WO2022244563A1 - 予測装置、学習装置、予測方法、学習方法、予測プログラム及び学習プログラム - Google Patents
予測装置、学習装置、予測方法、学習方法、予測プログラム及び学習プログラム Download PDFInfo
- Publication number
- WO2022244563A1 WO2022244563A1 PCT/JP2022/017833 JP2022017833W WO2022244563A1 WO 2022244563 A1 WO2022244563 A1 WO 2022244563A1 JP 2022017833 W JP2022017833 W JP 2022017833W WO 2022244563 A1 WO2022244563 A1 WO 2022244563A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- data
- prediction
- learning
- output
- input data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images














Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/02—Knowledge representation; Symbolic representation
- G06N5/022—Knowledge engineering; Knowledge acquisition
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
- G06N20/20—Ensemble learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0499—Feedforward networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/09—Supervised learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/0985—Hyperparameter optimisation; Meta-learning; Learning-to-learn
Definitions
- the present disclosure relates to a prediction device, a learning device, a prediction method, a learning method, a prediction program, and a learning program.
- the purpose of this disclosure is to improve the prediction accuracy of a prediction device that uses a trained model.
- a prediction device includes: A first trained model and a second trained model that output first output data and second output data, respectively, when input data to be predicted is input; an output unit that acquires the first and second output data and outputs prediction data by calculating a weighted average value or by taking a weighted majority vote,
- the first trained model is configured to have a higher prediction accuracy with respect to input data in the interpolation region than the second trained model, and the second trained model is adapted to input data in the extrapolation region.
- the prediction accuracy for data is configured to be higher than that of the first trained model.
- a second aspect of the present disclosure is the prediction device according to the first aspect, comprising: The output unit calculates the weighted average value based on a predetermined weight, or takes the weighted majority vote.
- a third aspect of the present disclosure is the prediction device according to the second aspect,
- the predetermined weight is between prediction data output from the output unit under a plurality of types of weights when input data of a verification data set is input, and correct data corresponding to the input data of the verification data set; Determined based on error.
- a fourth aspect of the present disclosure is the prediction device according to the second aspect,
- the first trained model, the second trained model and the predetermined weights are For each of the plurality of types of first trained models and the plurality of types of second trained models, when the input data of the verification data set is input, the output section under the plurality of types of weights respectively It is determined based on the error between the predicted data to be output and the correct data corresponding to the input data of the verification data set.
- a fifth aspect of the present disclosure is the prediction device according to the fourth aspect,
- the plurality of types of first trained models are set with mutually different hyperparameters and/or are trained under mutually different learning methods, Different hyperparameters are set for the plurality of types of second trained models, and/or learning is performed under different learning methods.
- a sixth aspect of the present disclosure is the prediction device according to the first aspect, further comprising a determination unit that determines whether the input data to be predicted is input data for an interpolation region or input data for an extrapolation region;
- the output unit calculates the weighted average value based on the weight according to the determination result of the determination unit, or takes the weighted majority vote.
- a seventh aspect of the present disclosure is the prediction device according to the first aspect, further comprising a determination unit that evaluates the strength of extrapolation of the input data to be predicted, The output unit calculates the weighted average value based on the weight according to the evaluation result by the determination unit, or takes the weighted majority vote.
- An eighth aspect of the present disclosure is the prediction device according to the seventh aspect,
- the determination unit is By using one or more of the evaluation method based on the uncertainty of random forest prediction, the evaluation method based on the uncertainty of Bayesian estimation, the evaluation method based on kernel density estimation, and the evaluation method based on distance, Evaluate the extrapolative strength of the input data.
- a ninth aspect of the present disclosure is the prediction device according to the sixth aspect, comprising:
- the weight according to the determination result includes a weight for an interpolation region and a weight for an extrapolation region
- the weights for the interpolation region are When the input data of the interpolation region of the verification data set is input, the prediction data output from the output unit under a plurality of types of weights, and the input data of the interpolation region of the verification data set determined based on the error between the corresponding correct data
- the weights for the extrapolation region are When the input data of the extrapolation region of the verification data set is input, the prediction data output from the output unit under a plurality of types of weights, and the input data of the extrapolation region of the verification data set It is determined based on the error between the corresponding correct data.
- a tenth aspect of the present disclosure is the prediction device according to the first aspect,
- the first trained model is trained under one or more learning techniques of decision tree, random forest, gradient boosting, bagging, AdaBoost, k-nearest neighbor method, and neural network. cage,
- the second trained model learns any one or more of Gaussian process, kernel ridge, support vector machine, linear, partial least squares, Lasso, linear ridge, elastic net, Bayesian ridge, neural network Learning is done under the method.
- a learning device includes: A first trained model and a second trained model that respectively output first output data and second output data by inputting input data of a verification data set; an output unit that acquires the first and second output data and outputs respective prediction data by calculating a weighted average value based on a plurality of types of weights, or by taking a weighted majority; a determination unit that determines one of the plurality of types of weights based on an error between each of the output prediction data and correct data corresponding to the input data of the verification data set; have.
- a twelfth aspect of the present disclosure is the learning device according to the eleventh aspect,
- the decision unit Between each prediction data output from the output unit by inputting the input data of the interpolation region of the verification data set and the correct data corresponding to the input data of the interpolation region of the verification data set Determine the weights for the interpolated region based on the error in Between each prediction data output from the output unit by inputting the input data of the extrapolation region of the verification data set and the correct data corresponding to the input data of the extrapolation region of the verification data set Determine the weights for the extrapolation region based on the error in .
- a thirteenth aspect of the present disclosure is the learning device according to the eleventh aspect,
- the output unit By inputting the input data of the verification data set to the plurality of types of first trained models and the plurality of types of second trained models, the plurality of types of first and second trained models Obtaining the first and second output data respectively output from and calculating a weighted average value based on the plurality of types of weights, or outputting each prediction data by taking a weighted majority vote ,
- the decision unit Based on the error between each output prediction data and the correct data corresponding to the input data of the verification data set, determining one of the first trained models of the plurality of types of first trained models; determining any second trained model from among the plurality of types of second trained models; Any one of the plurality of types of weights is determined.
- a fourteenth aspect of the present disclosure is the learning device according to the thirteenth aspect,
- the plurality of types of first trained models are set with mutually different hyperparameters and/or are trained under mutually different learning methods, Different hyperparameters are set for the plurality of types of second trained models, and/or learning is performed under different learning methods.
- a fifteenth aspect of the present disclosure is the learning device according to the eleventh aspect,
- the first trained model is configured to have a higher prediction accuracy with respect to input data in the interpolation region than the second trained model, and the second trained model is adapted to input data in the extrapolation region.
- the prediction accuracy for data is configured to be higher than that of the first trained model.
- a sixteenth aspect of the present disclosure is the learning device according to the fifteenth aspect,
- the first trained model is trained under one or more learning techniques of decision tree, random forest, gradient boosting, bagging, AdaBoost, k-nearest neighbor method, and neural network. cage,
- the second trained model learns any one or more of Gaussian process, kernel ridge, support vector machine, linear, partial least squares, Lasso, linear ridge, elastic net, Bayesian ridge, neural network Learning is done under the method.
- a prediction method includes: a step of outputting first output data and second output data from the first trained model and the second trained model, respectively, by inputting input data to be predicted; obtaining the first and second output data, calculating a weighted average value, or outputting prediction data by taking a weighted majority;
- the first trained model is configured to have a higher prediction accuracy with respect to input data in the interpolation region than the second trained model, and the second trained model is adapted to input data in the extrapolation region.
- the prediction accuracy for data is configured to be higher than that of the first trained model.
- a learning method comprises: a step of outputting first output data and second output data from the first trained model and the second trained model, respectively, by inputting the input data of the verification data set; A step of obtaining the first and second output data and outputting respective prediction data by calculating a weighted average value based on a plurality of types of weights, or by taking a weighted majority vote; determining one of the plurality of types of weights based on the error between each of the output prediction data and the correct data corresponding to the input data of the verification data set.
- a prediction program a step of outputting first output data and second output data from the first trained model and the second trained model, respectively, by inputting input data to be predicted;
- a prediction program for causing a computer to execute a step of obtaining the first and second output data, calculating a weighted average value, or outputting prediction data by taking a weighted majority vote,
- the first trained model is configured to have a higher prediction accuracy with respect to input data in the interpolation region than the second trained model, and the second trained model is adapted to input data in the extrapolation region.
- the prediction accuracy for data is configured to be higher than that of the first trained model.
- a learning program includes a step of outputting first output data and second output data from the first trained model and the second trained model, respectively, by inputting the input data of the verification data set; A step of obtaining the first and second output data and outputting respective prediction data by calculating a weighted average value based on a plurality of types of weights, or by taking a weighted majority vote; determining one of the plurality of types of weights based on the error between each of the output prediction data and the correct data corresponding to the input data of the verification data set; to execute.
- prediction accuracy can be improved in a prediction device using a trained model.
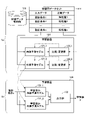
- FIG. 1 is a first diagram showing an example of functional configurations of a learning device in a learning phase and a prediction device in a prediction phase.
- FIG. 2 is a diagram illustrating an example of a hardware configuration of a learning device and a prediction device;
- FIG. 3 is a first flowchart showing the flow of learning processing and prediction processing.
- FIG. 4 is a second diagram illustrating an example of the functional configuration of the learning device in the learning phase and the prediction device in the prediction phase.
- FIG. 5 is a second flowchart showing the flow of learning processing and prediction processing.
- FIG. 6 is a first diagram showing an example of the functional configuration of the learning device in the optimization phase.
- FIG. 7 is a second diagram showing an example of the functional configuration of the learning device in the optimization phase.
- FIG. 1 is a first diagram showing an example of functional configurations of a learning device in a learning phase and a prediction device in a prediction phase.
- FIG. 2 is a diagram illustrating an example of a hardware configuration of
- FIG. 8 is a third flowchart showing the flow of learning processing and prediction processing.
- FIG. 9 is a first flowchart showing the flow of optimization processing.
- FIG. 10 is a third diagram showing an example of the functional configuration of the learning device in the learning phase.
- FIG. 11 is a third diagram showing an example of the functional configuration of the learning device in the optimization phase.
- FIG. 12 is a fourth flowchart showing the flow of learning processing and prediction processing.
- FIG. 13 is a second flowchart showing the flow of optimization processing.
- FIG. 14 is a fourth diagram showing an example of the functional configuration of the learning device in the learning phase.
- FIG. 15 is a fourth diagram showing an example of the functional configuration of the learning device in the optimization phase.
- FIG. 16 is a fifth flowchart showing the flow of learning processing and prediction processing.
- FIG. 17 is a third flowchart showing the flow of optimization processing.
- FIG. 18 is a diagram showing an example of prediction accuracy.
- the learning device according to the first embodiment will be described as an example of a learning device that performs learning using a learning data set that includes design conditions at the time of trial production and characteristic values of trial-produced materials.
- the prediction device according to the first embodiment will be described as an example of a prediction device that predicts the characteristic values of a material to be prototyped under new design conditions.
- the learning device and prediction device according to the first embodiment are not limited to the above uses, and may be used for purposes other than material design.
- FIG. 1 is a first diagram showing an example of functional configurations of a learning device in a learning phase and a prediction device in a prediction phase.
- a learning program is installed in the learning device 120, and by executing the program, the learning device 120: - Interpolation prediction model 121_1, A comparison/modification unit 122_1, - extrapolation prediction model 121_2, A comparison/modification unit 122_2, (see 1a in FIG. 1).
- the learning device 120 learns the interpolation prediction model 121_1 and the extrapolation prediction model 121_2 using the learning data set 111 stored in the material data storage unit 110, and learns the learned interpolation prediction model 131_1 and the learned extrapolation prediction model 131_1.
- An interpolation prediction model 131_2 is generated.
- the learning data set 111 includes "input data” and "correct data” as information items.
- "design condition 1" to “design condition n” are stored as “input data”
- "characteristic value 1" to “characteristic value n” are stored as "correct data”. indicates the case.
- the interpolation prediction model 121_1 is a pre-learning model that is configured to generate a trained interpolation prediction model 131_1 that has a higher prediction accuracy for input data in the interpolation region than the trained extrapolation prediction model 131_2. be.
- the interpolation prediction model 121_1 outputs output data when "design condition 1" to "design condition n” stored in the "input data" of the learning data set 111 are input.
- the comparison/modification unit 122_1 determines the error between the output data output from the interpolation prediction model 121_1 and the “characteristic value 1” to “characteristic value n” stored in the “correct data” of the learning data set 111. Accordingly, the model parameters of the interpolation prediction model 121_1 are updated.
- the learning device 120 generates a learned interpolation prediction model 131_1 (first learned model). Also, the learning device 120 applies the generated learned interpolation prediction model 131_1 (second learned model) to the prediction device 130 .
- the interpolation prediction model 121_1 that the learning device 120 learns uses, as a learning method, "Decision Trees, Random Forests, Gradient Boosting, Bagging, Adaboost, K Nearest Neighbors, Neural Networks", Suppose that it is a model in which learning is performed under any one or a plurality of learning methods among. That is, in the learning device 120, a model that is learned by a learning method suitable for the input data of the interpolation region is used as the interpolation prediction model 121_1.
- the hyperparameters of the interpolation prediction model 121_1 are set to values (hyperparameters for the interpolation prediction model) suitable for the input data of the interpolation region. shall be
- the extrapolation prediction model 121_2 is configured to generate a trained extrapolation prediction model 131_2 whose prediction accuracy for input data in the extrapolation region is higher than that of the learned interpolation prediction model 131_1. is a model.
- the extrapolation prediction model 121_2 outputs output data when "design condition 1" to "design condition n" stored in the "input data" of the learning data set 111 are input.
- the comparison/change unit 122_2 determines the error between the output data output from the extrapolation prediction model 121_2 and the “characteristic value 1” to “characteristic value n” stored in the “correct data” of the learning data set 111. Accordingly, the model parameters of the extrapolation prediction model 121_2 are updated.
- the learning device 120 generates a learned extrapolation prediction model 131_2. Also, the learning device 120 applies the generated learned extrapolation prediction model 131_2 to the prediction device 130 .
- the extrapolation prediction model 121_2 that the learning device 120 learns uses as a learning method, "Gaussian Process, Kernel Ridge, Support Vector Machine, Linear, Partial Least Squares, Lasso, Linear Ridge, Elastic Net, Bayesian Ridge, Neural Network", Suppose that it is a model in which learning is performed under any one or a plurality of learning methods among. That is, in the learning device 120, a model that is learned by a learning method suitable for the input data of the extrapolation region is used as the extrapolation prediction model 121_2.
- the hyperparameters of the extrapolation prediction model 121_2 are set to values (hyperparameters for the extrapolation prediction model) suitable for the input data of the extrapolation region. shall be
- a prediction program is installed in the prediction device 130, and by executing the program, the prediction device 130 - Learned interpolation prediction model 131_1, - Learned extrapolation prediction model 131_2, - output unit 132, (see FIG. 1, 1b).
- the learned interpolation prediction model 131_1 is generated by the learning device 120 learning the interpolation prediction model 121_1 using the learning data set 111 .
- the learned interpolation prediction model 131_1 predicts a first characteristic value (first output data) by inputting prediction target input data (design condition x) and outputs the first characteristic value (first output data) to the output unit 132 .
- the learned extrapolation prediction model 131_2 is generated by the learning device 120 learning the extrapolation prediction model 121_2 using the learning data set 111 .
- the learned extrapolation prediction model 131_2 predicts a second characteristic value (second output data) in response to input of the design condition x, and outputs the second characteristic value (second output data) to the output unit 132 .
- the output unit 132 outputs a characteristic value for the design condition x based on the first characteristic value predicted by the learned interpolation prediction model 131_1 and the second characteristic value predicted by the learned extrapolation prediction model 131_2. y is determined and output as prediction data.
- the output unit 132 determines the characteristic value y by calculating the weighted average value of the first characteristic value and the second characteristic value. Alternatively, the output unit 132 determines the characteristic value y by taking a weighted majority vote between the first characteristic value and the second characteristic value.
- the weights used when the output unit 132 calculates the weighted average value or the weights used when taking a weighted majority vote are optimized in advance.
- the prediction device 130 uses a trained interpolation prediction model suitable for the input data of the interpolation region and a trained extrapolation prediction model suitable for the input data of the extrapolation region to obtain an optimized Output prediction data under weight.
- prediction device 130 it is possible to obtain a certain degree of prediction accuracy for the input data in the interpolation region, and to obtain sufficient prediction accuracy for the input data in the extrapolation region. become able to. That is, according to this embodiment, prediction accuracy can be improved in a prediction device using a trained prediction model.
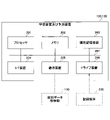
- FIG. 2 is a diagram showing an example of the hardware configuration of the learning device and prediction device.
- the learning device 120 and the prediction device 130 have a processor 201 , a memory 202 , an auxiliary storage device 203 , an I/F (Interface) device 204 , a communication device 205 and a drive device 206 .
- the hardware of the learning device 120 and the prediction device 130 are interconnected via a bus 207 .
- the processor 201 has various computing devices such as a CPU (Central Processing Unit) and a GPU (Graphics Processing Unit).
- the processor 201 reads various programs (for example, a learning program, a prediction program, etc.) onto the memory 202 and executes them.
- programs for example, a learning program, a prediction program, etc.
- the memory 202 has main storage devices such as ROM (Read Only Memory) and RAM (Random Access Memory).
- the processor 201 and the memory 202 form a so-called computer, and the processor 201 executes various programs read onto the memory 202, thereby realizing various functions of the computer.
- the auxiliary storage device 203 stores various programs and various data used when the various programs are executed by the processor 201 .
- the I/F device 204 is a connection device that connects with an external device (not shown).
- the communication device 205 is a communication device for communicating with an external device (for example, the material data storage unit 110) via a network.
- a drive device 206 is a device for setting a recording medium 210 .
- the recording medium 210 here includes media such as CD-ROMs, flexible disks, magneto-optical disks, etc. that record information optically, electrically, or magnetically.
- the recording medium 210 may also include a semiconductor memory or the like that electrically records information, such as a ROM or a flash memory.
- auxiliary storage device 203 Various programs to be installed in the auxiliary storage device 203 are installed by, for example, setting the distributed recording medium 210 in the drive device 206 and reading the various programs recorded in the recording medium 210 by the drive device 206. be done. Alternatively, various programs installed in the auxiliary storage device 203 may be installed by being downloaded from the network via the communication device 205 .
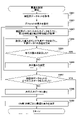
- FIG. 3 is a first flowchart showing the flow of learning processing and prediction processing.
- step S301 the learning device 120 acquires the learning data set 111.
- step S302 the learning device 120 uses the acquired learning data set 111 to learn the interpolation prediction model 121_1 and the extrapolation prediction model 121_2, and the learned interpolation prediction model 131_1 and the learned extrapolation prediction model 131_2.
- step S303 the prediction device 130 inputs the prediction target input data (design condition x) to the learned interpolation prediction model 131_1 and the learned extrapolation prediction model 131_2.
- step S304 the prediction device 130 acquires the first characteristic value and the second characteristic value predicted by the learned interpolation prediction model 131_1 and the learned extrapolation prediction model 131_2, respectively.
- step S305 the prediction device 130 calculates a weighted average value of the acquired first characteristic value and second characteristic value, or takes a weighted majority vote to determine the characteristic value.
- step S306 the prediction device 130 outputs the determined characteristic value as prediction data for the input data (design condition x) to be predicted.
- the prediction device 130 has a trained interpolation prediction model suitable for the input data of the interpolation region and a trained extrapolation prediction model suitable for the input data of the extrapolation region. ⁇ Calculate the weighted average value of the first characteristic value predicted by the trained interpolation prediction model and the second characteristic value predicted by the trained extrapolation prediction model under the optimized weights or by taking a weighted majority vote, the prediction data is output.
- prediction device 130 it is possible to obtain a certain degree of prediction accuracy for the input data in the interpolation region, and also for the input data in the extrapolation region. prediction accuracy can be obtained. That is, according to the first embodiment, prediction accuracy can be improved in a prediction device using a trained prediction model.
- the weights used when calculating the weighted average value or the weights used when taking weighted majority votes are optimized in advance.
- the weights used in calculating the weighted average value or the weights used in taking the weighted majority vote are optimized in advance for each input data to be predicted. The apparatus switches between different weights according to the input data to be predicted. The second embodiment will be described below, focusing on differences from the first embodiment.
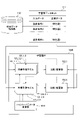
- FIG. 4 is a second diagram illustrating an example of the functional configuration of the learning device in the learning phase and the prediction device in the prediction phase.
- the difference from FIG. 1 is that the functional configuration of the prediction device 400 in FIG. 4 has an interpolation/extrapolation determination unit 410 (see 4b in FIG. 4).
- the interpolation/extrapolation determination unit 410 determines whether the input data to be predicted (design condition x) is the input data for the interpolation region or the input data for the extrapolation region. Interpolation/extrapolation determination section 410 also sets weights (weight for interpolation region, weight for extrapolation region) according to the determination result in output section 132 .
- the weight for the interpolation region is the first characteristic value.
- a weight of 0.8 and a weight of the second characteristic value of 0.2 are set in the output unit 132 .
- the weight for the extrapolation region is set to the first characteristic A value weight of 0.3 and a second characteristic value weight of 0.7 are set in the output section 132 .
- the weights set in the output unit 132 are arbitrary. Further, the method of determining the input data by the interpolation/extrapolation determination unit 410 is also arbitrary.
- the interpolation/extrapolation determination unit 410 uses the learning data set 111 to learn a one-class support vector machine in advance, and inputs input data to be predicted to the trained one-class support vector machine. It can be determined by In this case, when the input data to be predicted is determined to be an outlier, the interpolation/extrapolation determination unit 410 determines that the input data to be predicted is the input data of the extrapolation region. If the input data to be predicted is not determined to be an outlier, the interpolation/extrapolation determination unit 410 determines that the input data to be predicted is the input data of the interpolation region.
- the interpolation/extrapolation determination unit 410 predefines an interpolation region from the learning data set 111 using the local outlier factor method, so that the input data to be predicted is the interpolation region. You may make it discriminate
- the interpolation/extrapolation determination unit 410 uses a Gaussian mixture model to predefine an interpolation region from the learning data set 111, so that the input data to be predicted is the input data of the interpolation region. You may make it discriminate
- the interpolation/extrapolation determination unit 410 uses an isolation forest to predefine an interpolation region from the learning data set 111, so that the input data to be predicted is the input data of the interpolation region. You may make it discriminate
- FIG. 5 is a second flowchart showing the flow of learning processing and prediction processing. The difference from the first flowchart described using FIG. 3 is step S501.
- step S501 the prediction device 400 determines whether the input data to be predicted (design condition x) is the input data for the interpolation region or the input data for the extrapolation region. Also, the prediction device 400 sets weights (weights for interpolation regions and weights for extrapolation regions) according to the determined results.
- the prediction device 400 has, in addition to the functions of the prediction device 130 according to the first embodiment, ⁇ Determine whether the input data to be predicted is the input data for the interpolation region or the input data for the extrapolation region, and weight according to the determination result (weight for interpolation region, weight for extrapolation region weight).
- prediction device 130 it is possible to obtain a certain degree of prediction accuracy for the input data in the interpolation region, and also for the input data in the extrapolation region. prediction accuracy can be obtained. That is, according to the second embodiment, prediction accuracy can be improved in a prediction device using a learned prediction model.
- the strength of extrapolation (continuous value) of input data to be predicted is evaluated, and prediction data is output based on the weight according to the evaluation result.
- the third embodiment will be described below, focusing on differences from the second embodiment.
- the interpolation/extrapolation determination unit 410 of FIG. the strength of the extrapolative property of the input data to be predicted is evaluated. Also, in the prediction device 400 according to the third embodiment, the interpolation/extrapolation determination unit 410 in FIG. Instead, the weight corresponding to the evaluation result is set in the output unit 132 .
- interpolation/extrapolation determination unit 410 Any method can be used to evaluate the strength of extrapolation of input data by the interpolation/extrapolation determination unit 410 .
- One example is an evaluation method based on kernel density estimation. Specifically, interpolation/extrapolation determination unit 410 first constructs a kernel density estimation model using learning data set 111 and estimates the density of input data included in learning data set 111 . Subsequently, the interpolation/extrapolation determination unit 410 estimates the density of the prediction target input data (design condition x) using the constructed kernel density estimation model. Then, the interpolation/extrapolation determination unit 410 compares the density of the input data included in the learning data set 111 with the density of the input data to be predicted (design condition x), thereby determining the input data to be predicted. Evaluate the strength of extrapolation to (design condition x).
- another example is an evaluation method based on distance.
- the interpolation/extrapolation determination unit 410 first, among the input data included in the learning data set 111, ⁇ pieces of input data that are close to the prediction target input data (design condition x) to extract Note that ⁇ here is a value determined by the number of input data included in the learning data set 111 . Subsequently, the interpolation/extrapolation determination unit 410 calculates the average value of the distances between the extracted ⁇ pieces of input data and the prediction target input data (design condition x). Then, the interpolation/extrapolation determination unit 410 evaluates the strength of extrapolation from the calculated average value of the distances.
- another example is an evaluation method based on the uncertainty of random forest prediction.
- the interpolation/extrapolation determination unit 410 first, using the learning data set 111, a prediction model by random forest is constructed, and input data (design condition x) to be predicted is input. , compute the standard deviation of the distribution of the estimates for each tree. Then, the interpolation/extrapolation determination unit 410 evaluates the strength of extrapolation from the calculated standard deviation.
- another example is an evaluation method based on the uncertainty of Bayesian estimation.
- the interpolation/extrapolation determination unit 410 using the learning data set 111, a Bayesian neural network to which the variational Bayes method and the Markov chain Monte Carlo method are applied, and prediction by a non-parametric Bayesian Gaussian process. build a model; Subsequently, the interpolation/extrapolation determination unit 410 calculates the standard deviation of the estimated value distribution when the input data (design condition x) to be predicted is input to the prediction model based on the constructed Bayesian neural network or Gaussian process. do. Then, the interpolation/extrapolation determination unit 410 evaluates the strength of extrapolation from the calculated standard deviation.
- the prediction device 400 according to the third embodiment has, in addition to the functions of the prediction device 130 according to the first embodiment, ⁇ It has a function to evaluate the strength of extrapolation of the input data to be predicted and set the weight according to the evaluation result.
- ⁇ It has a function to evaluate the strength of extrapolation of the input data to be predicted and set the weight according to the evaluation result.
- the prediction device 400 it is possible to obtain a certain degree of prediction accuracy for the input data in the interpolation region, and also for the input data in the extrapolation region. prediction accuracy can be obtained. That is, according to the third embodiment, it is possible to improve the prediction accuracy of a prediction device using a learned prediction model.
- the output unit 132 outputs optimized weights (or weights according to the discrimination result or evaluation result of the input data to be predicted). Also, pre-optimized weights) have been set. In contrast, in the fourth embodiment, a method of optimizing the weights set in the output unit 132 will be described.
- FIG. 6 is a first diagram showing an example of the functional configuration of the learning device in the optimization phase.
- the learning device 620 in the optimization phase - Learned interpolation prediction model 131_1, - Learned extrapolation prediction model 131_2, - output unit 621, - weight change unit 622, - Error calculator 623, - decision unit 624, function as
- the learning device 620 uses the verification data set 610 stored in the material data storage unit 110 to optimize the weights set in the output unit 132 of the prediction device 130 .
- the verification data set 610 includes "input data” and "correct data” as information items.
- "design condition n+1" to “design condition n+m” are stored as “input data”
- "characteristic value n+1” to “characteristic value n+m” are stored as "correct data”. showing.
- the learning device 620 uses the verification data set 610 different from the learning data set 111 used for learning the interpolation prediction model 121_1 and the extrapolation prediction model 121_2. .
- the learned interpolation prediction model 131_1 and the learned extrapolation prediction model 131_2 are the same as the learned interpolation prediction model 131_1 and the learned extrapolation prediction model 131_2 described using FIG. 1 in the first embodiment. be.
- the learned interpolation prediction model 131_1 and the learned extrapolation prediction model 131_2 include “design condition n+1” to “design conditions n+m” are sequentially input.
- the learned interpolation prediction model 131_1 and the learned extrapolation prediction model 131_2 sequentially predict the first characteristic value and the second characteristic value.
- the output unit 621 sequentially outputs prediction data based on the first characteristic value and the second characteristic value under the weight changed by the weight change unit 622 .
- the output unit 621 for example, for the first characteristic value and the second characteristic value predicted by inputting “design condition n+1” to the learned interpolation prediction model 131_1 and the learned extrapolation prediction model 131_2, Then, a plurality of prediction data are sequentially output under a plurality of kinds of weights.
- the first characteristic value and the second characteristic value predicted by inputting the “design condition n+2” to the learned interpolation prediction model 131_1 and the learned extrapolation prediction model 131_2.
- it sequentially outputs a plurality of prediction data under a plurality of kinds of weights.
- the weight changing unit 622 sets the weights used when the output unit 621 sequentially outputs the prediction data.
- the error calculation unit 623 calculates a plurality of prediction data sequentially output from the output unit 621 and one of “characteristic value n+1” to “characteristic value n+m” stored in the “correct data” of the verification data set 610. is calculated and output to the determination unit 624 .
- the determination unit 624 determines the optimum weight by referring to the table 630 storing the calculated errors.
- a table 630 shows a list of errors calculated by the error calculator 623.
- the error A_n+1 is the prediction data output by the output unit 621 under the weight A based on the first characteristic value and the second characteristic value obtained by inputting the design condition n+1, and the correct answer. It refers to the error with the characteristic value n+1, which is data.
- the error B_n+1 is the prediction data output by the output unit 621 under the weight B based on the first characteristic value and the second characteristic value obtained by inputting the design condition n+1, and the correct answer. It refers to the error with the characteristic value n+1, which is data.
- the error C_n+1 is the prediction data output by the output unit 621 under the weight C based on the first characteristic value and the second characteristic value obtained by inputting the design condition n+1, and the correct answer It refers to the error with the characteristic value n+1, which is data.
- the error A_n+2 is the prediction data output by the output unit 621 under the weight A based on the first characteristic value and the second characteristic value obtained by inputting the design condition n+2, and the correct answer. It indicates the error from the characteristic value n+2 which is data.
- the error B_n+2 is the prediction data output by the output unit 621 under the weight B based on the first characteristic value and the second characteristic value obtained by inputting the design condition n+2, and the correct answer.
- the error C_n+2 is the prediction data output by the output unit 621 under the weight C based on the first characteristic value and the second characteristic value obtained by inputting the design condition n+2, and the correct answer It indicates the error from the characteristic value n+2 which is data.
- the error A_n+m is the prediction data output by the output unit 621 under the weight A based on the first characteristic value and the second characteristic value obtained by inputting the design condition n+m, and the correct answer It refers to the error with the characteristic value n+m, which is data.
- the error B_n+m is the prediction data output by the output unit 621 under the weight B based on the first characteristic value and the second characteristic value obtained by inputting the design condition n+m, and the correct answer It refers to the error with the characteristic value n+m, which is data.
- the error C_n+m is the prediction data output by the output unit 621 under the weight C based on the first characteristic value and the second characteristic value obtained by inputting the design condition n+m, and the correct answer It refers to the error with the characteristic value n+m, which is data.
- ⁇ The error index A is a statistical value (eg, average value) of errors A_n+1 to A_n+m
- ⁇ The error index B is the statistical value (for example, the average value) of the error B_n+1 to error B_n+m
- ⁇ The error index C is a statistical value (eg, average value) of errors C_n+1 to C_n+m
- the determining unit 624 for example, identifies the minimum value from error index A, error index B, error index C, . . . and determines the corresponding weight as the optimum weight. Also, the determination unit 624 sets the determined weights to the output unit 132 of the prediction device 130 .
- the prediction device 130 can perform prediction processing under optimized weights.
- FIG. 7 is a second diagram showing an example of the functional configuration of the learning device in the optimization phase. A difference from the functional configuration of learning device 620 shown in FIG.
- the determining unit 711 refers to the table 720 in FIG. 7 to determine the optimum weight for the interpolation region and the optimum weight for the extrapolation region.
- hatched errors (for example, error A_n+2, error B_n+2, error C_n+2, . . . ) indicate errors corresponding to the input data of the extrapolation area.
- the interpolation/extrapolation determination unit 410 is the same as the interpolation/extrapolation determination unit 410 in FIG.
- the error index A1 is the statistical value (eg, average value) of the errors (errors not hatched (eg, errors A_n+1, A_n+m)) corresponding to the input data in the interpolation region among the errors A_n+1 to error A_n+m
- the error index A2 is the statistic value (eg, average value) of the error (hatched error (eg, error A_n + 2)) corresponding to the input data in the extrapolation region among errors A_n+1 to error A_n+m
- the error index B1 is the statistical value (eg, average value) of the errors (errors not hatched (eg, errors B_n+1, B_n+m)) corresponding to the input data in the interpolation region among the errors B_n+1 to B_n+m.
- the error index B2 is the statistic value (eg, average value) of the error (hatched error (eg, error B_n+2)) corresponding to the input data in the extrapolation region among the error B_n+1 to error B_n+m
- the error index C1 is the statistical value (eg, average value) of the errors (unhatched errors (eg, errors C_n+1, C_n+m)) corresponding to the input data in the interpolation region among the errors C_n+1 to C_n+m.
- the error index C2 is the statistic value (eg, average value) of the error (hatched error (eg, error C_n + 2)) corresponding to the input data in the extrapolation region among the errors C_n+1 to C_n+m, point to
- the determination unit 711 identifies the minimum value among the error index A1, the error index B1, the error index C1, . . . and determines the corresponding weight as the optimum weight for the interpolation region. Further, the determination unit 711 notifies the prediction device 400 to set the determined optimal weight for the interpolation region to the output unit 132 of the prediction device 400 .
- the determination unit 711 identifies the minimum value among the error index A2, the error index B2, the error index C2, . . . and determines the corresponding weight as the optimum weight for the extrapolation region. Further, the determination unit 711 notifies the prediction device 400 so that the determined optimal weight for the extrapolation region is set to the output unit 132 of the prediction device 400 .
- FIG. 8 is a third flowchart showing the flow of learning processing and prediction processing. The difference from the first flowchart described using FIG. 1 is step S801.
- step S801 learning device 120 performs an optimization process of optimizing the weight (or the weight for each prediction target input data) set in output unit 132 of prediction device 130 (or output unit 132 of prediction device 400). Run. Details of the optimization process (step S801) will be described below.
- FIG. 9 is a first flowchart showing the flow of optimization processing.
- the learning device 120 acquires a verification data set.
- step S902 the learning device 120 sets a default weight among multiple types of weights.
- step S903 the learning device 120 inputs the input data of the verification data set to the learned interpolation prediction model and the learned extrapolation prediction model, respectively, thereby obtaining the first characteristic value and the second characteristic value. get.
- step S904 the learning device 120 outputs prediction data based on the set weights based on the acquired first characteristic value and second characteristic value.
- the learning device 120 also calculates the error between the prediction data and the corresponding correct data in the verification data set.
- step S905 the learning device 120 determines whether or not all of the multiple types of weights have been set. If it is determined in step S905 that there is an unset weight (NO in step S905), the process proceeds to step S906.
- step S906 the learning device 120 sets the next unset weight, and returns to step S904.
- step S905 determines whether all weights have been set (if YES in step S905). If it is determined in step S905 that all weights have been set (if YES in step S905), the process proceeds to step S907.
- step S907 the learning device 120 determines whether or not all the input data of the verification data set has been input to the learned interpolation prediction model and the learned extrapolation prediction model. If it is determined in step S907 that there is input data that has not been input (NO in step S907), the process proceeds to step S908.
- step S908 the learning device 120 processes the next input data in the verification data set, and returns to step S903.
- step S907 determines whether all the input data have been input (if YES in step S907). If it is determined in step S907 that all the input data have been input (if YES in step S907), the process proceeds to step S909.
- step S909 the learning device 120 calculates an error index for each set weight (or for each set weight and for each interpolation/extrapolation). Learning device 120 also determines the weight that minimizes the calculated error index as the optimum weight (or the optimum weight for the interpolation region or the optimum weight for the extrapolation region).
- the learning devices 620 and 710 has a trained interpolation prediction model suitable for the input data of the interpolation region and a trained extrapolation prediction model suitable for the input data of the extrapolation region.
- a trained interpolation prediction model suitable for the input data of the interpolation region
- a trained extrapolation prediction model suitable for the input data of the extrapolation region.
- prediction device 400 it is possible to obtain a certain degree of prediction accuracy for the input data in the interpolation region, and also for the input data in the extrapolation region. prediction accuracy can be obtained. That is, according to the fourth embodiment, prediction accuracy can be improved in a prediction device using a learned prediction model.
- the fifth embodiment a case will be described in which hyperparameters are also optimized when optimizing weights.
- the fifth embodiment will be described below, focusing on differences from the first and fourth embodiments.
- FIG. 10 is a third diagram showing an example of the functional configuration of the learning device in the learning phase. The difference from the functional configuration described using 1a of FIG.
- the hyperparameter changing unit 1010 changes hyperparameters for the interpolation prediction model set in the interpolation prediction model 121_1. In addition, the hyperparameter changing unit 1010 changes hyperparameters for the extrapolation prediction model set in the extrapolation prediction model 121_2.
- the learning device 1000 uses the learning data set 111 to learn the interpolation prediction model 121_1 and the extrapolation prediction model 121_2 each time the hyperparameter is changed. As a result, learning device 1000 generates a plurality of learned interpolation prediction models and a plurality of learned extrapolation prediction models.
- FIG. 11 is a third diagram showing an example of the functional configuration of the learning device in the optimization phase.
- the learning device 1100 in the optimization phase, the learning device 1100: - Learned interpolation prediction models 131_1_1, 131_1_2, 131_1_3, ..., - Learned extrapolation prediction models 131_2_1, 131_2_2, 131_2_3, ..., - output unit 621, - weight change unit 622, - Error calculator 623, ⁇ Determination unit 1101, function as
- the learning device 1100 optimizes the learned interpolation prediction model and the learned extrapolation prediction model applied to the prediction device 130 using the verification data set 610 stored in the material data storage unit 110, and outputs Optimize the weights set in section 132 .
- the input data of the verification data set 610 are sequentially input to the learned interpolation prediction models 131_1_1, 131_1_2, 131_1_3, .
- the learned interpolation prediction models 131_1_1, 131_1_2, 131_1_3, ... and the learned extrapolation prediction models 131_2_1, 131_2_2, 131_2_3, ... each have a plurality of first characteristic values and second characteristic values are predicted sequentially.
- the output unit 621 outputs prediction data based on the first characteristic value and the second characteristic value under the weight changed by the weight change unit 622 .
- a plurality of A plurality of prediction data are sequentially output based on the weight of the type.
- a plurality of prediction data are sequentially output under a plurality of kinds of weights.
- the weight changing unit 622 sets the weights used when the output unit 621 sequentially outputs the prediction data.
- the error calculation unit 623 calculates a plurality of prediction data sequentially output from the output unit 621 and one of “characteristic value n+1” to “characteristic value n+m” stored in the “correct data” of the verification data set 610. is calculated and output to the determination unit 1101 .
- the determining unit 1101 refers to tables 1111, 1112, 1113, .
- a table 1111 shows a list of errors calculated by the error calculator 623 .
- the hyperparameter 1 is a combination of the hyperparameters for the interpolation prediction model set in the learned interpolation prediction model 131_1_1 and the hyperparameters for the extrapolation prediction model set in the learned extrapolation prediction model 131_2_1, point to
- Hyperparameter 2 is a combination of hyperparameters for the interpolation prediction model set in the learned interpolation prediction model 131_1_2 and hyperparameters for the extrapolation prediction model set in the learned interpolation prediction model 131_1_2, point to
- the hyperparameter 3 is a combination of the hyperparameters for the interpolation prediction model set in the learned interpolation prediction model 131_1_3 and the hyperparameters for the extrapolation prediction model set in the learned interpolation prediction model 131_1_3, point to
- ⁇ is.
- the error A_n+1 is the prediction data output by the output unit 621 under the weight A based on the first characteristic value and the second characteristic value obtained by inputting the design condition n+1, and the correct answer. It refers to the error with the characteristic value n+1, which is data.
- the error B_n+1 is the prediction data output by the output unit 621 under the weight B based on the first characteristic value and the second characteristic value obtained by inputting the design condition n+1, and the correct answer. It refers to the error with the characteristic value n+1, which is data.
- the error C_n+1 is the prediction data output by the output unit 621 under the weight C based on the first characteristic value and the second characteristic value obtained by inputting the design condition n+1, and the correct answer It refers to the error with the characteristic value n+1, which is data.
- the error A_n+2 is the prediction data output by the output unit 621 under the weight A based on the first characteristic value and the second characteristic value obtained by inputting the design condition n+2, and the correct answer. It indicates the error from the characteristic value n+2 which is data.
- the error B_n+2 is the prediction data output by the output unit 621 under the weight B based on the first characteristic value and the second characteristic value obtained by inputting the design condition n+2, and the correct answer.
- the error C_n+2 is the prediction data output by the output unit 621 under the weight C based on the first characteristic value and the second characteristic value obtained by inputting the design condition n+2, and the correct answer It indicates the error from the characteristic value n+2 which is data.
- the error A_n+m is the prediction data output by the output unit 621 under the weight A based on the first characteristic value and the second characteristic value obtained by inputting the design condition n+m, and the correct answer It refers to the error with the characteristic value n+m, which is data.
- the error B_n+m is the prediction data output by the output unit 621 under the weight B based on the first characteristic value and the second characteristic value obtained by inputting the design condition n+m, and the correct answer It refers to the error with the characteristic value n+m, which is data.
- the error C_n+m is the prediction data output by the output unit 621 under the weight C based on the first characteristic value and the second characteristic value obtained by inputting the design condition n+m, and the correct answer It refers to the error with the characteristic value n+m, which is data.
- ⁇ The error index A is a statistical value (eg, average value) of errors A_n+1 to A_n+m
- ⁇ The error index B is the statistical value (for example, the average value) of the error B_n+1 to error B_n+m
- ⁇ The error index C is a statistical value (eg, average value) of errors C_n+1 to C_n+m
- the determining unit 1101 specifies the minimum value among the error index A, the error index B, the error index C, . Further, the determination unit 1101 selects the minimum value from among the minimum values specified in each hyperparameter (that is, from among the minimum values specified in the table 1111, the minimum values specified in the table 1112, . . . ). Identify.
- the determining unit 1101 determines the hyperparameters and weights corresponding to the specified minimum value as the optimum hyperparameters and optimum weights. Furthermore, the determining unit 1101 determines the optimum trained interpolation prediction model and the optimum trained extrapolation prediction model generated by performing learning by setting the combinations indicated by the determined hyperparameters. Optimal weights are reported to the prediction device 130 .
- the prediction device 130 can perform prediction processing based on the optimized learned interpolation prediction model, the learned extrapolation prediction model, and the optimized weights.
- FIG. 12 is a fourth flowchart showing the flow of learning processing and prediction processing. The differences from the first flowchart described using FIG. 1 are steps S1201 and S1202 to S1204.
- step S1201 the learning device 1000 sets default hyperparameters for the interpolation prediction model among the plurality of hyperparameters for the interpolation prediction model.
- the learning device 1000 sets default hyperparameters for the extrapolation prediction model among a plurality of hyperparameters for the extrapolation prediction model.
- step S1202 the learning device 1000 determines whether learning has been performed by setting all the multiple hyperparameters for the interpolation prediction model to the interpolation prediction model 121_1. In addition, the learning device 1000 determines whether learning has been performed by setting all the hyperparameters for the extrapolation prediction model to the extrapolation prediction model 121_2.
- step S1202 If it is determined in step S1202 that there are hyperparameters that have not been set (NO in step S1202), the process proceeds to step S1203.
- step S1203 the learning device 1000 sets the next hyperparameter for the interpolation prediction model to the interpolation prediction model, and sets the next hyperparameter for the extrapolation prediction model to the extrapolation prediction model. Return to S301.
- step S1202 determines whether all hyperparameters have been set (YES in step S1202) or not. If it is determined in step S1202 that all hyperparameters have been set (YES in step S1202), the process proceeds to step S1204.
- step S1204 the learning device 1100 executes optimization processing for optimizing hyperparameters and weights. Details of the optimization process (step S1204) for optimizing hyperparameters and weights will be described below.
- FIG. 13 is a second flowchart showing the flow of optimization processing. Differences from the optimization process shown in FIG. 9 are steps S1301 and S1302 to S1304.
- step S1301 the learning device 1100 selects a default learned interpolation prediction model and a learned extrapolation prediction model from among a plurality of learned interpolation prediction models and a plurality of learned extrapolation prediction models generated in the learning phase. Set model combinations.
- step S1302 learning device 1100 has performed the processing of steps S902 to S908 for all combinations of the plurality of trained interpolation prediction models and the plurality of trained extrapolation prediction models generated in the learning phase. judge.
- step S1302 If it is determined in step S1302 that there is a combination of a learned interpolation prediction model and a learned extrapolation prediction model that have not undergone the processing of steps S902 to S908 (if NO in step S1302), step Proceed to S1303.
- step S1303 the learning device 1100 sets the combination of the next learned interpolation prediction model and the next learned extrapolation prediction model, and returns to step S902.
- step S1302 determines whether the processing of steps S902 to S908 has been performed for all combinations (if YES in step S1302), the process proceeds to step S1304.
- step S1304 the learning device 1100 determines the optimal combination of hyperparameters and the optimal weight based on the error index.
- the learning devices 1000 and 1100 By setting a plurality of hyperparameters for the interpolation prediction model and learning the interpolation prediction model, a plurality of trained interpolation prediction models are generated. - Generate a plurality of trained extrapolation prediction models by respectively setting a plurality of hyperparameters for the extrapolation prediction model and learning the extrapolation prediction model. - input the input data of the verification data set to all combinations of the plurality of trained interpolation prediction models and the plurality of trained extrapolation prediction models, and predict the first characteristic value and the second characteristic value do.
- each prediction data is output under multiple types of weights, and the error with the correct data is calculated, so that each combination of hyperparameters First, an error index is calculated for each of a plurality of types of weights. ⁇ Determine a combination of hyperparameters and weights corresponding to the minimum error index, notify the prediction device of the optimal learned interpolation prediction model and the optimal learned extrapolation prediction model, and select the optimal weights to the prediction device. to notify.
- prediction device 130 it is possible to obtain a certain degree of prediction accuracy for the input data in the interpolation region, and also for the input data in the extrapolation region. prediction accuracy can be obtained. That is, according to the fifth embodiment, prediction accuracy can be improved in a prediction device using a learned prediction model.
- the interpolation prediction model and the extrapolation prediction model respectively optimize hyperparameters and weights on the premise that learning is performed under a specific learning method.
- the sixth embodiment a case of optimizing the learning method, set hyperparameters, and weights used in the interpolation prediction model and the extrapolation prediction model will be described.
- FIG. 14 is a fourth diagram showing an example of the functional configuration of the learning device in the learning phase.
- the learning device 1400 has - A plurality of interpolation prediction models 121_1_1, 121_1_2, 121_1_3, .
- the learning device 1400 uses the learning data set 111 to learn the interpolation prediction model 121_1_1 and the extrapolation prediction model 121_2_1 each time the hyperparameters are changed. As a result, the learning device 1400 generates a plurality of trained interpolation prediction models and a plurality of trained interpolation prediction models from the interpolation prediction model 121_1_1 and the extrapolation prediction model 121_2_1.
- the learning device 1400 uses the learning data set 111 to learn the interpolation prediction model 121_1_2 and the extrapolation prediction model 121_2_2 each time the hyperparameters are changed. As a result, the learning device 1400 generates a plurality of trained interpolation prediction models and a plurality of trained interpolation prediction models from the interpolation prediction model 121_1_2 and the extrapolation prediction model 121_2_2.
- the learning device 1400 uses the learning data set 111 to learn the interpolation prediction model 121_1_3 and the extrapolation prediction model 121_2_3 each time the hyperparameters are changed. As a result, the learning device 1400 generates a plurality of trained interpolation prediction models and a plurality of trained interpolation prediction models from the interpolation prediction model 121_1_3 and the extrapolation prediction model 121_2_3.
- FIG. 14 three interpolation prediction models with different learning methods and three extrapolation prediction models with different learning methods are shown for simplification of explanation.
- the number of extrapolation prediction models with different methods is not limited to three.
- FIG. 15 is a fourth diagram showing an example of the functional configuration of the learning device in the optimization phase.
- the learning device 1500 in the optimization phase, the learning device 1500: - Learned interpolation prediction models 131_1_1, 131_1_2, 131_1_3, ..., - Learned extrapolation prediction models 131_2_1, 131_2_2, 131_2_3, ..., - output unit 621, - weight change unit 622, - Error calculator 623, ⁇ Determination unit 1501, function as
- the learning device 1500 optimizes the learned interpolation prediction model and the learned extrapolation prediction model applied to the prediction device 130 using the verification data set 610 stored in the material data storage unit 110, and outputs Optimize the weights set in section 132 .
- the trained interpolation prediction models 131_1_1 to 131_1_3 are a plurality of trained internal prediction models generated by learning the interpolation prediction model 121_1_1 every time the hyperparameters for the interpolation prediction model are changed in the learning phase. It is an interpolation prediction model.
- the trained interpolation prediction models 131_1_4 to 131_1_6 are a plurality of training models generated by learning the interpolation prediction model 121_1_2 every time the hyperparameters for the interpolation prediction model are changed in the learning phase. It is a pre-interpolated prediction model.
- the learned interpolation prediction models 131_1_7 to 131_1_9 are a plurality of learned models generated by learning the interpolation prediction model 121_1_3 each time the hyperparameters for the interpolation prediction model are changed in the learning phase. It is a pre-interpolated prediction model.
- the trained extrapolation prediction models 131_2_1 to 131_2_3 are a plurality of learned models generated by learning the extrapolation prediction model 121_2_1 every time the hyperparameter for the extrapolation prediction model is changed in the learning phase. It is a pre-extrapolated prediction model.
- the learned extrapolation prediction models 131_2_4 to 131_2_6 are a plurality of learned models generated by learning the extrapolation prediction model 121_2_2 every time the hyperparameter for the extrapolation prediction model is changed in the learning phase. It is a pre-extrapolated prediction model.
- the learned extrapolation prediction models 131_2_7 to 131_2_9 are a plurality of learned models generated by learning the extrapolation prediction model 121_2_3 every time the hyperparameter for the extrapolation prediction model is changed in the learning phase. It is a pre-extrapolated prediction model.
- the input data of the verification data set 610 is sequentially input to the learned interpolation prediction model 131_1_1 and the like and the learned extrapolation prediction model 131_2_1 and the like.
- the learned interpolation prediction model 131_1_1 and the like and the learned extrapolation prediction model 131_2_1 and the like sequentially predict a plurality of first characteristic values and second characteristic values, respectively.
- the determining unit 1501 refers to tables 1511 to 1519 to determine the optimal learning method, optimal hyperparameters, and optimal weights.
- tables 1511 to 1519 list the errors calculated by the error calculator 623.
- - Learning method 1 is a combination of a learning method when the interpolation prediction model 121_1_1 is learned and a learning method when the extrapolation prediction model 121_2_1 is learned
- the learning method 2 is a combination of the learning method when the interpolation prediction model 121_1_2 is learned and the learning method when the extrapolation prediction model 121_2_2 is learned
- - Learning method 3 is a combination of a learning method when the interpolation prediction model 121_1_3 is learned and a learning method when the extrapolation prediction model 121_2_3 is learned, point to
- the hyperparameter 1 is a combination of the hyperparameters for the interpolation prediction model set in the learned interpolation prediction model 131_1_1 and the hyperparameters for the extrapolation prediction model set in the learned extrapolation prediction model 131_2_1,
- Hyperparameter 2 is a combination of hyperparameters for the interpolation prediction model set in the learned interpolation prediction model 131_1_2 and hyperparameters for the extrapolation prediction model set in the learned extrapolation prediction model 131_2_2,
- the hyperparameter 3 is a combination of the hyperparameters for the interpolation prediction model set in the learned interpolation prediction model 131_1_3 and the hyperparameters for the extrapolation prediction model set in the learned extrapolation prediction model 131_2_3, point to
- the error A_n+1 is the prediction data output by the output unit 621 under the weight A based on the first characteristic value and the second characteristic value obtained by inputting the design condition n+1, and the correct answer. It refers to the error with the characteristic value n+1, which is data.
- the error B_n+1 is the prediction data output by the output unit 621 under the weight B based on the first characteristic value and the second characteristic value obtained by inputting the design condition n+1, and the correct answer. It refers to the error with the characteristic value n+1, which is data.
- the error C_n+1 is the prediction data output by the output unit 621 under the weight C based on the first characteristic value and the second characteristic value obtained by inputting the design condition n+1, and the correct answer It refers to the error with the characteristic value n+1, which is data.
- the error A_n+2 is the prediction data output by the output unit 621 under the weight A based on the first characteristic value and the second characteristic value obtained by inputting the design condition n+2, and the correct answer. It indicates the error from the characteristic value n+2 which is data.
- the error B_n+2 is the prediction data output by the output unit 621 under the weight B based on the first characteristic value and the second characteristic value obtained by inputting the design condition n+2, and the correct answer.
- the error C_n+2 is the prediction data output by the output unit 621 under the weight C based on the first characteristic value and the second characteristic value predicted by inputting the design condition n+2, and the correct answer It indicates the error from the characteristic value n+2 which is data.
- the error A_n+m is the predicted data output by the output unit 621 under the weight A based on the first characteristic value and the second characteristic value predicted by inputting the design condition n+m, and the correct answer. It refers to the error with the characteristic value n+m, which is data.
- the error B_n+m is the predicted data output by the output unit 621 under the weight B based on the first characteristic value and the second characteristic value predicted by inputting the design condition n+m, and the correct answer. It refers to the error with the characteristic value n+m, which is data.
- the error C_n+m is the predicted data output by the output unit 621 under the weight C based on the first characteristic value and the second characteristic value predicted by inputting the design condition n+m, and the correct answer. It refers to the error with the characteristic value n+m, which is data.
- ⁇ The error index A is a statistical value (eg, average value) of errors A_n+1 to A_n+m
- ⁇ The error index B is the statistical value (for example, the average value) of the error B_n+1 to error B_n+m
- ⁇ The error index C is a statistical value (eg, average value) of errors C_n+1 to C_n+m
- the determining unit 1501 identifies the minimum value among the error index A, the error index B, the error index C, . Further, the determining unit 1501 further identifies the minimum value among the minimum values identified for each learning method and each hyperparameter. Accordingly, the determination unit 1501 determines the corresponding learning method, the corresponding hyperparameters, and the corresponding weights as the optimal learning method, the optimal hyperparameters, and the optimal weights.
- the determining unit 1501 sets the combination pointed to by the determined hyperparameter under the combination pointed to by the determined learning method, and the learned interpolation prediction model and the trained extrapolation generated by performing learning.
- the prediction model is notified to the prediction device 130 .
- determination section 1501 notifies prediction device 130 of the determined weights.
- the prediction device 130 can perform prediction processing based on the optimized learned interpolation prediction model, the learned extrapolation prediction model, and the optimized weights.
- FIG. 16 is a fifth flowchart showing the flow of learning processing and prediction processing.
- the differences from the fourth flowchart described using FIG. 12 are steps S1601 and S1602 to S1604.
- step S1601 the learning device 1400 sets an interpolation prediction model for which learning is performed under the default learning method among a plurality of interpolation prediction models for which learning is performed under mutually different learning methods.
- learning device 1500 sets an extrapolation prediction model for which learning is performed under the default learning method among a plurality of extrapolation prediction models for which learning is performed under mutually different learning methods.
- step S1602 the learning device 1400 learns the interpolation prediction model based on all of the plurality of learning methods prepared in advance, and determines whether or not the learned interpolation prediction model has been generated.
- the learning device 1400 learns the extrapolation prediction model based on all of the plurality of learning methods prepared in advance, and determines whether or not the learned extrapolation prediction model is generated.
- step S1602 If it is determined in step S1602 that there is a learning method that has not been learned (NO in step S1602), the process proceeds to step S1603.
- step S1603 the learning device 1400 sets an interpolation prediction model for which learning is performed under the next learning method or an extrapolation prediction model for which learning is performed under the next learning method, and returns to step S1201. .
- step S1602 determines whether learning has been performed under all the learning methods prepared in advance (YES in step S1602). If it is determined in step S1602 that learning has been performed under all the learning methods prepared in advance (YES in step S1602), the process proceeds to step S1604.
- step S1604 the learning device 1500 executes optimization processing for optimizing the learning method, hyperparameters, and weights. Details of the optimization processing (step S1604) for optimizing the learning method, hyperparameters, and weights will be described below.
- FIG. 17 is a third flowchart showing the flow of optimization processing. The difference from the optimization processing shown in FIG. 13 is step S1701.
- step S1701 the learning device 1500 determines the optimal learning method combination, the optimal hyperparameter combination, and the optimal weight based on the error index.
- the learning device 1500 ⁇ For multiple interpolation prediction models that are trained under different learning methods, by setting multiple hyperparameters for each interpolation prediction model and learning, multiple trained interpolation prediction models can be generated. Generate. ⁇ For multiple extrapolation prediction models that are trained under different learning methods, by setting multiple hyperparameters for each extrapolation prediction model and learning, multiple trained extrapolation prediction models can be generated. Generate. Input the input data of the verification data set to all combinations of the plurality of trained interpolation prediction models and the plurality of trained extrapolation prediction models, and predict the first characteristic value and the second characteristic value. .
- predicted data are output under a plurality of types of weights, and the error with the correct data is calculated.
- an error index for each of a plurality of types of weights is calculated for each combination of learning methods and each combination of hyperparameters. ⁇ Determine the combination of learning methods, the combination of hyperparameters, and the weight corresponding to the minimum error index, notify the prediction device of the optimal learned interpolation prediction model and the learned extrapolation prediction model, and the optimal weight is notified to the prediction device.
- the prediction device 130 it is possible to obtain a certain degree of prediction accuracy for the input data in the interpolation region, and also for the input data in the extrapolation region. prediction accuracy can be obtained. That is, according to the sixth embodiment, it is possible to improve the prediction accuracy of a prediction device using a learned prediction model.
- the material data storage unit 110 stores, for example, a solubility data set for 1311 molecules published by ALOGPS (http://www.vcclab.org/lab/alogps/). It is assumed that there is
- the processing is performed according to the following procedure, for example.
- Procedure 1 The molecular structure described in the SMILES format in the solubility data set was downloaded to rdkit. Chem. Descriptors are used to convert to a 187-dimensional feature vector.
- Procedure 2 Randomly divide the solubility data set converted into a 187-dimensional feature vector into a training data set/validation data set/prediction data set at a ratio of 56.25%/18.75%/25%. .
- Procedure 3 The learning data set is used to learn a scikit-learn random forest regression model, which is an interpolation prediction model. Also, the training data set is used to learn a Gaussian process regression model, which is an extrapolation prediction model.
- Procedure 4 The trained random forest regression model learned in procedure 3 is used as the interpolation/extrapolation discriminating unit 410, and each input data of the verification data set is input to calculate the standard deviation of each prediction value.
- the calculated standard deviation is less than 0.6
- the corresponding input data is determined to be the input data of the interpolation area.
- the calculated standard deviation is 0.6 or more
- the corresponding input data is determined to be the input data of the extrapolation region.
- Procedure 5-1 Among the input data of the verification data set, the input data of the interpolation region is input to a trained interpolation prediction model (learned random forest regression model) to predict the first characteristic value. Also, among the input data of the verification data set, the input data of the interpolation region is input to the learned extrapolation prediction model (learned Gaussian process regression model) to predict the second characteristic value.
- the weight of the first characteristic value By comparing the predicted first characteristic value and second characteristic value with the correct data in the verification data set, the weight of the first characteristic value: the weight of the second characteristic value is optimized. .
- Procedure 5-2 The input data of the extrapolation region among the input data of the verification data set is input to a trained interpolation prediction model (learned random forest regression model) to predict the first characteristic value. Also, among the input data of the verification data set, the input data of the extrapolation region is input to the learned extrapolation prediction model (learned Gaussian process regression model) to predict the second characteristic value.
- the weight of the first characteristic value the weight of the second characteristic value is optimized. .
- Procedure 7 Input each input data of the prediction data set to a trained interpolation prediction model (learned random forest regression model) to predict the first characteristic value. Also, each input data included in the prediction data set is input to a learned extrapolation prediction model (learned Gaussian process regression model) to predict the second characteristic value. Prediction data is output with respect to the predicted first characteristic value and second characteristic value under the weight according to the determination result in procedure 6.
- Procedure 8 The prediction accuracy of the prediction data calculated for each input data of the prediction data set is evaluated by R2 defined by the square of the correlation coefficient. At that time, each input data of the prediction data set is compared with the prediction accuracy of the prediction data when all the input data are input to the trained interpolation prediction model (learned random forest regression model) (Comparative Example 1). Furthermore, the prediction accuracy of the prediction data when all the input data of the prediction data set is input to the learned extrapolation prediction model (learned Gaussian process regression model) is compared (Comparative Example 2).
- FIG. 18 is a diagram showing an example of prediction accuracy. As shown in FIG. 18, the prediction accuracy of the present embodiment is higher than the prediction accuracy of Comparative Examples 1 and 2 regardless of whether the input data of the interpolation region is input or the input data of the extrapolation region is input. It can be seen that the accuracy is higher than the accuracy.
- the learning device and the prediction device have been described as separate devices. However, the learning device and the prediction device may be configured as an integrated device. Further, in the third to sixth embodiments, the learning device in the learning phase and the learning device in the optimization phase are separate devices. However, the learning device in the learning phase and the learning device in the optimization phase may be configured as an integrated device.
- the learning method used for learning the interpolation prediction model is preferably a decision tree ensemble method, such as decision tree, random forest, gradient boosting, bagging, and adaboost. This is because the decision tree ensemble method tends to overlearn and can achieve high prediction accuracy for the input data of the interpolation region.
- the learning method used when learning the interpolation prediction model may be the k-nearest neighbor method, which is strongly influenced by the learning data set.
- the learning method used when learning the interpolation prediction model may be a neural network.
- using a neural network with two or more intermediate layers tends to cause over-learning, and high prediction accuracy can be achieved for the input data in the interpolation region.
- the learning method used for learning the extrapolation prediction model is, for example, Gaussian process. This is because the Gaussian process tends to be less prone to over-learning and can achieve relatively high prediction accuracy for the input data in the extrapolation domain.
- the learning method used for learning the extrapolation prediction model is preferably a kernel-based learning method such as a Gaussian process, kernel ridge, or support vector machine. This is because the kernel-based learning method can achieve high prediction accuracy for the input data in the extrapolation region by appropriately setting the kernel function.
- the learning method used for learning the extrapolation prediction model may be a linear learning method such as linear, partial least squares, Lasso, linear ridge, elastic net, or Bayesian ridge.
- linear learning method when the material properties in the extrapolation region are expected to exhibit linear behavior, or by preprocessing the input data of the training data set, the behavior of the material properties becomes linear. This is because it is effective in cases where it is possible to
- the learning method used for learning the extrapolation prediction model may be a neural network.
- using a neural network with two hidden layers or less tends to prevent overfitting, and by appropriately setting the activation function, it achieves high prediction accuracy for the input data in the extrapolation domain. Because you can.
- the prediction data can be used, for example, to determine design conditions when manufacturing the target material.
- the prediction data can be used, for example, to determine design conditions when manufacturing the target material.
- the material is manufactured by the material manufacturing equipment under the determined design conditions, by measuring the characteristic values of the manufactured material, the determined design conditions and the measured characteristic values are It can be newly added to the training data set.
- the training data set is used to re-learn the interpolation prediction model or the extrapolation prediction model, the development cycle of the prediction model can be rotated.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Computing Systems (AREA)
- Artificial Intelligence (AREA)
- Mathematical Physics (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- General Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- General Health & Medical Sciences (AREA)
- Biophysics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Medical Informatics (AREA)
- Complex Calculations (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Priority Applications (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US18/558,467 US20240232659A1 (en) | 2021-05-18 | 2022-04-14 | Prediction device, training device, prediction method, training method, prediction program, and training program |
| JP2022567480A JP7298789B2 (ja) | 2021-05-18 | 2022-04-14 | 予測装置、学習装置、予測方法、学習方法、予測プログラム及び学習プログラム |
| CN202280035307.8A CN117396896A (zh) | 2021-05-18 | 2022-04-14 | 预测装置、学习装置、预测方法、学习方法、预测程序及学习程序 |
| EP22804477.2A EP4343620A4 (en) | 2021-05-18 | 2022-04-14 | PREDICTION DEVICE, METHOD AND PROGRAM AND LEARNING DEVICE, METHOD AND PROGRAM |
| JP2023096651A JP2023113928A (ja) | 2021-05-18 | 2023-06-13 | 材料の設計方法 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2021-083921 | 2021-05-18 | ||
| JP2021083921 | 2021-05-18 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022244563A1 true WO2022244563A1 (ja) | 2022-11-24 |
Family
ID=84141257
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/017833 Ceased WO2022244563A1 (ja) | 2021-05-18 | 2022-04-14 | 予測装置、学習装置、予測方法、学習方法、予測プログラム及び学習プログラム |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US20240232659A1 (https=) |
| EP (1) | EP4343620A4 (https=) |
| JP (2) | JP7298789B2 (https=) |
| CN (1) | CN117396896A (https=) |
| WO (1) | WO2022244563A1 (https=) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12554796B2 (en) * | 2021-05-28 | 2026-02-17 | Nvidia Corporation | Optimizing parameter estimation for training neural networks |
| US20250077372A1 (en) * | 2023-09-06 | 2025-03-06 | Dell Products L.P. | Proactive insights for system health |
| JP2025137162A (ja) | 2024-03-08 | 2025-09-19 | 富士通株式会社 | 施策特定プログラム、施策特定方法および情報処理装置 |
| JP2026004702A (ja) | 2024-06-26 | 2026-01-15 | 富士通株式会社 | 機械学習モデルの訓練プログラム、機械学習モデルの訓練方法および機械学習モデルの訓練装置 |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006309709A (ja) | 2005-03-30 | 2006-11-09 | Jfe Steel Kk | 結果予測装置、制御装置及び品質設計装置 |
| JP2019028949A (ja) | 2017-08-03 | 2019-02-21 | 新日鐵住金株式会社 | 製品の状態予測装置及び方法、製造プロセスの制御システム、並びにプログラム |
| US20200349434A1 (en) * | 2019-03-27 | 2020-11-05 | GE Precision Healthcare LLC | Determining confident data samples for machine learning models on unseen data |
| JP2021083921A (ja) | 2019-11-29 | 2021-06-03 | 株式会社エアウィーヴ | クッション体カバー、カバー付きクッション体、マットレス、およびマットレスの製造方法 |
Family Cites Families (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH10224990A (ja) * | 1997-02-10 | 1998-08-21 | Fuji Electric Co Ltd | 電力需要量予測値補正方法 |
| JP2001195379A (ja) * | 2000-01-14 | 2001-07-19 | Nippon Telegr & Teleph Corp <Ntt> | 多数決予測機械の構成方法、多数決予測機械及びその記録媒体 |
| JP4857597B2 (ja) * | 2005-05-02 | 2012-01-18 | 富士電機株式会社 | 油入電気機器の劣化診断方法 |
| JP6705570B2 (ja) * | 2018-03-27 | 2020-06-10 | 日本製鉄株式会社 | 解析システム、解析方法、およびプログラム |
| US11491729B2 (en) * | 2018-05-02 | 2022-11-08 | Carnegie Mellon University | Non-dimensionalization of variables to enhance machine learning in additive manufacturing processes |
| JP7269122B2 (ja) * | 2019-07-18 | 2023-05-08 | 株式会社日立ハイテク | データ分析装置、データ分析方法及びデータ分析プログラム |
-
2022
- 2022-04-14 CN CN202280035307.8A patent/CN117396896A/zh active Pending
- 2022-04-14 US US18/558,467 patent/US20240232659A1/en active Pending
- 2022-04-14 JP JP2022567480A patent/JP7298789B2/ja active Active
- 2022-04-14 WO PCT/JP2022/017833 patent/WO2022244563A1/ja not_active Ceased
- 2022-04-14 EP EP22804477.2A patent/EP4343620A4/en active Pending
-
2023
- 2023-06-13 JP JP2023096651A patent/JP2023113928A/ja active Pending
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006309709A (ja) | 2005-03-30 | 2006-11-09 | Jfe Steel Kk | 結果予測装置、制御装置及び品質設計装置 |
| JP2019028949A (ja) | 2017-08-03 | 2019-02-21 | 新日鐵住金株式会社 | 製品の状態予測装置及び方法、製造プロセスの制御システム、並びにプログラム |
| US20200349434A1 (en) * | 2019-03-27 | 2020-11-05 | GE Precision Healthcare LLC | Determining confident data samples for machine learning models on unseen data |
| JP2021083921A (ja) | 2019-11-29 | 2021-06-03 | 株式会社エアウィーヴ | クッション体カバー、カバー付きクッション体、マットレス、およびマットレスの製造方法 |
Non-Patent Citations (2)
| Title |
|---|
| R. POLIKAR: "Ensemble based systems in decision making", IEEE CIRCUITS AND SYSTEMS MAGAZINE., IEEE SERVICE CENTER, NEW YORK, NY., US, vol. 6, no. 3, 1 July 2006 (2006-07-01), US , pages 21 - 45, XP011222281, ISSN: 1531-636X, DOI: 10.1109/MCAS.2006.1688199 * |
| See also references of EP4343620A4 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7298789B2 (ja) | 2023-06-27 |
| EP4343620A4 (en) | 2025-04-30 |
| CN117396896A (zh) | 2024-01-12 |
| JPWO2022244563A1 (https=) | 2022-11-24 |
| EP4343620A1 (en) | 2024-03-27 |
| US20240232659A1 (en) | 2024-07-11 |
| JP2023113928A (ja) | 2023-08-16 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7298789B2 (ja) | 予測装置、学習装置、予測方法、学習方法、予測プログラム及び学習プログラム | |
| Montalto et al. | Neural networks with non-uniform embedding and explicit validation phase to assess Granger causality | |
| US10068186B2 (en) | Model vector generation for machine learning algorithms | |
| JP6555015B2 (ja) | 機械学習管理プログラム、機械学習管理装置および機械学習管理方法 | |
| Entezari-Maleki et al. | Comparison of classification methods based on the type of attributes and sample size. | |
| AU2019371339B2 (en) | Finite rank deep kernel learning for robust time series forecasting and regression | |
| Torija et al. | A general procedure to generate models for urban environmental-noise pollution using feature selection and machine learning methods | |
| Chang et al. | Divide and conquer local average regression | |
| Moradabadi et al. | Link prediction based on temporal similarity metrics using continuous action set learning automata | |
| CA3119533C (en) | Finite rank deep kernel learning with linear computational complexity | |
| van Hoof et al. | Hyperboost: Hyperparameter optimization by gradient boosting surrogate models | |
| Chen et al. | Learning multiple similarities of users and items in recommender systems | |
| CA3119351C (en) | Extending finite rank deep kernel learning to forecasting over long time horizons | |
| CN118503541B (zh) | 基于用户多兴趣建模的对话推荐方法及相关装置 | |
| Abanda et al. | Time series classifier recommendation by a meta-learning approach | |
| Soroush et al. | A hybrid customer prediction system based on multiple forward stepwise logistic regression mode | |
| Shukla et al. | Self-adaptive ensemble-based approach for software effort estimation | |
| US20240086762A1 (en) | Drift-tolerant machine learning models | |
| CN115730248A (zh) | 一种机器账号检测方法、系统、设备及存储介质 | |
| JPWO2016132683A1 (ja) | クラスタリングシステム、方法およびプログラム | |
| US11928562B2 (en) | Framework for providing improved predictive model | |
| Tan et al. | Strengthening network slicing for industrial Internet with deep reinforcement learning | |
| Zeng et al. | Approximate solutions of interactive dynamic influence diagrams using model clustering | |
| JP2023138928A (ja) | ニューラルネットワークを生成するための方法及び装置 | |
| WO2023208379A1 (en) | Method and system based on using a model collection for planation of machine learning results |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| ENP | Entry into the national phase |
Ref document number: 2022567480 Country of ref document: JP Kind code of ref document: A |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22804477 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 18558467 Country of ref document: US |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 202280035307.8 Country of ref document: CN |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2022804477 Country of ref document: EP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2022804477 Country of ref document: EP Effective date: 20231218 |