WO2024042736A1 - 情報処理方法、情報処理システム、及び情報処理プログラム - Google Patents
情報処理方法、情報処理システム、及び情報処理プログラム Download PDFInfo
- Publication number
- WO2024042736A1 WO2024042736A1 PCT/JP2023/005451 JP2023005451W WO2024042736A1 WO 2024042736 A1 WO2024042736 A1 WO 2024042736A1 JP 2023005451 W JP2023005451 W JP 2023005451W WO 2024042736 A1 WO2024042736 A1 WO 2024042736A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- attribute
- data
- information processing
- value
- mfcvae
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images













Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
- G06N3/0455—Auto-encoder networks; Encoder-decoder networks
Definitions
- the present invention relates to an information processing method, an information processing system, and an information processing program.
- the quality of an AI (Artificial Intelligence) model depends on the quality of the data used.
- it is useful to evaluate information regarding attributes of training data used when building an AI model and test data used when making inferences.
- Patent Document 1 For example, in Patent Document 1, three images corresponding to the same semantic feature are extracted from training data, and variational auto-processing is performed to minimize the loss function of the latent variable corresponding to the semantic feature for each of the three images. Update encoder parameters. This improves the identifiability of different images having the same semantic features.
- Non-Patent Document 1 by increasing the independence of latent variables so that the information given by each latent variable to the input value is unique, the content and size of attributes corresponding to changes in latent variables can be changed. It increases the interpretability of changes. As a result, it can be seen that, for example, in handwritten character data, the angle of the character changes continuously from diagonally left to diagonally right in response to a change in a certain latent variable.
- Non-Patent Document 2 a latent variable is expressed as a linear combination of orthogonal bases, and by associating the coefficients of the base obtained through learning with changes in the attributes of data, the attributes corresponding to changes in the coefficients of the base are This increases the interpretability of changes in the content and magnitude of the changes. As a result, it can be seen that, for example, in face image data, the color of hair changes continuously from gold to black in response to a change in a certain base coefficient.
- One aspect of the disclosure of the present application aims to improve the interpretability of attributes and attribute values corresponding to latent variables in training data and test data.
- One aspect of the disclosure of the present application is an information processing method executed by an information processing system having a processing unit and a storage unit, wherein the processing unit processes reference data in which attribute values are assigned to a plurality of attributes of the data.
- MFCVAE Multi-Facet Clustering Variational Auto-Encoder
- a fifth step of calculating a function value of a loss function obtained by adding an additional term based on the index for each attribute to the loss function of the MFCVAE which has the following: , a sixth step of updating the model parameters of the MFCVAE by error backpropagation based on the function value calculated in the fifth step, and from the first step to the sixth step, the prediction error is Alternatively, the MFCVAE model learning is performed by repeating this order in this order until the number of epochs satisfies a predetermined condition.
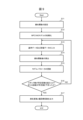
- FIG. 3 is a diagram for explaining the problems of the conventional technology (MFCVAE).
- FIG. 3 is a diagram for explaining the operation of the information processing system according to the first embodiment during model learning.
- FIG. 3 is a diagram for explaining the operation of the information processing system according to the first embodiment when assigning attribute values to evaluation data.
- FIG. 3 is a diagram for explaining the operation of the information processing system according to the first embodiment when generating data with specified attribute values.
- FIG. 3 is a diagram for explaining the transition of the coefficient of determination during model learning of the information processing system according to the first embodiment.
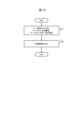
- FIG. 1 is a block diagram showing the configuration of an information processing system according to a first embodiment.
- FIG. 5 is a flowchart showing feature amount extraction processing according to the first embodiment.
- 7 is a flowchart showing attribute value assignment processing according to the first embodiment.
- 5 is a flowchart showing data generation processing according to the first embodiment.
- 7 is a flowchart showing data quality evaluation processing according to the first embodiment.
- 3 is a diagram showing an example 1 of outputting attributes and attribute values (attributes and attribute values for data) according to the first embodiment;
- FIG. FIG. 7 is a diagram showing an example 2 of outputting data, attributes, and attribute values (the number of data for each attribute and attribute value) according to the first embodiment;
- FIG. 2 is a block diagram showing the configuration of an information processing system according to a second embodiment.
- Identical or similar constituent elements may be given the same reference numerals, and the explanation of the previously mentioned components in the later embodiments may be omitted, or only the differences may be explained. Furthermore, when there are a plurality of identical or similar constituent elements, the same reference numerals may be given different subscripts for explanation. Furthermore, if there is no need to distinguish between these multiple components, the subscripts may be omitted from the description.
- various information will be explained in a table format, but the various information may be in a data format other than the table format.
- various names such as “XX information”, “XX table”, “XX list”, and “XX queue” are interchangeable.
- "XX table” may be called “XX list”.
- identification information expressions such as “identification information,” “identifier,” “name,” “ID,” and “number” are used, but these are interchangeable.
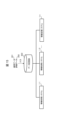
- FIG. 1 is a diagram for explaining problems in the prior art.
- MFCVAE is an extended variational auto-encoder (VAE) that can output latent variables from multiple viewpoints.
- a variational autoencoder is a generative model that uses a neural network and assumes a probability distribution as the space of latent variables.
- the viewpoint in MFCVAE is the type of latent variable (vector) output by MFCVAE, and in the case of character data, it corresponds to "type of character", “character shape (thickness, angle, etc.)", etc.
- the variational autoencoder is available in Document 1 “Diederik P Kingma, Max Welling, “Auto-Encoding Variational Bayes,” May 2014. [Retrieved August 1, 2020], Internet ⁇ URL: https:// arxiv.org/abs/1312.6114>” MFCVAE is based on Document 2 “Fabian Falck et.al, “Multi-Facet Clustering Variational Autoencoders,” Oct. 2021. [Retrieved August 1, 2020], Internet ⁇ URL: https://arxiv.org/abs/ 2106.05241>”.
- features are information that characterizes data (attributes, attribute values, latent variables, etc.).
- a feature amount is a value of a feature that can be expressed quantitatively.
- Attributes are properties that characterize data (in the case of character data, such as “thickness”, “slope”, “amount of noise”, “degree of character breakage”, etc.).
- Attribute value is a value indicating the degree of the attribute (in the example of character data, "1 mm” for the attribute "Thickness”, “10 degrees” for the attribute “Tilt”, “10%” for the attribute "Noise amount", "Level 2" for "degree of brokenness of letters”).
- Attribute values may be continuous values or discrete values.
- a latent variable is a feature quantity output from an encoder in variational autoencoder related technology. Variational autoencoder-related technology refers to all variational autoencoder technologies having variational Bayes algorithms, including VAE and MFCVAE.
- the group 101 of latent variable 1 and latent variable 2 corresponds to characters whose attribute "thickness" is thin.
- Group 102 is a group of latent variables that correspond to characters whose attribute "thickness” is medium.
- Group 103 is a group of latent variables whose attribute "thickness” corresponds to bold characters.
- Group 104 is a group of latent variables corresponding to characters with a small attribute "noise amount”.
- Group 105 is a group of latent variables corresponding to characters whose attribute "noise amount” is medium.
- Group 106 is a group of latent variables corresponding to characters with a large attribute "noise amount".
- "thick,” “medium,” and “thin” for the attribute “thickness,” and “large,” “medium,” and “small” for the attribute “noise amount” are merely illustrative expressions, and quantitative expressions or This is an example of a label given to .
- FIG. 2 is a diagram showing reference data and evaluation data (in the case of character data).
- each row is called data.
- attribute such as "character type,”"thickness,” and "slant.”
- attribute values are stored and data in which attribute values are not stored.
- “Character type” is image data of the corresponding character.
- data in which an attribute value is stored is reference data regarding that attribute
- data in which an attribute value is not stored is evaluation data regarding that attribute.
- the reference data is data whose attribute values are known and are used to determine the attribute values of the evaluation data.
- the evaluation data is target data that is assigned by determining an attribute value for an attribute whose attribute value is unknown.
- the data of "data number” "1" “2” “3" of "data attribute” "print” which has attribute values such as "thickness” and “slant” are standard data and have attribute values.
- Data with "data attributes”, “handwritten characters”, “data numbers”, "4" and "5" that are not included are evaluation data. More generally, the reference data includes printed and handwritten text, and the evaluation data includes handwritten text.
- FIG. 3 is a diagram showing reference data and evaluation data (in the case of general data).
- reference data and evaluation data are separated for each data attribute.
- the standard data and evaluation data are generalized, and for each data, the data in which the attribute value is stored for each attribute is the standard data for the corresponding attribute, and the data in which the attribute value is stored for each attribute is the standard data.
- the data is evaluation data regarding the corresponding attribute.
- the reference data is the data of "Data Number” “1”, “2”, “3”, “4", and the evaluation data is the data of "Data Number” “5".
- the reference data is the data of "data number” "1”, “2”, and “5", and the evaluation data is the data of "data number” "3" and "4".
- the purpose of the following embodiment is to estimate the attribute value of evaluation data for each attribute using the attribute value of reference data.
- FIG. 4 is a diagram for explaining the operation of the information processing system 1 according to the first embodiment during model learning.
- variational autoencoder-related technology is used to predict attribute values using a multiple regression model based on latent variables of the reference data 201 using reference data 201 in which attribute values are assigned to attributes in advance. Perform model training using the new loss function.
- the information processing system 1 has an MFCVAE 2.
- MFCVAE2 is configured to include an encoder 203 and a decoder 205.
- the data (training data set) input to the encoder 203 includes only the reference data 201 or includes both the reference data 201 and the evaluation data 202.
- Encoder 203 outputs latent variable 204, which is an intermediate output of MFCVAE2.
- MFCVAE2 sets a multiple regression model in which the latent variable 204 is an explanatory variable and the correct value (correct label) 208 of the attribute value is an objective variable.
- the model is not limited to a multiple regression model, and may be either a linear regression model or a nonlinear regression model. Since the multiple regression model has the advantage that the load of model calculation is small, the multiple regression model is adopted in this embodiment.
- the information processing system 1 calculates a partial regression coefficient 209 that minimizes the mean square error between the predicted value of the attribute value and the correct value 208 of the attribute value, and the predicted value 210 of the attribute value at that time, from the latent variable 204 and the correct value 208 of the attribute value. demand.
- the predicted value 210 of the attribute value is calculated as a linear combination of the latent variables 204 whose respective coefficients are the partial regression coefficients 209.
- the coefficient of determination 211 or prediction that can be an index representing the goodness of fit takes a smaller value as the fit to the multiple regression model (fitting of the multiple regression model) is better.
- An error 212 is determined.
- the coefficient of determination 211 and the prediction error 212 are learned using a loss function 213 that includes an index representing the degree of adaptation to the multiple regression model. Encoder 203 is trained in this way.
- the latent variable 204 is input to the decoder 205.
- the decoder 205 outputs reconstructed reference data 206, which is the reference data 201 reconstructed by the decoder 205, and reconstructed evaluation data 207, which is the evaluation data 202 reconstructed by the decoder 205.
- the reconstruction evaluation data 207 is data to which attribute values are assigned.
- Equation (1) the objective function, the variational lower bound (ELBO), is expressed as in equation (1).
- equation (1) the parameters of the MFCVAE model are learned so that a negative loss function in which the sign of the lower limit of variation in Equation (1) is made negative is minimized (see Document 2 mentioned above).
- equation (1) "D" is the training dataset, "x” is the training data included in the training dataset, "z ⁇ ” is the latent variable, " ⁇ ” is the encoder parameter, “ ⁇ ” is the decoder parameter, “KL(A
- the degree-of-freedom adjusted coefficient of determination at viewpoint j is R f,j 2
- the weighting coefficient of each degree-of-freedom adjusted coefficient of determination R f,j 2 is ⁇ j (>0).
- the objective function is set as shown in equation (2).
- the right side of equation (2) is obtained by adding the third term ⁇ j R f,j 2 to the expression in parentheses of the expected value E[*] on the right side of equation (1).
- a coefficient of determination R j 2 which will be described later, may be used instead of the degree-of-freedom adjusted coefficient of determination R f,j 2 .
- the coefficient of determination R j 2 and the degree of freedom adjusted coefficient of determination R f,j 2 are examples of the coefficient of determination 211.
- the first term in parentheses of the expected value E[*] in equation (2) is a reconstruction error term representing the error in data reconstruction by MFCVAE.
- the second term in parentheses of the expected value E[*] in equation (2) is a regularization term that imposes constraints on the distribution of the latent variables, such as suppressing variations in the latent variables of MFCVAE.
- the third term in parentheses of the expected value E[*] in Equation (2) is an additional term based on an index that takes a smaller value as the fit to the multiple regression model for the latent variables and attribute values for each attribute is better.
- loss function 213 (expressed as loss function Loss) is a negative objective function, it is expressed as in Expression (3) using the objective function of Expression (2).
- the parameters of the MFCVAE model are learned so that the loss function Loss is minimized, that is, the coefficient of determination R f,i 2 is maximized.
- each attribute of the data has a one-to-one correspondence with each of the J viewpoints of the MFCVAE. If the attribute value of attribute j is assigned to data n having index number n, data n is reference data in attribute j. On the other hand, if the attribute value of attribute j is not assigned to data n, data n is evaluation data for attribute j.
- B j be a set of indexes of reference data regarding a certain attribute j
- M j be the number of elements in the set B j .
- Set B j ⁇ b j,1 , b j,2 , ..., b j, Mj ⁇ .
- the predicted value of the attribute value is Let be y ⁇ n,j .
- the predicted value y ⁇ n,j of the attribute value is expressed as in equation (4).
- the mean squared error MSE j which is the prediction error between the attribute value y n,j (where n ⁇ B j ) regarding a certain attribute j and the predicted value y ⁇ n,j of the attribute value by the multiple regression model, is expressed by equation (6). It is expressed as follows.
- the mean square error MSEj is an example of the prediction error 212.
- the partial regression coefficient w j is a function of the latent variable Z j and the attribute value y j .
- the partial regression coefficient w j is an example of the partial regression coefficient 209.
- the prediction error between the attribute value y n,j (where n ⁇ B j ) regarding a certain attribute j and the predicted value y ⁇ n,j of the attribute value by the multiple regression model is not limited to the mean square error, but also the average error, Mean absolute error, mean squared error, mean error rate, mean absolute error rate, etc. may also be employed.
- the coefficient of determination R j 2 for a certain attribute j represents how much the explanatory variable explains the objective variable.
- the coefficient of determination R j 2 is expressed as in equation (10) using the average value y n,j of the attribute values.
- the coefficient of determination has the property that it approaches 1 as the number of explanatory variables increases, so when the number of explanatory variables is large, the degree of freedom adjusted coefficient of determination R f,j 2 that corrects this property is May be adopted.
- the degree of freedom adjusted coefficient of determination R f,j 2 is expressed as equation (11) since the number of explanatory variables is p and the number of samples of reference data is M j .
- the weighting coefficient ⁇ j can be obtained from a comparison of the absolute values of the reconstruction error term, the regularization term, and the coefficient of determination R j 2 (R f, j 2 ).
- the weighting coefficient ⁇ j for the coefficient of determination R j 2 is the reconstruction error term of the expression in parentheses of the expected value E[*] on the right side of equation ( 2 ), where the order of
- the weighting coefficient ⁇ j for the degree-of-freedom adjusted coefficient of determination R f, j 2 also has the order of
- the decoder 205 uses the attributes and attribute values of the reference data 201 and the evaluation data 202 (the assigned attribute values in the case of the evaluation data 202), and the last learning of the encoder 203.
- the partial regression coefficient 209 obtained in each epoch is used.
- a latent variable (latent variable vector Z n,j ) is calculated from equation (4) using the attributes and attribute values of the reference data 201 and evaluation data 202 and the partial regression coefficient 209.
- the decoder 205 inputs the calculated latent variables and outputs reconstructed reference data 206 and reconstructed evaluation data 207, which are obtained by reconstructing the input reference data 201 and evaluation data 202, respectively.
- FIG. 5 is a diagram for explaining the operation of the information processing system 1 according to the first embodiment when assigning attribute values to the evaluation data 202.
- the information processing system 1 first inputs the evaluation data 202 into the trained encoder 203 to obtain latent variables 204.
- the information processing system 1 uses the partial regression coefficients 209 obtained in the final epoch of learning of MFCVAE2 (FIG. 4) to create a linear combination equation of the latent variables 204 using the predicted value 210 of the attribute value and the partial regression coefficient 209 as each coefficient. Calculate with.
- the information processing system 1 assigns the predicted value 210 of the attribute value to the evaluation data 202.
- FIG. 6 is a diagram for explaining the operation of the information processing system 1 according to the first embodiment when generating data with specified attribute values.
- Data generation in variational autoencoder related technology, refers to outputting data from a decoder using latent variables as input.
- the information processing system 1 uses the attribute and attribute value 401 that the user wants to generate and the partial regression coefficient 209 obtained at the end of learning of MFCVAE2 (FIG. 4).
- a latent variable 204 is calculated.
- the information processing system 1 inputs the calculated latent variable 204 to the decoder 205 to generate data 405 having the attribute value 401 that is desired to be generated.
- FIG. 7 is a diagram for explaining the transition of the coefficient of determination during model learning of the information processing system 1 according to the first embodiment.
- latent variables are plotted on the horizontal axis
- attribute values are plotted on the vertical axis
- actual values of the attribute values are represented by points
- predicted values of the attribute values are represented by straight lines.
- the information processing system 1 adds an additional term to the loss function of MFCVAE2, including the coefficient of determination of a multiple regression model in which latent variables are explanatory variables and attribute values are objective functions, and trains MFCVAE2 so that the coefficient of determination becomes high. .
- the coefficient of determination is low at the early stage of learning ( Figure 7(a)), but as the number of epochs of learning progresses, it changes to the middle stage of learning ( Figure 7(b)) and then to the late stage ( Figure 7(c)). Accordingly, the coefficient of determination becomes high, and the accuracy of predicting attribute values based on latent variables becomes high.
- FIG. 8 is a block diagram showing the configuration of the information processing system 1 according to the first embodiment.
- the information processing system 1 includes a data storage section 602 , a feature extraction section 603 , an attribute value assignment section 608 , a data generation section 614 , and a data quality evaluation section 612 .
- the data storage unit 602 is a memory or storage, and receives and stores the reference data 201 and evaluation data 202.
- the data storage unit 602 may be a device included in the information processing system 1 or an external device to the information processing system 1.
- the feature extraction unit 603 executes model learning of MFCVAE2 based on the reference data 201 stored in the data storage unit 602 of MFCVAE2. Further, the feature amount extraction unit 603 performs attribute estimation of the evaluation data 202 stored in the data storage unit 602 of the MFCVAE2. Further, the feature extraction unit 603 generates data specifying attribute values.
- the feature extraction unit 603 includes a regression model fitness evaluation unit 604, a loss calculation unit 605, a model update unit 606, and an encoder unit 607. The processing function of the feature extraction unit 603 will be described later with reference to FIG.
- the attribute value assigning unit 608 estimates the attributes of the evaluation data 202 and outputs the attributes and attribute values 611 of the evaluation data 202.
- the attribute value assigning unit 608 includes an attribute value estimating unit 609 and an attribute and attribute value output unit 610. The processing function of the attribute value assigning unit 608 will be described later with reference to FIG.
- the data generation unit 614 inputs the attribute and attribute value 611 of the target data output by the attribute value assignment unit 608, generates data specifying the attribute value, and outputs the generated data 405.
- the data generation section 614 includes a latent variable calculation section 615, a decoding section 616, and a data output section 617. The processing functions of the data generation unit 614 will be described later with reference to FIG. 11.
- the data quality evaluation unit 612 evaluates the quality of the target data based on the attributes and attribute values 611 of the target data (reference data 201, evaluation data 202) output by the attribute value assigning unit 608, and outputs the data quality evaluation result 613. Output.
- the data quality evaluation unit 612 uses the attributes and attribute values 611 of the evaluation target data to evaluate the quality of the target data from the following viewpoints, for example.
- For quality evaluation see “Machine Learning Quality Management Guidelines,” National Institute of Advanced Industrial Science and Technology, [Retrieved August 1, 2020], Internet ⁇ URL: https://www.aist.go.jp/ aist_j/press_release/pr2020/pr20200630_2/pr20200630_2.html>.
- Sufficiency of data design Ensuring sufficient training data and test data for the various situations that the target system that uses the data must respond to.
- the feature amount extraction unit 603, the attribute value assignment unit 608, the data generation unit 614, and the data quality evaluation unit 612 may be realized on one computer, or may be realized on different computers. These forms of integration and distribution can be changed as appropriate.
- FIG. 9 is a flowchart showing feature extraction processing according to the first embodiment.
- the feature extraction process is executed by the feature extraction unit 603 (FIG. 8) in response to a user instruction.
- the regression model fit evaluation unit 604 uses an index indicating the goodness of fit of the MFCVAE model (in this embodiment, a multiple regression model) with the latent variables of the reference data 201 as explanatory variables and the attribute values as objective variables. is set to the loss function Loss.
- the index set to the loss function Loss is the degree-of-freedom adjusted coefficient of determination R f,j 2 at the viewpoint j.
- step S12 the regression model fitness evaluation unit 604 initializes the MFCVAE model.
- step S13 the regression model fitness evaluation unit 604 inputs the reference data 201 and the evaluation data 202 to the MFCVAE model.
- step S13 the regression model fitness evaluation unit 604 may input at least the reference data 201 to the MFCVAE model.
- step S14 the loss calculation unit 605 calculates the function value of the loss function Loss based on equation (3).
- the regression model fitness evaluation unit 604 performs the following process as a step before the loss calculation unit 605 calculates the function value of the loss function Loss. That is, the regression model suitability evaluation unit 604 sets a multiple regression model for each attribute, using the latent variable output from the MFCVAE model as an explanatory variable and the attribute value as an objective variable in response to the input data in step S13. .
- the regression model suitability evaluation unit 604 calculates, for each attribute, the predicted value of the attribute value and the regression coefficient of the multiple regression model that minimizes the prediction error for the attribute value, from the latent variable and the attribute value.
- the regression model fitness evaluation unit 604 sets an index for each attribute that takes a smaller value as the fit to the multiple regression model for the latent variables and attribute values is better. Calculated as follows. After that, the loss calculation unit 605 calculates the function value of the loss function Loss in step S14.
- the regression model fitness evaluation unit 604 calculates an additional term of the loss function Loss using the reference data 201.
- the loss calculation unit 605 calculates the reconstruction error term and the regularization term using either or both of the reference data 201 and the evaluation data 202. This is because the additional term of the loss function Loss is based on the goodness of fit to the multiple regression model between latent variables and attribute values, so the additional term of the loss function Loss can be calculated only for reference data that includes attribute values. .
- step S15 the model updating unit 606 updates the parameters of the MFCVAE model by error backpropagation.
- step S16 the model update unit 606 determines whether a predetermined condition (the number of epochs exceeds a predetermined number, or the error between the estimated value by the MFCVAE model and the actual value is less than a predetermined value) is satisfied. .
- the model update unit 606 moves the process to step S17 when the predetermined condition is satisfied (step S16 YES), and returns the process to step S13 when the predetermined condition is not satisfied (step S16 NO).
- step S17 the encoder unit 607 inputs the evaluation data 202 to the encoder 203 of the trained MFCVAE model, and outputs the latent variable 204 and the partial regression coefficient 209.
- FIG. 10 is a flowchart showing attribute value assignment processing according to the first embodiment.
- the attribute value assignment process is executed by the attribute value assignment unit 608 (FIG. 8) in response to a user instruction.
- step S21 the attribute value estimation unit 609 calculates the predicted value 210 of the attribute value of the evaluation data 202 from the latent variable 204 and the partial regression coefficient 209 obtained from the feature quantity extraction unit 603 (encoder 203).
- step S22 the attribute and attribute value output unit 610 calculates each attribute value for each attribute from the attributes and attribute values of the reference data 201 and the evaluation data 202 for which the predicted value 210 of the attribute value was calculated in step S21. A histogram of the appearance frequency of is obtained (see FIG. 14 described later). Then, the attribute and attribute value output unit 610 calculates the probability that each attribute value appears in each attribute of the reference data 201 and the evaluation data 202 as a data content rate based on this histogram, and outputs the result.
- FIG. 11 is a flowchart showing data generation processing according to the first embodiment.
- the data generation process is executed by the data generation unit 614 (FIG. 8) in response to a user instruction.
- step S31 the data generation unit 614 receives input from the user of attributes and attribute values 401 to be generated.
- step S32 the latent variable calculation unit 615 calculates and outputs the latent variable 204 from the attributes and attribute values 401 and the partial regression coefficients 209 received as input in step S31.
- step S33 the decoding unit 616 (decoder 205) uses the latent variable 204 calculated in step S32 as input to reconstruct data 405 (for example, character data) having the attribute and attribute value 401 to be generated.
- step S34 the data output section 617 outputs the data 405 reconstructed by the decoding section 616 (decoder 205).
- the latent variable calculation unit 615 skips step S32 and calculates the value corresponding to this reference data 201 in step S33. It is assumed that the data is reconstructed data 405.
- FIG. 12 is a flowchart showing data quality evaluation processing according to the first embodiment.
- the data quality evaluation process is executed by the data quality evaluation unit 612 (FIG. 8) in response to a user instruction.
- step S41 the data quality evaluation unit 612 evaluates, for example, the above-mentioned (1) sufficiency of data design, (2) coverage of the data set, (3) regarding the attributes and attribute values 611 output by the attribute value assigning unit 608. ) Assess at least one aspect of the homogeneity of the dataset.
- step S42 the data quality evaluation unit 612 outputs the data quality evaluation result 613 of step S41.
- FIG. 13 is a diagram showing an output example 1 of attributes and attribute values (attributes and attribute values for data).
- FIG. 13 shows that the attribute value estimating unit 609 (FIG. 8) of the attribute value assigning unit 608 assigns an attribute value to the data to which the attribute value shown in FIG. 2 or 3 was not assigned, and outputs the attribute and attribute value. 610.
- FIG. 14 is a diagram showing an output example 2 of data, attributes, and attribute values (the number of data for each attribute and attribute value).
- FIG. 14 is an example of output obtained by changing the display method of FIG. 13.
- FIG. 14 is a histogram of attributes of the attribute value assigning unit 608 and attribute values for each attribute output by the attribute value output unit 610 (FIG. 8).
- (2) data set coverage and (3) data uniformity for each attribute it is possible to check, for example, the above-mentioned (2) data set coverage and (3) data uniformity for each attribute.
- (2) Coverage of the data set is considered to be satisfied if the attribute values of each attribute in the histogram in FIG. 14 are distributed over a predetermined wide range and each frequency is equal to or greater than a predetermined number.
- (3) Data uniformity is considered to be satisfied if the attribute values of each attribute in the histogram in FIG. 14 are evenly distributed over a predetermined wide range.
- Such analysis makes it possible to confirm missing data for attribute values.
- the histogram 1101 in FIG. 14 shows the frequency distribution of attribute 1.
- the histogram 1101 has a data distribution range that is wider or equivalent to that of the histograms 1102 and 1103, there are attribute values that do not exist in this distribution range. In this respect, it can be said that the histogram 1101 does not satisfy (2) coverage of the data set.
- the distribution of attribute values is not uniform. The uniformity of the distribution of attribute values can be determined based on statistical values representing variations such as variance and standard deviation of attribute values. In this respect, it can be said that the histogram 1101 does not satisfy (3) data uniformity.
- the histogram 1102 in FIG. 14 shows the frequency distribution of attribute 2.
- Histogram 1102 has a narrower data distribution range than histograms 1101 and 1103, and there are attribute values that do not exist in this distribution range. In this respect, it can be said that the histogram 1102 does not satisfy (2) coverage of the data set. Further, in the histogram 1102, the distribution of attribute values is not uniform. In this respect, it can be said that the histogram 1102 does not satisfy (3) data uniformity.
- a histogram 1103 in FIG. 14 shows the frequency distribution of attribute J.
- the histogram 1103 has a data distribution range that is wider than or equivalent to that of the histograms 1101 and 1102, there are attribute values that do not exist in this distribution range. In this respect, it can be said that the histogram 1103 does not satisfy (2) coverage of the data set.
- the distribution of attribute values in the histogram 1103 is not uniform compared to the histograms 1101 and 1102. In this respect, it can be said that the histogram 1102 does not satisfy (3) data uniformity.
- each graph in FIG. 14 may be a graph in which the vertical axis is the "data content rate at which each attribute value appears in each attribute of the reference data 201 and the evaluation data 202" instead of the "number of data.”
- Embodiment 1 the user explicitly specifies attributes of training data and test data and expresses them with quantitative attribute values, thereby enabling attribute analysis with high interpretability for the user. Therefore, it is easy to discover missing data in training data or test data, or characteristics of data that are often misclassified.
- the user interprets the attributes that the latent variable should have. Since the attributes can be specified explicitly, attribute analysis can be performed according to the user's intention.
- attributes can only be known qualitatively, making it impossible to compare attributes between data learned with different datasets or different models.
- attribute values are determined quantitatively, so it is possible to compare attributes between data learned using different data sets or different models.
- attribute values can be assigned with a smaller amount of data or learning than when estimating attribute values using a regression model using supervised learning.
- data generation in data generation, data can be generated by specifying attribute values for a plurality of attributes, so required data can be easily generated. Further, when generating data, if reference data corresponding to the specified attribute and attribute value exists, the data corresponding to this reference data is adopted as the reconstructed data. Thereby, data can be quickly reconstructed compared to the case where latent variables are calculated from attributes, attribute values, and partial regression coefficients, and data is reconstructed by decoding with a decoder.
- one information processing system 1 is used to perform model learning (FIGS. 4 and 9), attribute value assignment and output of the relationship between attributes and attribute values (FIGS. 5 and 10), and data quality evaluation processing ( An example of executing Fig. 12) is shown.
- model learning, attribute value assignment, and data quality evaluation processing may be executed in parallel by a plurality of information processing systems 1 (1-1, 1-2, . . . , 1-n) shown in FIG. 15.
- steps S13 to S16 may be executed using input data including different reference data 201 for each of the plurality of information processing systems 1. . Then, at least one of the plurality of information processing systems 1 merges and outputs the learning results of the MFCVAE model obtained by each information processing system 1.
- each information processing system 1 assigns attribute values to each input data and outputs the relationship between attributes and attribute values (step S21 ⁇ S23 (FIG. 10)) may be executed. Then, at least one of the plurality of information processing systems 1 merges and outputs the relationship between attributes and attribute values (FIG. 14) obtained by each information processing system 1.
- the latent variables are quantitatively determined, the calculation results can be merged even if each model is processed in parallel in a separate system, so multiple systems can perform model learning, attribute value assignment, and It becomes possible to distribute the load of each process for outputting the relationship between attributes and attribute values. Therefore, these processes can be completed and necessary data can be generated in a shorter time than conventionally.
- Embodiments can be applied to character recognition of handwritten characters as described above.
- a rotation speed label may be attached to vibration data of factory equipment.
- the premise is that the vibration data of factory equipment acquired in the past is not labeled with the rotation speed, so a new device that can measure the rotation speed will be introduced, and the vibration data of the factory equipment acquired in the past will be compared with the rotation speed. This is the case when adding a label.
- an impression evaluation of the song may be performed. It is possible to label the impression of an unknown song based on the impression of the song (fun, sad, happy, lonely, etc.) evaluated by the user in advance.
- the research fields of academic papers may be visualized. Based on papers for which the degree of relationship with each field is known in advance (the degree of relationship with the image recognition field is 30, the degree of relationship with the reinforcement learning field is 50, etc.), the relationship of unknown papers with each field is calculated. This is a case of estimating the degree.
- FIG. 16 is a hardware diagram showing the configuration of computer 1000.
- the information processing system 1 or each system in which the information processing system 1 such as the feature amount extraction unit 603, the attribute value assignment unit 608, the data generation unit 614, and the data quality evaluation unit 612 is distributed as appropriate may be realized by the computer 1000. Ru.
- the computer 1000 includes a processor 1001 including a CPU, a main storage device 1002, an auxiliary storage device 1003, a network interface 1004, an input device 1005, and an output device 1006, which are interconnected via an internal communication line 1009 such as a bus. Be prepared.
- the processor 1001 controls the overall operation of the computer 1000.
- the main storage device 1002 is composed of, for example, a volatile semiconductor memory, and is used as a work memory of the processor 1001.
- the auxiliary storage device 1003 is an example of a non-temporary storage medium, and is composed of a large-capacity nonvolatile storage device such as a hard disk device, SSD (Solid State Drive), or flash memory, and stores various programs and data for a long period of time. used for holding.
- An executable program 1100 stored in the auxiliary storage device 1003 is loaded into the main storage device 1002 when the computer 1000 is started or when necessary, and the processor 1001 executes the executable program 1100 loaded into the main storage device 1002. This realizes a system that executes various processes.
- executable program 1100 may be recorded on a non-temporary recording medium, read from the non-temporary recording medium by a medium reading device, and loaded into the main storage device 1002.
- executable program 1100 may be obtained from an external computer via a network and loaded into main storage 1002.
- the network interface 1004 is an interface device for connecting the computer 1000 to each network in the system or for communicating with other computers.
- the network interface 1004 includes, for example, a NIC (Network Interface Card) such as a wired LAN (Local Area Network) or a wireless LAN.
- NIC Network Interface Card
- wired LAN Local Area Network
- wireless LAN Wireless Local Area Network
- the input device 1005 includes a keyboard, a pointing device such as a mouse, and is used by the user to input various instructions and information to the computer 1000.
- the output device 1006 includes, for example, a display device such as a liquid crystal display or an organic EL (Electro Luminescence) display, and an audio output device such as a speaker, and is used to present necessary information to the user when necessary.
- a display device such as a liquid crystal display or an organic EL (Electro Luminescence) display
- an audio output device such as a speaker
- the present invention is not limited to the embodiments described above, and includes various modifications and equivalent configurations within the scope of the appended claims.
- the embodiments described above have been described in detail to explain the present invention in an easy-to-understand manner, and the present invention is not necessarily limited to having all the configurations described.
- a part of the configuration of one embodiment may be replaced with the configuration of another embodiment.
- the configuration of one embodiment may be added to the configuration of another embodiment.
- other configurations may be added, deleted, or replaced with some of the configurations of each embodiment.
- each of the configurations, functions, processing units, processing means, etc. described above may be partially or entirely realized in hardware by, for example, designing an integrated circuit.
- the functions may be implemented in software by having a processor interpret and execute programs that implement the respective functions.
- Information such as programs, tables, files, etc. that realize each function is stored in storage devices such as memory, hard disks, SSDs (Solid State Drives), or non-standard storage devices such as IC (Integrated Circuit) cards, SD cards, and DVDs (Digital Versatile Discs). It can be stored on a temporary storage medium.
- storage devices such as memory, hard disks, SSDs (Solid State Drives), or non-standard storage devices such as IC (Integrated Circuit) cards, SD cards, and DVDs (Digital Versatile Discs). It can be stored on a temporary storage medium.
- control lines and information lines shown are those considered necessary for explanation, and do not necessarily show all control lines and information lines necessary for implementation. In reality, almost all configurations can be considered interconnected.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- Machine Translation (AREA)
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2022-133545 | 2022-08-24 | ||
| JP2022133545A JP7761545B2 (ja) | 2022-08-24 | 2022-08-24 | 情報処理方法、情報処理システム、及び情報処理プログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2024042736A1 true WO2024042736A1 (ja) | 2024-02-29 |
Family
ID=90012866
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2023/005451 Ceased WO2024042736A1 (ja) | 2022-08-24 | 2023-02-16 | 情報処理方法、情報処理システム、及び情報処理プログラム |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP7761545B2 (https=) |
| WO (1) | WO2024042736A1 (https=) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025204972A1 (ja) * | 2024-03-26 | 2025-10-02 | ソニーセミコンダクタソリューションズ株式会社 | 情報処理装置、情報処理方法、プログラム、データ生成装置、データ生成方法、学習システム |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2020144799A (ja) * | 2019-03-08 | 2020-09-10 | 富士通株式会社 | データ処理プログラム及びデータ処理方法 |
-
2022
- 2022-08-24 JP JP2022133545A patent/JP7761545B2/ja active Active
-
2023
- 2023-02-16 WO PCT/JP2023/005451 patent/WO2024042736A1/ja not_active Ceased
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2020144799A (ja) * | 2019-03-08 | 2020-09-10 | 富士通株式会社 | データ処理プログラム及びデータ処理方法 |
Non-Patent Citations (2)
| Title |
|---|
| FALCK FABIAN, ZHANG HAOTING, WILLETTS MATTHEW, NICHOLSON GEORGE, YAU CHRISTOPHER, HOLMES CHRIS: "Multi-Facet Clustering Variational Autoencoders", ARXIV (CORNELL UNIVERSITY), CORNELL UNIVERSITY LIBRARY, ARXIV.ORG, ITHACA, 9 June 2021 (2021-06-09), Ithaca, XP093142179, Retrieved from the Internet <URL:https://arxiv.org/pdf/2106.05241.pdf> [retrieved on 20240318], DOI: 10.48550/arxiv.2106.05241 * |
| MASATOSHI SEKINE, ATSUSUKE NIIHARA, TOMOYUKI MYOJIN, ERI IMAYA: "Application of multifaceted clustering variational autoencoder to handwritten character data for extracting diverse attribute information from datasets View usages", SOFTWARE ENGINEERING SYMPOSIUM 2022; SEPTEMBER 5 TO 7, 2022, 29 August 2022 (2022-08-29), JP, pages 145 - 146, XP009558367 * |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7761545B2 (ja) | 2025-10-28 |
| JP2024030579A (ja) | 2024-03-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN114255381B (zh) | 图像识别模型的训练方法、图像识别方法、装置及介质 | |
| CN110046707B (zh) | 一种神经网络模型的评估优化方法和系统 | |
| Zheng et al. | Resolving the bias in electronic medical records | |
| CN110210625B (zh) | 基于迁移学习的建模方法、装置、计算机设备和存储介质 | |
| US20190122097A1 (en) | Data analysis apparatus, data analysis method, and data analysis program | |
| WO2019160003A1 (ja) | モデル学習装置、モデル学習方法、プログラム | |
| US12321866B2 (en) | Data diversity visualization and quantification for machine learning models | |
| CN109948735A (zh) | 一种多标签分类方法、系统、装置及存储介质 | |
| CN118397382A (zh) | 一种基于标签平滑和分布正则化的图像增量学习方法 | |
| WO2024159819A1 (zh) | 训练方法、版面分析、质量评估方法、装置、设备和介质 | |
| CN114529191B (zh) | 用于风险识别的方法和装置 | |
| CN118196013A (zh) | 支持多医生协同监督的多任务医学图像分割方法及系统 | |
| US20220327394A1 (en) | Learning support apparatus, learning support methods, and computer-readable recording medium | |
| CN108108769B (zh) | 一种数据的分类方法、装置及存储介质 | |
| WO2024042736A1 (ja) | 情報処理方法、情報処理システム、及び情報処理プログラム | |
| CN113158068A (zh) | 基于大数据的终端信息推荐方法 | |
| JP4140915B2 (ja) | 利用者の行動を支援するシステム | |
| CN116018613A (zh) | 机器学习程序、机器学习方法以及推定装置 | |
| KR20210141150A (ko) | 이미지 분류 모델을 이용한 이미지 분석 방법 및 장치 | |
| JP7700542B2 (ja) | 情報処理装置、情報処理方法およびプログラム | |
| CN113297828B (zh) | 一种文本生成方法、装置、计算机设备及存储介质 | |
| CN117836786A (zh) | 用于机器学习的计算机模型的迭代训练 | |
| JP7056804B2 (ja) | 経験損失推定システム、経験損失推定方法および経験損失推定プログラム | |
| JP2022148878A (ja) | プログラム、情報処理装置、及び方法 | |
| RU2844157C1 (ru) | Способ и система для обучения глубокой нейронной сети с помощью дополнительных формируемых данных |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 23856862 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 23856862 Country of ref document: EP Kind code of ref document: A1 |