JP4767127B2 - ファイルサーバ、計算機システム及びファイルの先読み方法。 - Google Patents
ファイルサーバ、計算機システム及びファイルの先読み方法。 Download PDFInfo
- Publication number
- JP4767127B2 JP4767127B2 JP2006217938A JP2006217938A JP4767127B2 JP 4767127 B2 JP4767127 B2 JP 4767127B2 JP 2006217938 A JP2006217938 A JP 2006217938A JP 2006217938 A JP2006217938 A JP 2006217938A JP 4767127 B2 JP4767127 B2 JP 4767127B2
- Authority
- JP
- Japan
- Prior art keywords
- file
- information
- access
- acquired
- disk device
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images










Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0866—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches for peripheral storage systems, e.g. disk cache
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
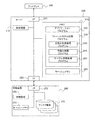
110 ファイルシステム
120 先読み処理部
130 先読み処理判定部
135 テーブル作成処理部
140 ディスク装置
150 ファイル
160 メタデータ
170 関連ファイル情報
180 ファイルのデータ
190 関連ファイル
200 キャッシュメモリ
Claims (12)
- 制御部と、クライアント計算機がアクセスするデータを一時的に格納するキャッシュメモリと、前記クライアント計算機とディスク装置とに接続するインタフェースと、を備え、前記ディスク装置に格納されたファイル及び前記ファイルを特定可能な情報であるメタデータを管理するファイルサーバであって、
前記制御部は、
前記メタデータに、前記クライアント計算機による第1のファイルへのアクセスに関連してアクセスされる第2のファイルを特定可能な情報と、前記アクセスの種別と、を含む関連ファイル情報を含め、
前記クライアント計算機によって前記第1のファイルがアクセスされた場合は、前記関連ファイル情報を参照して、前記第2のファイル及び前記アクセスの種別を取得し、
前記取得されたアクセスの種別が連続する領域を読み込むことを示す場合は、前記第2のファイルの先頭を含むデータを前記ディスク装置から読み出し、
前記取得されたアクセスの種別が追記書き込みを示す場合は、前記第2のファイルの終端を含むデータを前記ディスク装置から読み出し、
前記取得されたアクセスの種別が部分書き込みを示す場合は、前記第2のファイルの前記部分書き込み位置を含むデータを前記ディスク装置から読み出し、
前記読み出されたデータを前記キャッシュメモリに格納することを特徴とするファイルサーバ。 - 前記制御部は、
前記関連ファイル情報に、さらに、前記第1のファイルがアクセスされた直後に前記第2のファイルがアクセスされる頻度及び回数の情報を含め、
前記クライアント計算機によって前記第1のファイルがアクセスされた場合は、前記関連ファイル情報を参照して、前記第2のファイル、前記アクセスの種別及び前記頻度及び回数の情報を取得し、
前記取得された頻度の情報が第1の所定の値以上である場合は、前記第2のファイルのうち、前記取得されたアクセスの種別によって示される位置のデータを前記ディスク装置から読み出し、
前記取得された頻度の情報が前記第1の所定の値未満かつ第2の所定の値以上であり、かつ前記取得された回数の情報がアクセス回数が多いことを示し、かつ、前記キャッシュメモリの空き容量が十分である場合は、前記第2のファイルのうち、前記取得されたアクセスの種別によって示される位置のデータを前記ディスク装置から読み出し、
前記読み出されたデータを前記キャッシュメモリに格納し、
前記取得された頻度の情報が前記第2の所定の値未満である場合は、前記第2のファイルのデータを前記ディスク装置から読み出さないことを特徴とする請求項1に記載のファイルサーバ。 - 前記制御部は、
前記ディスク装置に第1のファイルが書き込まれたときに、前記第1のファイルに含まれる第2のファイルを参照する情報を取得し、
前記取得された情報から第2のファイル及びその参照の種別を取得し、
前記第1のファイルに含まれた第2のファイルの数及び前記取得した参照の種別に基づいて前記頻度を示す情報を生成し、
前記取得された第2のファイル及び前記生成された頻度を示す情報を、前記メタデータの関連ファイル情報に含めることを特徴とする請求項2に記載のファイルサーバ。 - 前記制御部は、
前記ディスク装置に格納されている前記第1のファイルに関するアクセスログを参照して、前記アクセスログに含まれる、前記第1のファイルのアクセスに関連してアクセスされた第2のファイルを取得し、
前記アクセスログに含まれる第2のファイルのアクセス回数に基づいて、前記頻度を示す情報を生成し、
前記取得された第2のファイル、前記生成された頻度を示す情報及び前記アクセスログに含まれる前記第2のファイルのアクセスの種別を、前記メタデータの関連ファイル情報に含めることを特徴とする請求項2に記載のファイルサーバ。 - ファイルをアクセスするクライアント計算機と、
ファイルを格納するディスク装置と、
制御部と、前記クライアント計算機がアクセスするデータを一時的に格納するキャッシュメモリと、前記クライアント計算機と前記ディスク装置とに接続するインタフェースと、を備え、前記ディスク装置に格納されたファイル及び前記ファイルを特定可能な情報であるメタデータを管理するファイルサーバと、
を備える計算機システムであって、
前記制御部は、
前記メタデータに、前記クライアント計算機による第1のファイルへのアクセスに関連してアクセスされる第2のファイルを特定可能な情報と、前記アクセスの種別と、を含む関連ファイル情報を含め、
前記クライアント計算機によって前記第1のファイルがアクセスされた場合は、前記関連ファイル情報を参照して、前記第2のファイル及び前記アクセスの種別を取得し、
前記取得されたアクセスの種別が連続する領域を読み込むことを示す場合は、前記第2のファイルの先頭を含むデータを前記ディスク装置から読み出し、
前記取得されたアクセスの種別が追記書き込みを示す場合は、前記第2のファイルの終端を含むデータを前記ディスク装置から読み出し、
前記取得されたアクセスの種別が部分書き込みを示す場合は、前記第2のファイルの前記部分書き込み位置を含むデータを前記ディスク装置から読み出し、
前記読み出されたデータを前記キャッシュメモリに格納することを特徴とする計算機システム。 - 前記制御部は、
前記関連ファイル情報に、さらに、前記第1のファイルがアクセスされた直後に前記第2のファイルがアクセスされる頻度及び回数の情報を含め、
前記クライアント計算機によって前記第1のファイルがアクセスされた場合は、前記関連ファイル情報を参照して、前記第2のファイル、前記アクセスの種別及び前記頻度及び回数の情報を取得し、
前記取得されたの情報が第1の所定の値以上である場合は、前記第2のファイルのうち、前記取得されたアクセスの種別によって示される位置のデータを前記ディスク装置から読み出し、
前記取得された頻度の情報が前記第1の所定の値未満かつ第2の所定の値以上であり、かつ前記取得された回数の情報がアクセス回数が多いことを示し、かつ、前記キャッシュメモリの空き容量が十分である場合は、前記第2のファイルのうち、前記取得されたアクセスの種別によって示される位置のデータを前記ディスク装置から読み出し、
前記読み出されたデータを前記キャッシュメモリに格納し、
前記取得された頻度の情報が前記第2の所定の値未満である場合は、前記第2のファイルのデータを前記ディスク装置から読み出さないことを特徴とする請求項5に記載の計算機システム。 - 前記制御部は、
前記ディスク装置に第1のファイルが書き込まれたときに、前記第1のファイルに含まれる第2のファイルを参照する情報を取得し、
前記取得された情報から第2のファイル及びその参照の種別を取得し、
前記第1のファイルに含まれた第2のファイルの数及び前記取得した参照の種別に基づいて前記頻度を示す情報を生成し、
前記取得された第2のファイル及び前記生成された頻度を示す情報を、前記メタデータの関連ファイル情報に含めることを特徴とする請求項6に記載の計算機システム。 - 前記制御部は、
前記ディスク装置に格納されている前記第1のファイルに関するアクセスログを参照して、前記アクセスログに含まれる、前記第1のファイルのアクセスに関連してアクセスされた第2のファイルを取得し、
前記アクセスログに含まれる第2のファイルのアクセス回数に基づいて、前記頻度を示す情報を生成し、
前記取得された第2のファイル、前記生成された頻度を示す情報及び前記アクセスログに含まれる前記第2のファイルのアクセスの種別を、前記メタデータの関連ファイル情報に含めることを特徴とする請求項6に記載の計算機システム。 - 制御部と、クライアント計算機がアクセスするデータを一時的に格納するキャッシュメモリと、前記クライアント計算機及びディスク装置と接続するインタフェースと、を備え、前記ディスク装置に格納されたファイル及び前記ファイルを特定可能な情報であるメタデータを管理するファイルサーバで実行されるファイル先読み方法あって、
前記メタデータは、前記クライアント計算機による第1のファイルへのアクセスに関連してアクセスされる第2のファイルを特定可能な情報と、前記アクセスの種別と、を含む関連ファイル情報を含み、
前記クライアント計算機によって前記第1のファイルがアクセスされた場合は、前記関連ファイル情報を参照して、前記第2のファイル及び前記アクセスの種別を取得する第1の手順と、
前記取得されたアクセスの種別が連続する領域を読み込むことを示す場合は、前記第2のファイルの先頭を含むデータを前記ディスク装置から読み出し、前記取得されたアクセスの種別が追記書き込みを示す場合は、前記第2のファイルの終端を含むデータを前記ディスク装置から読み出し、前記取得されたアクセスの種別が部分書き込みを示す場合は、前記第2のファイルの前記部分書き込み位置を含むデータを前記ディスク装置から読み出す第2の手順と、
前記読み出されたデータを前記キャッシュメモリに格納する第3の手順と、を含むことを特徴とするファイルの先読み方法。 - 前記関連ファイル情報は、さらに、前記第1のファイルがアクセスされた直後に前記第2のファイルがアクセスされる頻度及び回数の情報を含み、
前記第1の手順は、前記クライアント計算機によって前記第1のファイルがアクセスされた場合は、前記関連ファイル情報を参照して、前記第2のファイル、前記アクセスの種別及び前記頻度及び回数の情報を取得し、
前記第2の手順は、
前記取得された頻度の情報が第1の所定の値以上である場合は、前記第2のファイルのうち、前記取得されたアクセスの種別によって示される位置のデータを前記ディスク装置から読み出す手順と、
前記取得された頻度の情報が前記第1の所定の値未満かつ第2の所定の値以上であり、かつ前記取得された回数の情報がアクセス回数が多いことを示し、かつ、前記キャッシュメモリの空き容量が十分である場合は、前記第2のファイルのうち、前記取得されたアクセスの種別によって示される位置のデータを前記ディスク装置から読み出す手順と、
前記取得された頻度の情報が前記第2の所定の値未満である場合は、前記第2のファイルのデータを前記ディスク装置から読み出さない手順と、を含むことを特徴とする請求項9に記載のファイルの先読み方法。 - 前記ファイルの先読み方法は、さらに、各種データを関連ファイル情報を含める第4の手順を含み、
前記第4の手順は、
前記ディスク装置に第1のファイルが書き込まれたときに、前記第1のファイルに含まれる第2のファイルを参照する情報を取得する手順と、
前記取得された情報から第2のファイル及びその参照の種別を取得する手順と、
前記第1のファイルに含まれた第2のファイルの数及び前記取得した参照の種別に基づいて前記頻度を示す情報を生成する手順と、
前記取得された第2のファイル及び前記生成された頻度を示す情報を、前記メタデータの関連ファイル情報に含める手順と、を含むことを特徴とする請求項10に記載のファイルの先読み方法。 - 前記第4の手順は、
前記ディスク装置に格納されている前記第1のファイルに関するアクセスログを参照して、前記アクセスログに含まれる、前記第1のファイルのアクセスに関連してアクセスされた第2のファイルを取得する手順と、
前記アクセスログに含まれる第2のファイルのアクセス回数に基づいて、前記頻度を示す情報を生成する手順と、
前記取得された第2のファイル、前記生成された頻度を示す情報及び前記アクセスログに含まれる前記第2のファイルのアクセスの種別を、前記メタデータの関連ファイル情報に含める手順と、を含むことを特徴とする請求項10に記載のファイルの先読み方法。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2006217938A JP4767127B2 (ja) | 2006-08-10 | 2006-08-10 | ファイルサーバ、計算機システム及びファイルの先読み方法。 |
| US11/541,692 US7529892B2 (en) | 2006-08-10 | 2006-10-03 | File readahead method with the use of access pattern information attached to metadata |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2006217938A JP4767127B2 (ja) | 2006-08-10 | 2006-08-10 | ファイルサーバ、計算機システム及びファイルの先読み方法。 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2008041020A JP2008041020A (ja) | 2008-02-21 |
| JP2008041020A5 JP2008041020A5 (ja) | 2008-09-25 |
| JP4767127B2 true JP4767127B2 (ja) | 2011-09-07 |
Family
ID=39092705
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2006217938A Expired - Fee Related JP4767127B2 (ja) | 2006-08-10 | 2006-08-10 | ファイルサーバ、計算機システム及びファイルの先読み方法。 |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US7529892B2 (ja) |
| JP (1) | JP4767127B2 (ja) |
Families Citing this family (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8122196B2 (en) * | 2006-10-30 | 2012-02-21 | Netapp, Inc. | System and procedure for rapid decompression and/or decryption of securely stored data |
| US7984306B1 (en) * | 2006-11-28 | 2011-07-19 | Netapp, Inc. | System and method for reducing processing latency in a security appliance |
| JP5239398B2 (ja) * | 2008-02-28 | 2013-07-17 | 日本電気株式会社 | ファイル管理システム、ファイルサーバ、クライアント、ファイル管理方法、及びプログラム |
| US8019765B2 (en) * | 2008-10-29 | 2011-09-13 | Hewlett-Packard Development Company, L.P. | Identifying files associated with a workflow |
| US8825685B2 (en) * | 2009-11-16 | 2014-09-02 | Symantec Corporation | Selective file system caching based upon a configurable cache map |
| US8612374B1 (en) | 2009-11-23 | 2013-12-17 | F5 Networks, Inc. | Methods and systems for read ahead of remote data |
| WO2011111115A1 (ja) * | 2010-03-12 | 2011-09-15 | 株式会社日立製作所 | ストレージシステム及びそのファイルアクセス判定方法 |
| JP2013061846A (ja) | 2011-09-14 | 2013-04-04 | Sony Corp | 情報処理方法、情報処理システム、情報処理装置、及びプログラム |
| KR101978256B1 (ko) | 2012-09-27 | 2019-05-14 | 삼성전자주식회사 | 모바일 기기의 데이터 독출 방법 및 이를 이용하는 모바일 기기 |
| US9098413B2 (en) * | 2013-10-18 | 2015-08-04 | International Business Machines Corporation | Read and write requests to partially cached files |
| JP6199782B2 (ja) * | 2014-03-24 | 2017-09-20 | 株式会社日立製作所 | 計算機システム |
| CN103984640B (zh) * | 2014-05-14 | 2017-06-20 | 华为技术有限公司 | 实现数据预取方法及装置 |
| CN104462288B (zh) * | 2014-11-27 | 2017-10-17 | 华为技术有限公司 | 一种路径相似度分析方法以及系统 |
| CN105183366B (zh) * | 2015-07-08 | 2018-04-17 | 北京师范大学 | 基于预读缓写的数据分析处理方法及系统 |
| CN108810609A (zh) * | 2017-04-27 | 2018-11-13 | 深圳市优朋普乐传媒发展有限公司 | 一种存储管理方法、设备及系统 |
| US11855898B1 (en) | 2018-03-14 | 2023-12-26 | F5, Inc. | Methods for traffic dependent direct memory access optimization and devices thereof |
| US10901778B2 (en) | 2018-09-27 | 2021-01-26 | International Business Machines Corporation | Prefetch chaining for optimizing data read-ahead for workflow and analytics |
Family Cites Families (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS6482239A (en) | 1987-09-25 | 1989-03-28 | Nec Corp | Efficiency improving for disk cache system |
| JP3445912B2 (ja) * | 1997-01-24 | 2003-09-16 | シャープ株式会社 | ハイパーテキスト自動取得装置 |
| JPH10301847A (ja) * | 1997-04-30 | 1998-11-13 | Nec Corp | データ記憶装置 |
| JP2001256099A (ja) | 2000-03-09 | 2001-09-21 | Seiko Epson Corp | アクセス制御装置 |
| JP3535800B2 (ja) * | 2000-03-31 | 2004-06-07 | 松下電器産業株式会社 | ディスクメモリ装置、データ先読み方法、及び記録媒体 |
| JP2002149533A (ja) * | 2000-11-07 | 2002-05-24 | Nippon Telegr & Teleph Corp <Ntt> | 通信方法、キャッシュサーバ装置、クライアント装置および記録媒体 |
| JP2002185944A (ja) * | 2000-12-14 | 2002-06-28 | Sony Corp | キャッシュ装置 |
| JP4117656B2 (ja) | 2003-11-26 | 2008-07-16 | 株式会社日立製作所 | アクセスパターンを学習する記憶装置 |
| JP2005228170A (ja) * | 2004-02-16 | 2005-08-25 | Hitachi Ltd | 記憶装置システム |
| JP4239096B2 (ja) * | 2004-08-24 | 2009-03-18 | ソニー株式会社 | 情報処理装置および方法、並びにプログラム |
| JP2006338461A (ja) * | 2005-06-03 | 2006-12-14 | Hitachi Ltd | 電子的なファイルの記憶を制御するシステム及び方法 |
-
2006
- 2006-08-10 JP JP2006217938A patent/JP4767127B2/ja not_active Expired - Fee Related
- 2006-10-03 US US11/541,692 patent/US7529892B2/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| US20080040538A1 (en) | 2008-02-14 |
| US7529892B2 (en) | 2009-05-05 |
| JP2008041020A (ja) | 2008-02-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4767127B2 (ja) | ファイルサーバ、計算機システム及びファイルの先読み方法。 | |
| US8887039B2 (en) | Web page based program versioning | |
| JP5786105B2 (ja) | 情報処理装置、情報処理方法、情報処理プログラム、表示制御装置、および表示制御プログラム | |
| JP5385373B2 (ja) | ビューアクライアントにおける文書の高忠実度レンダリング | |
| JP4902285B2 (ja) | 情報閲覧装置、その制御方法及びプログラム | |
| JP2007264792A (ja) | 音声ブラウザプログラム | |
| US20100094822A1 (en) | System and method for determining a file save location | |
| JP2011108102A (ja) | ウェブサーバ、ウェブブラウザおよびウェブシステム | |
| US20080140997A1 (en) | Data Processing System and Method | |
| JP2015511347A5 (ja) | ||
| JP2006344234A5 (ja) | ||
| TWI461943B (zh) | 實現多個視窗同時對網路頁面進行解析顯示之方法和裝置 | |
| JP5274380B2 (ja) | 情報処理装置、データアクセスシステム及びそれらの制御方法 | |
| CN1818855A (zh) | 用于在多处理器系统中执行数据预取的方法和设备 | |
| US8990685B1 (en) | Systems and methods for creating and displaying web documents | |
| JP2005301853A (ja) | 情報処理装置および情報処理方法、並びにプログラムおよび記録媒体 | |
| JP2010079796A (ja) | 代理サーバならびにその制御方法およびその制御プログラム | |
| CN103164439A (zh) | 业务信息动态显示方法、服务器及在线文档浏览终端 | |
| US9081589B2 (en) | Persistent web plug-ins | |
| JP5538584B2 (ja) | コンテンツサーバの待ち時間の決定 | |
| JP2007287030A (ja) | 情報検索システム、情報検索方法、索引情報生成装置、情報処理装置、索引情報生成プログラム、情報処理プログラム及びプログラムを記憶したコンピュータ読み取り可能な記憶媒体 | |
| JP2006031446A (ja) | データ記憶装置、データ記憶方法およびデータ記憶プログラム | |
| WO2016088237A1 (ja) | 配信方法、装置、及びプログラム | |
| JP2010536100A5 (ja) | ||
| JP3647967B2 (ja) | 画面遷移システム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20080813 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20080813 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20110222 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110420 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20110517 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20110614 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20140624 Year of fee payment: 3 |
|
| LAPS | Cancellation because of no payment of annual fees |