WO2023181271A1 - 学習システム、学習方法、及びプログラム - Google Patents
学習システム、学習方法、及びプログラム Download PDFInfo
- Publication number
- WO2023181271A1 WO2023181271A1 PCT/JP2022/014019 JP2022014019W WO2023181271A1 WO 2023181271 A1 WO2023181271 A1 WO 2023181271A1 JP 2022014019 W JP2022014019 W JP 2022014019W WO 2023181271 A1 WO2023181271 A1 WO 2023181271A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- learning
- training image
- age
- numerical value
- result
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/74—Image or video pattern matching; Proximity measures in feature spaces
- G06V10/761—Proximity, similarity or dissimilarity measures
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/774—Generating sets of training patterns; Bootstrap methods, e.g. bagging or boosting
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/16—Human faces, e.g. facial parts, sketches or expressions
- G06V40/178—Human faces, e.g. facial parts, sketches or expressions estimating age from face image; using age information for improving recognition
Definitions
- the present disclosure relates to a learning system, a learning method, and a program.
- Non-Patent Document 1 describes a technique for cutting out parts showing parts such as eyes or nose from a photograph of a human face, which is an example of an object, and inputting the cut out parts to a learning model for estimating age.
- This learning model outputs a probability distribution that shows the probability for each age. Age is estimated by summing the values obtained by multiplying the age shown in this probability distribution by the probability.
- Non-Patent Document 2 as a learning method for a learning model that outputs scores for each age when facial photos are input, there is a softmax loss related to a softmax function, an average age according to the output of the learning model, and a correct answer.
- a technique is described that uses an average loss related to the deviation from the age and a variance loss related to the variance of the age depending on the output of the learning model.
- Non-Patent Document 3 describes a technique for estimating age by specifying a plurality of regions from a facial photograph and inputting each region to a learning model.
- Non-Patent Documents 1 to 3 in order to improve the accuracy of the learning model, it is necessary to prepare a large number of training images, which is very time-consuming. This point is not limited to learning models that estimate the age of objects, but also applies to learning models that estimate numerical values other than age (for example, height or weight). Therefore, even with a small amount of training images, it is necessary to improve the accuracy of learning models that estimate numerical values related to objects included in images.
- One of the objectives of the present disclosure is to improve the accuracy of a learning model that estimates numerical values regarding objects included in images.
- the learning system includes: a first acquisition unit that acquires a first training image regarding a first object having a first numerical value; a second acquisition unit that acquires a second training image regarding a second object having a second numerical value; a learning unit that executes a learning process of a learning model that estimates an estimation target numerical value regarding an estimation target object included in an estimation target image based on distance learning using the first training image and the second training image. .
- the accuracy of a learning model that estimates numerical values regarding objects included in images is increased.
- FIG. 1 is a diagram showing an example of the overall configuration of a learning system.
- FIG. 3 is a diagram illustrating an example of how a trained learning model is used.
- FIG. 3 is a diagram illustrating an example of learning processing of a learning model.
- FIG. 2 is a functional block diagram showing an example of functions realized by the learning system. It is a figure showing an example of a training database.
- FIG. 3 is a diagram illustrating an example of a method using cosine similarity loss.
- FIG. 3 is a diagram illustrating an example of a method using triplet margin loss. It is a figure showing an example of processing performed by a learning system.
- 7 is a diagram illustrating an example of triplet margin loss in Modification 2.
- FIG. 1 is a diagram showing an example of the overall configuration of a learning system.
- FIG. 3 is a diagram illustrating an example of how a trained learning model is used.
- FIG. 3 is a diagram illustrating an example of learning processing of a learning model.
- FIG. 1 is a diagram showing an example of the overall configuration of a learning system.
- the learning system 1 includes an estimation device 10 and a learning device 20.
- the estimation device 10 and the learning device 20 are communicably connected by a communication cable C, but the estimation device 10 and the learning device 20 are communicably connected by a network such as the Internet or a LAN. May be connected.
- the learning system 1 may include at least one computer, and is not limited to the example shown in FIG. 1.
- the learning system 1 may include only the learning device 20.
- the estimation device 10 is a computer that uses a trained learning model.
- the estimation device 10 is a personal computer, a smartphone, a tablet terminal, a wearable terminal, or a server computer.
- Control unit 11 includes at least one processor.
- the storage unit 12 includes a volatile memory such as a RAM, and a nonvolatile memory such as a hard disk.
- the communication unit 13 includes at least one of a communication interface for wired communication and a communication interface for wireless communication.
- the photographing unit 14 includes at least one camera.
- the learning device 20 is a computer that creates a trained learning model.
- the learning device 20 is a personal computer, a smartphone, a tablet terminal, a wearable terminal, or a server computer.
- the physical configurations of the control section 21, the storage section 22, and the communication section 23 may be the same as those of the control section 11, the storage section 12, and the communication section 13, respectively.
- the operation unit 24 is an input device such as a keyboard or a mouse.
- the display section 25 is a liquid crystal display or an organic EL display.
- the programs stored in the storage units 12 and 22 may be supplied via a network.
- the estimation device 10 or the learning device 20 may include a reading unit (for example, an optical disk drive or a memory card slot) that reads a computer-readable information storage medium, or an input/output unit (for example, an optical disk drive or a memory card slot) that inputs and outputs data with an external device.
- a reading unit for example, an optical disk drive or a memory card slot
- an input/output unit for example, an optical disk drive or a memory card slot
- a program stored in an information storage medium may be supplied via a reading section or an input/output section.
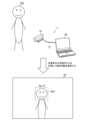
- FIG. 2 is a diagram illustrating an example of how a trained learning model is used.
- a learning model a learning model that estimates the age of a certain human based on an image of the human's face will be described.
- the learning device 20 transmits the learned learning model to the estimation device 10.
- the estimation device 10 records the trained learning model received from the learning device 20 in the storage unit 12.
- the estimation device 10 uses the photographing unit 14 to photograph the estimation target human EH whose age is to be estimated.
- the photographing section 14 photographs the estimation target human EH in the video mode, but the photographing section 14 may photograph the estimation target human EH in the still image mode.
- the estimation device 10 estimates the estimated age, which is the age of the estimation target person EH, based on the estimation target image EI in which the estimation target person EH is shown and the learned learning model.
- the estimation target image EI shows the face of the estimation target human EH.
- Estimated age can be used for any purpose. For example, if the person EH to be estimated is a customer of a store, the purpose of the estimation is to understand the customer demographics of the store, to confirm age when purchasing products such as alcohol or cigarettes, or to present advertisements according to age. , an estimated age may be estimated. In addition, the estimated age may be estimated for the purpose of identity verification at a facility such as an airport or an event venue.
- the learning device 20 causes the learning model to learn training data in which a training image is associated with an age that is a correct answer.
- the training image is an image that the learning model is made to learn.
- the training image shows a person whose features are being learned by the learning model.
- the correct age is the age of the person shown in the training image.
- a pair of a training image and a correct age corresponds to training data.
- the human shown in the training image will be referred to as the training human.
- the training human In order to improve the accuracy of the learning model, it is desirable to select a wide variety of people as training people. However, in this case, it is necessary to prepare a large amount of training data, which is very time-consuming. Therefore, in this embodiment, distance learning is used to create a highly accurate learning model even if there is little training data.
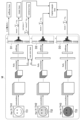
- FIG. 3 is a diagram illustrating an example of the learning process of the learning model.
- a first training image TI1 regarding a first training person TH1 who is 35 years old a second training image TI2 regarding a second training person TH2 who is 35 years old
- TI3 is used.
- the first training person TH1 to the third training person TH3 are not distinguished, they will simply be referred to as training humans TH.
- the first to third training images TI1 to TI3 are not distinguished, they are simply referred to as training images TI.
- the training image TI shows the face of the training human TH.
- FIG. 3 mainly shows the processing of the convolution layer, fully connected layer, and output layer in the learning model M.
- the learning model M itself can use various machine learning techniques, and is not limited to convolutional neural networks. For example, recurrent neural networks, deep neural networks, generative adversarial networks, or long/short-term memory models may be used.
- the machine learning method any of supervised learning, semi-supervised learning, or unsupervised learning can be used.
- the convolution layer of the learning model M performs convolution on the first training image TI1.
- the fully connected layer of the learning model M performs fully connecting the calculation results by the convolutional layer.
- the output layer of the learning model M outputs the estimation result of the age of the first training human TH1 based on the activation function.
- the learning model M outputs the estimation results of the ages of the second training human TH2 and the third training human TH3.
- the learning model M outputs a probability distribution as the age estimation result.
- the probability distribution output when the first training image TI1 is input will be referred to as a first distribution D1.
- the probability distribution output when the second training image TI2 is input is referred to as a second distribution D2.
- the probability distribution output when the third training image TI3 is input is referred to as a third distribution D3.
- the first distribution D1, the second distribution D2, and the third distribution D3 are not distinguished from each other, they are simply referred to as a probability distribution D.
- the probability pj of being this age is shown.
- Probability pj is sometimes called probability or score.
- the accuracy of the learning model M is high to some extent, and in any probability distribution D, the probability pj of age j that is the correct answer is the highest. However, if the learning process is in the middle of the learning process, the probability pj of age j that is the correct answer is not necessarily the highest.
- the learning device 20 executes learning processing based on the processing results of the current learning model M so as to obtain ideal processing results.
- a case will be described in which both an intermediate processing result of the learning model M and a final processing result of the learning model M are used as the processing result.
- the learning device 20 executes the learning process so that the loss, which is the difference between the current processing result and the ideal processing result, is reduced.
- the learning device 20 calculates a softmax loss, an average loss, and a variance loss based on the first training image TI1.
- the softmax loss is a loss corresponding to the difference between the age j at which the probability pj is highest in the first distribution D1 and the age at which the correct answer is given (35 years old in FIG. 3).
- the average loss is a loss according to the difference between the average age calculated based on the probability distribution D and the age that is the correct answer.
- the variance loss is a loss depending on the difference between age j and the average loss.
- FIG. 3 shows an example of a calculation formula for each loss, various calculation formulas can be used as the calculation formula for each loss.
- the learning device 20 calculates a cosine similarity loss based on the first training image TI1 and the second training image TI2.
- the cosine similarity loss is the first feature F1 of the first training image TI1 calculated by the fully connected layer of the learning model M, and the second feature of the second training image TI1 calculated by the fully connected layer of the learning model M.
- the loss depends on the cosine similarity of the amount F1.
- the learning device 20 calculates the triplet margin loss based on the first training image TI1, the second training image TI2, and the third training image TI3.
- the first training human TH1 and the second training human TH2 are of the same age, it is desirable that the processing results based on the first training image TI1 and the processing results based on the second training image TI2 are similar.
- the first training human TH1 and the third training human TH3 are of the same age, it is desirable that the processing results based on the first training image TI1 and the processing results based on the third training image TI3 are not similar.
- Triplet margin loss is calculated according to the relationship between these three processing results.
- the learning process is performed so that the total loss, which is the sum of softmax loss, average loss, variance loss, cosine similarity loss, and triplet margin loss, is small.
- the learning system 1 uses losses related to distance learning such as cosine similarity loss and triplet margin loss to increase the accuracy of the learning model M even if the training data is small.
- losses related to distance learning such as cosine similarity loss and triplet margin loss to increase the accuracy of the learning model M even if the training data is small.
- FIG. 4 is a functional block diagram showing an example of functions realized by the learning system 1.
- the data storage unit 100 is mainly realized by the storage unit 12.
- the estimation unit 101 is realized mainly by the control unit 11.
- the data storage unit 100 stores data necessary for estimating the age of the estimation target human EH.
- the data storage unit 100 stores a trained learning model M.
- the data storage unit 100 can store any data other than the trained learning model M.
- the data storage unit 100 may store the estimation target image EI and the age estimated by the trained learning model M in association with each other.
- the estimation unit 101 estimates the estimated age of the estimation target human EH based on the estimation target image EI and the trained learning model M. In this embodiment, a case will be described in which the estimation unit 101 acquires the estimation target image EI generated by the imaging unit 14. , the estimation target image EI may be acquired. The estimation unit 101 inputs the estimation target image EI to the trained learning model M.
- the convolution layer of the learning model M executes convolution of the input estimation target image EI.
- the fully connected layer of the learning model M performs fully connecting the convolution execution results and obtains the estimation target feature amount which is the feature amount of the estimation target image EI.
- the output layer of the learning model M outputs the estimation result of the estimated age based on the estimation target feature amount.
- the output layer of the learning model M outputs a probability distribution D as an estimation result
- the estimation unit 101 estimates the age j with the highest probability pj in the probability distribution D as the estimated age.
- the method for estimating the age of the estimation target human EH may be any other method and is not limited to the example of this embodiment.
- the estimation unit 101 may estimate the age j with the second or higher probability pj as the estimated age.
- the estimation unit 101 may estimate the average age calculated based on the age j of the probability distribution D and the probability pj as the age of the estimation target human EH.
- the estimation results output by the output layer of the learning model M may be estimation results other than the probability distribution D, and are not limited to the probability distribution D.
- the process described as being executed by the estimation unit 101 based on the probability distribution D may be executed by the output layer of the learning model M, and the execution result of the process may be output.
- the output layer of the learning model M may specify the age j with the highest probability pj in the probability distribution D, and output the specified age j.
- the output layer of the learning model M may calculate the average age and output the calculated average age. By replacing the output layer of the trained learning model M, it is possible to output such an estimation result.
- the data storage section 200 is mainly realized by the storage section 22.
- the first acquisition unit 201, the second acquisition unit 202, the third acquisition unit 203, and the learning unit 204 are mainly realized by the control unit 21.
- the data storage unit 200 stores data necessary for learning processing of the learning model M. For example, the data storage unit 200 stores the learning model M before the learning process is completed and the training database DB. Before the start of the learning process, the data storage unit 200 stores the learning model M whose parameters are initial values. If the learning process is being executed, the data storage unit 200 stores the learning model M whose parameters are being adjusted. After the learning process is completed, the data storage unit 200 stores the learned learning model M.
- the data storage unit 200 may store a plurality of learning models M that share parameters with each other.
- the process in FIG. 3 may be executed not based on one learning model M but on a plurality of learning models M.
- the first learning model M1, the second learning model M2, and the third learning model M3 share parameters with each other
- the first training image TI1 is input to the first learning model M1
- the second training image TI2 is input to the second learning model M1.
- the third training image TI3 may be input to the third learning model M3. If any parameter of the first learning model M1, second learning model M2, and third learning model M3 changes due to the learning process, the remaining two parameters also have the same value.
- the data storage unit 200 stores a program for the learning model M including a convolution layer, a fully connected layer, and an output layer.
- the parameters of the learning model M may be integrated with each layer (program part) of the learning model M as data, or may be separate. Even when using a machine learning method other than the convolutional neural network, the data storage unit 200 may store a learning model M in a format corresponding to the other machine learning method.
- FIG. 5 is a diagram showing an example of the training database DB.
- the training database DB is a database that stores a plurality of training data.
- the training data includes a pair of a training image TI regarding a certain training person TH and the age of this training person TH.
- the formats of the individual training images TI are assumed to be the same, but may be slightly different.
- the format here is the format of image data.
- the format is an extension, resolution (number of pixels), aspect ratio, number of colors, or a combination thereof.
- the training image TI may show only a part of the face of the training human TH.
- the creator of the learning model M creates the training database DB
- various methods can be used to create the training data itself. Since there are methods of automating the creation of training data using clustering or the like, such methods may be used to automate the creation of training data.
- the training image TI only needs to show an object corresponding to a first object, etc., which will be described later. Therefore, objects other than humans may be shown in the training image TI.
- the use of the training images TI stored in the training database DB is not specified.
- the usage here refers to whether the training image TI is used as a first training image TI1, a second training image TI2, or a third training image TI3. If the use of the training image TI is not limited as in this embodiment, the training image TI can be any of the first training image TI1, the second training image TI2, and the third training image TI3.
- the creator of the learning model M may specify the use of each training image TI.
- the training database DB stores information that can identify the purpose specified by the creator.
- Separate databases may be prepared for each purpose. For example, a first database storing only the first training image TI1, a second database storing only the second training image TI2, and a third database storing only the third training image TI3 may be prepared. .
- separate databases may be prepared for each age of the training human TH.
- the first acquisition unit 201 acquires a first training image TI1 regarding a first training human TH1 of a first age.
- the first acquisition unit 201 can acquire any first training image TI1 from the training database DB.
- the first acquisition unit 201 may randomly acquire the first training images TI1.
- the first acquisition unit 201 may acquire the first training image TI1 of an age that has not yet been trained by the learning model M.
- the first acquisition unit 201 may acquire first training images TI1 of a relatively small number of images trained by the learning model M.
- the first age is the age of the first training human TH1.
- the first age is an example of a first numerical value. Therefore, the portion where the first age is written can be read as the first numerical value.
- the first numerical value is a numerical value regarding the first training human TH1.
- the first numerical value is not limited to age, and may be any numerical value related to the first person H.
- the first numerical value may be a numerical value representing the characteristics of the first person H.
- the first numerical value may be the height, weight, size of parts (for example, head, legs, torso), or body shape of the first person H.
- a case will be exemplified in which the first numerical value is the same as the second numerical value described below.
- an example will be given in which the first numerical value is different from a third numerical value described below.
- the first training human TH1 is the human shown in the first training image TI1.
- the first training human TH1 is an example of the first object. Therefore, the part described as the first training human TH1 can be read as the first object.
- the first object is the object shown in the first training image TI1. If the first training image TI1 is a captured image generated by a camera, the first object is a subject placed in real space. If the first training image TI1 is a CG, the first object is a 3D object placed in a virtual space or an object such as a two-dimensionally drawn character. Only a part of the face of the first training person TH may be shown in the first training image TI1. The same applies to the second training image TI2 and the third training image TI3.
- the first object may be an object other than a human.
- the first object may be another animal such as a dog or a cat.
- other animals are shown in the first training image TI1.
- the ages of other animals are associated with the first training image TI1.
- Learning model M estimates the age of other animals. Even when the first object is another animal, the learning model M may estimate other numerical values such as the body length, weight, size, or body shape of the other animal instead of the age.
- the first object may be an object other than an animal.
- the first object may be a plant, furniture, an indoor wall, food or drink, a vehicle, a building, or other scenery in the natural world.
- the first training image TI1 includes these other objects. If the object is another object such as a plant or a building that has a concept equivalent to age (age of tree or age of building), the learning model M estimates this concept. If the object is another object for which such a concept does not exist, the learning model M may estimate other numerical values such as the weight or size of the other object.
- the second acquisition unit 202 acquires a second training image TI2 regarding a second training human TH2 of a second age.
- the second acquisition unit 202 can acquire any second training image TI2 from the training database DB.
- the second acquisition unit 202 acquires a second training image TI2 suitable for use in distance learning together with the first training image TI1 from the training database DB.
- the second acquisition unit 202 may randomly acquire the second training image TI2 regardless of the first training image TI1.
- the second age is the age of the second training human TH2.
- the second age is an example of a second numerical value. Therefore, the portion where the second age is written can be read as the second numerical value. Similar to the first numerical value, the second numerical value is not limited to age.
- the second training human TH2 is the human shown in the second training image TI2.
- the second training human TH2 is an example of the second object. Therefore, the part described as second training human TH2 can be read as second object.
- the second object is the object shown in the second training image TI2. Similar to the first object, the second object is not limited to humans.
- the first object and the second object are different training humans TH, but the first object and the second object may be the same training human TH.
- a training person TH may be photographed with a certain facial expression in the first training image TI1
- this training human TH may be photographed with a different facial expression in the second training image TI2.
- the first training image TI1 may include a training person TH photographed from a certain angle
- the second training image TI2 may include a training person TH photographing from a different angle.
- the second acquisition unit 202 selects the first training human TH1 from the training database DB.
- a training image TI of the same second age is searched and the training image TI is obtained as a second training image TI2. If a plurality of training images TI are found in the search, the second acquisition unit 202 may acquire any one of the plurality of training images TI as the second training image TI2.
- the second acquisition unit 202 specifies the second training image TI1 before the first training image TI1 is acquired.
- Image TI2 may also be acquired. For example, if the combination of the first training image TI1 and the second training image TI2 to be used together in distance learning is associated in advance with the training database DB, the second acquisition unit 202 A second training image TI2 associated with image TI1 may be obtained.
- the third acquisition unit 203 acquires a third training image TI3 regarding a third training human TH3 of a third age.
- the third acquisition unit 203 can acquire any third training image TI3 from the training database DB.
- the third acquisition unit 203 acquires a third training image TI3 suitable for use in distance learning together with the first training image TI1 and the second training image TI2 from the training database DB.
- the third acquisition unit 203 may randomly acquire the third training image TI3 regardless of the first training image TI1 and the second training image TI2.
- the third age is the age of the third training human TH3.
- the third age is an example of a third numerical value. Therefore, the portion where the third age is written can be read as the third numerical value. Similar to the first and second numerical values, the third numerical value is not limited to age.
- the third training human TH3 is the human shown in the third training image TI3.
- the third training human TH3 is an example of a third object. Therefore, the portion described as third training human TH3 can be read as third object.
- the third object is the object shown in the third training image TI3. Similar to the first and second objects, the third object is not limited to humans.
- the third object, the first object, and the second object are different training humans TH, but the third object, the first object, and the second object are the same as each other.
- It may be a training human TH.
- an old appearance of a certain training person TH for example, when he was 20 years old
- this training image is photographed.
- a recent appearance of the human TH for example, an appearance at the age of 40 may be photographed.
- the third acquisition unit 203 selects a first training image TI1 that is different from the first age from the training database DB.
- a training image TI of 3 years old is searched and the training image TI is obtained as a third training image TI3. If a plurality of training images TI are found in the search, the third acquisition unit 203 may acquire any one of the plurality of training images TI as the third training image TI2.
- the difference between the first age and the third age is fixed at 10 years, but the difference between the first age and the third age may change dynamically. For example, if the younger the first age is, the more the facial features change with age, the difference between the first age and the third age may be smaller. Conversely, the younger the first age, the larger the difference between the first age and the third age, as long as facial features do not change much with age.
- the third acquisition unit 203 may determine the third age based on the first age of the first training image TI1, and search for the third training image TI3 of the determined third age.
- the third acquisition unit 203 specifies the third age before the first training image TI1 is acquired.
- Image TI3 may also be acquired. For example, if the combination of the first training image TI1, second training image TI2, and third training image TI3 used together in distance learning is associated in advance in the training database DB, the third acquisition The unit 203 may obtain a third training image TI3 associated with the first training image TI1 and the second training image TI2.
- the learning unit 204 executes a learning process of a learning model M for estimating the estimated age of the estimation target human EH included in the estimation target image EI, based on distance learning using the first training image TI1 and the second training image TI2. do.
- Distance learning is a learning method based on the mutual relationship of multiple training data. For example, in distance learning, learning processing is performed so that the same or similar training data become closer to each other. For example, in distance learning, learning processing is performed so that dissimilar training data are separated from each other. In this embodiment, a case will be described in which distance learning includes both of these methods, but distance learning may also mean only one of these methods.
- the learning unit 204 may perform the learning process for the learning model M using a deep distance learning technique. As described above, the learning unit 204 of this embodiment executes the learning process of the learning model M.
- the estimation target human EH is an example of an estimation target object. Therefore, the portion described as estimation target human EH can be read as estimation target object.
- the estimation target object is an object shown in the estimation target image EI. Similar to the first object, second object, and third object, the estimation target object is not limited to humans.
- Estimated age is an example of a numerical value to be estimated. For this reason, the place where "estimated age" is written can be read as the numerical value to be estimated. Similar to the first to third numerical values, the numerical value to be estimated is not limited to age.
- the learning process is a process of adjusting the parameters of the learning model M based on training data.
- the learning model M is a convolutional neural network
- the learning process is a process of adjusting parameters such as weighting coefficients or biases.
- the learning process itself may be any process that is compatible with the machine learning method used as the learning model M, and is not limited to the example of this embodiment. In the learning process, parameters may be adjusted according to the machine learning method.
- the learning unit 204 executes a learning process based on distance learning using the first training image TI1, the second training image TI2, and the third training image TI3.
- 204 may perform the learning process based on the first training image TI1 and the second training image TI2 without using the third training image TI3.
- the learning unit 204 may perform learning processing based on two or more training images TI. For example, the learning unit 204 may perform the learning process based on four or more training images TI.
- the learning unit 204 may execute the learning process by using other methods in addition to distance learning.
- a method using softmax loss, average loss, and variance loss will be described as an example of another method.
- Various other methods can be used, and the method is not limited to the example of this embodiment.
- distance learning a method using cosine similarity loss and a method using triplet margin loss will be explained.
- the first loss is a loss related to the difference between the processing result of the current learning model M based on a certain training image TI and the ideal processing result. When calculating the first loss with a certain training image TI, other training images TI are not used.
- the learning unit 204 obtains the first processing result by the learning model M based on the first training image TI1.
- the first processing result is a result of processing executed when the first training image TI1 is input to the learning model M.
- the first processing result is a first estimation result by the learning model M
- the first processing result may be an internal calculation result of the learning model M. That is, although a case will be described in which the first processing result is an output from the output layer, the first processing result may be an output from an intermediate layer.
- the first estimation result is the estimated age output from the learning model M when the first training image TI1 is input to the learning model M.
- the first estimation result is a first distribution D1 that includes each of a plurality of ages j and a first probability pj that the first human training person TH1 is at that age.
- the multiple ages j are an example of multiple numerical values. Therefore, a portion where a plurality of ages j is explained can be read as a plurality of numerical values.
- the age j with the highest probability pj, the average age according to the first distribution D1, or the average variance according to the first distribution D1 may correspond to the first estimation result.
- the first estimation result is not limited to these examples, and for example, the age j having the second or subsequent probability pj may correspond to the first estimation result.
- the learning unit 204 calculates a plurality of first losses based on the first distribution D1, which is the first estimation result, and the first age. For example, the learning unit 204 identifies the age j with the highest probability pj based on the first distribution D1 that is the first estimation result. The learning unit 204 obtains the difference between the specified age j and the first age as a softmax loss. The learning unit 204 calculates the average age based on the first distribution D1 and the calculation formula shown in FIG. 3. The learning unit 204 obtains the difference between the calculated average age and the first age as an average loss. The learning unit 204 calculates the average variance based on the first distribution D1 and the calculation formula shown in FIG. 3. The learning unit 204 obtains the difference between the calculated average variance and the ideal variance according to the first age as a variance loss.
- the learning unit 204 obtains a second processing result using the learning model M based on the second training image TI2.
- the second processing result is a result of processing executed when the second training image TI2 is input to the learning model M. Similar to the first processing result, the second processing result may be an internal calculation result of the learning model M, or may be a second estimation result output from the learning model M.
- the first processing result and the second processing result are both internal calculation results of the learning model M.
- the second estimation result is the age estimated by the learning model M when the second training image TI2 is input to the learning model M.
- the second estimation result is a second distribution D2 that includes each of a plurality of ages j and a second probability pj that the second human training person TH2 is at that age.
- the second estimation result may be an estimation result other than the probability distribution D, similarly to the first estimation result.
- Other estimation results may be the same as those exemplified in the explanation of the first estimation result.
- FIG. 6 is a diagram illustrating an example of a method using cosine similarity loss.
- the learning unit 204 calculates the first feature amount F1 regarding the first training image TI1 based on the first training image TI1 and the learning model M.
- the learning unit 204 calculates the second feature amount F2 regarding the second training image TI2 based on the second training image TI2 and the learning model M.
- the first feature amount F1 and the second feature amount F2 are shown on the multidimensional vector space of the origin O.
- the first feature amount F1 is information regarding the feature of the first training image TI1.
- the second feature amount F2 is information regarding the feature of the second training image TI2.
- the first feature amount F1 and the second feature amount F2 are expressed as multidimensional vectors, but the first feature amount F1 and the second feature amount F2 can be expressed in any format. be.
- the first feature amount F1 and the second feature amount F2 may be expressed in other formats such as an array or a single numerical value.
- the learning unit 204 convolves the first training image TI1 based on the parameters of the current learning model M to obtain the first feature amount. Calculate F1.
- the learning unit 204 calculates the second feature amount F2 by convolving the second training image TI2 based on the parameters of the current learning model M.
- the method of calculating the first feature amount F1 and the second feature amount F2 is as described with reference to FIG. 3.
- the calculation method itself for the first feature amount F1 and the second feature amount F2 may be any calculation method that is compatible with the machine learning method used as the learning model M, and various methods can be used.
- the learning unit 204 executes a learning process based on the first feature amount F1 and the second feature amount F2.
- the learning unit 204 calculates the cosine similarity based on the first feature amount F1 and the second feature amount F2.
- the learning unit 204 executes learning processing based on this cosine similarity.
- the learning unit 204 executes learning processing so that the cosine similarity loss according to the cosine similarity becomes smaller (the cosine similarity becomes larger).
- the formula for calculating cosine similarity loss is shown in FIG. That is, the learning unit 204 executes the learning process so that the difference between the first process result and the second process result becomes small.
- Cosine similarity loss is an example of relational loss. Therefore, the portion that describes cosine similarity loss can be read as relational loss.
- the relational loss is a loss related to the relation among the plurality of training images TI.
- the learning unit 204 calculates a relational loss based on the relationship between the first processing result of the learning model M based on the first training image TI1 and the second processing result of the learning model M based on the second training image TI2. .
- the relational loss itself may be any loss and is not limited to a cosine similarity loss.
- the relational loss may be a loss calculated using a Euclidean distance system method or a loss calculated using a Mahalanobis distance system method.
- the learning unit 204 may calculate the third feature amount regarding the third training image TI3 based on the third training image TI3 and the learning model M. In this case, the learning unit 204 may calculate a cosine similarity based on the first feature amount and the third feature amount, and may perform the learning process based on this cosine similarity. That is, the learning unit 204 may perform the learning process so that the difference between the first process result and the third process result becomes large. Combining the above, the learning unit 204 executes learning processing so that the difference between the first processing result and the second processing result becomes small, and the difference between the first processing result and the third processing result becomes large. You may.
- the learning unit 204 may calculate a cosine similarity based on the second feature amount and the third feature amount, and perform the learning process based on this cosine similarity.
- the learning unit 204 may perform learning processing so that this cosine similarity becomes low. That is, the learning unit 204 may perform the learning process so that the difference between the second process result and the third process result becomes large.
- the learning unit 204 can reduce the difference between the first processing result and the second processing result, and increase the difference between the first processing result and the third processing result.
- the learning process may be performed so that the difference between the process result and the third process result becomes large.
- the learning unit 204 acquires the third processing result by the learning model M based on the third training image TI3.
- the third processing result is a result of processing executed when the third training image TI3 is input to the learning model M.
- the third processing result may be an internal calculation result of the learning model M. That is, although a case will be described in which the third processing result is an output from the output layer, the third processing result may be an output from an intermediate layer.
- the third estimation result is the age estimated by the learning model M when the third training image TI3 is input to the learning model M.
- the third estimation result is a third distribution D3 including each of a plurality of ages j and a third probability pj that the third training human TH3 is at the age j.
- the third estimation result may be an estimation result other than the probability distribution D, similarly to the first estimation result and the second estimation result.
- Other estimation results may be the same as those exemplified in the explanation of the first estimation result. In this embodiment, it is assumed that the triplet margin loss is calculated based on the first estimation result, the second estimation result, and the third estimation result.
- FIG. 7 is a diagram showing an example of a method using triplet margin loss.
- the first training image TI1 corresponds to an anchor image that is a reference when calculating triplet margin loss. Since the second training image TI2 is associated with the same second age as the first age, it corresponds to a positive image given the same label as the anchor image. Since the third training image TI3 is associated with a third age different from the first age, it corresponds to a negative image given a label different from the anchor image. In the method using triplet margin loss, learning processing is performed so that the anchor image and the positive image become closer, and the anchor image and the negative image move away from each other.
- a first average age AA1 calculated from the first distribution D1 a second average age AA2 calculated from the second distribution D2, and a third average age AA3 calculated from the third distribution D3 are shown.
- the calculation method of the second average age AA2 and the third side gold age AA3 is the same as that of the first average age AA1.
- the learning unit 204 performs the learning process so that the difference dp between the first average age AA1 and the second average age AA2 becomes small, and the difference dn between the first average age AA1 and the third average age AA3 becomes large. Execute.
- the learning unit 204 calculates the triplet margin loss based on the difference dp, the difference dn, and a predetermined calculation formula.
- An example of this calculation formula is as shown in FIG.
- the calculation formula itself may be another calculation formula used for triplet margin loss.
- ⁇ be a hyperparameter indicating the margin in triplet margin loss.
- the difference between the difference dn and the difference dp becomes the margin ⁇ , so the difference between the current difference dn and the difference dp and the margin ⁇ becomes the triplet margin loss.
- the learning unit 204 executes the learning process so that the triplet margin loss becomes small, so that the difference between the difference dn and the difference dp approaches the margin ⁇ .
- the difference between the first age, the second age, and the third age is 10 years, so the margin ⁇ has a value of about 10.
- the margin ⁇ may be a fixed value or may be determined dynamically.
- the learning unit 204 sums up the softmax loss, average loss, variance loss, cosine similarity loss, and triplet margin loss, and calculates the total loss.
- the learning unit 204 executes learning processing so that the total loss is small.
- Various methods can be used for the learning process itself according to the loss. For example, techniques such as error backpropagation or gradient descent may be used. In this embodiment, a case will be described in which the total loss is a simple total value, but a weighting coefficient may be added as in a modification described later.
- the softmax loss, the average loss, and the variance loss correspond to the first loss
- the cosine similarity loss and the triplet margin loss correspond to the relational loss.
- the learning process will be executed based on the loss. Furthermore, since a plurality of first losses such as a softmax loss, an average loss, and a variance loss are used, the learning unit 204 executes the learning process based on the plurality of first losses and relational losses. become.
- the learning unit 204 executes the learning process based on the first estimation result, the second estimation result, and the third estimation result. For example, the learning unit 204 executes the learning process so that the difference between the first estimation result and the second estimation result becomes small, and the difference between the first estimation result and the third estimation result becomes large. Since the probability distribution D is used for each loss other than the cosine similarity loss, the learning unit 204 executes the learning process based on the first distribution D1, the second distribution D2, and the third distribution D3. Become.
- the learning unit 204 may calculate the triplet margin loss using intermediate processing results instead of the estimation results of the learning model M. That is, the learning unit 204 may perform the learning process based on the first process result, the second process result, and the third process result. For example, the learning unit 204 may perform the learning process so that the difference between the first processing result and the second processing result becomes smaller, and the difference between the first processing result and the third processing result becomes larger. good.
- the learning unit 204 calculates the third feature amount F3 regarding the third training image TI3 based on the third training image TI3 and the learning model M.
- the third feature amount F3 is information regarding the feature of the third training image TI3.
- the third feature amount F3 can be expressed in any format like the first feature amount F1 and the second feature amount F2.
- the learning unit 204 performs learning so that the difference between the difference dn between the first feature amount F1 and the third feature amount F3 and the difference dp between the first feature amount F1 and the second feature amount F2 approaches the margin ⁇ . Processing may be executed.
- the learning unit 204 may perform the learning process so that the difference between the first process result and the third process result is a difference that corresponds to the difference between the first age and the third age.
- the learning unit 204 may determine the margin ⁇ based on the difference between the first age and the third age.
- the learning unit 204 determines the margin ⁇ such that the larger the difference between the first age and the third age, the larger the margin ⁇ .
- the learning unit 204 executes learning processing based on the determined margin ⁇ .
- the difference between the first and third ages is 10 years, but if the difference between the first and third ages is 5 years, the margin ⁇ is a difference of about 5 years. Good too.
- the learning unit 204 performs learning processing based on cosine similarity loss and triplet margin loss, which are examples of relational losses, without using softmax loss, average loss, and variance loss, which are examples of the first loss. may be executed.
- the learning unit 204 may perform the learning process based on either cosine similarity loss or triplet margin loss.
- the learning unit 204 may perform the learning process based only on one relational loss.
- FIG. 8 is a diagram illustrating an example of processing executed by the learning system 1.
- processing of the learning device 20 is shown.
- the learning device 20 acquires a first training image TI1 based on the training database DB (S1).
- S1 the learning device 20 acquires a training image TI that has not yet been learned by the learning model M from the training database DB as a first training image TI1.
- the learning device 20 obtains the first feature amount F1 and the first distribution D1 based on the current learning model M and the first training image TI1 (S2). In S2, the learning device 20 inputs the first training image TI1 to the learning model M, and executes calculation according to each layer of the learning model M. The learning device 20 acquires the first feature F1 calculated by the fully connected layer and the first distribution D1 output by the output layer.
- the learning device 20 calculates a first average age AA1, a softmax loss, an average loss, and a variance loss based on the first age associated with the first training image TI1 and the first distribution D1 acquired in S2. (S3). These calculation methods are as described above.
- the learning device 20 acquires a second training image TI2 of the same second age as the first age based on the training database DB (S4).
- the learning device 20 obtains the second feature amount F2 and the second distribution D2 based on the current learning model M and the second training image TI2 (S5).
- the process in S5 differs from the process in S2 in that the second training image TI2 is input to the learning model M, but is otherwise similar to the process in S2.
- the learning device 20 obtains a second average age AA2 based on the second distribution D2 (S6).
- the method of calculating the second average age AA2 is as described above.
- the learning device 20 acquires a third training image TI3 of a third age different from the first age based on the training database DB (S7).
- the learning device 20 acquires the third distribution D3 based on the current learning model M and the third training image TI3 (S8).
- the learning device 20 inputs the third training image TI3 to the learning model M, and obtains the third distribution D3 output from the learning model M.
- the learning device 20 obtains a third average age AA3 based on the third distribution D3 (S9).
- the method for calculating the third average age AA3 is as described above.
- the learning device 20 calculates a cosine similarity loss based on the first feature amount F1 and the second feature amount F2 (S10).
- the learning device 20 calculates triplet margin loss based on the first average age AA1, the second average age AA2, and the third average age AA3 (S11).
- the learning device 20 executes learning processing based on the softmax loss, average loss, variance loss, cosine similarity loss, and triplet margin loss (S12).
- the learning device 20 determines whether to end the learning process (S13).
- the learning process can be ended at any timing. For example, the process may end when all the training data in the training database DB has been learned, or it may end when a predetermined number of training data have been learned. If it is not determined that the learning process is finished (S13; N), the process returns to S1. If it is determined to end the learning process (S13; Y), the learning device 20 transmits the trained learning model M to the estimation device 10 (S14), and this process ends.
- the estimation device 10 records the trained learning model M in the storage unit 12 and starts actual operation.
- the learning system 1 of this embodiment is a learning system for estimating the estimated age of an estimation target human EH included in an estimation target image EI based on distance learning using a first training image TI1 and a second training image TI2. Execute the learning process for model M.
- distance learning efficient learning processing becomes possible even if there is little training data, so the accuracy of the learning model M increases. Since the creator of the learning model M does not have to prepare a large amount of training data, the effort of the creator can be reduced.
- the learning system 1 executes learning processing based on distance learning using the first training image TI1, the second training image TI2, and the third training image TI3.
- three training images TI instead of two, more efficient learning processing becomes possible, so the accuracy of the learning model M is further improved. Since a highly accurate learning model M can be created with less training data, the effort of the creator can be further reduced.
- the learning system 1 when the first age is the same as the second numerical value and different from the third numerical value, the difference between the first processing result and the second processing result is small, and the first age is the same as the second numerical value and different from the third numerical value.
- the learning process is performed so that the difference between the first process result and the third process result becomes large.
- the learning system 1 executes the learning process based on triplet margin loss using the first to third average ages AA1 to AA3, which are examples of the first to third processing results.
- the learning process can be executed using both the so-called relationship between the anchor image and the positive image, and the relationship between the anchor image and the negative image, so that the accuracy of the learning model M is further improved. That is, since a learning process is executed in which not only similar training images TI are brought closer to each other, but also different training images TI are moved away from each other, the accuracy of the learning model M is further improved.
- the learning system 1 executes the learning process so that the difference between the first process result and the third process result is a difference that corresponds to the difference between the first age and the third age.
- the margin ⁇ in the triplet margin loss is determined to be a value corresponding to the difference between the first age and the third age.
- the learning system 1 executes the learning process based on the first estimation result, the second estimation result, and the third estimation result. For example, the learning system 1 executes the learning process based on triplet margin loss using the first to third average ages AA1 to AA3, which are examples of the first to third estimation results. This allows optimal learning processing to be performed in consideration of the mutual relationships among the three training images TI, thereby further increasing the accuracy of the learning model M.
- the learning system 1 executes the learning process based on the first distribution D1, the second distribution D2, and the third distribution D3.
- the learning system 1 executes the learning process based on the first distribution D1 to the third distribution D3 that include probabilities pj according to individual ages j from 0 to 100 years old that can be estimated by the learning model M. .
- the learning process can be executed while more optimally considering the estimation results of the current learning model M, so that the accuracy of the learning model M is further improved.
- the learning system 1 executes a learning process based on the first feature amount F1 and the second feature amount F2. This allows the intermediate calculation results of the learning model M to be used in the learning process, thereby further increasing the accuracy of the learning model M.
- the learning system 1 calculates a cosine similarity based on the first feature amount F1 and the second feature amount F2, and executes the learning process based on the cosine similarity. This makes it possible to use cosine similarity that can more accurately evaluate the accuracy of the current learning model M, thereby further increasing the accuracy of the learning model M.
- the learning system 1 executes the learning process based on the first loss and the relational loss. For example, the learning system 1 executes the learning process based on the softmax loss, average loss, and variance loss that correspond to the first loss, and the cosine similarity loss and triplet margin loss that correspond to the relational loss.
- the accuracy of the current learning model M can be evaluated in a more multifaceted manner and the learning process can be executed, thereby further increasing the accuracy of the learning model M.
- the learning system 1 executes learning processing based on the plurality of first losses and relational losses. For example, the learning system 1 performs the learning process based not on a single first loss but on a plurality of first losses such as a softmax loss, an average loss, and a variance loss. As a result, the accuracy of the current learning model M can be evaluated in a more multifaceted manner and the learning process can be executed, thereby further increasing the accuracy of the learning model M.
- the first object and the second object are different people.
- the first numerical value is the age of the first object.
- the second numerical value is the age of the second object.
- the estimation target object is a person whose age is to be estimated.
- the estimation target numerical value is the age of the estimation target object.
- the first age is the same as the second age, but the first age may be different from the second age.
- Modification 1 an example is given in which the first age is different from both the second age and the third age.
- the second age shall be different from the third age. It is assumed that the difference between the first age and the third age is larger than the difference between the first age and the second age.
- modification 1 it is assumed that the second age is 37 years old in the example of FIG. It is assumed that the first age and the third age are 35 years old and 45 years old, respectively, similar to FIG. 3.
- the learning process was performed so that the first processing result and the second processing result became closer to each other.
- a learning process different from that of the embodiment is executed.
- the learning unit 204 executes the learning process so that the difference between the first process result and the third process result is larger than the difference between the first process result and the second process result.
- the learning unit 204 may perform the learning process so that the difference between the first processing result and the second processing result is a difference corresponding to the difference between the first age and the second age.
- the learning unit 204 performs learning processing so that the difference between the first processing result and the third processing result is a difference corresponding to the difference between the first age and the third age.
- the difference between the first and third ages is greater than the first and second ages, so the difference according to the difference between the first and third ages is the difference between the first and second ages. greater than the difference according to .
- the learning unit 204 determines that the difference between the first processing result and the second processing result is the first The learning process is performed so that the difference corresponds to the difference of 2 years, which is the difference between the child's age and the second age.
- the learning unit 204 executes learning processing so that the difference between the first processing result and the third processing result is a difference corresponding to the difference of 10 years old between the first age and the third age.
- the learning unit 204 may calculate triplet margin loss in the same manner as in the embodiment. However, since the first age and the second age are not the same, the margin ⁇ is assumed to be smaller than in the embodiment.
- the learning process is performed so that the difference between the first process result and the second process result is greater than the difference between the first process result and the second process result.
- the learning process can be executed by making more effective use of the training data, so the accuracy of the learning model M is further improved. Since less training data needs to be prepared, the burden on the creator of the learning model M is reduced.
- the learning unit 204 may perform the learning process based not only on the differences dp and dn but also on the difference between the second average loss AA2 and the third average loss AA3.
- FIG. 9 is a diagram showing an example of triplet margin loss in Modification 2.
- the first age is assumed to be the same as the second age, similar to the embodiment.
- the learning unit 204 calculates the average value of the difference dn1 between the first average loss AA1 and the third average loss AA3 and the difference dn2 between the second average loss AA2 and the third average loss AA3.
- the learning unit 204 calculates the triplet margin loss using this average value instead of the difference dn described in the embodiment.
- the learning unit 204 includes the difference dp between the first average loss AA1 and the second average loss AA2, the difference dp between the first average loss AA1 and the third
- the triplet margin loss may be calculated by substituting the difference dn1 between the average loss AA3 and the difference dn2 between the second average loss AA2 and the third average loss AA3.
- the learning unit 204 may calculate the triplet margin loss based on the sum of the difference between the difference dp and dn1 and the difference between the difference dp and the difference dn2.
- the learning unit 204 may calculate the triplet margin loss using the three differences. For example, the learning unit 204 calculates the average value of the difference dn1 between the first average loss AA1 and the third average loss AA3 and the difference dn2 between the second average loss AA2 and the third average loss AA3. The learning unit 204 may calculate the triplet margin loss using this average value instead of the difference dn described in the embodiment. In this case as well, the triplet margin loss may be calculated based on a calculation formula other than the calculation formula for calculating the average value.
- the learning system 1 of the second modification executes the learning process so that the difference between the second process result and the third process result becomes large. Thereby, the learning process can be executed by making more effective use of the training data, so the accuracy of the learning model M is further improved. Since less training data needs to be prepared, the burden on the creator of the learning model M is reduced.
- the learning unit 204 performs the learning process so that the difference between the second process result and the third process result is a difference that corresponds to the difference between the second age and the third age. Good too.
- the learning unit 204 sets the difference between the second average loss AA2 and the third average loss AA3 to be about 10 years. Then, the learning process is executed.
- the learning unit 204 determines that the difference between the second average loss AA2 and the third average loss AA3 is about 8 years. Execute the learning process as follows.
- the learning system 1 of the third modification executes the learning process so that the difference between the second process result and the third process result is a difference corresponding to the difference between the second age and the third age.
- the margin ⁇ in the triplet margin loss is determined to be a value corresponding to the difference between the second age and the third age.
- the learning unit 204 calculates the Kullback-Leibler information amount based on the first distribution D1 and the second distribution D2.
- the Kullback-Leibler information amount is an index for evaluating the difference between a plurality of probability distributions D.
- Various formulas can be used as the formula for calculating the amount of Kullback-Leibler information.
- the learning unit 204 executes learning processing based on the amount of Kullback-Leibler information. As in the embodiment, when the first age is the same as the second age, the learning unit 204 performs learning processing so that the difference indicated by the amount of Kullback-Leibler information becomes small. As in Modification 1, when the first age is different from the second age, the learning unit 204 executes the learning process so that the difference indicated by the amount of Kullback-Leibler information becomes large.
- the learning unit 204 may perform the learning process based on the first estimation result and the second estimation result using a method other than the Kullback-Leibler information amount. For example, if the first age is the same as the second age as in the embodiment, the learning unit 204 performs the learning process so that the first average age AA1 and the second average age AA2 become closer. May be executed. As in modification 1, when the first age is different from the second age, the learning unit 204 performs a learning process so that the first average age AA1 and the second average age AA2 become farther apart. Good too.
- the learning system 1 of modification 4 executes the learning process based on the first estimation result and the second estimation result. As a result, the learning process is completed with fewer estimation results, so the time required to complete the learning can be reduced while increasing the accuracy of the learning model M. Since the learning device 20 does not perform calculations to obtain the third estimation result, the processing load on the learning device 20 can be reduced.
- the learning system 1 calculates the amount of Kullback-Leibler information based on the first distribution D1 and the second distribution D2, and executes the learning process based on the amount of Kullback-Leibler information. This allows the learning process to be executed using more reliable indicators, thereby further increasing the accuracy of the learning model M.
- the learning unit 204 determines that the total value of the softmax loss, average loss, and variance loss that correspond to the first loss, and the cosine similarity loss and triplet margin loss that correspond to the relational loss becomes small.
- the learning process was executed as follows.
- the learning unit 204 may perform the learning process based on the first loss, the weighting coefficient regarding the relational loss, and the relational loss.
- the weighting factor may be greater than 1 so that the related loss is given more weight than the first loss.
- the learning unit 204 may calculate the final loss in consideration of the weighting coefficient, and perform the learning process so that the final loss becomes small.
- the learning system 1 of modification 5 executes the learning process based on the first loss, the weighting coefficient regarding the relational loss, and the relational loss. This allows, for example, to give more importance to the relational loss than the first loss, thereby increasing the accuracy of the learning model M.
- the learning process may be executed using only the relational loss, the first loss is still an important index, so the learning process can be executed while considering the first loss and the relational loss in a well-balanced manner.
- the learning unit 204 may calculate a plurality of relationship losses based on the first processing result and the second processing result.
- the learning unit 204 executes learning processing based on the first loss and the plurality of related losses. Other losses may be used as the related loss.
- the learning unit 204 calculates a total loss based on the first loss and the plurality of related losses, and executes a learning process based on the total loss.
- the learning system 1 of modification 6 executes the learning process based on the first loss and a plurality of related losses. As a result, the learning process can be executed with more relational losses taken into consideration, so that the accuracy of the learning model M is further improved.
- the first age is different from the second age and the third age, but the second age and the third age may be the same.
- the learning unit 204 should perform the learning process so that the difference between the first processing result and the second processing result becomes large, and the difference between the first processing result and the third processing result becomes large. good.
- the first age, the second age, and the third age may all be the same. In this case, the learning unit 204 should perform the learning process so that the difference between the first process result and the second process result becomes small, and the difference between the first process result and the third process result becomes small. good.
- the functions described as being realized by the learning device 20 may be realized by another computer, or may be shared among multiple computers. Data described as being stored in learning device 20 may also be stored in other computers or information storage media.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- General Physics & Mathematics (AREA)
- Evolutionary Computation (AREA)
- Software Systems (AREA)
- Artificial Intelligence (AREA)
- General Health & Medical Sciences (AREA)
- Computing Systems (AREA)
- Health & Medical Sciences (AREA)
- Medical Informatics (AREA)
- Multimedia (AREA)
- Databases & Information Systems (AREA)
- Data Mining & Analysis (AREA)
- General Engineering & Computer Science (AREA)
- Mathematical Physics (AREA)
- Human Computer Interaction (AREA)
- Oral & Maxillofacial Surgery (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Molecular Biology (AREA)
- Image Analysis (AREA)
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2022/014019 WO2023181271A1 (ja) | 2022-03-24 | 2022-03-24 | 学習システム、学習方法、及びプログラム |
| US18/686,882 US20240371129A1 (en) | 2022-03-24 | 2022-03-24 | Learning system, learning method, and program |
| JP2023513648A JP7369325B1 (ja) | 2022-03-24 | 2022-03-24 | 学習システム、学習方法、及びプログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2022/014019 WO2023181271A1 (ja) | 2022-03-24 | 2022-03-24 | 学習システム、学習方法、及びプログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023181271A1 true WO2023181271A1 (ja) | 2023-09-28 |
Family
ID=88100637
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/014019 Ceased WO2023181271A1 (ja) | 2022-03-24 | 2022-03-24 | 学習システム、学習方法、及びプログラム |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20240371129A1 (https=) |
| JP (1) | JP7369325B1 (https=) |
| WO (1) | WO2023181271A1 (https=) |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2021095085A1 (ja) * | 2019-11-11 | 2021-05-20 | 三菱電機株式会社 | 画像処理装置、画像処理システム、画像処理方法、及び画像処理プログラム |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| RU2641447C1 (ru) * | 2016-12-27 | 2018-01-17 | Общество с ограниченной ответственностью "ВижнЛабс" | Способ обучения глубоких нейронных сетей на основе распределений попарных мер схожести |
| KR20190140824A (ko) * | 2018-05-31 | 2019-12-20 | 한국과학기술원 | 트리플릿 기반의 손실함수를 활용한 순서가 있는 분류문제를 위한 딥러닝 모델 학습 방법 및 장치 |
-
2022
- 2022-03-24 JP JP2023513648A patent/JP7369325B1/ja active Active
- 2022-03-24 WO PCT/JP2022/014019 patent/WO2023181271A1/ja not_active Ceased
- 2022-03-24 US US18/686,882 patent/US20240371129A1/en active Pending
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2021095085A1 (ja) * | 2019-11-11 | 2021-05-20 | 三菱電機株式会社 | 画像処理装置、画像処理システム、画像処理方法、及び画像処理プログラム |
Non-Patent Citations (2)
| Title |
|---|
| GAO BIN-BIN, HONG-YU ZHOU , JIANXIN WU , XIN GENG: "Age Estimation Using Expectation of Label Distribution Learning", PROCEEDINGS OF THE TWENTY-SEVENTH INTERNATIONAL JOINT CONFERENCE ON ARTIFICIAL INTELLIGENCE (IJCAI-18), 13 July 2018 (2018-07-13), pages 712 - 718, XP093061479, Retrieved from the Internet <URL:http://palm.seu.edu.cn/xgeng/files/ijcai18d.pdf> [retrieved on 20230706] * |
| LIU, H ET AL.: "Label-Sensitive Deep Metric Learning for Facial Age Estimation", IEEE TRANSACTIONS ON INFORMATION FORENSICS AND SECURITY, vol. 13, no. 2, 29 August 2017 (2017-08-29), pages 292 - 305, XP011673384, Retrieved from the Internet <URL:https://ieeexplore.ieee.org/abstract/document/8017500> [retrieved on 20220607], DOI: 10.1109/TIFS.2017.2746062 * |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7369325B1 (ja) | 2023-10-25 |
| JPWO2023181271A1 (https=) | 2023-09-28 |
| US20240371129A1 (en) | 2024-11-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10319130B2 (en) | Anonymization of facial images | |
| EP3836070B1 (en) | Face pose estimation/three-dimensional face reconstruction method and apparatus, and electronic device | |
| JP7224323B2 (ja) | イメージ生成システム及びこれを利用したイメージ生成方法 | |
| US9158970B2 (en) | Devices, systems, and methods for visual-attribute refinement | |
| US9105119B2 (en) | Anonymization of facial expressions | |
| US20150347820A1 (en) | Learning Deep Face Representation | |
| CN104598871B (zh) | 一种基于相关回归的面部年龄计算方法 | |
| US20170177924A1 (en) | Attribute factor analysis method, device, and program | |
| US10115004B2 (en) | Methods and software for hallucinating facial features by prioritizing reconstruction errors | |
| CN111814620A (zh) | 人脸图像质量评价模型建立方法、优选方法、介质及装置 | |
| CN114913303A (zh) | 虚拟形象生成方法及相关装置、电子设备、存储介质 | |
| CN113158824B (zh) | 一种水下视频鱼类识别方法、系统及存储介质 | |
| CN116543306B (zh) | 一种基于知识图谱的场景识别方法、终端设备及存储介质 | |
| CN113221799A (zh) | 一种多头部姿态人脸表情识别方法及其应用 | |
| WO2022123619A1 (ja) | 学習システム、学習方法、及びプログラム | |
| Yan et al. | A parameter-free framework for general supervised subspace learning | |
| JP7369325B1 (ja) | 学習システム、学習方法、及びプログラム | |
| WO2025194748A1 (zh) | 基于元学习的人脸美丽度评价方法、装置、设备及介质 | |
| CN117635286A (zh) | 风险预测方法、装置、计算机设备及存储介质 | |
| CN105787423A (zh) | 人脸图像的属性信息识别方法和装置 | |
| Wang et al. | Correspondence propagation with weak priors | |
| CN113887653A (zh) | 一种基于三元网络的紧耦合弱监督学习的定位方法及系统 | |
| WO2022091299A1 (ja) | 検索装置、検索方法及び記録媒体 | |
| Adapa et al. | Deep learning based face shape classification system with binary feature selection model | |
| Deshmukh et al. | Human face aging based on deep learning: a survey |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WWE | Wipo information: entry into national phase |
Ref document number: 2023513648 Country of ref document: JP |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22933412 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 22933412 Country of ref document: EP Kind code of ref document: A1 |