WO2023204041A1 - 情報処理装置、情報処理方法、情報処理プログラム、ソフトウェア作成装置、ソフトウェア作成方法、及びソフトウェア作成プログラム - Google Patents
情報処理装置、情報処理方法、情報処理プログラム、ソフトウェア作成装置、ソフトウェア作成方法、及びソフトウェア作成プログラム Download PDFInfo
- Publication number
- WO2023204041A1 WO2023204041A1 PCT/JP2023/014229 JP2023014229W WO2023204041A1 WO 2023204041 A1 WO2023204041 A1 WO 2023204041A1 JP 2023014229 W JP2023014229 W JP 2023014229W WO 2023204041 A1 WO2023204041 A1 WO 2023204041A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- processing
- data
- convolution
- activation function
- software
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0464—Convolutional networks [CNN, ConvNet]
Definitions
- the present invention relates to an information processing device, an information processing method, an information processing program, a software creation device, a software creation method, and a software creation program.
- a first conventional example of a neural network processing device that performs information processing using a neural network that mimics the structure of neurons in the human brain is described in Patent Document 1.
- This neural network processing device performs a convolution process that performs a product-sum operation between multiple input data and multiple weight data to generate multiple intermediate data, and calculates a predetermined function using multiple intermediate data as input.
- Image recognition is performed by combining multiple layers that perform activation function processing that generates multiple output data.
- this conventional example describes the use of a circuit called a GPU (Graphics Processing Unit) that incorporates a large number of arithmetic units to perform convolution processing at high speed.
- GPU Graphics Processing Unit
- This neural network processing device enables high-speed processing by providing a dedicated inference calculation unit having a matrix calculation unit and an activation function calculation unit.
- Neural network processing devices are increasingly being used in environments with limited computing resources, such as recognition processing of surrounding images captured by cameras in automatic driving devices of automobiles.
- automatic driving systems for automobiles require recognition processing for a wide range of surrounding areas, and errors in recognition results may directly lead to accidents, so high recognition accuracy is required.
- neural network processing has become complex in structure, and requires recognition processing for a large number of images, resulting in an enormous amount of calculation. There is a problem in that when a huge amount of calculation is processed using limited calculation resources, the processing time becomes longer than expected, and the necessary processing performance cannot be obtained.
- the first conventional example above uses GPU to shorten processing time, but the effect of shortening processing time is limited in software processing on general-purpose hardware, and there are cases where the necessary processing performance cannot be achieved. many. Since the second conventional technology described above has a dedicated inference calculation unit, it may be possible to reduce processing time compared to using a GPU, but developing a dedicated inference calculation unit requires a huge development cost. Therefore, it is difficult to apply it to devices that are shipped in small quantities. Therefore, there is a need to shorten the processing time when neural network processing is performed using software on general-purpose hardware.
- the present invention aims to shorten the processing time of neural network processing.
- an information processing device of the present invention includes a processor and a memory, and the processor performs a product-sum operation between a plurality of input data and a plurality of weight data.
- perform neural network processing including convolution processing to generate a plurality of intermediate data using the plurality of intermediate data; and activation function processing to generate a plurality of output data by calculating the value of a predetermined function using the plurality of intermediate data as input.
- the method is characterized in that the activation function processing is executed within a loop processing of the convolution processing.
- the present invention since the capacity of intermediate data is reduced, it is possible to store intermediate data inside the processing unit, and data transfer between the processing unit and external memory is reduced, so that the neural network Processing time can be shortened.
- FIG. 1 is a diagram showing the configuration of a neural network processing device according to a first embodiment
- FIG. FIG. 2 is a diagram showing the configuration of neural network processing.
- FIG. 2 is a diagram illustrating an algorithm for processing one layer of neural network processing according to the first prior art.
- FIG. 2 is a diagram illustrating a processing mode during execution of a neural network processing algorithm according to the first prior art.
- FIG. 3 is a diagram showing an algorithm for processing one layer of neural network processing according to the first embodiment.
- FIG. 3 is a diagram showing a processing mode when an algorithm of neural network processing according to the first embodiment is executed.
- FIG. 7 is a diagram illustrating an algorithm for processing one layer of neural network processing according to a second prior art.
- FIG. 7 is a diagram illustrating a processing mode during execution of a neural network processing algorithm according to a second conventional technique.
- FIG. 7 is a diagram showing an algorithm for processing one layer of neural network processing according to the second embodiment.
- 7 is a diagram illustrating a processing mode when an algorithm of neural network processing according to the second embodiment is executed.
- FIG. 7 is a diagram illustrating an algorithm for processing one layer of neural network processing according to Embodiment 3;
- FIG. 7 is a diagram showing a processing mode during execution of a neural network processing algorithm according to a third embodiment.
- FIG. 7 is a diagram illustrating variations of an algorithm for performing product-sum calculation processing and examples of corresponding parameters according to the fourth embodiment.
- FIG. 7 is a diagram illustrating variations of an algorithm for performing product-sum calculation processing and examples of corresponding parameters according to the fourth embodiment.
- FIG. 12 is a diagram illustrating variations of an algorithm for performing activation function processing and examples of corresponding parameters according to the fourth embodiment.
- 12 is a diagram showing an example of parameter combinations of product-sum calculation processing and activation function processing for each layer of neural network processing according to the fourth embodiment.
- FIG. 12 is a diagram showing the result of selecting parameter combinations excluding duplicates from among parameter combinations according to the fourth embodiment.
- FIG. FIG. 12 is a diagram illustrating an example of hardware of a computer that executes software creation processing according to a fourth embodiment. 12 is a flowchart showing software creation processing according to the fourth embodiment.
- Computers such as servers and clients execute programs using processors (e.g., CPUs (Central Processing Units), GPUs), and use storage resources (e.g., memory), interface devices (e.g., communication ports), etc. to carry out the processing specified by the programs.
- processors e.g., CPUs (Central Processing Units), GPUs
- storage resources e.g., memory
- interface devices e.g., communication ports
- the main body of processing performed by executing a program may be a processor.
- the subject of processing performed by executing a program may be a controller, device, system, computer, or node having a processor.
- the main body of the processing performed by executing the program may be an arithmetic unit, and may include a dedicated circuit that performs specific processing.
- the dedicated circuit is, for example, an FPGA (Field Programmable Gate Array), an ASIC (Application Specific Integrated Circuit), a CPLD (Complex Programmable Logic Device), a quantum computer, or the like.
- the program may be installed on the computer from the program source.
- the program source may be, for example, a program distribution server or a computer readable storage medium.
- the program distribution server includes a processor and a storage resource for storing the program to be distributed, and the processor of the program distribution server may distribute the program to be distributed to other computers.
- two or more programs may be implemented as one program, or one program may be implemented as two or more programs.
- YYY (processing) unit "YYY step,” and “YYY procedure” are respectively corresponding components of different categories of apparatus (or system), method, and program.
- a processor or computer that executes a "YYY step” corresponds to a "YYY processing unit.”
- the "YYY procedure” executed by the processor or computer corresponds to the "YYY step.”
- "software” may be a component including programs and other files such as libraries, or may be the program itself.
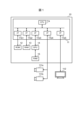
- FIG. 1 is a diagram showing the configuration of an information processing device 10 according to the first embodiment.
- the information processing device 10 includes a microprocessor 11, a ROM (Read Only Memory) 12, a RAM (Random Access Memory) 13, 15, and a GPU 14.
- the microprocessor 11 includes a CPU 11a and interface circuits 11b1, 11b2, 11b3, 11b4, and 11b5.
- the ROM 12 is connected to the microprocessor 11 via an interface circuit 11b1.
- RAM 13 is connected to microprocessor 11 via interface circuit 11b2.
- GPU14 is connected to RAM15.
- the GPU 14 is connected to the microprocessor 11 via an interface circuit 11b3.
- the cameras 111a and 111b are connected to the microprocessor 11 via an interface circuit 11b4.
- Display device 112 is connected to microprocessor 11 via interface circuit 11b5.
- the information processing device 10 inputs image data from the cameras 111a and 111b, performs recognition using neural network processing, and then displays the recognition results on the display device 112.
- the recognition result may be output as audio from a speaker. Note that although this embodiment shows an example of performing image recognition, the present invention is not limited to image recognition and can be applied to other general neural network processing such as voice recognition.
- the cameras 111a and 111b take images in different directions. This makes it possible to capture all images of the area to be recognized and perform recognition processing. Moreover, cameras with a large number of pixels and a wide photographing range may be used as the cameras 111a and 111b. As a result, even if the area to be recognized is wide, it is possible to cover the entire area with a small number of cameras. In this case, an image taken with one camera may be divided into multiple regions and recognition processing may be performed separately. This makes it possible to exclude areas that do not require recognition, such as the sky, and perform recognition processing only on necessary areas.
- the microprocessor 11 is an LSI (Large Scale Integration) in which a CPU 11a and interface circuits 11b1, 11b2, 11b3, 11b4, and 11b5 are integrated into one chip. This configuration is an example, and a part or all of the ROM 12, RAM 13, GPU 14, and RAM 15 may be built into the microprocessor 11.
- LSI Large Scale Integration
- the CPU 11a reads and executes software stored in the ROM 12 via the interface circuit 11b1. Note that since the ROM 12 often has a slower read/write speed than the RAM 13, the software may be copied from the ROM 12 to the RAM 13 at startup, and then the software may be read from the RAM 13. The CPU 11a performs the following series of processes according to software read from the ROM 12 or RAM 13.
- the CPU 11a acquires image data from the cameras 111a and 111b via the interface circuit 11b4, and stores it in the RAM 13 via the interface circuit 11b2.
- the CPU 11a reads the image data stored in the RAM 13 via the interface circuit 11b2, and transfers it to the GPU 14 via the interface circuit 11b3.
- the CPU 11a reads the software stored in the ROM 12 via the interface circuit 11b1 or the RAM 13 via the interface circuit 11b2, and transfers it to the GPU 14 via the interface circuit 11b3. The CPU 11a then instructs the GPU 14 to start calculation using software.
- the CPU 11a receives a notification of the completion of calculation from the GPU 14 via the interface circuit 11b3, the CPU 11a acquires the calculation result from the GPU 14 via the interface circuit 11b3, and stores it in the RAM 13 via the interface circuit 11b2.
- the CPU 11a reads the calculation result of the GPU 14 from the RAM 13 via the interface circuit 11b2, performs predetermined processing, and displays it on the display device 112 via the interface circuit 11b5.
- the GPU 14 When the GPU 14 receives image data from the CPU 11a via the interface circuit 11b3, it stores it in the RAM 15. Further, upon receiving software from the CPU 11a via the interface circuit 11b3, the GPU 14 executes the software and stores the calculation result in the RAM 15.
- the GPU 14 receives a request to read the calculation result from the CPU 11a via the interface circuit 11b3, the GPU 14 reads the calculation result from the RAM 15 and outputs it to the CPU 11a via the interface circuit 11b3.
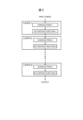
- FIG. 2 is a diagram showing the configuration of neural network processing. Note that FIG. 2 describes recognition processing for a single input image, and when recognition processing is performed for a plurality of images, the processing in FIG. 2 is executed for each input image. At this time, the processing contents may be the same for all images, or may be different for each image depending on the purpose of the recognition process.
- the neural network processing shown in FIG. 2 is composed of N layers i (Layer 1, Layer 2, . . . , Layer N).
- Layer 1 receives an input image and outputs the processing result to layer 2.
- Layer N receives data from the previous layer (N-1) and outputs the processing result as the recognition result of the input image.
- Each of the N layers i consists of a convolution process and an activation function process. Details of the convolution processing and activation function processing will be described later.
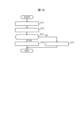
- FIG. 3 is a diagram showing an algorithm for processing one layer of neural network processing according to the first prior art.
- the hardware that executes the neural network processing of the first prior art is the same as the information processing device 10 of the first embodiment.
- the convolution process convolution_n()
- a sum of products operation is performed between input data (in[]) and weight data (k[]), and intermediate data (d[]) is generated.
- activation function processing (activation_n()) the value of a predetermined function (f()) is calculated using intermediate data (d[]) as input, and output data (out[]) is generated. .
- Convolution_n() and activation_n() are executed by the GPU 14.
- the present invention is not limited to this, and convolution_n() and activation_n() may be executed by the CPU 11a.
- the argument "H” of convolution_n() and activation_n() indicates the number of pixels in the vertical direction of the image.
- the loop processing regarding the variable h in the 9th to 19th lines of FIG. 3 indicates processing for each coordinate in the vertical direction of the image.
- the argument "W” indicates the number of pixels in the horizontal direction of the image.
- the loop processing regarding the variable "w” in lines 10 to 18 in FIG. 3 indicates processing for each coordinate in the horizontal direction of the image.
- the argument "CO” indicates the number of types of attribute information for each pixel of the output data.
- the loop processing regarding the variable “co” in lines 11 to 17 in FIG. 3 shows processing for each type of attribute information of a single pixel of output data.
- the value of the argument "CO” is often in the range of tens to hundreds.
- the argument "CI” indicates the number of types of attribute information for each pixel of input data.
- the loop processing regarding the variable “ci” in lines 13 to 16 in FIG. 3 shows processing for each type of attribute information of a single pixel of input data.
- the value of the argument "CI” is generally 3 (corresponding to the three primary colors of R (red), G (green), and B (blue)) in layer 1 that uses an input image as input data. For layers other than layer 1, the output of the previous layer is input, so the number is often from tens to hundreds.
- FIG. 4 is a diagram showing a processing mode during execution of a neural network processing algorithm according to the first prior art.
- convolution_n() input data (in[]) and weight data (k[]) are read from the memory, and intermediate data d[] is written to the memory.
- the memory includes a cache memory built into the processing unit (GPU 14 in this embodiment) and an external memory (RAM 15 in this embodiment) connected to the outside of the processing unit.
- a cache memory built into the processing unit (GPU 14 in this embodiment)
- RAM 15 external memory
- input data (in[]) and intermediate data (d[]) are large in capacity, so they cannot be stored in cache memory and access to external memory is difficult. Occur.
- the inventor of the present application believes that data transfer between a processing unit and external memory takes time compared to cache memory, and that the processing time for data transfer to and from external memory is a non-negligible amount compared to the calculation process itself. I found out that it is. The same applies to activation function processing (activation_n()), and the processing time for data transfer between the processing unit and the external memory is a non-negligible amount compared to the arithmetic processing itself.
- FIG. 5 is a diagram illustrating an algorithm for processing one layer of neural network processing according to the first embodiment.
- the CPU 11a When executing the layer processing (layer_n()) shown in FIG. 5, the CPU 11a only starts processing (convact_n()) that combines convolution processing and activation function processing, compared to FIG.
- FIG. 6 is a diagram illustrating a processing mode when the neural network processing algorithm according to the first embodiment is executed.
- the neural network processing algorithm according to the first embodiment shown in FIG. 5 is different from the first prior art algorithm shown in FIG. 3 because the intermediate data is stored in a one-dimensional variable d that is not an array. , it becomes possible to hold the data inside the GPU 14 (for example, in a cache memory), and data transfer between the RAM 15 and the RAM 15 becomes unnecessary. Therefore, the amount of data transferred between the GPU 14 and the RAM 15 is reduced, and processing time can be shortened.
- FIG. 7 is a diagram showing an algorithm for processing one layer of neural network processing according to the second prior art.
- the convolution process consists only of product-sum operations.
- bias value addition processing in lines 28 to 38 is added to the convolution processing in lines 13 to 38 in FIG.
- the bias value addition process is a process of adding the bias value for each layer of the neural network consisting of N layers to the calculation result of the product-sum calculation. It is known that there are cases where this improves recognition results.
- FIG. 8 is a diagram showing a processing mode during execution of a neural network processing algorithm according to the second prior art. Compared to FIG. 4, the processing of reading the bias addition input data (b[], d1[]) from the RAM 15 and writing the bias addition calculation result (d2[]) to the RAM 15 has been added. Therefore, the processing time for data transfer between the GPU 14 and the RAM 15 increases.
- FIG. 9 is a diagram showing an algorithm for processing one layer of neural network processing according to the second embodiment.
- the product-sum operation (multiadd_n() on lines 13 to 26 in FIG. 7), bias addition (Biasadd_n() on lines 28 to 38 in FIG. 7), and activation function processing (multiadd_n() in lines 28 to 38 in FIG. 7) in FIG. activation_n()) on lines 40 to 50 of is executed in one loop process (lines 8 to 19 in FIG. 9).
- an intermediate Intermediate data (d2) is calculated by adding a bias value (b[]) to data (d1). Then, as shown in the 16th line, the activation function processing in the 15th line is performed on the intermediate data (d2) to generate output data (out[]).
- FIG. 10 is a diagram illustrating a processing mode when the neural network processing algorithm according to the second embodiment is executed.
- the neural network processing algorithm according to the second embodiment shown in FIG. 9 differs from the second prior art algorithm shown in FIG. each is stored. Therefore, it becomes possible to hold the intermediate data d1 and d2 inside the GPU 14 (for example, in a cache memory), and data transfer to and from the RAM 15 becomes unnecessary. Therefore, the amount of data transferred between the GPU 14 and the RAM 15 is reduced, and processing time can be shortened.
- FIG. 11 is a diagram showing an algorithm for processing one layer of neural network processing according to the third embodiment. As shown in FIG. 11, the neural network processing algorithm according to Embodiment 3 differs from the algorithm of Embodiment 2 in FIG. Value addition processing and activation function processing are executed in one loop processing (lines 24 to 32).
- the sum of products operation requires a large amount of calculation, and the processing time occupies a large proportion of the entire neural network processing, so the processing time is often shortened by using an optimized library provided by a GPU manufacturer or the like.
- the algorithm of Embodiment 2 shown in FIG. 9 since bias value addition processing and activation function processing are incorporated in the same loop processing as the product-sum operation, the product-sum operation library cannot be used, and the product-sum operation cannot be used.
- the processing time for the sum operation may be longer than when using the library.
- the algorithm of the present embodiment shown in FIG. 11 only the processing portion of the product-sum operation can be replaced with the library, and an increase in the processing time of the product-sum operation can be prevented.
- FIG. 12 is a diagram illustrating a processing mode when the neural network processing algorithm according to the third embodiment is executed.
- the neural network processing according to the present embodiment is different from the second conventional technique shown in FIG. Since this becomes unnecessary, the amount of data transferred between the GPU 14 and the RAM 15 is reduced, and processing time can be shortened.
- the neural network processing according to the present embodiment is different from that in the second embodiment shown in FIG. As a result, the amount of data transferred between the GPU 14 and the RAM 15 increases, and the processing time also increases.
- the total processing time is It is possible to reduce the
- FIG. 13 is a diagram illustrating variations of an algorithm for performing product-sum calculation processing according to the fourth embodiment and examples of corresponding parameters.
- "INPUT FORM" in FIG. 13 indicates the order of input data, and there are two types: “CHW” and "HWC".
- "CHW” first arranges data along the axis of attribute information type, then arranges data with the same value on the attribute information type axis along the vertical axis of the image, and finally arranges data along the axis of the attribute information type. Arrange the data along the horizontal axis of the image if the values on the axis and the vertical axis of the image are the same.
- HWC first arranges data along the vertical axis of the image, then arranges the data along the horizontal axis of the image for data with the same value on the vertical axis, and finally arranges the data along the horizontal axis of the image. If the data has the same value on the axis and image horizontal axis, arrange the data on the attribute information type axis.
- “OUTPUT FORM” in FIG. 13 indicates the order of output data, and there are two types: “CHW” and “HWC”.
- CHW and “HWC”.
- the meanings of “CHW” and “HWC” are the same as in the input format.
- the algorithms shown in FIGS. 3, 5, 7, 9, and 11 are software compatible with the "HWC” output format, and cannot be applied when the output format is "CHW”.
- "WEIGHT SIZE” in FIG. 13 indicates the range of pixels of input data that affects each pixel of output data.
- each pixel of the output data is influenced only by pixels of the input data that have the same values on the vertical and horizontal axes. This is expressed as “1x1" in FIG. 13.
- CI in FIG. 13 is the number of types of attribute information for each pixel of input data, and as explained in FIG. 3, it can take a value of 3 for layer 1 and tens to hundreds for other layers.
- 3 due to space constraints, only two options, “3” and "32", are listed.
- CO in FIG. 13 is the number of types of attribute information for each pixel of the output data, and as explained in FIG. 3, it can take a value of several tens to hundreds. Here, due to space constraints, only one number, "32", is listed.
- FIG. 13 does not necessarily cover all the variations of the algorithm that performs the product-sum calculation process, there are still 32 variations.
- FIG. 14 is a diagram illustrating variations of an algorithm for performing activation function processing according to the fourth embodiment and examples of corresponding parameters.
- the name of each activation function is shown, and the calculation formula of the function is omitted.
- FIG. 14 does not necessarily cover all the variations, there are still 10 variations.
- Multiplying the product-sum operation processing variations shown in FIG. 13 and the activation function processing variations shown in FIG. 14 results in 320 variations.
- FIG. 15 is a diagram illustrating an example of a set of parameters for the product-sum calculation process and the activation function process for each layer of the neural network process according to the fourth embodiment.
- 100 or more layers are often executed, but for reasons of space, an example in which the number of layers is 30 is described here. As can be seen from FIG. 15, there are multiple layers with the same combination of parameters.
- FIG. 16 is a diagram showing the result of selecting parameter combinations excluding duplicates from the parameter combinations according to the fourth embodiment. As shown in FIG. 16, it can be confirmed that the parameter combinations are narrowed down to three types as a result of selecting parameter combinations excluding duplicates from the parameter combinations shown in FIG. Therefore, it can be seen that if the convolution process and the activation function process are executed in one loop process, it is sufficient to write three types of software.
- FIG. 17 is a hardware diagram showing a configuration example of a computer 100 that executes the software creation method according to the fourth embodiment.
- the computer 100 includes a processor 101 including a CPU, a main storage device 102, an auxiliary storage device 103, a network interface 104, an input device 105, and an output device 106, which are interconnected via an internal communication line 109 such as a bus. It is a computer equipped with
- the processor 101 controls the overall operation of the computer 100.
- the main memory device 102 is composed of, for example, a volatile semiconductor memory, and is used as a work memory of the processor 101.
- the auxiliary storage device 103 is composed of a large-capacity nonvolatile storage device such as a hard disk device, an SSD (Solid State Drive), or a flash memory, and is used to retain various programs and data for a long period of time.
- the software creation program 103a stored in the auxiliary storage device 103 is loaded into the main storage device 102 when the computer 100 is started or when necessary, and the processor 101 executes the software creation program 103a loaded into the main storage device 102.
- a software creation device that executes a software creation method is realized.
- the software creation program 103a may be recorded on a non-temporary recording medium, read from the non-temporary recording medium by a medium reading device, and loaded into the main storage device 102.
- the software creation program 103a may be obtained from an external computer via a network and loaded into the main storage device 102.
- the network interface 104 is an interface device for connecting the computer 100 to each network in the system or for communicating with other computers.
- the network interface 104 includes, for example, a NIC (Network Interface Card) such as a wired LAN (Local Area Network) or a wireless LAN.
- NIC Network Interface Card
- the input device 105 includes a keyboard, a pointing device such as a mouse, and is used by the user to input various instructions and information to the computer 100.
- the output device 106 includes, for example, a display device such as a liquid crystal display or an organic EL (Electro Luminescence) display, and an audio output device such as a speaker, and is used to present necessary information to the user when necessary.
- a display device such as a liquid crystal display or an organic EL (Electro Luminescence) display
- an audio output device such as a speaker
- FIG. 18 is a flowchart showing software creation processing according to the fourth embodiment.
- step S11 the computer 100 executes a first step of creating a list of combinations of parameters for convolution processing and activation function processing for each of the plurality of layer processes of the target neural network.
- step S12 the computer 100 executes a second step of selecting a combination of parameters excluding duplicates from the list of parameters created in step S11.
- step S13 the computer 100 determines whether the software to be created is for inference.
- the computer 100 moves the process to step S14 when the software to be created is for inference processing (step S13 YES), and moves the process to step S15 when the software to be created is for learning processing (step S13 NO).
- step S14 the computer 100 creates a third program that executes the activation function process within the loop process of the convolution process, regarding the convolution process and activation function process corresponding to the combination of parameters selected in step S13. Execute the steps.
- step S15 the computer 100 executes a program for executing the activation function process in a loop process different from the convolution process, regarding the convolution process and activation function process corresponding to the combination of parameters selected in step S13. Execute the fourth step to create.
- steps S11 to S15 may be performed manually.
- neural network processing is used for two types of purposes: learning processing and inference processing.
- learning processing known data is input as input data, and weight data is adjusted so that the output data approaches the expected value.
- inference processing inputs unknown data as input data and uses output data as recognition results.
- Learning processing is usually performed on servers with abundant computing resources, and processing time constraints are loose. Therefore, there is relatively little need to reduce processing time.
- the creation of software that executes the activation process in the loop of the inference convolution operation may be a burden on the user. This has the effect of achieving both accuracy.
- the burden on the user in creating software is reduced by providing a program creation method that reduces the number of algorithms of software to be created by narrowing down the combinations of overlapping parameters in Embodiment 4. Can be done.
- the present invention is not limited to the above-described embodiments, but includes various modifications.
- the above-described embodiments have been described in detail to explain the present invention in an easy-to-understand manner, and the present invention is not necessarily limited to having all the configurations described.
- the configurations and processes shown in the embodiments can be distributed, integrated, or replaced as appropriate based on processing efficiency or implementation efficiency.
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Physics (AREA)
- General Physics & Mathematics (AREA)
- Software Systems (AREA)
- General Engineering & Computer Science (AREA)
- Computing Systems (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Computational Linguistics (AREA)
- Biophysics (AREA)
- Biomedical Technology (AREA)
- Artificial Intelligence (AREA)
- Life Sciences & Earth Sciences (AREA)
- Evolutionary Computation (AREA)
- Algebra (AREA)
- Computational Mathematics (AREA)
- Mathematical Analysis (AREA)
- Mathematical Optimization (AREA)
- Pure & Applied Mathematics (AREA)
- Databases & Information Systems (AREA)
- Complex Calculations (AREA)
- Image Analysis (AREA)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP23790222.6A EP4513382A1 (en) | 2022-04-21 | 2023-04-06 | Information processing device, information processing method, information processing program, software creation device, software creation method, and software creation program |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2022-069885 | 2022-04-21 | ||
| JP2022069885A JP7784945B2 (ja) | 2022-04-21 | 2022-04-21 | 情報処理装置、情報処理方法、情報処理プログラム、ソフトウェア作成装置、ソフトウェア作成方法、及びソフトウェア作成プログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023204041A1 true WO2023204041A1 (ja) | 2023-10-26 |
Family
ID=88419875
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2023/014229 Ceased WO2023204041A1 (ja) | 2022-04-21 | 2023-04-06 | 情報処理装置、情報処理方法、情報処理プログラム、ソフトウェア作成装置、ソフトウェア作成方法、及びソフトウェア作成プログラム |
Country Status (3)
| Country | Link |
|---|---|
| EP (1) | EP4513382A1 (enExample) |
| JP (1) | JP7784945B2 (enExample) |
| WO (1) | WO2023204041A1 (enExample) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025239128A1 (ja) * | 2024-05-14 | 2025-11-20 | 株式会社日立製作所 | ニューラルネットワーク処理装置及びニューラルネットワーク処理方法 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2017151604A (ja) * | 2016-02-23 | 2017-08-31 | 株式会社デンソー | 演算処理装置 |
| JP2021517702A (ja) * | 2018-03-13 | 2021-07-26 | レコグニ インコーポレイテッド | 効率的な畳み込みエンジン |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6852365B2 (ja) * | 2016-11-25 | 2021-03-31 | 富士通株式会社 | 情報処理装置、情報処理システム、情報処理プログラムおよび情報処理方法 |
-
2022
- 2022-04-21 JP JP2022069885A patent/JP7784945B2/ja active Active
-
2023
- 2023-04-06 EP EP23790222.6A patent/EP4513382A1/en active Pending
- 2023-04-06 WO PCT/JP2023/014229 patent/WO2023204041A1/ja not_active Ceased
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2017151604A (ja) * | 2016-02-23 | 2017-08-31 | 株式会社デンソー | 演算処理装置 |
| JP2021517702A (ja) * | 2018-03-13 | 2021-07-26 | レコグニ インコーポレイテッド | 効率的な畳み込みエンジン |
Non-Patent Citations (1)
| Title |
|---|
| ONISHI RYOYA, YOSHIOKA MICHIFUMI, KATSUFUMI INOUE: "Domain Adaptation Method Using Activation Function with Convolution", PROCEEDINGS OF THE 35TH ANNUAL CONFERENCE OF THE JAPANESE SOCIETY FOR ARTIFICIAL INTELLIGENCE, 1 January 2021 (2021-01-01), pages 1 - 4, XP093102313 * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025239128A1 (ja) * | 2024-05-14 | 2025-11-20 | 株式会社日立製作所 | ニューラルネットワーク処理装置及びニューラルネットワーク処理方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7784945B2 (ja) | 2025-12-12 |
| JP2023159945A (ja) | 2023-11-02 |
| EP4513382A1 (en) | 2025-02-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11449576B2 (en) | Convolution operation processing method and related product | |
| US11699067B2 (en) | Arithmetic processing apparatus and control method therefor | |
| US20190147337A1 (en) | Neural network system for single processing common operation group of neural network models, application processor including the same, and operation method of neural network system | |
| JP2022538759A (ja) | 構成可能なニューラルネットワークカーネル | |
| US11468600B2 (en) | Information processing apparatus, information processing method, non-transitory computer-readable storage medium | |
| US20200394516A1 (en) | Filter processing device and method of performing convolution operation at filter processing device | |
| US20160148359A1 (en) | Fast Computation of a Laplacian Pyramid in a Parallel Computing Environment | |
| JP2019067084A (ja) | 情報処理システム、情報処理装置、及び、転送先決定方法 | |
| WO2023204041A1 (ja) | 情報処理装置、情報処理方法、情報処理プログラム、ソフトウェア作成装置、ソフトウェア作成方法、及びソフトウェア作成プログラム | |
| WO2016208260A1 (ja) | 画像認識装置および画像認識方法 | |
| US12167148B2 (en) | Image processing method and apparatus | |
| CN113553263A (zh) | 一种分层测试策略制定方法、装置和电子设备 | |
| CN120297221A (zh) | 一种版图及版图文件的裁剪方法、装置、设备和存储介质 | |
| CN112257859A (zh) | 特征数据处理方法及装置、设备、存储介质 | |
| US20240087291A1 (en) | Method and system for feature extraction using reconfigurable convolutional cluster engine in image sensor pipeline | |
| US11842273B2 (en) | Neural network processing | |
| CN118691482A (zh) | 具有超级采样功能的方法和装置 | |
| CN111027682A (zh) | 神经网络处理器、电子设备及数据处理方法 | |
| US11636321B2 (en) | Data processing apparatus and control method | |
| CN116431286A (zh) | 虚拟机系统、控制虚拟机的方法、计算机设备及存储介质 | |
| US12488556B2 (en) | Method and electronic device for processing input frame for on-device AI model | |
| WO2025239128A1 (ja) | ニューラルネットワーク処理装置及びニューラルネットワーク処理方法 | |
| CN112132274B (zh) | 特征图全连接卷积方法、装置、可读存储介质及电子设备 | |
| US12450884B1 (en) | Method for training custom model based on pre-trained base model and learning device using the same | |
| CN120179971A (zh) | 数据处理方法、电子设备、存储介质及程序产品 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 23790222 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2023790222 Country of ref document: EP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2023790222 Country of ref document: EP Effective date: 20241121 |