WO2022004601A1 - 分散強化学習システム及び分散強化学習方法 - Google Patents
分散強化学習システム及び分散強化学習方法 Download PDFInfo
- Publication number
- WO2022004601A1 WO2022004601A1 PCT/JP2021/024184 JP2021024184W WO2022004601A1 WO 2022004601 A1 WO2022004601 A1 WO 2022004601A1 JP 2021024184 W JP2021024184 W JP 2021024184W WO 2022004601 A1 WO2022004601 A1 WO 2022004601A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- reinforcement learning
- learner
- group
- distributed
- actor
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/004—Artificial life, i.e. computing arrangements simulating life
- G06N3/006—Artificial life, i.e. computing arrangements simulating life based on simulated virtual individual or collective life forms, e.g. social simulations or particle swarm optimisation [PSO]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/092—Reinforcement learning
Definitions
- This disclosure relates to a distributed reinforcement learning system and a distributed reinforcement learning method.
- Reinforcement learning is attracting attention as a method of machine learning.
- an agent observes the environment, selects an action according to a policy based on the observed environment, and obtains a reward (reward) from the environment for the state transition accompanying the action.
- the strategies used by the agent are learned so that the rewards earned for the selectable behavioral sequence are maximized.
- the policy to be learned is implemented as a deep learning model such as a neural network.
- a policy is distributed and learned by a plurality of Learner devices for training the policy and a plurality of Actor devices for providing empirical data to the Learner device.
- the subject of this disclosure is to provide a new distributed reinforcement learning system.
- one aspect of the present disclosure is a Play buffer group for storing empirical data used for reinforcement learning, a Learner device group for training a model based on the empirical data, and a Learner device group for training. It has an Actor device that acquires the empirical data using the model, and each Play buffer stores different empirical data from each other and is associated with one or more Learning devices of the Learner device group. Regarding the learning system.
- FIG. 1 is a schematic diagram showing the architecture of the distributed reinforcement learning system 10 according to the embodiment of the present disclosure.
- This distributed reinforcement learning system 10 uses a technique called ExperienceReplay in the reinforcement learning of the model to be learned.
- the distributed reinforcement learning system 10 has a plurality of computers (nodes) 20_1, 20_2, ..., And a plurality of computers (nodes) 30_1, 30_2, .... ..
- each computer 20_i includes a plurality of GPUs (Graphics Processing Units), and each Learning device 100 is realized by the GPU.
- GPUs Graphics Processing Units
- each Learner device 100 is one-to-one associated with one Play buffer 50 corresponding to itself, but the distributed reinforcement learning system according to the present disclosure is not limited to this architecture, and is limited to L Learners. M Play buffers 50 may be associated with the device.
- the Play buffer 50 stores experience data by reinforcement learning provided by the Actor device 200.
- the empirical data may be described, for example, in a data format (s, a, r, s'), where s indicates the state of the environment observed by the agent of the Actor device 200 and a indicates the state of the environment observed by the agent of the Actor device 200. Indicates the selected (determined) action, r indicates the reward obtained from the environment by the selected action a, and s'indicates the next state of the environment transitioned by the selected action a.
- the Actor device group 200 distributes the generated empirical data to each Play buffer 50 so that each Play buffer 50 has different empirical data from each other.
- the distributed reinforcement learning system 10 not only the Learner device 100 but also the Play buffer 50 is distributed. As a result, it is not necessary to configure a huge data store as compared with the case where the Learning device group 100 shares a single Play buffer 50, and it is possible to improve the speed and simplify the architecture.
- the Play buffer 50 is provided in the computer 20_i including the Learning device 100, but the Play buffer 50 according to the present disclosure is not limited to this, and is a device independent of the computer 20_i as described later. It may be realized in such cases.
- the Learning device 100 trains the measure ⁇ for determining the action a from the state s by the empirical data acquired from the associated Play buffer 50.
- the policy ⁇ is realized as a model of a function that outputs the action a or its distribution from the state s, and is realized as a neural network in this embodiment.
- the policy ⁇ may be realized as a model that approximates the action value function Q (s, a).
- a neural network that outputs an approximate value of the expected cumulative reward in the future when the state s and the action a are input, or an approximate value of the expected cumulative reward in the future for each of the possible actions a when the state s is input. It may be realized as a neural network whose output is. Since the policy ⁇ of this embodiment is realized by the neural network as described above, the parameters of the neural network (coupling load, bias, etc.) can be called the parameters of the policy ⁇ .
- each Learner device 100 first initializes the training target policy model ⁇ , and the Learner device group 100 holds the same initialized training target policy model ⁇ . Then, each Learning device 100 calculates the gradient of the neural network that improves the policy model ⁇ based on the empirical data acquired from the associated Play buffer 50. Then, each Learning device 100 transmits the calculated gradient to the other Learning device 100, and collects the gradient calculated by the other Learning device 100. Then, each Learning device 100 calculates the average of the gradients of the Learner device group 100, and updates the parameters of the training target policy model ⁇ based on the calculated gradient average. As a result of updating the same training target policy model ⁇ with a common gradient average, each Learning device 100 will have the same training target policy model ⁇ after updating the parameters.
- the Actor device 200 acquires empirical data by using the training target policy model ⁇ acquired from the Learner device group 100. Specifically, each Actor device 200 functions as both an agent and an environment in reinforcement learning, acquires a training target policy model ⁇ from the Learner device group 100, and initializes the environment. Since the environment is randomly initialized in each Actor device 200, the environment after initialization may be different for each Actor device 200.
- the Actor device 200 observes the environment, inputs the state s of the environment obtained by the observation into the policy model ⁇ acquired from the Learner device group 100, and acquires the action a from the policy model ⁇ . After that, the Actor device 200 acquires the reward r obtained as a result of the action a and the next state s', and generates empirical data (s, a, r, s').
- the Actor device 200 transmits the generated empirical data (s, a, r, s') to the Play buffer 50.
- the Actor device group 200 may transmit empirical data to the Play buffer group 50 so that the number of empirical data is evenly provided.
- a plurality of Actor devices 200 are provided, but the distributed reinforcement learning system 10 according to the present disclosure is not limited to this, and a single Actor device 200 generates empirical data and plays. It may be distributed to the buffer group 50.
- the model learning process of the Learner apparatus 100 is executed by the Learner device 100 described above, and for example, a program stored in one or more memories of the computer 20_i is executed by one or more processors (for example, GPU) that realize the Learner device 100. It can be realized by doing.
- each Learner device 100 of the Learner device group 100 is acquired from the Play buffer 50 associated with the Learner device 100 in the Play buffer group 50 storing different experience data.
- empirical data for example, according to synchronous SGD (Synchronous Stochastic Radiant Descent), distributed reinforcement learning is synchronously executed by the same model learning process.
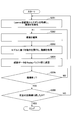
- FIG. 2 is a flowchart showing a model learning process of the Learner apparatus 100 according to an embodiment of the present disclosure.
- step S101 the Learning device 100 initializes the training target policy model ⁇ .
- the initialized policy model ⁇ is common among the Learner devices 100, for example, the policy model ⁇ initialized by the specific Learner device 100 may be delivered to the Learner device group 100.
- the training target policy model ⁇ according to this embodiment is realized as a neural network.
- step S102 the Learning device 100 acquires empirical data from the associated Play buffer 50 by random sampling.
- the empirical data acquired by the Learning device by random sampling will be shuffled.
- the Play buffer group 50 holds different empirical data from each other, and each Learner device 100 trains the training target policy model ⁇ with the different empirical data.
- step S103 the Learning device 100 calculates a gradient that improves the policy model ⁇ based on the acquired empirical data (s, a, r, s').
- the Learning device 100 acquires the gradient average of the Learning device group 100.
- each Learning device 100 may collect the gradient calculated by another Learning device 100 and calculate the gradient average of the Learner device group 100.
- a specific Learning device 100 may collect gradients from all Learning devices 100, calculate a gradient average of the collected gradients, and deliver it to the Learner device group 100.
- each Learning device obtains a gradient average common to other Learning devices.
- Such an operation of aggregating the array data possessed by all processes (Learner device) and then acquiring the results equally by all processes is called AllReduce, and there are some variations in the AllReduce algorithm. do.
- the Ring-type AllReduce algorithm can be applied as an algorithm in which each Learning device collects the gradients calculated by other Learning devices and calculates the gradient average by itself.
- step S105 the Learning device 100 updates the parameters of the training target policy model ⁇ that it has based on the acquired gradient average. Since the parameters of the training target policy model ⁇ common among the Learning devices 100 are updated by the gradient average common to the Learning device group 100, the updated policy model ⁇ will be the same among the Learning devices 100. Please note.
- step S106 the Learning device 100 determines whether steps S102 to S105 have been repeated a predetermined number of times.
- steps S102 to S105 are repeated a predetermined number of times (S105: YES)
- the Learner apparatus 100 ends the model learning process.
- steps S102 to S105 are not repeated a predetermined number of times (S105: NO)
- the Learning device 100 returns to step S102 and repeats the above-described processing for the next empirical data.
- the experience data acquisition process is executed by the above-mentioned Actor device 200, and for example, a program stored in one or more memories of the computer 30_i is transferred by one or more processors (for example, a CPU) that realizes the Actor device 200. It can be achieved by doing it. Further, in the distributed reinforcement learning system 10 according to the present embodiment, each actor device 200 of the actor device group 200 acquires the policy model ⁇ trained by the Learner device group 100, and acquires empirical data by the acquired policy model ⁇ . ..
- FIG. 3 is a flowchart showing an experience data acquisition process of the Actor device 200 according to an embodiment of the present disclosure.
- step S201 the Actor device 200 acquires the policy model ⁇ from the Learner device group 100 and initializes the environment in reinforcement learning. That is, one episode starts.
- each Actor device 200 randomly initializes the environment used by itself. Therefore, a different environment is set for each Actor device 200.
- this step S201 is executed following the step S206 described later, the Actor apparatus periodically repeats the acquisition of the policy model ⁇ from the Learner apparatus.
- step S202 the Actor device 200 observes the environment and identifies the state s of the environment.
- step S203 the Actor device 200 inputs the observed state s into the policy model ⁇ , operates according to the action a output from the policy model ⁇ , and rewards based on the state transition s ⁇ s'according to the action a from the environment. Get r.
- step S204 the Actor device 200 generates experience data (s, a, r, s') based on the observed state s, the selected action a, the reward r, and the next state s', and the generated experience.
- Data (s, a, r, s') is transmitted to any Play buffer 50.
- the Actor device 200 may evenly provide empirical data (s, a, r, s') to the associated Play buffer 50.
- step S205 the Actor device 200 determines whether to terminate the environment. That is, the Actor device 200 determines whether to end the episode starting from S201. Goals are set when performing tasks within the environment in reinforcement learning. A goal is, for example, lifting an object, moving to a destination, and the like. The end condition of the environment includes, for example, the case where the goal is achieved, the case where the goal cannot be achieved within a finite time, and the like.
- the environment is terminated (S205: YES)
- the experience data acquisition process proceeds to step S206.
- the Actor device 200 returns to step S202 and repeats the above-mentioned process.
- step S206 the Actor device 200 determines whether steps S202 to S205 have been repeated a predetermined number of times. When steps S202 to S205 are repeated a predetermined number of times (S206: YES), the experience data acquisition process ends. On the other hand, when steps S202 to S205 are not repeated a predetermined number of times (S206: NO), the Actor device 200 returns to step S201 and repeats the above-mentioned process.
- S206 YES
- steps S202 to S205 are not repeated a predetermined number of times
- FIG. 4 is a schematic diagram showing the architecture of the distributed reinforcement learning system 10 according to another embodiment of the present disclosure. As shown in FIG.
- a controller 60 is provided between the computer 20_i and the computer 30_j, and the empirical data provided by the controller device 200 is a play buffer via the control device 60. Delivered to group 50.
- the control device 60_i may be mounted in the computer 20_i.
- control device 60_i distributes the empirical data acquired from the Actor device group 200 of the associated computer 30_i to the Play buffer 50 of the associated computer 20_i.
- the control device 60_i may distribute the experience data acquired from the actor device group 200 of the computer 30_i to the play buffer group 50 so that the experience data is evenly distributed to the play buffer group 50 of the computer 20_i.
- control device 60 may exchange empirical data with another control device 60.
- the control device 60_1 exchanges empirical data with the control device 60_2, acquires the empirical data generated by the Actor device 200 of the computer 30_2 via the control device 60_2, and puts it in the Play buffer 50 of the computer 20_1. May be provided.
- control device 60 has a parameter cache function of the training target policy model ⁇ . With this cache function, the control device 60 can reduce the load on the Learner device by mediating the acquisition of the parameters of the policy model between the Learning device and the Actor device, and can speed up the acquisition of the parameters by the Actor device. Specifically, the control device 60 caches the parameters of the policy model ⁇ from the Learning device in its own memory. When the control device 60 receives the parameter acquisition request from the actor device, the control device 60 transmits the parameter cached in the memory to the actor device unless the parameter is old after a certain period of time (for example, 30 seconds) or more.
- a certain period of time for example, 30 seconds
- FIGS. 5 to 7 are schematic views showing the architecture of the distributed reinforcement learning system 10 according to another embodiment of the present disclosure.
- the Learner device group 100A in the computer 20_i is associated with one Play buffer 50A, and each Learner device 100A acquires different experience data from the common Play buffer 50A. Then, the training target policy model ⁇ is trained based on the acquired experience data.
- Each Actor device 200A acquires a policy model ⁇ from the Learner device group 100A, selects an action for the observed environment using the acquired policy model ⁇ , and acquires a reward from the environment based on the state transition due to the action. .. Then, each Actor device 200A transmits the empirical data acquired in this way to the associated Play buffer 50A.
- the Learner device 100B and the Play buffer 50B are mounted on different computers. Further, the Learning device 100B and the Play buffer 50B in the computer 20_i are associated one-to-one, and the Play buffer group 50B stores different empirical data. Each Learning device 100B acquires empirical data from the associated Play buffer 50B and trains the training target policy model ⁇ with the acquired empirical data. Each Actor device 200B acquires a policy model ⁇ from the Learner device group 100B, selects an action for the observed environment using the acquired policy model ⁇ , and acquires a reward from the environment based on the state transition due to the action. .. Then, each Actor device 200B transmits the empirical data acquired in this way to the associated Play buffer 50B.
- the Learner device 100C and the Play buffer 50C are mounted on different computers. Further, the Learning device group 100C in the computer 20_i is associated with one Play buffer 50C, and the Play buffer group 50B stores different empirical data from each other. Each Learning device 100C acquires empirical data from the associated Play buffer 50B and trains the training target policy model ⁇ with the acquired empirical data. Each Actor device 200C acquires a policy model ⁇ from the Learner device group 100C, selects an action for the observed environment using the acquired policy model ⁇ , and acquires a reward from the environment based on the state transition due to the action. .. Then, each Actor device 200C transmits the empirical data acquired in this way to the associated Play buffer 50C.
- control device 60 is not shown, but the Play buffer groups 50A, 50B and 50C and the Actor device groups 200A, 200B and the same as the modification shown in FIG. 4 are shown.
- a control device 60 may be provided between the 200C and the Play buffer groups 50A, 50B and 50C to control the transfer of empirical data between the Actor device groups 200A, 200B and 200C.
- the computer 20_i on which the Learner device 100 is mounted includes a plurality of GPUs, but the distributed reinforcement learning system 10 according to the present disclosure is not limited to such an architecture.
- the computer 20_i has only one GPU, it is possible to realize the distributed reinforcement learning system 10 by using the computer 20_i corresponding to the number of the Learner devices 100, for example, those skilled in the art. Can be easily understood.
- a part or all of each device (computer 20_i and computer 30_j) in the above-described embodiment may be configured by hardware, or may be executed by a CPU (Central Processing Unit), a GPU (Graphics Processing Unit), or the like. It may be composed of information processing of software (program).
- software that realizes at least a part of the functions of each device in the above-described embodiment is a flexible disk, a CD-ROM (Compact Disc-Read Only Memory), or a USB (Universal). Serial Bus)
- Software information processing may be executed by storing it in a non-temporary storage medium (non-temporary computer-readable medium) such as a memory and loading it into a computer. Further, the software may be downloaded via a communication network. Further, information processing may be executed by hardware by mounting the software on a circuit such as an ASIC (Application Specific Integrated Circuit) or an FPGA (Field Programmable Gate Array).
- ASIC Application Specific Integrated Circuit
- FPGA Field Programmable Gate Array
- the type of storage medium that stores the software is not limited.
- the storage medium is not limited to a removable one such as a magnetic disk or an optical disk, and may be a fixed type storage medium such as a hard disk or a memory. Further, the storage medium may be provided inside the computer or may be provided outside the computer.
- FIG. 8 is a block diagram showing an example of the hardware configuration of each device (computer 20_i and computer 30_j) in the above-described embodiment.
- each device includes a processor 71, a main storage device 72 (memory), an auxiliary storage device 73 (memory), a network interface 74, and a device interface 75, which are connected via a bus 76. It may be realized as a computer.
- the computer of FIG. 8 has one component for each component, but may include a plurality of the same components. Further, although one computer is shown in FIG. 8, even if the software is installed on a plurality of computers and each of the plurality of computers executes the same or different part of the software. good. In this case, it may be a form of distributed computing in which each computer communicates via a network interface 74 or the like to execute processing. That is, each device (computer 20_i and computer 30_j) in the above-described embodiment is configured as a system that realizes a function by executing an instruction stored in one or a plurality of storage devices by one or a plurality of computers. You may. Further, the information transmitted from the terminal may be processed by one or a plurality of computers provided on the cloud, and the processing result may be transmitted to the terminal.
- each device in the above-described embodiment may be executed in parallel processing by using one or a plurality of processors or by using a plurality of computers via a network. .. Further, various operations may be distributed to a plurality of arithmetic cores in the processor and executed in parallel processing. In addition, some or all of the processes, means, etc. of the present disclosure may be executed by at least one of a processor and a storage device provided on the cloud capable of communicating with a computer via a network. As described above, each device in the above-described embodiment may be in the form of parallel computing by one or a plurality of computers.
- the processor 71 may be an electronic circuit (processing circuit, Processing circuit, Processing circuitry, CPU, GPU, FPGA, ASIC, etc.) including a computer control device and an arithmetic unit. Further, the processor 71 may be a semiconductor device or the like including a dedicated processing circuit. The processor 71 is not limited to an electronic circuit using an electronic logic element, and may be realized by an optical circuit using an optical logic element. Further, the processor 71 may include a calculation function based on quantum computing.
- the processor 71 can perform arithmetic processing based on data and software (programs) input from each device or the like of the internal configuration of the computer, and output the arithmetic result or control signal to each device or the like.
- the processor 71 may control each component constituting the computer by executing an OS (Operating System) of the computer 1, an application, or the like.
- OS Operating System
- Each device (computer 20_i and computer 30_j) in the above-described embodiment may be realized by one or a plurality of processors 71.
- the processor 71 may refer to one or more electronic circuits arranged on one chip, or may refer to one or more electronic circuits arranged on two or more chips or two or more devices. You may point. When a plurality of electronic circuits are used, each electronic circuit may communicate by wire or wirelessly.
- the main storage device 72 is a storage device that stores instructions executed by the processor 71, various data, and the like, and the information stored in the main storage device 72 is read out by the processor 71.
- the auxiliary storage device 73 is a storage device other than the main storage device 72. It should be noted that these storage devices mean arbitrary electronic components capable of storing electronic information, and may be semiconductor memories. The semiconductor memory may be either a volatile memory or a non-volatile memory.
- the storage device for storing various data in each device (computer 20_i and computer 30_j) in the above-described embodiment may be realized by the main storage device 72 or the auxiliary storage device 73, and the built-in memory built in the processor 71. May be realized by.
- the storage unit in the above-described embodiment may be realized by the main storage device 72 or the auxiliary storage device 73.
- processors may be connected (combined) to one storage device (memory), or a single processor may be connected.
- a plurality of storage devices (memory) may be connected (combined) to one processor.
- each device (computer 20_i and computer 30_j) in the above-described embodiment is composed of at least one storage device (memory) and a plurality of processors connected (combined) to the at least one storage device (memory).
- a configuration in which at least one of a plurality of processors is connected (combined) to at least one storage device (memory) may be included. Further, this configuration may be realized by a storage device (memory) and a processor included in a plurality of computers. Further, a configuration in which the storage device (memory) is integrated with the processor (for example, a cache memory including an L1 cache and an L2 cache) may be included.
- the network interface 74 is an interface for connecting to the communication network 78 wirelessly or by wire. As the network interface 74, an appropriate interface such as one conforming to an existing communication standard may be used. The network interface 74 may exchange information with the external device 9A connected via the communication network 78.
- the communication network 78 may be any one of WAN (Wide Area Network), LAN (Local Area Network), PAN (Personal Area Network), or a combination thereof, and may be a combination of the computer 7 and the external device 9A. Anything can be used as long as information is exchanged between them.
- An example of a WAN is the Internet
- an example of a LAN is 802.11, Ethernet (registered trademark)
- an example of a PAN is Bluetooth (registered trademark), NFC (Near Field Communication), and the like.
- the device interface 75 is an interface such as USB that directly connects to the external device 9B.
- the external device 9A is a device connected to a computer via a network.
- the external device 9B is a device directly connected to the computer.
- the external device 9A or the external device 9B may be a storage device (memory).
- the external device 9A may be a network storage or the like, and the external device 9B may be a storage such as an HDD.
- the external device 9A or the external device 9B may be a device having some functions of the components of each device (computer 20_i and computer 30_j) in the above-described embodiment. That is, the computer may transmit or receive a part or all of the processing result of the external device 9A or the external device 9B.
- the expression (including similar expressions) of "at least one of a, b and c (one)" or "at least one of a, b or c (one)” is used. When used, it includes any of a, b, c, ab, ac, bc, or abc. It may also include multiple instances for any element, such as a-a, a-b-b, a-a-b-b-c-c, and the like. It also includes adding elements other than the listed elements (a, b and c), such as having d, such as a-b-c-d.
- connection when the terms "connected” and “coupled” are used, direct connection / connection and indirect connection / connection are used. , Electrically connected / combined, communicatively connected / combined, operatively connected / combined, physically connected / combined, etc. Intended as a term.
- the term should be interpreted as appropriate according to the context in which the term is used, but any connection / coupling form that is not intentionally or naturally excluded is not included in the term. It should be interpreted in a limited way.
- the physical structure of the element A can execute the operation B. It has a configuration and includes that the permanent or temporary setting (setting / configuration) of the element A is set (configured / set) to actually execute the operation B. good.
- the element A is a general-purpose processor
- the processor has a hardware configuration capable of executing the operation B, and the operation B is set by setting a permanent or temporary program (instruction). It suffices if it is configured to actually execute.
- the element A is a dedicated processor, a dedicated arithmetic circuit, or the like, the circuit structure of the processor actually executes the operation B regardless of whether or not the control instruction and data are actually attached. It only needs to be implemented.
- the respective hardware when a plurality of hardware performs a predetermined process, the respective hardware may cooperate to perform the predetermined process, or some hardware may perform the predetermined process. You may do all of the above. Further, some hardware may perform a part of a predetermined process, and another hardware may perform the rest of the predetermined process.
- expressions such as "one or more hardware performs the first process and the one or more hardware performs the second process" are used.
- the hardware that performs the first process and the hardware that performs the second process may be the same or different. That is, the hardware that performs the first process and the hardware that performs the second process may be included in the one or a plurality of hardware.
- the hardware may include an electronic circuit, a device including the electronic circuit, or the like.
- each storage device (memory) among the plurality of storage devices (memory) stores only a part of the data. It may be stored or the entire data may be stored.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Software Systems (AREA)
- Mathematical Physics (AREA)
- Artificial Intelligence (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Biomedical Technology (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Medical Informatics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2022533958A JPWO2022004601A1 (https=) | 2020-07-03 | 2021-06-25 | |
| US18/146,061 US20230125834A1 (en) | 2020-07-03 | 2022-12-23 | Distributed reinforcement learning system and distributed reinforcement learning method |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020-115849 | 2020-07-03 | ||
| JP2020115849 | 2020-07-03 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US18/146,061 Continuation US20230125834A1 (en) | 2020-07-03 | 2022-12-23 | Distributed reinforcement learning system and distributed reinforcement learning method |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022004601A1 true WO2022004601A1 (ja) | 2022-01-06 |
Family
ID=79315997
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2021/024184 Ceased WO2022004601A1 (ja) | 2020-07-03 | 2021-06-25 | 分散強化学習システム及び分散強化学習方法 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20230125834A1 (https=) |
| JP (1) | JPWO2022004601A1 (https=) |
| WO (1) | WO2022004601A1 (https=) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025191927A1 (ja) * | 2024-03-11 | 2025-09-18 | Kddi株式会社 | 通信制御システム及び通信制御方法 |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025151898A1 (en) * | 2024-01-11 | 2025-07-17 | The General Hospital Corporation | Systems and methods for managing multidrug delivery using infusion pumps |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2019149949A1 (en) * | 2018-02-05 | 2019-08-08 | Deepmind Technologies Limited | Distributed training using off-policy actor-critic reinforcement learning |
| WO2020095729A1 (ja) * | 2018-11-09 | 2020-05-14 | 日本電信電話株式会社 | 分散深層学習システムおよびデータ転送方法 |
-
2021
- 2021-06-25 WO PCT/JP2021/024184 patent/WO2022004601A1/ja not_active Ceased
- 2021-06-25 JP JP2022533958A patent/JPWO2022004601A1/ja active Pending
-
2022
- 2022-12-23 US US18/146,061 patent/US20230125834A1/en active Pending
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2019149949A1 (en) * | 2018-02-05 | 2019-08-08 | Deepmind Technologies Limited | Distributed training using off-policy actor-critic reinforcement learning |
| WO2020095729A1 (ja) * | 2018-11-09 | 2020-05-14 | 日本電信電話株式会社 | 分散深層学習システムおよびデータ転送方法 |
Non-Patent Citations (2)
| Title |
|---|
| HORGAN, DAN ET AL.: "Distributed Prioritized Experience Replay", 3 OUR CONTRIBUTION: DISTRIBUTED PRIORITIZED EXPERIRNCE REPLAY, 2 March 2018 (2018-03-02), pages 1 - 19, XP080866392, Retrieved from the Internet <URL:https://arxiv.org/pdf/1803.00933.pdf> [retrieved on 20210913] * |
| YAZDANBAKHSH, AMIR ET AL.: "Massively Large-Scale Distributed Reinforcement Learning with Menger", GOOGLE A1 BLOG, 2 October 2020 (2020-10-02), pages 1 - 6, XP055805455, Retrieved from the Internet <URL:https://ai.googleblog.com/2020/10/massively-large-scale-distributed.html> [retrieved on 20210913] * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025191927A1 (ja) * | 2024-03-11 | 2025-09-18 | Kddi株式会社 | 通信制御システム及び通信制御方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2022004601A1 (https=) | 2022-01-06 |
| US20230125834A1 (en) | 2023-04-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Lin et al. | Infinite-llm: Efficient llm service for long context with distattention and distributed kvcache | |
| JP5969486B2 (ja) | オンラインゲーム環境におけるサーバホストのリソース管理 | |
| WO2022004601A1 (ja) | 分散強化学習システム及び分散強化学習方法 | |
| CN113112006A (zh) | 用于深度学习应用的存储器带宽管理 | |
| JP2021057024A (ja) | 航空機を制御するためのニューラルネットワークを訓練するためのシステム及び方法 | |
| JP7632458B2 (ja) | 情報処理装置及び情報処理方法、コンピュータプログラム、並びに分散学習システム | |
| JPWO2018155232A1 (ja) | 情報処理装置、情報処理方法、並びにプログラム | |
| US20220230067A1 (en) | Learning device, learning method, and learning program | |
| WO2022009542A1 (ja) | 情報処理装置、情報処理方法及びプログラム | |
| CA3195959A1 (en) | Information processing system, method for processing information and program | |
| JP7453229B2 (ja) | データ処理モジュール、データ処理システム、およびデータ処理方法 | |
| US12499604B2 (en) | Updating shader scheduling policy at runtime | |
| US11562270B2 (en) | Straggler mitigation for iterative machine learning via task preemption | |
| CN110415160A (zh) | 一种gpu拓扑分区方法与装置 | |
| KR102190584B1 (ko) | 메타 강화 학습을 이용한 인간 행동패턴 및 행동전략 추정 시스템 및 방법 | |
| CN109964452A (zh) | 一种区块链系统的节点管理方法、装置及存储装置 | |
| JP7420228B2 (ja) | 分散処理システムおよび分散処理方法 | |
| KR20230099543A (ko) | 분산 병렬 학습 방법 및 분산 병렬 학습 제어 장치 | |
| CN117880145A (zh) | 多层级6g算力服务链异常检测机制部署方法、装置及设备 | |
| CN112637032B (zh) | 一种服务功能链的部署方法及装置 | |
| JP7704995B1 (ja) | 施設の運用コストを最適化するための最適化システム、最適化装置、最適化方法、およびプログラム | |
| CN117556933A (zh) | 基于Double DQN的物流机器人集群任务调度方法、装置及可读介质 | |
| WO2023154128A1 (en) | Training architecture using game consoles | |
| US10884755B1 (en) | Graph rewriting for large model support using categorized topological sort | |
| Kaveh et al. | Cuckoo search algorithm |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21833612 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022533958 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 21833612 Country of ref document: EP Kind code of ref document: A1 |