WO2021260945A1 - 訓練データ生成プログラム、装置、及び方法 - Google Patents
訓練データ生成プログラム、装置、及び方法 Download PDFInfo
- Publication number
- WO2021260945A1 WO2021260945A1 PCT/JP2020/025360 JP2020025360W WO2021260945A1 WO 2021260945 A1 WO2021260945 A1 WO 2021260945A1 JP 2020025360 W JP2020025360 W JP 2020025360W WO 2021260945 A1 WO2021260945 A1 WO 2021260945A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- attribute
- training data
- value
- degree
- data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images














Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/217—Validation; Performance evaluation; Active pattern learning techniques
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
- G06F18/2155—Generating training patterns; Bootstrap methods, e.g. bagging or boosting characterised by the incorporation of unlabelled data, e.g. multiple instance learning [MIL], semi-supervised techniques using expectation-maximisation [EM] or naïve labelling
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/217—Validation; Performance evaluation; Active pattern learning techniques
- G06F18/2178—Validation; Performance evaluation; Active pattern learning techniques based on feedback of a supervisor
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/23—Clustering techniques
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q10/00—Administration; Management
- G06Q10/10—Office automation; Time management
- G06Q10/105—Human resources
- G06Q10/1053—Employment or hiring
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q40/00—Finance; Insurance; Tax strategies; Processing of corporate or income taxes
- G06Q40/03—Credit; Loans; Processing thereof
Definitions
- the disclosed technology relates to a training data generation program, a training data generation device, and a training data generation method.
- a machine-learned model may be used to determine whether or not to apply for a loan and whether or not to pass or fail a recruitment test.
- the model used for such a judgment needs to be generated by fairness-oriented machine learning so that the judgment result is not discriminated against by sensitive attributes such as gender and race.
- sensitive attributes such as gender and race.
- the attributes such as gender and race that are not legally discriminated against in the judgment (hereinafter referred to as direct discrimination attributes)
- the address, occupation, etc. are seemingly discriminatory.
- Invisible attributes may be consistent with the tendency of direct discriminatory attributes and promote discriminatory outcomes.
- such an attribute that does not look discriminatory at first glance but causes a discriminatory judgment result is referred to as an indirect discrimination attribute.
- the direct discrimination attribute and the indirect discrimination attribute are collectively referred to as "discrimination attribute”.
- the disclosed technology aims to generate training data for machine learning a model in which the bias towards discriminatory judgment due to context-sensitive discriminatory attributes is appropriately reduced.
- the disclosed technique accepts an evaluation value for a value calculated based on the number of data for each attribute included in a plurality of data, and the received evaluation value and the number of data for each attribute. Based on, the reference value for each attribute is determined. Further, the disclosed technique generates training data for machine learning by changing the attributes of at least a part of the plurality of data according to the reference value for each attribute.
- it has the effect of being able to generate training data for machine learning of a model in which the bias toward discriminatory judgment due to discriminatory attributes in consideration of the context is appropriately reduced.
- a data set is input to the training data generation device 10 according to the present embodiment.
- Each data included in the data set is data that is a source of training data for generating a model by fairness-oriented machine learning, and includes attribute values for each of a plurality of attributes.
- the attributes are gender, race, income, occupation, loan purpose (hereinafter, also simply referred to as "purpose") for each user. ), Repayment period, address, age, judgment result, etc.
- the attribute value is a value according to the type of the attribute, for example, the attribute "gender” is a value indicating "male” or “female", and the attribute "judgment result” is "approved” or “rejected”. It is a value indicating.
- Each data can be a vector value in which the attribute values of each attribute are concatenated.
- the attribute "judgment result” is an example of the "attribute representing the judgment result” of the disclosed technology.
- the attribute "judgment result” is also referred to as "label”.
- the attributes other than the attribute "determination result” are an example of the "attribute used for determination” of the disclosed technology.
- the training data generation device 10 identifies an indirect discrimination attribute from attributes other than the direct discrimination attribute and the attribute "determination result" among the attributes included in the data. For example, in the above loan screening example, if gender and race are specified as direct discrimination attributes, the training data generator 10 will indirectly discriminate from income, occupation, loan purpose, repayment period, address, and age. Identify the attributes.
- the computer calculates the contribution of each attribute to the determination result of the attribute, and identifies the attribute whose calculated contribution exceeds a predetermined reference value as an indirect discrimination attribute. Conceivable.
- the degree of contribution is a value indicating the correlation between the attribute and the determination result, which is calculated based on the number of data for each attribute, such as elift in the prior art.
- the contribution effect is an effect that the reference value of the degree of contribution, which is the basis for judging the indirect discrimination attribute, is observed to be different for each attribute for humans. For example, some attributes are considered to be discriminatory if they contribute to the determination result even a little, and some attributes are considered to be discriminatory only if they contribute significantly to the determination result. As shown in FIG. 2, when the computer determines a uniform reference value for any attribute and identifies the indirect discrimination attribute based on whether or not the contribution exceeds the determined reference value, this attribute is used. It is not possible to specify each contribution effect in consideration.
- the training data generation device 10 determines the reference value of the contribution degree for each attribute. Specifically, the training data generation device 10 determines a reference value of the contribution degree for each attribute according to how discriminatory the attribute is with respect to the contribution degree of each attribute.
- the functional configuration of the training data generation device 10 according to the present embodiment will be described in detail.
- the training data generation device 10 functionally includes a calculation unit 12, a reception unit 14, a determination unit 16, and a generation unit 18.
- the calculation unit 12 calculates the contribution degree for each attribute from the data set input to the training data generation device 10.
- the contribution degree is a value calculated based on the number of data for each attribute, and is a value indicating the correlation between the attribute and the determination result.
- the calculation unit 12 has a reliability conf (X ⁇ Y) represented by the ratio of data having an attribute value of X for a certain attribute to data having an attribute value of Y for another attribute, or a conventional technique.
- the degree of contribution may be calculated using elift or the like.
- the degree of contribution is an example of the "value calculated based on the number of data for each attribute included in a plurality of data" of the disclosed technology.
- the calculation unit 12 has the attribute value of the attribute "judgment result” "approved” and the attribute value of the attribute "purpose” "approved” for the number of data for which the attribute value of the attribute "judgment result” is “approved”.
- the ratio of the number of data that is "purchase of used car” is calculated as the reliability of "purchase of used car”.
- the calculation unit 12 similarly calculates the reliability of the “budget during vacation”. Then, the calculation unit 12 calculates the difference or ratio between the reliability of "purchasing a used car” and the reliability of "budget during vacation” as the contribution to the determination result for the attribute "purpose”. This means that when the difference or ratio of the reliability for each attribute value is large for a certain attribute, the bias toward the determination result by the attribute value of the attribute is large.
- X is the attribute value "New York” of the attribute "address”
- Z is the attribute value "African American” of the attribute "race”
- Y is the attribute value "rejection” of the attribute "judgment result”.
- This elift represents the ratio of "the percentage of African-Americans living in New York whose loan screening has been rejected” to "the percentage of people living in New York whose loan screening has been rejected.”
- the calculation unit 12 calculates elift by assuming that X is the attribute value “Los Angeles” of the attribute “address” and Y and Z are the same as described above.
- the calculation unit 12 calculates the difference or ratio between these two elifts as the contribution of the attribute “address”.
- the degree of contribution in this case is an index for determining whether or not the attribute "address" is an indirect discrimination attribute by correlation with the direct discrimination attribute "race”.
- the difference or ratio between the maximum and minimum values of elift and reliability calculated for each attribute value may be calculated as the contribution.
- the method of calculating the degree of contribution is not limited to the above example, and any method may be used as long as the correlation between the attribute and the determination result is calculated based on the number of data for each attribute.
- the reception unit 14 receives an evaluation value for the contribution degree for each attribute calculated by the calculation unit 12. As an evaluation value, the reception unit 14 receives a degree of discrimination, which is determined based on the degree of contribution of each attribute used for the determination, and indicates the degree to which the attribute used for the determination contributes to the determination result in a discriminatory manner. In other words, the degree of discrimination can be said to be the rate at which the degree of contribution is reduced because each attribute is no longer discriminatory.
- the reception unit 14 displays a reception screen 30 as shown in FIG. 4, for example, on the display device of the information processing device used by each of the plurality of first evaluators included in the first evaluator group. It is displayed and the degree of discrimination for each attribute is accepted from each of the plurality of first evaluators.
- the degree of contribution is displayed in association with each attribute on the reception screen 30, and the slide bar for selecting the degree of discrimination for each attribute and the degree of discrimination selected by the slide bar are displayed. Is displayed.
- the degree of discrimination is a discrete value of 0, 1, 2, ..., 10, but the degree of discrimination is not limited to this example.
- each attribute is displayed in a random order for each of all evaluators, and the degree of discrimination received from each of all evaluators is totaled. There is a way to do it.
- the evaluator enters the pondering process, but this method does not consider the "contemplation process". In the pondering process, the evaluator considers as many scenarios as possible for one attribute and selects the degree of discrimination. For example, evaluators may be treated discriminatory when considering the attribute "address" is not usually discriminatory, but if a particular race lives in a particular area, etc.
- the training data generation device 10 reduces the cognitive load when the evaluator evaluates the degree of discrimination, and the evaluator quickly and appropriately discriminates or appropriately discriminates even for an attribute that is difficult to evaluate. Support the ability to make non-discriminatory assessments.
- the reception unit 14 determines whether or not there is an agreement on the degree of discrimination by the first evaluator group for a certain attribute. Attributes that have an agreement on the degree of discrimination within the first evaluator group have the same evaluation tendency of the degree of discrimination from each first evaluator. That is, the evaluation of the degree of discrimination is concentrated. On the other hand, for attributes for which there is no agreement within the first evaluator group, the evaluation of the degree of discrimination from each first evaluator is scattered. Therefore, the reception unit 14 determines whether or not there is an agreement within the first evaluator group based on the degree of dispersion of the degree of discrimination against the attribute.
- the reception unit 14 receives from each of the first evaluators when the degree of dispersion of the degree of discrimination received from the first evaluator group via the above-mentioned reception screen 30 is equal to or less than a predetermined value.
- the degree of discrimination is integrated and accepted as the agreed degree of discrimination by the first group of evaluators.
- the reception unit 14 calculates the variance of the degree of discrimination evaluated for each attribute as an example of the degree of dispersion of the degree of discrimination.
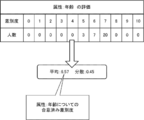
- FIG. 5 shows the aggregated results of the degree of discrimination regarding the attribute “age” received from the first evaluator group of 30 people.
- the variance of the degree of discrimination of the attribute "age” is calculated to be 0.45.
- the reception unit 14 refers to the attribute "age” as an attribute in which a single agreed degree of discrimination exists within the first evaluator group (hereinafter referred to as "agreeed attribute").
- an average discrimination level of 6.57 is set as an agreed discrimination level.
- the degree of dispersion is not limited to dispersion, but may be standard deviation or the like.
- the agreed degree of discrimination is not limited to the average, but may be the mode, median, or the like.
- the reception unit 14 clusters the degree of discrimination received from each of the first evaluators until the degree of dispersion becomes equal to or less than the predetermined value, and discriminates included in each cluster. Consolidate degrees and accept as each agreed degree of discrimination.
- FIG. 6 shows the aggregated result of the degree of discrimination regarding the attribute “purpose” received from the first evaluator group of 30 people.
- the variance of the degree of discrimination of the attribute "purpose” is calculated to be 1.45.
- the reception unit 14 determines that the attribute "purpose” is an attribute in which there is no single degree of discrimination agreement within the first evaluator group (hereinafter, "non-agreement"). Attribute ”).
- the reception unit 14 applies various discrimination modes to the non-agreement attribute. Applying different levels of discrimination is to set multiple agreed levels of discrimination for that attribute. Even if there is no consensus on a single degree of discrimination within the first group of evaluators, some attributes do not have any consensus, but the views on the degree of discrimination do not agree, and the first There may be agreements on varying degrees of discrimination within the evaluator group. For example, as shown in FIG. 7, when there are an evaluator who recognizes that the degree of discrimination is high and an evaluator who recognizes that the degree of discrimination is low with respect to the attribute "address", there are various degrees of discrimination. The mode will be applied. This is because attributes to which various discrimination modes are applied are likely to be attributes that easily trigger a pondering process, so by setting multiple agreed discrimination levels for one attribute, an evaluator group It expresses various standards of fairness within.
- the reception unit 14 clusters the degree of discrimination evaluated by the evaluator group so that the number of clusters is the number of clusters obtained by adding 1 to the number of clusters for which the presence or absence of the agreed degree of discrimination has been determined until immediately before.
- the reception unit 14 since the number of clusters immediately before is 1, the reception unit 14 sets the number of clusters to 2, and clusters the degree of discrimination by, for example, a k-means algorithm or the like. Then, the reception unit 14 calculates the variance of the degree of discrimination within the cluster for each cluster. In the example of FIG. 6, for cluster 1 (dashed line portion in FIG. 6), the variance is calculated as 0.14, and for cluster 2 (dashed line portion in FIG.
- the variance is calculated as 0.44. To. As in the above, if the predetermined value is 1, the variance of each cluster is equal to or less than the predetermined value. Therefore, the reception unit 14 sets each of the average discrimination levels included in each cluster to the agreed discrimination level for the attribute. Set as. In the example of FIG. 6, the reception unit 14 sets two agreed discrimination levels, 2.83 and 5, for the attribute “purpose”.
- the reception unit 14 accepts the agreed discrimination level as the final discrimination level for the attributes for which one agreed discrimination level is set. Further, the reception unit 14 presents each of the agreed discrimination levels as an option to each of the second evaluators included in the second evaluator group for the attributes for which a plurality of agreed discrimination levels are set. .. Then, the reception unit 14 causes each of the second evaluators to select an option, aggregates the selection results, and accepts it as the final evaluation value. This is a second evaluation of the "final discrimination" determination described below, based on the various fairness criteria within the first evaluator group expressed by the various discrimination modes described above. It encourages early agreement by a group of people.
- the reception unit 14 uses the agreed discrimination level as it is as the final discrimination level. Accept as.
- a plurality of agreed discrimination levels are set for the attributes "occupation", "purpose”, and "address”. Therefore, for example, the reception unit 14 displays the selection screen 32 as shown in FIG. 9 on the display device of the information processing device used by each of the second evaluators.
- the second evaluator may be an evaluator different from the first evaluator included in the first evaluator group, or at least a part of the second evaluator may be shared with the first evaluator. ..
- the selection screen 32 is a radio for selecting one of a plurality of agreed discrimination levels or not agreeing with any of the agreed discrimination levels (“none” in FIG. 9). Display parts such as buttons are displayed.
- the second evaluator chooses either agreed degree of discrimination, or "none".
- an attribute in which a plurality of agreed discrimination levels are set that is, an attribute in which the evaluation of the discrimination level is divided in the first evaluator group is the agreed discrimination level of the attribute.
- the reception unit 14 is as shown in FIG. 10, for example.
- the additional reception screen 34 is displayed on the display device of the information processing device used by the second evaluator.
- the additional reception screen 34 displays a slide bar for allowing the second evaluator to select the degree of discrimination for the attribute for which “None” is selected.
- the reception unit 14 receives the degree of discrimination from the second evaluator via the additional reception screen 34.
- the reception unit 14 starts over from the setting of the agreed discrimination level together with the discrimination level received from the second evaluator and the discrimination level received from the first evaluator group.
- the reception unit 14 aggregates the discrimination levels selected by the second evaluator via the selection screen 32, and for example, the agreed discrimination level most selected by the second evaluator is the final discrimination level.
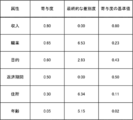
- FIG. 11 shows an example of the aggregated result of the degree of discrimination selected by the second evaluator.
- the second evaluator is 100 people.
- the reception unit 14 was selected most by the second evaluator among the agreed discrimination levels "2.11", “3.98", and "6.53". 6.53 ”is accepted as the final degree of discrimination.
- the lower part of FIG. 11 shows an example of the final degree of discrimination of each attribute. In the present embodiment, an attribute having a final degree of discrimination greater than 0 is specified as an indirect attribute.
- the determination unit 16 determines the reference value of the contribution degree for each attribute based on the final degree of discrimination received by the reception unit 14 and the number of data for each attribute in the data set. Specifically, as shown in FIG. 12, the determination unit 16 reduces the contribution calculated by the calculation unit 12 at a rate according to the magnitude of the final degree of discrimination, and the contribution for each attribute. Determined as a reference value for degrees. As a result, as shown in FIG. 12, the reference value for each attribute considering the contribution effect is determined.
- FIG. 13 shows a reference value of the contribution of each attribute calculated in the above calculation example.
- the generation unit 18 generates training data for machine learning by changing the attributes of at least a part of the data included in the data set according to the reference value of the contribution degree for each attribute determined by the determination unit 16. do. Specifically, the generation unit 18 includes at least a part of the data set so that the difference between the reference value of the contribution degree for each attribute and the contribution degree calculated by the calculation unit 12 is equal to or less than a predetermined value. Change the attribute value of the data attribute "judgment result", that is, the label. More specifically, the generation unit 18 sets the attribute value of the attribute "determination result” for at least a part of the data included in the data set so that the contribution calculated by the calculation unit 12 is equal to or less than the reference value. , Change to an attribute value that shows a judgment result different from the attribute value of the original data.
- the generation unit 18 changes the attributes of some data by using a technique called massage.
- FIG. 14 shows a case where the label is changed so that the contribution of the attribute “purpose” is equal to or less than the reference value by massage.
- the generation unit 18 classifies each data contained in the data set by a general classifier such as a random forest, and the certainty of each data is in the class indicated by the label of the data.
- a classification score indicating whether or not the data has been classified is calculated for each data.
- a circle with a number inside corresponds to each data, and the number represents the classification score of each data.
- the diagonal circle indicates that the label of the data is "approved"
- the white circle indicates that the label of the data is "rejected”. Further, in FIG.
- the generation unit 18 sorts the data for each attribute value so that the classification score becomes lower toward the boundary of the label. That is, the data closest to the boundary and labeled "approved” is the data with the lowest probability of being classified as "approved”, and the data closest to the boundary and labeled "rejected” is the data. Is the data with the lowest probability of being classified as "rejected”.
- the reference value of the contribution of the attribute “purpose” is 0.43, which is reduced from the contribution of 0.60 calculated by the calculation unit 12 according to the degree of discrimination. Therefore, the generation unit 18 changes the label to the other label in order from the data closest to the boundary so that the contribution degree becomes smaller.
- the generation unit 18 changes the label of the data whose attribute value is "purchase of used car", which is closest to the boundary and whose label is “approval”, to "reject” (white double in FIG. 14). Data indicated by circles). Further, the generation unit 18 changes the label of the data whose attribute value is "budget during vacation” to “approve” for the data whose label is “rejected”, which is the closest to the boundary (diagonal line 2 in FIG. 14). Data indicated by double circles). As a result, the contribution of the label corresponding to the difference in the number of data of "approval” among the attribute values for the attribute "purpose” becomes small, and approaches the reference value determined by the determination unit 16 (B in FIG. 14). ).
- the generation unit 18 repeats the above-mentioned label changes until the contribution becomes less than or equal to the reference value, and the data to which the label is attached when the degree of contribution becomes less than or equal to the reference value is used as training data.
- the generation unit 18 outputs a training data set including a plurality of generated training data.
- the label change is not limited to the case of performing the above-mentioned massage, and the data may be changed based on other criteria such as elift and reliability.
- the output training data set is used for machine learning of a model such as a neural network in the machine learning device 20.
- the output of the model when the attribute value of the attribute used for the determination included in the training data is input corresponds to the attribute value of the attribute indicating the determination result, that is, the label.
- Machine learning the parameters of the model so that.
- the training data generation device 10 can be realized by, for example, the computer 40 shown in FIG.
- the computer 40 includes a CPU (Central Processing Unit) 41, a memory 42 as a temporary storage area, and a non-volatile storage unit 43. Further, the computer 40 includes an input / output device 44 such as an input unit and a display unit, and an R / W (Read / Write) unit 45 that controls reading and writing of data to the storage medium 49. Further, the computer 40 includes a communication I / F (Interface) 46 connected to a network such as the Internet.
- the CPU 41, the memory 42, the storage unit 43, the input / output device 44, the R / W unit 45, and the communication I / F 46 are connected to each other via the bus 47.
- the storage unit 43 can be realized by an HDD (Hard Disk Drive), an SSD (Solid State Drive), a flash memory, or the like.
- the training data generation program 50 for making the computer 40 function as the training data generation device 10 is stored in the storage unit 43 as a storage medium.
- the training data generation program 50 has a calculation process 52, a reception process 54, a decision process 56, and a generation process 58.
- the CPU 41 reads the training data generation program 50 from the storage unit 43, expands it into the memory 42, and sequentially executes the process of the training data generation program 50.
- the CPU 41 operates as the calculation unit 12 shown in FIG. 1 by executing the calculation process 52. Further, the CPU 41 operates as the reception unit 14 shown in FIG. 1 by executing the reception process 54. Further, the CPU 41 operates as the determination unit 16 shown in FIG. 1 by executing the determination process 56. Further, the CPU 41 operates as the generation unit 18 shown in FIG. 1 by executing the generation process 58.
- the computer 40 that has executed the training data generation program 50 functions as the training data generation device 10.
- the CPU 41 that executes the program is hardware.
- the function realized by the training data generation program 50 can also be realized by, for example, a semiconductor integrated circuit, more specifically, an ASIC (Application Specific Integrated Circuit) or the like.
- a semiconductor integrated circuit more specifically, an ASIC (Application Specific Integrated Circuit) or the like.
- the training data generation process is an example of a training data generation method of the disclosed technique.
- step S11 the calculation unit 12 acquires the data set input to the training data generation device 10 and calculates the contribution degree for each attribute.
- step S12 the reception unit 14 displays a display device of the information processing device used by each of the plurality of first evaluators included in the first evaluator group, for example, a reception screen as shown in FIG. 30 is displayed. Then, the reception unit 14 receives the degree of discrimination for each attribute from each of the plurality of first evaluators.
- step S13 the reception unit 14 sets 1 in the variable k indicating the number of clusters in the clustering process executed in step S14 described later.
- step S15 the reception unit 14 determines whether or not the variance of the degree of discrimination included in each cluster is equal to or less than a predetermined value for each attribute. If the variance for all clusters is less than or equal to a predetermined value, the process proceeds to step S17. On the other hand, when the distribution of any of the clusters exceeds a predetermined value, the process proceeds to step S16, the reception unit 14 increments k by 1, and the process returns to step S14. In step S17, the reception unit 14 sets each of the average discrimination levels included in each cluster as the agreed discrimination level for the attribute for each attribute.
- step S18 the reception unit 14 displays the attribute of the agreed discrimination degree on the display device of the information processing device used by each of the second evaluators, for example, as shown in FIG.
- the selection screen 32 is displayed.
- the reception unit 14 presents to each of the second evaluators each of the agreed discrimination levels as an option for the attributes for which a plurality of agreed discrimination levels are set.
- step S19 the reception unit 14 determines whether or not any of the agreed discrimination levels has been selected by the second evaluator.
- the process proceeds to step S20, and the reception unit 14 aggregates the discrimination levels selected by the second evaluator via the selection screen 32, and the first The agreed degree of discrimination most selected by the two evaluators is accepted as the final degree of discrimination.
- step S21 the reception unit 14 displays, for example, the additional reception screen 34 as shown in FIG.
- the reception unit 14 receives the degree of discrimination from the second evaluator via the additional reception screen 34, and sets the degree of discrimination received from the second evaluator to the degree of discrimination received from the first evaluator group. The process returns to step S13.
- step S22 the determination unit 16 reduces the contribution calculated in step S11 at a rate corresponding to the magnitude of the final degree of discrimination received in step S20 for each attribute. It is determined as a reference value for the contribution of.
- step S23 the generation unit 18 has an attribute value (label) of the attribute "determination result" for at least a part of the data included in the data set so that the contribution degree is equal to or less than the reference value for each attribute. Is changed to an attribute value indicating a judgment result different from the attribute value of the original data.
- the generation unit 18 generates training data, outputs the generated training data as a training data set, and ends the training data generation process.
- the machine learning device 20 machine-learns a model such as a neural network using the training data set output from the training data generation device 10.
- the training data generation device accepts the evaluation value for the value calculated based on the number of data for each attribute included in the plurality of data, and the accepted evaluation value and the attribute.
- a reference value for each attribute is determined based on the number of data for each attribute.
- the training data generation device generates training data for machine learning by changing the attributes of at least a part of the plurality of data according to the reference value for each attribute. This makes it possible to generate training data for machine learning of a model in which the bias toward discriminatory judgment due to the discriminatory attribute considering the context is appropriately reduced.
- the training data generation device sets a plurality of agreed discrimination levels for the same attribute in the process of accepting the final discrimination level, so that various discriminations against the same attribute can be performed. It is possible to recognize the degree and encourage early agreement on the attributes that the evaluation is divided among the evaluators. For example, if the computer presents the average degree of discrimination evaluated by the first group of evaluators to the second group of evaluators as a single agreed degree of discrimination, then the presented agreed degree of discrimination is convincing. The number of evaluators of 2 will decrease, which may hinder early agreement. On the other hand, the training data generator according to the present embodiment presents a plurality of agreed discrimination levels so that more second evaluators can be convinced by the presented discrimination levels and promote early agreement. can do.
- the training data generation device presents to the second evaluator with a plurality of agreed discrimination levels as options for the attributes for which a plurality of agreed discrimination levels are set. That is, even if the number of attributes is enormous, the second evaluator may select the degree of discrimination from the options for some of the attributes among the plurality of attributes. Therefore, it is possible to prevent the second evaluator from entering the pondering process, or the second evaluator who has entered the pondering process can get out of the pondering process at an early stage. As a result, it is possible to reach an early agreement among a plurality of evaluators regarding the degree of discrimination of each attribute, as compared with the case where each of all the evaluators evaluates the degree of discrimination for all attributes.
- the mode in which the training data generation program is stored (installed) in the storage unit in advance has been described, but the present invention is not limited to this.
- the program according to the disclosed technology can also be provided in a form stored in a storage medium such as a CD-ROM, a DVD-ROM, or a USB memory.
- Training data generator 12 Calculation unit 14 Reception unit 16 Decision unit 18 Generation unit 20 Machine learning device 30 Reception screen 32 Selection screen 34 Additional reception screen 40 Computer 41 CPU 42 Memory 43 Storage unit 49 Storage medium 50 Training data generation program
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- General Engineering & Computer Science (AREA)
- Business, Economics & Management (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Life Sciences & Earth Sciences (AREA)
- Evolutionary Biology (AREA)
- Bioinformatics & Computational Biology (AREA)
- Software Systems (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Human Resources & Organizations (AREA)
- Mathematical Physics (AREA)
- Computing Systems (AREA)
- Strategic Management (AREA)
- Medical Informatics (AREA)
- Entrepreneurship & Innovation (AREA)
- Finance (AREA)
- Economics (AREA)
- Marketing (AREA)
- General Business, Economics & Management (AREA)
- Accounting & Taxation (AREA)
- Tourism & Hospitality (AREA)
- Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Quality & Reliability (AREA)
- Operations Research (AREA)
- Technology Law (AREA)
- Development Economics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP20942406.8A EP4174734A4 (en) | 2020-06-26 | 2020-06-26 | PROGRAM, DEVICE AND METHOD FOR GENERATION OF TRAINING DATA |
| PCT/JP2020/025360 WO2021260945A1 (ja) | 2020-06-26 | 2020-06-26 | 訓練データ生成プログラム、装置、及び方法 |
| JP2022532227A JP7367872B2 (ja) | 2020-06-26 | 2020-06-26 | 訓練データ生成プログラム、装置、及び方法 |
| US18/068,751 US20230117689A1 (en) | 2020-06-26 | 2022-12-20 | Non-transitory computer-readable storage medium for storing training data generation program, device, and method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/025360 WO2021260945A1 (ja) | 2020-06-26 | 2020-06-26 | 訓練データ生成プログラム、装置、及び方法 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US18/068,751 Continuation US20230117689A1 (en) | 2020-06-26 | 2022-12-20 | Non-transitory computer-readable storage medium for storing training data generation program, device, and method |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021260945A1 true WO2021260945A1 (ja) | 2021-12-30 |
Family
ID=79282159
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/025360 Ceased WO2021260945A1 (ja) | 2020-06-26 | 2020-06-26 | 訓練データ生成プログラム、装置、及び方法 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US20230117689A1 (https=) |
| EP (1) | EP4174734A4 (https=) |
| JP (1) | JP7367872B2 (https=) |
| WO (1) | WO2021260945A1 (https=) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2023108516A (ja) * | 2022-01-25 | 2023-08-04 | 富士通株式会社 | 機械学習プログラム,機械学習方法及び情報処理装置 |
| JP2023113047A (ja) * | 2022-02-02 | 2023-08-15 | 富士通株式会社 | 機械学習プログラム,機械学習方法及び情報処理装置 |
| WO2024058202A1 (ja) * | 2022-09-15 | 2024-03-21 | ソニーグループ株式会社 | 情報処理装置及び情報処理方法、並びにコンピュータプログラム |
| JP2024093528A (ja) * | 2022-12-27 | 2024-07-09 | 株式会社日立ソリューションズ | 教師データ編集支援システム、方法、およびプログラム |
| WO2024180775A1 (ja) * | 2023-03-02 | 2024-09-06 | 富士通株式会社 | 訓練データ生成プログラム、方法、及び装置 |
| WO2024180802A1 (ja) * | 2023-02-27 | 2024-09-06 | ソニーグループ株式会社 | 情報処理装置及び情報処理方法、コンピュータプログラム、並びにイメージセンサ |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20190147371A1 (en) * | 2017-11-13 | 2019-05-16 | Accenture Global Solutions Limited | Training, validating, and monitoring artificial intelligence and machine learning models |
| US20190188605A1 (en) * | 2017-12-20 | 2019-06-20 | At&T Intellectual Property I, L.P. | Machine Learning Model Understanding As-A-Service |
Family Cites Families (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20050073918A1 (en) * | 2003-10-01 | 2005-04-07 | Ryoichi Ishikawa | Optical disc apparatus and tracking control method and program for the optical disc apparatus |
| JP2010204966A (ja) * | 2009-03-03 | 2010-09-16 | Nippon Telegr & Teleph Corp <Ntt> | サンプリング装置、サンプリング方法、サンプリングプログラム、クラス判別装置およびクラス判別システム。 |
| US8832116B1 (en) * | 2012-01-11 | 2014-09-09 | Google Inc. | Using mobile application logs to measure and maintain accuracy of business information |
| US11068796B2 (en) * | 2013-11-01 | 2021-07-20 | International Business Machines Corporation | Pruning process execution logs |
| US10362062B1 (en) * | 2016-04-22 | 2019-07-23 | Awake Security, Inc. | System and method for evaluating security entities in a computing environment |
| US20210312362A1 (en) * | 2020-04-07 | 2021-10-07 | Microsoft Technology Licensing, Llc | Providing action items for an activity based on similar past activities |
-
2020
- 2020-06-26 WO PCT/JP2020/025360 patent/WO2021260945A1/ja not_active Ceased
- 2020-06-26 JP JP2022532227A patent/JP7367872B2/ja active Active
- 2020-06-26 EP EP20942406.8A patent/EP4174734A4/en not_active Withdrawn
-
2022
- 2022-12-20 US US18/068,751 patent/US20230117689A1/en active Pending
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20190147371A1 (en) * | 2017-11-13 | 2019-05-16 | Accenture Global Solutions Limited | Training, validating, and monitoring artificial intelligence and machine learning models |
| US20190188605A1 (en) * | 2017-12-20 | 2019-06-20 | At&T Intellectual Property I, L.P. | Machine Learning Model Understanding As-A-Service |
Non-Patent Citations (1)
| Title |
|---|
| DINO PEDRESCHISALVATORE RUGGIERIFRANCO TURINI: "Discrimination-aware Data Mining", KDD '08: PROCEEDINGS OF THE 14TH ACM SIGKDD INTERNATIONAL CONFERENCE ON KNOWLEDGE DISCOVERY AND DATA MINING, August 2008 (2008-08-01), pages 560 - 568, XP058362350, DOI: 10.1145/1401890.1401959 |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2023108516A (ja) * | 2022-01-25 | 2023-08-04 | 富士通株式会社 | 機械学習プログラム,機械学習方法及び情報処理装置 |
| JP2023113047A (ja) * | 2022-02-02 | 2023-08-15 | 富士通株式会社 | 機械学習プログラム,機械学習方法及び情報処理装置 |
| JP7764775B2 (ja) | 2022-02-02 | 2025-11-06 | 富士通株式会社 | 機械学習プログラム,機械学習方法及び情報処理装置 |
| WO2024058202A1 (ja) * | 2022-09-15 | 2024-03-21 | ソニーグループ株式会社 | 情報処理装置及び情報処理方法、並びにコンピュータプログラム |
| JP2024093528A (ja) * | 2022-12-27 | 2024-07-09 | 株式会社日立ソリューションズ | 教師データ編集支援システム、方法、およびプログラム |
| JP7798761B2 (ja) | 2022-12-27 | 2026-01-14 | 株式会社日立ソリューションズ | 教師データ編集支援システム、方法、およびプログラム |
| WO2024180802A1 (ja) * | 2023-02-27 | 2024-09-06 | ソニーグループ株式会社 | 情報処理装置及び情報処理方法、コンピュータプログラム、並びにイメージセンサ |
| WO2024180775A1 (ja) * | 2023-03-02 | 2024-09-06 | 富士通株式会社 | 訓練データ生成プログラム、方法、及び装置 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7367872B2 (ja) | 2023-10-24 |
| JPWO2021260945A1 (https=) | 2021-12-30 |
| EP4174734A4 (en) | 2023-06-14 |
| US20230117689A1 (en) | 2023-04-20 |
| EP4174734A1 (en) | 2023-05-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7367872B2 (ja) | 訓練データ生成プログラム、装置、及び方法 | |
| US10943186B2 (en) | Machine learning model training method and device, and electronic device | |
| US11157997B2 (en) | Systems and methods for analyzing data | |
| US20180308160A1 (en) | Risk assessment method and system | |
| CN111582651A (zh) | 用户风险分析模型训练方法、装置及电子设备 | |
| US20220156634A1 (en) | Training Data Augmentation for Machine Learning | |
| US12469075B2 (en) | Computing system and method for creating a data science model having reduced bias | |
| CN112927061A (zh) | 用户操作检测方法及程序产品 | |
| CN112200392A (zh) | 业务预测方法及装置 | |
| Kozodoi et al. | Shallow self-learning for reject inference in credit scoring | |
| Percy et al. | Lessons Learned from Problem Gambling Classification: Indirect Discrimination and Algorithmic Fairness. | |
| CN110851482B (zh) | 为多个数据方提供数据模型的方法及装置 | |
| CN115204322A (zh) | 行为链路异常识别方法和装置 | |
| KR102400804B1 (ko) | 기계학습 기반 신용평가 분류 모델의 평가 이유를 설명하는 장치 및 방법 | |
| TWI755774B (zh) | 損失函數的優化系統、優化方法及其電腦可讀取記錄媒體 | |
| Wang et al. | FIAO: Feature Information Aggregation Oversampling for imbalanced data classification | |
| Gadzinski et al. | Combining white box models, black box machines and humaninterventions for interpretable decision strategies | |
| CN115759750A (zh) | 金融风险评估方法、系统、计算机及可读存储介质 | |
| CN114169641A (zh) | 基于特征熵的客户利率敏感度预测方法 | |
| EP4287075A1 (en) | Training data generation device and method | |
| JP2023177116A (ja) | 情報処理方法、プログラム及び情報処理装置 | |
| EP4621666A1 (en) | Bias evaluation program, device, and method | |
| US20210201334A1 (en) | Model acceptability prediction system and techniques | |
| Güder et al. | Prediction of Home Loan Approval with Machine Learning | |
| KR102934109B1 (ko) | 삼각형 도법을 이용한 고객투자성향 분석 및 분류에 의한 고객 맞춤형 자산 할당 추천 방법 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20942406 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022532227 Country of ref document: JP Kind code of ref document: A |
|
| ENP | Entry into the national phase |
Ref document number: 2020942406 Country of ref document: EP Effective date: 20230126 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |