WO2023079703A1 - 処理実行システム、処理実行方法、及びプログラム - Google Patents
処理実行システム、処理実行方法、及びプログラム Download PDFInfo
- Publication number
- WO2023079703A1 WO2023079703A1 PCT/JP2021/040852 JP2021040852W WO2023079703A1 WO 2023079703 A1 WO2023079703 A1 WO 2023079703A1 JP 2021040852 W JP2021040852 W JP 2021040852W WO 2023079703 A1 WO2023079703 A1 WO 2023079703A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- data
- model
- effectiveness
- classification information
- estimation
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
- G06F18/2415—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches based on parametric or probabilistic models, e.g. based on likelihood ratio or false acceptance rate versus a false rejection rate
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/906—Clustering; Classification
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2455—Query execution
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/084—Backpropagation, e.g. using gradient descent
Definitions
- the present disclosure relates to a processing execution system, a processing execution method, and a program.
- Patent Literature 1 describes a technique of providing useful information to a user who has entered a search query by using a model that outputs estimated results of classification of keywords included in the search query.
- a domain indicating the type of search result, the type of search, the type of search target, or the like is listed as the output of the model.
- One of the purposes of the present disclosure is to obtain desired results even when the accuracy of the model is insufficient due to insufficient training data.
- a process execution system provides a first data class related to classification of second data based on a first model in which a relationship between first data and first classification information related to classification of the first data is learned.
- a second classification information acquisition unit that acquires two classification information; an effectiveness estimation unit that estimates effectiveness of a combination of the second data and the second classification information based on a predetermined estimation method; and an execution unit that executes a predetermined process based on the estimation result.
- FIG. 10 is a diagram showing an example of how a search is executed from a portal page;
- FIG. It is a figure which shows the outline
- 3 is a functional block diagram showing an example of functions implemented by the processing execution system;
- FIG. It is a figure which shows an example of a page database.
- FIG. 4 is a flow chart showing an example of processing executed by the processing execution system;
- FIG. 1 is a diagram showing an example of the overall configuration of a processing execution system.
- Network N is any network such as the Internet or a LAN.
- the processing execution system S only needs to include at least one computer, and is not limited to the example in FIG.
- the search server 10 is a server computer.
- Control unit 11 includes at least one processor.
- the storage unit 12 includes a volatile memory such as RAM and a nonvolatile memory such as a hard disk.
- the communication unit 13 includes at least one of a communication interface for wired communication and a communication interface for wireless communication.
- the learning server 20 is a server computer. Physical configurations of the control unit 21, the storage unit 22, and the communication unit 23 are the same as those of the control unit 11, the storage unit 12, and the communication unit 13, respectively.
- the searcher terminal 30 is the computer of the searcher who is the user who inputs the search query.
- the searcher terminal 30 is a personal computer, smart phone, tablet terminal, or wearable terminal.
- Physical configurations of the control unit 31, the storage unit 32, and the communication unit 33 are the same as those of the control unit 11, the storage unit 12, and the communication unit 13, respectively.
- the operation unit 34 is an input device such as a touch panel or mouse.
- the display unit 35 is a liquid crystal display or an organic EL display.
- the creator terminal 40 is the computer of the creator who creates the data to be searched.
- creator terminal 40 is a personal computer, a smart phone, a tablet terminal, or a wearable terminal.
- the physical configurations of the control unit 41, the storage unit 42, the communication unit 43, the operation unit 44, and the display unit 45 are the same as those of the control unit 11, the storage unit 12, the communication unit 13, the operation unit 34, and the display unit 35, respectively. be.
- each computer has a reading unit (for example, a memory card slot) for reading a computer-readable information storage medium, and an input/output unit (for example, a USB port) for inputting/outputting data with an external device. At least one may be included.
- a program or data stored in an information storage medium may be supplied via at least one of the reading section and the input/output section.
- FIG. 1 A case where the processing execution system S is applied to a web page search service will be taken as an example.
- a creator creates a web page and uploads it to the search server 10 or another server computer.
- the searcher searches for web pages using the browser of the searcher terminal 30 .
- the portal page of the search service is displayed on the display unit 35 .
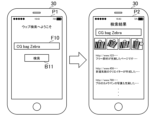
- FIG. 2 is a diagram showing an example of how a search is executed from a portal page.
- the searcher enters a search query into the input form F10 on the portal page P1.
- the search server 10 executes web page search processing based on this search query.
- the display unit 35 of the searcher terminal 30 displays a search result page P2 showing search results corresponding to the search query input by the searcher.
- a searcher enters a search query with some intention and uses the search service.
- a search query such as "CG bag Zebra” is entered.
- the searcher intends to search for "computer graphics with a zebra-patterned bag”. If the intention of a searcher can be estimated, it is very useful because it can be used for marketing in search services and can improve the accuracy of search results.
- the intent of the searcher is estimated based on a model using machine learning.
- the model for estimating the intent of the searcher will be referred to as the first model.
- the first model may be supervised learning, semi-supervised learning, or unsupervised learning.
- the first model may be a neural network.
- the first model learns the relationship between the title of the web page and the attributes and attribute values of the web page.
- the title is the string displayed in the browser's title bar.
- the title includes keywords that indicate the content of the web page.
- the title is used as an index for searching.
- the creator inputs the title, but the title may be automatically extracted from the character string included in the web page, or may be input by the administrator of the search service.
- the attribute of a web page is the classification of the web page.
- Web page attributes can also be referred to as web page types, categories, or genres. Attributes are represented by letters, numbers, other symbols, or combinations thereof. Any attribute can be used as long as the web page can be classified from a predetermined point of view, and the attribute can be set from any point of view. For example, a web page that provides images of free material is associated with the attribute "Image”. For example, a web page that provides documents such as news articles is associated with the attribute "Document”.
- the attribute value of a web page is the specific value of the attribute. Attributes are associated with at least one attribute value. A web page is associated with at least one of the attribute values associated with the attribute. Attribute values are represented by letters, numbers, other symbols, or combinations thereof.
- the attribute value may be any value that defines the details of the attribute from a predetermined point of view, and the attribute value can be set from any point of view.
- the attribute value "Image” is associated with the attribute value "Computer Graphic” and the attribute value "Photograph”
- the attribute value "Computer Graphic” or the attribute value " Photography” is associated.
- the attribute value "Document” is associated with the attribute value "News” and the attribute value "Advertisement”
- the attribute value "News” or the attribute value "Advertisement” is displayed on the web page of the attribute "Document”. associated with any of
- Creators create web pages with some intention. For example, a web page with an attribute "Image” and an attribute value "Computer Graphic” is created with the intention of distributing computer graphic images. For example, a web page with an attribute "Document” and an attribute value "News” is created with the intention of distributing news article documents.
- the author's intentions are believed to be expressed in the titles, attributes, and attribute values of web pages. Therefore, the relationship between the title of the web page and the attributes and attribute values of the web page is considered to be similar to the relationship between the search query input by the searcher and the intention of the searcher.
- a first model is used, which is trained on the relationship between the title of the web page and the attributes and attribute values of the web page as training data.
- a search query is input to the first model as information corresponding to the title of the web page.
- the first model outputs a searcher's intent as information corresponding to web page attributes and attribute values.
- the processing execution system S of the present embodiment even when the accuracy of the first model is not sufficient due to insufficient training data, it is possible to accurately estimate the intent of the searcher. .
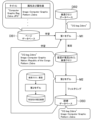
- FIG. 3 is a diagram showing an overview of the processing execution system S.
- the page database DB1 stores web page titles, web page attributes, and attribute values in association with each other. These pairs are learned into the first model M1 as training data. Search queries input in the past are stored in the search query database DB2. In this embodiment, the intent of the searcher who entered this search query is estimated.
- the first model M1 estimates attributes and attribute values as the intent of the searcher.
- the search query "CG bag Zebra" of FIG. 2 is input to the first model M1.
- the first model M1 has the attribute value "Computer Graphic” of the attribute "Image”, the attribute value "Republic of the Congo” of the attribute “Nation”, and the attribute value "Zebra” of the attribute "Pattern” as the intent of the searcher. Output three estimation results.
- the intent of the searcher who entered the search query in Figure 3 is to search for "computer graphics with a zebra-patterned bag". This intention is expressed in the attribute value "Computer Graphic” of the attribute "Image” and the attribute value "Zebra” of the attribute "Pattern” among the three estimation results output by the first model M1.
- the attribute value "Republic of the Congo” of the attribute "Nation” does not represent the user's intention.
- the accuracy of the first model M1 is insufficient due to insufficient training data, such an inappropriate estimation result may be output. This is probably because the first model M1 has learned for some reason that the character string "CG", which is part of the search query, is the country code of the Republic of the Congo.
- a second model M2 is prepared for removing inappropriate estimation results.
- the second model M2 is a model using machine learning.
- Various machine learning techniques are available for the second model M2.
- the second model M2 may be supervised learning, semi-supervised learning, or unsupervised learning.
- the second model may be a neural network.
- the second model M2 receives a pair of a search query and a searcher's intention (that is, a pair of a search query input to the first model M1 and an estimation result output from the first model M1). then print the validity of this pair.
- the second model M2 has the attribute value "Computer Graphic” of the attribute "Image” and the attribute value “Zebra” of the attribute "Pattern” among the three estimation results output by the first model M1. , is assumed to be valid.
- the second model M2 estimates that among the three estimation results output by the first model M1, the attribute value "Republic of the Congo” of the attribute "Nation” is not valid.
- training data for the first model M1 is generated based on the estimation result of the second model M2.
- training data including a pair of the search query "CG bag Zebra” and the attribute value "Computer Graphic” of the attribute "Image”, the search query "CG bag Zebra”, and the attribute "Pattern and training data including the pair of the attribute value "Zebra” of These two training data are learned in the first model M1.
- the processing execution system S estimates the intent of the searcher who entered the search query based on the first model M1. Based on the second model M2, the processing execution system S eliminates invalid estimation results from the estimation results of the first model M1, and generates training data of the first model M1. The processing execution system S causes the first model M1 to learn this training data. This increases the accuracy of the first model M1 even if the training data stored in the page database DB1 is not sufficient. It is also possible to save the trouble of creating training data for the first model M1.
- details of the processing execution system S will be described.
- FIG. 4 is a functional block diagram showing an example of functions realized by the process execution system S. As shown in FIG.
- the data storage unit 100 is realized mainly by the storage unit 12 .
- the search unit 101 is implemented mainly by the control unit 11 .
- the data storage unit 100 stores data necessary for providing search services.
- the data storage unit 100 stores a database in which web page indexes and web page URLs are associated and stored.
- An index is information to be compared with a search query. Any information can be used as an index.
- the title of the web page, attributes and attribute values of the web page, arbitrary keywords included in the web page, or a combination thereof are used as the index.
- the data storage unit 100 stores data (for example, HTML data) for displaying the portal page P1 and the search result page P2.
- the data storage unit 100 may store a history of search queries input in the past, or may store query selection data described later.
- the search unit 101 executes search processing based on a search query input by a searcher.
- Various search engines can be applied to the search process itself.
- the search unit 101 calculates the search score of the web page based on the search query input by the searcher and the web page index stored in the data storage unit 100 .
- a search score indicates the degree of matching between a search query and an index.
- calculation methods employed by various search engines can be applied.
- the search unit 101 selects a predetermined number of web pages in descending order of search score, and generates a search result page P2 including links to the selected web pages.
- the search unit 101 transmits data of the search result page P ⁇ b>2 to the searcher terminal 30 .
- the search unit 101 Upon receiving the selection result by the searcher from the searcher terminal 30, the search unit 101 causes the searcher terminal 30 to access the web page corresponding to the link selected by the searcher.
- the search unit 101 records in the data storage unit 100 the relationship between the search query input by the searcher and the web page corresponding to the link selected by the searcher. This relationship corresponds to query selection data described later.
- the data storage unit 200 is implemented mainly by the storage unit 22 .
- the first learning unit 201, the second classification information acquisition unit 202, the candidate generation unit 203, the third classification information acquisition unit 204, the second learning unit 205, the effectiveness estimation unit 206, and the execution unit 207 are each controlled by the control unit 21. is mainly realized.
- the data storage unit 200 stores data required for the processing described with reference to FIG.
- the data storage unit 200 stores a page database DB1, a search query database DB2, a training database DB3, a query selection database DB4, a first model M1, and a second model M2.
- FIG. 5 is a diagram showing an example of the page database DB1.
- the page database DB1 is a database that stores information about web pages.
- the page database DB1 stores web page titles, web page attributes, and attribute values in association with each other.
- the learning server 20 acquires pairs of web page titles, web page attributes, and attribute values from the search server 10 or other servers to which the creator has uploaded the web pages, and is stored in the page database DB1.
- the pairs stored in the page database DB1 are used as training data for the first model M1.
- This training data is used to generate an initial first model M1, which will be described later.
- the training data for the first model M1 includes pairs of input and output parts.
- the input portion of the training data for the first model M1 is in the same form as the data that is actually input to the first model M1.
- the input portion of the training data of the first model M1 is a character string.
- the output portion of the training data of the first model M1 is in the same form as the data that is actually output from the first model M1.
- a combination of a character string indicating an attribute and a character string indicating an attribute value is output from the first model M1. including.
- FIG. 6 is a diagram showing an example of the search query database DB2.
- the search query database DB2 is a database in which search queries input in the past are stored.
- the search server 10 executes search processing based on the search query input by the searcher, the search server 10 transmits the search query to the learning server 20 .
- the learning server 20 stores the search query received from the search server 10 in the search query database DB2.
- FIG. 7 is a diagram showing an example of the training database DB3.
- the training database DB3 is a database storing training data of the first model M1. This training data is generated by the execution unit 207, which will be described later. This training data is used to improve the accuracy of the initial first model M1, which will be described later.
- the format of the training data stored in the training database DB3 is the same format as the training data stored in the page database DB1. However, although the format of these training data is the same, the specific contents indicated by these training data are different from each other.
- the input part of the training data stored in the page database DB1 is a character string indicating the title of the web page
- the input part of the training data stored in the training database DB3 is a character string indicating the search query. is.
- the output portion of the training data stored in the page database DB1 is a character string representing each of the web page attributes and attribute values
- the output portion of the training data stored in the training database DB3 is a search A character string indicating the intent of the author.
- FIG. 8 is a diagram showing an example of the query selection database DB4.
- the query selection database DB4 is a database that stores query selection data.
- Query selection data is data indicating selection results for a search query.
- Query selection data is sometimes referred to as query click logs.
- the query selection database DB4 stores search queries and page information in association with each other.
- Page information is information about web pages. This web page is the web page indicated by the link selected on the search result page P2 by the searcher who entered the search query. Since this web page is actually selected by the searcher, it can be said that the web page matches the intention of the searcher.
- page information includes the web page title, attributes, and attribute values.
- the page information may include arbitrary information, and may include, for example, the URL of the web page and the viewing date and time.
- the data storage unit 200 stores the learned first model M1.
- the first model M1 includes a program part for executing processing such as convolution and a parameter part such as weights.
- the first model M1 is a multi-label model.
- a multi-label model can estimate multiple classifications for input data.
- the first model M1 learns the relationship between the title of the web page and the attributes and attribute values of the web page.
- the title of the web page is an example of the first data. Therefore, the part describing the title of the web page can be read as the first data.
- the first data is the input portion of the training data for the initial first model M1.
- the initial first model M1 is the first model M1 before the training data generated by the execution unit 207 is learned.
- the page database DB1 is used to generate initial training data for the first model M1, so the first data is the title of the web page stored in the page database DB1.
- the first data may be data that can be used for learning the first model M1, and is not limited to the web page title.
- the first data may be a character string other than the title included in the web page, a keyword used as an index of the web page, or a summary created from the web page.
- the first data may not be the character string itself, but may be a feature quantity indicating some characteristic of the character string.
- the first data may be in any format and is not limited to character strings.
- the first data may be image data, moving image data, document data, or any other data.
- the first data may be data called content.
- Web page attributes and attribute values are an example of the first classification information. Therefore, the description of the web page attributes and attribute values can be read as the first classification information.
- the first classification information is information relating to the classification of the first data.
- the first classification information is the output part of the initial training data of the first model M1.
- the initial training data of the first model M1 is generated using the page database DB1, so the first classification information is the attributes and attribute values stored in the page database DB1.
- the first data and the first classification information are data used as indexes during searches.
- the first classification information may be information that can be used for learning the first model M1, and is not limited to web page attributes and attribute values.
- the first classification information may indicate either the attribute or the attribute value of the web page.
- the first classification information may be in any format and is not limited to character strings.
- the first classification information may be information such as an ID or number that can uniquely identify the classification.
- each attribute/attribute value pair corresponds to the first classification information. Therefore, a plurality of pieces of first classification information may be associated with one piece of first data.
- a plurality of attribute and attribute value pairs may be treated as one piece of first classification information. In this case, one piece of first classification information is associated with one piece of first data.
- the relationship between the first data and the first classification information acquired based on the page database DB1 containing the candidates for the first data and the candidates for the first classification information. be learned.
- the page database DB1 is an example of a first database. Therefore, the description of the page database DB can be read as the first database.
- the first database is a database that stores data that are candidates for initial training data of the first model M1. All or part of the data in the first database is used as initial training data for the first model M1.
- the data storage unit 200 stores the learned second model M2.
- the second model M2 includes a program portion for executing processing such as convolution and a parameter portion such as weights.
- the second model M2 outputs information indicating whether it is valid (either a first value indicating valid or a second value indicating not valid).
- the second model M2 may output a score indicating effectiveness. That is, the output of the second model M2 may be information having an intermediate value such as a score instead of binary information such as whether or not it is valid.
- the relationship between combinations of search queries, attributes and attribute values, and effectiveness of the combinations is learned in the second model M2.
- a search query associated with attributes and attribute values is an example of third data. Therefore, the part describing the search query associated with the attribute and the attribute value can be read as the third data.
- the third data is the input portion of the training data for the second model M2.
- the training data for the second model M2 is generated using the query selection database DB4, so the search query stored in the query selection database DB4 corresponds to the third data.
- the initial estimation result of the first model M1 is also used in the learning of the second model M2, so the initial search query input to the first model M1 also corresponds to the third data.
- the third data is not limited to search queries as long as it can be used for learning the second model M2.
- the third data may be a web page title, a character string other than the title included in the web page, a keyword used as an index of the web page, or a summary created from the web page.
- the third data may not be the character string itself, but may be a feature quantity indicating some characteristic of the character string.
- the third data may be in any format and is not limited to character strings.
- the third data may be image data, moving image data, document data, or any other data.
- the third data may be data called content.
- Attributes and attribute values associated with search queries are an example of third classification information. Therefore, the description of the attributes and attribute values associated with the search query can be read as the third classification information.
- the third classification information is information regarding the classification of the third data.
- the third classification information is the output part of the training data of the second model M2.
- the query selection database DB4 is used to generate training data for the second model M2, so the attributes and attribute values stored in the query selection database DB4 correspond to the third classification information.
- the initial estimation results of the first model M1 are also used in the learning of the second model M2, so the attributes and attribute values estimated by the initial first model M1 also correspond to the third classification information. .
- the third classification information may be information that can be used for learning the second model M2, and is not limited to the attributes and attribute values associated with the search query.
- the third classification information may indicate only attributes or attribute values associated with the search query.
- the third classification information may be in any format and is not limited to character strings.
- the third classification information may be information such as an ID or number that can uniquely identify the classification.
- each attribute/attribute value pair corresponds to the third classification information. Therefore, a plurality of pieces of third classification information may be associated with one piece of third data.
- a plurality of attribute/attribute value pairs may be treated as one piece of third classification information. In this case, one piece of third classification information is associated with one piece of third data.
- the second model M2 learns the relationship between the combination of the third data and the third classification information and the validity indicating that the combination is valid.
- the second model M2 includes a query selection database DB4 including third data candidates and third classification information candidates, and the third data obtained based on the query selection database DB4, The relationship between the third classification information and the is learned.
- the query selection database DB4 is an example of a second database. Therefore, the description of the query selection database DB4 can be read as the second database.
- the second database is a database that stores candidate data for the training data of the second model M2. All or part of the data in the second database is used as training data for the second model M2.
- the second database is a database from a different viewpoint than the first database.
- a viewpoint is a specific content of data used as training data. Different types of data are used for the input portion included in the training data for the first model M1 and the input portion included in the training data for the second model M2.
- the input part included in the training data of the first model M1 is the web page title
- the input part included in the training data of the second model M2 is the search query.
- a web page title and a search query are the same in terms of character strings, but differ in specific content.
- the first learning unit 201 executes learning processing of the first model M1.
- the data stored in the page database DB1 is used as training data for the first model M1, so the first learning unit 201 executes learning processing for the first model M1 based on this training data.
- the first learning unit 201 outputs the attributes and attribute values, which are the output portion of the training data, when the title of the web page, which is the input portion of the training data, is input. Execute the learning process.
- Various algorithms can be used for the learning process itself of the first learning model M1, for example, error backpropagation or gradient descent can be used.
- the second classification information acquisition unit 202 acquires the attributes and attribute values of the search query (that is, the searcher intent estimation result).
- a search query that is not associated with attributes and attribute values is an example of second data. Therefore, the description of a search query that is not associated with attributes and attribute values can be read as second data.
- the second data is data input to the first model M1.
- the second data has the same format as the first data.
- search queries that are not associated with attributes and attribute values are stored in the search query database DB2, so the search queries stored in the search query database DB2 correspond to second data. That is, the second data is the search query input by the user.
- the second data is not limited to a search query as long as it is data to be estimated by the first model M1.
- the second data when estimating the intention of the creator instead of the intention of the searcher, includes the title of the web page, a character string other than the title contained in the web page, the keyword used as the index of the web page, Or it may be a summary created from a web page.
- the second data may not be the character string itself, but may be a feature quantity indicating some characteristic of the character string.
- the second data may be in any format and is not limited to character strings.
- the second data may be image data, moving image data, document data, or any other data.
- the second data may be data called content.
- Attributes and attribute values estimated for search queries are an example of second classification information. Therefore, the description of attributes and attribute values estimated for a search query can be read as second classification information.
- the second classification information is information relating to the classification of the second data.
- the second data is a search query, so the second classification information is information about the classification of the search query.
- the second classification information is information regarding the intention of the user to input the search query.
- the second classification information is attributes and attribute values estimated by the first model M1.
- the effectiveness is estimated by the second model M2, so the attributes and attribute values whose effectiveness is estimated by the second model M2 correspond to the second classification information.
- the second classification information may be any information indicating the estimation result of the first model M1, and is not limited to the attributes and attribute values of the search query.
- the second classification information may indicate either the attribute or the attribute value of the search query.
- the second classification information may be in any format and is not limited to character strings.
- the second classification information may be information such as an ID or number that can uniquely identify the classification. In this embodiment, a case will be described in which each attribute/attribute value pair corresponds to the second classification information. Therefore, a plurality of pieces of second classification information may be associated with one piece of second data. A plurality of attribute and attribute value pairs may be treated as one piece of second classification information. In this case, one piece of second classification information is associated with one piece of second data.
- the second classification information acquisition unit 202 inputs the search query stored in the search query database DB2 to the first model M1 as the second data.
- the first model M1 calculates the feature quantity of this search query, and outputs attributes and attribute values according to the feature quantity as estimation results.
- the second classification information acquisition unit 202 acquires the attributes and attribute values output from the first model M1 as second classification information.
- the second classification information acquisition unit 202 acquires a plurality of attributes and attribute values based on the first model M1. Even if the first model M1 supports multi-labels, only one attribute and one attribute value may be estimated.
- the calculation of the feature amount required for the processing of the first model M1 is performed within the first model M1.
- the second data is input to the first model M1 as it is will be described. Then, it may be input to the first model M1. That is, the second data may not be directly input to the first model M1, but may be input to the first model M1 after some processing is performed on the second data.
- the candidate generation unit 203 generates candidates for a search query as third data and attributes and attribute values as third classification information based on each of a plurality of generation methods.
- a candidate is data or information that can be the third data or the third classification information.
- two generation methods, a generation method using the query selection database DB4 and a generation method using the initial first model M1 are taken as examples.
- the candidate generator 203 may generate candidates based on only one of these two generation methods.
- FIG. 9 is a diagram showing an example of a method of generating training data for the second model M2.
- the candidate generation unit 203 acquires the search query stored in the query selection database DB4 and the attributes and attribute values of the web page selected by the searcher who entered the search query as candidates C1.
- the candidate generation unit 203 inputs the search query stored in the search query database DB2 to the initial first model M1, acquires the attributes and attribute values output from the initial first model M1, and generates candidates C2 to get
- Candidates C3 generated by a plurality of generation methods are learned in the second model M2 as third data and third classification information.
- the candidate C3 acquired by both the generation method using the query selection database DB4 and the generation method using the initial first model M1 is learned by the second model M2.
- Candidate C3 is the AND of candidate C1 and candidate C2. Candidates obtained by either the generation method using the query selection database DB4 or the generation method using the initial first model M1 are not learned by the second model M2.
- the third classification information acquisition unit 204 acquires attributes and attribute values, which are third classification information, based on the search query, which is third data, and the first model M1.
- This first model M1 is the initial first model M1.
- the third classification information acquisition unit 204 inputs the search query stored in the query selection database DB4 to the initial first model M1.
- the initial first model M1 calculates the feature amount of this search query, and outputs attributes and attribute values according to the feature amount as estimation results.
- the process itself of the first model M1 for acquiring the attributes and attribute values as the third classification information is the process for acquiring the attributes and attribute values as the second classification information (the function of the second classification information acquisition unit 202 ) is the same as the processing described in
- the attributes and attribute values acquired by the third classification information acquisition unit 204 are candidate C2 in FIG.
- candidates C2 that also appear in candidate C1 are training data for the second model M2, but candidate C2 may be training data for the second model M2 regardless of candidate C1. That is, the attributes and attribute values acquired by the third classification information acquisition unit 204 may be used as they are as training data for the second model M2.
- candidate C1 may be the training data for the second model M2, regardless of candidate C2.
- the second learning unit 205 executes learning processing of the second model M2.
- the data stored in the training database DB3 is used as training data for the second model M2, so the second learning unit 205 executes the learning process for the second model M2 based on this training data.
- the second learning unit 205 outputs the effectiveness of the combination.
- Various algorithms can be used for the learning process itself of the second learning model M2, for example, error backpropagation or gradient descent can be used.
- the validity estimation unit 206 estimates the validity of a combination of a search query that is second data and attributes and attribute values that are second classification information based on a predetermined estimation method. Effectiveness is whether or not the processing of the execution unit 207 is effective, or the degree of effectiveness for the processing of the execution unit 207 .
- the execution unit 207 executes training data generation processing, so whether or not the combination is suitable as training data or the degree of suitability as training data corresponds to effectiveness. Effectiveness can also be said to be aptitude in the processing of the execution unit 207 .
- the effectiveness estimation unit 206 will describe a case where determining whether the combination is effective corresponds to estimating effectiveness. may be equivalent to estimating effectiveness. Scores indicate high effectiveness. The score may be expressed numerically, or may be expressed by letters such as S rank, A rank, B rank, or other symbols.
- the effectiveness estimation unit 206 estimates effectiveness based on the second model M2.
- the effectiveness estimation unit 206 estimates effectiveness for each attribute and attribute value. For example, for each attribute and attribute value, the effectiveness estimating unit 206 inputs the combination of the search query and the attribute and the attribute value to the second model M2, and uses the effectiveness estimation result output from the second model M2 as get.
- the effectiveness estimating unit 206 inputs a first combination, which is a combination of the search query "CG bag Zebra” and the attribute value "Computer Graphic” of the attribute "Image”, into the second model M2. Obtain the estimated effectiveness of the first combination output from the model M2. In the example of FIG. 3, this estimation result indicates that the first combination is effective.
- the effectiveness estimation unit 206 inputs a second combination of the search query "CG bag Zebra” and the attribute value "Republic of the Congo” of the attribute "Nation” into the second model M2, Obtain the estimated effectiveness of the second combination output from the second model M2. In the example of FIG. 3, this estimation result indicates that the second combination is not valid.
- the effectiveness estimating unit 206 inputs a third combination, which is a combination of the search query "CG bag Zebra” and the attribute value "Zebra" of the attribute "Pattern", to the second model M2. Obtain the estimated effectiveness of the third combination output from M2. In the example of FIG. 3, this estimation result indicates that the third combination is effective.
- the estimation method of the effectiveness estimation unit 206 is a method using query selection data that indicates the relationship between search queries input in the past and selection results for search results based on the search queries.
- the effectiveness estimation unit 206 estimates effectiveness based on the query selection data.
- estimating the effectiveness based on the second model M2 means estimating the effectiveness based on the query selection data. corresponds to
- the estimation method of the effectiveness estimation unit 206 is not limited to the method using the second model M2.
- the effectiveness estimation unit 206 may estimate effectiveness based on a predetermined rule-based estimation method instead of a machine learning method.
- a rule for outputting validity when a combination of a search query as second data and an attribute and an attribute value as second classification information is input is prepared in advance.
- the rules may be like decision trees.
- Other estimation methods may be rule-based or statistical-based estimation methods such as modified examples described later.
- the execution unit 207 executes predetermined processing based on the effectiveness estimation result by the effectiveness estimation unit 206 .
- the execution unit 207 based on the combination of the search query that is the second data and the attribute and the attribute value that are the second classification information, and the effectiveness estimation result of the effectiveness estimation unit 206, As a predetermined process, a generation process is executed to generate training data to be learned by the first model M1. Generation processing is an example of predetermined processing. Therefore, the part describing the generation process can be read as the predetermined process.
- the predetermined process may be any process and is not limited to the generation process. Other examples of the predetermined processing will be described in modified examples below.
- the execution unit 207 sets a pair of a search query whose effectiveness is estimated by the effectiveness estimation unit 206 and an attribute and an attribute value for which an estimation result indicating effectiveness is obtained as training data.
- the generation process is executed by storing the A pair of a search query whose effectiveness is estimated by the effectiveness estimation unit 206 and an attribute and an attribute value for which an estimation result that does not indicate effectiveness is not generated as training data.
- the execution unit 207 executes generation processing based on the validity of each attribute and attribute value. For example, the execution unit 207 generates training data only for attributes and attribute values for which estimation results indicating that they are effective have been obtained, among a plurality of attributes and attribute values. Of the plurality of attributes and attribute values, attributes and attribute values for which estimation results that do not indicate validity are not generated as training data.
- Data storage unit 300 is realized mainly by storage unit 32 .
- the display control unit 301 and the reception unit 302 are realized mainly by the control unit 31 .
- the data storage unit 300 stores data necessary for searching.
- the data storage unit 300 stores a browser for displaying the portal page P1 and the search result page P2.
- the screen displayed on the retriever terminal 30 may use another application instead of the browser. In this case, the data storage unit 300 stores the application.
- the display control unit 301 causes the display unit 35 to display various screens. For example, when receiving data of the portal page P1 from the search server 10, the display control unit 301 causes the display unit 35 to display the portal page P1. When the data of the search result page P2 is received from the search server 10, the display control unit 301 causes the display unit 35 to display the search result page P2.
- the reception unit 302 receives various operations from the operation unit 34. For example, the reception unit 302 receives input of a search query for the input form F10 of the portal page P1. The searcher terminal 30 transmits the input search query to the search server 10 . For example, the reception unit 302 receives selection of a link included in the search results indicated by the search result page P2. The searcher terminal 30 transmits the selected link to the search server 10 .
- Data storage unit 400 is realized mainly by storage unit 32 .
- Each of the display control unit 401 and the reception unit 402 is implemented mainly by the control unit 41 .
- the data storage unit 400 stores applications for creating web pages.
- the display control unit 401 causes the display unit 45 to display various screens. For example, the display control unit 401 displays an application screen for creating a web page.
- a reception unit 402 receives various operations from the operation unit 44 . For example, the accepting unit 402 accepts an operation of creating a web page by a creator, or an operation of specifying the title, attributes, and attribute values of the web page.
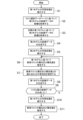
- FIG. 10 is a flow diagram showing an example of processing executed by the processing execution system S. As shown in FIG. In FIG. 10, the processing executed by the learning server 20 among the processing executed by the processing execution system S will be described. This processing is executed by the control unit 21 operating according to the program stored in the storage unit 22 .
- the learning server 20 executes learning processing for the first model M1 based on the page database DB1 (S1).
- S1 the learning server 20 sets the first model so that when a character string indicated by the title of a web page stored in the page database DB1 is input, attributes and attribute values associated with the title are output.
- the parameters of M1 are adjusted.
- the first model M1 that has undergone the learning process in S1 is the initial first model M1.
- the initial first model M1 is subjected to additional learning processing by the processing of S10 described later.
- the learning server 20 acquires training data candidates C1 for the second model M2 based on the query selection database DB4 (S2).
- the learning server 20 trains the second model M2 by combining the search query stored in the query selection database DB4 and the attribute and attribute value of the web page selected by the searcher who entered the search query. Obtained as data candidate C1.
- the learning server 20 acquires all or some pairs of the query selection database DB4.
- the learning server 20 acquires training data candidates C2 for the second model M2 based on the initial first model M1 (S3).
- the learning server 20 inputs the search query stored in the search query database DB2 to the initial first model M1, and acquires the attributes and attribute values output from the initial first model M1.
- the learning server 20 acquires pairs of the search query input to the first model M1 and the attribute and attribute value output from the first model M1 as training data candidates C2.
- the learning server 20 inputs a search query of all or part of the search query database DB2 to the learning server 20, and trains pairs of the search query and the attribute and attribute value output from the learning server 20. Obtained as data candidate C2.
- the learning server 20 generates training data for the second model M2 based on the candidate C1 obtained in S2 and the candidate C2 obtained in S3 (S4).
- the learning server 20 ANDs both the candidate C1 acquired in S2 and the candidate C2 acquired in S3, and generates the candidate C3 present in both of these as training data for the second model M2. do.
- the learning server 20 executes the learning process of the second model M2 based on the training data generated in S4 (S5).
- the learning server 20 constructs the second model so that when the character string of the input portion included in the training data generated in S4 is input, the attribute and attribute value associated with this character string are output.
- the parameters of M2 are adjusted.
- the learning server 20 estimates the attributes and attribute values of the search queries stored in the search query database DB2 based on the first model M1 (S6). In S6, the result of the processing in S3 may be used. Based on the second model M2, the learning server 20 estimates the effectiveness of the combination of the search query and the attributes and attribute values obtained in S6 (S7). In S7, the learning server 20 inputs a pair of the search query processed in S6 and the attribute and attribute value estimated in S6 to the second model M2, and the effective data output from the second model M2. Get gender estimation results.
- the learning server 20 generates training data for the first model M1 based on the effectiveness estimation result in S7 (S8).
- the learning server 20 stores pairs of search queries, attributes, and attribute values estimated to be effective in S7 as training data in the training database DB3.
- the learning server 20 determines whether or not a sufficient number of training data has been generated (S9).
- S9 it is determined whether or not the number of training data generated in S8 has reached a predetermined number. If it is determined that a sufficient number of training data has not been generated (S9; N), the process returns to S6 and the generation of training data is repeated.
- the learning server 20 executes learning processing of the first model M1 based on the training database DB3 (S10).
- the learning server 20 is configured so that, when a character string of an input portion included in the training data stored in the training database DB3 is input, attributes and attribute values associated with this character string are output. Parameters of the first model M2 are adjusted.
- the learning server 20 estimates the attributes and attribute values of the search query stored in the search query database DB2 based on the learned first model M1 (S11), and ends this process.
- the process of S11 is similar to S3 and S6, but differs in that the first model M1 that has been trained in the process of S10 is used instead of the initial first model M1.
- the learning server 20 records the attributes and attribute values estimated in S11 in the storage unit 22 in association with the search query.
- the recorded search queries, attributes and attribute values can be used for any purpose.
- the learning server 20 outputs these associations for marketing purposes or the like when an administrator of the processing execution system S requests to refer to these associations.
- the effectiveness of combinations of search queries and attributes and attribute values estimated by the first model M1 is estimated based on a predetermined estimation method. Since the processing execution system S executes the predetermined processing after estimating the effectiveness, even if the accuracy of the first model M1 is insufficient due to insufficient training data, the desired result can be obtained. Obtainable. For example, by executing the generating process as the predetermined process, the training data of the first model M1 can be generated after estimating the effectiveness, so the accuracy of the first model M1 is increased. As a result, the accuracy of estimating the attributes and attribute values of the search query by the first model M1 is increased, and it becomes easier to obtain desired results such as estimating the user's intention. In addition, for example, training data for the first model M1 can be created from a search query that has been input in the past, so it is possible to save the trouble of creating training data for the first model M1.
- the processing execution system S estimates the effectiveness of combinations of search queries, attributes, and attribute values based on the second model M2. This increases the accuracy of estimating the effectiveness of these combinations.
- the accuracy of the training data of the first model M1 generated as the predetermined process is also enhanced by increasing the estimation accuracy of effectiveness. As a result, the estimation accuracy of the first model M1 is enhanced, making it easier to obtain desired results.
- the relationship between the title of the web page, the attribute, and the attribute value acquired based on the page database DB1 is learned.
- the second model M2 learns the relationship between the search query, the attribute, and the attribute value acquired based on the query selection database DB4 from a different viewpoint from the page database DB1.
- the accuracy of estimation of effectiveness by the second model M2 is enhanced.
- the second model M2 learns the same training data as the first model M1, it is considered difficult to create the second model M2 that identifies an error in the estimation result of the first model M1.
- the second model M2 can be learned from a viewpoint different from that of the first model M1.
- the second model M2 can be created to identify errors in the estimation result of the first model M1, and the effectiveness estimation accuracy of the second model M2 increases.
- the accuracy of estimation of effectiveness by the second model M2 increases, the accuracy of the training data of the first model M1 generated as a predetermined process also increases.
- the estimation accuracy of the first model M1 is enhanced, making it easier to obtain desired results.
- the second model M2 learns the relationship between the combination of the search query, the attribute, and the attribute value estimated using the initial first model M1, and the effectiveness indicating that the combination is effective. be done. As a result, more training data for the second model M2 can be generated, so the accuracy of estimation of effectiveness by the second model M2 increases. It is also possible to save the trouble of generating training data for the second model M2. As the accuracy of estimation of effectiveness by the second model M2 increases, the accuracy of the training data of the first model M1 generated as a predetermined process also increases. As a result, the estimation accuracy of the first model M1 is enhanced, making it easier to obtain desired results.
- the processing execution system S generates candidates for combinations of search queries, attributes, and attribute values that are stored as training data in the training database DB3 based on each of the plurality of generation methods. Candidates generated by a plurality of generation methods are learned as training data for the second model M2. As a result, more training data for the second model M2 can be generated, so the accuracy of estimation of effectiveness by the second model M2 increases. It is also possible to save the trouble of generating training data for the second model M2. As the accuracy of estimation of effectiveness by the second model M2 increases, the accuracy of the training data of the first model M1 generated as a predetermined process also increases. As a result, the estimation accuracy of the first model M1 is enhanced, making it easier to obtain desired results.
- the search query input by the user is learned as second data, and the attributes and attribute values of the search query are learned as second classification information.
- the estimation accuracy of effectiveness by the second model M2 increases.
- the effectiveness estimation accuracy of the second model M2 increases, the accuracy of the training data of the first model M1 that is executed as the predetermined process also increases. As a result, the estimation accuracy of the first model M1 is enhanced, making it easier to obtain desired results.
- the method of estimating effectiveness is a method that uses query selection data that indicates the relationship between search queries that have been input in the past and selection results for search results based on the search queries.
- query selection data that easily expresses the user's intention
- the accuracy of the training data of the first model M1 generated as the predetermined process is also enhanced by increasing the estimation accuracy of effectiveness. As a result, the estimation accuracy of the first model M1 is enhanced, making it easier to obtain desired results.
- the web page titles, attributes, and attribute values learned by the first model M1 are data used as indexes during searches.
- the learning process of the first model M1 can be executed based on practical data that is used as an index during an actual search.
- the estimation accuracy of the first model M1 is enhanced, making it easier to obtain desired results.
- the attribute and attribute value which are the second classification information, are estimated as information related to the intention of the user to input the search query. This makes it possible to estimate the intention of the user who entered the search query. For example, estimating the intention of a user who entered a search query can be used for marketing of search services and improve the accuracy of search results.
- a generation process is executed to generate training data for the first model M1 to learn based on the combination of the search query, the attribute and the attribute value, and the effectiveness estimation result. This increases the estimation accuracy of the first model M1, making it easier to obtain desired results. It is also possible to save the trouble of creating training data for the first model M1.
- the first model M1 is a multi-label compatible model in which the relationship between the title of the web page and a plurality of attributes and attribute values has been learned. This allows multiple attributes and attribute values to be associated with a user-entered search query. This increases the estimation accuracy of the first model M1, making it easier to obtain desired results.
- Modification 1 For example, in the embodiment, a case has been described where the second model M2 outputs, as an estimation result, binary information indicating whether or not a combination of a search query, an attribute, and an attribute value is effective.
- the second model M2 may output a score regarding the effectiveness of this combination as an estimation result.
- the score is as described in the embodiment. Modification 1 describes a case where scores are represented by numbers. A higher score means higher effectiveness. Scores can also be referred to as probabilities or probabilities. For example, when a combination of a search query, an attribute, and an attribute value is input, the second model M2 outputs the score of this combination as an estimation result.
- the effectiveness estimating unit 206 of Modification 1 acquires the score output from the second model M2 based on the combination of the search query, the attribute, and the attribute value, and estimates the effectiveness based on the acquired score. presume. For example, when the score output from the second model M2 is less than the threshold, the effectiveness estimation unit 206 estimates that the combination of the search query, the attribute, and the attribute value is not effective, and outputs If the resulting score is equal to or greater than the threshold, then the combination of the search query and the attribute and attribute value is presumed to be valid.
- the score output from the second model M2 is obtained based on the combination of the search query, the attribute, and the attribute value, and the effectiveness is estimated based on the obtained score.
- the second model M2 It becomes easier to utilize the estimation results of For example, the score value makes it easier to understand with what degree of certainty the second model M2 is effective.
- the accuracy of the training data of the first model M1 that is executed as the predetermined process also increases. For example, the higher the score of the second model M2 acquired to generate the training data of the first model M1, the greater the weight of the first model M1. In this case, highly effective training data can be learned by the first model M1. As a result, the estimation accuracy of the first model M1 is improved, making it easier to obtain desired results.
- the estimation method may be a method using cosine similarity based on the search query, attributes and attribute values.
- Cosine similarity is a technique for calculating similarity between character strings. For example, when determining the similarity between a first character string and a second character string, the angle between the first vector that indicates the characteristics of the first character string and the second vector that indicates the characteristics of the second character string is Based on this, the cosine similarity is calculated. The more the first vector and the second vector point in the same direction, the higher the cosine similarity. That is, the more similar the features of the search query and the attributes and attribute values, the higher the cosine similarity.
- the effectiveness estimation unit 206 estimates effectiveness based on the cosine similarity based on the search query, attributes, and attribute values.
- the validity estimating unit 206 calculates the cosine similarity between the first vector representing the feature of the search query and the second vector representing the feature of the attribute and attribute value.
- the first vector and the second vector may be calculated by the second model M2 similar to the embodiment, or may be calculated by other models such as Word2Vec or Doc2Vec.
- the cosine similarity calculation method itself various calculation methods used in natural language processing can be used.
- the validity estimation unit 206 estimates that the combination of the search query, the attribute, and the attribute value is not valid when the cosine similarity based on the search query, the attribute, and the attribute value is less than the threshold, and the search query If the cosine similarity based on , the attribute and the attribute value is equal to or greater than the threshold, the combination of the search query and the attribute and the attribute value is estimated to be valid.
- Cosine similarity may be used as the score described in Modification 1 by combining Modification 1 and Modification 2.
- the validity of the estimation result of the first model M1 is estimated based on the cosine similarity.
- the cosine similarity which is relatively easy to calculate, the processing of the processing execution system S can be speeded up.
- effectiveness estimation section 206 may estimate effectiveness based on each of a plurality of estimation methods.
- the plurality of estimation methods include the estimation method described in the embodiment, the estimation method described in Modification 1, and the estimation method described in Modification 2.
- Other examples include estimation methods such as those described below.
- modification 3 arbitrary estimation methods can be combined.
- the effectiveness estimation unit 206 may estimate effectiveness based on an estimation method using a dictionary.
- a dictionary defines relationships between attributes and specific character strings of attribute values. The effectiveness estimating unit 206 estimates that the estimation result of the first model M1 is not effective when the attribute and the attribute value output by the first model M1 do not exist in the dictionary. If the attribute and the attribute value are present in the dictionary, it is assumed that the estimation result of the first model M1 is valid.
- the effectiveness estimation unit 206 may estimate effectiveness based on a dictionary that defines the relationship between a search query and valid attributes and attribute values. In this case, if the combination of the search query input to the first model M1 and the attribute and attribute value output from the first model M1 does not exist in the dictionary, the effectiveness estimation unit 206 Assume that the estimation result of M1 is not valid, and assume that the estimation result of the first model M1 is valid if this combination exists in the dictionary.
- the effectiveness estimation unit 206 may estimate effectiveness based on an estimation method using a multi-label classification tool such as extremeText.
- the effectiveness estimation unit 206 inputs a combination of a search query, an attribute, and an attribute value into a classification tool, and estimates that this combination is not effective if the score output from the classification tool is less than a threshold. and if this score is greater than or equal to the threshold, then the combination is presumed to be effective.
- the execution unit 207 executes generation processing based on the effectiveness estimation results obtained by each of the plurality of estimation methods.
- the execution unit 207 executes generation processing by comprehensively considering the effectiveness estimation results obtained by each of the plurality of estimation methods. That is, the execution unit 207 may execute the generation process using a statistical index based on estimation results of effectiveness by each of a plurality of estimation methods.
- the execution unit 207 stores, in the training database DB3, combinations of search queries, attributes, and attribute values for which the number of estimation methods estimated to be effective is equal to or greater than a predetermined number. Combinations of search queries and attributes and attribute values for which the number of estimation methods estimated to be valid is less than a predetermined number are not used as training data.
- the execution unit 207 may generate training data and store it in the training database DB3 based on majority votes by each of a plurality of estimation methods. Assuming that there are five estimation methods, the execution unit 207 estimates the effectiveness of combinations of search queries, attributes, and attribute values based on each of the five estimation methods. That is, the execution unit 207 acquires five estimation results. When three or more of the five estimation results are effective, the execution unit 207 generates training data indicating that the combination of the search query, the attribute, and the attribute value is effective. It is generated and stored in the training database DB3.
- the execution unit 207 may generate training data based on each average value of a plurality of estimation methods and store it in the training database DB3. Assuming that there are five estimation methods, the execution unit 207 estimates the effectiveness of combinations of search queries, attributes, and attribute values based on the five estimation methods. That is, the execution unit 207 acquires five estimation results. The execution unit 207 generates training data, which is a pair of a combination of a search query, an attribute and an attribute value, and an average value of the five estimation results, and stores the training data in the training database DB3. For example, if three out of five estimation results are effective, the average value is 0.6. This average value indicates a high degree of effectiveness.
- a programmable labeling model such as Snorkel may be used as a model for integrally using a plurality of estimation methods.
- the execution unit 207 may calculate a score indicating a comprehensive estimation result based on the effectiveness estimation results obtained by each of a plurality of estimation methods. In this case, the execution unit 207 does not execute the generation process when the total score is less than the threshold, and executes the generation process when the total score is equal to or greater than the threshold. For example, the execution unit 207 may determine the weight according to the number of estimation methods estimated to be effective or the overall score. In this case, the weight is determined so that the training data is more strongly learned by the first model M1 as the number of estimation methods estimated to be effective increases or as the overall score increases.
- the training data for the first model M1 is small, and there is a possibility that a sufficient amount of training data for learning the first model M1 cannot be obtained. be. Therefore, it is considered that there is a trade-off relationship between the accuracy of the training data of the first model M1 and the number of training data of the first model M1.
- Modification 4 For example, in the embodiment, the case where the process execution system S is applied to a web page search service has been described, but the process execution system S can be applied to any service.
- the processing execution system S can be used for electronic commerce services, travel reservation services, net auction services, facility reservation services, SNS (Social Networking Services), financial services, insurance services, video distribution services, or communication services.
- Modification 4 describes a case where the processing execution system S is applied to an electronic commerce service.
- the product page on which the product is posted corresponds to the web page described in the embodiment.
- the first data in Modification 4 is the product title used as an index when searching for products.
- the product title is a character string that briefly describes the product. For example, a product description is prepared separately from the product title. The product title is shorter than the product description. For example, the product title is a character string of about several to 100 characters, whereas the product description is a character string of about tens to thousands of characters.
- the product title is created by the person in charge of the store. Therefore, in Modification 4, the person in charge of the store in the electronic commerce service corresponds to the creator.
- a searcher is a user who purchases a product using an electronic commerce service.
- the first classification information in Modification 4 is product attribute information used as an index when searching for products.
- the product attribute information is information relating to product attributes.
- the product attribute information indicates at least one of attributes and attribute values.
- product attribute information may indicate either attributes or attribute values.
- the product attribute is the product genre or category.
- the attributes of the item may be features such as the color, size, pattern, or shape of the item.
- the page database DB1 of Modification 4 product titles, product attributes and attribute values are associated and stored.
- the initial first model M1 relationships between product titles, product attributes and attribute values are learned.
- search queries that have been input in the electronic commerce service in the past are stored as second data and third data.
- the second classification information acquisition unit 202 acquires attributes and attribute values corresponding to search queries stored in the search query database DB2 as second classification information based on the first model M1.
- the second model M2 learns the relationship between combinations of previously input search queries, product attributes and attribute values, and the effectiveness of these combinations.
- the effectiveness estimation unit 206 inputs a combination of the search query input to the first model M1 and the product attributes and attribute values output from the first model M1 to the second model M2.
- the effectiveness estimator 206 estimates the effectiveness of these combinations by acquiring the output from the second model M2.
- execution section 207 determines whether or not to generate a combination of these as training data for first model M1.
- the first data is the product title used as an index when searching for products
- the first classification information is product attribute information used as an index when searching for products.
- the predetermined process executed by the execution unit 207 is not limited to the generation process described in the embodiment.
- the execution unit 207 may execute search processing according to the search query as predetermined processing based on the effectiveness estimation result.
- the processes of the second classification information acquisition section 202, the validity estimation section 206, and the execution section 207 are executed.
- the second classification information acquisition unit 202 acquires attributes and attribute values corresponding to the search query input by the user based on the first model M1.
- This first model M1 may be a model that has been learned by a method similar to that of the embodiment, or may be a model that has been learned by another method.
- the effectiveness estimation unit 206 estimates the effectiveness of combinations of search queries, attributes, and attribute values.
- the method of estimating effectiveness is the same as in the embodiment.
- the execution unit 207 estimates that this combination is not valid, the execution unit 207 does not use the attributes and attribute values estimated by the first model M1 in the search process, and based on the search query input by the user, Execute the search process.
- the execution unit 207 estimates that this combination is valid, the execution unit 207 executes search processing so that the attributes and attribute values estimated by the first model M1 are used as a search query. In this case, the character string input as the search query input by the user and the attributes and attribute values estimated by the first model M1 are used as the search query.
- search processing is executed according to the search query based on the effectiveness estimation result.
- the estimation result of the first model M1 estimated to be effective can be used in the search process, so the accuracy of the search process is improved.
- the execution unit 207 may execute output processing for outputting a search query, an attribute, and an attribute value as predetermined processing based on the effectiveness estimation result.
- the execution unit 207 outputs to the terminal of the administrator in the process execution system S, a combination of the search query, the attribute, and the attribute value estimated to be valid.
- the execution unit 207 may output the estimation result of effectiveness and the combination of the search query, the attribute, and the attribute value to the administrator's terminal.
- the output to the administrator's terminal may be performed by displaying an image, or may be performed by data output.
- output processing is executed to output the search query, attributes, and attribute values based on the effectiveness estimation results. This makes it possible to notify the administrator of the relationship between the search query and the attributes and attribute values, which can be used for marketing and the like.
- the second data is a search query for a web page has been described, but the second data may be data related to a user's post. Posts include at least one of text and images.
- Modification 7 describes a case where a user posts to an SNS, but the user can post to any service. For example, it may be an Internet encyclopedia posting, a bulletin board posting, or a comment on a news article.
- the SNS post itself may be a variety of posts, such as a short text post, an image, a video, or a combination thereof.
- the second classification information is information about the classification of posts.
- this classification is information called a hash tag
- the second classification information in Modification 7 may be information other than hash tags.
- the second classification information acquisition unit 202 acquires hashtags corresponding to user posts based on the first model M1.
- This first model M1 may be a model that has been learned by a method similar to that of the embodiment, or may be a model that has been learned by another method.
- the validity estimation unit 206 estimates the validity of the combination of user posts and hashtags.
- the method of estimating effectiveness is the same as in the embodiment.
- the execution unit 207 estimates that this combination is not valid, it does not attach the hash tag estimated by the first model M1 to the user's post.
- the execution unit 207 estimates that this combination is valid, the execution unit 207 attaches the hashtag estimated by the first model M1 to the user's post.
- the second data is data related to the user's post
- the second classification information is information related to the classification of the post.
- the functions described as being implemented by the search server 10 may be implemented by another computer, or may be shared among multiple computers.
- the functions described as being realized by the learning server 20 may be realized by another computer, or may be shared among a plurality of computers.
- data to be stored in the data storage units 100 and 200 may be stored in a database server.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Databases & Information Systems (AREA)
- Computational Linguistics (AREA)
- Artificial Intelligence (AREA)
- Life Sciences & Earth Sciences (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Evolutionary Biology (AREA)
- Evolutionary Computation (AREA)
- Probability & Statistics with Applications (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- General Health & Medical Sciences (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Priority Applications (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2021/040852 WO2023079703A1 (ja) | 2021-11-05 | 2021-11-05 | 処理実行システム、処理実行方法、及びプログラム |
| EP22889595.9A EP4287040A4 (en) | 2021-11-05 | 2022-02-02 | PROCESSING EXECUTION SYSTEM, PROCESSING EXECUTION METHOD AND PROGRAM |
| JP2023511824A JP7316477B1 (ja) | 2021-11-05 | 2022-02-02 | 処理実行システム、処理実行方法、及びプログラム |
| PCT/JP2022/003988 WO2023079769A1 (ja) | 2021-11-05 | 2022-02-02 | 処理実行システム、処理実行方法、及びプログラム |
| US18/548,337 US12443681B2 (en) | 2021-11-05 | 2022-02-02 | Processing execution system, processing execution method, and program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2021/040852 WO2023079703A1 (ja) | 2021-11-05 | 2021-11-05 | 処理実行システム、処理実行方法、及びプログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023079703A1 true WO2023079703A1 (ja) | 2023-05-11 |
Family
ID=86240892
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2021/040852 Ceased WO2023079703A1 (ja) | 2021-11-05 | 2021-11-05 | 処理実行システム、処理実行方法、及びプログラム |
| PCT/JP2022/003988 Ceased WO2023079769A1 (ja) | 2021-11-05 | 2022-02-02 | 処理実行システム、処理実行方法、及びプログラム |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/003988 Ceased WO2023079769A1 (ja) | 2021-11-05 | 2022-02-02 | 処理実行システム、処理実行方法、及びプログラム |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US12443681B2 (https=) |
| EP (1) | EP4287040A4 (https=) |
| JP (1) | JP7316477B1 (https=) |
| WO (2) | WO2023079703A1 (https=) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20260087078A1 (en) * | 2024-09-20 | 2026-03-26 | Notion Labs, Inc. | Ranking system for improved search relevance |
| JP7659257B1 (ja) | 2024-10-04 | 2025-04-09 | AI inside株式会社 | 情報処理装置、方法、及びプログラム |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2017049681A (ja) * | 2015-08-31 | 2017-03-09 | 国立研究開発法人情報通信研究機構 | 質問応答システムの訓練装置及びそのためのコンピュータプログラム |
| JP2018124914A (ja) * | 2017-02-03 | 2018-08-09 | 日本電信電話株式会社 | パッセージ型質問応答装置、方法、及びプログラム |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH07282078A (ja) * | 1994-04-12 | 1995-10-27 | Hitachi Ltd | 階層的分類方法 |
| US9147129B2 (en) * | 2011-11-18 | 2015-09-29 | Honeywell International Inc. | Score fusion and training data recycling for video classification |
| US9846822B2 (en) * | 2015-12-31 | 2017-12-19 | Dropbox, Inc. | Generating and utilizing normalized scores for classifying digital objects |
| US10726022B2 (en) * | 2016-08-26 | 2020-07-28 | Facebook, Inc. | Classifying search queries on online social networks |
| JP7174551B2 (ja) | 2018-07-23 | 2022-11-17 | ヤフー株式会社 | 推定装置、推定方法及び推定プログラム |
| JP7261022B2 (ja) * | 2019-01-30 | 2023-04-19 | キヤノン株式会社 | 情報処理システム、端末装置及びその制御方法、プログラム、記憶媒体 |
| US11216705B2 (en) * | 2019-08-21 | 2022-01-04 | Anyvision Interactive Technologies Ltd. | Object detection based on machine learning combined with physical attributes and movement patterns detection |
| US11983674B2 (en) * | 2019-10-01 | 2024-05-14 | Microsoft Technology Licensing, Llc | Automatically determining and presenting personalized action items from an event |
| JP7371776B2 (ja) * | 2020-05-21 | 2023-10-31 | 株式会社Ihi | 画像分類装置、画像分類方法、及び、画像分類プログラム |
-
2021
- 2021-11-05 WO PCT/JP2021/040852 patent/WO2023079703A1/ja not_active Ceased
-
2022
- 2022-02-02 JP JP2023511824A patent/JP7316477B1/ja active Active
- 2022-02-02 US US18/548,337 patent/US12443681B2/en active Active
- 2022-02-02 WO PCT/JP2022/003988 patent/WO2023079769A1/ja not_active Ceased
- 2022-02-02 EP EP22889595.9A patent/EP4287040A4/en not_active Withdrawn
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2017049681A (ja) * | 2015-08-31 | 2017-03-09 | 国立研究開発法人情報通信研究機構 | 質問応答システムの訓練装置及びそのためのコンピュータプログラム |
| JP2018124914A (ja) * | 2017-02-03 | 2018-08-09 | 日本電信電話株式会社 | パッセージ型質問応答装置、方法、及びプログラム |
Non-Patent Citations (1)
| Title |
|---|
| KAI SHENG TAI, SOCHER RICHARD, MANNING CHRISTOPHER D.: "Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks", PROCEEDINGS OF THE 53RD ANNUAL MEETING OF THE ASSOCIATION FOR COMPUTATIONAL LINGUISTICS AND THE 7TH INTERNATIONAL JOINT CONFERENCE ON NATURAL LANGUAGE PROCESSING (VOLUME 1: LONG PAPERS), ASSOCIATION FOR COMPUTATIONAL LINGUISTICS, STROUDSBURG, PA, USA, 30 May 2015 (2015-05-30), Stroudsburg, PA, USA , pages 1556 - 1566, XP055442054, DOI: 10.3115/v1/P15-1150 * |
Also Published As
| Publication number | Publication date |
|---|---|
| US12443681B2 (en) | 2025-10-14 |
| WO2023079769A1 (ja) | 2023-05-11 |
| EP4287040A1 (en) | 2023-12-06 |
| EP4287040A4 (en) | 2024-06-26 |
| US20240143701A1 (en) | 2024-05-02 |
| JPWO2023079769A1 (https=) | 2023-05-11 |
| JP7316477B1 (ja) | 2023-07-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US12608418B2 (en) | Training image and text embedding models | |
| CN114238573B (zh) | 基于文本对抗样例的信息推送方法及装置 | |
| US20220405607A1 (en) | Method for obtaining user portrait and related apparatus | |
| CN112119388B (zh) | 训练图像嵌入模型和文本嵌入模型 | |
| Joulin et al. | Learning visual features from large weakly supervised data | |
| TWI557664B (zh) | Product information publishing method and device | |
| US20180181569A1 (en) | Visual category representation with diverse ranking | |
| KR20190117584A (ko) | 스트리밍 비디오 내의 객체를 검출하고, 필터링하고 식별하기 위한 방법 및 장치 | |
| CN109906455A (zh) | 视觉搜索查询中的对象检测 | |
| US10229190B2 (en) | Latent semantic indexing in application classification | |
| CN109716327A (zh) | 视觉搜索平台的视频摄取框架 | |
| CN110909536A (zh) | 用于自动生成产品的文章的系统和方法 | |
| Baishya et al. | SAFER: Sentiment analysis-based fake review detection in e-commerce using deep learning | |
| WO2018112696A1 (zh) | 一种内容推荐方法及内容推荐系统 | |
| CN115964560B (zh) | 基于多模态预训练模型的资讯推荐方法及设备 | |
| CN111488524B (zh) | 一种面向注意力的语义敏感的标签推荐方法 | |
| CN110490686A (zh) | 一种基于时间感知的商品评分模型构建、推荐方法及系统 | |
| Zhang et al. | Learning to match clothing from textual feature-based compatible relationships | |
| CN114022233A (zh) | 一种新型的商品推荐方法 | |
| JP7316477B1 (ja) | 処理実行システム、処理実行方法、及びプログラム | |
| Han et al. | Multimodal-adaptive hierarchical network for multimedia sequential recommendation | |
| JP7549706B2 (ja) | データ拡張システム、データ拡張方法、及びプログラム | |
| JP7598901B2 (ja) | クエリ整形システム、クエリ整形方法、及びプログラム | |
| Vaca-Castano et al. | Semantic image search from multiple query images | |
| TWM627311U (zh) | 電子行銷系統 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21963297 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 21963297 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: JP |