WO2024100890A1 - 機械学習装置、機械学習方法及び機械学習プログラム - Google Patents
機械学習装置、機械学習方法及び機械学習プログラム Download PDFInfo
- Publication number
- WO2024100890A1 WO2024100890A1 PCT/JP2022/042101 JP2022042101W WO2024100890A1 WO 2024100890 A1 WO2024100890 A1 WO 2024100890A1 JP 2022042101 W JP2022042101 W JP 2022042101W WO 2024100890 A1 WO2024100890 A1 WO 2024100890A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- learning
- data
- model
- target
- training
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
Definitions
- This disclosure relates to a method for training a machine learning model.
- Patent document 1 and non-patent documents 1 and 2 describe countermeasures against membership inference attacks.
- training data is divided into data that includes privacy information and data that does not.
- the training data that includes privacy information is used to train only the input layer of the machine learning model.
- the training data that does not include privacy information is used to retrain all layers of the machine learning model.
- the retrained machine learning model is resistant to membership inference attacks.
- Non-Patent Document 1 a machine learning model trained with training data including privacy information is used to assign labels (hereinafter, soft labels) to unlabeled training data that does not include privacy information.
- the training data that does not include privacy information is, for example, public data.
- Another machine learning model is trained with the training data with the soft labels. This trained machine learning model is resistant to membership inference attacks.
- initial training data is divided into a constant number of sets, n.
- n-1 sets excluding that set are set as training data.
- n training data having n-1 sets are set. Training is performed using each of the n training data, and a machine learning model corresponding to each of the n training data is generated.
- a set that is not included in the training data used to train the target machine learning model is given as input to the target machine learning model to obtain a soft label.
- the label of the set given as input is replaced with the soft label, and the new training data is used.
- the new training data is then used to train the machine learning model.
- This trained machine learning model is resistant to membership inference attacks.
- Patent Document 1 and Non-Patent Document 1 require training data that does not contain privacy information.
- sensitive data may be used for machine learning, so it is difficult to prepare training data that does not contain privacy information.
- the countermeasure described in Non-Patent Document 2 does not require training data that does not contain private information.
- the countermeasure described in Non-Patent Document 2 requires additional training of n x (n-1) pieces of learning data, depending on the number of divisions n of the learning data. Therefore, the countermeasure requires a larger amount of calculations than other conventional countermeasures.
- the purpose of this disclosure is to eliminate the need for training data that does not contain private information, reduce the amount of calculations, and provide resistance to membership inference attacks.
- the machine learning device includes: a first learning unit that generates n first learning models by performing training using the target learning data for each of n labeled learning data, where n is an integer equal to or greater than 3, and generating a first learning model corresponding to the target learning data; a model integration unit that integrates m first learning models selected from the n first learning models generated by the first learning unit for an integer m less than n to generate an integrated model; a data generation unit that generates new learning data by replacing the labels attached to the target data with soft labels obtained by inputting target data, which is learning data other than the learning data used in training when generating the m number of first learning models that are the basis of the integrated model, to the integrated model generated by the model integration unit; and The device further includes a second learning unit that performs training using the new learning data generated by the data generation unit to generate a second learning model.
- a first learning model generated by training using the target learning data is integrated to generate an integrated model, and new learning data is generated using the integrated model. This makes it possible to reduce the amount of calculations while eliminating the need for learning data that does not contain privacy information, and to provide resistance to membership inference attacks.
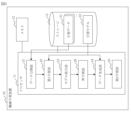
- FIG. 1 is a configuration diagram of a machine learning device 10 according to a first embodiment.
- 4 is a flowchart showing a processing flow of the machine learning device 10 according to the first embodiment.
- FIG. 4 is a diagram illustrating a specific example of the operation of the machine learning device 10 according to the first embodiment.
- FIG. 13 is a configuration diagram of a machine learning device 10 according to Modification 2.
- FIG. 13 is a configuration diagram of a machine learning device 10 according to a second embodiment.
- 11 is a flowchart showing a processing flow of the machine learning device 10 according to the second embodiment.
- FIG. 11 is a diagram illustrating a specific example of the operation of the machine learning device 10 according to the second embodiment.
- Embodiment 1 ***Configuration Description*** The configuration of a machine learning device 10 according to the first embodiment will be described with reference to FIG.
- the machine learning device 10 is a computer.
- the machine learning device 10 includes hardware such as a processor 11, a memory 12, and a storage 13.
- the processor 11 is connected to other hardware via signal lines and controls the other hardware.
- Processor 11 is an IC that performs processing.
- IC stands for Integrated Circuit.
- Specific examples of processor 11 include a CPU, DSP, and GPU.
- CPU stands for Central Processing Unit.
- DSP stands for Digital Signal Processor.
- GPU stands for Graphics Processing Unit.
- Memory 12 is a storage device that temporarily stores data. Specific examples of memory 12 include SRAM and DRAM. SRAM stands for Static Random Access Memory. DRAM stands for Dynamic Random Access Memory.
- Storage 13 is a storage device that stores data.
- a specific example of storage 13 is a HDD.
- HDD is an abbreviation for Hard Disk Drive.
- Storage 13 may also be a portable recording medium such as an SD (registered trademark) memory card, CompactFlash (registered trademark), NAND flash, a flexible disk, an optical disk, a compact disk, a Blu-ray (registered trademark) disk, or a DVD.
- SD is an abbreviation for Secure Digital.
- DVD is an abbreviation for Digital Versatile Disk.
- the machine learning device 10 includes, as functional components, a data division unit 21, a first learning unit 22, a model integration unit 23, a data generation unit 24, and a second learning unit 25.
- the functions of the functional components of the machine learning device 10 are realized by software.
- the storage 13 stores programs that realize the functions of each functional component of the machine learning device 10. These programs are loaded into the memory 12 by the processor 11 and executed by the processor 11. In this way, the functions of each functional component of the machine learning device 10 are realized.
- Storage 13 stores multiple pieces of training data 31 and a training model 32. Each piece of training data 31 is labeled and includes privacy information.
- FIG. 1 only one processor 11 is shown. However, there may be multiple processors 11, and the multiple processors 11 may work together to execute programs that realize each function.
- Step S11 Data division process
- the data division unit 21 reads a plurality of pieces of learning data 31 stored in the storage 13 into the memory 12.
- the data division unit 21 divides the read plurality of pieces of learning data 31 into a constant number of sets, n, where n is an integer equal to or greater than 3.
- n is an integer equal to or greater than 3.
- the data division unit 21 equally divides the plurality of pieces of learning data 31 such that the number of pieces of learning data 31 included in each set is approximately equal. This generates a data set of n pieces of learning data (hereinafter, learning data 33).
- the data division unit 21 writes the n pieces of learning data 33 into the memory 12.
- Step S12 First learning process
- the first learning unit 22 reads the n pieces of learning data 33 generated in step S11 and the learning model 32 from the memory 12.
- the first learning unit 22 sets each of the n pieces of learning data 33 as target learning data 33.
- the first learning unit 22 trains the learning model 32 using the target learning data 33, and generates a first learning model 34 corresponding to the target learning data 33. In this way, the n first learning models 34 are generated.
- the first learning unit 22 writes the n first learning models 34 to the memory 12.
- Step S13 Model integration process
- the model integration unit 23 reads the n first learning models 34 generated in step S12 from the memory 12.
- the model integration unit 23 integrates m first learning models 34 selected from the n first learning models 34 to generate an integrated model 35.
- m is an integer less than n.
- the model integration unit 23 generates an integrated model 35 for each combination of m first learning models 34 selectable from the n first learning models.
- the model integration unit 23 writes the integrated model 35 for each combination into the memory 12.
- the model integration unit 23 sums up the parameters of the m number of first learning models 34 and performs arithmetic processing such as arithmetic average or weighted average for each parameter. In this way, the model integration unit 23 integrates the m number of first learning models 34 to generate an integrated model 35.
- n n-1.
- n combinations for selecting n-1 first learning models 34 from n first learning models 34 That is, there are n combinations including a combination of the remaining n-1 first learning models 34 excluding the first first learning model 34 among the n first learning models 34, a combination of the remaining n-1 first learning models 34 excluding the second first learning model 34, and a combination of the remaining n-1 first learning models 34 excluding the nth first learning model 34. Therefore, for each of the n combinations, the model integration unit 23 integrates the first learning models 34 of that combination to generate an integrated model 35. As a result, n integrated models 35 are generated.
- Step S14 Data generation process
- the data generating unit 24 reads each integrated model 35 generated in step S13 from the memory 12.
- the data generating unit 24 sets each integrated model 35 as a target integrated model 35.
- the data generation unit 24 provides the target integrated model 35 with, as input, target data 36, which is learning data 33 other than the learning data 33 used in training when generating the m first learning models on which the target integrated model 35 is based, to cause the target integrated model 35 to perform inference.
- the data generation unit 24 acquires soft labels, which are the results obtained by inference using the target integrated model 35.
- the data generation unit 24 replaces the labels attached to the target data 36 with the soft labels to generate new learning data 37.
- the data generation unit 24 aggregates the new learning data 37 generated for each integrated model 35, and writes it into the memory 12 as a dataset of the new learning data 37.
- the data generating unit 24 reads n integrated models 35.
- the data generating unit 24 sets each of the n integrated models 35 as a target integrated model 35.
- the data generating unit 24 performs inference by providing the target integrated model 35 with the target data 36, which is the learning data 33 other than the learning data 33 used in training when generating the n-1 first learning models that are the basis of the target integrated model 35, as input. For example, when the target integrated model 35 is generated from a combination of the remaining n-1 first learning models 34 excluding the first first learning model 34, the first first learning model 34 becomes the target data 36.
- the target integrated model 35 is generated from a combination of the remaining n-1 first learning models 34 excluding the second first learning model 34
- the second first learning model 34 becomes the target data 36.
- the data generating unit 24 replaces the label attached to the target data 36 with the soft label to generate new learning data 37.
- the data generation unit 24 aggregates the new training data 37 generated for each of the n integrated models 35 and writes the aggregated data 37 into the memory 12 as a data set of the new training data 37 .
- Step S15 Second learning process
- the second learning unit 25 reads the data set of new learning data 37 generated in step S14 and the learning model 32 from the memory 12.
- the second learning unit 25 trains the learning model 32 using the data set of the new learning data 37 to generate a second learning model 38.
- FIG. 3 shows an example in which the division number n is 3 and m is n-1.
- step S12 the first learning unit 22 sets each of the three learning data 33 as target learning data 33.
- the first learning unit 22 trains the learning model 32 using the target learning data 33 to generate a first learning model 34 corresponding to the target learning data 33.
- This generates three pieces of learning data 33: a first learning model 34A trained with learning data 33A, a first learning model 34B trained with learning data 33B, and a first learning model 34C trained with learning data 33C.
- the model integration unit 23 generates an integrated model 35 by integrating the two first learning models 34 included in the target combination. This results in the generation of three integrated models 35: an integrated model 35A that integrates the first learning model 34A and the first learning model 34B; an integrated model 35B that integrates the first learning model 34B and the first learning model 34C; and an integrated model 35C that integrates the first learning model 34A and the first learning model 34C.
- step S14 the data generating unit 24 sets each of the three integrated models 35 as the target integrated model 35.
- the data generating unit 24 provides the target data 36, which is the learning data 33 not used in training the two first learning models 34 that are the basis of the target integrated model 35, as input to the target integrated model 35.
- the integrated model 35A is provided with the learning data 33C not used in training the first learning model 34A and the first learning model 34B as input.
- the integrated model 35B is provided with the learning data 33A not used in training the first learning model 34B and the first learning model 34C as input.
- the integrated model 35C is provided with the learning data 33B not used in training the first learning model 34A and the first learning model 34C as input.
- the data generation unit 24 replaces the labels attached to the target data 36 with the soft labels that are the results of inference obtained by the target integrated model 35, to generate new training data 37. That is, the labels of the training data 33C are replaced with the soft labels obtained by the integrated model 35A to generate new training data 37A. The labels of the training data 33A are replaced with the soft labels obtained by the integrated model 35B to generate new training data 37B. The labels of the training data 33B are replaced with the soft labels obtained by the integrated model 35C to generate new training data 37C. The data generating unit 24 aggregates the new learning data 37A, the new learning data 37B, and the new learning data 37C to generate a data set of the new learning data 37.
- step S15 the second learning unit 25 trains the learning model 32 using the data set of new learning data 37 to generate a second learning model 38.
- the training of the learning model 32 is performed, for example, by deep learning.
- the training of the learning model 32 is not limited to deep learning, and may be performed, for example, by calculations such as regression methods, decision tree learning, Bayesian methods, and clustering.
- the machine learning device 10 generates a plurality of first learning models 34 using the learning data 33 obtained by dividing the learning data 31 including privacy information, and integrates the first learning models 34 to generate the integrated model 35. Then, the machine learning device 10 generates new learning data 37 using the soft labels obtained by the integrated model 35, and trains the learning model 32 with the new learning data 37 to generate the second learning model 38.
- the second learning model 38 is generated by training the learning model 32 using the new learning data 37 from which the privacy information of the original learning data 31 has been removed.
- the machine learning device 10 according to the first embodiment can generate the second learning model 38 that is resistant to membership inference attacks. In other words, the machine learning device 10 can generate the second learning model 38 that is resistant to membership inference attacks without preparing learning data that does not contain privacy information, as in Patent Document 1 and Non-Patent Document 1.
- the machine learning device 10 generates a first learning model 34 for each of the multiple pieces of learning data 33 into which the learning data 31 is divided, and integrates the first learning models 34 to generate an integrated model 35. That is, the machine learning device 10 does not perform additional learning as in Non-Patent Document 2, but integrates the first learning models 34.
- (1) one additional training session is required, and (2) lightweight processing, such as average calculation of parameters of the first learning model 34 and assignment of soft labels.
- the additional training session is training of n pieces of learning data 33 according to the division number n of the learning data 31.
- the average calculation of parameters of the first learning model 34 is a calculation in the process of integrating the first learning model 34.
- the second learning unit 25 may perform training using data obtained by adding the learning data 31 to the data set of the new learning data 37 at a reference ratio. This is expected to improve the learning accuracy. However, the higher the ratio of the learning data 31 to the new learning data 37, the lower the resistance to membership inference attacks of the second learning model 38. Therefore, it is necessary to set a reference ratio in advance according to the required resistance to membership inference attacks.
- each functional component is realized by software.
- each functional component may be realized by hardware. The following describes the second modification, focusing on the differences from the first embodiment.
- the machine learning device 10 includes an electronic circuit 15 instead of the processor 11, the memory 12, and the storage 13.
- the electronic circuit 15 is a dedicated circuit for realizing the functions of each functional component, the memory 12, and the storage 13.
- the electronic circuit 15 may be a single circuit, a composite circuit, a programmed processor, a parallel programmed processor, a logic IC, a GA, an ASIC, or an FPGA.
- GA is an abbreviation for Gate Array.
- ASIC is an abbreviation for Application Specific Integrated Circuit.
- FPGA is an abbreviation for Field-Programmable Gate Array.
- Each functional component may be realized by one electronic circuit 15, or each functional component may be realized by distributing it among a plurality of electronic circuits 15.
- ⁇ Modification 3> As a third modification, some of the functional components may be realized by hardware, and other functional components may be realized by software.
- the processor 11, memory 12, storage 13, and electronic circuit 15 are referred to as the processing circuit.
- the functions of each functional component are realized by the processing circuit.
- Embodiment 2 differs from the first embodiment in that retraining of the integrated model 35 is performed. In the second embodiment, this difference will be described, and a description of the same points will be omitted.
- the configuration of a machine learning device 10 according to the second embodiment will be described with reference to FIG. 1 in that the machine learning device 10 includes a relearning unit 26 as a functional component.
- the relearning unit 26 is realized by software or hardware, like the other functional components.
- step S21 to S23 are the same as those in steps S11 to S13 in Fig. 2.
- steps S25 and S26 are the same as those in steps S14 and S15 in Fig. 2.
- step S25 new learning data 37 is generated using the integrated model 35 that has been retrained in step S24.
- Step S24 Re-learning process
- the re-learning unit 26 reads each integrated model 35 generated in step S23 from the memory 12.
- the re-learning unit 26 sets each integrated model 35 as a target integrated model 35.
- the re-learning unit 26 re-trains the target integrated model 35 using the learning data 33 used in training when generating the m first learning models 34 that are the basis of the target integrated model 35.
- Each first learning model 34 is generated using one piece of learning data 33. Therefore, the re-learning unit 26 performs training using the m pieces of learning data 33 used when generating the m first learning models 34.
- FIG. 7 A specific example of the operation of the machine learning device 10 according to the second embodiment will be described with reference to FIG. 7, like the example in FIG. 3, an example is shown in which the division number n is 3 and m is n-1.
- step S21 to step S23 three integrated models 35, integrated model 35A to integrated model 35C, are generated, similar to the example in FIG. 3.
- the re-learning unit 26 sets each of the three integrated models 35 as the target integrated model 35.
- the data generating unit 24 re-trains the target integrated model 35 by using the learning data 33 used in training the two first learning models 34 that were the basis of the target integrated model 35.
- the integrated model 35A is retrained using the learning data 33A and learning data 33B used in training the first learning model 34A and the first learning model 34B. This generates an integrated model 35A'.
- the integrated model 35B is retrained using the learning data 33B and learning data 33C used in training the first learning model 34B and the first learning model 34C. This generates an integrated model 35B'.
- the integrated model 35C is retrained using the learning data 33A and learning data 33C used in training the first learning model 34A and the first learning model 34C. This generates an integrated model 35C'.
- step S25 the data generation unit 24 sets each of the three retrained integrated models 35 as the target integrated model 35.
- the data generation unit 24 sets each of integrated models 35A', 35B', and 35C' as the target integrated model 35.
- the data generation unit 24 generates new learning data 37 using the target integrated model 35.
- step S26 the second learning unit 25 trains the learning model 32 using the data set of new learning data 37, as in the example of FIG. 3, to generate a second learning model 38.
- the machine learning device 10 retrains the integrated model 35. This makes it possible to improve the inference accuracy of the integrated model 35 compared to the first embodiment.
- the inference accuracy of the integrated model 35 is improved, it becomes possible to assign soft labels to the new learning data 37 with high accuracy.
- circuit In addition, the word "part” in the above explanation may be interpreted as “circuit,” “process,” “procedure,” “processing,” or “processing circuit.”
- Machine learning device 11 Processor, 12 Memory, 13 Storage, 15 Electronic circuit, 21 Data division unit, 22 First learning unit, 23 Model integration unit, 24 Data generation unit, 25 Second learning unit, 26 Re-learning unit, 31 Learning data, 32 Learning model, 33 Learning data, 34 First learning model, 35 Integration model, 36 Target data, 37 New learning data, 38 Second learning model.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Medical Informatics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Physics & Mathematics (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Artificial Intelligence (AREA)
- Machine Translation (AREA)
- Image Analysis (AREA)
Priority Applications (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2024541003A JP7546822B1 (ja) | 2022-11-11 | 2022-11-11 | 機械学習装置、機械学習方法及び機械学習プログラム |
| DE112022007716.6T DE112022007716T5 (de) | 2022-11-11 | 2022-11-11 | Maschinenlernvorrichtung, maschinenlernverfahren und maschinenlernprogramm |
| CN202280100963.1A CN120112920A (zh) | 2022-11-11 | 2022-11-11 | 机器学习装置、机器学习方法和机器学习程序 |
| PCT/JP2022/042101 WO2024100890A1 (ja) | 2022-11-11 | 2022-11-11 | 機械学習装置、機械学習方法及び機械学習プログラム |
| US19/080,628 US20250217711A1 (en) | 2022-11-11 | 2025-03-14 | Machine learning apparatus, machine learning method, and computer readable medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2022/042101 WO2024100890A1 (ja) | 2022-11-11 | 2022-11-11 | 機械学習装置、機械学習方法及び機械学習プログラム |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US19/080,628 Continuation US20250217711A1 (en) | 2022-11-11 | 2025-03-14 | Machine learning apparatus, machine learning method, and computer readable medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2024100890A1 true WO2024100890A1 (ja) | 2024-05-16 |
Family
ID=91032191
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/042101 Ceased WO2024100890A1 (ja) | 2022-11-11 | 2022-11-11 | 機械学習装置、機械学習方法及び機械学習プログラム |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US20250217711A1 (https=) |
| JP (1) | JP7546822B1 (https=) |
| CN (1) | CN120112920A (https=) |
| DE (1) | DE112022007716T5 (https=) |
| WO (1) | WO2024100890A1 (https=) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2026009283A1 (ja) * | 2024-07-01 | 2026-01-08 | Ntt株式会社 | 情報処理装置及び情報処理方法 |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110647765B (zh) * | 2019-09-19 | 2022-04-12 | 济南大学 | 协同学习框架下基于知识迁移的隐私保护方法及系统 |
-
2022
- 2022-11-11 CN CN202280100963.1A patent/CN120112920A/zh active Pending
- 2022-11-11 WO PCT/JP2022/042101 patent/WO2024100890A1/ja not_active Ceased
- 2022-11-11 JP JP2024541003A patent/JP7546822B1/ja active Active
- 2022-11-11 DE DE112022007716.6T patent/DE112022007716T5/de active Pending
-
2025
- 2025-03-14 US US19/080,628 patent/US20250217711A1/en active Pending
Non-Patent Citations (2)
| Title |
|---|
| JARIN ISMAT, ESHETE BIRHANU: "MIAShield: Defending Membership Inference Attacks via Preemptive Exclusion of Members", PROCEEDINGS ON PRIVACY ENHANCING TECHNOLOGIES, vol. 2023, no. 1, 2 March 2022 (2022-03-02), pages 400 - 416, XP093172177, ISSN: 2299-0984, DOI: 10.56553/popets-2023-0024 * |
| TANG XINYU, MAHLOUJIFAR SAEED; SONG LIWEI; SHEJWALKAR VIRAT; NASR MILAD; HOUMANSADR AMIR; MITTAL PRATEEK: "Mitigating Membership Inference Attacks by Self-Distillation Through a Novel Ensemble Architecture", 31ST USENIX SECURITY SYMPOSIUM, 1 August 2022 (2022-08-01), XP093172171, Retrieved from the Internet <URL:https://www.usenix.org/system/files/sec22fall_tang.pdf> * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2026009283A1 (ja) * | 2024-07-01 | 2026-01-08 | Ntt株式会社 | 情報処理装置及び情報処理方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN120112920A (zh) | 2025-06-06 |
| JP7546822B1 (ja) | 2024-09-06 |
| DE112022007716T5 (de) | 2025-06-18 |
| US20250217711A1 (en) | 2025-07-03 |
| JPWO2024100890A1 (https=) | 2024-05-16 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112651418B (zh) | 数据分类方法、分类器训练方法及系统 | |
| Pereira et al. | Toward hierarchical classification of imbalanced data using random resampling algorithms | |
| US9454725B2 (en) | Passage justification scoring for question answering | |
| US20160232444A1 (en) | Scoring type coercion for question answering | |
| EP3117338A1 (en) | Alternative training distribution data in machine learning | |
| CN112396085B (zh) | 识别图像的方法和设备 | |
| US20100017352A1 (en) | Enhancing performance of a constraint solver across individual processes | |
| US11604950B2 (en) | Methods and apparatuses for classifying data point using convex hull based on centroid of cluster | |
| US12112482B2 (en) | Techniques for interactive image segmentation networks | |
| JP7546822B1 (ja) | 機械学習装置、機械学習方法及び機械学習プログラム | |
| US10209958B2 (en) | Reproducible stochastic rounding for out of order processors | |
| Chereddy et al. | Evaluating the utility of GAN generated synthetic tabular data for class balancing and low resource settings | |
| JP2022062949A (ja) | 機械学習プログラム、機械学習装置、及び、機械学習方法 | |
| JP7492088B2 (ja) | 重み付き知識移転装置、方法、及びシステム | |
| Miller et al. | An algorithm for linear, affine and spectral classification of Boolean functions | |
| US20190311302A1 (en) | Electronic apparatus and control method thereof | |
| US20230153421A1 (en) | Genetic programming for dynamic cybersecurity | |
| US20240428137A1 (en) | Typicality of Batches for Machine Learning | |
| Chu et al. | BVQC: A backdoor-style watermarking scheme for variational quantum circuits | |
| Tudorache et al. | Implementation of the Bernstein-Vazirani quantum algorithm using the qiskit framework | |
| US12282829B2 (en) | Techniques for data type detection with learned metadata | |
| JP7524946B2 (ja) | データ処理装置、データ処理方法及び記録媒体 | |
| US20230196125A1 (en) | Techniques for ranked hyperparameter optimization | |
| Davis et al. | Decision-directed data decomposition | |
| KR102896124B1 (ko) | 명시적 특성 상호작용을 학습하는 신경망 모델을 활용하는 전자 장치 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22965214 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2024541003 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 202280100963.1 Country of ref document: CN |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 112022007716 Country of ref document: DE |
|
| WWP | Wipo information: published in national office |
Ref document number: 202280100963.1 Country of ref document: CN |
|
| WWP | Wipo information: published in national office |
Ref document number: 112022007716 Country of ref document: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 22965214 Country of ref document: EP Kind code of ref document: A1 |