WO2023105673A1 - Dispositif d'apprentissage, dispositif d'estimation, procédé d'apprentissage, procédé d'estimation et programme - Google Patents
Dispositif d'apprentissage, dispositif d'estimation, procédé d'apprentissage, procédé d'estimation et programme Download PDFInfo
- Publication number
- WO2023105673A1 WO2023105673A1 PCT/JP2021/045084 JP2021045084W WO2023105673A1 WO 2023105673 A1 WO2023105673 A1 WO 2023105673A1 JP 2021045084 W JP2021045084 W JP 2021045084W WO 2023105673 A1 WO2023105673 A1 WO 2023105673A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- data
- encoder
- attribute
- decoder
- type
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims description 17
- 238000013528 artificial neural network Methods 0.000 claims abstract description 16
- 230000006870 function Effects 0.000 claims description 36
- 230000001131 transforming effect Effects 0.000 claims 2
- 238000004891 communication Methods 0.000 description 32
- 238000013178 mathematical model Methods 0.000 description 14
- 238000012545 processing Methods 0.000 description 13
- 238000010586 diagram Methods 0.000 description 12
- 230000005540 biological transmission Effects 0.000 description 5
- 238000005516 engineering process Methods 0.000 description 4
- 238000010801 machine learning Methods 0.000 description 4
- 238000005401 electroluminescence Methods 0.000 description 3
- 230000014509 gene expression Effects 0.000 description 3
- 238000004458 analytical method Methods 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 230000010365 information processing Effects 0.000 description 2
- 239000004973 liquid crystal related substance Substances 0.000 description 2
- 239000004065 semiconductor Substances 0.000 description 2
- 230000006399 behavior Effects 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 238000013135 deep learning Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 230000008451 emotion Effects 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 238000012549 training Methods 0.000 description 1
Images









Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
Definitions
- the present invention relates to a learning device, an estimation device, a learning method, an estimation method and a program.
- Non-Patent Document 1 Given an image and text describing it, directly learning the relationship between the image feature and the text feature makes it possible to add a descriptive text to any image. .
- Non-Patent Document 2 autoencoders are used to learn new feature expressions common to multiple modals, making it possible to solve tasks in multiple modals with a single feature expression.
- the accuracy of the analysis increases as the accuracy of acquiring information common to the linked data increases. Therefore, in order to realize highly accurate recognition, it is necessary to use a large amount of data in which a plurality of pieces of modal information are linked to improve the accuracy of acquiring information common to the linked data. However, it is very difficult to prepare a large amount of data in which multiple pieces of modal information are linked. Therefore, in the conventional techniques such as the above-mentioned prior art documents, there are cases where a large amount of labor is required to estimate information common to a plurality of types of data.
- the present invention aims to provide a technology that reduces the effort required to estimate information common to multiple types of data.
- a first encoder that acquires a feature amount of input data
- a second encoder that acquires a feature amount of input data
- a first decoder that decodes the input data
- an input a multimodal network that is a neural network comprising: a second decoder that decodes input data; and input data transformed by the first encoder, the second encoder, the first decoder and the second decoder.
- a cross self-consistent loss indicating the difference between the resulting self-consistent result and the data
- data indicating the first attribute of the main subject, which is a person, living thing, thing, intangible object or event having a plurality of attributes.
- One aspect of the present invention provides type 1 target data indicating a first attribute of an estimation target, and type 2 target data indicating a second attribute different from the first attribute among attributes possessed by the estimation target.
- a data acquisition unit that acquires data, a first encoder that acquires the feature amount of the input data, a second encoder that acquires the feature amount of the input data, and a first decoder that decodes the input data. and a second decoder that decodes input data; and input data is processed by the first encoder, the second encoder, the first decoder, and the second decoder.
- a cross self-consistent loss that indicates the difference between a self-consistent result that is a transformed result and the data, and a first attribute of a main subject that is a person, living thing, thing, intangible or event having a plurality of attributes.
- the second encoder encodes data indicating a second attribute that is an attribute of the main object and is different from the first attribute.
- a network control unit that updates the multimodal network using a common loss. and an estimator that performs on seed target data.
- a first encoder that acquires a feature amount of input data
- a second encoder that acquires a feature amount of input data
- a first decoder that decodes the input data
- a network execution step for executing a multimodal network, which is a neural network, comprising: input data being the first encoder, the second encoder, the first decoder and the first decoder; 2 cross self-consistent loss that indicates the difference between the self-consistent result that is the result converted by the decoder and the data, and the first of the main object that is a person, creature, thing, intangible object or event having a plurality of attributes. and a result of encoding by the second encoder data indicating a second attribute of the main object that is different from the first attribute. and a network controller step of updating the multimodal network using a common loss that indicates the difference.
- One aspect of the present invention provides type 1 target data indicating a first attribute of an estimation target, and type 2 target data indicating a second attribute different from the first attribute among attributes possessed by the estimation target.
- a data acquisition step for acquiring data
- a first encoder for acquiring the feature amount of the input data
- a second encoder for acquiring the feature amount of the input data
- a first decoder for decoding the input data.
- a second decoder that decodes input data; and input data is processed by the first encoder, the second encoder, the first decoder, and the second decoder.
- a cross self-consistent loss that indicates the difference between a self-consistent result that is a transformed result and the data, and a first attribute of a main subject that is a person, living thing, thing, intangible or event having a plurality of attributes.
- the second encoder encodes data indicating a second attribute that is an attribute of the main object and is different from the first attribute.
- a network control unit that updates the multimodal network using a common loss. and an estimation step performed on species target data.
- One aspect of the present invention is a program for causing a computer to function as the above learning device.
- One aspect of the present invention is a program for causing a computer to function as the above estimation device.
- the present invention makes it possible to reduce the effort required to estimate information common to multiple types of data.
- FIG. 1 is a first explanatory diagram for explaining an overview of a learning device according to an embodiment
- FIG. FIG. 2 is a second explanatory diagram for explaining the overview of the learning device of the embodiment
- FIG. 3 is a third explanatory diagram for explaining the overview of the learning device of the embodiment
- FIG. 4 is a fourth explanatory diagram for explaining the overview of the learning device of the embodiment;
- 4 is a flowchart showing an example of the flow of processing executed by the learning device of the embodiment;
- 4 is a flowchart showing an example of the flow of processing executed by the estimation device of the embodiment;
- FIG. 1 An outline of a learning device 1 according to an embodiment will be described with reference to FIGS. 1 to 4.
- FIG. The learning device 1 updates a mathematical model for estimating information common to two types of data (hereinafter referred to as a "multimodal estimation model") through machine learning.
- the multimodal estimation model estimates information common to two types of data, if the two types of data indicate different attributes of the same subject, then the subject of estimation is the subject on which the two types of data indicate the attribute. .
- One of the two types of data indicating the attribute of the same object is called first type data, and the other of the two types of data is called second type data. That is, the first type data and the second type data are pieces of information with different attributes regarding the same object.
- a primary subject can be any person, living thing, thing, intangible, or event that has multiple attributes. That is, the main subject may be a person with multiple attributes, an organism with multiple attributes, an object with multiple attributes, or a subject with multiple attributes. It may be an intangible object or an event having multiple attributes.
- the multimodal estimation model estimates the target when two types of data indicate different attributes of the same target, so the main target is an example of the estimation target of the multimodal estimation model.
- the first type data indicates the first attribute of the main target
- the second type data indicates the second attribute of the main target.
- the second attribute (hereinafter referred to as "second attribute") is an attribute different from the first attribute (hereinafter referred to as "first attribute”) among the attributes possessed by the main subject.
- the second type data indicates the name of that object. That is, while the first attribute is shape, the second attribute is, for example, name.
- the difference between the type 1 data and the type 2 data is, specifically, the difference in attribute.
- a mathematical model is a set containing one or more processes whose execution conditions and order (hereinafter referred to as "execution rules") are predetermined.
- Learning means updating the mathematical model by means of machine learning. Updating the mathematical model means suitably adjusting the values of the parameters in the mathematical model.
- Execution of the mathematical model means executing each process included in the mathematical model according to execution rules.
- the mathematical model is updated through learning until a predetermined end condition (hereinafter referred to as "learning end condition") is satisfied.
- the learning end condition is, for example, that learning has been performed a predetermined number of times.
- the learning device 1 includes two encoders and two decoders, and updates the processing contents of each encoder and each decoder through learning until a learning end condition is satisfied.
- a neural network including two encoders and two decoders provided in the learning device 1 is a neural network that expresses a multimodal estimation model. Therefore, the update of the processing contents of each encoder and each decoder is the update of the multimodal estimation model.
- a neural network is a circuit such as an electronic circuit, an electric circuit, an optical circuit, or an integrated circuit that expresses a mathematical model. Updating the neural network means updating the parameter values of the mathematical model representing the neural network.
- FIG. 1 is a first explanatory diagram for explaining the overview of the learning device 1 of the embodiment.
- FIG. 2 is a second explanatory diagram for explaining the outline of the learning device 1 of the embodiment.
- FIG. 3 is a third explanatory diagram for explaining the overview of the learning device 1 of the embodiment.
- FIG. 4 is a fourth explanatory diagram for explaining the overview of the learning device 1 of the embodiment.
- the learning device 1 includes a first encoder 101, a second encoder 102, a first decoder 103 and a second decoder 104.
- a neural network including the first encoder 101, the second encoder 102, the first decoder 103 and the second decoder 104 (hereinafter referred to as "multimodal network") is an example of a neural network representing a multimodal estimation model. Therefore, updating the multimodal network means updating the multimodal estimation model.
- the first encoder 101, the second encoder 102, the first decoder 103, and the second decoder 104 are each neural networks updated by learning. In learning the multimodal network, the first encoder 101, the second encoder 102, the first decoder 103 and the second decoder 104 are updated respectively. In learning, each of the first encoder 101, the second encoder 102, the first decoder 103 and the second decoder 104 is updated so as to reduce the difference between the output of the first encoder 101 and the output of the second encoder 102.
- the first encoder 101 acquires the feature amount of the input data.
- the feature quantity acquired by the first encoder 101 is referred to as a first feature quantity.
- first type data (001) is input to the first encoder. Therefore, the first encoder 101 acquires, for example, the first feature amount of the first type data.
- the third type data may be input to the first encoder 101 .
- the third-type data indicates either the first attribute or the second attribute of a person, living thing, thing, intangible object, or event (hereinafter referred to as "sub-object") different from the main object.
- a subobject may or may not have multiple attributes.
- the first encoder 101 acquires the first feature amount of the third type data.
- the first type data is shown as an example of the data input to the first encoder 101, but in FIG. may be
- the second encoder 102 acquires the feature amount of the input data.
- the feature quantity acquired by the second encoder 102 is referred to as a second feature quantity.
- second type data (002) is input to the second encoder. Therefore, the second encoder 102 acquires, for example, the second feature amount of the second type data.
- the third type data may be input to the second encoder 102 .
- the second encoder 102 acquires the second feature amount of the third type data.
- the second type data is shown as an example of the data input to the second encoder 102, but in FIG. may be
- the first decoder 103 decodes the input data.
- the result of decoding by the first decoder 103 will be referred to as a first decoding result.
- the first decoder 103 decodes the first feature amount, as shown in FIG. 1, for example.
- the result of decoding the first feature amount by the first decoder 103 will be referred to as the first decoding result of the first feature amount.
- the first decoder 103 decodes the second feature amount, as shown in FIG. 2 or 3, for example.
- the result of decoding the second feature amount by the first decoder 103 will be referred to as the first decoding result of the second feature amount.
- the second decoder 104 decodes the input data.
- the result of decoding by the second decoder 104 will be referred to as a second decoding result.
- the second decoder 104 decodes the second feature amount, as shown in FIG. 1, for example.
- the result of decoding the second feature amount by the second decoder 104 will be referred to as the second decoding result of the second feature amount.
- the second decoder 104 decodes the first feature amount, as shown in FIG. 2 or 4, for example.
- the result of decoding the first feature amount by the second decoder 104 will be referred to as the second decoding result of the first feature amount.
- the second encoder 102 acquires the second decoding result of the first feature quantity, as shown in FIG. 3, for example.
- the first encoder 101 acquires the first decoding result of the second feature amount, as shown in FIG. 4, for example.
- the learning device 1 performs learning using a linked loss function as a loss function when a set of type 1 data and type 2 data is input as learning data.
- the learning device 1 performs learning using a non-linked loss function as a loss function when only one of the first type data, the second type data, and the third type data is input as learning data.
- the learning data is data used for learning by the learning device 1 . Note that learning is performed so that the difference indicated by the loss function becomes small.
- the tied loss function includes a reconstruction loss, a common loss and a cross reconstruction loss.
- the reconstruction loss includes a first secondary reconstruction loss and a second secondary reconstruction loss.
- the first sub-reconstruction loss indicates the difference between the first type data and the first decoding result of the first type first feature quantity.
- the first type first feature amount is the first feature amount of the first type data.
- the second sub-reconstruction loss indicates the difference between the second type data and the second decoding result of the second type second feature quantity.
- the reconstruction loss is represented, for example, by Equation (1) below.
- d1 indicates the first type data.
- d2 indicates second type data.
- E 1 indicates encoding processing by the first encoder 101 .
- E2 indicates the encoding process by the second encoder 102 .
- D1 indicates decoding processing by the first decoder 103 .
- D2 indicates the decoding process by the second decoder 104 .
- the first term on the right side of Equation (1) is an example of the first secondary reconstruction loss.
- the second term on the right side of Equation (2) is an example of the second secondary reconstruction loss.
- Equation (1) expresses that each output of an autoencoder configured by a first encoder 101 and a first decoder 103 and an autoencoder configured by a second encoder 102 and a second decoder 104 is output to each autoencoder. Indicates a difference from the entered data. Therefore, if learning is performed to reduce the reconstruction loss, each autoencoder is updated so that the difference between the input data and the output is reduced.
- the autoencoder configured by the first encoder 101 and the first decoder 103 is hereinafter referred to as the first autoencoder.
- An autoencoder configured by the second encoder 102 and the second decoder 104 is hereinafter referred to as a second autoencoder.
- the common loss indicates the difference between the first feature quantity and the second feature quantity.
- a common loss is represented by the following formula (2), for example.
- Expression (2) shows the difference between the intermediate representation of the first autoencoder (ie, the first feature) and the intermediate representation of the second autoencoder (ie, the second feature). Therefore, if learning is performed to reduce the common loss, the first autoencoder and the second autoencoder are updated so that the difference between the first feature quantity and the second feature quantity is reduced.
- both the first type data and the second type data are information indicating attributes of the main object. Therefore, the higher the accuracy with which the multimodal estimation model estimates information common to the first type data and the second type data, the more accurately the multimodal estimation model can estimate the main target.
- the cross-reconstruction loss includes a first secondary cross-reconstruction loss and a second secondary cross-reconstruction loss.
- the first sub-cross reconstruction loss indicates the difference between the first type data and the first decoding result of the second type second feature quantity.
- the second subcross reconstruction loss indicates the difference between the second type data and the second decoding result of the first type first feature quantity.
- the cross reconstruction loss is represented, for example, by Equation (3) below.
- the first term on the right side of Equation (3) is an example of the first subcrossing reconstruction loss.
- the second term on the right side of Equation (3) is an example of the second subcrossing reconstruction loss.
- the type 1 first feature amount and the type 2 second feature amount should be approximately the same. is. If the type 1 first feature amount and the type 2 second feature amount are substantially the same, even if the decoding of the type 1 first feature amount is executed by the second decoder 104 instead of the first decoder 103, , the second decoding result of the first feature quantity of the first type should be substantially the same as the first data.
- the second type second feature amount is decoded by the first decoder 103 instead of the second decoder 104. Even so, the first decoding result of the second type second feature quantity should be substantially the same as the second data. Therefore, when the cross-reconstruction loss is large, it means that the estimation accuracy of the multimodal estimation model is not good. Therefore, the accuracy of estimation of the multimodal estimation model is improved by performing learning so as to reduce the cross-reconstruction loss.
- the ties loss function includes the i-th sub-reconstruction loss, the common loss, and the i-th sub-intersection reconstruction loss. Note that i is 1 or 2. More specifically, the tied loss function is the first reconstruction loss (003), the second reconstruction loss (004), the common loss (005), the first cross reconstruction loss (006), and a second cross reconstruction loss (007).
- the i-th sub-reconstruction loss indicates the difference between the i-th data and the i-th decoding result of the i-th feature quantity of the i-th kind.
- the i-th type i-th feature amount is the i-th feature amount of the i-type data.
- the i-th subcross reconstruction loss indicates the difference between the i-th data and the i-th decoding result of the j-th feature of the j-th kind.
- j is 1 or 2
- j and i indicate mutually different values. That is, if i is 1, then j is 2; if i is 2, then j is 1;
- Non-tethered loss functions include cross self-consistent loss.
- the crossing self-consistent loss includes a first sub-crossing self-consistent loss and a second sub-crossing self-consistent loss.
- the first secondary cross self-consistent loss indicates the difference between the data input to the first encoder 101 (hereinafter referred to as "first input data") and the first cross self-consistent data of the first input data. .
- the first cross self-consistent data is the result of decoding the second feature amount of the second cross decoding result by the first decoder 103 .
- the second cross-decoding result is the result of decoding the first feature amount of the first input data by the second decoder 104 .
- the second crossing self-consistent loss indicates the difference between the data input to the second encoder 102 (hereinafter referred to as "second input data") and the second crossing self-consistent data of the second input data.
- the second cross self-consistent data is the result of decoding the first feature amount of the first cross decoding result by the second decoder 104 .
- the first cross-decoding result is the result of decoding the second feature amount of the second input data by the first decoder 103 .
- the first input data may be any data as long as it indicates the first attribute, and may be first type data, third type data indicating the first attribute of the sub-target may be
- the second input data may be any data as long as it indicates the second attribute. may be That is, the i-th input data may be any data that indicates the i-th attribute.
- the cross self-consistent loss includes the i-th subcross self-consistent loss.
- the i-th subcross self-consistent loss indicates the difference between the i-th input data, which is the data input to the i-th encoder, and the i-th cross self-consistent data of the i-th input data.
- the i-th cross self-consistent data is the result of decoding the j-th feature amount of the j-th cross decoding result by the i-th decoder.
- the j-th cross-decoding result is the result of decoding the i-th feature of the i-th input data by the j-th decoder.
- Equation (4) The cross self-consistent loss is expressed, for example, by Equation (4) below.
- Equation (4) The first term on the right side of Equation (4) is an example of the first subcrossing self-consistent loss.
- the second term on the right side of Equation (4) is an example of the second subcrossing self-consistent loss.
- the value of the j-th cross self-consistent loss is 0 when the i-th input data is input to the i-th encoder. That is, when the first input data is input to the multimodal estimation model, the value of the second term on the right side of Equation (4) is 0, and when the second input data is input to the multimodal estimation model, is 0 in the first term on the right side of equation (4).
- a set of Type 1 data and Type 2 data was input to the multimodal network.
- the user cannot always prepare both the first type data and the second type data.
- the user may prepare data that indicates either the first attribute or the second attribute, but is not the main target data. Even in such cases, it is the cross self-consistent loss that allows us to update the multimodal network to improve the accuracy of the estimation.
- the cross self-consistent loss indicates the difference between the self-consistent result of one data input to the multimodal network (hereinafter referred to as "single input data") and the short input data.
- single input data the self-consistent result of one data input to the multimodal network
- the short input data the short input data.
- Each of the first input data and the second input data is an example of single input data. The effect of using the cross self-consistent loss as an example of the first input data as the single input data will be described below.
- the self-consistent result is the result of converting the single input data by the first encoder 101 , the second encoder 102 , the first decoder 103 and the second decoder 104 . If the estimation accuracy of the multimodal estimation model is improved, the first feature amount and the second feature amount should be substantially the same. The second feature amount of the second decoding result of the feature amount should also be substantially the same. As a result, the result of decoding the second feature amount of the second decoding result obtained from the first feature amount of the first input data by the first decoder 103 should be substantially the same as the first input data. Therefore, the multimodal estimation model (that is, the multimodal network) is updated to improve estimation accuracy by learning to reduce the cross self-consistent loss.
- the non-tethered loss function includes the cross self-consistent loss. More specifically, the non-tethered loss function includes a first subcrossing self-consistent loss (008) and a second subcrossing self-consistent loss (009). As shown in FIG. 3 or 4, the value of the non-linked loss function can be obtained if any one of the first type data, the second type data, and the third type data is obtained. Therefore, by using the non-linked loss function, it is possible to update the multimodal estimation model without using two types of data, the first type data and the second type data.
- the learning device 1 can update the multimodal network using the link loss function when a set of type 1 data and type 2 data is input.
- the learning device 1 can update the multimodal network by using the non-linked loss function even when only one of the first type data, the second type data, and the third type data is input. It is possible.
- the multimodal It is possible to update the network to improve the accuracy of the estimation. In other part of learning in multiple times of learning, learning is performed using a set of type 1 data and type 2 data, so that the learning device 1 increases the accuracy of estimating the multimodal network. update to
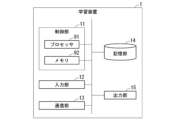
- FIG. 5 is a diagram showing an example of the hardware configuration of the learning device 1 according to the embodiment.
- the learning device 1 includes a control unit 11 including a processor 91 such as a CPU (Central Processing Unit) connected via a bus and a memory 92, and executes a program.
- the learning device 1 functions as a device including a control unit 11, an input unit 12, a communication unit 13, a storage unit 14, and an output unit 15 by executing a program.
- a control unit 11 including a processor 91 such as a CPU (Central Processing Unit) connected via a bus and a memory 92, and executes a program.
- the learning device 1 functions as a device including a control unit 11, an input unit 12, a communication unit 13, a storage unit 14, and an output unit 15 by executing a program.
- a control unit 11 including a processor 91 such as a CPU (Central Processing Unit) connected via a bus and a memory 92, and executes a program.
- the learning device 1 functions as a device including
- the learning device 1 causes the processor 91 to read the program stored in the storage unit 14 and store the read program in the memory 92 .
- the processor 91 executes the program stored in the memory 92 , whereby the learning device 1 functions as a device comprising the control section 11 , the input section 12 , the communication section 13 , the storage section 14 and the output section 15 .
- the control unit 11 controls the operations of various functional units included in the learning device 1.
- the input unit 12 includes input devices such as a mouse, keyboard, and touch panel.
- the input unit 12 may include an interface that connects these input devices to the learning device 1 .
- the communication unit 13 includes an interface for connecting the learning device 1 to an external device.
- the communication unit 13 communicates with an external device via wire or wireless.
- the external device is, for example, a device that is the transmission source of the third type data indicating the first attribute.
- the communication unit 13 acquires the third type data indicating the first attribute through communication with the device that is the transmission source of the third type data indicating the first attribute.
- the external device is, for example, the source device of the third type data indicating the second attribute.
- the communication unit 13 acquires the third type data indicating the second attribute by communicating with the device that is the transmission source of the third type data indicating the second attribute.
- the external device is, for example, the source device of the first type data.
- the communication unit 13 acquires the first type data through communication with the device that is the transmission source of the first type data.
- the external device is, for example, the source device of the second type data.
- the communication unit 13 acquires the second type data through communication with the device that is the transmission source of the second type data.
- the storage unit 14 is configured using a computer-readable storage medium device such as a magnetic hard disk device or a semiconductor storage device.
- the storage unit 14 stores various information about the learning device 1 .
- the storage unit 14 stores, for example, various information generated as a result of processing executed by the control unit 11 .
- the output unit 15 includes a display device such as a CRT (Cathode Ray Tube) display, a liquid crystal display, an organic EL (Electro-Luminescence) display, or the like.
- the output unit 15 may include an interface that connects these display devices to the study device 1 .
- FIG. 6 is a diagram showing an example of the functional configuration of the control unit 11 included in the learning device 1 of the embodiment.
- the control unit 11 includes a data acquisition unit 111 , a data input unit 112 , a learning unit 113 , a communication control unit 114 , a storage control unit 115 and an output control unit 116 .
- the data acquisition unit 111 acquires data input to the communication unit 13. Specifically, the data candidates acquired by the data acquisition unit 111 are the first type data, the second type data, and the third type data.
- the data input unit 112 outputs the data acquired by the data acquisition unit 111 to the output destination according to the attribute indicated by each data.
- the data input unit 112 outputs the first type data acquired by the data acquisition unit 111 to the first encoder 101, for example.
- the data input unit 112 outputs the second type data acquired by the data acquisition unit 111 to the second encoder 102, for example.
- the data input unit 112 outputs the third type data obtained by the data obtaining unit 111 and indicating the first attribute to the first encoder 101 , for example.
- the data input unit 112 outputs, for example, the third type data acquired by the data acquisition unit 111 and indicating the second attribute to the second encoder 102 .
- Each data of the first type data, the second type data, and the third type data has information indicating attributes indicated by each data.
- the information indicating the attribute may be any information as long as it indicates the attribute according to a predetermined rule.
- the information indicating attributes is, for example, information expressing differences in attributes based on differences in data formats.
- the difference in data format is, for example, the difference in data format between image data and text data.
- the attribute indicated by each data is indicated by information indicating the attribute. Therefore, the data input unit 112 can determine the attribute of each data based on the difference in the information indicating the attribute. As a result, the data input unit 112 can output the data acquired by the data acquisition unit 111 to the output destination according to the attribute indicated by each data.
- the information indicating the attribute of each data may be input by the user to the input section 12 or the communication section 13 .
- the learning unit 113 includes a multimodal network 131 and a network control unit 132.
- Multimodal network 131 is a multimodal network.
- Multimodal network 131 is therefore a neural network that represents a multimodal estimation model.
- the multimodal network 131 comprises a first encoder 101 , a second encoder 102 , a first decoder 103 and a second decoder 104 .
- the network control unit 132 updates the multimodal network 131 based on the results obtained by the multimodal network 131. More specifically, network control unit 132 updates multimodal network 131 based on the results obtained by multimodal network 131 and the data input to multimodal network 131 .
- the network control unit 132 uses the linked loss function to obtain the result obtained by the multimodal network 131. Based on this, the multimodal network 131 is updated.
- the network control unit 132 uses a non-linked loss function to obtain the result obtained by the multimodal network 131. update the multimodal network 131 based on .
- the communication control unit 114 controls the operation of the communication unit 13.
- a memory control unit 115 controls the operation of the memory unit 14 .
- the output control section 116 controls the operation of the output section 15 .
- FIG. 7 is a flowchart showing an example of the flow of processing executed by the learning device 1 according to the embodiment.
- the data acquisition unit 111 acquires data (step S101).
- the data input unit 112 inputs the data acquired by the data acquisition unit 111 to the input destination corresponding to the attribute indicated by each data (step S102).
- the input destination is the first encoder 101 or the second encoder 102 .
- the multimodal network 131 executes a multimodal estimation model on the data input in step S102 (step S103).
- the network control unit 132 updates the multimodal estimation model based on the result of executing the multimodal estimation model (step S104). More specifically, the network control unit 132 uses either the linked loss function or the unlinked loss function according to the data acquired by the data acquisition unit 111 based on the result of executing the multimodal estimation model. , to update the multimodal estimation model.
- step S105 determines whether or not the learning end condition is satisfied. If the learning end condition is satisfied (step S105: YES), the process ends. On the other hand, if the learning end condition is not satisfied (step S105: NO), the process returns to step S101.
- the learned multimodal estimation model obtained in this manner is an estimation target based on a set of data of the first attribute of the estimation target such as the estimation device 2 shown in FIG. 8 and data of the second attribute of the estimation target. is used in a device for estimating
- the trained multimodal estimation model is the multimodal estimation model at the time when the learning termination condition is satisfied.
- the estimation target of the estimation device 2 will be referred to as an attention target.
- the data of the first attribute of the object of interest will be referred to as type 1 target data.
- the data of the second attribute of the object of interest will be referred to as type 2 target data.
- the target of interest may be a different target than the main target.
- FIG. 8 is a diagram showing an example of the hardware configuration of the estimation device 2 of the embodiment.
- the estimation device 2 acquires a set of type 1 target data and type 2 target data, and uses a trained multimodal estimation model to show the acquired type 1 target data and type 2 target data. Estimate the target of interest.
- the estimation device 2 includes a control unit 21 including a processor 93 such as a CPU and a memory 94 connected by a bus, and executes a program.
- the estimation device 2 functions as a device including a control unit 21, an input unit 22, a communication unit 23, a storage unit 24, and an output unit 25 by executing a program.
- the estimating device 2 causes the processor 93 to read the program stored in the storage unit 24 and store the read program in the memory 94 .
- the processor 93 executes the program stored in the memory 94 so that the estimation device 2 functions as a device including the control unit 21 , the input unit 22 , the communication unit 23 , the storage unit 24 and the output unit 25 .
- the control unit 21 controls operations of various functional units included in the estimation device 2 .
- the control unit 21 executes, for example, a learned multimodal estimation model.
- the input unit 22 includes input devices such as a mouse, keyboard, and touch panel.
- the input unit 22 may include an interface that connects these input devices to the estimating device 2 .
- the communication unit 23 includes an interface for connecting the estimation device 2 to an external device.
- the communication unit 23 communicates with an external device via wire or wireless.
- the external device is, for example, a device that is the source of a set of type 1 target data and type 2 target data.
- the communication unit 23 acquires a set of the type 1 target data and the type 2 target data through communication with the device that is the source of the set of the type 1 target data and the type 2 target data.
- the external device is the learning device 1, for example.
- the communication unit 23 acquires a learned multimodal estimation model through communication with the learning device 1 .
- the storage unit 24 is configured using a computer-readable storage medium device such as a magnetic hard disk device or a semiconductor storage device.
- the storage unit 24 stores various information regarding the estimation device 2 .
- the storage unit 24 stores, for example, various information generated as a result of processing executed by the control unit 21 .
- the output unit 25 includes a display device such as a CRT display, a liquid crystal display, an organic EL display, or the like.
- the output unit 25 may include an interface that connects these display devices to the estimating device 2 .
- FIG. 9 is a diagram showing an example of the functional configuration of the control unit 21 included in the estimation device 2 of the embodiment.
- the control unit 21 includes a data acquisition unit 211 , an estimation unit 212 , a communication control unit 213 , a storage control unit 214 and an output control unit 215 .
- the data acquisition unit 211 acquires a set of data of type 1 target data and type 2 target data input to the communication unit 23 .
- the estimation unit 212 executes the learned multimodal estimation model on the data acquired by the data acquisition unit 211 . That is, the estimating unit 212 executes processing for estimating a target of interest by a trained multimodal network on the type 1 target data and the type 2 target data acquired by the data acquiring unit 211 .
- a communication control unit 213 controls the operation of the communication unit 23 .
- a memory control unit 214 controls the operation of the memory unit 24 .
- the output control section 215 controls the operation of the output section 25 .
- FIG. 10 is a flowchart showing an example of the flow of processing executed by the estimation device 2 of the embodiment.
- the data acquisition unit 211 acquires a set of data of type 1 target data and type 2 target data (step S201).
- the estimation unit 212 executes a learned multimodal estimation model on the data obtained in step S201 (step S202). That is, the estimating unit 212 executes the processing executed by the trained multimodal network on the type 1 target data and the type 2 target data acquired in step S201.
- the process executed by the trained multimodal network is specifically the process of estimating the target of interest.
- a target of interest is estimated by executing a trained multimodal estimation model on the data acquired in step S201.
- the output control unit 215 controls the operation of the output unit 25 and causes the output unit 25 to output the estimation result of the estimation unit 212 (step S203).
- the learning device 1 configured in this manner performs learning so as to increase the accuracy of estimation of a mathematical model that estimates information common to multiple types of data.
- information common to a plurality of types of data is specifically a main target.
- the learning device 1 can perform not only learning using the tied loss function, but also learning using the non-tied loss function.
- the learning device 1 is capable of learning. Therefore, the learning device 1 can obtain a mathematical model for estimating information common to a plurality of types of data with less effort than a mathematical model obtained by a technique in which learning can be performed only when linked information exists. can. That is, the learning device 1 can reduce the effort required to estimate information common to multiple types of data.
- the estimation device 2 configured in this way estimates the estimation target using the learned mathematical model obtained by the learning device 1 . Therefore, the estimating device 2 can reduce labor required for estimating information common to multiple types of data.
- learning using the third type data is preferably performed rather than the first type data or the second type data. This is because over-learning can be suppressed by learning not only the main target but also the sub-target.
- the non-tied loss function may include the i-th reconstruction loss in addition to the i-th cross self-consistent loss.
- the value of the j-th cross self-consistent loss is 0 when the learning data is input to the i-th encoder.
- the value of the j-th cross self-consistent loss is 0 when the learning data is input to the i-th encoder. If the non-tethered loss function also includes the i-th reconstruction loss, then the estimation accuracy of the trained multimodal estimation model is higher than if it does not include the i-th reconstruction loss.
- the learning device 1 and the estimation device 2 do not necessarily have to be implemented as different devices.
- the learning device 1 and the estimation device 2 may be implemented, for example, as one device or system having both functions.
- each functional unit included in each of the learning device 1 and the estimating device 2 may be implemented using a plurality of information processing devices that are communicably connected via a network.
- each of the learning device 1 and the estimation device 2 may be implemented using a plurality of information processing devices that are communicably connected via a network. All or part of each function of the learning device 1 and the estimation device 2 is implemented using hardware such as ASIC (Application Specific Integrated Circuit), PLD (Programmable Logic Device), FPGA (Field Programmable Gate Array), etc. may be implemented.
- the program may be recorded on a computer-readable recording medium.
- Computer-readable recording media include portable media such as flexible disks, magneto-optical disks, ROMs and CD-ROMs, and storage devices such as hard disks incorporated in computer systems.
- the program may be transmitted over telecommunications lines.
- 1... learning device 2... estimating device, 101... first encoder, 102... second encoder, 103... first decoder, 104... second decoder, 11... control unit, 12... input unit, 13... communication unit, 14 ... storage section, 15 ... output section, 111 ... data acquisition section, 112 ... data input section, 113 ... learning section, 131 ... multimodal network, 132 ... network control section, 114 ... communication control section, 115 ... storage control section, 116... output control unit, 21... control unit, 22... input unit, 23... communication unit, 24... storage unit, 25... output unit, 211... data acquisition unit, 212... estimation unit, 213... communication control unit, 214... Memory control unit 215... Output control unit 91, 93... Processor 92, 94... Memory
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- Image Analysis (AREA)
Abstract
Un dispositif d'apprentissage selon un aspect de la présente invention comprend : un réseau multimodal qui est un réseau neuronal comprenant un premier codeur destiné à acquérir une caractéristique de données d'entrée, un second codeur destiné à acquérir une caractéristique des données d'entrée, un premier décodeur destiné à décoder les données d'entrée et un second décodeur destiné à décoder les données d'entrée ; et une unité de commande de réseau qui met à jour le réseau multimodal en utilisant une perte autoconsistante croisée indiquant une différence entre les données d'entrée et un résultat autoconsistant qui est le résultat de la conversion des données d'entrée par le premier codeur, le second codeur, le premier décodeur et le second décodeur, ainsi qu'une perte commune indiquant une différence entre le résultat du premier codeur codant des données indiquant un premier attribut d'un sujet principal qui est une personne, un être vivant, un objet, un objet intangible ou phénomène ayant une pluralité d'attributs et le résultat du second codeur codant des données indiquant un second attribut qui est un attribut du sujet principal et qui est différent du premier attribut.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2021/045084 WO2023105673A1 (fr) | 2021-12-08 | 2021-12-08 | Dispositif d'apprentissage, dispositif d'estimation, procédé d'apprentissage, procédé d'estimation et programme |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2021/045084 WO2023105673A1 (fr) | 2021-12-08 | 2021-12-08 | Dispositif d'apprentissage, dispositif d'estimation, procédé d'apprentissage, procédé d'estimation et programme |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023105673A1 true WO2023105673A1 (fr) | 2023-06-15 |
Family
ID=86729938
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2021/045084 WO2023105673A1 (fr) | 2021-12-08 | 2021-12-08 | Dispositif d'apprentissage, dispositif d'estimation, procédé d'apprentissage, procédé d'estimation et programme |
Country Status (1)
| Country | Link |
|---|---|
| WO (1) | WO2023105673A1 (fr) |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019056957A (ja) * | 2017-09-19 | 2019-04-11 | キヤノン株式会社 | 情報処理装置、情報処理方法、コンピュータプログラム、及び記憶媒体 |
| WO2019221985A1 (fr) * | 2018-05-14 | 2019-11-21 | Quantum-Si Incorporated | Systèmes et procédés d'unification de modèles statistiques pour différentes modalités de données |
| JP2020052915A (ja) * | 2018-09-28 | 2020-04-02 | 日本電信電話株式会社 | データ処理装置、データ処理方法、及びプログラム |
| JP2020135424A (ja) * | 2019-02-20 | 2020-08-31 | Kddi株式会社 | 情報処理装置、情報処理方法、及びプログラム |
| JP2021076913A (ja) * | 2019-11-05 | 2021-05-20 | 株式会社日立製作所 | 計算機及びモデルの学習方法 |
-
2021
- 2021-12-08 WO PCT/JP2021/045084 patent/WO2023105673A1/fr unknown
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019056957A (ja) * | 2017-09-19 | 2019-04-11 | キヤノン株式会社 | 情報処理装置、情報処理方法、コンピュータプログラム、及び記憶媒体 |
| WO2019221985A1 (fr) * | 2018-05-14 | 2019-11-21 | Quantum-Si Incorporated | Systèmes et procédés d'unification de modèles statistiques pour différentes modalités de données |
| JP2020052915A (ja) * | 2018-09-28 | 2020-04-02 | 日本電信電話株式会社 | データ処理装置、データ処理方法、及びプログラム |
| JP2020135424A (ja) * | 2019-02-20 | 2020-08-31 | Kddi株式会社 | 情報処理装置、情報処理方法、及びプログラム |
| JP2021076913A (ja) * | 2019-11-05 | 2021-05-20 | 株式会社日立製作所 | 計算機及びモデルの学習方法 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2021254499A1 (fr) | Procédé et appareil de génération de modèle d'édition, procédé et appareil d'édition d'image faciale, dispositif et support | |
| WO2021027256A1 (fr) | Procédé et appareil de traitement de données de séquence interactive | |
| CN110750959A (zh) | 文本信息处理的方法、模型训练的方法以及相关装置 | |
| CN114511472B (zh) | 一种视觉定位方法、装置、设备及介质 | |
| CN106844518B (zh) | 一种基于子空间学习的不完整跨模态检索方法 | |
| JP6962747B2 (ja) | データ合成装置および方法 | |
| CN112699215B (zh) | 基于胶囊网络与交互注意力机制的评级预测方法及系统 | |
| CN113190754A (zh) | 一种基于异构信息网络表示学习的推荐方法 | |
| CN111967277A (zh) | 基于多模态机器翻译模型的翻译方法 | |
| CN116258145B (zh) | 多模态命名实体识别方法、装置、设备以及存储介质 | |
| CN116402063A (zh) | 多模态讽刺识别方法、装置、设备以及存储介质 | |
| JP6714268B1 (ja) | 質問文出力方法、コンピュータプログラム及び情報処理装置 | |
| CN117633516B (zh) | 多模态嘲讽检测方法、装置、计算机设备以及存储介质 | |
| CN115081615A (zh) | 一种神经网络的训练方法、数据的处理方法以及设备 | |
| CN113590965B (zh) | 一种融合知识图谱与情感分析的视频推荐方法 | |
| CN113850714A (zh) | 图像风格转换模型的训练、图像风格转换方法及相关装置 | |
| WO2023105673A1 (fr) | Dispositif d'apprentissage, dispositif d'estimation, procédé d'apprentissage, procédé d'estimation et programme | |
| CN115659987B (zh) | 基于双通道的多模态命名实体识别方法、装置以及设备 | |
| CN115906863B (zh) | 基于对比学习的情感分析方法、装置、设备以及存储介质 | |
| CN114547312B (zh) | 基于常识知识图谱的情感分析方法、装置以及设备 | |
| CN114937277B (zh) | 基于图像的文本获取方法、装置、电子设备及存储介质 | |
| CN116434023A (zh) | 基于多模态交叉注意力网络的情感识别方法、系统及设备 | |
| CN114972910A (zh) | 图文识别模型的训练方法、装置、电子设备及存储介质 | |
| WO2021095213A1 (fr) | Procédé d'apprentissage, programme d'apprentissage et dispositif d'apprentissage | |
| CN110659962A (zh) | 一种商品信息输出方法及相关装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21967172 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2023565771 Country of ref document: JP Kind code of ref document: A |