WO2023243020A1 - 訓練プログラム,訓練方法及び情報処理装置 - Google Patents
訓練プログラム,訓練方法及び情報処理装置 Download PDFInfo
- Publication number
- WO2023243020A1 WO2023243020A1 PCT/JP2022/024037 JP2022024037W WO2023243020A1 WO 2023243020 A1 WO2023243020 A1 WO 2023243020A1 JP 2022024037 W JP2022024037 W JP 2022024037W WO 2023243020 A1 WO2023243020 A1 WO 2023243020A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- data
- encoder
- feature amount
- training
- objects
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images














Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/774—Generating sets of training patterns; Bootstrap methods, e.g. bagging or boosting
- G06V10/7753—Incorporation of unlabelled data, e.g. multiple instance learning [MIL]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
- G06N3/0455—Auto-encoder networks; Encoder-decoder networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0464—Convolutional networks [CNN, ConvNet]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/0895—Weakly supervised learning, e.g. semi-supervised or self-supervised learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/70—Determining position or orientation of objects or cameras
- G06T7/73—Determining position or orientation of objects or cameras using feature-based methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/764—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using classification, e.g. of video objects
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/774—Generating sets of training patterns; Bootstrap methods, e.g. bagging or boosting
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20081—Training; Learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20084—Artificial neural networks [ANN]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V2201/00—Indexing scheme relating to image or video recognition or understanding
- G06V2201/07—Target detection
Definitions
- the present invention relates to a training program, a training method, and an information processing device.
- a technique for generating a knowledge graph called a scene graph from image data is known.
- a scene graph includes information about relationships between multiple objects in image data.
- supervised data labeled data
- machine learning model for calculating features about the relationships between objects. train. From the viewpoint of increasing the amount of information included in the scene graph, it is desirable to calculate concrete relationships between multiple objects rather than abstract relationships.
- One aspect of the present invention is to improve the classification accuracy of relationships by reflecting specific relationships between multiple objects in image data.
- the training program performs training on first data including first object features and position information of each of the plurality of objects in the first image data.
- the first object feature amount is a second object obtained for at least one other object classified into the same class as the target object in at least one second image data different from the first image data.
- a computer is caused to perform a process of generating at least one second data by replacing the object feature amount with the object feature amount, and inputting at least one of the second data to an encoder to train the encoder.
- FIG. 1 is a block diagram schematically showing a hardware configuration example of an information processing device in an embodiment.
- FIG. FIG. 3 is a diagram illustrating the definition of a scene graph.
- FIG. 2 is a diagram schematically showing an example of a scene graph.
- FIG. 2 is a diagram showing an example of self-supervised learning.
- FIG. 2 is a diagram showing an example of contrastive learning.
- 3 is a block diagram schematically showing a first example of a software configuration in a training phase of an encoder by the information processing apparatus shown in FIG. 2.
- FIG. FIG. 3 is a diagram showing an example of a training process for an object detector by the information processing apparatus shown in FIG.
- FIG. 2; 3 is a diagram illustrating an example of an encoder training process performed by the information processing apparatus illustrated in FIG. 2.
- FIG. 10 is a diagram illustrating an example of a process using contrastive learning in the encoder training process in FIG. 9.
- FIG. 3 is a block diagram schematically showing a second example of a software configuration in a training phase of an encoder by the information processing apparatus shown in FIG. 2.
- FIG. 3 is a block diagram schematically showing an example of a software configuration in a training phase of a classifier by the information processing apparatus shown in FIG. 2.
- FIG. FIG. 3 is a diagram illustrating an example of a classifier training process performed by the information processing apparatus illustrated in FIG.
- FIG. 3 is a block diagram schematically showing an example of a software configuration in an inference phase by the information processing apparatus shown in FIG. 2.
- FIG. 3 is a flowchart illustrating an example of an encoder training process in a training phase of the information processing apparatus shown in FIG. 2.
- FIG. 3 is a flowchart illustrating an example of a training process of a classifier in a training phase of the information processing apparatus shown in FIG. 2.
- FIG. 3 is a flowchart illustrating an example of scene graph creation processing in the inference phase of the information processing apparatus illustrated in FIG. 2.
- FIG. FIG. 3 is a diagram illustrating an example of the reproducibility results of relationship labels obtained by the information processing apparatus illustrated in FIG. 2;
- FIG. 1 is a diagram illustrating a training process for an encoder 23 in a related technology.
- the encoder 23 is trained by supervised learning using a deep neural network (DNN).
- DNN deep neural network
- Labeled data 30 is used as input image data.
- the labeled data 30 is also called supervised data.
- the labeled data 30 includes image data 31.
- the image data 31 includes a plurality of objects 32a (cow) and 32b (woman).
- the labeled data 30 may include object labels 33a, 33b and relationship labels 34.
- the object labels 33a and 33b are information indicating the type (class) of each of the plurality of objects 32a and 32b in the image data 31.
- the object label 33a is "cow”
- the object label 33b is "woman”.
- the relationship label 34 is information indicating the relationship between the plurality of objects 32a and 32b, and in FIG. 1, it is "feed”.
- the trained object detector 21 acquires object labels 33a, 33b and position information 36a, 36b of each target object 32a, 32b from the labeled data 30.
- the objects 32a and 32b may include a subject and an object.
- the object label 33a and position information 36a are acquired for the object "cow”.
- the object label 33b and position information 36b are acquired for the subject " woman”.
- the feature extractor 22 extracts a first object feature 37a for the object 32a (object) and a first object feature 37a for the object 32b (subject) based on position information 36a and 36b occupied by the objects 32a and 32b, respectively.
- the object feature amount 37b is calculated.
- the encoder 23 outputs the classification result 38 of the relationship label based on the first object feature amount 37a of the object and the first object feature amount 37b of the subject. In this example, the encoder 23 outputs the classification result 38 of the relationship label "feed".
- the encoder optimization unit 24 compares the relationship label classification result 38 output from the encoder 23 with the correct relationship label 34 of the labeled data 30, and reduces the error between the classification result 38 and the relationship label 34. The encoder 23 is trained to do so.
- the frequency of appearance of abstract relationships such as “on” and “have” is different from the frequency of occurrence of abstract relationships such as “on” and “have” compared to concrete relationships such as “sitting on” and “walking on.” may be higher than the frequency of occurrence of such relationships. In this case, it is not easy to assign a relationship label in consideration of specific relationships.
- FIG. 2 is a block diagram schematically showing a hardware configuration example of the information processing device 1 in the embodiment.
- the information processing device 1 is a computer. As shown in FIG. 2, the information processing device 1 includes a processor 11, a memory section 12, a display control section 13, a storage device 14, an input interface (IF) 15, an external recording medium processing section 16, and a communication IF 17.
- a processor 11 a processor 11, a memory section 12, a display control section 13, a storage device 14, an input interface (IF) 15, an external recording medium processing section 16, and a communication IF 17.
- IF input interface
- the memory unit 12 is an example of a storage unit, and examples thereof include Read Only Memory (ROM) and Random Access Memory (RAM).
- ROM Read Only Memory
- RAM Random Access Memory
- a program such as a Basic Input/Output System (BIOS) may be written in the ROM of the memory unit 12.
- BIOS Basic Input/Output System
- the software program in the memory unit 12 may be loaded into the processor 11 as appropriate and executed.
- the RAM of the memory unit 12 may be used as a temporary recording memory or a working memory.
- the display control unit 13 is connected to the display device 130 and controls the display device 130.
- the display device 130 is a liquid crystal display, an organic light-emitting diode (OLED) display, a cathode ray tube (CRT), an electronic paper display, or the like, and displays various information for the operator and the like.
- the display device 130 may be combined with an input device, for example, a touch panel.
- the storage device 14 is a storage device with high IO performance, and for example, Dynamic Random Access Memory (DRAM), Solid State Drive (SSD), Storage Class Memory (SCM), or Hard Disk Drive (HDD) may be used.
- DRAM Dynamic Random Access Memory
- SSD Solid State Drive
- SCM Storage Class Memory
- HDD Hard Disk Drive
- the input IF 15 is connected to input devices such as the mouse 151 and the keyboard 152, and may control the input devices such as the mouse 151 and the keyboard 152.
- the mouse 151 and keyboard 152 are examples of input devices, and the operator performs various input operations via these input devices.
- the external recording medium processing section 16 is configured such that a recording medium 160 can be attached thereto.
- the external recording medium processing unit 16 is configured to be able to read information recorded on the recording medium 160 when the recording medium 160 is attached.
- the recording medium 160 is portable.
- the recording medium 160 is a flexible disk, an optical disk, a magnetic disk, a magneto-optical disk, a semiconductor memory, or the like.
- the communication IF 17 is an interface for enabling communication with external devices.
- the processor 11 is a processing device that performs various controls and calculations.
- the processor 11 may include a CPU (Central Processing Unit).
- the processor 11 may include a dGPU (Discrete Graphics Processing Unit).
- the dGPU refers to a GPU that exists on a graphics chip or graphics board that is independent of the CPU.
- the processor 11 implements various functions by executing an Operating System (OS) and programs read into the memory unit 12.
- OS Operating System
- the processor 11 may realize a function as a control unit 100, which will be described later.
- the device for controlling the operation of the entire information processing device 1 is not limited to the CPU and dGPU, and may be, for example, any one of the MPU, DSP, ASIC, PLD, and FPGA. Further, the device for controlling the operation of the entire information processing device 1 may be a combination of two or more types of CPU, MPU, DSP, ASIC, PLD, and FPGA.
- MPU is an abbreviation for Micro Processing Unit
- DSP is an abbreviation for Digital Signal Processor
- ASIC is an abbreviation for Application Specific Integrated Circuit
- PLD is an abbreviation for Programmable Logic Device
- FPGA is an abbreviation for Field Programmable Gate Array.
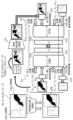
- FIG. 3 is a diagram illustrating the definition of the scene graph 300.
- the scene graph 300 is a directed graph in which objects (objects) in an image or a video are used as nodes, and relationships between objects are expressed as edges. Images and videos are examples of image data.
- the target object (object) may be a living thing including a person, an article, or a part of a living thing or an article.
- FIG. 4 is a diagram schematically showing an example of the scene graph 300.
- the data set shown in FIG. 4 includes image data 200 and a scene graph 300.
- objects in the image data 200 include a person, a computer, a table, a chair, and a window.
- Position information 211-1 to 211-5 for each object is given.
- the position information 211 may include information on coordinates (x, y), height, and width.
- the position information 211 may be expressed as a bounding box.
- a bounding box is a rectangular box surrounding an object.
- the scene graph 300 includes an object label 321-1 (man), an object label 321-2 (computer), an object label 321-3 (table), an object label 321-4 (chair), and It includes an object label 321-5 (window). Furthermore, the relationships between the respective objects are indicated by directional edges 323-1 to 328-4. Directed edge 323 may be a line with an arrow.
- the relationship label 322-1 indicates “using.” It is shown that the relationship label 322-2 between the computer and the table is “on”, and the relationship label 322-3 between the person and the chair is “sitting on”. It is shown that something is true.
- the relationship label 322 can increase the amount of information in the scene graph 300 by indicating a concrete relationship (for example, sitting on or standing on) rather than an abstract relationship (for example, on). .
- the information processing device 1 in this embodiment improves the classification accuracy of relationships by reflecting the specific relationships between multiple objects in image data.
- the information processing device 1 uses self-supervised learning, particularly contrastive learning.
- FIG. 5 is a diagram showing an example of self-supervised learning.
- image data showing a dog is input as the input data 51, and an object label "dog" is output as the output.
- the encoder 43 When the input data 51 is input to the encoder 43, the encoder 43 outputs a latent vector (in FIG. 5, an object feature vector) Z.
- the latent vector Z is input to the classifier 44, and the classifier 44 outputs a label.
- Self-supervised learning has a two-step training (learning) process.
- the encoder 43 is trained using unlabeled data. Unlabeled data requires less generation than labeled data. Therefore, compared to when learning is performed using labeled data, the amount of data can be increased when learning is performed using unlabeled data. Therefore, the encoder 43 can learn many variations and can improve training accuracy (learning accuracy).
- FIG. 6 is a diagram showing an example of contrastive learning. Contrastive learning is a type of self-supervised learning.
- Contrastive learning is a type of self-supervised learning.
- FIG. 6 as a simple example, a case will be explained in which image data showing a dog is input as the input data 51, and an object label "dog" is output as the output.
- T 1 , T 2 By performing two types of data expansion (T 1 , T 2 ) from input x (input data 51), two expansion data x i to T 1 (x) and x j to T 2 (x) are obtained.
- Data expansion can be obtained, for example, by subjecting the original image to transformations such as translation, rotation, scaling, vertical reversal, horizontal reversal, brightness adjustment, and combinations of a plurality of these.
- the two extended data x i -T 1 (x) and x j -T 2 (x) are data that have undergone different transformations without changing the essence of the object.
- FIGS. 5 and 6 a case has been described in which the encoder 43 that outputs the object label of the target object is trained, but in the information processing device 1 of this embodiment, the encoder 43 that calculates the relationship between multiple target objects Contrastive learning is applied to 143 training.
- the encoder 143 is an example of an encoder that calculates relationships between multiple objects.
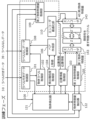
- FIG. 7 is a block diagram schematically showing a first example of the software configuration in the encoder training phase by the information processing apparatus 1 shown in FIG. 2.
- the control unit 100 includes a labeled data acquisition unit 101, an object label acquisition unit 102, a position information acquisition unit 103, a detection confidence acquisition unit 104, a first object feature acquisition unit 105, a pair creation unit 106, and an unlabeled data acquisition unit 108, a second object feature acquisition section 109, and an encoder optimization section 110.
- the control unit 100 implements learning processing (training processing) in machine learning using training data. That is, the information processing device 1 functions as a training device that trains a machine learning model using the control unit 100.
- the object detector 121, object feature extractor 122, and encoder 143 are an example of a machine learning model.
- the machine learning model may be, for example, a deep learning model (deep neural network).
- the neural network may be a hardware circuit or a virtual network using software that connects layers virtually constructed on a computer program by the processor 11 or the like.
- the labeled data acquisition unit 101 acquires the labeled data 30.
- the labeled data 30 may be a data set that includes image data, object labels, and relationship labels.
- the acquired labeled data 30 may be input to the object detector 121.
- the object detector 121 may be an existing object detector based on DNN.
- the object detector 121 may be a Faster Region-based Convolutional Neural Network (Faster RCNN) or a DEtection Transformer (DETR).
- Faster RCNN Faster Region-based Convolutional Neural Network
- DETR DEtection Transformer
- the object label acquisition unit 102 acquires object labels 33a and 33b of the objects 32a and 32b in the image data from the labeled data 30.
- the labeled data 30, image data 31, objects 32a, 32b, object labels 33a, 33b, relationship labels 34, position information 36a, 36b, and object features 37a, 37b are based on the related technology shown in FIG. It may be similar to that described.
- the position information acquisition unit 103 acquires position information 36a, 36b of the objects 32a, 32b in the image data 31, respectively.
- the position information acquisition unit 103 uses the object detector 121 to acquire position information 36a and 36b.
- the detection confidence acquisition unit 104 acquires the confidence (detection confidence) regarding the identification results of the object labels 33a and 33b by the object detector 121.
- the detection confidence may be the probability that the label predicted for each bounding box (for example, cow) is the label of the actual object when there are multiple bounding boxes identified in the image data 31.
- the detection reliability acquisition unit 104 uses the object detector 121 to acquire the detection reliability.
- the first object feature amount obtaining unit 105 obtains first object feature amounts 37a and 37b, which are object feature amounts for the objects 32a and 32b, based on the position information 36a and 36b.
- the first object features 37a and 37b are examples of first object features.
- the position information 36a, 36b specified by the object detector 121 is input to the object feature extractor 122, respectively.
- the object feature extractor 122 identifies object features 37a and 37b based on the image data within the bounding box, which is the position information 36a and 36b.
- the object detector 121 and the object feature extractor 122 may be formed as one machine learning model.
- the first object feature amount acquisition unit 105 may use the object feature amount extractor 122 to acquire the object feature amounts 37a and 37b.
- the pair creation unit 106 creates subject-object pairs for the plurality of objects 32a and 32b based on the detection confidence and a predetermined upper limit number of pairs.
- the pair creation unit 106 may extract only the pairs that occur between the correct rectangle and the covering rectangle from among the predicted bounding boxes (rectangles).
- the pair creation unit 106 creates pairs of subjects and objects such as "person and computer,” “computer and table,” “person and chair,” and “person and window.” create.
- the unlabeled data acquisition unit 108 acquires an image that includes at least one other object classified into the same class as at least one object 32a among the objects 32a and 32b (a plurality of objects of a pair of subjects and objects). Obtain unlabeled data 39 which is data.
- the unlabeled data acquisition unit 108 may use the object label of either the subject or the object as a key to extract images containing the same label from the external data set.
- the unlabeled data 39 is data that does not have relationship labels between multiple objects.
- the unlabeled data acquisition unit 108 can acquire image data classified into the same class "cow" as the object 32a, that is, image data of a cow.
- the unlabeled data acquisition unit 108 can widely acquire a large amount of unlabeled data 39 from outside the information processing device 1 via the Internet.
- the second object feature acquisition unit 109 acquires the second object feature 40 that is the object feature for the object in the unlabeled data 39.
- the second object feature amount 40 is an example of a second object feature amount.
- the second object feature acquisition unit 109 acquires the second object feature 40 based on the image data within the bounding box corresponding to the object in the unlabeled data 39.
- the second object feature acquisition unit 109 may use the object detector 121 and the object feature extractor 122 to acquire the second object feature 40 .
- the control unit 100 uses the position information acquisition unit 103 and the first object feature acquisition unit 105 to acquire a first object feature 37a of the object, a first object feature 37b of the subject, position information 36a of the object, and position information of the subject. 36b is obtained.
- the control unit 100 causes the position information acquisition unit 103 and the second object feature acquisition unit 109 to separate at least one of the first object feature 37a of the object and the first object feature 37b of the subject from among the first data.
- the second data replaced with the second object feature amount 40 is generated.
- the control unit 100 trains the encoder 143 by inputting the second data as extended data during encoder training using contrastive learning.
- the encoder 143 may be configured with a multilayer perceptron (MLP).
- MLP multilayer perceptron
- encoder 143 is composed of at least three layers of nodes.
- Training (learning) of the encoder 143 may be performed using a learning method called backpropagation.
- the encoder optimization unit 110 may obtain a first latent vector 62a (Z) regarding the relationship between the plurality of objects 32a and 32b, which is obtained by inputting the first data to the encoder 143.
- the encoder optimization unit 110 may obtain a second latent vector 62b (Z') regarding the relationship between the plurality of objects 32a and 32b, which is obtained by inputting the second data to the encoder 143.
- the encoder optimization unit 110 may perform machine learning on the encoder 143 to increase the degree of coincidence (similarity) between the first latent vector 62a (Z) and the second latent vector 62b (Z').
- the first latent vector 62a (Z) is an example of a first relationship feature amount regarding the relationship between the plurality of objects 32a and 32b
- the second latent vector 62b (Z) is an example of the first relational feature amount regarding the relationship between the plurality of objects 32a and 32b.
- 32b is an example of the second relationship feature amount regarding the relationship between.
- the function serving as a standard for evaluating the degree of matching (similarity) may be a function (InforNCE) used in contrastive learning (SimCLR, etc.).
- FIG. 8 is a diagram showing an example of training processing for the object detector 121 by the information processing device 1 shown in FIG. 2.
- the labeled data 30 including the image data 31 and correct labels and correct position information for the object labels 33a and 33b of the objects 32a and 32b in the image data 31 is used by the object detector 121. is input.
- the labeled data 30 may be a data set such as a visual genome.
- the object detector 121 Based on the image data 31, the object detector 121 outputs object labels 33a, 33b and position information 36a, 36b of the objects 32a, 32b, respectively.
- the object detector 121 may also output the detection reliability as described in FIG. 7 .
- the position information 36a, 36b may include information on plane coordinates (x, y), height (h), and width (w).
- the plane coordinates may be the coordinates of one vertex of a bounding box (rectangle).
- the height (h) may be the length of a side of the bounding box in the x direction, and the width (w) may be the length of a side of the bounding box in the y direction orthogonal to the x direction.
- FIG. 9 is a diagram showing an example of training processing for the encoder 143 by the information processing device 1 shown in FIG. 2. Once the training of the object detector 121 is completed, the parameters of the object detector 121 are fixed. Fixing the parameters of the object detector 121 is sometimes referred to as "freezing.”
- the first object of the object Second data is generated in which at least one of the feature amount 37a and the first object feature amount 37b of the subject is replaced with the second object feature amount 40.
- FIG. 9 shows a case where the second data 42 is generated by replacing the first object feature amount 37a with the second object feature amount 40
- the first object feature amount 37b is replaced with the second object feature amount 40.
- both the first object feature amount 37a and the first object feature amount 37b may be replaced with the second object feature amount 40.
- unlabeled data 39 that does not include a relationship label can be used.
- the unlabeled data 39 may be image data (image data of a cow, image data of a woman) classified into at least one class (cow, woman, etc.) of the object 32a and the object 32b. Therefore, a large amount of external data sets that can be used as unlabeled data 39 exist in the Internet space. Therefore, the encoder 143 can be trained (learning) using a large amount of relational unlabeled data.
- FIG. 10 is a diagram showing an example of a process using contrastive learning in the training process of the encoder 143 in FIG. 9.
- first data 41 including a first object feature amount 37a of the object, a first object feature amount 37b of the subject, position information 36a of the object, and position information 36b of the subject;
- the second data 42 replaced with the second feature amount 40 is input to the encoder 143.
- the encoder 143 outputs a first latent vector 62a (relationship feature vector Z) based on the input of the first data 41. Furthermore, the encoder 143 outputs a second latent vector 62b (relationship feature vector Z') based on the input of the second data 42. In other words, the second latent vector 62b (Z') is obtained by data expansion of the first data 41 that is input to the encoder 143.
- the position information 36a, 36b is the same as the first data 41 that is the original input.
- the class of another object (for example, cow) in the second data 42 is the same as the class of the object (object 32a) in the first data 41.
- the object feature amount of the subject object 32b in the second data 42 is the same as the object feature amount of the target object 32b in the first data 41. Therefore, the essential parts (position information, object labels) of the relationship between objects in the first data 41 and the relationship between objects in the second data 42 are maintained. Therefore, the first latent vector 62a (relationship feature vector Z) and the second latent vector 62b (relationship feature vector Z') should be similar.
- the encoder 143 performs contrastive learning to increase the degree of coincidence (similarity) between the first latent vector 62a (Z) and the second latent vector 62b (Z').
- FIG. 11 is a block diagram schematically showing a second example of the software configuration in the training phase of the encoder 143 by the information processing device 1 shown in FIG. 2.
- second data and third data are obtained by two types of data extension from the first data 41. may be generated.
- second and third object feature amount acquisition units 111 are provided in place of the second object feature amount acquisition unit 109 in FIG. 7 .
- control unit 100 converts at least one of the first object feature amount 37a of the object and the first object feature amount 37b of the subject out of the first data 41 to another second object corresponding to the subject or object.
- Second data 42 is generated as data replaced with the feature amount 40.
- control unit 100 converts at least one of the first object feature amount 37a of the object and the first object feature amount 37b of the subject out of the first data 41 into another third object feature amount corresponding to the subject or object.
- Third data 53 is generated as the data replaced with 54. Also in the second data 42 and the third data 53, the position information 36a, 36b of the first data may be maintained as the position information 36a, 36b.
- the generation of the third object feature amount 54 and the third data 53 is the same as the generation of the second object feature amount 40 and the second data 42.
- unlabeled data 39 without relationship labels can be used without being limited by the number of labeled data 30.
- the number of data on which encoder 143 is trained can be increased.
- FIG. 12 is a block diagram schematically showing an example of the software configuration in the training phase of the classifier 144 by the information processing device 1 shown in FIG. 2.
- FIG. 12 shows a state in which training of the object detector 121 and encoder 143 has been completed and the parameters have been fixed.
- the control unit 100 may include a labeled data acquisition unit 101, an object label acquisition unit 102, a position information acquisition unit 103, a first object feature acquisition unit 105, a pair creation unit 106, and a classifier optimization unit 112.
- FIG. 13 is a diagram showing an example of training processing of the classifier 144 by the information processing device 1 shown in FIG. 2.
- a first object feature amount 37a of the object, a first object feature amount 37b of the subject, position information 36a of the object, and position information 36b of the subject are acquired.
- Each acquired data is input to the encoder 143.
- a classifier 144 is used as an example of a machine learning model.
- the classifier 144 may be, for example, a deep learning model (deep neural network).
- the neural network may be a hardware circuit or a virtual network using software that connects layers virtually constructed on a computer program by the processor 11 or the like.
- the classifier 144 may be a logistic regression, which is a discriminative model comprised of only one fully connected layer, or may be comprised of a multilayer perceptron (MLP) having multiple layers.
- MLP multilayer perceptron
- the control unit 100 uses the position information acquisition unit 103 and the first object feature acquisition unit 105 to obtain the first object feature amount 37a of the object, the first object feature amount 37b of the subject, the position information 36a of the object, and the position information of the subject. Get 36b. Each acquired data is input to the encoder 143.
- the control unit 100 uses the encoder 143 to calculate the latent vector 62 (Z).
- Latent vector Z indicates a position in latent space.
- the latent vector 62 (Z) is input to the classifier 144.
- Classifier 144 outputs logits.
- the logit may be the final unnormalized score for the classification of relationship labels.
- the logit may be converted into a predicted value of the relationship label using a softmax function or the like.
- the classifier optimization unit 112 optimizes the parameters of the classifier 144 based on the correct label of the relationship label in the labeled data 30 and the logit.
- the unlabeled data 39 does not need to be used for training the classifier 144.
- FIG. 14 is a block diagram schematically showing an example of the software configuration in the inference phase by the information processing apparatus 1 shown in FIG. 2.
- the control unit 100 includes an object label acquisition unit 102, a position information acquisition unit 103, a first object feature acquisition unit 105, a pair creation unit 106, an input image acquisition unit 113, a relationship label acquisition unit 114, and a scene graph creation unit 115.
- the object label acquisition unit 102, the position information acquisition unit 103, the first object feature acquisition unit 105, and the pair creation unit 106 are configured so that the data to be processed is not the labeled training data 30 but the input image data.
- the same functions as those described using FIG. 7 may be provided except that the functions are the same as those described using FIG.
- the input image acquisition unit 113 acquires input image data to be processed.
- Input image data to be processed is input to a trained object detector 121.
- the object detector 121 uses the object detector 121 to acquire the object label and position information of the target object (object, subject) in the input image data are acquired.
- the object feature amount extractor 122 is used to obtain the object feature amount of the target object (object, subject).
- the encoder 143 receives position information and object feature amounts regarding the target object (object, subject) in the input image data.
- the encoder 143 infers a latent vector 62 (Z) based on the position information and object feature amount about the object (object, subject).
- the latent vector 62 (relationship feature vector) indicates the relationship between a plurality of objects (between an object and a subject).
- the latent vector 62 is input to the classifier 144.
- Classifier 144 outputs logits in one example.
- the relationship label acquisition unit 114 uses logit to acquire relationship labels that indicate relationships between a plurality of objects (objects and subjects).
- the scene graph creation unit 115 creates a scene graph 300.
- the scene graph creation unit 115 generates object labels for the subject and object acquired from the input image data by the object label acquisition unit 102 and relationships between the subject and object acquired from the input image data by the relationship label acquisition unit 114.
- the labels are summarized as a scene graph 300.
- the encoder 143 in training the encoder 143 to obtain relationships between a plurality of objects, in the first data 41, object features of at least one of the subject and the object are replaced with object features of another object in the same class. This will expand the data.
- the encoder 143 can learn many variations and can improve training accuracy.
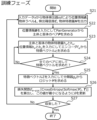
- the control unit 100 calculates position information 36a, 36b (B) of the objects 32a, 32b in the image data, object labels 33a, 32b (L), detection confidence C, and the 1 object feature amounts 37a, 37b (H) are acquired (step S11).
- the control unit 100 acquires each value by inputting the labeled data 30 to the object detector 121 (od).
- the first object features 37a and 37b (H) are obtained using the object feature extractor 122.
- the detection confidence C and the upper limit number of pairs Nmax are input to the pair generator 106 (PairGenerator).
- the pair creation unit 106 creates a subject-object pair P among the objects 32 (step S12).
- the control unit 100 generates a subject-object pair P from among the plurality of objects 32 (step S12).
- the first object features h si and hoi of the subject and object and the position information b si and b oi are input to the encoder 143 .
- the first latent vector 62a which is the feature vector Z i , is calculated from the encoder 143 (f ⁇ ) (step S13).
- the first object features h si and hoi of the subject and object and the position information b si and b oi are examples of first data.
- the unlabeled data acquisition unit 108 uses the object label l si , of the subject as a key to extract an image Xe (unlabeled data 39) containing another object corresponding to l si, from the external data set De. (Step S14). However, the unlabeled data acquisition unit 108 may extract an image Xe (unlabeled data 39) containing another object corresponding to loi , from the external data set De using the object label loi, of the object as a key. .
- the unlabeled data acquisition unit 108 uses both the object labels l si, and l oi of the subject and object as keys to obtain an image Xe containing another object corresponding to l si, and l oi, from the external data set De. An image Xe containing another object corresponding to may be extracted.
- the second object feature acquisition unit 109 inputs the image Xe (unlabeled data 39) to the object detector 121 (od), and from the output of the object detector 121 (od), the object label l si corresponding to the image Xe is determined.
- the second object feature amount 40 (h' si ) is extracted (step S15). If a plurality of second object features 40 (h' si ) exist, the second object feature acquisition unit 109 may randomly select the second object features 40 (h' si ).
- the control unit 100 sends the second object feature amount 40 (h′ si ), the first object feature amount ( hoi ), and the position information b si , b oi to the encoder 143 ( f ⁇ ).
- the control unit 100 calculates the second latent vector 62b, which is the feature vector Z i , based on the output of the encoder 143 (f ⁇ ) (step S16).
- the second object feature amount 40 (h ' si ), the first object feature amount ( hoi ), and the position information b si , b oi are examples of the second data 42 .
- the second data 42 is data in which at least one of the first object feature amounts h si and h oi in the first data 41 is replaced. However, the second data 42 maintains the position information b si and b oi in the first data 41 .
- First latent vector Zi f ⁇ (h si , hoi , b si , b oi )
- First latent vector Z'i f ⁇ (h ' si , h oi , b si , b oi )
- the control unit 100 determines whether feature vector calculation has been completed for all pairs (step S17). If feature vectors have not been calculated for all pairs (see No route in step S17), the process may return to step S13. If calculation of feature vectors has been completed for all pairs (see Yes route in step S17). The process advances to step S18.
- the encoder optimization unit 110 calculates the loss function E x ⁇ p(x) [-sim(Z, Z')] and updates the parameter ⁇ so that this value becomes the minimum (step S18).
- argmin means a function that obtains the parameter ⁇ that gives the minimum value.
- the control unit 100 repeats the processing in steps S11 to S19 until the processing converges (see No route in step S19).
- the control unit 100 waits for the processing to converge (see the Yes route in step S19), and then ends the training processing for the encoder 143 in the training phase.
- Step S21 is similar to step S11 in FIG. 15.
- Position information B is input to the pair generator 106 (PairGenerator).
- the pair creation unit 106 creates a subject-object pair P among the objects 32 (step S22).
- the control unit 100 generates a subject-object pair P from among the plurality of objects 32 (step S12).
- the first object features h si and hoi of the subject and object and the position information b si and b oi are input to the encoder 143 .
- a latent vector 62 (feature vector) that is the feature vector Z i is calculated from the encoder 143 (f ⁇ ) (step S23).
- Latent vector Zi f ⁇ (h si , hoi , b si , b oi )
- step S24 If there is a pair P for which latent vectors (feature vectors) have not been calculated (No route in step S24), the process returns to step S23. After waiting for latent vectors (feature vectors) to be calculated for all pairs P (Yes route in step S24), the feature vectors Z are input to the classifier 144 (g ⁇ ). Logit Y is calculated from the output of the classifier 144 (g ⁇ ) (step S25).
- the classifier optimization unit 112 calculates a loss function E x ⁇ p(x) based on the following equation.
- ⁇ argmin(E , is converted into a predicted value for the class classification of the relationship label.Then, the distance between the predicted value and the correct relationship label is calculated using the cross entropy function.Then, the predicted value and the correct answer are calculated using the argmin function.
- the parameter ⁇ is updated so as to minimize the distance from the relationship label (step S26).
- the control unit 100 repeats the processing in steps S21 to S27 until the processing converges (see No route in step S27).
- the control unit 100 waits for the processing to converge (see the Yes route in step S27), and then ends the training processing of the classifier 144 in the training phase.
- the input image acquisition unit 113 acquires input image data (input image x) to be processed. Except for the difference in input data, the processing in steps S31 to S35 is the same as the processing in steps S21 to S25 in FIG. 16.
- the relationship label acquisition unit 114 calculates the softmax value softmax(Y) of logit Y, and extracts the relationship label corresponding to the index (subscript) with the largest value of softmax(Y) (step S36 ).
- the scene graph creation unit 115 creates a scene graph 300 for the input image by putting together the object labels and relationship labels that make up each pair (step S37). If the process does not collect data, the process returns to step S31 (see No route in step S38). After the process waits for the data to be collected (see the Yes route in step S38), the scene graph creation process in the inference phase is completed.
- FIG. 18 is a diagram illustrating an example of the reproducibility results of relationship labels by the information processing device 1 illustrated in FIG. 2.
- the encoder 143 is trained using the related technology (supervised learning) shown in FIG.
- the case of sex is low.
- the re-limit can be improved even in the case of specific relationships, and the uneven distribution of the class distribution of relationship labels is alleviated.
- the reproducibility of specific relationship labels can be improved compared to related techniques. Therefore, when creating the scene graph 300, it is possible to create the scene graph 300 with improved expressiveness.
- the control unit 100 acquires first data 41 including first object feature amounts 37a, 37b and position information 36a, 36b of each of the plurality of objects 32a, 32b in the first image data.
- the control unit 100 replaces at least one first object feature amount 37a, 37b of the plurality of objects 32a, 32b with a second object feature amount 40 in the first data 41, and generates at least one second data item. 42 is generated.
- the second object feature amount 40 is an object feature amount obtained for at least one other object classified into the same class as the target object in at least one second image data different from the first image data. be.
- the control unit 100 inputs at least one of the second data 42 to the encoder 143 to train the encoder 143.
- control unit 100 trains the encoder 143 by inputting the first data 41 and the second data 42 to the encoder 143.
- the existing labeled data 30 can also be used as training data for the encoder 143, and unlabeled data 39 can be acquired and used. Therefore, the encoder 143 can be trained using a wide variety of training data. Therefore, training accuracy increases.
- the control unit 100 increases the degree of matching between the first relational feature (first latent vector Z) and the second relational feature (second latent vector Z'). machine learning.
- the first relationship feature is a feature related to the relationship between the plurality of objects 32a and 32b, and is obtained by inputting the first data 41 to the encoder 143.
- the second relationship feature is a feature related to the relationship between the plurality of objects 32a and 32b, and is obtained by inputting the second data 42 to the encoder 143.
- the control unit 100 acquires the first object features 37a, 37b and position information 36a, 36b by inputting the first image data to the trained object detector 121.
- the control unit 100 acquires the second object feature amount 40 by inputting the second image data to the trained object detector 121.
- Information processing device 11 Processor 12: Memory unit 13: Display control unit 130: Display device 14: Storage device 15: Input IF 151: Mouse 152: Keyboard 16: External recording medium processing unit 160: Recording medium 17: Communication IF 100: Control unit 101: Labeled data acquisition unit 102: Object label acquisition unit 103: Position information acquisition unit 104: Detection confidence acquisition unit 105: First object feature acquisition unit 106: Pair creation unit 108: Unlabeled data acquisition Unit 109: Second object feature acquisition unit 110: Encoder optimization unit 111: Second and third object feature acquisition units 112: Classifier optimization unit 113: Input image acquisition unit 114: Relationship label acquisition unit 115: Scene graph creation unit 121 : Object detector 122 : Object feature extractor 143 : Encoder 144 : Classifier
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Computing Systems (AREA)
- Software Systems (AREA)
- Databases & Information Systems (AREA)
- Medical Informatics (AREA)
- Multimedia (AREA)
- Biomedical Technology (AREA)
- Mathematical Physics (AREA)
- General Engineering & Computer Science (AREA)
- Molecular Biology (AREA)
- Data Mining & Analysis (AREA)
- Computational Linguistics (AREA)
- Biophysics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Image Analysis (AREA)
Priority Applications (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2022/024037 WO2023243020A1 (ja) | 2022-06-15 | 2022-06-15 | 訓練プログラム,訓練方法及び情報処理装置 |
| EP22946838.4A EP4542463A4 (en) | 2022-06-15 | 2022-06-15 | LEARNING PROGRAM, LEARNING METHOD AND INFORMATION PROCESSING DEVICE |
| CN202280095608.XA CN119213447A (zh) | 2022-06-15 | 2022-06-15 | 训练程序、训练方法以及信息处理装置 |
| JP2024528009A JP7794314B2 (ja) | 2022-06-15 | 2022-06-15 | 訓練プログラム,訓練方法及び情報処理装置 |
| US18/910,050 US20250029373A1 (en) | 2022-06-15 | 2024-10-09 | Computer-readable recording medium storing training program, training method, and information processing apparatus |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2022/024037 WO2023243020A1 (ja) | 2022-06-15 | 2022-06-15 | 訓練プログラム,訓練方法及び情報処理装置 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US18/910,050 Continuation US20250029373A1 (en) | 2022-06-15 | 2024-10-09 | Computer-readable recording medium storing training program, training method, and information processing apparatus |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023243020A1 true WO2023243020A1 (ja) | 2023-12-21 |
Family
ID=89192495
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/024037 Ceased WO2023243020A1 (ja) | 2022-06-15 | 2022-06-15 | 訓練プログラム,訓練方法及び情報処理装置 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US20250029373A1 (https=) |
| EP (1) | EP4542463A4 (https=) |
| JP (1) | JP7794314B2 (https=) |
| CN (1) | CN119213447A (https=) |
| WO (1) | WO2023243020A1 (https=) |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008059110A (ja) * | 2006-08-30 | 2008-03-13 | Nec Corp | 物体識別パラメータ学習システム、物体識別パラメータ学習方法および物体識別パラメータ学習用プログラム |
| JP2022508737A (ja) | 2018-10-13 | 2022-01-19 | アイ・ピー・ラリー テクノロジーズ オイ | 自然言語文書を検索するシステム |
| US20220147838A1 (en) * | 2020-11-09 | 2022-05-12 | Adobe Inc. | Self-supervised visual-relationship probing |
-
2022
- 2022-06-15 EP EP22946838.4A patent/EP4542463A4/en active Pending
- 2022-06-15 CN CN202280095608.XA patent/CN119213447A/zh active Pending
- 2022-06-15 JP JP2024528009A patent/JP7794314B2/ja active Active
- 2022-06-15 WO PCT/JP2022/024037 patent/WO2023243020A1/ja not_active Ceased
-
2024
- 2024-10-09 US US18/910,050 patent/US20250029373A1/en active Pending
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008059110A (ja) * | 2006-08-30 | 2008-03-13 | Nec Corp | 物体識別パラメータ学習システム、物体識別パラメータ学習方法および物体識別パラメータ学習用プログラム |
| JP2022508737A (ja) | 2018-10-13 | 2022-01-19 | アイ・ピー・ラリー テクノロジーズ オイ | 自然言語文書を検索するシステム |
| US20220147838A1 (en) * | 2020-11-09 | 2022-05-12 | Adobe Inc. | Self-supervised visual-relationship probing |
Non-Patent Citations (1)
| Title |
|---|
| See also references of EP4542463A4 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP4542463A1 (en) | 2025-04-23 |
| EP4542463A4 (en) | 2025-07-23 |
| JP7794314B2 (ja) | 2026-01-06 |
| US20250029373A1 (en) | 2025-01-23 |
| JPWO2023243020A1 (https=) | 2023-12-21 |
| CN119213447A (zh) | 2024-12-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Seo et al. | Machine learning techniques for biomedical image segmentation: an overview of technical aspects and introduction to state‐of‐art applications | |
| Mahapatra et al. | Efficient active learning for image classification and segmentation using a sample selection and conditional generative adversarial network | |
| Liu et al. | Towards more precise automatic analysis: a systematic review of deep learning-based multi-organ segmentation | |
| Ciompi et al. | Automatic classification of pulmonary peri-fissural nodules in computed tomography using an ensemble of 2D views and a convolutional neural network out-of-the-box | |
| Nithila et al. | Segmentation of lung from CT using various active contour models | |
| Yuan et al. | Particle filter re-detection for visual tracking via correlation filters | |
| GB2538847A (en) | Joint Depth estimation and semantic segmentation from a single image | |
| Zheng et al. | Marginal space learning | |
| Malygina et al. | Data augmentation with GAN: Improving chest X-ray pathologies prediction on class-imbalanced cases | |
| Ma et al. | Performance boosting of conventional deep learning-based semantic segmentation leveraging unsupervised clustering | |
| CN107146204A (zh) | 一种图像美颜方法及终端 | |
| He et al. | Cascade-refine model for cephalometric landmark detection in high-resolution orthodontic images | |
| Xiao et al. | Mining consistent correspondences using co-occurrence statistics | |
| CN107146196A (zh) | 一种图像美颜方法及终端 | |
| Gopinath et al. | Graph domain adaptation for alignment-invariant brain surface segmentation | |
| Arantes et al. | Csc-gan: Cycle and semantic consistency for dataset augmentation | |
| Belharbi et al. | Deep neural networks regularization for structured output prediction | |
| Chen et al. | Unsupervised domain adaptation of dynamic extension networks based on class decision boundaries | |
| WO2023243020A1 (ja) | 訓練プログラム,訓練方法及び情報処理装置 | |
| Ning et al. | HSBNet: fusing semantics and anisotropic thermal diffusion fields for boundary-aware point cloud segmentation | |
| Rahimi et al. | Learning to transform time series with a few examples | |
| You et al. | A human pose estimation algorithm based on the integration of improved convolutional neural networks and multi-level graph structure constrained model | |
| Subudhi et al. | A novel texture segmentation method based on co-occurrence energy-driven parametric active contour model | |
| Chopin et al. | Improving semantic segmentation with graph-based structural knowledge | |
| Zhao et al. | Discriminative dictionary-embedded network for comprehensive vertebrae tumor diagnosis |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22946838 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2024528009 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 202280095608.X Country of ref document: CN |
|
| WWP | Wipo information: published in national office |
Ref document number: 202280095608.X Country of ref document: CN |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2022946838 Country of ref document: EP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2022946838 Country of ref document: EP Effective date: 20250115 |
|
| WWP | Wipo information: published in national office |
Ref document number: 2022946838 Country of ref document: EP |