WO2021256055A1 - 情報処理装置、情報処理装置の作動方法、情報処理装置の作動プログラム - Google Patents
情報処理装置、情報処理装置の作動方法、情報処理装置の作動プログラム Download PDFInfo
- Publication number
- WO2021256055A1 WO2021256055A1 PCT/JP2021/014592 JP2021014592W WO2021256055A1 WO 2021256055 A1 WO2021256055 A1 WO 2021256055A1 JP 2021014592 W JP2021014592 W JP 2021014592W WO 2021256055 A1 WO2021256055 A1 WO 2021256055A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- information
- annotation information
- gene
- information processing
- biomarkers
- Prior art date
Links
- 230000010365 information processing Effects 0.000 title claims abstract description 71
- 238000000034 method Methods 0.000 title claims abstract description 68
- 238000005259 measurement Methods 0.000 claims abstract description 88
- 238000011156 evaluation Methods 0.000 claims abstract description 86
- 239000000090 biomarker Substances 0.000 claims abstract description 67
- 239000012472 biological sample Substances 0.000 claims abstract description 56
- 238000009795 derivation Methods 0.000 claims abstract description 31
- 238000012545 processing Methods 0.000 claims abstract description 29
- 108090000623 proteins and genes Proteins 0.000 claims description 279
- 210000004027 cell Anatomy 0.000 claims description 86
- 230000014509 gene expression Effects 0.000 claims description 72
- 210000003981 ectoderm Anatomy 0.000 claims description 20
- 210000001900 endoderm Anatomy 0.000 claims description 19
- 210000003716 mesoderm Anatomy 0.000 claims description 19
- 230000008569 process Effects 0.000 claims description 16
- 230000001965 increasing effect Effects 0.000 claims description 10
- 239000003550 marker Substances 0.000 claims description 5
- 238000007619 statistical method Methods 0.000 claims description 5
- 101150027068 DEGS1 gene Proteins 0.000 description 93
- 238000000605 extraction Methods 0.000 description 51
- 230000004069 differentiation Effects 0.000 description 35
- 238000009826 distribution Methods 0.000 description 31
- 230000006399 behavior Effects 0.000 description 28
- 230000006698 induction Effects 0.000 description 21
- 230000006870 function Effects 0.000 description 12
- 238000002493 microarray Methods 0.000 description 9
- 239000000523 sample Substances 0.000 description 9
- 238000003860 storage Methods 0.000 description 9
- 238000002474 experimental method Methods 0.000 description 8
- 238000005516 engineering process Methods 0.000 description 7
- 239000000284 extract Substances 0.000 description 6
- 238000011160 research Methods 0.000 description 5
- CURLTUGMZLYLDI-UHFFFAOYSA-N Carbon dioxide Chemical compound O=C=O CURLTUGMZLYLDI-UHFFFAOYSA-N 0.000 description 4
- 210000001654 germ layer Anatomy 0.000 description 4
- 210000003701 histiocyte Anatomy 0.000 description 4
- 230000001939 inductive effect Effects 0.000 description 4
- 238000012360 testing method Methods 0.000 description 4
- 238000003559 RNA-seq method Methods 0.000 description 3
- 238000007792 addition Methods 0.000 description 3
- 230000007815 allergy Effects 0.000 description 3
- 238000004458 analytical method Methods 0.000 description 3
- 238000004113 cell culture Methods 0.000 description 3
- 238000004891 communication Methods 0.000 description 3
- 230000000052 comparative effect Effects 0.000 description 3
- 238000012790 confirmation Methods 0.000 description 3
- 238000010586 diagram Methods 0.000 description 3
- 230000000694 effects Effects 0.000 description 3
- 230000004044 response Effects 0.000 description 3
- 208000035473 Communicable disease Diseases 0.000 description 2
- QXKAIJAYHKCRRA-BXXZVTAOSA-N D-ribonic acid Chemical compound OC[C@@H](O)[C@@H](O)[C@@H](O)C(O)=O QXKAIJAYHKCRRA-BXXZVTAOSA-N 0.000 description 2
- 102000053602 DNA Human genes 0.000 description 2
- 108020004414 DNA Proteins 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 238000004364 calculation method Methods 0.000 description 2
- 229910002092 carbon dioxide Inorganic materials 0.000 description 2
- 239000001569 carbon dioxide Substances 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 210000004263 induced pluripotent stem cell Anatomy 0.000 description 2
- 108020004999 messenger RNA Proteins 0.000 description 2
- 239000002207 metabolite Substances 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 238000007639 printing Methods 0.000 description 2
- 102000004169 proteins and genes Human genes 0.000 description 2
- 230000035945 sensitivity Effects 0.000 description 2
- 238000012163 sequencing technique Methods 0.000 description 2
- 102100024505 Bone morphogenetic protein 4 Human genes 0.000 description 1
- 102100025745 Cerberus Human genes 0.000 description 1
- 101000762379 Homo sapiens Bone morphogenetic protein 4 Proteins 0.000 description 1
- 101000914195 Homo sapiens Cerberus Proteins 0.000 description 1
- 101000967920 Homo sapiens Left-right determination factor 1 Proteins 0.000 description 1
- 101000967918 Homo sapiens Left-right determination factor 2 Proteins 0.000 description 1
- UFHFLCQGNIYNRP-UHFFFAOYSA-N Hydrogen Chemical compound [H][H] UFHFLCQGNIYNRP-UHFFFAOYSA-N 0.000 description 1
- 102100040508 Left-right determination factor 1 Human genes 0.000 description 1
- 102100040511 Left-right determination factor 2 Human genes 0.000 description 1
- 108700011259 MicroRNAs Proteins 0.000 description 1
- -1 NODAL Proteins 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 210000000601 blood cell Anatomy 0.000 description 1
- 210000002449 bone cell Anatomy 0.000 description 1
- 210000004413 cardiac myocyte Anatomy 0.000 description 1
- 230000032823 cell division Effects 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 210000000695 crystalline len Anatomy 0.000 description 1
- 238000007405 data analysis Methods 0.000 description 1
- 230000007812 deficiency Effects 0.000 description 1
- 239000003814 drug Substances 0.000 description 1
- 229940079593 drug Drugs 0.000 description 1
- 210000001671 embryonic stem cell Anatomy 0.000 description 1
- 210000003494 hepatocyte Anatomy 0.000 description 1
- 229910052739 hydrogen Inorganic materials 0.000 description 1
- 239000001257 hydrogen Substances 0.000 description 1
- 238000007689 inspection Methods 0.000 description 1
- 230000000968 intestinal effect Effects 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 239000002679 microRNA Substances 0.000 description 1
- 210000000663 muscle cell Anatomy 0.000 description 1
- 230000035772 mutation Effects 0.000 description 1
- 210000002569 neuron Anatomy 0.000 description 1
- 238000010606 normalization Methods 0.000 description 1
- 238000011017 operating method Methods 0.000 description 1
- 230000002250 progressing effect Effects 0.000 description 1
- 230000008672 reprogramming Effects 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 230000013707 sensory perception of sound Effects 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 210000001082 somatic cell Anatomy 0.000 description 1
- 239000000126 substance Substances 0.000 description 1
- 210000001519 tissue Anatomy 0.000 description 1
- 238000012800 visualization Methods 0.000 description 1
Images


























Classifications
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B50/00—ICT programming tools or database systems specially adapted for bioinformatics
- G16B50/10—Ontologies; Annotations
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B25/00—ICT specially adapted for hybridisation; ICT specially adapted for gene or protein expression
- G16B25/10—Gene or protein expression profiling; Expression-ratio estimation or normalisation
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B40/00—ICT specially adapted for biostatistics; ICT specially adapted for bioinformatics-related machine learning or data mining, e.g. knowledge discovery or pattern finding
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12M—APPARATUS FOR ENZYMOLOGY OR MICROBIOLOGY; APPARATUS FOR CULTURING MICROORGANISMS FOR PRODUCING BIOMASS, FOR GROWING CELLS OR FOR OBTAINING FERMENTATION OR METABOLIC PRODUCTS, i.e. BIOREACTORS OR FERMENTERS
- C12M41/00—Means for regulation, monitoring, measurement or control, e.g. flow regulation
- C12M41/48—Automatic or computerized control
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
Definitions
- the technology of the present disclosure relates to an information processing device, an operation method of the information processing device, and an operation program of the information processing device.
- Biomarkers include, for example, genes and proteins expressed by cells during culture, metabolites released from cells during culture, or elements related to the cell culture environment such as carbon dioxide concentration and pH (potential of Hydrogen).
- RNA (Ribonic Acid) sequencing (RNA-Seq (Sequencing) is known as a gene test that is a typical example of a biomarker. RNA-Seq can comprehensively measure the expression levels of tens of thousands of genes. For this reason, the elucidation of the characteristics of biological samples is progressing. However, it is difficult to develop into multi-level experiments because the inspection is time-consuming and relatively expensive.
- the first method is based on the researcher's empirical knowledge. Specifically, a previously known gene, which is a gene that is already known to affect the behavior of cells, is selected as a measurement target.
- the second method is a method of selecting a gene in a data-driven manner from the actual measurement result of the expression level of the gene. Specifically, a preliminary experiment was conducted with a small number of samples, the expression level of the gene was once comprehensively measured, and then the expression-variable genes (DEGs; Differentially Expressed Genes), which are genes whose expression level specifically fluctuates. ) Is selected as the measurement target.
- DEGs Differentially Expressed Genes
- the first method of selecting a priori gene as a measurement target there is a limit to the number of priori genes because it relies on the researcher's empirical knowledge, and genes that are considered to contribute to the elucidation of the characteristics of biological samples are appropriate. It was hard to say that I could choose.
- the second method of selecting a part of DEGs as a measurement target the variation amount is selected simply because it is specific, and as a result of developing it into a multi-level experiment, the researcher's knowledge is scarce. It was difficult to obtain guidance on how to improve cell culture performance when genes were found to contribute particularly to the elucidation of the characteristics of biological samples.
- One embodiment according to the technique of the present disclosure includes an information processing device, an operating method of the information processing device, and an information processing device capable of selecting a more appropriate biomarker to be measured, which leads to elucidation of the characteristics of a biological sample. Provides an operation program for.
- the method of operating the information processing apparatus of the present disclosure is an acquisition process for acquiring annotation information given to each of a plurality of biomarkers related to a biological sample, and an evaluation value for each of the plurality of biomarkers is derived based on the annotation information.
- the processor executes a derivation process and a selection process of selecting a biomarker to be measured from a plurality of biomarkers based on the evaluation value.
- the processor selects annotation information related to the characteristics of the biological sample of interest and derives an evaluation value based only on the selected annotation information.
- the processor refers to the database in which the annotation information for the biomarker is registered and imparts the annotation information to the biomarker.
- annotation information is associated with the type of biological sample.
- the processor accepts user specifications in a range of multiple categories defined according to the type of biological sample and the number of biomarkers to be measured for each of the multiple categories, and from the biomarkers prepared for each of the multiple categories. , It is preferable to select a number of biomarkers that satisfy the range and assign the selected biomarkers to each of a plurality of categories as biomarkers to be measured.
- the category preferably includes iPS cells, ectoderm, mesoderm, and endoderm.
- the processor counts the number of annotation information given for each of a plurality of biomarkers and derives an evaluation value based on the number of annotations.
- the processor weights the evaluation value according to the information value of the annotation information.
- the processor determines that the annotation information, which is relatively rare, has a high information value, and weights it heavily.
- the processor weights the evaluation value based on the orthogonality of the annotation information.
- the processor weights the evaluation value of the biomarker whose intensity index is within the preset threshold range.
- the processor accepts the user's designation of the prior knowledge marker, which is a biomarker already known to affect the characteristics of the biological sample, and weights the evaluation value of the prior knowledge marker.
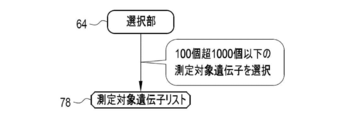
- the processor selects more than 100 biomarkers to be measured and 1000 or less.
- the biomarker preferably contains a gene.
- the gene preferably contains an expression-variable gene whose expression level is specifically varied.
- Annotation information is preferably a term defined by Gene Ontology.
- the processor acquires the measurement result of the biomarker to be measured, and based on the measurement result, the degree of influence on the characteristics of the biological sample is compared from the annotation information given to the biomarker to be measured by a statistical method. It is preferable to select highly relevant annotation information and present the selected annotation information to the user.
- the information processing apparatus of the present disclosure includes at least one processor, and the processor acquires annotation information given to each of a plurality of biomarkers relating to a biological sample, and evaluates each of the plurality of biomarkers based on the annotation information. A value is derived, and the biomarker to be measured is selected from a plurality of biomarkers based on the evaluation value.
- the operation program of the information processing apparatus of the present disclosure derives the evaluation value for each of the plurality of biomarkers based on the acquisition process for acquiring the annotation information given to each of the plurality of biomarkers related to the biological sample and the annotation information.
- the processor is made to execute the derivation process and the selection process of selecting the biomarker to be measured from a plurality of biomarkers based on the evaluation value.
- an information processing device an operation method of the information processing device, and an operation program of the information processing device capable of selecting a more appropriate biomarker to be measured, which leads to elucidation of the characteristics of the biological sample, are provided.
- the high-impact annotation information In the figure showing how the odds ratio and the p-value are calculated for each of the annotation information given to the highly expressed gene in the selection unit, and the annotation information having a p-value less than 0.05 is selected as the high-impact annotation information.
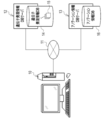
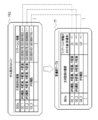
- the information processing apparatus 10 is, for example, a desktop personal computer, and is operated by a user such as a cell researcher, which is an example of a “biological sample” according to the technique of the present disclosure.
- the information processing device 10 is connected to the network 11.
- the network 11 is, for example, a WAN (Wide Area Network) such as the Internet or a public communication network.
- the information processing apparatus 10 is connected to a gene expression information database (hereinafter abbreviated as DB (Data Base)) server 12 and an annotation information DB server 13 via a network 11.
- the gene expression information DB server 12 has a gene expression information DB 14.
- the gene expression information DB 14 is, for example, GEO (Gene Expression Omnibus) provided by the National Center for Biotechnology Information (NCBI) in the United States.
- NCBI National Center for Biotechnology Information
- the gene expression information 15 is information on the amount of genes expressed by cells during culture, that is, the expression level.
- the gene is an example of a "biomarker" according to the technique of the present disclosure.
- the gene expression information DB server 12 receives the first distribution request 72 (see FIG. 8) from the information processing device 10.
- the gene expression information DB server 12 reads out the gene expression information 15 in response to the first distribution request 72 from the gene expression information DB 14. Then, the read gene expression information 15 is delivered to the information processing apparatus 10.
- the annotation information DB server 13 has the annotation information DB 16.
- the annotation information DB 16 is, for example, a DAVID (The Database for Annotation, Visualization, Bioinformatics, Bioinformatics Institute, National Institute of Allergy and Informatics) provided by the National Institute of Allergy and Infectious Diseases (NIAID), Bioinformatics Institute, Bioinformatics Institute, Bioinformatics Institute, National Institute of Allergy and Infectious Diseases (NIAID). InterPro provided by Tokoro (EBI; European Bioinformatics Institute).
- the annotation information DB 16 the corresponding annotation information is registered for each of the plurality of genes. That is, the annotation information DB 16 is an example of the "database" according to the technique of the present disclosure.
- the annotation information DB server 13 receives the second distribution request 75 (see FIG. 8) from the information processing device 10.
- the annotation information DB server 13 reads the annotation information corresponding to the second distribution request 75 from the annotation information DB 16. Then, the distribution information 76 (see FIG. 8) including the read annotation information is distributed to the information processing apparatus 10.
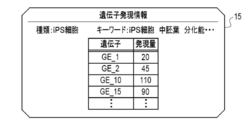
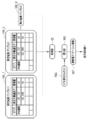
- the gene expression information 15 is information in which the expression level is registered for each gene.
- the type of the biological sample whose expression level was measured (“iPS cell” in FIG. 2) is registered.
- keywords such as "iPS cell”, “mesoderm”, and “differentiation ability” are registered for facilitating the search.
- the keyword is registered, for example, by the researcher who uploaded the gene expression information 15 or the provider of the gene expression information DB 14.
- the annotation information DB 16 stores the annotation information table 20 shown in FIG.
- the ID (Identification Data) of the annotation information is registered for each gene.
- the annotation information includes "embryonic axes specialization (specification of hypocotyl)” of ID “GO: 0.00578”, “Homeodomine-related” of ID “IPR012287”, and the like. It is a term defined by Gene Ontology (GO).
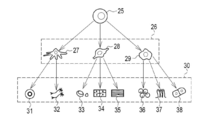
- the iPS cell 25 forms a trigerm 26 by cell division.
- the three germ layers 26 are ectoderm 27, mesoderm 28, and endoderm 29.
- Each of the three germ layers 26 differentiates into a plurality of types of histiocytes 30.
- the ectoderm 27 differentiates into a crystalline lens 31, a nerve cell 32, and the like.
- the mesoderm 28 differentiates into blood cells 33, bone cells 34, muscle cells 35 and the like.
- the endoderm 29 differentiates into alveolar cells 36, intestinal cells 37, hepatocytes 38 and the like.
- FIG. 6 shows an outline of the processing of the information processing apparatus 10.
- the information processing apparatus 10 first acquires annotation information from the annotation information DB server 13. Then, the evaluation value for each gene is derived based on the acquired annotation information. Next, a gene to be measured (hereinafter referred to as a gene to be measured) is selected from a plurality of genes based on the derived evaluation value. At this time, the information processing apparatus 10 selects the number of genes to be measured specified by the user. The number of genes to be measured is, for example, about 3000, and the number of genes to be measured is, for example, 1000. The information processing apparatus 10 presents the selected gene to be measured to the user.
- the gene to be measured is an example of the "biomarker to be measured" according to the technique of the present disclosure.
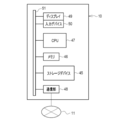
- the computer constituting the information processing apparatus 10 includes a storage device 45, a memory 46, a CPU (Central Processing Unit) 47, a communication unit 48, a display 49, and an input device 50. These are interconnected via a bus line 51.
- the storage device 45 is a hard disk drive built in the computer constituting the information processing device 10 or connected via a cable or a network. Alternatively, the storage device 45 is a disk array in which a plurality of hard disk drives are connected. The storage device 45 stores control programs such as an operating system, various application programs, and various data associated with these programs. A solid state drive may be used instead of the hard disk drive.
- the memory 46 is a work memory for the CPU 47 to execute a process.
- the CPU 47 loads the program stored in the storage device 45 into the memory 46 and executes the process according to the program. As a result, the CPU 47 controls each part of the computer in an integrated manner.
- the communication unit 48 is a network interface that controls the transmission of various information via the network 11.
- the display 49 displays various screens.
- the computer constituting the information processing apparatus 10 receives input of operation instructions from the input device 50 through various screens.
- the input device 50 is a keyboard, a mouse, a touch panel, or the like.
- the operation program 55 is stored in the storage device 45 of the information processing device 10.
- the operation program 55 is an application program for making the computer function as the information processing device 10. That is, the operation program 55 is an example of the "operation program of the information processing device" according to the technique of the present disclosure.
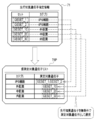
- the CPU 47 of the computer constituting the information processing device 10 cooperates with the memory 46 and the like to receive an instruction receiving unit 60, an extraction unit 61, an acquisition unit 62, a derivation unit 63, and a selection unit 64. , And functions as a display control unit 65.
- the CPU 47 is an example of a "processor" according to the technique of the present disclosure.
- the instruction receiving unit 60 receives various instructions by the user via the input device 50. For example, the instruction receiving unit 60 accepts a plurality of categories and a user's designation of a range of the number of genes to be measured for each of the plurality of categories (hereinafter referred to as a number range).
- the category is defined by the user according to the type of biological sample.
- the instruction receiving unit 60 generates the category and quantity range designation information 70 according to the designated category and quantity range, and outputs the category and quantity range designation information 70 to the selection unit 64.
- the instruction receiving unit 60 also accepts the designation by the user of the prior knowledge gene.
- the instruction receiving unit 60 generates the prior knowledge gene designation information 71 corresponding to the designated prior knowledge gene, and outputs the prior knowledge gene designation information 71 to the selection unit 64.
- the previously found gene is a gene that is already known to affect the behavior of iPS cells 25. That is, the prior knowledge gene is an example of the "prior knowledge marker" according to the technique of the present disclosure.
- the behavior of the iPS cell 25 is an example of "characteristics of a biological sample" according to the technique of the present disclosure.
- the instruction receiving unit 60 also accepts the first distribution instruction by the user, which instructs the gene expression information DB server 12 to distribute the gene expression information 15.
- the first delivery instruction is a search instruction composed of search keywords related to the iPS cell 25, for example, "iPS cell”, “ectoderm”, “endoderm”, “mesoderm”, and the like. ..
- the first distribution instruction is given through a search screen (not shown) provided with a search keyword input box and a search button.
- the instruction receiving unit 60 transmits the first distribution request 72 including the search keyword to the gene expression information DB server 12.
- the gene expression information DB server 12 searches for gene expression information 15 in which the registered keyword matches the search keyword from the gene expression information 15 in the gene expression information DB 14. Then, the searched gene expression information 15 is delivered to the information processing apparatus 10. In the information processing apparatus 10, the gene expression information 15 is input to the extraction unit 61 and the display control unit 65.
- the display control unit 65 displays the display screen (not shown) of the gene expression information 15 from the gene expression information DB server 12 on the display 49.
- the instruction receiving unit 60 receives the designation by the user of the gene expression information 15 (hereinafter referred to as extraction target 15E (see FIG. 22)) for which the DEGs are to be extracted from the displayed gene expression information 15.
- the instruction receiving unit 60 generates the extraction target designation information 73 according to the designated extraction target 15E, and outputs the extraction target designation information 73 to the extraction unit 61.
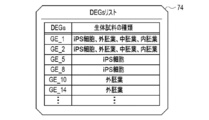
- the extraction unit 61 extracts DEGs from the extraction target 15E specified in the extraction target designation information 73. For example, the extraction unit 61 compares the expression level of each gene of the extraction target 15E with a preset threshold value, and extracts genes whose expression level is equal to or higher than the threshold value as DEGs. The extraction unit 61 generates a DEGs list 74 in which the extracted DEGs are registered, and outputs the DEGs list 74 to the acquisition unit 62.
- the acquisition unit 62 transmits the second distribution request 75 based on the DEGs list 74 from the extraction unit 61 to the annotation information DB server 13.
- the second delivery request 75 includes the DEGs registered in the DEGs list 74.
- the annotation information DB server 13 searches the annotation information table 20 in the annotation information DB 16 for the annotation information given to the DEGs included in the second distribution request 75. Then, the distribution information 76 composed of the searched annotation information and the set of DEGs is distributed to the information processing apparatus 10. In the information processing apparatus 10, the distribution information 76 is input to the acquisition unit 62.
- the acquisition unit 62 acquires the distribution information 76 from the annotation information DB server 13.
- the distribution information 76 includes annotation information as described above. Therefore, the acquisition unit 62 acquires the annotation information by acquiring the distribution information 76.
- the acquisition unit 62 adds annotation information to the DEGs list 74 based on the distribution information 76, and sets the DEGs list 74 as the assigned DEGs list 74G. That is, the acquisition unit 62 refers to the annotation information DB 16 and imparts annotation information to the gene.
- the acquisition unit 62 outputs the assigned DEGs list 74G to the out-licensing unit 63.
- the derivation unit 63 derives the evaluation value for each DEGs based on the assigned DEGs list 74G. Then, the evaluation value table 77, which is the result of deriving the evaluation values, is output to the selection unit 64.
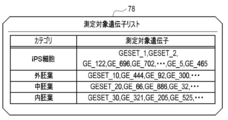
- the selection unit 64 unconditionally selects the prior knowledge gene as the measurement target gene according to the prior knowledge gene designation information 71. Further, the selection unit 64 selects the gene to be measured from the DEGs extracted by the extraction unit 61 according to the category and the number range designation information 70. The selection unit 64 outputs the measurement target gene list 78, which is the selection result of the measurement target gene, to the display control unit 65. The display control unit 65 generates a measurement target gene display screen 120 (see FIG. 24) based on the measurement target gene list 78, and displays this on the display 49.
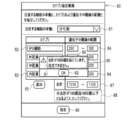
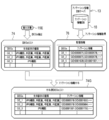
- the category designation screen 80 is displayed on the display 49 under the control of the display control unit 65 in order to accept the designation by the user of the category and the number range.
- the category designation screen 80 is provided with a pull-down menu 81 for selecting and inputting the behavior of the cell of interest, which is an example of the "characteristics of the biological sample of interest" according to the technique of the present disclosure.
- the category designation screen 80 is provided with an input box 82 for the category, an input box 83 for the lower limit of the number range, and an input box 84 for the upper limit.
- the input boxes 82 to 84 can be added by selecting the add button 85.
- the desired category and number range are input in the input boxes 82 to 84, and then the designation button 86 is selected, the instruction receiving unit 60 of the cell of interest Accepts behavior, category, and number range specifications.
- the category and the number range designation information 70 are output from the instruction receiving unit 60 to the selection unit 64.
- the category and number range designation information 70 includes the behavior of the cells of interest selected in the pull-down menu 81, the category entered in the input box 82, and the number range entered in the input boxes 83 and 84.
- FIG. 9 illustrates a case where "differentiation ability" is selected as the behavior of the cell of interest. Further, the case where "iPS cells”, “ectoderm”, “mesoderm”, and “endoderm” are specified as categories and "225 to 250" is specified for each category as the number range is exemplified. There is. In addition, only one category may be specified. Further, the same numerical value may be input to the input boxes 83 and 84.
- a display area 87 which is the total of the lower limit and the upper limit of the number range input to the input boxes 83 and 84 is provided.
- a message 88 urging the user to have a total of more than 100 and 1000 or less is displayed.
- the display control unit 65 pops up the warning screen 90 on the category designation screen 80. .. On the warning screen 90, a message 91 indicating that the total number is out of the range of more than 100 and 1000 or less and cannot be specified as it is is displayed.
- the OK button 92 is selected, the display control unit 65 turns off the display of the warning screen 90.
- the category specification screen 80 is configured so that it cannot be specified when the total number of pieces is out of the range of more than 100 pieces and 1000 pieces or less. Therefore, as shown in FIG. 11, as a result, the selection unit 64 selects more than 100 genes to be measured and 1000 or less.
- the prior knowledge gene designation screen 95 is displayed on the display 49 under the control of the display control unit 65 in order to accept the designation by the user of the prior knowledge gene.
- the prior knowledge gene designation screen 95 is provided with a pull-down menu 96 for selecting and inputting a set of prior knowledge genes.
- the pull-down menu 96 can be added by selecting the add button 97.
- a set of a plurality of previously found genes is prepared in advance as an option.
- a set of priori genes is prepared for each category.
- the set of prior knowledge genes includes, for example, a set of prior research genes used for gene analysis by TaqMan (registered trademark) scorecard, a set of prior research genes used for gene analysis by nCounter (registered trademark), and TruSeq (registered trademark). ) Includes a set of prior findings genes used for gene analysis.
- the instruction receiving unit 60 accepts the designation of the prior knowledge gene set.
- the prior knowledge gene designation information 71 is output from the instruction receiving unit 60 to the selection unit 64.
- the prior knowledge gene designation information 71 is information in which a set of prior knowledge genes and a category corresponding thereto are registered.
- FIG. 12 there are two sets of prior findings genes for the category “iPS cells” and one set of prior findings genes for the categories “ectoderm”, “mesoderm”, and “endoderm”, for a total of five prior findings. It illustrates the case where a set of genes is specified. In addition, instead of designating the set, or in addition, the prior knowledge genes may be designated one by one.
- the extraction target designation screen 105 is displayed on the display 49 under the control of the display control unit 65 in order to allow the user to specify the extraction target 15E from the gene expression information 15 from the gene expression information DB server 12. Will be done.
- the extraction target designation screen 105 is provided with an input box 106 for the extraction target 15E.
- the input box 106 can be added by selecting the add button 107.
- the extraction target designation information 73 is information in which the extraction target 15E input to the input box 106 and the type of the biological sample registered in the extraction target 15E are registered.
- FIG. 13 illustrates a case where an extraction target 15E is specified for each type of biological sample "iPS cell”, “ectoderm”, “mesoderm”, and “endoderm”. Two or more extraction targets 15E may be specified for one type of biological sample.
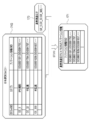
- the DEGs list 74 contains the DEGs and the types of biological samples registered in the extraction target 15E from which the DEGs are extracted.
- Some DEFs such as DEFs with IDs "GE_5" and “GE_10”, have only one type of biological sample registered, while others, such as DEFs with IDs "GE_1” and “GE_2”, are registered.
- IPS cells "ectoderm”, “mesoderm”, “endoderm”, and some other types of biological samples are registered. That is, some DEGs belong to only one type of biological sample, and some DEGs belong to a plurality of types of biological samples.
- the distribution information 76 is information in which the DEGs and the corresponding annotation information are registered.
- the assigned DEGs list 74G is the one in which the item of annotation information is added to the DEGs list 74 shown in FIG. By this granted DEGs list 74G, the type of the biological sample is associated with the annotation information.
- the acquisition unit 62 selects the annotation information related to the behavior of the cell of interest in the category and the number range designation information 70 from the annotation information registered in the distribution information 76. Then, only the selected annotation information is registered in the DEGs list 74, and the assigned DEGs list 74G is used.
- the acquisition unit 62 does not select annotation information having no relation to the differentiation ability such as IDs “GO: 00000075” and “GO: 0001028”, but is related to differentiation such as IDs “GO: 0000578” and “GO: 0001501”. Select and register only annotation information.
- the search keyword related to the behavior of the cell of interest may be included in the second distribution request 75, and the annotation information related to the behavior of the cell of interest may be selected in the annotation information DB server 13.
- the derivation unit 63 counts the number of annotation information given to each DEGs based on the given DEGs list 74G. Then, the counted number of grants itself is registered in the evaluation value table 77 as an evaluation value. For example, when 28 annotation information is given to the DEFs of the ID "GE_1”, "28", which is the same as the number given, is registered as an evaluation value in the evaluation value table 77.
- the selection unit 64 first unconditionally selects a set of prior knowledge genes designated in the prior knowledge gene designation information 71 as measurement target genes.
- a tentative measurement target gene list 78P in which a set of prior knowledge genes is registered as a measurement target gene is generated.
- An embodiment in which this set of prior knowledge genes is unconditionally selected as a measurement target gene is an example in which the weighting of the evaluation value of the prior knowledge gene is increased so that the prior knowledge gene is always selected as the measurement target gene. Is.
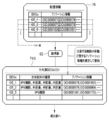
- the selection unit 64 generates the selection order table group 115 based on the evaluation value table 77.
- the selection order table group 115 is a selection order table 116A of the category “iPS cell” corresponding to the biological sample type “iPS cell” and a selection order table 116B of the category “ectoderm” corresponding to the biological sample type “ectoderm”.
- the selection unit 64 assigns a selection order to each category in order from the DEGs having the highest evaluation value (the number of annotation information given is large). That is, the selection order of the DEGs having the highest evaluation value is the first place, the selection order of the DEGs having the next highest evaluation value is the second place, the selection order of the next highest evaluation value is the third place, and so on. ..
- the selection unit 64 selects a gene to be measured that satisfies the number range from the DEGs prepared for each category with reference to the selection order table 116, and allocates the gene to each category.
- FIG. 20 illustrates how a gene to be measured in the category “iPS cell” is selected from the DEGs prepared for the category “iPS cell”. Further, in FIG. 20, as the number range of the category “iPS cells”, “225 to 250” shown in FIG. 9 is specified, and the number of prior knowledge genes of the category “iPS cells” selected in FIG. 18 is The case where the number is 100 is illustrated. In this case, it is necessary to select at least 125, and at most 150, DEGs in order to satisfy the number range. Therefore, the selection unit 64 selects a total of 150 DEGs from the 1st to 150th selection ranks in the selection order table 116A. Then, the selected 150 DEGs are registered in the provisional measurement target gene list 78P as the measurement target genes of the category “iPS cells”.
- the selection unit 64 is a number that satisfies the number range with reference to the selection order tables 116B to 116D in the same manner for the other categories “ectoderm”, “mesoderm”, and “endoderm”. Select DEFs. Then, the selected DEGs are registered in the provisional measurement target gene list 78P as the measurement target gene. By sequentially selecting the genes to be measured in this way, the selection unit 64 finally generates a gene list 78 to be measured, as shown in FIG. 21, in which the number range is satisfied in each category.
- the extraction unit 61 extracts DEGs from the extraction target 15E and generates a DEGs list 74.
- the acquisition unit 62 acquires the annotation information by acquiring the distribution information 76 from the annotation information DB server 13.
- the acquisition unit 62 assigns the annotation information of the distribution information 76 to the DEGs list 74, and sets it as the assigned DEGs list 74G.
- the derivation unit 63 counts the number of annotation information given to each DEGs and registers the number given as an evaluation value in the evaluation value table 77.
- the selection unit 64 selects a gene to be measured based on the evaluation value, and generates a gene list 78 to be measured.
- the measurement target gene registered in the measurement target gene list 78 is displayed on the measurement target gene display screen 120.
- the measurement target gene display screen 120 is provided with display areas 121A, 121B, 121C, and 121D for each category.
- the gene to be measured in the category “iPS cells” is displayed in the display area 121A.
- the measurement target genes of the category “ectoderm” are displayed in the display area 121B, the category “mesoderm” is displayed in the display area 121C, and the measurement target genes of the category "endoderm” are displayed in the display area 121D.
- a save button 122 is selected when the gene list 78 to be measured is saved in the storage device 45.
- the print button 123 is selected when printing the gene list 78 to be measured.
- the display control unit 65 turns off the display of the gene display screen 120 to be measured.
- the CPU 47 of the information processing device 10 includes an instruction receiving unit 60, an extraction unit 61, an acquisition unit 62, a derivation unit 63, and a selection unit. It functions as a unit 64 and a display control unit 65.
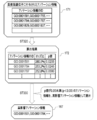
- the category designation screen 80 shown in FIG. 9 is displayed on the display 49 (step ST100).
- the user inputs the behavior of the cell of interest and the desired category and number range, and selects the designated button 86.
- the instruction receiving unit 60 receives the designation of the behavior of the cell of interest and the category and the number range (step ST110), and the category and the number range designation information 70 is generated.
- the category and number range designation information 70 is output from the instruction receiving unit 60 to the selection unit 64.
- the prior knowledge gene designation screen 95 shown in FIG. 12 is displayed on the display 49 (step ST120).
- the user inputs a desired set of prior findings genes and selects the designation button 98.
- the instruction receiving unit 60 receives the designation of the set of the prior knowledge genes (step ST130), and the prior knowledge gene designation information 71 is generated.
- the prior knowledge gene designation information 71 is output from the instruction receiving unit 60 to the selection unit 64.
- a search screen (not shown) is displayed on the display 49.
- the instruction receiving unit 60 receives the first distribution instruction by the user including the search keyword.
- the instruction receiving unit 60 transmits the first distribution request 72 including the search keyword to the gene expression information DB server 12 (step ST140).
- the gene expression information 15 is distributed from the gene expression information DB server 12 in response to the first distribution request 72.
- the gene expression information 15 is input to the display control unit 65. Then, under the control of the display control unit 65, the display screen of the gene expression information 15 (not shown) is displayed on the display 49 (step ST150).
- the extraction target designation screen 105 shown in FIG. 13 is displayed on the display 49 (step ST160).
- the user inputs the desired extraction target 15E and selects the designation button 108.
- the instruction receiving unit 60 receives the designation of the extraction target 15E (step ST170), and the extraction target designation information 73 is generated.
- the extraction target designation information 73 is output from the instruction receiving unit 60 to the extraction unit 61.
- DEGs are extracted from the extraction target 15E, and the DEGs list 74 shown in FIG. 14 is generated (step ST180).
- the DEGs list 74 is output from the extraction unit 61 to the acquisition unit 62.
- the second distribution request 75 based on the DEGs list 74 is transmitted from the acquisition unit 62 to the annotation information DB server 13 (step ST190).
- the distribution information 76 including the annotation information shown in FIG. 15 is distributed from the annotation information DB server 13.
- the distribution information 76 is input to the acquisition unit 62.
- the distribution information 76 and, by extension, the annotation information are acquired by the acquisition unit 62 (step ST200).
- step ST200 is an example of "acquisition processing" according to the technique of the present disclosure.
- the acquisition unit 62 assigns annotation information to the DEGs list 74 based on the distribution information 76, and makes the DEGs list 74 the assigned DEGs list 74G (step ST210). At this time, only the annotation information related to the behavior of the cell of interest is selected and given.
- the assigned DEGs list 74G is output from the acquisition unit 62 to the out-licensing unit 63.
- step ST220 the derivation unit 63 counts the number of annotation information given to each DEGs, and the number of annotations is registered in the evaluation value table 77 as an evaluation value (step ST220).
- the evaluation value table 77 is output from the derivation unit 63 to the selection unit 64. Note that step ST220 is an example of the "derivation process" according to the technique of the present disclosure.
- the prior knowledge gene is unconditionally selected as the measurement target gene by the selection unit 64 (step ST230).
- the selection unit 64 selects a number of DEGs that satisfy the number range from the DEGs prepared for each category in descending order of evaluation value. Then, the selected DEGs are assigned to each category as measurement target genes (step ST240). Through such a process, the gene list 78 to be measured shown in FIG. 21 is generated. The gene list 78 to be measured is output from the selection unit 64 to the display control unit 65. Note that step ST240 is an example of the "selection process" according to the technique of the present disclosure.
- the display control unit 65 displays the measurement target gene display screen 120 shown in FIG. 24 on the display 49 (step ST250). The user confirms the gene to be measured through the gene display screen 120 to be measured.
- the information processing apparatus 10 includes an acquisition unit 62, a derivation unit 63, and a selection unit 64.
- the acquisition unit 62 acquires the annotation information given to each of the plurality of genes.
- the derivation unit 63 derives evaluation values for each of a plurality of genes based on the annotation information.
- the selection unit 64 selects a gene to be measured from a plurality of genes based on the evaluation value. Therefore, it is possible to select the gene to be measured in a data-driven manner with the reliable support of the evaluation value based on the annotation information.
- the genes to be measured thus selected are easy to develop at multiple levels, but are customized for the cells to be studied. Therefore, it becomes possible to select a more appropriate gene to be measured, which leads to elucidation of cell behavior.
- the acquisition unit 62 selects annotation information related to the behavior of the cell of interest.
- the selection unit 64 derives an evaluation value based only on the selected annotation information. Therefore, the gene to be measured can be selected based only on the annotation information specific to the behavior of the cell of interest. In other words, it is possible to exclude annotation information that is not closely related to the behavior of the cell of interest as noise, and select the gene to be measured in a form that is limited to annotation information that is highly relevant to the behavior of the cell of interest. can.
- the acquisition unit 62 refers to the annotation information DB 16 in which the annotation information for the gene is registered, and adds the annotation information to the gene. Therefore, the annotation information can be easily added by using the existing annotation information DB 16.
- the type of biological sample is associated with the annotation information.
- the instruction receiving unit 60 accepts a plurality of categories defined according to the type of the biological sample, and a user's designation of a number range for each of the plurality of categories.
- the selection unit 64 selects a number of genes satisfying the number range from the genes prepared for each of the plurality of categories, and allocates the selected genes to each of the plurality of categories as measurement target genes. Therefore, the gene to be measured can be selected without excess or deficiency for each category.
- Categories include “iPS cells”, “ectoderm”, “mesoderm”, and “endoderm”. Therefore, it is possible to obtain a gene to be measured for each category related to iPS cells 25, which has been of great interest in recent years.
- the categories are the above-mentioned “iPS cells”, “ectoderm”, “mesoderm”, and “endoderm”. It is preferable to include.
- the category is not limited to the above-mentioned "iPS cells”, “ectoderm”, “mesoderm”, and “endoderm”.
- the derivation unit 63 counts the number of annotation information given for each of a plurality of genes, and derives an evaluation value based on the number of grants. Therefore, the evaluation value can be easily derived.
- Genes include prior knowledge genes. Then, the instruction receiving unit 60 accepts the designation by the user of the prior knowledge gene.
- the selection unit 64 unconditionally selects the prior knowledge gene as the measurement target gene as a form of increasing the weighting of the evaluation value of the prior knowledge gene. Therefore, it is possible to reflect the user's intention to measure the priori knowledge gene.
- prior knowledge genes which are condensed past findings, can be effectively incorporated as measurement target genes.
- the selection unit 64 selects more than 100 genes to be measured and 1000 or less. If the number of genes to be measured is 100 or less, it is not sufficient to elucidate the behavior of cells. On the other hand, if the number of genes to be measured is more than 1000, the test takes time and cost, and it becomes difficult to develop into a multi-level experiment.
- Genes include DEGs. Therefore, it is possible to select a gene to be measured, which is considered to contribute to the elucidation of cell behavior.
- prior knowledge gene was unconditionally selected as the gene to be measured, but it is not limited to this. Similar to DEGs, prior knowledge genes may be selected based on the derived evaluation values by acquiring annotation information and deriving the evaluation values. At this time, the weighting of the evaluation value of the previously found gene may be heavier than that of DEGs. Further, in this case, the importance may be set for each of the prior knowledge genes, and the evaluation value may be derived in consideration of the importance. Specifically, the higher the importance, the higher the evaluation value is derived. For genes other than the previously found genes, such as DEGs, the evaluation value may be derived with the lowest importance.
- the prior knowledge gene does not necessarily have to be specified. For example, if the cell to be studied is new and the priori-finding gene does not exist in the first place, the designation of the prioritizing gene may be omitted.
- the specification of the extraction target 15E may be omitted, and all the gene expression information 15 distributed from the gene expression information DB server 12 may be used as the extraction target 15E.
- the category does not necessarily have to be specified. However, even if the category is omitted, it is necessary to specify the range of the number of genes to be measured to be selected, at least the upper limit.
- the gene expression information DB 14 is not limited to a public DB such as an exemplary GEO.
- it may be a local DB in which the gene expression information 15 measured at the laboratory to which the user belongs is registered.
- the annotation information DB 16 is not limited to a public DB such as DAVID and InterPro, but may be a local DB prepared by a laboratory to which the user belongs, for example.
- the evaluation value is weighted according to the information value of the annotation information.
- FIG. 26 shows an example in which the number of annotations given is relatively small, that is, the annotation information having a relatively high rarity is judged to have high information value, and the number of annotations given is increased.
- the derivation unit 63 counts the number of annotations given to each of the annotation information given to the DEGs (hereinafter referred to as the total number of grants) based on the given DEGs list 74G.
- the derivation unit 63 compares the total number of grants with the preset threshold value.
- the derivation unit 63 counts the number of annotation information given for each DEFs, including the number of weighted grants, and generates an evaluation value table 77.
- FIG. 26 illustrates a case where "10” is set as a threshold value, the total number of grants is "6", and the number of annotation information of ID "GO: 00000578" which is less than the threshold value is "10".
- FIG. 27 shows an example of weighting the evaluation value based on the orthogonality of the annotation information.
- the derivation unit 63 determines that the orthogonality of the set of genes that can cover the annotation information as closely as possible and without duplication is high.
- Table 158 shows the addition status of the annotation information indicated by A1 to A7 for the three DEFs of the IDs "GE_1000", “GE_1001", and “GE_1002".
- annotation information of A1 to A7 "iPS cells” are associated with A1 to A4 as the type of biological sample, and "ectoderm” is associated with A5 to A7.
- the DEGs of ID "GE_1000” and ID “GE_1001” are preferentially selected as the measurement target genes over the DEGs of ID "GE_1002" only by looking at the number of annotation information given.
- the DEFs of the ID "GE_1002” are preferentially selected as the measurement target genes over the DEFs of the ID "GE_1001”. If the DEGs of ID "GE_1000” and ID “GE_1002” are finally selected as the genes to be measured, both “iPS cells” and "ectoderm” can be covered.
- the evaluation value may be derived based on the number of annotation information that can be covered by the combination with other genes. Taking Table 158 as an example, the number of annotation information that can be covered is 6 in the combination of the DEFs of the ID “GE_1000” and the ID “GE_1001”. In the combination of the DEGs of the ID “GE_1000” and the ID “GE_1002”, the number of annotation information that can be covered is seven. In the combination of the IDEs of the ID "GE_1001" and the ID "GE_1002", the number of annotation information that can be covered is five. From this result, the evaluation value of the DEFs of the ID "GE_1000” and the ID "GE_1002" is made higher than the evaluation value of the DEFs of the ID "GE_1001".
- the derivation unit 63 weights the evaluation value according to the information value of the annotation information. Therefore, for example, by increasing the weighting of the number of annotation information given that is determined to have high information value, a gene to which annotation information that is considered to have high information value is attached can be easily selected as a gene to be measured. Therefore, the validity and reliability of the gene to be measured can be enhanced.
- the derivation unit 63 determines that the annotation information having a relatively high rarity has a high information value, and weights it heavily. Therefore, a gene to which rare annotation information that is often overlooked can be selected as a measurement target gene.
- the derivation unit 63 weights the evaluation value based on the orthogonality of the annotation information. Therefore, a set of genes that can cover annotation information as closely as possible and without duplication can be selected as a gene to be measured.
- FIGS. 26 and 27 may be combined and carried out.
- 100 is added to the evaluation value of DEGs in which the annotation information whose total number of grants is less than the threshold value is given and the orthogonality of the annotation information is high.
- annotation information having a relatively high rarity is determined to be the annotation information having a high information value, but the example of the annotation information having a high information value is not limited to these.
- annotation information that is relatively frequently published in research papers may be determined to be annotation information with high information value.
- the number of annotation information given to the DEGs is weighted, but the weighting is not limited to this.
- the number of annotation information given to the prior knowledge gene may be weighted in the same manner as in the case shown in FIG. 26.
- the embodiment shown in FIG. 27 may be applied to the previously found gene.
- the added DEGs list 160G of the third embodiment is provided with an item of strength index information.
- the item of intensity index information whether or not the intensity index is within a preset threshold range is registered.
- the intensity index is, for example, a field-change, a q value (q-value) indicating a significant difference in expression corrected for multiple tests, and the like.
- the derivation unit 63 sets the number of annotation information of the DEGs whose strength index is within the threshold range to be larger than 1 when deriving the evaluation value. That is, the weighting of the evaluation values of the DEGs whose intensity index is within the threshold range is increased.
- the derivation unit 63 counts the number of annotation information given for each DEFs, including the number of weighted grants, and generates an evaluation value table 77.
- FIG. 28 illustrates a case where the intensity index of DEFs such as IDs “GE_2” and “GE_5” is within the threshold range and the number of these annotation information given is “2”.
- the derivation unit 63 makes the weighting of the evaluation value of the DEGs whose intensity index is within the threshold range heavy. Therefore, DEGs whose intensity index is within the threshold range, which is considered to be important for elucidating the characteristics of the biological sample, can be selected as the gene to be measured.
- the second embodiment and the third embodiment may be combined and implemented.
- the measurement result 166 of the gene to be measured is acquired. Then, based on the measurement result 166, from the annotation information 171 given to the gene to be measured by a statistical method, the annotation information having a relatively high influence on the cell behavior (hereinafter referred to as high-impact annotation information) 167. Is selected, and the selected high-impact annotation information 167 is presented to the user.
- high-impact annotation information the annotation information having a relatively high influence on the cell behavior
- the CPU 47 of the information processing apparatus 10 of the fourth embodiment functions as a selection unit 165 in addition to the processing units 60 to 65 shown in FIG. 8 (only the acquisition unit 62 is shown in FIG. 29).
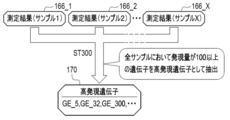
- the acquisition unit 62 acquires a plurality of measurement results 166_1, 166_2, ..., And 166_X.
- the measurement results 166_1 to 166_X are, for example, the expression levels of the genes to be measured at the stage of iPS cells 25 for a plurality of samples 1, 2, ..., X having low efficiency of inducing differentiation from iPS cells 25 to histiocytes 30. Is the result of actual measurement.
- the measurement results 166_1 to 166_X are transmitted to the information processing apparatus 10 from, for example, a measuring apparatus for measuring the expression level of a gene, and are input to the acquisition unit 62.
- the acquisition unit 62 outputs the measurement results 166_1 to 166_X to the selection unit 165.
- the selection unit 165 selects high-impact annotation information 167 based on the measurement results 166_1 to 166_X from the acquisition unit 62 and the assigned DEGs list 74G.
- the selection unit 165 outputs the high-impact annotation information 167 to the display control unit 65.
- FIGS. 30 to 33 show a procedure for selecting high-impact annotation information 167 in the selection unit 165.
- the selection unit 165 extracts the highly expressed gene 170 from the gene to be measured with reference to the measurement results 166_1 to 166_X.
- the highly expressed gene 170 is, for example, a gene whose expression level is equal to or higher than the threshold value in all the samples 1 to X.
- FIG. 31 illustrates a case where “100” is set as a threshold value and a gene to be measured such as IDs “GE_5”, “GE_32”, “GE_300”, and the like is extracted as a highly expressed gene 170.
- the selection unit 165 extracts the annotation information 171 given to the highly expressed gene 170 from the given DEGs list 74G. Subsequently, the selection unit 165 determines the odds ratio and p-value for each of the annotation information 171 given to the highly expressed gene 170, as shown in step ST320 of FIG. 30 and the calculation result 172 of FIG. 33. Is calculated. Finally, as shown in the latter part of step ST330 of FIG. 30 and the calculation result 172 of FIG. 33, the selection unit 165 statistics that the p-value of the annotation information 171 given to the highly expressed gene 170 is less than 0.05. The significantly significant annotation information 171 is selected as the high-impact annotation information 167. FIG.
- the high-impact annotation information display screen 180 is displayed on the display 49 under the control of the display control unit 65.
- the high-impact annotation information display screen 180 is provided with a display area 181 for the high-impact annotation information 167.
- the high-impact annotation information 167 and its contents are listed in the display area 181.
- the display control unit 65 turns off the display of the high-impact annotation information display screen 180.
- the acquisition unit 62 acquires the measurement result 166 of the gene to be measured. Based on the measurement result 166, the selection unit 165 selects high-impact annotation information 167, which has a relatively high degree of influence on the behavior of cells, from the annotation information 171 given to the gene to be measured by a statistical method.
- the display control unit 65 presents the high-impact annotation information 167 to the user by displaying the high-impact annotation information display screen 180 on the display 49. Therefore, the user can infer from the high-impact annotation information 167 the main factors for which the differentiation induction efficiency is low, and can utilize it for the next culture. Since the high-impact annotation information 167 is selected by a statistical method, it is possible to accurately infer the main factors and the like whose differentiation induction efficiency is low.
- the gene to which the high-impact annotation information 167 is added may be displayed on the high-impact annotation information display screen 180 in addition to the high-impact annotation information 167.
- Table 200 shown in FIG. 35 shows the priori genes designated for selecting the gene to be measured in this example and the extracted DEGs.
- Prior knowledge genes include those based on investigator hearings or well-known gene panels such as the TaqMan scorecard.
- the DEGs include iPS cells 25 or ES cells (Embryonic Stem cells), and those extracted from the extraction target 15E in an experiment in which iPS cells 25 or ES cells were differentiated into trigerm 26 or histiocyte 30. There is. In this example, from these approximately 2900 (partially duplicated) genes, approximately 1000 (specifically, 980) genes to be measured that satisfy the number range were selected.
- the expression level of comprehensive genes (about 21,000) was separately measured by a microarray for the iPS cells 25 before differentiation induction in 15 samples. ..
- FIG. 36 shows the measurement result 202 of the expression level of the microarray.
- Bar 203 represents the expression level of each gene.
- the group was divided into a group of 9 samples on the left side and a group of 6 samples on the right side by clustering, and the group of 6 samples included all 5 samples with low differentiation induction efficiency indicated by "Bad". .. That is, according to the measurement result 202 of the expression level of the microarray, the high and low accuracy of differentiation induction efficiency is relatively high at the stage of iPS cells 25 (the detection sensitivity of the sample with low differentiation induction efficiency is 100%, and the differentiation induction efficiency is low). It was found that the specificity of the sample (83%) is predictable. In addition, “Good” indicates a sample having high differentiation induction efficiency.
- Highly expressed genes 170 were extracted from the genes used for measurement on the microarray as in the fourth embodiment, and high-impact annotation information 167 was selected. The results are shown in Table 205 of FIG. 37 and Table 206 of FIG. 38. According to Table 205 and Table 206, various miscellaneous annotation information was selected as high-impact annotation information 167, and it was found that it is difficult to obtain effective knowledge that leads to elucidation of cell behavior.
- FIG. 39 shows the measurement result 208 of the expression level of C1000 performed on the iPS cells 25 before the induction of differentiation of 15 samples.
- the group was divided into a group of 9 samples on the right side and a group of 6 samples on the left side by clustering, and all 5 samples with low differentiation induction efficiency indicated by "Bad" were included in the group of 6 samples ("Bad”.
- the detection sensitivity of the sample with low differentiation induction efficiency is 100%, and the specificity of the sample with low differentiation induction efficiency is 83%). Therefore, according to C1000 according to the technique of the present disclosure, it was confirmed that it is possible to predict the differentiation induction efficiency at the same level as the comprehensive measurement by the microarray.
- Highly expressed genes 170 were extracted from C1000 as in the fourth embodiment, and high-impact annotation information 167 was selected.
- the results are shown in Table 210 of FIG. According to Table 210, it can be seen that a particularly large amount of annotation information regarding the expression of angioplastic function is selected.
- genes such as NODAL, LEFTY1, LEFTY2, CER1 and BMP4 are conspicuous, and it can be read that these genes are likely to determine the level of differentiation induction efficiency. That is, it was confirmed that if the evaluation value is derived from the annotation information and the gene to be measured is selected based on the evaluation value as in the technique of the present disclosure, it is very useful for elucidating the characteristics of the biological sample.
- the measurement result by the set of the measurement genes of the TaqMan scorecard is simulated by extracting 84 genes of the TaqMan scorecard from the measurement result of the comprehensive gene expression level by the microarray.
- FIG. 41 shows a bar graph 215 of the odds ratio according to the set of measurement genes of C1000
- FIG. 42 shows a bar graph 216 of the odds ratio according to the set of measurement genes of the TaqMan scorecard.
- the genes related to "mesoderm” and “endoderm” are enriched in the sample having low differentiation induction efficiency, and "iPS cells".
- the genes associated with were reduced.
- the odds ratio of the genes related to the type of each biological sample when the differentiation induction efficiency is low is statistically significantly different from 100% (q value (q-value) is 0) except for "ectoderm". It was less than 0.05 (q ⁇ 0.05). Therefore, it was found that the set of measurement genes of C1000 has a certain analytical ability for a sample having a low differentiation induction efficiency. It is considered that these results were obtained because a sufficiently large number of genes to be measured focusing on the type of each biological sample were distributed in a well-balanced manner.
- the gene related to "iPS cells” in the sample with high differentiation induction efficiency becomes “endoderm” in the sample with low differentiation induction efficiency.
- the related genes were each enriched. However, it was only the genes related to "iPS cells” when the differentiation induction efficiency was high that the odds ratio was statistically significantly different from 100%. Therefore, it was found that the set of measurement genes of the TaqMan scorecard has a limited ability to analyze samples with low differentiation induction efficiency. It is considered that these results were obtained because, unlike the case of C1000, the number of genes distributed to each type of biological sample was small, and an extreme ratio was likely to occur.
- RNA-Seq RNA-Seq
- the number of grants itself is derived as an evaluation value, but the present invention is not limited to this.
- the number of grants is 0, the number of grants is 0, the number of grants 1 to 10 is the evaluation value 1, the number of grants 11 to 20 is the evaluation value 2, and so on. May be good.
- the mode of presenting the measurement target gene to the user is not limited to the mode of displaying the measurement target gene display screen 120 shown in FIG. 24 on the display 49.
- An embodiment in which the measurement target gene list 78 is printed out, or an embodiment in which the measurement target gene list 78 is delivered to a terminal owned by the user by e-mail or the like may be adopted.
- the mode of presenting the high-impact annotation information 167 to the user is not limited to the mode of displaying the high-impact annotation information display screen 180 on the display 49.
- a mode of printing out the high-impact annotation information 167 and a mode of delivering the high-impact annotation information 167 to a terminal owned by the user by e-mail or the like may be adopted.
- iPS cells 25 are exemplified as a biological sample to be studied, but the present invention is not limited to this. It may be an ES cell, an extract from a cell in culture, or a piece of biological tissue.
- a gene has been exemplified as a biomarker, but the present invention is not limited thereto.
- gene sequences, mutations, expression, modifications DNA (Deoxyribonucleic acid), epigenome, mRNA (messenger RNA), miRNA (microRNA), proteins expressed by cells during culture, during culture.
- Factors related to the cell culture environment such as metabolites emitted from the cells, carbon dioxide concentration, and pH, may be used as biomarkers.
- biomarker in the present specification is simply a general term for substances showing various biofeatures.
- the hardware configuration of the computer constituting the information processing device 10 can be modified in various ways. It is also possible to configure the information processing apparatus 10 with a plurality of computers separated as hardware for the purpose of improving processing capacity and reliability. For example, the functions of the instruction receiving unit 60, the extraction unit 61, and the acquisition unit 62, and the functions of the derivation unit 63, the selection unit 64, and the display control unit 65 are distributed to two computers. In this case, the information processing device 10 is configured by two computers.
- the hardware configuration of the computer of the information processing apparatus 10 can be appropriately changed according to the required performance such as processing capacity, safety, and reliability. Furthermore, not only hardware but also application programs such as the operation program 55 can be duplicated or distributed and stored in multiple storage devices for the purpose of ensuring safety and reliability. be.
- a processing unit that executes various processes such as an instruction receiving unit 60, an extraction unit 61, an acquisition unit 62, a derivation unit 63, a selection unit 64, a display control unit 65, and a selection unit 165.
- various processors Processors
- the CPU 47 which is a general-purpose processor that executes software (operation program 55) and functions as various processing units, after manufacturing an FPGA (Field Programgable Gate Array) or the like.
- Dedicated processor with a circuit configuration specially designed to execute specific processing such as programmable logic device (PLD), ASIC (Application Specific Integrated Circuit), which is a processor whose circuit configuration can be changed. Includes electrical circuits and the like.
- One processing unit may be composed of one of these various processors, or may be a combination of two or more processors of the same type or different types (for example, a combination of a plurality of FPGAs and / or a CPU). It may be configured in combination with FPGA). Further, a plurality of processing units may be configured by one processor.
- one processor is configured by a combination of one or more CPUs and software, as represented by a computer such as a client and a server.
- the processor functions as a plurality of processing units.
- SoC System On Chip
- SoC system On Chip
- the various processing units are configured by using one or more of the above-mentioned various processors as a hardware-like structure.
- an electric circuit in which circuit elements such as semiconductor elements are combined can be used.
- the technique of the present disclosure can be appropriately combined with the various embodiments described above and various modifications. Further, it is of course not limited to each of the above embodiments, and various configurations can be adopted as long as they do not deviate from the gist. Further, the technique of the present disclosure extends to a storage medium for storing the program non-temporarily in addition to the program.
- a and / or B is synonymous with "at least one of A and B". That is, “A and / or B” means that it may be A alone, B alone, or a combination of A and B. Further, in the present specification, when three or more matters are connected and expressed by "and / or", the same concept as “A and / or B" is applied.
Landscapes
- Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Engineering & Computer Science (AREA)
- Medical Informatics (AREA)
- Theoretical Computer Science (AREA)
- Biophysics (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Biotechnology (AREA)
- Evolutionary Biology (AREA)
- General Health & Medical Sciences (AREA)
- Databases & Information Systems (AREA)
- Bioethics (AREA)
- Genetics & Genomics (AREA)
- Molecular Biology (AREA)
- Artificial Intelligence (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Data Mining & Analysis (AREA)
- Epidemiology (AREA)
- Evolutionary Computation (AREA)
- Public Health (AREA)
- Software Systems (AREA)
- Apparatus Associated With Microorganisms And Enzymes (AREA)
Abstract
生体試料に関する複数のバイオマーカーのそれぞれに付与されたアノテーション情報を取得する取得処理と、アノテーション情報に基づいて、複数のバイオマーカー毎の評価値を導出する導出処理と、評価値に基づいて、複数のバイオマーカーの中から測定対象のバイオマーカーを選択する選択処理と、をプロセッサが実行する情報処理装置の作動方法。
Description
本開示の技術は、情報処理装置、情報処理装置の作動方法、情報処理装置の作動プログラムに関する。
iPS細胞(induced Pluripotent Stem Cell)等の生体試料を研究対象とした分野では、細胞クローンのバリエーション、薬剤の投与量といったパラメータを種々変更した多水準の実験を組んで、それにより得られたバイオマーカーを参照して、分化能といった生体試料の特性を解明することが行われている。バイオマーカーは、例えば培養中に細胞が発現する遺伝子およびタンパク質、培養中に細胞から出される代謝物、あるいは、二酸化炭素濃度、pH(potential of Hydrogen)といった細胞の培養環境に関する要素を含む。
バイオマーカーの代表例である遺伝子の検査として、RNA(Ribonucleic Acid)シーケンシング(RNA-Seq(Sequencing))が知られている。RNA-Seqは、数万個の遺伝子の発現量を網羅的に測定可能である。このため生体試料の特性の解明は捗る。ただし検査に時間が掛かるうえ比較的高価であるので、多水準実験への展開は難しい。
遺伝子は非常に膨大な数があり、その中には生体試料の特性の解明にあまり貢献しないものもある。このため、多水準実験向けに、より効果的に生体試料の特性を解明するためには、膨大な数の遺伝子の中から、生体試料の特性の解明に貢献すると考えられる遺伝子を測定対象として選択して絞り込むことが重要である。
従来、測定対象の遺伝子を選択する方法としては、主に以下の2つがあった。第1の方法は、研究者の経験知に基づく方法である。具体的には、細胞の挙動に影響を与えることが既に知られている遺伝子である先行知見遺伝子を測定対象として選択する。第2の方法は、遺伝子の発現量の実際の測定結果からデータドリブンで遺伝子を選択する方法である。具体的には、少数のサンプルで予備実験を行い、いったん網羅的に遺伝子の発現量を測定した上で、発現量が特異的に変動している遺伝子である発現変動遺伝子(DEGs;Differentially Expressed Genes)の一部を測定対象として選択する。例えば<Aravind Subramanian他、「A Next Generation Connectivity Map: L1000 platform and the first 1,000,000 profiles」、2015年11月30日発行、Cell、Volume 171、 ISSUE 6、 P1437-1452.e17、インターネット〈URL:https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5990023/〉>には、高度なデータ解析手法によって、データドリブンで抽出したDEGsから、全遺伝子の挙動の80%以上を説明可能なDEGsを測定対象として選択することが記載されている。
しかしながら、先行知見遺伝子を測定対象として選択する第1の方法では、研究者の経験知に頼るために先行知見遺伝子の数に限界があり、生体試料の特性の解明に貢献すると考えられる遺伝子を適切に選択し得るとは言い難かった。また、DEGsの一部を測定対象として選択する第2の方法では、単純に変動量が特異的というだけで選択しているので、多水準実験に展開した結果、研究者の知見が乏しいマイナーな遺伝子が生体試料の特性の解明に特に貢献することが分かった場合に、どうすれば細胞の培養成績が向上するのかといった指針を得ることが難しかった。
本開示の技術に係る1つの実施形態は、生体試料の特性の解明に繋がる、より適切な測定対象のバイオマーカーを選択することが可能な情報処理装置、情報処理装置の作動方法、情報処理装置の作動プログラムを提供する。
本開示の情報処理装置の作動方法は、生体試料に関する複数のバイオマーカーのそれぞれに付与されたアノテーション情報を取得する取得処理と、アノテーション情報に基づいて、複数のバイオマーカー毎の評価値を導出する導出処理と、評価値に基づいて、複数のバイオマーカーの中から測定対象のバイオマーカーを選択する選択処理と、をプロセッサが実行する。
プロセッサは、注目する生体試料の特性に関するアノテーション情報を選定して、選定したアノテーション情報のみに基づいて評価値を導出することが好ましい。
プロセッサは、バイオマーカーに対するアノテーション情報が登録されたデータベースを参照して、バイオマーカーに対してアノテーション情報を付与することが好ましい。
アノテーション情報には、生体試料の種類が関連付けられていることが好ましい。
プロセッサは、生体試料の種類に応じて定義された複数のカテゴリ、および複数のカテゴリ毎の測定対象のバイオマーカーの個数の範囲のユーザによる指定を受け付け、複数のカテゴリ毎に用意されたバイオマーカーから、範囲を満たす数のバイオマーカーを選択し、選択したバイオマーカーを、測定対象のバイオマーカーとして複数のカテゴリのそれぞれに割り振ることが好ましい。
カテゴリは、iPS細胞、外胚葉、中胚葉、および内胚葉を含むことが好ましい。
プロセッサは、複数のバイオマーカー毎にアノテーション情報の付与数を計数し、付与数に基づいて評価値を導出することが好ましい。
プロセッサは、アノテーション情報の情報価値に応じて、評価値に対して重み付けを行うことが好ましい。
プロセッサは、稀少性が比較的高いアノテーション情報を情報価値が高いと判断して、重み付けを重くすることが好ましい。
プロセッサは、アノテーション情報の直交性に基づいて、評価値に対して重み付けを行うことが好ましい。
プロセッサは、強度指標が予め設定された閾値範囲内にあるバイオマーカーの評価値の重み付けを重くすることが好ましい。
プロセッサは、生体試料の特性に影響を与えることが既に知られているバイオマーカーである先行知見マーカーのユーザによる指定を受け付け、先行知見マーカーの評価値の重み付けを重くすることが好ましい。
プロセッサは、100個超1000個以下の測定対象のバイオマーカーを選択することが好ましい。
バイオマーカーは遺伝子を含むことが好ましい。
遺伝子は、発現量が特異的に変動している発現変動遺伝子を含むことが好ましい。
アノテーション情報は、遺伝子オントロジーで定義された用語であることが好ましい。
プロセッサは、測定対象のバイオマーカーの測定結果を取得し、測定結果に基づいて、統計的な手法によって、測定対象のバイオマーカーに付与されたアノテーション情報から、生体試料の特性への影響度が比較的高いアノテーション情報を選出し、選出したアノテーション情報をユーザに提示することが好ましい。
本開示の情報処理装置は、少なくとも1つのプロセッサを備え、プロセッサは、生体試料に関する複数のバイオマーカーのそれぞれに付与されたアノテーション情報を取得し、アノテーション情報に基づいて、複数のバイオマーカー毎の評価値を導出し、評価値に基づいて、複数のバイオマーカーの中から測定対象のバイオマーカーを選択する。
本開示の情報処理装置の作動プログラムは、生体試料に関する複数のバイオマーカーのそれぞれに付与されたアノテーション情報を取得する取得処理と、アノテーション情報に基づいて、複数のバイオマーカー毎の評価値を導出する導出処理と、評価値に基づいて、複数のバイオマーカーの中から測定対象のバイオマーカーを選択する選択処理と、をプロセッサに実行させる。
本開示の技術によれば、生体試料の特性の解明に繋がる、より適切な測定対象のバイオマーカーを選択することが可能な情報処理装置、情報処理装置の作動方法、情報処理装置の作動プログラムを提供することができる。
[第1実施形態]
図1において、情報処理装置10は、例えばデスクトップ型のパーソナルコンピュータであり、本開示の技術に係る「生体試料」の一例である細胞の研究者等のユーザにより操作される。情報処理装置10はネットワーク11に接続されている。ネットワーク11は、例えば、インターネットあるいは公衆通信網等のWAN(Wide Area Network)である。
図1において、情報処理装置10は、例えばデスクトップ型のパーソナルコンピュータであり、本開示の技術に係る「生体試料」の一例である細胞の研究者等のユーザにより操作される。情報処理装置10はネットワーク11に接続されている。ネットワーク11は、例えば、インターネットあるいは公衆通信網等のWAN(Wide Area Network)である。
情報処理装置10は、ネットワーク11を介して、遺伝子発現情報データベース(以下、DB(Data Base)と略す)サーバ12、およびアノテーション情報DBサーバ13と接続されている。遺伝子発現情報DBサーバ12は遺伝子発現情報DB14を有する。遺伝子発現情報DB14は、例えば、アメリカ国立バイオテクノロジーセンター(NCBI;National Center for Biotechnology Information)が提供するGEO(Gene Expression Omnibus)である。遺伝子発現情報DB14には、不特定多数の研究者からアップロードされた膨大な遺伝子発現情報15がオープンデータとして登録されている。遺伝子発現情報15は、培養中に細胞が発現する遺伝子の量、すなわち発現量に関する情報である。なお、遺伝子は、本開示の技術に係る「バイオマーカー」の一例である。
遺伝子発現情報DBサーバ12は、情報処理装置10から第1配信要求72(図8参照)を受信する。遺伝子発現情報DBサーバ12は、第1配信要求72に応じた遺伝子発現情報15を遺伝子発現情報DB14から読み出す。そして、読み出した遺伝子発現情報15を情報処理装置10に配信する。
アノテーション情報DBサーバ13はアノテーション情報DB16を有する。アノテーション情報DB16は、例えば、アメリカ国立アレルギー・感染症研究所(NIAID;National Institute of Allergy and Infectious Diseases)が提供するDAVID(The Database for Annotation, Visualization and Integrated Discovery)、および/または、欧州バイオインフォマティクス研究所(EBI;European Bioinformatics Institute)が提供するInterProである。アノテーション情報DB16には、複数の遺伝子のそれぞれについて、対応するアノテーション情報が登録されている。すなわち、アノテーション情報DB16は、本開示の技術に係る「データベース」の一例である。
アノテーション情報DBサーバ13は、情報処理装置10から第2配信要求75(図8参照)を受信する。アノテーション情報DBサーバ13は、第2配信要求75に応じたアノテーション情報をアノテーション情報DB16から読み出す。そして、読み出したアノテーション情報を含む配信情報76(図8参照)を情報処理装置10に配信する。
図2に示すように、遺伝子発現情報15は、遺伝子毎に発現量が登録された情報である。遺伝子発現情報15には、発現量を測定した生体試料の種類(図2では「iPS細胞」)が登録されている。また、遺伝子発現情報15には、「iPS細胞」、「中胚葉」、「分化能」等、検索を容易にするためのキーワードが登録されている。キーワードは、例えば遺伝子発現情報15をアップロードした研究者、あるいは遺伝子発現情報DB14の提供者によって登録される。
アノテーション情報DB16には、図3に示すアノテーション情報テーブル20が格納されている。アノテーション情報テーブル20は、遺伝子毎にアノテーション情報のID(Identification Data)が登録されたものである。
図4の表22に示すように、アノテーション情報は、ID「GO:0000578」の「embryonic axis specification(胚軸の仕様)」、ID「IPR012287」の「Homeodomain-related(ホメオドメイン関連)」等、遺伝子オントロジー(GO;Gene Ontology)で定義された用語である。
図5に示すように、以下では、ヒト体細胞を初期化して樹立されたiPS細胞25を研究対象とした場合を例示する。iPS細胞25は、細胞分裂することにより三胚葉26を形成する。三胚葉26は、外胚葉27、中胚葉28、および内胚葉29である。三胚葉26は、それぞれ複数種の組織細胞30に分化する。具体的には、外胚葉27は、水晶体31、神経細胞32等に分化する。中胚葉28は、血液細胞33、骨細胞34、筋細胞35等に分化する。内胚葉29は、肺胞細胞36、腸管細胞37、肝細胞38等に分化する。
図6に、情報処理装置10の処理の概要を示す。情報処理装置10は、まず、アノテーション情報DBサーバ13からアノテーション情報を取得する。そして、取得したアノテーション情報に基づいて、遺伝子毎の評価値を導出する。次いで、導出した評価値に基づいて、複数の遺伝子の中から測定対象の遺伝子(以下、測定対象遺伝子という)を選択する。この際、情報処理装置10は、ユーザにより指定された個数の測定対象遺伝子を選択する。測定対象遺伝子の候補となる遺伝子は例えば約3000個、測定対象遺伝子は例えば1000個である。情報処理装置10は、選択した測定対象遺伝子をユーザに提示する。測定対象遺伝子は、本開示の技術に係る「測定対象のバイオマーカー」の一例である。
図7において、情報処理装置10を構成するコンピュータは、ストレージデバイス45、メモリ46、CPU(Central Processing Unit)47、通信部48、ディスプレイ49、および入力デバイス50を備えている。これらはバスライン51を介して相互接続されている。
ストレージデバイス45は、情報処理装置10を構成するコンピュータに内蔵、またはケーブル、ネットワークを通じて接続されたハードディスクドライブである。もしくはストレージデバイス45は、ハードディスクドライブを複数台連装したディスクアレイである。ストレージデバイス45には、オペレーティングシステム等の制御プログラム、各種アプリケーションプログラム、およびこれらのプログラムに付随する各種データ等が記憶されている。なお、ハードディスクドライブに代えてソリッドステートドライブを用いてもよい。
メモリ46は、CPU47が処理を実行するためのワークメモリである。CPU47は、ストレージデバイス45に記憶されたプログラムをメモリ46へロードして、プログラムにしたがった処理を実行する。これにより、CPU47はコンピュータの各部を統括的に制御する。
通信部48は、ネットワーク11を介した各種情報の伝送制御を行うネットワークインターフェースである。ディスプレイ49は各種画面を表示する。情報処理装置10を構成するコンピュータは、各種画面を通じて、入力デバイス50からの操作指示の入力を受け付ける。入力デバイス50は、キーボード、マウス、タッチパネル等である。
図8において、情報処理装置10のストレージデバイス45には、作動プログラム55が記憶されている。作動プログラム55は、コンピュータを情報処理装置10として機能させるためのアプリケーションプログラムである。すなわち、作動プログラム55は、本開示の技術に係る「情報処理装置の作動プログラム」の一例である。
作動プログラム55が起動されると、情報処理装置10を構成するコンピュータのCPU47は、メモリ46等と協働して、指示受付部60、抽出部61、取得部62、導出部63、選択部64、および表示制御部65として機能する。CPU47は、本開示の技術に係る「プロセッサ」の一例である。
指示受付部60は、入力デバイス50を介したユーザによる様々な指示を受け付ける。例えば、指示受付部60は、複数のカテゴリ、および複数のカテゴリ毎の測定対象遺伝子の個数の範囲(以下、個数範囲という)のユーザによる指定を受け付ける。カテゴリは、生体試料の種類に応じてユーザにより定義される。指示受付部60は、指定されたカテゴリおよび個数範囲に応じたカテゴリおよび個数範囲指定情報70を生成し、カテゴリおよび個数範囲指定情報70を選択部64に出力する。
指示受付部60は、先行知見遺伝子のユーザによる指定も受け付ける。指示受付部60は、指定された先行知見遺伝子に応じた先行知見遺伝子指定情報71を生成し、先行知見遺伝子指定情報71を選択部64に出力する。なお、先行知見遺伝子は、iPS細胞25の挙動に影響を与えることが既に知られている遺伝子である。すなわち先行知見遺伝子は、本開示の技術に係る「先行知見マーカー」の一例である。そして、iPS細胞25の挙動は、本開示の技術に係る「生体試料の特性」の一例である。
指示受付部60は、遺伝子発現情報DBサーバ12に対して遺伝子発現情報15の配信を指示する、ユーザによる第1配信指示も受け付ける。第1配信指示は、具体的にはiPS細胞25に関する検索キーワード、例えば「iPS細胞」、「外胚葉」、「内胚葉」、「中胚葉」、・・・等で構成される検索指示である。第1配信指示は、検索キーワードの入力ボックスと検索ボタンが設けられた検索画面(図示省略)を通じて行われる。指示受付部60は、第1配信指示を受け付けた場合、上記検索キーワードを含む第1配信要求72を遺伝子発現情報DBサーバ12に送信する。遺伝子発現情報DBサーバ12は、遺伝子発現情報DB14にある遺伝子発現情報15の中から、登録されたキーワードが検索キーワードと一致する遺伝子発現情報15を検索する。そして、検索した遺伝子発現情報15を情報処理装置10に配信する。情報処理装置10において、遺伝子発現情報15は、抽出部61および表示制御部65に入力される。
表示制御部65は、遺伝子発現情報DBサーバ12からの遺伝子発現情報15の表示画面(図示省略)をディスプレイ49に表示する。指示受付部60は、表示された遺伝子発現情報15のうち、DEGsを抽出する対象とする遺伝子発現情報15(以下、抽出対象15E(図22参照)と表記する)のユーザによる指定を受け付ける。指示受付部60は、指定された抽出対象15Eに応じた抽出対象指定情報73を生成し、抽出対象指定情報73を抽出部61に出力する。
抽出部61は、抽出対象指定情報73で指定された抽出対象15EからDEGsを抽出する。抽出部61は、例えば、抽出対象15Eの各遺伝子の発現量と予め設定された閾値とを比較し、発現量が閾値以上である遺伝子をDEGsとして抽出する。抽出部61は、抽出したDEGsが登録されたDEGsリスト74を生成し、DEGsリスト74を取得部62に出力する。
取得部62は、抽出部61からのDEGsリスト74に基づく第2配信要求75をアノテーション情報DBサーバ13に送信する。第2配信要求75は、DEGsリスト74に登録されたDEGsを含む。アノテーション情報DBサーバ13は、アノテーション情報DB16にあるアノテーション情報テーブル20の中から、第2配信要求75に含まれるDEGsに付与されたアノテーション情報を検索する。そして、検索したアノテーション情報およびDEGsの組で構成される配信情報76を情報処理装置10に配信する。情報処理装置10において、配信情報76は、取得部62に入力される。
取得部62は、アノテーション情報DBサーバ13からの配信情報76を取得する。配信情報76には、前述のようにアノテーション情報が含まれる。このため、取得部62は、配信情報76を取得することで、アノテーション情報を取得していることになる。
取得部62は、配信情報76に基づいて、DEGsリスト74にアノテーション情報を付与し、DEGsリスト74を付与済DEGsリスト74Gとする。つまり、取得部62は、アノテーション情報DB16を参照して、遺伝子に対してアノテーション情報を付与する。取得部62は、付与済DEGsリスト74Gを導出部63に出力する。
導出部63は、付与済DEGsリスト74Gに基づいて、DEGs毎の評価値を導出する。そして、評価値の導出結果である評価値テーブル77を選択部64に出力する。
選択部64は、先行知見遺伝子指定情報71に応じて、先行知見遺伝子を無条件で測定対象遺伝子として選択する。また、選択部64は、カテゴリおよび個数範囲指定情報70に応じて、抽出部61において抽出されたDEGsの中から測定対象遺伝子を選択する。選択部64は、測定対象遺伝子の選択結果である測定対象遺伝子リスト78を表示制御部65に出力する。表示制御部65は、測定対象遺伝子リスト78に基づいて、測定対象遺伝子表示画面120(図24参照)を生成し、これをディスプレイ49に表示する。
図9において、カテゴリ指定画面80は、カテゴリおよび個数範囲のユーザによる指定を受け付けるために、表示制御部65の制御の下、ディスプレイ49に表示される。カテゴリ指定画面80には、本開示の技術に係る「注目する生体試料の特性」の一例である注目する細胞の挙動を選択入力するためのプルダウンメニュー81が設けられている。また、カテゴリ指定画面80には、カテゴリの入力ボックス82、および個数範囲の下限の入力ボックス83と上限の入力ボックス84が設けられている。入力ボックス82~84は、追加ボタン85を選択することで追加することが可能である。
プルダウンメニュー81で注目する細胞の挙動が選択され、入力ボックス82~84に所望のカテゴリおよび個数範囲が入力された後、指定ボタン86が選択された場合、指示受付部60は、注目する細胞の挙動、カテゴリ、および個数範囲の指定を受け付ける。これにより指示受付部60から選択部64にカテゴリおよび個数範囲指定情報70が出力される。カテゴリおよび個数範囲指定情報70は、プルダウンメニュー81で選択された注目する細胞の挙動、入力ボックス82に入力されたカテゴリ、並びに入力ボックス83および84に入力された個数範囲を含む。
図9では、注目する細胞の挙動として「分化能」が選択された場合を例示している。また、カテゴリとして「iPS細胞」、「外胚葉」、「中胚葉」、「内胚葉」が指定され、個数範囲として、各カテゴリに対して「225~250」が指定された場合を例示している。なお、指定するカテゴリは1つでもよい。また、入力ボックス83および84には同じ数値が入力されてもよい。
入力ボックス83および84の下部には、入力ボックス83および84に入力された個数範囲の下限および上限の合計の表示領域87が設けられている。表示領域87の下部には、合計が100個超1000個以下となるようユーザに促すメッセージ88が表示されている。
図10に示すように、合計が100個超1000個以下の範囲外である状態で指定ボタン86が選択された場合、表示制御部65は、カテゴリ指定画面80上に警告画面90をポップアップ表示する。警告画面90には、合計が100個超1000個以下の範囲外で、このままでは指定できない旨のメッセージ91が表示される。OKボタン92が選択された場合、表示制御部65は警告画面90の表示を消す。
カテゴリ指定画面80は、こうして個数範囲の合計が100個超1000個以下の範囲外である場合に指定ができないように構成される。このため図11に示すように、選択部64は、結果として100個超1000個以下の測定対象遺伝子を選択することとなる。
図12において、先行知見遺伝子指定画面95は、先行知見遺伝子のユーザによる指定を受け付けるために、表示制御部65の制御の下、ディスプレイ49に表示される。先行知見遺伝子指定画面95には、先行知見遺伝子のセットを選択入力するためのプルダウンメニュー96が設けられている。プルダウンメニュー96は、追加ボタン97を選択することで追加することが可能である。プルダウンメニュー96には、複数の先行知見遺伝子のセットが選択肢として予め用意されている。先行知見遺伝子のセットは、カテゴリ毎に用意されている。先行知見遺伝子のセットには、例えば、TaqMan(登録商標)スコアカードによる遺伝子解析に用いられる先行知見遺伝子のセット、nCounter(登録商標)による遺伝子解析に用いられる先行知見遺伝子のセット、TruSeq(登録商標)による遺伝子解析に用いられる先行知見遺伝子のセット等が含まれる。
プルダウンメニュー96で所望の先行知見遺伝子のセットが選択された後、指定ボタン98が選択された場合、指示受付部60は、先行知見遺伝子のセットの指定を受け付ける。これにより指示受付部60から選択部64に先行知見遺伝子指定情報71が出力される。先行知見遺伝子指定情報71は、先行知見遺伝子のセットと、これに対応するカテゴリとが登録された情報である。
図12では、カテゴリ「iPS細胞」について先行知見遺伝子のセットが2つ、カテゴリ「外胚葉」、「中胚葉」、「内胚葉」について先行知見遺伝子のセットが1つずつ、計5つの先行知見遺伝子のセットが指定された場合を例示している。なお、セットを指定する代わりに、あるいは加えて、先行知見遺伝子を1つずつ指定する構成としてもよい。
図13において、抽出対象指定画面105は、遺伝子発現情報DBサーバ12からの遺伝子発現情報15の中から抽出対象15Eをユーザに指定させるために、表示制御部65の制御の下、ディスプレイ49に表示される。抽出対象指定画面105には、抽出対象15Eの入力ボックス106が設けられている。入力ボックス106は、追加ボタン107を選択することで追加することが可能である。
抽出対象15Eが入力ボックス106に入力された後、指定ボタン108が選択された場合、指示受付部60において抽出対象15Eの指定が受け付けられる。これにより指示受付部60から抽出部61に抽出対象指定情報73が出力される。抽出対象指定情報73は、入力ボックス106に入力された抽出対象15Eと、当該抽出対象15Eに登録された生体試料の種類とが登録された情報である。
図13では、生体試料の種類「iPS細胞」、「外胚葉」、「中胚葉」、「内胚葉」のそれぞれに対して1つずつ、抽出対象15Eが指定された場合を例示している。なお、1つの生体試料の種類に対して2つ以上の抽出対象15Eを指定しても構わない。
図14に示すように、DEGsリスト74には、DEGsと、当該DEGsを抽出した抽出対象15Eに登録された生体試料の種類とが登録されている。DEGsには、ID「GE_5」、「GE_10」等のDEGsのように、1つの生体試料の種類だけが登録されているものもあれば、ID「GE_1」、「GE_2」等のDEGsのように、「iPS細胞」、「外胚葉」、「中胚葉」、「内胚葉」といった複数の生体試料の種類が登録されているものもある。つまり、1つの生体試料の種類にだけ属しているDEGsもあれば、複数の生体試料の種類にまたがって属しているDEGsもある。
図15に示すように、配信情報76は、DEGsと、これに対応するアノテーション情報とが登録された情報である。
図16において、付与済DEGsリスト74Gは、図14で示したDEGsリスト74に、アノテーション情報の項目が追加されたものである。この付与済DEGsリスト74Gによって、アノテーション情報に生体試料の種類が関連付けられる。
取得部62は、配信情報76に登録されたアノテーション情報の中から、カテゴリおよび個数範囲指定情報70の注目する細胞の挙動に関するアノテーション情報を選定する。そして、選定したアノテーション情報のみをDEGsリスト74に登録し、付与済DEGsリスト74Gとする。
図9で示したように、本例では、注目する細胞の挙動として「分化能」が指定されている。このため、取得部62は、ID「GO:0000075」、「GO:0001028」といった分化能に関りがないアノテーション情報は選定せず、ID「GO:0000578」、「GO:0001501」といった分化に関するアノテーション情報のみを選定して登録する。なお、注目する細胞の挙動に関する検索キーワードを第2配信要求75に含めておき、アノテーション情報DBサーバ13において、注目する細胞の挙動に関するアノテーション情報を選定してもよい。
図17において、導出部63は、付与済DEGsリスト74Gに基づいて、各DEGsに付与されたアノテーション情報の付与数を計数する。そして、計数した付与数自体を、評価値として評価値テーブル77に登録する。例えばID「GE_1」のDEGsに28個のアノテーション情報が付与されていた場合、評価値テーブル77には評価値として付与数と同じ「28」が登録される。
図18において、選択部64は、まず、先行知見遺伝子指定情報71で指定された先行知見遺伝子のセットを、無条件で測定対象遺伝子として選択する。これにより、先行知見遺伝子のセットが測定対象遺伝子として登録された仮測定対象遺伝子リスト78Pが生成される。この先行知見遺伝子のセットを無条件で測定対象遺伝子として選択する態様は、先行知見遺伝子の評価値の重み付けを重くして、必ず先行知見遺伝子が測定対象遺伝子として選択されるようにすることの一例である。
図19において、選択部64は、評価値テーブル77に基づいて、選択順位表群115を生成する。選択順位表群115は、生体試料の種類「iPS細胞」に対応するカテゴリ「iPS細胞」の選択順位表116A、生体試料の種類「外胚葉」に対応するカテゴリ「外胚葉」の選択順位表116B、生体試料の種類「中胚葉」に対応するカテゴリ「中胚葉」の選択順位表116C、および生体試料の種類「内胚葉」に対応するカテゴリ「内胚葉」の選択順位表116Dで構成される。選択部64は、各カテゴリについて、評価値が高い(アノテーション情報の付与数が多い)DEGsから順に選択順位をつけていく。すなわち、評価値が最も高いDEGsの選択順位を1位、次に評価値が高いDEGsの選択順位を2位、次の次に評価値が高いDEGsの選択順位を3位、・・・とする。
図20に示すように、選択部64は、選択順位表116を参照して、カテゴリ毎に用意されたDEGsから、個数範囲を満たす測定対象遺伝子を選択し、各カテゴリに割り振る。
図20は、カテゴリ「iPS細胞」のために用意されたDEGsから、カテゴリ「iPS細胞」の測定対象遺伝子を選択する様子を例示している。また、図20は、カテゴリ「iPS細胞」の個数範囲として、図9で示した「225~250」が指定され、かつ図18で選択された、カテゴリ「iPS細胞」の先行知見遺伝子の個数が100個であった場合を例示している。この場合、個数範囲を満たすためには、少なくとも125個、多くとも150個のDEGsを選択する必要がある。このため選択部64は、選択順位表116Aにおいて選択順位1位~150位までの計150個のDEGsを選択する。そして、選択した150個のDEGsを、カテゴリ「iPS細胞」の測定対象遺伝子として仮測定対象遺伝子リスト78Pに登録する。
図示は省略するが、選択部64は、他のカテゴリ「外胚葉」、「中胚葉」、「内胚葉」も同様にして、選択順位表116B~116Dを参照して、個数範囲を満たす数のDEGsを選択する。そして、選択したDEGsを測定対象遺伝子として仮測定対象遺伝子リスト78Pに登録する。選択部64は、こうして測定対象遺伝子を順次選択していくことで、最終的には図21に示すような、各カテゴリにおいて個数範囲が満たされた測定対象遺伝子リスト78を生成する。
図22および図23は、抽出部61、取得部62、導出部63、および選択部64による一連の処理をまとめた図である。まず、図22に示すように、抽出部61は、抽出対象15EからDEGsを抽出し、DEGsリスト74を生成する。取得部62は、アノテーション情報DBサーバ13からの配信情報76を取得することで、アノテーション情報を取得する。取得部62は、配信情報76のアノテーション情報をDEGsリスト74に付与し、付与済DEGsリスト74Gとする。
図23に示すように、導出部63は、各DEGsへのアノテーション情報の付与数を計数し、付与数を評価値として評価値テーブル77に登録する。選択部64は、評価値に基づいて測定対象遺伝子を選択し、測定対象遺伝子リスト78を生成する。
図24に示すように、測定対象遺伝子表示画面120には、測定対象遺伝子リスト78に登録された測定対象遺伝子が表示される。測定対象遺伝子表示画面120には、カテゴリ毎に表示領域121A、121B、121C、および121Dが設けられている。表示領域121Aにはカテゴリ「iPS細胞」の測定対象遺伝子が表示される。表示領域121Bにはカテゴリ「外胚葉」、表示領域121Cにはカテゴリ「中胚葉」、表示領域121Dにはカテゴリ「内胚葉」の測定対象遺伝子がそれぞれ表示される。
測定対象遺伝子表示画面120の下部には、保存ボタン122、印刷ボタン123、および確認ボタン124が設けられている。保存ボタン122は、測定対象遺伝子リスト78をストレージデバイス45に保存する場合に選択される。印刷ボタン123は、測定対象遺伝子リスト78を印刷する場合に選択される。確認ボタン124が選択された場合、表示制御部65は、測定対象遺伝子表示画面120の表示を消す。
次に、上記構成による作用について、図25のフローチャートを参照して説明する。まず、情報処理装置10において作動プログラム55が起動されると、図8で示したように、情報処理装置10のCPU47は、指示受付部60、抽出部61、取得部62、導出部63、選択部64、および表示制御部65として機能される。
表示制御部65の制御の下、図9で示したカテゴリ指定画面80がディスプレイ49に表示される(ステップST100)。ユーザは、注目する細胞の挙動と、所望のカテゴリおよび個数範囲とを入力し、指定ボタン86を選択する。これにより、指示受付部60において、注目する細胞の挙動と、カテゴリおよび個数範囲との指定が受け付けられ(ステップST110)、カテゴリおよび個数範囲指定情報70が生成される。カテゴリおよび個数範囲指定情報70は、指示受付部60から選択部64に出力される。
続いて、表示制御部65の制御の下、図12で示した先行知見遺伝子指定画面95がディスプレイ49に表示される(ステップST120)。ユーザは、所望の先行知見遺伝子のセットを入力し、指定ボタン98を選択する。これにより、指示受付部60において、先行知見遺伝子のセットの指定が受け付けられ(ステップST130)、先行知見遺伝子指定情報71が生成される。先行知見遺伝子指定情報71は、指示受付部60から選択部64に出力される。
表示制御部65の制御の下、図示省略した検索画面がディスプレイ49に表示される。そして、指示受付部60において、検索キーワードを含むユーザによる第1配信指示が受け付けられる。これにより、指示受付部60から、検索キーワードを含む第1配信要求72が遺伝子発現情報DBサーバ12に送信される(ステップST140)。
第1配信要求72に応じて、遺伝子発現情報DBサーバ12から遺伝子発現情報15が配信される。遺伝子発現情報15は表示制御部65に入力される。そして、表示制御部65の制御の下、図示省略した遺伝子発現情報15の表示画面がディスプレイ49に表示される(ステップST150)。
また、表示制御部65の制御の下、図13で示した抽出対象指定画面105がディスプレイ49に表示される(ステップST160)。ユーザは、所望の抽出対象15Eを入力し、指定ボタン108を選択する。これにより、指示受付部60において、抽出対象15Eの指定が受け付けられ(ステップST170)、抽出対象指定情報73が生成される。抽出対象指定情報73は、指示受付部60から抽出部61に出力される。
抽出部61において、抽出対象15EからDEGsが抽出され、図14で示したDEGsリスト74が生成される(ステップST180)。DEGsリスト74は、抽出部61から取得部62に出力される。続いて、DEGsリスト74に基づく第2配信要求75が取得部62からアノテーション情報DBサーバ13に送信される(ステップST190)。
第2配信要求75に応じて、アノテーション情報DBサーバ13から、図15で示したアノテーション情報を含む配信情報76が配信される。配信情報76は取得部62に入力される。これにより、配信情報76、ひいてはアノテーション情報が取得部62において取得される(ステップST200)。なお、ステップST200は、本開示の技術に係る「取得処理」の一例である。
図16で示したように、取得部62によって、配信情報76に基づいて、DEGsリスト74にアノテーション情報が付与され、DEGsリスト74が付与済DEGsリスト74Gとされる(ステップST210)。この際、注目する細胞の挙動に関するアノテーション情報のみが選定されて付与される。付与済DEGsリスト74Gは、取得部62から導出部63に出力される。
図17で示したように、導出部63によって、各DEGsに付与されたアノテーション情報の付与数が計数され、付与数が評価値として評価値テーブル77に登録される(ステップST220)。評価値テーブル77は、導出部63から選択部64に出力される。なお、ステップST220は、本開示の技術に係る「導出処理」の一例である。
図18で示したように、選択部64によって、先行知見遺伝子が無条件で測定対象遺伝子として選択される(ステップST230)。
さらに、図20で示したように、選択部64によって、カテゴリ毎に用意されたDEGsから、評価値が高い順に個数範囲を満たす数のDEGsが選択される。そして、選択されたDEGsが測定対象遺伝子として各カテゴリに割り振られる(ステップST240)。こうした過程を経て、図21で示した測定対象遺伝子リスト78が生成される。測定対象遺伝子リスト78は、選択部64から表示制御部65に出力される。なお、ステップST240は、本開示の技術に係る「選択処理」の一例である。
最後に、表示制御部65によって、図24で示した測定対象遺伝子表示画面120がディスプレイ49に表示される(ステップST250)。ユーザは、この測定対象遺伝子表示画面120を通じて、測定対象遺伝子を確認する。
以上説明したように、情報処理装置10は、取得部62と、導出部63と、選択部64とを備える。取得部62は、複数の遺伝子のそれぞれに付与されたアノテーション情報を取得する。導出部63は、アノテーション情報に基づいて、複数の遺伝子毎の評価値を導出する。選択部64は、評価値に基づいて、複数の遺伝子の中から測定対象遺伝子を選択する。このため、アノテーション情報に基づく評価値という確かな裏付けの下で、データドリブンで測定対象遺伝子を選択することが可能となる。このようにして選択された測定対象遺伝子は、多水準展開が容易でありながら、研究対象の細胞に合わせてカスタマイズされている。したがって、細胞の挙動の解明に繋がる、より適切な測定対象遺伝子を選択することが可能となる。
取得部62は、注目する細胞の挙動に関するアノテーション情報を選定する。選択部64は、選定したアノテーション情報のみに基づいて評価値を導出する。このため、注目する細胞の挙動に特化したアノテーション情報のみに基づいて、測定対象遺伝子を選択することができる。換言すれば、注目する細胞の挙動への関連性が薄いアノテーション情報をノイズとして排除し、注目する細胞の挙動への関連性が高いアノテーション情報に限定した形で、測定対象遺伝子を選択することができる。
取得部62は、遺伝子に対するアノテーション情報が登録されたアノテーション情報DB16を参照して、遺伝子に対してアノテーション情報を付与する。このため、既存のアノテーション情報DB16を用いて、簡単にアノテーション情報を付与することができる。
アノテーション情報には、生体試料の種類が関連付けられている。指示受付部60は、生体試料の種類に応じて定義された複数のカテゴリ、および複数のカテゴリ毎の個数範囲のユーザによる指定を受け付ける。選択部64は、複数のカテゴリ毎に用意された遺伝子から、個数範囲を満たす数の遺伝子を選択し、選択した遺伝子を、測定対象遺伝子として複数のカテゴリのそれぞれに割り振る。このため、カテゴリ毎に過不足なく測定対象遺伝子を選択することができる。
カテゴリは、「iPS細胞」、「外胚葉」、「中胚葉」、および「内胚葉」を含む。このため、近年非常に関心が高まっているiPS細胞25に関連するカテゴリ毎の測定対象遺伝子を得ることができる。なお、iPS細胞およびその分化工程を評価することを目的として遺伝子の発現量を測定する場合には、カテゴリは、上記の「iPS細胞」、「外胚葉」、「中胚葉」、および「内胚葉」を含むことが好ましい。ただし、上記以外の目的で遺伝子の発現量を測定する場合には、カテゴリとしては上記の「iPS細胞」、「外胚葉」、「中胚葉」、および「内胚葉」に限らない。
導出部63は、複数の遺伝子毎にアノテーション情報の付与数を計数し、付与数に基づいて評価値を導出する。このため、簡単に評価値を導出することができる。
遺伝子は先行知見遺伝子を含む。そして、指示受付部60は、先行知見遺伝子のユーザによる指定を受け付ける。選択部64は、先行知見遺伝子の評価値の重み付けを重くする一形態として、先行知見遺伝子を無条件で測定対象遺伝子として選択する。このため、先行知見遺伝子を測定したいというユーザの意図を反映させることができる。また、過去の知見が凝縮された先行知見遺伝子を、測定対象遺伝子として有効に取り入れることができる。
選択部64は、100個超1000個以下の測定対象遺伝子を選択する。測定対象遺伝子が100個以下であると、細胞の挙動の解明に十分でない。一方、測定対象遺伝子が1000個よりも多いと、検査に時間およびコストが掛かり、多水準実験への展開が困難となる。
遺伝子はDEGsを含む。このため、より細胞の挙動の解明に寄与すると考えられる測定対象遺伝子を選択することができる。
なお、先行知見遺伝子は無条件で測定対象遺伝子として選択するとしたが、これに限らない。先行知見遺伝子についてもDEGsと同様にアノテーション情報を取得して評価値を導出し、導出した評価値に基づいて選択してもよい。この際、先行知見遺伝子の評価値の重み付けを、DEGsよりも重くしてもよい。また、この場合、先行知見遺伝子の各々に対して重要度を設定し、重要度を加味して評価値を導出してもよい。具体的には、重要度が高い程、高い評価値を導出する構成とする。なお、先行知見遺伝子以外の遺伝子、例えばDEGs等は、重要度を最低と見なして評価値を導出してもよい。
先行知見遺伝子は、必ずしも指定しなくてもよい。例えば、研究対象の細胞が新規で、先行知見遺伝子がそもそも存在しない場合は、先行知見遺伝子の指定を省略してもよい。
抽出対象15Eの指定も省略し、遺伝子発現情報DBサーバ12から配信された全ての遺伝子発現情報15を抽出対象15Eとしてもよい。
カテゴリも、必ずしも指定しなくてもよい。ただし、カテゴリの指定は省略しても、選択する測定対象遺伝子の個数の範囲、少なくとも上限は指定する必要がある。
遺伝子発現情報DB14は、例示のGEOといった公共的なDBに限定されない。例えばユーザが所属する研究所で測定された遺伝子発現情報15が登録された、ローカルなDBであっても構わない。アノテーション情報DB16についても同様に、DAVID、InterProといった公共的なDBに限らず、例えばユーザが所属する研究所で用意されたローカルなDBであってもよい。
[第2実施形態]
図26および図27に示す第2実施形態では、アノテーション情報の情報価値に応じて、評価値に対して重み付けを行う。
図26および図27に示す第2実施形態では、アノテーション情報の情報価値に応じて、評価値に対して重み付けを行う。
図26は、付与数が比較的少ない、すなわち稀少性が比較的高いアノテーション情報を情報価値が高いと判断して、当該アノテーション情報の付与数を多くする例を示す。導出部63は、まず、表150に示すように、付与済DEGsリスト74Gに基づいて、DEGsに付与されたアノテーション情報のそれぞれの付与数(以下、トータル付与数という)を計数する。導出部63は、トータル付与数と予め設定された閾値とを比較する。そして、トータル付与数が閾値未満のアノテーション情報を情報価値が高いと判断して、表151に示すように、当該アノテーション情報の、評価値を導出する際の付与数を1よりも大きい値とする。つまり、情報価値が高いと判断したアノテーション情報の重み付けを重くする。導出部63は、重み付けがされた付与数を含めて、各DEGsのアノテーション情報の付与数を計数し、評価値テーブル77を生成する。
図26は、閾値として「10」が設定され、トータル付与数が「6」と閾値未満のID「GO:0000578」のアノテーション情報の付与数が「10」とされた場合を例示している。
図27は、アノテーション情報の直交性に基づいて、評価値に対して重み付けを行う例を示す。導出部63は、できる限り漏れなくかつ重複なくアノテーション情報をカバー可能な遺伝子のセットの直交性が高いと判断する。
表158は、ID「GE_1000」、「GE_1001」、および「GE_1002」の3個のDEGsに対する、A1~A7で示すアノテーション情報の付与状況を示したものである。A1~A7のアノテーション情報のうち、A1~A4には生体試料の種類として「iPS細胞」が、A5~A7には「外胚葉」がそれぞれ関連付けられている。
この場合、アノテーション情報の付与数だけをみれば、ID「GE_1000」およびID「GE_1001」のDEGsが、ID「GE_1002」のDEGsよりも優先的に測定対象遺伝子として選択される。しかし、アノテーション情報の直交性を考慮すると、ID「GE_1002」のDEGsが、ID「GE_1001」のDEGsよりも優先的に測定対象遺伝子として選択される。こうして最終的にID「GE_1000」およびID「GE_1002」のDEGsが測定対象遺伝子として選択されれば、「iPS細胞」および「外胚葉」の両方をカバーすることができる。
なお、他の遺伝子との組み合わせでカバーできるアノテーション情報の数に基づいて、評価値を導出してもよい。表158を例に説明すると、ID「GE_1000」およびID「GE_1001」のDEGsの組み合わせでは、カバーできるアノテーション情報の数は6個である。ID「GE_1000」およびID「GE_1002」のDEGsの組み合わせでは、カバーできるアノテーション情報の数は7個である。ID「GE_1001」およびID「GE_1002」のDEGsの組み合わせでは、カバーできるアノテーション情報の数は5個である。この結果から、ID「GE_1000」およびID「GE_1002」のDEGsの評価値を、ID「GE_1001」のDEGsの評価値よりも高くする。
このように、第2実施形態では、導出部63は、アノテーション情報の情報価値に応じて、評価値に対して重み付けを行う。このため、例えば情報価値が高いと判断したアノテーション情報の付与数の重み付けを重くすることで、情報価値が高いと思われるアノテーション情報が付与された遺伝子が、測定対象遺伝子として選択されやすくなる。したがって、測定対象遺伝子の妥当性、信頼性を高めることができる。
図26においては、導出部63は、稀少性が比較的高いアノテーション情報を情報価値が高いと判断して、重み付けを重くする。このため、見落としがちな稀少なアノテーション情報が付与された遺伝子を、測定対象遺伝子として選択することができる。
図27においては、導出部63は、アノテーション情報の直交性に基づいて、評価値に対して重み付けを行う。このため、できる限り漏れなくかつ重複なくアノテーション情報をカバー可能な遺伝子のセットを、測定対象遺伝子として選択することができる。
図26および図27の例を複合して実施してもよい。この場合、例えば、トータル付与数が閾値未満のアノテーション情報が付与され、かつアノテーション情報の直交性が高いDEGsの評価値に100を加算する。
なお、図26では、稀少性が比較的高いアノテーション情報を情報価値が高いアノテーション情報と判断したが、情報価値が高いアノテーション情報の例は、これらに限定されない。例えば、研究論文への掲載数が比較的多いアノテーション情報を、情報価値が高いアノテーション情報と判断してもよい。
図26では、DEGsに付与されたアノテーション情報の付与数に対して重み付けを行っているが、これに限定されない。先行知見遺伝子についても評価値を導出する場合は、先行知見遺伝子に付与されたアノテーション情報の付与数に対して、図26で示した場合と同様に重み付けを行ってもよい。図27で示した態様も同様に、先行知見遺伝子に対して適用してもよい。
[第3実施形態]
図28に示す第3実施形態では、強度指標が予め設定された閾値範囲内にある遺伝子の評価値の重み付けを重くする。
図28に示す第3実施形態では、強度指標が予め設定された閾値範囲内にある遺伝子の評価値の重み付けを重くする。
図28において、第3実施形態の付与済DEGsリスト160Gには、強度指標情報の項目が設けられている。強度指標情報の項目には、強度指標が予め設定された閾値範囲内であるか否かが登録されている。強度指標は、例えばfold-change、多重検定補正済の発現有意差を示すq値(q-value)等である。
導出部63は、表161に示すように、強度指標が閾値範囲内にあるDEGsのアノテーション情報の、評価値を導出する際の付与数を1よりも大きい値とする。つまり、強度指標が閾値範囲内にあるDEGsの評価値の重み付けを重くする。導出部63は、重み付けがされた付与数を含めて、各DEGsのアノテーション情報の付与数を計数し、評価値テーブル77を生成する。
図28は、ID「GE_2」、「GE_5」等のDEGsの強度指標が閾値範囲内で、これらのアノテーション情報の付与数が「2」とされた場合を例示している。
このように、第3実施形態では、導出部63は、強度指標が閾値範囲内にあるDEGsの評価値の重み付けを重くする。このため、生体試料の特性の解明により重要と考えられる、強度指標が閾値範囲内にあるDEGsを、測定対象遺伝子として選択することができる。なお、第2実施形態と第3実施形態を複合して実施してもよい。
[第4実施形態]
図29~図34に示す第4実施形態では、測定対象遺伝子の測定結果166を取得する。そして、測定結果166に基づいて、統計的な手法によって、測定対象遺伝子に付与されたアノテーション情報171から、細胞の挙動への影響度が比較的高いアノテーション情報(以下、高影響アノテーション情報という)167を選出し、選出した高影響アノテーション情報167をユーザに提示する。
図29~図34に示す第4実施形態では、測定対象遺伝子の測定結果166を取得する。そして、測定結果166に基づいて、統計的な手法によって、測定対象遺伝子に付与されたアノテーション情報171から、細胞の挙動への影響度が比較的高いアノテーション情報(以下、高影響アノテーション情報という)167を選出し、選出した高影響アノテーション情報167をユーザに提示する。
図29において、第4実施形態の情報処理装置10のCPU47は、図8で示した各処理部60~65(図29では取得部62のみ図示)に加えて、選出部165として機能する。
取得部62は、複数の測定結果166_1、166_2、・・・、および166_Xを取得する。測定結果166_1~166_Xは、例えば、iPS細胞25から組織細胞30への分化誘導効率が低かった複数のサンプル1、2、・・・、Xについて、iPS細胞25の段階における測定対象遺伝子の発現量を実際に測定した結果である。測定結果166_1~166_Xは、例えば、遺伝子の発現量を測定する測定装置から情報処理装置10に送信され、取得部62に入力される。取得部62は、測定結果166_1~166_Xを選出部165に出力する。
選出部165は、取得部62からの測定結果166_1~166_X、および付与済DEGsリスト74Gに基づいて、高影響アノテーション情報167を選出する。選出部165は、高影響アノテーション情報167を表示制御部65に出力する。
図30~図33に、選出部165において高影響アノテーション情報167を選出する処理の手順を示す。まず、選出部165は、図30のステップST300および図31に示すように、測定結果166_1~166_Xを参照して、測定対象遺伝子から高発現遺伝子170を抽出する。高発現遺伝子170は、例えば、全サンプル1~Xにおいて発現量が閾値以上の測定対象遺伝子である。図31は、閾値として「100」が設定され、ID「GE_5」、「GE_32」、「GE_300」、・・・といった測定対象遺伝子を、高発現遺伝子170として抽出した場合を例示している。
次に、選出部165は、図30のステップST310および図32に示すように、付与済DEGsリスト74Gから、高発現遺伝子170に付与されたアノテーション情報171を抜粋する。続いて、選出部165は、図30のステップST320および図33の算出結果172に示すように、高発現遺伝子170に付与されたアノテーション情報171の各々について、オッズ比およびp値(p-value)を算出する。最後に、選出部165は、図30のステップST330および図33の算出結果172の後段に示すように、高発現遺伝子170に付与されたアノテーション情報171のうち、p値が0.05未満と統計的に有意なアノテーション情報171を、高影響アノテーション情報167として選出する。図33は、p値が「0.0205」であるID「GO:0001501」のアノテーション情報171、p値が「0.0245」であるID「GO:0001704」のアノテーション情報171等を、高影響アノテーション情報167として選出した場合を例示している。
図34において、高影響アノテーション情報表示画面180は、表示制御部65の制御の下、ディスプレイ49に表示される。高影響アノテーション情報表示画面180には、高影響アノテーション情報167の表示領域181が設けられている。表示領域181には、高影響アノテーション情報167とその内容とが一覧表示される。確認ボタン182が選択された場合、表示制御部65は、高影響アノテーション情報表示画面180の表示を消す。
このように、第4実施形態では、取得部62は、測定対象遺伝子の測定結果166を取得する。選出部165は、測定結果166に基づいて、統計的な手法によって、測定対象遺伝子に付与されたアノテーション情報171から、細胞の挙動への影響度が比較的高い高影響アノテーション情報167を選出する。表示制御部65は、高影響アノテーション情報表示画面180をディスプレイ49に表示することで、高影響アノテーション情報167をユーザに提示する。このため、ユーザは、高影響アノテーション情報167から、分化誘導効率が低かった主要因等を類推することができ、次回の培養に活かすことができる。高影響アノテーション情報167は、統計的な手法によって選出されたものであるから、分化誘導効率が低かった主要因等の類推を的確に行うことができる。
なお、高影響アノテーション情報表示画面180に、高影響アノテーション情報167に加えて、高影響アノテーション情報167が付与された遺伝子を表示してもよい。
[実施例]
以下、図9の場合と同じく、注目する細胞の挙動としてiPS細胞25の「分化能」が選択された場合の実施例を示す。カテゴリおよび個数範囲も、図9で示した例と同じである。すなわち、カテゴリとして「iPS細胞」、「外胚葉」、「中胚葉」、「内胚葉」が指定され、個数範囲として各カテゴリに「225~250」が指定された例を示す。
以下、図9の場合と同じく、注目する細胞の挙動としてiPS細胞25の「分化能」が選択された場合の実施例を示す。カテゴリおよび個数範囲も、図9で示した例と同じである。すなわち、カテゴリとして「iPS細胞」、「外胚葉」、「中胚葉」、「内胚葉」が指定され、個数範囲として各カテゴリに「225~250」が指定された例を示す。
図35に示す表200は、本実施例において測定対象遺伝子を選択するために指定された先行知見遺伝子、および抽出されたDEGsを示すものである。先行知見遺伝子には、知見者ヒアリングに基づくもの、あるいはTaqManスコアカードといった有名遺伝子パネルも含まれている。DEGsには、iPS細胞25あるいはES細胞(Embryonic Stem cells)、および、iPS細胞25あるいはES細胞を三胚葉26または組織細胞30に分化させた実験における抽出対象15Eから抽出されたものが含まれている。本実施例では、これら約2900個(一部重複)の遺伝子の中から、個数範囲を満たす約1000個(具体的には980個)の測定対象遺伝子を選択した。より詳しくは、先行知見遺伝子およびDEGsに、アノテーション情報DB16から取得したアノテーション情報のうちで分化に関わるアノテーション情報のみを選定して付与した。そして、アノテーション情報に基づいて評価値を導出し、評価値が高い順に個数範囲を満たす数を選択した。また、先行知見遺伝子およびDEGsとは別に、正規化用遺伝子も測定対象遺伝子として選択した。以下、こうして選択した約1000個の測定対象遺伝子をC1000と呼ぶ。
iPS細胞25を心筋細胞に分化誘導する実験において、iPS細胞25の段階における15サンプルのC1000の発現量を測定した。15サンプルのうち、10サンプルは分化誘導効率が高く、一方で5サンプルは分化誘導効率が低かった。
ここで、本開示の技術の効果を確認するため、比較例として、15サンプルの分化誘導前のiPS細胞25について、別途マイクロアレイによる網羅的な遺伝子(約21000個)の発現量の測定も行った。
図36に、マイクロアレイの発現量の測定結果202を示す。バー203は各遺伝子の発現量を表す。測定結果202によれば、クラスタリングによって左側の9サンプルのグループと右側の6サンプルのグループとに分かれ、6サンプルのグループに、「Bad」で示す分化誘導効率が低かった5サンプルが全て包含された。つまり、マイクロアレイの発現量の測定結果202によれば、iPS細胞25の段階で、分化誘導効率の高低を比較的高い確度(分化誘導効率が低くなるサンプルの検出感度100%、分化誘導効率が低くなるサンプルの特異度83%)で予測可能であることが分かった。なお、「Good」は、分化誘導効率が高かったサンプルを示す。
マイクロアレイで測定に用いた遺伝子から、上記第4実施形態のごとく高発現遺伝子170を抽出し、さらに高影響アノテーション情報167を選出した。その結果を図37の表205および図38の表206に示す。表205および表206によれば、種々雑多なアノテーション情報が高影響アノテーション情報167として選出されており、細胞の挙動の解明に繋がる有効な知見を得ることは困難であることが分かった。
図39に、15サンプルの分化誘導前のiPS細胞25について行った、C1000の発現量の測定結果208を示す。測定結果208によれば、クラスタリングによって右側の9サンプルのグループと左側の6サンプルのグループに分かれ、6サンプルのグループに、「Bad」で示す分化誘導効率が低かった5サンプルが全て包含された(分化誘導効率が低くなるサンプルの検出感度100%、分化誘導効率が低くなるサンプルの特異度83%)。したがって、本開示の技術に係るC1000によれば、マイクロアレイによる網羅的な測定と同等のレベルの分化誘導効率の予測が可能であることが確認された。
C1000から上記第4実施形態のごとく高発現遺伝子170を抽出し、さらに高影響アノテーション情報167を選出した。その結果を図40の表210に示す。表210によれば、血管形成系機能発現に関するアノテーション情報が特に多く選出されていることが分かる。また、NODAL、LEFTY1、LEFTY2、CER1、BMP4等の遺伝子が目立っており、これらの遺伝子が分化誘導効率の高低を決定付けていそうなことが読み取れる。つまり、本開示の技術のように、アノテーション情報から評価値を導出し、評価値に基づいて測定対象遺伝子を選択すれば、生体試料の特性の解明に大いに役立つことが確認された。
続いて、本開示の技術により選択したC1000の測定遺伝子のセットと、従来手法を代表してTaqManスコアカードの測定遺伝子のセットとの解析能力を比較した。なお、TaqManスコアカードの測定遺伝子のセットによる測定結果は、マイクロアレイによる網羅的な遺伝子の発現量の測定結果から、TaqManスコアカードの84個の遺伝子を抽出して疑似的に作成したものである。
解析能力の比較として、DEGs抽出によって、TaqManスコアカードにおける生体試料の種類と、C1000における生体試料の種類のアノテーション情報とを対比させ、各アノテーション情報が付与された遺伝子に対して、DEGsがどの程度濃縮されたかを表すオッズ比を調べた。図41にC1000の測定遺伝子のセットによるオッズ比の棒グラフ215、図42にTaqManスコアカードの測定遺伝子のセットによるオッズ比の棒グラフ216を示す。
図41にの棒グラフ215によれば、C1000の測定遺伝子のセットでは、分化誘導効率が低いサンプルにおいて、「中胚葉」および「内胚葉」に関連する遺伝子が濃縮されており、かつ「iPS細胞」に関連する遺伝子が減少していた。また、分化誘導効率が低い場合の各生体試料の種類に関連する遺伝子は、「外胚葉」を除いて、オッズ比が統計的に有意に100%から乖離(q値(q-value)が0.05未満(q<0.05))していた。このため、C1000の測定遺伝子のセットは、分化誘導効率が低くなるサンプルに対する一定の解析能力を有していることが分かった。こうした結果が得られたのは、各生体試料の種類に焦点を当てた十分に多い測定対象遺伝子がバランスよく配分されているためと考えられる。
一方、図42の棒グラフ216によれば、TaqManスコアカードの測定遺伝子のセットでは、分化誘導効率が高いサンプルにおいて「iPS細胞」に関連する遺伝子が、分化誘導効率が低いサンプルにおいて「内胚葉」に関連する遺伝子が、それぞれ濃縮されていた。しかしながら、オッズ比が統計的に有意に100%から乖離しているのは、分化誘導効率が高い場合の「iPS細胞」に関連する遺伝子のみであった。このため、TaqManスコアカードの測定遺伝子のセットは、分化誘導効率が低くなるサンプルに対する解析能力に限界があることが分かった。こうした結果が得られたのは、C1000の場合と異なり、各生体試料の種類に配分された遺伝子の個数が少なく、極端な比率が生まれやすいためと考えられる。
以上のように、本開示の技術は、事前に知見が蓄積されていない場合においても、統計的に有意な解明が可能である。つまり、検査が短時間で済み、かつ比較的安価なPCRをベースとした手法を、RNA-Seqのように活用可能ということであり、幅広い応用が期待できる。
上記各実施形態では、付与数自体を評価値として導出しているが、これに限定されない。付与数0は評価値0、付与数1~10は評価値1、付与数11~20は評価値2、・・・というように、付与数に応じて予め設定された評価値を導出してもよい。
測定対象遺伝子をユーザに提示する態様としては、図24で示した測定対象遺伝子表示画面120をディスプレイ49に表示する態様に限定されない。測定対象遺伝子リスト78をプリントアウトする態様、あるいは、測定対象遺伝子リスト78をユーザが所有する端末に電子メール等で配信する態様を採用してもよい。上記第4実施形態において高影響アノテーション情報167をユーザに提示する態様も同様に、高影響アノテーション情報表示画面180をディスプレイ49に表示する態様に限らない。高影響アノテーション情報167をプリントアウトする態様、高影響アノテーション情報167をユーザが所有する端末に電子メール等で配信する態様を採用してもよい。
上記各実施形態では、研究対象の生体試料としてiPS細胞25を例示したが、これに限定されない。ES細胞、培養中の細胞からの抽出物、あるいは生体組織片でもよい。また、バイオマーカーとして遺伝子を例示したが、これに限定されない。遺伝子に代えて、あるいは加えて、遺伝子の配列、変異、発現、修飾、DNA(Deoxyribonucleic acid)、エピゲノム、mRNA(messenger RNA)、miRNA(microRNA)、培養中に細胞が発現するタンパク質、培養中に細胞から出される代謝物、二酸化炭素濃度、pHといった細胞の培養環境に関する要素を、バイオマーカーとしてもよい。ただし、遺伝子は種類が多く、より細胞の挙動の解明に寄与すると考えられるため、遺伝子をバイオマーカーに含めることが好ましい。なお、上記の例からも分かるように、本明細書における「バイオマーカー」とは、単に様々なバイオ特徴量を示す物の総称である。
情報処理装置10を構成するコンピュータのハードウェア構成は種々の変形が可能である。情報処理装置10を、処理能力および信頼性の向上を目的として、ハードウェアとして分離された複数台のコンピュータで構成することも可能である。例えば、指示受付部60、抽出部61、および取得部62の機能と、導出部63、選択部64、および表示制御部65の機能とを、2台のコンピュータに分散して担わせる。この場合は2台のコンピュータで情報処理装置10を構成する。
このように、情報処理装置10のコンピュータのハードウェア構成は、処理能力、安全性、信頼性等の要求される性能に応じて適宜変更することができる。さらに、ハードウェアに限らず、作動プログラム55等のアプリケーションプログラムについても、安全性および信頼性の確保を目的として、二重化したり、あるいは、複数のストレージデバイスに分散して格納することももちろん可能である。
上記各実施形態において、例えば、指示受付部60、抽出部61、取得部62、導出部63、選択部64、表示制御部65、および選出部165といった各種の処理を実行する処理部(Processing Unit)のハードウェア的な構造としては、次に示す各種のプロセッサ(Processor)を用いることができる。各種のプロセッサには、上述したように、ソフトウェア(作動プログラム55)を実行して各種の処理部として機能する汎用的なプロセッサであるCPU47に加えて、FPGA(Field Programmable Gate Array)等の製造後に回路構成を変更可能なプロセッサであるプログラマブルロジックデバイス(Programmable Logic Device:PLD)、ASIC(Application Specific Integrated Circuit)等の特定の処理を実行させるために専用に設計された回路構成を有するプロセッサである専用電気回路等が含まれる。
1つの処理部は、これらの各種のプロセッサのうちの1つで構成されてもよいし、同種または異種の2つ以上のプロセッサの組み合わせ(例えば、複数のFPGAの組み合わせ、および/または、CPUとFPGAとの組み合わせ)で構成されてもよい。また、複数の処理部を1つのプロセッサで構成してもよい。
複数の処理部を1つのプロセッサで構成する例としては、第1に、クライアントおよびサーバ等のコンピュータに代表されるように、1つ以上のCPUとソフトウェアの組み合わせで1つのプロセッサを構成し、このプロセッサが複数の処理部として機能する形態がある。第2に、システムオンチップ(System On Chip:SoC)等に代表されるように、複数の処理部を含むシステム全体の機能を1つのIC(Integrated Circuit)チップで実現するプロセッサを使用する形態がある。このように、各種の処理部は、ハードウェア的な構造として、上記各種のプロセッサの1つ以上を用いて構成される。
さらに、これらの各種のプロセッサのハードウェア的な構造としては、より具体的には、半導体素子等の回路素子を組み合わせた電気回路(circuitry)を用いることができる。
本開示の技術は、上述の種々の実施形態と種々の変形例を適宜組み合わせることも可能である。また、上記各実施形態に限らず、要旨を逸脱しない限り種々の構成を採用し得ることはもちろんである。さらに、本開示の技術は、プログラムに加えて、プログラムを非一時的に記憶する記憶媒体にもおよぶ。
以上に示した記載内容および図示内容は、本開示の技術に係る部分についての詳細な説明であり、本開示の技術の一例に過ぎない。例えば、上記の構成、機能、作用、および効果に関する説明は、本開示の技術に係る部分の構成、機能、作用、および効果の一例に関する説明である。よって、本開示の技術の主旨を逸脱しない範囲内において、以上に示した記載内容および図示内容に対して、不要な部分を削除したり、新たな要素を追加したり、置き換えたりしてもよいことはいうまでもない。また、錯綜を回避し、本開示の技術に係る部分の理解を容易にするために、以上に示した記載内容および図示内容では、本開示の技術の実施を可能にする上で特に説明を要しない技術常識等に関する説明は省略されている。
本明細書において、「Aおよび/またはB」は、「AおよびBのうちの少なくとも1つ」と同義である。つまり、「Aおよび/またはB」は、Aだけであってもよいし、Bだけであってもよいし、AおよびBの組み合わせであってもよい、という意味である。また、本明細書において、3つ以上の事柄を「および/または」で結び付けて表現する場合も、「Aおよび/またはB」と同様の考え方が適用される。
本明細書に記載された全ての文献、特許出願および技術規格は、個々の文献、特許出願および技術規格が参照により取り込まれることが具体的かつ個々に記された場合と同程度に、本明細書中に参照により取り込まれる。
Claims (19)
- 生体試料に関する複数のバイオマーカーのそれぞれに付与されたアノテーション情報を取得する取得処理と、
前記アノテーション情報に基づいて、複数の前記バイオマーカー毎の評価値を導出する導出処理と、
前記評価値に基づいて、複数の前記バイオマーカーの中から測定対象のバイオマーカーを選択する選択処理と、
をプロセッサが実行する情報処理装置の作動方法。 - 前記プロセッサは、
注目する生体試料の特性に関するアノテーション情報を選定して、
選定したアノテーション情報のみに基づいて前記評価値を導出する請求項1に記載の情報処理装置の作動方法。 - 前記プロセッサは、
前記バイオマーカーに対する前記アノテーション情報が登録されたデータベースを参照して、前記バイオマーカーに対して前記アノテーション情報を付与する請求項1または請求項2に記載の情報処理装置の作動方法。 - 前記アノテーション情報には、前記生体試料の種類が関連付けられている請求項1から請求項3のいずれか1項に記載の情報処理装置の作動方法。
- 前記プロセッサは、
前記生体試料の種類に応じて定義された複数のカテゴリ、および複数の前記カテゴリ毎の前記測定対象のバイオマーカーの個数の範囲のユーザによる指定を受け付け、
複数の前記カテゴリ毎に用意された前記バイオマーカーから、前記範囲を満たす数のバイオマーカーを選択し、選択した前記バイオマーカーを、前記測定対象のバイオマーカーとして複数の前記カテゴリのそれぞれに割り振る請求項4に記載の情報処理装置の作動方法。 - 前記カテゴリは、iPS細胞、外胚葉、中胚葉、および内胚葉を含む請求項5に記載の情報処理装置の作動方法。
- 前記プロセッサは、
複数の前記バイオマーカー毎に前記アノテーション情報の付与数を計数し、
前記付与数に基づいて前記評価値を導出する請求項1から請求項6のいずれか1項に記載の情報処理装置の作動方法。 - 前記プロセッサは、
前記アノテーション情報の情報価値に応じて、前記評価値に対して重み付けを行う請求項1から請求項7のいずれか1項に記載の情報処理装置の作動方法。 - 前記プロセッサは、
稀少性が比較的高いアノテーション情報を前記情報価値が高いと判断して、重み付けを重くする請求項8に記載の情報処理装置の作動方法。 - 前記プロセッサは、
前記アノテーション情報の直交性に基づいて、前記評価値に対して重み付けを行う請求項8または請求項9に記載の情報処理装置の作動方法。 - 前記プロセッサは、
強度指標が予め設定された閾値範囲内にある前記バイオマーカーの評価値の重み付けを重くする請求項1から請求項10のいずれか1項に記載の情報処理装置の作動方法。 - 前記プロセッサは、
前記生体試料の特性に影響を与えることが既に知られている前記バイオマーカーである先行知見マーカーのユーザによる指定を受け付け、
前記先行知見マーカーの評価値の重み付けを重くする請求項1から請求項11のいずれか1項に記載の情報処理装置の作動方法。 - 前記プロセッサは、
100個超1000個以下の前記測定対象のバイオマーカーを選択する請求項1から請求項12のいずれか1項に記載の情報処理装置の作動方法。 - 前記バイオマーカーは遺伝子を含む請求項1から請求項13のいずれか1項に記載の情報処理装置の作動方法。
- 前記遺伝子は、発現量が特異的に変動している発現変動遺伝子を含む請求項14に記載の情報処理装置の作動方法。
- 前記アノテーション情報は、遺伝子オントロジーで定義された用語である請求項1から請求項15のいずれか1項に記載の情報処理装置の作動方法。
- 前記プロセッサは、
前記測定対象のバイオマーカーの測定結果を取得し、
前記測定結果に基づいて、統計的な手法によって、前記測定対象のバイオマーカーに付与された前記アノテーション情報から、前記生体試料の特性への影響度が比較的高いアノテーション情報を選出し、
選出したアノテーション情報をユーザに提示する請求項1から請求項16のいずれか1項に記載の情報処理装置の作動方法。 - 少なくとも1つのプロセッサを備え、
前記プロセッサは、
生体試料に関する複数のバイオマーカーのそれぞれに付与されたアノテーション情報を取得し、
前記アノテーション情報に基づいて、複数の前記バイオマーカー毎の評価値を導出し、
前記評価値に基づいて、複数の前記バイオマーカーの中から測定対象のバイオマーカーを選択する、
情報処理装置。 - 生体試料に関する複数のバイオマーカーのそれぞれに付与されたアノテーション情報を取得する取得処理と、
前記アノテーション情報に基づいて、複数の前記バイオマーカー毎の評価値を導出する導出処理と、
前記評価値に基づいて、複数の前記バイオマーカーの中から測定対象のバイオマーカーを選択する選択処理と、
をプロセッサに実行させる情報処理装置の作動プログラム。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202180042892.XA CN115843381A (zh) | 2020-06-19 | 2021-04-06 | 信息处理装置、信息处理装置的工作方法、信息处理装置的工作程序 |
| JP2022532324A JP7459254B2 (ja) | 2020-06-19 | 2021-04-06 | 情報処理装置、情報処理装置の作動方法、情報処理装置の作動プログラム |
| EP21827034.6A EP4170027A4 (en) | 2020-06-19 | 2021-04-06 | INFORMATION PROCESSING APPARATUS, OPERATING METHOD FOR THE INFORMATION PROCESSING APPARATUS AND OPERATING PROGRAM FOR THE INFORMATION PROCESSING APPARATUS |
| US18/066,585 US20230118920A1 (en) | 2020-06-19 | 2022-12-15 | Information processing apparatus, operation method for information processing apparatus, and operation program for information processing apparatus |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020106417 | 2020-06-19 | ||
| JP2020-106417 | 2020-06-19 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US18/066,585 Continuation US20230118920A1 (en) | 2020-06-19 | 2022-12-15 | Information processing apparatus, operation method for information processing apparatus, and operation program for information processing apparatus |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021256055A1 true WO2021256055A1 (ja) | 2021-12-23 |
Family
ID=79267838
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2021/014592 WO2021256055A1 (ja) | 2020-06-19 | 2021-04-06 | 情報処理装置、情報処理装置の作動方法、情報処理装置の作動プログラム |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US20230118920A1 (ja) |
| EP (1) | EP4170027A4 (ja) |
| JP (1) | JP7459254B2 (ja) |
| CN (1) | CN115843381A (ja) |
| WO (1) | WO2021256055A1 (ja) |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008505638A (ja) * | 2004-07-09 | 2008-02-28 | サイセラ,インコーポレイテッド | 胚体内胚葉を分化させるための因子を同定する方法 |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA2812194C (en) * | 2010-09-17 | 2022-12-13 | President And Fellows Of Harvard College | Functional genomics assay for characterizing pluripotent stem cell utility and safety |
-
2021
- 2021-04-06 JP JP2022532324A patent/JP7459254B2/ja active Active
- 2021-04-06 CN CN202180042892.XA patent/CN115843381A/zh active Pending
- 2021-04-06 WO PCT/JP2021/014592 patent/WO2021256055A1/ja unknown
- 2021-04-06 EP EP21827034.6A patent/EP4170027A4/en active Pending
-
2022
- 2022-12-15 US US18/066,585 patent/US20230118920A1/en active Pending
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008505638A (ja) * | 2004-07-09 | 2008-02-28 | サイセラ,インコーポレイテッド | 胚体内胚葉を分化させるための因子を同定する方法 |
Non-Patent Citations (5)
| Title |
|---|
| ARAVIND SUBRAMANIAN ET AL.: "A Next Generation Connectivity Map: L1000 Platform and the First 1,000,000 profiles", CELL, vol. 171, 30 November 2015 (2015-11-30), pages 1437 - 1452, Retrieved from the Internet <URL:https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5990023> |
| HUANG BIAO, HAN WEI, SHENG ZU-FENG, SHEN GUO-LIANG: "Identification of immune-related biomarkers associated with tumorigenesis and prognosis in cutaneous melanoma patients", CANCER CELL INTERNATIONAL, vol. 20, no. 1, 1 December 2020 (2020-12-01), XP055890929, DOI: 10.1186/s12935-020-01271-2 * |
| RAHMAN MD HABIBUR, PENG SILONG, HU XIYUAN, CHEN CHEN, UDDIN SHAHADAT, QUINN JULIAN M.W., MONI MOHAMMAD ALI: "A Network-Based Bioinformatics Approach to Identify Molecular Biomarkers for Type 2 Diabetes that Are Linked to the Progression of Neurological Diseases", INTERNATIONAL JOURNAL OF ENVIRONMENTAL RESEARCH AND PUBLIC HEALTH, vol. 17, no. 3, 6 February 2020 (2020-02-06), pages 1 - 25, XP055890932, DOI: 10.3390/ijerph17031035 * |
| REN JIANTING, ZHANG BO, WEI DONGFENG, ZHANG ZHANJUN: "Identification of Methylated Gene Biomarkers in Patients with Alzheimer’s Disease Based on Machine Learning", BIOMED RESEARCH INTERNATIONAL, HINDAWI PUBLISHING CORPORATION, vol. 2020, 27 March 2020 (2020-03-27), pages 1 - 11, XP055890938, ISSN: 2314-6133, DOI: 10.1155/2020/8348147 * |
| See also references of EP4170027A4 |
Also Published As
| Publication number | Publication date |
|---|---|
| US20230118920A1 (en) | 2023-04-20 |
| CN115843381A (zh) | 2023-03-24 |
| JPWO2021256055A1 (ja) | 2021-12-23 |
| EP4170027A1 (en) | 2023-04-26 |
| JP7459254B2 (ja) | 2024-04-01 |
| EP4170027A4 (en) | 2023-12-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Kee et al. | Single-cell analysis reveals a close relationship between differentiating dopamine and subthalamic nucleus neuronal lineages | |
| Zhao et al. | Misuse of RPKM or TPM normalization when comparing across samples and sequencing protocols | |
| Stanfield et al. | Myometrial transcriptional signatures of human parturition | |
| CN106033502B (zh) | 鉴定病毒的方法和装置 | |
| Zhang et al. | Network‐based proteomic analysis for postmenopausal osteoporosis in Caucasian females | |
| LeDuc et al. | Accurate Estimation of Context-Dependent False Discovery Rates in Top-Down Proteomics*[S] | |
| Larsson et al. | Comparative microarray analysis | |
| Alfano et al. | A multi-omic analysis of birthweight in newborn cord blood reveals new underlying mechanisms related to cholesterol metabolism | |
| Dai et al. | LPIN1 is a regulatory factor associated with immune response and inflammation in sepsis | |
| Lauria et al. | SCUDO: a tool for signature-based clustering of expression profiles | |
| Yu et al. | ARG2, MAP4K5 and TSTA3 as diagnostic markers of steroid-induced osteonecrosis of the femoral head and their correlation with immune infiltration | |
| Ahsen et al. | NeTFactor, a framework for identifying transcriptional regulators of gene expression-based biomarkers | |
| WO2021256055A1 (ja) | 情報処理装置、情報処理装置の作動方法、情報処理装置の作動プログラム | |
| Li et al. | Sex differences orchestrated by androgens at single-cell resolution | |
| JP6623774B2 (ja) | パスウェイ解析プログラム、パスウェイ解析方法、及び、情報処理装置 | |
| Liu et al. | Cross-generation and cross-laboratory predictions of Affymetrix microarrays by rank-based methods | |
| Zhang et al. | Identification of immune cell function in breast cancer by integrating multiple single-cell data | |
| EP4148139A1 (en) | Biomarker identification method and cell production method | |
| CN113355426A (zh) | 用于预测肝癌预后的评估基因集及试剂盒 | |
| Lu et al. | Integrated identification of disease specific pathways using multi-omics data | |
| JP2013123420A (ja) | 遺伝子セット作成方法 | |
| Sibille et al. | Large-scale estimates of cellular origins of mRNAs: enhancing the yield of transcriptome analyses | |
| CN105243294B (zh) | 一种用于预测癌症病人预后相关的蛋白质对的方法 | |
| CN117743957B (zh) | 一种基于机器学习的Th2A细胞的数据分选方法及相关设备 | |
| An et al. | Pharmacological effects of novel peptide drugs on allergic rhinitis at the small ribonucleic acids level |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21827034 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022532324 Country of ref document: JP Kind code of ref document: A |
|
| ENP | Entry into the national phase |
Ref document number: 2021827034 Country of ref document: EP Effective date: 20230119 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |