WO2024095397A1 - 目標最適化装置、方法およびプログラム - Google Patents
目標最適化装置、方法およびプログラム Download PDFInfo
- Publication number
- WO2024095397A1 WO2024095397A1 PCT/JP2022/041006 JP2022041006W WO2024095397A1 WO 2024095397 A1 WO2024095397 A1 WO 2024095397A1 JP 2022041006 W JP2022041006 W JP 2022041006W WO 2024095397 A1 WO2024095397 A1 WO 2024095397A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- optimal
- goal
- target
- action
- reward
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images



Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N99/00—Subject matter not provided for in other groups of this subclass
Definitions
- One aspect of the present invention relates to a goal optimization device, method, and program for optimizing goals related to human behavior.
- modeling human behavior when trying to achieve a goal is important because such modeling can predict a person's future behavior and how that behavior will change when an intervention occurs, allowing us to determine appropriate interventions to help that person achieve their goal.
- Non-Patent Document 1 proposes a model based on graph theory.
- the states that a person can take are represented as vertices, and the actions that a person can take in each state are represented as edges.
- a cost is also assigned to each edge, and this cost represents the effort, or load, involved in taking an action.
- a reward is assigned to each vertex, which represents the reward for reaching the corresponding state.
- the agent evaluates its own payoffs for each possible course of action (path on the graph) it can take in the future on this graph, and chooses the action that offers the greatest payoff.
- the payoffs for a sequence of actions are calculated by weighting future costs lower and current costs higher, using a present bias known as quasi-hyperbolic discounting.
- This model has attracted attention as a model that can adequately explain irrational human behavior, and has been extended to include models that include other biases (see, for example, non-patent literature 2 or 3). Using these extended models, it becomes possible to solve optimization problems such as reward optimization and goal optimization.
- the above-mentioned model enables flexible modeling by being based on graph theory, its excessive degree of freedom can make analytical handling difficult.
- the above-mentioned existing models are not suitable for tasks with simple structures, such as tasks related to the behavior of "improving one numerical indicator" for each individual, such as completing a course of study in an online class or achieving a step count goal in a certain period of time.
- This invention was made with the above in mind, and aims to provide technology that makes it possible to calculate a user's optimal goal under the influence of present bias, thereby maximizing the degree of task achievement for each individual.
- one aspect of the goal optimization device or method according to the present invention is a graph consisting of a plurality of vertices and a plurality of edges connecting these vertices, the vertices indicating a state represented by the degree of achievement of an action and the time required for the action, the edges indicating the action that a person can take in the state, the vertices being set with a reward for achieving the state, and the edges being set with a cost for taking the action, the device or method using a model based on the graph, the device or method comprising a first processing unit or process for acquiring the reward, the maximum value of the required time, and a current bias parameter that weights the cost in a time series, a second processing unit or process for calculating the optimal goal, and a third processing unit or process for outputting the optimal goal calculated by the second processing unit or process.
- the second processing unit or process calculates the optimal goal for the action by substituting the reward, the maximum value of the required time, and the current bias parameter into
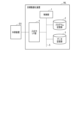
- FIG. 1 is a block diagram showing an example of a hardware configuration of a goal optimization device according to an embodiment of the present invention.
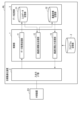
- FIG. 2 is a block diagram showing an example of a software configuration of a goal optimization device according to an embodiment of the present invention.
- FIG. 3 is a flowchart showing an example of a processing procedure and processing contents of a series of processing for calculating an optimal target executed by the control unit of the target optimization device shown in FIG.
- FIG. 4 is a diagram illustrating an example of input data stored in the input data storage unit illustrated in FIG.
- FIG. 5 is a diagram showing an example of the optimum target calculated value stored in the optimum target storage unit shown in FIG.
- a new model is devised that simplifies the model proposed by Kleinberg and Oren by limiting the shape of the graph to reflect the above-mentioned "present bias,” and the optimal goal for each individual is calculated using this model. In this way, it is possible to maximize the degree of task achievement for each individual.
- (Configuration example) 1 and 2 are block diagrams showing an example of a hardware configuration and a software configuration, respectively, of a goal optimization device according to an embodiment of the present invention.
- the target optimization device ML is configured, for example, by a server computer or a personal computer.
- the target optimization device ML has a control unit 1 that uses a hardware processor such as a central processing unit (CPU), and a storage unit having a program storage unit 2 and a data storage unit 3, and an input/output interface (hereinafter, the interface will be referred to as I/F) unit 4 are connected to this control unit 1 via a bus 5.
- the target optimization device ML may also have a communication I/F unit that transmits and receives information data between networks, etc.
- An external device EX used by an administrator or the like is connected to the input/output I/F unit 4 via a signal cable or network.
- the input/output I/F unit 4 receives input data used to calculate the optimal target from the external device EX, and outputs the optimal target calculated by the control unit 1 to the external device EX.
- the program storage unit 2 is configured, for example, by combining a non-volatile memory such as a HDD (Hard Disk Drive) or SSD (Solid State Drive) as a storage medium that can be written to and read from at any time, and a non-volatile memory such as a ROM (Read Only Memory), and stores various programs necessary to execute various control processes according to one embodiment of the present invention, in addition to middleware such as an OS (Operating System).
- a non-volatile memory such as a HDD (Hard Disk Drive) or SSD (Solid State Drive) as a storage medium that can be written to and read from at any time
- a non-volatile memory such as a ROM (Read Only Memory)
- middleware such as an OS (Operating System).
- the data storage unit 3 is configured, for example, by combining a non-volatile memory such as an HDD or SSD, which can be written to and read from at any time, as a storage medium, with a volatile memory such as a RAM (Random Access Memory), and includes an input data storage unit 31 and an optimal target storage unit 32 as storage areas required to implement one embodiment of the present invention.
- a non-volatile memory such as an HDD or SSD
- a volatile memory such as a RAM (Random Access Memory)
- RAM Random Access Memory
- the input data storage unit 31 is used to store input data that is input from the external device EX and that is the condition for calculating the optimal target.
- the optimal target storage unit 32 is used to store the optimal target value calculated by the control unit 1.
- the control unit 1 includes a data acquisition processing unit 11, an optimal target calculation processing unit 12, and an optimal target output processing unit 13 as processing functions according to one embodiment of the present invention.
- All of these processing units 11 to 13 are realized by having the hardware processor of the control unit 1 execute application programs stored in the program storage unit 2. Note that some or all of the processing units 11 to 13 may be realized using hardware such as an LSI (Large Scale Integration) or an ASIC (Application Specific Integrated Circuit).
- each of the above application programs does not have to be stored in advance in the program storage unit 2, and may be downloaded from the external device EX or other server device when necessary and stored in the program storage unit 2.
- the data acquisition processing unit 11 imports data input in the external device EX via the input/output I/F unit 4. The imported data is then stored in the input data storage unit 31.
- the input data includes the reward, the maximum number of days, and parameters that represent the strength of the current bias.
- the optimal goal calculation processing unit 12 reads the remuneration, maximum number of days, and current bias parameters from the input data storage unit 31. The input data thus read is then substituted as conditions into a pre-prepared optimal goal calculation formula, and the optimal goal is calculated by performing a calculation. The optimal goal calculation processing unit 12 stores the calculation result of the optimal goal in the optimal goal storage unit 32.
- the optimal target output processing unit 13 reads the optimal target from the optimal target storage unit 32, and outputs information representing the read optimal target from the input/output I/F unit 4 to the external device EX.
- Model used in One Embodiment is a simplified version of the model proposed by Kleinberg and Oren et al., which is achieved by restricting the shape of the graph by taking into account the “present bias” as described above.
- V ⁇ (i, x)
- E ⁇ ((i, x), (i+1, y))
- i is a discrete value
- x is a continuous value.
- the cost of edge ((i, x), (i+1, y)) is (y-x) 2
- the reward obtained at vertex (i, x) is r(i, x).
- i corresponds to the time
- x corresponds to the numerical index representing the progress of the task.
- i represents the current day
- x represents the number of steps walked to date.
- N is the maximum number of days, which in this example corresponds to "30 days.”
- the model of one embodiment restricts the shape of the graph by reflecting temporal conditions, which enables the analytical treatment described below. This is what makes it different from the model proposed by Kleinberg and Oren et al.
- the objective cost c(i, x) when starting from vertex (i, x) is It is determined by.
- the destination (zi) is It is determined by.
- ⁇ is a parameter that represents the strength of the present bias, in particular the strength of the quasi-hyperbolicity, and satisfies 0 ⁇ 1. If ⁇ is small, the agent will place particularly heavy weight on recent costs, and if ⁇ is large, the agent will also evaluate future costs.
- FIG. 3 is a flowchart showing an example of a series of processing steps and processing contents for calculating an optimal target executed by the control unit 1 of the target optimization device ML.
- (2-1) Acquisition of Input Data For example, when a subject tries to obtain an optimal target for the number of steps for dieting, the subject inputs the reward R, the number of time steps (e.g., the maximum number of days) N, and the current bias parameter ⁇ in the external device EX.
- the external device EX transmits the input reward R, the maximum number of days N, and the current bias parameter ⁇ to the goal optimization device ML together with a data input request.
- control unit 1 of the target optimization device ML receives the data input request in step S10, under the control of the data acquisition processing unit 11, in step S11 it receives the input data transmitted from the external device EX via the input/output I/F unit 4. Then, it stores the received input data in the input data storage unit 31.
- step S12 the control unit 1 executes a calculation process of the optimal target a as follows.
- the target a should be as large as possible while still satisfying this condition.
- the destination point zN is It becomes.
- the optimal solution a * is According to this formula, the optimal goal a can be obtained in time complexity O(1).
- step S12 the optimal target calculation processing unit 12 reads the reward R, the number of time steps (maximum number of days) N, and the current bias parameter ⁇ from the input data storage unit 31. Then, the optimal target calculation processing unit 12 calculates the optimal target a by substituting the read reward R, maximum number of days N, and the current bias parameter ⁇ into the calculation formula for the optimal solution a * . Then, the optimal target calculation processing unit 12 stores the calculated optimal target a in the optimal target storage unit 32.
- the target optimization device ML reads out the calculation result of the optimal target a from the optimal target storage unit 32 in step S13 under the control of the optimal target output processing unit 13. Then, the optimal target output processing unit 13 generates information for presenting the read calculation result of the optimal target a to the user, and transmits the generated presentation information from the input/output I/F unit 4 to the external device EX that is the request source.
- a model that is a simplified version of the model by Kleinberg and Oren et al. is prepared by limiting the shape of the graph to reflect the "current bias”, and the simplified model is analyzed to generate a calculation formula for the optimal goal. Then, the reward R, the number of time steps (maximum number of days) N, and the current bias parameter ⁇ are obtained as input data from the external device EX, and the optimal goal a is calculated by substituting the obtained reward R, the number of time steps (maximum number of days) N, and the current bias parameter ⁇ into the calculation formula for the optimal goal, and the optimal goal a is output to the external device EX.
- a model that enables analytical handling by restricting the shape of a graph is generated in advance by another device such as the external device EX.
- the generation processing function of the model may be provided in the target optimization device ML.
- the target optimization device ML is provided independently of the external device EX. However, this is not limiting, and each function of the target optimization device ML may be provided in the external device EX. This allows the external device EX to collectively perform all processing, including the optimal target calculation processing, for example.
- this invention is not limited to the above-described embodiment as it is, and in the implementation stage, the components can be modified and embodied without departing from the gist of the invention.
- various inventions can be formed by appropriately combining multiple components disclosed in the above-described embodiment. For example, some components may be deleted from all the components shown in the embodiment. Furthermore, components from different embodiments may be appropriately combined.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2022/041006 WO2024095397A1 (ja) | 2022-11-02 | 2022-11-02 | 目標最適化装置、方法およびプログラム |
| JP2024554006A JPWO2024095397A1 (https=) | 2022-11-02 | 2022-11-02 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2022/041006 WO2024095397A1 (ja) | 2022-11-02 | 2022-11-02 | 目標最適化装置、方法およびプログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2024095397A1 true WO2024095397A1 (ja) | 2024-05-10 |
Family
ID=90929969
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/041006 Ceased WO2024095397A1 (ja) | 2022-11-02 | 2022-11-02 | 目標最適化装置、方法およびプログラム |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JPWO2024095397A1 (https=) |
| WO (1) | WO2024095397A1 (https=) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025248590A1 (ja) * | 2024-05-27 | 2025-12-04 | Ntt株式会社 | 行動予測装置及びプログラム |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2022117452A (ja) * | 2021-01-29 | 2022-08-10 | 富士通株式会社 | ネットワークモチーフ解析を使用したグラフベース予測の説明 |
-
2022
- 2022-11-02 WO PCT/JP2022/041006 patent/WO2024095397A1/ja not_active Ceased
- 2022-11-02 JP JP2024554006A patent/JPWO2024095397A1/ja active Pending
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2022117452A (ja) * | 2021-01-29 | 2022-08-10 | 富士通株式会社 | ネットワークモチーフ解析を使用したグラフベース予測の説明 |
Non-Patent Citations (2)
| Title |
|---|
| "The science of "decision making"", 20 September 2020, KODANSHA CO., LTD., JP, ISBN: 978-4-06-520958-5, article SATOSHI KAWAGOE: "Passage; The science of "decision making"", pages: 164 - 179, XP009557018 * |
| MOSHE BABAIOFF: "Time-inconsistent planning : a computational problem in behavioral economics", PROCEEDINGS OF THE FIFTEENTH ACM CONFERENCE ON ECONOMICS AND COMPUTATION, ACM, NEW YORK, NY, USA, 6 May 2014 (2014-05-06), New York, NY, USA, pages 547 - 564, XP093167448, ISBN: 978-1-4503-2565-3 * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025248590A1 (ja) * | 2024-05-27 | 2025-12-04 | Ntt株式会社 | 行動予測装置及びプログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2024095397A1 (https=) | 2024-05-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Fenichel et al. | Adaptive human behavior in epidemiological models | |
| Peterman et al. | A comparison of popular approaches to optimize landscape resistance surfaces | |
| Wegmann et al. | ABCtoolbox: a versatile toolkit for approximate Bayesian computations | |
| Lakka et al. | Competitive dynamics in the operating systems market: Modeling and policy implications | |
| CA3037346C (en) | Transforming attributes for training automated modeling systems | |
| US20210406932A1 (en) | Information processing apparatus, information processing method and program thereof | |
| Isaac et al. | The use of EDGE (evolutionary distinct globally endangered) and EDGE-like metrics to evaluate taxa for conservation | |
| Wiedenmann et al. | An evaluation of acceptable biological catch (ABC) harvest control rules designed to limit overfishing | |
| JP5963320B2 (ja) | 情報処理装置、情報処理方法、及び、プログラム | |
| US10537801B2 (en) | System and method for decision making in strategic environments | |
| Geerdens et al. | Conditional copula models for right-censored clustered event time data | |
| Mei et al. | Constrained dimensionally aware genetic programming for evolving interpretable dispatching rules in dynamic job shop scheduling | |
| US9104978B2 (en) | System and method for parameter evaluation | |
| Stotter et al. | Behavioural investigations of financial trading agents using Exchange Portal (ExPo) | |
| WO2024095397A1 (ja) | 目標最適化装置、方法およびプログラム | |
| Gerst et al. | The interplay between risk attitudes and low probability, high cost outcomes in climate policy analysis | |
| CN112446763B (zh) | 服务推荐方法、装置及电子设备 | |
| US12481772B2 (en) | Automatically adjusting data access policies in data analytics | |
| JP2020181318A (ja) | 最適化装置、最適化方法、及びプログラム | |
| WO2023286234A1 (ja) | 学習データ評価装置、学習データ評価システム、学習データ評価方法及びプログラム | |
| Milocco et al. | A method to predict the response to directional selection using a Kalman filter | |
| CN117237053B (zh) | 一种机票分销平台及其控制方法 | |
| Byer et al. | Genetically-informed population models improve climate change vulnerability assessments | |
| Li et al. | Ethics in action: training reinforcement learning agents for moral decision-making in text-based adventure games | |
| Kołodziej et al. | Control sharing analysis and simulation |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22964417 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2024554006 Country of ref document: JP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 22964417 Country of ref document: EP Kind code of ref document: A1 |