WO2022013954A1 - 機械学習プログラム、機械学習方法および情報処理装置 - Google Patents
機械学習プログラム、機械学習方法および情報処理装置 Download PDFInfo
- Publication number
- WO2022013954A1 WO2022013954A1 PCT/JP2020/027411 JP2020027411W WO2022013954A1 WO 2022013954 A1 WO2022013954 A1 WO 2022013954A1 JP 2020027411 W JP2020027411 W JP 2020027411W WO 2022013954 A1 WO2022013954 A1 WO 2022013954A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- machine learning
- training data
- learning model
- data group
- generated
- Prior art date
Links
Images












Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
- G06N20/20—Ensemble learning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/09—Supervised learning
Definitions
- the embodiment of the present invention relates to a machine learning technique.
- a classification task that determines which category in a predefined set of categories belongs (for example, part-speech estimation, named entity extraction, word meaning determination of each word contained in a sentence). Etc.) are known to be solved using a machine learning model generated by machine learning.
- stacking executes machine learning by using the output result of the first machine learning model for the training data as an input to the second machine learning model.
- stacking executes machine learning by using the output result of the first machine learning model for the training data as an input to the second machine learning model.
- machine learning of the second machine learning model may be executed so as to correct an error in the determination result of the first machine learning model.
- the training data is divided into k subsets, and a first machine learning model generated by k-1 subsets is used. The judgment result is added to the remaining one subset.
- a method of generating training data of a second machine learning model by repeating the work of adding a determination result k times while exchanging a subset of the determination result addition targets.
- One aspect is to provide machine learning programs, machine learning methods and information processing devices that can execute efficient machine learning.
- the machine learning program causes the computer to execute the process of selecting, the process of generating the first machine learning model, and the process of generating the second training data group.
- the selection process selects a plurality of data from the first training data group based on the frequency of appearance of the same labeled data included in the first training data group.
- the process of generating the first machine learning model generates the first machine learning model by machine learning using a plurality of selected data.
- the first training data group and the result output by the first machine learning model when the data included in the first training data group are input are combined. Generate 2 training data groups.
- FIG. 1 is an explanatory diagram illustrating an outline of an embodiment.
- FIG. 2 is an explanatory diagram illustrating a conventional example.
- FIG. 3 is an explanatory diagram illustrating an outline of an embodiment in which noise is added.
- FIG. 4 is a block diagram showing a functional configuration example of the information processing apparatus according to the embodiment.
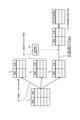
- FIG. 5A is an explanatory diagram illustrating an example of a training data set.
- FIG. 5B is an explanatory diagram illustrating an example of appearance frequency data.
- FIG. 5C is an explanatory diagram illustrating an example of entropy data.
- FIG. 5D is an explanatory diagram illustrating an example of self-information content data.
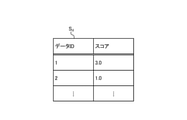
- FIG. 5E is an explanatory diagram illustrating an example of score data.
- FIG. 5A is an explanatory diagram illustrating an example of a training data set.
- FIG. 5B is an explanatory diagram illustrating an example of appearance frequency data.
- FIG. 5C is an explanatory diagram illustrating an
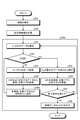
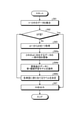
- FIG. 6A is a flowchart showing an example of training data stability determination processing.
- FIG. 6B is a flowchart showing an example of the training data stability determination process.
- FIG. 7 is a flowchart showing a modified example of the training data stability determination process.
- FIG. 8 is an explanatory diagram illustrating an outline of the determination method selection process.
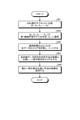
- FIG. 9 is a flowchart showing an example of the determination method selection process.
- FIG. 10A is a flowchart showing a processing example relating to the addition of the determination result.
- FIG. 10B is an explanatory diagram illustrating an example of the result data.
- FIG. 11A is a flowchart showing a processing example relating to the addition of the determination result.
- FIG. 11B is an explanatory diagram illustrating an example of the result data.
- FIG. 12A is a flowchart showing a processing example relating to the addition of the determination result.
- FIG. 12B is an explanatory diagram illustrating an example of the result data.
- FIG. 1 is an explanatory diagram illustrating an outline of the embodiment.
- a classification task for assigning a "unique expression label" indicating a unique expression to each word (sub-character string) in a sentence is machine-learned using a stacking method.
- the first machine learning model M1 and the second machine learning model M2 to be solved by the first machine learning model M1 and the second machine learning model M2 are generated by machine learning using the training data set D.
- the classification task is not limited to the above example, and may be part-speech estimation or word meaning determination of a word.
- the classification tax may be solved using a machine learning model generated by machine learning, and in addition to the classification of words in the document, the presence or absence of physical abnormalities is classified from biological data such as blood pressure and heart rate. It may be used to classify the pass / fail of the subject (examinee) based on the evaluation of each subject and the grade data such as the score of the mid-term / final examination. Therefore, the data included in the training data set used to generate the machine learning model (hereinafter referred to as “case”) may be a case to be learned according to the classification task. For example, when a machine learning model for classifying the presence or absence of a physical abnormality is generated, the biometric data for each learning target and the correct answer (presence or absence of physical abnormality) for the biometric data are included in each case.
- the training data set D is given a correct answer label indicating the "named entity label" of the correct answer in each case (for example, each word in the sentence).
- supervised learning using the training data set D generates a first machine learning model M1 and a second machine learning model M2 such as a gradient boosting tree (GBT) and a neural network.
- GBT gradient boosting tree
- the stability of the judgment by the machine learning model using the training data set D is estimated (S1).
- the frequency may be any of absolute frequency, relative frequency, and cumulative frequency.
- the stability of each case may be estimated based on the ratio calculated based on the frequency of appearance.
- the "cases with the same contents" are the same data with the same label, and in the present embodiment, the stability is estimated based on the appearance frequency of each such data.
- the stability of the judgment by the machine learning model using the training data set D for each case included in the training data set D means that each case can be stably judged by the machine learning model using the training data set D. It means whether or not there is. For example, in a case where stable determination is possible, it is presumed that the same determination result can be obtained even with a machine learning model obtained by dividing and learning the training data set D in the k-fold cross-validation test. Since there are many cases with the same content given the same correct label in the training data set D and cases with low ambiguity in the classification destination category, the cases that can be stably determined correspond to the same correct label. It can be estimated based on the frequency of appearance of cases with the same content given.
- the case where the determination result is unstable is a case where it is presumed that different determination results can be obtained depending on the division method in the k-validation cross test. Cases in which this judgment result is unstable correspond to cases in which there are few cases with the same content in the training data set D and cases in which the classification destination category is highly ambiguous. It can be estimated based on the frequency of appearance of.
- the training data set D1 in which a case that can be stably determined is selected from the training data set D based on the estimation result in S1 and the training data set D2 other than the training data set D1 are divided. ..
- machine learning is performed with the data (training data set D1) determined to be stably determineable, and the first machine learning model M1 is generated (S2).
- each data included in the training data set D is input to the first machine learning model M1, and the first determination result output by the first machine learning model M1 is added to the training data set D.
- Generate training data set D3 (S3).
- machine learning using the training data set D3 is performed to generate a second machine learning model M2.
- the training data set D3 in which the first determination result is added to the training data set D outputs the final determination result so as to correct the error in the determination result of the first machine learning model M1. It will be suitable for the generation of.
- FIG. 2 is an explanatory diagram illustrating a conventional example.
- the training data set D100 is divided into k subsets (D100 1 ... D100 k-1 , D100 k) (S101), and the training data set D100 is trained with the k-1 subsets.
- 1 Generate a machine learning model M101 (S102).
- the determination result obtained by inference by the first machine learning model M101 with the remaining one subset as an input is added to the subset (S103).
- the training data set D101 of the second machine learning model M102 is generated by repeating S102 and S103 k times while exchanging the data for adding the determination result in this way (S104).
- the second machine learning model M102 is created by machine learning using the created training data set D101 (S105).
- the training data set D3 of the second machine learning model M2 can be efficiently created without creating a plurality of machine learning models M1, and efficient machine learning is executed. can do. Further, even when compared with a simple method in which training data sets for each of the first machine learning model M1 and the second machine learning model M2 are prepared in advance, the amount of data to which the correct answer flag is given is small, which is efficient. Can perform machine learning.
- FIG. 3 is an explanatory diagram illustrating an outline of an embodiment when noise is added.
- the first determination result obtained by applying the first machine learning model M1 to the training data set D is added to the training data set D to generate the training data set D3 of the second machine learning model M2. May be added with noise.
- the first determination result obtained by adding noise to the input of the first machine learning model M1 may be added to the training data set D (S5a).
- the first machine learning model M1 may be applied to the training data set D to add noise to the result output by the first machine learning model M1 and add it to the training data set D (S5b).
- the learning model M1 When noise is added in this way, the case where the result is difficult to change even if noise is added can be stably determined by the first machine learning model M1, and the case where the result is likely to change when noise is added is the first machine.
- the determination result becomes unstable. Therefore, by adding the first determination result by the first machine learning model M1 to the training data set D, the second machine learning model M2 is generated so as to correct the error of the determination result of the first machine learning model M1.
- the training data set D3 for this purpose can be generated, and the accuracy of the final determination result by the second machine learning model M2 can be improved.
- FIG. 4 is a block diagram showing a functional configuration example of the information processing apparatus according to the embodiment.
- the information processing apparatus 1 has an input / output unit 10, a storage unit 20, and a control unit 30.
- a PC Personal Computer
- the like can be applied to the information processing device 1.
- the input / output unit 10 controls an input / output interface when the control unit 30 inputs / outputs various information.
- the input / output unit 10 controls an input / output interface with an input device such as a keyboard and a microphone connected to the information processing device 1 and a display device such as a liquid crystal display device.
- the input / output unit 10 controls a communication interface for performing data communication with an external device connected via a communication network such as a LAN (Local Area Network).
- a communication network such as a LAN (Local Area Network).
- the information processing device 1 receives an input such as a training data set D via the input / output unit 10 and stores it in the storage unit 20. Further, the information processing apparatus 1 reads out the first machine learning model information 21 and the second machine learning model information 22 regarding the generated first machine learning model M1 and the second machine learning model M2 from the storage unit 20, and the input / output unit 10 Output to the outside via.
- the storage unit 20 is realized by, for example, a semiconductor memory element such as a RAM (Random Access Memory) or a flash memory (Flash Memory), or a storage device such as an HDD (Hard Disk Drive).
- the storage unit 20 includes training data set D, appearance frequency data S f , entropy data Sh , self-information amount data S i , score data S d , training data set D 3, first machine learning model information 21 and second machine learning. Stores model information 22 and the like.
- the training data set D consists of a case to be learned (for example, each word contained in each of a plurality of sentences) and a set of correct answer labels (for example, "unique expression label") given to the case (case and correct answer label).
- FIG. 5A is an explanatory diagram illustrating an example of the training data set D.
- a word included in a sentence and a correct answer label (“unique expression label”) attached to the word are stored in the training data set D for each data ID corresponding to the training data of each of the plurality of sentences. ), That is, a pair of a case and a correct label is included.
- the named entity of the type "General” is the correct answer.
- the named entity of the type "Molecular” is the correct answer.
- the appearance frequency data S f is data obtained by summarizing the appearance frequency of the pair of the case included in the training data set D and the correct answer label.
- Figure 5B is an explanatory view for explaining an example of frequency data S f.
- the appearance frequency data S f includes the appearance frequency aggregated for each correct answer label for each case included in the training data set D. More specifically, the appearance frequency data S f includes cases with the same content and the appearance frequency aggregated for each of the same correct answer labels. For example, in the case of "solvent mixture”, the frequency of appearance of the correct label "General” is 3. Similarly, for the case of "n-propyl bromede”, the frequency of appearance of the correct label "Molecular” is 5. Further, in the case of "water”, the frequency of appearance of the correct label "Molecular” is 2083, and the frequency of appearance of the correct label "General” is 5.
- the entropy data S h is, for each case that is included in the training data set D, the total number of cases of cases to be included in the training data set D, and examples of the same content, appearance frequency obtained by aggregating the same answer every label.
- the entropy in the information theory calculated based on the above is shown.
- Figure 5C is an explanatory view for explaining an example of entropy data S h.
- the entropy data S h represents "Solvent Mixture”, "n-propyl bromide", the entropy of each case, such as "water”.
- the self-information amount data Si is the self-information amount calculated based on the total number of cases included in the training data set D, the cases with the same contents, and the appearance frequency for each correct answer label. show.
- FIG. 5D is an explanatory diagram for explaining an example of self-information amount data S i.
- the self information amount data S i is "Solvent Mixture” and "General” and “n-propyl bromide” and examples of the same contents such as "Molecular" self information of the same correct answer each label Is shown.
- the score data S d is data obtained by scoring the stability of the above-mentioned determination for each sentence included in the training data set D.
- Figure 5E is an explanatory view for explaining an example of the score data S d.
- the score data S d shows the score for the stability of the determination for each data ID corresponding to each of the plurality of sentences included in the training data set D.
- the first machine learning model information 21 is information about the first machine learning model M1 generated by performing supervised learning.
- the second machine learning model information 22 is information about the second machine learning model M2 generated by performing supervised learning.
- the first machine learning model information 21 and the second machine learning model information 22 are parameters for constructing a model such as a gradient boosting tree and a neural network.
- the control unit 30 has a first machine learning model generation unit 31, a training data generation unit 32, and a second machine learning model generation unit 33.
- the control unit 30 can be realized by a CPU (Central Processing Unit), an MPU (Micro Processing Unit), or the like. Further, the control unit 30 can also be realized by hard-wired logic such as ASIC (Application Specific Integrated Circuit) or FPGA (Field Programmable Gate Array).
- ASIC Application Specific Integrated Circuit
- FPGA Field Programmable Gate Array
- the first machine learning model generation unit 31 is a processing unit that generates the first machine learning model M1 using the training data set D. Specifically, the first machine learning model generation unit 31 selects a plurality of cases from the training data set D based on the appearance frequency of each case with the same content and the same correct label included in the training data set D. select. As a result, the first machine learning model generation unit 31 obtains a training data set D1 that selects a case that can be stably determined from the training data set D. Next, the first machine learning model generation unit 31 generates the first machine learning model M1 by machine learning using a plurality of cases included in the training data set D1. Next, the first machine learning model generation unit 31 stores the first machine learning model information 21 regarding the generated first machine learning model M1 in the storage unit 20.
- the training data generation unit 32 is a processing unit that generates a training data set D3 for generating the second machine learning model M2. Specifically, the training data generation unit 32 constructs the first machine learning model M1 based on the first machine learning model information 21. Next, the training data generation unit 32 adds the result output by the first machine learning model M1 to the training data set D when the cases included in the training data set D are input to the first machine learning model M1 constructed. To generate the training data set D3.
- the second machine learning model generation unit 33 is a processing unit that generates the second machine learning model M2 using the training data set D3. Specifically, the second machine learning model generation unit 33 has each case included in the training data set D3 and a determination result of the first machine learning model M1 for the case (result output by the first machine learning model M1). A second machine learning model M2 is generated by machine learning using and. Next, the second machine learning model generation unit 33 stores the second machine learning model information 22 regarding the generated second machine learning model M2 in the storage unit 20.
- the training data set D1 is obtained by calculating a score indicating the stability of the judgment result of each case based on the appearance frequency of each case in the training data set D.
- the training data stability determination process is performed (S10).
- FIG. 6A and 6B are flowcharts showing an example of training data stability determination processing.
- the first machine learning model generation unit 31 collects the pair of the case and the correct answer label from the training data set D and aggregates the frequency of appearance (S20). I do.
- the first machine learning model generation unit 31 stores a set of data IDs in the training data set D in an array (I) or the like for processing (S21). Next, the first machine learning model generation unit 31 determines whether or not the data ID in the array (I) is empty (S22), and processes S23 to S25 until it is determined to be empty (S22: Yes). repeat.
- the first machine learning model generation unit 31 acquires one data ID from the array (I) and is a variable for processing (S22: No). It is stored in id) (S23). At this time, the first machine learning model generation unit 31 deletes the acquired data ID from the array (I). Next, the first machine learning model generation unit 31 acquires a case of the same content and a pair of the same correct label from the data corresponding to the variable (id) in the training data set D (S24), and the acquired number (appearance). The appearance frequency data S f is updated based on the frequency) (S25).
- the first machine learning model generation unit 31 When the data ID in the array (I) is determined to be empty (S22: Yes), the first machine learning model generation unit 31 has the entropy for each collected case, the case with the same content, and the same correct label for each case. A process (S30) for calculating the amount of self-information is performed.
- the first machine learning model generating unit 31 stores such arrangement for processing the event set in the frequency data S f (E) (S31) . Next, the first machine learning model generation unit 31 determines whether or not the case in the array (E) is empty (S32), and processes S33 to S35 until it is determined to be empty (S32: Yes). repeat.
- the first machine learning model generation unit 31 When it is determined that the case in the sequence (E) is not empty (S32: No), the first machine learning model generation unit 31 has one case from the sequence (E). Acquire and store in the variable (ex) for processing (S33). At this time, the first machine learning model generation unit 31 deletes the acquired case from the array (E). Next, the first machine learning model generation unit 31 searches for cases corresponding to the variable (ex) in the training data set D, and totals the corresponding number for each correct answer label (S34). Next, the first machine learning model generation unit 31 calculates the entropy and the self-information amount in the known information theory for the pair of the case to be processed and the correct answer label based on the aggregation result of S34, and calculates the calculation result. Based on this, the entropy data Sh and the self-information amount data Si are updated (S35).
- the first machine learning model generation unit 31 When the case in the array (E) is determined to be empty (S32: Yes), as shown in FIG. 6B, the first machine learning model generation unit 31 has the same content and the same correct answer label as described above. A process for estimating the stability of the determined determination is performed (S40).
- the first machine learning model generation unit 31 stores a set of data IDs in the training data set D in an array (I) or the like for processing (S41). Next, the first machine learning model generation unit 31 determines whether or not the data ID in the array (I) is empty (S42), and processes S43 to S46 until it is determined to be empty (S42: Yes). repeat.
- the first machine learning model generation unit 31 acquires one data ID from the array (I) and is a variable for processing (S42: No). It is stored in id) (S43). At this time, the first machine learning model generation unit 31 deletes the acquired data ID from the array (I).
- the first machine learning model generation unit 31 acquires a case having the same content and a pair of the same correct label from the data corresponding to the variable (id) in the training data set D (S44). That is, the first machine learning model generation unit 31 acquires an example of the same content regarding the text of the data ID and a pair for each of the same correct answer labels.
- the first machine learning model generation unit 31 is the same based on the acquired case of the same content, the appearance frequency data S f of the pair for the same correct answer label, the entropy data S h , and the self-information amount data S i. Stability / instability is determined with respect to the example of the content and the stability of the above-mentioned determination for each of the same correct answer labels (S45).
- the appearance frequency is less than the threshold value (f), and the pair of the rare case and the correct answer label in the training data set D is regarded as an unstable case.
- the first machine learning model generation unit 31 sets the pair of the correct label and the case where the self-information amount is larger than the threshold value (i) and the entropy is less than the threshold value (h) as an unstable case. do.
- the pair of the correct label and the case that does not meet the above conditions shall be a stable case.
- the threshold values (f), (i), and (h) related to this determination may be arbitrarily set by the user, for example.
- the first machine learning model generation unit 31 performs data corresponding to the variable (id) based on the case of the same content regarding the text of the data ID and the result of stability / instability determined for each of the same correct answer labels (id).
- a score indicating the stability of the sentence calculates and adds the calculation result to the score data S d (S46). For example, the first machine learning model generation unit 31 calculates the score by using the number of unstable cases or the ratio of unstable cases to the total number as an index value and weighting according to the index value.
- the first machine learning model generating unit 31 based on the score data S d, remaining excluding the less stable sentences A process is performed in which the text data set is used as the training data set D1 for generating the first machine learning model M1 (S50).
- the first machine learning model generation unit 31 sorts the score data S d and excludes unstable data (sentences) having a low score from the training data set D (S51). Next, the first machine learning model generation unit 31 outputs the remaining data set as the training data set D1 (S52), and ends the process. In addition to excluding unstable data (sentences) with a low score, the first machine learning model generation unit 31 includes some cases (for example, cases determined to be unstable cases and correct answer labels) included in the sentences. (Pair with) may be selected and excluded.
- the training data set D1 for generating the first machine learning model M1 is selected from the training data set D by performing another process (another selection method) for S30 and S40 described above. good.
- the first machine learning model generation unit 31 sets each self-information amount as an initial value of a score indicating the stability of the pair of each collected case and the correct answer label, and the following ( ⁇ ) Repeat the procedure of.
- the first machine learning model generation unit 31 uses the remaining training data set as the training data set D1 for the first machine learning model M1.
- -For each sentence the sum of the scores of each case that appears is used as the score of that sentence, and the sentence with the highest score is excluded as a sentence with low stability.
- the score of the case included in the excluded sentences is set to "self-information amount / (N + 1)" (N is the number of times the corresponding case appears in all the sentences excluded so far).
- the first machine learning model generation unit 31 may repeat until the maximum value in the score of each sentence falls below the threshold value specified in advance, instead of repeating it a predetermined number of times.
- the self-information amount is divided by N + 1, but any calculation method may be used as long as it is a score update method in which the score becomes smaller each time it is excluded. ..
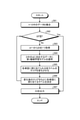
- FIG. 7 is a flowchart showing a modified example of the training data stability determination process, and is an example of the above-mentioned another selection method.
- the first machine learning model generation unit 31 performs a process of totaling the (appearance) frequency (S20) and a process of calculating the self-information amount (S30). After that, a process (S30a) relating to another selection method is performed.
- the first machine learning model generation unit 31 stores a set of data IDs in the training data set D in an array (I) or the like for processing (S41). Next, the first machine learning model generation unit 31 determines whether or not the data ID in the array (I) is empty (S42), and processes S43 to S46a until it is determined to be empty (S42: Yes). repeat.
- the first machine learning model generation unit 31 acquires one data ID from the array (I) and is a variable for processing (S42: No). It is stored in id) (S43). At this time, the first machine learning model generation unit 31 deletes the acquired data ID from the array (I).
- the first machine learning model generation unit 31 acquires a pair of a case and a correct answer label from the data corresponding to the variable (id) in the training data set D (S44). That is, the first machine learning model generation unit 31 acquires an example of the same content regarding the text of the data ID and a pair for each of the same correct answer labels. Next, the first machine learning model generation unit 31 obtains the score S i in the pair of each case and the correct answer label by using the score calculation method described above, and adds the sum to the score data S d (S46a).
- the first machine learning model generation unit 31 excludes the data d having the largest score data S d from the training data set D (S53). ). Next, the first machine learning model generation unit 31 updates the score S i corresponding to the pair of each case in the excluded data d and the correct answer label (S54), and determines whether or not the above-mentioned repetitive end condition is satisfied. Is determined (S55).
- the first machine learning model generation unit 31 When the repetition end condition (for example, repeating a predetermined number of times, the maximum value in the score of a sentence falls below a predetermined threshold value, etc.) is not satisfied (S55: No), the first machine learning model generation unit 31 The process is returned to S41. When the repetition end condition is satisfied (S55: Yes), the first machine learning model generation unit 31 outputs the remaining data set as the training data set D1 (S56), and ends the process.
- the repetition end condition for example, repeating a predetermined number of times, the maximum value in the score of a sentence falls below a predetermined threshold value, etc.
- the first machine learning model generation unit 31 performs a determination method selection process for selecting one of a plurality of determination methods from the plurality of determination methods (S11). Specifically, in the determination method selection process, which of the plurality of selection methods described above in S10 is to be adopted is determined.
- the determination method selection process is a process performed when the above-mentioned plurality of selection methods are implemented in S10, and is skipped when a single selection method is implemented in S10.
- FIG. 8 is an explanatory diagram illustrating an outline of the determination method selection process.
- the training data set D is divided into k subsets (D 1 ... D k-1 , D k) (S71), and training is performed using the k-1 subsets.
- the first machine learning model M1 is generated (S72).
- the judgment result obtained by applying the first machine learning model M1 to the remaining one subset is compared with the correct answer (S73), and the score of each sentence is calculated and sorted (match rate with the correct answer, Correct score, etc.).
- the sorted result is compared with the judgment result by a plurality of judgment methods, and the optimum judgment method is selected by using average passage or the like.
- FIG. 9 is a flowchart showing an example of the determination method selection process.
- the first machine learning model generation unit 31 divides the training data set D into k subsets (S61).
- the first machine learning model generation unit 31 generates the first machine learning model M1 with ⁇ D 1 ... D k-1 ⁇ , and applies D k to the generated first machine learning model M1 (S62).
- the first machine learning model generation unit 31 calculates and sorts the score of each data of Dk based on the application result (S63). Next, the first machine learning model generation unit 31 compares the results of each of the stability determination methods (selection method in S10) in each training data, and scores the degree of agreement (S64). Next, the first machine learning model generation unit 31 adopts the result of the method (selection method) having the highest degree of matching among the plurality of selection methods implemented in S10 (S65).
- the first machine learning model generation unit 31 generated and generated the first machine learning model M1 by machine learning using a plurality of cases included in the training data set D1 (S12).
- the first machine learning model information 21 relating to the first machine learning model M1 is stored in the storage unit 20.
- the training data generation unit 32 constructs the first machine learning model M1 based on the first machine learning model information 21, and inputs each case included in the training data set D into the first machine learning model M1. In this case, the determination result output by the first machine learning model M1 is added to the training data set D (S13). As a result, the training data generation unit 32 generates the training data set D3.
- FIG. 10A is a flowchart showing a processing example relating to the addition of the determination result, and is an example of a case where noise is added to the result output by the first machine learning model M1.
- the training data generation unit 32 stores the set of data IDs in the training data set D in the processing array (I) or the like (S81). Next, the training data generation unit 32 determines whether or not the data ID in the array (I) is empty (S82), and repeats the processes of S83 to S86 until it is determined to be empty (S82: Yes).
- the training data generation unit 32 acquires one data ID from the array (I) and sets it as a variable (id) for processing. Store (S83). At this time, the training data generation unit 32 deletes the acquired data ID from the array (I).
- the training data generation unit 32 applies the first machine learning model M1 to the data corresponding to the variable (id) in the training data set D (S84).
- the training data generation unit 32 randomly changes the score of each label assigned to each word (case) with respect to the determination result obtained from the first machine learning model M1 (S85).
- the training data generation unit 32 determines a label to be assigned to each word based on the score after the change (S86).
- FIG. 10B is an explanatory diagram illustrating an example of the result data.
- the result data K1 in FIG. 10B is an example of data when the label is determined after the score is randomly changed by S85.
- the score value changes because random noise is added to the estimated score included in the determination result obtained from the first machine learning model M1. Therefore, in S86, in some cases, a determination result different from the case where the score is not changed can be obtained. For example, in “mixture”, it is determined to be "I-General” before the score changes, but it is determined to be "O" due to the change in the score.
- the training data generation unit 32 adds the label determined for each case to the training data set D. Output D3 (S84) and end the process.
- FIG. 11A is a flowchart showing a processing example relating to the addition of the determination result, and is an example of adding noise to the result output by the first machine learning model M1.
- the training data generation unit 32 stores the set of data IDs in the training data set D in the processing array (I) or the like (S81). Next, the training data generation unit 32 determines whether or not the data ID in the array (I) is empty (S82), and repeats the processes of S83 to S86a until it is determined to be empty (S82: Yes).
- the training data generation unit 32 acquires one data ID from the array (I) and sets it as a variable (id) for processing. Store (S83). At this time, the training data generation unit 32 deletes the acquired data ID from the array (I).
- the training data generation unit 32 applies the first machine learning model M1 to the data corresponding to the variable (id) in the training data set D (S84).
- the training data generation unit 32 converts the score of each label assigned to each word (case) into a probability value for the determination result obtained from the first machine learning model M1 (S85a). Specifically, it is converted into a probability value according to the score so that the probability value becomes easy to be selected if the score is high.
- the training data generation unit 32 determines a label to be assigned to each word based on the converted probability value (S86a).
- FIG. 11B is an explanatory diagram illustrating an example of the result data.
- the result data K2 in FIG. 11B is an example of data when the label is determined based on the probability value after conversion from the score.
- the label is stochastically determined (selected) based on the estimated score converted into the probability value. Therefore, in some cases where the probability values are in equilibrium, a judgment result different from the judgment result based on the magnitude of the score may be obtained. For example, in “propyl”, the score is determined to be “I-Molecular”, but it is determined to be "B-Molecular” by probabilistic selection.
- FIG. 12A is a flowchart showing a processing example relating to the addition of the determination result, and is an example of a case where noise is added to the input of the first machine learning model M1.
- the training data generation unit 32 stores the set of data IDs in the training data set D in the processing array (I) or the like (S81). Next, the training data generation unit 32 determines whether or not the data ID in the array (I) is empty (S82), and repeats the processes of S83 to S84c until it is determined to be empty (S82: Yes).
- the training data generation unit 32 acquires one data ID from the array (I) and sets it as a variable (id) for processing. Store (S83). At this time, the training data generation unit 32 deletes the acquired data ID from the array (I).
- the training data generation unit 32 randomly selects a part of the words of the data corresponding to the variable (id) in the training data set D, and replaces the selected word with another word (S84a).
- the word to be replaced may be randomly selected from the data or may be selected based on the certainty (score) of the estimation result.
- the replacement with another word may be a replacement with any word.
- the replacement target word may be replaced with a synonym / related word using a synonym / related word dictionary, or may be replaced with a selected word using a word distributed expression.
- the training data generation unit 32 applies the first machine learning model M1 to the replaced data (S84b), and determines the label to be assigned to each word from the determination result obtained from the first machine learning model M1 (S84c). ).
- FIG. 12B is an explanatory diagram illustrating an example of the result data.
- the result data K3 in FIG. 12B is an example of data when the label is determined based on the replaced word (word in the second column).
- the content is replaced with another content in some cases (words). For example, “mixture” in the sixth row from the top is replaced with “compound”. In this way, noise may be added to the data input to the first machine learning model M1.
- the information processing apparatus 1 has a control unit 30 that executes processing related to the first machine learning model generation unit 31 and the training data generation unit 32.
- the first machine learning model generation unit 31 selects a plurality of cases from the training data set D based on the appearance frequency of each case included in the training data set D. Further, the first machine learning model generation unit 31 generates the first machine learning model M1 by machine learning using a plurality of selected cases.
- the training data generation unit 32 generates a training data set D3 that combines the training data set D and the result output by the first machine learning model M1 when each case included in the training data set D is input.
- control unit 30 executes a process related to the second machine learning model generation unit 33 that generates the second machine learning model M2 using the training data set D3.
- the control unit 30 inputs the data to be classified into the first machine learning model M1 and obtains the output result of the first machine learning model M1.
- the control unit 30 inputs the output result of the first machine learning model M1 to the second machine learning model M2, and obtains the classification result from the second machine learning model M2.
- the information processing apparatus 1 since the information processing apparatus 1 generates the first machine learning model M1 by machine learning using a plurality of cases selected based on the appearance frequency of each case included in the training data set D, the second machine.
- the training data set D3 for learning the training model M2 for example, the first machine learning model M1 is not repeatedly generated k times. Therefore, in the information processing apparatus 1, the training data set D3 for learning the second machine learning model M2 can be efficiently generated, and efficient machine learning can be executed.
- the first machine learning model generation unit 31 excludes cases in the training data set D whose appearance frequency is less than the threshold value from the selection target. As described above, in the information processing apparatus 1, in the training data set D, the case where the appearance frequency is less than the threshold value and the determination result by the first machine learning model M1 is presumed to be unstable is excluded from the selection target. The first machine learning model M1 is generated. Therefore, in the case where the result output by the first machine learning model M1 when each case included in the training data set D is presumed to be unstable, the result is different from the correct answer label of the training data set D. Is easy to obtain.
- the information processing apparatus 1 can generate the training data set D3 for generating the second machine learning model M2 so as to correct the error of the determination result of the first machine learning model M1, and the second machine learning.
- the accuracy of the final determination result by the model M2 can be improved.
- the first machine learning model generation unit 31 calculates the entropy and the self-information amount of each case based on the appearance frequency, and in the training data set D, the self-information amount is larger than the threshold and the entropy is less than the threshold. Exclude the case of.
- the self-information amount is larger than the threshold value and the entropy is less than the threshold value, and the determination result by the first machine learning model M1 becomes unstable.
- the first machine learning model M1 is generated after excluding the estimated cases from the selection target.
- the information processing apparatus 1 can generate the training data set D3 for generating the second machine learning model M2 so as to correct the error in the determination result of the first machine learning model M1, and the second machine learning.
- the accuracy of the final determination result by the model M2 can be improved.
- the training data generation unit 32 is the first when the training data set D and each case included in the data set after changing the contents of some cases of each case included in the training data set D are input.
- the training data set D3 for the second machine learning model M2 is generated together with the result output by the machine learning model M1.
- the judgment result of the first machine learning model M1 is likely to change by changing the contents of some of the cases included in the training data set D and adding noise to the training data set D.
- the result output by the first machine learning model M1 it becomes easy to obtain a result different from the correct answer label of the training data set D.
- the information processing apparatus 1 can generate the training data set D3 for generating the second machine learning model M2 so as to correct the error in the determination result of the first machine learning model M1, and the second machine learning.
- the accuracy of the final determination result by the model M2 can be improved.
- the training data generation unit 32 generates the training data set D3 by adding noise to the result output by the first machine learning model M1 at a specific ratio.
- the second machine learning model corrects the error of the determination result of the first machine learning model M1 by adding noise to the result output by the first machine learning model M1 at a specific ratio.
- the training data set D3 for generating M2 may be generated.
- control unit 30 executes the process related to the second machine learning model generation unit 33.
- the second machine learning model generation unit 33 generates the second machine learning model M2 by machine learning based on the generated training data set D3.
- the second machine learning model M2 can be generated by the generated training data set D3.
- each case included in the training data set D is a word included in each of a plurality of sentences as teachers.
- the information processing apparatus 1 efficiently uses the training data set D3 for generating the second machine learning model M2 that outputs the part word estimation, named entity extraction, word meaning determination, etc. of each word included in the sentence as the final result. Can be generated in.
- each component of each of the illustrated devices does not necessarily have to be physically configured as shown in the figure. That is, the specific form of distribution / integration of each device is not limited to the one shown in the figure, and all or part of them may be functionally or physically distributed / physically in any unit according to various loads and usage conditions. Can be integrated and configured.
- various processing functions performed by the information processing device 1 execute all or any part thereof on the CPU (or a microcomputer such as an MPU or MCU (MicroControllerUnit)) or a GPU (Graphics Processing Unit). You may try to do it.
- various processing functions are executed in whole or in any part on a program analyzed and executed by a CPU (or a microcomputer such as an MPU or MCU) or a GPU, or on hardware by wired logic. Needless to say, it's okay.
- various processing functions performed by the information processing apparatus 1 may be executed by a plurality of computers in cooperation by cloud computing.
- FIG. 13 is a block diagram showing an example of a computer configuration.
- the computer 200 includes a CPU 201 that executes various arithmetic processes, a GPU 201a that specializes in predetermined arithmetic processes such as image processing and machine learning processing, an input device 202 that accepts data input, and a monitor 203. And a speaker 204.
- the computer 200 has a medium reading device 205 for reading a program or the like from a storage medium, an interface device 206 for connecting to various devices, and a communication device 207 for communicating with an external device by wire or wirelessly.
- the computer 200 has a RAM 208 for temporarily storing various information and a hard disk device 209. Further, each part (201 to 209) in the computer 200 is connected to the bus 210.
- the hard disk device 209 is for executing various processes in the first machine learning model generation unit 31, the training data generation unit 32, the second machine learning model generation unit 33, and the like in the control unit 30 described in the above embodiment.
- Program 211 is stored. Further, the hard disk device 209 stores various data 212 such as the training data set D referred to by the program 211.
- the input device 202 receives, for example, an input of operation information from an operator.
- the monitor 203 displays, for example, various screens operated by the operator. For example, a printing device or the like is connected to the interface device 206.
- the communication device 207 is connected to a communication network such as a LAN (Local Area Network), and exchanges various information with an external device via the communication network.
- LAN Local Area Network
- the CPU 201 or GPU 201a reads out the program 211 stored in the hard disk device 209, expands it in the RAM 208, and executes it, so that the first machine learning model generation unit 31, the training data generation unit 32, and the second machine learning model generation unit are executed. Performs various processes related to 33 and the like.
- the program 211 may not be stored in the hard disk device 209.
- the computer 200 may read and execute the program 211 stored in a readable storage medium.
- the storage medium that can be read by the computer 200 is, for example, a CD-ROM, a DVD disk, a portable recording medium such as a USB (Universal Serial Bus) memory, a semiconductor memory such as a flash memory, a hard disk drive, or the like.
- the program 211 may be stored in a device connected to a public line, the Internet, a LAN, or the like, and the computer 200 may read the program 211 from these and execute the program 211.
- Second machine learning model generator 200 ... Computer 201 ... CPU 201a ... GPU 202 ... Input device 203 ... Monitor 204 ... Speaker 205 ... Media reader 206 ... Interface device 207 ... Communication device 208 ... RAM 209 ... Hard disk device 210 ... Bus 211 ... Program 212 ... Various data D, D1 to D3, D100, D101 ... Training data sets K1 to K3 ... Result data M1, M101 ... First machine learning model M2, M102 ... Second machine learning Model S f ... Appearance frequency data S h ... Entropy data S i ... Self-information amount data S d ... Score data
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Artificial Intelligence (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Medical Informatics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Machine Translation (AREA)
Abstract
実施形態の機械学習プログラムは、選択する処理と、第1の機械学習モデルを生成する処理と、第2の訓練データ群を生成する処理とをコンピュータに実行させる。選択する処理は、第1の訓練データ群に含まれる同一のラベルが付された同一のデータの出現頻度に基づいて、第1の訓練データ群から複数のデータを選択する。第1の機械学習モデルを生成する処理は、選択した複数のデータを用いた機械学習により第1の機械学習モデルを生成する。第2の訓練データ群を生成する処理は、第1の訓練データ群と、第1の訓練データ群に含まれるデータを入力した場合に第1の機械学習モデルが出力する結果とを合わせた第2の訓練データ群を生成する。
Description
本発明の実施形態は、機械学習技術に関する。
従来、入力データが与えられたとき、それが予め定義されたカテゴリ集合の中のどのカテゴリに属するかを判定する分類タスク(例えば、文章に含まれる各単語の品詞推定、固有表現抽出、語義判定等)を機械学習により生成した機械学習モデルを用いて解く手法が知られている。
また、訓練データに対する第1機械学習モデルによる出力結果を、第2機械学習モデルへの入力として使用して機械学習を実行するスタッキングと呼ばれる機械学習の手法がある。一般的に、アンサンブル学習の1手法であるスタッキングを用いて積み重ねられた複数の機械学習モデルの推論精度は、単一の機械学習モデルの推論精度よりも良いことが知られている。
このスタッキングにおいては、例えば、第1機械学習モデルの判定結果の誤りを修正するように第2機械学習モデルの機械学習が実行されても良い。このような第2機械学習モデルを生成するための訓練データを生成する従来技術としては、訓練データをk個のサブセットに分割し、k-1個のサブセットで生成した第1機械学習モデルを用いて残り1個のサブセットに判定結果を追加する。次いで、判定結果を追加する作業を判定結果の追加対象のサブセットを入れ替えながらk回繰り返すことで、第2機械学習モデルの訓練データを生成する手法が知られている。
Wu et al. N-fold Templated Piped Correction. Proc. of IJCNLP 2004
しかしながら、上記の従来技術では、分割したk個のサブセットを入れ替えながらk回繰り返すことで第1機械学習モデルをk個作らなければならず、効率よく機械学習を行うことが困難であるという問題がある。
1つの側面では、効率的な機械学習を実行できる機械学習プログラム、機械学習方法および情報処理装置を提供することを目的とする。
1つの案では、機械学習プログラムは、選択する処理と、第1の機械学習モデルを生成する処理と、第2の訓練データ群を生成する処理とをコンピュータに実行させる。選択する処理は、第1の訓練データ群に含まれる同一のラベルが付された同一のデータの出現頻度に基づいて、第1の訓練データ群から複数のデータを選択する。第1の機械学習モデルを生成する処理は、選択した複数のデータを用いた機械学習により第1の機械学習モデルを生成する。第2の訓練データ群を生成する処理は、第1の訓練データ群と、第1の訓練データ群に含まれるデータを入力した場合に第1の機械学習モデルが出力する結果とを合わせた第2の訓練データ群を生成する。
効率的な機械学習が実行される。
以下、図面を参照して、実施形態にかかる機械学習プログラム、機械学習方法および情報処理装置を説明する。実施形態において同一の機能を有する構成には同一の符号を付し、重複する説明は省略する。なお、以下の実施形態で説明する機械学習プログラム、機械学習方法および情報処理装置は、一例を示すに過ぎず、実施形態を限定するものではない。また、以下の各実施形態は、矛盾しない範囲内で適宜組みあわせてもよい。
図1は、実施形態の概要を説明する説明図である。図1に示すように、本実施形態では、文章中の各単語(部分文字列)に対して固有表現を示す「固有表現ラベル」を割り当てる分類タスクを、スタッキングの手法を用いて機械学習された第1機械学習モデルM1および第2機械学習モデルM2により解く際の、第1機械学習モデルM1および第2機械学習モデルM2が、訓練データセットDを用いた機械学習で生成される。
なお、分類タスクは、上記の例に限定するものではなく、単語の品詞推定や語義判定でもよい。また、分類タクスは、機械学習によって生成された機械学習モデルを用いて解くものであればよく、文書中の単語に関する分類以外にも、血圧、心拍数等の生体データより身体異常の有無を分類するものや、各教科の評価および中間・期末試験の得点などの成績データより対象者(受験者)の合否を分類するものであってもよい。よって、機械学習モデルの生成に用いる訓練データセットに含まれるデータ(以下、事例)については、分類タスクに応じて学習対象とする事例であればよい。例えば、身体異常の有無を分類する機械学習モデルを生成する場合は、学習対象ごとの生体データと、その生体データに対する正解(身体異常の有無)などが各事例に含まれることとなる。
訓練データセットDには、各事例(例えば文章中の各単語)について、その事例における正解の「固有表現ラベル」を示す正解ラベルが付与されている。本実施形態では、訓練データセットDを用いて教師あり学習を行うことで、勾配ブースティング木(GBT)、ニューラルネットワークなどの第1機械学習モデルM1および第2機械学習モデルM2が生成される。
具体的には、本実施形態では、訓練データセットDに含まれる各事例について、全事例の中で同じ正解ラベルが付与された同じ内容の事例が出現する頻度(出現頻度)をもとに、訓練データセットDを用いた機械学習モデルによる判定の安定性を推定する(S1)。頻度は、絶対頻度、相対頻度、累積頻度のいずれかであっても良い。また、出現頻度に基づいて算出される割合をもとに、各事例の安定性が推定されても良い。また、「同じ内容の事例」は、同一のラベルが付された同一のデータであり、本実施形態では、このようなデータ毎の出現頻度をもとに安定性を推定するものとする。
訓練データセットDに含まれる各事例についての、訓練データセットDを用いた機械学習モデルによる判定の安定性とは、各事例が訓練データセットDを用いた機械学習モデルで安定的に判定可能であるか否かを意味する。例えば、安定的に判定可能な事例では、k分割交差検定においてどのように訓練データセットDを分割・学習して得られた機械学習モデルであっても同じ判定結果が得られると推定される。この安定的に判定可能な事例は、訓練データセットDにおいて同一の正解ラベルが付与された同じ内容の事例が多いものや、分類先カテゴリの曖昧性が低いものが相当することから、同じ正解ラベルが付与された同じ内容の事例の出現頻度をもとに推定可能である。逆に、判定結果が不安定な事例は、k分割交差検定における分割方法によっては異なる判定結果が得られると推定される事例である。この判定結果が不安定な事例は、訓練データセットDにおいて同じ内容の事例が少ないものや、分類先カテゴリの曖昧性が高いものが相当することから、同じ正解ラベルが付与された同じ内容の事例の出現頻度をもとに推定可能である。
本実施形態では、S1での推定結果をもとに、訓練データセットDより、安定的に判定可能な事例を選択した訓練データセットD1と、訓練データセットD1以外の訓練データセットD2とに分ける。次いで、本実施形態では、安定的に判定可能と判断されたデータ(訓練データセットD1)で機械学習を行って第1機械学習モデルM1を生成する(S2)。次いで、本実施形態では、訓練データセットDに含まれる各データを第1機械学習モデルM1に入力して、第1機械学習モデルM1が出力した第1の判定結果を訓練データセットDに追加し、訓練データセットD3を生成する(S3)。次いで、本実施形態では、訓練データセットD3を用いた機械学習を行って第2機械学習モデルM2を生成する。
出現頻度をもとに安定的に判定可能と推定されたデータを用いた機械学習により生成した第1機械学習モデルM1では、訓練データセットDを入力データとして推論した場合の第1の判定結果において、不安定になると推定された事例で正解ラベルとは異なる結果(判定結果の誤り)が得られやすくなる。このため、訓練データセットDに第1の判定結果を追加した訓練データセットD3は、第1機械学習モデルM1の判定結果の誤りを修正するように最終判定結果を出力する第2機械学習モデルM2の生成に適したものとなる。
図2は、従来例を説明する説明図である。図2に示すように、従来例では、訓練データセットD100をk個のサブセット(D1001…D100k-1、D100k)に分割し(S101)、k-1個のサブセットで訓練して第1機械学習モデルM101を生成する(S102)。次いで、従来例では、残り1個のサブセットを入力として第1機械学習モデルM101が推論して得られた判定結果をそのサブセットに追加する(S103)。従来例では、このようにして判定結果を追加するデータを入れ替えながらS102、S103をk回繰り返すことで第2機械学習モデルM102の訓練データセットD101を生成する(S104)。次いで、従来例では、作成した訓練データセットD101を用いた機械学習によって第2機械学習モデルM102を作成する(S105)。
このように、従来例では、第2機械学習モデルM102の訓練データセットD101を生成する過程で、分割したk個のサブセット(D1001…D100k-1、D100k)を入れ替えながらk回繰り返すことから、第1機械学習モデルM101をk個作ることとなる。これに対し、本実施形態では、例えば、機械学習モデルM1を複数作成することなく、第2機械学習モデルM2の訓練データセットD3を効率的に作成することができ、効率的な機械学習を実行することができる。また、第1機械学習モデルM1および第2機械学習モデルM2それぞれの訓練データセットを事前に用意する単純な手法と比較しても、正解フラグを付与するデータ量が少なくて済むことから、効率的に機械学習を実行することができる。
図3は、ノイズを加える場合の実施形態の概要を説明する説明図である。図3に示すように、訓練データセットDに第1機械学習モデルM1を適用した第1の判定結果を訓練データセットDに追加し、第2機械学習モデルM2の訓練データセットD3を生成する際には、ノイズを加えてもよい。具体的には、第1機械学習モデルM1の入力にノイズを加えて得られた第1の判定結果を訓練データセットDに追加してもよい(S5a)。または、訓練データセットDに第1機械学習モデルM1を適用して第1機械学習モデルM1が出力する結果にノイズを加えて訓練データセットDに追加してもよい(S5b)。
このようにノイズを加えた場合、ノイズを加えても結果が変化しにくい事例は第1機械学習モデルM1で安定的に判定可能であり、ノイズを加えると結果が変化しやすい事例は第1機械学習モデルM1では判定結果が不安定となる。したがって、第1機械学習モデルM1による第1の判定結果を訓練データセットDに追加することで、第1機械学習モデルM1の判定結果の誤りを修正するように第2機械学習モデルM2を生成するための訓練データセットD3を生成することができ、第2機械学習モデルM2による最終判定結果の精度を向上させることができる。
図4は、実施形態にかかる情報処理装置の機能構成例を示すブロック図である。図4に示すように、情報処理装置1は、入出力部10と、記憶部20と、制御部30とを有する。例えば、情報処理装置1は、PC(Personal Computer)などを適用できる。
入出力部10は、制御部30が各種情報の入出力を行う際の入出力インタフェースを司る。例えば、入出力部10は、情報処理装置1に接続されるキーボードやマイク等の入力装置や液晶ディスプレイ装置などの表示装置との入出力インタフェースを司る。また、入出力部10は、LAN(Local Area Network)等の通信ネットワークを介して接続する外部機器との間でデータ通信を行う通信インタフェースを司る。
例えば、情報処理装置1は、入出力部10を介して訓練データセットDなどの入力を受け、記憶部20に格納する。また、情報処理装置1は、生成した第1機械学習モデルM1および第2機械学習モデルM2に関する第1機械学習モデル情報21および第2機械学習モデル情報22を記憶部20より読み出し、入出力部10を介して外部に出力する。
記憶部20は、例えば、RAM(Random Access Memory)、フラッシュメモリ(Flash Memory)などの半導体メモリ素子や、HDD(Hard Disk Drive)などの記憶装置によって実現される。記憶部20は、訓練データセットD、出現頻度データSf、エントロピーデータSh、自己情報量データSi、スコアデータSd、訓練データセットD3、第1機械学習モデル情報21および第2機械学習モデル情報22などを格納する。
訓練データセットDは、学習対象とする事例(例えば複数の文章それぞれに含まれる各単語)と、その事例に付与された正解ラベル(例えば「固有表現ラベル」)の組(事例と正解ラベルとのペア)についての複数の訓練データの集合である。なお、訓練データは、1文章単位のデータであって、複数の事例と正解ラベルとのペアを含むものとする。
図5Aは、訓練データセットDの一例を説明する説明図である。図5Aに示すように、訓練データセットDには、複数の文章それぞれの訓練データに対応するデータIDごとに、文章に含まれる単語と、その単語に付与された正解ラベル(「固有表現ラベル」)との組、すなわち事例と正解ラベルとのペアが含まれる。
「固有表現ラベル」については、「O」、「General」、「Molecular」がある。「O」は、固有表現(一部を含む)ではない単語を意味するラベルである。「General」は、「General」という型の固有表現(一部を含む)の単語を意味するラベルである。「Molecular」は、「Molecular」という型の固有表現(一部を含む)の単語を意味するラベルである。なお、「General」および「Molecular」では、先頭の単語には「B-」という接頭辞を付与し、2番目以降の単語には「I-」という接頭辞を付与するものとする。
例えば、図示例における訓練データセットDにおいて、「solvent mixture」という事例は、「General」という型の固有表現が正解となる。また、「n-propyl bromide」という事例は、「Molecular」という型の固有表現が正解となる。
図4に戻り、出現頻度データSfは、訓練データセットDに含まれる事例と正解ラベルとのペアの出現頻度を集計したデータである。
図5Bは、出現頻度データSfの一例を説明する説明図である。図5Bに示すように、出現頻度データSfは、訓練データセットDに含まれる各事例について、正解ラベルごとに集計した出現頻度が含まれる。より具体的には、出現頻度データSfは、同じ内容の事例と、同じ正解ラベル毎に集計した出現頻度が含まれる。例えば、「solvent mixture」という事例ついて、正解ラベルが「General」の出現頻度は3である。同様に、「n-propyl bromide」という事例について、正解ラベルが「Molecular」の出現頻度は5である。また、「water」という事例について、正解ラベルが「Molecular」の出現頻度は2083であり、正解ラベルが「General」の出現頻度は5である。
図4に戻り、エントロピーデータShは、訓練データセットDに含まれる各事例について、訓練データセットDに含まれる事例の総事例数、同じ内容の事例と、同じ正解ラベル毎に集計した出現頻度などをもとに計算した情報理論におけるエントロピーを示す。
図5Cは、エントロピーデータShの一例を説明する説明図である。図5Cに示すように、エントロピーデータShは、「solvent mixture」、「n-propyl bromide」、「water」等の各事例のエントロピーを示す。
図4に戻り、自己情報量データSiは、訓練データセットDに含まれる事例の総事例数、同じ内容の事例と、同じ正解ラベル毎の出現頻度などをもとに計算した自己情報量を示す。
図5Dは、自己情報量データSiの一例を説明する説明図である。図5Dに示すように、自己情報量データSiは、「solvent mixture」と「General」、「n-propyl bromide」と「Molecular」等の同じ内容の事例と、同じ正解ラベル毎の自己情報量を示す。
図4に戻り、スコアデータSdは、訓練データセットDに含まれる文章それぞれついて、前述した判定の安定性をスコア化したデータである。
図5Eは、スコアデータSdの一例を説明する説明図である。図5Eに示すように、スコアデータSdは、訓練データセットDに含まれる複数の文章それぞれに対応するデータIDごとの、判定の安定性についてのスコアを示す。
図4に戻り、第1機械学習モデル情報21は、教師あり学習を行うことで生成した第1機械学習モデルM1に関する情報である。第2機械学習モデル情報22は、教師あり学習を行うことで生成した第2機械学習モデルM2に関する情報である。この第1機械学習モデル情報21および第2機械学習モデル情報22は、例えば勾配ブースティング木、ニューラルネットワークなどのモデルを構築するためのパラメータ等である。
制御部30は、第1機械学習モデル生成部31、訓練データ生成部32および第2機械学習モデル生成部33を有する。制御部30は、CPU(Central Processing Unit)やMPU(Micro Processing Unit)などによって実現できる。また、制御部30は、ASIC(Application Specific Integrated Circuit)やFPGA(Field Programmable Gate Array)などのハードワイヤードロジックによっても実現できる。
第1機械学習モデル生成部31は、訓練データセットDを用いて第1機械学習モデルM1を生成する処理部である。具体的には、第1機械学習モデル生成部31は、訓練データセットDに含まれる同じ正解ラベルが付された同じ内容の事例毎の出現頻度に基づいて、訓練データセットDから複数の事例を選択する。これにより、第1機械学習モデル生成部31は、訓練データセットDより安定的に判定可能な事例を選択した訓練データセットD1を得る。次いで、第1機械学習モデル生成部31は、訓練データセットD1に含まれる複数の事例を用いた機械学習により第1機械学習モデルM1を生成する。次いで、第1機械学習モデル生成部31は、生成した第1機械学習モデルM1に関する第1機械学習モデル情報21を記憶部20に格納する。
訓練データ生成部32は、第2機械学習モデルM2を生成するための訓練データセットD3を生成する処理部である。具体的には、訓練データ生成部32は、第1機械学習モデル情報21をもとに第1機械学習モデルM1を構築する。次いで、訓練データ生成部32は、訓練データセットDに含まれる各事例を構築した第1機械学習モデルM1に入力した場合に第1機械学習モデルM1が出力する結果を訓練データセットDに追加して訓練データセットD3を生成する。
第2機械学習モデル生成部33は、訓練データセットD3を用いて第2機械学習モデルM2を生成する処理部である。具体的には、第2機械学習モデル生成部33は、訓練データセットD3に含まれる各事例と、その事例に対する第1機械学習モデルM1の判定結果(第1機械学習モデルM1が出力した結果)とを用いた機械学習により第2機械学習モデルM2を生成する。次いで、第2機械学習モデル生成部33は、生成した第2機械学習モデルM2に関する第2機械学習モデル情報22を記憶部20に格納する。
ここで、第1機械学習モデル生成部31および訓練データ生成部32の処理の詳細を説明する。先ず、第1機械学習モデル生成部31では、訓練データセットDの中の各事例の出現頻度をもとに、各事例の判定結果の安定性を示すスコアを算出して訓練データセットD1を得る訓練データ安定性判定処理を行う(S10)。
図6A、図6Bは、訓練データ安定性判定処理の一例を示すフローチャートである。図6Aに示すように、処理が開始されると、第1機械学習モデル生成部31は、事例と正解ラベルとのペアを訓練データセットDから収集してその出現頻度を集計する処理(S20)を行う。
具体的には、第1機械学習モデル生成部31は、訓練データセットD中のデータIDの集合を処理用の配列(I)等に格納する(S21)。次いで、第1機械学習モデル生成部31は、配列(I)内のデータIDが空であるか否かを判定し(S22)、空と判定(S22:Yes)されるまでS23~S25の処理を繰り返す。
配列(I)内のデータIDが空でないと判定された場合(S22:No)、第1機械学習モデル生成部31は、配列(I)からデータIDを1つ取得し、処理用の変数(id)に格納する(S23)。このとき、第1機械学習モデル生成部31は、取得したデータIDを配列(I)から消去する。次いで、第1機械学習モデル生成部31は、訓練データセットD中の変数(id)に対応するデータから同じ内容の事例と、同じ正解ラベルのペアを取得し(S24)、取得した数(出現頻度)をもとに出現頻度データSfを更新する(S25)。
配列(I)内のデータIDが空と判定された場合(S22:Yes)、第1機械学習モデル生成部31は、収集した事例ごとのエントロピーと、同じ内容の事例と、同じ正解ラベル毎の自己情報量を計算する処理(S30)を行う。
具体的には、第1機械学習モデル生成部31は、出現頻度データSf中の事例集合を処理用の配列(E)等の格納する(S31)。次いで、第1機械学習モデル生成部31は、配列(E)内の事例が空であるか否かを判定し(S32)、空と判定(S32:Yes)されるまでS33~S35の処理を繰り返す。
配列(E)内の事例が空でないと判定された場合(S32:No)、第1機械学習モデル生成部31は、第1機械学習モデル生成部31は、配列(E)から事例を1つ取得し、処理用の変数(ex)に格納する(S33)。このとき、第1機械学習モデル生成部31は、取得した事例を配列(E)から消去する。次いで、第1機械学習モデル生成部31は、訓練データセットD中の変数(ex)に対応する事例を検索し、正解ラベルごとに該当数を集計する(S34)。次いで、第1機械学習モデル生成部31は、S34の集計結果をもとに、処理対象の事例と正解ラベルとのペアについて、公知の情報理論におけるエントロピーと自己情報量を計算し、計算結果をもとにエントロピーデータShおよび自己情報量データSiを更新する(S35)。
配列(E)内の事例が空と判定された場合(S32:Yes)、図6Bに示すように、第1機械学習モデル生成部31は、同じ内容の事例と、同じ正解ラベル毎の、前述した判定の安定性を推定する処理を行う(S40)。
具体的には、第1機械学習モデル生成部31は、訓練データセットD中のデータIDの集合を処理用の配列(I)等に格納する(S41)。次いで、第1機械学習モデル生成部31は、配列(I)内のデータIDが空であるか否かを判定し(S42)、空と判定(S42:Yes)されるまでS43~S46の処理を繰り返す。
配列(I)内のデータIDが空でないと判定された場合(S42:No)、第1機械学習モデル生成部31は、配列(I)からデータIDを1つ取得し、処理用の変数(id)に格納する(S43)。このとき、第1機械学習モデル生成部31は、取得したデータIDを配列(I)から消去する。
次いで、第1機械学習モデル生成部31は、訓練データセットD中の変数(id)に対応するデータから同じ内容の事例と、同じ正解ラベルのペアを取得する(S44)。すなわち、第1機械学習モデル生成部31は、データIDの文章に関する同じ内容の事例と、同じ正解ラベル毎のペアを取得する。次いで、第1機械学習モデル生成部31は、取得した同じ内容の事例と、同じ正解ラベル毎のペアの出現頻度データSf、エントロピーデータSh、自己情報量データSiをもとに、同じ内容の事例と、同じ正解ラベル毎における前述した判定の安定性について、安定・不安定を判定する(S45)。
例えば、第1機械学習モデル生成部31は、出現頻度が閾値(f)未満であり、訓練データセットDにおいて稀な事例と正解ラベルとのペアを不安定な事例とする。または、第1機械学習モデル生成部31は、自己情報量が閾値(i)より大きく、かつ、エントロピーが閾値(h)未満の曖昧性が高い事例と正解ラベルとのペアを不安定な事例とする。また、上記の条件に該当しない事例と正解ラベルとのペアについては、安定な事例とする。なお、この判定に関する閾値(f)、(i)、(h)については、例えばユーザが任意に設定してもよい。
一例として、閾値それぞれがf=4、i=1.0、h=0.8とすると、図5Bの出現頻度データSfにおいては、「solvent mixture」・「General」が不安定な事例となる。同様に、図5CのエントロピーデータShおよび図5Dの自己情報量データSiにおいては、「water」・「General」が不安定な事例となる。
次いで、第1機械学習モデル生成部31は、データIDの文章に関する同じ内容の事例と、同じ正解ラベル毎について判定した安定・不安定の結果をもとに、変数(id)に対応するデータ(文章)の安定性を示すスコアを計算し、計算結果をスコアデータSdに追加する(S46)。例えば、第1機械学習モデル生成部31は、不安定な事例の数または全数に対する不安定な事例の割合を指標値とし、その指標値に応じた重み付けを行うことでスコアの計算を行う。
配列(I)内のデータIDが空と判定された場合(S42:Yes)、第1機械学習モデル生成部31は、スコアデータSdをもとに、安定性の低い文章を除外した残りの文章のデータセットを第1機械学習モデルM1を生成するための訓練データセットD1とする処理を行う(S50)。
具体的には、第1機械学習モデル生成部31は、スコアデータSdをソートし、スコアが低い不安定なデータ(文章)を訓練データセットDから除外する(S51)。次いで、第1機械学習モデル生成部31は、残ったデータセットを訓練データセットD1として出力し(S52)、処理を終了する。なお、第1機械学習モデル生成部31は、スコアが低い不安定なデータ(文章)を除外する以外に、文章に含まれる一部の事例(例えば不安定な事例と判定された事例と正解ラベルとのペア)を選択して除外してもよい。
なお、前述したS30、S40については別の処理(別の選択方法)を行うことで、訓練データセットDの中から第1機械学習モデルM1を生成するための訓練データセットD1を選択してもよい。
具体的には、第1機械学習モデル生成部31は、収集した各事例と正解ラベルとのペアの安定性を表すスコアの初期値として、それぞれの自己情報量を設定し、以下の(・)の手順を予め指定した回数繰り返す。次いで、第1機械学習モデル生成部31は、残った訓練データセットを第1機械学習モデルM1用の訓練データセットD1とする。
・各文章について、出現する各事例のスコアの総和をその文章のスコアとし、スコアが最大となる文章を安定性の低い文章として除外する。
・除外した文章に含まれる事例のスコアを、「自己情報量/(N+1)」とする(Nは、これまでに除外した全ての文章中で該当事例が出現した回数)。
・各文章について、出現する各事例のスコアの総和をその文章のスコアとし、スコアが最大となる文章を安定性の低い文章として除外する。
・除外した文章に含まれる事例のスコアを、「自己情報量/(N+1)」とする(Nは、これまでに除外した全ての文章中で該当事例が出現した回数)。
この別の選択方法において、第1機械学習モデル生成部31は、予め指定した回数繰り返す代わりに、各文章のスコアの中の最大値が、予め指定した閾値を下回るまで繰り返してもよい。
上述した別の選択方法では、除外した文章に含まれる事例のスコアを下げることにより、同じ事例を含む文章が除外されにくくなる。すなわち、同じ事例が、除外される側の文章と残される側の文章の両方に含まれるようにする。なお、スコアの計算方法について、上記の例ではN+1で自己情報量を割っているが、除外される度にスコアが小さくなるようなスコア更新方法であれば、いずれの計算方法であってもよい。
図7は、訓練データ安定性判定処理の変形例を示すフローチャートであり、上記の別の選択方法の一例である。図7に示すように、処理が開始されると、第1機械学習モデル生成部31は、(出現)頻度を集計する処理(S20)と、自己情報量を計算する処理(S30)とを行った後、別の選択方法に関する処理(S30a)を行う。
具体的には、第1機械学習モデル生成部31は、訓練データセットD中のデータIDの集合を処理用の配列(I)等に格納する(S41)。次いで、第1機械学習モデル生成部31は、配列(I)内のデータIDが空であるか否かを判定し(S42)、空と判定(S42:Yes)されるまでS43~S46aの処理を繰り返す。
配列(I)内のデータIDが空でないと判定された場合(S42:No)、第1機械学習モデル生成部31は、配列(I)からデータIDを1つ取得し、処理用の変数(id)に格納する(S43)。このとき、第1機械学習モデル生成部31は、取得したデータIDを配列(I)から消去する。
次いで、第1機械学習モデル生成部31は、訓練データセットD中の変数(id)に対応するデータから事例と正解ラベルとのペアを取得する(S44)。すなわち、第1機械学習モデル生成部31は、データIDの文章に関する同じ内容の事例と、同じ正解ラベル毎のペアを取得する。次いで、第1機械学習モデル生成部31は、前述したスコアの計算方法を用いて各事例と正解ラベルとのペアにおけるスコアSiを求め、その総和をスコアデータSdに加える(S46a)。
配列(I)内のデータIDが空と判定された場合(S42:Yes)、第1機械学習モデル生成部31は、スコアデータSdが最大のデータdを訓練データセットDから除外する(S53)。次いで、第1機械学習モデル生成部31は、除外したデータd中の各事例と正解ラベルとのペアに対応するスコアSiを更新し(S54)、前述した繰り返しの終了条件を満たすか否かを判定する(S55)。
繰り返しの終了条件(例えば、予め指定した回数繰り返す、文章のスコアの中の最大値が予め指定した閾値を下回る等)を満たさない場合(S55:No)、第1機械学習モデル生成部31は、S41に処理を戻す。繰り返しの終了条件を満たす場合(S55:Yes)、第1機械学習モデル生成部31は、残ったデータセットを訓練データセットD1として出力し(S56)、処理を終了する。
図4に戻り、第1機械学習モデル生成部31は、S10に次いで、複数の判定手法の中からいずれかの判定手法を選択する判定手法選択処理を行う(S11)。具体的には、判定手法選択処理では、S10において前述した複数通りの選択方法のうち、どの方法を採用するかを決定する。なお、判定手法選択処理は、S10において前述した複数通りの選択方法を実施している場合に行われる処理であり、S10において一通りの選択方法を実施している場合にはスキップされる。
図8は、判定手法選択処理の概要を説明する説明図である。図8に示すように、判定手法選択処理では、訓練データセットDをk個のサブセット(D1…Dk-1、Dk)に分割し(S71)、k-1個のサブセットで学習して第1機械学習モデルM1を生成する(S72)。次いで、残り1個のサブセットに第1機械学習モデルM1を適用して得られた判定結果と正解とを比較し(S73)、各文章のスコアを計算してソートする(正解との一致率、正解のスコア等)。次いで、ソートした結果と、複数の判定手法による判定結果とを比較し、average percision等を用いて最適な判定手法を選択する。
図9は、判定手法選択処理の一例を示すフローチャートである。図9に示すように、処理が開始されると、第1機械学習モデル生成部31は、訓練データセットDをk個のサブセットに分割する(S61)。次いで、第1機械学習モデル生成部31は、{D1…Dk-1}で第1機械学習モデルM1を生成し、生成した第1機械学習モデルM1にDkを適用する(S62)。
次いで、第1機械学習モデル生成部31は、適用結果をもとにDkの各データのスコアを計算してソートする(S63)。次いで、第1機械学習モデル生成部31は、各訓練データにおける安定性判定手法(S10における選択方法)それぞれの結果と比較し、一致の度合をスコア化する(S64)。次いで、第1機械学習モデル生成部31は、S10において実施した複数通りの選択方法の中で、最も一致の度合の高い手法(選択方法)の結果を採用する(S65)。
図4に戻り、S11に次いで、第1機械学習モデル生成部31は、訓練データセットD1に含まれる複数の事例を用いた機械学習により第1機械学習モデルM1を生成し(S12)、生成した第1機械学習モデルM1の関する第1機械学習モデル情報21を記憶部20に格納する。
次いで、訓練データ生成部32は、第1機械学習モデル情報21をもとに第1機械学習モデルM1を構築し、訓練データセットDに含まれる各事例を構築した第1機械学習モデルM1に入力した場合に第1機械学習モデルM1が出力する判定結果を訓練データセットDに追加する(S13)。これにより、訓練データ生成部32は、訓練データセットD3を生成する。
ここで、第2機械学習モデルM2の訓練データセットD3を生成する際にノイズを加える場合を説明する。図10Aは、判定結果の追加に関する処理例を示すフローチャートであり、第1機械学習モデルM1が出力する結果にノイズを加える場合の一例である。
図10Aに示すように、処理が開始されると、訓練データ生成部32は、訓練データセットD中のデータIDの集合を処理用の配列(I)等に格納する(S81)。次いで、訓練データ生成部32は、配列(I)内のデータIDが空であるか否かを判定し(S82)、空と判定(S82:Yes)されるまでS83~S86の処理を繰り返す。
配列(I)内のデータIDが空でないと判定された場合(S82:No)、訓練データ生成部32は、配列(I)からデータIDを1つ取得し、処理用の変数(id)に格納する(S83)。このとき、訓練データ生成部32は、取得したデータIDを配列(I)から消去する。
次いで、訓練データ生成部32は、訓練データセットD中の変数(id)に対応するデータに第1機械学習モデルM1を適用する(S84)。次いで、訓練データ生成部32は、第1機械学習モデルM1より得られた判定結果について、各単語(事例)に割り当てられる各ラベルのスコアをランダムに変化させる(S85)。次いで、訓練データ生成部32は、変化後のスコアをもとに、各単語に割り当てるラベルを決定する(S86)。
図10Bは、結果データの一例を説明する説明図である。図10Bの結果データK1は、S85によりスコアをランダムに変化させた後にラベルを決定した場合のデータ例である。
図10Bに示すように、結果データK1では、第1機械学習モデルM1より得られた判定結果に含まれる推定スコアにランダムなノイズが加えられているため、スコア値が変化している。このため、S86において、一部の事例では、スコアを変化させない場合とは異なる判定結果が得られる。例えば、「mixture」では、スコアの変化前では「I-General」と判定されるところ、スコアの変化により「O」と判定されている。
図10Aに戻り、配列(I)内のデータIDが空と判定された場合(S82:Yes)、訓練データ生成部32は、各事例について決定したラベルを訓練データセットDに追加した訓練データセットD3を出力し(S84)、処理を終了する。
図11Aは、判定結果の追加に関する処理例を示すフローチャートであり、第1機械学習モデルM1が出力する結果にノイズを加える場合の一例である。
図11Aに示すように、処理が開始されると、訓練データ生成部32は、訓練データセットD中のデータIDの集合を処理用の配列(I)等に格納する(S81)。次いで、訓練データ生成部32は、配列(I)内のデータIDが空であるか否かを判定し(S82)、空と判定(S82:Yes)されるまでS83~S86aの処理を繰り返す。
配列(I)内のデータIDが空でないと判定された場合(S82:No)、訓練データ生成部32は、配列(I)からデータIDを1つ取得し、処理用の変数(id)に格納する(S83)。このとき、訓練データ生成部32は、取得したデータIDを配列(I)から消去する。
次いで、訓練データ生成部32は、訓練データセットD中の変数(id)に対応するデータに第1機械学習モデルM1を適用する(S84)。次いで、訓練データ生成部32は、第1機械学習モデルM1より得られた判定結果について、各単語(事例)に割り当てられる各ラベルのスコアを確率値に変換する(S85a)。具体的には、スコアが高ければ選択されやすくなるような確率値となるように、スコアに応じた確率値に変換する。次いで、訓練データ生成部32は、変換した確率値をもとに、各単語に割り当てるラベルを決定する(S86a)。
図11Bは、結果データの一例を説明する説明図である。図11Bの結果データK2は、スコアから変換した後の確率値をもとにラベルを決定した場合のデータ例である。
図10Bに示すように、結果データK2では、確率値に変換された推定スコアをもとに、確率的にラベルを決定(選択)している。このため、確率値が均衡する一部の事例では、スコアの大小を元にした判定結果とは異なる判定結果が得られる場合がある。例えば、「propyl」では、スコアの大小では「I-Molecular」と判定されるところ、確率的な選択により「B-Molecular」とされている。
図12Aは、判定結果の追加に関する処理例を示すフローチャートであり、第1機械学習モデルM1の入力にノイズを加える場合の一例である。
図12Aに示すように、処理が開始されると、訓練データ生成部32は、訓練データセットD中のデータIDの集合を処理用の配列(I)等に格納する(S81)。次いで、訓練データ生成部32は、配列(I)内のデータIDが空であるか否かを判定し(S82)、空と判定(S82:Yes)されるまでS83~S84cの処理を繰り返す。
配列(I)内のデータIDが空でないと判定された場合(S82:No)、訓練データ生成部32は、配列(I)からデータIDを1つ取得し、処理用の変数(id)に格納する(S83)。このとき、訓練データ生成部32は、取得したデータIDを配列(I)から消去する。
次いで、訓練データ生成部32は、訓練データセットD中の変数(id)に対応するデータの一部の単語をランダムに選択し、選択した単語を別の単語に置換する(S84a)。なお、置換対象の単語は、データの中からランダムに選んだり、推定結果の確信度(スコア)をもとに選んだりしてもよい。また、別の単語への置換は、任意の単語への置換であってもよい。または、類義語・関連語辞書を利用して置換対象の単語の類義語・関連語への置換であってもよいし、単語分散表現を利用して選択した単語への置換であってもよい。
次いで、訓練データ生成部32は、置換後のデータに第1機械学習モデルM1を適用し(S84b)、第1機械学習モデルM1より得られた判定結果より各単語に割り当てるラベルを決定する(S84c)。
図12Bは、結果データの一例を説明する説明図である。図12Bの結果データK3は、置換後の単語(2列目の単語)をもとにラベルを決定した場合のデータ例である。
図12Bに示すように、結果データK3では、一部の事例(単語)において、その内容が別の内容に置換されている。例えば、上から6段目の「mixture」は「compound」に置換されている。このように、第1機械学習モデルM1に入力するデータに対してノイズを付加する構成であってもよい。
以上のように、情報処理装置1は、第1機械学習モデル生成部31と、訓練データ生成部32とに関する処理を実行する制御部30を有する。第1機械学習モデル生成部31は、訓練データセットDに含まれる各事例の出現頻度に基づいて、訓練データセットDから複数の事例を選択する。また、第1機械学習モデル生成部31は、選択した複数の事例を用いた機械学習により第1機械学習モデルM1を生成する。訓練データ生成部32は、訓練データセットDと、訓練データセットDに含まれる各事例を入力した場合に第1機械学習モデルM1が出力する結果とを合わせた訓練データセットD3を生成する。また、制御部30は、訓練データセットD3を用いて第2機械学習モデルM2を生成する第2機械学習モデル生成部33に関する処理を実行する。制御部30では、分類対象のデータを分類する分類タスクにおいて、第1機械学習モデルM1に分類対象のデータを入力し、第1機械学習モデルM1の出力結果を得る。次いで、制御部30では、第1機械学習モデルM1の出力結果を第2機械学習モデルM2に入力して、第2機械学習モデルM2より分類結果を得る。これにより、単一の機械学習モデルの分類精度よりも精度の良い分類結果を得ることができる。
このように、情報処理装置1では、訓練データセットDに含まれる各事例の出現頻度に基づいて選択した複数の事例を用いた機械学習により第1機械学習モデルM1を生成するので、第2機械学習モデルM2を学習するための訓練データセットD3を生成する際に、例えば第1機械学習モデルM1をk回繰り返して生成することがない。したがって、情報処理装置1では、第2機械学習モデルM2を学習するための訓練データセットD3を効率的に生成することができ、効率的な機械学習を実行することができる。
また、第1機械学習モデル生成部31は、訓練データセットDのうち出現頻度が閾値未満の事例を選択対象から除外する。このように、情報処理装置1では、訓練データセットDうち、出現頻度が閾値未満であり、第1機械学習モデルM1による判定結果が不安定になると推定される事例を選択対象から除外した上で第1機械学習モデルM1を生成する。このため、訓練データセットDに含まれる各事例を入力した場合に第1機械学習モデルM1が出力する結果において、不安定になると推定される事例では、訓練データセットDの正解ラベルとは異なる結果が得られやすくなる。したがって、情報処理装置1では、第1機械学習モデルM1の判定結果の誤りを修正するように第2機械学習モデルM2を生成するための訓練データセットD3を生成することができ、第2機械学習モデルM2による最終判定結果の精度を向上させることができる。
また、第1機械学習モデル生成部31は、出現頻度に基づいて各事例のエントロピーおよび自己情報量を計算し、訓練データセットDのうち、自己情報量が閾値より大きく、かつ、エントロピーが閾値未満の事例を選択対象から除外する。このように、情報処理装置1では、訓練データセットDのうち、自己情報量が閾値より大きく、かつ、エントロピーが閾値未満の事例であり、第1機械学習モデルM1による判定結果が不安定になると推定される事例を選択対象から除外した上で第1機械学習モデルM1を生成する。このため、訓練データセットDに含まれる各事例を入力した場合に第1機械学習モデルM1が出力する結果において、不安定になると推定される事例では、訓練データセットDの正解ラベルとは異なる結果が得られやすくなる。したがって、情報処理装置1では、第1機械学習モデルM1の判定結果の誤りを修正するように第2機械学習モデルM2を生成するための訓練データセットD3を生成することができ、第2機械学習モデルM2による最終判定結果の精度を向上させることができる。
また、訓練データ生成部32は、訓練データセットDと、訓練データセットDに含まれる各事例の一部の事例の内容を変更した後のデータセットに含まれる各事例を入力した場合に第1機械学習モデルM1が出力する結果とを合わせて第2機械学習モデルM2用の訓練データセットD3を生成する。このように、訓練データセットDに含まれる各事例の一部の事例の内容を変更し、訓練データセットDにノイズを加えることで、第1機械学習モデルM1の判定結果が変化しやすい事例では、第1機械学習モデルM1が出力する結果において、訓練データセットDの正解ラベルとは異なる結果が得られやすくなる。したがって、情報処理装置1では、第1機械学習モデルM1の判定結果の誤りを修正するように第2機械学習モデルM2を生成するための訓練データセットD3を生成することができ、第2機械学習モデルM2による最終判定結果の精度を向上させることができる。
また、訓練データ生成部32は、第1機械学習モデルM1が出力する結果に特定の割合でノイズを加えて訓練データセットD3を生成する。このように、情報処理装置1では、第1機械学習モデルM1が出力する結果に特定の割合でノイズを加え、第1機械学習モデルM1の判定結果の誤りを修正するように第2機械学習モデルM2を生成するための訓練データセットD3を生成してもよい。
また、制御部30は、第2機械学習モデル生成部33に関する処理を実行する。第2機械学習モデル生成部33は、生成した訓練データセットD3に基づいた機械学習により第2機械学習モデルM2を生成する。これにより、情報処理装置1では、生成した訓練データセットD3により第2機械学習モデルM2を生成することができる。
また、訓練データセットDに含まれる各事例は、教師とする複数の文章それぞれに含まれる単語である。これにより、情報処理装置1では、文章に含まれる各単語の品詞推定、固有表現抽出、語義判定等を最終結果として出力する第2機械学習モデルM2を生成するための訓練データセットD3を効率的に生成することができる。
なお、図示した各装置の各構成要素は、必ずしも物理的に図示の如く構成されていることを要しない。すなわち、各装置の分散・統合の具体的形態は図示のものに限られず、その全部または一部を、各種の負荷や使用状況などに応じて、任意の単位で機能的または物理的に分散・統合して構成することができる。
また、情報処理装置1で行われる各種処理機能は、CPU(またはMPU、MCU(Micro Controller Unit)等のマイクロ・コンピュータ)あるいはGPU(Graphics Processing Unit)上で、その全部または任意の一部を実行するようにしてもよい。また、各種処理機能は、CPU(またはMPU、MCU等のマイクロ・コンピュータ)あるいはGPUで解析実行されるプログラム上、またはワイヤードロジックによるハードウエア上で、その全部または任意の一部を実行するようにしてもよいことは言うまでもない。また、情報処理装置1で行われる各種処理機能は、クラウドコンピューティングにより、複数のコンピュータが協働して実行してもよい。
ところで、上記の実施形態で説明した各種の処理は、予め用意されたプログラムをコンピュータで実行することで実現できる。そこで、以下では、上記の実施形態と同様の機能を有するプログラムを実行するコンピュータ(ハードウエア)の一例を説明する。図13は、コンピュータ構成の一例を示すブロック図である。
図13に示すように、コンピュータ200は、各種演算処理を実行するCPU201と、画像処理や機械学習処理等の所定の演算処理に特化したGPU201aと、データ入力を受け付ける入力装置202と、モニタ203と、スピーカ204とを有する。また、コンピュータ200は、記憶媒体からプログラム等を読み取る媒体読取装置205と、各種装置と接続するためのインタフェース装置206と、有線または無線により外部機器と通信接続するための通信装置207とを有する。また、コンピュータ200は、各種情報を一時記憶するRAM208と、ハードディスク装置209とを有する。また、コンピュータ200内の各部(201~209)は、バス210に接続される。
ハードディスク装置209には、上記の実施形態で説明した制御部30における第1機械学習モデル生成部31、訓練データ生成部32および第2機械学習モデル生成部33等における各種の処理を実行するためのプログラム211が記憶される。また、ハードディスク装置209には、プログラム211が参照する訓練データセットD等の各種データ212が記憶される。入力装置202は、例えば、操作者から操作情報の入力を受け付ける。モニタ203は、例えば、操作者が操作する各種画面を表示する。インタフェース装置206は、例えば印刷装置等が接続される。通信装置207は、LAN(Local Area Network)等の通信ネットワークと接続され、通信ネットワークを介した外部機器との間で各種情報をやりとりする。
CPU201あるいはGPU201aは、ハードディスク装置209に記憶されたプログラム211を読み出して、RAM208に展開して実行することで、第1機械学習モデル生成部31、訓練データ生成部32および第2機械学習モデル生成部33等に関する各種の処理を行う。なお、プログラム211は、ハードディスク装置209に記憶されていなくてもよい。例えば、コンピュータ200が読み取り可能な記憶媒体に記憶されたプログラム211を読み出して実行するようにしてもよい。コンピュータ200が読み取り可能な記憶媒体は、例えば、CD-ROMやDVDディスク、USB(Universal Serial Bus)メモリ等の可搬型記録媒体、フラッシュメモリ等の半導体メモリ、ハードディスクドライブ等が対応する。また、公衆回線、インターネット、LAN等に接続された装置にこのプログラム211を記憶させておき、コンピュータ200がこれらからプログラム211を読み出して実行するようにしてもよい。
1…情報処理装置
10…入出力部
20…記憶部
21…第1機械学習モデル情報
22…第2機械学習モデル情報
30…制御部
31…第1機械学習モデル生成部
32…訓練データ生成部
33…第2機械学習モデル生成部
200…コンピュータ
201…CPU
201a…GPU
202…入力装置
203…モニタ
204…スピーカ
205…媒体読取装置
206…インタフェース装置
207…通信装置
208…RAM
209…ハードディスク装置
210…バス
211…プログラム
212…各種データ
D、D1~D3、D100、D101…訓練データセット
K1~K3…結果データ
M1、M101…第1機械学習モデル
M2、M102…第2機械学習モデル
Sf…出現頻度データ
Sh…エントロピーデータ
Si…自己情報量データ
Sd…スコアデータ
10…入出力部
20…記憶部
21…第1機械学習モデル情報
22…第2機械学習モデル情報
30…制御部
31…第1機械学習モデル生成部
32…訓練データ生成部
33…第2機械学習モデル生成部
200…コンピュータ
201…CPU
201a…GPU
202…入力装置
203…モニタ
204…スピーカ
205…媒体読取装置
206…インタフェース装置
207…通信装置
208…RAM
209…ハードディスク装置
210…バス
211…プログラム
212…各種データ
D、D1~D3、D100、D101…訓練データセット
K1~K3…結果データ
M1、M101…第1機械学習モデル
M2、M102…第2機械学習モデル
Sf…出現頻度データ
Sh…エントロピーデータ
Si…自己情報量データ
Sd…スコアデータ
Claims (18)
- 第1の訓練データ群に含まれる同一のラベルが付された同一のデータの出現頻度に基づいて、前記第1の訓練データ群から複数のデータを選択し、
選択した前記複数のデータを用いた機械学習により第1の機械学習モデルを生成し、
前記第1の訓練データ群と、前記第1の訓練データ群に含まれるデータを入力した場合に前記第1の機械学習モデルが出力する結果とを合わせた第2の訓練データ群を生成する、
処理をコンピュータに実行させることを特徴とする機械学習プログラム。 - 前記選択する処理は、前記第1の訓練データ群のうち前記出現頻度が閾値未満のデータを選択対象から除外する処理を含む、
ことを特徴とする請求項1に記載の機械学習プログラム。 - 前記選択する処理は、前記出現頻度に基づいて前記同一のラベルが付された同一のデータのエントロピーおよび自己情報量を計算し、前記第1の訓練データ群のうち、前記自己情報量が第1の閾値より大きく、かつ、前記エントロピーが第2の閾値未満のデータを選択対象から除外する処理を含む、
ことを特徴とする請求項1に記載の機械学習プログラム。 - 前記第2の訓練データ群を生成する処理は、前記第1の訓練データ群と、前記第1の訓練データ群に含まれる第1のデータの内容を変更して生成された第2のデータを入力した場合に前記第1の機械学習モデルが出力する第1の結果とを合わせて前記第2の訓練データ群を生成する処理を含む、
ことを特徴とする請求項1に記載の機械学習プログラム。 - 前記第2の訓練データ群を生成する処理は、前記第1の訓練データ群と、前記第1の訓練データ群に含まれる第1のデータを入力した場合に前記第1の機械学習モデルが出力する第1の結果の内容を変更して生成された第2の結果とを合わせて前記第2の訓練データ群を生成する処理を含む、
ことを特徴とする請求項1に記載の機械学習プログラム。 - 生成した前記第2の訓練データ群に基づいた機械学習により第2の機械学習モデルを生成する、
処理を前記コンピュータに実行させることを特徴とする請求項1に記載の機械学習プログラム。 - 第1の訓練データ群に含まれる同一のラベルが付された同一のデータの出現頻度に基づいて、前記第1の訓練データ群から複数のデータを選択し、
選択した前記複数のデータを用いた機械学習により第1の機械学習モデルを生成し、
前記第1の訓練データ群と、前記第1の訓練データ群に含まれるデータを入力した場合に前記第1の機械学習モデルが出力する結果とを合わせた第2の訓練データ群を生成する、
処理をコンピュータが実行することを特徴とする機械学習方法。 - 前記選択する処理は、前記第1の訓練データ群のうち前記出現頻度が閾値未満のデータを選択対象から除外する処理を含む、
ことを特徴とする請求項7に記載の機械学習方法。 - 前記選択する処理は、前記出現頻度に基づいて前記同一のラベルが付された同一のデータのエントロピーおよび自己情報量を計算し、前記第1の訓練データ群のうち、前記自己情報量が第1の閾値より大きく、かつ、前記エントロピーが第2の閾値未満のデータを選択対象から除外する処理を含む、
ことを特徴とする請求項7に記載の機械学習方法。 - 前記第2の訓練データ群を生成する処理は、前記第1の訓練データ群と、前記第1の訓練データ群に含まれる第1のデータの内容を変更して生成された第2のデータを入力した場合に前記第1の機械学習モデルが出力する第1の結果とを合わせて前記第2の訓練データ群を生成する処理を含む、
ことを特徴とする請求項7に記載の機械学習方法。 - 前記第2の訓練データ群を生成する処理は、前記第1の訓練データ群と、前記第1の訓練データ群に含まれる第1のデータを入力した場合に前記第1の機械学習モデルが出力する第1の結果の内容を変更して生成された第2の結果とを合わせて前記第2の訓練データ群を生成する処理を含む、
ことを特徴とする請求項7に記載の機械学習方法。 - 生成した前記第2の訓練データ群に基づいた機械学習により第2の機械学習モデルを生成する、
ことを特徴とする請求項7に記載の機械学習方法。 - 第1の訓練データ群に含まれる同一のラベルが付された同一のデータの出現頻度に基づいて、前記第1の訓練データ群から複数のデータを選択し、
選択した前記複数のデータを用いた機械学習により第1の機械学習モデルを生成し、
前記第1の訓練データ群と、前記第1の訓練データ群に含まれるデータを入力した場合に前記第1の機械学習モデルが出力する結果とを合わせた第2の訓練データ群を生成する、
処理を実行する制御部を含むことを特徴とする情報処理装置。 - 前記選択する処理は、前記第1の訓練データ群のうち前記出現頻度が閾値未満のデータを選択対象から除外する処理を含む、
ことを特徴とする請求項13に記載の情報処理装置。 - 前記選択する処理は、前記出現頻度に基づいて前記同一のラベルが付された同一のデータのエントロピーおよび自己情報量を計算し、前記第1の訓練データ群のうち、前記自己情報量が第1の閾値より大きく、かつ、前記エントロピーが第2の閾値未満のデータを選択対象から除外する処理を含む、
ことを特徴とする請求項13に記載の情報処理装置。 - 前記第2の訓練データ群を生成する処理は、前記第1の訓練データ群と、前記第1の訓練データ群に含まれる第1のデータの内容を変更して生成された第2のデータを入力した場合に前記第1の機械学習モデルが出力する第1の結果とを合わせて前記第2の訓練データ群を生成する処理を含む、
ことを特徴とする請求項13に記載の情報処理装置。 - 前記第2の訓練データ群を生成する処理は、前記第1の訓練データ群と、前記第1の訓練データ群に含まれる第1のデータを入力した場合に前記第1の機械学習モデルが出力する第1の結果の内容を変更して生成された第2の結果とを合わせて前記第2の訓練データ群を生成する処理を含む、
ことを特徴とする請求項13に記載の情報処理装置。 - 生成した前記第2の訓練データ群に基づいた機械学習により第2の機械学習モデルを生成する処理をさらに前記制御部が実行する、
ことを特徴とする請求項13に記載の情報処理装置。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/027411 WO2022013954A1 (ja) | 2020-07-14 | 2020-07-14 | 機械学習プログラム、機械学習方法および情報処理装置 |
| JP2022536027A JP7364083B2 (ja) | 2020-07-14 | 2020-07-14 | 機械学習プログラム、機械学習方法および情報処理装置 |
| EP20945102.0A EP4184397A4 (en) | 2020-07-14 | 2020-07-14 | MACHINE LEARNING PROGRAM, MACHINE LEARNING METHOD AND INFORMATION PROCESSING DEVICE |
| US18/060,188 US20230096957A1 (en) | 2020-07-14 | 2022-11-30 | Storage medium, machine learning method, and information processing device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/027411 WO2022013954A1 (ja) | 2020-07-14 | 2020-07-14 | 機械学習プログラム、機械学習方法および情報処理装置 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US18/060,188 Continuation US20230096957A1 (en) | 2020-07-14 | 2022-11-30 | Storage medium, machine learning method, and information processing device |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022013954A1 true WO2022013954A1 (ja) | 2022-01-20 |
Family
ID=79555365
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/027411 WO2022013954A1 (ja) | 2020-07-14 | 2020-07-14 | 機械学習プログラム、機械学習方法および情報処理装置 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US20230096957A1 (ja) |
| EP (1) | EP4184397A4 (ja) |
| JP (1) | JP7364083B2 (ja) |
| WO (1) | WO2022013954A1 (ja) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20220172108A1 (en) * | 2020-12-02 | 2022-06-02 | Sap Se | Iterative machine learning and relearning |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006252333A (ja) * | 2005-03-11 | 2006-09-21 | Nara Institute Of Science & Technology | データ処理方法、データ処理装置およびそのプログラム |
| JP2018045559A (ja) * | 2016-09-16 | 2018-03-22 | 富士通株式会社 | 情報処理装置、情報処理方法およびプログラム |
| JP2019016025A (ja) * | 2017-07-04 | 2019-01-31 | 株式会社日立製作所 | 情報処理システム |
| JP2020047079A (ja) * | 2018-09-20 | 2020-03-26 | 富士通株式会社 | 学習プログラム、学習方法および学習装置 |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH03105663A (ja) * | 1989-09-20 | 1991-05-02 | Fujitsu Ltd | 強化学習処理方式 |
| JP2009110064A (ja) * | 2007-10-26 | 2009-05-21 | Toshiba Corp | 分類モデル学習装置および分類モデル学習方法 |
-
2020
- 2020-07-14 JP JP2022536027A patent/JP7364083B2/ja active Active
- 2020-07-14 WO PCT/JP2020/027411 patent/WO2022013954A1/ja unknown
- 2020-07-14 EP EP20945102.0A patent/EP4184397A4/en not_active Withdrawn
-
2022
- 2022-11-30 US US18/060,188 patent/US20230096957A1/en active Pending
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006252333A (ja) * | 2005-03-11 | 2006-09-21 | Nara Institute Of Science & Technology | データ処理方法、データ処理装置およびそのプログラム |
| JP2018045559A (ja) * | 2016-09-16 | 2018-03-22 | 富士通株式会社 | 情報処理装置、情報処理方法およびプログラム |
| JP2019016025A (ja) * | 2017-07-04 | 2019-01-31 | 株式会社日立製作所 | 情報処理システム |
| JP2020047079A (ja) * | 2018-09-20 | 2020-03-26 | 富士通株式会社 | 学習プログラム、学習方法および学習装置 |
Non-Patent Citations (1)
| Title |
|---|
| WU ET AL.: "N-fold Templated Piped Correction", PROC. OF IJCNLP, 2004 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP4184397A1 (en) | 2023-05-24 |
| JPWO2022013954A1 (ja) | 2022-01-20 |
| JP7364083B2 (ja) | 2023-10-18 |
| US20230096957A1 (en) | 2023-03-30 |
| EP4184397A4 (en) | 2023-06-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Breve et al. | Particle competition and cooperation in networks for semi-supervised learning | |
| JP5668090B2 (ja) | 医療診断支援装置及び医療診断支援方法 | |
| JP6962532B1 (ja) | 事象予測装置および事象予測用プログラム | |
| Yang et al. | Cluster ensemble selection with constraints | |
| JP2015230570A (ja) | 学習モデル作成装置、判定システムおよび学習モデル作成方法 | |
| JP2010003106A (ja) | 分類モデル生成装置、分類装置、分類モデル生成方法、分類方法、分類モデル生成プログラム、分類プログラムおよび記録媒体 | |
| Li et al. | Ascent: Active supervision for semi-supervised learning | |
| Liu et al. | GO functional similarity clustering depends on similarity measure, clustering method, and annotation completeness | |
| WO2022013954A1 (ja) | 機械学習プログラム、機械学習方法および情報処理装置 | |
| Yousefnezhad et al. | A new selection strategy for selective cluster ensemble based on diversity and independency | |
| Garai et al. | A cascaded pairwise biomolecular sequence alignment technique using evolutionary algorithm | |
| Althagafi et al. | Prioritizing genomic variants through neuro-symbolic, knowledge-enhanced learning | |
| Villacorta et al. | Sensitivity analysis in the scenario method: A multi-objective approach | |
| Mendoza et al. | Reverse engineering of grns: An evolutionary approach based on the tsallis entropy | |
| Matiasz et al. | Computer-aided experiment planning toward causal discovery in neuroscience | |
| WO2023152617A1 (en) | System and method for identifying natural alternatives to synthetic additives in foods | |
| Dehmer et al. | Entropy bounds for hierarchical molecular networks | |
| Olteanu | Strategies for the incremental inference of majority-rule sorting models | |
| Gong et al. | Evolutionary nonnegative matrix factorization with adaptive control of cluster quality | |
| Olteanu et al. | Inferring a hierarchical majority-rule sorting model | |
| Lv et al. | Benchmarking Analysis of Evolutionary Neural Architecture Search | |
| Bevilacqua et al. | Bayesian Gene Regulatory Network Inference Optimization by means of Genetic Algorithms. | |
| Kotze | Resampling algorithms for multi-label classification | |
| WO2024069910A1 (ja) | 分子シミュレーションプログラム、分子シミュレーション方法および情報処理装置 | |
| JP7224263B2 (ja) | モデル生成方法、モデル生成装置及びプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20945102 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022536027 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2020945102 Country of ref document: EP Effective date: 20230214 |