WO2024189883A1 - 情報処理装置、情報処理方法、およびプログラム - Google Patents
情報処理装置、情報処理方法、およびプログラム Download PDFInfo
- Publication number
- WO2024189883A1 WO2024189883A1 PCT/JP2023/010286 JP2023010286W WO2024189883A1 WO 2024189883 A1 WO2024189883 A1 WO 2024189883A1 JP 2023010286 W JP2023010286 W JP 2023010286W WO 2024189883 A1 WO2024189883 A1 WO 2024189883A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- relationship
- knowledge
- knowledge data
- data
- relational
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images












Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/02—Knowledge representation; Symbolic representation
- G06N5/022—Knowledge engineering; Knowledge acquisition
Definitions
- the present invention relates to a technique for constructing relational knowledge.
- Non-Patent Document 1 describes a technology that uses a language model that can execute a target language processing task by providing examples of the language processing task, and generates new related knowledge data by referencing a small amount of related knowledge data as examples.
- Non-Patent Document 1 has the problem that the generated relational knowledge data may be appropriate in one context, but may not be appropriate in a different context.
- the accuracy of the generated relational knowledge data may depend on the accuracy of the referenced cases. In order to solve such problems, it is important to improve the accuracy of the relational knowledge data referenced as cases by the language model.
- One aspect of the present invention has been made in consideration of the above problems, and one example of its purpose is to improve the accuracy of relational knowledge data referenced as examples by a language model.
- An information processing device includes: an acquisition means for acquiring a first relationship knowledge dataset composed of first relationship knowledge data indicating a plurality of pieces of knowledge having a specific relationship, and information specifying the context of the knowledge; a generation means for generating a second relationship knowledge dataset composed of second relationship knowledge data corresponding to the context by referring to the first relationship knowledge dataset as an example using a language model; and an update means for updating the first relationship knowledge dataset using the second relationship knowledge data having the specific relationship from among the second relationship knowledge dataset.
- An information processing method is an information processing method executed by one or more processors, and includes acquiring a first relationship knowledge dataset composed of first relationship knowledge data indicating a plurality of pieces of knowledge having a specific relationship, and information specifying the context of the knowledge, using a language model to generate a second relationship knowledge dataset composed of second relationship knowledge data corresponding to the context by referring to the first relationship knowledge dataset as an example, and updating the first relationship knowledge dataset using the second relationship knowledge data having the specific relationship from among the second relationship knowledge dataset.
- a program causes a computer to function as: an acquisition means for acquiring a first relational knowledge dataset composed of first relational knowledge data indicating a plurality of pieces of knowledge having a specific relationship, and information specifying the context of the knowledge; a generation means for generating a second relational knowledge dataset composed of second relational knowledge data corresponding to the context by referring to the first relational knowledge dataset as an example using a language model; and an update means for updating the first relational knowledge dataset using the second relational knowledge data having the specific relationship from among the second relational knowledge dataset.
- FIG. 1 is a block diagram showing a configuration of an information processing device according to a first exemplary embodiment of the present invention.
- FIG. 2 is a flow chart showing the flow of an information processing method according to the first exemplary embodiment of the present invention.
- FIG. 11 is a block diagram showing a configuration of an information processing system according to an exemplary embodiment 2 of the present invention.
- FIG. 11 is a flow chart showing the flow of an information processing method according to an exemplary embodiment 2 of the present invention.
- 5 is a schematic diagram showing the transition of information generated in each step of the information processing method shown in FIG. 4 .
- FIG. 6 is a schematic diagram continuing from FIG. 5 .
- FIG. 13 is a diagram showing a specific example of a first relational knowledge data set.
- FIG. 13 is a diagram showing a specific example of a first relational knowledge data set.
- FIG. 11 is a diagram showing a specific example of a context list.
- FIG. 13 is a diagram illustrating a specific example of a first prompt.
- FIG. 13 is a diagram showing a specific example of a second antecedent data list.
- FIG. 13 is a diagram illustrating a specific example of a second prompt.
- FIG. 11 is a diagram showing a specific example of a second relational knowledge data set.
- FIG. 13 is a diagram showing a specific example of a third relationship knowledge data set.
- FIG. 13 is a diagram illustrating a specific example of a third prompt.
- 1 is a block diagram showing an example of a hardware configuration of an information processing device according to each exemplary embodiment of the present invention.
- Example embodiment 1 DETAILED DESCRIPTION OF THE PREFERRED EMBODIMENTS
- This exemplary embodiment is a basic form of the exemplary embodiments described below.
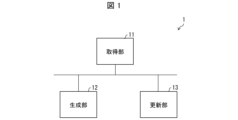
- Fig. 1 is a block diagram showing the configuration of the information processing device 1. As shown in Fig. 1, the information processing device 1 includes an acquisition unit 11, a generation unit 12, and an update unit 13.
- the acquisition unit 11 acquires a first relationship knowledge dataset composed of first relationship knowledge data indicating a plurality of pieces of knowledge having a specific relationship, and information specifying the context of the knowledge.
- the generation unit 12 uses a language model to generate a second relationship knowledge dataset composed of second relationship knowledge data corresponding to the context by referring to the first relationship knowledge dataset as an example.
- the update unit 13 updates the first relationship knowledge dataset using second relationship knowledge data having a specific relationship from the second relationship knowledge dataset.
- the present exemplary embodiment can be realized by a program stored in the memory.
- the program causes the computer to function as an acquisition unit 11 that acquires a first relational knowledge dataset constituted by first relational knowledge data indicating a plurality of pieces of knowledge having a specific relationship and information specifying the context of the knowledge, a generation unit 12 that uses a language model to generate a second relational knowledge dataset constituted by second relational knowledge data corresponding to the context by referring to the first relational knowledge dataset as an example, and an update unit 13 that updates the first relational knowledge dataset by using the second relational knowledge data having a specific relationship from among the second relational knowledge dataset.
- the information processing device 1 configured as above executes the information processing method S1 according to this exemplary embodiment.
- the information processing method S1 is realized, for example, by the one or more processors reading and executing the above-mentioned program.
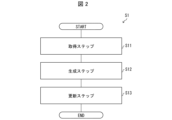
- FIG. 2 is a flow diagram showing the flow of information processing method S1.
- Information processing method S1 includes steps S11, S12, and S13.
- step S11 the acquisition unit 11 acquires a first relationship knowledge dataset composed of first relationship knowledge data indicating a plurality of pieces of knowledge having a specific relationship, and information specifying the context of the knowledge.
- step S12 the generation unit 12 uses a language model to generate a second relationship knowledge dataset composed of second relationship knowledge data corresponding to the context by referring to the first relationship knowledge dataset as an example.
- the update unit 13 updates the first relationship knowledge dataset by using the second relationship knowledge data having a specific relationship from the second relationship knowledge dataset.
- Exemplary embodiment 2 An information processing system 100 including an information processing device 1A according to a third exemplary embodiment of the present invention will be described in detail with reference to the drawings. Note that components having the same functions as those described in the first exemplary embodiment are given the same reference numerals, and descriptions thereof will be omitted as appropriate.
- the information processing system 100 is a system that generates relational knowledge data having a specific relationship in a specified context using a language model 3A.
- the relational knowledge data is composed of a plurality of pieces of knowledge having some kind of relationship.
- the relational knowledge data having a specific relationship is composed of a plurality of pieces of knowledge having a specific relationship.
- the knowledge is information expressed by a natural language sentence.
- the context is information that specifies the range or conditions in which a specific relationship is established between a plurality of pieces of knowledge. Examples of context include, but are not limited to, types of industries, countries, people, eras, etc.
- a relationship in which a context is specified is applied as the "specific relationship".
- knowledge in which the context is "before” is referred to as “antecedent knowledge”.
- knowledge in which the context is "after” is referred to as “consequent knowledge”.
- a relationship in which a context is specified is a relationship in which the original relationship does not hold if the antecedent knowledge and the consequent knowledge are interchanged. For example, when applying "causal relationship" as a "specific relationship,” knowledge of the antecedent indicates the cause, and knowledge of the consequent indicates the effect.
- Fig. 3 is a block diagram showing the configuration of the information processing system 100.
- the information processing system 100 includes an information processing device 1A, a relational knowledge database 2A, and a language model 3A.
- the information processing device 1A is communicably connected to each of the relational knowledge database 2A and the language model 3A.
- the relational knowledge database 2A is a device that stores relational knowledge data having a specific relation.
- the relational knowledge data in this exemplary embodiment includes antecedent data, consequent data, and context data.
- the antecedent data is a natural language sentence indicating knowledge of the antecedent.
- the consequent data is a natural language sentence indicating knowledge of the consequent.
- the context data is a natural language sentence indicating a context related to the antecedent and consequent knowledge.
- the language model 3A is a general-purpose large-scale language model trained to execute a language processing task by referring to examples of the language processing task.
- the examples are also referred to as samples.
- the language model 3A may be a model that uses a prompt as an input and generates information corresponding to the prompt.
- the prompt and the generated information are each natural language sentences.
- the prompt includes an instruction, a sample, and a query.
- the instruction indicates the content that instructs the language model 3A on the information to be generated by the language model 3A.
- the language model 3A generates information corresponding to the query by referring to the sample as an example based on the instruction.
- the language model 3A may also output a score indicating the appropriateness of the information together with the generated information.
- An example of the language model 3A includes, but is not limited to, GTP3 (Generative Pre-trained Transformer 3).
- the information processing device 1A includes a control unit 110 and a storage unit 120.
- the control unit 110 controls each unit of the information processing device 1A.
- the storage unit 120 stores various data used by the control unit 110.
- the control unit 110 includes an acquisition unit 11A, a generation unit 12A, a determination unit 16A, and an update unit 13A.
- the acquisition unit 11A acquires information specifying a first relational knowledge dataset and a context, similar to the acquisition unit 11 in the first exemplary embodiment.
- the context list shown in FIG. 3 is an example of information specifying a context, and includes one or more contexts.
- the first relational knowledge data constituting the first relational knowledge dataset includes first antecedent data indicating antecedent knowledge, and first consequent data indicating consequent knowledge having a specific relationship to the antecedent knowledge.
- the generation unit 12A uses the language model 3A to generate a second relationship knowledge dataset according to the context list by referring to the first relationship knowledge dataset as an example.
- the generation unit 12A also generates a new second relationship knowledge dataset by referring to the first relationship knowledge dataset updated by the update unit 13A as an example.
- the generation unit 12A includes a first generation unit 14A and a second generation unit 15A.
- the first generation unit 14A generates second antecedent data according to the context by referring to the first antecedent data as a case example.
- the second generation unit 15A generates second consequent data according to the second antecedent data by referring to the first relational knowledge data as a case example. In this way, the generation unit 12A generates second relational knowledge data including the second antecedent data and the second consequent data.
- the determination unit 16A uses the language model 3A to determine whether the second relationship knowledge data has the different relationship by referring to the third relationship knowledge data set constituted by the third relationship knowledge data as an example.
- the third relationship knowledge data indicates multiple pieces of knowledge having a relationship different from the specific relationship.
- the update unit 13A is configured similarly to the update unit 13 in the exemplary embodiment 1, and in addition, identifies "second relationship knowledge data having a specific relationship" to be used to update the first relationship knowledge dataset as follows. For example, the update unit 13A updates the first relationship knowledge dataset by using second relationship knowledge data that satisfies a condition based on the score calculated by the language model 3A as second relationship knowledge data having a specific relationship from the second relationship knowledge dataset. The update unit 13A also updates the first relationship knowledge dataset by using second relationship knowledge data selected by the user from the second relationship knowledge dataset as second relationship knowledge data having a specific relationship.
- the update unit 13A also updates the first relationship knowledge dataset using the second relationship knowledge data that is determined not to have the above-mentioned "different relationship" from the second relationship knowledge dataset as second relationship knowledge data having a specific relationship.
- the update unit 13A may use any one of the score-based conditions, the user's selection, and the judgment by the judgment unit 16A, or may use a partial or complete combination of them, to identify the "second relationship knowledge data having a specific relationship" to be used in updating the first relationship knowledge dataset.
- the update unit 13A also updates the third relationship knowledge dataset using the second relationship knowledge data that is determined to have the above-mentioned "different relationship" from the second relationship knowledge dataset.
- the update unit 13A may use score-based conditions, user selection, or a combination of these, instead of or in addition to the determination by the determination unit 16A, to identify the "second relationship knowledge data having a different relationship" to be used in updating the third relationship knowledge dataset.
- the storage unit 120 stores the first instruction data, the second instruction data, the third instruction data, the second relationship knowledge dataset, and the third relationship knowledge dataset.
- the first instruction data, the second instruction data, the third instruction data, and the third relationship knowledge dataset are stored before the execution of the information processing method S1A described below, and are updated by the execution of the information processing method S1A.
- the second relationship knowledge dataset does not need to be stored before the execution of the information processing method S1A, and is generated by the execution of the information processing method S1A.
- the first relationship knowledge dataset and a context list are input to the information processing device 1A.
- Fig. 4 is a flow diagram showing the flow of the information processing method S1A.
- Fig. 5 is a schematic diagram showing the transition of information generated in each step of the information processing method S1A.
- Fig. 6 is a schematic diagram following Fig. 5.
- Step S101 the acquisition unit 11A acquires a first relational knowledge data set and a context list.
- the first relational knowledge data set includes information to be input as a sample to the language model 3A.
- the information processing method S1A may be executed repeatedly, and the first relational knowledge data set acquired during the first execution may be created by a person or by another device. Furthermore, the first relational knowledge data set acquired after the second execution is updated by the previous execution of the information processing method S1A.
- the first relationship knowledge data set is composed of one or more first relationship knowledge data.
- the first relationship knowledge data has a specific relationship.
- the first relationship knowledge data includes first antecedent data, first consequent data, and first context data.
- FIG. 7 is a diagram showing a specific example of the first relational knowledge dataset.
- the first relational knowledge dataset includes first relational knowledge data D11, D12, D13, .... When there is no need to distinguish between them, each of them is also described as first relational knowledge data D1.
- the first relational knowledge data D1 has a "causal relationship" which is an example of a "specific relationship”.
- the first relational knowledge data D1 includes a first item "INDUSTRIY", a second item "CAUSE", and a third item "EFFECT".
- the natural language sentence following the item name "INDUSTRIY" in the first relational knowledge data D1 is an example of first context data and indicates the type of industry.
- the natural language sentence following the item name "CAUSE” is an example of first antecedent data and indicates knowledge of an antecedent that is a cause in the industry.
- the natural language sentence following the item name "EFFECT” is an example of first consequent data and indicates knowledge of a consequent that is a result of the cause.
- the first relational knowledge data D11 indicates that in the context "agriculture” indicated by the first context data, there is a causal relationship between the antecedent knowledge indicated by the first antecedent data, "There is a growing focus on functional fruits / Can clearly state the relationship between fruits and health.” and the consequent knowledge indicated by the first consequent data, "Enhance and add a variety of nutrients to fruits.”
- meaningless character strings such as "xxxxx” are shown as the first context data, first antecedent data, and first consequent data, but these character strings are schematic representations of natural language sentences. In the subsequent drawings, such meaningless character strings will also be regarded as schematic representations of natural language sentences.
- the context list is an example of information that specifies a context, and includes information that specifies one or more contexts.
- each context indicated by the context list will also be referred to as a "specified context”
- information indicating a specified context will also be referred to as "specified context data”.
- the specified context data is input to the language model 3A as a query.
- FIG. 8 is a diagram showing a specific example of a context list.
- the context list includes a plurality of specified context data expressed in natural language sentences, such as "agriculture”, “fishing”, “forestry”, ..., etc.
- Steps S102 to S103 Generation of second antecedent data 4 and 5
- steps S102 and S103 will be described.
- the first generation unit 14A executes steps S102 and S103 for each context specified by the context list to generate a second antecedent data list made up of second antecedent data corresponding to each specified context. Specifically, first, in step S102, the first generation unit 14A generates a first prompt to be input to the language model 3A.
- the first prompt is information to be input to the language model 3A in order to generate second antecedent data according to a specified context.
- the configuration of the first prompt will be described with reference to Fig. 5.
- the first prompt generated in step S102 includes first instruction data as "instruction”, first antecedent data and first context data as “sample”, and specified context data as "query”.
- the first generation unit 14A extracts some or all of the first relational knowledge data from the first relational knowledge dataset, and includes the first context data and the first antecedent data contained in each extracted first relational knowledge data in the first prompt as samples. Also, for example, the first generation unit 14A includes the specified context data in the first prompt as a "query”. Also, for example, the first generation unit 14A includes the first instruction data stored in the storage unit 120 in the first prompt as an "instruction". The first instruction data is a natural language sentence indicating the content that instructs the language model 3A on the information to be generated by the first prompt, and is stored in advance in the storage unit 120 as a template.
- FIG. 9 is a diagram illustrating a specific example of the first prompt.
- the first instruction data includes information that is to be generated by the first prompt, including the first item "INDUSTRIY" and the second item "STEEP", as well as a natural language sentence explaining the definition of each item.
- the item name "STEEP" may be any item name that corresponds to the first antecedent data, and is not limited to the above example.
- the samples included in the first prompt include sample SMP11.
- Sample SMP11 includes the first context data in the first relational knowledge data D12 shown in FIG. 7 as the first item "INDUSTRY" and the first antecedent data as the second item "STEEP".
- the first relational knowledge data D12 for generating the sample SMP11 may be extracted from the first relational knowledge dataset by the first generating unit 14A.
- the extraction process may be performed randomly, or samples that satisfy a predetermined condition may be extracted.
- the predetermined condition may be a condition based on the score, the generation date and time, past extraction history, etc.
- the process of generating the first prompt in step S102 may be performed individually for each context specified by the context list, or may be performed once for some or all of the multiple contexts.
- the samples included in the first prompt generated for each specified context may be different from each other. This reduces bias in the content of the samples, making it possible to generate more diverse second antecedent data.
- the example in Figure 9 shows one sample SMP11 included in the first prompt, the number of samples included in the first prompt may be multiple.
- the query included in the first prompt includes specified context data for the first item "INDUSTRIY", but includes only the item name for the second item "STEEP” and does not include a natural language sentence following the item name.
- Such a query indicates a request to generate a natural language sentence indicating "STEEP” that corresponds to the context "fishing" indicated by the specified context data.
- step S103 the first generation unit 14A generates second antecedent data according to the specified context by inputting the generated first prompt to the language model 3A.
- a second antecedent data list is generated as shown in FIG. 5.
- the second antecedent data list includes one or more pieces of second antecedent data generated for each specified context.
- FIG. 10 is a diagram showing a specific example of the second antecedent data list.
- the second antecedent data list includes second antecedent data and second context data indicating the context of knowledge indicated by the second antecedent data.
- the specified context data included in the first prompt as a query to generate the second antecedent data is applied.
- the first line in FIG. 10 is generated by inputting the first prompt shown in FIG. 9 to the language model 3A.
- the language model 3A generates the second item "The use of robots for fishing purposes is becoming more widespread.
- Robots can be used for a variety of tasks.” in response to the first item "fishing" included in the query, using the first instruction data shown in FIG. 9 as an example.
- the natural language sentence generated as the second item data is an example of the second antecedent data.
- "antecedent knowledge” that may be a cause of the specified context "fishing” is generated.
- the first generating unit 14A may repeat step S103 multiple times for one context. As a result, multiple second antecedent data may be generated for one context.
- Steps S104 to S105 Generation of second relational knowledge data set 4 and 5, steps S104 to S105 will be described.
- the second generation unit 15A executes steps S104 to S105 for each of the second antecedent data included in the second antecedent data list to generate a second relation knowledge data set made up of second relation knowledge data including each of the second antecedent data. Specifically, first, in step S104, the first generation unit 14A generates a second prompt to be input to the language model 3A.
- the second prompt is information to be input to the language model 3A in order to generate second consequent data corresponding to the specified second antecedent data.
- the configuration of the second prompt will be described with reference to Fig. 5.
- the second prompt generated in step S104 includes second instruction data as "instruction”, first relational knowledge data as “sample”, and second context data and second antecedent data as "query”.
- the first generation unit 14A extracts some or all of the first relational knowledge data from the first relational knowledge dataset, and includes each of the extracted first relational knowledge data as a sample in the second prompt.
- the first generation unit 14A includes the second context data and the second antecedent data included in the second antecedent data list as a "query" in the second prompt.
- the second generation unit 15A includes the second instruction data stored in the storage unit 120 as an "instruction" in the second prompt.
- the second instruction data is a natural language sentence indicating the content that instructs the language model 3A on the information to be generated by the second prompt, and is stored in advance in the storage unit 120 as a template.
- FIG. 11 is a diagram illustrating a specific example of the second prompt.
- the second instruction data includes natural language text that explains that the information to be generated by the second prompt includes the first item "INDUSTRIY,” the second item “CAUSE,” and the third item “EFFECT,” as well as the definition of each item.
- the samples included in the second prompt include sample SMP21.
- Sample SMP21 includes the first relationship knowledge data D13 shown in FIG. 7 as the first item "INDUSTRIY", the second item “CAUSE", and the third item "EFFECT".
- the first relationship knowledge data D13 for generating sample SMP21 may be extracted from the first relationship knowledge dataset by the second generating unit 15A.
- the extraction process may be performed randomly, or may extract data that satisfies a predetermined condition.
- the predetermined condition may be a condition based on the score, the generation date and time, past extraction history, etc.
- the process of generating the second prompt in step S104 may be executed individually for each piece of second antecedent data included in the second antecedent data list, or may be executed once for some or all of the multiple pieces of second antecedent data.
- the samples included in the second prompt generated for each piece of second antecedent data may be different from each other. This reduces bias in the content of the samples, making it possible to generate a greater variety of second consequent data. Note that, although the example in FIG. 11 shows one sample SMP21 included in the second prompt, the number of samples included in the second prompt may be multiple.
- the query included in the second prompt includes the second context data as the first item "INDUSTRIY” and the second antecedent data as the second item "CAUSE". Meanwhile, the query includes only the item name as the third item "EFFECT" and does not include a natural language sentence following the item name.
- Such a query indicates a request to generate a natural language sentence indicating "EFFECT" that corresponds to the context "fishing" indicated by the second context data and the second antecedent data "The use of robots".
- step S105 the second generation unit 15A generates second consequent data corresponding to the second context data and the second antecedent data by inputting the generated second prompt into the language model 3A.
- steps S104 to S105 for each piece of second antecedent data included in the second antecedent data list, a second relational knowledge data set corresponding to the specified context is generated, as shown in FIG. 5.
- the second relational knowledge data set includes one or more second antecedent data included in the second antecedent data list, second context data corresponding to the second antecedent data, and second consequent data corresponding to the second antecedent data.
- FIG. 12 is a diagram showing a specific example of the second relational knowledge data set. As shown in FIG. 12, the second relational knowledge data set includes second relational knowledge data D21, D22, .... When there is no need to particularly distinguish between them, each of them is also described as second relational knowledge data D2.
- the second relational knowledge data D2 includes second context data, second antecedent data, and second consequent data.
- the second relational knowledge data set is configured by adding a column of "second consequent data" to the second antecedent data list shown in FIG. 10. Since the second relational knowledge data D2 is generated by the language model 3A using the first relational knowledge data D1 as a sample, it is highly likely that the second relational knowledge data D2 has a "specific relationship” like the first relational knowledge data D1, but does not necessarily have a "specific relationship”. Therefore, the subsequent steps S106 to S108 are executed to perform processing according to the relationship contained in the second relationship knowledge data.
- Steps S106 to S108 Determine the relationship contained in the second relationship knowledge data
- Steps S106 to S108 will be described with reference to Figures 4 and 6 again.
- the determination unit 16A determines whether the relationship held by each piece of second relationship knowledge data is a "specific relationship,” a "different relationship,” or an “other relationship” by using the language model 3A.
- a plurality of pieces of knowledge having a "specific relationship” will also be referred to as positive examples, and a plurality of pieces of knowledge having a "different relationship” will also be referred to as negative examples.
- the determination unit 16A generates a third prompt to be input to the language model 3A.
- the third relationship knowledge data set is used in generating the third prompt.
- the third relation knowledge data set includes information to be input as a sample to the language model 3A.
- the information processing method S1A may be executed repeatedly, and the third relation knowledge data set stored in the storage unit 120 before the first execution may be created by a person or by another device. Furthermore, the third relation knowledge data set used from the second time onwards is the one updated by the previous execution of the information processing method S1A.
- the third relationship knowledge data set indicates one or more third relationship knowledge data.
- the third relationship knowledge data indicates a plurality of pieces of knowledge having a relationship different from the specific relationship.
- the third relationship knowledge data includes third context data, third antecedent data, and third consequent data.
- the third antecedent data and the third consequent data have a "different relationship” in the context indicated by the third context data.
- the "different relationship” may be, but is not limited to, a "synonymous relationship", an "implication relationship”, etc.
- the "different relationship” may be a relationship in which the context is not specified, such as a "synonymous relationship" or an "implication relationship".
- a relationship in which the context is not specified is a relationship in which the "different relationship” holds even if the third antecedent data and the third consequent data are swapped.
- the "different relationship” is not limited to this, and may also be a relationship in which the context is specified.
- FIG. 13 is a diagram showing a specific example of the third relational knowledge dataset.
- the third relational knowledge dataset includes third relational knowledge data D31, D32, D33, ....
- third relational knowledge data D3 has a "synonymous relationship", which is an example of a "different relationship”.
- the third relational knowledge data D3 includes a first item "INDUSTRY”, a second item “SENTENCE1", and a third item "SENTENCE2".
- the natural language sentence following the item name "INDUSTRY” is an example of third context data and indicates the type of industry.
- the natural language sentence following the item name "SENTENCE1” is an example of third antecedent data and indicates one of multiple pieces of knowledge having a "different relationship”.
- the natural language sentence following the item name "SENTENCE2" is an example of third consequent data, and indicates the other of multiple pieces of knowledge that have "different relationships.”
- the third related knowledge data D31 indicates that in the context "Nursing Care Business" indicated by the third context data, the knowledge indicated by the third antecedent data, "The use of robots in nursing care is becoming more widespread," and the knowledge indicated by the third consequent data, "Recently the use of robots in nursing care is very popular," have a synonymous relationship.
- the third prompt includes information to be input to the language model 3A in order to determine whether or not the second relational knowledge data is a negative example having a "different relation".
- the configuration of the third prompt will be described with reference to Fig. 6.
- the third prompt generated in step S106 includes the third instruction data as "instruction”, the third relational knowledge data as "negative example sample”, the first relational knowledge data as "non-negative example sample”, and the second relational knowledge data as "query”.
- the determination unit 16A extracts some or all of the third relationship knowledge data from the third relationship knowledge dataset, and includes each of the extracted third relationship knowledge data in the third prompt as a sample of a negative example.
- the determination unit 16A also extracts some or all of the first relationship knowledge data from the first relationship knowledge dataset, and includes each of the extracted first relationship knowledge data in the third prompt as a sample that is not a negative example.
- the determination unit 16A also includes each of the second relationship knowledge data included in the second relationship knowledge dataset as a "query" in the third prompt.
- the determination unit 16A also includes the third instruction data stored in the storage unit 120 as an "instruction" in the third prompt.
- the third instruction data is a natural language sentence indicating the content that instructs the language model 3A on the information to be generated by the third prompt, and is stored in advance in the storage unit 120 as a template.
- FIG. 14 is a diagram illustrating a specific example of the third prompt.
- the third instruction data includes information to be generated by the third prompt, including the first item "INDUSTRY”, the second item “SENTENCE1", the third item “SENTENCE2”, and the fourth item "Label”, as well as natural language sentences explaining the definitions of each item.
- the third instruction data includes a natural language sentence that explains that "e” indicates a different relationship and "x" indicates that the relationship is not different, as the definition of the fourth item "Label”.
- the samples included in the third prompt include a negative example sample SMP31 and a non-negative example sample SMP32.
- the negative example sample SMP31 includes the third relationship knowledge data D31 shown in FIG. 13 as the first to third items, and includes "e” as the fourth item "Label".
- e is a label indicating "different relationship”.
- the non-negative example sample SMP32 includes the first relationship knowledge data D12 shown in FIG. 7 as the first to third items, and includes "x" as the fourth item "Label”.
- "x" is a label indicating "not a different relationship”.
- the third relationship knowledge data D31 for generating the negative example sample SMP31 may be extracted from the third relationship knowledge dataset by the determination unit 16A.
- the first relationship knowledge data D12 for generating the non-negative example sample SMP32 may be extracted from the first relationship knowledge dataset by the determination unit 16A.
- the extraction process may be performed randomly, or data that satisfies a specified condition may be extracted.
- the specified condition may be a condition based on the score, the generation date and time, past extraction history, etc.
- the process of generating the third prompt in step S106 may be performed individually for each piece of second relationship knowledge data included in the second relationship knowledge data set, or may be performed once in common for some or multiple pieces of second relationship knowledge data.
- the samples included in the third prompt generated for each piece of second relationship knowledge data may be different from each other. This reduces bias in the content of the samples, making it possible to more accurately determine whether or not they are negative examples.
- one negative example sample SMP31 included in the third prompt is shown, but the number of negative example samples included in the third prompt may be multiple.
- one non-negative sample SMP32 included in the third prompt is shown, but the number of non-negative samples included in the third prompt may be multiple.
- the query included in the third prompt includes the second relational knowledge data as the first to third items, but includes only the item name as the fourth item, "Label," and does not include a natural language sentence following the item name.
- Such a query indicates a request to generate a natural language sentence indicating "Label" that corresponds to the second relational knowledge data included in the query.
- step S107 the determination unit 16A inputs the generated third prompt into the language model 3A to determine whether or not each piece of second relationship knowledge data included in the second relationship knowledge data set is a negative example. For example, the determination unit 16A determines that the second relationship knowledge data in which "e” is generated as the "Label” is a negative example (i.e., has a "different relationship”). Also, for example, the determination unit 16A determines that the second relationship knowledge data in which "x" is generated as the "Label” is not a negative example (i.e., does not have a different relationship).
- step S108 the determination unit 16A determines whether the second relationship knowledge data determined in step S107 to be not a negative example is a positive example or a negative example based on further input from the user.
- the user may input, for example, annotation information indicating whether the second relationship knowledge data determined to be not a negative example is a positive example having a specific relationship, a negative example having a different relationship, or something else. This makes it possible to identify "positive examples having a specific relationship" with greater accuracy than when all second relationship knowledge data determined by the language model 3A to be "not negative examples" are treated as positive examples.
- each piece of second relationship knowledge data included in the second relationship knowledge dataset is classified as a positive example or a negative example.
- the second relationship knowledge data classified as a positive example is determined not to be a negative example by the language model 3A and selected by the user to be a positive example.
- the second relationship knowledge data classified as a negative example includes data determined to be a negative example by the language model 3A.
- the second relationship knowledge data classified as a negative example may include data determined not to be a negative example by the language model 3A but selected by the user to be a negative example.
- Steps S109 to S111 will be described with reference to Figures 4 and 6 again.
- Steps S109 to S111 are steps for updating the first relationship knowledge data set, the third relationship knowledge data set, and the relationship knowledge database 2A.
- the second relationship knowledge data classified as a positive example is used to update the first relationship knowledge data set and the relationship knowledge database 2A.
- the second relationship knowledge data classified as a negative example is used to update the third relationship knowledge data set.
- step S109 the update unit 13A updates the third relationship knowledge dataset using the second relationship knowledge data classified as a negative example from the second relationship knowledge dataset.
- Updating the third relationship knowledge dataset may mean, for example, adding the second relationship knowledge data classified as a negative example to the third relationship knowledge dataset as new third relationship knowledge data.
- updating the third relationship knowledge dataset may mean, for example, replacing part or all of the third relationship knowledge dataset with the second relationship knowledge data classified as a negative example as new third relationship knowledge data.
- the language model 3A may output a score indicating the appropriateness of the fourth item "Label" generated for each piece of second relationship knowledge data in response to the third prompt.
- the update unit 13A may update the third relationship knowledge dataset using the second relationship knowledge data classified as negative examples whose scores satisfy a predetermined condition (e.g., the score is equal to or greater than a threshold, the score is within a predetermined rank from the top, within a predetermined percentage, etc.).
- the update unit 13A may update the third relationship knowledge dataset using the second relationship knowledge data classified as negative examples that is selected by the user.
- step S109 the first relational knowledge dataset that is referenced the next time information processing method S1A is repeated is updated, improving the accuracy of the second prompt generated based on the first relational knowledge dataset. As a result, the accuracy of the generated second relational knowledge data as a positive example is improved.
- step S110 the update unit 13A updates the first relationship knowledge dataset using the second relationship knowledge data classified as a positive example from the second relationship knowledge dataset.
- Updating the first relationship knowledge dataset may mean, for example, adding the second relationship knowledge data classified as a positive example to the first relationship knowledge dataset as new first relationship knowledge data.
- updating the first relationship knowledge dataset may mean, for example, replacing part or all of the first relationship knowledge dataset with the second relationship knowledge data classified as a positive example as new first relationship knowledge data.
- the updated first relationship knowledge dataset may be stored in the storage unit 120.
- the generation unit 12A may also output a score indicating the appropriateness of the second item "STEEP" (i.e., the second relationship knowledge data) generated for each context in response to the second prompt.
- the update unit 13A may update the first relationship knowledge dataset using the second relationship knowledge data classified as positive examples whose scores satisfy a predetermined condition (e.g., the score is equal to or greater than a threshold, the score is within a predetermined rank from the top, within a predetermined percentage, etc.).
- the update unit 13A may also update the first relationship knowledge dataset using the second relationship knowledge data classified as positive examples that is selected by the user.
- step S109 the third relationship knowledge dataset that is referenced the next time information processing method S1A is repeated is updated, improving the accuracy of the third prompt generated based on the third relationship knowledge dataset. As a result, the accuracy of determining negative examples for the second relationship knowledge data is improved. This makes it possible to accurately exclude negative examples from the second relationship knowledge dataset.
- step S111 the update unit 13A updates the relationship knowledge database 2A using the second relationship knowledge data classified as a positive example from the second relationship knowledge data set. For example, the update unit 13A adds the second relationship knowledge data classified as a positive example to the relationship knowledge database 2A as new "relationship knowledge data having a specific relationship.”
- the information processing device 1A repeats the information processing method S1A.
- the acquisition unit 11A acquires an updated first relationship knowledge dataset.
- the generation unit 12A generates a first prompt and a second prompt using the updated first relationship knowledge dataset.
- a new second relationship knowledge dataset is generated that references the updated first relationship knowledge dataset as an example.
- the judgment unit 16A generates a third prompt using the updated first relationship knowledge dataset and the updated third relationship knowledge dataset.
- the present exemplary embodiment employs a configuration in which a new second relationship knowledge data set is generated by referring to the updated first relationship knowledge data set as an example. Therefore, according to the present exemplary embodiment, since the first relationship knowledge data set, which has higher accuracy as having a specific relationship, can be referred to as an example, the relationship knowledge data having a specific relationship to be added to the relationship knowledge database 2A can be generated with high accuracy in accordance with the specified context.
- the relationship knowledge data stored in the relationship knowledge database 2A can be utilized for judgments, analyses, etc. in a specified context. In such cases, such judgments, analyses, etc. can be performed with high accuracy.
- the relationship knowledge data stored in the relationship knowledge database 2A can be utilized for management judgments, industry analysis, etc. in a specified industry. In such cases, changes/transformations in the industry can be accurately grasped, and future changes accompanying them can be accurately predicted.
- this exemplary embodiment employs a configuration in which the second relationship knowledge dataset, which satisfies a condition based on the score calculated by language model 3A, is used as second relationship knowledge data having a specific relationship to update the first relationship knowledge dataset. Therefore, according to this exemplary embodiment, the first relationship knowledge dataset can be updated using second relationship knowledge data that is highly likely to have a specific relationship based on the score, thereby improving the accuracy of the first relationship knowledge dataset that is referenced as an example having a specific relationship.
- this exemplary embodiment employs a configuration in which the second relationship knowledge data selected by the user from the second relationship knowledge data set is used as the second relationship knowledge data having a specific relationship to update the first relationship knowledge data set. Therefore, according to this exemplary embodiment, the first relationship knowledge data set can be updated using the second relationship knowledge data selected by the user as having a specific relationship, and therefore the accuracy of the first relationship knowledge data set referenced as an example having a specific relationship can be improved.
- this exemplary embodiment employs a configuration in which, by using the language model 3A, it is determined whether or not the second relationship knowledge data has a different relationship by referring to a third relationship knowledge dataset composed of third relationship knowledge data indicating a plurality of pieces of knowledge having a relationship different from the specific relationship as an example, and the second relationship knowledge data determined not to have a different relationship in the second relationship knowledge dataset is used as second relationship knowledge data having the specific relationship to update the first relationship knowledge dataset. Therefore, according to this exemplary embodiment, the same language model 3A is used to exclude negative examples from the second relationship knowledge dataset generated using the language model 3A, so accuracy can be ensured. Also, since it is not necessary to use a different model to exclude negative examples from the second relationship knowledge dataset generated using the language model 3A, negative examples can be more easily excluded.
- this exemplary embodiment employs a configuration in which the third relationship knowledge dataset is updated using the second relationship knowledge data determined to have a different relationship from the second relationship knowledge dataset. Therefore, according to this exemplary embodiment, the accuracy of the third relationship knowledge dataset having a relationship different from the specific relationship, which is referenced as a case to exclude negative examples from the second relationship knowledge dataset generated using the language model 3A, is improved, and as a result, it is possible to accurately extract relationship knowledge data having a specific relationship to be added to the relationship knowledge database 2A.
- the first relational knowledge data includes first antecedent data indicating knowledge of an antecedent, and first consequent data indicating knowledge of a consequent having a specific relationship to the antecedent knowledge
- the second relational knowledge data including the second antecedent data and the second consequent data is generated by using the language model 3A to generate second antecedent data corresponding to the context by referring to the first antecedent data as an example, and to generate second consequent data corresponding to the generated second antecedent data by referring to the first relational knowledge data as an example. Therefore, according to this exemplary embodiment, the second antecedent data corresponding to the specified context is first created, and then the second consequent data corresponding to the second antecedent data is generated, so that the second relational knowledge data corresponding to the specified context can be generated more accurately.
- the third relationship knowledge data set includes third relationship knowledge data having a first relationship different from the specific relationship, and third relationship knowledge data having a second relationship different from both the specific relationship and the first relationship.
- third relationship knowledge data having a second relationship different from both the specific relationship and the first relationship.
- a "causal relationship” is applied as the "specific relationship”
- a "synonymous relationship” may be applied as the "first relationship”
- an "implication relationship” may be applied as the second relationship.
- the first relationship and the second relationship are not limited to these examples.
- the judgment unit 16A judges whether each piece of second relationship knowledge data included in the second relationship knowledge data set has either the first relationship or the second relationship.
- a plurality of pieces of knowledge having the first relationship will also be referred to as first negative examples
- a plurality of pieces of knowledge having the second relationship will also be referred to as second negative examples.
- the samples included in the third prompt are modified as follows. Specifically, the determination unit 16A extracts some or all of the third relationship knowledge data having the first relationship from the third relationship knowledge dataset, and includes each of the extracted third relationship knowledge data as a sample of a first negative example in the third prompt. The determination unit 16A also extracts some or all of the third relationship knowledge data having the second relationship from the third relationship knowledge dataset, and includes each of the extracted third relationship knowledge data as a sample of a second negative example in the third prompt.
- the definition of the fourth item “Label” is transformed as follows.
- the definition of the fourth item “Label” is transformed into a natural language sentence explaining that "e” indicates the first negative example, “a” indicates the second negative example, and "x" indicates neither the first nor the second negative example.
- the determination unit 16A inputs the third prompt into the language model 3A to determine whether each piece of second relationship knowledge data included in the second relationship knowledge data set is a first negative example, a second negative example, or any other.
- the determination unit 16A may further determine whether the second relationship knowledge data determined by the language model 3A to be neither the first negative example nor the second negative example is a "positive example,” a "first negative example,” a "second negative example,” or "any other" based on the user's input.
- the update unit 13A updates the first relationship knowledge dataset using the second relationship knowledge data determined to be neither the first negative example nor the second negative example as the second relationship knowledge data having a specific relationship. Specifically, the update unit 13A updates the first relationship knowledge dataset using the second relationship knowledge data selected by the user as a "positive example” from the second relationship knowledge data determined to be neither the first negative example nor the second negative example. The update unit 13A also updates the third relationship knowledge dataset using the second relationship knowledge data selected by the user as a "first negative example" from the second relationship knowledge data determined to be neither the first negative example nor the second negative example. The update unit 13A also updates the third relationship knowledge dataset using the second relationship knowledge data selected by the user as a "second negative example" from the second relationship knowledge data determined to be neither the first negative example nor the second negative example.
- multiple types of negative examples are determined from the second relationship knowledge dataset to be excluded as they do not have a specific relationship, so negative examples that do not have a specific relationship can be excluded with greater accuracy. Note that, although an example in which there are two types of negative examples has been described here, there may be three or more types of negative examples.
- the determination unit 16A uses a first third prompt and a second third prompt.
- the first third prompt can be similarly explained by replacing "different relationship” with “first relationship” in the description of the third prompt in the exemplary embodiment 2.
- the second third prompt can be similarly explained by replacing "different relationship” with “second relationship” in the description of the third prompt in the exemplary embodiment.
- the determination unit 16A first determines whether each piece of second relationship knowledge data is a first negative example by inputting a first third prompt into the language model 3A. Furthermore, the determination unit 16A determines whether each piece of second relationship knowledge data determined not to be a first negative example is a second negative example by inputting a second third prompt into the language model 3A. This allows the determination unit 16A to determine whether each piece of second relationship knowledge data is a first negative example, a second negative example, or something else.
- multiple types of negative examples that are excluded from the second relationship knowledge dataset as not having a specific relationship are determined in stages, so that a binary determination is sufficient in one stage, and negative examples can be determined more accurately.
- the judgment unit 16A may judge whether each piece of second relationship knowledge data is a first negative example at one judgment stage, and judge whether it is either a second or third negative example at another judgment stage.
- the first relationship knowledge data, the second relationship knowledge data, and the third relationship knowledge data are each described as data indicating a relationship between two pieces of knowledge.
- these relationship knowledge data may be data indicating a relationship between three or more pieces of knowledge.
- Some or all of the functions of the information processing devices 1, 1A may be realized by hardware such as an integrated circuit (IC chip), or by software.
- the device is realized, for example, by a computer that executes instructions of a program, which is software that realizes each function.
- a computer that executes instructions of a program, which is software that realizes each function.
- FIG. 15 An example of such a computer (hereinafter referred to as computer C) is shown in FIG. 15.
- Computer C has at least one processor C1 and at least one memory C2.
- Memory C2 stores program P for operating computer C as the device.
- processor C1 reads and executes program P from memory C2, thereby realizing each function of the device.
- the processor C1 may be, for example, a CPU (Central Processing Unit), GPU (Graphic Processing Unit), DSP (Digital Signal Processor), MPU (Micro Processing Unit), FPU (Floating point number Processing Unit), PPU (Physics Processing Unit), TPU (Tensor Processing Unit), quantum processor, microcontroller, or a combination of these.
- the memory C2 may be, for example, a flash memory, HDD (Hard Disk Drive), SSD (Solid State Drive), or a combination of these.
- Computer C may further include a RAM (Random Access Memory) for expanding program P during execution and for temporarily storing various data.
- Computer C may further include a communications interface for sending and receiving data to and from other devices.
- Computer C may further include an input/output interface for connecting input/output devices such as a keyboard, mouse, display, and printer.
- the program P can also be recorded on a non-transitory, tangible recording medium M that can be read by the computer C.
- a recording medium M can be, for example, a tape, a disk, a card, a semiconductor memory, or a programmable logic circuit.
- the computer C can obtain the program P via such a recording medium M.
- the program P can also be transmitted via a transmission medium.
- a transmission medium can be, for example, a communications network or broadcast waves.
- the computer C can also obtain the program P via such a transmission medium.
- An information processing device comprising:
- the updating means updates the first relationship knowledge data set by using, among the second relationship knowledge data set, second relationship knowledge data that satisfies a condition based on the score calculated by the language model as second relationship knowledge data having the specific relationship.
- the updating means updates the first relationship knowledge data set by using the second relationship knowledge data selected by the user from the second relationship knowledge data set as the second relationship knowledge data having the specific relationship. 4.
- An information processing device according to any one of claims 1 to 3.
- (Appendix 5) a determination means for determining whether or not the second relational knowledge data has the different relationship by referring to a third relational knowledge data set, which is constituted by third relational knowledge data indicating a plurality of pieces of knowledge having a relationship different from the specific relationship, as an example, using the language model; Further comprising: the updating means updates the first relationship knowledge data set by using the second relationship knowledge data determined not to have the different relationship among the second relationship knowledge data set as the second relationship knowledge data having the specific relationship. 5.
- An information processing device according to any one of claims 1 to 4.
- the updating means updates the third relationship knowledge data set by using the second relationship knowledge data determined to have the different relationship among the second relationship knowledge data set. 6.
- the information processing device according to claim 5.
- the third relationship knowledge data set includes third relationship knowledge data having a first relationship different from the specific relationship, and third relationship knowledge data having a second relationship different from both the specific relationship and the first relationship, the determining means determines whether the second relationship knowledge data has either the first relationship or the second relationship; the updating means updates the first relationship knowledge data set by using the second relationship knowledge data determined to have neither the first relationship nor the second relationship as second relationship knowledge data having the specific relationship. 7.
- the information processing device according to claim 5 or 6.
- the first relational knowledge data includes first antecedent data indicating knowledge of an antecedent, and first consequent data indicating knowledge of a consequent having the specific relationship with the antecedent knowledge
- the generating means uses the language model to a first generating means for generating second antecedent data corresponding to the context by referring to the first antecedent data as a case; a second generating means for generating second consequent data corresponding to the second antecedent data by referring to the first relational knowledge data as a case; generating the second relational knowledge data including the second antecedent data and the second consequent data; 8.
- An information processing device according to any one of appendix 1 to 7.
- An information processing method executed by one or more processors comprising: Obtaining a first relational knowledge data set constituted by first relational knowledge data indicating a plurality of pieces of knowledge having a specific relationship, and information designating a context of the knowledge; generating a second relational knowledge data set composed of second relational knowledge data corresponding to the context by referring to the first relational knowledge data set as an example using a language model; updating the first relationship knowledge data set using second relationship knowledge data having the specific relationship among the second relationship knowledge data set;
- An information processing method comprising:
- At least one processor comprising: an acquisition process for acquiring a first relational knowledge data set constituted by first relational knowledge data indicating a plurality of pieces of knowledge having a specific relation, and information designating a context of the knowledge; a generation process for generating a second relational knowledge data set composed of second relational knowledge data corresponding to the context by referring to the first relational knowledge data set as an example using a language model; an update process for updating the first relationship knowledge data set by using second relationship knowledge data having the specific relationship among the second relationship knowledge data set; An information processing device that executes the above.
- the information processing device may further include a memory, and the memory may store a program for causing the processor to execute the acquisition process, the generation process, and the update process.
- the program may also be recorded on a computer-readable, non-transitory, tangible recording medium.
- Reference Signs List 1 Reference Signs List 1, 1A Information processing device 2A Relational knowledge database 3A Language model 11, 11A Acquisition unit 12, 12A Generation unit 13, 13A Update unit 14A First generation unit 15A Second generation unit 16A Determination unit 100 Information processing system 110 Control unit 120 Storage unit C1 Processor C2 Memory
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- General Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Physics & Mathematics (AREA)
- Computing Systems (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Artificial Intelligence (AREA)
- Medical Informatics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Computational Linguistics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2025506411A JPWO2024189883A1 (https=) | 2023-03-16 | 2023-03-16 | |
| PCT/JP2023/010286 WO2024189883A1 (ja) | 2023-03-16 | 2023-03-16 | 情報処理装置、情報処理方法、およびプログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2023/010286 WO2024189883A1 (ja) | 2023-03-16 | 2023-03-16 | 情報処理装置、情報処理方法、およびプログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2024189883A1 true WO2024189883A1 (ja) | 2024-09-19 |
Family
ID=92754894
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2023/010286 Ceased WO2024189883A1 (ja) | 2023-03-16 | 2023-03-16 | 情報処理装置、情報処理方法、およびプログラム |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JPWO2024189883A1 (https=) |
| WO (1) | WO2024189883A1 (https=) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20260080348A1 (en) * | 2024-09-17 | 2026-03-19 | Royal Bank Of Canada | System and method for content retrieval and evaluation |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022046087A1 (en) * | 2020-08-31 | 2022-03-03 | Siemens Aktiengesellschaft | Generation of novel knowledge representations |
| KR20220067808A (ko) * | 2020-11-18 | 2022-05-25 | 주식회사 케이티 | 지식 그래프를 생성하는 장치, 방법 및 컴퓨터 프로그램 |
-
2023
- 2023-03-16 WO PCT/JP2023/010286 patent/WO2024189883A1/ja not_active Ceased
- 2023-03-16 JP JP2025506411A patent/JPWO2024189883A1/ja active Pending
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022046087A1 (en) * | 2020-08-31 | 2022-03-03 | Siemens Aktiengesellschaft | Generation of novel knowledge representations |
| KR20220067808A (ko) * | 2020-11-18 | 2022-05-25 | 주식회사 케이티 | 지식 그래프를 생성하는 장치, 방법 및 컴퓨터 프로그램 |
Non-Patent Citations (1)
| Title |
|---|
| PETER WEST; CHANDRA BHAGAVATULA; JACK HESSEL; JENA D. HWANG; LIWEI JIANG; RONAN LE BRAS; XIMING LU; SEAN WELLECK; YEJIN CHOI: "Symbolic Knowledge Distillation: from General Language Models to Commonsense Models", ARXIV.ORG, CORNELL UNIVERSITY LIBRARY, 201 OLIN LIBRARY CORNELL UNIVERSITY ITHACA, NY 14853, 28 November 2022 (2022-11-28), 201 Olin Library Cornell University Ithaca, NY 14853, XP091380253 * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20260080348A1 (en) * | 2024-09-17 | 2026-03-19 | Royal Bank Of Canada | System and method for content retrieval and evaluation |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2024189883A1 (https=) | 2024-09-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN113254675B (zh) | 基于自适应少样本关系抽取的知识图谱构建方法 | |
| US11036483B2 (en) | Method for predicting the successfulness of the execution of a DevOps release pipeline | |
| CN109271521B (zh) | 一种文本分类方法及装置 | |
| JP6928371B2 (ja) | 分類器、分類器の学習方法、分類器における分類方法 | |
| US11308940B2 (en) | Counterfactual annotated dialogues for conversational computing | |
| CN111552766B (zh) | 使用机器学习来表征在引用图形上应用的参考关系 | |
| CN110019736B (zh) | 基于语言模型的问答匹配方法、系统、设备及存储介质 | |
| CN113407709A (zh) | 生成式文本摘要系统和方法 | |
| US20220180290A1 (en) | Using machine learning to assign developers to software defects | |
| KR20240167036A (ko) | 머신 러닝 파이프라인 생성 및 관리 | |
| CN116595170A (zh) | 一种基于软提示的医疗文本分类方法 | |
| JP2019219848A (ja) | ソースコード解析方法およびソースコード解析装置 | |
| WO2024189883A1 (ja) | 情報処理装置、情報処理方法、およびプログラム | |
| US12260301B2 (en) | Data generation and annotation for machine learning | |
| JP6770709B2 (ja) | 機械学習用モデル生成装置及びプログラム。 | |
| JP7779168B2 (ja) | 機械学習パイプラインスケルトンインスタンス化 | |
| CN108122613B (zh) | 基于健康预测模型的健康预测方法和装置 | |
| JP7024262B2 (ja) | 学習方法、学習結果の利用方法、学習プログラムおよび学習装置 | |
| WO2018174000A1 (ja) | 構成管理装置、構成管理方法および記録媒体 | |
| Hussain et al. | A framework for ranking of software design patterns | |
| CN114386414B (zh) | 一种命名实体抽取方法、装置、电子设备及存储介质 | |
| CN112114795B (zh) | 开源社区中辅助工具停用的预测方法及装置 | |
| JPWO2015049769A1 (ja) | データ分析システム及びその方法 | |
| Kaur et al. | A comparative research of rule based classification on dataset using WEKA TOOL | |
| US20220092260A1 (en) | Information output apparatus, question generation apparatus, and non-transitory computer readable medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 23927502 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2025506411 Country of ref document: JP Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2025506411 Country of ref document: JP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 23927502 Country of ref document: EP Kind code of ref document: A1 |