WO2022162155A1 - Nucleic acids containing abasic nucleotides - Google Patents
Nucleic acids containing abasic nucleotides Download PDFInfo
- Publication number
- WO2022162155A1 WO2022162155A1 PCT/EP2022/052070 EP2022052070W WO2022162155A1 WO 2022162155 A1 WO2022162155 A1 WO 2022162155A1 EP 2022052070 W EP2022052070 W EP 2022052070W WO 2022162155 A1 WO2022162155 A1 WO 2022162155A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- strand
- nucleic acid
- nucleotide
- nucleotides
- acid according
- Prior art date
Links
- 102000039446 nucleic acids Human genes 0.000 title claims abstract description 242
- 108020004707 nucleic acids Proteins 0.000 title claims abstract description 242
- 150000007523 nucleic acids Chemical class 0.000 title claims abstract description 242
- 125000003729 nucleotide group Chemical group 0.000 title claims description 417
- 239000002773 nucleotide Substances 0.000 title claims description 398
- 208000035657 Abasia Diseases 0.000 title claims description 146
- 238000012986 modification Methods 0.000 claims description 157
- 230000004048 modification Effects 0.000 claims description 157
- 108091032973 (ribonucleotides)n+m Proteins 0.000 claims description 113
- 239000003446 ligand Substances 0.000 claims description 111
- 230000014509 gene expression Effects 0.000 claims description 103
- 108090000623 proteins and genes Proteins 0.000 claims description 95
- MBLBDJOUHNCFQT-UHFFFAOYSA-N N-acetyl-D-galactosamine Natural products CC(=O)NC(C=O)C(O)C(O)C(O)CO MBLBDJOUHNCFQT-UHFFFAOYSA-N 0.000 claims description 80
- 230000000295 complement effect Effects 0.000 claims description 80
- OVRNDRQMDRJTHS-KEWYIRBNSA-N N-acetyl-D-galactosamine Chemical compound CC(=O)N[C@H]1C(O)O[C@H](CO)[C@H](O)[C@@H]1O OVRNDRQMDRJTHS-KEWYIRBNSA-N 0.000 claims description 77
- 235000000346 sugar Nutrition 0.000 claims description 61
- 102000040650 (ribonucleotides)n+m Human genes 0.000 claims description 31
- RYYWUUFWQRZTIU-UHFFFAOYSA-K thiophosphate Chemical compound [O-]P([O-])([O-])=S RYYWUUFWQRZTIU-UHFFFAOYSA-K 0.000 claims description 27
- 230000002401 inhibitory effect Effects 0.000 claims description 19
- 239000008194 pharmaceutical composition Substances 0.000 claims description 15
- 230000000368 destabilizing effect Effects 0.000 claims description 8
- 239000000546 pharmaceutical excipient Substances 0.000 claims description 8
- 108091093094 Glycol nucleic acid Proteins 0.000 claims description 7
- HMFHBZSHGGEWLO-SOOFDHNKSA-N D-ribofuranose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H]1O HMFHBZSHGGEWLO-SOOFDHNKSA-N 0.000 claims description 4
- PYMYPHUHKUWMLA-LMVFSUKVSA-N Ribose Natural products OC[C@@H](O)[C@@H](O)[C@@H](O)C=O PYMYPHUHKUWMLA-LMVFSUKVSA-N 0.000 claims description 4
- HMFHBZSHGGEWLO-UHFFFAOYSA-N alpha-D-Furanose-Ribose Natural products OCC1OC(O)C(O)C1O HMFHBZSHGGEWLO-UHFFFAOYSA-N 0.000 claims description 4
- 230000008018 melting Effects 0.000 claims description 2
- 238000002844 melting Methods 0.000 claims description 2
- 238000011282 treatment Methods 0.000 abstract description 23
- 230000006806 disease prevention Effects 0.000 abstract description 2
- 150000001875 compounds Chemical class 0.000 description 255
- 108020004999 messenger RNA Proteins 0.000 description 154
- 108091081021 Sense strand Proteins 0.000 description 119
- 210000004027 cell Anatomy 0.000 description 117
- YMWUJEATGCHHMB-UHFFFAOYSA-N Dichloromethane Chemical compound ClCCl YMWUJEATGCHHMB-UHFFFAOYSA-N 0.000 description 116
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 108
- 230000000692 anti-sense effect Effects 0.000 description 105
- 238000012228 RNA interference-mediated gene silencing Methods 0.000 description 99
- 108020004459 Small interfering RNA Proteins 0.000 description 99
- 230000009368 gene silencing by RNA Effects 0.000 description 99
- 108091034117 Oligonucleotide Proteins 0.000 description 98
- 239000003795 chemical substances by application Substances 0.000 description 89
- 125000005647 linker group Chemical group 0.000 description 87
- 230000008685 targeting Effects 0.000 description 82
- 239000000203 mixture Substances 0.000 description 81
- 210000002966 serum Anatomy 0.000 description 71
- 241000282414 Homo sapiens Species 0.000 description 67
- 238000000034 method Methods 0.000 description 64
- 108010071690 Prealbumin Proteins 0.000 description 63
- 102000009190 Transthyretin Human genes 0.000 description 63
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical group [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 62
- 238000011534 incubation Methods 0.000 description 62
- 241001465754 Metazoa Species 0.000 description 61
- WEVYAHXRMPXWCK-UHFFFAOYSA-N Acetonitrile Chemical compound CC#N WEVYAHXRMPXWCK-UHFFFAOYSA-N 0.000 description 57
- 238000004458 analytical method Methods 0.000 description 56
- 231100000673 dose–response relationship Toxicity 0.000 description 52
- 125000001424 substituent group Chemical group 0.000 description 50
- 239000011780 sodium chloride Substances 0.000 description 49
- 210000003494 hepatocyte Anatomy 0.000 description 47
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 45
- 239000000243 solution Substances 0.000 description 37
- 241000699670 Mus sp. Species 0.000 description 35
- 239000002904 solvent Substances 0.000 description 34
- 150000008163 sugars Chemical class 0.000 description 34
- 238000002360 preparation method Methods 0.000 description 32
- 239000000872 buffer Substances 0.000 description 31
- 125000000325 methylidene group Chemical group [H]C([H])=* 0.000 description 31
- 239000000047 product Substances 0.000 description 31
- XEKOWRVHYACXOJ-UHFFFAOYSA-N Ethyl acetate Chemical compound CCOC(C)=O XEKOWRVHYACXOJ-UHFFFAOYSA-N 0.000 description 30
- 230000005764 inhibitory process Effects 0.000 description 30
- 102000004169 proteins and genes Human genes 0.000 description 30
- 238000001890 transfection Methods 0.000 description 30
- 229910019142 PO4 Inorganic materials 0.000 description 28
- 238000006243 chemical reaction Methods 0.000 description 28
- -1 nucleic acid compounds Chemical class 0.000 description 28
- ZMXDDKWLCZADIW-UHFFFAOYSA-N N,N-Dimethylformamide Chemical compound CN(C)C=O ZMXDDKWLCZADIW-UHFFFAOYSA-N 0.000 description 27
- 108091028043 Nucleic acid sequence Proteins 0.000 description 27
- 238000002474 experimental method Methods 0.000 description 27
- 239000010452 phosphate Substances 0.000 description 27
- XKRFYHLGVUSROY-UHFFFAOYSA-N Argon Chemical compound [Ar] XKRFYHLGVUSROY-UHFFFAOYSA-N 0.000 description 26
- 210000004185 liver Anatomy 0.000 description 26
- 238000003556 assay Methods 0.000 description 25
- 230000030279 gene silencing Effects 0.000 description 25
- 230000015572 biosynthetic process Effects 0.000 description 24
- 230000015556 catabolic process Effects 0.000 description 24
- 238000006731 degradation reaction Methods 0.000 description 24
- 238000003786 synthesis reaction Methods 0.000 description 24
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 23
- AEMRFAOFKBGASW-UHFFFAOYSA-M Glycolate Chemical compound OCC([O-])=O AEMRFAOFKBGASW-UHFFFAOYSA-M 0.000 description 23
- 230000001681 protective effect Effects 0.000 description 23
- 239000001257 hydrogen Substances 0.000 description 22
- 229910052739 hydrogen Inorganic materials 0.000 description 22
- 241000699666 Mus <mouse, genus> Species 0.000 description 21
- ZMANZCXQSJIPKH-UHFFFAOYSA-N Triethylamine Chemical compound CCN(CC)CC ZMANZCXQSJIPKH-UHFFFAOYSA-N 0.000 description 21
- 125000000640 cyclooctyl group Chemical group [H]C1([H])C([H])([H])C([H])([H])C([H])([H])C([H])(*)C([H])([H])C([H])([H])C1([H])[H] 0.000 description 21
- 125000002467 phosphate group Chemical group [H]OP(=O)(O[H])O[*] 0.000 description 21
- 230000002829 reductive effect Effects 0.000 description 21
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 20
- 230000000694 effects Effects 0.000 description 20
- 230000021615 conjugation Effects 0.000 description 19
- 102000004506 Blood Proteins Human genes 0.000 description 18
- 108010017384 Blood Proteins Proteins 0.000 description 18
- 150000002431 hydrogen Chemical class 0.000 description 18
- 239000003921 oil Substances 0.000 description 17
- 235000019198 oils Nutrition 0.000 description 17
- 238000000746 purification Methods 0.000 description 17
- 239000007787 solid Substances 0.000 description 17
- 238000007920 subcutaneous administration Methods 0.000 description 17
- 238000012360 testing method Methods 0.000 description 17
- 102000005427 Asialoglycoprotein Receptor Human genes 0.000 description 16
- 108020004414 DNA Proteins 0.000 description 16
- 102100031181 Glyceraldehyde-3-phosphate dehydrogenase Human genes 0.000 description 16
- 108010006523 asialoglycoprotein receptor Proteins 0.000 description 16
- DDRJAANPRJIHGJ-UHFFFAOYSA-N creatinine Chemical compound CN1CC(=O)NC1=N DDRJAANPRJIHGJ-UHFFFAOYSA-N 0.000 description 16
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 16
- 108020004445 glyceraldehyde-3-phosphate dehydrogenase Proteins 0.000 description 16
- 238000004128 high performance liquid chromatography Methods 0.000 description 16
- 238000011068 loading method Methods 0.000 description 16
- 230000008569 process Effects 0.000 description 16
- 235000018102 proteins Nutrition 0.000 description 16
- 239000011541 reaction mixture Substances 0.000 description 16
- 239000000523 sample Substances 0.000 description 16
- 241000282567 Macaca fascicularis Species 0.000 description 15
- 206010028980 Neoplasm Diseases 0.000 description 15
- 210000004369 blood Anatomy 0.000 description 15
- 239000008280 blood Substances 0.000 description 15
- 201000010099 disease Diseases 0.000 description 15
- 238000003818 flash chromatography Methods 0.000 description 15
- 238000001727 in vivo Methods 0.000 description 15
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 14
- 238000006073 displacement reaction Methods 0.000 description 14
- 230000003301 hydrolyzing effect Effects 0.000 description 14
- 238000004895 liquid chromatography mass spectrometry Methods 0.000 description 14
- 230000009467 reduction Effects 0.000 description 14
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 13
- 229910052786 argon Inorganic materials 0.000 description 13
- 201000011510 cancer Diseases 0.000 description 13
- 150000003291 riboses Chemical class 0.000 description 13
- 230000001629 suppression Effects 0.000 description 13
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 12
- 230000008878 coupling Effects 0.000 description 12
- 238000010168 coupling process Methods 0.000 description 12
- 238000005859 coupling reaction Methods 0.000 description 12
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 12
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 12
- 102000040430 polynucleotide Human genes 0.000 description 12
- 108091033319 polynucleotide Proteins 0.000 description 12
- 239000002157 polynucleotide Substances 0.000 description 12
- 229910052717 sulfur Inorganic materials 0.000 description 12
- 238000001644 13C nuclear magnetic resonance spectroscopy Methods 0.000 description 11
- RYYWUUFWQRZTIU-UHFFFAOYSA-N Thiophosphoric acid Chemical class OP(O)(S)=O RYYWUUFWQRZTIU-UHFFFAOYSA-N 0.000 description 11
- 230000001419 dependent effect Effects 0.000 description 11
- 238000010828 elution Methods 0.000 description 11
- 238000000338 in vitro Methods 0.000 description 11
- 102100036475 Alanine aminotransferase 1 Human genes 0.000 description 10
- 108010082126 Alanine transaminase Proteins 0.000 description 10
- 239000007832 Na2SO4 Substances 0.000 description 10
- KDLHZDBZIXYQEI-UHFFFAOYSA-N Palladium Chemical compound [Pd] KDLHZDBZIXYQEI-UHFFFAOYSA-N 0.000 description 10
- PMZURENOXWZQFD-UHFFFAOYSA-L Sodium Sulfate Chemical compound [Na+].[Na+].[O-]S([O-])(=O)=O PMZURENOXWZQFD-UHFFFAOYSA-L 0.000 description 10
- VMHLLURERBWHNL-UHFFFAOYSA-M Sodium acetate Chemical compound [Na+].CC([O-])=O VMHLLURERBWHNL-UHFFFAOYSA-M 0.000 description 10
- NINIDFKCEFEMDL-UHFFFAOYSA-N Sulfur Chemical compound [S] NINIDFKCEFEMDL-UHFFFAOYSA-N 0.000 description 10
- 238000007792 addition Methods 0.000 description 10
- 239000003153 chemical reaction reagent Substances 0.000 description 10
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 10
- 235000019441 ethanol Nutrition 0.000 description 10
- 239000012044 organic layer Substances 0.000 description 10
- 230000007170 pathology Effects 0.000 description 10
- 239000002953 phosphate buffered saline Substances 0.000 description 10
- 229910052938 sodium sulfate Inorganic materials 0.000 description 10
- 235000011152 sodium sulphate Nutrition 0.000 description 10
- 241000894007 species Species 0.000 description 10
- 239000011593 sulfur Substances 0.000 description 10
- 210000001519 tissue Anatomy 0.000 description 10
- 239000003643 water by type Substances 0.000 description 10
- OVRNDRQMDRJTHS-CBQIKETKSA-N N-Acetyl-D-Galactosamine Chemical group CC(=O)N[C@H]1[C@@H](O)O[C@H](CO)[C@H](O)[C@@H]1O OVRNDRQMDRJTHS-CBQIKETKSA-N 0.000 description 9
- 238000005481 NMR spectroscopy Methods 0.000 description 9
- 238000011529 RT qPCR Methods 0.000 description 9
- 150000001720 carbohydrates Chemical group 0.000 description 9
- 239000013058 crude material Substances 0.000 description 9
- 125000001495 ethyl group Chemical group [H]C([H])([H])C([H])([H])* 0.000 description 9
- 239000006166 lysate Substances 0.000 description 9
- 239000000463 material Substances 0.000 description 9
- 125000006239 protecting group Chemical group 0.000 description 9
- URGAHOPLAPQHLN-UHFFFAOYSA-N sodium aluminosilicate Chemical compound [Na+].[Al+3].[O-][Si]([O-])=O.[O-][Si]([O-])=O URGAHOPLAPQHLN-UHFFFAOYSA-N 0.000 description 9
- 102100038837 2-Hydroxyacid oxidase 1 Human genes 0.000 description 8
- IAZDPXIOMUYVGZ-WFGJKAKNSA-N Dimethyl sulfoxide Chemical compound [2H]C([2H])([2H])S(=O)C([2H])([2H])[2H] IAZDPXIOMUYVGZ-WFGJKAKNSA-N 0.000 description 8
- BAVYZALUXZFZLV-UHFFFAOYSA-N Methylamine Chemical compound NC BAVYZALUXZFZLV-UHFFFAOYSA-N 0.000 description 8
- JUJWROOIHBZHMG-UHFFFAOYSA-N Pyridine Chemical compound C1=CC=NC=C1 JUJWROOIHBZHMG-UHFFFAOYSA-N 0.000 description 8
- XSQUKJJJFZCRTK-UHFFFAOYSA-N Urea Chemical compound NC(N)=O XSQUKJJJFZCRTK-UHFFFAOYSA-N 0.000 description 8
- 238000013459 approach Methods 0.000 description 8
- 230000037396 body weight Effects 0.000 description 8
- 235000014633 carbohydrates Nutrition 0.000 description 8
- 238000003776 cleavage reaction Methods 0.000 description 8
- 229940109239 creatinine Drugs 0.000 description 8
- BDAGIHXWWSANSR-UHFFFAOYSA-N methanoic acid Natural products OC=O BDAGIHXWWSANSR-UHFFFAOYSA-N 0.000 description 8
- 239000012071 phase Substances 0.000 description 8
- 230000007017 scission Effects 0.000 description 8
- HNSDLXPSAYFUHK-UHFFFAOYSA-N 1,4-bis(2-ethylhexyl) sulfosuccinate Chemical compound CCCCC(CC)COC(=O)CC(S(O)(=O)=O)C(=O)OCC(CC)CCCC HNSDLXPSAYFUHK-UHFFFAOYSA-N 0.000 description 7
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 7
- 238000001542 size-exclusion chromatography Methods 0.000 description 7
- 230000001225 therapeutic effect Effects 0.000 description 7
- 108010003415 Aspartate Aminotransferases Proteins 0.000 description 6
- 102000004625 Aspartate Aminotransferases Human genes 0.000 description 6
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 6
- 108700039887 Essential Genes Proteins 0.000 description 6
- WSFSSNUMVMOOMR-UHFFFAOYSA-N Formaldehyde Chemical compound O=C WSFSSNUMVMOOMR-UHFFFAOYSA-N 0.000 description 6
- 101001031589 Homo sapiens 2-Hydroxyacid oxidase 1 Proteins 0.000 description 6
- JGFZNNIVVJXRND-UHFFFAOYSA-N N,N-diisopropylethylamine Substances CCN(C(C)C)C(C)C JGFZNNIVVJXRND-UHFFFAOYSA-N 0.000 description 6
- UIIMBOGNXHQVGW-UHFFFAOYSA-M Sodium bicarbonate Chemical compound [Na+].OC([O-])=O UIIMBOGNXHQVGW-UHFFFAOYSA-M 0.000 description 6
- YXFVVABEGXRONW-UHFFFAOYSA-N Toluene Chemical compound CC1=CC=CC=C1 YXFVVABEGXRONW-UHFFFAOYSA-N 0.000 description 6
- DTQVDTLACAAQTR-UHFFFAOYSA-N Trifluoroacetic acid Chemical compound OC(=O)C(F)(F)F DTQVDTLACAAQTR-UHFFFAOYSA-N 0.000 description 6
- 238000005349 anion exchange Methods 0.000 description 6
- 238000011948 assay development Methods 0.000 description 6
- 239000007853 buffer solution Substances 0.000 description 6
- 238000004113 cell culture Methods 0.000 description 6
- 238000010511 deprotection reaction Methods 0.000 description 6
- 238000009472 formulation Methods 0.000 description 6
- 125000005843 halogen group Chemical group 0.000 description 6
- HQKMJHAJHXVSDF-UHFFFAOYSA-L magnesium stearate Chemical compound [Mg+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O HQKMJHAJHXVSDF-UHFFFAOYSA-L 0.000 description 6
- 238000005259 measurement Methods 0.000 description 6
- 239000002808 molecular sieve Substances 0.000 description 6
- 125000000449 nitro group Chemical group [O-][N+](*)=O 0.000 description 6
- 239000008188 pellet Substances 0.000 description 6
- 230000003285 pharmacodynamic effect Effects 0.000 description 6
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 6
- 150000008300 phosphoramidites Chemical class 0.000 description 6
- 238000004007 reversed phase HPLC Methods 0.000 description 6
- 229920006395 saturated elastomer Polymers 0.000 description 6
- 238000012216 screening Methods 0.000 description 6
- FTVLMFQEYACZNP-UHFFFAOYSA-N trimethylsilyl trifluoromethanesulfonate Chemical compound C[Si](C)(C)OS(=O)(=O)C(F)(F)F FTVLMFQEYACZNP-UHFFFAOYSA-N 0.000 description 6
- 238000011740 C57BL/6 mouse Methods 0.000 description 5
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 5
- 102000000574 RNA-Induced Silencing Complex Human genes 0.000 description 5
- 108010016790 RNA-Induced Silencing Complex Proteins 0.000 description 5
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical compound [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 description 5
- 239000013592 cell lysate Substances 0.000 description 5
- 239000003937 drug carrier Substances 0.000 description 5
- NPZTUJOABDZTLV-UHFFFAOYSA-N hydroxybenzotriazole Substances O=C1C=CC=C2NNN=C12 NPZTUJOABDZTLV-UHFFFAOYSA-N 0.000 description 5
- 230000000670 limiting effect Effects 0.000 description 5
- 238000012317 liver biopsy Methods 0.000 description 5
- YACKEPLHDIMKIO-UHFFFAOYSA-N methylphosphonic acid Chemical group CP(O)(O)=O YACKEPLHDIMKIO-UHFFFAOYSA-N 0.000 description 5
- 239000001301 oxygen Substances 0.000 description 5
- 229910052760 oxygen Inorganic materials 0.000 description 5
- 229910052698 phosphorus Inorganic materials 0.000 description 5
- 239000002336 ribonucleotide Substances 0.000 description 5
- 125000006413 ring segment Chemical group 0.000 description 5
- NSMOSDAEGJTOIQ-CRCLSJGQSA-N (2r,3s)-2-(hydroxymethyl)oxolan-3-ol Chemical compound OC[C@H]1OCC[C@@H]1O NSMOSDAEGJTOIQ-CRCLSJGQSA-N 0.000 description 4
- 238000005160 1H NMR spectroscopy Methods 0.000 description 4
- OSWFIVFLDKOXQC-UHFFFAOYSA-N 4-(3-methoxyphenyl)aniline Chemical compound COC1=CC=CC(C=2C=CC(N)=CC=2)=C1 OSWFIVFLDKOXQC-UHFFFAOYSA-N 0.000 description 4
- 102100032382 Activator of 90 kDa heat shock protein ATPase homolog 1 Human genes 0.000 description 4
- VHUUQVKOLVNVRT-UHFFFAOYSA-N Ammonium hydroxide Chemical compound [NH4+].[OH-] VHUUQVKOLVNVRT-UHFFFAOYSA-N 0.000 description 4
- XDTMQSROBMDMFD-UHFFFAOYSA-N Cyclohexane Chemical compound C1CCCCC1 XDTMQSROBMDMFD-UHFFFAOYSA-N 0.000 description 4
- 238000008157 ELISA kit Methods 0.000 description 4
- 101000797989 Homo sapiens Activator of 90 kDa heat shock protein ATPase homolog 1 Proteins 0.000 description 4
- GXCLVBGFBYZDAG-UHFFFAOYSA-N N-[2-(1H-indol-3-yl)ethyl]-N-methylprop-2-en-1-amine Chemical compound CN(CCC1=CNC2=C1C=CC=C2)CC=C GXCLVBGFBYZDAG-UHFFFAOYSA-N 0.000 description 4
- RWRDLPDLKQPQOW-UHFFFAOYSA-N Pyrrolidine Chemical compound C1CCNC1 RWRDLPDLKQPQOW-UHFFFAOYSA-N 0.000 description 4
- 108091028664 Ribonucleotide Proteins 0.000 description 4
- 229920005654 Sephadex Polymers 0.000 description 4
- 239000012507 Sephadex™ Substances 0.000 description 4
- 229920002472 Starch Polymers 0.000 description 4
- 238000008050 Total Bilirubin Reagent Methods 0.000 description 4
- PNNCWTXUWKENPE-UHFFFAOYSA-N [N].NC(N)=O Chemical compound [N].NC(N)=O PNNCWTXUWKENPE-UHFFFAOYSA-N 0.000 description 4
- 239000012190 activator Substances 0.000 description 4
- 238000000137 annealing Methods 0.000 description 4
- 238000012230 antisense oligonucleotides Methods 0.000 description 4
- PNXBXCRWXNESOV-UHFFFAOYSA-N benzylthiouracil Chemical compound N1C(=S)NC(=O)C=C1CC1=CC=CC=C1 PNXBXCRWXNESOV-UHFFFAOYSA-N 0.000 description 4
- 239000004202 carbamide Substances 0.000 description 4
- 238000005119 centrifugation Methods 0.000 description 4
- 229940125773 compound 10 Drugs 0.000 description 4
- 229940125782 compound 2 Drugs 0.000 description 4
- 230000009089 cytolysis Effects 0.000 description 4
- 239000003085 diluting agent Substances 0.000 description 4
- NAGJZTKCGNOGPW-UHFFFAOYSA-K dioxido-sulfanylidene-sulfido-$l^{5}-phosphane Chemical compound [O-]P([O-])([S-])=S NAGJZTKCGNOGPW-UHFFFAOYSA-K 0.000 description 4
- 239000012894 fetal calf serum Substances 0.000 description 4
- 235000019253 formic acid Nutrition 0.000 description 4
- 238000001802 infusion Methods 0.000 description 4
- ZLVXBBHTMQJRSX-VMGNSXQWSA-N jdtic Chemical compound C1([C@]2(C)CCN(C[C@@H]2C)C[C@H](C(C)C)NC(=O)[C@@H]2NCC3=CC(O)=CC=C3C2)=CC=CC(O)=C1 ZLVXBBHTMQJRSX-VMGNSXQWSA-N 0.000 description 4
- 210000005228 liver tissue Anatomy 0.000 description 4
- 238000004020 luminiscence type Methods 0.000 description 4
- 238000002515 oligonucleotide synthesis Methods 0.000 description 4
- 150000004713 phosphodiesters Chemical class 0.000 description 4
- 108090000765 processed proteins & peptides Proteins 0.000 description 4
- UMJSCPRVCHMLSP-UHFFFAOYSA-N pyridine Natural products COC1=CC=CN=C1 UMJSCPRVCHMLSP-UHFFFAOYSA-N 0.000 description 4
- 102000005962 receptors Human genes 0.000 description 4
- 108020003175 receptors Proteins 0.000 description 4
- 239000011347 resin Substances 0.000 description 4
- 229920005989 resin Polymers 0.000 description 4
- 125000002652 ribonucleotide group Chemical group 0.000 description 4
- 239000000377 silicon dioxide Substances 0.000 description 4
- 238000003998 size exclusion chromatography high performance liquid chromatography Methods 0.000 description 4
- JHJLBTNAGRQEKS-UHFFFAOYSA-M sodium bromide Chemical compound [Na+].[Br-] JHJLBTNAGRQEKS-UHFFFAOYSA-M 0.000 description 4
- 235000019698 starch Nutrition 0.000 description 4
- 239000000758 substrate Substances 0.000 description 4
- 238000004809 thin layer chromatography Methods 0.000 description 4
- 238000006177 thiolation reaction Methods 0.000 description 4
- GHYOCDFICYLMRF-UTIIJYGPSA-N (2S,3R)-N-[(2S)-3-(cyclopenten-1-yl)-1-[(2R)-2-methyloxiran-2-yl]-1-oxopropan-2-yl]-3-hydroxy-3-(4-methoxyphenyl)-2-[[(2S)-2-[(2-morpholin-4-ylacetyl)amino]propanoyl]amino]propanamide Chemical compound C1(=CCCC1)C[C@@H](C(=O)[C@@]1(OC1)C)NC([C@H]([C@@H](C1=CC=C(C=C1)OC)O)NC([C@H](C)NC(CN1CCOCC1)=O)=O)=O GHYOCDFICYLMRF-UTIIJYGPSA-N 0.000 description 3
- VKIGAWAEXPTIOL-UHFFFAOYSA-N 2-hydroxyhexanenitrile Chemical compound CCCCC(O)C#N VKIGAWAEXPTIOL-UHFFFAOYSA-N 0.000 description 3
- 125000002103 4,4'-dimethoxytriphenylmethyl group Chemical group [H]C1=C([H])C([H])=C(C([H])=C1[H])C(*)(C1=C([H])C([H])=C(OC([H])([H])[H])C([H])=C1[H])C1=C([H])C([H])=C(OC([H])([H])[H])C([H])=C1[H] 0.000 description 3
- YWZHEXZIISFIDA-UHFFFAOYSA-N 5-amino-1,2,4-dithiazole-3-thione Chemical compound NC1=NC(=S)SS1 YWZHEXZIISFIDA-UHFFFAOYSA-N 0.000 description 3
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 3
- 241000282693 Cercopithecidae Species 0.000 description 3
- 108010010803 Gelatin Proteins 0.000 description 3
- UFHFLCQGNIYNRP-UHFFFAOYSA-N Hydrogen Chemical compound [H][H] UFHFLCQGNIYNRP-UHFFFAOYSA-N 0.000 description 3
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 3
- 239000000908 ammonium hydroxide Substances 0.000 description 3
- 239000007864 aqueous solution Substances 0.000 description 3
- 230000008859 change Effects 0.000 description 3
- 238000007385 chemical modification Methods 0.000 description 3
- 229940125797 compound 12 Drugs 0.000 description 3
- 230000001268 conjugating effect Effects 0.000 description 3
- 238000013461 design Methods 0.000 description 3
- 238000010586 diagram Methods 0.000 description 3
- 238000010790 dilution Methods 0.000 description 3
- 239000012895 dilution Substances 0.000 description 3
- 239000003814 drug Substances 0.000 description 3
- MMXKVMNBHPAILY-UHFFFAOYSA-N ethyl laurate Chemical compound CCCCCCCCCCCC(=O)OCC MMXKVMNBHPAILY-UHFFFAOYSA-N 0.000 description 3
- 125000001153 fluoro group Chemical group F* 0.000 description 3
- 229920000159 gelatin Polymers 0.000 description 3
- 239000008273 gelatin Substances 0.000 description 3
- 235000019322 gelatine Nutrition 0.000 description 3
- 235000011852 gelatine desserts Nutrition 0.000 description 3
- 238000012226 gene silencing method Methods 0.000 description 3
- 238000011221 initial treatment Methods 0.000 description 3
- 239000007924 injection Substances 0.000 description 3
- 238000002347 injection Methods 0.000 description 3
- 238000001990 intravenous administration Methods 0.000 description 3
- 239000008101 lactose Substances 0.000 description 3
- 210000005229 liver cell Anatomy 0.000 description 3
- 235000019359 magnesium stearate Nutrition 0.000 description 3
- 238000004949 mass spectrometry Methods 0.000 description 3
- 239000006199 nebulizer Substances 0.000 description 3
- 239000002777 nucleoside Substances 0.000 description 3
- 210000000056 organ Anatomy 0.000 description 3
- 238000007911 parenteral administration Methods 0.000 description 3
- 125000004437 phosphorous atom Chemical group 0.000 description 3
- 229920001223 polyethylene glycol Polymers 0.000 description 3
- 230000001743 silencing effect Effects 0.000 description 3
- 239000001632 sodium acetate Substances 0.000 description 3
- 235000017281 sodium acetate Nutrition 0.000 description 3
- 229910000030 sodium bicarbonate Inorganic materials 0.000 description 3
- 239000008107 starch Substances 0.000 description 3
- 229940032147 starch Drugs 0.000 description 3
- 239000007929 subcutaneous injection Substances 0.000 description 3
- 239000000126 substance Substances 0.000 description 3
- 230000002459 sustained effect Effects 0.000 description 3
- 238000013268 sustained release Methods 0.000 description 3
- 239000012730 sustained-release form Substances 0.000 description 3
- 208000024891 symptom Diseases 0.000 description 3
- 239000000454 talc Substances 0.000 description 3
- 229910052623 talc Inorganic materials 0.000 description 3
- 235000012222 talc Nutrition 0.000 description 3
- 239000012096 transfection reagent Substances 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- SZUVGFMDDVSKSI-WIFOCOSTSA-N (1s,2s,3s,5r)-1-(carboxymethyl)-3,5-bis[(4-phenoxyphenyl)methyl-propylcarbamoyl]cyclopentane-1,2-dicarboxylic acid Chemical compound O=C([C@@H]1[C@@H]([C@](CC(O)=O)([C@H](C(=O)N(CCC)CC=2C=CC(OC=3C=CC=CC=3)=CC=2)C1)C(O)=O)C(O)=O)N(CCC)CC(C=C1)=CC=C1OC1=CC=CC=C1 SZUVGFMDDVSKSI-WIFOCOSTSA-N 0.000 description 2
- QFLWZFQWSBQYPS-AWRAUJHKSA-N (3S)-3-[[(2S)-2-[[(2S)-2-[5-[(3aS,6aR)-2-oxo-1,3,3a,4,6,6a-hexahydrothieno[3,4-d]imidazol-4-yl]pentanoylamino]-3-methylbutanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-4-[1-bis(4-chlorophenoxy)phosphorylbutylamino]-4-oxobutanoic acid Chemical compound CCCC(NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](Cc1ccc(O)cc1)NC(=O)[C@@H](NC(=O)CCCCC1SC[C@@H]2NC(=O)N[C@H]12)C(C)C)P(=O)(Oc1ccc(Cl)cc1)Oc1ccc(Cl)cc1 QFLWZFQWSBQYPS-AWRAUJHKSA-N 0.000 description 2
- WKSSGWRGSRLOKR-CPCJQFISSA-N 1-[(2R,3R,4S,5R)-3,4-dihydroxy-5-[1-hydroxy-2,2-bis(4-methoxyphenyl)-2-phenylethyl]oxolan-2-yl]pyrimidine-2,4-dione Chemical compound C1=CC(OC)=CC=C1C(C=1C=CC(OC)=CC=1)(C=1C=CC=CC=1)C(O)[C@@H]1[C@@H](O)[C@@H](O)[C@H](N2C(NC(=O)C=C2)=O)O1 WKSSGWRGSRLOKR-CPCJQFISSA-N 0.000 description 2
- PJUPKRYGDFTMTM-UHFFFAOYSA-N 1-hydroxybenzotriazole;hydrate Chemical compound O.C1=CC=C2N(O)N=NC2=C1 PJUPKRYGDFTMTM-UHFFFAOYSA-N 0.000 description 2
- PMNIHDBMMDOUPD-UHFFFAOYSA-N 2-[2-(2-azidoethoxy)ethoxy]ethanol Chemical compound OCCOCCOCCN=[N+]=[N-] PMNIHDBMMDOUPD-UHFFFAOYSA-N 0.000 description 2
- ZJSQZQMVXKZAGW-UHFFFAOYSA-N 2H-benzotriazol-4-ol hydrate Chemical compound O.OC1=CC=CC2=C1N=NN2 ZJSQZQMVXKZAGW-UHFFFAOYSA-N 0.000 description 2
- QUAHTHOQWXLYFQ-UHFFFAOYSA-N 3-fluorocyclooctyne Chemical compound FC1CCCCCC#C1 QUAHTHOQWXLYFQ-UHFFFAOYSA-N 0.000 description 2
- GONFBOIJNUKKST-UHFFFAOYSA-N 5-ethylsulfanyl-2h-tetrazole Chemical compound CCSC=1N=NNN=1 GONFBOIJNUKKST-UHFFFAOYSA-N 0.000 description 2
- KBDWGFZSICOZSJ-UHFFFAOYSA-N 5-methyl-2,3-dihydro-1H-pyrimidin-4-one Chemical group N1CNC=C(C1=O)C KBDWGFZSICOZSJ-UHFFFAOYSA-N 0.000 description 2
- ZCYVEMRRCGMTRW-UHFFFAOYSA-N 7553-56-2 Chemical compound [I] ZCYVEMRRCGMTRW-UHFFFAOYSA-N 0.000 description 2
- QTBSBXVTEAMEQO-UHFFFAOYSA-M Acetate Chemical compound CC([O-])=O QTBSBXVTEAMEQO-UHFFFAOYSA-M 0.000 description 2
- 102100026292 Asialoglycoprotein receptor 1 Human genes 0.000 description 2
- 101710200897 Asialoglycoprotein receptor 1 Proteins 0.000 description 2
- 101150069146 C5 gene Proteins 0.000 description 2
- BVKZGUZCCUSVTD-UHFFFAOYSA-L Carbonate Chemical compound [O-]C([O-])=O BVKZGUZCCUSVTD-UHFFFAOYSA-L 0.000 description 2
- KRKNYBCHXYNGOX-UHFFFAOYSA-K Citrate Chemical compound [O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O KRKNYBCHXYNGOX-UHFFFAOYSA-K 0.000 description 2
- 102000008186 Collagen Human genes 0.000 description 2
- 108010035532 Collagen Proteins 0.000 description 2
- 108010028773 Complement C5 Proteins 0.000 description 2
- 102100031506 Complement C5 Human genes 0.000 description 2
- CKTSBUTUHBMZGZ-UHFFFAOYSA-N Deoxycytidine Natural products O=C1N=C(N)C=CN1C1OC(CO)C(O)C1 CKTSBUTUHBMZGZ-UHFFFAOYSA-N 0.000 description 2
- 239000006145 Eagle's minimal essential medium Substances 0.000 description 2
- 108010067770 Endopeptidase K Proteins 0.000 description 2
- 239000001856 Ethyl cellulose Substances 0.000 description 2
- ZZSNKZQZMQGXPY-UHFFFAOYSA-N Ethyl cellulose Chemical compound CCOCC1OC(OC)C(OCC)C(OCC)C1OC1C(O)C(O)C(OC)C(CO)O1 ZZSNKZQZMQGXPY-UHFFFAOYSA-N 0.000 description 2
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical group OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 description 2
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 2
- 108090000288 Glycoproteins Proteins 0.000 description 2
- 102000003886 Glycoproteins Human genes 0.000 description 2
- 108010004889 Heat-Shock Proteins Proteins 0.000 description 2
- 102000002812 Heat-Shock Proteins Human genes 0.000 description 2
- 101001066129 Homo sapiens Glyceraldehyde-3-phosphate dehydrogenase Proteins 0.000 description 2
- 101000780643 Homo sapiens Protein argonaute-2 Proteins 0.000 description 2
- 239000012097 Lipofectamine 2000 Substances 0.000 description 2
- 241000124008 Mammalia Species 0.000 description 2
- 241000288906 Primates Species 0.000 description 2
- 102100034207 Protein argonaute-2 Human genes 0.000 description 2
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 2
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 2
- QAOWNCQODCNURD-UHFFFAOYSA-N Sulfuric acid Chemical compound OS(O)(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-N 0.000 description 2
- 101150091380 TTR gene Proteins 0.000 description 2
- IQFYYKKMVGJFEH-XLPZGREQSA-N Thymidine Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1 IQFYYKKMVGJFEH-XLPZGREQSA-N 0.000 description 2
- 125000003668 acetyloxy group Chemical group [H]C([H])([H])C(=O)O[*] 0.000 description 2
- 239000002253 acid Substances 0.000 description 2
- 150000001298 alcohols Chemical class 0.000 description 2
- 150000004781 alginic acids Chemical class 0.000 description 2
- 229910052782 aluminium Inorganic materials 0.000 description 2
- XAGFODPZIPBFFR-UHFFFAOYSA-N aluminium Chemical compound [Al] XAGFODPZIPBFFR-UHFFFAOYSA-N 0.000 description 2
- 239000004411 aluminium Substances 0.000 description 2
- WNROFYMDJYEPJX-UHFFFAOYSA-K aluminium hydroxide Chemical compound [OH-].[OH-].[OH-].[Al+3] WNROFYMDJYEPJX-UHFFFAOYSA-K 0.000 description 2
- 150000001413 amino acids Chemical class 0.000 description 2
- 239000000074 antisense oligonucleotide Substances 0.000 description 2
- 239000012300 argon atmosphere Substances 0.000 description 2
- 239000012298 atmosphere Substances 0.000 description 2
- 230000009286 beneficial effect Effects 0.000 description 2
- 230000008901 benefit Effects 0.000 description 2
- HSDAJNMJOMSNEV-UHFFFAOYSA-N benzyl chloroformate Chemical compound ClC(=O)OCC1=CC=CC=C1 HSDAJNMJOMSNEV-UHFFFAOYSA-N 0.000 description 2
- 239000000090 biomarker Substances 0.000 description 2
- 239000008366 buffered solution Substances 0.000 description 2
- OSGAYBCDTDRGGQ-UHFFFAOYSA-L calcium sulfate Chemical compound [Ca+2].[O-]S([O-])(=O)=O OSGAYBCDTDRGGQ-UHFFFAOYSA-L 0.000 description 2
- 238000001460 carbon-13 nuclear magnetic resonance spectrum Methods 0.000 description 2
- 239000011545 carbonate/bicarbonate buffer Substances 0.000 description 2
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 2
- 230000006037 cell lysis Effects 0.000 description 2
- 238000012512 characterization method Methods 0.000 description 2
- 238000012062 charged aerosol detection Methods 0.000 description 2
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 description 2
- 238000004587 chromatography analysis Methods 0.000 description 2
- 210000002806 clathrin-coated vesicle Anatomy 0.000 description 2
- 229920001436 collagen Polymers 0.000 description 2
- 229940126543 compound 14 Drugs 0.000 description 2
- 229940125898 compound 5 Drugs 0.000 description 2
- 239000005289 controlled pore glass Substances 0.000 description 2
- 239000012228 culture supernatant Substances 0.000 description 2
- 210000000805 cytoplasm Anatomy 0.000 description 2
- 230000003247 decreasing effect Effects 0.000 description 2
- 239000005547 deoxyribonucleotide Substances 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 150000002016 disaccharides Chemical class 0.000 description 2
- 230000009977 dual effect Effects 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 239000003797 essential amino acid Substances 0.000 description 2
- 235000020776 essential amino acid Nutrition 0.000 description 2
- 235000019325 ethyl cellulose Nutrition 0.000 description 2
- 229920001249 ethyl cellulose Polymers 0.000 description 2
- 238000011156 evaluation Methods 0.000 description 2
- 238000001704 evaporation Methods 0.000 description 2
- 230000008020 evaporation Effects 0.000 description 2
- 239000000945 filler Substances 0.000 description 2
- 239000000706 filtrate Substances 0.000 description 2
- 239000000499 gel Substances 0.000 description 2
- 208000005017 glioblastoma Diseases 0.000 description 2
- 108010062584 glycollate oxidase Proteins 0.000 description 2
- 229940029575 guanosine Drugs 0.000 description 2
- 230000036541 health Effects 0.000 description 2
- 238000010438 heat treatment Methods 0.000 description 2
- 231100000304 hepatotoxicity Toxicity 0.000 description 2
- 239000003112 inhibitor Substances 0.000 description 2
- 239000008011 inorganic excipient Substances 0.000 description 2
- NOESYZHRGYRDHS-UHFFFAOYSA-N insulin Chemical compound N1C(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(NC(=O)CN)C(C)CC)CSSCC(C(NC(CO)C(=O)NC(CC(C)C)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CCC(N)=O)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(N)=O)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CSSCC(NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2C=CC(O)=CC=2)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2NC=NC=2)NC(=O)C(CO)NC(=O)CNC2=O)C(=O)NCC(=O)NC(CCC(O)=O)C(=O)NC(CCCNC(N)=N)C(=O)NCC(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC(O)=CC=3)C(=O)NC(C(C)O)C(=O)N3C(CCC3)C(=O)NC(CCCCN)C(=O)NC(C)C(O)=O)C(=O)NC(CC(N)=O)C(O)=O)=O)NC(=O)C(C(C)CC)NC(=O)C(CO)NC(=O)C(C(C)O)NC(=O)C1CSSCC2NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)C(C)C)CC1=CN=CN1 NOESYZHRGYRDHS-UHFFFAOYSA-N 0.000 description 2
- 229910052740 iodine Inorganic materials 0.000 description 2
- 239000011630 iodine Substances 0.000 description 2
- 210000003734 kidney Anatomy 0.000 description 2
- 239000007788 liquid Substances 0.000 description 2
- 238000001294 liquid chromatography-tandem mass spectrometry Methods 0.000 description 2
- 230000007056 liver toxicity Effects 0.000 description 2
- 239000000314 lubricant Substances 0.000 description 2
- 239000012139 lysis buffer Substances 0.000 description 2
- 238000012423 maintenance Methods 0.000 description 2
- 230000003211 malignant effect Effects 0.000 description 2
- 125000000311 mannosyl group Chemical group C1([C@@H](O)[C@@H](O)[C@H](O)[C@H](O1)CO)* 0.000 description 2
- 238000004519 manufacturing process Methods 0.000 description 2
- 230000001404 mediated effect Effects 0.000 description 2
- 239000002609 medium Substances 0.000 description 2
- 230000002503 metabolic effect Effects 0.000 description 2
- 125000000956 methoxy group Chemical group [H]C([H])([H])O* 0.000 description 2
- 239000000178 monomer Substances 0.000 description 2
- 150000002772 monosaccharides Chemical class 0.000 description 2
- FEMOMIGRRWSMCU-UHFFFAOYSA-N ninhydrin Chemical compound C1=CC=C2C(=O)C(O)(O)C(=O)C2=C1 FEMOMIGRRWSMCU-UHFFFAOYSA-N 0.000 description 2
- 150000003833 nucleoside derivatives Chemical class 0.000 description 2
- 125000003835 nucleoside group Chemical group 0.000 description 2
- 229920001542 oligosaccharide Polymers 0.000 description 2
- 150000002482 oligosaccharides Chemical class 0.000 description 2
- 238000005457 optimization Methods 0.000 description 2
- 239000008012 organic excipient Substances 0.000 description 2
- 239000007800 oxidant agent Substances 0.000 description 2
- 230000001590 oxidative effect Effects 0.000 description 2
- 230000037361 pathway Effects 0.000 description 2
- 238000007747 plating Methods 0.000 description 2
- 229920001184 polypeptide Polymers 0.000 description 2
- 229920001282 polysaccharide Polymers 0.000 description 2
- 239000005017 polysaccharide Substances 0.000 description 2
- 150000004804 polysaccharides Chemical class 0.000 description 2
- 239000001267 polyvinylpyrrolidone Substances 0.000 description 2
- 229920000036 polyvinylpyrrolidone Polymers 0.000 description 2
- 235000013855 polyvinylpyrrolidone Nutrition 0.000 description 2
- 238000002953 preparative HPLC Methods 0.000 description 2
- 230000002265 prevention Effects 0.000 description 2
- 102000004196 processed proteins & peptides Human genes 0.000 description 2
- 238000003908 quality control method Methods 0.000 description 2
- 238000003762 quantitative reverse transcription PCR Methods 0.000 description 2
- 238000009790 rate-determining step (RDS) Methods 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 230000004044 response Effects 0.000 description 2
- 102220002645 rs104894309 Human genes 0.000 description 2
- 150000003839 salts Chemical class 0.000 description 2
- 238000013207 serial dilution Methods 0.000 description 2
- 235000017557 sodium bicarbonate Nutrition 0.000 description 2
- 235000019333 sodium laurylsulphate Nutrition 0.000 description 2
- 239000001488 sodium phosphate Substances 0.000 description 2
- 229910000162 sodium phosphate Inorganic materials 0.000 description 2
- 239000007790 solid phase Substances 0.000 description 2
- 238000010532 solid phase synthesis reaction Methods 0.000 description 2
- 238000005507 spraying Methods 0.000 description 2
- 239000007858 starting material Substances 0.000 description 2
- 238000003756 stirring Methods 0.000 description 2
- 238000005556 structure-activity relationship Methods 0.000 description 2
- 238000010254 subcutaneous injection Methods 0.000 description 2
- TYFQFVWCELRYAO-UHFFFAOYSA-N suberic acid Chemical compound OC(=O)CCCCCCC(O)=O TYFQFVWCELRYAO-UHFFFAOYSA-N 0.000 description 2
- 235000011149 sulphuric acid Nutrition 0.000 description 2
- 230000004083 survival effect Effects 0.000 description 2
- KPXODPHVWBQJEG-UHFFFAOYSA-N tert-butyl 3-[2-amino-3-[3-[(2-methylpropan-2-yl)oxy]-3-oxopropoxy]-2-[[3-[(2-methylpropan-2-yl)oxy]-3-oxopropoxy]methyl]propoxy]propanoate Chemical compound CC(C)(C)OC(=O)CCOCC(N)(COCCC(=O)OC(C)(C)C)COCCC(=O)OC(C)(C)C KPXODPHVWBQJEG-UHFFFAOYSA-N 0.000 description 2
- 150000004044 tetrasaccharides Chemical class 0.000 description 2
- 238000002560 therapeutic procedure Methods 0.000 description 2
- 238000013518 transcription Methods 0.000 description 2
- 230000035897 transcription Effects 0.000 description 2
- 230000001052 transient effect Effects 0.000 description 2
- 230000032258 transport Effects 0.000 description 2
- 150000004043 trisaccharides Chemical class 0.000 description 2
- RYFMWSXOAZQYPI-UHFFFAOYSA-K trisodium phosphate Chemical compound [Na+].[Na+].[Na+].[O-]P([O-])([O-])=O RYFMWSXOAZQYPI-UHFFFAOYSA-K 0.000 description 2
- 230000007306 turnover Effects 0.000 description 2
- 238000001195 ultra high performance liquid chromatography Methods 0.000 description 2
- 238000004704 ultra performance liquid chromatography Methods 0.000 description 2
- WCOORMFFUTXGQR-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 6-[(1-fluorocyclooct-2-yne-1-carbonyl)amino]hexanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCCCCNC(=O)C1(F)CCCCCC#C1 WCOORMFFUTXGQR-UHFFFAOYSA-N 0.000 description 1
- HSINOMROUCMIEA-FGVHQWLLSA-N (2s,4r)-4-[(3r,5s,6r,7r,8s,9s,10s,13r,14s,17r)-6-ethyl-3,7-dihydroxy-10,13-dimethyl-2,3,4,5,6,7,8,9,11,12,14,15,16,17-tetradecahydro-1h-cyclopenta[a]phenanthren-17-yl]-2-methylpentanoic acid Chemical compound C([C@@]12C)C[C@@H](O)C[C@H]1[C@@H](CC)[C@@H](O)[C@@H]1[C@@H]2CC[C@]2(C)[C@@H]([C@H](C)C[C@H](C)C(O)=O)CC[C@H]21 HSINOMROUCMIEA-FGVHQWLLSA-N 0.000 description 1
- BDNKZNFMNDZQMI-UHFFFAOYSA-N 1,3-diisopropylcarbodiimide Chemical compound CC(C)N=C=NC(C)C BDNKZNFMNDZQMI-UHFFFAOYSA-N 0.000 description 1
- MPCAJMNYNOGXPB-UHFFFAOYSA-N 1,5-Anhydro-mannit Natural products OCC1OCC(O)C(O)C1O MPCAJMNYNOGXPB-UHFFFAOYSA-N 0.000 description 1
- UNILWMWFPHPYOR-KXEYIPSPSA-M 1-[6-[2-[3-[3-[3-[2-[2-[3-[[2-[2-[[(2r)-1-[[2-[[(2r)-1-[3-[2-[2-[3-[[2-(2-amino-2-oxoethoxy)acetyl]amino]propoxy]ethoxy]ethoxy]propylamino]-3-hydroxy-1-oxopropan-2-yl]amino]-2-oxoethyl]amino]-3-[(2r)-2,3-di(hexadecanoyloxy)propyl]sulfanyl-1-oxopropan-2-yl Chemical compound O=C1C(SCCC(=O)NCCCOCCOCCOCCCNC(=O)COCC(=O)N[C@@H](CSC[C@@H](COC(=O)CCCCCCCCCCCCCCC)OC(=O)CCCCCCCCCCCCCCC)C(=O)NCC(=O)N[C@H](CO)C(=O)NCCCOCCOCCOCCCNC(=O)COCC(N)=O)CC(=O)N1CCNC(=O)CCCCCN\1C2=CC=C(S([O-])(=O)=O)C=C2CC/1=C/C=C/C=C/C1=[N+](CC)C2=CC=C(S([O-])(=O)=O)C=C2C1 UNILWMWFPHPYOR-KXEYIPSPSA-M 0.000 description 1
- IHPYMWDTONKSCO-UHFFFAOYSA-N 2,2'-piperazine-1,4-diylbisethanesulfonic acid Chemical compound OS(=O)(=O)CCN1CCN(CCS(O)(=O)=O)CC1 IHPYMWDTONKSCO-UHFFFAOYSA-N 0.000 description 1
- YEDUAINPPJYDJZ-UHFFFAOYSA-N 2-hydroxybenzothiazole Chemical compound C1=CC=C2SC(O)=NC2=C1 YEDUAINPPJYDJZ-UHFFFAOYSA-N 0.000 description 1
- 125000004200 2-methoxyethyl group Chemical group [H]C([H])([H])OC([H])([H])C([H])([H])* 0.000 description 1
- OYBOVXXFJYJYPC-UHFFFAOYSA-N 3-azidopropan-1-amine Chemical compound NCCCN=[N+]=[N-] OYBOVXXFJYJYPC-UHFFFAOYSA-N 0.000 description 1
- OEQKKDRHMMMVQR-UHFFFAOYSA-N 4-[2-(6-methyl-2-morpholin-4-yl-5-nitropyrimidin-4-yl)oxyethyl]morpholine Chemical compound [O-][N+](=O)C=1C(C)=NC(N2CCOCC2)=NC=1OCCN1CCOCC1 OEQKKDRHMMMVQR-UHFFFAOYSA-N 0.000 description 1
- 102100030755 5-aminolevulinate synthase, nonspecific, mitochondrial Human genes 0.000 description 1
- 108091027075 5S-rRNA precursor Proteins 0.000 description 1
- 229920001817 Agar Polymers 0.000 description 1
- 229920000856 Amylose Polymers 0.000 description 1
- 108020005544 Antisense RNA Proteins 0.000 description 1
- 102000018616 Apolipoproteins B Human genes 0.000 description 1
- 108010027006 Apolipoproteins B Proteins 0.000 description 1
- 102000018655 Apolipoproteins C Human genes 0.000 description 1
- 108010027070 Apolipoproteins C Proteins 0.000 description 1
- IYMAXBFPHPZYIK-BQBZGAKWSA-N Arg-Gly-Asp Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O IYMAXBFPHPZYIK-BQBZGAKWSA-N 0.000 description 1
- 108010002913 Asialoglycoproteins Proteins 0.000 description 1
- 241000416162 Astragalus gummifer Species 0.000 description 1
- 208000035473 Communicable disease Diseases 0.000 description 1
- 229920002261 Corn starch Polymers 0.000 description 1
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 1
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 1
- LVGKNOAMLMIIKO-UHFFFAOYSA-N Elaidinsaeure-aethylester Natural products CCCCCCCCC=CCCCCCCCC(=O)OCC LVGKNOAMLMIIKO-UHFFFAOYSA-N 0.000 description 1
- 239000005977 Ethylene Substances 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- 206010056522 Hepatic infection Diseases 0.000 description 1
- 101000843649 Homo sapiens 5-aminolevulinate synthase, nonspecific, mitochondrial Proteins 0.000 description 1
- 238000012404 In vitro experiment Methods 0.000 description 1
- 102000004877 Insulin Human genes 0.000 description 1
- 108090001061 Insulin Proteins 0.000 description 1
- 206010067125 Liver injury Diseases 0.000 description 1
- 235000019759 Maize starch Nutrition 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- 229920000168 Microcrystalline cellulose Polymers 0.000 description 1
- NQTADLQHYWFPDB-UHFFFAOYSA-N N-Hydroxysuccinimide Chemical compound ON1C(=O)CCC1=O NQTADLQHYWFPDB-UHFFFAOYSA-N 0.000 description 1
- UHCDOCHPRWRANJ-QRUMIJJDSA-N N-[9-[(2R,3R,4S,5R)-3,4-dihydroxy-5-[1-hydroxy-2,2-bis(4-methoxyphenyl)-2-phenylethyl]oxolan-2-yl]purin-6-yl]benzamide Chemical compound C1=CC(OC)=CC=C1C(C=1C=CC(OC)=CC=1)(C=1C=CC=CC=1)C(O)[C@@H]1[C@@H](O)[C@@H](O)[C@H](N2C3=NC=NC(NC(=O)C=4C=CC=CC=4)=C3N=C2)O1 UHCDOCHPRWRANJ-QRUMIJJDSA-N 0.000 description 1
- 101710163270 Nuclease Proteins 0.000 description 1
- 208000022873 Ocular disease Diseases 0.000 description 1
- 239000007990 PIPES buffer Substances 0.000 description 1
- 241000282577 Pan troglodytes Species 0.000 description 1
- 235000019483 Peanut oil Nutrition 0.000 description 1
- ABLZXFCXXLZCGV-UHFFFAOYSA-N Phosphorous acid Chemical class OP(O)=O ABLZXFCXXLZCGV-UHFFFAOYSA-N 0.000 description 1
- 229920002732 Polyanhydride Polymers 0.000 description 1
- 239000002202 Polyethylene glycol Substances 0.000 description 1
- 108010020346 Polyglutamic Acid Proteins 0.000 description 1
- 108010066816 Polypeptide N-acetylgalactosaminyltransferase Proteins 0.000 description 1
- 102100020950 Polypeptide N-acetylgalactosaminyltransferase 2 Human genes 0.000 description 1
- 108091030071 RNAI Proteins 0.000 description 1
- 235000019485 Safflower oil Nutrition 0.000 description 1
- 102000007562 Serum Albumin Human genes 0.000 description 1
- 108010071390 Serum Albumin Proteins 0.000 description 1
- 108091027568 Single-stranded nucleotide Proteins 0.000 description 1
- 239000004141 Sodium laurylsulphate Substances 0.000 description 1
- 235000021355 Stearic acid Nutrition 0.000 description 1
- 229930006000 Sucrose Natural products 0.000 description 1
- 229920001615 Tragacanth Polymers 0.000 description 1
- 102000004338 Transferrin Human genes 0.000 description 1
- 108090000901 Transferrin Proteins 0.000 description 1
- CNKFHNSQZAYLCO-PCCQLNMTSA-N [(2r,3r,4r,5r)-5-(2,4-dioxopyrimidin-1-yl)-3-hydroxy-4-methoxyoxolan-2-yl]methoxyphosphonamidous acid Chemical compound CO[C@@H]1[C@H](O)[C@@H](COP(N)O)O[C@H]1N1C(=O)NC(=O)C=C1 CNKFHNSQZAYLCO-PCCQLNMTSA-N 0.000 description 1
- WREOTYWODABZMH-DTZQCDIJSA-N [[(2r,3s,4r,5r)-3,4-dihydroxy-5-[2-oxo-4-(2-phenylethoxyamino)pyrimidin-1-yl]oxolan-2-yl]methoxy-hydroxyphosphoryl] phosphono hydrogen phosphate Chemical compound O[C@@H]1[C@H](O)[C@@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)O[C@H]1N(C=C\1)C(=O)NC/1=N\OCCC1=CC=CC=C1 WREOTYWODABZMH-DTZQCDIJSA-N 0.000 description 1
- DPXJVFZANSGRMM-UHFFFAOYSA-N acetic acid;2,3,4,5,6-pentahydroxyhexanal;sodium Chemical compound [Na].CC(O)=O.OCC(O)C(O)C(O)C(O)C=O DPXJVFZANSGRMM-UHFFFAOYSA-N 0.000 description 1
- 239000013543 active substance Substances 0.000 description 1
- 239000000654 additive Substances 0.000 description 1
- 239000000443 aerosol Substances 0.000 description 1
- 239000008272 agar Substances 0.000 description 1
- 235000010443 alginic acid Nutrition 0.000 description 1
- 239000000783 alginic acid Substances 0.000 description 1
- 229920000615 alginic acid Polymers 0.000 description 1
- 229960001126 alginic acid Drugs 0.000 description 1
- 125000003342 alkenyl group Chemical group 0.000 description 1
- 125000000217 alkyl group Chemical group 0.000 description 1
- 125000005600 alkyl phosphonate group Chemical group 0.000 description 1
- 125000000304 alkynyl group Chemical group 0.000 description 1
- 208000026935 allergic disease Diseases 0.000 description 1
- 150000001412 amines Chemical class 0.000 description 1
- 229940024606 amino acid Drugs 0.000 description 1
- 235000001014 amino acid Nutrition 0.000 description 1
- QGZKDVFQNNGYKY-UHFFFAOYSA-N ammonia Natural products N QGZKDVFQNNGYKY-UHFFFAOYSA-N 0.000 description 1
- 238000010171 animal model Methods 0.000 description 1
- 108010072041 arginyl-glycyl-aspartic acid Proteins 0.000 description 1
- 125000004429 atom Chemical group 0.000 description 1
- JPNZKPRONVOMLL-UHFFFAOYSA-N azane;octadecanoic acid Chemical class [NH4+].CCCCCCCCCCCCCCCCCC([O-])=O JPNZKPRONVOMLL-UHFFFAOYSA-N 0.000 description 1
- 150000001540 azides Chemical class 0.000 description 1
- 235000021028 berry Nutrition 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- 239000003613 bile acid Substances 0.000 description 1
- 239000011230 binding agent Substances 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 125000001246 bromo group Chemical group Br* 0.000 description 1
- 239000006172 buffering agent Substances 0.000 description 1
- 239000004067 bulking agent Substances 0.000 description 1
- FUFJGUQYACFECW-UHFFFAOYSA-L calcium hydrogenphosphate Chemical compound [Ca+2].OP([O-])([O-])=O FUFJGUQYACFECW-UHFFFAOYSA-L 0.000 description 1
- 235000011132 calcium sulphate Nutrition 0.000 description 1
- 239000001768 carboxy methyl cellulose Substances 0.000 description 1
- 150000001732 carboxylic acid derivatives Chemical class 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 230000004700 cellular uptake Effects 0.000 description 1
- 235000010980 cellulose Nutrition 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- 239000001913 cellulose Substances 0.000 description 1
- 229920002301 cellulose acetate Polymers 0.000 description 1
- 208000015114 central nervous system disease Diseases 0.000 description 1
- 125000001309 chloro group Chemical group Cl* 0.000 description 1
- 235000012000 cholesterol Nutrition 0.000 description 1
- 229940110456 cocoa butter Drugs 0.000 description 1
- 235000019868 cocoa butter Nutrition 0.000 description 1
- 229940075614 colloidal silicon dioxide Drugs 0.000 description 1
- 239000003184 complementary RNA Substances 0.000 description 1
- 229940125758 compound 15 Drugs 0.000 description 1
- 238000013270 controlled release Methods 0.000 description 1
- 235000012343 cottonseed oil Nutrition 0.000 description 1
- 239000002385 cottonseed oil Substances 0.000 description 1
- 125000002637 deoxyribonucleotide group Chemical group 0.000 description 1
- 230000000994 depressogenic effect Effects 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 235000019700 dicalcium phosphate Nutrition 0.000 description 1
- 230000003467 diminishing effect Effects 0.000 description 1
- 239000007884 disintegrant Substances 0.000 description 1
- 208000035475 disorder Diseases 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- NAGJZTKCGNOGPW-UHFFFAOYSA-N dithiophosphoric acid Chemical class OP(O)(S)=S NAGJZTKCGNOGPW-UHFFFAOYSA-N 0.000 description 1
- 239000002552 dosage form Substances 0.000 description 1
- 230000002222 downregulating effect Effects 0.000 description 1
- 238000002330 electrospray ionisation mass spectrometry Methods 0.000 description 1
- 150000002148 esters Chemical class 0.000 description 1
- LVGKNOAMLMIIKO-QXMHVHEDSA-N ethyl oleate Chemical compound CCCCCCCC\C=C/CCCCCCCC(=O)OCC LVGKNOAMLMIIKO-QXMHVHEDSA-N 0.000 description 1
- 229940093471 ethyl oleate Drugs 0.000 description 1
- 125000000524 functional group Chemical group 0.000 description 1
- 229920000370 gamma-poly(glutamate) polymer Polymers 0.000 description 1
- 239000008103 glucose Substances 0.000 description 1
- 235000011187 glycerol Nutrition 0.000 description 1
- 150000002334 glycols Chemical class 0.000 description 1
- 231100000234 hepatic damage Toxicity 0.000 description 1
- 238000000589 high-performance liquid chromatography-mass spectrometry Methods 0.000 description 1
- 125000004435 hydrogen atom Chemical group [H]* 0.000 description 1
- 239000008172 hydrogenated vegetable oil Substances 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-M hydroxide Chemical group [OH-] XLYOFNOQVPJJNP-UHFFFAOYSA-M 0.000 description 1
- 229920003063 hydroxymethyl cellulose Polymers 0.000 description 1
- 229940031574 hydroxymethyl cellulose Drugs 0.000 description 1
- 239000001866 hydroxypropyl methyl cellulose Substances 0.000 description 1
- 235000010979 hydroxypropyl methyl cellulose Nutrition 0.000 description 1
- 229920003088 hydroxypropyl methyl cellulose Polymers 0.000 description 1
- UFVKGYZPFZQRLF-UHFFFAOYSA-N hydroxypropyl methyl cellulose Chemical compound OC1C(O)C(OC)OC(CO)C1OC1C(O)C(O)C(OC2C(C(O)C(OC3C(C(O)C(O)C(CO)O3)O)C(CO)O2)O)C(CO)O1 UFVKGYZPFZQRLF-UHFFFAOYSA-N 0.000 description 1
- 208000027866 inflammatory disease Diseases 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 230000000266 injurious effect Effects 0.000 description 1
- 229940125396 insulin Drugs 0.000 description 1
- 238000001361 intraarterial administration Methods 0.000 description 1
- 238000007917 intracranial administration Methods 0.000 description 1
- 238000010255 intramuscular injection Methods 0.000 description 1
- 239000007927 intramuscular injection Substances 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 239000007928 intraperitoneal injection Substances 0.000 description 1
- 238000007913 intrathecal administration Methods 0.000 description 1
- 238000007914 intraventricular administration Methods 0.000 description 1
- 125000002346 iodo group Chemical group I* 0.000 description 1
- 230000007794 irritation Effects 0.000 description 1
- 150000002632 lipids Chemical class 0.000 description 1
- 230000008818 liver damage Effects 0.000 description 1
- 125000001921 locked nucleotide group Chemical group 0.000 description 1
- 230000005923 long-lasting effect Effects 0.000 description 1
- VTHJTEIRLNZDEV-UHFFFAOYSA-L magnesium dihydroxide Chemical compound [OH-].[OH-].[Mg+2] VTHJTEIRLNZDEV-UHFFFAOYSA-L 0.000 description 1
- 239000000347 magnesium hydroxide Substances 0.000 description 1
- 229910001862 magnesium hydroxide Inorganic materials 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 208000030159 metabolic disease Diseases 0.000 description 1
- 108091070501 miRNA Proteins 0.000 description 1
- 235000019813 microcrystalline cellulose Nutrition 0.000 description 1
- 229940016286 microcrystalline cellulose Drugs 0.000 description 1
- 239000008108 microcrystalline cellulose Substances 0.000 description 1
- 230000003278 mimic effect Effects 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 125000004573 morpholin-4-yl group Chemical group N1(CCOCC1)* 0.000 description 1
- VVNAKRLJBWUWGD-CBOOVVPGSA-N n-[1-[(2r,3r,4s,5r)-3,4-dihydroxy-5-[1-hydroxy-2,2-bis(4-methoxyphenyl)-2-phenylethyl]oxolan-2-yl]-2-oxopyrimidin-4-yl]benzamide Chemical compound C1=CC(OC)=CC=C1C(C=1C=CC(OC)=CC=1)(C=1C=CC=CC=1)C(O)[C@@H]1[C@@H](O)[C@@H](O)[C@H](N2C(N=C(NC(=O)C=3C=CC=CC=3)C=C2)=O)O1 VVNAKRLJBWUWGD-CBOOVVPGSA-N 0.000 description 1
- 239000012457 nonaqueous media Substances 0.000 description 1
- 231100000252 nontoxic Toxicity 0.000 description 1
- 230000003000 nontoxic effect Effects 0.000 description 1
- QIQXTHQIDYTFRH-UHFFFAOYSA-N octadecanoic acid Chemical compound CCCCCCCCCCCCCCCCCC(O)=O QIQXTHQIDYTFRH-UHFFFAOYSA-N 0.000 description 1
- OQCDKBAXFALNLD-UHFFFAOYSA-N octadecanoic acid Natural products CCCCCCCC(C)CCCCCCCCC(O)=O OQCDKBAXFALNLD-UHFFFAOYSA-N 0.000 description 1
- 239000004006 olive oil Substances 0.000 description 1
- 235000008390 olive oil Nutrition 0.000 description 1
- 150000002894 organic compounds Chemical class 0.000 description 1
- 239000012188 paraffin wax Substances 0.000 description 1
- 230000001575 pathological effect Effects 0.000 description 1
- 239000000312 peanut oil Substances 0.000 description 1
- 239000001814 pectin Substances 0.000 description 1
- 235000010987 pectin Nutrition 0.000 description 1
- 229920001277 pectin Polymers 0.000 description 1
- PTMHPRAIXMAOOB-UHFFFAOYSA-L phosphoramidate Chemical compound NP([O-])([O-])=O PTMHPRAIXMAOOB-UHFFFAOYSA-L 0.000 description 1
- 150000008298 phosphoramidates Chemical class 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 229920000058 polyacrylate Polymers 0.000 description 1
- 108010064470 polyaspartate Proteins 0.000 description 1
- 229920000515 polycarbonate Polymers 0.000 description 1
- 239000004417 polycarbonate Substances 0.000 description 1
- 229920000728 polyester Polymers 0.000 description 1
- 229920005862 polyol Polymers 0.000 description 1
- 150000003077 polyols Chemical class 0.000 description 1
- 229920001592 potato starch Polymers 0.000 description 1
- 239000000843 powder Substances 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 230000002685 pulmonary effect Effects 0.000 description 1
- 229920002477 rna polymer Polymers 0.000 description 1
- 235000005713 safflower oil Nutrition 0.000 description 1
- 239000003813 safflower oil Substances 0.000 description 1
- 239000012266 salt solution Substances 0.000 description 1
- 239000008159 sesame oil Substances 0.000 description 1
- 235000011803 sesame oil Nutrition 0.000 description 1
- 230000019491 signal transduction Effects 0.000 description 1
- RMAQACBXLXPBSY-UHFFFAOYSA-N silicic acid Chemical compound O[Si](O)(O)O RMAQACBXLXPBSY-UHFFFAOYSA-N 0.000 description 1
- 235000012239 silicon dioxide Nutrition 0.000 description 1
- 239000004055 small Interfering RNA Substances 0.000 description 1
- WXMKPNITSTVMEF-UHFFFAOYSA-M sodium benzoate Chemical compound [Na+].[O-]C(=O)C1=CC=CC=C1 WXMKPNITSTVMEF-UHFFFAOYSA-M 0.000 description 1
- 239000004299 sodium benzoate Substances 0.000 description 1
- 235000010234 sodium benzoate Nutrition 0.000 description 1
- 235000019812 sodium carboxymethyl cellulose Nutrition 0.000 description 1
- 229920001027 sodium carboxymethylcellulose Polymers 0.000 description 1
- 229920003109 sodium starch glycolate Polymers 0.000 description 1
- 239000008109 sodium starch glycolate Substances 0.000 description 1
- 229940079832 sodium starch glycolate Drugs 0.000 description 1
- 235000010356 sorbitol Nutrition 0.000 description 1
- 239000000600 sorbitol Substances 0.000 description 1
- 239000003549 soybean oil Substances 0.000 description 1
- 235000012424 soybean oil Nutrition 0.000 description 1
- 230000006641 stabilisation Effects 0.000 description 1
- 238000011105 stabilization Methods 0.000 description 1
- 230000000087 stabilizing effect Effects 0.000 description 1
- 239000008117 stearic acid Substances 0.000 description 1
- 150000003431 steroids Chemical class 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
- 239000005720 sucrose Substances 0.000 description 1
- 239000000829 suppository Substances 0.000 description 1
- 230000009885 systemic effect Effects 0.000 description 1
- 229940124597 therapeutic agent Drugs 0.000 description 1
- 238000011200 topical administration Methods 0.000 description 1
- 230000000699 topical effect Effects 0.000 description 1
- 230000001988 toxicity Effects 0.000 description 1
- 231100000419 toxicity Toxicity 0.000 description 1
- 235000010487 tragacanth Nutrition 0.000 description 1
- 239000000196 tragacanth Substances 0.000 description 1
- 229940116362 tragacanth Drugs 0.000 description 1
- 239000012581 transferrin Substances 0.000 description 1
- 238000013519 translation Methods 0.000 description 1
- 125000005500 uronium group Chemical group 0.000 description 1
- 239000003981 vehicle Substances 0.000 description 1
- 238000005406 washing Methods 0.000 description 1
- 239000001993 wax Substances 0.000 description 1
- 230000003442 weekly effect Effects 0.000 description 1
- 239000000080 wetting agent Substances 0.000 description 1
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/111—General methods applicable to biologically active non-coding nucleic acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
- C12N15/1137—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing against enzymes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/14—Type of nucleic acid interfering N.A.
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/31—Chemical structure of the backbone
- C12N2310/315—Phosphorothioates
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/31—Chemical structure of the backbone
- C12N2310/317—Chemical structure of the backbone with an inverted bond, e.g. a cap structure
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/33—Chemical structure of the base
- C12N2310/332—Abasic residue
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/34—Spatial arrangement of the modifications
- C12N2310/343—Spatial arrangement of the modifications having patterns, e.g. ==--==--==--
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/34—Spatial arrangement of the modifications
- C12N2310/344—Position-specific modifications, e.g. on every purine, at the 3'-end
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/35—Nature of the modification
- C12N2310/351—Conjugate
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y101/00—Oxidoreductases acting on the CH-OH group of donors (1.1)
- C12Y101/03—Oxidoreductases acting on the CH-OH group of donors (1.1) with a oxygen as acceptor (1.1.3)
- C12Y101/03015—(S)-2-Hydroxy-acid oxidase (1.1.3.15)
Definitions
- the present invention provides novel oligonucleotide compounds, which are nucleic acid compounds, suitable for therapeutic use. Additionally, the present invention provides methods of making these compounds, as well as methods of using such compounds for the treatment of various diseases and conditions.
- Oligonucleotide compounds have important therapeutic applications in medicine. Oligonucleotides can be used to silence genes that are responsible for a particular disease. Gene-silencing prevents formation of a protein by inhibiting translation. Importantly, genesilencing agents are a promising alternative to traditional small, organic compounds that inhibit the function of the protein linked to the disease. siRNA, antisense RNA, and micro- RNA are oligonucleotides that prevent the formation of proteins by gene-silencing.
- siRNA / RNAi therapeutic agents for the treatment of various diseases including central-nervous-system diseases, inflammatory diseases, metabolic disorders, oncology, infectious diseases, and ocular diseases.
- the present invention relates to such oligonucleotide compounds, which are nucleic acid compounds, for use in the treatment and / or prevention of disease.
- a nucleic acid for inhibiting expression of a target gene in a cell, comprising at least one duplex region that comprises at least a portion of a first strand and at least a portion of a second strand that is at least partially complementary to the first strand, wherein said first strand is at least partially complementary to at least a portion of RNA transcribed from said target gene to be inhibited, wherein the second strand comprises one or more abasic nucleotides in a terminal region of the second strand, and wherein said abasic nucleotide(s) is / are connected to an adjacent nucleotide through a reversed internucleotide linkage.
- a conjugate for inhibiting expression of a target gene in a cell said conjugate comprising a nucleic acid portion and one or more ligand moieties, said nucleic acid portion comprising a nucleic acid as disclosed herein.
- a pharmaceutical composition comprising a nucleic acid as disclosed herein or a conjugate as disclosed herein and a physiologically acceptable excipient.
- FIG. 1 shows analysis of hsC5 mRNA expression levels in a total of 45 human-derived cancer cell lysates and lysates of primary human hepatocytes (PHHs). mRNA expression levels are shown in relative light units [RLUs],
- FIG. 2 shows analysis of hsHAOl mRNA expression levels in a total of 45 human- derived cancer cell lysates and lysates of primary human hepatocytes (PHHs). mRNA expression levels are shown in relative light units [RLUs],
- FIG. 3 shows analysis of hsTTR mRNA expression levels in a total of 45 human-derived cancer cell lysates and lysates of primary human hepatocytes (PHHs). mRNA expression levels are shown in relative light units [RLUs],
- FIGs. 4A-B shows the results from the dose-response analysis of hsTTR targeting GalNAc-siRNAs in HepG2 cells in Example 1.
- FIGs. 5A-B shows the results from the dose-response analysis of hsC5 targeting GalNAc-siRNAs in HepG2 cells in Example 1.
- FIG. 6 shows the analysis of hsTTR (top), hsC5 (middle) and hsHAOl (bottom) mRNA expression levels in all three batches of primary human hepatocytes BHuf 16087 (left), CHF2101 (middle) and CyHuf 19009 (right) each after Oh, 24h, 48h and 72h in culture. mRNA expression levels are shown in relative light units [RLUs],
- FIG. 7 shows the analysis of hsGAPDH (top) and hsAHSAl (bottom) mRNA expression levels in all three batches of primary human hepatocytes BHufl6087 (left), CHF2101 (middle) and CyHuf 19009 (right) each after Oh, 24h, 48h and 72h in culture. mRNA expression levels are shown in relative light units [RLUs],
- FIGs. 8A-B shows the results from the dose-response analysis of hsHAOl targeting GalNAc-siRNAs in PHHs in Example 1.
- FIGs. 9A-B shows the results from the dose-response analysis of hsC5 targeting GalNAc-siRNAs in PHHs in Example 1.
- FIGs. 10A-B shows the results from the dose-response analysis of hsTTR targeting GalNAc-siRNAs in PHHs in Example 1.
- FIG. 11 A-B shows the results from the dose-response analysis of hsTTR targeting GalNAc-siRNAs in HepG2 cells in Example 3.
- FIG. 12 A-B shows the results from the dose-response analysis of hsC5 targeting GalNAc-siRNAs in HepG2 cells in Example 3.
- FIG. 13 A-B shows the results from the dose-response analysis of hsHAOl targeting GalNAc-siRNAs in PHHs in Example 3.
- FIG. 14 A-B shows the results from the dose-response analysis of hsC5 targeting GalNAc-siRNAs in PHHs in Example 3.
- FIG.15 A-B shows the results from the dose-response analysis of hsTTR targeting GalNAc-siRNAs in PHHs in Example 3.
- FIG 16. Single dose mouse pharmacology of ETX005. HAO1 mRNA expression is shown relative to the saline control group. Each point represents the mean and standard deviation of 3 mice.
- FIG. Single dose mouse pharmacology of ETX005. Serum glycolate concentration is shown. Each point represents the mean and standard deviation of 3 mice, except for baseline glycolate concentration (day 0) which was derived from a group of 5 mice.
- FIG 18. Single dose mouse pharmacology of ETX006. HA01 mRNA expression is shown relative to the saline control group. Each point represents the mean and standard deviation of 3 mice.
- FIG 19. Single dose mouse pharmacology of ETX006. Serum glycolate concentration is shown. Each point represents the mean and standard deviation of 3 mice, except for baseline glycolate concentration (day 0) which was derived from a group of 5 mice.
- FIG 20 Single dose mouse pharmacology of ETX014. C5 mRNA expression is shown relative to the saline control group. Each point represents the mean and standard deviation of 3 mice.
- FIG 21 Single dose mouse pharmacology of ETX0014. Serum C5 concentration is shown relative to the saline control group. Each point represents the mean and standard deviation of 3 mice.
- FIG 22 Single dose mouse pharmacology of ETX015. C5 mRNA expression is shown relative to the saline control group. Each point represents the mean and standard deviation of 3 mice.
- FIG 23 Single dose mouse pharmacology of ETX0015. Serum C5 concentration is shown relative to the saline control group. Each point represents the mean and standard deviation of 3 mice.
- FIG 24 Single dose NHP pharmacology of ETX023. Serum TTR concentration is shown relative to day 1 of the study. Each point represents the mean and standard deviation of 3 animals.
- FIG 25 Single dose NHP pharmacology of ETX024. Serum TTR concentration is shown relative to day 1 of the study. Each point represents the mean and standard deviation of 3 animals.
- FIG. 26 Single dose NHP pharmacology of ETX019. Serum TTR concentration is shown relative to day 1 of the study and also pre-dose.. Each point represents the mean and standard deviation of 3 animals. Time points up to 84 days are shown.
- FIG. 27 Single dose NHP pharmacology of ETX020. Serum TTR concentration is shown relative to day 1 of the study and also pre-dose.. Each point represents the mean and standard deviation of 3 animals. Time points up to 84 days are shown.
- FIG. 28a Single dose NHP pharmacology of ETX023. Serum TTR concentration is shown relative to day 1 of the study and also pre-dose. Each point represents the mean and standard deviation of 3 animals. Time points up to 84 days are shown.
- FIG 28b Sustained suppression of TTR gene expression in the liver after a single 1 mg/kg dose of ETX023. TTR mRNA is shown relative to baseline levels measured pre-dose. Each point represents the mean and standard deviation of 3 animals. Time points up to 84 days are shown. [0037] FIG 28c. Body weight of animals dosed with a single 1 mg/kg dose of ETX023. Each point represents the mean and standard deviation of 3 animals. Time points up to 84 days are shown.
- FIG 28d ALT concentration in serum from animals treated with a single 1 mg/kg dose of ETX023. Each point represents the mean and standard deviation of 3 animals. The dotted lines show the range of values considered normal for this species (Park et al. 2016 Reference values of clinical pathology parameter in cynomolgus monkeys used in preclinical studies. Lab Anim Res 32:79-86.) Time points up to 84 days are shown.
- FIG 28e AST concentration in serum from animals treated with a single 1 mg/kg dose of ETX023. Each point represents the mean and standard deviation of 3 animals. The dotted lines show the range of values considered normal for this species (Park et al. 2016 Reference values of clinical pathology parameter in cynomolgus monkeys used in preclinical studies. Lab Anim Res 32:79-86. Time points up to 84 days are shown.
- FIG. 29a Single dose NHP pharmacology of ETX024. Serum TTR concentration is shown relative to day 1 of the study and also pre-dose. Each point represents the mean and standard deviation of 3 animals. Time points up to 84 days are shown.
- FIG 29b Sustained suppression of TTR gene expression in the liver after a single 1 mg/kg dose of ETX024. TTR mRNA is shown relative to baseline levels measured pre-dose. Each point represents the mean and standard deviation of 3 animals. Time points up to 84 days are shown.
- FIG 29c Body weight of animals dosed with a single 1 mg/kg dose of ETX024. Each point represents the mean and standard deviation of 3 animals. Time points up to 84 days are shown.
- FIG 30 Linker and ligand portion of ETX005, 014, 023
- ETX005 as a product includes molecules based on the linker and ligand portions as specifically depicted in FIG 30 attached to an oligonucleotide moiety as also depicted herein
- this ETX005 product may alternatively further comprise, or consist essentially of, molecules wherein the linker and ligand portions are essentially as depicted in FIG 30 attached to an oligonucleotide moiety but having the F substituent as shown in FIG 30 on the cyclo-octyl ring replaced by a substituent occurring as a result of hydrolytic displacement, such as an OH substituent.
- ETX005 can consist essentially of molecules having linker and ligand portions specifically as depicted in FIG 30, with a F substituent on the cyclo-octyl ring; or (b) ETX005 can consist essentially of molecules having linker and ligand portions essentially as depicted in FIG 30 but having the F substituent as shown in FIG 30 on the cyclo-octyl ring replaced by a substituent occurring as a result of hydrolytic displacement, such as an OH substituent, or (c) ETX005 can comprise a mixture of molecules as defined in (a) and/or (b).
- ETX014 as a product includes molecules based on the linker and ligand portions as specifically depicted in FIG 30 attached to an oligonucleotide moiety as also depicted herein
- this ETX014 product may alternatively further comprise, or consist essentially of, molecules wherein the linker and ligand portions are essentially as depicted in FIG 30 attached to an oligonucleotide moiety but having the F substituent as shown in FIG 30 on the cyclo-octyl ring replaced by a substituent occurring as a result of hydrolytic displacement, such as an OH substituent.
- ETX014 can consist essentially of molecules having linker and ligand portions specifically as depicted in FIG 30, with a F substituent on the cyclo-octyl ring; or (b) ETX014 can consist essentially of molecules having linker and ligand portions essentially as depicted in FIG 30 but having the F substituent as shown in FIG 30 on the cyclo-octyl ring replaced by a substituent occurring as a result of hydrolytic displacement, such as an OH substituent, or (c) ETX014 can comprise a mixture of molecules as defined in (a) and/or (b).
- ETX023 as a product includes molecules based on the linker and ligand portions as specifically depicted in FIG 30 attached to an oligonucleotide moiety as also depicted herein
- this ETX023 product may alternatively further comprise, or consist essentially of, molecules wherein the linker and ligand portions are essentially as depicted in FIG 30 attached to an oligonucleotide moiety but having the F substituent as shown in FIG 30 on the cyclo-octyl ring replaced by a substituent occurring as a result of hydrolytic displacement, such as an OH substituent.
- ETX023 can consist essentially of molecules having linker and ligand portions specifically as depicted in FIG 30, with a F substituent on the cyclo-octyl ring; or (b) ETX023 can consist essentially of molecules having linker and ligand portions essentially as depicted in FIG 30 but having the F substituent as shown in FIG 30 on the cyclo-octyl ring replaced by a substituent occurring as a result of hydrolytic displacement, such as an OH substituent, or (c) ETX023 can comprise a mixture of molecules as defined in (a) and/or (b).
- ETX001 as a product includes molecules based on the linker and ligand portions as specifically depicted in FIG 31 attached to an oligonucleotide moiety as also depicted herein
- this ETX001 product may alternatively further comprise, or consist essentially of, molecules wherein the linker and ligand portions are essentially as depicted in FIG 31 attached to an oligonucleotide moiety but having the F substituent as shown in FIG 31 on the cyclo-octyl ring replaced by a substituent occurring as a result of hydrolytic displacement, such as an OH substituent.
- ETX001 can consist essentially of molecules having linker and ligand portions specifically as depicted in FIG 31, with a F substituent on the cyclo-octyl ring; or (b) ETX001 can consist essentially of molecules having linker and ligand portions essentially as depicted in FIG 31 but having the F substituent as shown in FIG 31 on the cyclo-octyl ring replaced by a substituent occurring as a result of hydrolytic displacement, such as an OH substituent, or (c) ETX001 can comprise a mixture of molecules as defined in (a) and/or (b).
- ETX010 as a product includes molecules based on the linker and ligand portions as specifically depicted in FIG 31 attached to an oligonucleotide moiety as also depicted herein
- this ETX010 product may alternatively further comprise, or consist essentially of, molecules wherein the linker and ligand portions are essentially as depicted in FIG 31 attached to an oligonucleotide moiety but having the F substituent as shown in FIG 31 on the cyclo-octyl ring replaced by a substituent occurring as a result of hydrolytic displacement, such as an OH substituent.
- ETX010 can consist essentially of molecules having linker and ligand portions specifically as depicted in FIG 31, with a F substituent on the cyclo-octyl ring; or (b) ETX010 can consist essentially of molecules having linker and ligand portions essentially as depicted in FIG 31 but having the F substituent as shown in FIG 31 on the cyclo-octyl ring replaced by a substituent occurring as a result of hydrolytic displacement, such as an OH substituent, or (c) ETX010 can comprise a mixture of molecules as defined in (a) and/or (b).
- ETX019 as a product includes molecules based on the linker and ligand portions as specifically depicted in FIG 31 attached to an oligonucleotide moiety as also depicted herein
- this ETX019 product may alternatively further comprise, or consist essentially of, molecules wherein the linker and ligand portions are essentially as depicted in FIG 31 attached to an oligonucleotide moiety but having the F substituent as shown in FIG 31 on the cyclo-octyl ring replaced by a substituent occurring as a result of hydrolytic displacement, such as an OH substituent.
- ETX019 can consist essentially of molecules having linker and ligand portions specifically as depicted in FIG 31, with a F substituent on the cyclo-octyl ring; or (b) ETX019 can consist essentially of molecules having linker and ligand portions essentially as depicted in FIG 31 but having the F substituent as shown in FIG 31 on the cyclo-octyl ring replaced by a substituent occurring as a result of hydrolytic displacement, such as an OH substituent, or (c) ETX019 can comprise a mixture of molecules as defined in (a) and/or (b).
- Fig. 33 Linker and ligand portion of ETX002, 011 and 020.
- Fig. 34 Total bilirubin concentration in serum from animals treated with a single 1 mg/kg dose of ETX023. Each point represents the mean and standard deviation of 3 animals. The dotted lines show the range of values considered normal for this species (Park et al. 2016 Reference values of clinical pathology parameter in cynomolgus monkeys used in preclinical studies. Lab Anim Res 32:79-86.)
- FIG 35 Blood urea nitrogen (BUN) concentration from animals treated with a single 1 mg/kg dose of ETX023. Each point represents the mean and standard deviation of 3 animals. The dotted lines show the range of values considered normal for this species (Park et al. 2016 Reference values of clinical pathology parameter in cynomolgus monkeys used in preclinical studies. Lab Anim Res 32:79-86.)
- FIG 36 Creatinine (CREA) concentration from animals treated with a single 1 mg/kg dose of ETX023. Each point represents the mean and standard deviation of 3 animals. The dotted lines show the range of values considered normal for this species (Park et al. 2016 Reference values of clinical pathology parameter in cynomolgus monkeys used in preclinical studies. Lab Anim Res 32:79-86.)
- FIG 37 Total bilirubin concentration in serum from animals treated with a single 1 mg/kg dose of ETX024. Each point represents the mean and standard deviation of 3 animals. The shaded are shows the range of values considered normal at the facility used for the study. The dotted lines show values considered normal for this species (Park et al. 2016 Reference values of clinical pathology parameter in cynomolgus monkeys used in preclinical studies. Lab Anim Res 32:79-86.)
- FIG 38 Blood urea nitrogen (BUN) concentration from animals treated with a single 1 mg/kg dose of ETX024. Each point represents the mean and standard deviation of 3 animals. The shaded are shows the range of values considered normal at the facility used for the study. The dotted lines show values considered normal for this species (Park et al. 2016 Reference values of clinical pathology parameter in cynomolgus monkeys used in preclinical studies. Lab Anim Res 32:79-86.)
- FIG. 40 - FIG 42 are described below.
- FIG. 43 shows the detail of the formulae described in Sentences 1-101 disclosed herein.
- FIG. 44 shows the detail of formulae described in Clauses 1-56 disclosed herein
- Figure 45a shows the underlying nucleotide sequences for the sense (SS) and antisense (AS) strands of constructs ETX001, ETX002 as described herein.
- SS sense
- AS antisense
- iaia as shown at the 3’ end region of the sense strand in Figure 45a represents (i) two abasic nucleotides provided as the penultimate and terminal nucleotides at the 3’ end region of the sense strand, (ii) wherein a 3 ’-3’ reversed linkage is provided between the antepenultimate nucleotide (namely A at position 21 of the sense strand, wherein position 1 is the terminal 5’ nucleotide of the sense strand, namely terminal G at the 5 ’end region of the sense strand) and the adjacent penultimate abasic residue of the sense strand, and (iii) the linkage between the terminal and penultimate abasic nucleotides is 5’-3’ when reading towards the 3’ end region comprising the terminal and penultimate abasic nucleotides.
- the sense strand of Figure 45a when reading from position 1 of the sense strand (which is the terminal 5’ nucleotide of the sense strand, namely terminal G at the 5 ’end region of the sense strand), then: (i) the nucleotides at positions 1 to 6, 8, and 12 to 21 have sugars that are 2’ O- methyl modified, (ii) the nucleotides at positions 7, and 9 to 11 have sugars that are 2’ F modified, (iii) the abasic nucleotides have sugars that have H at positions 1 and 2.
- the antisense strand of Figure 45a when reading from position 1 of the antisense strand (which is the terminal 5’ nucleotide of the antisense strand, namely terminal U at the 5 ’end region of the antisense strand), then: (i) the nucleotides at positions 1, 3 to 5, 7, 10 to 13, 15, 17 to 23 have sugars that are 2’ O-methyl modified, (ii) the nucleotides at positions 2, 6, 8, 9, 14, 16 have sugars that are 2’ F modified.
- Figure 45b shows the underlying nucleotide sequences for the sense (SS) and antisense (AS) strands of constructs ETX005, ETX006 as described herein.
- SS sense
- AS antisense
- iaia as shown at the 5’ end region of the sense strand in Figure 45b represents (i) two abasic nucleotides provided as the penultimate and terminal nucleotides at the 5’ end region of the sense strand, (ii) wherein a 5’ -5’ reversed linkage is provided between the antepenultimate nucleotide (namely G at position 1 of the sense strand, not including the iaia motif at the 5’ end region of the sense strand in the nucleotide position numbering on the sense strand) and the adjacent penultimate abasic residue of the sense strand, and (iii) the linkage between the terminal and penultimate abasic nucleotides is 3’-5’ when reading towards the 5’ end region comprising the terminal and penultimate abasic nucleotides.
- the sense strand of Figure 45b when reading from position 1 of the sense strand (which is the terminal 5’ nucleotide of the sense strand, namely terminal G at the 5 ’end region of the sense strand, not including the iaia motif at the 5’ end region of the sense strand in the nucleotide position numbering on the sense strand), then: (i) the nucleotides at positions 1 to 6, 8, and 12 to 21 have sugars that are 2’ O-methyl modified, (ii) the nucleotides at positions 7, and 9 to 11 have sugars that are 2’ F modified, (iii) the abasic nucleotides have sugars that have H at positions 1 and 2.
- the antisense strand of Figure 45b when reading from position 1 of the antisense strand (which is the terminal 5’ nucleotide of the antisense strand, namely terminal U at the 5 ’end region of the antisense strand), then: (i) the nucleotides at positions 1, 3 to 5, 7, 10 to 13, 15, 17 to 23 have sugars that are 2’ O-methyl modified, (ii) the nucleotides at positions 2, 6, 8, 9, 14, 16 have sugars that are 2’ F modified.
- Fig. 46a shows the underlying nucleotide sequences for the sense (SS) and antisense (AS) strands of constructs ETX010, ETX011 as described herein.
- SS sense
- AS antisense
- a galnac linker is attached to the 5’ end region of the sense strand in use (not depicted in Figure 46a).
- ETX010 the galnac linker is attached and as shown in Figure 31.
- ETXOl l the galnac linker is attached and as shown in Figure 33.
- iaia as shown at the 3’ end region of the sense strand in Figure 46a represents (i) two abasic nucleotides provided as the penultimate and terminal nucleotides at the 3’ end region of the sense strand, (ii) wherein a 3 ’-3’ reversed linkage is provided between the antepenultimate nucleotide (namely A at position 21 of the sense strand, wherein position 1 is the terminal 5’ nucleotide of the sense strand, namely terminal A at the 5 ’end region of the sense strand) and the adjacent penultimate abasic residue of the sense strand, and (iii) the linkage between the terminal and penultimate abasic nucleotides is 5’-3’ when reading towards the 3’ end region comprising the terminal and penultimate abasic nucleotides.
- the sense strand of Figure 46a when reading from position 1 of the sense strand (which is the terminal 5’ nucleotide of the sense strand, namely terminal A at the 5 ’end region of the sense strand), then: (i) the nucleotides at positions 1, 2, 4, 6, 8, 12, 14, 15, 17, 19 to 21 have sugars that are 2’ O-methyl modified, (ii) the nucleotides at positions 3, 5, 7, 9 to 11, 13, 16, 18 have sugars that are 2’ F modified, (iii) the abasic nucleotides have sugars that have H at positions 1 and 2.
- the antisense strand of Figure 46a when reading from position 1 of the antisense strand (which is the terminal 5’ nucleotide of the antisense strand, namely terminal U at the 5 ’end region of the antisense strand), then: (i) the nucleotides at positions 1, 4, 6, 7, 9, 11 to 13, 15, 17, 19 to 23 have sugars that are 2’ O-methyl modified, (ii) the nucleotides at positions 2, 3, 5, 8, 10, 14, 16, 18 have sugars that are 2’ F modified, (iii) the penultimate and terminal T nucleotides at positions 24, 25 at the 3’ end region of the antisense strand have sugars that have H at position 2.
- Figure 46b shows the underlying nucleotide sequences for the sense (SS) and antisense (AS) strands of constructs ETX014, ETX015 as described herein.
- SS sense
- AS antisense
- iaia as shown at the 5’ end region of the sense strand in Figure 46b represents (i) two abasic nucleotides provided as the penultimate and terminal nucleotides at the 5’ end region of the sense strand, (ii) wherein a 5’ -5’ reversed linkage is provided between the antepenultimate nucleotide (namely A at position 1 of the sense strand, not including the iaia motif at the 5’ end region of the sense strand in the nucleotide position numbering on the sense strand) and the adjacent penultimate abasic residue of the sense strand, and (iii) the linkage between the terminal and penultimate abasic nucleotides is 3’-5’ when reading towards the 5’ end region comprising the terminal and penultimate abasic nucleotides.
- the sense strand of Figure 46b when reading from position 1 of the sense strand (which is the terminal 5’ nucleotide of the sense strand, namely terminal A at the 5 ’end region of the sense strand, not including the iaia motif at the 5’ end region of the sense strand in the nucleotide position numbering on the sense strand), then: (i) the nucleotides at positions 1, 2, 4, 6, 8, 12, 14, 15, 17, 19 to 21 have sugars that are 2’ O-methyl modified, (ii) the nucleotides at positions 3, 5, 7, 9 to 11, 13, 16, 18 have sugars that are 2’ F modified, (iii) the abasic nucleotides have sugars that have H at positions 1 and 2.
- the antisense strand of Figure 46b when reading from position 1 of the antisense strand (which is the terminal 5’ nucleotide of the antisense strand, namely terminal U at the 5 ’end region of the antisense strand), then: (i) the nucleotides at positions 1, 4, 6, 7, 9, 11 to 13, 15, 17, 19 to 23 have sugars that are 2’ O-methyl modified, (ii) the nucleotides at positions 2, 3, 5, 8, 10, 14, 16, 18 have sugars that are 2’ F modified, (iii) the penultimate and terminal T nucleotides at positions 24, 25 at the 3’ end region of the antisense strand have sugars that have H at position 2.
- Figure 47a shows the underlying nucleotide sequences for the sense (SS) and antisense (AS) strands of constructs ETX019, ETX020 as described herein.
- SS sense
- AS antisense
- iaia as shown at the 3’ end region of the sense strand in Figure 47a represents (i) two abasic nucleotides provided as the penultimate and terminal nucleotides at the 3’ end region of the sense strand, (ii) wherein a 3 ’-3’ reversed linkage is provided between the antepenultimate nucleotide (namely A at position 21 of the sense strand, wherein position 1 is the terminal 5’ nucleotide of the sense strand, namely terminal U at the 5 ’end region of the sense strand) and the adjacent penultimate abasic residue of the sense strand, and (iii) the linkage between the terminal and penultimate abasic nucleotides is 5’-3’ when reading towards the 3’ end region comprising the terminal and penultimate abasic nucleotides.
- the sense strand of Figure 47a when reading from position 1 of the sense strand (which is the terminal 5’ nucleotide of the sense strand, namely terminal U at the 5 ’end region of the sense strand), then: (i) the nucleotides at positions 1 to 6, 8, and 12 to 21 have sugars that are 2’ O- methyl modified, (ii) the nucleotides at positions 7, and 9 to 11 have sugars that are 2’ F modified, (iii) the abasic nucleotides have sugars that have H at positions 1 and 2.
- the antisense strand of Figure 47a when reading from position 1 of the antisense strand (which is the terminal 5’ nucleotide of the antisense strand, namely terminal U at the 5 ’end region of the antisense strand), then: (i) the nucleotides at positions 1, 3 to 5, 7, 8, 10 to 13, 15, 17 to 23 have sugars that are 2’ O-methyl modified, (ii) the nucleotides at positions 2, 6, 9, 14, 16 have sugars that are 2’ F modified.
- Figure 47b shows the underlying nucleotide sequences for the sense (SS) and antisense (AS) strands of constructs ETX023, ETX024 as described herein.
- SS sense
- AS antisense
- iaia as shown at the 5’ end region of the sense strand in Figure 47b represents (i) two abasic nucleotides provided as the penultimate and terminal nucleotides at the 5’ end region of the sense strand, (ii) wherein a 5’ -5’ reversed linkage is provided between the antepenultimate nucleotide (namely U at position 1 of the sense strand, not including the iaia motif at the 5’ end region of the sense strand in the nucleotide position numbering on the sense strand) and the adjacent penultimate abasic residue of the sense strand, and (iii) the linkage between the terminal and penultimate abasic nucleotides is 3’-5’ when reading towards the 5’ end region comprising the terminal and penultimate abasic nucleotides.
- the sense strand of Figure 47b when reading from position 1 of the sense strand (which is the terminal 5’ nucleotide of the sense strand, namely terminal U at the 5 ’end region of the sense strand, not including the iaia motif at the 5’ end region of the sense strand in the nucleotide position numbering on the sense strand), then: (i) the nucleotides at positions 1 to 6, 8, and 12 to 21 have sugars that are 2’ O-methyl modified, (ii) the nucleotides at positions 7, and 9 to 11 have sugars that are 2’ F modified, (iii) the abasic nucleotides have sugars that have H at positions 1 and 2.
- the antisense strand of Figure 47b when reading from position 1 of the antisense strand (which is the terminal 5’ nucleotide of the antisense strand, namely terminal U at the 5 ’end region of the antisense strand), then: (i) the nucleotides at positions 1, 3 to 5, 7, 8, 10 to 13, 15, 17 to 23 have sugars that are 2’ O-methyl modified, (ii) the nucleotides at positions 2, 6, 9, 14, 16 have sugars that are 2’ F modified.
- the present invention provides nucleic acids such as inhibitory RNA molecules (which may be referred to as iRNA), and compositions containing the same which can affect expression of a target gene.
- the gene may be within a cell, e.g. a cell within a subject, such as a human.
- the nucleic acids can be used to prevent and/or treat medical conditions associated with the expression of a target gene.
- Inhibitory RNA (iRNA) is the preferred nucleic acid herein.
- the invention provides, in a first aspect, a nucleic acid, optionally an RNA, for inhibiting expression of a target gene in a cell, comprising at least one duplex region that comprises at least a portion of a first strand and at least a portion of a second strand that is at least partially complementary to the first strand, wherein said first strand is at least partially complementary to at least a portion of RNA transcribed from said target gene to be inhibited, wherein the second strand comprises one or more abasic nucleotides in a terminal region of the second strand, and wherein said abasic nucleotide(s) is / are connected to an adjacent nucleotide through a reversed internucleotide linkage.
- the invention in particular includes double stranded RNA molecules (dsRNA) which includes two RNA strands that are complementary and hybridize to form a duplex structure under conditions in which the dsRNA will be used.
- dsRNA double stranded RNA molecules
- One strand of a dsRNA includes a region of complementarity that is substantially complementary, and generally fully complementary, to a target sequence.
- the target sequence can be derived from the sequence of an mRNA formed during the expression of a gene of interest.
- the other strand (the sense strand) includes a region that is complementary to the antisense strand, such that the two strands hybridize and form a duplex structure when combined under suitable conditions.
- Complementary sequences of a dsRNA can also be self- complementary regions of a single nucleic acid molecule.
- the term "region of complementarity" refers to the region on the antisense strand that is substantially complementary to a sequence, for example a target sequence. Where the region of complementarity is not fully complementary to the target sequence, the mismatches can be in the internal or terminal regions of the molecule.
- a double stranded nucleic acid e.g. RNAi agent of the invention includes a nucleotide mismatch in the antisense strand.
- nucleic acid of the invention may be referred to as an oligonucleotide moiety.
- a double stranded nucleic acid e.g. RNAi agent of the invention includes a nucleotide mismatch in the sense strand.
- the nucleotide mismatch is, for example, within 5, 4, 3, 2, or 1 nucleotides from the 3 '-end of the nucleic acid e.g. iRNA.
- the nucleotide mismatch is, for example, in the 3'- terminal nucleotide of the nucleic acid e.g. iRNA.
- the “second strand” (also called the sense strand or passenger strand herein, and which can be used interchangeably herein), refers to the strand of a nucleic acid e.g. iRNA that includes a region that is substantially complementary to a region of the antisense strand as that term is defined herein.
- a "target sequence” (which may also be called a target RNA or a target mRNA) refers to a contiguous portion of the nucleotide sequence of an mRNA molecule formed during the transcription of a gene, including mRNA that is a product of RNA processing of a primary transcription product.
- the target sequence may be from about 10-35 nucleotides in length, e.g., about 15-30 nucleotides in length.
- the target sequence can be from about 15-30 nucleotides, 15-29, 15-28, 15-27, 15-26, 15-25, 15-24, 15-23, 15-22, 15-21, 15-20, 15-19, 15-18, 15-17,
- ribonucleotide or “nucleotide” can also refer to a modified nucleotide, as further detailed below.
- a nucleic acid can be a DNA or an RNA, and can comprise modified nucleotides.
- RNA is a preferred nucleic acid.
- RNAi agent refers to an agent that contains RNA, and which mediates the targeted cleavage of an RNA transcript via an RNA-induced silencing complex (RISC) pathway.
- RISC RNA-induced silencing complex
- iRNA directs the sequence-specific degradation of mRNA through RNA interference (RNAi).
- a double stranded RNA is referred to herein as a "double stranded RNAi agent,” “double stranded RNA (dsRNA) molecule,” “dsRNA agent,” or “dsRNA”, which refers to a complex of ribonucleic acid molecules, having a duplex structure comprising two anti-parallel and substantially complementary nucleic acid strands, referred to as having "sense” and “antisense” orientations with respect to a target RNA.
- dsRNAi agent double stranded RNA
- dsRNA agent double stranded RNA agent
- dsRNA agent double stranded RNA agent
- each strand of the nucleic acid e.g. a dsRNA molecule
- each or both strands can also include one or more non-ribonucleotides, e.g., a deoxyribonucleotide or a modified nucleotide.
- an "iRNA” may include ribonucleotides with chemical modifications.
- modified nucleotide refers to a nucleotide having, independently, a modified sugar moiety, a modified internucleotide linkage, or modified nucleobase, or any combination thereof.
- modified nucleotide encompasses substitutions, additions or removal of, e.g., a functional group or atom, to internucleoside linkages, sugar moieties, or nucleobases. Any such modifications, as used in a siRNA type molecule, are encompassed by "iRNA” or “RNAi agent” for the purposes of this specification and claims.
- the duplex region of a nucleic acid of the invention e.g. a dsRNA may range from about 9 to 40 base pairs in length such as 9 to 36 base pairs in length, e.g., about 15- 30 base pairs in length, for example, about 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, or 36 base pairs in length, such as about 15-30, 15-29, 15-28, 15-27, 15-26, 15-25, 15-24, 15-23, 15-22, 15-21, 15-20, 15-19, 15-18, 15-17, 18-30,
- the two strands forming the duplex structure may be different portions of one larger molecule, or they may be separate molecules e.g. RNA molecules.
- nucleotide overhang refers to at least one unpaired nucleotide that extends from the duplex structure of a double stranded nucleic acid.
- a ds nucleic acid can comprise an overhang of at least one nucleotide; alternatively the overhang can comprise at least two nucleotides, at least three nucleotides, at least four nucleotides, at least five nucleotides or more.
- a nucleotide overhang can comprise or consist of a nucleotide/nucleoside analog, including a deoxynucleotide/nucleoside.
- the overhang(s) can be on the sense strand, the antisense strand, or any combination thereof.
- the nucleotide(s) of an overhang can be present on the 5'-end, 3'-end, or both ends of either an antisense or sense strand.
- the antisense strand has a 1-10 nucleotide, e.g., 0-3, 1-3, 2-4, 2- 5, 4-10, 5-10, 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 nucleotide, overhang at the 3'-end or the 5'-end.
- “Blunt” or “blunt end” means that there are no unpaired nucleotides at that end of the double stranded nucleic acid, i.e., no nucleotide overhang.
- the nucleic acids of the invention include those with no nucleotide overhang at one end or with no nucleotide overhangs at either end.
- the term "complementary,” when used to describe a first nucleotide sequence in relation to a second nucleotide sequence, refers to the ability of an oligonucleotide or polynucleotide comprising the first nucleotide sequence to hybridize and form a duplex structure under certain conditions with an oligonucleotide or polynucleotide comprising the second nucleotide sequence, as will be understood by the skilled person.
- Such conditions can, for example, be stringent conditions, where stringent conditions can include: 400 mM NaCl, 40 mM PIPES pH 6.4, 1 mM EDTA, 50°C or 70°C for 12-16 hours followed by washing (see, e.g., "Molecular Cloning: A Laboratory Manual, Sambrook, et al. (1989) Cold Spring Harbor Laboratory Press).
- nucleic acid e.g. a dsRNA, as described herein, include base-pairing of the oligonucleotide or polynucleotide comprising a first nucleotide sequence to an oligonucleotide or polynucleotide comprising a second nucleotide sequence over the entire length of one or both nucleotide sequences.
- sequences can be referred to as "fully complementary" with respect to each other herein.
- first sequence is referred to as “substantially complementary” with respect to a second sequence herein
- the two sequences can be fully complementary, or they can form one or more mismatched base pairs, such as 2, 4, or 5 mismatched base pairs, but preferably not more than 5 , while retaining the ability to hybridize under the conditions most relevant to their ultimate application, e.g. , inhibition of gene expression via a RISC pathway.
- Overhangs shall not be regarded as mismatches with regard to the determination of complementarity.
- a nucleic acid e.g.
- dsRNA comprising one oligonucleotide 17 nucleotides in length and another oligonucleotide 19 nucleotides in length, wherein the longer oligonucleotide comprises a sequence of 17 nucleotides that is fully complementary to the shorter oligonucleotide, can yet be referred to as "fully complementary” .
- “Complementary” sequences can also include, or be formed entirely from, non- Watson-Crick base pairs or base pairs formed from non-natural and modified nucleotides, in so far as the above requirements with respect to their ability to hybridize are fulfilled.
- non- Watson- Crick base pairs include, but are not limited to, G:U Wobble or Hoogstein base pairing.
- a nucleic acid or polynucleotide that is "substantially complementary” to at least part of a messenger RNA refers to a polynucleotide that is substantially complementary to a contiguous portion of the mRNA of interest (e.g. , an mRNA encoding a gene).
- mRNA messenger RNA
- a polynucleotide is complementary to at least a part of an mRNA of a gene of interest if the sequence is substantially complementary to a non- interrupted portion of an mRNA encoding that gene.
- the sense strand polynucleotides and the antisense polynucleotides disclosed herein are fully complementary to the target gene sequence.
- the antisense polynucleotides disclosed herein are substantially complementary to a target RNA sequence and comprise a contiguous nucleotide sequence which is at least about 80% complementary over its entire length to the equivalent region of the target RNA sequence, such as at least about 85%, 86%, 87%, 88%, 89%, about 90%, 91 %, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% complementary or 100% complementary.
- a nucleic acid e.g. an iRNA of the invention includes a sense strand that is substantially complementary to an antisense polynucleotide which, in turn, is complementary to a target gene sequence and comprises a contiguous nucleotide sequence which is at least about 80% complementary over its entire length to the equivalent region of the nucleotide sequence of the antisense strand, such as about 85%, 86%, 87%, 88%, 89%, 90%, 91 %, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% complementary, or 100% complementary.
- a nucleic acid e.g. an iRNA of the invention includes an antisense strand that is substantially complementary to the target sequence and comprises a contiguous nucleotide sequence which is at least 80% complementary over its entire length to the target sequence such as about 85%, 86%, 87%, 88%, 89%, 90%, 91 %, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% complementary, or 100% complementary.
- a "subject" is an animal, such as a mammal, including a primate (such as a human, a non-human primate, e.g., a monkey, and a chimpanzee), or a non-primate or a bird that expresses the target gene, either endogenously or heterologously, when the target gene sequence has sufficient complementarity to the nucleic acid e.g. iRNA agent to promote target knockdown.
- the subject is a human.
- treating refers to a beneficial or desired result including, but not limited to, alleviation or amelioration of one or more symptoms associated with gene expression.
- Treatment can also mean prolonging survival as compared to expected survival in the absence of treatment. Treatment can include prevention of development of comorbidities, e.g. , reduced liver damage in a subject with a hepatic infection.
- “Therapeutically effective amount,” as used herein, is intended to include the amount of a nucleic acid e.g. an iRNA that, when administered to a patient for treating a subject having disease, is sufficient to effect treatment of the disease (e.g. , by diminishing, ameliorating or maintaining the existing disease or one or more symptoms of disease or its related comorbidities).
- phrases "pharmaceutically acceptable” is employed herein to refer to compounds, materials, compositions, or dosage forms which are suitable for use in contact with the tissues of human subjects and animal subjects without excessive toxicity, irritation, allergic response, or other problem or complication, commensurate with a reasonable benefit/risk ratio.
- pharmaceutically-acceptable carrier means a pharmaceutically- acceptable material, composition, or vehicle, such as a liquid or solid filler, diluent, excipient, manufacturing aid or solvent encapsulating material, involved in carrying or transporting the subject compound from one organ, or portion of the body, to another organ, or portion of the body.
- a pharmaceutically- acceptable material, composition, or vehicle such as a liquid or solid filler, diluent, excipient, manufacturing aid or solvent encapsulating material, involved in carrying or transporting the subject compound from one organ, or portion of the body, to another organ, or portion of the body.
- Each carrier must be “acceptable” in the sense of being compatible with the other ingredients of the formulation and not injurious to the subject being treated.
- sense strand or antisense strand is understood as “sense strand or antisense strand or sense strand and antisense strand.”
- the term "at least" prior to a number or series of numbers is understood to include the number adjacent to the term “at least”, and all subsequent numbers or integers that could logically be included, as clear from context.
- the number of nucleotides in a nucleic acid molecule must be an integer.
- "at least 18 nucleotides of a 21 nucleotide nucleic acid molecule” means that 18, 19, 20, or 21 nucleotides have the indicated property.
- nucleotide overhang As used herein, "no more than” or “less than” is understood as the value adjacent to the phrase and logical lower values or integers, as logical from context, to zero. For example, a duplex with an overhang of "no more than 2 nucleotides” has a 2, 1, or 0 nucleotide overhang. When “no more than” is present before a series of numbers or a range, it is understood that “no more than” can modify each of the numbers in the series or range.
- the terminal region of a strand is the last 5 nucleotides from the 5’ or the 3’ end.
- abasic nucleotides there are 1, e.g. 2, e.g. 3, e.g. 4 or more abasic nucleotides present in the nucleic acid.
- Abasic nucleotides are modified nucleotides because they lack the base normally seen at position 1 of the sugar moiety. Typically, there will be a hydrogen at position 1 of the sugar moiety of the abasic nucleotides present in a nucleic acid according to the present invention.
- the abasic nucleotides are in the terminal region of the second strand, preferably located within the terminal 5 nucleotides of the end of the strand.
- the terminal region may be the terminal 5 nucleotides, which includes abasic nucleotides.
- the second strand may comprise, as preferred features (which are all specifically contemplated in combination unless mutually exclusive):
- abasic nucleotides in either the 5’ or 3’ terminal region of the second strand, wherein the abasic nucleotides are present in an overhang as herein described;
- abasic nucleotide 2, or more than 2, consecutive abasic nucleotides in either the 5’ or 3’ terminal region of the second strand, wherein preferably one such abasic nucleotide is a terminal nucleotide in either the 5’ or 3’ terminal region of the second strand; and / or a reversed internucleotide linkage connects at least one abasic nucleotide to an adjacent basic nucleotide in a terminal region of the second strand; and / or a reversed internucleotide linkage connects at least one abasic nucleotide to an adjacent basic nucleotide in either the 5’ or 3’ terminal region of the second strand; and /or an abasic nucleotide as the penultimate nucleotide which is connected via the reversed linkage to the nucleotide which is not the terminal nucleotide (called the antepenultimate nucleotide herein); and
- the reversed linkage is a 5-5’ reversed linkage and the linkage between the terminal and penultimate abasic nucleotides is 3’5’ when reading towards the terminus comprising the terminal and penultimate abasic nucleotides; or
- the reversed linkage is a 3-3’ reversed linkage and the linkage between the terminal and penultimate abasic nucleotides is 5’3’ when reading towards the terminus comprising the terminal and penultimate abasic nucleotides.
- abasic nucleotide at the terminus of the second strand.
- abasic nucleotides in the terminal region of the second strand, preferably at the terminal and penultimate positions.
- abasic nucleotides are consecutive, for example all abasic nucleotides may be consecutive.
- terminal 1 or terminal 2 or terminal 3 or terminal 4 nucelotides may be abasic nucleotides.
- An abasic nucleotide may also be linked to an adjacent nucleotide through a 5 ’-3’ phosphodiester linkage or reversed linkage unless there is only 1 abasic nucleotide at the terminus, in which case it will have a reversed linkage to the adjacent nucleotide.
- a reversed linkage (which may also be referred to as an inverted linkage, which is also seen in the art), comprises either a 5’-5’, a 3’3’, a 3’-2’ or a 2’-3’ phosphodiester linkage between the adjacent sugar moi eties of the nucleotides.
- Abasic nucleotides which are not terminal will have 2 phosphodiester bonds, one with each adjacent nucleotide, and these may be a reversed linkage or may be a 5 ’-3 phosphodiester bond or may be one of each.
- a preferred embodiment comprises 2 abasic nucleotides at the terminal and penultimate positions of the second strand, and wherein the reversed internucleotide linkage is located between the penultimate (abasic) nucleotide and the antepenultimate nucleotide.
- abasic nucleotides at the terminal and penultimate positions of the second strand and the penultimate nucleotide is linked to the antepenultimate nucleotide through a reversed internucleotide linkage and is linked to the terminal nucleotide through a 5 ’-3’ or 3 ’-5’ phosphodiester linkage (reading in the direction of the terminus of the molecule).
- the reversed internucleotide linkage is a 3’3 reversed linkage.
- the reversed internucleotide linkage is at a terminal region which is distal to the 5’ terminal phosphate of the second strand.
- the reversed internucleotide linkage is a 5’5 reversed linkage.
- the reversed internucleotide linkage is at a terminal region which is distal to the 3’ terminal hydroxide of the second strand.
- RNA nucleotides shown are not limiting and could be any RNA nucleotide:
- a A 3’-3’ reversed bond (and also showing the 5’-3 direction of the last phosphodiester bond between the two abasic molecules reading towards the terminus of the molecule)
- the abasic nucleotide or abasic nucleotides present in the nucleic acid are provided in the presence of a reversed internucleotide linkage or linkages, namely a 5 ’-5’ or a 3 ’-3’ reversed internucleotide linkage.
- a reversed linkage occurs as a result of a change of orientation of an adjacent nucleotide sugar, such that the sugar will have a 3’ - 5’ orientation as opposed to the conventional 5’ - 3’ orientation (with reference to the numbering of ring atoms on the nucleotide sugars).
- the abasic nucleotide or nucleotides as present in the nucleic acids of the invention preferably include such inverted nucleotide sugars.
- the proximal 3’-3’ or 5’ -5’ reversed linkage as herein described may comprise the reversed linkage being directly adjacent / attached to a terminal nucleotide having an inverted orientation, such as a single terminal nucleotide having an inverted orientation.
- the proximal 3 ’-3’ or 5 ’-5’ reversed linkage as herein described may comprise the reversed linkage being adjacent 2, or more than 2, nucleotides having an inverted orientation, such as 2, or more than 2, terminal region nucleotides having an inverted orientation, such as the terminal and penultimate nucleotides. In this way, the reversed linkage may be attached to a penultimate nucleotide having an inverted orientation.
- nucleic acid molecules having overall 3’ - 3’ or 5’- 5’ end structures as described herein, it will also be appreciated that with the presence of one or more additional reversed linkages and / or nucleotides having an inverted orientation, then the overall nucleic acid may have 3’ - 5’ end structures corresponding to the conventionally positioned 5’ / 3’ ends.
- the nucleic acid may have a 3 ’-3’ reversed linkage, and the terminal sugar moiety may comprise a 5’ OH rather than a 5’ phosphate group at the 5’ position of that terminal sugar.
- the majority of the molecule will comprise conventional internucleotide linkages that run from the 3’ OH of the sugar to the 5’ phosphate of the next sugar, when reading in the standard 5’ [PO4] to 3’ [OH] direction of a nucleic acid molecule (with reference to the numbering of ring atoms on the nucleotide sugars), which can be used to determine the conventional 5’ and 3’ ends that would be found absent the inverted end configuration.
- the reversed bond is preferably located at the end of the nucleic acid eg RNA which is distal to a ligand moiety, such as a GalNAc containing portion, of the molecule.
- a ligand moiety such as a GalNAc containing portion
- GalNAc-siRNA constructs with a 5 ’-GalNAc on the sense strand can have a reversed linkage on the opposite end of the sense strand.
- GalNAc-siRNA constructs with a 3 ’-GalNAc on the sense strand can have a reversed linkage on the opposite end of the sense strand.
- the first strand of the nucleic acid has a length in the range of 15 to 30 nucleotides, preferably 19 to 25 nucleotides, more preferably 23 or 25; and / or ii) the second strand of the nucleic acid has a length in the range of 15 to 30 nucleotides, preferably 19 to 25 nucleotides, more preferably 23.
- the duplex structure of the nucleic acid e.g. an iRNA is about 15 to 30 base pairs in length, e.g., 15-29, 15-28, 15-27, 15-26, 15-25, 15-24, 15-23, 15-22, 15-21, 15-20, 15-19, 15-18, 15-17, 18-30, 18-29, 18-28, 18-27, 18-26, 18-25, 18-24, 18-23, 18-22, 18-21, 18-20, 19-30, 19-29, 19-28, 19-27, 19-26, 19-25, 19-24, 19- 23, 19-22, 19-21, 19-20, 20-30,
- the region of complementarity of an antisense sequence to a target sequence and/or the region of complementarity of an antisense sequence to a sense sequence is about 15 to 30 nucleotides in length, e.g., 15-29, 15-28, 15-27, 15-26, 15-25, 15-24, 15-23, 15-22, 15-21, 15-20, 15-19, 15-18, 15-17, 18-30, 18-29, 18-28, 18-27, 18-26, 18-25, 18-24, 18-23, 18-22, 18-21, 18-20, 19-30, 19-29, 19-28, 19-27, 19-26, 19-25, 19-24, 19-23, 19-22, 19-21, 19-20, 20-30, 20-29, 20-28, 20-27, 20-26, 20-25, 20- 24,20-23, 20-22, 20-21, 21-30, 21-29, 21-28, 21-27, 21-26, 21-25, 21-24, 21-23, or 21-22 nucleotides in
- the region of complementarity of an antisense sequence to a target sequence and/or the region of complementarity of an antisense sequence to a sense sequence is at least 17 nucleotides in length.
- the region of complementarity between the antisense strand and the target is 19 to 21 nucleotides in length, for example, the region of complementarity is 21 nucleotides in length.
- each strand is no more than 30 nucleotides in length.
- a nucleic acid e.g. a dsRNA as described herein can further include one or more singlestranded nucleotide overhangs e.g., 1-4, 2-4, 1-3, 2-3, 1, 2, 3, or 4 nucleotides.
- a nucleotide overhang can comprise or consist of a nucleotide/nucleoside analog, including a deoxynucleotide/nucleoside.
- the overhang(s) can be on the sense strand, the antisense strand, or any combination thereof.
- the nucleotide(s) of an overhang can be present on the 5'-end, 3'- end, or both ends of an antisense or sense strand of a nucleic acid e.g. a dsRNA.
- At least one strand comprises a 3' overhang of at least 1 nucleotide, e.g. , at least one strand comprises a 3' overhang of at least 2 nucleotides.
- the overhang is suitably on the antisense/ guide strand and/or the sense / passenger strand.
- the nucleic acid e.g. an RNA of the invention e.g., a dsRNA
- the nucleic acid does not comprise further modifications (beyond the required abasic modifications), e.g., chemical modifications or conjugations known in the art and described herein.
- the nucleic acid e.g. RNA of the invention e.g., a dsRNA
- nucleic acids featured in the invention can be synthesized or modified by methods well established in the art, such as those described in “Current protocols in nucleic acid chemistry,” Beaucage, S.L. et al. (Edrs.), John Wiley & Sons, Inc., New York, NY, USA, which is hereby incorporated herein by reference.
- Modifications include, for example, end modifications, e.g., 5'-end modifications (phosphorylation, conjugation, inverted linkages) or 3 '-end modifications (conjugation, DNA nucleotides within an RNA, or RNA nucleotides within a DNA, inverted linkages, etc.); base modifications, e.g., replacement with stabilizing bases, destabilizing bases, or bases that base pair with an expanded repertoire of partners, conjugated bases; sugar modifications (e.g. , at the 2'-position or 4'- position) or replacement of the sugar; or backbone modifications, including modification or replacement of the phosphodiester linkages.
- end modifications e.g., 5'-end modifications (phosphorylation, conjugation, inverted linkages) or 3 '-end modifications (conjugation, DNA nucleotides within an RNA, or RNA nucleotides within a DNA, inverted linkages, etc.
- base modifications e.g., replacement with stabilizing bases, destabilizing bases,
- nucleic acids such as iRNA compounds useful in the embodiments described herein include, but are not limited to RNAs containing modified backbones or no natural internucleoside linkages.
- Nucleic acids such as RNAs having modified backbones include, among others, those that do not have a phosphorus atom in the backbone.
- modified nucleic acids e.g. RNAs that do not have a phosphorus atom in their internucleoside backbone can also be considered to be oligonucleosides.
- a modified nucleic acid e.g. an iRNA will have a phosphorus atom in its internucleoside backbone.
- Modified nucleic acid e.g. RNA backbones include, for example, phosphorothioates, chiral phosphorothioates, phosphorodithioates, phosphotriesters, aminoalkylphosphotriesters, methyl and other alkyl phosphonates including 3 '-alkylene phosphonates and chiral phosphonates, phosphinates, phosphoramidates including 3 '-amino phosphoramidate and aminoalkylphosphoramidates, thionophosphoramidates, thionoalkylphosphonates, thionoalkylphosphotriesters, and boranophosphates having normal 3'-5' linkages, 2'-5'-linked analogs of these, and those having inverted polarity wherein the adjacent pairs of nucleoside units are linked 5'-3' or 5'-2'.
- Various salts, mixed salts and free acid forms are also included.
- Modified nucleic acids e.g. RNAs can also contain one or more substituted sugar moieties.
- the nucleic acids e.g. iRNAs, e.g., dsRNAs, featured herein can include one of the following at the 2'-position: OH; F; 0-, S-, or N-alkyl; 0-, S-, or N-alkenyl; 0-, S- or N- alkynyl; or O-alkyl-O-alkyl, wherein the alkyl, alkenyl and alkynyl can be substituted or unsubstituted. 2’ O- methyl and 2’ -F are preferred modifications.
- the nucleic acid comprises at least one modified nucleotide.
- the nucleic acid of the invention may comprise one or more modified nucleotides on the first strand and/or the second strand.
- substantially all of the nucleotides of the sense strand and all of the nucleotides of the antisense strand comprise a modification.
- all of the nucleotides of the sense strand and substantially all of the nucleotides of the antisense strand comprise a modification.
- all of the nucleotides of the sense strand and all of the nucleotides of the antisense strand comprise a modification.
- At least one of the modified nucleotides is selected from the group consisting of a deoxy- nucleotide, a 3 '-terminal deoxy-thymine (dT) nucleotide, a 2'-0- methyl modified nucleotide (also called herein 2’-Me, where Me is a methoxy) , a 2'-fluoro modified nucleotide, a 2'-deoxy- modified nucleotide, a locked nucleotide, an unlocked nucleotide, a conformationally restricted nucleotide, a constrained ethyl nucleotide, an abasic nucleotide, a 2' -amino- modified nucleotide, a 2'- O-allyl- modified nucleotide, 2' -C-alkyl- modified nucleotide, 2'-hydroxly-modified nucleotide, a 2'
- Modifications on the nucleotides may preferably be selected from the group including, but not limited to, LNA, HNA, CeNA, 2 -methoxyethyl, 2'-0-alkyl, 2 -0-allyl, 2'-C- allyl, 2'- fluoro, 2'-deoxy, 2'- hydroxyl, and combinations thereof.
- the modifications on the nucleotides are 2 -0-methyl (“2-Me”) or 2'-fluoro modifications.
- Preferred nucleic acid comprise one or more nucleotides on the first strand and / or the second strand which are modified, to form modified nucleotides, as follows:
- a nucleic acid wherein the modification is a modification at the 2’ -OH group of the ribose sugar, optionally selected from 2'-Me or 2’-F modifications.
- a nucleic acid wherein the first strand comprises a 2’-F at any of position 14, position 2, position 6, or any combination thereof, counting from position 1 of said first strand.
- a nucleic acid wherein the second strand comprises a 2’-F modification at position 7 and / or 9, and / or 11, and/or 13 , counting from position 1 of said second strand.
- a nucleic acid wherein the second strand comprises a 2’-F modification at position 7 and 9 and 11 counting from position 1 of said second strand.
- a nucleic acid wherein the first and second strand each comprise 2'-Me and 2’-F modifications.
- IMUNA modified unlocked nucleic acid
- GNA glycol nucleic acid
- the nucleic acid may be a double stranded molecule, preferably double stranded RNA, which has a melting temperature in the range of about 40 to 80°C.
- the nucleic acid may comprise at least one thermally destabilizing modification at position 7 of the first strand.
- a nucleic acid wherein the nucleic acid comprises 3 or more 2’-F modifications at positions 7 to 13 of the second strand, such as 4, 5, 6 or 7 2’-F modifications at positions 7 to 13 of the second strand, counting from position 1 of said second strand.
- a nucleic acid wherein said second strand comprises at least 3, such as 4, 5 or 6, 2’-Me modifications at positions 1 to 6 of the second strand, counting from position 1 of said second strand.
- a nucleic acid wherein said first strand comprises at least 5 2’ -Me consecutive modifications at the 3’ terminal region, preferably including the terminal nucleotide at the 3’ terminal region, or at least within 1 or 2 nucleotides from the terminal nucleotide at the 3’ terminal region.
- a nucleic acid wherein said first strand comprises 7 2’-Me consecutive modifications at the 3’ terminal region, preferably including the terminal nucleotide at the 3’ terminal region.
- Preferred modification patterns include:
- a nucleic acid wherein the second strand includes the following modification pattern:
- N represents a nucleotide with a first modification
- N A represents a nucleotide with a second modification different to the first modification of N
- N B represents a nucleotide with a third modification different to the first modification of N, but either the same or different to the second modification of N A ; and wherein said pattern has a 5’ to 3’ directionality along the second strand.
- a nucleic acid wherein the second strand includes the following modification pattern:
- a nucleic acid wherein the second strand includes the following modification pattern:
- a nucleic acid wherein the second strand includes the following modification pattern:
- a nucleic acid wherein the second strand includes the following modification pattern:
- a nucleic acid wherein the second strand includes the following modification pattern:
- N c and N D which may be the same or different, respectively denote a plurality of 5’ and 3’ terminal region chemically modified nucleotides, wherein at least N c comprises at least two differently modified nucleotides.
- a nucleic acid wherein the second strand includes the following modification pattern:
- a nucleic acid wherein the second strand includes the following modification pattern:
- a nucleic acid wherein the second strand includes the following modification pattern:
- a nucleic acid wherein the second strand includes the following modification pattern:
- a nucleic acid wherein the first strand includes the following modification pattern:
- M represents a nucleotide with a first modification and wherein typically (M) 3 -s are substantially aligned with (N) 3 -5 in said second strand;
- M A represents a nucleotide with a second modification different to the first modification of M
- M B represents a nucleotide with a third modification different to the first modification of M, but either the same or different to the second modification of M A .
- a nucleic acid, wherein the first strand includes the following modification pattern:
- a nucleic acid, wherein the first strand includes the following modification pattern:
- a nucleic acid wherein the first strand includes the following modification pattern:
- a nucleic acid wherein the first strand includes the following modification pattern:
- a nucleic acid, wherein the first strand includes the following modification pattern:
- M c and M D which may be the same or different, respectively denote a plurality of 5’ and 3’ terminal region chemically modified nucleotides each comprising at least two differently modified nucleotides.
- a nucleic acid wherein the first strand includes the following modification pattern:
- a nucleic acid wherein the first strand includes the following modification pattern:
- a nucleic acid wherein the first strand includes the following modification pattern:
- Position 1 of the first or the second strand is the nucleotide which is the closest to the end of the nucleic acid (ignoring any abasic nucleotides) and that is joined to an adjacent nucleotide (at Position 2) via a 3’ to 5’ internal bond, with reference to the bonds between the sugar moieties of the backbone, and reading in a direction away from that end of the molecule.
- position 1 of the sense strand is the 5’ most nucleotide (not including abasic nucleotides) at the conventional 5’ end of the sense strand.
- the nucleotide at this position 1 of the sense strand will be equivalent to the 5’ nucleotide of the selected target nucleic acid sequence, and more generally the sense strand will have equivalent nucleotides to those of the target nucleic acid sequence starting from this position 1 of the sense strand, whilst also allowing for acceptable mismatches between the sequences.
- position 1 of the antisense strand is the 5’ most nucleotide (not including abasic nucleotides) at the conventional 5’ end of the antisense strand. As hereinbefore described, there will be a region of complementarity between the sense and antisense strands, and in this way the antisense strand will also have a region of complementarity to the target nucleic acid sequence as referred to above.
- the nucleic acid e.g. RNAi agent further comprises at least one phosphorothioate or methylphosphonate intemucleotide linkage.
- the phosphorothioate or methylphosphonate intemucleotide linkage can be at the 3 '-terminus or in the terminal region of one strand, i.e. , the sense strand or the antisense strand; or at the ends of both strands, the sense strand and the antisense strand.
- the phosphorothioate or methylphosphonate intemucleotide linkage is at the 5 'terminus or in the terminal region of one strand, i.e. , the sense strand or the antisense strand; or at the ends of both strands, the sense strand and the antisense strand.
- a phosphorothioate or a methylphosphonate intemucleotide linkage is at both the 5'- and 3 '-terminus or in the terminal region of one strand, i.e. , the sense strand or the antisense strand; or at the ends of both strands, the sense strand and the antisense strand.
- Any nucleic acid may comprise one or more phosphorothioate (PS) modifications within the nucleic acid, such as at least two PS intemucleotide bonds at the ends of a strand.
- PS phosphorothioate
- At least one of the oligoribonucleotide strands preferably comprises at least two consecutive phosphorothioate modifications in the last 3 nucleotides of the oligonucleotide.
- the invention therefore also relates to: A nucleic acid disclosed herein which comprises phosphorothioate intemucleotide linkages respectively between at least two or three consecutive positions, such as in a 5’ and/or 3’ terminal region and/or near terminal region of the second strand, whereby said near terminal region is preferably adjacent said terminal region wherein said one or more abasic nucleotides of said second strand is / are located.
- a nucleic acid disclosed herein which comprises phosphorothioate internucleotide linkages respectively between at least two or three consecutive positions in a 5’ and / or 3’ terminal region of the first strand, whereby preferably the terminal position at the 5’ and / or 3’ terminal region of said first strand is attached to its adjacent position by a phosphorothioate internucleotide linkage.
- the nucleic acid strand may be an RNA comprising a phosphorothioate intemucleotide linkage between the three nucleotides contiguous with 2 terminally located abasic nucleotides.
- a preferred nucleic acid is a double stranded RNA comprising 2 adjacent abasic nucleotides at the 5’ terminus of the second strand and a ligand moiety comprising one or more GalNAc ligand moi eties at the opposite 3’ end of the second strand.
- the same nucleic acid may also comprise a phosphorothioate bond between nucelotides at positions 3-4 and 4-5 of the second strand, reading from the position 1 of the second strand.
- the same nucleic acid may also comprise a 2’ F modification at positions 7, 9 and 11 of the second strand.
- RNA e.g. an iRNA of the invention involves linking the nucleic acid e.g. the iRNA to one or more ligand moieties e.g. to enhance the activity, cellular distribution, or cellular uptake of the nucleic acid e.g. iRNA e.g. , into a cell.
- ligand moieties e.g. to enhance the activity, cellular distribution, or cellular uptake of the nucleic acid e.g. iRNA e.g. , into a cell.
- the ligand moiety described can be attached to a nucleic acid e.g. an iRNA oligonucleotide, via a linker that can be cleavable or non-cleavable.
- linker or “linking group” means an organic moiety that connects two parts of a compound, e.g., covalently attaches two parts of a compound.
- the ligand can be attached to the 3' or 5’ end of the sense strand.
- the ligand is preferably conjugated to 3’ end of the sense strand of the nucleic acid e.g. an RNAi agent.
- the invention therefore relates in a further aspect to a conjugate for inhibiting expression of a target gene in a cell, said conjugate comprising a nucleic acid portion and one or more ligand moieties, said nucleic acid portion comprising a nucleic acid as disclosed herein.
- the second strand of the nucleic acid is conjugated directly or indirectly (e.g. via a linker) to the one or more ligand moiety(s), wherein said ligand moiety is typically present at a terminal region of the second strand, preferably at the 3’ terminal region thereof.
- the ligand moiety comprises a GalNAc or GalNAc derivative attached to the nucleic acid eg dsRNA through a linker.
- the invention relates to a conjugate wherein the ligand moiety comprises i) one or more GalNAc ligands; and / or ii) one or more GalNAc ligand derivatives; and / or iii) one or more GalNAc ligands conjugated to said nucleic acid through a linker.
- Said GalNAc ligand may be conjugated directly or indirectly to the 5’ or 3’ terminal region of the second strand of the nucleic acid, preferably at the 3’ terminal region thereof.
- GalNAc ligands are well known in the art and described in, inter alia, EP3775207A1.
- the invention provides a cell containing a nucleic acid, such as inhibitory RNA [ RNAi] as described herein.
- a nucleic acid such as inhibitory RNA [ RNAi] as described herein.
- the invention provides a cell comprising a vector as described herein.
- the invention provides a pharmaceutical composition for inhibiting expression of a target gene, the composition comprising a nucleic acid as disclosed herein.
- the pharmaceutically acceptable composition may comprise an excipient and or carrier.
- Some examples of materials which can serve as pharmaceutically-acceptable carriers include: (1) sugars, such as lactose, glucose and sucrose; (2) starches, such as com starch and potato starch; (3) cellulose, and its derivatives, such as sodium carboxymethyl cellulose, ethyl cellulose and cellulose acetate; (4) powdered tragacanth; (5) malt; (6) gelatin; (7) lubricating agents, such as magnesium stearate, sodium lauryl sulfate and talc; (8) excipients, such as cocoa butter and suppository waxes; (9) oils, such as peanut oil, cottonseed oil, safflower oil, sesame oil, olive oil, com oil and soybean oil; (10) glycols, such as propylene glycol; (11) polyols, such as glycerin, sorbitol, mannitol and polyethylene glycol; (12) esters, such as ethyl oleate and
- Typical pharmaceutical carriers include, but are not limited to, binding agents (e.g., pregelatinized maize starch, polyvinylpyrrolidone or hydroxypropyl methylcellulose, etc.); fillers (e.g., lactose and other sugars, microcrystalline cellulose, pectin, gelatin, calcium sulfate, ethyl cellulose, polyacrylates or calcium hydrogen phosphate, etc.); lubricants (e.g.
- compositions of the present invention can also be used to formulate the compositions of the present invention.
- suitable pharmaceutically acceptable excipients include, but are not limited to, water, salt solutions, alcohols, polyethylene glycols, gelatin, lactose, amylose, magnesium stearate, talc, silicic acid, viscous paraffin, hydroxymethylcellulose, polyvinylpyrrolidone, and the like.
- Formulations for topical administration of nucleic acids can include sterile and non- sterile aqueous solutions, non-aqueous solutions in common solvents such as alcohols, or solutions of the nucleic acids in liquid or solid oil bases.
- the solutions can also contain buffers, diluents and other suitable additives.
- Pharmaceutically acceptable organic or inorganic excipients suitable for non- parenteral administration which do not deleteriously react with nucleic acids can be used.
- the nucleic acid or composition is administered in an unbuffered solution.
- the unbuffered solution is saline or water.
- the nucleic acid e.g. RNAi agent is administered in a buffered solution.
- the buffer solution can comprise acetate, citrate, prolamine, carbonate, or phosphate, or any combination thereof.
- the buffer solution can be phosphate buffered saline (PBS).
- compositions of the invention may be administered in dosages sufficient to inhibit expression of a gene.
- a suitable dose of a nucleic acid e.g. an iRNA of the invention will be in the range of about 0.001 to about 200.0 milligrams per kilogram body weight of the recipient per day, generally in the range of about 1 to 50 mg per kilogram body weight per day.
- a suitable dose of a nucleic acid e.g. an iRNA of the invention will be in the range of about 0.1 mg/kg to about 5.0 mg/kg, e.g., about 0.3 mg/kg and about 3.0 mg/kg.
- a repeat-dose regimen may include administration of a therapeutic amount of a nucleic acid e.g. iRNA on a regular basis, such as every other day or once a year.
- the nucleic acid e.g. iRNA is administered about once per month to about once per quarter (i.e., about once every three months).
- the nucleic acid e.g. RNAi agent is administered at a dose of about 0.01 mg/kg to about 10 mg/kg or about 0.5 mg/kg to about 50 mg/kg. In some embodiments, the nucleic acid e.g. RNAi agent is administered at a dose of about 10 mg/kg to about 30 mg/kg. In certain embodiments, the nucleic acid e.g. RNAi agent is administered at a dose selected from about 0.5 mg/kg 1 mg/kg, 1.5 mg/kg, 3 mg/kg, 5 mg/kg, 10 mg/kg, and 30 mg/kg. In certain embodiments, the nucleic acid e.g.
- RNAi agent is administered about once per week, once per month, once every other two months, or once a quarter (i.e., once every three months) at a dose of about 0.1 mg/kg to about 5.0 mg/kg.
- the nucleic acid e.g. RNAi agent is administered to the subject once a week.
- the nucleic acid e.g. RNAi agent is administered to the subject once a month.
- the nucleic acid e.g. RNAi agent is administered once per quarter (i.e. , every three months).
- the treatments can be administered on a less frequent basis. For example, after administration weekly or biweekly for three months, administration can be repeated once per month, for six months, or a year; or longer.
- the pharmaceutical composition can be administered once daily, or administered as two, three, or more sub-doses at appropriate intervals throughout the day or even using continuous infusion or delivery through a controlled release formulation.
- the nucleic acid e.g. iRNA contained in each sub-dose must be correspondingly smaller in order to achieve the total daily dosage.
- the dosage unit can also be compounded for delivery over several days, e.g. , using a conventional sustained release formulation which provides sustained release of the nucleic acid e.g. iRNA over a several day period. Sustained release formulations are well known in the art and are particularly useful for delivery of agents at a particular site, such as could be used with the agents of the present invention.
- the dosage unit contains a corresponding multiple of the daily dose.
- a single dose of the pharmaceutical compositions can be long lasting, such that subsequent doses are administered at not more than 3, 4, or 5 day intervals, or at not more than 1, 2, 3, or 4 week intervals.
- a single dose of the pharmaceutical compositions of the invention is administered once per week.
- a single dose of the pharmaceutical compositions of the invention is administered bimonthly.
- the iRNA is administered about once per month to about once per quarter (i.e. , about once every three months), or even every 6 months or 12 months.
- compositions of the present invention can be administered in a number of ways depending upon whether local or systemic treatment is desired and upon the area to be treated. Administration can be topical ⁇ e.g. , by a transdermal patch), pulmonary, e.g. , by inhalation or insufflation of powders or aerosols, including by nebulizer; intratracheal, intranasal, epidermal and transdermal, oral or parenteral. Parenteral administration includes intravenous, intraarterial, subcutaneous, intraperitoneal, or intramuscular injection or infusion; subdermal, e.g. , via an implanted device; or intracranial, e.g. , by intraparenchymal, intrathecal or intraventricular administration. In certain preferred embodiments, the compositions are administered by intravenous infusion or injection. In certain embodiments, the compositions are administered by subcutaneous injection.
- the nucleic acid e.g. RNAi agent is administered to the subject subcutaneously.
- the nucleic acid e.g. iRNA can be delivered in a manner to target a particular tissue ⁇ e.g. in particular liver cells).
- the present invention also provides methods of inhibiting expression of a gene in a cell.
- the methods include contacting a cell with an nucleic acid of the invention e.g. RNAi agent, such as double stranded RNAi agent, in an amount effective to inhibit expression of the gene in the cell, thereby inhibiting expression of the gene in the cell.
- an nucleic acid of the invention e.g. RNAi agent, such as double stranded RNAi agent
- RNAi agent e.g. a double stranded RNAi agent
- Contacting a cell in vivo with nucleic acid e.g. iRNA includes contacting a cell or group of cells within a subject, e.g., a human subject, with the nucleic acid e.g. iRNA. Combinations of in vitro and in vivo methods of contacting a cell are also possible. Contacting a cell may be direct or indirect, as discussed above.
- contacting a cell may be accomplished via a targeting ligand moiety, including any ligand moiety described herein or known in the art.
- the targeting ligand moiety is a carbohydrate moiety, e.g. a GalNAc3 ligand, or any other ligand moiety that directs the RNAi agent to a site of interest.
- inhibiting is used interchangeably with “reducing,” “silencing,” “downregulating”, “suppressing”, and other similar terms, and includes any level of inhibition.
- expression of a gene is inhibited by at least 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, or 95%, or to below the level of detection of the assay.
- the methods include a clinically relevant inhibition of expression of a target gene e.g. as demonstrated by a clinically relevant outcome after treatment of a subject with an agent to reduce the expression of the gene [00237] Inhibition of the expression of a gene may be manifested by a reduction of the amount of mRNA of the target gene of interest in comparison to a suitable control.
- inhibition of the expression of a gene may be assessed in terms of a reduction of a parameter that is functionally linked to gene expression, e.g , protein expression or signalling pathways.
- the present invention also provides methods of using nucleic acid e.g. an iRNA of the invention or a composition containing nucleic acid e.g. an iRNA of the invention to reduce or inhibit gene expression in a cell.
- the methods include contacting the cell with a nucleic acid e.g. dsRNA of the invention and maintaining the cell for a time sufficient to obtain degradation of the mRNA transcript of a gene, thereby inhibiting expression of the gene in the cell. Reduction in gene expression can be assessed by any methods known in the art.
- the cell may be contacted in vitro or in vivo, i.e., the cell may be within a subject.
- a cell suitable for treatment using the methods of the invention may be any cell that expresses a gene of interest associated with disease.
- the in vivo methods of the invention may include administering to a subject a composition containing a nucleic acid of the invention e.g. an iRNA, where the nucleic acid e.g. iRNA includes a nucleotide sequence that is complementary to at least a part of an RNA transcript of the gene of the mammal to be treated.
- a nucleic acid of the invention e.g. an iRNA
- the nucleic acid e.g. iRNA includes a nucleotide sequence that is complementary to at least a part of an RNA transcript of the gene of the mammal to be treated.
- the present invention further provides methods of treatment of a subject in need thereof.
- the treatment methods of the invention include administering a nucleic acid such as an iRNA of the invention to a subject, e.g., a subject that would benefit from a reduction or inhibition of the expression of a gene, in a therapeutically effective amount e.g. a nucleic acid such as an iRNA targeting a gene or a pharmaceutical composition comprising the nucleic acid targeting a gene.
- An nucleic acid e.g. iRNA of the invention may be administered as a "free” nucleic acid or “free iRNA, administered in the absence of a pharmaceutical composition.
- the naked nucleic acid may be in a suitable buffer solution.
- the buffer solution may comprise acetate, citrate, prolamine, carbonate, or phosphate, or any combination thereof.
- the buffer solution is phosphate buffered saline (PBS). The pH and osmolarity of the buffer solution can be adjusted such that it is suitable for administering to a subject.
- a nucleic acid e.g. iRNA of the invention may be administered as a pharmaceutical composition, such as a dsRNA liposomal formulation.
- the method includes administering a composition featured herein such that expression of the target gene is decreased, such as for about 1, 2, 3, 4, 5, 6, 7, 8, 12, 16, 18, 24 hours, 28, 32, or about 36 hours.
- expression of the target gene is decreased for an extended duration, e.g., at least about two, three, four days or more, e.g. , about one week, two weeks, three weeks, or four weeks or longer, e.g., about 1 month, 2 months, or 3 months.
- Subjects can be administered a therapeutic amount of nucleic acid e.g. iRNA, such as about 0.01 mg/kg to about 200 mg/kg.
- iRNA nucleic acid
- the nucleic acid e.g. iRNA can be administered by intravenous infusion over a period of time, on a regular basis. In certain embodiments, after an initial treatment regimen, the treatments can be administered on a less frequent basis. Administration of the iRNA can reduce gene product levels of a target gene , e.g., in a cell or tissue of the patient by at least about 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, or 95%, or below the level of detection of the assay method used. In certain embodiments, administration results in clinical stabilization or preferably clinically relevant reduction of at least one sign or symptom of a gene- associated disorder.
- the nucleic acid e.g. iRNA can be administered subcutaneously, i.e. , by subcutaneous injection.
- One or more injections may be used to deliver the desired daily dose of nucleic acid e.g. iRNA to a subject.
- the injections may be repeated over a period of time.
- the administration may be repeated on a regular basis.
- the treatments can be administered on a less frequent basis.
- a repeat-dose regimen may include administration of a therapeutic amount of nucleic acid on a regular basis, such as every other day or to once a year.
- the nucleic acid is administered about once per month to about once per quarter (i.e. , about once every three months).
- the present invention may be applied in the compounds, processes, compositions or uses of the following Sentences numbered 1-101 (wherein reference to any Formula in the Sentences 1-101 refers only to those Formulas that are defined within Sentences 1-101. These formulae are reproduced in Figure 43)
- Ri at each occurrence is independently selected from the group consisting of hydrogen, methyl and ethyl;
- Xi and X2 at each occurrence are independently selected from the group consisting of methylene, oxygen and sulfur; m is an integer of from 1 to 6; n is an integer of from 1 to 10; q, r, s, t, v are independently integers from 0 to 4, with the proviso that:
- Z is an oligonucleotide moiety.
- a compound according to any of Sentences 1 to 17, wherein m 3.
- a compound according to any of Sentences 1 to 18, wherein n 6.
- Zl, Z2, Z3, Z4 are independently at each occurrence oxygen or sulfur; and one the bonds between P and Z2, and P and Z3 is a single bond and the other bond is a double bond.
- RNA compound comprises an RNA duplex comprising first and second strands, wherein the first strand is at least partially complementary to an RNA sequence of a target gene, and the second strand is at least partially complementary to said first strand, and wherein each of the first and second strands have 5’ and 3’ ends.
- a composition comprising a compound of Formula (II) as defined in Sentence 27, and a compound of Formula (III) as defined in Sentence 28, optionally dependent on Sentence 29.
- RNA duplex comprising first and second strands, wherein the first strand is at least partially complementary to an RNA sequence of a target gene, and the second strand is at least partially complementary to said first strand, and wherein each of the first and second strands have 5’ and 3’ ends, and wherein said RNA duplex is attached at the 3’ end of its second strand to the adjacent phosphate.
- a composition comprising a compound of Formula (IV) as defined in Sentence 32, and a compound of Formula (V) as defined in Sentence 33, optionally dependent on Sentence 34.
- oligonucleotide comprises an RNA duplex which further comprises one or more riboses modified at the 2’ position, preferably a plurality of riboses modified at the 2’ position.
- a compound according to Sentence 39 wherein said one or more degradation protective moieties are not present at the end of the oligonucleotide strand that carries the ligand moieties, and / or wherein said one or more degradation protective moieties is selected from phosphorothioate intemucleotide linkages, phosphorodithioate internucleotide linkages and inverted abasic nucleotides, wherein said inverted abasic nucleotides are present at the distal end of the strand that carries the ligand moieties.
- a compound according to any of Sentences 1 to 29, or 32 to 34, or 37 to 40, wherein said ligand moiety as depicted in Formula (I) in Sentence 1 comprises one or more ligands.
- a compound according to Sentence 41, wherein said ligand moiety as depicted in Formula (I) in Sentence 1 comprises one or more carbohydrate ligands.
- a compound according to Sentence 42 wherein said one or more carbohydrates can be a monosaccharide, disaccharide, trisaccharide, tetrasaccharide, oligosaccharide or polysaccharide.
- a compound according to Sentence 43 wherein said one or more carbohydrates comprise one or more galactose moieties, one or more lactose moieties, one or more N- AcetylGalactosamine moieties, and / or one or more mannose moieties.
- a compound according to Sentence 45 which comprises two or three N- AcetylGalactosamine moieties.
- a compound according to Sentence 47 wherein said one or more ligands are attached as a biantennary or triantennary branched configuration.
- Moiety Moiety as depicted in Formula (I) in Sentence 1 is any of Formulae (Via), (VIb) or (Vic), preferably Formula (Via):
- Ai is hydrogen, or a suitable hydroxy protecting group; a is an integer of 2 or 3; and b is an integer of 2 to 5; or
- Ai is hydrogen, or a suitable hydroxy protecting group; a is an integer of 2 or 3; and c and d are independently integers of 1 to 6; or
- Ai is hydrogen, or a suitable hydroxy protecting group; a is an integer of 2 or 3; and e is an integer of 2 to 10.
- a compound according to Sentences 46 to 48, wherein said moiety: as depicted in Formula (I) in Sentence 1 is Formula (VII):
- Ai is hydrogen; a is an integer of 2 or 3.
- RNA duplex comprising first and second strands, wherein the first strand is at least partially complementary to an RNA sequence of a target gene, and the second strand is at least partially complementary to said first strand, and wherein each of the first and second strands have 5’ and 3’ ends, and wherein said RNA duplex is attached at the 5’ end of its second strand to the adjacent phosphate.
- a composition comprising a compound of Formula (VIII) as defined in Sentence 54, and a compound of Formula (IX) as defined in Sentence 55, optionally dependent on Sentence 56.
- a composition comprising a compound of Formula (X) as defined in Sentence 59, and a compound of Formula (XI) as defined in Sentence 60, optionally dependent on Sentence 61.
- a composition according to Sentence 62 wherein said compound of Formula (XI) as defined in Sentence 60 is present in an amount in the range of 10 to 15% by weight of said composition.
- Ri at each occurrence is independently selected from the group consisting of hydrogen, methyl and ethyl;
- Xi and X2 at each occurrence are independently selected from the group consisting of methylene, oxygen and sulfur; m is an integer of from 1 to 6; n is an integer of from 1 to 10; q, r, s, t, v are independently integers from 0 to 4, with the proviso that:
- Z is an oligonucleotide moiety; and where appropriate carrying out deprotection of the ligand and / or annealing of a second strand for the oligonucleotide moiety.
- Sentence 68 wherein a compound of Formula (XII) is prepared by reacting compounds of Formulae (XIV) and (XV):
- Ri at each occurrence is independently selected from the group consisting of hydrogen, methyl and ethyl;
- Xi and X2 at each occurrence are independently selected from the group consisting of methylene, oxygen and sulfur; q, r, s, t, v are independently integers from 0 to 4, with the proviso that:
- Z is an oligonucleotide moiety.
- oligonucleotide comprises an RNA duplex comprising first and second strands, wherein the first strand is at least partially complementary to an RNA sequence of a target gene, and the second strand is at least partially complementary to said first strand, and wherein each of the first and second strands have 5’ and 3’ ends, and wherein said RNA duplex is attached at the 5’ end of its second strand to the adjacent phosphate.
- oligonucleotide comprises an RNA duplex comprising first and second strands, wherein the first strand is at least partially complementary to an RNA sequence of a target gene, and the second strand is at least partially complementary to said first strand, and wherein each of the first and second strands have 5’ and 3’ ends, and wherein said RNA duplex is attached at the 5’ end of its second strand to the adjacent phosphate.
- oligonucleotide comprises an RNA duplex comprising first and second strands, wherein the first strand is at least partially complementary to an RNA sequence of a target gene, and the second strand is at least partially complementary to said first strand, and wherein each of the first and second strands have 5’ and 3’ ends, and wherein said RNA duplex is attached at the 3’ end of its second strand to the adjacent phosphate.
- oligonucleotide comprises an RNA duplex comprising first and second strands, wherein the first strand is at least partially complementary to an RNA sequence of a target gene, and the second strand is at least partially complementary to said first strand, and wherein each of the first and second strands have 5’ and 3’ ends, and wherein said RNA duplex is attached at the 3’ end of its second strand to the adjacent phosphate.
- Formula (XlVb) and compound of Formula (XV) is either Formula (XVa) or Formula (XlVb):
- Formula (XVb) wherein the oligonucleotide comprises an RNA duplex comprising first and second strands, wherein the first strand is at least partially complementary to an RNA sequence of a target gene, and the second strand is at least partially complementary to said first strand, and wherein each of the first and second strands have 5’ and 3’ ends, and wherein (i) said RNA duplex is attached at the 5’ end of its second strand to the adjacent phosphate in Formula (XVa), or (ii) said RNA duplex is attached at the 3’ end of its second strand to the adjacent phosphate in Formula (XVb).
- Ri at each occurrence is independently selected from the group consisting of hydrogen, methyl and ethyl;
- Xi and X2 at each occurrence are independently selected from the group consisting of methylene, oxygen and sulfur;
- q, r, s, t, v are independently integers from 0 to 4, with the proviso that:
- Z is an oligonucleotide moiety.
- Ri at each occurrence is independently selected from the group consisting of hydrogen, methyl and ethyl; m is an integer of from 1 to 6; n is an integer of from 1 to 10.
- Ri is selected from the group consisting of hydrogen, methyl and ethyl
- X2 is selected from the group consisting of methylene, oxygen and sulfur; s, t, v are independently integers from 0 to 4, with the proviso that s, t and v cannot all be 0 at the same time.
- R1 at each occurrence is independently selected from the group consisting of hydrogen, methyl and ethyl;
- XI is selected from the group consisting of methylene, oxygen and sulfur; q and r are independently integers from 0 to 4, with the proviso that q and r cannot both be 0 at the same time;
- Z is an oligonucleotide moiety.
- a pharmaceutical composition comprising of a compound according to any of Sentences 1 to 29, 32 to 34, 37 to 56, 59 to 61, and 64 to 67, and / or a composition according to any of Sentences 30, 31, 35, 36, 57, 58, 62 and 63, together with a pharmaceutically acceptable carrier, diluent or excipient.
- a compound comprising the following structure: Formula (I) wherein: r and s are independently an integer selected from 1 to 16; and
- Z is an oligonucleotide moiety.
- Zi, Z2, Z3, Z4 are independently at each occurrence oxygen or sulfur; and one the bonds between P and Z2, and P and Z 3 is a single bond and the other bond is a double bond.
- oligonucleotide is an RNA compound capable of modulating, preferably inhibiting, expression of a target gene.
- RNA compound comprises an RNA duplex comprising first and second strands, wherein the first strand is at least partially complementary to an RNA sequence of a target gene, and the second strand is at least partially complementary to said first strand, and wherein each of the first and second strands have 5’ and 3’ ends.
- oligonucleotide comprises an RNA duplex which further comprises one or more riboses modified at the 2’ position, preferably a plurality of riboses modified at the 2’ position.
- a compound according to Clause 21, wherein said one or more carbohydrates can be a monosaccharide, disaccharide, trisaccharide, tetrasaccharide, oligosaccharide or polysaccharide.
- Ai is hydrogen, or a suitable hydroxy protecting group; a is an integer of 2 or 3; and b is an integer of 2 to 5; or
- Ai is hydrogen, or a suitable hydroxy protecting group; a is an integer of 2 or 3; and c and d are independently integers of 1 to 6; or
- Ai is hydrogen, or a suitable hydroxy protecting group; a is an integer of 2 or 3; and e is an integer of 2 to 10.
- Ai is hydrogen; a is an integer of 2 or 3. 30.
- a compound according to Clause 28 or 29, wherein a 2.
- Formula (IX) A compound according to Clause 33 or 34, wherein the oligonucleotide comprises an RNA duplex which further comprises one or more riboses modified at the 2’ position, preferably a plurality of riboses modified at the 2’ position.
- a compound according to Clause 35, wherein the modifications are chosen from 2’-O- methyl, 2’-deoxy-fluoro, and 2’-deoxy.
- a compound according to Clause 37 wherein said one or more degradation protective moieties are not present at the end of the oligonucleotide strand that carries the linker / ligand moieties, and / or wherein said one or more degradation protective moieties is selected from phosphorothioate internucleotide linkages, phosphorodithioate intemucleotide linkages and inverted abasic nucleotides, wherein said inverted abasic nucleotides are present at the distal end of the same strand to the end that carries the linker / ligand moieties.
- the oligonucleotide comprises an RNA duplex comprising first and second strands, wherein the first strand is at least partially complementary to an RNA sequence of a target gene, and the second strand is at least partially complementary to said first strand, and wherein each of the first and second strands have 5’ and 3’ ends, and wherein said RNA duplex is attached at the 5’ end of its second strand to the adjacent phosphate.
- RNA duplex comprising first and second strands, wherein the first strand is at least partially complementary to an RNA sequence of a target gene, and the second strand is at least partially complementary to said first strand, and wherein each of the first and second strands have 5’ and 3’ ends, and wherein said RNA duplex is attached at the 3’ end of its second strand to the adjacent phosphate.
- Z is an oligonucleotide moiety; and where appropriate carrying out deprotection of the ligand and / or annealing of a second strand for the oligonucleotide.
- Formula (Xa) and compound of Formula (XI) is Formula (Xia):
- oligonucleotide comprises an RNA duplex comprising first and second strands, wherein the first strand is at least partially complementary to an RNA sequence of a target gene, and the second strand is at least partially complementary to said first strand, and wherein each of the first and second strands have 5’ and 3’ ends, and wherein said RNA duplex is attached at the 5’ end of its second strand to the adjacent phosphate.
- oligonucleotide comprises an RNA duplex comprising first and second strands, wherein the first strand is at least partially complementary to an RNA sequence of a target gene, and the second strand is at least partially complementary to said first strand, and wherein each of the first and second strands have 5’ and 3’ ends, and wherein said RNA duplex is attached at the 3’ end of its second strand to the adjacent phosphate.
- Z is an oligonucleotide moiety.
- a pharmaceutical composition comprising of a compound according to any of Clauses 1 to 40, together with a pharmaceutically acceptable carrier, diluent or excipient.
- references to (invabasic)(invabasic) refers to nucleotides in an overall polynucleotide which are the terminal 2 nucleotides which have sugar moieties that are (i) abasic, and (ii) in an inverted configuration, whereby the bond between the penultimate nucleotide and the antepenultimate nucleotide has a reversed linkage, namely either a 5-5 or a 3-3 linkage. Again, this similarly applies to all other references to (invabasic)(invabasic) herein.
- linker portions as shown in FIG 30 / FIG 31 which can be present in any of products ETX001, ETX005, ETX010, ETX014, ETX019, ETX023 according to the present invention, that while these products can include molecules based on the linker and ligand portions as specifically depicted in FIG 30 / FIG 31 attached to an oligonucleotide moiety as also depicted herein, these products may alternatively further comprise, or consist essentially of, molecules wherein the linker and ligand portions are essentially as depicted in FIG 30 / FIG 31 attached to an oligonucleotide moiety but having the F substituent as shown in FIG 30 / FIG 31 on the cyclo-octyl ring replaced by a substituent occurring as a result of hydrolytic displacement, such as an OH substituent.
- these products can consist essentially of molecules having linker and ligand portions specifically as depicted in FIG 30 / FIG 31, with a F substituent on the cyclo-octyl ring; or (b) these products can consist essentially of molecules having linker and ligand portions essentially as depicted in FIG 30 / FIG 31 but having the F substituent as shown in FIG 30 / FIG 31 on the cyclo-octyl ring replaced by a substituent occurring as a result of hydrolytic displacement, such as an OH substituent, or (c) these products can comprise a mixture of molecules as defined in (a) or (b).
- GalNAc-siRNAs targeting either hsHAOl, hsC5 or hsTTR mRNA were synthesized and QC-ed. The entire set of siRNAs (except siRNAs targeting HAO1) was first studied in a dose-response setup in HepG2 cells by transfection using RNAiMAX, followed by a doseresponse analysis in a gymnotic free uptake setup in primary human hepatocytes.
- the aim of this set of experiments was to analyze the in vitro activity of different GalNAc-ligands in the context of siRNAs targeting three different on-targets, namely hsHAO 1 , hsC5 or hsTTR mRNA.
- HepG2 cells were supplied by American Tissue Culture Collection (ATCC) (HB-8065, Lot # 63176294) and cultured in ATCC- formulated Eagle's Minimum Essential Medium supplemented to contain 10 % fetal calf serum (FCS).
- ATCC American Tissue Culture Collection
- FCS fetal calf serum
- Primary human hepatocytes (PHHs) were sourced from Primacyt (Schwerin, Germany) sf-4589539 (Lot#: CyHufl9009HEc). Cells are derived from a malignant glioblastoma tumor by explant technique. All cells used in this study were cultured at 37°C in an atmosphere with 5% CO2 in a humidified incubator.
- Control wells were transfected into HepG2 cells or directly incubated with primary human hepatocytes at the highest test siRNA concentrations studied on the corresponding plate. All control siRNAs included in the different project phases next to mock treatment of cells are summarized and listed in Table 2. For each siRNA and control, at least four wells were transfected/directly incubated in parallel, and individual data points were collected from each well.
- branched DNA (bDNA) assay was performed according to manufacturer’ s instructions. Luminescence was read using a 1420 Luminescence Counter (WALLAC VICTOR Light, Perkin Elmer, Rodgau-Jugesheim, Germany) following 30 minutes incubation in the presence of substrate in the dark. For each well, the on-target mRNA levels were normalized to the hsGAPDH mRNA levels. The activity of any siRNA was expressed as percent on-target mRNA concentration (normalized to hsGAPDH mRNA) in treated cells, relative to the mean on- target mRNA concentration (normalized to hsGAPDH mRNA) across control wells.
- bDNA probe sets were designed and synthesised specific for Homo sapiens GAPDH, AHSA1, hsHAOl, hsC5 and hsTTR.
- bDNA probe sets were initially tested by bDNA analysis according to manufacturer’s instructions, with evaluation of levels of mRNAs of interest in two different lysate amounts, namely lOpl and 50pl, of the following human and monkey cancer cell lines next to primary human hepatocytes: SJSA-1, TF1, NCI-H1650, Y-79, Kasumi-1, EAhy926, Caki-1, Colo205, RPTEC, A253, HeLaS3, Hep3B, BxPC3, DU145, THP-1, NCI-H460, IGR37, LS174T, Be(2)-C, SW 1573, NCI-H358, TC71, 22Rvl, BT474, HeLa, KBwt, Panc-1, U
- Fig. 1 to Fig. 3 show mRNA expression data for the three on-targets of interest, namely hsC5, hsHAOl and hsTTR, in lysates of a diverse set of human cancer cell lines plus primary human hepatocytes. Cell numbers per lysate volume are identical with each cell line tested, this is necessary to allow comparisons of expression levels amongst different cell types.
- Fig. 1 shows hsC5 mRNA expression data for all cell types tested.
- mRNA expression levels for all three on-targets of interest are high enough in primary human hepatocytes (PHHs).
- HepG2 cells could be used to screen GalNAc-siRNAs targeting hsC5 and hsTTR mRNAs, in contrast, no cancer cell line could be identified which would be suitable to test siRNAs specific for hsHAOl mRNA.
- Table 3 Target, incubation time, external ID, IC20/IC50/IC80 values and maximal inhibition of hsTTR targeting siRNAs in HepG2 cells. The listing is ordered according to external ID, with 4h of incubation listed on top and 24h of incubation on the bottom.
- hsTTR GalNAc-siRNAs have been identified that silence the on-target mRNA >95% with IC50 values in the low double-digit pM range.
- the second target of interest was tested in an identical dose-response setup (with minimally different final siRNA test concentrations, however) by transfection of HepG2 cells using RNAiMAX with GalNAc-siRNAs sharing identical linger/position/GalNAc-ligand variations as with hsTTR siRNAs, but sequences specific for the on-target hsC5 mRNA.
- Table 4 Target, incubation time, external ID, IC20/IC50/IC80 values and maximal inhibition of hsC5 targeting siRNAs in HepG2 cells. The listing is ordered according to external ID, with 4h of incubation listed on top and 24h of incubation on the bottom.
- the dose-response analysis of the two GalNAc-siRNA sets in human cancer cell line HepG2 should demonstrate (and ensure) that all new GalNAc-/linker/position/cap variants are indeed substrates for efficient binding to AGO2 and loading into RISC, and in addition, able to function in RNAi-mediated cleavage of target mRNA.
- dose-response analysis experiments should be done in primary human hepatocytes by gymnotic, free uptake setup.
- Hepatocytes do exclusively express the Asialoglycoprotein receptor (ASGR1) to high levels, and this receptor generally is used by the liver to remove target glycoproteins from circulation.
- ASGR1 Asialoglycoprotein receptor
- oligonucleotides e.g. siRNAs or ASOs
- GalNAc-ligands conjugated to GalNAc-ligands are recognized by this high turnover receptor and efficiently taken up into the cytoplasm via clathrin-coated vesicles and trafficking to endosomal compartments. Endosomal escape is thought to be the rate-limiting step for oligonucleotide delivery.
- FIG. 6 shows the absolute mRNA expression data for all three on-targets of interest - hsTTR, hsC5 and hsHAOl - in the primary human hepatocyte batches BHuf 16087, CHF2101 and CyHufl9009. mRNA expression levels of hsGAPDH and hsAHSAl are shown in Figure 7.
- Table 5 Target, incubation time, external ID, IC20/IC50/IC80 values and maximal inhibition of hsHAOl targeting GalNAc-siRNAs in primary human hepatocytes (PHHs). The listing is organized according to external ID, with 4h and 72h incubation listed on top and bottom, respectively.
- the second target of interest, hsC5 mRNA was tested in an identical dose-response setup by gymnotic, free uptake in PHHs with GalNAc-siRNAs sharing identical linker/position/GalNAc-ligand variations as with hsTTR and hsHAOl tested in the assays before, but sequences specific for the on-target hsC5 mRNA. Sequences for the GalNAc- siRNAs targeting hsC5 and all sequences and information about control siRNAs are listed in Table 1 and Table 2, respectively. The experiment ended after 4h and 72h direct incubation of PHHs. Table 6 lists activity data for all hsC5 targeting GalNAc-siRNAs studied.
- Table 6 Target, incubation time, external ID, IC20/IC50/IC80 values and maximal inhibition of hsC5 targeting GalNAc-siRNAs in PHHs. The listing is organized according to external ID, with 4h and 72h incubation listed on top and bottom, respectively.
- hsTTR mRNA The last target of interest, hsTTR mRNA, was again tested in a gymnotic, free uptake in PHHs in an identical dose-response setup as for the targets hsHAOl and hsC5, with the only difference being that specific siRNA sequences for the on-target hsTTR mRNA was used (see Table 1).
- Table 7 Target, incubation time, external ID, IC20/IC50/IC80 values and maximal inhibition of hsTTR targeting GalNAc-siRNAs in primary human hepatocytes (PHHs). The listing is organized according to external ID.
- Results are also shown in Figures 10A-B.
- Gymnotic, free uptake of GalNAc-siRNAs targeting hsTTR did lead to significant on- target silencing within 72h, ranging between 46 to 82.5% maximal inhibition.
- hsTTR GalNAc- siRNAs were identified that silence the on-target mRNA with IC50 values in the low doubledigit nM range.
- siRNA sets specific for each target were composed of siRNAs with different linker/cap/modification/GalNAc-ligand chemistries in the context of two different antisense strands each.
- GalNAc-siRNAs from Table 1 were identified that showed a high overall potency and low IC50 value.
- TLC Thin layer chromatography
- fluorescence indicator 254 nm from Macherey -Nagel.
- Compounds were visualized under UV light (254 nm), or after spraying with the 5% H2SO4 in methanol (MeOH) or ninhydrin reagent according to Stahl (from Sigma-Aldrich), followed by heating.
- Flash chromatography was performed with a Biotage Isolera One flash chromatography instrument equipped with a dual variable UV wavelength detector (200-400 nm) using Biotage Sfar Silica 10, 25, 50 or 100 g columns (Uppsala, Sweden).
- the solvent system consisted of solvent A with H2O containing 0.1% formic acid and solvent B with acetonitrile (ACN) containing 0.1% formic acid. A gradient from 5-100% of B over 15 min with a flow rate of 0.4 mL/min was employed.
- Detector and conditions Corona ultra-charged aerosol detection (from esa). Nebulizer Temp.: 25 °C. N2 pressure: 35.1 psi. Filter: Corona.
- A,A,A',A'-tetramethyl-O-(lH-benzotriazol-l-yl)uronium hexafluorophosphate (HBTU) (2.78 g, 7.44 mmol, 5.0 eq.), 1 -hydroxybenzotriazole hydrate (HOBt) (1.05 g, 7.44 mmol, 5.0 eq.) and A,A-diisopropylethylamine (DIPEA) (2.07 mL, 11.9 mmol, 8.0 eq.) were added to the solution and the reaction was stirred for 72 h.
- DIPEA 1,1-diisopropylethylamine
- TriGalNAc (12) Triantennary GalNAc compound 10 (0.35 g, 0.24 mmol, 1.0 eq.) and compound 11 (0.11 g, 0.31 mmol, 1.5 eq.) were dissolved in DCM (5 mL) under argon and triethylamine (0.1 mL, 0.61 mmol, 3.0 eq.) was added. The reaction was stirred at room temperature overnight. The solvent was removed under reduced pressure, the residue was dissolved in EtOAc (100 mL) and washed with water (100 mL). The organic layer was separated and dried over Na2SO4.
- RNA nucleotides a, c, g, u: 2’-O-Me RNA nucleotides dT DNA nucleotides s: Phosphorothioate invabasic: 1, 2-dideoxyribose
- Oligonucleotides were synthesized on solid phase according to the phosphoramidite approach. Depending on the scale either a Mermade 12 (BioAutomation Corporation) or an AKTA Oligopilot (GE Healthcare) was used.
- 2' -O-Methyl phosphoramidites include: 5'-(4,4'-dimethoxytrityl)-A-benzoyl-adenosine 2'-O-methyl-3'- [(2-cyanoethyl)-(A,A-diisopropyl)]-phosphoramidite, 5'-(4,4'-dimethoxytrityl)- A-benzoyl-cytidine 2'-O-methyl-3'- [(2-cyanoethyl)-(A,A-diisopropyl)]-phosphoramidite, 5'- (4,4'-dimethoxytrityl)-A-dimethylformamidine-guanosine 2'-O-methyl-3'-[(2-cyanoethyl)-(A,A- diisopropyl)]-phosphoramidite, 5'-(4,4'-dimethoxytrityl)-uridine 2'-
- 2’ -F phosphoramidites include: 5'-dimethoxytrityl-A-benzoyl-deoxyadenosine 2'- fluoro-3'-[(2-cyanoethyl)-(A,A-diisopropyl)]-phosphoramidite, 5'-dimethoxytrityl-A-acetyl- deoxycytidine 2'-fluoro-3'-[(2-cyanoethyl)-(A,A-diisopropyl)]-phosphoramidite, 5'- dimethoxytrityl-A-isobutyryl-deoxyguanosine 2'-fluoro-3'- [(2-cyanoethyl)-(A,A-diisopropyl)]- phosphoramidite and 5'-dimethoxytrityl-deoxyuridine 2'-fluoro-3'-[(2-cyanoethyl)-(A,A-di
- the invabasic modification was introduced using 5-O-dimethoxytrityl-l,2- dideoxyribose-3-[(2-cyanoethyl)-(A,A-diisopropyl)]-phosphoramidite (ChemGenes Cat. # ANP- 1422).
- the oligonucleotides were cleaved from the solid support using a 1 : 1 volume solution of 28-30% ammonium hydroxide (Sigma-Aldrich, Cat. #221228) and 40% aqueous methylamine (Sigma- Aldrich, Cat. #8220911000) for 16 hours at 6°C.
- the solid support was then filtered off, the filter was thoroughly washed with H2O and the volume of the combined solution was reduced by evaporation under reduced pressure.
- the pH of the resulting solution was adjusted to pH 7 with 10% AcOH (Sigma- Aldrich, Cat. # A6283).
- the crude materials were purified either by reversed phase (RP) HPLC or anion exchange (AEX) HPLC.
- RP HPLC purification was performed using a XBridge C18 Prep 19 x 50 mm column (Waters) on an AKTA Pure instrument (GE Healthcare).
- Buffer A was 100 mM tri ethylammonium acetate (TEAAc, Biosolve) pH 7 and buffer B contained 95% acetonitrile in buffer A.
- a flow rate of 10 mL/min and a temperature of 60°C were employed.
- UV traces at 280 nm were recorded.
- a gradient of 0% B to 100% B within 120 column volumes was employed. Appropriate fractions were pooled and precipitated in the freezer with 3 M sodium acetate (NaOAc) (Sigma- Aldrich), pH 5.2 and 85% ethanol (VWR).
- Pellets were isolated by centrifugation, redissolved in water (50 mL), treated with 5 M NaCl (5 mL) and desalted by Size exclusion HPLC on an Akta Pure instrument using a 50 x 165mm ECO column (YMC, Dinslaken, Germany) filled with Sephadex G25-Fine resin (GE Healthcare).
- AEX HPLC purification was performed using a TSK gel SuperQ-5PW 20 x 200 mm (BISCHOFF Chromatography) on an AKTA Pure instrument (GE Healthcare).
- Buffer A was 20 mM sodium phosphate (Sigma-Aldrich) pH 7.8 and buffer B was the same as buffer A with the addition of 1.4 M sodium bromide (Sigma- Aldrich).
- a flow rate of 10 mL/min and a temperature of 60°C were employed.
- UV traces at 280 nm were recorded.
- a gradient of 10% B to 100% B within 27 column volumes was employed.
- Appropriate fractions were pooled and precipitated in the freezer with 3 M NaOAc, pH 5.2 and 85% ethanol.
- Pellets were isolated by centrifugation, redissolved in water (50 mL), treated with 5 M NaCl (5 mL) and desalted by size exclusion chromatography.
- reaction mixture was diluted 15-fold with water, filtered through a 1.2 pm filter from Sartorius and then purified by reserve phase (RP HPLC) on an Akta Pure instrument (GE Healthcare).
- SUBSTITUTE SHEET (RULE 26) A. A flow rate of 10 mL/min and a temperature of 60°C were employed. UV traces at 280 nm were recorded. A gradient of 0-100% B within 60 column volumes was employed.
- RP HPLC purification was performed using a XBridge C18 Prep 19 x 50 mm column from Waters.
- Buffer A was 100 mM tri ethylammonium acetate pH 7 and buffer B contained 95% acetonitrile in buffer A.
- a flow rate of 10 mL/min and a temperature of 60°C were employed.
- UV traces at 280 nm were recorded.
- a gradient of 0-100% B within 60 column volumes was employed.
- conjugates were desalted by size exclusion chromatography using Sephadex G25 Fine resin (GE Healthcare) on an Akta Pure (GE Healthcare) instrument to yield the conjugated nucleotide in an isolated yield of 50-70%.
- the two complementary strands were annealed by combining equimolar aqueous solutions of both strands. The mixtures were placed into a water bath at 70°C for 5 minutes and subsequently allowed to cool to ambient temperature within 2 h. The duplexes were lyophilized for 2 days and stored at -20°C.
- duplexes were analyzed by analytical SEC HPLC on SuperdexTM 75 Increase 5/150 GL column 5 x 153-158 mm (Cytiva) on a Dionex Ultimate 3000 (Thermo Fisher Scientific) HPLC system.
- Mobile phase consisted of lx PBS containing 10% acetonitrile.
- An isocratic gradient was run in 10 min at a flow rate of 1.5 mL/min at room temperature. UV traces at 260 and 280 nm were recorded.
- Water (LC-MS grade) was purchased from Sigma-Aldrich and Phosphate-buffered saline (PBS; lOx, pH 7.4) was purchased from GIBCO (Thermo Fisher Scientific).
- GalNAc conjugates prepared are compiled in the table below. These were directed against 3 different target genes. siRNA coding along with the corresponding single strands, sequence information as well as purity for the duplexes is captured.
- GalNAc-siRNAs targeting either hsHAOl, hsC5 or hsTTR mRNA were synthesized and QC-ed. The entire set of siRNAs (except siRNAs targeting HA01) was first studied in a dose-response setup in HepG2 cells by transfection using RNAiMAX, followed by a doseresponse analysis in a gymnotic free uptake setup in primary human hepatocytes.
- the aim of this set of experiments was to analyze the in vitro activity of different GalNAc-ligands in the context of siRNAs targeting three different on-targets, namely hsHAOl, hsC5 or hsTTR mRNA.
- Work packages of this study included (i) assay development to design, synthesize and test bDNA probe sets specific for each and every individual on-target of interest, (ii) to identify a cell line suitable for subsequent screening experiments, (iii) dose-response analysis of potentially all siRNAs (by transfection) in one or more human cancer cell lines, and (iv) dose-response analysis of siRNAs in primary human hepatocytes in a gymnotic, free uptake setting. In both settings, IC50 values and maximal inhibition values should be calculated followed by ranking of the siRNA study set according to their potency.
- Oligonucleotide synthesis [00345] Standard solid-phase synthesis methods were used to chemically synthesize siRNAs of interest (see Table 12) as well as controls (see Table 13).
- HepG2 cells were supplied by American Tissue Culture Collection (ATCC) (HB-8065, Lot #: 63176294) and cultured in ATCC-formulated Eagle's Minimum Essential Medium supplemented to contain 10 % fetal calf serum (FCS).
- ATCC American Tissue Culture Collection
- FCS fetal calf serum
- Primary human hepatocytes (PHHs) were sourced from Primacyt (Schwerin, Germany) (Lot#: CyHufl 9009HEc). Cells are derived from a malignant glioblastoma tumor by explant technique. All cells used in this study were cultured at 37°C in an atmosphere with 5% CO2 in a humidified incubator.
- Control wells were transfected into HepG2 cells or directly incubated with primary human hepatocytes at the highest test siRNA concentrations studied on the corresponding plate. All control siRNAs included in the different project phases next to mock treatment of cells are summarized and listed in Table 13. For each siRNA and control, at least four wells were transfected/directly incubated in parallel, and individual data points were collected from each well.
- branched DNA (bDNA) assay was performed according to manufacturer’ s instructions. Luminescence was read using a 1420 Luminescence Counter (WALLAC VICTOR Light, Perkin Elmer, Rodgau-Jugesheim, Germany) following 30 minutes incubation in the presence of substrate in the dark. For each well, the on-target mRNA levels were normalized to the hsGAPDH mRNA levels. The activity of any siRNA was expressed as percent on-target mRNA concentration (normalized to hsGAPDH mRNA) in treated cells, relative to the mean on-target mRNA concentration (normalized to hsGAPDH mRNA) across control wells.
- bDNA probe sets were designed and synthesised specific for Homo sapiens GAPDH, AHSA1, hsHAOl, hsC5 and hsTTR.
- bDNA probe sets were initially tested by bDNA analysis according to manufacturer’s instructions, with evaluation of levels of mRNAs of interest in two different lysate amounts, namely lOpl and 50pl, of the following human and monkey cancer cell lines next to primary human hepatocytes: SJSA-1, TF1, NCLH1650, Y-79, Kasumi-1, EAhy926, Caki-1, Colo205, RPTEC, A253, HeLaS3, Hep3B, BxPC3, DU145, THP-1, NCI-H460, IGR37, LS174T, Be(2)-C, SW 1573, NCLH358, TC71, 22Rvl, BT474, HeLa, KBwt, Panc-1, U87MG
- Fig. 1 to Fig. 3 show mRNA expression data for the three on-targets of interest, namely hsC5, hsHAOl and hsTTR, in lysates of a diverse set of human cancer cell lines plus primary human hepatocytes. Cell numbers per lysate volume are identical with each cell line tested, this is necessary to allow comparisons of expression levels amongst different cell types.
- Fig. 1 shows hsC5 mRNA expression data for all cell types tested.
- the identical type of cells were also screened for expression of hsHAOl mRNA, results are shown in bar diagrams as part of Fig. 2.
- mRNA expression levels for all three on-targets of interest are high enough in primary human hepatocytes (PHHs).
- HepG2 cells could be used to screen GalNAc-siRNAs targeting hsC5 and hsTTR mRNAs, in contrast, no cancer cell line could be identified which would be suitable to test siRNAs specific for hsHAOl mRNA.
- HepG2 cells were transfected with the entire set of hsTTR targeting GalNAc-siRNAs (see Table 12) in a dose-response setup using RNAiMAX. The highest final siRNA test concentration was 24nM, going down in ninecells. Table 14 lists activity data for all hsTTR targeting GalNAC-siRNAs studied.
- Table 14 Target, incubation time, external ID, IC20/IC50/IC80 values and maximal inhibition of hsTTR targeting siRNAs in HepG2 cells. The listing is ordered according to external ID, with 4h of incubation listed on top and 24h of incubation on the bottom.
- hsTTR GalNAc-siRNAs have been identified that silence the on-target mRNA >95% with IC50 values in the low double-digit pM range.
- hsC5 mRNA The second target of interest, hsC5 mRNA, was tested in an identical dose-response setup (with minimally different final siRNA test concentrations, however) by transfection of HepG2 cells using RNAiMAX with GalNAc-siRNAs sharing identical linger/position/GalNAc-ligand variations as with hsTTR siRNAs, but sequences specific for the on-target hsC5 mRNA.
- Table 15 Target, incubation time, external ID, IC20/IC50/IC80 values and maximal inhibition of hsC5 targeting siRNAs in HepG2 cells. The listing is ordered according to external ID, with 4h of incubation listed on top and 24h of incubation on the bottom.
- Hepatocytes do exclusively express the Asialoglycoprotein receptor (ASGR1) to high levels, and this receptor generally is used by the liver to remove target glycoproteins from circulation.
- ASGR1 Asialoglycoprotein receptor
- oligonucleotides e.g. siRNAs or ASOs
- GalNAc-ligands conjugated to GalNAc-ligands are recognized by this high turnover receptor and efficiently taken up into the cytoplasm via clathrin-coated vesicles and trafficking to endosomal compartments. Endosomal escape is thought to be the ratelimiting step for oligonucleotide delivery.
- FIG. 6 shows the absolute mRNA expression data for all three on-targets of interest - hsTTR, hsC5 and hsHAOl - in the primary human hepatocyte batches BHufl6087, CHF2101 and CyHufl9009. mRNA expression levels of hsGAPDH and hsAHSAl are shown in Figure 7.
- Table 16 Target, incubation time, external ID, IC20/IC50/IC80 values and maximal inhibition ofhsHAOl targeting GalNAc-siRNAs in primary human hepatocytes (PHHs). The listing is organized according to external ID, with 4h and 72h incubation listed on top and bottom, respectively.
- Table 17 Target, incubation time, external ID, IC20/IC50/IC80 values and maximal inhibition of hsC5 targeting GalNAc-siRNAs in PHHs. The listing is organized according to external ID, with 4h and 72h incubation listed on top and bottom, respectively.
- Table 18 Target, incubation time, external ID, IC20/IC50/IC80 values and maximal inhibition ofhsTTR targeting GalNAc-siRNAs in primary human hepatocytes (PHHs). The listing is organized according to external ID.
- siRNA sets specific for each target were composed of siRNAs with different linker/cap/modification/GalNAc-ligand chemistries in the context of two different antisense strands each.
- GalNAc-siRNAs from Table 12 were identified that showed a high overall potency and low IC50 value.
- HPLC/ESI-MS was performed on a Dionex UltiMate 3000 RS UHPLC system and Thermo Scientific MSQ Plus Mass spectrometer using an Acquity UPLC Protein BEH C4 column from Waters (300A, 1.7 pm, 2.1 x 100 mm) at 60 °C.
- the solvent system consisted of solvent A with H2O containing 0.1% formic acid and solvent B with acetonitrile (ACN) containing 0.1% formic acid. A gradient from 5-100% of B over 15 min with a flow rate of 0.4 mL/min was employed.
- Detector and conditions Corona ultra-charged aerosol detection (from esa). Nebulizer Temp.: 25 °C. N2 pressure: 35.1 psi. Filter: Corona.
- N,N,N′,N′-tetramethyl-O-(1H-benzotriazol-1- yl)uronium hexafluorophosphate (HBTU) (2.78 g, 7.44 mmol, 5.0 eq.), 1- hydroxybenzotriazole hydrate (HOBt) (1.05 g, 7.44 mmol, 5.0 eq.) and N,N- diisopropylethylamine (DIPEA) (2.07 mL, 11.9 mmol, 8.0 eq.) were added to the solution and the reaction was stirred for 72 h. The solvent was removed under reduced pressure, the residue was dissolved in DCM (100 mL) and washed with saturated aq.
- DIPEA N,N,N′,N′-tetramethyl-O-(1H-benzotriazol-1- yl)uronium hexafluorophosphate
- TriGalNAc Triantennary GalNAc compound 14 (0.31 g, 0.15 mmol, 1.0 eq.) was dissolved in EtOAc (15 mL) and Pd/C (40 mg) was added. The reaction mixture was degassed by using vacuum/argon cycles (3x) and hydrogenated under balloon pressure overnight. The completion of the reaction was monitored by mass spectrometry and the resulting mixture was filtered through a thin pad of celite. The solvent was removed under reduced pressure and the resulting residue was dried under high vacuum over night. The residue was used for conjugations to oligonucleotides without further purification (0.28 g, quantitative yield). MS: calculated for C81H131N7O42, 1874.9. Found 1875.3. ix) Oligonucleotide Synthesis
- RNA nucleotides a, c, g, u: 2 ’-O-Me RNA nucleotides dT DNA nucleotides s: Phosphorothioate invabasic: 1, 2-dideoxyribose
- Oligonucleotides were synthesized on solid phase according to the phosphoramidite approach. Depending on the scale either a Mermade 12 (BioAutomation Corporation) or an KTA Oligopilot (GE Healthcare) was used.
- 2'-O-Methyl phosphoramidites include: 5'-(4,4'-dimethoxytrityl)-N-benzoyl-adenosine 2'-O-methyl-3'- [(2-cyanoethyl)-(N,N-diisopropyl)]-phosphoramidite, 5'-(4,4'- dimethoxytrityl)-N-benzoyl-cytidine 2'-O-methyl-3'- [(2-cyanoethyl)-(N,N-diisopropyl)]- phosphoramidite, 5'-(4,4'-dimethoxytrityl)-N-dimethylformamidine-guanosine 2'-O-methyl- 3'-[(2-cyanoethyl)-(N,N-diisopropyl)]-phosphoramidite, 5'-(4,4'-dimethoxytrityl)-uridine 2
- 2’-F phosphoramidites include: 5'-dimethoxytrityl-N-benzoyl-deoxyadenosine 2'- fluoro-3'-[(2-cyanoethyl)-(N,N-diisopropyl)]-phosphoramidite, 5'-dimethoxytrityl-N-acetyl- deoxycytidine 2'-fluoro-3'-[(2-cyanoethyl)-(N,N-diisopropyl)]-phosphoramidite, 5'- dimethoxytrityl-N-isobutyryl-deoxyguanosine 2'-fluoro-3'- [(2-cyanoethyl)-(N,N- diisopropyl)]-phosphoramidite and 5'-dimethoxytrityl-deoxyuridine 2'-fluoro-3'-[(2- cyanoethyl)-(N,N-
- the oligonucleotides were cleaved from the solid support using a 1 : 1 volume solution of 28-30% ammonium hydroxide (Sigma-Aldrich, Cat. #221228) and 40% aqueous methylamine (Sigma-Aldrich, Cat. #8220911000) for 16 hours at 6°C.
- the solid support was then filtered off, the filter was thoroughly washed with H2O and the volume of the combined solution was reduced by evaporation under reduced pressure.
- the pH of the resulting solution was adjusted to pH 7 with 10% AcOH (Sigma- Aldrich, Cat. # A6283).
- RP HPLC purification was performed using a XBridge C18 Prep 19 x 50 mm column (Waters) on an AKTA Pure instrument (GE Healthcare).
- Buffer A was 100 mM triethylammonium acetate (TEAAc, Biosolve) pH 7 and buffer B contained 95% acetonitrile in buffer A.
- a flow rate of 10 mL/min and a temperature of 60°C were employed.
- UV traces at 280 nm were recorded.
- a gradient of 0% B to 100% B within 120 column volumes was employed. Appropriate fractions were pooled and precipitated in the freezer with 3 M sodium acetate (NaOAc) (Sigma-Aldrich), pH 5.2 and 85% ethanol (VWR).
- NaOAc sodium acetate
- VWR 85% ethanol
- Pellets were isolated by centrifugation, redissolved in water (50 mL), treated with 5 M NaCl (5 mL) and desalted by Size exclusion HPLC on an Akta Pure instrument using a 50 x 165mm ECO column (YMC, Dinslaken, Germany) filled with Sephadex G25-Fine resin (GE Healthcare).
- AEX HPLC purification was performed using a TSK gel SuperQ-5PW 20 x 200 mm (BISCHOFF Chromatography) on an AKTA Pure instrument (GE Healthcare).
- Buffer A was 20 mM sodium phosphate (Sigma-Aldrich) pH 7.8 and buffer B was the same as buffer A with the addition of 1.4 M sodium bromide (Sigma- Aldrich).
- a flow rate of 10 mL/min and a temperature of 60°C were employed.
- UV traces at 280 nm were recorded.
- a gradient of 10% B to 100% B within 27 column volumes was employed. Appropriate fractions were pooled and precipitated in the freezer with 3 M NaOAc, pH 5.2 and 85% ethanol.
- Pellets were isolated by centrifugation, redissolved in water (50 mL), treated with 5 M NaCl (5 mL) and desalted by size exclusion chromatography. [00404] The MMT group was removed with 25% acetic acid in water. Once the reaction was complete the solution was neutralized and the samples were desalted by size exclusion chromatography.
- conjugates were desalted by size exclusion chromatography using Sephadex G25 Fine resin (GE Healthcare) on an Akta Pure (GE Healthcare) instrument to yield the conjugated oligonucleotides in an isolated yield of 60-80%.
- the conjugates were characterized by HPLC-MS analysis with a 2.1 x 50 mm XBridge C18 column (Waters) on a Dionex Ultimate 3000 (Thermo Fisher Scientific) HPLC system equipped with a Compact ESI-Qq-TOF mass spectrometer (Bruker Daltonics).
- Buffer A was 16.3 mM triethylamine, 100 mM HFIP in 1% MeOH in H2O and buffer B contained 95% MeOH in buffer A.
- a flow rate of 250 pL/min and a temperature of 60°C were employed.
- UV traces at 260 and 280 nm were recorded.
- a gradient of 1-100% B within 31 min was employed.
- the two complementary strands were annealed by combining equimolar aqueous solutions of both strands. The mixtures were placed into a water bath at 70°C for 5 minutes and subsequently allowed to cool to ambient temperature within 2 h. The duplexes were lyophilized for 2 days and stored at -20°C.
- duplexes were analyzed by analytical SEC HPLC on SuperdexTM 75 Increase 5/150 GL column 5 x 153-158 mm (Cytiva) on a Dionex Ultimate 3000 (Thermo Fisher Scientific) HPLC system.
- Mobile phase consisted of lx PBS containing 10% acetonitrile.
- An isocratic gradient was run in 10 min at a flow rate of 1.5 mL/min at room temperature. UV traces at 260 and 280 nm were recorded.
- Water (LC-MS grade) was purchased from Sigma- Aldrich and Phosphate-buffered saline (PBS; lOx, pH 7.4) was purchased from GIBCO (Thermo Fisher Scientific).
- GalNAc conjugates prepared are compiled in the table below. These were directed against 3 different target genes. siRNA coding along with the corresponding single strands, sequence information as well as purity for the duplexes is captured.
- mice with an age of about 8 weeks were randomly assigned into groups of 21 mice.
- the animals received a single subcutaneous dose of 0.3 or 3 mg/kg GalNAc-siRNA dissolved in saline (sterile 0.9% sodium chloride) or saline only as control.
- saline sterile 0.9% sodium chloride
- mice from each group were euthanised and serum and liver samples taken.
- Serum was taken from a group of 5 untreated mice at day 0 to provide a baseline measurement of glycolate concentration.
- Serum was stored at -80°C until further analysis. Liver sample (approximately 50 mg) were treated with RNAlater and stored overnight at 4°C, before being stored at -80°C.
- Liver samples were analysed using quantitative real-time PCR for HA01 mRNA (Thermo assay ID Mm00439249_ml) and the housekeeping gene GAPDH mRNA (Thermo assay ID Mm99999915_gl).
- the delta delta Ct method was used to calculated changes in HA01 expression normalised to GAPDH and relative to the saline control group.
- a single 3 mg/kg dose of ETX005 inhibited HA01 mRNA expression by greater than 80% after 7 days (FIG 16). The suppression of HAO 1 expression was durable, with a single 3 mg/kg dose of ETX005 maintaining greater than 60% inhibition of HAO 1 mRNA at the end of the study on day 28. A single dose of 0.3 mg/kg ETX005 also inhibited HA01 expression when compared with the saline control group, with HAO1 expression levels reaching normal levels only at day 28 of the study.
- HAO 1 mRNA expression is expected to cause an increase in serum glycolate levels.
- Serum glycolate concentration was measured using LC-MS/MS (FIG 17).
- a single 3 mg/kg dose of ETX005 caused a significant increase in serum glycolate concentration, reaching peak levels 14 days after dosing and remaining higher than baseline level (day 0) and the saline control group until the end of the study at day 28.
- a single 0.3 mg/kg dose of ETX005 showed a smaller and more transient increase in serum glycolate concentration above the level seen in a baseline and saline control group, demonstrating that a very small dose can suppress HA01 mRNA at a magnitude sufficient to affect the concentration of a metabolic biomarker in serum.
- FIG 16. Single dose mouse pharmacology of ETX005. HA01 mRNA expression is shown relative to the saline control group. Each point represents the mean and standard deviation of 3 mice.
- FIG. Single dose mouse pharmacology of ETX005. Serum glycolate concentration is shown. Each point represents the mean and standard deviation of 3 mice, except for baseline glycolate concentration (day 0) which was derived from a group of 5 mice.
- mice with an age of about 8 weeks were randomly assigned into groups of 21 mice.
- the animals received a single subcutaneous dose of 0.3 or 3 mg/kg GalNAc-siRNA dissolved in saline (sterile 0.9% sodium chloride) or saline only as control.
- saline sterile 0.9% sodium chloride
- mice from each group were euthanised and serum and liver samples taken.
- Serum was taken from a group of 5 untreated mice at day 0 to provide a baseline measurement of glycolate concentration.
- Serum was stored at -80°C until further analysis. Liver sample (approximately 50 mg) were treated with RNAlater and stored overnight at 4°C, before being stored at -80°C.
- Liver samples were analysed using quantitative real-time PCR for HA01 mRNA (Thermo assay ID Mm00439249_ml) and the housekeeping gene GAPDH mRNA (Thermo assay ID Mm99999915_gl).
- the delta delta Ct method was used to calculated changes in HA01 expression normalised to GAPDH and relative to the saline control group.
- a single 3 mg/kg dose of ETX006 inhibited HA01 mRNA expression by than 80% after 7 days (FIG 18). The suppression of HAO 1 expression was durable and continued until the end of the study, with ETX006 maintaining greater than 60% inhibition of HAO 1 mRNA at day 28.
- a single dose of 0.3 mg/kg also inhibited HA01 expression when compared with the saline control group, with HA01 expression levels reaching normal levels only at day 28 of the study.
- HAO 1 mRNA expression is expected to cause an increase in serum glycolate levels.
- Serum glycolate concentration was measured using LC-MS/MS (FIG 19).
- a single 3 mg/kg dose of ETX006 caused a significant increase in serum glycolate concentration, reaching peak levels 14 days after dosing and remaining higher than baseline levels (day 0) and the saline control group until the end of the study at day 28.
- a single 0.3 mg/kg dose of ETX006 showed a smaller and more transient increase in serum glycolate concentration above the level seen in a baseline and saline control groups, demonstrating that a very small dose can also affect the concentration of a metabolic biomarker in serum.
- FIG 18. Single dose mouse pharmacology of ETX006. HA01 mRNA expression is shown relative to the saline control group. Each point represents the mean and standard deviation of 3 mice.
- FIG 19. Single dose mouse pharmacology of ETX006. Serum glycolate concentration is shown. Each point represents the mean and standard deviation of 3 mice, except for baseline glycolate concentration (day 0) which was derived from a group of 5 mice.
- Serum was stored at -80°C until further analysis. Liver sample (approximately 50 mg) were treated with RNAlater and stored overnight at 4°C, before being stored at -80°C.
- liver samples were analysed using quantitative real-time PCR for C5 mRNA (Thermo assay ID Mm00439275_ml) and the housekeeping gene GAPDH mRNA (Thermo assay ID Mm99999915_g1).
- the delta delta Ct method was used to calculated changes in C5 expression normalised to GAPDH and relative to the saline control group.
- ETX014 inhibited C5 mRNA expression in a dose-dependent manner (FIG 20) with the 3 mg/kg dose achieving greater than 90% reduction in C5 mRNA at day 14.
- the suppression of C5 expression by ETX014 was durable, with the 3 mg/kg dose of each molecule showing clear knockdown of C5 mRNA until the end of the study at day 28.
- C5 protein level analysis serum samples were measured using a commercially available C5 ELISA kit (Abeam ab264609). Serum C5 levels were calculated relative to the saline group means at matching timepoints.
- Serum protein data support the mRNA analysis (FIG 21).
- Treatment with ETX014 caused a dose-dependent decrease in serum C5 protein concentration. All doses of ETX014 reduced C5 protein levels by greater than 70%, with the 3 mg/kg dose reducing C5 levels to almost undetectable levels at day 7 of the study. Reduction of serum C5 was sustained by all doses until study termination, with even the lowest dose of 0.3 mg/kg still showing inhibition of approximately 40% at day 28.
- FIG 20 Single dose mouse pharmacology of ETX014. C5 mRNA expression is shown relative to the saline control group. Each point represents the mean and standard deviation of 3 mice.
- FIG 21 Single dose mouse pharmacology of ETX0014. Serum C5 concentration is shown relative to the saline control group. Each point represents the mean and standard deviation of 3 mice.
- ETX015 Targeting C5 mRNA
- T2a inverted abasic
- mice with an age of about 8 weeks were randomly assigned into groups of 21 mice.
- the animals received a single subcutaneous dose of 0.3, 1, or 3 mg/kg GalNAc-siRNA dissolved in saline (sterile 0.9% sodium chloride) or saline only as control.
- saline sterile 0.9% sodium chloride
- mice from each group were euthanised and serum and liver samples taken.
- Serum was stored at -80°C until further analysis. Liver sample (approximately 50 mg) were treated with RNAlater and stored overnight at 4°C, before being stored at -80°C.
- Liver samples were analysed using quantitative real-time PCR for C5 mRNA (Thermo assay ID Mm00439275_ml) and the housekeeping gene GAPDH mRNA (Thermo assay ID Mm99999915_gl).
- the delta delta Ct method was used to calculated changes in C5 expression normalised to GAPDH and relative to the saline control group.
- ETX015 inhibited C5 mRNA expression in a dose-dependent manner (FIG 22) with the 3 mg/kg dose achieving greater than 85% reduction of C5 mRNA.
- the suppression of C5 expression was durable, with the 3 mg/kg dose of each molecule showing clear knockdown of C5 mRNA until the end of the study at day 28.
- Mice dosed with 3 mg/kg ETX015 still exhibited less than 50% of normal liver C5 mRNA levels 28 days after dosing.
- C5 protein level analysis serum samples were measured using a commercially available C5 ELISA kit (Abeam ab264609). Serum C5 levels were calculated relative to the saline group means at matching timepoints.
- FIG 23 Serum protein data support the mRNA analysis (FIG 23).
- ETX015 caused a dosedependent decrease in serum C5 protein concentration.
- the 3 mg/kg and 1 mg/kg doses of ETX015 achieved greater than 90% reduction of serum C5 protein levels.
- the highest dose exhibited durable suppression of C5 protein expression, with a greater than 70% reduction of C5 at day 28 of the study compared to saline control.
- FIG 22 Single dose mouse pharmacology of ETX015. C5 mRNA expression is shown relative to the saline control group. Each point represents the mean and standard deviation of 3 mice.
- FIG 23 Single dose mouse pharmacology of ETX0014. Serum C5 concentration is shown relative to the saline control group. Each point represents the mean and standard deviation of 3 mice.
- ETX023 pharmacology was evaluated in non-human primate (NHP) by quantifying serum transthyretin (TTR) protein levels.
- TTR serum transthyretin
- mice Male cynomolgus monkeys (3-5 years old, 2-3 kg) were assigned into groups of 3 animals. Animals were acclimatised for 2 weeks, and blood taken 14 days prior to dosing to provide baseline TTR concentration. A liver biopsy was performed 18 or 38 days prior to dosing to provide baseline mRNA levels. On day 0 of the study, the animals received a single subcutaneous dose of 1 mg/kg GalNAc-siRNA ETX023 dissolved in saline (sterile 0.9% sodium chloride). At day 3, day 14, day 28, day 42, day 56, day 70 and day 84 of the study, a liver biopsy was taken and RNA extracted for measurement of TTR mRNA. At day 1, day 3, day 7, day 14, day 28, day 42, day 56, day 70 and day 84 of the study, a blood sample was taken for measurement of serum TTR concentration and clinical blood chemistry analysis.
- TTR protein concentration was measured by a commercially available ELISA kit (Abeam ab231920). TTR concentration as a fraction of day 1 was calculated for each individual animal and this was plotted as mean and standard deviation for the group of 3 animals (FIG 24).
- a single 1 mg/kg dose of ETX023 caused a rapid and significant reduction in serum TTR concentration, reaching nadir 28 days after dosing and remaining suppressed until day 70.
- TTR mRNA was measured by real-time quantitative PCR using a TaqMan Gene expression kit TTR (Thermo, assay ID Mf02799963_ml). GAPDH expression was also measured (Thermo, assay ID Mf04392546_gl) to provide a reference. Relative TTR expression for each animal was calculated normalised to GAPDH and relative to pre-dose levels by the AACt method. A single 1 mg/kg dose of ETX023 also caused a rapid and significant reduction in liver TTR mRNA, reaching nadir 14 days after dosing and remaining suppressed until day 84 (FIG 28b).
- Serum was analysed within 2 hours using an automatic biochemical analyser.
- a significant increase in ALT (alanine transaminase) and AST (aspartate transaminase) are commonly used to demonstrate liver toxicity.
- No increase in ALT (FIG 28d) or ALT (FIG 28e) was associated with dosing of ETX023.
- ETX024 pharmacology was evaluated in non-human primate (NHP) by quantifying serum transthyretin (TTR) protein levels.
- TTR serum transthyretin
- mice Male cynomolgus monkeys (3-5 years old, 2-3 kg) were assigned into groups of 3 animals. Animals were acclimatised for 2 weeks, and blood taken 14 days prior to dosing to provide baseline TTR concentration. A liver biopsy was performed 18 or 38 days prior to dosing to provide baseline mRNA levels. On day 0 of the study, the animals received a single subcutaneous dose of 1 mg/kg GalNAc-siRNA ETX024 dissolved in saline (sterile 0.9% sodium chloride). At day 3, day 14, day 28, day 42, day 56, day 70 and day 84 of the study, a liver biopsy was taken and RNA extracted for measurement of TTR mRNA. At day 1, day 3, day 7, day 14, day 28, day 42, day 56, 70 and day 84 of the study, a blood sample was taken for measurement of serum TTR concentration and clinical blood chemistry analysis.
- TTR protein concentration was measured by a commercially available ELISA kit (Abeam ab231920). TTR concentration as a fraction of day 1 was calculated for each individual animal and this was plotted as mean and standard deviation for the group of 3 animals (FIG 25).
- a single 1 mg/kg dose of ETX024 caused a rapid and significant reduction in serum TTR concentration, reaching nadir 28 days after dosing and remaining suppressed until day 70.
- TTR mRNA was measured by real-time quantitative PCR using a TaqMan Gene expression kit TTR (Thermo, assay ID Mf02799963_ml). GAPDH expression was also measured (Thermo, assay ID Mf04392546_gl) to provide a reference. Relative TTR expression for each animal was calculated normalised to GAPDH and relative to pre-dose levels by the AACt method. A single 1 mg/kg dose of ETX024 caused a rapid and significant reduction in liver TTR mRNA, reaching nadir 14 days after dosing and remaining suppressed until day 84 (FIG 29b).
- ALT alanine transaminase
- AST aspartate transaminase
- compounds of the invention are able to depress serum protein level of a target protein to a value below the initial (starting) concentration at day 0, over a period of up to at least about 14 days after day 0, up to at least about 21 days after day 0, up to at least about 28 days after day 0, up to at least about 35 days after day 0, up to at least about 42 days after day 0, up to at least about 49 days after day 0, up to at least about 56 days after day 0, up to at least about 63 days after day 0, up to at least about 70 days after day 0, up to at least about 77 days after day 0, or up to at least about 84 days after day 0, hereinafter referred to as the “dose duration”.
- Day 0 as referred to herein is the day when dosing of a compound of the invention to a patient is initiated, in other words the start of the dose duration or the time post dose.
- compounds of the invention are able to depress serum protein level of a target protein to a value of at least about 90% or below of the initial (starting) concentration at day 0, such as at least about 85% or below, at least about 80% or below, at least about 75% or below, at least about 70% or below, at least about 65% or below, at least about 60% or below, at least about 55% or below, at least about 50% or below, at least about 45% or below, at least about 40% or below, at least about 35% or below, at least about 30% or below, at least about 25% or below, at least about 20% or below, at least about 15% or below, at least about 10% or below, at least about 5% or below, of the initial (starting) concentration at day 0.
- depression of serum protein can be maintained over a period of up to at least about 14 days after day 0, up to at least about 21 days after day 0, up to at least about 28 days after day 0, up to at least about 35 days after day 0, up to at least about 42 days after day 0, up to at least about 49 days after day 0, up to at least about 56 days after day 0, up to at least about 63 days after day 0, up to at least about 70 days after day 0, up to at least about 77 days after day 0, or up to at least about 84 days after day 0.
- the serum protein can be depressed to a value of at least about 90% or below of the initial (starting) concentration at day 0, such as at least about 85% or below, at least about 80% or below, at least about 75% or below, at least about 70% or below, at least about 65% or below, at least about 60% or below, at least about 55% or below, at least about 50% or below, at least about 45% or below, at least about 40% or below, of the initial (starting) concentration at day 0.
- compounds of the invention are able to achieve a maximum depression of serum protein level of a target protein to a value of at least about 50% or below of the initial (starting) concentration at day 0, such as at least about 45% or below, at least about 40% or below, at least about 35% or below, at least about 30% or below, at least about 25% or below, at least about 20% or below, at least about 15% or below, at least about 10% or below, at least about 5% or below, of the initial (starting) concentration at day 0.
- maximum depression of serum protein occurs at about day 14 after day 0, at about day 21 after day 0, at about day 28 after day 0, at about day 35 after day 0, or at about day 42 after day 0. More typically, such maximum depression of serum protein occurs at about day 14 after day 0, at about day 21 after day 0, or at about day 28 after day 0.
- Specific compounds of the invention can typically achieve a maximum % depression of serum protein level of a target protein and / or a % depression over a period of up to at least about 84 days as follows:
- ETX019 can typically achieve at least 50% depression of serum protein level of a target protein, typically TTR, typically at about 7 to 21 days after day 0, in particular at about 14 days after day 0, and / or can typically maintain at least 90% depression of serum protein level of a target protein, typically TTR, over a period of up to at least about 84 days after day 0 (as hereinbefore described, “day 0” as referred to herein is the day when dosing of a compound of the invention to a patient is initiated, and as such denotes the time post dose);
- ETX020 can typically achieve at least 30% depression of serum protein level of a target protein, typically TTR, typically at about 7 to 21 days after day 0, in particular at about 14 days after day 0, and / or can typically maintain at least 80% depression of serum protein level of a target protein, typically TTR, over a period of up to at least about 84 days after day 0 (as hereinbefore described, “day 0” as referred to herein is the day when dosing of a compound of the invention to a patient is initiated, and as such denotes the time post dose);
- ETX023 can typically achieve at least 20% depression of serum protein level of a target protein, typically TTR, typically at about 7 to 21 days after day 0, in particular at about 14 days after day 0, and / or can typically maintain at least 50% depression of serum protein level of a target protein, typically TTR, over a period of up to at least about 84 days after day 0 (as hereinbefore described, “day 0” as referred to herein is the day when dosing of a compound of the invention to a patient is initiated, and as such denotes the time post dose);
- ETX024 can typically achieve at least 20% depression of serum protein level of a target protein, typically TTR, typically at about 7 to 21 days after day 0, in particular at about 14 days after day 0, and / or can typically maintain at least 60% depression of serum protein level of a target protein, typically TTR, over a period of up to at least about 84 days after day 0 (as hereinbefore described, “day 0” as referred to herein is the day when dosing of a compound of the invention to a patient is initiated, and as such denotes the time post dose).
- day 0 as referred to herein is the day when dosing of a compound of the invention to a patient is initiated, and as such denotes the time post dose).
- the depression of serum level is determined in non-human primates by delivering a single subcutaneous dose of 1 mg/kg of the relevant active agent, eg ETX0023 or ETX0024, dissolved in saline (sterile 0.9% sodium chloride). Suitable methods are described herein. It will be appreciated that this is not limiting and other suitable methods with appropriate controls may be used.
- the relevant active agent eg ETX0023 or ETX0024
- saline sterile 0.9% sodium chloride
- Example 7 ETX023 (Targeting TTR mRNA) Tla inverted abasic
- Kidney health was monitored by assessment of urea (blood urea nitrogen, BUN) and creatinine concentration throughout the study. Both blood urea concertation (BUN) and creatinine levels remained stable and within the expected range after a single 1 mg/kg dose of ETX023 (FIG 35 and 36).
- Example 8 ETX024 (Targeting TTR mRNA) T2a inverted abasic
- Kidney health was monitored by assessment of urea (blood urea nitrogen, BUN) and creatinine concentration throughout the study. Both blood urea concertation (BUN) and creatinine levels remained stable and within the expected range after a single 1 mg/kg dose of ETX024 (FIG 38 and 39).
- FIG. 40A depicts a tri-antennary GalNAc (A-acetylgalactosamine) unit.
- FIG. 40B depicts an alternative tri-antennary GalNAc according to one embodiment of the invention, showing variance in linking groups.
- FIG. 41A depicts tri-antennary GalNAc-conjugated siRNA according to the invention, showing variance in the linking groups.
- FIG. 41B depicts a genera of tri-antennary GalNAc-conjugated siRNAs according to one embodiment of the invention.
- FIG. 41C depicts a genera of bi-antennary GalNAc-conjugated siRNAs according to one embodiment of the invention, showing variance in the linking groups.
- FIG. 41D depicts a genera of bi-antennary GalNAc-conjugated siRNAs according to another embodiment of the invention, showing variance in the linking groups.
- FIG. 42A depicts another embodiment of the tri-antennary GalNAc-conjugated siRNA according to one embodiment of the invention.
- FIG. 42B depicts a variant shown in Fig. 27A, having an alternative branching GalNAc conjugate.
- FIG. 42C depicts a genera of tri-antennary GalNAc-conjugated siRNAs according to one embodiment of the invention, showing variance in the linking groups.
- FIG. 42D depicts a genera of bi-antennary GalNAc-conjugated siRNAs according to one embodiment the invention, showing variance in the linking groups.
- the further aspect discloses forms of ASGP-R ligand-conjugated, chemically modified RNAi agents, and methods of making and uses of such conjugated molecules.
- the ASGP-R ligand comprises /'/-acetylgalactosamine (GalNAc).
- the invention provides an siRNA conjugated to tri- antennary or biantennary units of GalNAc of the following formula (I):
- n 0, 1, 2, 3, or 4.
- the number of the ethyleneglycol units may vary independently from each other in the different branches.
- Other embodiments my contain only two branches, as depicted in Formulae (Il-a)
- n is chosen from 0, 1, 2, 3, or 4.
- the number of the ethylene-glycol units may vary independently from each other in the different branches.
- GalNAc branches can also be added, for example, 4-, 5-, 6-, 7-, 8-, 9- branched GalNAc units may be used.
- the branched GalNAc can be chemically modified by the addition of another targeting moiety, e.g., a lipids, cholesterol, a steroid, a bile acid, targeting (poly)peptide, including polypeptides and proteins, (e.g., RGD peptide, transferrin, poly glutamate, polyaspartate, glycosylated peptide, biotin, asialoglycoprotein insulin and EGF.
- another targeting moiety e.g., a lipids, cholesterol, a steroid, a bile acid
- targeting (poly)peptide including polypeptides and proteins, (e.g., RGD peptide, transferrin, poly glutamate, polyaspartate, glycosylated peptide, biotin, asialoglycoprotein insulin and EGF.
- the GalNAc units may be attached to the RNAi agent via a tether, such as the one shown in Formula (III*):
- m is chosen from 0, 1, 2, 3, 4, or 5 and p is chosen from 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, or 14, independently of m, and X is either CH2 or O.
- Such an attachment of the GalNAc branched units via the specified tethers is preferably at a 3’ or a 5’ end of the sense strand of the RNAi agent.
- the attachment to the 3’ of RNAi agent is through C6 amino linker as shown in Formula (V*):
- This linker is the starting point of the synthesis as shown in Example 15.
- the same linkers and tethers as described above can be used with alternative branched
- the GalNAc units may be attached to the RNAi agent via a tether, such as the one shown in Formula (III*-2):
- q is chosen from 1, 2, 3, 4, 5, 6, 7, or 8.
- Such an attachment of the GalNAc branched units via the specified tethers preferably at a 3’ or a 5’ end of the sense strand of the double stranded RNAi agent.
- the attachment to the 3’ of RNAi agent is as shown in Example 17.
- the transitional linker between the tether and the 3’ end of the oligo comprises the structure of the formula (V*-a; see also Fig. 42C) or another suitable linker may be used, for example, C6 amino linker shown in Formula (V*-b):
- Additional and/or alternative conjugation sites may include any non-terminal nucleotide, including sugar residues, phosphate groups, or nucleic acid bases.
- the conjugated oligomeric compound (referred herein as RNA interference compound (RNAi compound)) comprises two strands, each having sequence of from 8 to 55 linked nucleotide monomer subunits (including inverted abasic (ia) nucleotide(s)) in either the antisense strand or in the sense strand.
- the conjugated oligomeric compound strands comprise, for example, a sequence of 16 to 55, 53, 49, 40, 25, 24, 23, 21, 20, 19, 18, 17, or up to (about) 18-25, 18-23, 21-23 linked nucleotide monomer subunits.
- RNAi agent of the invention may have a hairpin structure, having a single strand of the combined lengths of both strands as described above.
- nucleotide as used throughout, may also refer to nucleosides (i.e., nucleotides without phosphate/phosphonothioate groups) where context so requires.)
- the double stranded RNAi agent is blunt-ended or has an overhang at one or both ends.
- the overhang is 1-6, 1-5, 1-4, 1-3, 2-4, 4, 3, 2 or 1 nucleotide(s) (at 3’ end or at 5’ end) of the antisense strand as well as 2-4, 3, or 2 or 1 nucleotide(s) (at 3’ end or at 5’ end) of the sense strand.
- the RNAi agent comprises 2 nucleotide overhang at the 3’ end of the antisense strand and 2 nucleotide overhang at 3’ end of the sense strand.
- the RNAi agents comprise 2 nucleotide overhang at the 3’ end of the antisense strand and are blunt-ended on the other end.
- the construct is blunt-ended on both ends.
- the RNAi agent comprises 4 nucleotide overhang in the 3’ end of the antisense strand and blunt-ended on the other end.
- the constructs are modified with a degradation protective moiety that prevents or inhibits nuclease cleavage by using a terminal cap, one or more inverted abasic nucleotides, one or more phosphorothioate linkages, one of more deoxynucleotides (e.g., D-ribonucleotide, D-2'-deoxyribonucleotide or another modified nucleotide), or a combination thereof.
- Such degradation protective moieties may be present at any one or all ends that are not conjugated to the ASGP-R ligand.
- the degradation protective moiety is chosen alone or as any combination from a group consisting of 1-4, 1-3, 1-2, or 1 phosphorothioate linkages, 1-4 1-3, 1-2, or 1 deoxynucleotides, and 1-4, 1-3, 1-2, or 1 inverted abasic nucleotides.
- the degradation protective moieties are configured as in one of the constructs 9.1, 9.2, 9.3, 10.1, 10.2, 10.3, 11.1, 11.2, 11.3, 12.1, 12.2, and 12.3, as shown in the Examples 9-18.
- Such exemplary protective moieties’ configurations can be used in conjunction with any RNAi agents of the invention.
- all or some riboses of the nucleotides in the sense and/or antisense strand (s) are modified. In certain embodiments, at least 50%, 60%, 70%, 80%, 90% or more (e.g., 100%) of riboses in the RNAi agent are modified. In certain embodiments, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 or more riboses are not modified.
- ribose modifications include 2’ substituent groups such as 2’-O-alkyl modifications, including 2’-O-methyl, and 2’ -deoxyfluoro. Additional modifications are known in the art, including 2’-deoxy, LNA (e.g., 2'-O, 4'-C methylene bridge or 2'-O, 4'-C ethylene bridge), 2’-methoxythoxy (MOE), 2’-O-(CH2)OCH3, etc.
- LNA e.g., 2'-O, 4'-C methylene bridge or 2'-O, 4'-C ethylene bridge
- MOE 2’-methoxythoxy
- a number of modifications provide a distinct pattern of modifications, for example, as shown in constructs in the Examples 9-18, or as described in US Patents Nos. 7,452,987; 7,528,188; 8,273,866; 9,150,606; and 10,266,825; all of which are incorporated by reference herein.
- the siRNA comprises one or more thermally destabilizing nucleotides, e.g., GNA, ENA, etc., for example, at positions 11 (preferred), 12, 13 of the antisense strand and/or positions 9 and 10 (preferred) of the sense strand. .
- thermally destabilizing nucleotides e.g., GNA, ENA, etc.
- nucleic acid bases could be modified, for example, at the C4 position as described in US Patent No. 10,119,136.
- the RNAi agents of the invention are directed against therapeutic targets, inhibition of which will result in prevention, alleviation, or treatment of a disease, including undesirable or pathological conditions.
- targets include: ApoC, ApoB, ALAS1, TTR, GO, C5 (see Examples), etc.
- targets are human, while the RNAi agent comprise an antisense strand fully or partially complementary to such a target.
- the RNAi agents may comprise two or more chemically linked RNAi agents directed against the same or different targets.
- Example 9 Inverted abasic chemistry with 5’-GalNAc
- ia inverted abasic nucleotide
- m 2’-O-methyl nucleotide
- f 2 ’-deoxy-2’ -fluoro nucleotide
- s phosphorothioate internucleotide linkage
- Example 10 Inverted abasic chemistry with 3’-GalNAc
Abstract
Description














































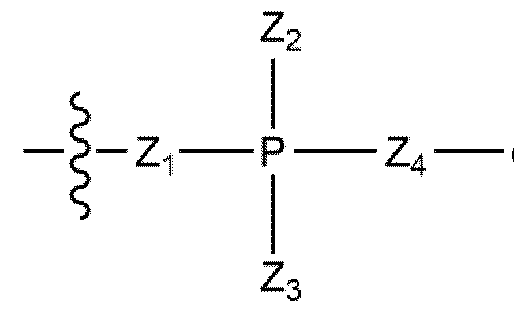



















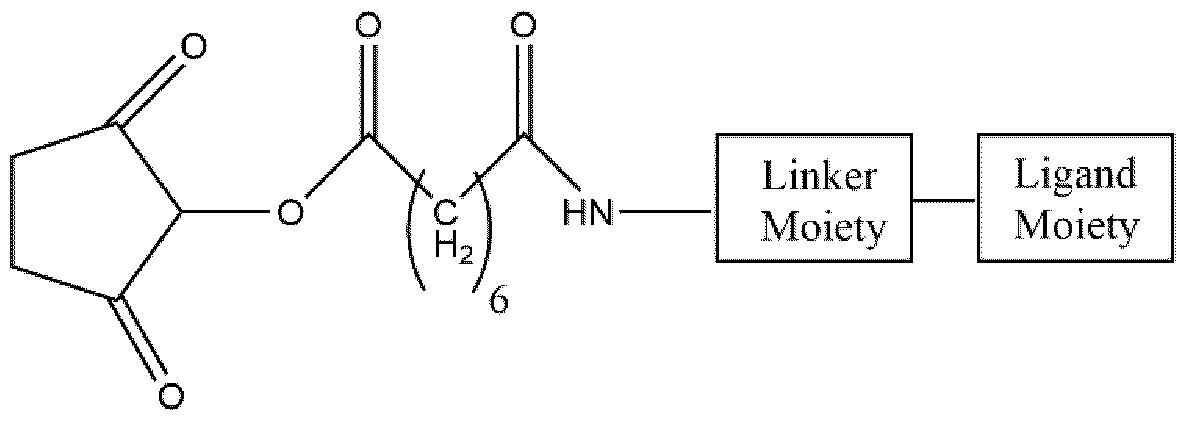








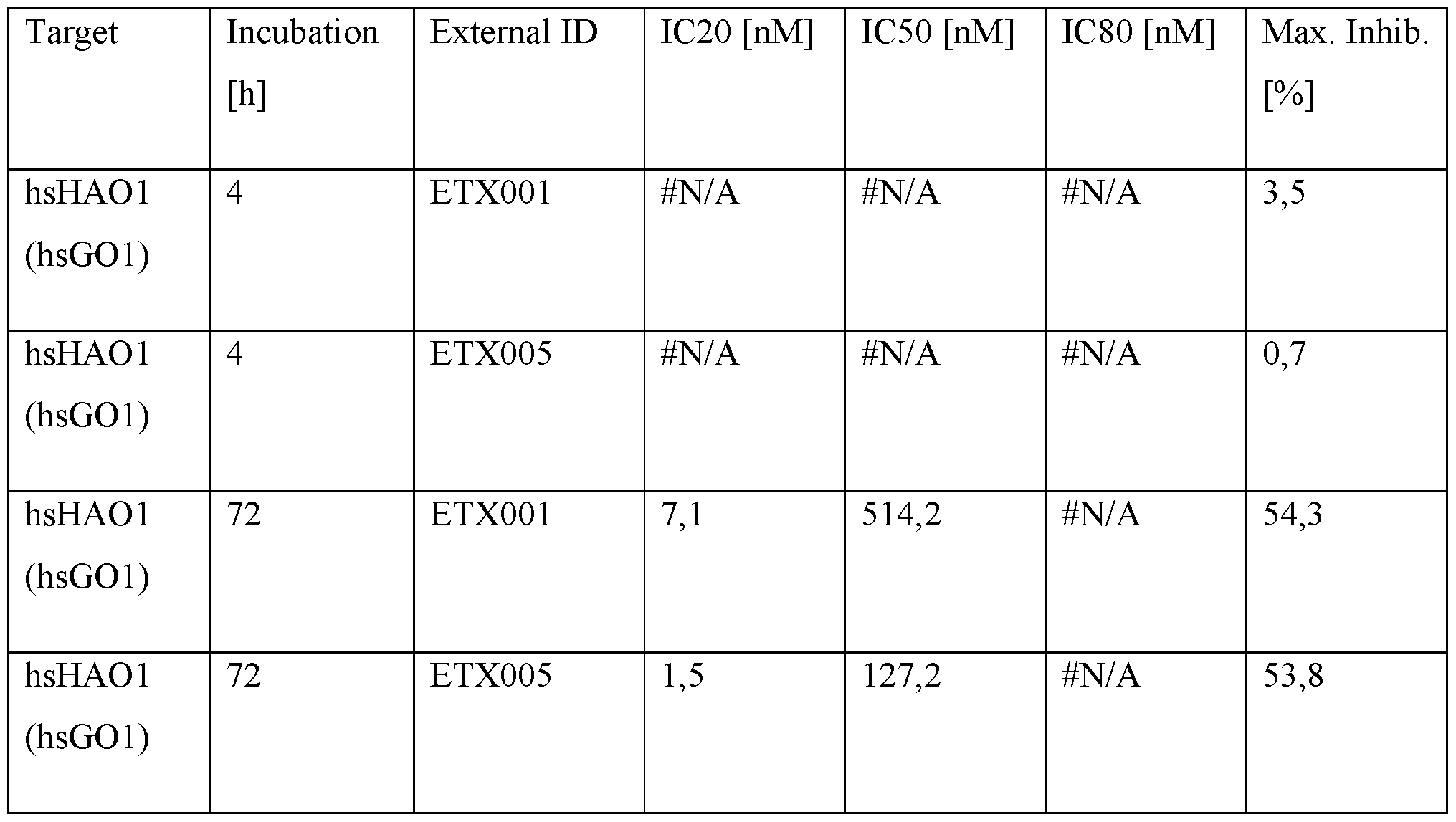









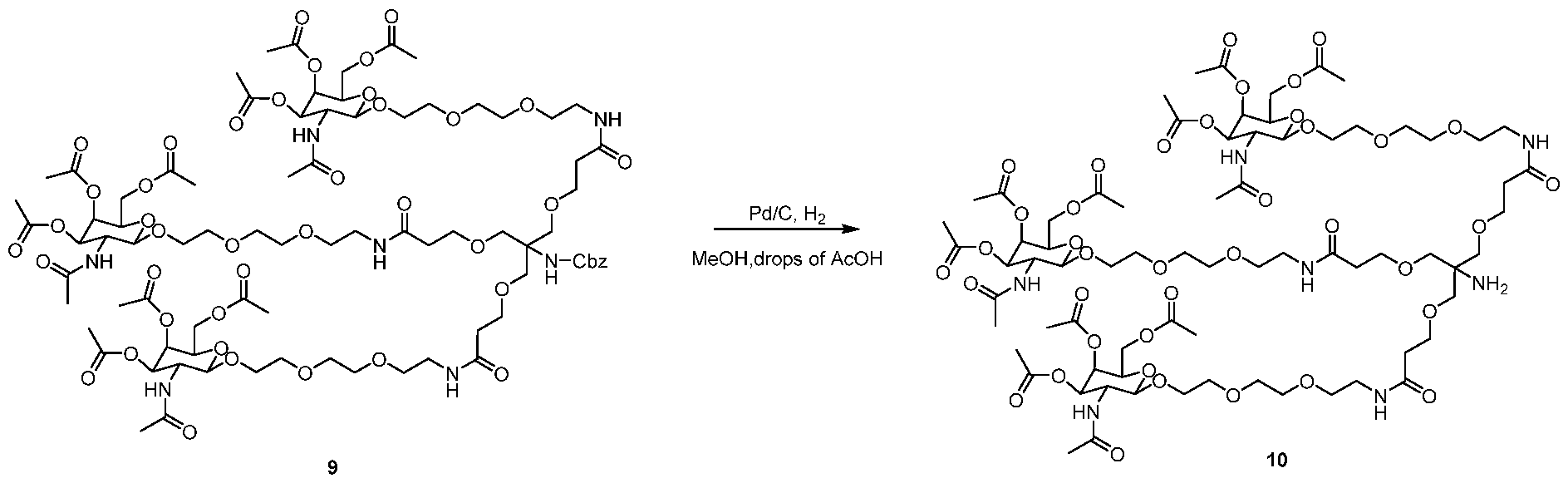














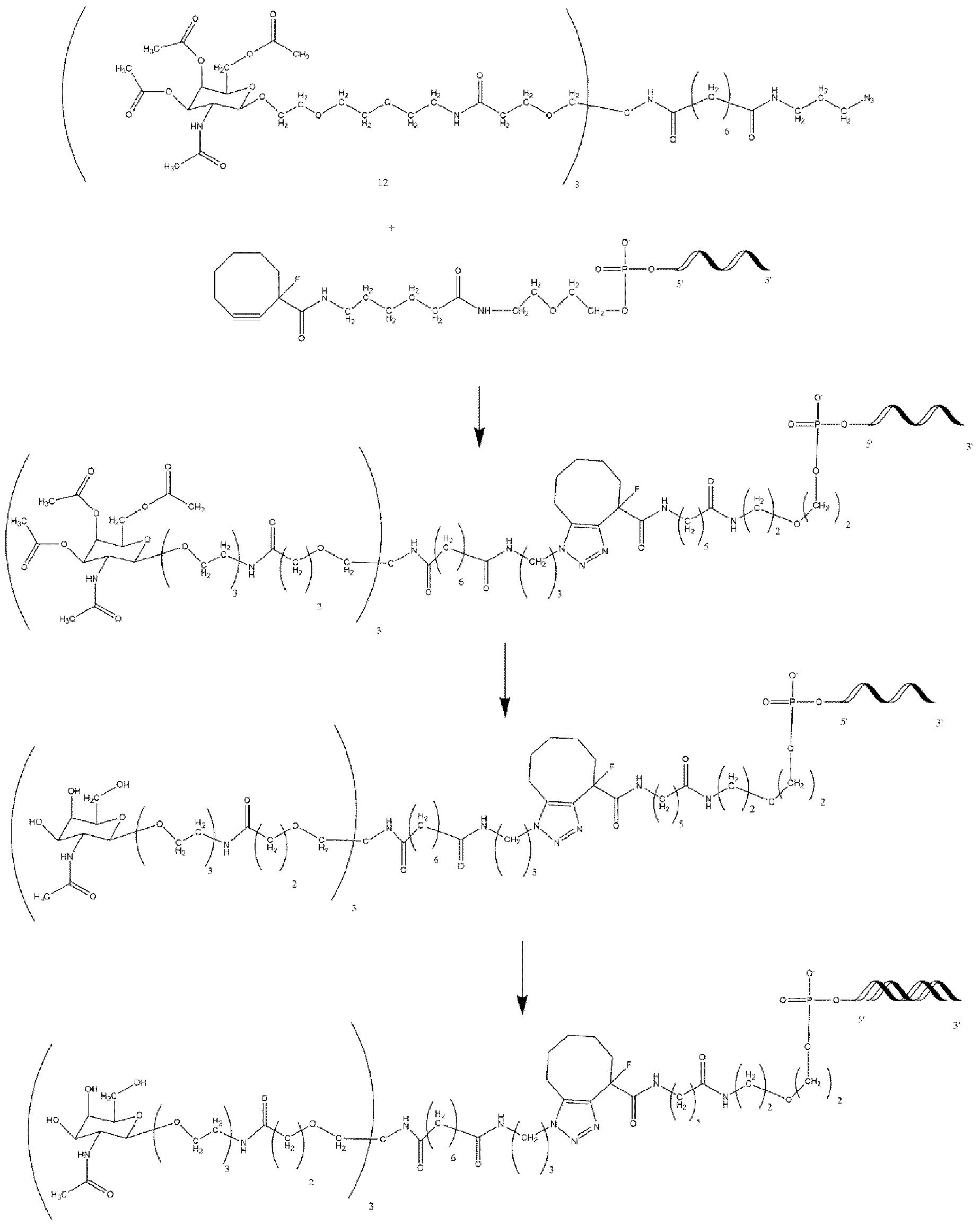







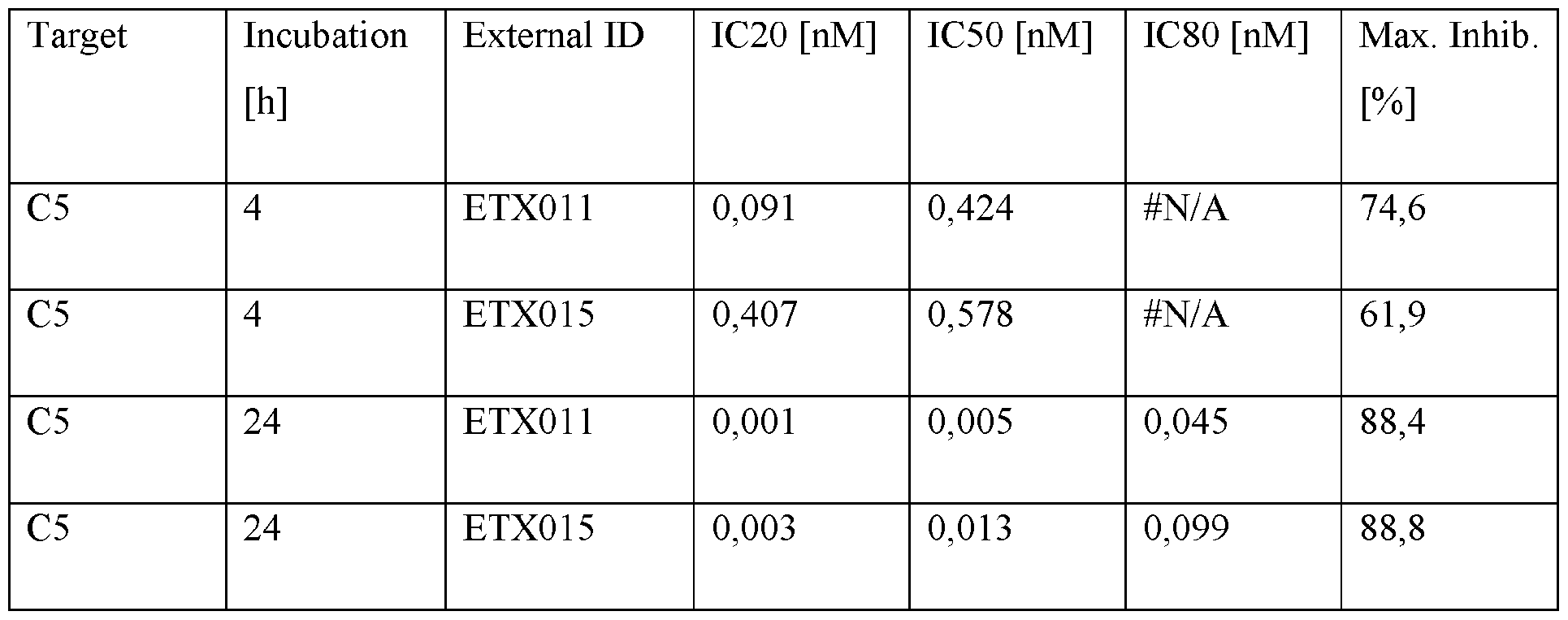










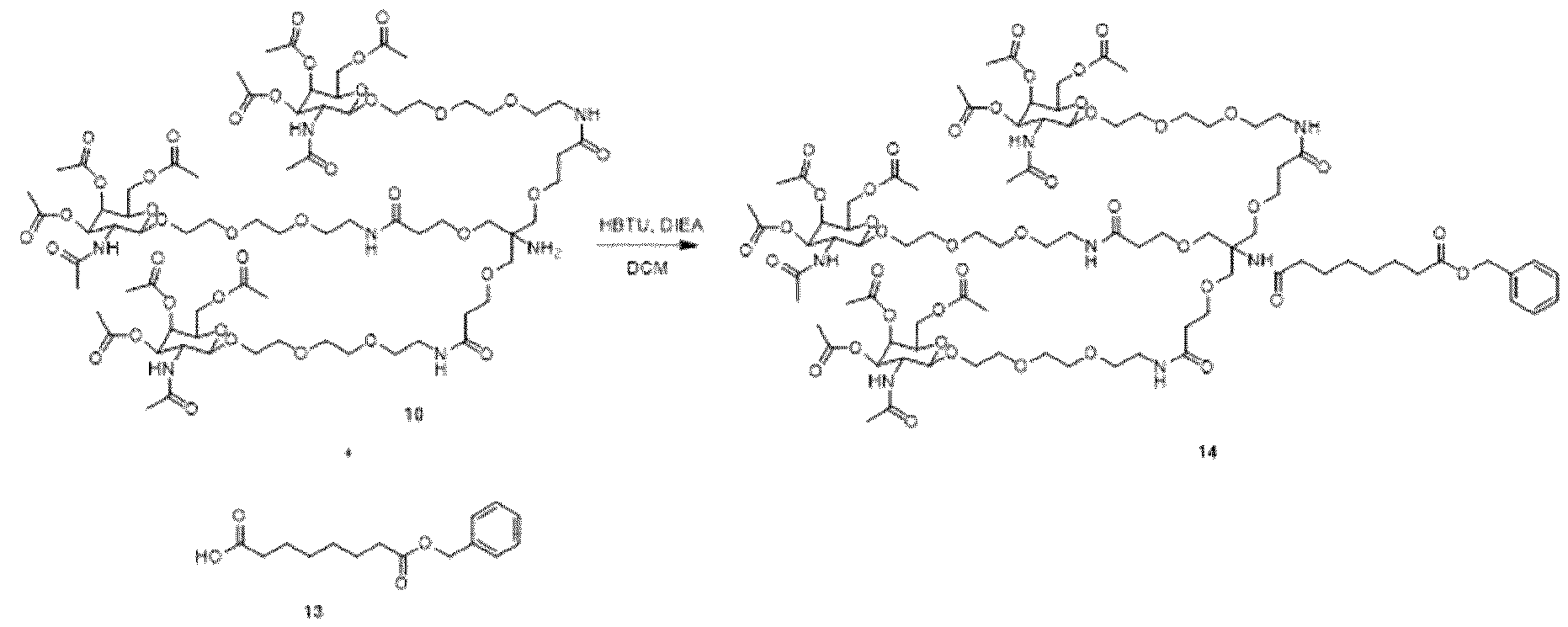











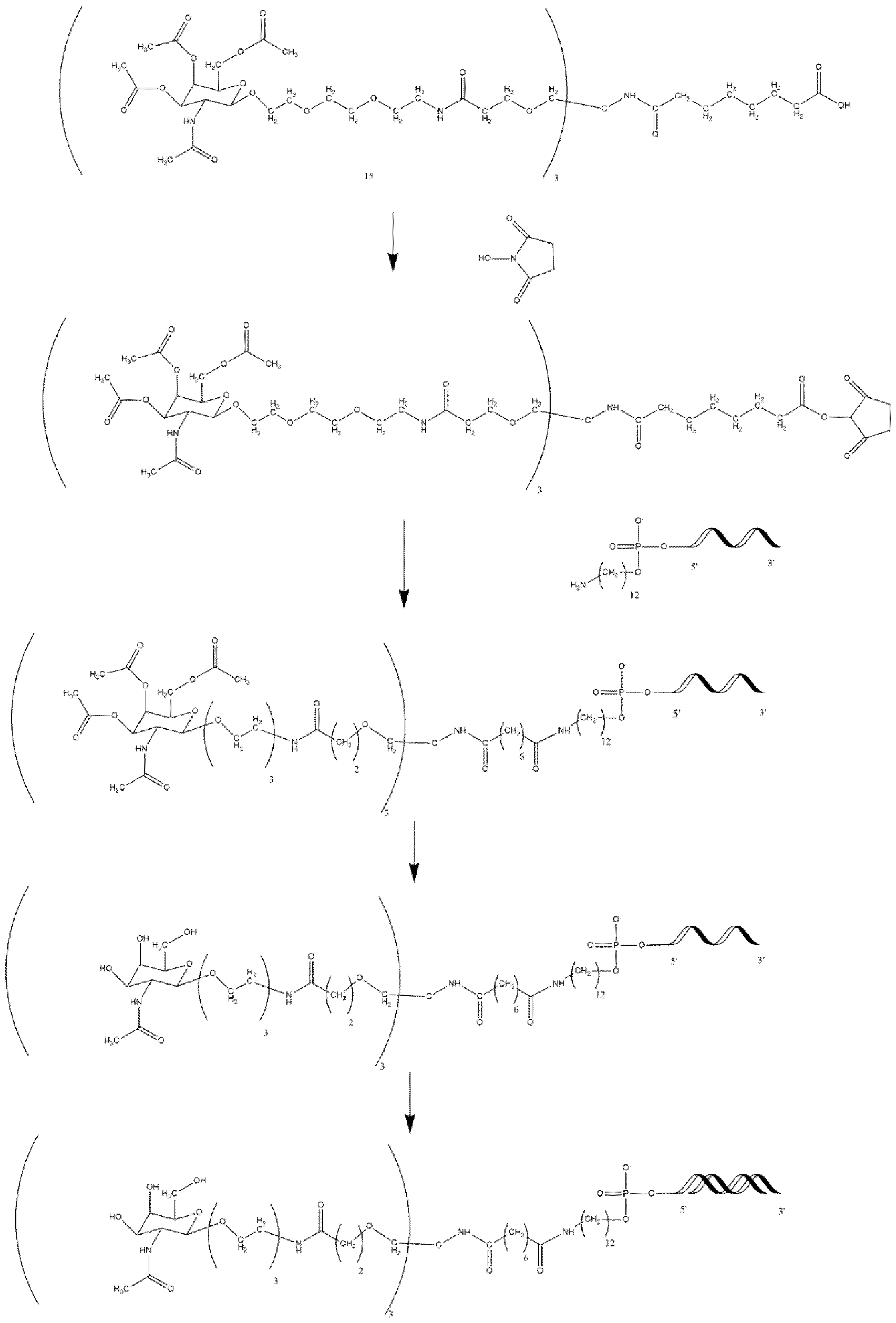





















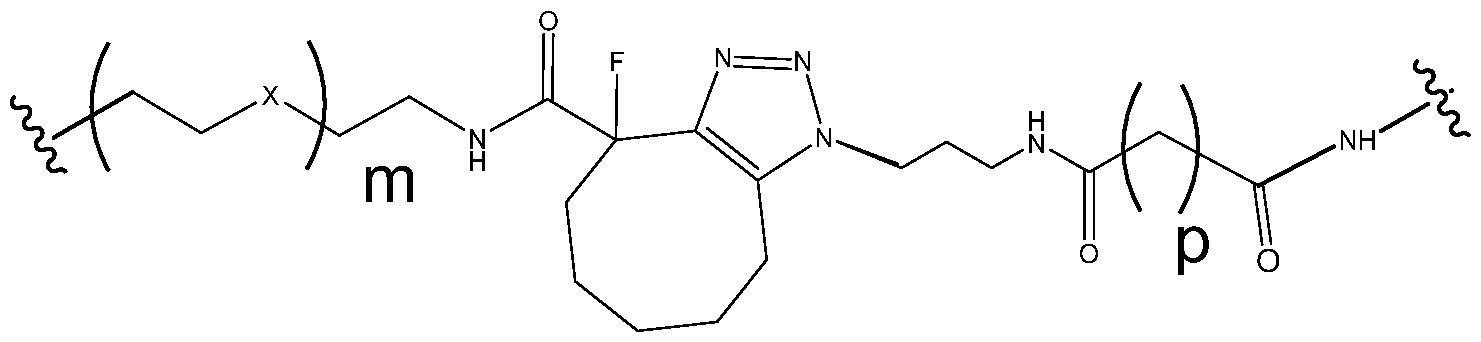


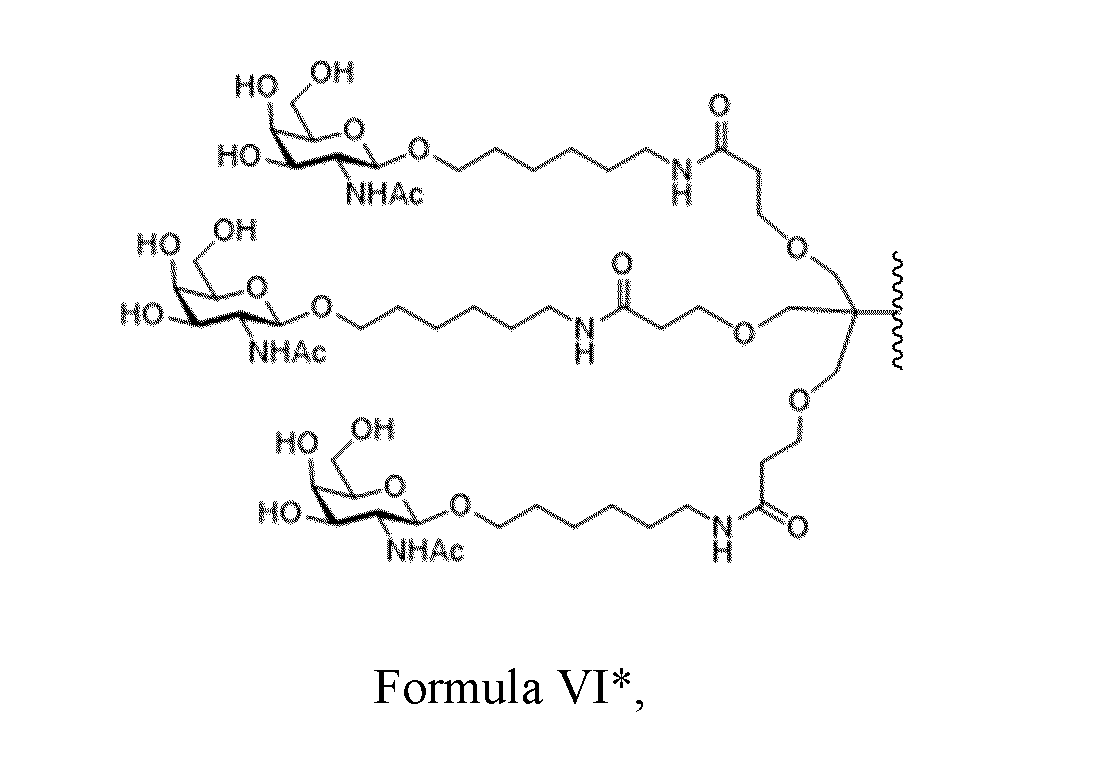









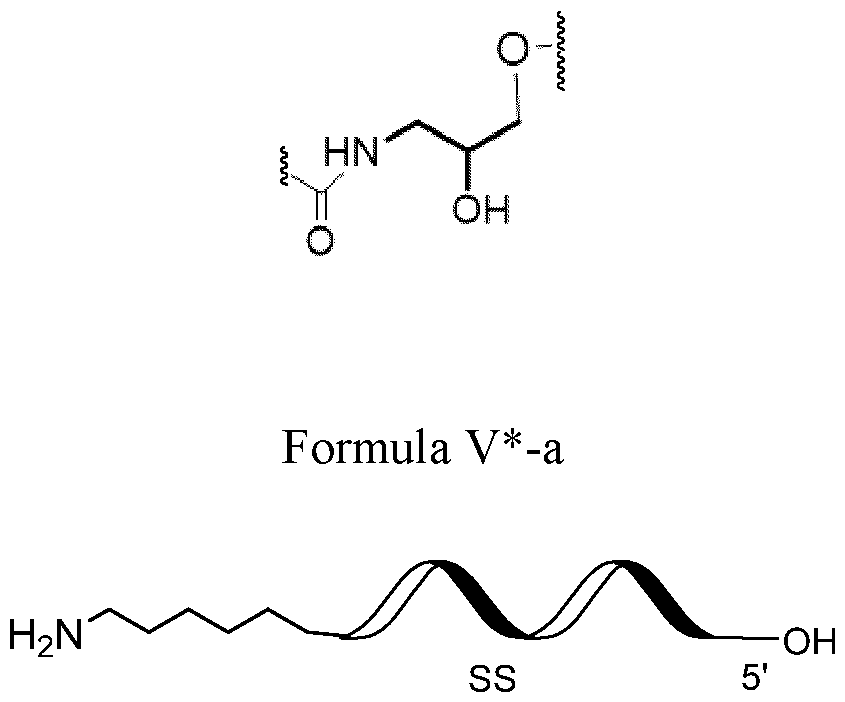













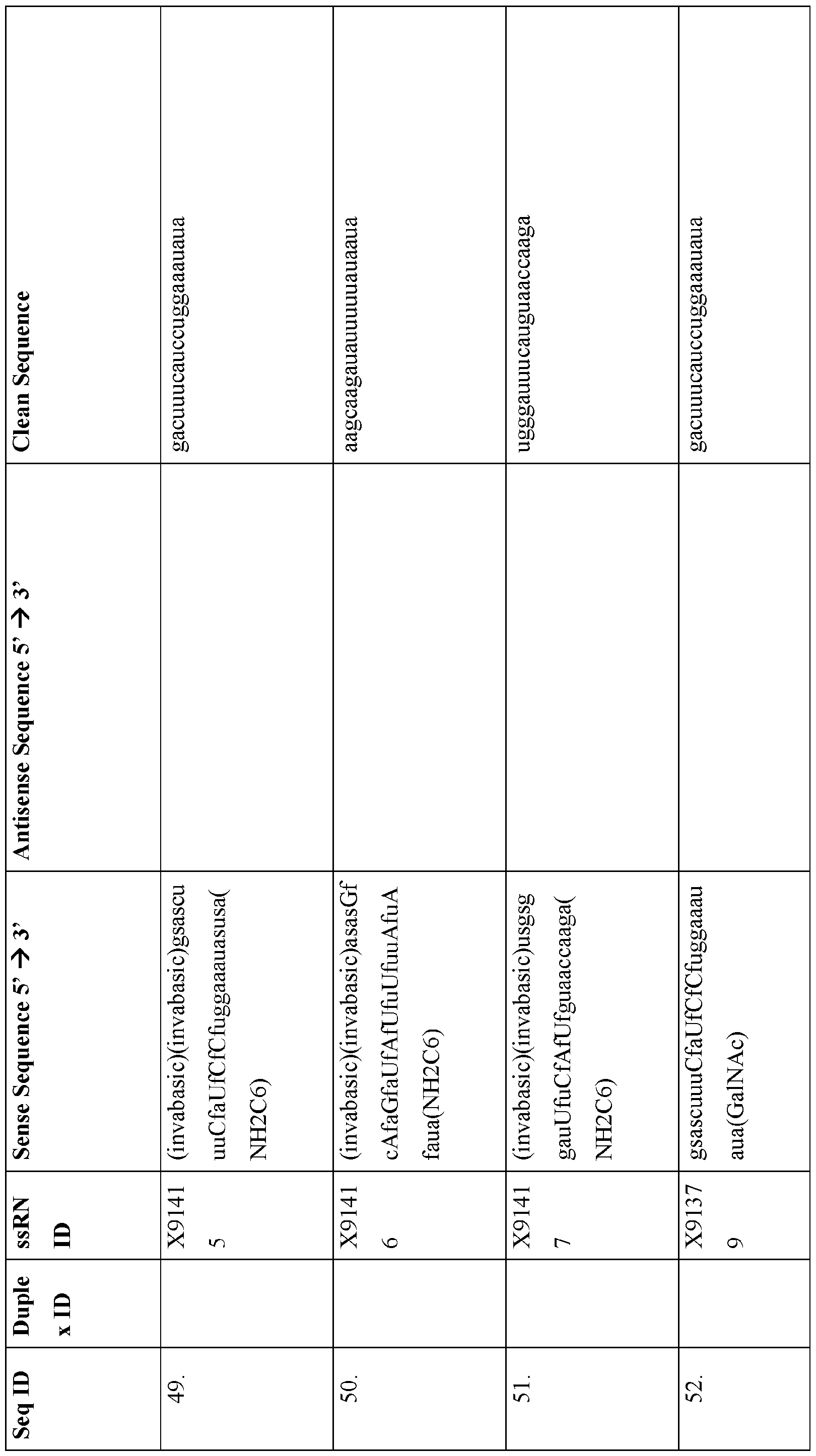































Claims
Priority Applications (10)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2023546403A JP2024504503A (en) | 2021-01-30 | 2022-01-28 | Nucleic acids containing abasic nucleotides |
| KR1020237029336A KR20230136644A (en) | 2021-01-30 | 2022-01-28 | Nucleic acids containing abasic nucleotides |
| AU2022212580A AU2022212580A1 (en) | 2021-01-30 | 2022-01-28 | Nucleic acids containing abasic nucleotides |
| BR112023014443A BR112023014443A2 (en) | 2021-01-30 | 2022-01-28 | NUCLEIC ACIDS CONTAINING ABASIC NUCLEOTIDES |
| EP22704882.4A EP4176061A1 (en) | 2021-01-30 | 2022-01-28 | Nucleic acids containing abasic nucleotides |
| CN202280016017.9A CN116829717A (en) | 2021-01-30 | 2022-01-28 | Nucleic acids containing abasic nucleotides |
| CA3204331A CA3204331A1 (en) | 2021-01-30 | 2022-01-28 | Nucleic acids containing abasic nucleotides |
| PCT/US2022/074223 WO2023059948A1 (en) | 2021-10-08 | 2022-07-27 | Nucleic acids containing abasic nucleosides |
| CA3232053A CA3232053A1 (en) | 2021-10-08 | 2022-07-27 | Nucleic acids containing abasic nucleosides |
| US18/106,166 US20230407311A1 (en) | 2021-01-30 | 2023-02-06 | Nucleic acids containing abasic nucleotides |
Applications Claiming Priority (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202163143805P | 2021-01-30 | 2021-01-30 | |
| US63/143,805 | 2021-01-30 | ||
| US202163262316P | 2021-10-08 | 2021-10-08 | |
| US63/262,316 | 2021-10-08 | ||
| US202163271684P | 2021-10-25 | 2021-10-25 | |
| US63/271,684 | 2021-10-25 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US18/106,166 Continuation US20230407311A1 (en) | 2021-01-30 | 2023-02-06 | Nucleic acids containing abasic nucleotides |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022162155A1 true WO2022162155A1 (en) | 2022-08-04 |
Family
ID=80445903
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/EP2022/052070 WO2022162155A1 (en) | 2021-01-30 | 2022-01-28 | Nucleic acids containing abasic nucleotides |
Country Status (2)
| Country | Link |
|---|---|
| EP (1) | EP4176061A1 (en) |
| WO (1) | WO2022162155A1 (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023059948A1 (en) * | 2021-10-08 | 2023-04-13 | E-Therapeutics Plc | Nucleic acids containing abasic nucleosides |
| WO2024023256A1 (en) * | 2022-07-27 | 2024-02-01 | E-Therapeutics Plc | Nucleic acid compounds |
| WO2024023254A1 (en) * | 2022-07-27 | 2024-02-01 | E-Therapeutics Plc | Nucleic acid compounds |
Citations (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7452987B2 (en) | 2002-08-05 | 2008-11-18 | Silence Therapeutics Aktiengesellschaft (Ag) | Interfering RNA molecules |
| US7528188B2 (en) | 2003-10-21 | 2009-05-05 | Samsung Electronics Co., Ltd. | Resin solution and method of forming a protection layer |
| WO2010145778A1 (en) * | 2009-06-15 | 2010-12-23 | Qiagen Gmbh | MODIFIED siNA |
| WO2011084193A1 (en) * | 2010-01-07 | 2011-07-14 | Quark Pharmaceuticals, Inc. | Oligonucleotide compounds comprising non-nucleotide overhangs |
| US8273866B2 (en) | 2002-02-20 | 2012-09-25 | Merck Sharp & Dohme Corp. | RNA interference mediated inhibition of gene expression using chemically modified short interfering nucleic acid (SINA) |
| WO2015051366A2 (en) * | 2013-10-04 | 2015-04-09 | Novartis Ag | Novel formats for organic compounds for use in rna interference |
| US9150606B2 (en) | 2002-11-05 | 2015-10-06 | Isis Pharmaceuticals, Inc. | Compositions comprising alternating 2'-modified nucleosides for use in gene modulation |
| EP3085784A1 (en) * | 2013-12-17 | 2016-10-26 | Encodegen Co., ltd. | Nucleic acid inducing rna interference modified for preventing off-target, and use thereof |
| WO2018098117A1 (en) * | 2016-11-23 | 2018-05-31 | Alnylam Pharmaceuticals, Inc. | SERPINA1 iRNA COMPOSITIONS AND METHODS OF USE THEREOF |
| US10119136B2 (en) | 2014-01-09 | 2018-11-06 | Alnylam Pharmaceuticals, Inc. | RNAi agents modified at the 4′-C position |
| WO2019051402A1 (en) * | 2017-09-11 | 2019-03-14 | Arrowhead Pharmaceuticals, Inc. | Rnai agents and compositions for inhibiting expression of apolipoprotein c-iii (apoc3) |
| US10266825B2 (en) | 2002-11-05 | 2019-04-23 | Ionis Pharmaceuticals, Inc. | Compositions comprising alternating 2′-modified nucleosides for use in gene modulation |
| EP3775207A1 (en) | 2018-04-05 | 2021-02-17 | Silence Therapeutics GmbH | Sirnas with vinylphosphonate at the 5' end of the antisense strand |
-
2022
- 2022-01-28 EP EP22704882.4A patent/EP4176061A1/en active Pending
- 2022-01-28 WO PCT/EP2022/052070 patent/WO2022162155A1/en active Application Filing
Patent Citations (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8273866B2 (en) | 2002-02-20 | 2012-09-25 | Merck Sharp & Dohme Corp. | RNA interference mediated inhibition of gene expression using chemically modified short interfering nucleic acid (SINA) |
| US7452987B2 (en) | 2002-08-05 | 2008-11-18 | Silence Therapeutics Aktiengesellschaft (Ag) | Interfering RNA molecules |
| US9150606B2 (en) | 2002-11-05 | 2015-10-06 | Isis Pharmaceuticals, Inc. | Compositions comprising alternating 2'-modified nucleosides for use in gene modulation |
| US10266825B2 (en) | 2002-11-05 | 2019-04-23 | Ionis Pharmaceuticals, Inc. | Compositions comprising alternating 2′-modified nucleosides for use in gene modulation |
| US7528188B2 (en) | 2003-10-21 | 2009-05-05 | Samsung Electronics Co., Ltd. | Resin solution and method of forming a protection layer |
| WO2010145778A1 (en) * | 2009-06-15 | 2010-12-23 | Qiagen Gmbh | MODIFIED siNA |
| WO2011084193A1 (en) * | 2010-01-07 | 2011-07-14 | Quark Pharmaceuticals, Inc. | Oligonucleotide compounds comprising non-nucleotide overhangs |
| WO2015051366A2 (en) * | 2013-10-04 | 2015-04-09 | Novartis Ag | Novel formats for organic compounds for use in rna interference |
| EP3085784A1 (en) * | 2013-12-17 | 2016-10-26 | Encodegen Co., ltd. | Nucleic acid inducing rna interference modified for preventing off-target, and use thereof |
| US10119136B2 (en) | 2014-01-09 | 2018-11-06 | Alnylam Pharmaceuticals, Inc. | RNAi agents modified at the 4′-C position |
| WO2018098117A1 (en) * | 2016-11-23 | 2018-05-31 | Alnylam Pharmaceuticals, Inc. | SERPINA1 iRNA COMPOSITIONS AND METHODS OF USE THEREOF |
| WO2019051402A1 (en) * | 2017-09-11 | 2019-03-14 | Arrowhead Pharmaceuticals, Inc. | Rnai agents and compositions for inhibiting expression of apolipoprotein c-iii (apoc3) |
| EP3775207A1 (en) | 2018-04-05 | 2021-02-17 | Silence Therapeutics GmbH | Sirnas with vinylphosphonate at the 5' end of the antisense strand |
Non-Patent Citations (4)
| Title |
|---|
| "Current protocols in nucleic acid chemistry", JOHN WILEY & SONS, INC. |
| J. LIU ET AL: "RNA duplexes with abasic substitutions are potent and allele-selective inhibitors of huntingtin and ataxin-3 expression", NUCLEIC ACIDS RESEARCH, vol. 41, no. 18, 1 October 2013 (2013-10-01), pages 8788 - 8801, XP055185879, ISSN: 0305-1048, DOI: 10.1093/nar/gkt594 * |
| PARK ET AL.: "Reference values of clinical pathology parameter in cynomolgus monkeys used in preclinical studies", LAB ANIM RES, vol. 32, 2016, pages 79 - 86 |
| SAMBROOK ET AL.: "Molecular Cloning: A Laboratory Manual", 1989, COLD SPRING HARBOR LABORATORY PRESS |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023059948A1 (en) * | 2021-10-08 | 2023-04-13 | E-Therapeutics Plc | Nucleic acids containing abasic nucleosides |
| WO2024023256A1 (en) * | 2022-07-27 | 2024-02-01 | E-Therapeutics Plc | Nucleic acid compounds |
| WO2024023254A1 (en) * | 2022-07-27 | 2024-02-01 | E-Therapeutics Plc | Nucleic acid compounds |
Also Published As
| Publication number | Publication date |
|---|---|
| EP4176061A1 (en) | 2023-05-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2022162155A1 (en) | Nucleic acids containing abasic nucleotides | |
| WO2023059948A1 (en) | Nucleic acids containing abasic nucleosides | |
| WO2022162157A1 (en) | Conjugated oligonucleotide compounds, methods of making and uses thereof | |
| EP4175965B1 (en) | Conjugated oligonucleotide compounds, methods of making and uses thereof | |
| EP3974532A1 (en) | Nucleic acid, pharmaceutical composition, conjugate, preparation method, and use | |
| CN113862268A (en) | AGT inhibitors and uses thereof | |
| CN115851723B (en) | RNA inhibitor for inhibiting LPA gene expression and application thereof | |
| AU2022212580A1 (en) | Nucleic acids containing abasic nucleotides | |
| CN116848127A (en) | Conjugated oligonucleotide compounds, methods of preparation and uses thereof | |
| Danielsen et al. | Cationic oligonucleotide derivatives and conjugates: A favorable approach for enhanced DNA and RNA targeting oligonucleotides | |
| WO2022162161A1 (en) | Conjugated oligonucleotide compounds, methods of making and uses thereof | |
| CN116801886A (en) | LPA inhibitors and uses thereof | |
| US20230310486A1 (en) | Conjugated oligonucleotide compounds, methods of making and uses thereof | |
| CN116829717A (en) | Nucleic acids containing abasic nucleotides | |
| WO2024023267A2 (en) | Nucleic acid compounds | |
| WO2024023252A2 (en) | Nucleic acid compounds | |
| WO2024023254A1 (en) | Nucleic acid compounds | |
| WO2024023256A1 (en) | Nucleic acid compounds | |
| WO2023232983A1 (en) | Inhibitors of expression and/or function | |
| CN117355534A (en) | Conjugated oligonucleotide compounds, methods of preparation and uses thereof | |
| WO2024023251A1 (en) | Double stranded nucleic acid compounds inhibiting zpi | |
| WO2024023262A2 (en) | Nucleic acid compounds | |
| WO2024026258A2 (en) | Rnai constructs and methods for inhibiting fam13a expression | |
| WO2023232978A1 (en) | Inhibitors of expression and/or function | |
| AU2021326521A1 (en) | RNAi constructs and methods for inhibiting MARC1 expression |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22704882 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022704882 Country of ref document: EP Effective date: 20230206 |
|
| ENP | Entry into the national phase |
Ref document number: 3204331 Country of ref document: CA |
|
| REG | Reference to national code |
Ref country code: BR Ref legal event code: B01A Ref document number: 112023014443 Country of ref document: BR |
|
| ENP | Entry into the national phase |
Ref document number: 2022212580 Country of ref document: AU Date of ref document: 20220128 Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2023546403 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 202280016017.9 Country of ref document: CN |
|
| ENP | Entry into the national phase |
Ref document number: 20237029336 Country of ref document: KR Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 1020237029336 Country of ref document: KR |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| REG | Reference to national code |
Ref country code: BR Ref legal event code: B01E Ref document number: 112023014443 Country of ref document: BR Free format text: COM BASE NA PORTARIA/INPI/NO 48/2022, APRESENTE NOVO CONTEUDO DE LISTAGEM DE SEQUENCIA INCLUINDO OS CAMPOS 140 E 141 . A EXIGENCIA DEVE SER RESPONDIDA EM ATE 60 (SESSENTA) DIAS DE SUA PUBLICACAO E DEVE SER REALIZADA POR MEIO DA PETICAO GRU CODIGO DE SERVICO 207. |
|
| ENP | Entry into the national phase |
Ref document number: 112023014443 Country of ref document: BR Kind code of ref document: A2 Effective date: 20230718 |