WO2023157439A1 - 画像処理装置及びその作動方法、推論装置並びに学習装置 - Google Patents
画像処理装置及びその作動方法、推論装置並びに学習装置 Download PDFInfo
- Publication number
- WO2023157439A1 WO2023157439A1 PCT/JP2022/045861 JP2022045861W WO2023157439A1 WO 2023157439 A1 WO2023157439 A1 WO 2023157439A1 JP 2022045861 W JP2022045861 W JP 2022045861W WO 2023157439 A1 WO2023157439 A1 WO 2023157439A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- image
- model
- sub
- learning
- feature map
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images



















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T3/00—Geometric image transformations in the plane of the image
- G06T3/40—Scaling of whole images or parts thereof, e.g. expanding or contracting
- G06T3/4046—Scaling of whole images or parts thereof, e.g. expanding or contracting using neural networks
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61B—DIAGNOSIS; SURGERY; IDENTIFICATION
- A61B1/00—Instruments for performing medical examinations of the interior of cavities or tubes of the body by visual or photographical inspection, e.g. endoscopes; Illuminating arrangements therefor
- A61B1/04—Instruments for performing medical examinations of the interior of cavities or tubes of the body by visual or photographical inspection, e.g. endoscopes; Illuminating arrangements therefor combined with photographic or television appliances
- A61B1/045—Control thereof
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T11/00—Two-dimensional [2D] image generation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/764—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using classification, e.g. of video objects
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/7715—Feature extraction, e.g. by transforming the feature space, e.g. multi-dimensional scaling [MDS]; Mappings, e.g. subspace methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/776—Validation; Performance evaluation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/778—Active pattern-learning, e.g. online learning of image or video features
- G06V10/7784—Active pattern-learning, e.g. online learning of image or video features based on feedback from supervisors
- G06V10/7792—Active pattern-learning, e.g. online learning of image or video features based on feedback from supervisors the supervisor being an automated module, e.g. "intelligent oracle"
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/70—Labelling scene content, e.g. deriving syntactic or semantic representations
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2210/00—Indexing scheme for image generation or computer graphics
- G06T2210/41—Medical
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V2201/00—Indexing scheme relating to image or video recognition or understanding
- G06V2201/03—Recognition of patterns in medical or anatomical images
Definitions
- the present invention relates to an image processing device that performs inference on an image using machine learning, an operating method thereof, an inference device, and a learning device.
- Patent Document 1 "a machine learning model having a plurality of layers for analyzing an input image, extracting features with different frequency bands of spatial frequencies contained in the input image for each layer, It is a learning device that gives training data to a machine learning model for implementing semantic segmentation that discriminates multiple classes in units of pixels, and trains it.
- a reception unit that accepts the specification of at least one of the required bandwidth and the omissible bandwidth that is estimated to be omissible in learning, and at least one of the machine learning model and the learning data to the specification accepted by the reception unit and a changing unit that changes to a corresponding mode.
- the decoder network gradually enlarges the image size of the minimum image feature map output from the encoder network. Then, the stepwise enlarged image feature map and the encoder network The image feature maps output in each layer are combined to generate an output image for learning having the same image size as the input image for learning.” Furthermore, it is described that "the trained model performs semantic segmentation on the input image, determines the class and contour of the object appearing in the input image, and outputs the output image as the determination result.”
- Patent Document 1 in a machine learning model for implementing semantic segmentation, a decoder network performs processing to gradually increase the image size.
- the trained machine learning model In training a machine learning model that performs such segmentation, if the correct data is a high-resolution image and training is performed by outputting a high-resolution image when inferring an unknown image, the trained machine learning model The discrimination accuracy is improved when the inference is performed.
- a trained machine learning model that has undergone such learning needs to process high-resolution data, resulting in an increased amount of calculation. If the output speed decreases due to the increase in the amount of calculation, it is not preferable in a scene in which inference should be performed quickly, especially in a scene in which inference should be performed in near real time.
- the purpose of the present invention is to provide an image processing device, its operation method, an inference device, and a learning device that achieve high-precision output results and high-speed output when unknown images are input.
- the image processing device of the present invention includes a processor.
- the processor outputs a first output image based on a first feature map extracted by inputting a learning input image to the first sub-model of the learning model including the first sub-model and the second sub-model.
- a second feature map extracted by inputting the first feature map into a second sub-model outputting a second output image having a resolution higher than that of the first output image, and using the second output image for the evaluation result and updating the learning model using the evaluation result
- the learning model is divided into a first sub-learned model that is a first sub-model that has been trained, and a second sub-model that has been trained.
- the processor compares the second output image with a learning correct image corresponding to the learning input image to calculate an evaluation result, and the learning correct image is a correct answer for each region constituting the learning correct image. It is preferably a labeled correct label image.
- the processor compares the first output image with a first correct label image as a correct label image having the resolution of the first output image to calculate a first evaluation result as an evaluation result, and a second output image. and a second correct label image as a correct label image having the resolution of the second output image to calculate a second evaluation result as an evaluation result, and using the first evaluation result and the second evaluation result, It is preferable to update the learning model.
- the first correct label image is preferably generated by performing resolution reduction processing on the second correct label image.
- the second output image preferably has the same resolution as the learning input image.
- the second output image preferably has a lower resolution than the learning input image.
- the first sub-model and the second sub-model are preferably constructed using a convolutional neural network.
- the first output image preferably has a lower resolution than the learning input image.
- the processor further outputs an intermediate feature map having a higher resolution than the first feature map using the first submodel, and further inputs the intermediate feature map to the second submodel.
- the input image for learning and the input image for inference are preferably medical images.
- the input images for inference are preferably images acquired in chronological order.
- the processor generates notification information based on the information contained in the inference result image, generates a notification image based on the notification information, and controls the display of the notification image.
- the notification image is preferably generated so that notification information is superimposed on the input image for inference, or an image obtained chronologically after the input image for inference.
- the notification image is preferably generated so that the input image for inference, or an image obtained chronologically after the input image for inference, and the notification information are displayed in mutually different positions.
- the notification information is preferably positional information of a specific shape surrounding a region indicating features included in the input image for inference.
- a method of operating an image processing apparatus is based on a first feature map extracted by inputting a learning input image to a first sub-model of a learning model including a first sub-model and a second sub-model. , outputting a first output image; and outputting a second output image having a higher resolution than the first output image based on a second feature map extracted by inputting the first feature map into a second sub-model. calculating the evaluation result using the second output image; and updating the learning model using the evaluation result, thereby converting the learning model into a first sub-learned model that is a trained first sub-model.
- a trained model including a second sub-trained model that is a second sub-model that has been trained, and inputting an inference input image to the first sub-trained model among the trained models and outputting a first output image as an inference result image based on the extracted first feature map.
- the inference device of the present invention includes a processor.
- the processor inputs the input image for inference to the first sub-learned model out of the trained models including the first sub-learned model and the second sub-learned model, and extracts the first sub-learned model based on the first feature map. , outputs a first output image as an inference result image.
- the learned model is a learning model including a first sub-model and a second sub-model, and the first sub-model is the first sub-learned model and the second sub-model is the second sub-learned model.
- Generated by The learning model outputs a first output image based on a first feature map extracted based on a learning input image input to the first submodel, and a first feature input to the second submodel. Based on the second feature map extracted based on the map, a second output image having a resolution higher than that of the first output image is output, and updated using the evaluation result calculated using the second output image. is learned by
- the learning device of the present invention includes a processor.
- the processor outputs a first output image based on a first feature map extracted by inputting a learning input image to the first sub-model of the learning model including the first sub-model and the second sub-model. , based on a second feature map extracted by inputting the first feature map into a second sub-model, outputting a second output image having a resolution higher than that of the first output image, and using the second output image for the evaluation result is calculated, and learning is performed by updating the learning model using the evaluation results.
- the second output image has a lower resolution than the learning input image.
- FIG. 1 is a schematic diagram of an image processing device;
- FIG. 3 is a block diagram showing functions of a learning device;
- FIG. 4 is a block diagram showing functions of a learning model;
- FIG. 4 is an explanatory diagram showing functions of a first submodel;
- FIG. 11 is an explanatory diagram showing functions of a second submodel;
- FIG. 4 is an explanatory diagram showing functions of an inference device;
- FIG. 10 is an explanatory diagram showing an example of a learning correct image in which small regions are classified by attaching three kinds of class labels;
- FIG. 10 is an explanatory diagram showing an example of a learning correct image in which small areas are classified by attaching two kinds of class labels;
- FIG. 4 is an explanatory diagram showing an example of mask data with class labels;
- FIG. 1 is a schematic diagram of an image processing device;
- FIG. 3 is a block diagram showing functions of a learning device;
- FIG. 4 is a block diagram showing functions of a learning model;
- FIG. 10 is an explanatory diagram showing a function of an evaluation unit that calculates a plurality of evaluation results using a plurality of learning correct images with mutually different resolutions;
- FIG. 4 is an explanatory diagram showing an example of a learning model using Unet;
- FIG. 10 is an explanatory diagram showing an example of a learning model that performs resolution enhancement processing so that a second output image has a resolution higher than that of an input image for learning;
- FIG. 8 is an explanatory diagram showing an example of a learning model that performs resolution enhancement processing so that a second output image has a resolution lower than that of a learning input image; It is a block diagram which shows the function of an information control part.
- FIG. 10 is an image diagram showing an example of a notification image displaying position information of a specific shape as a sub-image
- FIG. 10 is an explanatory diagram showing functions of a notification control unit when position information of a small area is generated as notification information
- FIG. 10 is an image diagram showing an example of a superimposed image in which position information of small areas is superimposed
- FIG. 11 is an image diagram showing an example of a notification image displaying position information of a small area as a sub-image
- 4 is a flow chart showing a method of operating the image processing device;
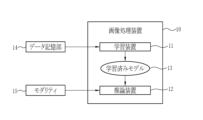
- the image processing device 10 includes a learning device 11 and an inference device 12.
- the learning device 11 and the inference device 12 are connected by wire or wirelessly via a network so as to be able to communicate with each other.
- the network is, for example, the Internet or a LAN (Local Area Network).
- the image processing device 10 causes the learning model 30 to learn by the learning device 11, infers the probability of belonging to the small region of the image, and extracts the region of interest, which is the region of interest included in the image.
- a trained model 13 is assumed.
- the trained model 13 is sent to the inference device 12 .
- By inputting an unknown image to the inference device 12, a region of interest included in the unknown image is extracted.
- a small area of an image refers to a pixel or a set of pixels that constitute an image.
- the learning model 30 is a model that performs feature extraction and resolution enhancement processing on the input image.
- a control unit (not shown), which is a processor provided in the image processing apparatus 10 , inputs a learning input image 21 from the learning data set 20 stored in the data storage unit 14 to the learning model 30 .
- the learning model 30 outputs a first output image 42 in which the features of the learning input image 21 are extracted, and a second output image 52 having a higher resolution than the first output image 42 .
- the learning device 11 uses the second output image to update the learning model 30 to a learned model 13 , and transmits the trained model 13 to the inference device 12 .
- the trained model 13 receives the inference input image 121, which is an unknown image, from the modality 15, the inference input image 121 performs at least feature extraction on the inference input image 121 to obtain the first output An image 42 is output.
- the data storage unit 14 may be provided either inside or outside the image processing apparatus 10 .
- the learning data set 20 is input from the data storage unit 14 to the learning device 11 via the network.
- the learning data set 20 is read by the learning device 11 and input to the learning model 30 .
- the learning device 11 includes a learning model 30, an evaluation unit 60, and an update unit 70, as shown in FIG.
- the learning model 30 outputs a first output image 42 and a second output image 52 using machine learning when the learning input image 21 is input.
- the learning model 30 includes a first sub-model 40 for extracting features of an input image, and a second sub-model 50 for performing resolution enhancement processing on input image data.
- the learning input image 21 in the learning data set 20 stored in the data storage unit 14 is input to the first submodel 40 .
- the learning model 30 is not limited to the number and configuration of sub-models as long as the model as a whole performs feature extraction and resolution enhancement processing for an input image.
- the first sub-model 40 and the second sub-model 50 are preferably configured using a layered structure convolutional neural network as shown in FIG.
- the learning input image 21 is input to the input layer 43 of the first submodel 40 .
- the first intermediate layer 44 which is the intermediate layer of the first submodel, a convolution operation using a plurality of filters is performed at least one time or more to extract the first feature map 41 that extracts the features of the learning input image 21. do.
- a first feature map 41 is input to a first output layer 45 and a second submodel 50 .
- the first intermediate layer 44 has one or more convolution layers.
- a filter is applied to the input image data, and a feature map indicating the positions of the patterns of the filter is extracted from the input image data.
- Filters are also called convolution kernels.
- the feature map is also included in the image data input to the convolutional layer. Feature maps are extracted for as many filters as are used in one convolutional layer.
- the first intermediate layer 44 may or may not have a pooling layer.
- the pooling layer is a layer that summarizes the values related to the local area of the input image data and performs the resolution reduction processing of the image data.
- the first intermediate layer 44 may be composed of one convolution layer, but is preferably composed of a plurality of convolution layers and pooling layers from the viewpoint of improving accuracy and speeding up feature extraction.
- the first feature map 41 is a feature map that is output from the convolutional layer or pooling layer at the rearmost stage of the first intermediate layer 44 .
- the first intermediate layer 44 is composed of a plurality of convolution layers and pooling layers, among the feature maps extracted in the first intermediate layer 44, the feature map extracted from the last-stage layer is referred to as the first feature map. 41, and a feature map extracted from a layer at a stage prior to the first feature map 41 is defined as a first intermediate feature map.
- a modification in which the first intermediate layer 44 is composed of a plurality of layers will be described later.
- the first feature map 41 extracted from the first intermediate layer 44 is input to the first output layer 45 .
- the first output layer 45 uses an activation function to output one first output image 42 from the plurality of first feature maps 41 .
- the first output image 42 is classified by calculating the belonging probability for each region with respect to the input image (the learning input image 21 in FIG. 4). For example, it is classified into an attention area 42a and an area 42b other than the attention area.
- the first feature map 41 extracted from the first hidden layer 44 is further sent to the second hidden layer 54 of the second sub-model 50 .
- the second intermediate layer 54 performs at least processing for increasing the resolution of the first feature map 41, and extracts the second feature map 51 (see FIG. 3).
- the second intermediate layer 54 has one or more upsampling layers 54a.
- the upsampling layer 54a performs enlargement processing (resolution enhancement processing) of the feature map.
- the second intermediate layer 54 preferably further includes a convolution layer 54b.
- Each of the upsampling layer 54a and the convolution layer 54b may be one each, but from the viewpoint of the accuracy of feature extraction, it is preferable that there are a plurality of them.
- the pixel values related to the pixels that make up the feature map are arranged at intervals of several pixels, and up-sampling that interpolates the pixel values in between, or up-sampling that does not interpolate the pixel values.
- the second intermediate layer 54 may be configured without the upsampling layer 54a. In this case, the second intermediate layer 54 uses, for example, a shift-and-stitch technique to perform high-resolution processing.
- the second feature map 51 is a feature map that is output from the convolutional layer at the rearmost stage of the second intermediate layer 54 .
- the feature map extracted from the last layer is A second feature map 51 is assumed to be a feature map extracted from a layer at a stage before the second feature map 51 is assumed to be a second intermediate feature map.
- the second feature map 51 is a feature map extracted from the layer at the latest stage among the feature maps extracted in the second intermediate layer 54 .
- a modification in which the second intermediate layer 54 is composed of a plurality of layers will be described later.
- the second feature map 51 extracted from the second intermediate layer 54 is input to the second output layer 55 .
- the second output layer 55 uses the same activation function as the first output layer 45 and outputs one second output image 52 from the plurality of second feature maps 51 .
- the resolution of the first output image 52 is higher than that of the first output image 42 because the resolution of the first feature map 41 is increased using the second intermediate layer 54 .
- the first feature map 41 extracted from the input image has a feature (region of interest 41a in FIG.
- the result of the processing is shown, and is divided into, for example, an attention area 52a and an area 52b other than the attention area.
- the first intermediate layer 44 of the first sub-model 40 performs the resolution reduction processing of the learning input image 21
- the second intermediate layer 54 of the second sub-model 50 performs the first feature map 41 shows an example in which resolution enhancement processing is performed to make the resolution of the image 41 approximately the same as that of the input image 21 for learning.
- the second output image 52 may have a lower resolution than the learning input image 21, or may have the same resolution as the learning input image 21, or , may have a higher resolution than the input image 21 for learning.
- the second output image 52 is sent to the evaluation unit 60 (see FIG. 2).
- the evaluation unit 60 outputs evaluation results using the second output image 52 .
- the evaluation unit 60 uses a loss function (also referred to as an error function), which is a model for evaluation, and uses loss is output, the accuracy of the output of the learning model 30 as a whole is evaluated.
- the evaluation result 61 is the loss (also referred to as error) calculated by the evaluation unit 60 using the loss function. The closer the evaluation result 61 is to 0, the smaller the difference between the second output image 52 and the learning correct image 22, indicating that the learning model 30 has higher output accuracy.
- the correct learning image 22 is an image in which the position of the region of interest is indicated in advance, or an image in which one type of class label (correct label) out of a plurality of types of class labels is attached to each small region. A specific example of the learning correct image 22 will be described later.
- the update unit 70 updates the learning model 30 according to the evaluation result calculated by the evaluation unit 60.
- the network parameters (weights and biases) of the first sub-model 40 and the second sub-model 50 are updated so that the loss approaches zero.
- the updating unit 70 updates the network parameters so as to minimize the loss using, for example, the stochastic gradient descent method.
- the learning rate defines the magnitude of the update amount, and the greater the learning rate, the greater the range of parameter change. Note that the update method is not limited to this.
- the evaluation unit 60 sets a loss function used for supervised learning as an objective function, which is a condition that a learning image without a correct label satisfies, and calculates a calculated value calculated from a function obtained by adding the loss function and the objective function. be the evaluation result.
- the updating unit 70 may update the parameters so as to minimize the calculated value calculated from the sum of the loss function and the objective function.
- the calculation of the evaluation result 61 by the evaluation unit 60 and the update of the learning model 30 by the update unit 70 are repeated until the evaluation result 61 reaches a preset value.
- the preset value may be a value within a certain range, or may be equal to or greater than or less than a certain threshold.
- the learning model 30 is the first sub-learned model that is the learned first sub-model 40 and the learned second sub-model 50. is a trained model 13 including a second sub-trained model.
- the learned model 13 finally generated by the learning device 11 has the same configuration as the learning model 30 .
- the learning model 30 has the configuration illustrated in FIG. 3, the learned model 13 also has the same configuration.
- the trained model 13 is transmitted from the learning device 11 to the inference device 12 (see FIG. 1).
- the trained model 13 transmitted from the learning device 11 to the inference device 12 includes a first sub-trained model that is a trained first sub-model.
- the trained model 13 sent to the inference device 12 may consist of the first sub-trained model and the second sub-trained model, but preferably consists of only the first sub-trained model. This is because, in terms of hardware, omitting the second sub-trained model from the inference device 12 has the advantage of saving memory.
- the inference device 12 receives an inference input image 121 from the modality 15 as shown in FIG.
- the inference input image 121 is input to the input layer 43 of the first sub-trained model among the trained models 13 .
- the first intermediate layer 44 of the first sub-trained model extracts the first feature maps 41
- the first output layer 45 outputs one first output image 42 from the plurality of first feature maps 41.
- the inference result image 142 is the first output image 42 output from the first sub-trained model. That is, the trained model 13 outputs the first output image 42 as the inference result image 142 by inputting the inference input image 121 .
- the output accuracy of the trained model 13 is improved. Furthermore, by providing the output layer in the first sub-model (the first sub-learned model 13 in the trained model 13) as in this example, the first output image 42 can be output quickly. That is, with the configuration shown in this example, it is possible to speed up the inference processing for an unknown image.
- the trained model 13 can perform inference processing that achieves high recognition accuracy faster than general machine learning models. In other words, the trained model 13 in this example can realize high-precision output in almost real time with respect to input of an unknown image.
- the second output image may be output from the second sub-trained model when outputting the inference result image 142.
- the second output image is not used for generating notification information.
- the inference input image 121 is input to the trained model 13
- the rapid output of the first output image 42 when the inference input image 121, which is an unknown image, is input to the trained model 13 can be sufficiently realized by installing the first sub-trained model in the inference device 12.
- the arithmetic processing in the inference device 12 can be made faster.
- the second sub-trained model is not used when outputting the inference result image 142, it is preferable not to input the first feature map extracted by the first sub-trained model to the second sub-trained model.
- the evaluation unit 60 compares the second output image 52 and the learning correct image 22, and calculates an evaluation result 61 that evaluates the calculation of the belonging probability for each small region and the accuracy of classification.
- the learning correct image 22 used in the learning device 11 is preferably a correct label image in which a correct label is assigned to each region forming the learning correct image 22 .
- the correct label refers to a class label indicating "correct answer" attached to each small region forming the learning correct image 22 .
- the correct label 23a of "normal mucous membrane” is attached to the small area 22a constituting the correct learning image 22
- the correct label 23b of "inflammation” is attached to the small area 22b
- the small area 22c is attached to the small area 22c. are attached with the correct label 23c of "malignant tumor”.
- the learning correct image 22 may be divided into a region of interest and regions other than the region of interest, and correct labels may be attached thereto.
- the small region 22d constituting the learning correct image 22 has a correct label 23d of "normal region” as a region other than the region of interest, and the small region 22e has a "abnormal region” as a region of interest. correct labels 23e are respectively attached.
- the example of the correct label is not limited to this.
- FIGS. 7 and 8 show a learning correct image 22 in which a small region corresponding to a learning input image 21 that can visually distinguish structures such as mucosal folds and redness of inflammation is labeled with a correct answer.
- the small regions to which the correct labels are assigned are divided into different colors, in which structures such as mucosal folds and redness of inflammation are not visually discernible.
- the mask data is In the specific example of FIG. 9, correct labels 23a, 23b, and 23c are assigned to the small regions 22a, 22b, and 22c in the same manner as in FIG. 22.
- the learning model 30 is a model that performs segmentation, and the first output image 42 and the second output image 52 constitute the learning input image 21.
- a class label is predicted for each subregion.
- the trained model 13 can be a model that performs segmentation on an unknown image and detects a region of interest with high accuracy and high speed.
- a focus area is an area that the user should pay attention to.
- areas showing abnormalities such as malignant tumors, benign tumors, polyps, inflammation, bleeding, vascular irregularities, ductal irregularities, hyperplasia, dysplasia, trauma, and fractures, or It refers to an abnormal area in a living body, such as a scar, a surgical scar, a drug solution, a fluorescent dye, an artificial joint, an artificial bone, or a foreign body such as gauze, or an area in which the living body has been treated.
- an area showing an abnormality such as a crack, tear, or scratch in the product is the attention area. Note that the example of the attention area is not limited to this.
- the learning correct image 22 may be an image in which only the region of interest is labeled with the correct answer.
- the learning model 30 may output a class label only for the small area that is the attention area without outputting the class label for the small area other than the attention area.
- the classification of small regions and the assignment of class labels to the correct learning image 22 in advance may be performed by the user, or may be performed using machine learning installed in a device other than the image processing device 10. good too.
- the user is, for example, a doctor who is proficient in diagnosing medical images.
- the evaluation result is preferably calculated by comparing the learning correct image 22 and the first output image 42 in addition to the comparison between the learning correct image 22 and the second output image 52 . That is, FIG. 2 shows a specific example in which the learning correct image 22 and the second output image 52 are compared and the evaluation result 61 is calculated. It is preferable that an evaluation result comparing the image 42 is further calculated.
- the learning data set 20 includes learning correct images 22 (second correct label images) having two types of resolution.
- the resolutions of the first correct label image and the first output image 42 are preferably as close as possible, and are more preferably the same.
- the resolutions of the second correct label image and the second output image 52 are preferably as close as possible, and more preferably the same.
- the resolutions of the first correct label image and the second correct label image are different from each other, and the resolution of the second correct label image is higher than the resolution of the first correct label image.
- the evaluation unit 60 as shown in FIG. A first evaluation result 62 is calculated as an evaluation result by comparing with the image 24 . Furthermore, the second output image 52 output by the second sub-model 50 is compared with the second correct label image 25 to calculate a second evaluation result 63 as an evaluation result.
- the calculated first evaluation result 62 and second evaluation result 63 are input to the updating unit 70 .
- the updating unit 70 updates the learning model 30 based on the first evaluation result 62 and the second evaluation result 63.
- the first evaluation result 62 is the loss indicating the difference between the first output image 42 and the first correct label image 24
- the second evaluation result 63 is the difference between the second output image 52 and the second correct label image 25. is a loss that indicates
- the first correct label image 24 and the second correct label image 25 may be generated separately, but the first correct label image 24 is generated by subjecting the second correct label image 25 to resolution reduction processing. is preferred.
- the image processing apparatus 10 is provided with a first correct label image generation section (not shown), and the first correct label image generation section reduces the resolution of the second correct label image 25 to generate the first correct label image 24.
- a device other than the image processing device 10 may generate the first correct label image 24 by lowering the resolution of the second correct label image 25 .
- the second correct label image 25 can be generated at low cost without newly generating the first correct label image 24 .
- the first sub-model 40 lowers the training input image 21.
- the first output image 42 may be output by performing a resolution operation, or the first output image 42 having the same resolution as that of the learning input image 21 may be output.
- the second sub-model 50 may output a second output image 52 having the same resolution as the training input image 21, or may output a second output image 52 having a higher resolution than the training input image 21.
- a second output image 52 having a resolution lower than that of the learning input image 21 may be output.
- Model 30 Learning in which the first sub-model 40 performs feature extraction and resolution reduction processing, and the second sub-model 50 performs resolution enhancement processing so that the second output image 52 has a higher resolution than the learning input image 21.
- Feature extraction and resolution reduction processing are performed by the first submodel 40, and the resolution of the second output image 52 by the second submodel 50 is lower than that of the learning input image 21 (however, the second output image Reference numeral 52 denotes a learning model 30 that performs resolution enhancement processing so that the resolution is higher than that of the first output image 42 .
- a learning model 30 that does not perform resolution reduction processing in the first sub-model 40 and performs resolution enhancement processing in the second sub-model 50 so that the second output image 52 has a higher resolution than the learning input image 21. .
- the first output image 42 preferably has a lower resolution than the learning input image 21.
- the output speed of the first output image 42 is increased. That is, by causing the first sub-model 40 to perform the resolution reduction process, the inference processing speed of the trained model 13 can be improved.
- the learning model 30 from (1) to (4) described above the learning model 30 from (1) to (3) in which the first sub-model performs the resolution reduction process is different from the learning model 30 from (4). Also, the output of the first output image 42 is fast.
- the resolution reduction process on the first sub-model 40, it is possible to extract the first feature map 41 that aggregates information in a wider range of the image.
- the resolution of the feature map obtained by convolution the information is further aggregated, and by repeating the convolution again, a wide range of information is aggregated, and as a result, it is determined that the edge is a polyp. There is something we can do.
- a first sub-model 40 extracts a first feature map 41 in which a wide range of information is aggregated by resolution reduction processing, and a second sub-model 50 performs resolution enhancement of the first feature map 41 in which information is aggregated. , it is possible to restore the position information in the entire image of the once aggregated local feature information, and update the learning model 30 so that the extracted features and their position information are accurate.
- the trained model 13 that has undergone such learning can perform highly accurate recognition even for unknown high-resolution images. In particular, in segmentation that classifies each small region of an image, it is possible to improve the recognition accuracy by performing learning for correcting the positional information of features.
- the second sub-model 50 performs a resolution enhancement process to make the second output image 52 higher in resolution than the learning input image 21 (2) and
- the learning model 30 of (4) has higher output accuracy for the learning input image 21 than the learning models 30 of (1) and (3).
- the second sub-model 50 performs a resolution enhancement process to make the resolution of the second output image 52 lower than that of the learning input image 21 (3).
- first intermediate feature map In addition to the first feature map 41 extracted from the first sub-model 40, it is preferable to input an intermediate feature map (first intermediate feature map) to the second sub-model 50.
- ResNet Residual Network
- Unet U-shaped Network
- a first intermediate layer 44 (see FIG. 3) of the first sub-model 40 has a plurality of convolutional layers 44a, 44c, 44e, 44g and a plurality of pooling layers 44b, 44d, 44f.
- the pooling layer 44b downsamples the feature map input from the convolution layer 44a to reduce the resolution of the feature map.
- pooling layer 44d reduces the resolution of the feature map input from convolution layer 44c
- pooling layer 44f reduces the resolution of the feature map input from convolution layer 44e.
- the pooling layers 44b, 44d, 44f provide robustness to the positional information of the extracted features and also contribute to extracting the features necessary for class classification.
- the first feature map 41 is the feature map extracted from the convolution layer 44g, which is the layer at the rearmost stage.
- Each feature map extracted from convolutional layers 44a, 44c, 44e other than convolutional layer 44g is a first intermediate feature map.
- the second hidden layer 54 (see FIG. 3) of the second submodel 50 has multiple upsampling layers 54c, 54e, 54g and multiple convolutional layers 54d, 54f, 54h.
- Upsampling layer 54c increases the resolution of first feature map 41 input from convolutional layer 44g of first submodel 40 .
- upsampling layer 54e increases the resolution of the feature map input from convolution layer 54d
- upsampling layer 54g increases the resolution of the feature map input from convolution layer 54f.
- the second feature map 51 is the feature map extracted from the convolution layer 54h, which is the layer at the rearmost stage.
- Each feature map extracted from convolutional layers 54d, 54f and upsampling layers 54c, 54e, 54g other than convolutional layer 54h is a second intermediate feature map.
- Hierarchies forming pairs in the specific example of FIG. 11 are as follows. (1; first layer) A layer of the convolutional layer 44a and the pooling layer 44b, and a layer of the upsampling layer 54g and the convolutional layer 54h. (2; Second Hierarchy) A hierarchy of the convolution layer 44c and the pooling layer 44d, and a hierarchy of the upsampling layer 54e and the convolution layer 54f.
- resolution reduction processing is performed stepwise from the first hierarchy to the third hierarchy
- resolution reduction processing is performed stepwise from the third hierarchy to the first hierarchy. High resolution processing is performed.
- the first intermediate feature map 41b extracted by the convolution layer 44a is input to the convolution layer 54h.
- the first intermediate feature map 41b extracted by the pooling layer 44d is input to the convolution layer 54f.
- the first intermediate feature map 41b extracted by the pooling layer 44f is input to the convolution layer 54d.
- an intermediate feature map may be transferred between layers forming a pair.
- An intermediate feature map may be input to the second submodel 50 . That is, in Unet, an intermediate feature map may be passed to a layer other than the paired layer. This method also makes it easier to recover the spatial resolution when performing upsampling.
- the learning model 30 as shown in FIG. This indicates that resolution enhancement processing is performed so that the second output image 52 has a resolution higher than that of the learning input image 21 . That is, (2) the first sub-model 40 performs feature extraction and resolution reduction processing, and the second sub-model 50 performs resolution reduction so that the second output image 52 has a higher resolution than the learning input image 21.
- An example of a learning model 30 that performs processing is shown. In this case, the resolution of the first intermediate feature map extracted from the convolution layer 44 a of the first sub-model 40 may be increased and input to the convolution layer 54 h of the second sub-model 50 .
- the learning model 30 as shown in FIG. 13, by reducing the number of the upsampling layers 54c, 54e of the second submodel 50 than the number of the pooling layers 44b, 44d, 44f of the first submodel 40, This indicates that the second output image 52 is subjected to resolution enhancement processing so that it has a lower resolution than the learning input image 21 . That is, (3) the first sub-model 40 performs feature extraction and resolution reduction processing so that the second output image 52 has a lower resolution than the learning input image 21 in the second sub-model 50 (however, 2 shows an example of the learning model 30 that performs resolution enhancement processing so that the resolution of the second output image 52 is higher than that of the first output image 42 .
- the input layer 43, the first intermediate layer 44 that performs feature extraction to extract the first feature map 41, the first feature map 41 based on the first feature map 41 A first output layer 45 for outputting a first output image 42 and a first feature map 41 are input, and a second intermediate layer 45 for extracting a second feature map 51 by performing resolution enhancement processing on at least the first feature map 41.
- the configuration includes the layer 54 and the second output layer 55 that outputs the second output image 52 based on the second feature map 51
- the learning model 30 may have one machine learning model.
- an intermediate layer and an output layer for feature extraction are provided before the intermediate layer for high resolution processing, and another output layer is provided after the intermediate layer for high resolution processing.
- the learning input image 21 and the inference input image 121 are preferably medical images.
- a medical image is an image that is acquired by a modality 15 such as an endoscope, a radiographic apparatus, an ultrasonic imaging apparatus, a nuclear magnetic resonance apparatus, and used for diagnosis by a doctor or the like.
- a modality 15 such as an endoscope, a radiographic apparatus, an ultrasonic imaging apparatus, a nuclear magnetic resonance apparatus, and used for diagnosis by a doctor or the like.
- a modality 15 such as an endoscope, a radiographic apparatus, an ultrasonic imaging apparatus, a nuclear magnetic resonance apparatus, and used for diagnosis by a doctor or the like.
- radiation images such as X-ray images, CT (Computed Tomography) images, ultrasound images, MRI (Magnetic Resonance Imaging) images, and the like.
- a learning model 30 that has been trained using a medical image as a learning input image 21 is used as a learned model 13, and furthermore, a medical image is used as an inference input image 121 and inference is performed using the learned model 13 to perform inference on a medical image.
- the accuracy of diagnosis can be improved by recognizing the region of interest with high accuracy and speed, and by supporting the diagnosis performed by the user who is a doctor.
- the learning device 11 of this example can perform learning so as to increase the output accuracy even in the medical field, where the amount of image data used as the learning data set 20 generally tends to be small.
- the learning input image 21 and the inference input image 121 may be images other than medical images.
- it may be an image including a road, a car, and a person as subjects, which is obtained by using a drive recorder as the modality 15 .
- the inference input image 121 is preferably an image acquired in chronological order.
- the modality 15 is a flexible endoscope inserted into the gastrointestinal tract of a patient
- the inference input image 121 is acquired in chronological order while the doctor moves the tip of the endoscope from the rectum to the ileocecal region.
- 1 is an endoscopic image of the surface of the mucosal membrane of the gastrointestinal tract.
- the modality 15 is an ultrasonic diagnostic imaging apparatus that emits ultrasonic waves by bringing a probe into contact with the skin of the patient's abdomen
- the inference input image 121 is an ultrasonic image.
- An ultrasound image is a medical image that is acquired while changing in time series according to patient's respiration and heartbeat.
- the inference result image 142 output by the trained model 13 of the inference device 12 is sent to the notification control unit 80 of the image processing device 10 (see FIG. 6).
- the notification control unit 80 includes a notification information generation unit 90 and a notification image generation unit 100, as shown in FIG.
- the notification information generation unit 90 generates notification information based on information obtained by extracting the features of the inference input image 121 included in the inference result image 142 .
- the notification information is information indicating at which position in the inference input image 121 the region of interest, which is the feature extracted from the trained model 13, is included.
- the notification image generation unit 100 uses notification information to generate a notification image that is an image that displays the notification information.
- the notification image is preferably a superimposed image obtained by superimposing notification information on the image acquired by the modality 15 .
- a sub-image which is an image that displays notification information at a position different from the position where the image acquired by the modality 15 is displayed.
- the image acquired by the modality 15 is preferably the inference input image 121 or an image acquired after the inference input image 121 in chronological order.
- the output of the inference result image 142 is performed substantially simultaneously with the acquisition of the inference input image 121, the position of the attention area indicated by the notification information is chronologically later than the inference input image 121 (in particular, after several frames). (immediately after) is almost unchanged in the acquired images. Therefore, even if a notification image (superimposed image or sub-image) is generated using an image acquired after the input image for inference 121 in chronological order and notification information, the user can still see the region of interest included in the notification information. position can be recognized.
- the notification information is preferably position information of a specific shape surrounding a region showing features included in the inference input image 121 transmitted from the modality 15 .
- a specific shape is, for example, a bounding box surrounding a region of interest.
- the shape of the specific shape is not limited to a rectangle, and may be an ellipse or a polygon.
- the display mode such as the color of the specific shape may be set arbitrarily, or may be set automatically.
- the display mode such as the shape and color of the specific shape may be different for each class.
- class labels such as "polyp” and "inflammation” may be displayed near the specific shape.
- FIG. 15 is used to illustrate the case where the notification image is a superimposed image.
- An inference result image 142 is output as the first output image 42 by inputting the inference input image 121 to the trained model 13 .
- the inference result image 142 includes a region of interest 142a as the extracted feature 121a.
- outputting an inference result image 142 having a resolution lower than that of the inference input image 121 is indicated by the size of the inference result image 142 being small.
- the feature 121a of the inference input image 121 that has been subjected to the resolution reduction processing indicates that it is classified as a region of interest 142a.
- the notification information generation unit 90 generates notification information 91 from the inference result image 142 .
- the notification information 91 is position information of a rectangle 91a surrounding the extracted attention area 142a.
- the region of interest 142a is indicated by a dashed line for explanation, but the notification information generation unit 90 generates as the notification information 91 only the position information of the rectangle 91a.
- the generated notification information 91 is transmitted to the notification image generation unit 100 . Furthermore, the image from the modality 15 (the input image for inference 121 or an image acquired after the input image for inference 121 in time series) is transmitted to the notification image generation unit 100 .
- the notification image generation unit 100 superimposes the notification information 91 on the image from the modality 15 to generate a superimposed image 101 as shown in FIG. Position information of a rectangle 91 a is superimposed as notification information 91 on the superimposed image 101 .
- the superimposed image 101 is transmitted to the display control unit 110 (see FIG. 6).
- the display control unit 53 controls the display of the notification image generated by the notification image generation unit 100 on the display 16 (see FIG. 6). Finally, the display 16 displays a notification image that can be visually recognized by the user.
- the notification information 91 By displaying the notification information 91 as the superimposed image 101 on the display 16 as in the above example, the notification information can be recognized without moving the user's line of sight.
- the notification image 103 generated by the notification image generation unit 100 includes, as shown in FIG. and a sub-section 103b displaying a sub-image 104 which is the image displaying the rectangle 91a).
- the main section 103a and the sub section 103b may have any positional relationship as long as they are located at mutually different positions on the notification image 103 . Also, the sizes of the main section 103a and the sub-section 103b can be set arbitrarily.
- the notification image 103 is transmitted to the display control section 110 .
- the notification information 91 it may not be preferable to superimpose the notification information on the image from the modality 15 displayed on the display 16. For example, if the user is a doctor, he or she may want to carefully observe an image containing a region of interest such as a lesion. In such a situation, if notification information is superimposed on the image, it rather hinders the user's observation. Therefore, by displaying the notification information 91 as a sub-image as in the above modified example, it is possible to display the position information of the attention area to be observed without interfering with the user's observation.
- FIG. 18 shows a modification in which positional information of small regions classified as regions of interest from the input image for inference 121 is generated as notification information, and a notification image indicating the positional information of the small regions is generated in a specific color.
- a description will be given using the specific example shown.
- First, an example of generating a superimposed image as a notification image will be described. In this case also, similarly to the example shown in FIG. 15, by inputting the inference input image 121 to the trained model 13, the inference result image 142 including the attention area 142a as the extracted feature 121a is output and notified. It is transmitted to the information generator 90 .
- the notification information generating unit 90 generates, as notification information 92, position information of the small area 92a that is the extracted attention area 142a.
- the notification image generation unit 100 superimposes an image in which the positional information of the small area 92a as the notification information 92 is expressed in a specific color on the image from the modality 15 to generate a superimposed image 101.
- FIG. On the superimposed image 101 position information of a small area 92a shown in a specific color is superimposed as notification information 92.
- FIG. The position information of the small area 92a shown in a specific color is preferably superimposed by adjusting the transparency so that the image from the modality 15, which is the background, can be seen through.
- the superimposed image 101 is transmitted to the display control section 110 .
- the color as the specific color can be arbitrarily set according to the modality 15 . With the above configuration, it is possible for the user to recognize the attention area as a color distribution.
- notification information 92 which is position information of a small area 92a shown in a specific color
- the flow until the notification information 92 and the image from the modality 15 are transmitted to the notification image generation unit 100 is the same as the example described using FIG.
- the notification image 103 as shown in FIG. 20, the image 15a from the modality 15 is displayed in the main section 103a, and the notification information 92 is displayed as the sub-image 104 in the sub section 103b.
- the sub-image 104 is preferably a mini-map showing the positional information of the small area 92a in a specific color.
- the learning input image 21 is input to the first sub-model 40 of the learning model 30 (step ST101).
- a first feature map 41 is extracted from the learning input image 21 using the first sub-model 40 (step ST102), and a first output image 42 is output based on the first feature map 41 (step ST103).
- the first feature map 41 is input to the second submodel 50 (step ST104).
- a second feature map 51 is extracted from the first feature map 41 using the second sub-model 50 (step ST105), and a second output image 52 having a higher resolution than the first output image 42 is produced based on the second feature map 51 It is output (step ST106).
- the evaluation unit 60 uses the second output image 52 to calculate the evaluation result 61 (step ST107).
- the update unit 70 updates the parameters of the learning model 30 using the evaluation result 61 (step ST108). Through repeated updating, the learning model 30 is generated as the learned model 13 (step ST109).
- the inference processing of the trained model 13 is performed, and an inference result image 142 is obtained from the trained model 13.
- a first output image 42 is output (step ST111).
- image refers to image data.
- the image data includes an input image for learning 21, a correct image for learning 22, an input image for inference 121, an inference result image 142, a first output image 42, a second output image 52, a first feature map 41, and a second feature map. 51, the first intermediate feature map, the second intermediate feature map, the correct label image, the first correct label image 24, the second correct label image 25, the image from the modality 15, the notification images 101 and 103, and the sub-image 104. included.
- a control unit configured by a processor implements the functions of the learning device 11, the inference device 12, the notification control unit 80, and the display control unit 110 by operating a program incorporated in a program storage memory. do.
- the learning device 11 may be separated from the image processing device 10. In this case, the learning device 11 is provided with a first control unit configured by a processor, and the image processing device 10 is provided with a second control unit configured by a processor. may be provided.
- the hardware structure of the learning device 11, the reasoning device 12, the notification control unit 80, the display control unit 110, and the processing unit that executes various processes such as the control unit is as follows.
- Various processors as shown.
- Various processors include CPU (Central Processing Unit), FPGA (Field Programmable Gate Array), etc., which are general-purpose processors that run software (programs) and function as various processing units.
- Programmable Logic Devices PLDs
- PLDs Programmable Logic Devices
- dedicated electric circuits which are processors with circuit configurations specifically designed to perform various types of processing.
- One processing unit may be composed of one of these various processors, or composed of a combination of two or more processors of the same type or different types (for example, a plurality of FPGAs or a combination of a CPU and an FPGA).
- a plurality of processing units may be configured by one processor.
- a plurality of processing units may be configured by one processor.
- this processor functions as a plurality of processing units.
- SoC System On Chip
- SoC System On Chip
- the various processing units are configured using one or more of the above various processors as a hardware structure.
- the hardware structure of these various processors is, more specifically, an electric circuit in the form of a combination of circuit elements such as semiconductor elements.
- the hardware structure of the storage unit is a storage device such as an HDD (hard disc drive) or SSD (solid state drive).
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Health & Medical Sciences (AREA)
- Software Systems (AREA)
- Databases & Information Systems (AREA)
- Multimedia (AREA)
- Computing Systems (AREA)
- Medical Informatics (AREA)
- General Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Computational Linguistics (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Data Mining & Analysis (AREA)
- Molecular Biology (AREA)
- General Engineering & Computer Science (AREA)
- Mathematical Physics (AREA)
- Surgery (AREA)
- Radiology & Medical Imaging (AREA)
- Pathology (AREA)
- Optics & Photonics (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Heart & Thoracic Surgery (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Image Analysis (AREA)
- Image Processing (AREA)
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2024500973A JPWO2023157439A1 (https=) | 2022-02-18 | 2022-12-13 | |
| US18/805,537 US20240404251A1 (en) | 2022-02-18 | 2024-08-15 | Image processing apparatus, operation method therefor, inference apparatus, and learning apparatus |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2022024090 | 2022-02-18 | ||
| JP2022-024090 | 2022-02-18 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US18/805,537 Continuation US20240404251A1 (en) | 2022-02-18 | 2024-08-15 | Image processing apparatus, operation method therefor, inference apparatus, and learning apparatus |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023157439A1 true WO2023157439A1 (ja) | 2023-08-24 |
Family
ID=87578038
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/045861 Ceased WO2023157439A1 (ja) | 2022-02-18 | 2022-12-13 | 画像処理装置及びその作動方法、推論装置並びに学習装置 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20240404251A1 (https=) |
| JP (1) | JPWO2023157439A1 (https=) |
| WO (1) | WO2023157439A1 (https=) |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2017059090A (ja) * | 2015-09-18 | 2017-03-23 | ヤフー株式会社 | 生成装置、生成方法、及び生成プログラム |
| US20190050667A1 (en) * | 2017-03-10 | 2019-02-14 | TuSimple | System and method for occluding contour detection |
| WO2020003434A1 (ja) * | 2018-06-28 | 2020-01-02 | 株式会社島津製作所 | 機械学習方法、機械学習装置、及び機械学習プログラム |
| JP2020154562A (ja) * | 2019-03-19 | 2020-09-24 | 大日本印刷株式会社 | 情報処理装置、情報処理方法及びプログラム |
| JP2020204863A (ja) * | 2019-06-17 | 2020-12-24 | 富士フイルム株式会社 | 学習装置、学習装置の作動方法、および学習装置の作動プログラム |
| US20210142107A1 (en) * | 2019-11-11 | 2021-05-13 | Five AI Limited | Image processing |
| JP2021513697A (ja) * | 2018-02-07 | 2021-05-27 | インターナショナル・ビジネス・マシーンズ・コーポレーションInternational Business Machines Corporation | 完全畳み込みニューラル・ネットワークを用いた心臓ctaにおける解剖学的構造のセグメンテーションのためのシステム |
-
2022
- 2022-12-13 WO PCT/JP2022/045861 patent/WO2023157439A1/ja not_active Ceased
- 2022-12-13 JP JP2024500973A patent/JPWO2023157439A1/ja active Pending
-
2024
- 2024-08-15 US US18/805,537 patent/US20240404251A1/en active Pending
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2017059090A (ja) * | 2015-09-18 | 2017-03-23 | ヤフー株式会社 | 生成装置、生成方法、及び生成プログラム |
| US20190050667A1 (en) * | 2017-03-10 | 2019-02-14 | TuSimple | System and method for occluding contour detection |
| JP2021513697A (ja) * | 2018-02-07 | 2021-05-27 | インターナショナル・ビジネス・マシーンズ・コーポレーションInternational Business Machines Corporation | 完全畳み込みニューラル・ネットワークを用いた心臓ctaにおける解剖学的構造のセグメンテーションのためのシステム |
| WO2020003434A1 (ja) * | 2018-06-28 | 2020-01-02 | 株式会社島津製作所 | 機械学習方法、機械学習装置、及び機械学習プログラム |
| JP2020154562A (ja) * | 2019-03-19 | 2020-09-24 | 大日本印刷株式会社 | 情報処理装置、情報処理方法及びプログラム |
| JP2020204863A (ja) * | 2019-06-17 | 2020-12-24 | 富士フイルム株式会社 | 学習装置、学習装置の作動方法、および学習装置の作動プログラム |
| US20210142107A1 (en) * | 2019-11-11 | 2021-05-13 | Five AI Limited | Image processing |
Also Published As
| Publication number | Publication date |
|---|---|
| US20240404251A1 (en) | 2024-12-05 |
| JPWO2023157439A1 (https=) | 2023-08-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111815766B (zh) | 基于2d-dsa图像重建血管三维模型处理方法及系统 | |
| JP7019815B2 (ja) | 学習装置 | |
| CN113506334A (zh) | 基于深度学习的多模态医学图像融合方法及系统 | |
| Yoshimi et al. | Image preprocessing with contrast-limited adaptive histogram equalization improves the segmentation performance of deep learning for the articular disk of the temporomandibular joint on magnetic resonance images | |
| CN113361689B (zh) | 超分辨率重建网络模型的训练方法和扫描图像处理方法 | |
| Singh et al. | Deep LF-Net: Semantic lung segmentation from Indian chest radiographs including severely unhealthy images | |
| JP7456928B2 (ja) | 胸部x線画像の異常表示制御方法、異常表示制御プログラム、異常表示制御装置、及びサーバ装置 | |
| CN116649995B (zh) | 基于颅内医学影像的血流动力学参数获取方法和装置 | |
| JP2023540950A (ja) | 病変セグメンテーションのためのアテンションを伴うマルチアーム機械学習モデル | |
| Li et al. | Inverted papilloma and nasal polyp classification using a deep convolutional network integrated with an attention mechanism | |
| JP2020062355A (ja) | 画像処理装置、データ生成装置及びプログラム | |
| Chi et al. | Low-dose CT image super-resolution with noise suppression based on prior degradation estimator and self-guidance mechanism | |
| CN112562058A (zh) | 一种基于迁移学习的颅内血管模拟三维模型快速建立方法 | |
| CN116934722B (zh) | 一种基于自校正坐标注意力的小肠微小目标检测方法 | |
| Sumathi et al. | Efficient two stage segmentation framework for chest x-ray images with u-net model fusion | |
| EP3928285B1 (en) | Systems and methods for calcium-free computed tomography angiography | |
| CN120807286A (zh) | 消化道气钡双重对比造影影像优化的超分辨率重建方法 | |
| Timothy et al. | Spectral bandwidth recovery of optical coherence tomography images using deep learning | |
| WO2023157439A1 (ja) | 画像処理装置及びその作動方法、推論装置並びに学習装置 | |
| Chen et al. | Denoising, segmentation and volumetric rendering of optical coherence tomography angiography (octa) image using deep learning techniques: a review | |
| CN109829921B (zh) | 一种头部的ct图像的处理方法及其系统、设备、存储介质 | |
| CN112508881A (zh) | 一种颅内血管图像配准方法 | |
| Kumar et al. | Enhancement of Low-Quality Images Using Image Super-Resolution | |
| Gatoula et al. | Enhanced CNN-based gaze estimation on wireless capsule endoscopy images | |
| TWI883424B (zh) | 醫學影像處理方法及系統 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22927325 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2024500973 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 22927325 Country of ref document: EP Kind code of ref document: A1 |