WO2023132029A1 - 情報処理装置、情報処理方法及びプログラム - Google Patents
情報処理装置、情報処理方法及びプログラム Download PDFInfo
- Publication number
- WO2023132029A1 WO2023132029A1 PCT/JP2022/000215 JP2022000215W WO2023132029A1 WO 2023132029 A1 WO2023132029 A1 WO 2023132029A1 JP 2022000215 W JP2022000215 W JP 2022000215W WO 2023132029 A1 WO2023132029 A1 WO 2023132029A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- record
- prediction
- record pair
- importance
- pair
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images












Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/21—Design, administration or maintenance of databases
- G06F16/215—Improving data quality; Data cleansing, e.g. de-duplication, removing invalid entries or correcting typographical errors
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
Definitions
- the present invention relates to technology for predicting the identity of record pairs.
- a process of identifying and correlating combinations of identical or similar records from records stored in different tables is performed. Such processing is also called name identification processing.
- Name identification processing enables unified management of tables and expansion of data.
- Techniques for matching by machine learning or rule base exist as techniques for name identification processing.
- Patent Literature 1 and Non-Patent Literature 1 describe techniques for performing name identification processing by machine learning.
- the name identification processing device described in Patent Document 1 includes an information processing device, a storage unit, and an operation terminal. This name identification processing apparatus calculates the similarity of record pairs using a plurality of similarity functions for calculating the similarity of record pairs, and learns the similarity weights by machine learning using training data.
- One aspect of the present invention has been made in view of the above problems, and an example of its purpose is to provide a technique that can more preferably predict the identity of a record pair.
- An information processing apparatus includes acquisition means for acquiring a record pair, similarity calculation means for calculating a plurality of degrees of similarity for the record pair using a plurality of similarity functions, and and a prediction means for predicting the identity of the record pair using the importance determined according to the record pair by referring to the plurality of similarities; and an output means for outputting a prediction result of the prediction means.
- an information processing apparatus includes acquisition means for acquiring training data including a plurality of pairs of record pairs and labels relating to the identity of the record pairs, and a plurality of similarity pairs for prediction target record pairs.
- acquisition means for acquiring training data including a plurality of pairs of record pairs and labels relating to the identity of the record pairs, and a plurality of similarity pairs for prediction target record pairs.
- Prediction means for predicting the identity of a record pair to be predicted using the determined importance, at least one of the one or more parameters included in the importance calculation model used to calculate the importance, and parameter generation means for generating with reference to the training data.
- an information processing method includes acquiring a record pair, calculating a plurality of degrees of similarity for the record pair using a plurality of similarity functions, the record pair, referring to the plurality of degrees of similarity and performing identity prediction of the record pair using an importance determined according to the record pair; and outputting a prediction result of the identity prediction of the record pair. ,including.
- an information processing method includes acquiring training data including a plurality of sets of record pairs and labels relating to the identity of the record pairs, and obtaining a plurality of similarities for the record pairs to be predicted. Determined according to the prediction target record pair by referring to one or more parameters of each of a plurality of similarity functions for calculating the prediction target record pair and the plurality of similarities The prediction means for predicting the identity of the record pair to be predicted using the importance, at least one of the one or more parameters of the importance calculation model used to calculate the importance, and generating with reference to training data.
- a manufacturing method includes obtaining training data including a plurality of sets of record pairs and labels relating to the identity of the record pairs, and calculating a plurality of similarities for the record pairs to be predicted.
- the prediction target using the importance determined according to the prediction target record pair generating at least one of the importance calculation models used for calculating the importance by the prediction means for performing identity prediction of the record pair with reference to the training data.
- a program provides a computer with an acquisition process of acquiring a record pair, a similarity calculation process of calculating a plurality of similarities for the record pair using a plurality of similarity functions, Prediction processing for predicting the identity of the record pair by referring to the record pair and the plurality of degrees of similarity, using an importance level determined according to the record pair, and outputting a prediction result of the prediction processing. Execute output processing.
- a program provides a computer with an acquisition process for acquiring training data including a plurality of sets of record pairs and labels relating to the identity of the record pairs, and a plurality of prediction target record pairs.
- the identity of record pairs can be predicted more favorably.
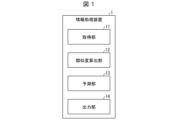
- FIG. 1 is a block diagram showing the configuration of an information processing apparatus according to Exemplary Embodiment 1;
- FIG. FIG. 3 is a flow diagram showing the flow of an information processing method according to exemplary embodiment 1;
- 1 is a block diagram showing the configuration of an information processing apparatus according to Exemplary Embodiment 1;
- FIG. 3 is a flow diagram showing the flow of an information processing method according to exemplary embodiment 1;
- FIG. 9 is a block diagram showing the configuration of an information processing apparatus according to Exemplary Embodiment 2;
- FIG. 10 is a diagram showing specific examples of first data and second data according to exemplary embodiment 2;
- FIG. 10 is a flow diagram showing the flow of an information processing method according to exemplary embodiment 2;
- FIG. 10 is a diagram showing a specific example of integrated data according to exemplary embodiment 2;
- FIG. 12 is a block diagram showing the configuration of an information processing apparatus according to exemplary embodiment 3;
- FIG. 11 is a flow diagram showing the flow of an information processing method according to exemplary embodiment 3;
- FIG. 12 is a block diagram showing the configuration of an information processing apparatus according to Exemplary Embodiment 4;
- FIG. 12 is a diagram showing a screen display example according to exemplary embodiment 4;
- 1 is a block diagram showing the configuration of a computer functioning as an information processing device according to each exemplary embodiment;
- FIG. 1 is a block diagram showing the configuration of an information processing device 1.
- the information processing device 1 is a device that performs identity prediction of record pairs.
- the information processing device 1 includes an acquisition unit 11 , a similarity calculation unit 12 , a prediction unit 13 and an output unit 14 .
- Acquisition unit 11 acquires a record pair.
- a record pair is a set of multiple records.
- a record is, for example, a row of a table and includes a set of one or more attribute names and attribute values corresponding to columns of the table.
- the number of records included in a record pair may be two, or three or more.
- a record pair is, for example, a set of records included in the first table and records included in the second table.
- the first table and the second table are, for example, tables that store customer information of businesses or tables that store product information.
- the first table and the second table are not limited to the examples described above, and may be other tables. Also, the first table and the second table may be the same or different.
- the similarity calculation unit 12 calculates a plurality of degrees of similarity for the record pair acquired by the acquisition unit 11 using a plurality of similarity functions. In other words, the similarity calculation unit 12 calculates k similarities for one record pair using k (where k is an integer of 2 or more) similarity functions ⁇ i (1 ⁇ i ⁇ k). .
- the similarity function ⁇ i is a function for calculating the similarity between records included in a record pair.
- the similarity function ⁇ i is also called a “similarity calculation model”.
- the input of the similarity function ⁇ i is a record pair
- the output of the similarity function ⁇ i is the similarity between records included in the record pair.
- a plurality of similarity functions ⁇ i may be objects of learning by the information processing device 2, which will be described later.
- the method of machine learning of the similarity function ⁇ i is not limited, and as an example, a decision tree-based, linear regression, or neural network method may be used. , or two or more of these techniques may be used.
- Decision tree bases include, for example, LightGBM (Light Gradient Boosting Machine), Random Forest, and XGBoost.
- Linear regression includes, for example, Bayesian regression, support vector regression, Ridge regression, Lasso regression, and ElasticNet.
- Neural networks include, for example, deep learning.
- the similarity function ⁇ i outputs a numerical value between 0 and 1 as similarity.
- the Jaccard coefficient can be used as the similarity function ⁇ i .
- the Jaccard coefficients compute
- the similarity function ⁇ i for example, the method described in Non-Patent Document 1 may be used.
- the similarity function ⁇ i for example, 2016” (hereinafter referred to as “Non-Patent Document 2”) may be used.
- the similarity function ⁇ i is not limited to the example described above, and other methods may be used to calculate the similarity between record pairs.
- the prediction unit 13 refers to the record pair and a plurality of degrees of similarity, and performs identity prediction of the record pair using the importance determined according to the record pair.
- the importance is calculated by referring to record pairs, for example. More specifically, as an example, the prediction unit 13 calculates the importance using an importance calculation model for calculating the importance. In this case, the input of the importance calculation model is a record pair. Also, the output of the importance calculation model is the importance.
- the importance calculation model can be a target of learning by the information processing device 2, which will be described later.
- the machine learning method of the importance calculation model is not limited, and as an example, a decision tree-based, linear regression, or neural network method may be used, and , two or more of these techniques may be used.
- the importance calculation model is generated using, for example, language models such as BERT (Bidirectional encoder representations from Transformers), fastText, word2vec, tf-idf, BM25, and the like.
- the importance calculation model may include a language model.
- a specific example of importance calculation processing when using a language model will be described.
- the prediction unit 13 converts the record pair into a vector using a language model, and further converts this vector into a vector on another feature amount space. Further, the prediction unit 13 inputs this vector to a k-class classifier (softmax function, etc.) to calculate k importances. Each of the k calculated degrees of importance corresponds to each of the k similarity functions ⁇ i .
- the method of calculating the degree of importance is not limited to the example described above, and the prediction unit 13 may calculate the degree of importance using another method.
- the prediction unit 13 may calculate the importance by rule-based processing.
- the prediction unit 13 may calculate the degree of importance by referring to a table that associates the degree of importance with information about record pairs.
- the information about the record pair may include, for example, the feature amount of the records included in the record pair, the classification result of the record, the name of the record, or the like.
- the prediction unit 13 predicts the identity of a record pair using a linear sum of a plurality of degrees of similarity calculated by the similarity calculation unit 12, with each degree of importance as a weighting factor.
- the method by which the prediction unit 13 performs identity prediction is not limited to the method using the linear sum, and the prediction unit 13 may perform identity prediction for record pairs by other methods.
- the prediction unit 13 may perform identity prediction of record pairs by inputting record pairs and similarities into a prediction model generated by machine learning.
- the input of the prediction model includes k similarity sets and record pairs, as an example.
- the output of the predictive model includes, as an example, a predictive result of identity.
- the prediction unit 13 calculates the parameter of the prediction model as the degree of importance.
- the method of machine learning of the prediction model is not limited, and as an example, a decision tree-based, linear regression, or neural network method may be used, or two or more of these methods may be used. .
- the output unit 14 outputs the result of prediction by the prediction unit 13 .
- the prediction result includes, for example, information indicating whether the records included in the record pair are the same or information indicating the degree of similarity of the records included in the record pair.
- the prediction result by the prediction unit 13 is used, for example, for table integration processing or information search processing.
- the prediction unit 13 performs identity prediction for a record pair of a record as a search key (for example, a record specified by a user) and any other record registered in a predetermined table. good too.
- the information processing apparatus 1 may output records included in the record pair predicted to be identical by the prediction unit 13 as the search result. This enables search processing in a table that is not associated with a record that is a search key.
- ⁇ Effects of information processing device 1> As described above, in the information processing apparatus 1 according to this exemplary embodiment, a plurality of similarities are calculated using a plurality of similarity functions for a record pair, and the record pair and the plurality of similarities are referred to. Therefore, a configuration is adopted in which identity prediction of a record pair is performed using an importance determined according to the record pair.
- identity prediction of a record pair is performed using an importance determined according to the record pair.
- the result of identity prediction based on multiple similarities is not based on a uniform method, but reflects the importance of each record pair. . Therefore, according to the information processing apparatus 1 according to the present exemplary embodiment, it is possible to more preferably predict the identity of a record pair.
- FIG. 2 is a flow diagram showing the flow of the information processing method S1.
- the acquisition unit 11 acquires a record pair.
- the similarity calculator 12 calculates a plurality of degrees of similarity for a pair of records using a plurality of similarity functions.
- the prediction unit 13 refers to the record pair and a plurality of degrees of similarity, and performs identity prediction of the record pair using the importance determined according to the record pair.
- the output unit 14 outputs the result of prediction by the prediction unit 13 .
- ⁇ Effect of information processing method S1> As described above, in the information processing method S1 according to the present exemplary embodiment, a plurality of similarities are calculated using a plurality of similarity functions for a record pair, and the record pair and the plurality of similarities are referred to. Therefore, a configuration is adopted in which identity prediction of a record pair is performed using an importance determined according to the record pair. Therefore, according to the information processing method S1 according to the present exemplary embodiment, it is possible to more preferably predict the identity of a record pair.
- FIG. 3 is a block diagram showing the configuration of the information processing device 2.
- the information processing device 2 is a device that generates parameters used for predicting the identity of a record pair.
- the information processing device 2 includes an acquisition unit 21 and a parameter generation unit 22 .
- the acquisition unit 21 acquires training data that includes a plurality of sets of record pairs and labels relating to the identity of the record pairs.
- the identity label indicates, for example, whether or not the records included in the record pair are the same.
- the parameter generation unit 22 generates (i) one or more parameters of each of a plurality of similarity functions ⁇ i for calculating a plurality of similarities for the record pair to be predicted, and (ii) the record pair to be predicted. and a plurality of similarities, and the prediction unit 13 that performs identity prediction of the prediction target record pair using the importance determined according to the prediction target record pair uses to calculate the importance At least one of the one or more parameters included in the importance calculation model is generated with reference to the training data.
- training data including a plurality of pairs of record pairs and labels relating to the identity of the record pairs is acquired, and a plurality of pairs of records to be predicted are acquired.
- Prediction means for predicting the identity of a record pair to be predicted using importance, at least one of one or more parameters of an importance calculation model used for calculating importance, and training data.
- a configuration that refers to and generates is adopted. Therefore, according to the information processing apparatus 2 according to the present exemplary embodiment, it is possible to generate a parameter that can more preferably predict the identity of a record pair.
- FIG. 4 is a flow diagram showing the flow of the information processing method S2.
- the acquisition unit 21 acquires training data including a plurality of sets of record pairs and labels relating to the identity of the record pairs.
- the parameter generation unit 22 generates (i) one or more parameters of each of a plurality of similarity functions for calculating a plurality of similarities for the record pair to be predicted, and (ii) the prediction target A prediction means that refers to a record pair and a plurality of similarities and performs identity prediction of a record pair to be predicted using an importance determined according to the record pair to be predicted to calculate the importance At least one of the one or more parameters of the importance calculation model to be used is generated by referring to the training data.
- training data including a plurality of sets of record pairs and labels relating to the identity of the record pairs is acquired, and a plurality of pairs of records to be predicted are acquired.
- Prediction means for predicting the identity of a record pair to be predicted using importance, at least one of one or more parameters of an importance calculation model used for calculating importance, and training data.
- a configuration that refers to and generates is adopted. For this reason, according to the information processing method S2 according to the present exemplary embodiment, it is possible to obtain the effect of being able to generate a parameter that can more preferably predict the identity of a record pair.
- the information processing device 2 can also be specified as a device that executes the method of manufacturing a trained model.
- the method for producing a trained model includes acquiring training data including a plurality of pairs of record pairs and labels relating to the identity of the record pairs, generating any model with reference to the training data.
- FIG. 5 is a block diagram showing the configuration of the information processing device 1A according to this exemplary embodiment.
- the information processing apparatus 1A includes a control section 10A, a storage section 20A, a communication section 30A and an input/output section 40A.
- the communication unit 30A communicates with an external device of the information processing device 1A via a communication line.
- a communication line includes wireless LAN (Local Area Network), wired LAN, WAN (Wide Area Network), public line network, mobile data communication network, or a combination thereof.
- the communication unit 30A transmits data supplied from the control unit 10A to other devices, and supplies data received from other devices to the control unit 10A.
- Input/output unit 40A Input/output devices such as a keyboard, mouse, display, printer, and touch panel are connected to the input/output unit 40A.
- the input/output unit 40A receives input of various kinds of information from the connected input device to the information processing apparatus 1A. Also, the input/output unit 40A outputs various kinds of information to the connected output device under the control of the control unit 10A.
- an interface such as a USB (Universal Serial Bus) can be used as the input/output unit 40A.
- control unit 10A includes an acquisition unit 11, a similarity calculation unit 12, a prediction unit 13, an output unit 14, and an integration unit 15A.
- the acquisition unit 11 acquires first data x including the first record e included in the record pair and second data x' including the second record e' included in the record pair.
- the first data x and the second data x' are, for example, tables containing a plurality of records.
- e' ( a1 : v1 , a2 : v2 ,..., ad' : v'd' )
- v l ⁇ V l and v′ m ⁇ V′ m are attribute values, and V l and V′ m are, for example, a string space or a real number space.
- d is the number of attributes that record e has
- d' is the number of attributes that record e' has.
- the first record e and the second record e' each include multiple sets of attribute names and attribute values.
- FIG. 6 shows tables T1 and T2, which are specific examples of the first data x and the second data x'.
- Tables T1 and T2 are composed of rows and columns, with rows corresponding to records and columns corresponding to attributes.
- table T1 includes a plurality of first records e 1 , e 2 , .
- the table T2 also includes a plurality of second records e'1 , e'2 , . . .
- the attribute value of the attribute whose attribute name is "product name” is "potato chips”
- the attribute value of the attribute whose attribute name is "price” is "198".
- the attribute name and attribute value of table T1 and the attribute name and attribute value of table T2 may be the same or different.
- the record pair (e, e') acquired by the acquisition unit 11 is any of the first records e 1 , e 2 , . It is a pair with any one of records e'1 , e'2 , . . .
- the similarity calculator 12 calculates k similarities for one record pair (e, e′) using k (k is an integer of 2 or more) similarity functions ⁇ i (1 ⁇ i ⁇ k). Calculate si .
- k similarities s i The details of the process of calculating k similarities s i by the similarity calculator 12 will be described later.
- the prediction unit 13 refers to the record pair (e, e') and a plurality of similarities si , and uses the importance determined according to the record pair (e, e') to predict the identity of the record pair. I do.
- the prediction unit 13 includes an importance calculation unit 131A that calculates the importance by referring to the record pair (e, e'). Details of the identity prediction processing performed by the prediction unit 13 and the importance calculation processing performed by the importance calculation unit 131A will be described later.
- the output unit 14 outputs the result of prediction by the prediction unit 13 .
- the prediction result includes, for example, information indicating whether or not the records included in the record pair are the same. Also, the prediction result may include information indicating the degree of similarity between records included in a record pair.
- the output unit 14 may output the prediction result by writing it in the storage unit 20A or an external storage device, or output it to an output device (display device, printer, etc.) connected to the input/output unit 40A. good too. Moreover, the output unit 14 may output the prediction result by transmitting the prediction result to another device via the communication unit 30A.
- the integration unit 15A refers to the prediction result output by the output unit 14 and generates integrated data from the first data and the second data. The details of the integrated data generation processing performed by the integration unit 15A will be described later.
- the storage unit 20 ⁇ /b>A stores the first data x and the second data x′ acquired by the acquisition unit 11 and also stores the prediction result PR of the prediction unit 13 .
- a plurality of similarity functions ⁇ i , importance calculation models g, and parameters P are stored in the storage unit 20A.
- the similarity function ⁇ 1 is a function to calculate.
- the similarity function ⁇ i is input by, for example, the user of the information processing device 1A.
- the similarity function ⁇ i outputs a numerical value from 0 to 1 as similarity to the record pair (e, e′). In this case, for example, the closer the output value is to 1, the higher the similarity, and the closer to 0, the lower the similarity.
- the similarity function ⁇ i is, for example, a function with learnable parameters.
- the importance calculation model g is a model used by the importance calculation unit 131A to calculate the importance.
- the importance calculation model g is generated using language models such as BERT, fastText, word2vec, tf-idf, BM25, etc., as shown in the first exemplary embodiment.
- the importance calculation model g may include a language model.
- the parameter P stored in the storage unit 20A is at least one of one or a plurality of parameters ⁇ i possessed by each of the k similarity functions ⁇ i and one or a plurality of parameters w possessed by the importance calculation model g. parameters.
- FIG. 7 is a flowchart showing the flow of an information processing method S1A, which is an example of the information processing method executed by the information processing apparatus 1A. Note that some steps may be performed in parallel or out of order. Also, the description of the already described contents will not be repeated.
- Step S101 the acquisition unit 11 acquires first data and second data.
- the acquisition unit 11 acquires first data and second data input by a user or the like of the information processing device 1A using an input device connected to the input/output unit 40A.
- the acquisition unit 11 may acquire the first data and the second data by receiving the first data and the second data from another device via the communication unit 30A.
- the acquisition unit 11 may acquire the first data and the second data by reading the first data and the second data from an externally connected storage device.
- the acquisition unit 11 stores the acquired first data and second data in the storage unit 20A.
- step S102 the acquisition unit 11 acquires the parameter P stored in the storage unit 20A.
- step S103 the acquisition unit 11 acquires the record pair (e, e') to be predicted.
- Step S104 the similarity calculator 12 calculates k similarities s i for the record pair (e, e′) using k similarity functions ⁇ i . Since the k similarity functions ⁇ i are different from each other, the calculated k similarities s i can also have different values. For example, in the case of a record pair of “ice” and “ice”, the similarity si calculated by changing the notation is a value indicating high similarity, while it is calculated by extracting a partial character string. The degree of similarity s i that is used is a value indicating that the similarity is low.
- the similarity si calculated by changing the notation is a value indicating that the similarity is low, while it is calculated by extracting the partial character string.
- the degree of similarity s i obtained is a value indicating that the similarity is high.
- step S105 the importance calculation unit 131A refers to the record pair (e, e') and calculates the importance g i for each of the plurality of similarities si. As an example, the importance calculation unit 131A calculates the importance g i using the importance calculation model g.
- the importance calculation model g is a model for calculating the importance g i for each of a plurality of similarities s i .
- the importance calculation model g is is represented.
- the sum of k importances ⁇ g(e, e′) ⁇ i calculated by the importance calculation model g is one.
- the importance calculation unit 131A converts the character strings of the attribute values of the first record e and the second record e' into vectors in the language model.
- the function serialize (e, e') that converts e, e') to a character string converts "[CLS] [COL] product name [VAL] potato chips [COL] price [VAL] 198 [SEP] [COL] product Name [VAL] Potato [COL] Rating [VAL] 5 [SEP]”.
- [CLS], [COL], [VAL], and [SEP] are symbols indicating the beginning of a sentence, attribute name, attribute value, and record delimiters, respectively.
- the importance calculation unit 131A converts the generated character string into a vector using a language model (eg, BERT). Subsequently, the importance calculation unit 131A converts the vector obtained by the language model into a new L-dimensional vector z by applying concatenation, summation, deep learning, or the like.
- a language model eg, BERT
- the importance calculation unit 131A converts the vector obtained by the language model into a new L-dimensional vector z by applying concatenation, summation, deep learning, or the like.
- the importance calculation unit 131A calculates k importances ⁇ g(e, e') ⁇ i by inputting the converted L-dimensional vector z to the k class classifier.
- the k-class classifier for example, techniques such as a linear classifier and deep learning are used.
- a k-class classifier for example, the technique described in the document "Robert A.
- the L-dimensional vector wi is an example of a learnable parameter w of the importance calculation model g.
- wi ⁇ T ⁇ z is the inner product of the L-dimensional vector wi and the L-dimensional vector z.
- Step S106 the prediction unit 13 predicts the identity of the record pair (e, e') using the similarity si calculated by the similarity calculation unit 12 and the record pair (e, e').
- the probability calculated by the prediction unit 13 indicates the result of prediction by integrating k similarities s i for the record pair (e, e′), and is a numerical value of 0 to 1, for example.
- the prediction unit 13 calculates the probability using a probability function h that receives the record pair (e, e') and the similarity si .
- the importance ⁇ g(e, e′) ⁇ i is the importance calculated by the importance calculation unit 131A
- the similarity s i ⁇ i (e, e′) is the similarity It is the similarity calculated for the record pair (e, e') by the degree function ⁇ i .
- the prediction unit 13 calculates a linear sum of a plurality of similarities s i with each importance ⁇ g(e, e′) ⁇ i as a weighting factor. are used to make identity predictions.
- the prediction result of the prediction unit 13 reflects not only the similarity s i but also the importance g i determined by the record pair. In this way, the method by which the prediction unit 13 predicts identity may differ depending on the record pair.
- step S107 In step S ⁇ b>107 , the output unit 14 outputs the prediction result of the prediction unit 13 . As an example, the output unit 14 stores the prediction result in the storage unit 20A.
- step S108 the prediction unit 13 determines whether identity prediction has been performed for all record pairs (e, e') to be predicted.
- the prediction unit 13 proceeds to the process of step S109.
- the prediction unit 13 returns to the process of step S103 and performs the same calculation for the next record pair (e, e'). make gender predictions. That is, the information processing device 1A executes the processes of steps S103 to S107 for all record pairs (e, e') to be predicted.
- step S109 the integration unit 15A refers to the prediction result output by the output unit 14 and generates integrated data from the first data and the second data.
- the integrated data includes, for example, a record obtained by integrating records included in a record pair predicted by the prediction unit 13 to be the same by the integration unit 15A.
- FIG. 8 is a diagram showing a table T3, which is an example of integrated data.
- Table T3 includes a plurality of records f 1 , f 2 , .
- a record f1 is a record obtained by integrating the first record e1 and the second record e'2 in FIG.
- a record f2 is a record obtained by integrating the first record e2 and the second record e'3 in FIG.
- Record f3 is a record obtained by integrating the first record e3 and the second record e'1 in FIG.
- the similarity functions ⁇ 1 to ⁇ 3 are used as the similarity functions ⁇ i ⁇ .
- the similarity function ⁇ 1 is a function for calculating the Jaccard coefficient of the product name of the record pair.
- the similarity function ⁇ 2 is a function for calculating the Jaccard coefficient after converting hiragana into katakana if the product name of the record pair is in hiragana.
- the similarity function ⁇ 3 is a function for calculating the similarity by the method described in Non-Patent Document 2 above.
- the similarity function ⁇ 3 has a learnable parameter ⁇ 3 .
- the similarity calculation unit 12 reads the parameter ⁇ 3 from the storage unit 20A and calculates the similarity s3 using the read parameter ⁇ 3 .
- the prediction unit 13 uses the function serialize(e, e') that connects the attribute name and attribute value of the record pair (e, e') to extract the character string "[CLS][ COL] Product Name [VAL] Soy Sauce Senbei [COL] Price [VAL] 268 [SEP] [COL] Product Name [VAL] Shoyu Senbei [COL] Rating [VAL] 4 [SEP]”. Also, the prediction unit 13 obtains an L-dimensional vector v, which is a vector representation of this character string, by BERT, which is a pretrained language model.
- w 1 , w 2 and w 3 are real vectors, and are examples of learnable parameters w of the importance calculation model g.
- step S107 the output unit 14 outputs the identity prediction result of the record pair (e, e').
- the above identity prediction and output are applied to all record pairs of the test data Dtest .
- the importance g i is calculated by referring to the record pair (e, e′), and the calculated importance g i is used to A configuration for performing identity prediction is adopted. Therefore, according to the information processing apparatus 1A according to the present exemplary embodiment, in addition to the effects of the information processing apparatus 1 according to the first exemplary embodiment, calculation is performed using the record pair (e, e') Identity prediction can be performed with importance g i taken into consideration, and the effect of more appropriately predicting identity of record pair (e, e′) can be obtained.
- the acquisition unit 11 further acquires the auxiliary data u
- the prediction unit 13 refers to the record pair (e, e′), the plurality of similarities s i and the auxiliary data u. Then, identity prediction of the record pair (e, e') may be performed using the importance g i determined according to the record pair (e, e') and the auxiliary data u.
- the auxiliary data u includes, for example, information indicating the name of the record, the feature amount of the record, and/or the classification result of the record (confectionery, person's name, etc.).
- the auxiliary data u may include, for example, information on records obtained from external data such as Wikipedia (registered trademark).
- the auxiliary data u may include, for example, the number of training data used in learning the parameter ⁇ of the similarity function ⁇ i and/or the parameter w of the importance calculation model g.
- the auxiliary data u is not limited to the above example, and may include other information.
- the auxiliary data u is, for example, a one-hot vector representing discrete information.
- auxiliary data u is input to the importance calculation model g in addition to the record pair (e, e').
- the auxiliary data u which is a vector, is concatenated with the L-dimensional vector z described above, and the concatenated vector and the parameter w are used to calculate the importance g i .
- the prediction unit 13 refers to the record pair (e, e'), the plurality of similarities si , and the auxiliary data u, and calculates the record pair (e, e') and the auxiliary data u Identity prediction of the record pair (e, e') is performed using the importance g i determined according to .
- the prediction unit 13 can further increase the accuracy of prediction of the identity of the record pair (e, e').
- FIG. 9 is a block diagram showing the configuration of an information processing device 1B according to this exemplary embodiment.
- the control unit 10A of the information processing apparatus 1B includes an acquisition unit 11, a similarity calculation unit 12, a prediction unit 13, an output unit 14, an integration unit 15A, and a learning unit 16B.
- the acquisition unit 11 obtains training data including a plurality of pairs of record pairs (e j , e′ j ) and labels y j relating to the identity of the record pairs (e j , e′ j ). Dtr is also obtained.
- the training data Dtr are used to learn the parameter P mentioned above.
- the training data Dtr is is expressed as where n is the total number of record pairs (e j , e′ j ).
- the label yj is, for example, '0' or '1'. "1" indicates that the first record ej and the second record e'j are the same, and "0" indicates that the first record ej and the second record e'j are the same. indicates that it is not
- the learning unit 16B calculates (i) one or more parameters ⁇ i of each of the plurality of similarity functions ⁇ i used by the similarity calculation unit 12 to calculate the similarity si, and (ii) importance calculation At least one parameter P of one or a plurality of parameters w included in the importance calculation model g used by the unit 131A to calculate the importance is generated with reference to the training data.
- the learning unit 16B is an example of the "parameter generating means" according to the present specification.
- FIG. 10 is a flow chart showing the flow of the information processing method S2B, which is an example of the information processing method executed by the information processing apparatus 1B. Note that some steps may be performed in parallel or out of order. Also, the description of the already described contents will not be repeated.
- step S201 the acquisition unit 11 acquires training data Dtr .
- the training data Dtr is input by the user of the information processing device 1B, as an example.
- step S202 the obtaining unit 11 obtains a plurality of similarity functions ⁇ i .
- the similarity function ⁇ i is input by the user of the information processing device 1B.
- Step S203 the learning unit 16B learns at least one of the parameter ⁇ i and the parameter w using the training data Dtr .
- the parameter ⁇ i is a set of parameters possessed by the similarity function ⁇ i .
- the parameter w is a set of parameters that the importance calculation model g has.
- the learning unit 16B optimizes the parameter ⁇ i and the parameter w using the objective function L, for example.
- An example of this optimization is represented.
- the evaluation index l is is. That is, the evaluation index l is the probability that the records included in the record pair (e j , e′ j ) of the training data D tr are identical (the output of the probability function h w ); a label y j of '0' or '1'; is an input and outputs a value of 0 or more.
- a cross-entropy error can be used as the evaluation index l.
- ⁇ is a non-negative hyperparameter.
- the hyperparameter ⁇ may be determined by the user or the like of the information processing device 1B, or may be a value automatically determined using a set of record pairs whose identity is known, different from the training data Dtr . good.
- ⁇ is a regularization term for the parameters, and the L2 norm may be used. It is also possible to fix the parameter ⁇ i in the above equation and optimize only the parameter w.
- the learning unit 16B stores the generated parameter w and parameter ⁇ i in the storage unit 20A.
- the parameter w and the parameter ⁇ i generated by the learning unit 16B are used in the similarity calculation unit 12 to calculate the similarity si and/or the prediction unit 13 to predict identity.
- Similarity functions ⁇ 1 to ⁇ 3 are used as the similarity functions ⁇ i ⁇ .
- the similarity functions ⁇ 1 to ⁇ 3 are similar to the similarity functions ⁇ 1 to ⁇ 3 shown in the example of the first illustrative embodiment above.
- the similarity function ⁇ 3 has a learnable parameter ⁇ 3 .
- step S201 the acquisition unit 11 acquires the training data Dtr . Further, in step S203 , the learning unit 16B, based on the cross- entropy error, sets the importance degree
- the parameter w of the calculation model g and the parameter ⁇ i of the similarity function ⁇ i are optimized using the stochastic gradient descent method.
- the optimized parameter w and parameter ⁇ i are stored in the storage unit 20A.
- the training data Dtr may include auxiliary data u.
- the training data Dtr is, as an example, is represented.
- the learning unit 16B optimizes the parameter w and the parameter ⁇ i using the training data Dtr including the auxiliary data u.
- FIG. 11 is a block diagram showing the configuration of an information processing device 1C according to this exemplary embodiment.
- the control unit 10A of the information processing device 1C includes an acquisition unit 11, a similarity calculation unit 12, a prediction unit 13, an output unit 14, a learning unit 16B, and a search result output unit 17C.
- the acquisition unit 11 acquires input data from the user as the first record e included in the record pair (e, e').
- Input data from the user is, for example, input by an input device (for example, a keyboard, a mouse, etc.) connected to the input/output unit 40A.
- an input device for example, a keyboard, a mouse, etc.
- the acquiring unit 11 acquires one of the plurality of records included in the target data as the second record e' included in the record pair (e, e').
- the target data is data to be searched, and includes, for example, one or more tables.
- the prediction unit 13 performs identity prediction for record pairs of the first record e and each of the plurality of records included in the target data.
- the search result output unit 17C refers to each prediction result PR output by the output unit 14, and outputs a search result based on the input data and having the target data as a search target.
- the search result output unit 17C outputs search results to an output device (display, printer, etc.) connected to the input/output unit 40A.
- the search result output unit 17C may output the search result by transmitting the search result to another device connected via the communication unit 30A.
- the search result output unit 17C may output the search result by storing the search result in the storage unit 20A or an external storage device.
- FIG. 12 is a diagram showing a specific example of screen display output by the search result output unit 17C.
- the input data is a character string entered by the user in the text box 51
- the target data are the tables T1 and T2 shown in FIG. 6 in the first exemplary embodiment.
- the prediction unit 13 performs identity prediction on record pairs of the first record e, which is the user's input data, and each of the records included in the table T1 and the record e' included in the table T2. Since the identity prediction processing performed by the prediction unit 13 has been described in the second exemplary embodiment, the description thereof will not be repeated.
- the search result output unit 17C refers to the prediction result PR of the prediction unit 13 and outputs search results 53 and 54 based on the input data.
- a search result 53 is a search result obtained by searching the table T1 using the character string "potato chips" as input data.
- a search result 54 is a search result obtained by searching the table T2 using the character string "potato chips" as input data.
- each prediction result output by the output unit 14 is referred to, and the search result based on the input data is the target data.
- a configuration is adopted in which the search results are output. Therefore, according to the information processing apparatus 1C according to the present exemplary embodiment, in addition to the effects of the information processing apparatus 1 according to the first exemplary embodiment, the search from the target data based on the input data is more preferably performed. You can get the effect of being able to
- the information processing device 1C can also be described as follows. Acquisition means for acquiring input data from a user and one of a plurality of records included in target data as a record pair; Similarity calculating means for calculating a plurality of similarities with respect to the record pair using a plurality of similarity functions; With respect to a record pair of the input data and each of a plurality of records included in the target data, the importance determined according to the record pair is determined by referring to the record pair and the plurality of similarities. a prediction means for predicting the identity of the record pair using an output means for outputting a search result based on the input data with reference to the prediction result by the prediction means and for the target data as a search target; Information processing device equipped with.
- Some or all of the functions of the information processing apparatuses 1, 1A, 1B, 1C, and 2 may be implemented by hardware such as integrated circuits (IC chips), It may be realized by software.
- the information processing device 1 and the like are implemented by, for example, a computer that executes instructions of a program that is software that implements each function.
- a computer that executes instructions of a program that is software that implements each function.
- An example of such a computer (hereinafter referred to as computer C) is shown in FIG.
- Computer C comprises at least one processor C1 and at least one memory C2.
- a program P for operating the computer C as the information processing apparatus 1 or the like is recorded in the memory C2.
- the processor C1 reads the program P from the memory C2 and executes it, thereby realizing each function of the information processing apparatus 1 and the like.
- processor C1 for example, CPU (Central Processing Unit), GPU (Graphic Processing Unit), DSP (Digital Signal Processor), MPU (Micro Processing Unit), FPU (Floating point number Processing Unit), PPU (Physics Processing Unit) , a microcontroller, or a combination thereof.
- memory C2 for example, a flash memory, HDD (Hard Disk Drive), SSD (Solid State Drive), or a combination thereof can be used.
- the computer C may further include a RAM (Random Access Memory) for expanding the program P during execution and temporarily storing various data.
- Computer C may further include a communication interface for sending and receiving data to and from other devices.
- Computer C may further include an input/output interface for connecting input/output devices such as a keyboard, mouse, display, and printer.
- the program P can be recorded on a non-temporary tangible recording medium M that is readable by the computer C.
- a recording medium M for example, a tape, disk, card, semiconductor memory, programmable logic circuit, or the like can be used.
- the computer C can acquire the program P via such a recording medium M.
- the program P can be transmitted via a transmission medium.
- a transmission medium for example, a communication network or broadcast waves can be used.
- Computer C can also obtain program P via such a transmission medium.
- (Appendix 1) an acquisition means for acquiring a record pair; Similarity calculating means for calculating a plurality of similarities with respect to the record pair using a plurality of similarity functions; a prediction unit that refers to the record pair and the plurality of similarities and performs identity prediction of the record pair using an importance determined according to the record pair; an output means for outputting a prediction result by the prediction means; Information processing device equipped with.
- the identity of record pairs can be predicted more appropriately.
- the acquisition means further acquires auxiliary data
- the prediction means refers to the record pair, the plurality of degrees of similarity, and the auxiliary data, and predicts the identity of the record pair using an importance determined according to the record pair and the auxiliary data. I do, The information processing device according to appendix 1.
- the importance is information that reflects not only the record pair but also the contents of the auxiliary data.
- the prediction means comprises importance calculation means for calculating the importance by referring to the record pair.
- the information processing device according to appendix 1 or 2.
- the accuracy of predicting the identity of a record pair can be further increased by predicting the identity of the record pair using the importance calculated by referring to the record pair.
- the importance calculating means calculates an importance for each of the plurality of similarities,
- the prediction means performs the identity prediction using a linear sum relating to the plurality of degrees of similarity, wherein each degree of importance is a weighting factor.
- the information processing device according to appendix 3.
- the acquisition means further acquires training data including a plurality of sets of record pairs and labels relating to the identity of the record pairs
- the information processing device is one or more parameters of each of the plurality of similarity functions used by the similarity calculation means to calculate the similarity; and one or more parameters of an importance calculation model used by the importance calculation means to calculate the importance; Further comprising parameter generation means for generating at least one parameter of with reference to the training data, The information processing device according to appendix 3 or 4.
- the identity of record pairs can be predicted more appropriately by using parameters generated by referring to training data.
- the information processing apparatus includes integration means for generating integrated data from the first data and the second data by referring to the prediction result output by the output means. 6.
- the information processing apparatus according to any one of Appendices 1 to 5.
- the first data and the second data can be more preferably integrated.
- the acquisition means is Obtaining input data from a user as a first record included in the record pair; obtaining one of a plurality of records included in the target data as a second record included in the record pair; the prediction means performs the identity prediction for a record pair of the first record and each of a plurality of records included in the target data;
- the information processing apparatus refers to each of the prediction results output by the output means, and outputs a search result based on the input data, the search result having the target data as a search target. is equipped with 6.
- the information processing apparatus according to any one of Appendices 1 to 5.
- retrieval from target data based on input data can be performed more preferably.
- (Appendix 8) Acquisition means for acquiring training data including a plurality of sets of record pairs and labels relating to the identity of the record pairs; One or more parameters of each of a plurality of similarity functions for calculating a plurality of similarities for a record pair to be predicted, and Prediction means for performing identity prediction of the prediction target record pair using an importance determined according to the prediction target record pair by referring to the prediction target record pair and the plurality of similarities, one or more parameters of the importance calculation model used to calculate the importance; parameter generation means for generating at least one parameter of with reference to the training data; Information processing device equipped with.
- (Appendix 9) obtaining a record pair; calculating a plurality of degrees of similarity for the record pair using a plurality of similarity functions; referring to the record pair and the plurality of similarities, and performing identity prediction of the record pair using an importance determined according to the record pair; outputting a prediction result by the prediction means;
- Information processing method including.
- (Appendix 10) Acquiring training data including a plurality of sets of record pairs and labels relating to the identity of the record pairs; One or more parameters of each of a plurality of similarity functions for calculating a plurality of similarities for a record pair to be predicted, and Prediction means for performing identity prediction of the prediction target record pair using an importance determined according to the prediction target record pair by referring to the prediction target record pair and the plurality of similarities, referring to the training data to generate at least one of the one or more parameters of the importance calculation model used to calculate the importance; Information processing method including.
- (Appendix 11) Acquiring training data including a plurality of sets of record pairs and labels relating to the identity of the record pairs; A plurality of similarity calculation models for calculating a plurality of similarities for a record pair to be predicted, and Prediction means for performing identity prediction of the prediction target record pair using an importance determined according to the prediction target record pair by referring to the prediction target record pair and the plurality of similarities, an importance calculation model used to calculate the importance; generating a model of at least one of with reference to the training data; A method of manufacturing a trained model including
- Appendix 12 to the computer, an acquisition process for acquiring a record pair; A similarity calculation process for calculating a plurality of similarities for the record pair using a plurality of similarity functions; a prediction process of performing identity prediction of the record pair using an importance determined according to the record pair by referring to the record pair and the plurality of similarities; an output process for outputting a prediction result obtained by the prediction process; program to run.
- At least one processor performs an acquisition process for acquiring a record pair, a similarity calculation process for calculating a plurality of similarities for the record pair using a plurality of similarity functions, and a similarity calculation process for the record pair. , a prediction process of referring to the plurality of degrees of similarity and using an importance level determined according to the record pair to predict the identity of the record pair; and an output process of outputting a prediction result of the prediction process.
- Information processing device to execute.
- this information processing apparatus may further include a memory, and this memory stores information for causing the processor to execute the acquisition process, the similarity calculation process, the prediction process, and the output process.
- program may be stored. Also, this program may be recorded in a computer-readable non-temporary tangible recording medium.
- At least one processor acquires training data including a plurality of sets of record pairs and labels related to the identity of the record pairs, and calculates a plurality of similarities for the record pairs to be predicted. Importance determined according to the record pair to be predicted by referring to one or more parameters of each of a plurality of similarity functions for performing the prediction, the record pair to be predicted, and the plurality of similarities.
- the prediction means for predicting the identity of the record pair to be predicted using the training data An information processing device that executes a parameter generation process generated by referring to.
- the information processing apparatus may further include a memory, and the memory may store a program for causing the processor to execute the acquisition process and the parameter generation process. Also, this program may be recorded in a computer-readable non-temporary tangible recording medium.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- General Engineering & Computer Science (AREA)
- Databases & Information Systems (AREA)
- Data Mining & Analysis (AREA)
- General Physics & Mathematics (AREA)
- Physics & Mathematics (AREA)
- Software Systems (AREA)
- Evolutionary Computation (AREA)
- Computing Systems (AREA)
- Medical Informatics (AREA)
- Mathematical Physics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Quality & Reliability (AREA)
- Artificial Intelligence (AREA)
- Computational Linguistics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2023572292A JP7775896B2 (ja) | 2022-01-06 | 2022-01-06 | 情報処理装置、情報処理方法、製造方法及びプログラム |
| PCT/JP2022/000215 WO2023132029A1 (ja) | 2022-01-06 | 2022-01-06 | 情報処理装置、情報処理方法及びプログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2022/000215 WO2023132029A1 (ja) | 2022-01-06 | 2022-01-06 | 情報処理装置、情報処理方法及びプログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023132029A1 true WO2023132029A1 (ja) | 2023-07-13 |
Family
ID=87073587
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/000215 Ceased WO2023132029A1 (ja) | 2022-01-06 | 2022-01-06 | 情報処理装置、情報処理方法及びプログラム |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP7775896B2 (https=) |
| WO (1) | WO2023132029A1 (https=) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7454156B1 (ja) * | 2023-12-26 | 2024-03-22 | ファーストアカウンティング株式会社 | 情報処理装置、情報処理方法及びプログラム |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2012164028A (ja) * | 2011-02-03 | 2012-08-30 | Fujitsu Ltd | レコード対選択装置、プログラム及び方法 |
| JP2019185244A (ja) * | 2018-04-05 | 2019-10-24 | 富士通株式会社 | 学習プログラム及び学習方法 |
| JP2020501255A (ja) * | 2016-11-25 | 2020-01-16 | アリババ・グループ・ホールディング・リミテッドAlibaba Group Holding Limited | 名前マッチング方法および装置 |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7702631B1 (en) * | 2006-03-14 | 2010-04-20 | Google Inc. | Method and system to produce and train composite similarity functions for product normalization |
-
2022
- 2022-01-06 JP JP2023572292A patent/JP7775896B2/ja active Active
- 2022-01-06 WO PCT/JP2022/000215 patent/WO2023132029A1/ja not_active Ceased
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2012164028A (ja) * | 2011-02-03 | 2012-08-30 | Fujitsu Ltd | レコード対選択装置、プログラム及び方法 |
| JP2020501255A (ja) * | 2016-11-25 | 2020-01-16 | アリババ・グループ・ホールディング・リミテッドAlibaba Group Holding Limited | 名前マッチング方法および装置 |
| JP2019185244A (ja) * | 2018-04-05 | 2019-10-24 | 富士通株式会社 | 学習プログラム及び学習方法 |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7454156B1 (ja) * | 2023-12-26 | 2024-03-22 | ファーストアカウンティング株式会社 | 情報処理装置、情報処理方法及びプログラム |
| WO2025141700A1 (ja) * | 2023-12-26 | 2025-07-03 | ファーストアカウンティング株式会社 | 情報処理装置、情報処理方法及びプログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2023132029A1 (https=) | 2023-07-13 |
| JP7775896B2 (ja) | 2025-11-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN108959246B (zh) | 基于改进的注意力机制的答案选择方法、装置和电子设备 | |
| US8738547B2 (en) | System and methods for finding hidden topics of documents and preference ranking documents | |
| CN112464641A (zh) | 基于bert的机器阅读理解方法、装置、设备及存储介质 | |
| JP2019527440A (ja) | マルチ関連ラベルを生成する方法及びシステム | |
| CN110968692B (zh) | 一种文本分类方法及系统 | |
| CN118113849B (zh) | 基于大数据的信息咨询服务系统及方法 | |
| WO2021128529A1 (zh) | 一种技术趋势预测方法和系统 | |
| US11983633B2 (en) | Machine learning predictions by generating condition data and determining correct answers | |
| CN117854734B (zh) | 基于历史病历信息的相似病例匹配系统及方法 | |
| CN117494815B (zh) | 面向档案的可信大语言模型训练、推理方法和装置 | |
| US20240020310A1 (en) | Information processing device, information processing method and program | |
| JP7775896B2 (ja) | 情報処理装置、情報処理方法、製造方法及びプログラム | |
| JPWO2023132029A5 (https=) | ||
| CN113535912B (zh) | 基于图卷积网络和注意力机制的文本关联方法及相关设备 | |
| Rathod et al. | Efficient usage of RAG systems in the world of LLMs | |
| JP2006338342A (ja) | 単語ベクトル生成装置、単語ベクトル生成方法およびプログラム | |
| JP7686923B2 (ja) | 情報処理装置、情報処理方法及び情報処理プログラム | |
| JP7285308B1 (ja) | 情報処理装置、情報処理方法、及びプログラム | |
| JP2005346223A (ja) | 文書クラスタリング方法、文書クラスタリング装置、文書クラスタリングプログラムならびにそのプログラムを記録した記録媒体 | |
| JP2021163134A (ja) | 論述構造推定方法、論述構造推定装置、および論述構造推定プログラム | |
| EP4167227B1 (en) | System and method for recognising chords in music | |
| JP7786465B2 (ja) | 情報処理装置、情報処理方法及び情報処理プログラム | |
| JP7736182B2 (ja) | 情報提供装置、情報提供方法及び情報提供プログラム | |
| CN116521880B (zh) | 基于证素分解的证型分类方法、装置、设备及介质 | |
| CN117316371B (zh) | 病例报告表的生成方法、装置、电子设备和存储介质 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22918618 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2023572292 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 22918618 Country of ref document: EP Kind code of ref document: A1 |