JP4672003B2 - 音声認証システム - Google Patents
音声認証システム Download PDFInfo
- Publication number
- JP4672003B2 JP4672003B2 JP2007503538A JP2007503538A JP4672003B2 JP 4672003 B2 JP4672003 B2 JP 4672003B2 JP 2007503538 A JP2007503538 A JP 2007503538A JP 2007503538 A JP2007503538 A JP 2007503538A JP 4672003 B2 JP4672003 B2 JP 4672003B2
- Authority
- JP
- Japan
- Prior art keywords
- keyword
- unit
- voice
- syllable
- similarity
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 238000000034 method Methods 0.000 claims description 60
- 238000004364 calculation method Methods 0.000 claims description 39
- 238000012790 confirmation Methods 0.000 claims description 38
- 238000006243 chemical reaction Methods 0.000 claims description 31
- 230000008569 process Effects 0.000 claims description 23
- 238000012545 processing Methods 0.000 claims description 19
- 230000001419 dependent effect Effects 0.000 claims description 14
- 230000010354 integration Effects 0.000 claims description 14
- 238000004590 computer program Methods 0.000 claims description 4
- 230000007812 deficiency Effects 0.000 claims description 2
- 241000102542 Kara Species 0.000 description 7
- 230000006978 adaptation Effects 0.000 description 6
- 238000010586 diagram Methods 0.000 description 5
- 239000000284 extract Substances 0.000 description 5
- 230000006870 function Effects 0.000 description 5
- 238000012795 verification Methods 0.000 description 4
- 239000000203 mixture Substances 0.000 description 3
- 102100024237 Stathmin Human genes 0.000 description 2
- 108050003387 Stathmin Proteins 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- 238000007476 Maximum Likelihood Methods 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 150000001768 cations Chemical class 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- 238000012417 linear regression Methods 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 230000011218 segmentation Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
Images







Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L17/00—Speaker identification or verification techniques
- G10L17/06—Decision making techniques; Pattern matching strategies
- G10L17/14—Use of phonemic categorisation or speech recognition prior to speaker recognition or verification
Landscapes
- Engineering & Computer Science (AREA)
- Human Computer Interaction (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Game Theory and Decision Science (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Business, Economics & Management (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Telephone Function (AREA)
- Telephonic Communication Services (AREA)
- Mobile Radio Communication Systems (AREA)
Description
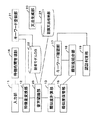
本発明にかかる音声認証システムの一実施形態について、以下に説明する。
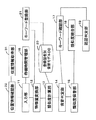
本発明にかかる音声認証システムの他の実施形態について、以下に説明する。なお、第1の実施形態で説明した構成と同様の機能を有する構成については、第1の実施形態で用いた参照記号と同じ記号を付記し、その詳細な説明は省略する。
この例では不特定話者音声認識で認識したが、登録時に適応した話者モデルを利用して認識させても良い。この場合、音声認識時に計算した類似度がそのまま話者モデルに対する類似度となるので、類似度計算部13での類似度計算は不要となる。
本発明にかかる音声認証システムのさらに他の実施形態について、以下に説明する。なお、第1または第2の実施形態で説明した構成と同様の機能を有する構成については、それらの実施形態で用いた参照記号と同じ記号を付記し、その詳細な説明は省略する。
本発明にかかる音声認証システムのさらに他の実施形態について、以下に説明する。なお、第1〜第3の実施形態で説明した構成と同様の機能を有する構成については、それらの実施形態で用いた参照記号と同じ記号を付記し、その詳細な説明は省略する。
Claims (10)
- キーワードを音声入力させて認証を行うテキスト依存型の音声認証システムであって、
発声が可能な単位を最小単位として複数の部分に分割されたキーワードの音声入力を、前記部分毎に時間間隔をおいて複数回にわたって受け付ける入力部と、
利用者の登録キーワードを、前記発声が可能な単位で作成された話者モデルとして予め格納した話者モデル格納部と、
前記入力部において1回の音声入力で受け付けられたキーワードの部分から、当該部分に含まれる音声の特徴量を求める特徴量変換部と、
前記特徴量変換部で求められた特徴量と前記話者モデルとの類似度を求める類似度計算部と、
前記類似度計算部で求められた類似度に基づき、前記複数回の音声入力により発声内容を判定する発声内容判定部と、前記複数回の音声入力の発声内容が過不足なく登録キーワードを構成しうるか否かを判定するキーワード確認部と、
前記キーワード確認部による判定結果と、前記類似度計算部で求められた類似度とに基づき、認証を受理するか棄却するかを判定する認証判定部とを備えた音声認証システム。 - 前記発声が可能な単位が音節である、請求項1に記載の音声認証システム。
- 前記話者モデル格納部において、登録キーワードを構成する各音節の話者モデルに個別のインデックスが付与されており、
前記特徴量変換部が、前記音声入力で受け付けられたキーワードの部分から、音節毎の特徴量を求め、
前記類似度計算部が、前記音節毎の特徴量と前記話者モデルとの類似度を求め、
前記類似度計算部により求められた類似度に基づき、前記音声入力で受け付けられたキーワードの部分が、登録キーワードのどの音節に最も類似するかを判定する音節判定部をさらに備え、
前記キーワード確認部が、前記音節判定部の判定結果に基づき、前記複数回の音声入力により判定された音節を用いて登録キーワードを構成しうるか否かを判定する、請求項2に記載の音声認証システム。 - 前記発声が可能な単位が、数字の読みまたはアルファベットの読みである、請求項1〜3のいずれかに記載の音声認証システム。
- 前記特徴量変換部により求められた特徴量から、不特定話者音声認識により、前記キーワードの部分の音韻を認識する音声認識部をさらに備え、
前記キーワード確認部が、前記音声認識部の認識結果に基づいて、前記複数回の音声入力により音声認識された結果を用いて、登録キーワードを構成しうるか否かを判定する、請求項1に記載の音声認証システム。 - 前記キーワードのある部分の音声入力の完了から所定の時間が経過しても次の部分の音声入力がなく、かつ、それまでの音声入力の発声内容の情報を用いて登録キーワードを構成できない場合、前記認証判定部が認証を棄却する、請求項1に記載の音声認証システム。
- 前記キーワードの部分の音声入力がある度に利用者の所在位置情報を取得する位置情報取得部と、
前回の音声入力時に前記位置情報取得部で取得された所在位置情報と、今回の音声入力時に前記位置情報取得部で取得された所在位置情報とを比較し、前回の音声入力時から今回の音声入力時までの間に利用者が所定の距離以上移動したかを確認する位置確認部とをさらに備えた、請求項1に記載の音声認証システム。 - 前記複数回の音声入力で受け付けられたキーワードの部分の全てについて、前記類似度計算部で求められた類似度を統合して統合類似度を求める類似度統合部をさらに備え、
前記認証判定部が、前記類似度統合部により求められた統合類似度に基づいて認証を受理するか棄却するかを判定する、請求項1に記載の音声認証システム。 - 前記入力部が、利用者の携帯端末より音声入力を受け付ける、請求項1に記載の音声認証システム。
- キーワードを音声入力させて認証を行うテキスト依存型の音声認証システムを具現化するコンピュータプログラムであって、
発声が可能な単位を最小単位として複数の部分に分割されたキーワードの音声入力を、前記部分毎に時間間隔をおいて複数回にわたって受け付ける入力処理と、
1回の音声入力で受け付けられたキーワードの部分から、当該部分に含まれる音声の特徴量を求める特徴量変換処理と、
利用者のキーワードが、前記発声が可能な単位で作成された話者モデルとして予め登録された話者モデル格納部を参照し、前記特徴量変換処理で求められた特徴量と、前記話者モデルとの類似度を求める類似度計算処理と、
前記類似度計算処理で求められた類似度に基づき、前記複数回の音声入力により発声内容を判定する発声内容判定処理と、
前記複数回の音声入力の発声内容が過不足なく登録キーワードを構成しうるか否かを判定するキーワード確認処理と、
前記キーワード確認処理による判定結果と、前記類似度計算処理で求められた類似度とに基づき、認証を受理するか棄却するかを判定する認証判定処理とをコンピュータに実行させることを特徴とするコンピュータプログラム。
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2005/002589 WO2006087799A1 (ja) | 2005-02-18 | 2005-02-18 | 音声認証システム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JPWO2006087799A1 JPWO2006087799A1 (ja) | 2008-07-03 |
| JP4672003B2 true JP4672003B2 (ja) | 2011-04-20 |
Family
ID=36916215
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2007503538A Expired - Fee Related JP4672003B2 (ja) | 2005-02-18 | 2005-02-18 | 音声認証システム |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US7657431B2 (ja) |
| JP (1) | JP4672003B2 (ja) |
| CN (1) | CN101124623B (ja) |
| WO (1) | WO2006087799A1 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11152008B2 (en) | 2017-12-19 | 2021-10-19 | Samsung Electronics Co., Ltd. | Electronic apparatus, method for controlling thereof and computer readable recording medium |
Families Citing this family (93)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9113001B2 (en) | 2005-04-21 | 2015-08-18 | Verint Americas Inc. | Systems, methods, and media for disambiguating call data to determine fraud |
| US20070280436A1 (en) * | 2006-04-14 | 2007-12-06 | Anthony Rajakumar | Method and System to Seed a Voice Database |
| US8073691B2 (en) * | 2005-04-21 | 2011-12-06 | Victrio, Inc. | Method and system for screening using voice data and metadata |
| US8930261B2 (en) * | 2005-04-21 | 2015-01-06 | Verint Americas Inc. | Method and system for generating a fraud risk score using telephony channel based audio and non-audio data |
| US20060248019A1 (en) * | 2005-04-21 | 2006-11-02 | Anthony Rajakumar | Method and system to detect fraud using voice data |
| US8510215B2 (en) * | 2005-04-21 | 2013-08-13 | Victrio, Inc. | Method and system for enrolling a voiceprint in a fraudster database |
| US8924285B2 (en) * | 2005-04-21 | 2014-12-30 | Verint Americas Inc. | Building whitelists comprising voiceprints not associated with fraud and screening calls using a combination of a whitelist and blacklist |
| US8903859B2 (en) | 2005-04-21 | 2014-12-02 | Verint Americas Inc. | Systems, methods, and media for generating hierarchical fused risk scores |
| US8793131B2 (en) | 2005-04-21 | 2014-07-29 | Verint Americas Inc. | Systems, methods, and media for determining fraud patterns and creating fraud behavioral models |
| US9571652B1 (en) | 2005-04-21 | 2017-02-14 | Verint Americas Inc. | Enhanced diarization systems, media and methods of use |
| US20120053939A9 (en) * | 2005-04-21 | 2012-03-01 | Victrio | Speaker verification-based fraud system for combined automated risk score with agent review and associated user interface |
| US8639757B1 (en) | 2011-08-12 | 2014-01-28 | Sprint Communications Company L.P. | User localization using friend location information |
| US7958539B2 (en) * | 2006-12-06 | 2011-06-07 | Motorola Mobility, Inc. | System and method for providing secure access to password-protected resources |
| KR100921867B1 (ko) * | 2007-10-17 | 2009-10-13 | 광주과학기술원 | 광대역 오디오 신호 부호화 복호화 장치 및 그 방법 |
| EP2065823A1 (en) * | 2007-11-26 | 2009-06-03 | BIOMETRY.com AG | System and method for performing secure online transactions |
| JP2009146263A (ja) * | 2007-12-17 | 2009-07-02 | Panasonic Corp | 本人認証システム |
| US8312033B1 (en) | 2008-06-26 | 2012-11-13 | Experian Marketing Solutions, Inc. | Systems and methods for providing an integrated identifier |
| US8190437B2 (en) * | 2008-10-24 | 2012-05-29 | Nuance Communications, Inc. | Speaker verification methods and apparatus |
| US8442824B2 (en) | 2008-11-26 | 2013-05-14 | Nuance Communications, Inc. | Device, system, and method of liveness detection utilizing voice biometrics |
| WO2010066269A1 (en) * | 2008-12-10 | 2010-06-17 | Agnitio, S.L. | Method for verifying the identify of a speaker and related computer readable medium and computer |
| US9767806B2 (en) * | 2013-09-24 | 2017-09-19 | Cirrus Logic International Semiconductor Ltd. | Anti-spoofing |
| DE112009004357B4 (de) * | 2009-01-30 | 2019-06-13 | Mitsubishi Electric Corp. | Spracherkennungssystem |
| US9652802B1 (en) | 2010-03-24 | 2017-05-16 | Consumerinfo.Com, Inc. | Indirect monitoring and reporting of a user's credit data |
| US9619826B1 (en) * | 2010-07-30 | 2017-04-11 | West Corporation | Third-party authentication systems and methods |
| CN102377736A (zh) * | 2010-08-12 | 2012-03-14 | 杭州华三通信技术有限公司 | 一种基于语音识别的认证方法和设备 |
| EP2676197B1 (en) | 2011-02-18 | 2018-11-28 | CSidentity Corporation | System and methods for identifying compromised personally identifiable information on the internet |
| JP5799586B2 (ja) * | 2011-05-27 | 2015-10-28 | 富士通株式会社 | 生体認証装置、生体認証方法及び生体認証用コンピュータプログラム |
| US9607336B1 (en) | 2011-06-16 | 2017-03-28 | Consumerinfo.Com, Inc. | Providing credit inquiry alerts |
| CN102238189B (zh) * | 2011-08-01 | 2013-12-11 | 安徽科大讯飞信息科技股份有限公司 | 声纹密码认证方法及系统 |
| US8819793B2 (en) | 2011-09-20 | 2014-08-26 | Csidentity Corporation | Systems and methods for secure and efficient enrollment into a federation which utilizes a biometric repository |
| KR101303939B1 (ko) * | 2011-10-17 | 2013-09-05 | 한국과학기술연구원 | 디스플레이 장치 및 컨텐츠 디스플레이 방법 |
| US11030562B1 (en) | 2011-10-31 | 2021-06-08 | Consumerinfo.Com, Inc. | Pre-data breach monitoring |
| CN202563514U (zh) * | 2012-02-23 | 2012-11-28 | 江苏华丽网络工程有限公司 | 具有多媒体认证加密保护功能的移动电子设备 |
| US9368116B2 (en) | 2012-09-07 | 2016-06-14 | Verint Systems Ltd. | Speaker separation in diarization |
| US10134400B2 (en) | 2012-11-21 | 2018-11-20 | Verint Systems Ltd. | Diarization using acoustic labeling |
| US9633652B2 (en) * | 2012-11-30 | 2017-04-25 | Stmicroelectronics Asia Pacific Pte Ltd. | Methods, systems, and circuits for speaker dependent voice recognition with a single lexicon |
| US9704486B2 (en) * | 2012-12-11 | 2017-07-11 | Amazon Technologies, Inc. | Speech recognition power management |
| US8812387B1 (en) | 2013-03-14 | 2014-08-19 | Csidentity Corporation | System and method for identifying related credit inquiries |
| US9633322B1 (en) | 2013-03-15 | 2017-04-25 | Consumerinfo.Com, Inc. | Adjustment of knowledge-based authentication |
| US10664936B2 (en) | 2013-03-15 | 2020-05-26 | Csidentity Corporation | Authentication systems and methods for on-demand products |
| CN103220286B (zh) * | 2013-04-10 | 2015-02-25 | 郑方 | 基于动态密码语音的身份确认系统及方法 |
| US9721147B1 (en) | 2013-05-23 | 2017-08-01 | Consumerinfo.Com, Inc. | Digital identity |
| CN104217149B (zh) * | 2013-05-31 | 2017-05-24 | 国际商业机器公司 | 基于语音的生物认证方法及设备 |
| US9754258B2 (en) * | 2013-06-17 | 2017-09-05 | Visa International Service Association | Speech transaction processing |
| US10846699B2 (en) | 2013-06-17 | 2020-11-24 | Visa International Service Association | Biometrics transaction processing |
| US9460722B2 (en) | 2013-07-17 | 2016-10-04 | Verint Systems Ltd. | Blind diarization of recorded calls with arbitrary number of speakers |
| US9984706B2 (en) | 2013-08-01 | 2018-05-29 | Verint Systems Ltd. | Voice activity detection using a soft decision mechanism |
| CN103971700A (zh) * | 2013-08-01 | 2014-08-06 | 哈尔滨理工大学 | 语音监控方法及装置 |
| US9813905B2 (en) * | 2013-10-14 | 2017-11-07 | U.S. Bank, National Association | DTMF token for automated out-of-band authentication |
| CN104598790A (zh) * | 2013-10-30 | 2015-05-06 | 鸿富锦精密工业(深圳)有限公司 | 手持装置解锁系统、方法及手持装置 |
| US9646613B2 (en) | 2013-11-29 | 2017-05-09 | Daon Holdings Limited | Methods and systems for splitting a digital signal |
| US9507852B2 (en) * | 2013-12-10 | 2016-11-29 | Google Inc. | Techniques for discriminative dependency parsing |
| US10373240B1 (en) | 2014-04-25 | 2019-08-06 | Csidentity Corporation | Systems, methods and computer-program products for eligibility verification |
| JP6316685B2 (ja) * | 2014-07-04 | 2018-04-25 | 日本電信電話株式会社 | 声まね音声評価装置、声まね音声評価方法及びプログラム |
| US9959863B2 (en) * | 2014-09-08 | 2018-05-01 | Qualcomm Incorporated | Keyword detection using speaker-independent keyword models for user-designated keywords |
| US10339527B1 (en) | 2014-10-31 | 2019-07-02 | Experian Information Solutions, Inc. | System and architecture for electronic fraud detection |
| EP3167399B1 (en) * | 2014-11-04 | 2019-04-10 | NEC Corporation | Method for providing encrypted information and encrypting entity |
| US9875742B2 (en) | 2015-01-26 | 2018-01-23 | Verint Systems Ltd. | Word-level blind diarization of recorded calls with arbitrary number of speakers |
| CN105096121B (zh) * | 2015-06-25 | 2017-07-25 | 百度在线网络技术(北京)有限公司 | 声纹认证方法和装置 |
| US11151468B1 (en) | 2015-07-02 | 2021-10-19 | Experian Information Solutions, Inc. | Behavior analysis using distributed representations of event data |
| CN106572049B (zh) * | 2015-10-09 | 2019-08-27 | 腾讯科技(深圳)有限公司 | 一种身份验证方法及装置 |
| US9633659B1 (en) * | 2016-01-20 | 2017-04-25 | Motorola Mobility Llc | Method and apparatus for voice enrolling an electronic computing device |
| US10235993B1 (en) * | 2016-06-14 | 2019-03-19 | Friday Harbor Llc | Classifying signals using correlations of segments |
| JP6682007B2 (ja) * | 2016-11-11 | 2020-04-15 | 旭化成株式会社 | 電子機器、電子機器の制御方法及び電子機器の制御プログラム |
| US10614797B2 (en) * | 2016-12-01 | 2020-04-07 | International Business Machines Corporation | Prefix methods for diarization in streaming mode |
| KR20180082033A (ko) * | 2017-01-09 | 2018-07-18 | 삼성전자주식회사 | 음성을 인식하는 전자 장치 |
| US10277590B2 (en) | 2017-01-17 | 2019-04-30 | International Business Machines Corporation | Cognitive intelligence based voice authentication |
| CN108630207B (zh) * | 2017-03-23 | 2021-08-31 | 富士通株式会社 | 说话人确认方法和说话人确认设备 |
| CN109146450A (zh) * | 2017-06-16 | 2019-01-04 | 阿里巴巴集团控股有限公司 | 支付方法、客户端、电子设备、存储介质和服务器 |
| CN109147770B (zh) | 2017-06-16 | 2023-07-28 | 阿里巴巴集团控股有限公司 | 声音识别特征的优化、动态注册方法、客户端和服务器 |
| US10354656B2 (en) * | 2017-06-23 | 2019-07-16 | Microsoft Technology Licensing, Llc | Speaker recognition |
| CN109215643B (zh) | 2017-07-05 | 2023-10-24 | 阿里巴巴集团控股有限公司 | 一种交互方法、电子设备及服务器 |
| JP7166780B2 (ja) * | 2017-08-03 | 2022-11-08 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカ | 車両制御装置、車両制御方法及びプログラム |
| US10304475B1 (en) * | 2017-08-14 | 2019-05-28 | Amazon Technologies, Inc. | Trigger word based beam selection |
| JP2019053165A (ja) * | 2017-09-14 | 2019-04-04 | 株式会社東芝 | 音声認識装置 |
| US10699028B1 (en) | 2017-09-28 | 2020-06-30 | Csidentity Corporation | Identity security architecture systems and methods |
| CN109754784B (zh) * | 2017-11-02 | 2021-01-29 | 华为技术有限公司 | 训练滤波模型的方法和语音识别的方法 |
| US10896472B1 (en) | 2017-11-14 | 2021-01-19 | Csidentity Corporation | Security and identity verification system and architecture |
| US10402149B2 (en) * | 2017-12-07 | 2019-09-03 | Motorola Mobility Llc | Electronic devices and methods for selectively recording input from authorized users |
| US10757323B2 (en) | 2018-04-05 | 2020-08-25 | Motorola Mobility Llc | Electronic device with image capture command source identification and corresponding methods |
| FR3080927B1 (fr) * | 2018-05-03 | 2024-02-02 | Proton World Int Nv | Authentification d'un circuit electronique |
| US11538128B2 (en) | 2018-05-14 | 2022-12-27 | Verint Americas Inc. | User interface for fraud alert management |
| US10911234B2 (en) | 2018-06-22 | 2021-02-02 | Experian Information Solutions, Inc. | System and method for a token gateway environment |
| US10887452B2 (en) | 2018-10-25 | 2021-01-05 | Verint Americas Inc. | System architecture for fraud detection |
| CN109920447B (zh) * | 2019-01-29 | 2021-07-13 | 天津大学 | 基于自适应滤波器振幅相位特征提取的录音欺诈检测方法 |
| JP7266448B2 (ja) * | 2019-04-12 | 2023-04-28 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカ | 話者認識方法、話者認識装置、及び話者認識プログラム |
| US11115521B2 (en) | 2019-06-20 | 2021-09-07 | Verint Americas Inc. | Systems and methods for authentication and fraud detection |
| US11941065B1 (en) | 2019-09-13 | 2024-03-26 | Experian Information Solutions, Inc. | Single identifier platform for storing entity data |
| US11868453B2 (en) | 2019-11-07 | 2024-01-09 | Verint Americas Inc. | Systems and methods for customer authentication based on audio-of-interest |
| US11508380B2 (en) * | 2020-05-26 | 2022-11-22 | Apple Inc. | Personalized voices for text messaging |
| US11436309B2 (en) | 2020-07-09 | 2022-09-06 | Bank Of America Corporation | Dynamic knowledge-based voice authentication |
| CN112101947A (zh) * | 2020-08-27 | 2020-12-18 | 江西台德智慧科技有限公司 | 一种提高语音支付安全性的方法 |
| CN113178199B (zh) * | 2021-06-29 | 2021-08-31 | 中国科学院自动化研究所 | 基于相位偏移检测的数字音频篡改取证方法 |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH1056449A (ja) * | 1996-08-09 | 1998-02-24 | Oki Electric Ind Co Ltd | セキュリティ強化システム |
| JPH10173644A (ja) * | 1996-12-11 | 1998-06-26 | Nippon Telegr & Teleph Corp <Ntt> | 本人認証方法 |
| JP2000099090A (ja) * | 1998-09-22 | 2000-04-07 | Kdd Corp | 記号列を用いた話者認識方法 |
| JP2003044445A (ja) * | 2001-08-02 | 2003-02-14 | Matsushita Graphic Communication Systems Inc | 認証システム、サービス提供サーバ装置および音声認証装置並びに認証方法 |
| JP2004118456A (ja) * | 2002-09-25 | 2004-04-15 | Japan Science & Technology Corp | 位置情報を用いた移動端末の認証システム |
| JP2004279770A (ja) * | 2003-03-17 | 2004-10-07 | Kddi Corp | 話者認証装置及び判別関数設定方法 |
Family Cites Families (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS6015990B2 (ja) | 1983-04-15 | 1985-04-23 | 富士通株式会社 | 有資格者判定方式 |
| JPS63207262A (ja) | 1987-02-23 | 1988-08-26 | Nec Corp | 暗証番号保護方式 |
| JPS63231496A (ja) | 1987-03-20 | 1988-09-27 | 富士通株式会社 | 音声認識応答システム |
| US5054083A (en) * | 1989-05-09 | 1991-10-01 | Texas Instruments Incorporated | Voice verification circuit for validating the identity of an unknown person |
| US5517558A (en) * | 1990-05-15 | 1996-05-14 | Voice Control Systems, Inc. | Voice-controlled account access over a telephone network |
| AU5359498A (en) * | 1996-11-22 | 1998-06-10 | T-Netix, Inc. | Subword-based speaker verification using multiple classifier fusion, with channel, fusion, model, and threshold adaptation |
| EP0896712A4 (en) | 1997-01-31 | 2000-01-26 | T Netix Inc | SYSTEM AND METHOD FOR DISCOVERING RECORDED LANGUAGE |
| JP2000148187A (ja) | 1998-11-18 | 2000-05-26 | Nippon Telegr & Teleph Corp <Ntt> | 話者認識方法、その方法を用いた装置及びそのプログラム記録媒体 |
| JP3835032B2 (ja) | 1998-12-18 | 2006-10-18 | 富士通株式会社 | 利用者照合装置 |
| IL145285A0 (en) * | 1999-03-11 | 2002-06-30 | British Telecomm | Speaker recognition |
| JP4328423B2 (ja) | 1999-10-04 | 2009-09-09 | セコム株式会社 | 音声識別装置 |
| JP2002312318A (ja) | 2001-04-13 | 2002-10-25 | Nec Corp | 電子装置、本人認証方法およびプログラム |
| JP4574889B2 (ja) | 2001-04-13 | 2010-11-04 | 富士通株式会社 | 話者認証装置 |
| JP4318475B2 (ja) * | 2003-03-27 | 2009-08-26 | セコム株式会社 | 話者認証装置及び話者認証プログラム |
| JP2004334377A (ja) * | 2003-05-01 | 2004-11-25 | Advanced Media Inc | 音声情報記憶システム |
| US7386448B1 (en) * | 2004-06-24 | 2008-06-10 | T-Netix, Inc. | Biometric voice authentication |
-
2005
- 2005-02-18 JP JP2007503538A patent/JP4672003B2/ja not_active Expired - Fee Related
- 2005-02-18 WO PCT/JP2005/002589 patent/WO2006087799A1/ja not_active Application Discontinuation
- 2005-02-18 CN CN2005800484916A patent/CN101124623B/zh not_active Expired - Fee Related
-
2007
- 2007-08-17 US US11/889,996 patent/US7657431B2/en not_active Expired - Fee Related
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH1056449A (ja) * | 1996-08-09 | 1998-02-24 | Oki Electric Ind Co Ltd | セキュリティ強化システム |
| JPH10173644A (ja) * | 1996-12-11 | 1998-06-26 | Nippon Telegr & Teleph Corp <Ntt> | 本人認証方法 |
| JP2000099090A (ja) * | 1998-09-22 | 2000-04-07 | Kdd Corp | 記号列を用いた話者認識方法 |
| JP2003044445A (ja) * | 2001-08-02 | 2003-02-14 | Matsushita Graphic Communication Systems Inc | 認証システム、サービス提供サーバ装置および音声認証装置並びに認証方法 |
| JP2004118456A (ja) * | 2002-09-25 | 2004-04-15 | Japan Science & Technology Corp | 位置情報を用いた移動端末の認証システム |
| JP2004279770A (ja) * | 2003-03-17 | 2004-10-07 | Kddi Corp | 話者認証装置及び判別関数設定方法 |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11152008B2 (en) | 2017-12-19 | 2021-10-19 | Samsung Electronics Co., Ltd. | Electronic apparatus, method for controlling thereof and computer readable recording medium |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2006087799A1 (ja) | 2008-07-03 |
| CN101124623B (zh) | 2011-06-01 |
| US7657431B2 (en) | 2010-02-02 |
| US20080172230A1 (en) | 2008-07-17 |
| CN101124623A (zh) | 2008-02-13 |
| WO2006087799A1 (ja) | 2006-08-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4672003B2 (ja) | 音声認証システム | |
| JP6394709B2 (ja) | 話者識別装置および話者識別用の登録音声の特徴量登録方法 | |
| JP4213716B2 (ja) | 音声認証システム | |
| Naik | Speaker verification: A tutorial | |
| Das et al. | Development of multi-level speech based person authentication system | |
| WO2018025025A1 (en) | Speaker recognition | |
| Justin et al. | Speaker de-identification using diphone recognition and speech synthesis | |
| JP2007133414A (ja) | 音声の識別能力推定方法及び装置、ならびに話者認証の登録及び評価方法及び装置 | |
| Mansour et al. | Voice recognition using dynamic time warping and mel-frequency cepstral coefficients algorithms | |
| CN111402862A (zh) | 语音识别方法、装置、存储介质及设备 | |
| JPH1173195A (ja) | 話者の申し出識別を認証する方法 | |
| JP2019219574A (ja) | 話者モデル作成システム、認識システム、プログラムおよび制御装置 | |
| US20230298564A1 (en) | Speech synthesis method and apparatus, device, and storage medium | |
| CN112309406A (zh) | 声纹注册方法、装置和计算机可读存储介质 | |
| JP7339116B2 (ja) | 音声認証装置、音声認証システム、および音声認証方法 | |
| Das et al. | Multi-style speaker recognition database in practical conditions | |
| JP4245948B2 (ja) | 音声認証装置、音声認証方法及び音声認証プログラム | |
| KR20110079161A (ko) | 이동 단말기에서 화자 인증 방법 및 장치 | |
| JP4440414B2 (ja) | 話者照合装置及び方法 | |
| WO2006027844A1 (ja) | 話者照合装置 | |
| JP3818063B2 (ja) | 個人認証装置 | |
| Nair et al. | A reliable speaker verification system based on LPCC and DTW | |
| JP2000099090A (ja) | 記号列を用いた話者認識方法 | |
| Rao et al. | Text-dependent speaker recognition system for Indian languages | |
| Singh et al. | Underlying text independent speaker recognition |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20070223 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20100216 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20100416 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20100416 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20110118 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20110118 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20140128 Year of fee payment: 3 |
|
| LAPS | Cancellation because of no payment of annual fees |