WO2024013831A1 - タスクスケジューラ装置、計算システム、タスクスケジューリング方法およびプログラム - Google Patents
タスクスケジューラ装置、計算システム、タスクスケジューリング方法およびプログラム Download PDFInfo
- Publication number
- WO2024013831A1 WO2024013831A1 PCT/JP2022/027327 JP2022027327W WO2024013831A1 WO 2024013831 A1 WO2024013831 A1 WO 2024013831A1 JP 2022027327 W JP2022027327 W JP 2022027327W WO 2024013831 A1 WO2024013831 A1 WO 2024013831A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- processor
- task
- cpu
- state
- core
- Prior art date
Links
- 238000004364 calculation method Methods 0.000 title claims abstract description 47
- 238000000034 method Methods 0.000 title claims description 27
- 238000012545 processing Methods 0.000 claims abstract description 43
- 230000007704 transition Effects 0.000 claims description 32
- 238000010586 diagram Methods 0.000 description 60
- 230000006870 function Effects 0.000 description 19
- 238000007726 management method Methods 0.000 description 19
- 230000008569 process Effects 0.000 description 14
- 230000002618 waking effect Effects 0.000 description 8
- 102100040605 1,2-dihydroxy-3-keto-5-methylthiopentene dioxygenase Human genes 0.000 description 7
- 101000966793 Homo sapiens 1,2-dihydroxy-3-keto-5-methylthiopentene dioxygenase Proteins 0.000 description 7
- 238000004891 communication Methods 0.000 description 5
- 230000007423 decrease Effects 0.000 description 5
- 230000000694 effects Effects 0.000 description 5
- 238000005516 engineering process Methods 0.000 description 5
- 238000011176 pooling Methods 0.000 description 4
- 238000011084 recovery Methods 0.000 description 4
- 230000003287 optical effect Effects 0.000 description 3
- 241000238876 Acari Species 0.000 description 2
- 241001522296 Erithacus rubecula Species 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 239000002184 metal Substances 0.000 description 2
- 101100268548 Caenorhabditis elegans apl-1 gene Proteins 0.000 description 1
- 238000003491 array Methods 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 230000001934 delay Effects 0.000 description 1
- 230000003111 delayed effect Effects 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000001788 irregular Effects 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 238000010801 machine learning Methods 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 238000012913 prioritisation Methods 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
Images






















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F1/00—Details not covered by groups G06F3/00 - G06F13/00 and G06F21/00
- G06F1/26—Power supply means, e.g. regulation thereof
- G06F1/32—Means for saving power
- G06F1/3203—Power management, i.e. event-based initiation of a power-saving mode
- G06F1/3234—Power saving characterised by the action undertaken
- G06F1/3287—Power saving characterised by the action undertaken by switching off individual functional units in the computer system
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F1/00—Details not covered by groups G06F3/00 - G06F13/00 and G06F21/00
- G06F1/26—Power supply means, e.g. regulation thereof
- G06F1/32—Means for saving power
- G06F1/3203—Power management, i.e. event-based initiation of a power-saving mode
- G06F1/3234—Power saving characterised by the action undertaken
- G06F1/329—Power saving characterised by the action undertaken by task scheduling
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Definitions
- the present invention relates to a task scheduler device, a calculation system, a task scheduling method, and a program.
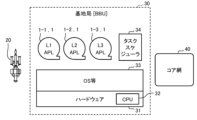
- FIG. 19 is a diagram illustrating an overview of the wireless access system.
- the radio access system includes a user terminal (UE: User Equipment), an antenna (base station antenna) 20, a base station (BBU: Base Band Unit) 30, and a core network 40 (not shown).
- UE User Equipment
- base station antenna base station antenna
- BBU Base Band Unit
- the antenna 20 is an antenna and a transmitting/receiving unit that wirelessly communicates with the UE 10 (hereinafter, “antenna” refers to the antenna, the transmitting/receiving unit, and its power supply unit collectively). Transmission and reception data is connected to the base station 30 by, for example, a dedicated cable.
- the base station 30 is a stationary wireless station located on land that communicates with the UE 10.
- a base station (BBU: Broad Band Unit) 30 that performs wireless signal processing is dedicated hardware (dedicated device) that performs wireless signal processing.
- the base station 30 is a vRAN (virtual radio access network) in which a general-purpose server performs radio signal processing in an LTE (Long Term Evolution) or 5G (five generation) signal processing intensive system.
- LTE Long Term Evolution
- 5G five generation
- general-purpose servers that are inexpensive and available in large quantities can be used as the hardware of the base station 30.
- the base station 30 includes hardware (HW) 31, a CPU (Central Processing Unit) 32 on the hardware, an OS etc. 33, and L1, L2, L3 protocol wireless signal processing applications 1-1, 1-2, 1. -3 (generally referred to as APL1), and a task scheduler device 34.
- HW hardware
- CPU Central Processing Unit
- the core network 40 is EPC (Evolved Packet Core)/(in the following description, "/" represents “or”), 5GC (5G Core Network), or the like.
- EPC Evolved Packet Core
- 5GC 5G Core Network
- Non-Patent Document 1 An example of a system that requires real-time performance is a base station (BBU) in RAN.
- BBU base station
- the task scheduler device 34 often performs calculations by assigning wireless signal processing tasks to the CPU core (Non-Patent Document 1).
- FIG. 20 is a diagram illustrating an example of task management for wireless access processing at a base station. Components that are the same as those in FIG. 19 are given the same reference numerals.
- the base station (BBU) 30 includes a task scheduler device 34.
- the task scheduler device 34 performs task management, prioritization, and task allocation.
- the task scheduler device 34 allocates the wireless signal processing task of APL1 to the task queue 37, and from the task queue 37 to the CPU cores (CPUcore #0, CPUcore #1, . . . ) 32.
- LPI Low Power Idle hardware control
- the CPU 32 has a function of controlling the idle state of the CPU 32 through hardware control, and is called LPI.
- LPI is often called CPUidle or C-state, and hereinafter LPI will be explained as C-state.
- the C-state attempts to save power by turning off the power to part of the circuit of the CPU 32 when the CPU load decreases (Non-Patent Document 2).
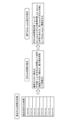
- FIG. 21 is a diagram showing an example of C-state states in a table. Note that since the state definition differs depending on the CPU hardware, FIG. 21 is just a reference example. As shown in FIG. 21, the CPUidle state has grades C0 to C6, and as the time when the CPU 32 is not loaded increases, the state transitions to a deep sleep state. A deep sleep state consumes less CPU power, but on the other hand, it lengthens the time it takes to return, which may pose a problem in terms of low latency.
- C-state differs depending on the CPU hardware. For example, there are variations such as a model without C4 or C5, and a model in which the state following C1 is C1E. As the state becomes deeper, the power saving effect increases, but the time required to return from the idle state also increases.
- the depth to which the CPUidle state transitions is controlled by the CPU hardware and depends on the CPU product (in many cases, it cannot be controlled from software such as the kernel).
- FIG. 22 is a table showing an example of the maximum values of the time it takes to transition to a state (RESIDENCY) and the time it takes to return (WAKE-UP LATENCY).
- FIG. 22 shows C-state information in Intel Xeon CPU E5-26X0 v4 (registered trademark).
- Linux kernel 4 (registered trademark) provides two types of governors to manage CPU idle state (C-state).
- FIG. 23 is a diagram illustrating the CPU Governor idle type. As shown in Figure 23, ladder is used for systems with ticks, and menu is used for systems with ticks. For example, the menu used in the tickless system is a method that estimates the depth of the idle state suitable for the next idle period from the results of the most recent idle period. menu can be effective for workloads with regular idle times, but has limited effectiveness for workloads with irregular idle times.
- FIG. 24 is a diagram illustrating an overview of menu logic.
- menu records the most recent idle time. Then, as shown in the middle diagram of FIG. 24, the next idle time is estimated. For example, based on the idle time shown in the left diagram of FIG. 24, if the deviation is small, the average value T_avr is adopted as the next idle time.
- menu estimates the appropriate idle state depth based on the estimation of the next idle time. For example, if the next idle time estimate T_avr is equal to the return time exit latency from the idle state (Cx), it is determined that the state is too deep and a transition is made to the idle state of Cx-1.
- the CPUidle state has grades, and as the time when the CPU is not loaded increases, the state transitions to a deep sleep state.
- a deep sleep state consumes less CPU power, but on the other hand, the time required for recovery becomes longer, which may pose a problem in terms of low latency.
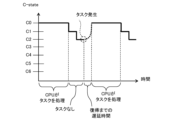
- FIG. 25 and 26 are C-state transition image diagrams of the CPU core used in calculations.
- FIG. 25 shows a case where the no-task time is short
- FIG. 26 shows a case where the no-task time is long.
- the CPU core is in a shallow sleep state, and the delay time from task generation to recovery is short.
- the CPU core is in a deep sleep state (CPUidle state: grade C6), and the delay time from task generation to recovery becomes longer.
- the CPU drops to a deep idle state, it takes a long time to recover, which impairs real-time performance.
- the base station (BBU) 30 shown in FIGS. 19 and 20 the base station (BBU) takes measures such as disabling the C-state or introducing settings that limit the transition of the idle state to a limited depth such as C1. In other words, tuning may be performed in favor of real-time performance at the expense of power saving.
- BBUs base stations
- the present invention was made in view of this background, and an object of the present invention is to perform calculations with low delay while achieving power saving.
- a task scheduler device that allocates tasks to a group of cores of the processor in a computing system that reduces power consumption by gradually reducing the operating state of the processor according to the processing load, Based on the processor usage rate acquisition unit that acquires the usage rate of the processor, and the usage rate of the processor acquired by the processor usage rate acquisition unit, continue processing is performed for the core or core group of the processor that is used more than a predetermined frequency.
- the present invention provides a task scheduler device comprising: a task allocation unit that allocates tasks in a specific manner.
- calculations can be performed with low delay while achieving power savings.
- FIG. 1 is a schematic configuration diagram of a calculation system according to an embodiment of the present invention. This is an example of a configuration in which a task scheduler device of a computing system according to an embodiment of the present invention is placed in a user space. 1 is a configuration example in which a task scheduler device of a calculation system according to an embodiment of the present invention is arranged in an OS.
- FIG. 3 is a table showing logic for estimating the required number of active CPU core groups of the task scheduler device of the arithmetic system according to the embodiment of the present invention.
- FIG. 3 is a diagram illustrating the task amount threshold determination and CPU usage rate threshold determination operations of the task scheduler device of the arithmetic system according to the embodiment of the present invention.
- FIG. 2 is a diagram showing an image of threshold value determination according to the amount of task inflow of the task scheduler device of the calculation system according to the embodiment of the present invention.
- FIG. 2 is a diagram illustrating an image of threshold value determination according to the CPU usage rate of the task scheduler device of the arithmetic system according to the embodiment of the present invention.
- FIG. 2 is a diagram illustrating the C-state upper limit setting of the task scheduler device of the arithmetic system according to the embodiment of the present invention.
- FIG. 6 is a diagram illustrating a case where there is no C-state upper limit setting/a case where there is a C-state upper limit setting in the arithmetic system according to the embodiment of the present invention.
- FIG. 2 is a diagram illustrating pooling of CPU cores with high usability in the task scheduler device of the arithmetic system according to the embodiment of the present invention.
- FIG. 2 is a diagram illustrating advance wake-up of the task scheduler device of the computing system according to the embodiment of the present invention.
- FIG. 2 is a diagram illustrating advance wake-up of the task scheduler device of the computing system according to the embodiment of the present invention.
- 3 is a flowchart showing task scheduling processing of the task scheduler device of the computing system according to the embodiment of the present invention.
- 1 is a hardware configuration diagram showing an example of a computer that implements the functions of a task scheduler device of a calculation system according to an embodiment of the present invention.
- 1 is a diagram showing an example in which a calculation system according to an embodiment of the present invention is applied to an interrupt model in a server virtualization environment with a general-purpose Linux kernel (registered trademark) and a VM configuration.
- 1 is a diagram showing an example in which a calculation system according to an embodiment of the present invention is applied to an interrupt model in a container-configured server virtualization environment.
- 1 is a diagram showing an example in which a calculation system according to an embodiment of the present invention is applied to an interrupt model in a server virtualization environment with a general-purpose Linux kernel (registered trademark) and a VM configuration.
- 1 is a diagram showing an example in which a calculation system according to an embodiment of the present invention is applied to an interrupt model in a container-configured server virtualization environment.
- FIG. 1 is a diagram illustrating an overview of a wireless access system.
- FIG. 2 is a diagram illustrating an example of task management for wireless access processing in a base station.
- FIG. 3 is a diagram illustrating an example of C-state states in a table form.
- FIG. 3 is a table showing an example of the maximum values of the time required to transition to a state (RESIDENCY) and the time required to return to a state (WAKE-UP LATENCY).
- FIG. 3 is a diagram illustrating CPU idle governor types.
- FIG. 2 is a diagram illustrating an overview of the logic of menu.
- FIG. 2 is an image diagram of C-state transition of a CPU core used for calculations.
- FIG. 2 is an image diagram of C-state transition of a CPU core used for calculations.
- FIG. 1 is a schematic configuration diagram of a calculation system according to an embodiment of the present invention. Components that are the same as those in FIG. 20 are given the same reference numerals.
- This embodiment is an example in which a CPU is used as a calculation system.
- the present invention is also applicable to processors such as GPUs (Graphic Processing Units), FPGAs (Field Programmable Gate Arrays), and ASICs (Application Specific Integrated Circuits), if they have an idle state function.
- GPUs Graphic Processing Units
- FPGAs Field Programmable Gate Arrays
- ASICs Application Specific Integrated Circuits
- the computing system 1000 includes hardware (HW) 31, CPU cores (CPUcore #0, CPUcore #1,...) 32 (processors) on the hardware 31, an OS 33, L1, L2 , L3 protocol wireless signal processing applications 1-1, 1-2, and 1-3 (collectively referred to as APL1), and a task scheduler device 100.
- the computing system 1000 is a computing system that reduces power consumption by gradually reducing the operating state of a processor depending on the processing load.
- the computing system 1000 includes a processor having a plurality of core groups, and a task scheduler device 100 that allocates tasks to the core groups of the processor.
- the task scheduler device 100 includes a management section 110, a task management section 120, and a CPU idle state control section 130.
- the management section 110 includes an operator setting section 111.
- an operator sets parameters regarding C-state.
- the administrator inputs the C-state upper limit setting in advance, taking into account the time lag from the input of the C-state upper limit setting to its reflection.
- the task management unit 120 includes a task priority assigning unit 121, a task amount/period prediction unit 122 (processor usage rate acquisition unit), and a task CPU allocation unit 123 (task assignment unit).
- the task priority assigning unit 121 assigns a task priority to the task sent from APL1 as necessary.
- the task management unit 120 executes priority control of allocation to CPU cores according to this priority.
- the most accurate representation of the CPU state is considered to be the "CPU usage rate per unit time of the CPU core in use.”
- the "CPU usage rate per unit time of the CPU core in use” can be estimated approximately based on the amount of tasks. How busy the CPU is can be estimated by the amount of tasks, but it cannot be measured by the amount of tasks alone; it also depends on how many processes the CPU is weak at. Furthermore, when the processor is a GPU, FPGA, or ASIC other than a CPU, the processing that the processor is good at/not good at also changes. In this embodiment, the amount of tasks is used as a physical quantity related to "CPU usage rate per unit time of the CPU core in use.”
- the task amount/cycle prediction unit 122 obtains the usage rate of the processor. Specifically, the task amount/cycle prediction unit 122 measures the amount of tasks per unit time and the CPU usage rate according to the judgment logic shown in FIG. 4, and determines whether it is necessary to increase or decrease the number of CPU cores used for calculations. Determine if there is. The task amount/cycle prediction unit 122 wakes up the newly used CPU core in advance. In many CPU products, when some processing is executed by the CPU core, the C-state returns to C0. For this reason, there is a method in which the corresponding CPU core executes processing such as small calculations and outputting character strings to standard output.
- the task CPU allocation unit 123 Based on the processor usage rate acquired by the task amount/cycle prediction unit 122 (processor usage rate acquisition unit), the task CPU allocation unit 123 continuously assigns processor cores or core groups that are used more than a predetermined frequency. Assign tasks to. For example, the task CPU allocation unit 123 reduces the number of CPU cores used. As a method of reducing the number of CPU cores, a CPU core that will no longer be used is determined, and tasks are no longer assigned to that CPU core. The task CPU allocation unit 123 allocates the arrived tasks to CPU cores (assignment to CPU cores may be done by round robin of the CPU cores in use, or by determining the remaining number of task queues prepared for each CPU core).
- tasks may be assigned to a CPU core with a small number of CPU cores), and tasks are scheduled in a task queue prepared for each CPU core. At this time, a task with a high priority may be preferentially assigned to a vacant CPU core according to the assigned priority. Further, the task queue for each CPU core may be rearranged according to priority.
- the CPU idle state control unit 130 includes a CPU pre-wake-up unit 131 (pre-wake-up unit) and a C-state setting unit 132 (operation state setting unit).
- the CPU pre-wake-up unit 131 performs pre-wake-up to restore the operating state of the processor to its original state when assigning a task to a newly used core or a core that is to be used again after not being used for a predetermined period of time. (See reference numeral c in FIG. 1).
- the C-state setting unit 132 sets an upper limit for a core or core group of a processor that is used more than a predetermined frequency so that the operating state of the processor cannot be transitioned to a deeper state. Specifically, the C-state setting unit 132 sets the C-state upper limit setting for the newly used CPU core.
- the upper limit state is determined by setting by the operator (see reference numeral b in FIG. 1). Note that if tasks are constantly flowing in and tasks can be continuously assigned, the active CPU core group will not transition to a deep C-state, so there may be no need to set an upper limit.
- a C-state upper limit may be set for a newly used CPU core before assigning a task to return it to a shallow state.
- the C-state setting unit 132 cancels the upper limit setting.
- the C-state setting unit 132 sets a core or core group to which the task CPU allocation unit 123 (task allocation unit) has not allocated a task so that the operating state of the processor can be transitioned to a deeper state.
- FIG. 2 and 3 are diagrams illustrating the arrangement of the task scheduler device 100 of FIG. 1.
- - Arrangement of task scheduler device in user space FIG. 2 is a configuration example in which the task scheduler device 100 of FIG. 1 is arranged in user space.
- the computing system 1000 shown in FIG. 2 the task scheduler device 100 is arranged in the user space 60.
- the computing system 1000 executes a packet processing APL1 located in the User space 60.
- the computing system 1000 executes packet processing APL1 on a server equipped with an OS.
- the present invention can be applied to a case where the user space 60 has a thread, such as Intel Data Plane Development Kit (DPDK) (registered trademark).
- DPDK Intel Data Plane Development Kit
- FIG. 3 is a configuration example in which the task scheduler device 100 of FIG. 1 is arranged in the OS 50.
- a task scheduler device 100 is arranged in the OS 50.
- the computing system 1000 executes packet processing APL1 on a server equipped with an OS 50.
- the present invention can be applied to cases where there is a thread inside the kernel, such as New API (NAPI) (registered trademark) (non-patent document 1) and KBP (kernel-based virtual machine).
- NAPI New API
- KBP kernel-based virtual machine
- FIG. 4 is a table showing the logic for estimating the required number of active CPU core groups.
- the estimation logic judgment includes ⁇ 1. Judgment based on task arrival pattern'' and ⁇ 2. Judgment based on CPU usage rate'', which are based on threshold value judgment, periodicity, and machine learning, respectively. .
- the applicable tasks are different for each determination logic, so logics are selected and used properly, taking into consideration the applicability listed in the right column of the table in FIG. Further, a plurality of determination logics may be used together.
- a task scheduler that allocates tasks to CPU cores takes into account the state of the C-state of the CPU cores when allocating tasks.
- Feature ⁇ 1> Continuous task allocation Securing frequently used CPU core groups and continuously assigning tasks prevents transitions to deep C-states ( Figures 5 to 7). As shown in the broken line box a in Fig. 5, depending on the amount of tasks, a frequently used CPU core group (active CPU core group) is secured using the judgment logic shown in Fig. 4, and the CPU core group is continuously assigned to the corresponding CPU core group. Assign tasks to. This prevents transitions to deep C-states and reduces the delay in returning from C-states. Except for the active CPU core, it is possible to transition to a deep C-state, thereby saving power.
- C-state upper limit setting As a countermeasure for cases where tasks cannot be continuously assigned, an upper limit of C-states that can be transitioned to is set for frequently used CPU core groups ( Figures 8 to 8). 10). As a countermeasure for cases where tasks cannot be continuously assigned to active CPU cores, by setting an upper limit on the C-state that can be transitioned to the active CPU core group, it is possible to prevent transitions to deep C-states and reduce the return delay. Reduce.
- Feature ⁇ 3> Wake-up in advance By waking up in advance before assigning a task to a CPU core that has transitioned to a deep state, the time to return from a deep state is reduced ( Figures 11 and 12). The time required to return from a deep C-state is reduced by pre-waking up a newly used CPU core (a CPU core that has not been used for a long time) before assigning a task to it.
- a newly used CPU core a CPU core that has not been used for a long time
- FIG. 5 is a diagram illustrating the task amount threshold determination and CPU usage rate threshold determination operations of the task scheduler device 100.
- the task management unit 120 performs a task amount threshold determination operation. As shown by the broken line arrow d in FIG. 5, the task priority assigning unit 121 assigns a priority to a task as necessary.
- the task amount/cycle prediction unit 122 measures the amount of tasks per unit time and CPU usage rate, and determines whether it is necessary to increase or decrease the number of CPU cores used for calculations, according to the judgment logic shown in FIG. 4. .
- FIG. 6 is a diagram showing an image of threshold value determination according to the amount of task inflow.
- the task management unit 120 manages the CPU cores according to the task inflow amount shown in FIG.
- the amount of task inflow per unit time: W_input is associated with the number of CPU cores to be used. For example, when W_input is "dd ⁇ ee", the number of CPU cores used is "4", and the active CPU core group (see broken line box a in FIG. 5) is "4".
- the task CPU allocation unit 123 allocates the arrived task to a CPU core, and schedules the task in a task queue prepared for each CPU core. At this time, tasks with high priority are preferentially allocated to vacant CPU cores according to the assigned priority. Further, the task queue for each CPU core is rearranged according to priority.
- the task management unit 120 designs the number of CPU cores required to calculate the task inflow amount per unit time according to the threshold determination table of FIG. 6. Further, when the amount of task inflow exceeds the threshold (W_input threshold) in the threshold determination table of FIG. 6, it is possible to determine whether it is necessary to increase the number of CPU cores to be used. In FIG. 6, the state is dd ⁇ W_input ⁇ ee, and four CPU cores are used. When the amount of task inflow becomes W_input ⁇ ee, increase the number of CPU cores from 4 to 5.
- the task management unit 120 calculates the required number of CPU cores. If the processing time of a task is fixed (or has small fluctuations), by defining the maximum waiting time Tw allowed by the service, we can use queuing theory to calculate the amount of time required to satisfy the maximum waiting time. It becomes possible to calculate the number N of CPU cores. Equation (3) of the calculation formula below does not include the time to return from the C-state into consideration, but if the time to return from the C-state can be made as close to zero as possible with this embodiment, consideration becomes unnecessary. .
- FIG. 7 is a diagram illustrating an image of threshold value determination according to CPU usage rate.
- the vertical axis represents the average CPU usage rate of the CPU cores in use, and the horizontal axis represents time.
- Two thresholds, Threshold_upper (see broken line e in FIG. 7) and Threshold_base (lower limit) (see broken line f in FIG. 7), are set for the average CPU usage rate of 100%.
- the task management unit 120 (FIG. 5) increases the number of CPU cores to be used when the average CPU usage rate exceeds the upper limit. Furthermore, when the average CPU usage rate falls below the lower limit, the CPU cores used are reduced.
- Threshold_upper upper limit
- Threshold_base lower limit
- FIG. 8 is a diagram illustrating the C-state upper limit setting of the task scheduler device 100.
- the C-state setting unit 132 of the CPU idle state control unit 130 sets an upper limit of C-states that can be transitioned to for frequently used CPU core groups (see reference numeral b in FIG. 8).
- an upper limit of the CPU idle state that can be transitioned to (for example, see C1 and C1E in FIG. 22) is determined, and Set it so that it cannot transition to state. As a result, it is possible to return from a shallow state when assigning a task, and the return delay time can be reduced.
- the number of CPU cores to be used for setting/cancelling the upper limit of the CPU idle state can be determined by using the determination logic shown in FIG. 4.
- the C-state setting unit 132 dynamically sets the upper limit of the CPU idle state using the determination logic shown in FIG.
- FIG. 9 is a diagram illustrating an image of C-state upper limit setting.
- the upper diagram in FIG. 9 shows a case where there is no C-state upper limit setting
- the lower diagram in FIG. 9 shows a case where there is a C-state upper limit setting.
- the CPU drops to the idle state (grade C2) and the delay time until returning to C0 becomes longer.
- the C-state upper limit for frequently used CPU core groups see symbol g in the lower diagram of Figure 9
- FIG. 10 is a diagram illustrating pooling of CPU cores with high usability in the task scheduler device 100.
- a CPU core group (broken line box h in FIG. 10) may be prepared that is set so that it will only fall into a shallow idle state.
- the CPU cores (CPUcore #4, CPUcore #5) 32 shown in FIG. 10 are pooled as a CPU core group that can only transition up to C1.
- the group of CPU cores that are likely to be used (h in the dashed line box in Figure 10) ) is set so that it can only transition to a shallow idle state (for example, up to C1). Then, active standby CPU cores are pooled and prepared so that they can be used immediately when needed. In this way, if future use is expected, prepare a group of CPU cores that are set to only fall into a shallow idle state (for example, pool a group of CPU cores that can only transition to C1). Take.
- the C-state upper limit setting has been explained above.
- FIG. 11 is a diagram illustrating how the task scheduler device 100 wakes up in advance.
- the CPU pre-wake-up unit 131 pre-wakes up a CPU core when using a CPU core that has fallen into a deep CPU idle state (C-state) (see reference numeral c in FIG. 11).
- FIG. 12 is a diagram illustrating how the task scheduler device 100 wakes up in advance.
- the upper diagram in FIG. 12 shows a case using the existing technology
- the lower diagram in FIG. 12 shows a case in which the task scheduler device 100 wakes up in advance.
- the upper diagram of Figure 12 in the case of the existing technology (when there is no advance wake-up), there is a large delay from task assignment (symbol i in the upper diagram of Figure 12) to the start of the calculation (in the upper diagram of Figure 12). code j).
- the delay from task assignment to the start of calculation is low (reference symbol k in the lower diagram of FIG. 12) due to the early wake-up (sign c in the lower diagram of FIG. ).
- FIG. 13 is a flowchart showing the task scheduling process of the task scheduler device 100.
- the APL 1 (FIG. 1) registers the task in the task management unit 120 (FIG. 1).
- step S12 the task priority assigning unit 121 (FIG. 1) assigns a priority to the task as necessary.
- the task CPU allocation unit 123 (FIG. 1) executes priority control of allocation to CPU cores according to this priority.
- step S13 the task amount/period prediction unit 122 (FIG. 1) measures the amount of tasks per unit time and the CPU usage rate, and increases/decreases the number of CPU cores used for calculations, according to the judgment logic shown in FIG. It is determined whether it is necessary (branches after the determination are steps S14 and S15 below).
- step S14 If it is necessary to reduce the number of CPU cores in step S14 (S14: Yes), the process proceeds to step S17, and if there is no need to reduce the number of CPU cores (S14: No), the process proceeds to step S15.
- step S15: Yes If it is necessary to increase the number of CPU cores in step S15 (S15: Yes), proceed to step S19, and if there is no need to increase the number of CPU cores (S15: No), proceed to step S16.
- step S16 the task CPU allocation unit 123 (FIG. 1) allocates the arrived task to the CPU core, schedules the task in a task queue prepared for each CPU core, and ends the processing of this flow.
- the allocation to the CPU cores may be performed by round robin among the CPU cores in use, or may be allocated to a CPU core with a small number of remaining tasks in the task queue prepared for each CPU core.
- the task CPU allocation unit 123 may preferentially allocate a task with a high priority to an empty CPU core according to the assigned priority, or may assign a task queue for each CPU core. , may be rearranged according to priority.
- the task CPU allocation unit 123 reduces the number of CPU cores to be used in step S17. For example, as a method of reducing the number of CPU cores, a CPU core that will no longer be used is determined, and tasks are no longer assigned to that CPU core.
- step S18 if the C-state upper limit setting is set for the CPU core that is determined not to be used, the C-state setting unit 132 (FIG. 1) cancels the C-state upper limit setting and restarts this flow. Finish the process.
- the task amount/period prediction unit 122 (FIG. 1) performs pre-wake-up on the newly used CPU core in step S19.
- the reason for pre-waking up a newly used CPU core is as follows. That is, in many CPU products, if some processing is executed in the CPU core, the C-state returns to C0. Therefore, by executing minor processing such as small calculations or outputting a character string to the standard output in the corresponding CPU core, the transition of the corresponding CPU core to a deep C-state is suppressed.
- step S20 the C-state setting unit 132 sets the C-state upper limit setting for the newly used CPU core, and ends the processing of this flow.
- the upper limit state is determined by setting it in advance by the operator.
- FIG. 14 is a hardware configuration diagram showing an example of a computer 900 that implements the functions of the task scheduler devices 100 and 100A (FIGS. 1 and 10).
- the computer 900 has a CPU 901, a ROM 902, a RAM 903, an HDD 904, a communication interface (I/F) 906, an input/output interface (I/F) 905, and a media interface (I/F) 907.
- the CPU 901 operates based on a program stored in the ROM 902 or HDD 904, and controls each part of the task scheduler device 100, 100A (FIGS. 1 and 10).
- the ROM 902 stores a boot program executed by the CPU 901 when the computer 900 is started, programs depending on the hardware of the computer 900, and the like.
- the CPU 901 controls an input device 910 such as a mouse and a keyboard, and an output device 911 such as a display via an input/output I/F 905.
- the CPU 901 acquires data from the input device 910 via the input/output I/F 905 and outputs the generated data to the output device 911.
- a GPU Graphics Processing Unit
- a GPU Graphics Processing Unit
- the HDD 904 stores programs executed by the CPU 901 and data used by the programs.
- the communication I/F 906 receives data from other devices via a communication network (for example, NW (Network) 920) and outputs it to the CPU 901, and also sends data generated by the CPU 901 to other devices via the communication network. Send to device.
- NW Network
- the media I/F 907 reads the program or data stored in the recording medium 912 and outputs it to the CPU 901 via the RAM 903.
- the CPU 901 loads a program related to target processing from the recording medium 912 onto the RAM 903 via the media I/F 907, and executes the loaded program.
- the recording medium 912 is an optical recording medium such as a DVD (Digital Versatile Disc) or a PD (Phase change rewritable disk), a magneto-optical recording medium such as an MO (Magneto Optical disk), a magnetic recording medium, a conductive memory tape medium, a semiconductor memory, or the like. It is.
- the CPU 901 of the computer 900 executes a program loaded on the RAM 903. This realizes the functions of the task scheduler devices 100, 100A. Furthermore, data in the RAM 903 is stored in the HDD 904 .
- the CPU 901 reads a program related to target processing from the recording medium 912 and executes it. In addition, the CPU 901 may read a program related to target processing from another device via a communication network (NW 920).
- [Application example] (format in which the task scheduler device is placed in User space 60)
- the present invention can be applied to a configuration example in which a task scheduler device 100 is arranged in a user space 60.
- the OS is not limited.
- it is not limited to being under a server virtualization environment. Therefore, the arithmetic system can be applied to each of the configurations shown in FIGS. 15 and 16.
- VM configuration ⁇ Example of application to VM configuration>
- NFV Network Functions Virtualization
- SFC Service Function Chaining
- a hypervisor environment composed of Linux (registered trademark) and KVM (kernel-based virtual machine) is known as a technology for configuring virtual machines.
- a Host OS with a built-in KVM module OS installed on a physical server is called a Host OS
- a hypervisor in a memory area called kernel space that is different from user space.
- a virtual machine operates in the user space, and a Guest OS (the OS installed on the virtual machine is called a Guest OS) operates within the virtual machine.
- a virtual machine running a Guest OS is different from a physical server running a Host OS; all HW (hardware) including network devices (typified by Ethernet card devices, etc.) are transferred from the HW to the Guest OS.
- HW hardware
- network devices typified by Ethernet card devices, etc.
- FIG. 15 is a diagram showing an example in which the arithmetic system 1000A is applied to an interrupt model in a server virtualization environment with a general-purpose Linux kernel (registered trademark) and a VM configuration. Components that are the same as those in FIG. 1 are given the same reference numerals.
- the computing system 1000A includes a Host OS 80 in which a virtual machine and an external process formed outside the virtual machine can operate, and the Host OS 80 includes a Kernel 81 and a Driver 82. Further, the computing system 1000A includes a CPU 71 of the HW 70 connected to the Host OS 80 and a KVM module 91 built into the hypervisor (HV) 90.
- HV hypervisor
- the computing system 1000A includes a Guest OS 95 that operates within a virtual machine, and the Guest OS 95 includes a Kernel 96 and a Driver 97.
- the computing system 1000A includes a task scheduler device 100 connected to the Guest OS 95 and placed in the User space 60.
- FIG. 16 is a diagram showing an example in which the calculation system 1000B is applied to an interrupt model in a container-configured server virtualization environment. Components that are the same as those in FIGS. 1 and 15 are designated by the same reference numerals.
- the computing system 1000B has a container configuration in which the Guest OS 95 in FIG. 15 is replaced with a Container 98.
- Container 98 has a vNIC (virtual NIC).
- the present invention can be applied to a configuration example in which a task scheduler device 100 is arranged within an OS 50.
- the OS is not limited.
- it is not limited to being under a server virtualization environment. Therefore, the arithmetic system can be applied to each of the configurations shown in FIGS. 17 and 18.
- FIG. 17 is a diagram showing an example in which the calculation system 1000C is applied to an interrupt model in a server virtualization environment with a general-purpose Linux kernel (registered trademark) and a VM configuration. Components that are the same as those in FIGS. 1 and 15 are designated by the same reference numerals.
- a task scheduler device 100 is arranged in Kernel 81 of Host OS 80, and a task scheduler device 100 is arranged in Kernel 96 of Guest OS 95.
- FIG. 18 is a diagram showing an example in which the calculation system 1000D is applied to an interrupt model in a server virtualization environment with a container configuration. Components that are the same as those in FIGS. 1 and 16 are given the same reference numerals.
- a task scheduler device 100 is arranged in the Kernel 81 of the Host OS 80.
- the present invention can be applied to a system with a non-virtualized configuration such as a bare metal configuration.
- calculations can be performed with low latency while achieving power savings.
- processors other than CPU ⁇ Application to processors other than CPU>
- the present invention is similarly applicable to processors other than CPUs, such as GPUs, FPGAs, and ASICs, if they have an idle state function.
- the present invention can also apply the advance wake-up according to the embodiment to a mechanism for restoring the frequency to the original level before task assignment when the processor operating frequency is low.
- the present invention can also be applied to functions other than the CPU, such as memory and storage (eg, HDD, SSD). Furthermore, when a component of an externally connected peripheral device or the like is in a power saving mode, it can be applied to wake up in advance and prepare it before use.
- functions other than the CPU such as memory and storage (eg, HDD, SSD).
- a task scheduler device that allocates tasks to a group of cores of a processor is used.
- 100, 100A which includes a processor usage rate acquisition unit (task amount/cycle prediction unit 122) that acquires the processor usage rate, and a processor usage rate acquisition unit that acquires the processor usage rate acquired by the processor usage rate acquisition unit.
- a task allocation unit (task CPU allocation unit 123) that continuously allocates tasks to a processor core or core group used more than a predetermined frequency is provided.
- a frequently used CPU core group (active CPU core group) is secured using the judgment logic shown in FIG.
- CPU cores other than the active CPU core can transition to a deep C-state (for example, C6), it is possible to save power.
- calculations can be performed with low delay while achieving power savings.
- an operating state setting is performed to set an upper limit so that the operating state of the processor cannot be transitioned to a deeper state. (C-state setting unit 132).
- the operating state setting unit selects a core or core group to which the task allocation unit (task CPU allocation unit 123) has not allocated a task. For example, the operating state of the processor is set so that it can transition to a deeper state.
- the computer when assigning a task to a newly used core or a core to be used again after not using it for a predetermined period, the operating state of the processor is
- the computer includes a pre-wake-up unit (CPU pre-wake-up unit 131) that performs pre-wake-up to return to the state.
- the basic idea is that if it takes a long time from when a task is assigned until the process is finished and the system returns, the system should wake up in advance for the time it takes to return and prepare the CPU to be ready for use. It is something to keep. By doing this, the time required to return from a deep state can be reduced by waking up in advance before assigning a task to a CPU core that has transitioned to a deep state. It is assumed that a core to be newly used or a core to be used again after not being used for a predetermined period is in a deep C-state. By waking up before assigning tasks, you can reduce the time it takes to return from a deep C-state.
- the computing system 1000 reduces power consumption by gradually reducing the operating state of a processor according to processing load, in which a processor (CPU) has a plurality of core groups (CPU cores (CPUcore #0, CPUcore #1, ...) 32), and includes task scheduler devices 100, 100A (Fig. 1, Fig. 10) that allocate tasks to core groups of processors. , a processor usage rate acquisition unit (task amount/period prediction unit 122) that acquires the processor usage rate, and a processor usage rate acquisition unit that calculates processor cores that are used more than a predetermined frequency based on the processor usage rate acquired by the processor usage rate acquisition unit.
- a task allocation unit (task CPU allocation unit 123) that continuously allocates tasks is provided.
- the calculation systems 1000 to 1000D are technologies that are extended not only to packet arrival/processing tasks but also to general tasks such as calculating ⁇ .
- By continuously assigning tasks to frequently used CPU core groups (active CPU core groups) according to the processor usage rate transitions to deep C-states are prevented and return from C-states is delayed. can be reduced.
- CPU cores other than the active CPU core can transition to a deep C-state, it is possible to save power. That is, pre-wake-up can maintain a deep LPI (C-state) for as long as possible while reducing the delay in returning from the C-state, thereby achieving both low latency and power saving.
- C-state deep LPI
- the above processor can be similarly applied to processors other than CPUs, such as GPUs, FPGAs, and ASICs, if they have an idle state function.
- each of the above-mentioned configurations, functions, processing units, processing means, etc. may be partially or entirely realized by hardware, for example, by designing an integrated circuit.
- each of the above-mentioned configurations, functions, etc. may be realized by software for a processor to interpret and execute a program for realizing each function.
- Information such as programs, tables, files, etc. that realize each function is stored in memory, storage devices such as hard disks, SSDs (Solid State Drives), IC (Integrated Circuit) cards, SD (Secure Digital) cards, optical disks, etc. It can be held on a recording medium.
- Hardware (HW) 32 CPU core (processor) 1, 1-1, 1-2, 1-3 Application (APL) 100, 100A Task scheduler device 110 Management unit 111 Setting unit for operator 120 Task management unit 121 Task priority assignment unit 122 Task amount/cycle prediction unit (processor usage rate acquisition unit) 123 Task CPU allocation unit (task allocation unit) 120 Task management unit 130 CPU idle state control unit 131 CPU pre-wake-up unit (pre-wake-up unit) 132 C-state setting section (operating state setting section) 1000, 1000A, 1000B, 1000C, 1000D Arithmetic system (calculation system) CPUcore #0, CPUcore #1,... CPU core
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- General Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Software Systems (AREA)
- Computer Hardware Design (AREA)
- Computing Systems (AREA)
- Power Sources (AREA)
Abstract
処理負荷に応じてプロセッサの動作状態を段階的に減らして消費電力量を削減する計算システム(1000)において、プロセッサのコア群へタスクを割り当てるタスクスケジューラ装置(100,100A)であって、プロセッサの使用率を取得するタスク量・周期 予測部(122)と、タスク量・周期 予測部(122)が取得したプロセッサの使用率をもとに、所定頻度以上で使用するプロセッサのコアまたはコア群については、継続的にタスクを割り当てるタスクCPU割当部(123)と、を備える。
Description
本発明は、タスクスケジューラ装置、計算システム、タスクスケジューリング方法およびプログラムに関する。
無線アクセスシステムの概要について述べる。
図19は、無線アクセスシステムの概要を説明する図である。
図19に示すように、無線アクセスシステムは、図示しないユーザ端末(UE:User Equipment)、アンテナ(基地局アンテナ)20、基地局(BBU:Base Band Unit)30、コア網40を備える。
図19は、無線アクセスシステムの概要を説明する図である。
図19に示すように、無線アクセスシステムは、図示しないユーザ端末(UE:User Equipment)、アンテナ(基地局アンテナ)20、基地局(BBU:Base Band Unit)30、コア網40を備える。
アンテナ20は、UE10と無線通信するアンテナおよび送受信部である(以下、「アンテナ」は、アンテナと送受信部、その電源部を総称して呼称する)。送受信データは、例えば専用ケーブルにより基地局30に接続される。
基地局30は、UE10と通信する陸上に開設する移動しない無線局である。無線信号処理を行う基地局(BBU:Broad Band Unit)30は、無線信号処理を行う専用ハードウェア(専用装置)である。または、基地局30は、LTE(Long Term Evolution)や5G(five generation)の信号処理集約システムにおける無線信号処理を、汎用サーバで処理を行うvRAN(virtual Radio Access Network)である。vRANにおいては、基地局30のハードウェアとして安価で大量に入手可能な汎用サーバを使用することができる。
基地局30は、ハードウェア(HW)31と、ハードウェア上のCPU(Central Processing Unit)32と、OS等33と、L1,L2,L3プロトコル無線信号処理アプリケーション1-1,1-2,1-3(総称する場合は、APL1と呼ぶ)と、タスクスケジューラ装置34と、を備える。
基地局30は、ハードウェア(HW)31と、ハードウェア上のCPU(Central Processing Unit)32と、OS等33と、L1,L2,L3プロトコル無線信号処理アプリケーション1-1,1-2,1-3(総称する場合は、APL1と呼ぶ)と、タスクスケジューラ装置34と、を備える。
コア網40は、EPC(Evolved Packet Core)/(以下の説明において、「/」は「または」を表記する)5GC(5G Core Network)等である。
リアルタイム性が求められるシステムとして、RANにおける基地局(BBU)が挙げられる。
CPU32を使用して演算を行うBBUでは、無線信号処理のタスクを、タスクスケジューラ装置34がCPUコアへ割り当てることで演算を行うことが多い(非特許文献1)。
CPU32を使用して演算を行うBBUでは、無線信号処理のタスクを、タスクスケジューラ装置34がCPUコアへ割り当てることで演算を行うことが多い(非特許文献1)。
図20は、基地局における無線アクセス処理のタスク管理例を説明する図である。図19と同一構成部分には同一符号を付している。
基地局(BBU)30は、タスクスケジューラ装置34を備える。タスクスケジューラ装置34は、タスク管理、優先度付け、およびタスク割り振りを行う。
タスクスケジューラ装置34は、APL1の無線信号処理のタスクを、タスクキュー37に割り振り、タスクキュー37からCPUコア(CPUcore #0,CPUcore #1,…)32へ割り当てる。
基地局(BBU)30は、タスクスケジューラ装置34を備える。タスクスケジューラ装置34は、タスク管理、優先度付け、およびタスク割り振りを行う。
タスクスケジューラ装置34は、APL1の無線信号処理のタスクを、タスクキュー37に割り振り、タスクキュー37からCPUコア(CPUcore #0,CPUcore #1,…)32へ割り当てる。
[LPI(Low Power Idle)ハードウェア制御]
CPU32には、ハードウェア制御によるCPU32のidle状態を制御する機能があり、LPIと呼ばれる。LPIは、CPUidleやC-stateと呼称されることも多く、以下、LPIをC-stateとして説明する。
C-stateは、は、CPU負荷が少なくなると、CPU32の回路の一部の電源をOFFにすることで、省電力化を試行する(非特許文献2)。
CPU32には、ハードウェア制御によるCPU32のidle状態を制御する機能があり、LPIと呼ばれる。LPIは、CPUidleやC-stateと呼称されることも多く、以下、LPIをC-stateとして説明する。
C-stateは、は、CPU負荷が少なくなると、CPU32の回路の一部の電源をOFFにすることで、省電力化を試行する(非特許文献2)。
図21は、C-stateの状態の一例を表にして示す図である。なお、CPUハードウェアに依って状態定義は異なるため、図21はあくまでも参考例である。
図21に示すように、CPUidle状態には、グレードC0~C6があり、CPU32の負荷がない時間が長くなるにつれ、深いsleep状態へ遷移する。深いsleep状態の方がCPU消費電力は小さくなるが、一方で、それだけ復帰までに要する時間が長延化するため、低遅延の観点で課題となる場合がある。
図21に示すように、CPUidle状態には、グレードC0~C6があり、CPU32の負荷がない時間が長くなるにつれ、深いsleep状態へ遷移する。深いsleep状態の方がCPU消費電力は小さくなるが、一方で、それだけ復帰までに要する時間が長延化するため、低遅延の観点で課題となる場合がある。
C-stateは、CPUハードウェアに依って状態定義が異なる。例えば、C4やC5が無い機種、C1の次がC1Eというステートである機種等のバリエーションがある。
ステートが深くなるにつれ省電力効果は大きくなるが、それだけ、idle状態から復帰に要する時間も大きくなる。
ステートが深くなるにつれ省電力効果は大きくなるが、それだけ、idle状態から復帰に要する時間も大きくなる。
また、どの深さまでCPUidle状態が遷移するかは、CPUのハードウェア制御になり、CPU製品依存となる(kernel等のソフトウェアから制御できない場合が多い)。
図22は、ステートまでに遷移する時間(RESIDENCY)と、復帰に要する時間(WAKE-UP LATENCY)の最大値の一例を表にして示す図である。図22は、Intel Xeon CPU E5-26X0 v4(登録商標)におけるC-state情報を表わしている。
[CPUidle state Governor]
Linux kernel4(登録商標)は、CPU idle state(C-state)を管理するため、2種類のGovernorを用意する。
Linux kernel4(登録商標)は、CPU idle state(C-state)を管理するため、2種類のGovernorを用意する。
図23は、CPU idle Governor種別を説明する図である。
図23に示すように、ladder はtick有りシステム向け、menu はticklessシステム向けで使用されている。
例えば、ticklessシステムで使用される menu は、直近のidle期間の実績から、次のidle期間に適するidle stateの深さを推定する方式である。menu は、idle時間が規則的なワークロードについては効果を得られるが、不規則なワークロードでの効果は限定的となる。
図23に示すように、ladder はtick有りシステム向け、menu はticklessシステム向けで使用されている。
例えば、ticklessシステムで使用される menu は、直近のidle期間の実績から、次のidle期間に適するidle stateの深さを推定する方式である。menu は、idle時間が規則的なワークロードについては効果を得られるが、不規則なワークロードでの効果は限定的となる。
図24は、menu のロジック概要を説明する図である。
図24左図に示すように、menu は、直近のidle時間を記録する。そして、図24中図に示すように、次のidle時間を推定する。例えば、図24左図に示すidle時間をもとに、偏差が小さい場合は平均値 T_avrを次のidle時間として採用する。図24右図に示すように、menu は、次のidle時間の推定をもとに、適するidle state深さを推定する。例えば、次のidle時間推定値 T_avr がidle state(Cx)からの復帰時間 exit latency と同等であれば、深いstateすぎると判断しCx-1のidle stateへ遷移させる。
図24左図に示すように、menu は、直近のidle時間を記録する。そして、図24中図に示すように、次のidle時間を推定する。例えば、図24左図に示すidle時間をもとに、偏差が小さい場合は平均値 T_avrを次のidle時間として採用する。図24右図に示すように、menu は、次のidle時間の推定をもとに、適するidle state深さを推定する。例えば、次のidle時間推定値 T_avr がidle state(Cx)からの復帰時間 exit latency と同等であれば、深いstateすぎると判断しCx-1のidle stateへ遷移させる。
図23に戻って、2種類のGovernorのladder、menu のうち、いずれのGovernorについても、新たなタスクが到着した際に、CPU idle stateから事前起床を命令し、復帰させて準備をさせておく機構は有していない。このため、深いStateに遷移している状態でのタスク割り当て時には、復帰時間分の遅延時間が発生する問題がある。
New API(NAPI),[online],[令和4年6月6日検索],インターネット 〈URL :https://www.kernel.org/doc/html/latest/admin-guide/pm/cpuidle.html〉
Daniel Molka & Michael Werner,Wake-up latencies for processor idle states on current x86 processors Robert Schone,[online],[令和4年6月6日検索],インターネット 〈 URL :https://link.springer.com/article/10.1007/s00450-014-0270-z#citeas〉
図21に示すように、CPUidle状態には、グレードがあり、CPUの負荷がない時間が長くなるにつれ、深いsleep状態へ遷移する。深いsleep状態の方がCPU消費電力は小さくなるが、一方で、それだけ復帰までに要する時間が長延化するため、低遅延の観点で課題となる場合がある。
図25および図26は、演算に使用するCPUコアのC-state遷移イメージ図である。図25は、タスクなし時間が短い場合を示し、図26は、タスクなし時間が長い場合を示す。
図25に示すように、タスクなし時間が短い場合は、CPUコアが浅いsleep状態にあり、タスク発生後、復帰までの遅延時間が短い。しかし、図26に示すように、タスクなし時間が長い場合は、CPUコアが深いsleep状態(CPUidle状態:グレードC6)にあり、タスク発生後、復帰までの遅延時間が長延化する。深いCPU idle stateまで落ちると、復帰するまでに大きな時間を要し、リアルタイム性が損なわれるという課題がある。
図25に示すように、タスクなし時間が短い場合は、CPUコアが浅いsleep状態にあり、タスク発生後、復帰までの遅延時間が短い。しかし、図26に示すように、タスクなし時間が長い場合は、CPUコアが深いsleep状態(CPUidle状態:グレードC6)にあり、タスク発生後、復帰までの遅延時間が長延化する。深いCPU idle stateまで落ちると、復帰するまでに大きな時間を要し、リアルタイム性が損なわれるという課題がある。
上記課題は、図19および図20に示す基地局(BBU)30のようにリアルタイム性が最優先されるシステムでは、看過できない問題である。
このため、基地局(BBU)にあっては、C-stateを無効にする、若しくは、idle stateの遷移をC1等の限られた深さに限定する設定を投入する対応が採られる。すなわち、省電力性を犠牲にし、リアルタイム性を指向するチューニングが行われる場合がある。
このため、基地局(BBU)にあっては、C-stateを無効にする、若しくは、idle stateの遷移をC1等の限られた深さに限定する設定を投入する対応が採られる。すなわち、省電力性を犠牲にし、リアルタイム性を指向するチューニングが行われる場合がある。
従来の基地局(BBU)にあっては、深いC-stateまで落ちたら最後、復帰するまで待つしかなかった。このため、省電力性を犠牲にし、深いところまでは落とさない対策が採られていた。
このような背景を鑑みて本発明がなされたのであり、本発明は、省電力を達成しつつ、低遅延に演算を行うことを課題とする。
前記した課題を解決するため、処理負荷に応じてプロセッサの動作状態を段階的に減らして消費電力量を削減する計算システムにおいて、前記プロセッサのコア群へタスクを割り当てるタスクスケジューラ装置であって、前記プロセッサの使用率を取得するプロセッサ使用率取得部と、前記プロセッサ使用率取得部が取得した前記プロセッサの使用率をもとに、所定頻度以上で使用する前記プロセッサのコアまたはコア群については、継続的にタスクを割り当てるタスク割当部と、を備えることを特徴とするタスクスケジューラ装置とした。
本発明によれば、省電力を達成しつつ、低遅延に演算を行うことができる。
以下、図面を参照して本発明を実施するための形態(以下、「本実施形態」という)における演算システム等について説明する。
[概要]
図1は、本発明の実施形態に係る演算システムの概略構成図である。図20と同一構成部分には、同一符号を付している。
本実施形態は、演算システムとしてCPUに適用した例である。CPU以外にも、GPU(Graphic Processing Unit),FPGA(Field Programmable Gate Array),ASIC(Application Specific Integrated Circuit)等のプロセッサに、idle stateの機能がある場合には、同様に適用可能である。
[概要]
図1は、本発明の実施形態に係る演算システムの概略構成図である。図20と同一構成部分には、同一符号を付している。
本実施形態は、演算システムとしてCPUに適用した例である。CPU以外にも、GPU(Graphic Processing Unit),FPGA(Field Programmable Gate Array),ASIC(Application Specific Integrated Circuit)等のプロセッサに、idle stateの機能がある場合には、同様に適用可能である。
図1に示すように、演算システム1000は、ハードウェア(HW)31と、ハードウェア31上のCPUコア(CPUcore #0,CPUcore #1,…)32(プロセッサ)と、OS33と、L1,L2,L3プロトコル無線信号処理アプリケーション1-1,1-2,1-3(総称する場合は、APL1と呼ぶ)と、タスクスケジューラ装置100と、を備える。
演算システム1000は、処理負荷に応じてプロセッサの動作状態を段階的に減らして消費電力量を削減する計算システムである。演算システム1000は、プロセッサが、複数のコア群を有しており、プロセッサのコア群へタスクを割り当てるタスクスケジューラ装置100を備える。
演算システム1000は、処理負荷に応じてプロセッサの動作状態を段階的に減らして消費電力量を削減する計算システムである。演算システム1000は、プロセッサが、複数のコア群を有しており、プロセッサのコア群へタスクを割り当てるタスクスケジューラ装置100を備える。
[タスクスケジューラ装置100]
タスクスケジューラ装置100は、管理部110と、タスク管理部120と、CPU idle state制御部130と、を備える。
タスクスケジューラ装置100は、管理部110と、タスク管理部120と、CPU idle state制御部130と、を備える。
<管理部110>
管理部110は、運用者向け設定部111を有する。
運用者向け設定部111は、運用者がC-stateに関するパラメータを設定する。例えば、運用者向け設定部111は、管理者が、C-state上限設定投入から反映までのタイムラグを考慮して、事前にC-state上限設定を投入する。
管理部110は、運用者向け設定部111を有する。
運用者向け設定部111は、運用者がC-stateに関するパラメータを設定する。例えば、運用者向け設定部111は、管理者が、C-state上限設定投入から反映までのタイムラグを考慮して、事前にC-state上限設定を投入する。
<タスク管理部120>
タスク管理部120は、タスク優先度付与部121と、タスク量・周期 予測部122(プロセッサ使用率取得部)と、タスクCPU割当部123(タスク割当部)と、を有する。
タスク管理部120は、タスク優先度付与部121と、タスク量・周期 予測部122(プロセッサ使用率取得部)と、タスクCPU割当部123(タスク割当部)と、を有する。
タスク優先度付与部121は、APL1から送られたタスクに対し、必要に応じてタスクの優先度を付与する。タスク管理部120は、この優先度に応じて、CPUコアへの割り当ての優先制御を実行する。
ここで、CPU状態を、もっとも精確に表しているのは、「使用しているCPUコアの単位時間当たりのCPU使用率」と考えられる。「使用しているCPUコアの単位時間当たりのCPU使用率」は、ほぼタスク量で推定することができる。CPUがどれだけ忙しいかは、タスク量で推計することができるが、タスク量だけでは測れない、CPUが苦手とする処理がどれだけあるかにもよる。さらに、プロセッサが、CPU以外のGPU,FPGA,ASICである場合には、プロセッサが得意/苦手とする処理についても変わる。本実施形態では、「使用しているCPUコアの単位時間当たりのCPU使用率」に関連する物理量として、タスク量を用いている。
タスク量・周期 予測部122は、プロセッサの使用率を取得する。具体的には、タスク量・周期 予測部122は、図4に示す判断ロジックに従い、単位時間当たりのタスク量や、CPU使用率を計測し、演算に使用するCPUコア数を増やす/減らす必要があるかを判断する。
タスク量・周期 予測部122は、新たに使用するCPUコアに対して、事前起床を行う。CPUコアにより何かしらの処理が実行されれば、C-stateはC0に戻るCPU製品が多い。そのため、小さな演算や標準出力に文字列を出力する等の処理を該当CPUコアで実行する方法がある。
タスク量・周期 予測部122は、新たに使用するCPUコアに対して、事前起床を行う。CPUコアにより何かしらの処理が実行されれば、C-stateはC0に戻るCPU製品が多い。そのため、小さな演算や標準出力に文字列を出力する等の処理を該当CPUコアで実行する方法がある。
タスクCPU割当部123は、タスク量・周期 予測部122(プロセッサ使用率取得部)が取得したプロセッサの使用率をもとに、所定頻度以上で使用するプロセッサのコアまたはコア群については、継続的にタスクを割り当てる。タスクCPU割当部123は、例えば、使用するCPUコアを減らす。CPUコアを減らす方法として、以降使用しないCPUコアを決定し、以降当該CPUコアへタスクを割り当てないようにする。
タスクCPU割当部123は、到着したタスクを、CPUコアに割り当て(CPUコアへの割り当ては、使用しているCPUコアをラウンドロビンしてもよいし、CPUコア毎に用意したタスクキューの残数が少ないCPUコアに割り当ててもよい)、CPUコア毎に用意したタスクキューにタスクをスケジューリングする。
この時、付与された優先度に応じて、優先度の高いタスクを空いているCPUコアへ優先的に割り当ててもよい。また、CPUコア毎のタスクキューを、優先度に応じて並び替えてもよい。
タスクCPU割当部123は、到着したタスクを、CPUコアに割り当て(CPUコアへの割り当ては、使用しているCPUコアをラウンドロビンしてもよいし、CPUコア毎に用意したタスクキューの残数が少ないCPUコアに割り当ててもよい)、CPUコア毎に用意したタスクキューにタスクをスケジューリングする。
この時、付与された優先度に応じて、優先度の高いタスクを空いているCPUコアへ優先的に割り当ててもよい。また、CPUコア毎のタスクキューを、優先度に応じて並び替えてもよい。
<CPU idle state制御部130>
CPU idle state制御部130は、CPU事前起床部131(事前起床部)と、C-state設定部132(動作状態設定部)と、を有する。
CPU事前起床部131は、新たに使用するコア、または、所定期間使用せずに再び使用するコアに対しては、タスクを割り当てる際に、プロセッサの動作状態を元の状態に復帰させる事前起床を行う(図1の符号c参照)。
CPU idle state制御部130は、CPU事前起床部131(事前起床部)と、C-state設定部132(動作状態設定部)と、を有する。
CPU事前起床部131は、新たに使用するコア、または、所定期間使用せずに再び使用するコアに対しては、タスクを割り当てる際に、プロセッサの動作状態を元の状態に復帰させる事前起床を行う(図1の符号c参照)。
C-state設定部132は、所定頻度以上で使用するプロセッサのコアまたはコア群については、プロセッサの動作状態をより深い状態に遷移できないように上限を設定する。具体的には、C-state設定部132は、新たに使用するCPUコアに対して、C-state上限設定を投入する。上限stateは、運用者が設定することにより決定する(図1の符号b参照)。
なお、定常的にタスクが流入し、継続的にタスクを割り当て続けられる場合は、ActiveなCPUコア群は深いC-stateに遷移しないため、上限設定は投入しなくてもよい場合もある。
なお、定常的にタスクが流入し、継続的にタスクを割り当て続けられる場合は、ActiveなCPUコア群は深いC-stateに遷移しないため、上限設定は投入しなくてもよい場合もある。
ここで、事前起床ではなく、新たに使用するCPUコアに対して、タスクを割り当てる前にC-state上限設定を入れて、浅いstateに戻しておいてもよい。この場合、C-state上限設定投入から反映までのタイムラグを考慮して、事前にC-state上限設定を投入する。
C-state設定部132は、使用しないと決定したCPUコアに対して、C-state上限設定が入っている場合は、上限設定を解除する。
C-state設定部132は、タスクCPU割当部123(タスク割当部)が、タスクを割り当てなかったコアまたはコア群については、プロセッサの動作状態をより深い状態に遷移できるように設定する。
C-state設定部132は、使用しないと決定したCPUコアに対して、C-state上限設定が入っている場合は、上限設定を解除する。
C-state設定部132は、タスクCPU割当部123(タスク割当部)が、タスクを割り当てなかったコアまたはコア群については、プロセッサの動作状態をより深い状態に遷移できるように設定する。
[タスクスケジューラ装置の配置]
図2および図3は、図1のタスクスケジューラ装置100の配置を説明する図である。
・user spaceへのタスクスケジューラ装置の配置
図2は、図1のタスクスケジューラ装置100をuser spaceに配置した構成例である。
図2に示す演算システム1000は、User space60にタスクスケジューラ装置100が配置される。演算システム1000は、User space60に配置されたパケット処理APL1を実行する。演算システム1000は、OSを備えるサーバ上で、パケット処理APL1を実行する。
図2および図3は、図1のタスクスケジューラ装置100の配置を説明する図である。
・user spaceへのタスクスケジューラ装置の配置
図2は、図1のタスクスケジューラ装置100をuser spaceに配置した構成例である。
図2に示す演算システム1000は、User space60にタスクスケジューラ装置100が配置される。演算システム1000は、User space60に配置されたパケット処理APL1を実行する。演算システム1000は、OSを備えるサーバ上で、パケット処理APL1を実行する。
本発明を、Intel DPDK(Intel Data Plane Development Kit)(DPDK)(登録商標)のように、user space60にthreadがある場合に適用することができる。
・OSへのタスクスケジューラ装置の配置
図3は、図1のタスクスケジューラ装置100をOS50に配置した構成例である。
図3に示す演算システム1000は、OS50にタスクスケジューラ装置100が配置される。演算システム1000は、OS50を備えるサーバ上で、パケット処理APL1を実行する。
図3は、図1のタスクスケジューラ装置100をOS50に配置した構成例である。
図3に示す演算システム1000は、OS50にタスクスケジューラ装置100が配置される。演算システム1000は、OS50を備えるサーバ上で、パケット処理APL1を実行する。
本発明を、New API(NAPI)(登録商標)(非特許文献1)やKBP(kernel-based virtual machine)のように、kernel内部にthreadがある場合に適用することができる。
[ActiveなCPUコア群の必要数推定ロジック]
ActiveなCPUコア群(図1の破線囲みa参照)の必要数推定ロジックについて説明する。
本発明者らは、ActiveなCPUコア群には、継続してタスクを割り当て、それ以外のCPUコアは、深いC-stateに遷移させて消費電力量を削減させることを考察した。
そのためには、ActiveなCPUコア群の管理に際して、流入するタスク量等をもとに、必要なCPUコア数を算出する必要がある。
ActiveなCPUコア群(図1の破線囲みa参照)の必要数推定ロジックについて説明する。
本発明者らは、ActiveなCPUコア群には、継続してタスクを割り当て、それ以外のCPUコアは、深いC-stateに遷移させて消費電力量を削減させることを考察した。
そのためには、ActiveなCPUコア群の管理に際して、流入するタスク量等をもとに、必要なCPUコア数を算出する必要がある。
図4は、ActiveなCPUコア群の必要数推定ロジックを表にして示す図である。
図4に示すように、推定ロジック判断は、「1.タスクの到着パターンによる判定」と「2.CPU使用率による判定」とがあり、それぞれ、閾値判定、周期性、機械学習による判定を行う。
図4に示すように、判断ロジック毎に、適用性のあるタスクが異なるため、図4の表の右列に記載した適用性を考慮して、ロジックを選択して使い分ける。また、複数の判断ロジックを併用してもよい。
図4に示すように、推定ロジック判断は、「1.タスクの到着パターンによる判定」と「2.CPU使用率による判定」とがあり、それぞれ、閾値判定、周期性、機械学習による判定を行う。
図4に示すように、判断ロジック毎に、適用性のあるタスクが異なるため、図4の表の右列に記載した適用性を考慮して、ロジックを選択して使い分ける。また、複数の判断ロジックを併用してもよい。
以下、上述のように構成された演算システム1000の動作を説明する。
[タスクスケジューラ装置100動作の基本的な考え方]
本発明は、リアルタイム性の求められる演算システムにおいて、CPUコアへタスクを割り当てるタスクスケジューラが、CPUコアのC-stateの状態を考慮して、タスクの割り当てを行う。
[タスクスケジューラ装置100動作の基本的な考え方]
本発明は、リアルタイム性の求められる演算システムにおいて、CPUコアへタスクを割り当てるタスクスケジューラが、CPUコアのC-stateの状態を考慮して、タスクの割り当てを行う。
特徴<1>:継続タスク割当
使用頻度の高いCPUコア群を確保し、継続してタスクを割り当てることで、深いC-stateへ遷移することを防ぐ(図5~図7)。
図5の破線囲みaに示すように、タスク量に応じて、頻繁に利用するCPUコア群(ActiveなCPUコア群)を、図4に示す判断ロジックにより確保し、該当CPUコア群へ継続的にタスクを割り当てる。これにより、深いC-stateへ遷移することを防ぎ、C-stateからの復帰遅延を軽減する。ActiveなCPUコア以外は、深いC-stateに遷移でき、省電力を図ることができる。
使用頻度の高いCPUコア群を確保し、継続してタスクを割り当てることで、深いC-stateへ遷移することを防ぐ(図5~図7)。
図5の破線囲みaに示すように、タスク量に応じて、頻繁に利用するCPUコア群(ActiveなCPUコア群)を、図4に示す判断ロジックにより確保し、該当CPUコア群へ継続的にタスクを割り当てる。これにより、深いC-stateへ遷移することを防ぎ、C-stateからの復帰遅延を軽減する。ActiveなCPUコア以外は、深いC-stateに遷移でき、省電力を図ることができる。
特徴<2>:C-state上限設定
タスクを継続して割り当てられない場合の対応策として、使用頻度の高いCPUコア群に対して、遷移可能なC-state上限を設定する(図8~図10)。
ActiveなCPUコアへ継続してタスクを割り当てられない場合の対応として、ActiveなCPUコア群へ遷移可能なC-state上限を設定することで、深いC-stateへ遷移できないようにし、復帰遅延を軽減する。
タスクを継続して割り当てられない場合の対応策として、使用頻度の高いCPUコア群に対して、遷移可能なC-state上限を設定する(図8~図10)。
ActiveなCPUコアへ継続してタスクを割り当てられない場合の対応として、ActiveなCPUコア群へ遷移可能なC-state上限を設定することで、深いC-stateへ遷移できないようにし、復帰遅延を軽減する。
特徴<3>:事前起床
深いstateに遷移したCPUコアへタスクを割り当てる前に、事前起床をすることで、深いstateからの復帰時間を軽減する(図11~図12)。
新たに使用するCPUコア(久しぶりに使用するCPUコア)に対して、タスクを割り当てる前に、事前起床を行うことで、深いC-stateからの復帰時間を軽減する。
以下、特徴<1>、特徴<2>、特徴<3>について順に説明する。
深いstateに遷移したCPUコアへタスクを割り当てる前に、事前起床をすることで、深いstateからの復帰時間を軽減する(図11~図12)。
新たに使用するCPUコア(久しぶりに使用するCPUコア)に対して、タスクを割り当てる前に、事前起床を行うことで、深いC-stateからの復帰時間を軽減する。
以下、特徴<1>、特徴<2>、特徴<3>について順に説明する。
[タスク量閾値判定およびCPU使用率閾値判定](特徴<1>:継続タスク割当)
図5は、タスクスケジューラ装置100のタスク量閾値判定およびCPU使用率閾値判定動作を説明する図である。
図5は、タスクスケジューラ装置100のタスク量閾値判定およびCPU使用率閾値判定動作を説明する図である。
<タスク量閾値判定動作>
まず、タスク量閾値判定動作を説明する。
タスク管理部120は、タスク量閾値判定動作を行う。
図5の破線矢印dに示すように、タスク優先度付与部121は、必要に応じてタスクの優先度を付与する。
タスク量・周期 予測部122は、図4に示す判断ロジックに従い、単位時間当たりのタスク量や、CPU使用率を計測し、演算に使用するCPUコア数を増やす/減らす必要があるかを判断する。
まず、タスク量閾値判定動作を説明する。
タスク管理部120は、タスク量閾値判定動作を行う。
図5の破線矢印dに示すように、タスク優先度付与部121は、必要に応じてタスクの優先度を付与する。
タスク量・周期 予測部122は、図4に示す判断ロジックに従い、単位時間当たりのタスク量や、CPU使用率を計測し、演算に使用するCPUコア数を増やす/減らす必要があるかを判断する。
図6は、タスク流入量に応じた閾値判定イメージを示す図である。
タスク管理部120は、図6に示すタスク流入量に従ってCPUコアを管理する。
図6において、単位時間当たりのタスク流入量:W_inputと使用するCPUコア数とを対応付ける。例えば、W_inputが「dd~ee」の場合、使用するCPUコア数は「4」であり、ActiveなCPUコア群(図5の破線囲みa参照)は、「4」である。
タスク管理部120は、図6に示すタスク流入量に従ってCPUコアを管理する。
図6において、単位時間当たりのタスク流入量:W_inputと使用するCPUコア数とを対応付ける。例えば、W_inputが「dd~ee」の場合、使用するCPUコア数は「4」であり、ActiveなCPUコア群(図5の破線囲みa参照)は、「4」である。
図5に戻って、タスクCPU割当部123は、到着したタスクを、CPUコアに割り当て、CPUコア毎に用意したタスクキューにタスクをスケジューリングする。この時、付与された優先度に応じて、優先度の高いタスクを空いているCPUコアへ優先的に割り当てる。また、CPUコア毎のタスクキューを、優先度に応じて並び替える。
タスク管理部120は、演算時間が固定時間で完了するタスクについては、単位時間のタスク流入量を、図6の閾値判定表に従って、タスク流入量の演算に必要なCPUコア数を設計する。また、タスク流入量が、図6の閾値判定表の閾値(W_inputの閾値)を超えた場合に、使用するCPUコア数を増やす必要があるかを判定することが可能となる。図6においては、dd<W_input<eeの状態であり、CPUコアは4つ使用している。タスク流入量が、W_input≧eeとなった場合に、CPUコアを4つ→5つに増やす。
<必要なCPUコア数算出例>
次に、必要なCPUコア数算出例について説明する。
タスク管理部120(図5)は、必要なCPUコア数算出を行う。
タスクの演算時間が固定的な(若しくは、変動が小さい)場合には、サービスで許容される最大待ち時間Twを定義すれば、待ち行列理論を用いて、最大待ち時間を満足するために必要なCPUコア数Nを算出することが可能になる。下記計算式の式(3)には、C-stateからの復帰時間は考慮に含まないが、本実施形態によりC-stateからの復帰時間を限りなくゼロに近づけることができれば、考慮不要となる。
次に、必要なCPUコア数算出例について説明する。
タスク管理部120(図5)は、必要なCPUコア数算出を行う。
タスクの演算時間が固定的な(若しくは、変動が小さい)場合には、サービスで許容される最大待ち時間Twを定義すれば、待ち行列理論を用いて、最大待ち時間を満足するために必要なCPUコア数Nを算出することが可能になる。下記計算式の式(3)には、C-stateからの復帰時間は考慮に含まないが、本実施形態によりC-stateからの復帰時間を限りなくゼロに近づけることができれば、考慮不要となる。
・必要なCPUコア数算出例
λ[個/s]:単位時間当たりのタスク流入量(W_input)
μ[個/s]:単位時間当たりにシステムが処理できるタスクの数
Ts[s]:システムが1つのタスクの処理に要する時間
t_s[s]:1つのCPUコアで1つのタスク演算に必要な時間
Tw[s]:サービスで許容される最大待ち時間
N[個]:使用しているCPUコア数
ρ=λ/μ: 混み具合
λ[個/s]:単位時間当たりのタスク流入量(W_input)
μ[個/s]:単位時間当たりにシステムが処理できるタスクの数
Ts[s]:システムが1つのタスクの処理に要する時間
t_s[s]:1つのCPUコアで1つのタスク演算に必要な時間
Tw[s]:サービスで許容される最大待ち時間
N[個]:使用しているCPUコア数
ρ=λ/μ: 混み具合
μ=N/t_s
Ts=1/μ=t_s/N
Ts=1/μ=t_s/N
Tw=(ρ/(1-ρ))*Ts …(1)
上記式(1)に、ρとTsを代入すると、式(2)となる。
Tw=((λ/μ)/(1-(λ/μ))*(t_s/N) …(2)
Tw=((λ/μ)/(1-(λ/μ))*(t_s/N) …(2)
上記式(2)に、μを代入し解くと、式(3)得る。
N2-λ・t_s・N-λ・t_s2/Tw=0 …(3)
この方程式を満たす最小の自然数を求めればよい。
N2-λ・t_s・N-λ・t_s2/Tw=0 …(3)
この方程式を満たす最小の自然数を求めればよい。
<CPU使用率閾値判定動作>
次に、CPU使用率閾値判定動作を説明する。
図7は、CPU使用率に応じた閾値判定イメージを説明する図である。縦軸は、使用しているCPUコアのCPU使用率平均、横軸は時間である。
CPU使用率平均の100%に対して、2つの閾値、Threshold_upper(上限)(図7の破線e参照)および、Threshold_base(下限)(図7の破線f参照)を設定する。
タスク管理部120(図5)は、CPU使用率平均が、上限を超えた場合、使用するCPUコアを増やす。また、CPU使用率平均が、下限を下回ったら、使用するCPUコアを減らす。
次に、CPU使用率閾値判定動作を説明する。
図7は、CPU使用率に応じた閾値判定イメージを説明する図である。縦軸は、使用しているCPUコアのCPU使用率平均、横軸は時間である。
CPU使用率平均の100%に対して、2つの閾値、Threshold_upper(上限)(図7の破線e参照)および、Threshold_base(下限)(図7の破線f参照)を設定する。
タスク管理部120(図5)は、CPU使用率平均が、上限を超えた場合、使用するCPUコアを増やす。また、CPU使用率平均が、下限を下回ったら、使用するCPUコアを減らす。
使用しているCPUコアのCPU使用率平均が、Threshold_upper(上限)を上回る場合は、使用しているCPUコアが足りなくなっている予兆であり、新しくCPUコア数を増やすようにする判断ができる。一方、使用しているCPUコアのCPU使用率平均が、Threshold_base(下限)を下回る場合は、CPUコアが過剰であり、使用しているCPUコアを縮退させる判断ができる。
ここで、上記、新しくCPUコア数を増やす場合、当該CPUコアは、いままで使用していなかったCPUコアであるため、深いC-stateまで落ちていることが想定される。特に、このような深いC-state状態に落ちているCPUコアを復帰させる場合の復帰時間の算出方法については、上記<必要なCPUコア数算出例>で説明した。
以上、タスク量閾値判定およびCPU使用率閾値判定について説明した。
以上、タスク量閾値判定およびCPU使用率閾値判定について説明した。
[C-state上限設定](特徴<2>:C-state上限設定)
<C-state上限設定動作>
図8は、タスクスケジューラ装置100のC-state上限設定を説明する図である。
CPU idle state制御部130のC-state設定部132は、使用頻度の高いCPUコア群に対して、遷移可能なC-state上限を設定する(図8の符号b参照)。
<C-state上限設定動作>
図8は、タスクスケジューラ装置100のC-state上限設定を説明する図である。
CPU idle state制御部130のC-state設定部132は、使用頻度の高いCPUコア群に対して、遷移可能なC-state上限を設定する(図8の符号b参照)。
使用する頻度の高いCPUコアについては、タスクを割り当てる可能性が高いため、深いidle stateに遷移させても、該当stateの滞在期間が短く省電力効果はあまり享受できない。省電力効果が享受できないにも関わらず、idle stateからの復帰時間オーバーヘッドが発生してしまうデメリットが生じる場合がある。
本実施形態では、この問題に対して、使用頻度の高いCPUコアについては、遷移可能なCPU idle stateの上限(例えば、図22のC1やC1E等参照)を定めておき、該当stateよりも深いstateに遷移できないように設定する。これにより、タスク割り当て時に浅いstateからの復帰にすることができ、復帰遅延時間を低減できる。
CPU idle stateの上限を設定/解除するCPUコアの対象は、図4に示す判断ロジックを用いることで、使用するCPUコア数を判断可能である。C-state設定部132は、図4に示す判断ロジックを使用して、CPU idle stateの上限を動的に設定する。
また、新たに(久しぶりに)使用するCPUコアを増やす場合に、新たに増やすCPUコアに対して、タスクを割り当てる前に。C-state上限設定を行い、浅いC-stateに戻しておいてもよい。
図9は、C-state上限設定イメージを説明する図である。図9上図は、C-state上限設定がない場合を示し、図9下図は、C-state上限設定がある場合を示す。
図9上図に示すように、C-state上限設定がない場合は、CPUidle状態(グレードC2)まで落ち、C0復帰までの遅延時間が長延化する。
これに対して、図9下図に示すように、使用頻度の高いCPUコア群に対して、C-state上限設定することで(図9下図の符号g参照)、深いstateに遷移できないようにし、浅いstateからの復帰の際の復帰遅延時間を低減する。
図9上図に示すように、C-state上限設定がない場合は、CPUidle状態(グレードC2)まで落ち、C0復帰までの遅延時間が長延化する。
これに対して、図9下図に示すように、使用頻度の高いCPUコア群に対して、C-state上限設定することで(図9下図の符号g参照)、深いstateに遷移できないようにし、浅いstateからの復帰の際の復帰遅延時間を低減する。
<使用可能性の高いCPUコアのプール化>
次に、C-state上限設定の拡張機能として、使用可能性の高いCPUコアのプール化について説明する。
図10は、タスクスケジューラ装置100の使用可能性の高いCPUコアのプール化を説明する図である。
図10に示すように、今後使用が見込まれる場合は、浅いidle stateにしか落ちないように設定したCPUコア群(図10の破線囲みh)を準備しておいてもよい。例えば、図10に示すCPUコア(CPUcore #4,CPUcore #5)32は、C1までしか遷移できないCPUコア群としてプール化しておく態様をとる。
次に、C-state上限設定の拡張機能として、使用可能性の高いCPUコアのプール化について説明する。
図10は、タスクスケジューラ装置100の使用可能性の高いCPUコアのプール化を説明する図である。
図10に示すように、今後使用が見込まれる場合は、浅いidle stateにしか落ちないように設定したCPUコア群(図10の破線囲みh)を準備しておいてもよい。例えば、図10に示すCPUコア(CPUcore #4,CPUcore #5)32は、C1までしか遷移できないCPUコア群としてプール化しておく態様をとる。
夜間/日中のトラヒック変動に対する処理のように、タスクの傾向から、今後使用する可能性の高いCPUコアを予測できる場合には、使用する可能性の高いCPUコア群(図10の破線囲みh)に対して、浅いidle stateにしか遷移できないように設定(例:C1まで等)しておく。そして、必要になった際に、直ちに使用できるように、アクティブスタンバイなCPUコアをプール化して準備しておく。
このように、今後使用が見込まれる場合は、浅いidle stateにしか落ちないように設定したCPUコア群を準備しておく(例えば、C1までしか遷移できないCPUコア群をプール化しておく)態様をとる。
以上、C-state上限設定について説明した。
このように、今後使用が見込まれる場合は、浅いidle stateにしか落ちないように設定したCPUコア群を準備しておく(例えば、C1までしか遷移できないCPUコア群をプール化しておく)態様をとる。
以上、C-state上限設定について説明した。
[事前起床](特徴<3>:事前起床)
図11は、タスクスケジューラ装置100の事前起床を説明する図である。
CPU事前起床部131は、深いCPU idle state(C-state)に落ちているCPUコアを使用する際に、CPUコアを事前起床させる(図11の符号c参照)。
図11は、タスクスケジューラ装置100の事前起床を説明する図である。
CPU事前起床部131は、深いCPU idle state(C-state)に落ちているCPUコアを使用する際に、CPUコアを事前起床させる(図11の符号c参照)。
図12は、タスクスケジューラ装置100の事前起床を説明する図である。図12上図は、既存技術の場合を示し、図12下図は、タスクスケジューラ装置100の事前起床を行う場合を示す。
図12上図に示すように、既存技術の場合(事前起床がない場合)は、タスク割り当て(図12上図の符号i)から、演算を開始するまでの遅延が大きい(図12上図の符号j)。
これに対して、図12下図に示すように、事前起床がある場合は、事前起床により(図12下図の符号c)、タスク割り当てから演算開始までが低遅延となる(図12下図の符号k)。
図12上図に示すように、既存技術の場合(事前起床がない場合)は、タスク割り当て(図12上図の符号i)から、演算を開始するまでの遅延が大きい(図12上図の符号j)。
これに対して、図12下図に示すように、事前起床がある場合は、事前起床により(図12下図の符号c)、タスク割り当てから演算開始までが低遅延となる(図12下図の符号k)。
このように、使用頻度の低いCPUコアは、深いC-stateに遷移させ、消費電力を削減することが可能となり、かつ、深いC-stateからの復帰に伴う遅延時間の影響を軽減することの両立が可能となる。
[タスクスケジューラ装置100の動作フロー]
図13は、タスクスケジューラ装置100のタスクスケジューリング処理を示すフローチャートである。
ステップS11でAPL1(図1)は、タスク管理部120(図1)へタスクを登録する。
図13は、タスクスケジューラ装置100のタスクスケジューリング処理を示すフローチャートである。
ステップS11でAPL1(図1)は、タスク管理部120(図1)へタスクを登録する。
ステップS12でタスク優先度付与部121(図1)は、必要に応じてタスクの優先度を付与する。タスクCPU割当部123(図1)は、この優先度に応じて、CPUコアへの割り当ての優先制御を実行する。
ステップS13でタスク量・周期 予測部122(図1)は、図4に示す判断ロジックに従い、単位時間当たりのタスク量や、CPU使用率を計測し、演算に使用するCPUコア数を増やす/減らす必要があるか判断する(判断後の分岐は、下記ステップS14,ステップS15)。
ステップS14でCPUコア数を減らす必要がある場合には(S14:Yes)、ステップS17に進み、CPUコア数を減らす必要がない場合には(S14:No)、ステップS15に進む。
ステップS15でCPUコア数を増やす必要がある場合には(S15:Yes)、ステップS19に進み、CPUコア数を増やす必要がない場合には(S15:No)、ステップS16に進む。
ステップS16でタスクCPU割当部123(図1)は、到着したタスクを、CPUコアに割り当て、CPUコア毎に用意したタスクキューにタスクをスケジューリングして本フローの処理を終了する。CPUコアへの割り当ては、使用しているCPUコアをラウンドロビンしてもよいし、CPUコア毎に用意したタスクキューの残数が少ないCPUコアに割り当ててもよい。
また、タスクCPU割当部123(図1)は、付与された優先度に応じて、優先度の高いタスクを空いているCPUコアへ優先的に割り当ててもよいし、CPUコア毎のタスクキューを、優先度に応じて並び替えてもよい。
上記ステップS14でCPUコア数を減らす必要がある場合には、ステップS17でタスクCPU割当部123(図1)は、使用するCPUコアを減らす。例えば、CPUコアを減らす方法として、以降使用しないCPUコアを決定し、以降該当CPUコアへタスクを割り当てないようにする。
ステップS18でC-state設定部132(図1)は、使用しないと決定したCPUコアに対して、C-state上限設定が入っている場合は、C-state上限設定を解除して本フローの処理を終了する。
上記ステップS15でCPUコア数を増やす必要がある場合には、ステップS19でタスク量・周期 予測部122(図1)は、新たに使用するCPUコアに対して、事前起床を行う。
新たに使用するCPUコアに対して、事前起床を行う理由は、下記の通りである。すなわち、CPUコアに何かしらの処理が実行されれば、C-stateはC0に戻るCPU製品が多い。そのため、小さな演算や標準出力に文字列を出力する等の軽微な処理を該当CPUコアで実行しておくことで、該当CPUコアが深いC-stateに遷移することを抑制する。
新たに使用するCPUコアに対して、事前起床を行う理由は、下記の通りである。すなわち、CPUコアに何かしらの処理が実行されれば、C-stateはC0に戻るCPU製品が多い。そのため、小さな演算や標準出力に文字列を出力する等の軽微な処理を該当CPUコアで実行しておくことで、該当CPUコアが深いC-stateに遷移することを抑制する。
ここで、事前起床ではなく、<C-state上限設定>(図8)で述べた、新たに使用するCPUコアに対して、タスクを割り当てる前にC-state上限設定を行い、浅いstateに戻しておいてもよい。この場合、C-state上限設定投入から反映までのタイムラグを考慮して、事前にC-state上限設定を投入する。
ステップS20でC-state設定部132は、新たに使用するCPUコアに対して、C-state上限設定を投入して本フローの処理を終了する。上限stateは、あらかじめ運用者が設定することにより決定する。
なお、定常的にタスクが流入し、継続的にタスクを割り当て続けられる場合は、ActiveなCPUコア群は深いC-stateに遷移しないため、C-state上限設定は投入しなくてもよい場合もある。
[ハードウェア構成]
上記実施形態に係るタスクスケジューラ装置100,100A(図1、図10)は、例えば図14に示すような構成のコンピュータ900によって実現される。
図14は、タスクスケジューラ装置100,100A(図1、図10)の機能を実現するコンピュータ900の一例を示すハードウェア構成図である。
コンピュータ900は、CPU901、ROM902、RAM903、HDD904、通信インターフェイス(I/F:Interface)906、入出力インターフェイス(I/F)905、およびメディアインターフェイス(I/F)907を有する。
上記実施形態に係るタスクスケジューラ装置100,100A(図1、図10)は、例えば図14に示すような構成のコンピュータ900によって実現される。
図14は、タスクスケジューラ装置100,100A(図1、図10)の機能を実現するコンピュータ900の一例を示すハードウェア構成図である。
コンピュータ900は、CPU901、ROM902、RAM903、HDD904、通信インターフェイス(I/F:Interface)906、入出力インターフェイス(I/F)905、およびメディアインターフェイス(I/F)907を有する。
CPU901は、ROM902またはHDD904に格納されたプログラムに基づいて動作し、タスクスケジューラ装置100,100A(図1、図10)の各部の制御を行う。ROM902は、コンピュータ900の起動時にCPU901によって実行されるブートプログラムや、コンピュータ900のハードウェアに依存するプログラム等を格納する。
CPU901は、入出力I/F905を介して、マウスやキーボード等の入力装置910、および、ディスプレイ等の出力装置911を制御する。CPU901は、入出力I/F905を介して、入力装置910からデータを取得するともに、生成したデータを出力装置911へ出力する。なお、プロセッサとしてCPU901とともに、GPU(Graphics Processing Unit)等を用いてもよい。
HDD904は、CPU901により実行されるプログラムおよび当該プログラムによって使用されるデータ等を記憶する。通信I/F906は、通信網(例えば、NW(Network)920)を介して他の装置からデータを受信してCPU901へ出力し、また、CPU901が生成したデータを、通信網を介して他の装置へ送信する。
メディアI/F907は、記録媒体912に格納されたプログラムまたはデータを読み取り、RAM903を介してCPU901へ出力する。CPU901は、目的の処理に係るプログラムを、メディアI/F907を介して記録媒体912からRAM903上にロードし、ロードしたプログラムを実行する。記録媒体912は、DVD(Digital Versatile Disc)、PD(Phase change rewritable Disk)等の光学記録媒体、MO(Magneto Optical disk)等の光磁気記録媒体、磁気記録媒体、導体メモリテープ媒体又は半導体メモリ等である。
例えば、コンピュータ900が本実施形態に係る一装置として構成されるタスクスケジューラ装置100,100A(図1、図10)として機能する場合、コンピュータ900のCPU901は、RAM903上にロードされたプログラムを実行することによりタスクスケジューラ装置100,100Aの機能を実現する。また、HDD904には、RAM903内のデータが記憶される。CPU901は、目的の処理に係るプログラムを記録媒体912から読み取って実行する。この他、CPU901は、他の装置から通信網(NW920)を介して目的の処理に係るプログラムを読み込んでもよい。
[適用例]
(User space60にタスクスケジューラ装置を配置する形態)
図2に示すように、User space60にタスクスケジューラ装置100を配置した構成例に適用できる。この場合、OSは限定されない。また、サーバ仮想化環境下であることも限定されない。したがって、演算システムは、図15および図16に示す各構成に適用が可能である。
(User space60にタスクスケジューラ装置を配置する形態)
図2に示すように、User space60にタスクスケジューラ装置100を配置した構成例に適用できる。この場合、OSは限定されない。また、サーバ仮想化環境下であることも限定されない。したがって、演算システムは、図15および図16に示す各構成に適用が可能である。
<VM構成への適用例>
NFV(Network Functions Virtualization:ネットワーク機能仮想化)による仮想化技術の進展などを背景に、サービス毎にシステムを構築して運用することが行われている。また、上記サービス毎にシステムを構築する形態から、サービス機能を再利用可能なモジュール単位に分割し、独立した仮想マシン(VM:Virtual Machineやコンテナなど)環境の上で動作させることで、部品のようにして必要に応じて利用し運用性を高めるといったSFC(Service Function Chaining)と呼ばれる形態が主流となりつつある。
NFV(Network Functions Virtualization:ネットワーク機能仮想化)による仮想化技術の進展などを背景に、サービス毎にシステムを構築して運用することが行われている。また、上記サービス毎にシステムを構築する形態から、サービス機能を再利用可能なモジュール単位に分割し、独立した仮想マシン(VM:Virtual Machineやコンテナなど)環境の上で動作させることで、部品のようにして必要に応じて利用し運用性を高めるといったSFC(Service Function Chaining)と呼ばれる形態が主流となりつつある。
仮想マシンを構成する技術としてLinux(登録商標)とKVM(kernel-based virtual machine)で構成されたハイパーバイザー環境が知られている。この環境では、KVMモジュールが組み込まれたHost OS(物理サーバ上にインストールされたOSをHost OSと呼ぶ)がハイパーバイザーとしてカーネル空間と呼ばれるユーザ空間とは異なるメモリ領域で動作する。この環境においてユーザ空間にて仮想マシンが動作し、その仮想マシン内にGuest OS(仮想マシン上にインストールされたOSをGuest OSと呼ぶ)が動作する。
Guest OSが動作する仮想マシンは、Host OSが動作する物理サーバとは異なり、(イーサネット(登録商標)カードデバイスなどに代表される)ネットワークデバイスを含むすべてのHW(hardware)が、HWからGuest OSへの割込処理やGuest OSからハードウェアへの書き込みに必要なレジスタ制御となる。このようなレジスタ制御では、本来物理ハードウェアが実行すべき通知や処理がソフトウェアで擬似的に模倣されるため、性能がHost OS環境に比べ、低いことが一般的である。
図15は、汎用Linux kernel(登録商標)およびVM構成のサーバ仮想化環境における割込モデルに、演算システム1000Aを適用した例を示す図である。図1と同一構成部分には、同一符号を付している。
図15に示すように、演算システム1000Aは、仮想マシンおよび仮想マシン外に形成された外部プロセスが動作可能なHost OS80を備え、Host OS80は、Kernel81およびDriver82を有する。また、演算システム1000Aは、Host OS80に接続されたHW70のCPU71、ハイパーバイザー(HV)90に組み込まれたKVMモジュール91を有する。さらに、演算システム1000Aは、仮想マシン内で動作するGuest OS95を備え、Guest OS95は、Kernel96およびDriver97を有する。
そして、演算システム1000Aは、Guest OS95に接続されUser space60に配置されたタスクスケジューラ装置100を備える。
図15に示すように、演算システム1000Aは、仮想マシンおよび仮想マシン外に形成された外部プロセスが動作可能なHost OS80を備え、Host OS80は、Kernel81およびDriver82を有する。また、演算システム1000Aは、Host OS80に接続されたHW70のCPU71、ハイパーバイザー(HV)90に組み込まれたKVMモジュール91を有する。さらに、演算システム1000Aは、仮想マシン内で動作するGuest OS95を備え、Guest OS95は、Kernel96およびDriver97を有する。
そして、演算システム1000Aは、Guest OS95に接続されUser space60に配置されたタスクスケジューラ装置100を備える。
このようにすることにより、VMの仮想サーバ構成のシステムにおいて、HostOS80とGuest OS95とのいずれのOSにおいても、省電力を達成しつつ、低遅延に演算を行うことができる。
<コンテナ構成への適用例>
図16は、コンテナ構成のサーバ仮想化環境における割込モデルに、演算システム1000Bを適用した例を示す図である。図1および図15と同一構成部分には、同一符号を付している。
図16に示すように、演算システム1000Bは、図15のGuest OS95をContainer98に代えた、コンテナ構成を備える。Container98は、vNIC(仮想NIC)を有する。
図16は、コンテナ構成のサーバ仮想化環境における割込モデルに、演算システム1000Bを適用した例を示す図である。図1および図15と同一構成部分には、同一符号を付している。
図16に示すように、演算システム1000Bは、図15のGuest OS95をContainer98に代えた、コンテナ構成を備える。Container98は、vNIC(仮想NIC)を有する。
コンテナなどの仮想サーバ構成のシステムにおいて、省電力を達成しつつ、低遅延に演算を行うことができる。
以上、user space60にタスクスケジューラ装置100を配置する形態について説明した。次にkernelにタスクスケジューラ装置100を配置する形態について説明する。
以上、user space60にタスクスケジューラ装置100を配置する形態について説明した。次にkernelにタスクスケジューラ装置100を配置する形態について説明する。
(OS内のkernelにタスクスケジューラ装置を配置する形態)
図3に示すように、OS50内にタスクスケジューラ装置100を配置した構成例に適用できる。この場合、OSは限定されない。また、サーバ仮想化環境下であることも限定されない。したがって、演算システムは、図17および図18に示す各構成に適用が可能である。
図3に示すように、OS50内にタスクスケジューラ装置100を配置した構成例に適用できる。この場合、OSは限定されない。また、サーバ仮想化環境下であることも限定されない。したがって、演算システムは、図17および図18に示す各構成に適用が可能である。
<VM構成への適用例>
図17は、汎用Linux kernel(登録商標)およびVM構成のサーバ仮想化環境における割込モデルに、演算システム1000Cを適用した例を示す図である。図1および図15と同一構成部分には、同一符号を付している。
図17に示すように、演算システム1000Cは、Host OS80のKernel81内にタスクスケジューラ装置100が配置され、Guest OS95のKernel96内にタスクスケジューラ装置100が配置される。
図17は、汎用Linux kernel(登録商標)およびVM構成のサーバ仮想化環境における割込モデルに、演算システム1000Cを適用した例を示す図である。図1および図15と同一構成部分には、同一符号を付している。
図17に示すように、演算システム1000Cは、Host OS80のKernel81内にタスクスケジューラ装置100が配置され、Guest OS95のKernel96内にタスクスケジューラ装置100が配置される。
このようにすることにより、VMの仮想サーバ構成のシステムにおいて、HostOS80とGuest OS95いずれのOSにおいても、省電力を達成しつつ、低遅延に演算を行うことができる。
<コンテナ構成への適用例>
図18は、コンテナ構成のサーバ仮想化環境における割込モデルに、演算システム1000Dを適用した例を示す図である。図1および図16と同一構成部分には、同一符号を付している。
図19に示すように、演算システム1000Dは、Host OS80のKernel81内にタスクスケジューラ装置100が配置される。
図18は、コンテナ構成のサーバ仮想化環境における割込モデルに、演算システム1000Dを適用した例を示す図である。図1および図16と同一構成部分には、同一符号を付している。
図19に示すように、演算システム1000Dは、Host OS80のKernel81内にタスクスケジューラ装置100が配置される。
コンテナなどの仮想サーバ構成のシステムにおいて、省電力を達成しつつ、低遅延に演算を行うことができる。
<ベアメタル構成(非仮想化構成)への適用例>
本発明は、ベアメタル構成のように非仮想化構成のシステムに適用できる。非仮想化構成のシステムにおいて、省電力を達成しつつ、低遅延に演算を行うことができる。
本発明は、ベアメタル構成のように非仮想化構成のシステムに適用できる。非仮想化構成のシステムにおいて、省電力を達成しつつ、低遅延に演算を行うことができる。
<CPU以外のプロセッサへの適用>
本発明は、CPU以外にも、GPU/FPGA/ASIC等のプロセッサに、idle stateの機能がある場合には、同様に適用可能である。
本発明は、CPU以外にも、GPU/FPGA/ASIC等のプロセッサに、idle stateの機能がある場合には、同様に適用可能である。
<CPU動作周波数制御への適用>
本発明は、実施形態に係る事前起床を、プロセッサ動作周波数が低くなっている際に、タスク割り当ての前に事前に周波数を元に戻しておく仕組みへの応用も可能である。
本発明は、実施形態に係る事前起床を、プロセッサ動作周波数が低くなっている際に、タスク割り当ての前に事前に周波数を元に戻しておく仕組みへの応用も可能である。
<CPU以外の機能に対する適用>
本発明は、CPU以外にも、メモリやストレージ(例えば、HDD,SSD)などCPU以外の機能に対する適用も可能である。さらに、外部接続周辺機器等への部品が省電力モードに入っていた際に、事前に起床させて使用するまでに準備させることに応用することも可能である。
本発明は、CPU以外にも、メモリやストレージ(例えば、HDD,SSD)などCPU以外の機能に対する適用も可能である。さらに、外部接続周辺機器等への部品が省電力モードに入っていた際に、事前に起床させて使用するまでに準備させることに応用することも可能である。
[効果]
以上説明したように、処理負荷に応じてプロセッサの動作状態を段階的に減らして消費電力量を削減する計算システム1000(図1、図10)において、プロセッサのコア群へタスクを割り当てるタスクスケジューラ装置100,100A(図1、図10)であって、プロセッサの使用率を取得するプロセッサ使用率取得部(タスク量・周期 予測部122)と、プロセッサ使用率取得部が取得したプロセッサの使用率をもとに、所定頻度以上で使用するプロセッサのコアまたはコア群については、継続的にタスクを割り当てるタスク割当部(タスクCPU割当部123)と、を備える。
以上説明したように、処理負荷に応じてプロセッサの動作状態を段階的に減らして消費電力量を削減する計算システム1000(図1、図10)において、プロセッサのコア群へタスクを割り当てるタスクスケジューラ装置100,100A(図1、図10)であって、プロセッサの使用率を取得するプロセッサ使用率取得部(タスク量・周期 予測部122)と、プロセッサ使用率取得部が取得したプロセッサの使用率をもとに、所定頻度以上で使用するプロセッサのコアまたはコア群については、継続的にタスクを割り当てるタスク割当部(タスクCPU割当部123)と、を備える。
このようにすることにより、プロセッサの使用率(例えば、タスク量)に応じて、頻繁に利用するCPUコア群(ActiveなCPUコア群)を図4に示す判断ロジックにより確保し、当該CPUコア群へ継続的にタスクを割り当てることで、深いC-stateへ遷移することを防ぐ。これにより、C-stateからの復帰遅延を軽減することができる。一方、ActiveなCPUコア以外は、深いC-state(例えばC6)に遷移できるので、省電力を図ることができる。その結果、計算システム1000全体からみて、省電力を達成しつつ、低遅延に演算を行うことができる。
CPUコアに対して、深いC-stateまで落とすことができるので、電力削減効果を最大限享受することができる一方、深いC-stateまで落ち復帰に時間がかかる課題を回避することができる。
また、タスク量やCPU使用率に応じて、動的に使用するCPUコア数を増減することが可能となるため、タスク量に応じた動的なスケールイン/アウトが可能となる。
また、タスク量やCPU使用率に応じて、使用するCPUコア数を変更する判断ロジック(図4)を複数選択することが可能であるため、多種多様なタスクに対応することが可能となる。
タスクスケジューラ装置100,100A(図1、図10)において、所定頻度以上で使用するプロセッサのコアまたはコア群については、プロセッサの動作状態をより深い状態に遷移できないように上限を設定する動作状態設定部(C-state設定部132)を備える。
このように、頻繁に使用するCPUコアに対して、遷移可能なCPU idle stateの上限を設定することにより、深いC-stateへ遷移できないようにし、復帰遅延を軽減する。これにより、タスク割り当てから演算開始までの遅延時間を抑制し、リアルタイム性高く演算することを可能とする。
特に、使用頻度の高いCPUコア群に対して、タスクを継続して割り当てられない場合の対応策として有効である。
また、タスクに対して優先度を付与することにより、優先したいタスクを、優先的に演算することが可能である。優先的に演算するタスクには、例えばQoS(Quality of Service)の保証がある。
タスクスケジューラ装置100,100A(図1、図10)において、動作状態設定部(C-state設定部132)は、タスク割当部(タスクCPU割当部123)が、タスクを割り当てなかったコアまたはコア群については、プロセッサの動作状態をより深い状態に遷移できるように設定する。
このようにすることにより、頻繁に利用するCPUコア群(ActiveなCPUコア群)へ継続的にタスクを割り当て、深いC-stateへ遷移することを防ぎつつ(C-stateからの復帰遅延軽減)、ActiveなCPUコア以外は、深いC-stateに遷移できるので、省電力を図ることができる。
タスクスケジューラ装置100,100A(図1、図10)において、新たに使用するコア、または、所定期間使用せずに再び使用するコアに対しては、タスクを割り当てる際に、プロセッサの動作状態を元の状態に復帰させる事前起床を行う事前起床部(CPU事前起床部131)を備える。
基本的な考え方としては、タスクを割当ててから、処理が終わり復帰するまでに時間がかかるのであれば、復帰するまでの時間分について事前に起床させ、CPUが使える状態までに事前に準備させておくものである。
このようにすることにより、深いstateに遷移したCPUコアへタスクを割り当てる前に、事前起床をすることで、深いstateからの復帰時間を軽減することができる。新たに使用するコア、または、所定期間使用せずに再び使用するコアは、深いC-stateにあることが想定される。タスクを割り当てる前に、事前起床を行うことで、深いC-stateからの復帰時間を軽減することができる。例えば、使用するCPUコア数を増やす際に、事前に該当CPUコアを起床させることにより、深いCPU idle stateに落ちていても、タスク割り当てから演算開始までの遅延時間を抑制し、リアルタイム性高く演算することを可能とする。
このようにすることにより、深いstateに遷移したCPUコアへタスクを割り当てる前に、事前起床をすることで、深いstateからの復帰時間を軽減することができる。新たに使用するコア、または、所定期間使用せずに再び使用するコアは、深いC-stateにあることが想定される。タスクを割り当てる前に、事前起床を行うことで、深いC-stateからの復帰時間を軽減することができる。例えば、使用するCPUコア数を増やす際に、事前に該当CPUコアを起床させることにより、深いCPU idle stateに落ちていても、タスク割り当てから演算開始までの遅延時間を抑制し、リアルタイム性高く演算することを可能とする。
また、処理負荷に応じてプロセッサの動作状態を段階的に減らして消費電力量を削減する計算システム1000(図1、図10)であって、プロセッサ(CPU)は、複数のコア群(CPUコア(CPUcore #0,CPUcore #1,…)32)を有しており、プロセッサのコア群へタスクを割り当てるタスクスケジューラ装置100,100A(図1、図10)を備え、タスクスケジューラ装置100,100Aは、プロセッサの使用率を取得するプロセッサ使用率取得部(タスク量・周期 予測部122)と、プロセッサ使用率取得部が取得したプロセッサの使用率をもとに、所定頻度以上で使用するプロセッサのコアまたはコア群については、継続的にタスクを割り当てるタスク割当部(タスクCPU割当部123)と、を備える。
計算システム1000~1000D(図1、図10、図15~図18)は、パケット到着・処理のタスクに限らず、一般のタスク、例えばπの計算などにも拡張した技術である。
プロセッサの使用率に応じて、頻繁に利用するCPUコア群(ActiveなCPUコア群)へ継続的にタスクを割り当てることで、深いC-stateへ遷移することを防ぎ、C-stateからの復帰遅延を軽減することができる。一方、ActiveなCPUコア以外は、深いC-stateに遷移できるので、省電力を図ることができる。すなわち、C-stateからの復帰遅延の軽減を図りつつ、事前起床は、なるべく深いLPI(C-state)をできるだけ長く保つことができるので、低遅延性と省電力化を両立させることができる。
プロセッサの使用率に応じて、頻繁に利用するCPUコア群(ActiveなCPUコア群)へ継続的にタスクを割り当てることで、深いC-stateへ遷移することを防ぎ、C-stateからの復帰遅延を軽減することができる。一方、ActiveなCPUコア以外は、深いC-stateに遷移できるので、省電力を図ることができる。すなわち、C-stateからの復帰遅延の軽減を図りつつ、事前起床は、なるべく深いLPI(C-state)をできるだけ長く保つことができるので、低遅延性と省電力化を両立させることができる。
上記プロセッサは、CPU以外にも、GPU/FPGA/ASIC等のプロセッサに、idle stateの機能がある場合には、同様に適用可能である。
計算システム1000(図1、図10)において、低遅延性を達成しつつ、省電力も同時に達成することができる。特に、頻繁に利用するCPUコア群(ActiveなCPUコア群)へ継続的にタスクを割り当てることで、CPUコアが深いidle stateに落ちることにより、復帰時に遅延時間が長大してしまう課題を、回避することができる。これにより、低遅延性を保証することができる。
なお、上記実施形態において説明した各処理のうち、自動的に行われるものとして説明した処理の全部又は一部を手動的に行うこともでき、あるいは、手動的に行われるものとして説明した処理の全部又は一部を公知の方法で自動的に行うこともできる。この他、上述文書中や図面中に示した処理手順、制御手順、具体的名称、各種のデータやパラメータを含む情報については、特記する場合を除いて任意に変更することができる。
また、図示した各装置の各構成要素は機能概念的なものであり、必ずしも物理的に図示の如く構成されていることを要しない。すなわち、各装置の分散・統合の具体的形態は図示のものに限られず、その全部又は一部を、各種の負荷や使用状況などに応じて、任意の単位で機能的又は物理的に分散・統合して構成することができる。
また、図示した各装置の各構成要素は機能概念的なものであり、必ずしも物理的に図示の如く構成されていることを要しない。すなわち、各装置の分散・統合の具体的形態は図示のものに限られず、その全部又は一部を、各種の負荷や使用状況などに応じて、任意の単位で機能的又は物理的に分散・統合して構成することができる。
また、上記の各構成、機能、処理部、処理手段等は、それらの一部又は全部を、例えば集積回路で設計する等によりハードウェアで実現してもよい。また、上記の各構成、機能等は、プロセッサがそれぞれの機能を実現するプログラムを解釈し、実行するためのソフトウェアで実現してもよい。各機能を実現するプログラム、テーブル、ファイル等の情報は、メモリや、ハードディスク、SSD(Solid State Drive)等の記録装置、または、IC(Integrated Circuit)カード、SD(Secure Digital)カード、光ディスク等の記録媒体に保持することができる。
31 ハードウェア(HW)
32 CPUコア(プロセッサ)
1,1-1,1-2,1-3 アプリケーション(APL)
100,100A タスクスケジューラ装置
110 管理部
111 運用者向け設定部
120 タスク管理部
121 タスク優先度付与部
122 タスク量・周期 予測部(プロセッサ使用率取得部)
123 タスクCPU割当部(タスク割当部) 120 タスク管理部
130 CPU idle state制御部
131 CPU事前起床部(事前起床部)
132 C-state設定部(動作状態設定部)
1000,1000A,1000B,1000C,1000D 演算システム(計算システム)
CPUcore #0,CPUcore #1,… CPUコア
32 CPUコア(プロセッサ)
1,1-1,1-2,1-3 アプリケーション(APL)
100,100A タスクスケジューラ装置
110 管理部
111 運用者向け設定部
120 タスク管理部
121 タスク優先度付与部
122 タスク量・周期 予測部(プロセッサ使用率取得部)
123 タスクCPU割当部(タスク割当部) 120 タスク管理部
130 CPU idle state制御部
131 CPU事前起床部(事前起床部)
132 C-state設定部(動作状態設定部)
1000,1000A,1000B,1000C,1000D 演算システム(計算システム)
CPUcore #0,CPUcore #1,… CPUコア
Claims (7)
- 処理負荷に応じてプロセッサの動作状態を段階的に減らして消費電力量を削減する計算システムにおいて、前記プロセッサのコア群へタスクを割り当てるタスクスケジューラ装置であって、
前記プロセッサの使用率を取得するプロセッサ使用率取得部と、
前記プロセッサ使用率取得部が取得した前記プロセッサの使用率をもとに、所定頻度以上で使用する前記プロセッサのコアまたはコア群については、継続的にタスクを割り当てるタスク割当部と、を備える
ことを特徴とするタスクスケジューラ装置。 - 所定頻度以上で使用する前記プロセッサのコアまたはコア群については、前記プロセッサの動作状態をより深い状態に遷移できないように上限を設定する動作状態設定部を備える
ことを特徴とする請求項1に記載のタスクスケジューラ装置。 - 前記動作状態設定部は、
タスク割当部が、タスクを割り当てなかったコアまたはコア群については、前記プロセッサの動作状態をより深い状態に遷移できるように設定する
ことを特徴とする請求項2に記載のタスクスケジューラ装置。 - 新たに使用するコア、または、所定期間使用せずに再び使用するコアに対しては、タスクを割り当てる際に、前記プロセッサの動作状態を元の状態に復帰させる事前起床を行う事前起床部を備える
ことを特徴とする請求項1に記載のタスクスケジューラ装置。 - 処理負荷に応じてプロセッサの動作状態を段階的に減らして消費電力量を削減する計算システムであって、
前記プロセッサは、複数のコア群を有しており、
前記プロセッサのコア群へタスクを割り当てるタスクスケジューラ装置を備え、
前記タスクスケジューラ装置は、
前記プロセッサの使用率を取得するプロセッサ使用率取得部と、
前記プロセッサ使用率取得部が取得した前記プロセッサの使用率をもとに、所定頻度以上で使用する前記プロセッサのコアまたはコア群については、継続的にタスクを割り当てるタスク割当部と、を備える
ことを特徴とする計算システム。 - 処理負荷に応じてプロセッサの動作状態を段階的に減らして消費電力量を削減する計算システムにおいて、前記プロセッサのコア群へタスクを割り当てるタスクスケジューラ装置のタスクスケジューリング方法であって、
前記プロセッサの使用率を取得するステップと、
取得した前記プロセッサの使用率をもとに、所定頻度以上で使用する前記プロセッサのコアまたはコア群については、継続的にタスクを割り当てるステップと、を実行する
ことを特徴とするタスクスケジューリング方法。 - コンピュータを、請求項1乃至4のいずれか一項に記載のタスクスケジューラ装置として機能させるためのプログラム。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2023567089A JPWO2024013831A1 (ja) | 2022-07-11 | 2022-07-11 | |
| PCT/JP2022/027327 WO2024013831A1 (ja) | 2022-07-11 | 2022-07-11 | タスクスケジューラ装置、計算システム、タスクスケジューリング方法およびプログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2022/027327 WO2024013831A1 (ja) | 2022-07-11 | 2022-07-11 | タスクスケジューラ装置、計算システム、タスクスケジューリング方法およびプログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2024013831A1 true WO2024013831A1 (ja) | 2024-01-18 |
Family
ID=89536171
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/027327 WO2024013831A1 (ja) | 2022-07-11 | 2022-07-11 | タスクスケジューラ装置、計算システム、タスクスケジューリング方法およびプログラム |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JPWO2024013831A1 (ja) |
| WO (1) | WO2024013831A1 (ja) |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20080244227A1 (en) * | 2006-07-13 | 2008-10-02 | Gee Timothy W | Design structure for asymmetrical performance multi-processors |
| US20150033055A1 (en) * | 2012-09-26 | 2015-01-29 | Sheshaprasad G. Krishnapura | Techniques for Managing Power and Performance of Multi-Socket Processors |
| JP2015513336A (ja) * | 2012-02-01 | 2015-05-07 | 日本テキサス・インスツルメンツ株式会社 | リアルタイムシステムにおける動的電力管理 |
| JP2018169882A (ja) * | 2017-03-30 | 2018-11-01 | 日本電気株式会社 | 消費電力削減装置、消費電力削減方法および消費電力削減プログラム |
-
2022
- 2022-07-11 JP JP2023567089A patent/JPWO2024013831A1/ja active Pending
- 2022-07-11 WO PCT/JP2022/027327 patent/WO2024013831A1/ja active Application Filing
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20080244227A1 (en) * | 2006-07-13 | 2008-10-02 | Gee Timothy W | Design structure for asymmetrical performance multi-processors |
| JP2015513336A (ja) * | 2012-02-01 | 2015-05-07 | 日本テキサス・インスツルメンツ株式会社 | リアルタイムシステムにおける動的電力管理 |
| US20150033055A1 (en) * | 2012-09-26 | 2015-01-29 | Sheshaprasad G. Krishnapura | Techniques for Managing Power and Performance of Multi-Socket Processors |
| JP2018169882A (ja) * | 2017-03-30 | 2018-11-01 | 日本電気株式会社 | 消費電力削減装置、消費電力削減方法および消費電力削減プログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2024013831A1 (ja) | 2024-01-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP3853731B1 (en) | Commitment-aware scheduler | |
| US10331492B2 (en) | Techniques to dynamically allocate resources of configurable computing resources | |
| US7962563B2 (en) | System and method for managing storage system performance as a resource | |
| CN107003887B (zh) | Cpu超载设置和云计算工作负荷调度机构 | |
| US9268394B2 (en) | Virtualized application power budgeting | |
| EP2430538B1 (en) | Allocating computing system power levels responsive to service level agreements | |
| EP2430541B1 (en) | Power management in a multi-processor computer system | |
| US8255910B2 (en) | Fair weighted proportional-share virtual time scheduler | |
| US11907762B2 (en) | Resource conservation for containerized systems | |
| CN111767134A (zh) | 一种多任务动态资源调度方法 | |
| US11023288B2 (en) | Cloud data center with reduced energy consumption | |
| JP2011515776A (ja) | 電力認識スレッドスケジューリングおよびプロセッサーの動的使用 | |
| US9336106B2 (en) | Dynamically limiting bios post for effective power management | |
| US20120297216A1 (en) | Dynamically selecting active polling or timed waits | |
| CN110795238B (zh) | 负载计算方法、装置、存储介质及电子设备 | |
| CN114710563A (zh) | 一种集群节能方法及装置 | |
| CN110806918A (zh) | 基于深度学习神经网络的虚拟机运行方法和装置 | |
| CN107636563B (zh) | 用于通过腾空cpu和存储器的子集来降低功率的方法和系统 | |
| CN110795323A (zh) | 负载统计方法、装置、存储介质及电子设备 | |
| CN111597044A (zh) | 任务调度方法、装置、存储介质及电子设备 | |
| WO2024013831A1 (ja) | タスクスケジューラ装置、計算システム、タスクスケジューリング方法およびプログラム | |
| US11106361B2 (en) | Technologies for lockless, scalable, and adaptive storage quality of service | |
| Garg et al. | Deadline aware energy-efficient task scheduling model for a virtualized server | |
| CN110955644A (zh) | 一种存储系统的io控制方法、装置、设备及存储介质 | |
| WO2024166168A1 (ja) | CPU idle機能制御装置、サーバ内演算システム、CPU idle機能制御方法およびプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WWE | Wipo information: entry into national phase |
Ref document number: 2023567089 Country of ref document: JP |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22951047 Country of ref document: EP Kind code of ref document: A1 |