WO2022050087A1 - 信号処理装置および方法、学習装置および方法、並びにプログラム - Google Patents
信号処理装置および方法、学習装置および方法、並びにプログラム Download PDFInfo
- Publication number
- WO2022050087A1 WO2022050087A1 PCT/JP2021/030599 JP2021030599W WO2022050087A1 WO 2022050087 A1 WO2022050087 A1 WO 2022050087A1 JP 2021030599 W JP2021030599 W JP 2021030599W WO 2022050087 A1 WO2022050087 A1 WO 2022050087A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- frequency information
- coefficient
- signal
- high frequency
- audio signal
- Prior art date
Links
- 238000012545 processing Methods 0.000 title claims abstract description 453
- 238000000034 method Methods 0.000 title claims abstract description 141
- 230000005236 sound signal Effects 0.000 claims abstract description 149
- 238000009877 rendering Methods 0.000 claims description 98
- 238000004364 calculation method Methods 0.000 claims description 52
- 238000013528 artificial neural network Methods 0.000 claims description 10
- 238000010801 machine learning Methods 0.000 claims description 6
- 238000003672 processing method Methods 0.000 claims description 3
- 238000005516 engineering process Methods 0.000 abstract description 26
- 239000013598 vector Substances 0.000 description 52
- 238000005070 sampling Methods 0.000 description 45
- 230000006870 function Effects 0.000 description 20
- 230000002194 synthesizing effect Effects 0.000 description 11
- 230000005540 biological transmission Effects 0.000 description 9
- 238000012546 transfer Methods 0.000 description 9
- 101100365087 Arabidopsis thaliana SCRA gene Proteins 0.000 description 6
- 230000015572 biosynthetic process Effects 0.000 description 5
- 210000005069 ears Anatomy 0.000 description 5
- 238000003786 synthesis reaction Methods 0.000 description 5
- 230000007274 generation of a signal involved in cell-cell signaling Effects 0.000 description 4
- 238000010606 normalization Methods 0.000 description 4
- 238000010521 absorption reaction Methods 0.000 description 3
- 238000004891 communication Methods 0.000 description 3
- 241000282414 Homo sapiens Species 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- 238000010586 diagram Methods 0.000 description 2
- 210000003128 head Anatomy 0.000 description 2
- 238000000691 measurement method Methods 0.000 description 2
- 230000015654 memory Effects 0.000 description 2
- 238000004091 panning Methods 0.000 description 2
- 238000007781 pre-processing Methods 0.000 description 2
- 238000001228 spectrum Methods 0.000 description 2
- 210000003454 tympanic membrane Anatomy 0.000 description 2
- 230000007423 decrease Effects 0.000 description 1
- 238000013135 deep learning Methods 0.000 description 1
- 230000006866 deterioration Effects 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 230000004807 localization Effects 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 238000011176 pooling Methods 0.000 description 1
- 230000000306 recurrent effect Effects 0.000 description 1
- 230000010076 replication Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 230000006403 short-term memory Effects 0.000 description 1
- 230000003595 spectral effect Effects 0.000 description 1
- 239000000126 substance Substances 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
Images














Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S7/00—Indicating arrangements; Control arrangements, e.g. balance control
- H04S7/30—Control circuits for electronic adaptation of the sound field
- H04S7/307—Frequency adjustment, e.g. tone control
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/008—Multichannel audio signal coding or decoding using interchannel correlation to reduce redundancy, e.g. joint-stereo, intensity-coding or matrixing
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/038—Speech enhancement, e.g. noise reduction or echo cancellation using band spreading techniques
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/044—Recurrent networks, e.g. Hopfield networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/038—Speech enhancement, e.g. noise reduction or echo cancellation using band spreading techniques
- G10L21/0388—Details of processing therefor
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S3/00—Systems employing more than two channels, e.g. quadraphonic
- H04S3/008—Systems employing more than two channels, e.g. quadraphonic in which the audio signals are in digital form, i.e. employing more than two discrete digital channels
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S7/00—Indicating arrangements; Control arrangements, e.g. balance control
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S7/00—Indicating arrangements; Control arrangements, e.g. balance control
- H04S7/30—Control circuits for electronic adaptation of the sound field
- H04S7/302—Electronic adaptation of stereophonic sound system to listener position or orientation
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S2400/00—Details of stereophonic systems covered by H04S but not provided for in its groups
- H04S2400/01—Multi-channel, i.e. more than two input channels, sound reproduction with two speakers wherein the multi-channel information is substantially preserved
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S2400/00—Details of stereophonic systems covered by H04S but not provided for in its groups
- H04S2400/11—Positioning of individual sound objects, e.g. moving airplane, within a sound field
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S2420/00—Techniques used stereophonic systems covered by H04S but not provided for in its groups
- H04S2420/01—Enhancing the perception of the sound image or of the spatial distribution using head related transfer functions [HRTF's] or equivalents thereof, e.g. interaural time difference [ITD] or interaural level difference [ILD]
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S2420/00—Techniques used stereophonic systems covered by H04S but not provided for in its groups
- H04S2420/03—Application of parametric coding in stereophonic audio systems
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S2420/00—Techniques used stereophonic systems covered by H04S but not provided for in its groups
- H04S2420/07—Synergistic effects of band splitting and sub-band processing
Definitions
- the present technology relates to signal processing devices and methods, learning devices and methods, and programs, and in particular, signal processing devices and methods, learning devices and methods that enable high-quality audio reproduction even in low-cost devices. And about the program.
- object audio technology has been used in movies, games, etc., and a coding method that can handle object audio has also been developed.
- MPEG Motion Picture Experts Group
- 3D audio standard is known (see, for example, Non-Patent Document 1).
- a moving sound source or the like is treated as an independent audio object (hereinafter, also simply referred to as an object), and the audio object is treated as an independent audio object. It is possible to encode the position information of the object together with the signal data as metadata.
- the decoding side decodes the bitstream, and obtains an object signal which is an audio signal of the object and metadata including object position information indicating the position of the object in space.
- a rendering process is performed to render the object signal to each of a plurality of virtual speakers virtually arranged in the space.
- a method called three-dimensional VBAP Vector Based Amplitude Panning
- VBAP Vector Based Amplitude Panning
- HRTF Head Related Transfer Function
- Non-Patent Document 1 a technique such as SBR (Spectral Band Replication) can be used as a technique for efficiently coding a high-resolution sound source.
- SBR Spectrum Band Replication
- the high frequency component of the spectrum is not encoded, and the average amplitude information of the high frequency subband signal is encoded and transmitted by the number of high frequency subbands.
- a final output signal including a low frequency component and a high frequency component is generated based on the low frequency subband signal and the high frequency average amplitude information. This makes it possible to realize higher quality audio reproduction.
- band expansion processing is performed in combination with rendering processing or HRTF processing for the above-mentioned object audio, band expansion processing is performed on the object signal of each object, and then rendering processing or HRTF processing is performed.
- the bandwidth expansion processing is performed independently for the number of objects, so the processing load, that is, the amount of calculation increases. Further, after the band expansion process, the rendering process and the HRTF process are performed on the signal having a higher sampling frequency obtained by the band expansion, so that the processing load is further increased.
- low-cost devices such as low-cost processors and battery devices, that is, devices with low computing power and devices with low battery capacity cannot expand the bandwidth, resulting in high-quality audio playback. You will not be able to do it.
- This technology was made in view of such a situation, and enables high-quality audio reproduction even with a low-cost device.
- the signal processing device of the first aspect of the present technology demultiplexes the input bit stream into the first audio signal, the metadata of the first audio signal, and the first high frequency information for band expansion.
- the decoding processing unit to be converted, the second audio signal obtained by performing signal processing based on the first audio signal and the metadata, and the first high frequency information generated based on the first high frequency information. It is provided with a band expansion unit that performs band expansion processing based on the high frequency information of 2 and generates an output audio signal.
- the signal processing method or program of the first aspect of the present technology converts an input bit stream into a first audio signal, metadata of the first audio signal, and first high frequency information for band expansion.
- a second audio signal obtained by demultiplexing and performing signal processing based on the first audio signal and the metadata, and a second high generated based on the first high frequency information. It includes a step of performing band expansion processing based on the region information and generating an output audio signal.
- the input bit stream is demultiplexed into a first audio signal, metadata of the first audio signal, and first high frequency information for band expansion.
- the first audio signal, the second audio signal obtained by performing signal processing based on the metadata, and the second high frequency information generated based on the first high frequency information.
- Band expansion processing is performed based on this, and an output audio signal is generated.
- the learning device of the second aspect of the present technology is based on the second audio signal generated by the signal processing based on the first audio signal and the first coefficient, and the first high region for band expansion.
- a second for band expansion based on a first high frequency information calculator that generates information and a third audio signal generated by the signal processing based on the first audio signal and the second coefficient.
- the second high frequency information calculation unit Based on the second high frequency information calculation unit that generates the high frequency information of 2, the first coefficient, the second coefficient, the first high frequency information, and the second high frequency information.
- the learning method or program of the second aspect of the present technology is based on the second audio signal generated by signal processing based on the first audio signal and the first coefficient, and the first for band expansion. Generates high frequency information and generates second high frequency information for band expansion based on the third audio signal generated by the signal processing based on the first audio signal and the second coefficient. Then, based on the first coefficient, the second coefficient, the first high frequency information, and the second high frequency information, learning is performed using the second high frequency information as teacher data. A step of generating coefficient data for obtaining the second high frequency information from the first coefficient, the second coefficient, and the first high frequency information is included.
- the first high frequency information for band expansion is based on the second audio signal generated by the signal processing based on the first audio signal and the first coefficient.
- the second high frequency information for band expansion is generated, said first.
- learning is performed using the second high frequency information as teacher data, and the first The coefficient data for obtaining the second high frequency information is generated from the coefficient of the above, the second coefficient, and the first high frequency information.
- This technology multiplexes and transmits general-purpose high-frequency information for band expansion processing for HRTF output signals in a bitstream in advance, and on the decoding side, a personal HRTF coefficient and a general-purpose HRTF coefficient. And based on the high frequency information, the high frequency information corresponding to the personal HRTF coefficient is generated.
- bitstream obtained by encoding with the MPEG-H Part 3: 3D audio standard coding method is decoded, and it is generally performed when the output audio signal of the object audio is generated. Processing will be explained.
- an object signal which is an audio signal for reproducing the sound of an object (audio object) constituting the content, and metadata including object position information indicating the position of the object in space can be obtained.
- the rendering processing unit 12 performs rendering processing for rendering an object signal to virtual speakers virtually arranged in space based on the object position information included in the metadata, and outputs the object signals from each virtual speaker.
- a virtual speaker signal is generated to reproduce the sound.
- the virtualization processing unit 13 performs virtualization processing based on the virtual speaker signal of each virtual speaker, and outputs sound from a playback device such as a headphone worn by the user or a speaker arranged in a real space.
- the output audio signal is generated.
- the virtualization process is a process for generating an audio signal to realize audio reproduction as if the channel configuration is different from the channel configuration in the actual playback environment.
- the process of generating a signal is the virtualize process.
- the virtualization process may be realized by any method, but in the following, the explanation will be continued assuming that the HRTF process is performed as the virtualize process.
- the sound is output from the actual headphones or speakers based on the output audio signal obtained by the virtualization process, it is possible to realize audio reproduction as if the sound is being reproduced from the virtual speaker.
- the speaker actually arranged in the real space will be referred to as a real speaker in particular.
- a predetermined method of rendering such as VBAP described above is performed.
- VBAP is one of the rendering methods generally called panning, and among the virtual speakers existing on the surface of the sphere whose origin is the user position, for the three virtual speakers closest to the object also existing on the surface of the sphere. Rendering is performed by distributing the gain.
- FIG. 2 it is assumed that there is a user U11 who is a listener in a three-dimensional space, and three virtual speakers SP1 to virtual speakers SP3 are arranged in front of the user U11.
- the position of the head of the user U11 is the origin O
- the virtual speaker SP1 or the virtual speaker SP3 is located on the surface of the sphere centered on the origin O.
- the gain is distributed to the virtual speaker SP1 to the virtual speaker SP3 around the position VSP1 for the object.
- the position VSP1 is represented by a three-dimensional vector P having the origin O as the start point and the position VSP1 as the end point.
- the vector P is a vector as shown in the following equation (1). It can be represented by the linear sum of L 1 to the vector L 3 .
- the coefficients g 1 to the coefficient g 3 multiplied by the vectors L 1 to L 3 are calculated, and these coefficients g 1 to the coefficient g 3 are used in the virtual speaker SP1 to the virtual speaker SP3. If the gain of the sound output from each is used, the sound image can be localized at the position VSP1.
- the triangular region TR11 surrounded by three virtual speakers on the surface of the sphere shown in FIG. 2 is called a mesh.
- the virtual speaker signal of each virtual speaker can be obtained by performing the calculation of the following equation (3).
- G (m, n) is multiplied by the object signal S (n, t) of the nth object in order to obtain the virtual speaker signal SP (m, t) for the mth virtual speaker. It shows the gain to be done. That is, the gain G (m, n) indicates the gain distributed to the m-th virtual speaker for the n-th object obtained by the above-mentioned equation (2).
- the calculation of this formula (3) is the process with the highest calculation cost. That is, the operation of the equation (3) is the process with the largest amount of calculation.
- FIG. 3 is an example in which a virtual speaker is arranged on a two-dimensional horizontal plane for the sake of simplicity.
- FIG. 3 five virtual speakers SP11-1 to virtual speakers SP11-5 are arranged in a circular shape in a space.
- the virtual speaker SP11-1 and the virtual speaker SP11-5 are also simply referred to as the virtual speaker SP11.
- the user U21 who is a listener is located at a position surrounded by five virtual speakers SP11, that is, at the center position of a circle in which the virtual speakers SP11 are arranged. Therefore, in the HRTF processing, an output audio signal is generated to realize audio reproduction as if the user U21 is listening to the sound output from each virtual speaker SP11.
- the position where the user U21 is located is set as the listening position, and the sound based on the virtual speaker signal obtained by rendering to each of the five virtual speakers SP11 is reproduced by the headphones.
- the sound output (radiated) from the virtual speaker SP11-1 based on the virtual speaker signal passes through the path shown by the arrow Q11 and reaches the eardrum of the left ear of the user U21. Therefore, the characteristics of the sound output from the virtual speaker SP11-1 should change depending on the spatial transmission characteristics from the virtual speaker SP11-1 to the left ear of the user U21, the shape of the face and ears of the user U21, and the reflection absorption characteristics. Is.
- the spatial transmission characteristics from the virtual speaker SP11-1 to the left ear of the user U21, the shape of the face and ears of the user U21, the reflection absorption characteristics, etc. are added to the virtual speaker signal of the virtual speaker SP11-1.
- the transmission function H_L_SP11 we can obtain an output audio signal that reproduces the sound from the virtual speaker SP11-1 that would be heard by the user U21's left ear.
- the sound output from the virtual speaker SP11-1 based on the virtual speaker signal passes through the path indicated by the arrow Q12 and reaches the eardrum of the right ear of the user U21. Therefore, the spatial transmission characteristics from the virtual speaker SP11-1 to the right ear of the user U21, the shape of the face and ears of the user U21, the reflection absorption characteristics, etc. are added to the virtual speaker signal of the virtual speaker SP11-1.
- the transmission function H_R_SP11 we can obtain an output audio signal that reproduces the sound from the virtual speaker SP11-1 that would be heard by the user U21's right ear.
- the transmission for the left ear of each virtual speaker is transmitted to each virtual speaker signal.
- the function may be convoluted and the resulting signals may be added together to form the left channel output audio signal.
- the transfer function for the right ear of each virtual speaker is convoluted with each virtual speaker signal, and the resulting signals are added together to obtain the output audio signal of the right channel. Just do it.
- ⁇ indicates the frequency
- the virtual speaker signal of the frequency ⁇ of is shown.
- the virtual speaker signal SP (m, ⁇ ) can be obtained by time-frequency converting the above-mentioned virtual speaker signal SP (m, t).
- H_L (m, ⁇ ) is multiplied by the virtual speaker signal SP (m, ⁇ ) for the m-th virtual speaker for obtaining the output audio signal L ( ⁇ ) of the left channel.
- the transfer function for the left ear is shown.
- H_R (m, ⁇ ) shows the transfer function for the right ear.
- the output audio signal is generated by performing the decoding process, the rendering process, and the HRTF process as described above, and the object audio is reproduced using headphones or a small number of real speakers, a large amount of calculation is required. In addition, this amount of calculation increases as the number of objects increases.
- the high frequency component of the spectrum of the audio signal is not encoded, and the average of the high frequency subband signals of the high frequency band, which is the high frequency band.
- the amplitude information is encoded by the number of high-frequency subbands and transmitted to the decoding side.
- the low-frequency subband signal which is an audio signal obtained by the decoding process (decoding)
- the normalized signal is copied to the high-frequency subband ( Will be duplicated).
- the signal obtained as a result is multiplied by the average amplitude information of each high-frequency subband to obtain a high-frequency subband signal, and the low-frequency subband signal and the high-frequency subband signal are subband-synthesized, and finally.
- Output audio signal is
- band expansion processing for example, audio reproduction of a high-resolution sound source having a sampling frequency of 96 kHz or higher can be performed.
- the 96 kHz obtained by decoding is performed regardless of whether band expansion processing such as SBR is performed. Rendering and HRTF processing will be performed on the object signal. Therefore, when the number of objects and the number of virtual speakers are large, the calculation cost of these processes becomes enormous, and a high-performance processor and high power consumption are required.
- FIG. 4 an example of processing performed when an output audio signal of 96 kHz is obtained by band expansion in object audio will be described.
- the same reference numerals are given to the portions corresponding to those in FIG. 1, and the description thereof will be omitted.
- the decoding processing unit 11 When the input bit stream is supplied, the decoding processing unit 11 performs demultiplexing and decoding processing, and the object signal obtained as a result and the object position information and high frequency information of the object are output.
- the high frequency information is the average amplitude information of the high frequency subband signal obtained from the object signal before encoding.
- the high frequency information indicates the magnitude of each subband component on the high frequency side of the uncoded object signal having a higher sampling frequency corresponding to the object signal obtained by the decoding process, for band expansion.
- Bandwidth expansion information Since SBR is used as an example here, the average amplitude information of the high-frequency subband signal is used as the band expansion information, but the band expansion information for the band expansion processing is before coding. It may be any information such as a representative value of the amplitude of each subband on the high frequency side of the object signal and information indicating the shape of the frequency envelope.
- the object signal obtained by the decoding process has a sampling frequency of 48 kHz, for example, and in the following, such an object signal is also referred to as a low FS object signal.
- the band expansion unit 41 After the decoding process, the band expansion unit 41 performs the band expansion process based on the high frequency information and the low FS object signal, and obtains an object signal having a higher sampling frequency.
- an object signal having a sampling frequency of 96 kHz can be obtained by band expansion processing, and in the following, such an object signal will also be referred to as a high FS object signal.
- the rendering processing unit 12 performs rendering processing based on the object position information obtained by the decoding processing and the high FS object signal obtained by the bandwidth expansion processing.
- the rendering process obtains a virtual speaker signal having a sampling frequency of 96 kHz, and in the following, such a virtual speaker signal is also referred to as a high FS virtual speaker signal.
- the virtualization processing unit 13 performs virtualization processing such as HRTF processing based on the high FS virtual speaker signal, and an output audio signal having a sampling frequency of 96 kHz is obtained.
- FIG. 5 shows the frequency amplitude characteristic of a predetermined object signal.
- the vertical axis indicates the amplitude (power), and the horizontal axis indicates the frequency.
- the polygonal line L11 shows the frequency amplitude characteristic of the low FS object signal supplied to the band expansion unit 41.
- This low FS object signal has a sampling frequency of 48 kHz, and the low FS object signal does not contain signal components in the frequency band of 24 kHz or higher.
- the frequency band up to 24 kHz is divided into a plurality of low frequency subbands including the low frequency subband sb-8 to the low frequency subband sb-1, and the signal component of each of these low frequency subbands is divided. Is a low frequency subband signal.
- the frequency band from 24 kHz to 48 kHz is divided into a high frequency subband sb to a high frequency subband sb + 13, and the signal component of each of these high frequency subbands is a high frequency subband signal.
- the straight line L12 shows the average amplitude information supplied as the high frequency information of the high frequency subband sb
- the straight line L13 shows the average supplied as the high frequency information of the high frequency subband sb + 1. It shows the amplitude information.
- the low frequency subband signal is normalized by the average amplitude value of the low frequency subband signal, and the signal obtained by the normalization is copied (mapped) to the high frequency side.
- the low frequency subband as the copy source and the high frequency subband as the copy destination of the low frequency subband are predetermined by the extended frequency band and the like.
- the low frequency subband signal of the low frequency subband sb-8 is normalized, and the signal obtained by the normalization is copied to the high frequency subband sb.
- the signal after normalization of the low frequency subband signal of the low frequency subband sb-8 is modulated and converted into the signal of the frequency component of the high frequency subband sb.
- the low frequency subband signal of the low frequency subband sb-7 is copied to the high frequency subband sb + 1 after normalization.
- the high of each high-frequency subband is relative to the copied signal of each high-frequency subband.
- the average amplitude information indicated by the region information is multiplied to generate a high frequency subband signal.
- the average indicated by the straight line L12 is obtained by normalizing the low-frequency subband signal of the low-frequency subband sb-8 and copying it to the high-frequency subband sb.
- the amplitude information is multiplied to obtain a high-frequency subband signal of the high-frequency subband sb.
- each low-frequency subband signal and each high-frequency subband signal are input to a band synthesis filter for 96 kHz sampling and filtered (synthesized).
- the resulting high FS object signal is output. That is, a high FS object signal whose sampling frequency is upsampled (band expanded) to 96 kHz can be obtained.
- the band expansion process for generating the high FS object signal as described above is independently performed for each low FS object signal included in the input bit stream, that is, for each object. It will be done.
- the rendering processing unit 12 must perform rendering processing of a high FS object signal of 96 kHz for each of the 32 objects.
- the virtualization processing unit 13 in the subsequent stage must also perform HRTF processing (virtualization processing) of the 96 kHz high FS virtual speaker signal for the number of virtual speakers.
- the processing load on the entire device becomes enormous. This is the same even when the sampling frequency of the audio signal obtained by the decoding process is 96 kHz without performing the band expansion process.
- decoding processing, rendering processing, and HRTF processing with a high processing load are performed at a low sampling frequency, and the band expansion processing based on the transmitted high frequency information is performed for the final signal after the HRTF processing. It can be performed.
- the overall processing load can be reduced, and high-quality audio reproduction can be realized even with a low-cost processor or battery.
- the signal processing device on the decoding side can be configured as shown in FIG. 6, for example.
- FIG. 6 the same reference numerals are given to the portions corresponding to those in FIG. 4, and the description thereof will be omitted as appropriate.
- the signal processing device 71 shown in FIG. 6 is composed of, for example, a smartphone or a personal computer, and has a decoding processing unit 11, a rendering processing unit 12, a virtualization processing unit 13, and a band expansion unit 41.
- each process is performed in the order of decoding process, bandwidth expansion process, rendering process, and virtualization process.
- each processing is performed in the order of decoding processing, rendering processing, virtualization processing, and band expansion processing. That is, the band expansion process is performed last.
- the decoding processing unit 11 performs demultiplexing and decoding processing of the input bit stream.
- the decoding processing unit 11 supplies the high frequency information obtained by the demultiplexing and decoding processing (decoding processing) to the band expansion unit 41, and supplies the object position information and the object signal to the rendering processing unit 12.
- the input bit stream contains high-frequency information corresponding to the output of the virtualize processing unit 13, and the decoding processing unit 11 supplies the high-frequency information to the band expansion unit 41.
- the rendering processing unit 12 performs rendering processing such as VBAP based on the object position information and the object signal supplied from the decoding processing unit 11, and the virtual speaker signal obtained as a result is supplied to the virtualization processing unit 13. Will be done.
- the virtualization processing unit 13 performs HRTF processing as virtualization processing. That is, in the virtualization processing unit 13, the convolution processing based on the virtual speaker signal supplied from the rendering processing unit 12 and the HRTF coefficient corresponding to the transfer function given in advance, and the addition of the resulting signals are added. The process is performed as an HRTF process.
- the virtualization processing unit 13 supplies the audio signal obtained by the HRTF processing to the band expansion unit 41.
- the object signal supplied from the decoding processing unit 11 to the rendering processing unit 12 is a low FS object signal having a sampling frequency of 48 kHz.
- the virtual speaker signal supplied from the rendering processing unit 12 to the virtualizing processing unit 13 is also a signal having a sampling frequency of 48 kHz, so that the audio supplied from the virtualizing processing unit 13 to the band expansion unit 41.
- the sampling frequency of the signal is also 48kHz.
- the audio signal supplied from the virtualization processing unit 13 to the band expansion unit 41 will also be referred to as a low FS audio signal in particular.
- a low FS audio signal is a drive signal that drives a playback device such as headphones or a real speaker to output sound, which is obtained by subjecting an object signal to signal processing such as rendering processing and virtualization processing. Is.
- the band expansion unit 41 generates an output audio signal by performing band expansion processing on the low FS audio signal supplied from the virtualization processing unit 13 based on the high frequency information supplied from the decoding processing unit 11. , Output to the latter stage.
- the output audio signal obtained by the band expansion unit 41 is, for example, a signal having a sampling frequency of 96 kHz.
- the HRTF coefficient used for the HRTF process as the virtualize process largely depends on the shape of the ear and face of the individual user who is the listener.
- the general-purpose HRTF coefficient measured or generated for the average human ear or face shape will also be referred to as the general-purpose HRTF coefficient.
- the HRTF coefficient corresponding to the shape of the ear or face of the individual user, which is measured or generated for the individual user, that is, the HRTF coefficient for each individual user will be referred to as a personal HRTF coefficient in particular.
- the personal HRTF coefficient is not limited to the one measured or generated for each individual user, but the user's ears and face are roughly selected from a plurality of HRTF coefficients measured or generated for each shape of the ear or face. It may be an HRTF coefficient suitable for the individual user, which is selected based on information about the individual user such as the shape, age, and gender of the face.
- each user has a different HRTF coefficient suitable for that user.
- the high frequency information used in the band expansion unit 41 also corresponds to the personal HRTF coefficient. Is desirable.
- the high-frequency information contained in the input bitstream is general-purpose high-frequency information that assumes that the audio signal obtained by performing HRTF processing using the general-purpose HRTF coefficient is subjected to band expansion processing. It has become.
- personal high-frequency information is generated on the playback device side (decoding side) using general-purpose high-frequency information premised on the general-purpose HRTF coefficient, general-purpose HRTF coefficient, and personal HRTF coefficient. I made it.
- high processing load decoding processing, rendering processing, and HRTF processing are performed at a low sampling frequency, and the final signal after HRTF processing is subjected to band expansion processing based on the generated personal high-frequency information. You will be able to. Therefore, it is possible to reduce the overall processing load and realize high-quality audio reproduction even with a low-cost processor or battery.
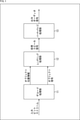
- FIG. 7 is a diagram showing a configuration example of an embodiment of the signal processing device 101 to which the present technology is applied.
- the same reference numerals are given to the portions corresponding to those in FIG. 6, and the description thereof will be omitted as appropriate.
- the signal processing device 101 includes, for example, a smartphone or a personal computer, and includes a decoding processing unit 11, a rendering processing unit 12, a virtualization processing unit 13, a personal high-frequency information generation unit 121, an HRTF coefficient recording unit 122, and a band expansion unit. Has 41.
- the configuration of the signal processing device 101 is different from the configuration of the signal processing device 71 in that a personal high frequency information generation unit 121 and an HRTF coefficient recording unit 122 are newly provided, and is the same configuration as the signal processing device 71 in other respects. It has become.
- the decoding processing unit 11 acquires an input bit stream including encoded object signals of object audio, metadata including object position information, general-purpose high frequency information, etc. from a server or the like (not shown). (Receive).
- the general-purpose high-frequency information included in the input bitstream is basically the same as the high-frequency information included in the input bitstream acquired by the decoding processing unit 11 of the signal processing device 71.
- the decoding processing unit 11 demultiplexes the input bit stream acquired by receiving or the like into encoded object signals, metadata, and general-purpose high-frequency information, and also demultiplexes the encoded object signals and metadata. Decode.
- the decoding processing unit 11 supplies the general-purpose high-frequency information obtained by demultiplexing and decoding the input bit stream to the personal high-frequency information generation unit 121, and supplies the object position information and the object signal to the rendering processing unit 12. Supply.
- the input bit stream contains general-purpose high-frequency information corresponding to the output of the virtualize processing unit 13 when the virtualize processing unit 13 performs HRTF processing using the general-purpose HRTF coefficient. That is, the general-purpose high-frequency information is high-frequency information for band expansion of the HRTF output signal obtained by performing HRTF processing using the general-purpose HRTF coefficient.
- the rendering processing unit 12 performs rendering processing such as VBAP based on the object position information and the object signal supplied from the decoding processing unit 11, and supplies the virtual speaker signal obtained as a result to the virtualization processing unit 13.
- the virtualization processing unit 13 is based on the virtual speaker signal supplied from the rendering processing unit 12 and the personal HRTF coefficient corresponding to the transfer function given in advance, which is supplied from the HRTF coefficient recording unit 122.
- the HRTF process is performed as the rise process, and the audio signal obtained as a result is supplied to the band expansion unit 41.
- the convolution processing of the virtual speaker signal for each virtual speaker and the personal HRTF coefficient, and the addition processing of adding the signals obtained by the convolution processing for each virtual speaker are performed.
- the HRTF output signal is a drive signal obtained by subjecting an object signal to signal processing such as rendering processing and virtualization processing to drive a playback device such as headphones to output sound.
- the object signal supplied from the decoding processing unit 11 to the rendering processing unit 12 is a low FS object signal having a sampling frequency of 48 kHz.
- the virtual speaker signal supplied from the rendering processing unit 12 to the virtualizing processing unit 13 is also a signal having a sampling frequency of 48 kHz, and therefore the HRTF supplied from the virtualizing processing unit 13 to the band expansion unit 41.
- the sampling frequency of the output signal is also 48kHz.
- the rendering processing unit 12 and the virtualizing processing unit 13 perform signal processing including rendering processing and virtualizing processing based on the metadata (object position information), personal HRTF coefficient, and object signal, and perform HRTF. It can be said that it functions as a signal processing unit that generates an output signal.
- the signal processing may include at least virtualization processing.
- the personal high frequency information generation unit 121 is based on the general-purpose high frequency information supplied from the decoding processing unit 11 and the general-purpose HRTF coefficient and personal HRTF coefficient supplied from the HRTF coefficient recording unit 122. Is generated and supplied to the band expansion unit 41.
- This personal high frequency information is high frequency information for band expansion of the HRTF output signal obtained by performing HRTF processing using the personal HRTF coefficient.
- the HRTF coefficient recording unit 122 records (holds) a general-purpose HRTF coefficient or a personal HRTF coefficient that has been recorded in advance or acquired from an external device as needed.
- the HRTF coefficient recording unit 122 supplies the recorded personal HRTF coefficient to the virtualization processing unit 13, and supplies the recorded general-purpose HRTF coefficient and personal HRTF coefficient to the personal high-frequency information generation unit 121. Or something.
- the general-purpose HRTF coefficient is stored in advance in the recording area of the playback device, the general-purpose HRTF coefficient is also recorded in advance in the HRTF coefficient recording unit 122 of the signal processing device 101 that functions as the playback device in this example as well. Can be done.
- the personal HRTF coefficient can be obtained from a server or the like on the network.
- the signal processing device 101 itself that functions as a playback device or a terminal device such as a smartphone connected to the signal processing device 101 generates image data such as a user's face image and ear image by shooting.
- image data such as a user's face image and ear image by shooting.
- the signal processing device 101 transmits the image data obtained about the user to the server, and the server performs conversion processing on the held HRTF coefficient based on the image data received from the signal processing device 101, and the individual user.
- HRTF coefficient for personal use is generated and transmitted to the signal processing device 101.
- the HRTF coefficient recording unit 122 acquires and records the personal HRTF coefficient transmitted from the server and received by the signal processing device 101 in this way.
- the band expansion unit 41 outputs by performing band expansion processing on the HRTF output signal supplied from the virtualization processing unit 13 based on the personal high frequency information supplied from the personal high frequency information generation unit 121. Generates an audio signal and outputs it to the subsequent stage.
- the output audio signal obtained by the band expansion unit 41 is, for example, a signal having a sampling frequency of 96 kHz.
- the personal high-frequency information generation unit 121 generates personal high-frequency information based on the general-purpose high-frequency information, the general-purpose HRTF coefficient, and the personal HRTF coefficient.
- the general-purpose high-frequency information is multiplexed in the input bit stream, and the personal HRTF coefficient and the general-purpose HRTF coefficient acquired by the personal high-frequency information generation unit 121 by some method are used for personal use. High frequency information is generated.
- the generation of personal high-frequency information by the personal high-frequency information generation unit 121 may be realized by any method, but as an example, a deep learning technique such as DNN (Deep Neural Network) is used. It can be realized.
- DNN Deep Neural Network
- the personal high frequency information generation unit 121 is based on the coefficients constituting the DNN generated in advance by machine learning, the general-purpose high frequency information to be input to the DNN, the general-purpose HRTF coefficient, and the personal HRTF coefficient. By performing calculations with a neural network), personal high-frequency information is generated.
- the personal high frequency information generation unit 121 is configured as shown in FIG. 8, for example.
- the personal high-frequency information generation unit 121 has an MLP (Multi-Layer Perceptron) 151, an MLP152, an RNN (Recurrent Neural Network) 153, a feature amount synthesis unit 154, and an MLP155.
- MLP Multi-Layer Perceptron
- RNN Recurrent Neural Network
- MLP 151 is an MLP composed of three or more layers of non-linearly activated nodes, that is, an input layer, an output layer, and one or more hidden layers. MLP is one of the commonly used techniques in DNN.
- the MLP 151 uses the general-purpose HRTF coefficient supplied from the HRTF coefficient recording unit 122 as a vector gh_in as an input of the MLP, and performs arithmetic processing based on the vector gh_in to obtain a vector gh_out which is data indicating some characteristics of the general-purpose HRTF coefficient. It is generated (calculated) and supplied to the feature amount synthesizing unit 154.
- the vector gh_in that is the input of the MLP may be the general-purpose HRTF coefficient itself, or it may be a feature quantity obtained by performing some preprocessing on the general-purpose HRTF coefficient in order to reduce the computational resources of the subsequent stage. good.
- the MLP152 is composed of the same MLP as the MLP151, and the personal HRTF coefficient supplied from the HRTF coefficient recording unit 122 is set as a vector ph_in as an input of the MLP, and the arithmetic processing based on the vector ph_in is performed to obtain the personal HRTF coefficient.
- a vector ph_out which is data indicating some feature, is generated and supplied to the feature amount synthesizing unit 154.
- the vector ph_in may also be the personal HRTF coefficient itself, or may be a feature quantity obtained by applying some kind of preprocessing to the personal HRTF coefficient.
- the RNN153 is generally composed of, for example, an RNN composed of three layers, an input layer, a hidden layer, and an output layer.
- the output of the hidden layer is fed back to the input of the hidden layer, and the RNN has a neural network structure suitable for time series data.
- LSTM Long Short Term Memory
- the RNN 153 is a vector ge_in (n) that inputs general-purpose high-frequency information supplied from the decoding processing unit 11, and performs arithmetic processing based on the vector ge_in (n) to show some features of the general-purpose high-frequency information.
- the vector ge_out (n) is generated (calculated) and supplied to the feature amount synthesizing unit 154.
- n in the vector ge_in (n) and the vector ge_out (n) represents the index of the time frame of the object signal.
- a vector ge_in (n) for a plurality of frames is used to generate personal high frequency information for one frame.
- the feature amount synthesizing unit 154 generates one vector co_out (n) by vector-connecting the vector gh_out supplied from MLP151, the vector ph_out supplied from MLP152, and the vector ge_out (n) supplied from RNN153. And supply to MLP155.
- the vector co_out (n) may be generated by any other method.
- the feature amount synthesis may be performed by a method called max-pooling so that the vector is synthesized into a compact size that can sufficiently express the features.
- the MLP 155 is composed of, for example, an input layer, an output layer, and an MLP having one or more hidden layers, and performs arithmetic processing based on the vector co_out (n) supplied from the feature amount synthesizing unit 154, and the resulting vector is obtained.
- pe_out (n) is supplied to the band expansion unit 41 as personal high frequency information.
- the coefficients that make up MLP and RNN such as MLP151, MLP152, RNN153, and MLP155 that make up the DNN that functions as the personal high-frequency information generation unit 121 as described above are obtained by performing machine learning using teacher data in advance. Obtainable.
- FIG. 9 shows an example of the syntax of the input bit stream supplied to the decoding processing unit 11, that is, an example of the format of the input bit stream.
- number_objects indicates the total number of objects
- object_compressed_data indicates an encoded (compressed) object signal
- position_azimuth indicates the horizontal angle in the spherical coordinate system of the object
- position_elevation indicates the vertical angle in the spherical coordinate system of the object
- position_radius indicates the distance from the origin of the spherical coordinate system to the object ( Radius) is shown.
- the information consisting of these horizontal angles, vertical angles, and distances is the object position information indicating the position of the object.
- the input bitstream contains the encoded object signal and the object position information for the number of objects indicated by "num_objects".
- number_output indicates the number of output channels, that is, the number of channels of the HRTF output signal
- output_bwe_data indicates general-purpose high-frequency information. Therefore, in this example, general-purpose high-frequency information is stored for each channel of the HRTF output signal.
- step S11 the decoding processing unit 11 performs demultiplexing and decoding processing on the supplied input bit stream, supplies the general-purpose high-frequency information obtained as a result to the personal high-frequency information generation unit 121, and at the same time, The object position information and the object signal are supplied to the rendering processing unit 12.
- the general-purpose high-frequency information indicated by "output_bwe_data" shown in FIG. 9 is extracted from the input bit stream and supplied to the personal high-frequency information generation unit 121.
- step S12 the rendering processing unit 12 performs rendering processing based on the object position information and the object signal supplied from the decoding processing unit 11, and supplies the virtual speaker signal obtained as a result to the virtualization processing unit 13.
- VBAP or the like is performed as a rendering process.
- step S13 the virtualization processing unit 13 performs the virtualization processing.
- the HRTF process is performed as a virtualize process.
- the virtualization processing unit 13 folds the virtual speaker signal of each virtual speaker supplied from the rendering processing unit 12 and the personal HRTF coefficient of each virtual speaker for each channel supplied from the HRTF coefficient recording unit 122.
- the process of adding the resulting signal for each channel is performed as HRTF processing.
- the virtualization processing unit 13 supplies the HRTF output signal obtained by the HRTF processing to the band expansion unit 41.
- step S14 the personal high frequency information generation unit 121 is personalized based on the general-purpose high frequency information supplied from the decoding processing unit 11 and the general-purpose HRTF coefficient and personal HRTF coefficient supplied from the HRTF coefficient recording unit 122. High frequency information is generated and supplied to the band expansion unit 41.
- step S14 personal high frequency information is generated by MLP 151 to MLP 155 of the personal high frequency information generation unit 121 constituting the DNN.
- the MLP 151 performs arithmetic processing based on the general-purpose HRTF coefficient supplied from the HRTF coefficient recording unit 122, that is, the vector gh_in, and supplies the vector gh_out obtained as a result to the feature quantity synthesizing unit 154.
- the MLP152 performs arithmetic processing based on the personal HRTF coefficient supplied from the HRTF coefficient recording unit 122, that is, the vector ph_in, and supplies the resulting vector ph_out to the feature amount synthesizing unit 154.
- the RNN 153 performs arithmetic processing based on the general-purpose high frequency information supplied from the decoding processing unit 11, that is, the vector ge_in (n), and supplies the vector ge_out (n) obtained as a result to the feature amount synthesizing unit 154.
- the feature amount synthesizing unit 154 vector-connects the vector gh_out supplied from MLP151, the vector ph_out supplied from MLP152, and the vector ge_out (n) supplied from RNN153, and the resulting vector co_out (n) is connected. ) Is supplied to MLP155.
- the MLP 155 performs arithmetic processing based on the vector co_out (n) supplied from the feature amount synthesizing unit 154, and supplies the vector pe_out (n) obtained as a result to the band expansion unit 41 as personal high frequency information.
- step S15 the band expansion unit 41 performs band expansion processing on the HRTF output signal supplied from the virtualize processing unit 13 based on the personal high frequency information supplied from the personal high frequency information generation unit 121. , The output audio signal obtained as a result is output to the subsequent stage. When the output audio signal is generated in this way, the signal generation process ends.
- the signal processing device 101 generates personal high frequency information using the general-purpose high frequency information extracted (read) from the input bit stream, and uses the personal high frequency information to band. Performs extended processing to generate an output audio signal.
- the processing load in the signal processing device 101 that is, the amount of calculation is reduced by performing the band expansion processing on the HRTF output signal having a low sampling frequency obtained by performing the rendering processing and the HRTF processing. Can be made to.
- a high-quality output audio signal can be obtained by generating personal high-frequency information corresponding to the personal HRTF coefficient used for HRTF processing and performing band expansion processing.
- the signal processing device 101 is a low-cost device, high-quality audio reproduction can be performed.
- Such a learning device is configured, for example, as shown in FIG.
- the learning device 201 includes a rendering processing unit 211, a personal HRTF processing unit 212, a personal high-frequency information calculation unit 213, a general-purpose HRTF processing unit 214, a general-purpose high-frequency information calculation unit 215, and a personal high-frequency information learning unit 216.
- a rendering processing unit 211 a personal HRTF processing unit 212, a personal high-frequency information calculation unit 213, a general-purpose HRTF processing unit 214, a general-purpose high-frequency information calculation unit 215, and a personal high-frequency information learning unit 216.
- the rendering processing unit 211 performs the same rendering processing as in the rendering processing unit 12 based on the supplied object position information and the object signal, and the virtual speaker signal obtained as a result is used by the personal HRTF processing unit 212 and the personal HRTF processing unit 212. It is supplied to the general-purpose HRTF processing unit 214.
- the virtual speaker signal that is the output of the rendering processing unit 211 that is, the object signal that is the input of the rendering processing unit 211 is high. Region information must be included.
- the HRTF output signal which is the output of the virtualization processing unit 13 of the signal processing device 101
- the sampling frequency of the object signal input to the rendering processing unit 211 is 96 kHz or the like.
- the rendering processing unit 211 performs rendering processing such as VBAP at a sampling frequency of 96 kHz, and generates a virtual speaker signal having a sampling frequency of 96 kHz.
- the HRTF output signal which is the output of the virtualization processing unit 13, will be described as a signal having a sampling frequency of 48 kHz, but in the present technology, the sampling frequency of each signal is limited to this example. It's not a thing.
- the sampling frequency of the HRTF output signal may be 44.1 kHz
- the sampling frequency of the object signal input to the rendering processing unit 211 may be 88.2 kHz.
- the personal HRTF processing unit 212 performs HRTF processing (hereinafter, also referred to as personal HRTF processing in particular) based on the supplied personal HRTF coefficient and the virtual speaker signal supplied from the rendering processing unit 211, and the result is The obtained personal HRTF output signal is supplied to the personal high frequency information calculation unit 213.
- the personal HRTF output signal obtained by personal HRTF processing is a signal with a sampling frequency of 96 kHz.
- the rendering processing unit 211 and the personal HRTF processing unit 212 are signals including rendering processing and virtualization processing (personal HRTF processing) based on metadata (object position information), personal HRTF coefficients, and object signals. It can be said that it functions as one signal processing unit that performs processing and generates a personal HRTF output signal.
- the signal processing may include at least virtualization processing.
- the personal high frequency information calculation unit 213 generates (calculates) personal high frequency information based on the personal HRTF output signal supplied from the personal HRTF processing unit 212, and learns the obtained personal high frequency information. It is supplied to the personal high-frequency information learning unit 216 as teacher data at the time.
- the average amplitude value of each high frequency subband of the personal HRTF output signal is obtained as personal high frequency information.
- the time frame of the high-frequency subband signal can be obtained by calculating the average amplitude value.
- the general-purpose HRTF processing unit 214 performs HRTF processing (hereinafter, also referred to as a general-purpose HRTF processing in particular) based on the supplied general-purpose HRTF coefficient and the virtual speaker signal supplied from the rendering processing unit 211, and is obtained as a result.
- the general-purpose HRTF output signal is supplied to the general-purpose high-frequency information calculation unit 215.
- the general-purpose HRTF output signal is a signal with a sampling frequency of 96 kHz.
- the rendering processing unit 211 and the general-purpose HRTF processing unit 214 perform signal processing including rendering processing and virtualization processing (general-purpose HRTF processing) based on metadata (object position information), general-purpose HRTF coefficient, and object signal. It can be said that it functions as one signal processing unit that generates a general-purpose HRTF output signal.
- the signal processing may include at least virtualization processing.
- the general-purpose high-frequency information calculation unit 215 generates (calculates) general-purpose high-frequency information based on the general-purpose HRTF output signal supplied from the general-purpose HRTF processing unit 214, and supplies it to the personal high-frequency information learning unit 216.
- the general-purpose high-frequency information calculation unit 215 the same calculation as in the case of the personal high-frequency information calculation unit 213 is performed, and general-purpose high-frequency information is generated.
- the input bit stream contains the same general-purpose high-frequency information obtained by the general-purpose high-frequency information calculation unit 215 as "output_bwe_data" shown in FIG.
- the processing performed by the general-purpose HRTF processing unit 214 and the general-purpose high-frequency information calculation unit 215 is paired with the processing performed by the personal HRTF processing unit 212 and the personal high-frequency information calculation unit 213.
- the processing is basically the same processing.
- the input of the personal HRTF processing unit 212 is the personal HRTF coefficient
- the input of the general-purpose HRTF processing unit 214 is the general-purpose HRTF coefficient. That is, only the input HRTF coefficients are different.
- the personal high-frequency information learning unit 216 has the general-purpose HRTF coefficient and the personal HRTF coefficient supplied, the personal high-frequency information supplied from the personal high-frequency information calculation unit 213, and the general-purpose high-frequency information calculation unit 215. Learning (machine learning) is performed based on the supplied general-purpose high-frequency information, and the personal high-frequency information generation coefficient data obtained as a result is output.
- the personal high frequency information learning unit 216 machine learning using personal high frequency information as teacher data is performed, and personal high frequency information is obtained from general-purpose HRTF coefficient, personal HRTF coefficient, and general-purpose high frequency information. Personal high frequency information generation coefficient data to be generated is generated.
- each coefficient constituting the personal high frequency information generation coefficient data thus obtained is used in MLP151, MLP152, RNN153, and MLP155 of the personal high frequency information generation unit 121 in FIG. 8, it is based on the learning result. It is possible to generate personal high frequency information.
- the learning process performed by the personal high-frequency information learning unit 216 is the vector pe_out (n) output as the processing result of the personal high-frequency information generation unit 121 and the personal high-frequency information as teacher data. It is done by evaluating the error with the vector tpe_out (n). That is, learning is performed so that the error between the vector pe_out (n) and the vector tpe_out (n) is minimized.
- the initial value of the weighting coefficient of each element such as MLP151 that constitutes DNN is generally random, and the method of adjusting each coefficient according to the error evaluation is also an error such as BPTT (BackPropagationThroughTime).
- BPTT BackPropagationThroughTime
- Various methods based on the backpropagation method can be applied.
- step S41 the rendering processing unit 211 performs rendering processing based on the supplied object position information and the object signal, and supplies the virtual speaker signal obtained as a result to the personal HRTF processing unit 212 and the general-purpose HRTF processing unit 214. do.
- step S42 the personal HRTF processing unit 212 performs personal HRTF processing based on the supplied personal HRTF coefficient and the virtual speaker signal supplied from the rendering processing unit 211, and the personal HRTF obtained as a result.
- the output signal is supplied to the personal high frequency information calculation unit 213.
- step S43 the personal high frequency information calculation unit 213 calculates the personal high frequency information based on the personal HRTF output signal supplied from the personal HRTF processing unit 212, and teaches the obtained personal high frequency information. It is supplied as data to the personal high frequency information learning unit 216.
- step S44 the general-purpose HRTF processing unit 214 performs general-purpose HRTF processing based on the supplied general-purpose HRTF coefficient and the virtual speaker signal supplied from the rendering processing unit 211, and the general-purpose HRTF output signal obtained as a result is general-purpose. It is supplied to the high frequency information calculation unit 215.
- step S45 the general-purpose high-frequency information calculation unit 215 calculates general-purpose high-frequency information based on the general-purpose HRTF output signal supplied from the general-purpose HRTF processing unit 214, and supplies it to the personal high-frequency information learning unit 216.
- step S46 the personal high-frequency information learning unit 216 calculates the general-purpose HRTF coefficient and the personal HRTF coefficient supplied, the personal high-frequency information supplied from the personal high-frequency information calculation unit 213, and the general-purpose high-frequency information calculation. Learning is performed based on the general-purpose high-frequency information supplied from the unit 215, and personal high-frequency information generation coefficient data is generated.
- the learning device 201 performs learning based on the general-purpose HRTF coefficient, the personal HRTF coefficient, and the object signal, and generates the personal high-frequency information generation coefficient data.
- the personal high frequency information generation unit 121 from the input general-purpose high-frequency information, general-purpose HRTF coefficient, and personal HRTF coefficient, appropriate personal high-frequency information corresponding to the personal HRTF coefficient is obtained. Can be obtained by prediction.
- the encoder 301 shown in FIG. 13 includes an object position information coding unit 311, a downsuppler 312, an object signal coding unit 313, a rendering processing unit 314, a general-purpose HRTF processing unit 315, a general-purpose high-frequency information calculation unit 316, and a multiplexing unit 317. have.
- the object signal of the object to be encoded and the object position information indicating the position of the object are input (supplied) to the encoder 301.
- the object signal input to the encoder 301 is, for example, a signal having a sampling frequency of 96 kHz (FS96K object signal).
- the object position information coding unit 311 encodes the input object position information and supplies it to the multiplexing unit 317.
- the coded object position information for example, the coded object position information (object position data) including the horizontal angle “position_azimuth”, the vertical angle “position_elevation”, and the radius “position_radius” shown in FIG. 9 is obtained. can get.
- the downsappler 312 performs downsampling processing, that is, band limitation, on an object signal whose input sampling frequency is 96 kHz, and object signal encodes an object signal (FS48K object signal) whose sampling frequency is 48 kHz as a result. Supply to unit 313.
- the object signal coding unit 313 encodes the 48 kHz object signal supplied from the downsuppler 312 and supplies it to the multiplexing unit 317. As a result, for example, the "object_compressed_data" shown in FIG. 9 is obtained as an encoded object signal.
- the coding method in the object signal coding unit 313 may be an MPEG-H Part 3: 3D audio standard coding method, or may be another coding method. That is, it suffices as long as the coding method in the object signal coding unit 313 and the decoding method in the decoding processing unit 11 correspond to each other (of the same standard).
- the rendering processing unit 314 performs rendering processing such as VBAP based on the input object position information and the object signal of 96 kHz, and supplies the virtual speaker signal obtained as a result to the general-purpose HRTF processing unit 315.
- the rendering process in the rendering process section 314 is not limited to VBAP but any other rendering process as long as it is the same process as in the rendering process section 12 of the signal processing device 101 on the decoding side (reproduction side). There may be.
- the general-purpose HRTF processing unit 315 performs HRTF processing using the general-purpose HRTF coefficient on the virtual speaker signal supplied from the rendering processing unit 314, and calculates the 96 kHz general-purpose HRTF output signal obtained as a result for general-purpose high-frequency information calculation. Supply to unit 316.
- the general-purpose HRTF processing unit 315 performs the same processing as the general-purpose HRTF processing in the general-purpose HRTF processing unit 214 of FIG.
- the general-purpose high-frequency information calculation unit 316 calculates general-purpose high-frequency information based on the general-purpose HRTF output signal supplied from the general-purpose HRTF processing unit 315, compresses and encodes the obtained general-purpose high-frequency information, and multiplexes the multiplexing unit 317. Supply to.
- the general-purpose high-frequency information generated by the general-purpose high-frequency information calculation unit 316 is, for example, the average amplitude information (average amplitude value) of each high-frequency subband shown in FIG.
- the general-purpose high-frequency information calculation unit 316 performs filtering based on the bandpass filter bank on the input 96 kHz general-purpose HRTF output signal to obtain a high-frequency subband signal of each high-frequency subband. Then, the general-purpose high-frequency information calculation unit 316 generates general-purpose high-frequency information by calculating the average amplitude value of the time frame of each of those high-frequency subband signals.
- output_bwe_data shown in FIG. 9 can be obtained as encoded general-purpose high-frequency information.
- the multiplexing unit 317 includes coded object position information supplied from the object position information coding unit 311, coded object signal supplied from the object signal coding unit 313, and general-purpose high-frequency information calculation unit 316. Multiplexes the coded general-purpose high-frequency information supplied from.
- the multiplexing unit 317 outputs an output bit stream obtained by multiplexing object position information, object signals, and general-purpose high-frequency information. This output bit stream is input to the signal processing device 101 as an input bit stream.
- step S71 the object position information coding unit 311 encodes the input object position information and supplies it to the multiplexing unit 317.
- step S72 the down supplement 312 downsamples the input object signal and supplies it to the object signal coding unit 313.
- step S73 the object signal coding unit 313 encodes the object signal supplied from the downsupplier 312 and supplies it to the multiplexing unit 317.
- step S74 the rendering processing unit 314 performs rendering processing based on the input object position information and the object signal, and supplies the virtual speaker signal obtained as a result to the general-purpose HRTF processing unit 315.
- step S75 the general-purpose HRTF processing unit 315 performs HRTF processing using the general-purpose HRTF coefficient on the virtual speaker signal supplied from the rendering processing unit 314, and the general-purpose HRTF output signal obtained as a result is used as general-purpose high-frequency information. It is supplied to the calculation unit 316.
- step S76 the general-purpose high-frequency information calculation unit 316 calculates general-purpose high-frequency information based on the general-purpose HRTF output signal supplied from the general-purpose HRTF processing unit 315, and compresses and encodes the obtained general-purpose high-frequency information to multiplex. It is supplied to the chemical unit 317.
- the multiplexing unit 317 includes coded object position information supplied from the object position information coding unit 311, coded object signal supplied from the object signal coding unit 313, and general-purpose high-frequency information.
- the coded general-purpose high frequency information supplied from the calculation unit 316 is multiplexed.
- the multiplexing unit 317 outputs the output bit stream obtained by the multiplexing, and the coding process ends.
- the encoder 301 calculates general-purpose high-frequency information and stores it in the output bit stream.
- an HRTF output signal may be generated from an audio signal (hereinafter, also referred to as a channel signal) of each channel based channel, and the band of the HRTF output signal may be expanded.
- the signal processing device 101 is not provided with the rendering processing unit 12, and the input bit stream contains the encoded channel signal.
- the channel signal of each channel of the multi-channel configuration obtained by the decoding processing unit 11 performing demultiplexing and decoding processing on the input bit stream is supplied to the virtualization processing unit 13.
- the channel signal of each of these channels corresponds to the virtual speaker signal of each virtual speaker.
- the virtualization processing unit 13 convolves the channel signal supplied from the decoding processing unit 11 and the personal HRTF coefficient for each channel supplied from the HRTF coefficient recording unit 122, and adds the resulting signal. Process as HRTF process.
- the virtualization processing unit 13 supplies the HRTF output signal obtained by such HRTF processing to the band expansion unit 41.
- the learning device 201 is not provided with the rendering processing unit 211, and the sampling frequency is high, that is, the channel signal including high frequency information. Is supplied to the personal HRTF processing unit 212 and the general-purpose HRTF processing unit 214.
- the rendering processing unit 12 may perform HOA (High Order Ambisonics) rendering processing.
- HOA High Order Ambisonics
- the rendering processing unit 12 performs rendering processing based on the ambisonic format supplied from the decoding processing unit 11, that is, the audio signal in the spherical harmonic region, and generates a virtual speaker signal in the spherical harmonic region. , Supply to the virtualize processing unit 13.
- the virtualization processing unit 13 HRTF in the spherical harmonic region based on the virtual speaker signal in the spherical harmonic region supplied from the rendering processing unit 12 and the personal HRTF coefficient in the spherical harmonic region supplied from the HRTF coefficient recording unit 122. Processing is performed, and the HRTF output signal obtained as a result is supplied to the band expansion unit 41. At this time, the HRTF output signal in the spherical harmonic region may be supplied to the band expansion unit 41, or the HRTF output signal in the time region obtained by performing conversion or the like as necessary may be supplied to the band expansion unit 41. It may be supplied.
- the encoder 301 since it is not necessary to multiplex the personal high frequency information in the input bit stream, the storage consumption of the server or the like, that is, the encoder 301 can be suppressed, and the encoding process (encoding) by the encoder 301 can be suppressed. It is also possible to suppress an increase in the processing time of the processing).
- decoding processing, rendering processing, and virtualization processing can be performed at a low sampling frequency, and the amount of calculation can be significantly reduced.
- a low-cost processor can be adopted, the power consumption of the processor can be reduced, and a mobile device such as a smartphone can continuously play a high-resolution sound source for a longer period of time. ..
- the series of processes described above can be executed by hardware or software.
- the programs constituting the software are installed on the computer.
- the computer includes a computer embedded in dedicated hardware and, for example, a general-purpose personal computer capable of executing various functions by installing various programs.
- FIG. 15 is a block diagram showing a configuration example of computer hardware that executes the above-mentioned series of processes programmatically.
- the CPU Central Processing Unit
- ROM Read Only Memory
- RAM Random Access Memory
- An input / output interface 505 is further connected to the bus 504.
- An input unit 506, an output unit 507, a recording unit 508, a communication unit 509, and a drive 510 are connected to the input / output interface 505.
- the input unit 506 includes a keyboard, a mouse, a microphone, an image pickup device, and the like.
- the output unit 507 includes a display, a speaker, and the like.
- the recording unit 508 includes a hard disk, a non-volatile memory, and the like.
- the communication unit 509 includes a network interface and the like.
- the drive 510 drives a removable recording medium 511 such as a magnetic disk, an optical disk, a magneto-optical disk, or a semiconductor memory.
- the CPU 501 loads the program recorded in the recording unit 508 into the RAM 503 via the input / output interface 505 and the bus 504 and executes the above-mentioned series. Is processed.
- the program executed by the computer (CPU501) can be recorded and provided on a removable recording medium 511 as a package medium or the like, for example.
- the program can also be provided via a wired or wireless transmission medium such as a local area network, the Internet, or digital satellite broadcasting.
- the program can be installed in the recording unit 508 via the input / output interface 505 by mounting the removable recording medium 511 in the drive 510. Further, the program can be received by the communication unit 509 and installed in the recording unit 508 via a wired or wireless transmission medium. In addition, the program can be pre-installed in the ROM 502 or the recording unit 508.
- the program executed by the computer may be a program in which processing is performed in chronological order according to the order described in the present specification, in parallel, or at a necessary timing such as when a call is made. It may be a program in which processing is performed.
- the embodiment of the present technology is not limited to the above-described embodiment, and various changes can be made without departing from the gist of the present technology.
- this technology can take a cloud computing configuration in which one function is shared by multiple devices via a network and processed jointly.
- each step described in the above flowchart can be executed by one device or shared by a plurality of devices.
- the plurality of processes included in the one step can be executed by one device or shared by a plurality of devices.
- this technology can also have the following configurations.
- a decoding processing unit that demultiplexes the input bitstream into the first audio signal, the metadata of the first audio signal, and the first high frequency information for bandwidth expansion.
- the first audio signal, the second audio signal obtained by performing signal processing based on the metadata, and the second high frequency information generated based on the first high frequency information A signal processing device including a band expansion unit that performs band expansion processing based on the above and generates an output audio signal.
- the first high frequency information is high frequency information for band expansion of the second audio signal obtained by performing the signal processing using the first coefficient.
- the second high-frequency information is high-frequency information for band expansion of the second audio signal obtained by performing the signal processing using the second coefficient.
- the band expansion unit includes the second audio signal obtained by performing the signal processing based on the first audio signal, the metadata, and the second coefficient, and the second high frequency band.
- the signal processing apparatus according to (2) which performs the band expansion processing based on the information.
- the signal processing according to (3) wherein the high frequency information generation unit generates the second high frequency information based on the first high frequency information, the first coefficient, and the second coefficient.
- the high-frequency information generation unit performs an operation based on a coefficient generated in advance by machine learning, the first high-frequency information, the first coefficient, and the second coefficient, thereby performing the second.
- the signal processing apparatus which generates high-frequency information of.
- the signal processing device according to (5), wherein the calculation is a calculation by a neural network.
- the signal processing device according to any one of (3) to (6), wherein the first coefficient is a general-purpose coefficient and the second coefficient is a coefficient for each user.
- the signal processing apparatus according to (7), wherein the first coefficient and the second coefficient are HRTF coefficients.
- the signal processing apparatus according to any one of (3) to (8), further comprising a coefficient recording unit for recording the first coefficient.
- the signal processing apparatus according to any one of (1) to (9), further comprising a signal processing unit that performs the signal processing to generate the second audio signal.
- the signal processing apparatus according to (10), wherein the signal processing is a process including a virtualization process.
- the signal processing apparatus according to (11), wherein the signal processing is a process including a rendering process.
- the signal processing device according to any one of (1) to (12), wherein the first audio signal is an object signal of an audio object or a channel-based audio signal.
- the signal processing device The input bitstream is demultiplexed into the first audio signal, the metadata of the first audio signal, and the first high frequency information for bandwidth expansion.
- the first audio signal, the second audio signal obtained by performing signal processing based on the metadata, and the second high frequency information generated based on the first high frequency information A signal processing method that performs band expansion processing based on this and generates an output audio signal.
- the input bitstream is demultiplexed into the first audio signal, the metadata of the first audio signal, and the first high frequency information for bandwidth expansion.
- the first audio signal, the second audio signal obtained by performing signal processing based on the metadata, and the second high frequency information generated based on the first high frequency information A program that causes a computer to perform processing that includes steps to generate an output audio signal by performing band expansion processing based on the above.
- a first high frequency information calculator that generates first high frequency information for bandwidth expansion based on a second audio signal generated by signal processing based on a first audio signal and a first coefficient.
- the learning unit Based on the first coefficient, the second coefficient, the first high frequency information, and the second high frequency information, learning is performed using the second high frequency information as teacher data, and the first A learning device including a coefficient of 1, the second coefficient, and a high-frequency information learning unit that generates coefficient data for obtaining the second high-frequency information from the first high-frequency information.
- the coefficient data is a coefficient constituting a neural network.
- the first coefficient is a general-purpose coefficient and the second coefficient is a coefficient for each user.
- the signal processing is a process including a virtualization process, and is a process including a virtualize process.
- the learning device wherein the first coefficient and the second coefficient are HRTF coefficients.
- the signal processing is a process including a rendering process.
- the learning device according to any one of (16) to (19), wherein the first audio signal is an object signal of an audio object or a channel-based audio signal.
- the learning device Based on the second audio signal generated by the signal processing based on the first audio signal and the first coefficient, the first high frequency information for band expansion is generated.
- the second high frequency information for band expansion is generated.
- the second coefficient, the first high frequency information, and the second high frequency information learning is performed using the second high frequency information as teacher data, and the first A learning method for generating coefficient data for obtaining the second high-frequency information from the coefficient of 1, the second coefficient, and the first high-frequency information.
- the first high frequency information for band expansion is generated.
- the second high frequency information for band expansion is generated.
- learning is performed using the second high frequency information as teacher data, and the first A program that causes a computer to perform a process including a step of generating coefficient data for obtaining the second high frequency information from the coefficient of 1, the second coefficient, and the first high frequency information.
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Signal Processing (AREA)
- Acoustics & Sound (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Multimedia (AREA)
- Theoretical Computer Science (AREA)
- Mathematical Physics (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Artificial Intelligence (AREA)
- Molecular Biology (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- General Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Software Systems (AREA)
- Quality & Reliability (AREA)
- Stereophonic System (AREA)
- Telephone Function (AREA)
Abstract
Description
〈本技術について〉
本技術は、予めHRTF出力信号を対象とした帯域拡張処理のための汎用の高域情報をビットストリーム中に多重化して伝送するとともに、復号側において、個人用のHRTF係数と、汎用のHRTF係数および高域情報とに基づいて、個人用のHRTF係数に対応する高域情報を生成するようにした。


図7は、本技術を適用した信号処理装置101の一実施の形態の構成例を示す図である。なお、図7において図6における場合と対応する部分には同一の符号を付してあり、その説明は適宜省略する。
上述のように、個人用高域情報生成部121では、汎用高域情報と、汎用HRTF係数と、個人用HRTF係数とに基づいて個人用高域情報が生成される。
信号処理装置101では、個人用高域情報の生成のために汎用高域情報が必要であり、入力ビットストリームには、汎用高域情報が格納されている。
次に、信号処理装置101の動作について説明する。すなわち、以下、図10のフローチャートを参照して、信号処理装置101による信号生成処理について説明する。
次に、個人用高域情報生成部121としてのDNN(ニューラルネットワーク)を構成する係数、すなわちMLP151、MLP152、RNN153、およびMLP155を構成する係数を、個人用高域情報生成係数データとして生成する学習装置について説明する。
続いて、学習装置201の動作について説明する。すなわち、以下、図12のフローチャートを参照して、学習装置201による学習処理について説明する。
続いて、図9に示したフォーマットの入力ビットストリームを生成するエンコーダ(符号化装置)について説明する。そのようなエンコーダは、例えば図13に示すように構成される。
次に、エンコーダ301の動作について説明する。すなわち、以下、図14のフローチャートを参照して、エンコーダ301による符号化処理について説明する。
ところで、上述した一連の処理は、ハードウェアにより実行することもできるし、ソフトウェアにより実行することもできる。一連の処理をソフトウェアにより実行する場合には、そのソフトウェアを構成するプログラムが、コンピュータにインストールされる。ここで、コンピュータには、専用のハードウェアに組み込まれているコンピュータや、各種のプログラムをインストールすることで、各種の機能を実行することが可能な、例えば汎用のパーソナルコンピュータなどが含まれる。
入力ビットストリームを第1のオーディオ信号と、前記第1のオーディオ信号のメタデータと、帯域拡張のための第1の高域情報とに非多重化するデコード処理部と、
前記第1のオーディオ信号および前記メタデータに基づいて信号処理を行うことで得られた第2のオーディオ信号と、前記第1の高域情報に基づいて生成された第2の高域情報とに基づいて帯域拡張処理を行い、出力オーディオ信号を生成する帯域拡張部と
を備える信号処理装置。
(2)
前記第1の高域情報に基づいて前記第2の高域情報を生成する高域情報生成部をさらに備える
(1)に記載の信号処理装置。
(3)
前記第1の高域情報は、第1の係数を用いて前記信号処理を行うことで得られる前記第2のオーディオ信号の帯域拡張のための高域情報であり、
前記第2の高域情報は、第2の係数を用いて前記信号処理を行うことで得られる前記第2のオーディオ信号の帯域拡張のための高域情報であり、
前記帯域拡張部は、前記第1のオーディオ信号、前記メタデータ、および前記第2の係数に基づいて前記信号処理を行うことで得られた前記第2のオーディオ信号と、前記第2の高域情報とに基づいて前記帯域拡張処理を行う
(2)に記載の信号処理装置。
(4)
前記高域情報生成部は、前記第1の高域情報、前記第1の係数、および前記第2の係数に基づいて、前記第2の高域情報を生成する
(3)に記載の信号処理装置。
(5)
前記高域情報生成部は、予め機械学習により生成された係数と、前記第1の高域情報、前記第1の係数、および前記第2の係数とに基づく演算を行うことで、前記第2の高域情報を生成する
(3)または(4)に記載の信号処理装置。
(6)
前記演算は、ニューラルネットワークによる演算である
(5)に記載の信号処理装置。
(7)
前記第1の係数は汎用の係数であり、前記第2の係数はユーザごとの係数である
(3)乃至(6)の何れか一項に記載の信号処理装置。
(8)
前記第1の係数および前記第2の係数はHRTF係数である
(7)に記載の信号処理装置。
(9)
前記第1の係数を記録する係数記録部をさらに備える
(3)乃至(8)の何れか一項に記載の信号処理装置。
(10)
前記信号処理を行って前記第2のオーディオ信号を生成する信号処理部をさらに備える
(1)乃至(9)の何れか一項に記載の信号処理装置。
(11)
前記信号処理は、バーチャライズ処理を含む処理である
(10)に記載の信号処理装置。
(12)
前記信号処理は、レンダリング処理を含む処理である
(11)に記載の信号処理装置。
(13)
前記第1のオーディオ信号は、オーディオオブジェクトのオブジェクト信号、またはチャネルベースのオーディオ信号である
(1)乃至(12)の何れか一項に記載の信号処理装置。
(14)
信号処理装置が、
入力ビットストリームを第1のオーディオ信号と、前記第1のオーディオ信号のメタデータと、帯域拡張のための第1の高域情報とに非多重化し、
前記第1のオーディオ信号および前記メタデータに基づいて信号処理を行うことで得られた第2のオーディオ信号と、前記第1の高域情報に基づいて生成された第2の高域情報とに基づいて帯域拡張処理を行い、出力オーディオ信号を生成する
信号処理方法。
(15)
入力ビットストリームを第1のオーディオ信号と、前記第1のオーディオ信号のメタデータと、帯域拡張のための第1の高域情報とに非多重化し、
前記第1のオーディオ信号および前記メタデータに基づいて信号処理を行うことで得られた第2のオーディオ信号と、前記第1の高域情報に基づいて生成された第2の高域情報とに基づいて帯域拡張処理を行い、出力オーディオ信号を生成する
ステップを含む処理をコンピュータに実行させるプログラム。
(16)
第1のオーディオ信号と第1の係数とに基づく信号処理により生成された第2のオーディオ信号に基づいて、帯域拡張のための第1の高域情報を生成する第1の高域情報計算部と、
前記第1のオーディオ信号と第2の係数とに基づく前記信号処理により生成された第3のオーディオ信号に基づいて、帯域拡張のための第2の高域情報を生成する第2の高域情報計算部と、
前記第1の係数、前記第2の係数、前記第1の高域情報、および前記第2の高域情報に基づいて、前記第2の高域情報を教師データとする学習を行い、前記第1の係数、前記第2の係数、および前記第1の高域情報から前記第2の高域情報を得るための係数データを生成する高域情報学習部と
を備える学習装置。
(17)
前記係数データは、ニューラルネットワークを構成する係数である
(16)に記載の学習装置。
(18)
前記第1の係数は汎用の係数であり、前記第2の係数はユーザごとの係数である
(16)または(17)に記載の学習装置。
(19)
前記信号処理は、バーチャライズ処理を含む処理であり、
前記第1の係数および前記第2の係数はHRTF係数である
(18)に記載の学習装置。
(20)
前記信号処理は、レンダリング処理を含む処理である
(19)に記載の学習装置。
(21)
前記第1のオーディオ信号は、オーディオオブジェクトのオブジェクト信号、またはチャネルベースのオーディオ信号である
(16)乃至(19)の何れか一項に記載の学習装置。
(22)
学習装置が、
第1のオーディオ信号と第1の係数とに基づく信号処理により生成された第2のオーディオ信号に基づいて、帯域拡張のための第1の高域情報を生成し、
前記第1のオーディオ信号と第2の係数とに基づく前記信号処理により生成された第3のオーディオ信号に基づいて、帯域拡張のための第2の高域情報を生成し、
前記第1の係数、前記第2の係数、前記第1の高域情報、および前記第2の高域情報に基づいて、前記第2の高域情報を教師データとする学習を行い、前記第1の係数、前記第2の係数、および前記第1の高域情報から前記第2の高域情報を得るための係数データを生成する
学習方法。
(23)
第1のオーディオ信号と第1の係数とに基づく信号処理により生成された第2のオーディオ信号に基づいて、帯域拡張のための第1の高域情報を生成し、
前記第1のオーディオ信号と第2の係数とに基づく前記信号処理により生成された第3のオーディオ信号に基づいて、帯域拡張のための第2の高域情報を生成し、
前記第1の係数、前記第2の係数、前記第1の高域情報、および前記第2の高域情報に基づいて、前記第2の高域情報を教師データとする学習を行い、前記第1の係数、前記第2の係数、および前記第1の高域情報から前記第2の高域情報を得るための係数データを生成する
ステップを含む処理をコンピュータに実行させるプログラム。
Claims (20)
- 入力ビットストリームを第1のオーディオ信号と、前記第1のオーディオ信号のメタデータと、帯域拡張のための第1の高域情報とに非多重化するデコード処理部と、
前記第1のオーディオ信号および前記メタデータに基づいて信号処理を行うことで得られた第2のオーディオ信号と、前記第1の高域情報に基づいて生成された第2の高域情報とに基づいて帯域拡張処理を行い、出力オーディオ信号を生成する帯域拡張部と
を備える信号処理装置。 - 前記第1の高域情報に基づいて前記第2の高域情報を生成する高域情報生成部をさらに備える
請求項1に記載の信号処理装置。 - 前記第1の高域情報は、第1の係数を用いて前記信号処理を行うことで得られる前記第2のオーディオ信号の帯域拡張のための高域情報であり、
前記第2の高域情報は、第2の係数を用いて前記信号処理を行うことで得られる前記第2のオーディオ信号の帯域拡張のための高域情報であり、
前記帯域拡張部は、前記第1のオーディオ信号、前記メタデータ、および前記第2の係数に基づいて前記信号処理を行うことで得られた前記第2のオーディオ信号と、前記第2の高域情報とに基づいて前記帯域拡張処理を行う
請求項2に記載の信号処理装置。 - 前記高域情報生成部は、前記第1の高域情報、前記第1の係数、および前記第2の係数に基づいて、前記第2の高域情報を生成する
請求項3に記載の信号処理装置。 - 前記高域情報生成部は、予め機械学習により生成された係数と、前記第1の高域情報、前記第1の係数、および前記第2の係数とに基づく演算を行うことで、前記第2の高域情報を生成する
請求項3に記載の信号処理装置。 - 前記演算は、ニューラルネットワークによる演算である
請求項5に記載の信号処理装置。 - 前記第1の係数は汎用の係数であり、前記第2の係数はユーザごとの係数である
請求項3に記載の信号処理装置。 - 前記第1の係数および前記第2の係数はHRTF係数である
請求項7に記載の信号処理装置。 - 前記信号処理を行って前記第2のオーディオ信号を生成する信号処理部をさらに備える
請求項1に記載の信号処理装置。 - 前記信号処理は、バーチャライズ処理またはレンダリング処理を含む処理である
請求項9に記載の信号処理装置。 - 前記第1のオーディオ信号は、オーディオオブジェクトのオブジェクト信号、またはチャネルベースのオーディオ信号である
請求項1に記載の信号処理装置。 - 信号処理装置が、
入力ビットストリームを第1のオーディオ信号と、前記第1のオーディオ信号のメタデータと、帯域拡張のための第1の高域情報とに非多重化し、
前記第1のオーディオ信号および前記メタデータに基づいて信号処理を行うことで得られた第2のオーディオ信号と、前記第1の高域情報に基づいて生成された第2の高域情報とに基づいて帯域拡張処理を行い、出力オーディオ信号を生成する
信号処理方法。 - 入力ビットストリームを第1のオーディオ信号と、前記第1のオーディオ信号のメタデータと、帯域拡張のための第1の高域情報とに非多重化し、
前記第1のオーディオ信号および前記メタデータに基づいて信号処理を行うことで得られた第2のオーディオ信号と、前記第1の高域情報に基づいて生成された第2の高域情報とに基づいて帯域拡張処理を行い、出力オーディオ信号を生成する
ステップを含む処理をコンピュータに実行させるプログラム。 - 第1のオーディオ信号と第1の係数とに基づく信号処理により生成された第2のオーディオ信号に基づいて、帯域拡張のための第1の高域情報を生成する第1の高域情報計算部と、
前記第1のオーディオ信号と第2の係数とに基づく前記信号処理により生成された第3のオーディオ信号に基づいて、帯域拡張のための第2の高域情報を生成する第2の高域情報計算部と、
前記第1の係数、前記第2の係数、前記第1の高域情報、および前記第2の高域情報に基づいて、前記第2の高域情報を教師データとする学習を行い、前記第1の係数、前記第2の係数、および前記第1の高域情報から前記第2の高域情報を得るための係数データを生成する高域情報学習部と
を備える学習装置。 - 前記係数データは、ニューラルネットワークを構成する係数である
請求項14に記載の学習装置。 - 前記第1の係数は汎用の係数であり、前記第2の係数はユーザごとの係数である
請求項14に記載の学習装置。 - 前記信号処理は、バーチャライズ処理またはレンダリング処理を含む処理であり、
前記第1の係数および前記第2の係数はHRTF係数である
請求項16に記載の学習装置。 - 前記第1のオーディオ信号は、オーディオオブジェクトのオブジェクト信号、またはチャネルベースのオーディオ信号である
請求項14に記載の学習装置。 - 学習装置が、
第1のオーディオ信号と第1の係数とに基づく信号処理により生成された第2のオーディオ信号に基づいて、帯域拡張のための第1の高域情報を生成し、
前記第1のオーディオ信号と第2の係数とに基づく前記信号処理により生成された第3のオーディオ信号に基づいて、帯域拡張のための第2の高域情報を生成し、
前記第1の係数、前記第2の係数、前記第1の高域情報、および前記第2の高域情報に基づいて、前記第2の高域情報を教師データとする学習を行い、前記第1の係数、前記第2の係数、および前記第1の高域情報から前記第2の高域情報を得るための係数データを生成する
学習方法。 - 第1のオーディオ信号と第1の係数とに基づく信号処理により生成された第2のオーディオ信号に基づいて、帯域拡張のための第1の高域情報を生成し、
前記第1のオーディオ信号と第2の係数とに基づく前記信号処理により生成された第3のオーディオ信号に基づいて、帯域拡張のための第2の高域情報を生成し、
前記第1の係数、前記第2の係数、前記第1の高域情報、および前記第2の高域情報に基づいて、前記第2の高域情報を教師データとする学習を行い、前記第1の係数、前記第2の係数、および前記第1の高域情報から前記第2の高域情報を得るための係数データを生成する
ステップを含む処理をコンピュータに実行させるプログラム。
Priority Applications (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| MX2023002255A MX2023002255A (es) | 2020-09-03 | 2021-08-20 | Dispositivo y método de procesamiento de señales, dispositivo y método de aprendizaje y programa. |
| JP2022546230A JPWO2022050087A1 (ja) | 2020-09-03 | 2021-08-20 | |
| US18/023,183 US20230300557A1 (en) | 2020-09-03 | 2021-08-20 | Signal processing device and method, learning device and method, and program |
| BR112023003488A BR112023003488A2 (pt) | 2020-09-03 | 2021-08-20 | Dispositivos e métodos de processamento de sinal e de aprendizado, e, programa |
| KR1020237005227A KR20230060502A (ko) | 2020-09-03 | 2021-08-20 | 신호 처리 장치 및 방법, 학습 장치 및 방법, 그리고 프로그램 |
| CN202180052388.8A CN116018641A (zh) | 2020-09-03 | 2021-08-20 | 信号处理装置和方法、学习装置和方法以及程序 |
| EP21864145.4A EP4210048A4 (en) | 2020-09-03 | 2021-08-20 | SIGNAL PROCESSING APPARATUS AND METHOD, LEARNING APPARATUS AND METHOD AND PROGRAM |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020-148234 | 2020-09-03 | ||
| JP2020148234 | 2020-09-03 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022050087A1 true WO2022050087A1 (ja) | 2022-03-10 |
Family
ID=80490814
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2021/030599 WO2022050087A1 (ja) | 2020-09-03 | 2021-08-20 | 信号処理装置および方法、学習装置および方法、並びにプログラム |
Country Status (8)
| Country | Link |
|---|---|
| US (1) | US20230300557A1 (ja) |
| EP (1) | EP4210048A4 (ja) |
| JP (1) | JPWO2022050087A1 (ja) |
| KR (1) | KR20230060502A (ja) |
| CN (1) | CN116018641A (ja) |
| BR (1) | BR112023003488A2 (ja) |
| MX (1) | MX2023002255A (ja) |
| WO (1) | WO2022050087A1 (ja) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2021261235A1 (ja) * | 2020-06-22 | 2021-12-30 | ソニーグループ株式会社 | 信号処理装置および方法、並びにプログラム |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2015194666A (ja) * | 2014-03-24 | 2015-11-05 | ソニー株式会社 | 符号化装置および方法、復号装置および方法、並びにプログラム |
| JP2016529544A (ja) * | 2013-07-22 | 2016-09-23 | フラウンホーファーゲゼルシャフト ツール フォルデルング デル アンゲヴァンテン フォルシユング エー.フアー. | ジョイント符号化残留信号を用いたオーディオエンコーダ、オーディオデコーダ、方法、およびコンピュータプログラム |
| WO2018110269A1 (ja) | 2016-12-12 | 2018-06-21 | ソニー株式会社 | Hrtf測定方法、hrtf測定装置、およびプログラム |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10038966B1 (en) * | 2016-10-20 | 2018-07-31 | Oculus Vr, Llc | Head-related transfer function (HRTF) personalization based on captured images of user |
| KR102002681B1 (ko) * | 2017-06-27 | 2019-07-23 | 한양대학교 산학협력단 | 생성적 대립 망 기반의 음성 대역폭 확장기 및 확장 방법 |
| ES2965741T3 (es) * | 2017-07-28 | 2024-04-16 | Fraunhofer Ges Forschung | Aparato para codificar o decodificar una señal multicanal codificada mediante una señal de relleno generada por un filtro de banda ancha |
| US10650806B2 (en) * | 2018-04-23 | 2020-05-12 | Cerence Operating Company | System and method for discriminative training of regression deep neural networks |
| EP3827603A1 (en) * | 2018-07-25 | 2021-06-02 | Dolby Laboratories Licensing Corporation | Personalized hrtfs via optical capture |
-
2021
- 2021-08-20 JP JP2022546230A patent/JPWO2022050087A1/ja active Pending
- 2021-08-20 WO PCT/JP2021/030599 patent/WO2022050087A1/ja active Application Filing
- 2021-08-20 EP EP21864145.4A patent/EP4210048A4/en active Pending
- 2021-08-20 CN CN202180052388.8A patent/CN116018641A/zh active Pending
- 2021-08-20 KR KR1020237005227A patent/KR20230060502A/ko unknown
- 2021-08-20 US US18/023,183 patent/US20230300557A1/en active Pending
- 2021-08-20 BR BR112023003488A patent/BR112023003488A2/pt not_active Application Discontinuation
- 2021-08-20 MX MX2023002255A patent/MX2023002255A/es unknown
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2016529544A (ja) * | 2013-07-22 | 2016-09-23 | フラウンホーファーゲゼルシャフト ツール フォルデルング デル アンゲヴァンテン フォルシユング エー.フアー. | ジョイント符号化残留信号を用いたオーディオエンコーダ、オーディオデコーダ、方法、およびコンピュータプログラム |
| JP2015194666A (ja) * | 2014-03-24 | 2015-11-05 | ソニー株式会社 | 符号化装置および方法、復号装置および方法、並びにプログラム |
| WO2018110269A1 (ja) | 2016-12-12 | 2018-06-21 | ソニー株式会社 | Hrtf測定方法、hrtf測定装置、およびプログラム |
Non-Patent Citations (1)
| Title |
|---|
| See also references of EP4210048A4 |
Also Published As
| Publication number | Publication date |
|---|---|
| BR112023003488A2 (pt) | 2023-04-11 |
| MX2023002255A (es) | 2023-05-16 |
| CN116018641A (zh) | 2023-04-25 |
| KR20230060502A (ko) | 2023-05-04 |
| JPWO2022050087A1 (ja) | 2022-03-10 |
| EP4210048A1 (en) | 2023-07-12 |
| US20230300557A1 (en) | 2023-09-21 |
| EP4210048A4 (en) | 2024-02-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20190149936A1 (en) | Binaural decoder to output spatial stereo sound and a decoding method thereof | |
| EP2962298B1 (en) | Specifying spherical harmonic and/or higher order ambisonics coefficients in bitstreams | |
| US9794686B2 (en) | Controllable playback system offering hierarchical playback options | |
| KR101723332B1 (ko) | 회전된 고차 앰비소닉스의 바이노럴화 | |
| JP6612337B2 (ja) | 高次アンビソニックオーディオデータのスケーラブルコーディングのためのレイヤのシグナリング | |
| US9313599B2 (en) | Apparatus and method for multi-channel signal playback | |
| US9219972B2 (en) | Efficient audio coding having reduced bit rate for ambient signals and decoding using same | |
| US20150170657A1 (en) | Multiplet-based matrix mixing for high-channel count multichannel audio | |
| EP3204942B1 (en) | Signaling channels for scalable coding of higher order ambisonic audio data | |
| CN105340009A (zh) | 声场的经分解表示的压缩 | |
| Cobos et al. | An overview of machine learning and other data-based methods for spatial audio capture, processing, and reproduction | |
| JP7447798B2 (ja) | 信号処理装置および方法、並びにプログラム | |
| WO2022050087A1 (ja) | 信号処理装置および方法、学習装置および方法、並びにプログラム | |
| CN102576531B (zh) | 用于处理多信道音频信号的方法、设备 | |
| WO2021261235A1 (ja) | 信号処理装置および方法、並びにプログラム | |
| Wang | Soundfield analysis and synthesis: recording, reproduction and compression. |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21864145 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022546230 Country of ref document: JP Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 202317005482 Country of ref document: IN |
|
| REG | Reference to national code |
Ref country code: BR Ref legal event code: B01A Ref document number: 112023003488 Country of ref document: BR |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2021864145 Country of ref document: EP Effective date: 20230403 |
|
| ENP | Entry into the national phase |
Ref document number: 112023003488 Country of ref document: BR Kind code of ref document: A2 Effective date: 20230224 |