WO2022113340A1 - 情報処理装置、情報処理方法、及び、記録媒体 - Google Patents
情報処理装置、情報処理方法、及び、記録媒体 Download PDFInfo
- Publication number
- WO2022113340A1 WO2022113340A1 PCT/JP2020/044486 JP2020044486W WO2022113340A1 WO 2022113340 A1 WO2022113340 A1 WO 2022113340A1 JP 2020044486 W JP2020044486 W JP 2020044486W WO 2022113340 A1 WO2022113340 A1 WO 2022113340A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- error
- model
- training
- prediction
- student
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
- G06N20/20—Ensemble learning
Definitions
- the present invention relates to a technique for improving the accuracy of a machine learning model.
- Active learning is known as a technique for improving the accuracy of machine learning models through supervised learning. Active learning is the accuracy of a model by a teacher (Oracle) assigning a label to an example that cannot be predicted well with the current machine learning model, generating an example, and retraining the machine learning model using the example. It is a method to improve.
- the active learning method basically regards "an example in which the student model outputs ambiguous or inconsistent predictions" as an example that cannot be predicted well, and labels the example and retrains it.
- Uncertainty sampling and Query-by-committee (QBC) are known as examples of active learning.
- Uncertainty sampling is a method of labeling examples near the decision boundary created by the student model
- Query-by-committee is a method of labeling examples where multiple student models give inconsistent answers. ..
- Non-Patent Document 1 proposes a method that combines GAN (Generative Adversarial Network) and active learning.
- GAN Geneative Adversarial Network
- active learning In this method, GAN is used to create an artificial example in which the target classifier outputs ambiguous predictions.
- the student model outputs an ambiguous prediction and the student model makes a mistake in the prediction.
- the prediction of the student model may be incorrect even if it is far from the decision boundary.
- the prediction may actually be wrong. This is especially true when the predictions of the student model are unreliable. Therefore, with the above-mentioned active learning method, it is difficult to efficiently find an example that greatly improves the prediction accuracy.
- One object of the present invention is to efficiently find an example that greatly improves the prediction accuracy.
- One aspect of the present invention is an information processing apparatus.
- An input means that accepts training examples consisting of features,
- a label generation means for assigning a label to the training example using a teacher model,
- One or more student models are generated using at least a portion of the labeled training example, and the prediction by the student model is performed using an error calculation example different from the example used to generate the student model.
- An error calculation means for calculating an error from the prediction by the teacher model,
- a data holding means for holding an example consisting of features,
- a data extraction means for extracting from the data holding means and outputting an example in which the error is predicted to be large based on the error calculated by the error calculating means is provided.
- Another aspect of the present invention is an information processing method.
- Accepting training examples consisting of features Label the training example using the teacher model and One or more student models are generated using at least a portion of the labeled training example, and the prediction by the student model is performed using an error calculation example different from the example used to generate the student model.
- Calculate the error from the prediction by the teacher model Based on the calculated error, the example expected to have a large error is extracted from the data holding means for holding the example consisting of the feature amount, and output.
- Another aspect of the present invention is a recording medium, which is a recording medium.
- Accepting training examples consisting of features Label the training example using the teacher model and One or more student models are generated using at least a portion of the labeled training example, and the prediction by the student model is performed using an error calculation example different from the example used to generate the student model. Calculate the error from the prediction by the teacher model, Based on the calculated error, the example that is expected to have a large error is extracted from the data holding means that holds the example consisting of the feature amount, and the program that causes the computer to execute the output process is recorded.
- a teacher model that can be regarded as outputting an absolutely correct prediction is prepared, and the prediction of the student model is evaluated by comparing it with the prediction of the teacher model.
- the prediction of the student model is considered to be reliable.
- the prediction of the student model is far from the prediction of the teacher model, the prediction of the student model is considered suspicious. Therefore, if an example having a large error between the prediction of the student model and the prediction of the teacher model is selected as the example for retraining, it is possible to obtain an example that greatly contributes to the improvement of accuracy.
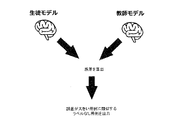
- FIG. 1 is a diagram conceptually showing the method of the present embodiment.
- a teacher model that can be regarded as outputting the absolutely correct prediction described above is prepared.
- predictions are made for each of the student model and the teacher model for multiple examples, and the prediction error is calculated.
- the example used when calculating the error of prediction is different from the training example used for training the student model (hereinafter, also referred to as “student model training example”) (hereinafter, “error calculation example””. Also called.).
- error calculation example an example with a large error calculated using the error calculation example is selected, and an unlabeled example similar to the example is output. This makes it possible to output an example that contributes to improving the accuracy of the student model.
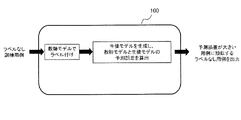
- FIG. 2 is a diagram conceptually showing the information processing apparatus of the present embodiment.
- a plurality of unlabeled training examples are input to the information processing apparatus 100.
- the information processing apparatus 100 labels the input unlabeled training example with the above-mentioned teacher model. This label corresponds to the prediction by the teacher model.
- the information processing apparatus 100 generates a student model using the labeled training example.
- the information processing apparatus 100 predicts an error calculation example using the generated student model and teacher model, and calculates an error between the prediction of the student model and the prediction of the student model. Then, the information processing apparatus 100 outputs an unlabeled example similar to the training example in which the calculated error is large.
- the unlabeled example thus obtained is an example in which the error is expected to be large when the teacher model and the student model predict the example. Therefore, it can be expected that the accuracy of the student model will be improved by assigning a label to this example and retraining the student model.
- FIG. 3 is a block diagram showing a hardware configuration of the information processing apparatus 100 of the first embodiment.
- the information processing apparatus 100 includes an input IF (Interface) 11, a processor 12, a memory 13, a recording medium 14, and a database (DB) 15.
- IF Interface
- DB database
- Input IF11 inputs and outputs data. Specifically, the input IF 11 acquires an example composed of a feature amount and outputs an unlabeled example similar to the example having a large error.
- the processor 12 is a computer such as a CPU (Central Processing Unit) and a GPU (Graphics Processing Unit), and controls the entire information processing device 100 by executing a program prepared in advance. In particular, the processor 12 performs a process of outputting an unlabeled example similar to the example having a large error.
- a CPU Central Processing Unit
- GPU Graphics Processing Unit
- the memory 13 is composed of a ROM (Read Only Memory), a RAM (Random Access Memory), and the like.
- the memory 13 stores various programs executed by the processor 12.
- the memory 13 is also used as a working memory during execution of various processes by the processor 12.
- the recording medium 14 is a non-volatile, non-temporary recording medium such as a disk-shaped recording medium or a semiconductor memory, and is configured to be removable from the information processing device 100.
- the recording medium 14 records various programs executed by the processor 12.
- DB15 stores an example input from the input IF11. Further, the DB 15 stores an unlabeled example to be output from the information processing apparatus 100.
- FIG. 4 is a block diagram showing a functional configuration of the information processing apparatus 100.
- the information processing apparatus 100 includes an input unit 21, a label generation unit 22, a prediction error calculation unit 23, a data extraction unit 24, a data holding unit 25, and an output unit 26.
- An unlabeled training example used for training a student model and a trained teacher model are input to the input unit 21.
- the training example is composed of multidimensional features.
- the input unit 21 outputs the unlabeled training example and the trained teacher model to the label generation unit 22. Further, the input unit 21 outputs an unlabeled training example to the prediction error calculation unit 23.
- the label generation unit 22 uses the trained teacher model to generate a label for the input unlabeled training example, and outputs the label to the prediction error calculation unit 23. It should be noted that this label corresponds to the prediction of the teacher model for the input unlabeled training example.
- the prediction error calculation unit 23 acquires an unlabeled training example from the input unit 21, and also acquires a label given to each training example from the label generation unit 22. As a result, the prediction error calculation unit 23 is provided with a labeled training example. The prediction error calculation unit 23 trains a student model using this labeled training example and generates a trained student model.
- the prediction error calculation unit 23 makes a prediction using the generated student model. Then, the prediction error calculation unit 23 calculates the error between the prediction by the student model and the label input from the label generation unit 22, that is, the error between the prediction by the student model and the prediction by the teacher model, and the data extraction unit 24. Output to. In the calculation of this prediction error, an error calculation example, which is an example different from the training example used for training the student model, is used. The calculated prediction error is output to the data extraction unit 24.
- the prediction error calculation unit 23 calculates the prediction error by using an example different from the training example used for training the student model.
- a labeled training example is generated by using a teacher model for an unlabeled training example input from the input unit 21, and a student model is generated using the labeled training example. Is training. Therefore, if the prediction error calculation unit 23 calculates the prediction error of the teacher model and the student model using the same training example used for training the student model, the prediction of the teacher model and the student model in each training example is calculated. Because of the match, the calculated prediction error will be zero at all points corresponding to the training example. That is, overfitting occurs in the error prediction itself, and an error smaller than the original error is predicted. This is called "overfitting of prediction error".
- FIG. 5 is a diagram illustrating overfitting of prediction error.
- a plurality of points 71 indicate a training example
- a solid line graph 72 indicates a teacher model. Since the student model is trained using the label given by the teacher model to the training example as teacher data, the prediction error with the teacher model is zero at the position of the training example 71 as shown by the graph 73 of the broken line. Be trained in. Therefore, if the prediction error between the teacher model and the student model is calculated using the same training example used for training the student model, the prediction error between the teacher model and the student model cannot be estimated correctly.
- the prediction error between the teacher model and the student model is calculated by using an error calculation example which is an example different from the training example used for training the student model.
- an error calculation example which is an example different from the training example used for training the student model.
- the error is calculated by the formula (1), but this norm does not have to be the Euclidean norm, and any norm can be used. Further, the prediction error calculation unit 23 may calculate the error by converting the outputs of the predictions by the teacher model and the student model into probability distributions and then taking the Kullback-Leibler divergence of the two outputs.
- Method 2 The training example is divided and an error calculation example is generated.
- the training example labeled by the teacher model is divided, and the divided training example is used as the student model training example to train the student model.
- the remaining divided training examples are used as error calculation examples, and the prediction errors of the teacher model and the student model are calculated.
- FIG. 6 shows a specific example of dividing a training example by method 2 and generating an error calculation example.
- N 5 in the example of FIG. 6
- the label generation unit 22 assigns labels to all the data of the training example using the teacher model (step P1).
- each bootstrap sample group is generated by random sampling due to duplication of training examples, there are samples included in the training examples but not selected in each bootstrap sample group. This is called OOB (Out-Of-Bag). OOB is not included in the bootstrap sample group and is not used to generate student models. Therefore, the prediction error calculation unit 23 uses the OOB of each bootstrap sample group as an error calculation example, and calculates the prediction error of the teacher model and the student model.
- Method 3 Obtain another example.
- all the training examples input to the input unit 21 are used as the student model training examples, and the student model is generated.
- an unlabeled example different from the training example is separately acquired and used as an error calculation example.
- an unlabeled example exists in advance, it may be used. In this method, it is not necessary to perform the above-mentioned duplicate sampling for the unlabeled example.
- the prediction error calculation unit 23 calculates the prediction error of the teacher model and the student model by using an error calculation example different from the training example used for training the student model, so that over-learning of the prediction error occurs. It is possible to suppress the above and calculate the prediction error accurately.
- the data holding unit 25 stores a plurality of unlabeled examples in advance.
- the unlabeled example stored in the data holding unit 25 may include an example artificially generated from a training example by an oversampling method (SMOTE or the like).
- the data extraction unit 24 extracts an unlabeled example similar to the example with a large error input from the prediction error calculation unit 23 from the data holding unit 25. Specifically, first, the data extraction unit 24 selects an example having a large error based on the error output from the prediction error calculation unit 23.
- the data extraction unit 24 may select, for example, a predetermined number of examples from the one with the largest error, an example with an error larger than a predetermined threshold value, and the like as the above-mentioned "example with a large error".
- the data extraction unit 24 may consider the distribution (degree of appearance) of the example, instead of simply selecting the example having a large error. Specifically, the data extraction unit 24 may estimate the density of the example by density estimation or the like, and select the example in which the weighted sum of the distribution and the error becomes large as the “example with a large error”. For example, the data extraction unit 24 first uses each example x 1 ,. .. .. , X n , distribution (appearance) p (x 1 ) ,. .. .. , P (x n ) is estimated.
- the data extraction unit 24 uses the hyperparameters ⁇ and ⁇ (0 ⁇ ⁇ , ⁇ ⁇ 1) fixed to the error e i of the example x i to make an error. Is calculated, and an example x i with a large error e i new (x i ) is output.
- the data extraction unit 24 acquires an unlabeled example similar to the selected example from the data holding unit 25. Specifically, the data extraction unit 24 uses a method for measuring the distance between the examples, such as the cosine similarity or the k-nearest neighbor method, and the data holding unit 25 is an unlabeled example that is close to the selected example. Get from. Then, the data extraction unit 24 outputs this unlabeled example to the output unit 26.
- a method for measuring the distance between the examples such as the cosine similarity or the k-nearest neighbor method
- the data extraction unit 24 may consider the similarity between each example and the unlabeled example stored in the data holding unit 25. For example, the data extraction unit 24 measures the similarity between each example and the unlabeled example, adds the errors for each example using the similarity as a weight, and outputs the unlabeled example having the largest total to the output unit 26. You may.
- the data extraction unit 24 has the example x 1 ,. .. .. , X n similarity
- the data extraction unit 24 sets the error of the example xi as ei, and the weighted sum.
- the data extraction unit 24 outputs the unlabeled example z that maximizes the weighted sum.
- the output unit 26 outputs an example input from the data extraction unit 24 as "an example in which an error is expected to increase".
- the example output in this way is used for retraining the student model.
- the output example may be labeled using the teacher model used in the label generation unit 22 to be used as a training example, and may be used for retraining the student model.
- the output example may be labeled by a teacher model different from the teacher model used in the label generation unit 22 or by hand.
- FIG. 7 is a flowchart of a process for outputting an example. This process is realized by the processor 12 shown in FIG. 3 executing a program prepared in advance and operating as each element shown in FIG.
- the input unit 21 acquires an unlabeled training example and a teacher model (step S11).
- the label generation unit 22 assigns a label to the unlabeled training example using the teacher model (step S12).
- the prediction error calculation unit 23 generates a student model using the training example labeled in step S12 (step S13).
- the prediction error calculation unit 23 calculates the prediction error of the teacher model and the student model for the error calculation example (step S14).
- the data extraction unit 24 selects an example having a large error (step S15), acquires an unlabeled example similar to the example from the data holding unit 25, and outputs the example from the output unit 26 (step S16). Then, the process ends.
- the label generation unit 22 attaches a label to the unlabeled training example input to the input unit 21 by using a trained teacher model prepared in advance. Instead, when a labeled training example is input to the input unit 21, the label generation unit 22 may first generate a teacher model using the labeled training example. Further, the label generation unit 22 may manually assign a label instead of assigning the label using the teacher model. Further, in the above embodiment, the prediction error calculation unit 23 generates a student model using a training example to which the label generation unit 22 has a label, but instead, the trained student model prepared in advance is used. May be obtained.
- the output unit 26 outputs an unlabeled example similar to the example having a large error, but a labeling unit may be provided after the output unit 26.
- the labeling unit assigns a label to the unlabeled example output by the output unit 26, so that a labeled training example that can be used for retraining the student model can be generated.
- the label assigning unit may assign a label using the teacher model used by the label generation unit 22, and the label may be assigned using a teacher model different from the teacher model used by the label generation unit 22.
- the label may be given, or the label may be given manually.
- FIG. 8 is a block diagram showing a functional configuration of the information processing apparatus 50 according to the second embodiment.
- the information processing apparatus 50 includes an input means 51, a label generation means 52, an error calculation means 53, a data holding means 54, and a data extraction means 55.
- the input means 51 receives a training example composed of a feature amount.
- the label generation means 52 assigns a label to the training example using the teacher model.
- the error calculation means 53 generates one or more student models using at least a part of the labeled training examples, and uses an error calculation example different from the example used to generate the student model. Calculate the error between the prediction by the teacher model and the prediction by the teacher model.
- the data holding means 54 holds an example composed of a feature amount.
- the data extracting means 55 extracts from the data holding means 54 an example in which the error is predicted to be large based on the error calculated by the error calculating means 53, and outputs the example.
- FIG. 9 is a flowchart of processing by the information processing apparatus 50 of the second embodiment.
- the input means 51 receives a training example composed of a feature amount (step S21).
- the label generation means 52 assigns a label to the training example using the teacher model (step S22).
- the error calculation means 53 generates one or more student models using at least a part of the labeled training examples, and uses an error calculation example different from the example used to generate the student model.
- the error between the prediction by the teacher model and the prediction by the teacher model is calculated (step S23).
- the data extracting means 55 extracts from the data holding means 54 an example in which the error is predicted to be large based on the error calculated by the error calculating means 53, and outputs the example (step S24).
- an example in which the prediction error between the teacher model and the student model is predicted to be large is output. Therefore, the accuracy of the student model can be efficiently improved by retraining the student model using the output example.
- An input means that accepts training examples consisting of features
- a label generation means for assigning a label to the training example using a teacher model
- One or more student models are generated using at least a portion of the labeled training example, and the prediction by the student model is performed using an error calculation example different from the example used to generate the student model.
- An error calculation means for calculating an error from the prediction by the teacher model
- a data holding means for holding an example consisting of features
- a data extraction means for extracting and outputting an example in which an error is expected to be large based on the error calculated by the error calculation means from the data holding means, and a data extraction means.
- Information processing device equipped with is
- the data extraction means selects an example having a large error calculated by the error calculation means, extracts an example similar to the selected example from the data holding means, and outputs the example as an example in which the error is predicted to be large.
- the information processing apparatus according to Appendix 1.
- Appendix 3 The information processing according to Appendix 2, wherein the data extraction means calculates the appearance degree of the error calculation example, and determines that the error calculation example having a large weighted sum of the appearance degree and the error is the example having a large error. Device.
- the error calculation means is any one of Supplementary note 1 to 3 for generating the student model using a part of the training example and using the remaining part of the training example as the error calculation example to calculate the error.
- the error calculation means generates a plurality of sample groups by random sampling with duplication from the training example, generates a student model using each of the sample groups, and is included in the training example for each student model.
- the error is calculated using a sample not included in the sample group as an example of error calculation, and the average of the errors calculated for the plurality of student models is the error between the prediction by the student model and the prediction by the teacher model.
- the information processing apparatus according to any one of Supplementary note 1 to 3, which is calculated as described above.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Medical Informatics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Physics & Mathematics (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Artificial Intelligence (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/044486 WO2022113340A1 (ja) | 2020-11-30 | 2020-11-30 | 情報処理装置、情報処理方法、及び、記録媒体 |
| JP2022564996A JP7529041B2 (ja) | 2020-11-30 | 2020-11-30 | 情報処理装置、情報処理方法、及び、プログラム |
| US18/037,149 US20240005217A1 (en) | 2020-11-30 | 2020-11-30 | Information processing device, information processing method, and recording medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/044486 WO2022113340A1 (ja) | 2020-11-30 | 2020-11-30 | 情報処理装置、情報処理方法、及び、記録媒体 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022113340A1 true WO2022113340A1 (ja) | 2022-06-02 |
Family
ID=81755509
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/044486 Ceased WO2022113340A1 (ja) | 2020-11-30 | 2020-11-30 | 情報処理装置、情報処理方法、及び、記録媒体 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20240005217A1 (https=) |
| JP (1) | JP7529041B2 (https=) |
| WO (1) | WO2022113340A1 (https=) |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2008047835A1 (fr) * | 2006-10-19 | 2008-04-24 | Nec Corporation | Système, procédé et programme d'étude active |
| JP2017107386A (ja) * | 2015-12-09 | 2017-06-15 | 日本電信電話株式会社 | 事例選択装置、分類装置、方法、及びプログラム |
| JP2019159654A (ja) * | 2018-03-12 | 2019-09-19 | 国立研究開発法人情報通信研究機構 | 時系列情報の学習システム、方法およびニューラルネットワークモデル |
| WO2020008878A1 (ja) * | 2018-07-02 | 2020-01-09 | ソニー株式会社 | 測位装置、測位方法、及びプログラム |
| WO2020162048A1 (ja) * | 2019-02-07 | 2020-08-13 | 国立大学法人山梨大学 | 信号変換システム、機械学習システムおよび信号変換プログラム |
-
2020
- 2020-11-30 JP JP2022564996A patent/JP7529041B2/ja active Active
- 2020-11-30 US US18/037,149 patent/US20240005217A1/en active Pending
- 2020-11-30 WO PCT/JP2020/044486 patent/WO2022113340A1/ja not_active Ceased
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2008047835A1 (fr) * | 2006-10-19 | 2008-04-24 | Nec Corporation | Système, procédé et programme d'étude active |
| JP2017107386A (ja) * | 2015-12-09 | 2017-06-15 | 日本電信電話株式会社 | 事例選択装置、分類装置、方法、及びプログラム |
| JP2019159654A (ja) * | 2018-03-12 | 2019-09-19 | 国立研究開発法人情報通信研究機構 | 時系列情報の学習システム、方法およびニューラルネットワークモデル |
| WO2020008878A1 (ja) * | 2018-07-02 | 2020-01-09 | ソニー株式会社 | 測位装置、測位方法、及びプログラム |
| WO2020162048A1 (ja) * | 2019-02-07 | 2020-08-13 | 国立大学法人山梨大学 | 信号変換システム、機械学習システムおよび信号変換プログラム |
Non-Patent Citations (3)
| Title |
|---|
| ISHIGAMI, S.: "RandomForest R package", 21 February 2018 (2018-02-21), pages 34, Retrieved from the Internet <URL:https://www.slideshare.net/Shumalshigami/randomforestr-package/34> [retrieved on 20210121] * |
| YOO DONGGEUN; KWEON IN SO: "Learning Loss for Active Learning", 2019 IEEE/CVF CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION (CVPR), IEEE, 15 June 2019 (2019-06-15), pages 93 - 102, XP033687105, DOI: 10.1109/CVPR.2019.00018 * |
| ZHU JINGBO, HOVY EDUARD: "Active Learning for Word Sense Disambiguation with Methods for Addressing the Class Imbalance Problem", PROCEEDINGS OF THE 2007 JOINT CONFERENCE ON EMPIRICAL METHODS IN NATURAL LANGUAGE PROCESSING AND COMPUTATIONAL NATURAL LANGUAGE LEARNING, ASSOCIATION FOR COMPUTATIONAL LINGUISTICS, 30 June 2007 (2007-06-30), pages 783 - 790, XP055941305, Retrieved from the Internet <URL:https://aclanthology.org/D07-1082.pdf> [retrieved on 20220712] * |
Also Published As
| Publication number | Publication date |
|---|---|
| US20240005217A1 (en) | 2024-01-04 |
| JPWO2022113340A1 (https=) | 2022-06-02 |
| JP7529041B2 (ja) | 2024-08-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6781415B2 (ja) | ニューラルネットワーク学習装置、方法、プログラム、およびパターン認識装置 | |
| JP2022550326A (ja) | 言語タスクのための対照事前トレーニング | |
| WO2019158927A1 (en) | A method of generating music data | |
| JP2016091166A (ja) | 機械学習装置、機械学習方法、分類装置、分類方法、プログラム | |
| US20230394106A1 (en) | Calculation method and information processing apparatus | |
| CN114822497B (zh) | 语音合成模型的训练及语音合成方法、装置、设备和介质 | |
| JP2022102095A (ja) | 情報処理装置、情報処理方法およびプログラム | |
| CN114863091A (zh) | 一种基于伪标签的目标检测训练方法 | |
| JP7192995B2 (ja) | 判定装置、学習装置、判定方法及び判定プログラム | |
| CN115543762A (zh) | 一种磁盘smart数据扩充方法、系统及电子设备 | |
| CN113850314A (zh) | 客户价值等级预测模型建立方法、装置、介质及设备 | |
| CN113392890B (zh) | 一种基于数据增强的分布外异常样本检测方法 | |
| CN112163106A (zh) | 二阶相似感知的图像哈希码提取模型建立方法及其应用 | |
| CN113553401B (zh) | 一种文本处理方法、装置、介质和电子设备 | |
| JP2019153078A (ja) | 記号列生成装置、文圧縮装置、記号列生成方法及びプログラム | |
| EP3975062A1 (en) | Method and system for selecting data to train a model | |
| CN111950619A (zh) | 一种基于双重生成对抗网络的主动学习方法 | |
| JP7529040B2 (ja) | 情報処理装置、情報処理方法、及び、プログラム | |
| CN114925808B (zh) | 一种基于云网端资源中不完整时间序列的异常检测方法 | |
| WO2022113340A1 (ja) | 情報処理装置、情報処理方法、及び、記録媒体 | |
| He et al. | Probabilistic quantum svm training on ising machine | |
| US20250054584A1 (en) | Computer-readable recording medium storing active learning program, method, and apparatus | |
| CN119129768B (zh) | 一种面向非完整多元时间序列预测的学习方法 | |
| CN118352090B (zh) | 一种基于电子死亡卡信息的根本死因推断方法及设备 | |
| CN114334068B (zh) | 一种放射学报告生成方法、装置、终端及存储介质 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20963604 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 18037149 Country of ref document: US |
|
| ENP | Entry into the national phase |
Ref document number: 2022564996 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 20963604 Country of ref document: EP Kind code of ref document: A1 |