WO2023279862A1 - 图像处理方法、装置和电子设备 - Google Patents
图像处理方法、装置和电子设备 Download PDFInfo
- Publication number
- WO2023279862A1 WO2023279862A1 PCT/CN2022/093914 CN2022093914W WO2023279862A1 WO 2023279862 A1 WO2023279862 A1 WO 2023279862A1 CN 2022093914 W CN2022093914 W CN 2022093914W WO 2023279862 A1 WO2023279862 A1 WO 2023279862A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- image
- field
- view
- images
- frame
- Prior art date
Links
- 238000003672 processing method Methods 0.000 title claims abstract description 55
- 238000012545 processing Methods 0.000 claims abstract description 275
- 238000000034 method Methods 0.000 claims abstract description 119
- 230000004927 fusion Effects 0.000 claims abstract description 56
- 238000013507 mapping Methods 0.000 claims abstract description 54
- 238000013135 deep learning Methods 0.000 claims abstract description 44
- 230000008569 process Effects 0.000 claims description 54
- 230000035945 sensitivity Effects 0.000 claims description 50
- 238000012937 correction Methods 0.000 claims description 28
- 230000009467 reduction Effects 0.000 claims description 25
- 238000003860 storage Methods 0.000 claims description 21
- 238000004590 computer program Methods 0.000 claims description 18
- 230000009466 transformation Effects 0.000 claims description 16
- 230000011218 segmentation Effects 0.000 claims description 15
- 238000006243 chemical reaction Methods 0.000 claims description 13
- 238000007499 fusion processing Methods 0.000 claims description 12
- 238000010586 diagram Methods 0.000 description 26
- 230000006870 function Effects 0.000 description 25
- 238000004891 communication Methods 0.000 description 21
- 230000000694 effects Effects 0.000 description 11
- 206010034972 Photosensitivity reaction Diseases 0.000 description 10
- 210000000988 bone and bone Anatomy 0.000 description 10
- 238000010295 mobile communication Methods 0.000 description 10
- 230000036211 photosensitivity Effects 0.000 description 10
- 230000009977 dual effect Effects 0.000 description 8
- 238000005516 engineering process Methods 0.000 description 8
- 238000003384 imaging method Methods 0.000 description 7
- 238000007726 management method Methods 0.000 description 7
- 239000004065 semiconductor Substances 0.000 description 7
- 230000000007 visual effect Effects 0.000 description 7
- 238000004364 calculation method Methods 0.000 description 6
- 238000009825 accumulation Methods 0.000 description 5
- 238000001514 detection method Methods 0.000 description 5
- 238000011282 treatment Methods 0.000 description 5
- 229920001621 AMOLED Polymers 0.000 description 4
- 238000013528 artificial neural network Methods 0.000 description 4
- 239000003086 colorant Substances 0.000 description 4
- 230000000295 complement effect Effects 0.000 description 4
- 230000001133 acceleration Effects 0.000 description 3
- 230000008859 change Effects 0.000 description 3
- 238000001914 filtration Methods 0.000 description 3
- 229910044991 metal oxide Inorganic materials 0.000 description 3
- 150000004706 metal oxides Chemical class 0.000 description 3
- 230000003190 augmentative effect Effects 0.000 description 2
- 238000010009 beating Methods 0.000 description 2
- 230000006399 behavior Effects 0.000 description 2
- 230000009286 beneficial effect Effects 0.000 description 2
- 230000005540 biological transmission Effects 0.000 description 2
- 230000036772 blood pressure Effects 0.000 description 2
- 238000005282 brightening Methods 0.000 description 2
- 238000013500 data storage Methods 0.000 description 2
- 239000010985 leather Substances 0.000 description 2
- 230000007774 longterm Effects 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 230000002093 peripheral effect Effects 0.000 description 2
- 239000002096 quantum dot Substances 0.000 description 2
- 230000005855 radiation Effects 0.000 description 2
- 239000007787 solid Substances 0.000 description 2
- 239000000758 substrate Substances 0.000 description 2
- 241001270131 Agaricus moelleri Species 0.000 description 1
- 206010034960 Photophobia Diseases 0.000 description 1
- 230000002159 abnormal effect Effects 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 238000003491 array Methods 0.000 description 1
- 230000000712 assembly Effects 0.000 description 1
- 238000000429 assembly Methods 0.000 description 1
- 230000003416 augmentation Effects 0.000 description 1
- 230000002146 bilateral effect Effects 0.000 description 1
- 238000004422 calculation algorithm Methods 0.000 description 1
- 239000003990 capacitor Substances 0.000 description 1
- 230000008094 contradictory effect Effects 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000005538 encapsulation Methods 0.000 description 1
- 230000005484 gravity Effects 0.000 description 1
- 238000005286 illumination Methods 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 208000013469 light sensitivity Diseases 0.000 description 1
- 239000004973 liquid crystal related substance Substances 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 239000013307 optical fiber Substances 0.000 description 1
- 230000008447 perception Effects 0.000 description 1
- 238000011946 reduction process Methods 0.000 description 1
- 238000009877 rendering Methods 0.000 description 1
- 230000008439 repair process Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 230000006641 stabilisation Effects 0.000 description 1
- 238000011105 stabilization Methods 0.000 description 1
- 238000011269 treatment regimen Methods 0.000 description 1
- 230000001960 triggered effect Effects 0.000 description 1
- 230000001755 vocal effect Effects 0.000 description 1
Images
























Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T5/00—Image enhancement or restoration
- G06T5/50—Image enhancement or restoration using two or more images, e.g. averaging or subtraction
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T3/00—Geometric image transformations in the plane of the image
- G06T3/40—Scaling of whole images or parts thereof, e.g. expanding or contracting
- G06T3/4015—Image demosaicing, e.g. colour filter arrays [CFA] or Bayer patterns
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T3/00—Geometric image transformations in the plane of the image
- G06T3/40—Scaling of whole images or parts thereof, e.g. expanding or contracting
- G06T3/4046—Scaling of whole images or parts thereof, e.g. expanding or contracting using neural networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T5/00—Image enhancement or restoration
- G06T5/60—Image enhancement or restoration using machine learning, e.g. neural networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T5/00—Image enhancement or restoration
- G06T5/70—Denoising; Smoothing
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T5/00—Image enhancement or restoration
- G06T5/90—Dynamic range modification of images or parts thereof
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/30—Determination of transform parameters for the alignment of images, i.e. image registration
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/40—Extraction of image or video features
- G06V10/56—Extraction of image or video features relating to colour
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/40—Extraction of image or video features
- G06V10/60—Extraction of image or video features relating to illumination properties, e.g. using a reflectance or lighting model
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N9/00—Details of colour television systems
- H04N9/64—Circuits for processing colour signals
- H04N9/73—Colour balance circuits, e.g. white balance circuits or colour temperature control
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/10—Image acquisition modality
- G06T2207/10016—Video; Image sequence
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/10—Image acquisition modality
- G06T2207/10024—Color image
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/10—Image acquisition modality
- G06T2207/10141—Special mode during image acquisition
- G06T2207/10144—Varying exposure
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20081—Training; Learning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20084—Artificial neural networks [ANN]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20212—Image combination
- G06T2207/20221—Image fusion; Image merging
Definitions
- the present application relates to the field of image processing, in particular to an image processing method, device and electronic equipment.
- the mobile phone is configured with two cameras, one is a main camera, and the other is a wide-angle camera or a telephoto camera.
- the field of view of the wide-angle camera is larger than that of the main camera, which is suitable for close-up shooting
- the field of view of the telephoto camera is smaller than that of the main camera, which is suitable for long-range shooting.
- the fused image will have poor stereoscopic effect and poor quality because the field of view angles of the two cameras do not match. poor.
- the two images obtained by a mobile phone using such a dual camera there are parts where the field of view overlaps, and there are also parts where the field of view does not overlap. If the two images are directly fused, then the part of the final captured image where the field of view angles overlap has high definition, and the part that does not overlap has low definition, so that the captured image will have inconsistencies in the definition of the central part and surrounding parts.
- the problem is that there will be a fusion boundary on the image, which will affect the imaging effect.
- the application provides an image processing method, device and electronic equipment, by adding a reference coordinate layer to one of the two images with different viewing angles, and then inputting it into the deep learning network model for processing to obtain the corresponding image to improve shooting image quality.
- an image processing method comprising:
- the multiple frames of original images are images taken for the same scene to be shot.
- the multiple frames of original images include: a first field of view image and a second field of view image, and the field of view corresponding to the first field of view image
- the field angle is different from the field angle corresponding to the second field of view image;
- a reference coordinate layer is added to the second field of view image, and the reference coordinate layer is used to reflect the field angle corresponding to the second field of view image and the first
- the mapping relationship between the viewing angles corresponding to the viewing angle images; according to the first viewing angle image, the second viewing angle image and the reference coordinate layer, the layer set is obtained; the deep learning network model is used to process the layer set,
- a first enhanced image is obtained; the first enhanced image is located in RGB color space; and a second enhanced image is obtained according to the first enhanced image.
- the embodiment of the present application provides an image processing method, by obtaining the first field of view image and the second field of view image corresponding to different field of view, and adding a reference coordinate layer to the second field of view image to form a map
- the layer set and then use the deep learning network model to process the layer set to obtain the first enhanced image, and then obtain the second enhanced image according to the first enhanced image.
- the reference coordinate layer reflects the mapping relationship between the field angle corresponding to the second field of view image and the field angle corresponding to the first field of view image, thus, by adding a reference coordinate layer, different viewing angles can be added.
- the mapping relationship information between field angles enables subsequent adjustments to be made according to the mapping relationship between different field angles, so that more details can be preserved, and the fusion is more natural, thereby achieving the purpose of improving image quality.
- the deep learning network model can perform multiple processes on the layer set at the same time, such as noise reduction, demosaicing, color fusion and field of view fusion, etc., avoiding the accumulation of errors caused by serial processing, thus, also The sharpness of the image can be improved.
- the method before adding a reference coordinate layer to the second FOV image, the method further includes: performing the first FOV image and/or the second FOV image A first process is performed, and the first process includes: registration.
- the accuracy in subsequent image processing can be improved.
- the first field of view image includes one or more of the following: multiple frames of the first image, multiple frames of the second image, and at least one frame of the third image; wherein, the multiple frames
- the first image includes at least one frame of long-exposure image and at least one frame of short-exposure image
- the second image is a Bayer pattern image with normal exposure
- the third image is a grayscale image.
- the first image is a Bayer format image or a grayscale image.
- the second field-of-view image is a Bayer pattern image or a grayscale image.
- registering the second field of view images includes: taking the first frame of the second image as a reference frame , to perform registration on the second field of view image.
- the method further includes: according to the second image in the first frame and the registered second FOV image, The preset coordinate layer performs perspective transformation to obtain a reference coordinate layer, and the preset coordinate layer is used to reflect the difference between the field angle corresponding to the preset second field of view image and the field angle corresponding to the first field of view image mapping relationship between them.
- the second field of view image is registered, so the preset coordinate layer can be adjusted according to the registered second field of view image , to obtain a reference coordinate layer that can more accurately reflect the mapping relationship between the field angle corresponding to the first field of view image and the field angle corresponding to the second field of view image.
- the preset coordinate layer includes an overlapping area; the overlapping area is used to represent: the image sticker with a smaller viewing angle in the first frame of the second image and the second viewing angle image The area corresponding to an image with a larger field of view.
- the first processing further includes: black level correction.
- the first processing further includes : Automatic white balance.
- the first processing further includes: channel splitting; wherein, channel splitting refers to splitting a Bayer format image into multiple single-channel sublayers to be enhanced, each The single-channel sublayer to be enhanced contains only one color channel signal.
- channel splitting refers to splitting a Bayer format image into multiple single-channel sublayers to be enhanced, each The single-channel sublayer to be enhanced contains only one color channel signal.
- the first processing further includes: adding a variance layer; wherein, the variance layer includes a plurality of pixels, and the variance value corresponding to each pixel is determined by the sensitivity corresponding to the original image.
- the variance layer includes a plurality of pixels, and the variance value corresponding to each pixel is determined by the sensitivity corresponding to the original image.
- the prior information can be increased, so that the follow-up can be based on different noises Different levels of noise reduction can be performed to preserve more details and achieve the purpose of improving the clarity of the image.
- the deep learning network model is used to process the layer set to obtain the first enhanced image, including: using the deep learning network model to perform noise reduction, demosaicing, color fusion and visual The field angles are fused to obtain the first enhanced image.
- the deep learning network model can perform multiple processes at the same time, the accumulation of errors caused by serial processing is avoided, thereby improving the clarity of the image.
- obtaining the second enhanced image according to the first enhanced image includes: performing enhancement processing on the first enhanced image to obtain the second enhanced image, and the enhancement processing includes color enhancement processing and / or brightness enhancement processing.
- performing color enhancement and/or brightness enhancement on the first enhanced image can enhance the visual effect of the image, so that the enhanced image content and image color can better meet the user's visual needs.
- performing enhancement processing on the first enhanced image to obtain a second enhanced image includes: segmenting the first enhanced image by using a segmentation model to obtain a mask map; according to the first enhanced image and a mask map, using a tone mapping model to obtain a gain coefficient map; the gain coefficient map includes a plurality of pixels and a corresponding gain value for each pixel; multiplying the first enhanced image by the gain coefficient map to obtain a second enhanced image.
- non-linear enhancement can be performed on the first enhanced image, thus, the first enhanced image can be processed more delicately.
- the gain coefficient map includes 3 frames of color gain coefficient map and/or 1 frame of brightness gain coefficient map, and each frame of color gain coefficient map only enhances one color, and the brightness gain The coefficient map is used to enhance the brightness.
- the first processing when the first processing is not performed on multiple frames of first images in the first field of view image, but the first processing is performed on the second field of view image, according to the first The field of view image, the second field of view image and the reference coordinate layer to obtain the layer set, including: according to the first field of view image except for the images of multiple frames of the first image, the second field of view image and Refer to the coordinate layer to get the layer set.
- the method before using the segmentation model to obtain the mask map corresponding to the first enhanced image, the method further includes: using the long-exposure image and the short-exposure image in the multiple frames of the first image, Perform long and short exposure fusion processing on the first enhanced image to obtain an intermediate enhanced image; use the intermediate enhanced image as the first enhanced image.
- the long and short exposure fusion processing is performed on the first enhanced image, so that the details of the dark area and the overexposed area in the first enhanced image can be improved, and an intermediate enhanced image with higher definition can be obtained.
- the long-exposure image and the short-exposure image are used to perform long-short-exposure fusion processing on the first enhanced image to obtain an intermediate enhanced image, including: combining the first enhanced image with the first image to be fused Perform fusion to obtain a first intermediate fusion image; fuse the first intermediate fusion image and the second image to be fused to obtain the intermediate enhanced image; wherein, the first image to be fused and the second image to be fused are respectively long exposure images and short exposure images.
- the method further includes: performing color space conversion on the second enhanced image to obtain the first target image in the YUV color space.
- performing color space conversion can reduce the amount of subsequent calculations and save storage space.
- the deep learning network model and the segmentation model are respectively any one of the Unet model, the Resnet model and the PSPnet model.
- the tone mapping model is any one of Unet model, Resnet model and Hdrnet model.
- an image processing apparatus in a second aspect, includes a unit for performing each step in the above first aspect or any possible implementation manner of the first aspect.
- an image processing device including: a receiving interface and a processor; the receiving interface is used to obtain multiple frames of original images from an electronic device, the multiple frames of original images are images taken for the same scene to be shot, and multiple The frame original image includes: a first field of view image and a second field of view image, and the field of view corresponding to the first field of view image is different from the field of view corresponding to the second field of view image; the processor is used to call
- the computer program stored in the memory is used to execute the processing steps in the image processing method provided in the first aspect or any possible implementation manner of the first aspect.
- an electronic device including a camera module, a processor, and a memory; the camera module is used to obtain multiple frames of original images, and the multiple frames of original images are images taken for the same scene to be shot, and the multiple frames
- the original image includes: a first field of view image and a second field of view image, and the field of view corresponding to the first field of view image is different from the field of view corresponding to the second field of view image; the memory is used for storing A computer program running on the processor; the processor is configured to execute the processing steps in the image processing method provided in the first aspect or any possible implementation manner of the first aspect.
- the camera module includes a color camera, a black-and-white camera, and a third camera
- the color camera and the black-and-white camera are used to take pictures of the same scene to be shot at a first field of view
- the third The camera is used to take pictures of the scene to be shot with a second field of view; the first field of view is different from the second field of view; the color camera is used to obtain multiple frames of the first image and multiple frames after the processor obtains the photographing instruction
- the second image, the multi-frame first image includes at least one frame of long exposure image and one frame of short exposure image; the second image is a Bayer format image with normal exposure; the black and white camera is used to obtain at least one frame after the processor obtains the camera instruction
- the camera module includes a color camera, a black-and-white camera, and a third camera
- the color camera and the black-and-white camera are used to take pictures of the same scene to be shot at a first field of view
- the third The camera is used to take pictures of the scene to be shot with a second field of view; the first field of view is different from the second field of view; the color camera is used to obtain multiple frames of second images after the processor obtains the photographing instruction,
- the second image is a Bayer format image with normal exposure;
- the black and white camera is used to obtain multiple frames of the first image and at least one frame of the third image after the processor obtains the camera instruction, and the multiple frames of the first image include at least one frame of long-exposure image and a short-exposure image;
- the third image is a grayscale image; and the third camera is used to acquire at least one frame of a second field-of-view image after the processor acquires the photographing instruction.
- a chip including: a processor, configured to call and run a computer program from a memory, so that a device installed with the chip executes the chip as provided in the first aspect or any possible implementation manner of the first aspect. The steps of processing in the image processing method.
- a computer-readable storage medium stores a computer program, and the computer program includes program instructions.
- the program instructions When executed by a processor, the processor executes the first aspect or the first method. Steps of performing processing in the image processing method provided in any possible implementation manner of the aspect.
- a computer program product includes a computer-readable storage medium storing a computer program, and the computer program enables the computer to execute the image provided in the first aspect or any possible implementation manner of the first aspect The step in the processing method that performs the processing.
- the image processing method, device and electronic equipment provided by this application form The layer set, and then use the deep learning network model to process the layer set to obtain a first enhanced image, and then obtain a second enhanced image based on the first enhanced image.
- the reference coordinate layer reflects the mapping relationship between the field angle corresponding to the second field of view image and the field angle corresponding to the first field of view image, thus, by adding a reference coordinate layer, different viewing angles can be added.
- the mapping relationship information between field angles enables subsequent adjustments to be made according to the mapping relationship between different field angles, so that more details can be preserved, and the fusion is more natural, thereby achieving the purpose of improving image quality.
- the deep learning network model can perform multiple processes on the layer set at the same time, such as noise reduction, demosaicing, color fusion and field of view fusion, etc., avoiding the accumulation of errors caused by serial processing, thus, also The sharpness of the image can be improved.
- FIG. 1 is a schematic diagram of processing images captured by dual cameras provided by the related art
- FIG. 2 is a schematic structural diagram of an electronic device provided in an embodiment of the present application.
- FIG. 3 is a hardware architecture diagram of an image processing device provided in an embodiment of the present application.
- FIG. 4 is a schematic flow diagram of an image processing method provided in an embodiment of the present application.
- FIG. 5 is a schematic flow chart of registering multiple frames of second images provided by an embodiment of the present application.
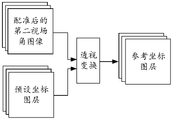
- FIG. 6 is a schematic diagram of obtaining a reference coordinate layer provided by an embodiment of the present application.
- FIG. 7 is a schematic diagram of performing perspective transformation processing on a preset coordinate layer according to an embodiment of the present application.
- FIG. 8 is a schematic diagram of performing black level correction on a second image according to an embodiment of the present application.
- FIG. 9 is a schematic diagram of channel splitting of a second image provided by an embodiment of the present application.
- FIG. 10 is a schematic diagram of performing channel splitting on a second image and adding a variance layer according to an embodiment of the present application
- Fig. 11 is a schematic diagram of the variance layer provided by the embodiment of the present application.
- FIG. 12 is a schematic flow diagram of obtaining the first enhanced image corresponding to the layer set by using the deep learning network model provided by the embodiment of the present application;
- FIG. 13 is a schematic flowchart of another image processing method provided by the embodiment of the present application.
- FIG. 14 is a schematic flow diagram for obtaining a second enhanced image by performing enhancement processing on the first enhanced image according to an embodiment of the present application
- FIG. 15 is a schematic flowchart of another image processing method provided by the embodiment of the present application.
- FIG. 16 is another schematic flow diagram of performing enhancement processing on the first enhanced image to obtain the second enhanced image provided by the embodiment of the present application;
- FIG. 17 is a schematic flowchart of another image processing method provided by the embodiment of the present application.
- FIG. 18 is a schematic flowchart of another image processing method provided by the embodiment of the present application.
- FIG. 19 is a schematic flowchart of another image processing method provided by the embodiment of the present application.
- FIG. 20 is a schematic flowchart of another image processing method provided in the embodiment of the present application.
- FIG. 21 is a schematic flowchart of another image processing method provided by the embodiment of the present application.
- FIG. 22 is a schematic flowchart of another image processing method provided by the embodiment of the present application.
- FIG. 23 is a schematic flowchart of another image processing method provided by the embodiment of the present application.
- FIG. 24 is a schematic structural diagram of an image processing device provided by an embodiment of the present application.
- Fig. 25 is a schematic structural diagram of a chip provided by the embodiment of the application.
- a relationship means that there may be three kinds of relationships, for example, A and/or B means: A exists alone, A and B exist simultaneously, and B exists alone.
- plural refers to two or more than two.
- first and second are used for descriptive purposes only, and cannot be understood as indicating or implying relative importance or implicitly specifying the quantity of indicated technical features. Thus, a feature defined as “first” and “second” may explicitly or implicitly include one or more of these features. In the description of this embodiment, unless otherwise specified, “plurality” means two or more.
- RGB (red, green, blue) color space refers to a color model related to the structure of the human visual system. According to the structure of the human eye, all colors are seen as different combinations of red, green and blue.
- YUV color space refers to a color coding method, Y represents brightness, U and V represent chroma.
- RGB color space focuses on the human eye's perception of color, while the YUV color space focuses on the sensitivity of vision to brightness.
- RGB color space and YUV color space can be converted to each other.
- the pixel value refers to a group of color components corresponding to each pixel in the color image located in the RGB color space.
- each pixel corresponds to a group of three primary color components, wherein the three primary color components are red component R, green component G and blue component B respectively.
- Bayer pattern color filter array when the image is converted from the actual scene to image data, usually the image sensor receives the red channel signal, the green channel signal and the blue channel signal respectively, three information of three channel signals, and then synthesize the information of three channel signals into a color image.
- CFA color filter array
- the surface is covered with a color filter array to obtain the information of the three channel signals.
- the Bayer format color filter array means that the filters are arranged in a checkerboard format. For example, the smallest repeating unit in the Bayer format color filter array is: one filter for obtaining the red channel signal, two filters for obtaining the green channel signal , a filter for obtaining the blue channel signal is arranged in a 2 ⁇ 2 manner.
- a Bayer image that is, an image output by an image sensor based on a Bayer format color filter array.
- the pixels of multiple colors in this image are arranged in a Bayer pattern.
- each pixel in the Bayer format image only corresponds to a channel signal of one color.
- green pixels pixels corresponding to the green channel signal
- blue pixels pixels corresponding to the blue channel signal
- red pixels pixels corresponding to the blue channel signal
- Pixels corresponding to the red channel signal each account for 25% of all pixels.
- the minimum repeating unit of the Bayer format image is: one red pixel, two green pixels and one blue pixel are arranged in a 2 ⁇ 2 manner.
- Grayscale image a grayscale image is a single-channel image, used to represent different brightness levels, the brightest is all white, and the darkest is all black. That is, each pixel in a grayscale image corresponds to a different degree of brightness between black and white.
- 256 gray scales (0th grayscale to grayscale 255 grayscale).
- Binary image means that each pixel on the image has only two possible values or grayscale states.
- the gray value corresponding to the pixel included in the image can only be 0 or 255, 0 and 255 represent white and black respectively; or in other words, the corresponding value of the pixel in the image can only be 0 or 1, 0 and 1 respectively Represents white and black.
- Registration refers to the matching of geographic coordinates of different images obtained by different imaging methods in the same area. Among them, it includes the processing of three aspects: geometric correction, projection transformation and unified scale.
- Black level correction due to the presence of dark current in the image sensor, when there is no light, the pixels also have a certain output voltage, and the pixels at different positions may correspond to different output voltages, therefore, it is necessary to correct The output voltage corresponding to the bright (ie, black) pixel is corrected.
- dead point is the white point in the output image in a completely black environment, and the black point in the output image in a bright environment.
- the three primary color channel signals should have a linear response relationship with the ambient brightness, but due to poor signal output by the image sensor, white or black spots may appear, for this, it can be automatically detected and repaired automatically, or, establish The bad pixel linked list repairs bad pixels at fixed positions.
- a point refers to a pixel.
- Noise reduction refers to the process of reducing noise in an image. Common methods include mean filtering, Gaussian filtering, and bilateral filtering.
- Field of view which is used to indicate the maximum angle range that the camera can capture. If the object to be photographed is within the angle range, the object to be photographed will be captured by the camera. If the object to be photographed is outside the angle range, the object to be photographed will not be captured by the camera.
- FOV Field of view
- the camera can be divided into a main camera, a wide-angle camera, and a telephoto camera due to different field of view angles.
- the field of view of the wide-angle camera is larger than that of the main camera, and the focal length is smaller, which is suitable for close-up shooting; while the field of view of the telephoto camera is smaller than that of the main camera, and the focal length is longer. Suitable for remote shooting.
- the mobile phone is configured with two cameras, one is a main camera, and the other is a wide-angle camera or a telephoto camera, or the two cameras are respectively a wide-angle camera and a telephoto camera.
- the angle of view of the wide-angle camera is larger than that of the main camera, and the angle of view of the telephoto camera is smaller than that of the main camera. Then, the image taken by the main camera and the image taken by the wide-angle camera, or; the image taken by the main camera and the image taken by the telephoto camera are simply fused; Simple fusion.
- FIG. 1 shows a schematic diagram of processing images captured by dual cameras in a related technology.
- the first field of view image taken by the main camera is usually filled in the second field of view image taken by the wide-angle camera according to the size of the field of view, or the telephoto camera
- the captured image of the first field of view is filled in the image of the second field of view captured by the main camera or the wide-angle camera.
- the fused image will have poor stereoscopic effect and poor quality.
- the two images obtained by a mobile phone using such a dual camera there are parts where the field of view overlaps, and there are also parts where the field of view does not overlap. If the two images are fused directly, the overlapping parts and non-overlapping parts of the final captured image may not be in alignment, and part of the content may be broken or deformed.
- the overlapping part of the field of view may have high definition, and the non-overlapping part may have low definition, so that the captured image will have the problem of inconsistency in the definition of the central part and the surrounding part, that is, there will be a fusion boundary on the image, which will affect the imaging. Effect.
- the embodiment of the present application provides an image processing method, by acquiring the first field of view image and the second field of view image corresponding to different field of view, and adding a reference coordinate map to the second field of view image Layers to form a layer set, and then use the deep learning network model to process the layer set to obtain the first enhanced image, and then obtain the second enhanced image based on the first enhanced image.
- the reference coordinate layer reflects the mapping relationship between the field angle corresponding to the second field of view image and the field angle corresponding to the first field of view image, thus, by adding a reference coordinate layer, different viewing angles can be added.
- the mapping relationship information between field angles enables subsequent adjustments to be made according to the mapping relationship between different field angles, so that more details can be preserved, and the fusion is more natural, thereby achieving the purpose of improving image quality.
- the image processing method provided in the embodiment of the present application may be applicable to various electronic devices, and correspondingly, the image processing apparatus provided in the embodiment of the present application may be electronic devices in various forms.
- the electronic device may be various camera devices such as SLR cameras and card players, mobile phones, tablet computers, wearable devices, vehicle-mounted devices, augmented reality (augmented reality, AR)/virtual reality (virtual reality) reality, VR) equipment, notebook computer, ultra-mobile personal computer (ultra-mobile personal computer, UMPC), netbook, personal digital assistant (personal digital assistant, PDA), etc., or other equipment or devices capable of image processing,
- camera devices such as SLR cameras and card players, mobile phones, tablet computers, wearable devices, vehicle-mounted devices, augmented reality (augmented reality, AR)/virtual reality (virtual reality) reality, VR) equipment, notebook computer, ultra-mobile personal computer (ultra-mobile personal computer, UMPC), netbook, personal digital assistant (personal digital assistant, PDA), etc., or other equipment or devices capable of image processing
- the embodiment of the present application does not set any limitation on the specific type of the electronic device.
- FIG. 2 shows a schematic structural diagram of an electronic device 100 provided in an embodiment of the present application.
- the electronic device 100 may include a processor 110, an external memory interface 120, an internal memory 121, a universal serial bus (universal serial bus, USB) interface 130, a charging management module 140, a power management module 141, a battery 142, an antenna 1, and an antenna 2 , mobile communication module 150, wireless communication module 160, audio module 170, speaker 170A, receiver 170B, microphone 170C, earphone jack 170D, sensor module 180, button 190, motor 191, indicator 192, camera 193, display screen 194, and A subscriber identification module (subscriber identification module, SIM) card interface 195 and the like.
- SIM subscriber identification module
- the sensor module 180 may include a pressure sensor 180A, a gyroscope sensor 180B, an air pressure sensor 180C, a magnetic sensor 180D, an acceleration sensor 180E, a distance sensor 180F, a proximity light sensor 180G, a fingerprint sensor 180H, a temperature sensor 180J, a touch sensor 180K, an ambient light sensor 180L, bone conduction sensor 180M, etc.
- the processor 110 may include one or more processing units, for example: the processor 110 may include an application processor (application processor, AP), a modem processor, a graphics processing unit (graphics processing unit, GPU), an image signal processor (image signal processor, ISP), controller, video codec, digital signal processor (digital signal processor, DSP), baseband processor, and/or neural network processor (neural-network processing unit, NPU), etc. Wherein, different processing units may be independent devices, or may be integrated in one or more processors.
- application processor application processor, AP
- modem processor graphics processing unit
- GPU graphics processing unit
- image signal processor image signal processor
- ISP image signal processor
- controller video codec
- digital signal processor digital signal processor
- baseband processor baseband processor
- neural network processor neural-network processing unit
- the controller may be the nerve center and command center of the electronic device 100 .
- the controller can generate an operation control signal according to the instruction opcode and timing signal, and complete the control of fetching and executing the instruction.
- a memory may also be provided in the processor 110 for storing instructions and data.
- the memory in processor 110 is a cache memory.
- the memory may hold instructions or data that the processor 110 has just used or recycled. If the processor 110 needs to use the instruction or data again, it can be called directly from the memory. Repeated access is avoided, and the waiting time of the processor 110 is reduced, thereby improving the efficiency of the system.
- the processor 110 may run the software code of the image processing method provided in the embodiment of the present application to capture an image with higher definition.
- processor 110 may include one or more interfaces.
- the interface may include an integrated circuit (inter-integrated circuit, I2C) interface, an integrated circuit built-in audio (inter-integrated circuit sound, I2S) interface, a pulse code modulation (pulse code modulation, PCM) interface, a universal asynchronous transmitter (universal asynchronous receiver/transmitter, UART) interface, mobile industry processor interface (mobile industry processor interface, MIPI), general-purpose input and output (general-purpose input/output, GPIO) interface, subscriber identity module (subscriber identity module, SIM) interface, and /or universal serial bus (universal serial bus, USB) interface, etc.
- I2C integrated circuit
- I2S integrated circuit built-in audio
- PCM pulse code modulation
- PCM pulse code modulation
- UART universal asynchronous transmitter
- MIPI mobile industry processor interface
- GPIO general-purpose input and output
- subscriber identity module subscriber identity module
- SIM subscriber identity module
- USB universal serial bus
- the MIPI interface can be used to connect the processor 110 with peripheral devices such as the display screen 194 and the camera 193 .
- MIPI interface includes camera serial interface (camera serial interface, CSI), display serial interface (display serial interface, DSI), etc.
- the processor 110 communicates with the camera 193 through the CSI interface to realize the shooting function of the electronic device 100 .
- the processor 110 communicates with the display screen 194 through the DSI interface to realize the display function of the electronic device 100 .
- the GPIO interface can be configured by software.
- the GPIO interface can be configured as a control signal or as a data signal.
- the GPIO interface can be used to connect the processor 110 with the camera 193 , the display screen 194 , the wireless communication module 160 , the audio module 170 , the sensor module 180 and so on.
- the GPIO interface can also be configured as an I2C interface, I2S interface, UART interface, MIPI interface, etc.
- the USB interface 130 is an interface conforming to the USB standard specification, specifically, it can be a Mini USB interface, a Micro USB interface, a USB Type C interface, and the like.
- the USB interface 130 can be used to connect a charger to charge the electronic device 100 , and can also be used to transmit data between the electronic device 100 and peripheral devices. It can also be used to connect headphones and play audio through them. This interface can also be used to connect other electronic devices, such as AR devices.
- the interface connection relationship between the modules shown in the embodiment of the present application is only a schematic illustration, and does not constitute a structural limitation of the electronic device 100 .
- the electronic device 100 may also adopt different interface connection manners in the foregoing embodiments, or a combination of multiple interface connection manners.
- the charging management module 140 is configured to receive a charging input from a charger.
- the power management module 141 is used for connecting the battery 142 , the charging management module 140 and the processor 110 .
- the power management module 141 receives the input from the battery 142 and/or the charging management module 140 to provide power for the processor 110 , the internal memory 121 , the display screen 194 , the camera 193 , and the wireless communication module 160 .
- the wireless communication function of the electronic device 100 can be realized by the antenna 1 , the antenna 2 , the mobile communication module 150 , the wireless communication module 160 , a modem processor, a baseband processor, and the like.
- Antenna 1 and Antenna 2 are used to transmit and receive electromagnetic wave signals.
- Each antenna in electronic device 100 may be used to cover single or multiple communication frequency bands. Different antennas can also be multiplexed to improve the utilization of the antennas.
- Antenna 1 can be multiplexed as a diversity antenna of a wireless local area network.
- the antenna may be used in conjunction with a tuning switch.
- the mobile communication module 150 can provide wireless communication solutions including 2G/3G/4G/5G applied on the electronic device 100 .
- the mobile communication module 150 may include at least one filter, switch, power amplifier, low noise amplifier (low noise amplifier, LNA) and the like.
- the mobile communication module 150 can receive electromagnetic waves through the antenna 1, filter and amplify the received electromagnetic waves, and send them to the modem processor for demodulation.
- the mobile communication module 150 can also amplify the signals modulated by the modem processor, and convert them into electromagnetic waves through the antenna 1 for radiation.
- at least part of the functional modules of the mobile communication module 150 may be set in the processor 110 .
- at least part of the functional modules of the mobile communication module 150 and at least part of the modules of the processor 110 may be set in the same device.
- the wireless communication module 160 can provide wireless local area networks (wireless local area networks, WLAN) (such as wireless fidelity (Wireless Fidelity, Wi-Fi) network), bluetooth (bluetooth, BT), global navigation satellite, etc. applied on the electronic device 100.
- System global navigation satellite system, GNSS
- frequency modulation frequency modulation, FM
- near field communication technology near field communication, NFC
- infrared technology infrared, IR
- the wireless communication module 160 may be one or more devices integrating at least one communication processing module.
- the wireless communication module 160 receives electromagnetic waves via the antenna 2, frequency-modulates and filters the electromagnetic wave signals, and sends the processed signals to the processor 110.
- the wireless communication module 160 can also receive the signal to be sent from the processor 110 , frequency-modulate it, amplify it, and convert it into electromagnetic waves through the antenna 2 for radiation.
- the antenna 1 of the electronic device 100 is coupled to the mobile communication module 150, and the antenna 2 is coupled to the wireless communication module 160, so that the electronic device 100 can communicate with the network and other devices through wireless communication technology.
- the wireless communication technology may include global system for mobile communications (GSM), general packet radio service (general packet radio service, GPRS), code division multiple access (code division multiple access, CDMA), broadband Code division multiple access (wideband code division multiple access, WCDMA), time division code division multiple access (time-division code division multiple access, TD-SCDMA), long term evolution (long term evolution, LTE), BT, GNSS, WLAN, NFC , FM, and/or IR techniques, etc.
- GSM global system for mobile communications
- GPRS general packet radio service
- code division multiple access code division multiple access
- CDMA broadband Code division multiple access
- WCDMA wideband code division multiple access
- time division code division multiple access time-division code division multiple access
- TD-SCDMA time-division code division multiple access
- the GNSS may include a global positioning system (global positioning system, GPS), a global navigation satellite system (global navigation satellite system, GLONASS), a Beidou navigation satellite system (beidou navigation satellite system, BDS), a quasi-zenith satellite system (quasi -zenith satellite system (QZSS) and/or satellite based augmentation systems (SBAS).
- GPS global positioning system
- GLONASS global navigation satellite system
- Beidou navigation satellite system beidou navigation satellite system
- BDS Beidou navigation satellite system
- QZSS quasi-zenith satellite system
- SBAS satellite based augmentation systems
- the electronic device 100 realizes the display function through the GPU, the display screen 194 , and the application processor.
- the GPU is a microprocessor for image processing, and is connected to the display screen 194 and the application processor. GPUs are used to perform mathematical and geometric calculations for graphics rendering.
- Processor 110 may include one or more GPUs that execute program instructions to generate or change display information.
- the display screen 194 is used to display images, videos and the like.
- the display screen 194 includes a display panel.
- the display panel can be a liquid crystal display (LCD), an organic light-emitting diode (OLED), an active matrix organic light emitting diode or an active matrix organic light emitting diode (active-matrix organic light emitting diode, AMOLED), flexible light-emitting diode (flex light-emitting diode, FLED), Miniled, MicroLed, Micro-oLed, quantum dot light emitting diodes (quantum dot light emitting diodes, QLED), etc.
- the electronic device 100 may include 1 or N display screens 194 , where N is a positive integer greater than 1.
- Camera 193 is used to capture images. It can be triggered by an application command to realize the camera function, such as capturing images of any scene.
- a camera may include components such as an imaging lens, an optical filter, and an image sensor. The light emitted or reflected by the object enters the imaging lens, passes through the filter, and finally converges on the image sensor.
- the image sensor is mainly used for converging and imaging the light emitted or reflected by all objects in the camera perspective (also called the scene to be shot, the target scene, or the scene image that the user expects to shoot); the filter is mainly used to It is used to filter out redundant light waves (such as light waves other than visible light, such as infrared) in the light; the image sensor is mainly used to perform photoelectric conversion on the received light signal, convert it into an electrical signal, and input it into the processor 130 for subsequent processing .
- the camera 193 may be located at the front of the electronic device 100, or at the back of the electronic device 100, and the specific number and arrangement of the cameras may be set according to requirements, which are not limited in this application.
- the electronic device 100 includes a front camera and a rear camera.
- a front camera or a rear camera may include one or more cameras.
- the image processing method provided in the embodiment of the present application may be used.
- the camera is arranged on an external accessory of the electronic device 100, the external accessory is rotatably connected to the frame of the mobile phone, and the angle formed between the external accessory and the display screen 194 of the electronic device 100 is 0-360 degrees any angle between.
- the electronic device 100 takes a selfie
- the external accessory drives the camera to rotate to a position facing the user.
- the mobile phone has multiple cameras, only some of the cameras may be set on the external accessories, and the rest of the cameras may be set on the electronic device 100 body, which is not limited in this embodiment of the present application.
- the internal memory 121 may be used to store computer-executable program codes including instructions.
- the internal memory 121 may include an area for storing programs and an area for storing data.
- the stored program area can store an operating system, at least one application program required by a function (such as a sound playing function, an image playing function, etc.) and the like.
- the storage data area can store data created during the use of the electronic device 100 (such as audio data, phonebook, etc.) and the like.
- the internal memory 121 may include a high-speed random access memory, and may also include a non-volatile memory, such as at least one magnetic disk storage device, flash memory device, universal flash storage (universal flash storage, UFS) and the like.
- the processor 110 executes various functional applications and data processing of the electronic device 100 by executing instructions stored in the internal memory 121 and/or instructions stored in a memory provided in the processor.
- the internal memory 121 can also store the software code of the image processing method provided by the embodiment of the present application.
- the processor 110 runs the software code, it executes the process steps of the image processing method to obtain an image with higher definition.
- the internal memory 121 can also store captured images.
- the external memory interface 120 can be used to connect an external memory card, such as a Micro SD card, so as to expand the storage capacity of the electronic device 100.
- the external memory card communicates with the processor 110 through the external memory interface 120 to implement a data storage function. Such as saving files such as music in an external memory card.
- the software code of the image processing method provided in the embodiment of the present application can also be stored in an external memory, and the processor 110 can run the software code through the external memory interface 120 to execute the process steps of the image processing method to obtain a high-definition image.
- Image Images captured by the electronic device 100 may also be stored in an external memory.
- the user can designate whether to store the image in the internal memory 121 or the external memory.
- the electronic device 100 when the electronic device 100 is currently connected to the external memory, if the electronic device 100 captures one frame of image, a prompt message may pop up to remind the user whether to store the image in the external memory or the internal memory; of course, there may be other specified ways , the embodiment of the present application does not impose any limitation on this; or, when the electronic device 100 detects that the amount of memory in the internal memory 121 is less than a preset amount, it may automatically store the image in the external memory.
- the electronic device 100 can implement audio functions through the audio module 170 , the speaker 170A, the receiver 170B, the microphone 170C, the earphone interface 170D, and the application processor. Such as music playback, recording, etc.
- the pressure sensor 180A is used to sense the pressure signal and convert the pressure signal into an electrical signal.
- pressure sensor 180A may be disposed on display screen 194 .
- the gyro sensor 180B can be used to determine the motion posture of the electronic device 100 .
- the angular velocity of the electronic device 100 around three axes ie, x, y and z axes
- the gyro sensor 180B can be used for image stabilization.
- the air pressure sensor 180C is used to measure air pressure.
- the electronic device 100 calculates the altitude based on the air pressure value measured by the air pressure sensor 180C to assist positioning and navigation.
- the magnetic sensor 180D includes a Hall sensor.
- the electronic device 100 may use the magnetic sensor 180D to detect the opening and closing of the flip leather case.
- the electronic device 100 when the electronic device 100 is a clamshell machine, the electronic device 100 can detect opening and closing of the clamshell according to the magnetic sensor 180D. Then according to the detected opening and closing state of the holster or the opening and closing state of the flip cover, features such as automatic unlocking of the flip cover are set.
- the acceleration sensor 180E can detect the acceleration of the electronic device 100 in various directions (generally three axes). When the electronic device 100 is stationary, the magnitude and direction of gravity can be detected. It can also be used to identify the posture of electronic devices, and can be used in applications such as horizontal and vertical screen switching, pedometers, etc.
- the distance sensor 180F is used to measure the distance.
- the electronic device 100 may measure the distance by infrared or laser. In some embodiments, when shooting a scene, the electronic device 100 may use the distance sensor 180F for distance measurement to achieve fast focusing.
- Proximity light sensor 180G may include, for example, light emitting diodes (LEDs) and light detectors, such as photodiodes.
- the light emitting diodes may be infrared light emitting diodes.
- the electronic device 100 emits infrared light through the light emitting diode.
- Electronic device 100 uses photodiodes to detect infrared reflected light from nearby objects. When sufficient reflected light is detected, it may be determined that there is an object near the electronic device 100 . When insufficient reflected light is detected, the electronic device 100 may determine that there is no object near the electronic device 100 .
- the electronic device 100 can use the proximity light sensor 180G to detect that the user is holding the electronic device 100 close to the ear to make a call, so as to automatically turn off the screen to save power.
- the proximity light sensor 180G can also be used in leather case mode, automatic unlock and lock screen in pocket mode.
- the ambient light sensor 180L is used for sensing ambient light brightness.
- the electronic device 100 can adaptively adjust the brightness of the display screen 194 according to the perceived ambient light brightness.
- the ambient light sensor 180L can also be used to automatically adjust the white balance when taking pictures.
- the ambient light sensor 180L can also cooperate with the proximity light sensor 180G to detect whether the electronic device 100 is in the pocket, so as to prevent accidental touch.
- the fingerprint sensor 180H is used to collect fingerprints.
- the electronic device 100 can use the collected fingerprint characteristics to implement fingerprint unlocking, access to application locks, take pictures with fingerprints, answer incoming calls with fingerprints, and the like.
- the temperature sensor 180J is used to detect temperature.
- the electronic device 100 uses the temperature detected by the temperature sensor 180J to implement a temperature treatment strategy. For example, when the temperature reported by the temperature sensor 180J exceeds the threshold, the electronic device 100 may reduce the performance of the processor located near the temperature sensor 180J, so as to reduce power consumption and implement thermal protection.
- the electronic device 100 when the temperature is lower than another threshold, the electronic device 100 heats the battery 142 to prevent the electronic device 100 from being shut down abnormally due to the low temperature.
- the electronic device 100 boosts the output voltage of the battery 142 to avoid abnormal shutdown caused by low temperature.
- the touch sensor 180K is also called “touch device”.
- the touch sensor 180K can be disposed on the display screen 194, and the touch sensor 180K and the display screen 194 form a touch screen, also called a “touch screen”.
- the touch sensor 180K is used to detect a touch operation on or near it.
- the touch sensor can pass the detected touch operation to the application processor to determine the type of touch event.
- Visual output related to the touch operation can be provided through the display screen 194 .
- the touch sensor 180K may also be disposed on the surface of the electronic device 100 , which is different from the position of the display screen 194 .
- the bone conduction sensor 180M can acquire vibration signals. In some embodiments, the bone conduction sensor 180M can acquire the vibration signal of the vibrating bone mass of the human voice. The bone conduction sensor 180M can also contact the human pulse and receive the blood pressure beating signal. In some embodiments, the bone conduction sensor 180M can also be disposed in the earphone, combined into a bone conduction earphone.
- the audio module 170 can analyze the voice signal based on the vibration signal of the vibrating bone mass of the vocal part acquired by the bone conduction sensor 180M, so as to realize the voice function.
- the application processor can analyze the heart rate information based on the blood pressure beating signal acquired by the bone conduction sensor 180M, so as to realize the heart rate detection function.
- the keys 190 include a power key, a volume key and the like.
- the key 190 may be a mechanical key. It can also be a touch button.
- the electronic device 100 can receive key input and generate key signal input related to user settings and function control of the electronic device 100 .
- the motor 191 can generate a vibrating reminder.
- the motor 191 can be used for incoming call vibration prompts, and can also be used for touch vibration feedback.
- touch operations applied to different applications may correspond to different vibration feedback effects.
- the indicator 192 can be an indicator light, and can be used to indicate charging status, power change, and can also be used to indicate messages, missed calls, notifications, and the like.
- the SIM card interface 195 is used for connecting a SIM card.
- the SIM card can be connected and separated from the electronic device 100 by inserting it into the SIM card interface 195 or pulling it out from the SIM card interface 195 .
- the structure illustrated in the embodiment of the present application does not constitute a specific limitation on the electronic device 100 .
- the electronic device 100 may include more or fewer components than shown in the figure, or combine certain components, or separate certain components, or arrange different components.
- the illustrated components can be realized in hardware, software or a combination of software and hardware.
- FIG. 3 shows a hardware architecture diagram of an image processing apparatus 200 provided by an embodiment of the present application.
- the image processing device 200 may be, for example, a processor chip.
- the hardware architecture diagram shown in FIG. 3 may be the processor 110 in FIG. 2 , and the image processing method provided in the embodiment of the present application may be applied on the processor chip.
- the image processing apparatus 200 includes: at least one CPU, a memory, a microcontroller (microcontroller unit, MCU), a GPU, an NPU, a memory bus, a receiving interface, a sending interface, and the like.
- the image processing device 200 may also include an AP, a decoder, a dedicated graphics processor, and the like.
- the connectors include various interfaces, transmission lines or buses, etc. These interfaces are usually electrical communication interfaces, but they may also be mechanical interfaces or other forms The interface of this application does not impose any restrictions on it.
- the CPU may be a single-core (single-CPU) processor or a multi-core (multi-CPU) processor.
- the CPU may be a processor group composed of multiple processors, and the multiple processors are coupled to each other through one or more buses.
- the connection interface can be the data input interface of the processor chip.
- the receiving interface and the sending interface can be high definition multimedia interface (high definition multimedia interface, HDMI), V-By-One Interface, embedded display port (embedded display port, eDP), mobile industry processor interface (mobile industry processor interface, MIPI) display port (DP), etc.
- the memory can refer to the above description of the internal memory 121.
- the above-mentioned parts are integrated on the same chip.
- the CPU, GPU, decoder, receiving interface, and sending interface are integrated on one chip, and each part inside the chip accesses an external memory through a bus.
- a dedicated graphics processor can be a dedicated ISP.
- the NPU can also be used as an independent processor chip.
- the NPU is used to implement related operations of various neural networks or deep learning.
- the image processing method provided in the embodiment of the present application may be implemented by a GPU or an NPU, or may be implemented by a dedicated graphics processor.
- the chip involved in the embodiment of the present application is a system manufactured on the same semiconductor substrate by an integrated circuit process, also called a semiconductor chip, which may be an integrated circuit formed on the substrate by using an integrated circuit process. Assemblies whose outer layers are usually encapsulated by semiconductor encapsulation materials.
- the integrated circuit may include various functional devices, and each type of functional device includes transistors such as logic gate circuits, metal oxide semiconductor (MOS) transistors, and diodes, and may also include other components such as capacitors, resistors, or inductors.
- MOS metal oxide semiconductor
- Each functional device can work independently or under the action of necessary driver software, and can realize various functions such as communication, calculation or storage.
- FIG. 4 is a schematic flowchart of an image processing method shown in an embodiment of the present application. As shown in FIG. 4, the image processing method 10 includes: S10 to S50.
- the multiple frames of original images include: a first viewing angle image and a second viewing angle image, and the viewing angle corresponding to the first viewing angle image is different from the viewing angle corresponding to the second viewing angle image.
- the execution subject of the image processing method may be the electronic device 100 provided with the camera module as shown in FIG. 2 , or the image processing apparatus 200 shown in FIG. 3 .
- the execution subject is the electronic device 100
- multiple frames of original images are obtained through the cameras in the camera module, specifically through several cameras or which camera is used to obtain them, which can be set and changed as required, and this embodiment of the application does not make any limit.
- the execution subject is an image processing device
- multiple frames of original images can be obtained through the receiving interface, and the multiple frames of original images are captured by a camera module of an electronic device connected to the image processing device.
- the aforementioned original image may also be called a RAW image.
- the multi-frame original image can be a Bayer format image, or a grayscale image, or part of it can be a Bayer format image, and part of it can be a grayscale image. Specifically, it can be acquired as needed, and this embodiment of the present application does not impose any restrictions on this .
- the first field-of-view image and the second field-of-view image may each include one frame, or may include multiple frames, but at least the acquired multi-frame original images include one frame of the first field of view image and 1 frame of the second field of view image. It should be understood that the multiple frames of the first field of view image and the multiple frames of the second field of view image may not be shot at the same time, but they should be images shot for the same scene to be shot in the same time period.
- the difference between the viewing angle corresponding to the first viewing angle image and the viewing angle corresponding to the second viewing angle image can be expressed as: the viewing angle corresponding to the first viewing angle image is larger than the viewing angle corresponding to the second viewing angle image The viewing angle, or, the viewing angle corresponding to the first viewing angle image is smaller than the viewing angle corresponding to the second viewing angle image.
- the first field-of-view image includes one or more of the following: multiple frames of the first image, multiple frames of the second image, and at least one frame of the third image.
- the multiple frames of the first image include at least one frame of long-exposure image and at least one frame of short-exposure image
- the second image is a Bayer pattern image with normal exposure
- the third image is a grayscale image
- Multiple frames of first images, multiple frames of second images, and at least one frame of third images are acquired, and a second field of view image is acquired.
- first image, the second image, and the third image all belong to the first field of view image, so the field of view corresponding to the first image, the field of view corresponding to the second image, and the field of view corresponding to the third image
- the angles are all the same, and are different from the angle of view corresponding to the second angle of view image.
- the long-exposure image refers to an image obtained after a long time exposure during shooting
- the short-exposure image refers to an image obtained after a short time exposure during shooting, wherein both long-exposure and short-exposure are relatively normal in terms of exposure time.
- the exposure time is the time used for photoelectric conversion when the image sensor captures an image.
- the 2 frames of first images are respectively 1 frame of long-exposure image and 1 frame of short-exposure image; when 3 or more frames of first images are acquired, the multi-frame Except that one frame of the first image is a long-exposure image and one frame is a short-exposure image, the other images may be long-exposure images or short-exposure images, which can be acquired according to needs, which is not limited in this embodiment of the present application.
- the first image is a Bayer image or a grayscale image.
- the long-exposure image may be a long-exposure Bayer pattern image or a long-exposure grayscale image
- the short-exposure image may be a short-exposure Bayer pattern image or a short-exposure grayscale image.
- both the long-exposure image and the short-exposure image are Bayer format images
- the first image and the second image can be captured by the same camera.
- both the long-exposure image and the short-exposure image are grayscale images
- the first image and the third image can be captured by the same camera.
- it may also be obtained separately by multiple different cameras, which is not limited in this embodiment of the present application.
- the second field-of-view image is a Bayer pattern image or a grayscale image.
- the dimensions of multiple frames of original images may all be the same.
- the sizes of the multiple frames of original images may also be partly the same, partly different; or completely different.
- the embodiment of the present application does not impose any limitation on this.
- the acquired multiple frames of images of the first field of view may be enlarged or reduced so that all the images of the first field of view are of the same size, so as to facilitate subsequent processing and calculation.
- zooming in and out may be performed, so that all the second field of view images have the same size, so as to facilitate subsequent processing and calculation.
- multiple frames of original images may be acquired continuously, and the acquisition intervals may be the same or different.
- multiple frames of original images may not be acquired continuously.
- the multiple frames of first images may be acquired continuously.
- the multiple frames of second images may be acquired continuously.
- the multiple frames of third images may also be acquired continuously.
- the multiple frames of second viewing angle images may be acquired continuously.
- the reference coordinate layer is used to reflect the mapping relationship between the viewing angle corresponding to the second viewing angle image and the viewing angle corresponding to the first viewing angle image.
- reference coordinate layer is newly added for the second FOV image, and has not been changed or fused with the second FOV image.
- first and second are just names for images with different viewing angles for the convenience of distinction.
- the images indicated by the first FOV image and the second FOV image may be interchanged.
- a reference coordinate layer can also be added to the first field of view image, and a reference coordinate layer can also be added to both the first field of view image and the second field of view image, which can be set and changed according to needs.
- the application embodiment does not impose any limitation on this.
- the first field of view image not only includes content in the second field angle image, but also includes content outside the field angle range corresponding to the second field angle image.
- the second field of view image not only includes the content in the first field of view image, but also includes the first field of view content outside the field of view corresponding to the angular image. That is to say, the first field of view image and the second field of view image are different according to the size of the field of view, and there is a mapping relationship in content, that is, the field of view corresponding to the first field of view image and the second field of view There is a mapping relationship between the field angles corresponding to the images.
- the mapping relationship between the viewing angle corresponding to the second viewing angle image and the viewing angle corresponding to the first viewing angle image may be used as prior information, that is, the reference coordinate layer may be used as prior information. Therefore, by adding a reference coordinate layer, subsequent processing can be performed more accurately according to the mapping relationship of the viewing angle, thereby improving the fusion effect of images with different viewing angles, and achieving the purpose of improving the quality of the finally acquired image.
- the method 10 also includes:
- a first process is performed on the first FOV image and/or the second FOV image, where the first process includes: registration.
- the first processing of the first field of view image may be: the first At least one of the field-of-view images is subjected to first processing.
- the first field of view image includes one of multiple frames of first images, multiple frames of second images, and at least one frame of third images, for multiple frames of first images, multiple frames of second images, or at least one frame of third images performing the first processing on the image, and not performing the first processing on the image at the second viewing angle;
- the first processing is performed on the multiple frames of the first image and/or the multiple frames of the second image, and the second field of view image is not carry out the first treatment;
- the first field of view image includes multiple frames of the first image and at least one frame of the third image, performing the first processing on the multiple frames of the first image and/or at least one frame of the third image, and performing the first processing on the second frame of the field of view image no first treatment;
- the first field of view image includes multiple frames of second images and at least one frame of third images
- the first processing is performed on multiple frames of second images and/or at least one frame of third images, and the second field of view The image is not subjected to the first processing
- the first field of view image includes multiple frames of first images, multiple frames of second images, and at least one frame of third images, for at least one of multiple frames of first images, multiple frames of second images, and at least one frame of third images
- One item performs the first processing, and does not perform the first processing on the second field of view image, or;
- the first field of view image includes multiple frames of the first image, multiple frames of the second image and at least one frame of the third image
- the first processing is not performed on the first field of view image, and only the second field of view image is processed first processing, or;
- the first field of view image includes one of multiple frames of first images, multiple frames of second images, and at least one frame of third images, for multiple frames of first images, multiple frames of second images, or at least one frame of third images performing the first processing on the image, and performing the first processing on the second field of view image;
- the first processing is performed on the multiple frames of the first image and/or the multiple frames of the second image
- the second processing is performed on the second field of view image a treatment
- the first field of view image includes multiple frames of the first image and at least one frame of the third image, performing the first processing on the multiple frames of the first image and/or at least one frame of the third image, and performing the first processing on the second frame of the field of view image first treatment;
- the first field of view image includes multiple frames of second images and at least one frame of third images
- the first processing is performed on multiple frames of second images and/or at least one frame of third images, and the second field of view image carry out the first treatment
- the first field of view image includes multiple frames of first images, multiple frames of second images, and at least one frame of third images, for at least one of multiple frames of first images, multiple frames of second images, and at least one frame of third images.
- the first image of the first frame may be used as a reference frame, and based on the first image of the first frame, the first images of other frames may be registered with the first image of the first frame.
- the long exposure image of the first frame when registering multiple frames of the first image, can be used as a reference frame, and based on the long exposure image of the first frame, the long exposure images of other frames and the long exposure image of the first frame are respectively registered,
- the short exposure image of the first frame may also be used as a reference frame, and based on the short exposure image of the first frame, the short exposure images of other frames may be registered with the short exposure image of the first frame.
- the second image of the first frame may be used as a reference frame, and based on the second image of the first frame, the second images of other frames may be registered with the second image of the first frame.
- the first field-of-view image includes only one frame of the third image
- registration may not be performed on the third image.
- the third image of the first frame may be used as a reference frame, and based on the third image of the first frame, the third image of other frames may be matched with the third image of the first frame. allow.
- FIG. 5 is a schematic flow chart of registering multiple frames of second images provided in an embodiment of the present application.
- the first frame and the second image are used as the reference frame, and feature point detection is performed on it; feature point detection is also performed on any frame in the second image of other frames, and then the feature points obtained by the two detections are combined Points are matched, and then the transformation matrix is calculated for transformation.
- the method for registering multiple frames of first images and multiple frames of third images is the same, and will not be repeated here.
- registering the second field of view images includes: taking the first frame of the second image as a reference frame, and registering the second field of view images for registration.
- the first frame of the second image may be used as a reference frame, and each frame of the second field of view image is registered respectively.
- the method 10 further includes:
- perspective transformation is performed on the preset coordinate layer to obtain the reference coordinate layer.
- the preset coordinate layer is used to reflect the mapping relationship between the preset viewing angle corresponding to the second viewing angle image and the viewing angle corresponding to the first viewing angle image.
- the preset coordinate layer may indicate in advance the mapping relationship between the field angle corresponding to the second field-of-view image and the field-of-view angle corresponding to the first field-of-view image as required, and the specific illustration method may be performed as required.
- the settings and changes are not limited in this embodiment of the present application.
- the second image in the first frame is used as the reference frame, after the registration of the second FOV image, operations such as stretching, rotation, and scaling may be performed on the second FOV image.
- the image is deformed, so after registration, the mapping relationship between the field angle corresponding to the second field of view image and the field angle corresponding to the second image in the first frame also changes.
- the new mapping relationship formed between the field angle corresponding to the second field of view image of the first frame and the field angle corresponding to the second image of the first frame performs perspective transformation on the preset coordinate layer, that is, according to the registration
- the second field of view image after adjustment adjusts the two field of view mapping relationships shown in the preset coordinate layer, and after adjustment, a more accurate field of view mapping relationship can be obtained, so that relative to the preset coordinate map Layers are more accurate reference coordinate layers.
- FIG. 6 is a schematic diagram of obtaining a reference coordinate layer according to an embodiment of the present application.
- the preset coordinate layer can be preset to reflect the difference between the field angle corresponding to the second image in the first frame and the field angle corresponding to the unregistered second field of view image. Mapping relationship; then, register the second field of view image according to the second image of the first frame, and then according to the field of view corresponding to the second image of the first frame and the field of view corresponding to the registered second field of view image The mapping relationship between field angles is used to perform perspective transformation on the preset coordinate layer to obtain the corresponding reference coordinate layer.
- the preset coordinate layer includes an overlapping area, which is used to indicate that: among the second image and the second viewing angle image in the first frame, the image with a smaller viewing angle is pasted to the image with a larger viewing angle The area corresponding to the above time.
- the area other than the overlapping area can be called the non-overlapping area, and different values can be set for the pixels located in the overlapping area and the non-overlapping area for distinction.
- the shapes and positions of the overlapping area and the non-overlapping area may be set as required, and this embodiment of the present application does not impose any limitation on this. Since images are generally rectangular, the following example illustrates that the overlapped area is a rectangle and the non-overlapped area surrounds the overlapped area.
- the preset coordinate layer can be a binary image, assuming that the values corresponding to the pixels are only 0 and 255, representing white and black respectively, then the values corresponding to the pixels in the overlapping area can be set to 0, not The value corresponding to the pixels in the overlapping area is 255, or, the value corresponding to the pixel in the overlapping area is set to 255, and the value corresponding to the pixel in the non-overlapping area is 0.
- the field angle corresponding to the second image in the first frame is greater than the field angle corresponding to the second field of view image, then correspondingly, the second image in the first frame contains the content of the second field of view image, thus , you can set the size of the preset coordinate layer to be the same as the size of the second image in the first frame, and set the corresponding position when the second field of view image is pasted on the second image in the first frame in the preset coordinate layer
- the area in the overlapping area is the overlapping area, and the gray value corresponding to the pixels in the overlapping area in the preset coordinate layer is set to 0, while the gray value corresponding to the pixels outside the overlapping area, that is, in the non-overlapping area, is 255. This is for distinction.
- the preset coordinates can be set
- the size of the layer is the same as the size of the second field of view image, and in the preset coordinate layer, set the corresponding area when the first frame image is pasted on the second field of view image as the overlapping area, and set at the same time
- the grayscale value corresponding to the pixels in the overlapped area in the preset coordinate layer is 255, and the grayscale value corresponding to the pixels outside the overlapped area, that is, the non-overlapped area is 0, so as to distinguish them.
- FIG. 7 is a schematic diagram of performing perspective transformation on a preset coordinate layer according to an embodiment of the present application.
- A1 in Fig. 7 is the second image in the first frame
- B1 is unregistered The second field of view image.
- a preset coordinate layer can be set according to the area where B1 is pasted in A1.
- the size of the default coordinate layer (C1) can be set to be the same as the size of A1.
- the area corresponding to B1 is set as the overlapping area ch1, and other areas are non-overlapping areas fch1, and set
- the grayscale value corresponding to the pixel in the overlapping region ch1 is 0, and the grayscale value corresponding to the pixel in the non-overlapping region fch1 is 255.
- A1 as the reference frame to register B1.
- the area pasted in A1 after the offset of the registered B1 is shown in B2.
- the mapping relationship between the viewing angles can perform perspective transformation on the preset coordinate layer C1, so that the overlapping area ch1 is shifted to the position of the overlapping area ch2, and correspondingly, the non-overlapping area fch1 becomes the non-overlapping area fch2, thus , can be transformed to obtain a reference coordinate layer composed of the coincident area ch2 and the non-overlapping area fch2, as shown in C2.
- the above-mentioned second viewing Field angle images for registration may include:
- the first frame and the third image are used as the reference frame, and the second field of view image is registered.
- perspective transformation can be performed on the preset coordinate layer to obtain the reference coordinate layer.
- perspective transformation may be performed on the preset coordinate layer according to the third image in the first frame and the registered second field-of-view image to obtain the reference coordinate layer.
- the first image of the first frame is used as the reference frame, or the third image of the first frame is used as the reference frame to register the second field of view image, and then the method of obtaining the reference coordinate layer is the same as that of the first frame
- the second image of the frame is the reference frame, and the method of registering the second field of view image and obtaining the reference coordinate layer is the same, and will not be repeated here.
- the first processing further includes: black level correction.
- the above-mentioned first processing of the first field of view image can be expressed It is: performing black level correction on one or more of the following: multiple frames of the first image, multiple frames of the second image, and at least one frame of the third image.
- the black level correction can be performed on at least one frame of the first image in the multiple frames of the first image
- the black level correction can be performed on at least one frame of the second image in the multiple frames of the second image
- the black level correction can be performed on the multiple frames of the third image Perform black level correction on at least one frame of the third image.
- FIG. 8 is a schematic diagram of performing black level correction on a second image according to an embodiment of the present application.
- the first processing further includes: bad pixel correction.
- the first processing includes: automatic white balance.
- the first processing may Including: Automatic White Balance. Wherein, automatic white balance may be performed for each frame of the first image.
- the first processing may include: automatic white balance.
- automatic white balance may be performed for each frame of the second image.
- the first processing may include: automatic white balance.
- the first processing includes at least two items of black level correction, bad pixel correction, and automatic white balance, the order thereof may be adjusted as required, which is not limited in this embodiment of the present application.
- black level correction may be performed first, and then automatic white balance is performed.
- the first processing further includes: channel splitting (bayer to canvas ).
- channel splitting refers to splitting the Bayer format image into multiple single-channel sub-layers to be enhanced, and each single-channel sub-layer to be enhanced contains only one color channel signal, thus, more many details.
- the Bayer format image when the Bayer format image includes red pixels corresponding to the red channel signal, green pixels corresponding to the green channel signal and blue pixels corresponding to the blue channel signal, the Bayer format image can be split into three single-channel Among them, a single-channel sub-layer to be enhanced only contains the red channel signal, a single-channel sub-layer to be enhanced only contains the green channel signal, and another single-channel sub-layer to be enhanced only contains Contains the blue channel signal.
- the first process further includes: Channel splitting.
- channel splitting may be performed for each frame of the first image, for example, each frame of the first image is split into three single-channel sublayers to be enhanced.
- FIG. 9 is a schematic diagram of channel splitting for the second image provided in an embodiment of the present application. As shown in FIG. 9 , the Each frame of the second image is split into three single-channel sublayers to be enhanced.
- the Grayscale images do not need channel splitting.
- the first process further includes: adding a variance layer, where the variance layer includes a plurality of pixels, and the variance value corresponding to each pixel is determined by the sensitivity corresponding to the original image.
- a variance layer is added for each frame of the original image.
- each frame of original images can determine its corresponding exposure parameters, including sensitivity.
- Sensitivity is related to the noise level of the original image. The higher the sensitivity, the more noise in the original image. When the noise reduction process is performed in the later stage, correspondingly, the higher the noise reduction intensity is required.
- the size of the variance layer is the same as that of the original image, thus, the number of included pixels is also the same, and the variance value corresponding to each pixel is determined by the sensitivity corresponding to the original image.
- one frame of variance layer can be added for each frame of the original image, and the variance value corresponding to the pixel in the added variance layer is determined by The sensitivity of the corresponding original image is determined.
- exposure parameters may also be set and changed as required, which is not limited in this embodiment of the present application.
- FIG. 10 is a schematic diagram of performing channel splitting on a second image and adding a variance layer according to an embodiment of the present application. As shown in FIG. 10 , each frame of the second image is split into three single-channel sublayers to be enhanced, and one frame of variance layer is added.
- a variance layer is added to the multiple frames of original images.
- the variance layer includes a first variance layer, a second variance layer, a third variance layer and a fourth variance layer.
- a first variance layer is added to the first images of multiple frames, and the variance value corresponding to each pixel in the first variance layer is determined by any one of the first variance layers.
- the sensitivity corresponding to an image is determined.
- a second variance layer is added to multiple frames of second images, and the variance value corresponding to each pixel in the second variance layer is determined by any second image The corresponding sensitivity is determined.
- a third difference layer is added to multiple frames of third images, and the variance value corresponding to each pixel in the third difference layer is determined by any third image The corresponding sensitivity is determined.
- a fourth variance layer is added to the multiple frames of the second viewing angle images, and the variance value corresponding to each pixel in the fourth variance layer is given by The sensitivity corresponding to any second field of view image is determined.
- the variance layers determined by the photosensitivity corresponding to each frame of the first image are the same, therefore, it can be determined by the photosensitivity corresponding to any one of the first images
- the variance layer is output, and it is used as the first variance layer added.
- the variance layers determined by the photosensitivity corresponding to each frame of the second image are the same, therefore, it can be determined by the photosensitivity corresponding to any one of the second images
- the variance layer is output, and it is used as the second variance layer added.
- the variance layers determined by the photosensitivity corresponding to each frame of the third image are the same, therefore, it can be determined by the photosensitivity corresponding to any third image
- the variance layer is used as an additional third variance layer.
- any second field of view image can be composed of any The sensitivity corresponding to the field of view image determines the variance layer and serves as the fourth variance layer added.
- the variance value corresponding to each pixel in the variance layer is the sensitivity, or;
- the variance value corresponding to each pixel is the ratio of the sensitivity to the preset reference value, or;
- the variance layer includes a plurality of sub-areas, each sub-area includes a plurality of pixels, and the variance values corresponding to pixels in different sub-areas are products of sensitivity and different coefficients.
- the variance layer includes different variance values, which is equivalent to adding different prior information
- the noise reduction intensity is increased for a sub-region with a large variance value, that is, a large noise
- the noise reduction intensity is decreased for a sub-region with a small variance value, that is, a small noise.
- the ratio of the sensitivity to the preset reference value is used as the square corresponding to each pixel.
- the difference, that is, the variance value corresponding to each pixel is 8.
- the sub-region F in the variance layer is the area where the face is located, and the others are non-face areas, then the pixels located in the sub-area F and those located in the non-face area can be combined
- the variance values corresponding to the pixels in the sub-region F are distinguished, for example, the variance value corresponding to the pixel located in the sub-region F is 20, and the variance value corresponding to other pixels is 100.
- the first field of view image includes one or more of the following: multiple frames of the first image, multiple frames of the second image, at least one frame of the third image, and at least one of the first field of view images
- the above S30 can be expressed as:
- the first field of view image includes multiple frames of the first image
- the first processing is performed on the multiple frames of the first image
- the data after the first processing is performed according to the first image, and/or the second field of view
- the image has undergone the first processed data, and the reference coordinate layer, to obtain the layer set.
- the first field of view image includes multiple frames of second images
- the second image is subjected to the first processing
- the data after the first processing is performed on the second image, and/or the second field of view image is processed
- the first processed data and the reference coordinate layer are obtained to obtain a layer set.
- the first field of view image includes at least one frame of a third image
- the first processing is performed on the third image
- the data after the first processing is performed according to the third image, and/or the second field of view image
- the first processed data and the reference coordinate layer are used to obtain a layer set.
- the first field of view image includes multiple frames of first images and multiple frames of second images
- the first processing is performed on multiple frames of first images and/or multiple frames of second images, according to multiple frames of first images, multiple frames of The first-processed data of at least one of the second images in the frame, and/or the first-processed data of the second field of view image, and the reference coordinate layer to obtain a layer set.
- the first field of view image includes multiple frames of second images and at least one frame of third images
- at least one of the second images and the third images is subjected to the first processing
- the third images At least one of the first-processed data, and/or, the first-processed data and reference coordinate layer of the second field of view image, to obtain a layer set.
- the first field of view image includes multiple frames of the first image and at least one frame of the third image
- at least one of the first image and the third image is subjected to the first processing
- the third image At least one of the first-processed data, and/or, the first-processed data and the reference coordinate layer of the second field of view image, to obtain a layer set.
- the first field of view image includes multiple frames of the first image, multiple frames of the second image and at least one frame of the third image
- the first processing is performed on at least one of the first image, the second image and the third image , according to at least one of the first image, the second image and the third image, the first processed data, and/or, the second field of view image, the first processed data, and the reference coordinate map layer to get the layer set.
- the first enhanced image is in RGB color space.
- the layer set includes variance layers corresponding to the original images, image data corresponding to the original image after the first processing, and an added reference coordinate layer. Based on this, the images included in the layer set The data is simultaneously input into the deep learning network model for processing, and then the corresponding first enhanced image is output.
- the deep learning network model can be selected and changed according to needs, which is not limited in this embodiment of the present application.
- each pixel included in the first enhanced image located in the RGB color space includes three color components, that is, each pixel includes a red component, a green component and a blue component.
- the size of the first enhanced image is the same as that of the images in the layer set and the original image.
- the deep learning network model can perform noise reduction, demosaicing, color fusion (mono color fusion, MCF) and field of view fusion (fov fusion), and can also perform multiple exposure fusion (mutiexpo fusion) and other processing.
- demosaicing and noise reduction are operations related to detail restoration, performing demosaic processing first will affect the effect of noise reduction, and noise reduction first will affect the effect of demosaicing. Therefore, the embodiment of the present application will denoise and Demosaicing is implemented through a deep learning network model, which avoids the interaction between different processes and the accumulation of errors when multiple processes are performed in series, and improves the effect of image detail restoration.
- color fusion refers to the fusion of multiple frames of images of different colors.
- Field of view fusion refers to the fusion of multiple frames of images with different field of view.
- Multi-exposure fusion refers to the fusion of multiple frames of images with different exposures.
- FIG. 12 is a schematic flowchart of obtaining a first enhanced image corresponding to a layer set by using a deep learning network model according to an embodiment of the present application.
- the layer set is obtained from multiple frames of the first image, multiple frames of the second image, one frame of the third image and one frame of the second field of view image, and all the layer sets are input into the deep learning network model, After performing various processing, such as noise reduction, demosaicing, color fusion, field of view fusion, etc., a corresponding first enhanced image is output.
- the first enhanced image is an image located in the RGB color space, including a single-channel image of three colors.
- the deep learning network model can be any one of Unet model, Resnet model and PSPnet model.
- the deep learning network model may also be other models, which are not limited in this embodiment of the present application.
- the above S50 may include:
- Enhancement processing includes color enhancement processing and/or brightness enhancement processing.
- enhancement processing can also be performed on the first enhanced image, such as edge enhancement processing, etc., which can be set and changed according to needs, which is not limited in this embodiment of the present application.
- the size of the second enhanced image is the same as that of the first enhanced image.
- the above S50 may include:
- the segmentation model can be used to segment the content of human body and non-human body, human face and non-human face, object and non-object in the first enhanced image, and the specific segmentation basis can be set and changed according to needs.
- the embodiment of the present application There are no restrictions on this.
- the segmentation model can be any one of Unet model, Resnet model and PSPnet model.
- the segmentation model may also be other models, which are not limited in this embodiment of the present application.
- the mask image may be a binary image, that is, the grayscale values corresponding to the pixels included in the mask image are 0 and 255, and 0 and 255 represent white and black respectively, or, the mask image The values of the pixels correspond to 0 and 1, and 0 and 1 represent white and black, respectively.
- a segmentation model is used to divide the first enhanced image into a human body area and a non-human body area, and pixels included in the human body area all correspond to white, and pixels included in the non-human body area all correspond to black.
- the size of the mask image is the same as that of the first enhanced image.
- the gain coefficient map includes a plurality of pixels and a gain value corresponding to each pixel.
- the tone mapping model may be any one of Unet model, Resnet model and Hdrnet model.
- the tone mapping model may also be another model, which is not limited in this embodiment of the present application.
- the size of the gain coefficient map is the same as that of the first enhanced image and the mask map.
- S530 can be expressed as: multiplying the pixel value corresponding to the pixel in the first enhanced image with the gain value corresponding to the pixel at the corresponding position in the gain coefficient map to obtain the value of the pixel at the corresponding position in the second enhanced image Pixel values.
- the gain coefficient map includes multiple pixels, and the gain values corresponding to each pixel may be the same or different.
- the gain values corresponding to the pixels in the gain coefficient map are different, different enhancements may be performed on the pixels in the first enhanced image, and the processing is more delicate.
- the gain coefficient map includes 3 frames of color gain coefficient map and/or 1 frame of brightness gain coefficient map, each frame of color gain coefficient map only enhances one color, and the brightness gain coefficient map is used to enhance brightness.
- the gain coefficient map may include 3 frames of color gain coefficient maps, wherein the red gain The coefficient map is used to enhance red, the green gain coefficient map is used to enhance green, and the blue gain coefficient map is used to enhance blue.
- the corresponding red component is multiplied by the gain value at the corresponding position of the red gain coefficient map
- the green component is multiplied by the gain value at the corresponding position of the green gain coefficient map
- the blue The component is multiplied by the gain value at the corresponding location on the blue gain factor graph.
- the pixel value corresponding to a certain pixel in the first enhanced image is (10, 125, 30), and the gain values at the corresponding positions of the three frames of color gain coefficient maps are 2, 1 and 3 respectively, then after multiplication,
- the pixel value of the pixel at the corresponding position in the second enhanced image is (20, 125, 90).
- the red component, the green component and the blue component corresponding to the pixel in the first enhanced image are all multiplied by the gain value at the corresponding position in the brightness gain coefficient map, so that the brightness can be enhanced.
- the effect of multiplying the first enhanced image by the color gain coefficient map is equivalent to performing brightness enhancement on the first enhanced image.
- FIG. 14 is a schematic flowchart of performing enhancement processing on a first enhanced image to obtain a second enhanced image according to an embodiment of the present application.
- the first enhanced image is input into the segmentation model, and the mask map corresponding to the first enhanced image can be obtained.
- the mask map is a binary image, for example, the first enhanced image is divided into human body area and non-human body area . Then, the first enhanced image and the mask image are input into the tone mapping model at the same time, and processed by the tone mapping model, a corresponding color gain coefficient map and/or brightness gain coefficient map can be obtained.
- the first enhanced image is multiplied by the color gain coefficient map and/or the brightness gain coefficient map, thereby obtaining a second enhanced image with enhanced color and/or enhanced brightness.
- the embodiment of the present application provides an image processing method, by obtaining the first field of view image and the second field of view image corresponding to different field of view, and adding a reference coordinate layer to the second field of view image to form a map
- the layer set and then use the deep learning network model to process the layer set to obtain the first enhanced image, and then obtain the second enhanced image according to the first enhanced image.
- the reference coordinate layer reflects the mapping relationship between the field angle corresponding to the second field of view image and the field angle corresponding to the first field of view image, thus, by adding a reference coordinate layer, different viewing angles can be added.
- the mapping relationship information between field angles enables subsequent adjustments to be made according to the mapping relationship between different field angles, so that more details can be preserved, and the fusion is more natural, thereby achieving the purpose of improving image quality.
- the deep learning network model can perform multiple processes on the layer set at the same time, such as noise reduction, demosaicing, color fusion and field of view fusion, etc., avoiding the accumulation of errors caused by serial processing, thus, also The sharpness of the image can be improved.
- color enhancement and/or brightness enhancement is performed on the first enhanced image to enhance the visual effect of the image, so that the enhanced image content and image color can better meet the visual needs of users.
- the first field of view image includes multiple frames of the first image
- the first field of view image further includes multiple frames of the second image and/or at least one frame of the third image
- the above S30 includes:
- a layer set is obtained according to the images in the first field of view image except the multiple frames of the first image, the second field of view image and the reference coordinate layer.
- Solution 1 When the first field of view image includes multiple frames of first images and multiple frames of second images, and the first processing is not performed on multiple frames of first images, but only multiple frames of second images are subjected to the first processing, A layer set is obtained according to the first-processed data of multiple frames of second images, the second field of view image and the reference coordinate layer.
- the third image is the data after the first processing, the second field of view image and the reference coordinate layer to obtain a layer set.
- Solution 3 When the first field-of-view image includes multiple frames of first images, multiple frames of second images, and at least one frame of third images, and the first processing is not performed on multiple frames of first images, only the second images and the first frames are processed. When at least one of the three images has undergone the first processing, according to the data after the first processing of at least one of the second image and the third image of multiple frames, the second field of view image and the reference coordinate layer, it is obtained layer set.
- the method 10 further includes the following S508-S509.
- the above S508 may include:
- the first enhanced image is fused with the first image to be fused to obtain a first intermediate fused image.
- the first intermediate fused image is fused with the second image to be fused to obtain an intermediate enhanced image.
- the first image to be fused and the second image to be fused are a long exposure image and a short exposure image respectively.
- the above S408 may be expressed as: fusing the first enhanced image and the long-exposure image to obtain a first intermediate fused image; Then, the first intermediate fused image is fused with the short-exposure image to obtain an intermediate enhanced image.
- the first enhanced image may be fused with the long-exposure image, and then fused with the short-exposure image.
- the above S408 can be expressed as: merging the first enhanced image and the short-exposure image to obtain a first intermediate fused image; then, The intermediate fusion image is fused with the long exposure image to obtain an intermediate enhanced image.
- the first enhanced image may be fused with the short-exposure image, and then fused with the long-exposure image.
- the fusion of the first enhanced image and the long-exposure image can improve the details of the under-exposed dark areas in the first enhanced image, and the fusion with the short-exposure image can improve the details of the over-exposed dark areas in the first enhanced image. Details of the exposure area. Therefore, performing long-short exposure fusion processing on the first enhanced image can simultaneously improve the details of dark areas and over-exposed areas in the first enhanced image, improve the dynamic range, and thereby achieve the purpose of improving the clarity of the image.
- registration may also be performed on the first image to be fused and the second image to be fused.
- the first enhanced image may be used as a reference frame to register the first image to be fused.
- the first intermediate fused image is used as a reference frame to register the second image to be fused.
- the first image to be fused is a long-exposure image and the second image to be fused is a short-exposure image
- the first enhanced image can be used as a reference frame
- Registration is performed on long-exposure images.
- the short-exposure image may be registered using the first intermediate fusion image as a reference frame.
- the first enhanced image can be used as a reference frame to Exposure images for registration.
- the long exposure image may be registered using the first intermediate fused image as a reference frame.
- brightening can also be performed before registering the short-exposure images.
- the pixel value corresponding to each pixel in the short-exposure image may be multiplied by a preset coefficient to brighten the short-exposure image.
- bit width of the memory can be increased to store more image data.
- Fig. 16 is another schematic flowchart of performing enhancement processing on the first enhanced image to obtain the second enhanced image provided by the embodiment of the present application.
- the first image to be fused is a long exposure image
- registration processing is performed on the long exposure image
- the second image to be fused is a short exposure image
- brightening and registration processing is performed on the short exposure image
- the first enhanced image is fused with the registered long-exposure image to obtain the first intermediate fused image
- the first intermediate fused image is fused with the short-exposure image that has been brightened and registered to obtain the intermediate Enhance images.
- the intermediate enhanced image can be used as the second enhanced image, or the intermediate enhanced image can be used as the first enhanced image, and the corresponding mask map can be continuously obtained, and the intermediate enhanced image and mask image can be used according to the method from S510 to S530 , to obtain the corresponding second enhanced image.
- the method 10 further includes:
- the first enhanced image is located in the RGB color space, and after the enhancement processing is performed on the first enhanced image, the obtained second enhanced image is still located in the RGB color space.
- converting the second enhanced image located in the RGB color space into the first target image located in the YUV color space can reduce subsequent calculations and save storage space.
- At least one item of color, brightness, sharpness and size may be adjusted for the first enhanced image and the first target image.
- Embodiment 1 an image processing method, as shown in FIG. 17 , the method includes the following steps S1010 to S1050.
- the two frames of original images include: one frame of a first viewing angle image and one frame of a second viewing angle image, and the viewing angle corresponding to the first viewing angle image is different from the viewing angle corresponding to the second viewing angle image.
- the second field-of-view image is a Bayer pattern image.
- the reference coordinate layer is used to reflect the mapping relationship between the FOV corresponding to the second FOV image and the FOV corresponding to the first FOV image .
- the reference coordinate layer may be preset, that is, the reference coordinate layer is a preset coordinate layer.
- the preset coordinate layer includes coincident area and non-overlapping area, and the values corresponding to the pixels in the overlapping area and non-overlapping area are different; among them, the overlapping area is used to represent: the first field of view image and the second field of view In the corner image, the area corresponding to when the image with a smaller field of view is pasted on the image with a larger field of view.
- the first enhanced image is located in RGB color space.
- the deep learning network model is any one of Unet model, Resnet model and PSPnet model.
- Embodiment 2 an image processing method, as shown in FIG. 18 , the method includes the following S2010 to S2070.
- S2010 Acquiring multiple frames of first viewing angle images and one frame of second viewing angle images.
- the multiple frames of first viewing angle images include multiple frames of second images.
- the multiple frames of the second image and the second field-of-view image are images captured for the same scene to be captured.
- the viewing angles corresponding to the multiple frames of the second image are different from the viewing angles corresponding to the second viewing angle image, and the multiple frames of the second image are normally exposed Bayer format images.
- the second field-of-view image is also a Bayer pattern image.
- S2020. Perform first processing on multiple frames of second images.
- the first processing is also performed on the second viewing angle image.
- This first process includes registration, black level correction, automatic white balance, channel splitting and adding a variance layer.
- the first frame of second images is used as a reference frame, and other frames of second images are respectively registered.
- the second image of the first frame may be used as a reference frame, and then the registration of the images of the second viewing angle may be performed.
- channel splitting refers to splitting each frame of the first image into three single-channel sublayers to be enhanced, and each single-channel sublayer to be enhanced contains only one color channel signal.
- one frame of variance layer may be added to each frame of the first image, the variance layer includes a plurality of pixels, and the variance value corresponding to each pixel is determined by the sensitivity corresponding to the first image.
- the variance value corresponding to each pixel in the variance layer is: the sensitivity of the original image corresponding to the variance layer, or; the variance value corresponding to each pixel is: the sensitivity of the original image corresponding to the variance layer
- the ratio of the degree to the preset reference value, or; the variance layer includes multiple sub-areas, and each sub-area includes multiple pixels.
- the variance values corresponding to pixels in different sub-areas are different, and the coefficients corresponding to pixels in different sub-areas Differently, the variance value corresponding to the pixels in the first sub-region is: the product of the sensitivity of the original image corresponding to the variance layer and the first coefficient.
- the reference coordinate layer is used to reflect the mapping relationship between the FOV corresponding to the second FOV image and the FOV corresponding to the first FOV image .
- perspective transformation can be performed on the preset coordinate layer to obtain a reference coordinate layer, and then the reference coordinate layer can be added to Second FOV image.
- the preset coordinate layer is used to reflect the mapping relationship between the preset or unregistered viewing angle corresponding to the second viewing angle image and the viewing angle corresponding to the first viewing angle image.
- the preset coordinate layer includes overlapping areas and non-overlapping areas, and the corresponding values of pixels located in the overlapping areas and non-overlapping areas are different; wherein, the overlapping area is used to represent: the second image and the second view in the first frame In the field angle image, the area corresponding to when the image with a smaller field of view is attached to the image with a larger field of view.
- the multi-frame first image that has undergone the first processing includes: multiple sublayers to be enhanced and the added variance layer that have been split from the channels; the second field of view image that has undergone the first processing includes: the channel Multiple split sublayers to be enhanced and additional variance layers.
- the first enhanced image is located in RGB color space.
- the deep learning network model is any one of Unet model, Resnet model and PSPnet model.
- S2060 may include S2061-S2063.
- the segmentation model is any one of Unet model, Resnet model and PSPnet model.
- the tone mapping model uses the tone mapping model to obtain a gain coefficient map; the gain coefficient map includes a plurality of pixels and a corresponding gain value of each pixel.
- the tone mapping model is any one of Unet model, Resnet model and Hdrnet model.
- the gain coefficient map includes 3 frames of color gain coefficient map and/or 1 frame of brightness gain coefficient map, each frame of color gain coefficient map only enhances one color, and the brightness gain coefficient map is used to enhance brightness.
- Embodiment 3 an image processing method, as shown in FIG. 19 , the method includes the following steps S3010 to S3070.
- S3010 Acquire multiple frames of images of the first angle of view and one frame of images of the second angle of view.
- the multiple frames of first viewing angle images include 2 frames of first images and multiple frames of second images.
- the 2 frames of the first image, the multiple frames of the second image and the second field of view image are images captured for the same scene to be captured.
- the 2 frames of first images include 1 frame of long exposure image and 1 frame of short exposure image, and the 2 frames of first images are Bayer format images.
- the second image is a normally exposed Bayer pattern image.
- the second field-of-view image is also a Bayer pattern image.
- S3020 Perform the first processing on both the 2 frames of the first image and the multiple frames of the second images.
- the first processing is also performed on the second field-of-view image.
- This first process includes: registration, black level correction, automatic white balance, channel splitting and adding a variance layer.
- the first image of the first frame when registering two frames of the first image, the first image of the first frame may be used as a reference frame to register the first image of the second frame.
- the first frame of the second image When registering multiple frames of second images, the first frame of the second image is used as a reference frame, and the other frames of second images are respectively registered.
- the second image of the first frame When registering the images of the second viewing angle, the second image of the first frame may be used as a reference frame, and then the registration of the images of the second viewing angle may be performed.
- channel splitting is the same as the description of channel splitting in S2020 above, and will not be repeated here.
- a first variance layer can be added for each frame of the first image, and a second variance layer can be added for each frame of the second image; 1 sheet of the fourth variance layer.
- the first variance layer includes a plurality of pixels, and the variance value corresponding to each pixel is determined by the sensitivity corresponding to the first image;
- the second variance layer includes a plurality of pixels, and the variance value corresponding to each pixel is determined by the second The sensitivity corresponding to the image is determined;
- the fourth variance layer includes a plurality of pixels, and the variance value corresponding to each pixel is determined by the sensitivity corresponding to the second field of view image.
- the description of the first variance layer, the second variance layer, and the fourth variance layer is the same as the description of the variance layer in S2020 above, and will not be repeated here.
- the reference coordinate layer is used to reflect the mapping relationship between the FOV corresponding to the second FOV image and the FOV corresponding to the first FOV image .
- the process of obtaining the reference coordinate layer is the same as the process of obtaining the reference coordinate layer in S2030 above, and will not be repeated here.
- the multi-frame first image that has undergone the first processing includes: multiple sub-layers to be enhanced and the first variance layer added after channel splitting;
- the multi-frame second image that has undergone the first processing includes : multiple sub-layers to be enhanced and the second variance layer added after channel splitting;
- the second field of view image after the first processing includes: multiple sub-layers to be enhanced and added after channel splitting The fourth variance layer of .
- the first enhanced image is located in RGB color space.
- the deep learning network model is any one of Unet model, Resnet model and PSPnet model.
- S3060 Perform enhancement processing on the first enhanced image to obtain a second enhanced image, where the enhancement processing includes color enhancement processing and/or brightness enhancement processing.
- S3060 may include the above-mentioned S2061 to S2063, and the specific process may refer to the above-mentioned description, which will not be repeated here.
- Embodiment 4 an image processing method, as shown in FIG. 20 , the method includes the following steps S4010 to S4070.
- S4010 Acquire multiple frames of images of the first angle of view and one frame of images of the second angle of view.
- the multiple frames of first viewing angle images include multiple frames of second images and 2 frames of third images.
- the multiple frames of the second image, the two frames of the third image and the second field of view image are images captured for the same scene to be captured.
- the multi-frame second image is a normally exposed Bayer pattern image
- the third image is a gray scale image
- the second field of view image is a Bayer pattern image.
- S4020 Perform first processing on multiple frames of the second image and the third image.
- the first processing is also performed on the second field-of-view image.
- the first processing performed on the multi-frame second image and the second field of view image includes: registration, black level correction, automatic white balance, channel splitting and adding a variance layer;
- the first processing performed on the third image Processing includes: registration, black level correction, and addition of variance layers.
- the first frame of second images when registering multiple frames of second images, is used as a reference frame, and other frames of second images are respectively registered.
- the first frame of the third image When performing registration on two frames of the third image, the first frame of the third image may be used as a reference frame to perform registration on the second frame of the third image.
- the second image of the first frame When registering the images of the second viewing angle, the second image of the first frame may be used as a reference frame, and then the registration of the images of the second viewing angle may be performed.
- channel splitting is the same as the description of channel splitting in S2020 above, and will not be repeated here.
- a second variance layer when adding the variance layer, a second variance layer can be added for the second image of each frame, and a third variance layer can be added for the third image of each frame; A fourth variance layer.
- the second variance layer includes multiple pixels, and the variance value corresponding to each pixel is determined by the sensitivity corresponding to the second image;
- the third variance layer includes multiple pixels, and the variance value corresponding to each pixel is determined by the third image The corresponding sensitivity is determined;
- the fourth variance layer includes a plurality of pixels, and the variance value corresponding to each pixel is determined by the sensitivity corresponding to the second field of view image.
- the reference coordinate layer is used to reflect the mapping relationship between the FOV corresponding to the second FOV image and the FOV corresponding to the first FOV image .
- the process of obtaining the reference coordinate layer is the same as the process of obtaining the reference coordinate layer in S2030 above, and will not be repeated here.
- the multi-frame second image that has undergone the first processing includes: multiple sub-layers to be enhanced and the added second variance layer obtained by channel splitting;
- the multi-frame third image that has undergone the first processing includes: The third image and the added third variance layer;
- the second field-of-view image subjected to the first processing includes: multiple sub-layers to be enhanced obtained by channel splitting and the added fourth variance layer.
- the first enhanced image is located in RGB color space.
- the deep learning network model is any one of Unet model, Resnet model and Hdrnet model.
- S4060 Perform enhancement processing on the first enhanced image to obtain a second enhanced image, where the enhancement processing includes color enhancement processing and/or brightness enhancement processing.
- S4060 may include the above-mentioned S2061 to S2063, and the specific process may refer to the above-mentioned description, which will not be repeated here.
- Embodiment 5 an image processing method, as shown in FIG. 21 , the method includes the following steps S5010 to S5070.
- S5010 Acquire multiple frames of images of the first angle of view and one frame of images of the second angle of view.
- the multiple frames of first viewing angle images include 2 frames of the first image, multiple frames of the second image, and 2 frames of the third image.
- 2 frames of the first image, multiple frames of the second image, 2 frames of the third image and the second field of view image are images captured for the same scene to be captured.
- the 2 frames of first images include 1 frame of long exposure image and 1 frame of short exposure image, and the 2 frames of first images are Bayer format images.
- the second image is a normally exposed Bayer pattern image.
- the third image is a grayscale image, and the second field-of-view image is also a Bayer pattern image.
- S5020 Perform first processing on 2 frames of the first image, multiple frames of the second image, and 2 frames of the third image.
- the first processing is also performed on the second field-of-view image.
- the first processing performed on the 2 frames of the first image, multiple frames of the second image and the second field of view image includes: registration, black level correction, automatic white balance, channel splitting and adding a variance layer.
- the first processing performed on the 2 frames of the third image includes: registration, black level correction and adding a variance layer.
- the first image of the first frame when registering two frames of the first image, may be used as a reference frame to register the first image of the second frame.
- the first frame of the second image When registering multiple frames of second images, the first frame of the second image is used as a reference frame, and the other frames of second images are respectively registered.
- the first frame of the third image When performing registration on two frames of the third image, the first frame of the third image may be used as a reference frame to perform registration on the second frame of the third image.
- the second image of the first frame When registering the images of the second viewing angle, the second image of the first frame may be used as a reference frame, and then the registration of the images of the second viewing angle may be performed.
- channel splitting is the same as the description of channel splitting in S2020 above, and will not be repeated here.
- one first variance layer can be added for the first image of each frame
- one second variance layer can be added for the second image of each frame
- one second variance layer can be added for the third image of each frame
- a fourth variance layer is added for each frame of the second field of view image.
- the first variance layer includes a plurality of pixels, and the variance value corresponding to each pixel is determined by the sensitivity corresponding to the first image; the second variance layer includes a plurality of pixels, and the variance value corresponding to each pixel is determined by the second The sensitivity corresponding to the image is determined; the third variance layer includes multiple pixels, and the variance value corresponding to each pixel is determined by the sensitivity corresponding to the third image; the fourth variance layer includes multiple pixels, and each pixel corresponds to The variance value is determined by the sensitivity corresponding to the second field of view image.
- the description of the first variance layer, the second variance layer, the third variance layer and the fourth variance layer is the same as the description of the variance layer in S2020 above, and will not be repeated here .
- the reference coordinate layer is used to reflect the mapping relationship between the FOV corresponding to the second FOV image and the FOV corresponding to the first FOV image .
- the process of obtaining the reference coordinate layer is the same as the process of obtaining the reference coordinate layer in S2030 above, and will not be repeated here.
- the multi-frame first image that has undergone the first processing includes: multiple sub-layers to be enhanced and the first variance layer added after channel splitting;
- the multi-frame second image that has undergone the first processing includes : a plurality of sub-layers to be enhanced and an additional second variance layer obtained by channel splitting;
- the multi-frame third image that has undergone the first processing includes: the third image and the additional second variance layer;
- a processed second field-of-view image includes: a plurality of sublayers to be enhanced obtained by channel splitting and an added fourth variance layer.
- the first enhanced image is located in RGB color space.
- the deep learning network model is any one of Unet model, Resnet model and PSPnet model.
- S5060 Perform enhancement processing on the first enhanced image to obtain a second enhanced image, where the enhancement processing includes color enhancement processing and/or brightness enhancement processing.
- S5060 may include the above-mentioned S2061 to S2063, and the specific process may refer to the above-mentioned description, which will not be repeated here.
- Embodiment 6 an image processing method, as shown in FIG. 22 , the method includes the following steps S6010 to S6080.
- S6010 Acquire multiple frames of first field of view images and one frame of second field of view images.
- the multiple frames of first viewing angle images include 2 frames of first images and multiple frames of second images.
- the 2 frames of the first image, the multiple frames of the second image and the second field of view image are images captured for the same scene to be captured.
- the 2 frames of first images include 1 frame of long exposure image and 1 frame of short exposure image, and the 2 frames of first images are Bayer format images.
- the second image is a normally exposed Bayer pattern image.
- the second field-of-view image is also a Bayer pattern image.
- This first process includes: registration, black level correction, automatic white balance, channel splitting and adding a variance layer.
- the first frame of second images is used as a reference frame, and other frames of second images are respectively registered.
- the second image of the first frame may be used as a reference frame, and then the registration of the images of the second viewing angle may be performed.
- channel splitting is the same as the description of channel splitting in S2020 above, and will not be repeated here.
- a second variance layer may be added for each frame of the second image; and a fourth variance layer may be added for each frame of the second field-of-view image.
- the second variance layer includes a plurality of pixels, and the variance value corresponding to each pixel is determined by the sensitivity corresponding to the second image; the fourth variance layer includes a plurality of pixels, and the variance value corresponding to each pixel is determined by the second image.
- the light sensitivity corresponding to the field angle image is determined.
- the reference coordinate layer is used to reflect the mapping relationship between the FOV corresponding to the second FOV image and the FOV corresponding to the first FOV image .
- the process of obtaining the reference coordinate layer is the same as the process of obtaining the reference coordinate layer in S2030 above, and will not be repeated here.
- the multi-frame second image that has undergone the first processing includes: multiple sublayers to be enhanced and the second variance layer added after channel splitting;
- the second field of view image that has undergone the first processing includes : Multiple sub-layers to be enhanced and the added fourth variance layer obtained from channel splitting.
- the first enhanced image is located in RGB color space.
- the deep learning network model is any one of Unet model, Resnet model and PSPnet model.
- S6070 Perform enhancement processing on the first enhanced image to obtain a second enhanced image, where the enhancement processing includes color enhancement processing and/or brightness enhancement processing.
- S6070 may include the above-mentioned S2061 to S2063, and the specific process may refer to the above-mentioned description, which will not be repeated here.
- Embodiment 7 an image processing method, as shown in FIG. 23 , the method includes the following steps S7010 to S7080.
- S7010 Acquire multiple frames of images of the first angle of view and one frame of images of the second angle of view.
- the multiple frames of first viewing angle images include 2 frames of the first image, multiple frames of the second image, and 2 frames of the third image.
- 2 frames of the first image, multiple frames of the second image, 2 frames of the third image and the second field of view image are images captured for the same scene to be captured.
- the 2 frames of first images include 1 frame of long exposure image and 1 frame of short exposure image, and the 2 frames of first images are Bayer format images.
- the second image is a normally exposed Bayer pattern image
- the third image is a gray scale image
- the second field of view image is also a Bayer pattern image.
- the first processing performed on the multiple frames of the second image and the image of the second viewing angle includes: registration, black level correction, automatic white balance, channel splitting, and adding a variance layer.
- the first processing performed on the 2 frames of the third image includes: registration, black level correction and adding a variance layer.
- the first frame of second images when registering multiple frames of second images, is used as a reference frame, and other frames of second images are respectively registered.
- the first frame of the third image When performing registration on two frames of the third image, the first frame of the third image may be used as a reference frame to perform registration on the second frame of the third image.
- the second image of the first frame When registering the images of the second viewing angle, the second image of the first frame may be used as a reference frame, and then the registration of the images of the second viewing angle may be performed.
- channel splitting is the same as the description of channel splitting in S2020 above, and will not be repeated here.
- one second variance layer when adding the variance layer, one second variance layer can be added for the second image of each frame; one third variance layer can be added for the third image of each frame; one third variance layer can be added for the second field of view image of each frame A fourth variance layer.
- the second variance layer includes multiple pixels, and the variance value corresponding to each pixel is determined by the sensitivity corresponding to the second image;
- the third variance layer includes multiple pixels, and the variance value corresponding to each pixel is determined by the third image The corresponding sensitivity is determined;
- the fourth variance layer includes a plurality of pixels, and the variance value corresponding to each pixel is determined by the sensitivity corresponding to the second field of view image.
- the reference coordinate layer is used to reflect the mapping relationship between the FOV corresponding to the second FOV image and the FOV corresponding to the first FOV image .
- the process of obtaining the reference coordinate layer is the same as the process of obtaining the reference coordinate layer in S2030 above, and will not be repeated here.
- the multi-frame second image that has undergone the first processing includes: multiple sub-layers to be enhanced and the added second variance layer obtained by channel splitting;
- the multi-frame third image that has undergone the first processing includes: The third image and the added third variance layer;
- the second field-of-view image subjected to the first processing includes: multiple sub-layers to be enhanced obtained by channel splitting and the added fourth variance layer.
- S7050 Perform noise reduction, demosaicing, color fusion, and field of view fusion on the layer set by using the deep learning network model, to obtain a first enhanced image corresponding to the acquired layer set.
- the first enhanced image is located in RGB color space.
- the deep learning network model is any one of Unet model, Resnet model and PSPnet model.
- S7070 Perform enhancement processing on the first enhanced image to obtain a second enhanced image, where the enhancement processing includes color enhancement processing and/or brightness enhancement processing.
- S7070 may include the above S2061 to S2063.
- the electronic equipment and the image processing apparatus include corresponding hardware structures or software modules for performing each function, or a combination of both.
- the present application can be implemented in the form of hardware or a combination of hardware and computer software in combination with the units and algorithm steps of each example described in the embodiments disclosed herein. Whether a certain function is executed by hardware or computer software drives hardware depends on the specific application and design constraints of the technical solution. Skilled artisans may use different methods to implement the described functions for each specific application, but such implementation should not be regarded as exceeding the scope of the present application.
- the embodiment of the present application can divide the functional modules of the electronic equipment and the image processing device according to the above-mentioned method example, for example, each functional module can be divided corresponding to each function, or two or more functions can be integrated into one processing module.
- the above-mentioned integrated modules can be implemented in the form of hardware or in the form of software function modules. It should be noted that the division of modules in the embodiment of the present application is schematic, and is only a logical function division, and there may be other division methods in actual implementation. The following is an example of dividing each functional module corresponding to each function:
- FIG. 24 is a schematic structural diagram of an image processing device provided by an embodiment of the present application.
- the image processing apparatus 300 includes an acquisition module 310 and a processing module 320, and the processing module 320 may include a first processing module, a second processing module, and a third processing module.
- the image processing device can perform the following schemes:
- An acquisition module 310 configured to acquire multiple frames of original images.
- the multi-frame original image is an image taken on the same scene to be photographed.
- the multi-frame original image includes: a first field of view image and a second field of view image, and the field of view corresponding to the first field of view image and the second field of view Field angle images correspond to different field angles.
- the first processing module is configured to add a reference coordinate layer to the second field of view image.
- the reference coordinate layer is used to reflect the mapping relationship between the viewing angle corresponding to the second viewing angle image and the viewing angle corresponding to the first viewing angle image.
- the first processing module is further configured to obtain a layer set according to the first field of view image, the second field of view image and the reference coordinate layer.
- the second processing module is configured to use the deep learning network model to process the layer set to obtain the first enhanced image.
- the third processing module is used to obtain the second enhanced image according to the first enhanced image.
- the first processing module is further configured to perform a first processing on the first FOV image and/or the second FOV image, where the first processing includes: registration.
- the first field-of-view image includes one or more of the following: multiple frames of the first image, multiple frames of the second image, and at least one frame of the third image.
- the multiple frames of the first image include at least one frame of long-exposure image and at least one frame of short-exposure image
- the second image is a Bayer pattern image with normal exposure
- the third image is a grayscale image
- the first image is a Bayer image or a grayscale image.
- the second field-of-view image is a Bayer pattern image or a grayscale image.
- the first processing module is further configured to:
- the first frame and the second image are used as the reference frame, and the second field of view image is registered.
- the first processing module is further configured to:
- perspective transformation is performed on the preset coordinate layer to obtain the reference coordinate layer.
- the preset coordinate layer is used to reflect the mapping relationship between the preset viewing angle corresponding to the second viewing angle image and the viewing angle corresponding to the first viewing angle image.
- the preset coordinate layer includes an overlapping area, which is used to indicate that: among the second image and the second viewing angle image in the first frame, the image with a smaller viewing angle is pasted to the image with a larger viewing angle The area corresponding to the above time.
- the first processing further includes: black level correction.
- the first processing further includes: automatic white balance.
- the first processing further includes: channel splitting.
- channel splitting refers to splitting the Bayer format image into multiple single-channel sublayers to be enhanced, and each single-channel sublayer to be enhanced contains only one color channel signal.
- the first processing also includes: adding a variance layer;
- the variance layer includes a plurality of pixels, and the variance value corresponding to each pixel is determined by the sensitivity corresponding to the original image.
- the second processing module is further configured to: use the deep learning network model to perform noise reduction, demosaicing, color fusion, and field of view fusion to obtain the first enhanced image corresponding to the layer set.
- the first enhanced image is located in RGB color space.
- the third processing module is further configured to: perform enhancement processing on the first enhanced image to obtain the second enhanced image, where the enhancement processing includes color enhancement processing and/or brightness enhancement processing.
- Enhancement processing includes color enhancement processing and/or brightness enhancement processing.
- the third processing module is also used for:
- the gain coefficient map includes 3 frames of color gain coefficient map and/or 1 frame of brightness gain coefficient map, each frame of color gain coefficient map only enhances one color, and the brightness gain coefficient map is used to enhance brightness.
- the first field-of-view image includes multiple frames of the first image, and also includes multiple frames of the second image and/or at least one frame of the third image
- the first processing module does not process the multiple frames of the first image Perform the first processing
- the first processing module is also used to generate the second field of view image according to the images other than the first image in the first field of view image And the reference coordinate layer to get the layer set.
- the second processing module is further configured to: use the long exposure image and the short exposure image to perform long and short exposure fusion processing on the first enhanced image to obtain an intermediate enhanced image; and use the intermediate enhanced image as the first enhanced image.
- the second processing module is further configured to fuse the first enhanced image with the first image to be fused to obtain an intermediate fused image; and fuse the intermediate fused image with the second image to be fused to obtain an intermediate enhanced image.
- the first image to be fused and the second image to be fused are a long exposure image and a short exposure image respectively.
- the image processing device may further include a fourth processing module, configured to perform color space conversion on the second enhanced image to obtain the first target image in the YUV color space.
- a fourth processing module configured to perform color space conversion on the second enhanced image to obtain the first target image in the YUV color space.
- the acquisition module 310 in FIG. 24 can be realized by the receiving interface in FIG. 3, and the processing module 320 in FIG. At least one of a processor, a microcontroller, and a neural network processor, which is not limited in this embodiment of the present application.
- the embodiment of the present application also provides another image processing device, including: a receiving interface and a processor.
- the receiving interface is used to obtain multiple frames of original images from the electronic device.
- the multiple frames of original images are images taken for the same scene to be photographed.
- the multiple frames of original images include: a first field of view image and a second field of view image, the first The viewing angle corresponding to the first viewing angle image is different from the viewing angle corresponding to the second viewing angle image.
- the processor is used for invoking the computer program stored in the memory to execute the processing steps in the above-mentioned image processing method 10 .
- the embodiment of the present application also provides another electronic device, including a camera module, a processor, and a memory.
- the camera module is used to obtain multiple frames of original images.
- the multiple frames of original images are images taken for the same scene to be shot.
- the multiple frames of original images include: a first field of view image and a second field of view image, the first field of view image
- the field angle corresponding to the field angle image is different from the field angle corresponding to the second field angle image.
- Memory which stores computer programs that run on the processor.
- the processor is configured to execute the processing steps in the above-mentioned image processing method 10 .
- the camera module includes a color camera, a black-and-white camera and a third camera; the color camera and the black-and-white camera are used to take pictures of the same scene to be shot with a first angle of view, and the third camera is used to take pictures of the scene to be shot with a second angle of view. Two viewing angles are used to take pictures, and the first viewing angle is different from the second viewing angle.
- the color camera is used to obtain a multi-frame first image and a multi-frame second image after the processor obtains a camera instruction, and the multi-frame first image includes at least one long-exposure image and one short-exposure image; the second image is normal An exposed Bayer format image; a black-and-white camera, configured to acquire at least one frame of a third image after the processor acquires a photographing instruction, and the third image is a grayscale image.
- the third camera is configured to acquire at least one frame of a second field of view image after processing and acquiring the photographing instruction.
- the camera module includes a color camera, a black-and-white camera and a third camera; the color camera and the black-and-white camera are used to take pictures of the same scene to be shot with a first angle of view, and the third camera is used to take pictures of the scene to be shot with a second angle of view. Take pictures at two angles of view. The first angle of view is different from the second angle of view.
- the color camera is used to acquire multiple frames of second images after the processor acquires the camera instruction, and the second images are normally exposed Bayer format images.
- the black-and-white camera is used to obtain multiple frames of the first image and at least one frame of the third image after the processor obtains the camera instruction, and the multiple frames of the first image include at least one frame of long-exposure image and one frame of short-exposure image; the third image is grayscale image.
- the third camera is configured to acquire at least one frame of a second field of view image after the processor acquires the photographing instruction.
- the image is obtained by the image processor in the color camera and the black and white camera.
- the image sensor may be, for example, a charge-coupled device (charge-coupled device, CCD), a complementary metal oxide semiconductor (complementary metal oxide semiconductor, CMOS) and the like.
- the acquired first image, second image and third image correspond to the first viewing angle
- the acquired second viewing angle image corresponds to the second viewing angle
- the embodiment of the present application also provides a computer-readable storage medium, where computer instructions are stored in the computer-readable storage medium; when the computer-readable storage medium is run on an image processing device, the image processing device executes the following steps: The method shown in FIG. 4 , FIG. 13 , or any one of FIG. 15 to FIG. 23 .
- the computer instructions may be stored in or transmitted from one computer-readable storage medium to another computer-readable storage medium, for example, the computer instructions may be transmitted from a website, computer, server, or data center Transmission to another website site, computer, server or data center by wired (such as coaxial cable, optical fiber, digital subscriber line (DSL)) or wireless (such as infrared, wireless, microwave, etc.).
- wired such as coaxial cable, optical fiber, digital subscriber line (DSL)
- wireless such as infrared, wireless, microwave, etc.
- the computer-readable storage medium may be any available medium that can be accessed by a computer, or may be a data storage device including one or more servers, data centers, etc. that can be integrated with the medium.
- the available medium may be a magnetic medium (for example, a floppy disk, a hard disk, or a magnetic tape), an optical medium, or a semiconductor medium (for example, a solid state disk (solid state disk, SSD)) and the like.
- the embodiment of the present application also provides a computer program product containing computer instructions.
- the image processing device can execute the program shown in any one of Fig. 4, Fig. 13, or Fig. 15 to Fig. 23. Methods.
- FIG. 25 is a schematic structural diagram of a chip provided by an embodiment of the present application.
- the chip shown in FIG. 25 may be a general-purpose processor or a special-purpose processor.
- the chip includes a processor 401 .
- the processor 401 is configured to support the image processing apparatus to execute the technical solution shown in FIG. 4 , FIG. 13 , or any one of FIG. 15 to FIG. 23 .
- the chip further includes a transceiver 402, the transceiver 402 is used to accept the control of the processor 401, and is used to support the communication device to execute the technical solutions shown in any one of Figure 4, Figure 13, or Figure 15 to Figure 23 .
- the chip shown in FIG. 25 may further include: a storage medium 403 .
- the chip shown in Figure 25 can be implemented using the following circuits or devices: one or more field programmable gate arrays (field programmable gate array, FPGA), programmable logic device (programmable logic device, PLD) , controllers, state machines, gate logic, discrete hardware components, any other suitable circuitry, or any combination of circuitry capable of performing the various functions described throughout this application.
- field programmable gate array field programmable gate array, FPGA
- programmable logic device programmable logic device
- controllers state machines, gate logic, discrete hardware components, any other suitable circuitry, or any combination of circuitry capable of performing the various functions described throughout this application.
- the electronic equipment, image processing device, computer storage medium, computer program product, and chip provided by the above-mentioned embodiments of the present application are all used to execute the method provided above. Therefore, the beneficial effects that it can achieve can refer to the above-mentioned The beneficial effects corresponding to the method will not be repeated here.
- sequence numbers of the above processes do not mean the order of execution, and the execution order of each process should be determined by its functions and internal logic, and should not constitute any limitation on the implementation process of the embodiment of the present application.
- presetting and predefining can be realized by pre-saving corresponding codes, tables or other methods that can be used to indicate related information in devices (for example, including electronic devices) , the present application does not limit its specific implementation.
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Multimedia (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Software Systems (AREA)
- Signal Processing (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- Image Processing (AREA)
Abstract
本申请提供了一种图像处理方法、装置和电子设备,涉及图像技术领域,该图像处理方法包括:获取多帧原始图像;对第二视场角图像增设参考坐标图层;根据第一视场角图像、第二视场角图像以及参考坐标图层,得到图层集;利用深度学习网络模型处理图层集,得到第一增强图像;根据第一增强图像,得到第二增强图像。在该方法中,由于增设的参考坐标图层反映了第一视场角图像对应的视场角和第二视场角图像对应的视场角之间的映射关系,所以,通过增设参考坐标图层,可以增加先验信息,使得后续可以根据不同的视场角关系进行不同的调整,从而使得两个不同视场角的图像融合的更加自然,实现提高图像的质量的目的。
Description
本申请要求于2021年07月07日提交国家知识产权局、申请号为202110771029.X、申请名称为“图像处理方法、装置和电子设备”的中国专利申请的优先权,其全部内容通过引用结合在本申请中。
本申请涉及图像处理领域,尤其涉及一种图像处理方法、装置和电子设备。
随着电子设备的广泛使用,使用电子设备进行拍照已经成为人们生活中的一种日常行为方式。以电子设备为手机为例,相关技术中,为了提高拍照质量,业界提出了在手机上设置双摄像头,利用两个摄像头获取的图像信息之间的差异,进行图像信息的互补,由此来提升拍摄的图像质量。
但是实际上,目前配置有双摄像头的手机在拍摄图像时,只是将两个摄像头获取的图像进行简单的融合,而这种方式无法在各种场景下均拍摄出质量较高的图像。
示例性的,手机配置了两个摄像头,一个是主摄像头,另一个是广角摄像头或者是长焦摄像头。其中,广角摄像头的视场角相对于主摄像头的视场角较大,适合近景拍摄,长焦摄像头的视场角相对于主摄像头的视场角较小,适合远景拍摄。此时,若将主摄像头拍摄的图像和广角摄像头或者和长焦摄像头拍摄的图像进行简单融合,由于两个摄像头的视场角不匹配,将会导致融合得到的图像立体感较差,质量也较差。
例如,采用这种双摄像头的手机得到的两种图像中有视场角重合的部分,也有视场角不重合的部分。如果直接将两张图像进行融合,那么最终拍摄得到的图像中视场角重合的部分清晰度高,不重合的部分清晰度低,使得拍摄得到的图像会出现中心部分和四周部分的清晰度不一致的问题,即图像上会出现融合边界,影响成像效果。
因此,亟待一种新的图像处理方法,来有效提高获取的图像的质量。
发明内容
本申请提供一种图像处理方法、装置和电子设备,通过为两个不同视场角的图像中的一个增设参考坐标图层,然后输入深度学习网络模型中处理,获取对应的图像,来提高拍摄的图像的质量。
为达到上述目的,本申请采用如下技术方案:
第一方面,提供一种图像处理方法,该方法包括:
获取多帧原始图像,多帧原始图像为对相同的待拍摄场景拍摄的图像,多帧原始图像包括:第一视场角图像和第二视场角图像,第一视场角图像对应的视场角与第二视场角图像对应的视场角不同;对第二视场角图像增设参考坐标图层,参考坐标图层用于反映第二视场角图像对应的视场角与第一视场角图像对应的视场角之间的映射关系;根据第一视场角图像、第二视场角图像以及参考坐标图层,得到图层集;利用深 度学习网络模型处理图层集,得到第一增强图像;第一增强图像位于RGB颜色空间;根据第一增强图像,得到第二增强图像。
本申请实施例提供了一种图像处理方法,通过获取对应不同视场角的第一视场角图像和第二视场角图像,并对第二视场角图像增设参考坐标图层,形成图层集,然后,再利用深度学习网络模型对图层集进行处理,得到第一增强图像,再根据第一增强图像,得到第二增强图像。由于参考坐标图层反映了第二视场角图像对应的视场角与第一视场角图像对应的视场角之间的映射关系,由此,通过增设参考坐标图层,可以增加不同视场角之间的映射关系信息,使得后续可以根据不同视场角之间的映射关系进行不同调整,从而可以保留更多细节,融合的更加自然,进而实现提高图像的质量的目的。
又因为深度学习网络模型可以对图层集同时进行多种处理,例如,进行降噪、去马赛克、彩色融合和视场角融合等,避免了串行处理所造成的错误累积,由此,也可以提高图像的清晰度。
在第一方面一种可能的实现方式中,在对第二视场角图像增设参考坐标图层之前,该方法还包括:对第一视场角图像,和/或,第二视场角图像进行第一处理,第一处理包括:配准。在该实现方式中,通过进行配准,可以提高后续图像处理过程中的准确性。
在第一方面一种可能的实现方式中,第一视场角图像包括以下的一项或多项:多帧第一图像、多帧第二图像、至少一帧第三图像;其中,多帧第一图像包括至少一帧长曝光图像和至少一帧短曝光图像,第二图像为正常曝光的拜耳格式图像,第三图像为灰阶图像。
在第一方面一种可能的实现方式中,第一图像为拜耳格式图像或为灰阶图像。
在第一方面一种可能的实现方式中,第二视场角图像为拜耳格式图像或为灰阶图像。
在第一方面一种可能的实现方式中,当第一视场角图像包括多帧第二图像时,对第二视场角图像进行配准,包括:以第1帧第二图像为参考帧,对第二视场角图像进行配准。
在第一方面一种可能的实现方式中,在对第二视场角图像进行配准之后,该方法还包括:根据第1帧第二图像和配准后的第二视场角图像,对预设坐标图层进行透视变换,得到参考坐标图层,预设坐标图层用于反映预设的第二视场角图像对应的视场角与第一视场角图像对应的视场角之间的映射关系。在该实现方式中,由于以第1帧第二图像为参考帧,对第二视场角图像进行了配准,所以,根据配准后的第二视场角图像可以调整预设坐标图层,得到更能准确反应第一视场角图像对应的视场角和第二视场角图像对应的视场角之间的映射关系的参考坐标图层。
在第一方面一种可能的实现方式中,预设坐标图层包括重合区;重合区用于表示:第1帧第二图像和第二视场角图像中,视场角较小的图像贴到视场角较大的图像上时所对应的区域。
在第一方面一种可能的实现方式中,第一处理还包括:黑电平校正。
在第一方面一种可能的实现方式中,针对为拜耳格式图像的第一图像、针对第二 图像、针对为拜耳格式图像的第二视场角图像中的至少一项,第一处理还包括:自动白平衡。
在第一方面一种可能的实现方式中,第一处理还包括:通道拆分;其中,通道拆分指的是将拜耳格式图像拆分成多个单通道的待增强子图层,每个单通道的待增强子图层只包含一种颜色通道信号。在该实现方式中,通过进行通道拆分,可以保留拜耳格式图像中更多的细节。
在第一方面一种可能的实现方式中,第一处理还包括:增设方差图层;其中,方差图层包括多个像素,每个像素对应的方差值由原始图像对应的感光度确定。在该实现方式中,由于增设的方差图层所包括的像素对应的方差值由原始图像对应的感光度确定,所以,通过增设方差图层,可以增加先验信息,使得后续可以根据不同噪声水平来进行不同强度的降噪,从而保留更多细节,实现提高图像的清晰度的目的。
在第一方面一种可能的实现方式中,利用深度学习网络模型处理图层集,得到第一增强图像,包括:利用深度学习网络模型对图层集进行降噪、去马赛克、彩色融合和视场角融合,得到第一增强图像。在该实现方式中,由于深度学习网络模型均可以同时进行多个处理,避免了串行处理所造成的错误累积,由此,可以提高图像的清晰度。
在第一方面一种可能的实现方式中,根据所述第一增强图像,得到第二增强图像,包括:对第一增强图像进行增强处理,得到第二增强图像,增强处理包括颜色增强处理和/或亮度增强处理。在该实现方式中,对第一增强图像进行颜色增强和/或亮度增强,可以增强图像的视觉效果,从而使得增强后的图像内容和图像色彩都更能满足用户的视觉需求。
在第一方面一种可能的实现方式中,对第一增强图像进行增强处理,得到第二增强图像,包括:利用分割模型对第一增强图像进行分割,得到掩膜图;根据第一增强图像和掩膜图,利用色调映射模型,得到增益系数图;增益系数图包括多个像素,以及每个像素对应的增益值;将第一增强图像与增益系数图相乘,得到第二增强图像。在该实现方式中,可对第一增强图像进行非线性的增强,由此,针对第一增强图像可以处理的更加细腻。
在第一方面一种可能的实现方式中,增益系数图包括3帧颜色增益系数图和/或1帧亮度增益系数图,每帧颜色增益系数图只对一种颜色进行增强,所述亮度增益系数图用于对亮度进行增强。
在第一方面一种可能的实现方式中,当对第一视场角图像中的多帧第一图像未进行第一处理,而对第二视场角图像进行第一处理时,根据第一视场角图像、第二视场角图像以及参考坐标图层,得到图层集,包括:根据第一视场角图像中除多帧第一图像之外的图像,第二视场角图像以及参考坐标图层,得到图层集。
在第一方面一种可能的实现方式中,在利用分割模型,得到第一增强图像对应的掩膜图之前,该方法还包括:利用多帧第一图像中的长曝光图像和短曝光图像,对第一增强图像进行长短曝光融合处理,得到中间增强图像;将中间增强图像作为第一增强图像。在该实现方式中,对第一增强图像进行长短曝光融合处理,可以提升第一增强图像中暗区和过曝区域的细节,得到清晰度更高的中间增强图像。
在第一方面一种可能的实现方式中,利用长曝光图像和短曝光图像,对第一增强图像进行长短曝光融合处理,得到中间增强图像,包括:将第一增强图像与第一待融合图像进行融合,得到第一中间融合图像;将第一中间融合图像与第二待融合图像进行融合,得到所述中间增强图像;其中,第一待融合图像、第二待融合图像分别为长曝光图像和短曝光图像。
在第一方面一种可能的实现方式中,在得到第二增强图像之后,该方法还包括:对第二增强图像进行色彩空间转换,得到位于YUV颜色空间的第一目标图像。在该实现方式中,进行色彩空间转换可以减少后续计算量,节省存储空间。
在第一方面一种可能的实现方式中,深度学习网络模型、分割模型分别为Unet模型、Resnet模型和PSPnet模型中的任意一种。
在第一方面一种可能的实现方式中,色调映射模型为Unet模型、Resnet模型和Hdrnet模型中的任意一种。
第二方面,提供了一种图像处理装置,该装置包括用于执行以上第一方面或第一方面的任意可能的实现方式中各个步骤的单元。
第三方面,提供了一种图像处理装置,包括:接收接口和处理器;接收接口用于从电子设备处获取多帧原始图像,多帧原始图像为对相同的待拍摄场景拍摄的图像,多帧原始图像包括:第一视场角图像和第二视场角图像,第一视场角图像对应的视场角与第二视场角图像对应的视场角不同;处理器,用于调用存储器中存储的计算机程序,以执行如第一方面或第一方面的任意可能的实现方式中提供的图像处理方法中进行处理的步骤。
第四方面,提供了一种电子设备,包括摄像头模组、处理器和存储器;摄像头模组,用于获取多帧原始图像,多帧原始图像为对相同的待拍摄场景拍摄的图像,多帧原始图像包括:第一视场角图像和第二视场角图像,第一视场角图像对应的视场角与第二视场角图像对应的视场角不同;存储器,用于存储可在处理器上运行的计算机程序;处理器,用于执行如第一方面或第一方面的任意可能的实现方式中提供的图像处理方法中进行处理的步骤。
在第四方面一种可能的实现方式中,摄像头模组包括彩色摄像头、黑白摄像头和第三摄像头,彩色摄像头和黑白摄像头用于对相同的待拍摄场景以第一视场角进行拍照,第三摄像头用于对待拍摄场景以第二视场角进行拍照;第一视场角与第二视场角不同;彩色摄像头,用于在处理器获取拍照指令后,获取多帧第一图像和多帧第二图像,多帧第一图像至少包括一帧长曝光图像和一帧短曝光图像;第二图像为正常曝光的拜耳格式图像;黑白摄像头,用于在处理器获取拍照指令后,获取至少一帧第三图像,第三图像为灰阶图像;第三摄像头,用于在处理器获取所述拍照指令后,获取至少一帧第二视场角图像。
在第四方面一种可能的实现方式中,摄像头模组包括彩色摄像头、黑白摄像头和第三摄像头,彩色摄像头和黑白摄像头用于对相同的待拍摄场景以第一视场角进行拍照,第三摄像头用于对待拍摄场景以第二视场角进行拍照;第一视场角与所述第二视场角不同;彩色摄像头,用于在处理器获取拍照指令后,获取多帧第二图像,第二图像为正常曝光的拜耳格式图像;黑白摄像头,用于在处理器获取拍照指令后,获取多 帧第一图像和至少一帧第三图像,多帧第一图像至少包括一帧长曝光图像和一帧短曝光图像;第三图像为灰阶图像;第三摄像头,用于在处理器获取所述拍照指令后,获取至少一帧第二视场角图像。
第五方面,提供了一种芯片,包括:处理器,用于从存储器中调用并运行计算机程序,使得安装有芯片的设备执行如如第一方面或第一方面的任意可能的实现方式中提供的图像处理方法中进行处理的步骤。
第六方面,提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序包括程序指令,程序指令当被处理器执行时,使处理器执行如第一方面或第一方面的任意可能的实现方式中提供的图像处理方法中进行处理的步骤。
第七方面,提供了一种计算机程序产品,计算机程序产品包括存储了计算机程序的计算机可读存储介质,计算机程序使得计算机执行如第一方面或第一方面的任意可能的实现方式中提供的图像处理方法中进行处理的步骤。
本申请提供的图像处理方法、装置和电子设备,通过获取对应不同视场角的第一视场角图像和第二视场角图像,并对第二视场角图像增设参考坐标图层,形成图层集,然后,再利用深度学习网络模型对图层集进行处理,得到第一增强图像,再根据第一增强图像,得到第二增强图像。由于参考坐标图层反映了第二视场角图像对应的视场角与第一视场角图像对应的视场角之间的映射关系,由此,通过增设参考坐标图层,可以增加不同视场角之间的映射关系信息,使得后续可以根据不同视场角之间的映射关系进行不同调整,从而可以保留更多细节,融合的更加自然,进而实现提高图像的质量的目的。
又因为深度学习网络模型可以对图层集同时进行多种处理,例如,进行降噪、去马赛克、彩色融合和视场角融合等,避免了串行处理所造成的错误累积,由此,也可以提高图像的清晰度。
图1为相关技术提供的一种对双摄像头拍摄的图像进行处理的示意图;
图2为本申请实施例提供的一种电子设备的结构示意图;
图3为本申请实施例提供的一种图像处理装置的硬件架构图;
图4为本申请实施例提供的一种图像处理方法的流程示意图;
图5为本申请实施例提供的一种对多帧第二图像进行配准的流程示意图;
图6为本申请实施例提供的一种获取参考坐标图层的示意图;
图7为本申请实施例提供的一种对预设坐标图层进行透视变换处理的示意图;
图8为本申请实施例提供的一种对第二图像进行黑电平校正的示意图;
图9为本申请实施例提供的一种对第二图像进行通道拆分的示意图;
图10为本申请实施例提供的一种对第二图像进行通道拆分并增设方差图层的示意图;
图11为本申请实施例提供的方差图层的示意图;
图12为本申请实施例提供的利用深度学习网络模型获取图层集对应的第一增强图像的流程示意图;
图13为本申请实施例提供的又一种图像处理方法的流程示意图;
图14为本申请实施例提供一种对第一增强图像进行增强处理,得到第二增强图像的流程示意图;
图15为本申请实施例提供的又一种图像处理方法的流程示意图;
图16为本申请实施例提供的另一种对第一增强图像进行增强处理,得到第二增强图像的流程示意图;
图17为本申请实施例提供的又一种图像处理方法的流程示意图;
图18为本申请实施例提供的又一种图像处理方法的流程示意图;
图19为本申请实施例提供的又一种图像处理方法的流程示意图;
图20为本申请实施例提供的又一种图像处理方法的流程示意图;
图21为本申请实施例提供的又一种图像处理方法的流程示意图;
图22为本申请实施例提供的又一种图像处理方法的流程示意图;
图23为本申请实施例提供的又一种图像处理方法的流程示意图;
图24为本申请实施例提供的一种图像处理装置的结构示意图;
图25为申请实施例提供的一种芯片的结构示意图。
下面将结合附图,对本申请中的技术方案进行描述。
在本申请实施例的描述中,除非另有说明,“/”表示或的意思,例如,A/B可以表示A或B;本文中的“和/或”仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,A和/或B,可以表示:单独存在A,同时存在A和B,单独存在B这三种情况。另外,在本申请实施例的描述中,“多个”是指两个或多于两个。
以下,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本实施例的描述中,除非另有说明,“多个”的含义是两个或两个以上。
首先,对本申请实施例中的部分用语进行解释说明,以便于本领域技术人员理解。
1、RGB(red,green,blue)颜色空间,指的是一种与人的视觉系统结构相关的颜色模型。根据人眼睛的结构,将所有颜色都当作是红色、绿色和蓝色的不同组合。
2、YUV颜色空间,指的是一种颜色编码方法,Y表示亮度,U和V表示的则是色度。上述RGB颜色空间着重于人眼对色彩的感应,YUV颜色空间则着重于视觉对亮度的敏感程度,RGB颜色空间和YUV颜色空间可以互相转换。
3、像素值,指的是位于RGB颜色空间的彩色图像中每个像素对应的一组颜色分量。例如,每个像素对应一组三基色分量,其中,三基色分量分别为红色分量R、绿色分量G和蓝色分量B。
4、拜耳格式(bayer pattern)彩色滤波阵列(color filter array,CFA),图像由实际的景物转换为图像数据时,通常是图像传感器分别接收红色通道信号、绿色通道信号和蓝色通道信号,三个通道信号的信息,然后将三个通道信号的信息合成彩色图像,但是,这种方案中每个像素位置处都对应需要三块滤镜,价格昂贵且不好制作,因此,可以在图像传感器表面覆盖一层彩色滤波阵列,以获取三个通道信号的信息。拜耳格式彩色滤波阵列指的是滤镜以棋盘格式进行排布,例如,该拜耳格式彩色滤波阵列中 的最小重复单元为:一个获取红色通道信号的滤镜、两个获取绿色通道信号的滤镜、一个获取蓝色通道信号的滤镜以2×2的方式排布。
5、拜耳格式图像(bayer image),即基于拜耳格式彩色滤波阵列的图像传感器输出的图像。该图像中的多种颜色的像素以拜耳格式进行排布。其中,拜耳格式图像中的每个像素仅对应一种颜色的通道信号。示例性的,由于人的视觉对绿色较为敏感,所以可以设定绿色像素(对应绿色通道信号的像素)占全部像素的50%,蓝色像素(对应蓝色通道信号的像素)和红色像素(对应红色通道信号的像素)各占全部像素的25%。其中,拜耳格式图像的最小重复单元为:一个红色像素、两个绿色像素和一个蓝色像素以2×2的方式排布。
6、灰阶图像(gray image),灰阶图像是单通道图像,用于表示不同亮度程度,最亮为全白,最暗为全黑。也就是说,灰阶图像中的每个像素对应黑色到白色之间的不同程度的亮度。通常为了对最亮到最暗之间的亮度变化进行描述,将其进行划分,例如划分为256份,即代表256个等级的亮度,并称之为256个灰阶(第0灰阶~第255灰阶)。
7、二值图像(binary image),指的是图像上的每一个像素只有两种可能的取值或灰度等级状态。例如,图像所包括的像素对应的灰度值只能为0或255,0和255分别表示白色和黑色;或者说,图像中的像素对应的取值只能为0或1,0和1分别代表白色和黑色。
8、配准,指的是在同一区域内以不同成像手段所获得的不同图像的地理坐标的匹配。其中,包括几何纠正、投影变换与统一比例尺三方面的处理。
9、黑电平校正,由于图像传感器存在暗电流,导致在没有光线照射的时候,像素也对应有一定的输出电压,并且,不同位置处的像素可能对应不同的输出电压,因此,需要对没有光亮时(即,黑色)像素对应的输出电压进行校正。
10、坏点校正,坏点即为全黑环境下输出图像中的白点,高亮环境下输出图像中的黑点。一般情况下,三基色通道信号应与环境亮度呈线性响应关系,但是由于图像传感器输出的信号不良,就可能出现白点或黑点,对此,可以自动检测坏点并自动修复,或者,建立坏点像素链表进行固定位置的坏像素点修复。其中,一个点即指的是一个像素。
11、降噪,指的是减少图像中噪声的过程。一般方法有均值滤波、高斯滤波、双边滤波等。
12、自动白平衡,为了消除光源对图像传感器成像的影响,模拟人类视觉的颜色恒常性,保证在任何场景下看到的白色是真正的白色,因此,需要对色温进行校正,自动将白平衡调到合适的位置。
13、视场角(field of view,FOV),用于指示摄像头所能拍摄到的最大的角度范围。若待拍摄物体处于这个角度范围内,该待拍摄物体便会被摄像头捕捉到。若待拍摄物体处于这个角度范围之外,该待拍摄物体便不会被摄像头捕捉到。
通常,摄像头的视场角越大,则拍摄范围就越大,焦距就越短;而摄像头的视场角越小,则拍摄范围就越小,焦距就越长。因此,摄像头因视场角的不同可以被划分主摄像头、广角摄像头和长焦摄像头。其中,广角摄像头的视场角相对于主摄像头的 视场角较大,焦距较小,适合近景拍摄;而长焦摄像头的视场角相对于主摄像头的视场角较小,焦距较长,适合远景拍摄。
以上是对本申请实施例所涉及的名词的简单介绍,以下不再赘述。
随着电子设备的广泛使用,使用电子设备进行拍照已经成为人们生活中的一种日常行为方式。以手机为例,相关技术中,为了提高拍照质量,业界提出了在手机上设置双摄像头,利用两个摄像头获取的图像信息之间的差异,进行图像信息的互补,由此来提升拍摄的图像质量。
但是实际上,目前配置有双摄像头的手机在拍摄图像时,只是将两个摄像头获取的图像进行简单的融合,而这种方式无法在各种场景下均拍摄出质量较高的图像。
示例性的,手机配置了两个摄像头,一个是主摄像头,另一个是广角摄像头或者是长焦摄像头,或者,两个摄像头分别为广角摄像头和长焦摄像头。其中,广角摄像头的视场角相对于主摄像头的视场角较大,长焦摄像头的视场角相对于主摄像头的视场角较小。然后,将主摄像头拍摄的图像和广角摄像头拍摄的图像,或者;将主摄像头拍摄的图像和长焦摄像头拍摄的图像进行简单融合,或者;将广角摄像头拍摄的图像和长焦摄像头拍摄的图像进行简单融合。
图1示出了一种相关技术对双摄像头拍摄的图像进行处理的示意图。
如图1所示,在相关技术中,通常会根据视场角大小,将主摄像头拍摄的第一视场角图像填充在广角摄像头拍摄的第二视场角图像中,或者,将长焦摄像头拍摄的第一视场角图像填充在主摄像头或广角摄像头拍摄的第二视场角图像中。但是,在这种方式中,由于两个摄像头的视场角不匹配,将会导致融合得到的图像立体感较差,质量也较差。
例如,采用这种双摄像头的手机得到的两种图像中有视场角重合的部分,也有视场角不重合的部分。如果直接将两张图像进行融合,那么最终拍摄得到的图像中视场角重合的部分与不重合的部分可能对位对不上,部分内容产生断裂或畸形。此外,视场角重合的部分可能清晰度高,不重合的部分清晰度低,使得拍摄得到的图像会出现中心部分和四周部分的清晰度不一致的问题,即图像上会出现融合边界,影响成像效果。
有鉴于此,本申请实施例提供了一种图像处理方法,通过获取对应不同视场角的第一视场角图像和第二视场角图像,并对第二视场角图像增设参考坐标图层,形成图层集,然后,再利用深度学习网络模型对图层集进行处理,得到第一增强图像,再根据第一增强图像,得到第二增强图像。由于参考坐标图层反映了第二视场角图像对应的视场角与第一视场角图像对应的视场角之间的映射关系,由此,通过增设参考坐标图层,可以增加不同视场角之间的映射关系信息,使得后续可以根据不同视场角之间的映射关系进行不同调整,从而可以保留更多细节,融合的更加自然,进而实现提高图像的质量的目的。
本申请实施例提供的图像处理方法可以适用于各种电子设备,对应的,本申请实施例提供的图像处理装置可以为多种形态的电子设备。
在本申请的一些实施例中,该电子设备可以为单反相机、卡片机等各种摄像装置、手机、平板电脑、可穿戴设备、车载设备、增强现实(augmented reality,AR)/虚拟现实(virtual reality,VR)设备、笔记本电脑、超级移动个人计算机(ultra-mobile personal computer,UMPC)、上网本、个人数字助理(personal digital assistant,PDA)等,或者可以为其他能够进行图像处理的设备或装置,对于电子设备的具体类型,本申请实施例不作任何限制。
下文以电子设备为手机为例,图2示出了本申请实施例提供的一种电子设备100的结构示意图。
电子设备100可以包括处理器110,外部存储器接口120,内部存储器121,通用串行总线(universal serial bus,USB)接口130,充电管理模块140,电源管理模块141,电池142,天线1,天线2,移动通信模块150,无线通信模块160,音频模块170,扬声器170A,受话器170B,麦克风170C,耳机接口170D,传感器模块180,按键190,马达191,指示器192,摄像头193,显示屏194,以及用户标识模块(subscriber identification module,SIM)卡接口195等。其中传感器模块180可以包括压力传感器180A,陀螺仪传感器180B,气压传感器180C,磁传感器180D,加速度传感器180E,距离传感器180F,接近光传感器180G,指纹传感器180H,温度传感器180J,触摸传感器180K,环境光传感器180L,骨传导传感器180M等。
处理器110可以包括一个或多个处理单元,例如:处理器110可以包括应用处理器(application processor,AP),调制解调处理器,图形处理器(graphics processing unit,GPU),图像信号处理器(image signal processor,ISP),控制器,视频编解码器,数字信号处理器(digital signal processor,DSP),基带处理器,和/或神经网络处理器(neural-network processing unit,NPU)等。其中,不同的处理单元可以是独立的器件,也可以集成在一个或多个处理器中。
其中,控制器可以是电子设备100的神经中枢和指挥中心。控制器可以根据指令操作码和时序信号,产生操作控制信号,完成取指令和执行指令的控制。
处理器110中还可以设置存储器,用于存储指令和数据。在一些实施例中,处理器110中的存储器为高速缓冲存储器。该存储器可以保存处理器110刚用过或循环使用的指令或数据。如果处理器110需要再次使用该指令或数据,可从所述存储器中直接调用。避免了重复存取,减少了处理器110的等待时间,因而提高了系统的效率。
处理器110可以运行本申请实施例提供的图像处理方法的软件代码,拍摄得到清晰度较高的图像。
在一些实施例中,处理器110可以包括一个或多个接口。接口可以包括集成电路(inter-integrated circuit,I2C)接口,集成电路内置音频(inter-integrated circuit sound,I2S)接口,脉冲编码调制(pulse code modulation,PCM)接口,通用异步收发传输器(universal asynchronous receiver/transmitter,UART)接口,移动产业处理器接口(mobile industry processor interface,MIPI),通用输入输出(general-purpose input/output,GPIO)接口,用户标识模块(subscriber identity module,SIM)接口,和/或通用串行总线(universal serial bus,USB)接口等。
MIPI接口可以被用于连接处理器110与显示屏194,摄像头193等外围器件。MIPI 接口包括摄像头串行接口(camera serial interface,CSI),显示屏串行接口(display serial interface,DSI)等。在一些实施例中,处理器110和摄像头193通过CSI接口通信,实现电子设备100的拍摄功能。处理器110和显示屏194通过DSI接口通信,实现电子设备100的显示功能。
GPIO接口可以通过软件配置。GPIO接口可以被配置为控制信号,也可被配置为数据信号。在一些实施例中,GPIO接口可以用于连接处理器110与摄像头193,显示屏194,无线通信模块160,音频模块170,传感器模块180等。GPIO接口还可以被配置为I2C接口,I2S接口,UART接口,MIPI接口等。
USB接口130是符合USB标准规范的接口,具体可以是Mini USB接口,Micro USB接口,USB Type C接口等。USB接口130可以用于连接充电器为电子设备100充电,也可以用于电子设备100与外围设备之间传输数据。也可以用于连接耳机,通过耳机播放音频。该接口还可以用于连接其他电子设备,例如AR设备等。
可以理解的是,本申请实施例示意的各模块间的接口连接关系,只是示意性说明,并不构成对电子设备100的结构限定。在本申请另一些实施例中,电子设备100也可以采用上述实施例中不同的接口连接方式,或多种接口连接方式的组合。
充电管理模块140用于从充电器接收充电输入。
电源管理模块141用于连接电池142,充电管理模块140与处理器110。电源管理模块141接收电池142和/或充电管理模块140的输入,为处理器110,内部存储器121,显示屏194,摄像头193,和无线通信模块160等供电。
电子设备100的无线通信功能可以通过天线1,天线2,移动通信模块150,无线通信模块160,调制解调处理器以及基带处理器等实现。
天线1和天线2用于发射和接收电磁波信号。电子设备100中的每个天线可用于覆盖单个或多个通信频带。不同的天线还可以复用,以提高天线的利用率。例如:可以将天线1复用为无线局域网的分集天线。在另外一些实施例中,天线可以和调谐开关结合使用。
移动通信模块150可以提供应用在电子设备100上的包括2G/3G/4G/5G等无线通信的解决方案。移动通信模块150可以包括至少一个滤波器,开关,功率放大器,低噪声放大器(low noise amplifier,LNA)等。移动通信模块150可以由天线1接收电磁波,并对接收的电磁波进行滤波,放大等处理,传送至调制解调处理器进行解调。移动通信模块150还可以对经调制解调处理器调制后的信号放大,经天线1转为电磁波辐射出去。在一些实施例中,移动通信模块150的至少部分功能模块可以被设置于处理器110中。在一些实施例中,移动通信模块150的至少部分功能模块可以与处理器110的至少部分模块被设置在同一个器件中。
无线通信模块160可以提供应用在电子设备100上的包括无线局域网(wireless local area networks,WLAN)(如无线保真(wireless fidelity,Wi-Fi)网络),蓝牙(bluetooth,BT),全球导航卫星系统(global navigation satellite system,GNSS),调频(frequency modulation,FM),近距离无线通信技术(near field communication,NFC),红外技术(infrared,IR)等无线通信的解决方案。无线通信模块160可以是集成至少一个通信处理模块的一个或多个器件。无线通信模块160经由天线2接收电磁波,将电磁波信号 调频以及滤波处理,将处理后的信号发送到处理器110。无线通信模块160还可以从处理器110接收待发送的信号,对其进行调频,放大,经天线2转为电磁波辐射出去。
在一些实施例中,电子设备100的天线1和移动通信模块150耦合,天线2和无线通信模块160耦合,使得电子设备100可以通过无线通信技术与网络以及其他设备通信。所述无线通信技术可以包括全球移动通讯系统(global system for mobile communications,GSM),通用分组无线服务(general packet radio service,GPRS),码分多址接入(code division multiple access,CDMA),宽带码分多址(wideband code division multiple access,WCDMA),时分码分多址(time-division code division multiple access,TD-SCDMA),长期演进(long term evolution,LTE),BT,GNSS,WLAN,NFC,FM,和/或IR技术等。所述GNSS可以包括全球卫星定位系统(global positioning system,GPS),全球导航卫星系统(global navigation satellite system,GLONASS),北斗卫星导航系统(beidou navigation satellite system,BDS),准天顶卫星系统(quasi-zenith satellite system,QZSS)和/或星基增强系统(satellite based augmentation systems,SBAS)。
电子设备100通过GPU,显示屏194,以及应用处理器等实现显示功能。GPU为图像处理的微处理器,连接显示屏194和应用处理器。GPU用于执行数学和几何计算,用于图形渲染。处理器110可包括一个或多个GPU,其执行程序指令以生成或改变显示信息。
显示屏194用于显示图像,视频等。显示屏194包括显示面板。显示面板可以采用液晶显示屏(liquid crystal display,LCD),有机发光二极管(organic light-emitting diode,OLED),有源矩阵有机发光二极体或主动矩阵有机发光二极体(active-matrix organic light emitting diode的,AMOLED),柔性发光二极管(flex light-emitting diode,FLED),Miniled,MicroLed,Micro-oLed,量子点发光二极管(quantum dot light emitting diodes,QLED)等。在一些实施例中,电子设备100可以包括1个或N个显示屏194,N为大于1的正整数。
摄像头193用于捕获图像。可以通过应用程序指令触发开启,实现拍照功能,如拍摄获取任意场景的图像。摄像头可以包括成像镜头、滤光片、图像传感器等部件。物体发出或反射的光线进入成像镜头,通过滤光片,最终汇聚在图像传感器上。图像传感器主要是用于对拍照视角中的所有物体(也可称为待拍摄场景、目标场景,也可以理解为用户期待拍摄的场景图像)发出或反射的光汇聚成像;滤光片主要是用于将光线中的多余光波(例如除可见光外的光波,如红外)滤去;图像传感器主要是用于对接收到的光信号进行光电转换,转换成电信号,并输入处理器130进行后续处理。其中,摄像头193可以位于电子设备100的前面,也可以位于电子设备100的背面,摄像头的具体个数以及排布方式可以根据需求设置,本申请不做任何限制。
示例性的,电子设备100包括前置摄像头和后置摄像头。例如,前置摄像头或者后置摄像头,均可以包括1个或多个摄像头。以电子设备100具有3个后置摄像头为例,这样,电子设备100启动启动3个后置摄像头进行拍摄时,可以使用本申请实施例提供的图像处理方法。或者,摄像头设置于电子设备100的外置配件上,该外置配件可旋转的连接于手机的边框,该外置配件与电子设备100的显示屏194之间所形成的角度为0-360度之间的任意角度。比如,当电子设备100自拍时,外置配件带动摄 像头旋转到朝向用户的位置。当然,手机具有多个摄像头时,也可以只有部分摄像头设置在外置配件上,剩余的摄像头设置在电子设备100本体上,本申请实施例对此不进行任何限制。
内部存储器121可以用于存储计算机可执行程序代码,所述可执行程序代码包括指令。内部存储器121可以包括存储程序区和存储数据区。其中,存储程序区可存储操作系统,至少一个功能所需的应用程序(比如声音播放功能,图像播放功能等)等。存储数据区可存储电子设备100使用过程中所创建的数据(比如音频数据,电话本等)等。此外,内部存储器121可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件,闪存器件,通用闪存存储器(universal flash storage,UFS)等。处理器110通过运行存储在内部存储器121的指令,和/或存储在设置于处理器中的存储器的指令,执行电子设备100的各种功能应用以及数据处理。
内部存储器121还可以存储本申请实施例提供的图像处理方法的软件代码,当处理器110运行所述软件代码时,执行图像处理方法的流程步骤,得到清晰度较高的图像。
内部存储器121还可以存储拍摄得到的图像。
外部存储器接口120可以用于连接外部存储卡,例如Micro SD卡,实现扩展电子设备100的存储能力。外部存储卡通过外部存储器接口120与处理器110通信,实现数据存储功能。例如将音乐等文件保存在外部存储卡中。
当然,本申请实施例提供的图像处理方法的软件代码也可以存储在外部存储器中,处理器110可以通过外部存储器接口120运行所述软件代码,执行图像处理方法的流程步骤,得到清晰度较高的图像。电子设备100拍摄得到的图像也可以存储在外部存储器中。
应理解,用户可以指定将图像存储在内部存储器121还是外部存储器中。比如,电子设备100当前与外部存储器相连接时,若电子设备100拍摄得到1帧图像时,可以弹出提示信息,以提示用户将图像存储在外部存储器还是内部存储器;当然,还可以有其他指定方式,本申请实施例对此不进行任何限制;或者,电子设备100检测到内部存储器121的内存量小于预设量时,可以自动将图像存储在外部存储器中。
电子设备100可以通过音频模块170,扬声器170A,受话器170B,麦克风170C,耳机接口170D,以及应用处理器等实现音频功能。例如音乐播放,录音等。
压力传感器180A用于感受压力信号,可以将压力信号转换成电信号。在一些实施例中,压力传感器180A可以设置于显示屏194。
陀螺仪传感器180B可以用于确定电子设备100的运动姿态。在一些实施例中,可以通过陀螺仪传感器180B确定电子设备100围绕三个轴(即,x,y和z轴)的角速度。陀螺仪传感器180B可以用于拍摄防抖。
气压传感器180C用于测量气压。在一些实施例中,电子设备100通过气压传感器180C测得的气压值计算海拔高度,辅助定位和导航。
磁传感器180D包括霍尔传感器。电子设备100可以利用磁传感器180D检测翻盖皮套的开合。在一些实施例中,当电子设备100是翻盖机时,电子设备100可以根据磁传感器180D检测翻盖的开合。进而根据检测到的皮套的开合状态或翻盖的开合状 态,设置翻盖自动解锁等特性。
加速度传感器180E可检测电子设备100在各个方向上(一般为三轴)加速度的大小。当电子设备100静止时可检测出重力的大小及方向。还可以用于识别电子设备姿态,应用于横竖屏切换,计步器等应用。
距离传感器180F,用于测量距离。电子设备100可以通过红外或激光测量距离。在一些实施例中,拍摄场景,电子设备100可以利用距离传感器180F测距以实现快速对焦。
接近光传感器180G可以包括例如发光二极管(LED)和光检测器,例如光电二极管。发光二极管可以是红外发光二极管。电子设备100通过发光二极管向外发射红外光。电子设备100使用光电二极管检测来自附近物体的红外反射光。当检测到充分的反射光时,可以确定电子设备100附近有物体。当检测到不充分的反射光时,电子设备100可以确定电子设备100附近没有物体。电子设备100可以利用接近光传感器180G检测用户手持电子设备100贴近耳朵通话,以便自动熄灭屏幕达到省电的目的。接近光传感器180G也可用于皮套模式,口袋模式自动解锁与锁屏。
环境光传感器180L用于感知环境光亮度。电子设备100可以根据感知的环境光亮度自适应调节显示屏194亮度。环境光传感器180L也可用于拍照时自动调节白平衡。环境光传感器180L还可以与接近光传感器180G配合,检测电子设备100是否在口袋里,以防误触。
指纹传感器180H用于采集指纹。电子设备100可以利用采集的指纹特性实现指纹解锁,访问应用锁,指纹拍照,指纹接听来电等。
温度传感器180J用于检测温度。在一些实施例中,电子设备100利用温度传感器180J检测的温度,执行温度处理策略。例如,当温度传感器180J上报的温度超过阈值,电子设备100执行降低位于温度传感器180J附近的处理器的性能,以便降低功耗实施热保护。在另一些实施例中,当温度低于另一阈值时,电子设备100对电池142加热,以避免低温导致电子设备100异常关机。在其他一些实施例中,当温度低于又一阈值时,电子设备100对电池142的输出电压执行升压,以避免低温导致的异常关机。
触摸传感器180K,也称“触控器件”。触摸传感器180K可以设置于显示屏194,由触摸传感器180K与显示屏194组成触摸屏,也称“触控屏”。触摸传感器180K用于检测作用于其上或附近的触摸操作。触摸传感器可以将检测到的触摸操作传递给应用处理器,以确定触摸事件类型。可以通过显示屏194提供与触摸操作相关的视觉输出。在另一些实施例中,触摸传感器180K也可以设置于电子设备100的表面,与显示屏194所处的位置不同。
骨传导传感器180M可以获取振动信号。在一些实施例中,骨传导传感器180M可以获取人体声部振动骨块的振动信号。骨传导传感器180M也可以接触人体脉搏,接收血压跳动信号。在一些实施例中,骨传导传感器180M也可以设置于耳机中,结合成骨传导耳机。音频模块170可以基于所述骨传导传感器180M获取的声部振动骨块的振动信号,解析出语音信号,实现语音功能。应用处理器可以基于所述骨传导传感器180M获取的血压跳动信号解析心率信息,实现心率检测功能。
按键190包括开机键,音量键等。按键190可以是机械按键。也可以是触摸式按 键。电子设备100可以接收按键输入,产生与电子设备100的用户设置以及功能控制有关的键信号输入。
马达191可以产生振动提示。马达191可以用于来电振动提示,也可以用于触摸振动反馈。例如,作用于不同应用(例如拍照,音频播放等)的触摸操作,可以对应不同的振动反馈效果。
指示器192可以是指示灯,可以用于指示充电状态,电量变化,也可以用于指示消息,未接来电,通知等。
SIM卡接口195用于连接SIM卡。SIM卡可以通过插入SIM卡接口195,或从SIM卡接口195拔出,实现和电子设备100的接触和分离。
可以理解的是,本申请实施例示意的结构并不构成对电子设备100的具体限定。在本申请另一些实施例中,电子设备100可以包括比图示更多或更少的部件,或者组合某些部件,或者拆分某些部件,或者不同的部件布置。图示的部件可以以硬件,软件或软件和硬件的组合实现。
本申请实施例提供的图像处理方法,还可以适用于各种图像处理装置。图3示出了本申请实施例提供的一种图像处理装置200的硬件架构图。如图3所示,该图像处理装置200例如可以为处理器芯片。示例性的,图3所示的硬件架构图可以是图2中的处理器110,本申请实施例提供的图像处理方法可以应用在该处理器芯片上。
如图3所示,该图像处理装置200包括:至少一个CPU,存储器、微控制器(microcontroller unit,MCU)、GPU、NPU、内存总线、接收接口和发送接口等。除此之外,该图像处理装置200还可以包括AP、解码器以及专用的图形处理器等。
该图像处理装置200的上述各个部分通过连接器相耦合,示例性的,连接器包括各类接口、传输线或总线等,这些接口通常是电性通信接口,但是,也可能是机械接口或其他形式的接口,本申请实施例对此不做任何限制。
可选地,CPU可以是一个单核(single-CPU)处理器或多核(multi-CPU)处理器。
可选地,CPU可以是多个处理器构成的处理器组,多个处理器之间通过一个或多个总线彼此耦合。该连接接口可以为处理器芯片的数据输入的接口,在一种可选地情况下,该接收接口和发送接口可以是高清晰度多媒体接口(high definition multimedia interface,HDMI)、V-By-One接口、嵌入式显示端口(embedded display port,eDP)、移动产业处理器接口(mobile industry processor interface,MIPI)display port(DP)等,该存储器可以参考上述对内部存储器121部分的描述。在一种可能实现的方式中,上述各部分集成在同一个芯片上。在另一个可能实现的方式中,CPU、GPU、解码器、接收接口以及发送接口集成在一个芯片上,该芯片内部的各部分通过总线访问外部的存储器。专用图形处理器可以为专用ISP。
可选地,NPU也可以作为独立的处理器芯片。该NPU用于实现各种神经网络或者深度学习的相关运算。本申请实施例提供的图像处理方法可以由GPU或NPU实现,也可以由专门的图形处理器来实现。
应理解,在本申请实施例中涉及的芯片是以集成电路工艺制造在同一个半导体衬底上的系统,也叫半导体芯片,其可以是利用集成电路工艺制作在衬底上形成的集成 电路的集合,其外层通常被半导体封装材料封装。所述集成电路可以包括各类功能器件,每一类功能器件包括逻辑门电路、金属氧化物半导体(metal oxide semiconductor,MOS)晶体管、二极管等晶体管,也可以包括电容、电阻或电感等其他部件。每个功能器件可以独立工作或者在必要的驱动软件的作用下工作,可以实现通信、运算或存储等各类功能。
下面结合说明书附图,对本申请实施例所提供的图像处理方法进行详细介绍。
图4为本申请实施例所示的一种图像处理方法的流程示意图。如图4所示,该图像处理方法10包括:S10至S50。
S10、获取多帧原始图像。多帧原始图像为对相同的待拍摄场景拍摄的图像。
多帧原始图像包括:第一视场角图像和第二视场角图像,第一视场角图像对应的视场角与第二视场角图像对应的视场角不同。
该图像处理方法的执行主体可以是上述图2所示的设置有摄像头模组的电子设备100,还可以是上述图3所示的图像处理装置200。当执行主体是电子设备100时,通过摄像头模组中的摄像头获取多帧原始图像,具体通过几个摄像头或者通过哪个摄像头获取,可以根据需要进行设置和更改,本申请实施例对此不进行任何限制。当执行主体是图像处理装置时,可以通过接收接口获取多帧原始图像,而该多帧原始图像为与图像处理装置连接的电子设备的摄像头模组所拍摄得到的。
上述原始图像也可称为RAW图。多帧原始图像可以是拜耳格式图像,也可以是灰阶图像,或者,也可以部分是拜耳格式图像,部分是灰阶图像,具体可以根据需要进行获取,本申请实施例对此不进行任何限制。
在获取的多帧原始图像中,第一视场角图像和第二视场角图像分别可以包括1帧,也可以包括多帧,但至少获取的多帧原始图像包括1帧第一视场角图像和1帧第二视场角图像。应理解,多帧第一视场角图像和多帧第二视场角图像可以不是同时拍摄的,但应为同一时间段内对相同的待拍摄场景拍摄的图像。
其中,第一视场角图像对应的视场角与第二视场角图像对应的视场角不同可以表述为:第一视场角图像对应的视场角大于第二视场角图像对应的视场角,或者,第一视场角图像对应的视场角小于第二视场角图像对应的视场角。
可选地,第一视场角图像包括以下的一项或多项:多帧第一图像、多帧第二图像、至少一帧第三图像。
其中,多帧第一图像包括至少一帧长曝光图像和至少一帧短曝光图像,第二图像为正常曝光的拜耳格式图像,第三图像为灰阶图像。
可选地,上述S10可以表述为:
获取多帧第一图像,并获取第二视场角图像,或者;
获取多帧第二图像,并获取第二视场角图像,或者;
获取至少一帧第三图像,并获取第二视场角图像,或者;
获取多帧第一图像和多帧第二图像,并获取第二视场角图像,或者;
获取多帧第二图像和至少一帧第三图像,并获取第二视场角图像,或者;
获取多帧第一图像和至少一帧第三图像,并获取第二视场角图像,或者;
获取多帧第一图像、多帧第二图像和至少一帧第三图像,并获取第二视场角图像。
应理解,第一图像、第二图像和第三图像均属于第一视场角图像,所以,第一图像对应的视场角、第二图像对应的视场角和第三图像对应的视场角均相同,且均与第二视场角图像对应的视场角不同。
应理解,长曝光图像指的是拍摄时经过较长时间曝光所得到的图像,短曝光图像指的是拍摄时经过较短时间曝光所得到的图像,其中,长曝光和短曝光都是相对正常曝光的时间而言的。曝光时间即为图像传感器采集图像时,进行光电转换所使用的时间。
应理解,当获取到2帧第一图像时,该2帧第一图像分别为1帧长曝光图像和1帧短曝光图像;当获取到3帧以及更多帧第一图像时,该多帧第一图像除了1帧是长曝光图像,1帧是短曝光图像,其他图像可以是长曝光图像也可以短曝光图像,具体可以根据需要进行获取,本申请实施例对此不进行任何限制。
可选地,第一图像为拜耳格式图像或为灰阶图像。
即,长曝光图像可以为长曝光的拜耳格式图像或长曝光的灰阶图像,短曝光图像可以为短曝光的拜耳格式图像或短曝光的灰阶图像。
此处,当长曝光图像和短曝光图像均为拜耳格式图像时,第一图像和第二图像可以由同一个摄像头捕捉得到。当长曝光图像和短曝光图像均为灰阶图像时,第一图像和第三图像可以由同一个摄像头捕捉得到。当然,也可以分开由多个不同的摄像头得到,本申请实施例对此不进行限制。
可选地,第二视场角图像为拜耳格式图像或为灰阶图像。
以下实施例以第一图像、第二视场角图像均为拜耳格式图像为例进行说明。
可选地,多帧原始图像的尺寸可以全部相同。当然,多帧原始图像的尺寸也可以部分相同,部分不同;也可以完全不相同。本申请实施例对此不进行任何限制。
当获取的多帧第一视场角图像尺寸不同时,可以进行放大或缩小,使得所有第一视场角图像尺寸一致,以便于后续进行处理和计算。
当获取的多帧第二视场角图像尺寸不同时,可以进行放大和缩小,使得所有第二视场角图像尺寸一致,以便于后续进行处理和计算。
可选地,多帧原始图像可以是连续获取的,获取的间隔时间可以相同也可以不同。当然,多帧原始图像也可以不是连续获取的。
可选地,当获取多帧第一图像时,多帧第一图像可以是连续获取的。当获取多帧第二图像时,多帧第二图像可以是连续获取的。当获取多帧第三图像时,多帧第三图像也可以是连续获取的。当获取多帧第二视场角图像时,多帧第二视场角图像可以是连续获取的。
S20、对第二视场角图像增设参考坐标图层。参考坐标图层用于反应第二视场角图像对应的视场角与第一视场角图像对应的视场角之间的映射关系。
应理解,参考坐标图层是为第二视场角图像新增的,并未对第二视场角图像做变动,也未与第二视场角图像做融合。
应理解,“第一”和“第二”只是为了方便区分,对不同视场角的图像进行的命名而已。第一视场角图像和第二视场角图像所指示的图像可以互换。此外,也可以对第一 视场角图像增设参考坐标图层,还可以对第一视场角图像和第二视场角图像均增设参考坐标图层,具体可以根据需要进行设置和更改,本申请实施例对此不进行任何限制。
应理解,基于多帧原始图像是对相同的待拍摄场景拍摄的图像,那么,当第一视场角图像对应的视场角大于第二视场角图像对应的视场角时,第一视场角图像不仅包括第二视场角图像中的内容,还包括第二视场角图像对应的视场角范围之外的内容。
当第一视场角图像对应的视场角小于第二视场角图像对应的视场角时,第二视场角图像不仅包括第一视场角图像中的内容,还包括第一视场角图像对应的视场角范围之外的内容。也就是说,第一视场角图像和第二视场角图像根据视场角大小不同,内容上存在映射关系,也即,第一视场角图像对应的视场角和第二视场角图像对应的视场角之间存在映射关系。
由此,可以将第二视场角图像对应的视场角与第一视场角图像对应的视场角之间的映射关系作为先验信息,即,以参考坐标图层作为先验信息。由此,通过增设参考坐标图层,可以使得后续根据视场角的映射关系进行更准确的处理,从而提高不同视场角的图像的融合效果,实现提升最终获取的图像的质量的目的。
可选地,在上述S20之前,该方法10还包括:
对第一视场角图像,和/或,第二视场角图像进行第一处理,第一处理包括:配准。
当第一视场角图像包括以下多项(多帧第一图像、多帧第二图像、至少一帧第三图像)时,对第一视场角图像进行第一处理可以为:对第一视场角图像中的至少一项进行第一处理。
上述还可以表述为:
当第一视场角图像包括多帧第一图像、多帧第二图像、至少一帧第三图像中的一项时,对多帧第一图像、多帧第二图像或至少一帧第三图像进行第一处理,并且,对第二视场角图像不进行第一处理;
当第一视场角图像包括多帧第一图像和多帧第二图像时,对多帧第一图像和/或多帧第二图像进行第一处理,并且,对第二视场角图像不进行第一处理;
当第一视场角图像包括多帧第一图像和至少一帧第三图像,对多帧第一图像和/或至少一帧第三图像进行第一处理,并且,对第二视场角图像不进行第一处理;
当第一视场角图像包括多帧第二图像和至少一帧第三图像时,对多帧第二图像和/或至少一帧第三图像进行第一处理,并且,对第二视场角图像不进行第一处理;
当第一视场角图像包括多帧第一图像、多帧第二图像和至少一帧第三图像时,对多帧第一图像、多帧第二图像和至少一帧第三图像中的至少一项进行第一处理,并且,对第二视场角图像不进行第一处理,或者;
当第一视场角图像包括多帧第一图像、多帧第二图像和至少一帧第三图像时,对第一视场角图像不进行第一处理,仅对第二视场角图像进行第一处理,或者;
当第一视场角图像包括多帧第一图像、多帧第二图像、至少一帧第三图像中的一项时,对多帧第一图像、多帧第二图像或至少一帧第三图像进行第一处理,并对第二视场角图像进行第一处理;
当第一视场角图像包括多帧第一图像和多帧第二图像时,对多帧第一图像和/或多帧第二图像进行第一处理,并对第二视场角图像进行第一处理;
当第一视场角图像包括多帧第一图像和至少一帧第三图像,对多帧第一图像和/或至少一帧第三图像进行第一处理,并对第二视场角图像进行第一处理;
当第一视场角图像包括多帧第二图像和至少一帧第三图像时,对多帧第二图像和/或至少一帧第三图像进行第一处理,并对第二视场角图像进行第一处理;
当第一视场角图像包括多帧第一图像、多帧第二图像和至少一帧第三图像时,对多帧第一图像、多帧第二图像和至少一帧第三图像中的至少一项进行第一处理,并对第二视场角图像进行第一处理。
对多帧第一图像进行配准时,可以以第1帧第一图像为参考帧,基于第1帧第一图像,将其他帧第一图像和第1帧第一图像分别进行配准。
其中,对多帧第一图像进行配准时,可以以第1帧长曝光图像为参考帧,基于第1帧长曝光图像,将其他帧长曝光图像和第1帧长曝光图像分别进行配准,并且,还可以以第1帧短曝光图像为参考帧,基于第1帧短曝光图像,将其他帧短曝光图像和第1帧短曝光图像分别进行配准。
对多帧第二图像进行配准时,可以以第1帧第二图像为参考帧,基于第1帧第二图像,将其他帧第二图像和第1帧第二图像进行配准。
当第一视场角图像包括的第三图像仅有1帧时,对第三图像可以不进行配准。
当第一视场角图像包括多帧第三图像时,可以以第1帧第三图像为参考帧,基于第1帧第三图像,将其他帧第三图像和第1帧第三图像进行配准。
示例性的,图5为本申请实施例提供的一种对多帧第二图像进行配准的流程示意图。
如图5所示,以第1帧第二图像为参考帧,对其进行特征点检测;对其他帧第二图像中的任意1帧也进行特征点检测,然后,将两者检测得到的特征点进行匹配,再计算变换矩阵进行变换。对多帧第一图像、对多帧第三图像进行配准的方法相同,在此不再赘述。
可选地,当第一视场角图像包括多帧第二图像时,对第二视场角图像进行配准,包括:以第1帧第二图像为参考帧,对第二视场角图像进行配准。
应理解,当第二视场角图像包括多帧时,可以以第1帧第二图像为参考帧,分别对每帧第二视场角图像进行配准。
可选地,在对第二视场角图像进行配准之后,该方法10还包括:
根据第1帧第二图像和配准后的第二视场角图像,对预设坐标图层进行透视变换(warp),得到参考坐标图层。
其中,预设坐标图层用于反映预设的第二视场角图像对应的视场角与第一视场角图像对应的视场角之间的映射关系。
应理解,预设坐标图层可以根据需要预先示意出第二视场角图像对应的视场角与第一视场角图像对应的视场角之间的映射关系,具体示意方式可以根据需要进行设定和更改,本申请实施例对此不进行任何限制。
应理解,由于以第1帧第二图像为参考帧,对第二视场角图像进行配准后,第二视场角图像可能会进行拉伸、旋转、缩放等操作,第二视场角图像发生了形变,所以,配准之后,第二视场角图像对应的视场角和第1帧第二图像对应的视场角之间的映射 关系也发生了变化,因此,根据配准后的第二视场角图像对应的视场角和第1帧第二图像对应的视场角之间形成的新的映射关系,对预设坐标图层进行透视变换,也就是说,根据配准后的第二视场角图像对预设坐标图层中所示意的两个视场角映射关系进行调整,调整后可以得到更准确的视场角映射关系,从而可以得到相对于预设坐标图层更为准确的参考坐标图层。
应理解,以第1帧第二图像为参考帧,对第二视场角图像进行配准,当多帧第二视场角图像之间由于手抖等因素导致拍摄时就存在有差异时,对每帧第二视场角图像配准后所进行的调整也并不相同,由此,根据配准后的不同的第二视场角图像,对预设坐标图层进行的透视变换也不相同,进而各自得到的参考坐标图层也不相同。
示例性的,图6为本申请实施例提供的一种获取参考坐标图层的示意图。
如图6所示,可以预先设定预设坐标图层,以用于反映第1帧第二图像对应的视场角和未配准的第二视场角图像对应的视场角之间的映射关系;然后,根据第1帧第二图像对第二视场角图像进行配准,再根据第1帧第二图像对应的视场角和配准后的第二视场角图像对应的视场角之间的映射关系,对预设坐标图层进行透视变换,从而得到相应的参考坐标图层。
可选地,预设坐标图层包括重合区,重合区用于表示:第1帧第二图像和第二视场角图像中,视场角较小的图像贴到视场角较大的图像上时所对应的区域。
在预设坐标图层中,除过重合区之外的区域可以称为非重合区,针对位于重合区和非重合区中的像素可以设定不同的数值,以作区分。
应理解,在预设坐标图层中,重合区和非重合区的形状和位置可以根据需要进行设定,本申请实施例对此不进行任何限制。由于图像通常为矩形,下面以重合区为矩形,非重合区环绕重合区为例进行示意。
示例性的,预设坐标图层可以为二值图像,假设像素对应的取值仅为0和255,分别代表白色和黑色,则可以设定重合区中的像素对应的取值为0,非重合区中的像素对应的取值为255,或者,设定重合区中的像素对应的取值为255,非重合区中的像素对应的取值为0。
应理解,若第1帧第二图像对应的视场角大于第二视场角图像对应的视场角,则相应的,第1帧第二图像包含第二视场角图像的内容,由此,可以设定预设坐标图层的大小与第1帧第二图像的大小相同,并在预设坐标图层中设定第二视场角图像贴到第1帧第二图像上时所对应的区域为重合区,同时设定预设坐标图层中重合区的像素对应的灰度值为0,而重合区之外,也就是非重合区中的像素对应的灰度值为255,以此来作区分。
若第1帧第二图像的视场角小于第二视场角图像对应的视场角,则相应的,第二视场角图像包含第二图像的内容,由此,可以设定预设坐标图层的大小与第二视场角图像的大小相同,并在预设坐标图层中设定第1帧图像贴到第二视场角图像上时所对应的区域为重合区,同时设定预设坐标图层中重合区的像素对应的灰度值为255,而重合区之外,也就是非重合区中的像素对应的灰度值为0,以此来作区分。
示例性的,图7为本申请实施例提供的一种对预设坐标图层进行透视变换的示意图。如图7所示,以第1帧第二图像的视场角大于第二视场角图像对应的视场角为例, 图7中的A1为第1帧第二图像,B1为未配准的第二视场角图像。
首先,根据A1的视场角和B1的视场角之间的映射关系,将B1贴在A1中,由此,根据B1贴在A1中的区域,可以设定出预设坐标图层。例如,可以设定预设坐标图层(C1)的尺寸与A1的尺寸相同,在预设坐标图层中,设定对应B1的区域为重合区ch1,其他区域为非重合区fch1,并设定重合区ch1中的像素对应的灰度值为0,非重合区fch1中的像素对应的灰度值为255。
然后,以A1为参考帧,对B1进行配准,配准后的B1发生偏移后贴在A1中的区域如B2所示,此时,根据A1的视场角和配准后的B2的视场角之间的映射关系,可以对预设坐标图层C1进行透视变换,使得重合区ch1偏移至重合区ch2的位置,相应的,非重合区fch1变为非重合区fch2,由此,可以变换得到由重合区ch2和非重合区fch2组成的参考坐标图层,如C2所示。
可选地,当第一视场角图像未包括多帧第二图像时,也就是说,仅包括多帧第一图像和/或至少一帧第三图像时,上述所述的对第二视场角图像进行配准,可以包括:
以第1帧第一图像为参考帧,对第二视场角图像进行配准,或者;
以第1帧第三图像为参考帧,对第二视场角图像进行配准。
由此,相应的,可以根据第1帧第一图像和配准后的第二视场角图像,对预设坐标图层进行透视变换,得到参考坐标图层。
或者,可以根据第1帧第三图像和配准后的第二视场角图像,对预设坐标图层进行透视变换,得到参考坐标图层。
此处,以第1帧第一图像为参考帧,或以第1帧第三图像为参考帧,对第二视场角图像进行配准,再得到参考坐标图层的方法与上述以第1帧第二图像为参考帧,对第二视场角图像进行配准,再得到参考坐标图层的方法相同,在此不再赘述。
可选地,第一处理还包括:黑电平校正。
当第一视场角图像包括以下一项或多项:多帧第一图像、多帧第二图像、至少一帧第三图像时,上述对第一视场角图像进行第一处理,可以表述为:对以下一项或多项进行黑电平校正:多帧第一图像、多帧第二图像、至少一帧第三图像。
其中,可以对多帧第一图像中的至少一帧第一图像进行黑电平校正,对多帧第二图像中的至少一帧第二图像进行黑电平校正,对多帧第三图像中的至少一帧第三图像进行黑电平校正。
示例性的,图8为本申请实施例提供的一种对第二图像进行黑电平校正的示意图。
可选地,第一处理还包括:坏点校正。
可选地,针对为拜耳格式图像的第一图像、针对第二图像、针对为拜耳格式图像的第二视场角图像中的至少一项,第一处理包括:自动白平衡。
当多帧第一图像均为拜耳格式图像时,即,当长曝光图像为长曝光的拜耳格式图像,短曝光图像为短曝光的拜耳格式图像时,针对多帧第一图像,第一处理可以包括:自动白平衡。其中,可以针对每帧第一图像进行自动白平衡。
针对多帧第二图像,第一处理可以包括:自动白平衡。其中,可以针对每帧第二图像进行自动白平衡。
当第二视场角图像为拜耳格式图像时,针对第二视场角图像,第一处理可以包括: 自动白平衡。
应理解,当第一处理包括黑电平校正、坏点校正、自动白平衡中的至少两项时,其顺序可以根据需要进行调整,本申请实施例对此不进行任何限制。
示例性的,当第一处理包括黑电平校正和自动白平衡时,可以先进行黑电平校正,再进行自动白平衡。
可选地,针对为拜耳格式图像的第一图像,针对第二图像、针对为拜耳格式图像的第二视场角图像中的至少一项,第一处理还包括:通道拆分(bayer to canvas)。
其中,通道拆分指的是将拜耳格式图像拆分成多个单通道的待增强子图层,每个单通道的待增强子图层只包含一种颜色通道信号,由此,可以保留更多的细节。
示例性的,当拜耳格式图像包括由对应红色通道信号的红色像素、对应绿色通道信号的绿色像素和对应蓝色通道信号的蓝色像素组成时,该拜耳格式图像可以拆分成3个单通道的待增强子图层,其中,一个单通道的待增强子图层只包含红色通道信号,一个单通道的待增强子图层只包含绿色通道信号,另一个单通道的待增强子图层只包含蓝色通道信号。
基于此,当第一图像为拜耳格式图像时,即,当长曝光图像为长曝光的拜耳格式图像,短曝光图像为短曝光的拜耳格式图像时,针对第一图像,第一处理还包括:通道拆分。其中,可以针对每帧第一图像进行通道拆分,示例性的,将每帧第一图像拆分成3个单通道的待增强子图层。
针对第二图像,可以针对每帧第二图像进行通道拆分,示例性的,图9为本申请实施例提供的一种对第二图像进行通道拆分的示意图,如图9所示,将每帧第二图像拆分成3个单通道的待增强子图层。
应理解,当第一图像为灰阶图像时,当第二视场角图像为灰阶图像时,以及针对为灰阶图像的第三图像,由于灰阶图像本身为单通道图像,所以,对灰阶图像不用进行通道拆分。
可选地,第一处理还包括:增设方差图层,方差图层包括多个像素,每个像素对应的方差值由原始图像对应的感光度确定。
可选地,针对每帧原始图像增设1张方差图层。
应理解,获取多帧原始图像时,每帧原始图像都可以确定出其对应的各项曝光参数,其中,包括感光度。感光度与原始图像的噪声水平相关,感光度越高,原始图像中的噪点越多,后期进行降噪处理时,相应的,就需要越高的降噪强度。
在本申请实施例中,方差图层与原始图像的尺寸相同,由此,所包括的像素个数也相同,每个像素对应的方差值由原始图像对应的感光度确定。
应理解,无论多帧原始图像中的每帧原始图像对应的感光度相同或者不相同,针对每帧原始图像都可以增设1帧方差图层,增设的方差图层中像素对应的方差值由对应的原始图像的感光度确定。此外,还可以根据需要对曝光参数进行设置和更改,本申请实施例对此不进行任何限制。
示例性的,图10为本申请实施例提供的一种对第二图像进行通道拆分并增设方差图层的示意图。如图10所示,将每帧第二图像拆分成3个单通道的待增强子图层,并增设1帧方差图层。
可选地,当多帧原始图像对应的感光度均相同时,对多帧原始图像增设1张方差图层。
应理解,由于多帧原始图像对应的感光度均相同,所以由每帧原始图像对应的感光度确定的方差图层是一样的,因此,可以仅增设1张方差图层。
可选地,方差图层包括第一方差图层,第二方差图层、第三方差图层和第四方差图层。
当多帧第一图像对应的感光度均相同时,对多帧第一图像增设1张第一方差图层,第一方差图层中每个像素对应的方差值由任意一张第一图像对应的感光度确定。
当多帧第二图像对应的感光度均相同时,对多帧第二图像增设1张第二方差图层,第二方差图层中每个像素对应的方差值由任意一张第二图像对应的感光度确定。
当多帧第三图像对应的感光度均相同时,对多帧第三图像增设1张第三方差图层,第三方差图层中每个像素对应的方差值由任意一张第三图像对应的感光度确定。
当多帧第二视场角图像对应的感光度均相同时,对多帧第二视场角图像增设1张第四方差图层,第四方差图层中每个像素对应的方差值由任意一张第二视场角图像对应的感光度确定。
应理解,当多帧第一图像对应的感光度均相同时,由每帧第一图像对应的感光度确定的方差图层均相同,因此,可以由任意一张第一图像对应的感光度确定出方差图层,并作为增设的第一方差图层。
应理解,当多帧第二图像对应的感光度均相同时,由每帧第二图像对应的感光度确定的方差图层均相同,因此,可以由任意一张第二图像对应的感光度确定出方差图层,并作为增设的第二方差图层。
应理解,当多帧第三图像对应的感光度均相同时,由每帧第三图像对应的感光度确定的方差图层均相同,因此,可以由任意一张第三图像对应的感光度确定出方差图层,并作为增设的第三方差图层。
应理解,当多帧第二视场角图像对应的感光度均相同时,由每帧第二视场角图像对应的感光度确定的方差图层均相同,因此,可以由任意一张第二视场角图像对应的感光度确定出方差图层,并作为增设的第四方差图层。
可选地,方差图层中每个像素对应的方差值为感光度,或者;
每个像素对应的方差值为感光度与预设基准值的比值,或者;
方差图层包括多个子区域,每个子区域包括多个像素,位于不同子区域中的像素对应的方差值为感光度与不同系数的乘积。
应理解,预设基准值或者子区域的划分均可以根据需要进行设定,本申请实施例对此不进行任何限制。
应理解,对不同子区域设定不同的系数,将感光度与不同系数相乘得到不同的方差值,也即方差图层包括不同的方差值,相当于增设了不同的先验信息,后续进行降噪时,即可根据先验信息进行区分,对不同子区域进行不同强度的降噪。例如,对方差值大,即噪声大的子区域提高降噪强度,而对方差值小,即噪声小的子区域降低降噪强度。
示例性的,如图11中的(a)所示,假设某帧原始图像对应的感光度为800,则 方差图层中每个像素对应的方差值为800。
或者,如图11中的(b)所示,假设预设基准值为100,原始图像对应的感光度为800,此时,将感光度与预设基准值的比值作为每个像素对应的方差值,也即,每个像素对应的方差值为8。
或者,如图11中的(c)所示,假设方差图层中的子区域F为人脸所在区域,其他为非人脸区域,则可以将位于子区域F中的像素和位于非人脸区域中的像素所对应的方差值进行区分,例如,位于子区域F中的像素对应的方差值为20,其他像素对应的方差值为100。
S30、根据第一视场角图像、第二视场角图像以及参考坐标图层,得到图层集。
可选地,当第一视场角图像包括以下一项或多项:多帧第一图像、多帧第二图像、至少一帧第三图像时,并对第一视场角图像中的至少一项,和/或,对第二视场角图像进行第一处理时,上述S30可以表述为:
当第一视场角图像包括多帧第一图像,并对多帧第一图像进行了第一处理时,根据第一图像进行了第一处理后的数据,和/或,第二视场角图像进行了第一处理后的数据,以及参考坐标图层,得到图层集。
当第一视场角图像包括多帧第二图像,并对第二图像进行了第一处理时,根据第二图像进行了第一处理后的数据,和/或,第二视场角图像进行了第一处理后的数据,以及参考坐标图层,得到图层集。
当第一视场角图像包括至少一帧第三图像,并对第三图像进行了第一处理时,根据第三图像进行了第一处理后的数据,和/或,第二视场角图像进行了第一处理后的数据,以及参考坐标图层,得到图层集。
当第一视场角图像包括多帧第一图像和多帧第二图像,并对多帧第一图像和/或多帧第二图像进行了第一处理时,根据多帧第一图像、多帧第二图像中至少一项进行了第一处理后的数据,和/或,第二视场角图像进行了第一处理后的数据,以及参考坐标图层,得到图层集。
当第一视场角图像包括多帧第二图像和至少一帧第三图像,并对第二图像、第三图像中的至少一项进行了第一处理时,根据第二图像、第三图像中的至少一项进行了第一处理后的数据,和/或,第二视场角图像进行了第一处理后的数据和参考坐标图层,得到图层集。
当第一视场角图像包括多帧第一图像和至少一帧第三图像,并对第一图像、第三图像中的至少一项进行了第一处理时,根据第一图像、第三图像中至少一项进行了第一处理后的数据,和/或,第二视场角图像进行了第一处理后的数据和参考坐标图层,得到图层集。
当第一视场角图像包括多帧第一图像、多帧第二图像和至少一帧第三图像,并对第一图像、第二图像和第三图像中的至少一项进行了第一处理时,根据第一图像、第二图像和第三图像中至少一项进行了第一处理后的数据,和/或,第二视场角图像进行了第一处理后的数据,以及参考坐标图层,得到图层集。
S40、利用深度学习网络模型进行处理,获取图层集对应的第一增强图像。
第一增强图像位于RGB颜色空间。
应理解,图层集包括原始图像分别对应的方差图层,还包括原始图像进行第一处理后所对应的图像数据,以及增设的参考坐标图层,基于此,将图层集所包括的图像数据同时输入深度学习网络模型中进行处理,然后,输出对应的第一增强图像。
其中,深度学习网络模型可以根据需要进行选择和更改,本申请实施例对此不进行任何限制。
应理解,位于RGB颜色空间的第一增强图像包括的每个像素均包括三个颜色分量,即,每个像素均包括红色分量、绿色分量和蓝色分量。此处,第一增强图像的尺寸与图层集中的图像、原始图像的尺寸均相同。
可选地,深度学习网络模型可以进行降噪、去马赛克、彩色融合(mono color fusion,MCF)和视场角融合(fov fusion),还可以进行多曝光融合(mutiexpo fusion)等多种处理。
应理解,在使用图像传感器获取多帧原始图像时,光照程度和图像传感器本身的性能将使得生成的原始图像具有大量噪声,这些噪声会使得原始图像整体变得模糊,丢失很多细节,所以需要进行降噪,以降低噪声的影响。
应理解,由于去马赛克和降噪均为与细节恢复相关的运算,而先进行去马赛克处理会影响降噪效果,先降噪会影响去马赛克的效果,因此,本申请实施例将降噪和去马赛克均通过一个深度学习网络模型来实现,避免了多种处理串行进行时,不同处理之间的相互影响,以及所带来的错误累计,提升了图像细节恢复的效果。
应理解,彩色融合指的是多帧不同颜色的图像进行融合。
视场角融合指的是将多帧不同视场角的图像进行融合。
多曝光融合指的是将多帧不同曝光度的图像进行融合。
示例性的,图12为本申请实施例提供的一种利用深度学习网络模型获取图层集对应的第一增强图像的流程示意图。
如图12所示,图层集由多帧第一图像、多帧第二图像、1帧第三图像和1帧第二视场角图像得到,将图层集全部输入深度学习网络模型中,进行多种处理,例如进行降噪、去马赛克、彩色融合和视场角融合等之后,输出对应的第一增强图像。该第一增强图像为位于RGB颜色空间的图像,包括3种颜色的单通道图像。
可选地,深度学习网络模型可以为Unet模型、Resnet模型和PSPnet模型中的任意一种。当然,深度学习网络模型也可以为其他模型,本申请实施例对此不进行任何限制。
S50、根据第一增强图像,得到第二增强图像。
可选地,上述S50可以包括:
对第一增强图像进行增强处理,得到第二增强图像。增强处理包括颜色增强处理和/或亮度增强处理。
应理解,还可以对第一增强图像进行其他增强处理,例如进行边缘增强处理等,具体可以根据需要设置和更改,本申请实施例对此不进行任何限制。
此处,第二增强图像的尺寸与第一增强图像的尺寸相同。
可选地,如图13所示,上述S50可以包括:
S510、利用分割模型对第一增强图像进行分割,得到掩膜图。
其中,利用分割模型可以对第一增强图像中的人体与非人体、人脸与非人脸、物体与非物体等内容进行分割,具体分割依据可以根据需要进行设定和更改,本申请实施例对此不进行任何限制。
可选地,分割模型可以为Unet模型、Resnet模型和PSPnet模型中的任意一种。当然,分割模型也可以为其他模型,本申请实施例对此不进行任何限制。
在本申请实施例中,掩膜图可以为二值图像,即,掩膜图所包括的像素对应的灰度值为0和255,0和255分别代表白色和黑色,或者,掩膜图中的像素的取值对应为0和1,0和1分别代表白色和黑色。
示例性的,利用分割模型将第一增强图像划分为人体区域和非人体区域,并且,人体区域中包括的像素均对应白色,非人体区域中包括的像素均对应黑色。
此处,掩膜图的尺寸与第一增强图像的尺寸相同。
S520、根据第一增强图像和掩膜图,利用色调映射模型,得到增益系数图。增益系数图包括多个像素,以及每个像素对应的增益值。
可选地,色调映射模型可以为Unet模型、Resnet模型和Hdrnet模型中的任意一种。当然,色调映射模型也可以为其他模型,本申请实施例对此不进行任何限制。
此处,增益系数图与第一增强图像、掩膜图的尺寸均相同。
S530、将第一增强图像与增益系数图相乘,得到第二增强图像。
应理解,上述S530可以表述为:将第一增强图像中像素对应的像素值与增益系数图对应位置处的像素所对应的增益值进行相乘,得到第二增强图像中对应位置处的像素的像素值。
应理解,增益系数图包括多个像素,每个像素对应的增益值可以相同也可以不相同。当增益系数图中的像素对应的增益值不相同时,可以对第一增强图像中的像素进行不同的增强,处理的更加细腻。
可选地,增益系数图包括3帧颜色增益系数图和/或1帧亮度增益系数图,每帧颜色增益系数图只对一种颜色进行增强,亮度增益系数图用于对亮度进行增强。
应理解,由于第一增强图像位于RGB颜色空间,也即,每个像素对应一组红色分量、绿色分量和蓝色分量,因此,增益系数图可以包括3帧颜色增益系数图,其中,红色增益系数图用于对红色进行增强,绿色增益系数图用于对绿色进行增强,蓝色增益系数图用于对蓝色进行增强。此处,针对第一增强图像中的任意一个像素,对应的红色分量与红色增益系数图对应位置处的增益值相乘,绿色分量与绿色增益系数图对应位置处的增益值相乘,蓝色分量与蓝色增益系数图对应位置处的增益值相乘。
示例性的,第一增强图像中某个像素对应的像素值为(10,125,30),3帧颜色增益系数图对应位置处的增益值分别为2、1和3,则相乘后,第二增强图像中对应位置处的像素的像素值为(20,125,90)。
应理解,第一增强图像中像素对应的红色分量、绿色分量和蓝色分量均与亮度增益系数图中对应位置处的增益值进行相乘,由此,可以对亮度增强。
此处,当3帧颜色增益系数图均相同时,将第一增强图像与颜色增益系数图相乘,效果等同于对第一增强图像进行亮度增强。
示例性的,图14为本申请实施例提供的一种对第一增强图像进行增强处理,得到 第二增强图像的流程示意图。
如图14所示,将第一增强图像输入分割模型,可以得到第一增强图像对应的掩膜图,该掩膜图为二值图像,例如将第一增强图像分割为人体区和非人体区。然后,将第一增强图像和掩膜图同时输入色调映射模型,通过色调映射模型进行处理,可以得到相应的颜色增益系数图和/或亮度增益系数图。
基于此,将第一增强图像与颜色增益系数图和/或亮度增益系数图进行相乘,由此,可以得到颜色增强和/或亮度增强了的第二增强图像。
本申请实施例提供了一种图像处理方法,通过获取对应不同视场角的第一视场角图像和第二视场角图像,并对第二视场角图像增设参考坐标图层,形成图层集,然后,再利用深度学习网络模型对图层集进行处理,得到第一增强图像,再根据第一增强图像,得到第二增强图像。由于参考坐标图层反映了第二视场角图像对应的视场角与第一视场角图像对应的视场角之间的映射关系,由此,通过增设参考坐标图层,可以增加不同视场角之间的映射关系信息,使得后续可以根据不同视场角之间的映射关系进行不同调整,从而可以保留更多细节,融合的更加自然,进而实现提高图像的质量的目的。
又因为深度学习网络模型可以对图层集同时进行多种处理,例如,进行降噪、去马赛克、彩色融合和视场角融合等,避免了串行处理所造成的错误累积,由此,也可以提高图像的清晰度。
此外,还对第一增强图像进行了颜色增强和/或亮度增强,增强了图像的视觉效果,从而使得增强后的图像内容和图像色彩都更能满足用户的视觉需求。
可选地,在第一视场角图像包括多帧第一图像,并且第一视场角图像还包括多帧第二图像和/或至少一帧第三图像的情况下,当对多帧第一图像未进行第一处理,而对第二视场角图像进行第一处理时,上述S30包括:
根据第一视场角图像中除多帧第一图像之外的图像,第二视场角图像以及参考坐标图层,得到图层集。
上述可以进一步表述为:
方案一、当第一视场角图像包括多帧第一图像和多帧第二图像,且未对多帧第一图像进行第一处理,仅对多帧第二图像进行了第一处理时,根据多帧第二图像进行了第一处理后的数据,第二视场角图像以及参考坐标图层,得到图层集。
方案二、当第一视场角图像包括多帧第一图像和至少一帧第三图像,且未对多帧第一图像进行第一处理,仅对第三图像进行了第一处理时,根据第三图像进行了第一处理后的数据,第二视场角图像以及参考坐标图层,得到图层集。
方案三、当第一视场角图像包括多帧第一图像、多帧第二图像和至少一帧第三图像,且未对多帧第一图像进行第一处理,仅对第二图像和第三图像中的至少一项进行了第一处理时,根据多帧第二图像和第三图像中至少一项进行了第一处理后的数据,第二视场角图像以及参考坐标图层,得到图层集。
针对上述方案一至方案三,在上述S510之前,该方法10还包括以下S508~S509。
S508、利用多帧第一图像中的长曝光图像和短曝光图像,对第一增强图像进行长短曝光融合处理,得到中间增强图像。
可选地,上述S508可以包括:
将第一增强图像与第一待融合图像进行融合,得到第一中间融合图像。
将第一中间融合图像与第二待融合图像进行融合,得到中间增强图像。
其中,第一待融合图像、第二待融合图像分别为长曝光图像和短曝光图像。
应理解,当第一待融合图像为长曝光图像,第二待融合图像为短曝光图像时,上述S408可以表述为:将第一增强图像与长曝光图像进行融合,得到第一中间融合图像;然后,将第一中间融合图像与短曝光图像进行融合,得到中间增强图像。
其中,当第一图像包括长曝光图像和短曝光图像时,可以将第一增强图像与长曝光图像进行融合,然后,再与短曝光图像进行融合。
当第一待融合图像为短曝光图像,第二待融合图像为长曝光图像时,上述S408可以表述为:将第一增强图像与短曝光图像进行融合,得到第一中间融合图像;然后,将中间融合图像与长曝光图像进行融合,得到中间增强图像。
其中,当第一图像包括长曝光图像和短曝光图像时,可以将第一增强图像与短曝光图像进行融合,然后,再与长曝光图像进行融合。
在本申请实施例中,将第一增强图像与长曝光图像进行融合,可以提升第一增强图像中曝光不够的暗区的细节,而与短曝光图像进行融合,可以提升第一增强图像中过曝区域的细节。因此,对第一增强图像进行长短曝光融合处理,可以同时提升第一增强图像中暗区和过曝区域的细节,提升动态范围,从而实现提升图像的清晰度的目的。
可选地,在进行融合之前,还可以对第一待融合图像、第二待融合图像分别进行配准。
此处,在将第一增强图像与第一待融合图像进行融合之前,可以以第一增强图像为参考帧,对第一待融合图像进行配准。在将第一中间融合图像和第二待融合图像进行融合之前,以第一中间融合图像为参考帧,对第二待融合图像进行配准。
也就是说,当第一待融合图像为长曝光图像,第二待融合图像为短曝光图像时,在将第一增强图像与长曝光图像进行融合之前,可以以第一增强图像为参考帧,对长曝光图像进行配准。在将第一中间融合图像和短曝光图像进行融合之前,可以以第一中间融合图像为参考帧,对短曝光图像进行配准。
或者,当第一待融合图像为短曝光图像,第二待融合图像为长曝光图像时,在将第一增强图像与短曝光图像进行融合之前,可以以第一增强图像为参考帧,对短曝光图像进行配准。在将第一中间融合图像和长曝光图像进行融合之前,可以以第一中间融合图像为参考帧,对长曝光图像进行配准。
可选地,对短曝光图像进行配准之前,还可以进行提亮。
应理解,可以对短曝光图像中每个像素对应的像素值乘以预设系数,以对短曝光图像进行提亮。
S509、将中间增强图像作为第一增强图像。
应理解,当进行融合或增强处理后,可以增加存储器的位宽,以储存更多的图像数据。
示例性的,图16为本申请实施例提供的另一种对第一增强图像进行增强处理,得 到第二增强图像的流程示意图。
如图16所示,假设第一待融合图像为长曝光图像,对该长曝光图像进行配准处理,第二待融合图像为短曝光图像,对该短曝光图像进行提亮和配准处理;然后,将第一增强图像与配准后的长曝光图像进行融合,得到第一中间融合图像,再将第一中间融合图像和进行了提亮和配准处理的短曝光图像进行融合,得到中间增强图像。
基于此,可以将中间增强图像作为第二增强图像,或者,可以将中间增强图像作为第一增强图像,继续获取对应的掩膜图,并利用中间增强图像和掩膜图按照S510至S530的方法,得到对应的第二增强图像。
可选地,在上述S50或S530之后,该方法10还包括:
对第二增强图像进行色彩空间转换,得到位于YUV颜色空间的第一目标图像。
应理解,第一增强图像位于RGB颜色空间,对第一增强图像进行增强处理后,得到的第二增强图像还是位于RGB颜色空间。
此处,将位于RGB颜色空间的第二增强图像转换为位于YUV颜色空间的第一目标图像,可以减少后续计算量,节省存储空间。
可选地,对第一增强图像、第一目标图像还可以进行颜色、亮度、锐度和尺寸等至少一项进行调整。
结合以上,本申请还提供如下实施例:
实施例1,一种图像处理方法,如图17所示,该方法包括以下S1010至S1050。
S1010、获取2帧原始图像。该2帧原始图像为对相同的待拍摄场景拍摄的图像。
该2帧原始图像包括:1帧第一视场角图像和1帧第二视场角图像,第一视场角图像对应的视场角与第二视场角图像对应的视场角不同。
其中,第二视场角图像为拜耳格式图像。
S1020、对第二视场角图像增设参考坐标图层,参考坐标图层用于反映第二视场角图像对应的视场角与第一视场角图像对应的视场角之间的映射关系。
此处,参考坐标图层可以为预设的,也即,该参考坐标图层为预设坐标图层。
其中,预设坐标图层包括重合区和非重合区,位于重合区和非重合区中的像素对应的取值不同;其中,重合区用于表示:第一视场角图像和第二视场角图像中,视场角较小的图像贴到视场角较大的图像上时所对应的区域。
S1030、根据第一视场角图像,第二视场角图像以及参考坐标图层,得到图层集。
S1040、利用深度学习网络模型处理图层集,得到第一增强图像。
其中,第一增强图像位于RGB颜色空间。
深度学习网络模型为Unet模型、Resnet模型和PSPnet模型中的任意一种。
S1050、根据第一增强图像,得到第二增强图像。
实施例2,一种图像处理方法,如图18所示,该方法包括以下S2010至S2070。
S2010、获取多帧第一视场角图像和1帧第二视场角图像。多帧第一视场角图像包括多帧第二图像。
其中,多帧第二图像和第二视场角图像为对相同的待拍摄场景拍摄的图像。多帧 第二图像对应的视场角与第二视场角图像对应的视场角不同,多帧第二图像为正常曝光的拜耳格式图像。第二视场角图像也为拜耳格式图像。
S2020、对多帧第二图像进行第一处理。并且,对第二视场角图像也进行第一处理。该第一处理包括配准、黑电平校正、自动白平衡、通道拆分和增设方差图层。
其中,对多帧第二图像进行配准时,以第1帧第二图像为参考帧,对其他帧第二图像分别进行配准。而对第二视场角图像进行配准时,可以以第1帧第二图像为参考帧,然后,对第二视场角图像进行配准。
应理解,通道拆分指的是将每帧第一图像拆分成3个单通道的待增强子图层,每个单通道的待增强子图层只包含一种颜色通道信号。
应理解,增设方差图层时,可以对每帧第一图像增设1帧方差图层,该方差图层包括多个像素,每个像素对应的方差值由第一图像对应的感光度确定。
其中,方差图层中每个像素对应的方差值为:与方差图层对应的原始图像的感光度,或者;每个像素对应的方差值为:与方差图层对应的原始图像的感光度和预设基准值的比值,或者;方差图层包括多个子区域,每个子区域包括多个像素,位于不同子区域中的像素对应的方差值不同,位于不同子区域的像素对应的系数不同,第一子区域中的像素对应的方差值为:与方差图层对应的原始图像的感光度和第一系数的乘积。
S2030、对第二视场角图像增设参考坐标图层,参考坐标图层用于反映第二视场角图像对应的视场角与第一视场角图像对应的视场角之间的映射关系。
其中,可以根据第1帧第二图像和上述S2020中配准后的第二视场角图像,对预设坐标图层进行透视变换,得到参考坐标图层,再将该参考坐标图层增设给第二视场角图像。预设坐标图层用于反映预设的或者未配准的第二视场角图像对应的视场角与第一视场角图像对应的视场角之间的映射关系。
应理解,预设坐标图层包括重合区和非重合区,位于重合区和非重合区中的像素对应的取值不同;其中,重合区用于表示:第1帧第二图像和第二视场角图像中,视场角较小的图像贴到视场角较大的图像上时所对应的区域。
S2040、根据进行了第一处理的多帧第一图像,以及进行了第一处理的第二视场角图像以及参考坐标图层,得到图层集。
应理解,进行了第一处理的多帧第一图像包括:通道拆分出的多个待增强子图层和增设的方差图层;进行了第一处理的第二视场角图像包括:通道拆分出的多个待增强子图层和增设的方差图层。
S2050、利用深度学习网络模型对图层集进行降噪、去马赛克、彩色融合和视场角融合,得到第一增强图像。
其中,第一增强图像位于RGB颜色空间。
深度学习网络模型为Unet模型、Resnet模型和PSPnet模型中的任意一种。
S2060、对第一增强图像进行增强处理,得到第二增强图像,增强处理包括颜色增强处理和/或亮度增强处理。
应理解,上述S2060可以包括S2061~S2063。
S2061、利用分割模型对第一增强图像进行分割,得到掩膜图。
分割模型为Unet模型、Resnet模型和PSPnet模型中的任意一种。
S2062、根据第一增强图像和掩膜图,利用色调映射模型,得到增益系数图;增益系数图包括多个像素,以及每个像素对应的增益值。
色调映射模型为Unet模型、Resnet模型和Hdrnet模型中的任意一种。
S2063、将第一增强图像与增益系数图相乘,得到第二增强图像。
其中,增益系数图包括3帧颜色增益系数图和/或1帧亮度增益系数图,每帧颜色增益系数图只对一种颜色进行增强,亮度增益系数图用于对亮度进行增强。
S2070、对第二增强图像进行色彩空间转换,得到位于YUV颜色空间的第一目标图像。
实施例3,一种图像处理方法,如图19所示,该方法包括以下S3010至S3070。
S3010、获取多帧第一视场角图像和1帧第二视场角图像。多帧第一视场角图像包括2帧第一图像和多帧第二图像。
其中,2帧第一图像、多帧第二图像和第二视场角图像为对相同的待拍摄场景拍摄的图像。2帧第一图像包括1帧长曝光图像和1帧短曝光图像,2帧第一图像均为拜耳格式图像。第二图像为正常曝光的拜耳格式图像。第二视场角图像也为拜耳格式图像。
S3020、对2帧第一图像和多帧第二图像均进行第一处理。对第二视场角图像也进行第一处理。该第一处理包括:配准、黑电平校正、自动白平衡、通道拆分和增设方差图层。
其中,对2帧第一图像进行配准时,可以以第1帧第一图像为参考帧,对第2帧第一图像进行配准。对多帧第二图像进行配准时,以第1帧第二图像为参考帧,对其他帧第二图像分别进行配准。而对第二视场角图像进行配准时,可以以第1帧第二图像为参考帧,然后,对第二视场角图像进行配准。
通道拆分的过程与上述S2020中对通道拆分的描述相同,在此不再赘述。
其中,增设方差图层时,可以针对每帧第一图像增设1张第一方差图层,针对每帧第二图像增设1张第二方差图层;针对每帧第二视场角图像增设1张第四方差图层。
第一方差图层包括多个像素,每个像素对应的方差值由第一图像对应的感光度确定;第二方差图层包括多个像素,每个像素对应的方差值由第二图像对应的感光度确定;第四方差图层包括多个像素,每个像素对应的方差值由第二视场角图像对应的感光度确定。
应理解,此处,对第一方差图层、第二方差图层和第四方差图层的描述与上述S2020中对方差图层的描述相同,在此不再赘述。
S3030、对第二视场角图像增设参考坐标图层,参考坐标图层用于反映第二视场角图像对应的视场角与第一视场角图像对应的视场角之间的映射关系。
此处,得到参考坐标图层的过程与上述S2030中得到参考坐标图层的过程相同,在此不再赘述。
S3040、根据进行了第一处理的2帧第一图像,进行了第一处理的多帧第二图像,进行了第一处理的第二视场角图像以及参考坐标图层,得到图层集。
应理解,进行了第一处理的多帧第一图像包括:通道拆分出的多个待增强子图层和增设的第一方差图层;进行了第一处理的多帧第二图像包括:通道拆分出的多个待增强子图层和增设的第二方差图层;进行了第一处理的第二视场角图像包括:通道拆分出的多个待增强子图层和增设的第四方差图层。
S3050、利用深度学习网络模型对图层集进行降噪、去马赛克、色彩融合和视场角融合,得到第一增强图像。
其中,第一增强图像位于RGB颜色空间。
深度学习网络模型为Unet模型、Resnet模型和PSPnet模型中的任意一种。
S3060、对第一增强图像进行增强处理,得到第二增强图像,增强处理包括颜色增强处理和/或亮度增强处理。
其中,S3060可以包括上述S2061至S2063,具体过程可以参考上述描述,在此不再赘述。
S3070、对第二增强图像进行色彩空间转换,得到位于YUV颜色空间的第一目标图像。
实施例4,一种图像处理方法,如图20所示,该方法包括以下S4010至S4070。
S4010、获取多帧第一视场角图像和1帧第二视场角图像。多帧第一视场角图像包括多帧第二图像和2帧第三图像。
其中,多帧第二图像和2帧第三图像和第二视场角图像为对相同的待拍摄场景拍摄的图像。多帧第二图像为正常曝光的拜耳格式图像,第三图像为灰阶图像,第二视场角图像为拜耳格式图像。
S4020、对多帧第二图像和第三图像均进行第一处理。对第二视场角图像也进行第一处理。对该多帧第二图像和第二视场角图像进行的第一处理包括:配准、黑电平校正、自动白平衡、通道拆分和增设方差图层;对第三图像进行的第一处理包括:配准、黑电平校正和增设方差图层。
其中,对多帧第二图像进行配准时,以第1帧第二图像为参考帧,对其他帧第二图像分别进行配准。对2帧第三图像进行配准时,可以以第1帧第三图像为参考帧,对第2帧第三图像进行配准。而对第二视场角图像进行配准时,可以以第1帧第二图像为参考帧,然后,对第二视场角图像进行配准。
通道拆分的过程与上述S2020中对通道拆分的描述相同,在此不再赘述。
其中,增设方差图层时,可以针对每帧第二图像增设1张第二方差图层,针对每帧第三图像增设1张第三方差图层;针对每帧第二视场角图像增设1张第四方差图层。
第二方差图层包括多个像素,每个像素对应的方差值由第二图像对应的感光度确定;第三方差图层包括多个像素,每个像素对应的方差值由第三图像对应的感光度确定;第四方差图层包括多个像素,每个像素对应的方差值由第二视场角图像对应的感光度确定。
应理解,此处,对第二方差图层、第三方差图层和第四方差图层的描述与上述S2020中对方差图层的描述相同,在此不再赘述。
S4030、对第二视场角图像增设参考坐标图层,参考坐标图层用于反映第二视场角 图像对应的视场角与第一视场角图像对应的视场角之间的映射关系。
此处,得到参考坐标图层的过程与上述S2030中得到参考坐标图层的过程相同,在此不再赘述。
S4040、根据进行了第一处理的多帧第二图像和进行了第一处理的2帧第三图像,进行了第一处理的第二视场角图像以及增设的参考坐标图层,得到图层集。
应理解,进行了第一处理的多帧第二图像包括:通道拆分出的多个待增强子图层和增设的第二方差图层;进行了第一处理的多帧第三图像包括:第三图像和增设的第三方差图层;进行了第一处理的第二视场角图像包括:通道拆分出的多个待增强子图层和增设的第四方差图层。
S4050、利用深度学习网络模型对图层集进行降噪、去马赛克、色彩融合和视场角融合,得到第一增强图像。
其中,第一增强图像位于RGB颜色空间。
深度学习网络模型为Unet模型、Resnet模型和Hdrnet模型中的任意一种。
S4060、对第一增强图像进行增强处理,得到第二增强图像,增强处理包括颜色增强处理和/或亮度增强处理。
其中,S4060可以包括上述S2061至S2063,具体过程可以参考上述描述,在此不再赘述。
S4070、对第二增强图像进行色彩空间转换,得到位于YUV颜色空间的第一目标图像。
实施例5,一种图像处理方法,如图21所示,该方法包括以下S5010至S5070。
S5010、获取多帧第一视场角图像和1帧第二视场角图像。多帧第一视场角图像包括2帧第一图像、多帧第二图像、2帧第三图像。
其中,2帧第一图像、多帧第二图像、2帧第三图像和第二视场角图像为对相同的待拍摄场景拍摄的图像。2帧第一图像包括1帧长曝光图像和1帧短曝光图像,2帧第一图像均为拜耳格式图像。第二图像为正常曝光的拜耳格式图像。第三图像为灰阶图像,第二视场角图像也为拜耳格式图像。
S5020、对2帧第一图像、多帧第二图像、2帧第三图像均进行第一处理。对第二视场角图像也进行第一处理。对2帧第一图像、多帧第二图像和第二视场角图像进行的第一处理包括:配准、黑电平校正、自动白平衡、通道拆分和增设方差图层。对2帧第三图像进行的第一处理包括:配准、黑电平校正和增设方差图层。
其中,对2帧第一图像进行配准时,可以以第1帧第一图像为参考帧,对第2帧第一图像进行配准。对多帧第二图像进行配准时,以第1帧第二图像为参考帧,对其他帧第二图像分别进行配准。对2帧第三图像进行配准时,可以以第1帧第三图像为参考帧,对第2帧第三图像进行配准。而对第二视场角图像进行配准时,可以以第1帧第二图像为参考帧,然后,对第二视场角图像进行配准。
通道拆分的过程与上述S2020中对通道拆分的描述相同,在此不再赘述。
其中,增设方差图层时,可以针对每帧第一图像增设1张第一方差图层,针对每帧第二图像增设1张第二方差图层;针对每帧第三图像增设1张第三方差图层,针对 每帧第二视场角图像增设1张第四方差图层。
第一方差图层包括多个像素,每个像素对应的方差值由第一图像对应的感光度确定;第二方差图层包括多个像素,每个像素对应的方差值由第二图像对应的感光度确定;第三方差图层包括多个像素,每个像素对应的方差值由第三图像对应的感光度确定;第四方差图层包括多个像素,每个像素对应的方差值由第二视场角图像对应的感光度确定。
应理解,此处,对第一方差图层、第二方差图层、第三方差图层和第四方差图层的描述与上述S2020中对方差图层的描述相同,在此不再赘述。
S5030、对第二视场角图像增设参考坐标图层,参考坐标图层用于反映第二视场角图像对应的视场角与第一视场角图像对应的视场角之间的映射关系。
此处,得到参考坐标图层的过程与上述S2030中得到参考坐标图层的过程相同,在此不再赘述。
S5040、根据进行了第一处理的2帧第一图像、进行了第一处理的多帧第二图像、进行了第一处理的2帧第三图像,以及进行了第一处理的第二视场角图像和增设的参考坐标图层,得到图层集。
应理解,进行了第一处理的多帧第一图像包括:通道拆分出的多个待增强子图层和增设的第一方差图层;进行了第一处理的多帧第二图像包括:通道拆分出的多个待增强子图层和增设的第二方差图层;进行了第一处理的多帧第三图像包括:第三图像和增设的第二方差图层;进行了第一处理的第二视场角图像包括:通道拆分出的多个待增强子图层和增设的第四方差图层。
S5050、利用深度学习网络模型对图层集进行降噪、去马赛克、色彩融合和视场角融合,得到第一增强图像。
其中,第一增强图像位于RGB颜色空间。
深度学习网络模型为Unet模型、Resnet模型和PSPnet模型中的任意一种。
S5060、对第一增强图像进行增强处理,得到第二增强图像,增强处理包括颜色增强处理和/或亮度增强处理。
其中,S5060可以包括上述S2061至S2063,具体过程可以参考上述描述,在此不再赘述。
S5070、对第二增强图像进行色彩空间转换,得到位于YUV颜色空间的第一目标图像。
实施例6,一种图像处理方法,如图22所示,该方法包括以下S6010至S6080。
S6010、获取多帧第一视场角图像和1帧第二视场角图像。多帧第一视场角图像包括2帧第一图像和多帧第二图像。
其中,2帧第一图像、多帧第二图像和第二视场角图像为对相同的待拍摄场景拍摄的图像。2帧第一图像包括1帧长曝光图像和1帧短曝光图像,2帧第一图像均为拜耳格式图像。第二图像为正常曝光的拜耳格式图像。第二视场角图像也为拜耳格式图像。
S6020、对2帧第一图像不进行第一处理,仅对多帧第二图像和第二视场角图像进 行第一处理。该第一处理包括:配准、黑电平校正、自动白平衡、通道拆分和增设方差图层。
其中,对多帧第二图像进行配准时,以第1帧第二图像为参考帧,对其他帧第二图像分别进行配准。而对第二视场角图像进行配准时,可以以第1帧第二图像为参考帧,然后,对第二视场角图像进行配准。
通道拆分的过程与上述S2020中对通道拆分的描述相同,在此不再赘述。
其中,增设方差图层时,可以针对每帧第二图像增设1张第二方差图层;针对每帧第二视场角图像增设1张第四方差图层。
第二方差图层包括多个像素,每个像素对应的方差值由第二图像对应的感光度确定;第四方差图层包括多个像素,每个像素对应的方差值由第二视场角图像对应的感光度确定。
应理解,此处,对第二方差图层和第四方差图层的描述与上述S2020中对方差图层的描述相同,在此不再赘述。
S6030、对第二视场角图像增设参考坐标图层,参考坐标图层用于反映第二视场角图像对应的视场角与第一视场角图像对应的视场角之间的映射关系。
此处,得到参考坐标图层的过程与上述S2030中得到参考坐标图层的过程相同,在此不再赘述。
S6040、根据进行了第一处理的多帧第二图像,以及进行了第一处理的第二视场角图像和增设的参考坐标图层,得到图层集。
应理解,进行了第一处理的多帧第二图像包括:通道拆分出的多个待增强子图层和增设的第二方差图层;进行了第一处理的第二视场角图像包括:通道拆分出的多个待增强子图层和增设的第四方差图层。
S6050、利用深度学习网络模型对图层集进行降噪、去马赛克、色彩融合和视场角融合,得到第一增强图像。
其中,第一增强图像位于RGB颜色空间。
深度学习网络模型为Unet模型、Resnet模型和PSPnet模型中的任意一种。
S6060、利用2帧第一图像中的长曝光图像和短曝光图像,对第一增强图像进行长短曝光融合处理,得到中间增强图像。然后,将中间增强图像作为第一增强图像。
其中,利用第一图像中的长曝光图像和短曝光图像,对第一增强图像进行长短曝光融合处理的过程如图16所示,在此不再赘述。
S6070、对第一增强图像进行增强处理,得到第二增强图像,增强处理包括颜色增强处理和/或亮度增强处理。
其中,S6070可以包括上述S2061至S2063,具体过程可以参考上述描述,在此不再赘述。
S6080、对第二增强图像进行色彩空间转换,得到位于YUV颜色空间的第一目标图像。
实施例7,一种图像处理方法,如图23所示,该方法包括以下S7010至S7080。
S7010、获取多帧第一视场角图像和1帧第二视场角图像。多帧第一视场角图像包 括2帧第一图像、多帧第二图像、2帧第三图像。
其中,2帧第一图像、多帧第二图像、2帧第三图像和第二视场角图像为对相同的待拍摄场景拍摄的图像。2帧第一图像包括1帧长曝光图像和1帧短曝光图像,2帧第一图像均为拜耳格式图像。第二图像为正常曝光的拜耳格式图像,第三图像为灰阶图像,第二视场角图像也为拜耳格式图像。
S7020、对2帧第一图像不进行第一处理,仅对多帧第二图像、2帧第三图像和1帧第二视场角图像均进行第一处理。对多帧第二图像和第二视场角图像进行的第一处理包括:配准、黑电平校正、自动白平衡、通道拆分和增设方差图层。对2帧第三图像上进行的第一处理包括:配准、黑电平校正和增设方差图层。
其中,对多帧第二图像进行配准时,以第1帧第二图像为参考帧,对其他帧第二图像分别进行配准。对2帧第三图像进行配准时,可以以第1帧第三图像为参考帧,对第2帧第三图像进行配准。而对第二视场角图像进行配准时,可以以第1帧第二图像为参考帧,然后,对第二视场角图像进行配准。
通道拆分的过程与上述S2020中对通道拆分的描述相同,在此不再赘述。
其中,增设方差图层时,可以针对每帧第二图像增设1张第二方差图层;针对每帧第三图像增设1张第三方差图层;针对每帧第二视场角图像增设1张第四方差图层。
第二方差图层包括多个像素,每个像素对应的方差值由第二图像对应的感光度确定;第三方差图层包括多个像素,每个像素对应的方差值由第三图像对应的感光度确定;第四方差图层包括多个像素,每个像素对应的方差值由第二视场角图像对应的感光度确定。
应理解,此处,对第二方差图层、第三方差图层和第四方差图层的描述与上述S2020中对方差图层的描述相同,在此不再赘述。
S7030、对第二视场角图像增设参考坐标图层,参考坐标图层用于反映第二视场角图像对应的视场角与第一视场角图像对应的视场角之间的映射关系。
此处,得到参考坐标图层的过程与上述S2030中得到参考坐标图层的过程相同,在此不再赘述。
S7040、根据进行了第一处理的多帧第二图像和进行了第一处理的2帧第三图像,进行了第一处理的第二视场角图像、以及增设的参考坐标图层,得到图层集。
应理解,进行了第一处理的多帧第二图像包括:通道拆分出的多个待增强子图层和增设的第二方差图层;进行了第一处理的多帧第三图像包括:第三图像和增设的第三方差图层;进行了第一处理的第二视场角图像包括:通道拆分出的多个待增强子图层和增设的第四方差图层。
S7050、利用深度学习网络模型对图层集进行降噪、去马赛克、色彩融合和视场角融合,得到获取图层集对应的第一增强图像。
其中,第一增强图像位于RGB颜色空间。
深度学习网络模型为Unet模型、Resnet模型和PSPnet模型中的任意一种。
S7060、利用第一图像中的长曝光图像和短曝光图像,对第一增强图像进行长短曝光融合处理,得到中间增强图像。然后,将中间增强图像作为第一增强图像。
其中,利用第一图像中的长曝光图像和短曝光图像,对第一增强图像进行长短曝 光融合处理的过程如图16所示,在此不再赘述。
S7070、对第一增强图像进行增强处理,得到第二增强图像,增强处理包括颜色增强处理和/或亮度增强处理。
其中,S7070可以包括上述S2061至S2063。
S7080、对第二增强图像进行色彩空间转换,得到位于YUV颜色空间的第一目标图像。
上述主要从电子设备或图像处理装置的角度对本申请实施例提供的方案进行了介绍。可以理解的是,电子设备和图像处理装置,为了实现上述功能,其包含了执行每一个功能相应的硬件结构或软件模块,或两者结合。本领域技术人员应该很容易意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,本申请能够以硬件或硬件和计算机软件的结合形式来实现。某个功能究竟以硬件还是计算机软件驱动硬件的方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本申请的范围。
本申请实施例可以根据上述方法示例对电子设备和图像处理装置进行功能模块的划分,例如,可以对应每一个功能划分每一个功能模块,也可以将两个或两个以上的功能集成在一个处理模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。需要说明的是,本申请实施例中对模块的划分是示意性的,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式。下面以采用对应每一个功能划分每一个功能模块为例进行说明:
图24为本申请实施例提供的一种图像处理装置的结构示意图。如图24所示,该图像处理装置300包括获取模块310和处理模块320,处理模块320可以包括第一处理模块、第二处理模块和第三处理模块。
该图像处理装置可以执行以下方案:
获取模块310,用于获取多帧原始图像。多帧原始图像为对相同的待拍摄场景拍摄的图像,多帧原始图像包括:第一视场角图像和第二视场角图像,第一视场角图像对应的视场角与第二视场角图像对应的视场角不同。
第一处理模块,用于对第二视场角图像增设参考坐标图层。参考坐标图层用于反映第二视场角图像对应的视场角与第一视场角图像对应的视场角之间的映射关系。
第一处理模块,还用于根据第一视场角图像,以及第二视场角图像和参考坐标图层,得到图层集。
第二处理模块,用于利用深度学习网络模型对图层集进行处理,得到第一增强图像。
第三处理模块,用于根据第一增强图像,得到第二增强图像。
可选地,第一处理模块,还用于对第一视场角图像,和/或,第二视场角图像进行第一处理,第一处理包括:配准。
可选地,第一视场角图像包括以下的一项或多项:多帧第一图像、多帧第二图像、至少一帧第三图像。
其中,多帧第一图像包括至少一帧长曝光图像和至少一帧短曝光图像,第二图像为正常曝光的拜耳格式图像,第三图像为灰阶图像。
可选地,第一图像为拜耳格式图像或为灰阶图像。
可选地,第二视场角图像为拜耳格式图像或为灰阶图像。
可选地,当第一视场角图像包括多帧第二图像时,第一处理模块,还用于:
以第1帧第二图像为参考帧,对第二视场角图像进行配准。
可选地,在对第二视场角图像进行配准之后,第一处理模块,还用于:
根据第1帧第二图像和配准后的第二视场角图像,对预设坐标图层进行透视变换,得到参考坐标图层。预设坐标图层用于反映预设的第二视场角图像对应的视场角与第一视场角图像对应的视场角之间的映射关系。
可选地,预设坐标图层包括重合区,重合区用于表示:第1帧第二图像和第二视场角图像中,视场角较小的图像贴到视场角较大的图像上时所对应的区域。
可选地,第一处理还包括:黑电平校正。
可选地,针对为拜耳格式图像的第一图像、针对第二图像、针对为拜耳格式图像的第二视场角图像中的至少一项,第一处理还包括:自动白平衡。
可选地,第一处理还包括:通道拆分。
其中,通道拆分指的是将拜耳格式图像拆分成多个单通道的待增强子图层,每个单通道的待增强子图层只包含一种颜色通道信号。
可选地,第一处理还包括:增设方差图层;
其中,方差图层包括多个像素,每个像素对应的方差值由原始图像对应的感光度确定。
可选地,第二处理模块,还用于:利用深度学习网络模型进行降噪、去马赛克、彩色融合和视场角融合,获取图层集对应的第一增强图像。
其中,第一增强图像位于RGB颜色空间。
可选地,第三处理模块,还用于:对所述第一增强图像进行增强处理,得到所述第二增强图像,所述增强处理包括颜色增强处理和/或亮度增强处理。
增强处理包括颜色增强处理和/或亮度增强处理。
可选地,第三处理模块,还用于:
利用分割模型对第一增强图像进行分割,得到掩膜图;根据第一增强图像和掩膜图,利用色调映射模型,得到增益系数图;增益系数图包括多个像素,以及每个像素对应的增益值;将第一增强图像与增益系数图相乘,得到第二增强图像。
可选地,增益系数图包括3帧颜色增益系数图和/或1帧亮度增益系数图,每帧颜色增益系数图只对一种颜色进行增强,亮度增益系数图用于对亮度进行增强。
可选地,在第一视场角图像包括多帧第一图像,还包括多帧第二图像和/或至少一帧第三图像的情况下,当第一处理模块对多帧第一图像未进行第一处理,而对第二视场角图像进行第一处理时,第一处理模块,还用于根据第一视场角图像中除第一图像之外的图像,第二视场角图像以及参考坐标图层,得到图层集。
可选地,第二处理模块,还用于:利用长曝光图像和短曝光图像,对第一增强图像进行长短曝光融合处理,得到中间增强图像;将中间增强图像作为第一增强图像。
可选地,第二处理模块,还用于将第一增强图像与第一待融合图像进行融合,得到中间融合图像;将中间融合图像与第二待融合图像进行融合,得到中间增强图像。
其中,第一待融合图像、第二待融合图像分别为长曝光图像和短曝光图像。
可选地,该图像处理装置,还可以包括第四处理模块,该第四处理模块,用于对第二增强图像进行色彩空间转换,得到位于YUV颜色空间的第一目标图像。
作为一个示例,结合图3所示的图像处理装置,图24中的获取模块310可以由图3中的接收接口来实现,图24中的处理模块320可以由图3中的中央处理器、图形处理器、微控制器和神经网络处理器中的至少一项来实现,本申请实施例对此不进行任何限制。
本申请实施例还提供另一种图像处理装置,包括:接收接口和处理器。
接收接口用于从电子设备处获取多帧原始图像,多帧原始图像为对相同的待拍摄场景拍摄的图像,多帧原始图像包括:第一视场角图像和第二视场角图像,第一视场角图像对应的视场角与第二视场角图像对应的视场角不同。
处理器,用于调用存储器中存储的计算机程序,以执行如上述所述的图像处理方法10中进行处理的步骤。
本申请实施例还提供另一种电子设备,包括摄像头模组、处理器和存储器。
摄像头模组,用于获取多帧原始图像,多帧原始图像为对相同的待拍摄场景拍摄的图像,多帧原始图像包括:第一视场角图像和第二视场角图像,第一视场角图像对应的视场角与第二视场角图像对应的视场角不同。
存储器,用于存储可在处理器上运行的计算机程序。
处理器,用于执行如上述所述的图像处理方法10中进行处理的步骤。
可选地,摄像头模组包括彩色摄像头、黑白摄像头和第三摄像头;彩色摄像头和黑白摄像头用于对相同的待拍摄场景以第一视场角进行拍照,第三摄像头用于对待拍摄场景以第二视场角进行拍照,第一视场角与第二视场角不同。
彩色摄像头,用于在处理器获取拍照指令后,获取多帧第一图像和多帧第二图像,多帧第一图像至少包括一帧长曝光图像和一帧短曝光图像;第二图像为正常曝光的拜耳格式图像;黑白摄像头,用于在处理器获取拍照指令后,获取至少一帧第三图像,第三图像为灰阶图像。
第三摄像头,用于在处理获取拍照指令后,获取至少一帧第二视场角图像。
可选地,摄像头模组包括彩色摄像头、黑白摄像头和第三摄像头;彩色摄像头和黑白摄像头用于对相同的待拍摄场景以第一视场角进行拍照,第三摄像头用于对待拍摄场景以第二视场角进行拍照。第一视场角与第二视场角不同。
彩色摄像头,用于在处理器获取拍照指令后,获取多帧第二图像,第二图像为正常曝光的拜耳格式图像。
黑白摄像头,用于在处理器获取拍照指令后,获取多帧第一图像和至少一帧第三图像,多帧第一图像至少包括一帧长曝光图像和一帧短曝光图像;第三图像为灰阶图像。
第三摄像头,用于在处理器获取拍照指令后,获取至少一帧第二视场角图像。
严格来说,是通过彩色摄像头和黑白摄像头中的图像处理器来获取图像。其中,图像传感器例如可以为电荷耦合元件(charge-coupled device,CCD)、互补金属氧化物半导体(complementary metal oxide semiconductor,CMOS)等。
应理解,获取的第一图像、第二图像和第三图像对应第一视场角,获取的第二视场角图像对应第二视场角。
本申请实施例还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机指令;当所述计算机可读存储介质在图像处理装置上运行时,使得该图像处理装置执行如图4、图13、或者图15至图23任一项所示的方法。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或者数据中心通过有线(例如同轴电缆、光纤、数字用户线(digital subscriber line,DSL))或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输。所述计算机可读存储介质可以是计算机能够存取的任何可用介质或者是包含一个或多个可以用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质(例如,软盘、硬盘、磁带),光介质、或者半导体介质(例如固态硬盘(solid state disk,SSD))等。
本申请实施例还提供了一种包含计算机指令的计算机程序产品,当其在图像处理装置上运行时,使得图像处理装置可以执行图4、图13、或者图15至图23任一项所示的方法。
图25为本申请实施例提供的一种芯片的结构示意图。图25所示的芯片可以为通用处理器,也可以为专用处理器。该芯片包括处理器401。其中,处理器401用于支持图像处理装置执行图4、图13、或者图15至图23任一项所示的技术方案。
可选的,该芯片还包括收发器402,收发器402用于接受处理器401的控制,用于支持通信装置执行图4、图13、或者图15至图23任一项所示的技术方案。
可选的,图25所示的芯片还可以包括:存储介质403。
需要说明的是,图25所示的芯片可以使用下述电路或者器件来实现:一个或多个现场可编程门阵列(field programmable gate array,FPGA)、可编程逻辑器件(programmable logic device,PLD)、控制器、状态机、门逻辑、分立硬件部件、任何其他适合的电路、或者能够执行本申请通篇所描述的各种功能的电路的任意组合。
上述本申请实施例提供的电子设备、图像处理装置、计算机存储介质、计算机程序产品、芯片均用于执行上文所提供的方法,因此,其所能达到的有益效果可参考上文所提供的方法对应的有益效果,在此不再赘述。
应理解,上述只是为了帮助本领域技术人员更好地理解本申请实施例,而非要限制本申请实施例的范围。本领域技术人员根据所给出的上述示例,显然可以进行各种等价的修改或变化,例如,上述检测方法的各个实施例中某些步骤可以是不必须的,或者可以新加入某些步骤等。或者上述任意两种或者任意多种实施例的组合。这样的修改、变化或者组合后的方案也落入本申请实施例的范围内。
还应理解,上文对本申请实施例的描述着重于强调各个实施例之间的不同之处,未提到的相同或相似之处可以互相参考,为了简洁,这里不再赘述。
还应理解,上述各过程的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本申请实施例的实施过程构成任何限定。
还应理解,本申请实施例中,“预先设定”、“预先定义”可以通过在设备(例如,包括电子设备)中预先保存相应的代码、表格或其他可用于指示相关信息的方式来实现,本申请对于其具体的实现方式不做限定。
还应理解,本申请实施例中的方式、情况、类别以及实施例的划分仅是为了描述的方便,不应构成特别的限定,各种方式、类别、情况以及实施例中的特征在不矛盾的情况下可以相结合。
还应理解,在本申请的各个实施例中,如果没有特殊说明以及逻辑冲突,不同的实施例之间的术语和/或描述具有一致性、且可以相互引用,不同的实施例中的技术特征根据其内在的逻辑关系可以组合形成新的实施例。
最后应说明的是:以上所述,仅为本申请的具体实施方式,但本申请的保护范围并不局限于此,任何在本申请揭露的技术范围内的变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应以所述权利要求的保护范围为准。
Claims (26)
- 一种图像处理方法,其特征在于,所述方法包括:获取多帧原始图像,所述多帧原始图像为对相同的待拍摄场景拍摄的图像,所述多帧原始图像包括:第一视场角图像和第二视场角图像,所述第一视场角图像对应的视场角与所述第二视场角图像对应的视场角不同;对所述第二视场角图像增设参考坐标图层,所述参考坐标图层用于反映所述第二视场角图像对应的视场角与所述第一视场角图像对应的视场角之间的映射关系;根据所述第一视场角图像、所述第二视场角图像以及所述参考坐标图层,得到图层集;利用深度学习网络模型处理所述图层集,得到第一增强图像;所述第一增强图像位于RGB颜色空间;根据所述第一增强图像,得到第二增强图像。
- 根据权利要求1所述的方法,其特征在于,在对所述第二视场角图像增设参考坐标图层之前,所述方法还包括:对所述第一视场角图像,和/或,所述第二视场角图像进行第一处理,所述第一处理包括:配准。
- 根据权利要求2所述的方法,其特征在于,所述第一视场角图像包括以下的一项或多项:多帧第一图像、多帧第二图像、至少一帧第三图像;其中,多帧所述第一图像包括至少一帧长曝光图像和至少一帧短曝光图像,所述第二图像为正常曝光的拜耳格式图像,所述第三图像为灰阶图像。
- 根据权利要求3所述的方法,其特征在于,所述第一图像为所述拜耳格式图像或为灰阶图像。
- 根据权利要求1至4中任一项所述的方法,其特征在于,所述第二视场角图像为拜耳格式图像或为灰阶图像。
- 根据权利要求3所述的方法,其特征在于,当所述第一视场角图像包括多帧所述第二图像时,对所述第二视场角图像进行配准,包括:以第1帧第二图像为参考帧,对所述第二视场角图像进行配准。
- 根据权利要求6所述的方法,其特征在于,在对所述第二视场角图像进行配准之后,所述方法还包括:根据所述第1帧第二图像和配准后的第二视场角图像,对预设坐标图层进行透视变换,得到所述参考坐标图层,所述预设坐标图层用于反映预设的所述第二视场角图像对应的视场角与所述第一视场角图像对应的视场角之间的映射关系。
- 根据权利要求7所述的方法,其特征在于,所述预设坐标图层包括重合区;所述重合区用于表示:所述第1帧第二图像和所述第二视场角图像中,视场角较小的图像贴到视场角较大的图像上时所对应的区域。
- 根据权利要求2所述的方法,其特征在于,所述第一处理还包括:黑电平校正。
- 根据权利要求3所述的方法,其特征在于,针对为所述拜耳格式图像的所述第一图像、针对所述第二图像、针对为所述拜耳格式图像的所述第二视场角图像中的至少一项,所述第一处理还包括:自动白平衡。
- 根据权利要求10所述的方法,其特征在于,所述第一处理还包括:通道拆分;其中,通道拆分指的是将所述拜耳格式图像拆分成多个单通道的待增强子图层,每个单通道的待增强子图层只包含一种颜色通道信号。
- 根据权利要求2、9至11中任一项所述的方法,其特征在于,所述第一处理还包括:增设方差图层;其中,所述方差图层包括多个像素,每个所述像素对应的方差值由所述原始图像对应的感光度确定。
- 根据权利要求1至12中任一项所述的方法,其特征在于,所述利用深度学习网络模型处理所述图层集,得到第一增强图像,包括:利用所述深度学习网络模型对所述图层集进行降噪、去马赛克、彩色融合和视场角融合,得到所述第一增强图像。
- 根据权利要求1至13中任一项所述的方法,其特征在于,所述根据所述第一增强图像,得到第二增强图像,包括:对所述第一增强图像进行增强处理,得到所述第二增强图像,所述增强处理包括颜色增强处理和/或亮度增强处理。
- 根据权利要求14所述的方法,其特征在于,所述对所述第一增强图像进行增强处理,得到第二增强图像,包括:利用分割模型对所述第一增强图像进行分割,得到掩膜图;根据所述第一增强图像和所述掩膜图,利用色调映射模型,得到增益系数图;所述增益系数图包括多个像素,以及每个所述像素对应的增益值;将所述第一增强图像与所述增益系数图相乘,得到所述第二增强图像。
- 根据权利要求15所述的方法,其特征在于,所述增益系数图包括3帧颜色增益系数图和/或1帧亮度增益系数图,每帧颜色增益系数图只对一种颜色进行增强,所述亮度增益系数图用于对亮度进行增强。
- 根据权利要求10所述的方法,其特征在于,当对所述第一视场角图像中的多帧所述第一图像未进行所述第一处理,而对所述第二视场角图像进行第一处理时,所述根据所述第一视场角图像、所述第二视场角图像以及所述参考坐标图层,得到图层集,包括:根据所述第一视场角图像中除多帧所述第一图像之外的图像,所述第二视场角图像以及所述参考坐标图层,得到所述图层集。
- 根据权利要求17所述的方法,其特征在于,在所述利用分割模型,得到所述第一增强图像对应的掩膜图之前,所述方法还包括:利用多帧所述第一图像中的所述长曝光图像和所述短曝光图像,对所述第一增强图像进行长短曝光融合处理,得到中间增强图像;将所述中间增强图像作为所述第一增强图像。
- 根据权利要求18所述的方法,其特征在于,所述利用所述长曝光图像和所述短曝光图像,对所述第一增强图像进行长短曝光融合处理,得到中间增强图像,包括:将所述第一增强图像与第一待融合图像进行融合,得到第一中间融合图像;将所述第一中间融合图像与第二待融合图像进行融合,得到所述中间增强图像;其中,所述第一待融合图像、所述第二待融合图像分别为所述长曝光图像和所述短曝光图像。
- 根据权利要求1至19中任一项所述的方法,其特征在于,在得到所述第二增强图像之后,所述方法还包括:对所述第二增强图像进行色彩空间转换,得到位于YUV颜色空间的第一目标图像。
- 一种图像处理装置,其特征在于,包括:接收接口和处理器;所述接收接口用于从电子设备处获取多帧原始图像,所述多帧原始图像为对相同的待拍摄场景拍摄的图像,所述多帧原始图像包括:第一视场角图像和第二视场角图像,所述第一视场角图像对应的视场角与所述第二视场角图像对应的视场角不同;所述处理器,用于调用存储器中存储的计算机程序,以执行如权利要求1至20中任一项所述的图像处理方法中进行处理的步骤。
- 一种电子设备,其特征在于,包括摄像头模组、处理器和存储器;所述摄像头模组,用于获取多帧原始图像,所述多帧原始图像为对相同的待拍摄场景拍摄的图像,所述多帧原始图像包括:第一视场角图像和第二视场角图像,所述第一视场角图像对应的视场角与所述第二视场角图像对应的视场角不同;所述存储器,用于存储可在所述处理器上运行的计算机程序;所述处理器,用于执行如权利要求1至20中任一项所述的图像处理方法中进行处理的步骤。
- 根据权利要求22所述的电子设备,其特征在于,所述摄像头模组包括彩色摄像头、黑白摄像头和第三摄像头,所述彩色摄像头和所述黑白摄像头用于对相同的待拍摄场景以第一视场角进行拍照,所述第三摄像头用于对所述待拍摄场景以第二视场角进行拍照;所述第一视场角与所述第二视场角不同;所述彩色摄像头,用于在所述处理器获取拍照指令后,获取多帧第一图像和多帧第二图像,多帧所述第一图像至少包括一帧长曝光图像和一帧短曝光图像;所述第二图像为正常曝光的拜耳格式图像;所述黑白摄像头,用于在所述处理器获取所述拍照指令后,获取至少一帧第三图像,所述第三图像为灰阶图像;所述第三摄像头,用于在所述处理器获取所述拍照指令后,获取至少一帧第二视场角图像。
- 根据权利要求22所述的电子设备,其特征在于,所述摄像头模组包括彩色摄像头、黑白摄像头和第三摄像头,所述彩色摄像头和所述黑白摄像头用于对相同的待拍摄场景以第一视场角进行拍照,所述第三摄像头用于对所述待拍摄场景以第二视场角进行拍照;所述第一视场角与所述第二视场角不同;所述彩色摄像头,用于在所述处理器获取拍照指令后,获取多帧第二图像,所述第二图像为正常曝光的拜耳格式图像;所述黑白摄像头,用于在所述处理器获取所述拍照指令后,获取多帧第一图像和至少一帧第三图像,多帧所述第一图像至少包括一帧长曝光图像和一帧短曝光图像;所述第三图像为灰阶图像;所述第三摄像头,用于在所述处理器获取所述拍照指令后,获取至少一帧第二视场角图像。
- 一种芯片,其特征在于,包括:处理器,用于从存储器中调用并运行计算机程序,使得安装有所述芯片的设备执行如权利要求1至20中任一项所述的图像处理方法。
- 一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有计算机程序,所述计算机程序包括程序指令,所述程序指令当被处理器执行时,使所述处理器执行如权利要求1至20中任一项所述的图像处理方法。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP22836618.3A EP4280152A1 (en) | 2021-07-07 | 2022-05-19 | Image processing method and apparatus, and electronic device |
| US18/277,060 US20240119566A1 (en) | 2021-07-07 | 2022-05-19 | Image processing method and apparatus, and electronic device |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110771029.X | 2021-07-07 | ||
| CN202110771029.XA CN115601274A (zh) | 2021-07-07 | 2021-07-07 | 图像处理方法、装置和电子设备 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023279862A1 true WO2023279862A1 (zh) | 2023-01-12 |
Family
ID=84800338
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/CN2022/093914 WO2023279862A1 (zh) | 2021-07-07 | 2022-05-19 | 图像处理方法、装置和电子设备 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US20240119566A1 (zh) |
| EP (1) | EP4280152A1 (zh) |
| CN (1) | CN115601274A (zh) |
| WO (1) | WO2023279862A1 (zh) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN117115197A (zh) * | 2023-08-09 | 2023-11-24 | 幂光新材料科技(上海)有限公司 | 一种led灯珠电路板设计数据智能处理方法及系统 |
| CN117274227A (zh) * | 2023-10-23 | 2023-12-22 | 宁波市宇星水表有限公司 | 水表表面状态管理系统 |
| CN117528262A (zh) * | 2023-12-29 | 2024-02-06 | 江西赛新医疗科技有限公司 | 一种医疗设备数据传输的控制方法及系统 |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN117132629A (zh) * | 2023-02-17 | 2023-11-28 | 荣耀终端有限公司 | 图像处理方法和电子设备 |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20180070015A1 (en) * | 2016-09-06 | 2018-03-08 | Apple Inc. | Still image stabilization/optical image stabilization synchronization in multi-camera image capture |
| CN110430357A (zh) * | 2019-03-26 | 2019-11-08 | 华为技术有限公司 | 一种图像拍摄方法与电子设备 |
| CN112087580A (zh) * | 2019-06-14 | 2020-12-15 | Oppo广东移动通信有限公司 | 图像采集方法和装置、电子设备、计算机可读存储介质 |
| CN112529775A (zh) * | 2019-09-18 | 2021-03-19 | 华为技术有限公司 | 一种图像处理的方法和装置 |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2018081924A1 (zh) * | 2016-11-01 | 2018-05-11 | 深圳岚锋创视网络科技有限公司 | 一种全景图像的生成方法、系统及拍摄装置 |
| CN109191415B (zh) * | 2018-08-22 | 2020-12-15 | 成都纵横自动化技术股份有限公司 | 图像融合方法、装置及电子设备 |
| CN109345485B (zh) * | 2018-10-22 | 2021-04-16 | 北京达佳互联信息技术有限公司 | 一种图像增强方法、装置、电子设备及存储介质 |
| CN110493587B (zh) * | 2019-08-02 | 2023-08-11 | 深圳市灵明光子科技有限公司 | 图像获取装置和方法、电子设备、计算机可读存储介质 |
| CN111147924B (zh) * | 2019-12-24 | 2022-10-04 | 书行科技(北京)有限公司 | 一种视频增强处理方法及系统 |
-
2021
- 2021-07-07 CN CN202110771029.XA patent/CN115601274A/zh active Pending
-
2022
- 2022-05-19 EP EP22836618.3A patent/EP4280152A1/en active Pending
- 2022-05-19 US US18/277,060 patent/US20240119566A1/en active Pending
- 2022-05-19 WO PCT/CN2022/093914 patent/WO2023279862A1/zh active Application Filing
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20180070015A1 (en) * | 2016-09-06 | 2018-03-08 | Apple Inc. | Still image stabilization/optical image stabilization synchronization in multi-camera image capture |
| CN110430357A (zh) * | 2019-03-26 | 2019-11-08 | 华为技术有限公司 | 一种图像拍摄方法与电子设备 |
| CN112087580A (zh) * | 2019-06-14 | 2020-12-15 | Oppo广东移动通信有限公司 | 图像采集方法和装置、电子设备、计算机可读存储介质 |
| CN112529775A (zh) * | 2019-09-18 | 2021-03-19 | 华为技术有限公司 | 一种图像处理的方法和装置 |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN117115197A (zh) * | 2023-08-09 | 2023-11-24 | 幂光新材料科技(上海)有限公司 | 一种led灯珠电路板设计数据智能处理方法及系统 |
| CN117115197B (zh) * | 2023-08-09 | 2024-05-17 | 幂光新材料科技(上海)有限公司 | 一种led灯珠电路板设计数据智能处理方法及系统 |
| CN117274227A (zh) * | 2023-10-23 | 2023-12-22 | 宁波市宇星水表有限公司 | 水表表面状态管理系统 |
| CN117528262A (zh) * | 2023-12-29 | 2024-02-06 | 江西赛新医疗科技有限公司 | 一种医疗设备数据传输的控制方法及系统 |
| CN117528262B (zh) * | 2023-12-29 | 2024-04-05 | 江西赛新医疗科技有限公司 | 一种医疗设备数据传输的控制方法及系统 |
Also Published As
| Publication number | Publication date |
|---|---|
| US20240119566A1 (en) | 2024-04-11 |
| CN115601274A (zh) | 2023-01-13 |
| EP4280152A1 (en) | 2023-11-22 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2023279862A1 (zh) | 图像处理方法、装置和电子设备 | |
| WO2023279863A1 (zh) | 图像处理方法、装置和电子设备 | |
| WO2023015981A1 (zh) | 图像处理方法及其相关设备 | |
| US9451173B2 (en) | Electronic device and control method of the same | |
| KR102263537B1 (ko) | 전자 장치와, 그의 제어 방법 | |
| CN113810600B (zh) | 终端的图像处理方法、装置和终端设备 | |
| CN113810601B (zh) | 终端的图像处理方法、装置和终端设备 | |
| CN113452898B (zh) | 一种拍照方法及装置 | |
| CN114095666B (zh) | 拍照方法、电子设备和计算机可读存储介质 | |
| US20240073496A1 (en) | Auto exposure for spherical images | |
| WO2023131070A1 (zh) | 一种电子设备的管理方法、电子设备及可读存储介质 | |
| WO2022267608A1 (zh) | 一种曝光强度调节方法及相关装置 | |
| CN116416122A (zh) | 图像处理方法及其相关设备 | |
| WO2022267466A1 (zh) | 图像处理方法、装置和电子设备 | |
| CN113630558B (zh) | 一种摄像曝光方法及电子设备 | |
| CN117135471A (zh) | 一种图像处理方法和电子设备 | |
| CN115514948B (zh) | 图像调节方法以及电子设备 | |
| US20230058472A1 (en) | Sensor prioritization for composite image capture | |
| CN116055855B (zh) | 图像处理方法及其相关设备 | |
| CN115526786B (zh) | 图像处理方法及其相关设备 | |
| CN115705663B (zh) | 图像处理方法与电子设备 | |
| CN115631250B (zh) | 图像处理方法与电子设备 | |
| WO2023035919A1 (zh) | 控制曝光的方法、装置与电子设备 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22836618 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 18277060 Country of ref document: US |
|
| ENP | Entry into the national phase |
Ref document number: 2022836618 Country of ref document: EP Effective date: 20230814 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |