WO2023013613A1 - 特定の立体構造を誘導する人工核酸 - Google Patents
特定の立体構造を誘導する人工核酸 Download PDFInfo
- Publication number
- WO2023013613A1 WO2023013613A1 PCT/JP2022/029566 JP2022029566W WO2023013613A1 WO 2023013613 A1 WO2023013613 A1 WO 2023013613A1 JP 2022029566 W JP2022029566 W JP 2022029566W WO 2023013613 A1 WO2023013613 A1 WO 2023013613A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- nucleic acid
- complementary
- conformation
- sequence
- domain
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images






















Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P43/00—Drugs for specific purposes, not provided for in groups A61P1/00-A61P41/00
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/111—General methods applicable to biologically active non-coding nucleic acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/11—Antisense
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/11—Antisense
- C12N2310/113—Antisense targeting other non-coding nucleic acids, e.g. antagomirs
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/32—Chemical structure of the sugar
- C12N2310/321—2'-O-R Modification
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/50—Physical structure
- C12N2310/53—Physical structure partially self-complementary or closed
- C12N2310/531—Stem-loop; Hairpin
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2330/00—Production
Definitions
- the present invention provides an artificial nucleic acid that hybridizes to a nucleic acid of interest that does not form a functional three-dimensional structure to induce a specific three-dimensional structure, a gene expression inhibitor and a nucleic acid detection agent containing the same as an active ingredient, and an artificial nucleic acid. Regarding the method.
- Nucleic acid molecules such as DNA and RNA are composed of nucleotides with four types of bases: adenine (A), thymine (T) (uracil (U) in RNA), guanine (G), and cytosine (C).
- A tends to base pair with T or U, and C with G, and this property is called base pair complementarity.
- base pair complementarity Based on this base pair complementarity, various phenomena such as DNA double helix formation, semi-conservative replication of DNA, and transcription of RNA using DNA as a template occur in vivo.
- the rules for this complementarity are clear, it is applied to almost all biotechnology techniques involving nucleic acids, such as PCR, DNA sequencing, gene knockdown, and gene knockout.
- the gene knockdown method has been widely applied as a third-generation drug called "nucleic acid drug", and in recent years, the number of pharmaceutical approvals has been increasing.
- ASOs and siRNAs are easy to design, but have the problem that their efficacy is not stable when the target sequence is mutated. This is because the formation of base pairs ignoring complementarity weakens the binding between the target and these molecules. Therefore, there was no choice but to exclude gene regions containing individual diversity mutations, typified by single nucleotide variants (SNVs), from target sequence candidates.
- SNVs single nucleotide variants
- Non-Patent Document 1 discloses that about 150 kinds of non-complementary base pairs form a stable three-dimensional structure in a single-stranded nucleic acid that forms a functional three-dimensional structure.
- An object of the present invention is to develop a method for inducing the formation of a conformation containing non-complementary base pairs, and to provide an artificial nucleic acid that can stably bind to a target sequence without being affected by its mutation. That is.
- the present inventors have advanced research and development, resulting in the development of an artificial nucleic acid that induces a specific three-dimensional structure by hybridizing with a target nucleic acid that does not form a three-dimensional structure.
- the stability of the double-stranded nucleic acid was further increased by introducing modifications into the artificial nucleic acid.
- the invention is based on the above new findings and provides the following.
- an artificial nucleic acid that induces a specific conformation by hybridizing to a nucleic acid of interest that does not form a functional conformation
- the artificial nucleic acid comprises a conformation-inducing domain that forms a conformation with the target domain of the nucleic acid of interest
- the target domain and the conformation-inducing domain constitute a double-stranded sequence motif that constitutes a specific conformation
- the three-dimensional structure formation-inducing domain and the target domain comprise complementary regions consisting of sequences complementary to each other
- the conformation-inducing domain and/or the target domain comprise a non-complementary-containing region of 1 or more nucleotides containing sequences that are non-complementary to each other, the non-complementary-containing region comprises non-complementary sequences at both ends thereof, Said artificial nucleic acid.
- the artificial nucleic acid according to (1) wherein the conformation-inducing domain and/or the target domain comprise a plurality of complementary regions, and the non-complementary-containing region is located between the plurality of complementary regions.
- the non-complementary-containing region consists of 2 to 7 bases.
- the specific three-dimensional structure includes one or more selected from the group consisting of a kink turn structure, a bulged G structure, a reverse kink turn structure, a 5S loop E structure, a C loop structure, and a tandem GA structure; The artificial nucleic acid according to any one of (3).
- the kink turn structure is SEQ ID NO: 3 (5'-NNNNGAN-3') and SEQ ID NO: 4 (5'-NGAN-3');
- the bulged G structure is SEQ ID NO: 1 (5'-NNNGUAN-3') and SEQ ID NO: 2 (5'-NGANNN-3')
- the reverse kink-turn structure is SEQ ID NO: 5 (5'-NNNNAAN-3') and SEQ ID NO: 6 (5'-NGAN-3')
- the 5S loop E structures are SEQ ID NO: 7 (5'-NGUAN-3') and SEQ ID NO: 8 (5'-NGAUN-3')
- the C-loop structure is SEQ ID NO: 9 (5'-NCACU-3') and SEQ ID NO: 10 (5'-ANN-3'), or the tandem GA structure is SEQ ID NO: 11 (5'-NGAN-3') and SEQ ID NO: 12 (5'-NGAN-3') consists of The artificial nucleic acid according to (4), wherein N is A,
- the modified nucleotide is from 2'-OMe RNA, 2'-MOE RNA, LNA, 2'-O,5'-N BNA, 2'-deoxy-trans-3',4'-BNA and DNA
- the artificial nucleic acid according to (8) which is selected from the group consisting of: (10) The artificial nucleic acid according to (8) or (9), wherein the modified nucleotide contains a fluoro group modification at the 2'-position of ribose.
- a gene expression inhibitor comprising the artificial nucleic acid according to any one of (1) to (13) as an active ingredient.
- a nucleic acid detection agent comprising the artificial nucleic acid according to any one of (1) to (13) as an active ingredient.
- a method for producing an artificial nucleic acid that induces a specific three-dimensional structure by hybridizing to a nucleic acid of interest that does not form a functional three-dimensional structure A target domain selection step of searching the sequence information of one of the sequence motifs consisting of a double strand that constitutes a specific three-dimensional structure in the nucleic acid of interest, and selecting one or more of them as a target domain; a conformation-formation-inducing domain determining step of determining the sequence of the conformation-inducing domain so as to form a sequence motif with the target domain; and the artificial nucleic acid based on the sequence information determined in the conformation-formation-inducing domain determining step.
- the target domain and the conformation-inducing domain comprise complementary regions consisting of sequences complementary to each other, Furthermore, in the sequence motif, the target domain and/or the conformation-inducing domain comprise a non-complementary-containing region of one or more bases containing sequences that are non-complementary to each other, the non-complementary-containing region comprises non-complementary sequences at both ends thereof, the aforementioned method.
- the artificial nucleic acid of the present invention a specific conformation can be induced in a nucleic acid that does not form a functional conformation.
- the gene expression inhibitor of the present invention can suppress the expression of a target gene.
- the nucleic acid detection agent of the present invention can detect target nucleic acids.
- the artificial nucleic acid of the present invention can be produced.
- FIG. 3 shows the three-dimensional structure and secondary structure of the bulged G (BG) structure.
- A shows an exemplary conformation.
- B shows an exemplary secondary structure.
- the upper chain is the ⁇ chain
- the lower chain is the ⁇ chain
- the frame indicates the consensus sequence
- N indicates an arbitrary base. Bars between bases indicate complementary pairings
- open circles indicate significant non-complementary pairings.
- ⁇ 1 to ⁇ 6 and ⁇ 1 to ⁇ 5 indicate the position of each base in the ⁇ chain and ⁇ chain in the consensus sequence
- * indicates the position of the nucleotide that has been shown to take the C2'-endo conformation.
- FIG. 3 shows the three-dimensional structure and secondary structure of the kink turn (KT) structure.
- A shows an exemplary conformation.
- B shows exemplary secondary structures of canonical motifs.
- C shows exemplary secondary structures of non-canonical motifs.
- the upper chain is the ⁇ chain
- the lower chain is the ⁇ chain
- the frame indicates the consensus sequence
- N indicates an arbitrary base.
- Bold bars between bases indicate complementary pairings
- open circles indicate significant non-complementary pairings
- thin bars indicate internucleotide linkages.
- FIG. 3 shows the three-dimensional structure and secondary structure of the reverse kink turn (RKT) structure.
- A shows an exemplary conformation.
- B shows an exemplary secondary structure.
- the upper chain is the ⁇ chain
- the lower chain is the ⁇ chain
- the frame indicates the consensus sequence
- N indicates an arbitrary base.
- FIG. 3 shows the three-dimensional structure and secondary structure of the 5S loop E (5S) structure.
- A shows an exemplary conformation.
- B shows exemplary secondary structures of simple motifs.
- C shows exemplary secondary structures of complex motifs.
- FIG. 3 shows the three-dimensional structure and secondary structure of the C-loop (CL) structure.
- A shows an exemplary conformation.
- B shows an exemplary secondary structure.
- FIG. 3 shows the three-dimensional structure and secondary structure of the tandem GA (GA) structure.
- A shows an exemplary conformation.
- B shows an exemplary secondary structure.
- the upper chain is the ⁇ chain
- the lower chain is the ⁇ chain
- the frame indicates the consensus sequence
- N indicates an arbitrary base. Bars between bases indicate complementary pairings, open circles indicate significant non-complementary pairings.
- ⁇ 1 to ⁇ 2 and ⁇ 1 to ⁇ 2 indicate the position of each base in the ⁇ and ⁇ chains in the consensus sequence, and # indicates the position of the nucleotide where the 2'-hydroxy group of ribose participates in hydrogen bonding.
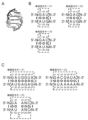
- 1 shows the base sequence and secondary structure of the double-stranded nucleic acid molecule used in Example 1. FIG.
- a (ROI / RNA-ASO) is the target RNA (RNA of interest: ROI) and its completely complementary nucleic acid (RNA-ASO), B (ROI / RNA-BG) forms a bulged G structure with ROI Nucleic acid (RNA-BG) obtained, C (ROI/RNA-KT) is a nucleic acid (RNA-KT) that can form a kink-turn structure with ROI, and D (ROI/RNA-RKT) forms a reverse kink-turn structure with ROI.
- RNA-RKT Obtained nucleic acid
- E ROI / RNA-5S
- F ROI / RNA-CL
- G ROI/RNA-GA
- RNA-GA nucleic acid
- the area within the dashed frame indicates the region containing the sequences forming the three-dimensional structures described above. Bars between bases indicate complementary pairings, open circles indicate significant non-complementary pairings.
- FIG. 8 is a diagram showing melting curves of each double-stranded nucleic acid molecule shown in FIG. 7.
- a to G correspond to the double-stranded nucleic acid molecules A to G shown in FIG. 7, respectively.
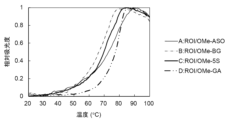
- FIG. 2 shows melting curves of double-stranded nucleic acid molecules of nucleic acids of interest and nucleic acids containing 2′-O-methyl (2′-OMe) modifications.
- a (ROI/OMe-ASO) is a double-stranded nucleic acid of ROI and its completely complementary modified nucleic acid (OMe-ASO)
- B ROI/OMe-BG
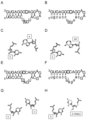
- FIG. 4 shows a nucleic acid with a bulged G (BG) structure.
- A shows the secondary structure of the base sequence of the unmodified nucleic acid (unmodified BG) used for crystal structure analysis.
- B shows the result of crystal structure analysis of crystal I of nucleic acid of A.
- C shows the result of crystal structure analysis of crystal II of nucleic acid of A.
- D shows the secondary structure of the base sequence of the modified nucleic acid (modified BG) used for crystal structure analysis.
- E shows the result of crystal structure analysis of crystal I of nucleic acid of D.
- F shows the result of crystal structure analysis of crystal II of nucleic acid of D.
- the area within the dashed frame indicates the region forming the bulged G structure.
- upper case letters indicate unmodified RNA nucleotides
- lower case letters indicate 2'-OMe modified RNA nucleotides
- italic lower case letters indicate DNA nucleotides. Bars between bases indicate complementary pairings, open circles indicate significant non-complementary pairings.
- FIGS. 11A and 11B show the secondary structure of the nucleotide sequence of unmodified BG.
- B shows the secondary structure of the base sequence of modified BG.
- C shows the results of crystallographic analysis of the G-A base pair in unmodified BG.
- D shows the results of crystallographic analysis of the G-A base pair in modified BG.
- E shows the secondary structure of the base sequence of unmodified BG.
- F shows the secondary structure of the base sequence of modified BG.
- the solid boxed GU-A triplets indicate the positions of the base triplets shown in G and H below, respectively.
- G shows the results of crystallography of the GU-A triad in unmodified BG.
- H shows the results of crystallographic analysis of the GU-A triad shown in D in modified BG.
- bars between bases indicate complementary pairings and open circles indicate non-complementary pairings.
- 2'-OMeA and 2'-OMeU in Figures 11D and H respectively indicate that A and U are 2'-OMe modified RNA nucleotides.
- dG in FIG. 11H indicates that G is a DNA nucleotide. Also, dashed lines indicate hydrogen bonds.
- FIGS. 12A and 12B show the sets of CA bases surrounded by solid lines indicate the positions of the sets of bases shown in C and D below, respectively.
- C shows the results of crystallographic analysis of the set of CA bases in unmodified BG.
- D shows the results of crystallographic analysis of the set of CA bases in modified BG.
- E shows the secondary structure of the base sequence of unmodified BG.
- F shows the secondary structure of the base sequence of modified BG.
- FIG. 12E and F the pairs of CU bases enclosed in solid lines indicate the positions of the pairs of bases shown in G and H below, respectively.
- G shows the results of crystallography of the set of CU bases in unmodified BG.
- H shows the results of crystallographic analysis of the set of CU bases in modified BG.
- bars between bases indicate complementary pairings and open circles indicate non-complementary pairings.
- dA in FIG. 12D indicates that A is a DNA nucleotide.
- 2'-OMeU in Figure 12H indicates that U is a 2'-OMe modified RNA nucleotide.
- FIG. 2 shows a nucleic acid with two kink-turn (KT) structures (dashed frame).
- A shows the secondary structure of the base sequence of the unmodified nucleic acid (unmodified KT) used for crystal structure analysis.
- B shows the result of crystal structure analysis of the nucleic acid of A.
- C shows the secondary structure of the base sequence of the modified nucleic acid (modified KT) used for crystal structure analysis.
- D shows the result of crystal structure analysis of the nucleic acid of C.
- upper case letters indicate unmodified RNA nucleotides
- lower case letters indicate 2'-OMe modified RNA nucleotides
- italic lower case letters indicate DNA nucleotides. Bars between bases indicate complementary pairings, open circles indicate significant non-complementary pairings.
- Figure 14 shows one kink turn (KT) structure for each nucleic acid of Figure 13;
- A shows the secondary structure of the nucleotide sequence containing one kink-turn structure of unmodified KT.
- B shows the result of crystal structure analysis of the nucleic acid of A.
- C shows the secondary structure of the nucleotide sequence containing one kink-turn structure of the modified KT.
- D shows the result of crystal structure analysis of the nucleic acid of C.
- upper case letters indicate unmodified RNA nucleotides
- lower case letters indicate 2'-OMe modified RNA nucleotides
- italic lower case letters indicate DNA nucleotides. Bars between bases indicate complementary pairings, open circles indicate significant non-complementary pairings.
- FIGS. 15A and B show the secondary structure of the nucleotide sequence of unmodified KT.
- B shows the secondary structure of the base sequence of modified KT.
- C shows the results of crystallography of the G-AG triad in unmodified KT.
- D shows the results of crystallographic analysis of the G-AG triad in modified KT.
- E shows the secondary structure of the nucleotide sequence of unmodified KT.
- F shows the secondary structure of the base sequence of modified KT.
- the solid boxed G-AG triplets indicate the positions of the triplets shown in G and H below, respectively.
- G shows the results of crystallography of the G-AG triad in unmodified KT.
- H shows the results of crystallography of the G-AG triad in modified KT.
- the bases of the nucleotides shown in each figure are indicated by solid-line frames.
- bars between bases indicate complementary pairings, and open circles indicate representative non-complementary pairings.
- dA and dG indicate that A and G are DNA nucleotides, respectively.
- FIG. 2 shows a nucleic acid forming a kink turn (KT) structure.
- A shows the secondary structure of the nucleotide sequence of unmodified KT.
- B shows the secondary structure of the base sequence of modified KT.
- the G-A base pair surrounded by a solid line frame indicates the position of the base pair shown in C and D below, respectively.
- C shows the result of crystal structure analysis of the base at the position shown in A in unmodified KT.
- D shows the result of crystal structure analysis of the base at the position shown in B in modified KT.
- FIG. 16A and B bars between bases indicate complementary pairings, and open circles indicate non-complementary pairings.
- 2'-OMeG indicates that G is a 2'-OMe modified RNA nucleotide.
- the dashed line indicates a hydrogen bond, and the solid circle indicates the functional group at the 2'-position of G's ribose.
- FIG. 2 shows nucleic acids forming a tetraloop (TL) structure and a tetraloop receptor (TLR) structure.
- A shows the secondary structure of the base sequence of the unmodified nucleic acid (unmodified TLR) used for crystal structure analysis.
- B shows the result of crystal structure analysis of the nucleic acid of A.
- C shows the secondary structure of the base sequence of a nucleic acid (modified TLR) in which some of the RNA nucleotides used for crystal structure analysis are replaced with DNA nucleotides.
- D shows the result of crystal structure analysis of the nucleic acid of C.
- uppercase letters indicate unmodified RNA nucleotides and italic lowercase letters indicate DNA nucleotides.
- bars between bases indicate complementary pairings and open circles indicate significant non-complementary pairings.
- the solid line frame indicates the region forming the tetraloop receptor structure
- the dashed line frame indicates the region forming the tetraloop structure.
- FIG. 2 shows the interaction of tetraloop (TL) and tetraloop receptor (TLR) structures.
- A shows the state of binding between the tetraloop structure and the tetraloop receptor structure between unmodified TLR molecules.
- B shows the state of binding between the tetraloop structure and the tetraloop receptor structure between modified TLR molecules.
- the dashed frame shows the tetraloop structure, and the gray image on the right side of the figure shows the space-filling model of the tetraloop receptor structure.
- FIG. 2 shows the interaction of tetraloop (TL) and tetraloop receptor (TLR) structures.
- A shows the crystal structure analysis result of interaction.
- the positions of the U-A-A triads shown in B and C below are shown in solid lines.
- B shows the results of crystallography of the U-A-A triad in the unmodified TLR.
- C shows the results of crystallography of the U-A-A triad in the modified TLR.
- D shows the crystal structure analysis result of interaction.
- E shows the results of crystallography of the UG-A triad in unmodified TLRs.
- F shows the results of crystallography of the UG-A triad in the modified TLR.
- FIG. 2 shows the interaction of tetraloop (TL) and tetraloop receptor (TLR) structures.
- A shows the crystal structure analysis result of interaction.
- the positions of the C-G-A triad shown in B and C below are shown within the solid line frame.
- B shows the results of crystallography of the C-G-A triad in unmodified TLR.
- C shows the results of crystallography of the C-G-A triad in the modified TLR.
- dG indicates that G is a DNA nucleotide.
- the dashed line indicates a hydrogen bond, and the solid circle indicates the functional group at the 2'-position of ribose with G as the base.
- FIG. 4 shows the base sequence and secondary structure of the nucleic acid molecule used in Example 6.
- a (ROI-U / ASO-A) is the target RNA (ROI-U) with a UUU base sequence near the center and a nucleic acid that is completely complementary to it (ASO-A)
- B (ROI-A / ASO- A) is the target RNA (ROI-A) and ASO-A whose base sequence near the center is mutated to AAA
- C (ROI-U/KT-SKIP) is ROI-U and the above-mentioned mutation part is included in the bulge structure.
- RNA molecule that induces kink turn structure KT-SKIP
- D (ROI-A/KT-SKIP) indicates ROI-A and KT-SKIP.
- FIG. 22 shows a melting curve of the double-stranded nucleic acid shown in FIG. 21; A shows the melting curve of the nucleic acid of interest and the double-stranded nucleic acid of ASO-A. B shows the melting curve of the nucleic acid of interest and the double-stranded nucleic acid of KT-SKIP.
- FIG. 10 shows the base sequence and secondary structure of the nucleic acid molecule used in Example 7.
- A is the sequence of the hybridization target region (SO-GFP) and its completely complementary nucleic acid (ASO-GFP)
- B is an RNA molecule that induces a tandem GA structure with SO-GFP (GA-GFP)
- C is SO -GFP and an RNA molecule (KT-GFP) that induces a kink-turn structure.
- each sequence on the upper side shows the sequence of the specific target region in the mRNA of pUC-frGFP used as the target region for hybridization.
- the dashed frame indicates the region containing the sequences forming the three-dimensional structures described above. Bars between bases indicate complementary pairings, open circles indicate significant non-complementary pairings.
- FIG. 10 shows a state in which a fluorescently labeled RNA probe (RNA-2AP: lower sequence) is hybridized to target RNA (upper sequence) in Example 8.
- RNA-2AP lower sequence
- X represents 2-aminopurine (2AP).
- FIG. 26A shows the results of measuring the fluorescence spectra of a solution containing RNA-2AP (control) and a solution to which equimolar target RNA or non-target RNA was added to RNA-2AP using an excitation wavelength of 305 nm.
- FIG. 4 is a diagram showing;
- FIG. 26B is a diagram showing the rate of change ( ⁇ F) in fluorescence intensity at a wavelength of 370 nm when target RNA or non-target RNA was added to RNA-2AP.
- FIG. 1 is a diagram schematically showing the configuration of an artificial nucleic acid of the present invention
- FIG. A shows the schematic arrangement of each domain of the artificial nucleic acid.
- B shows a schematic layout of the target domain of the nucleic acid of interest.
- C is a diagram showing how the artificial nucleic acid of A and the target nucleic acid of B are hybridized.
- the complementary region of each domain is shown in italics, the non-complementary containing region of each domain is shown in bold, and the sequence motif is shown in a dashed frame.
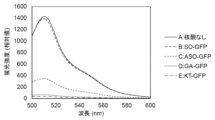
- FIG. 10 shows the base sequence and secondary structure of the nucleic acid molecule used in Example 7.
- A is the sequence of the hybridization target region (SO-GFP) and its completely complementary nucleic acid (ASO-GFP)
- B is an RNA molecule that induces a tandem GA structure with SO-GFP (GA-GFP)
- C is SO -GFP and an RNA molecule (KT-GFP) that induces a kink-turn structure.
- each sequence on the upper side shows the sequence in the mRNA of pUC-frGFP used as the target region for hybridization.
- the dashed frame indicates the region containing the sequences forming the three-dimensional structures described above. Bars between bases indicate complementary pairings, open circles indicate significant non-complementary pairings.
- a first aspect of the present invention is an artificial nucleic acid.
- the artificial nucleic acid of the present invention contains a conformation-inducing domain as an essential component, and forms a specific conformation upon hybridizing with a nucleic acid of interest.
- the artificial nucleic acid of the present invention can be an active ingredient of the gene expression inhibitor and nucleic acid detection agent of the present invention, which will be described later.
- nucleic acid or “nucleic acid molecule” refers to a biopolymer having nucleotides as constituent units linked by phosphodiester bonds. Although they can be broadly classified into natural nucleic acids and artificial nucleic acids, both are included in the present specification.
- RNA refers to nucleic acids that exist in nature.
- DNA and RNA correspond.
- RNA include mRNA and miRNA.
- miRNA is a single-stranded non-coding RNA with a length of 18 to 25 bases that exists in vivo and regulates the expression of a specific gene (gene of interest).
- artificial nucleic acid refers to a nucleic acid molecule artificially synthesized by a biological method or a chemical synthesis method. Unless otherwise specified, the artificial nucleic acids of the present specification may, for example, consist entirely of unmodified natural nucleotides, or may contain unnatural nucleotides or modified nucleotides.
- Nucleotide refers to a molecule in which a phosphate group is covalently bonded to the sugar moiety of a nucleoside. Nucleotides containing a pentofuranosyl sugar usually have a phosphate group attached to the hydroxyl group at the 3' or 5' position of the sugar.
- Nucleoside generally refers to a molecule consisting of a combination of a base and a sugar.
- Sugars are typically, but not exclusively, composed of pentofuranosyl sugars. Examples of pentofuranosyl sugars include ribose and deoxyribose.
- Bases also include, for example, adenine (A), guanine (G), cytosine (C), thymine (T), and uracil (U). As used herein, unless otherwise specified, bases may be modified or unmodified bases.
- sucrose moiety conformation refers to the three-dimensional structure taken by the ribose or deoxyribose of nucleotides. Major conformations include C2'-endo and C3'-endo, as exemplified by deoxyribose below.
- Base indicates the base moiety and the numbers indicate the position of each carbon in the ribose ring.
- the C2'-endo type is a conformation in which the 2'-position carbon is overhanging on the base side of the ribose ring plane. Also called South type, S type, etc.
- the C3'-endo form is a conformation in which the 3'-position carbon is overhanging the base side of the ribose ring plane. It also includes exo-type, and is also called North-type, N-type, and the like. Both ribose and deoxyribose can take either conformation, but usually ribose tends to take the C3'-endo form and deoxyribose tends to take the C2'-endo form.
- the term "hydroxy group at the 2'-position of ribose" refers to a hydroxy group bonded to the carbon at the 2'-position of ribose.
- modification refers to the substitution of a part or all of a nucleotide, which is a constituent unit of a nucleic acid, or a nucleoside, which is a constituent thereof, with other atomic groups, or addition of a functional group or the like. Point. Specific examples include sugar modifications, base modifications, or modifications of phosphodiester bonds.
- modified nucleotide refers to a nucleotide partially or wholly substituted with other atomic groups, or to which a functional group or the like has been added.
- unmodified nucleotide refers to nucleotides other than modified nucleotides. In principle, most natural nucleotides fall into this category.
- Modified nucleotides include both artificially constructed modified nucleotides and naturally occurring modified nucleotides. Artificial nucleotides (nucleotide analogues) having similar properties and / or structures to unmodified nucleotides, or modified nucleosides having properties and / or structures similar to unmodified nucleosides or unmodified bases that are constituents of unmodified nucleotides or Artificial nucleotides containing modified bases are applicable.
- Specific examples of modified nucleosides include abasic nucleosides, arabinonucleosides, 2'-deoxyuridine, ⁇ -deoxyribonucleosides and ⁇ -L-deoxyribonucleosides.
- modified bases include 2-oxo(1H)-pyridin-3-yl group, 5-substituted-2-oxo(1H)-pyridin-3-yl group, 2-amino-6-(2 -thiazolyl)purin-9-yl group, 2-amino-6-(2-thiazolyl)purin-9-yl group, 2-amino-6-(2-oxazolyl)purin-9-yl group and the like.
- sugar modification refers to a substitution and/or any change in the sugar moiety of a nucleic acid molecule. Specifically, for example, the hydroxy group at the 2' position is replaced with a methoxy group (2'-O-methyl ribose) (2'-OMe), an ethoxy group is replaced with 2'-O-ethyl ribose, a propoxy group is 2'-O-propyl ribose substituted, or 2'-O-butyl ribose substituted with a butoxy group, 2'-deoxy-2'-fluoro ribose substituted with a fluoro group for a hydroxy group, or 2'-O -Methoxy-ethyl group-substituted 2'-O-methoxyethyl ribose (2'-MOE) and the like.
- a methoxy group (2'-O-methyl ribose) (2'-OMe)
- an ethoxy group
- Hydroxy groups may be substituted with functional groups other than hydrocarbons. Specific examples include substitution with H, halogen elements, and the like. Also, the (deoxy)ribose portion of the nucleoside may be replaced with other molecules such as sugars, morpholino rings, PNA and XNA. Specifically, for example, arabinose in the ribose moiety, 2'-fluoro- ⁇ -D-arabinose, a ribose derivative obtained by bridging the hydroxy group at the 2'-position and the carbon atom at the 4'-position of ribose, and the 4'-position of the ribose ring and substitution with a ribose derivative in which oxygen is substituted with sulfur.
- nucleotides with bridged ribose derivatives are called bridged nucleic acids, e.g., 2'-OMe RNA, 2'-MOE RNA, LNA, 2'-O,5'-N BNA, and 2'-deoxy-trans -3',4'-BNA and the like.
- Modified base refers to nucleobases other than natural adenine, cytosine, guanine, thymine, or uracil
- base modification refers to changes to those nucleobases.
- modified nucleobases include 5-methylcytosine, 5-fluorocytosine, 5-bromocytosine, 5-iodocytosine or N4-methylcytosine; N6-methyladenine or 8-bromoadenine; 2-thio-thymine; -methylguanine or 8-bromoguanine; and 5-fluorouracil, 5-bromouracil, 5-iodouracil or 5-hydroxyuracil.
- non-complementary means that nucleic acid bases do not form so-called Watson-Crick base pairs (natural base pairs).
- non-complementary pairing refers to the fact that two non-complementary bases face each other and interact via hydrogen bonding
- non-complementary base pair refers to the refers to two bases that are Also, when two bases face each other to form a base pair, it is called "forming a base pair”. Examples of specific non-complementary base pairs include sheared base pairs.
- shared base pair refers to a type of non-complementary base pair formed between two nucleic acid strands, and the shallow groove side of one base A functional group is one that participates in hydrogen bonding.
- the numbers in the ring structure indicate the positions at which the respective functional groups are located.
- the term "shallow groove edge functional group” refers to functional groups at positions 2 to 4 for purine bases and functional groups at position 2 for pyrimidine bases.
- a functional group on the shallow groove side is also called a functional group on the sugar edge.
- Specific Sheared base pairs include, for example, G-A base pairs, A-A base pairs, U-C base pairs, and C-C base pairs.
- Mutation refers to the diversity of base sequences present in the genome of a species population. Usually, those seen at a frequency of 1% or more in the population are distinguished from polymorphisms, and those seen at a frequency of less than 1% are distinguished from mutations. frequency is irrelevant.
- single nucleotide variant refers to a type of nucleotide sequence variation mutation that exists in the genome of a species population, and refers to a mutation with a size of 1 base. Usually, when mutation is observed at a frequency of 1% or more within a population, it is particularly called single nucleotide polymorphism (SNP). The single-nucleotide variant in the present specification does not care about the frequency of mutation within the population.
- insertion-deletion mutation refers to a type of nucleotide sequence variation mutation present in the genome of a species population, and the size of the mutation is 2 bases or more and less than 50 bases. point to something
- the type of mutation is not particularly limited. For example, variations in the repeat number of short repeats (usually 2-7 bases) (short tandem repeats (STRs; also called microsatellite polymorphisms)) and repeats with a size of less than 50 bases Including repetitive sequence polymorphism (VNTR: variable number of tandem repeat), etc.
- the insertion-deletion mutation used herein does not matter the frequency of mutation within a population.
- Structural Variant is a type of nucleotide sequence variation that exists in the genome of a species population, and refers to a variation with a size of 50 bases or more. Specific mutations include, for example, inversions, translocations, deletions, copy number changes and insertions. Structural polymorphisms include repetitive sequence polymorphisms (VNTR), etc., in which the size of the repetitive sequence is 50 bases or more. Structural polymorphism in the present specification does not matter the frequency of mutation within a population.
- secondary structure refers to base pair formation and base overhang between two nucleic acid strands.
- secondary structure refers to a structure that includes a characteristic shape.
- secondary structures include bulge structures, loop structures, stem structures, and the like. The bulge structure, which is a typical secondary structure, will be described below.
- the term "bulge structure” refers to a portion that forms a non-complementary base pair between two nucleic acid strands, among the secondary structures found in the hybridized double-stranded nucleic acid as a whole. and refers to the three-dimensional structure of the portion in which the bases partially or completely protrude outside the double-stranded nucleic acid molecule on one or both strands.
- a bulge structure herein includes any structure such as, for example, a bulge loop, an internal loop, and a multi-branch loop. The actual conformation in the region of the bulge structure need not be bulging compared to other regions.
- three-dimensional structure refers to any three-dimensional structure other than the double helix structure formed by a completely complementary double-stranded nucleic acid molecule.
- the term "specific conformation” refers to the target conformation induced by the artificial nucleic acid of the present invention.
- the term "functional (na) conformation” refers to a conformation that has at least one function in vivo.
- steric structures and hairpin structures of ribozymes, aptamers, transfer RNAs, ribosomal RNAs (rRNAs), etc. are functional steric structures.
- rRNAs ribosomal RNAs
- a conformation that is formed accidentally by a single-stranded RNA and is not related to the function of that RNA is not a functional conformation.
- inducing a three-dimensional structure refers to forming a three-dimensional structure by hybridizing an artificial nucleic acid with a target nucleic acid. For example, the conformation seen in rRNA is induced.
- sequence motif refers to a motif containing double-stranded sequence information that can induce a specific conformation. In the schematic diagram shown in FIG. 27C, it corresponds to the inside of the dashed line frame.
- the duplexes that make up the sequence motif each contain a complementary region ( Figure 27C italic) and one or both nucleic acid strands further contain a non-complementary containing region ( Figure 27C bold).
- sequence motif refers to sequence information conserved among multiple sequences that form the same conformation.
- complementary region refers to a region consisting of sequences complementary to each other.
- italicized bases correspond to complementary regions of each nucleic acid strand.
- non-complementary-containing region refers to a region of two or more bases containing non-complementary sequences.
- bases shown in bold correspond to complementary regions of each nucleic acid strand.
- said region includes non-complementary sequences at both ends thereof.
- Examples of specific three-dimensional structures include bulged G structure, kink turn structure, reverse kink turn structure, 5S loop E structure, C loop structure and tandem GA structure. Specific examples of conformations and sequence motifs are described below.
- (i) Bulged G structure refers to a three-dimensional structure in which both nucleic acid strands form a bulge structure, sandwiched between a bulge structure and a sheared GA base pair. Refers to a conformation characterized in sequence by base triplets (two bases from one strand and one base from the other strand).
- a view of an exemplary bulged G structure is shown in FIG. 1A.
- Each bulge structure contained in the bulge G structure typically consists of 3 to 5 bases.
- the bulged G structure is also known by many other names, such as the sarcin/ricin loop structure, the ⁇ -sarcin and ricin sensitive loop structure, the SRL, or the S motif.
- sequence motif of the bulged G structure is not particularly limited, it includes, for example, the motif shown in FIG. 1B.
- motif 1 for example, the region within the dashed frame of each nucleic acid strand can be the non-complementary-containing region of each nucleic acid strand.
- Suitable sequence motifs of the baldide G structure include, for example, Correll, C. C., et al., Nucleic Acids Research, 2003, Vol. 31, No. 23, 6806-6818; Correll, C. C., et al., Proc. Natl. Acad. Sci., 1998, Vol. 95, pp. 13436-13441.
- the bulged G structure is recognized by proteins such as ⁇ -sarcin, and has been reported to have functions such as involvement in RNA cleavage (for example, Gluck, A. and Wool, I. G., J. Mol. Biol., 1996, 256: 838-848).
- Kink-turn structure refers to a three-dimensional structure in which a double-stranded nucleic acid is folded by a bulge structure formed in one strand, and a Sheared-type GA base pair following the bulge structure is arranged. Refers to the structure characterized above. A view of an exemplary kink-turn structure is shown in FIG. 2A. A bulge structure typically consists of 3 or more bases. In the strand forming the bulge structure, guanine (G) is present on the 3' side of the bulge structure and forms the Sheared-type GA base pair with adenine (A) of the other strand.
- the sequence motif of the kink-turn structure is not particularly limited, but includes, for example, the motifs shown in FIGS. 2B and 2C.
- the kink turn structure includes, for example, FIG. N includes a canonical kink turn structure as shown in A, C, G or U)), a non-canonical kink turn structure having variations in the sheared G-A base pair portion, for example, as shown in FIG. 2C, and the like.
- the kink-turn structure herein includes any of these.
- the bases at positions ⁇ 4 and ⁇ 1, and at positions ⁇ 5 and ⁇ 2 form Sheared type G-A base pairs.
- the region within the dashed frame of each nucleic acid strand can be the non-complementary-containing region of each nucleic acid strand.
- kink turn structures include, for example, Huang, L. and Lilley, D. M., Journal of Molecular Biology, 2016, 428(5Part A): 790-801; Huang, L. and Lilley, D M., Quarterly Reviews of Biophysics, 2018, 51(e5), and the like.
- the kink turn structure is known to be recognized by, for example, proteins belonging to the L7Ae family.
- Reverse Kink-turn structure refers to a three-dimensional structure in which a double-stranded nucleic acid is folded in the direction opposite to the kink-turn structure.
- FIG. 3A A view of an exemplary reverse kink-turn structure is shown in FIG. 3A.
- the biggest sequence difference from the kink-turn structure is that the bulge structure is flanked by AA base pairs instead of sheared GA base pairs.
- the sequence motif of the reverse kink-turn structure is not particularly limited, but includes, for example, the motif shown in FIG. 3B.
- the motif in Figure 3B differs from the standard motif 1 of the kink turn structure ( Figure 2B) in that the base pairs at the ⁇ 4 and ⁇ 1 positions are A-A base pairs.
- Motif of FIG. 3B ⁇ chain: SEQ ID NO: 5 (5′-NNNNAAN-3′: N is A, C, G or U), ⁇ chain: SEQ ID NO: 6 (5′-NGAN-3′: N is A, In C, G or U)
- the region within the dashed frame of each nucleic acid strand can be the non-complementary-containing region of each nucleic acid strand.
- sequence motif of the reverse kink-turn structure encompasses a wide range of sequence motifs, similar to the kink-turn structure, with motif 1 (FIG. 3B) as the standard sequence motif.
- Specific sequence motifs of the reverse kink turn structure include, for example, sequence motifs described in Strobel, S. A., et al., Rna, 2004, 10(12), 1852-1854.
- 5S loop E structure refers to a partially twisted double helix structure found in prokaryotic 5S ribosomal RNA. It refers to a structure characterized in sequence by three or more non-complementary base pairs including complementary AU base pairs and sheared GA base pairs.
- a view of an exemplary 5S loop E structure is shown in FIG. 4A. Typically, the smallest unit of a 5S loop E structure typically consists of 3 base pairs.
- the 5S loop E structure is also called the loop E structure.
- a 5S loop E structure sequence motif may include multiple submotifs, which are also referred to herein simply as 5S loop E structure sequence motifs. A submotif typically consists of three base pairs.
- the sequence motif of the 5S loop E structure is not particularly limited, but includes, for example, the motifs shown in Figures 4B and C.
- 5S loop E structures are roughly divided into simple and complex types.
- a simple form is a structure consisting of three base pairs, eg, as shown in simple motifs 1-3 in FIG. 4B.
- a complex type is, for example, a structure containing multiple simple motifs as shown in complex motifs 1 and 2 in FIG. 4C, or a structure containing an extra base pair in the middle as shown in complex motif 3 in FIG. 4C. etc. are included.
- complex motif 1 includes two submotifs consisting of bases at positions ⁇ 1 to ⁇ 3 and ⁇ 1 to ⁇ 3, and bases at positions ⁇ 5 to ⁇ 7 and ⁇ 5 to ⁇ 7.
- each nucleic acid strand can be the non-complementary-containing region of each nucleic acid strand.
- 5S loop E structure Specific sequence motifs of the 5S loop E structure include, for example, Correll, C. C., et al., Cell, 1997, 91(5), 705-712; Leontis, N. B. and Westhof, E. Rna, 1998, 4 ( 9), 1134-1153 and the like. It is known that cations such as Mg + bind to the 5S loop E structure, and double-strand cleavage by nucleases is likely to occur in the vicinity of the 5S loop E structure.
- C-loop structure refers to a three-dimensional structure in which both nucleic acid strands form a bulge structure and the double helix structure is partially twisted. Refers to a structure characterized in sequence by a UA base pair following the structure. A view of an exemplary C-loop structure is shown in FIG. 5A. Typically, the bulge structures of both nucleic acid strands differ in size, eg, the longer bulge contains C's.
- the sequence motif of the C-loop structure is not particularly limited, but includes, for example, the motif shown in FIG. 5B.
- the standard C-loop structure is, for example, a structure in which a large bulge structure consists of three bases and a small bulge structure consists of one base, as shown in motif 1.
- small bulge structures such as those shown in motif 2
- large bulge structures such as those shown in motif 3
- Motif 1 ( ⁇ chain; SEQ ID NO: 9 (5'-NCACU-3': N is A, C, G or U), ⁇ chain: SEQ ID NO: 10 (5'-ANN-3': N is A, C, In G or U)), for example, the ⁇ 1 to ⁇ 3 region of the ⁇ chain and the ⁇ 1 region of the ⁇ chain can be the non-complementary-containing region of each nucleic acid chain.
- sequence motifs of the C-loop structure include, for example, Klein, D. J., et al., Journal of molecular biology, 2004, 340(1), 141-177; Lescoute, A., et al., Examples include sequence motifs described in Nucleic acids research, 2005, 33(8), 2395-2409 and the like.
- the C-loop structure it is known that double-stranded nucleic acids having a C-loop structure easily form a complex.
- Tandem GA structure refers to a three-dimensional structure in which bulges are formed in both nucleic acid strands, and includes two consecutive Sheared GA base pairs. Refers to a feature structure on an array.
- a view of an exemplary tandem GA structure is shown in FIG. 6A.
- a tandem GA structure is also called a GA/AG loop.
- the sequence motif of the tandem GA structure is not particularly limited, but includes, for example, the motif shown in FIG. 6B.
- Motif 1 ( ⁇ chain; SEQ ID NO: 11 (5'-NGAN-3': N is A, C, G or U), ⁇ chain: SEQ ID NO: 12 (5'-NGAN-3': N is A, C, G or U)), for example, the region within the dashed frame of each nucleic acid strand can be the non-complementary-containing region of each nucleic acid strand.
- sequence motifs of the tandem GA structure include, for example, sequence motifs described in Jang, S. B., et al., Acta Crystallographica Section D: Biological Crystallography, 2004, 60(5), 829-835, etc. is mentioned.
- the artificial nucleic acid of the present invention contains a conformation-inducing domain as an essential component, and optionally a hybridizing domain. Each domain will be specifically described below.
- Conformation-Inducing Domain is a domain that forms a conformation with a target domain of a nucleic acid of interest.
- nucleic acid of interest refers to a nucleic acid to which an artificial nucleic acid can hybridize.
- target domain refers to a region containing sequence information on one side of a double-stranded sequence motif that constitutes a specific three-dimensional structure in a nucleic acid of interest (Fig. 27B).
- Nucleic acids of interest herein are in particular nucleic acids that do not form functional conformations.
- the nucleic acid of interest is not particularly limited as long as it is a nucleic acid that does not form a functional three-dimensional structure, and specific examples thereof include any RNA such as mRNA and microRNA (miRNA).
- the nucleic acid of interest may be a naturally occurring nucleic acid or an artificial nucleic acid.
- multiple types of target nucleic acids may be present.
- the artificial nucleic acid may be specifically hybridizable with one type of nucleic acid as the target nucleic acid, may be non-specifically hybridizable with a plurality of types of nucleic acids, or may be non-specifically hybridizable with a plurality of types of nucleic acids. of nucleic acids simultaneously.
- an artificial nucleic acid that induces a three-dimensional structure only when hybridized with a part of the nucleic acids even if it can hybridize with a plurality of types of nucleic acids is also included in the artificial nucleic acid of this embodiment.
- the conditions under which the three-dimensional structure is induced are not particularly limited as long as the nucleic acid of interest and the artificial nucleic acid can hybridize. For example, it may be induced in vivo or in vitro. Also, conformation can be induced in one or both nucleic acid strands.
- the induced three-dimensional structure is not particularly limited. It may be all or part of a three-dimensional structure found in a nucleic acid that forms a functional three-dimensional structure such as rRNA, or may be a three-dimensional structure that has not been confirmed to exist in nature. Moreover, neither the type nor the number of induced stereostructures are particularly limited.
- one artificial nucleic acid may induce a plurality of one type of three-dimensional structures, or may induce a plurality of types of three-dimensional structures in combination.
- one type of steric structure includes one composite steric structure formed by combining a plurality of steric structures.
- an aptamer can be induced as one steric structure, or a steric structure in which multiple aptamers are fused can be induced as one steric structure.
- the desired three-dimensional structure induced by the artificial nucleic acid of the present invention is called a specific three-dimensional structure.
- specific three-dimensional structures include three-dimensional structures based on double strands (three-dimensional structures other than the following "stereostructures based on nucleic acid folding": e.g., kink turn structure, bulged G structure, reverse kink turn structure, 5S loop E structure, C loop structure, tandem GA structure, tetraloop receptor structure, hook-turn structure (Hook-turn), ⁇ -turn structure and ⁇ -turn structure, etc.), three-dimensional structures based on nucleic acid folding (single-stranded nucleic acid folding three-dimensional structures consisting only of parts: for example, tetraloop structures including GNRA tetraloop, UNCG tetraloop and CUUG tetraloop, etc.), or combinations thereof.
- the specified conformation comprises a duplex-based conformation.
- specific examples of the specific three-dimensional structure include one or more selected from the group consisting of a kink turn structure, a bulged G structure, a reverse kink turn structure, a 5S loop E structure, a C loop structure, and a tandem GA structure.
- a derived conformation may be, for example, one with no known consensus sequence or an unnamed conformation.
- the conformation formed may be stable or unstable. For example, it may be a steric structure that is formed only under specific conditions, or the steric structure that is formed may change depending on the conditions.
- the three-dimensional structure may be formed asymmetrically with the target nucleic acid and the artificial nucleic acid, in which case a larger three-dimensional structure may be formed.
- the ⁇ chain may be the target nucleic acid and the ⁇ chain may be the artificial nucleic acid, or vice versa.
- Whether or not the desired three-dimensional structure can be formed can be known using a method known in the art. For example, when a sequence motif or consensus sequence known to form a specific conformation is used, it can be assumed that the specific conformation will be formed. In this case, it is not necessary to confirm whether or not a specific three-dimensional structure was actually formed. When confirming that a specific three-dimensional structure is actually formed by an artificial nucleic acid, it can be confirmed, for example, by in silico analysis, by structural analysis, or by observing a phenomenon that occurs specifically to a specific three-dimensional structure. .
- RNAComposer for in silico analysis, for example, three-dimensional structure prediction programs known in the art such as RNAComposer, RNAMotifScan, 3dRNA, ModeRNA, MacroMoleculeBuilder, NAST, iFoldRNA, Vfold3D, SimRNA, or combinations thereof can be used.
- the three-dimensional structure can be observed by structural analysis of a complex of a nucleic acid having the same base sequence as all or part of the target nucleic acid and an artificial nucleic acid.
- the conditions and methods used for crystallization and structural analysis are not particularly limited.
- Specific methods include, for example, neutron crystallography, small angle neutron scattering (SANS), nuclear magnetic resonance (NMR), X-ray crystallography, small angle X-ray scattering, cryo-electron microscopy, or combinations thereof. be done. Furthermore, the formation of a three-dimensional structure can also be confirmed by observing a phenomenon that occurs specifically to a specific three-dimensional structure. For example, it is known that proteins belonging to the L7Ae family bind to kink-turn structures. Therefore, formation of a kink-turn structure can be confirmed by detecting the binding of this protein. Phenomena that can occur in each steric structure during formation are exemplified in the definition of each steric structure.
- a “conformation-inducing domain” is a domain that forms a conformation with the target domain of the nucleic acid of interest (Fig. 27A).
- the conformation-inducing and targeting domains constitute a specific conformational sequence motif (Fig. 27C).
- the conformation-inducing domain and the target domain contain complementary regions (in italics in FIG. 27C) consisting of mutually complementary nucleotide sequences, and the conformation-inducing domain and/or the target domain contain non-complementary bases.
- the non-complementary-containing region contains non-complementary sequences at both ends.
- the region is the region between the 5′-most non-complementary base and the 3′-most non-complementary base of the domain to which it belongs.
- the conformation-inducing domain and/or the target domain contain non-complementary-containing regions
- the complementary region is adjacent to one or both of the non-complementary-containing regions in the domain containing the non-complementary-containing regions.
- conformation-inducing domains can be located at the ends of an artificial nucleic acid, in which case the base pairs located at the ends can be non-complementary.
- the number of bases that make up the complementary region is not particularly limited.
- the specific number of bases is, for example, 1 or more, 2 or more, 3 or more, 4 or more, 5 or more, 10 or more, 20 or more, or 30 or more.
- the base sequence of the complementary region is not particularly limited.
- the number of complementary regions contained in the conformation-inducing domain and target domain is not particularly limited.
- the number of complementary regions contained in the conformation-inducing domain and the number of complementary regions contained in the target domain need not be the same. Since the complementary region usually consists of mutually complementary nucleotide sequences, the total number of bases contained in the complementary region is the same in the three-dimensional structure formation-inducing domain and the complementary region.
- the non-complementary-containing region is located between the multiple complementary regions.
- the conformation-inducing domain and/or targeting domain comprises multiple complementary regions, and the non-complementary-containing region is located between the multiple complementary regions.
- the size of the non-complementary containing region is not particularly limited as long as it is 1 base or more. Specific numbers of bases are, for example, 1 to 1000 bases, 1 to 500 bases, 1 to 400 bases, 1 to 200 bases, 1 to 100 bases, 1 to 80 bases, 1 to 60 bases, 1 to 40 bases, 1-30 bases, 2-20 bases, 2-15 bases, 2-10 bases, 2-9 bases, 2-8 bases, or 2-7 bases.
- the base sequence of the non-complementary containing region is not particularly limited as long as it contains non-complementary base sequences at both ends.
- the non-complementary-containing regions can contain base sequences that are complementary to each other.
- the non-complementary bases can be considered to be the non-complementary bases at both ends of the non-complementary-containing region.
- the non-complementary containing region of one nucleic acid strand consists of 3 bases, the two bases at both ends are non-complementary bases, but the one base positioned between them is complementary even if it is a non-complementary base. base.
- the number of non-complementary regions contained in the conformation-inducing domain and target domain is not particularly limited. At least one of the conformation-inducing domain and the target domain should contain at least one non-complementary-containing region.
- the conformation-inducing domain and the target domain should contain at least one non-complementary-containing region.
- the non-complementary-containing region is the core region of the steric structure, the number of non-complementary-containing regions depends on the type and number of induced steric structures.
- the conformation-inducing domain and target domain constitute a sequence motif that constitutes a specific conformation.
- a sequence motif need not constitute the entire conformation-inducing domain and/or targeting domain.
- the entire sequence motif may be contained in the non-complementary-containing region, or a portion of the sequence motif may be contained in the non-complementary-containing region.
- the sequence motifs contained in the conformation-inducing domain and the target domain are not particularly limited.
- a consensus sequence can be used, or part or all of the base sequence of a nucleic acid that forms a functional three-dimensional structure can be used as it is or after being partially modified.
- kink turn structure SEQ ID NO: 3 (5'-NNNNGAN-3': N is A, C, G or U) and SEQ ID NO: 4 (5'-NGAN- 3': N is A, C, G or U) (the first N of SEQ ID NO: 3 and the fourth N of SEQ ID NO: 4, the seventh N of SEQ ID NO: 3 and the first N of SEQ ID NO: 4 are complementary to each other), the bulged G structures are SEQ ID NO: 1 (5'-NNNGUAN-3': N is A, C, G or U) and SEQ ID NO: 2 (5'-NGANNN-3': N is A, C, G or U) (the 1st N of SEQ ID NO: 1 and the 6th N of SEQ ID NO: 2, and the 7th N of SEQ ID NO: 1 and the 1st N of SEQ ID NO: 2 are complementary to each other), reverse The kink turn structure is SEQ ID NO: 5 (5'-NNNGAN-3': N is A, C, G or U
- hybridizing domains flanked by one or both of the conformation-inducing domains can comprise hybridizing domains flanked by one or both of the conformation-inducing domains.
- a hybridizing domain is a domain that is capable of hybridizing with a nucleic acid of interest. When there are multiple hybridizing domains, the individual domains are called hybridizing subdomains.
- a hybridizing domain consists of two subdomains that are both flanked by a conformation-inducing domain. The size of the hybridizing domain may be 6 to 120 bases.
- nucleotide sequence of the hybridizing domain is not particularly limited as long as it can hybridize with the nucleic acid of interest. Preferably, hybridization with the nucleic acid of interest can be performed under highly stringent conditions.
- Hybridize means that polynucleotides having base sequences that are completely or partially complementary to each other form a double strand.
- Hybridization conditions are not particularly limited, and may be various stringent conditions such as low stringent conditions and high stringent conditions.
- low stringent conditions is meant conditions under which nucleic acids readily hybridize.
- Low stringency conditions refer to conditions of low temperature and high salt concentration in washing after hybridization.
- conditions include washing at 42° C. to 50° C. with a buffer containing 5 ⁇ SSC and 0.1% SDS.
- Highly stringent conditions means conditions under which non-specific hybrids are not formed.
- the low salt concentration as used herein specifically means, for example, 15 to 750 mM, preferably 15 to 500 mM, 15 to 300 mM or 15 to 200 mM.
- the high temperature referred to here is specifically, for example, 50 to 68°C or 55 to 70°C.
- Specific highly stringent conditions include, for example, washing at 65°C with 0.1 x SSC and 0.1% SDS.
- 1 ⁇ SSC contains 150 mM sodium chloride and 15 mM sodium citrate.
- hybridize can be known using a method known in the art. For example, it can be known based on base identity. Usually, a second nucleic acid having a sequence completely complementary to the base sequence of the first nucleic acid and a base sequence having a certain or more base identity is hybridizable with the first nucleic acid. Specifically, for example, hybridizing when the base identity is 70% or more, 80% or more, 90% or more, 95% or more, 96% or more, 97% or more, 98% or more, 99% or more, or 100% It is possible.
- base identity means that the base sequences of two polynucleotides are aligned (aligned), and if necessary, gaps are introduced into one of the base sequences so that the degree of base identity between the two is the highest. Refers to the ratio (%) of identical bases in one polynucleotide to the total number of bases in the other polynucleotide when the number of bases is increased. % identity using a known program such as homology search program BLAST (Basic local alignment search tool; Altschul, S. F. et al, J. Mol. Biol., 215, 403-410, 1990) search Easy to determine.
- BLAST Basic local alignment search tool
- a second nucleic acid having a base sequence in which one or more bases in a sequence completely complementary to the base sequence of the first nucleic acid is replaced with another base is hybridized with the first nucleic acid.
- a plurality refers to two or more, specifically, for example, 2 to 30, 2 to 14, 2 to 12, 2 to 10, for example, 2 to 8, 2 to Refers to 6, 2-5, 2-4 or 2-3.
- the artificial nucleic acid of the present invention may contain any additional sequence of any length adjacent to one or both ends of the conformation-inducing domain and/or hybridization domain.
- the artificial nucleic acids of this embodiment can contain one or more modified nucleotides. Modifications to be introduced are not particularly limited. For example, phosphodiester linkages, sugar moieties and/or bases in the hybridizing domain can be modified.
- the conformation-inducing domain may contain one or more modified nucleotides.
- the modified nucleotide in the conformation-inducing domain comprises a modification of the sugar moiety, preferably the modification does not affect the conformation of the sugar moiety during conformation.
- the modified nucleotide is preferably capable of adopting a C3'-endo conformation.
- modified nucleotides capable of adopting a C3'-endo conformation include, for example, 2'-OMe RNA, 2'-MOE RNA, LNA and DNA. Further, for example, when a modified nucleotide is introduced at a position of a nucleotide whose conformation of the sugar moiety is C2'-endo type at the time of formation of the three-dimensional structure, the modified nucleotide can assume a C2'-endo conformation. preferable.
- modified nucleotides capable of adopting a C2'-endo conformation include 2'-O,5'-N BNA, 2'-deoxy-trans-3',4'-BNA and DNA. is mentioned. Also, for example, the conformation of the sugar moiety is generally not affected when the phosphodiester bond or base is modified.
- the modified nucleotide when introducing a modified nucleotide at a position of a nucleotide where the hydroxy group at the 2' position of ribose participates in hydrogen bonding during conformation formation, the modified nucleotide is capable of forming that hydrogen bond, or at the 2' position of ribose It is preferred to have non-bulky substituents.
- a hydroxy group that participates in hydrogen bonding during formation of a conformation may be either electron donating or electron accepting.
- Specific non-bulky substituents include, for example, hydrogen groups, halogen groups (eg, fluoro, chloro, and bromo groups), methyl groups, amino groups, cyano groups, and the like.
- the conformation of the sugar moiety and the presence or absence of hydrogen bond formation during the formation of the three-dimensional structure can be known using methods known in the art.
- crystal structure analysis results of three-dimensional structures can be downloaded from databases such as the Nucleic Acid Database and Protein Data Bank and examined visually or using software such as 3DNA.
- the conformation of sugar moieties and the presence or absence of hydrogen bond formation are exemplified in the definition of each stereostructure.
- the artificial nucleic acid of this embodiment can stably hybridize with the target nucleic acid while forming a specific three-dimensional structure.
- the partial nucleotide sequence can contain mutations.
- a region of a target nucleic acid that has individual differences due to mutation can form a double strand with equivalent stability regardless of individual differences in the base sequence. It is possible.
- the type of mutation is not particularly limited, it includes, for example, single nucleotide variants, insertion-deletion mutations, structural polymorphisms, and combinations thereof.
- the canonical motif 1 of the kink turn structure can contain mutations at the ⁇ 1 position, the ⁇ 2 position, the ⁇ 3 position, or one or more positions thereof, with the ⁇ chain as the target domain.
- a second aspect of the present invention is a gene expression inhibitor.
- the gene expression inhibitor of the present invention contains the artificial nucleic acid according to the first aspect as an active ingredient, and has an inhibitory effect on gene expression in a subject. INDUSTRIAL APPLICABILITY By using the gene expression inhibitor of the present invention, it is possible to more efficiently inhibit the expression of genes that have been difficult to stably suppress.
- gene expression inhibitor refers to a drug that has a gene expression inhibitory effect.
- the term “gene expression suppression” means suppression of transcription product expression and/or protein expression of a target gene by an artificial nucleic acid.
- “transcript” refers to any RNA synthesized by RNA polymerase from a gene region in DNA. Specifically, for example, mRNA transcribed from a gene (including, for example, mature mRNA, pre-mRNA, and mRNA not subjected to base modification), non-coding RNA (ncRNA: non-coding RNA) such as miRNA , long non-coding RNA (lncRNA), and natural antisense RNA.
- the method for suppressing expression is not particularly limited.
- RNA molecules having RNA interference (RNAi) activity such as siRNA, shRNA, and double-stranded RNA, or precursors thereof; miRNA, antisense nucleic acids (e.g., antisense DNA, antisense RNA, etc.), and ribozymes
- RNAi RNA interference
- miRNA miRNA
- antisense nucleic acids e.g., antisense DNA, antisense RNA, etc.
- ribozymes e.g., ribozymes
- the effect of suppressing gene expression in the present specification includes, for example, all effects known to be obtained by conventional methods for suppressing gene expression.
- suppression or reduction of gene expression or transcription product expression level translation inhibition, RNA editing, splicing function modification effect (including, for example, splicing switch, exon inclusion, exon skipping, etc.), and transcript and the like.
- the artificial nucleic acid of the present invention By using the artificial nucleic acid of the present invention and including the mutated portion of the nucleic acid of interest in the bulge structure, it is possible to design an artificial nucleic acid that exerts a gene expression-suppressing effect to the same extent regardless of the mutation. Moreover, according to the artificial nucleic acid of the present invention, gene expression can be suppressed with higher efficiency than conventional ASOs.
- the gene whose expression is suppressed by this embodiment is not particularly limited, but includes, for example, genes whose expression is increased in various diseases.
- the target disease is not particularly limited, for example, it involves overexpression of normal protein, abnormal protein expression, and overexpression of RNA that directly or indirectly regulates protein expression.
- Overexpression of a normal protein refers to abnormally high production of a protein that is also expressed in a normal individual, and is seen, for example, in inflammatory diseases, autoimmune diseases, and the like.
- Abnormal protein expression refers to the production of a protein that is not expressed in a normal individual, at least under certain conditions. This includes cases where the timing and cells are different from normal. This abnormality is seen, for example, in neurodegenerative diseases and the like.
- RNA that directly or indirectly regulates protein expression means overexpression of RNA that positively or negatively regulates protein expression (e.g., miRNA, etc.) to the expression of the regulated protein. Indicates that an abnormality has occurred. This abnormality is found in, for example, cancer.
- Specific diseases to which the gene expression inhibitor of this embodiment is applied include, for example, muscular dystrophy; cancer; cardiovascular disease; hypertension; infectious disease; renal disease; Neurodegenerative diseases such as lateral sclerosis, Huntington's disease, Creutzfeldt-Jakob disease; autoimmune diseases such as lupus, rheumatoid arthritis; endocarditis; Graves' disease; ALD; respiratory diseases such as asthma or cystic fibrosis skin diseases such as psoriasis or eczema; eye diseases; ear, nose and throat diseases; other neurological diseases such as Tourette's syndrome, schizophrenia, depression, autism or stroke; Examples include metabolic diseases such as glycogen storage disease and diabetes.
- the degree of gene expression suppression by the gene expression inhibitor of this embodiment is not particularly limited. Specifically, for example, when the transcription product and / or protein expression level of the gene is used as an indicator, the expression of the gene is 100% or 90% compared to the case where the gene expression inhibitor is not introduced. 75% or more, 60% or more, 50% or more, 40% or more, 30% or more, 25% or more, 20% or more, or 10% or more. Alternatively, gene expression may be significantly suppressed as compared to the case where the gene expression inhibitor is not introduced.
- the degree of gene expression suppression can be determined using the transcription product or protein expression level of the target gene as an index. For example, the expression level of transcripts can be determined by Northern hybridization, RT-PCR, or the like. In addition, the protein expression level can be determined, for example, by Western blotting, ELISA, protein activity measurement, fluorescence intensity from a fluorescent protein, or the like.
- the gene expression inhibitor of this embodiment can be formulated into a pharmaceutical composition by formulating it together with a carrier and the like as one of the active ingredients.
- the carrier used can include, for example, a pharmaceutically acceptable carrier.
- “Pharmaceutically acceptable carrier” refers to additives commonly used in the field of formulation technology. For example, solvents, bases, emulsifiers, suspending agents, surfactants, pH adjusters, stabilizers, flavoring agents, fragrances, excipients, vehicles, preservatives, binders, diluents, tonicity agents , soothing agents, bulking agents, disintegrating agents, buffering agents, coating agents, lubricants, coloring agents, sweetening agents, thickening agents, flavoring agents, solubilizing agents, and other additives.
- the solvent may be, for example, water or other pharmaceutically acceptable aqueous solution, or a pharmaceutically acceptable organic solvent (vegetable oil, etc.).
- Aqueous solutions include, for example, physiological saline, isotonic solutions containing glucose and other adjuvants, phosphate buffers, and sodium acetate buffers.
- auxiliary agents include D-sorbitol, D-mannose, D-mannitol, sodium chloride, low-concentration nonionic surfactants, polyoxyethylene sorbitan fatty acid esters, and the like.
- the carrier is used to avoid or suppress enzymatic degradation of the artificial nucleic acid, which is the active ingredient, in vivo, facilitate formulation and administration methods, and maintain the dosage form and efficacy. It may be used appropriately as necessary.
- the dosage form of the pharmaceutical composition delivers the gene expression inhibitor according to this aspect, which is an active ingredient, to the target site without inactivating it by decomposition or the like, and the pharmacological effect of the active ingredient in vivo (gene expression inhibition Effect) is not particularly limited as long as the form can exhibit.
- Specific dosage forms differ depending on the administration method and/or prescription conditions. Since administration methods can be broadly classified into parenteral administration and oral administration, dosage forms suitable for each administration method may be used.
- the preferred dosage form of the pharmaceutical composition is not particularly limited, and may be either oral administration or parenteral administration.
- parenteral administration include intramuscular administration, intravenous administration, intraarterial administration, intraperitoneal administration, subcutaneous administration (including implantable continuous subcutaneous administration), intradermal administration, tracheal/bronchial administration, rectal administration, and blood transfusion.
- administration intracerebroventricular administration, intrathecal administration, intranasal administration, intramuscular administration, and the like.
- the preferred dosage form is a liquid formulation that can be administered directly to the target site or systemically administered via the circulatory system.
- liquid formulations include injections. Injections are appropriately combined with the aforementioned excipients, elixirs, emulsifiers, suspending agents, surfactants, stabilizers, pH adjusters, etc., and mixed in unit dosage forms generally accepted for pharmaceutical practice. It can be formulated by Other formulations include ointments, plasters, cataplasms, transdermal formulations, lotions, inhalants, aerosols, eye drops, and suppositories.
- each dosage form described above are not particularly limited as long as they are within the range of dosage forms known in the art for each dosage form.
- the method for producing the pharmaceutical composition of the present invention it may be formulated according to a conventional method in the technical field.
- the amount (content) of the gene expression inhibitor contained in the pharmaceutical composition varies depending on the type of artificial nucleic acid, the delivery site, the dosage form of the pharmaceutical composition, the dosage of the pharmaceutical composition, and the type of carrier. Therefore, it is sufficient to determine them as appropriate in consideration of each condition.
- a single dose of the pharmaceutical composition is arranged to contain an effective amount of the gene expression inhibitor.
- the term “effective amount” refers to an amount necessary for the gene expression inhibitor to exhibit its function as an active ingredient, and an amount that imparts little or no harmful side effects to the living body to which it is applied. . This effective amount may vary depending on various conditions such as subject information, route of administration, and frequency of administration. Ultimately, it is determined by the judgment of a doctor, veterinarian, pharmacist, or the like.
- Subject information is various individual information of a living body to which the pharmaceutical composition is applied. For example, if the subject is a human, the information includes age, weight, sex, dietary habits, health condition, disease progression and severity, drug sensitivity, presence or absence of concomitant drugs, and the like.
- a third aspect of the present invention is a nucleic acid detection agent.
- the nucleic acid detection agent of the present invention contains the artificial nucleic acid according to the first aspect as an active ingredient, and forms a specific three-dimensional structure in the presence of the nucleic acid of interest.
- a target nucleic acid can be detected from a test sample by using the nucleic acid detection agent of the present invention.
- the nucleic acid detection agent of the present invention contains an artificial nucleic acid as an essential component and a detectable label as an optional component. Each component will be specifically described.
- nucleic acid detection agent refers to an agent that detects a nucleic acid of interest from a test sample. According to the nucleic acid detection agent of the present invention, by including the mutated portion of the target nucleic acid in the bulge structure, the target nucleic acid can be detected to the same extent regardless of the mutation.
- test sample is a substance to be tested for the presence or amount of a nucleic acid of interest.
- the test sample is not particularly limited as long as it can contain the nucleic acid of interest.
- Specific test samples include, for example, blood, serum, blood cells, urine, stool, sweat, saliva, oral mucosa, sputum, lymph, cerebrospinal fluid, tears, breast milk, amniotic fluid, semen, tissue, biopsy and culture.
- Biological substances such as cells, environmental substances collected from the environment, artificially synthesized nucleic acids, mixtures thereof, and the like are included.
- the test sample may be subjected to known pretreatments such as mincing, homogenization and extraction before application of the nucleic acid detection agent of this embodiment.
- the artificial nucleic acid is as described in the first aspect. Therefore, detailed description here is omitted.
- Nucleic acid detection agents of this embodiment optionally include a detectable label.
- the type of detectable label is not particularly limited, and may be appropriately determined according to the detection method.
- Examples of specific detectable labels include fluorescent dyes (e.g., FITC, Texas, Cy3, Cy5, Cy7, FAM, HEX, VIC, JOE, Rox, TET, Bodipy493, NBD and TAMRA), luminescent substances ( acridinium esters, etc.), non-colored small molecules that act as enzyme substrates or antigens (e.g., biotin and DIG), and radioisotopes (e.g., 32 P, 3 H and 14 C, etc.).
- fluorescent dyes e.g., FITC, Texas, Cy3, Cy5, Cy7, FAM, HEX, VIC, JOE, Rox, TET, Bodipy493, NBD and TAMRA
- luminescent substances acridinium esters, etc.
- Fluorescent bases can also be used as labels.
- the type of fluorescent base is not particularly limited as long as it is a nucleic acid base that emits fluorescence. Specific fluorescent bases are described, for example, in Glen Research's catalog (https://www.glenresearch.com/media//folio3/productattachments/product_catalog/Glen_Product_Catalog_2021.pdf).
- Fluorescent bases include, but are not limited to, 2-aminopurine, pyrrolocytosine, 9-aminoethyl-1,3-diaza-2-oxophenoxazine, 1, N6 -ethenoadenine, 5-(1-pyrenyl-ethynyl) Uracil, 1,3-diaza-2-oxophenothiazine, 1,3-diaza-2-oxophenothiazine, and the like.
- a fluorescent base may be attached, for example, to the 1' position of the sugar.
- a nucleotide having a fluorescent base may be, for example, a nucleotide having 2-aminopurine or pyrrolocytosine.
- a target nucleic acid can be detected from a test sample.
- the detection method is not particularly limited as long as the target nucleic acid hybridized with the nucleic acid detection agent can be detected.
- detection can be performed without a detectable label or the like, via a detectable label, via a detectable conformation recognition molecule, or a combination thereof.
- the nucleic acid of interest can be detected without using a detectable label or the like.
- the detection method in this case is not particularly limited as long as it is a nucleic acid detection method. Specific examples include a method using electrophoresis, a method using a nuclease, and a method using a melting curve of a double-stranded nucleic acid.
- the artificial nucleic acid of the present invention and the nucleic acid of interest hybridize with a specific conformation. Therefore, the migration properties of the double-stranded nucleic acids of the artificial nucleic acid and the target nucleic acid are different from those of a normal complementary double-stranded nucleic acid having approximately the same number of bases.
- a target nucleic acid can be detected by detecting a double-stranded nucleic acid with the same migration as that expected when forming a specific three-dimensional structure.
- the double-stranded nucleic acid of the artificial nucleic acid and the target nucleic acid may contain a single-stranded portion having a specific nucleotide sequence in the target domain and/or conformation-inducing domain. Therefore, for example, the target nucleic acid can be detected by detecting the nucleic acid having the specific base sequence after treating the double-stranded nucleic acid obtained from the test sample with a nuclease that specifically cleaves. .
- the melting curve of the double-stranded nucleic acid of the artificial nucleic acid of the present invention and the target nucleic acid is different from that of a normal complementary double-stranded nucleic acid consisting of approximately the same number of bases. Therefore, for example, a nucleic acid of interest can be detected by detecting a double-stranded nucleic acid that exhibits the same melting curve as that expected when forming a specific three-dimensional structure.
- the nucleic acid detection agent of this embodiment can be detected via a detectable label.
- the detection method is not particularly limited, it is usually determined according to the type of label used and the properties of the test sample.
- a fluorescent dye or luminescent substance is used, for example, by visual inspection, using a microscope (for example, a fluorescence microscope, etc.), a detector (for example, fluorescence activated cell sorting (FACS), a luminometer, an absorption photometer etc.) or a combination thereof.
- FACS fluorescence activated cell sorting
- a luminometer for example, an absorption photometer etc.
- a non-colored low-molecular-weight molecule that functions as an enzyme substrate or antigen is used as a label
- detection can be performed by the same detection method as in the case of using a fluorescent dye or a luminescent substance after treatment such as enzyme treatment.
- radioisotopes are used as labels, they can be detected, for example, by autoradiography, scintillation counting
- the nucleic acid detection agent of this embodiment can be detected via a recognition molecule upon formation of a three-dimensional structure.
- the artificial nucleic acid of the present invention forms a specific three-dimensional structure with the target nucleic acid and hybridizes. Therefore, the nucleic acid of interest can be detected by observing a phenomenon that occurs specifically during the formation of a specific three-dimensional structure. For example, by detecting binding of a specific protein (including, for example, an antibody against a specific conformation), binding of a specific type of nucleic acid, cleavage of a double-stranded nucleic acid at a specific position relative to the conformation, etc., Nucleic acids of interest can be detected. Phenomena that can occur during the formation of each steric structure are exemplified in the definition of each steric structure.
- the detection method to be used may be appropriately determined according to the phenomenon to be detected.
- the nucleic acid detection agent of this embodiment can be provided as a composition by mixing with other molecules and reagents required for detection, or as a kit together with other molecules and reagents required for detection.
- Other molecules required for detection may include part or all of the molecules required for detection, depending on the intended detection method described above.
- the nucleic acid detection agent of the present invention can also be used for Southern blotting, Northern blotting, in situ hybridization, and the like.
- a fourth aspect of the present invention is a method for producing an artificial nucleic acid.
- the method for producing an artificial nucleic acid of this embodiment includes a target domain selection step, a conformation-inducing domain determination step, and a nucleic acid synthesis step as essential steps, and includes a hybridization domain determination step as an optional step.
- the artificial nucleic acid according to the first aspect can be synthesized.
- the method of this embodiment includes a target domain selection step, a conformation-inducing domain determination step, and a nucleic acid synthesis step as essential steps, and includes a hybridizing domain determination step as an optional step. Each step will be specifically described below.
- Target domain selection step the sequence information of one of the sequence motifs consisting of a double strand that constitutes a specific three-dimensional structure is searched in the nucleic acid of interest, and one or more of them is selected as the target domain. It is a process to do.
- the base sequence of the nucleic acid of interest and the sequence information of one of the sequence motifs of a specific three-dimensional structure are compared to select a target domain that can form a specific three-dimensional structure.
- the target nucleic acid and specific three-dimensional structure can be appropriately selected according to the description of the first aspect.
- the target domain and the conformation-inducing domain comprise complementary regions consisting of sequences complementary to each other, and the target domain and/or the conformation-inducing domain , a non-complementary-containing region of one or more bases containing sequences that are non-complementary to each other, and the non-complementary-containing regions contain non-complementary sequences at both ends thereof.
- the complementary region can flank one or both of the non-complementary containing regions, if any, but this selection criterion is not particularly limited. For example, it may be determined randomly or based on past reports.
- sequence information on one side of a sequence motif refers to using the sequence information of a double-stranded sequence motif separately for each single strand for searching.
- a search may be performed using only the sequence information of one strand of the sequence motif, or the sequence information of both strands may be used separately for each single strand.
- identity search program such as identity search program BLAST (Basic local alignment search tool; Altschul, S. F. et al, J. Mol. Biol., 215, 403-410, 1990) can be searched by At this time, the specific three-dimensional structure to be searched may be one type or a plurality of types.
- sequence motif used at this time is not particularly limited.
- a consensus sequence may be used as a sequence motif, or a sequence whose entire base sequence has been determined may be used as a sequence motif.
- the nucleic acid of interest is searched for regions in which the arrangement of conserved bases matches.
- a sequence whose entire base sequence has been determined not only a region that completely matches that sequence, but also a region that has a certain degree of identity with that sequence is used as a target domain candidate. can be selected. For example, substitutions of 1, 2, 3, 4, 5, or 6 bases can be candidate target domains.
- target domain candidates can be target domain candidates (hereinafter referred to as target domain candidates).
- target domain candidates can be target domain candidates (hereinafter referred to as target domain candidates).
- the number of sequence motifs used for searching is not limited. For example, multiple types of sequence motifs can be searched at once.
- target domain candidates are obtained, one or more of them can be selected as the target domain.
- the selection criteria are not particularly limited. For example, randomly based on the region on the gene containing the target domain candidate, based on the conformation that can be induced in each target domain candidate, based on the sequence identity with the sequence motif, base sequence and conformation Selections can be made based on information regarding ease of formation, or by a combination thereof.
- the selected candidate target domain sequences may be sequences that have already been shown to form conformations.
- the candidate target domain is preferably included in a region where the artificial nucleic acid is expected to hybridize to achieve a desired effect.
- target domain candidates corresponding to base positions where the position of the mutation is not uniquely determined in the sequence motif can be preferentially selected.
- the plurality of continuous small target domain candidates may be combined into one large target domain.
- the order in which the search for sequence motifs and the selection of target domains are performed is not particularly limited, but preferably the selection of target domains is performed simultaneously with or after the search for sequence motifs.
- the “conformation-forming-inducing domain determining step” is a step of determining the sequence of the conformation-inducing domain so as to form a sequence motif with the target domain. This step can be performed simultaneously with or after the target domain selection step described above.
- the sequence of the conformation-inducing domain is determined according to the sequence information of the strand corresponding to the artificial nucleic acid in the sequence motif containing the sequence information of the target domain.
- bases can be determined arbitrarily. Also, for example, if a sequence that is not uniquely determined is uniquely determined by the base at the corresponding position on the other strand, it can be followed.
- the base selection criteria are not particularly limited. For example, if there are many examples of having a specific base at that position in RNAs that form a specific three-dimensional structure, that base may be selected.
- nucleotides in the conformation-inducing domain are modified nucleotides.
- Introduction of modified nucleotides in the conformation-inducing domain follows the content described in the first aspect.
- this step is performed at the same time as the target domain selection step, for example, it is possible to determine the sequences of conformation-inducing domains for all target domain candidates, and then select a target domain from the target domain candidates. can.
- sequence determination and modified nucleotide introduction are performed is not particularly limited, but preferably, determination of modified nucleotide introduction is performed simultaneously with or after sequence determination.
- hybridization domain determination step is a step of determining the base sequence of a hybridization domain consisting of 6 to 120 bases adjacent to one or both of the conformation-inducing domains. This step is an optional step, and can be performed simultaneously with or after the conformation-forming-inducing domain determination step described above.
- the nucleotide sequence of the hybridization domain in the artificial nucleic acid is determined.
- the hybridizing domain can be flanked by one or both of the conformation-inducing domains, either of which is optional. For example, if a hybridizing domain flanks both of a single conformation-inducing domain, the hybridizing domain will contain two subdomains.
- the nucleotide sequence of the hybridizing domain can be determined according to the nucleotide sequence of the region other than the target domain in the nucleic acid of interest.
- the method for determining the base sequence is not particularly limited. Also, the degree of base identity of the base sequences is not particularly limited as long as the bases are hybridizable.
- the method of this embodiment may further include the step of determining any additional sequence to be included in the modification or artificial nucleic acid.
- the timing of performing these steps is not particularly limited. Further, the details regarding these are as described in the first aspect, and the determination method is not particularly limited.
- nucleic acid synthesis step is a step of synthesizing an artificial nucleic acid based on the sequence information determined in the three-dimensional structure formation-inducing domain determination step. This step can be performed at the same time as or after the three-dimensional structure formation-inducing domain determination step described above. Moreover, when the step of determining a hybridizing domain is carried out, it can be carried out simultaneously with or after the above steps.
- the artificial nucleic acid of the present invention can be produced by a person skilled in the art by appropriately selecting a known method. Based on the nucleotide sequence information of the artificial nucleic acid determined in the three-dimensional structure formation-inducing domain determination step, artificial nucleic acids are produced using commercially available automatic nucleic acid synthesizers such as GE Healthcare, Thermo Fisher Scientific, and Beckman Coulter. should be synthesized.
- the hybridizing domain determination step is carried out, the artificial nucleic acid can be synthesized based on the base sequence information of the artificial nucleic acid determined in the three-dimensional structure formation-inducing domain determination step and the three-dimensional structure formation-inducing domain determination step. After the synthesis, for example, the artificial nucleic acid obtained may be subjected to post-treatment such as purification using a reversed-phase column or the like.
- Example 1 Evaluation of the stability of an RNA molecule and a nucleic acid molecule that hybridizes thereto to induce a three-dimensional structure> (the purpose) Confirm whether or not a three-dimensional structure can be actively formed between two nucleic acid strands, and examine the stability of the double-stranded nucleic acid in which the three-dimensional structure is induced.
- RNA molecule having the nucleotide sequence shown in SEQ ID NO: 13 was designed as the nucleic acid of interest (ROI: upper part of FIGS. 7A to 7G).
- ROI upper part of FIGS. 7A to 7G.
- an RNA molecule that induces a bulged G structure RNA-BG; SEQ ID NO: 14: lower part of FIG. 7B
- an RNA molecule that induces a kink-turn structure RNA-KT; sequence No. 15: FIG. 7C lower side
- RNA-RKT reverse kink turn structure
- RNA-ASO As a control, an RNA molecule (RNA-ASO; SEQ ID NO: 20: FIG. 7A bottom) having a sequence complementary to the nucleic acid of interest was designed.
- NTS-M2-MX An automatic nucleic acid synthesizer NTS-M2-MX (Nihon Techno Service Co, Ltd) was used to synthesize RNA molecules.
- the synthesized sample was purified by gel filtration using NAP-10 columns (Cytiva). After purification, 20% denaturing polyacrylamide gel electrophoresis containing 7 M urea was performed to confirm that the sample was highly pure and properly synthesized.
- relative absorbance was calculated from the measured absorbance using the following formula.
- A ( At - Amin )/( Amax - Amin ) (A t : absorbance at t°C, A min : minimum absorbance, A max : maximum absorbance)
- the inflection point of the thermal melting curve created as a sigmoid curve is approximately calculated as the point where the straight line approximated by the least squares method in the linear region of the temperature change data and the linear region intersect. was taken as the melting temperature (T m ).
- the sigmoidal melting curve was obtained with any of the nucleic acids, indicating that a stable double strand can be formed with the target nucleic acid with any nucleic acid (Fig. 8).
- Fig. 8A thermal melting curves of the nucleic acid of interest and the control double-stranded nucleic acid (Fig. 8A)
- Fig. 8B-G the thermal properties of the double-stranded nucleic acid with the nucleic acid of interest
- the melting curve was shifted to the lower temperature side and the T m value was also low (Table 1).
- the duplex was found to be sufficiently stable.
- RNA-GA was the most stable (Fig. 8G)
- RNA-BG was the most unstable (Fig. 8B).
- Example 2 Evaluation of influence of modification on stability of double-stranded nucleic acid> (the purpose) To examine the stability of double-stranded nucleic acids when modified nucleotides are used.
- Example 1 An experiment was conducted according to the method of Example 1.
- the nucleic acids used are as follows. Similar to Example 1, an RNA molecule (ROI) having the nucleotide sequence shown in SEQ ID NO: 13 was used as the nucleic acid of interest.
- As artificial nucleic acids three types of nucleic acid molecules having the same base sequences as in Example 1 but having all nucleotides modified with 2'-O-methyl (2'-OMe) were used.
- a nucleic acid molecule that induces a bulged G structure (OMe-BG; SEQ ID NO: 21), a nucleic acid molecule that induces a 5S loop E structure (OMe-5S; SEQ ID NO: 22), and a nucleic acid molecule that induces a tandem GA structure (OMe-GA ; SEQ ID NO: 23) was used.
- OMe-BG bulged G structure
- OMe-5S a nucleic acid molecule that induces a 5S loop E structure
- OMe-GA nucleic acid molecule that induces a tandem GA structure
- RNA-GA was the most stable after modification (Fig. 9D) and RNA-BG was the most unstable (Fig. 9B). From this, it was shown that the order of stability of artificial nucleic acids does not change significantly before and after modification when similar modifications are performed.
- the artificial nucleic acid can form a stable double strand with the target nucleic acid, even though it has multiple non-complementary bases to the target nucleic acid. It was also found that nucleotide modification with 2'-OMe or the like is effective as a means of improving double-strand stability.
- Example 3 Evaluation of effect of nucleotide modification on three-dimensional structure (Buljide G structure)> (the purpose) Examine the effect of nucleotide modifications on the bulged G structure.
- Modified BG; FIG. 10D; SEQ ID NO: 26 was used.
- • 2'-OMe modifications were introduced in all nucleotides in which the conformation of the sugar moiety is C3'-endo type and the hydroxy group at the 2' position is not involved in hydrogen bonding (Fig. 10D, lower case letters).
- - All nucleotides in which the conformation of the sugar moiety is the C2'-endo type were replaced with DNA ( Figure 10D, italic lower case letters).
- Each nucleic acid molecule was chemically synthesized using an automatic nucleic acid synthesizer. Then, it was purified by 20% denaturing polyacrylamide gel electrophoresis (30 cm ⁇ 40 cm) containing 7 M urea, and desalted by gel filtration using NAP-10 columns.
- Crystallization was performed by the hanging drop vapor diffusion method. Drops were prepared by mixing 0.2 ⁇ L each of 1 mM or 2 mM crystallization oligonucleotide and crystallization buffer, and equilibrated against the reservoir solution. For each nucleic acid, crystallization was performed under two types of crystallization conditions. Details of the crystallization conditions are shown in Table 3.
- a single crystal was scooped with a CryoLoop (Hampton Research) and immersed in a 40% 2-methyl-2,4-pentadiol (MPD) solution for several seconds. After that, they were quickly frozen in liquid nitrogen and used for X-ray diffraction experiments.
- CryoLoop Hampton Research
- MPD 2-methyl-2,4-pentadiol
- X-ray diffraction experiments were performed using Photon Factory's structural biology beamlines BL-17A and ARNE-3A.
- the program XDS was used to process the diffraction data. Determination of the initial phase was performed by the molecular replacement method using the program Phaser (Phenix). Refinement of atomic parameters was performed using the program phenix.refine (Phenix).
- Example 4 Evaluation of effect of nucleotide modification on three-dimensional structure (kink turn structure)> (the purpose) Examine the effects of nucleotide modifications on kink-turn structures.
- Example 5 Evaluation of effect of nucleotide modification on conformation (tetraloop receptor structure)> (the purpose) Examine the effect of nucleotide modifications on the tetraloop receptor structure.
- Crystals of the modified TLR were obtained under two types of crystallization conditions (referred to as Crystal I and Crystal II, respectively), and structural analysis was successful in both cases (Table 9, and the three-dimensional structure of Crystal I is shown in Figure 17D).
- RNA molecules containing mutations and nucleic acid molecules that hybridize thereto to induce conformation> (the purpose) The stability of a double-stranded nucleic acid induced to conform by hybridization is examined when the RNA molecule contains mutations.
- RNA molecule whose nucleotide sequence near the center is UUU (ROI-U; FIG. 21A and C upper; SEQ ID NO: 31) and an RNA molecule whose nucleotide sequence near the center is mutated to AAA (ROI- A; FIG. 21B and D top; SEQ ID NO: 32) was designed.
- an RNA molecule KT-SKIP; FIG.
- RNA molecule ASO-A; bottom of FIGS. 21A and B; SEQ ID NO: 33
- ASO-A ASO-A; bottom of FIGS. 21A and B; SEQ ID NO: 33
- the results are shown in FIG.
- the sigmoidal melting curve was obtained with any of the nucleic acids, indicating that any nucleic acid can form a double strand with the target nucleic acid (Fig. 22).
- ASO-A as a control was used, the thermal melting curve of the double-stranded nucleic acid with ROI-A shifted significantly to the low temperature side compared to the double-stranded nucleic acid with ROI-U (Fig. 22A).
- the T m value was 86°C for the double-stranded nucleic acid with ROI-U, while it was 78°C for the double-stranded nucleic acid with ROI-A, indicating that the mutation has a significant effect on the stability of the double-stranded nucleic acid.
- KT-SKIP whose conformation is induced to include the mutated portion in the bulge structure
- the thermal melting curve of the double-stranded nucleic acid with ROI-U and the thermal melting curve of the double-stranded nucleic acid with ROI-A are , there was no significant difference (Fig. 22B), and the T m value was 75°C.
- Example 7 Suppression of protein expression using a nucleic acid molecule that hybridizes to induce conformation> (the purpose) It is confirmed that protein expression can be suppressed using a nucleic acid molecule that induces a three-dimensional structure upon hybridization, and is compared with the suppression effect when using an antisense nucleic acid.
- mRNA which is a transcription product of pUC-frGFP DNA (SEQ ID NO: 35) attached to the protein synthesis kit “Asakun N Mini” (Taiyo Nippon Sanso), was used.
- a specific region (positions 277 to 301 of SEQ ID NO: 35; FIG. 23A-C upper side and FIG. 28A-C upper side; SEQ ID NO: 36) was used as a target region for hybridization.
- an RNA molecule (GA-GFP; FIG. 23B lower side and FIG.
- RNA molecule that induces a tandem GA structure by hybridizing with the target region based on the consensus sequence of the three-dimensional structure, kink turn An RNA molecule (KT-GFP; FIG. 23C bottom and FIG. 28C bottom; SEQ ID NO: 39) was designed to induce the structure.
- a control RNA molecule an RNA molecule having the same sequence as the target region (SO-GFP; FIG. 23A-C upper side and FIG. 28A-C upper side; SEQ ID NO: 36) and RNA having a sequence complementary to the target region A molecule (ASO-GFP; FIG. 23A bottom and FIG. 28A bottom; SEQ ID NO: 37) was designed. Nucleic acid synthesis was carried out according to Example 1.
- Protein synthesis was performed without the addition of the designed nucleic acid molecule or with the addition of the designed nucleic acid molecule. Protein synthesis was carried out using a protein synthesis kit "Asensai-kun N Mini" (Taiyo Nippon Sanso) according to the protocol recommended by the manufacturer. The outline is as follows. Reaction solution premix of “Asensai-kun N Mini”, pUC-frGFP DNA (final concentration 0.5 nM) and designed RNA molecules (SO-GFP, ASO-GFP, GA-GFP, KT-GFP: final concentration 20 ⁇ M each) ) were mixed to prepare 50 ⁇ l of reaction solution. As a negative control, a reaction solution without RNA was also prepared.
- reaction solutions were incubated at 30°C for 90 minutes in a PCR Thermal Cycler Dice Touch (Takara) for protein synthesis reaction, and then incubated at 4°C for 5 minutes to terminate the reaction.
- the reaction solution was used for the following experiments.
- Fluorescence spectra were measured to examine the protein synthesis inhibitory effect. Fluorescence spectra were measured in the range of 500 to 600 nm using FP-8300 (Jasco) at an excitation wavelength of 480 nm. Note that the above experiments were performed at room temperature.
- Example 8 Detection of target RNA by fluorescence-labeled RNA probe containing 2-aminopurine (fluorescence-labeled nucleic acid probe having RNA as the main constituent nucleotide)> SEQ ID NOS: 40 to 43 were used as target RNA and non-target RNA (Table 10), and the detection of target RNA by fluorescence-labeled RNA probes containing 2-aminopurine was examined.
- RNA-2AP The fluorescently labeled RNA probe
- target RNA target RNA
- non-target RNA 1-3 three types of non-target RNA (non-target RNA 1-3) were subjected to phosphorescence using an automated nucleic acid synthesizer NTS-M2-MX (Nippon Techno Service Co., Ltd.). It was chemically synthesized by the loamidite method.
- 2-Aminopurine-CE Phosphoramidite (Glen Research) was used as a phosphoramidite of a nucleotide containing 2-aminopurine.
- the sample obtained by the above chemical synthesis was purified by gel filtration using NAP-10 columns (Cytiva), and the desired RNA was highly purified by electrophoresis using a 20% denaturing polyacrylamide gel containing 7 M urea. I've verified that it's been merged correctly.
- RNA-2AP synthesized fluorescence-labeled RNA probe
- RNA-2AP RNA-2AP and 0.01 mM of target RNA or non-target RNA to a solution containing 10 mM sodium cacodylate (pH 7) and 100 mM sodium chloride to a final concentration of 0.01 mM each. bottom.
- a solution (control solution) was prepared by adding only 0.01 mM RNA-2AP to a solution containing 10 mM sodium cacodylate (pH 7) and 100 mM sodium chloride.
- the 3D fluorescence spectrum of the control solution was measured using the FP-8300 (Jasco) to determine the maximum excitation wavelength and maximum fluorescence wavelength. Based on the results, the measurement conditions (excitation wavelength and range of fluorescence wavelengths to be detected) used for subsequent fluorescence spectrum measurement were determined.
- the fluorescence spectrum of the test solution was measured with FP-8300 (Jasco) using the measurement conditions determined as above. Specifically, fluorescence spectra in the range of 330-450 nm were measured using an excitation wavelength of 305 nm.
- ⁇ F (FF 0 )/F (F: Fluorescence intensity at a specific wavelength of the test solution, F 0 : Fluorescence intensity at the same wavelength of the control solution)
- RNA-2AP can detect target RNAs in a nucleotide sequence-specific manner. All publications, patents and patent applications cited herein are hereby incorporated by reference in their entirety.
Landscapes
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Genetics & Genomics (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Biomedical Technology (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biotechnology (AREA)
- General Engineering & Computer Science (AREA)
- Molecular Biology (AREA)
- General Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- Microbiology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Plant Pathology (AREA)
- Analytical Chemistry (AREA)
- Immunology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Medicinal Chemistry (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP22853032.5A EP4382603A4 (en) | 2021-08-02 | 2022-08-01 | ARTIFICIAL NUCLEIC ACID TO INDUCE A SPECIFIC THREE-DIMENSIONAL STRUCTURE |
| US18/292,449 US20250346892A1 (en) | 2021-08-02 | 2022-08-01 | Artificial nucleic acid for inducing specific three-dimensional structure |
| JP2023540349A JP7832424B2 (ja) | 2021-08-02 | 2022-08-01 | 特定の立体構造を誘導する人工核酸 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2021126578 | 2021-08-02 | ||
| JP2021-126578 | 2021-08-02 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023013613A1 true WO2023013613A1 (ja) | 2023-02-09 |
Family
ID=85155666
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/029566 Ceased WO2023013613A1 (ja) | 2021-08-02 | 2022-08-01 | 特定の立体構造を誘導する人工核酸 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US20250346892A1 (https=) |
| EP (1) | EP4382603A4 (https=) |
| JP (1) | JP7832424B2 (https=) |
| WO (1) | WO2023013613A1 (https=) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024201048A1 (en) * | 2023-03-30 | 2024-10-03 | The Chancellor, Masters And Scholars Of The University Of Oxford | Rna silencing |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2021126578A (ja) | 2019-09-16 | 2021-09-02 | 株式会社藤商事 | 遊技機 |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE69333698T2 (de) * | 1992-07-20 | 2005-12-01 | Isis Pharmaceutical, Inc., Carlsbad | Pseudo-halbknoten ausbildende rna durch hybridisierung von antisenseoligonnukleotiden an gezielte rna sekundärstrukturen |
-
2022
- 2022-08-01 WO PCT/JP2022/029566 patent/WO2023013613A1/ja not_active Ceased
- 2022-08-01 US US18/292,449 patent/US20250346892A1/en active Pending
- 2022-08-01 EP EP22853032.5A patent/EP4382603A4/en active Pending
- 2022-08-01 JP JP2023540349A patent/JP7832424B2/ja active Active
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2021126578A (ja) | 2019-09-16 | 2021-09-02 | 株式会社藤商事 | 遊技機 |
Non-Patent Citations (22)
| Title |
|---|
| ALEMAN, LOURDES M. ET AL.: "Comparison of siRNA-induced off-target RNA and protein effects", RNA, vol. 13, 2007, pages 385 - 395, XP002553412, DOI: 10.1261/rna.352507 * |
| ALTSCHUL, S. F. ET AL., J. MOL. BIOL., vol. 215, 1990, pages 403 - 410 |
| BOONE E., SCHUSTER GARY B: "Long-range oxidative damage in duplex DNA: the effect of bulged G in a G-C tract and tandem G/A mispairs", NUCLEIC ACIDS RESEARCH, OXFORD UNIVERSITY PRESS, vol. 30, no. 3, 1 February 2002 (2002-02-01), pages 830 - 837, XP093033676, DOI: 10.1093/nar/30.3.830 * |
| COONROD, L. A. ET AL., BIOCHEMISTRY, vol. 51, no. 42, 2012, pages 8330 - 8337 |
| CORRELL, C. C. ET AL., CELL, vol. 91, no. 5, 1997, pages 705 - 712 |
| CORRELL, C. C. ET AL., NUCLEIC ACIDS RESEARCH, vol. 31, no. 23, 2003, pages 6806 - 6818 |
| CORRELL, C. C. ET AL., PROC. NATL. ACAD. SCI., vol. 95, 1998, pages 13436 - 13441 |
| GLUCK, A.WOOL, I. G., J. MOL. BIOL., vol. 256, 1996, pages 838 - 848 |
| HUANG, L.LILLEY, D. M., JOURNAL OF MOLECULAR BIOLOGY, vol. 428, 2016, pages 790 - 801 |
| HUANG, L.LILLEY, D. M., QUARTERLY REVIEWS OF BIOPHYSICS, vol. 51, no. e5, 2018 |
| JANG, S. B. ET AL., ACTA CRYSTALLOGRAPHICA SECTION D: BIOLOGICAL CRYSTALLOGRAPHY, vol. 60, no. 5, 2004, pages 829 - 835 |
| KLEIN, D. J. ET AL., JOURNAL OF MOLECULAR BIOLOGY, vol. 340, no. 1, 2004, pages 141 - 177 |
| LEONTIS, N. B.WESTHOF, E, RNA, vol. 4, no. 9, 1998, pages 1134 - 1153 |
| LEONTIS, N.B. ET AL., NUCLEIC ACIDS RES., vol. 30, no. 16, 15 August 2002 (2002-08-15), pages 3497 - 3531 |
| LESCOUTE, A. ET AL., NUCLEIC ACIDS RESEARCH, vol. 33, no. 8, 2005, pages 2395 - 2409 |
| MCPHEE, S. A. ET AL., NATURE COMMUNICATIONS, vol. 5, no. 1, 2014, pages 1 - 6 |
| SCHROEDER KERSTEN T., DALDROP PETER, MCPHEE SCOTT A., LILLEY DAVID M.J.: "Structure and folding of a rare, natural kink turn in RNA with an A•A pair at the 2b•2n position", RNA, COLD SPRING HARBOR LABORATORY PRESS, US, vol. 18, no. 6, 1 June 2012 (2012-06-01), US , pages 1257 - 1266, XP093033681, ISSN: 1355-8382, DOI: 10.1261/rna.032409.112 * |
| See also references of EP4382603A4 |
| STROBEL, S. A. ET AL., RNA, vol. 10, no. 12, 2004, pages 1852 - 1854 |
| WIMBERLY BRIAN, VARANI GABRIELE, TINOCO IGNACIO: "The Conformation of Loop E of Eukaryotic 5S Ribosomal RNA", BIOCHEMISTRY, vol. 32, 1 January 1993 (1993-01-01), pages 1078 - 1087, XP093033682 * |
| Y L CHIU AND T M RANA: "RNAi in human cells: Basic structural and functional features of small interfering RNA", MOLECULAR CELL, ELSEVIER, vol. 10, no. 3, 1 September 2002 (2002-09-01), AMSTERDAM, NL, pages 549 - 561, XP002978510, ISSN: 1097-2765, DOI: 10.1016/S1097-2765(02)00652-4 * |
| YANG, MEI (MONICA ET AL.: "Comparative Stability Determination of Oligonucleotide Duplexes in Gas and Solution Phas e", J. AM. SOC. MASS SPECTROM, vol. 15, 2004, pages 1354 - 1359, XP004548380, DOI: 10.1016/j.jasms.2004.06.008 * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024201048A1 (en) * | 2023-03-30 | 2024-10-03 | The Chancellor, Masters And Scholars Of The University Of Oxford | Rna silencing |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7832424B2 (ja) | 2026-03-18 |
| EP4382603A1 (en) | 2024-06-12 |
| JPWO2023013613A1 (https=) | 2023-02-09 |
| EP4382603A4 (en) | 2025-10-15 |
| US20250346892A1 (en) | 2025-11-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Seok et al. | Position-specific oxidation of miR-1 encodes cardiac hypertrophy | |
| AU2012322788B2 (en) | Micrornas in neurodegenerative disorders | |
| Kim et al. | Superior structure stability and selectivity of hairpin nucleic acid probes with an L-DNA stem | |
| Owczarzy et al. | Stability and mismatch discrimination of locked nucleic acid–DNA duplexes | |
| EP1959012A2 (en) | Novel oligonucleotide compositions and probe sequences useful for detection and analysis of microRNAs and their target mRNAs | |
| Rapireddy et al. | Strand invasion of mixed-sequence, double-helical B-DNA by γ-peptide nucleic acids containing G-clamp nucleobases under physiological conditions | |
| AU2010207975A1 (en) | Methods of detecting sepsis | |
| WO2006074108A2 (en) | Compositions and methods for modulating gene expression using self-protected oligonucleotides | |
| Magner et al. | Influence of mismatched and bulged nucleotides on SNP-preferential RNase H cleavage of RNA-antisense gapmer heteroduplexes | |
| Østergaard et al. | Glowing locked nucleic acids: brightly fluorescent probes for detection of nucleic acids in cells | |
| JP7832424B2 (ja) | 特定の立体構造を誘導する人工核酸 | |
| US11174505B2 (en) | Simple one-step real-time molecular system for microRNA detection | |
| Maier et al. | Reinforced HNA backbone hydration in the crystal structure of a decameric HNA/RNA hybrid | |
| US20230203493A1 (en) | Biomarkers Related to Oral Squamous Cell Carcinoma and Methods of Diagnosis and Treatment Thereof | |
| Booy et al. | lncRNA BC200 is processed into a stable Alu monomer | |
| Ren et al. | A general strategy for engineering GU base pairs to facilitate RNA crystallization | |
| Kato et al. | Interarm interaction of DNA cruciform forming at a short inverted repeat sequence | |
| EP4660306A1 (en) | Artificially synthesized nucleic acid for increasing protein expression | |
| WO2021158589A1 (en) | Treatment of ophthalmic conditions with son of sevenless 2 (sos2) inhibitors | |
| Barrett et al. | Structure of a DNA base-excision product resembling a cisplatin inter-strand adduct | |
| EP3265581B1 (en) | Simultaneous detection of oligonucleotides, a kit and a use related thereto | |
| EP0672171A1 (en) | Formation of triple helix complexes of double stranded dna using nucleoside oligomers which comprise purine base analogs | |
| Tomaszewska-Antczak et al. | Acyclic Nucleic Acids with Phosphodiester Linkages—Synthesis, Properties and Potential Applications | |
| Huppert | Studies on genomic G-quadruplexes | |
| JP7773764B2 (ja) | 蛍光標識核酸プローブ |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22853032 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2023540349 Country of ref document: JP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2022853032 Country of ref document: EP Effective date: 20240304 |
|
| WWP | Wipo information: published in national office |
Ref document number: 18292449 Country of ref document: US |