WO2022049681A1 - 相関索引構築装置、相関テーブル探索装置、方法およびプログラム - Google Patents
相関索引構築装置、相関テーブル探索装置、方法およびプログラム Download PDFInfo
- Publication number
- WO2022049681A1 WO2022049681A1 PCT/JP2020/033309 JP2020033309W WO2022049681A1 WO 2022049681 A1 WO2022049681 A1 WO 2022049681A1 JP 2020033309 W JP2020033309 W JP 2020033309W WO 2022049681 A1 WO2022049681 A1 WO 2022049681A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- correlation
- column
- index
- size
- search
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images














Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/22—Indexing; Data structures therefor; Storage structures
- G06F16/2282—Tablespace storage structures; Management thereof
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2458—Special types of queries, e.g. statistical queries, fuzzy queries or distributed queries
- G06F16/2465—Query processing support for facilitating data mining operations in structured databases
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/22—Indexing; Data structures therefor; Storage structures
- G06F16/221—Column-oriented storage; Management thereof
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/22—Indexing; Data structures therefor; Storage structures
- G06F16/2228—Indexing structures
- G06F16/2237—Vectors, bitmaps or matrices
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/211—Selection of the most significant subset of features
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/22—Matching criteria, e.g. proximity measures
Definitions
- the present invention relates to a correlation table search device for searching a table containing correlated data, a correlation table search method and a correlation table search program, and a correlation index construction device, a correlation index construction device method, and a correlation index construction device for constructing an index used for the search. Regarding the correlation index construction program.
- Patent Document 1 describes a method of joining two tables.
- a joinable row pair between two tables is determined, and a conversion model is generated from the determined joinable row pair.
- the columns of the first table are transformed based on the generated transformation model, and the converted first table is joined with the second table.
- Non-Patent Document 1 describes a method of calculating the correlation with standardized data.
- Patent Document 1 Since the method described in Patent Document 1 is a method of joining two tables, the data contained in the joined tables is not always the data that promotes value creation.
- the present invention provides a correlation table search device, a correlation table search method and a correlation table search program, and an index used for such a search, which can quickly identify a table containing data that is correlated with the data of the target column. It is an object of the present invention to provide a correlation index construction device, a correlation index construction device method, and a correlation index construction program capable of constructing a correlation index.
- the correlation table search device is an index that can search columns whose correlation value indicating the degree of correlation between columns is equal to or higher than a predetermined correlation value threshold from an external table, and is a feature vector indicating the characteristics of column data.
- the target is targeted by using an index specifying means for specifying the size-based correlation index used for the search and the specified size-based correlation index.
- Search the external table for columns whose distance to the column is less than or equal to the distance threshold calculate the correlation value indicating the degree of correlation between the searched column and the target column, and select the column whose correlation value is greater than or equal to the correlation value threshold. It is characterized by having a candidate column search means for searching as a candidate column and an output unit for outputting an external table including the candidate column.
- the correlation index construction device provides a correlation index, which is an index capable of searching from an external table for columns whose correlation value indicating the degree of correlation between columns is equal to or higher than a predetermined correlation value threshold for each column of the external table.
- a means for generating a correlation index is provided, and the means for generating a correlation index generates a feature vector indicating the characteristics of each column, generates a standardized vector obtained by standardizing the generated feature vector, and determines a predetermined value from the elements of the generated standardized vector.
- a size-based vector is generated by extracting the elements of the number of elements in ascending order, and a size-based correlation index, which is a correlation index for each size of the above number, is generated from the generated size-based vector.
- the function to be calculated is defined using the distance from the size vector, and the correlation value calculated by the distance between the feature vector of the target column and the size vector using the defined function is equal to or greater than the correlation value threshold. It is characterized by generating a correlation index that searches the columns of the table.
- the correlation table search method is an index that allows a computer to search an external table for a column in which a correlation value indicating the degree of correlation between columns is equal to or greater than a predetermined correlation value threshold, and features column data.
- a predetermined number of elements are extracted from the size-specific vector in ascending order, and the distance to the size-specific vector is within the distance threshold determined based on the correlation value threshold.
- the computer accepts the input of the size-based correlation index from the storage device that stores the size-based correlation index, which is an index for extracting the columns from the external table, and the computer selects the base table including the target column and the external from the size-based correlation index.
- the size-based correlation index used for the search is specified based on a predetermined number of record pairs that are determined to be joinable when joining the table, and the computer uses the specified size-based correlation index.
- Search the external table for columns whose distance to the target column is less than or equal to the distance threshold calculate the correlation value indicating the degree of correlation between the searched column and the target column, and select columns whose correlation value is greater than or equal to the correlation value threshold. It is characterized in that it searches as a candidate column and the computer outputs an external table containing the candidate column.
- a computer In the correlation index construction device method according to the present invention, a computer generates a feature vector showing the features of each column of the external table, generates a standardized vector obtained by standardizing the generated feature vector, and uses the elements of the generated standardized vector.
- a size-based vector obtained by extracting a predetermined number of elements in ascending order is generated, and a size-based correlation index, which is a correlation index for each size of the above number, is generated from the generated size-based vector. It is an index that can search columns whose correlation value indicating the degree of is equal to or higher than the predetermined correlation value threshold from an external table, and the computer defines and defines a function to calculate the correlation value using the distance from the vector for each size. It is characterized in that a correlation index for searching a column of an external table whose correlation value calculated by the distance between the feature vector of the target column and the vector for each size is equal to or larger than the correlation value threshold is generated by using the obtained function.
- the correlation table search program is an index that allows a computer to search for columns whose correlation value indicating the degree of correlation between columns is equal to or greater than a predetermined correlation value threshold from an external table, and features column data.
- a predetermined number of elements are extracted from the size-specific vector in ascending order, and the distance to the size-specific vector is within the distance threshold determined based on the correlation value threshold.
- Input processing that accepts the input of the size-based correlation index from the storage device that stores the size-based correlation index, which is an index that extracts the columns from the external table.
- Index identification processing that identifies the size-based correlation index used for the search based on the predetermined number of record pairs that are determined to be joinable when joining the table, using the specified size-based correlation index , Search the external table for columns whose distance to the target column is less than or equal to the distance threshold, calculate the correlation value indicating the degree of correlation between the searched column and the target column, and select the column whose correlation value is greater than or equal to the correlation value threshold. It is characterized in that a candidate column search process for searching as a candidate column and an output process for outputting an external table including the candidate column are executed.
- the correlation index construction program is an index that allows a computer to search from an external table for columns whose correlation value indicating the degree of correlation between columns is equal to or higher than a predetermined correlation value threshold for each column of the external table.
- a correlation index generation process for generating a correlation index is executed, a feature vector showing the characteristics of each column is generated in the correlation index generation process, a standardized vector that standardizes the generated feature vector is generated, and the generated standardized vector is generated.
- a size-based vector is generated by extracting a predetermined number of elements from the elements of the above in ascending order, and a size-based correlation index, which is a correlation index for each size of the above number, is generated from the generated size-based vector.
- the function to calculate the correlation value is defined by using the distance from the size vector, and the correlation value calculated by the distance between the feature vector of the target column and the size vector using the defined function is the correlation value threshold. It is characterized in that a correlation index for searching the columns of the above-mentioned external table is generated.
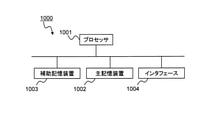
- FIG. 1 is a block diagram showing a configuration example of an embodiment of a join table specifying system according to the present invention.
- the join table specifying system 100 of the present embodiment is a system that specifies an outer table (hereinafter referred to as a join table) that can be joined to the join source table (that is, the base table). More specifically, a join table is a table that includes any of the columns contained in the base table and columns that can be joined.
- the join table specifying system 100 of the present embodiment uses a function for calculating the similarity between records (hereinafter referred to as a similarity function) to determine whether or not the records can be joined.
- a similarity function a function for calculating the similarity between records
- Examples of the similarity function include Jaccard similarity, editing distance, Euclidean distance of a character string converted based on Word2vec, and the like.
- the similarity function used in this embodiment is not limited to these three types of similarity functions.
- the similarity functions as illustrated above have different viewpoints, it is not possible to uniquely determine the optimum similarity function.
- the similarity between "ramune” and “ramune 250 ml” is calculated as 0.375 in the case of editing distance and 0.5 in the case of Jaccard similarity.
- the similarity between "champ orange” and “champ orange” is calculated to be 0.875 in the case of editing distance and 0.5 in the case of Jaccard similarity. In this way, the value of similarity changes according to the contents of the records to be compared.
- FIG. 2 is an explanatory diagram showing an example of a process for determining a table that can be joined.
- FIG. 2 shows an example of determining whether the outer table FT1 can be joined to the base table BT1.
- the threshold value Tr 0.5 of the similarity used for determining whether or not the records can be combined
- the threshold value T c 2 of the record pair used for determining whether or not the columns can be combined.
- the Jaccard similarity is 0.5
- the editing distance is 0.37
- the similarity after Word2vec conversion is 0.8 for "ramune” and "ramune 250 ml” illustrated in FIG. 2.
- the maximum similarity is calculated to be 0.8, which is larger than the threshold value Tr , so that it is determined that the two records can be combined.
- the amount of calculation of O is required as described above. Therefore, in the present embodiment, the amount of calculation (cost) at the time of searching is reduced by constructing an index of the external table group in advance.
- the join table specifying system 100 exemplified in FIG. 1 includes an external table storage device 10, a join index construction device 110, a join index storage unit 120, a join table search device 130, and a join table storage unit 140. ..
- the external table storage device 10 stores a plurality of external tables (that is, external table groups) that are candidates to be joined to the base table.
- An example of the external table is the external table FT1 illustrated in FIG.
- the external table storage device 10 is realized by, for example, a storage server, a magnetic disk, or the like.
- join table specifying system 100 includes the external table storage device 10
- the join index construction device 110 may acquire an external table group from a storage (not shown) or the like connected through a communication line.
- the join table specifying system 100 does not have to include the external table storage device 10.
- the join index construction device 110 is a device that builds an index (hereinafter referred to as a join index) of a group of external tables used for joining with a base table.
- the join index construction device 110 includes a join column candidate extraction unit 112 and a join index generation unit 114.
- the join column candidate extraction unit 112 extracts a column including a record that can be a join key with another table from each outer table included in the outer table group as a join column candidate.
- the join column candidate extraction unit 112 estimates, for example, the types of all the columns in the outer table group, and determines whether or not the column of the estimated type can be joined with the columns of other tables.
- the column type here may be a type such as a "character string type" or a "numeric type" indicating a character attribute, or may indicate a concept represented by a column. ..
- the method of estimating the column type is arbitrary, and a known method may be used.
- the combined column candidate extraction unit 112 may estimate the type (meaning of the column) of each column by using, for example, the method described in Patent Document 2. Then, the join column candidate extraction unit 112 joins the column when, for example, the estimated column type indicates a predetermined meaning or is an attribute of a predetermined character (for example, a character string type). It may be extracted as a candidate.
- FIG. 3 is an explanatory diagram showing an example of a process of estimating the column type. For example, based on the record illustrated in FIG. 3, column 1 containing a character string means "name”, column 2 containing numbers means “age”, and column 3 containing alphanumericals means “grade”. It is presumed that the column means ".”
- the join column candidate extraction unit 112 may determine that the data of the column meaning "name" is likely to be the join key, and may extract column 1 as the join column candidate. Further, for example, a numeric column or a column having few unique values is unlikely to be a join key, and a character string type column is likely to be a join key. Therefore, the join column candidate extraction unit 112 has a unique value.
- the character string type column 1 in which the number may increase may be extracted as a join column candidate.
- the join index generation unit 114 generates a join index of the outer table group. Specifically, the join index generation unit 114 generates a join index of the extracted join column candidates. By limiting the index target to the join column candidates in this way, the cost required to generate the join index and the size of the generated join index can be reduced.
- the join index generation unit 114 creates, as the join index, an index that can search for records whose similarity calculated by the similarity function is equal to or higher than a predetermined threshold value for each similarity function.
- the join index generation unit 114 may generate a join index by any method according to the similarity function.
- index-LSH Large-sensitive Hashing
- FISS Fidelity-sensitive Hashing
- index corresponding to the similarity function for calculating the Euclidean similarity a method of generating a set (matrix) of vectors in a memory and a library (FAISS) are known.
- an inverted index is known as an index according to a similarity function that calculates whether or not an exact match is obtained. Since the methods for generating these indexes are widely known, detailed description thereof will be omitted here.
- the join index generation unit 114 stores the generated join index in the join index storage unit 120.
- the join column candidate extraction unit 112 and the join index generation unit 114 are realized by a computer processor (for example, a CPU (Central Processing Unit) or a GPU (Graphics Processing Unit)) that operates according to a program (join index generation program). ..
- a computer processor for example, a CPU (Central Processing Unit) or a GPU (Graphics Processing Unit)
- a program join index generation program
- the program is stored in a storage unit (not shown) included in the join index construction device 110, and the processor reads the program and operates as a join column candidate extraction unit 112 and a join index generation unit 114 according to the program. May be good.
- the function of the join index construction device 110 may be provided in the SAAS (Software as a Service) format.
- join column candidate extraction unit 112 and the join index generation unit 114 may each be realized by dedicated hardware. Further, a part or all of each component of each device may be realized by a general-purpose or dedicated circuit (circuitry), a processor, or a combination thereof. These may be composed of a single chip or may be composed of a plurality of chips connected via a bus. A part or all of each component of each device may be realized by the combination of the circuit or the like and the program described above.
- each component of the join index construction device 110 when a part or all of each component of the join index construction device 110 is realized by a plurality of information processing devices, circuits, etc., the plurality of information processing devices, circuits, etc. may be centrally arranged. , May be distributed.
- the information processing device, the circuit, and the like may be realized as a form in which each is connected via a communication network, such as a client-server system and a cloud computing system.
- the join index storage unit 120 stores the join index according to the similarity function. In the present embodiment, the case where the join index storage unit 120 stores the join index generated by the join index construction device 110 is described, but the join index storage unit 120 is generated by another device (not shown). It may remember the joined index that was created.
- the join table search device 130 searches for a table that can be joined to the target column (hereinafter referred to as a target column) in the base table from the outer table group by using the join index.
- the join table search device 130 includes an input unit 132, a search plan generation unit 134, a record search unit 136, and a join table output unit 138.
- the input unit 132 accepts the input of the target column that attempts to join with the outer table among the columns included in the base table. Further, the input unit 132 reads the join index stored in the join index storage unit 120. The input unit 132 may read the join index from a storage device (not shown) other than the join index storage unit 120.
- the search plan generation unit 134 analyzes the records of the target column before executing the search using the join index of each similarity function, and generates a search plan that defines the order of use of the join index at the time of search. ..
- the search plan generation unit 134 joins the number of record pairs that can be joined (hereinafter referred to as the number of results) estimated when the records in the target column are searched using the join index of each similarity function. Calculated for each index. Examples of the method for estimating the number of results using the join index of the similarity function include kernel density estimation (KernelDensityEstimation) and cardinality estimation (CardinalityEstimation). The search plan generation unit 134 may use these known estimation methods to estimate the number of results for each join index.
- kernel density estimation KernelDensityEstimation
- CardinalityEstimation cardinality estimation
- the search plan generation unit 134 generates a search plan that defines the order of use of the join index in descending order of the number of calculated results.
- the reasons for defining the order of use in this way are as follows. It is highly possible that many record pairs that can be joined can be found by performing a search using the join index that is estimated to have a large number of results. Then, since the records of the outer table group already determined to be joinable can be excluded from the search target in the subsequent join index, the search process can be omitted. As a result, the cost of searching can be further reduced.
- N 10
- M 1
- the number of results when the join index A is used for the record of a certain target column is 2, and the number of results when the join index B is used is 5.
- the amount of calculation is log (10) + log (8).
- the amount of calculation is log (10) + log (5). In this way, the amount of calculation can be reduced by defining the order of use of the join index in descending order of the number of results.
- the record search unit 136 searches for records in the target column using the join index in the order specified in the search plan. At that time, the record search unit 136 excludes the records of the external table searched by the already used join index from the search target, and performs a search using the subsequent join index. Then, the record search unit 136 identifies the external table in which the record having the threshold value T c or more determined in advance is searched as a result of searching the record of the target column using all the join indexes as the join table.
- FIG. 4 is an explanatory diagram showing an example of a process for specifying the join table of the target column.
- the search plan generation unit 134 generates a search plan.
- the search plan is generated as "Order 1: Exact match join index, Order 2: Jaccard similarity join index, Order 3: Euclidean distance join index".
- the record search unit 136 searches the record R1 of the target column using the join index in the order specified in the search plan.
- the record search unit 136 first searches the record R1 of the target column by using the exact match join index.
- the matching record group hereinafter referred to as the first record group
- the record search unit 136 searches the record R1 of the target column by excluding the first record group by using the Jaccard similarity degree join index.
- the matching record group hereinafter referred to as the second record group in the external table group is further searched.
- the record search unit 136 searches the record R1 of the target column by excluding the first record group and the second record group by using the Euclidean distance join index. As a result, the matching record group (hereinafter referred to as the third record group) in the external table group is further searched.
- the record search unit 136 identifies the table A including the record "Ramune 250 ml” as a table (join table) that can be joined in column 1, and the table C containing the record "HATA Ramune” can be joined in column 3. Specify as (join table).
- the join table output unit 138 outputs the searched join table.
- the join table output unit 138 may store the searched join table in the join table storage unit 140.
- the join table storage unit 140 stores a table that can be joined to the target column in the base table.
- the join table storage unit 140 may store, for example, a joinable base table in association with the join table.
- the join table storage unit 140 may store the join table searched by the join table search device 130, or may store the join table generated by another device (not shown).
- the join index storage unit 120 and the join table storage unit 140 are realized by, for example, a magnetic disk or the like.
- the input unit 132, the search plan generation unit 134, the record search unit 136, and the join table output unit 138 are realized by a computer processor that operates according to a program (join table search program).
- the program is stored in a storage unit (not shown) included in the join table search device 130, the processor reads the program, and according to the program, the input unit 132, the search plan generation unit 134, the record search unit 136, and the join. It may operate as a table output unit 138. Further, the function of the join table search device 130 may be provided in SaaS format.
- FIG. 5 is a flowchart showing an operation example of the join index construction device 110 of the present embodiment.
- the join column candidate extraction unit 112 extracts the join column candidates from each table included in the outer table group (step S11).
- the join index generation unit 114 generates a join index of the extracted join column candidates for each similarity function (step S12). Then, the join index generation unit 114 stores the generated join index in the join index storage unit 120 (step S13).
- FIG. 6 is a flowchart showing an operation example of the join table search device 130 of the present embodiment.
- the input unit 132 receives the input of the join index from the join index storage unit 120 (step S21). Further, the input unit 132 accepts the input of the target column among the columns included in the base table (step S22).
- the search plan generation unit 134 calculates the number of results for each join index estimated for the records in the target column (step S23). Then, the search plan generation unit 134 generates a search plan that defines the order of use of the join index in descending order of the number of calculated results (step S24).
- the record search unit 136 searches for records in the target column using the join index in the order specified in the search plan (step S25). At that time, the record search unit 136 excludes the records of the external table searched by the already used join index from the search target, and performs a search using the subsequent join index. Then, the record search unit 136 identifies an external table in which records equal to or greater than a predetermined threshold value are searched for as a join table (step S26).
- the input unit 132 accepts the input of the join index
- the search plan generation unit 134 calculates the number of results for each join index, and the order of use of the join index is in descending order of the calculated number of results.
- the record search unit 136 searches for the records of the target column using the join index in the order specified in the search plan, and identifies the external table in which the records of the predetermined threshold value or more are searched as the join table.
- the record search unit 136 excludes the records of the external table searched by the already used join index from the search target, and performs a search using the subsequent join index. Therefore, the cost for specifying the table that can be joined to the target column can be reduced.
- the join table specifying system 100 of the present embodiment since the search space can be pruned by using the join index of different similarity functions, the data that can be joined to the base data from the external table group can be obtained at high speed and with high accuracy. It becomes possible to extract.
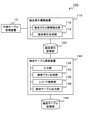
- FIG. 7 is a block diagram showing a configuration example of an embodiment of the correlation table specifying system according to the present invention.
- the correlation table specifying system 200 of the present embodiment is a system for specifying an external table (hereinafter, referred to as a correlation table) including a column having a correlation with the target column.
- the column having a correlation with the target column means a column of an external table group that is assumed to have some correlation with the data contained in the target column, and more specifically, it is included in the target column. It means a column of an external table group containing data groups having similar characteristics or distributions. This correlation also includes both positive and negative correlations.
- the target column is a column containing the sales data included in the base table.
- the correlated column corresponds to a column containing an explanatory variable used as a feature amount that can affect the objective variable. Therefore, by specifying the correlation table, more effective explanatory variables (features) can be added to the prediction model for realizing the task of "predicting sales", and as a result, the performance of the task can be improved. It will be possible to improve.
- FIG. 8 is an explanatory diagram showing an example of a process for extracting correlated columns.
- the reason for extracting the correlated columns is to determine which table in the external table group is useful for improving the performance of the task. For example, suppose that each table is joined via the "trade name" column of the base table BT2 illustrated in FIG. 8 and the "drink name" column of the external table FT2. In this case, it is determined whether the columns other than the join column of the outer table FT2 (“attribute 1” column, “attribute 2” column) are useful for improving the performance of the task of predicting the column “sales” included in the base table. It is desirable to be able to do it.
- the table that contributes to the performance improvement of the task is defined as follows. That is, one external table can be joined to the base table via the number of records equal to or more than the threshold value Tc , and the column of the base table corresponding to the objective variable is included in the column associated with the join.
- the external table is used as a table that contributes to the improvement of task performance.
- the main purpose is to identify a column that has a correlation with the target column, and it does not necessarily matter whether or not the combination with the base table is possible.
- the threshold value Tp of this correlation value may be referred to as a correlation value threshold value.
- the correlation table specifying system 200 illustrated in FIG. 7 includes an external table storage device 10, a correlation index construction device 210, a correlation index storage unit 220, a correlation table search device 230, and a correlation table storage unit 240. ..
- the external table storage device 10 stores a plurality of external tables (that is, a group of external tables) as in the first embodiment.
- the external table storage device 10 is realized by, for example, a storage server, a magnetic disk, or the like.
- the correlation table specifying system 200 includes the external table storage device 10
- the correlation index construction device 210 may acquire an external table group from a storage (not shown) or the like connected through a communication line.
- the correlation table specifying system 200 does not have to include the external table storage device 10.
- the correlation index construction device 210 is a device that constructs an index of an external table group (hereinafter referred to as a correlation index) used for searching a column that has a correlation with the target column.
- the correlation index construction device 210 includes a non-joined column candidate extraction unit 212 and a correlation index generation unit 214.
- the non-joined column candidate extraction unit 212 extracts as a non-joined column candidate a column containing a record that is not expected to be a join key with another table from each external table included in the outer table group.
- the non-bonded column candidate extraction unit 212 extracts columns other than the combined column candidates extracted by the combined column candidate extraction unit 112 of the first embodiment as non-bonded column candidates.
- the non-joined column candidate extraction unit 212 estimates the types of all the columns in the outer table group, and the column of the estimated type is another column. It may be determined whether or not it can be combined with the column of the table, and when it is determined that it cannot be combined, that column may be extracted as a non-joinable column candidate.
- the non-bonded column candidate extraction unit 212 is similar to the combined column candidate extraction unit 112 of the first embodiment, for example, when the estimated column type indicates a predetermined meaning or an attribute of a predetermined character. In the case of (for example, numerical type), the column may be extracted as a non-joined column candidate.
- the non-binding column candidate extraction unit 212 determines that the data of the column meaning "age” or "grade” is unlikely to be the binding key, and determines that the column 2 and the column 3 are selected. It may be extracted as a non-bonded column candidate. Further, for example, since a numerical column or a column having a small unique value is unlikely to be a join key, the join column candidate extraction unit 112 is a numerical column 2 or a sentence alphanumeric type in which it is assumed that the unique value is small. Column 3 may be extracted as a non-bonded column candidate.
- Correlation index generation unit 214 generates a correlation index of external table groups. Specifically, the correlation index generation unit 214 generates a join index of the extracted non-join column candidates. By limiting the index target to non-joined column candidates in this way, the cost required to generate the correlated index and the size of the generated correlated index can be reduced.
- the correlation index generation unit 214 generates, as a correlation index, an index from which each column of the external table can be searched for a column whose correlation value is equal to or greater than a predetermined correlation value threshold value.
- a predetermined correlation value threshold value As described above, in the present embodiment, in order to specify a table including a column composed of correlated data, it is specified at high speed a table including a column whose correlation value with the column of the base table is equal to or higher than the threshold value Tp . Target. However, it is difficult to build an index that calculates the correlation value.
- the correlation index generation unit 214 first generates a feature vector indicating the features of each column.
- the feature vectors of the two columns are X and Y.
- the correlation index generation unit 214 calculates a vector (hereinafter referred to as a standardized vector) (X', Y') obtained by standardizing the generated feature vector.
- the correlation index generation unit 214 defines a function for calculating the correlation value based on the distance between the standardized vectors. That is, it can be said that this process converts the calculation of the correlation value into the calculation based on the distance.
- the function for calculating the correlation value is corr (X', Y'), and the function for calculating the distance is d (X', Y').
- d (X', Y') is a function for calculating the Euclidean distance
- the correlation index generation unit 214 exemplifies the correlation value below, for example, as described in Non-Patent Document 1. It may be calculated as in Equation 1.
- the correlation index generation unit 214 defines a function that calculates the correlation value using the distance, and the correlation value calculated by the distance from the feature vector of the target column using the defined function is the correlation value. Generate a correlation index to search for columns above the threshold. Further, according to this definition, the correlation index generation unit 214 may convert the correlation value threshold value Tp and define the threshold value T d as shown in the following equation 2. That is, Is. In the following description, the threshold value T d determined based on the correlation value threshold value T p may be referred to as a distance threshold value.
- the correlation index generation unit 214 may use columns calculated with a threshold distance T d or less as correlated columns. By making it possible to calculate the correlation value based on the Euclidean distance in this way, for example, a known method (method of generating an index according to the similarity function) as described in the first embodiment is used. Therefore, it becomes possible to generate an index that can search for records having a correlation value equal to or higher than a predetermined threshold value.
- the method of calculating the correlation value based on the Euclidean distance was explained.
- the method of calculating the correlation value is not limited to the method based on the Euclidean distance.
- the method for calculating the correlation value is arbitrary as long as it is a method that can generate an index that can search for records having a correlation value equal to or higher than a predetermined threshold value.
- the correlation index generation unit 214 generates a correlation index based on the standardized vector (X', Y'). By generating such a correlation index, it becomes possible to quickly search the external table group for a column whose distance from the target column is smaller than the threshold value Td .
- a distance index In order to further improve the search speed, it is possible to generate a distance index.
- the columns to join with the outer tables are unknown in advance, so using a distance index cannot solve this problem. Therefore, in the present embodiment, a correlation index is created so that the amount of data in the columns to be compared can be reduced and the calculation cost required for the search can be reduced.
- the correlation index generation unit 214 extracts predetermined elements in ascending order of the elements of the standardized vector (X', Y'), and constructs a correlation index based on the extracted elements.
- the method for constructing the correlation index is the same as the method for generating the join index in the first embodiment.
- the correlation index generation unit 214 may generate the correlation index of the Euclidean distance search shown above based on the extracted elements, for example.
- the number of extracted elements is referred to as size
- the vector extracted from the feature vector (standardized vector) in ascending order of the elements of a predetermined size is referred to as a size-specific vector.
- a correlation index generated based on a size-based vector is referred to as a size-based correlation index. That is, the correlation index generation unit 214 generates a size-based vector obtained by extracting elements of a predetermined size from the standardized vector elements in ascending order, and generates a size-based correlation index from the generated size-based vector.
- the method of generating the size-based correlation index from the size-based vector is the same as the method of creating an index that can search columns whose distance is equal to or greater than a predetermined threshold value.
- the size-based correlation index generated in this way is an index in which columns whose correlation value indicating the degree of correlation between columns is equal to or higher than the correlation value threshold Tp can be searched from an external table, and the elements of the feature vector of each column can be searched. This is an index generated for each size from the size-specific vectors extracted from the elements of the predetermined size in ascending order.
- the size-based correlation index is an index for extracting columns whose distance from the size-based vector is within the distance threshold T d determined based on the correlation value threshold T p .
- the correlation index generation unit 214 may extract a predetermined number of elements from the standardized vector, or may determine the number (size) of the elements to be extracted based on the distribution of the number of elements in each column. For example, the correlation index generation unit 214 may determine the maximum value of the number of elements, the minimum value of the number of elements, and the average value of the number of elements as sizes. Further, the correlation index generation unit 214 may generate one correlation index for each size, or may generate a plurality of correlation indexes.
- the correlation index generation unit 214 generates a correlation index having a maximum value of 6 elements, a correlation index having a minimum number of elements of 2, and a correlation index having an average value of 4. You may.
- the correlation index generation unit 214 may generate correlation indexes of three types of sizes illustrated below.
- -Correlation index of size 2 A [1,2], B [0,3]
- -Correlation index of size 4 A [1,2,3,4], B [0,3,4,5]
- -Correlation index of size 6 A [1,2,3,4,5,7], B [0,3,4,5,7,9]
- the correlation index generation unit 214 stores the generated correlation index in the correlation index storage unit 220. Further, the correlation index generation unit 214 stores the generated size-specific correlation index in the correlation index storage unit 220.
- the non-joined column candidate extraction unit 212 and the correlation index generation unit 214 are realized by a computer processor that operates according to a program (correlation index generation program).
- a program correlation index generation program
- the program is stored in a storage unit (not shown) included in the correlation index construction device 210, and the processor reads the program and operates as the unjoined column candidate extraction unit 212 and the correlation index generation unit 214 according to the program. You may. Further, the function of the correlation index construction device 210 may be provided in the SaaS format.
- the correlation index storage unit 220 stores the correlation index and the correlation index by size. In the present embodiment, the case where the correlation index storage unit 220 stores the correlation index and the correlation index by size generated by the correlation index construction device 210 will be described, but the correlation index storage unit 220 is another device (FIG. The correlation index generated by (not shown) and the correlation index by size may be stored.
- the correlation table search device 230 searches the external table group for a table including columns that are correlated with the target column (that is, referred to as the target column) in the base table by using the correlation index.
- the correlation table search device 230 includes an input unit 232, an index identification unit 234, a candidate column search unit 236, and a correlation table output unit 238.
- the input unit 232 accepts the input of the target column for searching the columns of the external table group having a correlation among the columns included in the base table. Further, the input unit 232 reads the correlation index stored in the correlation index storage unit 220. The input unit 232 may read the correlation index from a storage device (not shown) other than the correlation index storage unit 220.
- the index specifying unit 234 identifies the correlation index used for the search. Specifically, the index specifying unit 234 specifies the correlation index used for the search based on the threshold value T c of the number of record pairs determined to be joinable when the base table and the external table are joined.
- the value of the threshold value T c is predetermined by the user or the like.
- the index specifying unit 234 may decide to use a join index having the same size as the value of the threshold T c for the search. If a join index having the same size as the value of the threshold value T c does not exist, the index specifying unit 234 uses the join index having the largest size among the join indexes having a size smaller than the value of the threshold value T c for the search. May be decided. This is because it is guaranteed that all the data of the candidate columns can be searched by using the join index having a size smaller than the value of the threshold value T c .
- the index specifying unit 234 determines that the correlation index having a size of 3 or less is used for the search.
- the threshold T c When the threshold T c is given, the size of the column to be joined to the outer table is always T c or more. Therefore, the lower limit of the distance can be calculated by listing the elements of the column including the objective variable and the elements of the feature vector in ascending order. Then, by comparing the lower limit of the distance with the threshold value T d , it can be determined whether or not to exclude the feature vector (that is, each column of the external table).
- FIG. 9 is an explanatory diagram showing an example of a process for determining whether or not to exclude the feature vector. It is assumed that the data in the "sales" column of the base table BT3 illustrated in FIG. 9 and the data in the "attribute 1" column and the “attribute 2" column of the external table FT3 are standardized data, respectively. That is, each surrounded by the broken line illustrated in FIG. 9 corresponds to the feature vector.
- the feature vector of the "sales” column used as the objective variable is [1,3,5]
- the feature vector of the "attribute 1" column is [2,1,5], "attribute”.
- the candidate column search unit 236 searches the external table group using the correlation index determined for the target column, and searches for candidate columns that are considered to have a correlation. Specifically, the candidate column search unit 236 searches the external table group for columns having or equal to a predetermined threshold value (here, the distance threshold value T d ) or more by using the correlation index. Since a method of searching a column having a predetermined threshold value (here, the distance threshold value T d ) or more by using a correlation index (for example, a correlation index of Euclidean distance search) is widely known, a detailed description thereof will be given here. Is omitted.
- the candidate column search unit 236 calculates the correlation value between the target column and the searched column, and specifies a column having or equal to a predetermined threshold value (here, the threshold value T p of the correlation value) or more as the candidate column. In this way, the candidate column search unit 236 searches for columns using the correlation index and calculates the correlation values for the searched columns, so that the correlation values can be calculated only for the columns that are expected to be more correlated. , It becomes possible to reduce the calculation cost.
- a predetermined threshold value here, the threshold value T p of the correlation value
- Correlation table output unit 238 outputs an external table including candidate columns as a correlation table.
- the correlation table output unit 238 may store the correlation table in the correlation table storage unit 240.
- FIG. 10 is an explanatory diagram showing an example of a process for specifying a correlation table.
- the index specifying unit 234 determines that the correlation index of size 2 below the threshold value is used for the search.
- the candidate column search unit 236 searches for columns containing highly correlated features using a size 2 correlation index. In the example shown in FIG. 10, it is shown that the column 2 of the table A is searched as the column containing the feature amount a, and the column 5 of the table C is searched as the column containing the feature amount b. Then, the candidate column search unit 236 calculates the correlation value between the target column and the candidate column again, and the correlation table output unit 238 outputs the table A and the table C including the candidate column.
- the correlation table storage unit 240 stores a correlation table including candidate columns.
- the correlation table storage unit 240 may store the correlated column (that is, the candidate column) in association with the target column of the base table.
- the correlation table storage unit 240 may store the “sales” column, which is a target column that can be the objective variable of the task, in association with the candidate column in the correlation table.
- the correlation table storage unit 240 may store the correlation table output by the correlation table search device 230, or may store the correlation table generated by another device (not shown).
- the correlation index storage unit 220 and the correlation table storage unit 240 are realized by, for example, a magnetic disk or the like.
- the input unit 232, the index identification unit 234, the candidate column search unit 236, and the correlation table output unit 238 are realized by a computer processor that operates according to a program (correlation table search program).
- the program is stored in a storage unit (not shown) included in the correlation table search device 230, the processor reads the program, and according to the program, the input unit 232, the index identification unit 234, the candidate column search unit 236, and the correlation. It may operate as a table output unit 238.
- FIG. 11 is a flowchart showing an operation example of the correlation index construction device 210 of the present embodiment.
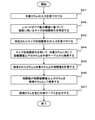
- the non-joining column candidate extraction unit 212 extracts the non-joining column candidate from the outer table (step S31).
- the correlation index generation unit 214 generates a feature vector showing the features of the non-joined column candidate (step S32), and generates a standardized vector obtained by standardizing the generated feature vector (step S33).
- the correlation index generation unit 214 generates a size-based vector obtained by extracting elements of a predetermined size from the generated standardized vector elements in ascending order (step S34), and size-based from the generated size-based vector. Generate a correlation index (step S35). Then, the correlation index generation unit 214 stores the generated size-specific correlation index in the correlation index storage unit 220 (step S36).
- FIG. 12 is a flowchart showing an operation example of the correlation table search device 230 of the present embodiment.
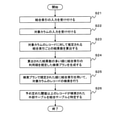
- the input unit 232 receives the input of the target column among the columns included in the base table (step S41).
- the index specifying unit 234 identifies the size-based correlation index used for the search from the size-based correlation indexes stored in the correlation index storage unit 220 based on the threshold value Tc of the number of pairs of records (step S42).
- the input unit 232 accepts the input of the specified size-based correlation index (step S43).
- the candidate column search unit 236 searches the external table for columns having a distance threshold value or less with respect to the target column using the specified size-specific correlation index (step S44).
- the candidate column search unit 236 calculates the correlation value between the searched column and the target column (step S45), and searches for a column whose correlation value is equal to or greater than the correlation value threshold value as a candidate column (step S46).
- the correlation table output unit 238 outputs an external table including the candidate column as a correlation table (step S47).
- the input unit 232 receives the input of the correlation index by size, and the index specifying unit 234 searches the correlation index by size based on the threshold value Tc of the number of pairs of records. Identify the size-based correlation index used for.
- the candidate column search unit 236 searches the external table for columns whose distance from the target column is equal to or less than the distance threshold T d by using the specified size-specific correlation index, and the correlation between the searched column and the target column. A correlation value indicating the degree of is calculated, and a column whose correlation value is equal to or greater than the correlation value threshold T p is searched as a candidate column. Then, the correlation table output unit 238 outputs an external table including the candidate columns. Therefore, it is possible to quickly identify a table containing data that is correlated with the data of the target column.
- the correlation index generation unit 214 generates the correlation index.
- the correlation index generation unit 214 generates a feature vector showing the features of each column of the external table, generates a standardized vector obtained by standardizing the generated feature vector, and has a predetermined size from the elements of the generated standardized vector. Generate a size-based vector by extracting the elements of the above in ascending order, and generate a size-based correlation index from the generated size-based vector.
- the correlation index generation unit 214 and the function for calculating the correlation value are defined by using the distance from the size-based vector, and are calculated by the distance between the feature vector of the target column and the size-based vector using the defined function.
- the correlation table search device 230 can quickly identify a table containing data that is correlated with the data of the target column. do.
- FIG. 13 is a block diagram showing a configuration example of an embodiment of the table integration system according to the present invention.
- the table integration system 300 of the present embodiment is a system that integrates columns having a correlation with the target columns included in the base table.
- integrating an external table into a base table means that, as shown in the first embodiment, an external table that can be joined (that is, a join table) is joined to the base table to create a new table. The process to be generated is shown.
- an external table that can be joined that is, a join table
- the target column is a column composed of data targeted in the assumed task, and is, for example, a column including the objective variable of the prediction model.
- the task means a prediction (estimation) process such as regression and classification performed using the selected feature amount, and specifically, it is given by a function showing a prediction model or the like.
- the column having a correlation with the target column means a column of an external table group that is assumed to have some correlation with the data contained in the target column, as in the second embodiment. More specifically, it means a column of an external table group including data groups having similar characteristics or distributions of the data groups included in the target column. This correlation also includes both positive and negative correlations.
- the correlated column corresponds to the column including the explanatory variable used as the feature amount that can affect the objective variable as in the second embodiment, such a column is integrated into the base table. As a result, it becomes possible to improve the performance of the task.
- the table integrated system 300 illustrated in FIG. 13 includes a table storage device 20, an integrated table generation device 310, and an integrated table storage unit 330.
- the table storage device 20 stores a plurality of external tables (that is, external table groups).
- the table storage device 20 of the present embodiment stores an external table group extracted from a predetermined viewpoint, unlike the external table storage device 10 of the first embodiment and the second embodiment.
- the table storage device 20 includes a join table storage unit 21 and a correlation table storage unit 22.
- the join table storage unit 21 stores the join table shown in the first embodiment (that is, an outer table that can be joined to the base table). It is assumed that the join table storage unit 21 stores the joinable base table in association with the join table.
- the join table storage unit 21 may store the join table specified by the join table specifying system 100 of the first embodiment, and stores the join table generated by another system (not shown) or the like. May be.
- the correlation table storage unit 22 stores the correlation table shown in the second embodiment (that is, an external table including a column that correlates with the target column).
- the correlation table storage unit 22 may store the correlation table specified by the correlation table specifying system 200 of the second embodiment, and stores the correlation table generated by another system (not shown) or the like. You may be.
- the correlation table storage unit 22 associates a column (that is, a candidate column) containing data having a correlation with the data of the target column with the target column of the base table. I remember it. Further, the correlation table storage unit 22 of the present embodiment may store information that can identify the column of the table that correlates with the target column, and does not necessarily have to store the data of each column. That is, the correlation table storage unit 22 may store the candidate column shown in the second embodiment (that is, the column whose correlation value with the target column is equal to or higher than a predetermined threshold value Tp ).
- join table is generated in advance by the method shown in the first embodiment and stored in the join table storage unit 21. Further, it is assumed that the candidate column is also generated in advance by the method shown in the second embodiment and stored in the correlation table storage unit 22.
- the integrated table generation device 310 is an device that generates an integrated table by combining a base table and a candidate column.
- the integrated table generation device 310 includes an input unit 312, a table coupling unit 314, a feature amount processing unit 316, a feature amount selection unit 318, and an integrated table output unit 320.
- the input unit 312 accepts the input of the base table and the designation of the target column. Further, the input unit 312 accepts the input of the join table and the candidate column. The input unit 312 may accept the designation of the objective variable of the task. In this case, the input unit 312 may specify the target column of the corresponding base table from the designated objective variable.
- the input unit 312 When the input unit 312 receives the input of the base table and the designation of the target column, the input unit 312 acquires the input join table of the base table from the join table storage unit 21 and the candidate column of the target column in the correlation table storage unit 22. May be obtained from.
- the table join unit 314 joins the column corresponding to the candidate column in the join table to the base table. Specifically, the table join unit 314 extracts a candidate column from the join table and joins the extracted candidate column of the join table to the base table.
- the table join method is arbitrary.
- the table join unit 314 may join the join table to the base table by any method such as Left-join or out-join.
- the table after joining may be referred to as an integrated table.
- FIG. 14 is an explanatory diagram showing an example of a process of joining tables.
- a base table BT4 that includes a “sales” column consisting of data used as an objective variable as a target column, and an outer table (join table) FT4 that can be joined.
- the external table FT4 is a correlation table including an "attribute 1" column and an "attribute 2" column, which are columns (correlation columns) that are considered to have a correlation with the target column.
- the "drink name" column corresponds to the binding column candidate
- the "attribute 1 to n" column corresponds to the non-binding column candidate.
- the table join unit 314 extracts the "attribute 1" column and the "attribute 2" column from the external table FT4. In other words, the table join unit 314 deletes columns (non-join column candidates) other than the "drink name” column, the "attribute 1" column, and the “attribute 2" column from the outer table FT4. Then, the table joining unit 314 joins the "product name” column and the "drink name” column of the base table BT4, and joins the "attribute 1" column and the "attribute 2" column to generate the integrated table IT. ..
- the feature amount processing unit 316 generates a feature amount for the data of the target column from the data of the column included in the integrated table.
- the feature amount processing unit 316 can use various methods for generating the feature amount. For example, it is assumed that a missing value exists in the integrated table due to the join method (for example, led-join) or the state of the original table. In this case, the feature amount processing unit 316 may compensate for the missing value by estimating the data distribution by a known method or by using external knowledge information or the like.
- the feature quantity processing unit 316 may generate one or more column sets (clusters) by clustering each selected column based on the distribution of data in each column.
- the method of clustering the columns is also arbitrary, and the feature amount processing unit 316 may cluster the columns by using, for example, the method described in Non-Patent Document 2.
- the feature amount processing unit 316 may generate a feature amount for each clustered column set (cluster).
- the method for generating the feature amount is also arbitrary, and the feature amount may be generated based on a predetermined method.
- the feature quantity processing unit 316 may, for example, combine all the columns included in one cluster to generate a feature quantity.
- the feature quantity processing unit 316 selects one column from one cluster by a predetermined method (for example, selecting the column having the largest number of unique values). You may generate a quantity.
- the feature amount selection unit 318 selects a feature amount that improves the performance of a predetermined task based on the data included in the combined candidate columns or the feature amount generated from the candidate columns.
- improving the performance of a task means improving some evaluation index related to the task, and more specifically, improving the prediction accuracy and the like.
- the evaluation index used at the time of selection is arbitrary and predetermined.
- the feature amount selection unit 318 selects a feature amount that improves the performance of the task of predicting the data of the target column.
- each record in the integrated table corresponds to the training data.
- the mode of the learning model is arbitrary, and examples thereof include a linear model and a random forest.
- the feature amount selection unit 318 selects one or more feature amounts from the generated feature amounts by a predetermined method.
- the method of selecting the feature amount is not limited, and the feature amount selection unit 318 may select the feature amount by using an arbitrary feature amount selection technique. Then, the feature amount selection unit 318 learns the model using the selected feature amount.
- the feature amount selection unit 318 evaluates the learning model based on a predetermined evaluation method, and selects a feature amount that improves the calculated evaluation index.
- the evaluation method is not particularly limited, and the feature amount selection unit 318 may evaluate the learning model based on, for example, the f1 score of cross-validation.
- the feature amount selection unit 318 may generate a plurality of learning models of the same embodiment and aggregate the evaluation results of each of the plurality of learning models (average, weighted average, etc.), and may have different embodiments (for example, linear model, random). A plurality of learning models of forest) may be generated, and the evaluation results of each of the plurality of learning models may be aggregated.
- the feature amount selection unit 318 selects one or more feature amounts having a higher evaluation result. For example, when the feature amount is selected and learned by the forward method (Step Forward), the feature amount selection unit 318 may select the combination of the feature amount having the highest evaluation index.
- the method for selecting the feature amount is not limited to this method, and any method may be used.
- the integrated table output unit 320 outputs an integrated table in which the column including the selected feature amount and the base table are combined. In other words, the integrated table output unit 320 outputs an integrated table that retains the column from which the selected feature amount is generated.
- the integrated table output unit 320 may store the integrated table in the integrated table storage unit 330.
- the integrated table storage unit 330 stores a table (that is, an integrated table) in which columns of an external table are joined to a base table.
- the join table storage unit 21, the correlation table storage unit 22, and the integrated table storage unit 330 are realized by, for example, a magnetic disk or the like.
- the input unit 312, the table connection unit 314, the feature amount processing unit 316, the feature amount selection unit 318, and the integrated table output unit 320 are realized by a computer processor that operates according to a program (integrated table generation program). ..
- the program is stored in a storage unit (not shown) included in the integrated table generator 310, the processor reads the program, and according to the program, the input unit 312, the table connection unit 314, the feature amount processing unit 316, and the feature. It may operate as a quantity selection unit 318 and an integrated table output unit 320. Further, the function of the integrated table generation device 310 may be provided in the SaaS format.
- FIG. 15 is a flowchart showing an operation example of the integrated table generation device 310 of the present embodiment.
- the input unit 312 accepts the inputs of the join table, the candidate column, and the base table (step S51).
- the table join unit 314 joins the column corresponding to the candidate column in the join table to the base table (step S52).
- the feature amount processing unit 316 may generate a feature amount from the data contained in the combined columns.
- the feature amount selection unit 318 selects a feature amount that improves the performance of the task based on the data included in the combined candidate columns (step S53). Then, the integrated table output unit 320 outputs an integrated table in which the column including the selected feature amount and the base table are combined (step S54).
- the input unit 312 accepts the input of the join table, the candidate column, and the base table
- the table join unit 314 uses the column corresponding to the candidate column of the join table as the base table.
- the feature amount selection unit 318 selects a feature amount that improves the performance of the task based on the data included in the combined candidate columns
- the integrated table output unit 320 sets the column containing the selected feature amount. Output the integrated table that is joined with the base table. Therefore, the correlated data can be efficiently integrated into the table including the target column.
- Embodiment 4 Next, a fourth embodiment of the present invention will be described.
- a method of combining the systems from the first embodiment to the third embodiment to efficiently integrate correlated data into a table including a target column will be described.
- FIG. 16 is a block diagram showing a configuration example of an embodiment of the external data utilization system according to the present invention.
- the external data utilization system 400 illustrated in FIG. 16 includes the join table specifying system 100 in the first embodiment, the correlation table specifying system 200 in the second embodiment, and the table integration system 300 in the third embodiment. It is equipped with.
- the join table specifying system 100 stores the join table for the base table generated based on the process shown in the first embodiment in the join table storage unit 140. Further, the correlation table specifying system 200 stores the correlation table and the candidate column generated based on the process shown in the second embodiment in the correlation table storage unit 240. Then, the table integration system 300 acquires the join table for the base table from the join table storage unit 140 based on the process shown in the third embodiment, and the correlation table (candidate column) for the target column from the correlation table storage unit 240. Is acquired, an integrated table is generated, and the integrated table storage unit 330 stores the integrated table.
- join table generation process by the join table specifying system 100 and the correlation table generation process by the correlation table specifying system 200 can be performed independently and independently at any timing. Therefore, it is possible to efficiently integrate data that is correlated with the base table at the required timing.
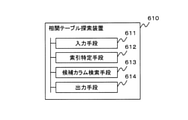
- FIG. 17 is a block diagram showing an outline of the correlation table search device according to the present invention.
- the correlation table search device 610 (for example, the correlation table search device 230) of the present invention selects a column from an external table whose correlation value indicating the degree of correlation between columns is equal to or higher than a predetermined correlation value threshold (for example, threshold T p ). It is a searchable index, and it is generated for each size of the number of elements of the feature vector that shows the characteristics of the data in the column, and the elements of the predetermined number are extracted in ascending order.
- a storage device for example, correlation index storage unit 220 that stores a size-based correlation index, which is an index for extracting columns whose distance is within a distance threshold (for example, threshold T d ) determined based on a correlation value threshold. Therefore, it is determined that the input means 611 (for example, the input unit 232) that accepts the input of the size-based correlation index and the size-based correlation index can be joined when the base table including the target column and the external table are joined.
- Index specifying means 612 for example, index specifying unit 234) for specifying the size-based correlation index used for the search based on a predetermined number of pairs of records (for example, the threshold T c ) and the specified size.
- a column whose distance to the target column is less than or equal to the distance threshold is searched from the external table, a correlation value indicating the degree of correlation between the searched column and the target column is calculated, and the correlation value is the correlation value.
- a candidate column search means 613 for example, a candidate column search unit 236) for searching a column having a threshold value or more as a candidate column
- an output means 614 for example, a correlation table output unit 238) for outputting an external table including the candidate columns.
- the index specifying means 612 may specify the size-specific correlation index having the largest size with a value equal to or less than the threshold value of the number of record pairs. Such a configuration guarantees that all data in the candidate columns can be retrieved.
- FIG. 18 is a block diagram showing an outline of the correlation index construction device according to the present invention.
- the correlation index construction device 620 (for example, the correlation index construction device 110) of the present invention has a correlation value threshold value (for example, a threshold value Tp ) in which a correlation value indicating the degree of correlation between columns is predetermined for each column of the external table.
- a correlation index generation means 621 (for example, a correlation index generation unit 214) for generating a correlation index, which is an index capable of searching the above columns from an external table, is provided.
- the correlation index generation means 621 generates a feature vector showing the features of each column, generates a standardized vector obtained by standardizing the generated feature vector, and extracts a predetermined number of elements from the elements of the generated standardized vector in ascending order.
- a size-based vector is generated, and a size-based correlation index, which is a correlation index for each of the above numbers of sizes, is generated from the generated size-based vector.
- the correlation index generation means 621 defines a function for calculating the correlation value using the distance from the size-based vector, and uses the defined function to calculate the function based on the distance between the feature vector of the target column and the size-based vector. Generates a correlation index that retrieves columns in an external table whose correlation value is greater than or equal to the correlation value threshold.
- the correlation index construction device 620 extracts as a non-joining column candidate a column containing a record that is not expected to be a join key with another table from each outer table included in the outer table group.
- a candidate extraction means for example, a non-bonded column candidate extraction unit 212
- the correlation index generation means 621 may generate a feature vector showing the characteristics of the non-joining column candidate, and may generate a correlation index for the non-joining column candidate. Such a configuration can reduce the cost of generating a correlation index.
- the correlation index generation means 621 may determine each size of the correlation index by size according to the number of elements of the generated feature vector.
- the correlation index generation means 621 determines each size of the correlation index by size based on the generated feature vector, the maximum value of the number of elements of the feature vector, the minimum value of the number of elements of the feature vector, and the like. Further, the size may be determined to be at least one or more of the average values of the number of elements of the feature vector.
- FIG. 19 is a schematic block diagram showing a configuration of a computer according to at least one embodiment.
- the computer 1000 includes a processor 1001, a main storage device 1002, an auxiliary storage device 1003, and an interface 1004.
- the above-mentioned correlation table search device 610 or correlation index construction device 620 is mounted on the computer 1000.
- the operation of each of the above-mentioned processing units is stored in the auxiliary storage device 1003 in the form of a program (correlation table search program, correlation index construction program).
- the processor 1001 reads a program from the auxiliary storage device 1003, expands it to the main storage device 1002, and executes the above processing according to the program.
- the auxiliary storage device 1003 is an example of a non-temporary tangible medium.
- non-temporary tangible media include magnetic disks, magneto-optical disks, CD-ROMs (Compact Disc Read-only memory), DVD-ROMs (Read-only memory), which are connected via interface 1004. Examples include semiconductor memory.
- the program may be for realizing a part of the above-mentioned functions. Further, the program may be a so-called difference file (difference program) that realizes the above-mentioned function in combination with another program already stored in the auxiliary storage device 1003.
- difference file difference program
- the size-based correlation used for the search is based on a predetermined number of record pairs that are determined to be joinable when the base table including the target column and the external table are joined.
- Index identification means to identify the index and Using the identified size-specific correlation index, a column whose distance from the target column is equal to or less than the distance threshold value is searched from the external table, and the correlation indicating the degree of correlation between the searched column and the target column is shown.
- a correlation table search device including an output unit that outputs an external table including the candidate column.
- the index specifying means is the correlation table search device according to Appendix 1, which identifies the size-specific correlation index having the largest size with a value equal to or less than the threshold value of the number of pairs of records.
- a correlation index that generates a correlation index that can search columns whose correlation value indicating the degree of correlation between columns is equal to or higher than a predetermined correlation value threshold from the external table. Equipped with a generation means, The correlation index generation means generates a feature vector showing the features of each column, generates a standardized vector obtained by standardizing the generated feature vector, and selects a predetermined number of elements from the generated elements of the standardized vector. A size-based vector extracted in ascending order is generated, and a size-based correlation index, which is a correlation index for each size of the number, is generated from the generated size-based vector.
- the correlation index generation means defines a function for calculating the correlation value using the distance from the size-based vector, and uses the defined function to form the feature vector and the size-based vector of the target column.
- a correlation index constructing apparatus for generating a correlation index for searching a column of the external table whose correlation value calculated by a distance is equal to or greater than the correlation value threshold.
- a non-join column candidate extraction means for extracting a column containing a record that is not expected to be a join key with another table as a non-join column candidate is provided.
- the correlation index building apparatus according to Appendix 3, wherein the correlation index generation means generates a feature vector showing the characteristics of the non-joining column candidate and generates a correlation index for the non-joining column candidate.
- the correlation index generation means determines each size of the correlation index by size based on the generated feature vector, the maximum value of the number of elements of the feature vector, the minimum value of the number of elements of the feature vector, and the like.
- the correlation index construction device according to any one of Supplementary note 3 to Supplementary note 5, which determines the size of at least one or more of the average values of the number of elements of the feature vector.
- a column in which a predetermined number of elements are extracted in ascending order from a size-based vector and the distance to the size-based vector is within the distance threshold determined based on the correlation value threshold is described above. Accepts the input of the size-based correlation index from the storage device that stores the size-based correlation index, which is an index extracted from the external table.
- the computer uses the size-based correlation index for a search based on a predetermined number of record pairs that are determined to be joinable when the base table including the target column and the outer table are joined. Identify the size-specific correlation index and Using the identified size-based correlation index, the computer searches the external table for columns whose distance from the target column is equal to or less than the distance threshold value, and the degree of correlation between the searched column and the target column. The correlation value indicating the above is calculated, and a column whose correlation value is equal to or greater than the correlation value threshold value is searched as a candidate column.
- a correlation table search method characterized in that the computer outputs an external table containing the candidate columns.
- a computer generates a feature vector showing the features of each column of the external table, generates a standardized vector obtained by standardizing the generated feature vector, and generates a predetermined number of elements of the generated standardized vector.
- a size-based vector obtained by extracting elements in ascending order is generated, and a size-based correlation index, which is a correlation index for each size of the number, is generated from the generated size-based vector.
- the correlation index is an index that can search columns whose correlation value indicating the degree of correlation between columns is equal to or higher than a predetermined correlation value threshold value from the external table.
- the computer defines a function for calculating the correlation value using the distance from the size-based vector, and uses the defined function to calculate the function based on the distance between the feature vector and the size-based vector of the target column.
- a method for constructing a correlation index which comprises generating a correlation index for searching a column of the external table whose correlation value is equal to or greater than the correlation value threshold.
- Input processing that accepts the input of the correlation index by size from the storage device that stores the correlation index by size. From the size-based correlation index, the size-based correlation used for the search is based on a predetermined number of record pairs that are determined to be joinable when the base table including the target column and the external table are joined.
- Index identification process to identify the index, Using the identified size-specific correlation index, a column whose distance from the target column is equal to or less than the distance threshold value is searched from the external table, and the correlation indicating the degree of correlation between the searched column and the target column is shown.
- Candidate column search processing that calculates a value and searches for a column whose correlation value is equal to or greater than the correlation value threshold value as a candidate column, and A program storage medium that stores a correlation table search program for executing output processing that outputs an external table containing the candidate columns.
- the correlation index generation process To the computer For each column of the external table, execute the correlation index generation process to generate the correlation index, which is an index that can search the column whose correlation value indicating the degree of correlation between the columns is equal to or greater than the predetermined correlation value threshold value.
- a feature vector showing the features of each column is generated, a standardized vector obtained by standardizing the generated feature vector is generated, and a predetermined number of elements are selected from the generated elements of the standardized vector.
- a size-based vector extracted in ascending order is generated, and a size-based correlation index, which is a correlation index for each size of the number, is generated from the generated size-based vector.
- a function for calculating the correlation value is defined using the distance from the size-based vector, and the defined function is used to set the feature vector and the size-based vector of the target column.
- Input processing that accepts the input of the correlation index by size from the storage device that stores the correlation index by size. From the size-based correlation index, the size-based correlation used for the search is based on a predetermined number of record pairs that are determined to be joinable when the base table including the target column and the external table are joined.
- Index identification process to identify the index, Using the identified size-specific correlation index, a column whose distance from the target column is equal to or less than the distance threshold value is searched from the external table, and the correlation indicating the degree of correlation between the searched column and the target column is shown.
- Candidate column search processing that calculates a value and searches for a column whose correlation value is equal to or greater than the correlation value threshold value as a candidate column, and
- a correlation table search program for executing output processing that outputs an external table containing the candidate columns.
- the correlation index generation process To the computer For each column of the external table, execute the correlation index generation process to generate the correlation index, which is an index that can search the column whose correlation value indicating the degree of correlation between the columns is equal to or greater than the predetermined correlation value threshold value.
- a feature vector showing the features of each column is generated, a standardized vector obtained by standardizing the generated feature vector is generated, and a predetermined number of elements are selected from the generated elements of the standardized vector.
- a size-based vector extracted in ascending order is generated, and a size-based correlation index, which is a correlation index for each size of the number, is generated from the generated size-based vector.
- a function for calculating the correlation value is defined using the distance from the size-based vector, and the defined function is used to set the feature vector and the size-based vector of the target column.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Databases & Information Systems (AREA)
- Software Systems (AREA)
- Bioinformatics & Computational Biology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Evolutionary Biology (AREA)
- Evolutionary Computation (AREA)
- Computational Linguistics (AREA)
- Probability & Statistics with Applications (AREA)
- Mathematical Physics (AREA)
- Fuzzy Systems (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2022546786A JP7485057B2 (ja) | 2020-09-02 | 2020-09-02 | 相関索引構築装置、相関テーブル探索装置、方法およびプログラム |
| PCT/JP2020/033309 WO2022049681A1 (ja) | 2020-09-02 | 2020-09-02 | 相関索引構築装置、相関テーブル探索装置、方法およびプログラム |
| US18/024,188 US12147409B2 (en) | 2020-09-02 | 2020-09-02 | Correlation index construction device, correlation table search device, method, and program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/033309 WO2022049681A1 (ja) | 2020-09-02 | 2020-09-02 | 相関索引構築装置、相関テーブル探索装置、方法およびプログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022049681A1 true WO2022049681A1 (ja) | 2022-03-10 |
Family
ID=80491865
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/033309 Ceased WO2022049681A1 (ja) | 2020-09-02 | 2020-09-02 | 相関索引構築装置、相関テーブル探索装置、方法およびプログラム |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US12147409B2 (https=) |
| JP (1) | JP7485057B2 (https=) |
| WO (1) | WO2022049681A1 (https=) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12182091B2 (en) * | 2022-12-30 | 2024-12-31 | Sap Se | Semantic vectorization for feature engineering |
| US12450289B2 (en) * | 2023-08-31 | 2025-10-21 | International Business Machines Corporation | Dataset preparation |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2018156549A (ja) * | 2017-03-21 | 2018-10-04 | 日本電気株式会社 | データ種別を推定するための情報処理方法、情報処理装置および情報処理プログラム |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7966327B2 (en) * | 2004-11-08 | 2011-06-21 | The Trustees Of Princeton University | Similarity search system with compact data structures |
| US10402414B2 (en) * | 2015-01-30 | 2019-09-03 | Nec Corporation | Scalable system and method for weighted similarity estimation in massive datasets revealed in a streaming fashion |
| WO2017170459A1 (ja) | 2016-03-31 | 2017-10-05 | スマートインサイト株式会社 | 異種データソース混在環境におけるフィールド間の関係性の自動的発見のための方法、プログラム、および、システム |
| GB201615745D0 (en) | 2016-09-15 | 2016-11-02 | Gb Gas Holdings Ltd | System for analysing data relationships to support query execution |
| US11093494B2 (en) | 2016-12-06 | 2021-08-17 | Microsoft Technology Licensing, Llc | Joining tables by leveraging transformations |
| JP6249505B1 (ja) | 2016-12-26 | 2017-12-20 | 三菱電機インフォメーションシステムズ株式会社 | 特徴抽出装置およびプログラム |
| US20190050436A1 (en) * | 2017-08-14 | 2019-02-14 | International Business Machines Corporation | Content-based predictive organization of column families |
| US20210216514A1 (en) * | 2020-01-13 | 2021-07-15 | International Business Machines Corporation | Automatically organizing data sets |
-
2020
- 2020-09-02 JP JP2022546786A patent/JP7485057B2/ja active Active
- 2020-09-02 WO PCT/JP2020/033309 patent/WO2022049681A1/ja not_active Ceased
- 2020-09-02 US US18/024,188 patent/US12147409B2/en active Active
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2018156549A (ja) * | 2017-03-21 | 2018-10-04 | 日本電気株式会社 | データ種別を推定するための情報処理方法、情報処理装置および情報処理プログラム |
Non-Patent Citations (2)
| Title |
|---|
| DEKIRU SERIES EDITORIAL DEPT: "320. I Want to Use Multiple Tables in a Query", YOU CAN MASTER [DEKIRU] ACCESS - PERFECT BOOK: THIS IS TOUGH! FULL COLLECTION OF HELPFUL TRICKS, 21 December 2016 (2016-12-21), pages 169 * |
| ZHU ERKANG EKZHU@CS.TORONTO.EDU; DENG DONG DONG.DENG@INCEPTIONIAI.ORG; NARGESIAN FATEMEH FNARGESIAN@CS.TORONTO.EDU; MILLER REN: "JOSIE Overlap Set Similarity Search for Finding Joinable Tables in Data Lakes", DESIGNING INTERACTIVE SYSTEMS CONFERENCE, ACM, 2 PENN PLAZA, SUITE 701NEW YORKNY10121-0701USA, 25 June 2019 (2019-06-25) - 28 June 2019 (2019-06-28), 2 Penn Plaza, Suite 701New YorkNY10121-0701USA , pages 847 - 864, XP058637317, ISBN: 978-1-4503-5850-7, DOI: 10.1145/3299869.3300065 * |
Also Published As
| Publication number | Publication date |
|---|---|
| US20230273911A1 (en) | 2023-08-31 |
| JP7485057B2 (ja) | 2024-05-16 |
| JPWO2022049681A1 (https=) | 2022-03-10 |
| US12147409B2 (en) | 2024-11-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN103838857B (zh) | 一种基于语义的自动服务组合系统及方法 | |
| Liu et al. | ProtDet-CCH: protein remote homology detection by combining long short-term memory and ranking methods | |
| JP7103496B2 (ja) | 関連スコア算出システム、方法およびプログラム | |
| MX2012011923A (es) | Asignacion de atributis aplicables para datos que describen la identidad personal. | |
| KR102438923B1 (ko) | 시계열 분포 특징을 고려한 딥러닝 기반 비트코인 블록 데이터 예측 시스템 | |
| JP2014059754A (ja) | 情報処理システム、及び、情報処理方法 | |
| EP3477505B1 (en) | Fingerprint clustering for content-based audio recogntion | |
| JP7485057B2 (ja) | 相関索引構築装置、相関テーブル探索装置、方法およびプログラム | |
| CN119761376A (zh) | 基于语义对齐的项目研究内容查重方法、装置及电子设备 | |
| CN117992575A (zh) | 文本匹配方法、装置、计算机设备、存储介质、程序产品 | |
| JP5406794B2 (ja) | 検索クエリ推薦装置及び検索クエリ推薦プログラム | |
| JP7424501B2 (ja) | 結合テーブル特定システム、結合テーブル探索装置、方法およびプログラム | |
| CN109241360B (zh) | 组合字符串的匹配方法及装置和电子设备 | |
| JP6145562B2 (ja) | 情報構造化システム及び情報構造化方法 | |
| CN119474479B (zh) | 一种基于同态加密的数据安全检索方法 | |
| JP5362807B2 (ja) | ドキュメントランク付け方法および装置 | |
| CN120804394A (zh) | 基于大模型检索增强生成的服务推荐决策方法和相关设备 | |
| JP2007219929A (ja) | 感性評価システム及び方法 | |
| JP7444269B2 (ja) | テーブル統合システム、方法およびプログラム | |
| CN116228483B (zh) | 基于量子驱动的学习路径推荐方法及装置 | |
| CN118013023A (zh) | 科技文献推荐方法、装置、电子设备及存储介质 | |
| CN116228484B (zh) | 基于量子聚类算法的课程组合方法及装置 | |
| JP2011100302A (ja) | ランキング関数生成装置、ランキング関数生成方法、ランキング関数生成プログラム | |
| JP7646091B2 (ja) | 情報処理装置、検索方法、及び検索プログラム | |
| US20230281275A1 (en) | Identification method and information processing device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20952421 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022546786 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 20952421 Country of ref document: EP Kind code of ref document: A1 |