WO2022144968A1 - 情報処理装置、情報処理方法、及びプログラム - Google Patents
情報処理装置、情報処理方法、及びプログラム Download PDFInfo
- Publication number
- WO2022144968A1 WO2022144968A1 PCT/JP2020/049128 JP2020049128W WO2022144968A1 WO 2022144968 A1 WO2022144968 A1 WO 2022144968A1 JP 2020049128 W JP2020049128 W JP 2020049128W WO 2022144968 A1 WO2022144968 A1 WO 2022144968A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- vector
- relation
- attention
- entities
- sentence
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images








Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
- G06F16/353—Clustering; Classification into predefined classes
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/3331—Query processing
- G06F16/334—Query execution
- G06F16/3347—Query execution using vector based model
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/12—Use of codes for handling textual entities
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/289—Phrasal analysis, e.g. finite state techniques or chunking
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/044—Recurrent networks, e.g. Hopfield networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
Definitions
- the present invention relates to a technique for classifying relationships between a plurality of entities.
- Non-Patent Document 1 describes a related technique for classifying the relationship between pairs based on the similarity of sentence expressions that describe the relationship between pairs of entities.
- a sentence expression describing the relationship of the pair is determined by using the syntactic structure of the sentence. Further, the related technique determines whether or not the relationship between a certain pair and the relationship between another pair are the same depending on whether or not the determined sentence expressions are similar.
- Non-Patent Document 1 In the related technique described in Non-Patent Document 1, there is room for improvement in the accuracy of classifying relationships between a plurality of entities. The reason will be explained.
- the relationship between multiple entities may be determined according to the characteristics of each entity. For example, for the entities X and Y, the relationship "X is the head of state of Y" holds when X is a person rather than an animal.
- the related technique classifies pair relationships based on the similarity of sentence expressions determined by using the syntactic structure of sentences, it may not be possible to classify relationships according to the characteristics of each entity.
- One aspect of the present invention has been made in view of the above problems, and one example of the purpose is to provide a technique for more accurately classifying relationships between a plurality of entities.
- the information processing apparatus generates a relation vector representing the relationship of the plurality of attention entities from at least one relation vector generation sentence in which a plurality of attention entities appear, which is selected from the sentence set. From the relation vector generation means and at least one feature vector generation sentence in which the attention entity appears, which is selected from the sentence set for each of the plurality of attention entities, a feature vector representing the feature of the attention entity is obtained. Using the feature vector generation means to be generated, the relation vector generated by the relation vector generation means, and the feature vector generated by the feature vector generation means, the relation classification that classifies the relation between the plurality of attention entities. It has the means.
- the information processing method generates a relation vector representing the relationship of the plurality of attention entities from at least one relation vector generation sentence in which a plurality of attention entities appear, which is selected from a sentence set. That is, for each of the plurality of attention entities, a feature vector representing the characteristics of the attention entity is generated from at least one feature vector generation statement in which the attention entity appears, which is selected from the sentence set. And using the feature vector generated for each of the relationship vector and the plurality of attention entities to categorize the relationships between the plurality of attention entities.
- the program according to one aspect of the present invention is a program for making a computer function as an information processing device, and is for generating at least one relation vector in which a plurality of notable entities selected from a set of statements appear.
- a relation vector generation means for generating a relation vector representing the relationship of the plurality of attention entities from a sentence, and at least one selected from the sentence set in which the attention entity appears for each of the plurality of attention entities.
- a feature vector generation means for generating a feature vector representing the feature of the entity of interest from a feature vector generation sentence, a relation vector generated by the relation vector generation means, and a feature vector generated by the feature vector generation means. Is used as a relational classification means for classifying the relations between the plurality of attention entities.
- the information processing apparatus uses an algorithm including a plurality of parameters to select the plurality of attentions from at least one relation vector generation sentence in which a plurality of attention entities appear, which is selected from the sentence set.
- the degree of similarity between the relation vector generation means for generating the relation vector representing the relationship between the entities and the plurality of relation vectors generated from the plurality of statements in which the plurality of attention entities appear in common by the relation vector generation means is increased.
- a relation vector generation parameter updating means for updating the plurality of parameters and a relation classification means for classifying the relation between the plurality of attention entities by using the relation vector generated by the relation vector generation means. I have.
- the information processing method uses an algorithm including a plurality of parameters, and is selected from a sentence set from at least one relation vector generation sentence in which a plurality of attention entities appear.
- the plurality of relation vectors representing the relations of the entities are generated, and the similarity of the plurality of relation vectors generated from the plurality of statements in which the plurality of attention entities appear in common by the relation vector generation means is increased. It includes updating the parameters of the above, and classifying the relationship between the plurality of notable entities by using the relationship vector generated by the relationship vector generation means.
- the program according to one aspect of the present invention is a program for making a computer function as an information processing device, and the computer is selected from a set of statements using an algorithm including a plurality of parameters, and a plurality of notable entities.
- a relation vector generation means for generating a relation vector representing the relationship of the plurality of attention entities from at least one relation vector generation statement in which Using the relation vector generation parameter updating means for updating the plurality of parameters and the relation vector generated by the relation vector generation means so that the similarity of the plurality of relation vectors generated from the above sentence is high, It functions as a relation categorizing means for categorizing the relation between the plurality of attention entities.
- relationships between a plurality of entities can be categorized more accurately.
- the information processing device is a device that classifies the relationship between the plurality of attention entities by referring to a sentence set in which a plurality of attention entities appear.
- An entity is an element that constitutes an event represented by a sentence. Each entity is distinguished from other entities by its name.
- the entity may be tangible or intangible. Further, the entity may be a subject or an object expressed by a noun, an action or a relationship expressed by a verb, or a state or degree expressed by an adjective or an adjective verb. good.
- entities There are different types of entities. For example, the type of entity whose name is "Japan” is "nation”, the type of entity whose name is "Shinzo Abe” is "person”, and the type of entity whose name is “blue” is , "Color”.
- the reference numerals will be given to e1, e2, ..., And each of them will be described.
- a plurality of notable entities are a plurality of notable entities among the entities appearing in the statement set.
- the number of the entity of interest will be described as 2. However, the number of the entity of interest is not limited to 2, and may be 3 or more.
- a sentence set is a set of sentences.
- a statement set contains statements in which some or all of the entities of interest appear.
- a sentence consists of one or more words.
- an entity When an entity appears in a statement, it means that the entity is referenced in that statement. Further, when an entity is referred to in a sentence, it means that one or more words constituting the sentence represent the entity. In other words, the sentence in which an entity appears contains a word that represents that entity.
- the word representing a certain entity is not limited to one. For example, as an example of a word representing the entity "Shinzo Abe", there are a plurality of words “former Prime Minister Abe", "Shinzo Abe” and the like. Also, a word that indicates an entity can be considered as a kind of word that represents that entity.
- the pronoun "he” that indicates the entity “Shinzo Abe” can also be regarded as a word that represents the entity "Shinzo Abe”. For example, when one sentence contains the word “former Prime Minister Abe”, another sentence contains the word “Shinzo Abe”, and another sentence contains "he” pointing to "Shinzo Abe", these sentences contain , The entity "Shinzo Abe” has appeared in common.
- FIG. 1 is a block diagram showing the configuration of the information processing apparatus 1.
- the information processing apparatus 1 includes a relation vector generation unit 11, a feature vector generation unit 12, and a relation classification unit 13.
- the relationship vector generation unit 11 is an example of a configuration that realizes the “relationship vector generation means” described in the claims.
- the relation classification unit 13 is an example of a configuration for realizing the “relationship classification means” described in the claims. This is an example of a configuration that realizes the "relationship classification means” described in the claims.
- the relation vector generation unit 11 generates a relation vector representing the relation of a plurality of attention entities from at least one relation vector generation sentence selected from the sentence set.
- the relation vector generation unit 11 generates the relation vector as follows. Specifically, (1) First, the relation vector generation unit 11 converts the relation vector generation sentence into a sequence of words or a graph in which the words are nodes. When performing this conversion, the relation vector generation unit 11 may use the information obtained by parsing the relation vector generation sentence. (2) Next, the relation vector generation unit 11 converts each word included in the word sequence or graph generated in (1) into a vector to obtain a word vector. For example, the relation vector generation unit 11 corresponds to a one-hot-vector in which the elements of each vector correspond to different kinds of words, only the element corresponding to each word is 1, and the other elements are 0. Used as a word vector corresponding to a word.
- the relation vector generation unit 11 calculates the relation vector using the word vector of each word generated in (2).
- the relationship vector generation unit 11 calculates the relationship vector by inputting the word vector of each word into a calculation model that performs processing that reflects the structure of the word sequence or graph. Examples of such a calculation model include, but are not limited to, a recurrent neural network, a graph neural network, or a Transformer.
- relation vector generation unit 11 As a technique for the relation vector generation unit 11 to generate a relation vector, for example, the technique described in the above-mentioned non-patent document 1, the following reference 1 or the following reference 2 can be applied.
- the relation vector generation statement is a statement selected from the statement set in which a plurality of noteworthy entities appear.
- the statement set includes n relation vector generation statements in which the entities e1 and e2 of interest appear.
- the n relation vector generation sentences will be described by adding a reference numeral S (e1, e2) i. Note that n is an integer of 1 or more, and i is an integer of 1 or more and n or less.
- the feature vector generation unit 12 generates a feature vector representing the feature of the attention entity from at least one feature vector generation statement in which the attention entity appears for each of the plurality of attention entities.
- the feature vector represents, for example, the type of the attention entity estimated from the sentence in which the attention entity appears.
- the feature vector generation unit 12 generates a feature vector as follows. Specifically, (1) First, the feature vector generation unit 12 converts a feature vector generation sentence into a sequence of words or a graph in which words are nodes. When performing this conversion, the feature vector generation unit 12 may use the information obtained by parsing the feature vector generation sentence. (2) Next, the feature vector generation unit 12 converts each word included in the word sequence or graph generated in (1) into a vector to obtain a word vector. For example, the feature vector generation unit 12 corresponds to a one-hot-vector in which the elements of each vector correspond to different kinds of words, only the element corresponding to each word is 1, and the other elements are 0. Used as a word vector corresponding to a word.
- the feature vector generation unit 12 calculates the feature vector using the word vector of each word generated in (2).
- the feature vector generation unit 12 calculates the feature vector by inputting the word vector of each word into a calculation model that performs processing that reflects the structure of the word sequence or graph. Examples of such a calculation model include, but are not limited to, a recurrent neural network, a graph neural network, or a Transformer.
- a technique for generating a feature vector from a feature vector generation sentence for example, Word2Vec or a known technique described in Reference 3 below can be applied.
- Reference 3 Liang, Chen, et al. "Bond: Bert-assisted open-domain named entity recognition with distant supervision.” Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020.
- the technique described in Reference 3 uses a classification model to classify the types of entities.
- the feature vector generation unit 12 may use the vector input to the classification model as the feature vector by using the technique.
- the feature vector generation sentence is a sentence selected from a sentence set in which one of a plurality of noteworthy entities appears.
- the statement set includes m1 feature vector generation statements in which the entity of interest e1 appears.
- the sentence set includes m2 feature vector generation sentences in which the entity of interest e2 appears.
- the relation classification unit 13 classifies the relations between a plurality of notable entities by using the relation vector generated by the relation vector generation unit 11 and the feature vector generated by the feature vector generation unit 12.
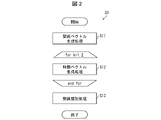
- FIG. 2 is a flow chart showing the flow of the information processing method S1.
- the information processing method S1 includes steps S11 to S13.
- the entities e1 and e2 will be described as the entity of interest.
- step S11 the relation vector generation unit 11 represents the relation between the attention entities e1 and e2 from at least one relation vector generation sentence S (e1, e2) selected from the sentence set, and the relation vector V (e1, e2). ) Is generated.
- step S12 the feature vector generation unit 12 generates a feature vector V (ek) representing the features of the entity of interest ek from at least one feature vector generation sentence S (ek) selected from the sentence set.
- step S13 the relation classification unit 13 pays attention by using the relation vector V (e1, e2) generated in step S11 and the feature vectors V (e1) and V (e2) generated in step S12.
- the relationship between the entities e1 and e2 is categorized.
- the relation classification unit 13 generates one vector based on the relation vector V (e1, e2), the feature vector V (e1), and the feature vector V (e2), and based on the similarity of the generated vectors.
- the relationship between the notable entities e1 and e2 is categorized.
- the relation classification unit 13 may categorize the relation by clustering the generated vectors.
- Examples of the method for generating the one vector include, but are not limited to, a method of combining the relation vector V (e1, e2), the feature vector V (e1), and the feature vector V (e2). ..
- the relationship classification unit 13 classifies the "attention entity e1, e2" and the "attention entity e3, e4" into those having the same relationship.
- the relation classification unit 13 may determine whether or not these vectors are similar to each other based on, for example, whether or not the internal product of the vectors or whether or not the cosine similarity exceeds the threshold value.
- the relation vector generated from the relation vector generation statement in which a plurality of attention entities appear and the feature vector generated from the feature vector generation statement in which each attention entity appears are used.
- the characteristics of each attention entity are taken into consideration, so that the relationship between the plurality of attention entities can be categorized more accurately.
- the information processing apparatus 1A modifies and executes step S11 (relationship vector generation process) included in the information processing method S1 according to the exemplary embodiment 1.
- the information processing apparatus 1A is an embodiment in which the information processing apparatus 1 according to the exemplary embodiment 1 is modified so as to be suitable for transforming and executing step S11.
- FIG. 3 is a block diagram showing the configuration of the information processing apparatus 1A.
- the information processing apparatus 1A includes a relation vector generation unit 11A instead of the relation vector generation unit 11, and further includes a relation vector generation parameter update unit 14A. It is different from the information processing apparatus 1 according to the above. Since the other configurations are the same as those of the information processing apparatus 1, detailed description will not be repeated.
- the relation vector generation unit 11A generates a relation vector from at least one relation vector generation statement by using an algorithm including a plurality of parameters.
- the relationship vector generation unit 11A is an example of a configuration that realizes the “relationship vector generation means” described in the claims.
- a specific example of an algorithm containing a plurality of parameters is a recurrent neural network.
- the recurrent neural network is a neural network that inputs a word vector sequence and outputs a vector corresponding to each word vector constituting the word vector sequence.
- the recurrent neural network used by the relation vector generation unit 11A will also be referred to as a first RNN.
- the plurality of parameters included in the first RNN are updated by the relation vector generation parameter update unit 14A.
- the relation vector generation parameter update unit 14A updates the plurality of parameters described above so that the similarity of the plurality of relation vectors becomes high.
- the plurality of relational vectors are generated by the relational vector generation unit 11A from a plurality of sentences in which a plurality of notable entities appear in common. Details and specific examples of the update process for updating a plurality of parameters will be described later.
- the relationship vector generation parameter update unit 14A is an example of a configuration that realizes the “relationship vector generation parameter update means” described in the claims.
- FIG. 4 is a flow chart showing a detailed flow of the relationship vector generation process S11A, which is a modification of step S11.
- the relationship vector generation process S11A includes steps S111 to S114.
- the relation vector generation unit 11A executes steps S111 to S113 for each of the n relation vector generation sentences S (e1, e2) i.
- step S111 the relation vector generation unit 11A generates a word vector sequence for the relation vector generation sentence S (e1, e2) i. Specifically, the relationship vector generation unit 11A replaces the words representing each of the entity of interest e1 and e2 with a predetermined word vector. Further, the relation vector generation unit 11A replaces a word representing a plurality of notable entities other than the entities e1 and e2 with a word vector representing the word. As a result, the relation vector generation unit 11A generates a word vector sequence corresponding to the relation vector generation sentence S (e1, e2) i.
- the process of this step is an example of the "first word vector string generation process" described in the claims.
- the relation vector generation sentence S (e1, e2) i is "I saw Star Wars by George Lucas at theater.”
- the word representing the attention entity e1 is “Star Wars”, and the word representing the attention entity e2.
- the relation vector generation unit 11A generates a word vector sequence (VI, Vsaw, V *, Vby, V **, Vat, Vtheater).
- VI is a word vector representing the word "I”.
- Vsaw is a word vector representing the word "saw”.
- Vby is a word vector representing the word "by”.
- “Vat” is a word vector representing the word "at”.
- “Vtheater” is a word vector representing the word “theater”.
- “V *” and "V **" are predetermined word vectors, respectively.
- Step S112 the relation vector generation unit 11A inputs the word vector string generated in step S111 to the first RNN, and thereby the relation vector generation sentence S (e1, e2) i corresponds to the RNN output vector string.
- the first RNN is as described above.
- the plurality of parameters included in the first RNN have been updated by the relation vector generation parameter update unit 14A.
- the process of this step is an example of the "first RNN output vector string generation process" described in the claims.
- step S112 A specific example of step S112 executed corresponding to the specific example of step S111 will be described.
- the relation vector generation unit 11A inputs an RNN output vector string (WI, Wsaw, W *,) to the first RNN by inputting a word vector string (VI, Vsaw, V *, Vby, V **, Vat, Vtheater). Wby, W **, Wat, Wtheater) is generated.
- WI is a vector that is output corresponding to the input of the word vector "VI”.
- Wsaw is a vector output corresponding to the input of the word vector "Vsaw”.
- Wby is a vector output corresponding to the input of the word vector "Vby”.
- “Wat” is a vector output corresponding to the input of the word vector "Vat”.
- “W theater” is a vector output corresponding to the input of the word vector “V theater”.
- “W *” is a vector output corresponding to the input of the word vector "V *”.
- “W **” is a vector output corresponding to the input of the word vector "V **”.
- step S113 the relation vector generation unit 11A calculates the sentence relation vector Vi corresponding to the relation vector generation sentence by averaging the vectors constituting the RNN output vector string generated in step S112 for each element. do.
- the process of this step is an example of the "sentence-related vector calculation process" described in the claims.
- one sentence relation vector Vi is generated from one relation vector generation sentence S (e1, e2) i is described.
- one sentence relation vector Vi may be generated from a plurality of relation vector generation sentences S (e1, e2) i1, S (e1, e2) i2, ....
- step S113 A specific example of step S113 executed corresponding to the specific example of steps S111 to S112 will be described.
- the relation vector generation unit 11A divides the sum of the seven vectors WI, Wsaw, W *, Wby, W **, Wat, and Wtheater constituting the RNN output vector sequence by the number of vectors 7 to form a sentence.
- the relation vector Vi is calculated.
- the relation vector generation unit 11A executes the processing of the next step S114.
- step S114 the relation vector generation unit 11A averages the sentence relation vector Vi corresponding to each of the n relation vector generation sentences S (e1, e2) i calculated in step S113 for each element.
- the relation vector V (e1, e2) is calculated.
- the relation vector V (e1, e2) is calculated by dividing the sum of n sentence relation vectors Vi by n.
- the process of this step is an example of the "relationship vector calculation process" described in the claims.
- the relation vector generation parameter update unit 14A performs the same processing as in steps S111 to S113 for the n relation vector generation sentences S (e1, e2) i in which the notable entities e1 and e2 appear in common.
- n sentence relation vectors Vi are calculated.
- n is an integer of 2 or more.
- the relation vector generation parameter update unit 14A calculates the relation vector V (e1, e2) 1 by using n1 out of n sentence relation vectors Vi.
- the relation vector generation parameter update unit 14A calculates the relation vector V (e1, e2) 2 by using n2 of the n sentence relation vectors Vi other than the above-mentioned n1.
- n1 is an integer of 1 or more and n or less.
- n2 is an integer of 1 or more (n ⁇ n1) or less.
- the relation vector generation parameter update unit 14A updates a plurality of parameters so that the relation vectors V (e1, e2) 1 and V (e1, e2) 2 are similar to each other.
- the relation vector generation parameter update unit 14A calculates the similarity between the relation vectors V (e1, e2) 1 and V (e1, e2) 2. Examples of the degree of similarity include, but are not limited to, the inner product or the distance between vectors multiplied by a negative number. Further, the relation vector generation parameter update unit 14A updates a plurality of parameters included in the first RNN by the gradient method so that the similarity is increased.
- the relation vector generation parameter update unit 14A is not limited to one set of "attention entities e1 and e2", but a plurality of sets of "attention entities ep and eq" are updated by performing the above-mentioned update process. You may update the parameters. Note that p and q are integers of 1 or more and n or less, and p ⁇ q. Further, the relation vector generation parameter update unit 14A repeats the above-mentioned update process while changing one or both of the combination of n1 sentence relation vectors Vi and the combination of n2 sentence relation vectors Vi. You may update the parameters of.
- This exemplary embodiment can generate a relationship vector that more appropriately represents the relationship between a plurality of notable entities as compared to the related techniques described in Non-Patent Document 1. Further, as a result, the relationship between the entity of interest can be classified more accurately by using such a relationship vector and the feature vector.
- the relation vector generated by this exemplary embodiment more appropriately represents the relation will be described.
- Non-Patent Document 1 generates a relation vector by inputting information indicating the syntactic structure of a sentence in which a pair of entities of interest appears into an algorithm including a plurality of parameters. do.
- this related technique updates a plurality of parameters so that the syntactic structure of another sentence in which the pair appears can be predicted from a plurality of relation vectors generated from the sentence in which the pair appears.
- this related technique considers the syntactic structure of the sentence in the process of generating the relationship vector and the process of updating the parameters, but does not consider the characteristics of each entity.
- a word vector string is generated from each of a plurality of relation vector generation sentences in which a plurality of attention entities appear in common.
- This word vector sequence not only contains information about the syntactic structure of the sentence by the sequence of words, but also represents the characteristics of the entity to which each word vector corresponds.
- the characteristics of each entity represented by the word vector sequence the appearance position of the entity in the sentence can be mentioned.
- the characteristics of each entity represented by the word vector string there is a type of the entity inferred from the word strings before and after the appearance position.
- a plurality of relational vectors are generated by inputting the generated word vector sequence into an algorithm including a plurality of parameters.
- a relationship vector not only represents a relationship based on the syntactic structure of the sentence, but also represents a relationship based on the characteristics of each entity of interest.
- the relationship based on the characteristics of each attention entity represented by the relationship vector there is a relationship based on the appearance position of the attention entity in the sentence.
- the relationship based on the characteristics of each attention entity represented by the relationship vector there is a relationship based on the type of the attention entity inferred from the word strings before and after the appearance position.
- the relation vector generated by this exemplary embodiment is generated in consideration of the characteristics of each entity of interest, it is different from the relation vector of the related technique generated only based on the syntactic structure of the sentence. By comparison, it better represents the relationship between multiple entities of interest.
- the information processing apparatus 1B modifies and executes step S12 (feature vector generation process) included in the information processing method S1 according to the exemplary embodiment 1.
- the information processing apparatus 1B is an embodiment in which the information processing apparatus 1 according to the exemplary embodiment 1 is modified so as to be suitable for transforming and executing step S12.
- FIG. 5 is a block diagram showing the configuration of the information processing apparatus 1B.
- the information processing apparatus 1B includes a feature vector generation unit 12B instead of the feature vector generation unit 12, and further includes a feature vector generation parameter update unit 15B. It is different from the information processing apparatus 1 according to the above. Since the other configurations are the same as those of the information processing apparatus 1, detailed description will not be repeated.
- the feature vector generation unit 12B generates a feature vector from at least one feature vector generation statement by using an algorithm including a plurality of parameters for each of the plurality of attention entities.
- the feature vector generation unit 12B is an example of a configuration that realizes the "feature vector generation means" described in the claims.
- a specific example of an algorithm containing a plurality of parameters is a recurrent neural network.
- the recurrent neural network is a neural network that inputs a word vector sequence and outputs a vector corresponding to each word vector constituting the word vector sequence.
- the recurrent neural network used by the feature vector generation unit 12B will also be referred to as a second RNN.
- the plurality of parameters included in the second RNN are updated by the feature vector generation parameter update unit 15B.
- the feature vector generation parameter update unit 15B updates the plurality of parameters described above so that the similarity between the feature vector and the word vector representing the entity of interest is high.
- the feature vector is generated from a sentence in which the entity of interest appears by the feature vector generation unit 12B.
- the feature vector generation parameter update unit 15B updates the plurality of parameters described above so that the degree of similarity between the sentence feature vector described later and the word vector representing the entity of interest is high. Details and specific examples of the update process for updating a plurality of parameters will be described later.
- the feature vector generation parameter update unit 15B is an example of a configuration that realizes the “feature vector generation parameter update means” described in the claims.
- FIG. 6 is a flow chart showing a detailed flow of the feature vector generation process S12B, which is a modification of step S12.
- the feature vector generation process S12B includes steps S121 to S124.
- the feature vector generation unit 12B executes steps S121 to S123 for each of mk feature vector generation sentences S (ek) j.
- step S121 the feature vector generation unit 12B generates a word vector sequence for the feature vector generation sentence S (ek) j. Specifically, the feature vector generation unit 12B replaces the word representing the entity of interest ek with a predetermined word vector. Further, the feature vector generation unit 12B replaces a word representing a word other than the entity of interest ek with a word vector representing the word. As a result, the feature vector generation unit 12B generates a word vector sequence corresponding to the feature vector generation sentence S (ek) j.
- the process of this step is an example of the "second word vector string generation process" described in the claims.
- step S121 For example, a specific example in which the feature vector generation sentence S (e1) j is "I saw Star Wars by George Lucas at theater.” And the word representing the entity e1 is "Star Wars" will be described.
- the feature vector generation unit 12B generates a word vector sequence (VI, Vsaw, V *, Vby, VGeorge Lucas, Vat, Vtheater).
- V George is a word vector representing the word "George”.
- the other word vectors constituting the word vector sequence are as described in the specific example of step S111.
- Step S122 the feature vector generation unit 12B generates an RNN output vector string corresponding to the feature vector generation sentence S (ek) j by inputting the word vector string generated in step S121 to the second RNN. do.
- the second RNN is as described above.
- the plurality of parameters included in the second RNN have been updated by the feature vector generation parameter update unit 15B.
- the process of this step is an example of the "second RNN output vector string generation process" described in the claims.
- step S122 A specific example of step S122 executed corresponding to the specific example of step S121 will be described.
- the feature vector generation unit 12B inputs an RNN output vector sequence (WI, Wsaw, W *, Wby) to the second RNN by inputting a word vector sequence (VI, Vsaw, V *, Vby, VGeorge Lucas, Vat, Vtheater). , Wgeorge Lucas, Wat, Wtheater).
- Wgeorge is a vector that is output corresponding to the input of the word vector "Vgeorge”.
- the other vectors constituting the RNN output vector sequence are as described in the specific example of step S112.
- step S123 the feature vector generation unit 12B corresponds to the vector corresponding to the feature entity ek among the vectors constituting the RNN output vector sequence generated in step S122, and corresponds to the feature vector generation sentence S (ek) j. Let the sentence feature vector Vj be.
- step S123 A specific example of step S123 executed corresponding to the specific example of steps S121 to S122 will be described.
- the feature vector generation unit 12B uses the vector "W *" corresponding to the attention entity e1 among the vectors constituting the RNN output vector sequence as the sentence feature vector Vj.
- the process of this step is an example of the "sentence feature vector setting process" described in the claims.
- the feature vector generation unit 12B executes the processing of the next step S124.
- Step S124 the feature vector generation unit 12B averages the sentence feature vector Vj corresponding to each feature vector generation sentence S (ek) j set in step S123 for each element, thereby performing the feature vector V ( ek) is calculated.
- the process of this step is an example of the "feature vector calculation process" described in the claims.
- the feature vector generation parameter update unit 15B performs the same processing as in steps S121 to S123 for m1 feature vector generation statements S (e1) j in which the entity of interest e1 appears, so that m1 pieces are generated.
- the sentence feature vector Vj is calculated.
- m1 is an integer of 2 or more.
- the feature vector generation parameter update unit 15B has a high degree of similarity between the word vector of the word representing the entity of interest e1 and the sentence feature vector Vj for each of the m1 feature vector generation sentences S (e1) j. Update multiple parameters so that. Further, the feature vector generation parameter update unit 15B calculates m2 sentence feature vectors Vj in the same manner for the attention entity e2.
- the feature vector generation parameter update unit 15B has a high degree of similarity between the word vector of the word representing the attention entity e2 and the sentence feature vector Vj for each of the m2 feature vector generation sentences S (e2) j. Update multiple parameters so that.
- the feature vector generation parameter update unit 15B calculates the similarity between the sentence feature vector Vj and the word vector, for example, the inner product or the distance between the vectors multiplied by a negative number. However, the degree of similarity is not limited to these. Further, the feature vector generation parameter update unit 15B updates a plurality of parameters included in the second RNN by the gradient method so that the similarity is increased.
- This exemplary embodiment can generate a feature vector that more appropriately represents the features of the entity of interest as compared to the related techniques described in Non-Patent Document 1. The reason will be explained.
- the sentence set includes the feature parameter generation sentence S (e1) j1 "" I found movies by John Doe at a theater. ", And the feature parameter generation sentence S (e1) j2" "I found books by John Doe at.” It is assumed to include more than "a book store.”
- "movies” and "books” are words representing the entity of interest e1.
- the feature vector generation parameter update unit 15B inputs a word vector sequence in which the word "movies” in the feature parameter generation sentence S (e1) j1 is replaced with the word vector "V *" in the second RNN, and the sentence feature vector. Obtain Vj1.
- the feature vector generation parameter update unit 15B updates the parameter of the second RNN so that the sentence feature vector Vj1 resembles the original word vector “Vmovies”. Further, the feature vector generation parameter update unit 15B inputs a word vector sequence in which the word "books" in the feature parameter generation sentence S (e1) j2 is replaced with the word vector "V *" in the second RNN, and the sentence feature vector Vj2 To get. Then, the feature vector generation parameter update unit 15B updates the parameter of the second RNN so that the sentence feature vector Vj2 resembles the original word vector “Vbooks”.
- the plurality of parameters are said to be "the entity e1 of interest is more likely to be found in the theater than in the bookstore". It is updated to output the feature vector V (e1) representing the feature.
- the feature vector V (e1) output from the second RNN including the updated plurality of parameters embeds the information that "the entity e1 of interest is more likely to be a movie than a book”.
- the feature vector V (e1) provides information consistent with the feature of the entity of interest e1 inferred from the relative magnitude of the number of S (e1) j1 and the number of S (e1) j2 in the sentence set. It is embedded. Therefore, the feature vector generated by this exemplary embodiment more appropriately represents the feature of the entity of interest.
- the present exemplary embodiment has a better relationship between a plurality of notable entities as compared with the related technique described in Non-Patent Document 1. It can be categorized with high accuracy. The reason will be explained.
- Non-Patent Document 1 categorizes the relationships between entities based on the syntactic structure between the words corresponding to the two entities of interest. Therefore, this related technique does not directly correspond to the relationship between the two notable entities (“some story” and “John Doe”) in the following sentences 1 and 2 (“at a theater” and “at a theater” and “John Doe”). I can't tell the difference between "at a book store”). Therefore, this related technique cannot distinguish the relationship between these two notable entities in these two sentences.
- Sentence 1 “I found Some Story by John Doe at a theater.”
- Sentence 2 “I found Some Story by John Doe at a book store.”
- the feature vector V (e1) of the entity of interest e1 corresponding to the word “some story” is generated using the above-mentioned second RNN.
- the feature vector V (e1) represents the feature that "the entity of interest e1 is more likely to be found in the theater than in the book store”.
- the feature vector V (e1) represents the feature that "the entity of interest e1 is more likely to be found in the book store than in the theater". Therefore, in this exemplary embodiment, in a sentence set containing many sentences 1, the relationship between "some story” and "Jone Doe” can be categorized as "a work produced by a movie director". Further, in this exemplary embodiment, in a sentence set containing many sentences 2, the relationship between "some story” and “Jone Doe” can be categorized as "a book written by a writer". As described above, in this exemplary embodiment, since the relationship is categorized using the feature vector reflecting the feature in the sentence set of the entity of interest, the relationship is categorized more accurately than the related technique described in the non-patent document. can do.
- the information processing apparatus 1C modifies and executes step S13 (relationship classification processing) included in the information processing method S1 according to the exemplary embodiment 1.
- the information processing apparatus 1C is an embodiment in which the information processing apparatus 1 according to the exemplary embodiment 1 is modified so as to be suitable for transforming and executing step S13.
- FIG. 7 is a block diagram showing the configuration of the information processing apparatus 1C.
- the information processing apparatus 1C is exemplified by a point including the relation classification unit 13C instead of the relation classification unit 13 and a point including the relation vector clustering unit 16C and the feature vector clustering unit 17C. It is different from the information processing apparatus 1 according to the first embodiment. Since the other configurations are the same as those of the information processing apparatus 1, detailed description will not be repeated.
- the relation vector clustering unit 16C clusters the relation vector.
- Known techniques such as the K-Means method can be applied to the process of clustering relational vectors, but the process is not limited to this.
- the relation vector clustering unit 16C classifies a plurality of relation vectors to generate a plurality of clusters.
- the relationship vector clustering unit 16C is an example of a configuration that realizes the “relationship vector clustering means” described in the claims.
- the feature vector clustering unit 17C clusters the feature vectors.
- Known techniques such as the K-Means method can be applied to the process of clustering feature vectors, but the process is not limited to this.
- the feature vector clustering unit 17C classifies a plurality of feature vectors to generate a plurality of clusters.
- the feature vector clustering unit 17C is an example of a configuration that realizes the "feature vector clustering means" described in the claims.
- the relation classification unit 13C executes the relation vector classification processing, the feature vector classification processing, and the classification result synthesis processing.
- the relation vector classification process is a process for classifying the relation vectors generated by the relation vector generation unit 11.
- the feature vector classification process is a process for classifying each feature vector generated by the feature vector generation unit 12.
- the categorization result synthesis process is a process of categorizing the relationship between a plurality of notable entities by synthesizing the categorization result obtained by the relation vector categorization process and the categorization result obtained by the feature vector categorization process.
- the relation classification unit 13C is an example of a configuration for realizing the “relationship classification means” described in the claims.
- FIG. 8 is a flow chart showing a detailed flow of the relational classification process S13C, which is a modification of step S13.
- the relation classification process S13C includes steps S131 to S133.
- step S131 the relation classification unit 13C executes the relation vector classification processing. Specifically, the relation classification unit 13C determines whether the relation vector V (e1, e2) generated by the relation vector generation unit 11 belongs to any of the clusters generated by the relation vector clustering unit 16C. Hereinafter, the determined clusters will be referred to as related clusters C (e1, e2). When weights are obtained for each of a plurality of clusters in the relation vector classification process, the cluster with the largest weight is the relation cluster C (e1, e2).
- step S132 the relation classification unit 13C executes the feature vector classification process. Specifically, the relation classification unit 13C determines whether each of the feature vectors V (ek) generated by the feature vector generation unit 12 belongs to any of the clusters generated by the feature vector clustering unit 17C. Hereinafter, the determined cluster will be referred to as a feature cluster C (ek). When weights are obtained for each of a plurality of clusters in the feature vector classification process, the cluster with the largest weight is the feature cluster C (ek).
- Step S133 the relation classification unit 13C executes the classification result synthesis process. Specifically, the relationship classification unit 13C classifies the relationships between the plurality of notable entities e1 and e2 by synthesizing the classification results obtained in steps S131 and S132. For example, the relation classification unit 13C may use the direct product of the relation cluster C (e1, e2), the feature cluster C (e1), and the feature cluster C (e2) as the classification result of the relation between the plurality of attention entities e1 and e2. good.
- the relationship between a plurality of attention entities is categorized by synthesizing the relationship cluster to which the relationship vector corresponding to the plurality of attention entities belongs and the feature cluster to which the feature vector corresponding to each attention entity belongs. do.
- the dimension of the vector to be considered becomes smaller than the case where these vectors are collectively classified.
- the relationship categorization process becomes easier and the accuracy is improved.
- the relationship between a plurality of notable entities is categorized into different types, which are different only in the product of the total number of related clusters and the total number of characteristic clusters, by performing the categorization result synthesis process at the maximum. Is possible. Therefore, even if the total number of clusters required for each of the relation vector categorization processing and the feature vector categorization processing is reduced, the ability to categorize a sufficient kind of relation is secured. As a result, the relationship categorization process becomes easier and the accuracy is improved.
- this exemplary embodiment can more accurately classify the relationships between a plurality of notable entities.
- Example ⁇ In this embodiment, the above-mentioned exemplary embodiments 2 to 4 are combined and implemented, and verification is performed to classify the relationships between a plurality of notable entities. That is, in this embodiment, the classification result was obtained by executing the relation vector generation processing S11A, the feature vector generation processing S12B, and the relation classification processing S13C. The categorized result is described as the categorized result of the example.
- Open IE 5.1 is a known technique for categorizing relationships between entities based on the syntactic structure of a sentence.
- the targeted sentence set is part of the large corpus BlueWeb12.
- the large corpus BlueWeb12 is a public dataset obtained by crawling from the web.
- the FACC1 database was also used in the examples and comparative examples.
- the FACC1 database contains annotation data as to which entity in the sentence contained in BlueWeb12 corresponds to which entity registered in the online database Freebase or which does not correspond to any entity.
- the following correct answer data was used to calculate the accuracy of the categorized results of the examples and comparative examples. That is, the predicate that holds for a certain pair of entities in Freebase is treated as correct answer data that is the categorization result of the correct relationship.
- the predicates registered in Freebase about 100 kinds of predicates in which the pair of entities for which the predicate is established frequently appear in BlueWeb12 were selected. Then, among the pairs of entities registered that those predicates are established in Freebase, those appearing in the target sentence set are set as the pair of attention entities to be categorized.
- the correct answer data is used to calculate the accuracy of the classification result, and is not referred to in the update processing and the classification processing in the examples and comparative examples.
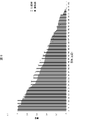
- FIG. 9 is a graph comparing the categorized results according to the examples and the categorized results according to the comparative examples.
- the horizontal axis shows the relationship defined by each predicate.
- the vertical axis shows the accuracy of the categorization result for the pair of the entity of interest having the relationship. More specifically, the degree of agreement between the relationship obtained by categorizing the pair of the entity of interest by the examples and the comparative examples and the relationship defined by each predicate shown on the horizontal axis is categorized into each relationship. Evaluated by the degree of duplication of pairs of noteworthy entities.
- the categorized results according to the present example were able to be categorized with respect to the relationship in which the accuracy of the categorized results according to the comparative example was relatively high, although the accuracy was lower than that of the comparative example.
- the categorized results according to this example could be categorized with higher accuracy than the comparative examples for the relationship in which the accuracy of the categorized results according to the comparative example was low.
- this embodiment can accurately classify relationships even for pairs of notable entities that are difficult to classify relationships in comparative examples.
- this example can classify more relationships as compared with the comparative example.
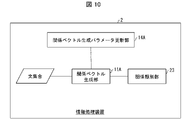
- FIG. 10 is a block diagram showing the configuration of the information processing apparatus 2.
- the information processing apparatus 2 does not include the feature vector generation unit 12, and includes the relation classification unit 23 instead of the relation classification unit 13, which is the information processing according to the exemplary embodiment 2.
- the relation classification unit 23 instead of the relation classification unit 13 which is the information processing according to the exemplary embodiment 2.
- Different for device 1A Since the other configurations are the same as those of the information processing apparatus 1A, detailed description thereof will not be repeated.
- the relation classification unit 23 classifies the relation between a plurality of notable entities by using the relation vector generated by the relation vector generation unit 11A.
- the relation classification unit 23 is an example of a configuration for realizing the “relationship classification means” described in the claims.
- FIG. 11 is a flow chart showing the flow of the information processing method S2. As shown in FIG. 11, the information processing method S2 includes steps S21 to S22.
- Step S21 The process of step S21 is the same as the process of step S11A according to the exemplary embodiment 2.
- the relation vector generation unit 11A generates the relation vector V (e1, e2) from at least one relation vector generation sentence S (e1, e2) by using an algorithm including a plurality of parameters.
- step S22 the relation classification unit 23 classifies the relation between the plurality of attention entities e1 and e2 by using the relation vector V (e1, e2) generated by the relation vector generation unit 11A. For example, the relation classification unit 23 may categorize the relation by clustering the relation vectors V (e1, e2).
- This exemplary embodiment can generate a relationship vector that more appropriately represents the relationship between a plurality of notable entities as compared to the related techniques described in Non-Patent Document 1. The reason is as described in the effect of the exemplary embodiment 2. As a result, since the present exemplary embodiment uses such a relation vector, the relation between a plurality of notable entities can be categorized more accurately.
- Some or all the functions of the information processing devices 1, 1A, 1B, 1C, and 2 may be realized by hardware such as an integrated circuit (IC chip) or by software.
- the information processing devices 1, 1A, 1B, 1C, and 2 are realized by, for example, a computer that executes an instruction of a program that is software that realizes each function.
- a computer that executes an instruction of a program that is software that realizes each function.
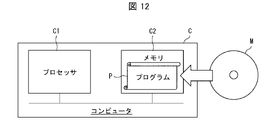
- An example of such a computer (hereinafter referred to as computer C) is shown in FIG.
- the computer C includes at least one processor C1 and at least one memory C2.
- a program P for operating the computer C as the information processing devices 1, 1A, 1B, 1C, and 2 is recorded in the memory C2.
- the processor C1 reads the program P from the memory C2 and executes it to realize the functions of the information processing devices 1, 1A, 1B, 1C, and 2.
- Examples of the processor C1 include CPU (Central Processing Unit), GPU (Graphic Processing Unit), DSP (Digital Signal Processor), MPU (Micro Processing Unit), FPU (Floating point number Processing Unit), and PPU (Physics Processing Unit). , Microcontrollers, or combinations thereof.
- the memory C2 for example, a flash memory, an HDD (Hard Disk Drive), an SSD (Solid State Drive), or a combination thereof can be used.
- the computer C may further include a RAM (RandomAccessMemory) for expanding the program P at the time of execution and temporarily storing various data. Further, the computer C may further include a communication interface for transmitting / receiving data to / from another device. Further, the computer C may further include an input / output interface for connecting an input / output device such as a keyboard, a mouse, a display, and a printer.
- RAM RandomAccessMemory
- the computer C may further include a communication interface for transmitting / receiving data to / from another device. Further, the computer C may further include an input / output interface for connecting an input / output device such as a keyboard, a mouse, a display, and a printer.
- the program P can be recorded on a non-temporary tangible recording medium M that can be read by the computer C.
- a recording medium M for example, a tape, a disk, a card, a semiconductor memory, a programmable logic circuit, or the like can be used.
- the computer C can acquire the program P via such a recording medium M.
- the program P can be transmitted via the transmission medium.
- a transmission medium for example, a communication network, a broadcast wave, or the like can be used.
- the computer C can also acquire the program P via such a transmission medium.
- a relation vector generation means for generating a relation vector representing the relation of the plurality of attention entities from at least one relation vector generation sentence in which a plurality of attention entities appear selected from a sentence set.
- a feature vector generation means for generating a feature vector representing the characteristics of the attention entity from at least one feature vector generation sentence in which the attention entity appears, which is selected from the sentence set for each of the plurality of attention entities.
- the relationship vector generated from the relation vector generation statement in which a plurality of attention entities appear and the feature vector generated from the feature vector generation statement in which each attention entity appears are used between the plurality of attention entities. Categorize relationships. As a result, in addition to the relationship between the plurality of attention entities, the characteristics of each attention entity are taken into consideration, so that the relationship between the attention entities can be categorized more accurately.
- the relation vector generation means generates the relation vector from the at least one relation vector generation statement by using an algorithm including a plurality of parameters.
- the information processing apparatus updates the plurality of parameters so that the similarity of the plurality of relation vectors generated from the plurality of sentences in which the plurality of attention entities appear in common by the relation vector generation means is high.
- the relation vector generation means is For each relation vector generation sentence, (1) the word representing each of the plurality of attention entities is replaced with a predetermined word vector, and the word representing other than the plurality of attention entities is replaced with a word vector representing the word. By doing so, it corresponds to the first word vector string generation process that generates the word vector string corresponding to the relation vector generation sentence, and (2) each word vector that constitutes the word vector string by inputting the word vector string. By inputting the word vector string generated by the first word vector string generation process into the recurrent neural network that outputs a vector, the first RNN that generates the RNN output vector string corresponding to the relation vector generation sentence is generated.
- a statement corresponding to the relation vector generation statement by averaging the vectors constituting the output vector string generation process and (3) the RNN output vector string generated by the first RNN output vector string generation process for each element.
- the relation vector calculation process for calculating the relation vector is executed by averaging the sentence relation vectors corresponding to each relation vector generation sentence calculated in the sentence relation vector calculation process for each element.
- the relation vector generation parameter updating means sets the parameters of the recurrent neural network so that the similarity of the plurality of relation vectors generated from the plurality of statements in which the plurality of entities appear in common by the relation vector generation means is high.
- the information processing device according to Appendix 2 to be updated.
- the recurrent neural network can be trained so as to generate a relationship vector that more appropriately represents the relationship between a plurality of objects of interest.
- the feature vector generation means generates the feature vector from the at least one feature vector generation statement by using an algorithm including a plurality of parameters for each of the plurality of attention entities.
- the information processing apparatus updates the plurality of parameters so that the feature vector generated from the sentence in which the attention entity appears by the feature vector generation means and the word vector representing the attention entity have a high degree of similarity.
- the information processing apparatus according to any one of Supplementary note 1 to 3, further comprising a vector generation parameter updating means.
- the feature vector generation means is used for each of the plurality of attention entities. For each feature vector generation sentence, (1) the feature vector is replaced with a predetermined word vector by replacing the word representing the attention entity with a predetermined word vector, and by replacing the word representing other than the attention entity with the word vector representing the word.
- the second word vector string generation process that generates the word vector string corresponding to the generation sentence, and (2) the recurrent that inputs the word vector string and outputs the vector corresponding to each word vector that constitutes the word vector string.
- With the second RNN output vector string generation process that generates the RNN output vector string corresponding to the feature vector generation sentence by inputting the word vector string generated by the second word vector string generation process into the neural network.
- the vector corresponding to the entity of interest is the sentence feature vector corresponding to the feature vector generation statement.
- Sentence feature vector setting process and while executing (4)
- the feature vector calculation process for calculating the feature vector is executed by averaging the sentence feature vectors corresponding to each feature vector generation sentence set in the sentence feature vector setting process for each element.
- the feature vector generation parameter updating means is a recurrent neural network so that the sentence feature vector generated from the sentence in which the feature vector generation means appears and the word vector representing the feature entity have a high degree of similarity.
- the information processing apparatus according to Appendix 4, which updates the parameters of the above.
- the recurrent neural network can be trained to generate a feature vector that more appropriately represents the features of each entity of interest.
- the relation classification means includes a relation vector classification process for classifying the relation vector generated by the relation vector generation means, a feature vector classification process for classifying each feature vector generated by the feature vector generation means, and the above-mentioned.
- the categorization result synthesis process for categorizing the relationship between the plurality of attention entities is executed.
- the information processing device according to any one of Supplementary note 1 to 5.
- Relational vector clustering means for clustering relational vectors, Further equipped with a feature vector clustering means for clustering feature vectors,
- the relational classification means executes the relational vector classification processing by determining whether the relational vector generated by the relational vector generation means belongs to any of the clusters generated by the relational vector clustering means.
- the feature vector classification process is executed by determining whether each feature vector generated by the feature vector generation means belongs to any of the clusters generated by the feature vector clustering means, according to Appendix 6.
- Information processing device is executed by determining whether each feature vector generated by the feature vector generation means belongs to any of the clusters generated by the feature vector clustering means, according to Appendix 6.
- a relation vector generation means for generating a relation vector representing the relation of the plurality of attention entities from at least one relation vector generation sentence in which a plurality of attention entities appear selected from a sentence set.
- a feature vector generation means for generating a feature vector representing the characteristics of the attention entity from at least one feature vector generation sentence in which the attention entity appears, which is selected from the sentence set for each of the plurality of attention entities.
- An information processing apparatus comprising: a relation categorizing means for categorizing a relation between a plurality of notable entities by using a relation vector generated by the relation vector generating means.
- a relation vector representing the relationship between the plurality of attention entities is generated from at least one relation vector generation statement in which a plurality of attention entities appear, which is selected from a statement set.
- the plurality of parameters are updated so that the similarity of the plurality of relation vectors generated from the plurality of sentences in which the plurality of attention entities appear in common is high, and the plurality of said relation vectors are used.
- Information processing methods including categorizing relationships between the entities of interest.
- a relation vector generation process that generates a relation vector representing the relation of the plurality of attention entities from at least one relation vector generation sentence in which a plurality of attention entities appear selected from a sentence set. For each of the plurality of attention entities, a feature vector generation process for generating a feature vector representing the feature of the attention entity from at least one feature vector generation statement selected from the sentence set in which the attention entity appears.
- Information processing that executes a relationship classification process that classifies relationships between a plurality of notable entities using the relationship vector generated by the relationship vector generation process and the feature vector generated by the feature vector generation process.
- a relation vector that generates a relation vector representing the relation of the plurality of attention entities from at least one relation vector generation sentence in which a plurality of attention entities appear selected from a sentence set using an algorithm including a plurality of parameters.
- Generation process and The relationship vector generation parameter update process for updating the plurality of parameters so that the similarity of the relationship vectors generated from each of the plurality of sentences in which the plurality of attention entities appear in common by the relationship vector generation process is high.
- An information processing device that executes a relationship classification process for classifying relationships between a plurality of notable entities using the relationship vector generated in the relationship vector generation process.
- the information processing apparatus described in Appendix 14 may further include a memory, in which the processor executes the relational vector generation processing, the feature vector generation processing, and the relational classification processing.
- the program for making the information may be stored.
- the program may also be recorded on a computer-readable, non-temporary, tangible recording medium.
- the program may also be recorded on a computer-readable, non-temporary, tangible recording medium.
- the information processing apparatus may further include a memory, in which the processor includes the relation vector generation process, the relation vector generation parameter update process, and the relation classification process.
- the program to be executed may be stored in the memory.
- the program may also be recorded on a computer-readable, non-temporary, tangible recording medium.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- General Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Health & Medical Sciences (AREA)
- Computing Systems (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Evolutionary Computation (AREA)
- Molecular Biology (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Databases & Information Systems (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Machine Translation (AREA)
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2022572828A JP7529048B2 (ja) | 2020-12-28 | 2020-12-28 | 情報処理装置、情報処理方法、及びプログラム |
| PCT/JP2020/049128 WO2022144968A1 (ja) | 2020-12-28 | 2020-12-28 | 情報処理装置、情報処理方法、及びプログラム |
| US18/269,180 US12572580B2 (en) | 2020-12-28 | 2020-12-28 | Information processing device, information processing method, and program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/049128 WO2022144968A1 (ja) | 2020-12-28 | 2020-12-28 | 情報処理装置、情報処理方法、及びプログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022144968A1 true WO2022144968A1 (ja) | 2022-07-07 |
Family
ID=82260351
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/049128 Ceased WO2022144968A1 (ja) | 2020-12-28 | 2020-12-28 | 情報処理装置、情報処理方法、及びプログラム |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US12572580B2 (https=) |
| JP (1) | JP7529048B2 (https=) |
| WO (1) | WO2022144968A1 (https=) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20240062052A1 (en) * | 2022-08-18 | 2024-02-22 | Optum, Inc. | Attention-based machine learning techniques using temporal sequence data and dynamic co-occurrence graph data objects |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2012027845A (ja) * | 2010-07-27 | 2012-02-09 | Sony Corp | 情報処理装置、関連文提供方法、及びプログラム |
| JP2012243125A (ja) * | 2011-05-20 | 2012-12-10 | Nec Corp | 因果単語対抽出装置、因果単語対抽出方法および因果単語対抽出用プログラム |
| US20150052098A1 (en) * | 2012-04-05 | 2015-02-19 | Thomson Licensing | Contextually propagating semantic knowledge over large datasets |
| JP2018206263A (ja) * | 2017-06-08 | 2018-12-27 | 日本電信電話株式会社 | 述語項構造モデル生成装置、述語項構造解析装置、方法、及びプログラム |
| WO2020240870A1 (ja) * | 2019-05-31 | 2020-12-03 | 日本電気株式会社 | パラメータ学習装置、パラメータ学習方法、及びコンピュータ読み取り可能な記録媒体 |
| WO2020240871A1 (ja) * | 2019-05-31 | 2020-12-03 | 日本電気株式会社 | パラメータ学習装置、パラメータ学習方法、及びコンピュータ読み取り可能な記録媒体 |
Family Cites Families (21)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2011227688A (ja) | 2010-04-20 | 2011-11-10 | Univ Of Tokyo | テキストコーパスにおける2つのエンティティ間の関係抽出方法及び装置 |
| US9201964B2 (en) * | 2012-01-23 | 2015-12-01 | Microsoft Technology Licensing, Llc | Identifying related entities |
| US9619571B2 (en) * | 2013-12-02 | 2017-04-11 | Qbase, LLC | Method for searching related entities through entity co-occurrence |
| US10867256B2 (en) * | 2015-07-17 | 2020-12-15 | Knoema Corporation | Method and system to provide related data |
| US11210324B2 (en) * | 2016-06-03 | 2021-12-28 | Microsoft Technology Licensing, Llc | Relation extraction across sentence boundaries |
| US10372743B2 (en) * | 2016-07-20 | 2019-08-06 | Baidu Usa Llc | Systems and methods for homogeneous entity grouping |
| DE102016223193A1 (de) | 2016-11-23 | 2018-05-24 | Fujitsu Limited | Verfahren und Vorrichtung zum Komplettieren eines Wissensgraphen |
| US10255273B2 (en) * | 2017-06-15 | 2019-04-09 | Microsoft Technology Licensing, Llc | Method and system for ranking and summarizing natural language passages |
| JP2019008368A (ja) | 2017-06-20 | 2019-01-17 | 日本電信電話株式会社 | 単語ベクトル学習装置、方法、プログラム、及び記憶媒体 |
| CN109284497B (zh) | 2017-07-20 | 2021-01-12 | 京东方科技集团股份有限公司 | 用于识别自然语言的医疗文本中的医疗实体的方法和装置 |
| US11328006B2 (en) | 2017-10-26 | 2022-05-10 | Mitsubishi Electric Corporation | Word semantic relation estimation device and word semantic relation estimation method |
| CN107798136B (zh) * | 2017-11-23 | 2020-12-01 | 北京百度网讯科技有限公司 | 基于深度学习的实体关系抽取方法、装置及服务器 |
| US10565443B2 (en) * | 2018-02-16 | 2020-02-18 | Wipro Limited | Method and system for determining structural blocks of a document |
| JP6462970B1 (ja) | 2018-05-21 | 2019-01-30 | 楽天株式会社 | 分類装置、分類方法、生成方法、分類プログラム及び生成プログラム |
| CN108763445B (zh) * | 2018-05-25 | 2019-09-17 | 厦门智融合科技有限公司 | 专利知识库的构建方法、装置、计算机设备和存储介质 |
| US10699069B2 (en) * | 2018-10-11 | 2020-06-30 | International Business Machines Corporation | Populating spreadsheets using relational information from documents |
| CN109754012A (zh) * | 2018-12-29 | 2019-05-14 | 新华三大数据技术有限公司 | 实体语义关系分类方法、模型训练方法、装置及电子设备 |
| JP7281905B2 (ja) | 2019-01-15 | 2023-05-26 | 株式会社日立ソリューションズ西日本 | 文書評価装置、文書評価方法及びプログラム |
| US11151325B2 (en) | 2019-03-22 | 2021-10-19 | Servicenow, Inc. | Determining semantic similarity of texts based on sub-sections thereof |
| US11216614B2 (en) * | 2019-07-25 | 2022-01-04 | Wipro Limited | Method and device for determining a relation between two or more entities |
| US12541694B2 (en) * | 2020-11-25 | 2026-02-03 | Fmr Llc | Generating a domain-specific knowledge graph from unstructured computer text |
-
2020
- 2020-12-28 WO PCT/JP2020/049128 patent/WO2022144968A1/ja not_active Ceased
- 2020-12-28 US US18/269,180 patent/US12572580B2/en active Active
- 2020-12-28 JP JP2022572828A patent/JP7529048B2/ja active Active
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2012027845A (ja) * | 2010-07-27 | 2012-02-09 | Sony Corp | 情報処理装置、関連文提供方法、及びプログラム |
| JP2012243125A (ja) * | 2011-05-20 | 2012-12-10 | Nec Corp | 因果単語対抽出装置、因果単語対抽出方法および因果単語対抽出用プログラム |
| US20150052098A1 (en) * | 2012-04-05 | 2015-02-19 | Thomson Licensing | Contextually propagating semantic knowledge over large datasets |
| JP2018206263A (ja) * | 2017-06-08 | 2018-12-27 | 日本電信電話株式会社 | 述語項構造モデル生成装置、述語項構造解析装置、方法、及びプログラム |
| WO2020240870A1 (ja) * | 2019-05-31 | 2020-12-03 | 日本電気株式会社 | パラメータ学習装置、パラメータ学習方法、及びコンピュータ読み取り可能な記録媒体 |
| WO2020240871A1 (ja) * | 2019-05-31 | 2020-12-03 | 日本電気株式会社 | パラメータ学習装置、パラメータ学習方法、及びコンピュータ読み取り可能な記録媒体 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7529048B2 (ja) | 2024-08-06 |
| US20240045895A1 (en) | 2024-02-08 |
| JPWO2022144968A1 (https=) | 2022-07-07 |
| US12572580B2 (en) | 2026-03-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110377686B (zh) | 一种基于深度神经网络模型的地址信息特征抽取方法 | |
| CN111095259B (zh) | 使用n-gram机器的自然语言处理 | |
| CN111191002B (zh) | 一种基于分层嵌入的神经代码搜索方法及装置 | |
| US12197869B2 (en) | Concept system for a natural language understanding (NLU) framework | |
| CN116681810B (zh) | 虚拟对象动作生成方法、装置、计算机设备和存储介质 | |
| JPWO2018131259A1 (ja) | 文章評価装置、及び文章評価方法 | |
| US12499313B2 (en) | Ensemble scoring system for a natural language understanding (NLU) framework | |
| Lee et al. | Ensembles of lasso screening rules | |
| US12118314B2 (en) | Parameter learning apparatus, parameter learning method, and computer readable recording medium | |
| US12106050B2 (en) | Debiasing pre-trained sentence encoders with probabilistic dropouts | |
| CN109117474A (zh) | 语句相似度的计算方法、装置及存储介质 | |
| JP2019082931A (ja) | 検索装置、類似度算出方法、およびプログラム | |
| JP2017076281A (ja) | 単語埋込学習装置、テキスト評価装置、方法、及びプログラム | |
| Han et al. | Multi-view interaction learning for few-shot relation classification | |
| CN120596600A (zh) | 一种基于稀疏图神经网络的检索增强生成方法及系统 | |
| CN112836491B (zh) | 面向NLP基于GSDPMM和主题模型的Mashup服务谱聚类方法 | |
| Zhang et al. | HARPA: hierarchical attention with relation paths for knowledge graph embedding adversarial learning | |
| JP7529048B2 (ja) | 情報処理装置、情報処理方法、及びプログラム | |
| CN117313138A (zh) | 基于nlp的社交网络隐私感知系统及方法 | |
| Yang et al. | A sentiment and syntactic-aware graph convolutional network for aspect-level sentiment classification | |
| JP5184464B2 (ja) | 単語クラスタリング装置及び方法及びプログラム及びプログラムを格納した記録媒体 | |
| US20260030261A1 (en) | Multi-Level Deep Learning Model | |
| WO2026020636A1 (zh) | 文本生成方法、装置、电子设备及存储介质 | |
| CN117033546B (zh) | 相似代码搜索方法及系统 | |
| Wang et al. | Inter-class distance enhanced prototypical network for few-shot text classification: Y. Wang, C. Li |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20967981 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022572828 Country of ref document: JP Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 18269180 Country of ref document: US |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 20967981 Country of ref document: EP Kind code of ref document: A1 |
|
| WWG | Wipo information: grant in national office |
Ref document number: 18269180 Country of ref document: US |