WO2023188354A1 - モデル訓練方法,モデル訓練プログラムおよび情報処理装置 - Google Patents
モデル訓練方法,モデル訓練プログラムおよび情報処理装置 Download PDFInfo
- Publication number
- WO2023188354A1 WO2023188354A1 PCT/JP2022/016770 JP2022016770W WO2023188354A1 WO 2023188354 A1 WO2023188354 A1 WO 2023188354A1 JP 2022016770 W JP2022016770 W JP 2022016770W WO 2023188354 A1 WO2023188354 A1 WO 2023188354A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- data
- processed data
- training
- confidence
- classification model
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F21/00—Security arrangements for protecting computers, components thereof, programs or data against unauthorised activity
- G06F21/50—Monitoring users, programs or devices to maintain the integrity of platforms, e.g. of processors, firmware or operating systems
- G06F21/57—Certifying or maintaining trusted computer platforms, e.g. secure boots or power-downs, version controls, system software checks, secure updates or assessing vulnerabilities
- G06F21/577—Assessing vulnerabilities and evaluating computer system security
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0475—Generative networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
Definitions
- the present invention relates to a model training method, a model training program, and an information processing device.
- a membership estimation attack for example, it is estimated whether the data of interest to the attacker is included in the training data of the machine learning model targeted for attack.
- Pseudo data may be generated by adding noise to basic data, or may be generated from basic data by machine learning.
- a training data selection device that selects training data that can shorten training time (see Patent Document 1).
- the property that it is difficult to estimate whether or not specific data is included in the training data is sometimes referred to as resistance to membership estimation attacks.
- the various pseudo data may include data that affects resistance to membership estimation attacks (hereinafter abbreviated as "membership estimation resistance").
- membership estimation resistance data that affects resistance to membership estimation attacks
- a machine learning model is trained by dividing pseudo data into several groups, and each group is repeatedly evaluated based on its membership estimation resistance. This process is repeated several times by changing the grouping method, and data that is commonly used in models with low resistance is identified as data that reduces the resistance of membership estimation, and is excluded from the training data. It is.
- the present invention aims to efficiently generate a machine learning model that is resistant to membership estimation.
- the first classification model trained using the basic data associated with the correct label is added to the first class classification model, which is trained using the basic data associated with the correct label.
- the confidence level of the correct label is obtained for each of the multiple processed data, the processed data corresponding to the confidence level that is less than the first reference value is identified, and the identified processed data is trained.
- a computer executes a process that uses the data as data to train a new classification model.
- a machine learning model with resistance to membership estimation can be efficiently generated.
- FIG. 1 is a diagram illustrating a hardware configuration of an information processing device as an example of an embodiment.
- FIG. 1 is a diagram illustrating a functional configuration of an information processing device as an example of an embodiment.
- FIG. 7 is a diagram for explaining an example of a second training execution unit and a second confidence vector acquisition unit in an information processing device as an example of an embodiment.
- FIG. 2 is a diagram illustrating processing contents in an information processing device as an example of an embodiment.
- FIG. 2 is a diagram illustrating an overview of a training phase and an inference phase of a class classification model in an information processing device as an example of an embodiment.
- 3 is a flowchart for explaining a model training method in an information processing device as an example of an embodiment.
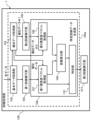
- FIG. 1 is a diagram illustrating the hardware configuration of an information processing device 1 as an example of an embodiment.
- the information processing device 1 includes a processor 11, a memory 12, a storage device 13, a graphic processing device 14, an input interface 15, an optical drive device 16, a device connection interface 17, and a network interface 18. have as. These components 11 to 18 are configured to be able to communicate with each other via a bus 19.
- the information processing device 1 is an example of a computer.
- the processor 11 controls the entire information processing device 1.
- Processor 11 may be a multiprocessor.
- the processor 11 includes, for example, a CPU, an MPU (Micro Processing Unit), a DSP (Digital Signal Processor), an ASIC (Application Specific Integrated Circuit), a PLD (Programmable Logic Device), an FPGA (Field Programmable Gate Array), and a GPU (Graphics Processing Unit). It may be any one of the following. Further, the processor 11 may be a combination of two or more types of elements among CPU, MPU, DSP, ASIC, PLD, FPGA, and GPU.
- the information processing device 1 realizes the function of the training processing unit 100 by executing a model training program 13a or an OS (Operating System) program, which is a program recorded on a computer-readable non-temporary recording medium, for example. do.
- a model training program 13a or an OS (Operating System) program which is a program recorded on a computer-readable non-temporary recording medium, for example. do.
- a program that describes the processing content to be executed by the information processing device 1 can be recorded on various recording media.
- a model training program 13a to be executed by the information processing device 1 can be stored in the storage device 13.
- the processor 11 loads at least a portion of the model training program 13a in the storage device 13 into the memory 12, and executes the loaded model training program 13a.
- model training program 13a to be executed by the information processing device 1 can be recorded on a non-temporary portable recording medium such as an optical disk 16a, a memory device 17a, a memory card 17c, or the like.
- the model training program 13a stored in the portable recording medium becomes executable after being installed in the storage device 13 under the control of the processor 11, for example.
- the processor 11 can directly read the model training program 13a from a portable recording medium and execute it.
- the memory 12 is a storage memory including ROM (Read Only Memory) and RAM (Random Access Memory).
- the RAM of the memory 12 is used as a main storage device of the information processing device 1. At least part of the OS program and control program to be executed by the processor 11 is temporarily stored in the RAM.
- the memory 12 also stores various data necessary for processing by the processor 11.
- the storage device 13 is a storage device such as a hard disk drive (HDD), SSD (Solid State Drive), or storage class memory (SCM), and stores various data.
- the storage device 13 is used as an auxiliary storage device of the information processing device 1.
- the storage device 13 stores an OS program, a control program, and various data.
- the control program includes a model training program 13a.
- auxiliary storage device a semiconductor storage device such as an SCM or a flash memory can also be used. Further, a plurality of storage devices 13 may be used to configure RAID (Redundant Arrays of Inexpensive Disks).
- the storage device 13 also stores information acquired by a third training execution unit 101, a basic data acquisition unit 102, a pseudo data acquisition unit 103, a first training execution unit 104, a second training execution unit 105, and a specific training data generation unit 106, which will be described later. Alternatively, various generated data may be stored.
- a monitor 14a is connected to the graphic processing device 14.
- the graphics processing device 14 displays images on the screen of the monitor 14a according to instructions from the processor 11.
- Examples of the monitor 14a include a display device using a CRT (Cathode Ray Tube), a liquid crystal display device, and the like.
- the optical drive device 16 uses laser light or the like to read data recorded on the optical disc 16a.
- the optical disc 16a is a portable, non-temporary recording medium on which data is readably recorded by light reflection. Examples of the optical disc 16a include a DVD (Digital Versatile Disc), a DVD-RAM, a CD-ROM (Compact Disc Read Only Memory), and a CD-R (Recordable)/RW (ReWritable).
- the device connection interface 17 is a communication interface for connecting peripheral devices to the information processing device 1.
- a memory device 17a or a memory reader/writer 17b can be connected to the device connection interface 17.
- the memory device 17a is a non-temporary recording medium equipped with a communication function with the device connection interface 17, such as a USB (Universal Serial Bus) memory.
- the memory reader/writer 17b writes data to or reads data from the memory card 17c.
- the memory card 17c is a card-type non-temporary recording medium.
- the network interface 18 is connected to a network (not shown). Other information processing devices, communication devices, etc. may be connected to the network interface 18 via a network. For example, data related to diseases, etc. may be input via a network.
- FIG. 2 is a diagram illustrating the functional configuration of the information processing device 1 as an example of the embodiment.
- the information processing device 1 has a function as a training processing section 100, as shown in FIG.
- the function of the training processing section 100 is realized by the processor 11 executing the control program (model training program 13a).
- the training processing unit 100 implements learning processing (training processing) in machine learning using training data. That is, the information processing device 1 functions as a training device that uses the training processing unit 100 to train a machine learning model.
- the training processing unit 100 includes a third training execution unit 101 that implements learning processing in machine learning using training data (teacher data) assigned with correct answer labels.
- the training processing section 100 includes a data selection section 100a that selects (specifies) training data input to the third training execution section 101.
- the "correct label" may be correct information given to each piece of data.
- the training data input to the third training execution unit 101 may be a plurality of pseudo data generated by adding noise or the like to raw data in order to protect against membership estimation attacks.
- "Pseudo data” is an example of processed data obtained by processing original data.
- the data selection unit 100a removes data that affects the membership estimation resistance, that is, data that lowers the membership estimation resistance, from among the plurality of pseudo data.
- the data selection unit 100a selects training data to be used for a new classification model (third classification model C) to be trained in the third training execution unit 101.
- a class classification model is a machine learning model for classifying data into multiple classes.
- the machine learning model may be, for example, a deep learning model (deep neural network).
- the neural network may be a hardware circuit or a virtual network using software that connects layers virtually constructed on a computer program by the processor 11 or the like.
- the data selection section 100a may include a basic data acquisition section 102, a pseudo data acquisition section 103, a first training execution section 104, a second training execution section 105, and a specific training data generation section 106. .
- the basic data acquisition unit 102 acquires basic data.
- the basic data is data (teacher data) associated with the correct label.
- the basic data is training data used by the first training execution unit 104 to implement learning processing in machine learning.
- the basic data may be data generated (processed) based on the collected unprocessed raw data, or may be the raw data itself. However, it is preferable that the basic data be data processed based on the raw data rather than the raw data itself. If the raw data is data whose confidentiality level exceeds a predetermined level, such as disease-related data, it is desirable to avoid using the raw data itself for training as much as possible from the viewpoint of maintaining confidentiality. However, depending on the content of the data, raw data may be used as the basic data.
- the basic data acquisition unit 102 may acquire basic data generated by an external device, or may generate basic data within the information processing device 1.
- the pseudo data acquisition unit 103 acquires a plurality of pseudo data.
- the pseudo data acquisition unit 103 may generate pseudo data based on the raw data.
- Each of the pseudo data is an example of processed data that is generated (processed) based on the collected raw data.
- the pseudo data acquisition unit 103 may generate pseudo data using various known techniques. For example, pseudo data may be generated by adding noise to raw data. In one example, the pseudo data acquisition unit 103 may generate each piece of pseudo data by adding random noise to the raw data. The noise may be Gaussian noise or Laplace noise. In one example, each of the pseudo data may be data obtained by processing basic data.
- the degree of processing of each of the pseudo data may be greater than the degree of processing of the basic data.
- the degree of processing means the degree of processing from raw data. In one example, the greater the noise added to the raw data, the greater the degree of processing.
- the pseudo data acquisition unit 103 may obtain pseudo data generated by a device external to the information processing device 1, or may generate pseudo data within the information processing device 1. In particular, the pseudo data acquisition unit 103 may generate a plurality of pseudo data within the information processing device 1 based on the basic data acquired by the basic data acquisition unit 102.
- the first training execution unit 104 trains a first class classification model A (model A: see FIG. 4) using the basic data as training data, and generates a trained first class classification model A.
- the first class classification model A is an example of a first class classification model.
- the basic data is configured, for example, as a combination of input data x and correct output data y. It is desirable that the first training execution unit 104 executes training of the first class classification model A using a plurality of basic data.
- the first training execution unit 104 can execute training of the first class classification model A using a known method.
- the training of the first class classification model A performed by the first training execution unit 104 using basic data may be referred to as first training.
- the class classification model before training by the first training execution unit 104 may be an empty machine learning model.
- a machine learning model can simply be called a model.
- the second training execution unit 105 trains a second class classification model B (model B) using a plurality of pseudo data as training data, and generates a trained second class classification model B.
- the second class classification model is an example of a second class classification model.
- each of the plurality of pseudo data is configured as a combination of input data x and correct output data y.
- the second training execution unit 105 can execute training of the second class classification model B using a known method.
- the second training execution unit 105 uses two or more first pseudo data (for example, pseudo data #1 described below: see FIG. 3) among the plurality of pseudo data as training data, and uses the second class classification model B ( For example, model B1 (see FIG. 3) may be trained.
- first pseudo data for example, pseudo data #1 described below: see FIG. 3
- second class classification model B For example, model B1 (see FIG. 3) may be trained.
- the training of the second class classification model B performed by the second training execution unit 105 using a plurality of pseudo data may be referred to as second training.
- the class classification model before being trained by the second training execution unit 105 may be the same empty machine learning model as the class classification model before being trained by the first training execution unit 104.
- the second training execution unit 105 also trains a plurality of (for example, two) second class classification models B (for example, models B1 and B2) using the pseudo data as training data, and A second class classification model B may also be generated.
- a plurality of (for example, two) second class classification models B for example, models B1 and B2
- a second class classification model B may also be generated.
- FIG. 3 is a diagram for explaining an example of the processing of the second training execution unit 105 and the second confidence vector acquisition unit 108 in the information processing device 1 as an example of the embodiment.
- the second training execution unit 105 trains two second class classification models B1 and B2.
- the second training execution unit 105 may include a distribution unit 111.
- the sorting unit 111 sorts the plurality of pseudo data acquired from the pseudo data acquisition unit 103 into a plurality of groups.
- the sorting unit 111 may randomly sort the plurality of pseudo data into a plurality of groups.
- the pseudo data includes pseudo data #1 (first converted data) belonging to one group, and pseudo data #2 (second converted data) belonging to another group different from the first group. data).
- the pseudo data may be divided into three or more groups.
- Pseudo data #1 and pseudo data #2 are each two or more pieces of pseudo data.
- the second training execution unit 105 trains the second class classification model B1 using the pseudo data #1.
- the second training execution unit 105 trains the second class classification model B2 using pseudo data #2.
- the specific training data generation unit 106 shown in FIG. 2 specifies (selects and generates) training data used by the third training execution unit 101 to implement learning processing in machine learning.
- the specific training data generation unit 106 may remove data that may worsen membership estimation resistance from among the plurality of pseudo data.
- the specific training data generation unit 106 may specify training data that maintains membership estimation resistance from among the plurality of pseudo data.
- the specific training data generation unit 106 uses the trained first class classification model A, the trained second class classification model B, and the plurality of pseudo data to be evaluated to generate the training data of the third training execution unit 101. Training data may be filtered.
- the specific training data generation unit 106 may acquire the trained first class classification model A, the trained second class classification model B, and the plurality of pseudo data to be evaluated from outside the information processing device 1. good.
- the functions of the basic data acquisition section 102, the pseudo data acquisition section 103, the first training execution section 104, and the second training execution section 105 may be provided in a device external to the information processing device 1.
- the specific training data generation unit 106 includes a first confidence vector acquisition unit 107, a second confidence vector acquisition unit 108, a distance calculation unit 109, and a specification unit 110.
- the first certainty vector obtaining unit 107 obtains a first certainty vector VA for each of the plurality of pseudo data by inputting the plurality of pseudo data to the first class classification model A.
- Generation of the first confidence vector VA is one of the inference processes using the trained first class classification model A, and is referred to as first inference.
- the confidence vector includes as elements the confidence of each label, which is the result of data discrimination by the class classification model.
- the "label” may be an item for classifying data using a classification model.
- the confidence level is the probability that the pair of data of interest and label (item) is correct.
- each label of element (A), element (B), element (C), and element (D) for each label Confidence is calculated. Furthermore, the confidence level of the correct label of the input data is calculated.
- the confidence vector includes the confidence of each label as an element.
- the second certainty vector acquisition unit 108 obtains, for each of the two or more pieces of second processed data, a second certainty vector VB whose elements are the certainty factors of each of the plurality of labels that are the discrimination results.
- Generation of the second confidence vector VB is one of the inference processes using the trained second class classification model B, and is referred to as second inference.
- the second confidence vector acquisition unit 108 inputs the pseudo data to the second class classification model B, causes it to perform inference, and obtains the second confidence vector VB.
- the second certainty vector acquisition unit 108 may include a switching unit 112.
- the switching unit 112 exchanges (swaps) the pseudo data input to the respective second class classification models B1 and B2 in the training phase and the evaluation phase.
- the switching unit 112 inputs the pseudo data #2 as the pseudo data to be evaluated to the second class classification model B1 trained using the pseudo data #1.
- the switching unit 112 inputs the pseudo data #1 as the pseudo data to be evaluated to the second class classification model B2 trained using the pseudo data #2.
- the switching unit 112 exchanges the pseudo data input to the second class classification models B1 and B2 between the training phase and the evaluation phase, thereby changing the second class classification trained using the pseudo data #1.
- Model B1 allows us to avoid evaluating the same pseudo data #1 as in the training phase.
- the second class classification model B2 trained using pseudo data #2 can avoid evaluating the same pseudo data #2 as used during training.
- the switching unit 112 evaluates the membership estimation resistance of the pseudo data #1 and the pseudo data #2 as a whole by exchanging (swapping) the pseudo data input to the respective second class classification models B1 and B2. I can do it.
- the second reliability vector acquisition unit 108 acquires two or more first pseudo data (for example, pseudo data #1, #2: The second class classification models B1 and B2 (see FIG. 3) trained using the second class classification models B1 and B2 (see FIG. 3) may be used.
- pseudo data #1, #2 The second class classification models B1 and B2 (see FIG. 3) trained using the second class classification models B1 and B2 (see FIG. 3) may be used.
- the second confidence vector acquisition unit 108 converts two or more second pseudo data (for example, pseudo data #1 and #2 described below: see FIG. 3) out of the plurality of pseudo data into a trained second class.
- a second confidence vector VB (see FIG. 4) is generated by inputting it to the classification models B2 and B1 (see FIG. 3).
- the first pseudo data (for example, pseudo data #1) and the second pseudo data (for example, pseudo data #2) may be different.
- the distance calculation unit 109 shown in FIG. 2 obtains the distance between the first certainty vector VA and the second certainty vector VB.
- the distance may be the KL distance (Kullback-Leibler distance) or the L1 distance (also referred to as the Manhattan distance).
- the first certainty vector VA is VA(p1,...pn) (where p1,...pn is the certainty factor of each label in the first certainty vector VA).
- the second certainty vector VB be VB(q1,...qn) (where q1,...qn is the certainty factor of each label in the second certainty vector VB).
- between the first certainty vector VA and the second certainty vector VB is given by the following equation (1). sqrt((p1-q1) 2 +...+(pn-qn) 2 )...(1)
- the identifying unit 110 identifies pseudo data to be input to the third training execution unit 101 from among a plurality of pseudo data.
- the identification unit 110 may identify the pseudo data based on the first certainty vector VA.
- the identification unit 110 may identify the pseudo data based on the first certainty vector VA.
- the specifying unit 110 determines whether the confidence of the correct label of the first confidence vector VA is less than the first reference value.
- the identifying unit 110 may identify pseudo data corresponding to a confidence level that is less than the first reference value as data that does not adversely affect membership estimation resistance.
- the pseudo data thus identified as data that does not adversely affect the membership estimation resistance may be used as training data for training the third class classification model C (Model C) by the third training execution unit 101.
- the first reference value may be a predetermined threshold value.
- the identification unit 110 may further identify the pseudo data based on the distance
- the specifying unit 110 sets the condition that the confidence of the correct label of the first confidence vector VA is less than the first reference value, or that the distance
- the identifying unit 110 selects from among the plurality of pseudo data that the confidence of the correct label of the first confidence vector VA is equal to or greater than the first reference value, and that the distance
- the specifying unit 110 determines only when the confidence of the correct label of the first confidence vector VA is less than the first reference value and the distance
- the corresponding pseudo data may be specified as training data for the third class classification model C.
- the third training execution unit 101 trains the third class classification model C using the pseudo data identified by the identification unit 110 as training data.
- the third class classification model C is the model actually used for estimation.
- the pseudo data identified by the identifying unit 110 is configured, for example, as a combination of input data x and correct output data y.
- the training of the third class classification model C performed by the third training execution unit 101 using a plurality of identified pseudo data may be referred to as third training.
- the class classification model before being trained by the third training execution unit 101 is an empty machine learning model that is the same as the class classification model at the previous stage before being trained by the first training execution unit 104 or the second training execution unit 105. It can be a model.
- FIG. 4 shows the processing contents of the first training execution unit 104, the second training execution unit 105, the first confidence vector acquisition unit 107, and the second confidence vector acquisition unit 108 in the information processing device 1 as an example of the embodiment. It is a figure for explaining.
- the second training execution unit 105 trains two second class classification models B1 and B2, and the second confidence vector acquisition unit 108 trains these second class classification models B1 and B2.
- An example will be shown in which the second confidence vector VB is obtained using B2.
- processing #1 is a training phase for the first class classification model A and the second class classification models B1 and B2.
- Process #2 is an evaluation phase of pseudo data #1 and #2.
- the evaluation phase is an example of an inference phase using the first class classification model A and the second class classification models B1 and B2.
- Process #1 includes first training and second training.
- the first training execution unit 104 trains the first class classification model A using the basic data as training data.
- the second training execution unit 105 trains the second class classification model B1 using the pseudo data #1 as training data.
- the second training execution unit 105 further trains the second class classification model B2 using the pseudo data #2 as training data.
- Process #2 includes a first inference and a second inference.
- the first confidence vector acquisition unit 107 inputs pseudo data (both pseudo data #1 and pseudo data #2) into the trained first class classification model A, thereby obtaining a first confidence vector.
- the second confidence vector acquisition unit 108 inputs the pseudo data #1 to the trained second class classification model B2. As a result, the second certainty vector acquisition unit 108 obtains the second certainty vector VB for pseudo data #1.
- the second confidence vector acquisition unit 108 inputs the pseudo data #2 to the trained second class classification model B1. As a result, the second certainty vector acquisition unit 108 obtains the second certainty vector VB for pseudo data #2.
- the second certainty vector acquisition unit 108 can obtain the second certainty vector VB for the pseudo data (both pseudo data #1 and pseudo data #2).
- the specifying unit 110 determines that the confidence of the correct label of the first confidence vector VA is equal to or greater than the first reference value, and the distance
- the identifying unit 110 can determine pseudo data that affects membership estimation resistance based on the confidence of the correct label and the distance
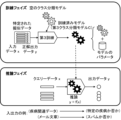
- FIG. 5 is a diagram showing an overview of the training phase and inference phase of the class classification model in the information processing device 1 as an example of the embodiment.
- the process shown in FIG. 5 includes a training phase.
- the training phase includes third training in which the third class classification model C is trained using the pseudo data identified by the process shown in FIG. 4 as training data.
- the third class classification model C is a new class classification model and is a model actually used in the inference phase.
- the third training execution unit 101 sets parameters of the machine learning model by training an empty machine learning model using the identified pseudo data as training data.
- the third class classification model C In the inference phase, when query data x to be classified is input to the third class classification model C, the third class classification model C outputs the class classification result as output data y.
- the information processing device 1 of this embodiment in the inference phase, for example, by inputting disease-related data etc. to the third class classification model C as query data x, it is inferred whether or not there is a suspicion of a specific disease. It can be used as a device for However, the information processing device 1 is not limited to this case, and may be utilized as various classification devices such as a device for inferring whether an email text is spam or not.
- step S1 the pseudo data acquisition unit 103 generates a plurality of pseudo data.
- the pseudo data acquisition unit 103 may generate a plurality of pseudo data based on the basic data.
- Information constituting the pseudo data is stored in a predetermined storage area such as the storage device 13.
- step S2 the first training execution unit 104 executes first training to train the first class classification model A using the basic data as training data.
- An empty classification model before executing the first training may be stored in the storage device 13 in advance.
- the trained first class classification model A may be stored in the storage device 13.
- step S4 the data selection unit 100a identifies (selects) pseudo data that is input to the third training execution unit 101 in order to train the third class classification model C.
- the first certainty vector acquisition unit 107 generates a first certainty vector VA for each of the plurality of pseudo data by inputting the plurality of pseudo data to the first class classification model A.
- the first reliability vector VA may include as elements the reliability of each of the plurality of labels that are the discrimination results.
- the first confidence vector VA contains the confidence of the correct label.
- the identifying unit 110 identifies pseudo data based on at least one of the certainty of the accurate label inferred by the first class classification model A and the distance
- the pseudo data acquisition unit 103 may obtain a plurality of pseudo data generated by a device external to the information processing device 1. Further, the information processing device 1 may acquire the first class classification model A and the second class classification model B generated by a device external to the information processing device 1. In these cases, the processes of steps S1, S2, and S3 may be omitted.
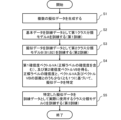
- FIG. 7 is a flowchart (steps S11 to S18) for explaining a first example of a method for identifying pseudo data in the information processing device 1 as an example of the embodiment.
- the flowchart shown in FIG. 7 is an example of the process of step S4 in FIG.
- step S11 a first class classification model A trained using only basic data and a second class classification model B trained only using pseudo data are prepared.
- the data selection unit 100a determines whether unevaluated pseudo data remains (step S12). As a result of the determination, if no unevaluated pseudo data remains (see NO route in step S12), the pseudo data identification process ends. If unevaluated pseudo data remains (see YES route in step S12), the process proceeds to step S13.
- the first certainty vector acquisition unit 107 selects one unevaluated pseudo data from among the plurality of pseudo data.
- the first certainty vector obtaining unit 107 obtains the first certainty vector VA by inputting the selected pseudo data into the first class classification model A and performing inference.
- the first confidence vector VA includes the confidence of the correct label.
- step S14 the second certainty vector acquisition unit 108 obtains the second certainty vector VB by inputting the pseudo data selected in step S13 to the second class classification model B and inferring it.
- step S14 as shown in FIG. 4, a plurality of second class classification models B1 and B2 are prepared, and the respective second class classification models B1 and B2 are used for training and evaluation.
- the second confidence vector VB may be obtained by exchanging (swapping) the pseudo data input to B2.
- step S15 the specifying unit 110 determines whether the confidence for the correct label in the first confidence vector VA is greater than or equal to the first reference value. If the confidence level for the correct label is greater than or equal to the first reference value (see YES route in step S15), the process proceeds to step S16. On the other hand, if the confidence level for the correct label is less than the first reference value (see NO route in step S15), the process proceeds to step S17.
- step S16 the identifying unit 110 determines whether the distance
- step S17 the identifying unit 110 identifies the corresponding pseudo data as training data for the third class classification model C, and the process returns to step S12. Therefore, even if the confidence of the correct label of the first confidence vector VA is less than the first criterion, and even if the confidence is greater than or equal to the first criterion, the distance
- step S18 the identifying unit 110 excludes the corresponding pseudo data from the training data of the third class classification model C, and the process returns to step S12. Therefore, if the confidence of the correct label of the first confidence vector VA is greater than or equal to the first reference value and the distance
- FIG. 8 is a flowchart (steps S21 to S28) for explaining a second example of the pseudo data identification method in the information processing device 1 as an example of the embodiment.
- the flowchart shown in FIG. 8 is another example of the process of step S4 in FIG.
- steps S21 to S24 are the same as the processes in steps S11 to S14 in FIG. 7, and a description of each process will be omitted.
- step S25 the specifying unit 110 determines whether the confidence for the correct label in the first confidence vector VA is greater than or equal to the first reference value. If the confidence level for the correct label is less than the first reference value (see NO route in step S25), the process proceeds to step S26. On the other hand, if the confidence level for the correct label is greater than or equal to the first reference value (see YES route in step S25), the process proceeds to step S28.
- step S26 the specifying unit 110 determines whether the distance
- step S27 the identifying unit 110 identifies the corresponding pseudo data as training data for the third class classification model C, and the process returns to step S22. Therefore, when the confidence of the correct label of the first confidence vector VA is less than the first standard and the distance
- step S28 the identifying unit 110 excludes the corresponding pseudo data from the training data of the third class classification model C, and the process returns to step S22. Therefore, if the confidence of the correct label of the first confidence vector VA is greater than or equal to the first reference value, or if the distance
- each of the first class classification model A, second class classification model B, and third class classification model C is stored in a predetermined storage area of the storage device 13 or the like.
- a plurality of pseudo data are input to the first class classification model A trained using basic data associated with a correct label, and a plurality of pseudo data
- the computer executes processing to obtain the confidence level of the correct label for each of the following. Then, the computer executes a process of identifying pseudo data corresponding to a confidence level that is less than the first reference value.
- the computer executes a process of training a third class classification model C, which is a new class classification model, using the identified pseudo data as training data.
- the third class classification model C is trained by removing pseudo data that affects membership estimation resistance. This makes it possible to generate a machine learning model that is resistant to membership estimation.
- the basic data and processed data are generated based on the collected raw data.
- the processed data has a greater degree of processing from the raw data than the basic data. Therefore, since each of the plurality of pseudo data is input to the first class classification model A trained with basic data that is closer to raw data, it is possible to effectively remove pseudo data that affects membership estimation resistance.
- the information processing device 1 calculates, for each of the plurality of pseudo data, the certainty factor of each of the plurality of labels, which is the discrimination result, as an element.
- a process for generating a first certainty vector VA is executed.
- the information processing device 1 adds two or more pseudo data #1 (first pseudo data) different from pseudo data #1 to a second class classification model B1 trained using two or more pseudo data #1 (first pseudo data) out of a plurality of pseudo data.
- the above pseudo data #2 (second pseudo data) is input.
- the information processing device 1 generates, for each of the two or more second processed data, a second reliability vector VB whose elements are the reliability of each of the plurality of labels that are the discrimination results. Then, the information processing device 1 executes a process of obtaining the distance
- the pseudo data is can be specified as training data.
- is larger than the second reference value is identified as training data. You can. In this case, pseudo data that affects membership estimation resistance can be removed.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Software Systems (AREA)
- Mathematical Physics (AREA)
- Artificial Intelligence (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Biomedical Technology (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Medical Informatics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Priority Applications (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2022/016770 WO2023188354A1 (ja) | 2022-03-31 | 2022-03-31 | モデル訓練方法,モデル訓練プログラムおよび情報処理装置 |
| JP2024511098A JP7743921B2 (ja) | 2022-03-31 | 2022-03-31 | モデル訓練方法,モデル訓練プログラムおよび情報処理装置 |
| EP22935494.9A EP4502877A4 (en) | 2022-03-31 | 2022-03-31 | Model training method, model training program, and information processing device |
| CN202280094107.XA CN118946897A (zh) | 2022-03-31 | 2022-03-31 | 模型训练方法、模型训练程序以及信息处理装置 |
| US18/886,539 US20250005361A1 (en) | 2022-03-31 | 2024-09-16 | Model training method, computer-readable recording medium storing model training program, and information processing apparatus |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2022/016770 WO2023188354A1 (ja) | 2022-03-31 | 2022-03-31 | モデル訓練方法,モデル訓練プログラムおよび情報処理装置 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US18/886,539 Continuation US20250005361A1 (en) | 2022-03-31 | 2024-09-16 | Model training method, computer-readable recording medium storing model training program, and information processing apparatus |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023188354A1 true WO2023188354A1 (ja) | 2023-10-05 |
Family
ID=88200375
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/016770 Ceased WO2023188354A1 (ja) | 2022-03-31 | 2022-03-31 | モデル訓練方法,モデル訓練プログラムおよび情報処理装置 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US20250005361A1 (https=) |
| EP (1) | EP4502877A4 (https=) |
| JP (1) | JP7743921B2 (https=) |
| CN (1) | CN118946897A (https=) |
| WO (1) | WO2023188354A1 (https=) |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20070143284A1 (en) | 2005-12-09 | 2007-06-21 | Lee Chang K | Apparatus and method for constructing learning data |
| JP2019159961A (ja) | 2018-03-14 | 2019-09-19 | オムロン株式会社 | 検査システム、画像識別システム、識別システム、識別器生成システム、及び学習データ生成装置 |
| JP2021107970A (ja) | 2019-12-27 | 2021-07-29 | 川崎重工業株式会社 | 訓練データ選別装置、ロボットシステム及び訓練データ選別方法 |
-
2022
- 2022-03-31 EP EP22935494.9A patent/EP4502877A4/en active Pending
- 2022-03-31 WO PCT/JP2022/016770 patent/WO2023188354A1/ja not_active Ceased
- 2022-03-31 CN CN202280094107.XA patent/CN118946897A/zh active Pending
- 2022-03-31 JP JP2024511098A patent/JP7743921B2/ja active Active
-
2024
- 2024-09-16 US US18/886,539 patent/US20250005361A1/en active Pending
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20070143284A1 (en) | 2005-12-09 | 2007-06-21 | Lee Chang K | Apparatus and method for constructing learning data |
| JP2019159961A (ja) | 2018-03-14 | 2019-09-19 | オムロン株式会社 | 検査システム、画像識別システム、識別システム、識別器生成システム、及び学習データ生成装置 |
| JP2021107970A (ja) | 2019-12-27 | 2021-07-29 | 川崎重工業株式会社 | 訓練データ選別装置、ロボットシステム及び訓練データ選別方法 |
Non-Patent Citations (4)
| Title |
|---|
| CHRISTOPHER A. CHOQUETTE-CHOO; FLORIAN TRAMER; NICHOLAS CARLINI; NICOLAS PAPERNOT: "Label-Only Membership Inference Attacks", ARXIV.ORG, 5 December 2021 (2021-12-05), XP091108432 * |
| See also references of EP4502877A4 |
| SENZAKI YUYA, SATSUYA OHATA, KANTA MATSUURA: "Negative Side Effect of Adversarial Training in Deep Learning and Its Mitigation", COMPUTER SECURITY SYMPOSIUM 2017, 1 October 2017 (2017-10-01), pages 385 - 392, XP093094336 * |
| SHORTEN, Connor. KHOSHGOFTAAR, Taghi M. A survey on Image Data Augmentation for Deep Learning. Journal of Big Data. vol. 6, Article number: 60, 06 July 2019, [retrieval date 14 June 2022], Internet<URL: https://journalofbigdata.springeropen.com/track/pdf/10.1186/s40537-019-0197-0.pdf>, <DOI: https://doi.org/10.1186/s40537-019-0197-0> * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN118946897A (zh) | 2024-11-12 |
| US20250005361A1 (en) | 2025-01-02 |
| EP4502877A4 (en) | 2025-05-21 |
| JPWO2023188354A1 (https=) | 2023-10-05 |
| EP4502877A1 (en) | 2025-02-05 |
| JP7743921B2 (ja) | 2025-09-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Attenberg et al. | Beat the machine: Challenging humans to find a predictive model's “unknown unknowns” | |
| JP5142135B2 (ja) | データを分類する技術 | |
| Ullah et al. | Detecting high‐risk factors and early diagnosis of diabetes using machine learning methods | |
| JP2018520419A (ja) | コンピュータセキュリティアプリケーション用のカスケード型分類器 | |
| US20220277174A1 (en) | Evaluation method, non-transitory computer-readable storage medium, and information processing device | |
| JP7047498B2 (ja) | 学習プログラム、学習方法および学習装置 | |
| US9906551B2 (en) | Forecasting and classifying cyber-attacks using crossover neural embeddings | |
| Hasan et al. | A novel data balancing technique via resampling majority and minority classes toward effective classification | |
| Michelucci | Feature importance and selection | |
| JP2020123097A (ja) | 学習装置、学習方法および学習プログラム | |
| Yayli et al. | Deep learning in gonarthrosis classification: a comparative study of model architectures and single vs. multi-model methods | |
| JP7733300B2 (ja) | アンケート結果分析プログラム、アンケート結果分析方法、および情報処理装置 | |
| US20220215228A1 (en) | Detection method, computer-readable recording medium storing detection program, and detection device | |
| WO2024013939A1 (ja) | 機械学習プログラム、機械学習方法、および情報処理装置 | |
| WO2023188354A1 (ja) | モデル訓練方法,モデル訓練プログラムおよび情報処理装置 | |
| JP7517613B2 (ja) | 設計空間削減装置、制御方法、及びプログラム | |
| JP2022188894A (ja) | 相関ルール生成プログラム、装置、及び方法 | |
| Park et al. | Concept evolution in deep learning training: A unified interpretation framework and discoveries | |
| JP7679630B2 (ja) | 情報処理プログラム,情報処理方法および情報処理装置 | |
| US10467258B2 (en) | Data categorizing system, method, program software and recording medium therein | |
| JP7547956B2 (ja) | 修正対象エッジ決定方法および修正対象エッジ決定プログラム | |
| Pratama et al. | Measuring Resampling Methods on Imbalanced Educational Dataset’s Classification Performance | |
| Veedhi et al. | Sampling strategies for handling data imbalance problem: An extensive review | |
| WO2023127062A1 (ja) | データ生成方法,機械学習方法,情報処理装置,データ生成プログラムおよび機械学習プログラム | |
| WO2021245850A1 (ja) | 診断支援プログラム、装置、及び方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22935494 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2024511098 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 202280094107.X Country of ref document: CN |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2022935494 Country of ref document: EP |
|
| ENP | Entry into the national phase |
Ref document number: 2022935494 Country of ref document: EP Effective date: 20241031 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |