WO2023166557A1 - 音声認識システム、音声認識方法、及び記録媒体 - Google Patents
音声認識システム、音声認識方法、及び記録媒体 Download PDFInfo
- Publication number
- WO2023166557A1 WO2023166557A1 PCT/JP2022/008597 JP2022008597W WO2023166557A1 WO 2023166557 A1 WO2023166557 A1 WO 2023166557A1 JP 2022008597 W JP2022008597 W JP 2022008597W WO 2023166557 A1 WO2023166557 A1 WO 2023166557A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- speech
- speech recognition
- data
- real
- conversion
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images


















Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/02—Methods for producing synthetic speech; Speech synthesisers
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/06—Creation of reference templates; Training of speech recognition systems, e.g. adaptation to the characteristics of the speaker's voice
- G10L15/065—Adaptation
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/16—Speech classification or search using artificial neural networks
Definitions
- This disclosure relates to the technical fields of speech recognition systems, speech recognition methods, and recording media.
- Japanese Patent Application Laid-Open No. 2002-200000 discloses generating synthetic speech by converting a feature value representing the tone of voice using a trained conversion model.
- Patent Document 2 discloses generating a sentence in a target language from text data obtained as a result of speech recognition, and generating synthesized speech from the sentence in the target language.
- Patent Document 3 discloses training a speech conversion model using a training corpus.
- the purpose of this disclosure is to improve the technology disclosed in prior art documents.
- One aspect of the speech recognition system disclosed herein includes: speech data acquisition means for acquiring real speech data uttered by a speaker; text conversion means for converting the real speech data into text data; Speech synthesis means for generating corresponding synthesized speech corresponding to said real utterance data by speech synthesis, and a conversion model for generating a conversion model for converting input speech into synthesized speech using said real utterance data and said corresponding synthesized speech. and a speech recognition means for recognizing the synthesized speech converted using the conversion model.
- sign language data acquisition means for acquiring sign language data
- text conversion means for converting the sign language data into text data
- speech synthesis using the text data are used to generate the sign language data.
- a conversion model generating means for generating a conversion model for converting input sign language into synthesized speech using the sign language data and the corresponding synthesized speech; and the conversion model voice recognition means for recognizing the synthesized voice converted using
- At least one computer acquires real speech data uttered by a speaker, converts the real speech data into text data, and performs speech synthesis using the text data. generating a corresponding synthetic speech corresponding to the real utterance data, using the real utterance data and the corresponding synthetic speech to generate a conversion model for converting the input speech into the synthetic speech, and converting the input speech into the synthetic speech using the conversion model. speech recognition of the synthesized speech.
- At least one computer acquires real speech data uttered by a speaker, converts the real speech data into text data, and performs speech synthesis using the text data. generating a corresponding synthesized speech corresponding to the real utterance data, using the real utterance data and the corresponding synthesized speech to generate a conversion model for converting the input speech into the synthesized speech, and converting the input speech into the synthesized speech using the conversion model
- a computer program is recorded for executing a speech recognition method for speech recognition of said synthesized speech.
- FIG. 2 is a block diagram showing the hardware configuration of the speech recognition system according to the first embodiment
- FIG. 1 is a block diagram showing a functional configuration of a speech recognition system according to a first embodiment
- FIG. 4 is a flowchart showing the flow of conversion model generation operation by the speech recognition system according to the first embodiment
- 4 is a flow chart showing the flow of speech recognition operation by the speech recognition system according to the first embodiment
- FIG. 11 is a block diagram showing the functional configuration of a speech recognition system according to a second embodiment
- FIG. 9 is a flow chart showing the flow of conversion model learning operation by the speech recognition system according to the second embodiment.
- FIG. 11 is a block diagram showing the functional configuration of a speech recognition system according to a third embodiment
- FIG. 14 is a flow chart showing the flow of speech recognition model generation operation by the speech recognition system according to the third embodiment
- FIG. 12 is a block diagram showing the functional configuration of a speech recognition system according to a fourth embodiment
- FIG. FIG. 14 is a flow chart showing the flow of speech recognition model learning operation by the speech recognition system according to the fourth embodiment
- FIG. FIG. 12 is a block diagram showing the functional configuration of a speech recognition system according to a fifth embodiment
- FIG. FIG. 16 is a flow chart showing the flow of conversion model generation operation by the speech recognition system according to the fifth embodiment
- FIG. FIG. 12 is a block diagram showing the functional configuration of a speech recognition system according to a sixth embodiment
- FIG. 16 is a flow chart showing the flow of conversion model generation operation by the speech recognition system according to the sixth embodiment;
- FIG. FIG. 21 is a block diagram showing the functional configuration of a speech recognition system according to a seventh embodiment;
- FIG. FIG. 16 is a flow chart showing the flow of conversion model generation operation by the speech recognition system according to the seventh embodiment;
- FIG. FIG. 21 is a block diagram showing a functional configuration of a speech recognition system according to a modified example of the seventh embodiment;
- FIG. FIG. 22 is a flow chart showing the flow of conversion model generation operation by the speech recognition system according to the modification of the seventh embodiment;
- FIG. FIG. 22 is a block diagram showing a functional configuration of a speech recognition system according to a modified example of the eighth embodiment;
- FIG. FIG. 22 is a flow chart showing the flow of conversion model generation operation by the speech recognition system according to the eighth embodiment;
- FIG. FIG. 22 is a flow chart showing the flow of speech recognition operation by the speech recognition system according to the eighth embodiment;
- FIG. 1 A speech recognition system according to the first embodiment will be described with reference to FIGS. 1 to 4.
- FIG. 1 A speech recognition system according to the first embodiment will be described with reference to FIGS. 1 to 4.
- FIG. 1 is a block diagram showing the hardware configuration of the speech recognition system according to the first embodiment.
- the speech recognition system 10 includes a processor 11, a RAM (Random Access Memory) 12, a ROM (Read Only Memory) 13, and a storage device 14. Speech recognition system 10 may further comprise input device 15 and output device 16 .
- the processor 11 , RAM 12 , ROM 13 , storage device 14 , input device 15 and output device 16 are connected via a data bus 17 .
- the processor 11 reads a computer program.
- processor 11 is configured to read a computer program stored in at least one of RAM 12, ROM 13 and storage device .
- the processor 11 may read a computer program stored in a computer-readable recording medium using a recording medium reader (not shown).
- the processor 11 may acquire (that is, read) a computer program from a device (not shown) arranged outside the speech recognition system 10 via a network interface.
- the processor 11 controls the RAM 12, the storage device 14, the input device 15 and the output device 16 by executing the read computer program.
- the processor 11 may function as a controller that executes each control in the speech recognition system 10 .
- the processor 11 includes, for example, a CPU (Central Processing Unit), GPU (Graphics Processing Unit), FPGA (Field-Programmable Gate Array), DSP (Demand-Side Platform), ASIC (Application Specific Integral ted circuit).
- the processor 11 may be configured with one of these, or may be configured to use a plurality of them in parallel.
- the RAM 12 temporarily stores computer programs executed by the processor 11.
- the RAM 12 temporarily stores data temporarily used by the processor 11 while the processor 11 is executing the computer program.
- the RAM 12 may be, for example, a D-RAM (Dynamic Random Access Memory) or an SRAM (Static Random Access Memory). Also, instead of the RAM 12, other types of volatile memory may be used.
- the ROM 13 stores computer programs executed by the processor 11 .
- the ROM 13 may also store other fixed data.
- the ROM 13 may be, for example, a P-ROM (Programmable Read Only Memory) or an EPROM (Erasable Read Only Memory). Also, instead of the ROM 13, other types of non-volatile memory may be used.
- the storage device 14 stores data that the speech recognition system 10 saves over a long period of time.
- Storage device 14 may act as a temporary storage device for processor 11 .
- the storage device 14 may include, for example, at least one of a hard disk device, a magneto-optical disk device, an SSD (Solid State Drive), and a disk array device.
- the input device 15 is a device that receives input instructions from the user of the speech recognition system 10 .
- Input device 15 may include, for example, at least one of a keyboard, mouse, and touch panel.
- the input device 15 may be configured as a mobile terminal such as a smart phone or a tablet.
- the input device 15 may be a device capable of voice input including, for example, a microphone.
- the output device 16 is a device that outputs information about the speech recognition system 10 to the outside.
- output device 16 may be a display device (eg, display) capable of displaying information about speech recognition system 10 .
- the output device 16 may be a speaker or the like capable of outputting information about the speech recognition system 10 by voice.
- the output device 16 may be configured as a mobile terminal such as a smart phone or a tablet.
- the output device 16 may be a device that outputs information in a format other than an image.
- the output device 16 may be a speaker that audibly outputs information about the speech recognition system 10 .
- FIG. 1 shows an example of the speech recognition system 10 including a plurality of devices, all or part of these functions may be implemented as a single device (speech recognition device).
- the speech recognition apparatus is configured with, for example, only the processor 11, RAM 12, and ROM 13 described above, and the other components (that is, the storage device 14, the input device 15, and the output device 16) are included in the speech recognition device. It may be provided in an external device to be connected.
- the speech recognition device may be one in which a part of the arithmetic functions is realized by an external device (for example, an external server, cloud, etc.).
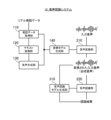
- FIG. 2 is a block diagram showing the functional configuration of the speech recognition system according to the first embodiment
- the speech recognition system 10 includes speech data acquisition section 110, text conversion section 120, speech synthesis section 130, conversion It comprises a model generation unit 140 , a speech conversion unit 210 and a speech recognition unit 220 .
- Each of the speech data acquisition unit 110, the text conversion unit 120, the speech synthesis unit 130, the conversion model generation unit 140, the speech conversion unit 210, and the speech recognition unit 220 performs processing realized by, for example, the processor 11 (see FIG. 1) described above. can be blocks.
- the utterance data acquisition unit 110 is configured to be able to acquire real utterance data uttered by the speaker.
- Real speech data may be audio data (eg, waveform data).
- Real speech data may be obtained from a database (real speech corpus) that accumulates a plurality of pieces of real speech data, for example.
- the real speech data acquired by the speech data acquisition section 110 is configured to be output to the text conversion section 120 and the conversion model generation section 140 .
- the text conversion unit 120 is configured to be able to convert real speech data acquired by the speech data acquisition unit 110 into text data. That is, the text conversion unit 120 is configured to be able to execute processing for converting voice data into text. It should be noted that existing techniques may be appropriately adopted as a specific technique for text conversion.
- the text data converted by the text conversion section 120 (that is, the text data corresponding to the real speech data) is configured to be output to the speech synthesis section 130 .
- the speech synthesizing unit 130 is configured to be capable of synthesizing the text data changed by the text converting unit 120 into speech, thereby generating corresponding synthesized speech corresponding to the real speech data. It should be noted that existing techniques can be appropriately adopted as a specific technique for speech synthesis.
- the corresponding synthesized speech generated by the speech synthesizing unit 130 is configured to be output to the transformation model generating unit 140 .
- the corresponding synthetic speech may be stored in a database (synthetic speech corpus) capable of storing a plurality of corresponding syntheses, and then output to the transformation model generation unit 140 .
- the conversion model generation unit 140 can generate a conversion model that converts input speech into synthesized speech using the real speech data acquired by the speech data acquisition unit 110 and the corresponding synthesized speech synthesized by the speech synthesis unit 130. It is configured.
- the conversion model for example, converts input speech uttered by a speaker (ie, human speech) to approximate synthesized speech (ie, mechanical speech).
- the transformation model generation unit 140 may be configured to generate a transformation model using, for example, a GAN (Generative Adversarial Network).
- the conversion model generated by the conversion model generation unit 140 is configured to be output to the speech conversion unit 210 .
- the speech conversion unit 210 is configured to be able to convert input speech into synthesized speech using the conversion model generated by the conversion model generation unit 140 .
- the input voice input to the voice conversion unit 210 may be voice input using a microphone or the like, for example.
- the synthesized speech converted by the speech conversion section 210 is output to the speech recognition section 220 .
- the speech recognition unit 220 is configured to be able to speech-recognize the synthesized speech converted by the speech conversion unit 210 .
- the speech recognition unit 220 is configured to be able to execute a process of converting synthesized speech into text.
- the speech recognition unit 220 may be configured to be capable of outputting a speech recognition result of synthesized speech. Note that the method of using the speech recognition result is not particularly limited.
- FIG. 3 is a flow chart showing the flow of conversion model generation operation by the speech recognition system according to the first embodiment.
- the speech data acquisition unit 110 acquires real speech data (step S101).
- the text conversion unit 120 converts the real speech data acquired by the speech data acquisition unit 110 into text data (step S102).
- the speech synthesizing unit 130 speech-synthesizes the text data converted by the text converting unit 120, and generates corresponding synthetic speech corresponding to the real speech data (step S103). Then, the conversion model generation unit 140 generates a conversion model based on the real speech data acquired by the speech data acquisition unit 110 and the corresponding synthesized speech generated by the speech synthesis unit 130 (step S104). After that, the conversion model generation unit 140 outputs the generated conversion model to the speech conversion unit 210 (step S105).
- FIG. 3 is a flow chart showing the flow of speech recognition operation by the speech recognition system according to the first embodiment.
- the speech conversion unit 210 first acquires input speech (step S151). Then, the speech conversion unit 210 reads the conversion model generated by the conversion model generation unit 140 (step S152). After that, the speech conversion unit 210 performs speech conversion using the read conversion model, and converts the input speech into synthesized speech (step S153).
- the speech recognition unit 220 reads a speech recognition model (that is, a model for speech recognition) (step S154). Then, the speech recognition unit 220 uses the read speech recognition model to recognize the synthetic speech synthesized by the speech conversion unit 210 (step S155). After that, the speech recognition unit 220 outputs the speech recognition result (step S156).
- a speech recognition model that is, a model for speech recognition
- the speech recognition system 10 uses real speech data and corresponding synthetic speech corresponding to the real speech data when generating a conversion model.
- corresponding synthetic speech corresponding to real speech data is generated by converting the real speech data into text and synthesizing the text data into speech.
- the conversion model is generated. It is possible to suppress the cost required to do so. As a result, it is possible to realize speech recognition with low cost and high recognition accuracy.
- FIG. 5 A speech recognition system 10 according to the second embodiment will be described with reference to FIGS. 5 and 6.
- FIG. 5 The second embodiment may differ from the above-described first embodiment only in a part of configuration and operation, and the other parts may be the same as those of the first embodiment. Therefore, in the following, portions different from the already described first embodiment will be described in detail, and descriptions of other overlapping portions will be omitted as appropriate.
- FIG. 5 is a block diagram showing the functional configuration of the speech recognition system according to the second embodiment.
- symbol is attached
- the speech recognition system 10 includes speech data acquisition section 110, text conversion section 120, speech synthesis section 130, conversion It comprises a model generation unit 140 , a speech conversion unit 210 and a speech recognition unit 220 .
- a model generation unit 140 a speech conversion unit 210 and a speech recognition unit 220 .
- an input speech input to the speech conversion unit 210 and a recognition result by the speech recognition unit 220 are input to the conversion model generation unit 140 .
- the conversion model generation unit 140 according to the second embodiment is configured to be able to learn a conversion model based on the input speech input to the speech conversion unit 210 and the recognition result of the speech recognition unit 220 .
- FIG. 6 is a flow chart showing the flow of conversion model generation operation by the speech recognition system according to the second embodiment.
- the conversion model generation unit 140 first acquires the input speech input to the speech conversion unit 210 (step S201). Then, the conversion model generation unit 140 further acquires the speech recognition result when the input speech is input (that is, the speech recognition result output in step S156 shown in FIG. 4) (step S202).
- the conversion model generation unit 140 learns a conversion model based on the acquired input speech and speech recognition results (step S203). At this time, the conversion model generation unit 140 may adjust the parameters of the already generated conversion model. After that, the conversion model generation unit 140 outputs the learned conversion model to the speech conversion unit 210 (step S204).
- conversion models are learned based on input speech and speech recognition results.
- the conversion model can be learned so as to perform more appropriate speech conversion.
- the conversion model can be learned so as to improve the accuracy of speech recognition performed using synthesized speech that has been converted into speech.
- FIG. 7 A speech recognition system 10 according to the third embodiment will be described with reference to FIGS. 7 and 8.
- FIG. 7 A speech recognition system 10 according to the third embodiment will be described with reference to FIGS. 7 and 8.
- FIG. 7 A speech recognition system 10 according to the third embodiment will be described with reference to FIGS. 7 and 8.
- FIG. 7 A speech recognition system 10 according to the third embodiment will be described with reference to FIGS. 7 and 8.
- FIG. 7 A speech recognition system 10 according to the third embodiment will be described with reference to FIGS. 7 and 8.
- FIG. 7 A speech recognition system 10 according to the third embodiment will be described with reference to FIGS. 7 and 8.
- FIG. 7 is a block diagram showing the functional configuration of the speech recognition system according to the third embodiment.
- symbol is attached
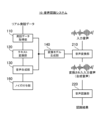
- the speech recognition system 10 includes speech data acquisition section 110, text conversion section 120, speech synthesis section 130, conversion It comprises a model generator 140 , a speech converter 210 , a speech recognizer 220 and a speech recognition model generator 310 . That is, the speech recognition system 10 according to the third embodiment further includes a speech recognition model generator 310 in addition to the configuration of the first embodiment (see FIG. 2). Note that the speech recognition model generation unit 310 may be a processing block realized by, for example, the above-described processor 11 (see FIG. 1).
- the speech recognition model generation unit 310 is configured to be able to generate a speech recognition model that converts input speech into synthesized speech. Specifically, the speech recognition model generation unit 310 is configured to be able to generate a speech recognition model using the corresponding synthesized speech generated by the speech synthesizing means. Note that the speech recognition model may be generated using the corresponding synthesized speech and other synthesized speech. The speech recognition model generation unit 310 may be configured to directly acquire the corresponding synthesized speech from the speech synthesis unit 130, or to obtain the corresponding synthesized speech from a synthetic speech corpus storing a plurality of corresponding synthesized speeches generated by the speech synthesis means. may be configured to obtain The speech recognition model generated by the speech recognition model generation section 310 is configured to be output to the speech recognition section 220 .
- FIG. 8 is a flow chart showing the flow of speech recognition model generation operation by the speech recognition system according to the third embodiment.
- the speech recognition model generation unit 310 converts the corresponding synthesized speech generated by the speech synthesis unit 130 into Acquire (step S301).
- the speech recognition model generation unit 310 generates a speech recognition model using the acquired corresponding synthesized speech (step S302). After that, the speech recognition model generation unit 310 outputs the generated speech recognition model to the speech recognition unit 220 (step S303).
- a speech recognition model is generated using corresponding synthesized speech.
- synthesized speech that is, the corresponding synthesized speech used to generate the speech conversion model can be used
- speech recognition can be performed efficiently. It is possible to generate a model.
- FIG. 9 A speech recognition system 10 according to the fourth embodiment will be described with reference to FIGS. 9 and 10.
- FIG. The fourth embodiment may differ from the above-described third embodiment only in a part of configuration and operation, and the other parts may be the same as those of the first to third embodiments. Therefore, in the following, portions different from the already described embodiments will be described in detail, and descriptions of other overlapping portions will be omitted as appropriate.
- FIG. 9 is a block diagram showing the functional configuration of the speech recognition system according to the fourth embodiment.
- symbol is attached
- the speech recognition system 10 includes speech data acquisition section 110, text conversion section 120, speech synthesis section 130, conversion It comprises a model generator 140 , a speech converter 210 , a speech recognizer 220 and a speech recognition model generator 310 .
- the synthesized speech converted by the speech conversion unit 210 and the recognition result by the speech recognition unit 220 are input to the speech recognition model generation unit 310 .
- the speech recognition model generation unit 310 according to the fourth embodiment is configured to be able to learn a speech recognition model based on the synthesized speech converted by the speech conversion unit 210 and the recognition result of the speech recognition unit 220 .
- FIG. 10 is a flow chart showing the flow of speech recognition model learning operation by the speech recognition system according to the third embodiment.
- the speech recognition model generation unit 310 converts the synthesized speech converted by the speech conversion unit 210 (that is, , synthesized speech input to the speech recognition unit 220) is obtained (step S401). Then, the speech recognition model generation unit 310 further acquires the speech recognition result of the synthesized speech (that is, the speech recognition result output in step S156 shown in FIG. 4) (step S402).
- the speech recognition model generation unit 310 learns a speech recognition model based on the obtained synthesized speech and speech recognition results (step S403). At this time, the speech recognition model generator 310 may adjust the parameters of the conversion model that has already been generated. After that, the speech recognition model generation unit 310 outputs the learned speech recognition model to the speech conversion unit 210 (step S404).
- conversion models are learned based on synthesized speech and speech recognition results.
- the speech recognition model can be learned so as to perform more appropriate speech recognition.
- a speech recognition model can be trained to improve the accuracy of speech recognition.
- FIG. 11 A speech recognition system 10 according to the fifth embodiment will be described with reference to FIGS. 11 and 12.
- FIG. 11 A speech recognition system 10 according to the fifth embodiment will be described with reference to FIGS. 11 and 12.
- FIG. 11 A speech recognition system 10 according to the fifth embodiment will be described with reference to FIGS. 11 and 12.
- FIG. 11 A speech recognition system 10 according to the fifth embodiment will be described with reference to FIGS. 11 and 12.
- FIG. 11 A speech recognition system 10 according to the fifth embodiment will be described with reference to FIGS. 11 and 12.
- FIG. 11 A speech recognition system 10 according to the fifth embodiment will be described with reference to FIGS. 11 and 12.
- FIG. 11 A speech recognition system 10 according to the fifth embodiment will be described with reference to FIGS. 11 and 12.
- FIG. 11 is a block diagram showing the functional configuration of the speech recognition system according to the fifth embodiment.
- symbol is attached
- the speech recognition system 10 includes speech data acquisition section 110, text conversion section 120, speech synthesis section 130, conversion It comprises a model generation unit 140 , an attribute information acquisition unit 150 , a voice conversion unit 210 and a voice recognition unit 220 . That is, the speech recognition system 10 according to the fifth embodiment further includes an attribute information acquisition section 150 in addition to the configuration of the first embodiment (see FIG. 2).
- the attribute information acquisition unit 150 may be a processing block realized by, for example, the above-described processor 11 (see FIG. 1).
- the attribute information acquisition unit 150 is configured to be able to acquire attribute information about the speaker of the real utterance data. Attribute information may include, for example, information on the speaker's gender, age, occupation, and the like.
- the attribute information acquisition unit 150 may be configured to be able to acquire attribute information from, for example, a terminal or ID card owned by the speaker. Alternatively, the attribute information acquisition unit 150 may be configured to acquire attribute information input by the speaker.
- the attribute information acquired by the attribute information acquisition section 150 is configured to be output to the speech synthesis section 130 .
- the attribute information may be stored in the real speech corpus while being linked to the real speech data. In this case, the attribute information may be configured to be output from the real speech corpus to the speech synthesizing unit 130 .
- FIG. 12 is a flow chart showing the flow of conversion model generation operation by the speech recognition system according to the fifth embodiment.
- the same reference numerals are given to the same processes as those shown in FIG.
- the speech data acquisition unit 110 acquires real speech data (step S101).
- the attribute information acquisition unit 150 acquires attribute information about the speaker of the real utterance data (step S501). Note that the processes of steps S101 and S102 may be executed in succession, or may be executed in parallel at the same time.
- the text conversion unit 120 converts the real speech data acquired by the speech data acquisition unit 110 into text data (step S102).
- the speech synthesis unit 130 speech-synthesizes the text data converted by the text conversion unit 120, and generates a corresponding synthesized speech corresponding to the real speech data. (step S502).
- the speech synthesis unit 130 may perform speech synthesis in consideration of the sex, age, occupation, etc. of the speaker of the real speech data.
- the conversion model generation unit 140 generates the real utterance data acquired by the utterance data acquisition unit 110 and the corresponding synthesized speech generated by the speech synthesis unit 130 (here, synthesized speech synthesized based on the attribute information).
- a conversion model is generated based on (step S104). Attribute information may be added to the set of the real utterance data and the corresponding synthesized speech input to the transformation model generation unit 140 . In that case, the conversion model generation unit 140 may generate the conversion model in consideration of the attribute information as well. After that, the conversion model generation unit 140 outputs the generated conversion model to the speech conversion unit 210 (step S105).
- corresponding synthesized speech is generated using the speaker's attribute information.
- the corresponding synthesized speech is generated with consideration given to the attributes of the speaker, so it is possible to generate a more appropriate speech conversion model.
- the use of the corresponding synthesized speech with attributes taken into consideration enables more An appropriate speech recognition model can be generated.
- FIG. 13 A speech recognition system 10 according to the sixth embodiment will be described with reference to FIGS. 13 and 14.
- FIG. 13 A speech recognition system 10 according to the sixth embodiment will be described with reference to FIGS. 13 and 14.
- FIG. 13 A speech recognition system 10 according to the sixth embodiment will be described with reference to FIGS. 13 and 14.
- FIG. 13 A speech recognition system 10 according to the sixth embodiment will be described with reference to FIGS. 13 and 14.
- FIG. 13 A speech recognition system 10 according to the sixth embodiment will be described with reference to FIGS. 13 and 14.
- FIG. 13 A speech recognition system 10 according to the sixth embodiment will be described with reference to FIGS. 13 and 14.
- FIG. 13 A speech recognition system 10 according to the sixth embodiment will be described with reference to FIGS. 13 and 14.
- FIG. 13 is a block diagram showing the functional configuration of the speech recognition system according to the sixth embodiment.
- symbol is attached
- the speech recognition system 10 includes a plurality of real speech corpora 105a, 105b, and 105c (hereinafter collectively referred to as "real a speech data acquisition unit 110, a text conversion unit 120, a speech synthesis unit 130, a conversion model generation unit 140, a speech conversion unit 210, and a speech recognition unit 220. configured as follows. That is, the speech recognition system 10 according to the sixth embodiment further includes a plurality of real speech corpora 105 in addition to the configuration of the first embodiment (see FIG. 2). Note that the plurality of real speech corpora 105 may be configured by, for example, the above-described storage device 14 (see FIG. 1).
- a plurality of real speech corpora 105 store real speech data for each predetermined condition.
- the "predetermined condition" here is, for example, a condition set for classifying real speech data.
- each of the plurality of real speech corpora 105 may store real speech data for each field.
- the real utterance voice corpus 105a stores real utterance data related to the legal field
- the real utterance voice corpus 105b stores real utterance data related to the scientific field
- the real utterance voice corpus 105c stores real utterance data related to the medical field.
- the speech data acquisition unit 110 is configured to be capable of acquiring real speech data by selecting one from the plurality of real speech corpora 105 described above.
- Information about the real speech corpus 105 selected here may be output to the transformation model generation unit 140 together with the real speech data.
- the transformation model generation unit 140 may use information about the selected real speech corpus 105 when generating the transformation model.
- information regarding the selected real speech corpus 105 may be output to the speech recognition model generation unit 310 .
- the speech recognition model generation unit 310 may use information about the real utterance speech corpus 105 selected when generating the speech recognition model.
- FIG. 14 is a flow chart showing the flow of conversion model generation operation by the speech recognition system according to the sixth embodiment.
- the same reference numerals are given to the same processes as those shown in FIG.
- the speech data acquisition unit 110 acquires speech data from a plurality of real speech corpora 105. A corpus to be acquired is selected (step S601). Then, the speech data acquisition unit 110 acquires real speech data from the selected real speech corpus (step S602).
- the text conversion unit 120 converts the real speech data acquired by the speech data acquisition unit 110 into text data (step S102). Then, the speech synthesizing unit 130 speech-synthesizes the text data converted by the text converting unit 120 to generate corresponding synthetic speech corresponding to the real speech data (step S103).
- the conversion model generation unit 140 generates a conversion model based on the real speech data acquired by the speech data acquisition unit 110 and the corresponding synthesized speech generated by the speech synthesis unit 130. , information about the selected real speech corpus is also used (step S606). After that, the conversion model generation unit 140 outputs the generated conversion model to the speech conversion unit 210 (step S105).
- information on the real speech corpus 105 selected when acquiring real speech data is used to generate a conversion model. be done. In this way, a more appropriate conversion model can be generated because the predetermined condition (for example, field) used to classify the real speech data is taken into consideration.
- FIG. 15 A speech recognition system 10 according to the seventh embodiment will be described with reference to FIGS. 15 and 16.
- FIG. 15 A speech recognition system 10 according to the seventh embodiment will be described with reference to FIGS. 15 and 16.
- FIG. 15 A speech recognition system 10 according to the seventh embodiment will be described with reference to FIGS. 15 and 16.
- FIG. 15 A speech recognition system 10 according to the seventh embodiment will be described with reference to FIGS. 15 and 16.
- FIG. 15 A speech recognition system 10 according to the seventh embodiment will be described with reference to FIGS. 15 and 16.
- FIG. 15 and 16 A speech recognition system 10 according to the seventh embodiment will be described with reference to FIGS. 15 and 16.
- FIG. 15 is a block diagram showing the functional configuration of the speech recognition system according to the seventh embodiment.
- symbol is attached
- the speech recognition system 10 includes speech data acquisition section 110, text conversion section 120, speech synthesis section 130, conversion It comprises a model generation unit 140 , a noise addition unit 160 , a speech conversion unit 210 and a speech recognition unit 220 . That is, the voice recognition system 10 according to the seventh embodiment further includes a noise adding section 160 in addition to the configuration of the first embodiment (see FIG. 2). Note that the noise adding unit 160 may be a processing block implemented by, for example, the above-described processor 11 (see FIG. 1).
- the noise addition unit 160 is configured to be able to add noise to the text data generated by the text conversion unit 120.
- the noise adding unit 160 may add noise to the text data by adding noise to the real speech data before text conversion, or may add noise to the text data after text conversion. can be Alternatively, the noise adding section 160 may add noise when the text conversion section 120 converts the real speech data into text.
- the noise adding unit 160 may add preset noise, or randomly set noise.
- FIG. 16 is a flow chart showing the flow of conversion model generation operation by the speech recognition system according to the seventh embodiment.
- the same reference numerals are given to the same processes as those shown in FIG.
- the speech data acquisition unit 110 acquires real speech data (step S101).
- the noise addition unit 160 outputs noise information to the text conversion unit 120 (step S701).
- the text conversion unit 120 converts the real speech data acquired by the speech data acquisition unit 110 into text data to which noise is added (step S702).
- the speech synthesizing unit 130 speech-synthesizes the text data converted by the text converting unit 120 (here, the text data to which noise is added), and generates corresponding synthesized speech corresponding to the real speech data (step S103).
- the conversion model generation unit 140 generates a conversion model based on the real speech data acquired by the speech data acquisition unit 110 and the corresponding synthesized speech generated by the speech synthesis unit 130 (step S104). After that, the conversion model generation unit 140 outputs the generated conversion model to the speech conversion unit 210 (step S105).
- real speech data is converted into text data to which noise is added.
- a conversion model is generated using data containing noise, so a conversion model that is resistant to noise (for example, a conversion model that can properly convert even if the input voice contains noise). It is possible to generate
- FIG. 17 A speech recognition system 10 according to a modification of the seventh embodiment will be described with reference to FIGS. 17 and 18.
- FIG. It should be noted that the modification of the seventh embodiment may be different from the above-described seventh embodiment only in a part of configuration and operation, and other parts may be the same as those of the first to seventh embodiments. Therefore, in the following, portions different from the already described embodiments will be described in detail, and descriptions of other overlapping portions will be omitted as appropriate.
- FIG. 17 is a block diagram showing a functional configuration of a speech recognition system according to a modification of the seventh embodiment.
- symbol is attached
- the speech recognition system 10 includes speech data acquisition section 110, text conversion section 120, and speech synthesis section 130 as components for realizing its functions. , a transformation model generation unit 140 , a noise addition unit 160 , a speech conversion unit 210 , and a speech recognition unit 220 .
- the noise addition section 160 is configured to be able to output noise information to the speech synthesis section 130 . That is, in the modification of the seventh embodiment, noise is added when the speech synthesizing unit 130 synthesizes speech.
- FIG. 18 is a flow chart showing the flow of conversion model generation operation by the speech recognition system according to the modification of the seventh embodiment.
- the same reference numerals are given to the same processes as those shown in FIG.
- the speech data acquisition unit 110 first acquires real speech data (step S101). Then, the text conversion unit 120 converts the real speech data acquired by the speech data acquisition unit 110 into text data (step S102).
- the noise addition unit 160 outputs noise information to the speech synthesis unit 130 (step S751). Then, the speech synthesizing unit 130 speech-synthesizes the text data converted by the text converting unit 120, and generates corresponding synthesized speech to which noise is added (step S752).
- the conversion model generation unit 140 generates the corresponding synthesized speech generated by the real speech data acquired by the speech data acquisition unit 110 and the speech synthesis unit 130 (here, the corresponding synthesized speech to which noise is added). , to generate a conversion model (step S104). After that, the conversion model generation unit 140 outputs the generated conversion model to the speech conversion unit 210 (step S105).
- corresponding synthetic speech to which noise is added is generated.
- a conversion model is generated using data containing noise, so a conversion model that is resistant to noise (for example, a conversion model that can properly convert even if the input voice contains noise). It is possible to generate
- FIG. 19 A speech recognition system 10 according to the eighth embodiment will be described with reference to FIGS. 19 to 21.
- FIG. It should be noted that the eighth embodiment may differ from the above-described first to seventh embodiments only in a part of configuration and operation, and other parts may be the same as those of the first to seventh embodiments. Therefore, in the following, portions different from the already described embodiments will be described in detail, and descriptions of other overlapping portions will be omitted as appropriate.
- FIG. 19 is a block diagram showing the functional configuration of the speech recognition system according to the eighth embodiment.
- the speech recognition system 10 includes a sign language data acquisition unit 410, a text conversion unit 420, a speech synthesis unit 430, a conversion It comprises a model generation unit 440 , a speech conversion unit 510 and a speech recognition unit 520 .
- the sign language data acquisition unit 410, the text conversion unit 420, the speech synthesis unit 430, the conversion model generation unit 440, the speech conversion unit 510, and the speech recognition unit 520 are each processed by, for example, the above-described processor 11 (see FIG. 1). can be blocks.
- the sign language data acquisition unit 410 is configured to be able to acquire sign language speech data.
- the sign language data may be sign language video data, for example.
- the sign language data may be obtained, for example, from a database (sign language corpus) that accumulates a plurality of sign language data.
- the sign language data acquired by the sign language data acquisition unit 410 is configured to be output to the text conversion unit 120 and the conversion model generation unit 140 .
- the text conversion unit 420 is configured to be able to convert the sign language data acquired by the sign language data acquisition unit 410 into text data.
- the text conversion unit 420 is configured to be able to execute a process of converting the content of sign language included in the sign language data into text. It should be noted that existing techniques may be appropriately adopted as a specific technique for text conversion.
- the text data converted by the text conversion section 420 (that is, the text data corresponding to the sign language data) is configured to be output to the speech synthesis section 430 .
- the speech synthesizing unit 430 is configured to be capable of synthesizing the text data changed by the text converting unit 420 into a corresponding synthesized speech corresponding to the sign language data. It should be noted that existing techniques can be appropriately adopted as a specific technique for speech synthesis.
- the corresponding synthesized speech generated by the speech synthesizing section 430 is configured to be output to the conversion model generating section 440 .
- the corresponding synthetic speech may be stored in a database (synthetic speech corpus) capable of storing a plurality of corresponding syntheses, and then output to the transformation model generation unit 440 .
- the conversion model generation unit 440 is configured to be capable of generating a conversion model for converting input sign language into synthesized speech using the sign language data acquired by the sign language data acquisition unit 410 and the corresponding synthesized speech synthesized by the speech synthesis unit 430. It is The conversion model converts, for example, an input sign language input (eg, sign language animation) into synthesized speech (ie, mechanical speech). Transformation model generator 440 may be configured to generate a transformation model using, for example, a GAN. The conversion model generated by the conversion model generation unit 440 is configured to be output to the speech conversion unit 510 .
- the speech conversion unit 510 is configured to be able to convert input sign language into synthesized speech using the conversion model generated by the conversion model generation unit 440 .
- the input sign language input to the voice conversion unit 510 may be, for example, a moving image input using a camera or the like.
- the synthesized speech converted by the speech conversion section 510 is output to the speech recognition section 520 .
- the speech recognition unit 520 is configured to be able to speech-recognize the synthesized speech converted by the speech conversion unit 510 .
- the speech recognition unit 520 is configured to be able to execute a process of converting synthesized speech into text.
- the speech recognition unit 520 may be configured to be capable of outputting a speech recognition result of synthesized speech. Note that the method of using the speech recognition result is not particularly limited.
- FIG. 20 is a flow chart showing the flow of conversion model generation operation by the speech recognition system according to the eighth embodiment.
- the sign language data acquisition unit 410 first acquires sign language data (step S801). Then, the text conversion unit 420 converts the sign language data acquired by the sign language data acquisition unit 410 into text data (step S802).
- the speech synthesizing unit 430 speech-synthesizes the text data converted by the text converting unit 420, and generates corresponding synthetic speech corresponding to the sign language data (step S403).
- conversion model generation unit 140 generates a conversion model based on the sign language data acquired by sign language data acquisition unit 410 and the corresponding synthesized speech generated by speech synthesis unit 430 (step S804).
- the conversion model generation unit 440 outputs the generated conversion model to the speech conversion unit 510 (step S805).
- FIG. 21 is a flow chart showing the flow of speech recognition operation by the speech recognition system according to the eighth embodiment.
- the speech conversion unit 510 first acquires input sign language (step S851). Then, the speech conversion unit 510 reads the conversion model generated by the conversion model generation unit 440 (step S852). After that, the speech conversion unit 210 performs speech conversion using the read conversion model, and converts the input sign language into synthesized speech (step S853).
- the speech recognition unit 520 reads the speech recognition model (step S854). Then, the speech recognition unit 520 uses the read speech recognition model to recognize the synthetic speech synthesized by the speech conversion unit 510 (step S855). After that, the speech recognition unit 520 outputs the speech recognition result (step S856).
- the speech recognition system 10 uses sign language data and corresponding synthesized speech corresponding to the sign language data when generating a conversion model.
- corresponding synthesized speech corresponding to sign language data is generated by converting the sign language data into text and synthesizing the text data into speech.
- the corresponding synthesized speech can be generated by preparing only the sign language data.
- a processing method is also implemented in which a program for operating the configuration of each embodiment described above is recorded on a recording medium, the program recorded on the recording medium is read as code, and executed by a computer. Included in the category of form. That is, a computer-readable recording medium is also included in the scope of each embodiment. In addition to the recording medium on which the above program is recorded, the program itself is also included in each embodiment.
- a floppy (registered trademark) disk, hard disk, optical disk, magneto-optical disk, CD-ROM, magnetic tape, non-volatile memory card, and ROM can be used as recording media.
- the program recorded on the recording medium alone executes the process, but also the one that operates on the OS and executes the process in cooperation with other software and functions of the expansion board. included in the category of Furthermore, the program itself may be stored on the server, and part or all of the program may be downloaded from the server to the user terminal.
- the speech recognition system described in appendix 1 includes speech data acquisition means for acquiring real speech data uttered by a speaker, text conversion means for converting the real speech data into text data, and speech synthesis using the text data.
- speech synthesizing means for generating corresponding synthesized speech corresponding to said real utterance data
- conversion model generating means for generating a conversion model for converting input speech into synthesized speech using said real utterance data and said corresponding synthesized speech
- speech recognition means for recognizing the synthesized speech converted using the conversion model.
- the speech recognition system according to appendix 3 further comprises speech recognition model generation means for generating a speech recognition model using data including the corresponding synthesized speech, and the speech recognition means uses the speech recognition model to perform speech recognition. 3.
- the speech recognition model generating means generates parameters of the speech recognition model using the synthesized speech converted using the conversion model and the recognition result of the speech recognition means 4.
- the speech recognition system according to appendix 5 further includes attribute acquisition means for acquiring attribute information indicating the attribute of the speaker, and the speech synthesis means performs speech synthesis using the attribute information to obtain the correspondence synthesis 5.
- attribute acquisition means for acquiring attribute information indicating the attribute of the speaker
- the speech synthesis means performs speech synthesis using the attribute information to obtain the correspondence synthesis 5.
- a speech recognition system according to any one of clauses 1 to 4 for generating speech.
- the speech recognition system according to appendix 6 further comprises a plurality of real speech corpora that store the real speech data for each predetermined condition, and the speech data acquisition means selects one from the plurality of real speech corpora. 6.
- the speech recognition system according to appendix 7 is the speech recognition system according to any one of appendices 1 to 6, further comprising noise applying means for applying noise to at least one of the text data and the corresponding synthesized speech. .
- the speech recognition system corresponds to the sign language data by means of sign language data acquisition means for acquiring sign language data, text conversion means for converting the sign language data into text data, and speech synthesis using the text data.
- speech synthesizing means for generating a corresponding synthesized speech that corresponds to the corresponding synthesized speech;
- conversion model generating means for generating a conversion model for converting input sign language into synthesized speech using the sign language data and the corresponding synthesized speech; and using the conversion model and a voice recognition means for recognizing the synthesized voice converted by the voice recognition system.
- the speech recognition method acquires real speech data uttered by a speaker by at least one computer, converts the real speech data into text data, and performs speech synthesis using the text data. generating corresponding synthesized speech corresponding to real utterance data; generating a conversion model for converting input speech into synthesized speech using said real utterance data and said corresponding synthesized speech; This is a speech recognition method for recognizing synthesized speech.
- At least one computer acquires real speech data uttered by a speaker, converts the real speech data into text data, and uses the text data to synthesize the real speech data. generating a corresponding synthesized speech corresponding to the utterance data; generating a conversion model for converting the input speech into the synthesized speech using the real utterance data and the corresponding synthesized speech; and generating the synthesized speech converted using the conversion model.
- the computer program according to Supplementary Note 11 acquires real speech data uttered by a speaker in at least one computer, converts the real speech data into text data, and performs speech synthesis using the text data to generate the real speech data. generating a corresponding synthesized speech corresponding to the utterance data; generating a conversion model for converting the input speech into the synthesized speech using the real utterance data and the corresponding synthesized speech; and generating the synthesized speech converted using the conversion model.
- the speech recognition apparatus includes speech data acquisition means for acquiring real speech data uttered by a speaker, text conversion means for converting the real speech data into text data, and speech synthesis using the text data.
- speech synthesizing means for generating corresponding synthesized speech corresponding to said real utterance data
- conversion model generating means for generating a conversion model for converting input speech into synthesized speech using said real utterance data and said corresponding synthesized speech
- speech recognition means for recognizing the synthesized speech converted using the conversion model.
- At least one computer acquires sign language data, converts the sign language data into text data, and performs speech synthesis using the text data to generate correspondence synthesis corresponding to the sign language data. generating speech, using the sign language data and the corresponding synthesized speech to generate a conversion model for converting the input sign language into synthesized speech, and recognizing the synthesized speech converted using the conversion model; It is a speech recognition method.
- At least one computer acquires sign language data, converts the sign language data into text data, and generates corresponding synthesized speech corresponding to the sign language data by speech synthesis using the text data. , generating a conversion model for converting input sign language into synthesized speech using the sign language data and the corresponding synthesized speech, and recognizing the synthesized speech converted using the conversion model.
- appendix 15 The computer program according to appendix 15 acquires sign language data in at least one computer, converts the sign language data into text data, and generates corresponding synthesized speech corresponding to the sign language data by speech synthesis using the text data. , generating a conversion model for converting input sign language into synthesized speech using the sign language data and the corresponding synthesized speech, and recognizing the synthesized speech converted using the conversion model.
- the speech recognition device corresponds to the sign language data by means of sign language data acquisition means for acquiring sign language data, text conversion means for converting the sign language data into text data, and speech synthesis using the text data.
- speech synthesizing means for generating a corresponding synthesized speech that corresponds to the corresponding synthesized speech;
- conversion model generating means for generating a conversion model for converting input sign language into synthesized speech using the sign language data and the corresponding synthesized speech; and using the conversion model and a speech recognition means for recognizing the synthesized speech converted by the speech recognition device.
- speech recognition system 11 processor 14 storage device 105 real speech corpus 110 speech data acquisition unit 120 text conversion unit 130 speech synthesis unit 140 conversion model generation unit 150 attribute information acquisition unit 160 noise addition unit 210 speech conversion unit 220 speech recognition unit 310 Speech recognition model generation unit 410 Sign language data acquisition unit 420 Text conversion unit 430 Speech synthesis unit 440 Conversion model generation unit 510 Speech conversion unit 520 Speech recognition unit
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Artificial Intelligence (AREA)
- Machine Translation (AREA)
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US18/724,673 US20250061884A1 (en) | 2022-03-01 | 2022-03-01 | Speech recognizing system, and speech recognizing method |
| JP2024504041A JP7691027B2 (ja) | 2022-03-01 | 2022-03-01 | 音声認識システム、音声認識方法、及び記録媒体 |
| PCT/JP2022/008597 WO2023166557A1 (ja) | 2022-03-01 | 2022-03-01 | 音声認識システム、音声認識方法、及び記録媒体 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2022/008597 WO2023166557A1 (ja) | 2022-03-01 | 2022-03-01 | 音声認識システム、音声認識方法、及び記録媒体 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023166557A1 true WO2023166557A1 (ja) | 2023-09-07 |
Family
ID=87883147
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/008597 Ceased WO2023166557A1 (ja) | 2022-03-01 | 2022-03-01 | 音声認識システム、音声認識方法、及び記録媒体 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20250061884A1 (https=) |
| JP (1) | JP7691027B2 (https=) |
| WO (1) | WO2023166557A1 (https=) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20230386446A1 (en) * | 2022-05-25 | 2023-11-30 | AuthenticVoice Inc. | Modifying an audio signal to incorporate a natural-sounding intonation |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003522978A (ja) * | 2000-02-10 | 2003-07-29 | コーニンクレッカ フィリップス エレクトロニクス エヌ ヴィ | 手話を音声へ変換する方法及び装置 |
| JP2019008120A (ja) * | 2017-06-23 | 2019-01-17 | 株式会社日立製作所 | 声質変換システム、声質変換方法、及び声質変換プログラム |
-
2022
- 2022-03-01 JP JP2024504041A patent/JP7691027B2/ja active Active
- 2022-03-01 WO PCT/JP2022/008597 patent/WO2023166557A1/ja not_active Ceased
- 2022-03-01 US US18/724,673 patent/US20250061884A1/en active Pending
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003522978A (ja) * | 2000-02-10 | 2003-07-29 | コーニンクレッカ フィリップス エレクトロニクス エヌ ヴィ | 手話を音声へ変換する方法及び装置 |
| JP2019008120A (ja) * | 2017-06-23 | 2019-01-17 | 株式会社日立製作所 | 声質変換システム、声質変換方法、及び声質変換プログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7691027B2 (ja) | 2025-06-11 |
| US20250061884A1 (en) | 2025-02-20 |
| JPWO2023166557A1 (https=) | 2023-09-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10553201B2 (en) | Method and apparatus for speech synthesis | |
| CN112786007A (zh) | 语音合成方法、装置、可读介质及电子设备 | |
| CN111599343B (zh) | 用于生成音频的方法、装置、设备和介质 | |
| WO2019196306A1 (zh) | 基于语音的口型动画合成装置、方法及可读存储介质 | |
| US20210020160A1 (en) | Sample-efficient adaptive text-to-speech | |
| CN112397047A (zh) | 语音合成方法、装置、电子设备及可读存储介质 | |
| CN107705782B (zh) | 用于确定音素发音时长的方法和装置 | |
| CN114038484B (zh) | 语音数据处理方法、装置、计算机设备和存储介质 | |
| CN107481715B (zh) | 用于生成信息的方法和装置 | |
| CN112289305B (zh) | 韵律预测方法、装置、设备以及存储介质 | |
| JP2020187340A (ja) | 音声認識方法及び装置 | |
| CN113808572A (zh) | 语音合成方法、装置、电子设备和存储介质 | |
| CN103098124A (zh) | 用于文本到语音转换的方法和系统 | |
| US12211488B2 (en) | Adaptive visual speech recognition | |
| US10923106B2 (en) | Method for audio synthesis adapted to video characteristics | |
| CN112383721B (zh) | 用于生成视频的方法、装置、设备和介质 | |
| CN112381926B (zh) | 用于生成视频的方法和装置 | |
| WO2023166557A1 (ja) | 音声認識システム、音声認識方法、及び記録媒体 | |
| CN114255737B (zh) | 语音生成方法、装置、电子设备 | |
| CN111862933A (zh) | 用于生成合成语音的方法、装置、设备和介质 | |
| CN119864014B (zh) | 基于情感分析的语音转换方法、装置、设备及存储介质 | |
| Mukherjee et al. | A Bengali speech synthesizer on Android OS | |
| CN119864010A (zh) | 非自回归语音合成方法、装置、计算机设备及存储介质 | |
| CN114999450B (zh) | 同形异义字的识别方法、装置、电子设备及存储介质 | |
| CN117711372A (zh) | 语音合成方法、装置、计算机设备和存储介质 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22929705 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 18724673 Country of ref document: US |
|
| ENP | Entry into the national phase |
Ref document number: 2024504041 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 22929705 Country of ref document: EP Kind code of ref document: A1 |