WO2024184975A1 - 符号化装置、学習方法、及びプログラム - Google Patents
符号化装置、学習方法、及びプログラム Download PDFInfo
- Publication number
- WO2024184975A1 WO2024184975A1 PCT/JP2023/008133 JP2023008133W WO2024184975A1 WO 2024184975 A1 WO2024184975 A1 WO 2024184975A1 JP 2023008133 W JP2023008133 W JP 2023008133W WO 2024184975 A1 WO2024184975 A1 WO 2024184975A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- image
- unit
- context
- encoding unit
- information selection
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images
















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/205—Parsing
- G06F40/216—Parsing using statistical methods
Definitions
- the present invention relates to technology for extracting features from information such as images and text.
- references are indicated by numbers such as "[1]", and the names of the references corresponding to the numbers are listed at the end of the specification.
- image recognition models [3], [4]
- language models [5]
- image recognition models [3], [4]
- language models [5]
- Non-Patent Document 1 [6]
- the present invention has been made in consideration of the above points, and aims to provide technology for realizing a high-quality model for extracting features from information that can be trained at low cost.
- an encoding device that extracts features from information using a neural network model, comprising: A context coding unit and an image coding unit,
- the context encoding unit is A context attention mechanism and a context feature conversion unit, which are pre-trained models; a context information selection unit having a GAU module;
- the image encoding unit includes: A pre-trained model of an image attention mechanism and an image feature conversion unit;
- An encoding device is provided, comprising: an image information selection unit having a GAU module.
- the disclosed technology provides a technology for realizing a high-quality model for extracting features from information that can be trained at low cost.
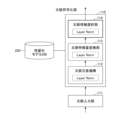
- FIG. 1 illustrates an example of the configuration of a search device 100.
- 2 is a flowchart showing an outline of a process flow of the search device 100.
- FIG. 2 is a diagram illustrating an example of the configuration of a context encoding unit 110.
- FIG. 2 illustrates an example of the configuration of an image encoding unit 120.
- 1 is a diagram for explaining a specific example configuration of a context encoding unit 110 and an image encoding unit 120.
- FIG. FIG. 1 is a diagram showing a specific example of the configuration of a text encoder (context encoder 110) and an image encoder (image encoder 120).
- FIG. 1 is a diagram showing a specific configuration example of pattern 1.
- FIG. 13 is a diagram showing a specific configuration example of pattern 3.
- FIG. 13 is a diagram showing a specific configuration example of pattern 3.
- FIG. 2 illustrates an example of the configuration of a learning device 200. This diagram shows the Layer Norm of each component of the context encoding unit 110 (pattern 1).
- 11 is a flowchart illustrating a method for updating a model parameter.
- FIG. 1 is a diagram illustrating an example of the overall configuration of a system. 4 is a flowchart for explaining the operation of the system.
- FIG. 2 illustrates an example of a hardware configuration of the apparatus.
- FIG. 1 shows the experimental setup.
- FIG. 13 is a diagram showing experimental results.
- examples 1 and 2 are described as specific examples relating to embodiments of the present invention.
- example 1 an example of performing a search using features obtained by the encoding unit is described.
- example 2 a learning method for a model used as the encoding unit in example 1 is described.
- Example 1 First, a description will be given of Example 1.
- Example 1 a description will be given of an apparatus that executes a search task of extracting images related to a search text query when a search target image is given, and the processing content thereof.
- FIG. 1 shows an example of the configuration of a search device 100 in the first embodiment.
- the search device 100 includes an encoding unit 130 having a context encoding unit 110 and an image encoding unit 120, a ranking unit 140, a trained model DB 150, and an image feature DB 160.
- the encoding unit 130 i.e., the context encoding unit 110 and the image encoding unit 120, are each implemented as a neural network model. All computational processing in the neural network is performed based on pre-trained parameters corresponding to each model.
- a trained model (trained parameters) is stored in trained model DB 150, and the trained parameters are set in the context encoding unit 110 and the image encoding unit 120.
- the context encoding unit 110 and the image encoding unit 120 may each be considered as a "model.”
- the search device 100 receives a search query Q and a set of images to be searched ⁇ I 0 , I 1 , . . . , I m ⁇ .
- the encoding unit 130 extracts the features of the search query Q and the search target image. Note that the features of the search target image may be extracted in advance and stored in the image feature DB 160.
- the ranking unit 140 performs a ranking process using the feature amount extracted by the encoding unit 130.
- the ranking unit 140 outputs an ordered set of images related to the search query ⁇ I 0 , I, ..., I k ⁇ and their relevance ⁇ S 0 , S 1 , ..., S k ⁇ , where m is the number of images to be searched, and k is the number of related images obtained by the search.
- the context encoding unit 110 receives an arbitrary sentence of the search query Q as input, and outputs a feature quantity u of the search query based on the parameters of the model.
- FIG. 3 shows an example of the configuration of the context encoding unit 110.
- the configuration of the context encoding unit 110 has variations, for example, patterns 1 to 3. Here, we will first explain with reference to pattern 1.
- the context encoding unit 110 has a context input unit 111, a context attention mechanism 112, a context feature conversion unit 113, and a context information selection unit 114.
- “*N” means that there are N layers. In other words, this means that there are N “context attention mechanisms 112, context feature conversion units 113, and context information selection units 114.”
- the context attention mechanism 112 generates information indicating where in a sentence to focus attention.
- the context feature conversion unit 113 converts features.
- the context information selection unit 114 selectively converts information.
- any model may be used as long as it is a context-aware pre-learning model using a transformer and encodes text information.
- any model may be used as long as it can selectively convert the "vectors obtained by the context attention mechanism 112 and the context feature conversion unit 113" and the “vectors converted inside the context information selection unit 114" of each layer using a gate mechanism in accordance with the input.
- a module called GAU Gate Adapter Unit
- a module called highway network proposed in reference [8] can be used.
- H for example, a transformation composed of feed-forward, sigmoid function, and feed-forward
- a nonlinear transformation T which does not have to be nonlinear
- h′ H(h,W H ) ⁇ T(h,W T )+h ⁇ (1 ⁇ T(h,W T ))
- the transformation is as follows. " ⁇ " is the Hadamard product.
- a similar module proposed in reference [9] may be used as the context information selection unit 114.
- the model in reference [8] is lighter in weight, and it is expected that the quality of the model in reference [8] will be sufficiently guaranteed.
- the GAU Gate Adapter Unit
- the GAU is not limited to the model in reference [8].
- the context information selection unit 114 may be inserted at any position after the context attention mechanism 112 of each layer. For example, it may be arranged as shown in pattern 2 or pattern 3. Also, the text encoder (context encoding unit 110) is basically composed of multiple layers, and the context information selection unit 114 may be inserted in all layers or only in some layers.
- FIG. 4 shows an example configuration of the image encoding unit 120.
- the image encoding unit 120 has an image input unit 121, an image attention mechanism 122, an image feature conversion unit 123, and an image information selection unit 124.
- the image attention mechanism 122 generates information indicating where in the image to focus attention.
- the image feature conversion unit 123 converts the features.
- the image information selection unit 124 selectively converts the information.
- Specific neural network models for the image input unit 121, image attention mechanism 122, and image feature conversion unit 123 may be any model that receives an image as input and outputs a d-dimensional vector, and uses a transformer as the basic structure.
- the dimension d of the output vectors of the context encoding unit 110 and the image encoding unit 120 must be the same.
- the image encoding unit 120 for example, the image encoder model used in reference [1] can be used.
- the model in reference [1] is based on ViT proposed in reference [4] as a method for inputting an image and outputting d-dimensional features. In this embodiment, these may be used, or other methods may be used as long as they fall within the range of conditions.
- any model may be used as long as it can selectively convert the "vectors obtained by the image attention mechanism 122 and image feature conversion unit 123" and the "vectors converted inside the image information selection unit 124" of each layer using a gate mechanism in accordance with the input.
- the image information selection unit 124 can be, for example, a GAU module, such as the highway network proposed in reference [8].
- the structure of the GAU may be the same as that of the text encoder (context encoding unit 110), or it may be different.
- the image information selection unit 124 may be inserted at any position after the image attention mechanism 122 of each layer. For example, it may be arranged as shown in pattern 2 or pattern 3. This insertion position may also be the same as that of the text encoder (context encoding unit 110), or it may be different. Also, the image encoder (image encoding unit 120) is basically composed of multiple layers, and the image information selection unit 124 may be inserted in all layers, or only in some layers. Again, the rules for which layers to insert it in may be the same as those for the text encoder, or it may be different.
- Fig. 5 shows the encoding unit 10 as a configuration applicable to either the context encoding unit 110 or the image encoding unit 120.
- the encoding unit 10 has an input unit 11, an attention mechanism 12, a feature conversion unit 13, and an information selection unit 14.
- the input unit 11 corresponds to the context input unit 111/image input unit 121
- the attention mechanism 12 corresponds to the context attention mechanism 112/image attention mechanism 122
- the feature conversion unit 13 corresponds to the context feature conversion unit 113/context feature conversion unit 123
- the information selection unit 14 corresponds to the context information selection unit 114/image information selection unit 124.
- Figures 7 to 9 show specific configuration examples of the above-mentioned patterns 1 to 3 for the text encoder (context encoding unit 110) and image encoder (image encoding unit 120).
- the ranking unit 140 receives as input the feature u of the search query obtained by the context encoding unit 110 and the feature set ⁇ v 1 , ..., v i , ..., v m ⁇ obtained by the image encoding unit 120, and outputs an ordered set of related images ⁇ I 1 , ..., I i , ..., I k ⁇ and their relevance ⁇ S 0 , S 1 , ..., S k ⁇ .
- d may be the inverse of the inner product of u and v i .
- the input to the ranking unit 120 is two vectors of the same dimension, and the output is a scalar. Note that a distance function capable of measuring the distance between vectors other than the inverse of the inner product may also be used.
- Example 2 Next, a second embodiment will be described.
- learning of model parameters of the parts (the context encoding unit 110 and the image encoding unit 120) using a neural network in the search device 100 described in the first embodiment will be described.
- FIG. 10 shows an example of the configuration of a learning device 200 that trains the context encoding unit 110 and the image encoding unit 130.
- the search device 100 and the learning device 200 may be separate devices, or the search device 100 may be provided with a learning function (such as an update unit) and used as the learning device 200.
- the learning device 200 includes an encoding unit 130 having a context encoding unit 110 and an image encoding unit 120, an update unit 210, and a learning model DB 220. The learning process is described below.
- learning data (which may be called training data) of pairs of images and text captions that describe the images is collected in advance.
- a set of images Ii ⁇ Ij
- Ij images related to Ti ⁇ related to text Ti is labeled as correct answer data.
- one image is randomly extracted from the set of images Ii related to the search query for each Ti , and Ii + is used to create training data, with ( Ti , Ii + ) being one set.
- the encoding unit 130 (context encoding unit 110, image encoding unit 120) is initialized with a pre-trained model, except for the context information selection unit 114 and the image information selection unit 124.
- the pre-trained model used for initialization may be a model trained on language and image tasks as proposed in references [7] and [4], or a model that trains on the association between language and images as in reference [1].
- pre-trained parameters trained in the target language are used as initial values.
- the image encoder of reference [1] may be used as the image encoding unit 130, or a model pre-trained with an image classification task may be used.
- the context information selection unit 114 and the image information selection unit 124 are randomly initialized.
- model parameters other than those of the "context information selection unit 114 and image information selection unit 124" in the context encoding unit 110 and image encoding unit 120 are basically excluded from the learning targets (i.e., the parameters are not updated from their initial values).
- model parameters other than the "context information selection unit 114 and image information selection unit 124" may also be learned as necessary. For example, a better model is likely to be obtained if only parameters related to layer normalization (Layer Norm) are the learning targets.
- Figure 11 shows the Layer Norm of each component, using the context encoding unit 110 (pattern 1) as an example.
- the context information selection unit 114 may be located anywhere.
- the context feature conversion unit 113 and context attention mechanism 112 may also be located anywhere, but it is generally best to match them to the structure of the pre-training model used for initialization.
- model parameters other than the "context information selection unit 114 and image information selection unit 124" may be learned as needed, but increasing the number of parameters to be learned too much will increase the learning cost, and the effect of this embodiment, which is to reduce the learning cost and stabilize the learning, will be lost. The more the number is increased, the less the effect is guaranteed.
- model in reference [6] also takes a measure not to include image encoder parameters in the learning process, but in this embodiment, by introducing the GAU mechanism, it is possible to exclude text encoder parameters from the learning process.
- the update unit 210 updates the model parameters (parameters to be learned) of the context encoding unit 110 and the image encoding unit 120 through supervised learning.
- the update unit 210 updates the model parameters to be learned for all learning data, and repeats this any number of times. This repetitive process is called an epoch, and the number of repetitions is called the number of epochs.
- the parameter updating method can be performed by general neural network learning. A specific model parameter updating method will be explained here with reference to the flowchart in Figure 12. Figure 12 shows that the epoch process (S201 to S203) is repeated.
- the training data is randomly divided into mini-batches (S201).
- the training device 200 executes the following processes (S1 to S3) for each of the mini-batches.
- text T i and image I i + obtained from learning data are input to the encoding unit 130 (context encoding unit 110, image encoding unit 130), and the update unit 210 obtains feature quantities u i and v i + from the encoding unit 130.
- This learning is based on mini-batch processing, and the features obtained from one batch process are text features: ⁇ u 1 , u 2 , ..., u b ⁇ (where b is the mini-batch size) and image features: ⁇ v 1 + , v 2 + , ..., v b + ⁇ .
- the update unit 210 uses the above features to calculate the cross entropy loss (loss) from text to image and from image to text, and uses the sum or average of these as the loss during training.
- the update unit 210 calculates the gradient for each model parameter using the backpropagation method from the loss calculated in S2, and updates the model parameters using any optimization method.
- the update unit 210 stores the updated model parameters in the learning model DB 220.
- S1 to S3 are executed using the context coding unit 110/image coding unit 120 that has these updated model parameters.
- the update unit 210 repeats S201 to S203 until a termination condition is met.
- the update unit 210 may determine the degree of association for each associated pair of text and image and each unassociated pair of text and image, calculate the loss (difference from the correct answer) from the obtained degree, and update the parameters so as to reduce the loss.
- the search device 100 is configured to include both the context encoding unit 110 and the image encoding unit 120. However, the search device 100 may be configured not to include the image encoding unit 120.
- the learning unit 230 in FIG. 13 includes the encoding unit 130 (context encoding unit 110 and image encoding unit 120) and the update unit 210.
- the image encoding unit 120 in FIG. 13 may be a standalone device (image encoding device). Note that in the configuration of FIG. 13, a configuration having the context encoding unit 110 in the search device 100 and an external image encoding unit 120 may be called an "encoding device.”
- the learning device 200 learns a model for the encoding unit 130.
- the image encoding unit 120 vectorizes the image to be searched using the trained model.
- the set of vectorized images i.e., image features
- the context encoding unit 110 of the search device 100 uses the trained model to vectorize the search query and obtain features.
- the ranking unit 140 performs ranking processing by searching for a set of image features using the features of the search query (by finding the distance).
- either or both of the context coding unit 110 and the image coding unit 120 may be configured as a standalone device. Such a device may be called a "coding device.”
- a general device including either or both of the context encoding unit 110 and the image encoding unit 120 may be referred to as a "coding device.” Both the search device 100 and the learning device 200 are examples of coding devices.
- Any of the devices described in this embodiment can be realized, for example, by causing a computer to execute a program.
- This computer may be a physical computer or a virtual machine on the cloud.
- the device can be realized by using hardware resources such as a CPU and memory built into a computer to execute a program corresponding to the processing performed by the device.
- the program can be recorded on a computer-readable recording medium (such as a portable memory) and then stored or distributed.
- the program can also be provided via a network such as the Internet or email.
- FIG. 15 is a diagram showing an example of the hardware configuration of the computer.
- the computer in FIG. 15 has a drive device 1000, an auxiliary storage device 1002, a memory device 1003, a CPU 1004, an interface device 1005, a display device 1006, an input device 1007, an output device 1008, etc., all of which are interconnected by a bus BS.
- the computer may further include a GPU.
- the program that realizes the processing on the computer is provided by a recording medium 1001, such as a CD-ROM or a memory card.
- a recording medium 1001 storing the program is set in the drive device 1000, the program is installed from the recording medium 1001 via the drive device 1000 into the auxiliary storage device 1002.
- the program does not necessarily have to be installed from the recording medium 1001, but may be downloaded from another computer via a network.
- the auxiliary storage device 1002 stores the installed program as well as necessary files, data, etc.
- the memory device 1003 When an instruction to start a program is received, the memory device 1003 reads out and stores the program from the auxiliary storage device 1002.
- the CPU 1004 realizes the functions related to the device in accordance with the program stored in the memory device 1003.
- the interface device 1005 is used as an interface for connecting to a network, etc.
- the display device 1006 displays a GUI (Graphical User Interface) based on a program, etc.
- the input device 1007 is composed of a keyboard and mouse, buttons, a touch panel, etc., and is used to input various operational instructions.
- the output device 1008 outputs the results of calculations.
- conventional technology has the problem that the computational costs are very high when creating a new model, but in this embodiment, most of the parameters of the image recognition model and language model are excluded from the learning target, and a GAU module is introduced and only this module is trained, making it possible to create a model at low cost.
- An encoding device that extracts features from information using a neural network model, Memory, at least one processor coupled to the memory; Including, The processor implements a context coding unit and an image coding unit;
- the context encoding unit is A context attention mechanism and a context feature conversion unit, which are pre-trained models; a context information selection unit having a GAU module;
- the image encoding unit includes: A pre-trained model of an image attention mechanism and an image feature conversion unit;
- An encoding device comprising: an image information selection unit having a GAU module.
- parameters of normalization layers in each of the context encoding unit and the image encoding unit are parameters that are updated by training that is not the pre-training.
- Additional Note 3 3.
- a learning method executed by an encoding device that extracts features from information using a neural network model comprising:
- the encoding device includes a context encoding unit and an image encoding unit,
- the context encoding unit includes a context attention mechanism and a context feature conversion unit, which are pre-trained models, and a context information selection unit having a GAU module;
- the image encoding unit includes an image attention mechanism and an image feature conversion unit, which are pre-trained models, and an image information selection unit having a GAU module; updating parameters of the context information selection unit and the image information selection unit using features obtained by the context encoding unit and the image encoding unit based on learning data.
- a non-transitory storage medium storing a program for causing a computer to function as each unit in the encoding device according to any one of claims 1 to 3.
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Probability & Statistics with Applications (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Image Analysis (AREA)
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2023/008133 WO2024184975A1 (ja) | 2023-03-03 | 2023-03-03 | 符号化装置、学習方法、及びプログラム |
| JP2025504912A JPWO2024184975A1 (https=) | 2023-03-03 | 2023-03-03 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2023/008133 WO2024184975A1 (ja) | 2023-03-03 | 2023-03-03 | 符号化装置、学習方法、及びプログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2024184975A1 true WO2024184975A1 (ja) | 2024-09-12 |
Family
ID=92674233
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2023/008133 Ceased WO2024184975A1 (ja) | 2023-03-03 | 2023-03-03 | 符号化装置、学習方法、及びプログラム |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JPWO2024184975A1 (https=) |
| WO (1) | WO2024184975A1 (https=) |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20210089571A1 (en) * | 2017-04-10 | 2021-03-25 | Hewlett-Packard Development Company, L.P. | Machine learning image search |
| WO2021095212A1 (ja) * | 2019-11-14 | 2021-05-20 | 富士通株式会社 | 出力方法、出力プログラム、および出力装置 |
| JP2022180942A (ja) * | 2021-05-25 | 2022-12-07 | ソフトバンク株式会社 | 情報処理装置、情報処理方法及び情報処理プログラム |
-
2023
- 2023-03-03 JP JP2025504912A patent/JPWO2024184975A1/ja active Pending
- 2023-03-03 WO PCT/JP2023/008133 patent/WO2024184975A1/ja not_active Ceased
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20210089571A1 (en) * | 2017-04-10 | 2021-03-25 | Hewlett-Packard Development Company, L.P. | Machine learning image search |
| WO2021095212A1 (ja) * | 2019-11-14 | 2021-05-20 | 富士通株式会社 | 出力方法、出力プログラム、および出力装置 |
| JP2022180942A (ja) * | 2021-05-25 | 2022-12-07 | ソフトバンク株式会社 | 情報処理装置、情報処理方法及び情報処理プログラム |
Non-Patent Citations (1)
| Title |
|---|
| FUKUI, AKIRA: "The forefront of vision and language fusion Chapter 3 VQA (Visual Question Answering): Research into technology for answering questions related to images", THE JOURNAL OF THE INSTITUTE OF IMAGE INFORMATION AND TELEVISION ENGINEERS, EIZO JOHO MEDIA GAKKA, JP, vol. 72, no. 5, 1 September 2018 (2018-09-01), JP , pages 659 (17) - 663 (21), XP009557273, ISSN: 1342-6907 * |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2024184975A1 (https=) | 2024-09-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2022267976A1 (zh) | 多模态知识图谱的实体对齐方法、装置及存储介质 | |
| US8533195B2 (en) | Regularized latent semantic indexing for topic modeling | |
| CN104615767B (zh) | 搜索排序模型的训练方法、搜索处理方法及装置 | |
| WO2022007823A1 (zh) | 一种文本数据处理方法及装置 | |
| CN108733742A (zh) | 全局归一化阅读器系统和方法 | |
| JP2022169757A (ja) | 探索装置、探索方法及び探索プログラム | |
| JP6772213B2 (ja) | 質問応答装置、質問応答方法及びプログラム | |
| CN112368697A (zh) | 经由对偶分解评估损失函数或损失函数的梯度的系统和方法 | |
| Yang et al. | xMoCo: Cross momentum contrastive learning for open-domain question answering | |
| EP4586144A1 (en) | Data processing method and related apparatus | |
| CN113761152B (zh) | 一种问答模型的训练方法、装置、设备及存储介质 | |
| US12118314B2 (en) | Parameter learning apparatus, parameter learning method, and computer readable recording medium | |
| CN114861654A (zh) | 一种中文文本中基于词性融合的对抗训练的防御方法 | |
| JP6517537B2 (ja) | 単語ベクトル学習装置、自然言語処理装置、方法、及びプログラム | |
| WO2020170881A1 (ja) | 質問応答装置、学習装置、質問応答方法及びプログラム | |
| CN113220865A (zh) | 一种文本相似词汇检索方法、系统、介质及电子设备 | |
| CN112052865A (zh) | 用于生成神经网络模型的方法和装置 | |
| EP4432130A1 (en) | Text to image generation using k-nearest-neighbor diffusion | |
| CN114490926A (zh) | 一种相似问题的确定方法、装置、存储介质及终端 | |
| Fang et al. | Looking deeper and transferring attention for image captioning | |
| JP6586026B2 (ja) | 単語ベクトル学習装置、自然言語処理装置、方法、及びプログラム | |
| CN120723920A (zh) | 一种基于交互提示的联邦跨模态检索方法及系统 | |
| CN109117471B (zh) | 一种词语相关度的计算方法及终端 | |
| CN119359904B (zh) | 一种基于统一解码器的场景图生成方法 | |
| WO2024184975A1 (ja) | 符号化装置、学習方法、及びプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 23926190 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2025504912 Country of ref document: JP Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2025504912 Country of ref document: JP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 23926190 Country of ref document: EP Kind code of ref document: A1 |