WO2022049704A1 - 情報処理システム、情報処理方法、及びコンピュータプログラム - Google Patents
情報処理システム、情報処理方法、及びコンピュータプログラム Download PDFInfo
- Publication number
- WO2022049704A1 WO2022049704A1 PCT/JP2020/033474 JP2020033474W WO2022049704A1 WO 2022049704 A1 WO2022049704 A1 WO 2022049704A1 JP 2020033474 W JP2020033474 W JP 2020033474W WO 2022049704 A1 WO2022049704 A1 WO 2022049704A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- index
- information processing
- reliability
- series data
- processing system
- Prior art date
Links
- 230000010365 information processing Effects 0.000 title claims abstract description 122
- 238000004590 computer program Methods 0.000 title claims description 18
- 238000003672 processing method Methods 0.000 title claims description 8
- 238000004364 calculation method Methods 0.000 claims abstract description 179
- 238000000034 method Methods 0.000 claims description 25
- 238000010801 machine learning Methods 0.000 claims description 7
- 238000012549 training Methods 0.000 claims description 3
- 238000010586 diagram Methods 0.000 description 17
- 238000012545 processing Methods 0.000 description 16
- 239000010754 BS 2869 Class F Substances 0.000 description 9
- 230000000694 effects Effects 0.000 description 8
- 230000006870 function Effects 0.000 description 8
- 238000003384 imaging method Methods 0.000 description 7
- 238000001514 detection method Methods 0.000 description 4
- 238000001617 sequential probability ratio test Methods 0.000 description 2
- 238000007476 Maximum Likelihood Methods 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 238000013528 artificial neural network Methods 0.000 description 1
- 238000004422 calculation algorithm Methods 0.000 description 1
- 239000000470 constituent Substances 0.000 description 1
- 230000006866 deterioration Effects 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 230000036449 good health Effects 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 230000005195 poor health Effects 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 230000035922 thirst Effects 0.000 description 1
Images











Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/16—Human faces, e.g. facial parts, sketches or expressions
- G06V40/172—Classification, e.g. identification
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/764—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using classification, e.g. of video objects
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/50—Information retrieval; Database structures therefor; File system structures therefor of still image data
- G06F16/55—Clustering; Classification
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
- G06F18/2415—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches based on parametric or probabilistic models, e.g. based on likelihood ratio or false acceptance rate versus a false rejection rate
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/0002—Inspection of images, e.g. flaw detection
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/40—Extraction of image or video features
- G06V10/62—Extraction of image or video features relating to a temporal dimension, e.g. time-based feature extraction; Pattern tracking
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/72—Data preparation, e.g. statistical preprocessing of image or video features
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/98—Detection or correction of errors, e.g. by rescanning the pattern or by human intervention; Evaluation of the quality of the acquired patterns
- G06V10/993—Evaluation of the quality of the acquired pattern
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/19—Recognition using electronic means
- G06V30/191—Design or setup of recognition systems or techniques; Extraction of features in feature space; Clustering techniques; Blind source separation
- G06V30/19173—Classification techniques
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/40—Spoof detection, e.g. liveness detection
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/30—Subject of image; Context of image processing
- G06T2207/30168—Image quality inspection
Definitions
- This disclosure relates to, for example, the technical fields of information processing systems, information processing methods, and computer programs that process information related to biometrics.
- Patent Document 1 discloses a technique for selecting one of target detection, target non-detection, and determination pending by SPRT.
- Patent Document 2 discloses a technique for identifying whether a plurality of input time-series data belong to the registered self or other objects.
- the log-likelihood ratio (LLR: Log Likelihood Ratio) of the entire series is used.
- This disclosure improves the related technology described above.
- One aspect of the information processing system of the present disclosure is an acquisition means for sequentially acquiring a plurality of elements included in the series data, and a first aspect indicating which of the plurality of classes each of the plurality of elements belongs to.
- the first calculation means for calculating the index of the above
- the weight calculation means for calculating the weight according to the reliability related to the calculation of the first index for each of the plurality of elements, and the first weighting by the weight.
- One aspect of the information processing method of the present disclosure is to sequentially acquire a plurality of elements included in the series data, and for each of the plurality of elements, a first index indicating which of the plurality of classes belongs to is used. For each of the plurality of elements, a weight corresponding to the reliability related to the calculation of the first index is calculated, and the series data is the plurality of the series data based on the first index weighted by the weight. A second index indicating which of the classes belongs to is calculated, and the series data is classified into one of the plurality of classes based on the second index.
- One aspect of the computer program of this disclosure is to sequentially acquire a plurality of elements contained in the series data and calculate a first index indicating which of the plurality of classes each of the plurality of elements belongs to. Then, for each of the plurality of elements, a weight corresponding to the reliability related to the calculation of the first index is calculated, and the series data is the plurality of the series data based on the first index weighted by the weight. A second index indicating which of the classes it belongs to is calculated, and the computer is operated so as to classify the series data into one of the plurality of classes based on the second index.
- FIG. 1 It is a block diagram which shows the hardware composition of the information processing system which concerns on 1st Embodiment. It is a block diagram which shows the functional structure of the information processing system which concerns on 1st Embodiment. It is a flowchart which shows the flow of operation of the information processing system which concerns on 1st Embodiment. It is a figure (the 1) which shows an example of the image data processed by the information processing system which concerns on 2nd Embodiment. It is a figure (the 2) which shows an example of the image data processed by the information processing system which concerns on 2nd Embodiment. It is a figure (the 3) which shows an example of the image data processed by the information processing system which concerns on 2nd Embodiment.
- FIG. 1 is a block diagram showing a hardware configuration of an information processing system according to the first embodiment.
- the information processing system 10 includes a processor 11, a RAM (Random Access Memory) 12, a ROM (Read Only Memory) 13, and a storage device 14.
- the information processing system 10 may further include an input device 15 and an output device 16.
- the processor 11, the RAM 12, the ROM 13, the storage device 14, the input device 15, and the output device 16 are connected via the data bus 17.
- Processor 11 reads a computer program.
- the processor 11 is configured to read a computer program stored in at least one of the RAM 12, the ROM 13, and the storage device 14.
- the processor 11 may read a computer program stored in a computer-readable recording medium using a recording medium reading device (not shown).
- the processor 11 may acquire (that is, read) a computer program from a device (not shown) located outside the information processing system 10 via a network interface.
- the processor 11 controls the RAM 12, the storage device 14, the input device 15, and the output device 16 by executing the read computer program.
- a functional block for classifying the series data is realized in the processor 11.
- processor 11 a CPU (Central Processing Unit), a GPU (Graphics Processing Unit), an FPGA (field-programmable get array), a DSP (Demand-Side Platform), and an ASIC (Application) are used. Alternatively, a plurality of them may be used in parallel.
- CPU Central Processing Unit
- GPU Graphics Processing Unit
- FPGA field-programmable get array
- DSP Demand-Side Platform
- ASIC Application Specific integrated circuit
- the RAM 12 temporarily stores the computer program executed by the processor 11.
- the RAM 12 temporarily stores data temporarily used by the processor 11 while the processor 11 is executing a computer program.
- the RAM 12 may be, for example, a D-RAM (Dynamic RAM).
- the ROM 13 stores a computer program executed by the processor 11.
- the ROM 13 may also store fixed data.
- the ROM 13 may be, for example, a P-ROM (Programmable ROM).
- the storage device 14 stores data stored in the information processing system 10 for a long period of time.
- the storage device 14 may operate as a temporary storage device of the processor 11.
- the storage device 14 may include, for example, at least one of a hard disk device, a magneto-optical disk device, an SSD (Solid State Drive), and a disk array device.
- the input device 15 is a device that receives an input instruction from the user of the information processing system 10.
- the input device 15 may include, for example, at least one of a keyboard, a mouse and a touch panel.
- the output device 16 is a device that outputs information about the information processing system 10 to the outside.
- the output device 16 may be a display device (for example, a display) capable of displaying information about the information processing system 10.
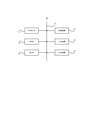
- FIG. 2 is a block diagram showing a functional configuration of the information processing system according to the first embodiment.
- the information processing system 10 has the acquisition unit 50, the first calculation unit 110, the second calculation unit 120, and weights as processing blocks for realizing the function. It includes a calculation unit 130 and a classification unit 60.
- Each of the acquisition unit 50, the first calculation unit 110, the second calculation unit 120, the weight calculation unit 130, and the classification unit 60 may be realized by the processor 11 (see FIG. 1) described above.
- the acquisition unit 50 is configured to be able to sequentially acquire a plurality of elements included in the series data.
- the acquisition unit 50 acquires, for example, a plurality of elements one by one.
- the acquisition unit 50 may acquire data directly from an arbitrary data acquisition device (for example, a camera or the like), or may read data previously acquired by the data acquisition device and stored in the storage or the like. You may.
- the elements of the series data acquired by the acquisition unit 50 are configured to be output to the first calculation unit 110.
- the first calculation unit 110 has a first index calculation unit 111 and a first storage unit 112.
- the first index calculation unit 111 is configured to be able to calculate a first index for the acquired element by using the element acquired by the acquisition unit 50 and the first index in the past.
- the "first index” is an index indicating which of the plurality of classes the element of the series data belongs to. Specific examples and specific calculation methods of the first index will be described in detail in other embodiments described later.
- the first storage unit 112 is configured to be able to store the first index in the past calculated by the first index calculation unit 111 or the past elements acquired by the acquisition unit 50.
- the information stored in the first storage unit 112 is configured to be readable by the first index calculation unit 111.
- the first index calculation unit 111 reads out the stored first index in the past and sets the first index for the acquired element. It should be calculated.
- the first index calculation unit 111 calculates and acquires the first index in the past from the stored past elements.
- the first index for the element may be calculated.
- the class may be about the truth of the event about the object or about the presence or absence of certain attributes of the object.
- the class may be about the positive and negative of the state of the object. For example, the class may indicate whether the person's face is real (true) or disguised as a mask (impersonation) (false).
- the class may indicate whether the person is wearing (with) or not (without) any accessories.
- the class may relate to whether the person is in good health (yang) or in poor health (yin).
- the class is not limited to the above example.
- the second calculation unit 120 has a second index calculation unit 121 and a second storage unit 122.
- the second index calculation unit 121 is configured to be able to calculate a second index for the acquired element by using the first index calculated by the first calculation unit 110 and the second index in the past. There is.
- the "second index" here is an index indicating which of the plurality of classes the series data belongs to.
- the second index calculated by the second calculation unit 120 is a value weighted by the weight calculated by the weight calculation unit 130. Specific examples and specific calculation methods of the second index will be described in detail in other embodiments described later.
- the second storage unit 122 is configured to be able to store the past second index calculated by the second index calculation unit 111.
- the information stored in the second storage unit 122 is configured to be readable by the second index calculation unit 121.
- the second index calculation unit 121 may read out the past second index stored in the second storage unit 122 and calculate the second index for the acquired element.
- the weight calculation unit 130 is configured to be able to calculate the weight used when calculating the second index.
- the "weight” here is for adjusting the degree of influence of the first index used for calculating the second index and the second index in the past on the new second index to be calculated. It is a value of, and is calculated according to the reliability of the acquired element. The weight is calculated, for example, as a real number value. The weight may be calculated as binary, such as "1" or "0".
- the "reliability” is the degree of reliability related to the calculation of the first index. For example, the reliability of the element from which an appropriate first index is calculated becomes high, and an inappropriate first index is calculated. The reliability of the element is low. Specific examples of reliability and specific setting methods will be described in detail in other embodiments described later.
- the weight calculated by the weight calculation unit 130 is applied (that is, weighted) when the second index is calculated, but the timing of weighting is not particularly limited, and finally. It suffices if the calculated second index (specifically, the second index used for classification in the classification unit 60) is weighted. Therefore, the weight calculation unit 130 may weight the elements of the series data at the timing acquired by the acquisition unit 50. Alternatively, the weight calculation unit 130 may weight the acquired element or the first index at the timing of being stored in the first storage unit 112 or the timing of being read from the first storage unit 112. Further, the weight calculation unit 130 may weight the second index at the timing of being stored in the second storage unit 122 or the timing of being read from the second storage unit 122.
- the classification unit 60 classifies the series data into one of a plurality of classes based on the second index calculated by the second calculation unit 120. It should be noted that a plurality of classes may be set in advance, and only two classes may be set, or three or more classes may be set. A specific classification method based on the second index will be described in detail in another embodiment described later.
- the classification unit 60 may have a function of instructing the acquisition unit 50 to acquire further elements when the class to be classified cannot be determined from the second index.
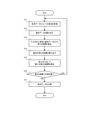
- FIG. 3 is a flowchart showing an operation flow of the information processing system according to the first embodiment.
- the acquisition unit 50 first acquires one element from the series data (step S11).
- the acquisition unit 50 outputs the elements of the acquired series data to the first calculation unit 110.
- the first index calculation unit 111 in the first calculation unit 110 reads past data from the first storage unit 112 (step S12).
- the past data is, for example, the processing result in the first index calculation unit 111 of the element acquired immediately before the element acquired this time by the acquisition unit 50 (in other words, the first calculated element for the previous element). 1 index) may be used. Alternatively, the past data may be the element itself acquired immediately before the element acquired by acquisition.
- the first index calculation unit 111 uses a new first index (that is, the acquisition unit 50 this time) based on the elements acquired by the acquisition unit 50 and the past data read from the first storage unit 112.
- the first index for the acquired element is calculated (step S13).
- the first index calculation unit 111 outputs the calculated first index to the second calculation unit 120.
- the first index calculation unit 111 may store the calculated first index in the first storage unit 112.
- the second index calculation unit 121 in the second calculation unit 120 reads out the past second index from the second storage unit 122 (step S14).
- the second index in the past is, for example, the processing result of the second index calculation unit 121 (in other words, the previous element) for the element acquired before the element acquired this time by the acquisition unit 50. It may be the second index) calculated for the above.
- the second index calculation unit 121 uses a new second index based on the first index calculated by the first calculation unit 110 and the past second index read from the second storage unit 122.
- An index (that is, a second index for the element acquired this time by the acquisition unit 50) is calculated (step S15).
- the second index calculation unit 121 calculates a new second index by weighting with the weight calculated by the weight calculation unit 130.
- the second index calculation unit 121 outputs the calculated second index to the classification unit 60.
- the second index calculation unit 121 may store the calculated second index in the second storage unit 122.
- the classification unit 60 determines whether or not the series data can be classified into any of a plurality of classes by using the second index calculated by the second calculation unit 120 (step S16).
- the specific processing content of this determination will be described in detail in another embodiment described later.
- the information processing system 10 according to the first embodiment processes again from step S11. To understand. Specifically, the information processing system 10 according to the first embodiment repeats the same processing for the next element of the element of the series data acquired this time.
- step S16 when it is determined that the series data can be classified into any of a plurality of classes using the second index (step S16: YES), the classification unit 60 classifies the series data based on the second index. Classify into one of a plurality of classes (step S17). In this case, a series of processes will be completed.
- the series data is classified into one of a plurality of classes by using the first index and the second index calculated from the elements included in the series data.
- the second index used when classifying is calculated from the first index weighted by the weight calculated according to the reliability of each element. That is, the influence of each element included in the series data on the classification result can be biased. For example, for elements with high reliability, a large weight is given to the first index to increase the influence on the classification result, while for elements with low reliability, a small weight is given to the first index. By giving it, the influence on the classification result can be reduced. As a result, it becomes possible to classify the series data more appropriately as compared with the case where the weighting is not performed.
- the classification process in the information processing system 10 according to the first embodiment is more effective when the correlation between the elements of the series data is strong. If an algorithm is used that does not consider the relationships between the elements of the series data, the series data that are actually strongly related between the elements are classified as having no relationship between the elements. On the other hand, in the classification process in the information processing system 10 of the first embodiment, the relationship between the elements of the series data is taken into consideration, so that the classification accuracy is improved for the series data having a strong relationship between the elements. be able to.
- cases where the correlation between the elements of the series data is strong include time series data such as video data or audio data.
- time series data such as video data or audio data.
- one frame and the next frame often have similar characteristics. Therefore, the classification process in the information processing system 10 according to the first embodiment is more effective in the process of time series data.
- a tree structure, a flowchart, and the like can be mentioned.
- the information processing system 10 according to the second embodiment will be described with reference to FIGS. 4 (a) and 4 (b).
- the second embodiment is for explaining a specific example of the reliability described in the first embodiment, and the system configuration and operation are the same as those of the first embodiment (see FIGS. 1 to 3). May be. Therefore, in the following, the description of the portion overlapping with the first embodiment will be omitted as appropriate. In the second embodiment, the description will proceed on the premise that the series data is acquired as time series image data.
- FIGS. 4 (a) and 4 (b) are diagrams (No. 1) showing an example of image data processed by the information processing system according to the second embodiment.
- the reliability of each element included in the series data may be set based on the sharpness of the image data. For example, for image data having high sharpness as shown in FIG. 4A, high reliability may be set. On the other hand, for image data having low sharpness as shown in FIG. 4B, the reliability may be set low.
- the reliability is a value calculated from a parameter indicating less blurring of the region of interest (the region including the imaging target) and / or less blurring of the imaging target in the image data sharpness. It may be there.
- a first parameter indicating the relationship between the depth of field of the image data and the position of the imaging target
- a second parameter indicating the relationship between the moving speed of the imaging target and the shutter speed
- a calculation formula including the third parameter sharpness indicating the sharpness is prepared in advance, the weight calculation unit 130 can use the above calculation formula for the first parameter, the second parameter, and / or the third. By substituting the parameters, the reliability can be easily calculated.
- the first to third parameters are referred to as "index of sharpness" of image data or simply “sharpness”.
- the sharpness of the image data may be acquired by the acquisition unit 50 together with the image data, or may be estimated and acquired from the image data.
- the calculation unit 130 may use the depth of field and face of the camera that captured the image instead of the sharpness of the image data.
- the reliability may be set based on whether or not the sharpness of the image data is equal to or higher than a predetermined threshold value.
- the weight calculation unit 130 sets the reliability to "high” if the sharpness of the image data is equal to or higher than a predetermined threshold, and sets the reliability to "high” if the sharpness of the image data is less than the predetermined threshold. It may be set to "low”.
- the weight calculation unit 130 may set a plurality of predetermined threshold values for sharpness. For example, if the sharpness of the image data is equal to or higher than the first threshold value, the weight calculation unit 130 sets the reliability to "high”, and if the sharpness of the image data is less than the first threshold value and equal to or higher than the second threshold value. The weight calculation unit 130 may set the reliability to "medium", and if the sharpness of the image data is less than the second threshold value, the weight calculation unit 130 may set the reliability to "low”. good.
- the reliability is set according to the high sharpness of the image data, the influence of each image data on the classification can be reduced. For example, by weighting by weighting according to the reliability, it is possible to increase the influence on the classification of image data having high sharpness (that is, high reliability). On the other hand, for image data with low sharpness (that is, low reliability), the influence on the classification can be reduced. As described above, if the reliability is set according to the sharpness of the image data, appropriate weighting is performed and the series data can be appropriately classified.
- 5 (a) and 5 (b) are diagrams (No. 2) showing an example of image data processed by the information processing system according to the second embodiment.
- the weight calculation unit 130 determines the reliability of each element included in the series data in the vicinity of the image pickup target in the image data. (Specifically, it may be set based on the closeness of the distance between the camera that captures the image data and the image pickup target). For example, the weight calculation unit 130 may set a high reliability for image data in which the distance of the image pickup target (here, a person) is short as shown in FIG. 5A. On the other hand, for image data with a short distance to be imaged as shown in FIG. 5B, the weight calculation unit 130 may set the reliability low.
- the reliability may be a value calculated from a parameter indicating the distance from the image pickup target in the image data.
- the weight calculation unit 130 can easily calculate the reliability from the sharpness of the imaging target.
- the distance of the image pickup target in the image data may be acquired together with the image data, or may be estimated and acquired from the image data.
- the distance of the image pickup target may be calculated from, for example, the size of the image pickup target in the image (for example, the ratio of the image pickup target to the entire image) or the like.
- the distance to be imaged may be measured using a distance measuring sensor.
- the reliability may be set based on whether or not the distance to the image capture target in the image data is less than a predetermined threshold value. In this case, if the distance to the image pickup target is less than a predetermined threshold value, the weight calculation unit 130 sets the reliability to "high", and if the distance to the image pickup target is greater than or equal to the predetermined threshold value, the weight calculation unit 130. The 130 may set the reliability to "low”. Further, the weight calculation unit 130 may set a plurality of predetermined threshold values regarding the distance. For example, if the distance to the image pickup target is less than the first threshold value, the weight calculation unit 130 sets the reliability to "high”, and if the distance to the image pickup target is greater than or equal to the first threshold value and less than the second threshold value. The weight calculation unit 130 sets the reliability to "medium”, and if the distance to the image pickup target is equal to or greater than the second threshold value, the weight calculation unit 130 may set the reliability to "low”. good.
- the reliability is set according to the closeness of the image data to the image pickup target, the influence of each image data on the classification can be reduced. For example, by weighting by weighting according to the reliability, it is possible to increase the influence on the classification of image data having a short distance (that is, having a high reliability). On the other hand, for image data with a long distance (that is, low reliability), the influence on the classification can be reduced. As described above, if the reliability is set according to the distance of the image pickup target in the image data, appropriate weighting is performed and the series data can be appropriately classified.
- FIG. 6 is a diagram (No. 3) showing an example of image data processed by the information processing system according to the second embodiment.
- the reliability of each element included in the series data may be set based on the acquisition timing of the image data.
- time-series image data in which a person to be imaged gradually approaches the camera is acquired.
- the reliability of the image data for the first few frames may be set low.
- the reliability of the image data of the subsequent frames may be set low.
- the criteria for determining the first frame are not limited.
- the first frame may be the frame in which the face of the person is detected for the first time, or the frame in which the person is detected for the first time by the motion sensor.
- the reliability may be a value calculated from a parameter indicating the order in which the image data was acquired. For example, if a calculation formula for calculating a lower value as the acquisition timing is earlier is prepared in advance, the weight calculation unit 130 can easily calculate the reliability from the acquisition timing of the image data.
- the parameter indicating the acquisition timing of the image data may be the number of frames of the image data or may be a parameter indicating the time when the image data is acquired, as in the example shown in FIG. 6, for example. Further, the acquisition timing here may correspond to the timing at which the image data is captured, or may correspond to the timing at which the image data is acquired by the acquisition unit 50.
- the reliability may be set based on whether or not the acquisition timing of the image data is equal to or higher than a predetermined threshold value. In this case, if the image data acquisition timing is equal to or higher than a predetermined threshold value, the weight calculation unit 130 sets the reliability to "high", and if the image data acquisition timing is less than the predetermined threshold value, the weight calculation unit 130. The 130 may set the reliability to "low”. Further, a plurality of predetermined threshold values regarding the acquisition timing may be set. For example, if the image data acquisition timing is equal to or higher than the first threshold value, the weight calculation unit 130 sets the reliability to “high”, and if the image data acquisition timing is less than the first threshold value and equal to or higher than the second threshold value. The weight calculation unit 130 may set the reliability to "medium”, and if the image data acquisition timing is less than the second threshold value, the weight calculation unit 130 may set the reliability to "low”. good.
- the quality and properties of image data may change significantly depending on the acquisition timing.
- the reliability is set according to the acquisition timing of the image data, the influence of each image data on the classification can be reduced.
- the influence on the classification of the image data whose acquisition timing is late that is, the reliability is high.
- the influence on the classification can be reduced. Contrary to the example described so far, the reliability of the image data whose acquisition timing is late may be lowered, and the reliability of the image data whose acquisition timing is early may be increased.
- This example can be applied to the case where time-series image data is acquired such that the image pickup target gradually moves away from the camera. As described above, if the reliability is set according to the difference in the appropriate acquisition timing, appropriate weighting is performed and the series data can be appropriately classified.
- the information processing system 10 according to the third embodiment will be described with reference to FIGS. 7 (a) and 7 (b) and FIGS. 8 (a) and 8 (b).
- the third embodiment is for explaining a specific example of reliability as in the second embodiment described above, and the system configuration and operation are described in the first embodiment (see FIGS. 1 to 3). ) May be the same. Therefore, in the following, the description of the portion overlapping with the first embodiment will be omitted as appropriate.
- FIGS. 7 (a) and 7 (b) are diagrams showing an example of the difference of the first index calculated by the information processing system according to the third embodiment.
- each element acquired based on the difference of the first index calculated by the first calculation unit 110 sets the reliability. Specifically, it is acquired in the nth position based on the difference between the first index calculated for the nth acquired element n and the first index calculated for the n + 1th acquired element n + 1.
- the reliability of the element n to be generated and / or the reliability of the element n + 1 acquired thirst to n + 1 is set.
- the difference of the first index is calculated as the difference of the first index of the two elements acquired consecutively as described above.
- the reliability of each element included in the series data is set so that the smaller the difference of the first index, the higher the reliability. For example, as shown in FIG. 7A, when the difference between the first index calculated for the element n and the first index calculated for the element n + 1 is small, the reliability may be set high. On the other hand, as shown in FIG. 7B, when the difference between the first index calculated for the element n and the first index calculated for the element n + 1 is large, the reliability may be set low.
- the reliability may be a value calculated from the difference value of the first index. For example, if a calculation formula for calculating a higher value as the difference of the first index is smaller is prepared in advance, the reliability can be easily calculated from the difference of the first index.
- the reliability may be set based on whether or not the difference of the first index is less than a predetermined threshold value. In this case, if the difference of the first index is less than the predetermined threshold value, the weight calculation unit 130 sets the reliability to "high", and if the difference of the first index is equal to or more than the predetermined threshold value, the weight is set.
- the calculation unit 130 may set the reliability to "low”.
- the weight calculation unit 130 may set a plurality of predetermined threshold values regarding the difference of the first index. For example, if the difference of the first index is less than the first threshold value, the weight calculation unit 130 sets the reliability to "high”, and the difference of the first index is equal to or more than the first threshold value and less than the second threshold value. If so, the weight calculation unit 130 sets the reliability to "medium”, and if the difference between the first indicators is equal to or greater than the second threshold value, the weight calculation unit 130 sets the reliability to "low”. You may do it.
- each element can have an influence on the classification. For example, by weighting by a weight according to the reliability, it is possible to increase the influence on the classification of the element having a small difference of the first index. On the other hand, for an element having a large difference in the first index, the influence on the classification can be reduced. As described above, if the reliability is set according to the difference of the first index, appropriate weighting is performed and the series data can be appropriately classified.
- FIGS. 8 (a) and 8 (b) are diagrams showing an example of the volatility of the first index calculated by the information processing system according to the third embodiment.
- each element acquired based on the volatility of the first index calculated by the first calculation unit 110. Set the reliability. Specifically, the first index calculated for the nth acquired element n, the first index calculated for the n + 1st acquired element n + 1, and the n + second acquired element n + 2. The nth acquired element n, n + 1st based on the magnitude of the fluctuation between the calculated first index and the first index calculated for the n + 3rd acquired element n + 3. At least one reliability of the acquired element n + 1, n + second acquired element n + 2, and n + third acquired element n + 3 is set.
- the reliability of each element included in the series data is set so that the smaller the volatility of the first index, the higher the reliability. For example, as shown in FIG. 8A, when the volatility of the first index calculated for element n, element n + 1, element n + 2, and element n + 3 is small, the reliability may be set high. On the other hand, as shown in FIG. 8B, when the volatility of the first index calculated for the element n, the element n + 1, the element n + 2, and the element n + 3 is large, the reliability may be set low.
- the reliability may be a value calculated from a value indicating the volatility of the first index. For example, if a calculation formula for calculating a higher value as the volatility of the first index is smaller is prepared in advance, the reliability can be easily calculated from the volatility of the first index. Since the value indicating the volatility of the first index can be calculated by appropriately adopting an existing method, a specific description thereof will be omitted here.
- the reliability may be set based on whether or not the volatility of the first index is less than a predetermined threshold. In this case, if the volatility of the first index is less than a predetermined threshold value, the weight calculation unit 130 sets the reliability to "high", and if the volatility of the first index is greater than or equal to the predetermined threshold value, the weight is set.
- the calculation unit 130 may set the reliability to "low”.
- the weight calculation unit 130 may set a plurality of predetermined threshold values regarding the volatility of the first index. For example, if the volatility of the first index is less than the first threshold, the weight calculation unit 130 sets the reliability to "high”, and the volatility of the first index is equal to or more than the first threshold and less than the second threshold. If so, the weight calculation unit 130 sets the reliability to "medium”, and if the volatility of the first index is equal to or higher than the second threshold value, the weight calculation unit 130 sets the reliability to "low”. You may do it.
- the reliability is set according to the volatility of the first index, the influence of each element on the classification can be reduced. For example, by weighting by weighting according to the reliability, it is possible to increase the influence on the classification of the element having a small volatility of the first index. On the other hand, for elements with high volatility of the first index, the influence on the classification can be reduced. As described above, if the reliability is set according to the volatility of the first index, appropriate weighting is performed and the series data can be appropriately classified.
- the information processing system 10 according to the fourth embodiment will be described with reference to FIG.
- the fourth embodiment is different in some configurations from the first to third embodiments described above, and the hardware configuration and the operation of the entire system described above are described in the first embodiment (the first embodiment). It may be the same as in FIGS. 1 and 3). Therefore, in the following, the parts different from the above-mentioned first to third embodiments will be described in detail, and the description of other overlapping parts will be omitted as appropriate.
- FIG. 9 is a block diagram showing a functional configuration of the information processing system according to the fourth embodiment.
- the same reference numerals are given to the same components as those shown in FIG. 2.
- the information processing system 20 according to the fourth embodiment has the acquisition unit 50, the first calculation unit 110, the second calculation unit 120, and weights as processing blocks for realizing the function. It includes a calculation unit 130, a classification unit 60, and a reliability learning unit 200. That is, the information processing system 20 according to the fourth embodiment is configured to further include a reliability learning unit 200 in addition to the configuration of the first embodiment (see FIG. 2).
- the reliability learning unit 200 may be realized by the processor 11 (see FIG. 1) described above.
- the reliability learning unit 200 is configured to be able to execute machine learning regarding the reliability of each element included in the series data.
- the reliability learning unit 200 is configured to include a neural network, and optimizes a model for determining the reliability of each element included in the series data by learning.
- the reliability learning unit 200 executes machine learning by using a pair of an element and its reliability, for example, as training data.
- the reliability learning unit 200 determines the reliability of each element acquired by the acquisition unit 50 using the result of machine learning.
- the reliability learning unit 200 acquires the information of the element acquired from the acquisition unit 50, and determines the reliability of the element using the learning result.
- the reliability determined by the reliability learning unit 200 is output to, for example, the weight calculation unit 130 and used for weight calculation.
- the reliability determined by the reliability learning unit 200 may be stored in the first storage unit 112 or the like in association with the element acquired by the acquisition unit 50.
- the reliability learning unit 200 may use the reliability between the elements included in the series data instead of the reliability of the element alone. In this case, the reliability between the elements may represent the high probability that the elements are connected.
- the reliability learning unit 200 determines the reliability of each element included in the series data. Therefore, the reliability of each element included in the series data can be easily determined, and as a result, an appropriate weight can be calculated.
- the information processing system 10 according to the fifth embodiment will be described with reference to FIGS. 10 to 12.
- the fifth embodiment is different from the first to fourth embodiments described above in some configurations and operations.
- the hardware configuration is the same as that of the first embodiment (see FIG. 1). May be. Therefore, in the following, the parts different from the first to fourth embodiments described above will be described in detail, and the description of other overlapping parts will be omitted as appropriate.
- FIG. 10 is a block diagram showing a functional configuration of the information processing system according to the fifth embodiment.
- the same reference numerals are given to the same components as those shown in FIG. 2.
- the information processing system 10 has the acquisition unit 50, the first calculation unit 110, the second calculation unit 120, and weights as processing blocks for realizing the function. It includes a calculation unit 130 and a classification unit 60. Further, the information processing system 10 according to the fifth embodiment includes a likelihood ratio calculation unit 113 instead of the first index calculation unit 111 of the first embodiment, and replaces the second index calculation unit 121. The integrated likelihood ratio calculation unit 123 is provided. Each of the confidence likelihood ratio calculation unit 113 and the integrated likelihood ratio calculation unit 123 may be realized by the processor 11 (see FIG. 1) described above.
- the likelihood ratio calculation unit 113 is configured to be able to calculate the likelihood ratio as a first index.
- the likelihood ratio calculation unit 113 calculates the likelihood ratio based on the acquired elements and past data.
- the likelihood ratio is a value indicating the likelihood that each of the plurality of elements belongs to a certain class among the plurality of classes.
- a specific example of the likelihood ratio will be described.
- the N elements constituting the series data be x1, ..., XN , and let the plurality of classes be R and F. That is, in this example, for the sake of simplification, it is assumed that the classification is a binary classification in which the number of classes is 2.
- the result calculated for the probability that the element x i belongs to the class R without considering the past data is expressed as p (R
- the result of calculating the probability that the element x i belongs to the class F without considering the past data is expressed as p (F
- these likelihood ratios are expressed by the following equation (1).
- the likelihood ratio of the above equation (1) shows the ratio of the probability that the element x i belongs to the class R and the probability that the element x i belongs to the class F. For example, when the likelihood ratio exceeds 1, p (R
- the likelihood ratio calculation unit 113 can calculate in consideration of a plurality of elements (that is, the relationship between the input element and the past data) as described above.
- the likelihood ratio calculated in consideration of the two elements x i and x i-1 is expressed by the following equation (2).
- the integrated likelihood ratio calculation unit 123 is configured to be able to calculate the integrated likelihood ratio as a second index.
- the integrated likelihood ratio calculation unit 123 calculates the integrated likelihood ratio using the likelihood ratio calculated by the likelihood ratio calculation unit 113 and the past integrated likelihood ratio.
- the integrated likelihood ratio is a value indicating the likelihood that the series data belongs to a certain class among a plurality of classes.
- a specific example of the likelihood ratio will be described. Similar to the description of the likelihood ratio described above, the case of the two-class classification in which the number of classes is two will be described.
- Equation (3) is called the integrated likelihood ratio.
- the integrated likelihood ratio can be calculated by decomposing it into terms for each element as shown in the following equation (4).
- each element is decomposed into a sum by using the logarithm of the likelihood ratio to simplify the calculation, but this is not essential.
- the term likelihood ratio or integrated likelihood ratio may be used for such a log-likelihood ratio.
- the notation of the base of the logarithm is omitted, the value of the base is arbitrary.
- the likelihood ratio and the integrated likelihood ratio are calculated in consideration of two or more elements, the assumption that each element is independent is often not established. Therefore, unlike the equation (4), it cannot be decomposed into terms for each element, and the integrated likelihood ratio is calculated by a different calculation formula depending on the number of elements considering the relationship.
- the integrated likelihood ratio can be calculated using the following equation (5).
- the integrated likelihood ratio calculation unit 123 calculates the integrated likelihood ratio by weighting with weights according to the reliability of each element.
- the weights are ⁇ i 1 and ⁇ i 2
- the integrated likelihood ratio on the right side of the equation (5) can be expressed as in the equation (6).
- Equation (6) shows an example of a two-class classification that calculates the likelihood ratio between class R and class F, but the number of classes may be 3 or more.
- the equation (6) can be used to calculate the integrated likelihood ratio between the kth class among the M classes and all the classes other than the kth class.
- An example of such an extension is one that uses the maximum likelihood of all classes other than the k-th, as in the following equation (7).
- the method of calculating the integrated likelihood ratio when the number of classes is 3 or more is not limited to these. Further, although the cases where two elements are considered are illustrated in the equations (6) to (8), three or more elements may be considered.
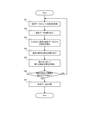
- FIG. 11 is a flowchart showing an operation flow of the information processing system according to the fifth embodiment.
- the acquisition unit 50 acquires one element from the series data (step S21).
- the acquisition unit 50 outputs the elements of the acquired series data to the first calculation unit 110.
- the likelihood ratio standard calculation unit 113 in the first calculation unit 110 reads past data from the first storage unit 112 (step S22).
- the past data is, for example, the processing result in the first index calculation unit 111 of the element acquired immediately before the element acquired this time by the acquisition unit 50 (in other words, the likelihood calculated for the previous element). It may be (degree ratio). Alternatively, the past data may be the element itself acquired immediately before the element acquired by acquisition.
- the likelihood ratio calculation unit 113 acquires a new likelihood ratio (that is, this time by the acquisition unit 50) based on the elements acquired by the acquisition unit 50 and the past data read from the first storage unit 112. The likelihood ratio to the added elements) is calculated (step S23). The likelihood ratio calculation unit 113 outputs the calculated likelihood ratio to the second calculation unit 120. The likelihood ratio calculation unit 113 may store the calculated likelihood ratio in the first storage unit 112.
- the integrated likelihood ratio calculation unit 123 in the second calculation unit 120 reads out the past integrated likelihood ratio from the second storage unit 122 (step S24).
- the past integrated likelihood ratio is, for example, the processing result of the integrated likelihood ratio calculation unit 123 (in other words, the previous element) for the element acquired before the element acquired this time by the acquisition unit 50. It may be the integrated likelihood ratio calculated with respect to.
- the integrated likelihood ratio calculation unit 123 newly integrates the likelihood ratio based on the likelihood ratio calculated by the likelihood ratio calculation unit 113 and the past integrated likelihood ratio read from the second storage unit 122.
- the degree ratio (that is, the integrated likelihood ratio with respect to the element acquired this time by the acquisition unit 50) is calculated (step S25).
- the integrated likelihood ratio calculation unit 123 calculates a new integrated likelihood ratio by weighting with the weight calculated by the weight calculation unit 130 (see the above-mentioned equation (6) and the like).
- the integrated likelihood ratio calculation unit 123 outputs the calculated integrated likelihood ratio to the classification unit 60.
- the integrated likelihood ratio calculation unit 123 may store the calculated integrated likelihood ratio in the second storage unit 122.
- the classification unit 60 determines whether or not there is a class in which the integrated likelihood ratio calculated by the integrated likelihood ratio calculation unit 123 exceeds the threshold value (step S26).
- the threshold value here is preset as a threshold value for determining which of the plurality of classes the series data belongs to. Therefore, the threshold value is set for each of the plurality of classes. In the following, a specific example will be given for further explanation.
- the classification process of the classification unit 60 is assumed to be two-class classification into class R or class F, and the threshold values used for the determination of class R and class F are T 1 and T 2 , respectively. Further, the integrated likelihood ratio is L. In this case, if L ⁇ T 1 (step S26: YES), the classification unit 60 classifies the series data into class R (step S27). On the other hand, when L> T 2 (step S26: YES), the classification unit 60 classifies the series data into class F (step S27). By doing so, by comparing the integrated likelihood ratio with the threshold value of each class, it is possible to appropriately determine which class the series data belongs to.
- step S26 NO
- the classification unit 140 determines that the series data cannot be classified, and the acquisition unit 50 acquires the next element.
- the integrated likelihood ratio can be calculated in consideration of the elements to be acquired, so that the integrated likelihood ratio exceeds the threshold value of any class (that is, the series data is used in any of the series data). You can continue processing while updating the integration likelihood ratio (until you can classify it into a class).
- M threshold values can be prepared and the classification process can be performed by comparing the integrated likelihood ratios of M with the thresholds of M.
- the classification unit 60 may classify the series data into a class in which the integrated likelihood ratio first exceeds the threshold value. If the integrated likelihood ratio does not exceed any of the thresholds, the classification unit 60 determines that the series data cannot be classified, and the acquisition unit 50 acquires the next element.
- the above classification method is an example and is not limited to this. For example, if the number of input elements is larger than the predetermined value (maximum number of elements), the series data is forcibly selected even if there is no class whose integrated likelihood ratio exceeds the threshold value.
- the procedure may be modified to classify into classes and end the process. This can prevent the calculation time from becoming too long. In this example, it is desirable that the criteria be mutually exclusive to ensure that they are classified into one of the classes.
- FIG. 12 is a graph showing an example of classification by the information processing system according to the fifth embodiment.
- the information processing system 10 according to the fifth embodiment classifies a real face and a fake face. That is, it is assumed that the information processing system 10 according to the fifth embodiment classifies the face information input as series data into a real face class or a fake face class.
- the integrated likelihood ratio shown by line A reaches the threshold value + T corresponding to the real face at a relatively early stage. Therefore, it can be determined that the series data corresponding to the line A is a real face that can be easily determined. Further, the integrated likelihood ratio shown by the line B reaches the threshold value + T corresponding to the real face at a slightly later stage than the integrated likelihood ratio shown by the line A. Therefore, it can be determined that the series data corresponding to the line B is a real face that is difficult to determine. On the other hand, the integrated likelihood ratio shown by the line C finally reaches the threshold value ⁇ T corresponding to the fake face. Therefore, it can be determined that the series data corresponding to the line C is a fake face.
- the integrated likelihood ratio shown by the line D is timed out without reaching either the threshold value + T corresponding to the real face and the threshold value-T corresponding to the fake face (that is, from the start of processing). The specified time has passed). For such series data, the processing may be terminated without classifying into any class. In this case, the information processing system 10 according to the fifth embodiment may output information indicating that the determination cannot be made.
- the above-mentioned threshold value + T and threshold value-T may be different values from each other. That is, "+ T" and "-T” may be set as values whose absolute values are different from each other. For example, if the threshold value + T is set to be larger than the threshold value ⁇ T, it is easy to determine that the face is a real face, but it is difficult to determine that the face is a fake face. On the contrary, if the threshold value + T is set smaller than the threshold value ⁇ T, it is difficult to determine that the face is a real face, but it is easy to determine that the face is a fake face.
- the likelihood ratio and the integrated likelihood ratio are calculated from the elements included in the series data, and the series data is classified into one of a plurality of classes.
- the likelihood ratio is a value indicating the likelihood that each of the plurality of elements belongs to a certain class among the plurality of classes, as described above. Therefore, if the likelihood ratio is used as the first index, the second index (that is, the integrated likelihood ratio) can be appropriately calculated.
- the integrated likelihood ratio is a value indicating the likelihood that the series data belongs to a certain class among a plurality of classes. Therefore, if the integrated likelihood ratio is used as the second index, the series data can be appropriately classified into a plurality of classes.
- the integrated likelihood ratio is calculated in a state of being weighted for each element. Therefore, it is possible to effectively suppress the occurrence of the above-mentioned problems.
- the personal identification system according to the sixth embodiment will be described with reference to FIG.
- the sixth embodiment describes an application example of the information processing system according to the first to fifth embodiments described above.
- the hardware configuration is the same as that of the first embodiment (see FIG. 1). May be. Therefore, in the following, the parts different from the first to fifth embodiments described above will be described in detail, and the description of other overlapping parts will be omitted as appropriate.
- FIG. 13 is a block diagram showing a functional configuration of the personal identification system according to the sixth embodiment.
- the personal identification system 300 collates the biometric information of the identification target person such as a face image, a fingerprint image, and an iris image with the biometric information registered in advance to identify an individual. It is configured as an identification system.
- the personal identification system 300 may be provided with a device for acquiring biometric information (for example, a camera or the like) and may operate standalone, and may acquire biometric information from another device in the personal identification system. It may identify an individual. Further, the personal identification system 300 may be composed of a plurality of devices that are communicated with each other.
- the personal identification system 300 may be configured as, for example, an authentication device for a face recognition gate.
- the personal identification device 300 may be configured as an intelligent camera.
- the intelligent camera here is an IP (Internet Protocol) camera or a network camera having an analysis function inside, and is sometimes called a smart camera.
- the personal identification system 300 includes a classification unit 301, a biometric information acquisition unit 302, and a biometric information storage unit 103 as processing blocks for realizing the function.
- the classification unit 301 includes the information processing system 10 of each of the above-described embodiments.
- the information processing system 100 of the first embodiment is used as the classification device 301.
- the classification unit 310 acquires series data having biometric information as an element.
- the classification unit 301 classifies the input series data into one of a plurality of predetermined classes while referring to the information stored in the biometric information storage unit 303.
- the plurality of classes here may be, for example, a class indicating that the input series data matches any of the registered persons.
- the plurality of classes may include a class indicating that the input series data has spoofing and a class indicating that the input series data does not have spoofing.
- the biometric information acquisition unit 302 is a device for acquiring biometric information.
- the biological information acquisition unit 302 may be configured to include, for example, a digital camera capable of shooting a moving image.
- the feature amount for collation may be extracted from the image or the like acquired by the biometric information acquisition unit 302.
- This feature amount extraction process may be performed by the classification unit 301, may be performed by the biometric information acquisition unit 302 at the time of biometric information acquisition, or may be performed by another device.
- the image itself acquired by the biological information acquisition unit 302 and the feature amount extracted from the image itself may be collectively referred to as biological information.
- the biometric information storage unit 303 is configured to be able to record various information such as biometric information used in the personal identification system 300.
- the biometric information acquired by the biometric information acquisition unit 302 may be stored in the biometric information storage unit 303.
- the information stored in the biological information storage unit 303 may be stored in a state that can be appropriately read by the classification unit 301. Further, information regarding the classification result of the classification unit 301 may also be stored in the biological information storage unit 303.
- spoofing methods in biometric authentication such as face authentication
- a method using a non-living body such as a face photograph or a face model of the person
- a method for detecting such spoofing there is a method in which a plurality of images are taken and it is determined that the image is not a living body when the difference between the plurality of images is small.
- the classification device 301 of the present embodiment inputs a time-series image of the person to be authenticated as series data, and uses the difference between the images as a feature amount to perform class classification indicating whether or not the series data is spoofed. This makes it possible to detect spoofing depending on which class the series data is classified into.
- the time variation of the images included in the input time series data is very small, and the correlation between the images is often strong. Therefore, when classifying spoofing detection, the classification process of the information processing system 100 of the first to fifth embodiments described above is used, in which the classification accuracy is less likely to deteriorate for the series data having a strong relationship between the elements. Is effective.
- the information processing system 10 according to the seventh embodiment will be described with reference to FIG.
- the seventh embodiment shows the basic configuration of the information processing system according to the first to fifth embodiments described above, and the configuration and operation thereof are the same as those of the above-described embodiments. It's okay. Therefore, in the following, the parts different from the first to fifth embodiments described above will be described in detail, and the description of other overlapping parts will be omitted as appropriate.
- FIG. 14 is a block diagram showing a functional configuration of the information processing system according to the seventh embodiment.
- the same reference numerals are given to the same elements as those of the constituent elements shown in FIG.
- the information processing system 10 has the acquisition unit 50, the first calculation unit 110, the second calculation unit 120, and weights as processing blocks for realizing the function. It includes a calculation unit 130 and a classification unit 60.
- the acquisition unit 50 is configured to be able to sequentially acquire a plurality of elements included in the series data.
- the first calculation unit 110 is configured to be able to calculate a first index indicating which of the plurality of classes belongs to each of the plurality of elements included in the series data.
- the weight calculation unit 130 is configured to be able to calculate the weight according to the reliability related to the calculation of the first index.
- the second calculation unit 120 is configured to be able to calculate a second index indicating which of the plurality of classes the series data belongs to, based on the first index weighted by the weight calculated by the weight calculation unit 130. There is.
- the classification unit 60 is configured to be able to classify the series data into any of a plurality of classes based on the second index calculated by the second calculation unit 120.
- the series data is classified into one of a plurality of classes by using the first index and the second index calculated from the elements included in the series data.
- the second index used in the classification is weighted by the weight calculated according to the reliability of each element.
- the information processing system is an acquisition means for sequentially acquiring a plurality of elements included in the series data, and a first index indicating which of the plurality of classes each of the plurality of elements belongs to.
- the first calculation means for calculating the above
- the weight calculation means for calculating the weight according to the reliability related to the calculation of the first index for each of the plurality of elements, and the first index weighted by the weight.
- the series data is of the plurality of classes. It is an information processing system characterized by being provided with a classification means for classifying into any one.
- Appendix 2 In the information processing system described in Appendix 2, the series data is image data, and the weight calculation means has a high degree of sharpness of the image data and is between the image pickup means that has acquired the image data and the image pickup target.
- the weight calculation means has a small difference between the first indexes calculated in two consecutively acquired elements among the plurality of elements, or is continuous.
- the information processing system according to Appendix 1, wherein the weight is calculated with the smallness of the volatility between the first indexes calculated in the predetermined number of elements acquired in the above as the reliability.
- Appendix 4 The information processing system according to Appendix 4 executes machine learning related to the reliability using the training data associated with the reliability, and the reliability of each of the plurality of elements is based on the result of the machine learning.
- the information processing system according to Appendix 5 is characterized in that the first index includes a likelihood ratio indicating the likelihood that each of the plurality of elements belongs to a certain class among the plurality of classes.
- the information processing system according to Appendix 6 is characterized in that the second index includes a likelihood ratio indicating the likelihood that the series data belongs to a certain class among the plurality of classes.
- the information processing system according to any one of 5 to 5.
- the classification means sets the series data and the second index to the predetermined threshold when there is a class in which the second index exceeds a predetermined threshold.
- Appendix 8 In the information processing system according to Appendix 8, when there is no class in which the second index exceeds a predetermined threshold value, the classification means does not classify the series data into any class, and the acquisition is performed.
- the means is the information processing system according to any one of Supplementary Provisions 1 to 7, further comprising acquiring an element.
- Appendix 9 The information processing method described in Appendix 9 sequentially acquires a plurality of elements included in the series data, and calculates a first index indicating which of the plurality of classes each of the plurality of elements belongs to. , Each of the plurality of elements is weighted according to the reliability related to the calculation of the first index, and the series data is in the plurality of classes based on the first index weighted by the weight. It is an information processing method characterized by calculating a second index indicating which of the two indexes it belongs to and classifying the series data into one of the plurality of classes based on the second index.
- the computer program according to the appendix 10 sequentially acquires a plurality of elements included in the series data, calculates a first index indicating which of the plurality of classes belongs to each of the plurality of elements, and calculates the first index. For each of the plurality of elements, a weight according to the reliability related to the calculation of the first index is calculated, and based on the first index weighted by the weight, the series data is of the plurality of classes.
- a computer program characterized in that a second index indicating which one belongs to is calculated, and the computer is operated so as to classify the series data into one of the plurality of classes based on the second index. Is.
- Appendix 11 The recording medium described in Appendix 11 is a recording medium characterized in that the computer program described in Appendix 10 is recorded.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Multimedia (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Databases & Information Systems (AREA)
- Health & Medical Sciences (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- General Health & Medical Sciences (AREA)
- Software Systems (AREA)
- Medical Informatics (AREA)
- Computing Systems (AREA)
- Quality & Reliability (AREA)
- Data Mining & Analysis (AREA)
- Human Computer Interaction (AREA)
- General Engineering & Computer Science (AREA)
- Probability & Statistics with Applications (AREA)
- Oral & Maxillofacial Surgery (AREA)
- Life Sciences & Earth Sciences (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Evolutionary Biology (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Image Analysis (AREA)
Abstract
情報処理システム(10)は、系列データに含まれる複数の要素を逐次的に取得する取得手段(50)と、複数の要素の各々について、複数のクラスのいずれに属するかを示す第1の指標を算出する第1算出手段(110)と、複数の要素の各々について、第1の指標の算出に係る信頼度に応じた重みを算出する重み算出手段(130)と、重みにより重み付けした第1の指標に基づいて、系列データが複数のクラスのいずれに属するかを示す第2の指標を算出する第2算出手段(120)と、第2の指標に基づいて、系列データを複数のクラスのいずれかに分類する分類手段(60)とを備える。このような情報処理システムによれば、系列データを適切に分類することが可能である。
Description
この開示は、例えば生体認証に関する情報を処理する情報処理システム、情報処理方法、及びコンピュータプログラムの技術分野に関する。
この種のシステムとして、逐次確率比検定(SPRT:Sequential Probability Ratio Test)を用いるものが知られている。例えば特許文献1では、SPRTにより、目標検出、目標不検出、判定保留のいずれかを選択する技術が開示されている。特許文献2では、入力される複数の時系列データが、登録された自分或いはその他のオブジェクトのいずれに属するかを識別する技術が開示されている。上述した特許文献では、系列全体の対数尤度比(LLR:Log Likelihood Ratio)が用いられる。
この開示は、上述した関連する技術を改善する。
この開示の情報処理システムの一の態様は、系列データに含まれる複数の要素を逐次的に取得する取得手段と、前記複数の要素の各々について、複数のクラスのいずれに属するかを示す第1の指標を算出する第1算出手段と、前記複数の要素の各々について、前記第1の指標の算出に係る信頼度に応じた重みを算出する重み算出手段と、前記重みにより重み付けした前記第1の指標に基づいて、前記系列データが前記複数のクラスのいずれに属するかを示す第2の指標を算出する第2算出手段と、前記第2の指標に基づいて、前記系列データを前記複数のクラスのいずれかに分類する分類手段とを備える。
この開示の情報処理方法の一の態様は、系列データに含まれる複数の要素を逐次的に取得し、前記複数の要素の各々について、複数のクラスのいずれに属するかを示す第1の指標を算出し、前記複数の要素の各々について、前記第1の指標の算出に係る信頼度に応じた重みを算し、前記重みにより重み付けした前記第1の指標に基づいて、前記系列データが前記複数のクラスのいずれに属するかを示す第2の指標を算出し、前記第2の指標に基づいて、前記系列データを前記複数のクラスのいずれかに分類する。
この開示のコンピュータプログラムの一の態様は、系列データに含まれる複数の要素を逐次的に取得し、前記複数の要素の各々について、複数のクラスのいずれに属するかを示す第1の指標を算出し、前記複数の要素の各々について、前記第1の指標の算出に係る信頼度に応じた重みを算し、前記重みにより重み付けした前記第1の指標に基づいて、前記系列データが前記複数のクラスのいずれに属するかを示す第2の指標を算出し、前記第2の指標に基づいて、前記系列データを前記複数のクラスのいずれかに分類するようにコンピュータを動作させる。
以下、図面を参照しながら、情報処理システム、情報処理方法、及びコンピュータプログラムの実施形態について説明する。
<第1実施形態>
第1実施形態に係る情報処理システムについて、図1から図3を参照して説明する。
第1実施形態に係る情報処理システムについて、図1から図3を参照して説明する。
(ハードウェア構成)
まず、図1を参照しながら、第1実施形態に係る情報処理システムのハードウェア構成について説明する。図1は、第1実施形態に係る情報処理システムのハードウェア構成を示すブロック図である。
まず、図1を参照しながら、第1実施形態に係る情報処理システムのハードウェア構成について説明する。図1は、第1実施形態に係る情報処理システムのハードウェア構成を示すブロック図である。
図1に示すように、第1実施形態に係る情報処理システム10は、プロセッサ11と、RAM(Random Access Memory)12と、ROM(Read Only Memory)13と、記憶装置14とを備えている。情報処理システム10は更に、入力装置15と、出力装置16とを備えていてもよい。プロセッサ11と、RAM12と、ROM13と、記憶装置14と、入力装置15と、出力装置16とは、データバス17を介して接続されている。
プロセッサ11は、コンピュータプログラムを読み込む。例えば、プロセッサ11は、RAM12、ROM13及び記憶装置14のうちの少なくとも一つが記憶しているコンピュータプログラムを読み込むように構成されている。或いは、プロセッサ11は、コンピュータで読み取り可能な記録媒体が記憶しているコンピュータプログラムを、図示しない記録媒体読み取り装置を用いて読み込んでもよい。プロセッサ11は、ネットワークインタフェースを介して、情報処理システム10の外部に配置される不図示の装置からコンピュータプログラムを取得してもよい(つまり、読み込んでもよい)。プロセッサ11は、読み込んだコンピュータプログラムを実行することで、RAM12、記憶装置14、入力装置15及び出力装置16を制御する。本実施形態では特に、プロセッサ11が読み込んだコンピュータプログラムを実行すると、プロセッサ11内には、系列データを分類するための機能ブロックが実現される。また、プロセッサ11として、CPU(Central Processing Unit)、GPU(Graphics Processing Unit)、FPGA(field-programmable gate array)、DSP(Demand-Side Platform)、ASIC(Application Specific Integrated Circuit)のうち一つを用いてもよいし、複数を並列で用いてもよい。
RAM12は、プロセッサ11が実行するコンピュータプログラムを一時的に記憶する。RAM12は、プロセッサ11がコンピュータプログラムを実行している際にプロセッサ11が一時的に使用するデータを一時的に記憶する。RAM12は、例えば、D-RAM(Dynamic RAM)であってもよい。
ROM13は、プロセッサ11が実行するコンピュータプログラムを記憶する。ROM13は、その他に固定的なデータを記憶していてもよい。ROM13は、例えば、P-ROM(Programmable ROM)であってもよい。
記憶装置14は、情報処理システム10が長期的に保存するデータを記憶する。記憶装置14は、プロセッサ11の一時記憶装置として動作してもよい。記憶装置14は、例えば、ハードディスク装置、光磁気ディスク装置、SSD(Solid State Drive)及びディスクアレイ装置のうちの少なくとも一つを含んでいてもよい。
入力装置15は、情報処理システム10のユーザからの入力指示を受け取る装置である。入力装置15は、例えば、キーボード、マウス及びタッチパネルのうちの少なくとも一つを含んでいてもよい。
出力装置16は、情報処理システム10に関する情報を外部に対して出力する装置である。例えば、出力装置16は、情報処理システム10に関する情報を表示可能な表示装置(例えば、ディスプレイ)であってもよい。
(機能的構成)
次に、図2を参照しながら、第1実施形態に係る情報処理システム10の機能的構成について説明する。図2は、第1実施形態に係る情報処理システムの機能的構成を示すブロック図である。
次に、図2を参照しながら、第1実施形態に係る情報処理システム10の機能的構成について説明する。図2は、第1実施形態に係る情報処理システムの機能的構成を示すブロック図である。
図2に示すように、第1実施形態に係る情報処理システム10は、その機能を実現するための処理ブロックとして、取得部50と、第1算出部110と、第2算出部120と、重み算出部130と、分類部60とを備えている。なお、取得部50、第1算出部110、第2算出部120、重み算出部130、及び分類部60の各々は、上述したプロセッサ11(図1参照)によって実現されてよい。
取得部50は、系列データに含まれる複数の要素を逐次的に取得可能に構成されている。取得部50は、例えば複数の要素を1つずつ取得する。取得部50は、任意のデータ取得装置(例えば、カメラ等)から直接データを取得するものであってもよいし、あらかじめデータ取得装置で取得されストレージ等に記憶されているデータを読み出すものであってもよい。取得部50で取得された系列データの要素は、第1算出部110に出力される構成となっている。
第1算出部110は、第1指標算出部111と、第1記憶部112とを有している。第1指標算出部111は、取得部50によって取得された要素と、過去の第1の指標とを用いて、取得された要素に対する第1の指標を算出可能に構成されている。ここでの「第1の指標」は、系列データの要素が、複数のクラスのいずれに属するかを示す指標である。第1指標の具体例や具体的な算出方法については、後述する他の実施形態において詳しく説明する。第1記憶部112は、第1指標算出部111で算出された過去の第1の指標、又は取得部50で取得された過去の要素を記憶可能に構成されている。第1記憶部112で記憶されている情報は、第1指標算出部111によって読み出し可能に構成されている。第1記憶部112が過去の第1の指標を記憶している場合、第1指標算出部111は、記憶された過去の第1の指標を読み出して、取得された要素に対する第1の指標を算出すればよい。一方、第1記憶部112が過去に取得された要素を記憶している場合、第1指標算出部111は、記憶された過去の要素から過去の第1の指標を算出して、取得された要素に対する第1の指標を算出すればよい。クラスは、物体についての事象の真偽に関するものであってもよいし、物体の特定の属性の有無に関するものであってもよい。クラスは、物体の状態の陽と陰に関するものであってもよい。例えば、クラスは、人物の顔が本物か(真)、あるいは、仮面等による変装(なりすまし)をしているか(偽)を示してもよい。他の例では、クラスは、人物が何らかのアクセサリを装着しているか(有)、していないか(無)を示してもよい。その他の例では、クラスは、人物の健康状態が良好か(陽)、あるいは、健康状態が悪いか(陰)に関するものであってもよい。しかしながら、クラスは上述した例には限定されない。
第2算出部120は、第2指標算出部121と、第2記憶部122とを有している。第2指標算出部121は、第1算出部110で算出された第1の指標と、過去の第2の指標とを用いて、取得された要素に対する第2の指標を算出可能に構成されている。ここでの「第2の指標」は、系列データが複数のクラスのいずれに属するかを示す指標である。第2算出部120で算出される第2の指標は、重み算出部130で算出された重みによって重み付けされた値である。第2の指標の具体例や具体的な算出方法については、後述する他の実施形態において詳しく説明する。第2記憶部122は、第2指標算出部111で算出された過去の第2の指標を記憶可能に構成されている。第2記憶部122で記憶されている情報は、第2指標算出部121によって読み出し可能に構成されている。第2指標算出部121は、第2記憶部122に記憶された過去の第2の指標を読み出して、取得された要素に対する第2の指標を算出すればよい。
重み算出部130は、第2の指標を算出する際に用いる重みを算出可能に構成されている。ここでの「重み」は、第2の指標の算出に用いられる第1の指標と、及び過去の第2の指標とが、算出される新たな第2の指標に与える影響度を調整するための値であり、取得された要素の信頼度に応じて算出される。重みは、例えば実数の値として算出される。重みは、「1」又は「0」のように2値的なものとして算出されてもよい。「信頼度」は、第1の指標の算出に係る信頼性の度合いであり、例えば適切な第1の指標が算出される要素の信頼度は高くなり、適切でない第1の指標が算出される要素の信頼度は低くなる。信頼度の具体例や、具体的な設定方法については、後述する他の実施形態において詳しく説明する。なお、重み算出部130で算出された重みは、第2の指標を算出する際に適用される(即ち、重み付けされる)が、重み付けのタイミングについては特に限定されるものではなく、最終的に算出される第2の指標(具体的には、分類部60での分類に利用される第2の指標)が重み付けされたものになっていればよい。このため、重み算出部130は、系列データの要素に対して、取得部50で取得されたタイミングで重み付けを行ってもよい。または、重み算出部130は、取得された要素や第1の指標に対して、第1記憶部112に記憶されるタイミング又は第1記憶部112から読み出されるタイミングで重み付けを行ってもよい。更にまたは、重み算出部130は、第2の指標に対して、第2記憶部122に記憶されるタイミング又は第2記憶部122から読み出されるタイミングで重み付けを行ってもよい。
分類部60は、第2算出部120で算出された第2の指標に基づいて、系列データを複数のクラスのいずれかに分類する。なお、複数のクラスは予め設定されていればよく、2つのクラスだけが設定されていてもよいし、3つ以上のクラスが設定されていてもよい。第2の指標に基づく具体的な分類手法については、後述する他の実施形態で詳しく説明する。分類部60は、第2の指標から分類するクラスを決定できない場合に、取得部50に対して更に要素を取得するように指示する機能を有していてもよい。
(動作の流れ)
次に、図3を参照しながら、第1実施形態に係る情報処理システム10の動作の流れについて説明する。図3は、第1実施形態に係る情報処理システムの動作の流れを示すフローチャートである。
次に、図3を参照しながら、第1実施形態に係る情報処理システム10の動作の流れについて説明する。図3は、第1実施形態に係る情報処理システムの動作の流れを示すフローチャートである。
図3に示すように、第1実施形態に係る情報処理システム10では、まず取得部50が、系列データから1つの要素を取得する(ステップS11)。取得部50は、取得した系列データの要素を、第1算出部110に出力する。
続いて、第1算出部110における第1指標算出部111が、第1記憶部112から過去データを読み出す(ステップS12)。過去データは、例えば取得部50で今回取得された要素の1つ前に取得された要素の第1指標算出部111での処理結果(言い換えれば、1つ前の要素に対して算出された第1の指標)であってよい。或いは、過去データは、取得で取得された要素の1つ前に取得された要素そのものであってもよい。
続いて、第1指標算出部111は、取得部50で取得された要素と、第1記憶部112から読みだした過去データに基づいて、新たな第1の指標(即ち、取得部50で今回取得された要素に対する第1の指標)を算出する(ステップS13)。第1指標算出部111は、算出した第1の指標を、第2算出部120に出力する。第1指標算出部111は、算出した第1の指標を、第1記憶部112に記憶してもよい。
続いて、第2算出部120における第2指標算出部121が、第2記憶部122から過去の第2の指標を読み出す(ステップS14)。過去の第2の指標は、例えば取得部50で今回取得された要素の1つ前に取得された要素についての、第2指標算出部121での処理結果(言い換えれば、1つ前の要素に対して算出された第2の指標)であってよい。
続いて、第2指標算出部121は、第1算出部110で算出された第1の指標と、第2記憶部122から読みだした過去の第2の指標に基づいて、新たな第2の指標(即ち、取得部50で今回取得された要素に対する第2の指標)を算出する(ステップS15)。ここで特に、第2指標算出部121は、重み算出部130で算出された重みによる重み付けをして、新たな第2の指標を算出する。第2指標算出部121は、算出した第2の指標を、分類部60に出力する。第2指標算出部121は、算出した第2の指標を、第2記憶部122に記憶してもよい。
続いて、分類部60が、第2算出部120で算出された第2の指標を用いて、系列データが複数のクラスのいずれかに分類可能であるか否かを判定する(ステップS16)。なお、この判定の具体的な処理内容については、後述する他の実施形態において詳しく説明する。第2の指標を用いて系列データを複数のクラスのいずれかに分類することができないと判定した場合(ステップS16:NO)、第1実施形態に係る情報処理システム10は、再びステップS11から処理を解する。具体的には、第1実施形態に係る情報処理システム10は、今回取得した系列データの要素の次の要素について、同様の処理を繰り返す。一方、第2の指標を用いて複数のクラスのいずれかに系列データを分類することができると判定した場合(ステップS16:YES)、分類部60は、第2の指標に基づいて系列データを複数のクラスのいずれかに分類する(ステップS17)。この場合、一連の処理は終了することになる。
(技術的効果)
次に、第1実施形態に係る情報処理システム10によって得られる技術的効果について説明する。
次に、第1実施形態に係る情報処理システム10によって得られる技術的効果について説明する。
第1実施形態に係る情報処理システム10では、系列データに含まれる要素から算出される第1の指標及び第2の指標を用いて、系列データが複数のクラスのいずれかに分類される。第1実施形態では特に、クラス分類する際に用いられる第2の指標が、各要素の信頼度に応じて算出された重みによって重み付けされた第1の指標から算出されている。即ち、系列データに含まれる各要素が分類結果に与える影響に、偏りを持たせることができる。例えば、信頼度が高い要素については、第1の指標に大きい重みを付与することで、分類結果に与える影響を大きくする一方で、信頼度が低い要素については、第1の指標に小さい重みを付与することで、分類結果に与える影響を小さくすることができる。この結果、重み付けを行わない場合と比較して、より適切に系列データを分類することが可能となる。
第1実施形態に係る情報処理システム10における分類処理は、系列データの要素間の相関が強い場合により効果的である。仮に、系列データの要素間の関連性が考慮されないアルゴリズムが用いられる場合、実際には要素間の関連性が強い系列データに対しても要素間に関連性が無いものとして分類が行われる。これに対し、第1実施形態の情報処理システム10における分類処理は、系列データの要素間の関連性が考慮されるため、要素間の関連性が強い系列データに対して、分類精度を向上することができる。
系列データの要素間の相関が強い場合の具体例としては、動画データまたは音声データ等の時系列データが挙げられる。例えば、動画データにおいては、一般的には、あるフレームとその次のフレームは似た特徴を有していることが多いためである。したがって、第1実施形態に係る情報処理システム10における分類処理は、時系列データの処理において更に有効である。あるいはまた、系列データの要素間の相関が強い場合の他の具体例としては、ツリー構造、フローチャートなどが挙げられる。
<第2実施形態>
第2実施形態に係る情報処理システム10について、図4(a)(b)から図6を参照して説明する。なお、第2実施形態は、第1実施形態で説明した信頼度の具体例を説明するためのものであり、システム構成や動作については、第1実施形態(図1から図3参照)と同様であってよい。このため、以下では、第1実施形態と重複する部分については適宜説明を省略するものとする。なお、第2実施形態では、系列データが時系列の画像データとして取得される前提で説明を進める。
第2実施形態に係る情報処理システム10について、図4(a)(b)から図6を参照して説明する。なお、第2実施形態は、第1実施形態で説明した信頼度の具体例を説明するためのものであり、システム構成や動作については、第1実施形態(図1から図3参照)と同様であってよい。このため、以下では、第1実施形態と重複する部分については適宜説明を省略するものとする。なお、第2実施形態では、系列データが時系列の画像データとして取得される前提で説明を進める。
(鮮明度に基づく信頼度)
まず、図4(a)(b)を参照しながら、画像の鮮明度に基づく信頼度について説明する。図4(a)(b)は、第2実施形態に係る情報処理システムで処理される画像データの一例を示す図(その1)である。
まず、図4(a)(b)を参照しながら、画像の鮮明度に基づく信頼度について説明する。図4(a)(b)は、第2実施形態に係る情報処理システムで処理される画像データの一例を示す図(その1)である。
図4(a)(b)に示すように、第2実施形態に係る情報処理システム10では、系列データに含まれる各要素の信頼度が、画像データの鮮明度に基づいて設定されてよい。例えば、図4(a)に示すような鮮明度が高い画像データについては、信頼度が高く設定されてよい。一方、図4(b)に示すような鮮明度が低い画像データについては、信頼度が低く設定されてよい。
より具体的には、信頼度は、画像データ鮮明度における注目領域(撮像対象を含む領域)のボケの少なさ、および/または、撮像対象のブレの少なさを示すパラメータから算出される値であってよい。例えば、画像データの被写界深度と撮像対象の位置との関係を示す第1のパラメータ、撮像対象の動く速度とシャッタースピードとの関係を示す第2のパラメータ、および/または、撮像対象の暗さを示す第3のパラメータ鮮明度を含む計算式を予め用意しておけば、重み算出部130は、鮮明度上記の計算式に、第1のパラメータ、第2のパラメータおよび/または第3のパラメータを代入することで、容易に信頼度を算出することができる。以下、第1のパラメータから第3のパラメータを、画像データの「鮮明度の指標」あるいは単に「鮮明度」と呼ぶ。画像データの鮮明度は、取得部50により画像データと共に取得されてもよいし、画像データから推定して取得されてもよい。あるいは、算出部130は、画像データの鮮明度に代えて、画像を撮影したカメラの被写界深度および顔
或いは、信頼度は、画像データの鮮明度が所定の閾値以上であるか否かに基づいて設定されてよい。この場合、重み算出部130は、画像データの鮮明度が所定の閾値以上であれば、信頼度を「高」に設定し、画像データの鮮明度が所定の閾値未満であれば、信頼度を「低」に設定するようにしてもよい。また、重み算出部130は、鮮明度に関する所定の閾値を複数設定してもよい。例えば、画像データの鮮明度が第1閾値以上であれば、重み算出部130は、信頼度を「高」に設定し、画像データの鮮明度が第1閾値未満且つ第2閾値以上であれば、重み算出部130は、信頼度を「中」に設定し、画像データの鮮明度が第2閾値未満であれば、重み算出部130は、信頼度を「低」に設定するようにしてもよい。
画像データの鮮明度が低いと、画像に写り込んでいる撮像対象を正確に識別することが難しくなる。よって、このような画像データがクラス分類に大きな影響を与えてしまうと、適切な分類を行うことができなくなるおそれがある。しかるに、画像データの鮮明度の高さに応じて信頼度を設定するようにすれば、各画像データがクラス分類に与える影響を低減することができる。例えば、信頼度に応じた重みによる重み付けをすることで、鮮明度の高い(即ち、信頼度の高い)画像データについては、クラス分類に与える影響を大きくすることができる。一方で、鮮明度の低い(即ち、信頼度の低い)画像データについては、クラス分類に与える影響を小さくすることができる。以上のように、画像データの鮮明度に応じて信頼度を設定すれば、適切な重み付けが行われ、系列データを適切に分類することが可能となる。
(対象物との距離に基づく信頼度)
次に、図5(a)(b)を参照しながら、対象物との距離に基づく信頼度について説明する。図5(a)(b)は、第2実施形態に係る情報処理システムで処理される画像データの一例を示す図(その2)である。
次に、図5(a)(b)を参照しながら、対象物との距離に基づく信頼度について説明する。図5(a)(b)は、第2実施形態に係る情報処理システムで処理される画像データの一例を示す図(その2)である。
図5(a)(b)に示すように、第2実施形態に係る情報処理システム10では、重み算出部130は、系列データに含まれる各要素の信頼度を、画像データにおける撮像対象の近さ(具体的には、画像データを撮像するカメラと撮像対象との距離の近さ)に基づいて設定してよい。例えば、図5(a)に示すような撮像対象(ここでは、人物)の距離が近い画像データについては、重み算出部130は、信頼度を高く設定してよい。一方、図5(b)に示すような撮像対象の距離が低い画像データについては、重み算出部130は、信頼度を低く設定してよい。
より具体的には、信頼度は、画像データにおける撮像対象との距離を示すパラメータから算出される値であってよい。例えば、撮像対象の距離が近いほど高い値が算出される計算式を予め用意しておけば、重み算出部130は、撮像対象の鮮明度から容易に信頼度を算出することができる。画像データにおける撮像対象の距離は、画像データと共に取得されてもよいし、画像データから推定して取得されてもよい。撮像対象の距離は、例えば画像における撮像対象の大きさ(例えば、撮像対象が画像全体に占める割合)等から算出されてもよい。あるいは、撮像対象の距離は、測距センサを用いて計測されてもよい。
或いは、信頼度は、画像データにおける撮像対象との距離が所定の閾値未満であるか否かに基づいて設定されてよい。この場合、撮像対象との距離が所定の閾値未満であれば、重み算出部130は、信頼度を「高」に設定し、撮像対象との距離が所定の閾値以上であれば、重み算出部130は、信頼度を「低」に設定するようにしてもよい。また、重み算出部130は、距離に関する所定の閾値を複数設定してもよい。例えば、撮像対象との距離が第1閾値未満であれば、重み算出部130は、信頼度を「高」に設定し、撮像対象との距離が第1閾値以上且つ第2閾値未満であれば、重み算出部130は、信頼度を「中」に設定し、撮像対象との距離が第2閾値以上であれば、重み算出部130は、信頼度を「低」に設定するようにしてもよい。
画像データにおける撮像対象との距離が遠いと、画像に写り込んでいる撮像対象を正確に識別することが難しくなる。よって、このような画像データがクラス分類に大きな影響を与えてしまうと、適切な分類を行うことができなくなるおそれがある。しかるに、画像データにおける撮像対象との距離の近さに応じて信頼度を設定するようにすれば、各画像データがクラス分類に与える影響を低減することができる。例えば、信頼度に応じた重みによる重み付けをすることで、距離の近い(即ち、信頼度の高い)画像データについては、クラス分類に与える影響を大きくすることができる。一方で、距離の遠い(即ち、信頼度の低い)画像データについては、クラス分類に与える影響を小さくすることができる。以上のように、画像データにおける撮像対象の距離に応じて信頼度を設定すれば、適切な重み付けが行われ、系列データを適切に分類することが可能となる。
(取得タイミングに基づく信頼度)
次に、図6を参照しながら、画像の取得タイミングに基づく信頼度について説明する。図6は、第2実施形態に係る情報処理システムで処理される画像データの一例を示す図(その3)である。
次に、図6を参照しながら、画像の取得タイミングに基づく信頼度について説明する。図6は、第2実施形態に係る情報処理システムで処理される画像データの一例を示す図(その3)である。
図6に示すように、第2実施形態に係る情報処理システム10では、系列データに含まれる各要素の信頼度が、画像データの取得タイミングに基づいて設定されてよい。例えば、図6に示す例では、撮像対象である人物が徐々にカメラに近づいてくる時系列の画像データが取得されている。このような場合、最初の数フレームの画像データについては、画像中の撮像対象が小さいため、撮像対象を正確に識別することが難しい。よって、最初の数フレーム分の画像データについては、信頼度が低く設定されてよい。一方、その後のフレームの画像データについては、信頼度が低く設定されてよい。ここで、最初のフレームを決定する基準は限定されない。例えば、時系列の画像データにおいて、最初のフレームは、人物の顔が初めて検出されたフレームであってもよいし、人感センサによって、人物が初めて検出されたフレームであってもよい。
より具体的には、信頼度は、その画像データが何番目に取得されたものであるのかを示すパラメータから算出される値であってよい。例えば、取得されたタイミングが早いほど低い値が算出される計算式を予め用意しておけば、重み算出部130は、画像データの取得タイミングから容易に信頼度を算出することができる。画像データの取得タイミングを示すパラメータは、例えば図6に示す例のように、画像データのフレーム数であってもよいし、画像データが取得された時刻を示すパラメータであってもよい。また、ここでの取得タイミングは、画像データが撮像されたタイミングに対応するものであってよいし、画像データが取得部50によって取得されたタイミングに対応するものであってもよい。
或いは、信頼度は、画像データの取得タイミングが所定の閾値以上であるか否かに基づいて設定されてよい。この場合、画像データの取得タイミングが所定の閾値以上であれば、重み算出部130は、信頼度を「高」に設定し、画像データの取得タイミングが所定の閾値未満であれば、重み算出部130は、信頼度を「低」に設定するようにしてもよい。また、取得タイミングに関する所定の閾値を複数設定してもよい。例えば、画像データの取得タイミングが第1閾値以上であれば、重み算出部130は、信頼度を「高」に設定し、画像データの取得タイミングが第1閾値未満且つ第2閾値以上であれば、重み算出部130は、信頼度を「中」に設定し、画像データの取得タイミングが第2閾値未満であれば、重み算出部130は、信頼度を「低」に設定するようにしてもよい。
画像データは、取得タイミングの違いによって、その品質や性質(例えば、撮像対象の写り込み方等)が大きく変化することがある。このような場合には、画像データの取得タイミングに応じて信頼度を設定するようにすれば、各画像データがクラス分類に与える影響を低減することができる。例えば、信頼度に応じた重みによる重み付けをすることで、取得タイミングの遅い(即ち、信頼度の高い)画像データについては、クラス分類に与える影響を大きくすることができる。一方で、取得タイミングの早い(即ち、信頼度の低い)画像データについては、クラス分類に与える影響を小さくすることができる。なお、ここまで説明した例とは逆に、取得タイミングの遅い画像データの信頼度を低くし、取得タイミングの早い画像データの信頼度を高くするようにしてもよい。この例は、撮像対象がカメラから徐々に遠ざかるような時系列の画像データが取得される場合等に適用できる。以上のように、適取得タイミングの違いに応じて信頼度を設定すれば、適切な重み付けが行われ、系列データを適切に分類することが可能となる。
<第3実施形態>
第3実施形態に係る情報処理システム10について、図7(a)(b)及び図8(a)(b)を参照して説明する。なお、第3実施形態は、上述した第2実施形態と同様に、信頼度の具体例を説明するためのものであり、システム構成や動作については、第1実施形態(図1から図3参照)と同様であってよい。このため、以下では、第1実施形態と重複する部分については適宜説明を省略するものとする。
第3実施形態に係る情報処理システム10について、図7(a)(b)及び図8(a)(b)を参照して説明する。なお、第3実施形態は、上述した第2実施形態と同様に、信頼度の具体例を説明するためのものであり、システム構成や動作については、第1実施形態(図1から図3参照)と同様であってよい。このため、以下では、第1実施形態と重複する部分については適宜説明を省略するものとする。
(第1の指標の差分に基づく信頼度)
まず、図7(a)(b)を参照しながら、第1の指標の差分に基づく信頼度について説明する。図7(a)(b)は、第3実施形態に係る情報処理システムで算出される第1の指標の差分の一例を示す図である。
まず、図7(a)(b)を参照しながら、第1の指標の差分に基づく信頼度について説明する。図7(a)(b)は、第3実施形態に係る情報処理システムで算出される第1の指標の差分の一例を示す図である。
図7(a)(b)に示すように、第3実施形態に係る情報処理システム10では、第1算出部110で算出される第1の指標の差分に基づいて、取得される各要素の信頼度を設定する。具体的には、n番目に取得された要素nについて算出される第1の指標と、n+1番目に取得された要素n+1について算出される第1の指標との差分に基づいて、n番目に取得される要素nの信頼度、及び/又はn+1番目に取得された要素n+1の信頼度が設定される。なお、第1の指標の差分は、上述したように連続して取得される2つの要素の第1の指標の差分として算出される。
系列データに含まれる各要素の信頼度は、第1の指標の差分が小さいほど、高くなるように設定される。例えば、図7(a)に示すように、要素nについて算出される第1の指標と、要素n+1について算出される第1の指標との差分が小さい場合、信頼度は高く設定されてよい。一方、図7(b)に示すように、要素nについて算出される第1の指標と、要素n+1について算出される第1の指標との差分が大きい場合、信頼度は低く設定されてよい。
より具体的には、信頼度は、第1の指標の差分の値から算出される値であってよい。例えば、第1の指標の差分が小さいほど高い値が算出される計算式を予め用意しておけば、第1の指標の差分から容易に信頼度を算出することができる。
或いは、信頼度は、第1の指標の差分が所定の閾値未満であるか否かに基づいて設定されてよい。この場合、第1の指標の差分が所定の閾値未満であれば、重み算出部130は、信頼度を「高」に設定し、第1の指標の差分が所定の閾値以上であれば、重み算出部130は、信頼度を「低」に設定するようにしてもよい。また、重み算出部130は、第1の指標の差分に関する所定の閾値を複数設定してもよい。例えば、第1の指標の差分が第1閾値未満であれば、重み算出部130は、信頼度を「高」に設定し、第1の指標の差分が第1閾値以上且つ第2閾値未満であれば、重み算出部130は、信頼度を「中」に設定し、第1の指標の差分が第2閾値以上であれば、重み算出部130は、信頼度を「低」に設定するようにしてもよい。
第1の指標の差分が大きい場合、連続する2つの要素に大きな差異が生じていることが想定される。このような場合、2つの要素のいずれか一方は、第1の指標を算出するのに適さない要素である可能性が高い。しかるに、第1の指標の差分に応じて信頼度を設定するようにすれば、各要素がクラス分類に与える影響をすることができる。例えば、信頼度に応じた重みによる重み付けをすることで、第1の指標の差分が小さい要素については、クラス分類に与える影響を大きくすることができる。一方で、第1の指標の差分が大きい要素については、クラス分類に与える影響を小さくすることができる。以上のように、第1の指標の差分に応じて信頼度を設定すれば、適切な重み付けが行われ、系列データを適切に分類することが可能となる。
(第1の指標のボラティリティに基づく信頼度)
次に、図8(a)(b)を参照しながら、第1の指標のボラティリティに基づく信頼度について説明する。図8(a)(b)は、第3実施形態に係る情報処理システムで算出される第1の指標のボラティリティの一例を示す図である。
次に、図8(a)(b)を参照しながら、第1の指標のボラティリティに基づく信頼度について説明する。図8(a)(b)は、第3実施形態に係る情報処理システムで算出される第1の指標のボラティリティの一例を示す図である。
図8(a)(b)に示すように、第3実施形態に係る情報処理システム10では、第1算出部110で算出される第1の指標のボラティリティに基づいて、取得される各要素の信頼度を設定する。具体的には、n番目に取得された要素nについて算出される第1の指標と、n+1番目に取得された要素n+1について算出される第1の指標と、n+2番目に取得された要素n+2について算出される第1の指標と、n+3番目に取得された要素n+3について算出される第1の指標との間での揺らぎの大きさに基づいて、n番目に取得される要素n、n+1番目に取得された要素n+1、n+2番目に取得された要素n+2、及びn+3番目に取得された要素n+3の少なくとも1つの信頼度が設定される。
系列データに含まれる各要素の信頼度は、第1の指標のボラティリティが小さいほど、高くなるように設定される。例えば、図8(a)に示すように、要素n、要素n+1、要素n+2、及び要素n+3について算出される第1の指標のボラティリティが小さい場合、信頼度は高く設定されてよい。一方、図8(b)に示すように、要素n、要素n+1、要素n+2、及び要素n+3について算出される第1の指標のボラティリティが大きい場合、信頼度は低く設定されてよい。
より具体的には、信頼度は、第1の指標のボラティリティを示す値から算出される値であってよい。例えば、第1の指標のボラティリティが小さいほど高い値が算出される計算式を予め用意しておけば、第1の指標のボラティリティから容易に信頼度を算出することができる。なお、第1の指標のボラティリティを示す値は、既存の手法を適宜採用して算出することができるため、ここでの具体的な説明は省略する。
或いは、信頼度は、第1の指標のボラティリティが所定の閾値未満であるか否かに基づいて設定されてよい。この場合、第1の指標のボラティリティが所定の閾値未満であれば、重み算出部130は、信頼度を「高」に設定し、第1の指標のボラティリティが所定の閾値以上であれば、重み算出部130は、信頼度を「低」に設定するようにしてもよい。また、重み算出部130は、第1の指標のボラティリティに関する所定の閾値を複数設定してもよい。例えば、第1の指標のボラティリティが第1閾値未満であれば、重み算出部130は、信頼度を「高」に設定し、第1の指標のボラティリティが第1閾値以上且つ第2閾値未満であれば、重み算出部130は、信頼度を「中」に設定し、第1の指標のボラティリティが第2閾値以上であれば、重み算出部130は、信頼度を「低」に設定するようにしてもよい。
第1の指標のボラティリティが大きい場合、各要素に大きな差異が生じていることが想定される。このような場合、それらの複数の要素のうち少なくとも1つは、第1の指標を算出するのに適さない要素である可能性が高い。しかるに、第1の指標のボラティリティに応じて信頼度を設定するようにすれば、各要素がクラス分類に与える影響を低減することができる。例えば、信頼度に応じた重みによる重み付けをすることで、第1の指標のボラティリティが小さい要素については、クラス分類に与える影響を大きくすることができる。一方で、第1の指標のボラティリティが大きい要素については、クラス分類に与える影響を小さくすることができる。以上のように、第1の指標のボラティリティに応じて信頼度を設定すれば、適切な重み付けが行われ、系列データを適切に分類することが可能となる。
<第4実施形態>
第4実施形態に係る情報処理システム10について、図9を参照して説明する。なお、第4実施形態は、上述した第1から第3実施形態と比べて一部の構成が異なるものであり、ハードウェア構成、及び上述したシステム全体としての動作については、第1実施形態(図1及び図3参照)と同様であってよい。このため、以下では、上述した第1から第3実施形態と異なる部分について詳しく説明し、他の重複する部分については適宜説明を省略するものとする。
第4実施形態に係る情報処理システム10について、図9を参照して説明する。なお、第4実施形態は、上述した第1から第3実施形態と比べて一部の構成が異なるものであり、ハードウェア構成、及び上述したシステム全体としての動作については、第1実施形態(図1及び図3参照)と同様であってよい。このため、以下では、上述した第1から第3実施形態と異なる部分について詳しく説明し、他の重複する部分については適宜説明を省略するものとする。
(機能的構成)
まず、図9を参照しながら、第4実施形態に係る情報処理システム20の機能的構成について説明する。図9は、第4実施形態に係る情報処理システムの機能的構成を示すブロック図である。なお、図9では、図2で示した各構成要素と同様の要素に同一の符号を付している。
まず、図9を参照しながら、第4実施形態に係る情報処理システム20の機能的構成について説明する。図9は、第4実施形態に係る情報処理システムの機能的構成を示すブロック図である。なお、図9では、図2で示した各構成要素と同様の要素に同一の符号を付している。
図9に示すように、第4実施形態に係る情報処理システム20は、その機能を実現するための処理ブロックとして、取得部50と、第1算出部110と、第2算出部120と、重み算出部130と、分類部60と、信頼度学習部200とを備えている。即ち、第4実施形態に係る情報処理システム20は、第1実施形態の構成(図2参照)に加えて、信頼度学習部200を更に備えて構成されている。なお、信頼度学習部200は、上述したプロセッサ11(図1参照)によって実現されてよい。
信頼度学習部200は、系列データに含まれる各要素の信頼度に関する機械学習を実行可能に構成されている。例えば、信頼度学習部200は、ニューラルネットワークを含んで構成されており、系列データに含まれる各要素の各々の信頼度を決定するモデルを学習により最適化する。信頼度学習部200は、例えば訓練データとして、要素とその信頼度とのペアを利用して機械学習を実行する。信頼度学習部200は、機械学習の結果を用いて、取得部50で取得される各要素の信頼度を決定する。例えば、信頼度学習部200は、取得部50から取得した要素の情報を取得し、学習結果を用いてその要素の信頼度を決定する。信頼度学習部200で決定された信頼度は、例えば重み算出部130に出力され、重みの算出に用いられる。或いは、信頼度学習部200で決定された信頼度は、取得部50で取得された要素に紐付けて第1記憶部112等に記憶されてもよい。あるいは、信頼度学習部200は、要素単独の信頼度に変えて、系列データに含まれる要素間の信頼度を用いることもできる。この場合、要素間の信頼度は、それらの要素が連なる確率の高さを表してもよい。
(技術的効果)
次に、第4実施形態に係る情報処理システム20によって得られる技術的効果について説明する。
次に、第4実施形態に係る情報処理システム20によって得られる技術的効果について説明する。
第4実施形態に係る情報処理システム20では、信頼度学習部200によって系列データに含まれる各要素の信頼度が決定される。よって、系列データに含まれる各要素の信頼度を容易に決定することができ、結果として適切な重みを算出することが可能である。
<第5実施形態>
第5実施形態に係る情報処理システム10について、図10から図12を参照して説明する。なお、第5実施形態は、上述した第1から第4実施形態と比べて一部の構成及び動作が異なるものであり、例えばハードウェア構成については、第1実施形態(図1参照)と同様であってよい。このため、以下では、上述した第1から第4実施形態と異なる部分について詳しく説明し、他の重複する部分については適宜説明を省略するものとする。
第5実施形態に係る情報処理システム10について、図10から図12を参照して説明する。なお、第5実施形態は、上述した第1から第4実施形態と比べて一部の構成及び動作が異なるものであり、例えばハードウェア構成については、第1実施形態(図1参照)と同様であってよい。このため、以下では、上述した第1から第4実施形態と異なる部分について詳しく説明し、他の重複する部分については適宜説明を省略するものとする。
(機能的構成)
まず、図10を参照しながら、第5実施形態に係る情報処理システム10の機能的構成について説明する。図10は、第5実施形態に係る情報処理システムの機能的構成を示すブロック図である。なお、図10では、図2で示した各構成要素と同様の要素に同一の符号を付している。
まず、図10を参照しながら、第5実施形態に係る情報処理システム10の機能的構成について説明する。図10は、第5実施形態に係る情報処理システムの機能的構成を示すブロック図である。なお、図10では、図2で示した各構成要素と同様の要素に同一の符号を付している。
図10に示すように、第5実施形態に係る情報処理システム10は、その機能を実現するための処理ブロックとして、取得部50と、第1算出部110と、第2算出部120と、重み算出部130と、分類部60とを備えている。また、第5実施形態に係る情報処理システム10は、第1実施形態の第1指標算出部111に代えて、尤度比算出部113を備えており、第2指標算出部121に代えて、統合尤度比算出部123を備えている。なお、信尤度比算出部113及び統合尤度比算出部123の各々は、上述したプロセッサ11(図1参照)によって実現されてよい。
尤度比算出部113は、第1の指標として尤度比を算出可能に構成されている。尤度比算出部113は、取得した要素と、過去データに基づいて尤度比を算出する。尤度比は、複数の要素の各々が複数のクラスのうちのあるクラスに属することの尤もらしさを示す値である。以下では、尤度比の具体例を説明する。
系列データを構成するN個の要素を、x1,… ,xNとし、複数のクラスをR,Fとする。すなわち、本例では、簡略化のため、クラスの数が2である2クラス分類であるものとする。ここで、要素xiがクラスRに属する確率について、過去データを考慮せずに算出した結果をp(R|xi)と表記する。また、要素xiがクラスFに属する確率について、過去データを考慮せずに算出した結果をp(F|xi)と表記する。このとき、これらの尤度比は、以下の式(1)で表される。
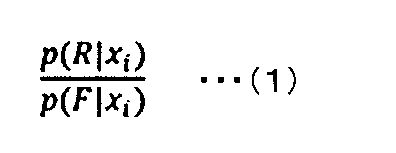
上記式(1)の尤度比は、要素xiがクラスRに属する確率と、要素xiがクラスFに属する確率との尤もらしさの比を示している。例えば、尤度比が1を超えている場合には、p(R|xi)>p(R|xi)であるため、要素xiはクラスFよりもクラスRに分類すればよい。このように、式(1)の尤度比は、入力された要素がクラスRとクラスFのいずれに属するのかを示す指標として機能する。
また、尤度比算出部113は、上述のように複数の要素(即ち、入力された要素と過去データとの関連性)を考慮して算出することができる。この場合、例えば、2つの要素xi,xi-1を考慮して算出された尤度比は、以下の式(2)のように表される。

統合尤度比算出部123は、第2の指標として統合尤度比を算出可能に構成されている。統合尤度比算出部123は、尤度比算出部113で算出された尤度比と、過去の統合尤度比とを用いて統合尤度比を算出する。統合尤度比は、系列データが複数のクラスのうちのあるクラスに属することの尤もらしさを示す値である。以下では、尤度比の具体例を説明する。なお、上述した尤度比の説明と同様に、クラスの数が2である2クラス分類の場合について説明する。
統合尤度比の算出時点において、N個の要素が入力されている場合、このN個の要素は、x1,…,xNと表される。ここで、系列データの全体がクラスRに属する確率をp(x1,…,xN|R)と表記する。また、系列データの全体がクラスFに属する確率をp(x1,…,xN|F)と表記する。この場合、これらの尤度比は以下の式(3)で表される。式(3)を統合尤度比と呼ぶ。
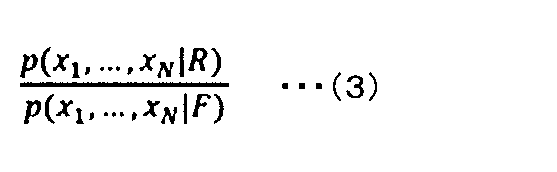
系列データの各要素が独立であることを仮定する場合には、統合尤度比は、以下の式(4)のように1要素ごとの項に分解して算出することができる。
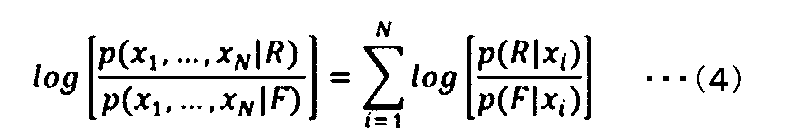
上記式(4)では、計算の簡略化のため尤度比の対数を用いることにより各要素を和に分解しているが、これは必須ではない。なお、以下では、このような対数尤度比に対しても尤度比又は統合尤度比という用語が用いられることがある。また、対数の底の表記は省略されているが、底の値は任意である。
しかしながら、上述したように本実施形態では、2以上の要素を考慮して尤度比及び統合尤度比を算出するため、各要素が独立であるという仮定が成立しないことが多い。したがって、式(4)のように1要素ごとの項に分解することはできず、関係性を考慮する要素の数に応じて異なる計算式により統合尤度比の計算が行われる。
例えば、ある要素とその1つ前の要素の2つの要素を考慮する場合には、以下の式(5)を用いて統合尤度比を算出することができる。

また、本実施形態に係る統合尤度比算出部123は、各要素の信頼度に応じた重みによる重み付けをして統合尤度比を算出する。ここで、重みをδi
1及びδi
2であるとすると、式(5)の右辺の統合尤度比を、式(6)のように表すことができる。

式(6)では、クラスRとクラスFとの尤度比を算出する2クラス分類の場合の例を示しているが、クラスの数は3以上であってもよい。例えば、クラスの数がM個である場合には、M個のクラスのうちのk番目のクラスとk番目以外のすべてのクラスとの間の統合尤度比を算出できるように式(6)を拡張したものを用いることができる。そのような拡張の例としては、以下の式(7)のようにk番目以外のすべてのクラスのうちの最大尤度を用いるものが挙げられる。
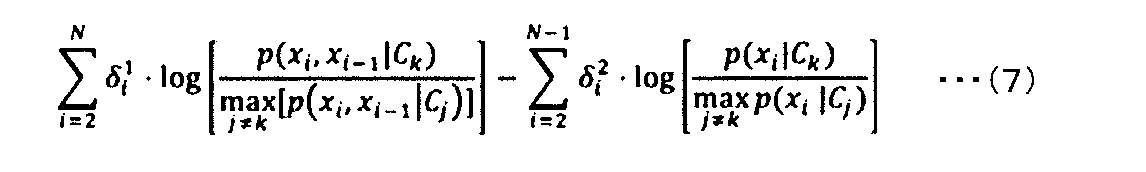
また、別の例としては、以下の式(8)のように、k番目以外のすべてのクラスの尤度の和を用いるものが挙げられる。

なお、クラスの数が3以上である場合における統合尤度比の算出方法はこれらに限られるものではない。また、式(6)から式(8)では2つ要素を考慮する場合について例示しているが、3つ以上の要素を考慮してもよい。
(動作の流れ)
次に、図11を参照しながら、第5実施形態に係る情報処理システム10の動作の流れについて説明する。図11は、第5実施形態に係る情報処理システムの動作の流れを示すフローチャートである。
次に、図11を参照しながら、第5実施形態に係る情報処理システム10の動作の流れについて説明する。図11は、第5実施形態に係る情報処理システムの動作の流れを示すフローチャートである。
図11に示すように、第5実施形態に係る情報処理システム10は、取得部50が、系列データから1つの要素を取得する(ステップS21)。取得部50は、取得した系列データの要素を、第1算出部110に出力する。
続いて、第1算出部110における尤度比標算出部113が、第1記憶部112から過去データを読み出す(ステップS22)。過去データは、例えば取得部50で今回取得された要素の1つ前に取得された要素の第1指標算出部111での処理結果(言い換えれば、1つ前の要素に対して算出された尤度比)であってよい。或いは、過去データは、取得で取得された要素の1つ前に取得された要素そのものであってもよい。
続いて、尤度比算出部113は、取得部50で取得された要素と、第1記憶部112から読みだした過去データに基づいて、新たな尤度比(即ち、取得部50で今回取得された要素に対する尤度比)を算出する(ステップS23)。尤度比算出部113は、算出した尤度比を、第2算出部120に出力する。尤度比算出部113は、算出した尤度比を、第1記憶部112に記憶してもよい。
続いて、第2算出部120における統合尤度比算出部123が、第2記憶部122から過去の統合尤度比を読み出す(ステップS24)。過去の統合尤度比は、例えば取得部50で今回取得された要素の1つ前に取得された要素についての、統合尤度比算出部123での処理結果(言い換えれば、1つ前の要素に対して算出された統合尤度比)であってよい。
続いて、統合尤度比算出部123は、尤度比算出部113で算出された尤度比と、第2記憶部122から読みだした過去の統合尤度比に基づいて、新たな統合尤度比(即ち、取得部50で今回取得された要素に対する統合尤度比)を算出する(ステップS25)。ここで特に、統合尤度比算出部123は、重み算出部130で算出された重みによる重み付けをして、新たな統合尤度比を算出する(上述した式(6)等を参照)。統合尤度比算出部123は、算出した統合尤度比を、分類部60に出力する。統合尤度比算出部123は、算出した統合尤度比を、第2記憶部122に記憶してもよい。
続いて、分類部60が、統合尤度比算出部123で算出された統合尤度比が閾値を超えるクラスがあるか否かを判定する(ステップS26)。ここでの閾値は、系列データが複数のクラスのいずれに属するか判定するための閾値として予め設定されている。このため、閾値は複数のクラスの各々に設定されている。以下では、具体的な例を挙げてより説明を進める。
分類部60の分類処理は、クラスR又はクラスFへの2クラス分類であるものとし、クラスRとクラスFの判定に用いる閾値をそれぞれT1、T2とする。また、統合尤度比をLとする。この場合、L<T1である場合には(ステップS26:YES)、分類部60は、系列データをクラスRに分類する(ステップS27)。一方、L>T2である場合には(ステップS26:YES)、分類部60は、系列データをクラスFに分類する(ステップS27)。このようにすれば、統合尤度比と各クラスの閾値とを比較することで、系列データがいずれのクラスに属するかを適切に判定することができる。また、T1≦L且つL≦T2である場合には(ステップS26:NO)、分類部140は、系列データを分類可能でないと判定し、取得部50は次の要素を取得する。このようにすれば、更に取得される要素を考慮して統合尤度比を算出することができるため、統合尤度比がいずれかのクラスの閾値を超えるまで(即ち、系列データをいずれかのクラスに分類できるまで)、統合尤度比を更新しながら処理を続行することができる。
なお、M種類のクラスを分類する場合には、M個の閾値を準備しておき、M個の統合尤度比とM個の閾値とをそれぞれ比較することにより分類処理を行うことができる。このとき、分類部60は、統合尤度比が最初に閾値を超えたクラスに系列データを分類すればよい。統合尤度比がいずれの閾値も超えない場合には、分類部60は、系列データを分類可能でないと判定し、取得部50は次の要素を取得する。
上述の分類手法は例示であり、これに限られない。例えば、入力された要素数が所定値(最大要素数)よりも多い場合には、統合尤度比が閾値を超えているクラスが存在しない場合であっても系列データを強制的にいずれかのクラスに分類して処理を終了するように手順を変形してもよい。これにより、計算時間が長くなりすぎることを防ぐことができる。この例では、いずれかのクラスに確実に分類されるように判定基準を相互排他的なものとすることが望ましい。
(具体的な分類例)
次に、図12を参照しながら、第5実施形態に係る情報処理システム10による具体的な分類例について説明する。図12は、第5実施形態に係る情報処理システムによるクラス分類の一例を示すグラフである。
次に、図12を参照しながら、第5実施形態に係る情報処理システム10による具体的な分類例について説明する。図12は、第5実施形態に係る情報処理システムによるクラス分類の一例を示すグラフである。
図12に示すように、第5実施形態に係る情報処理システム10が、本物の顔と、偽物の顔とを分類するものであるとする。即ち、第5実施形態に係る情報処理システム10が、系列データとして入力される顔情報を、本物の顔のクラス又は偽物の顔のクラスに分類するものであるとする。
まず、線Aで示す統合尤度比は、比較的早い段階で本物の顔に対応する閾値+Tに到達している。よって、線Aに対応する系列データは、判定が容易な本物の顔であると判断できる。また、線Bで示す統合尤度比は、線Aで示す統合尤度比と比べると少し遅い段階で本物の顔に対応する閾値+Tに到達している。よって、線Bに対応する系列データは、判定が難しい本物の顔であると判断できる。一方、線Cで示す統合尤度比は、最終的に偽物の顔に対応する閾値-Tに到達している。よって、線Cに対応する系列データは、偽物の顔であると判断できる。なお、線Dで示す統合尤度比は、本物の顔に対応する閾値+T、及び偽物の顔に対応する閾値-Tのいずれにも到達することなくタイムアウトとなっている(即ち、処理開始から所定時間が経過している)。このような系列データについては、いずれのクラスにも分類することなく処理を終了してもよい。この場合、第5実施形態に係る情報処理システム10は、判定不能であることを示す情報を出力するようにしてもよい。
なお、上述した閾値+Tと閾値-Tとは、互いに異なる値であってよい。即ち、「+T」及び「-T」は、その絶対値が互いに異なる値として設定されてもよい。例えば、閾値+Tを閾値-Tよりも大きく設定すると、本物の顔であると判定され易くする一方で、偽物の顔であると判定され難くすることができる。逆に、閾値+Tを閾値-Tよりも小さく設定すると、本物の顔であると判定され難くする一方で、偽物の顔であると判定され易くすることができる。
(技術的効果)
次に、第5実施形態に係る情報処理システム10によって得られる技術的効果について説明する。
次に、第5実施形態に係る情報処理システム10によって得られる技術的効果について説明する。
第5実施形態に係る情報処理システム10では、系列データに含まれる要素から尤度比、及び統合尤度比が算出され、系列データが複数のクラスのいずれかに分類される。尤度比は、すでに説明したように、複数の要素の各々が複数のクラスのうちのあるクラスに属することの尤もらしさを示す値である。よって、尤度比を第1の指標として用いれば、適切に第2の指標(即ち、統合尤度比)を算出することができる。また、統合尤度比は、系列データが複数のクラスのうちのあるクラスに属することの尤もらしさを示す値である。よって、統合尤度比を第2の指標として用いれば、適切に系列データを複数のクラスに分類することができる。
なお、統合尤度比を用いる場合、その一部に適切でないデータが含まれていることで、予期せぬ不具合が発生し得る。具体的には、系列全体の要素を考慮するが故に、一部の適切なデータについても考慮され、その結果として分類精度悪化や、分類時間遅延等の問題が生ずるおそれがある。しかるに本実施形態では、各要素に対して重み付けされた状態で統合尤度比が算出される。よって、上記のような不具合の発生を効果的に抑制することが可能である。
<第6実施形態>
第6実施形態に係る個人識別システムについて、図13を参照して説明する。なお、第6実施形態は、上述した第1から第5実施形態に係る情報処理システムの適用例を説明するものであり、例えばハードウェア構成については、第1実施形態(図1参照)と同様であってよい。このため、以下では、上述した第1から第5実施形態と異なる部分について詳しく説明し、他の重複する部分については適宜説明を省略するものとする。
第6実施形態に係る個人識別システムについて、図13を参照して説明する。なお、第6実施形態は、上述した第1から第5実施形態に係る情報処理システムの適用例を説明するものであり、例えばハードウェア構成については、第1実施形態(図1参照)と同様であってよい。このため、以下では、上述した第1から第5実施形態と異なる部分について詳しく説明し、他の重複する部分については適宜説明を省略するものとする。
(機能的構成)
まず、図13を参照しながら、第6実施形態に係る個人識別システム300の機能的構成について説明する。図13は、第6実施形態に係る個人識別システムの機能的構成を示すブロック図である。
まず、図13を参照しながら、第6実施形態に係る個人識別システム300の機能的構成について説明する。図13は、第6実施形態に係る個人識別システムの機能的構成を示すブロック図である。
図13において、第6実施形態に係る個人識別システム300は、例えば、顔画像、指紋画像、虹彩画像等の識別対象者の生体情報を予め登録されている生体情報と照合することにより、個人を識別するシステムとして構成されている。個人識別システム300は、生体情報を取得するための装置(例えば、カメラ等)を備え、スタンドアローンで動作するものであってもよく、個人識別システム内の他の装置から生体情報を取得して個人の識別を行うものであってもよい。また、個人識別システム300は互いに通信接続された複数の装置により構成されていてもよい。
個人識別システム300は、例えば、顔認証ゲート用の認証装置として構成されてもよい。或いは、個人識別装置300は、インテリジェントカメラとして構成されてもよい。ここでのインテリジェントカメラとは、内部に解析機能を備えるIP(Internet Protocol)カメラ又はネットワークカメラであり、スマートカメラと呼ばれることもある。
第6実施形態に係る個人識別システム300は、その機能を実現するための処理ブロックとして、分類部301と、生体情報取得部302と、生体情報記憶部103を備えている。
分類部301は、上述した各実施形態の情報処理システム10を含んで構成される。分類装置301には、第1実施形態の情報処理システム100が用いられる。分類部310は、生体情報を要素とする系列データを取得する。分類部301は、生体情報記憶部303に記憶された情報を参照しつつ、入力された系列データを予め定められた複数のクラスのうちのいずれかに分類する。ここでの複数のクラスは、例えば入力された系列データが登録された人物のいずれかと合致したことを示すクラスであってよい。或いは、複数のクラスは、入力された系列データになりすましが存在することを示すクラスと、入力された系列データになりすましが存在しないことを示すクラスとを含んでいてもよい。
生体情報取得部302は、生体情報を取得する装置である。生体情報取得部302は、例えば動画を撮影可能なデジタルカメラを含んで構成されてよい。なお、生体情報の識別において、生体情報取得部302で取得された画像等から照合用の特徴量を抽出する場合がある。この特徴量抽出処理は、分類部301で行われてもよく、生体情報取得部302で生体情報取得時に行われてもよく、その他の装置により行われてもよい。以下では、生体情報取得部302で取得された画像等そのものと、これから抽出された特徴量とをまとめて生体情報と称することがある。
生体情報記憶部303は、個人識別システム300で用いる生体情報等の各情報を記録可能に構成されている。例えば、生体情報取得部302で取得された生体情報は、生体情報記憶部303に記憶されてよい。生体情報記憶部303に記憶されている情報は、分類部301によって適宜読み出し可能な状態で記憶されていてもよい。また、分類部301の分類結果に関する情報も、生体情報記憶部303に記憶されてよい。
(動作例)
次に、第6実施形態に係る個人識別システム300の動作例について説明する。以下では、個人識別システム300が、なりすまし検出を行う例を説明する。
次に、第6実施形態に係る個人識別システム300の動作例について説明する。以下では、個人識別システム300が、なりすまし検出を行う例を説明する。
顔認証等の生体認証におけるなりすまし手法の1つとして、本人の顔写真、顔模型等の非生体を用いる手法が知られている。このようななりすましを検出する手法として、複数の画像を撮影し、複数の画像間の差異が少ない場合に生体ではないと判定する手法がある。本実施形態の分類装置301は、系列データとして認証対象者の時系列画像を入力し、画像間の差異を特徴量として、系列データをなりすましの有無を示すクラス分類を行う。これにより、系列データがどのクラスに分類されたかによって、なりすまし検出が可能である。この手法では、入力される時系列データに含まれる画像の時間変化が非常に少なく、画像間の相関が強い場合が多い。そのため、なりすまし検出の分類を行う場合においては、要素間の関連性が強い系列データに対して分類精度が劣化しにくい上述した第1から第5実施形態の情報処理システム100の分類処理を用いることが効果的である。
<第7実施形態>
第7実施形態に係る情報処理システム10について、図14を参照して説明する。なお、第7実施形態は、上述した第1から第5実施形態に係る情報処理システムの基本的な構成を示すものであり、その構成や動作については、すでに説明した各実施形態と同様であってよい。このため、以下では、上述した第1から第5実施形態と異なる部分について詳しく説明し、他の重複する部分については適宜説明を省略するものとする。
第7実施形態に係る情報処理システム10について、図14を参照して説明する。なお、第7実施形態は、上述した第1から第5実施形態に係る情報処理システムの基本的な構成を示すものであり、その構成や動作については、すでに説明した各実施形態と同様であってよい。このため、以下では、上述した第1から第5実施形態と異なる部分について詳しく説明し、他の重複する部分については適宜説明を省略するものとする。
(機能的構成)
まず、図14を参照しながら、第7実施形態に係る情報処理システム10の機能的構成について説明する。図14は、第7実施形態に係る情報処理システムの機能的構成を示すブロック図である。なお、図14では、図2で示した各構成要素と同様の要素に同一の符号を付している。
まず、図14を参照しながら、第7実施形態に係る情報処理システム10の機能的構成について説明する。図14は、第7実施形態に係る情報処理システムの機能的構成を示すブロック図である。なお、図14では、図2で示した各構成要素と同様の要素に同一の符号を付している。
図14に示すように、第7実施形態に係る情報処理システム10は、その機能を実現するための処理ブロックとして、取得部50と、第1算出部110と、第2算出部120と、重み算出部130と、分類部60とを備えている。
取得部50は、系列データに含まれる複数の要素を逐次的に取得可能に構成されている。第1算出部110は、系列データに含まれる複数の要素の各々について、複数のクラスのいずれに属するかを示す第1の指標を算出可能に構成されている。重み算出部130は、第1の指標の算出に係る信頼度に応じた重みを算出可能に構成されている。第2算出部120は、重み算出部130で算出した重みにより重み付けした第1の指標に基づいて、系列データが複数のクラスのいずれに属するかを示す第2の指標を算出可能に構成されている。分類部60は、第2算出部120で算出された第2の指標に基づいて、系列データを複数のクラスのいずれかに分類可能に構成されている。
(技術的効果)
次に、第7実施形態に係る情報処理システム10によって得られる技術的効果について説明する。
次に、第7実施形態に係る情報処理システム10によって得られる技術的効果について説明する。
第7実施形態に係る情報処理システム10では、系列データに含まれる要素から算出される第1の指標及び第2の指標を用いて、系列データが複数のクラスのいずれかに分類される。第7実施形態では特に、クラス分類する際に用いられる第2の指標が、各要素の信頼度に応じて算出された重みによって重み付けされている。この結果、重み付けを行わない場合と比較して、より適切に系列データを分類することが可能となる。
<付記>
以上説明した実施形態に関して、更に以下の付記のようにも記載されうるが、以下には限られない。
以上説明した実施形態に関して、更に以下の付記のようにも記載されうるが、以下には限られない。
(付記1)
付記1に記載の情報処理システムは、系列データに含まれる複数の要素を逐次的に取得する取得手段と、前記複数の要素の各々について、複数のクラスのいずれに属するかを示す第1の指標を算出する第1算出手段と、前記複数の要素の各々について、前記第1の指標の算出に係る信頼度に応じた重みを算出する重み算出手段と、前記重みにより重み付けした前記第1の指標に基づいて、前記系列データが前記複数のクラスのいずれに属するかを示す第2の指標を算出する第2算出手段と、前記第2の指標に基づいて、前記系列データを前記複数のクラスのいずれかに分類する分類手段とを備えることを特徴とする情報処理システムである。
付記1に記載の情報処理システムは、系列データに含まれる複数の要素を逐次的に取得する取得手段と、前記複数の要素の各々について、複数のクラスのいずれに属するかを示す第1の指標を算出する第1算出手段と、前記複数の要素の各々について、前記第1の指標の算出に係る信頼度に応じた重みを算出する重み算出手段と、前記重みにより重み付けした前記第1の指標に基づいて、前記系列データが前記複数のクラスのいずれに属するかを示す第2の指標を算出する第2算出手段と、前記第2の指標に基づいて、前記系列データを前記複数のクラスのいずれかに分類する分類手段とを備えることを特徴とする情報処理システムである。
(付記2)
付記2に記載の情報処理システムは、前記系列データは画像データであり、前記重み算出手段は、前記画像データの鮮明度の高さ、前記画像データを取得した撮像手段と撮像対象との間の距離の近さ、又は前記画像データを取得したタイミング、を前記信頼度として前記重みを算出することを特徴とする付記1に記載の情報処理システムである。
付記2に記載の情報処理システムは、前記系列データは画像データであり、前記重み算出手段は、前記画像データの鮮明度の高さ、前記画像データを取得した撮像手段と撮像対象との間の距離の近さ、又は前記画像データを取得したタイミング、を前記信頼度として前記重みを算出することを特徴とする付記1に記載の情報処理システムである。
(付記3)
付記3に記載の情報処理システムは、前記重み算出手段は、前記複数の要素のうち、連続して取得される2つの要素において算出される前記第1の指標間の差分の小ささ、又は連続して取得される所定数の要素において算出される第1の指標間のボラティリティの小ささ、を前記信頼度として重みを算出することを特徴とする付記1に記載の情報処理システムである。
付記3に記載の情報処理システムは、前記重み算出手段は、前記複数の要素のうち、連続して取得される2つの要素において算出される前記第1の指標間の差分の小ささ、又は連続して取得される所定数の要素において算出される第1の指標間のボラティリティの小ささ、を前記信頼度として重みを算出することを特徴とする付記1に記載の情報処理システムである。
(付記4)
付記4に記載の情報処理システムは、前記信頼度が紐付けられた訓練データを用いて前記信頼度に関する機械学習を実行し、前記機械学習の結果に基づいて前記複数の要素の各々の前記信頼度を決定する学習手段を更に備えることを特徴とする付記1から3のいずれか一項に記載の情報処理システムである。
付記4に記載の情報処理システムは、前記信頼度が紐付けられた訓練データを用いて前記信頼度に関する機械学習を実行し、前記機械学習の結果に基づいて前記複数の要素の各々の前記信頼度を決定する学習手段を更に備えることを特徴とする付記1から3のいずれか一項に記載の情報処理システムである。
(付記5)
付記5に記載の情報処理システムは、前記第1の指標は、前記複数の要素の各々が前記複数のクラスのうちのあるクラスに属することの尤もらしさを示す尤度比を含むことを特徴とする付記1から4のいずれか一項に記載の情報処理システムである。
付記5に記載の情報処理システムは、前記第1の指標は、前記複数の要素の各々が前記複数のクラスのうちのあるクラスに属することの尤もらしさを示す尤度比を含むことを特徴とする付記1から4のいずれか一項に記載の情報処理システムである。
(付記6)
付記6に記載の情報処理システムは、前記第2の指標は、前記系列データが前記複数のクラスのうちのあるクラスに属することの尤もらしさを示す尤度比を含むことを特徴とする付記1から5のいずれか一項に記載の情報処理システムである。
付記6に記載の情報処理システムは、前記第2の指標は、前記系列データが前記複数のクラスのうちのあるクラスに属することの尤もらしさを示す尤度比を含むことを特徴とする付記1から5のいずれか一項に記載の情報処理システムである。
(付記7)
付記7に記載の情報処理システムは、前記分類手段は、前記第2の指標が所定の閾値を超えているクラスが存在する場合に、前記系列データを前記第2の指標が前記所定の閾値を超えているクラスに分類することを特徴とする付記1から6のいずれか一項に記載の情報処理システムである。
付記7に記載の情報処理システムは、前記分類手段は、前記第2の指標が所定の閾値を超えているクラスが存在する場合に、前記系列データを前記第2の指標が前記所定の閾値を超えているクラスに分類することを特徴とする付記1から6のいずれか一項に記載の情報処理システムである。
(付記8)
付記8に記載の情報処理システムは、前記第2の指標が所定の閾値を超えているクラスが存在しない場合に、前記分類手段は、前記系列データをいずれのクラスにも分類せず、前記取得手段は、更に要素を取得することを特徴とする付記1から7のいずれか一項に記載の情報処理システムである。
付記8に記載の情報処理システムは、前記第2の指標が所定の閾値を超えているクラスが存在しない場合に、前記分類手段は、前記系列データをいずれのクラスにも分類せず、前記取得手段は、更に要素を取得することを特徴とする付記1から7のいずれか一項に記載の情報処理システムである。
(付記9)
付記9に記載の情報処理方法は、系列データに含まれる複数の要素を逐次的に取得し、前記複数の要素の各々について、複数のクラスのいずれに属するかを示す第1の指標を算出し、前記複数の要素の各々について、前記第1の指標の算出に係る信頼度に応じた重みを算し、前記重みにより重み付けした前記第1の指標に基づいて、前記系列データが前記複数のクラスのいずれに属するかを示す第2の指標を算出し、前記第2の指標に基づいて、前記系列データを前記複数のクラスのいずれかに分類することを特徴とする情報処理方法である。
付記9に記載の情報処理方法は、系列データに含まれる複数の要素を逐次的に取得し、前記複数の要素の各々について、複数のクラスのいずれに属するかを示す第1の指標を算出し、前記複数の要素の各々について、前記第1の指標の算出に係る信頼度に応じた重みを算し、前記重みにより重み付けした前記第1の指標に基づいて、前記系列データが前記複数のクラスのいずれに属するかを示す第2の指標を算出し、前記第2の指標に基づいて、前記系列データを前記複数のクラスのいずれかに分類することを特徴とする情報処理方法である。
(付記10)
付記10に記載のコンピュータプログラムは、系列データに含まれる複数の要素を逐次的に取得し、前記複数の要素の各々について、複数のクラスのいずれに属するかを示す第1の指標を算出し、前記複数の要素の各々について、前記第1の指標の算出に係る信頼度に応じた重みを算し、前記重みにより重み付けした前記第1の指標に基づいて、前記系列データが前記複数のクラスのいずれに属するかを示す第2の指標を算出し、前記第2の指標に基づいて、前記系列データを前記複数のクラスのいずれかに分類するようにコンピュータを動作させることを特徴とするコンピュータプログラムである。
付記10に記載のコンピュータプログラムは、系列データに含まれる複数の要素を逐次的に取得し、前記複数の要素の各々について、複数のクラスのいずれに属するかを示す第1の指標を算出し、前記複数の要素の各々について、前記第1の指標の算出に係る信頼度に応じた重みを算し、前記重みにより重み付けした前記第1の指標に基づいて、前記系列データが前記複数のクラスのいずれに属するかを示す第2の指標を算出し、前記第2の指標に基づいて、前記系列データを前記複数のクラスのいずれかに分類するようにコンピュータを動作させることを特徴とするコンピュータプログラムである。
(付記11)
付記11に記載の記録媒体は、付記10に記載のコンピュータプログラムが記録されていることを特徴とする記録媒体である。
付記11に記載の記録媒体は、付記10に記載のコンピュータプログラムが記録されていることを特徴とする記録媒体である。
この開示は、請求の範囲及び明細書全体から読み取ることのできる発明の要旨又は思想に反しない範囲で適宜変更可能であり、そのような変更を伴う情報処理システム、情報処理方法、及びコンピュータプログラムもまたこの開示の技術思想に含まれる。
10,20 情報処理システム
11 プロセッサ
50 取得部
110 第1算出部
111 第1指標算出部
112 第1記憶部
113 尤度比算出部
120 第2算出部
121 第2指標算出部
122 第2記憶部
123 統合尤度比算出部
130 重み算出部
200 信頼度学習部
300 個人識別システム
301 分類装置
302 生体情報取得部
303 生体情報記憶部
11 プロセッサ
50 取得部
110 第1算出部
111 第1指標算出部
112 第1記憶部
113 尤度比算出部
120 第2算出部
121 第2指標算出部
122 第2記憶部
123 統合尤度比算出部
130 重み算出部
200 信頼度学習部
300 個人識別システム
301 分類装置
302 生体情報取得部
303 生体情報記憶部
Claims (10)
- 系列データに含まれる複数の要素を逐次的に取得する取得手段と、
前記複数の要素の各々について、複数のクラスのいずれに属するかを示す第1の指標を算出する第1算出手段と、
前記複数の要素の各々について、前記第1の指標の算出に係る信頼度に応じた重みを算出する重み算出手段と、
前記重みにより重み付けした前記第1の指標に基づいて、前記系列データが前記複数のクラスのいずれに属するかを示す第2の指標を算出する第2算出手段と、
前記第2の指標に基づいて、前記系列データを前記複数のクラスのいずれかに分類する分類手段と
を備えることを特徴とする情報処理システム。 - 前記系列データは画像データであり、
前記重み算出手段は、前記画像データの鮮明度の高さ、前記画像データを取得した撮像手段と撮像対象との間の距離の近さ、又は前記画像データを取得したタイミング、を前記信頼度として前記重みを算出する
ことを特徴とする請求項1に記載の情報処理システム。 - 前記重み算出手段は、前記複数の要素のうち、連続して取得される2つの要素において算出される前記第1の指標間の差分の小ささ、又は連続して取得される所定数の要素において算出される第1の指標間のボラティリティの小ささ、を前記信頼度として重みを算出することを特徴とする請求項1に記載の情報処理システム。
- 前記信頼度が紐付けられた訓練データを用いて前記信頼度に関する機械学習を実行し、前記機械学習の結果に基づいて前記複数の要素の各々の前記信頼度を決定する学習手段を更に備えることを特徴とする請求項1から4のいずれか一項に記載の情報処理システム。
- 前記第1の指標は、前記複数の要素の各々が前記複数のクラスのうちのあるクラスに属することの尤もらしさを示す尤度比を含むことを特徴とする請求項1から4のいずれか一項に記載の情報処理システム。
- 前記第2の指標は、前記系列データが前記複数のクラスのうちのあるクラスに属することの尤もらしさを示す尤度比を含むことを特徴とする請求項1から5のいずれか一項に記載の情報処理システム。
- 前記分類手段は、前記第2の指標が所定の閾値を超えているクラスが存在する場合に、前記系列データを前記第2の指標が前記所定の閾値を超えているクラスに分類することを特徴とする請求項1から6のいずれか一項に記載の情報処理システム。
- 前記第2の指標が所定の閾値を超えているクラスが存在しない場合に、
前記分類手段は、前記系列データをいずれのクラスにも分類せず、
前記取得手段は、更に要素を取得する
ことを特徴とする請求項1から7のいずれか一項に記載の情報処理システム。 - 系列データに含まれる複数の要素を逐次的に取得し、
前記複数の要素の各々について、複数のクラスのいずれに属するかを示す第1の指標を算出し、
前記複数の要素の各々について、前記第1の指標の算出に係る信頼度に応じた重みを算し、
前記重みにより重み付けした前記第1の指標に基づいて、前記系列データが前記複数のクラスのいずれに属するかを示す第2の指標を算出し、
前記第2の指標に基づいて、前記系列データを前記複数のクラスのいずれかに分類する
ことを特徴とする情報処理方法。 - 系列データに含まれる複数の要素を逐次的に取得し、
前記複数の要素の各々について、複数のクラスのいずれに属するかを示す第1の指標を算出し、
前記複数の要素の各々について、前記第1の指標の算出に係る信頼度に応じた重みを算し、
前記重みにより重み付けした前記第1の指標に基づいて、前記系列データが前記複数のクラスのいずれに属するかを示す第2の指標を算出し、
前記第2の指標に基づいて、前記系列データを前記複数のクラスのいずれかに分類する
ようにコンピュータを動作させることを特徴とするコンピュータプログラム。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US17/640,183 US12087035B2 (en) | 2020-09-03 | 2020-09-03 | Information processing system, information processing method, and computer program |
| EP20952441.2A EP4209932A4 (en) | 2020-09-03 | 2020-09-03 | INFORMATION PROCESSING SYSTEM, INFORMATION PROCESSING METHOD AND COMPUTER PROGRAM |
| PCT/JP2020/033474 WO2022049704A1 (ja) | 2020-09-03 | 2020-09-03 | 情報処理システム、情報処理方法、及びコンピュータプログラム |
| JP2022546802A JP7509212B2 (ja) | 2020-09-03 | 2020-09-03 | 情報処理システム、情報処理方法、及びコンピュータプログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/033474 WO2022049704A1 (ja) | 2020-09-03 | 2020-09-03 | 情報処理システム、情報処理方法、及びコンピュータプログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022049704A1 true WO2022049704A1 (ja) | 2022-03-10 |
Family
ID=80491903
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/033474 WO2022049704A1 (ja) | 2020-09-03 | 2020-09-03 | 情報処理システム、情報処理方法、及びコンピュータプログラム |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US12087035B2 (ja) |
| EP (1) | EP4209932A4 (ja) |
| JP (1) | JP7509212B2 (ja) |
| WO (1) | WO2022049704A1 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024189833A1 (ja) * | 2023-03-15 | 2024-09-19 | 日本電気株式会社 | 情報処理装置、情報処理方法、及び情報処理プログラム |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11947633B2 (en) * | 2020-11-30 | 2024-04-02 | Yahoo Assets Llc | Oversampling for imbalanced test data |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5061382B2 (ja) | 2008-03-31 | 2012-10-31 | Kddi株式会社 | 時系列データの識別装置および動画像への人物メタ情報付与装置 |
| JP2017040616A (ja) | 2015-08-21 | 2017-02-23 | 株式会社東芝 | 目標検出装置、目標検出方法及び目標検出プログラム |
| JP2017156148A (ja) * | 2016-02-29 | 2017-09-07 | 株式会社東芝 | 信号検出装置、信号検出方法及び信号検出プログラム |
Family Cites Families (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7444325B2 (en) * | 2005-01-14 | 2008-10-28 | Im2, Inc. | Method and system for information extraction |
| JP5787845B2 (ja) * | 2012-08-24 | 2015-09-30 | 株式会社東芝 | 画像認識装置、方法、及びプログラム |
| US20170109448A1 (en) * | 2015-10-18 | 2017-04-20 | James Joseph Adamy | System and method for enhanced user matching based on multiple data sources |
| US10452935B2 (en) * | 2015-10-30 | 2019-10-22 | Microsoft Technology Licensing, Llc | Spoofed face detection |
| US10147200B2 (en) | 2017-03-21 | 2018-12-04 | Axis Ab | Quality measurement weighting of image objects |
| WO2020058931A1 (en) * | 2018-09-20 | 2020-03-26 | Aivf Ltd | Image feature detection |
| US11475358B2 (en) * | 2019-07-31 | 2022-10-18 | GE Precision Healthcare LLC | Annotation pipeline for machine learning algorithm training and optimization |
| JP2021051573A (ja) * | 2019-09-25 | 2021-04-01 | キヤノン株式会社 | 画像処理装置、および画像処理装置の制御方法 |
| KR20210087792A (ko) * | 2020-01-03 | 2021-07-13 | 엘지전자 주식회사 | 사용자 인증 |
| JP7354063B2 (ja) * | 2020-05-14 | 2023-10-02 | 株式会社東芝 | 分類システム、プログラム及び学習システム |
-
2020
- 2020-09-03 EP EP20952441.2A patent/EP4209932A4/en active Pending
- 2020-09-03 JP JP2022546802A patent/JP7509212B2/ja active Active
- 2020-09-03 US US17/640,183 patent/US12087035B2/en active Active
- 2020-09-03 WO PCT/JP2020/033474 patent/WO2022049704A1/ja unknown
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5061382B2 (ja) | 2008-03-31 | 2012-10-31 | Kddi株式会社 | 時系列データの識別装置および動画像への人物メタ情報付与装置 |
| JP2017040616A (ja) | 2015-08-21 | 2017-02-23 | 株式会社東芝 | 目標検出装置、目標検出方法及び目標検出プログラム |
| JP2017156148A (ja) * | 2016-02-29 | 2017-09-07 | 株式会社東芝 | 信号検出装置、信号検出方法及び信号検出プログラム |
Non-Patent Citations (2)
| Title |
|---|
| AKINORI F. EBIHARA; TAIKI MIYAGAWA; KAZUYUKI SAKURAI; HITOSHI IMAOKA: "Sequential Density Ratio Estimation for Simultaneous Optimization of Speed and Accuracy", ARXIV.ORG, CORNELL UNIVERSITY LIBRARY, 201 OLIN LIBRARY CORNELL UNIVERSITY ITHACA, NY 14853, 6 February 2021 (2021-02-06), 201 Olin Library Cornell University Ithaca, NY 14853 , XP081875509 * |
| See also references of EP4209932A4 |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024189833A1 (ja) * | 2023-03-15 | 2024-09-19 | 日本電気株式会社 | 情報処理装置、情報処理方法、及び情報処理プログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| US20220415018A1 (en) | 2022-12-29 |
| EP4209932A4 (en) | 2023-09-13 |
| JP7509212B2 (ja) | 2024-07-02 |
| US12087035B2 (en) | 2024-09-10 |
| EP4209932A1 (en) | 2023-07-12 |
| JPWO2022049704A1 (ja) | 2022-03-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN106557726B (zh) | 一种带静默式活体检测的人脸身份认证系统及其方法 | |
| CN107423690B (zh) | 一种人脸识别方法及装置 | |
| JP5010905B2 (ja) | 顔認証装置 | |
| CN106557723B (zh) | 一种带交互式活体检测的人脸身份认证系统及其方法 | |
| JP6204199B2 (ja) | 画像品質の評価 | |
| JP6482195B2 (ja) | 画像認識装置、画像認識方法及びプログラム | |
| US6661907B2 (en) | Face detection in digital images | |
| CN110348270B (zh) | 影像物件辨识方法与影像物件辨识系统 | |
| US7925093B2 (en) | Image recognition apparatus | |
| JP4479478B2 (ja) | パターン認識方法および装置 | |
| JP4682820B2 (ja) | オブジェクト追跡装置及びオブジェクト追跡方法、並びにプログラム | |
| JP2010520542A (ja) | 分類器チェーンを用いた照明検出 | |
| JP2004348674A (ja) | 領域検出方法及びその装置 | |
| JP2019057815A (ja) | 監視システム | |
| JP2014093023A (ja) | 物体検出装置、物体検出方法及びプログラム | |
| KR101330636B1 (ko) | 얼굴시점 결정장치 및 방법과 이를 채용하는 얼굴검출장치및 방법 | |
| WO2011092865A1 (ja) | 物体検出装置及び物体検出方法 | |
| WO2022049704A1 (ja) | 情報処理システム、情報処理方法、及びコンピュータプログラム | |
| JP2021516824A (ja) | 群集レベル推定のための方法、システム及びプログラム | |
| JP2021516825A (ja) | 群集推定手法の統合及び自動切り替えのための方法、システム及びプログラム | |
| US20120169860A1 (en) | Method for detection of a body part gesture to initiate a web application | |
| JP4708835B2 (ja) | 顔検出装置、顔検出方法、及び顔検出プログラム | |
| JP2011128916A (ja) | オブジェクト検出装置および方法並びにプログラム | |
| Guha | A report on automatic face recognition: Traditional to modern deep learning techniques | |
| Borhade et al. | Advanced driver assistance system |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20952441 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022546802 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2020952441 Country of ref document: EP Effective date: 20230403 |