WO2025041292A1 - Training device, inference device, training inference device, program, training inference system, training method, and inference method - Google Patents
Training device, inference device, training inference device, program, training inference system, training method, and inference method Download PDFInfo
- Publication number
- WO2025041292A1 WO2025041292A1 PCT/JP2023/030253 JP2023030253W WO2025041292A1 WO 2025041292 A1 WO2025041292 A1 WO 2025041292A1 JP 2023030253 W JP2023030253 W JP 2023030253W WO 2025041292 A1 WO2025041292 A1 WO 2025041292A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- learning
- data
- true
- image
- training
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images













Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
Definitions
- This disclosure relates to a learning device, an inference device, a learning inference device, a program, a learning inference system, a learning method, and an inference method.
- Machine learning is divided into CNN (Convolutional Neural Network) and RNN (Recurrent Neural Network).
- CNN is a deep learning technology that has been improving the accuracy of static pattern detection.
- RNN has been used exclusively for time series signal learning because it has recurrent connections that CNN does not have.
- CNN requires large-scale hardware resources compared to RNN
- reservoir computing which is a technique for RNN
- reservoir computing has the advantage of being able to learn with fewer resources compared to other CNN and RNN techniques.
- reservoir computing has the advantage that it does not require learning inside the intermediate layer, so the intermediate layer can be implemented as a circuit using ordinary physical media.
- Reservoir computing has been widely applied to time-series signal learning, but the scope of application of reservoir computing can be expanded by applying reservoir computing to the learning and detection of static two-dimensional patterns.
- a method for implementing two-dimensional pattern detection learning using reservoir computing is shown in Non-Patent Document 1.
- one or more aspects of the present disclosure aim to make it possible to easily build a learning network using reservoir computing.
- the learning device is characterized by comprising: a learning data generation unit that generates learning data in which a plurality of feature vectors corresponding to a plurality of learning target images are arranged in a time series; a true-value data construction unit that constructs true-value data in which a plurality of true-value vectors indicating the truth or falsity of each of the plurality of learning target images are arranged so as to correspond to the time series of the plurality of feature vectors; and a learning unit that uses the learning data and the true-value data to train a three-layer neural network using reservoir computing.
- the inference device is characterized by comprising: an application data generation unit that generates a feature vector as application data from an inference target image, which is an image to be inferred; and a processing unit that uses training data in which a plurality of feature vectors corresponding to each of a plurality of training target images are arranged in a time series, and true value data in which a plurality of true value vectors indicating the authenticity of each of the plurality of training target images are arranged so as to correspond to the time series of the plurality of feature vectors, to train a three-layer neural network using reservoir computing, generates a trained three-layer neural network using the coupling constants of the three-layer neural network obtained as a result of the training, and inputs the application data into the trained three-layer neural network to infer the authenticity of the inference target image.
- the learning and inference device is characterized by comprising: a learning data generation unit that generates learning data in which a plurality of feature vectors corresponding to each of a plurality of learning target images are arranged in a time series; a true-value data construction unit that constructs true-value data in which a plurality of true-value vectors indicating the authenticity of each of the plurality of learning target images are arranged so as to correspond to the time series of the plurality of feature vectors; a learning unit that uses the learning data and the true-value data to train a three-layered neural network using reservoir computing and obtains coupling constants of the three-layered neural network as a result of the training; an application data generation unit that generates feature vectors as application data from an inference target image, which is an image that is the subject of inference; and a processing unit that uses the obtained coupling constants to generate a trained three-layered neural network and inputs the application data to the trained three-layered neural network to infer the authenticity of the inference target image
- the program according to the first aspect of the present disclosure causes a computer to function as a training data generation unit that generates training data in which a plurality of feature vectors corresponding to a plurality of training target images are arranged in a time series, a true-value data construction unit that constructs true-value data in which a plurality of true-value vectors indicating the truth or falsity of each of the plurality of training target images are arranged so as to correspond to the time series of the plurality of feature vectors, and a learning unit that uses the training data and the true-value data to train a three-layer neural network using reservoir computing.
- the program according to the second aspect of the present disclosure causes a computer to function as an application data generation unit that generates a feature vector as application data from an inference target image, which is an image to be inferred, and a processing unit that uses training data in which a plurality of feature vectors corresponding to each of a plurality of training target images are arranged in a time series and true-value data in which a plurality of true-value vectors indicating the truth or falsehood of each of the plurality of training target images are arranged so as to correspond to the time series of the plurality of feature vectors, trains a three-layer neural network using reservoir computing, generates a trained three-layer neural network using the coupling constants of the three-layer neural network obtained as a result of the training, and inputs the application data into the trained three-layer neural network to infer the truth or falsehood of the inference target image.
- the learning inference system includes a learning data generation unit that generates learning data in which a plurality of feature vectors corresponding to each of a plurality of learning target images are arranged in a time series; a true-value data construction unit that constructs true-value data in which a plurality of true-value vectors indicating the authenticity of each of the plurality of learning target images are arranged so as to correspond to the time series of the plurality of feature vectors; a learning unit that uses the learning data and the true-value data to train a three-layer neural network using reservoir computing and obtains coupling constants of the three-layer neural network as a result of the training; an application data generation unit that generates feature vectors as application data from an inference target image, which is an image that is the subject of inference; and a processing unit that uses the obtained coupling constants to generate a trained three-layer neural network and inputs the application data to the trained three-layer neural network to infer the authenticity of the inference target image.
- a learning method is characterized in that it generates learning data in which a plurality of feature vectors corresponding to a plurality of training target images are arranged in a time series, constructs true-value data in which a plurality of true-value vectors indicating the truth or falsehood of each of the plurality of training target images are arranged to correspond to the time series of the plurality of feature vectors, and uses the learning data and the true-value data to train a three-layered neural network using reservoir computing.
- the inference method is characterized in that it generates a feature vector as application data from an inference target image, which is an image that is the subject of inference, and trains a three-layered neural network using reservoir computing using training data in which a plurality of feature vectors corresponding to each of a plurality of training target images are arranged in time series, and true-value data in which a plurality of true-value vectors indicating the authenticity of each of the plurality of training target images are arranged so as to correspond to the time series of the plurality of feature vectors, generates a trained three-layered neural network using the coupling constants of the three-layered neural network obtained as a result of the training, and inputs the application data into the trained three-layered neural network to infer the authenticity of the inference target image.
- a learning network can be easily constructed using reservoir computing.
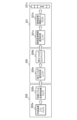
- FIG. 1 is a block diagram illustrating a schematic configuration of a pattern detection device as a learning and inference device according to a first embodiment.
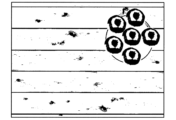
- 1 is a schematic diagram showing an example of a learning image that is a sample image including a pattern detection target
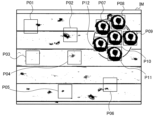
- 10 is a schematic diagram showing an example of extracting a plurality of partial images for determining whether the image is a genuine image or a false image from a learning image
- FIG. 11 is a schematic diagram for explaining an example of a learning image set.
- FIG. 4 is a schematic diagram for explaining processing in a learning phase in the first embodiment.
- FIG. 2 is a schematic diagram for explaining an example of learning a plurality of learning images in the first embodiment.
- FIG. 11 is a schematic diagram for explaining a process in an application phase in the first embodiment.
- FIG. 11 is a block diagram illustrating a schematic configuration of a pattern detection device as a learning and inference device according to a second embodiment.
- 13 is a schematic diagram for explaining the processing in a learning input data designation unit and an orthogonal filter application unit in the learning phase in embodiment 2.
- FIG. 11 is a schematic diagram for explaining processing in an application phase in the second embodiment.
- FIG. 11 is a block diagram illustrating a schematic configuration of a pattern detection device according to a third embodiment.
- FIG. 13 is a schematic diagram for explaining the processing in a learning input data designation unit, an orthogonal filter application unit, and a range conversion unit in the learning phase in embodiment 3.
- FIG. 1 is a graph showing a hyperbolic tangent function.
- FIG. 13 is a schematic diagram for explaining processing in an application phase in the third embodiment.
- FIG. 1 is a block diagram illustrating a schematic functional configuration of a pattern detection device 100 serving as a learning and inference device according to the first embodiment.
- the pattern detection device 100 includes a learning data generating unit 101 , a true value data constructing unit 104 , a reservoir circuit learning unit 107 , an application data input unit 111 , a reservoir circuit processing unit 112 , and an application data output unit 113 .
- the pattern detection device 100 operates in two phases, a learning phase and an application phase, for a processing process that uses an Echo State Network, which is a discrete-time implementation of reservoir computing.
- the learning data generating unit 101 generates learning data in which a plurality of feature vectors corresponding to a plurality of learning target images are arranged in time series.
- the training data generation unit 101 extracts pixel values in a predetermined order from each of a plurality of training target images, which are two-dimensional images, and generates each of a plurality of feature vectors by arranging the extracted pixel values in the order in which they were extracted.
- the learning data generating unit 101 includes a learning input data specifying unit 102 and a learning feature vector storage unit 103 .
- the learning input data designation unit 102 transforms one learning image to generate a feature vector. Note that each partial image included in the learning image is also referred to as a learning target image.
- the learning input data designation unit 102 transforms multiple learning target images to generate multiple feature vectors. Then, in the learning phase, the learning input data designation unit 102 configures these multiple feature vectors to have a fixed time length, thereby generating learning feature vectors as learning data.
- the learning feature vector storage unit 103 stores the learning feature vectors generated by the learning input data designation unit 102 during the learning phase.
- the true value data construction unit 104 constructs true value data in which a plurality of true value vectors indicating the true or false status of each of the plurality of training target images are arranged to correspond to a time series of a plurality of feature vectors generated from the plurality of training target images.
- the true-value data constructing unit 104 includes a learning output data specifying unit 105 and a learning true-value vector storing unit 106 .
- the learning output data specification unit 105 In the learning phase, the learning output data specification unit 105 generates a learning true value vector that indicates true value data corresponding to each feature vector included in the learning feature vector, so that the true value vector corresponds one-to-one to the true values of each feature vector included in the learning feature vector generated by the learning input data specification unit 102.
- the training true value vector storage unit 106 stores the individual true value vectors included in the training true value vector generated by the training output data designation unit 105 so that the individual true value vectors correspond to the individual feature vectors included in the training feature vector stored in the training feature vector storage unit 103. Then, the learning true-value vector storage unit 106 inputs the learning true-value vector as true-value data to the reservoir circuit learning unit 107 .
- the reservoir circuit learning unit 107 functions as a learning unit that uses the learning data generated by the learning data generation unit 101 and the true value data constructed by the true value data construction unit 104 to train the three-layer neural network using reservoir computing.
- the reservoir circuit learning unit 107 applies an Echo State Network learning algorithm to the three-layer neural network based on the learning feature vectors stored in the learning feature vector storage unit 103 and the learning true-value vectors stored in the learning true-value vector storage unit 106. Then, the reservoir circuit learning unit 107 stores the coupling constants of the three-layered neural network as the learning result obtained by the Echo State Network learning algorithm.
- the application data input unit 111 in the first embodiment functions as an application data generation unit that generates, as application data, a feature vector from an inference target image, which is an image to be inferred.
- the application data input unit 111 extracts pixel values in a predetermined order from the inference target image, which is a two-dimensional image, and generates application data by arranging the extracted pixel values in the order in which they were extracted.
- the application data input unit 111 accepts a new input of a two-dimensional image and converts the two-dimensional image to obtain its feature vector. This two-dimensional image becomes the inference target image.
- the reservoir circuit processing unit 112 generates a trained three-layer neural network using the coupling constants of the three-layer neural network obtained as a result of learning in the reservoir circuit learning unit 107, and functions as a processing unit that infers the authenticity of the inference target image by inputting application data from the application data input unit 111 to the trained three-layer neural network.
- the reservoir circuit processing unit 112 constructs a trained three-layer neural network using the coupling constants stored in the reservoir circuit learning unit 107.
- the reservoir circuit processing unit 112 applies a trained Echo State Network to the trained three-layer network.
- the trained Echo State Network includes an input layer 112a, an intermediate layer 112b, and an output layer 112c. Then, the reservoir circuit processing unit 112 inputs the feature vector acquired by the application data input unit 111 to the input layer 112a as input data.
- the application data output unit 113 obtains the output data from the output layer 112c and outputs it as the judgment result.
- a two-dimensional image will be taken as an example of a pattern detection target.
- a set of partial images extracted from a learning image is defined as a learning input image set, and each of the partial images is a learning target image.
- the partial image containing the detection target is defined as a true image
- the other partial images are defined as false images.
- the true vector (1,0) T T is the transpose of the vector
- the true vector (0,1) T is used.
- FIG. 2 is a schematic diagram showing an example of a learning image, which is a sample image including a pattern detection target.
- a learning image which is a sample image including a pattern detection target.
- six apples present in a learning image are used as an example of a detection target.
- FIG. 4 is a schematic diagram for explaining an example of a learning image set.
- positive images that are the detection targets are indicated as "true,” and false images that are not the detection targets are indicated as “false.”
- the normal image shown in Fig. 4 is a partial image extracted from a rectangular frame including six apples present in the learning image IM shown in Fig. 3.
- a true value vector (1, 0) T is given as true value data.
- the fake image shown in Fig. 4 is a partial image extracted from a randomly specified rectangular frame in an area not including six apples present in the learning image IM shown in Fig. 3. To learn this fake image as a detection target, a true value vector (0, 1) T is given as true value data.
- FIG. 5 is a schematic diagram for explaining the processing in the learning phase.
- two-dimensional image data showing one partial image used for learning the Echo State Network is stored in the learning image input buffer 102 a of the learning input data designation unit 102 .
- the training input data designation unit 102 converts the resolution of the partial image and stores the converted data in the feature vector conversion image buffer 102b.
- the learning input data specification unit 102 converts the resolution-converted converted partial image into a feature vector and stores it in the feature vector buffer 102c.
- the learning input data specification unit 102 may, for example, start with the upper left corner pixel of the converted partial image and read out the pixel values one pixel at a time in the leftward direction, proceed from the top row to the bottom row, and so on down to the bottom right pixel, thereby vectorizing the image.
- the true value of one partial image input to the learning input data specification unit 102 in other words, the true value vector associated with a positive image if the image contains the detection target, or a false image if not, is stored in the true value vector storage buffer 105a of the learning output data specification unit 105.
- the number of elements of the true vector may be specified as a number equal to or greater than 1.
- the number of elements of the true vector may be set to 2, and learning may be performed by associating a column vector (1,0) T with a positive image and a column vector (0,1) T with a false image.
- the learning of the Echo State Network requires learning only the coupling constants from the intermediate layer to the output layer, and a specific calculation method for this will be described.
- the coupling constant matrix from the input layer 107a to the intermediate layer 107b is W in
- the mutual coupling constant matrix of the internal units of the intermediate layer 107b is W res
- the coupling constant matrix from the output layer 107c to the intermediate layer 107b is W fb .
- ⁇ is called the leaking rate, and indicates the extent to which the activity of x[k] from one time point before is reflected in the activity of x[k+1], in other words, how much of the past internal state history of the hidden layer is dragged along the time axis.
- W out can be calculated from the feature vector derived from the partial image, X configured from the internal state of the intermediate layer 107b, and Y target configured from the true value vector.
- equation (3) shows the calculation process of Ridge Regression
- ⁇ is an optimization parameter in Ridge Regression. If Ridge Regression is not used for equation (2) and W out is directly calculated using the Moore-Penrose pseudoinverse matrix, the solution is obtained by the following equation (4).
- the feature vectors converted by the learning input data designation unit 102 are used as the learning images, which are multiple two-dimensional images that are trained by the Echo State Network.
- the process of converting each two-dimensional image into a feature vector can be performed using the procedure described above with reference to FIG. 5.
- n (n is an integer of 2 or more) true images T1 , T2 , ..., Tn and m (m is an integer of 2 or more) false images F1 , F2 , ..., Fm are stored in chronological order in the form of feature vectors in the learning input data designation unit 102. Furthermore, l consecutive feature vectors are stored for each of the true and false images.
- a total of l ⁇ (n+m) feature vectors are stored in the learning input data designation unit 102 in chronological order, constituting the column vectors of the matrix X in the above formula (2).
- a total of l ⁇ (n+m) true value vectors associated with each of the positive and false images are stored in the learning output data designation unit 105 in chronological order, constituting the column vectors of the matrix Y target in the above formula (2).
- a column vector (1,0) T may be associated with a true image, and a column vector (0,1) T may be associated with a false image.
- two-dimensional image data representing one partial image is stored in the application image input buffer 111 a of the application data input unit 111 .
- the application data input unit 111 converts the resolution of the partial image and stores the converted data in the image buffer for feature vector conversion 111b.
- the application data input unit 111 converts the resolution-converted converted partial image into a feature vector and stores it in the feature vector buffer 111c.
- the application data input unit 111 may, for example, start with the upper left corner pixel of the converted partial image and read out the pixel values one pixel at a time in the leftward direction, proceed from the top row to the bottom row, and so on down to the bottom right pixel, thereby vectorizing the image.
- the reservoir circuit processing unit 112 generates a trained three-layered neural network using the coupling constants of the three-layered neural network acquired as a result of training by the reservoir circuit training unit 107.
- the reservoir circuit processing unit 112 applies a trained Echo State Network to the trained three-layered neural network.
- the reservoir circuit processing unit 112 having the trained Echo State Network accepts input of a feature vector constructed by the application data input unit 111 with a new two-dimensional image as a column vector.
- the trained Echo State Network includes an input layer 112 a, an intermediate layer 112 b, and an output layer 112 c.
- the reservoir circuit processing unit 112 calculates an output vector using the trained Echo State Network, and stores the output vector in an output vector storage buffer 113 a of the application data output unit 113.
- the judgment circuit 113b judges whether the output vector is a positive image, meaning that it is a detection target, or a false image, meaning that it is not a detection target.
- the judgment circuit 113b may, for example, apply a threshold judgment to each element of an output vector having two elements, or may use linear separation or other machine learning methods to make the judgment.
- a learning network using reservoir computing can be easily constructed. Then, it becomes possible to detect a specific object contained in a static two-dimensional image as a rectangular position of a partial image using the Echo State Network.
- a machine learning technique called ensemble learning described in Reference 2 below is known, and high discrimination performance can be ensured by combining multiple discrimination functions with low discrimination performance.
- a trained Echo State Network can be regarded as one discrimination function, and multiple Echo State Networks can be combined to construct a discrimination function with higher accuracy.
- Reference 2 I. D. Mienye and Y. Sun, “A Survey of Ensemble Learning: Concepts, Algorithms, Applications, and Prospects”, IEEE Access Vol. 10, pp. 99129-99149, 2022.
- the input pattern to the reservoir computing circuit is expressed as a column vector, each column vector has a certain time length and constitutes an input pattern.
- the input pattern can be associated with the dynamic equilibrium point of the intermediate layer of the reservoir computing circuit during learning of the reservoir computing circuit. This makes it possible to realize pattern detection using the reservoir computing circuit.
- the above-described pattern detection apparatus 100 can be realized by, for example, a computer 10 as shown in FIG.
- the computer 10 includes a storage 11 such as a hard disk drive (HDD) or a solid state drive (SSD), a memory 12 , a processor 13 such as a central processing unit (CPU), a processing circuit 14 , and a reservoir circuit 15 .
- a storage 11 such as a hard disk drive (HDD) or a solid state drive (SSD)
- a memory 12 such as a central processing unit (CPU), a processing circuit 14 , and a reservoir circuit 15 .
- the processing circuit 14 is composed of a single circuit, a composite circuit, a processor operated by a program, a parallel processor operated by a program, an ASIC (Application Specific Integrated Circuit), an FPGA (Field Programmable Gate Array), etc.
- the learning input data designation unit 102 , the learning output data designation unit 105 and the application data input unit 111 can be configured by the processing circuitry 14 .
- the learning feature vector storage unit 103 and the learning true value vector storage unit 106 can be configured by the memory 12 .
- the reservoir circuit learning unit 107 and the reservoir circuit processing unit 112 can be configured by loading a program stored in the storage 11 into the memory 12, having the processor 13 execute the program, and having the processor 13 utilize the reservoir circuit 15.
- the application data output unit 113 can be realized by loading a program stored in the storage 11 into the memory 12 and having the processor 13 execute the program.
- the above programs may be downloaded to the storage 11 from a recording medium (not shown) via a reader/writer (not shown) or from a network via a communication I/F (Interface) (not shown), and then loaded onto the memory 12 and executed by the processor 13.
- the programs may be directly loaded onto the memory 12 from a recording medium (not shown) via a reader/writer or from a network via a communication I/F (not shown), and executed by the processor 13.
- the program may be provided by a program product such as a recording medium.
- the pattern detection apparatus 100 can be realized by a processing circuit network.
- FIG. 9 is a block diagram showing a schematic configuration of a pattern detection apparatus 200 as a learning and inference apparatus according to the second embodiment.
- the pattern detection device 200 includes a learning data generation unit 201 , a true value data construction unit 104 , a reservoir circuit learning unit 107 , an application data generation unit 210 , a reservoir circuit processing unit 112 , and an application data output unit 113 .
- an orthogonal filter application unit 220 that functions as a part of the learning data generation unit 201 and the application data generation unit 210 is provided.
- the true value data construction unit 104, the reservoir circuit learning unit 107, the reservoir circuit processing unit 112, and the application data output unit 113 of the pattern detection device 200 according to the second embodiment are similar to the true value data construction unit 104, the reservoir circuit learning unit 107, the reservoir circuit processing unit 112, and the application data output unit 113 of the pattern detection device 100 according to the first embodiment.
- the reservoir circuit processing unit 112 of the pattern detection device 200 inputs the feature vector filtered by the orthogonal filter application unit 220 to the input layer 112a as input data.
- the learning data generating unit 201 generates learning data in which a plurality of feature vectors corresponding to a plurality of learning target images are arranged in time series.
- the training data generation unit 201 extracts pixel values in a predetermined order from a processed image, which is the result of applying an orthogonal filter to each of a plurality of training images, which are two-dimensional images, and generates each of a plurality of feature vectors by arranging the extracted pixel values in the order in which they were extracted.
- the learning data generating unit 201 includes a learning input data specifying unit 202 , an orthogonal filter applying unit 220 , and a learning feature vector storage unit 103 .
- the training feature vector storage unit 103 of the pattern detection device 200 according to the second embodiment is similar to the training feature vector storage unit 103 of the pattern detection device 100 according to the first embodiment.
- the learning input data specification unit 202 provides the orthogonal filter application unit 220 with an image in which the resolution of one learning image has been converted.
- the application data generation unit 210 extracts pixel values in a predetermined order from a processed image, which is the result of applying an orthogonal filter to the inference target image, which is a two-dimensional image, and generates application data by arranging the extracted pixel values in the order in which they were extracted.
- the application data generating unit 210 includes an application data input unit 211 and an orthogonal filter application unit 220 .
- the application data input unit 211 accepts new input of a two-dimensional image and provides the two-dimensional image with its resolution converted to the orthogonal filter application unit 220.
- the orthogonal filter application unit 220 generates a feature vector by applying an orthogonal filter to the image from the learning input data designation unit 202.
- the orthogonal filter application unit 220 then generates a learning feature vector by configuring a plurality of filtered feature vectors to have a certain time length, and provides the feature vector to the learning feature vector storage unit 103.
- the orthogonal filter application unit 220 applies an orthogonal filter to the image from the application data input unit 211 to generate a feature vector, and provides the feature vector to the reservoir circuit processing unit 112 .
- FIG. 10 is a schematic diagram for explaining the processing in the learning input data designation unit 202 and the orthogonal filter application unit 220 in the learning phase in the second embodiment.
- a Walsh-Hadamard filter having filter coefficients of two values, "1" and "-1" is used as the orthogonal filter used in the orthogonal filter application unit 220.
- a process in the learning phase when one image having a true image or a false image as a true value from the learning image set is learned by the Echo State Network will be described.
- two-dimensional image data showing one partial image to be used for learning the Echo State Network is stored in the learning image input buffer 202a of the learning input data designation unit 202.
- the training input data designation unit 202 converts the resolution of the partial image and stores the converted data in the feature vector conversion image buffer 202b.
- the orthogonal filter application processing unit 220a of the orthogonal filter application section 220 performs filter processing on the two-dimensional image stored in the feature vector conversion image buffer 202b, and stores the result in the orthogonal filter output buffer 220b.
- the orthogonal filter application unit 220 generates a feature vector from the data stored in the orthogonal filter output buffer 220b, in the same manner as in embodiment 1, and stores the feature vector in the feature vector buffer 220c.
- the learning phase processing by the Echo State Network is the same as in embodiment 1.
- an example of an orthogonal filter used in the orthogonal filter application processing unit 220a of the orthogonal filter application section 220 is the Walsh-Hadamard filter described in Reference 3 below.
- a Walsh-Hadamard filter is defined as one-dimensional, and a two-dimensional Walsh-Hadamard filter can be further defined as the product of a first dimension and a first dimension.
- this Walsh-Hadamard filter when applying this Walsh-Hadamard filter to an image of 8 ⁇ 8 pixels, no multiplication is required, and the filter calculation is performed only by addition and subtraction, enabling high-speed calculation of spatial frequency decomposition.
- two-dimensional image data representing one partial image is stored in the application image input buffer 211 a of the application data input unit 211 .
- the application data input unit 211 converts the resolution of the partial image and stores the converted data in the image buffer for feature vector conversion 211b.
- the orthogonal filter application processing unit 220a of the orthogonal filter application section 220 performs filter processing on the two-dimensional image stored in the feature vector conversion image buffer 211b, and stores the result in the orthogonal filter output buffer 220b.
- the orthogonal filter application unit 220 generates a feature vector from the data stored in the orthogonal filter output buffer 220b, as in the first embodiment, and stores the feature vector in the feature vector buffer 220c.
- the reservoir circuit processing unit 112 having the trained echo state network receives an input of a feature vector constructed by the orthogonal filter application unit 220 with a new two-dimensional image as a column vector.
- the trained Echo State Network includes an input layer 112 a, an intermediate layer 112 b, and an output layer 112 c.
- the reservoir circuit processing unit 112 calculates an output vector using the trained Echo State Network, and stores the output vector in an output vector storage buffer 113 a of the application data output unit 113.
- the determination circuit 113b determines whether the output vector is a positive image, meaning that it is a detection target, or a false image, meaning that it is not a detection target.
- a plurality of learning images may be stored in the learning input data designation unit 202, and a plurality of true value vectors linked to each learning image may be stored in the learning output data designation unit 105, and then the reservoir circuit learning unit 107 may learn the Echo State Network.
- a Walsh-Hadamard filter was used as the orthogonal filter used in the orthogonal filter application unit 220, but another orthogonal filter may be used.
- a two-dimensional image may be converted into a feature vector using a discrete cosine transform (DCT) or a fast Fourier transform (FFT) as introduced in the above reference 3.
- DCT discrete cosine transform
- FFT fast Fourier transform
- the distance in the feature space of the learning patterns having different true values can be expanded using an orthogonal transformation, so that a learning network using reservoir computing can be easily constructed and the discrimination performance of pattern detection using the reservoir computing circuit can be improved.
- the above-described pattern detection apparatus 200 can also be realized by a computer 10 as shown in FIG.
- the orthogonal filter application unit 220 can also be configured by loading a program stored in the storage 11 into the memory 12 and having the processor 13 execute the program, or by the processing circuit 14 .
- FIG. 13 is a block diagram illustrating a schematic configuration of a pattern detection apparatus 300 according to the third embodiment.
- the pattern detection device 300 includes a learning data generation unit 301 , a true value data construction unit 104 , a reservoir circuit learning unit 107 , an application data generation unit 310 , a reservoir circuit processing unit 112 , and an application data output unit 113 .
- an orthogonal filter application unit 320 and a range conversion unit 321 that function as part of the learning data generation unit 301 and the application data generation unit 310 are provided.
- the true value data construction unit 104, the reservoir circuit learning unit 107, the reservoir circuit processing unit 112, and the application data output unit 113 of the pattern detection device 300 of embodiment 3 are similar to the true value data construction unit 104, the reservoir circuit learning unit 107, the reservoir circuit processing unit 112, and the application data output unit 113 of the pattern detection device 100 of embodiment 1.
- the reservoir circuit processing unit 112 of the pattern detection device 300 according to the third embodiment inputs the feature vector converted by the range conversion unit 321 to the input layer 112a as input data.
- the learning data generating unit 301 generates learning data in which a plurality of feature vectors corresponding to a plurality of learning target images are arranged in time series.
- the training data generation unit 301 extracts pixel values in a predetermined order from a transformed image, which is the result of applying a function that transforms pixel values into a predetermined range, to a processed image, which is the result of applying an orthogonal filter to each of a plurality of training images, which are two-dimensional images, and generates each of a plurality of feature vectors by arranging the extracted pixel values in the order in which they were extracted.
- the learning data generation unit 301 includes a learning input data specification unit 202 , an orthogonal filter application unit 320 , a range conversion unit 321 , and a learning feature vector storage unit 103 .
- the learning input data specifying unit 202 of the pattern detection device 300 according to the third embodiment is similar to the learning input data specifying unit 202 of the pattern detection device 200 according to the second embodiment.
- the training feature vector storage unit 103 of the pattern detection device 300 according to the third embodiment is similar to the training feature vector storage unit 103 of the pattern detection device 300 according to the first embodiment.
- the application data generating unit 310 generates, as application data, a feature vector from an inference target image, which is an image to be inferred.
- the application data generation unit 310 extracts pixel values in a predetermined order from a transformed image, which is the result of applying a function that transforms pixel values into a predetermined value range, to a processed image, which is the result of applying an orthogonal filter to an inference target image, which is a two-dimensional image, and generates application data by arranging the extracted pixel values in the order in which they were extracted.
- the application data generation unit 310 includes an application data input unit 211 , an orthogonal filter application unit 320 , and a range conversion unit 321 .
- the application data input unit 211 of the pattern detection device 300 according to the third embodiment is similar to the application data input unit 211 of the pattern detection device 200 according to the third embodiment.
- the orthogonal filter application unit 320 applies an orthogonal filter to the image from the learning input data designation unit 202 , and provides the image data after the filter processing to a value range conversion unit 321 . Furthermore, the orthogonal filter application unit 320 applies an orthogonal filter to the image from the application data input unit 211 , and provides the image data after the filter processing to the value range conversion unit 321 .
- the value range conversion unit 321 applies a function that converts a value range to image data that has been filtered by the orthogonal filter application unit 320 for the image from the learning input data designation unit 202, thereby generating a feature vector.
- the value range conversion unit 321 then configures a plurality of feature vectors to which such a function has been applied so as to have a certain time length, thereby generating a learning feature vector, and provides the feature vector to the learning feature vector storage unit 103.
- the value range conversion unit 321 applies a function that converts the value range to the image data filtered by the orthogonal filter application unit 320 for the image from the application data input unit 211, generates a feature vector, and provides the feature vector to the reservoir circuit processing unit 112.
- FIG. 14 is a schematic diagram for explaining the processing in the learning input data designation unit 202, the orthogonal filter application unit 320, and the range conversion unit 321 in the learning phase in the third embodiment.
- a Walsh-Hadamard filter having filter coefficients of two values, "1" and "-1”
- the hyperbolic tangent function (tanh(x)) is used as a nonlinear function for range conversion used in the range conversion unit 321
- the output value of the Walsh-Hadamard filter output from the orthogonal filter application unit 320 is limited to a range between "-1" and "1" to construct a feature vector.
- two-dimensional image data showing one partial image to be used for learning the Echo State Network is stored in the learning image input buffer 202a of the learning input data designation unit 202.
- the training input data designation unit 202 converts the resolution of the partial image and stores the converted data in the feature vector conversion image buffer 202b.
- the orthogonal filter application processing unit 320a of the orthogonal filter application section 320 performs filtering on the two-dimensional image stored in the feature vector conversion image buffer 202b, and stores the result in the orthogonal filter output buffer 320b.
- the range conversion unit 321 converts the values of the filtered image data stored in the orthogonal filter output buffer 320b using the range conversion function possessed by the range conversion function application processing unit 321a, and data having the converted values is stored in the range conversion function output buffer 321b.
- the range conversion unit 321 generates a feature vector from the data stored in the range conversion function output buffer 321b, in the same manner as in embodiment 1, and stores the feature vector in the feature vector buffer 321c.
- an example of the range conversion function that the range conversion function application processing unit 321a has is a hyperbolic tangent function.
- the hyperbolic tangent function tanh(x) is expressed by the following equation (6), and FIG. 15 shows a graph thereof.
- the feature vector is constructed directly from each value of the orthogonal filter output buffer 220b, which is the calculation result of the orthogonal filter application unit 220.
- the value range conversion unit 321 ensures that tanh(x) falls within the range -1 ⁇ f(x) ⁇ 1, so that the operation of the reservoir circuit learning unit 107 during learning can be stabilized.
- two-dimensional image data representing one partial image is stored in the application image input buffer 211 a of the application data input unit 211 .
- the application data input unit 211 converts the resolution of the partial image and stores the converted data in the image buffer for feature vector conversion 211b.
- the orthogonal filter application processing unit 320a of the orthogonal filter application section 320 performs filter processing on the two-dimensional image stored in the feature vector conversion image buffer 211b, and stores the result in the orthogonal filter output buffer 320b.
- the range conversion unit 321 converts the values of the filtered image data stored in the orthogonal filter output buffer 320b using the range conversion function possessed by the range conversion function application processing unit 321a, and data having the converted values is stored in the range conversion function output buffer 321b.
- the range conversion unit 321 generates a feature vector from the data stored in the range conversion function output buffer 321b, in the same manner as in embodiment 1, and stores the feature vector in the feature vector buffer 321c.
- the reservoir circuit processing unit 112 having a trained echo state network receives an input of a feature vector constructed by the range conversion unit 321 with a new two-dimensional image as a column vector.
- the trained Echo State Network includes an input layer 112 a, an intermediate layer 112 b, and an output layer 112 c.
- the reservoir circuit processing unit 112 calculates an output vector using the trained Echo State Network, and stores the output vector in an output vector storage buffer 113 a of the application data output unit 113.
- the determination circuit 113b determines whether the output vector is a positive image, meaning that it is a detection target, or a false image, meaning that it is not a detection target.
- multiple learning images may be stored in the learning input data designation unit 202, and multiple true value vectors linked to each learning image may be stored in the learning output data designation unit 105, and then the reservoir circuit learning unit 107 may learn the Echo State Network.
- the value of each element constituting the feature vector can be kept between "-1" and "1" by the value range conversion unit 321. This makes it possible to easily construct a learning network using reservoir computing and stabilize the processing operation of the reservoir circuit processing unit 112.
- the operation of the reservoir computing circuit becomes stable, and it becomes possible to improve the discrimination performance of pattern detection using the reservoir computing circuit.
- the pattern detection devices 100 to 300 have been described as devices that perform processing in both the learning phase and the inference phase, but embodiments 1 to 3 are not limited to such devices.
- the first to third embodiments can be configured as a learning device that performs processing in the learning phase and an inference device that performs processing in the inference phase.
- the processes performed by the pattern detection devices 100 to 300 according to the first to third embodiments may be distributed among a plurality of computers that are connected to a network and capable of transmitting and receiving data to and from each other.
- the first to third embodiments may be configured as a pattern detection system that serves as a learning inference system made up of a plurality of computers.
Landscapes
- Engineering & Computer Science (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Image Analysis (AREA)
Abstract
Description
本開示は、学習装置、推論装置、学習推論装置、プログラム、学習推論システム、学習方法及び推論方法に関する。 This disclosure relates to a learning device, an inference device, a learning inference device, a program, a learning inference system, a learning method, and an inference method.
機械学習は、CNN(Convolutional Neural Network)と、RNN(Recurrent Neural Network)に分かれる。
CNNでは、深層学習技術として静的パターン検出の高精度化が進んでいる。一方、RNNは、CNNが有さない再帰的結合を持つため、時系列信号学習に専ら利用されてきた。
Machine learning is divided into CNN (Convolutional Neural Network) and RNN (Recurrent Neural Network).
CNN is a deep learning technology that has been improving the accuracy of static pattern detection. On the other hand, RNN has been used exclusively for time series signal learning because it has recurrent connections that CNN does not have.
一般に、CNNは、RNNに比べて大規模のハードウェアリソースを必要とするのに対し、RNNの一技術であるリザバーコンピューティングは、CNN及びRNNの他の手法と比べて、低リソースで学習が可能という利点を持つ。また、リザバーコンピューティングは、中間層内部を学習する必要がないことから、中間層を一般の物理媒体で回路実装できるという利点も持つ。 Generally, CNN requires large-scale hardware resources compared to RNN, whereas reservoir computing, which is a technique for RNN, has the advantage of being able to learn with fewer resources compared to other CNN and RNN techniques. In addition, reservoir computing has the advantage that it does not require learning inside the intermediate layer, so the intermediate layer can be implemented as a circuit using ordinary physical media.
リザバーコンピューティングは、時系列信号学習に数多く応用されてきたが、リザバーコンピューティングを静的な二次元パターンの学習及び検出に応用することで、リザバーコンピューティングの適用範囲を拡大することができる。そうした技術の例として、リザバーコンピューティングを利用した二次元パターン検出学習の実装手法が非特許文献1に示されている。
Reservoir computing has been widely applied to time-series signal learning, but the scope of application of reservoir computing can be expanded by applying reservoir computing to the learning and detection of static two-dimensional patterns. As an example of such technology, a method for implementing two-dimensional pattern detection learning using reservoir computing is shown in Non-Patent
従来の技術では、リザバーコンピューティングの中間層ユニット間の結合定数を学習する必要があるため、本来のリザバーコンピューティングが持つ、中間層の構築に一般の物理媒体が利用できるという特徴が失われる。このため、仮に中間層構築に利用できる物理媒体があったとしても、それによる学習ネットワークの構築の難易度が上がるという問題がある。 In conventional technology, it is necessary to learn the coupling constants between the intermediate layer units of reservoir computing, which means that the original feature of reservoir computing, that is, the ability to use ordinary physical media to construct the intermediate layer, is lost. For this reason, even if there were physical media that could be used to construct the intermediate layer, there is the problem that it would be more difficult to construct a learning network using them.
そこで、本開示の一又は複数の態様は、リザバーコンピューティングによる学習ネットワークを容易に構築することができるようにすることを目的とする。 Therefore, one or more aspects of the present disclosure aim to make it possible to easily build a learning network using reservoir computing.
本開示の一態様に係る学習装置は、複数の学習対象画像のそれぞれに対応する複数の特徴ベクトルが時系列で配置された学習データを生成する学習データ生成部と、前記複数の学習対象画像のそれぞれの正偽を示す複数の真値ベクトルが、前記複数の特徴ベクトルの時系列に対応するように配置された真値データを構築する真値データ構築部と、前記学習データ及び前記真値データを用いて、リザバーコンピューティングを利用した三層ニューラルネットワークの学習を行う学習部と、を備えることを特徴とする。 The learning device according to one aspect of the present disclosure is characterized by comprising: a learning data generation unit that generates learning data in which a plurality of feature vectors corresponding to a plurality of learning target images are arranged in a time series; a true-value data construction unit that constructs true-value data in which a plurality of true-value vectors indicating the truth or falsity of each of the plurality of learning target images are arranged so as to correspond to the time series of the plurality of feature vectors; and a learning unit that uses the learning data and the true-value data to train a three-layer neural network using reservoir computing.
本開示の一態様に係る推論装置は、推論対象となる画像である推論対象画像から特徴ベクトルを適用データとして生成する適用データ生成部と、複数の学習対象画像のそれぞれに対応する複数の特徴ベクトルが時系列で配置された学習データと、前記複数の学習対象画像のそれぞれの正偽を示す複数の真値ベクトルが、前記複数の特徴ベクトルの時系列に対応するように配置された真値データとを用いて、リザバーコンピューティングを利用した三層ニューラルネットワークの学習を行い、前記学習の結果として取得された、前記三層ニューラルネットワークの結合定数を用いて、学習済み三層ニューラルネットワークを生成し、前記適用データを前記学習済み三層ニューラルネットワークに入力することで、前記推論対象画像の正偽を推論する処理部と、を備えることを特徴とする。 The inference device according to one aspect of the present disclosure is characterized by comprising: an application data generation unit that generates a feature vector as application data from an inference target image, which is an image to be inferred; and a processing unit that uses training data in which a plurality of feature vectors corresponding to each of a plurality of training target images are arranged in a time series, and true value data in which a plurality of true value vectors indicating the authenticity of each of the plurality of training target images are arranged so as to correspond to the time series of the plurality of feature vectors, to train a three-layer neural network using reservoir computing, generates a trained three-layer neural network using the coupling constants of the three-layer neural network obtained as a result of the training, and inputs the application data into the trained three-layer neural network to infer the authenticity of the inference target image.
本開示の一態様に係る学習推論装置は、複数の学習対象画像のそれぞれに対応する複数の特徴ベクトルが時系列で配置された学習データを生成する学習データ生成部と、前記複数の学習対象画像のそれぞれの正偽を示す複数の真値ベクトルが、前記複数の特徴ベクトルの時系列に対応するように配置された真値データを構築する真値データ構築部と、前記学習データ及び前記真値データを用いて、リザバーコンピューティングを利用した三層ニューラルネットワークの学習を行い、前記三層ニューラルネットワークの結合定数と、前記学習の結果として取得する学習部と、推論対象となる画像である推論対象画像から特徴ベクトルを適用データとして生成する適用データ生成部と、前記取得された結合定数を用いて、学習済み三層ニューラルネットワークを生成し、前記適用データを前記学習済み三層ニューラルネットワークに入力することで、前記推論対象画像の正偽を推論する処理部と、を備えることを特徴とする。 The learning and inference device according to one aspect of the present disclosure is characterized by comprising: a learning data generation unit that generates learning data in which a plurality of feature vectors corresponding to each of a plurality of learning target images are arranged in a time series; a true-value data construction unit that constructs true-value data in which a plurality of true-value vectors indicating the authenticity of each of the plurality of learning target images are arranged so as to correspond to the time series of the plurality of feature vectors; a learning unit that uses the learning data and the true-value data to train a three-layered neural network using reservoir computing and obtains coupling constants of the three-layered neural network as a result of the training; an application data generation unit that generates feature vectors as application data from an inference target image, which is an image that is the subject of inference; and a processing unit that uses the obtained coupling constants to generate a trained three-layered neural network and inputs the application data to the trained three-layered neural network to infer the authenticity of the inference target image.
本開示の第1の態様に係るプログラムは、コンピュータを、複数の学習対象画像のそれぞれに対応する複数の特徴ベクトルが時系列で配置された学習データを生成する学習データ生成部、前記複数の学習対象画像のそれぞれの正偽を示す複数の真値ベクトルが、前記複数の特徴ベクトルの時系列に対応するように配置された真値データを構築する真値データ構築部、及び、前記学習データ及び前記真値データを用いて、リザバーコンピューティングを利用した三層ニューラルネットワークの学習を行う学習部、として機能させることを特徴とする。 The program according to the first aspect of the present disclosure causes a computer to function as a training data generation unit that generates training data in which a plurality of feature vectors corresponding to a plurality of training target images are arranged in a time series, a true-value data construction unit that constructs true-value data in which a plurality of true-value vectors indicating the truth or falsity of each of the plurality of training target images are arranged so as to correspond to the time series of the plurality of feature vectors, and a learning unit that uses the training data and the true-value data to train a three-layer neural network using reservoir computing.
本開示の第2の態様に係るプログラムは、コンピュータを、推論対象となる画像である推論対象画像から特徴ベクトルを適用データとして生成する適用データ生成部、及び、複数の学習対象画像のそれぞれに対応する複数の特徴ベクトルが時系列で配置された学習データと、前記複数の学習対象画像のそれぞれの正偽を示す複数の真値ベクトルが、前記複数の特徴ベクトルの時系列に対応するように配置された真値データとを用いて、リザバーコンピューティングを利用した三層ニューラルネットワークの学習を行い、前記学習の結果として取得された、前記三層ニューラルネットワークの結合定数を用いて、学習済み三層ニューラルネットワークを生成し、前記適用データを前記学習済み三層ニューラルネットワークに入力することで、前記推論対象画像の正偽を推論する処理部、として機能させることを特徴とする。 The program according to the second aspect of the present disclosure causes a computer to function as an application data generation unit that generates a feature vector as application data from an inference target image, which is an image to be inferred, and a processing unit that uses training data in which a plurality of feature vectors corresponding to each of a plurality of training target images are arranged in a time series and true-value data in which a plurality of true-value vectors indicating the truth or falsehood of each of the plurality of training target images are arranged so as to correspond to the time series of the plurality of feature vectors, trains a three-layer neural network using reservoir computing, generates a trained three-layer neural network using the coupling constants of the three-layer neural network obtained as a result of the training, and inputs the application data into the trained three-layer neural network to infer the truth or falsehood of the inference target image.
本開示の一態様に係る学習推論システムは、複数の学習対象画像のそれぞれに対応する複数の特徴ベクトルが時系列で配置された学習データを生成する学習データ生成部と、前記複数の学習対象画像のそれぞれの正偽を示す複数の真値ベクトルが、前記複数の特徴ベクトルの時系列に対応するように配置された真値データを構築する真値データ構築部と、前記学習データ及び前記真値データを用いて、リザバーコンピューティングを利用した三層ニューラルネットワークの学習を行い、前記三層ニューラルネットワークの結合定数と、前記学習の結果として取得する学習部と、推論対象となる画像である推論対象画像から特徴ベクトルを適用データとして生成する適用データ生成部と、前記取得された結合定数を用いて、学習済み三層ニューラルネットワークを生成し、前記適用データを前記学習済み三層ニューラルネットワークに入力することで、前記推論対象画像の正偽を推論する処理部と、を備えることを特徴とする。 The learning inference system according to one aspect of the present disclosure includes a learning data generation unit that generates learning data in which a plurality of feature vectors corresponding to each of a plurality of learning target images are arranged in a time series; a true-value data construction unit that constructs true-value data in which a plurality of true-value vectors indicating the authenticity of each of the plurality of learning target images are arranged so as to correspond to the time series of the plurality of feature vectors; a learning unit that uses the learning data and the true-value data to train a three-layer neural network using reservoir computing and obtains coupling constants of the three-layer neural network as a result of the training; an application data generation unit that generates feature vectors as application data from an inference target image, which is an image that is the subject of inference; and a processing unit that uses the obtained coupling constants to generate a trained three-layer neural network and inputs the application data to the trained three-layer neural network to infer the authenticity of the inference target image.
本開示の一態様に係る学習方法は、複数の学習対象画像のそれぞれに対応する複数の特徴ベクトルが時系列で配置された学習データを生成し、前記複数の学習対象画像のそれぞれの正偽を示す複数の真値ベクトルが、前記複数の特徴ベクトルの時系列に対応するように配置された真値データを構築し、前記学習データ及び前記真値データを用いて、リザバーコンピューティングを利用した三層ニューラルネットワークの学習を行うことを特徴とする。 A learning method according to one aspect of the present disclosure is characterized in that it generates learning data in which a plurality of feature vectors corresponding to a plurality of training target images are arranged in a time series, constructs true-value data in which a plurality of true-value vectors indicating the truth or falsehood of each of the plurality of training target images are arranged to correspond to the time series of the plurality of feature vectors, and uses the learning data and the true-value data to train a three-layered neural network using reservoir computing.
本開示の一態様に係る推論方法は、推論対象となる画像である推論対象画像から特徴ベクトルを適用データとして生成し、複数の学習対象画像のそれぞれに対応する複数の特徴ベクトルが時系列で配置された学習データと、前記複数の学習対象画像のそれぞれの正偽を示す複数の真値ベクトルが、前記複数の特徴ベクトルの時系列に対応するように配置された真値データとを用いて、リザバーコンピューティングを利用した三層ニューラルネットワークの学習を行い、前記学習の結果として取得された、前記三層ニューラルネットワークの結合定数を用いて、学習済み三層ニューラルネットワークを生成し、前記適用データを前記学習済み三層ニューラルネットワークに入力することで、前記推論対象画像の正偽を推論することを特徴とする。 The inference method according to one aspect of the present disclosure is characterized in that it generates a feature vector as application data from an inference target image, which is an image that is the subject of inference, and trains a three-layered neural network using reservoir computing using training data in which a plurality of feature vectors corresponding to each of a plurality of training target images are arranged in time series, and true-value data in which a plurality of true-value vectors indicating the authenticity of each of the plurality of training target images are arranged so as to correspond to the time series of the plurality of feature vectors, generates a trained three-layered neural network using the coupling constants of the three-layered neural network obtained as a result of the training, and inputs the application data into the trained three-layered neural network to infer the authenticity of the inference target image.
本開示の一又は複数の態様によれば、リザバーコンピューティングによる学習ネットワークを容易に構築することができる。 According to one or more aspects of the present disclosure, a learning network can be easily constructed using reservoir computing.
実施の形態1.
図1は、実施の形態1に係る学習推論装置としてのパターン検出装置100の機能構成を概略的に示すブロック図である。
パターン検出装置100は、学習データ生成部101と、真値データ構築部104と、リザバー回路学習部107と、適用データ入力部111と、リザバー回路処理部112と、適用データ出力部113とを備える。
FIG. 1 is a block diagram illustrating a schematic functional configuration of a
The
パターン検出装置100は、リザバーコンピューティングの実装形態として離散時間実装版であるEcho State Networkを利用した処理プロセスに関し、学習フェーズと、適用フェーズとからなる2つのフェーズで動作する。
The
学習データ生成部101は、複数の学習対象画像のそれぞれに対応する複数の特徴ベクトルが時系列で配置された学習データを生成する。
実施の形態1では、学習データ生成部101は、二次元画像である複数の学習対象画像の各々において予め定められた順番で画素値を抽出して、抽出された順番でその抽出された画素値を並べることで複数の特徴ベクトルの各々を生成する。
学習データ生成部101は、学習用入力データ指定部102と、学習用特徴ベクトル格納部103とを備える。
The learning
In
The learning
学習用入力データ指定部102は、学習フェーズにおいて、一つの学習用画像を変換して特徴ベクトルを生成する。なお、学習用画像に含まれる個々の部分画像を学習対象画像ともいう。学習用入力データ指定部102は、複数の学習対象画像を変換して、複数の特徴ベクトルを生成する。そして、学習用入力データ指定部102は、学習フェーズにおいて、これらの複数の特徴ベクトルが一定の時間長を持つように構成することで、学習データとしての学習用特徴ベクトルを生成する。
In the learning phase, the learning input
学習用特徴ベクトル格納部103は、学習フェーズにおいて、学習用入力データ指定部102で生成された学習用特徴ベクトルを記憶する。
The learning feature
真値データ構築部104は、複数の学習対象画像のそれぞれの正偽を示す複数の真値ベクトルが、複数の学習対象画像から生成された複数の特徴ベクトルの時系列に対応するように配置された真値データを構築する。
真値データ構築部104は、学習用出力データ指定部105と、学習用真値ベクトル格納部106とを備える。
The true value
The true-value
学習用出力データ指定部105は、学習フェーズにおいて、学習用特徴ベクトルに含まれる個々の特徴ベクトルに対応した真値データを示す真値ベクトルを、学習用入力データ指定部102において生成された学習用特徴ベクトルに含まれている個々の特徴ベクトルが持つ真値と一対一に対応するように、学習用真値ベクトルとして生成する。
In the learning phase, the learning output
学習用真値ベクトル格納部106は、学習フェーズにおいて、学習用出力データ指定部105により生成された学習用真値ベクトルに含まれている個々の真値ベクトルが、学習用特徴ベクトル格納部103において記憶されている学習用特徴ベクトルに含まれている個々の特徴ベクトルに対応するように記憶する。
そして、学習用真値ベクトル格納部106は、真値データとしての学習用真値ベクトルを、リザバー回路学習部107に入力する。
In the learning phase, the training true value
Then, the learning true-value
リザバー回路学習部107は、学習データ生成部101で生成された学習データ及び真値データ構築部104で構築された真値データを用いて、リザバーコンピューティングを利用した三層ニューラルネットワークの学習を行う学習部として機能する。
The reservoir
リザバー回路学習部107は、学習フェーズにおいて、学習用特徴ベクトル格納部103に保持されている学習用特徴ベクトルと、学習用真値ベクトル格納部106に保持されている学習用真値ベクトルとを元に、三層ニューラルネットワークに対してEcho State Network学習アルゴリズムを適用する。
そして、リザバー回路学習部107は、その三層ニューラルネットワークの結合定数を、Echo State Network学習アルゴリズムによる学習結果として保存する。
In the learning phase, the reservoir
Then, the reservoir
実施の形態1における適用データ入力部111は、推論対象となる画像である推論対象画像から特徴ベクトルを適用データとして生成する適用データ生成部として機能する。
実施の形態1では、適用データ入力部111は、二次元画像である推論対象画像において予め定められた順番で画素値を抽出して、抽出された順番でその抽出された画素値を並べることで適用データを生成する。
The application
In
例えば、適用データ入力部111は、適用フェーズにおいて、新たに二次元画像の入力を受け付けて、その二次元画像を変換することで、その特徴ベクトルを取得する。ここでの二次元画像が推論対象画像となる。
For example, in the application phase, the application
リザバー回路処理部112は、リザバー回路学習部107での学習の結果として取得された、三層ニューラルネットワークの結合定数を用いて、学習済み三層ニューラルネットワークを生成し、適用データ入力部111からの適用データをその学習済み三層ニューラルネットワークに入力することで、推論対象画像の正偽を推論する処理部として機能する。
The reservoir
例えば、リザバー回路処理部112は、適用フェーズにおいて、リザバー回路学習部107に保存された結合定数を利用して、学習済み三層ニューラルネットワークを構築する。リザバー回路処理部112は、学習済み三層ネットワークに対して学習済みのEcho State Networkを適用する。後述の図7に示すとおり、学習済みのEcho State Networkは、入力層112a、中間層112b及び出力層112cを備える。
そして、リザバー回路処理部112は、適用データ入力部111で取得された特徴ベクトルを、入力データとして、入力層112aに入力する。
For example, in the application phase, the reservoir
Then, the reservoir
適用データ出力部113は、出力層112cからの出力データを取得し、判定結果として出力する。
The application
本実施の形態では、パターン検出対象として二次元画像を例として、説明する。
学習用画像から抽出された複数の部分画像を学習用入力画像セットとする。なお、複数の部分画像の各々が学習対象画像となる。
複数の部分画像の内、検出対象を含む部分画像を正画像(true)、それ以外の部分画像を偽画像(false)として、部分画像が正画像の場合、真値ベクトル(1,0)T(Tはベクトルの転置)を、部分画像が偽画像の場合、真値ベクトル(0,1)Tを、2個の出力層ユニット数における真値データとして、学習用入力画像セットに含まれている複数の部分画像に対応付けた学習用出力データセットとする。
ここでは、学習用入力画像セットと、学習用出力データセットとから構成される学習用画像セットを、Echo State Networkで学習した際の動作例について、学習フェーズと、適用フェーズとに分けて説明する。
In this embodiment, a two-dimensional image will be taken as an example of a pattern detection target.
A set of partial images extracted from a learning image is defined as a learning input image set, and each of the partial images is a learning target image.
Of the multiple partial images, the partial image containing the detection target is defined as a true image, and the other partial images are defined as false images. If the partial image is a true image, the true vector (1,0) T (T is the transpose of the vector) is used. If the partial image is a false image, the true vector (0,1) T is used. These are used as true data for two output layer units, and correspond to the multiple partial images included in the learning input image set, forming a learning output data set.
Here, an example of operation when a learning image set consisting of a learning input image set and a learning output data set is learned by an Echo State Network will be described, divided into a learning phase and an application phase.
まず、学習フェーズについて説明する。
図2は、パターンの検出対象を含むサンプル画像である学習用画像の一例を示す概略図である。
ここでは、検出対象の例として、学習用画像中に存在する6個のりんごを学習するものとする。
First, the learning phase will be described.
FIG. 2 is a schematic diagram showing an example of a learning image, which is a sample image including a pattern detection target.
In this example, six apples present in a learning image are used as an example of a detection target.
このため、例えば、図3に示されているように、学習用画像IMから、正画像又は偽画像を判定するために、複数の矩形枠を指定して、その複数の矩形枠内の画像が部分画像P01~P12として抽出される。 For this reason, for example, as shown in FIG. 3, in order to determine whether an image is genuine or fake from the learning image IM, multiple rectangular frames are specified, and the images within the multiple rectangular frames are extracted as partial images P01 to P12.
図4は、学習用画像セットの一例を説明するための概略図である。
学習用画像セットは、検知対象である正画像が「true」として示されており、非検知対象である偽画像が「false」として示されている。
FIG. 4 is a schematic diagram for explaining an example of a learning image set.
In the learning image set, positive images that are the detection targets are indicated as "true," and false images that are not the detection targets are indicated as "false."
図4に示されている正画像は、図3に示されている学習用画像IM中に存在する6個のりんごを含む矩形枠から抽出された部分画像である。この正画像を検出対象として学習するために、真値ベクトル(1,0)Tが真値データとして与えられる。 The normal image shown in Fig. 4 is a partial image extracted from a rectangular frame including six apples present in the learning image IM shown in Fig. 3. In order to learn this normal image as a detection target, a true value vector (1, 0) T is given as true value data.
また、図4に示されている偽画像は、図3に示されている学習用画像IM中に存在する6個のりんごを含まない領域から、ランダムに指定された矩形枠から抽出された部分画像である。この偽画像を検出対象として学習するために、真値ベクトル(0,1)Tが真値データとして与えられる。 The fake image shown in Fig. 4 is a partial image extracted from a randomly specified rectangular frame in an area not including six apples present in the learning image IM shown in Fig. 3. To learn this fake image as a detection target, a true value vector (0, 1) T is given as true value data.
ここでは、学習用画像セットから、正画像又は偽画像を真値として持つ一つの部分画像を、Echo State Networkで学習する場合の処理について、図5を用いて説明する。 Here, we will use Figure 5 to explain the process of learning a partial image from a learning image set, which has a true or false image as its true value, using the Echo State Network.
図5は、学習フェーズでの処理を説明するための概略図である。
まず、Echo State Networkの学習に用いる一つの部分画像を示す二次元画像データが、学習用入力データ指定部102が有する学習画像入力バッファ102aに格納される。
FIG. 5 is a schematic diagram for explaining the processing in the learning phase.
First, two-dimensional image data showing one partial image used for learning the Echo State Network is stored in the learning
次に、学習画像入力バッファ102aに格納されている二次元画像データで示される部分画像を特徴ベクトル化するために、学習用入力データ指定部102は、その部分画像の解像度を変換して、変換後のデータを特徴ベクトル変換用画像バッファ102bに格納する。
Next, in order to convert the partial image represented by the two-dimensional image data stored in the training
次に、学習用入力データ指定部102は、解像度変換された変換部分画像を特徴ベクトル化して特徴ベクトル用バッファ102cに保存する。この変換部分画像をベクトル化するためには、学習用入力データ指定部102は、例えば、変換部分画像の左上隅画素をスタートとして順に左行方向に1画素ずつ画素値を読み出し、順次上端行から下端行へ進み、右下端画素まで画素値を読み出すことにより、ベクトル化すればよい。
Next, the learning input
次に、学習用入力データ指定部102に入力された一つの部分画像が持つ真値、言い換えると、検出対象を含む画像であれば正画像、そうでなければ偽画像に対応付けられた真値ベクトルが、学習用出力データ指定部105が有する真値ベクトル格納バッファ105aに格納される。
Next, the true value of one partial image input to the learning input
ここで、真値ベクトルの要素数は、1個以上の数が指定されればよい。例えば、真値ベクトル要素数を2個として、正画像には、列ベクトル(1,0)T、偽画像には列ベクトル(0,1)Tを対応付けて、学習が行われればよい。 Here, the number of elements of the true vector may be specified as a number equal to or greater than 1. For example, the number of elements of the true vector may be set to 2, and learning may be performed by associating a column vector (1,0) T with a positive image and a column vector (0,1) T with a false image.
以上のように、特徴ベクトル用バッファ102cに保存された、部分画像から得られる特徴ベクトルと、真値ベクトル格納バッファ105aに保存された真値ベクトルと、リザバー回路学習部107が有するEcho State Networkに関して適切なネットワーク初期設定を行えば、下記の参考文献1に記載された学習アルゴリズムにより、正画像と、偽画像とを併せて2枚の画像をEcho State Networkで学習できる。

ここで、Echo State Networkの学習は、中間層から出力層に至る結合定数のみを学習すればよく、その具体的計算手法について説明する。
まず、リザバー回路学習部107は、Echo State Networkの入力層107a、中間層107b及び出力層107cを相互に結合する結線について、入力層107aから中間層107bへの結合定数行列をWin、中間層107bの内部ユニットの相互的な結合定数行列をWres、出力層107cから中間層107bへの結合定数行列をWfbとする。また、離散時刻kにおける入力層107aへの入力信号をu[k]、中間層107bの内部ユニットの状態をx[k]、出力層107cの出力信号をy[k]としたとき、下記の(1)式の関係がある。
Here, the learning of the Echo State Network requires learning only the coupling constants from the intermediate layer to the output layer, and a specific calculation method for this will be described.
First, in the reservoir
![]()
![]()
(1)式において、λは、leaking rateと呼ばれ、1時刻前のx[k]の活動をx[k+1]の活動にどの程度反映させるか、言い換えると、過去の中間層の内部状態履歴をどれだけ時間軸方向に引きずるかを意味する。λ=1のとき、x[k]は、x[k+1]の更新に一切反映されない、言い換えると、内部状態履歴を時間軸方向に一切引きずらないことを意味する。 In equation (1), λ is called the leaking rate, and indicates the extent to which the activity of x[k] from one time point before is reflected in the activity of x[k+1], in other words, how much of the past internal state history of the hidden layer is dragged along the time axis. When λ=1, x[k] is not reflected at all in the update of x[k+1], in other words, the internal state history is not dragged along the time axis at all.
さらに、中間層107bから出力層107cへの結合定数行列をWout、時刻1からTまでのu[k]と、x[k]とを列ベクトルとしてまとめた行列をX、真値データであるy[k]を列ベクトルとしてまとめた行列をYtargetとしたとき、Xと、Ytargetとには、下記の(2)式の関係がある。
Furthermore, when the coupling constant matrix from the
![]()
![]()
上記の参考文献1に記載されているRidge Regressionを用いて、(1)式をWoutについて解くと、下記の(3)式のようになる。
When equation (1) is solved for W out using the Ridge Regression described in the above-mentioned
![]()
![]()
これにより、部分画像から導いた特徴ベクトルと、中間層107bの内部状態から構成されるXと、真値ベクトルから構成されるYtargetとから、Woutを算出することができる。
As a result, W out can be calculated from the feature vector derived from the partial image, X configured from the internal state of the
なお、(3)式は、Ridge Regressionの計算プロセスを示しており、βは、Ridge Regressionにおける最適化パラメータである。
仮に、(2)式に対してRidge Regressionを利用せず、Moore-Penroseの擬似逆行列を利用して、Woutを直接算出する場合の解は、下記の(4)式で得られる。
It should be noted that equation (3) shows the calculation process of Ridge Regression, and β is an optimization parameter in Ridge Regression.
If Ridge Regression is not used for equation (2) and W out is directly calculated using the Moore-Penrose pseudoinverse matrix, the solution is obtained by the following equation (4).
![]()
![]()
しかしながら、(4)式は、Xの次元が大きい場合に擬似逆行列の計算量が嵩むため、Ridge Regressionを利用して擬似逆行列計算を回避し、計算量を抑え込む。この場合のRidge Regressionによる最適化計算は、下記の(5)式で与えられる。 However, since the amount of calculation required for the pseudo-inverse matrix in equation (4) increases when the dimension of X is large, Ridge Regression is used to avoid the pseudo-inverse matrix calculation and reduce the amount of calculation. The optimization calculation using Ridge Regression in this case is given by the following equation (5).
![]()
![]()
(5)式で、仮にβ||Wout||2の項がない場合、Woutのノルムサイズが巨大になると、Echo State Networkの出力が不安定になる。このため、(5)式の計算過程にβ||Wout||2の項を含めて最適化計算を実行し、ノルムサイズが調節されたWoutを得る。 In formula (5), if the term β∥W out ∥ 2 is not present, when the norm size of W out becomes large, the output of the Echo State Network becomes unstable. For this reason, the term β∥W out ∥ 2 is included in the calculation process of formula (5) to perform optimization calculations and obtain W out with an adjusted norm size.
以上では、一つの部分画像をEcho State Networkに学習させる例を説明したが、ここでは、正画像又は偽画像の真値が付与された複数枚の学習用画像をEcho State Networkで学習する例について、図6を用いて説明する。 Above, we have explained an example of training the Echo State Network on one partial image, but here we will use Figure 6 to explain an example of training multiple learning images with true values of either positive or false images assigned to them using the Echo State Network.
なお、図6においては、Echo State Networkに学習させる複数枚の二次元画像である学習用画像として、いずれも、学習用入力データ指定部102によって変換された特徴ベクトルが利用される。個々の二次元画像を特徴ベクトルに変換する過程については、図5を用いて説明した上述の手続きが利用されればよい。
In FIG. 6, the feature vectors converted by the learning input
図6において、学習用入力データ指定部102には、n枚(nは、2以上の整数)の正画像T1,T2,・・・,Tnと、m枚(mは、2以上の整数)の偽画像F1,F2,・・・,Fmが特徴ベクトルの形式で時系列順に格納されている。さらに、個々の正画像及び偽画像については、いずれも、特徴ベクトルがl枚連続して格納されている。
6, n (n is an integer of 2 or more) true images T1 , T2 , ..., Tn and m (m is an integer of 2 or more) false images F1 , F2 , ..., Fm are stored in chronological order in the form of feature vectors in the learning input
言い換えると、学習用入力データ指定部102には、合計l×(n+m)個の特徴ベクトルが時系列順に格納され、上記の(2)式における行列Xの列ベクトルを構成している。この時系列順に呼応する形で、学習用出力データ指定部105には個々の正画像及び偽画像に対応付けられた合計l×(n+m)個の真値ベクトルが、時系列順に格納され、上記の(2)式における行列Ytargetの列ベクトルを構成している。
In other words, a total of l×(n+m) feature vectors are stored in the learning input
具体的な真値ベクトルとして、上述同様、正画像には、列ベクトル(1,0)T、偽画像には、列ベクトル(0,1)Tが対応付けられればよい。 As a specific true vector, as described above, a column vector (1,0) T may be associated with a true image, and a column vector (0,1) T may be associated with a false image.
次に、実施の形態1における適用フェーズについて、図7を用いて説明する。
まず、一つの部分画像を示す二次元画像データが、適用データ入力部111が有する適用画像入力バッファ111aに格納される。
Next, the application phase in the first embodiment will be described with reference to FIG.
First, two-dimensional image data representing one partial image is stored in the application
次に、適用画像入力バッファ111aに格納されている二次元画像データで示される部分画像を特徴ベクトル化するために、適用データ入力部111は、その部分画像の解像度を変換して、変換後のデータを特徴ベクトル変換用画像バッファ111bに格納する。
Next, in order to convert the partial image represented by the two-dimensional image data stored in the application
次に、適用データ入力部111は、解像度変換された変換部分画像を特徴ベクトル化して特徴ベクトル用バッファ111cに保存する。この変換部分画像をベクトル化するためには、適用データ入力部111は、例えば、変換部分画像の左上隅画素をスタートとして順に左行方向に1画素ずつ画素値を読み出し、順次上端行から下端行へ進み、右下端画素まで画素値を読み出すことにより、ベクトル化すればよい。
Next, the application
リザバー回路処理部112は、リザバー回路学習部107での学習の結果として取得された、三層ニューラルネットワークの結合定数を用いて、学習済み三層ニューラルネットワークを生成する。リザバー回路処理部112は、学習済み三層ニューラルネットワークに対して学習済みのEcho State Networkを適用する。学習済みのEcho State Networkを有したリザバー回路処理部112は、新たな二次元画像を列ベクトルとして適用データ入力部111が構築した特徴ベクトルの入力を受け入れる。
学習済のEcho State Networkは、入力層112a、中間層112b及び出力層112cを備える。そして、リザバー回路処理部112は、学習済みのEcho State Networkにより出力ベクトルを算出して、適用データ出力部113の出力ベクトル格納バッファ113aに、その出力ベクトルを格納する。
The reservoir
The trained Echo State Network includes an
そして、適用データ出力部113では、判定回路113bが、出力ベクトルが検知対象であることを意味する正画像か、あるいは非検知対象である偽画像かを判定する。この正画像あるいは偽画像の判定については、判定回路113bは、例えば、要素数2の出力ベクトルに対し、各要素についてしきい値判定を適用して判定してもよく、あるいは線形分離又はその他の機械学習手法を利用して判定を行ってもよい。
Then, in the application
以上により、リザバーコンピューティングによる学習ネットワークを容易に構築することができる。そして、Echo State Networkを利用して静的な二次元画像に含まれる特定の対象を、部分画像の矩形位置として検出することが可能になる。この識別能力をさらに高めるために、下記の参考文献2に記載されたアンサンブル学習と呼ばれる機械学習の手法が知られており、識別性能の低い識別関数を複数組み合わせることで、高い識別性能を確保することができる。このアンサンブル学習を利用して、学習済みのEcho State Networkを一つの識別関数と見て、複数のEcho State Networkを組み合わせることにより、より高精度の識別関数を構築することができる。
参考文献2:I. D. Mienye and Y. Sun, “A Survey of Ensemble Learning: Concepts, Algorithms, Applications, and Prospects”, IEEE Access Vol. 10, pp. 99129-99149, 2022.
As a result, a learning network using reservoir computing can be easily constructed. Then, it becomes possible to detect a specific object contained in a static two-dimensional image as a rectangular position of a partial image using the Echo State Network. In order to further improve this discrimination ability, a machine learning technique called ensemble learning described in
Reference 2: I. D. Mienye and Y. Sun, “A Survey of Ensemble Learning: Concepts, Algorithms, Applications, and Prospects”, IEEE Access Vol. 10, pp. 99129-99149, 2022.
なお、実施の形態1では、リザバーコンピューティング回路への入力パターンを列ベクトルとして表現し、各列ベクトルが一定の時間長を持って入力パターンを構成し、出力データには入力パターンの識別カテゴリに相当する教師信号を対応づけることにより、リザバーコンピューティング回路の学習でリザバーコンピューティング回路の中間層が持つ動的平衡点に入力パターンを対応付けることができる。これにより、リザバーコンピューティング回路を利用してパターン検出を実現することが可能になる。 In the first embodiment, the input pattern to the reservoir computing circuit is expressed as a column vector, each column vector has a certain time length and constitutes an input pattern. By associating the output data with a teacher signal corresponding to the classification category of the input pattern, the input pattern can be associated with the dynamic equilibrium point of the intermediate layer of the reservoir computing circuit during learning of the reservoir computing circuit. This makes it possible to realize pattern detection using the reservoir computing circuit.
以上に記載されたパターン検出装置100は、例えば、図8に示されているようなコンピュータ10により実現することができる。
コンピュータ10は、HDD(Hard Disk Drive)又はSSD(Solid State Drive)等のストレージ11と、メモリ12と、CPU(Central Processing Unit)等のプロセッサ13と、処理回路14と、リザバー回路15とを備える。
The above-described
The
処理回路14は、 単一回路、複合回路、プログラムで動作するプロセッサ、プログラムで動作する並列プロセッサ、ASIC(Application Specific Integrated Circuit)又はFPGA(Field Programmable Gate Array)等により構成される。
The
例えば、学習用入力データ指定部102、学習用出力データ指定部105及び適用データ入力部111は、処理回路14により構成することができる。
学習用特徴ベクトル格納部103及び学習用真値ベクトル格納部106は、メモリ12により構成することができる。
リザバー回路学習部107及びリザバー回路処理部112は、ストレージ11に記憶されているプログラムをメモリ12にロードして、そのプログラムをプロセッサ13が実行して、プロセッサ13がリザバー回路15を利用することで構成することができる。
適用データ出力部113は、ストレージ11に記憶されているプログラムをメモリ12にロードして、そのプログラムをプロセッサ13が実行することで実現することができる。
For example, the learning input
The learning feature
The reservoir
The application
以上のプログラムは、図示しないリーダ/ライタを介して、図示しない記録媒体から、あるいは、図示しない通信I/F(InterFace)を介してネットワークから、ストレージ11にダウンロードされ、それから、メモリ12上にロードされてプロセッサ13により実行されてもよい。また、リーダ/ライタを介して、図示しない記録媒体から、あるいは、図示しない通信I/Fを介してネットワークから、メモリ12上に直接ロードされ、プロセッサ13により実行されてもよい。
言い換えると、プログラムは、記録媒体等のプログラムプロダクトにより提供されてもよい。
以上のように、パターン検出装置100は、処理回路網により実現することができる。
The above programs may be downloaded to the
In other words, the program may be provided by a program product such as a recording medium.
As described above, the
実施の形態2.
図9は、実施の形態2に係る学習推論装置としてのパターン検出装置200の構成を概略的に示すブロック図である。
パターン検出装置200は、学習データ生成部201と、真値データ構築部104と、リザバー回路学習部107と、適用データ生成部210と、リザバー回路処理部112と、適用データ出力部113とを備える。
実施の形態2では、学習データ生成部201及び適用データ生成部210の一部として機能する直交フィルタ適用部220が設けられている。
FIG. 9 is a block diagram showing a schematic configuration of a
The
In the second embodiment, an orthogonal
実施の形態2に係るパターン検出装置200の真値データ構築部104、リザバー回路学習部107、リザバー回路処理部112及び適用データ出力部113は、実施の形態1に係るパターン検出装置100の真値データ構築部104、リザバー回路学習部107、リザバー回路処理部112及び適用データ出力部113と同様である。
The true value
但し、実施の形態2に係るパターン検出装置200のリザバー回路処理部112は、適用フェーズにおいて、直交フィルタ適用部220においてフィルタ処理された特徴ベクトルを、入力データとして、入力層112aに入力する。
However, in the application phase, the reservoir
学習データ生成部201は、複数の学習対象画像のそれぞれに対応する複数の特徴ベクトルが時系列で配置された学習データを生成する。
実施の形態2では、学習データ生成部201は、二次元画像である複数の学習対象画像の各々に対して直交フィルタを適用した結果である処理画像において予め定められた順番で画素値を抽出して、抽出された順番でその抽出された画素値を並べることで複数の特徴ベクトルの各々を生成する。
The learning
In
学習データ生成部201は、学習用入力データ指定部202と、直交フィルタ適用部220と、学習用特徴ベクトル格納部103とを備える。
実施の形態2に係るパターン検出装置200の学習用特徴ベクトル格納部103は、実施の形態1に係るパターン検出装置100の学習用特徴ベクトル格納部103と同様である。
The learning
The training feature
学習用入力データ指定部202は、学習フェーズにおいて、一つの学習用画像の解像度を変換した画像を、直交フィルタ適用部220に与える。
In the learning phase, the learning input
適用データ生成部210は、二次元画像である推論対象画像に対して直交フィルタを適用した結果である処理画像において予め定められた順番で画素値を抽出して、抽出された順番でその抽出された画素値を並べることで適用データを生成する。
適用データ生成部210は、適用データ入力部211と、直交フィルタ適用部220とを備える。
The application
The application
適用データ入力部211は、適用フェーズにおいて、新たに二次元画像の入力を受け付けて、その二次元画像の解像度を変換した画像を、直交フィルタ適用部220に与える。
In the application phase, the application
直交フィルタ適用部220は、学習用入力データ指定部202からの画像に直交フィルタを適用して特徴ベクトルを生成する。そして、直交フィルタ適用部220は、フィルタ処理された複数の特徴ベクトルが一定の時間長を持つように構成することで、学習用特徴ベクトルを生成し、その特徴ベクトルを学習用特徴ベクトル格納部103に与える。
また、直交フィルタ適用部220は、適用データ入力部211からの画像に直交フィルタを適用して特徴ベクトルを生成し、その特徴ベクトルをリザバー回路処理部112に与える。
The orthogonal
Moreover, the orthogonal
図10は、実施の形態2における学習フェーズにおける学習用入力データ指定部202及び直交フィルタ適用部220での処理を説明するための概略図である。
ここでは、直交フィルタ適用部220で用いる直交フィルタとして、フィルタ係数が「1」と、「-1」との2値からなるWalsh-Hadamardフィルタが利用される例を示す。また、実施の形態1と同様に、学習用入力データ指定部202に保持されている入力データを変換する動作のうち、学習用画像セットから正画像又は偽画像を真値として持つ一つの画像をEcho State Networkで学習する場合の学習フェーズでの処理について説明する。
FIG. 10 is a schematic diagram for explaining the processing in the learning input
Here, an example is shown in which a Walsh-Hadamard filter having filter coefficients of two values, "1" and "-1", is used as the orthogonal filter used in the orthogonal
まず、Echo State Networkの学習に用いる一つの部分画像を示す二次元画像データが、学習用入力データ指定部202が有する学習画像入力バッファ202aに格納される。
First, two-dimensional image data showing one partial image to be used for learning the Echo State Network is stored in the learning
次に、学習画像入力バッファ202aに格納されている二次元画像データで示される部分画像を特徴ベクトル化するために、学習用入力データ指定部202は、その部分画像の解像度を変換して、変換後のデータを特徴ベクトル変換用画像バッファ202bに格納する。
Next, in order to convert the partial image represented by the two-dimensional image data stored in the training
次に、直交フィルタ適用部220の直交フィルタ適用処理ユニット220aは、特徴ベクトル変換用画像バッファ202bに格納されている二次元画像に対し、フィルタ処理を行い、その結果を直交フィルタ出力バッファ220bに格納する。
Next, the orthogonal filter
次に、直交フィルタ適用部220は、直交フィルタ出力バッファ220bに保存されているデータから、実施の形態1と同様に、特徴ベクトルを生成し、その特徴ベクトルを、特徴ベクトル用バッファ220cに格納する。
Next, the orthogonal
以降、Echo State Networkによる学習フェーズの処理は実施の形態1と同様である。ここで、直交フィルタ適用部220が有する直交フィルタ適用処理ユニット220aにおいて使用する直交フィルタの例として、下記の参考文献3に記載されているWalsh-Hadamardフィルタがある。
Then, the learning phase processing by the Echo State Network is the same as in
参考文献3:Y. Hel-Or and H. Hel-Or, “Real-Time Pattern Matching Using Projection Kernels”, IEEE Transactions on Pattern Analysis and Machine Intelligence, 27(9), pp.1430-1445, 2005. Reference 3: Y. Hel-Or and H. Hel-Or, “Real-Time Pattern Matching Using Projection Kernels”, IEEE Transactions on Pattern Analysis and Machine Intelligence, 27(9), pp. 1430-1445, 2005.
Walsh-Hadamardフィルタは、1次元として定義され、さらに1次元と1次元の積として二次元のWalsh-Hadamardフィルタを定義することができる。 A Walsh-Hadamard filter is defined as one-dimensional, and a two-dimensional Walsh-Hadamard filter can be further defined as the product of a first dimension and a first dimension.
図11は、二次元のWalsh-Hadamardフィルタの階数N=8の例であり、8×8個の係数からなる1個の要素フィルタを、空間周波数を細かくする形で縦方向及び横方向に8×8個の要素フィルタを並べたもので、縦横8×8画素の画像に適用可能である。 Figure 11 shows an example of a two-dimensional Walsh-Hadamard filter with rank N=8, where one element filter made up of 8x8 coefficients is arranged vertically and horizontally in a way that refines the spatial frequency, and can be applied to an image with 8x8 pixels vertically and horizontally.
ここでWalsh-Hadamardフィルタの階数Nは2のべき乗である必要があり、N=2,4,8,16,32,・・・を取り得る。
図11に示されている個々のフィルタについて、白は「+1」、黒は「-1」の係数を意味する。言い換えると、このWalsh-Hadamardフィルタを8×8画素の画像に適用する際は乗算を必要とせず、加減算だけでフィルタ演算がなされるため、空間周波数分解の高速演算が可能になる。
Here, the rank N of the Walsh-Hadamard filter must be a power of 2, and can be N=2, 4, 8, 16, 32, . . .
11, white means a coefficient of "+1" and black means a coefficient of "-1." In other words, when applying this Walsh-Hadamard filter to an image of 8×8 pixels, no multiplication is required, and the filter calculation is performed only by addition and subtraction, enabling high-speed calculation of spatial frequency decomposition.
次に、実施の形態2における適用フェーズについて、図12を用いて説明する。
まず、一つの部分画像を示す二次元画像データが、適用データ入力部211が有する適用画像入力バッファ211aに格納される。
Next, the application phase in the second embodiment will be described with reference to FIG.
First, two-dimensional image data representing one partial image is stored in the application
次に、適用画像入力バッファ211aに格納されている二次元画像データで示される部分画像を特徴ベクトル化するために、適用データ入力部211は、その部分画像の解像度を変換して、変換後のデータを特徴ベクトル変換用画像バッファ211bに格納する。
Next, in order to convert the partial image represented by the two-dimensional image data stored in the application
次に、直交フィルタ適用部220の直交フィルタ適用処理ユニット220aは、特徴ベクトル変換用画像バッファ211bに格納されている二次元画像に対し、フィルタ処理を行い、その結果を直交フィルタ出力バッファ220bに格納する。
Next, the orthogonal filter
次に、直交フィルタ適用部220は、直交フィルタ出力バッファ220bに保存されているデータから、実施の形態1と同様に、特徴ベクトルを生成し、その特徴ベクトルを、特徴ベクトル用バッファ220cに格納する。
Next, the orthogonal
学習済みのEcho State Networkを有したリザバー回路処理部112は、新たな二次元画像を列ベクトルとして直交フィルタ適用部220が構築した特徴ベクトルの入力を受け入れる。
学習済のEcho State Networkは、入力層112a、中間層112b及び出力層112cを備える。そして、リザバー回路処理部112は、学習済みのEcho State Networkにより出力ベクトルを算出して、適用データ出力部113の出力ベクトル格納バッファ113aに、その出力ベクトルを格納する。
The reservoir
The trained Echo State Network includes an
そして、適用データ出力部113では、判定回路113bが、出力ベクトルが検知対象であることを意味する正画像か、あるいは非検知対象である偽画像かを判定する。
Then, in the application
なお、実施の形態2においては、実施の形態1と同様、学習フェーズにおいて、学習用入力データ指定部202に複数枚の学習用画像、学習用出力データ指定部105に、個々の学習用画像に紐づけられた真値ベクトルを複数個束ねて格納した上で、リザバー回路学習部107がEcho State Networkの学習を行ってもよい。
In the second embodiment, similarly to the first embodiment, in the learning phase, a plurality of learning images may be stored in the learning input
なお、実施の形態2では、直交フィルタ適用部220で用いる直交フィルタとして、Walsh-Hadamardフィルタを利用した例を説明したが、別の直交フィルタが利用されてもよい。例えば、上記の参考文献3で紹介されている、離散コサイン変換(DCT:Discrete Cosine Transform)又は高速フーリエ変換(FFT:Fast Fourier Transform)を使って、二次元画像が特徴ベクトルに変換されてもよい。
In the second embodiment, an example was described in which a Walsh-Hadamard filter was used as the orthogonal filter used in the orthogonal
なお、実施の形態2では、リザバーコンピューティング回路に学習させる学習用パターンを特徴空間にマッピングしたときに、直交変換を利用して、真値の異なる学習用パターンの特徴空間内における距離を拡大することができるため、リザバーコンピューティングによる学習ネットワークを容易に構築することができるとともに、リザバーコンピューティング回路を利用したパターン検出の識別性能を向上させることが可能になる。 In addition, in the second embodiment, when the learning patterns to be trained by the reservoir computing circuit are mapped into the feature space, the distance in the feature space of the learning patterns having different true values can be expanded using an orthogonal transformation, so that a learning network using reservoir computing can be easily constructed and the discrimination performance of pattern detection using the reservoir computing circuit can be improved.
以上に記載されたパターン検出装置200も、図8に示されているようなコンピュータ10で実現することができる。
例えば、直交フィルタ適用部220も、ストレージ11に記憶されているプログラムをメモリ12にロードして、そのプログラムをプロセッサ13が実行すること、又は、処理回路14により構成することができる。
The above-described
For example, the orthogonal
実施の形態3.
図13は、実施の形態3に係るパターン検出装置300の構成を概略的に示すブロック図である。
パターン検出装置300は、学習データ生成部301と、真値データ構築部104と、リザバー回路学習部107と、適用データ生成部310と、リザバー回路処理部112と、適用データ出力部113とを備える。
実施の形態3では、学習データ生成部301及び適用データ生成部310の一部として機能する直交フィルタ適用部320及び値域変換部321が設けられている。
Embodiment 3.
FIG. 13 is a block diagram illustrating a schematic configuration of a
The
In the third embodiment, an orthogonal
実施の形態3に係るパターン検出装置300の真値データ構築部104、リザバー回路学習部107、リザバー回路処理部112及び適用データ出力部113は、実施の形態1に係るパターン検出装置100の真値データ構築部104、リザバー回路学習部107、リザバー回路処理部112及び適用データ出力部113と同様である。
但し、実施の形態3に係るパターン検出装置300のリザバー回路処理部112は、適用フェーズにおいて、値域変換部321において変換処理された特徴ベクトルを、入力データとして、入力層112aに入力する。
The true value
However, in the application phase, the reservoir
学習データ生成部301は、複数の学習対象画像のそれぞれに対応する複数の特徴ベクトルが時系列で配置された学習データを生成する。
実施の形態3では、学習データ生成部301は、二次元画像である複数の学習対象画像の各々に対して直交フィルタを適用した結果である処理画像に対して、画素値を予め定められた値域内に変換する関数を適用した結果である変換画像において予め定められた順番で画素値を抽出して、抽出された順番でその抽出された画素値を並べることで複数の特徴ベクトルの各々を生成する。
The learning
In embodiment 3, the training
学習データ生成部301は、学習用入力データ指定部202と、直交フィルタ適用部320と、値域変換部321と、学習用特徴ベクトル格納部103とを備える。
実施の形態3に係るパターン検出装置300の学習用入力データ指定部202は、実施の形態2に係るパターン検出装置200の学習用入力データ指定部202と同様である。
また、実施の形態3に係るパターン検出装置300の学習用特徴ベクトル格納部103は、実施の形態1に係るパターン検出装置300の学習用特徴ベクトル格納部103と同様である。
The learning
The learning input
Moreover, the training feature
適用データ生成部310は、推論対象となる画像である推論対象画像から特徴ベクトルを適用データとして生成する。
実施の形態3では、適用データ生成部310は、二次元画像である推論対象画像に対して直交フィルタを適用した結果である処理画像に対して、画素値を予め定められた値域内に変換する関数を適用した結果である変換画像において予め定められた順番で画素値を抽出して、抽出された順番でその抽出された画素値を並べることで適用データを生成する。
The application
In embodiment 3, the application
適用データ生成部310は、適用データ入力部211と、直交フィルタ適用部320と、値域変換部321とを備える。
実施の形態3に係るパターン検出装置300の適用データ入力部211は、実施の形態3に係るパターン検出装置200の適用データ入力部211と同様である。
The application
The application
直交フィルタ適用部320は、学習用入力データ指定部202からの画像に直交フィルタを適用して、フィルタ処理後の画像データを値域変換部321に与える。
また、直交フィルタ適用部320は、適用データ入力部211からの画像に直交フィルタを適用して、フィルタ処理後の画像データを値域変換部321に与える。
The orthogonal
Furthermore, the orthogonal
値域変換部321は、学習フェーズにおいて、学習用入力データ指定部202からの画像に対して直交フィルタ適用部320によりフィルタ処理された画像データに値域を変換する関数を適用して、特徴ベクトルを生成する。そして、値域変換部321は、そのような関数が適用された複数の特徴ベクトルが一定の時間長を持つように構成することで、学習用特徴ベクトルを生成し、その特徴ベクトルを学習用特徴ベクトル格納部103に与える。
また、値域変換部321は、学習フェーズにおいて、適用データ入力部211からの画像に対して直交フィルタ適用部320によりフィルタ処理された画像データに値域を変換する関数を適用して、特徴ベクトルを生成し、その特徴ベクトルをリザバー回路処理部112に与える。
In the learning phase, the value
In addition, during the learning phase, the value
図14は、実施の形態3における学習フェーズにおける学習用入力データ指定部202、直交フィルタ適用部320及び値域変換部321での処理を説明するための概略図である。
ここでは、実施の形態2と同様に、直交フィルタ適用部320で用いる直交フィルタとして、フィルタ係数が「1」と、「-1」との2値からなるWalsh-Hadamardフィルタが利用される例を示す。
そして、値域変換部321で用いる値域変換のための非線形関数として、双曲線正接関数(tanh(x))が利用され、直交フィルタ適用部320から出力される、Walsh-Hadamardフィルタの出力値を「-1」から「1」の間に収めて、特徴ベクトルを構築する動作について説明する。
FIG. 14 is a schematic diagram for explaining the processing in the learning input
Here, as in the second embodiment, an example is shown in which a Walsh-Hadamard filter having filter coefficients of two values, "1" and "-1", is used as the orthogonal filter used in orthogonal
Next, the hyperbolic tangent function (tanh(x)) is used as a nonlinear function for range conversion used in the
まず、Echo State Networkの学習に用いる一つの部分画像を示す二次元画像データが、学習用入力データ指定部202が有する学習画像入力バッファ202aに格納される。
First, two-dimensional image data showing one partial image to be used for learning the Echo State Network is stored in the learning
次に、学習画像入力バッファ202aに格納されている二次元画像データで示される部分画像を特徴ベクトル化するために、学習用入力データ指定部202は、その部分画像の解像度を変換して、変換後のデータを特徴ベクトル変換用画像バッファ202bに格納する。
Next, in order to convert the partial image represented by the two-dimensional image data stored in the training
次に、直交フィルタ適用部320の直交フィルタ適用処理ユニット320aは、特徴ベクトル変換用画像バッファ202bに格納されている二次元画像に対し、フィルタ処理を行い、その結果を直交フィルタ出力バッファ320bに格納する。
Next, the orthogonal filter
次に、値域変換部321では、直交フィルタ出力バッファ320bに格納されているフィルタ処理された画像データの値を、値域変換関数適用処理ユニット321aが有する値域変換関数により変換し、変換された値を有するデータが値域変換関数出力バッファ321bに格納される。
Next, the
そして、値域変換部321は、値域変換関数出力バッファ321bに保存されているデータから、実施の形態1と同様に、特徴ベクトルを生成し、その特徴ベクトルを、特徴ベクトル用バッファ321cに格納する。
Then, the
ここで、値域変換関数適用処理ユニット321aが有する値域変換関数の例として、双曲線正接関数(hyperbolic tangent)がある。
双曲線正接関数tanh(x)は、下記の(6)式で示され、図15は、そのグラフを示す。
Here, an example of the range conversion function that the range conversion function
The hyperbolic tangent function tanh(x) is expressed by the following equation (6), and FIG. 15 shows a graph thereof.
![]()
![]()
実施の形態2においては、直交フィルタ適用部220の算出結果である直交フィルタ出力バッファ220bの各値から直接特徴ベクトルが構築されているが、実施の形態3においては、値域変換部321によって、入力画像に対する直交フィルタの適用値の分布が大きくばらつく場合であっても、tanh(x)が値域を-1<f(x)<1の間に収めるため、リザバー回路学習部107の学習時の動作を安定させることができる。
In the second embodiment, the feature vector is constructed directly from each value of the orthogonal
次に、実施の形態3における適用フェーズについて、図16を用いて説明する。
まず、一つの部分画像を示す二次元画像データが、適用データ入力部211が有する適用画像入力バッファ211aに格納される。
Next, the application phase in the third embodiment will be described with reference to FIG.
First, two-dimensional image data representing one partial image is stored in the application
次に、適用画像入力バッファ211aに格納されている二次元画像データで示される部分画像を特徴ベクトル化するために、適用データ入力部211は、その部分画像の解像度を変換して、変換後のデータを特徴ベクトル変換用画像バッファ211bに格納する。
Next, in order to convert the partial image represented by the two-dimensional image data stored in the application
次に、直交フィルタ適用部320の直交フィルタ適用処理ユニット320aは、特徴ベクトル変換用画像バッファ211bに格納されている二次元画像に対し、フィルタ処理を行い、その結果を直交フィルタ出力バッファ320bに格納する。
Next, the orthogonal filter
次に、値域変換部321では、直交フィルタ出力バッファ320bに格納されているフィルタ処理された画像データの値を、値域変換関数適用処理ユニット321aが有する値域変換関数により変換し、変換された値を有するデータが値域変換関数出力バッファ321bに格納される。
Next, the
そして、値域変換部321は、値域変換関数出力バッファ321bに保存されているデータから、実施の形態1と同様に、特徴ベクトルを生成し、その特徴ベクトルを、特徴ベクトル用バッファ321cに格納する。
Then, the
学習済みのEcho State Networkを有したリザバー回路処理部112は、新たな二次元画像を列ベクトルとして値域変換部321が構築した特徴ベクトルの入力を受け入れる。
学習済のEcho State Networkは、入力層112a、中間層112b及び出力層112cを備える。そして、リザバー回路処理部112は、学習済みのEcho State Networkにより出力ベクトルを算出して、適用データ出力部113の出力ベクトル格納バッファ113aに、その出力ベクトルを格納する。
The reservoir
The trained Echo State Network includes an
そして、適用データ出力部113では、判定回路113bが、出力ベクトルが検知対象であることを意味する正画像か、あるいは非検知対象である偽画像かを判定する。
Then, in the application
なお、実施の形態3においても、実施の形態1と同様、学習フェーズにおいて、学習用入力データ指定部202に複数枚の学習用画像、学習用出力データ指定部105に、個々の学習用画像に紐づけられた真値ベクトルを複数個束ねて格納した上で、リザバー回路学習部107がEcho State Networkの学習を行ってもよい。
In the third embodiment, as in the first embodiment, in the learning phase, multiple learning images may be stored in the learning input
以上のように、実施の形態3によれば、学習済みのEcho State Networkを有したリザバー回路処理部112に特徴ベクトルを入力する前に、値域変換部321によって特徴ベクトルを構成する各要素の値を「-1」から「1」の間に収めることができるため、リザバーコンピューティングによる学習ネットワークを容易に構築することができるとともに、リザバー回路処理部112の処理動作を安定させることができる。
As described above, according to the third embodiment, before inputting a feature vector to the reservoir
なお、実施の形態3では、リザバーコンピューティング回路に入力する入力データの値域を狭めることにより、リザバーコンピューティング回路の動作が安定するため、リザバーコンピューティング回路を利用したパターン検出の識別性能を向上させることが可能になる。 In addition, in the third embodiment, by narrowing the range of values of the input data input to the reservoir computing circuit, the operation of the reservoir computing circuit becomes stable, and it becomes possible to improve the discrimination performance of pattern detection using the reservoir computing circuit.
以上に記載された実施の形態1~3では、パターン検出装置100~300は、学習フェーズ及び推論フェーズの両方の処理を行う装置として説明したが、実施の形態1~3は、以上のような装置に限定されない。
例えば、実施の形態1~3は、学習フェーズでの処理を行う学習装置及び推論フェーズでの処理を行う推論装置として構成することもできる。
また、実施の形態1~3に係るパターン検出装置100~300が行っている処理を、ネットワークに接続されて、互いにデータを送受信することのできる複数のコンピュータが分散して行ってもよい。言い換えると、実施の形態1~3は、複数のコンピュータからなる学習推論システムとしてのパターン検出システムとして構成されてもよい。
In the above-described
For example, the first to third embodiments can be configured as a learning device that performs processing in the learning phase and an inference device that performs processing in the inference phase.
Furthermore, the processes performed by the
100,200,300 パターン検出装置、 101,201,301 学習データ生成部、 102,202 学習用入力データ指定部、 103 学習用特徴ベクトル格納部、 104 真値データ構築部、 105 学習用出力データ指定部、 106 学習用真値ベクトル格納部、 107 リザバー回路学習部、 210,310 適用データ生成部、 111,211 適用データ入力部、 112 リザバー回路処理部、 113 適用データ出力部、 220,320 直交フィルタ適用部、 321 値域変換部。 100, 200, 300 Pattern detection device; 101, 201, 301 Learning data generation unit; 102, 202 Learning input data specification unit; 103 Learning feature vector storage unit; 104 True value data construction unit; 105 Learning output data specification unit; 106 Learning true value vector storage unit; 107 Reservoir circuit learning unit; 210, 310 Application data generation unit; 111, 211 Application data input unit; 112 Reservoir circuit processing unit; 113 Application data output unit; 220, 320 Orthogonal filter application unit; 321 Value range conversion unit.
Claims (14)
前記複数の学習対象画像のそれぞれの正偽を示す複数の真値ベクトルが、前記複数の特徴ベクトルの時系列に対応するように配置された真値データを構築する真値データ構築部と、
前記学習データ及び前記真値データを用いて、リザバーコンピューティングを利用した三層ニューラルネットワークの学習を行う学習部と、を備えること
を特徴とする学習装置。 a learning data generation unit that generates learning data in which a plurality of feature vectors corresponding to a plurality of learning target images are arranged in time series;
a true-value data constructing unit that constructs true-value data in which a plurality of true-value vectors indicating true or false of each of the plurality of learning target images are arranged in correspondence with a time series of the plurality of feature vectors;
a learning unit that uses the training data and the true value data to train a three-layer neural network using reservoir computing.
前記学習データ生成部は、前記二次元画像において予め定められた順番で画素値を抽出して、抽出された順番で前記抽出された画素値を並べることで前記複数の特徴ベクトルの各々を生成すること
を特徴とする請求項1に記載の学習装置。 each of the plurality of training images is a two-dimensional image;
2. The learning device according to claim 1, wherein the learning data generation unit generates each of the plurality of feature vectors by extracting pixel values in a predetermined order in the two-dimensional image and arranging the extracted pixel values in the extraction order.
前記学習データ生成部は、前記二次元画像に対して直交フィルタを適用した結果である処理画像において予め定められた順番で画素値を抽出して、抽出された順番で前記抽出された画素値を並べることで前記複数の特徴ベクトルの各々を生成すること
を特徴とする請求項1に記載の学習装置。 each of the plurality of training images is a two-dimensional image;
2. The learning device according to claim 1, wherein the learning data generation unit extracts pixel values in a predetermined order from a processed image that is a result of applying an orthogonal filter to the two-dimensional image, and generates each of the plurality of feature vectors by arranging the extracted pixel values in the extraction order.
前記学習データ生成部は、前記二次元画像に対して直交フィルタを適用した結果である処理画像に対して、画素値を予め定められた値域内に変換する関数を適用した結果である変換画像において予め定められた順番で画素値を抽出して、抽出された順番で前記抽出された画素値を並べることで前記複数の特徴ベクトルの各々を生成すること
を特徴とする請求項1に記載の学習装置。 each of the plurality of training images is a two-dimensional image;
2. The learning device according to claim 1, wherein the learning data generation unit extracts pixel values in a predetermined order from a transformed image, which is a result of applying a function that transforms pixel values into a predetermined range, to a processed image, which is a result of applying an orthogonal filter to the two-dimensional image, and generates each of the plurality of feature vectors by arranging the extracted pixel values in the order in which they were extracted.
複数の学習対象画像のそれぞれに対応する複数の特徴ベクトルが時系列で配置された学習データと、前記複数の学習対象画像のそれぞれの正偽を示す複数の真値ベクトルが、前記複数の特徴ベクトルの時系列に対応するように配置された真値データとを用いて、リザバーコンピューティングを利用した三層ニューラルネットワークの学習を行い、前記学習の結果として取得された、前記三層ニューラルネットワークの結合定数を用いて、学習済み三層ニューラルネットワークを生成し、前記適用データを前記学習済み三層ニューラルネットワークに入力することで、前記推論対象画像の正偽を推論する処理部と、を備えること
を特徴とする推論装置。 an application data generation unit that generates a feature vector as application data from an inference target image that is an image to be inferred;
a processing unit that uses training data in which a plurality of feature vectors corresponding to each of a plurality of training target images are arranged in a time series and true-value data in which a plurality of true-value vectors indicating the authenticity of each of the plurality of training target images are arranged to correspond to the time series of the plurality of feature vectors, generates a trained three-layered neural network using a coupling constant of the three-layered neural network obtained as a result of the training, and infers the authenticity of the inference target image by inputting the application data to the trained three-layered neural network.
前記適用データ生成部は、前記二次元画像において予め定められた順番で画素値を抽出して、抽出された順番で前記抽出された画素値を並べることで前記適用データを生成すること
を特徴とする請求項5に記載の推論装置。 The inference target image is a two-dimensional image,
The inference device according to claim 5 , wherein the application data generation unit generates the application data by extracting pixel values in a predetermined order in the two-dimensional image and arranging the extracted pixel values in the order in which they were extracted.
前記適用データ生成部は、前記二次元画像に対して直交フィルタを適用した結果である処理画像において予め定められた順番で画素値を抽出して、抽出された順番で前記抽出された画素値を並べることで前記適用データを生成すること
を特徴とする請求項5に記載の推論装置。 The inference target image is a two-dimensional image,
The inference device according to claim 5, wherein the application data generation unit generates the application data by extracting pixel values in a predetermined order from a processed image that is a result of applying an orthogonal filter to the two-dimensional image, and arranging the extracted pixel values in the order in which they were extracted.
前記適用データ生成部は、前記二次元画像に対して直交フィルタを適用した結果である処理画像に対して、画素値を予め定められた値域内に変換する関数を適用した結果である変換画像において予め定められた順番で画素値を抽出して、抽出された順番で前記抽出された画素値を並べることで前記適用データを生成すること
を特徴とする請求項5に記載の推論装置。 The inference target image is a two-dimensional image,
The inference device according to claim 5, wherein the application data generation unit generates the application data by extracting pixel values in a predetermined order from a transformed image, which is a result of applying a function that transforms pixel values into a predetermined value range, to a processed image, which is a result of applying an orthogonal filter to the two-dimensional image, and arranging the extracted pixel values in the order in which they were extracted.
前記複数の学習対象画像のそれぞれの正偽を示す複数の真値ベクトルが、前記複数の特徴ベクトルの時系列に対応するように配置された真値データを構築する真値データ構築部と、
前記学習データ及び前記真値データを用いて、リザバーコンピューティングを利用した三層ニューラルネットワークの学習を行い、前記三層ニューラルネットワークの結合定数と、前記学習の結果として取得する学習部と、
推論対象となる画像である推論対象画像から特徴ベクトルを適用データとして生成する適用データ生成部と、
前記取得された結合定数を用いて、学習済み三層ニューラルネットワークを生成し、前記適用データを前記学習済み三層ニューラルネットワークに入力することで、前記推論対象画像の正偽を推論する処理部と、を備えること
を特徴とする学習推論装置。 a learning data generation unit that generates learning data in which a plurality of feature vectors corresponding to a plurality of learning target images are arranged in time series;
a true-value data constructing unit that constructs true-value data in which a plurality of true-value vectors indicating true or false of each of the plurality of learning target images are arranged in correspondence with a time series of the plurality of feature vectors;
A learning unit that uses the learning data and the true value data to learn a three-layered neural network using reservoir computing, and obtains a coupling constant of the three-layered neural network and a result of the learning;
an application data generation unit that generates a feature vector as application data from an inference target image that is an image to be inferred;
a processing unit that uses the acquired coupling constants to generate a trained three-layered neural network and inputs the application data into the trained three-layered neural network to infer whether the inference target image is true or false.
複数の学習対象画像のそれぞれに対応する複数の特徴ベクトルが時系列で配置された学習データを生成する学習データ生成部、
前記複数の学習対象画像のそれぞれの正偽を示す複数の真値ベクトルが、前記複数の特徴ベクトルの時系列に対応するように配置された真値データを構築する真値データ構築部、及び、
前記学習データ及び前記真値データを用いて、リザバーコンピューティングを利用した三層ニューラルネットワークの学習を行う学習部、として機能させること
を特徴とするプログラム。 Computer,
a learning data generation unit that generates learning data in which a plurality of feature vectors corresponding to a plurality of learning target images are arranged in time series;
a true-value data constructing unit that constructs true-value data in which a plurality of true-value vectors indicating true or false of each of the plurality of learning target images are arranged in correspondence with a time series of the plurality of feature vectors; and
a program that functions as a learning unit that uses the training data and the true value data to train a three-layer neural network using reservoir computing.
推論対象となる画像である推論対象画像から特徴ベクトルを適用データとして生成する適用データ生成部、及び、
複数の学習対象画像のそれぞれに対応する複数の特徴ベクトルが時系列で配置された学習データと、前記複数の学習対象画像のそれぞれの正偽を示す複数の真値ベクトルが、前記複数の特徴ベクトルの時系列に対応するように配置された真値データとを用いて、リザバーコンピューティングを利用した三層ニューラルネットワークの学習を行い、前記学習の結果として取得された、前記三層ニューラルネットワークの結合定数を用いて、学習済み三層ニューラルネットワークを生成し、前記適用データを前記学習済み三層ニューラルネットワークに入力することで、前記推論対象画像の正偽を推論する処理部、として機能させること
を特徴とするプログラム。 Computer,
an application data generation unit that generates a feature vector as application data from an inference target image that is an image to be inferred;
a processing unit that performs training of a three-layered neural network using reservoir computing, using training data in which a plurality of feature vectors corresponding to each of a plurality of training target images are arranged in a time series, and true-value data in which a plurality of true-value vectors indicating the authenticity of each of the plurality of training target images are arranged so as to correspond to the time series of the plurality of feature vectors, generates a trained three-layered neural network using a coupling constant of the three-layered neural network obtained as a result of the training, and inputs the application data into the trained three-layered neural network, thereby functioning as a processing unit that infers the authenticity of the inference target image.
前記複数の学習対象画像のそれぞれの正偽を示す複数の真値ベクトルが、前記複数の特徴ベクトルの時系列に対応するように配置された真値データを構築する真値データ構築部と、
前記学習データ及び前記真値データを用いて、リザバーコンピューティングを利用した三層ニューラルネットワークの学習を行い、前記三層ニューラルネットワークの結合定数と、前記学習の結果として取得する学習部と、
推論対象となる画像である推論対象画像から特徴ベクトルを適用データとして生成する適用データ生成部と、
前記取得された結合定数を用いて、学習済み三層ニューラルネットワークを生成し、前記適用データを前記学習済み三層ニューラルネットワークに入力することで、前記推論対象画像の正偽を推論する処理部と、を備えること
を特徴とする学習推論システム。 a learning data generation unit that generates learning data in which a plurality of feature vectors corresponding to a plurality of learning target images are arranged in time series;
a true-value data constructing unit that constructs true-value data in which a plurality of true-value vectors indicating true or false of each of the plurality of learning target images are arranged in correspondence with a time series of the plurality of feature vectors;
A learning unit that uses the learning data and the true value data to learn a three-layered neural network using reservoir computing, and obtains a coupling constant of the three-layered neural network and a result of the learning;
an application data generation unit that generates a feature vector as application data from an inference target image that is an image to be inferred;
a processing unit that uses the acquired coupling constants to generate a trained three-layered neural network and inputs the application data into the trained three-layered neural network to infer whether the inference target image is true or false.
前記複数の学習対象画像のそれぞれの正偽を示す複数の真値ベクトルが、前記複数の特徴ベクトルの時系列に対応するように配置された真値データを構築し、
前記学習データ及び前記真値データを用いて、リザバーコンピューティングを利用した三層ニューラルネットワークの学習を行うこと
を特徴とする学習方法。 generating training data in which a plurality of feature vectors corresponding to a plurality of training target images are arranged in a time series;
constructing true-value data in which a plurality of true-value vectors indicating the authenticity of each of the plurality of learning target images are arranged to correspond to a time series of the plurality of feature vectors;
A learning method comprising: learning a three-layer neural network using reservoir computing by using the learning data and the true value data.
複数の学習対象画像のそれぞれに対応する複数の特徴ベクトルが時系列で配置された学習データと、前記複数の学習対象画像のそれぞれの正偽を示す複数の真値ベクトルが、前記複数の特徴ベクトルの時系列に対応するように配置された真値データとを用いて、リザバーコンピューティングを利用した三層ニューラルネットワークの学習を行い、前記学習の結果として取得された、前記三層ニューラルネットワークの結合定数を用いて、学習済み三層ニューラルネットワークを生成し、
前記適用データを前記学習済み三層ニューラルネットワークに入力することで、前記推論対象画像の正偽を推論すること
を特徴とする推論方法。 A feature vector is generated as application data from an inference target image, which is an image to be inferred;
training a three-layered neural network using reservoir computing, using training data in which a plurality of feature vectors corresponding to each of a plurality of training target images are arranged in a time series, and true-value data in which a plurality of true-value vectors indicating the authenticity of each of the plurality of training target images are arranged so as to correspond to the time series of the plurality of feature vectors; and generating a trained three-layered neural network using coupling constants of the three-layered neural network obtained as a result of the training;
and inputting the application data into the trained three-layer neural network to infer whether the inference target image is true or false.
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2025541238A JPWO2025041292A1 (en) | 2023-08-23 | 2023-08-23 | |
| PCT/JP2023/030253 WO2025041292A1 (en) | 2023-08-23 | 2023-08-23 | Training device, inference device, training inference device, program, training inference system, training method, and inference method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2023/030253 WO2025041292A1 (en) | 2023-08-23 | 2023-08-23 | Training device, inference device, training inference device, program, training inference system, training method, and inference method |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2025041292A1 true WO2025041292A1 (en) | 2025-02-27 |
Family
ID=94731815
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2023/030253 Pending WO2025041292A1 (en) | 2023-08-23 | 2023-08-23 | Training device, inference device, training inference device, program, training inference system, training method, and inference method |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JPWO2025041292A1 (en) |
| WO (1) | WO2025041292A1 (en) |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20200082540A1 (en) * | 2018-09-07 | 2020-03-12 | Volvo Car Corporation | Methods and systems for providing fast semantic proposals for image and video annotation |
| CN112686801A (en) * | 2021-01-05 | 2021-04-20 | 金陵科技学院 | Water quality monitoring method based on aerial image and series echo state network |
| JP2023087931A (en) * | 2021-12-14 | 2023-06-26 | 国立大学法人九州工業大学 | Information processing device, information processing method, and program |
-
2023
- 2023-08-23 JP JP2025541238A patent/JPWO2025041292A1/ja active Pending
- 2023-08-23 WO PCT/JP2023/030253 patent/WO2025041292A1/en active Pending
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20200082540A1 (en) * | 2018-09-07 | 2020-03-12 | Volvo Car Corporation | Methods and systems for providing fast semantic proposals for image and video annotation |
| CN112686801A (en) * | 2021-01-05 | 2021-04-20 | 金陵科技学院 | Water quality monitoring method based on aerial image and series echo state network |
| JP2023087931A (en) * | 2021-12-14 | 2023-06-26 | 国立大学法人九州工業大学 | Information processing device, information processing method, and program |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2025041292A1 (en) | 2025-02-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Alshazly et al. | Deep convolutional neural networks for unconstrained ear recognition | |
| Coates et al. | Selecting receptive fields in deep networks | |
| Zhang et al. | Motor current signal analysis using hypergraph neural networks for fault diagnosis of electromechanical system | |
| KR102545128B1 (en) | Client device with neural network and system including the same | |
| Khaw et al. | Image noise types recognition using convolutional neural network with principal components analysis | |
| CN113627163B (en) | A kind of attention model, feature extraction method and related device | |
| EP4040378B1 (en) | Burst image-based image restoration method and apparatus | |
| CN113191390A (en) | Image classification model construction method, image classification method and storage medium | |
| Gigante et al. | Visualizing the phate of neural networks | |
| Zeebaree et al. | Csaernet: An efficient deep learning architecture for image classification | |
| US20210374613A1 (en) | Anomaly detection in high dimensional spaces using tensor networks | |
| Lu et al. | Linear programming support vector regression with wavelet kernel: A new approach to nonlinear dynamical systems identification | |
| ur Rehman et al. | Hybrid feature selection and tumor identification in brain MRI using swarm intelligence | |
| CN115053256B (en) | Spatially adaptive image filtering | |
| Park et al. | Vortex Feature Positioning: Bridging tabular IIoT data and image-based deep learning | |
| Costa et al. | Fusion of image representations for time series classification with deep learning | |
| WO2025041292A1 (en) | Training device, inference device, training inference device, program, training inference system, training method, and inference method | |
| Zhu et al. | Persistence image from 3D medical image: Superpixel and optimized gaussian coefficient | |
| Zhai et al. | Quantum neural compressive sensing for ghost imaging | |
| Shekar et al. | Local DCT-based deep learning architecture for image forgery detection | |
| BanTeng et al. | Channel-wise dense connection graph convolutional network for skeleton-based action recognition | |
| Grüning et al. | Efficient coding in human vision as a useful bias in computer vision and machine learning | |
| CN114902240B (en) | Neural network channel number searching method and device | |
| Kage | An algorithm for two-dimensional pattern detection by combining Echo State Network-based weak classifiers | |
| Goswami | Application of capsule networks for image classification on complex datasets |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 23949750 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2025541238 Country of ref document: JP Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2025541238 Country of ref document: JP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |