integerghn alpha FG-GAP repeat containing 1]
- ITGA1 integerghn, alpha 1
- ITGA2 integratedin, alpha 2 (CD49B, alpha 2 subunit of VLA-2 receptor)]
- ITGA2B integratedin, alpha 2b (platelet glycoprotein Mb of llb/llla complex, antigen CD41 )]
- ITGA3 integratedin, alpha 3 (antigen CD49C, alpha 3 subunit of VLA-3 receptor)]
- ITGA4 integratedin, alpha 4 (antigen CD49D, alpha 4 subunit of VLA-4 receptor)]
- ITGA5 integratedin, alpha 5
- ITK IL2-inducible T-cell kinase
- ITPA inosine triphosphatase (nucleoside triphosphate pyrophosphatase)]; ITPR1 [inositol 1 ,4,5-thphosphate receptor, type 1]; ITPR3 [inositol 1 ,4,5-triphosphate receptor, type 3]; IVD [isovaleryl Coenzyme A dehydrogenase]; IVL [involucrin]; IVNS1ABP [influenza virus NS1A binding protein]; JAG1 [jagged 1 (Alagille syndrome)]; JAK1 [Janus kinase 1]; JAK2 [Janus kinase 2]; JAK3 [Janus kinase 3]; JAKMIP1 [janus kinase and microtubule interacting protein 1]; JMJD6 [junnonji domain containing 6]; JPH4 [jun
- KIR2DL3 killer cell immunoglobulin-like receptor, two domains, long cytoplasmic tail, 3]
- KIR2DL5A killer cell immunoglobulin-like receptor, two domains, long
- KIR2DS1 killer cell immunoglobulin-like receptor, two domains, short cytoplasmic tail, 1]
- KIR2DS2 killer cell immunoglobulin-like receptor, two domains, short cytoplasmic tail, 2]
- KIR2DS5 killer cell
- KIR3DL1 killer cell immunoglobulin-like receptor, three domains, long cytoplasmic tail, 1]
- KIR3DS1 killer cell immunoglobulin-like receptor, three domains, short cytoplasmic tail, 1]
- KISS1 KiSS-1 metastasis-suppressor]
- KISS1 R KISS1 receptor
- KIT v-kit Hardy-Zuckerman 4 feline sarcoma viral oncogene homolog]
- KITLG KIT ligand]
- KLF2 Kruppel-like factor 2 (lung)]
- KLF4 Kruppel-like factor 4 (gut)]
- KLK1 kallikrein 1]
- KLK11 kallikrein-related peptidase 11]
- KLKB1 kallikrein B, plasma (Fletcher factor) 1]
- KLRB1 killer cell lectin-like receptor subfamily B, member 1]
- KLRC1 killer cell lectin-like receptor subfamily C, member 1]
- KLRD1 killer cell lectin-like receptor subfamily D, member 1]
- KLRK1 killer cell lectin-like receptor subfamily K, member 1]
- KNG1 [kininogen 1]
- KPNA1 Karyopherin alpha 1 (importin alpha 5)]
- KPNA2 Karyopherin alpha 2 (RAG cohort 1 , importin alpha 1 )]
- KPNB1 KPNB1
- LBR lipopolysaccharide binding protein
- LBR lamin B receptor
- LBXCOR1 Longer than COR1
- LCAT lecithin-cholesterol acyltransferase
- LCK lecithin-cholesterol acyltransferase
- LCN1 lipocalin 1 (tear prealbumin)]
- LCN2 lipocalin 1 (tear prealbumin)
- LMAN1 [lectin, mannose-binding, 1]; LMLN [leishmanolysin-like (metallopeptidase M8 family)]; LMNA [lamin AZC]; LMNB1 [lamin B1]; LMNB2 [lamin B2]; LOC646627 [phospholipase inhibitor]; LOX [lysyl oxidase]; LOXHD1 [lipoxygenase homology domains 1]; LOXL1 [lysyl oxidase-like 1]; LPA
- LPCAT2 [lipoprotein, Lp(a)]; LPAR3 [lysophosphatidic acid receptor 3]; LPCAT2
- LPO lipoprotein lipase
- LRP1 low density lipoprotein receptor-related protein 1
- LRP6 low density lipoprotein receptor-related protein 6
- LRPAP1 low density lipoprotein receptor- related protein associated protein 1
- LRRC32 leucine rich repeat containing 32]
- LRRC37B leucine rich repeat containing 37B]
- LRRC8A leucine rich repeat containing 8 family, member A]
- LRRK2 leucine-rich repeat kinase 2]
- LRTOMT leucine rich transmembrane and O-methyltransferase domain containing]
- LSM1 LSM1 homolog, U6 small nuclear RNA associated (S.
- LSM2 LSM2 homolog, U6 small nuclear RNA associated (S. cerevisiae)]
- LSP1 lymphocyte-specific protein 1
- LTA lymphotoxin alpha (TNF superfamily, member 1 )];
- LTA4H leukothene A4 hydrolase]; LTB [lymphotoxin beta (TNF superfamily, member 3)]; LTB4R [leukotriene B4 receptor]; LTB4R2 [leukotriene B4 receptor 2]; LTBR [lymphotoxin beta receptor (TNFR superfamily, member 3)]; LTC4S [leukotriene C4 synthase]; LTF [lactotransferhn]; LY86 [lymphocyte antigen 86]; LY9 [lymphocyte antigen 9]; LYN [v-yes-1 Yamaguchi sarcoma viral related oncogene homolog]; LYRM4 [LYR motif containing 4]; LYST [lysosomal trafficking regulator]; LYZ [lysozyme (renal amyloidosis)]; LYZL6 [lysozyme-like 6]; LZTR1 [leucine-zipper-like transcription regulator 1]; M6
- MAP2K1 mitogen- activated protein kinase kinase 1]
- MAP2K2 mitogen-activated protein kinase kinase 2
- MAP2K3 mitogen-activated protein kinase kinase 3]
- MAP2K4 mitogen-activated protein kinase kinase 4
- MAP3K5 [mitogen-activated protein kinase kinase kinase 5]; MAP3K7 [mitogen- activated protein kinase kinase 7]; MAP3K9 [mitogen-activated protein kinase kinase kinase 9]; MAPK1 [mitogen-activated protein kinase 1]; MAPK10 [mitogen-activated protein kinase 10]; MAPK11 [mitogen-activated protein kinase 11]; MAPK12 [mitogen-activated protein kinase 12]; MAPK13 [mitogen-activated protein kinase 13]; MAPK14 [mitogen-activated protein kinase 14]; MAPK3
- MDC1 [melanocortin 4 receptor]; MCCC2 [methylcrotonoyl-Coenzyme A carboxylase 2 (beta)]; MCHR1 [melanin-concentrating hormone receptor 1]; MCL1 [myeloid cell leukemia sequence 1 (BCL2-related)]; MCM2 [minichromosonne maintenance complex component 2]; MCM4 [minichromosome maintenance complex component 4]; MCOLN1 [mucolipin 1]; MCPH1 [microcephalin 1]; MDC1
- MEN1 multiple endocrine neoplasia I]; MEPE [matrix extracellular phosphoglycoprotein]; MERTK [c-mer proto- oncogene tyrosine kinase]; MESP2 [mesoderm posterior 2 homolog (mouse)]; MET [met proto-oncogene (hepatocyte growth factor receptor)]; MGAM [maltase- glucoamylase (alpha-glucosidase)]; MGAT1 [mannosyl (alpha-1 ,3-)-glycoprotein beta-1 ,2-N-acetylglu
- MICA MHC class I polypeptide-related sequence A
- MICB MHC class I polypeptide-related sequence B
- MKI67 antigen identified by monoclonal antibody Ki-67
- MKS1 Meckel syndrome, type 1
- MLH1 mutant L homolog 1 , colon cancer, nonpolyposis type 2 (E. coli)]
- MLL myeloid/lymphoid or mixed-lineage leukemia (trithorax homolog, Drosophila)]
- MLLT4 myeloid/lymphoid or mixed-lineage leukemia (trithorax homolog,
- Drosophila Drosophila
- translocated to, 4]; MLN motilin]; MLXIPL [MLX interacting protein- like]; MMAA [methylmalonic aciduria (cobalamin deficiency) cblA type]; MMAB [methylmalonic aciduria (cobalamin deficiency) cblB type]; MMACHC
- MME membrane metallo-endopeptidase
- MMP1 matrix metallopeptidase 1 (interstitial collagenase)]
- MMP10 matrix metallopeptidase 10 (stromelysin 2)]
- MMP12 matrix metallopeptidase 12 (macrophage elastase)]
- MMP13 matrix metallopeptidase 13 (collagenase 3)]
- MMP14 matrix metallopeptidase 14 (membrane-inserted)]
- MMP15 matrix metallopeptidase 15 (membrane- inserted)]
- MMP17 matrix metallopeptidase 17 (membrane-inserted)]
- MMP2 matrix metallopeptidase 2 (gelatinase
- MMP28 matrix metallopeptidase 28
- MMP3 matrix metallopeptidase 3 (stromelysin 1 , progelatinase)]
- MMP7 matrix metallopeptidase 7
- MMP8 matrix metallopeptidase 8 (neutrophil collagenase)]
- MMP9 matrix metallopeptidase 9 (gelatinase B, 92kDa gelatinase, 92kDa type IV collagenase)]
- MMRN1 multimerin 1]
- MNAT1 multimerin 1
- MRGPRX1 MAS-related GPR, member X1]
- MRPL28 mitochondrial ribosomal protein L28
- MRPL40 mitochondrial ribosomal protein L40
- MRPS16 mitochondrial ribosomal protein S16
- MRPS22 mitochondrial ribosomal protein S22
- MS4A1 membrane- spanning 4-domains, subfamily A, member 1]
- MS4A2 membrane-spanning 4- domains, subfamily A, member 2 (Fc fragment of IgE, high affinity I, receptor for; beta polypeptide)]
- MS4A3 membrane-spanning 4-domains, subfamily A, member 3 (hematopoietic cell-specific)]
- MSH2 mutant S homolog 2, colon cancer, nonpolyposis type 1 (E.
- MSH5 [mutS homolog 5 (E. coli)]; MSH6 [mutS homolog 6 (E. coli)]; MSLN [mesothelin]; MSN [moesin]; MSR1 [macrophage scavenger receptor 1]; MST1 [macrophage stimulating 1 (hepatocyte growth factor-like)]; MST1 R [macrophage stimulating 1 receptor (c-met-related tyrosine kinase)]; MSTN [myostatin]; MSX2 [msh homeobox 2]; MT2A [metallothionein 2A]; MTCH2 [mitochondrial carrier homolog 2 (C.
- MT-CO2 mitochondrially encoded cytochrome c oxidase II
- MTCP1 matrix T-cell proliferation 1
- MT-CYB mitochondrially encoded cytochrome b
- NADP+ dependent [methylenetetrahydrofolate dehydrogenase (NADP+ dependent) 1 ,
- MTOR mechanistic target of rapamycin (serine/threonine kinase)]; MTR [5-methyltetrahydrofolate- homocysteine methyltransferase]; MTRR [5-methyltetrahydrofolate-homocysteine methyltransferase reductase]; MTTP [microsomal triglyceride transfer protein]; MTX1 [metaxin 1]; MUC1 [mucin 1 , cell surface associated]; MUC12 [mucin 12, cell surface associated]; MUC16 [mucin 16, cell surface associated]; MUC19 [mucin 19, oligomehc]; MUC2 [mucin 2, oligomehc mucus/gel-forming]; MUC3A [mucin 3A, cell surface associated]; MUC3B [mucin 3B, cell surface associated]; MUC4
- MVP major vault protein
- MX1 myxovirus (influenza virus) resistance 1 , interferon-inducible protein p78 (mouse)]
- MYB v-myb
- MYBPH myosin binding protein H
- MYC v-myc myelocytomatosis viral oncogene homolog (avian)]
- MYCN v- myc myelocytomatosis viral related oncogene, neuroblastoma derived (avian)]
- MYD88 myeloid differentiation primary response gene (88)]
- MYH1 myosin, heavy chain 1 , skeletal muscle, adult]
- MYH10 myosin, heavy chain 10, non- muscle]
- MYH11 myosin, heavy chain 11 , smooth muscle]
- MYH14 myosin, heavy chain 14, non-muscle
- MYH2 myosin, heavy chain 2, skeletal muscle, adult]
- MYH3 myosin, heavy chain 3, skeletal muscle, embryonic]
- MYH6 myosin, heavy chain 6, cardiac muscle, alpha];
- NAT2 N-acetyltransferase 2 (arylamine N- acetyltransferase)]
- NAT9 N-acetyltransferase 9 (GCN5-related, putative)];
- NBEA neurorobeachin
- NBN nobrin
- NCAM1 noural cell adhesion molecule 1
- NCF1 neurotrophil cytosolic factor 1
- NCF2 neutral cell adhesion molecule 2
- NCF4 neutral cell cytosolic factor 4, 4OkDa]
- NCK1 NCK adaptor protein 1]
- NCL nucleophilicity factor 1
- nucleolin [nucleolin]; NCOA1 [nuclear receptor coactivator 1]; NCOA2 [nuclear receptor coactivator 2]; NCOR1 [nuclear receptor co-repressor 1]; NCR3 [natural cytotoxicity triggering receptor 3]; NDUFA13 [NADH dehydrogenase (ubiquinone) 1 alpha subcomplex, 13]; NDUFAB1 [NADH dehydrogenase (ubiquinone) 1 , alpha/beta subcomplex, 1 , 8kDa]; NDUFAF2 [NADH dehydrogenase
- NEDD4 nerve growth factor 4
- NEFL neuroofilament, light polypeptide
- NEFM neuroofilament, medium polypeptide
- NEGRI neuroal growth regulator 1
- NEK6 NIMA (never in mitosis gene a)-related kinase 6]
- NELF neuronic LHRH factor
- NELL1 NELL1 [NEL-like 1 (chicken)]
- NEU1 sialidase 1 (lysosomal sialidase)]; NEUROD1 [neurogenic differentiation 1]; NF1 [neurofibromin 1]; NF2 [neurofibromin 2 (merlin)]; NFAT5 [nuclear factor of activated T-cells 5, tonicity-responsive]; NFATC1 [nuclear factor of activated T-cells, cytoplasmic, calcineuhn-dependent 1]; NFATC2 [nuclear factor of activated T-cells, cytoplasmic, calcineurin-dependent 2]; NFATC4
- NFE2L2 nuclear factor (erythroid-dehved 2)-like 2
- NFKB1 nuclear factor of kappa light polypeptide gene enhancer in B-cells 1
- NFKB2 nuclear factor of kappa light polypeptide gene enhancer in B-cells 2 (p49/p100)
- NFKBIA nuclear factor of kappa light polypeptide gene enhancer in B-cells inhibitor, alpha
- NFKBIB nuclear factor of kappa light polypeptide gene enhancer in B-cells inhibitor, beta
- NFKBIL1 nuclear factor of kappa light polypeptide gene enhancer in B-cells inhibitor-like 1
- NFU1 NFU1 iron-sulfur cluster scaffold homolog (S. cerevisiae)]
- NGF nerve growth factor (beta polypeptide)]
- NGFR nerve growth factor receptor (TNFR superfamily, member 16)]
- NID1 nonhomologous end-joining factor 1
- NKAP NFkB activating protein
- NKX2-1 ,NK2 homeobox 1
- NKX2-3 NK2 transcription factor related, locus 3 (Drosophila)]
- NLRP3 NLR family, pyrin domain containing 3]
- NMB nonhomologous end-joining factor 1
- NID1 nonhomologous end-joining factor 1
- NKAP NFkB activating protein
- NKX2-1 ,NK2 homeobox 1
- NKX2-3 NK2 transcription factor related, locus 3 (Drosophila)]
- NLRP3 NLR family, pyrin domain containing 3]
- NMB nonhomologous end-joining factor 1
- NME1 [non-metastatic cells 1 , protein (NM23A) expressed in]; NME2 [non-metastatic cells 2, protein (NM23B) expressed in]; NMU [neuromedin U]; NNAT [neuronatin]; NOD1 [nucleotide-binding oligomerization domain containing 1]; NOD2 [nucleotide-binding oligomerization domain containing 2]; NONO [non-POU domain containing, octamer-binding]; NOS1 [nitric oxide synthase 1 (neuronal)]; NOS2 [nitric oxide synthase 2, inducible]; NOS3 [nitric oxide synthase 3 (endothelial cell)]; NOTCH1 [Notch homolog 1 , translocation- associated ⁇ Drosophila)]; NOTCH2 [Notch homolog 2 ⁇ Drosophila)]; NOTCH3 [Notch homolog 3
- NPHS2 nephrosis 2, idiopathic, steroid-resistant (podocin)
- NPLOC4 nuclear protein localization 4 homolog
- NPM1 [nucleophosmin (nucleolar phosphoprotein B23, numatrin)]; NPPA [natriuretic peptide precursor A]; NPPB [natriuretic peptide precursor B]; NPPC [natriuretic peptide precursor C]; NPR1 [natriuretic peptide receptor A/guanylate cyclase A (atrionatriuretic peptide receptor A)]; NPR3 [natriuretic peptide receptor C/guanylate cyclase C (atrionatriuretic peptide receptor C)]; NPS [neuropeptide S]; NPSR1 [neuropeptide S receptor 1]; NPY [neuropeptide Y]; NPY2R [neuropeptide Y receptor Y2]; NQO1 [NAD(P)H dehydrogenase, quinone 1]; NR0B1 [nuclear
- nuclear receptor subfamily 1 group I, member 3
- NR2F2 nuclear receptor subfamily 2, group F, member 2
- NR3C1 nuclear receptor subfamily 3, group C, member 1 (glucocorticoid receptor)]
- NR3C2 nuclear receptor subfamily 3, group C, member 2
- NR4A1 nuclear receptor subfamily 4, group A, member 1];
- NR4A3 [nuclear receptor subfamily 4, group A, member 3]; NR5A1 [nuclear receptor subfamily 5, group A, member 1]; NRF1 [nuclear respiratory factor 1]; NRG1 [neuregulin 1]; NRIP1 [nuclear receptor interacting protein 1]; NRIP2
- NTF3 [nuclear receptor interacting protein 2]; NRP1 [neuropilin 1]; NSD1 [nuclear receptor binding SET domain protein 1]; NSDHL [NAD(P) dependent steroid dehydrogenase-like]; NSF [N-ethylmaleimide-sensitive factor]; NT5E [5'- nucleotidase, ecto (CD73)]; NTAN1 [N-terminal asparagine amidase]; NTF3
- NTF4 neurotrophin 4
- NTN1 [netrin 1]
- NTRK1 neurotrophic tyrosine kinase, receptor, type 1]
- NTRK2 neurotrophic tyrosine kinase, receptor, type 2]
- NTRK3 neurotrophic tyrosine kinase, receptor, type 3]
- NTS neurorotensin
- NUCB2 [nucleobindin 2]
- NUDT1 [nudix (nucleoside diphosphate linked moiety X)-type motif 1]
- NUDT2 [nudix (nucleoside diphosphate linked moiety X)-type motif 2]
- NUDT6 nuudix (nucleoside diphosphate linked moiety X)- type motif 6]
- NUFIP2 nuclear fragile X mental retardation protein interacting protein 2]
- NUP98 [nucleoporin 98
- decarboxylase 1 oral-facial-digital syndrome 1]; OGDH [oxoglutarate (alpha-ketoglutarate) dehydrogenase (lipoamide)]; OGG1 [8-oxoguanine DNA glycosylase]; OGT [O-linked N-acetylglucosamine (GIcNAc) transferase (UDP-N- acetylglucosamine:polypeptide-N-acetylglucosaminyl transferase)]; OLR1
- OSBP oxysterol binding protein
- OSGIN2 oxidative stress induced growth inhibitor family member 2
- OSM oncostatin M
- OTC ornithine carbamoyltransferase
- OTOP2 otopethn 2
- OTOP3 otopetrin 3
- OTUD1 OTU domain containing 1]
- OXA1 L oxidase (cytochrome c) assembly 1 -like]
- OXER1 oxoeicosanoid (OXE) receptor 1]
- OXT oxytocin, prepropeptide]
- OXTR oxidative stress induced growth inhibitor family member 2
- OTC ornithine carbamoyltransferase
- OTOP2 otopethn 2
- OTOP3 otopetrin 3
- OTUD1 OTU domain containing 1]
- OXA1 L oxidase (cytochrome c) assembly 1 -like
- acetylhydrolase 1 b regulatory subunit 1 (45kDa)]; PAH [phenylalanine hydroxylase]; PAK1 [p21 protein (Cdc42/Rac)-activated kinase 1]; PAK2 [p21 protein (Cdc42/Rac)-activated kinase 2]; PAK3 [p21 protein (Cdc42/Rac)- activated kinase 3]; PAM [peptidylglycine alpha-amidating monooxygenase]; PAPPA [pregnancy-associated plasma protein A, pappalysin 1]; PARG [poly (ADP-ribose) glycohydrolase]; PARK2 [Parkinson disease (autosomal recessive, juvenile) 2, parkin]; PARP1 [poly (ADP-ribose) polymerase 1]; PAWR [PRKC, apoptosis, WT1 , regulator]; PAX
- PCM1 phosphoenolpyruvate carboxykinase 1 (soluble)]
- PCM1 pericentriolar material 1
- PCNA proliferating cell nuclear antigen
- PCNT peripheral antigen
- PCSK6 proprotein convertase subtilisin/kexin type 6
- PCSK7 proprotein convertase subtilisin/kexin type 7
- PCYT1A phosphate cytidylyltransferase 1 , choline, alpha
- PCYT2 phosphate cytidylyltransferase 2, ethanolamine
- PDCD1 programmeed cell death 1]
- PDCD1 LG2 [programmed cell death 1 ligand 2]; PDCD6 [programmed cell death 6]; PDE3B [phosphodiesterase 3B, cGMP-inhibited]; PDE4A [phosphodiesterase 4A, cAMP-specific (phosphodiesterase E2 dunce homolog, Drosophila)]; PDE4B [phosphodiesterase 4B, cAMP-specific (phosphodiesterase E4 dunce homolog, Drosophila)]; PDE4D [phosphodiesterase 4D, cAMP-specific (phosphodiesterase E3 dunce homolog, Drosophila)]; PDE7A [phosphodiesterase 7A]; PDGFA
- PDGFB platelet-derived growth factor beta polypeptide (simian sarcoma viral (v-sis) oncogene homolog)]
- PDGFRA platelet-derived growth factor receptor, alpha polypeptide
- PDGFRB platelet-derived growth factor receptor, beta polypeptide
- PDIA2 protein disulfide isomerase family A, member 2]
- PDIA3 protein disulfide isomerase family A, member 3]
- PDK1 pyruvate dehydrogenase kinase, isozyme 1];
- PDLIM1 [PDZ and LIM domain 1]; PDLIM5 [PDZ and LIM domain 5]; PDLIM7 [PDZ and LIM domain 7 (enigma)]; PDP1 [pyruvate dehyrogenase phosphatase catalytic subunit 1]; PDX1 [pancreatic and duodenal homeobox 1]; PDXK
- PEMT phosphatidylethanolamine N-methyltransferase
- PENK proenkephalin
- PEPD peptidase D
- PER1 period homolog 1 (Drosophila)]
- PEX1 peroxisomal biogenesis factor 1]
- PEX10 peroxisomal biogenesis factor 1
- PEX12 [peroxisomal biogenesis factor 12]; PEX13 [peroxisomal biogenesis factor 13]; PEX14 [peroxisomal biogenesis factor 14]; PEX16 [peroxisomal biogenesis factor 16]; PEX19 [peroxisomal biogenesis factor 19]; PEX2 [peroxisomal biogenesis factor 2]; PEX26
- PHB [phosphohbosylformylglycinamidine synthase]; PFDN4 [prefoldin subunit 4]; PFN1 [profilin 1]; PGC [progastricsin (pepsinogen C)]; PGD [phosphogluconate dehydrogenase]; PGF [placental growth factor]; PGK1 [phosphoglycerate kinase 1]; PGM1 [phosphoglucomutase 1]; PGR [progesterone receptor]; PHB
- PIK3CA phosphoinositide-3-kinase, catalytic, alpha polypeptide
- PIK3CB phosphoinositide-3-kinase, catalytic, beta polypeptide
- PIK3CD phosphoinositide-3-kinase, catalytic, delta polypeptide]
- PIK3CG phosphoinositide-3-kinase, catalytic, gamma polypeptide]
- PIK3R1 phosphoinositide-3-kinase, regulatory subunit 1 (alpha)]
- PIK3R2 phosphoinositide-3-kinase, regulatory subunit 2 (beta)]
- PIN1 peptidylprolyl cis/trans isomerase, NIMA-interacting 1
- PINK1 PTEN induced putative kinase 1
- PIP prolactin-induced protein
- PIP5KL1 phosphatidylinositol-4-phosphate 5-kinase- like 1
- PITPNM1 phosphatidylinositol transfer protein, membrane-associated 1
- PITRM1 pitrilysin metallopeptidase 1]
- PITX2 paired-like homeodomain 2]
- PKD2 polycystic kidney disease 2 (autosomal dominant)]
- PKLR pyruvate kinase, liver and RBC]
- PKM2 pyruvate kinase, muscle]
- PKN1 protein kinase N1]
- PL-5283 PL-5283 protein]
- PLA2 phosphoinositide kinase, FYVE finger containing
- PLA2G2A phospholipase A2, group MA (platelets, synovial fluid)]
- PLA2G2D phospholipase A2, group MD]
- PLA2G4A phospholipase A2, group IVA (cytosolic, calcium-dependent)]
- PLA2G6 phospholipase A2, group Vl (cytosolic, calcium-independent)]
- PLA2G7 [phospholipase A2, group VII
- PLA2R1 phospholipase A2 receptor 1 , 18OkDa
- PLAT plasminogen activator, tissue]
- PLAU plasminogen activator, urokinase
- PLAUR plasminogen activator, urokinase receptor
- PLCB1 phospholipase C, beta 1 (phosphoinositide-specific)]
- PLCB2 phospholipase C, beta 2]
- PLCB4 phospholipase C, beta 4]
- PLCD1 phospholipase C, delta 1]
- PLCG1 phospholipase C, gamma 1]
- PLCG2 phospholipase C, gamma 2 (phosphatidylinositol-specific)]
- PLD1 phospholipase D1 , phosphatidylcholine- specific]
- PLEC phosphatidylinositol-specific
- PMAIP1 phorbol-12-myristate-13-acetate- induced protein 1
- PMCH pro-melanin-concentrating hormone
- RNA Rimerase (RNA) Il (DNA directed) polypeptide D
- POLR2E polymerase (RNA) Il (DNA directed) polypeptide E, 25kDa]
- POLR2F polymerase (RNA) Il (DNA directed) polypeptide F]
- POLR2G polymerase (RNA) Il (DNA directed) polypeptide G]
- POLR2H polymerase (RNA) Il (DNA directed) polypeptide H]
- POLR2I polymerase (RNA) Il (DNA directed) polypeptide I, 14.5kDa]
- POLR2J polymerase (RNA) Il (DNA directed) polypeptide J, 13.3kDa]
- POLR2K polymerase (RNA) Il (DNA directed) polypeptide J
- PPARD peroxisome proliferator-activated receptor delta
- PPARG peroxisome proliferator-activated receptor gamma
- PPARGC1A peroxisome proliferator-activated receptor gamma, coactivator 1 alpha
- PPAT phosphoribosyl pyrophosphate
- amidotransferase amidotransferase
- PPBP pro-platelet basic protein (chemokine (C-X-C motif) ligand 7)
- PPFIA1 protein tyrosine phosphatase, receptor type, f polypeptide (PTPRF), interacting protein (liprin), alpha 1]
- PPIA protein tyrosine phosphatase, receptor type, f polypeptide (PTPRF), interacting protein (liprin), alpha 1
- PPIA peptidylprolyl isomerase A (cyclophilin A)]
- PPIB peptidylprolyl isomerase B (cyclophilin B)]
- PPIG protein tyrosine phosphatase, receptor type, f polypeptide
- PPIA protein tyrosine phosphatase, receptor type, f polypeptide (PTPRF), interacting protein (liprin), alpha 1]
- PPIA peptidylprolyl isome
- PRKAR2A protein kinase, cAMP-dependent, regulatory, type II, alpha
- PRKAR2B protein kinase, cAMP-dependent, regulatory, type II, beta
- PRKCA protein kinase C, alpha
- PRKCB protein kinase C, beta]
- PRKCD protein kinase C, beta
- PTPRE protein tyrosine phosphatase, receptor type, E
- PTPRJ protein tyrosine phosphatase, receptor type, J
- PTPRN protein tyrosine phosphatase, receptor type, N
- PTPRT protein tyrosine phosphatase, receptor type, T]
- PTPRU protein tyrosine phosphatase, receptor type, T
- PXK PX domain containing serine/threonine kinase]; PXN [paxillin]; PYCR1 [pyrrol ine-5-carboxylate reductase 1]; PYCR2 [pyrrol ine-5-carboxylate reductase family, member 2]; PYGB [phosphorylase, glycogen; brain]; PYGM [phosphorylase, glycogen, muscle]; PYY [peptide YY]; PZP [pregnancy-zone protein]; QDPR [quinoid dihydropteridine reductase];
- RAB11A [RAB11A, member RAS oncogene family]; RAB11 FIP1 [RAB11 family interacting protein 1 (class I)]; RAB27A [RAB27A, member RAS oncogene family]; RAB37 [RAB37, member RAS oncogene family]; RAB39 [RAB39, member RAS oncogene family]; RAB7A [RAB7A, member RAS oncogene family]; RAB9A [RAB9A, member RAS oncogene family]; RAC1 [ras-related C3 botulinum toxin substrate 1 (rho family, small GTP binding protein Rac1 )]; RAC2 [ras-related C3 botulinum toxin substrate 2 (rho family, small GTP binding protein Rac2)]; RAD17 [RAD17 homolog (S.
- RAD50 [RAD50 homolog (S. cerevisiae)]; RAD51 [RAD51 homolog (RecA homolog, E. coli) (S. cerevisiae)]; RAD51 C [RAD51 homolog C (S. cerevisiae)]] RAD51 L1 [RAD51-like 1 (S.
- RAF 1 [v-raf-1 murine leukemia viral oncogene homolog 1]; RAG1 [recombination activating gene 1]; RAG2 [recombination activating gene 2]; RAN [RAN, member RAS oncogene family]; RANBP1 [RAN binding protein 1]; RAP1A [RAP1A, member of RAS oncogene family]; RAPGEF4 [Rap guanine nucleotide exchange factor (GEF) 4]; RARA [retinoic acid receptor, alpha]; RARB [retinoic acid receptor, beta]; RARG [retinoic acid receptor, gamma]; RARRES2 [retinoic acid receptor responder (tazarotene induced) 2]; RARS [arginyl-tRNA synthetase]; RASA1 [RAS p21 protein activator (GTPase activating protein) 1]; RASGRP1 [RAS guanyl
- RNASE1 Ribonuclease, RNase A family, 1 (pancreatic)]
- RNASE2 Ribonuclease, RNase A family, 2 (liver, eosinophil- derived neurotoxin)]
- RNASE3 Ribonuclease, RNase A family, 3 (eosinophil cationic protein)]
- RNASEH1 Ribonuclease H1]
- RNASEH2A Riclease H2, subunit A]
- RNASEL ribonuclease L (2' [5'-oligoisoadenylate synthetase- dependent)]
- RNASEN Rionuclease type III, nuclear]
- RNF123 Ring finger protein 123]
- RNF13 Ring finger protein 13]
- RNF135 Ring finger protein 135
- RNF138 Ring finger protein 138
- RNF4 Ring finger protein 4]
- RNH1 Ribonuclease type III, nuclear]
- RNA-binding region RNP1 , RRM
- RNPEP arginyl aminopeptidase (aminopeptidase B)]
- ROCK1 Rho-associated, coiled-coil containing protein kinase 1]
- ROM1 Retinal outer segment membrane protein 1]
- ROR2 Receptor tyrosine kinase-like orphan receptor 2]
- RORA RORA [RAR-related orphan receptor A]
- RPA1 replication protein A1 , 7OkDa]
- RPA2 [replication protein A2, 32kDa]
- RPGRIP1 L RGRIP1 -like]
- RPLP1 Ribonuclease/angiogenin inhibitor 1
- RNPEP RNA-binding region (RNP1 , RRM) containing 3]
- RNPEP arginyl aminopeptidase (aminopeptidase B)]
- ROCK1 Rho-associated, coiled-
- RUNX1 [runt-related transcription factor 1]; RUNX3 [runt-related transcription factor 3]; RXRA [retinoid X receptor, alpha]; RXRB [retinoid X receptor, beta]; RYR1 [ryanodine receptor 1 (skeletal)]; RYR3 [ryanodine receptor 3]; S100A1 [S100 calcium binding protein A1]; S100A12 [S100 calcium binding protein A12]; S100A4 [S100 calcium binding protein A4]; S100A7 [S100 calcium binding protein A7]; S100A8 [S100 calcium binding protein A8]; S100A9 [S100 calcium binding protein A9]; S100B [S100 calcium binding protein B]; S100G [S100 calcium binding protein G]; S1 PR1 [sphingosine-1 -phosphate receptor 1]; SAA1 [serum amyloid A1]; SAA4 [serum amyloid A4, constitutive]; SAFB [scaffold attachment factor
- SCAMP3 secretory carrier membrane protein 3
- SCAP SREBF chaperone
- SCARB1 scavenger receptor class B, member 1
- SCD stearoyl-CoA
- SCG2 secretogranin M
- SCG3 secretogranin III
- SCG5 secretogranin V (7B2 protein)
- SCGB1A1 secretoglobin, family 1A, member 1 (uteroglobin)
- SCGB3A2 secretoglobin, family 3A, member 2];
- SCN4A sodium channel, voltage-gated, type IV, alpha subunit
- SDC2 [syndecan 2]; SDC4 [syndecan 4]; SDHB [succinate dehydrogenase complex, subunit B, iron sulfur (Ip)]; SDHD [succinate dehydrogenase complex, subunit D, integral membrane protein]; SEC14L2 [SEC14-like 2 (S. cerevisiae)]; SEC16A [SEC16 homolog A (S. cerevisiae)]; SEC23B [Sec23 homolog B (S.
- SERPINE1 mRNA binding protein 1 SERPINA1 [serpin peptidase inhibitor, clade A (alpha-1 antiproteinase, antitrypsin), member 1]; SERPINA2 [serpin peptidase inhibitor, clade A (alpha-1 antiproteinase, antitrypsin), member 2]; SERPINA3 [serpin peptidase inhibitor, clade A (alpha-1 antiproteinase, antitrypsin), member 3]; SERPINA5 [serpin peptidase inhibitor, clade A (alpha-1 antiproteinase, antitrypsin), member 5]; SERPINA6 [serpin peptidase inhibitor, clade A (alpha-1 antiproteinase, antitrypsin), member 6]; SERPINA7 [serpin peptidase inhibitor, clade A (alpha-1 antiproteinase, antitrypsin), member 7]; SERPINB1 [serpin
- SERPINB2 serotonin-1 [serpin peptidase inhibitor, clade B (ovalbumin), member 2];
- SERPINB3 serotonin peptidase inhibitor, clade B (ovalbumin), member 3
- SERPINB4 serpin peptidase inhibitor, clade B (ovalbumin), member 4
- SERPINB5 serpin peptidase inhibitor, clade B (ovalbumin), member 5
- SERPINB6 serpin peptidase inhibitor, clade B (ovalbumin), member 6
- SERPINB9 serotonin peptidase inhibitor, clade B (ovalbumin), member 9
- SERPINC1 serpin peptidase inhibitor, clade C (antithrombin), member 1
- SERPIND1 [serpin peptidase inhibitor, clade D (heparin cofactor), member 1]; SERPINE1 [serpin peptidase inhibitor, clade E (nexin, plasminogen activator inhibitor type 1 ), member 1]; SERPINE2 [serpin peptidase inhibitor, clade E (nexin, plasminogen activator inhibitor type 1 ), member 2]; SERPINF2 [serpin peptidase inhibitor, clade F (alpha-2 antiplasmin, pigment epithelium derived factor), member 2]; SERPING1 [serpin peptidase inhibitor, clade G (C1 inhibitor), member 1]; SERPINH1 [serpin peptidase inhibitor, clade H (heat shock protein 47), member 1 , (collagen binding protein 1 )]; SET [SET nuclear oncogene]; SETDB2 [SET domain, bifurcated 2]; SETX [senataxin]
- SGCB sarcoglycan, beta (43kDa dystroph in-associated
- SLP2 S-phase kinase- associated protein 2 (p45)]; SLAMF1 [signaling lymphocytic activation molecule family member 1]; SLAMF6 [SLAM family member 6]; SLC11A1 [solute carrier family 11 (proton-coupled divalent metal ion transporters), member 1]; SLC11A2 [solute carrier family 11 (proton-coupled divalent metal ion transporters), member 2]; SLC12A1 [solute carrier family 12 (sodium/potassium/chloride transporters), member 1]; SLC12A2 [solute carrier family 12 (sodium/potassium/chloride transporters), member 2]; SLC14A1 [solute carrier family 14 (urea transporter), member 1 (Kidd blood group)]; SLC15A1 [solute carrier family 15 (oligopeptide transporter), member 1]; SLC16
- SLC17A6 solute carrier family 17 (sodium- dependent inorganic phosphate cotransporter), member 6]; SLC17A7 [solute carrier family 17 (sodium-dependent inorganic phosphate cotransporter), member 7]; SLC19A1 [solute carrier family 19 (folate transporter), member 1]; SLC1A1 [solute carrier family 1 (neuronal/epithelial high affinity glutamate transporter, system Xag), member 1]; SLC1A2 [solute carrier family 1 (glial high affinity glutamate transporter), member 2]; SLC1 A4 [solute carrier family 1 (glutamate/neutral amino acid transporter), member 4]; SLC22A12 [solute carrier family 22 (organic anion/urate transporter), member 12]; SLC22A2 [solute carrier family 22 (organic cation transporter), member 2]; SLC22A23 [solute carrier family 22, member 23]; SLC22A12 [solute carrier family 17 (sodium
- SLC25A3 [solute carrier family 25 (mitochondrial carrier; phosphate carrier), member 3]; SLC25A32 [solute carrier family 25, member 32]; SLC25A33 [solute carrier family 25, member 33]; SLC25A4 [solute carrier family 25 (mitochondrial carrier; adenine nucleotide translocator), member 4]; SLC26A4 [solute carrier family 26, member 4]; SLC27A4 [solute carrier family 27 (fatty acid transporter), member 4]; SLC28A1 [solute carrier family 28 (sodium-coupled nucleoside transporter), member 1]; SLC2A1 [solute carrier family 2 (facilitated glucose transporter), member 1]; SLC2A13 [solute carrier family 2 (facilitated glucose transporter), member 13]; SLC2A3 [solute carrier family 2 (facilitated glucose transporter), member 3]; SLC2A4 [solute carrier family 2 (facilitated glucose transporter), member 4]; SLC30A1 [solute carrier family 30
- SLC7A4 solute carrier family 7 (cationic amino acid transporter, y+ system), member 4]; SLC7A5 [solute carrier family 7 (cationic amino acid transporter, y+ system), member 5]; SLC8A1 [solute carrier family 8 (sodium/calcium exchanger), member 1]; SLC9A1 [solute carrier family 9 (sodium/hydrogen exchanger), member 1]; SLC9A3R1 [solute carrier family 9 (sodium/hydrogen exchanger), member 3 regulator 1]; SLCO1A2 [solute carrier organic anion transporter family, member 1 A2]; SLCO1 B1 [solute carrier organic anion transporter family, member 1 B1]; SLCO1 B3 [solute carrier organic anion transporter family, member 1 B3]; SLPI [secretory leukocyte peptidase inhibitor]; SMAD1 [SMAD family member 1]; SMAD2
- SMPD1 structural maintenance of chromosomes 1A
- SMC3 structural maintenance of chromosomes 3
- SMG1 SMG1 homolog, phosphatidylinositol 3-kinase-related kinase (C. elegans)]
- SMN1 survival of motor neuron 1 , telomeric]
- SMPD1 structural maintenance of chromosomes 1A
- SMC3 structural maintenance of chromosomes 3
- SMG1 SMG1 homolog, phosphatidylinositol 3-kinase-related kinase (C. elegans)]
- SMN1 survival of motor neuron 1 , telomeric]
- SMPD2 sphingomyelin phosphodiesterase 2, neutral membrane (neutral sphingomyelinase)]; SMTN [smoothelin]; SNAI2 [snail homolog 2 (Drosophila)]; SNAP25 [synaptosomal- associated protein, 25kDa]; SNCA [synuclein, alpha (non A4 component of amyloid precursor)]; SNCG [synuclein, gamma (breast cancer-specific protein 1 )]; SNURF [SNRPN upstream reading frame]; SNW1 [SNW domain containing 1]; SNX9 [sorting nexin 9]; SOAT1 [sterol O-acyltransferase 1]; SOCS1
- SPARC secreted protein, acidic, cysteine-rich
- SPRED1 prouty-related, EVH 1 domain containing 1]; SPRR2A [small proline- rich protein 2A]; SPRR2B [small proline-rich protein 2B]; SPTB [spectrin, beta, erythrocytic]; SRC [v-src sarcoma (Schmidt-Ruppin A-2) viral oncogene homolog (avian)]; SRD5A1 [steroid-5-alpha-reductase, alpha polypeptide 1 (3-oxo-5 alpha-steroid delta 4-dehydrogenase alpha 1 )]; SREBF1 [sterol regulatory element binding transcription factor 1]; SREBF2 [sterol regulatory element binding transcription factor 2]; SRF [serum response factor (c-fos serum response element-binding transcription factor)]; SRGN [serglycin]; SRP9 [signal recognition particle 9kDa]; SRP9 [signal recognition particle 9kDa]; SRP9 [
- TAP1 transporter 1 , ATP-binding cassette, sub-family B (MDR/TAP)]; TAP2 [transporter 2, ATP-binding cassette, sub-family B (MDR/TAP)]; TARDBP [TAR DNA binding protein]; TARP [TCR gamma alternate reading frame protein]; TAT [tyrosine aminotransferase]; TBK1 [TANK- binding kinase 1]; TBP [TATA box binding protein]; TBX1 [T-box 1]; TBX2 [T-box 2]; TBX21 [T-box 21]; TBX3 [T-box 3]; TBX5 [T-box 5]; TBXA2R [thromboxane A2 receptor]; TBXAS1
- TCEAL1 transcription elongation factor A (Sll)-like 1]
- TCF4 transcription factor 4]
- TCF7L2 transcription factor 7-like 2 (T-cell specific, HMG-box)]
- TCL1A T-cell leukemia/lymphoma 1A]
- TCL1 B T- cell leukemia/lymphoma 1 B
- TCN1 transcobalamin I (vitamin B12 binding protein, R binder family)]
- TCN2 transcobalamin II; macrocytic anemia]
- TDP1 tyrosyl-DNA phosphodiesterase 1]
- TEC detect protein tyrosine kinase]
- TECTA tectorin alpha]
- TEK TEK tyrosine kinase, endothelial
- TERF1 telomehc repeat binding factor (NIMA-interacting) 1]
- TERF2 telomehc repeat binding factor (NIMA-interacting) 1]
- TGFBR1 transformed growth factor, beta receptor 1
- TGFBR2 transformed growth factor, beta receptor Il (70/8OkDa)]
- TGIF1 TGFB-induced factor homeobox 1]
- TGM1 transglutaminase 1 (K polypeptide epidermal type I, protein-glutamine-gamma-glutamyltransferase)]
- TGM2 transglutaminase 2 (C polypeptide, protein-glutamine-gamma-glutamyltransferase)]
- TGM3 transglutaminase 3 (E polypeptide, protein-glutamine-gannnna- glutamyltransferase)]
- TH tyrosine hydroxylase]
- THAP1 THAP domain containing, apoptosis associated protein 1]
- THBD thrombomodulin
- THBS1 thrombospondin
- TIRAP toll-interleukin 1 receptor (TIR) domain containing adaptor protein]
- TJP1 tight junction protein 1 (zona occludens 1 )]
- TK1 thymidine kinase 1 , soluble]
- TK2 thymidine kinase 2, mitochondrial]
- TKT transketolase
- TLE4 transducin-like enhancer of split 4 (E(sp1 ) homolog, Drosophila)]
- TLR1 toll-like receptor 1]
- TLR10 toll-like receptor 10]
- TLR2 toll- like receptor 2]
- TLR3 toll-like receptor 3]
- TLR4 toll-like receptor 4]
- TLR5 toll- like receptor 5]
- TLR6 toll-like receptor 6]
- TLR7 toll-like receptor I]
- TLR8 toll-like receptor 8]
- TLR9 toll-like receptor
- TMPRSS15 transmembrane protease, serine 15
- TMSB4X thymosin beta 4, X- linked
- TNC tenascin C
- TNF tumor necrosis factor (TNF superfamily, member 2)
- TNFAIP1 tumor necrosis factor, alpha-induced protein 1 (endothelial)]
- TNFAIP3 tumor necrosis factor, alpha-induced protein 3
- TNFAIP6 tumor necrosis factor, alpha-induced protein 6
- TNFRSF10A tumor necrosis factor receptor superfamily, member 1 Oa
- TNFRSF10B tumor necrosis factor receptor superfamily, member 1 Ob
- TNFRSF10C tumor necrosis factor receptor superfamily, member 10c, decoy without an intracellular domain
- TNFRSF10D [tumor necrosis factor receptor superfamily, member 10d, decoy with truncated death domain]
- TNFRSF11A [tumor necrosis factor receptor superfamily, member 11 a, NFKB activator]
- TNFRSF11 B tumorumor necrosis factor receptor superfamily, member 11 b]
- TNFRSF13B tumorumor necrosis factor receptor superfamily, member 13B]
- TNFRSF13C tumor necrosis factor receptor superfamily, member 13
- TNFRSF25 tumor necrosis factor receptor
- TNFRSF4 tumor necrosis factor receptor superfamily, member 4
- TNFRSF6B tumor necrosis factor receptor superfamily, member 6b, decoy
- TNFRSF8 tumor necrosis factor receptor superfamily, member 8]
- TNFRSF9 tumor necrosis factor receptor superfamily, member 9]; TNFSF10 [tumor necrosis factor (ligand) superfamily, member 10]; TNFSF11 [tumor necrosis factor (ligand) superfamily, member 11]; TNFSF12 [tumor necrosis factor (ligand) superfamily, member 12]; TNFSF13 [tumor necrosis factor (ligand) superfamily, member 13]; TNFSF13B [tumor necrosis factor (ligand) superfamily, member 13b]; TNFSF14 [tumor necrosis factor (ligand) superfamily, member 14]; TNFSF15 [tumor necrosis factor (ligand) superfamily, member 15]; TNFSF18 [tumor necrosis factor (ligand) superfamily, member 18]; TNFSF4 [tumor necrosis factor (ligand) superfamily, member 4]; TNFSF8 [tumor necrosis factor (ligand) superfamily, member 8]; TNFSF10
- TNNI3 troponin I type 3 (cardiac)]
- TNNT3 troponin T type 3 (skeletal, fast)]
- TNPO1 transportin 1]
- TNS1 tensin 1
- TNXB tenascin XB
- TOM1 L2 target of myb1 -like 2 (chicken)]
- TOP1 topoisomerase (DNA) I];
- TOP1 MT topoisomerase (DNA) I, mitochondrial
- TOP2A topoisomerase (DNA) Il alpha 17OkDa
- TOP2B topoisomerase (DNA) Il beta 18OkDa]
- TOP3A topoisomerase (DNA) I, mitochondrial
- TRAF1 [TNF receptor-associated factor 1]; TRAF2 [TNF receptor-associated factor 2]; TRAF3IP2 [TRAF3 interacting protein 2]; TRAF6 [TNF receptor-associated factor 6]; TRAIP [TRAF interacting protein]; TRAPPC10 [trafficking protein particle complex 10]; TRDN [triadin]; TREX1 [three prime repair exonuclease 1]; TRH [thyrotropin-releasing hormone]; TRIB1 [tribbles homolog 1 (Drosophila)]; TRIM21 [tripartite motif- containing 21]; TRIM22 [tripartite motif-containing 22]; TRIM26 [tripartite motif- containing 26]; TRIM28 [tripartite motif-containing 28]; TRIM29 [tripartite motif-containing 29]; TRIM68 [tripartite motif-containing 68]; TRPA1 [transient receptor potential cation
- thyroid stimulating hormone receptor [thyroid stimulating hormone receptor]; TSLP [thymic stromal lymphopoietin]; TSPAN7 [tetraspanin I]; TSPO [translocator protein (18kDa)]; TSSK2 [testis- specific serine kinase 2]; TSTA3 [tissue specific transplantation antigen P35B]; TTF2 [transcription termination factor, RNA polymerase II]; TTN [titin]; TTPA
- TYMS thymidylate synthetase
- TYR tyrosinase
- TYRO3 TYRO3 protein tyrosine kinase
- TYROBP TYRO protein tyrosine kinase binding protein
- TYRP1 tyrosinase- related protein 1
- UBB ubiquitin B
- UBC ubiquitin C
- UBE2C ubiquitin- conjugating enzyme E2C
- UBE2N ubiquitin-conjugating enzyme E2N (UBC13 homolog, yeast)]
- UBE2U ubiquitin-conjugating enzyme E2U (putative)]
- UBE3A ubiquitin protein ligase E3A]
- UBE4A ubiquitination factor E4A (UFD2 homolog, yeast)]
- UCHL1 ubiquitin carboxyl-terminal esterase L1 (ubiquitin thiolesterase)]
- UCN urocortin]
- UCN2 urocortin 2
- UCP1 uncoupling protein 1 (mitochondrial, proton carrier)]
- UCP2 uncoupling protein
- glycosyltransferase 8 glycosyltransferase 8]; UIMC1 [ubiquitin interaction motif containing 1]; ULBP1 [UL16 binding protein 1]; ULK2 [unc-51-like kinase 2 (C. elegans)]; UMOD
- UMPS uridine monophosphate synthetase
- UNCI 3D unc-13 homolog D (C. elegans)]
- UNC93B1 unc-93 homolog B1 (C. elegans)]
- UNG uracil-DNA glycosylase
- UQCRFS1 ubiquinol-cytochrome c reductase, Rieske iron-sulfur polypeptide 1]
- UROD uroporphyrinogen decarboxylase
- upstream transcription factor 1 [upstream transcription factor 1]; USF2 [upstream transcription factor 2, c-fos interacting]; USP18 [ubiquitin specific peptidase 18]; USP34 [ubiquitin specific peptidase 34]; UTRN [utrophin]; UTS2 [urotensin 2]; VAMP8 [vesicle-associated membrane protein 8 (endobrevin)]; VAPA [VAMP (vesicle-associated membrane protein)-associated protein A, 33kDa]; VASP [vasodilator-stimulated
- VAV1 vav 1 guanine nucleotide exchange factor
- VA V3 vav 3 guanine nucleotide exchange factor
- VCAM 1 vascular cell adhesion molecule 1]
- VCAN versican]
- VCL vinculin
- VDAC1 voltage-dependent anion channel 1]
- VDR vitamin D (1 [25- dihydroxyvitamin D3) receptor
- VEGFA vascular endothelial growth factor A]
- VEGFC vascular endothelial growth factor C]
- VHL von Hippel-Lindau tumor suppressor]
- VIL1 villin 1]
- VIM vimentin]
- VRR1 vasoactive intestinal peptide receptor 1
- VIPR2 vasoactive intestinal peptide receptor 2
- VLDLR very low density lipoprotein receptor
- VMAC vimentin-type intermediate filament associated coiled-coil protein
- VPREB1 pre-B lymphocyte 1
- VPS39 vacuum protein sorting 39 homolog
- VTN vitronectin
- VWF von Willebrand factor
- WARS tryptophanyl-tRNA synthetase
- WAS WAS [Wiskott-Aldrich syndrome (eczema-thrombocytopenia)]
- WASF1 WAS protein family, member 1]
- WASF2 WAS protein family, member 2]
- WASL WASL [Wiskott-Aldrich syndrome-like]
- WDFY3 WD repeat and FYVE domain containing 3]
- WDR36 WD repeat domain 36]
- WEE1 WEE1 homolog (S. pombe)]
- WIF1 WNT inhibitory factor 1]
- WIPF1 WIPF1
- WNK1 [WNK lysine deficient protein kinase 1]; WNT5A [wingless-type MMTV integration site family, member 5A]; WRN [Werner syndrome, RecQ helicase-like]; WT1 [Wilms tumor 1]; XBP1 [X-box binding protein 1]; XCL1 [chemokine (C motif) ligand 1]; XDH [xanthine dehydrogenase]; XIAP [X-linked inhibitor of apoptosis]; XPA [xeroderma pigmentosum, complementation group A]; XPC [xeroderma pigmentosum, complementation group C]; XPO5 [exportin 5]; XRCC1 [X-ray repair
- YBX1 Y box binding protein 1]; YES1 [v-yes-1 Yamaguchi sarcoma viral oncogene homolog 1]; YPEL1 [yippee-like 1 ⁇ Drosophila)]; YPEL2 [yippee- like 2 (Drosophila)]; YWHAB [tyrosine 3-monooxygenase/tryptophan 5- monooxygenase activation protein, beta polypeptide]; YWHAQ [tyrosine 3- monooxygenase/tryptophan 5-monooxygenase activation protein, theta polypeptide]; YWHAZ [tyrosine 3-monooxygenase/tryptophan 5-monooxygenase activation protein, zeta polypeptide]; YY1 [YY1 transcription factor]; ZAP70 [zeta- chain (TCR) associated protein kinase 7OkDa]; ZB
- an animal created by a method of the invention may be used to study the effects of mutations on the animal and development and/or progression of an immunodeficiency using measures commonly used in the study of immunodeficiencies.
- the genetically modified animals e.g., knock-out and transgenic animals created by a method of the invention may include genes altered singly or in combination, including alteration to any one or more of Rag1 , Rag2, FoxN1 , and DNAPK. Accordingly, for example, animals including a single, double or triple gene knock-out are contemplated. Any of these may be used in various methods in which alteration of one or more immunodeficiency genes may be useful.
- genetically modified animals as described herein may be used in studies of hematopoietic cells, such as in the identification of progenitor cells including lymphoid progenitors and pluripotential stem cells; in the identification of new cytokines which play a role in the growth and differentiation of hematopoietic cells; in the analysis of the effect of known cytokines; and in the analysis of drugs effects on hematopoietic cells.
- Such animals can also be used in studies on pathogenetic mechanisms in disease caused by viral infections such as but not limited to influenza, West Nile virus, herpesviruses, picornaviruses, neurotropic coronavirus, Varicella-zoster (chicken pox), respiratory syncytial virus, cowpox, hepatitis B, rabies, and Dengue virus, and lymphotropic viruses including human immunodeficiency virus (HIV), human T lymphotropic virus (HTLV-1 ), and Epstein Barr virus (EBV), and also a virus that specifically infects rats but models the effects of a human-specific virus on its host, for example the rat-adapted influenza virus (see, e.g., H. Lebrec and G. R. Burleson (1994) Toxicology. JuI 1 ;91 (2):179-88).
- viral infections such as but not limited to influenza, West Nile virus, herpesviruses, picornaviruses, neurotropic coronavirus, Varicella-zo
- a genetically modified animal created by a method of the invention may also be useful in studies of defense
- genetically modified animals such as for example knock-out rats can be subjects for pre-clinical evaluation of a specific "gene therapy".
- genes may be introduced into hematopoietic progenitor cells, preferably into pluripotential stem cells with self-renewal capacity from patients with inherited genetic defects, or into pluripotential stem cells with self- renewal capacity from rat models of inherited genetic defects, and the cells reintroduced into the genetically modified rats for the purpose of determining therapeutic usefulness of the modified cells.
- Genetically modified animals may also be useful for studying the biological mechanisms underlying
- immunodeficiency diseases and conditions caused by or linked to a mutation in an immunodeficiency gene such as Rag1 , Rag2, FoxN1 , or DNAPK.
- a genetically modified animal created by a method of the invention may be used to develop a diagnostic assay for an immunodeficiency disorder including but not limited to a leukemia, in which the animal, either untreated or previously treated with a therapeutic agent, is assessed for the presence of one or more biomarkers relative to a non-affected control animal.
- Such a genetically modified animal may be used in a method of screening a candidate therapy or therapeutic compound for treating an immunodeficiency disorder such as a leukemia, using a genetically modified animal in which one or more immunodeficiency genes including but not limited to Rag1 , Rag2, FoxN1 , or DNAPK are knocked out, and the animal, either untreated or previously treated with another therapeutic agent which may be a drug, microbe, transplanted cells, or other agent, is then treated with the candidate therapy or candidate therapeutic agent, a biological sample is obtained from the animal, and the biological sample evaluated relative to a sample from a non-affected wild-type control sample, or a sample from a genetically modified animal not subjected to the candidate therapy or therapeutic agent.
- an immunodeficiency disorder such as a leukemia
- a genetically modified animal in which one or more immunodeficiency genes including but not limited to Rag1 , Rag2, FoxN1 , or DNAPK are knocked out
- another therapeutic agent which may be a drug
- a method for modeling an autoimmune disease may involve the adoptive transfer of B cells reacting to an antigen for an autoimmune disease, or T cells activated for an autoimmune disease.
- the appropriate non-human mammal with the antigen target of the autoimmune disease can be immunized as follows.
- Immune cells may be prepared from the immunized animal and may be then transplanted to a genetically modified animal as described herein such as a Rag1 , Rag2, FoxN1 , or DNAPK knock-out rat, or a rat with any combination of these genes knocked out.
- a genetically modified animal as described herein such as a Rag1 , Rag2, FoxN1 , or DNAPK knock-out rat, or a rat with any combination of these genes knocked out.
- the development of autoimmune phenotypes in the recipient knock-out animal may then evaluated as compared to either a non-transplanted knock-out animal, or as compared to a knock-out animal transplanted with non-pathologic immune cells that lack auto-reactivity, or as compared to a wild type animal transplanted with immune cells as described above.
- a method for creating a combined immunodeficiency syndrome model may include providing a genetically modified animal such as a rat wherein Rag1 , Rag2, FoxN1 , or DNAPK are knocked out as described herein, and the knock-out animal may be further rendered deficient for natural killer (NK) cells by any one of several possible methods.
- a genetically modified animal such as a rat wherein Rag1 , Rag2, FoxN1 , or DNAPK are knocked out as described herein, and the knock-out animal may be further rendered deficient for natural killer (NK) cells by any one of several possible methods.
- Non-limiting examples of methods of rendering the knock-out animal deficient for NK include i) disruption of the Lyst gene; or ii) treatment of FoxN1 mutant animals with a compound that inhibits NK cell activity including but not limited to NSAIDs (nonsteroidal anti-inflammatory drugs), statins, allostehc LFA-1 inhibitors, vinblastine, paclitaxel, docetaxel, cladhbine, chlorambucil, bortezomib, or MG-132.
- NSAIDs nonsteroidal anti-inflammatory drugs
- Trinucleotide repeat expansion disorders are divided into two categories determined by the type of repeat.
- the most common repeat is the triplet CAG, which, when present in the coding region of a gene, codes for the amino acid glutamine (Q). Therefore, these disorders are referred to as the polyglutamine (polyQ) disorders and may include Huntington Disease (HD);
- SBMA Spinobulbar Muscular Atrophy
- SCA types 1 , 2, 3, 6, 7, and 17 Spinocerebellar Ataxias
- DPLA Dentatorubro-Pallidoluysian Atrophy
- Other trinucleotide repeat expansion disorders either do not involve the CAG triplet, or the CAG triplet is not in the coding region of the gene and are referred to as the non-polyglutamine disorders.
- Non-polyglutamine disorders may include Fragile X Syndrome (FRAXA); Fragile XE Mental Retardation (FRAXE); Friedreich Ataxia (FRDA); Myotonic Dystrophy (DM); and Spinocerebellar Ataxias (SCA types 8, and 12).
- a method of the invention may be used to create a genetically modified animal or cell in which at least one chromosomal sequence associated with a trinucleotide repeat disorder has been edited.
- Suitable chromosomal edits may include, but are not limited to, the type of edits detailed in section l(f) above.
- chromosomal sequences associated with a trinucleotide repeat disorder may be edited.
- a trinucleotide repeat disorder associated protein or control sequence may typically be selected based on an experimental association of the protein or sequence to a trinucleotide repeat expansion disorder.
- Trinucleotide repeat expansion proteins may include proteins associated with susceptibility for developing a trinucleotide repeat expansion disorder, the presence of a trinucleotide repeat expansion disorder, the severity of a trinucleotide repeat expansion disorder or any combination thereof.
- the production rate or circulating concentration of a protein associated with a trinucleotide repeat expansion disorder may be elevated or depressed in a population having a trinucleotide repeat expansion disorder relative to a population lacking the trinucleotide repeat expansion disorder. Differences in protein levels may be assessed using proteomic or genomic analysis techniques known in the art.
- trinucleotide repeat expansion disorders include AR (androgen receptor), FMR1 (fragile X mental retardation 1 ), HTT (huntingtin), DMPK (dystrophia myotonica- protein kinase), FXN (frataxin), ATXN2 (ataxin 2), ATN1 (atrophin 1 ), FEN1 (flap structure-specific endonuclease 1 ), TNRC6A (trinucleotide repeat containing 6A), PABPN1 (poly(A) binding protein, nuclear 1 ), JPH3 (junctophilin 3), MED15 (mediator complex subunit 15), ATXN1 (ataxin 1 ), ATXN3 (ataxin 3), TBP (TATA box binding protein), CACNA1A (calcium channel, voltage-dependent, P/Q type, alpha 1A subunit), ATXN8OS (ATXN8 opposite strand (non-protein coding)), PPP2R2B (protein
- G protein guanine nucleotide binding protein
- beta polypeptide 2 ribosomal protein L14
- ATXN8 ataxin 8
- INSR insulin receptor
- TTR transthyretin
- EP400 E1A binding protein p400
- GIGYF2 GYF protein 2
- MAGUK family calcium/calmodulin-dependent serine protein kinase
- MAPT microtubule-associated protein tau
- SP1 Sp1 transcription factor
- POLG polymerase (DNA directed), gamma
- AFF2 AF4/FMR2 family, member 2
- THBS1 thrombospondin 1
- TP53 tumor protein p53
- ESR1 esterogen receptor 1
- CGGBP1 CGG triplet repeat binding protein 1
- ABT1 activator of basal transcription 1
- KLK3 kallikrein-related peptidase 3
- PRNP prion protein
- JUN jun oncogene
- KCNN3 potassium intermediate/small conductance calcium- activated channel, subfamily N, member 3
- BAX BCL2-associated X protein
- FRAXA fragmentile site, folic acid type, rare, fra(X)(q27.3) A (macroorchidism, mental retardation)
- KBTBD10 KBTBD10
- coli (S. cerevisiae)
- NCOA3 nuclear receptor coactivator 3
- ERDA1 expanded repeat domain, CAG/CTG 1
- TSC1 tuberous sclerosis 1
- COMP cartilage oligomeric matrix protein
- GCLC glycolutamate-cysteine ligase, catalytic subunit
- RRAD Ras-related associated with diabetes
- MSH3 mutant S homolog 3
- DRD2 dopamine receptor D2
- CD44 CD44 molecule (Indian blood group)
- CTCF CCCTC-binding factor (zinc finger protein)
- CCND1 cyclin D1
- CLSPN claspin homolog (Xenopus laevis)
- MEF2A MEF2A
- TRIM22 myocyte enhancer factor 2A
- PTPRU protein tyrosine phosphatase, receptor type, U
- GAPDH glycosyl transfer protein dehydrogenase
- TMEM158 meencephalic astrocyte-derived neurotrophic factor
- transmembrane protein 158 (gene/pseudogene)
- ENSG00000078687 transmembrane protein 158 (gene/pseudogene)
- Exemplary proteins associated with trinucleotide repeat expansion disorders include HTT (Huntingtin), AR (androgen receptor), FXN (frataxin), Atxn3 (ataxin), Atxni (ataxin), Atxn2 (ataxin), Atxn7 (ataxin), Atxni O (ataxin), DMPK (dystrophia myotonica-protein kinase), Atn1 (atrophin 1 ), CBP (creb binding protein), VLDLR (very low density lipoprotein receptor), and any combination thereof.
- an animal created by a method of the invention may be used to study the effects of mutations on the animal and the development and/or progression of a trinucleotide repeat disorder using measures commonly used in the study of a trinucleotide repeat disorder.
- Non-limiting examples of a neurotransmission disorder include amylotropic lateral sclerosis (ALS), spinocerebellar ataxias (SCA) including SCA2, Alzheimer's; autism, mental retardation, Rett's syndrome, fragile X syndrome, depression, schizophrenia, bi-polar disorders, disorders of learning, memory or behavior, anxiety, brain injury, seizure disorders, Huntington's disease (chorea), mania, neuroleptic malignant syndrome, pain, Parkinsonism, Parkinson's disease, tardive dyskinesia, myasthenia gravis, episodic ataxias, hyperkalemic periodic paralysis, hypokalemic periodic paralysis, Lambert-Eaton syndrome, paramyotonia congenita, Rasmussen's encephalitis, startle disease (hyperexplexia, stiff baby syndrome), and the effects of poisoning such as botulism, mushroom poisoning, organophosphates, snake venom such as from Bungarus multicinctus (Taiwanese band
- a method of the invention may be used to create an animal or cell in which at least one chromosomal sequence associated with a neurotransmission disorder has been edited.
- Suitable chromosomal edits may include, but are not limited to, the type of edits detailed in section l(f) above.
- chromosomal sequences associated with a neurotransmission disorder may be edited.
- a neurotransmission disorder associated protein or control sequence may typically be selected based on an experimental association of the protein to a neurotransmission disorder.
- Neurotransmission disorder-related proteins include proteins associated with the susceptibility for developing a neurotransmission disorder, the presence of a neurotransmission disorder, the severity of a neurotransmission disorder or any combination thereof. For example, the production rate or circulating concentration of a neurotransmission disorder- related protein may be elevated or depressed in a population having a
- neurotransmission disorder relative to a population lacking the neurotransmission disorder. Differences in protein levels may be assessed using proteomic or genomic analysis techniques known in the art.
- Non-limiting examples of neurotransmission disorder-related proteins include SST (somatostatin), NOS1 (nitric oxide synthase 1 (neuronal)), ADRA2A (adrenergic, alpha-2A-, receptor), ADRA2C (adrenergic, alpha-2C-, receptor), TACR1 (tachykinin receptor 1 ), HTR2C (5-hydroxytryptamine
- GABA gamma-aminobutyric acid
- CACNA1 B calcium channel, voltage- dependent, N type, alpha 1 B subunit
- NOS2 nitric oxide synthase 2, inducible
- SLC6A5 excute carrier family 6 (neurotransmitter transporter, glycine), member 5
- GABRG1 gamma-aminobutyric acid (GABA) A receptor, gamma 1
- NOS3 nitric oxide synthase 3 (endothelial cell)
- GRM3 glutamate receptor
- HTR6 (5-hydroxytryptamine (serotonin) receptor 6
- SLC1A3 (solute carrier family 1 (glial high affinity glutamate transporter), member 3
- GRM7 (glutamate receptor, metabotropic 7)
- HRH1 histamine receptor H1
- SLC1A1 (solute carrier family 1 (neuronal/epithelial high affinity glutamate transporter, system Xag), member 1 )
- GRM4 (glutamate receptor, metabotropic 4
- GLUD2 (glutamate dehydrogenase 2)
- ADRA2B adrenergic, alpha-2B-, receptor
- SLC1A6 (solute carrier family 1 (high affinity aspartate/glutamate transporter), member 6
- GRM6 (glutamate receptor, metabotropic 6)
- SLC1A7 (solute carrier family 1 (glutamate transporter), member 7
- SLC6A11 (solute carrier family 6 (neurotransmitter transporter,
- CACNA1 H (calcium channel, voltage- dependent, T type, alpha 1 H subunit), GRM8 (glutamate receptor, metabotropic 8), CHRNA3 (cholinergic receptor, nicotinic, alpha 3), P2RY2 (puhnergic receptor P2Y, G-protein coupled, 2), TRPV6 (transient receptor potential cation channel, subfamily V, member 6), CACNA1 E (calcium channel, voltage-dependent, R type, alpha 1 E subunit), ACCN1 (amiloride-sensitive cation channel 1 , neuronal), CACNA1 I (calcium channel, voltage-dependent, T type, alpha 11 subunit), GABARAP (GABA (A) receptor-associated protein), P2RY1 (purinergic receptor P2Y, G-protein coupled, 1 ), P2RY6 (pyrimidinergic receptor P2Y, G-protein coupled, 6), RPH3A (rabphilin 3A homolog (mouse)), HDC
- P2RY14 purinergic receptor P2Y, G-protein coupled, 14
- P2RY4 pyrimidinergic receptor P2Y, G-protein coupled, 4
- P2RY10 purinergic receptor P2Y, G-protein coupled, 10
- SLC28A3 synthetic carrier family 28
- HTR3A (5- hydroxytryptamine (serotonin) receptor 3A), DRD2 (dopamine receptor D2), HTR2A (5-hydroxytryptamine (serotonin) receptor 2A), TH (tyrosine
- CN R1 cannabinoid receptor 1 (brain)
- VIP vasoactive intestinal peptide
- NPY neuropeptide Y
- GAL galanin prepropeptide
- TAC1 tachykinin, precursor 1
- SYP serophysin
- SLC6A4 solute carrier family 6
- GABA gamma-aminobutyric acid A receptor, alpha 1 ), GCH1 (GTP
- DDC dopa decarboxylase (aromatic L-amino acid
- MAOB monoamine oxidase B
- DRD5 dopamine receptor D5
- GABRE gamma-aminobutyric acid (GABA) A receptor, epsilon
- SLC6A2 solute carrier family 6 (neurotransmitter transporter, noradrenalin), member 2)
- GABRR2 gamma-aminobutyric acid (GABA) receptor, rho 2), SV2A (synaptic vesicle glycoprotein 2A), GABRR1 (gamma-aminobutyric acid (GABA) receptor, rho 1 ), GHRH (growth hormone releasing hormone), CCK (cholecystokinin), PDYN (prodynorphin), SLC6A9 (solute carrier family 6 (neurotransmitter transporter, glycine), member 9), KCND1 (potassium voltage-gated channel, Shal-related subfamily, member 1 ), SRR (serine racemase), DYT10 (dystonia 10), MAPT (microtubule-associated protein tau), APP (amyloid beta (A4) precursor protein), CTSB (cathepsin B), ADA (adenosine deaminase), AKT1 (v- akt murine thymoma
- decarboxylase 1 (brain, 67kDa)), NSF (N-ethylmaleimide-sensitive factor), GRIN2D (glutamate receptor, ionotropic, N-methyl D-aspartate 2D), ADORA1 (adenosine A1 receptor), GABRA2 (gamma-aminobutyric acid (GABA) A receptor, alpha 2), GLRA1 (glycine receptor, alpha 1 ), CHRM3 (cholinergic receptor, muscarinic 3), CHAT (choline acetyltransferase), KNG1 (kininogen 1 ), HMOX2 (heme oxygenase (decycling) 2), DRD4 (dopamine receptor D4), MAOA (monoamine oxidase A), CHRM2 (cholinergic receptor, muscarinic 2), ADORA2A (adenosine A2a receptor), STXBP1 (syntaxin binding protein 1 ), GABRA3 (gam
- epidermal growth factor (beta-urogastrone)), GRIA3 (glutamate receptor, ionotrophic, AMPA 3), NCAM1 (neural cell adhesion molecule 1 ), CDKN1A (cyclin-dependent kinase inhibitor 1A (p21 , Cip1 )), BCL2L1 (BCL2-like 1 ), TP53 (tumor protein p53), CASP9 (caspase 9, apoptosis-related cysteine peptidase), CCKBR (cholecystokinin B receptor), PARK2 (Parkinson's disease (autosomal recessive, juvenile) 2, parkin), ADRA1 B (adrenergic, alpha-1 B-, receptor), CASP3 (caspase 3, apoptosis-related cysteine peptidase), PRNP (prion protein), CRHR1 (corticotropin releasing hormone receptor 1 ), L1 CAM (L1 cell adhesion molecule),
- AGT angiotensinogen (serpin peptidase inhibitor, clade A, member 8)
- AGTR1 angiotensin Il receptor, type 1
- CDK5 cyclin-dependent kinase 5
- LRP1 low density lipoprotein receptor-related protein 1
- ARRB2 arrestin, beta 2
- PLD2 phospholipase D2
- OPRD1 opioid receptor, delta 1
- GNB3 guanine nucleotide binding protein (G protein), beta polypeptide 3
- PIK3CG phosphoinositide-3-kinase, catalytic, gamma polypeptide
- APAF1 apoptotic peptidase activating factor 1
- SSTR2 somatostatin receptor 2
- IL2 interleukin 2
- ADORA3 adenosine A3 receptor
- ADRA1A adrenergic, alpha-1
- serotonin receptor 7 (adenylate cyclase-coupled)), ADRBK2 (adrenergic, beta, receptor kinase 2), ALOX5 (arachidonate 5-lipoxygenase), NPR1 (natriuretic peptide receptor A/guanylate cyclase A (athonathuretic peptide receptor A)), AVPR1A (arginine vasopressin receptor 1A), CHRNB1 (cholinergic receptor, nicotinic, beta 1 (muscle)), SET (SET nuclear oncogene), PAH (phenylalanine hydroxylase), POMC (proopiomelanocortin), LEPR (leptin receptor), SDC2 (syndecan 2), VIPR1 (vasoactive intestinal peptide receptor 1 ), DBI (diazepam binding inhibitor (GABA receptor modulator, acyl-Coenzyme A binding protein)), NPY1 R (neuropeptide Y receptor Y
- B/guanylate cyclase B (athonathuretic peptide receptor B)), CNR2 (cannabinoid receptor 2 (macrophage)), LEP (leptin), CCKAR (cholecystokinin A receptor), GLRB (glycine receptor, beta), KCNQ2 (potassium voltage-gated channel, KQT- like subfamily, member 2), CHRNA2 (cholinergic receptor, nicotinic, alpha 2 (neuronal)), BDKRB2 (bradykinin receptor B2), CHRNA1 (cholinergic receptor, nicotinic, alpha 1 (muscle)), CHRND (cholinergic receptor, nicotinic, delta), CHRNA7 (cholinergic receptor, nicotinic, alpha 7), PLD1 (phospholipase D1 , phosphatidylcholine-specific), NRXN1 (neurexin 1 ), NRP1 (neuropilin 1 ), DLG3 (
- Glutamate receptor (glutamate receptor, ionotropic, kainate 3), NPY2R (neuropeptide Y receptor Y2), GRIK5 (glutamate receptor, ionotropic, kainate 5), GRIA4 (glutamate receptor, ionotrophic, AMPA 4), EDN1 (endothelin 1 ), PRLR (prolactin receptor), GABRB1 (gamma-aminobutyhc acid (GABA) A receptor, beta 1 ), GARS (glycyl-tRNA synthetase), GRIK2 (glutamate receptor, ionotropic, kainate 2), ALOX12
- PLCD1 phospholipase C, delta 1
- NTF3 neurotrophin 3
- NFE2L2 neuroar factor (erythroid-dehved 2)-like 2)
- PLCB4 phospholipase C, beta 4
- GNRHR gonadotropin-releasing hormone receptor
- NLGN1 neuroligin 1
- PPP2R4 protein phosphatase 2A activator, regulatory subunit 4
- SSTR3 somatostatin receptor 3
- CRHR2 corticotropin releasing hormone receptor 2
- NGF nerve growth factor (beta polypeptide)
- NRCAM neuroonal cell adhesion molecule
- NRXN3 neuroexin 3
- GNRH1 gonadotropin- releasing hormone 1 (luteinizing-releasing hormone)
- TRHR thyrotropin- releasing hormone
- GABRP gamma-aminobutyric acid
- GABA gamma-aminobutyric acid
- pi GLRA2
- PRKG2 protein kinase, cGMP-dependent, type II
- GLS glutaminase
- TACR3 tachykinin receptor 3
- ALDH7A1 aldehyde dehydrogenase 7 family, member A1
- GABBR2 gamma-aminobutyric acid (GABA) B receptor, 2)
- GDNF glial cell derived neurotrophic factor
- CNTFR ciliary neurotrophic factor receptor
- CNTN2 contactin 2 (axonal)
- TOR1 A torsin family 1 , member A (torsin A)
- CNTN1 contactin 1
- CAMK1 CAMK1
- somatostatin receptor 4 somatostatin receptor 4
- NPPA neuropeptide precursor A
- SNAP23 serotonin 23kDa
- AKAP9 A kinase (PRKA) anchor protein (yotiao) 9
- NRXN2 neuroexin 2
- FHL2 four and a half LIM domains 2
- TJP1 tight junction protein 1 (zona occludens 1 )
- NRG1 neutralregulin 1
- CAMK4 calcium/calmodulin-dependent protein kinase IV
- CAV3 caveolin 3
- VAMP2 vesicle-associated membrane protein 2 (synaptobrevin 2)
- GALR1 galanin receptor 1
- GHRHR growth hormone releasing hormone receptor
- HTR1 E (5- hydroxytryptamine (serotonin) receptor 1 E
- PENK proenkephalin
- ENTPD1 ectonucleoside triphosphate diphosphohydrolase 1
- GRIP1 Glutamate receptor interacting protein 1
- GRP Gastrin-releasing peptide
- NCAM2 Neural cell adhesion molecule 2
- SSTR1 somatostatin receptor 1
- CLTB clathhn, light chain (Lcb)
- DAO D-amino-acid oxidase
- QDPR quinoid dihydropteridine reductase
- PYY peptide YY
- NTSR1 neuropeptide receptor 1 (high affinity)
- NTS neurorotensin
- HCRT hypercretin (orexin) neuropeptide precursor
- SNAP29 serotosomal-associated protein, 29kDa
- SNAP91 serotosomal- associated protein, 91 kDa homolog (mouse)
- MADD MAP-kinase activating death domain
- IDO1 indoleamine 2,3-dioxygenase 1
- TPH2 tryptophan hydroxylase 2
- TAC3 tachykinin 3
- GRIN3A glycolutamate receptor, ionotropic, N- methyl-D-aspartate 3A
- REN renin
- GALR3 galanin receptor 3
- MAGI2 membrane associated guanylate kinase, WW and PDZ domain containing 2
- KCNJ9 potassium in
- DPEP1 dipeptidase 1 (renal)
- SLC1A4 synthetic carrier family 1 (glutamate/neutral amino acid transporter), member 4
- DNM3 dynamin 3
- SLC6A12 synthetic carrier family 6 (neurotransmitter transporter, betaine/GABA), member 12
- SLC6A6 synthetic carrier family 6 (neurotransmitter transporter, taurine), member 6
- YME1 L1 YME1 -like 1 (S.
- SLC17A7 solute carrier family 17 (sodium-dependent inorganic phosphate cotransporter), member 7), HOMER2 (homer homolog 2 (Drosophila)), SYT7 (synaptotagmin VII), TFIP11 (tuftelin interacting protein 11 ), GMFB (glia maturation factor, beta), PREB (prolactin regulatory element binding), NTSR2 (neurotensin receptor 2), NTF4 (neurotrophin 4), PPP1 R9B (protein phosphatase 1 , regulatory (inhibitor) subunit 9B), DISC1 (disrupted in schizophrenia 1 ), NRG3 (neuregulin 3), OXT (oxytocin, prepropeptide), TRH (thyrotropin-releasing hormone), NISCH (nischarin), CRHBP (corticotropin releasing hormone binding protein), SLC6A13 (solute carrier family 17 (sodium-dependent inorganic phosphate cotransporter), member 7),
- SLC17A6 (solute carrier family 17 (sodium-dependent inorganic phosphate cotransporter), member 6), GABRR3 (gamma-aminobutyric acid (GABA) receptor, rho 3), DAOA (D-amino acid oxidase activator), ENSG00000123384, nd NOS2P1 (nitric oxide synthase 2 pseudogene 1 ).
- Exemplary neurotransmission-related proteins include 5-HTT
- an animal created by a method of the invention may be used to study the effects of mutations on the animal and on the development and/or progression of a neurotransmission disorder using measures commoningly used in the study of a neurotransmission disorder. / ' / ' . pharmacological models
- a method of the invention may be used to create an animal or cell that may be used as a pharmacological model.
- a pharmacological model may be a model for pharmacokinetics or a model for pharmacodynamics.
- a method of the invention may be used to create an animal or cell that comprises a chromosomal edit in one or more nucleic acid sequences associated with the metabolism of a pharmaceutically active compound.
- Such an animal or cell may be used to study the effect of the nucleic acid sequence on the pharmaceutical compound.
- a method of the invention may be used to create an animal or cell that comprises a chromosomal edit in a disease associated sequence.
- Such an animal or cell may be used for assessing the effect(s) of a therapeutic agent in the development or progression of the disease.
- the effect(s) of a therapeutic agent may be measured in a
- the method comprises contacting a genetically modified animal comprising at least one edited
- chromosomal sequence encoding a protein associated with the disease with the therapeutic agent, and comparing results of a selected parameter to results obtained from contacting a wild-type animal with the same agent.
- suitable diseases include those listed in section ll(a)i.
- the role of a particular protein associated with a disease in the metabolism of a particular agent may be determined using such methods.
- substrate specificity and pharmacokinetic parameters may be readily determined using such methods.
- a method of the invention may be used to create an animal or cell in which at least one chromosomal sequence associated with toxicology has been edited.
- Suitable chromosomal edits may include, but are not limited to, the type of edits detailed in section l(f) above. Any chromosomal sequence or protein involved in absorption, distribution,
- ADME metabolism, and excretion
- toxicology may be utilized for purposes of the present invention.
- the ADME and toxicology-related proteins are typically selected based on an experimental association of the protein to an ADME and toxicology-related disorder. For example, the production rate or circulating concentration of an ADME and toxicology-related protein may be elevated or depressed in a population having an ADME and toxicology disorder relative to a population lacking the ADME and toxicology disorder. Differences in protein levels may be assessed using proteomic or genomic analysis techniques known in the art.
- Exemplary non-limiting examples of the chromosomal sequence or protein involved in ADME and toxicology may be chosen from Oct 1 , Oct 2, Hfe2, Ppar(alpha) MDRI a (ABC Transporter ABCBI a), MDRI b
- BCRP BCRP
- MRP1 ABCG2
- MRP2 ABCC2, cMOAT
- a further aspect of the present disclosure encompasses a method for assessing the effect(s) of an agent.
- Suitable agents include without limit pharmaceutically active ingredients, drugs, food additives, pesticides, herbicides, toxins, industrial chemicals, household chemicals, and other environmental chemicals.
- the effect(s) of an agent may be measured in a "humanized" genetically modified animal, such that the information gained therefrom may be used to predict the effect of the agent in a human.
- the method comprises contacting a genetically modified animal comprising at least one inactivated chromosomal sequence involved in ADME and toxicology and at least one chromosomally integrated sequence encoding an orthologous human protein involved in ADME and toxicology with the agent, and comparing results of a selected parameter to results obtained from contacting a wild-type animal with the same agent.
- Selected parameters include but are not limited to (a) rate of elimination of the agent or its metabolite(s); (b) circulatory levels of the agent or its metabolite(s); (c)bioavailability of the agent or its metabolite(s); (d) rate of metabolism of the agent or its metabolite(s); (e) rate of clearance of the agent or its metabolite(s); (f) toxicity of the agent or its metabolite(s); (g) efficacy of the agent or its metabolite(s); (h) disposition of the agent or its metabolite(s); and (i) extrahepatic contribution to metabolic rate and clearance of the agent or its metabolite(s).
- methods to assess the effect(s) of an agent in an isolated cell comprising at least one edited chromosomal sequence involved in ADME and toxicology as well as methods of using lysates of such cells (or cells derived from a genetically modified animal disclosed herein) to assess the effect(s) of an agent.
- the role of a particular protein involved in ADME and toxicology in the metabolism of a particular agent may be determined using such methods.
- pharmacokinetic parameters may be readily determined using such methods. Those of skill in the art are familiar with suitable tests and/or procedures.
- ADME and toxicology are the ABC transporters, also known as efflux transport proteins.
- the genetically modified animals as described herein containing an edited chromosomal sequences encoding an ABC transporter can be useful for screening biologically active agents including drugs and for investigating their distribution, efficacy, metabolism and/or toxicity. These screening methods are of particular use for assessing with improved
- a candidate therapeutic agent i.e, a candidate drug can be
- the knock-out or knock-in gene is associated with at least one aspect of the drug ADME profile or toxicology, and/or metabolism, and may be derived from a mouse, rat, or human genome.
- a method of screening for the target of a test compound can make use of a genetically modified animal in which any one or more of an ABC transporter such as Mdr1 a, MdM b, PXR, BCRP, MRP1 , or MRP2 are knocked out, thus inhibiting or eliminating transmembrane transport mediated by the knocked out protein(s).
- an animal can be exposed to a test compound suspected of inhibiting transporter activity of the knocked-out protein(s).
- Inhibition of transport by the compound in the genetically modified animal can be determined using any of a number of routine laboratory tests and techniques, and the inhibition of transport may be compared to that observed in a wild-type animal treated with the same test compound.
- a difference in the effect of the test compound in the two animals can be indicative of the target of the test compound.
- inhibition of one or more ABC transporter proteins such as Mdri a, MdM b, PXR, BCRP, MRP1 , or MRP2
- Mdri a, MdM b, PXR, BCRP, MRP1 , or MRP2 may improve certain ADME characteristics of a candidate therapeutic agent.
- the absorption or efficacy of a candidate therapeutic compound may be improved by knock-ing out expression of one or more ABC transporter proteins such as Mdri a, MdM b, PXR, BCRP, MRP1 , or MRP2, in a particular tissue.
- genetically modified animals and cells as described herein for example genetically modified animals and cells including a genetic modification of one or more ABC transporter proteins, can be used advantageously in many methods that evaluate the ADME and toxicology characteristics of a candidate therapeutic compound, to identify targets of a test compound, or to identify ways in which the ADME characteristics and toxicology of a candidate compound may be improved.
- the overwhelming need to accurately predict how drugs and environmental chemicals may affect large populations can be readily.
- genetically modified animals, embryos, cells and cell lines described herein can be used to analyze how various compounds may interact with biological systems.
- Genetically modified cells and cell lines can be used, for example, to control many of the known complexities in biological systems to improve the predictive ability of cell-based assay systems, such as those used to evaluate new molecular entities and possible drug-drug interactions. More specifically, it is recognized that biological systems typically include multiple components that respond to exposure to new, potentially harmful compounds.
- the "ADMET system” has been described as including five components.
- the first component are those biological systems that when disrupted signal the drug metabolism system to turn on, and may include stress response and DNA repair pathways.
- xenosensors surveil for exogenous molecules that need removal. Detection of an exogenous molecule by the xenosensors then activates a cascade of gene inductions that up-regulate the enzymes responsible for metabolizing exogenous molecules into forms for easier removal.
- the enzymes of the third ADMET component include Phase I enzymes that include at least three classes of oxidases, of which the best known class is the cytochrome P450 s class.
- Cytochrome 450 enzymes typically add reactive hydroxyl moieties to potential toxins to inactivate and render the toxins more polar (soluble).
- the fourth component of the ADMET system includes at least seven classes of enzymes that further alter the products of Phase I enzymatic modification.
- these enzymes are conjugating enzymes that add hydrophilic moieties to make the now oxidized xenobiotics even more water soluble ADMET, and readily collected and excreted through urine or bile.
- the last component is the transporter system involving transporter proteins, such as the ABC transporters, that function as molecular pumps to facilitate the movement of the xenobiotics from one tissue to another.
- transporter proteins are responsible for moving drugs into a cell, out of a cell, or through a cell.
- Each component of the ADMET system has its own set of substrate structural specificities, which must be taken into account by any assay. Making predictability an even larger challenge is that, for critical members of each of the five component classes, a constellation of genetic polymorphisms exists in the population and these can dramatically affect activity towards specific xenobiotic chemical structures. The growing field of pharmacogenomics addresses the challenges created by such genetic variation. In addition, gender differences in how the different components of the xenobiotic system respond are also known to play a role in variations in drug metabolism.
- cell-based assays can be created that are representative of the target tissue where metabolism or toxicity of a drug compound is likely to occur.
- standard assays are usually run in transformed cell lines that are derived from the target tissue and have some concordant functional properties.
- genetically modified and differentiated pluripotent cells could be used to replace the immortalized cell components.
- genetically modified cell lines can be used in more highly predictive cell-based assays suitable for high-throughput, high-content compound screening.
- the present disclosure contemplates ZFN- mediated genetic modifications of genes relevant to each part of the xenobiotic metabolism machinery.
- Such modifications include knock-outs, knock-ins of reporter tags, the introduction of specific mutations known to affect activity, or combinations of these.
- the genetically modified cells and cell lines can be used to create tissue-specific, gender-specific, and/or population- reflective transporter panels; cell-based xenosenor assay panels that are tissue- specific and functionally reflective of the population; and induction assays that measure the genetic activation of different drug metabolism components and overt toxicological responses such as genotoxicity, cardiotoxicity, and apoptosis.
- tissue-specific lines can be established that have been modified to isolate specific transporter activities and predict the reaction of populations to individual chemical entities.
- ZFNs can be used to create transporter gene knock-outs in enterocyte cell lines, such as to introduce important, common polymorphisms into
- enterocyte cell lines and in cell lines representative of liver, blood-brain-barrier (brain micro-vasculature endothelial cells), kidney and any relevant tissue- specific cell lines.
- Panels of cell lines can include enterocytes (Caco2 or BBeI ) with knock-outs of individual transporter proteins (e.g. MDR-1 , MRP1 , 2, 3, 4, 6, BCRP), knock-out combinations to isolate effects of individual transporters (e.g. BCRP and MRP2, MDR-1 and MRP2, MRP-3 and MRP1 ), and a transporter null line (i.e. all 7 transporters knocked out).
- Panels of enterocytes may include knock-outs of OATP-2B1 , PEPT-1 , and OCT-N2. Panels of enterocytes may be created which include prevalent polymorphisms in the major transporter genes that affect drug transport and are of concern to pharmaceutical researchers.
- the three xenosensors in humans are known to have overlapping specificities in response to xenobiotics. Knowing which xenosensors are activated and to what extent by any particular chemical compound is also an important consideration for understanding drug responses, and drug-drug interactions. Creating panels of cells that report induction by the xenosensors can delineate the specificities. Further modifying the cells to address functionally important polymorphisms in the xenosensors would permit population predictions.
- ZFNs can be used to create knock-out cell lines analogous to transporter knockout cell lines as described above, and to create reporter cell lines that express different fluorescent proteins upon induction of different xenosensors.
- cell lines can be created in which green FP is expressed if PXR is induced, red FP if CAR activity is induced, blue FP if AhR is induced. All lines may be constructed in the relevant tissue-type cell lines, i.e. intestine, liver, kidney, brain, and heart. Panels of cells can be created that represent the tissues most involved with drug toxicity and metabolism, and in which each xenosensor (CAR, PXR, AhR) is knocked out. Cell lines can also be produced that produce fluorescent proteins upon the activation of each of the three xenosensors.
- ZFNs can be used to create genetically modified cell lines as described herein that can provide the basis for assays that can measure the up/down regulation of key Phase I and Phase Il enzymes, along with genes involved in a toxicological response.
- ZFNs can be used to build lines that have a reporter gene (e.g. encoding fluorescent protein or luciferase) inserted proximal to the promoter of the gene being measured.
- Tissue-specific panels of cells can also be created, which report on the activation of genes encoding either the Phase I or Phase Il enzymes, the transporters, or toxicity response pathways (e.g., genotoxicity or apoptosis).
- a method of the invention may be used to create an animal or cell that may be used as a developmental model. Such a model may be used to study embryogenesis, organ development, organ system development, or the like. For instance, in one embodiment, a method of the invention may be used to create an animal or cell that comprises a chromosomal edit in one or more nucleic acid sequences associated with the development of an organ or organ system.
- Non-limiting examples of organs include the brain, eyes, nose, ears, throat, mouth (including teeth, tongue, lips, gums), spinal cord, bones, heart, blood vessels, lungs, liver, pancreas, gall bladder, spleen, esophagus, stomach, small intestines, large intestines, appendix, rectum, bladder, organs of the reproductive system, organs of the immune system (including thyroid, lymph nodes, lymph vessels), and organs of the endocrine system.
- organ systems include the nervous system, the circulatory system, the digestive system, the respiratory system, the skeletal system, the lymphatic system, the reproductive system, the muscular system, the integumentary system, the excretory system, and the endocrine system.
- a method of the invention may be used to create an animal or cell in which at least one chromosomal sequence associated with neurodevelopment has been edited.
- Suitable chromosomal edits may include, but are not limited to, the type of edits detailed in section l(f) above.
- a chromosomal sequence associated with neurodevelopment may be a protein coding sequence or a control sequence. In certain embodiments, a
- neurodevelopmental sequence may be associated with a neurodevelopmental disorder, with biochemical pathways associated with a neurodevelopmental disorder, or associated with a disorder such as phenylketonuria that is closely associated with neurodevelopmental disorders.
- Non-limiting examples of neurodevelopmental-associated sequences include A2BP1 [ataxin 2-binding protein 1], AADAT [aminoadipate aminotransferase], AANAT [arylalkylamine N-acetyltransferase], ABAT [4- aminobutyrate aminotransferase], ABCA1 [ATP-binding cassette, sub-family A (ABC1 ), member 1], ABCA13 [ATP-binding cassette, sub-family A (ABC1 ), member 13], ABCA2 [ATP-binding cassette, sub-family A (ABC1 ), member 2], ABCB1 [ATP-binding cassette, sub-family B (MDR/TAP), member 1], ABCB11 [ATP-binding cassette, sub-family B (MDR/TAP), member 11], ABCB4 [ATP- binding cassette, sub-family B (MDR/TAP), member 4], ABCB6 [ATP-binding cassette, sub-family B (MDR/TAP), member 6], ABCB7 [
- ADAM11 [ADAM metallopeptidase domain 11]
- ADAM12 [ADAM metallopeptidase domain 12]
- ADAM15 [ADAM
- ADAM17 [ADAM metallopeptidase domain 17]
- ADAM18 [ADAM metallopeptidase domain 18]
- ADAM19 [ADAM
- ADAM2 [ADAM metallopeptidase domain 2]
- ADAM20 [ADAM metallopeptidase domain 20]
- ADAM21 [ADAM metallopeptidase domain 21]
- ADAM22 [ADAM metallopeptidase domain 22]
- ADAM23 [ADAM metallopeptidase domain 23]
- ADAM28 [ADAM
- ADAM metallopeptidase domain 28 ADAM29 [ADAM metallopeptidase domain 29], ADAM30 [ADAM metallopeptidase domain 30], ADAM8 [ADAM metallopeptidase domain 8], ADAM9 [ADAM metallopeptidase domain 9 (meltrin gamma)], ADAMTS1 [ADAM metallopeptidase with thrombospondin type 1 motif, 1], ADAMTS13 [ADAM metallopeptidase with thrombospondin type 1 motif, 13], ADAMTS4 [ADAM metallopeptidase with thrombospondin type 1 motif, 4], ADAMTS5 [ADAM metallopeptidase with thrombospondin type 1 motif, 5], ADAP2 [ArfGAP with dual PH domains 2], ADAR [adenosine deaminase, RNA- specific], ADARB1 [adenosine deaminase, RNA-
- dehydrogenase 1A (class I), alpha polypeptide], ADIPOQ [adiponectin, C1Q and collagen domain containing], ADK [adenosine kinase], ADM [adrenomedullin], ADNP [activity-dependent neuroprotector homeobox], ADORA1 [adenosine A1 receptor], ADORA2A [adenosine A2a receptor], ADORA2B [adenosine A2b receptor], ADORA3 [adenosine A3 receptor], ADRA1 B [adrenergic, alpha-1 B-, receptor], ADRA2A [adrenergic, alpha-2A-, receptor], ADRA2B [adrenergic, alpha-2B-, receptor], ADRA2C [adrenergic, alpha-2C-, receptor], ADRB1
- ADRB2 [adrenergic, beta-1 -, receptor], ADRB2 [adrenergic, beta-2-, receptor, surface], ADRB3 [adrenergic, beta-3-, receptor], ADRBK2 [adrenergic, beta, receptor kinase 2], ADSL [adenylosuccinate lyase], AFF2 [AF4/FMR2 family, member 2], AFM [afamin], AFP [alpha-fetoprotein], AGAP1 [ArfGAP with GTPase domain, ankyrin repeat and PH domain 1], AGER [advanced glycosylation end product- specific receptor], AGFG1 [ArfGAP with FG repeats 1], AGPS [alkylglycerone phosphate synthase], AGRN [agrin], AGRP [agouti related protein homolog (mouse)], AGT [angiotensinogen (serpin peptidase inhibitor, clade A, member 8)], AG
- AIFM1 [activation-induced cytidine deaminase], AIFM1 [apoptosis-inducing factor, mitochondrion-associated, 1], AIRE [autoimmune regulator], AKAP12 [A kinase (PRKA) anchor protein 12], AKAP9 [A kinase (PRKA) anchor protein (yotiao) 9], AKR1A1 [aldo-keto reductase family 1 , member A1 (aldehyde reductase)], AKR1 B1 [aldo-keto reductase family 1 , member B1 (aldose reductase)], AKR1 C3 [aldo-keto reductase family 1 , member C3 (3-alpha hydroxysteroid
- AKT1 [v-akt murine thymoma viral oncogene homolog 1]
- AKT2 [v-akt murine thymoma viral oncogene homolog 2]
- AKT3 [v-akt murine thymoma viral oncogene homolog 3 (protein kinase B, gamma)]
- ALAD v-akt murine thymoma viral oncogene homolog 3 (protein kinase B, gamma)]
- ANK1 [ankyrin 1 , erythrocytic], ANK3 [ankyrin 3, node of Ranvier (ankyrin G)], ANKRD1 [ankyrin repeat domain 1 (cardiac muscle)], ANP32E [acidic (leucine-rich) nuclear phosphoprotein 32 family, member E], ANPEP [alanyl (membrane) aminopeptidase], ANXA1
- AP1 [annexin A1], ANXA2 [annexin A2], ANXA5 [annexin A5], AP1 S1 [adaptor-related protein complex 1 , sigma 1 subunit], AP1 S2 [adaptor-related protein complex 1 , sigma 2 subunit], AP2A1 [adaptor-related protein complex 2, alpha 1 subunit], AP2B1 [adaptor-related protein complex 2, beta 1 subunit], APAF1 [apoptotic peptidase activating factor 1], APBA1 [amyloid beta (A4) precursor protein- binding, family A, member 1], APBA2 [amyloid beta (A4) precursor protein- binding, family A, member 2], APBB1 [amyloid beta (A4) precursor protein- binding, family B, member 1 (Fe65)], APBB2 [amyloid beta (A4) precursor protein-binding, family B, member 2], APC [adenomatous polyposis coli], APCS [amyloid P component
- APLP1 [amyloid beta (A4) precursor-like protein 1], APOA1 [apolipoprotein A-I], APOA5 [apolipoprotein A-V], APOB [apolipoprotein B (including Ag(x) antigen)], APOC2 [apolipoprotein C-Il], APOD [apolipoprotein D], APOE [apolipoprotein E], APOM [apolipoprotein M], APP [amyloid beta (A4) precursor protein], APPL1 [adaptor protein, phosphotyrosine interaction, PH domain and leucine zipper containing 1], APRT [adenine phosphohbosyltransferase], APTX [aprataxin], AQP1 [aquaporin 1 (Colton blood group)], AQP2 [aquapohn 2 (collecting duct)], AQP3 [aquaporin 3 (Gill blood group)], AQP4 [aquaporin
- ARFGEF2 [ADP-ribosylation factor guanine nucleotide-exchange factor 2 (brefeldin A-inhibited)], ARG1 [arginase, liver], ARHGAP1 [Rho GTPase activating protein 1], ARHGAP32 [Rho GTPase activating protein 32], ARHGAP4 [Rho GTPase activating protein 4], ARHGAP5 [Rho GTPase activating protein 5], ARHGDIA [Rho GDP dissociation inhibitor (GDI) alpha], ARHGEF1 [Rho guanine nucleotide exchange factor (GEF) 1], ARHGEF10 [Rho guanine nucleotide exchange factor (GEF) 10], ARHGEF11 [Rho guanine nucleotide exchange factor (GEF) 11], ARHGEF12 [Rho guanine nucleotide exchange factor (GEF) 12], ARHGEF15 [Rh
- ARHGEF16 Rho guanine nucleotide exchange factor (GEF) 16
- GEF2 Rho guanine nucleotide exchange factor (GEF) 16
- ARPC1A [actin related protein 2/3 complex, subunit 1A, 41 kDa]
- ARPC1 B [actin related protein 2/3 complex, subunit 1 B, 41 kDa]
- ARPC2 [actin related protein 2/3 complex, subunit 2, 34kDa]
- ARPC3 [actin related protein 2/3 complex, subunit 3, 21 kDa]
- ARPC4 [actin related protein 2/3 complex, subunit 4, 2OkDa]
- ARPC5 [actin related protein 2/3 complex, subunit 5, 16kDa]
- ARPC5L [actin related protein 2/3 complex, subunit 5-like]
- ARPP19 [cAMP-regulated phosphoprotein, 19kDa]
- ARR3 arrestin 3, retinal (X-arrestin)]
- ARRB2 [arrestin, beta 2]
- ARSA arylsulfatase A
- ATP2B4 [ATPase, Ca++ transporting, plasma membrane 4], ATP5O [ATP synthase, H+ transporting, mitochondrial F1 complex, O subunit], ATP6AP1 [ATPase, H+ transporting, lysosomal accessory protein 1], ATP6V0C [ATPase, H+ transporting, lysosomal 16kDa, VO subunit c], ATP7A [ATPase, Cu++ transporting, alpha polypeptide], ATP8A1 [ATPase, aminophospholipid transporter (APLT), class I, type 8A, member 1], ATR [ataxia telangiectasia and Rad3 related], ATRN [attractin], ATRX [alpha
- CACNA2D1 [calcium channel, voltage-dependent, T type, alpha 1 H subunit]
- CADM1 cell adhesion molecule 1]
- CADPS2 [Ca++-dependent secretion activator 2]
- CALB2 [calbindin 2]
- CALCA calcium-dependent polypeptide alpha]
- CALCR calcium-dependent receptor
- CALM3 calcium-driven receptor for CALR
Landscapes
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Engineering & Computer Science (AREA)
- Biotechnology (AREA)
- Zoology (AREA)
- Biomedical Technology (AREA)
- Organic Chemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Wood Science & Technology (AREA)
- Chemical & Material Sciences (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Environmental Sciences (AREA)
- Veterinary Medicine (AREA)
- Biochemistry (AREA)
- Microbiology (AREA)
- Biophysics (AREA)
- Plant Pathology (AREA)
- Molecular Biology (AREA)
- Physics & Mathematics (AREA)
- Animal Behavior & Ethology (AREA)
- Animal Husbandry (AREA)
- Biodiversity & Conservation Biology (AREA)
- Cell Biology (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Enzymes And Modification Thereof (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
Abstract
Description












































































































































































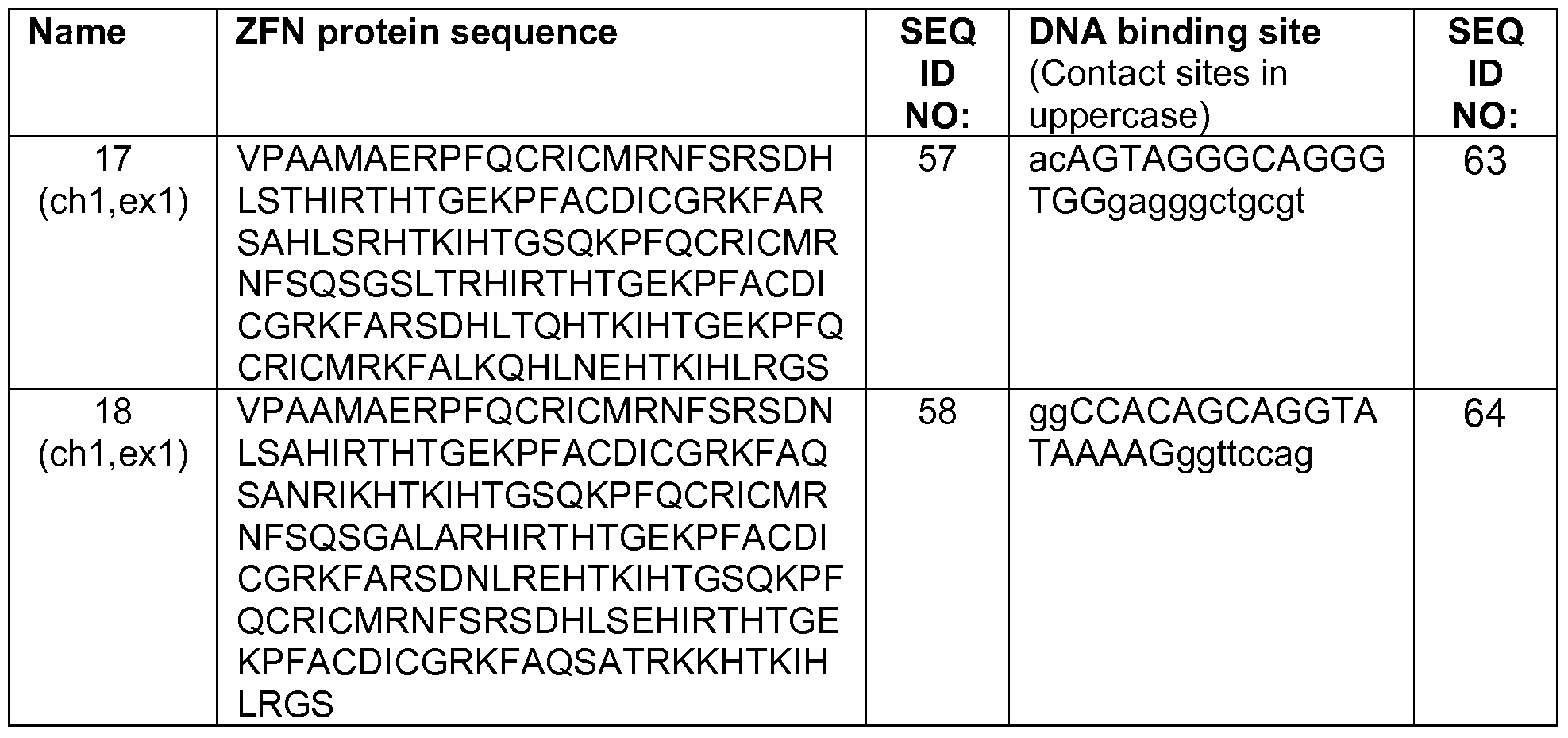









Claims
Priority Applications (8)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN2010800420582A CN102858985A (en) | 2009-07-24 | 2010-07-23 | Method for genome editing |
| US13/386,394 US20120192298A1 (en) | 2009-07-24 | 2010-07-23 | Method for genome editing |
| SG2012004131A SG177711A1 (en) | 2009-07-24 | 2010-07-23 | Method for genome editing |
| JP2012521867A JP2013500018A (en) | 2009-07-24 | 2010-07-23 | Methods for genome editing |
| AU2010275432A AU2010275432A1 (en) | 2009-07-24 | 2010-07-23 | Method for genome editing |
| EP20100803004 EP2456877A4 (en) | 2009-07-24 | 2010-07-23 | Method for genome editing |
| CA2767377A CA2767377A1 (en) | 2009-07-24 | 2010-07-23 | Method for genome editing |
| IL217409A IL217409A0 (en) | 2009-07-24 | 2012-01-05 | Method for genome editing |
Applications Claiming Priority (80)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US22841909P | 2009-07-24 | 2009-07-24 | |
| US61/228,419 | 2009-07-24 | ||
| US23262009P | 2009-08-10 | 2009-08-10 | |
| US61/232,620 | 2009-08-10 | ||
| US24587709P | 2009-09-25 | 2009-09-25 | |
| US61/245,877 | 2009-09-25 | ||
| US26369609P | 2009-11-23 | 2009-11-23 | |
| US61/263,696 | 2009-11-23 | ||
| US26390409P | 2009-11-24 | 2009-11-24 | |
| US61/263,904 | 2009-11-24 | ||
| US33600010P | 2010-01-14 | 2010-01-14 | |
| US61/336,000 | 2010-01-14 | ||
| US30808910P | 2010-02-25 | 2010-02-25 | |
| US61/308,089 | 2010-02-25 | ||
| US30972910P | 2010-03-02 | 2010-03-02 | |
| US61/309,729 | 2010-03-02 | ||
| US32369810P | 2010-04-13 | 2010-04-13 | |
| US32371910P | 2010-04-13 | 2010-04-13 | |
| US32370210P | 2010-04-13 | 2010-04-13 | |
| US61/323,719 | 2010-04-13 | ||
| US61/323,698 | 2010-04-13 | ||
| US61/323,702 | 2010-04-13 | ||
| US34328710P | 2010-04-26 | 2010-04-26 | |
| US61/343,287 | 2010-04-26 | ||
| US12/842,897 US20110023148A1 (en) | 2008-12-04 | 2010-07-23 | Genome editing of addiction-related genes in animals |
| US12/842,678 US20110023145A1 (en) | 2008-12-04 | 2010-07-23 | Genomic editing of genes involved in autism spectrum disorders |
| US12/843,000 | 2010-07-23 | ||
| US12/842,982 | 2010-07-23 | ||
| US12/842,994 US20110030072A1 (en) | 2008-12-04 | 2010-07-23 | Genome editing of immunodeficiency genes in animals |
| US12/842,999 US20110016543A1 (en) | 2008-12-04 | 2010-07-23 | Genomic editing of genes involved in inflammation |
| US12/842,269 US20110023154A1 (en) | 2008-12-04 | 2010-07-23 | Silkworm genome editing with zinc finger nucleases |
| US12/842,980 US20110023150A1 (en) | 2008-12-04 | 2010-07-23 | Genome editing of genes associated with schizophrenia in animals |
| US12/842,678 | 2010-07-23 | ||
| US12/842,708 US20110016540A1 (en) | 2008-12-04 | 2010-07-23 | Genome editing of genes associated with trinucleotide repeat expansion disorders in animals |
| US12/842,893 US20110016546A1 (en) | 2008-12-04 | 2010-07-23 | Porcine genome editing with zinc finger nucleases |
| US12/842,269 | 2010-07-23 | ||
| US12/842,976 | 2010-07-23 | ||
| US12/842,897 | 2010-07-23 | ||
| US12/842,886 | 2010-07-23 | ||
| US12/842,719 US20110016541A1 (en) | 2008-12-04 | 2010-07-23 | Genome editing of sensory-related genes in animals |
| US12/842,219 US20110023156A1 (en) | 2008-12-04 | 2010-07-23 | Feline genome editing with zinc finger nucleases |
| US12/842,893 | 2010-07-23 | ||
| US12/842,666 | 2010-07-23 | ||
| US12/842,978 | 2010-07-23 | ||
| US12/842,198 | 2010-07-23 | ||
| US12/842,208 | 2010-07-23 | ||
| US12/842,204 US20110023159A1 (en) | 2008-12-04 | 2010-07-23 | Ovine genome editing with zinc finger nucleases |
| US12/842,982 US20110023151A1 (en) | 2008-12-04 | 2010-07-23 | Genome editing of abc transporters |
| US12/842,839 | 2010-07-23 | ||
| US12/842,188 US20110023158A1 (en) | 2008-12-04 | 2010-07-23 | Bovine genome editing with zinc finger nucleases |
| US12/842,694 US20110023146A1 (en) | 2008-12-04 | 2010-07-23 | Genomic editing of genes involved in secretase-associated disorders |
| US12/842,839 US20110016542A1 (en) | 2008-12-04 | 2010-07-23 | Canine genome editing with zinc finger nucleases |
| US12/842,999 | 2010-07-23 | ||
| US12/842,993 US20110023153A1 (en) | 2008-12-04 | 2010-07-23 | Genomic editing of genes involved in alzheimer's disease |
| US12/842,208 US20110023140A1 (en) | 2008-12-04 | 2010-07-23 | Rabbit genome editing with zinc finger nucleases |
| US12/842,694 | 2010-07-23 | ||
| US12/842,198 US20110023139A1 (en) | 2008-12-04 | 2010-07-23 | Genomic editing of genes involved in cardiovascular disease |
| US12/842,620 | 2010-07-23 | ||
| US12/842,713 US20110023147A1 (en) | 2008-12-04 | 2010-07-23 | Genomic editing of prion disorder-related genes in animals |
| US12/842,219 | 2010-07-23 | ||
| US12/842,708 | 2010-07-23 | ||
| US12/842,578 | 2010-07-23 | ||
| US12/842,886 US20110023157A1 (en) | 2008-12-04 | 2010-07-23 | Equine genome editing with zinc finger nucleases |
| US12/842,719 | 2010-07-23 | ||
| US12/842,976 US20120159653A1 (en) | 2008-12-04 | 2010-07-23 | Genomic editing of genes involved in macular degeneration |
| US12/842,994 | 2010-07-23 | ||
| US12/842,217 US20110023141A1 (en) | 2008-12-04 | 2010-07-23 | Genomic editing of genes involved with parkinson's disease |
| US12/842,188 | 2010-07-23 | ||
| US12/842,978 US20110023149A1 (en) | 2008-12-04 | 2010-07-23 | Genomic editing of genes involved in tumor suppression in animals |
| US12/842,993 | 2010-07-23 | ||
| US12/842,991 | 2010-07-23 | ||
| US12/842,991 US20110023152A1 (en) | 2008-12-04 | 2010-07-23 | Genome editing of cognition related genes in animals |
| US12/842,666 US20110023144A1 (en) | 2008-12-04 | 2010-07-23 | Genomic editing of genes involved in amyotrophyic lateral sclerosis disease |
| US12/843,000 US20120159654A1 (en) | 2008-12-04 | 2010-07-23 | Genome editing of genes involved in adme and toxicology in animals |
| US12/842,980 | 2010-07-23 | ||
| US12/842,713 | 2010-07-23 | ||
| US12/842,204 | 2010-07-23 | ||
| US12/842,217 | 2010-07-23 | ||
| US12/842,578 US20110023143A1 (en) | 2008-12-04 | 2010-07-23 | Genomic editing of neurodevelopmental genes in animals |
| US12/842,620 US20110016539A1 (en) | 2008-12-04 | 2010-07-23 | Genome editing of neurotransmission-related genes in animals |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2011011767A1 true WO2011011767A1 (en) | 2011-01-27 |
Family
ID=43499447
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US2010/043167 WO2011011767A1 (en) | 2009-07-24 | 2010-07-23 | Method for genome editing |
Country Status (8)
| Country | Link |
|---|---|
| EP (1) | EP2456877A4 (en) |
| JP (1) | JP2013500018A (en) |
| KR (1) | KR20120097483A (en) |
| AU (1) | AU2010275432A1 (en) |
| CA (1) | CA2767377A1 (en) |
| IL (1) | IL217409A0 (en) |
| SG (1) | SG177711A1 (en) |
| WO (1) | WO2011011767A1 (en) |
Cited By (67)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102296073A (en) * | 2011-08-11 | 2011-12-28 | 中国农业科学院北京畜牧兽医研究所 | Specific target site for site-directed knockout of gene Myostatin by zinc finger nuclease |
| EP2461819A2 (en) * | 2009-07-28 | 2012-06-13 | Sangamo BioSciences, Inc. | Methods and compositions for treating trinucleotide repeat disorders |
| CN102660642A (en) * | 2012-04-24 | 2012-09-12 | 西北农林科技大学 | Screening system for screening zinc finger protein |
| EP2566972A1 (en) * | 2010-05-03 | 2013-03-13 | Sangamo BioSciences, Inc. | Compositions for linking zinc finger modules |
| WO2013063315A3 (en) * | 2011-10-27 | 2013-06-20 | Sangamo Biosciences, Inc. | Methods and compositions for modification of the hprt locus |
| US20130216579A1 (en) * | 2012-01-23 | 2013-08-22 | The Trustees Of Columbia University In The City Of New York | Methods and compostitions for gene editing of a pathogen |
| WO2014011237A1 (en) * | 2012-07-11 | 2014-01-16 | Sangamo Biosciences, Inc. | Methods and compositions for the treatment of lysosomal storage diseases |
| JP2014509195A (en) * | 2011-02-25 | 2014-04-17 | リコンビネティクス・インコーポレイテッド | Genetically modified animal and method for producing the same |
| US20140123330A1 (en) * | 2012-10-30 | 2014-05-01 | Recombinetics, Inc. | Control of sexual maturation in animals |
| US20140155468A1 (en) * | 2012-12-05 | 2014-06-05 | The Children's Hospital Of Philadelphia | Methods and compositions for regulation of metabolic disorders |
| JP2014526279A (en) * | 2011-09-21 | 2014-10-06 | サンガモ バイオサイエンシーズ, インコーポレイテッド | Methods and compositions for controlling transgene expression |
| WO2014161821A1 (en) | 2013-04-02 | 2014-10-09 | Bayer Cropscience Nv | Targeted genome engineering in eukaryotes |
| US20140335063A1 (en) * | 2013-05-10 | 2014-11-13 | Sangamo Biosciences, Inc. | Delivery methods and compositions for nuclease-mediated genome engineering |
| CN104450887A (en) * | 2014-11-12 | 2015-03-25 | 兰州百源基因技术有限公司 | DNA probe and gene chip for detecting endometrial carcinoma and application thereof |
| CN104540382A (en) * | 2012-06-12 | 2015-04-22 | 弗·哈夫曼-拉罗切有限公司 | Methods and compositions for generating conditional knock-out alleles |
| JP2015519923A (en) * | 2012-06-21 | 2015-07-16 | リコンビネティクス・インコーポレイテッドRecombinetics,Inc. | Genetically modified animal and method for producing the same |
| US20150240263A1 (en) * | 2014-02-24 | 2015-08-27 | Sangamo Biosciences, Inc. | Methods and compositions for nuclease-mediated targeted integration |
| JP2016501531A (en) * | 2012-12-12 | 2016-01-21 | ザ・ブロード・インスティテュート・インコーポレイテッド | Delivery, engineering and optimization of systems, methods and compositions for sequence manipulation and therapeutic applications |
| US9260752B1 (en) | 2013-03-14 | 2016-02-16 | Caribou Biosciences, Inc. | Compositions and methods of nucleic acid-targeting nucleic acids |
| CN105420232A (en) * | 2011-12-05 | 2016-03-23 | 菲克特生物科学股份有限公司 | Methods and products for transfection |
| WO2016112961A1 (en) * | 2015-01-13 | 2016-07-21 | Institut National De La Sante Et De La Recherche Medicale (Inserm) | Caspase-2 conditional knockouts and methods |
| US20160264999A1 (en) * | 2013-11-15 | 2016-09-15 | The United States of America, as represented by the Secretary, Department of Health & Human | Engineering neural stem cells using homologous recombination |
| US9512444B2 (en) | 2010-07-23 | 2016-12-06 | Sigma-Aldrich Co. Llc | Genome editing using targeting endonucleases and single-stranded nucleic acids |
| US9528124B2 (en) | 2013-08-27 | 2016-12-27 | Recombinetics, Inc. | Efficient non-meiotic allele introgression |
| EP3067419A4 (en) * | 2013-11-06 | 2017-08-30 | Hiroshima University | Vector for nucleic acid insertion |
| WO2017180989A3 (en) * | 2016-04-15 | 2017-12-14 | Memorial Sloan Kettering Cancer Center | Transgenic t cell and chimeric antigen receptor t cell compositions and related methods |
| US9885026B2 (en) | 2011-12-30 | 2018-02-06 | Caribou Biosciences, Inc. | Modified cascade ribonucleoproteins and uses thereof |
| RU2650819C2 (en) * | 2012-05-07 | 2018-04-17 | Сангамо Терапьютикс, Инк. | Methods and compositions for nuclease-mediated targeting of transgenes |
| US10000772B2 (en) | 2012-05-25 | 2018-06-19 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US20180214485A1 (en) * | 2013-03-21 | 2018-08-02 | Sangamo Therapeutics, Inc. | Targeted disruption of t cell receptor genes using engineered zinc finger protein nucleases |
| CN108441577A (en) * | 2018-05-25 | 2018-08-24 | 兰州大学 | Primer pair, kit and purposes and detection alfalfa product in whether the method containing soybean |
| WO2018222667A1 (en) * | 2017-05-31 | 2018-12-06 | 22Nd Century Limited, Llc | Genome editing methods for producing low-nicotine tobacco products |
| WO2019125187A1 (en) * | 2017-12-21 | 2019-06-27 | Livestock Improvement Corporation Limited | Genetic markers and uses therefor |
| CN110269047A (en) * | 2014-05-07 | 2019-09-24 | 瑞泽恩制药公司 | Humanization IL-4 and IL-4R α animal |
| US10494621B2 (en) | 2015-06-18 | 2019-12-03 | The Broad Institute, Inc. | Crispr enzyme mutations reducing off-target effects |
| US10550372B2 (en) | 2013-12-12 | 2020-02-04 | The Broad Institute, Inc. | Systems, methods and compositions for sequence manipulation with optimized functional CRISPR-Cas systems |
| US10577630B2 (en) | 2013-06-17 | 2020-03-03 | The Broad Institute, Inc. | Delivery and use of the CRISPR-Cas systems, vectors and compositions for hepatic targeting and therapy |
| CN111073900A (en) * | 2019-12-09 | 2020-04-28 | 温氏食品集团股份有限公司 | Method for improving pig cloned embryo development efficiency |
| US10648001B2 (en) | 2012-07-11 | 2020-05-12 | Sangamo Therapeutics, Inc. | Method of treating mucopolysaccharidosis type I or II |
| CN111235153A (en) * | 2020-04-01 | 2020-06-05 | 陕西慧康生物科技有限责任公司 | sgRNA for targeted knockout of human MC1R gene and cell strain constructed by sgRNA |
| CN111235154A (en) * | 2020-04-01 | 2020-06-05 | 陕西慧康生物科技有限责任公司 | sgRNA for targeted knockout of human MC1R gene and cell strain constructed by sgRNA |
| US10696986B2 (en) | 2014-12-12 | 2020-06-30 | The Board Institute, Inc. | Protected guide RNAS (PGRNAS) |
| US10711285B2 (en) | 2013-06-17 | 2020-07-14 | The Broad Institute, Inc. | Optimized CRISPR-Cas double nickase systems, methods and compositions for sequence manipulation |
| US10731181B2 (en) | 2012-12-06 | 2020-08-04 | Sigma, Aldrich Co. LLC | CRISPR-based genome modification and regulation |
| CN111684078A (en) * | 2018-02-12 | 2020-09-18 | 豪夫迈·罗氏有限公司 | Method for predicting response to treatment by assessing tumor genetic heterogeneity |
| US10781444B2 (en) | 2013-06-17 | 2020-09-22 | The Broad Institute, Inc. | Functional genomics using CRISPR-Cas systems, compositions, methods, screens and applications thereof |
| US10851357B2 (en) | 2013-12-12 | 2020-12-01 | The Broad Institute, Inc. | Compositions and methods of use of CRISPR-Cas systems in nucleotide repeat disorders |
| US10893667B2 (en) | 2011-02-25 | 2021-01-19 | Recombinetics, Inc. | Non-meiotic allele introgression |
| US10930367B2 (en) | 2012-12-12 | 2021-02-23 | The Broad Institute, Inc. | Methods, models, systems, and apparatus for identifying target sequences for Cas enzymes or CRISPR-Cas systems for target sequences and conveying results thereof |
| US10946108B2 (en) | 2013-06-17 | 2021-03-16 | The Broad Institute, Inc. | Delivery, use and therapeutic applications of the CRISPR-Cas systems and compositions for targeting disorders and diseases using viral components |
| US11008588B2 (en) | 2013-06-17 | 2021-05-18 | The Broad Institute, Inc. | Delivery, engineering and optimization of tandem guide systems, methods and compositions for sequence manipulation |
| WO2021168412A1 (en) * | 2020-02-21 | 2021-08-26 | University Of Pittsburgh - Of The Commonwealth System Of Higher Education | Non-human animal models for aging and/or neurodegeneration |
| CN113355356A (en) * | 2021-07-05 | 2021-09-07 | 西北农林科技大学 | CSN1S1 gene knockout vector and preparation method of CSN1S1 gene knockout mammary epithelial cell |
| US11155795B2 (en) | 2013-12-12 | 2021-10-26 | The Broad Institute, Inc. | CRISPR-Cas systems, crystal structure and uses thereof |
| US11179479B2 (en) * | 2018-01-05 | 2021-11-23 | Animatus Biosciences, Llc | Enhanced cardiomyocyte regeneration |
| CN113881646A (en) * | 2021-09-28 | 2022-01-04 | 北京市农林科学院 | Related protein TaFAH1 participating in plant disease resistance and gene and application thereof |
| CN113916754A (en) * | 2021-10-12 | 2022-01-11 | 四川大学华西医院 | Cell surface marker for detecting circulating tumor cells of breast cancer patient and application |
| EP3491131B1 (en) * | 2016-07-29 | 2022-05-25 | Max-Planck-Gesellschaft zur Förderung der Wissenschaften e.V. | Targeted in situ protein diversification by site directed dna cleavage and repair |
| WO2022145495A1 (en) * | 2021-01-04 | 2022-07-07 | Modalis Therapeutics Corporation | Method for treating spinocerebellar ataxias (sca) by targeting atxn7 gene |
| IL282597B (en) * | 2021-04-22 | 2022-08-01 | B G Negev Technologies And Applications Ltd At Ben Gurion Univ | Birds for producing female hatchling and methods of producing same |
| US11407985B2 (en) | 2013-12-12 | 2022-08-09 | The Broad Institute, Inc. | Delivery, use and therapeutic applications of the CRISPR-Cas systems and compositions for genome editing |
| US11459587B2 (en) | 2016-07-06 | 2022-10-04 | Vertex Pharmaceuticals Incorporated | Materials and methods for treatment of pain related disorders |
| WO2022240649A1 (en) * | 2021-05-12 | 2022-11-17 | Alkahest, Inc. | Methods and compositions for treating aging-associated impairments with trefoil factor family member 2 modulators |
| US11578312B2 (en) | 2015-06-18 | 2023-02-14 | The Broad Institute Inc. | Engineering and optimization of systems, methods, enzymes and guide scaffolds of CAS9 orthologs and variants for sequence manipulation |
| US11692203B2 (en) | 2011-12-05 | 2023-07-04 | Factor Bioscience Inc. | Methods and products for transfecting cells |
| US11801313B2 (en) | 2016-07-06 | 2023-10-31 | Vertex Pharmaceuticals Incorporated | Materials and methods for treatment of pain related disorders |
| US11827877B2 (en) | 2018-06-28 | 2023-11-28 | Crispr Therapeutics Ag | Compositions and methods for genomic editing by insertion of donor polynucleotides |
Families Citing this family (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3730615A3 (en) * | 2013-05-15 | 2020-12-09 | Sangamo Therapeutics, Inc. | Methods and compositions for treatment of a genetic condition |
| US20140359796A1 (en) * | 2013-05-31 | 2014-12-04 | Recombinetics, Inc. | Genetically sterile animals |
| JP6300302B2 (en) * | 2013-11-27 | 2018-03-28 | 国立研究開発法人農業・食品産業技術総合研究機構 | Silkworm sericin 1 mutant strain |
| US20170002413A1 (en) * | 2014-01-17 | 2017-01-05 | The University Of Tokyo | Molecule associated with onset of gout, and method and kit for evaluating diathesis of uric acid-related diseases and inflammation-related diseases, and inspection object and drug |
| EP3330710B1 (en) * | 2015-07-31 | 2020-09-09 | Sapporo Medical University | Method and kit for evaluating prognosis, distant recurrence risk and invasion of glioma, and pharmaceutical composition for treating glioma |
| US20190330660A1 (en) * | 2016-03-04 | 2019-10-31 | Martin D. Chapman | Fel d 1 knockouts and associated compositions and methods based on crispr-cas9 genomic editing |
| CN111172274B (en) * | 2020-01-22 | 2021-10-15 | 清华大学 | Application of Synaptotagmin-7 in diagnosis and treatment of bidirectional affective disorder |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2009042186A2 (en) * | 2007-09-27 | 2009-04-02 | Sangamo Biosciences, Inc. | Genomic editing in zebrafish using zinc finger nucleases |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA2474486C (en) * | 2002-01-23 | 2013-05-14 | The University Of Utah Research Foundation | Targeted chromosomal mutagenesis using zinc finger nucleases |
-
2010
- 2010-07-23 WO PCT/US2010/043167 patent/WO2011011767A1/en active Application Filing
- 2010-07-23 CA CA2767377A patent/CA2767377A1/en not_active Abandoned
- 2010-07-23 SG SG2012004131A patent/SG177711A1/en unknown
- 2010-07-23 KR KR1020127004819A patent/KR20120097483A/en not_active Application Discontinuation
- 2010-07-23 EP EP20100803004 patent/EP2456877A4/en not_active Withdrawn
- 2010-07-23 AU AU2010275432A patent/AU2010275432A1/en not_active Abandoned
- 2010-07-23 JP JP2012521867A patent/JP2013500018A/en active Pending
-
2012
- 2012-01-05 IL IL217409A patent/IL217409A0/en unknown
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2009042186A2 (en) * | 2007-09-27 | 2009-04-02 | Sangamo Biosciences, Inc. | Genomic editing in zebrafish using zinc finger nucleases |
Non-Patent Citations (5)
| Title |
|---|
| GEURTS ET AL.: "Knockout Rats Produced Using Designed Zinc Finger Nucleases.", SCIENCE, vol. 325, no. 5939, 24 July 2009 (2009-07-24), pages 433, XP002580718 * |
| SANTIAGO ET AL.: "Targeted gene knockout in mammalian cells by using engineered zinc-finger nucleases.", PROC NAT ACAD SCI, vol. 105, no. 15, 15 April 2008 (2008-04-15), pages 5809 - 5814, XP009143037 * |
| See also references of EP2456877A4 * |
| URNOV ET AL.: "Genome editing with engineered zinc finger nucleases.", NAT REV GENET, vol. 11, September 2010 (2010-09-01), pages 636 - 646, XP008150557 * |
| ZOU ET AL.: "Gene targeting of a disease-related gene in human induced pluripotent stem and embryonic stem cells.", CELL STEM CELL, vol. 5, no. 1, 2 July 2009 (2009-07-02), pages 97 - 100, XP009143029 * |
Cited By (202)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP2727600A1 (en) * | 2009-07-28 | 2014-05-07 | Sangamo BioSciences, Inc. | Methods and compositions for treating trinucleotide repeat disorders |
| EP2461819A2 (en) * | 2009-07-28 | 2012-06-13 | Sangamo BioSciences, Inc. | Methods and compositions for treating trinucleotide repeat disorders |
| US9943565B2 (en) | 2009-07-28 | 2018-04-17 | Sangamo Therapeutics, Inc. | Methods and compositions for treating trinucleotide repeat disorders |
| US9234016B2 (en) | 2009-07-28 | 2016-01-12 | Sangamo Biosciences, Inc. | Engineered zinc finger proteins for treating trinucleotide repeat disorders |
| US10646543B2 (en) | 2009-07-28 | 2020-05-12 | Sangamo Therapeutics, Inc. | Methods and compositions for treating trinucleotide repeat disorders |
| EP2461819A4 (en) * | 2009-07-28 | 2013-07-31 | Sangamo Biosciences Inc | Methods and compositions for treating trinucleotide repeat disorders |
| US8772453B2 (en) | 2010-05-03 | 2014-07-08 | Sangamo Biosciences, Inc. | Compositions for linking zinc finger modules |
| EP2566972A4 (en) * | 2010-05-03 | 2014-01-01 | Sangamo Biosciences Inc | Compositions for linking zinc finger modules |
| US9163245B2 (en) | 2010-05-03 | 2015-10-20 | Sangamo Biosciences, Inc. | Compositions for linking zinc finger modules |
| AU2011249019B2 (en) * | 2010-05-03 | 2015-01-22 | Sangamo Therapeutics, Inc. | Compositions for linking zinc finger modules |
| EP2566972A1 (en) * | 2010-05-03 | 2013-03-13 | Sangamo BioSciences, Inc. | Compositions for linking zinc finger modules |
| EP3636766A1 (en) * | 2010-05-03 | 2020-04-15 | Sangamo Therapeutics, Inc. | Compositions for linking zinc finger modules |
| US9512444B2 (en) | 2010-07-23 | 2016-12-06 | Sigma-Aldrich Co. Llc | Genome editing using targeting endonucleases and single-stranded nucleic acids |
| JP2020010692A (en) * | 2011-02-25 | 2020-01-23 | リコンビネティクス・インコーポレイテッドRecombinetics,Inc. | Genetically modified animals and methods for making the same |
| JP2014509195A (en) * | 2011-02-25 | 2014-04-17 | リコンビネティクス・インコーポレイテッド | Genetically modified animal and method for producing the same |
| US10893667B2 (en) | 2011-02-25 | 2021-01-19 | Recombinetics, Inc. | Non-meiotic allele introgression |
| US10920242B2 (en) | 2011-02-25 | 2021-02-16 | Recombinetics, Inc. | Non-meiotic allele introgression |
| US10959415B2 (en) | 2011-02-25 | 2021-03-30 | Recombinetics, Inc. | Non-meiotic allele introgression |
| CN102296073B (en) * | 2011-08-11 | 2014-04-23 | 中国农业科学院北京畜牧兽医研究所 | Specific target site for site-directed knockout of gene Myostatin by zinc finger nuclease |
| CN102296073A (en) * | 2011-08-11 | 2011-12-28 | 中国农业科学院北京畜牧兽医研究所 | Specific target site for site-directed knockout of gene Myostatin by zinc finger nuclease |
| US11859190B2 (en) | 2011-09-21 | 2024-01-02 | Sangamo Therapeutics, Inc. | Methods and compositions for regulation of transgene expression |
| US9777281B2 (en) | 2011-09-21 | 2017-10-03 | Sangamo Therapeutics, Inc. | Methods and compositions for regulation of transgene expression |
| US10975375B2 (en) | 2011-09-21 | 2021-04-13 | Sangamo Therapeutics, Inc. | Methods and compositions for regulation of transgene expression |
| US11639504B2 (en) | 2011-09-21 | 2023-05-02 | Sangamo Therapeutics, Inc. | Methods and compositions for regulation of transgene expression |
| JP2014526279A (en) * | 2011-09-21 | 2014-10-06 | サンガモ バイオサイエンシーズ, インコーポレイテッド | Methods and compositions for controlling transgene expression |
| JP2019080588A (en) * | 2011-09-21 | 2019-05-30 | サンガモ セラピューティクス, インコーポレイテッド | Method and composition for regulation of transgene expression |
| JP2017217002A (en) * | 2011-09-21 | 2017-12-14 | サンガモ セラピューティクス, インコーポレイテッド | Method and composition for regulation of transgene expression |
| JP2014532410A (en) * | 2011-10-27 | 2014-12-08 | サンガモ バイオサイエンシーズ, インコーポレイテッド | Methods and compositions for modifying the HPRT locus |
| US8895264B2 (en) | 2011-10-27 | 2014-11-25 | Sangamo Biosciences, Inc. | Methods and compositions for modification of the HPRT locus |
| WO2013063315A3 (en) * | 2011-10-27 | 2013-06-20 | Sangamo Biosciences, Inc. | Methods and compositions for modification of the hprt locus |
| US9222105B2 (en) | 2011-10-27 | 2015-12-29 | Sangamo Biosciences, Inc. | Methods and compositions for modification of the HPRT locus |
| US11708586B2 (en) | 2011-12-05 | 2023-07-25 | Factor Bioscience Inc. | Methods and products for transfecting cells |
| CN105420232A (en) * | 2011-12-05 | 2016-03-23 | 菲克特生物科学股份有限公司 | Methods and products for transfection |
| US11692203B2 (en) | 2011-12-05 | 2023-07-04 | Factor Bioscience Inc. | Methods and products for transfecting cells |
| CN105420232B (en) * | 2011-12-05 | 2020-07-31 | 菲克特生物科学股份有限公司 | Methods and products for transfecting cells |
| US10711257B2 (en) | 2011-12-30 | 2020-07-14 | Caribou Biosciences, Inc. | Modified cascade ribonucleoproteins and uses thereof |
| US11939604B2 (en) | 2011-12-30 | 2024-03-26 | Caribou Biosciences, Inc. | Modified cascade ribonucleoproteins and uses thereof |
| US10435678B2 (en) | 2011-12-30 | 2019-10-08 | Caribou Biosciences, Inc. | Modified cascade ribonucleoproteins and uses thereof |
| US9885026B2 (en) | 2011-12-30 | 2018-02-06 | Caribou Biosciences, Inc. | Modified cascade ribonucleoproteins and uses thereof |
| US10954498B2 (en) | 2011-12-30 | 2021-03-23 | Caribou Biosciences, Inc. | Modified cascade ribonucleoproteins and uses thereof |
| US20130216579A1 (en) * | 2012-01-23 | 2013-08-22 | The Trustees Of Columbia University In The City Of New York | Methods and compostitions for gene editing of a pathogen |
| CN102660642A (en) * | 2012-04-24 | 2012-09-12 | 西北农林科技大学 | Screening system for screening zinc finger protein |
| US10174331B2 (en) | 2012-05-07 | 2019-01-08 | Sangamo Therapeutics, Inc. | Methods and compositions for nuclease-mediated targeted integration of transgenes |
| RU2650819C2 (en) * | 2012-05-07 | 2018-04-17 | Сангамо Терапьютикс, Инк. | Methods and compositions for nuclease-mediated targeting of transgenes |
| US10597680B2 (en) | 2012-05-25 | 2020-03-24 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US11293034B2 (en) | 2012-05-25 | 2022-04-05 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US11970711B2 (en) | 2012-05-25 | 2024-04-30 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US11814645B2 (en) | 2012-05-25 | 2023-11-14 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US11674159B2 (en) | 2012-05-25 | 2023-06-13 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US11634730B2 (en) | 2012-05-25 | 2023-04-25 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US11549127B2 (en) | 2012-05-25 | 2023-01-10 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US11479794B2 (en) | 2012-05-25 | 2022-10-25 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US11473108B2 (en) | 2012-05-25 | 2022-10-18 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US11401532B2 (en) | 2012-05-25 | 2022-08-02 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US11332761B2 (en) | 2012-05-25 | 2022-05-17 | The Regenis of Wie University of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10000772B2 (en) | 2012-05-25 | 2018-06-19 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US11274318B2 (en) | 2012-05-25 | 2022-03-15 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US11242543B2 (en) | 2012-05-25 | 2022-02-08 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US11186849B2 (en) | 2012-05-25 | 2021-11-30 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US11028412B2 (en) | 2012-05-25 | 2021-06-08 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10113167B2 (en) | 2012-05-25 | 2018-10-30 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US11008590B2 (en) | 2012-05-25 | 2021-05-18 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US11008589B2 (en) | 2012-05-25 | 2021-05-18 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US11001863B2 (en) | 2012-05-25 | 2021-05-11 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10988780B2 (en) | 2012-05-25 | 2021-04-27 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10227611B2 (en) | 2012-05-25 | 2019-03-12 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10266850B2 (en) | 2012-05-25 | 2019-04-23 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10988782B2 (en) | 2012-05-25 | 2021-04-27 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10301651B2 (en) | 2012-05-25 | 2019-05-28 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10982231B2 (en) | 2012-05-25 | 2021-04-20 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10308961B2 (en) | 2012-05-25 | 2019-06-04 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10982230B2 (en) | 2012-05-25 | 2021-04-20 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10900054B2 (en) | 2012-05-25 | 2021-01-26 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10337029B2 (en) | 2012-05-25 | 2019-07-02 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10351878B2 (en) | 2012-05-25 | 2019-07-16 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10358658B2 (en) | 2012-05-25 | 2019-07-23 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10358659B2 (en) | 2012-05-25 | 2019-07-23 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10793878B1 (en) | 2012-05-25 | 2020-10-06 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10385360B2 (en) | 2012-05-25 | 2019-08-20 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10400253B2 (en) | 2012-05-25 | 2019-09-03 | The Regents Of The University Of California | Methods and compositions or RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10407697B2 (en) | 2012-05-25 | 2019-09-10 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10415061B2 (en) | 2012-05-25 | 2019-09-17 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10774344B1 (en) | 2012-05-25 | 2020-09-15 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10421980B2 (en) | 2012-05-25 | 2019-09-24 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10428352B2 (en) | 2012-05-25 | 2019-10-01 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10752920B2 (en) | 2012-05-25 | 2020-08-25 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10443076B2 (en) | 2012-05-25 | 2019-10-15 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10487341B2 (en) | 2012-05-25 | 2019-11-26 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10676759B2 (en) | 2012-05-25 | 2020-06-09 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10513712B2 (en) | 2012-05-25 | 2019-12-24 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10519467B2 (en) | 2012-05-25 | 2019-12-31 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10526619B2 (en) | 2012-05-25 | 2020-01-07 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10533190B2 (en) | 2012-05-25 | 2020-01-14 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10669560B2 (en) | 2012-05-25 | 2020-06-02 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10640791B2 (en) | 2012-05-25 | 2020-05-05 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10550407B2 (en) | 2012-05-25 | 2020-02-04 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10563227B2 (en) | 2012-05-25 | 2020-02-18 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10570419B2 (en) | 2012-05-25 | 2020-02-25 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10626419B2 (en) | 2012-05-25 | 2020-04-21 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10577631B2 (en) | 2012-05-25 | 2020-03-03 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| US10612045B2 (en) | 2012-05-25 | 2020-04-07 | The Regents Of The University Of California | Methods and compositions for RNA-directed target DNA modification and for RNA-directed modulation of transcription |
| CN104540382A (en) * | 2012-06-12 | 2015-04-22 | 弗·哈夫曼-拉罗切有限公司 | Methods and compositions for generating conditional knock-out alleles |
| JP2015519082A (en) * | 2012-06-12 | 2015-07-09 | ジェネンテック, インコーポレイテッド | Methods and compositions for generating conditional knockout alleles |
| JP2015519923A (en) * | 2012-06-21 | 2015-07-16 | リコンビネティクス・インコーポレイテッドRecombinetics,Inc. | Genetically modified animal and method for producing the same |
| US9956247B2 (en) | 2012-07-11 | 2018-05-01 | Sangamo Therapeutics, Inc. | Method of treating lysosomal storage diseases |
| US9877988B2 (en) | 2012-07-11 | 2018-01-30 | Sangamo Therapeutics, Inc. | Method of treating lysosomal storage diseases using nucleases and a transgene |
| EP3196301A1 (en) * | 2012-07-11 | 2017-07-26 | Sangamo BioSciences, Inc. | Methods and compositions for the treatment of monogenic diseases |
| US10648001B2 (en) | 2012-07-11 | 2020-05-12 | Sangamo Therapeutics, Inc. | Method of treating mucopolysaccharidosis type I or II |
| EP3196301B1 (en) | 2012-07-11 | 2018-10-17 | Sangamo Therapeutics, Inc. | Methods and compositions for the treatment of monogenic diseases |
| AU2013289206B2 (en) * | 2012-07-11 | 2018-08-09 | Sangamo Therapeutics, Inc. | Methods and compositions for the treatment of lysosomal storage diseases |
| WO2014011237A1 (en) * | 2012-07-11 | 2014-01-16 | Sangamo Biosciences, Inc. | Methods and compositions for the treatment of lysosomal storage diseases |
| US11898158B2 (en) | 2012-07-11 | 2024-02-13 | Sangamo Therapeutics, Inc. | Methods and compositions for the treatment of lysosomal storage diseases |
| US11040115B2 (en) | 2012-07-11 | 2021-06-22 | Sangamo Therapeutics, Inc. | Method for the treatment of lysosomal storage diseases |
| US10293000B2 (en) | 2012-07-11 | 2019-05-21 | Sangamo Therapeutics, Inc. | Methods and compositions for the treatment of lysosomal storage diseases |
| EP3444342A1 (en) * | 2012-07-11 | 2019-02-20 | Sangamo Therapeutics, Inc. | Methods and compositions for the treatment of lysosomal storage diseases |
| EP3816281A1 (en) * | 2012-07-11 | 2021-05-05 | Sangamo Therapeutics, Inc. | Methods and compositions for the treatment of lysosomal storage diseases |
| US20140123330A1 (en) * | 2012-10-30 | 2014-05-01 | Recombinetics, Inc. | Control of sexual maturation in animals |
| US20140155468A1 (en) * | 2012-12-05 | 2014-06-05 | The Children's Hospital Of Philadelphia | Methods and compositions for regulation of metabolic disorders |
| US20160143953A1 (en) * | 2012-12-05 | 2016-05-26 | Sangamo Biosciences, Inc. | Methods and compositions for regulation of metabolic disorders |
| US9255250B2 (en) | 2012-12-05 | 2016-02-09 | Sangamo Bioscience, Inc. | Isolated mouse or human cell having an exogenous transgene in an endogenous albumin gene |
| WO2014089212A1 (en) * | 2012-12-05 | 2014-06-12 | Sangamo Biosciences, Inc. | Methods and compositions for regulation of metabolic disorders |
| US10731181B2 (en) | 2012-12-06 | 2020-08-04 | Sigma, Aldrich Co. LLC | CRISPR-based genome modification and regulation |
| US10745716B2 (en) | 2012-12-06 | 2020-08-18 | Sigma-Aldrich Co. Llc | CRISPR-based genome modification and regulation |
| US10930367B2 (en) | 2012-12-12 | 2021-02-23 | The Broad Institute, Inc. | Methods, models, systems, and apparatus for identifying target sequences for Cas enzymes or CRISPR-Cas systems for target sequences and conveying results thereof |
| JP2022040308A (en) * | 2012-12-12 | 2022-03-10 | ザ・ブロード・インスティテュート・インコーポレイテッド | Delivery, engineering and optimization of systems, methods and compositions for sequence manipulation and therapeutic applications |
| JP7013406B2 (en) | 2012-12-12 | 2022-02-15 | ザ・ブロード・インスティテュート・インコーポレイテッド | Delivery, engineering and optimization of systems, methods and compositions for sequence manipulation and therapeutic applications |
| JP7228059B2 (en) | 2012-12-12 | 2023-02-22 | ザ・ブロード・インスティテュート・インコーポレイテッド | Delivery, engineering and optimization of systems, methods and compositions for sequence engineering and therapeutic applications |
| JP2019103513A (en) * | 2012-12-12 | 2019-06-27 | ザ・ブロード・インスティテュート・インコーポレイテッド | Delivery, engineering and optimization of systems, methods and compositions for sequence manipulation and therapeutic applications |
| JP2016501531A (en) * | 2012-12-12 | 2016-01-21 | ザ・ブロード・インスティテュート・インコーポレイテッド | Delivery, engineering and optimization of systems, methods and compositions for sequence manipulation and therapeutic applications |
| US11041173B2 (en) | 2012-12-12 | 2021-06-22 | The Broad Institute, Inc. | Delivery, engineering and optimization of systems, methods and compositions for sequence manipulation and therapeutic applications |
| US11312953B2 (en) | 2013-03-14 | 2022-04-26 | Caribou Biosciences, Inc. | Compositions and methods of nucleic acid-targeting nucleic acids |
| US9809814B1 (en) | 2013-03-14 | 2017-11-07 | Caribou Biosciences, Inc. | Compositions and methods of nucleic acid-targeting nucleic acids |
| US9909122B2 (en) | 2013-03-14 | 2018-03-06 | Caribou Biosciences, Inc. | Compositions and methods of nucleic acid-targeting nucleic acids |
| US9803194B2 (en) | 2013-03-14 | 2017-10-31 | Caribou Biosciences, Inc. | Compositions and methods of nucleic acid-targeting nucleic acids |
| US10125361B2 (en) | 2013-03-14 | 2018-11-13 | Caribou Biosciences, Inc. | Compositions and methods of nucleic acid-targeting nucleic acids |
| US9725714B2 (en) | 2013-03-14 | 2017-08-08 | Caribou Biosciences, Inc. | Compositions and methods of nucleic acid-targeting nucleic acids |
| US9260752B1 (en) | 2013-03-14 | 2016-02-16 | Caribou Biosciences, Inc. | Compositions and methods of nucleic acid-targeting nucleic acids |
| US9410198B2 (en) | 2013-03-14 | 2016-08-09 | Caribou Biosciences, Inc. | Compostions and methods of nucleic acid-targeting nucleic acids |
| US10918668B2 (en) * | 2013-03-21 | 2021-02-16 | Sangamo Therapeutics, Inc. | Targeted disruption of T cell receptor genes using engineered zinc finger protein nucleases |
| US20180214485A1 (en) * | 2013-03-21 | 2018-08-02 | Sangamo Therapeutics, Inc. | Targeted disruption of t cell receptor genes using engineered zinc finger protein nucleases |
| WO2014161821A1 (en) | 2013-04-02 | 2014-10-09 | Bayer Cropscience Nv | Targeted genome engineering in eukaryotes |
| US20140335063A1 (en) * | 2013-05-10 | 2014-11-13 | Sangamo Biosciences, Inc. | Delivery methods and compositions for nuclease-mediated genome engineering |
| US10604771B2 (en) * | 2013-05-10 | 2020-03-31 | Sangamo Therapeutics, Inc. | Delivery methods and compositions for nuclease-mediated genome engineering |
| US10946108B2 (en) | 2013-06-17 | 2021-03-16 | The Broad Institute, Inc. | Delivery, use and therapeutic applications of the CRISPR-Cas systems and compositions for targeting disorders and diseases using viral components |
| US11008588B2 (en) | 2013-06-17 | 2021-05-18 | The Broad Institute, Inc. | Delivery, engineering and optimization of tandem guide systems, methods and compositions for sequence manipulation |
| US11597949B2 (en) | 2013-06-17 | 2023-03-07 | The Broad Institute, Inc. | Optimized CRISPR-Cas double nickase systems, methods and compositions for sequence manipulation |
| US10711285B2 (en) | 2013-06-17 | 2020-07-14 | The Broad Institute, Inc. | Optimized CRISPR-Cas double nickase systems, methods and compositions for sequence manipulation |
| US10781444B2 (en) | 2013-06-17 | 2020-09-22 | The Broad Institute, Inc. | Functional genomics using CRISPR-Cas systems, compositions, methods, screens and applications thereof |
| US10577630B2 (en) | 2013-06-17 | 2020-03-03 | The Broad Institute, Inc. | Delivery and use of the CRISPR-Cas systems, vectors and compositions for hepatic targeting and therapy |
| US10959414B2 (en) | 2013-08-27 | 2021-03-30 | Recombinetics, Inc. | Efficient non-meiotic allele introgression |
| US9528124B2 (en) | 2013-08-27 | 2016-12-27 | Recombinetics, Inc. | Efficient non-meiotic allele introgression |
| US11477969B2 (en) | 2013-08-27 | 2022-10-25 | Recombinetics, Inc. | Efficient non-meiotic allele introgression in livestock |
| EP3067419A4 (en) * | 2013-11-06 | 2017-08-30 | Hiroshima University | Vector for nucleic acid insertion |
| EP3865575A1 (en) * | 2013-11-06 | 2021-08-18 | Hiroshima University | Vector for nucleic acid insertion |
| US20160264999A1 (en) * | 2013-11-15 | 2016-09-15 | The United States of America, as represented by the Secretary, Department of Health & Human | Engineering neural stem cells using homologous recombination |
| US9951353B2 (en) * | 2013-11-15 | 2018-04-24 | The United States Of America, As Represented By The Secretary, Dept. Of Health And Human Services | Engineering neural stem cells using homologous recombination |
| US11155795B2 (en) | 2013-12-12 | 2021-10-26 | The Broad Institute, Inc. | CRISPR-Cas systems, crystal structure and uses thereof |
| US10851357B2 (en) | 2013-12-12 | 2020-12-01 | The Broad Institute, Inc. | Compositions and methods of use of CRISPR-Cas systems in nucleotide repeat disorders |
| US11591581B2 (en) | 2013-12-12 | 2023-02-28 | The Broad Institute, Inc. | Compositions and methods of use of CRISPR-Cas systems in nucleotide repeat disorders |
| US11597919B2 (en) | 2013-12-12 | 2023-03-07 | The Broad Institute Inc. | Systems, methods and compositions for sequence manipulation with optimized functional CRISPR-Cas systems |
| US10550372B2 (en) | 2013-12-12 | 2020-02-04 | The Broad Institute, Inc. | Systems, methods and compositions for sequence manipulation with optimized functional CRISPR-Cas systems |
| US11407985B2 (en) | 2013-12-12 | 2022-08-09 | The Broad Institute, Inc. | Delivery, use and therapeutic applications of the CRISPR-Cas systems and compositions for genome editing |
| US11591622B2 (en) | 2014-02-24 | 2023-02-28 | Sangamo Therapeutics, Inc. | Method of making and using mammalian liver cells for treating hemophilia or lysosomal storage disorder |
| US20150240263A1 (en) * | 2014-02-24 | 2015-08-27 | Sangamo Biosciences, Inc. | Methods and compositions for nuclease-mediated targeted integration |
| US10370680B2 (en) * | 2014-02-24 | 2019-08-06 | Sangamo Therapeutics, Inc. | Method of treating factor IX deficiency using nuclease-mediated targeted integration |
| CN110269047A (en) * | 2014-05-07 | 2019-09-24 | 瑞泽恩制药公司 | Humanization IL-4 and IL-4R α animal |
| CN110269047B (en) * | 2014-05-07 | 2021-11-02 | 瑞泽恩制药公司 | Humanized IL-4 and IL-4R alpha animals |
| CN104450887A (en) * | 2014-11-12 | 2015-03-25 | 兰州百源基因技术有限公司 | DNA probe and gene chip for detecting endometrial carcinoma and application thereof |
| US10696986B2 (en) | 2014-12-12 | 2020-06-30 | The Board Institute, Inc. | Protected guide RNAS (PGRNAS) |
| US11624078B2 (en) | 2014-12-12 | 2023-04-11 | The Broad Institute, Inc. | Protected guide RNAS (pgRNAS) |
| WO2016112961A1 (en) * | 2015-01-13 | 2016-07-21 | Institut National De La Sante Et De La Recherche Medicale (Inserm) | Caspase-2 conditional knockouts and methods |
| US11578312B2 (en) | 2015-06-18 | 2023-02-14 | The Broad Institute Inc. | Engineering and optimization of systems, methods, enzymes and guide scaffolds of CAS9 orthologs and variants for sequence manipulation |
| US10876100B2 (en) | 2015-06-18 | 2020-12-29 | The Broad Institute, Inc. | Crispr enzyme mutations reducing off-target effects |
| US10494621B2 (en) | 2015-06-18 | 2019-12-03 | The Broad Institute, Inc. | Crispr enzyme mutations reducing off-target effects |
| EP4180519A1 (en) * | 2016-04-15 | 2023-05-17 | Memorial Sloan Kettering Cancer Center | Transgenic t cell and chimeric antigen receptor t cell compositions and related methods |
| WO2017180989A3 (en) * | 2016-04-15 | 2017-12-14 | Memorial Sloan Kettering Cancer Center | Transgenic t cell and chimeric antigen receptor t cell compositions and related methods |
| US11377637B2 (en) | 2016-04-15 | 2022-07-05 | Memorial Sloan Kettering Cancer Center | Transgenic T cell and chimeric antigen receptor T cell compositions and related methods |
| US11801313B2 (en) | 2016-07-06 | 2023-10-31 | Vertex Pharmaceuticals Incorporated | Materials and methods for treatment of pain related disorders |
| US11459587B2 (en) | 2016-07-06 | 2022-10-04 | Vertex Pharmaceuticals Incorporated | Materials and methods for treatment of pain related disorders |
| EP3491131B1 (en) * | 2016-07-29 | 2022-05-25 | Max-Planck-Gesellschaft zur Förderung der Wissenschaften e.V. | Targeted in situ protein diversification by site directed dna cleavage and repair |
| WO2018222667A1 (en) * | 2017-05-31 | 2018-12-06 | 22Nd Century Limited, Llc | Genome editing methods for producing low-nicotine tobacco products |
| WO2019125187A1 (en) * | 2017-12-21 | 2019-06-27 | Livestock Improvement Corporation Limited | Genetic markers and uses therefor |
| US11179479B2 (en) * | 2018-01-05 | 2021-11-23 | Animatus Biosciences, Llc | Enhanced cardiomyocyte regeneration |
| CN111684078A (en) * | 2018-02-12 | 2020-09-18 | 豪夫迈·罗氏有限公司 | Method for predicting response to treatment by assessing tumor genetic heterogeneity |
| CN111684078B (en) * | 2018-02-12 | 2024-04-19 | 豪夫迈·罗氏有限公司 | Methods for predicting response to treatment by assessing tumor genetic heterogeneity |
| CN108441577B (en) * | 2018-05-25 | 2021-05-14 | 兰州大学 | Primer pair, kit and application thereof, and method for detecting whether alfalfa product contains soybeans |
| CN108441577A (en) * | 2018-05-25 | 2018-08-24 | 兰州大学 | Primer pair, kit and purposes and detection alfalfa product in whether the method containing soybean |
| US11827877B2 (en) | 2018-06-28 | 2023-11-28 | Crispr Therapeutics Ag | Compositions and methods for genomic editing by insertion of donor polynucleotides |
| CN111073900A (en) * | 2019-12-09 | 2020-04-28 | 温氏食品集团股份有限公司 | Method for improving pig cloned embryo development efficiency |
| CN111073900B (en) * | 2019-12-09 | 2023-05-02 | 温氏食品集团股份有限公司 | Method for improving development efficiency of pig cloned embryo |
| WO2021168412A1 (en) * | 2020-02-21 | 2021-08-26 | University Of Pittsburgh - Of The Commonwealth System Of Higher Education | Non-human animal models for aging and/or neurodegeneration |
| CN111235154A (en) * | 2020-04-01 | 2020-06-05 | 陕西慧康生物科技有限责任公司 | sgRNA for targeted knockout of human MC1R gene and cell strain constructed by sgRNA |
| CN111235153A (en) * | 2020-04-01 | 2020-06-05 | 陕西慧康生物科技有限责任公司 | sgRNA for targeted knockout of human MC1R gene and cell strain constructed by sgRNA |
| CN111235153B (en) * | 2020-04-01 | 2023-05-26 | 陕西慧康生物科技有限责任公司 | sgRNA for targeted knockout of human MC1R gene and cell strain constructed by same |
| WO2022145495A1 (en) * | 2021-01-04 | 2022-07-07 | Modalis Therapeutics Corporation | Method for treating spinocerebellar ataxias (sca) by targeting atxn7 gene |
| IL282597B (en) * | 2021-04-22 | 2022-08-01 | B G Negev Technologies And Applications Ltd At Ben Gurion Univ | Birds for producing female hatchling and methods of producing same |
| WO2022240649A1 (en) * | 2021-05-12 | 2022-11-17 | Alkahest, Inc. | Methods and compositions for treating aging-associated impairments with trefoil factor family member 2 modulators |
| CN113355356A (en) * | 2021-07-05 | 2021-09-07 | 西北农林科技大学 | CSN1S1 gene knockout vector and preparation method of CSN1S1 gene knockout mammary epithelial cell |
| CN113881646B (en) * | 2021-09-28 | 2023-08-04 | 北京市农林科学院 | Related protein TaFAH1 involved in plant disease resistance, gene and application thereof |
| CN113881646A (en) * | 2021-09-28 | 2022-01-04 | 北京市农林科学院 | Related protein TaFAH1 participating in plant disease resistance and gene and application thereof |
| CN113916754A (en) * | 2021-10-12 | 2022-01-11 | 四川大学华西医院 | Cell surface marker for detecting circulating tumor cells of breast cancer patient and application |
| CN113916754B (en) * | 2021-10-12 | 2023-11-10 | 四川大学华西医院 | Cell surface marker for detecting circulating tumor cells of breast cancer patient and application thereof |
Also Published As
| Publication number | Publication date |
|---|---|
| AU2010275432A1 (en) | 2012-02-02 |
| IL217409A0 (en) | 2012-02-29 |
| EP2456877A1 (en) | 2012-05-30 |
| JP2013500018A (en) | 2013-01-07 |
| KR20120097483A (en) | 2012-09-04 |
| CA2767377A1 (en) | 2011-01-27 |
| EP2456877A4 (en) | 2012-05-30 |
| SG177711A1 (en) | 2012-02-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20190390204A1 (en) | Inducible dna binding proteins and genome perturbation tools and applications thereof | |
| US20120192298A1 (en) | Method for genome editing | |
| WO2011011767A1 (en) | Method for genome editing | |
| US20110023143A1 (en) | Genomic editing of neurodevelopmental genes in animals | |
| JP7228059B2 (en) | Delivery, engineering and optimization of systems, methods and compositions for sequence engineering and therapeutic applications | |
| US20110030072A1 (en) | Genome editing of immunodeficiency genes in animals | |
| CN102858985A (en) | Method for genome editing | |
| US20200340015A1 (en) | Delivery, use and therapeutic applications of the crispr-cas systems and compositions for targeting disorders and diseases using particle delivery components | |
| JP6793699B2 (en) | CRISPR enzyme mutations that reduce off-target effects | |
| JP6738729B2 (en) | Delivery, engineering and optimization of systems, methods and compositions for targeting and modeling postmitotic cell diseases and disorders | |
| US20180066307A1 (en) | Exosomes and uses thereof | |
| US20210107993A1 (en) | Cartyrin compositions and methods for use | |
| JP6702858B2 (en) | Delivery, use and therapeutic applications of CRISPR-Cas systems and compositions for targeting disorders and diseases using viral components | |
| JP2017501149A6 (en) | Delivery, use and therapeutic applications of CRISPR-CAS systems and compositions for targeting disorders and diseases using particle delivery components | |
| JP2023062119A (en) | Artificial fabrication method of human tissue-specific stem/precursor cell | |
| WO2023081756A1 (en) | Precise genome editing using retrons | |
| US20220249701A1 (en) | Compositions and methods for targeting multinucleated cells |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WWE | Wipo information: entry into national phase |
Ref document number: 201080042058.2 Country of ref document: CN |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 10803004 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2010275432 Country of ref document: AU |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2767377 Country of ref document: CA |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 217409 Country of ref document: IL |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2012521867 Country of ref document: JP Ref document number: 779/CHENP/2012 Country of ref document: IN |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2010275432 Country of ref document: AU Date of ref document: 20100723 Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2010803004 Country of ref document: EP |
|
| ENP | Entry into the national phase |
Ref document number: 20127004819 Country of ref document: KR Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 13386394 Country of ref document: US |
|
| REG | Reference to national code |
Ref country code: BR Ref legal event code: B01A Ref document number: 112012001568 Country of ref document: BR |
|
| REG | Reference to national code |
Ref country code: BR Ref legal event code: B01E Ref document number: 112012001568 Country of ref document: BR |
|
| ENPW | Started to enter national phase and was withdrawn or failed for other reasons |
Ref document number: 112012001568 Country of ref document: BR |